ПЕРЕКРЕСТНАЯ ССЫЛКА К РОДСТВЕННЫМ ЗАЯВКАМ
Данная заявка испрашивает приоритет по параграфу 120 раздела 35 Кодекса законов США как частичное продолжение (CIP) заявки США № 10/911067, озаглавленной «Lossless Multi-Channel Audio Codec», поданной 4 августа 2004, все содержимое которой заключено посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
Область техники, к которой относится изобретение
Данное изобретение относится к аудиокодекам без потерь, а более конкретно - к многоканальному аудиокодеку без потерь, который использует адаптивную сегментацию с возможностью точек произвольного доступа (RAP) и возможностью множества наборов параметров предсказания (MPPS).
Описание родственного уровня техники
Множество систем кодирования аудио с потерями с низкой скоростью передачи битов используются в настоящее время в широком диапазоне потребительских и профессиональных продуктов и услуг воспроизведения аудио. Например, система кодирования аудио Dolby AC3 (Dolby Digital) является международным стандартом для кодирования стереофонических и 5.1-канальных звуковых дорожек аудио для лазерных дисков, кодированных с помощью NTSC видео-DVD и ATV, используя скорость передачи битов до 640 кбит/с. Стандарты кодирования аудио MPEG I и MPEG II широко используются для кодирования стереофонических и многоканальных звуковых дорожек для кодированных с помощью PAL видео-DVD, наземного цифрового радиовещания в Европе и спутникового вещания в США на скорости передачи битов до 768 кбит/с. Система кодирования аудио Coherent Acoustics компании DTS (Digital Theatre System - цифровые системы для кинотеатров) часто используется для 5.1-канальных звуковых дорожек аудио студийного качества для компакт-дисков, видео-DVD, спутникового вещания в Европе и лазерных дисков и для скорости передачи битов до 1536 кбит/с.
В последнее время многие потребители проявляют интерес к так называемым кодекам «без потерь». Кодеки «без потерь» основаны на алгоритмах, которые сжимают данные, не отказываясь ни от какой информации, и производят декодированный сигнал, который идентичен (оцифрованному) исходному сигналу. Эти характеристики увеличивают стоимость: такие кодеки обычно требуют большей полосы пропускания, чем кодеки с потерями, и сжимают данные к меньшей степени.
Фиг.1 - представление структурной схемы операций, которые используют при сжатии без потерь одного аудио канала. Хотя каналы в многоканальном аудио в общем случае не являются независимыми, данная зависимость является часто слабой и ее трудно принимать во внимание. Поэтому, каналы обычно сжимают отдельно. Однако, некоторые кодеры попытаются удалять корреляцию с помощью формирования простого остаточного сигнала и кодирования (Ch1, Ch1-CH2). Более сложные подходы используют, например, несколько этапов последовательных ортогональных проекций на размерности канала. Все методики основаны на принципе сначала удаления избыточности из сигнала и затем кодирования результирующего сигнала с помощью схемы эффективного цифрового кодирования. Кодеки без потерь включают в себя кодеки MPL (аудио-DVD), Monkey's audio (компьютерные приложения), кодек без потерь Apple, кодек без потерь Windows Media Pro, AudioPak, DVD, LTAC, MUSICcompress, OggSquish, Philips, Shorten, Sonarc и WA. Обзор многих из этих кодеков предоставлен в Mat Hans, Ronald Schafer «Lossless Compression of Digital Audio» Hewlett Packard, 1999.
Разделение на кадры 10 вводят для предоставления возможности редактирования, большой объем данных запрещает периодически повторяющуюся распаковку всего сигнала, который предшествует области, которая будет редактироваться. Аудиосигнал делят на независимые кадры равной продолжительности времени. Эта продолжительность не должна быть слишком короткой, так как значительное количество служебной информации может быть результатом присоединения заголовка к каждому кадру. С другой стороны, продолжительность кадра не должна быть слишком длительной, так как это лимитировало бы возможность адаптирования во временной области и сделало бы редактирование более трудным. Во многих применениях размер кадра ограничивается пиковой скоростью передачи битов носителя, на котором аудио переносят, емкостью буфера декодера и требованием, чтобы каждый кадр можно было независимо декодировать.
Внутриканальная декорреляция 12 удаляет избыточность с помощью декорреляции аудиовыборок в каждом канале в пределах кадра. Большинство алгоритмов удаляет избыточность с помощью некоторого вида моделирования сигнала с помощью линейного предсказания. При таком подходе модуль линейного предсказания применяют к аудиовыборкам в каждом кадре, что приводит к последовательности ошибок предсказания выборок. Вторым, менее обычным, подходом является получение представления сигнала, квантованного с низкой скоростью передачи битов, или с потерями, и затем сжатие без потерь разности между версией с потерями и исходной версией. Энтропийное кодирование 14 удаляет избыточность из ошибок остаточного сигнала, не теряя информации. Типичные способы включают в себя кодирование методом Хаффмана, кодирование длины серий и кодирование Райса. Выходным является сжатый сигнал, который может быть восстановлен без потерь.
Существующая спецификация DVD и предварительная спецификация DVD HD устанавливают жесткий лимит на размер одного модуля доступа к данным, который представляет часть аудио потока, который при извлечении можно полностью декодировать и восстановленные аудиовыборки можно посылать в выходной буфер. Для потока без потерь это означает, что количество времени, которое может представлять каждый модуль доступа, должно быть достаточно маленьким, чтобы в самом плохом случае пиковой скорости передачи битов кодированная полезная информация не превышала жесткий лимит. Продолжительность времени необходимо также уменьшать для увеличения частот выборки и увеличения количества каналов, которые увеличивают пиковую скорость передачи битов.
Для обеспечения совместимости эти существующие кодеры должны устанавливать продолжительность всего кадра достаточно короткой, чтобы не превысить жесткий лимит в самой плохой конфигурации канала/частоты выборок/битовой разрядности. В большинстве конфигураций это будет крайней ситуацией и может серьезно ухудшить производительность сжатия. Кроме того, этот подход самого плохого случая нельзя масштабировать с дополнительными каналами.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение предоставляет аудиокодек, который генерирует битовый поток с переменной скоростью передачи битов (VBR) без потерь с возможностью точек произвольного доступа (RAP) для инициирования декодирования без потерь в заданном сегменте в пределах кадра и/или возможности разделения с множеством наборов параметров предсказания (MPPS) для подавления влияния транзиентов.
Это достигается с помощью методики адаптивной сегментации, которая определяет начальные точки сегмента для обеспечения ограничений границ на сегменты, налагаемых наличием необходимой RAP и/или одним или более транзиентов в кадре, и выбора оптимальной продолжительности сегмента в каждом кадре для уменьшения кодированной полезной информации кадра, при условии ограничения кодированной полезной информации сегмента. В общем случае ограничения границ задают так, что необходимая RAP или транзиент должны находиться в пределах определенного количества блоков анализа от начала сегмента. В примерном варианте осуществления, в котором сегменты в пределах кадра имеют одинаковую продолжительность и степень двойки продолжительности блока анализа, максимальную продолжительность сегмента определяют для обеспечения соблюдения необходимых условий. RAP и MPPS, в частности, применяют для повышения общей производительности для более длительной продолжительности кадра.
В примерном варианте осуществления битовый поток аудио VBR без потерь кодируют с RAP (сегментами RAP), выровненными в пределах заданного допуска необходимой RAP, предоставленной во временном коде кодера. Каждый кадр блокируют в последовательность блоков анализа, причем каждый сегмент имеет продолжительность, равную продолжительности одного или более блоков анализа. В каждом последовательном кадре из временного кода определяют до одного блока анализа RAP. Расположение блока анализа RAP и ограничение, что блок анализа RAP должен находиться в пределах М блоков анализа от начала сегмента RAP, устанавливает начало сегмента RAP. Параметры предсказания определяют для кадра, два набора параметров (в канале), если MPPS допускается, и транзиент обнаруживают в канале. Выборки в аудио кадре сжимают с отключением предсказания для первых выборок по порядку предсказания после начала сегмента RAP. Адаптивную сегментацию используют для остаточных выборок для определения продолжительности сегмента и параметров энтропийного кодирования для каждого сегмента для минимизации кодированной полезной информации кадра, при условии установленного начала сегмента RAP и ограничений кодированной полезной информации сегмента. Параметры RAP, указывающие наличие и расположение сегмента RAP, и навигационные данные упаковывают в заголовок. В ответ на навигационную команду для инициирования воспроизведения, такую как выбор пользователем сцены или случайное перемещение, декодер распаковывает заголовок следующего кадра в битовом потоке для считывания параметров RAP до тех пор, пока кадр, включающий в себя сегмент RAP, не будет обнаружен. Декодер извлекает продолжительность сегмента и навигационные данные для перемещения к началу сегмента RAP. Декодер отключает предсказание для первых выборок до тех пор, пока хронология предсказания не будет восстановлена, и затем декодирует остальную часть сегментов и последующие кадры по порядку, отключая модуль предсказания каждый раз, когда встречается сегмент RAP. Эта конструкция позволяет декодеру инициировать декодирование в или очень близко от заданных кодером RAP с разрешающей способностью субкадра. Это особенно удобно при более длительной продолжительности кадра, когда пытаются синхронизировать воспроизведение аудио с временным кодом видео, который задает RAP, например, в начале глав.
В другом примерном варианте осуществления битовый поток аудио VBR без потерь, который кодируют с MPPS, разделяют таким образом, чтобы обнаруженные транзиенты были расположены в пределах L первых блоков анализа сегмента в их соответствующих каналах. В каждом последовательном кадре обнаруживают до одного транзиента в канале в наборе каналов и его расположение в пределах кадра. Параметры предсказания определяют для каждой части, учитывая начальную точку(ки) сегмента, предписанную с помощью транзиента(ов). Выборки в каждой части сжимают с помощью соответствующего набора параметров. Адаптивная сегментация используется для остаточных выборок для определения продолжительности сегмента и параметров энтропийного кодирования для каждого сегмента для минимизации кодированной полезной информации кадра, при условии ограничений начала сегмента, предписанного с помощью транзиента(ов) (и RAP), и ограничений кодированной полезной информации сегмента. Параметры транзиента, указывающие наличие и расположение первого сегмента с транзиентом (в канале), и навигационные данные упаковывают в заголовок. Декодер распаковывает заголовок кадра, чтобы извлечь параметры транзиента и дополнительный набор параметров предсказания. Для каждого канала в наборе каналов декодер использует первый набор параметров предсказания до тех пор, пока не встречается сегмент с транзиентом, и переключается на второй набор для остальных сегментов. Хотя сегментация кадра является одинаковой по каналам и множеству наборов каналов, расположение транзиента (если есть) может изменяться между наборами и в пределах наборов. Эта конструкция позволяет декодеру переключать наборы параметров предсказания в или около начала обнаруженных транзиентов с разрешающей способностью субкадра. Это особенно удобно при более длительной продолжительности кадров для повышения общей эффективности кодирования.
Производительность сжатия можно дополнительно увеличивать, формируя М/2 декоррелированных каналов для M-канального аудио. Триплет каналов (основной, коррелированный, декоррелированный) предоставляет две возможных комбинации пар (основной, коррелированный) и (основной, декоррелированный), которые можно учитывать во время оптимизации сегментации и энтропийного кодирования для дополнительного повышения производительности сжатия. Пары каналов можно задавать для сегмента или для кадра. В примерном варианте осуществления кодер разделяет на кадры аудио данные и затем извлекает упорядоченные пары каналов, включающие в себя основной канал и коррелированный канал, и генерирует декоррелированный канал для формирования по меньшей мере одного триплета (основной, коррелированный, декоррелированный). Если количество каналов является нечетным, то дополнительно обрабатывают основной канал. Адаптивное или фиксированное полиномиальное предсказание применяют к каждому каналу для формирования остаточных сигналов. Для каждого триплета выбирают пару канала (основной, коррелированный) или (основной, декоррелированный) с наименьшей кодированной полезной информацией. Используя выбранную пару каналов, глобальный набор параметров кодирования можно определять для каждого сегмента по всем каналам. Кодер выбирает глобальный набор или отличающиеся наборы параметров кодирования, основываясь на том, какие из них имеют наименьшую полную кодированную полезную информацию (заголовок и аудио данные).
При любом подходе, когда оптимальный набор параметров кодирования и пар каналов для текущего разделения (продолжительности сегментов) определен, кодер вычисляет кодированную полезную информацию в каждом сегменте по всем каналам. Предполагая, что ограничения на начало сегмента и на максимальный размер полезной информации сегмента для всех необходимых RAP или обнаруженных транзиентов удовлетворяются, кодер определяет, является ли полная кодированная полезная информация для всего кадра для текущего разделения меньше текущего оптимума для более раннего разделения. Если «да», то текущий набор параметров кодирования и кодированную полезную информацию сохраняют, и продолжительность сегмента увеличивают. Алгоритм сегментации, соответственно, начинают с деления кадра на минимальные сегменты, размер которых равен размеру блока анализа, и увеличивают продолжительность сегмента с помощью степени двойки на каждом этапе. Этот процесс повторяют или до нарушения размером сегмента максимального ограничения размера, или пока продолжительность сегмента не увеличится до максимальной продолжительности сегмента. Включение признаков RAP или MPPS и наличие необходимой RAP или обнаруженного транзиента в пределах кадра могут привести к тому, что подпрограмма адаптивной сегментации выберет меньшую продолжительность сегмента, чем это иначе было бы.
Эти и другие признаки и преимущества изобретения будут очевидны специалистам из последующего подробного описания предпочтительных вариантов осуществления при рассмотрении с сопроводительными чертежами, на которых:
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1, как описано выше, является структурной схемой стандартного аудиокодера без потерь;
фиг.2a и 2b - структурные схемы аудиокодера и аудиодекодера без потерь, соответственно, в соответствии с настоящим изобретением;
фиг.3 - схема информации заголовка, которая относится к сегментации и выбору энтропийного кода;
фиг.4a и 4b - структурные схемы обработки оконного анализа и обработки обратного оконного анализа;
фиг.5 - последовательность операций межканальной декорреляции;
фиг.6a и 6b - структурные схемы анализа и обработки адаптивного предсказания и обработки обратного адаптивного предсказания;
фиг.7a и 7b - последовательности операций оптимальной сегментации и выбора энтропийного кода;
фиг.8a и 8b - последовательности операций выбора энтропийного кода для набора каналов;
фиг.9 - структурная схема основного кодека плюс кодека расширения без потерь;
фиг.10 - схема кадра битового потока, в котором каждый кадр включает в себя заголовок и множество сегментов;
фиг.11a и 11b - схемы информации дополнительного заголовка, относящегося к спецификации RAP и MPPS;
фиг.12 - последовательность операций для определения границы сегмента или максимальной продолжительности сегмента для необходимых RAP или обнаруженных транзиентов;
фиг.13 - последовательность операций для определения MPPS;
фиг.14 - схема кадра, на которой показывают выбор начальных точек сегмента или максимальной продолжительности сегмента;
фиг.15a и 15b - схемы, показывающие битовый поток и декодирование битового потока в сегменте RAP и сегменте с транзиентом; и
фиг.16 - схема, показывающая адаптивную сегментацию, основанную на ограничениях максимальной полезной информации сегмента и максимальной продолжительности сегмента.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение предоставляет алгоритм адаптивной сегментации, который генерирует битовый поток с переменной скоростью передачи битов (VBR) без потерь с возможностью точек произвольного доступа (RAP) для инициирования декодирования без потерь в заданном сегменте в пределах кадра, и/или возможностью множества наборов параметров предсказания (MPPS), при разделении для подавления влияния транзиентов. Методика адаптивной сегментации определяет и устанавливает начальные точки сегмента для обеспечения, чтобы они соответствовали граничным условиям, налагаемым необходимыми RAP и/или обнаруженными транзиентами, и выбирает оптимальную продолжительность сегмента в каждом кадре для уменьшения кодированной полезной информации кадра, при условии ограничений кодированной полезной информации сегмента и установленных начальных точек сегмента. В общем случае, ограничения границ задают так, что необходимая RAP или транзиент должны находиться в пределах определенного количества блоков анализа от начала сегмента. Необходимая RAP может находиться плюс-минус определенное количество блоков анализа от начала сегмента. Транзиент находится в пределах определенного количества первых блоков анализа сегмента. В примерном варианте осуществления, в котором сегменты в пределах кадра имеют одинаковую продолжительность, равную степени двойки продолжительности блока анализа, максимальная продолжительность сегмента определяется, чтобы обеспечить необходимые условия. RAP и MPPS, в частности, можно применять для повышения общей производительности для более длительной продолжительности кадра.
АУДИОКОДЕК БЕЗ ПОТЕРЬ
Как показано на фиг.2a и 2b, основные рабочие блоки аналогичны существующим кодерам и декодерам без потерь за исключением изменения в обработке оконного анализа для определения условий начала сегмента для RAP и/или транзиентов и сегментации и выбора энтропийного кода. Блок обработки оконного анализа подвергает многоканальное аудио PCM (импульсно-кодовой модуляции (ИКМ)) 20 обработке 22 оконного анализа, который блокирует данные в кадры постоянной продолжительности, устанавливает начальные точки сегмента, основываясь на необходимых RAP и/или обнаруженных транзиентах, и удаляет избыточность с помощью декорреляции аудиовыборок в каждом канале в пределах кадра. Декорреляцию выполняют, используя предсказание, которое широко описано, как любой процесс, который использует старые восстановленные аудиовыборки (хронологию предсказания) для оценки значения текущей исходной выборки и определяет остаток. Методики предсказания охватывают фиксированное или адаптивное предсказание и линейное или нелинейное предсказание среди других. Вместо энтропийного кодирования непосредственно остаточных сигналов, модуль адаптивной сегментации выполняет процесс 24 выбора оптимальной сегментации и энтропийного кода, который делит данные на множество сегментов и определяет продолжительность сегмента и параметры кодирования, например, выбирает определенный энтропийный кодер и его параметры для каждого сегмента, которые минимизируют кодированную полезную информацию для всего кадра, при условии ограничения, что каждый сегмент должен иметь возможность полностью и без потерь декодироваться, иметь меньше максимального количества байтов, которое меньше размера кадра, меньше продолжительности кадра, и что любая необходимая RAP и/или обнаруженный транзиент должны находиться в пределах конкретного количества блоков анализа (разрешающей способности субкадра) от начало сегмента. Наборы параметров кодирования оптимизируют для каждого отличающегося канала, и их можно оптимизировать для глобального набора параметров кодирования. Энтропийный кодер кодирует 26 с помощью энтропийного кодирования каждый сегмент согласно определенному для него набору параметров кодирования. Модуль упаковывания упаковывает 28 кодированные данные и информацию заголовка в битовый поток 30.
Как показано на фиг.2b, для выполнения операции декодирования, декодер перемещается к точке в битовом потоке 30 в ответ, например, на выбор пользователем видео-сцены или главы или произвольное перемещение пользователя, и модуль распаковывания распаковывает 40 битовый поток, чтобы извлечь информацию заголовка и кодированные данные. Декодер распаковывает информацию заголовка для определения следующего сегмента RAP, в котором может начаться декодирование. Декодер затем перемещается к сегменту RAP и инициирует декодирование. Декодер отключает предсказание для определенного количества выборок, когда он обнаруживает каждый из сегментов RAP. Если декодер обнаруживает присутствие транзиента в кадре, то декодер использует первый набор параметров предсказания для декодирования первой части, и затем использует второй набор параметров предсказания для декодирования, начиная с транзиента и далее в пределах кадра. Энтропийный декодер выполняет энтропийное декодирование 42 каждого сегмента каждого канала согласно назначенным параметрам кодирования для восстановления без потерь остаточных сигналов. Модуль обработки обратного оконного анализа подвергает эти сигналы обработке 44 обратного оконного анализа, которая выполняет обратное предсказание для восстановления без потерь исходного аудио PCM 20.
НАВИГАЦИЯ ПО БИТОВОМУ ПОТОКУ И ФОРМАТ ЗАГОЛОВКА
Как показано на фиг.10, кадр 500 в битовом потоке 30 включает в себя заголовок 502 и множество сегментов 504. Заголовок 502 включает в себя синхронизацию 506, обычный заголовок 508, подзаголовок 510 для одного или более наборов каналов, и навигационные данные 512. В данном варианте осуществления навигационные данные 512 включают в себя модуль данных NAVI 514 и код исправления ошибок CRC16 516. В модуле данных NAVI предпочтительно разделяют навигационные данные на наименьшие части битового потока для получения возможности полной навигации. Модуль данных включает в себя NAVI-сегменты 518 для каждого сегмента, и каждый NAVI-сегмент включает в себя размер полезной информации набора каналов NAVI ChSet 520 для каждого набора каналов. Кроме всего прочего, это позволяет декодеру перемещаться к началу сегмента RAP для любого указанного набора каналов. Каждый сегмент 504 включает в себя энтропийно кодированные остатки 522 (и исходные выборки, когда предсказание отключено для RAP) для каждого канала в каждом наборе каналов.
Битовый поток включает в себя информацию заголовка и кодированные данные по меньшей мере для одного, а предпочтительно, - для множества различных наборов каналов. Например, первый набор каналов может иметь конфигурацию 2.0, второй набор каналов может иметь дополнительные 4 канала, составляя 5.1-канальное представление, и третий набор каналов может иметь дополнительные 2 окружающие канала, составляющие вместе 7.1-канальное представление. 8-канальный декодер извлекает и декодирует все 3 набора каналов, создавая на своем выходе 7.1-канальное представление. 6-канальный декодер извлекает и декодирует набор каналов 1 и набор каналов 2, полностью игнорируя набор каналов 3, создавая 5.1-канальное представление. 2-канальный декодер извлекает и декодирует только набор каналов 1 и игнорирует наборы каналов 2 и 3, создавая 2-канальное представление. Структурирование потока этим способом позволяет масштабировать сложность декодера.
Во время кодирования временной кодер выполняет так называемое «внедренное понижающее микширование», так что понижающее микширование 7.1->5.1 легко доступно в 5.1 каналах, которые закодированы в наборах каналов 1 и 2. Так же понижающее микширование 5.1->2.0 легко доступно в 2.0 каналах, которые закодированы, как набор каналов 1. 6-канальный декодер с помощью декодирования наборов каналов 1 и 2 получит понижающее микширование к 5.1 после отмены операции внедренного понижающего микширования 5.1->2.0, выполненное на кодирующей стороне. Так же полный 8-канальный декодер получит исходное 7.1 представление с помощью декодирования наборов каналов 1, 2 и 3 и отмены операций внедренного понижающего микширования 7.1->5.1 и 5.1->2.0, выполненные на кодирующей стороне.
Как показано на фиг.3, заголовок 32 включает в себя дополнительную информацию кроме той, которую обычно предоставляют для кодека без потерь, для осуществления сегментации и выбора энтропийного кода. Более конкретно, заголовок включает в себя информацию 34 общего заголовка, например, количество сегментов (NumSegments) и количество выборок в каждом сегменте (NumSamplesInSegm), информацию 36 заголовка набора каналов, например, квантованные коэффициенты декорреляции (QuantChDecorrCoeff [ ] [ ]), и информацию 38 заголовка сегмента, например, количество байтов в текущем сегменте для набора каналов (ChSetByteCOns), флаг глобальной оптимизации (AllChSameParamFlag) и флаги энтропийного кодера (RiceCodeFlag [ ], CodeParam [ ]), которые указывают, используется ли кодирование Райса или двоичное кодирование, и параметр кодирования. Эта определенная конфигурация заголовка предполагает сегменты равной продолжительности в пределах кадра и сегменты, которые являются степенью двойки продолжительности блока анализа. Сегментация кадра равномерна по каналам в пределах набора каналов и по наборам каналов.
Как показано на фиг.11a, заголовок дополнительно включает в себя параметры 530 RAP в обычном заголовке, которые задают наличие и расположение RAP в пределах данного кадра. В этом варианте осуществления заголовок включает в себя флаг RAP = «истина», если RAP присутствует. ИД (идентификатор) RAP задает номер сегмента RAP для инициирования декодирования при доступе к битовому потоку в необходимой RAP. В свою очередь, RAP_MASK можно использовать для указания сегментов, которые являются или не являются RAP. RAP будет согласована по всем наборам каналов.
Как показано на фиг.11b, заголовок включает в себя AdPredOrder [0] [ch] = порядок адаптивного предиктора или FixedPredOrder [0] [ch] = порядок фиксированного предиктора для канала ch или во всем кадре, или в случае транзиента, - в первой части кадра до транзиента. Когда выбирают адаптивное предсказание (AdPredOrder [0] [ch]>0), коэффициенты адаптивного предсказания кодируют и упаковывают в AdPredCodes [0] [ch] [AdPredOrder [0] [ch]].
В случае MPPS заголовок дополнительно включает в себя параметры 532 транзиента в информации заголовка набора каналов. В этом варианте осуществления каждый заголовок набора каналов включает в себя флаг ExtraPredSetsPrsent [ch] = «истина», если транзиент обнаружен в канале ch, StartSegment [ch] = индекс, указывающий сегмент начала транзиента для канала ch, и AdPredOrder [1] [ch] = порядок адаптивного предиктора, или FixedPredOrder [1] [ch] = порядок фиксированного предиктора для канала ch, применяемого ко второму разделению в кадре после транзиента и включающем его в себя. Когда выбирают адаптивное предсказание (AdPredOrder[1][ch]>0), второй набор коэффициентов адаптивного предсказания кодируют и упаковывают в AdPredCodes[1][ch][AdPredOrder[1][ch]]. Наличие и расположение транзиента может меняться по каналам в пределах набора каналов и по наборам каналов.
ОБРАБОТКА ОКОННОГО АНАЛИЗА
Как показано на фиг.4a и 4b, примерном варианте осуществления обработки 22 оконного анализа осуществляют выбор или из адаптивного предсказания 46, или из фиксированного полиномиального предсказания 48 для декорреляции каждого канала, что является довольно обычным подходом. Как будет описано подробно в отношении фиг.6a, оптимальный порядок предиктора оценивают для каждого канала. Если порядок больше нуля, то применяют адаптивное предсказание. Иначе используют более простое фиксированное полиномиальное предсказание. Точно так же в декодере обратную обработку 44 оконного анализа выбирают или из обратного адаптивного предсказания 50, или из обратного фиксированного полиномиального предсказания 52 для восстановления аудио PCM из остаточных сигналов. Порядок адаптивного предиктора и индексы коэффициентов адаптивного предсказания и порядок фиксированного предиктора упаковывают 53 в информации заголовка набора каналов.
Межканальная декорреляция
В соответствии с настоящим изобретением, производительность сжатия можно дополнительно увеличивать с помощью осуществления межканальной декорреляции 54, которая упорядочивает М входных каналов в пары каналов согласно показателю межканальной корреляции (другое «М», чем ограничение М блоков анализа для необходимой точки RAP). Один из каналов назначают, как «основной» канал, а другой назначают как «коррелированный» канал. Декоррелированный канал генерируют для каждой пары каналов для формирования «триплета» (основной, коррелированный, декоррелированный). Формирование триплета предоставляет две возможные комбинации пар (основной, коррелированный) и (основной, декоррелированный), которые можно учитывать во время оптимизации сегментации и энтропийного кодирования для дополнительного повышения производительности сжатия (см. фиг.8a).
Принятие решения между парами (основной, коррелированный) и (основной, декоррелированный) можно выполнять или до (основываясь на некотором показателе энергии), или вместе с адаптивной сегментацией. Первый подход уменьшает сложность, в то время как последний увеличивает эффективность. Можно использовать «гибридный» подход, где для триплетов, у которых есть декоррелированный канал со значительно (основываясь на пороговом значении) меньшей дисперсией, чем коррелированный канал, используется простая замена коррелированного канала декоррелированным каналом до адаптивной сегментации, в то время как для всех других триплетов принятие решения о кодировании коррелированного или декоррелированного канала оставляют для процесса адаптивной сегментации. Это несколько упрощает сложность процесса адаптивной сегментации, не жертвуя эффективностью кодирования.
Исходный М-канальное аудио PCM 20 и M/2-канальное декоррелированное аудио PCM 56 направляют и к операции адаптивного предсказания, и к операции фиксированного полиномиального предсказания, которые генерируют остаточные сигналы для каждого из каналов. Как показано на фиг.3, индексы (OrigChOrder [ ]), которые указывают исходный порядок каналов до сортировки, выполняемой во время процесса попарной декорреляции, и флаг PWChDecorrFlag [ ] для каждой пары каналов, указывающий присутствие кода для квантованных коэффициентов декорреляции, сохраняют в заголовке 36 набора каналов на фиг.3.
Как показано на фиг.4b, для выполнения операцию декодирования для обработки 44 обратного оконного анализа, информацию заголовка распаковывают 58, и остаточные сигналы (исходные выборки в начале RAP сегмента) передают или через обратное фиксированное полиномиальное предсказание 52, или через обратное адаптивное предсказание 50 согласно информации заголовка, а именно, согласно порядку адаптивного и фиксированного предикторов для каждого канала. В присутствии транзиентного сигнала в канале у набора каналов будут два различных набора параметров предсказания для этого канала. M-канальный декоррелированное аудио PCM (М/2 каналов отбрасывают во время сегментации) передают через обратную межканальную декорреляцию 60, при которой считывают индексы OrigChOrder [ ] и флаг PWChDecorrFlagg [ ] из заголовка набора каналов и без потерь восстанавливают M-канальное аудио PCM 20.
Примерный процесс выполнения межканальной декорреляции 54 показывают на фиг.5. Для примера аудио PCM предоставляют как M=6 отличающихся каналов, L, R, C, Ls, РТС и LFE, которые также непосредственно соответствуют одной конфигурации набора каналов, сохраненной в кадре. Другим набором каналов может быть, например, левый центральный задний окружающий и правый центральный задний окружающий, для создания 7.1-канального окружающего аудио. Процесс начинают с запуска цикла кадров и цикла наборов каналов (этап 70). Вычисляют оценку автокорреляции с нулевой задержкой для каждого канала (этап 72) и оценку взаимной корреляции с нулевой задержкой для всех возможных комбинаций пар каналов в наборе каналов (этап 74). Затем, коэффициенты попарной корреляции каналов CORCOEF оценивают, как оценку взаимной корреляции с нулевой задержкой, деленную на результат оценки автокорреляции с нулевой задержкой для участвующих в паре каналов (этап 76). CORCOEF сортируют от наибольшего абсолютного значения до наименьшего и сохраняют в таблице (этап 78). Начиная с вершины таблицы, извлекают соответствующие индексы пар каналов, пока все пары не будут сконфигурированы (этап 80). Например, 6 каналов можно объединять в пары, основываясь на их CORCOEF, как (L, R), (Ls, Rs) и (C, LFE).
Процесс начинает цикл пар каналов (этап 82) и выбирает «основной» канал, как канал с наименьшей оценкой автокорреляции с нулевой задержкой, которая указывает более низкую энергию (этап 84). В этом примере каналы L, Ls и C формируют основные каналы. Коэффициент декорреляции пары каналов (ChPairDecorrCoeff) вычисляют как оценку взаимной корреляции с нулевой задержкой, деленную на оценку автокорреляции с нулевой задержкой основного канала (этап 86). Декоррелированный канал генерируют, умножая выборки основного канала на CHPairDecorrCoeff и вычитая этот результат из соответствующих выборок коррелированного канала (этап 88). Пары каналов и связанный с ними декоррелированный канал обозначают «триплеты» (L,R,R-ChPairDecorrCoeff[1]*L), (Ls,РТС,РТС-ChPairDecorrCoeff[2]*Ls), (C,LFE,LFE-ChPairDecorrCoeff[3]*C) (этап 89). ChPairDecorrCoeff[ ] для каждой пары каналов (и каждого набора каналов) и индексы канала, которые обозначают конфигурацию пары, сохраняют в информации заголовка набора каналов (этап 90). Этот процесс повторяют для каждого набора каналов в кадре и затем для каждого кадра в обработанном оконной функцией аудио PCM (этап 92).
Определение начальной точки сегмента для RAP и транзиентов
Примерный подход для определения начала сегмента и ограничения продолжительности для настройки необходимых RAP и/или обнаруженных транзиентов показывают на фиг.12-14. Минимальный блок аудио данных, которые обрабатывают, упоминается как «блок анализа». Блоки анализа видимы только в кодере, декодер обрабатывает только сегменты. Например, блок анализа может представлять 0,5 мс аудио данные в кадрах 32 мс, включающих в себя 64 блока анализа. Сегменты состоят из одного или более блоков анализа. В идеале, кадр разделяют так, чтобы необходимая RAP или обнаруженный транзиент находились в первом блоке анализа RAP или транзиента. Однако, в зависимости от расположения необходимой RAP или транзиента обеспечение этого условия может привести к недостаточно оптимальной сегментации (чрезмерно короткой продолжительности сегмента), что слишком увеличивает кодированную полезную информацию кадра. Поэтому, компромиссным решением является задать, что любая необходимая RAP находится в пределах М блоков анализа (другое «М», чем M каналов в подпрограмме декорреляции канала) от начала сегмента RAP, и что любой транзиент находится в пределах L первых блоков анализа после начала сегмента с транзиентом в соответствующем канале. М и L - меньше общего количества блоков анализа в кадре, и их выбирают так, чтобы обеспечить необходимый допуск выравнивания для каждого условия. Например, если кадр включает в себя 64 блока анализа, то М и/или L могут быть 1, 2, 4, 8 или 16. Как правило, используют некоторую степень двойки, которая меньше общего количества и обычно является его небольшой частью (не более 25%), для предоставления реальной разрешающей способности субкадра. Кроме того, хотя можно позволять изменять продолжительность сегмента в пределах кадра, это сильно усложняет алгоритм адаптивной сегментации и увеличивает количество битов служебной информации заголовка с относительно небольшим повышением эффективности кодирования. Следовательно, обычный вариант осуществления ограничивает сегменты так, чтобы они имели одинаковую продолжительность в пределах кадра и имели продолжительность, равную степени двойки продолжительности блока анализа, например, продолжительность сегмента = 2P * продолжительность блока анализа, где P=0, 1, 2, 4, 8 и т.д. В более общем случае алгоритм задает начало сегментов RAP или транзиентов. В ограниченном случае алгоритм задает максимальную продолжительность сегмента для каждого кадра, которая обеспечивает соблюдение условия.
Как показано на фиг.12, временной код кодирования, включающий в себя необходимые RAP, такой как временной код видео, который задает начало главы или сцены, предоставляют с помощью прикладного уровня (этап 600). Предоставляют (этап 602) ограничения по выравниванию, которые предписывают приведенные выше максимальные значения М и L. Кадры блокируют во множество блоков анализа и синхронизируют с временным кодом для выравнивания необходимых RAP с блоками анализа (этап 603). Если необходимая RAP находится в пределах кадра, то кодер устанавливает начало сегмента RAP, причем блок анализа RAP должен находиться в пределах М блоков анализа до или после начала сегмента RAP (этап 604). Следует отметить, что необходимая RAP может фактически находиться в сегменте, предшествующем сегменту RAP в пределах М блоков анализа от начала сегмента RAP. При данном подходе начинают анализ адаптивного/фиксированного предсказания (этап 605), начинают цикл наборов каналов (этап 606) и начинают анализ адаптивного/фиксированного предсказания в наборе каналов (этап 608) с помощью вызова подпрограммы, показанной на фиг.13. Цикл наборов каналов заканчивают (этап 610) с возвращением подпрограммой одного набора параметров предсказания (AdPredOrder [0] [ ], FixedPredOrder [0] [ ] и AdPredCodes [0] [ ] [ ]) для случая, когда ExtraPredSetsPresent [ ] = «ложь», или двух наборов параметров предсказания (AdPredOrder [0] [ ], FixedPredOrder [0] [ ], AdPredCodes [0] [ ] [ ], AdPredOrder [1] [ ], FixedPredOrder [1] [ ] и AdPredCodes [1] [ ] [ ]) для случая, когда ExtraPredSetsPresent [ ] = «истина», остатков и расположения всех обнаруженных транзиентов (StartSegment [ ]) в канале (этап 612). Этап 608 повторяют для каждого набора каналов, который закодирован в битовом потоке. Начальные точки сегмента для каждого кадра определяют из начальной точки сегмента RAP и/или начальных точек сегментов с обнаруженными транзиентами и передают к алгоритму адаптивной сегментации на фиг.16 и 7a-7b (этап 614). Если продолжительности сегмента ограничивают так, чтобы она была одинаковой и равна степени двойки длины блока анализа, то максимальную продолжительность сегмента выбирают, основываясь на установленных точках начала, и переходят к алгоритму адаптивной сегментации (этап 616). Ограничение максимальной продолжительности сегмента поддерживает установленные точки начала плюс добавление ограничения на продолжительность.
Примерный вариант осуществления начала анализа адаптивного/фиксированного предсказания в подпрограмме набора каналов (этап 608) предоставляют на фиг.13. Подпрограмма начинает цикл каналов, индексированный с помощью ch (этап 700), вычисляет основанные на кадре коэффициенты предсказания и основанные на разделении коэффициенты предсказания (если обнаружен транзиент), и выбирает подход с лучшей эффективностью кодирования в канале. Возможно даже, что если обнаружен транзиент, то самым эффективным кодированием будет игнорирование транзиента. Подпрограмма восстанавливает наборы параметров предсказания, остатки и расположение всех кодированных транзиентов.
Более конкретно, подпрограмма выполняет основанный на кадре анализ предсказания с помощью вызова подпрограммы адаптивного предсказания, схематически показанной на фиг.6a (этап 702), для выбора набора основанных на кадре параметров предсказания (этап 704). Этот один набор параметров затем используют для выполнения предсказания в кадре аудиовыборок, учитывая начало любого сегмента RAP в кадре (этап 706). Более конкретно, предсказание отключают в начале сегмента RAP для первых выборок по порядку предсказания. Показатель основанного на кадре остаточного среднего значения, например, остатоную энергию, оценивают из остаточных значений и исходных выборок, когда предсказание отключено.
Параллельно, подпрограмма обнаруживает наличие каких-нибудь транзиентов в исходном сигнале для каждого канала в пределах текущего кадра (этап 708). Пороговое значение используется для уравновешивания между собой ложного обнаружения и пропущенного обнаружения. Индексы блока анализа, содержащего транзиент, регистрируют. Если транзиент обнаружен, то подпрограмма устанавливает точку начала сегмента с транзиентом, позицию которой определяют для обеспечения, чтобы транзиент находился в пределах L первых блоков анализа сегмента (этап 709), и делит кадр на первую и вторую части, причем вторая часть совпадает с началом сегмента с транзиентом (этап 710). Данная подпрограмма затем дважды вызывает подпрограмму адаптивного предсказания, схематически показанную на фиг.6a (этап 712), для выбора наборов первой и второй частей, основываясь на параметрах предсказания для первой и второй частей (этап 714). Два набора параметров затем используют для выполнения предсказания для первой и второй частей аудиовыборок, соответственно, также учитывая начало любого сегмента RAP в кадре (этап 716). Показатель основанного на разделении остаточного среднего значения (например, остаточную энергию) оценивают из остаточных значений и исходных выборок, когда предсказание отключено.
Подпрограмма сравнивает основанное на кадре остаточное среднее значение с основанным на разделении остаточным средним значением, умноженным на пороговое значение, для учета увеличенной информации заголовка, требуемой для множества разделений для каждого канала (этап 716). Если основанная на кадре остаточная энергия меньше, то возвращают основанные на кадре остатки и параметры предсказания (этап 718), иначе, возвращают основанные на разделении остатки, два набора параметров предсказания и индексы зарегистрированных транзиентов для этого канала (этап 720). Цикл канала, индексированный каналом (этап 722), и анализ адаптивного/фиксированного предсказания в наборе каналов (этап 724), выполняют итерацию по каналам в наборе и по всем наборам каналов до его окончания.
Определение начальных точек сегмента или максимальной продолжительности сегмента для одного кадра 800 показывают на фиг.14. Предполагают, что кадр 800 имеет длину 32 мс и содержит 64 блока анализа 802, каждый имеет продолжительность 0,5 мс. Временной код 804 видео задает необходимую RAP 806, которая находится в пределах 9-го блока анализа. В CH 1 и 2 обнаруживают транзиенты 808 и 810, которые находятся в 5-м и 18-м блоках анализа, соответственно. В неограниченном случае подпрограмма может задавать начальные точки сегмента в блоках анализа 5, 9 и 18 для обеспечения, что RAP и транзиенты находятся в 1-ом блоке анализа их соответствующих сегментов. Алгоритм адаптивной сегментации может дополнительно делить кадр так, чтобы он соответствовал другим ограничениям и минимизировал полезную информацию кадра, пока эти начальные точки поддерживаются. Алгоритм адаптивной сегментации может изменять границы сегмента и все равно соответствовать условию, что необходимая RAP или транзиент находятся в пределах конкретного количества блоков анализа для выполнения других ограничений или для лучшей оптимизации полезной информации.
В ограниченном случае подпрограмма определяет максимальную продолжительность сегмента, которая, в данном примере, удовлетворяет условиям в каждой необходимой RAP и в этих двух транзиентах. Так как необходимая RAP 806 находится в пределах 9-ого блока анализа, максимальная продолжительность сегмента, которая обеспечивает, что RAP находится в 1-ом блоке анализа сегмента RAP, равна 8x (масштабированная продолжительностью блока анализа). Поэтому, позволительные размеры сегмента (как кратное двойки блоков анализа) 1, 2, 4 и 8. Точно так же, поскольку транзиент 808 Ch 1 находятся в пределах 5-го блока анализа, максимальная продолжительность сегмента равна 4. Транзиент 810 в CH 2 более проблематичен, т.к. для обеспечения, чтобы он имел место в первом блоке анализа, требуется продолжительность сегмента, равная блоку анализа (1X). Однако, если транзиент можно разместить во втором блоке анализа, тогда максимальная продолжительность сегмента равна 16x. При этих ограничениях подпрограмма может выбирать максимальную продолжительность сегмента, равную 4, таким образом позволяя алгоритму адаптивной сегментации выбирать из 1x, 2x и 4x, чтобы минимизировать полезную информацию кадра и удовлетворять другим ограничениям.
В альтернативном варианте осуществления первый сегмент каждого n-го кадра может по умолчанию быть сегментом RAP, если временной код не задает другой сегмент RAP в этом кадре. Заданные по умолчанию RAP могут быть удобными, например, для позволения пользователю выполнять скачкообразные переходы или «случайно перемещаться» в пределах битового потока аудио вместо того, чтобы быть ограниченным только теми RAP, которые задает временной код видео.
Адаптивное предсказание
Анализ адаптивного предсказания и генерация остатков
Линейное предсказание пытается удалить корреляцию между выборками аудиосигнала. Основным принципом линейного предсказания является предсказание значения выборки s(n), используя предыдущие выборки s(n-1), s(n-2)…, и вычитание предсказанного значения ŝ(n) из исходной выборки s(n). Результирующий остаточный сигнал e(n)=s(n)+ŝ(n) будет идеально некоррелированным и, следовательно, иметь плоский спектр частот. Кроме того, у остаточного сигнала будет меньшая дисперсия, чем у исходного сигнала, что подразумевает, что меньше битов необходимо для его цифрового представления.
В примерном варианте осуществления аудиокодека модель модуля предсказания FIR описана следующим уравнением:
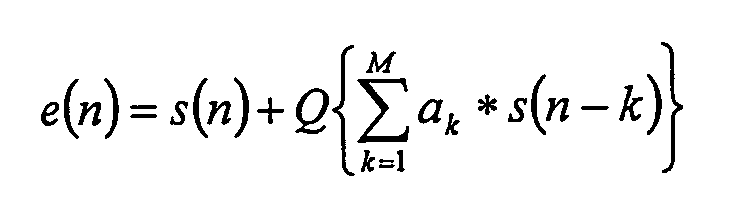
где Q{} обозначает операцию квантования, М обозначает порядок предиктора, и ak - квантованные коэффициенты предсказания. Точное квантование Q{} необходимо для сжатия без потерь, так как исходный сигнал восстанавливают на декодирующей стороне, используя другую архитектуру процессора с конечной точностью. Определение Q{} доступно и для кодера, и для декодера, и восстановление исходного сигнала просто получают с помощью:
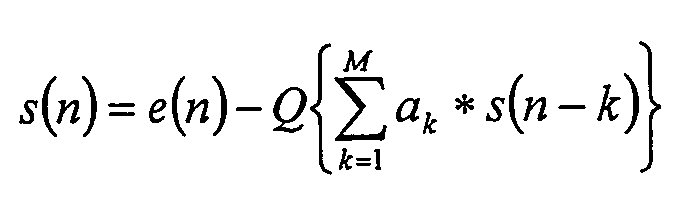
где предполагается, что квантованные коэффициенты предсказания того же самого ak доступны и для кодера, и для декодера. Новый набор параметров модуля предсказания передают в каждом окне анализа (кадре), позволяя модулю предсказания адаптироваться к изменяющейся во времени структуре аудиосигнала. В случае обнаружения транзиента два новых набора параметров предсказания передают для кадра для каждого канала, в котором обнаружен транзиент; один - для декодирования остатков до транзиента, и один - для декодирования остатков, которые включают в себя транзиент и следуют после него.
Коэффициенты предсказания предназначены для минимизации среднеквадратичного остатка предсказания. Квантование Q{} делает модуль предсказания нелинейным модулем предсказания. Однако в примерном варианте осуществления квантование выполняют с 24-битовой точностью, и разумно предположить, что результирующие нелинейные эффекты можно проигнорировать во время оптимизации коэффициентов модуля предсказания. Игнорируя квантование Q{}, основная проблема оптимизации может быть представлена как набор линейных уравнений, вовлекающих задержки последовательности автокорреляции сигнала и неизвестные коэффициенты модуля предсказания. Этот набор линейных уравнений может быть эффективно решен, используя алгоритм Левинсона-Дарбина (LD).
Результирующие коэффициенты линейного предсказания (LPC) необходимо квантовать таким образом, чтобы их можно эффективно передавать в кодированном потоке. К сожалению, прямое квантование LPC не является самым эффективным подходом, так как небольшие ошибки квантования могут вызывать большие спектральные ошибки. Альтернативное представление LPC - представление коэффициента отражения (RC), которое имеет меньшую чувствительность к ошибкам квантования. Это представление может также быть получено из алгоритма LD. По определению алгоритма LD, у RC, как гарантируют, будет величина ≤ 1 (игнорируя числовые ошибки). Когда абсолютное значение RC близко к 1, чувствительность линейного предсказания к ошибкам квантования, присутствующим в квантованных RC, становится высокой. Решение состоит в том, чтобы выполнить неоднородное квантование RC с более частыми шагами квантования около единицы. Это может быть достигнуто двумя этапами:
1) преобразовывают RC в представление отношения в логарифмической области (LAR) посредством функции сопоставления,
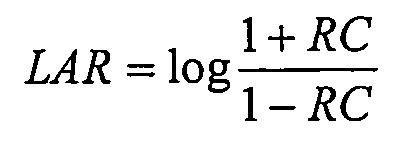
где log обозначает натуральный логарифм.
2) квантуют равномерно LAR.
Преобразование RC->LAR изменяет масштаб амплитуды параметров таким образом, что результат этапов 1 и 2 эквивалентен неоднородному квантованию с более частыми шагами квантования около единицы.
Как показано на фиг.6a, в примерном варианте осуществления анализа адаптивного предсказания квантованные параметры LAR используются для представления параметров модуля адаптивного предсказания, и их передают в кодированном битовом потоке. Выборки в каждом входном канале обрабатывают независимо друг от друга, и, следовательно, описание учитывает обработку только в одном канале.
Первым этапом является вычисление последовательности автокорреляции по продолжительности окна анализа (весь кадр или разделение перед и после обнаруженного транзиента) (этап 100). Для минимизации влияния блокирования, которое вызвано нарушением непрерывности на границах кадров, данные сначала обрабатывают оконной функцией. Последовательность автокорреляции для конкретного количества задержек (равного максимальному порядку LP +1) оценивают из обработанной оконной функцией совокупности данных.
Алгоритм Левинсона-Дарбина (Levinson-Durbin (LD)) применяют к набору предполагаемых задержек автокорреляции, и вычисляют (этап 102) набор коэффициентов отражения (RC) до максимального порядка LP. Промежуточный результат алгоритма (LD) - набор предполагаемых дисперсий остатков предсказания для каждого порядка линейного предсказания до максимального порядка LP. В следующем блоке, используя этот набор дисперсий остатков, выбирают порядок линейного предиктора (AdPredOrder) (этап 104).
Для выбранного порядка предиктора набор коэффициентов отражения (RC) преобразовывают в набор параметров отношения в логарифмической области (LAR), используя указанную выше функцию сопоставления (этап 106). Лимитирование RC вводят перед преобразованием для предотвращения деления на 0:
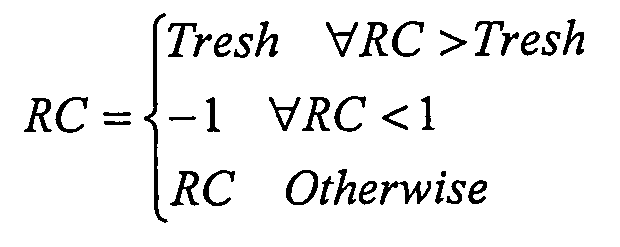
где Tresh обозначает число, близкое к 1, но меньше 1.
Параметры LAR квантуют (этап 108) согласно следующему правилу:
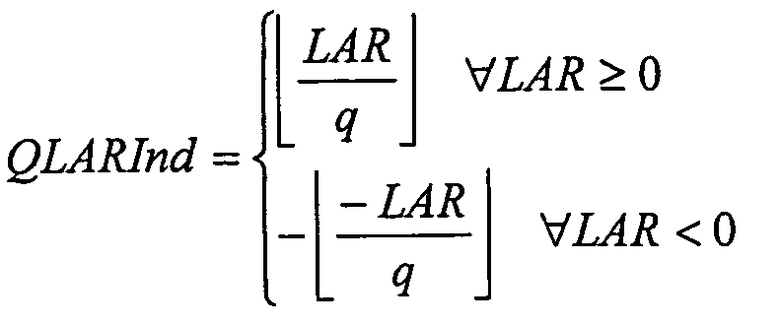
где QLARInd обозначает квантованные индексы LAR, 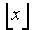
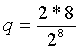

QLARInd преобразовывает значения со знаком в значения без знака, используя следующее сопоставление:
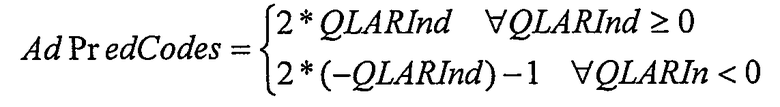
В блоке «RC LUT» обратное квантование параметров LAR и преобразование в параметры RC выполняют в одном этапе, используя таблицу поиска (этап 112). Таблица поиска состоит из квантованных значений обратного сопоставления RC->LAR, т.е. сопоставления LAR->RC, задаваемого с помощью:
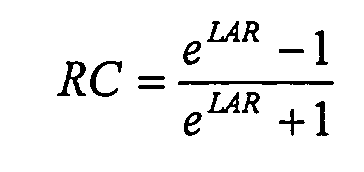
Таблицу поиска вычисляют в квантованных значениях LAR, равных 0, 1,5*q, 2,5*q,... 127,5*q. Соответствующие значения RC, после масштабирования с помощью 216, округляют до 16-битных целых чисел без знака и сохраняют как числа с фиксированной точкой без знака формата Q16 в таблице из 128 элементов.
Квантованные параметры RC вычисляют из таблицы и индексов квантования LAR QLARInd, как:
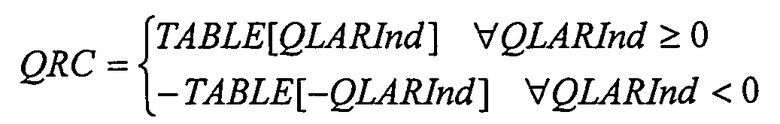
Квантованные параметры RC QRCord для ord=1, … AdPredOrder преобразовывают в квантованные параметры линейного предсказания (LPord для ord=1,... AdPredOrder) согласно следующему алгоритму (этап 114):
For ord = 0 to AdPredOrder -1 do
For m = 1 to ord do
Cord+1,m = Cord,m + (QRCord+1* Cord,ord+1-m + (1<<15))>>16
end
Cord+1,ord+1 = QRCord+1
end
For ord = 0 to AdPredOrder -1 do
LPord+1 = CAdPredOrder,ord+1
end
Так как квантованные коэффициенты RC были представлены в формате Q16 с фиксированной точкой со знаком, указанный выше алгоритм генерирует коэффициенты LP также в формате Q16 с фиксированной точкой со знаком. Способ вычисления декодера без потерь разработан для поддержания до 24-битовых промежуточных результатов. Поэтому необходимо выполнять проверку насыщения после вычисления каждого Cord+1,m. Если насыщение имеет место на каком-нибудь этапе алгоритма, то устанавливают флаг насыщения, и порядок адаптивного предиктора AdPredOrder для определенного канала сбрасывают в 0 (этап 116). Для этого определенного канала с AdPredOrder=0 фиксированное предсказание коэффициентов будут выполнять вместо адаптивного предсказания (см. фиксированное предсказание коэффициентов). Следует отметить, что индексы квантования LAR без знака (PackLARInd[n] для n=1,... AdPredOrder[Ch]) упаковывают в кодированный поток только для каналов с AdPredOrder[Ch]>0.
Наконец, для каждого канала с AdPredOrder>0 выполняют адаптивное линейное предсказание, и остатки предсказания e(n) вычисляют согласно следующим уравнениям (этап 118):

Limit
e(n) = s(n)+
Limit e(n) to 24-bit range (-223 to 223 -1)
для n = AdPredOrder + 1, … NumSamples
Так как цель разработки в примерном варианте осуществления состоит в том, чтобы заданные сегменты RAP определенных кадров были «точками произвольного доступа», хронологию выборок не переносят из предыдущего сегмента в сегмент RAP. Вместо этого предсказание применяют только в выборке AdPredOrder+1 в сегменте RAP.
Остатки адаптивного предсказания e(n) дополнительно энтропийно кодируют и упаковывают в кодированный битовый поток.
Обратное адаптивное предсказание на декодирующей стороне
На декодирующей стороне первым этапом при выполнении обратного адаптивного предсказания является распаковывание информации заголовка (этап 120). Если декодер пытается инициировать декодирование согласно временному коду воспроизведения (например, выбору пользователем главы или произвольному доступу), то декодер обращается к битовому потоку аудио около, но перед данной точкой, и ищет заголовок следующего кадра до тех пор, пока он не найдет RAP_Flag = «истина», который указывает наличие сегмента RAP в кадре. Декодер затем извлекает номер сегмента RAP (ИД RAP) и навигационные данные (NAVI) для перемещения к началу сегмента RAP, отключает предсказание до тех пор, пока индекс > pred_order, и инициирует декодирование без потерь. Декодер декодирует остальные сегменты в данном кадре и в последующих кадрах, отключая предсказание каждый раз, когда встречается сегмент RAP. Если ExtraPredSetsPrsnt = «истина» встречается в кадре для канала, то декодер извлекает первый и второй наборы параметров предсказания и начальный сегмент для второго набора.
Порядок адаптивного предсказания AdPredOrder[Ch] извлекают для каждого канала Ch=1,... NumCh. Затем для каналов с AdPredOrder[Ch]>0 извлекают версию без знака индексов квантования LAR (AdPredCodes[n] для n=1, AdPredOrder[Ch]). Для каждого канала Ch с порядком предсказания AdPredOrder[Ch]>0, AdPredCodes[n] без знака сопоставляют со значением со знаком QLARInd[n], используя следующее сопоставление:
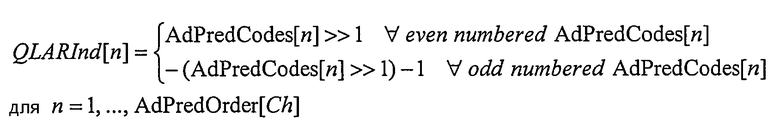
где >> обозначает целочисленную операцию правого сдвига.
Обратное квантование параметров LAR и преобразование в параметры RC выполняют на одном этапе, используя Quant RC LUT (этап 122). Это - та же самая таблица поиска TABLE{ }, которую определяют на кодирующей стороне. Квантованные коэффициенты отражения для каждого канала Ch (QRC[n] для n=1,... AdPredOrder[Ch]), вычисляют из TABLE{}, и индексы квантования LAR QLARInd[n], как
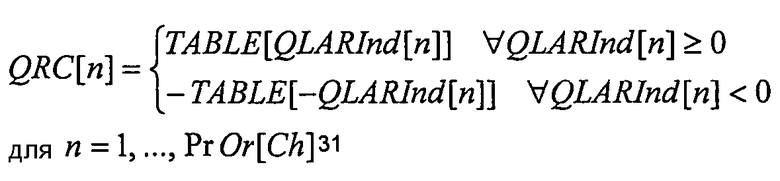
Для каждого канала Ch, квантованные параметры RC QRCord для ord=1,... AdPredOrder[Ch] преобразовывают в квантованные параметры линейного предсказания (LPord для ord=1,... AdPredOrder[Ch]) согласно следующему алгоритму (этап 124):
For ord = 0 to AdPredOrder -1 do
For m = 1 to ord do
Cord+1,m = Cord,m + (QRCord+1* Cord,ord+1-m + (1<<15))>>16
end
Cord+1,ord+1 = QRCord+1
end
For ord = 0 to AdPredOrder -1 do
LPord+1 = CAdPredOrder,ord+1
end
Любую возможность насыщения промежуточных результатов удаляют на кодирующей стороне. Поэтому на декодирующей стороне нет никакой необходимости выполнять проверку насыщения после вычисления каждого Cord+1,m.
Наконец, для каждого канала с AdPredOrder[Ch]>0 выполняют обратное адаптивное линейное предсказание (этап 126). Предполагая, что остатки предсказания e(n) ранее извлечены и энтропийно декодированы, восстановленные исходные сигналы s(n) вычисляют согласно следующим уравнениям:
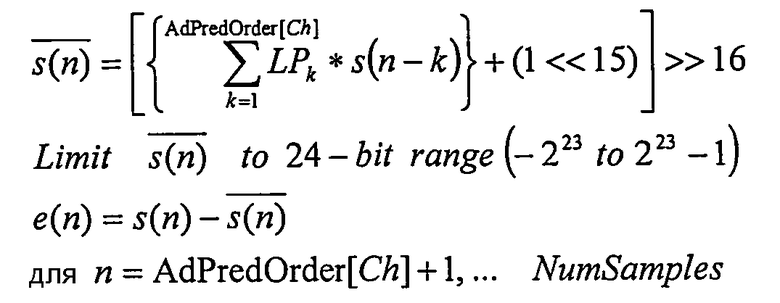
Limit
e(n) = s(n)+
для n = AdPredOrder[Ch] +1, … NumSamples
Так как хронологию выборок не сохраняют в сегменте RAP, обратное адаптивное предсказание необходимо начинать с выборки (AdPredOrder [Ch]+1) в сегменте RAP.
Фиксированное предсказание коэффициентов
Было обнаружено, что очень простая форма фиксированного предсказания коэффициентов модуля линейного предсказания является удобной. Коэффициенты фиксированного предсказания получают согласно очень простому способу полиномиального приближения, который был впервые предложен Shorten (T. Robinson. SHORTEN: Simple lossless and near lossless waveform compression. Technical report 156. Cambridge University Engineering Department Trumpington Street, Cambridge CB2 IPZ, UK December 1994). В этом случае коэффициенты предсказания являются коэффициентами, заданными с помощью соответствия полинома порядка p с последним p точкам данных. Подробно останавливаются на четырех приближениях.
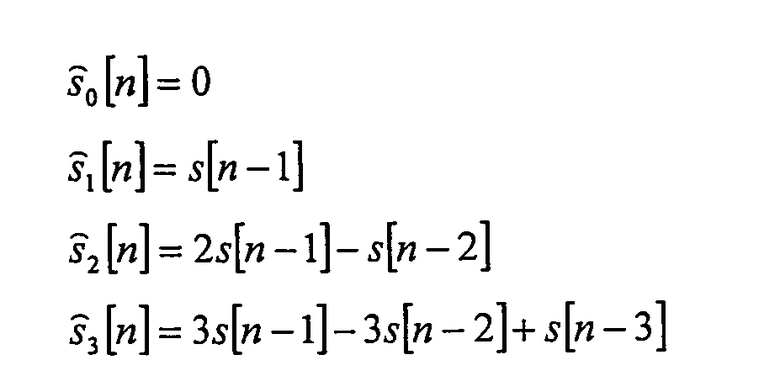
Интересное свойство этих полиномиальных приближений - то, что результирующий остаточный сигнал ek[n]=s[n]-ŝk[n] можно эффективно воплощать следующим рекурсивным способом.
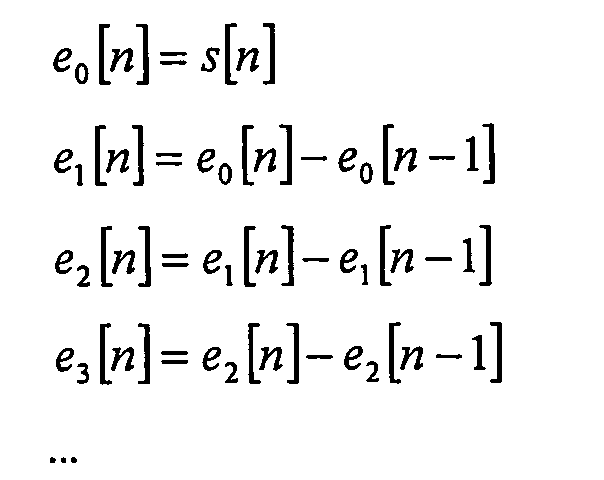
Анализ фиксированного предсказания коэффициентов применяют на основе кадра, и он не основывается на выборках, вычисленных в предыдущем кадре (ek[-1] = 0). Набор остатков с наименьшей величиной суммы по всему кадру определяют как лучшее приближение. Оптимальный порядок остатков вычисляют для каждого канала отдельно и упаковывают в поток как порядок фиксированного предсказания (FPO[Ch]). Остатки eFPO[Ch][n] в текущем кадре дополнительно энтропийно кодируют и упаковывают в поток.
Процесс обратного фиксированного предсказания коэффициентов на декодирующей стороне определяют с помощью формулы рекурсивного порядка для вычисления остатков k-го порядка в момент выборки n:
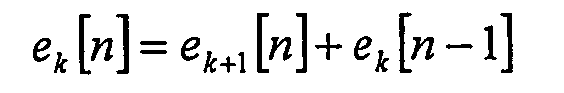
где необходимый исходный сигнал s[n] задают с помощью
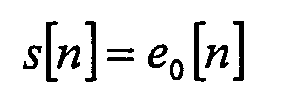
и где для каждого остатка k-го порядка ek[-1] = 0. В качестве примера представлены рекурсии для фиксированного предсказания коэффициентов 3-го порядка, где остатки e3[n] кодируют, передают в потоке и распаковывают на декодирующей стороне:
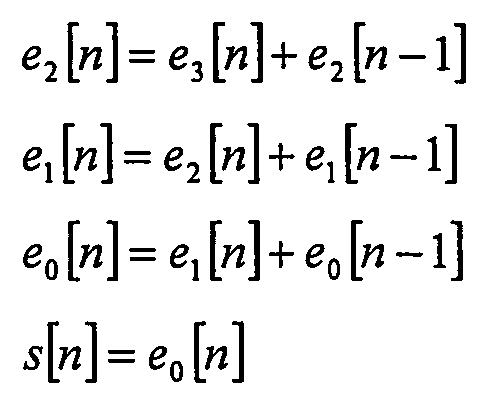
Обратное линейное предсказание, адаптивное или фиксированное, выполняемое на этапе 126, показывают для случая, когда сегмент m+1 - сегмент 900 RAP на фиг.15a, и когда сегмент m+1 - сегмент 902 с транзиентом на фиг.15b. 5-отводный модуль предсказания 904 используется для восстановления аудиовыборки без потерь. В общем случае, модуль предсказания повторно объединяет 5 предыдущих восстановленных без потерь выборок для генерации предсказанного значения 906, которое добавляют к текущему остатку 908 для восстановления без потерь текущей выборки 910. В примере RAP 1-е 5 выборок в битовом потоке 912 сжатого аудио являются распакованными аудиовыборками. Следовательно, модуль предсказания может инициировать декодирование без потерь при сегменте m+1 без какой-либо хронологии от предыдущей выборки. Другими словами, сегмент m+1 является сегментом RAP битового потока. Следует отметить, что если транзиент также обнаружен в сегменте m+1, то параметры предсказания для сегмента m+1 и остальной части кадра отличаются от параметров, используемых в сегментах 1 - m. В примере транзиента все выборки в сегментах m и m+1 являются остатками, а не RAP. Декодирование инициировано, и хронология предсказания доступна для модуля предсказания. Как показано, для восстановления без потерь аудиовыборок в сегментах m и m+1 используются различные наборы параметров предсказания. Для генерации 1-й выборки без потерь в сегменте m+1, модуль предсказания использует параметры для сегмента m+1, используя последние пять восстановленных выборок без потерь от сегмента m. Следует отметить, что если сегмент m+1 является также сегментом RAP, то первые пять выборок сегмента m+1 являются исходными выборками, а не остатками. В общем случае, данный кадр может не содержать ни одной RAP или транзиента, что фактически является более обычным результатом. В свою очередь, кадр может включать в себя сегмент RAP или сегмент с транзиентом, или даже оба. Один сегмент может быть и сегментом RAP, и сегментом с транзиентом.
Поскольку условие начала сегмента и максимальную продолжительность сегмента устанавливают, основываясь на позволительном расположении необходимой RAP или обнаруженном транзиенте в пределах сегмента, выбор оптимальной продолжительности сегмента может генерировать битовый поток, в котором необходимая RAP или обнаруженный транзиент фактически находятся в пределах сегментов, следующих за сегментами RAP или сегментами с транзиентом. Это может происходить, если границы М и L являются относительно большими, и оптимальная продолжительность сегмента меньше М и L. Необходимая RAP может фактически находиться в сегменте, предшествующем сегменту RAP, но все равно находиться в пределах заданного допуска. Условия допуска на выравнивание на кодирующей стороне все равно поддерживаются, и декодер не понимает разницу. Декодер просто получает доступ к RAP и транзиенту.
СЕГМЕНТАЦИЯ И ВЫБОР ЭНТРОПИЙНОГО КОДА
Проблему ограниченной оптимизации, к которой обращается алгоритм адаптивной сегментации, показывают на фиг.16. Проблемой является кодирование одного или более наборов каналов многоканального аудио в битовый потоке VBR таким способом, чтобы минимизировать кодированную полезную информацию кадра, при условии ограничений, чтобы каждый аудио сегмент можно было полностью и без потерь декодировать, причем кодированная полезная информация сегмента меньше максимального количества байтов. Максимальное количество байтов меньше размера кадра, и обычно его устанавливают с помощью максимального размера модуля доступа для считывания битового потока. Проблема дополнительно ограничена настройкой произвольного доступа и транзиентов, требуя, чтобы сегменты выбирали так, чтобы необходимая RAP находилась плюс-минус М блоков анализа от начала сегмента RAP, и транзиент находился в пределах L первых блоков анализа сегмента. Максимальная продолжительность сегмента может быть дополнительно ограничена размером выходного буфера декодера. В данном примере сегменты в пределах кадра ограничивают так, чтобы они имели одинаковую длину, равную степени двойки продолжительности блока анализа.
Как показано на фиг.16, оптимальная продолжительность сегмента для минимизации кодированной полезной информации кадра 930 находит оптимальное сочетание улучшения предсказания для большего количества более коротких сегментов продолжительности со стоимостью дополнительных служебных битов. В этом примере 4 сегмента в кадре предоставляют меньшую полезную информацию кадра, чем или 2, или 8 сегментов. Решение с двумя сегментами непригодно, потому что полезная информация сегмента для второго сегмента превышает ограничение 932 на максимальную полезную информацию сегмента. Продолжительность сегмента для разделения и на два, и на четыре сегмента превышает максимальную продолжительность сегмента 934, которую устанавливают с помощью некоторой комбинации, например, размера выходного буфера декодера, расположения начальной точки сегмента RAP и/или расположения начальной точки сегмента с транзиентом. Следовательно, алгоритм адаптивной сегментации выбирает 8 сегментов 936 равной продолжительности и параметры предсказания и энтропийного кодирования, оптимизированные для этого разделения.
Примерный вариант осуществления сегментации и выбора энтропийного кода 24 для ограниченного случая (одинаковые сегменты, степень двойки продолжительности блока анализа) показывают на фиг.7a-b и 8a-b. Для установки оптимальных продолжительности сегмента, параметров кодирования (выбора энтропийного кода и параметров) и пар каналов, параметры кодирования и пары каналов определяют для множества различных продолжительностей сегмента до максимальной продолжительности сегмента, и из множества этих кандидатов выбирают кандидат с минимальной кодированной полезной информацией в кадре, который удовлетворяет ограничению, по которому каждый сегмент должен полностью и без потерь декодироваться и не превышать максимальный размер (количество байтов). «Оптимальные» сегментация, параметры кодирования и пары каналов, конечно, подчиняются ограничениям процесса кодирования, а так же ограничению на размер сегмента. Например, в примерном процессе, когда продолжительность времени всех сегментов в кадре равна, поиск оптимальной продолжительности выполняют в двоичной структуре, начиная с продолжительности сегмента, равной продолжительности блока анализа, и увеличивая ее с помощью степени двойки, и выбор пары каналов действует по всему кадру. За счет дополнительной сложности кодера и количества служебных битов, можно позволять изменять продолжительность времени в пределах кадра, поиск оптимальной продолжительности можно более точно выполнять, и выбор пары каналов можно выполнять на основе сегмента. В этом «ограниченном» случае ограничение, которое обеспечивает, что любая необходимая RAP или обнаруженный транзиент выровнены к началу сегмента в пределах заданной разрешающей способности, воплощают в максимальной продолжительности сегмента.
Примерный процесс начинают с инициализации параметров сегмента (этап 150), например, минимального количества выборок в сегменте, максимального позволительного размера кодированной полезной информации сегмента, максимального количества сегментов и максимального количества разделений и максимальной продолжительности сегмента. После этого, обработка начинает цикл разделений, которые индексируют от 0 до максимального количества разделений минус единица (этап 152), и инициализирует параметры разделения, включающие в себя количество сегментов, количество выборок в сегменте и количество байтов, используемых при данном разделении (этап 154). В этом конкретном варианте осуществления сегменты имеют равную продолжительность времени и количество сегментов, масштабируемое как степень двойки при каждой итерации разделения. Количество сегментов предпочтительно устанавливают в максимальное значение, следовательно, устанавливают минимальную продолжительность времени сегмента, равную одному блоку анализа. Однако, процесс может использовать сегменты переменной продолжительности времени, которые могут предоставлять лучшее сжатие аудио данных, но за счет дополнительных служебных данных и дополнительной сложности, для удовлетворения условий RAP и транзиентов. Кроме того, количество сегментов не должно быть лимитировано степенями двойки или определено от минимального до максимального значения продолжительности. В этом случае, начальные точки сегмента, определенные необходимой RAP и обнаруженными транзиентами, являются дополнительными ограничениями на алгоритм адаптивной сегментации.
После инициализации, процесс начинает цикл наборов каналов (этап 156) и определяет оптимальные параметры энтропийного кодирования и выбор пары каналов для каждого сегмента и соответствующего количества используемых байтов (этап 158). Сохраняют параметры кодирования PWChDecorrFlag [ ] [ ], AllChSameParamFlag [ ] [ ], RiceCodeFlag [ ] [ ] [ ], CodeParam [ ] [ ] [ ] и ChSetByteCons [ ] [ ] (этап 160). Это повторяют для каждого набора каналов до окончания цикла набора каналов (этап 162).
Процесс начинает цикл сегментов (этап 164) и вычисляет количество используемых байтов (SegmByteCons) в каждом сегменте по всем наборам каналов (этап 166) и обновляет количество используемых байтов (ByteConsInPart) (этап 168). В этот момент времени размер сегмента (кодированную полезную информацию сегмента в байтах) сравнивают с ограничением максимального размера (этап 170). Если ограничение нарушено, то от текущего разделения отказываются. Кроме того, из-за того, что процесс начинается с наименьшей продолжительности времени, когда размер сегмента становится слишком большим, цикл разделений заканчивают (этап 172), и лучшее решение (продолжительность времени, пары каналов, параметры кодирования) для этого момента времени упаковывают в заголовок (этап 174), и процесс переходит на следующий кадр. Если ограничение минимального размера сегмента нарушается (этап 176), то процесс заканчивают и сообщают об ошибке (этап 178), потому что ограничение максимального размера не может быть удовлетворено. Предполагая, что ограничение удовлетворяется, этот процесс повторяют для каждого сегмента при текущем разделении до окончания цикла сегмента (этап 180).
Когда цикл сегмента закончен, и количество используемых байтов для всего кадра вычислено, как представлено ByteConsinPart, эту полезную информацию сравнивают с текущей минимальной полезной информацией (MinByteInPart) от предыдущей итерации разделения (этап 182). Если текущее разделение представляет улучшение, то текущее разделение (PartInd) сохраняют как оптимальное разделение (OptPartind), и минимальную полезную информацию обновляют (этап 184). Эти параметры и сохраненные параметры кодирования затем сохраняют как текущее оптимальное решение (этап 186). Это повторяют до окончания цикла разделения с максимальной продолжительностью сегмента (этап 172), в данный момент времени информацию сегментации и параметры кодирования упаковывают в заголовок (этап 150), как показано на фиг.3 и 11a и 11b.
Примерный вариант осуществления для определения оптимальных параметров кодирования и соответствующего количества используемых битов для набора каналов для текущего разделения (этап 158) показывают на фиг.8a и 8b. Процесс начинает цикл сегментов (этап 190) и цикл каналов (этап 192), в котором каналы для текущего примера:
Ch1: L,
Ch2: R
Ch3: R-ChPairDecorrCoeff[1]*L
Ch4: Ls
Ch5: Rs
Ch6: Rs-ChPairDecorrCoeff[2]*Ls
Ch7: C
Ch8: LFE
Ch9: LFE-ChPairDecorrCoeff[3]*C)
Процесс определяет тип энтропийного кода, соответствующий параметр кодирования и соответствующее количество используемых битов для основного и коррелированного каналов (этап 194). В этом примере процесс вычисляет оптимальные параметры кодирования для двоичного кода и кода Райса и затем выбирает код с самым низким количеством используемых битов для канала и каждого сегмента (этап 196). В общем случае, оптимизацию можно выполнять для одного, двух или более возможных энтропийных кодов. Для двоичных кодов количество битов вычисляют из максимального абсолютного значения всех выборок в сегменте текущего канала. Параметр кодирования Райса вычисляют из среднего абсолютного значения всех выборок в сегменте текущего канала. Основываясь на выборе, устанавливают RiceCodeFlag, устанавливают BitCons и устанавливают CodeParam или в NumBitsBinary, или в RiceKParam (этап 198).
Если текущий обрабатываемый канал является коррелированным каналом (этап 200), то ту же самую оптимизацию повторяют для соответствующего декоррелированного канала (этап 202), выбирают лучший энтропийный код (этап 204) и устанавливают параметры кодирования (этап 206). Процесс повторяют до окончания цикла канала (этап 208) и окончания цикла сегмента (этап 210).
В этой точке определяют оптимальные параметры кодирования для каждого сегмента и для каждого канала. Эти параметры кодирования и величину полезной информации можно восстанавливать для пар каналов (основной, коррелированный) из исходного аудио PCM. Однако, производительность сжатия можно повышать, выбирая между каналами (основной, коррелированный) и (основной, декоррелированный) в триплетах.
Для определения, какие пары каналов (основной, коррелированный) или (основной, декоррелированный) использовать для этих трех триплетов, начинают цикл пар каналов (этап 211), и вычисляют вклад каждого коррелированного канала (Ch2, Ch5 и Ch8) и каждого декоррелированного канала (Ch3, Ch6 и Ch9) в количество используемых битов всего кадра (этап 212). Вклад в количество используемых битов кадра для каждого коррелированного канала сравнивают с вкладом в количество используемых битов кадра для соответствующих декоррелированных каналов, т.е. Ch2 с Ch3, Ch5 с Ch6, и Ch8 с Ch9 (этап 214). Если вклад декоррелированного канала больше, чем вклад коррелированного канала, то PWChDecorrrFlag устанавливают в «ложь» (этап 216). Иначе, коррелированный канал заменяют декоррелированным каналом (этап 218), и PWChDecorrrFlag устанавливают в «истину», и пары каналов конфигурируют как (основной, декоррелированный) (этап 220).
Основываясь на этих сравнениях, алгоритм выбирает:
1. или Ch2, или Ch3 в качестве канала, который объединяют в пару с соответствующим основным каналом Ch1;
2. или Ch5, или Ch6 в качестве канала, который объединяют в пару с соответствующим основным каналом Ch4; и
3. или Ch8, или Ch9 в качестве канала, который объединяют в пару с соответствующим основным каналом Ch7.
Эти этапы повторяют для всех пар каналов до тех пор, пока цикл не закончится (этап 222).
В этой точке определяют оптимальные параметры кодирования для каждого сегмента и каждого отличающегося канала и оптимальных пар каналов. Эти параметры кодирования для каждой отличающейся пары каналов и величину полезной информации можно возвращать в цикл разделения. Однако, дополнительная производительность сжатия может быть доступна с помощью вычисления глобального набора параметров кодирования для каждого сегмента по всем каналам. В лучшем случае часть данных кодированной полезной информации будет иметь тот же самый размер, как параметры кодирования, оптимизированные для каждого канала, а наиболее вероятно - несколько больший. Однако, уменьшение количества служебных битов может более чем компенсировать эффективность кодирования данных.
Используя те же самые пары каналов, процесс начинает цикл сегментов (этап 230), вычисляет количество используемых битов (ChSetByteCons[seg]) в сегменте для всех каналов, используя отличающиеся наборы параметров кодирования (этап 232), и сохраняет ChSetByteCons[seg] (этап 234). Глобальный набор параметров кодирования (выбранный энтропийный код и параметры) затем определяют для сегмента по всем каналам (этап 236), используя те же самые вычисления двоичного кода и кода Райса как прежде, за исключением всех каналов. Выбирают лучшие параметры, и вычисляют количество используемых байтов (SegmByteCons) (этап 238). SegmByteCons сравнивают с CHSetByteCons[seg] (этап 240). Если использование глобальных параметров не уменьшает количество используемых битов, то AllChSamParamFlag[seg] устанавливают в «ложь» (этап 242). Иначе, AllChSameParamFlag [seg] устанавливают в «истину» (этап 244), и сохраняют глобальные параметры кодирования и соответствующее количество используемых битов в сегменте (этап 246). Этот процесс повторяют до достижения окончания цикла сегмента (этап 248). Весь процесс повторяют до окончания цикла набора каналов (этап 250).
Процесс кодирования структурируют таким образом, что различные функциональные возможности могут быть отключены с помощью управления несколькими флагами. Например, один флаг управляет, должен ли выполняться анализ попарной декорреляции каналов или нет. Другой флаг управляет, должен ли выполняться анализ адаптивного предсказания (еще один флаг для фиксированного предсказания) или нет. Кроме того, один флаг управляет, должен ли выполняться поиск глобальных параметров по всем каналам или нет. Сегментацией также можно управлять, определяя количество разделений и минимальную продолжительность сегмента (в самой простой форме, это может быть одним разделением с предопределенной продолжительностью сегмента). Флаг указывает наличие сегмента RAP, а другой флаг указывает наличие транзиента. В основном, устанавливая несколько флагов в кодере, кодер может превратиться в простое средство формирования кадра и энтропийного кодирования.
ОБРАТНО СОВМЕСТИМЫЙ АУДИОКОДЕК БЕЗ ПОТЕРЬ
Кодек без потерь может использоваться в качестве «кодера расширения» в комбинации с основным кодером с потерями. Основной поток кода «с потерями» упаковывают как основной битовый поток, и кодированный разностный сигнал без потерь упаковывают как отдельный битовый поток расширения. При декодировании в декодере с расширенными признаками декодирования без потерь, потоки без потерь и с потерями объединяют для создания восстановленного сигнала без потерь. В декодере предшествующего поколения игнорируют поток без потерь, и основной поток «с потерями» декодируют для предоставления высококачественного многоканального аудиосигнала с полосой пропускания и характеристикой отношения сигнал-шум основного потока.
Фиг.9 показывает представление системного уровня обратно совместимого кодера 400 без потерь для одного канала многоканального сигнала. Оцифрованный аудиосигнал, соответственно М-битовые аудиовыборки PCM, предоставляет на входе 402. Предпочтительно, оцифрованный аудиосигнал имеет частоту выборки и полосу пропускания, которые превышают частоту выборки и полосу пропускания измененного основного кодера с потерями 404. В одном из вариантов осуществления частота выборки оцифрованного аудиосигнала составляет 96 кГц (соответствует полосе пропускания 48 кГц для дискретизированного аудио). Следует также подразумевать, что входное аудио может быть, и предпочтительно является, многоканальным сигналом, причем дискретизацию каждого канала выполняют с частотой 96 кГц. Последующее обсуждение сконцентрировано на обработке одного канала, но расширение на множество каналов является простым. Входной сигнал дублируют в узле 406 и обрабатывают в параллельных ветвях. В первой ветви прохождения сигнала измененный широкополосный кодер 404 с потерями кодирует сигнал. Измененный основной кодер 404, который описан подробно ниже, генерирует кодированный основной битовый поток 408, который передают к модулю упаковывания или к мультиплексору 410. Основной битовый поток 408 также передают на измененный основной декодер 412, который генерирует в качестве выходного сигнала измененный восстановленный основной сигнал 414.
В это время входной оцифрованный аудиосигнал 402 в параллельном тракте подвергается компенсирующей задержке 416, по существу равной задержке, введенной в восстановленный аудио поток (с помощью измененного кодера и измененного декодера), для генерации задержанного оцифрованного аудио потока. Аудио поток 400 вычитают из задержанного оцифрованного аудио потока 414 с помощью узла 420 суммирования.
Узел 420 суммирования генерирует разностный сигнал 422, который представляет исходный сигнал и восстановленный основной сигнал. Для достижения кодирования совсем «без потерь», необходимо кодировать и передавать разностный сигнал с помощью методик кодирования без потерь. Соответственно, разностный сигнал 422 кодируют с помощью кодера 424 без потерь, и битовый поток 426 расширения упаковывают с основным битовым потоком 408 в модуле 410 упаковывания для генерации выходного битового потока 428.
Следует отметить, что кодирование без потерь генерирует битовый поток 426 расширения, который имеет переменную скорость передачи битов, для удовлетворения потребности кодера без потерь. Упакованный поток затем можно подвергать дополнительным уровням кодирования, включающим в себя канальное кодирование, и затем передавать или регистрировать. Следует отметить, что в целях этого раскрытия, регистрацию можно рассматривать, как передачу через канал.
Основной кодер 404 описывают как «измененный», потому что в варианте осуществления, который может обрабатывать расширенную полосу пропускания, основной кодер требует изменений. 64-полосный ряд 430 фильтров анализа в пределах кодера аннулирует половину его выходных данных 432, и основной субполосный кодер 434 кодирует только нижние 32 диапазона частот. Эта информация, которую аннулируют, не представляет интереса для существующих декодеров, которые не способны в любом случае восстанавливать верхнюю половину спектра сигнала. Остальную информацию кодируют согласно неизмененному кодеру для формирования обратно совместимого основного выходного потока. Однако, в другом варианте осуществления, работающем на частоте выборки 48 кГц или ниже ее, основной кодер может быть по существу неизмененной версией предшествующего основного кодера. Точно так же для работы выше частоты выборки существующих декодеров, измененный основной декодер 412 включает в себя основной субполосный декодер 436, который декодирует выборки в нижних 32 субполосах. Измененный основной декодер берет субполосные выборки из нижних 32 субполос и обнуляет непереданные субполосные выборки для верхних 32 полос 438 и восстанавливает все 64 полосы, используя 64-полосный фильтр синтеза QMF 440. Для работы с обычной частотой выборки (например, 48 кГц и ниже) основной декодер может быть по существу неизмененной версией предшествующего основного декодера или эквивалентен ему. В некоторых вариантах осуществления выбор частоты выборки можно делать во время кодирования, и с помощью модулей кодирования и декодирования, реконфигурируемых в это время с помощью программного обеспечения при необходимости.
Так как кодер без потерь используется для кодирования разностного сигнала, то может казаться, что было бы достаточно простого энтропийного кода. Однако, из-за лимитирования скорости передачи битов на существующие основные кодеки с потерями, значительное количество полных битов, требуемых для предоставления битового потока без потерь, все еще остается. Кроме того, из-за лимитирования полосы пропускания основного кодека информация выше 24 кГц в разностном сигнале все еще коррелированна. Например, многие гармонические компоненты, включающие в себя трубу, гитару, «треугольник»..., достигают далеко за 30 кГц). Поэтому более сложные кодеки без потерь, которые повышают производительность сжатия, добавляют значение. Кроме того, в некоторых применениях основной битовый поток и битовый поток расширения должны все равно удовлетворять ограничению, что декодируемые модули не должны превышать максимальный размер. Кодек без потерь по настоящему изобретению предоставляет и повышенную производительность сжатия, и улучшенную настраиваемость для удовлетворения этих ограничений.
Для примера 8 каналов 24-битового аудио PCM на 96 кГц требуют 18,5 Мбит/с. Сжатие без потерь может уменьшать это приблизительно до 9 Мбит/с. Кодер Coherent Acoustics DTS закодирует основной сигнал со скоростью передачи битов 1,5 Мбит/с, оставляя разностный сигнал 7,5 Мбит/с. Для максимального размера сегмента, равного 2-кбайта, средняя продолжительность сегмента - 2048*8/7500000=2,18 мс или примерно 209 выборок с частотой 96 кГц. Обычный размер кадра для основного кодирования с потерями для соответствия максимальному размеру находится между 10 и 20 мс.
На системном уровне кодек без потерь и обратно совместимый кодек без потерь можно объединять для кодирования без потерь дополнительных аудио каналов в расширенной полосе пропускания, поддерживая совместимость вниз с существующими кодеками с потерями. Например, 8-канальное аудио с частотой 96 кГц и скоростью передачи битов 18,5 Мбит/с можно без потерь кодировать так, чтобы он включал в себя 5.1-канальное аудио с частотой 48 кГц и скоростью передачи битов 1,5 Мбит/с. Основной кодер плюс кодер без потерь можно использовать для кодирования этих 5.1 каналов. Кодер без потерь будет использоваться для кодирования разностных сигналов в этих 5.1 каналах. Остальные 2 канала кодируют в отдельном наборе каналов, используя кодер без потерь. Поскольку необходимо учитывать все наборы каналов, когда пытаются оптимизировать продолжительность сегмента, все средства кодирования будут использоваться так или иначе. Совместимый декодер декодирует все 8 каналов и без потерь восстанавливает аудиосигналы 96 кГц 18,5 Мбит/с. Более старый декодер декодирует только эти 5.1 каналов и восстанавливает аудиосигналы 48 кГц 1,5 Мбит/с.
В общем случае, более одного набора каналов полностью без потерь можно предоставлять с целью масштабирования сложности декодера. Например, для исходного микшированного сигнала формата 10.2, наборы каналов можно организовывать таким образом, чтобы:
- CHSET1 переносил сигнал формата 5.1 (с внедренным понижающим микшированием 10.2 к 5.1), и его кодируют с использованием основного кодирования + кодирования без потерь,
- CHSET1 и CHSET2 переносили сигнал формата 7.1 (с внедренным понижающим микшированием 10.2 к 7.1), где CHSET2 кодирует 2 канала, используя кодирование без потерь,
- CHSET1+CHSET2+CHSET3 переносили полный дискретный микшированный сигнал формата 10.2, где CHSET3 кодирует остальные 3.1 каналов, используя только кодирование без потерь.
Декодер, который может декодировать только 5.1, декодирует только CHSET1 и игнорирует все другие наборы каналов. Декодер, который может декодировать только 7.1, декодирует CHSET1 и CHSET2 и игнорирует все другие наборы каналов….
Кроме того, основное кодирование с потерями плюс без потерь не лимитировано форматом 5.1. Существующие реализации поддерживают до 6.1, используя кодирование с потерями (основное кодирование + XCh) и без потерь, и могут поддерживать в общем случае m.n каналов, организованных в любом количестве наборов каналов. Кодирование с потерями будет иметь 5.1 обратно совместимых кодированных каналов, и все другие каналы, которые закодированы с помощью кодека с потерями, войдут в расширение XXCh. Это предоставляет полное кодирование без потерь со значительной гибкостью конструкции для того, чтобы оставалась обратная совместимость с существующими декодерами при поддержке дополнительных каналов.
Хотя показаны и описаны некоторые иллюстративные варианты осуществления изобретения, множество разновидностей и дополнительных вариантов осуществления будут придуманы специалистами. Такие разновидности и дополнительные варианты осуществления предусматриваются, и их можно делать, не отступая от объема и формы изобретения, которое описано в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОКАНАЛЬНЫЙ АУДИОКОДЕР БЕЗ ПОТЕРЬ | 2005 |
|
RU2387023C2 |
| МАСШТАБИРУЕМЫЙ АУДИОКОДЕР БЕЗ ПОТЕРЬ И АВТОРСКОЕ ИНСТРУМЕНТАЛЬНОЕ СРЕДСТВО | 2005 |
|
RU2387022C2 |
| ПОДДЕРЖКА СМЕШАННЫХ СНИМКОВ IRAR И HE-IRAR В ПРЕДЕЛАХ ЕДИНИЦЫ ДОСТУПА В МНОГОСЛОЙНЫХ БИТОВЫХ ВИДЕОПОТОКАХ | 2020 |
|
RU2822714C1 |
| УСТРОЙСТВО И СПОСОБ ФОРМИРОВАНИЯ РАСШИРЕННОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ЗАПОЛНЕНИЯ НЕЗАВИСИМЫМ ШУМОМ | 2015 |
|
RU2667376C2 |
| УСТРОЙСТВО И СПОСОБ ФОРМИРОВАНИЯ РАСШИРЕННОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ЗАПОЛНЕНИЯ НЕЗАВИСИМЫМ ШУМОМ | 2015 |
|
RU2665913C2 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2013 |
|
RU2603531C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СИГНАЛИЗАЦИИ ПАРАМЕТРОВ КВАНТОВАНИЯ ЦВЕТНОСТИ | 2020 |
|
RU2833184C1 |
| ОГРАНИЧЕНИЯ ВРЕМЕННОГО ИДЕНТИФИКАТОРА ДЛЯ СООБЩЕНИЙ SEI | 2020 |
|
RU2823614C1 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2013 |
|
RU2710908C2 |
| ПРЕДСКАЗАНИЕ ВЕКТОРА БЛОКА В КОДИРОВАНИИ/ДЕКОДИРОВАНИИ ВИДЕО И ИЗОБРАЖЕНИЙ | 2014 |
|
RU2669005C2 |
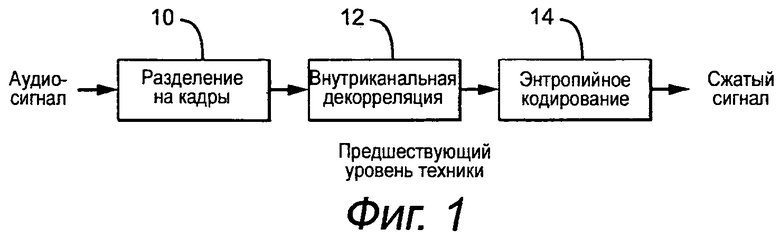
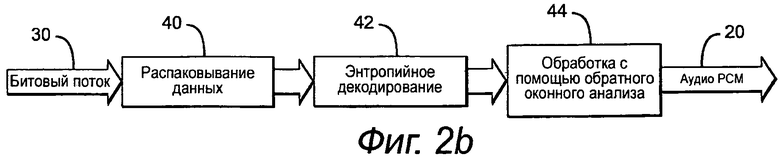
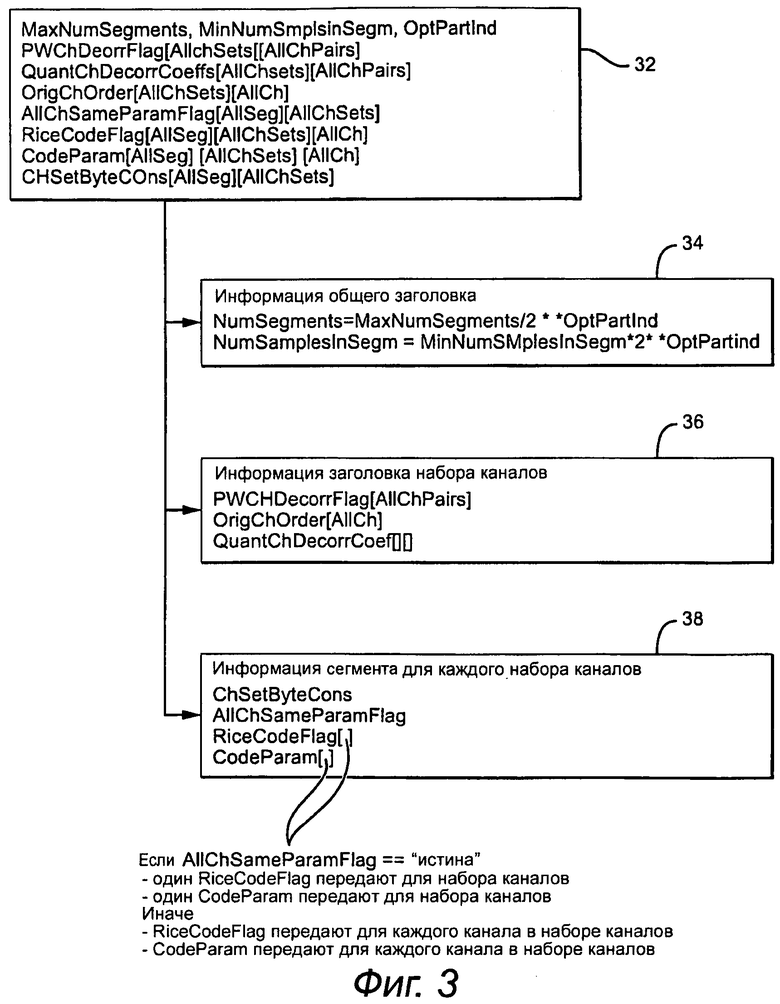
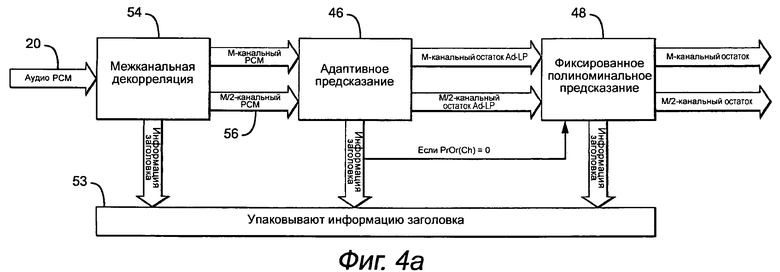
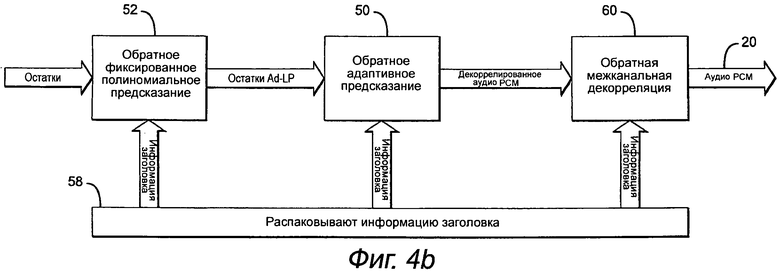
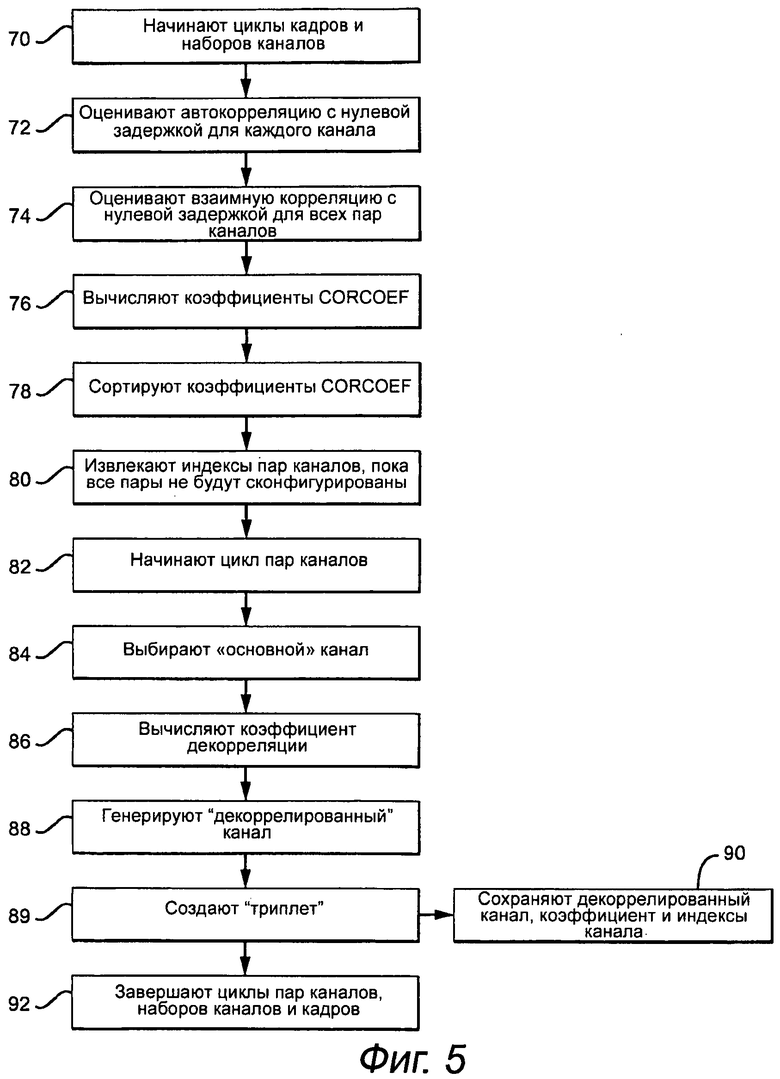
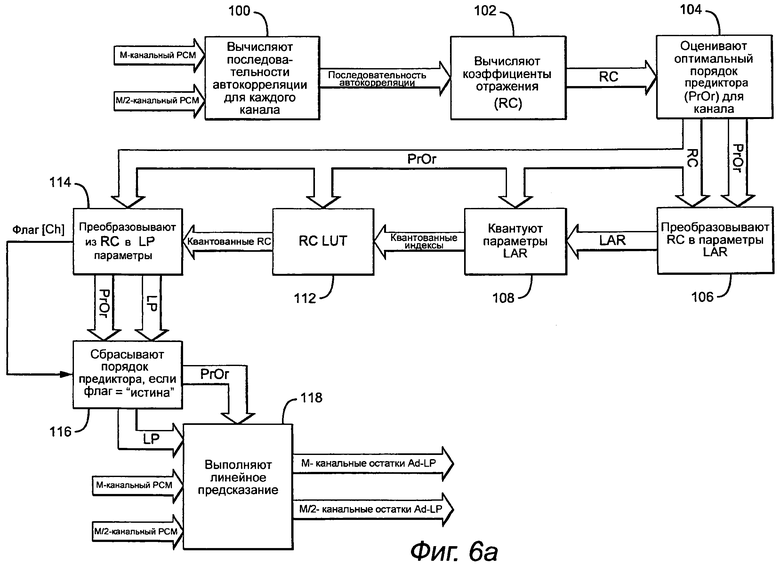
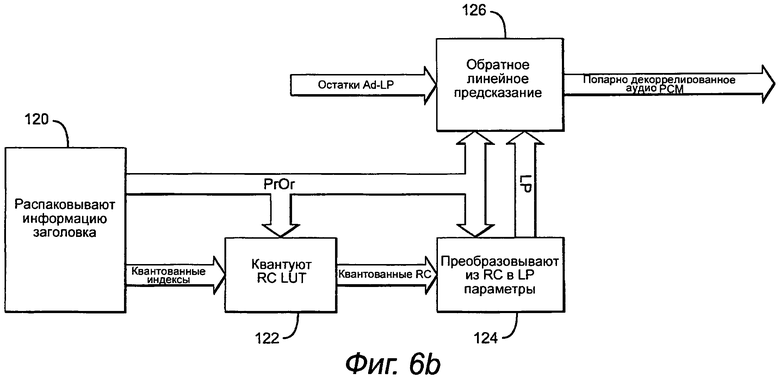
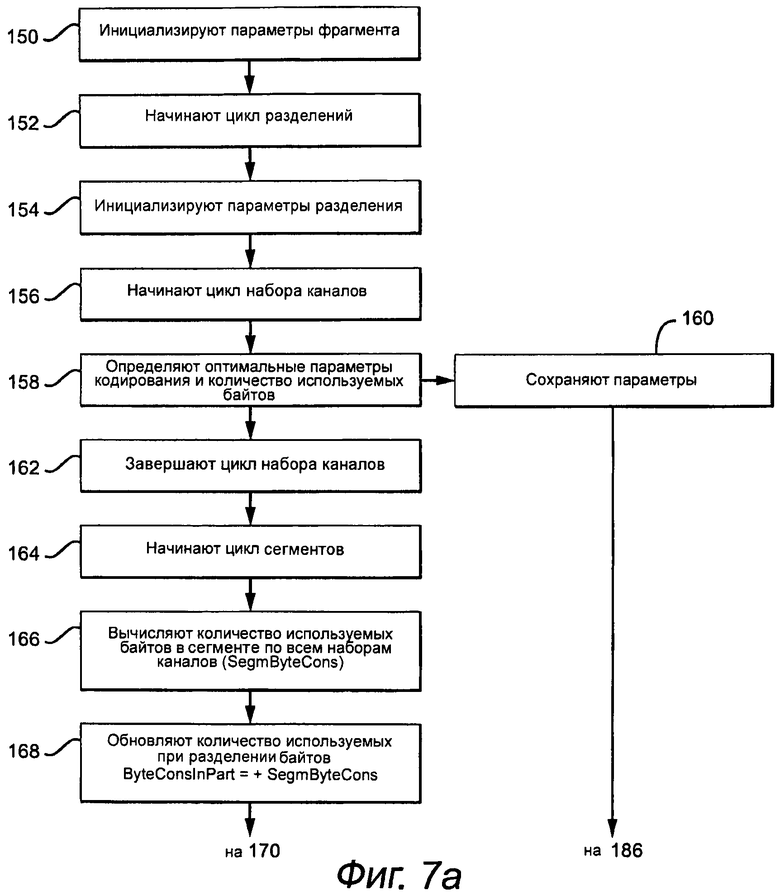
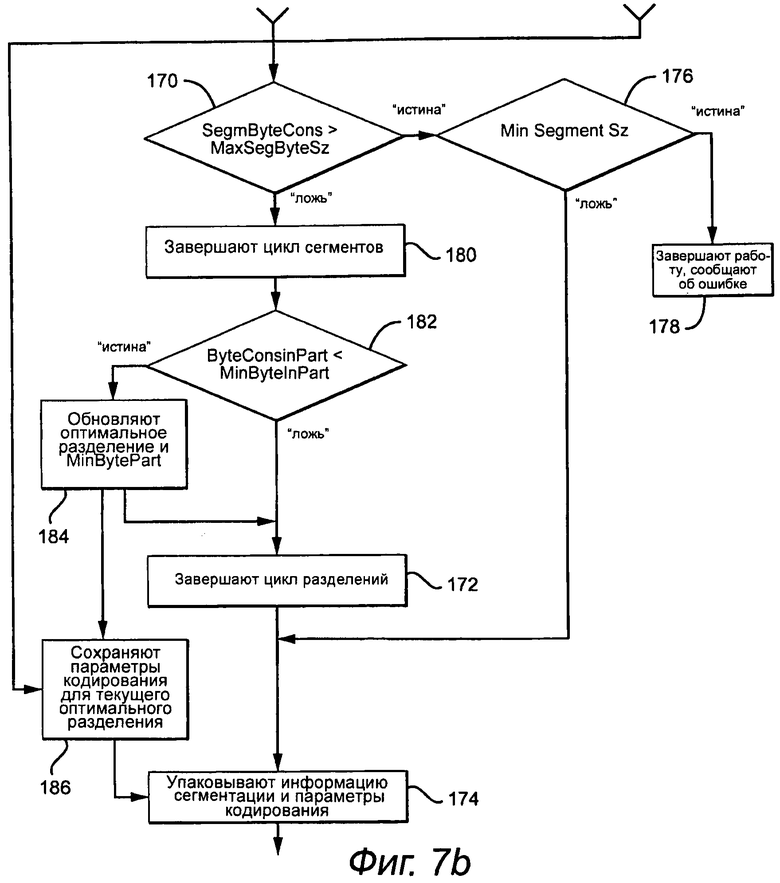
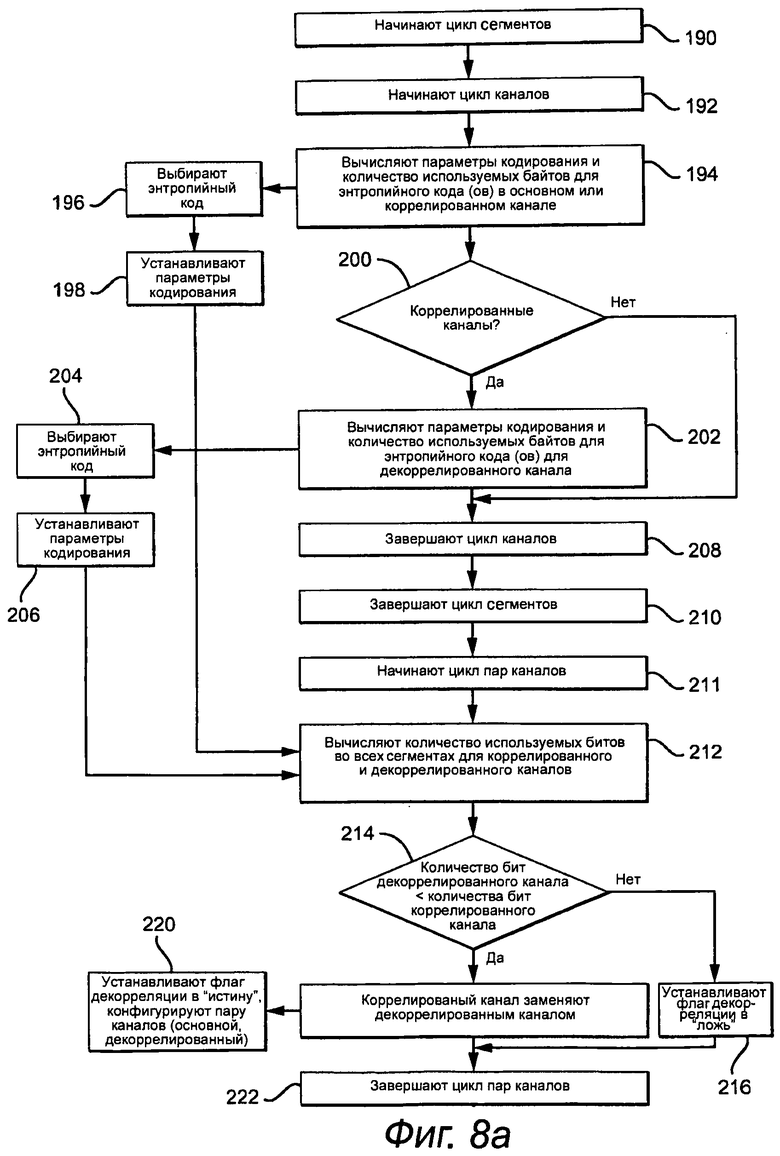
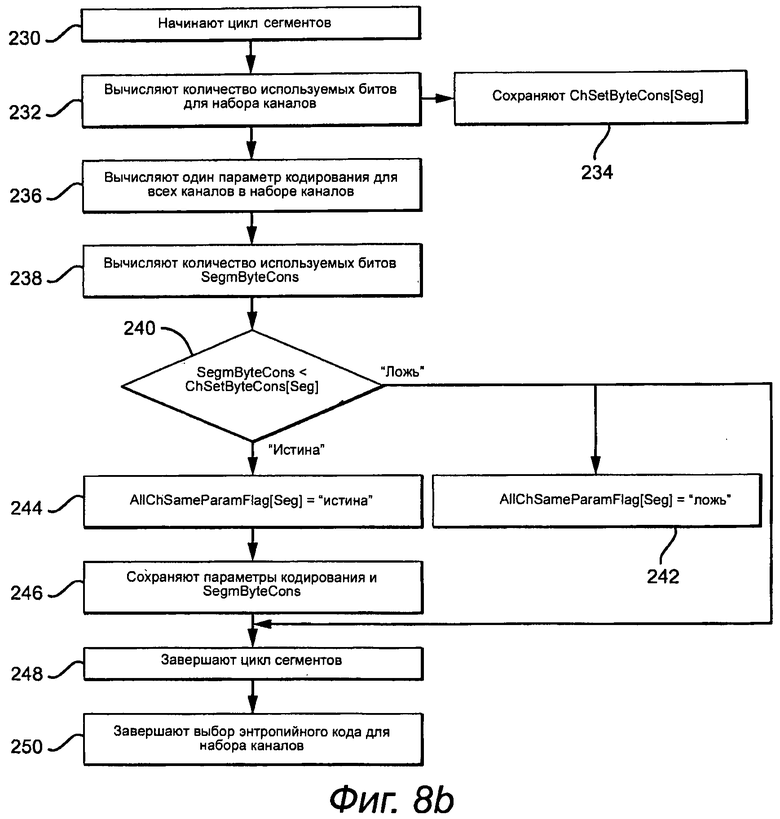
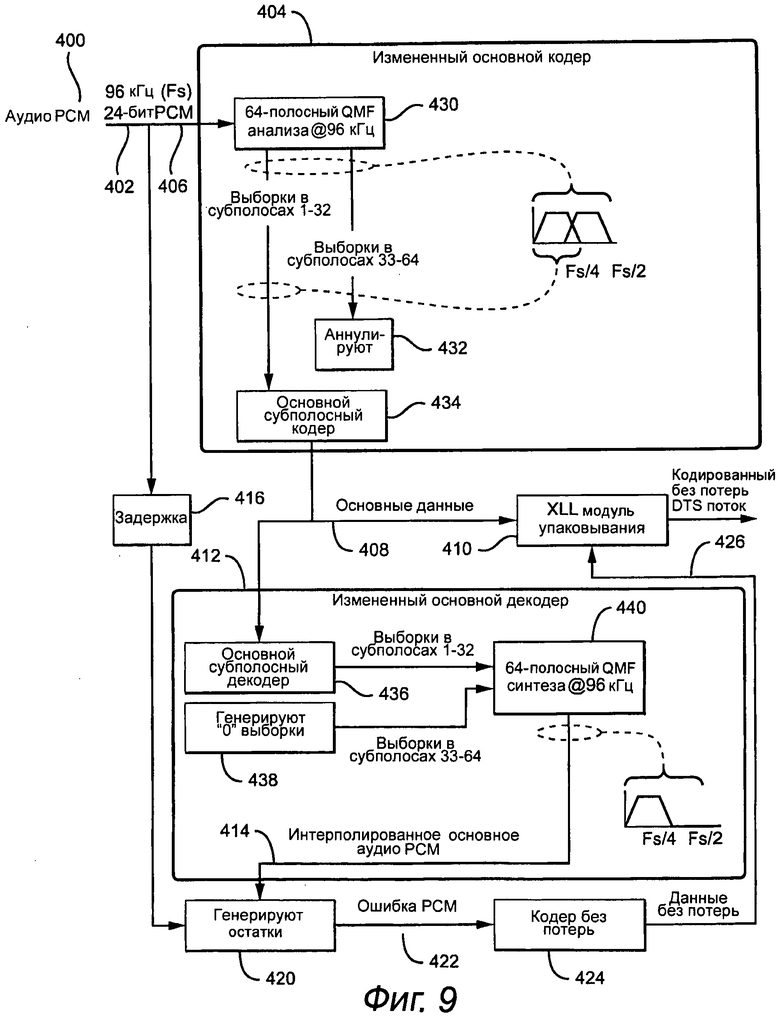
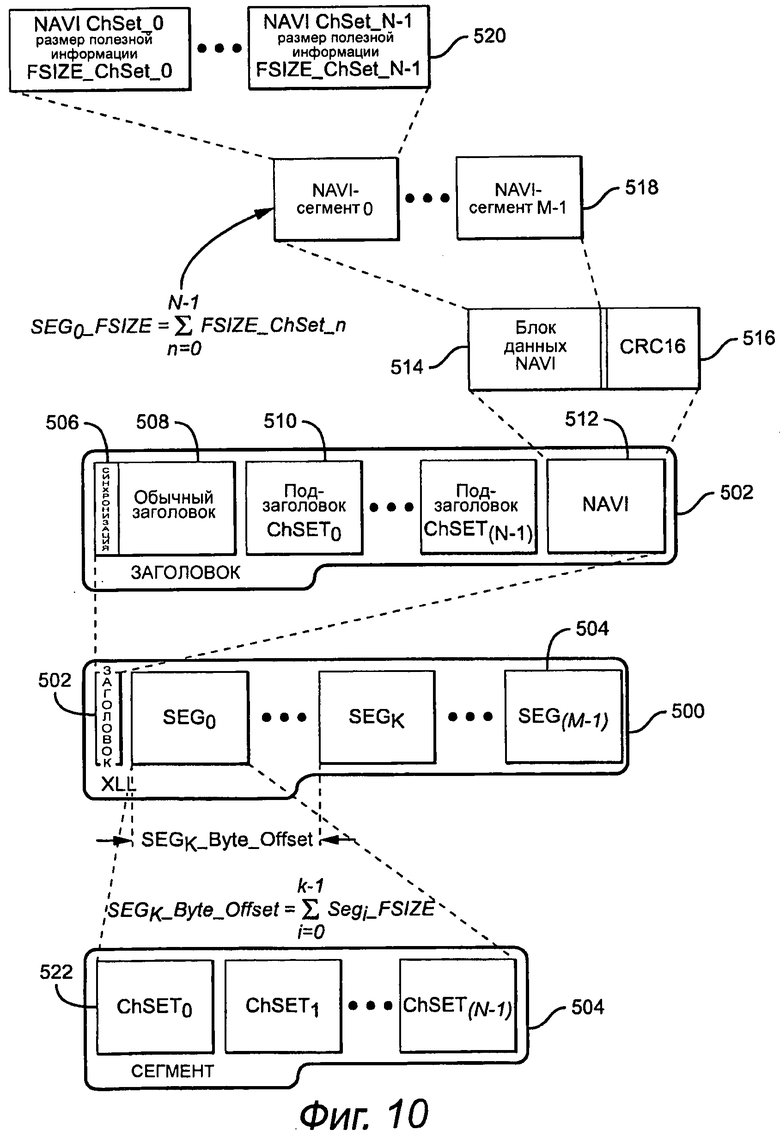
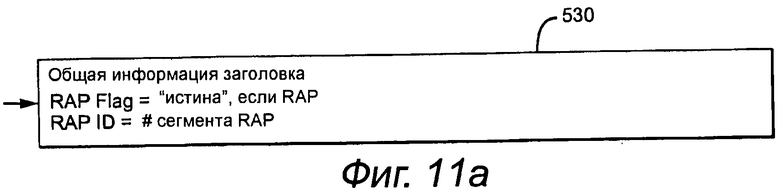
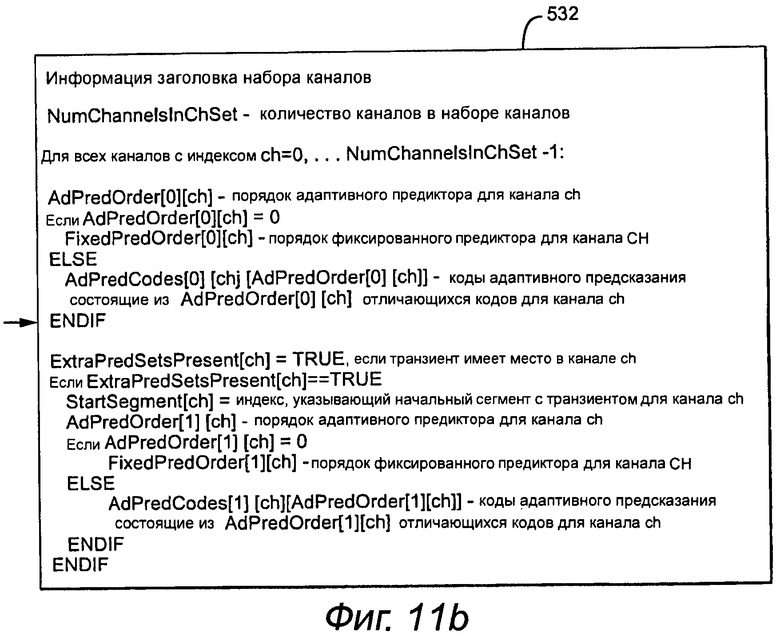
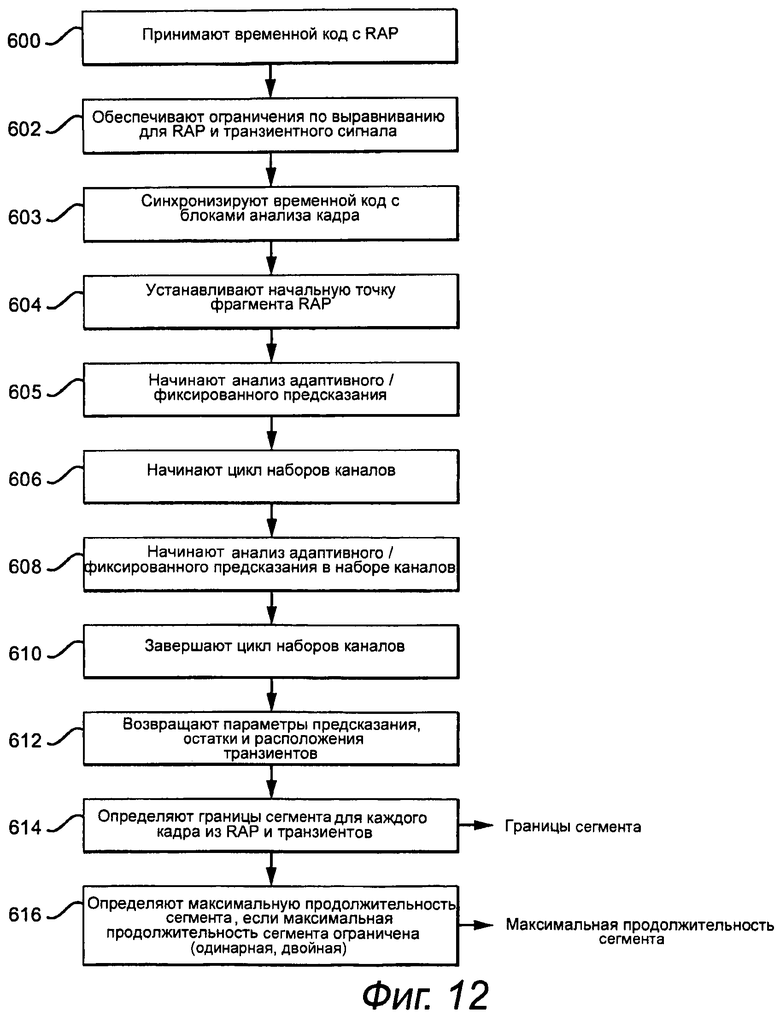
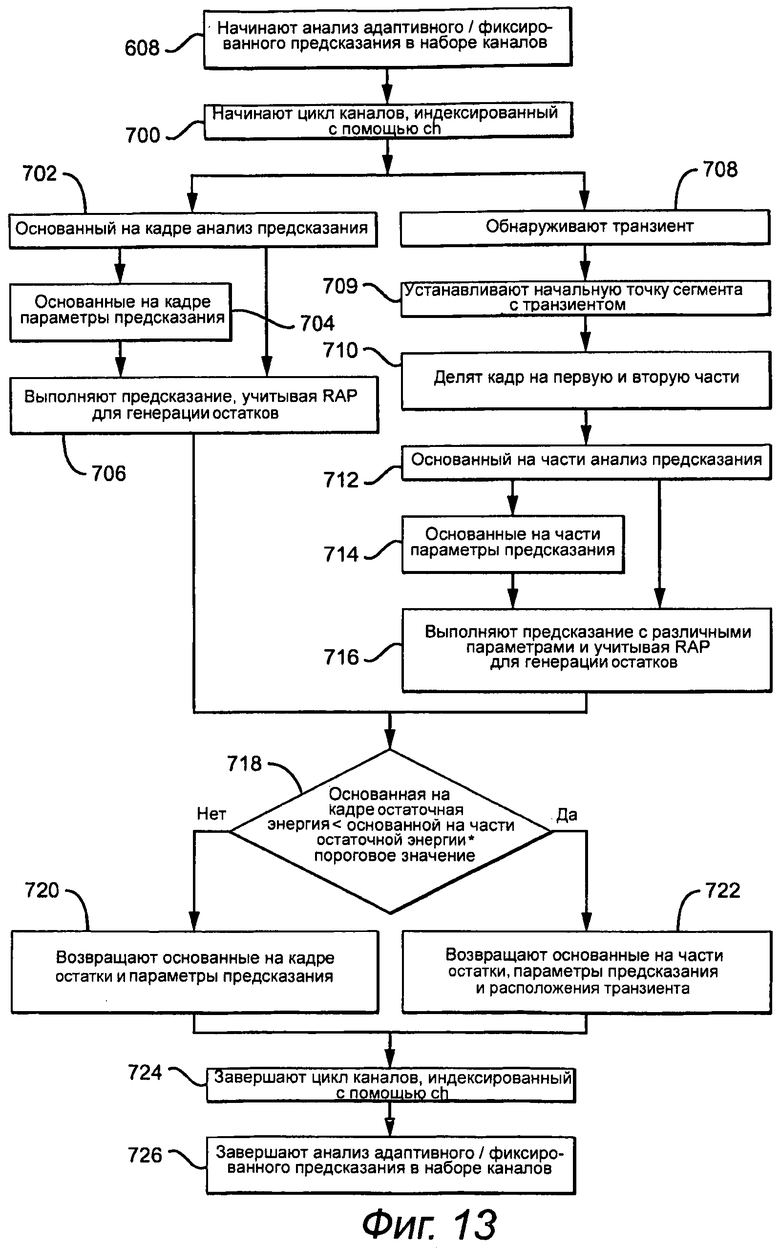
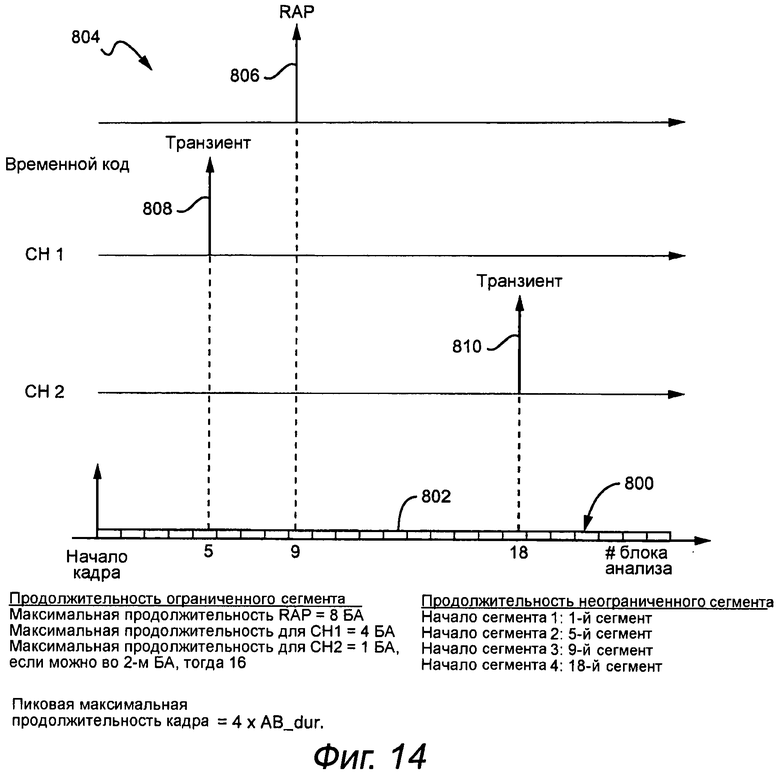
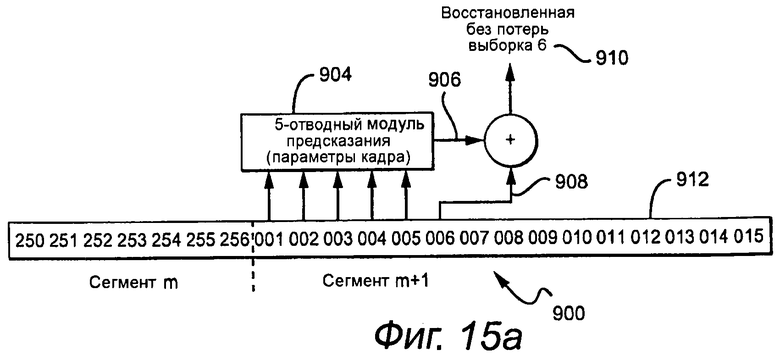
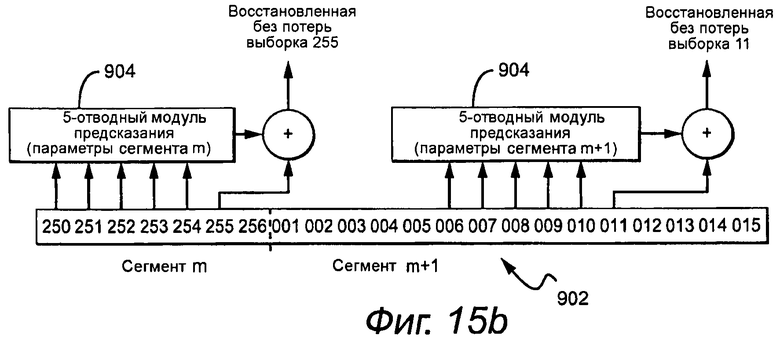
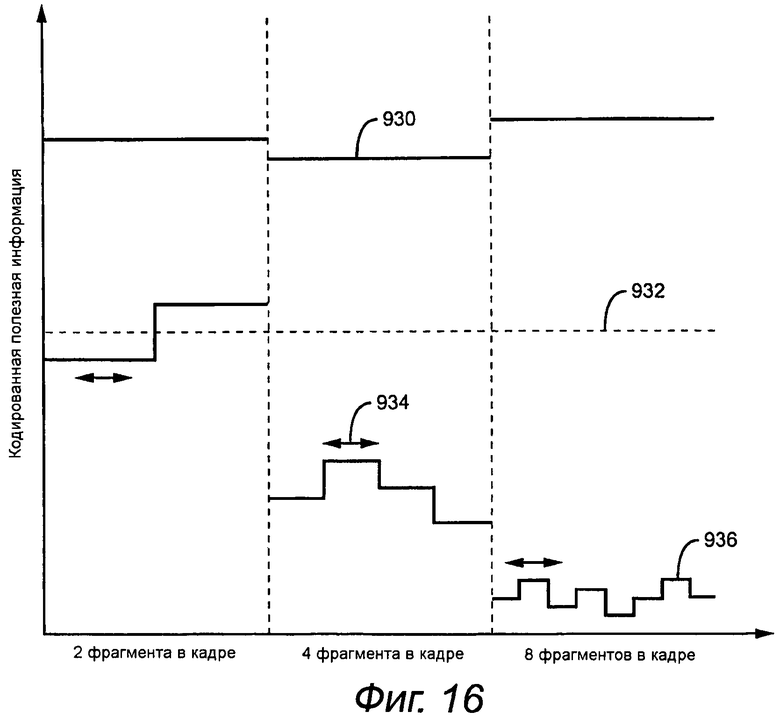
Изобретение относится к аудиокодекам без потерь, а более конкретно, к многоканальному аудиокодеку без потерь, который использует адаптивную сегментацию с возможностью точек произвольного доступа (RAP) и возможностью множества наборов параметров предсказания (MPPS). Аудиокодек без потерь кодирует/декодирует битовый поток с переменной скоростью передачи битов (VBR) без потерь с возможностью точек произвольного доступа (RAP) для инициирования декодирования без потерь в заданном сегменте в пределах кадра и/или возможностью множества набора параметров предсказания (MPPS), разделяемого для подавления влияния транзиентов. Это достигается с помощью методики адаптивной сегментации, которая устанавливает начальные точки сегмента, основываясь на ограничениях, предписываемых наличием необходимой RAP и/или обнаруженным транзиентом в кадре, и выбирает оптимальную продолжительность сегмента в каждом кадре для уменьшения кодированной полезной информации кадра, при условии ограничения кодированной полезной информации сегмента, RAP и MPPS в частности можно применять, чтобы повысить общую производительность для более длительной продолжительности кадра. Технический результат - повышение общей эффективности кодирования. 14. н.п. и 34 з.п. ф-лы, 23 ил.
1. Способ кодирования многоканального аудио с точками произвольного доступа (RAP) в битовый поток аудио с переменной скоростью передачи битов (VBR) без потерь, содержащий этапы, на которых:
принимают временной код кодирования, который задает необходимые точки произвольного доступа (RAP) в битовом потоке аудио;
блокируют многоканальное аудио, включающее в себя, по меньшей мере, один набор каналов, в кадры равной продолжительности времени, каждый кадр включает в себя заголовок и множество сегментов;
блокируют каждый кадр во множество блоков анализа равной продолжительности, каждый упомянутый сегмент имеет продолжительность одного или более блоков анализа;
синхронизируют временной код кодирования с последовательностью кадров для выравнивания необходимых RAP с блоками анализа;
для каждого последовательного кадра,
определяют до одного блока анализа RAP, который выровнен с необходимой RAP во временном коде кодирования;
устанавливают начало сегмента RAP, посредством чего блок анализа RAP находится в пределах M блоков анализа от начала;
определяют, по меньшей мере, один набор параметров предсказания для кадра для каждого канала в наборе каналов;
сжимают аудиокадр для каждого канала в наборе каналов согласно параметрам предсказания, упомянутое предсказание отключают для первых выборок по порядку предсказания после начала сегмента RAP, чтобы генерировать исходные аудиовыборок, которые предшествуют и/или следуют за остаточными аудиовыборками;
определяют продолжительность сегмента и параметры энтропийного кодирования для каждого сегмента из исходных и остаточных аудиовыборок для уменьшения кодированной с переменным размером полезной информации кадра, при условии ограничений, по которым каждый сегмент должен полностью и без потерь декодироваться, иметь продолжительность меньше продолжительности кадра и иметь кодированную полезную информацию сегмента меньше максимального количества байтов, которое меньше размера кадра;
упаковывают информацию заголовка, включающую в себя продолжительность сегмента, параметры RAP, указывающие наличие и расположение RAP, параметры предсказания и энтропийного кодирования и данные навигации по битовому потоку, в заголовок кадра в битовом потоке и
упаковывают сжатые и энтропийно кодированные аудиоданные для каждого сегмента в сегменты кадра в битовом потоке.
2. Способ по п.1, в котором временной код кодирования является временным кодом видео, задающим необходимые RAP, которые соответствуют началу заданных частей видеосигнала.
3. Способ по п.1, в котором расположение блока анализа RAP в пределах М блоков анализа от начала сегмента RAP в битовом потоке аудио обеспечивает возможность декодирования в пределах заданного допуска выравнивания необходимой RAP.
4. Способ по п.1, в котором первый сегмент всех N кадров является сегментом RAP по умолчанию, если необходимая RAP не находится в пределах кадра.
5. Способ по п.1, дополнительно содержащий этапы, на которых:
обнаруживают наличие транзиента в блоке анализа в кадре для одного или более каналов из набора каналов;
разделяют кадр так, чтобы любые обнаруженные транзиенты были расположены в пределах первых L блоков анализа сегмента в их соответствующих каналах; и
определяют первый набор параметров предсказания для сегментов, которые находятся перед обнаруженным транзиентом и не включают его в себя, и второй набор параметров предсказания для сегментов, включающих в себя и следующих за транзиентом для каждого канала в наборе каналов; и
определяют продолжительность сегмента, причем блок анализа RAP должен находиться в пределах М блоков анализа от начала сегмента RAP и транзиент должен находиться в пределах первых L блоков анализа сегмента в соответствующем канале.
6. Способ по п.5, дополнительно содержащий этап, на котором:
используют расположение блока анализа RAP и/или расположение транзиента, чтобы определить максимальную продолжительность сегмента как степень двойки продолжительности блока анализа, таким образом, чтобы упомянутый блок анализа RAP находился в пределах M блоков анализа от начала сегмента RAP и транзиент находился в пределах L первых блоков анализа сегмента,
причем одинаковая продолжительность сегментов, которая равна степени двойки продолжительности блока анализа и не превышает максимальную продолжительность сегмента, определяется для уменьшения кодированной полезной информации кадра при условии ограничений.
7. Способ по п.1, дополнительно содержащий этап, на котором:
используют расположение блока анализа RAP, чтобы определить максимальную продолжительность сегмента как степень двойки продолжительности блока анализа, таким образом, чтобы упомянутый блок анализа RAP находился в пределах М блоков анализа от начала сегмента RAP,
причем одинаковая продолжительность сегментов, которая является степенью двойки продолжительности блока анализа и не превышает максимальную продолжительность сегмента, определяется для уменьшения кодированной полезной информации кадра при условии ограничений.
8. Способ по п.7, в котором максимальная продолжительность сегмента дополнительно ограничивается размером выходного буфера, имеющегося в декодере.
9. Способ по п.1, в котором максимальное количество байтов для кодированной полезной информации сегмента предписывается размером модуля доступа для битового потока аудио.
10. Способ по п.1, в котором параметры RAP включают в себя флаг RAP, указывающий наличие RAP, и идентификатор (ID) RAP, указывающий расположение RAP.
11. Способ по п.1, в котором первый набор каналов включает в себя многоканальное аудио формата 5.1 и второй набор каналов включает в себя по меньшей мере один дополнительный канал аудио.
12. Способ по п.1, дополнительно содержащий этапы, на которых:
генерируют декоррелированный канал для пар каналов для формирования триплета, включающего в себя основной, коррелированный и декоррелированный каналы;
выбирают или первую пару каналов, включающую в себя основной и коррелированный каналы, или вторую пару каналов, включающую в себя основной и декоррелированный канал; и
энтропийно кодируют каналы в выбранных парах каналов.
13. Способ по п.12, в котором пары каналов выбирают следующим образом:
если дисперсия декоррелированного канала меньше дисперсии коррелированного канала на пороговое значение, то выбирают вторую пару каналов перед определением продолжительности сегмента; и
иначе задерживают выбор первой или второй пары каналов до определения продолжительности сегмента и делают его, основываясь на том, какая пара каналов вносит наименьшее количество битов в кодированную полезную информацию.
14. Считываемый компьютером носитель, содержащий исполняемые компьютером команды, которые при исполнении выполняют способ по п.1.
15. Полупроводниковое устройство для кодирования многоканального аудио с точками произвольного доступа (RAP) в битовый поток аудио с переменной скоростью передачи битов (VBR) без потерь, содержащее цифровые схемы, сконфигурированные с возможностью выполнения способа по п.1.
16. Способ инициированного декодирования многоканального битового потока аудио с переменной скоростью передачи битов (VBR) без потерь в точке произвольного доступа (RAP), содержащий этапы, на которых:
принимают многоканальный битовый поток аудио VBR без потерь как последовательность кадров, разделенных на множество сегментов, имеющих полезную информацию кадра переменной длины и включающих в себя по меньшей мере один независимо декодируемый и без потерь восстанавливаемый набор каналов, включающий в себя множество аудиоканалов для многоканального аудиосигнала, каждый кадр содержит информацию заголовка, включающую в себя продолжительность сегмента, параметры RAP, которые указывают наличие и расположение до одного сегмента RAP, навигационные данные, информацию заголовка набора каналов, которая включает в себя коэффициенты предсказания для каждого упомянутого канала в каждом упомянутом наборе каналов, и информацию заголовка сегмента для каждого упомянутого набора каналов, которая включает в себя по меньшей мере один флаг энтропийного кода и по меньшей мере один параметр энтропийного кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы, хранящиеся в упомянутом количестве сегментов;
распаковывают заголовок следующего кадра в битовом потоке, чтобы извлечь параметры RAP, вплоть до обнаружения кадра, имеющего сегмент RAP;
распаковывают заголовок выбранного кадра, чтобы извлечь продолжительность сегмента и навигационные данные для перемещения к началу сегмента RAP;
распаковывают заголовок по меньшей мере для одного упомянутого набора каналов, чтобы извлечь флаг энтропийного кода, и параметр кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы и выполнить энтропийное декодирование сегмента RAP, используя выбранный энтропийный код и параметр кодирования, чтобы генерировать сжатые аудиосигналы для сегмента RAP, причем упомянутые первые аудиовыборки сегмента RAP по порядку предсказания являются несжатыми; и
распаковывают заголовок, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь коэффициенты предсказания и восстановления сжатых аудиосигналов, причем упомянутое предсказание отключают для первых аудиовыборок по порядку предсказания, чтобы восстановить без потерь аудиоРСМ для каждого аудиоканала в упомянутом наборе каналов для сегмента RAP; и
декодируют остальные сегменты в кадре и последующие кадры по порядку.
17. Способ по п.16, в котором необходимая RAP, заданная во временном коде кодирования, находится в пределах допуска выравнивания от начала сегмента RAP в битовом потоке.
18. Способ по п.17, в котором расположение сегмента RAP в пределах кадра изменяется по всему битовому потоку, основываясь на расположении необходимых RAP во временном коде кодирования.
19. Способ по п.16, в котором после того, как декодирование было инициировано, предсказание отключают для первых аудиовыборок по порядку предсказания, когда встречается другой сегмент RAP в последующем кадре, чтобы продолжить без потерь восстанавливать аудиоРСМ.
20. Способ по п.16, в котором продолжительность сегмента уменьшает полезную информацию кадра при условии ограничений, чтобы необходимая RAP была выровнена в пределах заданного допуска от начала сегмента RAP и каждая полезная информация кодированного сегмента была меньше размера максимальной полезной информации, меньше размера кадра и полностью декодировалась и без потерь восстанавливалась, когда сегмент распаковывают.
21. Способ по п.16, в котором количество и продолжительность сегментов изменяют от кадра к кадру для минимизации полезной информации переменной длины каждого кадра при условии ограничений, чтобы кодированная полезная информация сегмента была меньше максимального количества байтов, без потерь восстанавливалась и необходимая RAP, заданная во временном коде кодирования, находилась в пределах допуска выравнивания от начала сегмента RAP.
22. Способ по п.16, дополнительно содержащий этапы, на которых:
принимают каждый кадр, включающий в себя информацию заголовка, включающую в себя параметры транзиентов, которые указывают наличие и расположение сегмента с транзиентом в каждом канале, коэффициенты предсказания для каждого упомянутого канала, включающие в себя один набор основанных на кадре коэффициентов предсказания, если транзиент не присутствует, и первый и второй наборы основанных на разделении коэффициентов предсказания, если транзиент присутствует в каждом упомянутом наборе каналов,
распаковывают заголовок, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь параметры транзиента для определения наличия и расположения сегментов с транзиентом в каждом канале в наборе каналов;
распаковывают заголовок, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь один набор основанных на кадре коэффициентов предсказания или первый и второй наборы основанных на разделении коэффициентов предсказания для каждого канала в зависимости от наличия транзиента; и
для каждого канала в наборе каналов или применяют один набор коэффициентов предсказания к сжатым аудиосигналам для всех сегментов в кадре для восстановления без потерь аудиоРСМ, или применяют первый набор коэффициентов предсказания к сжатым аудиосигналам, начиная с первого сегмента, и применяют второй набор коэффициентов предсказания к сжатым аудиосигналам, начиная с сегмента с транзиентом.
23. Способ по п.16, в котором битовый поток дополнительно содержит информацию заголовка набора каналов, включающую в себя флаг попарной декорреляции каналов, исходный порядок каналов и квантованные коэффициенты декорреляции канала, упомянутое восстановление генерирует декоррелированный аудиоРСМ, данный способ дополнительно содержит этап, на котором:
распаковывают заголовок, чтобы извлечь исходный порядок каналов, флаг попарной декорреляции каналов и квантованные коэффициенты декорреляции каналов и выполнить обратную межканальную декорреляцию для восстановления аудиоРСМ для каждого аудиоканала в упомянутом наборе каналов.
24. Способ по п.23, в котором флаг попарной декорреляции каналов указывает, была ли закодирована первая пара каналов, включающая в себя основной и коррелированный каналы, или вторая пара каналов, включающая в себя основной и декоррелированный каналы, для триплета, включающего в себя основной, коррелированный и декоррелированный каналы, данный способ дополнительно содержит этап, на котором:
если флаг указывает вторую пару каналов, то умножают основной канал на квантованный коэффициент декорреляции каналов и добавляют его к декоррелированному каналу для генерации аудио РСМ в коррелированном канале.
25. Считываемый компьютером носитель, содержащий исполняемые компьютером команды, которые при исполнении выполняют способ по п.16.
26. Полупроводниковое устройство для инициированного декодирования многоканального битового потока аудио с переменной скоростью передачи битов (VBK) без потерь в точке произвольного доступа (RAP), содержащее цифровые схемы, сконфигурированные с возможностью выполнения способа по п.16.
27. Способ кодирования многоканального аудио в битовый поток аудио с переменной скоростью передачи битов (VBR) без потерь, содержащий этапы, на которых:
блокируют многоканальное аудио, включающее в себя, по меньшей мере, один набор каналов, на кадры равной продолжительности времени, каждый кадр включает в себя заголовок и множество сегментов, каждый упомянутый сегмент имеет продолжительность одного или более блоков анализа;
для каждого последовательного кадра
обнаруживают наличие транзиента в блоке анализа транзиентов в кадре для каждого канала из набора каналов;
разделяют кадр так, чтобы любые блоки анализа транзиентов были расположены в пределах первых L блоков анализа сегмента в их соответствующих каналах;
определяют первый набор параметров предсказания для сегментов до и не включая в себя блок анализа транзиентов и второй набор параметров предсказания для сегментов, включающих в себя и следующих за блоком анализа транзиентов для каждого канала в наборе каналов;
сжимают аудиоданные, используя первый и второй наборы параметров предсказания в первой и второй частях соответственно для генерации остаточных аудиосигналов;
определяют продолжительность сегмента и параметры энтропийного кодирования для каждого сегмента из остаточных аудиовыборок для уменьшения кодированной с переменным размером полезной информации кадра при условии ограничений, по которым каждый сегмент должен полностью и без потерь декодироваться, иметь продолжительность меньше продолжительности кадра и иметь кодированную полезную информацию сегмента меньше максимального количества байтов, которое меньше размера кадра;
упаковывают информацию заголовка, включающую в себя продолжительность сегмента, параметры транзиента, указывающие наличие и расположение транзиента, параметры предсказания, параметры энтропийного кодирования и данные навигации по битовому потоку в заголовок кадра в битовом потоке; и
упаковывают сжатые и энтропийно кодированные аудиоданные для каждого сегмента в сегменты кадра в битовом потоке.
28. Способ по п.27, дополнительно для каждого канала в наборе каналов содержащий этапы, на которых:
определяют третий набор параметров предсказания для всего кадра;
сжимают аудио данные, используя третий набор параметров предсказания для всего кадра для генерации остаточных аудиосигналов; и
выбирают или третий набор, или первый и второй наборы параметров предсказания, основываясь на показателе эффективности кодирования из их соответствующих остаточных аудиосигналов,
причем если выбирают упомянутый третий набор, то отключают ограничение на продолжительность сегмента, предполагая расположение транзиента в пределах L блоков анализа от начала сегмента.
29. Способ по п.27, дополнительно содержащий этапы, на которых:
принимают временной код, который задает необходимые точки произвольного доступа (RAP) в битовом потоке аудио;
определяют до одного блока анализа RAP в пределах кадра из временного кода;
устанавливают начало сегмента RAP так, чтобы блок анализа RAP находился в пределах M блоков анализа от начала;
учитывают границы сегмента, предписываемые сегментом RAP, когда разделяют кадр для определения первого и второго наборов параметров предсказания;
отключают упомянутое предсказание для первых выборок по порядку предсказания после начала сегмента RAP для генерации исходных аудиовыборок, которые предшествуют и/или следуют за остаточными аудиовыборками для упомянутых первого, второго и третьего наборов параметров предсказания;
определяют продолжительность сегмента, которая уменьшает кодированную полезную информацию кадра, при удовлетворении ограничения, что блок анализа RAP
находится в пределах М блоков анализа от начала сегмента RAP и/или блоки анализа транзиентов должны находиться в пределах первых L блоков анализа сегмента; и
упаковывают параметры RAP, указывающие наличие и расположение RAP и данные навигации по битовому потоку, в заголовок кадра.
30. Способ по п.27, дополнительно содержащий этап, на котором:
используют обнаруженное расположение блока анализа транзиентов для определения максимальной продолжительности сегмента как степень двойки продолжительности блока анализа таким образом, что упомянутый транзиент находится в пределах L первых блоков анализа сегмента,
причем одинаковая продолжительность сегментов, которая равна степени двойки продолжительности блока анализа и не превышает максимальную продолжительность сегмента, определяется для уменьшения кодированной полезной информации кадра, при условии ограничений.
31. Способ по п.30, в котором максимальная продолжительность сегмента дополнительно ограничивается размером выходного буфера, имеющегося в декодере.
32. Способ по п.27, в котором максимальное количество байтов для кодированной полезной информации сегмента предписывают с помощью ограничения на размер модуля доступа для битового потока аудио.
33. Способ по п.27, в котором упомянутый битовый поток включает в себя первый и второй наборы каналов, упомянутый способ выбирает первый и второй наборы параметров предсказания для каждого канала в каждом наборе каналов, основываясь на обнаружении транзиентов в различных расположениях по меньшей мере для одного канала в соответствующих наборах каналов,
причем упомянутую продолжительность сегмента определяют так, чтобы каждый упомянутый транзиент находился в пределах первых L блоков анализа сегмента, в котором имеет место транзиент.
34. Способ по п.33, в котором первый набор каналов включает в себя многоканальное аудио формата 5.1 и второй набор каналов включает в себя, по меньшей мере, один дополнительный аудиоканал.
35. Способ по п.27, в котором параметры транзиента включают в себя флаг транзиента, указывающий наличие транзиента, и идентификатор транзиента, указывающий номер сегмента, в котором имеет место транзиент.
36. Способ по п.27, дополнительно содержащий этапы, на которых:
генерируют декоррелированный канал для пар каналов для формирования триплета, включающего в себя основной, коррелированный и декоррелированный каналы;
выбирают или первую пару каналов, включающую в себя основной и коррелированный каналы, или вторую пары каналов, включающую в себя основной и декоррелированный каналы; и
энтропийно кодируют каналы в выбранных парах каналов.
37. Способ по п.36, в котором пары каналов выбирают следующим образом:
если дисперсия декоррелированного канала меньше дисперсии коррелированного канала на пороговое значение, то выбирают вторую пару каналов до определения продолжительности сегмента; и
иначе задерживают выбор первой или второй пары каналов до определения продолжительности сегмента и делают его, основываясь на том, какая пара каналов вносит наименьшее количество битов в кодированную полезную информацию.
38. Считываемый компьютером носитель, содержащий исполняемые компьютером команды, которые при исполнении выполняют способ по п.27.
39. Полупроводниковое устройство для кодирования многоканального аудио в битовый поток аудио с переменной скоростью передачи битов (VBR) без потерь, содержащее цифровые схемы, сконфигурированные с возможностью выполнения способа по п.27.
40. Способ декодирования многоканального битового потока аудио с переменной скоростью передачи битов (VBR) без потерь, содержащий этапы, на которых:
принимают многоканальный битовый поток аудио VBR без потерь как последовательность кадров, разделенных на множество сегментов, имеющих полезную информацию кадра переменной длины и включающих в себя по меньшей мере один независимо декодируемый и восстанавливаемый без потерь набор каналов, включающий в себя множество аудиоканалов для многоканального аудиосигнала, каждый кадр содержит информацию заголовка, включающую в себя продолжительность сегмента, информацию заголовка набора каналов, которая включает в себя параметры транзиента, которые указывают наличие и расположение сегмента транзиента в каждом канале, коэффициенты предсказания для каждого упомянутого канала, включающие в себя один набор основанных на кадре коэффициентов предсказания, если транзиент не присутствует, и первый и второй наборы основанных на разделении коэффициентов предсказания, если транзиент присутствует в каждом упомянутом наборе каналов, и информацию заголовка сегмента для каждого упомянутого набора каналов, которая включает в себя по меньшей мере один флаг энтропийного кодирования и по меньшей мере один параметр энтропийного кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы, хранящиеся в упомянутом количестве сегментов;
распаковывают заголовок, чтобы извлечь продолжительность сегмента;
распаковывают заголовок, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь флаг энтропийного кодирования, и параметр кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы для каждого сегмента, и выполнить энтропийное декодирование каждого сегмента, используя выбранное энтропийное кодирование и параметр кодирования для генерации сжатых аудиосигналов для каждого сегмента;
распаковывают заголовок, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь параметры транзиента для определения наличия и расположения сегментов с транзиентом в каждом канале в наборе каналов;
распаковывают заголовок, по меньшей мере, для одного упомянутого набора каналов для извлечения одного набора основанных на кадре коэффициентов предсказания или первого и второго наборов основанных на разделении коэффициентов предсказания для каждого канала в зависимости от существования транзиентов; и
для каждого канала в наборе каналов или применяют один набор коэффициентов предсказания к сжатым аудиосигналам для всех сегментов в кадре для восстановления без потерь аудиоPCM, или применяют первый набор коэффициентов предсказания к сжатым аудиосигналам, начиная с первого сегмента, и применяют второй набор коэффициентов предсказания к сжатым аудиосигналам, начиная с сегмента транзиента.
41. Способ по п.40, в котором битовый поток дополнительно содержит информацию заголовка набора каналов, включающую в себя флаг попарной декорреляции каналов, исходный порядок каналов и квантованные коэффициенты декорреляции канала, упомянутое восстановление генерирует декоррелированное аудиоPCM, данный способ дополнительно содержит этап, на котором:
распаковывают заголовок, чтобы извлечь исходный порядок каналов, флаг попарной декорреляции каналов и квантованные коэффициенты декорреляции канала и выполнить обратную межканальную декорреляцию для восстановления аудиоPCM для каждого аудиоканала в упомянутом наборе каналов.
42. Способ по п.41, в котором флаг попарной декорреляции каналов указывает, была ли закодирована первая пара каналов, включающая в себя основной и коррелированный каналы, или вторая пара каналов, включающая в себя основной и декоррелированный каналы, для триплета, включающего в себя основной, коррелированный и декоррелированный каналы, способ дополнительно содержит этап, на котором:
если флаг указывает вторую пару каналов, то умножают основной канал на квантованный коэффициент декорреляции канала и добавляют его к декоррелированному каналу для генерации аудиоРСМ в коррелированном канале.
43. Способ по п.40, дополнительно содержащий этапы, па которых:
принимают кадр, имеющий информацию заголовка, включающую в себя параметры RAP, которые указывают наличие и расположение до одного сегмента RAP, и навигационные данные;
распаковывают заголовок следующего кадра в битовом потоке, чтобы извлечь параметры RAP, и если пытаются инициировать декодирование в RAP, то выполняют пропуск до следующего кадра до тех пор, пока кадр, имеющий сегмент RAP, не будет обнаружен, и используют навигационные данные для перемещения к началу сегмента RAP; и,
когда обнаруживают сегмент RAP, отключают предсказание для первых аудиовыборок по порядку предсказания, чтобы восстановить без потерь аудиоPCM.
44. Способ по п.40, в котором количество и продолжительность сегментов изменяют от кадра к кадру для минимизации полезной информации переменной длины каждого кадра при условии ограничений, чтобы кодированная полезная информация сегмента была меньше максимального количества байтов, которое меньше размера кадра, и без потерь восстанавливалась.
45. Считываемый компьютером носитель, содержащий исполняемые компьютером команды, которые при исполнении выполняют способ по п.40.
46. Полупроводниковое устройство для декодирования многоканального битового потока аудио с переменной скоростью передачи битов (VBR) без потерь, содержащее цифровые схемы, сконфигурированные с возможностью выполнения способа по п.40.
47. Многоканальный аудиодекодер для инициирования декодирования многоканального битового потока аудио с переменной скоростью передачи битов (VBR) без потерь в точке произвольного доступа (RAP), причем упомянутый декодер сконфигурирован с возможностью:
приема многоканального битового потока аудио VBR без потерь как последовательности кадров, разделенных на множество сегментов, имеющих полезную информацию кадра переменной длины и включающих в себя по меньшей мере один независимо декодируемый и восстанавливаемый без потерь набор каналов, включающий в себя множество аудиоканалов для многоканального аудиосигнала, каждый кадр содержит информацию заголовка, включающую в себя продолжительность сегмента, параметры RAP, которые указывают наличие и расположение до одного сегмента RAP, навигационные данные, информацию заголовка набора каналов, которая включает в себя коэффициенты предсказания для каждого упомянутого канала в каждом упомянутом наборе каналов, и информацию заголовка сегмента для каждого упомянутого набора каналов, которая включает в себя по меньшей мере один флаг энтропийного кода и по меньшей мере один параметр энтропийного кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы, хранящиеся в упомянутом количестве сегментов;
распаковывания заголовка следующего кадра в битовом потоке, чтобы извлекать параметры RAP до тех пор, пока кадр, имеющий сегмент RAP, не будет обнаружен;
распаковывания заголовка выбранного кадра, чтобы извлечь продолжительность сегмента и навигационных данных для перемещения к началу сегмента RAP;
распаковывания заголовка по меньшей мере для одного упомянутого набора каналов, чтобы извлечь флаг энтропийного кода, и параметр кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы и выполнить энтропийное декодирование сегмента RAP, используя выбранный энтропийный код и параметр кодирования для генерации сжатых аудиосигналов для сегмента RAP, упомянутые первые аудиовыборки сегмента RAP по порядку предсказания являются несжатыми; и
распаковывания заголовка по меньшей мере для одного упомянутого набора каналов, чтобы извлечь коэффициенты предсказания и восстановления сжатых аудиосигналов, упомянутое предсказание отключают для первых аудиовыборок по порядку предсказания, чтобы восстановить без потерь аудиоPCM для каждого аудиоканала в упомянутом наборе каналов для сегмента RAP; и
декодирования остальных сегментов в кадре и последующих кадров по порядку.
48. Многоканальный аудиодекодер для декодирования многоканального битового потока аудио с переменной скоростью передачи битов (VBR) без потерь, в котором упомянутый декодер сконфигурирован с возможностью:
приема многоканального битового потока VBR аудио без потерь как последовательности кадров, разделенных на множество сегментов, имеющих полезную информацию кадра переменной длины и включающих в себя по меньшей мере один независимо декодируемый и восстанавливаемый без потерь набор каналов, включающий в себя множество аудиоканалов для многоканального аудиосигнала, каждый кадр содержит информацию заголовка, включающую в себя продолжительность сегмента, информацию заголовка набора каналов, которая включает в себя параметры транзиента, которые указывают наличие и расположение сегмента с транзиентом в каждом канале, коэффициенты предсказания для каждого упомянутого канала, включающие в себя один набор основанных на кадре коэффициентов предсказания, если транзиент не присутствует, и первый и второй наборы основанных на разделении коэффициентов предсказания, если транзиент присутствует в каждом упомянутом наборе каналов, и информацию заголовка сегмента для каждого упомянутого набора каналов, которая включает в себя по меньшей мере один флаг энтропийного кода и по меньшей мере один параметр энтропийного кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы, хранящиеся в упомянутом количестве сегментов;
распаковывания заголовка, чтобы извлечь продолжительность сегмента;
распаковывания заголовка, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь флаг энтропийного кода, и параметр кодирования, и энтропийно кодированные сжатые многоканальные аудиосигналы для каждого сегмента, и выполнить энтропийное декодирование каждого сегмента, используя выбранный энтропийный код и параметр кодирования для генерации сжатых аудиосигналов для каждого сегмента;
распаковывания заголовка, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь параметры транзиента для определения наличия и расположения сегментов с транзиентом в каждом канале в наборе каналов;
распаковывания заголовка, по меньшей мере, для одного упомянутого набора каналов, чтобы извлечь один набор основанных на кадре коэффициентов предсказания, или первый и второй наборы основанных на разделении коэффициентов предсказания для каждого канала в зависимости от наличия транзиента; и
для каждого канала в наборе каналов или применения одного набора коэффициентов предсказания к сжатым аудиосигналам для всех сегментов в кадре для восстановления без потерь аудиоPCM, или применения первого набора коэффициентов предсказания к сжатым аудиосигналам, начиная с первого сегмента, и применения второго набора коэффициентов предсказания к сжатым аудиосигналам, начиная с сегмента с транзиентом.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СИСТЕМА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ БЕЗ ПОТЕРЬ | 1999 |
|
RU2158057C1 |
| US 7193538 B2, 20.03.2007 | |||
| EP 1396843 A1, 10.03.2004 | |||
| US 6675148 B2, 06.01.2004. | |||

