ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к способу оценки вектора движения, способу кодирования многовидового видеосигнала, способу декодирования многовидового видеосигнала, устройству оценки вектора движения, устройству кодирования многовидового видеосигнала, устройству декодирования многовидового видеосигнала, программе оценки вектора движения, программе кодирования многовидового видеосигнала и программе декодирования многовидового видеосигнала.
Приоритет испрашивается по заявке на патент Японии № 2010-037434, поданной 23 февраля 2010 г., содержание которой включается в этот документ посредством ссылки.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[0002] Многовидовые киноизображения (многовидовой видеосигнал) являются группой киноизображений, полученных путем фотографирования одного и того же объекта и фона с использованием множества камер. В типичном кодировании киноизображения эффективное кодирование осуществляется с использованием предсказания с компенсацией движения, которое использует высокую корреляцию между кадрами в разные моменты в киноизображениях. Предсказание с компенсацией движения является методикой, принятой в последних международных стандартах схем кодирования киноизображения, представленных H.264. То есть предсказание с компенсацией движения является способом для генерирования изображения путем компенсации движения объекта между целевым кадром кодирования и уже кодированным опорным кадром, вычисления межкадровой разности между сгенерированным изображением и целевым кадром кодирования и кодирования только разностного сигнала.
[0003] При многовидовом кодировании киноизображения высокая корреляция существует не только между кадрами в разные моменты, но также между кадрами в разных видах. Таким образом, используется методика, называемая предсказанием с компенсированной диспаратностью, в которой межкадровая разность вычисляется между целевым кадром кодирования и изображением (кадром), сгенерированным путем компенсации диспаратности между видами, а не движением, и кодируется только разностный сигнал. Предсказание с компенсированной диспаратностью принимается в международных стандартах типа H.264, Приложение H (касательно подробностей H.264 см., например, Непатентный документ 1).
[0004] Диспаратность, используемая в этом документе, является разностью между положениями, в которых объект проецируется на плоскости изображений камер, размещенных в разных положениях. В предсказании с компенсированной диспаратностью кодирование выполняется путем представления этого в качестве двумерного вектора. Так как диспаратность является информацией, сгенерированной в зависимости от камер и положения (глубины) объекта относительно камер, как проиллюстрировано на фиг. 20, имеется схема, использующая этот принцип, называемая предсказанием с синтезом вида (предсказанием с интерполяцией вида).
[0005] Предсказание с синтезом вида (предсказание с интерполяцией вида) является схемой, которая в качестве предсказанного изображения использует изображение, полученное путем синтезирования (интерполирования) кадра в другом виде, который подвергается процессу кодирования или декодирования, использующему часть многовидового видеосигнала, которая уже обработана и для которой получается результат декодирования, на основе трехмерного взаимного расположения между камерами и объектом (например, см. Непатентный документ 2).
[0006] Обычно, чтобы представить трехмерное положение объекта, используется карта глубин (также называемая изображением диапазона, изображением диспаратности или картой диспаратности), которая представляет расстояния (глубину) от камер до объекта для каждого пикселя. В дополнение к карте глубин также может использоваться информация о многоугольниках объекта или информация о вокселях пространства объекта.
[0007] Нужно отметить, что способы для получения карты глубин грубо классифицируются на способ для генерирования карты глубин путем измерения, использующего инфракрасные импульсы или т.п., и способ для генерирования карты глубин путем оценивания глубины из точек в многовидовом видеосигнале, в которых один и тот же объект фотографируется, используя принцип триангуляции. В предсказании с синтезом вида не является серьезной проблемой то, какая из карт глубин, полученная этими способами, используется. К тому же также не является серьезной проблемой то, где выполняется оценка, при условии, что можно получить карту глубин.
[0008] Однако обычно, когда выполняется кодирование с предсказанием, если карта глубин, используемая на кодирующей стороне, не идентична карте глубин, используемой на декодирующей стороне, возникает искажение кодирования, называемое сдвигом. Таким образом, карта глубин, используемая на кодирующей стороны, передается декодирующей стороны, либо используется способ, в котором кодирующая сторона и декодирующая сторона оценивают карты глубин с использованием полностью одинаковых данных и методики.
Документы предшествующего уровня техники
Непатентные документы
[0009] Непатентный документ 1: Rec. ITU-T H.264 "Advanced video coding for generic audiovisual services", март 2009 г.
Непатентный документ 2: S. Shimizu, M. Kitahara, H. Kimata, K. Kamikura и Y. Yashima, "View Scalable Multiview Video Coding Using 3-D Warping with Depth Map", Протоколы IEEE по схемам и системе для видеотехники, том 17, № 11, стр. 1485-1495, ноябрь 2007 г.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Проблемы, которые должны быть решены изобретением
[0010] В вышеописанном традиционном способе избыточность в видеосигналах между камерами можно устранить путем использования предсказания с компенсированной диспаратностью или предсказания с синтезом вида. Таким образом, можно выполнять кодирование со сжатием многовидового видеосигнала с высокой эффективностью по сравнению со случаем, в котором видеосигналы, полученные соответствующими камерами, кодируются независимо.
[0011] Однако в многовидовом видеосигнале корреляция между камерами и временная корреляция существуют одновременно. Таким образом, когда используется только предсказание с компенсированной диспаратностью или предсказание с синтезом вида, временную избыточность нельзя устранить с использованием временной корреляции, и соответственно невозможно осуществить эффективное кодирование.
[0012] Непатентный документ 1 пытается использовать как корреляцию между камерами, так и временную корреляцию путем представления адаптивного выбора между предсказанием с компенсацией движения и предсказанием с компенсированной диспаратностью для каждого блока. С помощью этого способа можно осуществить эффективное кодирование по сравнению со случаем, в котором используется только одна из корреляций.
[0013] Однако выбор любой из них для каждого блока всего лишь уменьшает большую степень избыточности, используя более сильную корреляцию для каждого блока, и невозможно уменьшить избыточность, существующую одновременно между камерами и между кадрами, снятыми в разные моменты.
[0014] В качестве решения этой проблемы можно легко вывести способ, использующий среднее взвешенное между предсказанным изображением, сгенерированным по методике, использующей временную корреляцию, например предсказание с компенсацией движения, и предсказанным изображением, сгенерированным по методике, использующей корреляцию между камерами, например предсказание с компенсированной диспаратностью или предсказание с синтезом вида. С помощью этой методики можно получить полезный результат, что в известной мере повышается эффективность кодирования.
[0015] Однако генерирование предсказанного изображения с использованием среднего взвешенного всего лишь распределяет коэффициенты, с которыми используются корреляции, между временной корреляцией и корреляцией между камерами. То есть, поскольку оно всего лишь гибче использует любую из корреляций вместо одновременного использования двух корреляций, нельзя уменьшить одновременно существующую избыточность.
[0016] Настоящее изобретение создано с учетом таких обстоятельств, и его цель - предоставить способ оценки вектора движения, способ кодирования многовидового видеосигнала, способ декодирования многовидового видеосигнала, устройство оценки вектора движения, устройство кодирования многовидового видеосигнала, устройство декодирования многовидового видеосигнала, программу оценки вектора движения, программу кодирования многовидового видеосигнала и программу декодирования многовидового видеосигнала, которые могут точно оценивать вектор движения даже в ситуации, в которой нельзя получить изображение обработки, и которые могут реализовать эффективное кодирование многовидового видеосигнала, использующее две корреляции одновременно путем использования временной корреляции при предсказании видеосигнала.
Средство для решения проблем
[0017] Чтобы решить вышеописанные проблемы, первым аспектом настоящего изобретения является способ оценки вектора движения, включающий в себя: этап генерирования изображения синтезированного вида, на котором генерируют из видеосигнала опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовой видеосигнал, изображения синтезированного вида в момент, когда изображение обработки получено на основе такой же установки, что и установка камеры обработки; и этап оценки соответствующей области, на котором оценивают вектор движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, не используя изображение обработки, полученное в момент, в который должен быть оценен вектор движения.
[0018] В первом аспекте настоящего изобретения может дополнительно включаться этап установки степени надежности, на котором устанавливают степень надежности, указывающую достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида, и на этапе оценки соответствующей области вес может назначаться стоимости соответствия на основе степени надежности, когда ищется соответствующая область.
[0019] К тому же, чтобы решить вышеописанные проблемы, вторым аспектом настоящего изобретения является способ кодирования многовидового видеосигнала для выполнения кодирования многовидового видеосигнала с предсказанием, и способ включает в себя: этап генерирования изображения синтезированного вида, на котором генерируют из уже кодированного кадра опорного вида, полученного одновременно с целевым кадром кодирования в опорном виде, отличном от целевого вида кодирования многовидового видеосигнала, изображения синтезированного вида в целевом виде кодирования; этап оценки вектора движения, на котором оценивают вектор движения путем поиска соответствующей области на уже кодированном опорном кадре в целевом виде кодирования для каждого единичного блока для кодирования изображения синтезированного вида; этап генерирования изображения предсказания с компенсацией движения, на котором генерируют изображение предсказания с компенсацией движения для целевого кадра кодирования с использованием оцененного вектора движения и опорного кадра; и этап кодирования остатка, на котором кодируют разностной сигнал между целевым кадром кодирования и изображением предсказания с компенсацией движения.
[0020] Во второй аспект настоящего изобретения может дополнительно включаться этап установки степени надежности, на котором устанавливают степень надежности, указывающую достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида, и на этапе оценки вектора движения вес может назначаться стоимости соответствия каждого пикселя на основе степени надежности, когда ищется соответствующая область.
[0021] Во второй аспект настоящего изобретения может дополнительно включаться этап поиска движения, на котором генерируют оптимальный вектор движения путем поиска соответствующей области между опорным кадром и каждым единичным блоком для кодирования целевого кадра кодирования; и этап кодирования вектора разности, на котором кодируют вектор разности между вектором движения и оптимальным вектором движения, и на этапе генерирования изображения предсказания с компенсацией движения может генерироваться изображение предсказания с компенсацией движения, используя оптимальный вектор движения и опорный кадр.
[0022] Во второй аспект настоящего изобретения может дополнительно включаться этап генерирования вектора предсказания, на котором генерируют вектор предсказания с использованием вектора движения и группы оптимальных векторов движения, используемой в областях, соседствующих с целевой областью кодирования, и на этапе кодирования вектора разности может кодироваться вектор разности между вектором предсказания и оптимальным вектором движения.
[0023] К тому же, чтобы решить вышеописанные проблемы, третьим аспектом настоящего изобретения является способ декодирования многовидового видеосигнала для декодирования видеосигнала для вида многовидового видеосигнала из кодированных данных, и способ включает в себя: этап генерирования изображения синтезированного вида, на котором генерируют из кадра опорного вида, полученного одновременно с целевым кадром декодирования в опорном виде, отличном от целевого вида декодирования, изображения синтезированного вида на целевом виде декодирования; этап оценки вектора движения, на котором оценивают вектор движения путем поиска соответствующей области на уже декодированном опорном кадре в целевом виде декодирования для каждого единичного блока для декодирования изображения синтезированного вида; этап генерирования изображения предсказания с компенсацией движения, на котором генерируют изображение предсказания с компенсацией движения для целевого кадра декодирования с использованием оцененного вектора движения и опорного кадра; и этап декодирования изображения, на котором декодируют целевой кадр декодирования, который подвергнут кодированию с предсказанием, из кодированных данных с использованием изображения предсказания с компенсацией движения в качестве сигнала предсказания.
[0024] В третий аспект настоящего изобретения может дополнительно включаться этап установки степени надежности, на котором устанавливают степень надежности, указывающую достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида, и на этапе оценки вектора движения вес может назначаться стоимости соответствия каждого пикселя на основе степени надежности, когда ищется соответствующая область.
[0025] В третий аспект настоящего изобретения может дополнительно включаться этап декодирования вектора, на котором декодируют оптимальный вектор движения, который подвергнут кодированию с предсказанием, из кодированных данных с использованием вектора движения в качестве вектора предсказания, и на этапе генерирования изображения предсказания с компенсацией движения можно генерировать изображение предсказания с компенсацией движения, используя оптимальный вектор движения и опорный кадр.
[0026] В третий аспект настоящего изобретения может дополнительно включаться этап генерирования вектора предсказания, на котором генерируют оцененный вектор предсказания с использованием вектора движения и группы оптимальных векторов движения, используемой в областях, соседствующих с целевой областью декодирования, и на этапе декодирования вектора можно декодировать оптимальный вектор движения, используя оцененный вектор предсказания в качестве вектора предсказания.
[0027] К тому же, чтобы решить вышеописанные проблемы, четвертым аспектом настоящего изобретения является устройство оценки вектора движения, включающее в себя: средство генерирования изображения синтезированного вида для генерирования из видеосигнала опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовой видеосигнал, изображения синтезированного вида в момент, когда изображение обработки получено на основе такой же установки, что и установка камеры обработки; и средство оценки соответствующей области для оценивания вектора движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, не используя изображение обработки, полученное в момент, в который должен быть оценен вектор движения.
[0028] В четвертый аспект настоящего изобретения может дополнительно включаться средство установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида, и средство оценки соответствующей области может назначать вес стоимости соответствия на основе степени надежности, когда ищется соответствующая область.
[0029] К тому же, чтобы решить вышеописанные проблемы, пятым аспектом настоящего изобретения является устройство кодирования многовидового видеосигнала для выполнения кодирования многовидового видеосигнала с предсказанием, и устройство включает в себя: средство генерирования изображения синтезированного вида для генерирования из уже кодированного кадра опорного вида, полученного одновременно с целевым кадром кодирования в опорном виде, отличном от целевого вида кодирования многовидового видеосигнала, изображения синтезированного вида в целевом виде кодирования; средство оценки вектора движения для оценивания вектора движения путем поиска соответствующей области на уже кодированном опорном кадре в целевом виде кодирования для каждого единичного блока для кодирования изображения синтезированного вида; средство генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра кодирования с использованием оцененного вектора движения и опорного кадра; и средство кодирования остатка для кодирования разностного сигнала между целевым кадром кодирования и изображением предсказания с компенсацией движения.
[0030] В пятый аспект настоящего изобретения может дополнительно включаться средство установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида, и средство оценки вектора движения на основе степени надежности может назначать вес стоимости соответствия каждого пикселя, когда ищется соответствующая область.
[0031] К тому же, чтобы решить вышеописанные проблемы, шестым аспектом настоящего изобретения является устройство декодирования многовидового видеосигнала для декодирования видеосигнала для вида многовидового видеосигнала из кодированных данных, и устройство включает в себя: средство генерирования изображения синтезированного вида для генерирования из кадра опорного вида, полученного одновременно с целевым кадром декодирования в опорном виде, отличном от целевого вида декодирования, изображения синтезированного вида в целевом виде декодирования; средство оценки вектора движения для оценивания вектора движения путем поиска соответствующей области на уже декодированном опорном кадре в целевом виде декодирования для каждого единичного блока для декодирования изображения синтезированного вида; средство генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра декодирования с использованием оцененного вектора движения и опорного кадра; и средство декодирования изображения для декодирования целевого кадра декодирования, который подвергнут кодированию с предсказанием, из кодированных данных с использованием изображения предсказания с компенсацией движения в качестве сигнала предсказания.
[0032] В шестом аспекте настоящего изобретения может дополнительно включаться средство установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида, и средство оценки вектора движения на основе степени надежности может назначать вес стоимости соответствия каждого пикселя, когда ищется соответствующая область.
[0033] К тому же, чтобы решить вышеописанные проблемы, седьмым аспектом настоящего изобретения является программа оценки вектора движения для побуждения компьютера устройства оценки вектора движения исполнять: функцию генерирования изображения синтезированного вида, состоящую в генерировании из видеосигнала опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовой видеосигнал, изображения синтезированного вида в момент, когда изображение обработки получено на основе такой же установки, что и установка камеры обработки; и функцию оценки соответствующей области, состоящую в оценивании вектора движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, не используя изображение обработки, полученное в момент, в который должен быть оценен вектор движения.
[0034] К тому же, чтобы решить вышеописанные проблемы, восьмым аспектом настоящего изобретения является программа кодирования многовидового видеосигнала для побуждения компьютера устройства кодирования многовидового видеосигнала для выполнения кодирования многовидового видеосигнала с предсказанием исполнять: функцию генерирования изображения синтезированного вида, состоящую в генерировании из уже кодированного кадра опорного вида, полученного одновременно с целевым кадром кодирования в опорном виде, отличном от целевого вида кодирования многовидового видеосигнала, изображения синтезированного вида в целевом виде кодирования; функцию оценки вектора движения, состоящую в оценивании вектора движения путем поиска соответствующей области на уже кодированном опорном кадре в целевом виде кодирования для каждого единичного блока для кодирования изображения синтезированного вида; функцию генерирования изображения предсказания с компенсацией движения, состоящую в генерировании изображения предсказания с компенсацией движения для целевого кадра кодирования с использованием оцененного вектора движения и опорного кадра; и функцию кодирования остатка, состоящую в кодировании разностного сигнала между целевым кадром кодирования и изображением предсказания с компенсацией движения.
[0035] К тому же, чтобы решить вышеописанные проблемы, девятым аспектом настоящего изобретения является программа декодирования многовидового видеосигнала для побуждения компьютера устройства декодирования многовидового видеосигнала для декодирования видеосигнала для вида многовидового видеосигнала из кодированных данных исполнять: функцию генерирования изображения синтезированного вида, состоящую в генерировании из кадра опорного вида, полученного одновременно с целевым кадром декодирования в опорном виде, отличном от целевого вида декодирования, изображения синтезированного вида в целевом виде декодирования; функцию оценки вектора движения, состоящую в оценивании вектора движения путем поиска соответствующей области на уже декодированном опорном кадре в целевом виде декодирования для каждого единичного блока для декодирования изображения синтезированного вида; функцию генерирования изображения предсказания с компенсацией движения, состоящую в генерировании изображения предсказания с компенсацией движения для целевого кадра декодирования с использованием оцененного вектора движения и опорного кадра; и функцию декодирования изображения, состоящую в декодировании целевого кадра декодирования, который подвергнут кодированию с предсказанием, из кодированных данных с использованием изображения предсказания с компенсацией движения в качестве сигнала предсказания.
К тому же десятым аспектом настоящего изобретения является способ оценки вектора движения, включающий в себя: этап генерирования изображения синтезированного вида, на котором генерируют из видеосигнала опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовой видеосигнал, первого изображения синтезированного вида в момент, когда получено изображение обработки, и второго изображения синтезированного вида в момент, когда опорное изображение получено камерой обработки, на основе такой же установки, что и установка камеры обработки, где вектор движения должен быть получен между опорным изображением и изображением обработки; и этап оценки соответствующей области, на котором оценивают вектор движения путем поиска соответствующей области во втором изображении синтезированного вида, соответствующем опорному изображению, с использованием сигнала изображения на первом изображении синтезированного вида, соответствующем области обработки на изображении обработки, не используя изображение, полученное камерой обработки.
К тому же одиннадцатым аспектом настоящего изобретения является устройство оценки вектора движения, включающее в себя: средство генерирования изображения синтезированного вида для генерирования из видеосигнала опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовой видеосигнал, первого изображения синтезированного вида в момент, когда получено изображение обработки, и второго изображения синтезированного вида в момент, когда опорное изображение получено камерой обработки, на основе такой же установки, что и установка камеры обработки, где вектор движения должен быть получен между опорным изображением и изображением обработки; и средство оценки соответствующей области для оценивания вектора движения путем поиска соответствующей области во втором изображении синтезированного вида, соответствующем опорному изображению, с использованием сигнала изображения на первом изображении синтезированного вида, соответствующем области обработки на изображении обработки, не используя изображение, полученное камерой обработки.
К тому же двенадцатым аспектом настоящего изобретения является программа оценки вектора движения для побуждения компьютера устройства оценки вектора движения исполнять: функцию генерирования изображения синтезированного вида, состоящую в генерировании из видеосигнала опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовой видеосигнал, первого изображения синтезированного вида в момент, когда получено изображение обработки, и второго изображения синтезированного вида в момент, когда опорное изображение получено камерой обработки, на основе такой же установки, что и установка камеры обработки, где вектор движения должен быть получен между опорным изображением и изображением обработки; и функцию оценки соответствующей области, состоящую в оценивании вектора движения путем поиска соответствующей области во втором изображении синтезированного вида, соответствующем опорному изображению, с использованием сигнала изображения на первом изображении синтезированного вида, соответствующем области обработки на изображении обработки, не используя изображение, полученное камерой обработки.
Полезные результаты изобретения
[0036] Настоящее изобретение может точно оценивать вектор движения даже в ситуации, в которой нельзя получить изображение обработки, и может осуществлять эффективное кодирование многовидового видеосигнала с использованием двух корреляций одновременно (то есть корреляцию между камерами и временную корреляцию) путем использования временной корреляции при предсказании видеосигнала.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0037] Фиг. 1 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала в первом варианте осуществления настоящего изобретения.
Фиг. 2 - блок-схема последовательности операций, описывающая работу устройства кодирования многовидового видеосигнала в первом варианте осуществления.
Фиг. 3 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала во втором варианте осуществления настоящего изобретения.
Фиг. 4 - блок-схема последовательности операций, описывающая работу устройства кодирования многовидового видеосигнала во втором варианте осуществления.
Фиг. 5 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в третьем варианте осуществления настоящего изобретения.
Фиг. 6 - блок-схема последовательности операций, описывающая работу устройства декодирования многовидового видеосигнала в третьем варианте осуществления.
Фиг. 7 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в четвертом варианте осуществления настоящего изобретения.
Фиг. 8 - блок-схема последовательности операций, описывающая работу устройства декодирования многовидового видеосигнала в четвертом варианте осуществления.
Фиг. 9 - блок-схема, иллюстрирующая конфигурацию устройства оценки вектора движения в пятом варианте осуществления настоящего изобретения.
Фиг. 10 - блок-схема последовательности операций, описывающая работу устройства оценки вектора движения в пятом варианте осуществления.
Фиг. 11 - блок-схема, иллюстрирующая другой пример конфигурации устройства оценки вектора движения в пятом варианте осуществления.
Фиг. 12 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала в шестом варианте осуществления настоящего изобретения.
Фиг. 13 - блок-схема последовательности операций, описывающая работу устройства кодирования многовидового видеосигнала в шестом варианте осуществления.
Фиг. 14 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала в седьмом варианте осуществления настоящего изобретения.
Фиг. 15 - блок-схема последовательности операций, описывающая работу устройства кодирования многовидового видеосигнала в седьмом варианте осуществления.
Фиг. 16 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в восьмом варианте осуществления настоящего изобретения.
Фиг. 17 - блок-схема последовательности операций, описывающая работу устройства декодирования многовидового видеосигнала в восьмом варианте осуществления.
Фиг. 18 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в девятом варианте осуществления настоящего изобретения.
Фиг. 19 - блок-схема последовательности операций, описывающая работу устройства декодирования многовидового видеосигнала в девятом варианте осуществления.
Фиг. 20 - концептуальная диаграмма, иллюстрирующая связь между расстояниями (глубинами) от камер до объектов и диспаратностью.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[0038] Ниже по тексту будут описываться варианты осуществления настоящего изобретения со ссылкой на чертежи.
[0039] В традиционном способе предсказание с компенсацией движения осуществляется путем получения соответствующей области на опорном изображении, используя сигнал изображения входного целевого изображения кодирования. В этом случае, поскольку входное изображение нельзя получить на декодирующей стороне, необходимо кодировать информацию о векторе движения, представляющую соответствующую область. В вариантах осуществления настоящего изобретения синтезированное изображение, соответствующее целевому изображению кодирования, генерируется с использованием видеосигнала, полученного другой камерой (описанный ниже этап Sa2), и соответствующая область на опорном изображении получается с использованием сигнала изображения синтезированного изображения (описанный ниже этап Sa5). Так как можно сгенерировать такое же синтезированное изображение на декодирующей стороне, вектор движения получается путем выполнения такого же поиска на декодирующей стороне, как на кодирующей стороне. В результате варианты осуществления настоящего изобретения предоставляют полезный результат в том, что не нужно кодировать вектор движения, несмотря на то, что выполняется предсказание с компенсацией движения, так что можно уменьшить соответствующую частоту следования битов.
[0040] Нужно отметить, что в нижеследующем описании информация (значение координаты, индекс, допускающий ассоциацию со значением координаты, область и индекс, допускающий ассоциацию с областью), допускающая указание положения, которая вставляется между символами [], добавляется к видеосигналу (кадру), посредством этого представляя пиксель в положении или видеосигнал, соответствующий области.
[0041] А. Первый вариант осуществления
Сначала будет описываться первый вариант осуществления настоящего изобретения.
Фиг. 1 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала в первом варианте осуществления. Как проиллюстрировано на фиг. 1, устройство 100 кодирования многовидового видеосигнала снабжается модулем 101 ввода целевого кадра кодирования, запоминающим устройством 102 целевого изображения кодирования, модулем 103 ввода кадра опорного вида, запоминающим устройством 104 изображения опорного вида, модулем 105 синтеза вида, запоминающим устройством 106 изображения синтезированного вида, модулем 107 установки степени надежности, модулем 108 поиска соответствующей области, модулем 109 предсказания с компенсацией движения, модулем 110 кодирования остатка предсказания, модулем 111 декодирования остатка предсказания, запоминающим устройством 112 декодированного изображения, модулем 113 вычисления остатка предсказания и модулем 114 вычисления декодированного изображения.
[0042] Модуль 101 ввода целевого кадра кодирования вводит видеокадр (целевой кадр кодирования), служащий в качестве целевого объекта кодирования. Запоминающее устройство 102 целевого изображения кодирования сохраняет входной целевой кадр кодирования. Модуль 103 ввода кадра опорного вида вводит видеокадр (кадр опорного вида) для некоторого вида (опорного вида), отличного от вида целевого кадра кодирования. Запоминающее устройство 104 изображения опорного вида сохраняет входной кадр опорного вида. Модуль 105 синтеза вида генерирует изображение синтезированного вида, соответствующее целевому кадру кодирования, используя кадр опорного вида.
[0043] Запоминающее устройство 106 изображения синтезированного вида сохраняет сгенерированное изображение синтезированного вида. Модуль 107 установки степени надежности задает степень надежности для каждого пикселя сгенерированного изображения синтезированного вида. Модуль 108 поиска соответствующей области ищет вектор движения, представляющий соответствующий блок в уже кодированном кадре, который служит в качестве опорного кадра в предсказании с компенсацией движения и получен в том же виде, что и целевой кадр кодирования, используя степени надежности для каждого единичного блока для кодирования изображения синтезированного вида. То есть путем назначения веса для стоимости соответствия на основе степени надежности, когда ищется соответствующая область, точно синтезированный пиксель рассматривается как важный, и осуществляется высокоточная оценка вектора движения, не подвергаясь влиянию ошибки при синтезе вида.
[0044] Модуль 109 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения, используя опорный кадр на основе определенного соответствующего блока. Модуль 113 вычисления остатка предсказания вычисляет разность (сигнал остатка предсказания) между целевым кадром кодирования и изображением предсказания с компенсацией движения. Модуль 110 кодирования остатка предсказания кодирует сигнал остатка предсказания. Модуль 111 декодирования остатка предсказания декодирует сигнал остатка предсказания из кодированных данных. Модуль 114 вычисления декодированного изображения вычисляет декодированное изображение целевого кадра кодирования путем суммирования декодированного сигнала остатка предсказания и изображения предсказания с компенсацией движения. Запоминающее устройство 112 декодированного изображения сохраняет декодированное изображение.
[0045] Фиг. 2 - блок-схема последовательности операций, описывающая работу устройства 100 кодирования многовидового видеосигнала в первом варианте осуществления. Процесс, выполняемый устройством 100 кодирования многовидового видеосигнала из первого варианта осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0046] Сначала целевой кадр Org кодирования вводится модулем 101 ввода целевого кадра кодирования и сохраняется в запоминающем устройстве 102 целевого изображения кодирования (этап Sa1). В дополнение, кадр Refn опорного вида (n=1, 2, …, N), полученный в опорном виде одновременно с целевым кадром Org кодирования, вводится модулем 103 ввода кадра опорного вида и сохраняется в запоминающем устройстве 104 изображения опорного вида (этап Sa1). Здесь предполагается, что входной кадр опорного вида получается путем декодирования уже кодированного изображения. Это нужно для предотвращения генерирования шума кодирования, например сдвига, путем использования такой же информации, как информация, которую можно получить в устройстве декодирования. Однако, когда разрешено генерирование шума кодирования, может вводиться исходное изображение до кодирования. Нужно отметить, что n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов.
[0047] Затем модуль 105 синтеза вида синтезирует изображение, полученное в том же виде одновременно с целевым кадром кодирования, из информации кадра опорного вида и сохраняет сгенерированное изображение Syn синтезированного вида в запоминающем устройстве 106 изображения синтезированного вида (этап Sa2). Любой способ может использоваться в качестве способа для генерирования изображения синтезированного вида. Например, если информация о глубине кадра опорного вида задается в дополнение к видеоинформации кадра опорного вида, то можно использовать методику, раскрытую в Непатентном документе 2, Непатентном документе 3 (Y. Mori, N. Fukushima, T. Fujii и M. Tanimoto, "View Generation with 3D Warping Using Depth Information for FTV", Известия конференции 3DTV-CON2008, стр. 229-232, май 2008 г.) или т.п.
[0048] К тому же, если получена информация о глубине для целевого кадра кодирования, то также можно использовать методику, раскрытую в Непатентном документе 4 (S. Yea и A. Vetro, "View Synthesis Prediction for Rate-Overhead Reduction in FTV", Известия конференции 3DTV-CON2008, стр. 145-148, май 2008 г.) или т.п.
[0049] Если не получается никакая информация о глубине, то можно сгенерировать изображение синтезированного вида путем применения вышеописанной методики после создания информации о глубине для кадра опорного вида или целевого кадра кодирования, используя методику, называемую стереоскопическим способом или способом оценки глубины, раскрытую в Непатентном документе 5 (J. Sun, N. Zheng и H. Shum, "Stereo Matching Using Belief Propagation", Протоколы IEEE по анализу образов и искусственному интеллекту, том 25, № 7, стр. 787-800, июль 2003 г.) или т.п. (Непатентный документ 6: S. Shimizu, Y. Tonomura, H. Kimata и Y. Ohtani, "Improved View Interpolation Prediction for Side Information in Multiview Distributed Video Coding", Известия конференции ICDSC2009, август 2009 г.).
[0050] Также существует способ для генерирования изображения синтезированного вида непосредственно из кадра опорного вида без явного генерирования информации о глубине (Непатентный документ 7: K. Yamamoto, M. Kitahara, H. Kimata, T. Yendo, T. Fujii, M. Tanimoto, S. Shimizu, K. Kamikura и Y. Yashima, "Multiview Video Coding Using View Interpolation and Color Correction", Протоколы IEEE по схемам и системе для видеотехники, том 17, № 11, стр. 1436-1449, ноябрь 2007 г.).
[0051] Нужно отметить, что когда используются эти методики, в основном необходимы параметры камеры, которые представляют взаимное расположение между камерами и процессы проецирования камер. Эти параметры камеры также можно оценить из кадра опорного вида. Нужно отметить, что если декодирующая сторона не оценивает информацию о глубине, параметры камеры и так далее, то необходимо кодировать и передавать эти порции дополнительной информации, используемые в устройстве кодирования.
[0052] Далее модуль 107 установки степени надежности генерирует степень ρ надежности, указывающую достоверность того, что можно было осуществить синтез для каждого пикселя изображения синтезированного вида (этап Sa3). В первом варианте осуществления степень ρ надежности предполагается являющейся вещественным числом от 0 до 1; однако степень надежности может быть представлена любым способом при условии, что она больше либо равна 0 и чем больше ее значение, чем выше степень надежности. Например, степень надежности может быть представлена как 8-разрядное целое число, которое больше либо равно 1.
[0053] В качестве степени ρ надежности может использоваться любая степень надежности при условии, что она может указывать то, насколько точно выполнен синтез, как описано выше по тексту. Например, самый простой способ включает в себя использование значения дисперсии пиксельных значений пикселей в кадре опорного вида, соответствующих пикселям изображения синтезированного вида. Чем ближе пиксельные значения соответствующих пикселей, тем выше точность выполнения синтеза вида, потому что можно было идентифицировать один и тот же объект, и, соответственно, чем меньше дисперсия, чем выше степень надежности. То есть степень надежности представляется обратной величиной дисперсии. Когда пиксель каждого кадра опорного вида, используемый для синтеза изображения Syn[P] синтезированного вида, обозначается с помощью Refn[pn], можно представить степень надежности с использованием следующего Уравнения (1) или (2):
[0054] [Формула 1]

[0055] [Формула 2]

[0056] Так как минимальным значением дисперсии является 0, необходимо установить степень надежности с использованием функции max. Нужно отметить, что max является функцией, которая возвращает максимальное значение для заданного набора. К тому же другие функции представлены следующими Уравнениями (3):
[0057] [Формула 3]
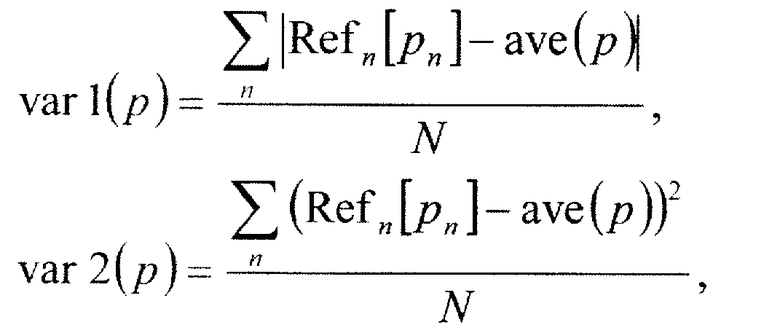

[0058] В дополнение к дисперсии также существует способ, использующий diff(p) между максимальным значением и минимальным значением пикселей соответствующего кадра опорного вида, представленный следующим Уравнением (4). К тому же степень надежности можно задать с использованием экспоненциальной функции, которая показана в следующем Уравнении (4)', вместо обратной дроби. Нужно отметить, что функция f может быть любой из var1, var2 и diff, описанных выше по тексту. В этом случае можно установить степень надежности, даже когда 0 включается в диапазон функции f.
[0059] [Формула 4]

[0060] Хотя эти способы простые, оптимальная степень надежности не получается постоянно, потому что не учитывается генерирование окклюзии. Соответственно, учитывая генерирование окклюзии, кадр опорного вида можно объединять на основе пиксельных значений соответствующих пикселей, и значение дисперсии или разность между максимальным значением и минимальным значением может вычисляться и использоваться для пиксельных значений соответствующих пикселей в кадре опорного вида, который принадлежит наибольшей группе.
[0061] Кроме того, в качестве другого способа степень надежности может задаваться с использованием значения вероятности, соответствующего величине ошибки каждого пикселя, полученной с помощью diff в описанном выше Уравнении (4) или т.п., предполагая, что ошибки между соответствующими точками видов подчиняются нормальному распределению или распределению Лапласа, и используя среднее значение или значение дисперсии распределения в качестве параметра. В этом случае может использоваться модель распределения, его среднее значение и значение дисперсии, которые предопределены, или информация об используемой модели может кодироваться и передаваться. Вообще, если объект обладает равномерно-диффузным отражением, то среднее значение распределения теоретически может считаться равным 0, и, соответственно, модель можно упростить.
[0062] К тому же предполагая, что величина ошибки пиксельного значения соответствующего пикселя минимизируется в окрестности глубины, на которой получается соответствующая точка, когда генерируется изображение синтезированного вида, можно использовать способ для оценивания модели распределения ошибок по изменению величины ошибки, когда глубина ежеминутно меняется, и для установки степени надежности с использованием самой модели распределения ошибок или значения на основе модели распределения ошибок и пиксельного значения соответствующего пикселя в кадре опорного вида, когда генерируется изображение синтезированного вида.
[0063] В качестве определения, использующего только модель распределения ошибок, существует способ для установки степени надежности как вероятности того, что ошибка входит в заданный диапазон, когда вероятность того, что генерируется ошибка, подчиняется распределению ошибок. В качестве определения, использующего модель распределения ошибок и пиксельное значение соответствующего пикселя в кадре опорного вида, когда генерируется изображение синтезированного вида, существует способ для предположения того, что вероятность генерирования ошибки подчиняется оцененному распределению ошибок, и для установки степени надежности как вероятности того, что возникает ситуация, представленная пиксельным значением соответствующего пикселя в кадре опорного вида, когда генерируется изображение синтезированного вида.
[0064] Кроме того, в качестве еще одного способа значение вероятности для диспаратности (глубины), полученное с использованием методики (описанный выше Непатентный документ 5), называемой распространением доверия, когда оценивается диспаратность (глубина), которая необходима для выполнения синтеза вида, может использоваться в качестве степени надежности. В дополнение к распространению доверия в случае алгоритма оценки глубины, который внутренне вычисляет достоверность решения для каждого пикселя в изображении синтезированного вида, можно использовать его информацию в качестве степени надежности.
[0065] Если выполняется поиск соответствующих точек, стереоскопический способ или оценка глубины, когда генерируется изображение синтезированного вида, то часть процесса получения информации о соответствующих точках или информации о глубине может быть такой же, как часть вычисления степеней надежности. В таких случаях можно уменьшить объем вычисления путем одновременного выполнения генерирования изображения синтезированного вида и вычисления степеней надежности.
[0066] Когда вычисление степеней ρ надежности завершается, целевой кадр кодирования делится на блоки, а видеосигнал целевого кадра кодирования кодируется, пока поиск соответствующих точек и генерирование предсказанного изображения выполняется для каждой области (этапы Sa4 - Sa12). То есть, когда индекс целевого блока кодирования обозначается blk, а общее количество целевых блоков кодирования обозначается numBlks, после того, как blk инициализируется в 0 (этап Sa4), следующий процесс (этапы Sa5-Sa10) повторяется, пока blk не достигнет numBlks (этап Sa12), увеличивая при этом blk на 1 (этап Sa11).
[0067] Нужно отметить, что если можно выполнить описанные выше генерирование изображения синтезированного вида и вычисление степени ρ надежности для каждого целевого блока кодирования, то эти процессы также могут выполняться как часть процесса, повторяемого для каждого целевого блока кодирования. Например, это включает в себя случай, в котором задается информация о глубине для целевого блока кодирования.
[0068] В процессе, повторяемом для каждого целевого блока кодирования, сначала модуль 108 поиска соответствующей области находит соответствующий блок в опорном кадре, соответствующий блоку blk, используя изображение синтезированного вида (этап Sa5). Здесь опорный кадр является локальным декодированным изображением, полученным путем выполнения декодирования над данными, которые уже закодированы. Данные локального декодированного изображения являются данными, сохраненными в запоминающем устройстве 112 декодированного изображения.
[0069] Нужно отметить, что локальное декодированное изображение используется для предотвращения генерирования искажения кодирования, называемого сдвигом, путем использования таких же данных, что и данные, допускающие получение с одинаковым расписанием на декодирующей стороне. Если допускается генерирование искажения кодирования, то вместо локального декодированного изображения можно использовать входной кадр, кодированный перед целевым кадром кодирования. Нужно отметить, что первый вариант осуществления использует изображение, полученное той же камерой, что и камера для целевого кадра кодирования, в момент, отличный от такового у целевого кадра кодирования. Однако любой кадр, полученный камерой, отличной от камеры для целевого кадра кодирования, может использоваться при условии, что это кадр, обработанный до целевого кадра кодирования.
[0070] Процесс получения соответствующего блока является процессом получения соответствующего блока, который максимизирует согласие или минимизирует степень расходимости в локальном декодированном изображении, сохраненном в запоминающем устройстве 112 декодированного изображения, путем использования изображения Syn[blk] синтезированного вида в качестве шаблона. В первом варианте осуществления используется стоимость соответствия, указывающая степень расходимости. Нижеследующие Уравнения (5) и (6) являются характерными примерами стоимости соответствия, указывающей степень расходимости.
[0071] [Формула 5]

[0072] [Формула 6]

[0073] Здесь vec является вектором между соответствующими блоками, а t является значением индекса, указывающим одно из локальных декодированных изображений Dec, сохраненных в запоминающем устройстве 112 декодированного изображения. В дополнение к этим существует способ, использующий значение, полученное путем преобразования значения разности между синтезированным изображением вида и локальным декодированным изображением, используя дискретное косинусное преобразование (DCT), преобразование Адамара или т.п. Когда преобразование обозначается матрицей A, оно может быть представлено следующим Уравнением (7) или (8). Нужно отметить, что ||X|| обозначает норму X.
[0074] [Формула 7]
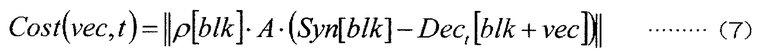
[0075] [Формула 8]

[0076] То есть пара (best_vec, best_t), представленная следующим Уравнением (9), получается с помощью этих процессов получения блока, который минимизирует стоимость соответствия. Здесь argmin обозначает процесс получения параметра, который минимизирует заданную функцию. Набор параметров, который должен быть выведен, является набором, который показан под argmin.
[0077] [Формула 9]

[0078] Любой способ может использоваться в качестве способа для определения количества кадров, которое нужно искать, диапазона поиска, порядка поиска и прекращения поиска. Однако необходимо использовать такие же параметры, как на декодирующей стороне, чтобы точно выполнять декодирование. Нужно отметить, что диапазон поиска и способ прекращения значительно влияет на издержки вычисления. В качестве способа для обеспечения высокой точности соответствия, использующего меньший диапазон поиска, существует способ для подходящей установки центра поиска. В качестве примера существует способ для установки в качестве центра поиска соответствующей точки, представленной вектором движения, используемым в соответствующей области на кадре опорного вида.
[0079] К тому же в качестве способа для уменьшения издержек вычисления, необходимых для поиска на декодирующей стороне, существует способ для ограничения целевого кадра, который нужно искать. Способ для определения целевого кадра, который нужно искать, может быть предопределенным. Например, он включает в себя способ для определения кадра, для которого кодирование завершилось совсем недавно, в качестве цели поиска. К тому же в качестве другого способа существует способ для кодирования информации, указывающей, какой кадр является целью, и для сообщения кодированной информации декодирующей стороне. В этом случае декодирующей стороне необходим механизм для декодирования информации, например значения индекса, указывающего целевой кадр поиска, и для определения на его основе целевого кадра поиска.
[0080] Когда определен соответствующий блок, модуль 109 предсказания с компенсацией движения генерирует предсказанное изображение Pred для блока blk (этап Sa6). Самым простым способом является способ для определения пиксельных значений соответствующего блока в качестве предсказанного изображения, которое представляется Уравнением (10).
[0081] [Формула 10]

[0082] В качестве другого способа предсказанное изображение генерируется с учетом непрерывности с соседним блоком, используя методику, называемую компенсацией движения с наложением (MC) или фильтром уменьшения блочности. В этом случае, поскольку невозможно сгенерировать предсказанное изображение для каждого блока, предсказанное изображение генерируется после того, как поиск соответствующей области повторен для каждого блока, а потом генерирование остатка и процесс, например кодирование, повторяется для каждого блока.
[0083] Когда генерирование предсказанного изображения для блока blk завершено, модуль 113 вычисления остатка предсказания генерирует сигнал Res остатка, представленный разностью между целевым кадром Org кодирования и предсказанным изображением Pred, а модуль 110 кодирования остатка предсказания кодирует сигнал остатка (этап Sa7). Кодированные данные, выведенные в качестве результата кодирования, являются выводом устройства 100 кодирования многовидового видеосигнала, и они также отправляются в модуль 111 декодирования остатка предсказания. Любой способ может использоваться для кодирования остатка предсказания. Например, в H.264, раскрытом в Непатентном документе 1, кодирование выполняется путем последовательного применения частотного преобразования, например DCT, квантования, преобразования в двоичную форму и энтропийного кодирования.
[0084] Модуль 111 декодирования остатка предсказания декодирует декодированный остаток DecRes предсказания из входных кодированных данных (этап Sa8). Нужно отметить, что способ для выполнения декодирования над кодированными данными, полученными по методике, используемой в кодировании, используется для декодирования. В случае H.264 декодированный остаток предсказания получается путем последовательного применения процессов энтропийного декодирования, обратного преобразования в двоичную форму, обратного квантования и обратного частотного преобразования, например обратного дискретного косинусного преобразования (IDCT). Как показано в Уравнении (11), модуль 114 вычисления декодированного изображения генерирует локальное декодированное изображение Deccur[blk] путем сложения предсказанного сигнала Pred с полученным декодированным остатком DecRes предсказания (этап Sa9). Для использования в будущем предсказании сгенерированное локальное декодированное изображение сохраняется в запоминающем устройстве 112 декодированного изображения (этап Sa10).
[0085] [Формула 11]

[0086] В первом варианте осуществления один соответствующий блок определяется с помощью поиска соответствующего блока на этапе Sa5. Однако сигнал предсказания также можно сгенерировать таким образом, что множество блоков выбирается с использованием предопределенного способа, и когда сигнал предсказания с компенсацией движения генерируется на этапе Sa6, к множеству блоков применяется предопределенный процесс, например среднее значение и срединное значение. В качестве способа для заблаговременного определения количества блоков существует способ для непосредственного указания количества блоков, способ для задания условия, имеющего отношение к стоимости соответствия и выбора всех блоков, удовлетворяющих этому условию, и способ на основе сочетания обоих этих способов.
[0087] В качестве способа на основе сочетания обоих этих способов существует, например, способ для выбора предопределенного количества блоков, в котором их стоимости соответствия имеют меньшие значения среди стоимостей соответствия, которые меньше порогового значения. К тому же, когда количество блоков заранее не определяется, существует способ для кодирования информации, указывающей количество блоков, и передачи ее декодирующей стороне. В качестве способа для генерирования предсказанного сигнала из множества возможных вариантов один способ может определяться заранее либо может кодироваться и передаваться информация, указывающая, какой способ должен быть использован.
[0088] К тому же в первом варианте осуществления кадр с таким же временем, как целевой кадр кодирования, не включается в целевые кадры поиска; однако уже декодированная область может использоваться в качестве цели поиска.
[0089] В вышеописанном первом варианте осуществления изображение синтезированного вида, соответствующее изображению обработки, генерируется с использованием способа, аналогичного предсказанию с синтезом вида или предсказанию с интерполяцией вида, и соответствующая точка на опорном изображении отыскивается с использованием изображения синтезированного вида, посредством этого оценивается вектор движения. В результате можно точно оценить вектор движения даже в ситуации, в которой нельзя получить изображение обработки.
[0090] Нужно отметить, что в качестве традиционной схемы оценивания вектора движения в ситуации, в которой отсутствует изображение обработки, существует способ для предположения, что объект имеет плавное линейное перемещение, и оценивания вектора движения изображения обработки из вектора движения, полученного между множеством кадров в разные моменты помимо изображения обработки (Непатентный документ 8: J. Ascenso, C. Brites и F. Pereira, "Improving frame interpolation with spatial motion smoothing for pixel domain distributed video coding", 5ая Конференция EURASIP по обработке речи и изображений, мультимедийным коммуникациям и услугам, июль 2005 г.). Нужно отметить, что эта идея используется в качестве временного прямого режима в H.264, раскрытом в Непатентном документе 1.
[0091] Например, когда интервал времени между кадрами очень небольшой или когда объект постоянно движется, можно оценить вектор движения с некоторой точностью, используя даже способ, который допускает такое движение объекта. Однако, поскольку движение объекта обычно нелинейно и сложно смоделировать это движение, с помощью такой методики сложно оценить вектор движения с высокой точностью.
[0092] К тому же существует способ для оценивания вектора движения с использованием пространственной непрерывности векторов движения, не допуская движение объекта. Непатентный документ 9 (S. Kamp, M. Evertz и M. Wien, "Decoder side motion vector derivation for inter frame video coding", ICIP 2008, стр. 1120-1123, октябрь 2008) раскрывает способ для оценивания вектора движения области обработки путем получения области, соответствующей соседней области у области обработки, когда изображение обработки получено в соседней области.
[0093] Поскольку движение зависит от объекта и один и тот же объект обычно фотографируется в соседней области, можно оценить вектор движения с некоторой точностью, используя эту методику. Однако необходимо изображение соседней области, и невозможно оценить правильный вектор движения, если один и тот же объект не фотографируется в соседней области. К тому же, поскольку даже один и тот же объект может иметь разное движение, невозможно осуществить высокоточную оценку вектора движения за исключением ограниченных ситуаций.
[0094] В отличие от такой традиционной схемы в методике из настоящего варианта осуществления видеосигнал области, для которой должно быть получено движение, синтезируется с использованием межвидовой корреляции, и соответствующая область ищется с использованием синтезированного результата. Таким образом, не нужно предполагать временную регулярность и пространственное сходство для движения, и можно оценить высокоточный вектор движения для любого видеосигнала.
[0095] К тому же в вышеописанном первом варианте осуществления степень надежности, указывающая достоверность изображения синтезированного вида, задается для каждого пикселя изображения синтезированного вида, и на основе степени надежности вес назначается стоимости соответствия для каждого пикселя. Ошибка может генерироваться в изображении синтезированного вида, синтезированном с использованием корреляции между камерами. Когда поиск соответствующей области выполняется с использованием шаблона, включающего в себя такую ошибку, точность оценки вектора движения ухудшается из-за влияния этой ошибки. Таким образом, в первом варианте осуществления степень надежности, указывающая достоверность изображения синтезированного вида, задается для каждого пикселя синтезированного изображения, и на основе степени надежности вес назначается стоимости соответствия для каждого пикселя. При этом точно синтезированный пиксель рассматривается как важный, и можно оценить высокоточный вектор движения, не подвергаясь влиянию ошибки при синтезе вида.
[0096] В качестве информации, указывающей достоверность синтеза, необходимую для установки степени надежности, можно использовать дисперсию или значение разности для пиксельных значений группы соответствующих пикселей в видеосигнале опорной камеры (видеосигнале, полученном опорной камерой), используемом, когда синтезируется пиксель. К тому же, когда оценивается диспаратность или глубина, которые необходимы для выполнения синтеза вида, если используется методика, называемая распространением доверия (Непатентный документ 5), то распределение вероятностей диспаратности или глубины получается для каждого пикселя, и поэтому его информация может использоваться. К тому же, даже когда распространение доверия не используется, существует способ для моделирования изменения величины ошибки или значения дисперсии пиксельных значений группы соответствующих пикселей в видеосигнале опорной камеры, когда меняется значение глубины, с использованием нормального распределения или распределения Лапласа и для установки степени надежности на основе его значения дисперсии.
[0097] B. Второй вариант осуществления
Далее будет описываться второй вариант осуществления настоящего изобретения.
Фиг. 3 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала во втором варианте осуществления. Как проиллюстрировано на фиг. 3, устройство 200 кодирования многовидового видеосигнала снабжается модулем 201 ввода целевого кадра кодирования, запоминающим устройством 202 целевого изображения кодирования, модулем 203 ввода кадра опорного вида, модулем 204 синтеза вида, запоминающим устройством 205 изображения синтезированного вида, модулем 206 оценки движения, модулем 207 предсказания с компенсацией движения, модулем 208 кодирования изображения, модулем 209 декодирования изображения, запоминающим устройством 210 декодированного изображения, модулем 211 поиска соответствующей области, модулем 212 генерирования вектора предсказания, модулем 213 кодирования векторной информации и запоминающим устройством 214 векторов движения.
[0098] Модуль 201 ввода целевого кадра кодирования вводит видеокадр, служащий в качестве целевого объекта кодирования. Запоминающее устройство 202 целевого изображения кодирования сохраняет входной целевой кадр кодирования. Модуль 203 ввода кадра опорного вида вводит видеокадр для некоторого вида, отличного от вида целевого кадра кодирования. Модуль 204 синтеза вида генерирует изображение синтезированного вида для целевого кадра кодирования, используя входной кадр опорного вида.
[0099] Запоминающее устройство 205 изображения синтезированного вида сохраняет сгенерированное изображение синтезированного вида. Модуль 206 оценки движения оценивает движение между целевым кадром кодирования и опорным кадром для каждого единичного блока для кодирования целевого кадра кодирования. Модуль 207 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения на основе результата оценки движения. Модуль 208 кодирования изображения принимает изображение предсказания с компенсацией движения, выполняет кодирование целевого кадра кодирования с предсказанием и выводит кодированные данные. Модуль 209 декодирования изображения принимает изображение предсказания с компенсацией движения и кодированные данные, декодирует целевой кадр кодирования и выводит декодированное изображение.
[0100] Запоминающее устройство 210 декодированного изображения сохраняет декодированное изображение целевого кадра кодирования. Модуль 211 поиска соответствующей области ищет оцененный вектор, представляющий соответствующий блок в опорном кадре предсказания с компенсацией движения для каждого единичного блока для кодирования изображения синтезированного вида. Модуль 212 генерирования вектора предсказания генерирует вектор предсказания для вектора движения целевого блока кодирования из оцененного вектора и векторов движения, используемых для компенсации движения в блоках, соседствующих с целевым блоком кодирования. Модуль 213 кодирования векторной информации выполняет кодирование с предсказанием вектора движения, используя сгенерированный вектор предсказания. Запоминающее устройство 214 векторов движения сохраняет вектор движения.
[0101] Фиг. 4 - блок-схема последовательности операций, описывающая работу устройства 200 кодирования многовидового видеосигнала во втором варианте осуществления. Процесс, выполняемый устройством 200 кодирования многовидового видеосигнала во втором варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0102] Сначала целевой кадр Org кодирования вводится модулем 201 ввода целевого кадра кодирования и сохраняется в запоминающем устройстве 202 целевого изображения кодирования (этап Sb1). К тому же кадр Refn опорного вида (n=1, 2, …, N), полученный в опорном виде одновременно с целевым кадром Org кодирования, вводится модулем 203 ввода кадра опорного вида (этап Sb1). Здесь предполагается, что входной кадр опорного вида получается путем декодирования уже кодированного изображения. Это нужно для предотвращения генерирования шума кодирования, например сдвига, путем использования такой же информации, как информация, полученная в устройстве декодирования. Однако, когда разрешено генерирование шума кодирования, может вводиться исходное изображение до кодирования. Нужно отметить, что n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов.
[0103] Затем модуль 204 синтеза вида синтезирует изображение, полученное в том же виде одновременно с целевым кадром кодирования, используя кадр опорного вида, и сохраняет сгенерированное изображение Syn синтезированного вида в запоминающем устройстве 205 изображения синтезированного вида (этап Sb2). Выполняемый здесь процесс является таким же, как этап Sa2 из первого варианта осуществления.
[0104] Когда генерируется изображение синтезированного вида для целевого кадра кодирования, целевой кадр кодирования делится на блоки, а видеосигнал целевого кадра кодирования кодируется, пока поиск соответствующих точек и генерирование предсказанного изображения выполняется для каждой области (этапы Sb3 - Sb14). То есть, когда индекс целевого блока кодирования обозначается blk, а общее количество целевых блоков кодирования обозначается numBlks, после того, как blk инициализируется в 0 (этап Sb3), следующий процесс (этапы Sb4-Sb12) повторяется, пока blk не достигнет numBlks (этап Sb14), увеличивая при этом blk на 1 (этап Sb13). Нужно отметить, что если можно сгенерировать изображение синтезированного вида для каждого целевого блока кодирования, то этот процесс также может выполняться как часть процесса, повторяемого для каждого целевого блока кодирования. Например, это включает в себя случай, в котором задается информация о глубине для целевого блока кодирования.
[0105] В процессе, повторяемом для каждого целевого блока кодирования, сначала модуль 206 оценки движения находит блок в опорном кадре, соответствующий целевому блоку Org[blk] кодирования (этап Sb4). Этот процесс называется предсказанием движения, и для него может использоваться любой способ. Двумерный вектор, который представляет смещение от блока blk для назначения соответствующего блока, называется вектором движения, который обозначается mv во втором варианте осуществления. Вектор mv движения сохраняется в запоминающем устройстве 214 векторов движения для использования в обработке для последующих блоков.
[0106] Когда оценка движения завершается, модуль 207 предсказания с компенсацией движения генерирует сигнал Pred[blk] предсказания с компенсацией движения для целевого блока Org[blk] кодирования, как показано в следующем Уравнении (12) (этап Sb5):
[0107] [Формула 12]
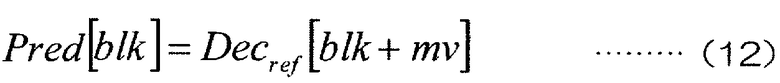
[0108] Нужно отметить, что ref является индексом, указывающим опорный кадр. К тому же во втором варианте осуществления описан пример способа предсказания, использующего только один опорный кадр; однако его можно расширить до схемы, использующей множество опорных кадров, например двунаправленного предсказания (bi-prediction), используемого в H.264 или т.п. Когда используются два опорных кадра, оценка движения выполняется для соответствующих опорных кадров, а сигнал предсказания генерируется с использованием их среднего значения.
[0109] Когда получается сигнал предсказания с компенсацией движения, модуль 208 кодирования изображения выполняет кодирование с предсказанием целевого блока Org[blk] кодирования, используя сигнал Pred[blk] предсказания с компенсацией движения. В частности, получается и кодируется сигнал Res остатка, представленный разностью между целевым блоком Org кодирования и сигналом Pred предсказания с компенсацией движения (этап Sb6). Любой способ может использоваться для кодирования сигнала остатка. Например, в H.264, раскрытом в Непатентном документе 1, кодирование выполняется путем последовательного применения частотного преобразования, например DCT, квантования, преобразования в двоичную форму и энтропийного кодирования. Данные этого результата кодирования становятся частью вывода устройства 200 кодирования многовидового видеосигнала во втором варианте осуществления.
[0110] Модуль 209 декодирования изображения выполняет декодирование над данными результата кодирования для использования в предсказании, когда кодируются последующие кадры. При декодировании сначала декодируется сигнал остатка предсказания, который кодирован (этап Sb7), и сигнал Pred предсказания с компенсацией движения добавляется к полученному декодированному сигналу DecRes остатка предсказания, чтобы генерировалось локальное декодированное изображение Deccur[blk] (этап Sb8). Полученное локальное декодированное изображение сохраняется в запоминающем устройстве 210 декодированного изображения (этап Sb9). Нужно отметить, что способ для выполнения декодирования над кодированными данными, полученными по методике, используемой в кодировании, используется для декодирования. В случае H.264 декодированный сигнал остатка предсказания получается путем последовательного применения процессов энтропийного декодирования, обратного преобразования в двоичную форму, обратного квантования и обратного частотного преобразования, например IDCT.
[0111] Далее кодируется вектор mv движения, полученный путем оценки движения на этапе Sb4 и используемый для предсказания с компенсацией движения на этапе Sb5. С этой целью сначала модуль 211 поиска соответствующей области находит соответствующий блок в опорном кадре, соответствующий изображению Syn[blk] синтезированного вида (этап Sb10). Во втором варианте осуществления двумерный вектор, который представляет смещение от блока blk для назначения соответствующего блока, называется оцененным вектором vec. Здесь процесс аналогичен этапу Sa5 из первого варианта осуществления. Однако, поскольку второй вариант осуществления показывает пример, в котором степень ρ надежности не используется, все ρ равны 1, и, соответственно, умножение на ρ можно пропустить. Конечно, степень надежности может задаваться и использоваться, как в первом варианте осуществления.
[0112] Когда получается оцененный вектор vec, модуль 212 генерирования вектора предсказания генерирует вектор pmv предсказания для вектора mv движения целевого блока кодирования, используя оцененный вектор и векторы движения, используемые в блоках, соседствующих с целевым блоком кодирования, сохраненные в запоминающем устройстве 214 векторов движения (этап Sb11).
[0113] Оптимальные векторы движения, фактически используемые в соседних областях, являются векторами, обладающими большей точностью в соседних областях, чем вектор движения (то есть оцененный вектор), оцененный с использованием изображения синтезированного вида. Поэтому, если имеется пространственное сходство, то можно уменьшить величину вектора разности, которая должна быть кодирована, путем генерирования вектора предсказания с использованием этих векторов. Однако, если пространственное сходство с соседними областями отсутствует, то величина вектора разности может быть, наоборот, увеличена. Поэтому настоящий вариант осуществления определяет, имеется ли пространственное сходство, используя вектор движения, оцененный с использованием изображения синтезированного вида, и если определяется наличие пространственного сходства, то вектор предсказания генерируется с использованием группы оптимальных векторов соседних областей; в противном случае используется вектор движения, оцененный с использованием изображения синтезированного вида. При этом величина кодированного вектора разности постоянно уменьшается, и достигается эффективное кодирование многовидового видеосигнала.
[0114] В качестве способа для генерирования вектора предсказания из вектора движения, оцененного с использованием изображения синтезированного вида, и группы оптимальных векторов движения, используемой в соседних областях, можно использовать способ для вычисления среднего значения или срединного значения для каждой составляющей вектора. К тому же существует способ для определения в качестве вектора предсказания вектора, имеющего наименьшее отличие от вектора движения, оцененного с использованием изображения синтезированного вида, среди группы оптимальных векторов движения, используемой в соседних областях.
[0115] К тому же, в качестве другого способа для генерирования вектора предсказания существует способ для генерирования вектора путем вычисления среднего значения или срединного значения только у группы оптимальных векторов движения, используемой в соседних областях, для каждой составляющей вектора, сравнения вектора с вектором движения, оцененным с использованием изображения синтезированного вида, определения вектора движения, оцененного с использованием изображения синтезированного вида, в качестве вектора предсказания, если разность между ними больше либо равна отдельно заданному пороговому значению, и определения сгенерированного вектора в качестве вектора предсказания, если разность меньше порогового значения. С другой стороны, также существует способ для определения сгенерированного вектора в качестве вектора предсказания, если разность больше либо равна пороговому значению, и определения вектора движения, оцененного с использованием изображения синтезированного вида, в качестве вектора предсказания, если разность меньше порогового значения. Эти два способа зависят от того, насколько точно сгенерировано изображение синтезированного вида. Таким образом, можно применить способ, в котором вектор предсказания определяется по первому алгоритму, если изображение синтезированного вида сгенерировано с высокой точностью; в противном случае вектор предсказания определяется по второму алгоритму.
[0116] То есть можно использовать различные способы для генерирования вектора предсказания при условии, что используется такой же способ, как на декодирующей стороне. Например, оцененный вектор vec может использоваться в качестве вектора pmv предсказания без использования векторов движения соседних блоков, либо вектор движения соседнего блока, ближайший к оцененному вектору vec, может использоваться в качестве вектора pmv предсказания. К тому же вектор pmv предсказания может генерироваться путем вычисления срединного значения или среднего значения оцененного вектора и векторов движения соседних блоков для каждой составляющей. В качестве еще одного способа также существует способ для генерирования вектора pmv', используя срединное значение или среднее значение векторов движения соседних блоков, и для определения вектора pmv предсказания на основе разности между вектором pmv' и оцененным вектором vec.
[0117] Когда генерирование вектора предсказания завершается, модуль 213 кодирования векторной информации выполняет кодирование вектора mv движения с предсказанием (этап Sb12). То есть кодируется вектор остатка предсказания, представленный разностью между вектором mv движения и вектором pmv предсказания. Результат кодирования является одним из выводов устройства 200 кодирования многовидового видеосигнала.
[0118] Во втором варианте осуществления опорный кадр является предопределенным, либо информация, указывающая используемый опорный кадр, кодируется как в H.264, чтобы выбор опорного кадра согласовывался с декодирующей стороной. Однако этап Sb10 может выполняться до этапа Sb4, декодированный кадр, который минимизирует стоимость соответствия, может определяться из множества возможных вариантов, и определенный кадр может использоваться в качестве опорного кадра. К тому же, когда информация, указывающая используемый опорный кадр, кодируется как в H.264, можно снизить скорость передачи битов путем переключения таблиц кодирования, чтобы стала небольшой скорость передачи битов информации, указывающей кадр, который минимизирует стоимость соответствия.
[0119] В вышеописанном втором варианте осуществления вектор движения для использования временной корреляции предсказывается с использованием изображения в целевом виде кодирования, полученном путем синтеза вида, использующего корреляцию между камерами. В силу этого можно уменьшить скорость передачи битов у вектора движения, необходимого для предсказания с компенсацией движения, и, соответственно, можно реализовать эффективное кодирование многовидового видеосигнала. Нужно отметить, что в настоящем варианте осуществления корреляция между камерами используется для генерирования вектора движения, а временная корреляция используется для предсказания видеосигнала, и, соответственно, можно одновременно использовать две корреляции.
[0120] К слову, может генерироваться ошибка в изображении синтезированного вида, синтезированном с использованием корреляции между камерами. Когда поиск соответствующей области выполняется с использованием шаблона, включающего в себя такую ошибку, точность оценки вектора движения ухудшается из-за влияния этой ошибки. Таким образом, второй вариант осуществления предлагает способ, в котором степень надежности, указывающая достоверность изображения синтезированного вида, задается для каждого пикселя синтезированного изображения, и на основе степени надежности вес назначается стоимости соответствия для каждого пикселя. При этом точно синтезированный пиксель рассматривается как важный, и можно надлежащим образом предсказать вектор движения, не подвергаясь влиянию ошибки при синтезе вида.
[0121] К тому же, если изображение синтезированного вида можно сгенерировать с высокой точностью, то на основе первого варианта осуществления можно сгенерировать вектор движения, необходимый для предсказания с компенсацией движения. Однако изображение синтезированного вида не постоянно генерируется с высокой точностью. Таким образом, при поиске соответствующей области с использованием изображения синтезированного вида, включающего в себя ошибку, оптимальный вектор движения в плане эффективности кодирования не обнаруживается постоянно с точностью до подпикселя. К тому же, когда нельзя задать подходящий вектор движения, невозможно реализовать эффективное кодирование со сжатием, потому что увеличивается величина остатка, которая должна кодироваться на основе результата предсказания с компенсацией движения. В отличие от этого оптимальная соответствующая область в плане эффективности кодирования может постоянно обнаруживаться с любой точностью путем поиска соответствующей области, использующего целевой кадр кодирования. Таким образом, предсказанное изображение генерируется с использованием оптимального вектора движения, обнаруженного путем поиска соответствующей области, использующего целевой кадр кодирования, и когда кодируется оптимальный вектор движения, кодирование выполняется с использованием отличия от вектора движения, который оценен с постоянным уровнем точности, используя изображение синтезированного вида. При этом также можно снизить скорость передачи битов, необходимую для кодирования оптимального вектора движения, наряду с предотвращением увеличения величины остатка, которая должна быть кодирована. То есть во втором варианте осуществления можно снизить скорость передачи битов вектора движения, выполняя при этом предсказание с компенсацией движения, использующее подходящий вектор движения, даже когда ошибка генерируется в изображении синтезированного вида. Таким образом, можно надежнее реализовать эффективное кодирование со сжатием.
[0122] Нужно отметить, что на этапе поиска движения (этап Sb4) разность в пиксельном значении между соответствующими областями может использоваться в качестве стоимости соответствия, и поиск соответствующей области может выполняться с использованием стоимости случайного искажения, которая допускает оценивание в целом скорости передачи битов, необходимой для кодирования вектора разности, и величины остатка предсказания с компенсацией движения, которая должна быть кодирована. Вообще, когда используется последняя функция стоимости, эффективность кодирования многовидового видеосигнала становится высокой. Однако, если используется стоимость случайного искажения, то необходимо выполнять этапы Sb10 и Sb11 перед этапом Sb4 во втором варианте осуществления. Поскольку эти два этапа независимы от процесса этапов Sb4-Sb9, порядки могут чередоваться.
[0123] Нужно отметить, что в Непатентном документе 1, когда кодируется вектор движения, кодирование выполняется на основе разности между вектором движения и вектором предсказания, оцененным из векторов движения в соседних областях с использованием пространственного сходства, посредством этого осуществляя эффективное кодирование. Однако, например, если объект, отличный от объекта в соседней области, фотографируется в обрабатываемом в настоящее время блоке, то становится большой разность между вектором движения и вектором предсказания, сгенерированным путем допущения пространственного сходства, и поэтому нельзя осуществить эффективное кодирование. В настоящем варианте осуществления видеосигнал для обрабатываемого в настоящее время блока получается путем предсказания между камерами, и оцененный на его основе вектор используется в качестве вектора предсказания. При этом можно сгенерировать вектор предсказания ближе к вектору движения, даже когда пространственное сходство отсутствует.
[0124] C. Третий вариант осуществления
Далее будет описываться третий вариант осуществления настоящего изобретения.
Фиг. 5 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в третьем варианте осуществления. Как проиллюстрировано на фиг. 5, устройство 300 декодирования многовидового видеосигнала снабжается модулем 301 ввода кодированных данных, запоминающим устройством 302 кодированных данных, модулем 303 ввода кадра опорного вида, запоминающим устройством 304 изображения опорного вида, модулем 305 синтеза вида, запоминающим устройством 306 изображения синтезированного вида, модулем 307 установки степени надежности, модулем 308 поиска соответствующей области, модулем 309 предсказания с компенсацией движения, модулем 310 декодирования остатка предсказания, запоминающим устройством 311 декодированного изображения и модулем 312 вычисления декодированного изображения.
[0125] Модуль 301 ввода кодированных данных вводит кодированные данные видеокадра, служащего в качестве целевого объекта декодирования. Запоминающее устройство 302 кодированных данных сохраняет входные кодированные данные. Модуль 303 ввода кадра опорного вида вводит видеокадр (кадр опорного вида) для некоторого вида (опорного вида), отличного от вида (целевого вида декодирования), в котором получен целевой кадр декодирования. Запоминающее устройство 304 изображения опорного вида сохраняет входной кадр опорного вида.
[0126] Модуль 305 синтеза вида генерирует изображение синтезированного вида для целевого кадра декодирования, используя кадр опорного вида. Запоминающее устройство 306 изображения синтезированного вида сохраняет сгенерированное изображение синтезированного вида. Модуль 307 установки степени надежности задает степень надежности для каждого пикселя сгенерированного изображения синтезированного вида. Модуль 308 поиска соответствующей области ищет вектор движения, представляющий соответствующий блок в уже декодированном кадре, который служит в качестве опорного кадра в предсказании с компенсацией движения и получен в том же виде, что и целевой кадр декодирования, для каждого единичного блока для кодирования изображения синтезированного вида, используя степени надежности.
[0127] Модуль 309 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения, используя опорный кадр на основе определенного соответствующего блока. Модуль 310 декодирования остатка предсказания декодирует сигнал остатка предсказания из кодированных данных. Модуль 312 вычисления декодированного изображения вычисляет декодированное изображение целевого кадра декодирования путем суммирования декодированного сигнала остатка предсказания и изображения предсказания с компенсацией движения. Запоминающее устройство 311 декодированного изображения сохраняет декодированное изображение.
[0128] Фиг. 6 - блок-схема последовательности операций, описывающая работу устройства 300 декодирования многовидового видеосигнала в третьем варианте осуществления. Процесс, который должен быть выполнен устройством 300 декодирования многовидового видеосигнала в третьем варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0129] Сначала кодированные данные целевого кадра декодирования вводятся модулем 301 ввода кодированных данных и сохраняются в запоминающем устройстве 302 кодированных данных (этап Sc1). К тому же кадр Refn опорного вида (n=1, 2, …, N), полученный в опорном виде одновременно с целевым кадром декодирования, вводится модулем 303 ввода кадра опорного вида и сохраняется в запоминающем устройстве 304 изображения опорного вида (этап Sc1). Здесь n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов.
[0130] Затем модуль 305 синтеза вида синтезирует изображение, полученное в том же виде одновременно с целевым кадром декодирования, из информации кадра опорного вида и сохраняет сгенерированное изображение Syn синтезированного вида в запоминающем устройстве 306 изображения синтезированного вида (этап Sc2). Этот процесс является таким же, как этап Sa2 из первого варианта осуществления. Модуль 307 установки степени надежности затем генерирует степень ρ надежности, указывающую достоверность того, что можно было осуществить синтез каждого пикселя изображения синтезированного вида (этап Sc3). Этот процесс является таким же, как этап Sa3 из первого варианта осуществления.
[0131] Аналогично первому варианту осуществления, если выполняется поиск соответствующих точек, стереоскопический способ или оценка глубины, когда генерируется изображение синтезированного вида, то часть процесса получения информации о соответствующих точках или информации о глубине может быть такой же, как часть вычисления степеней надежности. В таких случаях можно уменьшить объем вычисления путем одновременного выполнения генерирования изображения синтезированного вида и вычисления степеней надежности.
[0132] Когда вычисление степеней надежности завершается, видеосигнал целевого кадра декодирования декодируется, пока поиск соответствующих точек и генерирование предсказанного изображения выполняются для каждого предопределенного блока (этапы Sc4-Sc10). То есть, когда индекс целевого блока декодирования обозначается blk, а общее количество целевых блоков декодирования обозначается numBlks, после того, как blk инициализируется в 0 (этап Sc4), следующий процесс (этапы Sc5-Sc8) повторяется, пока blk не достигнет numBlks (этап Sb10), увеличивая при этом blk на 1 (этап Sc9).
[0133] Нужно отметить, что если можно выполнить описанные выше генерирование изображения синтезированного вида и вычисление степеней надежности для каждого целевого блока декодирования, то эти процессы также могут выполняться как часть процесса, повторяемого для каждого целевого блока декодирования. Например, это включает в себя случай, в котором задается информация о глубине для целевого блока декодирования.
[0134] В процессе, повторяемом для каждого целевого блока декодирования, сначала модуль 308 поиска соответствующей области находит соответствующий блок в опорном кадре, соответствующий блоку blk, используя изображение синтезированного вида (этап Sc5). Этот процесс является таким же, как этап Sa5 из первого варианта осуществления, и используются такая же стоимость соответствия, такой же диапазон поиска и т.п., как на кодирующей стороне. Нужно отметить, что опорный кадр является декодированным изображением, полученным с помощью уже завершенного процесса декодирования. Эти данные являются данными, которые должны быть сохранены в запоминающем устройстве 311 декодированного изображения.
[0135] Нужно отметить, что третий вариант осуществления использует изображение, полученное той же камерой, что и камера для целевого кадра декодирования, в момент, отличный от такового у целевого кадра декодирования. Однако любой кадр, полученный камерой, отличной от камеры для целевого кадра декодирования, может также использоваться при условии, что это кадр, обработанный до целевого кадра декодирования.
[0136] Когда определяется соответствующий блок, модуль 309 предсказания с компенсацией движения генерирует предсказанное изображение Pred для блока blk таким же способом, как на этапе Sa6 из первого варианта осуществления (этап Sc6). Модуль 310 декодирования остатка предсказания затем получает декодированный остаток DecRes предсказания путем декодирования остатка предсказания из входных кодированных данных (этап Sc7). Этот процесс является таким же, как этап Sa8 из первого варианта осуществления, и декодирование выполняется с помощью процесса, обратного способу, используемому для кодирования остатка предсказания на кодирующей стороне.
[0137] Затем, как и на этапе Sa9 из первого варианта осуществления, модуль 312 вычисления декодированного изображения генерирует декодированное изображение Deccur[blk] для блока blk путем добавления сигнала Pred предсказания к полученному декодированному остатку DecRes предсказания (этап Sc8). Сгенерированное декодированное изображение служит в качестве вывода устройства 300 декодирования многовидового видеосигнала и сохраняется в запоминающем устройстве 311 декодированного изображения для использования в предсказании для последующих кадров.
[0138] D. Четвертый вариант осуществления
Далее будет описываться четвертый вариант осуществления настоящего изобретения.
Фиг. 7 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в четвертом варианте осуществления. Как проиллюстрировано на фиг. 7, устройство 400 декодирования многовидового видеосигнала снабжается модулем 401 ввода кодированных данных, запоминающим устройством 402 кодированных данных, модулем 403 ввода кадра опорного вида, модулем 404 синтеза вида, запоминающим устройством 405 изображения синтезированного вида, модулем 406 поиска соответствующей области, модулем 407 генерирования вектора предсказания, модулем 408 декодирования вектора движения, запоминающим устройством 409 векторов движения, модулем 410 предсказания с компенсацией движения, модулем 411 декодирования изображения и запоминающим устройством 412 декодированного изображения.
[0139] Модуль 401 ввода кодированных данных вводит кодированные данные видеокадра, служащего в качестве целевого объекта декодирования. Запоминающее устройство 402 кодированных данных сохраняет входные кодированные данные. Модуль 403 ввода кадра опорного вида вводит видеокадр для некоторого вида, отличного от вида целевого кадра декодирования. Модуль 404 синтеза вида генерирует изображение синтезированного вида для целевого кадра декодирования, используя входной кадр опорного вида.
[0140] Запоминающее устройство 405 изображения синтезированного вида сохраняет сгенерированное изображение синтезированного вида. Модуль 406 поиска соответствующей области ищет оцененный вектор, указывающий соответствующий блок в опорном кадре предсказания с компенсацией движения для каждого единичного блока для декодирования изображения синтезированного вида. Модуль 407 генерирования вектора предсказания генерирует вектор предсказания для вектора движения целевого блока декодирования из оцененного вектора и векторов движения, используемых для компенсации движения в блоках, соседствующих с целевым блоком декодирования.
[0141] Модуль 408 декодирования вектора движения декодирует вектор движения, подвергнутый кодированию с предсказанием, из кодированных данных с использованием сгенерированного вектора предсказания. Запоминающее устройство 409 векторов движения сохраняет вектор движения. Модуль 410 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения на основе декодированного вектора движения. Модуль 411 декодирования изображения принимает изображение предсказания с компенсацией движения, декодирует целевой кадр декодирования, подвергнутый кодированию с предсказанием, и выводит декодированное изображение. Запоминающее устройство 412 декодированного изображения сохраняет декодированное изображение.
[0142] Фиг. 8 - блок-схема последовательности операций, описывающая работу устройства 400 декодирования многовидового видеосигнала в четвертом варианте осуществления. Процесс, который должен быть выполнен устройством 400 декодирования многовидового видеосигнала в четвертом варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0143] Сначала кодированные данные целевого кадра декодирования вводятся модулем 401 ввода кодированных данных и сохраняются в запоминающем устройстве 402 кодированных данных (этап Sd1). К тому же кадр Refn опорного вида (n=1, 2, …, N), полученный в опорном виде одновременно с целевым кадром декодирования, вводится модулем 403 ввода кадра опорного вида (этап Sd1). Здесь n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов. Нужно отметить, что кодированные данные включают в себя по меньшей мере два типа данных: остаток предсказания видеосигнала и остаток предсказания вектора движения, используемые в предсказании для видеосигнала.
[0144] Затем модуль 404 синтеза вида синтезирует изображение, полученное в том же виде одновременно с целевым кадром декодирования, используя кадр опорного вида, и сохраняет сгенерированное изображение Syn синтезированного вида в запоминающем устройстве 405 изображения синтезированного вида (этап Sd2). Выполняемый здесь процесс является таким же, как этап Sb2 из второго варианта осуществления.
[0145] Когда генерируется изображение синтезированного вида для целевого кадра декодирования, видеосигнал целевого кадра декодирования и вектор движения декодируются, пока поиск соответствующих точек и генерирование предсказанного изображения выполняются для каждого предопределенного блока (этапы Sd3 - Sd11). То есть, когда индекс целевого блока декодирования обозначается blk, а общее количество целевых блоков декодирования обозначается numBlks, после того, как blk инициализируется в 0 (этап Sd3), следующий процесс (этапы Sd4 - Sd9) повторяется, пока blk не достигнет numBlks (этап Sd11), увеличивая при этом blk на 1 (этап Sd10). Нужно отметить, что если можно сгенерировать изображение синтезированного вида для каждого целевого блока декодирования, то этот процесс также может выполняться как часть процесса, повторяемого для каждого целевого блока декодирования. Например, это включает в себя случай, в котором задается информация о глубине для целевого блока декодирования.
[0146] В процессе, повторяемом для каждого целевого блока декодирования, сначала модуль 406 поиска соответствующей области находит соответствующий блок в опорном кадре, соответствующий изображению Syn[blk] синтезированного вида (этап Sd4). В четвертом варианте осуществления двумерный вектор, который представляет смещение от блока blk для назначения соответствующего блока, называется оцененным вектором vec. Этот процесс аналогичен этапу Sb10 из второго варианта осуществления. Однако четвертый вариант осуществления показывает пример, в котором не используется степень надежности. Степень надежности может задаваться и использоваться, как в третьем варианте осуществления.
[0147] Когда получается оцененный вектор vec, модуль 407 генерирования вектора предсказания генерирует вектор pmv предсказания для вектора mv движения целевого блока декодирования, используя оцененный вектор и векторы движения, используемые в блоках, соседствующих с целевым блоком декодирования, сохраненные в запоминающем устройстве 409 векторов движения (этап Sd5). Этот процесс является таким же, как этап Sb11 из второго варианта осуществления.
[0148] Когда генерирование вектора предсказания завершается, модуль 408 декодирования вектора движения декодирует вектор mv движения целевого блока blk декодирования из кодированных данных (этап Sd6). Вектор mv движения подвергнут кодированию с предсказанием, использующему вектор pmv предсказания, и вектор mv движения получается путем декодирования вектора dmv остатка предсказания из кодированных данных и добавления вектора pmv предсказания к вектору dmv остатка предсказания. Декодированный вектор mv движения отправляется в модуль 410 предсказания с компенсацией движения, сохраняется в запоминающем устройстве 409 векторов движения и используется, когда декодируется вектор движения последующего целевого блока декодирования.
[0149] Когда получается вектор движения для целевого блока декодирования, модуль 410 предсказания с компенсацией движения генерирует сигнал Pred[blk] предсказания с компенсацией движения для целевого блока декодирования (этап Sd7). Этот процесс является таким же, как этап Sb5 из второго варианта осуществления.
[0150] Когда получается сигнал предсказания с компенсацией движения, модуль 411 декодирования изображения декодирует целевой кадр декодирования, подвергнутый кодированию с предсказанием. В частности, сигнал DecRes остатка предсказания декодируется из кодированных данных (этап Sd8), и декодированное изображение Deccur[blk] для блока blk генерируется путем добавления сигнала Pred предсказания с компенсацией движения к полученному декодированному остатку DecRes предсказания (этап Sd9). Сгенерированное декодированное изображение становится выводом устройства 400 декодирования многовидового видеосигнала и сохраняется в запоминающем устройстве 412 декодированного изображения для использования в предсказании для последующих кадров.
[0151] Хотя изображение синтезированного вида и опорный кадр сами используются в вышеописанных вариантах осуществления с первого по четвертый, когда шум, например зернистость пленки и искажение кодирования, генерируется в изображении синтезированного вида и/или опорном кадре, точность поиска соответствующей области, скорее всего, ухудшается из-за его влияния. Поскольку шум может предполагаться как высокочастотная составляющая, можно уменьшить его влияние путем выполнения поиска после того, как фильтр нижних частот применяется к кадрам (изображению синтезированного вида и опорному кадру) для использования в поиске соответствующей области. К тому же в качестве другого способа можно предотвратить оценивание неверного вектора движения из-за шума с помощью применения фильтра среднего или медианного фильтра к вектору движения, оцененному для каждого блока, пользуясь тем, что векторы движения обладают пространственной корреляцией.
[0152] E. Пятый вариант осуществления
Далее будет описываться пятый вариант осуществления настоящего изобретения.
Фиг. 9 - блок-схема, иллюстрирующая конфигурацию устройства оценки вектора движения в пятом варианте осуществления. Как проиллюстрировано на фиг. 9, устройство 500 оценки вектора движения снабжается модулем 501 ввода видеосигнала опорного вида, модулем 502 ввода информации о камере, модулем 503 синтеза вида, модулем 504 фильтра нижних частот, модулем 505 поиска соответствующей области и модулем 506 сглаживания вектора движения.
[0153] Модуль 501 ввода видеосигнала опорного вида вводит видеокадр, полученный в виде (опорном виде), отличном от целевого вида обработки, в котором получен кадр, для которого нужно получить векторы движения. Модуль 502 ввода информации о камере вводит внутренние параметры, указывающие фокусные расстояния или т.п., и внешние параметры, указывающие положения и направления камер для целевого вида обработки и опорного вида.
[0154] Модуль 503 синтеза вида формирует синтезированный видеосигнал вида для целевого вида обработки, используя видеосигнал опорного вида. Модуль 504 фильтра нижних частот уменьшает шум, включенный в синтезированный видеосигнал вида, путем применения к нему фильтра нижних частот. Для каждого единичного блока для оценки движения кадра в синтезированном видеосигнале вида модуль 505 поиска соответствующей области ищет вектор движения, указывающий соответствующий блок в другом кадре синтезированного видеосигнала вида. Модуль 506 сглаживания вектора движения пространственно сглаживает вектор движения, чтобы увеличить пространственную корреляцию вектора движения.
[0155] Фиг. 10 - блок-схема последовательности операций, описывающая работу устройства 500 оценки вектора движения в пятом варианте осуществления. Процесс, который должен быть выполнен устройством 500 оценки вектора движения в пятом варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0156] Сначала кадры Ref(n, t) опорного вида (n=1, 2, …, N и t=T1, T2), полученные в опорном виде, вводятся модулем 501 ввода изображения опорного вида и отправляются в модуль 503 синтеза вида (этап Se1). К тому же внутренние параметры, указывающие фокусные расстояния, и внешние параметры, указывающие положения и направления камер для целевого вида обработки и опорного вида, вводятся модулем 502 ввода информации о камере и отправляются в модуль 503 синтеза вида (этап Se1). Здесь n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов. Более того, t является индексом, указывающим момент фотографирования кадра, и настоящий вариант осуществления описывает пример, в котором вектор движения оценивается между блоком кадра с моментом T1 и каждым блоком кадра с моментом T2.
[0157] Далее модуль 503 синтеза вида синтезирует изображение, полученное в целевом виде обработки для каждого момента фотографирования, используя кадры опорного вида и информацию о камере (этап Se2). Этот процесс аналогичен этапу Sa2 из первого варианта осуществления. Однако здесь синтезируются изображения Synt синтезированного вида для кадров с моментами T1 и T2.
[0158] Когда синтез изображений Synt синтезированного вида завершается, модуль 504 фильтра нижних частот применяет фильтр нижних частот к синтезированным изображениям вида и генерирует малошумные изображения LPFSynt синтезированного вида (этап Se3). Нужно отметить, что хотя может использоваться любой фильтр нижних частот, типичным представителем является фильтр среднего. Фильтр среднего является фильтром для замены пиксельного сигнала средним значением сигналов изображения соседних пикселей.
[0159] Когда процесс фильтрации нижних частот завершается, модуль 505 поиска соответствующей области делит на блоки изображение LPFSynT2 синтезированного вида, для которого должны быть оценены векторы движения, выполняет поиск соответствующей области для каждой области и генерирует векторы движения (этапы Se4-Se7). То есть, когда индекс единичного блока для оценки движения обозначается blk, а общее количество единичных блоков для оценки движения обозначается numBlks, после того, как blk инициализируется в 0 (этап Se4), процесс (этап Se5) поиска блока, соответствующего изображению LPFSynT2[blk] синтезированного вида, на изображении LPFSynT1 синтезированного вида повторяется до тех пор, пока blk не достигнет numBlks (этап Se7), увеличивая при этом blk на 1 (этап Se6).
[0160] Процесс поиска соответствующей области (этап Se5) аналогичен этапу Sa5 из первого варианта осуществления за исключением того, что используются разные кадры. То есть это процесс получения пары (best_vec, best_t), представленной Уравнением (9), с использованием стоимости соответствия, в котором Syn заменяется LPFSynT2, а Dect заменяется LPFSynT1 в Уравнениях с (5) по (8). Однако в настоящем варианте осуществления диапазоном поиска t является только T1, и, соответственно, best_t становится T1.
[0161] Когда векторы движения получаются для всех блоков, модуль 506 сглаживания вектора движения сглаживает набор полученных векторов движения {MVblk}, чтобы увеличить пространственную корреляцию (этап Se8). Набор сглаженных векторов становится выводом устройства 500 оценки вектора движения.
[0162] Хотя может использоваться любой способ для сглаживания вектора движения, существует, например, способ для применения фильтра среднего. Процесс фильтра среднего, используемый в этом документе, является процессом определения вектора, представленного средним значением векторов движения у блоков, соседствующих с блоком blk, в качестве вектора движения у блока blk. Нужно отметить, что поскольку этот вектор движения является двумерной информацией, процесс вычисления среднего значения выполняется для каждого измерения. В качестве другого характерного примера существует способ для применения векторного медианного фильтра. Векторный медианный фильтр сначала генерирует набор векторов движения X={MVk} ближайших блоков для блока blk. Затем MV'blk, полученный по следующему Уравнению (13), определяется в качестве сглаженного вектора для блока blk.
[0163] [Формула 13]

[0164] Нужно отметить, что ||v|| обозначает норму v. Хотя может использоваться любая норма, норма L1 и норма L2 являются показательными нормами. Норма L1 является суммой абсолютных значений соответствующих компонентов v, а норма L2 является суммой квадратов соответствующих компонентов v. К тому же wi является весом и может задаваться с использованием некоторого способа. Например, может использоваться значение, заданное следующим Уравнением (14):
[0165] [Формула 14]

[0166] Нужно отметить, что хотя степени надежности изображений синтезированного вида не вычисляются в пятом варианте осуществления, степени надежности изображений синтезированного вида могут вычисляться и использоваться, как в первом варианте осуществления. Фиг. 11 - блок-схема, иллюстрирующая конфигурацию устройства 500a оценки вектора движения в этом случае. Устройство 500a оценки вектора движения снабжается модулем 507 установки степени надежности в дополнение к составляющим элементам, предоставленным в устройстве 500 оценки вектора движения, проиллюстрированном на фиг. 9. Например, конфигурация модуля 507 установки степени надежности аналогична конфигурации модуля 107 установки степени надежности, проиллюстрированной на фиг. 1. Однако устройство 500a оценки вектора движения отличается от устройства 500 оценки вектора движения в том, что вводится видеосигнал, а не кадр (изображение). К тому же в пятом варианте осуществления кадр, из которого ищется соответствующая область, также является синтезированным изображением вида, и, соответственно, степени надежности также можно вычислять и использовать для изображения синтезированного вида, служащего в качестве области поиска. Кроме того, степени надежности для соответствующих изображений могут вычисляться и одновременно использоваться. Когда степени надежности используются одновременно, уравнения для вычисления стоимостей соответствия, соответствующие Уравнениями (5)-(8), являются следующими Уравнениями (15)-(18). Нужно отметить, что ξ является степенью надежности для целевого изображения вида, служащего в качестве области поиска.
[0167] [Формула 15]

[Формула 16]

[Формула 17]

[Формула 18]

[0168] F. Шестой вариант осуществления
Далее будет описываться шестой вариант осуществления настоящего изобретения.
Фиг. 12 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала в шестом варианте осуществления. Как проиллюстрировано на фиг. 12, устройство 600 кодирования многовидового видеосигнала снабжается модулем 601 ввода целевого кадра кодирования, запоминающим устройством 602 целевого изображения кодирования, модулем 603 ввода кадра опорного вида, запоминающим устройством 604 изображения опорного вида, модулем 605 синтеза вида, модулем 606 фильтра нижних частот, запоминающим устройством 607 изображения синтезированного вида, модулем 608 установки степени надежности, модулем 609 поиска соответствующей области, модулем 610 сглаживания вектора движения, модулем 611 предсказания с компенсацией движения, модулем 612 кодирования изображения, модулем 613 декодирования изображения и запоминающим устройством 614 декодированного изображения.
[0169] Модуль 601 ввода целевого кадра кодирования вводит видеокадр, служащий в качестве целевого объекта кодирования. Запоминающее устройство 602 целевого изображения кодирования сохраняет входной целевой кадр кодирования. Модуль 603 ввода кадра опорного вида вводит видеокадр для некоторого вида, отличного от вида целевого кадра кодирования. Запоминающее устройство 604 изображения опорного вида сохраняет входной кадр опорного вида. Модуль 605 синтеза вида генерирует синтезированные изображения вида для целевого кадра кодирования и опорного кадра, используя кадр опорного вида.
[0170] Модуль 606 фильтра нижних частот уменьшает шум, включенный в синтезированный видеосигнал вида, путем применения к нему фильтра нижних частот. Запоминающее устройство 607 изображения синтезированного вида сохраняет изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот. Модуль 608 установки степени надежности задает степень надежности для каждого пикселя сгенерированного изображения синтезированного вида. Модуль 609 поиска соответствующей области ищет вектор движения, представляющий соответствующий блок в уже кодированном кадре, который служит в качестве опорного кадра в предсказании с компенсацией движения и получен в том же виде, что и целевой кадр кодирования для каждого единичного блока для кодирования изображения синтезированного вида, используя изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот, сгенерированное для опорного кадра, и степени надежности. То есть путем назначения на основе степеней надежности веса для стоимости соответствия, когда ищется соответствующая область, точно синтезированный пиксель рассматривается как важный, и осуществляется высокоточная оценка вектора движения, не подвергаясь влиянию ошибки при синтезе вида. Модуль 610 сглаживания вектора движения пространственно сглаживает вектор движения, чтобы увеличить пространственную корреляцию вектора движения.
[0171] Модуль 611 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения, используя опорный кадр на основе определенного соответствующего блока. Модуль 612 кодирования изображения принимает изображение предсказания с компенсацией движения, выполняет кодирование целевого кадра кодирования с предсказанием и выводит кодированные данные. Модуль 613 декодирования изображения принимает изображение предсказания с компенсацией движения и кодированные данные, декодирует целевой кадр кодирования и выводит декодированное изображение. Запоминающее устройство 614 декодированного изображения сохраняет декодированное изображение целевого кадра кодирования.
[0172] Фиг. 13 - блок-схема последовательности операций, описывающая работу устройства 600 кодирования многовидового видеосигнала в шестом варианте осуществления. Процесс, который должен быть выполнен устройством 600 кодирования многовидового видеосигнала в шестом варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0173] Сначала целевой кадр Org кодирования вводится модулем 601 ввода целевого кадра кодирования и сохраняется в запоминающем устройстве 602 целевого изображения кодирования (этап Sf1). К тому же кадр Ref(n, t) опорного вида (n=1, 2, …, N), полученный в опорном виде, вводится модулем 603 ввода кадра опорного вида и сохраняется в запоминающем устройстве 604 изображения опорного вида (этап Sf1). Здесь предполагается, что входной кадр опорного вида получается путем декодирования уже кодированного изображения. Это нужно для подавления генерирования шума кодирования, например сдвига, путем использования такой же информации, как информация, полученная в устройстве декодирования. Однако, когда разрешено генерирование шума кодирования, может вводиться исходное изображение до кодирования. Нужно отметить, что n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов. К тому же t является индексом, указывающим момент фотографирования кадра, и он обозначает любой из момента фотографирования (T) целевого кадра Org кодирования и моментов фотографирования (T1, T2, …, и Tm) опорных кадров. Здесь m обозначает количество опорных кадров.
[0174] Далее модуль 605 синтеза вида синтезирует изображение, полученное в том же виде, что и целевой кадр кодирования для каждого момента фотографирования, используя информацию о кадре опорного вида (этап Sf2). Этот процесс аналогичен этапу Sa2 из первого варианта осуществления. Однако здесь изображения Synt синтезированного вида синтезируются для кадров с моментами T, T1, T2, …, и Tm.
[0175] Когда синтез изображений Synt синтезированного вида завершается, модуль 606 фильтра нижних частот применяет фильтр нижних частот к синтезированным изображениям вида, чтобы сгенерировать малошумные изображения LPFSynt синтезированного вида, которые сохраняются в запоминающем устройстве 607 изображения синтезированного вида (этап Sf3). Нужно отметить, что хотя может использоваться любой фильтр нижних частот, типичным представителем является фильтр среднего. Фильтр среднего является фильтром, который определяет среднее значение входных сигналов изображения соседних пикселей в качестве выходного пиксельного сигнала.
[0176] Далее модуль 608 установки степени надежности генерирует степень ρ надежности, указывающую достоверность того, что можно было осуществить синтез для каждого пикселя изображения синтезированного вида (этап Sf4). Этот процесс является таким же, как этап Sa3 из первого варианта осуществления.
[0177] Аналогично первому варианту осуществления, если выполняется поиск соответствующих точек, стереоскопический способ или оценка глубины, когда генерируется изображение синтезированного вида, то часть процесса получения информации о соответствующих точках или информации о глубине может быть такой же, как часть вычисления степеней надежности. В таких случаях можно уменьшить объем вычисления путем одновременного выполнения генерирования изображения синтезированного вида и вычисления степеней надежности.
[0178] Когда вычисление степеней надежности завершается, модуль 609 поиска соответствующей области делит целевой кадр кодирования на блоки и выполняет поиск соответствующей области для каждой области (этап Sf5). В дальнейшем индекс разделенного блока обозначается с помощью blk. Процесс поиска соответствующей области (этап Sf5) аналогичен этапу Sa5 из первого варианта осуществления за исключением того, что используются разные кадры. То есть это процесс получения пары (best_vec, best_t), представленной Уравнением (9), с использованием стоимости соответствия, в котором Syn заменяется LPFSynT, а Dec заменяется LPFSyn в Уравнениях с (5) по (8). Однако в настоящем варианте осуществления диапазоном поиска t является T1-Tm.
[0179] Когда получаются векторы движения всех блоков, модуль 610 сглаживания вектора движения сглаживает набор полученных векторов движения {MVblk}, чтобы увеличить пространственную корреляцию (этап Sf6). Этот процесс является таким же, как этап Se8 из пятого варианта осуществления. Однако, когда имеется множество опорных кадров, момент и временное направление меняются в зависимости от выбранного опорного кадра, когда возникло движение объекта, представленное вектором движения. Временное направление движения указывает, является ли движение прошлым движением или будущим движением относительно целевого кадра кодирования, служащего в качестве начала отсчета. Поэтому, когда выполняется процесс среднего значения или процесс срединного значения, необходимо выполнять вычисление с использованием только векторов движения, ассоциированных с одним и тем же опорным кадром. То есть в случае процесса фильтрации среднего среднее значение вычисляется с использованием только векторов движения соседних блоков, которые ассоциируются с одним и тем же опорным кадром. В примере векторного медианного фильтра необходимо задать набор X векторов движения в качестве набора векторов, которые используют один и тот же опорный кадр в качестве вектора MVblk движения среди векторов движения ближайших блоков.
[0180] Когда сглаживание векторов движения завершается, модуль 611 предсказания с компенсацией движения генерирует сигнал Pred предсказания с компенсацией движения на основе полученных векторов движения (этап Sf7). Этот процесс является таким же, как этап Sa6 из первого варианта осуществления. Нужно отметить, что поскольку получены векторы движения всех блоков, генерируется сигнал предсказания с компенсацией движения для всего кадра.
[0181] Когда получается сигнал предсказания с компенсацией движения, модуль 612 кодирования изображения выполняет кодирование с предсказанием целевого кадра Org кодирования, используя сигнал Pred предсказания с компенсацией движения. В частности, получается и кодируется сигнал Res остатка, представленный разностью между целевым кадром Org кодирования и сигналом Pred предсказания с компенсацией движения (этап Sf8). Для кодирования сигнала остатка может использоваться любой способ. Например, в H.264, раскрытом в Непатентном документе 1, кодирование выполняется путем последовательного применения частотного преобразования, например DCT, квантования, преобразования в двоичную форму и энтропийного кодирования. Данные этого результата кодирования становятся выводом устройства 600 кодирования многовидового видеосигнала в шестом варианте осуществления.
[0182] Модуль 613 декодирования изображения выполняет декодирование над данными результата кодирования для использования в предсказании, когда кодируются последующие кадры. При декодировании сначала декодируется сигнал остатка предсказания, который кодирован (этап Sf9), и сигнал Pred предсказания с компенсацией движения добавляется к полученному декодированному сигналу DecRes остатка предсказания, чтобы сгенерировать локальное декодированное изображение Deccur (этап Sf10). Полученное локальное декодированное изображение сохраняется в запоминающем устройстве 614 декодированного изображения. Нужно отметить, что способ для выполнения декодирования над кодированными данными, полученными по методике, используемой в кодировании, используется для декодирования. В случае H.264 декодированный сигнал остатка предсказания получается путем последовательного применения процессов энтропийного декодирования, обратного преобразования в двоичную форму, обратного квантования и обратного частотного преобразования, например IDCT.
[0183] Нужно отметить, что процесс кодирования и процесс декодирования могут выполняться для всего кадра, либо они могут выполняться для каждого блока, как в H.264. Когда эти процессы выполняются для каждого блока, можно уменьшить объем временной памяти для хранения сигнала предсказания с компенсацией движения путем повторения этапов Sf7, Sf8, Sf9 и Sf10 для каждого блока.
[0184] Настоящий вариант осуществления отличается от вышеописанных вариантов осуществления с первого по четвертый в том, что сам опорный кадр не используется для получения соответствующей области на опорном кадре, а соответствующая область получается с использованием изображения синтезированного вида, сгенерированного для опорного кадра. Поскольку изображение Syn синтезированного вида и декодированное Dec изображение рассматриваются как практически идентичные, когда процесс синтеза вида можно выполнить с высокой точностью, полезный результат настоящего варианта осуществления в равной степени получается, даже когда используется изображение Syn синтезированного вида.
[0185] В этом случае необходимо ввести кадр опорного вида, полученный одновременно с опорным кадром, и сгенерировать и сохранить изображение синтезированного вида для опорного кадра. Когда процессы кодирования и декодирования в настоящем варианте осуществления постоянно применяются к множеству кадров, можно предотвратить синтезирование изображения синтезированного вида для опорного кадра для каждого целевого кадра кодирования путем постоянного сохранения изображения синтезированного вида в запоминающее устройство изображения синтезированного вида, пока кадр, который обработан, сохраняется в запоминающее устройство декодированного изображения.
[0186] Нужно отметить, что поскольку обработанный кадр, сохраненный в запоминающем устройстве декодированного изображения, не требуется при поиске соответствующей области, когда используется изображение синтезированного вида, соответствующее опорному кадру, то не нужно выполнять процесс поиска соответствующей области синхронно с процессом кодирования или процессом декодирования. В результате можно получить полезный результат в том, что может выполняться параллельное вычисление или т.п., и можно сократить общее время вычисления.
[0187] G. Седьмой вариант осуществления
Далее будет описываться седьмой вариант осуществления настоящего изобретения.
Фиг. 14 - блок-схема, иллюстрирующая конфигурацию устройства кодирования многовидового видеосигнала в седьмом варианте осуществления. Как проиллюстрировано на фиг. 7, устройство 700 кодирования многовидового видеосигнала снабжается модулем 701 ввода целевого кадра кодирования, запоминающим устройством 702 целевого изображения кодирования, модулем 703 оценки движения, модулем 704 предсказания с компенсацией движения, модулем 705 кодирования изображения, модулем 706 декодирования изображения, запоминающим устройством 707 декодированного изображения, модулем 708 ввода кадра опорного вида, модулем 709 синтеза вида, модулем 710 фильтра нижних частот, запоминающим устройством 711 изображения синтезированного вида, модулем 712 поиска соответствующей области, модулем 713 сглаживания вектора, модулем 714 генерирования вектора предсказания, модулем 715 кодирования векторной информации и запоминающим устройством 716 векторов движения.
[0188] Модуль 701 ввода целевого кадра кодирования вводит видеокадр, служащий в качестве целевого объекта кодирования. Запоминающее устройство 702 целевого изображения кодирования сохраняет входной целевой кадр кодирования. Модуль 703 оценки движения оценивает движение между целевым кадром кодирования и опорным кадром для каждого единичного блока для кодирования целевого кадра кодирования. Модуль 704 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения на основе результата оценки движения. Модуль 705 кодирования изображения принимает изображение предсказания с компенсацией движения, выполняет кодирование целевого кадра кодирования с предсказанием и выводит кодированные данные. Модуль 706 декодирования изображения принимает изображение предсказания с компенсацией движения и кодированные данные, декодирует целевой кадр кодирования и выводит декодированное изображение. Запоминающее устройство 707 декодированного изображения сохраняет декодированное изображение целевого кадра кодирования.
[0189] Модуль 708 ввода кадра опорного вида вводит видеокадр для некоторого вида, отличного от вида целевого кадра кодирования. Модуль 709 синтеза вида генерирует синтезированные изображения вида для целевого кадра кодирования и опорных кадров, используя кадр опорного вида. Модуль 710 фильтра нижних частот уменьшает шум, включенный в синтезированный видеосигнал вида, путем применения к нему фильтра нижних частот. Запоминающее устройство 711 изображения синтезированного вида сохраняет изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот.
[0190] Модуль 712 поиска соответствующей области ищет вектор, представляющий соответствующий блок в уже кодированном кадре, который служит в качестве опорного кадра в предсказании с компенсацией движения и получен в том же виде, что и целевой кадр кодирования для каждого единичного блока для кодирования изображения синтезированного вида, используя изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот, сгенерированное для опорного кадра. Модуль 713 сглаживания вектора пространственно сглаживает полученный вектор, чтобы сгенерировать оцененный вектор для увеличения пространственной корреляции вектора.
[0191] Модуль 714 генерирования вектора предсказания генерирует вектор предсказания для вектора движения целевого блока кодирования из оцененного вектора и векторов движения, используемых для компенсации движения в соседних блоках. Модуль 715 кодирования векторной информации выполняет кодирование с предсказанием вектора движения, используя сгенерированный вектор предсказания. Запоминающее устройство 716 векторов движения сохраняет вектор движения.
[0192] Фиг. 15 - блок-схема последовательности операций, описывающая работу устройства 700 кодирования многовидового видеосигнала в седьмом варианте осуществления. Процесс, который должен быть выполнен устройством 700 кодирования многовидового видеосигнала в седьмом варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0193] Сначала целевой кадр Org кодирования вводится модулем 701 ввода целевого кадра кодирования и сохраняется в запоминающем устройстве 702 целевого изображения кодирования (этап Sg1). Далее целевой кадр кодирования делится на блоки, и видеосигнал целевого кадра кодирования кодируется, пока выполняется предсказание с компенсацией движения для каждой области (этапы Sg2-Sg5). В дальнейшем индекс целевого блока кодирования обозначается с помощью blk.
[0194] В процессе кодирования сначала модуль 703 оценки движения находит блок на опорном кадре, соответствующий целевому блоку Org[blk] кодирования, для каждого блока blk (этап Sg2). Этот процесс называется предсказанием движения и является таким же, как этап Sb4 из второго варианта осуществления. Двумерный вектор, который представляет смещение от блока blk для назначения соответствующего блока, называется вектором движения, который обозначается mv в седьмом варианте осуществления. Вектор mv движения сохраняется в запоминающем устройстве 716 векторов движения для использования в обработке для последующих блоков. Нужно отметить, что когда опорный кадр выбирается для каждого блока, как в H.264, информация, указывающая выбранный опорный кадр, также сохраняется в запоминающем устройстве 716 векторов движения.
[0195] Когда оценка движения завершается, модуль 704 предсказания с компенсацией движения генерирует сигнал Pred предсказания с компенсацией движения для целевого кадра Org кодирования (этап Sg3). Этот процесс является таким же, как этап Sb5 из второго варианта осуществления. Когда получается сигнал предсказания с компенсацией движения, модуль 705 кодирования изображения выполняет кодирование с предсказанием целевого блока кодирования, используя сигнал Pred предсказания с компенсацией движения (этап Sg4). Этот процесс является таким же, как этап Sb6 из второго варианта осуществления. Данные этого результата кодирования становятся частью вывода устройства 700 кодирования многовидового видеосигнала в седьмом варианте осуществления. Модуль 706 декодирования изображения выполняет декодирование над данными результата кодирования для использования в предсказании, когда кодируются последующие кадры (этап Sg5). Этот процесс является таким же, как процесс этапов Sb7 и Sb8 из второго варианта осуществления. Локальное декодированное изображение Deccur сохраняется в запоминающем устройстве 707 декодированного изображения.
[0196] Нужно отметить, что хотя блок-схема последовательности операций, проиллюстрированная на фиг. 15, показывает пример, в котором процесс этапов Sg3-Sg5 выполняется для каждого кадра, этапы Sg3-Sg5 можно выполнять многократно для каждого блока. В этом случае, поскольку достаточно, чтобы сигнал предсказания с компенсацией движения сохранялся для каждого блока, можно уменьшить объем памяти для временного использования.
[0197] Когда кодирование сигнала изображения целевого кадра кодирования завершается, кодируется вектор mv движения для генерирования сигнала предсказания с компенсацией движения, используемого при кодировании. С этой целью сначала кадр Ref(n, t) опорного вида (n=1, 2, …, N), полученный в опорном виде, вводится модулем 708 ввода кадра опорного вида (этап Sg6). Здесь предполагается, что входной кадр опорного вида получается путем декодирования уже кодированного изображения. Это нужно для предотвращения генерирования шума кодирования, например сдвига, путем использования такой же информации, как информация, полученная в устройстве декодирования. Однако, когда разрешено генерирование шума кодирования, может вводиться исходное изображение до кодирования. Нужно отметить, что n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов. К тому же t является индексом, указывающим момент фотографирования кадра, и он обозначает любой из момента фотографирования (T) целевого кадра Org кодирования и моментов фотографирования (T1, T2, …, и Tm) опорных кадров. Здесь m обозначает количество опорных кадров.
[0198] Далее модуль 709 синтеза вида синтезирует изображение, полученное в том же виде, что и целевой кадр кодирования для каждого момента фотографирования, используя информацию о кадре опорного вида (этап Sg7). Этот процесс является таким же, как этап Sf2 из шестого варианта осуществления.
[0199] Когда синтез изображений Synt синтезированного вида завершается, модуль 710 фильтра нижних частот применяет фильтр нижних частот к синтезированным изображениям вида, чтобы сгенерировать малошумные изображения LPFSynt синтезированного вида, которые сохраняются в запоминающем устройстве 711 изображения синтезированного вида (этап Sg8). Этот процесс является таким же, как этап Sf3 из шестого варианта осуществления.
[0200] Когда процесс фильтрации нижних частот завершается, модуль 712 поиска соответствующей области делит на блоки изображение LPFSynT синтезированного вида, сгенерированное для целевого кадра кодирования, и выполняет поиск соответствующей области для каждой области (этап Sg9). Нужно отметить, что когда изображение LPFSynT синтезированного вида делится на блоки, деление выполняется с использованием такого же положения и размера блока, что и у блоков, для которых предсказание с компенсацией движения выполняется на этапе Sg3. Здесь процессом является процесс получения пары (best_vec, best_t), удовлетворяющей Уравнению (9), с использованием стоимости соответствия, в котором Syn заменяется LPFSynT, а Dec заменяется LPFSyn в Уравнениях с (5) по (8) для каждого разделенного блока. Однако в настоящем варианте осуществления best_vec получается для каждого из T1-Tm в качестве t. То есть набор best_vec получается для каждого блока. Нужно отметить, что хотя настоящий вариант осуществления не использует степени надежности в синтезе вида, степени надежности могут вычисляться и использоваться, как описано в шестом варианте осуществления.
[0201] Когда векторы движения получаются для всех блоков, модуль 713 сглаживания вектора движения генерирует набор оцененных векторов {vec(blk, t)} путем сглаживания набора полученных векторов движения {MVblk}, чтобы увеличить пространственную корреляцию (этап Sg10). Этот процесс является таким же, как этап Se8 из пятого варианта осуществления. Нужно отметить, что процесс сглаживания выполняется для каждого из моментов фотографирования опорных кадров.
[0202] Когда получается набор оцененных векторов, модуль 714 генерирования вектора предсказания генерирует вектор pmv предсказания для вектора mv движения целевого блока кодирования с использованием оцененных векторов блока обработки и векторов движения, используемых в блоках, соседствующих с блоком обработки, сохраненных в запоминающем устройстве 716 векторов движения для каждого блока (этап Sg11). Нужно отметить, что этот процесс аналогичен этапу Sb11 из второго варианта осуществления. Однако настоящий вариант осуществления выбирает оптимальный кадр для каждого блока из множества опорных кадров и генерирует вектор движения, и, соответственно, может использоваться способ генерирования вектора предсказания, учитывающий опорный кадр каждого вектора.
[0203] Нижеследующий способ может использоваться в качестве способа генерирования вектора предсказания, учитывающего опорный кадр вектора. Сначала опорный кадр вектора движения блока обработки сравнивается с опорными кадрами векторов движения, используемыми в блоках, соседствующих с блоком обработки, и векторы движения, ассоциированные с опорными кадрами, которые совпадают с опорным кадром вектора движения блока обработки среди векторов движения, используемых в соседних блоках, задаются в качестве возможных векторов предсказания. Если никакого возможного вектора предсказания не обнаружено, то оцененный вектор блока обработки, который ассоциируется с тем же опорным кадром, определяется в качестве вектора предсказания. Если обнаружены возможные векторы предсказания, то вектор, ближайший к оцененному вектору блока обработки, который ассоциируется с тем же опорным кадром среди возможных вариантов, определяется в качестве вектора предсказания. В этом случае можно исключить вектор, отделенный предопределенным расстоянием или более от оцененного вектора блока обработки, который ассоциируется с тем же опорным кадром. Нужно отметить, что если никакой возможный вектор предсказания не присутствует в качестве результата процесса исключения, то оцененный вектор блока обработки, который ассоциируется с тем же опорным кадром, определяется в качестве вектора предсказания.
[0204] К тому же нижеследующий способ может использоваться в качестве способа генерирования вектора предсказания, учитывающего опорный кадр вектора. Сначала набор блоков, ассоциированных с одним и тем же опорным кадром, задается в ближайших блоках для блока обработки. Если этот набор является пустым набором, то оцененный вектор блока обработки, который ассоциируется с тем же опорным кадром, определяется в качестве вектора предсказания. Если этот набор не является пустым набором, то степень подобия между оцененным вектором каждого блока, включенного в набор, который ассоциируется с тем же опорным кадром, и оцененным вектором блока обработки, который ассоциируется с тем же опорным кадром, вычисляется для каждого блока, включенного в набор. Затем вектор движения блока, имеющего наибольшую степень подобия, определяется в качестве вектора предсказания. Нужно отметить, что если степени подобия для всех блоков меньше некоторого постоянного значения, то оцененный вектор блока обработки, который ассоциируется с тем же опорным кадром, может определяться в качестве вектора предсказания. К тому же, если имеется множество блоков, имеющих степени подобия, больше либо равные тому постоянному значению, то средний вектор векторов движения, соответствующих блокам, может определяться в качестве вектора предсказания.
[0205] Когда генерирование вектора предсказания завершается, модуль 715 кодирования векторной информации выполняет кодирование вектора mv движения с предсказанием для каждого блока (этап Sg12). Этот процесс является таким же, как этап Sb12 из второго варианта осуществления. Результат кодирования становится одним из выводов устройства 700 кодирования многовидового видеосигнала.
[0206] Блок-схема последовательности операций, проиллюстрированная на фиг. 15, показывает пример, в котором этапы Sg11 и Sg12 выполняются для каждого кадра. В этом случае, когда вектор предсказания генерируется на этапе Sg11, учитывая порядок кодирования на этапе Sg12, должно быть установлено ограничение, чтобы только кодированные блоки использовались в качестве соседних блоков. Это нужно, чтобы избежать ситуации, в которой декодирование нельзя выполнить, потому что для декодирования необходима информация, которая еще не декодирована. Нужно отметить, что этапы Sg11 и Sg12 могут выполняться поочередно для каждого блока. В этом случае можно идентифицировать кодированную соседнюю область без учета порядка кодирования. К тому же достаточно, чтобы вектор предсказания сохранялся для каждого блока, и поэтому можно уменьшить объем памяти для временного использования.
[0207] К тому же в настоящем варианте осуществления вектор генерируется для каждого опорного кадра на этапе Sg9. Однако вектор может генерироваться только для опорного кадра, ассоциированного с вектором движения блока обработки, либо вектор может генерироваться только для опорного кадра, ассоциированного с вектором движения любого из блока обработки и ближайших блоков к блоку обработки. При этом можно уменьшить издержки вычисления на этапе Sg9. Однако в этом случае процесс сглаживания вектора на этапе Sg10 должен выполняться с использованием только векторов движения, ассоциированных с тем же опорным кадром, что и на этапе Sf6 из шестого варианта осуществления.
[0208] H. Восьмой вариант осуществления
Далее будет описываться восьмой вариант осуществления настоящего изобретения.
Фиг. 16 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в восьмом варианте осуществления. Как проиллюстрировано на фиг. 16, устройство 800 декодирования многовидового видеосигнала снабжается модулем 801 ввода кодированных данных, запоминающим устройством 802 кодированных данных, модулем 803 ввода кадра опорного вида, запоминающим устройством 804 изображения опорного вида, модулем 805 синтеза вида, модулем 806 фильтра нижних частот, запоминающим устройством 807 изображения синтезированного вида, модулем 808 установки степени надежности, модулем 809 поиска соответствующей области, модулем 810 сглаживания вектора движения, модулем 811 предсказания с компенсацией движения, модулем 812 декодирования изображения и запоминающим устройством 813 декодированного изображения.
[0209] Модуль 801 ввода кодированных данных вводит кодированные данные видеокадра, служащего в качестве целевого объекта декодирования. Запоминающее устройство 802 кодированных данных сохраняет входные кодированные данные. Модуль 803 ввода кадра опорного вида вводит видеокадр для некоторого вида, отличного от вида целевого кадра декодирования. Запоминающее устройство 804 изображения опорного вида сохраняет входной кадр опорного вида. Модуль 805 синтеза вида генерирует синтезированные изображения вида для целевого кадра декодирования и опорного кадра, используя кадр опорного вида.
[0210] Модуль 806 фильтра нижних частот уменьшает шум, включенный в синтезированный видеосигнал вида, путем применения к нему фильтра нижних частот. Запоминающее устройство 807 изображения синтезированного вида сохраняет изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот. Модуль 808 установки степени надежности задает степень надежности для каждого пикселя сгенерированного изображения синтезированного вида. Модуль 809 поиска соответствующей области ищет вектор движения, представляющий соответствующий блок в уже декодированном кадре, который служит в качестве опорного кадра в предсказании с компенсацией движения и получен в том же виде, что и целевой кадр декодирования для каждого единичного блока для декодирования изображений синтезированного вида, используя изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот, сгенерированное для опорного кадра, и степени надежности. То есть путем назначения на основе степеней надежности веса для стоимости соответствия, когда ищется соответствующая область, точно синтезированный пиксель рассматривается как важный, и осуществляется высокоточная оценка вектора движения, не подвергаясь влиянию ошибки при синтезе вида. Модуль 810 сглаживания вектора движения пространственно сглаживает вектор движения, чтобы увеличить пространственную корреляцию вектора движения.
[0211] Модуль 811 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения, используя опорный кадр на основе определенного соответствующего блока. Модуль 812 декодирования изображения принимает изображение предсказания с компенсацией движения и кодированные данные, декодирует целевой кадр декодирования и выводит декодированное изображение. Запоминающее устройство 813 декодированного изображения сохраняет декодированное изображение целевого кадра декодирования.
[0212] Фиг. 17 - блок-схема последовательности операций, описывающая работу устройства 800 декодирования многовидового видеосигнала в восьмом варианте осуществления. Процесс, который должен быть выполнен устройством 800 декодирования многовидового видеосигнала в восьмом варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0213] Сначала кодированные данные целевого кадра декодирования вводятся модулем 801 ввода кодированных данных и сохраняются в запоминающем устройстве 802 кодированных данных (этап Sh1). К тому же кадр Ref(n, t) опорного вида (n=1, 2, …, N), полученный в опорном виде, вводится модулем 803 ввода кадра опорного вида и сохраняется в запоминающем устройстве 804 изображения опорного вида (этап Sh1). Здесь n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов. К тому же t является индексом, указывающим момент фотографирования кадра, и обозначает любой из момента фотографирования (T) целевого кадра Deccur декодирования и моментов фотографирования (T1, T2, …, и Tm) опорных кадров. Здесь m обозначает количество опорных кадров.
[0214] Далее модуль 805 синтеза вида синтезирует изображение, полученное в том же виде, что и целевой кадр декодирования для каждого момента фотографирования, используя информацию о кадре опорного вида (этап Sh2). Этот процесс является таким же, как этап Sf2 из шестого варианта осуществления. То есть здесь изображения Synt синтезированного вида синтезируются для кадров с моментами T, T1, T2, …, и Tm.
[0215] Когда синтез изображений Synt синтезированного вида завершается, модуль 806 фильтра нижних частот применяет фильтр нижних частот к синтезированным изображениям вида, а запоминающее устройство 807 изображения синтезированного вида сохраняет малошумные изображения LPFSynt синтезированного вида (этап Sh3). Этот процесс является таким же, как этап Sf3 из шестого варианта осуществления. Нужно отметить, что хотя может использоваться любой фильтр нижних частот, типичным представителем является фильтр среднего. Фильтр среднего является фильтром, который определяет среднее значение входных сигналов изображения у соседних пикселей в качестве выходного пиксельного сигнала.
[0216] Далее модуль 808 установки степени надежности генерирует степень ρ надежности, указывающую достоверность того, что можно было осуществить синтез для каждого пикселя изображения синтезированного вида (этап Sh4). Этот процесс является таким же, как этап Sf4 из шестого варианта осуществления.
[0217] Аналогично шестому варианту осуществления, если выполняется поиск соответствующих точек, стереоскопический способ или оценка глубины, когда генерируется изображение синтезированного вида, то часть процесса получения информации о соответствующих точках или информации о глубине может быть такой же, как часть вычисления степеней надежности. В таких случаях можно уменьшить объем вычисления путем одновременного выполнения генерирования изображения синтезированного вида и вычисления степеней надежности.
[0218] Когда вычисление степеней надежности завершается, модуль 809 поиска соответствующей области выполняет поиск соответствующей области для каждого предопределенного блока (этап Sh5). В дальнейшем индекс блока обозначается с помощью blk. Этот процесс является таким же, как этап Sf5 из шестого варианта осуществления.
[0219] Когда получаются векторы движения всех блоков, модуль 810 сглаживания вектора движения сглаживает набор полученных векторов движения {MVblk}, чтобы увеличить пространственную корреляцию (этап Sh6). Этот процесс является таким же, как этап Sf6 из шестого варианта осуществления.
[0220] Когда сглаживание векторов движения завершается, модуль 811 предсказания с компенсацией движения генерирует сигнал Pred предсказания с компенсацией движения на основе полученных векторов движения (этап Sh7). Этот процесс является таким же, как этап Sf7 из шестого варианта осуществления.
[0221] Когда получается сигнал предсказания с компенсацией движения, модуль 812 декодирования изображения декодирует целевой кадр Deccur декодирования (декодированное изображение) из входных кодированных данных, используя сигнал Pred предсказания с компенсацией движения (этап Sh8). Этот процесс является таким же, как сочетание этапов Sf9 и Sf10 из шестого варианта осуществления, и декодирование выполняется по процессу, обратному к процессу, выполненному в способе, используемом для кодирования. Сгенерированное декодированное изображение становится выводом устройства 800 декодирования многовидового видеосигнала и сохраняется в запоминающем устройстве 813 декодированного изображения для использования в предсказании для последующих кадров.
[0222] Нужно отметить, что процесс декодирования может выполняться для всего кадра либо он может выполняться для каждого блока, как в H.264. Если процесс декодирования выполняется для каждого блока, то можно уменьшить объем временной памяти для хранения сигнала предсказания с компенсацией движения путем поочередного выполнения этапов Sh7 и Sh8 для каждого блока.
[0223] I. Девятый вариант осуществления
Далее будет описываться девятый вариант осуществления настоящего изобретения.
Фиг. 18 - блок-схема, иллюстрирующая конфигурацию устройства декодирования многовидового видеосигнала в девятом варианте осуществления. На фиг. 9 устройство 900 декодирования многовидового видеосигнала снабжается модулем 901 ввода кодированных данных, запоминающим устройством 902 кодированных данных, модулем 903 ввода кадра опорного вида, модулем 904 синтеза вида, модулем 905 фильтра нижних частот, запоминающим устройством 906 изображения синтезированного вида, модулем 907 поиска соответствующей области, модулем 908 сглаживания вектора, модулем 909 генерирования вектора предсказания, модулем 910 декодирования вектора движения, запоминающим устройством 911 векторов движения, модулем 912 предсказания с компенсацией движения, модулем 913 декодирования изображения и запоминающим устройством 914 декодированного изображения.
[0224] Модуль 901 ввода кодированных данных вводит кодированные данные видеокадра, служащего в качестве целевого объекта декодирования. Запоминающее устройство 902 кодированных данных сохраняет входные кодированные данные. Модуль 903 ввода кадра опорного вида вводит видеокадр для опорного вида, отличного от вида целевого кадра декодирования. Модуль 904 синтеза вида генерирует синтезированные изображения вида для целевого кадра декодирования и опорных кадров, используя кадр опорного вида. Модуль 905 фильтра нижних частот уменьшает шум, включенный в синтезированные изображения вида, путем применения к ним фильтра нижних частот. Запоминающее устройство 906 изображения синтезированного вида сохраняет изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот.
[0225] Модуль 907 поиска соответствующей области ищет вектор, представляющий соответствующий блок в уже декодированном кадре, который служит в качестве опорного кадра в предсказании с компенсацией движения и получен в том же виде, что и целевой кадр декодирования для каждого единичного блока для декодирования изображения синтезированного вида, используя изображение синтезированного вида, подвергнутое процессу фильтрации нижних частот, сгенерированное для опорного кадра. Модуль 908 сглаживания вектора пространственно сглаживает полученный вектор, чтобы сгенерировать оцененный вектор для увеличения пространственной корреляции вектора.
[0226] Модуль 909 генерирования вектора предсказания генерирует вектор предсказания для вектора движения целевого блока декодирования из оцененного вектора и векторов движения, используемых для компенсации движения в блоках, соседствующих с целевым блоком декодирования. Модуль 910 декодирования вектора движения декодирует вектор движения, который подвергнут кодированию с предсказанием, из кодированных данных с использованием сгенерированного вектора предсказания. Запоминающее устройство 911 векторов движения сохраняет декодированный вектор движения. Модуль 912 предсказания с компенсацией движения генерирует изображение предсказания с компенсацией движения на основе декодированного вектора движения. Модуль 913 декодирования изображения принимает изображение предсказания с компенсацией движения, декодирует целевой кадр декодирования, который подвергнут кодированию с предсказанием, и выводит декодированное изображение. Запоминающее устройство 914 декодированного изображения сохраняет декодированное изображение.
[0227] Фиг. 19 - блок-схема последовательности операций, описывающая работу устройства 900 декодирования многовидового видеосигнала в девятом варианте осуществления. Процесс, который должен быть выполнен устройством 900 декодирования многовидового видеосигнала в девятом варианте осуществления, будет подробно описываться на основе этой блок-схемы последовательности операций.
[0228] Сначала кодированные данные целевого кадра декодирования вводятся модулем 901 ввода кодированных данных и сохраняются в запоминающем устройстве 902 кодированных данных (этап Si1). К тому же кадр Ref(n, t) опорного вида (n=1, 2, …, N), полученный в опорном виде, вводится модулем 903 ввода кадра опорного вида (этап Si1). Здесь n является индексом, указывающим опорный вид, а N является количеством доступных опорных видов. К тому же t является индексом, указывающим момент фотографирования кадра, и обозначает любой из момента фотографирования (T) целевого кадра Deccur декодирования и моментов фотографирования (T1, T2, …, и Tm) опорных кадров. Здесь m обозначает количество опорных кадров. Нужно отметить, что кодированные данные включают в себя по меньшей мере два типа данных: остаток предсказания видеосигнала и остаток предсказания вектора движения, используемые в предсказании для видеосигнала.
[0229] Далее модуль 904 синтеза вида синтезирует изображение, полученное в том же виде, что и целевой кадр декодирования для каждого момента фотографирования, используя информацию о кадре опорного вида (этап Si2). Этот процесс является таким же, как этап Sg7 из седьмого варианта осуществления.
[0230] Когда синтез изображений Synt синтезированного вида завершается, модуль 905 фильтра нижних частот применяет фильтр нижних частот к синтезированным изображениям вида, чтобы сгенерировать малошумные изображения LPFSynt синтезированного вида, которые сохраняются в запоминающем устройстве 906 изображения синтезированного вида (этап Si3). Этот процесс является таким же, как этап Sg8 из седьмого варианта осуществления.
[0231] Когда процесс фильтрации нижних частот завершается, модуль 907 поиска соответствующей области делит на блоки изображение LPFSynT синтезированного вида, сгенерированное для целевого кадра декодирования, и выполняет поиск соответствующей области для каждой области (этап Si4). Этот процесс является таким же, как этап Sg9 из седьмого варианта осуществления. Нужно отметить, что хотя настоящий вариант осуществления не использует степени надежности в синтезе вида, степени надежности могут вычисляться и использоваться, как в шестом варианте осуществления.
[0232] Когда векторы движения получаются для всех блоков, модуль 908 сглаживания вектора движения генерирует набор оцененных векторов {vec(blk, t)} путем сглаживания набора полученных векторов {MVblk}, чтобы увеличить пространственную корреляцию (этап Si5). Этот процесс является таким же, как этап Sg10 из седьмого варианта осуществления. Нужно отметить, что процесс сглаживания выполняется для каждого из моментов фотографирования опорных кадров.
[0233] Когда получается набор оцененных векторов, видеосигнал целевого кадра декодирования и вектор движения декодируются для каждого предопределенного блока (этапы Si6 - Si13). То есть, когда индекс целевого блока декодирования обозначается blk, а общее количество целевых блоков декодирования обозначается numBlks, после того, как blk инициализируется в 0 (этап Si6), следующий процесс (этапы Si7 - Si11) повторяется, пока blk не достигнет numBlks (этап Si13), увеличивая при этом blk на 1 (этап Si12).
[0234] В процессе, повторяемом для каждого целевого блока декодирования, сначала модуль 909 генерирования вектора предсказания генерирует вектор pmv предсказания для вектора mv движения целевого блока декодирования, используя оцененные векторы и векторы движения, используемые в блоках, соседствующих с целевым блоком декодирования, сохраненные в запоминающем устройстве 911 векторов движения (этап Si7). Этот процесс аналогичен этапу Sg11 из седьмого варианта осуществления. Однако в настоящем варианте осуществления вектор предсказания генерируется только для блока blk, а не для всего кадра. Тот же способ, что и выполнен при кодировании, используется для генерирования вектора предсказания.
[0235] Когда генерирование вектора предсказания завершается, модуль 910 декодирования вектора движения декодирует вектор mv движения целевого блока blk декодирования из кодированных данных (этап Si8). Вектор mv движения подвергнут кодированию с предсказанием, использующему вектор pmv предсказания, и вектор mv движения получается путем декодирования вектора dmv остатка предсказания из кодированных данных и добавления вектора pmv предсказания к вектору dmv остатка предсказания. Декодированный вектор mv движения отправляется в модуль 912 предсказания с компенсацией движения, сохраняется в запоминающем устройстве 911 векторов движения и используется, когда декодируется вектор движения последующего целевого блока декодирования.
[0236] Когда получается вектор движения для целевого блока декодирования, модуль 912 предсказания с компенсацией движения генерирует сигнал Pred[blk] предсказания с компенсацией движения для целевого блока декодирования (этап Si9). Этот процесс является таким же, как этап Sg3 из седьмого варианта осуществления.
[0237] Когда получается сигнал предсказания с компенсацией движения, модуль 913 декодирования изображения декодирует целевой кадр декодирования, подвергнутый кодированию с предсказанием. В частности, сигнал DecRes остатка предсказания декодируется из кодированных данных (этап Si10), и декодированное изображение Deccur[blk] для блока blk генерируется путем добавления сигнала Pred предсказания с компенсацией движения к полученному декодированному остатку DecRes предсказания (этап Si11). Сгенерированное декодированное изображение становится выводом устройства 900 декодирования многовидового видеосигнала и сохраняется в запоминающем устройстве 914 декодированного изображения для использования в предсказании для последующих кадров.
[0238] В вышеописанных вариантах осуществления с пятого по девятый процесс фильтрации нижних частот и процесс сглаживания вектора движения для изображений синтезированного вида предотвращают ухудшение точности поиска соответствующей области из-за шума, например зернистости пленки, и искажения кодирования в кадре опорного вида, искажения синтеза при синтезе вида, и т.п. Однако, когда величина шума небольшая, можно получить соответствующую область с высокой точностью без выполнения процесса фильтрации нижних частот и/или процесса сглаживания вектора движения. В таких случаях можно уменьшить объем всего вычисления путем пропуска процесса фильтрации нижних частот и/или процесса сглаживания вектора движения в вышеописанных вариантах осуществления с пятого по девятый.
[0239] Описанные выше варианты осуществления с первого по четвертый и варианты осуществления с шестого по девятый описывают случай, в котором единичный блок для кодирования и единичный блок для декодирования имеют такой же размер, как блок предсказания с компенсацией движения. Однако можно легко вывести расширение для случая, в котором единичный блок для кодирования и/или единичный блок для декодирования имеет размер, отличный от блока предсказания с компенсацией движения, как в H.264.
[0240] Хотя вышеописанные варианты осуществления с первого по девятый описывают предсказание с компенсацией движения, можно применять идею настоящего изобретения ко всем межкадровым предсказаниям. То есть при условии, что опорный кадр является кадром, полученным другой камерой, диспаратность оценивается с помощью поиска соответствующей области. К тому же при условии, что опорный кадр является кадром, полученным другой камерой в другое время, оценивается вектор, включающий движение и диспаратность. Кроме того, это также применимо к случаю, в котором опорная область в кадре определяется, как при фрактальном кодировании.
[0241] К тому же, хотя описанные выше варианты осуществления с первого по четвертый и варианты осуществления с шестого по девятый описывают, что блоки кодируются с использованием межкадрового предсказания, кодирование может выполняться с использованием другой схемы предсказания для каждого блока, как в H.264. В этом случае настоящее изобретение применяется только к блокам, использующим межкадровое предсказание. Блоки, для которых выполняется межкадровое предсказание, могут кодироваться наряду с переключением использования традиционной схемы и использования схемы из настоящего изобретения. В этом случае необходимо передавать декодирующей стороне информацию, указывающую используемую схему, с использованием некоторого способа.
[0242] Вышеописанный процесс также может осуществляться компьютером и компьютерной программой. К тому же можно предоставить программу путем записи программы на считываемый компьютером носитель записи и предоставить программу по сети.
[0243] К тому же, хотя вышеописанные варианты осуществления преимущественно описывают устройство кодирования многовидового видеосигнала и устройство декодирования многовидового видеосигнала, способ кодирования многовидового видеосигнала и способ декодирования многовидового видеосигнала могут быть реализованы с помощью этапов, соответствующих операциям соответствующих модулей в устройстве кодирования многовидового видеосигнала и устройстве декодирования многовидового видеосигнала.
[0244] Хотя выше со ссылкой на чертежи описаны варианты осуществления настоящего изобретения, эти варианты осуществления являются примерными для настоящего изобретения, и очевидно, что настоящее изобретение не ограничивается этими вариантами осуществления. Поэтому добавления, исключения, замены и другие модификации составляющих элементов могут выполняться без отклонения от сущности и объема настоящего изобретения.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
[0245] Настоящее изобретение используется, например, для кодирования и декодирования многовидовых киноизображений. В настоящем изобретении вектор движения можно точно оценить даже в ситуации, в которой нельзя получить изображение обработки. К тому же, используя временную корреляцию при предсказании видеосигнала, корреляция между камерами и временная корреляция используются одновременно, и можно реализовать эффективное кодирование многовидового видеосигнала.
Описание ссылочных позиций
[0246] 100, 200 Устройство кодирования многовидового видеосигнала
101, 201 Модуль ввода целевого кадра кодирования
102, 202 Запоминающее устройство целевого изображения кодирования
103, 203 Модуль ввода кадра опорного вида
104 Запоминающее устройство изображения опорного вида
105, 204 Модуль синтеза вида
106, 205 Запоминающее устройство изображения синтезированного вида
107 Модуль установки степени надежности
108, 211 Модуль поиска соответствующей области
109, 207 Модуль предсказания с компенсацией движения
110 Модуль кодирования остатка предсказания
111 Модуль декодирования остатка предсказания
112, 210 Запоминающее устройство декодированного изображения
113 Модуль вычисления остатка предсказания
114 Модуль вычисления декодированного изображения
206 Модуль оценки движения
208 Модуль кодирования изображения
209 Модуль декодирования изображения
212 Модуль генерирования вектора предсказания
213 Модуль кодирования векторной информации
214 Запоминающее устройство векторов движения
300, 400 Устройство декодирования многовидового видеосигнала
301, 401 Модуль ввода кодированных данных
302, 402 Запоминающее устройство кодированных данных
303, 403 Модуль ввода кадра опорного вида
304 Запоминающее устройство изображения опорного вида
305, 404 Модуль синтеза вида
306, 405 Запоминающее устройство изображения синтезированного вида
307 Модуль установки степени надежности
308, 406 Модуль поиска соответствующей области
309, 410 Модуль предсказания с компенсацией движения
310 Модуль декодирования остатка предсказания
311, 412 Запоминающее устройство декодированного изображения
312 Модуль вычисления декодированного изображения
407 Модуль генерирования вектора предсказания
408 Модуль декодирования вектора движения
409 Запоминающее устройство векторов движения
411 Модуль декодирования изображения
500, 500a Устройство оценки вектора движения
600, 700 Устройство кодирования многовидового видеосигнала
800, 900 Устройство декодирования многовидового видеосигнала











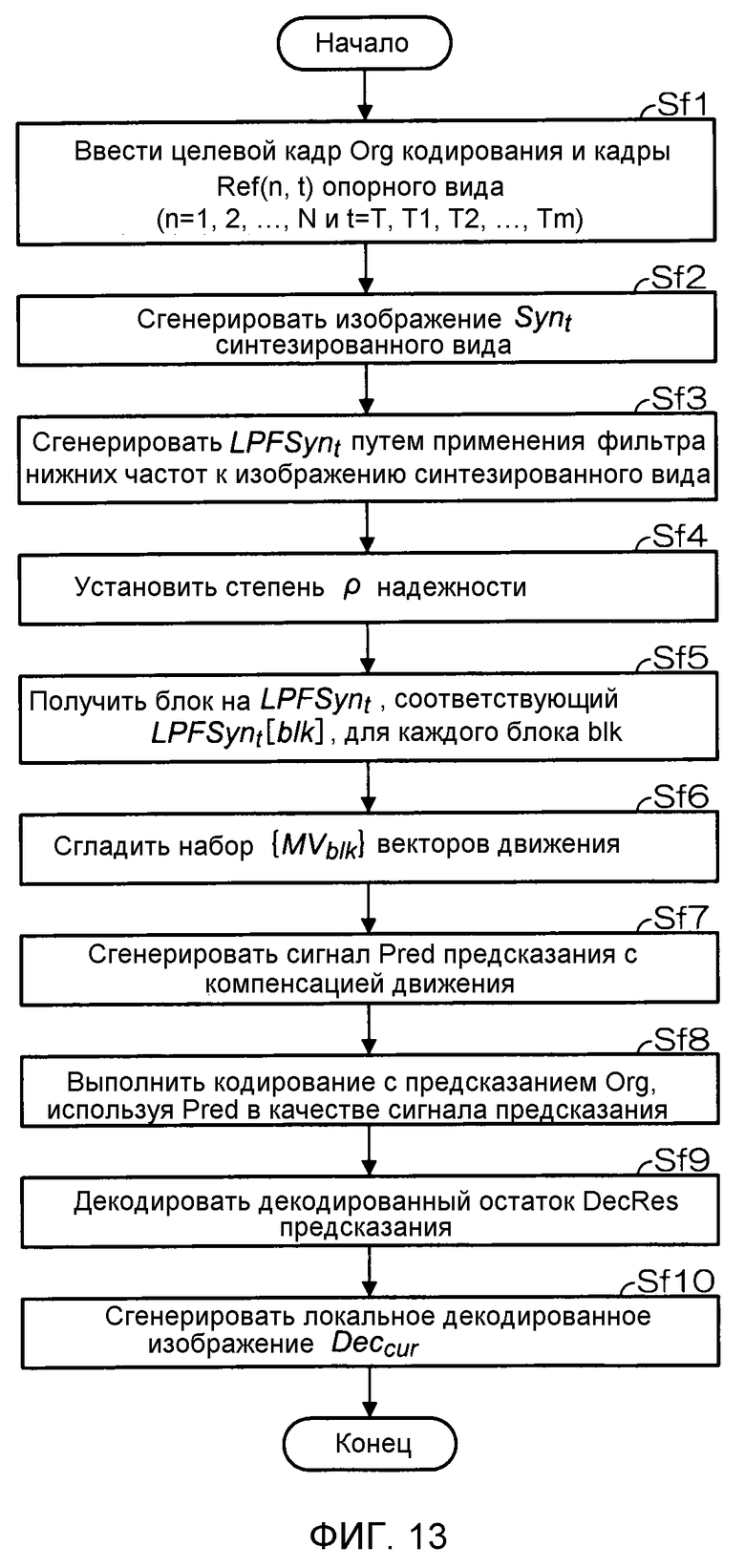


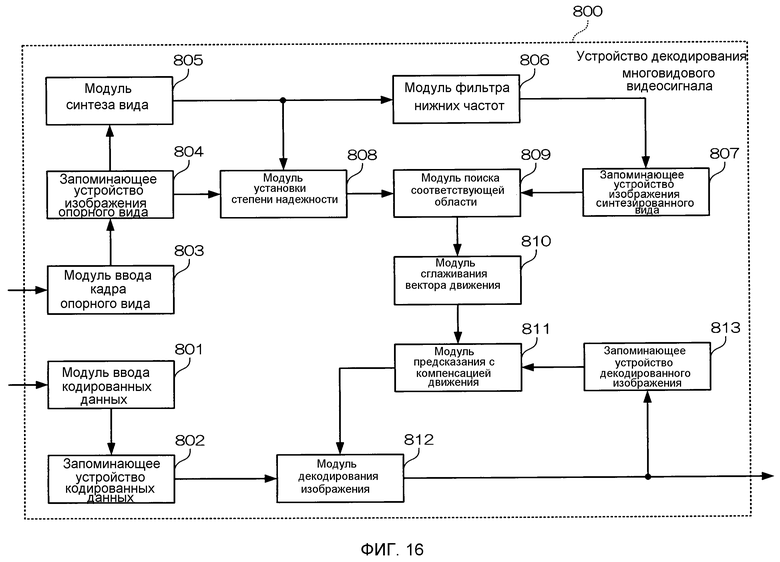
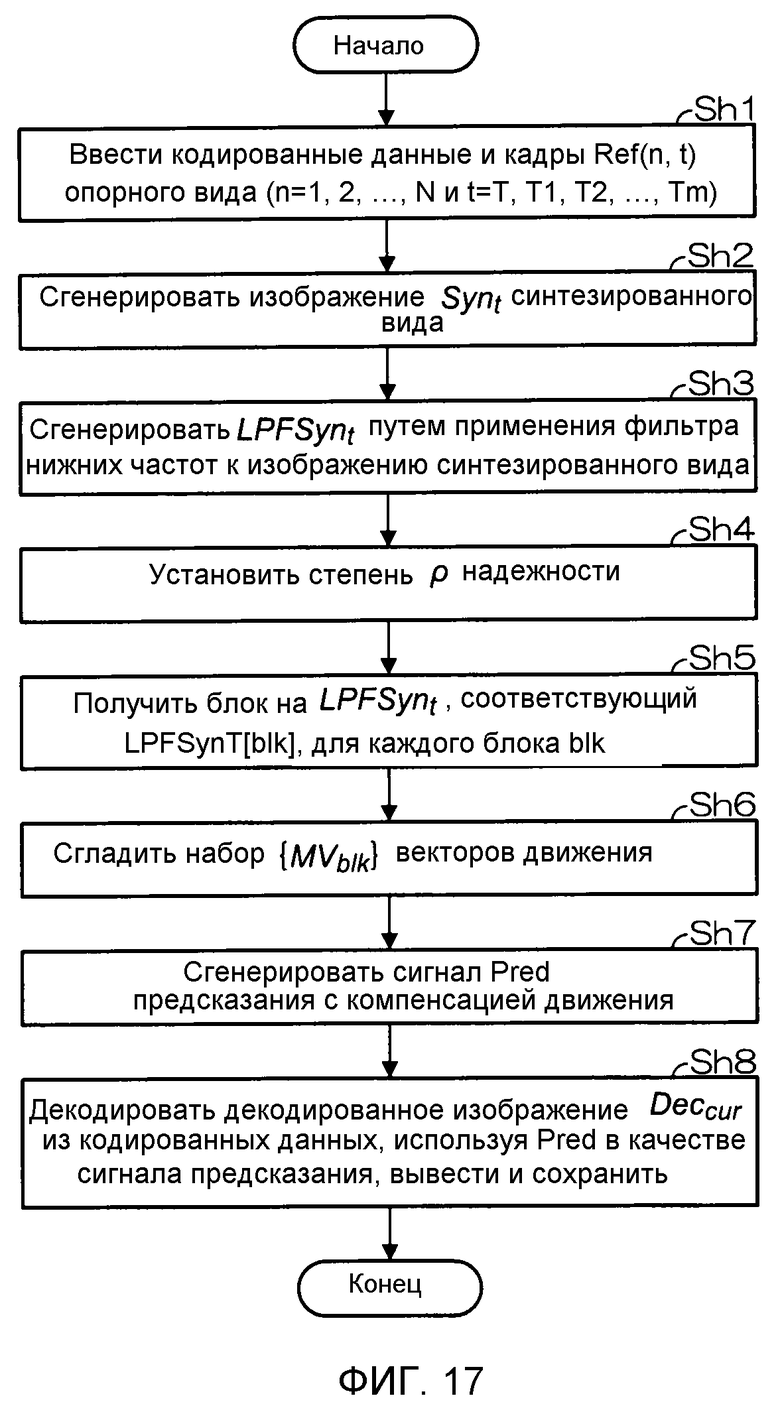



Изобретение относится к способу оценки вектора движения, способу кодирования и декодирования многовидового видеосигнала. Технический результат - точная оценка вектора движения и реализация эффективного кодирования многовидового видеосигнала. Способ оценки вектора движения содержит: этап генерирования изображения синтезированного вида для генерирования из видео опорной камеры, изображения синтезированного вида в момент времени, когда изображение обработки было получено; и этап оценки соответствующей области для оценки вектора движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения обработки, полученного в момент времени, в который должен быть оценен вектор движения. 12 н. и 10 з.п. ф-лы, 20 ил.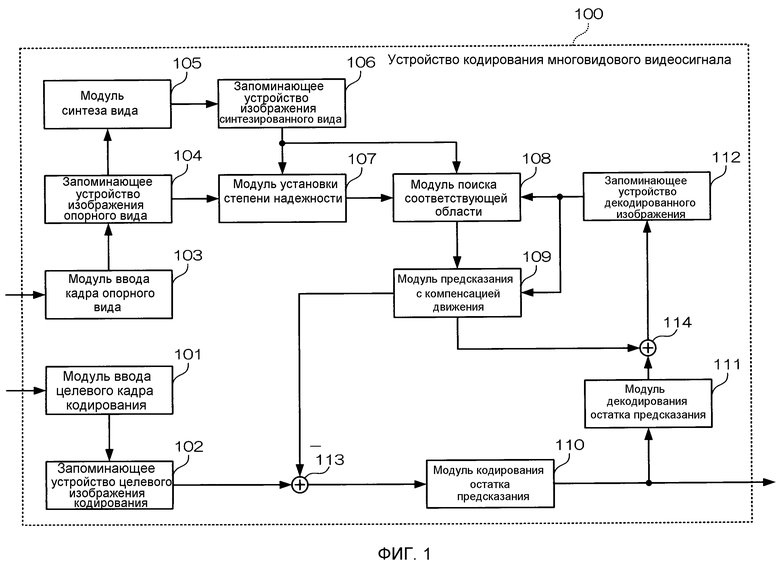
1. Способ оценки вектора движения, содержащий:
этап генерирования изображения синтезированного вида для генерирования из видео опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовое видео, изображения синтезированного вида в момент времени, когда изображение обработки было получено на основе такой же установки, что и установка камеры обработки; и
этап оценки соответствующей области для оценки вектора движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения обработки, полученного в момент времени, в который должен быть оценен вектор движения.
2. Способ оценки вектора движения по п.1, дополнительно содержащий этап установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида,
где на этапе оценки соответствующей области вес назначается стоимости соответствия на основе степени надежности, когда ищется соответствующая область.
3. Способ кодирования многовидового видео для выполнения кодирования с предсказанием многовидового видео, содержащий:
этап генерирования изображения синтезированного вида для генерирования из уже закодированного кадра опорного вида, полученного одновременно с целевым кадром кодирования в опорном виде, отличном от целевого вида кодирования многовидового видео, изображения синтезированного вида в целевом виде кодирования;
этап оценки вектора движения для оценки вектора движения путем поиска соответствующей области на уже закодированном опорном кадре в целевом виде кодирования для каждого единичного блока для кодирования изображения синтезированного вида;
этап генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра кодирования с использованием оцененного вектора движения и опорного кадра; и
этап кодирования остатка для кодирования разностного сигнала между целевым кадром кодирования и изображением предсказания с компенсацией движения.
4. Способ кодирования многовидового видео по п.3, дополнительно содержащий этап установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида,
где на этапе оценки вектора движения вес назначается стоимости соответствия каждого пикселя на основе степени надежности, когда ищется соответствующая область.
5. Способ кодирования многовидового видео по п.3 или 4, дополнительно содержащий:
этап поиска движения для генерирования оптимального вектора движения путем поиска соответствующей области между опорным кадром и каждым единичным блоком для кодирования целевого кадра кодирования; и
этап кодирования вектора разности для кодирования вектора разности между вектором движения и оптимальным вектором движения,
где на этапе генерирования изображения предсказания с компенсацией движения изображение предсказания с компенсацией движения генерируется с использованием оптимального вектора движения и опорного кадра.
6. Способ кодирования многовидового видео по п.5, дополнительно содержащий этап генерирования вектора предсказания для генерирования вектора предсказания с использованием вектора движения и группы оптимальных векторов движения, используемой в областях, соседствующих с целевой областью кодирования,
где на этапе кодирования вектора разности кодируется вектор разности между вектором предсказания и оптимальным вектором движения.
7. Способ декодирования многовидового видео для декодирования видео для вида многовидового видео из закодированных данных, содержащий:
этап генерирования изображения синтезированного вида для генерирования из кадра опорного вида, полученного одновременно с целевым кадром декодирования в опорном виде, отличном от целевого вида декодирования, изображения синтезированного вида в целевом виде декодирования;
этап оценки вектора движения для оценки вектора движения путем поиска соответствующей области на уже декодированном опорном кадре в целевом виде декодирования для каждого единичного блока для декодирования изображения синтезированного вида;
этап генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра декодирования с использованием оцененного вектора движения и опорного кадра; и
этап декодирования изображения для декодирования целевого кадра декодирования, который был подвергнут кодированию с предсказанием, из закодированных данных с использованием изображения предсказания с компенсацией движения в качестве сигнала предсказания.
8. Способ декодирования многовидового видео по п.7, дополнительно содержащий этап установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида, для каждого пикселя изображения синтезированного вида,
где на этапе оценки вектора движения вес назначается стоимости соответствия каждого пикселя на основе степени надежности, когда ищется соответствующая область.
9. Способ декодирования многовидового видео по п.7 или 8, дополнительно содержащий этап декодирования вектора для декодирования оптимального вектора движения, который был подвергнут кодированию с предсказанием, из закодированных данных с использованием вектора движения в качестве вектора предсказания,
где на этапе генерирования изображения предсказания с компенсацией движения изображение предсказания с компенсацией движения генерируется с использованием оптимального вектора движения и опорного кадра.
10. Способ декодирования многовидового видео по п.9, дополнительно содержащий этап генерирования вектора предсказания для генерирования оцененного вектора предсказания с использованием вектора движения и группы оптимальных векторов движения, используемой в областях, соседствующих с целевой областью декодирования,
где на этапе декодирования вектора оптимальный вектор движения декодируется с использованием оцененного вектора предсказания в качестве вектора предсказания.
11. Устройство оценки вектора движения, содержащее:
средство генерирования изображения синтезированного вида для генерирования из видео опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовое видео, изображения синтезированного вида в момент времени, когда изображение обработки было получено на основе такой же установки, что и установка камеры обработки; и
средство оценки соответствующей области для оценки вектора движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения обработки, полученного в момент времени, в который должен быть оценен вектор движения.
12. Устройство оценки вектора движения по п.11, дополнительно содержащее средство установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида,
где средство оценки соответствующей области назначает вес стоимости соответствия на основе степени надежности, когда ищется соответствующая область.
13. Устройство кодирования многовидового видео для выполнения кодирования с предсказанием многовидового видео, причем устройство содержит:
средство генерирования изображения синтезированного вида для генерирования из уже закодированного кадра опорного вида, полученного одновременно с целевым кадром кодирования в опорном виде, отличном от целевого вида кодирования многовидового видео, изображения синтезированного вида в целевом виде кодирования;
средство оценки вектора движения для оценки вектора движения путем поиска соответствующей области на уже закодированном опорном кадре в целевом виде кодирования для каждого единичного блока для кодирования изображения синтезированного вида;
средство генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра кодирования с использованием оцененного вектора движения и опорного кадра; и
средство кодирования остатка для кодирования разностного сигнала между целевым кадром кодирования и изображением предсказания с компенсацией движения.
14. Устройство кодирования многовидового видео по п.13, дополнительно содержащее средство установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида,
где средство оценки вектора движения назначает вес стоимости соответствия каждого пикселя на основе степени надежности, когда ищется соответствующая область.
15. Устройство декодирования многовидового видео для декодирования видео для вида многовидового видео из закодированных данных, причем устройство содержит:
средство генерирования изображения синтезированного вида для генерирования из кадра опорного вида, полученного одновременно с целевым кадром декодирования в опорном виде, отличном от целевого вида декодирования, изображения синтезированного вида в целевом виде декодирования;
средство оценки вектора движения для оценки вектора движения путем поиска соответствующей области на уже декодированном опорном кадре в целевом виде декодирования для каждого единичного блока для декодирования изображения синтезированного вида;
средство генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра декодирования с использованием оцененного вектора движения и опорного кадра; и
средство декодирования изображения для декодирования целевого кадра декодирования, который был подвергнут кодированию с предсказанием, из закодированных данных с использованием изображения предсказания с компенсацией движения в качестве сигнала предсказания.
16. Устройство декодирования многовидового видео по п.15, дополнительно содержащее средство установки степени надежности для установки степени надежности, указывающей достоверность изображения синтезированного вида для каждого пикселя изображения синтезированного вида,
где средство оценки вектора движения назначает вес стоимости соответствия каждого пикселя на основе степени надежности, когда ищется соответствующая область.
17. Считываемый компьютером носитель, хранящий программу оценки вектора движения для побуждения компьютера устройства оценки вектора движения исполнять:
функцию генерирования изображения синтезированного вида для генерирования из видео опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовое видео, изображения синтезированного вида в момент времени, когда изображение обработки было получено на основе такой же установки, что и установка камеры обработки; и
функцию оценки соответствующей области для оценки вектора движения путем поиска соответствующей области в опорном изображении, полученном камерой обработки, с использованием сигнала изображения на изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения обработки, полученного в момент времени, в который должен быть оценен вектор движения.
18. Считываемый компьютером носитель, хранящий программу кодирования многовидового видео для побуждения компьютера устройства кодирования многовидового видео для выполнения кодирования с предсказанием многовидового видео исполнять:
функцию генерирования изображения синтезированного вида для генерирования из уже закодированного кадра опорного вида, полученного одновременно с целевым кадром кодирования в опорном виде, отличном от целевого вида кодирования многовидового видео, изображения синтезированного вида в целевом виде кодирования;
функцию оценки вектора движения для оценки вектора движения путем поиска соответствующей области на уже закодированном опорном кадре в целевом виде кодирования для каждого единичного блока для кодирования изображения синтезированного вида;
функцию генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра кодирования с использованием оцененного вектора движения и опорного кадра; и
функцию кодирования остатка для кодирования разностного сигнала между целевым кадром кодирования и изображением предсказания с компенсацией движения.
19. Считываемый компьютером носитель, хранящий программу декодирования многовидового видео для побуждения компьютера устройства декодирования многовидового видео для декодирования видео для вида многовидового видео из закодированных данных исполнять:
функцию генерирования изображения синтезированного вида для генерирования, из кадра опорного вида, полученного одновременно с целевым кадром декодирования в опорном виде, отличном от целевого вида декодирования, изображения синтезированного вида в целевом виде декодирования;
функцию оценки вектора движения для оценки вектора движения путем поиска соответствующей области на уже декодированном опорном кадре в целевом виде декодирования для каждого единичного блока для декодирования изображения синтезированного вида;
функцию генерирования изображения предсказания с компенсацией движения для генерирования изображения предсказания с компенсацией движения для целевого кадра декодирования с использованием оцененного вектора движения и опорного кадра; и
функцию декодирования изображения для декодирования целевого кадра декодирования, который был подвергнут кодированию с предсказанием, из закодированных данных с использованием изображения предсказания с компенсацией движения в качестве сигнала предсказания.
20. Способ оценки вектора движения, содержащий:
этап генерирования изображения синтезированного вида для генерирования из видео опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовое видео, первого изображения синтезированного вида в момент времени, когда изображение обработки было получено, и второго изображения синтезированного вида в момент времени, когда опорное изображение было получено камерой обработки, на основе такой же установки, что и установка камеры обработки, где вектор движения должен быть получен между опорным изображением и изображением обработки; и
этап оценки соответствующей области для оценки вектора движения путем поиска соответствующей области во втором изображении синтезированного вида, соответствующем опорному изображению, с использованием сигнала изображения на первом изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения, полученного камерой обработки.
21. Устройство оценки вектора движения, содержащее:
средство генерирования изображения синтезированного вида для генерирования из видео опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовое видео, первого изображения синтезированного вида в момент времени, когда изображение обработки было получено, и второго изображения синтезированного вида в момент времени, когда опорное изображение было получено камерой обработки, на основе такой же установки, что и установка камеры обработки, где вектор движения должен быть получен между опорным изображением и изображением обработки; и
средство оценки соответствующей области для оценки вектора движения путем поиска соответствующей области во втором изображении синтезированного вида, соответствующем опорному изображению, с использованием сигнала изображения на первом изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения, полученного камерой обработки.
22. Считываемый компьютером носитель, хранящий программу оценки вектора движения для побуждения компьютера устройства оценки вектора движения исполнять:
функцию генерирования изображения синтезированного вида для генерирования из видео опорной камеры, полученного камерой, отличной от камеры обработки, которая получила изображение обработки, включенное в многовидовое видео, первого изображения синтезированного вида в момент времени, когда изображение обработки было получено, и второго изображения синтезированного вида в момент времени, когда опорное изображение было получено камерой обработки, на основе такой же установки, что и установка камеры обработки, где вектор движения должен быть получен между опорным изображением и изображением обработки; и
функцию оценки соответствующей области для оценки вектора движения путем поиска соответствующей области во втором изображении синтезированного вида, соответствующем опорному изображению, с использованием сигнала изображения на первом изображении синтезированного вида, соответствующем области обработки на изображении обработки, без использования изображения, полученного камерой обработки.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| RU 2006126660 A, 27.01.2008 | |||
| RU 2007141925 A, 20.05.2009 | |||

