Изобретение имеет отношение к способу и устройству для генерирования бинаурального звукового сигнала и, в частности, но не исключительно, к генерированию бинаурального звукового сигнала из моносигнала понижающего микширования.
В последнее десятилетие существует тенденция к использованию многоканального звукового, а именно пространственного звукового сигнала, простирающегося за рамки обычных стереосигналов. Например, традиционная стереозапись сигналов включает только два канала, тогда как современные передовые звуковые системы типично используют пять или шесть каналов, как, например, в популярных 5.1 системах объемного звучания. Это предусматривает более качественное прослушивание, когда пользователь может быть окружен источниками звука.
Были разработаны различные методы и стандарты для передачи таких многоканальных сигналов. Например, шесть дискретных каналов, представляющих 5.1 систему объемного звучания, могут быть переданы в соответствии со стандартами, такими как Перспективное Звуковое Кодирование (ААС) или Долби Цифровой.
Однако чтобы обеспечить обратную совместимость, используется понижающее микширование большего числа каналов до меньшего числа, а именно, часто используется понижающее микширование 5.1 сигнала объемного звучания до стереосигнала, позволяющее воспроизводить стереосигнал традиционными (стерео) декодерами, а 5.1 сигнал декодерами объемного звучания.
Один пример - это MPEG2 (MPEG - Экспертная группа по движущимся изображениям) метод обратного совместимого кодирования. Многоканальный сигнал понижающе микшируется в стереосигнал. Дополнительные сигналы кодируются во вспомогательную часть данных, что позволяет многоканальному декодеру MPEG2 создавать отображение многоканального сигнала. Декодер MPEG1 игнорирует вспомогательные данные и, таким образом, декодирует только понижающее стереомикширование.
Есть несколько параметров, которые могут использоваться, чтобы описать пространственные свойства звуковых сигналов. Один из таких параметров - межканальная взаимная корреляция, такая как взаимная корреляция между левым каналом и правым каналом для стереосигналов. Другой параметр - коэффициент мощности каналов. В так называемых (параметрических) пространственных звуковых кодерах эти и другие параметры извлекаются из оригинального звукового сигнала, чтобы произвести звуковой сигнал, имеющий уменьшенное число каналов, например, только один канал, плюс ряд параметров, описывающих пространственные свойства оригинального звукового сигнала. В так называемых (параметрических) пространственных звуковых декодерах восстанавливаются пространственные свойства, как описано переданными пространственными параметрами.
Размещение трехмерного источника звука в настоящее время приобретает интерес, особенно в области мобильной связи. Качество воспроизведения музыки и звуковые эффекты в мобильных играх могут существенно улучшаться, когда размещены в трехмерном пространстве, эффективно создавая трехмерный эффект «без головы». А именно, записываются и воспроизводятся бинауральные звуковые сигналы, которые содержат определенную направленную информацию, к которой чувствительно человеческое ухо. Бинауральная запись типично осуществляется при помощи двух микрофонов, установленных на макете человеческой головы так, чтобы записанный звук соответствовал звуку, улавливаемому человеческим ухом, и включал любые воздействия из-за формы головы и ушей. Бинауральная запись отличается от стереозаписи (то есть, стереофонической), так как воспроизведение бинауральной записи вообще предназначено для гарнитуры или наушников, тогда как стереозапись вообще осуществляется для воспроизведения громкоговорителями. В то время как бинауральная запись позволяет воспроизведение всей пространственной информации при использовании только двух каналов, стереозапись не обеспечила бы то же самое пространственное восприятие.
Регулярная двуканальная (стереофоническая) или многоканальная (например, 5.1) запись может быть преобразована в бинауральную запись посредством свертывания каждого одномерного сигнала с рядом перцепционных передаточных функций. Такие перцепционные передаточные функции моделируют влияние головы человека, и возможно, других объектов, на сигнал. Хорошо известный тип пространственной перцепционной передаточной функции - так называемая Функция Моделирования Восприятия Звука (HRTF). Альтернативным типом пространственной перцепционной передаточной функции, которая также принимает во внимание отражения сигнала от стен, потолка и пола комнаты, является Бинауральная Импульсная Характеристика Помещения (BRIR).
Как правило, трехмерные позиционные алгоритмы используют HRTFs (или BRIRs), которые описывают передачу от определенного положения источника звука до барабанных перепонок посредством импульсной характеристики. Трехмерное размещение источника звука может быть применено к многоканальным сигналам посредством HRTFs, таким образом, позволяя бинауральному сигналу предоставлять пространственную звуковую информацию пользователю, например использующему пару наушников.
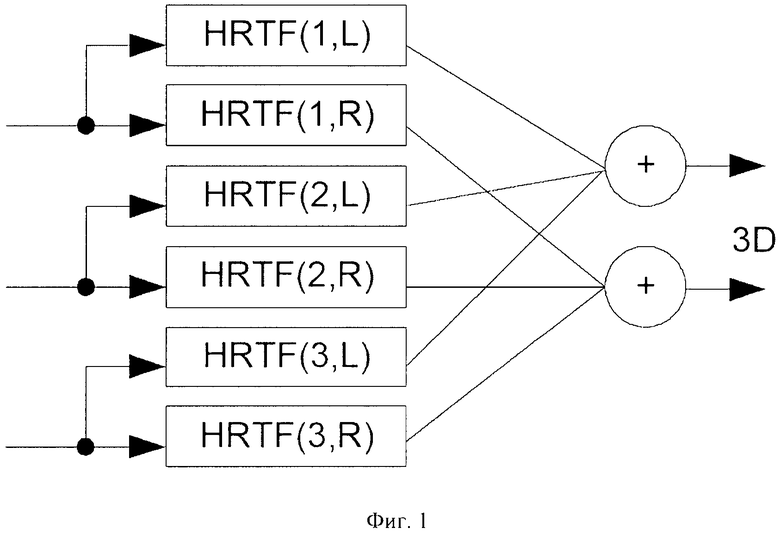
Обычный бинауральный алгоритм синтеза обрисован в общих чертах на фиг.1. Ряд входных каналов фильтруется рядом HRTFs. Каждый входной сигнал разделен на два сигнала (левый «L» и правый «R» компонент); каждый из этих сигналов впоследствии фильтруется при помощи HRTF, соответствующим желаемому положению источника звука. Все сигналы левого уха впоследствии суммируются, чтобы получить левый выходной бинауральный сигнал, и сигналы правого уха суммируются, чтобы получить правый выходной бинауральный сигнал.
Существуют системы декодера, которые могут получать кодированный сигнал объемного звука и генерировать впечатление объемного звука от бинаурального сигнала. Например, существуют системы наушников, которые позволяют преобразовывать сигнал объемного звука в бинауральный сигнал объемного звука, чтобы создать впечатление объемного звучания у пользователя наушников.
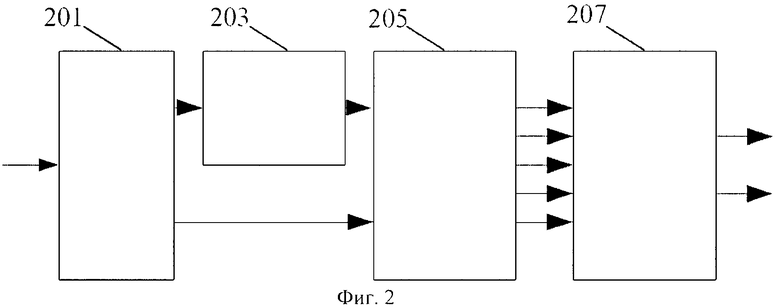
Фиг.2 показывает систему, где MPEG декодер объемного звука получает стереосигнал с пространственными параметрическими данными. Входной поток битов демультиплексируется (разуплотняется) демультиплексором (201) для получения пространственных параметров и потока битов понижающего микширования. Последний поток битов расшифровывается при помощи обычного моно- или стереодекодера (203). Декодированное понижающее микширование декодируется пространственным декодером (205), который обеспечивает многоканальный выход, основанный на переданных пространственных параметрах. Наконец, многоканальный выход обрабатывается на стадии бинауральной синтеза (207) (подобный показанному на фиг.1), производящего бинауральный выходной сигнал, обеспечивающий впечатление объемного звучания пользователю.
Однако такой подход сложен и требует существенного вычислительного ресурса и может далее ухудшить качество звука и ввести слышимые артефакты.
Чтобы преодолеть некоторые из этих недостатков, было предложено объединить параметрический многоканальный звуковой декодер с бинауральным алгоритмом синтеза таким образом, что многоканальный сигнал мог быть воспроизведен в наушниках без необходимости первоначального формирования многоканального сигнала из переданного сигнала понижающего микширования, сопровождаемого понижающим микшированием многоканального сигнала при помощи фильтров HRTF.
В таких декодерах пространственные параметры повышающего микширования для восстановления многоканального сигнала объединяются с фильтрами HRTF, чтобы генерировать объединенные параметры, которые могут непосредственно быть применены к сигналу понижающего микширования для получения бинаурального сигнала. Чтобы сделать это, фильтры HRTF параметризуются.
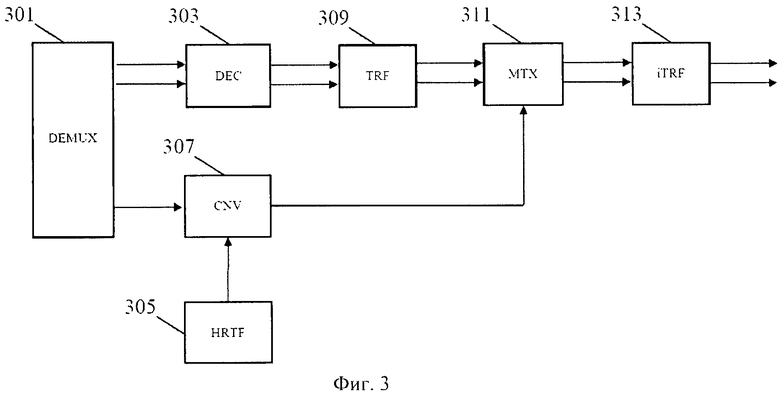
Пример такого декодера показан на фиг.3 и далее описан в работе Брибаарта Дж. «Анализ и синтез бинауральных параметров для эффективного трехмерного воспроизведения звукового сигнала в MPEG объемном звучании». Изд. ICME, Пекин, Китай (2007) и в работе Брибаарта Дж., Фоллера К. «Пространственная звуковая обработка: MPEG объемное звучание и другие применения», Уайли & Санз, Нью-Йорк (2007).
Входной поток битов, содержащий пространственные параметры и сигнал понижающего микширования, получается при помощи демультиплексора 301. Сигнал понижающего микширования декодируется обычным декодером 303, в результате чего получается моно или стерео понижающее микширование.
Дополнительно, данные HRTF преобразуются в область значений параметра посредством узла извлечения параметров HRTF 305. Получающиеся параметры HRTF объединяются в узле преобразования 307 для генерирования объединенных параметров, называемых бинауральными параметрами. Эти параметры описывают объединенный эффект пространственных параметров и обработки HRTF.
Пространственный декодер синтезирует бинауральный выходной сигнал, изменяя декодированный сигнал понижающего микширования, зависящий от бинауральных параметров. А именно, сигнал понижающего микширования передается в область преобразований или область блока фильтров при помощи узла преобразований 309 (или обычный декодер 303 может непосредственно обеспечивать декодированный сигнал понижающего микширования как преобразованный сигнал). Узел преобразований 309 может, в частности, включать блок фильтров QMF (квадратурный зеркальный фильтр), чтобы генерировать поддиапазоны QMF. Сигнал понижающего микширования поддиапазона подается в декодер (матричный узел) 311, который выполняет 2×2 матричную операцию в каждом поддиапазоне.
Если переданный сигнал понижающего микширования является стереосигналом, то два входных сигнала в матричный узел 311 являются двумя стереосигналами. Если переданный сигнал понижающего микширования является моносигналом, один из входных сигналов в матричный узел 311 является моносигналом, а другой сигнал является декоррелированным сигналом (подобно обычному повышающему микшированию моносигнала в стереосигнал).
И для моно и для стерео понижающего микширования матричный узел 311 выполняет операцию:
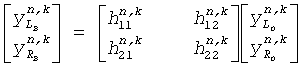
где k - индекс поддиапазона, n - щелевой (область преобразований) индекс, 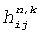 - матричные элементы для поддиапазона k,
- матричные элементы для поддиапазона k, 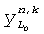 ,
, 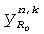 - два входных сигнала для поддиапазона k, и
- два входных сигнала для поддиапазона k, и 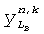 ,
, 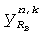 - образцы бинаурального выходного сигнала.
- образцы бинаурального выходного сигнала.
Матричный узел 311 подает образцы бинаурального выходного сигнала в инверсный узел преобразований 313, который преобразовывает сигнал обратно во временную область. Получающаяся временная область бинаурального сигнала может затем подаваться в наушники, чтобы создать впечатление объемного звука.
У описанного подхода есть много преимуществ:
Обработка HRTF может быть выполнена в области преобразования, которая во многих случаях может сократить число необходимых преобразований, поскольку та же самая область преобразований может использоваться для декодирования сигнала понижающего микширования.
Обработка достаточно проста (она использует только умножение на 2×2 матрицы) и фактически не зависит от числа одновременных звуковых каналов. Она может применяться и к моно, и к стерео понижающему микшированию; HRTFs представлены в очень компактном виде и, следовательно, могут быть переданы и сохранены очень эффективно.
Однако у подхода также есть некоторые недостатки. А именно, подход пригоден только для HRTFs, имеющих относительно короткие импульсные характеристики (обычно меньше, чем область преобразований), поскольку более длинные импульсные характеристики не могут быть представлены величинами параметризуемого поддиапазона HRTF. Таким образом, подход не пригоден для звуковой окружающей среды, имеющей длительное эхо или реверберации. А именно, подход обычно не работает со звукоподражательными HRTFs или Бинауральными Импульсными Характеристиками Помещения (BRIRs), которые могут быть длительными и поэтому очень трудно поддающимися правильному моделированию посредством параметрического подхода.
Следовательно, улучшенная система для генерирования бинаурального звукового сигнала была бы очень полезна и, в частности, система, обеспечивающая увеличение гибкости, улучшение работы, облегчение реализации, уменьшение потребления ресурса и/или улучшение пригодности для различной звуковой окружающей среды, была бы очень полезна.
Таким образом, изобретение направлено на поиск возможности смягчить, облегчить или устранить один или несколько вышеупомянутых недостатков отдельно или в любой комбинации.
Согласно первому аспекту изобретения предоставлено устройство для генерирования бинаурального звукового сигнала; устройство включает: средства для получения звуковых данных, включающие звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; параметрические данные предназначены для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; преобразование предназначено для превращения звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; и коэффициент предназначен для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию.
Изобретение позволит произвести улучшенный бинауральный звуковой сигнал. В частности, осуществления изобретения могут использовать комбинацию частотной и временной обработки для генерирования бинауральных сигналов, отражающих звукоподражательную окружающую среду и/или HRTF или BRIRs с длинными импульсными характеристиками. Может быть достигнута относительная простота. Обработка может быть осуществлена с низкой потребностью вычислительного и/или запоминающего ресурса.
Звуковой сигнал понижающего микширования М-канала может быть, в частности, моно- или стереосигналом, включающим понижающее микширование более высокого числа пространственных каналов, такое как понижающее микширование 5.1, или 7.1 объемного сигнала. Пространственные параметрические данные могут, в частности, включать межканальные различия и/или различия взаимной корреляции для звукового сигнала N-канала. Бинауральная перцепционная передаточная функция(и) может быть HRTF или BRIR передаточной функцией(ями).
Согласно дополнительной характеристике изобретения, устройство далее включает преобразование, предназначенное для преобразования звукового сигнала М-канала из временной области в область поддиапазона, и где средства преобразования и стереофильтр устроены так, чтобы обеспечить индивидуальную обработку каждого поддиапазона области поддиапазона.
Техническая характеристика может обеспечить облегченную реализацию, пониженное потребление ресурса и/или совместимость со многими звукообрабатывающими применениями, такими как обычные алгоритмы декодирования.
Согласно дополнительной технической характеристике изобретения продолжительность импульсной характеристики бинауральной перцепционной передаточной функции превышает преобразованный интервал обновления.
Изобретение может обеспечить генерирование улучшенного бинаурального сигнала и/или может уменьшить сложность. В частности, изобретение может генерировать бинауральные сигналы, соответствующие звуковой окружающей среде с характеристиками длительного эха или реверберации.
Согласно дополнительной технической характеристике изобретения средства преобразования устроены так, чтобы, по существу, генерировать выходные стереообразцы для каждого поддиапазона:
 ,
,
где, по крайней мере, один из LI и RI является образцом звукового канала звукового сигнала М-канала в поддиапазоне, и конверсионные средства устроены так, чтобы определить матричные коэффициенты hxy и в ответ на пространственные параметрические данные, и в ответ, по крайней мере, на одну бинауральную перцепционную передаточную функцию.
Техническая характеристика может обеспечить генерирование улучшенного бинаурального сигнала и/или может уменьшить сложность.
Согласно дополнительной технической характеристике изобретения коэффициентные средства включают: средства для обеспечения представления поддиапазона импульсной характеристики множества бинауральных перцепционных передаточных функций, соответствующих различным источникам звука в сигнале N-канала; средства для определения коэффициентов фильтрации посредством взвешенной комбинации соответствующих коэффициентов представлений поддиапазона; и средства для определения весовых коэффициентов для представлений поддиапазона для взвешенной комбинации в ответ на пространственные параметрические данные.
Изобретение может обеспечить генерирование улучшенного бинаурального сигнала и/или может уменьшить сложность. В частности, может быть определена низкая сложность и высококачественные коэффициенты фильтрации.
Согласно дополнительной технической характеристике изобретения первые бинауральные параметры включают параметры когерентности, указывающие на корреляцию между каналами бинаурального звукового сигнала.
Техническая характеристика может обеспечить генерирование улучшенного бинаурального сигнала и/или может уменьшить сложность. В частности, желаемая корреляция может быть эффективно обеспечена посредством осуществления несложной операции до фильтрования. А именно, несложное умножение матрицы поддиапазона может быть выполнено для введения желаемой корреляции или свойств когерентности в бинауральный сигнал. Такие свойства могут быть введены до фильтрования без модификации фильтров. Таким образом, техническая характеристика может обеспечить эффективный несложный контроль корреляции или характеристик когерентности.
Согласно дополнительной технической характеристике изобретения первые бинауральные параметры не включают, по крайней мере, один из параметров локализации, показывающий местоположение любого звукового источника бинаурального звукового сигнала, и параметры реверберации, показывающие реверберацию любого звукового компонента бинаурального звукового сигнала.
Техническая характеристика может обеспечить генерирование улучшенного бинаурального сигнала и/или может уменьшить сложность. В частности, техническая характеристика может обеспечить эффективный контроль информации о локализации и/или параметров реверберации исключительно фильтрами, таким образом, облегчая операцию и/или обеспечивая улучшенное качество. Когерентность или корреляция бинауральных стереоканалов может контролироваться конверсионными средствами, таким образом, обеспечивая контроль корреляции/когерентности и локализации и/или реверберации независимо там, где это является практичным или эффективным.
Согласно дополнительной технической характеристике изобретения коэффициентные средства устроены так, чтобы определить коэффициенты фильтрации, чтобы отразить, по крайней мере, одну из реплик локализации и реплик реверберации для бинаурального звукового сигнала.
Техническая характеристика может обеспечить генерирование улучшенного бинаурального сигнала и/или может уменьшить сложность. В частности, желаемая локализация или свойства реверберации могут быть эффективно обеспечены фильтрацией поддиапазона, таким образом, обеспечивая улучшенное качество и, в частности, делая возможным эффективное моделирование, например, звукоподражательную окружающую среду.
Согласно дополнительной технической характеристике изобретения звуковой сигнал М-канала является моно звуковым сигналом, и конверсионные средства устроены так, чтобы генерировать декоррелированный сигнал от моно звукового сигнала, и генерировать первый стереосигнал посредством матричного умножения образцов стереосигнала, включающего декоррелированный сигнал и моно звуковой сигнал.
Техническая характеристика может обеспечить генерирование улучшенного бинаурального сигнала от моносигнала и/или может уменьшить сложность. В частности, изобретение может обеспечить все необходимые параметры для генерирования высококачественного бинаурального звукового сигнала от типично доступных пространственных параметров.
Согласно другому аспекту изобретения предоставлен способ генерирования бинаурального звукового сигнала; способ включает: получение звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; преобразование пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; преобразование звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; генерирование бинаурального звукового сигнала посредством фильтрации первого стереосигнала; и определение коэффициентов фильтрации для стереофильтра в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию.
Согласно другому аспекту изобретения предоставлен передатчик для передачи бинаурального звукового сигнала; передатчик включает: средства для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся понижающим микшированием звукового сигнала N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; параметрические данные предназначены для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; преобразование предназначено для преобразования звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; коэффициент предназначен для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию; и средства для передачи бинаурального звукового сигнала.
Согласно другому аспекту изобретения предоставлена система передачи для передачи звукового сигнала; система передачи включает передатчик, включающий: средства для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся понижающим микшированием звукового сигнала N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; параметрические данные предназначены для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию, конверсионные средства предназначены для преобразования звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; коэффициент предназначен для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию, и средства для передачи бинаурального звукового сигнала; и приемник для получения бинаурального звукового сигнала.
Согласно другому аспекту изобретения предоставлено звукозаписывающее устройство для записи бинаурального звукового сигнала; звукозаписывающее устройство включает средства для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; параметрические данные предназначены для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; средства преобразования предназначены для превращения звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр предназначен для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; коэффициентный процессор (419) предназначен для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию и для записи бинаурального звукового сигнала.
Согласно другому аспекту изобретения предоставлен способ передачи бинаурального звукового сигнала; метод включает: получение звуковых данных, включающих звуковой сигнал М-канала, являющийся понижающим микшированием звукового сигнала N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; преобразование пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; преобразование звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; генерирование бинаурального звукового сигнала посредством фильтрации первого стереосигнала в фильтре; определение коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию; и передача бинаурального звукового сигнала.
Согласно другому аспекту изобретения предоставлен способ передачи и получения бинаурального звукового сигнала; метод включает: передатчик, выполняющий следующие шаги: получение звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; преобразование пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию, преобразование звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; генерирование бинаурального звукового сигнала посредством фильтрации первого стереосигнала в стереофильтре; определение коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию, и передача бинаурального звукового сигнала; и приемник, осуществляющий получение бинаурального звукового сигнала.
Согласно другому аспекту изобретения предоставлен компьютерный программный продукт для осуществления любого из вышеупомянутых описанных способов.
Эти и другие аспекты, технические характеристики и преимущества изобретения станут очевидны и объяснимы при ссылке на осуществление(я), описанное далее.
Осуществления изобретения будут описаны, только в качестве примера, со ссылкой на чертежи, где:
Фиг.1 - иллюстрация подхода к генерированию бинаурального сигнала в соответствии с прототипом;
Фиг.2 - иллюстрация подхода к генерированию бинаурального сигнала в соответствии с прототипом;
Фиг.3 - иллюстрация подхода к генерированию бинаурального сигнала в соответствии с прототипом;
Фиг.4 иллюстрирует устройство для генерирования бинаурального звукового сигнала в соответствии с некоторыми осуществлениями изобретения;
Фиг.5 иллюстрирует блок-схему примера способа генерирования бинаурального звукового сигнала в соответствии с некоторыми осуществлениями изобретения; и
Фиг.6 иллюстрирует пример системы передачи звукового сигнала в соответствии с некоторыми осуществлениями изобретения
Следующее описание сосредоточено на осуществлениях изобретения, применимого к синтезу бинаурального стереосигнала от понижающего микширования моносигнала множества пространственных каналов. В частности, описание будет соответствовать генерированию бинаурального сигнала для воспроизведения через наушники от MPEG потока битов объемного звука, закодированного при помощи так называемой «5151» конфигурации, имеющей 5 каналов для входа (обозначены первой «5»), понижающее микширование монозвука (первая «1»), 5-канальная реконструкция (вторая «5») и пространственная параметризация согласно древовидной структуре «1». Подробная информация относительно различных древовидных структур может быть найдена в работах Херре Дж., Кьерлинга К., Брибаарта Дж., Фоллера К., Диша С., Пурнхагена X., Коппенса Дж., Гилперта Дж., Редена Дж., Оомена У., Линзмейера К., Чонга К.S. «MPEG объемный звук - стандарт ISO/MPEG для эффективного и совместимого многоканального звукового кодирования», Свид. 122 AES соглашения, Вена, Австрия (2007) и Брибаарта Дж., Хото Г., Коппенса Дж., Шуйерса Е., Оомена У., Ван де Пара С. «Фон, концепция и архитектура современного стандарта MPEG объемного звука на многоканальном звуковом сжатии» журнал Общества Звукотехники, 55, стр.331-351 (2007). Однако следует отметить, что изобретение не ограничивается только этим применением, а может, например, быть применено ко многим другим звуковым сигналам, включая, например, объемные звуковые сигналы, понижающе микшированные до стереосигнала.
В известных устройствах, таких как устройство на фиг.3, длительные HRTFs или BRIRs не могут быть эффективно представлены параметризованными данными и матричной операцией, выполненной при помощи матричного узла 311. В действительности, умножение матричного поддиапазона ограничивается, чтобы представить импульсные ответы (характеристики) временного интервала, имеющие продолжительность, соответствующую временному интервалу преобразования, использовавшегося для превращения во временной интервал поддиапазона. Например, если преобразование является Быстрым Преобразованием Фурье (FFT), каждый интервал FFT образцов N передается в образцы поддиапазона N, которые подаются в матричный узел. Однако импульсные ответы длиннее, чем образцы N, не будут представлены в достаточной мере.
Одно решение этой проблемы состоит в том, чтобы использовать метод фильтрации области поддиапазона, где матричная операция заменена методом матричной фильтрации, где фильтруются индивидуальные поддиапазоны. Таким образом, в таких осуществлениях обработка поддиапазона может вместо простого матричного умножения быть представлена как:
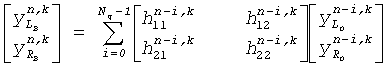 ,
,
где Nq - число отводов, используемых для фильтра, чтобы представить функцию(и) HRTF/BRIR.
Такой подход эффективно соответствует применению четырех фильтров к каждому поддиапазону (один для каждой перестановки входного канала и выходного канала матричного узла 311).
Хотя такой подход может быть полезным в некоторых осуществлениях, у него также есть некоторые связанные недостатки. Например, система требует четырех фильтров для каждого поддиапазона, что значительно увеличивает сложность и потребление ресурса для обработки. Кроме того, во многих случаях может быть сложно, трудно или даже невозможно генерировать параметры, которые точно соответствуют желаемым импульсным ответам HRTF/BRIR.
А именно, для простого матричного умножения (фиг.3) когерентность бинаурального сигнала может быть оценена при помощи параметров HRTF и переданных пространственных параметров, потому что оба типа параметров существуют в той же самой (параметрической) области. Когерентность бинаурального сигнала зависит от когерентности между индивидуальными источниками звуковых сигналов (как описано пространственными параметрами) и акустической дорожкой от индивидуальных позиций до барабанных перепонок (описывается HRTFs). Если относительные уровни сигнала, парные величины когерентности, и передаточные функции HRTF все описаны статистическим (параметрическим) способом, чистая когерентность, являющаяся результатом объединенного эффекта пространственного представления и обработки HRTF, может быть оценена непосредственно в параметрической области. Этот процесс описан в работах Брибаарта Дж. «Анализ и синтез бинауральных параметров для эффективного трехмерного звукового представления в MPEG объемном звуке», Изд. ICME, Пекин, Китай (2007) и Брибаарта Дж., Фоллера К. «Пространственная звуковая обработка: MPEG объемный звук и другие применения», Уайли & Санз, Нью-Йорк (2007). Если желаемая когерентность известна, выходной сигнал с когерентностью согласно указанной величине может быть получен при помощи комбинации сигнала декоррелятора и моносигнала посредством матричной операции. Этот процесс описан в работах Брибаарта Дж., Ван де Пара С., Колрауша А., Шуйерса Е. «Параметрическое кодирование звукового стереосигнала», ЕВРАСИП Журн. Прикладной Сигнал, №9, стр.1305-1322 (2005) и Энгегарда Дж., Пурнхагена X., Редена Дж., Лильерида Л. «Искусственная среда в параметрическом стереокодировании», изд. 116-го соглашения AES, Берлин, Германия (2004).
В результате элементы матрицы сигнала декоррелятора (h12 и h22) следуют из относительно простых отношений между пространственными и HRTF параметрами. Однако для ответов (характеристик) фильтра, таких как вышеописанные, значительно труднее вычислить чистую когерентность, являющуюся результатом пространственного декодирования и бинаурального синтеза, потому что желаемая величина когерентности отличается для первой части (прямой звук) BRIR и для остальной части (последующая реверберация).
А именно, для BRIRs необходимые свойства могут значительно изменяться с течением времени. Например, первая часть BRIR может описывать прямой звук (без эффектов комнаты). Эта часть, поэтому, высоконаправлена (с отчетливыми свойствами локализации, отраженными, например, различиями уровня и различиями времени прибытия, и высокой когерентностью). Ранние отражения и поздняя реверберация, с другой стороны, часто относительно менее направлены. Таким образом, различия уровня между ушами менее явные, различия времени прибытия бывает трудно определить точно из-за их вероятностной природы, а когерентность во многих случаях весьма низкая. Это изменение свойств локализации весьма важно для точного захвата, но это может быть трудно, потому что возникнет необходимость того, чтобы когерентность ответов (характеристик) фильтра изменялась в зависимости от положения в пределах фактического ответа фильтра, в то время как полный ответ фильтра будет зависеть от пространственных параметров и HRTF коэффициентов. Эта комбинация требований является трудновыполнимой при ограниченном числе шагов обработки.
Таким образом, определение правильной когерентности между бинауральными выходными сигналами и гарантия ее правильного поведения во времени являются очень трудными для понижающего микширования моносигнала и типично невозможными при использовании подходов, известных как прототипный подход матричного умножения.
Фиг.4 иллюстрирует устройство для генерирования бинаурального звукового сигнала в соответствии с некоторыми осуществлениями изобретения. В описанном подходе параметрическое матричное умножение объединено с фильтрацией низкой сложности, позволяющей эмулировать звуковую окружающую среду с длинным эхом или реверберацией. В частности, система позволяет использовать долгие HRTFs/BRIRs, одновременно поддерживая низкую сложность и осуществляя практическое выполнение.
Устройство включает демультиплексор 401, который получает звуковой информационный битовый поток, который включает звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала. Кроме того, данные включают пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала. В конкретном примере сигнал понижающего микширования является моносигналом, то есть звуковой сигнал М=1 и звуковой сигнал N-канала является 5.1 объемным сигналом, то есть N=6. Звуковые данные являются, в частности, MPEG объемными кодированными сигналами окружающей среды, а пространственные данные включают Межуровневые Различия (ILDs) и параметры Межканальной Взаимной корреляции (ICC).
Звуковые данные моносигнала подаются в декодер 403, соединенный с демультиплексором 401. Декодер 403 декодирует моносигнал, используя подходящий обычный алгоритм декодирования, хорошо известный специалисту, квалифицированному в этой области. Таким образом, в примере выход декодера 403 является декодированным моно звуковым сигналом.
Декодер 403 соединен с процессором преобразований 405, который преобразует декодированный моносигнал от временного интервала (области) до частотного интервала (области) поддиапазона. В некоторых осуществлениях процессор преобразований 405 может быть устроен так, чтобы разделять сигнал на интервалы преобразований (соответствующие выборочным блокам, включающим подходящее число образцов) и действовать как Быстрое Преобразование Фурье (FFT) в каждом временном интервале преобразований. Например, FFT может быть 64-точечным FFT с моно звуковыми образцами, разделенными на 64 выборочных блока, к которым применяется FFT, чтобы генерировать 64 сложные выборки поддиапазона.
В конкретном примере процессор преобразований 405 включает блок фильтров QMF, действующий с 64 образцами интервала преобразований. Таким образом, для каждого блока 64 образцов временного интервала генерируются 64 образца поддиапазона в частотной области (интервале).
В примере полученный сигнал является моносигналом, который должен быть микширован с повышением до бинаурального стереосигнала. Соответственно, частотный поддиапазон моносигнала подается в декоррелятор 407, который генерирует декоррелированную версию моносигнала. Следует заметить, что любой подходящий способ генерирования декоррелированного сигнала может использоваться, не умаляя значения изобретения.
Процессор преобразований 405 и декоррелятор 407 подаются в матричный процессор 409. Таким образом, матричный процессор 409 выдает представление поддиапазона моносигнала, а также представление поддиапазона генерированного декоррелированного сигнала. Матричный процессор 409 продолжает преобразовывать моносигнал в первый стереосигнал. А именно, матричный процессор 409 выполняет матричное умножение в каждом поддиапазоне, представленном:
,
где LI и RI - образец входных сигналов в матричный процессор 409, то есть, в конкретном примере, LI, и RI - образцы поддиапазона для моносигнала и декоррелированного сигнала.
Преобразование, выполненное матричным процессором 409, зависит от бинауральных параметров, генерированных в ответ на HRTFs/BRIRs. В примере преобразование также зависит от пространственных параметров, которые связывают полученный моносигнал и (дополнительные) пространственные каналы.
А именно, матричный процессор 409 соединен с конверсионным процессором 411, который, кроме того, соединен с демультиплексором 401 и запоминающим устройством HRTF 413, включающим данные, представляющие желаемые HRTF(s) (или эквиваленты желаемых BRIR(s). Следующее будет для краткости относиться только к HRTF(s), но следует заметить, что BRIR(s) могут использоваться вместо (или так же как) HRTFs). Конверсионный процессор 411 получает пространственные данные от демультиплексора, и данные, представляющие HRTF от запоминающего устройства HRTF 413. Конверсионный процессор 411 затем продолжает генерировать бинауральные параметры, используемые матричным процессором 409, преобразовывая пространственные параметры в первые бинауральные параметры в ответ на HRTF данные.
Однако в примере полная параметризация HRTF и пространственные параметры, необходимые для генерирования выходного бинаурального сигнала, не вычислены. Бинауральные параметры, используемые в матричном умножении, скорее, только отражают часть желаемого ответа HRTF. В частности, бинауральные параметры оценены для прямой части (исключая ранние отражения и поздние реверберации) HRTF/BRIR только. Это достигается посредством использования обычного процесса оценки параметров, использующего первый пик импульсного ответа временного интервала HRTF только во время процесса параметризации HRTF. Только получающаяся в результате когерентность для прямой части (исключая реплики локализации, такие как различия уровня и/или времени) впоследствии используется в 2×2 матрице. Действительно, в конкретном примере матричные коэффициенты генерируются, только чтобы отразить желаемую когерентность или корреляцию бинаурального сигнала и не рассматривать характеристики локализации или реверберации.
Таким образом, матричное умножение выполняет только часть желаемой обработки, и выход матричного процессора 409 не является заключительным бинауральным сигналом, а является скорее промежуточным (бинауральным) сигналом, который отражает желаемую когерентность прямого звука между каналами.
Бинауральные параметры в форме матричных коэффициентов hxy в примере генерируются посредством первого вычисления относительных мощностей сигнала в различных звуковых каналах сигнала N-канала, основанного на пространственных данных и, в частности, основанных на параметрах различия уровня, содержавшихся там. Относительные мощности в каждом из бинауральных каналов тогда вычисляются, основываясь на этих величинах и HRTFs, связанных с каждым из каналов N. Кроме того, ожидаемая величина взаимной корреляции между бинауральными сигналами вычисляется, основываясь на мощностях сигнала в каждом из N-каналов и HRTFs. Основанная на взаимной корреляции и объединенной мощности бинаурального сигнала мера когерентности для канала впоследствии вычисляется, а матричные параметры определяются, чтобы обеспечить эту корреляцию. Конкретные детали того, как бинауральные параметры могут быть генерированы, будут описаны позже.
Матричный процессор 409 соединен с двумя фильтрами 415, 417, которые работают, чтобы генерировать выходной бинауральный звуковой сигнал посредством фильтрации стереосигнала, генерированного матричным процессором 409. А именно, каждый из двух сигналов фильтруется индивидуально как моносигнал, и не вводится никакая перекрестная связь сигнала от одного канала с другим. Соответственно, используются только два монофильтра, таким образом, уменьшая сложность по сравнению с, например, подходами, требующими четырех фильтров.
Фильтры 415, 417 являются поддиапазонными фильтрами, где каждый поддиапазон фильтруется индивидуально. А именно, каждый из фильтров может быть фильтром Конечного Импульсного Ответа (FIR) в каждом поддиапазоне, выполняющим фильтрование, представленное главным образом:
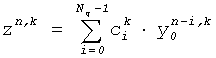
где y представляет образцы поддиапазона, полученные от матричного процессора 409, с - коэффициенты фильтрации, n - число образцов (соответствующее интервальному числу преобразований), k - поддиапазон, и N - длина импульсного ответа фильтра. Таким образом, в каждом индивидуальном поддиапазоне фильтрование «временного интервала» выполняется посредством расширения обработки от одиночного интервала преобразований, чтобы учитывать образцы поддиапазона от множества интервалов преобразований.
Модификации сигнала MPEG объемного выполняются в области сложного смодулированного блока фильтров QMF, который выбран не критически. Его конкретный проект учитывает данный фильтр временного интервала, который будет осуществлен с высокой точностью посредством фильтрации каждого сигнала поддиапазона в направлении времени при помощи отдельного фильтра. Получившееся в результате полное ОТНОШЕНИЕ СИГНАЛ/ШУМ (SNR) для выполнения фильтрации находится в диапазоне 50 децибелов, притом что часть совмещения имен ошибки значительно меньше. Кроме того, эти доменные фильтры поддиапазона могут быть получены непосредственно из данного фильтра временного интервала. Особенно привлекательный метод вычисления доменного фильтра поддиапазона, соответствующего фильтру временного интервала h(ν), должен использовать второй сложный смодулированный анализ блока фильтров с FIR прототипным фильтром q(ν), полученным от прототипного фильтра блока фильтров QMF. А именно,
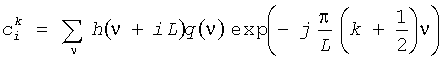 ,
,
где L=64. Для MPEG объемного QMF блока прототипный фильтр q(ν) конвертора имеет 192 отвода. Например, фильтр временного интервала с 1024 отводами будет преобразован в набор из 64 поддиапазонных фильтров, имеющих 18 отводов в направлении времени.
Технические характеристики фильтра в примере генерированы, чтобы отражать оба аспекта пространственных параметров, а также аспекты желаемых HRTFs. А именно, коэффициенты фильтрации определяются в ответ на импульсные ответы HRTF и пространственное местоположение реплик таким образом, что характеристики реверберации и локализации генерированного бинаурального сигнала вводятся и регулируются фильтрами. Корреляция или когерентность прямой части бинауральных сигналов не затрагивается фильтрованием, при условии, что прямая часть фильтров (почти) когерентна, и следовательно, когерентность прямого звука бинаурального выхода полностью определяется предыдущей матричной операцией. С другой стороны, часть фильтров поздней реверберации считается некоррелированной между фильтрами левого и правого уха и, следовательно, выход этой конкретной части всегда будет некоррелированным, независимым от когерентности сигнала, подаваемого в эти фильтры. Следовательно, не требуется никакой модификации для фильтров в ответ на желаемую когерентность. Таким образом, матричная операция, продолжающаяся в фильтрах, определяет желаемую когерентность прямой части, в то время как оставшаяся реверберационная часть автоматически будет иметь правильную (низкую) корреляцию, независимую от фактических матричных величин. Таким образом, фильтрование поддерживает желаемую когерентность, введенную матричным процессором 409.
Таким образом, в устройстве фиг.4 бинауральные параметры (в форме матричных коэффициентов), используемые матричным процессором 409, являются параметрами когерентности, указывающими на корреляцию между каналами бинаурального звукового сигнала. Однако эти параметры не включают параметры локализации, указывающие на местоположение любого звукового источника бинаурального звукового сигнала, или параметры реверберации, указывающие на реверберацию любого звукового компонента бинаурального звукового сигнала. Скорее эти параметры/характеристики вводятся последующей фильтрацией поддиапазона посредством определения коэффициентов фильтрации таким образом, что они отражают реплики локализации и реверберации для бинаурального звукового сигнала.
А именно, фильтры присоединяются к коэффициентному процессору 419, который далее присоединяется к демультиплексору 401 и запоминающему устройству HRTF 413. Коэффициентный процессор 419 определяет коэффициенты фильтрации для стереофильтров 415, 417 в ответ на бинауральную перцепционную передаточную функцию(и). Кроме того, коэффициентный процессор 419 получает пространственные данные от демультиплексора 401 и использует это для определения коэффициентов фильтрации.
А именно, импульсные ответы HRTF преобразовываются в область поддиапазона и, поскольку импульсный ответ превышает одиночный интервал преобразований, это приводит к импульсному ответу для каждого канала в каждом поддиапазоне, а не в едином коэффициенте поддиапазона. Импульсные ответы для каждого фильтра HRTF, соответствующего каждому из каналов N, тогда складываются во взвешенном суммировании. Весовые коэффициенты, которые прикладываются к каждому из N HRTF импульсных ответов фильтра, определяются в ответ на пространственные данные и, в частности, определяются, чтобы привести к соответствующему распределению мощности между различными каналами. Конкретные детали того, как коэффициенты фильтрации могут генерироваться, будут описаны позже.
Выходы фильтров 415, 417 являются, таким образом, стереопредставлением поддиапазона бинаурального звукового сигнала, который эффективно эмулирует полный объемный сигнал, поступающий в наушники. Фильтры 415, 417 присоединяются к процессору обратного преобразования 421, который выполняет обратное преобразование, чтобы преобразовать сигнал поддиапазона во временной интервал. А именно, процессор обратного преобразования 421 может выполнять обратное QMF преобразование.
Таким образом, выход процессора обратного преобразования 421 является бинауральным сигналом, который может обеспечить впечатление объемного звука от ряда наушников. Сигнал может, например, кодироваться посредством обычного стерео кодирующего устройства и/или может быть преобразован в аналоговую область в аналоговом цифровом преобразователе, чтобы обеспечить сигнал, который может подаваться непосредственно к наушникам.
Таким образом, устройство фиг.4 объединяет параметрическую HRTF матричную обработку и фильтрацию поддиапазона для обеспечения бинаурального сигнала. Разделение матричного умножения корреляции/когерентности и локализации, базированной на фильтрации, и фильтрование реверберации обеспечивает систему, где необходимые параметры могут быть легко вычислены для, например, моносигнала. А именно, в отличие от подхода чистого фильтрования, где параметр когерентности трудно или невозможно определить и осуществить, комбинация различных типов обработки позволяет эффективно регулировать когерентность даже для применений, основанных на понижающем микшировании моносигнала.
Таким образом, у описанного подхода есть то преимущество, что синтез правильной когерентности (посредством матричного умножения) и генерирование реплик локализации и реверберации (посредством фильтров) полностью разделяется и регулируется независимо. Кроме того, число фильтров ограничено двумя, поскольку не требуется никакого взаимного фильтрования каналов. Поскольку фильтры типично более сложны, чем простое матричное умножение, сложность уменьшается.
Далее будет показано на конкретном примере, как могут быть вычислены необходимые матричные бинауральные параметры и коэффициенты фильтрации. В примере полученный сигнал является MPEG объемным битовым потоком, закодированным при помощи «5151» древовидной структуры.
В описании будут использоваться следующие аббревиатуры:
l или L: левый канал
r или R: правый канал
f: передний канал(ы)
s: объемный канал(ы)
с: центральный канал
ls: левый объемный
rs: правый объемный
lf: левый передний
lr: левый правый
Пространственные данные, содержащиеся в потоке данных MPEG, включают следующие параметры:
Во-первых, будет описано генерирование бинауральных параметров, используемых для матричного умножения матричным процессором 409.
Конверсионный процессор 411 сначала делает предварительный расчет бинауральной когерентности, которая является параметром, отражающим желаемую когерентность между каналами бинаурального выходного сигнала. Оценка использует пространственные параметры, а также параметры HRTF, определенные для функций HRTF.
А именно, используются следующие параметры HRTF:
Pl, который является среднеквадратичным значением мощности в пределах определенного диапазона частот HRTF, соответствующем левому уху;
Pr, который является среднеквадратичным значением мощности в пределах определенного диапазона частот HRTF, соответствующем правому уху;
ρ, который является когерентностью в пределах определенного диапазона частот между HRTF левого и правого уха для определенного положения виртуального источника звука;
φ, который является средней разностью фаз в пределах определенного диапазона частот между HRTF левым и правым ухом для определенного положения виртуального источника звука.
С учетом того, что частотная область HRTF представлена Hl(f), Hr(f) для левого и правого уха соответственно, и f - частотный индекс, эти параметры могут быть вычислены согласно:
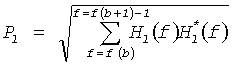
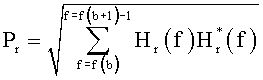
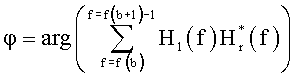
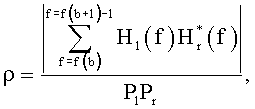
где суммирование через f выполняется для каждого диапазона параметров, чтобы в результате получить один набор параметров для каждого диапазона параметров b. Более подробную информацию относительно этого HRTF процесса параметризации можно найти в работе Брибаарта Дж. «Анализ и синтез бинауральных параметров для эффективного трехмерного воспроизведения звукового сигнала в MPEG объемном звучании», Изд. ICME, Пекин, Китай (2007) и в работе Брибаарта Дж., Фоллера К. «Пространственная звуковая обработка: MPEG объемное звучание и другие применения», Уайли & Санз, Нью-Йорк (2007).
Вышеупомянутый процесс параметризации выполняется независимо для каждого диапазона параметров и каждого положения виртуального громкоговорителя. В дальнейшем положение громкоговорителя обозначено P1(X), где Х - идентификатор громкоговорителя (lf, rf, с, ls или ls).
В качестве первого шага, приведенные мощности (с учетом мощности моно входного сигнала) сигнала с 5.1 каналами вычисляются, используя переданные параметры CLD. Приведенная мощность левого переднего канала получают по:
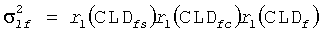 , где
, где
 ,
,
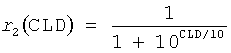 .
.
Точно так же приведенные мощности других каналов получают по:
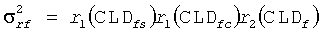
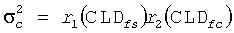
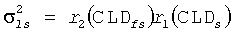
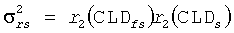
Данные мощности σ каждого виртуального громкоговорителя, параметры ICC, которые представляют величины когерентности между определенными парами громкоговорителей, и HRTF параметры Pl, Pr, p и φ для каждого виртуального громкоговорителя, статистические свойства результирующего бинаурального сигнала могут быть определены. Это достигается путем добавления вклада в единицах мощности σ для каждого виртуального громкоговорителя, умноженного на мощность HRTF Pl, Pr для каждого уха индивидуально, чтобы отражать изменение мощности, введенной HRTF. Дополнительные единицы необходимы, чтобы включать эффект взаимных корреляций между сигналами виртуального громкоговорителя (ICC) и различия длины пути HRTF (представленные параметром φ) (ссылка, например, на работу Брибаарта Дж., Фоллера К. «Пространственная звуковая обработка: MPEG объемное звучание и другие применения», Уайли & Санз, Нью-Йорк (2007)).
Ожидаемую величину приведенной мощности левого бинаурального выходного канала 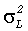 (с учетом моно входного канала) получают по:
(с учетом моно входного канала) получают по:

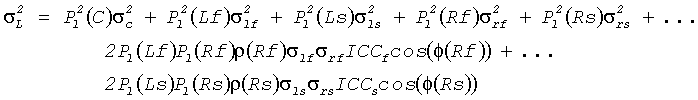
Точно такую же величину (приведенной) мощности для правого канала получают по:
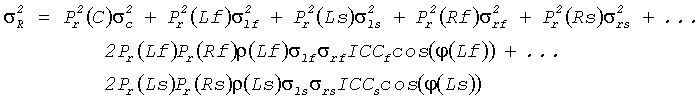
Основанная на аналогичных предположениях и использующая аналогичные методики ожидаемая величина векторного произведения 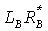 бинауральной пары сигналов может быть вычислена из
бинауральной пары сигналов может быть вычислена из
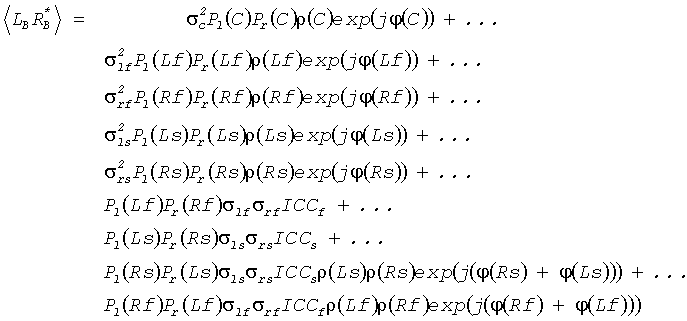
Когерентность бинаурального выхода (ICCB) тогда получают по:
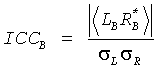
Основываясь на определенной когерентности бинаурального выходного сигнала ICCB (и игнорируя реплики локализации и характеристики реверберации), матричные коэффициенты, необходимые для восстановления параметров ICCB, могут тогда быть вычислены, используя обычные методы, как показано в работе Брибаарта Дж., Ван де Пара С., Колрауша А., Шуйерса Е. «Параметрическое кодирование звукового стереосигнала», ЕВРАСИП Журн. Прикладной Сигнал, №9, стр.1305-1322 (2005):
h11=cos(α+β)
h12=sin(α+β)
h21=cos(-α+β)
h22=sin(-α+β)
где
α=0.5arccos(ICCB)
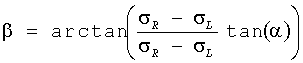
В дальнейшем будет описано генерирование коэффициентов фильтрации коэффициентным процессором 419.
Во-первых, генерируются представления поддиапазона импульсных ответов бинауральной перцепционной передаточной функции, соответствующей различным источникам звука в бинауральном звуковом сигнале.
А именно, HRTFs (или BRIRs) преобразуются в область QMF, результирующую в представления QMF-области 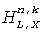 ,
, 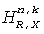 для импульсных ответов левого и правого уха, соответственно, при использовании метода фильтрующего конвертера, обрисованного в общих чертах в описании Фиг.4. В представлении Х обозначает исходный канал (X=Lf, Rf, С, Ls, Rs), R и L обозначают левый и правый бинауральный канал соответственно, n - номер блока преобразований, и k обозначает поддиапазон.
для импульсных ответов левого и правого уха, соответственно, при использовании метода фильтрующего конвертера, обрисованного в общих чертах в описании Фиг.4. В представлении Х обозначает исходный канал (X=Lf, Rf, С, Ls, Rs), R и L обозначают левый и правый бинауральный канал соответственно, n - номер блока преобразований, и k обозначает поддиапазон.
Коэффициентный процессор 419 продолжает определять коэффициенты фильтрации как взвешенную комбинацию соответствующих коэффициентов представлений поддиапазона , . А именно, коэффициенты фильтрации для FIR фильтров 415, 417 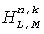 ,
, 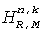 получают по:
получают по:
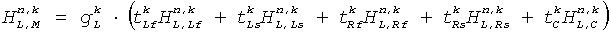 ,
,
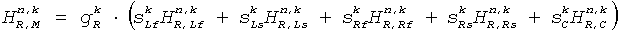 .
.
Коэффициентный процессор 419 вычисляет весовые коэффициенты tk и sk как описано далее.
Во-первых, модули линейных комбинированных весовых коэффициентов выбраны таким образом, что:
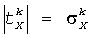 ,
, 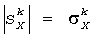
Таким образом, весовой коэффициент данного HRTF, соответствующий данному пространственному каналу, отбирается, чтобы он соответствовал уровню мощности этого канала.
Во-вторых, масштабные коэффициенты усиления 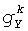 вычисляются следующим образом.
вычисляются следующим образом.
Пусть нормализованная заданная бинауральная выходная мощность смешанного диапазона k обозначена 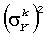 для выходного канала Y=L,R, и пусть коэффициент усиления мощности фильтра
для выходного канала Y=L,R, и пусть коэффициент усиления мощности фильтра 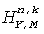 обозначен
обозначен 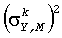 , тогда коэффициенты усиления приспосабливаются, чтобы достигнуть
, тогда коэффициенты усиления приспосабливаются, чтобы достигнуть
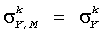 .
.
Следует отметить, что если это может быть приблизительно достигнуто с использованием масштабных коэффициентов усиления, которые являются постоянными в каждом диапазоне параметров, тогда масштабирование может быть исключено из трансформации фильтра и выполнено при помощи модификации матричных элементов из предыдущего раздела:
h11=gL cos(α+β)
h12=gL sin(α+β)
h21=gR cos(-α+β)
h22=gR sin(-α+β).
Чтобы это оставалось справедливым, необходимо, чтобы немасштабированная взвешенная комбинация:
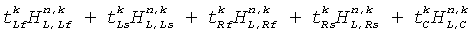
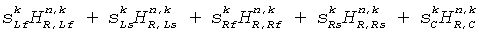
имела коэффициенты усиления мощности, которые бы не очень сильно изменялись внутри диапазона параметров. Как правило, основной вклад в такие изменения возникает в результате главных различий запаздывания между ответами HRTF. В некоторых осуществлениях данного изобретения предварительное выравнивание во временном интервале выполняется для доминирующих HRTF фильтров, и могут быть применены простые фактические значения комбинированных весовых коэффициентов:
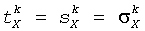 .
.
В других осуществлениях данного изобретения эти различия запаздывания адаптивно противодействуют на доминирующих HRTF парах посредством введения комплекснозначных весовых коэффициентов. В случае передних/задних пар это эквивалентно использованию следующих весовых коэффициентов:
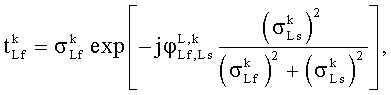
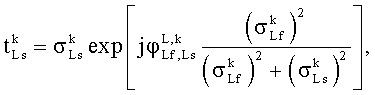
и 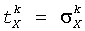 для X=C, Rf, Rs.
для X=C, Rf, Rs.
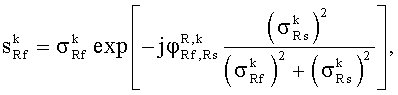
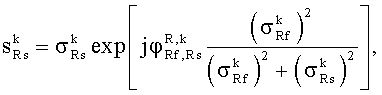
и  для X=C, Lf, Ls.
для X=C, Lf, Ls.
Здесь 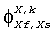 - развернутый фазовый угол сложной взаимной корреляции между подполосовыми фильтрами
- развернутый фазовый угол сложной взаимной корреляции между подполосовыми фильтрами 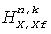 и
и 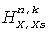 . Эта взаимная корреляция определяется по
. Эта взаимная корреляция определяется по
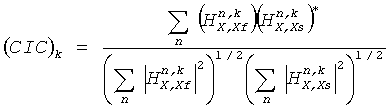 ,
,
где звездочка обозначает комплексное сопряжение.
Цель развертывания фазы состоит в том, чтобы свободно выбирать фазовый угол до кратных 2π, чтобы получить фазовую кривую, которая изменяется насколько возможно медленно как функция индекса k поддиапазона.
Роль угловых фазовых параметров в комбинированных формулах, приведенных выше, является двойной. Во-первых, она выполняет компенсацию запаздывания передних/задних фильтров до суперпозиции, что приводит к объединенному ответу, который моделирует главное время запаздывания, соответствующее исходному положению между передним и задним громкоговорителем. Во-вторых, она уменьшает изменчивость коэффициентов усиления мощности немасштабированных фильтров.
Если когерентность ICCM объединенных фильтров HL,M, HR,M в диапазоне параметров или смешанном диапазоне меньше единицы, бинауральный выход может стать менее когерентным, чем предполагалось, как это следует из отношения
ICCB,Out=ICCM·ICCB.
Решение этой проблемы в соответствии с некоторыми осуществлениями данного изобретения состоит в том, чтобы использовать измененную величину ICCB для определения матричного элемента, определяемого по:
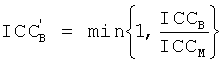 .
.
Фиг.5 иллюстрирует блок-схему примера способа генерирования бинаурального звукового сигнала в соответствии с некоторыми осуществлениями изобретения.
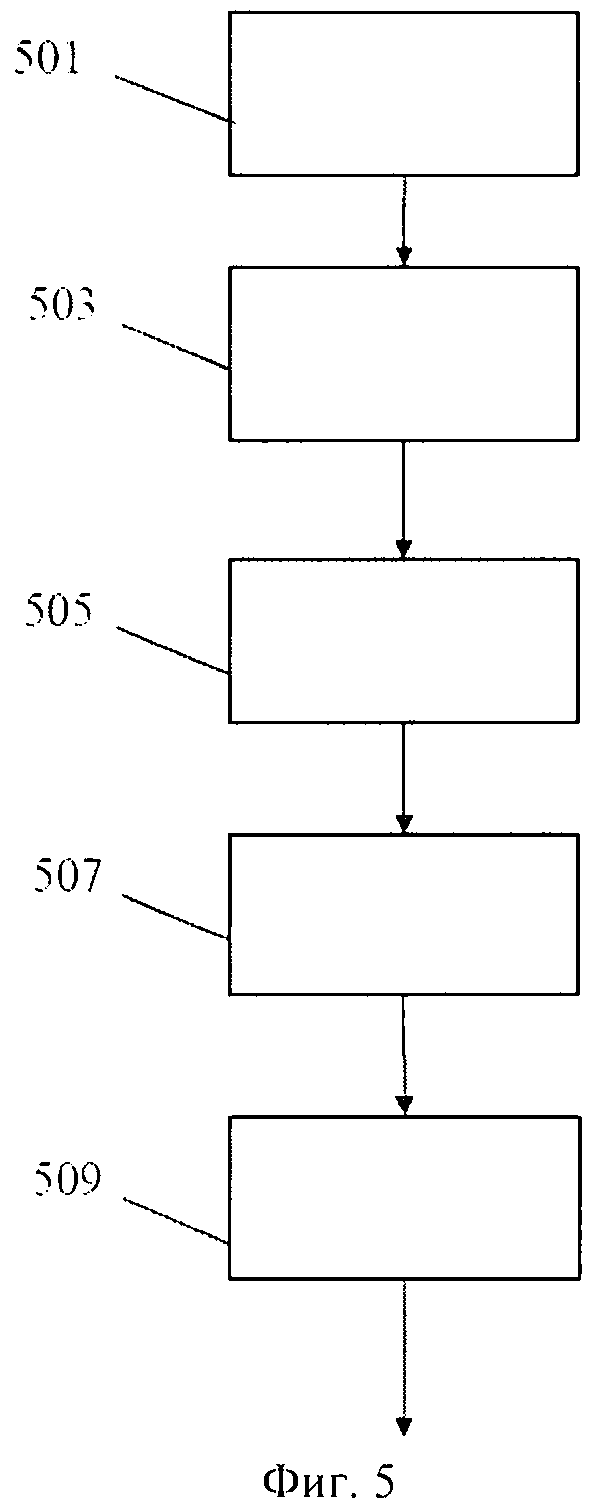
Способ начинается с шага 501, где получаются звуковые данные, включающие звуковой сигнал М-канала, являющегося звуковым сигналом понижающего микширования канала N, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала канала N.
Шаг 501 сопровождается шагом 503, где пространственные параметры пространственных параметрических данных преобразуются в первые бинауральные параметры в ответ на бинауральную перцепционную передаточную функцию.
Шаг 503 сопровождается шагом 505, где звуковой сигнал М-канала преобразуется в первый стереосигнал в ответ на первые бинауральные параметры.
Шаг 505 сопровождается шагом 507, где коэффициенты фильтрации определяются для стереофильтра в ответ на бинауральную перцепционную передаточную функцию.
Шаг 507 сопровождается шагом 509, где бинауральный звуковой сигнал генерируется посредством фильтрации первого стереосигнала в стереофильтре.
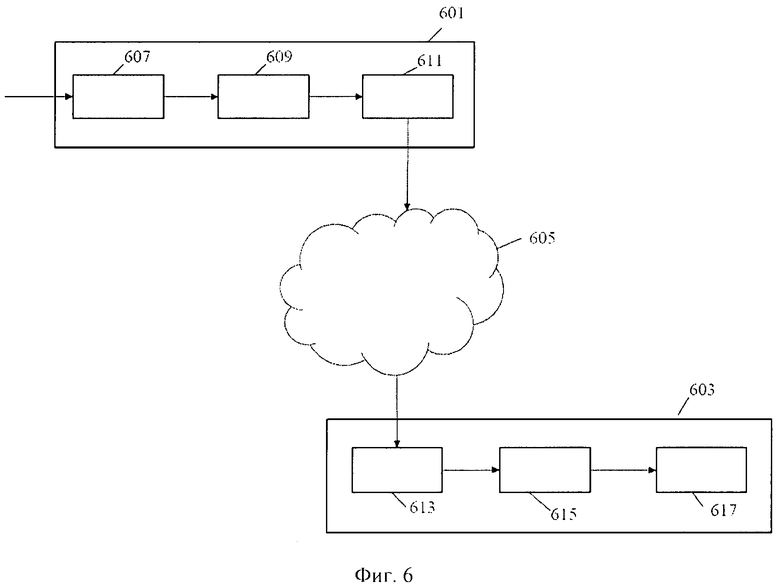
Устройство Фиг.4 может, например, использоваться в системе передачи. Фиг.6 иллюстрирует пример системы передачи для пересылки звукового сигнала в соответствии с некоторыми осуществлениями изобретения. Система передачи включает передатчик 601, который соединяется с приемником 603 через сеть 605, которая, в частности, может быть Интернетом.
В конкретном примере передатчик 601 является устройством, записывающим сигнал, а приемник 603 является устройством, воспроизводящим сигнал, но следует заметить, что в других осуществлениях передатчик и приемник могут использоваться в других применениях и в других целях. Например, передатчик 601 и/или приемник 603 может быть частью функциональных возможностей перекодировки и может, например, осуществить стыковку с другими источниками сигнала или адресами назначения. А именно, приемник 603 может получить закодированный объемный звуковой сигнал и генерировать закодированный бинауральный сигнал, эмулирующий объемный звуковой сигнал. Закодированный бинауральный сигнал может затем быть распределен по другим источникам.
В конкретном примере, где поддерживается функция записи сигнала, передатчик 601 включает цифровой преобразователь 607, который получает аналоговый многоканальный (объемный) сигнал, который преобразуется в цифровой РСМ (Импульсный Кодовый Модулированный) сигнал посредством выборки и аналого-цифрового преобразования.
Цифровой преобразователь 607 соединен с кодирующим устройством 609 Фиг.1, который кодирует РСМ многоканальный канал в соответствии с алгоритмом кодирования. В конкретном примере кодирующее устройство 609 кодирует сигнал, как MPEG закодированный объемный звуковой сигнал. Кодирующее устройство 609 соединено с сетевым передатчиком 611, который получает закодированный сигнал и соединяется с Интернетом 605. Сетевой передатчик может передавать закодированный сигнал приемнику 603 через Интернет 605.
Приемник 603 включает сетевой приемник 613, который соединяется с Интернетом 605 и который устроен так, чтобы получать кодируемый сигнал от передатчика 601.
Сетевой приемник 613 соединен с бинауральным декодером 615, который в примере является устройством Фиг.4.
В конкретном примере, где поддерживается функция воспроизведения сигнала, приемник 603 далее включает проигрыватель сигнала 1617, который получает бинауральный звуковой сигнал от бинаурального декодера 615 и воспроизводит его пользователю. А именно, проигрыватель сигнала 117 может включать цифроаналоговый преобразователь, усилители и громкоговорители, как требуется для вывода бинаурального звукового сигнала на ряд наушников.
Следует заметить, что вышеупомянутое описание осуществлений изобретения для ясности производится со ссылкой на различные функциональные узлы и процессоры. Однако очевидно, что может использоваться любое подходящее распределение функциональных возможностей между различными функциональными узлами или процессорами, не умаляя значения изобретения. Например, проиллюстрированные функциональные возможности, которые могут быть выполнены отдельными процессорами или контроллерами, могут быть выполнены тем же самым процессором или контроллером. Следовательно, ссылки на конкретные функциональные узлы должны рассматриваться только как ссылки на подходящие средства для обеспечения описанных функциональных возможностей, а не указывающие на строго логические или физические структуры или устройства.
Изобретение может быть осуществлено в любой подходящей форме, включая аппаратные средства, программное обеспечение, программно-аппаратные средства или любую их комбинацию. Изобретение может быть дополнительно осуществлено, по крайней мере, частично, как программное обеспечение, запущенное на одном или нескольких процессорах данных и/или цифровых процессорах сигнала. Элементы и компоненты осуществления изобретения могут быть физически, функционально и логически осуществлены любым подходящим способом. Действительно, функциональные возможности могут быть осуществлены в едином узле, во множестве узлов или как часть других функциональных узлов. По существу, изобретение может быть осуществлено в едином узле или может быть физически и функционально распределено между различными узлами и процессорами.
Хотя данное изобретение было описано в связи с некоторыми осуществлениями, оно не ограничивается определенной формой, изложенной здесь. Область данного изобретения скорее ограничивается только сопровождающей патентной формулой. Дополнительно, хотя какая-то техническая характеристика может быть описана в связи с конкретными осуществлениями, специалист, квалифицированный в этой области, поймет, что различные технические характеристики описанных осуществлений могут быть объединены в соответствии с изобретением. Содержащиеся в патентной формуле термины не исключает присутствия других элементов или шагов.
Кроме того, хотя перечислены отдельно, многие средства, элементы или шаги способа могут быть осуществлены, например, посредством единого узла или процессора. Дополнительно, хотя индивидуальные технические характеристики могут быть включены в различные пункты патентной формулы, они могут, возможно, быть преимущественно объединены, и включение в различные пункты патентной формулы не подразумевает того, что объединение технических характеристик невыполнимо и/или невыгодно. Также включение технической характеристики в одну категорию патентной формулы не подразумевает ограничение только этой категорией, а скорее указывает на то, что техническая характеристика одинаково применима к другим категориям патентной формулы, если пригодны. Кроме того, порядок технических характеристик в патентной формуле не подразумевает определенного порядка, в котором технические характеристики должны обрабатываться, и, в частности, порядок индивидуальных шагов в патентной формуле способа не подразумевает того, что шаги должны выполняться в этом порядке. Скорее шаги могут быть выполнены в любом подходящем порядке. Кроме того, одиночные ссылки не исключают множества. Так, ссылки на «какой-то», «первый», «второй» и т.д. не исключают множества. Опорные признаки в патентной формуле предоставлены просто, как разъясняющий пример, и не должны рассматриваться как ограничение области патентной формулы в любом случае.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ АУДИО | 2007 |
|
RU2427978C2 |
| БИНАУРАЛЬНАЯ ВИЗУАЛИЗАЦИЯ МУЛЬТИКАНАЛЬНОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2512124C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409911C2 |
| ФОРМИРОВАНИЕ БИНАУРАЛЬНЫХ СИГНАЛОВ | 2009 |
|
RU2505941C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409912C9 |
| БИНАУРАЛЬНАЯ АУДИООБРАБОТКА | 2014 |
|
RU2656717C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРИМЕНЕНИЯ РЕВЕРБЕРАЦИИ К МНОГОКАНАЛЬНОМУ ЗВУКОВОМУ СИГНАЛУ С ИСПОЛЬЗОВАНИЕМ ПАРАМЕТРОВ ПРОСТРАНСТВЕННЫХ МЕТОК | 2009 |
|
RU2509442C2 |
| УСТРОЙСТВО И СПОСОБ ИЗВЛЕЧЕНИЯ ПРЯМОГО СИГНАЛА/СИГНАЛА ОКРУЖЕНИЯ ИЗ СИГНАЛА ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ И ПРОСТРАНСТВЕННОЙ ПАРАМЕТРИЧЕСКОЙ ИНФОРМАЦИИ | 2011 |
|
RU2568926C2 |
| АУДИОСИСТЕМА И СПОСОБ ОПЕРИРОВАНИЯ ЕЮ | 2012 |
|
RU2595943C2 |
| ГЕНЕРИРОВАНИЕ БИНАУРАЛЬНОГО ЗВУКОВОГО СИГНАЛА В ОТВЕТ НА МНОГОКАНАЛЬНЫЙ ЗВУКОВОЙ СИГНАЛ С ИСПОЛЬЗОВАНИЕМ ПО МЕНЬШЕЙ МЕРЕ ОДНОЙ СХЕМЫ ЗАДЕРЖКИ С ОБРАТНОЙ СВЯЗЬЮ | 2021 |
|
RU2831385C2 |
Изобретение относится к способу и устройству для генерирования бинаурального звукового сигнала и, в частности, к генерированию бинаурального звукового сигнала из моносигнала понижающего микширования. Техническим результатом является повышение качества генерируемого бинаурального сигнала при снижении потребления вычислительного или запоминающего ресурса. Указанный результат достигается тем, что устройство для генерирования бинаурального звукового сигнала включает демультиплексор (401) и декодер (403), который получает звуковые данные, включающие звуковой сигнал M-канала, являющийся сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала M-канала до звукового сигнала N-канала. Конверсионный процессор (411) преобразует пространственные параметры пространственных параметрических данных в первые бинауральные параметры в ответ на бинауральную перцепционную передаточную функцию. Матричный процессор (409) преобразует звуковой сигнал M-канала в первый стереосигнал в ответ на первые бинауральные параметры. Стереофильтр (415, 417) генерирует бинауральный звуковой сигнал посредством фильтрации первого стереосигнала. Коэффициенты фильтрации для стереофильтра определяются в ответ на бинауральную перцепционную передаточную функцию посредством коэффициентного процессора (419). 9 н. и 8 з.п. ф-лы, 6 ил.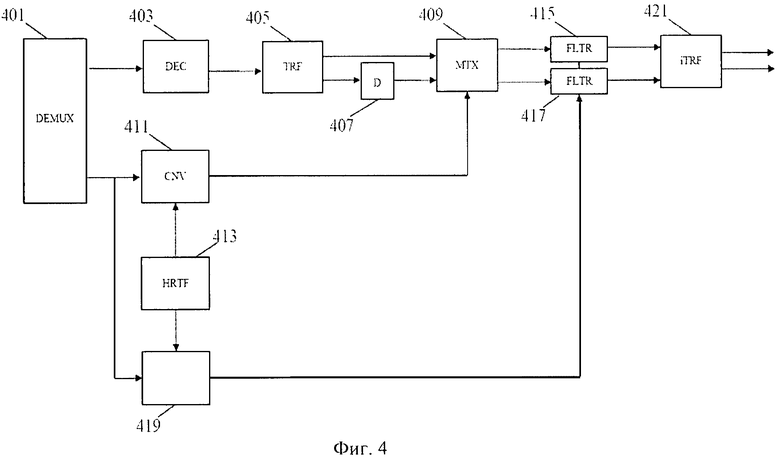
1. Устройство для генерирования бинаурального звукового сигнала, характеризующееся тем, что включает средства (401, 403) для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования М-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; средства параметрических данных (411) для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; конверсионные средства (409) для преобразования звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр (415, 417) для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; и коэффициентные средства (419) для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию.
2. Устройство по п.1, характеризующееся тем, что включает дополнительно средства преобразования (405) для преобразования звукового сигнала М-канала от временного интервала до области поддиапазона, и где конверсионные средства и стереофильтр устроены так, чтобы индивидуально обрабатывать каждый поддиапазон области поддиапазонов.
3. Устройство по п.2, характеризующееся тем, что продолжительность импульсного ответа бинауральной перцепционной передаточной функции превышает интервал обновления преобразований.
4. Устройство по п.2, характеризующееся тем, что конверсионные средства (409) устроены так, чтобы для каждого поддиапазона генерировать выходные стереообразцы в основном как:
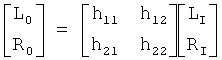 ,
,
где, по крайней мере, один из LI и RI является образцом звукового канала звукового сигнала М-канала в поддиапазоне, и конверсионные средства устроены так, чтобы определять матричные коэффициенты hxy в ответ на пространственные параметрические данные и в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию.
5. Устройство по п.2, характеризующееся тем, что коэффициентные средства (419) включают средства для обеспечения представления поддиапазона импульсных ответов множества бинауральных перцепционных передаточных функций, соответствующих различным источникам звука в сигнале N-канала; средства для определения коэффициентов фильтрации взвешенной комбинацией соответствующих коэффициентов представлений поддиапазона; и средства для определения весовых коэффициентов для представлений поддиапазона для взвешенной комбинации в ответ на пространственные параметрические данные.
6. Устройство по п.1, характеризующееся тем, что первые бинауральные параметры включают параметры когерентности, указывающие на корреляцию между каналами бинаурального звукового сигнала.
7. Устройство по п.1, характеризующееся тем, что первые бинауральные параметры не включают, по крайней мере, один из параметров локализации, указывающий на местоположение любого источника звука сигнала N-канала и параметров реверберации, указывающих на реверберацию любого звукового компонента бинаурального звукового сигнала.
8. Устройство по п.1, характеризующееся тем, что коэффициентные средства (419) устроены так, чтобы определять коэффициенты фильтрации для отражения, по крайней мере, одной из реплик локализации и реплик реверберации для бинаурального звукового сигнала.
9. Устройство по п.1, характеризующееся тем, что звуковой сигнал М-канала является монозвуковым сигналом, и конверсионные средства (407, 409) устроены так, чтобы генерировать декорреляционный сигнал от монозвукового сигнала, и генерировать первый стереосигнал посредством матричного умножения, применяемого к образцам стереосигнала, включающим декорреляционный сигнал и монозвуковой сигнал.
10. Способ генерирования бинаурального звукового сигнала, характеризующийся тем, что включает получение (501) звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала М-канала; преобразование (503) пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; преобразование (505) звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; генерирование (509) бинаурального звукового сигнала посредством фильтрации первого стереосигнала; и определение (507) коэффициентов фильтрации для стереофильтра в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию.
11. Передатчик для передачи бинаурального звукового сигнала, характеризующийся тем, что включает средства (401, 403) для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; средства параметрических данных (411) для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; конверсионные средства (409) для преобразования звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр (415, 417) для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; и коэффициентные средства (419) для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию, средства для передачи бинаурального звукового сигнала.
12. Система передачи для передачи звукового сигнала, характеризующаяся тем, что включает передатчик, содержащий средства (401, 403) для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала, средства параметрических данных (411) для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию, конверсионные средства (409) для преобразования звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры, стереофильтр (415, 417) для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала, коэффициентные средства (419) для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию, и средства для передачи бинаурального звукового сигнала; и приемник для получения бинаурального звукового сигнала.
13. Устройство для записи звукового сигнала для записи бинаурального звукового сигнала, характеризующееся тем, что включает средства (401, 403) для получения звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; средства параметрических данных (411) для преобразования пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; конверсионные средства (409) для преобразования звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; стереофильтр (415, 417) для генерирования бинаурального звукового сигнала посредством фильтрации первого стереосигнала; коэффициентные средства (419) для определения коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию; и средства для записи бинаурального звукового сигнала.
14. Способ передачи бинаурального звукового сигнала, характеризующийся тем, что включает получение звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала; преобразование пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию; преобразование звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры; генерирование бинаурального звукового сигнала посредством фильтрации первого стереосигнала в стереофильтре; определение коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию; и передачу бинаурального звукового сигнала.
15. Способ передачи и получения бинаурального звукового сигнала, характеризующийся тем, что включает передатчик, выполняющий шаги: получение звуковых данных, включающих звуковой сигнал М-канала, являющийся звуковым сигналом понижающего микширования N-канала, и пространственные параметрические данные для повышающего микширования звукового сигнала М-канала до звукового сигнала N-канала, преобразование пространственных параметров пространственных параметрических данных в первые бинауральные параметры в ответ на, по крайней мере, одну бинауральную перцепционную передаточную функцию, преобразование звукового сигнала М-канала в первый стереосигнал в ответ на первые бинауральные параметры, генерирование бинаурального звукового сигнала посредством фильтрации первого стереосигнала в стереофильтре, определение коэффициентов фильтрации для стереофильтра в ответ на бинауральную перцепционную передаточную функцию и передача бинаурального звукового сигнала; и приемник, выполняющий шаг получения бинаурального звукового сигнала.
16. Машиночитаемый носитель, содержащий сохраненный на нем компьютерный программный продукт с кодом программы для выполнения способа по п.14.
17. Машиночитаемый носитель, содержащий сохраненный на нем компьютерный программный продукт с кодом программы для выполнения способа по п.15.
| BREEBAART J | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| FALLER С | |||
| Parametric coding of spatial audio, Proc | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |

