ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к сети Ethernet и, более конкретно к способу и устройству для обмена маршрутной информацией и установлению возможности связи через множество сегментов сети.
ИЗВЕСТНЫЙ УРОВЕНЬ ТЕХНИКИ
В архитектуре сети Ethernet устройства, соединенные с сетью, конкурируют за возможность совместного использования телекоммуникационных путей в любой данный момент времени. Там, где используется множество мостов или узлов для соединения сегментов сети, часто существует множество потенциальных путей к тому же самому месту назначения. Преимущество этой архитектуры заключается в том, что она обеспечивает избыточность путей между мостами и позволяет увеличить производительность сети в виде дополнительных каналов. Однако для предотвращения зацикливания, связующее дерево, в основном, использовалось для ограничения способа, по которому трафик широковещательно передавался по сети. Поскольку маршруты устанавливались путем широковещательной передачи фрейма и ожидания ответа, и поскольку и запрос и ответ будут следовать за связующим деревом, большая часть, если не весь трафик, следовала за каналами, которые были частью связующего дерева. Это часто приводило к чрезмерному использованию каналов, которые были на связующем дереве без использования каналов, которые не были частью связующего дерева.
Чтобы преодолеть некоторые из ограничений, присущих сетям Ethernet, управляемая сеть Ethernet протокола по состоянию канала была раскрыта в патентной заявке США №11/537,775, зарегистрированный 2 октября 2006 года под названием "Маршрутизация по состоянию канала провайдера", содержание которой включено здесь в качестве ссылки. Как подробно описано в этой заявке, узлы в протоколе маршрутизации по состоянию канала управляются обменом приветствий в сети Ethernet, чтобы изучить соседние узлы в сети и передать сообщения о состоянии канала типа «рекламные сообщения», чтобы позволить каждому узлу в сети создать базу данных о состоянии канала. В пакеты по состоянию канала включена метрика, связанная с рекламируемым каналом. Как правило, эта метрика интерпретируется как расстояние. База данных по состоянию канала затем может быть использована для вычисления кратчайшего пути прохождения сигнала через сеть. Каждый узел затем заполняет базу пересылки информации (FIB), которая будет использоваться узлом, чтобы принять решения по пересылке с тем, чтобы фреймы были бы переданы в место назначения по кратчайшему пути. Поскольку к определенному месту назначения всегда используется кратчайший путь, сетевой трафик будет распределен по большему числу каналов и следовать оптимальным путем для большего числа узлов, чем через одиночное связующее дерево или даже через множество связующих деревьев, которые используются для переноса трафика в сети.
Когда трафик клиента вводится в сеть провайдера, клиентский адрес назначения фрейма MAC (DA C-MAC) передается по МАС-адресу провайдера (DA B-MAC) с тем, чтобы провайдер мог передать трафик в сети, используя пространство МАС-адреса провайдера. Дополнительно в сети провайдера конфигурируются сетевые элементы, чтобы передать трафик на основе идентификатора виртуальной локальной сети (VID) так, чтобы различные фреймы были бы адресованы тому же самому получателю, но при наличии различных VID могут быть переданы через сеть по различным путям. При работе сеть Ethernet, управляемая протоколом состояния канала, может связать один диапазон VID с передачей по кратчайшему пути для передачи одноадресного и многоадресного трафика, используя VID этого диапазона, и трафик может быть передан в сети по путям, кроме кратчайшего пути, используя второй диапазон VID. Использование путей разработанного трафика (ТЕ) через протокол по состоянию канала управляемой сети Ethernet более подробно описано в патентной заявке США №11/732,381, зарегистрированной 3 апреля 2007 года под названием "Инжиниринговые пути в протоколе А по состоянию канала в управляемой сети Ethernet", содержание которой включается здесь в качестве ссылки.
Протоколы маршрутизации по состоянию канала включают открытый кратчайший путь (OSPF) и промежуточную систему к промежуточной системе (IS-IS). Эти сети по состоянию канала могут только увеличиться в точке, где время пересходимости для плоскости управления состоянием канала становится недопустимым из-за сложности необходимых вычислений, которое растет по экспоненте в пропорции к размеру сети. Для прохождения этой точки используют протоколы по состоянию канала для разделения сетей на сегменты. Как IS-IS, так и OSPF ограничиваются двумя иерархиями уровня: одиночная магистральная зона (уровень 2 в IS-IS) с тупиковыми сегментами уровня 1 (L1).
Маршрутизация с учетом состояния канала провайдера (PLSB), в которой протокол IS-IS применяется к мостам в сетях Ethernet провайдеров, мост, который соединяет два (или несколько) сегментов, называется мостом граничных сегментов сети (ABB). Для надежности желательно иметь множество мостов ABB между любым сегментом L1 и сегментом одиночного уровня 2 (L2). Применение протокола IS-IS в сетях IP хорошо известно в данной области техники. Однако имеется существенная разница между протоколом Интернета (IP) и PLSB, которая приводит к пробным и истинным путям, по которыми IP трафик, направляемый между сегментами, не всегда применим для PLSB. Например, если IP основан на подсетях, проверка возможности передачи пакета по направлению к граничным сегментам является простой.
IP выполняется без установления соединения, так что передача пакета самому близкому маршрутизатору граничных сегментов (ABR), где сеть IP эквивалентна самому близкому ABB, всегда будет работать. IP не требует симметрии по путям, таким образом, пакет может выйти из области по одному ABB, и обратный пакет может прибыть по другому ABB, тогда как, по причинам, относящимся к многоадресной передаче Ethernet и к операционному инструментарию, в PLSB путь между двумя конечными точками должен быть одним и тем же по обоим направлениям. Кроме того, протоколы IS-IS для IP и OSPF не поддерживают многоадресную маршрутизацию, хотя многоадресные деревья являются основной частью PLSB. Для Ethernet желательно (и обязательно для проектного решения PLSB), чтобы многоадресные пакеты следовали по одним и тем же маршрутам, как одноадресные пакеты, передаваемые одним и тем же пунктам назначения.
В настоящий момент протокол IS-IS позволяет каналу быть как в сегменте L1, так и в локальных сетях L2, но PLSB не обеспечивает индикации для ABB, чтобы определить, должен ли входящий пакет быть обработан как поступивший от L1 или от L2 при определении его следующего транзитного участка. Также нет никаких условий для обработки сценария, по которому одиночный ABB обслуживает множество не пересекающихся сегментов L1.
Следовательно, необходима система и способ для пересылки пакетов без зацикливания в сети PLSB с множеством сегментов, где сегменты L1 могут обслуживаться множеством ABB, и один ABB может обслужить множество сегментов.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение обеспечивает способ, устройство и систему, гарантирующие, что многоадресные пакеты следуют одним и тем же незацикленным путем, как путь, по которому следуют одноадресные пакеты в сети пакетной передачи. В основном, для сетей пакетной передачи, где сегмент (L1) любого уровня может обслуживаться множеством мостов граничных сегментов сети (ABB), когда одиночная база пересылки информации (FIB) недостаточна. Настоящее изобретение предусматривает использование конкретных и различных FIB, в зависимости от того, прибывает ли пакет в порт уровня L1 или в порт уровня 2 (L2).
В соответствии с одним объектом настоящего изобретения, способ гарантирует, что многоадресные пакеты следуют по одному и тому же незацикленному пути, что и одноадресные пакеты в сети пакетной передачи. Сеть пакетной передачи включает, по меньшей мере, один первый сегмент, определенный первым уровнем. Каждый первый сегмент включает первое множество узлов, соединенных первым набором каналов. Каждый первый сегмент соединяется, по меньшей мере, через один узел граничных сегментов со вторым сегментом, определенным вторым уровнем. Второй сегмент включает второе множество узлов, соединенных вторым набором каналов. Каждый узел граничных сегментов включает, по меньшей мере, один порт первого уровня, соединенный с каждым первым сегментом, и порт второго уровня, соединенный со вторым сегментом. Каждый многоадресный пакет, переданный по незацикленному пути, включает заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева. По меньшей мере, один пакет данных принимается узлом граничных сегментов сети, реагирующим на получение многоадресного пакета в порту второго уровня узла граничных сегментов сети, при этом корневой идентификатор многоадресного пакета анализируется. Если многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня узла граничных сегментов сети, другой корневой идентификатор вводится в пакет прежде, чем передать пакет, по меньшей мере, на один порт первого уровня.
В соответствии с другим объектом настоящего изобретения, обеспечивается узел граничных сегментов для использования в сети пакетной передачи. Сеть пакетной передачи включает, по меньшей мере, один первый сегмент, определенный первым уровнем. Каждый первый сегмент включает первое множество узлов, соединенных первым набором каналов. Каждый первый сегмент соединяется со вторым сегментом, определенным вторым уровнем. Второй сегмент включает второе множество узлов, соединенных вторым набором каналов. Узел граничных сегментов включает, по меньшей мере, один порт первого уровня, соответствующий каждому первому сегменту, порт второго уровня, соответствующий второму сегменту, и, по меньшей мере, один процессор. Порт первого уровня используется для приема пакетов данных из соответствующего сегмента и для передачи пакетов данных соответствующему первому сегменту. Порт второго уровня используется для приема пакетов данных из соответствующего сегмента и для передачи пакетов данных второму сегменту. По меньшей мере, один процессор электрически соединен с каждым портом первого уровня и с портом второго уровня. Реагирующий на получение многоадресного пакета порт второго уровня получает пакет, содержащий заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева; по меньшей мере, один процессор используется для анализа корневого идентификатора многоадресного пакета и определения, должен ли многоадресный пакет быть передан, по меньшей мере, на один из портов первого уровня узла граничных сегментов сети. Если многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, процессор заменяет корневой идентификатор в пакете до инициирования передачи пакета порту первого уровня.
В соответствии с еще одним объектом настоящего изобретения, система пакетной связи включает второй сегмент, по меньшей мере, один первый сегмент и, по меньшей мере, один узел граничных сегментов. По меньшей мере, один первый сегмент соединяется со вторым сегментом. Второй сегмент и каждый первый сегмент конфигурируются по протоколу состояния канала, управляемого сегментом сети Ethernet, включающего множество узлов, соединенных рядом каналов. По меньшей мере, один узел граничных сегментов соединяет каждый первый сегмент со вторым сегментом и используется для обслуживания двух или более непересекающихся первых сегментов. Каждый узел граничных сегментов включает порт второго уровня, по меньшей мере, один порт первого уровня и, по меньшей мере, один процессор. Второй порт используется для приема пакетов данных из соответствующего сегмента и для передачи пакетов данных вторым сегментам. Каждый порт первого уровня используется для приема пакетов данных из соответствующего сегмента и для передачи пакетов данных соответствующему первому сегменту. По меньшей мере, один процессор электрически соединен с портом второго уровня и с каждым портом первого уровня. Реагирующий на получение многоадресного пакета порт второго уровня получает пакет, содержащий заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева. Процессор используется для анализа корневого идентификатора многоадресного пакета и определения, должен ли многоадресный пакет быть передан, по меньшей мере, на один из портов первого уровня узла граничных сегментов. Если многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, процессор заменяет корневой идентификатор в пакете до инициирования передачи пакета порту первого уровня.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Объекты настоящего изобретения перечислены в пунктах формулы изобретения. Настоящее изобретение иллюстрируется примерами в приложенных чертежах, на которых одинаковыми цифровыми позициями обозначены аналогичные элементы. Чертежи раскрывают различные варианты воплощения настоящего изобретения только в целях иллюстрации и не ограничивают контекст изобретения. Для ясности не каждый компонент может быть обозначен соответствующим символом.
На чертежах:
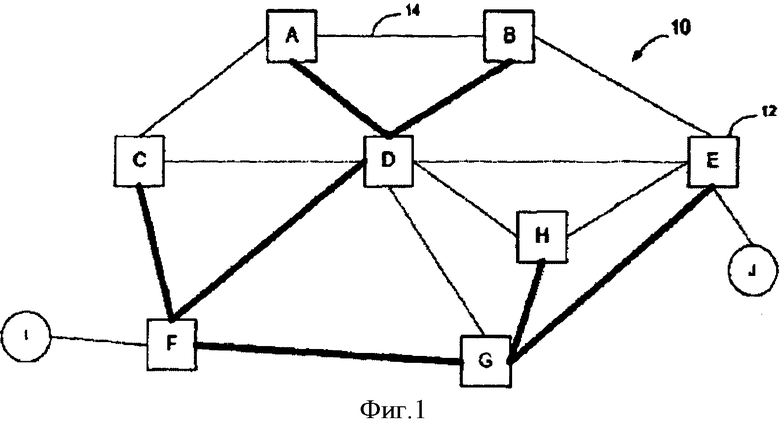
Фигура 1 - функциональная блок-схема одного примера, протокола состояния канала, управляемого сетью Ethernet;
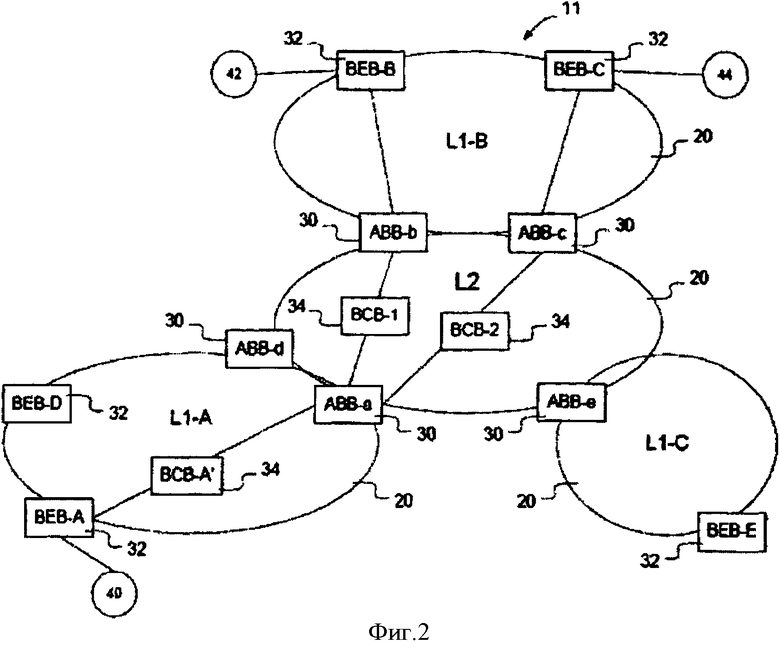
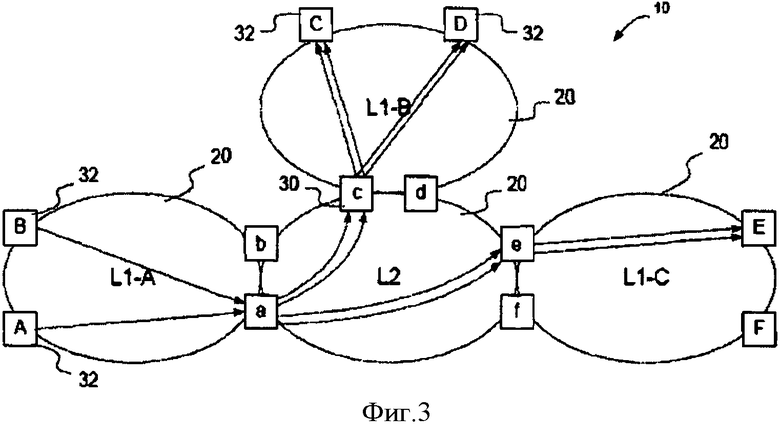
Фигуры 2 и 3 - функциональные блок-схемы примерного набора сегментов сети Ethernet, управляемой по протоколу состояния канала согласно одному варианту воплощения изобретения;
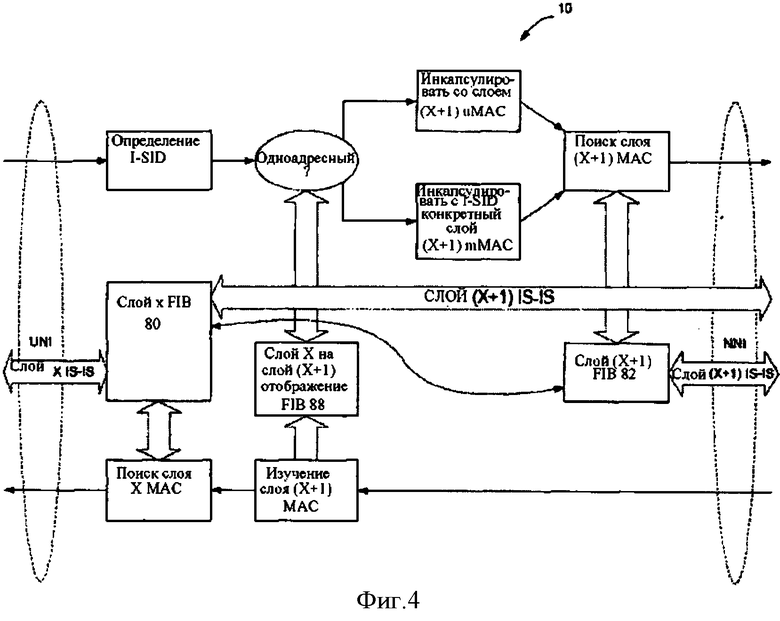
Фигура 4 - функциональная блок-схема разбиения ABB, который выполняет разделение сети на сегменты и иерархическую маршрутизацию, и на который показан процесс, используемый для размещения информации об идентификаторе общности интересов между сегментами сети так, чтобы пути могли проходить между управляемыми сегментами сети Ethernet по протоколу состояния канала согласно одному варианту воплощения изобретения;
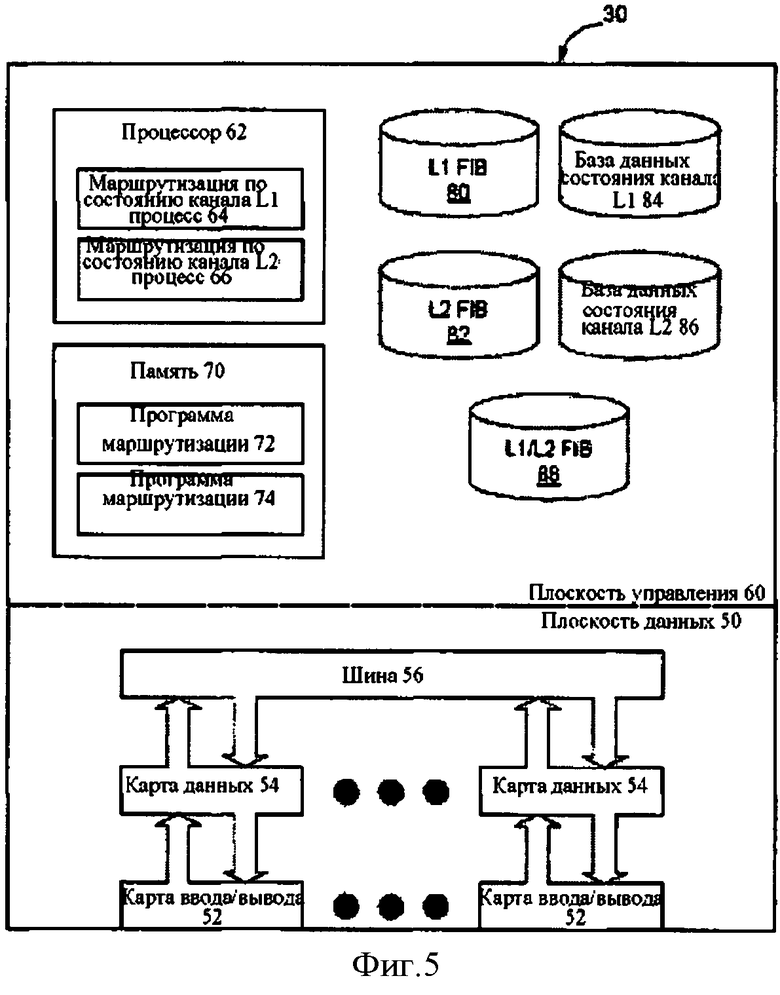
Фигура 5 - функциональная блок-схема сетевого элемента, который может использоваться как мост граничных сегментов (ABB) на границе между двумя сетями Ethernet, управляемых протоколом состояния канала согласно одному варианту воплощения изобретения;
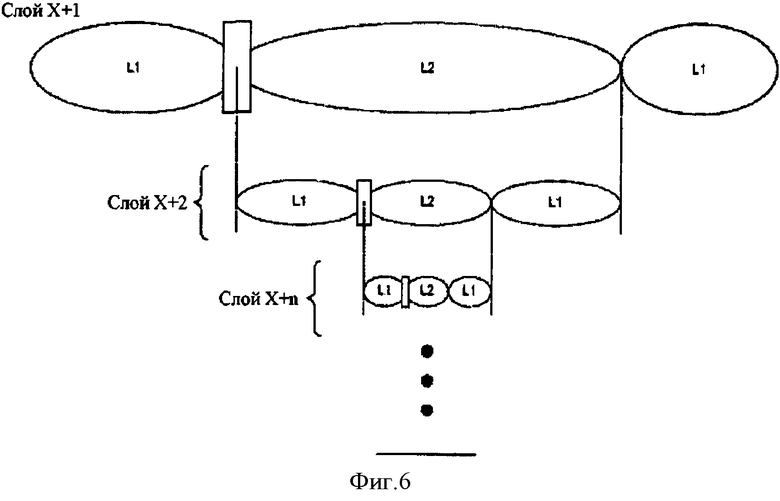
Фигура 6 - функциональная блок-схема сети, сконфигурированной для использования рекурсии, чтобы обеспечить разделение сети согласно одному варианту воплощения изобретения; и
Фигура 7 - функциональная блок-схема двухуровневой маршрутизации по состоянию сетевого канала провайдера ("PLSB"), имеющего ABB с несколькими интерфейсами, созданными в соответствии с принципами настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Стандарт IEEE 802.1ah-2008, определяющий магистральные мосты провайдера, определяет новый заголовок Ethernet, неофициально известный как "MAC в MAC", предусматривает полное разделение адресации клиента и Ethernet провайдера и позволяет сети провайдера предлагать большие количества объектов обслуживания клиентов, таких как объекты прозрачного обслуживания сегментов LAN. Использование протокола состояния канала 802.1 ah для управления магистральной сетью Ethernet провайдера позволяет сети Ethernet масштабироваться от пространства LAN до пользователя и до глобальной сети (WAN), обеспечивая более эффективное использование пропускной способности сети с передачей незацикленного кратчайшего пути. Вместо использования неизученного сетевого представления в каждом узле при использовании протокола связующего дерева (STP), алгоритм, объединенный с прозрачным мостовым соединением в протоколе по состоянию канала, управляет маршрутизацией сети Ethernet, формируя сотовую сеть обмена широковещательными сообщениями о состоянии канала, чтобы позволить каждому узлу иметь синхронизируемое представление о топологии сети. Это достигается через хорошо понятый механизм маршрутизация по состоянию канала системы. Мосты в сети имеют синхронизируемое представление топологии сети, знание необходимой одноадресной пересылки и возможности многоадресной передачи, могут вычислить возможность связи по кратчайшему пути между любой парой мостов в сети и индивидуально могут заполнить свои информационные базы пересылки (FIB) согласно вычисленному представлению сети.
Когда все узлы определили свою роль в синхронизируемом сетевом представлении и заполнили свои базы FIB, сеть будет иметь одноадресное незацикленное дерево по направлению к любому данному мосту от набора равноправных мостов (тех, которые по любой причине требуют пересылки к данному мосту); и конгруэнтное и незацикленное дерево от одной точки ко многим точкам (р2mp), от любого данного моста до того же самого набора или подмножества равноправных мостов на объект обслуживания, размещенный в мосту. В результате создается путь между данной парой мостов, не ограниченных передачей корневого моста связующего дерева, и общий результат может заключаться в лучшем использовании ширины ячейки сотовой связи. В основном, каждый мост является корнем одного или нескольких связующих деревьев, которые определяют возможность одноадресной связи к этому мосту, и возможность многоадресной передачи от этого моста.
Протокол состояния канала управляемых сетей Ethernet обеспечивает эквивалент мостового соединения Ethernet, но достигает этого через конфигурацию FIB сетевого элемента, а не путем лавинной адресации и обучения. По существу он может быть использован в новых стандартах, таких как стандарт IEEE 802.1ah, Института инженеров по электронике и радиотехнике, черновой вариант которого называется «маршрутизация магистральной линии провайдера или MAC-in-MAC с конфигурацией передачи В-МАС (магистральный MAC), и тривиальные модификации функции адаптации ВЕВ, к широковещательному поведению клиента при многоадресной передаче, так что сети Ethernet клиента могут использовать возможности связи, предлагаемые протоколом состояния канала, управляемой сети Ethernet без модификации. Конфигурация MAC может быть использована для создания возможности связи по кратчайшему пути без зацикливания (для целей одноадресной и многоадресной передачи) между рядом (слегка измененных по стандарту IEEE 802.1ah) магистральных мостов провайдера, чтобы обеспечить прозрачную услугу LAN по уровню С-МАС (клиентский MAC) или сети другого уровня, которые могут использовать прозрачное обслуживание LAN.
Обратимся теперь к фигурам, на которых одинаковыми знаками обозначены одни и те же элементы. На фигуре 1 показана функциональная блок-схема одного примера части протокола состояния канала, управляемой сети Ethernet 10. Как показано на фигуре 1, сеть 10 в этом примере включает множество узлов моста 12, соединенных каналами 14. Узлы моста 12 обмениваются "приветствием", чтобы изучить соседние узлы и обмениваться сообщениями о состоянии канала, позволяя каждому узлу создать базу данных по состоянию канала, которая может быть использована для вычисления кратчайших путей между входными и выходными узлами сети. Дополнительные детали, связанные с этим примером, включают протокол состояния канала, управляемой сети Ethernet, описанный в патентной заявке США №11/537,775, зарегистрированном 2 октября 2006 года под названием "маршрутизация по состоянию канала провайдера", содержание включено здесь в качестве ссылки.
Два примера протоколов маршрутизации по состоянию канала включают открытый протокол кратчайшего пути (OSPF) и протокол маршрутизации промежуточных систем (IS-IS), хотя также могут использоваться другие протоколы маршрутизации по состоянию канала. IS-IS описывается, например, в ISO 10589, и RFC 1195 IETF; содержание каждого из них включено здесь в качестве ссылки. Хотя имеются текущие версии этого протокола, изобретение не ограничено вариантом воплощения на основе текущего варианта стандарта, поскольку оно может быть адаптировано для работы с будущими вариантами стандарта по мере их разработки. Точно так же, изобретение не ограничено вариантом воплощения, который работает в связи с одним из этих конкретных протоколов, поскольку другие протоколы также могут быть использованы для обмена маршрутной информацией.
В дополнение к установке состояния одноадресной пересылки по кратчайшему пути узлы могут также установить состояние пересылки для многоадресных деревьев в сети. Пример способа реализации многоадресной пересылки по протоколу состояния канала в управляемой сети Ethernet описан более подробно в патентной заявке США №11/702,263, зарегистрированный 5 февраля 2007 года, под названием "Многоадресный вариант воплощения в протоколе маршрутизации по состоянию канала в управляемой сети Ethernet" содержание которой включено здесь в качестве ссылки. Как описано в этой заявке, оповещения о состоянии канала могут быть использованы для анонсирования группе многоадресной пересылки, инициировать состояние пересылки в сети. В частности, каждому дереву, поддерживающему данную группу многоадресной пересылки, может быть назначен уникальный идентификатор, например, корневой идентификатор, который используется в качестве целевого МАС-адреса (DA) для того, чтобы передавать многоадресные фреймы в сети. Узлы в состояния пересылки в сети устанавливают для дерева корня/группы кратчайший путь от многоадресного корня до одного из узлов назначения к группе многоадресной пересылки. На фигуре 1 показано многоадресное дерево, имеющее корень в узле F, когда узлы назначения (А, В, С, Е и Н) проявляют интерес к одной или нескольким группам многоадресной пересылки, т.е. «имеют интерес» в одной или нескольких многоадресных группах, которые имеют элемент в F. Узел D, например, установлен в дереве (установка состояния пересылки для корня), потому что он находится на кратчайшем пути между узлом F и узлом А.
Интерес к многоадресной передаче может быть основан на общем интересе к идентификатору защиты (SID), такому как I-SID, так что узел в сети установит состояние пересылки для группы многоадресной пересылки, когда она будет на кратчайшем пути между источником и местом назначения, когда они сообщают об интересе к идентификатору общности интересов, связанному с группой многоадресной пересылки. Однако состояние пересылки основано на адресе многоадресного получателя (DA) и идентификаторе виртуальной локальной сети (VID), связанном с многоадресной передачей. В процессе работы, когда внутренний узел принимает фрейм, он выполнит поиск в своей базе пересылки информации (FIB) на основе DA и VID, связанных с фреймом, и перешлет фрейм. Как упомянуто выше, хотя будет описан вариант воплощения изобретения, в котором I-SID используется в качестве идентификатора общности интересов, изобретение не ограничено этим вариантом воплощения, поскольку также могут использоваться другие типы идентификаторов общности интересов.
Инжиниринг трафика может быть использован для создания пути, который не обязательно является кратчайшим путем в протоколе по состоянию канала управляемой сети Ethernet. Состояние пересылки для организации путей трафика может дифференцироваться от состояния пересылки, которое было установлено в соединении с вариантом воплощения протокола маршрутизации кратчайшего пути, идентифицируя организацию трафика, до состояния пересылки, используя другой VID. Один способ создания пути трафика через управляемую сеть Ethernet по протоколу состояния канала раскрыт в патентной заявке США №11/732,381, зарегистрированной 3 апреля 2007 года, под названием "Спроектированные пути в протоколе состояния канала управляемой сети Ethernet", содержание которой включено здесь в качестве ссылки.
Когда фрейм достигает сетевого элемента, например, если элемент пользовательской сети I должен передать фрейм элементу пользовательской сети I, фрейм будет получен сетевым элементом F провайдера. Сетевой элемент F определит, известно ли, какие из узлов в сети провайдера в состоянии достичь МАС-адреса узла назначения J (С-МАС). Если F уже знает, что сетевой элемент Е провайдера может достичь элемента пользовательской сети J, сетевой элемент F добавит заголовок MAC, чтобы выполнить инкапсуляцию Mac-in-Mac фрейма клиента. Внешний заголовок будет включать целевой МАС-адрес сетевого элемента Е, чтобы обеспечить передачу фрейма по сети.
Точно так же, если фрейм является многоадресным фреймом, сетевой элемент F провайдера определит многоадресный DA провайдера, который должен быть использован для передачи фрейма в сети провайдера. Входной сетевой элемент F затем передаст фрейм через сеть провайдера по кратчайшему пути или, альтернативно, используя любой доступный путь инжиниринга трафика через сеть. Входной узел выполняет разрешение С-МАС→В-МАС и инкапсулирует фрейм клиента, используя новый заголовок MAC с тем, чтобы инкапсулированный фрейм адресовался, используя пространство адресации В-МАС. Инкапсуляция MAC-in-MAC известна в уровне техники, и поэтому подробное описание процессов, включенных в этот тип инкапсуляции, будет опущено.
Если входной узел F не знает, какой узел провайдера может достичь клиента узла J, входной узел будет просто использовать многоадресное дерево, связанное с общностью интересов (или I-SID), чтобы лавинно разослать пакет ко всем другим краевым магистральным мостам (ВЕВ) в общности интересов. Любое последующее сообщение от J позволит F узнать, какой DA провайдера нужно использовать для внешнего заголовка MAC. Кроме того, распределенная хэш-таблица может быть использована как хранилище корреляций С-МАС к В-МАС с тем, чтобы входной узел мог передать запрос одному или нескольким узлам, используя распределенную хэш-таблицу вместо широковещательной передачи запроса на определение адресов. Один способ применения распределенной хэш-таблицы раскрыт в патентной заявке США №11/714,508, зарегистрированный 6 марта 2007 года, под названием "Распределенное хранение маршрутной информации в протоколе состояния канала управляемой сети Ethernet", содержание которой включено здесь в качестве ссылки.
Когда увеличивается размер сети, и в сеть включается большее число узлов, может оказаться желательным разделить сеть на два или несколько небольших сегментов. Это позволит разделить плоскость управления и связанную с ней сетевую базу данных на два или несколько объектов с тем, чтобы подробные обновления маршрутов могли содержаться в пределах небольшого сетевого сегмента, и изменения в пределах одного сегмента не влияют на смежные сегменты. Это экономически выгодно, поскольку количество широковещательных оповещений о состоянии канала может быть сокращено, размер баз данных по состоянию канала может быть уменьшен, и общая скорость сходимости сети на изменение в топографии может быть увеличена. Однако деление сети на два или несколько сегментов имеет недостаток, заключающийся в необходимости установлении связи, которая охватывает все сегменты сети.
Как только сеть достигает определенного размера, разделения на сегменты, возможно, будет недостаточно для решения проблемы масштабирования, и может оказаться необходимым уменьшить величину состояния в ядре сети (сеть L2), чтобы продолжать наращивать сеть. Это может быть достигнуто, иерархически и рекурсивно, преобразуя сеть (MACinMACinMAC) в плоскости управления и в плоскости данных, и в предпочтительном варианте воплощения, снова используя MAC для анализа согласно 802.1ah, чтобы установить связь между уровнем В-МАС и в рекурсивном уровне MAC.
Зацикливание в пути передачи для Ethernet может быть катастрофическим, особенно если путь передачи является многоадресным путем, поскольку это может привести к неограниченному тиражированию пакетов. Следовательно, выгодно ограничить иерархическую взаимосвязь сегментов по сравнению с разрешением сотового соединения сегментов для облегчения решения проблемы зацикливания. Системы маршрутизации имеют такую концепцию в виде понятия уровень 1/уровень 2 (L1/L2) в IS-IS, в котором сегменты L1 соединяются только с одним сегментом L2.
На фигуре 2 показан один пример сети связи 11, в которой множество каналов управляемой сети Ethernet 20 соединены через мосты граничных сегментов (ABB) 30. Конкретно, на фигуре 2 сеть 11 включает первый набор управляемой сети Ethernet протокола состояния канала L1А, L1В и L1С. Первый набор управляемых сетей Ethernet протокола состояния канала может быть, например, сетями центральной зоны, хотя изобретение не ограничено этим конкретным примером. Сети L1A, L1B и L1C соединяются управляемой сетью Ethernet L2 протокола состояния другого канала. Сегментом сети L2 может быть, например, базовая сеть провайдера, сконфигурированная для соединения с сетью L1. Изобретение не ограничено конкретным примером, показанным на фигуре 2, поскольку сеть фигуры 2 приведена просто как иллюстрация одной примерной среды, в которой может быть реализовано изобретение. В IS-IS формальный интерфейс между L1 и L2 определяется как установленный в соединении за пределами узла. В этом документе ABB определяется как мост, имеющий интерфейсы, по меньшей мере, к одному каналу L1 и, по меньшей мере, одному каналу L2.
Клиенты присоединены к сетям через краевые магистральные мосты (ВЕВ) 32. В пределах сети соединения устанавливаются через корневые магистральные мосты (ВСВ) 34. Предположим, что, как показано на фигуре 2, клиент 40, который соединен с сетью L1 через ВЕВ-А, может связаться с клиентом 42, который соединен с сетью L1-B через ВЕВ-В, и может связаться с клиентом 44, который соединен с сетью L1-B через ВЕВ-С. Чтобы обеспечить такую связь, будет необходимо установить маршрут между А и В через сегменты сети L1-A, L2 и L1-B, и также установить маршрут между А и С через сегменты сети L1-A, L2, и L1-B.
В соответствии с одним вариантом воплощения настоящего изобретения, сеть связи 10 включает одиночный сегмент L2. Хотя ABB может обслуживать множество непересекающихся сегментов L1, каждый порт на ABB рассчитан только на один сегмент. Однако если имеется прямой физический канал между двумя ABB, обслуживающими один и тот же сегмент, и желательно использовать канал для трафика L1 и L2, используются два логических порта вместе со схемой мультиплексирования. Каждый сегмент L1 является тупиковым сегментом, т.е. там нет никаких ABB между двумя сегментами L1, которые также не соединяются с сегментами L2. Чтобы облегчить вычисление незацикленных путей, трафик между сегментами L1 не должен использовать каналы L2. Узлы L2 не используют каналы L1 в качестве транзита к другим узлам L2, даже если L2 разделена на сегменты иным образом; однако узел L2 может использовать путь магистрального транзита провайдера (РВТ) через сегмент L1: в этом случае трафик L2 пересекает сегмент L1 с дополнительным уровнем инкапсуляции Ethernet и наиболее удаленных различных VID того же трафика L1. При трафике, входящем из различных сегментов, сигналы всегда прибывают в различные физические или логические порты, и ABB может легко поддерживать и использовать различные базы информации о пересылке (FIB), по одной для каждого обслуживаемого сегмента. Таким образом, когда пакет прибывает в порт L2, ABB консультируется с FIB L2, чтобы определить, куда это должно быть передано.
Имеется ряд ограничений, которые должны быть рассмотрены при принятии решения по множеству сегментов. Например, в противоположность телефонным номерам, МАС-адреса Ethernet не могут быть суммированы, благодаря чему сокращение представляет группу (такую как 613 кодов сегментов, например, код сегментов, определяющий все номера телефонов в Оттаве, Канада). Кроме того, сегменты сети должны обеспечивать симметричную передачу с тем, чтобы трафик мог следовать через сеть по одному и тому же пути в обоих направлениях.
В примере на фигуре 2 сегмента L1-A, L2 и L1-B являются управляемыми сегментами сети Ethernet протокола состояния всего канала, каждая из которых выполняет свой собственный пример протокола маршрутизации по состоянию канала. Таким образом, маршрутная информация, в основном, содержится в различных локальных вычислительных сетях, и ограничена только общим количеством маршрутной информации обмена между сегментами. Однако, как описано ниже более подробно, ABB могут позволить идентификаторам общности интересов, таким как I-SID и некоторая связанная информация о ВЕВ пропущенными между сегментами, таким образом, маршруты, связанные с ВЕВ вместе с I-SID, могут быть установлены в большей степени, чем через один сегмент. Конкретно, поскольку интерес к I-SID может быть пропущен через границу сети, сегменты маршрута могут быть установлены для I-SID в каждой из локальных вычислительных сетей, которые все вместе формируют маршрут между сегментами. Поскольку прохождение I-SID может быть сделано без вмешательства системы управления сетью, маршруты между сегментами могут быть установлены автоматически плоскостями управления множества сетевых сегментов.
Согласно одному варианту воплощения изобретения, ABB на границе между двумя сетями распространяются в каждой сетевой сегментом с возможностью достичь другой сети. Таким образом, например, на фигуре 2 АББА и ABB-d, каждый, находится на границе между сегментами сети L1-A и L2. Соответственно, каждый из этих ABB будет сообщать о возможности достижения сетевой сегмента L2 в пределах сетевой сегмента Ll-A, и сообщит о возможности достижения сетевой сегмента Ll-A в пределах сегмента сети L2. Согласно одному варианту воплощения изобретения, ABB могут объявить сегмент сети L2 как "псевдоузел" (также известный как виртуальный ВЕВ) в сегменте сети L1 с тем, чтобы ВСВ могли автоматически определить, какой ABB должен обработать трафик для данного набора самых близких ВЕВ путем установления состояния пересылки для кратчайших путей между самыми близкими ВЕВ и виртуальным ВЕВ, объявляющими об ABB. Таким образом, сеть L1 может сама выбрать ABB, чтобы представить наборы ВЕВ в смежный сегмент сети L2. Если все ABB объявляют сегмент сети L2 как один и тот же виртуальный ВЕВ, кратчайшие пути от ВЕВ в сегменте сети L1 будут автоматически установлены через ABB, который является ближайшим к виртуальному ВЕВ, и, следовательно, от набора ВЕВ, которые являются ближайшими к определенному ABB.
Мосты ABB, обслуживающие определенную L1, самостоятельно выбирают для представления определенные ВЕВ в L2 каждого ABB, определяющим, какие ВЕВ в L1 ближе к нему, чем любой другой ABB. Таким образом, на фигуре 2 АВВ-а является ближайшим к ВЕВ-А. Таким образом, маршруты от А, которые должны выйти из сегмента сети L1-A, будут установлены через корневые магистральные мосты (ВСВ), такие как ВСВ-А', чтобы пройти через АВВ-А. Точно так же, маршруты от BEB-D будут установлены через ABB-d. Имеется много способов сделать это, но самое простое (и не требующее никаких специальных правил для ВЕВ и ВСВ в L1) заключается в том, что L2 представляется в L1 узлом ABB как одиночный псевдоузел, т.е. виртуальный ВЕВ, соединенный с ABB равноценными каналами. Как упомянуто выше, трафик между сегментами L1 не должен использовать каналы L2: стоимость "каналов" к псевдоузлу, представляющему L2, должна быть достаточно большой, чтобы самый короткий путь между любой парой узлов в сегменте L1 не включал бы виртуальный ВЕВ. В одном варианте воплощения изобретения это обеспечивается установкой метрики стоимости расстояния для "каналов", которое больше половины диаметра сегмента L1. Диаметр сегментов L1 является самым большим расстоянием между любыми двумя узлами в сегменте L1.
Имеются определенные правила для того, как ABB пропускают информацию между сегментами. ABB, наиболее близкий к ВЕВ в L1, распространит адреса I-SID и MAC ВЕВ, связанные с этим сегментом в L2, без априорного знания, какие I-SID представляют интерес для множества сегментов. ABB только пропустят информацию ВЕВ и I-SID, собранную от других сегментов L1, из L2 в L1, где один или несколько ВЕВ в L1 уже указали на свой интерес к I-SID. Следовательно, узлы в L2 будут иметь полное отображение I-SID и ВЕВ в плоскости управления. Узлы в L1 будут иметь только отображение интереса ВЕВ и I-SID ограниченного района и тех, которые являются по-настоящему множеством сегментов.
Из вышеописанного можно видеть, что в L2 соответствующие соединения плоскости данных будут созданы на идентификаторе общности интересов, т.е. на I-SID, между ABB, выбирающими представление связанных ВЕВ в L1. Также в L1, ABB, представляющие ВЕВ в другом L1s, создадут соответствующие соединения, включающие локальные ВЕВ, которые являются частью той же самой общности интересов, как идентифицировано идентификатором общности интересов.
ВЕВ в сегменте сети L1 рекламируют интерес на идентификатор общности интересов, такой как I-SID, путем оповещения о состоянии канала, или используя другие сообщения в сегменте сети L1. В этом примере предполагается, что идентификатором общности интересов является I-SID. Также могут использоваться другие идентификаторы общности интересов.
ABB получают сообщения, указывающие, что один или несколько ВЕВ в сегменте сети L1 интересуются I-SID. ABB пропустит I-SID, изученные в сегменте сети L1, которые были рекламированы теми ВЕВ, которые являются ближайшими к сегменту сети L2. При рекламе I-SID, обозначенная набором ВЕВ, только ближайшая к ВЕВ сеть L2 может получить сведения о том, какой должен быть ABB, используемый для передачи трафика по маршруту к ВЕВ. ABB будет также прослушивать эфир в поисках I-SID, рекламируемых другими ABB в сегменте сети L2. Там, где больше чем один ABB, соответственно соединенный с другой И в сегменте сети L2, рекламирует интерес в тому же самому I-SID, где I-SID представляет интерес множества сегментов. Обнаружение I-SID в больше чем одной L1 гарантирует, что сеть L2 не установит состояние пересылки между двумя ABB в той же самой сети L1. Если одиночная L1 имеет более одного ABB, внутренняя топология этой L1 может инициировать несколько ABB рекламировать I-SID в L2, но это должно быть проигнорировано в L2, если другая L1 также не рекламирует этот I-SID. В этом случае ABB, которые рекламировали I-SID в сети L2, также передадут I-SID обратно в соединенный с ним сегмент сети L1 с тем, чтобы соединения в сегменте сети L1 могли быть установлены в сегменте сети L1 от ВЕВ до ABB. Если множество ABB передает I-SID обратно в L1, соединения между самими ABB для этого I-SID в L1 не устанавливаются. В примере на фигуре 2, соединения между АВВ-b и АВВ-с в L1-B не установлены. В примере, показанном на фигуре 2, предполагается, что ВЕВ-А рекламировал интерес к I-SID-x в сегменте сети L1-A, и что ВЕВ-В и ВЕВ-С проявили интерес к I-SID-x в сегменте сети L1-B. ABB, ABB-b, АВВ-с все вместе рекламируют интерес ко всем I-SID в L2, которые рекламируют ВЕВ, которые они представляют. Таким образом, в этом примере, АВВ-а рекламируют MAC-BEB-A/I-SID-x, ABB-b рекламируют MAC-BEB-B/I-SID-x и АВВ-С рекламируют MAC-BEB-C/I-SID-x. АВВ-а, ABB-b и АВВ-с все вместе решат, что I-SID-x представляет интерес для множества сегментов, получая оповещения от других ABB на L2, и решая, что I-SID-x рекламируется как от L1-A, так и от L1-B. Соответственно, ABB рекламируют MAC-BEB-B/I-SID-x, и MAC-BEB-C/I-SID-x в сегмент сети L1-A, и АВВ-b и АВВ-с рекламируют MAC-BEB-A/I-SID-x в сегмент сети L1-B. Как объяснено ниже, эти рекламные сообщения в сегменте L1 делаются так, как будто они получены из псевдоузла L2, распространенного ABB в сегменте L1. Инициируя каждый ABB на рекламу всех I-SID, полученных из его смежной сегмента сети L1 в сегмент сети L2, ABB на L2 могут определить, какие I-SID должны быть расширены между сегментами сети L1 выборочно предоставить информацию о MAK/I-SID только для этих маршрутов в их сегменте сети L1.
ABB пропустит все представляющие интерес I-SID для их набора ВЕВ в L1 из L1 в L2, ABB в L2 рекламируют все I-SID L1 между собой, но рекламируют I-SID из L2 в L1 только, когда тот же самый I-SID будет,а также уже был распространен этой L1. Таким образом, конечный результат состоит в том, что в пределах L1 для всех ВЕВ, заинтересованных определенным I-SID, соединения будут установлены системой маршрутизации. Только если этот I-SID существует в другом сегменте, ABB будет рекламировать интерес к этому I-SID в этой L1 (когда будут созданы соединения из сегментов через ABB). В сегменте сети L2 ВСВ установят соединения между ABB различных сегментов L1, которые выявили интерес к этому же I-SID с тем, чтобы могли быть установлены соединения в пределах сети L2. Если какая-либо сеть L1 имеет более одного ABB, сообщения о I-SID в L2, соединения для этого I-SID между этими ABB не будут установлены в L2.
ABB рекламирует все I-SID и распространяет соответствующую информацию о ВЕВ от L1 в L2. Информация о I-SID, которая поступает от сегмента сети L1 в сегмент сети L2, будет в виде МАС-адреса ABB, I-SID и МАС-адресов ВЕВ, связанных с I-SID. Когда ABB получает рекламу I-SID от другого ABB в L2 и также получает рекламу от местной L1 с интересом к тому же самому I-SID, он рекламирует I-SID и распространяет информацию о ВЕВ, полученную из L2 в L1.
I-SID будет рекламироваться в сети L2. Подобно одиночному сегменту, ВСВ в сегменте L2 установят состояние пересылки, чтобы обеспечить кратчайшие пути между ABB, соединенными с различными сегментами L1, которые объявляют о своем интересе к тому же самому I-SID. Например, предположим, что АВВ-а, АВВ-b и АВВ-с все вместе объявляют об интересе к I-SID=x. ВСВ 1 распознает, по какому именно кратчайшему пути между двумя ABB рекламировать интерес к общему I-SID, и устанавливает состояние пересылки, чтобы разрешить передачу фреймов от АВВ-а к АВВ-b и наоборот. Точно так же, ВСВ 2 установит состояние пересылки, чтобы разрешить передачу фреймов от АВВ-а к АВВ-с и наоборот.
АВВ-b и АВВ-с пропустят I-SID от сегмента сети L2 в сегмент сети L1-B, как будто оно было получено от виртуального ВЕВ, расположенного сзади ABB b&c. ВСВ в пределах сети L1-B затем установят в состояние пересылки, если они будут на кратчайших путях между ВЕВ, который рекламировал интерес к I-SID и виртуальным ВЕВ (в котором ABB также сообщил об интересе к I-SID). ABB создают рекламные сообщения, которые как бы прибыли из виртуального ВЕВ, когда имеются два или больше ABB, пропускающие I-SID от сегмента сети L2 в сегмент L1. В одном варианте воплощения ABB конфигурируются, чтобы всегда направлять в сегмент L1 рекламные сообщения, которые представляются как рекламные сообщения от виртуальных ВЕВ. В другом варианте воплощения ABB конфигурируются только для использования виртуальных ВЕВ для пропуска I-SID в определенную L1, когда имеется множество ABB, соединенных с этим сегментом L1. Имеются другие возможные варианты воплощения, в которых ABB решает, что он является единственным, кто должен посылать рекламные сообщения I-SID в сегмент L1 (такой как ABB на фигуре 2), и таким образом, рекламирует интерес к I-SID от самого себя.
При этом отметим, что, предоставляя ABB самому выбирать, какие ВЕВ представить в соединении с маршрутами, которые выходят из L1-B, параллельные пути были созданы между АВВ-b и ВЕВ-В, и АВВ-с и ВЕВ-с. Однако использование множества ABB, чтобы достичь различных ВЕВ, не вызовет конфликтов при пересылке, что фактически имеет место в связующем дереве к виртуальному ВЕВ, который представляет L2, что естественно приводит к маршрутам между ВЕВ и ABB, устанавливаемым только от ВЕВ до самого близкого ABB. Там, где имеются равноценные пути между данным ВЕВ и двумя или больше ABB, система маршрутизации будет использовать нормальный механизм разрушения связей между сегментами, чтобы определить, какой ABB должен представить ВЕВ в смежном сегменте.
I-SID обычно имеет возможность многоадресной связи. Конкретно, многоадресный режим может быть установлен в сети, инициируя ВЕВ, заинтересованные в многоадресной пересылке рекламных объявлений об интерес к I-SID, связанному с многоадресной пересылкой. Затем для многоадресной передачи будет установлено состояние пересылки, описанное более подробно в патентной заявке США №11/702,263, упомянутой выше. Вместо I-SID могут использоваться другие идентификаторы общности интересов, и изобретение не ограничено вариантом воплощения, который использует I-SID в качестве идентификатора общности интересов. Как упомянуто выше, желательно разместить информацию ВЕВ между сегментами, но используя механизм, который минимизирует изменения в одном сегменте, влияющие на другие сегменты. Один способ достижения этого заключается в связи ВЕВ с ABB с одноранговым сегментом так, что как будто они расположены рядом, и чтобы никакое знание топологии однорангового сегмента (в виде фактических метрик) не использовалось бы совместно с другими сегментами. Это было упрощено к простому соединению ВЕВ с самым близким ABB. Результатом было то, что многоадресное дерево для данного I-SID, расположенного в ABB, идентично для всех ВЕВ, которые находятся позади ABB. Это означает, что масштабируемость может быть улучшена при использовании общего целевого группового адреса для многоадресных потоков для данного I-SID, которые передают ABB транзитом.
Поскольку ABB может быть введен во множество многоадресных сообщений L2 в наборе ближайших ВЕВ, он может суммировать многоадресные сообщения, пропуская маршрутную информацию в смежный сегмент L2. Например, ABB может суммировать информацию о многоадресной маршрутизации mМАС (ВЕВ, I-SID), распространяя вместо этого mMAC (ABB, I-SID). Конкретно, ABB может заменить своим собственным DA DA ВЕВ для данного I-SID. Это может также быть повторено на границе между L2 и L1.
Для иллюстрации:
- Перемещаясь от L1 до L2, многоадресное дерево в L2 с корнем в данном ABB характерно для всех ВЕВ в L1, которые были ближайшими к этому ABB.
- Перемещаясь от L2 к конкретной L1, многоадресное дерево в этом L1 с корнем в данном ABB характерно для всех ABB в L2, чей корень является общим для любого другого L1. Отметим, что это дерево расширится в L1 только до ВЕВ, которые являются ближайшими к данному ABB.
- Никакой ABB на данной границе сегментов никогда не будет листом на многоадресном дереве, с корнем в другом ABB на той границе сегментов, как в L1, так и в L2.
С точки зрения конструкции пути в сети L1-A ВСВ-А' определит, что оно находится на кратчайшем пути от ВЕВ-А до L2 (через АВВ-а). ВСВ-А' также определит, что ВЕВ-А и АВВ-а вместе имеют I-SID. Таким образом, ВСВ-А' сформирует и установит адрес группы многоадресной передачи для BEB-A/I-SID=x. Он также установит индивидуальные адреса для удаленных ВЕВ, которые проявили интерес к I-SID-X (ВЕВ-В и ВЕВ-С в этом примере), установят индивидуальный адрес для локального ВЕВ-А, и сформируют и установят групповой адрес для ABB-a/I-SID=x.
В сети L2 ВСВ 1 определит, что он находится на кратчайшем пути между АВВ-а и АВВ-b в L2 и что оба вместе имеют I-SID (I-SID=x). ВСВ 1 сформирует и установит групповые адреса для ABB-a/I-SID=x и ABB-b/I-SID=x и установит индивидуальные адреса для ВЕВ-А и ВЕВ-В.
В данной сети L1, такой как сеть L1-B, множество ABB могут проявить интерес или знание данного I-SID. Чтобы позволить ВСВ в сети (сеть L1-B) установить состояние пересылки, ABB рекламируют I-SID в соединении с виртуальным ВЕВ, представляющим сеть L2. Это позволит ВСВ устанавливать состояние пересылки только для маршрутов, которые проходят между сегментами через ближайший ABB к заинтересованному ВЕВ. Это также препятствует установлению различных путей между данным ВЕВ и больше чем одним ABB, поскольку будет установлен только один кратчайший путь от ВЕВ до виртуального ВЕВ, представляющего сеть L2, который автоматически пройдет к этому ВЕВ. ВСВ могут быть сконфигурированы, чтобы не устанавливать состояние пересылки между ABB на общей сетевой границе (например, LI A-L2) даже при том, что два или больше ABB могут проявить интерес к тому же самому I-SID.
В сети L2 данный ABB может иметь много ВЕВ позади себя, что представлено в сегменте сети L2. Для упрощения вычисления кратчайшего пути на ВСВ в сегменте сети L2 ВСВ будут выполнять вычисления маршрутизации на ABB, а не на ВЕВ, которые представляют ABB. В этом случае, каждый ВСВ в L2 может определить, находится ли он на кратчайшем пути между двумя ABB, и раз так, имеют ли ABB I-SID в общем пользовании. Если существуют оба эти условия, ВСВ может затем установить состояние пересылки для многоадресного МАС-адреса mMAC (ABB, I-SID=x) и одноадресных МАС-адресов uМАС (ВЕВ) для тех ВЕВ, участвующих в наборе I-SID, характерных для этих двух ABB.
Инициируя ABB на самостоятельный выбор, одноадресная пересылка может быть установлена через множество доменов без требования установления точных путей.
Скорее, система маршрутизации может реализовать одноадресные пути и разрешит состояние пересылки, которое будет установлено для одноадресных путей даже там, где одноадресные пути проходят через множество сегментов сети.
Поскольку каждый сегмент сети имеет свою собственную плоскость управления, изменения топологии часто могут быть изолированы в пределах данного сегмента. Однако, когда происходит изменение топологии, причем эти изменения в некотором роде происходят в ABB ближайшими к ВЕВ, такое изменение топологии будет также влиять на смежную сеть. В частности, предположим, что произошел отказ в сети L1-A, что привело к изменению кратчайшего пути к L2 для ВЕВ-А так, что он проходит транзитом через ABB-d. В этом случае система маршрутизации в L1-A установит новый кратчайший путь от ВЕВ-А к ABB-d и инициирует ABB-d на рекламирование BEB-A/I-SID=x в L2. Это приводит к установлению новых кратчайших путей в L2 между АВВ-с и ABB-d, и между АВВ-с и ABB-d. Однако изменение в сети не повлияет на другие сегменты L1 так, что местные сбои не приведут к каскадным изменениям маршрутов по всем сегментам сети. Кроме того, хотя некоторые сбои в сети L1-A могут повлиять на систему маршрутизации в L2, многие сбои в сети L1-A не повлияют на выбор ABB для ВЕВ, в результате, эти сбои будут локализованы в пределах L1-A, не влияя на маршрутизацию в L2.
Одним последствием моделирования L2 как виртуального ВЕВ в L1 является то, что из L2 в L1 может быть перенесено множество копий многоадресного пакета. Однако, поскольку общее поведение является поведением связующего дерева, с корнем в виртуальном ВЕВ в L2, каждый ВЕВ в L1 получит одну и только одну копию данного многоадресного пакета.
Хотя пример был приведен и подробно описан в связи с определенной сетью, показанной на фигуре 2, изобретение не ограничивается этим примером, поскольку описанные здесь методики могут использоваться во многих различных сетевых настройках, чтобы создать пути через множество сегментов. Таким образом, изобретение не будет ограничено вариантом воплощения в сети, соединяющей сегменты сети, как показано на фигуре 2, а скорее может использоваться в связи с любой сетью, в которой сегменты управляемой сети Ethernet протокола состояния двух или нескольких каналов соединяются одним или несколькими ABB. Точно так же, хотя I-SID использовался в качестве примера идентификатора общности интересов, который может быть использован для определения общностей интересов, расположенных между сегментами, изобретение этим не ограничивается, поскольку также могут использоваться другие идентификаторы общности интересов.
Если данный ВЕВ имеет два или несколько путей, которые являются равноценными для двух или нескольких ABB и расходятся, может оказаться необходимым использовать различные VID, чтобы дифференцировать трафик к различным ABB. Также могут использоваться и другие способы разрешения конфликтов между ABB, и изобретение не будет ограничено вариантом воплощения, который использует различные VID для идентификации трафика, назначенного различным ABB.
ABB и ВСВ в L2 имеют дополнительное требование, заключающиеся в том, что ABB на данной границе сегментов не может быть листом многоадресного дерева от ABB на той же самой границе сегментов. Это предотвращает зацикливание на границах сегментов.
Когда трафик передается из одного сегмента сети в другой сегмент сети, например из сегмента L1 в сегмент L2, трафик может инкапсулироваться с тем, чтобы пересылка через второй сегмент произошла, используя пространство МАС-адресации сегментов. Например, когда фрейм принимается узлом ВЕВ-А от клиента 16, который адресован клиенту 18 на ВЕВ-В, фрейм первоначально будет иметь адрес места назначения DA=C-МАС клиента 18. ВЕВ-А определит, какой ВЕВ может достичь клиента МАС-адреса и инкапсулировать клиентский фрейм, используя заголовок провайдера Ethernet. Например, ВЕВ-А может выполнить инкапсуляцию MAC-in-MAC так, чтобы фрейм мог быть передан по сети L1-A, используя пространство МАС-адреса провайдера, а не клиентское пространство МАС-адреса. Для ВЕВ-А имеется несколько способов, чтобы определить, какой ВЕВ в сети может достичь клиента 18, и изобретение не будет ограничено определенным способом, которым рекламируется эта информация.
После передачи фрейма через сегмент сети L1-A он достигнет АВВ-а, где он будет передан в сегмент сети L2. В связи с этим предполагается, что пути были установлены, как подробно описано выше. Согласно одному варианту воплощения изобретения, ABB может далее инкапсулировать фрейм для передачи через сеть L2, выполняя инкапсуляцию "МАС-in-МАС-in-МАС" так, чтобы передача фрейма в пределах сети L2 могла использовать пространство МАС-адреса L2. Конкретно, ABB может определить, какой другой ABB на L2 может передать фрейм в нужное место назначения (В-МАС-АДРЕС), определит МАС-адрес целевого ABB в сети L2 (А-МАС-АДРЕС) и затем добавит заголовок MAC L2, чтобы затем инкапсулировать фрейм для передачи в сети L2. Это позволяет суммировать адреса L1 в L2 в ABB через инкапсуляцию с тем, чтобы ВСВ в сети L2 должны только установить маршруты на основе адресного пространства MAC L2 (А-МАС).
Информация С-МАС/В-МАС в пространстве сети L1 может быть распространена обычным образом. Точно так же, информация L1-MAC/L2-MAC (B-MAC-address→A-MAC-address) может быть распространена нормальным процессом обучения, например лавинной рассылкой запроса на L1-MAC/L2-MAC, и ожидая ответа, или путем использования распределенной хэш-таблицы.
На фигуре 3 визуально показано, что происходит в связи с процессом инкапсуляции. Конкретно, метрики L1-A остаются локальными для сегмента сети L1-A. L2 просто фильтрует маршруты сегментов inter-L1 по I-SID. Это включает конгруэтность uMAC/mMAC в L1, L2 и "MAC-in-MAC-in-MAC". Многоадресные МАС-адреса от L1-A отображаются через I-SID через дерево в L2. ABB должна знать, что путь к ВЕВ-Е проходит через АВВ-е. Эта ассоциация может быть изучена, лавинно рассылая запрос и ожидая ответа. Лавинная рассылка в сетевых сегментов ограничивается в краевых узлах ABB, однако запросы ассоциации В-МАС/А-МАС не должны лавинно рассылаться в другие сегменты сети. После изучения входным ABB ассоциации В-МАС/А-МАС, ABB может использовать этот адрес, чтобы инкапсулировать фреймы для передачи в сети L2. Кроме того, самоназначенный многоадресный МАС-адрес L2 может использоваться там, где данный I-SID мог рекламироваться для более одного целевого ABB в сети L2.
На фигуре 4 показаны адаптивная, обучающая и межуровневая функции между уровнями, когда система маршрутизации рекурсивно изменяется. Как упомянуто выше, сеть L2 может стать слишком большой, и может оказаться желательным дополнительно рекурсивно изменить сеть, чтобы разбить сеть L2 на сеть второго уровня L1/L2/L1, как показано на фигуре 6. На фигуре 4 показан процесс, позволяющий инкапсулировать фрейм для передачи по рекурсивно измененной L2 из L1 (иногда не инкапсулированный уровень называют "уровнем X" и инкапсулированный уровень упоминается как "уровень х+1"), и также показан процесс, позволяющий инкапсулировать фрейм после получения от рекурсивно измененного сегмента сети L2 для передачи по сегменту сети L1 на данном уровне.
Фигура 4 представляет собой функциональную блок-схему ABB, который выполняет и разделение сети на сегменты, и иерархическую маршрутизацию. Как таковой, этот узел связан с другими одноранговыми узлами в каждой части L1 и L2 текущего уровня соответственно. Он также взаимодействует на рекурсивном уровне Х+1.
FIB L1 для уровня Х заполняется через маршрутизацию обмена с равноправными устройствами в L1 (включая переданные через L2), так же FIB L1 для уровня Х+1 (уровень инкапсуляции) заполняется через маршрутизацию обмена с равноправными устройствами на уровне Х+1.
Как показано на фигуре 4, когда фрейм получен от L1 на уровне X, ABB проверит, может ли уровень Х целевого MAC пройти на уровень Х+1 MAC через поиск отображения от Х к FIB Х+1, или является ли фрейм широковещательным или многоадресным фреймом. В этих случаях он будет инкапсулирован, используя уровень Х+1 MAC ВЕВ как источник и многоадресный МАС-адрес для I-SID, используемого ВЕВ на уровне Х+1, как место назначения, и передан на уровень FIB Х+1. Если уровень Х целевого адреса MAC может быть разрешен для передачи на уровень Х+1 адреса MAC, пакет инкапсулируется с адресом MAC ВЕВ, как источник, и уровень адреса Х+1 MAC, полученный из отображения Х+1 от Х до FIB, как место назначения, и пересылается согласно уровню Х+1 FIB.
Когда пакет получен от уровня Х+1, MAC источника связан с уровнем Х MAC источника и привязка вставляется в отображение FIB из Х в Х+1. Пакет деинкапсулируется и пересылается согласно информации на "уровне X" FIB. Это является результатом изучения связок Х к Х+1 с помощью повторного использования протокола 802.1ah процесса обучения MAC, который устраняет потребность к исключительной привязке промежуточного уровня к уровню системы маршрутизации Х+1.
Следует отметить, что сеть может фактически использовать эту методику рекурсии произвольное число раз. Можно также отметить, что упомянутое в примере может также быть подразделено без рекурсии с тем, чтобы смесь рекурсии и подразделения на каждом уровне рекурсии может использоваться для масштабирования сети. Это показано на фигуре 6. Например, как показано на фигуре 6, сеть L2 может быть сформирована как уровень Х+1 L1/L2/L1 сеть, имеющая множество сетей L1 (Х+1), соединенных с сетевым сегментом. Точно так же, сегмент сети L2 (Х+1) может быть сформирован как набор L1/L2/L1 сегментов сетей (Х+2). Процесс, описанный со ссылкой на фигуру 4, может быть использован для установления границы между уровнем L1(X) и уровнем L1/L2/L1 (Х+1), границы между уровнем L1(X+1) и уровнем L1/L2/L1(X+2) или дополнительной границы между сетевым сегментом и еще одним рекурсивным уровнем L1/L2/L1(X+n).
С точки зрения маршрутизации UNI интерфейс на уровне Х стороны сети ABB будет хранить информацию уровня XI-SID, полученную через уровень Х сетевых протоколов маршрутизации по состоянию канала на уровне Х FIB. Точно так же, интерфейс NNI на уровне (Х+1) стороны сети ABB сохранит уровень информация о I-SID Х+1, полученной через уровень Х+1 сети протокола маршрутизации по состоянию канала на уровне FIB Х+1. Однако, согласно одному варианту воплощения изобретения, информация о I-SID пропускается между уровнем Х и уровнем Х+1 сети, чтобы позволить уровню Х+1 сети выборочно установить маршруты через уровень Х+1 сети для I-SID, которые характерны для различных сегментов уровня Х сетей.
С точки зрения плоскости управления, информация о плоскости управления суммируется/агрегируется через уровень Х+1 сети, чтобы уменьшить количество информации, которая должна быть обработана в плоскости управления и установлена на уровне таблицы переадресации Х+1. Это выгодно с точки зрения масштабирования, поскольку ВСВ на уровне Х+1 сети требуют только сохранения передаваемой информации для уровня адреса MAC Х+1.
На уровне обмена Х и на уровне обмена Х+1 происходит обмен информацией о принадлежности к одноранговым устройствам I-SID, что позволяет другим ABB знать, какие I-SID должны быть пропущены. Информация о I-SID затем используется многоадресными соединениями на уровне сегмента сети Х+1, чтобы изучить межуровневые связи. Там, где уровень Х сети использует инкапсуляцию Mac-Mac, и уровень Х+1 сети использует инкапсуляцию Mac-in-Mac-in-Mac, использование информации о I-SID позволяет ABB изучить связи Mac-in-Mac/Мас-in-Мас-in-Мас с тем, чтобы ABB могли бы инкапсулировать трафик на основе "одного SID".
Если для межсоединения сетей L1/L2 должны быть использованы альтернативные ABB, альтернативному ABB можно обеспечить большую метрику с тем, чтобы он не был похож на ABB, выбранный для обеспечения кратчайшего пути для любого ВЕВ в сегменте сети L1. Однако альтернативный ABB все еще может пропустить информацию о I-SID в сегмент сети L1 и, с другой стороны, разрешить сетевым элементам иметь информацию о ABB и обеспечить более быструю сходимость в случае отказа на первичном ABB.
При сбое ABB весь трафик для I-SID должен быть восстановлен. Трафик для I-SID должен быть связан с другим ABB, которому потребуется ВСВ в сети L1 для установки нового состояния пересылки. Один способ, с помощью которого это может быть достигнуто, состоит в установке нового состояния пересылки, используя другой VID, чтобы установить два набора путей связи: первый набор путей для первичного ABB и второй набор путей для вторичного ABB. Состояния пересылки может быть установлено после определения неисправности или, альтернативно, может быть предварительно вычислено и установлено прежде, чем произойдет отказ. Установка резервного копирования состояния пересылки, используя другой VID, позволяет установить в сети различное состояние пересылки заранее с тем, чтобы при отказе ABB трафик мог бы быть автоматически переключен на альтернативные пути с теговым трафиком, используя альтернативный VID.
На фигуре 5 показан пример сетевого элемента, который может быть использован для реализации варианта воплощения изобретения. Как показано на фигуре 5, сетевой элемент включает плоскость данных 50 и плоскость управления 60. Плоскость данных 50 в основном включает карты входа/выхода, используемые для взаимодействия с каналами в сети через интерфейс, карты данных 54, используемые для выполнения функций с данными, полученных по картам ввода-вывода 52, и структура переключателя 56, используемая для переключения данных между картами ввода-вывода. Плоскость управления содержит процессор 62, содержащий логику управления, предназначенную для реализации процесса маршрутизации по состоянию канала в L1 64 и процесса маршрутизации по состоянию канала в L2 66. В логике управления также могут быть реализованы и другие процессы.
Данные и команды, связанные с L1 процессом маршрутизации по состоянию канала L1 64 и процессом маршрутизации по состоянию канала L2 66, могут быть сохранены как программное обеспечение маршрутизации L1 72 и программное обеспечение маршрутизации L2 74 в памяти 70. Один или несколько баз данных или таблицы могут поддерживаться АВВ-30, а также инициировать ABB на хранение информации, связанной с маршрутами, которые были установлены в сетях L1 и L2. Например, АВВ-30 может включать L1 FIB 80, L2 FIB 82, база данных состояния канала 84, L2 база данных состояния канала L1 86 и FIB 88 L1/L2, содержащий идентификатор общности интересов (например, I-SID) с ассоциацией между информацией передачи в этих двух сетях.
ABB может содержать другое программное обеспечение, процессы и хранилища информации, чтобы выполнять описанные выше функции и выполнить другие функции, обычно реализуемые в элементе сети связи.
Описанные выше функции могут быть реализованы как ряд команд программы, которые сохранены в памяти, считаемой компьютером, и выполняются в одном или нескольких процессорах на компьютерной платформе, связанной с сетевым элементом. Однако для квалифицированного специалиста очевидно, что вся описанная здесь логика может быть реализована, используя дискретные компоненты, интегральную схемотехнику, например специализированную интегральную схему (ASIC), программируемую логику, используемую в связи с программируемым логическим устройством, таким как программируемый на месте массив логических элементов (FPGA) или микропроцессор, конечный автомат или любое другое устройство, включая любую их комбинацию. Программируемая логика может быть встроена временно или постоянно в материальный носитель, такой как микросхема постоянной памяти, память компьютера, диск или другой носитель. Программируемая логика также может быть встроена в компьютерный сигнал данных на несущей частоте, позволяя передать программируемую логику по интерфейсу, такому как компьютерная шина или сеть связи. Все такие варианты воплощения находятся в пределах объема настоящего изобретения. Маршрутизация по состоянию канала
Возможно предположить изменения заявки США №11/537,775, зарегистрированный 2 октября 2006 года, под названием "Маршрутизация по состоянию канала провайдера", относящиеся как к источнику, так и к группе многоадресной передачи интереса, кодированной в плоскости данных, который может быть размещен основными методиками для создания дерева кратчайшего пути, описанного выше, но с небольшими модификациями функции передачи в плоскости данных, выполняемой в ABB.
В одной модификации адрес группы многоадресной передачи для данной группы интереса характерен для всех групп ВЕВ, которые поддерживают группу интереса и определенного источника ВЕВ, или ABB (многоадресный источник) кодируется в поле VLAN. В этом случае уплотнение групповых адресов MAC невозможно, но уплотнение информации VLAN между сегментами возможно. Это полезно, поскольку такая методика не экономна для VLAN и, следовательно, решение по множеству сегментов может существенно увеличить масштабируемость сети. Уплотнение может быть выполнено хорошо известным преобразованием VLAN на выходе ABB, посредством чего ABB перезаписывает VLAN многоадресного пакета с величиной VLAN, которая была назначена для ABB как источник многоадресной передачи. Изобретение не будет ограничено конкретным способом, которым величины VLAN назначаются для ABB как многоадресные источники.
В этой вариации дерево кратчайшего пути от данного ВЕВ будет иметь уникальную надстройку VLAN на каждое дерево так, что дерево кратчайшего пути от ВЕВ А будет видеть (например) все пакеты от тегового ВЕВ с VLAN 1, все пакеты от тегового ВЕВ В с VLAN, 2 и т.д. Затем будет выполнена проверка маршрута обратного пути (RFPC) на VLAN вместо адреса источника MAC. Пакеты, которые требуются для транзита между сегментами, будут проходить через ABB и на дерево кратчайшего пути в смежном сегменте. Пакеты, передаваемые по дереву кратчайшего пути от ABB, были бы просто повторно тегированы с VID, назначенным для ABB как многоадресный источник с тем, чтобы ABB стал "узким местом" для набора многоадресных источников, которые передают сегмент транзитом через этот ABB. Таким образом, учитывая, что имеется 4000 нечетных доступных тегов VLAN, конечный результат состоит в том, что каждый "сегмент» или "уровень" может иметь 4000 узлов (сумма ВЕВ, ВСВ и ABB), хотя уплотнение ABB (и замена VID ABB) разрешает каждому из сегментов иметь свое собственное пространство VID, и сеть может вырасти в размере до 4000 узлов на сегмент.
В другой модификации адрес группы многоадресной передачи рекламируется, как описано выше, но источник кодируется только в адресе MAC, и используемая VLAN характерна для всех ВЕВ. В этом случае никакое уплотнение групповой адресации в ABB невозможно, и пакеты передаются в первоначальном виде.
Обратимся теперь к фигуре 7, на которой показана примерная сеть связи 100 PLSB, в которой ABB может быть "размещен" во множестве сегментов L1. Иными словами, ABB может обслужить множество непересекающихся сегментов сети L1. Сеть связи 100 PLSB изображена с сегментом сети L2 110, которая географически расширяется, чтобы охватить несколько сегментов L1 116, что имело бы место, когда сегментами L1 являются центральные сети, и сегментом L2 является национальная магистральная сеть. Одиночный сегмент L2 110 включает пять ABB, т.е. ABB 1 112а, ABB-2 112b, ABB-3 112c, ABB 4 112-d и ABB 5 112е (все вместе обозначенные как ABB 112), и три других ВВ, т.е. ВВ 1 114а, ВВ 2 114b и ВВ 3 114с (все вместе обозначенные как ВВ 114). Сеть связи 100 PLSB также включает три тупиковых сегмента L1, т.е. 11-116а, L1-B 116b и L1-C 116с (все вместе обозначенные как сегмент L1 116). L1-A 116а обслуживается одиночным ABB, а именно, ABB-2 112b. L1-B 116b обслуживается двумя ABB, а именно, ABB 1 112a и ABB-2 112b. L1-C 116 с обслуживается тремя ABB, а именно, АВВ-3 112с, ABB 4 112d и ABB 5 112e. Отметим, что сегмент L2 110 представлен на фигуре 7 как псевдоузел L2 PN в каждом из сегментов L1 116.
Когда сегмент L1 116 обслуживается более чем одним ABB 112, узлы в этом сегменте L1 116 делятся на непересекающиеся "подмножества" узлов, по одному на каждый ABB, где все узлы раздела находятся "ближе" к конкретному ABB чем к другим ABB в сегменте L1. Как правило, в поле протоколов маршрутизации "ближе" в этой спецификации означает, что сумма метрик канала для кратчайшего пути между узлом и определенным ABB меньше чем или равна этому кратчайшему пути к любому другому ABB и, где имеется связка, которая является суммой метрик канала, то же самое между узлом и двумя или несколькими ABB, затем механизм разрушения связки решает, что определенный ABB находится "ближе". В системе связи 100, поскольку L1-B 116b обслуживается двумя ABB, она делится на два подмножества, показанные разделительными линиями 118а. Подмножество L1-B1 120а обслуживается АВВ-1 112a, и подмножество L1-B2 120b обслуживается АВВ-2 112b. Аналогичным образом, поскольку L1-C 116с обслуживается тремя ABB, она делится на три подмножества линиями 118b и 118 с. L1-CI подмножество 122а обслуживается АВВ-3 112с, подмножество L1-C2 122b обслуживается ABB 4 112d и подмножество, L1-C3 122с обслуживается АВВ-5 112е.
Следует отметить, что АВВ-2 112b обслуживает два непересекающиеся сегмента L1, а именно L1-A 116а и L1-B 116b. Обычно, когда ABB 112 обслуживает одиночный сегмент L1 116, ABB 112 относится к одиночному FIB L1 для передачи пакетов данных, как описано выше. Однако ABB, обслуживающие множество сегментов L1, должны иметь множество FIB L1, по одному FIB L1 для пакетов, прибывающих во все порты.
Канал к псевдоузлу L2 PN 110, представляющий сегмент L2, рекламируется каждым ABB 112 в сегменте L1 116. Метрика стоимости, связанная с рекламой, обычно идентична для всех ABB. Однако в данном случае метрика больше половины максимального диаметра сегмента L1 116, так что L2 PN 110 не появляется ни на каких кратчайших путях между сегментами. Эта большая метрика эффективно делит сегмент L1 116 в непересекающиеся подмножества узлов, которые являются "ближайшими" к каждому ABB 112. "Port MAC" и ISID для полного набора "внешних" MAC также рекламируются с L2 PN. Для каждого подмножества сегментов предполагаемой сети L1 каждый ABB 112 передает сообщение на уровень 2 "port MAC" и ISID для подмножества. Корневой идентификатор для подмножества включается в пакет по состоянию канала для этого подмножества. Можно видеть, что L2 PN 110 является корневым узлом для общего дерева, следовательно, используя его название как корневой идентификатор для любого многоадресного трафика, можно войти в сегмент L1.
Псевдоузел L2 110 выполняет много функций, включая следующие три. Во-первых, использование большой метрики гарантирует, что внутри L1 трафик сегментов не передает транзитом уровень 2. Во-вторых, вычисление "ближайшего" подмножества узлов L1 для ABB упрощается для узлов на кратчайшем пути к L2PN. Наконец, весь внешний порт MAC связывается с одиночным узлом.
Для одноадресных сообщений трафик, прибывающий в порты L2, пересылается FIB L2, и трафик на портах L1 пересылается FIB L1. Эти FIB отличаются для случая, где место назначения находится в сегменте L1, а не в "ближайшем" подмножестве ABB. В этом случае FIB L1 диктует передачу пакета другом порту L1, хотя FIB L2 уже передали пакет через порт L2 другого ABB.
Многоадресное дерево L2 с источником ABB 2 112b показано на фигуре 7 сплошными жирными линиями 124. Для многоадресных пакетов "ближайшие" подмножества в L1 116 необходимы, чтобы гарантировать получение копии одиночного пакета для пакетов, прибывающих в порты L2 во множестве ABB той же самой сети L1. В примере показано многоадресное дерево L2, при этом многоадресный пакет, сформированный через ABB-2 112b, будет передан на три ABB, обслуживающих сегмент L1 С 116с: а именно АВВ-3 112с, ABB 4 112-d и ABB 5 112е. Дерево с корнем в ABB 112 не ограничивается "ближайшим" подмножеством, так что корневой идентификатор для дерева, которое покрывает только "ближайшее" подмножество, не может быть псевдонимом ABB. Однако корневой идентификатор может иметь псевдоним L2PN. Рекламирование L2PN, как описано выше, естественно, создает "ближайшее" подмножество и многоадресные деревья. Отметим, что "ближайшее" подмножество для каждого B-VID не обязательно включает тот же самый набор узлов, т.е. равноценная многопутевая маршрутизация (ЕСМР) к L2PN 110 может использовать различные ABB 112.
Таким образом, в одном варианте воплощения настоящего изобретения, когда многоадресный пакет достигает ABB 112 через порт уровня 2, анализируется корневой идентификатор входящего пакета. Если корневой идентификатор является корневым идентификатором другого "ближайшего" подмножества того же самого сегмента L1, пакет отбрасывается. В противном случае корневой идентификатор заменяется корневым идентификатором L2PN и передается по дереву L1, покрывающему это "ближайшее" подмножество ABB.
Чтобы обеспечить симметрию, многоадресная передача от узла L1 переходит к L2 110, только когда ABB 112 обслуживает свое "ближайшее" подмножество. Это означает, что многоадресное дерево L2 должно быть изоморфным по отношению к многоадресному дереву L2 с корнем в ABB 112. Однако корневой идентификатор не может иметь псевдоним ABB, чтобы избежать повторно входа многоадресного трафика в сегмент L1 116 от другого ABB 122. Таким образом, снова обращаясь к примерной сети связи 100 на фигуре 7, ABB-1 112а должен тиражировать пакеты от АВВ-2 112b в L1-B 116b, если они пришли из L1-A 116а, но не делать этого, если они пришли из L1-B 116b.
Корневой идентификатор в L2 для всех деревьев с корнями в ABB 112, обслуживающий тот же самый сегмент L1 116, не должен быть одним и тем же, потому что деревья от каждого ABB являются пересекающимися. Корневой идентификатор должен быть различным и легко тестируемым на идентификацию сегментов с тем, чтобы ABB 112 мог бы удалить, а не передавать пакеты, которые пришли из его собственной сегмента. Таким образом, для многоадресного пакета уровня 1, если корневой идентификатор пакета принадлежит "ближайшему" подмножеству ABB, этот идентификатор подкачивается к уникальному "ближайшему" корневому идентификатору подмножества и передается на всех портах уровня 2, которые являются частью "ближайшего" многоадресного дерева подмножества для пакета ISID.
Типичная комбинация аппаратного и программного обеспечения может быть специализированной компьютерной системой, имеющей один или несколько элементов обработки и компьютерную программу, хранящуюся на носителе, которая после загрузки и выполнения управляет компьютерной системой для осуществления описанных здесь способов. Настоящее изобретение может также быть встроено в продукт компьютерной программы, который содержит все признаки, позволяющие реализовать вариант воплощения описанных здесь способов и, когда он загружен в вычислительную систему, может выполнить эти способы. Носителем может быть любое устройство в виде энергозависимой или энергонезависимой памяти.
Компьютерная программа или приложение в настоящем контексте означают любое выражение на любом языке, код или запись, ряд команд, инициирующие систему, предназначенную для обработки информации, выполнять определенную функцию либо непосредственно, либо после следующего (а) преобразования в другой язык, код или запись; (b) воспроизведение в различном материальном виде.
Кроме того, если выше не было упомянуто иначе, отметим, что все сопроводительные чертежи не должны масштабироваться. Важно, что это изобретение может быть воплощено в других конкретных формах, не выходя из духа или объема изобретения, и, соответственно, упор должен быть сделан на приведенную ниже формулу изобретения, а не на предшествующее описание изобретения.
Следует понимать, что различные изменения и модификации вариантов воплощения, показанные в чертежах и описанные выше, могут быть сделаны, не выходя из духа и контекста настоящего изобретения. Соответственно, весь материал, содержащийся в вышеупомянутом описании и показанный на сопроводительных чертежах, является иллюстративным, а не ограничительным. Изобретение ограничено только прилагаемой формулой изобретения.
Изобретение относится к устройствам обмена маршрутной информацией. Технический результат заключается в уменьшении вероятности зацикливания при пересылке пакетов в сети с множеством сегментов. Система содержит, по меньшей мере, один первый сегмент, соединенный, по меньшей мере, через один узел граничных сегментов ("ABN") со вторым сегментом, каждый узел ABN имеет порт первого уровня, соединенный с каждым первым сегментом, и порт второго уровня, соединенный со вторым сегментом, каждый переданный многоадресный пакет включает заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева, пакет данных поступает в узел ABN, в ответ на получение многоадресного пакета через порт второго уровня узла граничных сегментов, выполняется анализ корневого идентификатора многоадресного пакета, и если многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, в пакет вставляется другой корневой идентификатор прежде, чем пакет будет передан порту первого уровня. 3 н. и 17 з.п. ф-лы, 7 ил.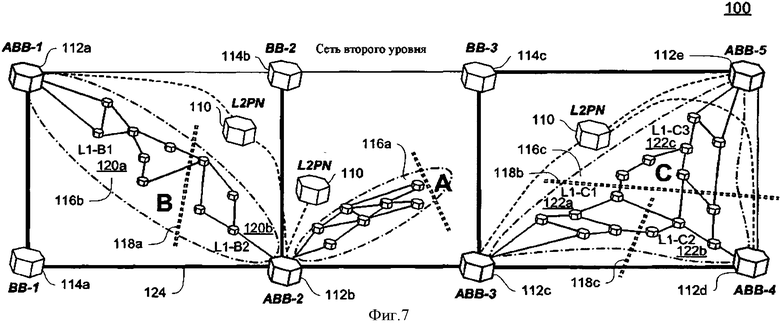
1. Способ, гарантирующий, что многоадресные пакеты следуют по одному и тому же пути без зацикливания, как и путь, по которому следуют одноадресные пакеты в сети пакетной передачи, сеть пакетной передачи включает, по меньшей мере, один первый сегмент, определенный первым уровнем, при этом каждый первый сегмент включает первое множество узлов, соединенных первым набором каналов; каждый первый сегмент соединен, по меньшей мере, через один узел граничных сегментов со вторым сегментам, определенным вторым уровнем; второй сегмент включает второе множество узлов, соединенных вторым набором каналов, при этом каждый узел граничных сегментов имеет, по меньшей мере, один порт первого уровня, соединенный, по меньшей мере, с одним первым сегментом, и порт второго уровня, соединенный со вторым сегментом, каждый многоадресный пакет, переданный по пути без зацикливания, включает заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева; указанный способ содержит следующие стадии:
получение, по меньшей мере, одного пакета данных в узле граничных сегментов; и
отклик на получение многоадресного пакета через порт второго уровня узла граничных сегментов:
изучение корневого идентификатора многоадресного пакета;
определение, должен ли многоадресный пакет быть передан, по меньшей мере, на один из портов первого уровня узла граничных сегментов; и
реакцию на определение, что многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, заменяя корневой идентификатор в пакете другим до передачи пакета, по меньшей мере, одному порту первого уровня.
2. Способ по п.1, в котором сетью пакетной передачи является сеть Ethernet.
3. Способ по п.1, в котором, по меньшей мере, один первый сегмент обслуживается более чем одним узлом граничных сегментов, причем способ дополнительно содержит деление, по меньшей мере, одного первого сегмента на группу подмножеств; группа подмножеств включает количество подмножеств, равное количеству узлов граничных сегментов, обслуживающих первый сегмент, при этом каждое подмножество связано с узлом границы конкретного сегмента.
4. Способ по п.3, в котором каждое подмножество включает узлы, имеющие кратчайший путь к соответствующему узлу граничных сегментов.
5. Способ по п.3, в котором деление, по меньшей мере, одного первого сегмента на группу подмножеств содержит:
каждый узел граничных сегментов формирует рекламу для канала к псевдоузлу, представляющему второй сегмент, при этом реклама включает ассоциированную метрику размером более половины максимального логического диаметра соответствующих первых сегментов; и
передачу рекламных сообщений в соответствующие первые сегменты.
6. Способ по п.5, дополнительно содержащий назначение уникального идентификатора каждому подмножеству.
7. Способ по п.6, в котором уникальный идентификатор для подмножества включается в рекламу как корневой идентификатор.
8. Способ по п.7, в котором, по меньшей мере, один полученный пакет данных является многоадресным пакетом, полученным в порту первого уровня, при этом, по меньшей мере, один полученный пакет данных включает корневой идентификатор; указанный способ дополнительно содержит:
определение, что корневой идентификатор идентифицирует узел в пределах подмножества, связанного с приемным узлом граничных сегментов;
замену корневого идентификатора уникальным идентификатором подмножества, связанным с приемным узлом граничных сегментов; и
передачу, по меньшей мере, одного пакета данных через порт второго уровня.
9. Способ по п.3, в котором отклик к определению, что многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, дополнительно содержит:
отклик на определение, что корневой идентификатор идентифицирует другое подмножество в первом сегменте, обслуживаемом приемным узлом граничных сегментов, отбрасывая, по меньшей мере, один полученный пакет данных; и
отклик на определение, что корневой идентификатор не идентифицирует другое подмножество в первом сегменте, обслуживаемом приемным узлом граничных сегментов:
замену корневого идентификатора другим корневым идентификатором; и
передачу, по меньшей мере, одного пакета данных через подмножество, связанное с приемным узлом граничных сегментов.
10. Способ по п.3, в котором, по меньшей мере, один полученный пакет данных является одноадресным пакетом, включающим одиночный адрес назначения, при этом адрес получателя идентифицирует узел в первом сегменте, не связанном с подмножеством приемного узла граничных сегментов, указанный способ дополнительно содержит:
отклик на получение, по меньшей мере, одного пакета данных в порту первого уровня, передавая, по меньшей мере, один пакет данных через другой порт первого уровня; и
отклик на получение, по меньшей мере, одного пакета данных в порту второго уровня, передавая, по меньшей мере, один пакет данных через порт второго уровня на другой узел граничных сегментов.
11. Узел граничных сегментов для использования в сети пакетной передачи, при этом сеть пакетной передачи включает, по меньшей мере, один первый сегмент, определенный первым уровнем, каждый первый сегмент включает первое множество узлов, соединенных с первым набором каналов, причем каждый первый сегмент соединен, по меньшей мере, через узел граничных сегментов со вторым сегментам, определенным вторым уровнем; узел граничных сегментов содержит:
по меньшей мере, один порт первого уровня, соединенный с каждым первым сегментом, по меньшей мере, один порт первого уровня служит для получения пакетов данных из соответствующего сегмента данных передачи соответствующему первому сегменту;
порт второго уровня, соединенный со вторым сегментам, порт второго уровня используется для получения пакетов данных из соответствующего сегмента и для передачи пакетов данных второму сегменту;
по меньшей мере, один процессор, электрически соединенный, по меньшей мере, с одним портом первого уровня и с портом второго уровня, реагирующим на получение многоадресного пакета через порт второго уровня, при этом многоадресный пакет включает заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева,
указанный процессор сконфигурирован для:
изучения корневого идентификатора многоадресного пакета;
определения, должен ли многоадресный пакет быть передан, по меньшей мере, на один из портов первого уровня узла граничных сегментов; и
отклика на определение, что многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, вставляя другой корневой идентификатор в пакет до инициирования передачи пакета, по меньшей мере, одному порту первого уровня.
12. Узел граничных сегментов по п.11, дополнительно содержащий:
по меньшей мере, одну память, электрически соединенную, по меньшей мере, с одним процессором, при этом, по меньшей мере, одна память содержит:
первую базу пересылки информации ("FIB"), связанную, по меньшей мере, с одним портом первого уровня; и
вторую базу пересылки информации ("FIB"), связанную с портом второго уровня;
в котором, по меньшей мере, один процессор сконфигурирован для:
передачи пакета данных, полученного, по меньшей мере, через один порт первого уровня в соответствии с первой базой FIB; и
передачи пакета данных, полученного через порт второго уровня в соответствии со второй базой FIB.
13. Узел граничных сегментов по п.11, в котором, по меньшей мере, один первый сегмент обслуживается более чем одним узлом граничных сегментов, процессор, дополнительно сконфигурирован для разделения, по меньшей мере, одного первого сегмента на группу подмножеств, передавая рекламу через канал псевдоузла, представляющего собой второй сегмент, в соответствующие первые сегменты, по меньшей мере, через один порт первого уровня, при этом группа подмножеств включает количество подмножеств, равное количеству узлов граничных сегментов, обслуживающих, по меньшей мере, один первый сегмент; каждое подмножество, связанное с конкретным узлом граничных сегментов, подмножество, связанное с узлом граничных сегментов, включает только узлы, имеющие кратчайший путь к соответствующему узлу граничных сегментов; указанная реклама включает ассоциированную метрику размером более половины максимального диаметра соответствующих первых сегментов.
14. Узел граничных сегментов по п.13, в котором уникальный идентификатор назначается каждому подмножеству, причем уникальный идентификатор для одного подмножества включен в рекламу как корневой идентификатор.
15. Узел граничных сегментов по п.14, реагирующий на получение многоадресного пакета в порту первого уровня многоадресного пакета, включающего заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева,
по меньшей мере, один процессор, сконфигурирован для:
определения, что корневой идентификатор идентифицирует узел в пределах подмножества, связанного с приемным узлом граничных сегментов;
замены корневого идентификатора уникальным идентификатором подмножества, связанным с приемными узлом граничных сегментов; и
передачу, по меньшей мере, одного пакета данных через порт второго уровня.
16. Узел граничных сегментов по п.13, в котором отклик на получение пакета служит для определения, что многоадресный пакет должен быть передан, по меньшей мере, в один из портов первого уровня, и указанный процессор сконфигурирован для:
определения, что корневой идентификатор идентифицирует другое подмножество в первом сегменте, обслуживаемом узлом граничных сегментов и удаления, по меньшей мере, одного полученного пакета данных; и
определения, что корневой идентификатор не идентифицирует другое подмножество в первом сегменте, обслуживаемом узлом граничных сегментов:
замены корневого идентификатора другим корневым идентификатором для псевдоузла второго уровня; и
передачи, по меньшей мере, одного пакета данных через подмножество, связанное с узлом граничных сегментов.
17. Узел граничных сегментов по п.13, в котором осуществляется отклик на получение одноадресного пакета, включая одиночный адрес назначения, адрес назначения, идентифицирующий узел в первом сегменте, не связанном с подмножеством узла граничных сегментов, при этом процессор сконфигурирован для:
реакции на получение, по меньшей мере, одного пакета данных через порт первого уровня и передачи, по меньшей мере, одного пакета данных через другой порт первого уровня; и
реакции на получение, по меньшей мере, одного пакета данных через порт второго уровня и пересылки, по меньшей мере, одного пакета данных через порт второго уровня другому узлу граничных сегментов.
18. Система пакетной связи, содержащая:
по меньшей мере, один первый сегмент, при этом каждый первый сегмент сконфигурирован как протокол состояния канала управляемой сети Ethernet, каждый первый сегмент включает первое множество узлов, соединенных первым набором каналов; и
второй сегмент, сконфигурированный как протокол состояния канала управляемой сети Ethernet, при этом второй сегмент включает второе множество узлов, соединенных вторым набором каналов, и второй сегмент соединен с каждым первым сегментом;
по меньшей мере, один узел граничных сегментов, соединяющий второй сегмент с каждым первым сегментом, по меньшей мере, один узел граничных сегментов используется для обслуживания двух или нескольких непересекающихся первых сегментов, каждый узел граничных сегментов включает:
порт второго уровня, соединенный со вторым сегментам, при этом порт второго уровня используется для получения пакетов данных из соответствующего сегмента и для передачи пакетов данных второму сегменту;
по меньшей мере, один порт первого уровня, соединенный с каждым первым сегментом, по меньшей мере, один порт первого уровня используется для получения пакетов данных из соответствующего сегмента для передачи данных соответствующих первому сегменту;
по меньшей мере, один процессор, электрически соединенный с портом второго уровня и, по меньшей мере, с одним портом первого уровня,
отклик на получение многоадресного пакета в порту второго уровня, указанный многоадресный пакет включает заголовок, имеющий корневой идентификатор, идентифицирующий корень многоадресного дерева,
по меньшей мере, один процессор, сконфигурирован для:
изучения корневого идентификатора многоадресного пакета;
определения, должен ли многоадресный пакет быть передан, по меньшей мере, на один из портов первого уровня узла граничных сегментов; и
реакции на определение, что многоадресный пакет должен быть передан, по меньшей мере, на один из портов первого уровня, вставляя другой корневой идентификатор в пакет до инициирования передачи пакета, по меньшей мере, одному порту первого уровня.
19. Система пакетной связи по п.18, в которой, по меньшей мере, один первый сегмент обслуживается более чем одним узлом граничных сегментов, по меньшей мере, один первый сегмент делится на группу подмножеств, при этом группа подмножеств имеет количество подмножеств, равное количеству узлов граничных сегментов, обслуживающих соответствующий первый сегмент, каждое подмножество связано с узлом границы соответствующего сегмента, при этом подмножество, связанное с узлом граничных сегментов, включает только узлы, имеющие кратчайший путь к соответствующему узлу граничных сегментов.
20. Система пакетной связи по п.19, в которой узел граничных сегментов представлен в рекламе, переданной в соответствующие первые сегменты, по меньшей мере, через один порт первого уровня, имеющий канал к псевдоузлу, представляющему второй сегмент, при этом реклама включает ассоциированную метрику размером более половины максимального диаметра соответствующих первых сегментов.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| ПЕРЕДАЧА ИНФОРМАЦИИ В ПАКЕТНО-ОРИЕНТИРОВАННЫХ КОММУНИКАЦИОННЫХ СЕТЯХ | 2002 |
|
RU2338327C2 |

