Область техники
Изобретение в основном относится к предоставлению специальной информации пользователю на основании идентификации тренда в потоке данных.
Предпосылки создания изобретения
В проводных сетях, например Интернете, веб-реклама обеспечивает относительно большой источник дохода для поставщиков веб-содержимого и других услуг. Веб-реклама включает целенаправленные рекламные объявления, которые предоставляются конкретным пользователям на основании информации, ассоциированной с пользователями, с указанием, что пользователи могут заинтересоваться целенаправленными рекламными объявлениями. Обычный подход к получению информации, ассоциированной с пользователями, для реализации созданных целенаправленных рекламных объявлений предусматривает вставку триггеров обнаружения в рамках обычно используемых услуг, как, например, веб-поиск, покупка онлайн или электронная почта, а также хранение записей событий по каждому пользователю, содержащих информацию на основании обнаруженных триггеров.
Записи событий могут включать широкий спектр собранной информации, включая поисковые темы, ключевые слова, посещаемые унифицированные указатели ресурсов (URL), объекты электронной почты, используемые услуги, время использования и т.д. Затем к собранной информации применяются методы получения данных для извлечения информации из записей событий, чтобы определить целенаправленные рекламные объявления, которые могут представлять интерес для соответствующих пользователей. Несмотря на то что обычные методы получения данных, в общем, эффективны при создании целенаправленных рекламных объявлений, они предусматривают хранение относительно большого объема данных, которые требуют обеспечения большой и дорогостоящей памяти для хранения данных и инфраструктуры управления.
Несмотря на то что целенаправленные рекламные объявления могут обеспечить относительно большой источник дохода поставщикам услуг, дорогостоящая инфраструктура, которую, вероятно, придется создать для получения данных, может убедить некоторых поставщиков услуг, включая поставщиков услуг беспроводных сетей, отказаться от реализации такой возможности дохода.
Сущность изобретения
Предлагается способ предоставления специальной информации пользователю, который включает прием, в узле сети, потока данных, ассоциированных с пользователем. Тренд, ассоциированный, как минимум, с одним атрибутом в потоке данных, идентифицируется и на основании идентифицированного тренда специальная информация направляется для представления пользователю на пользовательской станции.
Другие или альтернативные особенности станут очевидными из следующего описания, из рисунков и из патентной формулы.
Краткое описание чертежей
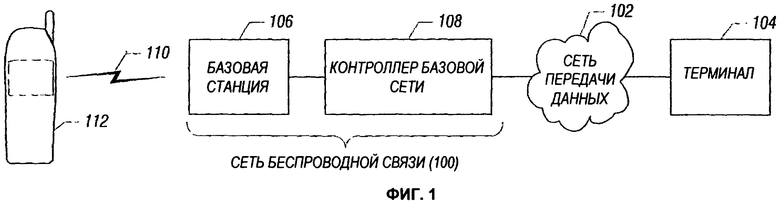
Фиг.1 - блок-схема коммуникационной сети, которая включает беспроводную сеть, в которую может быть встроен механизм для предоставления целенаправленных рекламных объявлений в соответствии с примером осуществления изобретения.
Фиг.2 - блок-схема узла беспроводной связи и системы анализа данных, в соответствии с примером осуществления изобретения.
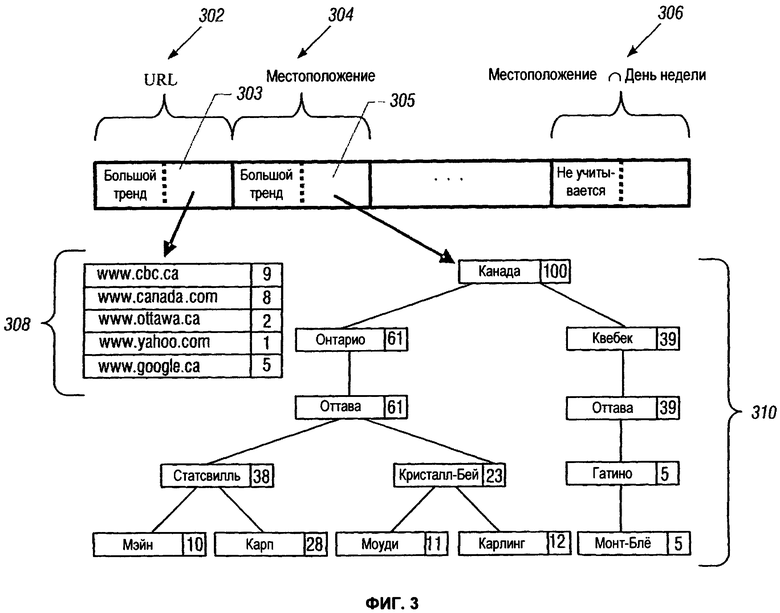
На Фиг.3 показаны структуры данных, используемые в предоставлении целенаправленных рекламных объявлений в соответствии с примером осуществления изобретения.
Фиг.4-6 - блок-схемы процессов предоставления целенаправленных рекламных объявлений пользователям в беспроводной сети, в соответствии с некоторыми альтернативными примерами осуществления изобретения.
Подробное описание изобретения
В следующем описании для понимания некоторых примеров осуществления изобретения представлен ряд подробных сведений. Однако специалистам в данной области понятно, что некоторые примеры осуществления изобретения могут быть осуществлены без этих подробных сведений и что возможны различные изменения или модификации описанных примеров осуществления изобретения.
В соответствии с некоторыми примерами осуществления изобретения предусматривается механизм обеспечения возможности идентификации специальной информации, представляемой пользователю в коммуникационной сети (например, сети проводной или беспроводной связи). В некоторых примерах специальная информация включает рекламную информацию, когда «рекламная информация» относится к информации, которая описывает товары или услуги, предлагаемые различными юридическими лицами, например торговыми предприятиями, розничными магазинами онлайн, учебными организациями, правительственными учреждениями и т.д. Рекламная информация, которая отбирается для представления пользователям, называется целенаправленной рекламной информацией (или целенаправленными рекламными объявлениями). «Целенаправленная» рекламная информация или рекламные объявления относятся к рекламной информации, которая может с большей вероятностью представлять интерес для конкретного пользователя на основании информации, ассоциированной с конкретным пользователем. Предоставление целенаправленной рекламной информации определенным пользователям обычно бывает более эффективным, чем предоставление общей рекламной информации широкой аудитории.
Механизм в соответствии с некоторыми примерами осуществления изобретения получения информации с целью создания целенаправленной рекламной информации для конкретного пользователя (или группы пользователей) использует методику, которая не требует хранения и получения всех записей данных, ассоциированных с конкретным пользователем (или группой пользователей). Вместо этого механизм идентифицирует тренд (или множество трендов), ассоциированный с одним или несколькими атрибутами потока данных. Наборы данных, относящихся к тренду(ам), могут храниться для дальнейшего последующего анализа. Оставшиеся данные можно отбросить. Таким образом, объем данных, который должен храниться для обеспечения предоставления целенаправленных рекламных объявлений, значительно уменьшается. Инфраструктуру хранения данных и управления, необходимую для возможности получения данных с целью предоставления целенаправленных рекламных объявлений, можно сделать менее сложной и, следовательно, менее дорогостоящей.
С помощью механизма в соответствии с некоторыми примерами осуществления изобретения поставщик услуг в сети беспроводной связи может воспользоваться преимуществами получения повышенного дохода за счет целенаправленных рекламных объявлений. Поставщик услуг сети беспроводной связи относится к юридическому лицу, управляющему услугами связи и оказывающему услуги связи в сети беспроводной связи.
Обычно в соответствии с некоторыми примерами осуществления изобретения в узел в сети беспроводной связи поступает поток данных, ассоциированных с пользователем. Тренд, ассоциированный, как минимум, с одним атрибутом в потоке данных, идентифицируется и на основании идентифицированного тренда специальная информация (например, целенаправленная рекламная информация) направляется для представления пользователю на мобильной станции. «Тренд» относится к уровню использования или активности, ассоциированных с конкретным пользователем (или группой пользователей), который превышает некоторый предопределенный порог.
В следующем описании ссылка сделана на предоставление целенаправленной рекламной информации пользователю. Однако такие же или подобные методы могут применяться для представления других форм специальной информации пользователю. Кроме того, хотя ссылка сделана на передачу специальной информации на мобильную станцию, ассоциированную с пользователем в сети беспроводной связи, следует отметить, что специальную информацию можно также передавать на пользовательскую станцию в проводной сети.
На Фиг.1 показана иллюстративная система связи, включающая сеть беспроводной связи 100 и сеть передачи данных 102. Сеть передачи данных 102 может представлять собой сеть передачи пакетов данных, как, например, Интернет, или какой-либо другой тип сети передачи данных. Проводные терминалы 104 соединены с сетью передачи данных 102. Примеры терминалов 104 включают компьютеры, Интернет-телефоны, серверы (например, веб-серверы или другие серверы содержимого), и т.д.
Сеть беспроводной связи 100 включает базовую станцию 106, соединенную с контроллером базовой сети 108, который в свою очередь связан с сетью передачи данных 102.
Сообщение базовой станции 106 может обеспечиваться с помощью беспроводной связи по беспроводному каналу 110 (например, каналу высокой частоты) с мобильной станцией 112, которая находится в пределах зоны охвата базовой станции. Базовая станция 106 может по существу работать с множеством узлов, включая базовую приемопередающую станцию (BTS), имеющую одну или несколько антенн для осуществления беспроводной связи с мобильной станцией 112. Базовая станция 106 может также включать контроллер базовой станции или контроллер беспроводной связи, который выполняет управляющие задачи, ассоциированные с сообщением с мобильными станциями. Контроллер базовой сети 108 управляет сообщением между сетью беспроводной связи 100 и внешней сетью, как, например, сеть передачи данных 102, а также управляет сообщением между мобильными станциями в сети беспроводной связи 100. Хотя изображена только одна базовая станция 106, следует иметь в виду, что типичная сеть беспроводной связи 100 содержит много базовых станций для соответствующих зон охвата (например, соты) в беспроводной сети.
В качестве технологии беспроводного доступа сети беспроводной связи 100 может быть одна или несколько из следующих систем: Глобальная Система Мобильных Коммуникаций (GSM), определенная Проектом партнерства третьего поколения (3GPP); Универсальная система мобильных телекоммуникаций (UMTS), определенная 3GPP; Множественный доступ с кодовым разделением каналов 2000 (CDMA 2000), определенный Проектом партнерства 2 третьего поколения (3GPP2); Долгосрочное развитие сетей связи (LTE), определенное 3GPP, которое направлено на расширение технологии UMTS [Универсальная система мобильной связи]; Глобальная совместимость для микроволнового доступа (WiMAX), как определено IEEE (Институт инженеров по электротехнике и электронике) 802.16; и другие.
Пользователь, ассоциированный с мобильной станцией 112, может осуществлять различные коммуникации (например, голосовая связь или передача данных) с помощью мобильной станции 112. Например, пользователь может общаться с другим пользователем в сети беспроводной связи 100. Альтернативно, пользователь может общаться с пользователем, связанным с компьютером или телефоном, соединенным с сетью передачи данных 102. В качестве еще одного примера, пользователь может использовать мобильную станцию 112 для просмотра веб-страниц, что включает обращение к веб-сайтам в сети передачи данных 102 для осуществления поисковых мероприятий, действий по покупкам онлайн и других действий.
Узел в сети беспроводной связи 100 или ассоциированный с сетью беспроводной связи 100 может отслеживать поток данных, ассоциированных с различными коммуникациями, осуществляемыми мобильной станцией 112, для идентификации любых трендов, ассоциированных с одним или несколькими атрибутами в потоке данных. На основании идентифицированных трендов могут создаваться целенаправленные рекламные объявления.
Узел, который можно использовать для мониторинга потока данных с целью обнаружения трендов, может быть любым из узлов в сети беспроводной связи 100, включая базовую станцию 106 или контроллер базовой сети 108. Альтернативно, другой узел в сети беспроводной связи 100 или ассоциированный с сетью беспроводной связи 100 может использоваться для мониторинга потока данных, ассоциированных с каждым пользователем в сети беспроводной связи 100. Такой узел называется «узлом беспроводной связи».
На Фиг.2 изображен узел беспроводной связи, представляемый в общем как 200. Узел беспроводной связи 200 имеет модуль обнаружения тренда 202 (для исполнения алгоритма обнаружения тренда), выполняемого на одном или нескольких центральных обрабатывающих модулях (ЦП) 204 в узле беспроводной связи 200. ЦП 204 соединен(ы) с запоминающим устройством 206.
Модуль обнаружения тренда 202 принимает «непрерывный» поток данных 208, ассоциированный с различными коммуникациями, выполняемыми различными пользователями в сети беспроводной связи 100. Каждый блок в потоке данных 208, изображенный на Фиг.2, может представлять пакет данных. «Непрерывный» поток данных относится к потоку (или потокам) пакетов данных, который(ые) непрерывно поступает (ют) в узел беспроводной связи 200, пока такие данные передаются. Если нет сообщаемых данных, то непрерывный поток данных временно прерывается. Пакет данных может содержать какой-либо идентификатор (например, идентификатор мобильного узла связи, идентификатор пользователя или какой-либо другой тип идентификатора, ассоциированного с пользователем мобильной станции) для распознавания пакетов данных, ассоциированных с соответствующими различными пользователями.
Модуль обнаружения тренда 202 отслеживает следующий имеющийся в наличии элемент в непрерывном потоке данных 208. Модуль обнаружения тренда 202 затем анализирует элемент, идентифицирует соответствующего пользователя, а после этого определяет, имеет ли отношение элемент к конкретному тренду (или трендам). Если да, то структура данных тренда 212, хранящаяся в памяти 206, может обновляться, когда структура данных тренда 212 используется для хранения информации о тренде и наборов данных, ассоциированных с каждым трендом.
Элементы данных, не связанные ни с одним трендом, идентифицированным модулем обнаружения тренда 202, можно исключить (исключенные элементы данных представлены как 214 на Фиг.2). Исключенные элементы данных не должны храниться в модуле обнаружения тренда 202, что уменьшает размер и сложность подсистемы хранения, необходимой для поддержания алгоритма обнаружения тренда и алгоритма целенаправленной рекламы в соответствии с некоторыми примерами осуществления изобретения.
Путем идентификации тренда (или трендов) на основании такого (их) тренда(ов) может разрабатываться целенаправленная рекламная информация. В одном примере тренд может быть таким, что из определенного местоположения (например, город, район, жилище и т.д.) поступает относительно высокий процент запросов от определенного пользователя. В ответ на обнаружение такого географического тренда может быть создана целенаправленная рекламная информация, относящаяся к определенному местоположению (например, целенаправленная реклама, которая относится к розничным магазинам в определенном местоположении). Другой тренд связан с относительно частыми посещениями пользователем самого большого числа (например, 10) веб-сайтов. Часто посещаемые веб-сайты можно затем использовать, чтобы сделать заключение об интересах пользователя, на основании которых могут разрабатываться целенаправленные рекламные объявления. Другой тренд, который можно обнаружить, является трендом, основанным как на времени, так и на местоположении сеансов связи. Например, пользователь может размещать наибольшее количество дневных запросов из одного местоположения и наибольшее количество вечерних запросов из другого местоположения. На основании этого можно предоставить целенаправленные рекламные объявления, основанные как на времени, так и на местоположении. Другой тренд, который можно обнаружить, включает тренд, основанный на адресатах, которых часто вызывает пользователь. Этот «круг друзей» можно использовать для идентификации потенциального сообщества пользователей с одинаковыми интересами и демографией, на основании чего можно создавать целенаправленные рекламные объявления.
На Фиг.2 также показана система анализа данных 216, которая включает модуль целенаправленной рекламы 218, имеющий доступ к структуре данных тренда 220, содержащей относящуюся к тренду информацию, которая хранится в памяти 222. Модуль целенаправленной рекламы 218 может быть программным модулем, выполняемым на одном или нескольких центральных процессорах 224 системы анализа данных 216. Модуль целенаправленной рекламы 218 генерирует целенаправленные рекламные объявления, которые отправляются для представления пользователям на основании информации в структуре данных тренда 220. Структура данных тренда 220 может представлять собой копию структуры данных тренда 212, содержащейся в памяти 206 узла беспроводной связи 200.
Несмотря на то что модуль обнаружения тренда 202 и модуль целенаправленной рекламы 218 изображены в двух отдельных системах на Фиг.2, следует иметь в виду, что эти два модуля могут быть выполнены в одной и той же системе, например узле беспроводной связи 200 или системе анализа данных 216.
В соответствии с некоторыми примерами осуществления изобретения обнаружение тренда базируется на следующих предположениях:
А=число атрибутов (например, атрибут местоположения, атрибут времени, атрибут веб-сайта и т.д.), на которые конфигурирован модуль обнаружения тренда 202 для распознавания;
U=число пользователей, данные о которых присутствуют в непрерывном потоке данных 208; и
Т=число трендов, на которые модуль обнаружения тенденции 202 конфигурирован для обнаружения.
Набор атрибутов, которые может распознать модуль детектора тренда 202, определяется как нумерованный набор следующим образом:
Атрибуты={a j|1≤j≤A}.
Некоторые атрибуты аj имеют возможные значения, которые являются несвязными и не упорядоченными в любых иерархических отношениях. Их называют плоскими атрибутами. Примеры плоских атрибутов включают дни недели и определенные ключевые слова.
Некоторые атрибуты не являются плоскими, а вместо этого имеют значения, представляющие иерархию. Имеется много примеров иерархических атрибутов, например географическое местоположение, IP-адреса и временные метки. Географическое местоположение является иерархическим, потому что местоположение пользователя может быть обозначено как большая географическая область (например, государство) или малая географическая область (например, город, район). Город расположен в государстве, государство расположено в стране, и т.д., что обеспечивает иерархию отношений среди различных местоположений.
Иерархические атрибуты могут быть представлены с помощью системы символов, подобной способу, которым представлены адреса IP (Интернет-протокол); в частности:
a=a1, a2, …, a h, где глубина иерархии равна h и h>0.
Иерархические атрибуты могут иметь значения полностью квалифицированные (например, IP-адрес 47.99.88.77) или они могут быть частично квалифицированными (например, 47.*.*.*).
Пользователи системы представлены как:
Пользователи={ui|0≤i≤U}.
Тренд t определяется как пересечение одного или нескольких атрибутов. Тренд, состоящий из одного атрибута, называется одномерным трендом и представлен как:
tk1=a j, где 0≤j≤A.
В общем, тренд, который создан пересечением d атрибутов, называется d-мерным трендом и представлен равенством:
tkd=a j1 ∩…∩a jd where 0≤j≤A and d>0.
tkd=a j1…a jd где 0≤j≤A, а d>0.
Число измерений в тренде может быть любым положительным целым значением. Одним примером двумерного тренда может быть тренд, основанный как на времени, так и на местоположении. В некоторых иллюстративных осуществлениях изобретения модуль обнаружения тренда 202 конфигурирован на распознавание относительно небольшого набора Т трендов с высоким значением (самые интересные тренды, основанные на некоторых предопределенных критериях). Этот набор конфигурированных трендов описан как:
Тренды={tkd|0≤k≤T, d>0}.
Модуль обнаружения тренда 202 просматривает поток данных (208) и без сохранения всех записей индивидуального использования обнаруживает тренды, ассоциированные с каждым пользователем.
Определение тренда будет изменяться для различных атрибутов и для различных применений. Например, для приложения мобильной рекламы тот факт, что пользователь размещает 70% своих мобильных запросов из одного и того же местоположения во время нормального рабочего времени, может быть достаточным для идентификации тренда. Однако для других атрибутов или других приложений процентное отношение, возможно, не существенно. Например, тренд для портала поставщика услуг в Интернете может быть определен как набор связей, которые пользователь щелкнул более одного раза.
В некоторых примерах осуществления изобретения тренды могут быть одного из следующих типов: основанное на процентном соотношении использование; основанное на кардинальности использование; основанное на интервале использование; и основанное на объеме использование. Тренды типа основанного на процентном соотношении использования относятся к тренду, который идентифицируется на основании уровня использования или активности, превышающем некоторый процентный порог. Тренд типа основанного на мощности использования относится к тренду, который идентифицируется на основании уровня использования или активности, превышающем некоторый порог размера. Тренд типа основанного на интервале использования относится к тренду, который идентифицируется на основании порога времени, а тренд типа основанного на объеме использования относится к тренду, который идентифицируется на основании порога объема. Следует отметить, что упомянутые выше типы не являются полными, поскольку в других доменах могут использоваться другие типы трендов.
Каждый тренд может быть связан с функцией тренда, которая выполняется для обнаружения соответствующего тренда. Функция тренда может осуществляться, например, с помощью системной программы. Каждый тренд может иметь один или несколько порогов, которые разграничивают значения тренда. Например, один порог может указывать, присутствует тренд или нет: значение, превышающее (больше чем или меньше чем) порог, свидетельствует о присутствии тренда, тогда как значение, не превышающее порог, указывает, что тренд не присутствует. Альтернативно можно определить много порогов; например, первый порог может определить малый тренд, а второй порог может определить большой тренд. В одном примере индикатор, именуемый «Trendjndicator» [«Тренд_Индикатор»], может иметь следующее значение:
Тренд_Индикатор={тренд отсутствует, малый тренд, большой тренд, не учитывается},
где «тренд отсутствует» обозначает, что тренд не обнаружен, «малый тренд» обозначает, что обнаружен малый тренд (использование, превышающее первый порог), «большой тренд» обозначает, что обнаружен большой тренд (использование, превышающее второй порог), и «не учитывается» обозначает, что этим трендом нужно пренебречь.
В этом примере можно определить кортеж тренд-порог из порогов двух трендов для представления границ, которые разграничивают значения малого и большого трендов:
Trend_Thold [Тренд__Порог]=(Тип тренда, малый1b, большой1b), где 0≤малый1b≤большой1b, малый1b - порог малого тренда, большой1b - порог большого тренда, и тип тренда {процент, мощность, интервал или объем}.
Альтернативно может использоваться упорядоченный подсчет трендов вместо отображения до конечных значений.
В качестве другой альтернативы индикатор тренда, Trend_ndicator, может иметь значение {тренд отсутствует, тренд не учитывается}, если понятие «малый» и «большой» тренды не используется.
В некоторых примерах осуществления изобретения вектор тренда можно определить для каждого пользователя, который анализируется с помощью модуля обнаружения тренда 202. Цель вектора тренда - идентифицировать все атрибуты, которые проверяются в отношении этого пользователя, значение тренда, ассоциированного с каждым из этих атрибутов, и указатель на данные, которые составляют этот тренд.
Каждый элемент в векторе тренда - это Trend_Element [Тренд_Элемент], как определено ниже:
Тренд_Элемент={Тренд_Индикатор, указатель Тренд_Данных}, где Тренд_Индикатор определен выше, а указатель Тренд_Данных - это указатель (например, адрес, идентификатор местоположения, унифицированный указатель ресурсов и т.д.) на местоположение набора данных, характерных для соответствующего тренда.
Вектор тренда определяется как последовательность Тренд_Элементов, причем один элемент для каждого тренда прослеживается модулем обнаружения тренда 202:
Тренд_Вектор=последовательность[K]Тренд_Элементы, 0≤k≤Т.
При такой структуре возможно приложение, которое требует информацию о тренде для пользователя для быстрого определения набора тренда(ов) для этого пользователя. Например, приложение мобильной рекламы (например, модуль целенаправленной рекламы 218 на Фиг.2), направляющее рекламные объявления конкретному пользователю, может использовать тренд(ы), который(ые) обнаружен(ы) в пользовательской предыстории использования, и выбрать рекламную информацию, которая лучше всего соответствует предпочтениям и интересам данного пользователя. Этого можно достичь просмотром Тренд_Вектора пользователя, определением тренда(ов) пользователя, выбором представляющего интерес тренда и поиском соответствующих данных тренда.
Следует обратить внимание, что Тренд_Вектор может работать с многими разными алгоритмами выбора в зависимости от того, как приложение хочет расположить по приоритетам различные тренды или как приложение хочет оперировать большими против малых трендами.
Несмотря на то что выше шла речь о различных структурах для обеспечения идентификации трендов, следует отметить, что в альтернативных примерах осуществления изобретения вместо них могут использоваться другие типы структур.
Задача обнаружения трендов в непрерывном потоке данных является относительно простой для плоских атрибутов, и, прежде всего, предусматривает подсчет появлений значений конкретного атрибута. Однако задача усложняется, когда рассматриваются иерархические атрибуты, поскольку возникает необходимость определения уровня в иерархии, на котором появляется тренд. Также необходимо определить, является ли число появлений на конкретном уровне в иерархии трендом или на него оказывает влияние тот факт, что один из его предков является трендом. Примеры в следующем разделе помогают проиллюстрировать трудность обнаружения трендов в иерархических атрибутах.
В одном примере рассматриваются следующие атрибуты:
- День недели (DOW): плоский атрибут со значениями Sun, Mon, Tues, Wed, Thurs, Fri и Sat [Bс, Пн, Вт, Ср, Чт, Пт и Сб];
- Местоположение (Loc): иерархический атрибут со значениями формы country.province/state.city.neighborhood. street [страна. область/государство.город.район.улица];
- Временная метка (Time): иерархический атрибут со значениями формы year.month.day.hour.minute [год.месяц.день.час.минута];
- Посещаемый унифицированный указатель ресурса (URL): URL являются по определению иерархическими, таким образом можно рассматривать их как иерархический атрибут. Однако, в целях приложения мобильной рекламы, вероятно, интереснее рассматривать полностью квалифицированные URL (имя хоста и домен). Поэтому URL можно трактовать как плоский атрибут.
В вышеупомянутом примере А=4, а Атрибуты={DOW, Loc, Time, URL}. Рассматриваются следующие одномерные тренды: URL; Loc; Time; и DOW.
Кроме того, рассматриваются следующие двумерные тренды: Loc и Time; а также Loc и DOW. Таким образом, T=6, и Тренды={Loc, URL, Time, DOW, Loc∩Time, Loc∩DOW}.
Тренд URL можно определить как основанный на мощности со следующими порогами:
Тренд отсутствует: <2 посещений URL,
Малый тренд: ≥2, но <5 посещений URL,
Большой тренд: ≥5 посещений URL.
Для вышеупомянутого примера пороговый кортеж тренда URL, Trend_TholduRL, следующий:
Trend_TholdurL=(мощность, 2, 5).
Аналогично для Loc пороги тренда можно определить следующим образом:
Тренд отсутствует: <5% трафика от конкретного местоположения,
Малый тренд: ≥5%, но <20% трафика от конкретного местоположения,
Большой тренд: ≥20% трафика от конкретного местоположения.
Этот пороговый кортеж может быть представлен как:
Trend_TholdLoc=(процент, 5%, 20%),
Следующие пороги тренда определяются для других порогов следующим образом:
Trend_TholdTime=(процент, 20%, 50%)
Trend_TholdDOW=(объем, 1М, 10M)
Trend_TholdLoc и Time=(процент, 10%, 20%)
Trend_TholdLoc и Dow=(процент, 10%, 20%).
На Фиг.3 показан Trend_Vector [Тренд_Вектор] для вышеупомянутого примера. Следует отметить, что Тренд_Вектор включает ряд Trend_Elements [Тренд_Элементов], где каждый Тренд_Элемент содержит Trend_ndicator [Тренд_Индикатор] и Trend_Data pointer [Указатель Тренд_Данных]. На Фиг.3 Trend_Element 302 представлен для тренда URL, Trend_EIement 304 представлен для тренда Loc, a Trend_Element 306 представлен для тренда Loc∩DOW.
Trend_EIement 302 для тренда URL имеет значение Trend_ndicator «большого тренда», которое указывает, что большой тренд идентифицирован для тренда URL. Указатель Тренд_Данных 303 для Тренд_Элемента 302 URL указывает на структуру данных 308, в которой перечислены различные URL и указано соответствующее число посещений. Таким образом, пользователь посетил URL www.cbc.ca<http://www.cbc.ca >9 раз, и 8 раз посетил www.canada.com<http://www.canada.com>. Пользователь также посетил www.ottawa.ca 2 раза, www.yahoo.com 1 раз, и www.google.ca 5 раз. На основании больших и малых порогов, определенных в вышеприведенном примере, три из веб-сайтов, которые посетили согласно вышеупомянутому описанию, представляют большие тренды: www.cbc.ca; www.canada.com; и www.google.ca. Из тренда URL веб-рекламное приложение может вывести конкретную информацию о пользователе. Например, веб-рекламное приложение может сделать заключение, что пользователь - житель Канады, пользователь больше всего интересуется канадским контентом и пользователь интересуется канадскими новостями. Пользовательский тренд URL также содержит некоторые атрибуты, не являющиеся большими трендами, а могут входить в малый тренд. В вышеупомянутом примере один малый тренд - это www.ottawa.ca. Хотя информация этого тренда не достаточно доминантная, чтобы вывести конкретный тренд в данных, она может быть полезна для дальнейшей корректировки обнаруженных больших трендов. Например, в вышеупомянутом примере веб-рекламное приложение может использовать малый тренд для выбора рекламных объявлений, обращенных к жителям Оттавы, которые пользуются сопутствующим новостям контентом.
Пример на Фиг.3 также демонстрирует иерархический тренд Loc. Тренд_Элемент 304 для тренда Loc имеет Указатель Тренд_Данных 305, который указывает на структуру данных 310. Так как тренд Loc является иерархическим трендом, структура данных 310, на которую показывает указатель Тренд_Данных 305, может быть представлена как древовидная структура.
На Фиг.3 самый верхний уровень древовидной структуры 310 представляет Канаду (который указывает на то, что были ограниченные действия (например, запросы)), касающийся Канады. Более низкие уровни древовидной структуры 310 указывают на действия, касающиеся областей, городов и других более мелких географических регионов в Канаде. Порог тренда для этого тренда может быть сконфигурирован как:
Trend_TholdLoc=(процент, 5%, 20%).
Цифра, ассоциированная с каждым узлом в древовидной структуре 310, указывает на процент трафика, начавшегося от соответствующего местоположения. Например, 100% трафик, начавшийся из Канады, 61%, начавшийся из Оттавы, и т.д. Идентифицировать тренд для концевого узла (концевые узлы "Main," "Carp," "Moodie," "Carling," и "Mont-Bleu") относительно легко. Подсчеты в концевых узлах можно сравнить непосредственно с порогами Trend_TholdLoc. Для концевых узлов идентифицируется только местоположение ""Carp" как большой тренд (так как 28% больше 20%).
Относительно верхних уровней древовидной структуры 310 обнаружение тренда может быть немного труднее. Например, необходимо определить, следует ли рассматривать район "Stittsville", ассоциированный с подсчетом 38%, как большой тренд. Следует отметить, что верхнее значение 38% для местоположения "Stittsville" основано в значительной степени на относительно большом значении (28%) для местоположения "Carp". Если подсчет потомка большого тренда, как, например, "Carp", удаляется из подсчета предка, "Stittsville", то "Stittsville" имеет метку только 10%, что не представляет большой тренд. В этом случае, в некоторых примерах осуществления изобретения местоположение "Stittsville" не будет идентифицировано как соответствующее большому тренду. Однако в другом примере осуществления изобретения местоположение "Stittsville" может идентифицироваться как соответствующее большому тренду даже несмотря на то, что такой большой тренд вызван потомком, ассоциированным с высоким подсчетом.
Другим примером в древовидной структуре является высокоуровневый узел, соответствующий городу Outaouais, который имеет подсчет 39%. Однако следует отметить, что потомки местоположения Outaouais включают местоположение района Gatineau, у которого есть только один потомок в виде улицы Mont-Bleu. В этом сценарии было бы более уместно идентифицировать город Outaouais как соответствующий большому тренду, а не его потомкам.
Определение наличия тренда находится в контексте интервала выборки, определяемого как период сбора данных (Р), во время которого модуль обнаружения тренда 202 осуществляет просмотр непрерывного потока данных с целью обнаружения трендов. Существуют различные способы, с помощью которых можно измерить период сбора Р, например временной интервал, число зарегистрированных событий, и т.д. Период сбора Р должен быть достаточно большим для гарантии, что для распознания тренда взяли достаточное количество выборок. Если период сбора Р слишком короткий, возможно искажение результатов по тренду событиями мелкого уровня и результаты не смогут должным образом описать тренды.
Тренды должны быть очевидными в конце периода сбора P. Перед переходом к следующему периоду сбора модуль обнаружения тренда 202 (Фиг.2) нормализует данные, отслеженные в течение последнего периода сбора Р, как если бы процесс обнаружения тренда закончился. Это позволяет структурам данных тренда обеспечивать обновленную перспективу тренда, которую затем можно использовать для создания позиций выбора рекламы. После начального периода сбора структурами данных могут быть обеспечены два вида данных: (1) точный прогноз трендов, основанный на предыдущих периодах наблюдения; и (2) сводка последних наблюдений, в течение текущего периода наблюдения.
Нормализация, которая может выполняться в конце каждого периода сбора Р, включает преобразование подсчетов в проценты или вероятности, или другие задачи нормализации. Нормализация может быть выполнена с помощью функции Нормализовав) [Normalize()]. Функция Нормализовав) также отвечает за обрезание древовидной структуры тренда (для иерархического тренда) для удаления любых данных о наступлении небольших событий, которые не составляют тренд. Это желательно, поскольку будет предотвращено объединение редко наступающих событий с течением времени и ложного проявления в виде тренда через некоторый большой промежуток времени.
Существует вероятность, что алгоритм обнаружения тренда может включать некоторое количество ошибок из-за ошибочных результатов исследования. Например, алгоритм обнаружения тренда может неправильно предположить, что тренд присутствует на основании нескольких наблюдений. Однако, поскольку собрано больше наблюдений за дополнительные периоды сбора, алгоритм обнаружения тренда может понять, что эти наблюдения не представляют тренд. Если эти ошибки не удалены из структур данных, то эти ошибочные наблюдения могут объединиться с течением времени и могут ошибочно появиться как большие тренды. Чтобы избежать таких ошибок, структуры данных можно сканировать и любые ошибки или погрешности можно удалить.
Можно определить функцию Уплотнить() для сканирования структуры данных тренда с целью обнаружения любых погрешностей и реструктурировать структуру данных по обстоятельствам. Можно определить интервал уплотнения, чтобы обозначить интервал, на котором функция Уплотнить() должна выполнить свои задачи обнаружения ошибки и реструктурирования. Относительные размеры Р и C будут изменяться в зависимости от конкретного приложения. Р может быть таким же, как C, Р может быть меньше C или Р может быть больше C.
Алгоритм обнаружения тренда может также определять функцию Обновить(), которая отвечает за осуществление последнего наблюдения потока данных и хранение наблюдений потока данных в пользовательской структуре данных тренда (например, структуре данных тренда 212 на Фиг.2). Этот шаг обычно предусматривает осуществление прогнозов о том, входит ли наблюденный случай в тренд, и соответственную настройку структуры данных.
На Фиг.4 изображено обнаружение тренда, выполненное модулем обнаружения тренда 202 на Фиг.2, для атрибута, соответствующего плоскому тренду. По мере получения непрерывного потока данных подсчет трендов обновляется (в 402), если получен пакет данных, который соответствует тренду. Например, если получен пакет данных, который указывает, что пользователь посетил конкретный URL, тогда подсчет для соответствующего тренда URL может увеличиться. Обновление может осуществляться с помощью вышеупомянутой функции Обновить().
Следует принять во внимание, что структура данных тренда (212 на Фиг.2), ассоциированная с трендом, также может обновляться (в 403). Например, функция Обновить() может определить, что собраны некоторые выборки каждого тренда.
Модуль обнаружения тренда 202 может также нормализовать (в 404) подсчеты и удалить не относящуюся к тренду информацию из структуры данных тренда, например, при помощи вышеупомянутой функции Нормализовало. Нормализация включает преобразование грубых подсчетов в проценты, например, или другие типы нормализации. На основании нормализованного подсчета модуль обнаружения тренда 202 идентифицирует (в 406) малые или большие тренды на основании порогов тренда. Структура данных тренда обновляется для отражения любых таких идентифицированных малых/больших трендов.
Вышеупомянутый процесс повторяется (в 408) в течение текущего периода сбора Р.
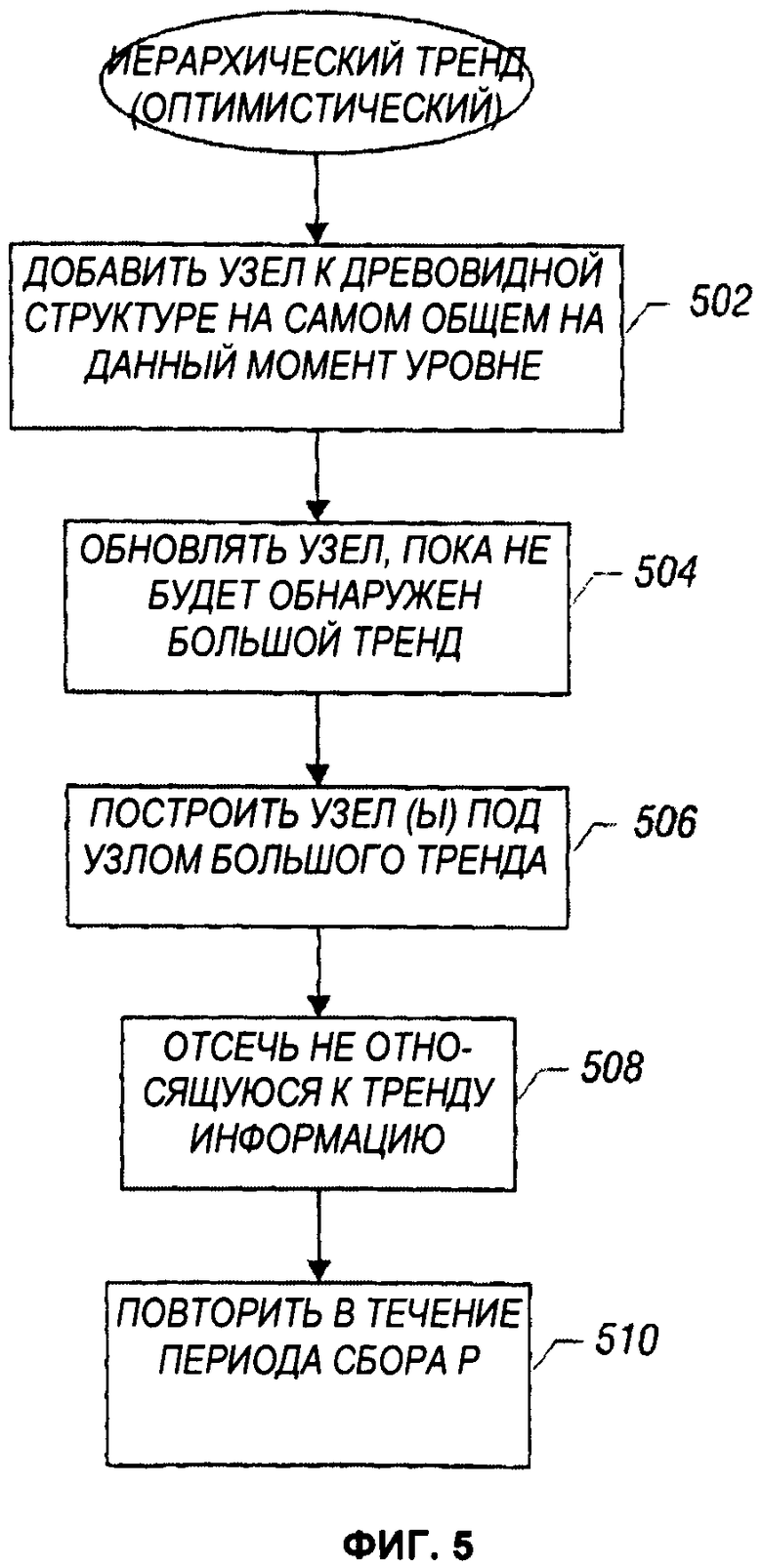
Для иерархического тренда можно использовать несколько различных возможных алгоритмов. Оптимистический алгоритм изображен на Фиг.5. Оптимистический алгоритм обновляет древовидную структуру (например, 310 на Фиг.3) для иерархического тренда нисходящим образом. Изначально к структуре данных дерева (в 502) добавляется узел на самом общем на данный момент уровне. В начале самый общий на данный момент уровень представляет собой корневой уровень древовидной структуры. Однако, поскольку этот процесс итерационно продвигается вниз по древовидной структуре, самый общий на данный момент уровень может быть более низкого уровня.
На основании элементов полученных данных этот добавленный узел обновляется (в 504), например, с помощью функции Обновить() до пересечения порога большого тренда. Другими словами, используя нисходящий подход, узлы низкого уровня в структуре дерева не добавляются к структуре данных дерева до тех пор, пока высокоуровневый узел не покажет, что появился большой тренд.
Как только идентифицируется узел большого тренда, строятся узлы под этим узлом большого тренда (в 506). Не относящаяся к тренду информация отсекается (в 508), например, при помощи функции Нормализовав). Процесс повторяется (в 510) в течение периода сбора Р, чтобы постепенно обновить узлы древовидной структуры.
При оптимистическом подходе новые узлы добавляются к древовидной структуре тренда, если эти узлы находятся ниже узла, ассоциированного с большими трендами. Однако оптимистический подход может пропустить узлы. Для адресации к этому может использоваться алгоритм прогнозирования, чтобы предсказать узлы, которые могут быть узлами большого тренда, и такие предсказуемые узлы можно затем добавить к древовидной структуре тренда. Такие прогнозы можно выполнять, например, при помощи функции Уплотнить(). Любые некорректно предсказанные узлы можно отсечь позже с помощью функции Нормализовав).
Оптимистический подход вычислительно эффективен, поскольку узлы более низкого уровня не добавляются к древовидной структуре тренда, пока не обнаружен большой тренд на более высоком уровне. Оптимистический подход применяется при идентификации трендов в отношении приложений, в которых существуют доминантные тренды, и не может применяться также успешно в отношении приложений с менее доминантными трендами.
На Фиг.6 показан пессимистический подход обнаружения тренда для иерархического тренда. При пессимистическом подходе древовидная структура тренда строится (в 602) снизу вверх путем добавления каждой записи данных к древовидной структуре тренда. Подсчет, ассоциированный с каждым узлом, добавленным к древовидной структуре тренда, обновляется (в 604), например, при помощи функции Обновить().
Не относящаяся к тренду информация может отсекаться из древовидной структуры тренда (в 606) при помощи функции Нормализовав). Кроме того, концевые узлы стягиваются (в 608) в узлы тренда на более высоких уровнях. Это предполагает объединение подсчетов, ассоциированных с узлами более низкого уровня для определения, является ли узел более высокого уровня показателем большого тренда. Процесс повторяется (в 610) в течение периода сбора P.
Пессимистический подход вычислительно интенсивен, особенно для потоков данных с большим количеством менее доминантных трендов, так как все записи данных добавляются к древовидной структуре и позже отсекаются, если записи данных не ассоциированы с большими трендами. Пессимистический подход применяется в отношении приложений с менее доминантными трендами, но чрезмерно вычислительно интенсивен для приложений с доминантными трендами.
Можно использовать алгоритм компромисса, подобный оптимистическому алгоритму, изображенному на Фиг.5. Алгоритм компромисса учитывает малые тренды, также как и большие тренды. При использовании алгоритма компромисса каждый внутренний узел в древовидной структуре тренда включает перечень пропущенных событий (события, ассоциированные с записями данных, не идентифицированными как большие тренды). В конце периода сбора Р сохраняются любые из этих событий, которые соответствуют малому тренду; все другие незначительные события отбрасываются. С помощью функции Уплотнить() древовидная структура реконструируется с целью включения событий малого тренда (добавлением узла потомка от одного из внутренних узлов древовидной структуры тренда).
На основании идентифицированных больших трендов с помощью описанных выше методов можно создавать целенаправленные рекламные объявления и предоставлять пользователю на мобильную станцию в сети беспроводной связи.
При использовании методов в соответствии с некоторыми примерами осуществления изобретения обеспечивается эффективный метод предоставления целенаправленных рекламных объявлений (или другой специальной информации), который не предусматривает хранения всех записей данных, полученных во входном потоке. Таким образом, добывание записей данных можно будет осуществлять без необходимости создания большой и дорогостоящей памяти для хранения данных и инфраструктуры управления. Операторы связи, ассоциированные с сетями беспроводной связи, могут таким образом использовать возможности получения дохода без инвестиций в дорогостоящую инфраструктуру.
Инструкции, ассоциированные с описанным выше программным обеспечением (например, модуль обнаружения тренда 202, модуль целенаправленной рекламы 218, и т.д., на Фиг.1), могут загружаться для выполнения в процессоре (например, центральные процессоры 204 и 224 на Фиг.1). Процессор включает микропроцессоры, микроконтроллеры, модули или подсистемы процессора (включая один или более микропроцессоров или микроконтроллеров) или другие контрольные или вычислительные устройства. «Процессор» может относиться к одному компоненту или к множеству компонентов.
Данные и инструкции (программного обеспечения) хранятся в соответствующих устройствах памяти, которые реализуются как один или несколько носителей данных, читаемых или используемых на компьютере. Носители данных включают различные формы памяти, включающие полупроводниковые запоминающие устройства, например динамические или статические оперативные запоминающие устройства (DRAM или SRAM), стираемые и программируемые постоянные запоминающие устройства (EPROM), электрически стираемые и программируемые постоянные запоминающие устройства (EEPROM) и флэш-ПЗУ; магнитные диски, например, стационарные, гибкие и съемные диски; другие магнитные носители, включая ленту; и оптические носители, например компакт-диски (CD) или цифровые видеодиски (DVD).
В вышеприведенном описании для понимания настоящего изобретения представлены многочисленные детали. Однако специалистам в данной области ясно, что настоящее изобретение может быть реализовано на практике без этих деталей. Несмотря на то что изобретение раскрыто со ссылкой на ограниченное число примеров осуществления, специалисты в данной области должны принять во внимание возможность различных модификаций и вариантов на основании данного изобретения. Предусматривается, что прилагаемая патентная формула охватывает такие модификации и варианты, как попадающие в рамки сущности и объема изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБЫ ДЛЯ ОПТИМИЗАЦИИ ТРАНСПОРТИРОВКИ ДЛЯ ДОСТАВКИ КОНТЕНТА ГРАФИЧЕСКИХ ИНТЕРФЕЙСНЫХ ЭЛЕМЕНТОВ | 2009 |
|
RU2464638C2 |
| МНОЖЕСТВО ДЕЙСТВИЙ И ЗНАЧКОВ ДЛЯ РЕКЛАМЫ В МОБИЛЬНЫХ УСТРОЙСТВАХ | 2009 |
|
RU2467394C2 |
| ОБЕСПЕЧЕНИЕ ВОЗМОЖНОСТИ РЕКЛАМОДАТЕЛЯМ ПРЕДЛАГАТЬ ЦЕНУ НА АБСТРАКТНЫЕ ОБЪЕКТЫ | 2011 |
|
RU2589872C2 |
| СИСТЕМА И СПОСОБЫ ОПРЕДЕЛЕНИЯ МЕСТОПОЛОЖЕНИЯ С ПРИВЯЗКОЙ ПО ВРЕМЕНИ ДЛЯ ОБНАРУЖЕНИЯ КОНТЕКСТА МОБИЛЬНОГО ПОЛЬЗОВАТЕЛЯ | 2014 |
|
RU2661773C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| УПРАВЛЕНИЕ ЗАПУСКОМ ПЕРЕДАЧИ ОБСЛУЖИВАНИЯ МЕЖДУ ОДНОАДРЕСНОЙ И МНОГОАДРЕСНОЙ УСЛУГАМИ | 2012 |
|
RU2604424C2 |
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ДИСПЕТЧЕРИЗАЦИИ ОБНОВЛЕНИЙ ВИДЖЕТОВ | 2009 |
|
RU2469383C2 |
| СИСТЕМЫ И СПОСОБЫ ДОСТАВКИ ИНФОРМАЦИОННОГО СОДЕРЖАНИЯ | 2010 |
|
RU2549113C2 |
| СПОСОБ ОЦЕНКИ ЭФФЕКТИВНОСТИ ИСПОЛЬЗОВАНИЯ ПРИГЛАШЕНИЙ, РАСПРОСТРАНЯЕМЫХ С МОБИЛЬНОГО САЙТА, И СИСТЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 2013 |
|
RU2550546C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПОДДЕРЖКИ ОТПЕЧАТКА БЕСПРОВОДНОЙ СЕТИ | 2010 |
|
RU2439852C1 |


Изобретение относится к компьютерной технике, а именно к способам предоставления рекламной информации в сетях Интернет. Техническим результатом является снижение объема данных, который должен храниться для обеспечения предоставления целенаправленных рекламных объявлений, необходимых для хранения, за счет механизма идентификации тренда, ассоциированных с одним или несколькими атрибутами потока данных. Способ предоставления информации включает в себя прием в узле беспроводной связи потока данных. А также, согласно способу, осуществляют идентификацию в узле сети беспроводной связи первого тренда, ассоциированного с первым атрибутом в потоке данных путем выполнения алгоритма обнаружения первого тренда, если первый атрибут ассоциирован с плоским трендом. Кроме того, выполняют алгоритм обнаружения второго тренда, если первый атрибут ассоциирован с иерархическим трендом. 2 н. и 19 з.п. ф-лы, 6 ил. 
1. Способ предоставления информации, содержащий:
прием в узле сети беспроводной связи потока данных;
идентификацию в узле сети беспроводной связи первого тренда, ассоциированного, как минимум, с первым атрибутом в потоке данных, путем выполнения алгоритма обнаружения первого тренда, если первый атрибут ассоциирован с плоским трендом; и выполнение алгоритма обнаружения второго тренда, если первый атрибут ассоциирован с иерархическим трендом, тренд, являющийся уровнем использования, ассоциированным с пользователем, который превышает предопределенный порог;
на основании идентифицированного первого тренда осуществляют отправку через узел сети беспроводной связи информации для предоставления пользователю на мобильной станции, причем тренд относится к уровню использования или активности, ассоциированному с конкретным пользователем, который превышает некоторый предопределенный порог;
получение информации, основанной на идентифицированном первом тренде; и
передачу информации мобильной станции через беспроводную сеть связи.
2. Способ по п.1, в котором отправка информации включает отправку рекламной информации на основании идентифицированного первого тренда.
3. Способ по п.1, дополнительно включающий:
хранение отобранных элементов данных, характерных для первого тренда; и
отбрасывание других элементов данных, не характерных для первого тренда.
4. Способ по п.3, дополнительно включающий:
идентификацию второго тренда, ассоциированного со вторым атрибутом в потоке данных.
5. Способ по п.4, дополнительно включающий:
хранение дополнительных отобранных элементов данных, характерных для второго тренда; и
отбрасывание других элементов данных, не характерных ни для первого тренда, ни для второго тренда.
6. Способ по п.3, в котором отобранные элементы хранятся в структуре данных, причем отсечение элементов из структуры осуществляют в отношении данных, не характерных для первого тренда.
7. Способ по п.3, в котором первый тренд является иерархическим трендом и в котором отобранные элементы хранятся в древовидной структуре, имеющей узлы на многих уровнях, и способ дополнительно включает:
построение древовидной структуры нисходящим образом.
8. Способ по п.3, в котором первый тренд является иерархическим трендом и в котором отобранные элементы хранятся в древовидной структуре, имеющей узлы на многих уровнях, и способ дополнительно включает:
построение древовидной структуры восходящим образом.
9. Способ по п.1, в котором получение включает прием специализированной информации от второго сервера.
10. Способ по п.9, дополнительно включающий отправку идентифицированного первого тренда второму серверу.
11. Способ по п.1, в котором получение включает выбор информации, основанной на идентифицированном первом тренде.
12. Способ по п.1, дополнительно включающий:
хранение отобранных элементов данных, которые являются характерными для первого тренда в первом типе структуры данных в ответ на определение, что первый атрибут связан с плоским трендом; и
хранение отобранных элементов данных, которые являются характерными для первого тренда в древовидной структуре в ответ на определение, что первый атрибут связан с иерархическим трендом.
13. Способ по п.1, дополнительный включающий:
определение первого порога, указывающего на малый тренд для первого атрибута;
определение второго порога, указывающего на большой тренд для первого атрибута, причем идентификация первого тренда включает идентификацию большого тренда для первого атрибута.
14. Способ по п.1, в котором идентифицированный первый тренд является одним из следующих типов:
основанного на процентном соотношении использования;
основанного на мощности использования;
основанного на интервале использования;
основанного на объеме использования, причем способ дополнительно включает:
определение одного или нескольких порогов для идентифицированного первого тренда на основании типа первого тренда.
15. Сетевой узел для использования в системе коммуникаций, для идентификации тренда в потоке данных, полученных в сетевом узле, содержащий процессор, реализующий функции:
идентификации первого тренда, ассоциированного с, по меньшей мере, атрибутом в потоке данных путем выполнения первого алгоритма обнаружения тренда, если первый атрибут ассоциирован с плоским трендом, и выполнение второго алгоритма обнаружения тренда, если первый атрибут ассоциирован с иерархическим трендом, при этом тренд является уровнем использования, ассоциированным с пользователем, который превышает предопределенный порог; и
получения информации, включая рекламную информацию, основанную на идентифицированном первом тренде; и
отправки через узел сети беспроводной связи информации для представления пользователю на мобильной станции; и
обеспечения указателя на отобранные элементы данных, которые сохранены для идентифицированного первого тренда.
16. Узел сети по п.15, в котором процессор выполнен с возможностью отбрасывать другие данные, не ассоциированные с идентифицированным первым трендом.
17. Узел сети по п.15, в котором процессор выполнен с возможностью:
хранить отобранные пункты в первом типе структуры данных в ответ на определение, что атрибут связан с плоским трендом; и
хранить отобранные элементы данных в древовидной структуре в ответ на определение, что атрибут ассоциирован с иерархическим трендом.
18. Узел сети по п.15, в котором информация включает адресную рекламную информацию.
19. Узел сети по п.15, в котором получение включает получение информации от второго сервера.
20. Узел сети по п.19, в котором процессор дополнительно сконфигурирован для отправки идентифицированного первого тренда второму серверу.
21. Узел сети по п.15, в котором получение включает выбор информации, основанной на идентифицированном первом тренде.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 6360249 B1, 19.03.2002 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ ПРЕДОСТАВЛЕНИЯ ПОЛЬЗОВАТЕЛЯМ МОБИЛЬНЫХ УСТРОЙСТВ ЭЛЕКТРОННОЙ СВЯЗИ АКТУАЛЬНОЙ КОММЕРЧЕСКОЙ ИНФОРМАЦИИ НА АЛЬТЕРНАТИВНОЙ ОСНОВЕ (ВАРИАНТЫ) И ИНФОРМАЦИОННАЯ СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ (ВАРИАНТЫ) | 2003 |
|
RU2254611C2 |
| СПОСОБ РАСПРОСТРАНЕНИЯ РЕКЛАМНО-ИНФОРМАЦИОННЫХ СООБЩЕНИЙ (ВАРИАНТЫ) | 2001 |
|
RU2192049C1 |
| ПРЕДОСТАВЛЕНИЕ УСЛУГИ В СИСТЕМЕ СВЯЗИ | 1999 |
|
RU2233034C2 |
| УСТРОЙСТВО ДЛЯ АДРЕСАЦИИ РЕКЛАМЫ, УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ДАННЫХ, ОТНОСЯЩИХСЯ К РЕКЛАМАМ В ПРОГРАММАХ, И СПОСОБ АДРЕСАЦИИ РЕКЛАМЫ | 1993 |
|
RU2192103C2 |

