Перекрестная ссылка на родственную заявку
Данная заявка заявляет приоритет предварительной заявки на патент США №61/122647, поданной 15 декабря 2008 г., которая ссылкой полностью включается в настоящее описание.
Область техники изобретения
Изобретение относится к системам виртуализации окружающего звука и способам генерирования выходных сигналов, предназначенных для воспроизведения парой физических акустических систем (наушников или громкоговорителей), расположенных в определенных выходных положениях, в ответ на, по меньшей мере, два входных звуковых сигнала, являющихся признаками звука из нескольких положений источников, включая, по меньшей мере, два тыловых положения. Как правило, выходные сигналы генерируются в ответ на набор из пяти входных сигналов, являющихся признаками звука из трех передних положений (левого, центрального и правого передних положений) и двух тыловых положений (левого окружающего и правого окружающего тыловых источников).
Предпосылки изобретения
Во всем данном раскрытии, включая формулу изобретения, термин «виртуализатор» (или «система виртуализатора») обозначает систему, которая подключена и сконфигурирована для приема N входных звуковых сигналов (являющихся признаками звука из ряда положений источников) и генерирования М выходных звуковых сигналов, которые предназначены для воспроизведения рядом из М физических акустических систем (например, наушниками или громкоговорителями), расположенными в выходных положениях, которые отличаются от положений источников, где N и M - числа, каждое из которых больше единицы. N может быть равно M или отличаться от M. Виртуализатор генерирует (или пытается генерировать) выходные звуковые сигналы так, чтобы при их воспроизведении слушатель воспринимал воспроизводимые сигналы как сигналы, испускаемые из положений источников, которые отличаются от выходных положений физических акустических систем (источники и выходные положения располагаются относительно слушателя). Например, в случае, когда M=2, а N>3, виртуализатор выполняет понижающее микширование N выходных сигналов для стереофонического воспроизведения. В другом примере, где N=М=2, входные сигналы являются признаками звука из двух тыловых положений источников (позади головы слушателя), и виртуализатор генерирует два выходных звуковых сигнала для воспроизведения стереофоническими громкоговорителями, расположенными перед слушателем, так, чтобы слушатель воспринимал воспроизводимые сигналы как сигналы, испускаемые от положений источников (позади головы слушателя), а не от положений громкоговорителей (перед головой слушателя).
Во всем данном описании, включая формулу изобретения, выражение «тыловое» положение (например, «тыловое положение источника») обозначает положение позади головы слушателя, а выражение «переднее» положение (например, «переднее положение источника») обозначает положение перед головой слушателя. Сходным образом, выражение «передние» динамики обозначает динамики, расположенные перед головой слушателя, а «задние динамики» - обозначает динамики, расположенные позади головы слушателя.
Во всем данном описании, включая формулу изобретения, выражение «система» используется в широком смысле для обозначения устройства, системы или подсистемы. Например, подсистема, которая реализует виртуализатор может быть названа «системой виртуализатора», а система, включающая эту подсистему (например, система, генерирующая М выходных сигналов в ответ на X+Y входных сигналов, в которой подсистема генерирует X входных сигналов, а остальные Y входных сигналов принимаются от внешнего источника), также может быть названа системой виртуализатора.
Во всем данном описании, включая формулу изобретения, выражение «воспроизведение» сигналов динамиками обозначает создание условий для вывода звука акустическими системами в ответ на сигналы, включая любое необходимое усиление и/или другую обработку сигналов.
Виртуальный окружающий звук может способствовать созданию восприятия того, что присутствует большее количество источников звука, чем имеется в наличии физических акустических систем (например, наушников или громкоговорителей). Как правило, нормальному слушателю для того, чтобы ощущать воспроизводимый звук так, будто бы он испускается множеством источников звука, необходимо, по меньшей мере, две акустические системы.
Например, рассмотрим простой виртуализатор окружающего звука, подключенный и сконфигурированный для приема входных звуковых сигналов от трех источников (левого, центрального и правого) и для генерирования выходных звуковых сигналов для двух физических громкоговорителей (симметрично расположенных перед слушателем) в ответ на входные звуковые сигналы. Такой виртуализатор направляет входной сигнал от левого источника к левой акустической системе, направляет входной сигнал от правого источника к правой акустической системе и разделяет входной сигнал от центрального источника поровну между левой и правой акустическими системами. Выходной сигнал виртуализатора, который является признаком входного сигнала от центрального источника, обычно называется «фантомным» центральным каналом. Слушатель воспринимает воспроизводимый выходной звуковой сигнал так, будто бы он включает центральный канал, испускаемый центральной акустической системой, которая находится между левой и правой акустическими системами, а левый и правый каналы - как испускаемые левой и правой акустическими системами.
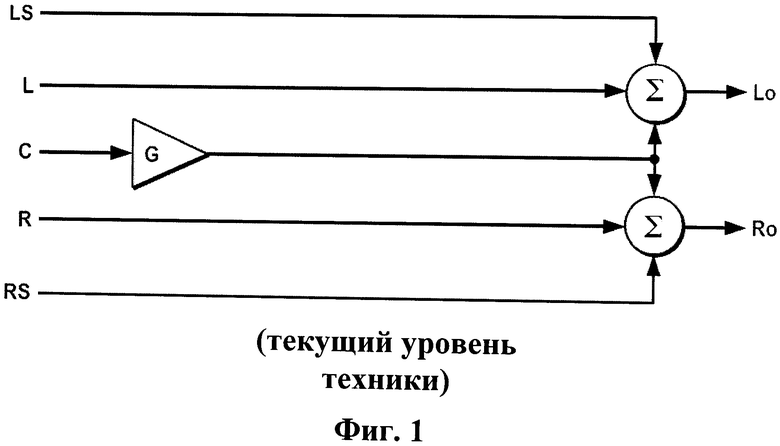
Другой традиционный виртуализатор окружающего звука (показанный на фиг.1) известен как "LoRo", или виртуализатор с понижающим микшированием только левого и только правого передних каналов. Виртуализатор подключается для приема пяти входных звуковых сигналов: левого ("L"), центрального ("C") и правого ("R") передних каналов, а также левого окружающего ("LS") и правого окружающего ("RS") тыловых каналов. Виртуализатор по фиг.1 комбинирует входные сигналы указанным образом для воспроизведения через левый и правый физические громкоговорители (которые должны располагаться перед слушателем): входной центральный сигнал С усиливается в усилителе G, и усиленный выходной сигнал усилителя G складывается с входными сигналами L и LS, образуя левый выходной сигнал ("Lo"), направляемый к левой акустической системе, и складывается с входными сигналами R и RS, образуя правый выходной сигнал ("Ro"), направляемый к правой акустической системе.
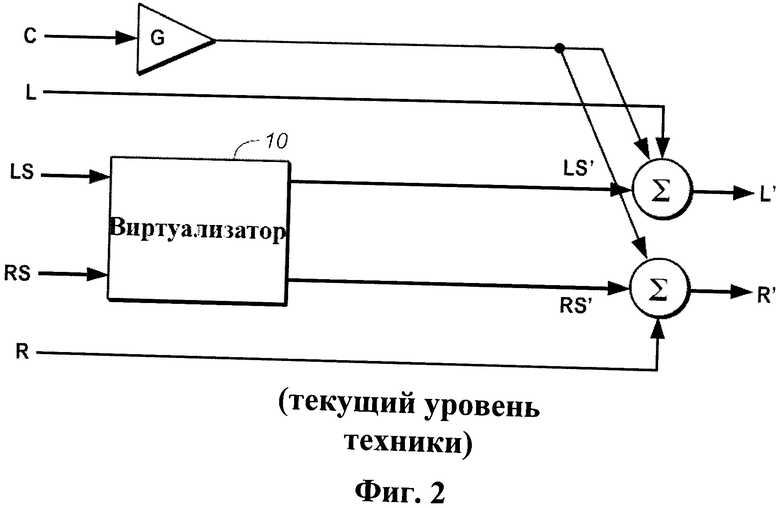
Другой традиционный виртуализатор окружающего звука показан на фиг.2. Этот виртуализатор подключается для приема пяти входных звуковых сигналов (левого ("L"), центрального ("C") и правого ("R") передних каналов, являющихся признаками передних источников L, C и R, и левого окружающего ("LS") и правого окружающего ("RS") тыловых каналов, являющихся признаками тыловых источников LS и RS) и конфигурируется для генерирования фантомного центрального канала путем разделения входного сигнала от центрального канала С поровну между левым и правым сигналами для приведения в действие пары физических передних громкоговорителей (расположенных перед слушателем). Виртуализатор по фиг.2 также конфигурируется с целью использования подсистемы 10 виртуализатора для того, чтобы генерировать левый и правый выходные сигналы LS' и RS', пригодные для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, воспроизводимый тыловой (окружающий) звук, испускаемый источниками RS и LS позади слушателя. Точнее, подсистема 10 виртуализатора конфигурируется для генерирования выходных звуковых сигналов LS' и RS' в ответ на входные сигналы тыловых каналов (LS и RS), что заключается в преобразовании входных сигналов в соответствии с функцией моделирования восприятия звука (HRTF). Реализуя надлежащую HRTF, подсистема 10 виртуализации может генерировать пару выходных сигналов, которые могут воспроизводиться двумя физическими громкоговорителями, расположенными перед слушателем так, чтобы слушатель воспринимал выходные сигналы громкоговорителей как сигналы, испускаемые парой источников, расположенных в любом из большого количества возможных положений (например, положений позади головы слушателя). Виртуализатор по фиг.2 также усиливает входной центральный сигнал С в усилителе G, и усиленный выходной сигнал усилителя G складывается с входным сигналом L и выходным сигналом LS' подсистемы 10, образуя левый выходной сигнал ("L'"), предназначенный для направления к левому громкоговорителю, и складывается с входным сигналом R и выходным сигналом RS' подсистемы 10, образуя правый выходной сигнал ("R'"), предназначенный для направления к правому громкоговорителю.
Для генерирования звуковых сигналов, которые при воспроизведении парой физических акустических систем, расположенных перед слушателем, воспринимаются барабанными перепонками слушателя как звук из громкоговорителей, находящихся в любом из большого количества возможных положений (включая положения позади слушателя), системы виртуального окружающего звука традиционно используют функции моделирования восприятия звука (HRTF). Недостатком традиционно используемой одной стандартной HRTF (или ряда стандартных HRTF) при генерировании звуковых сигналов, пригодных для использования многими слушателями (например, широкой публикой) является то, что точная HRTF для каждого конкретного слушателя должна зависеть от характерных особенностей слухового аппарата слушателя. Поэтому функции HRTF должны широко варьироваться для различных слушателей, и единичная HRTF, в общем, не будет пригодной для всех или многих слушателей.
Если для представления выходных сигналов виртуализатора используются (в отличие от наушников) два громкоговорителя, необходимо приложить усилия для изоляции звука от левого громкоговорителя к левому уху, и от правого громкоговорителя - к правому уху. Традиционно для достижения такой изоляции используется устройство подавления перекрестных помех. Для реализации подавления перекрестных помех виртуализаторы традиционно реализуют пару функций HRTF (для каждого источника звука), генерируя выходные сигналы, которые при воспроизведении воспринимаются как испускаемые от положения источника. Недостатком традиционного подавления перекрестных помех является то, что, для ощущения преимуществ подавления, слушатель должен оставаться в фиксированном положении в «зоне наилучшего восприятия». Обычно зона наилучшего восприятия представляет собой положение, в котором громкоговорители располагаются в симметричных положениях по отношению к слушателю, хотя возможны и асимметричные положения.
Виртуализаторы могут реализовываться для широкого выбора мультимедийных устройств, которые содержат громкоговорители (телевизоры, ПК, iPod док-станции) или предназначаются для использования со стереофоническими громкоговорителями или наушниками.
Существует потребность в виртуализаторе с низкими требованиями к быстродействию процессора (например, с низким числом MIPS (миллион команд в секунду)) и низкими требованиями к памяти, а также с улучшенными акустическими характеристиками. Типичные варианты осуществления настоящего изобретения достигают улучшенных акустических характеристик в сочетании со сниженными вычислительными потребностями посредством новой упрощенной топологии фильтра.
Также существует потребность в виртуализаторе окружающего звука, который бы выделял виртуализированные источники (например, виртуализированные тыловые каналы окружающего звука) в смешанном выходном звуковом сигнале, который, в случае необходимости, определяется выходными сигналами виртуализатора (например, когда виртуализированные источники генерируются в ответ на входные сигналы низкого уровня от тыловых источников), избегая при этом придания избыточного значения виртуальным каналам (например, избегая виртуальных тыловых акустических систем, воспринимаемых как чрезмерно громкие).
Для достижения указанных улучшенных акустических характеристик при воспроизведении выходных сигналов виртуализатора, варианты осуществления настоящего изобретения в ходе генерирования виртуализированных каналов окружающего звука (например, виртуализированных тыловых каналов) применяют динамическое сжатие диапазона. Для обеспечения улучшенных акустических характеристик (включая улучшенную локализацию) в ходе воспроизведения выходных сигналов виртуализатора, типичные варианты осуществления настоящего изобретения также применяют для виртуализированных источников декорреляцию и подавление перекрестных помех.
Краткое описание изобретения
В некоторых вариантах осуществления, изобретение представляет собой систему и способ виртуализации окружающего звука, предназначенные для генерирования выходных сигналов с целью их воспроизведения парой физических акустических систем (например, наушников или громкоговорителей, расположенных в выходных положениях) в ответ на ряд из N входных звуковых сигналов (где N - число не меньше двух), где входные звуковые сигналы являются признаками звука из нескольких положений источников, включая, по меньшей мере, два тыловых положения. Обычно, N=5, и входные сигналы являются признаками звука из трех передних положений (левого, центрального и правого передних положений) и двух тыловых положений (левого окружающего и правого окружающего тыловых положений).
В типичных вариантах осуществления изобретения виртуализатор согласно изобретению генерирует левый и правый выходные сигналы (L' или R') для приведения в действие пары передних громкоговорителей в ответ на пять входных звуковых сигналов: левый ("L") канал является признаком звука из левого переднего источника, центральный канал («C») является признаком звука из центрального переднего источника, правый канал ("R") является признаком звука из правого переднего источника, левый окружающий канал ("LS") является признаком звука из левого тылового источника, а правый окружающий канал ("RS") является признаком звука из правого тылового источника. Виртуализатор генерирует фантомный центральный канал путем разделения входного сигнала центрального канала поровну между правым и левым выходными сигналами. Виртуализатор включает подсистему виртуализатора (окружающего) тылового канала, сконфигурированную для генерирования левого и правого окружающих выходных сигналов (LS' и RS'), которые пригодны для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый источниками RS и LS позади слушателя. Подсистема виртуализатора окружающего звука сконфигурирована для генерирования выходных сигналов LS' и RS' в ответ на входные сигналы тыловых каналов (LS и RS) путем преобразования входных сигналов тыловых каналов в соответствии с функцией моделирования восприятия звука (HRTF). Виртуализатор комбинирует выходные сигналы LS' и RS' с входными сигналами передних каналов L, C и R, генерируя левый и правый выходные сигналы (L' и R'). Когда выходные сигналы L' и R' воспроизводятся передними громкоговорителями, слушатель воспринимает конечный звук как звук, испускаемый тыловыми источниками RS и LS, а также передними источниками L, C, и R.
В одном из классов вариантов осуществления изобретения, способ и система изобретения реализует модель HRTF, которая является простой для реализации и настраиваемой для любого положения источника и положения физической акустической системы относительно каждого из ушей слушателя. Предпочтительно, модель HRTF используется для вычисления обобщенной HRTF, которая используется для генерирования левого и правого окружающих выходных сигналов (LS' и RS') в ответ на входные сигналы тыловых каналов (LS и RS), а также для вычисления функций HRTF, которые используется для выполнения подавления перекрестных помех на левом и правом окружающих выходных сигналах (LS' и RS') для данного ряда положений физических акустических систем.
Для того чтобы обеспечить тому, кто слушает воспроизводимые виртуальные выходные сигналы, хорошую слышимость виртуальных каналов (например, левого окружающего и правого окружающего виртуальных тыловых каналов) в присутствии других каналов, виртуализатор выполняет сжатие динамического диапазона на входных сигналах тыловых источников (в ходе генерирования в ответ на входные сигналы тыловых источников окружающих сигналов, используемых для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из положений тыловых источников), что способствует нормализации воспринимаемой громкости виртуальных тыловых каналов.
В данном описании, выполнение сжатия динамического диапазона «на» входных сигналах (в ходе генерирования окружающих сигналов), в более широком смысле, обозначает выполнение сжатия динамического диапазона непосредственно на входных сигналах или на обработанных версиях входных сигналов (например, на версиях входных сигналов, которые были подвергнуты декорреляции или другой фильтрации). Для генерирования окружающих сигналов может потребоваться дальнейшая обработка сигналов, подвергнутых сжатию динамического диапазона, или окружающие сигналы могут являться выходными сигналами средств сжатия динамического диапазона. В более общем смысле, выражение «выполнение операции» (например, фильтрации, декорреляции или преобразования в соответствии с HRTF) «на» входных сигналах (в ходе генерирования входных сигналов окружающих сигналов) в данном описании, включая формулу изобретения, используется, в широком смысле, для обозначения выполнения операции непосредственно на входных сигналах или на обработанных версиях входных сигналов. Сжатие динамического диапазона, предпочтительно, выполняется путем нелинейного усиления входных сигналов (окружающих) тыловых источников или их частично обработанных версий (например, усиления входных сигналов тыловых источников нелинейно относительно сигналов передних каналов). Предпочтительно, в ответ на входные окружающие сигналы (являющиеся признаками звука из левого окружающего и правого окружающего тыловых источников), которые не превышают заранее установленное пороговое значение, а также в ответ на входные передние сигналы, входные окружающие сигналы усиливаются относительно передних сигналов (к окружающим сигналам применяется больший коэффициент усиления, чем к передним сигналам) перед тем, как они подвергаются декорреляции и преобразованию в соответствии с функцией моделирования восприятия звука. Предпочтительно, входные окружающие сигналы (или их частично обработанные версии) усиливаются нелинейно в зависимости от величины, на которую входные окружающие сигналы меньше порогового значения. Когда входные окружающие сигналы выше порогового значения, они, как правило, не усиливаются (необязательно, входные передние сигналы и входные окружающие сигналы усиливаются на одинаковую величину тогда, когда входные окружающие сигналы превышают пороговое значение, например, на величину, которая зависит от заранее заданного коэффициента сжатия). Сжатие динамического диапазона согласно изобретению может приводить к усилению входных тыловых каналов на несколько децибел относительно передних каналов, что, когда это необходимо, способствует выводу виртуальных тыловых каналов в смешанном выходном звуковом сигнале (т.е. когда входные сигналы тыловых каналов не превышают пороговое значение) без избыточного усиления виртуальных тыловых каналов тогда, когда входные сигналы тыловых каналов превышают пороговое значение (во избежание восприятия виртуальных тыловых акустических систем как чрезмерно громких).
В одном из классов вариантов осуществления изобретения, способ и система изобретения реализуют декорреляцию виртуализированных источников с целью обеспечения улучшенной локализации и во избежание трудностей, вызванных симметрией физических акустических систем в присутствии виртуальных акустических систем. В отсутствие указанной декорреляции, если физические акустические системы (например, громкоговорители перед слушателем) симметричны относительно слушателя (например, когда слушатель находится в зоне наилучшего восприятия), воспринимаемые положения виртуальных акустических систем также симметричны относительно слушателя. В этом случае, если оба виртуальных тыловых канала (являющихся признаками входных сигналов левого окружающего и правого окружающего тыловых источников) идентичны, то воспроизводимые сигналы для обоих ушей также идентичны, и тыловые источники больше не являются виртуализированными (слушатель не воспринимает воспроизводимый звук как звук, испускаемый из-за спины слушателя). Кроме того, в отсутствие декорреляции при симметричном размещении физических акустических систем перед слушателем, воспроизводимые выходные сигналы виртуализатора в ответ на панорамирование входных сигналов тыловых источников (входные сигналы являются признаками звука, панорамированного от левого окружающего тылового источника к правому окружающему тыловому источнику) в середине панорамирования источника звука будут казаться приходящими спереди. Указанный класс вариантов осуществления изобретения позволяет избежать этих проблем (обычно называемых «коллапсом изображения») путем реализации декорреляции входных сигналов (окружающих) тыловых источников. Декорреляция входных сигналов тыловых источников в тех случаях, когда они идентичны друг другу, устраняет общность между ними и позволяет избежать коллапса изображения.
В типичных вариантах осуществления изобретения, система согласно изобретению представляет собой или содержит универсальный или специализированный процессор, программируемый посредством программного обеспечения (или встроенного программного обеспечения) и/или иначе сконфигурированный для выполнения варианта осуществления способа изобретения. В некоторых вариантах осуществления изобретения, система виртуализатора согласно изобретению представляет собой универсальный процессор, который подключен для приема входных данных, являющихся признаками входных звуковых каналов, и программируется (посредством надлежащего программного обеспечения) для генерирования выходных данных, являющихся признаками выходных сигналов (предназначенных для воспроизведения парой физических акустических систем) в ответ на входные данные путем выполнения одного из вариантов осуществления способа изобретения. В других вариантах осуществления изобретения, система виртуализатора согласно изобретению реализуется путем надлежащего конфигурирования (например, путем программирования) перестраиваемого цифрового процессора для обработки звука (DSP). DSP для обработки звука может представлять собой традиционный DSP для обработки звука, который является перестраиваемым (например, программируемым посредством надлежащего программного обеспечения или встроенного программного обеспечения, или иначе конфигурируемым в ответ на управляющие данные) для выполнения любой из множества операций на входных звуковых сигналах. В ходе работы, DSP для обработки звука, сконфигурированный для выполнения виртуализации окружающего звука в соответствии с изобретением, подключается для приема нескольких входных звуковых сигналов (являющихся признаками звука из нескольких положений источников, включая, по меньшей мере, два тыловых положения), и, как правило, DSP выполняет ряд операций на входных звуковых сигналах помимо и в дополнение к виртуализации. В соответствии с различными вариантами осуществления изобретения, DSP для обработки звука пригоден для выполнения варианта осуществления способа изобретения после конфигурирования (например, программирования) с целью генерирования выходных звуковых сигналов (для воспроизведения парой физических акустических систем) в ответ на входные звуковые сигналы путем выполнения способа на входных звуковых сигналах.
В некоторых вариантах осуществления, изобретение представляет собой способ виртуализации звука с целью генерирования выходных сигналов для воспроизведения парой физических акустических систем, находящихся в определенных физических положениях относительно слушателя, где ни одно из указанных положений не является положением из ряда из, по меньшей мере, двух положений тыловых источников, при этом указанный способ включает следующие этапы:
(a) в ответ на входные звуковые сигналы, являющиеся признаками звука из положений тыловых источников - генерирование окружающих сигналов, пригодных для приведения акустических систем в определенных физических положениях в состояние испускания звука таким образом, чтобы слушатель воспринимал его как звук, испускаемый указанными положениями тыловых источников, в том числе, включая выполнение сжатия динамического диапазона на входных звуковых сигналах; и
(b) генерирование выходных сигналов в ответ на окружающие сигналы и, по меньшей мере, еще один входной звуковой сигнал, где каждый указанный еще один входной сигнал является признаком звука из соответствующего положения переднего источника, так чтобы выходные сигналы были пригодны для приведения акустических систем в определенных физических положениях в состояние испускания звука таким образом, чтобы слушатель воспринимал его как звук, испускаемый из положений тыловых источников и из каждого указанного положения переднего источника.
Как правило, физические акустические системы представляют собой передние громкоговорители в физических положениях перед слушателем, и этап (a) включает этап генерирования левого и правого окружающих сигналов (LS' и RS') в ответ на левый и правый тыловые входные сигналы (LS и RS), где левый и правый окружающие сигналы (LS' и RS'') пригодны для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из левого тылового и правого тылового источников позади слушателя. В альтернативном варианте, физические акустические системы могут представлять собой наушники или громкоговорители, расположенные иначе, чем в положениях тыловых источников (например, громкоговорители, расположенные слева и справа от слушателя). Предпочтительно, физические акустические системы являются передними громкоговорителями в физических положениях перед слушателем, и этап (а) включает этап генерирования левого и правого окружающих сигналов (LS' и RS'), пригодных для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из левого тылового и правого тылового источников позади слушателя, а этап (b) включает этап генерирования выходных сигналов в ответ на: окружающие сигналы, левый входной звуковой сигнал, являющийся признаком звука из положения левого переднего источника, правый входной звуковой сигнал, являющийся признаком звука из положения правого переднего источника, и центральный входной звуковой сигнал, являющийся признаком звука из положения центрального переднего источника. Предпочтительно, этап (b) включает этап генерирования фантомного центрального канала в ответ на центральный входной звуковой сигнал.
Предпочтительно, сжатие динамического диапазона способствует нормализации воспринимаемой громкости виртуальных тыловых каналов. Также предпочтительно, чтобы сжатие динамического диапазона выполнялось путем усиления входных звуковых сигналов нелинейно относительно каждого из указанных других входных звуковых сигналов. Предпочтительно, этап (а) включает этап выполнения сжатия динамического диапазона, которое заключается в усилении каждого из входных звуковых сигналов, имеющего уровень (например, средний уровень по временному окну), который не превышает заранее заданное пороговое значение, нелинейно в зависимости от величины, на которую указанный уровень меньше порогового значения.
Предпочтительно, этап (а) включает этап генерирования окружающих сигналов, который заключается в преобразовании входных звуковых сигналов в соответствии с функцией моделирования восприятия звука (HRTF), и/или путем выполнения декорреляции на входных звуковых сигналах, и/или путем выполнения подавления перекрестных помех на входных звуковых сигналах. В данном описании, выражение «выполнение» операции (например, преобразования в соответствии с HRTF или сжатия динамического диапазона, или декорреляции) «на» входных звуковых сигналах используется, в широком смысле, для обозначения выполнения операции на входных звуковых сигналах или на обработанных версиях входных звуковых сигналов (например, на версиях входных звуковых сигналов, которые были подвергнуты декорреляции или другой фильтрации).
Особенности изобретения включают систему виртуализатора, сконфигурированную (например, запрограммированную) для выполнения любого варианта осуществления способа изобретения, а также компьютерный программный носитель (например, диск), на котором хранится программный код для реализации любого варианта осуществления способа изобретения.
Краткое описание графических материалов
Фиг.1 - блок-схема традиционной системы виртуализатора окружающего звука.
Фиг.2 - блок-схема другой традиционной системы виртуализатора окружающего звука.
Фиг.3 - блок-схема одного из вариантов осуществления системы виртуализатора окружающего звука согласно изобретению.
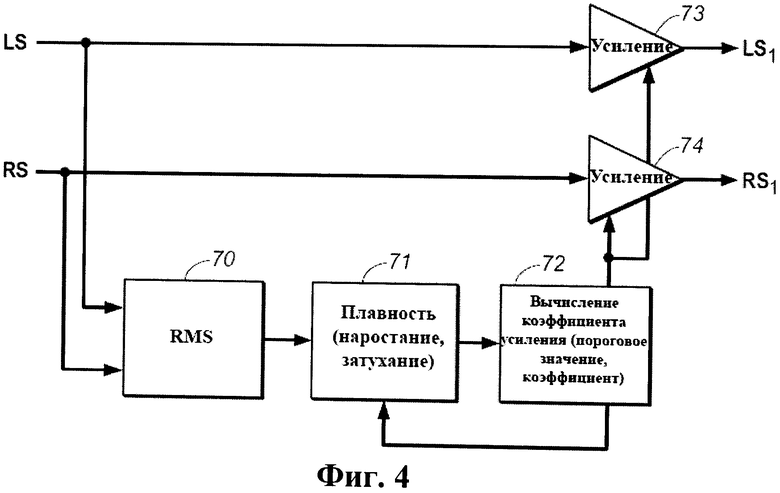
Фиг.4 - блок-схема реализации этапа 41 подсистемы виртуализатора 40 по фиг.3.
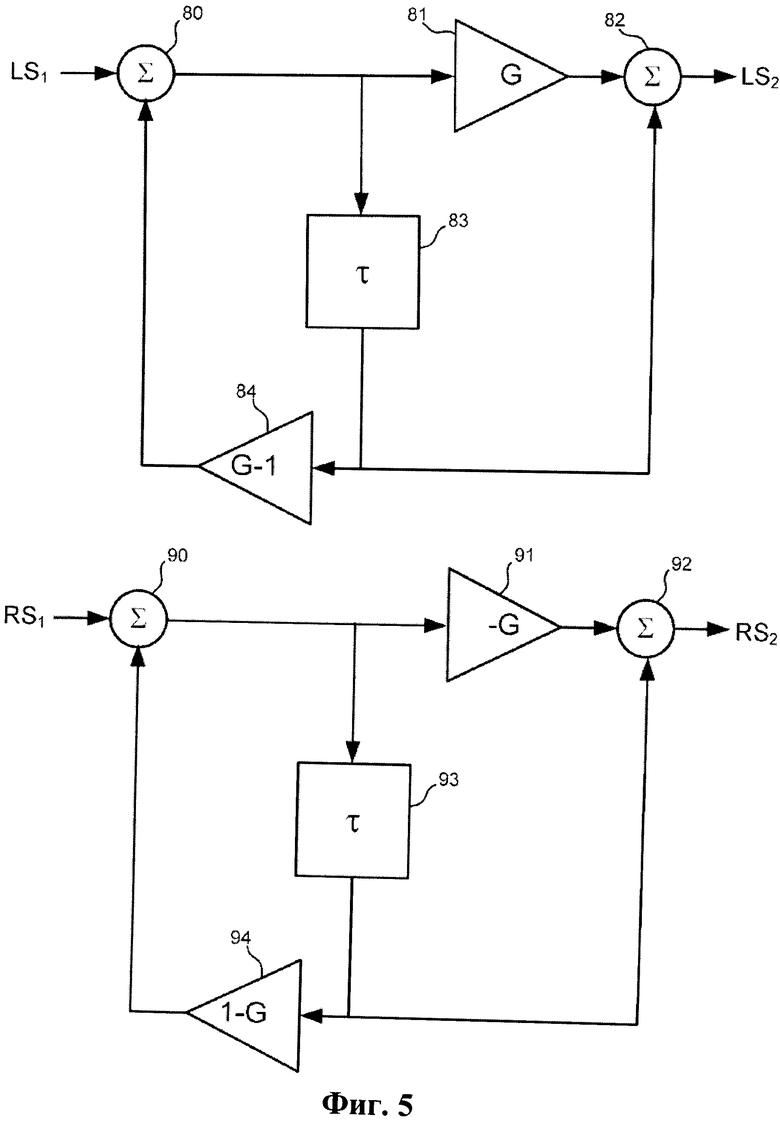
Фиг.5 - блок-схема реализации этапа 42 подсистемы виртуализатора 40 по фиг.3.
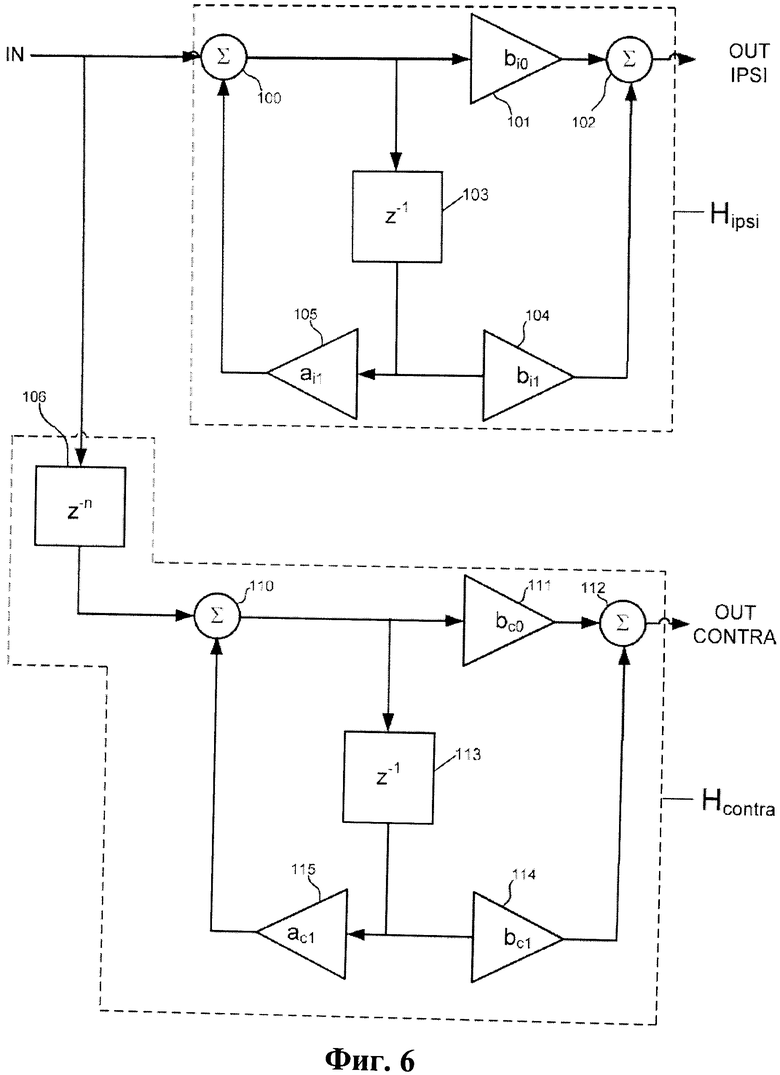
Фиг.6 - блок-схема реализации одной из схем HRTF на этапе 43 подсистемы виртуализатора 40.
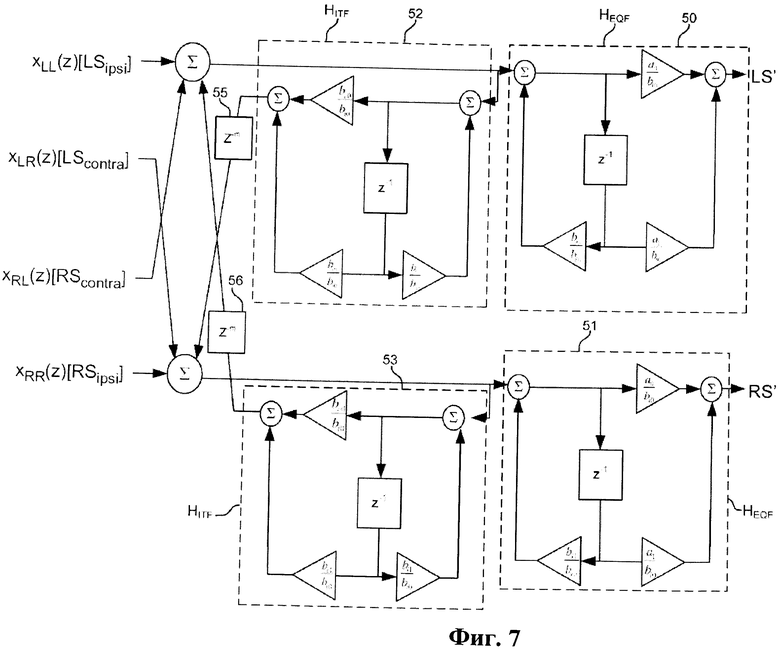
Фиг.7 - блок-схема реализации этапа 44 подсистемы виртуализатора 40.
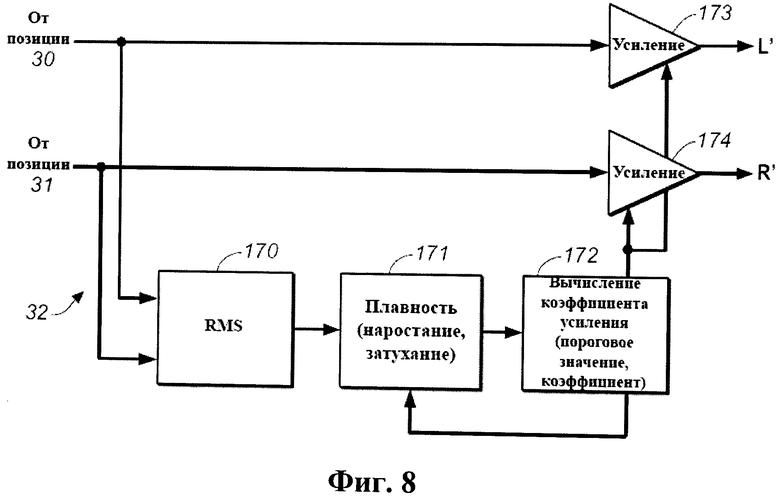
Фиг.8 - детальная блок-схема реализации лимитера 32 системы виртуализатора по фиг.3.
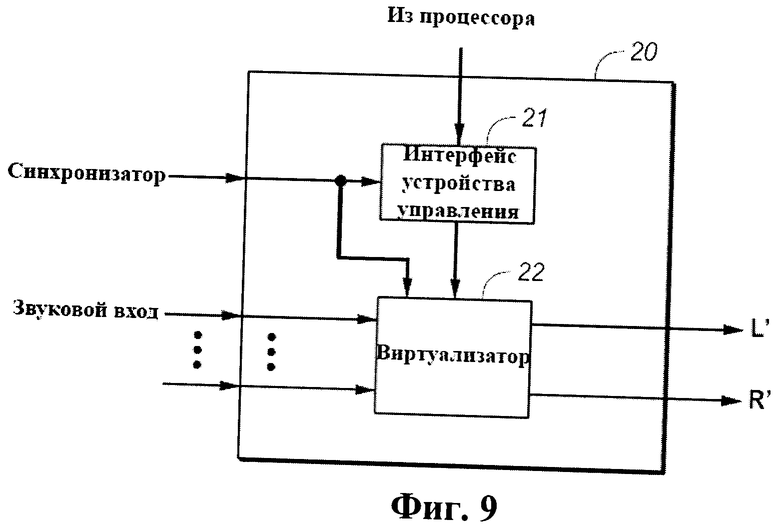
Фиг.9 - блок-схема процессора цифровой обработки звуковых сигналов (DSP), представляющего собой один из вариантов осуществления системы виртуализатора окружающего звука согласно изобретению.
Подробное описание предпочтительных вариантов осуществления изобретения
Технологически выполнимо множество вариантов осуществления настоящего изобретения. Из данного раскрытия средним специалистам в данной области станет ясно, каким образом их реализовывать. Варианты осуществления системы изобретения, способа изобретения и носителя будут описаны с отсылкой к фиг.3-9.
В некоторых вариантах осуществления, изобретение представляет собой способ виртуализации звука, предназначенный для генерирования выходных сигналов (например, сигналов L' и R' по фиг.3) для их воспроизведения парой физических акустических систем, находящихся в определенных физических положениях относительно слушателя, где ни одно из физических положений не является положением из ряда из, по меньшей мере, двух положений тыловых источников, при этом указанный способ включает следующие этапы:
(a) в ответ на входные звуковые сигналы (например, левый и правый тыловые входные сигналы, LS и RS, фиг.3), являющиеся признаками звука из положений тыловых источников - генерирование окружающих сигналов (например, сигналов окружающего звука LS' and RS', фиг.3), пригодных для приведения акустических систем в физических положениях в состояние испускания звука таким образом, чтобы слушатель воспринимал его как звук, испускаемый из указанных положений тыловых источников, которое заключается в выполнении сжатия динамического диапазона на входных звуковых сигналах; и
(b) генерирование выходных сигналов в ответ на сигналы окружающего звука (например, сигналы окружающего звука LS' и RS' по фиг.3) и, по меньшей мере, еще один входной звуковой сигнал (например, входной звуковой сигнал С, L или R по фиг.3), где каждый указанный еще один входной звуковой сигнал является признаком звука из соответствующего положения переднего источника таким образом, чтобы выходные сигналы были пригодны для приведения акустических систем, находящихся в определенных физических положениях, в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из положений тыловых источников и из каждого указанного положения переднего источника.
Как правило, физические акустические системы представляют собой передние громкоговорители в определенных физических положениях перед слушателем, и этап (а) включает этап генерирования левого и правого сигналов окружающего звука (например, сигналов LS' и RS' по фиг.3) в ответ на левый и правый тыловые входные сигналы (например, сигналы LS и RS по фиг.3), где левый и правый сигналы окружающего звука пригодны для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из левого тылового и правого тылового источников позади слушателя. Физические акустические системы альтернативно могут представлять собой наушники или громкоговорители, расположенные в положениях, отличающихся от положений тыловых источников (например, громкоговорителей, расположенных слева и справа от слушателя). Предпочтительно, физические акустические системы представляют собой передние громкоговорители, находящиеся в физических положениях перед слушателем, и этап (а) включает этап генерирования левого и правого сигналов окружающего звука (например, LS' и RS' по фиг.3), пригодных для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из левого тылового и правого тылового источников позади слушателя, а этап (b) включает этап генерирования выходных сигналов в ответ на: сигналы окружающего звука, левый входной звуковой сигнал, являющийся признаком звука из положения левого переднего источника, правый входной звуковой сигнал, являющийся признаком звука из положения правого переднего источника и центральный входной звуковой сигнал, являющийся признаком звука из положения центрального переднего источника. Предпочтительно, этап (b) включает этап генерирования фантомного центрального канала в ответ на центральный входной звуковой сигнал.
В некоторых вариантах осуществления, изобретение представляет собой способ и систему виртуализации окружающего звука, которые предназначены для генерирования выходных сигналов с целью воспроизведения парой физических акустических систем (например, наушников или громкоговорителей, расположенных в определенных выходных положениях) в ответ на ряд из N входных звуковых сигналов (где N - число не меньше двух), где входные звуковые сигналы являются признаками звука из нескольких положений источников, включающих, по меньшей мере, два тыловых положения. Как правило, N=5, и входные сигналы являются признаками звука из трех передних положений (левого, центрального и правого передних источников) и двух тыловых положений (левого окружающего и правого окружающего тыловых источников).
Фиг.3 представляет собой блок-схему одного из вариантов осуществления системы виртуализатора согласно изобретению. Виртуализатор по фиг.3 конфигурируется для генерирования левого и правого выходных сигналов (L' и R'), предназначенных для приведения в действие пары передних громкоговорителей (или других акустических систем) в ответ на пять входных звуковых сигналов: левого ("L") канала, являющегося признаком звука из левого переднего источника, центрального ("C") канала, являющегося признаком звука из центрального переднего источника, правого ("R") канала, являющегося признаком звука из правого переднего источника, левого окружающего ("LS") канала, являющегося признаком звука из левого тылового источника LS, и правого окружающего ("RS") канала, являющегося признаком звука из правого тылового источника RS. Виртуализатор генерирует фантомный центральный канал (и комбинирует его с левым и правым передними каналами L и R и виртуальным левым и виртуальным правым каналами) путем усиления центрального входного сигнала C в усилителе G, сложения усиленного выходного сигнала усилителя G с входным сигналом L и левым входным сигналом окружающего звука LS' (будет описано ниже) в элементе 30 сложения для генерирования неограниченного левого выходного сигнала, и сложения усиленного выходного сигнала усилителя G с входным сигналом R и правым окружающим выходным сигналом RS' (как будет описано ниже) в элементе 31 сложения для генерирования неограниченного правого выходного сигнала.
Неограниченные левый и правый выходные сигналы обрабатываются лимитером 32 во избежание насыщения. В ответ на неограниченный левый выходной сигнал лимитер 32 генерирует левый выходной сигнал (L'), который направляется к левой передней акустической системе. В ответ на неограниченный правый выходной сигнал лимитер 32 генерирует правый выходной сигнал (R'), который направляется к правой передней акустической системе. Когда выходные сигналы L' и R' воспроизводятся передними громкоговорителями, слушатель воспринимает результирующий звук как звук, испускаемый из тыловых источников RS и LS, а также из передних источников L, C и R.
Подсистема 40 виртуализатора (окружающих) тыловых каналов по фиг.3 генерирует левый и правый окружающие выходные сигналы LS' и RS', пригодные для приведения передних акустических систем в состояние испускания звука таким образом, чтобы слушатель воспринимал его как звук, испускаемый из правого тылового источника RS и левого тылового источника LS позади слушателя. Подсистема виртуализатора 40 включает этап 41 сжатия динамического диапазона, этап 42 декорреляции, этап 43 бинауральной модели (этап HRTF) и этап 44 подавления перекрестных помех, которые соединены так, как показано. Подсистема 40 виртуализатора генерирует выходные сигналы LS' и RS' в ответ на входные сигналы тыловых каналов (LS и RS) путем выполнения сжатия динамического диапазона на входных сигналах LS и RS на этапе 41, декорреляции выходного сигнала этапа 41 на этапе 42, преобразования выходного сигнала этапа 42 в соответствии с функцией моделирования восприятия звука (HRTF) на этапе 43 и выполнения подавления перекрестных помех на выходном сигнале этапа 43 на этапе 44, выходными сигналами которого являются сигналы LS' и RS'.
В вариантах осуществления настоящего изобретения, где физические акустические системы реализованы в виде наушников, подавление перекрестных помех, как правило, не требуется. Такие варианты осуществления изобретения могут быть реализованы изменениями системы по фиг.3, в которых этап 44 опущен.
Этап 43 HRTF применяет HRTF, включающую две передаточные функции, HRTFipsi(t) и HRTFcontra(t), к выходному сигналу этапа 42 так, как описано ниже. В ответ на декоррелированный левый тыловой входной сигнал L(t) из этапа 42 (идентифицированный на фиг.5 как «LS2»), этап 43 генерирует звуковые сигналы xLL(t) и xLR(t), путем следующего применения передаточных функций: HRTFipsi(t)L(t)=xLL(t), где xLL(t) - звук, слышимый левым ухом слушателя (попадающий в левое ухо слушателя), в ответ на входной сигнал L(t), и HRTFcontra(t)=L(t)=xLR(t), где xLR(t) - звук, слышимый правым ухом слушателя (попадающий в правое ухо слушателя), в ответ на входной сигнал L(t). Сходным образом, в ответ на декоррелированный правый тыловой входной сигнал R(t) из этапа 42 (идентифицируемый на фиг.5 как "RS2"), этап 43 генерирует звуковые сигналы xLR(t) и xRR(t) путем следующего применения передаточных функций: HRTFipsi(t)R(t)=xRL(t), где xRL(t) - звук, слышимый левым ухом слушателя в ответ на входной сигнал R(t), и HRTFcontra(t)R(t)=xRR(t), где xRR(t) - звук, слышимый правым ухом слушателя в ответ на входной сигнал R(t). Таким образом, HRTFipsi(t) представляет собой ипсилатеральный фильтр для уха, ближайшего к акустической системе (которая на этапе 43 является виртуальной акустической системой), а HRTFcontra(t) - контралатеральный фильтр для уха, удаленного от акустической системы (которая на этапе 43 также является виртуальной акустической системой). Этап 43 применяет HRTFipsi(t) к L(t) для генерирования звука, который будет испускаться из левой передней акустической системы и восприниматься левым ухом как звук L(t) из виртуальной левой тыловой акустической системы, и применяет HRTFcontra(t) к L(t) для генерирования звука, который будет испускаться из правой передней акустической системы и восприниматься правым ухом как звук L(t) из виртуальной левой тыловой акустической системы. Этап 43 применяет HRTFipsi(t) к R(t) для генерирования звука, который будет испускаться из правой передней акустической системы и восприниматься правым ухом как звук L(t) из виртуальной правой тыловой акустической системы, и применяет HRTFcontra(t) к R(t) для генерирования звука, который будет испускаться из правой передней акустической системы и восприниматься левым ухом как звук L(t) из виртуальной правой тыловой акустической системы.
Предпочтительно, этап HRTF 43 реализует модель HRTF, которая является простой и настраиваемой для любых положений источников (и, необязательно, также и для любых положений физических акустических систем) относительно каждого из ушей слушателя. Например, этап 43 может реализовывать модель HRTF, которая относится к типу, описанному в статье Brown, P., Duda, R., "A Structural Model for Binaural Sound Synthesis," IEEE Transactions on Speech and Audio Processing, September 1998, Vol.6, No.5, pp.476-488. Несмотря на то, что в этой модели есть недостаток некоторых тонких особенностей фактически измеряемой HRTF, она обладает рядом важных преимуществ, которые включают простоту ее реализации, настраиваемость для любого положения и, таким образом, большую универсальность, чем в случае измеряемой HRTF. В типичных реализациях, для вычисления обобщенных передаточных функций HRTFipsi(t) и HRTFcontra(t), применяемых на этапе 43, используется та же модель HRTF, что и для вычисления передаточных функций HRTFTTF и HRTFEQF (которые будут описаны ниже), применяемых на этапе 44 для выполнения подавления перекрестных помех на выходных сигналах этапа 43 при заданном ряде положений физических акустических систем. HRTF, применяемая на этапе 43, предполагает определенные углы виртуальных тыловых акустических систем; функции HRTF, применяемые на этапе 44, предполагают определенные углы физических передних громкоговорителей по отношению к слушателю.
Этап 41 реализует сжатие динамического диапазона, обеспечивающее хорошую слышимость левого окружающего и правого окружающего тыловых каналов в присутствии других каналов слушателем, который слушает выходные сигналы, воспроизводимые виртуализатором по фиг.3. Этап 41 способствует выводу низкоуровневых виртуальных каналов, которые в обычных условиях маскируются другими каналами, в результате чего содержимое тылового окружающего звука слышится чаще и более надежно, чем в отсутствие сжатия динамического диапазона. Этап 41 способствует нормализации воспринимаемой громкости виртуальных тыловых каналов путем усиления (окружающих) входных сигналов тыловых источников LS и RS нелинейно относительно входных сигналов передних каналов L, R и С.Точнее, в ответ на определение того, что входной окружающий сигнал LS не превышает заранее заданное пороговое значение, входной сигнал LS усиливается (нелинейно) относительно входных сигналов передних каналов (к сигналу LS применяется больший коэффициент усиления, чем к входным сигналам передних каналов), а в ответ на определение того, что входной сигнал RS не превышает заранее заданное пороговое значение, входной сигнал RS усиливается (нелинейно) относительно входных сигналов передних каналов (к сигналу RS применяется больший коэффициент усиления, чем к входным сигналам передних каналов). Предпочтительно, входные сигналы LS и RS, не превышающие пороговое значение, усиливаются нелинейно в зависимости от величины (если она имеет место), на которую каждый из них ниже порогового значения. Выходной сигнал этапа 41 затем претерпевает декорреляцию на этапе 42.
Если хотя бы один из входных сигналов LS и RS превышает пороговое значение, то он не усиливается выше величины входных передних сигналов. Точнее, этап 41 усиливает каждый из сигналов LS и RS, превышающий пороговое значение на величину, которая зависит от заранее заданного коэффициента сжатия, который, как правило, имеет то же значение, что и коэффициент сжатия, в соответствии с которым усиливаются входные передние сигналы (посредством усилителя G и других средств усиления, которые не показаны). Если коэффициент сжатия представляет собой соотношение N:1, то уровень усиленного сигнала в дБ составляет N·I, где I - уровень входного сигнала в дБ. Как правило, осуществляется широкополосная реализация этапа 41 (для усиления всех, или широкого диапазона, частотных составляющих входных сигналов LS и RS), однако, в альтернативном варианте, могут задействоваться многополосные реализации (для усиления частотных составляющих входных сигналов только в определенных полосах частот, или усиление частотных составляющих входных сигналов по-разному в разных полосах частот). Коэффициент сжатия и пороговое значение выбираются способом, который известен средним специалистам в данной области, так, чтобы этап 41 делал типичное, низкоуровневое содержимое окружающего звука четко слышимым (в смешанном выходном звуковом сигнале, определяемом выходным сигналом виртуализатора по фиг.3).
Фиг.4 представляет собой блок-схему типичной реализации этапа 41, который включает элемент 70 определения среднеквадратичной мощности (RMS), элемент 71 определения плавности, элемент 72 вычисления коэффициента усиления и элементы 73 и 74 усиления, соединенные так, как показано на фиг.4. В данной реализации, средний уровень (средняя громкость, усредненная по интервалу времени, т.е. по заранее заданному временному окну) каждого входного LS и RS определяется в элементе 70, а плавность выходного сигнала этапа 41 (быстрота, с которой элемент 72 вычисления коэффициента усиления изменяет коэффициент усиления, применяемый усилителями 73 и 74 к каждому входному сигналу в ответ на каждое увеличение и уменьшение среднего уровня входного сигнала) определяется элементом 71 в ответ на средние уровни входных сигналов и коэффициент усиления, применяемый к каждому входному сигналу. Типичное время нарастания (постоянная времени отклика на увеличение уровня входного сигнала) составляет 1 мс, а типичное время затухания (постоянная времени отклика на уменьшение уровня входного сигнала) составляет 250 мс. Элемент 72 вычисления коэффициента усиления определяет величину коэффициента усиления, который применяется усилителем 73 к входному сигналу LS (для генерирования усиленного выходного сигнала LS1) в зависимости от величины, на которую текущий средний уровень LS превышает или не превышает пороговое значение (и от текущего времени нарастания и времени затухания), а также величину коэффициента усиления, применяемого усилителем 74 к входному сигналу RS (для генерирования усиленного выходного сигнала RSQ в зависимости от величины, на которую текущий средний уровень RS превышает или не превышает пороговое значение (и от текущего времени нарастания и времени затухания). Типичное пороговое значение составляет 50% полной шкалы, а типичный коэффициент сжатия составляет 2:1 для усиления каждого входного сигнала, когда его уровень выше порогового значения.
В типичных реализациях сжатие динамического диапазона на этапе 41 усиливает тыловые входные каналы на несколько децибел относительно передних входных каналов для того, чтобы помочь выделить виртуальные тыловые каналы в смешанном выходном звуковом сигнале в тех случаях, когда их уровни достаточно низки для того, чтобы сделать желательным их выделение (т.е. когда тыловые входные сигналы не превышают заранее заданное пороговое значение), избегая при этом избыточного усиления виртуальных тыловых каналов тогда, когда входные сигналы тыловых каналов превышают пороговое значение (во избежание восприятия виртуальных тыловых акустических систем как чрезмерно громких).
Этап 42 декоррелирует левый и правый выходные сигналы этапа 41, обеспечивая улучшенную локализацию и препятствуя возникновению трудностей, которые могут быть связаны с симметрией (по отношению к слушателю) физических акустических систем, которые представляют виртуальные каналы, определяемые выходным сигналом виртуализатора по фиг.3. В отсутствие такой декорреляции, если физические громкоговорители (перед слушателем) располагаются симметрично по отношению к слушателю, то воспринимаемые положения виртуальных акустических систем также симметричны по отношению к слушателю. При такой симметрии и в отсутствие декорреляции, если оба виртуальных тыловых канала (являющихся признаками тыловых входных сигналов LS и RS) идентичны, воспроизводимые сигналы на обоих ушах также будут идентичными, и тыловые источники больше не будут являться виртуализированными (слушатель не будет воспринимать воспроизводимый звук как звук, испускаемый источниками позади слушателя). Кроме того, при такой симметрии в отсутствие декорреляции воспроизодимый выходной сигнал виртуализатора в ответ на панорамирование входного сигнала тылового источника (входного сигнала, являющегося признаком звука, панорамированного от левого окружающего тылового источника к правому окружающему тыловому источнику) в середине панорамирования будет казаться приходящим непосредственно спереди (между физическими передними акустическими системами). Этап 42 позволяет избежать этих трудностей (обычно называемых «коллапсом изображения») путем декорреляции левого и правого выходных сигналов этапа 41 в случае, когда они идентичны друг другу, устраняя общность между ними и, таким образом, позволяя избежать коллапса изображения.
На этапе декорреляции 42 для декорреляции двух выходных сигналов этапа 41 используются дополнительные декорреляторы (по одному декоррелятору на каждый из сигналов LS1 и RS1). Каждый декоррелятор, предпочтительно, реализуется как ревербератор Шредера, пропускающий все частоты, относящийся к типу, описанному в статье Schroeder, M. R., "Natural Sounding Artificial Reverberation," Journal of the Audio Engineering Society, July 1962, vol.10, No.3, pp.219-223. В тех случаях, когда активен только один входной канал, этап 42 не вносит в его входной сигнал никакого заметного изменения тембра. Когда активны оба входных канала, и источники каждого канала идентичны, этап 42 вносит изменение тембра, но его действие таково, что стереоизображение становится широким, а не панорамированное в центр.
Фигура 5 представляет собой блок-схему типичной реализации этапа 42 в виде пары ревербераторов Шредера, пропускающих все частоты. Один из ревербераторов в реализации по фиг.5 представляет собой контур обратной связи, включающий элемент 80 сложения входного сигнала, который содержит вход, подключенный для приема левого входного сигнала LS1 из этапа 41, выходной сигнал которого направляется к элементу 83 задержки, применяющему к нему задержку τ, и к усилителю 81, применяющему к нему коэффициент усиления G. Выходной сигнал этого усилителя направляется к элементу 82 сложения выходного сигнала (к которому также направляется выходной сигнал элемента 83 задержки), который выводит левый сигнал LS2. Выходной сигнал элемента 83 задержки направляется к другому усилителю 84, который применяет к нему коэффициент усиления G-1, и выходной сигнал усилителя 84 направляется ко второму входу элемента 80 сложения входного сигнала. Второй ревербератор в реализации этапа 42 по фиг.5 представляет собой контур обратной связи, включающий элемент 90 сложения входного сигнала, который содержит вход, подключенный для приема правого входного сигнала RS1 из этапа 41, выходной сигнал которого направляется к элементу 93 задержки, который применяет к нему задержку τ, и к усилителю 91, который применяет к нему коэффициент усиления -G. Выходной сигнал усилителя 91 направляется к элементу 92 сложения выходного сигнала (к которому также направляется выходной сигнал элемента 93 задержки), который выводит правый сигнал RS2 (сигнал RS2 декоррелирован с сигналом LS2). Выходной сигнал элемента 93 задержки направляется ко второму усилителю 94, который применяет к нему коэффициент усиления 1-G, а выходной сигнал усилителя 94 направляется ко второму входу элемента 90 сложения входного сигнала. Типичное значение параметра усиления G=0,5, типичное значение времени задержки τ=2 мс.
В других реализациях этап 42 представляет собой декоррелятор. относящийся к иному типу, чем декоррелятор, описанный с отсылкой к фиг.5.
В типичной реализации, этап 43 бинауральной модели включает две схемы HRTF, относящиеся к типу, показанному на фиг.6: одна подключается для фильтрации левого сигнала LS2 из этапа 42; вторая - для фильтрации правого сигнала RS2 из этапа 42. Как видно на фиг.6, каждая схема HRTF применяет две передаточные функции, HRTFipsi(z) и HRTFcontra(z), к выходному сигналу этапа 42, как изложено ниже (где «z» - значение дискретного временного интервала сигнала, подверженного фильтрации). Каждая из передаточных функций, HRTFipsi(z) и HRTFcontra(z), реализует простую однополюсную двоичную сферическую модель восприятия звука, относящуюся к типу, описанному в процитированной выше статье Brown и др., "A Structural Model for Binaural Sound Synthesis," IEEE Transactions on Speech and Audio Processing, September 1998.
Точнее, каждая схема HRTF этапа 43 (реализованная, как описано на фиг.6) применяет две передаточные функции, HRTFipsi(z) («Hipsi(z)») и HRTFcontra(z) («Hcontra(z)»), к каждому выходному сигналу этапа 42 (сигналу, отмеченному на фиг.6 как «IN») в дискретном временном интервале, как описано ниже. В ответ на левый тыловой входной сигнал L2(z) этапа 42, одна схема HRTF генерирует звуковые сигналы xLL(z) («OUTIpsi» на фиг.6) и xLR(z) («OUTContra» на фиг.6) путем следующего применения передаточных функций: HRTFipsi(z)L2(z)=xLL(z), где xLL(z) - звук, слышимый левом ухом слушателя в ответ на входной сигнал L2(z), и HRTFcontra(z)L2(z)=xLL(z), где xLR(z) - звук, слышимый правым ухом слушателя в ответ на входной сигнал L2(z). В ответ на правый тыловой входной сигнал R2(z) этапа 42 вторая схема HRTF на этапе 43 (реализованная, как показано на фиг.6) генерирует звуковые сигналы xRL(z) и xRR(z), путем следующего применения передаточных функций: HRTFcontra(z)R2(z)=xRL(z), где xRL(z) - звук, слышимый левым ухом слушателя в ответ на входной сигнал R2(z), и HRTFipsi(z)R2(z)=xRR(z), где xRR(z) - звук, слышимый правым ухом слушателя в ответ на входной сигнал R2(z). HRTFipsi(z) представляет собой ипсилатеральный фильтр для уха, ближайшего к акустической системе (которая на этапе 43 является виртуальной акустической системой), а HRTFcontra(z) является контралатеральным фильтром для уха, удаленного от акустической системы (которая на этапе 43 также является виртуальной акустической системой). Виртуальные акустические системы устанавливаются под углом, приблизительно, ±90°. Временные задержки z-n (реализуемые каждым из элементов задержки, которые на фиг.6 обозначены как z-n) так же, как и обычно, соответствуют 90°.
Схема HRTF этапа 43 (реализованная, как показано на фиг.6) для применения передаточной функции HRTFipsi(z) включает элемент 103 задержки, элементы 101, 104 и 105 усиления (для применения определяемых ниже коэффициентов усиления, bi0, bi1 и a i1 соответственно) и элементы 100 и 102 сложения, подключенные так, как показано на фиг.6. Схема HRTF этапа 43 (реализованная, как показано на фиг.6) для применения передаточной функции HRTFcontra(z) включает элементы 106 и 113 задержки, элементы 111, 114 и 115 усиления (для применения определяемых ниже коэффициентов усиления bc0, bc1 и a c1 соответственно) и элементы сложения 110 и 112, подключенные так, как показано на фиг.6.
Интерауральная временная задержка (ITD), реализуемая на этапе 43 (реализованном так, как показано на фиг.6), представляет собой задержку, которая вводится каждым элементом задержки, обозначаемым «z-n». Интерауральная временная задержка для горизонтальной плоскости получается следующим образом:
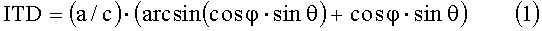
где θ - азимутальный угол, φ - угол возвышения, a - радиус головы слушателя, c - скорость звука. Следует отметить, что, для вычисления ITD, углы в уравнении (1) выражаются в радианах (а не в градусах). Также следует отметить, что θ=0 радиан (0°) - это прямо, а θ=π/2 (90°) - это строго направо.
Для φ=0 (горизонтальная плоскость):
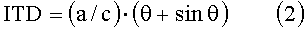
где θ находится в диапазоне 0-π/2 включительно.
В непрерывном временном интервале модель HRTF, реализуемая фильтром по фиг.6, выражается следующим образом:
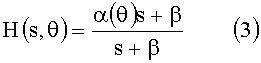
где α(θ)=1+cos(θ) и 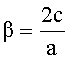
Для преобразования этой модели HRTF к дискретному временному интервалу (где z - это значение дискретного временного интервала входного сигнала) используется билинейное преобразование:
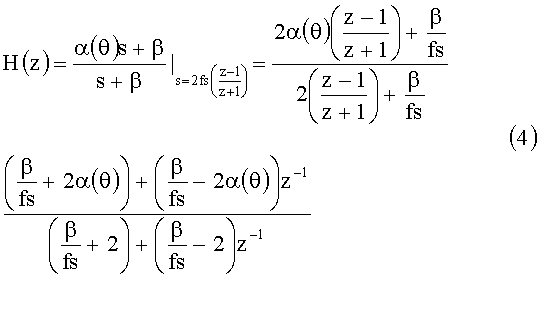
Если параметр β из уравнения (4) доопределить как
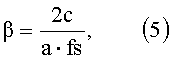
где fs - частота дискретизации, то, следовательно,
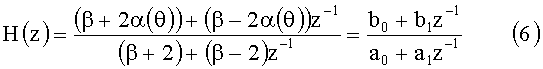
Фильтр согласно уравнению (6) предназначен для звука, попадающего в одно ухо слушателя. Для двух ушей (ближнего и дальнего по отношению к источнику), ипсилатеральный и контралатеральный фильтры по фиг.6 определяются из уравнения (6) следующим образом:
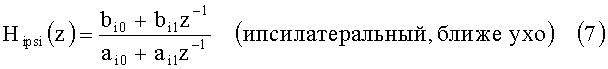
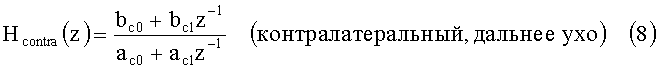
где
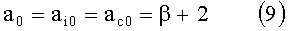
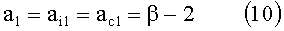
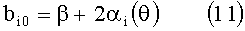
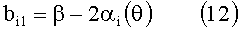
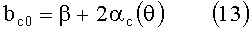
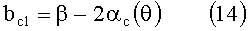
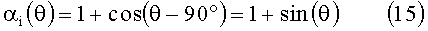
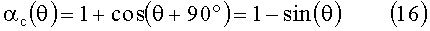
В альтернативных вариантах осуществления изобретения, каждая применяемая HRTF (или каждая HRTF из подмножества применяемых HRTF), которая применяется в соответствии с изобретением, определяется и применяется в частотной области (например, каждый сигнал, подвергаемый преобразованию в соответствии с указанными HRTF, подвергается преобразованию из временного интервала к частотной области, затем к результирующим частотным составляющим применяется HRFT, и преобразованные составляющие затем подвергаются преобразованию от частотной области к временному интервалу).
Фильтрованный выходной сигнал этапа 43 подвергается подавлению перекрестных помех на этапе 44. Подавление перекрестных помех является традиционной операцией. Например, реализация подавления перекрестных помех в виртуализаторе окружающего звука описана в патенте США №6449368, переуступленном Dolby Laboratories Licensing Corporation, с отсылкой к фиг.4А этого патента.
Этап 44 подавления перекрестных помех в варианте осуществления изобретения по фиг.3 фильтрует выходной сигнал этапа 43, применяя для этого две передаточные функции HITF (фильтры 52 и 53, подключенные так, как показано на фиг.3) и две передаточные функции HEQF (фильтры 50 и 51, подключенные так, как показано на фиг.3). Каждая передаточная функция HITF и HEQF реализует ту же однополюсную двоичную сферическую модель восприятия звука, что и модель, описанная в процитированной выше статье Brown и др. ("А Structural Model for Binaural Sound Synthesis," IEEE Transactions on Speech and Audio Processing, September 1998) и реализуемая передаточными функциями HRTFipsi(z) и HRTFcontra(z) на этапе 43.
На этапе 44 варианта осуществления изобретения по фиг.3 временная задержка z-m применяется к выходному сигналу фильтра 52 HITF посредством элемента 55 задержки по фигуре 7, комбинируется с выходными сигналами xLL(z) и xRL(z) этапа 43 в элементе сложения, и выходной сигнал этого элемента сложения преобразовывется в фильтре 50 HETF. Временная задержка z-m также применяется к выходному сигналу фильтра 53 HITF посредством элемента 56 задержки по фигуре 7, комбинируется с выходными сигналами xLR(z) и zRR(z) этапа 43 во втором элементе сложения, и выходной сигнал второго элемента сложения преобразуется в фильтре 51 HETF. Выходной сигнал xLL(z) этапа 43 преобразуется в фильтре 52 HITF, а выходной сигнал xRR(z) этапа 43 преобразуется в фильтре 53 HITF. В фильтрах 50, 51, 52, и 53 углы акустических систем устанавливаются в положения физических акустических систем. Задержки (z-m) определяются соответствующими углами.
Фильтр перекрестных помех и фильтры выравнивания HITF и HETF имеют следующую форму:
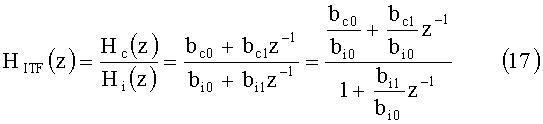
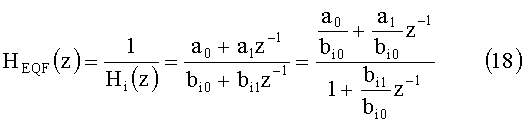
где a и b - те же параметры, что и в вышеприведенных уравнениях (9)-(16).
Если сумма сигналов, входящих в элемент 30 (или 31) по фиг.3 больше максимально допустимого уровня, может возникнуть клиппирование. Однако, во избежание подобной отсечки, используется лимитер 32 по фиг.3. Левый окружающий выходной сигнал LS' этапа 44 комбинируется с усиленным входным сигналом центрального канала С и левым передним входным сигналом L в элементе сложения левого канала 30, и выходной сигнал элемента 30 подвергается ограничению в лимитере 32 так, как показано на фиг.3. Правый окружающий выходной сигнал RS' этапа 44 комбинируется с усиленным входным сигналом центрального канала С и правым передним входным сигналом R в элементе сложения правого канала 31, и выходной сигнал элемента 31 также подвергается ограничению в лимитере 32 так, как показано на фиг.3. В ответ на неограниченный левый выходной сигнал элемента 30, лимитер 32 генерирует левый выходной сигнал (L'), который направляется к левой передней акустической системе. В ответ на неограниченный левый выходной сигнал элемента 31, лимитер 32 генерирует правый выходной сигнал (R'), который направляется к правой передней акустической системе.
Лимитер по фиг.3 может быть реализован так, как показано на фиг.8. Лимитер 32 по фиг.8 имеет ту же конструкцию, что и на этапе 41 реализации сжатия динамического диапазона, и включает элемент 170 определения среднеквадратичной мощности, элемент 171 определения плавности, элемент 172 вычисления коэффициента усиления и элементы 173, 174 усиления, подключенные так, как показано на фиг.3. Вместо поднятия низких уровней входных сигналов, элементы усиления 173, 174 лимитера 32 снижают максимальные уровни входных сигналов (когда уровень хотя бы одного из входных сигналов превышает заранее заданное пороговое значение). Типичные время нарастания и время затухания для лимитера 32 по фиг.8 составляют 22 мс и 50 мс соответственно. Типичная величина заранее определенного порогового значения, используемая в лимитере 32 составляет 25% полной шкалы, а типичный коэффициент сжатия составляет 2: 1 для усиления каждого входного сигнала, когда его уровень превышает пороговое значение.
В некоторых вариантах осуществления изобретения, система виртуализатора согласно изобретению представляет собой или включает в себя универсальный процессор, подключенный для приема или генерирования входных данных, являющихся признаками нескольких звуковых входных каналов, и программируемый посредством программного обеспечения (или встроенного программного обеспечения) и/или иначе конфигурируемый (например, в ответ на управляющие данные) для выполнения одной или ряда операций на входных данных, включая вариант осуществления способа изобретения. Указанный универсальный процессор, как правило, может подключаться к устройству ввода (например, к мыши и/или клавиатуре), памяти или устройству отображения. Например, система по фиг.3 может быть реализована в универсальном процессоре, где входные данные С, L, R, LS и RS представляют собой данные, являющиеся признаками центрального, левого переднего, правого переднего, левого тылового и правого тылового звуковых входных каналов, а выходные данные L' и R' представляют собой выходные данные, являющиеся признаками выходных звуковых сигналов. Традиционный цифроаналоговый преобразователь (DAC) может действовать на эти выходные данные и генерировать аналоговые версии выходных звуковых сигналов, предназначенные для воспроизведения парой физических передних акустических систем.
Фигура 9 представляет собой блок-схему системы 20 виртуализатора, которая является программируемым DSP для обработки звука, сконфигурированным для выполнения варианта осуществления способа изобретения. Система 20 включает программируемую схему 22 DSP (подсистему виртуализатора системы 20), подключенную для приема входных звуковых сигналов, являющихся признаками звука из нескольких положений источников, включающих, по меньшей мере, два тыловых положения (например, пяти звуковых сигналов С, L, LS RS и R, как показано на фиг.3). Схема 22 конфигурируется в ответ на управляющие данные интерфейса 21 устройства управления для выполнения варианта осуществления способа изобретения с целью генерирования левого и правого каналов выходных звуковых сигналов L' и R' и их воспроизведения парой физических акустических систем в ответ на входные звуковые сигналы. Для программирования системы 20 к интерфейсу 21 устройства управления направляется надлежащее программное обеспечение, а интерфейс 21 направляет надлежащие управляющие данные к схеме 22 для выполнения способа изобретения.
В ходе работы, DSP для обработки звука, сконфигурированный для выполнения виртуализации окружающего звука в соответствии с изобретением (например, система 20 виртуализатора по фиг.9), подключается для приема нескольких входных звуковых сигналов (являющихся признаками звука из нескольких положений источников, включающих, по меньшей мере, два тыловых положения) и DSP, как правило, выполняет ряд операций на входных звуковых сигналах помимо и в дополнение к виртуализации. В соответствии с различными вариантами осуществления изобретения, DSP для обработки звука становится пригодным для выполнения одного из вариантов осуществления способа изобретения после конфигурирования (например, программирования) с целью генерирования выходных звуковых сигналов (для их воспроизведения парой физических акустических систем) в ответ на входные звуковые сигналы путем выполнения способа на входных звуковых сигналах.
Несмотря на то, что в данном раскрытии описаны некоторые варианты осуществления настоящего изобретения и применения изобретения, средние специалисты в данной области должны понимать, что возможно множество изменений описанных здесь вариантов осуществления изобретения и применений изобретения без отступления от объема изобретения, описанного и заявленного в данном раскрытии. Следует понимать, что, несмотря на то, что были показаны и описаны некоторые варианты изобретения, изобретение не ограничивается описанными конкретными вариантами осуществления изобретения или описанными конкретными способами.
Способ и система генерирования выходных сигналов, предназначенных для воспроизведения двумя физическими акустическими системами в ответ на входные звуковые сигналы, являющиеся признаками звука из ряда положений источников, включающих, по меньшей мере, два тыловых положения. Как правило, входные сигналы являются признаками звука из трех передних положений и двух тыловых положений (левого и правого окружающих источников). Виртуализатор генерирует левый и правый окружающие выходные сигналы, пригодные для приведения передних громкоговорителей в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из тыловых источников. Как правило, виртуализатор генерирует левый и правый выходные сигналы путем преобразования входных сигналов тыловых источников в соответствии с функцией моделирования восприятия звука. Для обеспечения хорошей слышимости указанных виртуальных каналов в присутствии других каналов виртуализатор выполняет сжатие динамического диапазона на входных сигналах тыловых источников. Сжатие динамического диапазона, предпочтительно, осуществляется путем усиления входных сигналов тыловых источников, или их частично обработанных версий, нелинейно относительно входных сигналов передних источников. Технический результат - выделение виртуальных источников, избегая при этом придания избыточного значения виртуальным каналам. 2 н. и 32 з.п. ф-лы, 9 ил.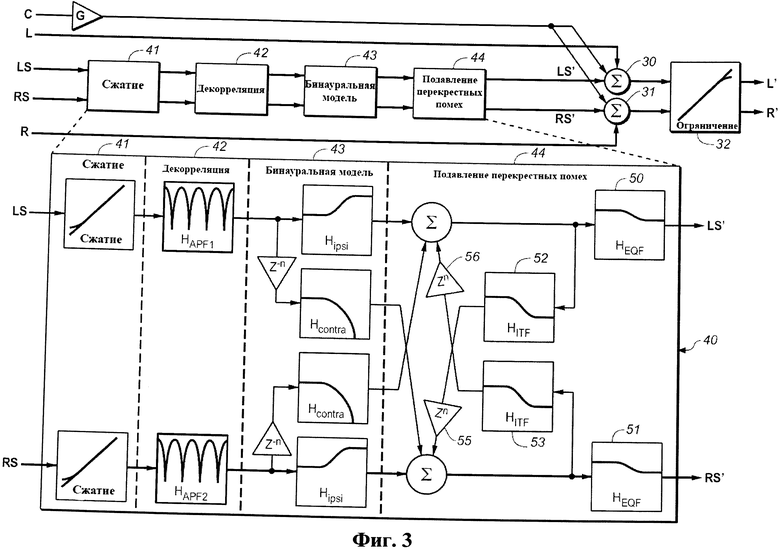
1. Способ виртуализации окружающего звука для получения выходных сигналов с целью их воспроизведения парой физических акустических систем, находящихся в определенных физических положениях по отношению к слушателю, где ни одно из физических положений не является положением из ряда положений тыловых источников, где указанный способ включает следующие этапы, на которых
(a) в ответ на входные звуковые сигналы, являющиеся признаками звука из положений тыловых источников, генерируют окружающие сигналы, пригодные для приведения акустических систем в определенных физических положениях в состояние испускания звука, воспринимаемого слушателем как звук, испускаемый из указанных положений тыловых источников, которое заключается в сжатии динамического диапазона на входных звуковых сигналах; и
(b) генерируют выходные сигналы в ответ на окружающие сигналы и, по меньшей мере, еще один входной звуковой сигнал, где каждый указанный еще один входной звуковой сигнал является признаком звука из соответствующего положения переднего источника, так, чтобы выходные сигналы были пригодны для приведения акустических систем в определенных физических положениях в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из положений тыловых источников и из каждого указанного положения переднего источника.
2. Способ по п.1, отличающийся тем, что сжатие динамического диапазона выполняют путем нелинейного усиления входных звуковых сигналов.
3. Способ по п.1, отличающийся тем, что этап (а) включает этап выполнения сжатия динамического диапазона, включающий усиление каждого из входящих звуковых сигналов, который имеет уровень, не превышающий заранее заданное пороговое значение, нелинейно в зависимости от величины, на которую этот уровень меньше порогового значения.
4. Способ по п.3, отличающийся тем, что уровень представляет собой средний, по временному окну, уровень указанного каждого из входных звуковых сигналов.
5. Способ по п.1, отличающийся тем, что сжатие динамического диапазона обеспечивает улучшенную локализацию звука из положений тыловых источников относительно звука из, по меньшей мере, одного указанного положения переднего источника, в ходе воспроизведения выходных сигналов акустическими системами, находящимися в определенных физических положениях.
6. Способ по п.1, отличающийся тем, что физические акустические системы представляют собой передние громкоговорители, находящиеся в определенных физических положениях перед слушателем, и этап (а) включает этап генерирования левого и правого окружающих сигналов в ответ на левый и правый тыловые входные сигналы.
7. Способ по п.6, отличающийся тем, что этап (b) включает этап генерирования выходных сигналов в ответ на окружающие сигналы и в ответ на левый входной звуковой сигнал, являющийся признаком звука из положения левого переднего источника, правый входной звуковой сигнал, являющийся признаком звука из положения правого переднего источника, и центрального входного звукового сигнала, являющегося признаком звука из положения центрального переднего источника.
8. Способ по п.7, отличающийся тем, что этап (b) включает этап генерирования фантомного центрального канала в ответ на центральный входной звуковой сигнал.
9. Способ по п.7, отличающийся тем, что сжатие динамического диапазона обеспечивает улучшенную локализацию звука из положений тыловых источников относительно звука из, по меньшей мере, одного указанного положения переднего источника, в ходе воспроизведения выходных сигналов акустическими системами, находящимися в определенных физических положениях.
10. Способ по п.7, отличающийся тем, что сжатие динамического диапазона выполняют путем нелинейного усиления входных звуковых сигналов.
11. Способ по п.7, отличающийся тем, что этап (а) включает этап выполнения сжатия динамического диапазона, включающий усиление каждого из входных звуковых сигналов, который имеет уровень, не превышающий заранее заданное пороговое значение, нелинейно в зависимости от величины, на которую этот уровень меньше порогового значения.
12. Способ по п.1, отличающийся тем, что этап (а) включает этап генерирования окружающих сигналов, который включает преобразование входных звуковых сигналов в соответствии с функцией моделирования восприятия звука.
13. Способ по п.12, отличающийся тем, что входные звуковые сигналы представляют собой левый тыловой входной сигнал, являющийся признаком звука из левого тылового источника, и правый тыловой входной сигнал, являющийся признаком звука из правого тылового источника, и этап (а) включает следующие этапы, на которых
преобразовывают левый тыловой входной сигнал в соответствии с функцией моделирования восприятия звука для генерирования первого виртуализированного звукового сигнала, являющегося признаком звука из левого тылового источника, как попадающего в левое ухо слушателя, и второго виртуализированного звукового сигнала, являющегося признаком звука из левого тылового источника, как попадающего в правое ухо слушателя; и
преобразовывают правый тыловой входной сигнал в соответствии с функцией моделирования восприятия звука для генерирования третьего виртуализированного звукового сигнала, являющегося признаком звука из правого тылового источника, как попадающего в левое ухо слушателя, и четвертого виртуализированного звукового сигнала, являющегося признаком звука из правого тылового источника, как попадающего в правое ухо слушателя.
14. Способ по п.1, отличающийся тем, что этап (а) включает этап генерирования окружающих сигналов, который включает выполнение декорреляции на входных звуковых сигналах.
15. Способ по п.1, отличающийся тем, что этап (а) включает этап генерирования окружающих сигналов, который включает выполнение подавления перекрестных помех на входных звуковых сигналах.
16. Способ по п.1, отличающийся тем, что физические громкоговорители представляют собой наушники, и этап (а) выполняют без выполнения подавления перекрестных помех на входных звуковых сигналах.
17. Способ по п.1, отличающийся тем, что этап (а) включает следующие этапы, на которых
выполняют сжатие динамического диапазона на входных звуковых сигналах с целью генерирования сжатых звуковых сигналов;
выполняют декорреляцию на сжатых звуковых сигналах с целью генерирования декоррелированных звуковых сигналов;
преобразуют декоррелированные звуковые сигналы в соответствии с функцией моделирования восприятия звука с целью генерирования виртуализированных звуковых сигналов; и
выполняют подавления перекрестных помех на виртуализированных звуковых сигналах с целью генерирования окружающих сигналов.
18. Система виртуализации окружающего звука, сконфигурированная для получения выходных сигналов с целью их воспроизведения парой физических акустических систем, находящихся в определенных физических положениях по отношению к слушателю, отличающаяся тем, что ни одно из физических положений не является положением из ряда положений тыловых источников, содержащая
подсистему виртуализатора окружающего звука, подключенную и сконфигурированную для генерирования окружающих сигналов в ответ на входные звуковые сигналы, которое заключается в выполнении сжатия динамического диапазона на входных звуковых сигналах, где входные звуковые сигналы являются признаками звука из положений тыловых источников, а окружающие сигналы пригодны для приведения акустических систем в определенных физических положениях в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из указанных положений тыловых источников; и
вторую подсистему, подключенную и сконфигурированную для генерирования выходных сигналов в ответ на окружающие сигналы и, по меньшей мере, еще одного входного звукового сигнала, где каждый указанный еще один входной звуковой сигнал является признаком звука из соответствующего положения переднего источника, так, чтобы выходные сигналы были пригодны для приведения акустических систем, находящихся в определенных физических положениях, в состояние испускания звука, который слушатель воспринимает как звук, испускаемый из положений тыловых источников и из каждого указанного положения переднего источника.
19. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для выполнения сжатия динамического диапазона путем нелинейного усиления входных звуковых сигналов.
20. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для выполнения сжатия динамического диапазона, которое заключается в усилении каждого из входных звуковых сигналов, имеющего уровень, который не превышает заранее заданное пороговое значение, нелинейно в зависимости от величины, на которую этот уровень меньше порогового значения.
21. Система по п.18, отличающаяся тем, что указанная система представляет собой цифровой процессор для обработки звука, причем подсистема виртуализатора сигналов окружающего звука подключена для приема входных звуковых сигналов, вторая подсистема подключена к подсистеме виртуализатора звуковых сигналов для приема окружающих сигналов, и вторая подсистема подключена для приема каждого указанного еще одного входного звукового сигнала.
22. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для выполнения сжатия динамического диапазона таким образом, чтобы указанное сжатие динамического диапазона обеспечивало улучшенную локализацию звука из положений тыловых источников относительно звука из, по меньшей мере, одного указанного положения переднего источника, в ходе воспроизведения выходных сигналов акустическими системами, находящимися в определенных физических положениях.
23. Система по п.18, отличающаяся тем, что физические акустические системы представляют собой передние громкоговорители, находящиеся в определенных физических положениях перед слушателем, входные звуковые сигналы представляют собой левый и правый тыловые входные сигналы, и подсистема виртуализатора окружающего звука сконфигурирована для генерирования левого и правого окружающих сигналов в ответ на левый и правый тыловые входные сигналы.
24. Система по п.23, отличающаяся тем, что вторая подсистема сконфигурирована для генерирования выходных сигналов в ответ на окружающие сигналы и в ответ на левый входной звуковой сигнал, являющийся признаком звука из положения левого переднего источника, правый входной звуковой сигнал, являющийся признаком звука из положения правого переднего источника, и центральный входной звуковой сигнал, являющийся признаком звука из положения центрального переднего источника.
25. Система по п.24, отличающаяся тем, что вторая подсистема сконфигурирована для генерирования фантомного центрального канала в ответ на центральный входной звуковой сигнал.
26. Система по п.24, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для выполнения сжатия динамического диапазона таким образом, чтобы указанное сжатие динамического диапазона обеспечивало улучшенную локализацию звука из положений тыловых источников относительно звука из, по меньшей мере, одного указанного положения переднего источника, в ходе воспроизведения выходных сигналов акустическими системами, находящимися в определенных физических положениях.
27. Система по п.24, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для выполнения сжатия динамического диапазона путем нелинейного усиления входных звуковых сигналов.
28. Система по п.24, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для выполнения сжатия динамического диапазона, которое заключается в усилении каждого из входных звуковых сигналов, имеющего уровень, который не превышает заранее заданное пороговое значение, нелинейно в зависимости от величины, на которую этот уровень меньше порогового значения.
29. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для генерирования окружающих сигналов, которое заключается в преобразовании входных звуковых сигналов в соответствии с функцией моделирования восприятия звука.
30. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для генерирования окружающих сигналов, которое заключается в выполнении декорреляции на входных звуковых сигналах.
31. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука сконфигурирована для генерирования окружающих сигналов, которое заключается в выполнении подавления перекрестных помех на входных звуковых сигналах.
32. Система по п.18, отличающаяся тем, что физические акустические системы представляют собой наушники, и подсистема виртуализатора окружающего звука сконфигурирована для генерирования окружающих сигналов без выполнения подавления перекрестных помех на входных звуковых сигналах.
33. Система по п.18, отличающаяся тем, что подсистема виртуализатора окружающего звука включает
этап сжатия, подключенный для приема входных звуковых сигналов и сконфигурированный для выполнения сжатия динамического диапазона на указанных входных звуковых сигналах с целью генерирования сжатых звуковых сигналов;
этап декорреляции, подключенный и сконфигурированный для выполнения декорреляции на сжатых звуковых сигналах с целью генерирования декоррелированных звуковых сигналов;
этап преобразования, подключенный и сконфигурированный для выполнения преобразования декоррелированных звуковых сигналов в соответствии с функцией моделирования восприятия звука с целью генерирования виртуализированных звуковых сигналов; и
этап подавления перекрестных помех, подключенный и сконфигурированный для выполнения подавления перекрестных помех на виртуализированных звуковых сигналах с целью генерирования окружающих сигналов.
34. Система по п.33, отличающаяся тем, что входные звуковые сигналы представляют собой левый тыловой входной сигнал, являющийся признаком звука из левого тылового источника, и правый тыловой входной сигнал, являющийся признаком звука из правого тылового источника, этап декорреляции сконфигурирован для генерирования левого декоррелированного звукового сигнала и правого декоррелированного звукового сигнала, этап преобразования сконфигурирован для преобразования левого декоррелированного звукового сигнала в соответствии с функцией моделирования восприятия звука для генерирования первого виртуализированного звукового сигнала, являющегося признаком звука из левого тылового источника, как попадающего в левое ухо слушателя, и второго виртуализированного звукового сигнала, являющегося признаком звука из левого тылового источника, как попадающего в правое ухо слушателя, и
этап преобразования сконфигурирован для преобразования правого декоррелированного звукового сигнала в соответствии с функцией моделирования восприятия звука для генерирования третьего виртуализированного звукового сигнала, являющегося признаком звука из правого тылового источника, как попадающего в правое ухо слушателя, и четвертого виртуализированного звукового сигнала, являющегося признаком звука из правого тылового источника, как попадающего в правое ухо слушателя.
| RU 2006117987 С2, 10.08.2009 | |||
| RU 2006122948/09 С2, 10.01.2008 | |||
| Устройство приема сигналов с частотным разделением каналов | 1988 |
|
SU1626410A1 |
| WO 2007110103 A1, 04.10.2007 | |||
| US 6449368 B1, 10.09.2002 | |||
| US 5471651 A, 28.11.1995. | |||

