УРОВЕНЬ ТЕХНИКИ
Традиционным подходом к аннотированию цифровых изображений является ручная аннотация каждого цифрового изображения с помощью одного или более семантически связанных ключевых слов. Такие ключевые слова часто используются, чтобы облегчить поиск изображения на основе ключевого слова и поисковые операции в компьютерных поисковых средах (например, в вычислительных устройствах, базах данных, Интернете и т.д.). Из-за очень большого числа цифровых изображений, которые, как правило, существуют в таких поисковых средах, ручное аннотирование цифровых изображений для того, чтобы облегчить поиск изображения и поисковые операции, представляет собой очень трудоемкую и длительную задачу.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Описано аннотирование посредством поиска. В одном аспекте в хранилище данных отыскиваются изображения, которые семантически связаны с базисной аннотацией данного изображения и визуально похожи на данное изображение. Данное изображение затем аннотируется с помощью общих концепций аннотаций, ассоциированных, по меньшей мере, с поднабором семантически и визуально связанных изображений.
Эта сущность изобретения предоставлена, чтобы ввести понятие выбора концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Эта сущность не предназначена для того, чтобы идентифицировать ключевые признаки или важнейшие признаки заявляемого предмета изобретения, а также не предназначена для того, чтобы быть использованной в качестве помощи при определении объема заявляемого предмета изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На чертежах самая левая цифра номера ссылки на компонент идентифицирует конкретный чертеж, где компонент показан первый раз.
Фиг.1 показывает примерную систему для аннотирования посредством поиска согласно одному варианту осуществления.
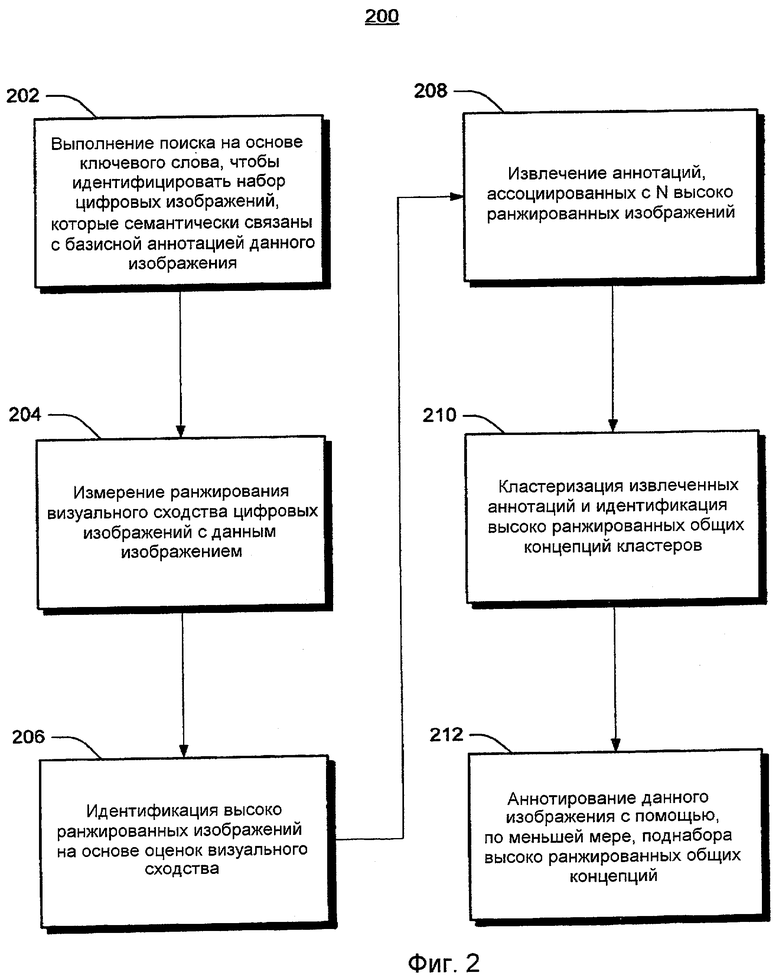
Фиг.2 показывает примерную процедуру аннотирования посредством поиска согласно одному варианту осуществления.
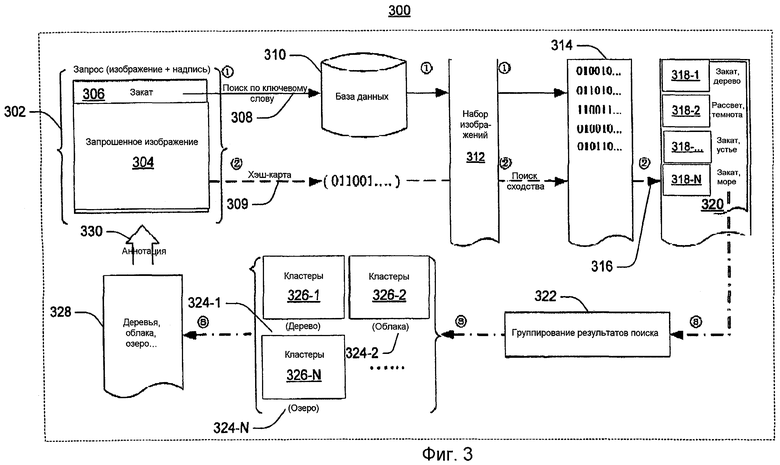
Фиг.3 показывает примерные данные и ход процесса аннотирования посредством поиска согласно одному варианту осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
Обзор
Описываются системы и способы для аннотации посредством поиска. Системы и способы выполняют поиск на основе ключевых слов в локальной и/или удаленной базе(ах) данных, чтобы найти цифровые изображения, которые семантически связаны с базисной аннотацией данного изображения. Системы и способы оценивают визуальную схожесть каждого из семантически связанных изображений с данным изображением. Эти оценки визуального сходства используются, чтобы выбрать изображения, которые более релевантные в визуальном пространстве для данного изображения, чем другие семантически связанные изображения. Эти выбранные изображения похожи в текстовом и визуальном пространстве на данное изображение. Возможные дополнительные аннотации, ассоциированные с выбранными изображениями, извлекаются из соответствующих контекстов выбранных изображений. Извлеченные аннотации кластеризуются. Каждый кластер включает в себя аннотации с общей или связанной концепцией(ями). Например, кластер аннотаций, ассоциированных с изображением пчелы на розе, может содержать аннотации, связанные с пчелой, розой и т.д. Системы и способы характеристической классификации концепций используют один или более критериев подсчета, чтобы идентифицировать набор высоко ранжированных концепций. Системы и способы аннотируют данное изображение, по меньшей мере, с помощью поднабора информации, предоставленной высоко ранжированными концепциями.
Эти и другие аспекты систем и способов аннотирования посредством поиска теперь описываются более подробно.
Примерная система
Хотя и не требуется, системы и способы аннотирования посредством поиска описываются в общем контексте машиноисполняемых инструкций, выполняемых вычислительным устройством, таким как персональный компьютер. Программные модули в общем случае включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют отдельные задачи или реализуют отдельные абстрактные типы данных. В то время как системы и способы описываются в упомянутом выше контексте, действия и операции, описанные далее в данном документе, могут также быть осуществлены в аппаратных средствах.
Фиг.1 показывает примерную систему 100 для аннотирования изображений согласно одному варианту осуществления. Система 100 включает в себя, например, вычислительное устройство 102. Вычислительное устройство 102 представляет любой тип вычислительного устройства, например вычислительное устройство общего назначения, сервер, настольный компьютер, мобильное вычислительное устройство и т.д. Вычислительное устройство 102 включает в себя один или более процессоров 104, соединенных с системной памятью 106. Системная память 106 включает в себя энергозависимую память (например, RAM) и энергонезависимую память (например, ROM, флэш-память, жесткий диск, оптический диск и т.д.). Системная память 106 включает в себя вычислительные программные модули 108 и программные данные 110. Процессор(ы) 104 выбирают и выполняют вычислительные программные инструкции из соответствующих программных модулей 108. Программные модули 108 включают в себя, например, модуль 112 аннотирования, чтобы автоматически аннотировать данное изображение 114 характеристическими и комплиментарными аннотациями 116 из неограниченного запаса слов. Программные модули 108 также включают в себя, например, другие программные модули 118, такие как операционная система, чтобы предоставить среду выполнения, приложение поиска на основе ключевого слова, приложение сравнения и классификации изображения, приложение кластеризации текстов/документов, приложение веб-червя и/или т.д.
Чтобы идентифицировать характеристические и комплиментарные аннотации 116, модуль 112 аннотирования выполняет стандартный поиск на основе ключевого слова в удаленной базе(ах) 119 данных и/или локальной базе(ах) данных, чтобы найти набор цифровых изображений (т.е. добываемые изображения 120), которые семантически связаны с базисной аннотацией 122 данного изображения 114. В одном осуществлении базисная аннотация 112 представляет местоположение, наименование события, наименование папки, описание и т.д., ассоциированные с данным изображением 114, текст, окружающий данное изображение 114 на веб-странице, текст, ассоциированный с другими изображениями в отношении (например, на той же веб-странице, в той же папке и т.д.) с данным изображением 114, ввод запроса, принятый от пользователя и/или т.д. Локальные и/или удаленные базы данных представляют любой тип хранилища данных для цифровых изображений. Например, хранилище(а) данных может быть одним или более из CD, гибкого диска и/или любого другого съемного носителя хранения, жесткого диска и т.д. В целях примерной иллюстрации локальная база(ы) данных показана(ы) как соответствующая часть "других программных данных" 124. В одном осуществлении локальные и/или удаленные базы данных были заполнены аннотированными цифровыми изображениями программным модулем-обходчиком, выгружены людьми и/или т.д. В этом осуществлении удаленная база 119 данных показана связанной с вычислительным устройством 102 через сеть 123. Сеть 123 может включать в себя любую комбинацию сред связи в локальной вычислительной сети (LAN) и всеобщей глобальной вычислительной сети (WAN), таких как те, которые широко распространены в офисах, компьютерных сетях масштаба предприятия, интрасетях и Интернете.
Оценка визуального сходства
Описанные операции поиска на основе ключевого слова возвращают добытые изображения 120, которые семантически связаны с базисной аннотацией 122. Однако словари, используемые авторами содержимого, могут быть очень большими, и большинство слов в обычном языке имеет свойственную двусмысленность. В результате, ключевые слова не всегда являются хорошими описателями соответствующего содержимого документа. Такая двусмысленность часто приводит к проблемам несоответствия элементов ключевое слово/документ при поиске на основе ключевых слов. Так как ключевые слова, представляющие аннотации, могут быть двусмысленными, модуль 112 аннотирования дополнительно оценивает добытые изображения 120, чтобы идентифицировать изображение(я), которые также, по меньшей мере, концептуально связаны в визуальном пространстве с данным изображением 114 (идентифицированное изображение(я) может также быть копией и/или, по существу, визуально похожим на данное изображение 114). Более подробно, модуль 112 аннотирования сравнивает визуальные признаки добытых изображений 120 с визуальными признаками данного изображения 114, чтобы сформировать оценки визуального сходства (т.е. ранжировать), чтобы идентифицировать изображения, которые связаны не только в текстовом пространстве (т.е. семантически связаны), но также и в визуальном пространстве данному изображению 114. (Оценки визуального сходства показаны как соответствующая часть "других программных данных" 124). Существует множество известных технологий, чтобы сравнить визуальное сходство между цифровыми изображениями.
В этом осуществлении, например, модуль 112 аннотирования кодирует визуальные признаки данного изображения 114 и добытых изображений 120, чтобы сформировать соответствующие хэш-сигнатуры для каждого цифрового изображения как следующие. В этом осуществлении модуль 112 аннотирования создает соответствующие векторы признаков для данного изображения 114 и каждого добытого изображения 120 с помощью хорошо известных операций на основе N-бинной (например, 36 бин) цветовой коррелограммы. Другие известные технологии, кроме тех, которые основаны на цветовой коррелограмме, могут также использоваться, чтобы сформировать векторы признаков. Модуль 112 аннотирования умножает сформированные векторы признаков с помощью модели PCA-преобразования, сформированной из большого числа цифровых изображений (например, миллионов изображений) для последующего квантования в двоичные разряды для сравнения. Например, если элемент вектора признака больше, чем среднее значение наибольшего собственного вектора, ассоциированного с моделью PCA-преобразования, модуль 112 аннотирования квантует (кодирует) элемент в 1, иначе элемент кодируется в 0. Эти бинарные кодирования представляют соответствующие хэш-сигнатуры.
Модуль 112 аннотирования использует хэш-сигнатуру каждого добытого изображения 120 и хэш-сигнатуру данного изображения 114, чтобы оценить визуальное сходство между каждым добытым изображением 120 и данным изображением 114. Модуль 120 аннотирования может использовать одну или более известных технологий, чтобы оценить такое визуальное сходство. Например, модуль 112 аннотирования может осуществить одну или более технологий дистанционного измерения визуального пространства цифрового изображения, такого как устранение дубликатов хэш-кода плюс Евклидово расстояние, хэш-расстояние, взвешенное хэш-расстояние, или другие технологии могут использоваться, чтобы оценить визуальное сходство. В одном осуществлении, например, модуль 112 аннотирования использует устранение дубликатов хэш-кода плюс Евклидово расстояние, чтобы оценить визуальное сходство между добытым изображением 120 и данным изображением 114. В этом примере модуль 112 аннотирования использует фрагменты старших n бит хэш-сигнатуры данного изображения 114 в качестве индекса, чтобы измерить визуальное сходство. (Старшие биты соответствуют большим собственным значениям, которые означают большее расстояние в визуальном пространстве). Модуль 112 аннотирования вычисляет Евклидово расстояние на основе коррелограмм, ассоциированных с семантически связанными изображениями.
В другом примере модуль 112 аннотирования использует хэш-расстояние, чтобы измерить визуальное сходство между добытым изображением 120 и данным изображением 114. Например, в одном осуществлении модуль 112 аннотирования использует расстояние Хэмминга, чтобы измерить число разных битов между двумя соответствующими изображениями и определить оценку схожести изображения. Что касается использования взвешенного хэш-расстояния, и так как старшие биты обычно рассматриваются как более значимые, чем младшие биты, модуль 112 аннотирования предоставляет разницу между старшими битами (ассоциированными со сравниваемыми изображениями) с большим весом, чем разницу между младшими битами. Модуль 112 аннотирования равномерно разделяет хэш-сигнатуры на бины (например, 32-битные хэш-коды в 8 бинов) и взвешивает i-й бин числом 28-i, 1<=i<=8. Это уравнение может быть модифицировано, чтобы настроить его на лучшие результаты. Например, если число бинов не равно восьми, уравнение настраивается, чтобы представлять число используемых бинов. Таким образом, визуальное расстояние (классификация) между первым изображением и вторым изображением является взвешенным расстоянием Хэмминга.
Модуль 112 аннотирования идентифицирует N высоко ранжированных изображений 126 из добытых изображений 120 на основе измерений визуального сходства между соответствующими взвешенными изображениями 120 и данным изображением 114. В этом осуществлении параметр N является конфигурируемым на основе отдельного осуществления системы 100. Например, в одном осуществлении, N равно 2000, хотя N может также быть другим значением.
Примерное предсказание аннотации
Модуль 112 аннотирования находит или извлекает другие аннотации, ассоциированные с высоко ранжированным изображением(ми) 126. Эти другие аннотации показаны как извлеченные аннотации 128. Эти другие аннотации находятся в модуле аннотирования или в другом программном модуле, таком как модуль веб-обходчика, из контекста(ов) высоко ранжированного изображения(ий) 126 и их соответствующих местоположений в локальных и/или удаленных базах данных. Такие контексты включают в себя, например, заголовок ресурса (высоко ранжированное изображение 126), имя папки каталога, ассоциированной с ресурсом, описание ресурса, текст в ассоциативной связи с ресурсом на веб-странице или в документе, текст, ассоциированный с другими изображениями в соотношении (например, на одной и той же веб-странице, в одной и той же папке, документе и т.д.) с ресурсом, универсальный идентификатор ресурса (URI), определяющий местоположение ресурса, категорию ресурса и/или т.д.
Модуль 112 аннотирования кластеризует извлеченные аннотации 128 (т.е. обрабатывает каждую из извлеченных аннотаций 128 как соответствующий документ), чтобы идентифицировать высоко ранжированные концепции (например, слова и/или фразы) извлеченных аннотаций 128. В целях примерной иллюстрации такие кластеры и концепции показаны как соответствующие части "других программных данных" 124. В одном осуществлении, например, модуль 112 аннотирования идентифицирует эти концепции посредством выполнения (или иного обращения из "других программных модулей" 118) операций кластеризации, таких как описанные в "Learning to Cluster Web Search Results", Zeng H.J., He, Q.C., Chen, Z., и Ma W.-Y. 27-я ежегодная международная конференция по исследованию и развитию поиска информации, Шеффилд, Великобритания (июль 2004), сс. 210-217, хотя также могут использоваться другие методики кластеризации. Операции кластеризации формируют ряд кластеров, каждому кластеру назначается соответствующая общая концепция (или характеристическая фраза).
Чтобы получить общую концепцию для каждого кластера (имя кластера), операции кластеризации извлекают фразы (n-граммы) из извлеченных аннотаций 128 и вычисляют одно или более свойств для каждой извлеченной фразы (например, частые повторения фразы, частые повторения документа (т.е. частые повторения фразы в аннотации) и т.д.). Операции кластеризации применяют предварительно сконфигурированную модель регрессии, чтобы объединить вычисленные свойства в одну характеристическую оценку для каждого кластера. С помощью характеристических оценок операции кластеризации используют высоко ранжированные фразы в качестве общих концепций (имен) возможных кластеров. Эти возможные кластеры дополнительно соединяются согласно их соответствующим документам (т.е. ассоциированным цифровым изображениям), чтобы назначить окончательную характеристическую оценку каждому кластеру.
В этом осуществлении, и для каждого кластера, используется пороговое значение, чтобы соединить (отфильтровать) возможные высоко ранжированные изображения 126 для кластера (также могут использоваться другие технологии, чтобы объединить изображения с соответствующими кластерами). Пороговое значение равно: весовой коэффициент сходства изображения * средняя оценка визуального сходства. В этом осуществлении весовой коэффициент сходства выбирается из диапазона 0,8~1,6 на основе конкретного осуществления операции кластеризации, хотя также могут использоваться другие диапазоны. Например, в этом осуществлении весовой коэффициент сходства равен 1,2 (когда весовой коэффициент сходства равен 1,6, нет больше изображений, используемых для кластеризации, тогда как, когда весовой коэффициент сходства был установлен в 0,8, почти все изображения использовались для кластеризации). Средняя оценка визуального сходства изображения равна сумме визуального сходства изображения i с данным изображением 114, (т.е. выведенным посредством вышеописанного ключевого слова и операций визуальной фильтрации), разделенной на число добытых изображений 120.
Конечная характеристическая оценка кластера может быть определена с помощью различных критериев. Например, конечные характеристические оценки кластеров могут быть определены с помощью критерия максимального размера кластера, критерия средней оценки изображений-членов и т.д. Что касается критерия максимального размера кластера, который является максимальной апостериорной оценкой (MAP), этот критерий предполагает, что общие концепции с самой большой заметностью для данного изображения 114 являются фразами доминирующих концепций изображений-членов кластера. Таким образом, согласно этой методике, конечная характеристическая оценка кластера равна числу его изображений-членов. В этом варианте осуществления, например, используется критерий максимального размера кластера, и выбираются 3 самых крупных кластера (и ассоциированные имена кластеров).
Что касается использования критерия средней оценки изображения-члена, чтобы назначить характеристические оценки кластерам, эта технология использует среднее число сходства изображения-члена в качестве оценки кластера. Если все изображения в кластере являются наиболее релевантными базисной аннотации 122, общая концепция этого кластера, вероятно, представит концепцию данного изображения 114. Для этого пороговое значение (или другие критерии) используются в качестве интервала, чтобы определить, должны ли быть пропущены низко ранжированные кластеры из конечного набора кластеров. В этом осуществлении пороговое значение устанавливается согласно следующему: 0,95 * (оценка кластера, который ранжирован i-1), при этом i представляет ранжирование текущего кластера. Если оценка текущего кластера (т.е. кластер, который ранжирован i) меньше, чем пороговое значение, текущий кластер и все другие более низкие по рангу кластеры не используются. Если более чем определенное число кластеров (например, 3 или некоторое другое число кластеров) превышает это пороговое значение, только высоко ранжированное конкретное число (например, 3 или некоторое другое число) кластеров используется, чтобы идентифицировать конечные извлеченные концепции.
В этом осуществлении модуль 112 аннотирования формирует характеристические и комплиментарные аннотации 116 посредством удаления дублирующих ключевых слов, терминов и т.д. из общих концепций (имен кластеров), ассоциированных с кластерами, имеющими конечные характеристические оценки (ранги), которые превышают пороговое значение. Модуль 112 аннотирования аннотирует данное изображение 114 с помощью характеристических и комплиментарных аннотаций 116.
Примерная процедура
Фиг.2 показывает примерную процедуру 200 аннотирования посредством поиска согласно одному варианту осуществления. В целях примерной иллюстрации и описания операции процедуры 200 описываются относительно компонентов на фиг.1. На этапе 202 идентифицируется набор цифровых изображений (т.е. добытые изображения 120), которые семантически связаны с базисной аннотацией 122 данного изображения 114. В качестве одного примера модуль 112 аннотирования выполняет поиск на основе ключевого слова в локальной/удаленной базе(ах) данных, чтобы найти набор цифровых изображений (т.е. добытые изображения 120), которые семантически связаны с базисной аннотацией 122 данного изображения 114. В одном осуществлении данное изображение 114 и базисная аннотация 122 представляют поисковый запрос (показанный в "других программных данных" 124) от пользователя вычислительного устройства 102. Пользователь может ввести команды и информацию в компьютер 102 через устройства ввода (не показаны), такие как клавиатура, указывающее устройство, распознавание голоса и т.д. В другом осуществлении данное изображение 114 и базисная аннотация 122 представляют поисковый запрос 130 от пользователя удаленного вычислительного устройства 132, которое соединено с вычислительным устройством 102 через сеть 123. Например, пользователя удаленного вычислительного устройства 130.
На этапе 204 оценивается (ранжируется) визуальное сходство каждого добытого изображения 120 с данным изображением 114. В одном осуществлении, например, модуль 112 аннотирования оценивает визуальное сходство каждого добытого изображения 120 с данным изображением 114. Существует множество возможных технологий, чтобы оценить визуальное сходство между каждым добытым изображением 120 и данным изображением 114. Такие технологии включают в себя, например, устранение дубликатов хэш-кода плюс Евклидово расстояние, хэш-расстояние, взвешенное хэш-расстояние и т.д.
На этапе 206 идентифицируются (получаются) высоко ранжированные изображения 126 из добытых изображений 120, которые наиболее визуально похожи на данное изображение 114. В одном примере модуль 112 аннотирования идентифицирует высоко ранжированные изображения 126 из добытых изображений 120 на основе оценок визуального сходства (т.е. классификации визуального сходства) между соответствующими добытыми изображениями 120 и данным изображением 114. В этом осуществлении число высоко ранжированных изображений 126 является конфигурируемым на основе отдельного осуществления системы 100. На этапе 208 другие аннотации (т.е. извлеченная аннотация(и) 128), ассоциированные с высоко ранжированным изображением(ми) 126, извлекаются из контекстов высоко ранжированных изображений 126. Такие контексты включают в себя, например, заголовок ресурса (высоко ранжированное изображение 126), имя папки каталога, ассоциированной с ресурсом, описание ресурса, текст в ассоциативной связи с ресурсом на веб-странице или в документе, текст, ассоциированный с другими изображениями в соотношении с ресурсом (например, на одной и той же веб-странице, в одной и той же папке, документе и т.д.), универсальный идентификатор ресурса (URI), определяющий местоположение ресурса, категорию ресурса и/или т.д. В одном примере модуль 112 аннотирования находит или извлекает другие аннотации (т.е. извлеченную аннотацию(и) 128), ассоциированные с высоко ранжированным изображением(и) 126.
На этапе 210 извлеченные аннотации 128 кластеризуются, чтобы идентифицировать высоко ранжированные общие концепции (например, слова и/или фразы, которые содержат характеристические и дополнительные аннотации 116) из извлеченных аннотаций 128. Эти высоко ранжированные концепции показаны как характеристические и комплиментарные аннотации 116. В одном осуществлении модуль 112 аннотирования кластеризует извлеченные аннотации 128, чтобы идентифицировать характеристические и комплиментарные аннотации 116. В блоке 212 данное изображение 114 аннотируется (дополняется), по меньшей мере, поднабором характеристических и комплиментарных аннотаций 116. Например, в одном осуществлении, дублирующие ключевые слова, термины и т.д. удаляются из характеристических и дополнительных аннотаций 116 перед аннотированием данного изображения 114 с помощью характеристических и комплиментарных аннотаций 116. В одном осуществлении модуль 112 аннотирования аннотирует данное изображение 114, по меньшей мере, с помощью поднабора характеристических и комплиментарных аннотаций 116.
Фиг.3 показывает примерную структуру 300 данных и ход процесса аннотирования посредством поиска системы 100 согласно одному варианту осуществления. В целях примерного описания и ссылки аспекты структуры 300 описаны относительно компонентов и/или операций на фиг.1 и 2. В описании самая левая цифра в номере ссылки указывает первый чертеж, на котором представлен компонент или операция.
Обращаясь к фиг.3, структура 300 показывает три стадии аннотирования посредством поиска, включающих в себя стадию поиска на основе ключевого слова (показана цифрами (1)), стадию поиска визуального признака (показана цифрами (2)) и стадию кластеризации аннотаций или обучения (показана цифрами (3)). Данные 302 представляют запрос, ассоциированный с изображением 304 (т.е. данным изображением 114) и названием 306 (т.е. базисной аннотацией 122). В одном осуществлении запрос 302 является поисковым запросом, принятым от пользователя вычислительного устройства 102 или удаленного вычислительного устройства 132 (например, см. запрос 130 на фиг.1). В этом примере запрошенное изображение 304 является пейзажем, включающим в себя, по меньшей мере, озеро, облака и деревья. Следует понимать, что запрошенное изображение 304 может представлять любой тип изображения. В этом примере название 306 указывает слово "закат", чтобы аннотировать запрошенное изображения 304.
Операция 308, использующая название 306 ("закат"), выполняет поиск на основе ключевого слова в базе 310 данных, чтобы идентифицировать набор изображений 312 (т.е. добытые изображения 120), которые семантически связаны с запрошенным изображением. База 310 данных представляет любую комбинацию локальных и/или удаленных баз данных изображений системы 100 на фиг.1. Поток данных информации, ассоциированной с названием 306, показан на фиг.3 с помощью сплошных линий. Операция 309 формирует соответствующие хэш-карты/сигнатуры 314 для каждого запрошенного изображения 304 и семантически связанных изображений 312 для последующих операций поиска сходства. Поток данных информации, ассоциированной с данным изображением 114, показан на фиг.3 с помощью штриховых линий.
Операция 316 ранжирует (т.е. оценивает) визуальное сходство семантически связанных изображений 312 с запрошенным изображением 304 посредством использования соответствующей хэш-сигнатуры 314 каждого изображения 312 и хэш-сигнатуры 314 запрошенного изображения. Существуют различные технологии, чтобы оценить это визуальное сходство (или расстояние) с помощью хэш-сигнатур 314. Такие технологии включают в себя, например, устранение дубликатов хэш-кода плюс Евклидово расстояние, хэш-расстояние, взвешенное хэш-расстояние и т.д. Структура 300 использует ранжирования визуального сходства, чтобы выбрать конфигурируемое число изображений 312, которые визуально более похожи на запрошенное изображение 304, чем другие изображения 312. Эти более визуально похожие изображения 312 показаны как высоко ранжированные изображения 318 (318-1 по 318-N). Высоко ранжированные изображения 318 представляют высоко ранжированные изображения 126 на фиг.1.
Структура 300 извлекает аннотации из контекстов, ассоциированных с высоко ранжированными изображениями 318. Как обсуждалось выше, такие контексты включают в себя, например, заголовок изображения 318, имя папки каталога, ассоциированной с изображением 318, описание изображения 318, текст в ассоциативной связи с изображением 318 на веб-странице или в документе, текст, ассоциированный с другими изображениями в соотношении (например, на одной и той же веб-странице, в одной и той же папке, документе и т.д.) с изображением 318, универсальный идентификатор ресурса (URI), определяющий местоположение изображения 318, категорию изображения 318 и/или т.д. Эти извлеченные аннотации показаны как извлеченные аннотации 320 (т.е. извлеченные аннотации 128 на фиг.1). Поток данных, ассоциированный с извлеченными аннотациями 320, показан с помощью штриховых и пунктирных линий, ассоциированных со стадией (3).
В блоке 320 структура 300 выполняет операции кластеризации (т.е группирования) результатов поиска, чтобы идентифицировать высоко ранжированные общие концепции (например, дополнительные аннотации 324-1 по 324-N) из кластеров (например, кластеров 326-1 по 326-N) извлеченных аннотаций 320. В этом осуществлении эти общие концепции определяются с помощью операций, описанных в "Learning to Cluster Web Search Results", Zeng H.J., He, Q.C., Chen, Z., и Ma W.-Y. 27-я ежегодная международная конференция по исследованию и развитию поиска информации, Шеффилд, Великобритания (июль 2004), сс. 210-217, хотя другие технологии кластеризации также могут использоваться.
Хотя каждый кластер 326 иллюстрируется с соответствующим набором изображений и лежащей в основе общей концепцией 324, кластеры 326 не содержат изображений. Вместо этого каждый кластер 326 включает в себя определенные извлеченные аннотации 320. Эта иллюстрация изображений в кластере является просто символической, чтобы показать связь каждой общей концепции 324 с каждым высоко ранжированным изображением 318, ассоциированным с одной или более соответствующей извлеченной аннотацией 320. Структура 300 удаляет дублирующие ключевые слова, термины и/или т.д. из общих концепций 324, чтобы сформировать дополнительные аннотации 328. Дополнительные аннотации 328 представляют характеристические и дополнительные аннотации 116 на фиг.1. В операциях 330 структура 300 аннотирует запрошенное изображение 304 с помощью дополнительных аннотаций 328.
В одном осуществлении описанные операции структуры 300 выполняются соответствующим программным модулем 108 на фиг.1. Например, в одном осуществлении модуль 112 аннотирования выполняет операции структуры 300.
Заключение
Хотя системы и способы аннотирования посредством поиска были описаны на языке, характерном для структурных признаков и/или методологических операций или действий, необходимо понимать, что осуществления, определенные в прилагаемой формуле, необязательно ограничены описанными выше характерными признаками или действиями. Например, хотя система 100 была описана как сначала идентифицирующая семантически связанные изображения и затем определяющая визуальное сходство семантически связанных изображений, чтобы сформировать высоко ранжированные изображения 126, в другом осуществлении, система 100 формирует высоко ранжированные изображения 126 с помощью только одного из следующего: (a) описанные операции поиска по ключевому слову; или (b) поиск в локальных и/или удаленных базах данных визуально похожих изображений. Когда высоко ранжированные изображения 126 сформированы только из визуально похожих изображений, данное изображение 114 может быть введено в качестве запрошенного изображения независимо от базисной аннотации 122. В другом примере, в одном осуществлении вычислительное устройство 102 предоставляет аннотацию посредством поисковой службы удаленным вычислительным устройствам 132 по сети 123. Ввиду вышесказанного характерные признаки и операции 100 раскрыты как примерные формы осуществления заявленного предмета изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРЕДЛОЖЕНИЕ РОДСТВЕННЫХ ТЕРМИНОВ ДЛЯ МНОГОСМЫСЛОВОГО ЗАПРОСА | 2005 |
|
RU2393533C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| Способ обработки видео для целей визуального поиска | 2018 |
|
RU2693994C1 |
| ПРОВЕРКА РЕЛЕВАНТНОСТИ МЕЖДУ КЛЮЧЕВЫМИ СЛОВАМИ И СОДЕРЖАНИЕМ ВЕБ-САЙТА | 2005 |
|
RU2375747C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| МОБИЛЬНЫЙ ВИДЕОПОИСК | 2013 |
|
RU2647696C2 |
| АННОТИРОВАНИЕ ДОКУМЕНТОВ В СОВМЕСТНО РАБОТАЮЩИХ ПРИЛОЖЕНИЯХ ДАННЫМИ В РАЗРОЗНЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМАХ | 2006 |
|
RU2427896C2 |
| СПОСОБ ОБРАБОТКИ ЦЕЛЕВОГО СООБЩЕНИЯ, СПОСОБ ОБРАБОТКИ НОВОГО ЦЕЛЕВОГО СООБЩЕНИЯ И СЕРВЕР (ВАРИАНТЫ) | 2014 |
|
RU2589856C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КЛАСТЕРИЗАЦИИ ФИШИНГОВЫХ ВЕБ-РЕСУРСОВ НА ОСНОВЕ ИЗОБРАЖЕНИЯ ВИЗУАЛЬНОГО КОНТЕНТА | 2021 |
|
RU2778460C1 |
Изобретение относится к аннотированию посредством поиска. Техническим результатом является расширение функциональных возможностей информационного поиска за счет аннотирования посредством поиска. В одном аспекте в хранилище данных выполняется поиск изобретений, которые семантически связаны с базисной аннотацией данного изображения и визуально похожи на данное изображение. Данное изображение затем аннотируется с помощью общих концепций аннотаций, ассоциированных, по меньшей мере, с поднабором семантически и визуально связанных изображений. 3 н. и 17 з.п. ф-лы, 3 ил.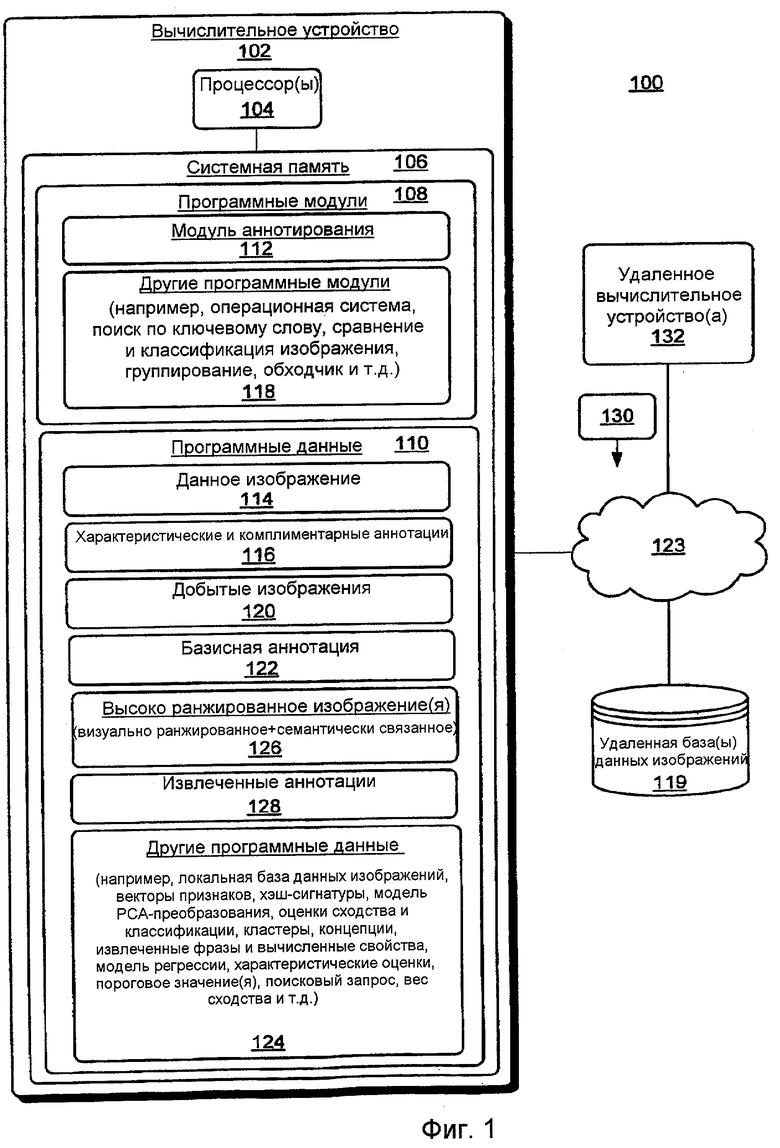
1. Машиночитаемый носитель данных, содержащий инструкции компьютерной программы, исполняемые процессором, причем инструкции компьютерной программы включают в себя инструкции для:
поиска в одном или более хранилищах данных изображений, которые семантически связаны с базисной аннотацией заданного изображения и визуально похожи на заданное изображение; и
аннотирования заданного изображения с помощью общих концепций аннотаций, ассоциированных с, по меньшей мере, поднабором этих изображений.
2. Машиночитаемый носитель данных по п.1, в котором инструкции компьютерной программы дополнительно содержат инструкции для удаления дублирующих терминов из общих концепций перед аннотированием заданного изображения.
3. Машиночитаемый носитель данных по п.1, в котором инструкции компьютерной программы дополнительно содержат инструкции для приема поискового запроса, содержащего заданное изображение и базисную аннотацию.
4. Машиночитаемый носитель данных по п.1, в котором инструкции компьютерной программы дополнительно содержат инструкции для измерения визуального сходства семантически связанных изображений с заданным изображением, при этом упомянутый, по меньшей мере, поднабор изображений содержит конкретные изображения, определенные как более визуально похожие на заданное изображение, чем другие изображения.
5. Машиночитаемый носитель данных по п.4, в котором инструкции компьютерной программы дополнительно содержат инструкции для:
вычисления свойств для фраз, извлеченных из соответствующих аннотаций, причем аннотации группируются в соответствующий кластер из множества кластеров;
объединения для каждого кластера ассоциированных свойств, чтобы сформировать характеристическую оценку для этого кластера; и
при этом общие концепции ассоциированы с кластерами, имеющими более высокие характеристические оценки по сравнению с характеристическими оценками, ассоциированными с другими из кластеров.
6. Компьютерно-реализуемый способ аннотирования изображений, содержащий этапы, на которых:
отыскивают первый набор изображений, которые семантически связаны с базисной аннотацией заданного изображения;
оценивают каждое изображение в первом наборе изображений, чтобы идентифицировать второй набор изображений, которые, по меньшей мере, концептуально связаны с заданным изображением;
идентифицируют аннотации, ассоциированные со вторым набором изображений;
определяют концепции, общие для соответствующих аннотаций; и
аннотируют заданное изображение с помощью, по меньшей мере, поднабора концепций в качестве комплементарных аннотаций.
7. Способ по п.6, дополнительно содержащий этап, на котором принимают входные данные, содержащие заданное изображение и базисную аннотацию.
8. Способ по п.6, в котором при поиске дополнительно коррелируют базисную аннотацию с текстами, ассоциированными с первым набором изображений.
9. Способ по п.6, в котором при оценке дополнительно сравнивают закодированные с помощью хэш-сигнатуры визуальные признаки заданного изображения с соответствующими закодированными с помощью хэш-сигнатуры визуальными признаками каждого изображения в первом наборе изображений.
10. Способ по п.6, в котором при оценке дополнительно:
измеряют визуальное сходство каждого изображения в первом наборе изображений с заданным изображением;
идентифицируют на основе результатов измерений визуального сходства, определенных при измерении, набор высоко ранжированных изображений, которые более визуально связаны с заданным изображением, чем другие изображения из первого набора изображений; и
при этом второй набор изображений - это упомянутые высоко ранжированные изображения.
11. Способ по п.6, в котором при идентификации аннотаций дополнительно извлекают текст из контекстов второго набора изображений.
12. Способ по п.6, в котором при определении концепций дополнительно:
кластеризуют аннотации так, чтобы каждый кластер из упомянутых кластеров был ассоциирован с характеристической концепцией кластера;
определяют характеристические оценки для каждой характеристической концепции из множества характеристических концепций, ассоциированных с кластерами;
выбирают набор высоко ранжированных характеристических концепций из множества характеристических концепций на основе соответствующих характеристических оценок; и
при этом, по меньшей мере, поднабор высоко ранжированных характеристических концепций - это комплементарные аннотации.
13. Вычислительное устройство, содержащее:
процессор; и
память, связанную с процессором, причем память содержит инструкции компьютерной программы, которыми при их исполнении процессором выполняются операции:
приема поискового запроса, содержащего заданное изображение и базисную аннотацию заданного изображения; и
дополнения заданного изображения дополнительными аннотациями, ассоциированными с первым набором изображений, причем каждое изображение в первом наборе изображений является визуально похожим на заданное изображение и ассоциировано с аннотациями, которые семантически связаны с базисной аннотацией.
14. Вычислительное устройство по п.13, в котором дополнительные аннотации представляют общие концепции соответствующих групп аннотаций.
15. Вычислительное устройство по п.13, в котором дополнительные аннотации представляют одно или более из заголовка, описания, категории, информации с Web-страницы, имени папки, по меньшей мере, части универсального идентификатора информационного ресурса и текста в ассоциативной связи с другим изображением, которое не находится в первом наборе изображений.
16. Вычислительное устройство по п.13, в котором первый набор изображений является поднабором более крупного набора изображений, причем каждое изображение в этом более крупном наборе изображений является семантически связанным с базисной аннотацией и независимым от визуального сходства с заданным изображением.
17. Вычислительное устройство по п.13, в котором инструкции компьютерной программы дополнительно содержат инструкции для получения первого набора изображений из второго набора изображений, добытых из одной или более баз данных изображений, причем каждое изображение во втором наборе изображений добывается на основе текста, ассоциированного с заданным изображением.
18. Вычислительное устройство по п.13, в котором инструкции компьютерной программы дополнительно содержат инструкции для:
выполнения поиска на основе ключевого слова, чтобы найти второй поднабор изображений, которые семантически связаны с базисной аннотацией;
поиска во втором наборе изображений одного или более изображений, которые имеют существенное визуальное сходство с заданным изображением;
извлечения текста из одного или более контекстов этих одного или более изображений, причем текст содержит, по меньшей мере, дополнительные аннотации.
19. Вычислительное устройство по п.18, в котором инструкции компьютерной программы дополнительно содержат инструкции для:
идентификации фраз в тексте;
назначения характеристических оценок фразам на основе соответствующих свойств фразы; и
при этом дополнительные аннотации содержат, по меньшей мере, часть текста с более высокими характеристическими оценками по сравнению с характеристическими оценками, ассоциированными с другими частями текста.
20. Вычислительное устройство по п.19, в котором соответствующие свойства фразы содержат одно или более из частоты повторения фразы и частоты повторения фразы в аннотации.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| УСТРОЙСТВО АССОЦИАТИВНОЙ ПАМЯТИ (ВАРИАНТЫ) И СПОСОБ РАСПОЗНАВАНИЯ ОБРАЗОВ (ВАРИАНТЫ) | 1991 |
|
RU2193797C2 |
| JP 2005011079 А, 13.01.2005 | |||
| JP 2003186889 А, 04.07.2003 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| KR 20040054901 А, 26.06.2004. | |||

