Уровень техники
Кодирование с преобразованием является методом сжатия, используемым во многих системах сжатия цифровых мультимедийных данных (например, аудио, изображений и видео). Несжатое цифровое изображение и видео, как правило, представляется или захватывается как выборки элементов или цветов рисунка в определенных местоположениях кадра изображения или видео, которые скомпонованы в двумерную сетку. Это называют представлением изображения или видео в области пространства. Например, типовой формат для изображений состоит из потока выборок 24-битовых цветных элементов рисунка, скомпонованных как сетка. Каждая выборка представляет собой число, представляющее цветовые компоненты в местоположении пикселя в сетке в цветовом пространстве, таком как RGB или YIQ. В различных системах изображений и видео при дискретизации может использоваться разное разрешение цвета, пространства и времени. Аналогично, цифровое аудио, как правило, представляется как поток временных выборок аудиосигнала. Например, типовой аудиоформат состоит из потока 16-битных выборок аудиосигнала, полученных через регулярные интервалы времени.
Несжатые цифровые сигналы аудио, изображения и видео могут занимать значительную долю хранилища и пропускной способности. Кодирование с преобразованием уменьшает размер цифрового аудио, изображения и видео путем преобразования представления сигнала в пространственной области в представление в частотной области (или представления в другой области преобразования) и последующего уменьшения разрешения определенных, менее заметных частотных компонентов представления в области преобразования. Это, как правило, приводит к значительно менее заметному ухудшению цифрового сигнала по сравнению с уменьшением цветового или пространственного разрешения изображений или видео в пространственной области, или аудио во временной области.
В частности, показанная на Фиг.1 типовая система 100 кодера/декодера (которую также называют "кодеком") на основе блочного преобразования разделяет пиксели несжатого цифрового изображения на двумерные блоки (X1,..., Xn) фиксированного размера, где каждый блок, возможно, частично перекрывает другие блоки. К каждому блоку применяется линейное преобразование 120-121, которое выполняет пространственно-частотный анализ, в результате чего пространственные выборки внутри блока преобразуются в набор коэффициентов частот (или преобразования), которые, обычно, представляют силу цифрового сигнала в соответствующих частотных полосах через интервал блока. Для сжатия коэффициенты преобразования могут быть селективно квантованы 130 (то есть, может быть уменьшено разрешение, такое как удаление младших разрядов величин коэффициентов или иное сопоставление величин с более высокого разрешения к меньшему разрешению) и кодированы 130 на схеме статистического кода или неравномерного кода в сжатый поток данных. При декодировании коэффициенты преобразования будут обратно преобразованы 170-171, чтобы почти реконструировать исходный сигнал изображения/видео, оцифрованный по цвету/пространству (реконструированные блоки 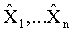 ).
).
Блочное преобразование 120-121 может быть определено как математическая операция с вектором x размера N. Чаще всего, эта операция является линейным умножением, в результате которого получается вывод y=Mx в области преобразования, где M представляет собой матрицу преобразования. Когда входные данные имеют произвольную длину, они сегментируются на векторы размера N, и к каждому сегменту применяется блочное преобразование. Для целей сжатия данных выбирают обратимое блочное преобразование. Иначе говоря, матрица M является обратимой. Во множестве измерений (например, для изображений и видео) блочное преобразование, как правило, выполняется как отделимые операции. Умножение матрицы применяется по отдельности по каждой размерности данных (то есть, по строкам и столбцам).
Для сжатия коэффициенты преобразования (компоненты вектора y) могут быть селективно квантованы (то есть, может быть уменьшено разрешение, такое как удаление младших разрядов величин коэффициентов или иное сопоставление величин с более высокого разрешения к меньшему разрешению) и кодированы по схеме статистического кода или неравномерного кода в сжатый поток данных.
При декодировании в декодере 150, на стороне декодера 150 применяются операции, обратные упомянутым выше (деквантизация/статистическое декодирование 160 и обратное блочное преобразование 170-171), как показано на Фиг.1. При реконструкции данных обращенная матрица M-1 (обратное преобразование 170-171) применяется как умножитель к данным области преобразования. При применении к данным области преобразования обратное преобразование почти точно реконструирует исходные цифровые мультимедийные данные временной области или пространственной области.
Во многих приложениях кодирования на основе блочного преобразования желательно обеспечивать обратимость преобразования, чтобы поддерживать сжатие как с потерями, так и без потерь, в зависимости от фактора квантизации. В случае отсутствия квантизации (что обычно представляется как фактор квантизации, равный 1), например, кодек на основе обратимого преобразования может в точности воспроизводить входные данные при декодировании. Тем не менее, требование обратимости в этих приложениях ограничивает выбор преобразований, на которых может быть основан кодек.
Многие системы сжатия изображений и видео, такие как MPEG и Windows Media, используют преобразования, основанные на Дискретном Косинусном Преобразовании (Discrete Cosine Transform, DCT). Известно, что DCT имеет высокие свойства уплотнения, в результате чего обеспечивается почти оптимальное сжатие данных. В этих системах сжатия, Обратное DCT (Inverse DCT, IDCT) используется в контурах реконструкции как в кодере, так и в декодере системы сжатия для реконструкции отдельных блоков изображения.
Квантизация
Квантизация является основным механизмом большинства кодеков изображения и видео для управления качеством сжатого изображения и коэффициентом сжатия. Согласно одному определению термин квантизация используется для аппроксимации необратимой функции отображения, используемой для сжатия с потерями, где есть конкретный набор возможных выходных величин, и каждый элемент из этого набора возможных выходных величин имеет связанный набор входных величин, в результате чего определяется выбор конкретной выходной величины. Существует множество способов квантизации, включая скалярную или векторную квантизацию, однородную или неоднородную квантизацию, квантизацию с мертвой зоной или без нее, а также адаптивную или неадаптивную квантизацию.
Операция квантизации, по существу, является разделением со смещением на Параметр Квантизации (Quantization Parameter, QP), которое выполняется в кодере. Операция обратной квантизации или умножения является операцией умножения на QP, выполняемой в декодере. В сочетании эти процессы создают потери в исходных данных коэффициента преобразования, что выражается как ошибки сжатия или артефакты в декодированном изображении.
Сущность изобретения
Следующее подробное описание представляет инструменты и методы для управления вычислительной сложностью и точностью декодирования посредством кодека цифровых мультимедийных данных. В одном аспекте способа, кодер передает сигнал режима точности с масштабированием или без масштабирования для использования в декодере. В режиме точности с масштабированием, входное изображение предварительно умножается (например, на 8) в кодере. Вывод декодера также масштабируется путем разделения с округлением. В режиме точности без масштабирования, подобные операции масштабирования не применяются. В режиме точности без масштабирования, кодер и декодер могут эффективно работать с меньшим динамическим диапазоном коэффициента преобразования, что приводит к меньшей вычислительной сложности.
В еще одном аспекте способа, кодер также может сигнализировать точность, необходимую для выполнения операций преобразования в декодере. В одной реализации, элемент синтаксиса битового потока сигнализирует, требуется ли использовать арифметические операции с меньшей точностью для преобразования в декодере.
Раздел "Сущность изобретения" приведен, чтобы представить в упрощенной форме выборку концепций, которые подробно описываются ниже, в разделе "Подробное описание". Раздел "Сущность изобретения" не предназначен ни для определения ключевых или существенных отличительных признаков сущности формулы изобретения, ни для использования в качестве вспомогательного средства при определении объема сущности формулы изобретения. Дополнительные отличительные признаки и преимущества настоящего изобретения станут очевидны из следующего подробного описания вариантов осуществления, которое содержит ссылки на прилагаемые чертежи.
Краткое описание чертежей
Фиг.1 - структурная схема обычного кодека на основе блочного преобразования согласно предшествующему уровню техники;
Фиг.2 - схема последовательности операций иллюстративного кодера, в котором применятся блочное кодирование;
Фиг.3 - схема последовательности операций иллюстративного декодера, в котором применяется кодирование шаблона блока;
Фиг.4 - схема обратного преобразования внахлест, включающего в себя базовое преобразование и операцию постфильтра (перекрытия), в одной реализации иллюстративного кодера/декодера с Фиг.2 и 3;
Фиг.5 - схема идентификации точек входных данных для операций преобразования;
Фиг.6 - структурная схема подходящего вычислительного окружения для реализации кодера/декодера мультимедийных данных с Фиг.2 и 3.
Подробное описание
Следующее описание относится к способам для управления точностью и вычислительной сложностью кодека цифровых мультимедийных данных на основе преобразования. В настоящем разделе описан пример реализации данного способа в контексте системы или кодека сжатия цифровых мультимедийных данных. Система цифровых мультимедийных данных кодирует цифровые мультимедийные данные в сжатую форму для их передачи или хранения и декодирует эти данные для воспроизведения или иной обработки. Для целей иллюстрации, этот пример системы сжатия, имеющий функцию управления вычислительной сложностью и точностью, является системой сжатия изображений или видео. Альтернативно, данный способ также может быть включен в системы или кодеки сжатия, предназначенные для других типов цифровых мультимедийных данных. Настоящий способ управления вычислительной сложностью и точностью не требует, чтобы система сжатия цифровых мультимедийных данных кодировала сжатые цифровые мультимедийные данные в конкретном формате кодирования.
1. Кодер/Декодер
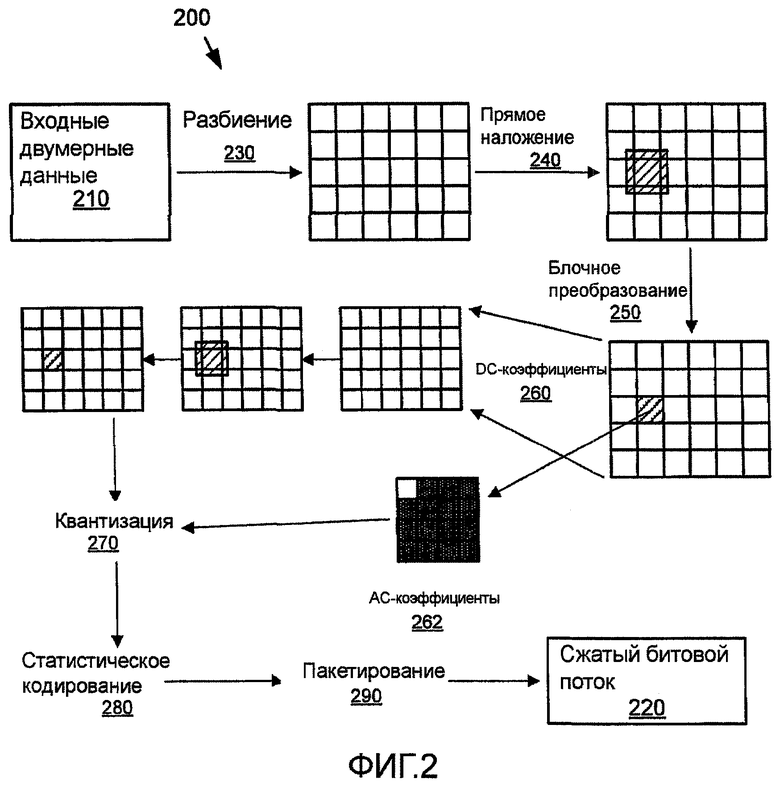
Фиг.2 и 3 представляют собой обобщенные схемы процессов, применяемых в иллюстративном кодере 200 и декодере 300 двумерных данных. Эти схемы являют собой обобщенную или упрощенную иллюстрацию системы сжатия, содержащей кодер и декодер двумерных данных, которые выполняют сжатие с использованием способов управления вычислительной сложностью и точностью. В альтернативных системах сжатия, в которых используются настоящие способы управления, для сжатия двумерных данных может применяться большее или меньшее количество процессов, чем проиллюстрировано для этих иллюстративных кодера и декодера. Например, некоторые кодеры/декодеры могут также включать в себя преобразование цвета, форматы цвета, кодирование с масштабированием, кодирование без потерь, режимы макроблоков и т.п. Данная система сжатия (кодер и декодер) может предоставлять сжатие двумерных данных без потерь и/или с потерями, в зависимости от квантизации, которая может быть основана на параметре квантизации, который варьирует от значения без потерь до значения с потерями.
Кодер 200 двумерных данных производит сжатый битовой поток 220, который является более компактным представлением (для типового ввода) двумерных данных 210, представленных как ввод в кодер. Например, входные двумерные данные могут представлять собой изображение, кадр видеопоследовательности или другие данные с двумя измерениями. Кодер двумерных данных разделяет кадр входных данных на блоки (на Фиг.2 это обозначено как Разбиение 230), которые в проиллюстрированной реализации являют собой неперекрывающиеся блоки пикселей 4x4, которые образуют регулярный образ по плоскости кадра. Эти блоки группируются в кластеры, которые называются макроблоками и которые в данном иллюстративном кодере имеют размер 16x16 пикселей. В свою очередь, макроблоки группируются в регулярные структуры, обозначаемые термином "элемент мозаичного изображения". Элементы мозаичного изображения также образуют регулярный образ, так что элементы мозаичного изображения в горизонтальной строке имеют равную высоту и выровнены по одной линии, а элементы мозаичного изображения в вертикальном столбце имеют равную ширину и выровнены по одной линии. В данном иллюстративном кодере, элементы мозаичного изображения могут иметь произвольный размер, который кратен 16 в горизонтальном и/или вертикальном направлении. Реализации адаптивного кодера могут разделять изображение на блоки, макроблоки, элементы мозаичного изображения или другие единицы с другим размером и структурой.
Оператор 240 "прямого наложения" применяется к каждому краю между блоками, после чего каждый блок 4x4 преобразуется путем блочного преобразования 250. Это блочное преобразование 250 может быть обратимым, двумерным преобразованием без масштабирования, описанным в патенте США 11/015,707 "Обратимое преобразование для сжатия двумерных данных с потерями и без потерь", Сринивасан, поданном 17-декабря 2004. Оператор 240 наложения может представлять собой оператор обратимого наложения, описанный в патенте США 11/015148 "Оператор обратимого наложения для эффективного сжатия данных без потерь", Ту и др., поданном 17-го декабря 2004, и в патенте США 11/035,991 "Обратимая двумерная предварительная фильтрация/постфильтрация для биортогонального преобразования внахлест", Ту и др., поданном 14-го января 2005. Альтернативно, могут быть использованы операторы дискретного косинусного преобразования или другие операторы блочного преобразования и наложения. После преобразования, DC-коэффициент 260 каждого блока 4×4 подвергается схожей цепочке обработки (разбиение на элементы мозаичного преобразования, прямое наложение, за которым следует блочное преобразование 4×4). Получающиеся в результате DC-коэффициенты преобразования и AC-коэффициенты преобразования квантуются 270, подвергаются статистическому кодированию 280 и пакетируются 290.
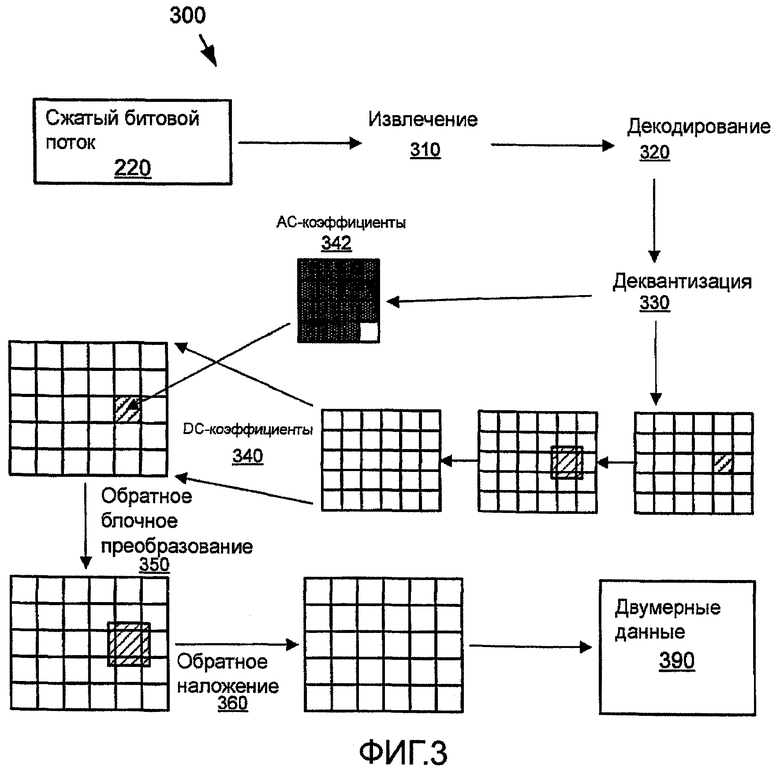
Декодер выполняет обратный процесс. На стороне декодера, биты коэффициентов преобразования извлекаются 310 из их соответствующих пакетов, и сами коэффициенты декодируются 320 и деквантуются 330. DC-коэффициенты 340 регенерируются путем применения обратного преобразования, и плоскость DC-коэффициентов "обратно накладывается", используя подходящий оператор сглаживания, применяемый по краям DC-блока. Далее, все данные регенерируются путем применения обратного преобразования 4×4 350 к DC-коэффициентам и AC-коэффициентам 342, декодированным из битового потока. В завершение, края блоков в результирующих плоскостях изображения фильтруются 360 с обратным наложением. В результате производится вывод реконструированных двумерных данных.
В иллюстративной реализации, кодер 200 (Фиг.2) сжимает входное изображение в сжатый битовой поток 220 (например, файл), а декодер 300 (Фиг.3) реконструирует исходный ввод или его аппроксимацию, в зависимости от того, какое кодирование используется - с потерями или без потерь. Процесс кодирования включает в себя применение Прямого Преобразования с Наложением (ППН), описанного ниже, что реализуется посредством обратимой двумерной предварительной фильтрации/постфильтрации, также подробно описанной ниже. Процесс декодирования включает в себя применение Обратного Преобразования с Наложением (ОПН), выполняемого посредством обратимой двумерной предварительной фильтрации/постфильтрации.
Проиллюстрированные ППН и ОПН являются обратными относительно друг друга, в прямом смысле слова, и в совокупности они обозначаются термином Обратимое Преобразование с Наложением. Пара ППН/ОПН может быть использована для сжатия изображения без потерь в качестве обратимого преобразования.
Входные данные 210, сжимаемые посредством проиллюстрированного кодера 200/декодера 300, могут представлять собой изображения различных цветовых форматов (например, RGB/YUV4:4:4, YUV4:2:2 или YUV4:2:0). Как правило, входные данные всегда содержат компонент яркости (Y). Для форматов RGB/YUV4:4:4, YUV4:2:2 или YUV4:2:0, изображение также содержит компоненты цветности, такие как компонент U и компонент V. Разные цветовые плоскости или компоненты изображения могут иметь разное пространственное разрешение. Например, в случае входного изображения в цветовом формате YUV 4:2:0, компоненты U и V имеют половину высоты компонента Y.
Как описано выше, кодер 200 разбивает входное изображение или рисунок на макроблоки. В иллюстративной реализации, кодер 200 разбивает входное изображение на области размером 16×16 (которые называют "макроблоками") в канале Y (причем эти области могут иметь размер 16×16, 16×8 или 8x8 для каналов U и V в зависимости от цветового формата). Каждая цветовая плоскость макроблока разбивается на области или блоки размером 4×4. Следовательно, для разных цветовых форматов в настоящем примере реализации кодера макроблок формируется следующим образом:
1. Для изображения в оттенках серого, каждый макроблок содержит 16 блоков яркости (Y) размером 4x4.
2. Для изображения цветового формата YUV4:2:0, каждый макроблок содержит 16 Y-блоков размером 4×4 и по 4 блока цветности (U и V) размером 4×4.
3. Для изображения цветового формата YUV4:2:2, каждый макроблок содержит 16 Y-блоков размером 4×4 и по 8 блоков цветности (U и V) размером 4×4.
4. Для изображения формата RGB или YUV4:4:4, каждый макроблок содержит по 16 блоков каналов Y, U и V.
Соответственно, после преобразования макроблок в этом иллюстративном кодере 200/декодере 300 имеет три частотных поддиапазона: поддиапазон DC (DC-макроблок), низкочастотный поддиапазон (низкочастотный макроблок) и высокочастотный поддиапазон (высокочастотный макроблок). В иллюстративной системе, низкочастотный и/или высокочастотный поддиапазоны являются опциональными в битовом потоке и эти поддиапазоны могут быть целиком отброшены.
Кроме того, сжатые данные могут быть упакованы в битовой поток в двух порядках: пространственном порядке и частотном порядке. Для пространственного порядка, разные поддиапазоны одного макроблока внутри одного элемента мозаичного изображения компонуются вместе, и результирующий битовой поток каждого элемента мозаичного изображения записывается в один пакет. Для частотного порядка, одинаковые поддиапазоны из разных макроблоков в одном элементе мозаичного изображения группируются вместе, и, таким образом, битовой поток одного элемента мозаичного изображения записывается в три пакета: DC-пакет элемента мозаичного изображения, низкочастотный пакет элемента мозаичного изображения и высокочастотный пакет элемента мозаичного изображения. В добавление, могут присутствовать другие слои данных.
Таким образом, для иллюстративной системы изображение организуется в следующих "измерениях":
Пространственное измерение: Кадр→Элемент Мозаичного Изображения→Макроблок;
Частотное измерение: DC | Низкие частоты | Высокие частоты;
Измерение каналов: Яркость | Цветность_0 | Цветность_1... (например, Y | U | V).
В показанной структуре стрелки обозначают иерархию, а вертикальные черты обозначают разделение.
Несмотря на то что в иллюстративной системе сжатые данные организованы в измерениях пространства, частоты и каналов, описанный в настоящем документе гибкий подход квантизации может быть применен в альтернативных системах кодера/декодера, где данные организованы в меньшем или большем количестве измерений, или в других измерениях. Например, гибкий подход квантизации может быть применен к кодированию с большим количеством частотных диапазонов, другим форматом цветовых каналов (например, YIQ, RGB и т.п.), дополнительными каналами изображения (например, для стереоизображения или матриц из множества камер).
2. Обратное преобразование ядра и преобразование с наложением
Обзор
В одной реализации кодера 200/декодера 300, обратное преобразование на стороне декодера принимает форму двухуровневого преобразования с наложением. Выполняются следующие этапы:
• Обратное Преобразование Ядра (Inverse Core Transform, ICT) применяется к каждому блоку 4×4, соответствующему реконструированному DC-коэффициенту и низкочастотным коэффициентам, расположенным в плоской матрице, известной как DC-плоскость.
• Операция постфильтра, опционально применяется к областям 4×4 равномерно распределенных блоков в DC-плоскости. Кроме того, постфильтр применяется к границе областей 2×4 и 4×2, и четыре угловые области 2x2 оставляются нетронутыми.
• Получающаяся в результате матрица содержит DC-коэффициенты блоков 4×4, соответствующих преобразованию первого уровня. DC-коэффициенты (фигурально) копируются в большую матрицу и реконструированные высокочастотные коэффициенты заполняют остающиеся позиции.
• Обратное Преобразование Ядра применяется к каждому блоку 4×4.
• Операция постфильтра опционально применяется к областям 4x4 равномерно распределенных блоков в DC-плоскости. Кроме того, постфильтр применяется к границе областей 2×4 и 4×2, и четыре угловые области 2×2 оставляются нетронутыми.
Этот процесс показан на Фиг.4.
Применение постфильтров регулируется посредством синтаксического элемента OVERLAP_INFO в сжатом битовом потоке 220. OVERLAP_INFO может принять одно из трех значений:
• Если OVERLAP_INFO = 0, то постфильтрация не выполняется.
• Если OVERLAP_INFO = 1, то выполняется только внешняя постфильтрация.
• Если OVERLAP_INFO = 2, то выполняется внутренняя и внешняя постфильтрация.
Обратное Преобразование Ядра
Мотивом создания Преобразования Ядра было известное Дискретное Косинусное Преобразование 4×4, однако они фундаментально отличаются. Первая ключевая разница заключает в том, что DCT является линейным, тогда как CT является нелинейным. Вторая ключевая разница заключается в том, что поскольку оно определяется в действительных числах, DCT является операцией с потерями в пространстве целых чисел. CT определяется в целых числах и является операцией без потерь в этом пространстве. Третья ключевая разница заключается в том, что двумерное DCT является отделимой операцией. CT является неразделимым по своей природе.
Весь процесс обратного преобразования может быть записан как каскад из следующих трех элементов операций преобразования 2x2:
• Преобразование Адамара 2×2: T_h
• Обратное одномерное вращение: InvT_odd
• Обратное двумерное вращение: InvT_odd_odd
Эти преобразования реализуются как неразделимые операции.
Двумерное Преобразование T_h Адамара 2x2
Кодер/декодер выполняет преобразование T_h Адамара 2×2, как показано в следующей таблице псевдокода. R представляет собой фактор округления, который может принимать только два значения: 0 или 1. T_h является инволюционным (то есть, два применения T_h к вектору данных [a b c d] обеспечивают восстановление исходных значений [a b c d] при условии, что R не меняется между применениями). Обратное T_h равно самому T_h.
T_h(a,b,c,d,R){
a+=d;
b-=c;
int t1=((a-b+R)>>1);
int t2=c;
c=t1-d;
d=t1-t2;
a-=d;
b+=c;
}
Обратное одномерное вращение InvT_odd
Обратное T_odd без потерь определяется псевдокодом в следующей таблице.
Invt_odd (a,b,c,d,){
b+=d;
a-=c;
d-=(b>>1);
c+=((a+1)>>1);
a-=((3*b+4)>>3);
b+=((3*a+4)>>3);
c-=((3*d+4)>>3);
d+= ((3*c+4)>>3);
c-=((b+1)>>1);
d=((a+1)>>1)-d;
b+=c;
a-=d;
}
Обратное двумерное вращение InvT_odd_odd
Обратное двумерное вращение InvT_odd_odd определяется псевдокодом в следующей таблице.
Invt_odd_odd (a,b,c,d,){
int t1, t2;
d+=a;
c-=b;
a-=(t1=d>>1);
b+=(t2=c>>1);
a-=((b*3+3)>>3);
b+=((a*3+3)>>2);
a -= ((b * 3 + 4) >> 3);
b-=t2;
a+=t1;
c+=b;
d-=a;
b=-b
c=-c
{
Операции Обратного Преобразования Ядра
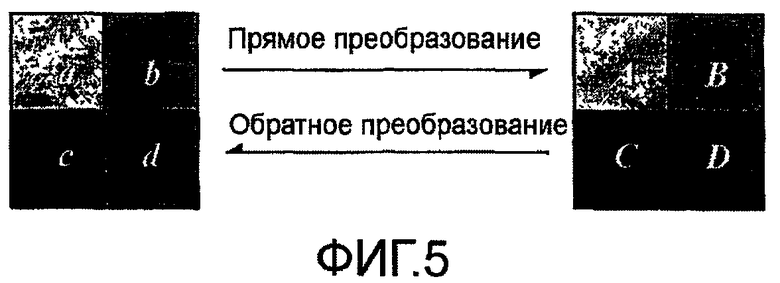
Соответствие между данными 2×2 и вышеприведенным псевдокодом показано на Фиг.5. В данном примере описано кодирование цвета посредством четырех уровней серого для индикации четырех точек данных, чтобы облегчить описание преобразования в следующем разделе.
Двумерное ICT по 4×4 точкам строится посредством T_h, обратного T_odd и обратного T_odd_odd. Следует отметить, что обратное T_h равно самому T_h. ICT состоит из двух стадий, которые показаны в следующем псевдокоде. Каждая стадия состоит из четырех преобразований 2×2, которые могут быть выполнены в произвольной последовательности или одновременно.
Если входным блоком данных является 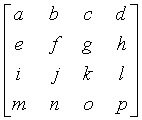

4×4_IPCT (a...p){
T_h(a,c,I,k);
InvT_odd(b,d,j,l);
InvT_odd(e, m, g, o);
Invt_odd_odd(f, h, n, p);
T_h(a, d, m, p);
T_h(k,j,g,f);
T_h(c, b, o, n);
T_h(i, l, e, h);
}
Функция 2×2_ICT равна T_h.
Обзор Постфильтрации
Четыре оператора определяют постфильтры, используемые в обратном преобразовании с наложением. Этими операторами являются:
• Постфильтр 4x4
• 4-точечный постфильтр
• Постфильтр 2x2
• 2-точечный постфильтр
Постфильтр использует T_h, InvT_odd_odd, invScale и invRotate. invRotate и invScale определены в нижеприведенных таблицах, соответственно.
invRotate(a,b){
a-=((b*3+8)>>4);
b+=((a*3+4)>>3);
a-=((b*3+8)>>4);
{
invScale (a,b){
b+=a;
a-=((b+1)>>1);
b+=((a*3+0)>>3);
a+=((b*3+8)>>4);
b+=((a*3+4)>>3);
a+=((b+1)>>1;
b-=a;
}
Постфильтр 4 × 4
Изначально, постфильтр 4×4 применяется ко всем стыкам блоков (областям, равномерно разделяющим 4 блока) во всех цветовых плоскостях, когда OVERLAP_INFO равно 1 или 2. Кроме того, фильтр 4×4 применяется ко всем стыкам блоков в DC-плоскости для всех плоскостей, когда OVERLAP_INFO равно 2, и только для плоскости яркости, когда OVERLAP_INFO равно 2 и цветовым форматом является либо YUV 4:2:0, либо YUV 4:2:2.
Если блоком входных данных является
4x4PostFilter (a,b,...,p){
T_h(a,d,m,p,0);
T_h(b,c,n,o,0);
T_h(e,h,i,l,0);
T_h(f,g,j,k,0);
invRotate (n,m);
invRotate (j,i);
invRotate (h,d);
invRotate (g,c);
invT_odd_odd (k,l,o,p);
invScale(a,p);
invScale(b,l);
invScale(e,o);
invScale(f,k);
T_h(a,m,d,p,0);
T_h(b,n,c,o,0);
T_h(e,i,h,l,0);
T_h(f,j,g,k,0);
}
4-точечный постфильтр
Линейные 4-точечные фильтры применяются к областям 2×4 и 4×2, охватывающим края на границе изображения. Если входными данными является [a b c d], то 4-точечный постфильтр - 4PostFilter(a, b, c, d) - определяется следующим образом:
4PostFilter(a,b,c,d){
a+=d;
b+=c;
d-=((a+1)>>1;
c-=((b+1)>>1;
invRotate(c,d);
d+=(a+1)>>1;
c+=(b+1)>>1;
a-=d-((d*3+16)>>5);
b-=c-((c*3+16)>>5);
d+=((a*3+8)>>4);
c+=((b*3+8)>>4);
a+=((d*3+16)>>5);
b+=((c*c+16)>>5);
}
Постфильтр 2 × 2
Постфильтр 2×2 применяется к блокам, охватывающим области в DC-плоскости для каналов цветности данных YUV 4:2:0 и YUV 4:2:2. Если входными данными являются 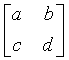
2x2PostFilter (a,b,c,d){
a+=d;
b+=c;
d-=((a+1)>>1);
c-=((b+1)>>1);
b+=((a+2)>>2);
a+=((b+1)>>1);
b+=((a+2)>>2);
d+=((a+1)>>1);
c+=((b+1)>>1);
a-=d;
b-=c;
}
2-точечный постфильтр
2-точечный постфильтр применяется к граничным выборкам 2×1 и 1×2, которые охватывают блоки. 2-точечный постфильтр - 2PostFilter (a, b) - определяется следующим образом:
2PostFilter(a,b){
b+=((a+4)>>3);
a+=((b+2)>>2);
b+=((a+4)>>3);
}
Сигнализация точности, необходимой для выполнения операций преобразования вышеописанного преобразования с наложением, может быть выполнена в заголовке структуры сжатого изображения. В иллюстративной реализации, LONG_WORD_FLAG и NO_SCALED_FLAG являются синтаксическими элементами, которые передаются в сжатом битовом потоке (например, в заголовке изображения), чтобы сигнализировать точность и вычислительную сложность, которые должны быть применены декодером.
3. Точность и длина слова
Иллюстративный кодер/декодер выполняет целочисленные операции. Сверх того, иллюстративный кодер/декодер поддерживает кодирование и декодирование без потерь. Следовательно, первичная машинная точность, требуемая иллюстративным кодером/декодером, является целым числом.
Тем не менее, целочисленные операции, определенные в иллюстративном кодере/декодере, приводят к ошибкам округления при кодировании с потерями. Эти ошибки малы по природе, однако они могут вызвать падения в кривой случайного искажения. В целях улучшения эффективности кодирования путем уменьшения ошибок округления, иллюстративный кодер/декодер определяет вторичную машинную точность. В этом режиме, вход предварительно умножается на 8 (то есть, сдвигается влево на 3 бита), а окончательный вывод разделяется на 8 с округлением (то есть, сдвигается вправо на 3 бита). Эти операции выполняются перед входом в кодер и после выхода из декодера, и они по существу незаметны для остальных процессов. Сверх того, уровни квантизации соответственно масштабируются таким образом, что поток, созданный с первичной машинной точностью и декодированный со вторичной машинной точностью (и наоборот), производит приемлемое изображение.
Вторичная машинная точность не может быть использована, когда требуется сжатие без потерь. Машинная точность, использованная при создании сжатого файла, явно отмечается в заголовке.
Вторичная машинная точность эквивалентна использованию арифметики с разбиением чисел на целую и дробную части в кодеке и этот режим называют режимом с масштабированием. Первичная машинная точность обозначается термином режимом без масштабирования.
Иллюстративный кодер/декодер устроен так, чтобы обеспечивать хорошую скорость кодирования и декодирования. Целью иллюстративного кодера/декодера является то, чтобы величины данных в кодере и декодере не превышали 16 битов со знаком для 8 входных битов. (Тем не менее, промежуточная операция на стадии преобразования может превышать это значение). Это справедливо для обоих режимов машинной точности.
В отличие от этого, когда выбирается вторичная машинная точность, расширение диапазона промежуточных величин составляет 8 битов. Поскольку для первичной машинной точности предварительное умножение на 8 не выполняется, то в этом случае расширение диапазона составляет 8-3=5 битов.
Первый пример кодера/декодера использует две разные длины слова для промежуточных величин. Этими длинами слов являются 16 битов и 32 бита.
Второй пример синтаксиса и семантики битового потока
Второй пример синтаксиса и семантики битового потока является иерархическим и содержит следующие слои: Изображение, Элемент Мозаичного Изображения, Макроблок и Блок.
Некоторые элементы битового потока из второго примера синтаксиса и семантики битового потока описаны ниже.
Флаг Длинного Слова (LONG_WORD_FLAG) (1 бит)
LONG_WORD_FLAG представляет собой 1-битный синтаксический элемент, который специфицирует, могут ли использоваться 16-битные целые числа для вычисления преобразования. В этом втором примере синтаксиса битового потока, если LONG_WORD_FLAG == 0 (FALSE), то 16-битные целые числа и массивы могут использоваться для внешней стадии вычислений преобразования (промежуточные операции при преобразовании (такие как (3*a+1)>>1) выполняются с более высокой точностью). Если LONG_WORD_FLAG == TRUE, то для вычислений преобразования должны быть использованы 32-битные целые числа и массивы.
Следует отметить, что 32-битная арифметика может быть использована для декодирования изображения независимо от величины LONG_WORD_FLAG. Этот синтаксический элемент может быть использован декодером для выбора наиболее эффективной длины слова.
Флаг Режима Без Масштабирования (NO_SCALED_FLAG)(1 бит)
NO_SCALED_FLAG представляет собой 1-битный синтаксический элемент, который специфицирует, используется ли масштабирование при преобразовании. Если NO_SCALED_FLAG == 1, то масштабирование не должно быть применено. Если NO_SCALED_FLAG == 0, то масштабирование должно быть применено. В этом случае, масштабирование должно быть применено путем соответствующего округления в меньшую сторону вывода последней стадии (преобразования цвета) на 3 бита.
Следует отметить, что NO_SCALED_FLAG должно быть установлено в значение TRUE, если требуется кодирование без потерь, даже если кодирование без потерь используется только для подобласти изображения. При кодировании с потерями может использоваться любой из этих режимов.
Следует отметить, что характеристика искажения скорости для кодирования с потерями имеет больший приоритет, когда используется масштабирование (то есть, когда NO_SCALED_FLAG == FALSE), в особенности при низких значениях QP.
4. Сигнализация и использование Флага Длинного Слова
Один пример формата изображения для иллюстративного кодера/декодера поддерживает различные форматы пикселей, включая форматы высокого динамического диапазона и широкого спектра. Поддерживаемые типы данных включают в себя целые со знаком, целые без знака, числа с фиксированной запятой и числа с плавающей запятой. Поддерживаемые битовые глубины включают в себя 8, 16, 24 и 32 битов на цветовой канал. Пример формата изображения обеспечивает возможность сжатия изображений без потерь, где используется до 24 битов на цветовой канала, и сжатие изображений с потерями, где используется до 32 битов на цветовой канал.
В то же время, данный пример формата изображения был разработан так, чтобы предоставлять высококачественные изображения и высокую эффективность сжатия, и позволять выполнять кодирование и декодирование с малой сложностью.
Для поддержки реализации малой сложности, преобразование в примере формата изображения было разработано таким образом, чтобы минимизировать расширение динамического диапазона. Двухстадийное преобразование увеличивает динамический диапазон только на пять битов. Следовательно, если битовая глубина изображения составляет восемь битов на цветовой канал, то 16 битная арифметика может быть достаточной для выполнения всех операций преобразования в декодере. В случае других битовых глубин, для операций преобразования может потребоваться более точная арифметика.
Вычислительная сложность декодирования конкретного битового потока может быть уменьшена, если точность, необходимая для выполнения операций преобразования, будет известна в декодере. Эта информация может быть сигнализирована в декодер посредством синтаксического элемента (например, однобитного флага в заголовке изображения). Описанные способы сигнализации и синтаксические элементы могут уменьшить вычислительную сложность при декодировании битового потока.
В одной иллюстративной реализации используется 1-битный синтаксический элемент LONG_WORD_FLAG. Например, если LONG_WORD_FLAG == FALSE, то для внешней стадии вычислений преобразования может использоваться 16-битные целые числа и массивы, а если LONG_WORD_FLAG = TRUE, то для вычислений преобразования должны использоваться 32-битные целые числа и массивы.
В одной реализации иллюстративного кодера/декодера, операции преобразования могут быть выполнены на 16-битных словах, но промежуточные операции при преобразовании (такие как вычисление произведения 3*a для этапа "подъема" по выражению b += (3*a+1)>>1)) выполняются с большей точностью (например, 18 битов или больше). Тем не менее, в этом примере сами величины a и b преобразования могут храниться в 16-битных целых числах.
32-битная арифметика может быть использована для декодирования изображения независимо от величины элемента LONG_WORD_FLAG. Элемент LONG_WORD_FLAG может быть использован кодером/декодером для выбора наиболее эффективной длины слова. Например, кодер может установить элемент LONG_WORD_FLAG в значение FALSE, если он может верифицировать, что этапы преобразования с 16-битной точностью и 32-битной точностью производят одинаковую выходную величину.
5. Сигнализация и использование NO_SCALED_FLAG
Один пример формата изображения для иллюстративного кодера/декодера поддерживает различные форматы пикселей, включая форматы высокого динамического диапазона и широкого спектра. Вместе с тем, структура иллюстративного кодера/декодера оптимизирует качество и эффективность сжатия и обеспечивает возможность кодирования и декодирования низкой сложности.
Как описано выше, иллюстративный кодер/декодер использует двухстадийное иерархическое блочное преобразование, где все этапы преобразования представляют собой целочисленные операции. Малые ошибки округления, присутствующие в этих целочисленных операциях, приводят к потере эффективности сжатия во время сжатия с потерями. Для устранения этой проблемы в одной реализации иллюстративного кодера/декодера определено два разных режима работы декодера - режим с масштабированием и режим без масштабирования.
В режиме точности с масштабированием, входное изображение предварительно умножается на 8 (то есть, сдвигается влево на 3 бита), а окончательный вывод в декодере разделяется на 8 с округлением (то есть, сдвигается вправо на 3 бита). Операция в режиме точности с масштабированием минимизирует ошибки округления, что приводит к улучшению характеристики искажения.
В режиме точности без масштабирования, подобное масштабирование не применяется. В режиме точности без масштабирования, кодер и декодер должны действовать в меньшем динамическом диапазоне для коэффициентов преобразования и, соответственно, с меньшей вычислительной сложностью. Тем не менее, есть небольшая потеря в эффективности сжатия при работе в этом режиме. Кодирование без потерь (без квантизации, то есть, когда параметр квантизации или QP равен 1) может использовать только режим точности без масштабирования для гарантирования обратимости.
Режим точности, использованный кодером при создании сжатого файла, в явной форме сигнализируется в заголовке изображения сжатого битового потока 220 (Фиг.2), посредством флага NO_SCALED_FLAG. Рекомендуется, чтобы декодер 300 использовал для своих операций тот же режим точности.
NO_SCALED_FLAG представляет собой 1-битный синтаксический элемент в заголовке изображения, который специфицирует режим точности следующим образом:
Если NO_SCALED_FLAG == TRUE, то для операций декодера должен использоваться режим без масштабирования.
Если NO_SCALED_FLAG == FALSE, то должно быть применено масштабирование. В этом случае, режим с масштабированием должен быть использован для операции путем соответствующего округления в меньшую сторону вывода последней стадии (преобразования цвета) на 3 бита.
Характеристика искажения скорости для кодирования с потерями имеет больший приоритет, когда используется режим с масштабированием (то есть, когда NO_SCALED_FLAG == FALSE), в особенности при низких значениях QP. Тем не менее, когда используется режим без масштабирования, вычислительная сложность меньше по двум следующим причинам:
Меньшее расширение динамического диапазона в режиме без масштабирования означает, что для вычисления преобразования могут использоваться более короткие слова, в особенности в сочетании с флагом LONG_WORD_FLAG. В реализациях VLSI, уменьшение расширения динамического диапазона означает, что вентильная логика, реализующая старшие биты, может быть отключена.
Режим с масштабированием требует добавления и сдвига вправо на 3 бита (что соответствует делению на 8 с округлением) на стороне декодера. На стороне кодера требуется сдвиг влево на 3 бита. Это немного более требовательно с вычислительной точки зрения, чем при режиме без масштабирования.
Сверх того, режим без масштабирования позволяет выполнять сжатие большего количества старших значащих битов, чем в режиме с масштабированием. Например, режим без масштабирования позволяет выполнять сжатие без потерь (и распаковку) до 27 значащих битов на выборку, используя 32-битную арифметику. В отличие от этого, режим с масштабированием позволяет тоже только для 24 битов. Это имеет место из-за трех дополнительных битов динамического диапазона, добавляемых в результате процесса масштабирования.
Величины данных в декодере не превышают 16 битов со знаком для 8-битного ввода для обоих режимов точности. (Тем не менее, промежуточная операция на стадии преобразования может превышать это значение).
Следует отметить, что NO_SCALED_FLAG устанавливается кодером в значение TRUE, если требуется кодирование без потерь (QP=1), даже если кодирование без потерь используется только для подобласти изображения.
Кодер может использоваться любой режим для сжатия с потерями. Рекомендуется, чтобы декодер использовал для своих операций режим точности, сигнализируемый посредством флага NO_SCALED_MODE. Тем не менее, уровни квантизации соответственно масштабируются таким образом, что поток, созданный в режиме точности с масштабированием и декодированный в режиме точности без масштабирования (и наоборот), производит приемлемое изображение в большинстве случаев.
6. Арифметика с разделением чисел на целую и дробную часть для повышенной точности
В одной реализации иллюстративного кодера/декодера, преобразования (включая цветовые преобразования) являют собой целочисленные преобразования и реализуются путем последовательностей этапов сдвига. В этих этапах сдвига ошибки округления ухудшают эффективность преобразования. Для сжатия с потерями, чтобы минимизировать вред от ошибок округления и, соответственно, максимизировать эффективность преобразования, входные данные требуется сдвинуть влево на несколько битов. Тем не менее, еще одной желательной особенностью является то, что если входное изображение является 8-битным, то вывод каждого преобразования должен быть не более 16 бит. Соответственно, количество битов сдвига влево не может быть большим. Иллюстративный декодер реализует способ арифметики с разделением чисел на целую и дробную части, чтобы достичь выполнения обеих этих задач. Способ арифметики с разделением чисел на целую и дробную часть максимизирует эффективность преобразования путем минимизации вреда от ошибок округления и, в то же время, ограничивает вывод каждого этапа преобразования в пределах 16 бит, если входное изображение является 8-битным. Это обеспечивает возможность простой 16-битной реализации.
Преобразования, используемые в иллюстративном кодере/декодере, являются целочисленными преобразованиями, которые реализуются этапами сдвигов. Большая часть этапов сдвигов является сдвигами вправо, в результате которых возникают ошибки округления. Преобразование, обычно, включает в себя множество этапов сдвигов, и накопительные ошибки округления заметно ухудшают эффективность преобразования.
Одним из путей уменьшения вреда ошибок округления является выполнение сдвига входных данных влево до преобразования в кодере и выполнение сдвига вправо на то же количество битов после преобразования (в сочетании с квантизацией) в декодере. Как описано выше, иллюстративный кодер/декодер имеет структуру двухстадийного преобразования: опциональное наложение первого этапа + преобразование ядра первого этапа + опциональное наложение второго этапа + преобразование ядра второго этапа. Эксперименты показывают, что для минимизации ошибок округления требуется сдвиг влево на 3 бита. Соответственно, в случаях сжатия с потерями, до цветового преобразования входные данные могут быть сдвинуты влево на 3 бита, то есть умножены или масштабированы посредством коэффициента 8 (например, для режима с масштабированием, описанного выше).
Тем не менее, преобразование цвета и само преобразование расширяют данные. Если входные данные сдвигаются на 3 бита, то вывод второй стадии 4×4 DCT имеет 17-битный динамический диапазон, если входные данные являются 8-битными (вывод каждого другого преобразования все же остается в пределах 16 бит). Это крайне нежелательно, поскольку создаются препятствия для 16-битной реализации, которая является желательной функцией. Для преодоления этой проблемы, до преобразования ядра 4×4 второй стадии, входные данные сдвигаются вправо на 1 бит, так что вывод остается в пределах 16 бит. Поскольку преобразование ядра 4×4 второй стадии применяется только к 1/16 данных (DC-коэффициенты DCT первой стадии) и данные уже были отмасштабированы в сторону увеличения посредством преобразования первой стадии), вред от ошибок округления минимален.
Соответственно, в случае сжатия с потерями для 8-битных изображений, на стороне кодера вход сдвигается влево на 3 бита до преобразования цвета и сдвигается вправо на 1 бит до преобразования ядра 4×4 второй стадии. На стороне декодера вход сдвигается влево на 1 бит до 4×4 IDCT и сдвигается вправо на 3 бита после преобразования цвета.
7. Вычислительное окружение
Вышеописанные способы обработки для сигнализации вычислительной сложности и точности в кодеке цифровых мультимедийных данных могут быть реализованы в различных системах кодирования и/или декодирования цифровых мультимедийных данных, включающих в себя, например, компьютеры (различных форм-факторов, включая серверы, настольные компьютеры, ноутбуки, карманные компьютеры и т.п.); устройства записи и воспроизведения цифровых мультимедийных данных; устройства захвата изображений и видео (такие как камеры, сканнеры и т.п.); оборудование связи (такое как телефоны, мобильные телефоны, оборудование конференц-связи и т.п.); устройства отображения, печати и другого представления; и т.п. Способы сигнализации вычислительной сложности и точности в кодеке цифровых мультимедийных данных могут быть реализованы в аппаратной схеме, в программно-аппаратном обеспечении, управляющем аппаратным обеспечением, которое обрабатывает цифровые мультимедийные данные, а также в сочетании с программным обеспечением, выполняемым в компьютере или другом вычислительном окружении, таком как показанное на Фиг.6.
Фиг.6 представляет собой обобщенный пример подходящего вычислительного окружения (600), в котором могут быть реализованы описанные варианты осуществления. Вычислительное окружение (600) не предназначено для определения объема использования или функциональности настоящего изобретения, поскольку настоящее изобретение может быть реализовано в различных вычислительных окружениях общего назначения или специального назначения.
Ссылаясь на Фиг.6, вычислительное окружение (600) включает в себя, по меньшей мере, один процессорный блок (610) и память (620). На Фиг.6 эта базовая конфигурация (630) заключена в пунктирную линию. Процессорный блок (610) выполняет выполняемые компьютером инструкции, и он может представлять собой действительный или виртуальный процессор. В мультипроцессорной системе множество блоков обработки выполняют выполняемые компьютером инструкции, чтобы увеличить общую мощность обработки. Память (620) может представлять собой энергозависимую память (например, регистры, кэш-память, ОЗУ), энергонезависимую память (например, ПЗУ, ЭЭППЗУ, флэш-память и т.п.) или некоторую комбинацию перечисленных двух типов памяти. Память (620) хранит в себе программное обеспечение (680), реализующее описанное кодирование/декодирование цифровых мультимедийных данных со способами сигнализации вычислительной сложности и точности.
Вычислительное окружение может содержать дополнительные элементы. Например, вычислительное окружение (600) включает в себя хранилище (640), одно или более устройств (650) ввода, одно или более устройств (660) вывода, а также одно или более соединений (670) связи. Механизм взаимосвязи (не показан), такой как шина, котроллер или сеть, объединяет компоненты вычислительного окружения (600). Как правило, операционная система (не показана) предоставляет рабочее окружение для другого программного обеспечения, выполняемого в вычислительном окружении (600), и координирует действия компонентов вычислительного окружения (600).
Хранилище (640) может быть съемным или несъемным и может включать в себя магнитные диски, магнитные ленты или кассеты, диски CD-ROM, CD-RW, DVD или любые другие носители, которые могут быть использованы для хранения информации и к которым может быть выполнен доступ в вычислительном окружении (600). Хранилище (640) хранит в себе инструкции для программного обеспечения (680), реализующего описанное кодирование/декодирование цифровых мультимедийных данных со способами сигнализации вычислительной сложности и точности.
Устройство(а) (650) ввода могут представлять собой сенсорные устройства ввода, такие как клавиатура, мышь, ручка или трекбол, голосовое устройство ввода, сканирующее устройство или другое устройство, которое предоставляет ввод в вычислительное окружение (600). В случае аудио, устройство(а) (650) ввода могут представлять собой звуковую карту или схожее устройство, которое принимает аудиовход в аналоговой или цифровой форме с микрофона или микрофонной матрицы, или считывающее устройство CD-ROM, которое предоставляет выборки аудио в вычислительное окружение. Устройство(а) (660) вывода могут представлять собой дисплей, принтер, громкоговоритель, записывающее устройство для CD или другое устройство, которое предоставляет вывод из вычислительного окружения (600).
Соединение(я) (670) связи обеспечивают связь через среду передачи с другим вычислительным объектом. Среда передачи переносит информацию, такую как выполняемые компьютером инструкции, сжатое аудио или видео или другие данные в модулированном сигнале данных. Термин "модулированный сигнал данных" обозначает сигнал, у которого одна или более характеристик установлены или изменены таким образом, чтобы кодировать в сигнал информацию. В качестве неограничивающего примера, среда передачи включает в себя проводные или беспроводные способы, реализуемые посредством электрического, оптического, инфракрасного, акустического или другого носителя.
Кодирование/декодирование цифровых мультимедийных данных со способами гибкой квантизации могут быть описаны в общем контексте машиночитаемых носителей. Машиночитаемые носители могут быть любым доступным носителем, к которому может быть выполнен доступ в вычислительном окружении. В качестве неограничивающего примера машиночитаемые носители включают в себя память (620), хранилище (640), среду передачи или любую комбинацию перечисленных.
Кодирование/декодирование цифровых мультимедийных данных со способами сигнализации вычислительной сложности и точности могут быть описаны в общем контексте выполняемых компьютером инструкций, таких как инструкции, содержащиеся в программных модулях, которые выполняются в вычислительном окружении на целевом действительном или виртуальном процессоре. В общем, программные модули включают в себя рутинные процедуры, программы, библиотеки, объекты, классы, компоненты, структуры данных и т.п., которые выполняют конкретные задачи или осуществляют конкретные абстрактные типы данных. Функциональность программных модулей может быть комбинирована или распределена между программными модулями согласно требованиям в различных вариантах осуществления. Выполняемые компьютером инструкции для программных модулей могут выполняться в локальном или распределенном вычислительном окружении.
Для целей представления, в настоящем подробном описании используются такие термины, как "определять", "генерировать", "регулировать" и "применять", чтобы описывать операции компьютера в вычислительном окружении. Эти термины являют собой абстракции высокого уровня для операций, выполняемых компьютером, и их нельзя путать с действиями, выполняемыми человеком. Фактические операции компьютера, соответствующие этим терминам, варьируют в зависимости от реализации.
Ввиду множества возможных вариантов осуществления, к которым могут быть применены принципы настоящего изобретения, настоящее изобретение определяется объемом и сущностью прилагаемой формулы изобретения и ее эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| МЕТОДИКИ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОГО ВИДЕО С ПЕРЕМЕННЫМ РАЗРЕШЕНИЕМ | 2007 |
|
RU2497302C2 |
| ОБРАТИМАЯ ДВУМЕРНАЯ ПРЕДВАРИТЕЛЬНАЯ И ПОСТФИЛЬТРАЦИЯ ДЛЯ ПЕРЕКРЫВАЮЩЕГОСЯ БИОРТОГОНАЛЬНОГО ПРЕОБРАЗОВАНИЯ | 2005 |
|
RU2412473C2 |
| ОПЕРАТОР ОБРАТИМОГО ПЕРЕКРЫТИЯ ДЛЯ ЭФФЕКТИВНОГО СЖАТИЯ ДАННЫХ БЕЗ ПОТЕРЬ | 2005 |
|
RU2377653C2 |
| КОДЕР, ДЕКОДЕР И СООТВЕТСТВУЮЩИЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ КОМПАКТНОГО MV ХРАНИЛИЩА | 2019 |
|
RU2783385C2 |
| КОДЕР, ДЕКОДЕР И СООТВЕТСТВУЮЩИЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ КОМПАКТНОГО MV ХРАНИЛИЩА | 2019 |
|
RU2771925C1 |
| УМЕНЬШЕННОЕ РАССОГЛАСОВАНИЕ КОЭФФИЦИЕНТОВ УСИЛЕНИЯ ПОСТОЯННОЙ СОСТОВЛЯЮЩЕЙ (DC) И DC-УТЕЧКИ ПРИ ОБРАБОТКЕ ПРЕОБРАЗОВАНИЯ С ПЕРЕКРЫТИЕМ | 2009 |
|
RU2518932C2 |
| ЗЕРКАЛЬНОЕ ОТОБРАЖЕНИЕ БЛОКОВ И РЕЖИМ ПРОПУСКА В ИНТРА-ОСНОВАННОМ НА КОПИИ БЛОКА ПРЕДСКАЗАНИИ | 2014 |
|
RU2657210C2 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ И ОСТАТКА ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2022 |
|
RU2840061C2 |
| КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ И ОСТАТКА ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2022 |
|
RU2838396C2 |
| ОСНОВАННЫЕ НА ХЕШАХ РЕШЕНИЯ КОДЕРА ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2014 |
|
RU2679981C2 |

Изобретение относится к кодированию на основе блочного преобразования. Техническим результатом является обеспечение управления вычислительной сложностью и точностью декодирования посредством кодека цифровых мультимедийных данных. Предложенный кодер/декодер цифровых мультимедийных данных включает в себя сигнализацию различных режимов, относящихся к вычислительной сложности и точности при декодировании. Кодер может передавать синтаксический элемент, указывающий арифметическую точность (например, применение 16-битных или 32-битных операций) операций преобразования, выполняемых при декодировании. Кодер также может сигнализировать, необходимо ли применять масштабирование к выводу декодера, что обеспечивает более широкий динамический диапазон промежуточных данных при декодировании, но увеличивает вычислительную сложность из-за операции масштабирования. 6 н. и 21 з.п. ф-лы, 6 ил. 
1. Способ декодирования цифровых мультимедийных данных, содержащий этапы, на которых:
принимают сжатый битовый поток цифровых мультимедийных данных в декодере цифровых мультимедийных данных;
посредством анализа из битового потока извлекают первый синтаксический элемент, сигнализирующий степень арифметической точности, которую необходимо использовать для вычислений преобразования в течение обработки цифровых мультимедийных данных;
посредством анализа из битового потока извлекают второй синтаксический элемент, сигнализирующий выбор режимов точности с масштабированием для вычислений преобразования во время обработки цифровых мультимедийных данных;
в случае если второй синтаксический элемент сигнализирует первый режим точности с масштабированием, в котором используется масштабирование, масштабируют выходные данные декодера;
в случае если второй синтаксический элемент сигнализирует второй режим точности с масштабированием, в котором не используется масштабирование, пропускают применение масштабирования к упомянутым выходным данным; и
выводят реконструированное изображение.
2. Способ декодирования цифровых мультимедийных данных по п.1, в котором первый синтаксический элемент сигнализирует использовать либо высокую арифметическую точность, либо низкую арифметическую точность.
3. Способ декодирования цифровых мультимедийных данных по п.2, в котором высокая арифметическая точность является обработкой с 32-битными числами, а низкая арифметическая точность является обработкой с 16-битными числами.
4. Способ декодирования цифровых мультимедийных данных по п.2, дополнительно содержащий этапы, на которых:
декодируют блоки коэффициентов преобразования из сжатого битового потока цифровых мультимедийных данных;
в случае если первый синтаксический элемент сигнализирует использовать высокую арифметическую точность, применяют обратное преобразование к коэффициентам преобразования, используя обработку с высокой арифметической точностью; и
в случае если первый синтаксический элемент сигнализирует использовать низкую арифметическую точность, применяют обратное преобразование к коэффициентам преобразования, используя обработку с низкой арифметической точностью.
5. Способ декодирования цифровых мультимедийных данных по п.4, в котором высокая арифметическая точность является обработкой с 32-битными числами, а низкая арифметическая точность является обработкой с 16-битными числами.
6. Способ декодирования цифровых мультимедийных данных по п.2, дополнительно содержащий этапы, на которых:
декодируют блоки коэффициентов преобразования из сжатого битового потока цифровых мультимедийных данных;
применяют обратное преобразование к коэффициентам преобразования, используя обработку с высокой арифметической точностью, независимо от степени арифметической точности, сигнализируемой посредством первого синтаксического элемента.
7. Способ декодирования цифровых мультимедийных данных по п.1, при этом способ выполняется в карманном компьютерном устройстве.
8. Способ кодирования цифровых мультимедийных данных, содержащий этапы, на которых:
принимают цифровые мультимедийные данные в кодере цифровых мультимедийных данных;
принимают решение касаемо того, использовать ли более низкую арифметическую точность для вычислений преобразования в течение обработки цифровых мультимедийных данных;
представляют это решение касаемо того, использовать ли более низкую арифметическую точность для вычислений преобразования, посредством первого синтаксического элемента в кодированном битовом потоке, причем первый синтаксический элемент приспособлен сообщать упомянутое решение в декодер цифровых мультимедийных данных;
принимают решение касаемо того, применять ли масштабирование входных цифровых мультимедийных данных до кодирования с преобразованием; и
представляют это решение касаемо того, применять ли масштабирование, посредством второго синтаксического элемента в кодированном битовом потоке; и
выводят кодированный битовый поток.
9. Способ кодирования цифровых мультимедийных данных по п.8, в котором при упомянутом принятии решения касаемо использования более низкой арифметической точности:
верифицируют, производит ли более низкая арифметическая точность для вычислений преобразования такие же выходные данные декодера, как при использовании более высокой арифметической точности для вычислений преобразования; и
на основе упомянутой верификации принимают решение, использовать ли более низкую арифметическую точность.
10. Способ кодирования цифровых мультимедийных данных по п.8, в котором упомянутая более низкая арифметическая точность представляет собой 16-битную арифметическую точность.
11. Способ кодирования цифровых мультимедийных данных по п.8, в котором при упомянутом принятии решения касаемо применения масштабирования принимают решение не применять масштабирование входных цифровых мультимедийных данных, когда применяется кодирование цифровых мультимедийных данных без потерь.
12. Способ декодирования цифровых мультимедийных данных, содержащий этапы, на которых:
принимают сжатый битовый поток цифровых мультимедийных данных в декодере цифровых мультимедийных данных;
посредством анализа из сжатого битового потока цифровых мультимедийных данных извлекают синтаксический элемент, сигнализирующий выбор режимов точности для вычислений преобразования в течение обработки цифровых мультимедийных данных из сжатого битового потока цифровых мультимедийных данных;
реконструируют изображение из цифровых мультимедийных данных, при этом:
в случае если сигнализируется первый режим точности, в котором используется масштабирование, масштабируют выходные данные декодера,
в случае если сигнализируется второй режим точности, в котором не используется масштабирование, пропускают применение масштабирования к выходным данным декодера; и выводят реконструированное изображение.
13. Способ декодирования цифровых мультимедийных данных по п.12, в котором при упомянутом масштабировании выходных данных декодера выполняют деление выходных данных на некоторое число с округлением.
14. Способ декодирования цифровых мультимедийных данных по п.12, в котором упомянутое деление выходных данных с округлением представляет собой деление на число 8 с округлением.
15. Способ декодирования цифровых мультимедийных данных по п.12, в котором упомянутый синтаксический элемент является первым синтаксическим элементом, при этом способ декодирования цифровых мультимедийных данных дополнительно содержит этапы, на которых:
посредством анализа из сжатого битового потока цифровых мультимедийных данных извлекают второй синтаксический элемент, сигнализирующий, использовать ли более низкую арифметическую точность для вычислений преобразования в течение обработки цифровых мультимедийных данных;
как часть упомянутого реконструирования:
декодируют блоки коэффициентов преобразования из сжатого битового потока цифровых мультимедийных данных; и
в случае если сигнализируется второй режим точности, в котором не используется масштабирование, и использование более низкой арифметической точности, выполняют обработку по обратному преобразованию коэффициентов преобразования, используя более низкую арифметическую точность.
16. Способ декодирования цифровых мультимедийных данных по п.15, в котором упомянутая более низкая арифметическая точность представляет собой 16-битную арифметическую точность.
17. Способ декодирования цифровых мультимедийных данных по п.12, в котором цифровые мультимедийные данные кодированы с использованием двухстадийной структуры преобразования, в которой после первой стадии преобразования следует вторая стадия преобразования DC-коэффициентов преобразования первой стадии преобразования, причем упомянутый способ декодирования цифровых мультимедийных данных дополнительно содержит этапы, на которых, как как часть упомянутого реконструирования:
декодируют коэффициенты преобразования из цифровых мультимедийных данных;
применяют обратное преобразование второй стадии;
применяют обратное преобразование первой стадии;
выполняют преобразование цвета;
причем при масштабировании выходных данных декодера в случае если сигнализируется первый режим точности, в котором используется масштабирование:
выполняют сдвиг влево на один бит до ввода в обратное преобразование первой стадии; и
выполняют сдвиг вправо на три бита после преобразования цвета.
18. Способ декодирования цифровых мультимедийных данных по п.12, в котором упомянутый сжатый битовый поток цифровых мультимедийных данных кодирован согласно синтаксической схеме, определяющей отдельную первичную плоскость изображения и альфа-плоскость изображения для изображения, причем выбор режима точности, сигнализируемый синтаксическим элементом, сигнализируется для каждой плоскости изображения, причем режимы точности первичной плоскости изображения и альфа-плоскости изображения сигнализируются независимым образом, при этом при извлечении посредством анализа синтаксического элемента из сжатого потока цифровых мультимедийных данных, посредством анализа извлекают синтаксический элемент, сигнализирующий выбор режима точности для каждой плоскости изображения, и в случае если для соответствующей плоскости изображения сигнализируется первый режим точности, в котором используется масштабирование, масштабируют выходные данные декодера для соответствующей плоскости изображения.
19. Способ декодирования цифровых мультимедийных данных по п.12, при этом способ выполняется в карманном компьютерном устройстве.
20. Машиночитаемый носитель, на котором сохранен программный код для предписания устройству обработки цифровых мультимедийных данных выполнять способ декодирования цифровых мультимедийных данных, содержащий этапы, на которых:
принимают сжатый битовый поток цифровых мультимедийных данных в декодере цифровых мультимедийных данных;
посредством анализа из битового потока извлекают первый синтаксический элемент, сигнализирующий степень арифметической точности, которую необходимо использовать для вычислений преобразования в течение обработки цифровых мультимедийных данных;
посредством анализа из битового потока извлекают второй синтаксический элемент, сигнализирующий выбор режимов точности с масштабированием для вычислений преобразования во время обработки цифровых мультимедийных данных;
в случае если второй синтаксический элемент сигнализирует первый режим точности с масштабированием, в котором используется масштабирование, масштабируют выходные данные декодера;
в случае если второй синтаксический элемент сигнализирует второй режим точности с масштабированием, в котором не используется масштабирование, пропускают применение масштабирования к упомянутым выходным данным; и
выводят реконструированное изображение.
21. Машиночитаемый носитель по п.20, при этом первый синтаксический элемент сигнализирует использовать либо высокую арифметическую точность, либо низкую арифметическую точность.
22. Машиночитаемый носитель по п.21, в котором способ дополнительно содержит этапы, на которых:
декодируют блоки коэффициентов преобразования из сжатого битового потока цифровых мультимедийных данных;
в случае если первый синтаксический элемент сигнализирует использовать высокую арифметическую точность, применяют обратное преобразование к коэффициентам преобразования, используя обработку с высокой арифметической точностью; и
в случае если первый синтаксический элемент сигнализирует использовать низкую арифметическую точность, применяют обратное преобразование к коэффициентам преобразования, используя обработку с низкой арифметической точностью.
23. Машиночитаемый носитель по п.21, в котором способ дополнительно содержит этапы, на которых:
декодируют блоки коэффициентов преобразования из сжатого битового потока цифровых мультимедийных данных;
применяют обратное преобразование к коэффициентам преобразования, используя обработку с высокой арифметической точностью, независимо от степени арифметической точности, сигнализируемой посредством первого синтаксического элемента.
24. Машиночитаемый носитель, на котором сохранен программный код для предписания устройству обработки цифровых мультимедийных данных выполнять способ кодирования цифровых мультимедийных данных, содержащий этапы, на которых:
принимают цифровые мультимедийные данные в кодере цифровых мультимедийных данных;
принимают решение касаемо того, использовать ли более низкую арифметическую точность для вычислений преобразования в течение обработки цифровых мультимедийных данных;
представляют это решение касаемо того, использовать ли более низкую арифметическую точность для вычислений преобразования, посредством первого синтаксического элемента в кодированном битовом потоке, причем первый синтаксический элемент приспособлен сообщать упомянутое решение в декодер цифровых мультимедийных данных;
принимают решение касаемо того, применять ли масштабирование входных цифровых мультимедийных данных до кодирования с преобразованием; и
представляют это решение касаемо того, применять ли масштабирование, посредством второго синтаксического элемента в кодированном битовом потоке; и
выводят кодированный битовый поток.
25. Машиночитаемый носитель по п.24, в котором при упомянутом принятии решения касаемо использования более низкой арифметической точности:
верифицируют, производит ли более низкая арифметическая точность для вычислений преобразования такие же выходные данные декодера, как при использовании более высокой арифметической точности для вычислений преобразования; и
на основе упомянутой верификации принимают решение, использовать ли более низкую арифметическую точность.
26. Машиночитаемый носитель, на котором сохранен программный код для предписания устройству обработки цифровых мультимедийных данных выполнять способ декодирования цифровых мультимедийных данных, содержащий этапы, на которых:
принимают сжатый битовый поток цифровых мультимедийных данных в декодере цифровых мультимедийных данных;
посредством анализа из сжатого битового потока цифровых мультимедийных данных извлекают синтаксический элемент, сигнализирующий выбор режимов точности для вычислений преобразования в течение обработки цифровых мультимедийных данных из сжатого битового потока цифровых мультимедийных данных;
реконструируют изображение из цифровых мультимедийных данных, при этом:
в случае если сигнализируется первый режим точности, в котором используется масштабирование, масштабируют выходные данные декодера,
в случае если сигнализируется второй режим точности, в котором не используется масштабирование, пропускают применение масштабирования к выходным данным декодера; и выводят реконструированное изображение.
27. Машиночитаемый носитель по п.26, в котором упомянутый синтаксический элемент является первым синтаксическим элементом, при этом способ дополнительно содержит этапы, на которых:
посредством анализа из сжатого битового потока цифровых мультимедийных данных извлекают второй синтаксический элемент, сигнализирующий, использовать ли более низкую арифметическую точность для вычислений преобразования в течение обработки цифровых мультимедийных данных;
как часть упомянутого реконструирования:
декодируют блоки коэффициентов преобразования из сжатого битового потока цифровых мультимедийных данных; и
в случае если сигнализируется второй режим точности, в котором не используется масштабирование, и использование более низкой арифметической точности, выполняют обработку по обратному преобразованию коэффициентов преобразования, используя более низкую арифметическую точность.
| US 2003147463 A1, 2003-08-07 | |||
| US 2005018774 A1, 2005-01-27 | |||
| US 2003093452 A1, 2003-05-15 | |||
| WO 2005076614 A1, 2005-08-18 | |||
| US 6574651 B1, 2003-06-0 | |||
| US 5559557 A, 1996-09-24 | |||
| US 2005259729 A1, 2005-11-24 | |||
| WO 2007010690 A, 2007-01-25 | |||
| RU 2005107478 A, 2006-07-27 | |||
| СПОСОБ НИЗКОШУМОВОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ | 1997 |
|
RU2201654C2 |
| YONGYING G | |||
| et al, Bit Depth Scalability, Joint Video Team | |||

