ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Настоящая заявка притязает на преимущество предварительной заявки США №61/205,033, поданной 14 января 2009 года, содержание которой включено в настоящий документ путем ссылки.
УРОВЕНЬ ТЕХНИКИ
Настоящее изобретение относится в общем к системе и способу для управления данными по вирусам, включая данные по гепатиту С.
Вирусом гепатита С (ВГС), в частности, инфицировано около 4 млн человек в США, и он является основной причиной хронического заболевания печени. Связанное с ВГС заболевание печени на конечной стадии сейчас является одной из основных причин смерти среди ВИЧ-положительных пациентов. Патология ВГС включает фиброз, цирроз и гепатоцеллюлярный рак. Вирус гепатита С трудно исследовать и его нельзя эффективно вылечить, используя противовирусные лекарства, причем благоприятная реакция на современные способы терапии наблюдается меньше чем в 50% случаев; на поиск эффективных способов потребует годы.
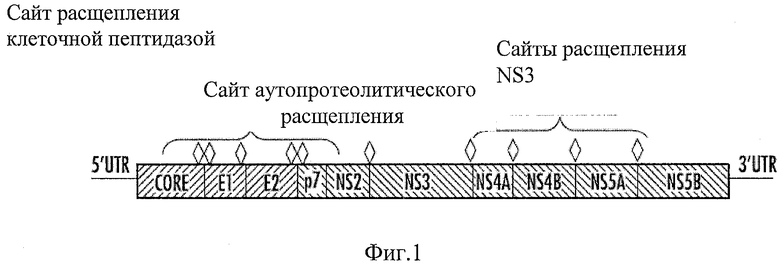
Частицы ВГС имеют оболочку и содержат плюс-цепь РНК 9 кб. Геном РНК имеет одну открытую рамку считывания (ОРС), кодирующую полибелок, который протеолитически расщеплен на набор из 10 четких продуктов (см. Фиг.1, где алмазами показаны точки расщепления), которые содержат вирусную частицу и механизм вирусной репликации. Нетранслированная область 5' направляет трансляцию ОРС ВГС через свое связывание клеточных рибосом и белков. ВГС инфицирует макрофаги и гепатоциты и, в отличие от ретровирусов, не внедряется в хозяйский геном.
Мутации накапливаются на участках вдоль генома ВГС, составляя горячие точки мутаций. Эти гипервариабельные участки сконцентрированы в пяти областях, которые включают белок NS5B, области в и между белками Е1 и Е2 и в капсидном белке. ВГС имеет шесть идентифицированных генотипов и свыше 50 подтипов ВГС, которые отличаются друг от друга своими нуклеотидными последовательностями на 31-35%.
Белки ВГС легко мутируют, вызывая стойкость к лекарствам. ВГС - это явно успешный патоген. Он имеет способность избегать реакций хозяйской иммунной системы, что он делает путем быстрой репликации и поощрения мутаций через подверженную ошибкам РНК-зависимую полимеразу ВГС, у которой нет способностей к исправлению ошибок. Когда ВГС заражает пациента, новые варианты (квази виды, изменяющиеся от одного к другому в их последовательностях на 1-9%) непрерывно возникают из доминирующего заражающего генотипа во время вирусной репликации, давая сотни гетерологичных геномов ВГС. Наиболее подходящие из этих вариантов непрерывно выбираются в репликационной среде на основании их способностей к репликации и давлений отбора, включая все давления противовирусных лекарств. В какой-то момент времени во время инфицирования распределение квази видов ВГС отражает баланс между непрерывным созданием новых вариантов, необходимостью сохранять существенные вирусные функции и положительными давлениями отбора, оказываемые репликационной средой. Так, инфекция ВГС создает сложную проблему для выработки лекарства, поскольку ученые пытаются отслеживать генетическое изменение ВГС с течением времени между передачей вируса и после лечения терапевтическими средствами. Инфекция ВГС представляет четкий набор проблем для анализа. Высокая скорость мутации ВГС приводит к накапливанию огромных количеств новых генетических последовательностей и соответствующих биологических данных в повседневных лабораторных исследованиях и клинических испытаниях. Управление данными является постоянной проблемой. В настоящее время исследователи полагаются на самодельные базы данных, многофункциональное программное обеспечение и средства из открытых источников в Интернете для сортировки, организации и анализа своих геномных и биологических данных. В таблице 1 (ниже) представлены девять этапов, которые обычно выполняют для организации и анализа данных по последовательностям ВГС (левая колонка). В правой колонке указаны соответствующие программы или ручные этапы, которые обычно используют для управления этими данными.
В Исследовательской лаборатории научный сотрудник, имеющий ученую степень, будет проводить исследования и управлять данными, которые он получит. Рассмотрим проект, который включает повседневный отбор 100 клонов ВГС для секвенирования в день (т.е. 500-600 клонов в неделю). Ежедневно новые последовательности сохраняются на сервере или в файлах в папках на настольных компьютерах, и на этих последовательностях выполняется серия обычных действий (таблица 1). Вполне обычно, что данные по нескольким дням работы накапливаются и создают очень трудные проблемы с управлением ими, которые задерживают выполнение проекта.
В отрасли испытания часто проводят на тысячах пациентов. Забор крови у 1000-2000 пациентов в неделю требует создания 1000-2000 последовательностей в неделю или приблизительно 200 в день. Управление данными представляет собой реальную проблему. Обычные действия, выполняемые ежедневно на последовательностях, подобны таковым в исследовательской лаборатории (см. таблицу 1). Обычно управлением накапливаемыми данными занимаются один или несколько человек, работающих полный рабочий день.
Высокая скорость мутации результатов ВГС дает огромное количество новых генетических и соответствующих биологических данных при ежедневных лабораторных исследованиях и клинических испытаниях при сопутствующих серьезных проблемах с управлением данными. В настоящее время исследователи используют самодельные базы данных, многофункциональное программное обеспечение и средства из открытых источников в Интернете для сортировки, организации и анализа геномных и биологических данных. Эти средства часто связаны с определенными конфигурациями аппаратного или программного обеспечения. Эти средства не приспособлены для работы с геномом ВГС, и перемещение данных из одной программы в другую требует много усилий, времени и не исключает ошибок.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к системе и способу для управления данными по вирусом, включая данные по гепатиту С. Система может включать программное обеспечение для настольного компьютера, приспособленное для быстрого, эффективного и гибкого управления данными по вирусам, включая данные по ВГС. Система может облегчать для ученых преодоление проблем, связанных с управлением данными. Более того, система может упорядочить управление данными, значительно сократив время между сбором данных и определением способа лечения.
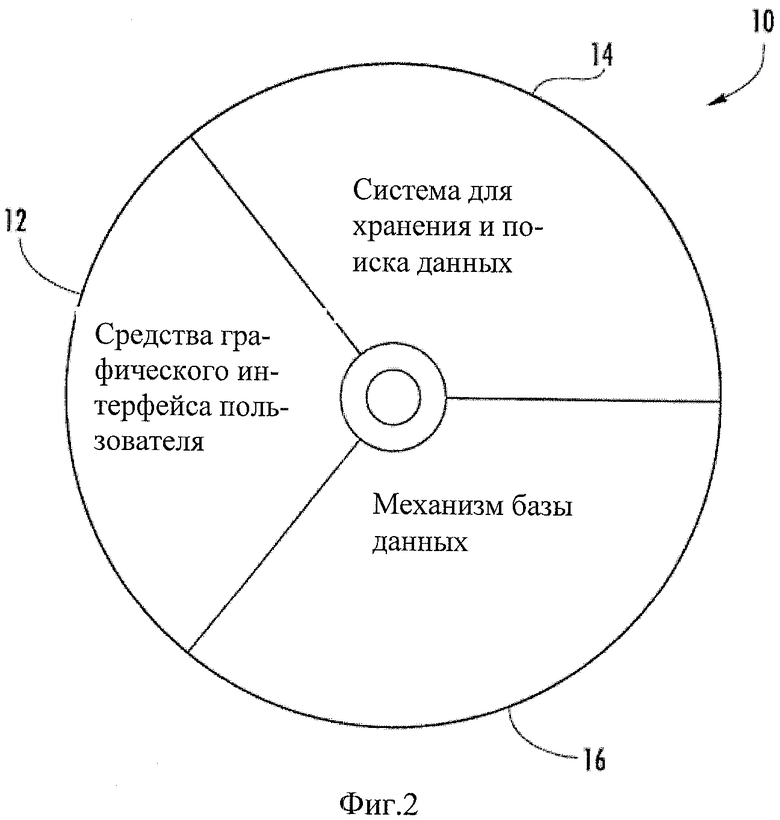
Система может состоять из средств графического интерфейса пользователя (ГИП) и системы для хранения и поиска данных (СХПД), которая может быть конкретно предназначена для анализа конкретного вируса (например, ВГС). Она также может включать коммерческий механизм СУБД.
Система может включать средство аннотирования, которое может упрощать получение, сохранение и управление критическими результатами обработки экспериментальных данных и вводить эти определенные пользователем результаты (аннотации) в тот же поисковый контекст, который уже содержит систематизированные и структурированные данные.
Система может, кроме того, включать средства для выравнивания, филогенетики и анализа мутаций, которые могут быть конкретно приспособлены к математике скорости репликации вируса (например, ВГС) и его точкам генезиса мутаций (например, полимераза, подверженная ошибкам).
Система может включать архитектуру программного обеспечения, которая имеет три уровня: уровень представления (ГИП), уровень связующего ПО (предметный) и уровень системы управления реляционной базой данных (СУРБД).
Средство для выравнивания может быть связано со средством представления запроса и включать средство сборки фрагментов для анализа полных и частичных геномных последовательностей. Средство для филогении может собирать выравнивания в эволюционные деревья, которые могут кодировать цветом вводимые последовательности и ставить временные метки. Графическое средство может представлять необработанные данные электроферограммы (следы) и собирать линейные и гистограммы для нанесения данных по переменным на график.
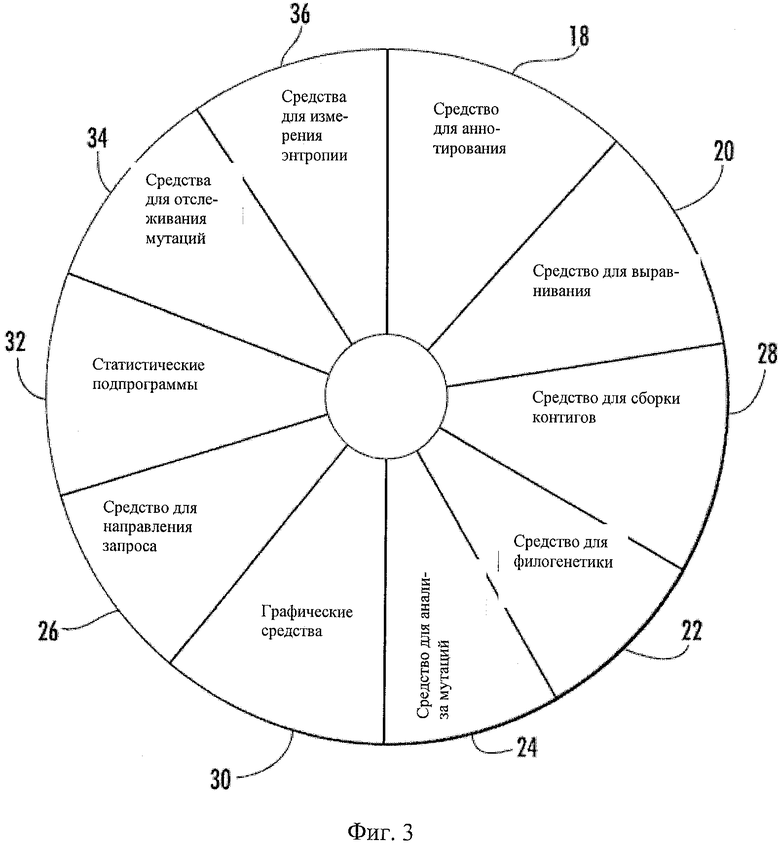
Система может включать дополнительные средства для отслеживания мутаций, создания отчетов и измерения энтропии, а также статистические подпрограммы и пакеты безопасности и установки.
Система может объединять информатику с базовыми исследованиями для быстрого обнаружения. Система может способствовать быстрому развитию рынка исследований ВГС. В результате система может в значительной степени повысить аналитические возможности и сократить время обработки данных. Система также может способствовать базовым исследованиям в области биоинформатики и теории информации и дать огромную выгоду обществу.
Система может иметь структуру из N уровней, которая позволяет легко масштабировать программное обеспечение среди разных ресурсов аппаратного обеспечения без необходимости в замене средств. Например, отдельные уровни могут быть реализованы на разных машинах с разными операционными системами, при этом вся система останется способной к связи между ними и эффективной обработке данных по вирусам.
Различные преимущества настоящего изобретения станут очевидны специалистам в данной области из нижеследующего подробного описания предпочтительного варианта осуществления, взятого вместе с прилагаемыми чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 - схематическое представление генома ВГС.
Фиг.2 - схематическое представление частей примера системы для управления данными по вирусам.
Фиг.3 - схематическое представление примера набора средств для управления данными по вирусам.
Фиг.4 - пример архитектуры приложений.
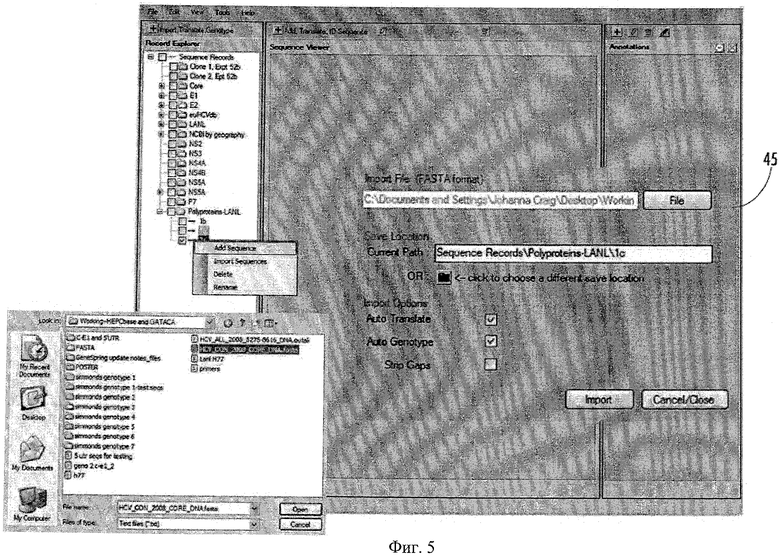
Фиг.5 - пример средства импорта данных.
Фиг.6 - пример окна администратора данных.
Фиг.7 и 8 - иерархические структуры папок и файлов.
Фиг.9 - окна примера средства аннотирования.
Фиг.10 - пример экрана редактирования.
Фиг.11 - пример окна конструктора запросов и пример окна результатов запроса.
Фиг.12 - примеры окон средства для направления запроса.
Фиг.13 - схематическое представление примера средства для выравнивания.
Фиг.14 - схематическое представление примера средства для сборки контигов.
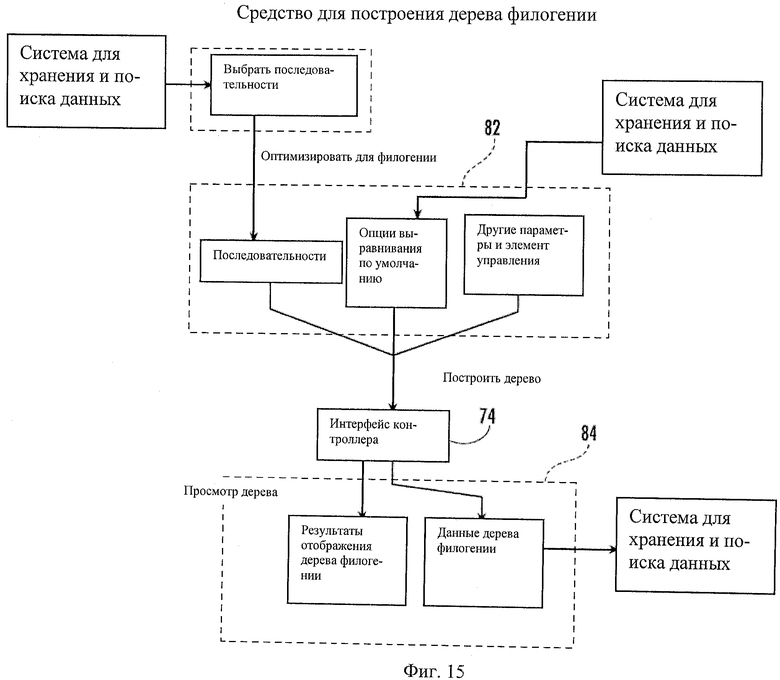
Фиг.15 - схематическое представление примера средства для создания дерева филогенетики.
Фиг.16 - схематическое представление примера варианта осуществления многоуровневой структуры.
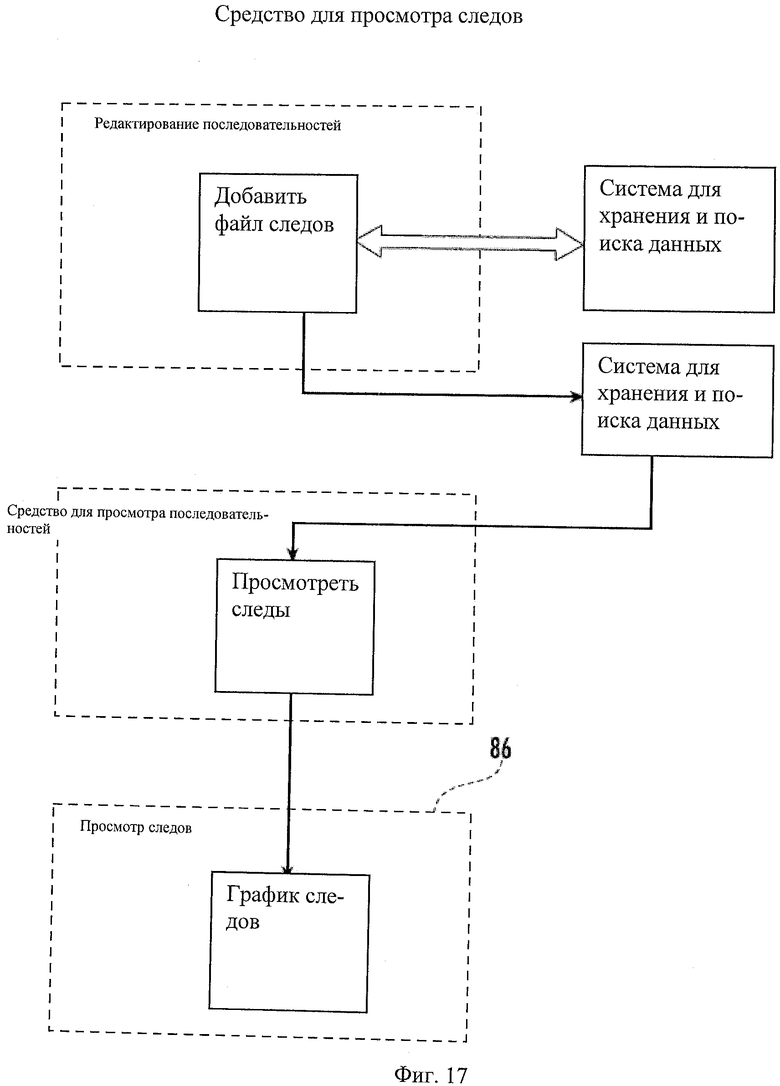
Фиг.17 - схематическое представление примера средства для просмотра следов.
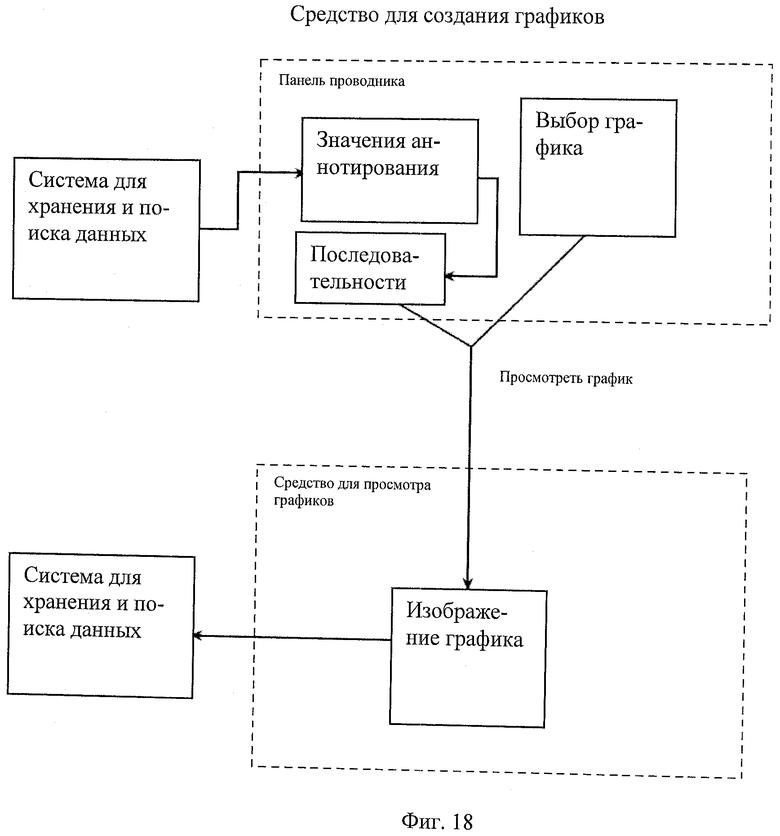
Фиг.18 - схематическое представление примера графического средства.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНОГО ВАРИАНТА ОСУЩЕСТВЛЕНИЯ
Теперь со ссылкой на Фиг.2, где показан пример системы, которая может решать и преодолевать основные проблемы с управлением данными, которые обычно встречаются при работе с вирусами, такими как ВГС. Система 10 может состоять из средств 12 графического интерфейса пользователя (ГИП) (например, графических иконок и визуальных указателей, которые представляют информацию и действия, доступные для пользователя), и системы для хранения и поиска данных (СХПД) 14, причем и то, и другое может быть разработано конкретно для анализа ВГС или анализа других вирусов. Система 10 также может включать коммерческий механизм 16 реляционной базы данных (например, компонент программного обеспечения, который можно использовать для создания, поиска, обновления и удаления данных). Эти компоненты могут позволить осуществлять интегрирование, анализ и хранение генетических, биологических, клинических и фенотипических данных и обеспечивать способность направления запроса о таких данных (смотрите ниже).
Как показано на Фиг.3, система может содержать разные средства. Показанная система включает средство для аннотирования 18, которое может упростить сбор, хранение и управление критическими результатами обработки экспериментальных данных и вводить эти определенные пользователем результаты (аннотации) в тот же поисковый контекст, который уже содержит систематизированные и структурированные данные. Кроме того, средство для аннотирования 18 может упростить язык манипулирования данными (ЯМД) для поиска таких данных. В результате пользователь может получить беспримерную гибкость добычи и анализа данных из массивов большого размера. Вирусные последовательности, включая последовательности ВГС, могут быть ассоциированы с многими измеренными биологическими параметрами, такими как вирусная нагрузка, антивирусный ингибитор, клеточная линия, длина эксперимента, профиль ферментов печени и т.д. Так, последовательности могут иметь большую размерность, которая уникальна для вируса (например, ВГС). Эти биологические параметры могут сопровождать каждую последовательность при хранении и манипулировании (в настоящее время биологи ВГС прикрепляют такие комментарии вручную). Следует отметить, что средства 20, 22, 24 для выравнивания, филогенетики и анализа мутаций могут быть специально подстроены под математику скорости репликации вируса (например, ВГС) и точки генезиса мутаций (например, полимеразы, подверженной ошибкам). Сочетание этих средств 20, 22, 24 в одном месте может значительно упростить проблемы управления и манипулирования данными, так что вирусолог сможет более эффективно выполнять свои исследования.
Средство для выравнивания 20 может быть связано со средством для направления запроса 26, которое может быть существующим средством для направления запроса. Средство для выравнивания 20 может включать средство для сборки фрагментов 28 для сборки фрагментов геномных последовательностей в консенсусную последовательность вируса (например, ВГС). Средство для выравнивания 20 может подавлять ложные прогнозы мутаций, возникающие из-за технической ошибки или невыравнивания, и итеративно улучшать выравнивания в нуклеотидных и аминокислотных последовательностях (например, в пяти гипервариабельных участках ВГС (см. Фиг.1), которые рассеяны между консервативными областями). Оно может делать это со специальными указателями последовательностей и модифицированными алгоритмами, которые могут вычислять расстояния на основе кумулятивных мутаций от базовой линии в этих областях. Средство для филогении 22 может предназначаться, помимо прочего, для сборки этих специализированных выравниваний в эволюционные деревья, и проставлять цветные коды и время на вводимых последовательностях, например, на основании желательных наборов результатов, например, согласно квази видам от одного пациента или от проб клонов. Графическое средство 30 может представлять необработанные данные электроферограмм (следы) и собирать линейные графики и гистограммы для нанесения переменных на график.
Могут быть предусмотрены дополнительные средства для отслеживания мутаций, измерения энтропии и создания отчетов. Система 10 также может включать статистические подпрограммы 32 и пакеты безопасности и установки. Средство для филогении 22, средства 34, 36 для отслеживания мутаций и измерения энтропии и статистические процедуры 32 могут совместно квантифицировать степень изменения вируса в последовательностях квази видов и в них путем, например, вычисления профилей мутации нуклеотидных и аминокислотных последовательностей (разнообразие), энтропии (сложность) и генетических расстояний (расхождение). Средство для отслеживания мутаций 34 может быть связано со средством для филогении 22 для определения скорости эволюции типов мутаций и вклада рекомбинации в разнообразие квази видов и в адаптивную эволюцию вируса (например, ВГС) при давлениях окружающей среды.
Статистические подпрограммы 32 могут формировать вывод из средства для филогении 22, средств для отслеживания мутаций и измерения энтропии 24, 36 для вычисления генетической изменчивости вируса (например, ВГС). Используемые в сочетании со средствами для аннотирования и направления запроса 18, 26, эти средства 32, 34, 36 могут позволить исследователям выполнять критические анализы относительно чувствительности генотипа к противовирусным лекарствам, включая: 1) исследование распределений квази видов и уничтожение вируса, 2) сравнение генетической неоднородности среди противовирусных респондеров и нереспондеров и 3) определение, перемещают ли квази виды вируса (например, ВГС) резистивные мутации в пределах или между генами вируса, чтобы повысить разнообразие для генотипов, стойких к лекарствам. Статистические подпрограммы 32 могут также включать формулы, например, для вычисления ковариантности инфицирующих генотипов для определения того, влияет ли изменение в нуклеотиде или аминокислоте в положении А на мутацию или рекомбинацию в положении В в какой-то данной последовательности.
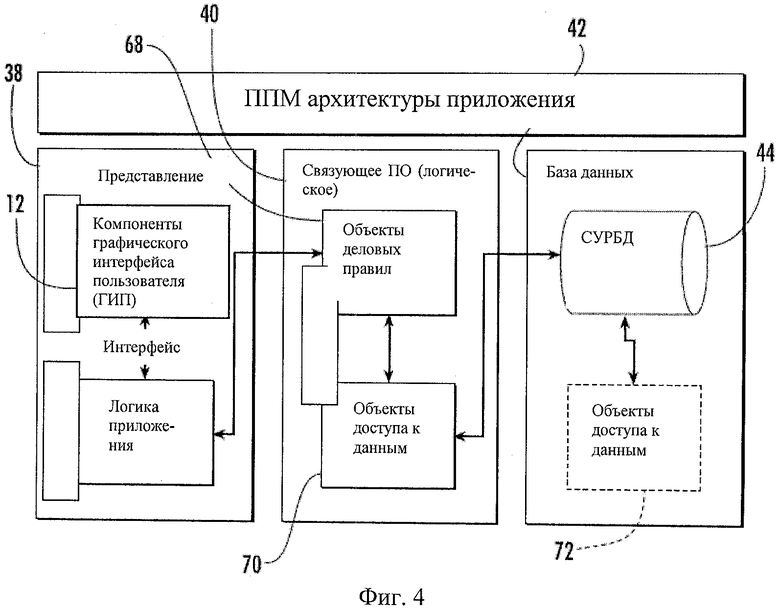
Пример системы 10 может состоять из компонентов программного обеспечения, которые облегчают хранение, интегрирование и анализ генетических, клинических и фенотипических данных и имеют способность запрашивать такие данные. Например, как показано на Фиг.4, архитектура программного обеспечения может состоять из уровней 38, 40, 42 представления, ПО промежуточного/логического уровня и базы данных при взаимодействии с объектными слоями. Например, эти уровни могут включать ГИП, связующее ПО и компоненты данных. Компоненты ГИП могут включать формы (например, формы окон), которые могут быть предоставлены пользователю с уровня представления, как средства 12 ГИП, с которыми пользователь может взаимодействовать. Компоненты ГИП могут принимать данные, вводимые пользователем, и отображать результаты. Компоненты связующего ПО могут включать логику обработки (например, способы), используемую системой 10 для обработки введенных данных и возврата результатов компонентам ГИП (например, объектам ГИП). Компоненты связующего ПО (например, объекты связующего ПО) могут взаимодействовать с компонентами базы данных, например, путем подготовки и передачи данных для хранения и поиска данных в компонентах базы данных. Уровень базы данных может включать систему управления реляционной базой данных (СУРБД) 44 для постоянного хранения данных и модель данных. Архитектура программного обеспечения описана более подробно ниже. Ввод последовательностей может быть легко осуществлен через многочисленные опции во время сеанса пользователя. Вирусные последовательности могут быть введены в систему 10, например, посредством любого подходящего средства ввода, способного вводить вирусные последовательности или данные по вирусным последовательностям. Необходимо понять, что последовательности могут быть введены в систему 10 целиком с использованием средства для импорта всей последовательности. Пример средства для импорта 45 показан в центре Фиг.5. Средство для импорта может быть конфигурировано так, чтобы позволить вводимым последовательностям оставаться как необработанные импортированные данные или каким-то образом автоматически обрабатываться, например автоматически транслироваться или автоматически идентифицироваться. Может быть разработано подходящее средство для приема генетических последовательностей в форме отдельных файлов, файлов формата FASТА или любых других подходящих источников данных. Это позволит осуществлять прямой импорт данных из секвенирующего устройства или машины. Секвенирующая машина может быть прямо соединена с системой или программным обеспечением, или же программное обеспечение может быть введено в секвенирующее устройство или машину для работы без создания файлов. Это средство также может быть предназначено для приема разных типов последовательностей, таких как нуклеиновокислотные (ntd) или аминокислотные (аа) последовательности. Пользователь может выбрать определение генотипа, трансляцию и идентификацию нативных и частичных белков вируса (например, ВГС), используя идентификатор последовательности (см. Фиг.5). Средство-транслятор последовательности может транслировать данные по нуклеинокислотной последовательности в данные по аминокислотной последовательности. Идентификатор последовательности может иметь форму средства, состоящего из алгоритмов, используемых для идентификации всех известных генотипов и подтипов вируса (например, ВГС). После ввода последовательности система 10 может автоматически вычислять чистые заряды белков и помечать все сайты гликозилирования и фосфорилирования. Генотипирование и трансляция могут быть представлены пользователю как опции.
На Фиг.6 показан пример средства-администратора данных (например, окно 46), которое пользователь может видеть после ввода последовательностей. Окно 46 администратора данных может включать проводник записей 48, который может иметь гибкий организатор 50 по типу листов и узлов дерева, позволяющий пользователям легко работать с их данными по последовательностям. Пользователи могут создавать иерархические структуры папок и файлов (см. Фиг.7 и 8), в которые они могут загружать различные объекты, включая без ограничения банки последовательностей, результаты выравнивания, следы и результаты запросов.
Система 10 может, кроме того, иметь средство для просмотра последовательностей 51 (например, средство отображения и редактирования, которое позволяет пользователям просматривать хранящиеся последовательности). Пользователи могут выбрать для отображения один или несколько банков последовательностей 52. После отображения для работы с выбранными последовательностями могут быть доступны различные опции, такие как редактирование, аннотирование, просмотр содержащихся белков или просмотр нуклеотидных участков. В соответствующий банк могут быть добавлены новые последовательности, или несколько последовательностей могут быть выбраны для выравнивания. Это является общим рабочим пространством, где пользователи могут манипулировать последовательностями и просматривать последовательности, которые хранятся в их банках последовательностей. Система 10 может позволять использовать разные средства из этого и других рабочих пространств.
Выделив последовательность в средстве просмотра 51 (как показано на Фиг.6), пользователь может просматривать отдельные белки, идентифицированные в этой последовательности в экране просмотра участка/белка 53 (показан в нижней панели окна 46 администратора данных на Фиг.6). Средство для просмотра участка/белка 53 может быть способно отображать нуклеотидные и/или белковые последовательности, сегментированные на составляющие белки или участки, соответственно. Одиночные последовательности могут быть выбраны в средстве для просмотра последовательностей для отображения в этом средстве. Пользователи могут переключаться для просмотра белкового участка и нуклеотидного участка. Система 10 может разрешать соотносить участки кодирования нуклеиновой кислоты и белки с необработанными данными. Пользователь может выбирать опции в пунктах меню для редактирования, трансляции, генотипирования, аннотирования, сохранения или удаления последовательностей, что более подробно описано ниже. Хотя администратор данных 46 может работать как графический интерфейс пользователя (ГИП), посредством которого пользователи могут взаимодействовать с системой, неграфический администратор данных может быть реализован отдельно или в сочетании с ГИП.
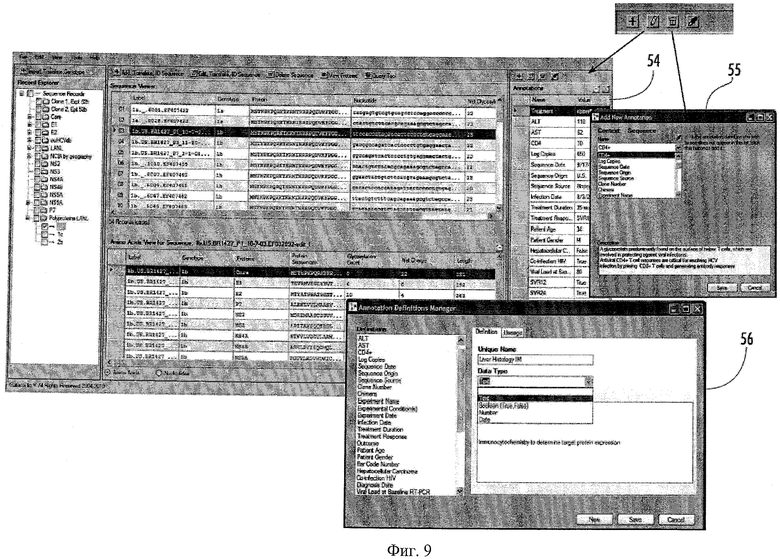
Определенные пользователем аннотации также могут быть связаны с одной или несколькими последовательностями с помощью средства для аннотирования 18 (см. экран аннотирования 54 вверху справа в окне 46 администратора данных на Фиг.6). Средство для аннотирования может работать как средство представления данных, определенных пользователем, которое позволяет пользователям просматривать и прикреплять введенные данные к последовательностям для справки. Стандартные и определенные пользователем аннотации могут быть связаны с последовательностями в любое время в сеансе. Экран аннотирования 54 может позволять пользователям создавать определения для значений или текста, представляющего клинические, экспериментальные и/или биологические данные, которые они хотели бы связать с их генетическими данными. Эта определяемая пользователем система аннотирования может позволять исследователям легко сохранять конфиденциальность пациента и стандарты HIPPА, поскольку они могут выбирать, как хранить собранную ими информацию.
Пользователь в любое время сеанса может добавлять аннотации к последовательностям. Аннотации, уже определенные в системе, могут быть прикреплены к последовательности для элементов выбора, как показано в окне 55 «Добавить новую аннотацию» (правая панель на Фиг.9). Новые аннотации могут быть созданы в Администраторе определения аннотаций 56 (нижняя панель на Фиг.9). Пользователь может ввести название аннотации, определить тип аннотации в выпадающем меню и выбрать, ограничена ли аннотация определенными значениями. Примеры вариантов осуществления системы 10 могут разрешать аннотациям принимать в сущности любую форму, включая текст, числа, изображения, гиперссылки, ассоциации файлов или другие полезные данные. Возможность определить аннотацию с большой точностью позволяет выполнять сложные поиски, используя средство для направления запроса 26.
Пользователи могут выбирать последовательности, которые они хотят аннотировать, и делать это в средстве для аннотирования 18, которое может отображаться для удобства рядом со средством для просмотра последовательности. По аннотациям можно проводить поиск. Администратор определения аннотаций 56 может позволять пользователям использовать предварительно определенные метки и типы ассоциированных данных для настройки аннотаций (например, идентификационные данные по пациенту, тип биопсии, последовательные даты и т.д.). Средство для аннотирования 18 также может позволять пользователям настраивать функции, например находить и возвращать специальные модели в определенных положениях в последовательности. Средство для аннотирования 18 может, кроме того, позволять пользователям просматривать, добавлять новые и редактировать существующие аннотации для отдельных последовательностей или наборов последовательностей.
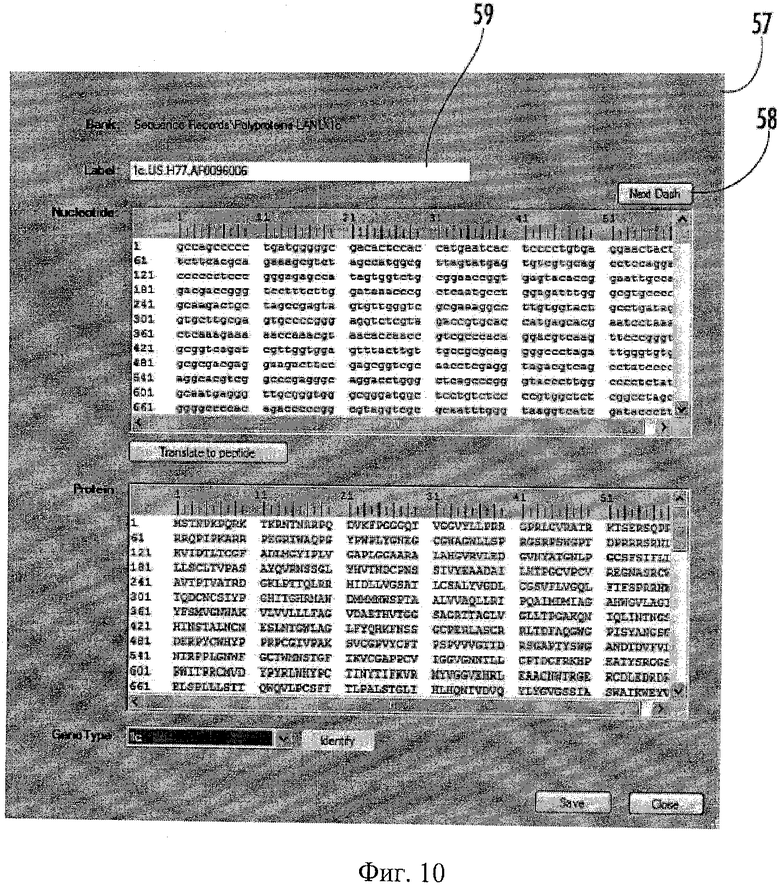
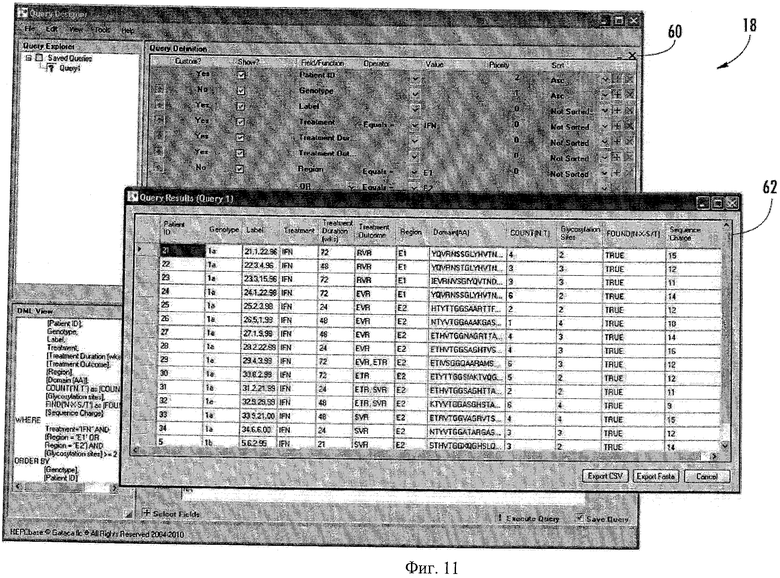
Щелчок мышью на любом из пунктов меню редактирования последовательности из меню редактирования 57 (показано на Фиг.6) или на иконке средства для редактирования (не показана) может открывать требуемую последовательность для редактирования, трансляции или повторной трансляции, генотипирования и сохранения. Пример средства для редактирования последовательности 57 показан на Фиг.10. Средство для редактирования последовательности 57 может позволять пользователю добавлять и редактировать данные по последовательности. Кнопка «Следующее тире» 58 может легко переводить курсор от тире до тире, устраняя ручное повторение редактирования. Это окно также может разрешать ввод одной последовательности путем простой вставки последовательности в формате FASTA (ntd или аа) в соответствующее окно. Метка последовательности FASTA может быть автоматически вставлена в бокс "Метка" 59. Связь геномных, клинических и экспериментальных данных по вирусу (например, ВГС) дает системе 10 дополнительную способность направления запросов. Пример средства для направления запросов 26 показан на Фиг.11 и 12. Средство для направления запросов 26 может включать окно 60 конструктора запроса и окно 62 результатов или отчета. Окно 60 конструктора позволяет пользователю выбирать атрибуты, такие как реакция на лечение, количество сайтов гликозилирования и заряд последовательности. Легко конструируемые запросы, направленные на наборы реляционных данных, могут помочь в идентификации и корреляции особых генетических вирусных изменений с терапевтическими, биологическими, демографическими и клиническими признаками. Пользователи могут выделить наборы данных через определенные пользователем генетические характеристики (модифицировать поиски, идентификационные данные по участку) или через аннотации, ассоциированные с последовательностью.
Отчет по результатам запроса может быть представлен в окне результатов 62. Окно результатов 62 может обеспечивать легкий просмотр найденных данных. В показанном примере окно результатов 62 показывает продолжительность лечения, результат реакции и количество сайтов гликозилирования, найденных для областей Е1 и Е2. Результаты запроса могут быть выровнены с помощью средства для выравнивания 18 или обработаны другим средством в системе 10 для расширенного анализа. Используя средство для аннотирования 18, пользователь может проводить поиск и аннотировать последовательности для этих специальных модифицированных сайтов после трансляции, которые дали возможность сделать этот запрос.
Из окна результатов 62 пользователь может запросить вычисление процентов изменения в любом положении в выравнивании. Щелчок правой кнопкой мыши на последовательности может вызвать средство для редактирования 52, чтобы можно было редактировать последовательности или аннотации, или и те, и другие. Окно результатов 62 можно экспортировать в разные форматы, например в файл Excel, или отправить в средство для выравнивания 20 (например, щелчком правой кнопки мыши).
Средство для направления запросов 26 может позволять пользователям получать данные об их последовательностях, ограниченные только аннотациями. Это средство может быть введено в удобный для пользователя указательный интерфейс для определения параметров запроса и полей вывода для облегчения отчетов и получения данных по последовательности. Пользователи могут выбирать из перечней полей в стандартной структуре данных, но также могут вести поиск пользовательских полей (аннотаций), определенных пользователем в средстве для аннотирования 18. Результаты запроса могут быть отображены в разных форматах, например, в формате с сеткой, и могут быть экспортированы в разные форматы, такие как CVS или FASTA, в зависимости от случая.
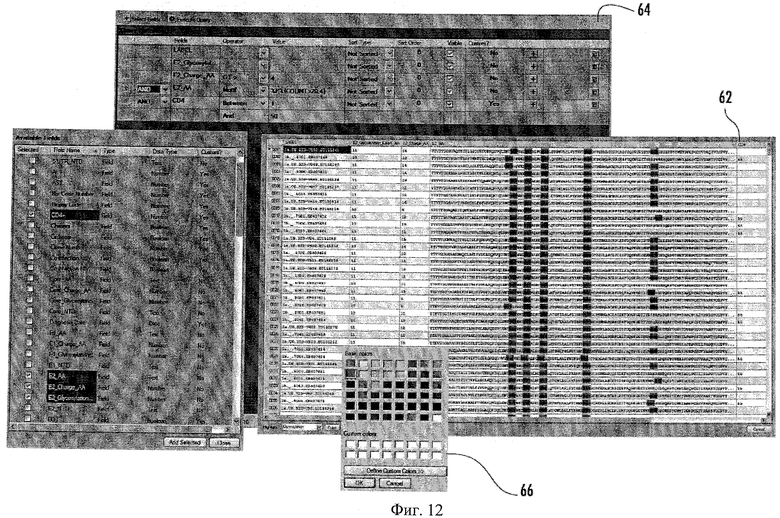
Пример использования средства для направления запросов 26 состоит в следующем. Пользователь может захотеть исследовать предварительную корреляцию между вирусной инфективностью и иммунной функцией. Белки вирусной оболочки играют основные роли в тропизме, инфективности и иммунной реакции хозяйской клетки. Уровень положительного заряда на Е2 ВГС может усиливать вирусную инфективность, количество остатков пролина влияет на формирование альфа-спирали в Е2 и, таким образом, на вход вируса, а пониженное количество CD4+ предполагает снижение иммунной функции и прогрессирование инфекции ВГС.
Для исследования вышеупомянутой корреляции пользователь может направить запрос в систему 10, чтобы: i) установить места всех последовательностей Е2 с зарядом аа больше (>) 4, Количество D4+ от 1 до 55 и количество пролина >20 (см. панель выбора оператора 64 на Фиг.12) и ii) найти данные по всем последовательностям Е2 аа, заряд Е2 и количество гликозилирования, идентификационные номера пациентов и количества CD4+ в наборе результатов. Этот простой запрос может дать набор результатов (показанный в окне результатов 62 на Фиг.12), который позволяет исследователю коррелировать последовательности, ассоциированные с тропизмом клеток, с параметром прогрессирования заболевания. Все задачи и количества по специальным участкам, таким как сайты гликозилирования и фосфорилирования, могут быть выделены, например, с использованием средства выделения 66 (показано как нижняя панель на Фиг.12). Запросы могут быть при необходимости сохранены и аннотированы. Средство выравнивания 20 может быть связано со средством для направления запросов 18, позволяя в выравнивании выделить все ассоциированные атрибуты запроса.
Теперь снова со ссылкой на Фиг.4, где показано связующее ПО 40 (т.е. доменный слой), который может состоять из нескольких логических слоев. В одном примере системы 10 связующее ПО 40 может содержать два слоя. Один предназначен для обработки доменной логики и называется "деловые правила" 68. Этот логический слой 68 может располагаться между слоями представления и доступа к данным 70 и может отвечать за обработку запросов, направляемых от слоя представления и к нему и от слоя доступа к данным 70 и к нему. Все классы, которые существуют в деловых правилах 68, могут в соответствующих случаях иметь дополнительные классы в слое доступа к данным. Слой доступа к данным 70 может существовать между слоем доменной логики 68 и СУРБД 44 и может называться "Доступ к данным". Слой доступа к данным 70 может включать все классы, ответственные за запрос данных из системы СУРБД 44 и представления данных в нее. Все классы, которые существуют в слое доступа к данным 70 могут иметь дополнительный класс в слое деловых правил 68, а также дополнительные таблицы в модели данных 72, описанной ниже.
База данных (СУРБД) 44 может использоваться для постоянного хранения данных приложений. Она может содержать систему управления реляционной базой данных (СУРБД) третьих лиц и модель данных 72. Модель данных 72 может определить табличные записи, взаимозависимости которых определяются посредством первичных отношений и отношений внешних ключей. Модель 72 может содержать записи, включающие последовательности, аннотации, контрольные последовательности и дополнительные данные (справочные генотипы, типы данных аннотации и т.д.). В одном примере СУРБД 44 может использоваться бесплатная версия ПО Microsoft SQL Server 2005 express.
Один пример описанной выше системы 10 может использовать следующую технологию.
Программное обеспечение:
Структура приложений: Microsoft ASP .NET
Языки:
VB .Net: Объекты просмотра и презентатора
С# .Net: Объекты деловых правил и доступа к данным
С++: Интеграция алгоритмов третьих лиц
Формы окон.NET: Представление
T-SQL: Хранящиеся процедуры для сбора данных в виде дерева
XML: Схема представления в виде дерева
SQL: DDL и ЯМД
СУРБД (Microsoft SQL Server 2005 Express)
IDE (Microsoft Visual Studio .NET 2005)
Аппаратное обеспечение:
Память: 2 Гб DDL Ram
ЦП: 1 ГГц Pentium
Жесткий диск: 80 Гб 7800 об/мин Seagate
Как сказано выше, система 10 может использовать N-уровневую архитектуру, содержащую уровни представления, связующего ПО и системы реляционной базы данных (для постоянного хранения данных). Слой представления 38 может состоять из компонентов для просмотра, таких как средства ГИП 12 (например, формы окон), и классов презентатора (например, процессоров для обработки событий и логических приложений). Слой связующего ПО 40 может состоять из основных доменных слоев, таких как слой доменной логики (т.е. деловые правила) 68 и слой доступа к данным 70. Масштабируемость, подразумеваемая этим архитектурным подходом, может быть использована так, что система 10 может быть масштабирована к нагрузке без необходимости изменения средств. Таким образом, система 10 может быть легко реализована на нескольких компьютерах и нескольких операционных системах без необходимости значительной перестройки системы 10. Система 10 может быть разработана с использованием шаблона разработки презентатора для просмотра модели (ППМ). Программное приложение системы может быть написано главным образом на С# .NET (или другом подходящем языке) и может быть разделено на три слоя, включая интерфейс пользователя (просмотр), приложение (презентатор) и доменный слой (модель). Слой интерфейса пользователя может давать пользователю элементы управления формами окон и передавать потребности в обработке, например, через обработчики событий и запросы, соответствующим объектам презентатора. Слой просмотра может не содержать логики обработки, относящейся к объектам доменного слоя или слоя приложения. Классы слоя приложения могут обрабатывать все передачи информации к соответствующим классам просмотра и от них через интерфейс. Обработчики событий для соответствующих объектов просмотра могут находиться на слое представления. Объекты слоя представления могут обрабатывать делегирование потока данных приложения, подтверждение данных, вводимых пользователем, обмен сообщениями и запросы интерфейса доменного слоя. Слой приложения также может принимать запросы от вспомогательных фоновых служб по автоматизированным подпрограммам тестирования независимо от просмотра. Доменный слой может включать все классы, относящиеся к обработке логических запросов информации, передаваемой от слоя приложения или пропускаемой обратно через запросы из постоянной памяти. Соответствующие объекты на доменном слое и слое презентатора (например, алгоритмическая обработка выравнивания и получаемый перечень объектов для отображения на слое просмотра) могут быть связаны двунаправлено через интерфейс.
Далее будут описаны примеры систем 10 и средств 17.
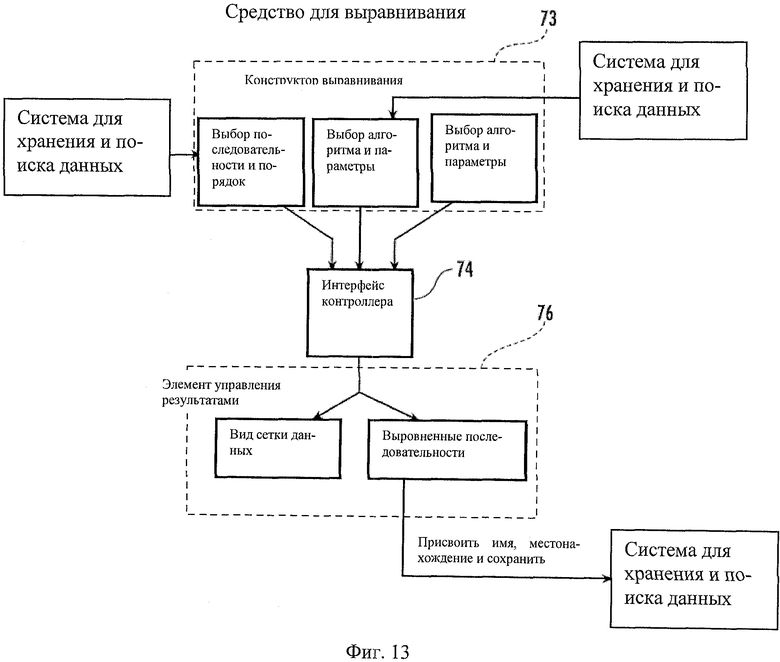
Пример средства для выравнивания последовательности в общем указан как позиция 20 на Фиг.13. Средство для выравнивания последовательности 20 может позволять пользователям располагать первичные ДНК, РНК или белковые последовательности для идентификации участков сходства, которое может быть следствием функциональных, структурных или эволюционных отношений между последовательностями. Выравнивания могут проявлять тенденцию к меньшей точности при быстро мутирующих вирусах, таких как ВГС. Так, могут быть включены алгоритмы для выравнивания гипервариабельных участков (например, пяти, показанных для ВГС) отдельно от рассеянных консервативных последовательностей вдоль генома и вычисления расстояний на основании совокупных оценок комбинированного профиля мутации инфицирующего генома (или геномов).
Средство для выравнивания последовательности 20 может позволять пользователю: а) выбирать последовательности в окне навигации; b) настроить систему 10 на автоматическое различение между вариантами попарного и множественного выравнивания на основании того, выбирает ли пользователь две или больше последовательностей, соответственно; с) выбирать из нескольких подходящих алгоритмов, матриц количественной оценки и штрафных значений разрыва; d) выбирать подавление ложных отрицательных мутаций путем выбора из меню полимераз, купленных у биотехнологических компаний (например, TaqMan) (алгоритм может включать частоту ошибок полимеразы в формуле); е) выбор для рассмотрения всех или поднабора из пяти гипервариабельных участков, кроме консервативных областей для сборки; f) настроить программу на цветовое кодирование различных конкретных информационных точек заболевания (например, гликозилирование, фосфорилирование, мутация или определенное пользователем декорирование); g) просматривать, сохранять, аннотировать и экспортировать полученные выравнивания; h) собирать, редактировать и сохранять выравнивания или замены; и/или выполнять другие соответствующие задачи.
Могут быть созданы элементы управления формами окон пользователя, классы логических областей и объекты базы данных для решения этих задач. Пользователи могут выбрать в средстве для просмотра каждую последовательность, которую они хотят выровнять. После выбора больше чем одной последовательности в средстве для просмотра последовательностей может быть включена кнопка выравнивания на верху средства для просмотра последовательностей, которая после включения может вызывать подъем панели горизонтального разделения и загрузку пользовательского элемента управления, который может быть предназначен для сбора параметров выравнивания. Этот элемент управления может называться, например, "Конструктор выравнивания".
Конструктор выравнивания 73 может иметь разделенный контейнер, который может быть разделен на две панели, например на левую и правую. Левая панель может содержать элемент управления списком, который может содержать список меток, ассоциированных с выбранными последовательностями средств для просмотра последовательностей. Справа от элемента управления списком могут быть расположены кнопки изображения (например, кнопки стрелок вверх и вниз), которые позволяют пользователям переупорядочивать последовательности по желанию (они также могут позволять пользователю определять порядок, в котором последовательности могут появляться на выходе). Правая панель может содержать список алгоритмов выравнивания, которые может выбирать пользователь. Список алгоритмов может содержать названия различных алгоритмов локального и полного, попарного и множественного выравнивания белков и/или нуклеотидов. Список алгоритмов может быть составлен в соответствии с количеством последовательностей, которые будут выровнены (например, если пользователь выбирает две последовательности, ему может быть выведен список названий доступных алгоритмов попарного выравнивания, а если пользователь выбирает больше двух последовательностей, может быть представлен список алгоритмов множественного выравнивания). После выбора алгоритма из списка ниже выпадающего элемента управления списком алгоритмов может появляться список опций параметров, который может позволять пользователям добавлять параметры, соответствующие требованиям выбранного алгоритма (например, штрафы за разрывы, матрицы количественной оценки и т.д.). Ниже значений параметров алгоритмов может быть представлен список параметров, специфических по типам мутаций или других определяемых пользователем параметров, таких как элементы управления цветовым кодированием, например в форме выпадающих списков с закрепленными элементами управления подбором цвета. Эти параметры могут использоваться приложением для выделения важных изменений в РНК и аминокислотных последовательностях на экране, появляющемся после выравнивания. Такие мутации могут включать мутацию РНК, которая придает функциональное изменение соответствующей аминокислоте, так что мутация заново делает аминокислоту целью пост-трансляционной модификации (например, сайт гликозилирования или фосфорилирования), или причину структурных изменений в белке. После того, как пользователь адекватно определил значения всех параметров, может быть включена кнопка с названием "Выравнивание".
Когда пользователь активирует эту кнопку "Выравнивание", информация по параметрам может быть передана в интерфейс 74 контроллера, через который могут быть вызваны логические процессоры доменов, предназначенные для выполнения выравнивания. Чтобы дополнить этот процесс, может быть создано контрольное окно индикатора прогресса. Контрольное окно индикатора прогресса может содержать строку индикатора прогресса, управление метками (которое может выводить текст относительно состояния прогресса) и кнопку отмены, которая при активации может прерывать и отменять текущий процесс. Может быть создан элемент управления результатами 76. Элемент управления результатами может содержать дисплей результатов, выводимых из средства, такой как управление "Просмотр сетки данных", и кнопки, такие как кнопка отмены и кнопка сохранения. Этот элемент управления будет отображать для пользователя выровненные последовательности. Затем пользователь может активировать кнопку отмены, чтобы закрыть этот элемент управления (таким образом возвращаясь к управлению параметрами) или активировать кнопку сохранения для сохранения данных выравнивания. Для дополнения действия по сохранению может быть создан элемент управления. Этот элемент управления может содержать управление текстовым полем, которое позволяет пользователю дать название средству для выравнивания и навигации, такому как выпадающий список поискового типа, чтобы позволить пользователю указать папку в проводнике записей, где будет храниться запись о выравнивании и будет представлена как иконка с точкой данных метки, проставленной пользователем. Пользователь может иметь возможность связать пользовательские аннотации с контейнерами выравнивания и, при необходимости, возможность проводить поиск таких объектов, пользуясь средством для направления запросов.
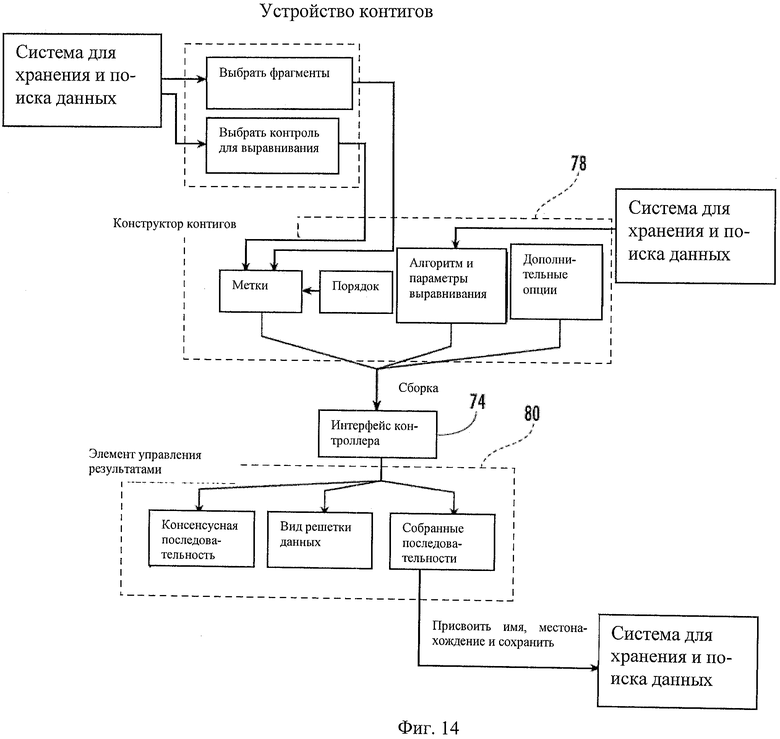
Пример средства для сборки контигов в общем показан в позиции 28 на Фиг.14. Средство для сборки контигов 28 может быть одним аспектом средства для выравнивания 20 или может быть реализовано отдельно. Средство для сборки контигов 28 может собирать данные по фрагментам от проектов секвенирования любого размера, от нескольких до десятков тысяч фрагментов, в одну консенсусную последовательность. Средство для сборки контигов 28 может быть выполнено так, чтобы позволить пользователю: а) представлять фрагменты последовательностей в средство для выравнивания 20 для множественного выравнивания; b) представлять контрольную последовательность для средства для сборки контигов, чтобы выровнять фрагменты; с) разработать проект сборки контигов для идентификации и удаления ненадежных данных, включая концы 3' или 5' плохого качества, считанные данные субминимальной длины и векторные последовательности; d) сохранять полученную консенсусную последовательность и е) вызывать сохраненную последовательность для манипулирования параметрами и повторной сборки и/или выполнять другие связанные с этим задачи. Могут быть созданы элементы управления пользовательскими окнами, логическими классами доменов и объекты базы данных для выполнения этих требований. Пользователи могут выбрать набор фрагментов из объекта банка последовательностей в проводнике записей 48, который может в свою очередь поместить сохраненные фрагменты в средство для просмотра последовательностей 51. Пользователи также могут выбрать последовательность для использования в качестве контрольной при выравнивании. Пользователи могут выбрать каждую последовательность в средстве для просмотра последовательностей 51, которую они хотят использовать для средства для сборки контигов 28. После выбора больше чем одной последовательности в средстве для просмотра последовательностей 51 кнопка конструктора контигов может быть включена вверху средства для просмотра последовательностей 51, которая после включения может вызывать подъем горизонтальной панели разделения контейнера и загружать пользовательский элемент управления, который может быть предназначен для определения параметров сборки контигов. Этот элемент управления может называться "Конструктор контигов". Конструктор контигов 78 может использовать признаки, сходные с таковыми у конструктора выравнивания, поскольку контиги могут сначала быть выровнены по контрольной последовательности, а затем объединены в непрерывную последовательность.
Конструктор контигов 78 может иметь разделенный контейнер, который может быть разделен на две панели, например, на левую и правую. Левая панель может содержать элемент управления списком, который может содержать список меток, ассоциированных с выбранными средствами для просмотра последовательностей, последовательностями фрагментов и контрольной последовательностью. Справа от элемента управления списком могут быть расположены кнопки изображения (например, кнопки стрелок вверх и вниз), которые позволяют пользователям переупорядочивать последовательности по желанию (они также могут позволять пользователю определять порядок, в котором последовательности могут появляться при предварительной сборке контигов, на выходе выравнивания (сканирования). Правая панель может содержать список алгоритмов выравнивания, которые может выбирать пользователь. После выбора алгоритма из списка ниже выпадающего элемента управления списком алгоритмов может появляться список опций параметров, который может позволять пользователям добавлять параметры, соответствующие требованиям выбранного алгоритма (например, штрафы за разрывы, матрицы количественной оценки и т.д.). Может быть установлена конфигурация по умолчанию для оптимального выравнивания контигов перед сборкой (например, отсутствие штрафов за концевые разрывы, высокая стоимость внутренних разрывов, короткое совпадение с высокой оценкой/остатком). Ниже значений параметров алгоритмов может быть представлен флаговых кнопок. Эти флаговые кнопки могут быть связаны с дополнительными опциями перед сборкой, которые может выбирать пользователь, например: а) автоматическое удаление векторной последовательности (настоятельно рекомендуется при использовании данных Сангера); b) удаление загрязняющей последовательности; с) идентификация повторяющихся последовательностей; d) автоматическая обрезка концов 5' и 3'; е) ручная установка конца; f) разрешение средству сборки оптимизировать порядок, в котором он собирает фрагменты; и/или другие соответствующие опции. После того, как пользователь завершит конструирование сборки, может быть включена кнопка, называемая "Сборка". Когда пользователь активирует кнопку "Сборка", информация по параметрам может быть передана в интерфейс контроллера 74, посредством которого могут быть вызваны логические процессоры доменов для выполнения множественного выравнивания и последующей сборки консенсусной последовательности. Чтобы дополнить этот процесс, может быть создано контрольное окно индикатора прогресса. Контрольное окно индикатора прогресса может содержать строку индикатора прогресса, управление метками (которое может выводить текст относительно состояния прогресса) и кнопку отмены, которая при активации может прерывать и отменять текущий процесс. Может быть создан элемент управления результатами 80. Элемент управления 80 может содержать дисплей результатов, выводимых из средства для сборки контигов 28, такой как текстовое поле, элемент управления "Просмотр сетки данных", и кнопки, такие как кнопка отмены и кнопка сохранения. В текстовое поле может быть введена консенсусная последовательность. Текстовое поле может иметь возможность прокрутки (вправо или влево). Средство для просмотра сетки данных будет содержать все выровненные фрагменты последовательности. Затем пользователь может активировать кнопку отмены, чтобы закрыть этот элемент управления (таким образом возвращаясь в конструктор контигов) или активировать кнопку сохранения для сохранения результатов средства для сборки контигов 28. Для дополнения действия по сохранению может быть создан элемент управления. Этот элемент управления может содержать управление текстовым полем, которое позволяет пользователю дать название средству для выравнивания и навигации, такому как выпадающий список поискового типа, чтобы позволить пользователю указать папку в проводнике записей 48, где будет храниться запись о сборнике и будет представлена как иконка с точкой данных метки, проставленной пользователем. Пользователь может иметь возможность связать пользовательские аннотации с контейнерами выравнивания и, при необходимости, возможность проводить поиск таких объектов, пользуясь средством для направления запросов 26.
Пример средства для филогении в общем показан в позиции 22 на Фиг.15. Средство для филогении 22 может собирать специализированные выравнивания, которые учитывают гипервариабельные участки в эволюционных деревьях, и может проставлять цветовые коды и временные метки на вводимых последовательностях согласно желательным аспектам, таким как квази виды от одного пациента или клональные пробы. Средство для филогении 22 может позволить пользователю: а) конструировать и выполнять множественное выравнивание, которое описано по этапам выше; b) кодировать цветом последовательности или участки последовательностей для легкого отслеживания квази видов по типу мутации или участкам под селективным давлением у одного пациента или клона из дерева; с) создавать и графически отображать корневые деревья филогении; d) сохранять полученные деревья в распознаваемом формате, таком как формат PAUP (*.pau или *.nex); и/или выполнять другие соответствующие задачи. Могут быть созданы элементы управления формами окон пользователя, Могут быть созданы элементы управления формами окон пользователя, классы логических областей и объекты базы данных для решения этих задач. Пользователи могут выбирать последовательности из устройства для просмотра последовательностей 51 для конструктора выравнивания (который описан выше). Правый разделенный контейнер конструктора выравнивания 73 может иметь кнопку управления, названную "оптимизировать для филогении". Если пользователь щелкнет на этой кнопке, опции выравнивания, используемые по умолчанию, могут быть введены во вводимые параметры конструктора, выбирая алгоритм выравнивания, лучше всего подходящий для построения дерева филогении (например, ClustalV), и автоматически вводя для ассоциированных элементов управления параметрами значения, оптимизированные для построения филогении (см. оптимизатор филогении 82 на Фиг.15). Могут быть созданы и отображены дополнительные элементы управления параметрами (такие как средства выбора цвета для легкого отслеживания квази видов). После определения всех требуемых параметров выравнивания может быть активирована кнопка "Построить дерево". После активации пользователем кнопки "Построить дерево" информация по параметрам может быть передана в интерфейс контроллера 74, посредством которого могут быть вызваны логические процессоры доменов, предназначенные для выполнения множественного выравнивания и последующей сборки дерева. Чтобы дополнить этот процесс, может быть создано контрольное окно индикатора прогресса. Контрольное окно индикатора прогресса может содержать строку индикатора прогресса, управление метками (которое может выводить текст относительно состояния прогресса) и кнопку отмены, которая при активации может прерывать и отменять процесс построения дерева. Может быть создан пользовательский элемент управления 84 "Просмотр дерева". Этот элемент управления 84 может быть элементом управления, который может выдавать результаты процесса построения дерева. Для завершения создания выхода этого элемента управления можно использовать графические объекты окон или другие подобные средства. Опции цветового кодирования могут отображаться в соответствии с параметрами, введенными пользователем (в соответствующих случаях). Могут быть доступны опции сохранения результатов процесса построения дерева.
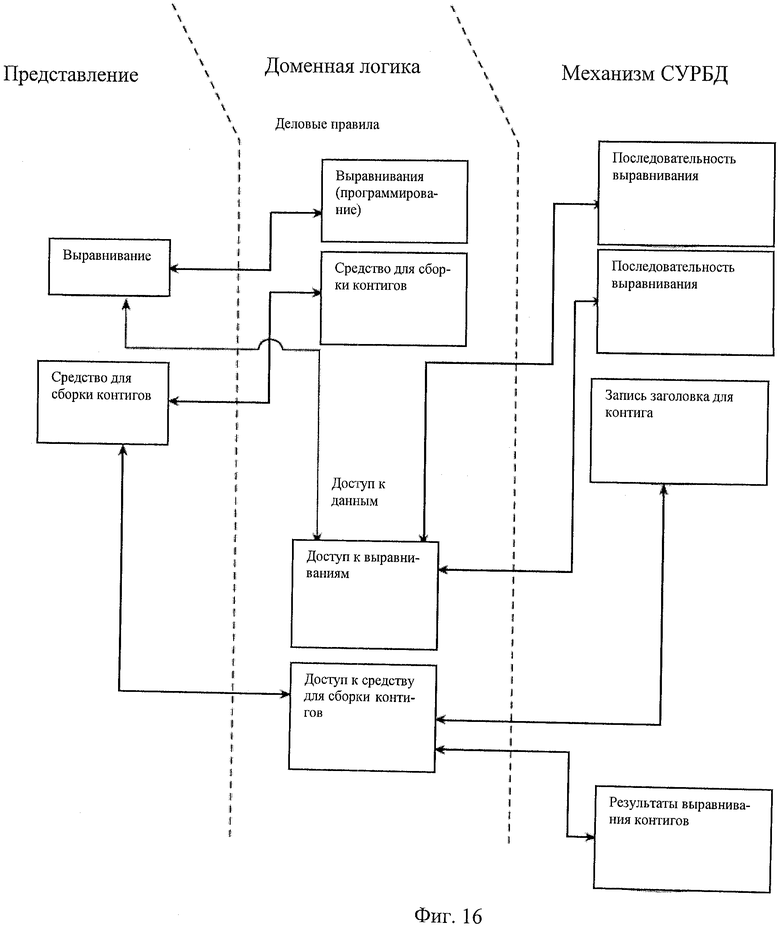
Соответствующие доменные объекты могут быть созданы, например, на языке С#, чтобы облегчить обработку различных средств. Доменная логика может быть разделена на категории, например, деловые правила 68 и доступ к данным 70. Соответствующие объекты, относящиеся к каждой части различных средств, могут быть созданы на доменном уровне, например, один для деловых правил 68 и другой для доступа к данным 70.
В примере системы, в общем показанном в позиции 10 на Фиг.16, может быть создан объект деловых правил с названием "Выравнивания" для обработки запросов от имени дополнительного объекта слоя приложения, который также может быть назван "Выравнивания". Может быть создан объект доступа к данным с названием "Доступ к выравниваниям", чтобы обрабатывать взаимодействие с базой данных по запросам от доменного объекта "Выравнивания". Объект "Выравнивания" может быть составлен из свойств для получения и установки вводных данных от конструктора выравнивания, свойств, которые могут содержать результаты выравнивания, способов выполнения выравнивания или способов, которые сопряжены с компонентами третьих лиц, предназначенными для обработки выравниваний и выдачи результатов. Объект "Доступ к выравниваниям" может включать способы, которые включают ЯМД для конкретной СУРБД, который может ускорить сохранение и поиск постоянных вводов и выводов для механизма 44 СУРБД. Может быть создан объект деловых правил с названием "Средство для сборки контигов" для обработки запросов от имени дополнительного объекта слоя приложения, также называемого "Выравнивания". Объект доступа к данным с названием "Доступ к средству для сборки контигов" может быть создан для обработки взаимодействия с базой данных по запросам доменного объекта "Средство для сборки контигов". Объект "Средство для сборки контигов" может состоять из свойств для получения и установки вводных данных конструктора смежных объектов, свойств, которые могут содержать результаты выполнения проектов смежных объектов, способов выполнения выравниваний или способов, которые сопряжены с компонентами третьих лиц, которые обрабатывают выравнивания и выдают результаты, и способов сборки консенсусной последовательности. Объект "Доступ к выравниваниям" может содержать способы, которые могут включать ЯМД для конкретной СУРБД, который может ускорять сохранение и поиск постоянных вводов и выводов из механизма 44 СУРБД.
Модель опорных данных 72 может включать множественные записи. В одном примере системы 10 модель данных 72 состоит из четырех записей. Первая запись может быть названа "выравнивание последовательности" и может использоваться для хранения записи заголовка выравнивания последовательности. Она может включать следующие поля: поле первичного ключа/идентификации (UIP), поле имени (метка) и поле параметра/заголовка (params). Вторая запись может быть названа "последовательность выравнивания" и может хранить указатели на отдельные последовательности, которые составляют выравнивание, и выровненную последовательность. Она может включать поле первичного ключа/идентификатора (UIP), поле внешнего ключа (seq_align_uid), UIP строки последовательности, которая хранится в таблице последовательностей (sequence_uid), и поле, содержащее последовательность в том виде, как она появляется в результатах выравнивания. Третья запись может быть записью заголовка для сеанса сборки контигов и может включать поле первичного ключа/идентификатора (UIP), поле имени (метка) и поле параметра/заголовка (params). Четвертая запись может содержать результаты выравнивания контигов и может иметь следующие поля: поле первичного ключа/идентификатора (UIP), поле внешнего ключа (contig_assembly_uid), UIP строки последовательности, которая хранится в таблице последовательностей, и флаг, который можно использовать как индикатор с тремя состояниями, который указывает системе, является ли последовательность фрагментом, контигом или контрольной.
В одном примере системы 10 объект деловых правил с названием "Дерево филогении", например, для обработки запросов от имени дополнительного объекта слоя приложения, также называемого "Дерево филогении". Объект доступа к данным с названием "Доступ к дереву филогении" может быть создан для обработки взаимодействия с базой данных по запросам доменного объекта "Дерево филогении". Объект "Дерево филогении" может состоять из свойств для получения и установки вводных данных конструктора выравнивания, свойства, которые могут включать результаты выравнивания, способы выполнения выравниваний и способы создания филогенного дерева (например, соединение соседей). Объект "Доступ к дереву филогении" может включать способы, которые включают ЯМД для конкретной СУРБД, который может ускорять хранение и поиск постоянных данных в СУРБД 44.
Модель опорных данных 72 может содержать множественные записи. В одном примере системы 10 модель опорных данных 72 может содержать две записи. Первая запись может называться "выравнивания филогенной последовательности" и может использоваться для хранения записи заголовка начального выравнивания последовательности и получаемого дерева. Она может содержать следующие поля: поле первичного ключа/идентификатора (UIP), поле имени (метка), поле параметра/заголовка выравнивания (alignment_params) и второе поле параметра/заголовка (phylo_params).
Вторая запись может называться "филогенная последовательность" и может хранить указатели на отдельные последовательности, которые могут составлять начальное выравнивание. Она может содержать поле первичного ключа/идентификатора (UIP), поле внешнего ключа (seq_align_uid), UIP строки последовательности, хранящейся в таблице последовательностей (sequence_uid), и поле, включающее последовательности, как они появляются в результатах предварительного множественного выравнивания.
Могут быть разработаны графические средства для помощи исследователю в анализе данных по ВГС. Графические средства могут представлять необработанные данные электроферограммы (следы) и собирать линейные графики и гистограммы для нанесения на две переменных. Графические средства могут позволять пользователю сохранять и просматривать файлы следов, ассоциированные с их последовательностями, и наносить собранные приложением линейные графики и гистограммы на две переменных.
Пользовательские элементы управления могут позволять пользователям выполнять эти задачи. Первым элементом управления может быть средство для просмотра следов, показанное на Фиг.17, и вторым может быть генератор графиков, показанный на Фиг.18. Элемент управления формами окон может позволять пользователям просматривать файлы следов хроматограмм, ассоциированные с последовательностями, введенными в систему. Средства для редактирования и добавления последовательностей могут быть расширены, чтобы позволить хранить файлы следов. В одном примере системы 10 кнопка управления "Добавить файл следов" может быть добавлена к элементу управления редактированием последовательности 51. Когда пользователь активирует эту кнопку, может появиться диалоговое окно по файловой системе, запрашивающее у пользователя выбор места нахождения файла следов из локальной файловой системы или по сети. После того как пользователь укажет файл следов, который должен быть ассоциирован с этой последовательностью, пользователь может выбрать этот файл. После этого диалоговое окно файловой системы может закрыться, и путь к файлу следов может быть передан в доменный способ, который может передать содержимое файла и полный путь к нему в свойства последовательности, которая будет сохранена. Затем пользователь может активировать кнопку сохранения для сохранения данных; последовательность может быть обновлена, и окно редактирования последовательности может закрыться. Строка последовательности, представленная в средстве для просмотра последовательностей 51, может быть обновлена, чтобы включить иконку, указывающую, что запись последовательности включает соответствующий файл следов. Когда пользователь активирует эту иконку, может открыться окно средства для просмотра файла следов.
Пользовательский элемент управления с названием "просмотр следов" 86 может представлять элемент управления, который может читать и интерпретировать файл следов. Для завершения создания этого выхода элемента управления могут быть использованы графические объекты окон. Могут быть созданы классы для интерпретации каждого типа поддерживаемых файлов следов (такого как ABI и SCF) и окраски последовательности (цветовое кодирование, например, нуклеотидом) и соответствующего графика следов (цветовое кодирование, например, нуклеотидом). Пользователи могут быть способны осуществлять прокрутку влево и вправо для полного просмотра следов.
Пользовательские элементы управления формами окон могут позволять пользователям просматривать графики, относящиеся к специализированным, специфичным для вируса (например, ВГС) значениям пользовательских аннотаций, ассоциированных с последовательностями в системе. Элементы управления в виде флаговых кнопок могут быть добавлены в панель проводника аннотаций, ассоциированную с конкретными аннотациями, которые могут быть общими для всех последовательностей в средстве для просмотра. Эти аннотации могут иметь общий тип данных. После выбора общих аннотаций могут быть активированы радиокнопка управления с двумя пунктами перечня, один, например, помеченный "линейный график", другой помеченный "гистограмма" и кнопка управления с названием "просмотр графика". После выбора любого пункта радиокнопки и активации кнопки "просмотр графика может всплыть новое окно с названием "средство для просмотра графиков". Это окно может содержать пользовательский элемент управления изображением, который может отображать полученное изображение графика, созданное системой в соответствии с точками данных вместе с общими зарегистрированными значениями аннотации последовательности, и кнопку экспорта, позволяющую пользователю сохранить полученное изображение в файловой системе (для экспорта в другие программы и форматы, такие как Excel или PowerPoint).
Соответствующие доменные объекты на языке С# могут ускорять обработку вышеупомянутых средств. Доменная логика может быть разделена на категории, например, деловые правила 68 и доступ к данным 70. Соответствующие объекты, относящиеся к каждому средству, могут быть созданы на доменном уровне, например, один для деловых правил 68 и другой для доступа к данным 70. В одном примере системы 10 объект деловых правил 68 с названием "Следы" может быть включен для обработки запросов от имени дополнительного объекта слоя приложения также с названием "Следы". Объект доступа к данным может быть назван "Доступ к следам" и может обрабатывать взаимодействие с базой данных по запросам доменного объекта "Следы" (а именно проводить поиски двоичных данных по следам в записи последовательности). Объект "Следы" доменной логики может состоять из свойств для получения и установки параметра просмотра следов (такого как цветовое кодирование нуклеотидов и знаковых волн) и способов для анализа точек двоичных данных и взаимодействия с графическими объектами окон для создания визуального выхода следов. Объект "Доступ к следам" может включать способы, которые включают ЯМД для конкретной СУРБД, который может ускорять сохранение и поиск постоянных вводов и выводов механизма 44 СУРБД, относящегося к файлу следов, ассоциированному с последовательностью. Объект деловых правил может обрабатывать интерпретацию данных графиков и выдавать результаты этого процесса в битовый образ для отображения и экспорта.
Существует фундаментальное отсутствие понимания того, как многочисленные варианты вируса (например, ВГС) влияют на геномную реакцию организма-хозяина. Для измерения этой реакции исследователи изучают инфицированный хозяйский геном на уровне транскрипции путем анализа профилей экспрессии генов с использованием технологий микроматрицы. Система 10 может включать базу данных для данных микроматрицы от, например, 50000 транскриптов и может связывать последовательности вируса (например, ВГС) непосредственно с профилем хозяйской микроматрицы. Система 10 также может позволять выполнять нормализацию данных чипа микроматрицы, созданных различными химическими платформами (например, двухцветные системы, литографический синтез и т.д.). Белок вируса (например, ВГС) и файлы микроматрицы связаны с общим идентификационным номером. Система 10 поддерживать реляционную иерархию с сохранением возможностей исследования. Также система 10 может реализовать возможность боковой связи, чтобы пользователь имел выбор, связывать или не связывать последующие данные по экспрессии и последовательности. Средство для определения генотипа может идентифицировать генотип и серотип вводимой последовательности путем сравнения (например, трех) небольших нуклеотидных домена на (например, трех) участках (например, "C/E1/NS5B/5'UTR" для ВГС) в вирусной контрольной последовательности конкретного генотипа/серотипа с вводимым геномом вируса. Эта стратегия генотипирования, основанная на консервативных данных Мерфи и др. (Murphy et al.) (2007), очень точная, распознает серотипы всех известных вирусов (например, n=77 для ВГС) и представляет новейший способ идентификации вируса по сравнению со всеми другими. Средство для определения генотипа может использовать схему ориентации последовательности, которая основана на консервативных областях, для ориентации и идентификации в одном домене (например, NS5B для ВГС), затем другом домене (например, С/Е1 для ВГС) и до последнего домена (например, 5'UTR для ВГС). Эта многоуровневый (например, трехуровневый) подход в подтверждению может обеспечить приблизительно 90% точность идентификации генотипа/серотипа. Это средство можно легко модифицировать для определения генотипа и серотипа других вирусных последовательностей.
В данной области понимается, что любое вышеупомянутое использование элементов управления формами окон может быть осуществлено различными другими средствами программирования и на других операционных платформах.
В соответствии с положениями патентного законодательства принцип и режим работы настоящего изобретения были объяснены и проиллюстрированы на предпочтительном варианте осуществления. Однако следует понимать, что настоящее изобретение может быть осуществлено на практике иначе, чем оно конкретно объяснено и проиллюстрировано, но без нарушения его сущности или объема.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА УПРАВЛЕНИЯ ФАЙЛАМИ, ИСПОЛЬЗУЮЩАЯ ОСНОВАННОЕ НА ВРЕМЕННОЙ ШКАЛЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ | 2005 |
|
RU2406132C2 |
| СИСТЕМА И СПОСОБ ИНТЕРПРЕТАЦИИ АЛЛЕЛЕЙ С ПРИМЕНЕНИЕМ РЕФЕРЕНСНОГО ГЕНОМА НА ОСНОВЕ ГРАФА | 2019 |
|
RU2809124C2 |
| РЕГУЛИРУЕМЫЙ И ПРОГРЕССИВНЫЙ УЛИЧНЫЙ ВИД МОБИЛЬНОГО УСТРОЙСТВА | 2011 |
|
RU2580064C2 |
| ТРЕНИРОВКА МОДЕЛИ НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2788482C2 |
| СПОСОБЫ ДЛЯ АННОТИРОВАНИЯ ИЗОБРАЖЕНИЙ ВИДА УЛИЦЫ КОНТЕКСТНОЙ ИНФОРМАЦИЕЙ | 2011 |
|
RU2598808C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| СПОСОБ, ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЕРВЕР ОРГАНИЗАЦИИ ИСТОРИИ БРАУЗЕРА | 2015 |
|
RU2640299C2 |
| АННОТАЦИЯ ПОСРЕДСТВОМ ПОИСКА | 2007 |
|
RU2439686C2 |
| АННОТИРОВАНИЕ ДОКУМЕНТОВ В СОВМЕСТНО РАБОТАЮЩИХ ПРИЛОЖЕНИЯХ ДАННЫМИ В РАЗРОЗНЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМАХ | 2006 |
|
RU2427896C2 |
| ГРАФИЧЕСКИЙ ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС ДЛЯ ПОЛУЧЕНИЯ ЗАПИСИ СОБЫТИЯ МЕДИЦИНСКОЙ ПОМОЩИ В РЕЖИМЕ РЕАЛЬНОГО ВРЕМЕНИ | 2013 |
|
RU2636683C2 |

Изобретение относится к системе и способу для управления данными по вирусам. Техническим результатом является обеспечение быстрого и гибкого управления данными по вирусам. Система содержит набор средств графического интерфейса пользователя (ГИП), включающий средство импорта, средство аннотирования, средство просмотра, обеспечивающее представление видов нуклеотидов и аминокислот, средство для направления запросов, обеспечивающее изолирование определенных пользователем генетических характеристик посредством определенных пользователем аннотаций, ассоциированных с последовательностями, средство для выравнивания, связанное со средством для направления запросов для выделения одного или более атрибутов запроса в функции выравнивания, средство для сборки контигов генома, средство для филогении, которое собирает выравнивания в эволюционные деревья, и средство для анализа мутаций, и систему для хранения и поиска данных (СХПД), реализованной в системе управления реляционной базой данных, СХПД хранит генетические, биологические, клинические, фенотипические и микроматричные геномные данные, и набор средств ГИП для осуществления управления системой, чтобы управлять данными и анализировать данные, набор средств ГИП и СХПД интегрированы для управления геномными данными без экспорта данных. 3 н., 18 з.п. ф-лы, 18 ил.
1. Система для управления данными по вирусам, причем система включает:
одно или несколько средств графического интерфейса пользователя (ГИП) и систему для хранения и поиска данных (СХПД), причем СХПД хранит генетические, биологические, клинические и фенотипические данные по вирусам, и одно или несколько средств ГИП работают для осуществления управления системой, чтобы управлять данными и анализировать данные, и причем одно или несколько средств ГИП и СХПД интегрированы для управления данными по вирусам без экспорта данных.
2. Система по п.1, кроме того, включающая средство аннотирования, которое управляет аннотациями в форме определенных пользователем точек данных и интегрирует аннотации в поисковый контекст, который является неотъемлемой частью системы.
3. Система по п.1, кроме того, включающая средство импорта, которое автоматизирует задачу отделения одной или более вирусных последовательностей по меньшей мере в одно из, включающее отдельные белки и области.
4. Система по п.1, отличающаяся тем, что по меньшей одно из средств ГИП обеспечивает просмотр нуклеотидов и аминокислот и способно переключаться между такими просмотрами.
5. Система по п.1, отличающаяся тем, что по меньшей мере одно из средств ГИП включает средство для направления запросов и по меньшей мере одно дополнительное средство ГИП, причем средство для направления запросов выполнено с возможностью изолирования в изолированный набор по меньшей мере одного набора данных посредством по меньшей мере одной определенной пользователем генетической характеристики и аннотаций, ассоциированных с последовательностями, и причем средство для направления запросов выполнено с возможностью передачи изолированного набора по меньшей мере одному дополнительному средству ГИП.
6. Система по п.5, отличающаяся тем, что по меньшей мере одно дополнительное средство ГИП включает средство для выравнивания, связанное со средством для направления запросов, чтобы позволить выделить один или несколько атрибутов запроса в функции выравнивания.
7. Система по п.6, отличающаяся тем, что средство для выравнивания включает средство для сборки контигов, собирает набор фрагментов геномной последовательности по меньшей мере одного набора вирусов, распознанных системой.
8. Система по п.1, кроме того, включающая средство для филогении, которое собирает выравнивания в эволюционные деревья, которые кодируют цветом и проставляют временные метки на последовательностях данных.
9. Система по п.1, кроме того, включающая графическое средство, которое представляет необработанные данные электроферограммы и собирает по меньшей мере один из линейного графика или гистограммы для нанесения переменных на графики и представления этих графиков.
10. Система по п.1, кроме того, включающая средство для направления запросов, которое связывает реляционные наборы данных по вирусам.
11. Система по п.1, кроме того, включающая средство для направления запросов, которое выбирает вирусные последовательности по атрибутам, определенным пользователем, из списка аннотаций, предварительно ассоциированных с последовательностями.
12. Система по п.11, отличающаяся тем, что средство для направления запросов содержит аннотации и операторы, которые выбраны пользователем и установлены для управления результатами запроса.
13. Система по п.1, кроме того, включающая средство для выравнивания, средство для филогенетики и средство для анализа мутаций, причем средства для выравнивания, филогенетики и анализа мутаций интегрированы в одном месте.
14. Система по п.13, отличающаяся тем, что средства для выравнивания, филогенетики и анализа мутаций специально приспособлены к свойствам репликации вируса соответствующего вируса.
15. Система по п.1, имеющая архитектуру, состоящую из трех уровней, включая уровень представления, уровень связующего ПО и уровень базы данных с взаимодействием объектных слоев, причем уровень представления содержит один или несколько компонентов ГИП, включающих одно или несколько средств ГИП, уровень связующего ПО содержит один или несколько компонентов связующего ПО и включает логику обработки, используемую системой, и уровень базы данных содержит один или несколько компонентов данных, включающих систему хранения и поиска данных.
16. Система по п.15, отличающаяся тем, что по меньшей мере одно из средств ГИП имеет одно или несколько форм окон, предоставляемых пользователю с уровня представления, причем эти одно или несколько окон принимают данные, вводимые пользователем, и отображают выходные данные, и причем логика обработки обрабатывает вводимые данные и возвращает выходные данные в одну или несколько форм окон.
17. Система по п.1, кроме того, включающая средство для аннотирования, средство для выравнивания, средство для сборки контигов, средство для филогенетики, средство для анализа мутаций, графическое средство, средство для направления запросов, средство для отслеживания мутаций, средство для энтропии, средство для обработки данных микроматрицы и средство для определения генотипа.
18. Система по п.5, отличающаяся тем, что средство для направления запросов выполнено с возможностью сохранения и аннотирования запроса.
19. Система для управления геномными данными, содержащая:
набор средств графического интерфейса пользователя (ГИП), включающий средство импорта, средство аннотирования, средство просмотра, обеспечивающее представление видов нуклеотидов и аминокислот, средство для направления запросов, обеспечивающее изолирование определенных пользователем генетических характеристик посредством определенных пользователем аннотаций, ассоциированных с последовательностями, средство для выравнивания, связанное со средством для направления запросов для выделения одного или более атрибутов запроса в функции выравнивания, средство для сборки контигов генома, средство для филогении, которое собирает выравнивания в эволюционные деревья, и средство для анализа мутаций, и
систему для хранения и поиска данных (СХПД), реализованной в системе управления реляционной базой данных, причем СХПД хранит генетические, биологические, клинические, фенотипические и микроматричные геномные данные, и набор средств ГИП для осуществления управления системой, чтобы управлять данными и анализировать данные, причем набор средств ГИП и СХПД интегрированы для управления геномными данными без экспорта данных.
20. Система для управления геномными данными, содержащая:
систему для хранения и поиска данных (СХПД), хранящую генетические, биологические, клинические, фенотипические и микроматричные геномные данные, и
одно или более средств графического интерфейса пользователя (ГИП), которые отображаются пользователю и обрабатывают и анализируют геномные данные посредством взаимодействия с одним или более графическими представлениями геномных данных в ГИП,
причем одно или более средств ГИП и СХПД интегрированы для управления геномными данными без экспорта данных.
21. Система по п.20, кроме того, включающая секвенирующее устройство для генерирования набора секвенирующих данных, причем СХПД выполнена с возможностью доступа и хранения набора секвенирующих данных.
| US 20080195612 A1, 14.08.2008 | |||
| US 20030028501 A1, 06.02.2003 | |||
| US 20040215401 A1, 28.10.2004 | |||
| US 20040012633 A1, 22.01.2004 | |||
| СПОСОБ ХРАНЕНИЯ, ОБРАБОТКИ И ИСПОЛЬЗОВАНИЯ ИНФОРМАЦИИ В СЛУЖБЕ КРОВИ (ИНФОРМАЦИОННАЯ ТЕХНОЛОГИЯ "ПЕЛИКАН") | 1997 |
|
RU2145114C1 |

