ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Системы для обеспечения совместной работы c документами на сетевой основе позволяют нескольким пользователям одновременно осуществлять доступ к и быть соавторами документа. Хотя нескольким пользователям и разрешается быть соавторами документа, в целях предотвращения конфликтов система может ограничить области в документе, в которых каждый пользователь может осуществлять редакцию, чтобы минимизировать шансы для конфликтующих изменений, когда копии документов объединяются.
Устаревшие системы, как правило, не могут обеспечить возможность соавторства документов, созданных на устаревших системах. Документы, созданные на этих системах, следовательно, могут не быть должным образом сконфигурированы для поддержки соавторства в системах для обеспечения совместной работы с документами. Это может привести к нежелательным конфликтующим редакциям.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Варианты воплощения этого раскрытия изобретения направлены на способ слияния метаданных документа на клиентском компьютере. Документ получают от серверного компьютера посредством пользователя на клиентском компьютере, и документ открывают на клиентском компьютере. В ответ на открытие документа на клиентском компьютере, выполняют определение того, включает ли в себя документ идентификаторы блока. Если определено, что документ не включает в себя идентификаторы блока, идентификатор блока назначают каждому блоку в документе.
Принимают от серверного компьютера первое сообщение, обеспечивающее уведомление о том, что, по меньшей мере, один другой пользователь осуществляет авторскую разработку этого документа. В ответ на прием первого сообщения от серверного компьютера, обеспечивающего уведомление о том, что, по меньшей мере, один другой пользователь осуществляет авторскую разработку этого документа, отправляют второе сообщение на серверный компьютер, причем второе сообщение включает в себя первые метаданные для документа. В ответ на отправку второго сообщения на серверный компьютер, принимают третье сообщение от серверного компьютера, причем третье сообщение включает в себя вторые метаданные для документа. В ответ на прием третьего сообщения от серверного компьютера, выполняют определение того, должны ли быть первые метаданные и вторые метаданные слиты вместе. Если определено, что первые метаданные и вторые метаданные должны быть слиты вместе, на основании вторых метаданных устанавливают идентификаторы блока в документе.
Подробности одной или более методик изложены в прилагаемых чертежах и нижеприведенном описании. Другие особенности, объекты и преимущества этих методик будут видны из описания, чертежей и формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 показывает примерную систему для поддержки быстрого слияния устаревших документов.
Фиг. 2 показывает примерные модули примерного клиентского компьютера с Фиг. 1, которые реализуют поддержку быстрого слияния устаревших документов.
Фиг. 3 изображает пример перенумерации идентификаторов документа во время операции слияния метаданных.
Фиг. 4 показывает логическую блок-схему способа слияния метаданных документа на клиентском компьютере.
Фиг. 5 показывает логическую блок-схему способа определения того, должны ли быть метаданные слиты вместе на клиентском компьютере.
Фиг. 6 показывает пример компонентов клиентского компьютера с Фиг. 2.
ПОДРОБНОЕ ОПИСАНИЕ
Настоящая заявка направлена на системы и способы для создания идентификаторов блока для устаревших документов, созданных на устаревших сетевых системах обеспечения совместной работы с документами, которые не предусматривают идентификаторы блока.
В примерном варианте воплощения документ разбит на блоки. Блоки могут быть любыми подразделами документа, например предложения, абзацы, заголовки, рисунки, таблицы и т.д. Документ может содержать в себе только один блок, например одну таблицу, предложение, либо несколько блоков, таких как несколько таблиц, предложений или абзацев. Для примерного варианта воплощения, раскрытого здесь, блок документа является абзацем документа.
Устаревшие документы - это те документы, которые были созданы устаревшими системами, которые не предусматривают соавторство. Устаревшие документы, следовательно, не включают в себя идентификаторы абзаца. Идентификаторы абзаца создаются для устаревшего документа, когда документ сохраняется в системе обеспечения совместной работы с документами или когда два или более авторов редактируют документ в системе обеспечения совместной работы с документами.
Поскольку идентификаторы абзаца создаются для устаревшего документа таким образом, то когда два или более авторов, использующих систему обеспечения совместной работы с документами, осуществляют доступ к одному и тому же устаревшему документу, идентифицируются абзацы, редактируемые в настоящее время одним из авторов, и блокировки абзаца распространяются на других авторов. Блокировки абзаца предотвращают редактирование заблокированного абзаца авторами, не редактирующими в настоящее время заблокированный абзац, до тех пор пока блокировка не будет снята. В этом раскрытии автор определен как пользователь, который создает или редактирует документ.
Системы и способы также предусматривают сравнение и слияние идентификаторов абзаца в документах и обеспечение слияния идентификаторов абзаца и распространение блокировки абзаца. Уникальный набор идентификаторов абзаца создается каждый раз, когда автор осуществляет доступ к устаревшему документу, который не включает в себя идентификаторы абзаца. Когда второй автор осуществляет доступ к тому же самому устаревшему документу, идентификаторы абзаца сравниваются и сливаются вместе так, чтобы у каждого автора был синхронизированный набор идентификаторов абзаца для устаревшего документа.
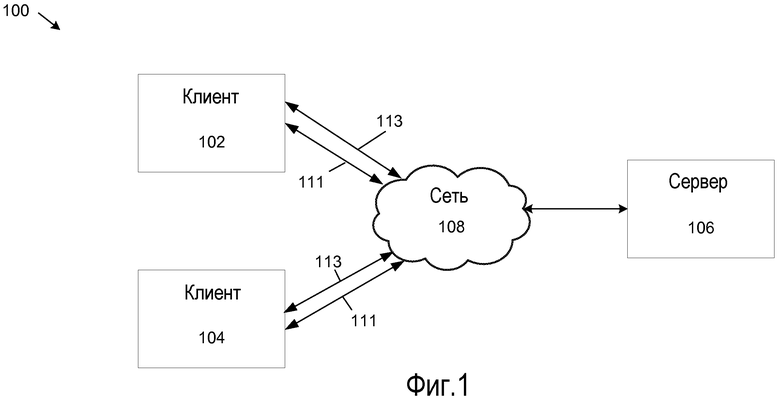
Фиг. 1 показывает пример системы 100, которая поддерживает быстрое слияние устаревших документов. Система 100 включает в себя клиенты 102, 104, сервер 106 и сеть 108. Могут использоваться большее или меньшее количество клиентов и серверов. В этом раскрытии термины «клиент» и «клиентский компьютер» используются взаимозаменяемо, и термины «сервер» и «серверный компьютер» используются взаимозаменяемо.
Среди многочисленной информации, хранящейся на клиентах 102, 104, есть операционная система ("OS") клиента и клиентские приложения. OS клиента - это программа, которая управляет ресурсами аппаратного и программного обеспечения клиентской системы. Клиентские приложения используют ресурсы клиентов 102, 104, чтобы непосредственно выполнять задачи, определенные пользователем, например пользователем, который осуществляет авторскую разработку документа. Например, клиенты 102, 104 включают в себя одно или более программных приложений, таких как программы обработки текста, которые используются для создания и редактирования файлов документа. Одним примером такого приложения является Microsoft Word от Microsoft Corporation, Редмонд, Вашингтон. Другие примеры таких приложений также применимы.
Сервер 106 является файловым сервером, доступным по сети. Сервер 106 хранит множество файлов. Эти файлы могут включать в себя как программные приложения, так и документы, как дополнительно описано в этом документе. Сервер 106 управляет доступом к документам, хранимым сервером 106.
В примерном варианте воплощения сервер 106 может быть расположен в пределах организации или может быть частью системы обеспечения совместной работы с документами. Примерной системой обеспечения совместной работы с документами является «SHAREPOINT(R) team services portal server services» (сервисы серверного портала сервисных задач), предлагаемая Microsoft Corporation. Примерным сервером общих документов является Microsoft Office SharePoint Server 2007, предлагаемый Microsoft Corporation. Могут быть использованы другие конфигурации.
В примерных вариантах воплощения идентификаторы абзаца сливаются вместе, и блокировки абзаца распространяются через канал 111 метаданных, который отделен от канала 113 данных, используемого для хранения редактированного контента документа. Передавая метаданные отдельно от контента документа, авторы имеют возможность быстро принимать блокировки абзаца, независимо от операции сохранения контента. Поскольку блокировки абзаца препятствуют двум или более авторам редактировать один и тот же контент одновременно, целостность процесса соавторства усиливается.
Фиг. 2 показывает детальное представление логических модулей клиентского компьютера 102. Клиентский компьютер 102 включает в себя примерный модуль 202 обработки документа, примерный модуль 204 обработки метаданных и примерный модуль 206 слияния метаданных. Примерный модуль 202 обработки документа поддерживает создание, редактирование и сохранение контента документа, такого как текст, заголовки, таблицы, иллюстрации и т.д. Примерный модуль 202 обработки документа также поддерживает обработку информации о контенте документа, известной как метаданные. Примерный модуль 202 обработки документа реализует приложение обработки текстов, например, приложение текстовый редактор Microsoft Word от Microsoft Corporation.
Примерный модуль 204 обработки метаданных обрабатывает метаданные в документе. Некоторыми примерами метаданных являются имя документа, дата создания или последнего редактирования, идентификатор документа, идентификатор версии, идентификаторы абзаца, размер абзаца и блокировки абзаца. Возможны другие виды метаданных документа.
Идентификатором абзаца является число, которое идентифицирует каждый абзац в документе. В примерных вариантах воплощения идентификаторы абзаца могут включать в себя идентификаторы для подблоков документа, таких как верхние колонтитулы и нижние колонтитулы, в дополнение к фактическим абзацам.
Блокировка абзаца является метаданными, которые указывают, что автор редактирует абзац документа. Во избежание конфликтов, только одному автору разрешается редактировать один и тот же контент в одно и то же время. Когда один автор редактирует абзац документа, для этого абзаца для всех других авторов, которые открыли документ, принимается блокировка абзаца. Блокировка документа препятствует другим авторам редактировать абзац до тех пор, пока блокировка не снята.
Дополнительные подробности, касающиеся таких блокировок, можно найти в патентной заявке США с серийным номером 12/145536, поданной 25 июня 2008 года, которая во всей полноте включена сюда посредством ссылки.
Когда автор на клиентском компьютере 102 открывает устаревший документ, который не включает в себя идентификаторы абзаца, примерный модуль 204 обработки метаданных генерирует идентификатор документа для этого документа. Идентификатор документа, как правило, является числом, которое генерируется случайным образом из определенного диапазона чисел. Например, идентификатор документа может быть 32-разрядным числом, который находится в диапазоне от 1 до 0x7fffffff.
Примерный модуль 204 обработки метаданных назначает идентификатор документа первому абзацу в этом документе. Остальные абзацы затем последовательно нумеруются от идентификатора документа. Например, если имеется пять абзацев в документе и случайно сгенерированным идентификатором документа является 1000, пяти абзацам присваиваются идентификаторы абзаца 1000, 1001, 1002, 1003 и 1004 соответственно.
Примерный модуль 204 обработки метаданных также идентифицирует в качестве метаданных следующий номер абзаца в последовательности идентификаторов абзаца. В этом примере следующий идентификатор абзаца - это 1005. Хотя идентификаторы абзаца генерируются последовательно, когда документ изначально открыт, идентификаторы абзаца для любых абзацев, которые могут быть добавлены в результате редактирования документа, генерируются случайным образом.
Когда автор на клиенте 102 открывает документ, примерный модуль 204 обработки метаданных также получает идентификатор версии для этого документа. Каждый документ, хранимый в примерной системе обеспечения совместной работы с документами, включает в себя идентификатор версии, который идентифицирует номер версии документа. В некоторых примерных вариантах воплощения идентификатор версии может быть частью идентификатора файловой системы для этого документа. Примерный модуль 204 обработки метаданных отслеживает идентификатор версии как метаданные.
Поскольку в это время автор на клиенте 102 является единственным автором, который открыл документ, документ не содержит ни одной блокировки абзаца. Автор на клиенте 102 может свободно редактировать документ по своему желанию, редактируя существующие абзацы, удаляя абзацы, добавляя новые абзацы, делая изменения форматирования и т.п. Пока автор на клиенте 102 не сохранит эти изменения, сервер 106 не узнает об изменениях.
Когда автор на клиенте 104 открывает копию того же документа, сервер 106 представляет автору на клиенте 104 версию документа, которая не включает в себя изменений автора на клиенте 102, внесенных в документ, если автор на клиенте 102 не сохранил документ перед тем, как клиент 104 открыл этот документ.
Когда документ открывается на клиенте 104, примерный модуль 204 обработки метаданных на клиенте 104 случайным образом генерирует идентификатор документа для версии документа, открытого на клиенте 104. Примерный модуль 204 обработки метаданных на примерном клиенте 104 назначает идентификатор документа первому абзацу документа, открытого на клиенте 104, и последовательно назначает номера абзацев остальным абзацам документа, открытого на клиенте 104.
Поскольку идентификаторы документа генерируются случайным образом, идентификаторы абзаца и документа для копий документа, открытых на клиентах 102 и 104, различны. Для того чтобы распространить блокировки абзаца на эти два открытых документа, идентификаторы абзаца для каждого открытого документа должны быть слиты вместе и синхронизированы. Это потому, что блокировки абзаца связаны с конкретными абзацами. Таким образом, абзацы, имеющие общий контент в нескольких копиях открытых документов, должны иметь одинаковые идентификаторы абзаца.
Примерный модуль 206 слияния метаданных сравнивает и синхронизирует идентификаторы абзаца между документами. Когда автор на клиенте 104 открывает документ, сервер 106 сообщает автору на клиенте 104, что есть, по меньшей мере, один другой пользователь, который уже осуществляет авторскую разработку документа. Сервер 106 также информирует автора на клиенте 102, что другой автор открыл этот документ. Когда автор на клиенте 102 обнаруживает, что другой автор открыл документ, примерный модуль 206 слияния метаданных на клиенте 102 отправляет метаданные на сервер 106. Аналогичным образом, когда автор на клиенте 104 обнаруживает, что другой автор открыл документ, примерный модуль 206 слияния метаданных на клиенте 104 отправляет метаданные на сервер 106 с использованием канала 111 метаданных.
Примерные метаданные отправляются на сервер 106 клиентами 102 и 104 и включают в себя три компонента метаданных - идентификатор документа, идентификатор следующего абзаца и идентификатор версии. В примерных вариантах воплощения эти три компонента называются начальным значением метаданных. Когда сервер 106 принимает начальные значения метаданных от клиентов 102 и 104, 106 сервер определяет, какое начальное значение метаданных прибыло первым. Начальное значение метаданных, которое прибыло на сервер 106 первым, считается выигрышным. Информация о выигрышном начальном значении метаданных затем распространяется к другим авторам. Например, если сервер 106 принимает начальное значение метаданных от клиента 104 первым, информация о начальном значении метаданных на клиенте 102 сливается с информацией о начальном значении метаданных от клиента 104.
Фиг. 3 изображает пример того, как примерный модуль 206 слияния метаданных сливает вместе метаданные, используя метаданные от двух авторов. Когда автор на клиенте 102 первоначально открывает документ, который не включает в себя идентификаторы абзаца (например, документ, созданный в устаревшей системе, которая не поддерживает соавторство), модуль 204 операций с метаданными присваивает идентификаторы абзаца каждому абзацу документа. Примерный набор идентификаторов абзаца показан для примерной копии 302 документа. В этом примере есть шесть абзацев в документе с идентификаторами абзаца 1000, 1001 1002, 1003, 1004 и 1005, соответственно.
Во время редактирования документа автор на клиенте 102 удаляет абзац 1003 и добавляет абзацы с идентификаторами абзаца 2002, 8123 и 9123. Это показано на примерной копии 304 документа. Автор на клиенте 102 способен изменять, добавлять и/или удалять любой абзац в документе, поскольку в настоящее время нет никаких других пользователей, осуществляющих авторскую разработку документа, следовательно, нет и блокировок абзаца в документе. Добавленные абзацы имеют идентификаторы абзаца, которые случайным образом сгенерированы, как описано выше.
После того как автор в клиенте 102 делает изменения в документе, показанные в примерной копии 304 документа, автор на клиенте 104 открывает копию этого документа. Копию документа получают с сервера 106. Поскольку изменения в документе, сделанные автором на клиенте 102, еще не были сохранены на сервере 106, документ, открытый автором на клиенте 104, содержит тот же контент, как показано в примерной копии 302 документа.
Когда документ открывается на клиенте 104, модуль 204 операций с метаданными на клиенте 104 случайным образом генерирует идентификатор документа для открытого документа на клиенте 104. В этом примере идентификатор документа является 2000. Примерный модуль 204 операций с метаданными на клиенте 104 назначает идентификатор документа 2000 первому абзацу документа, открытого на клиенте 104. Примерный модуль 204 операций с метаданными на клиенте 104 затем последовательно нумерует остальные абзацы в документе. Итоговая нумерация абзацев показана в примерной копии 306 документа.
На некотором заданном интервале оба клиента 102, 104 синхронизируют метаданные, связанные с документом. Эта синхронизация происходит по каналу 111 метаданных, как описано выше. В примерных вариантах воплощения интервал синхронизации может быть задан для прохождения с определенным периодом, например каждые 2 секунды, 5 секунд, 10 секунд, 20 секунд, 30 секунд, 1 минута, 5 минут, 10 минут или 30 минут. Могут быть использованы другие интервалы.
В этом примере начальное значение метаданных от клиента 104 принимается на сервер 106 первым. Когда сервер 106 определяет, что начальное значение метаданных от клиента 104 было принято первым и является выигрышным, сервер 106 посылает начальное значение метаданных, принятое от клиента 104, на клиент 102. Когда клиент 102 принимает начальное значение метаданных от сервера 106, примерный модуль 206 слияния метаданных на клиенте 102 сливает вместе начальное значение метаданных, принятое от сервера 106, с метаданными абзаца на клиенте 102. Результат слияния показан на примере копии 308 документа.
Примерная копия 308 документа показывает, что в результате слияния идентификаторы 1000, 1001, 1002, 1004 и 1005 абзаца (из примерной копии 304 документа) заменяются на 2000, 2001, 2002, 2004 и 2005 соответственно. Поскольку идентификатор документа выигрышного начального значения - это 2000, примерный модуль 206 слияния метаданных на клиенте 102 перенумеровывает абзацы в диапазоне абзацев, определенном из начального значения метаданных, принятого от сервера 106. Перенумерация делает абзацы в диапазоне абзацев согласующимися с идентификатором 2000 документа. Диапазон абзацев может быть определен из начального значения метаданных, поскольку начальное значение метаданных включает в себя идентификатор документа (который является также первым абзацем диапазона абзаца) и следующий идентификатор абзаца (который является следующим по счету идентификатором абзаца, следующим за последним идентификатором абзаца в диапазоне абзацев) и поскольку все абзацы в диапазоне абзацев последовательно пронумерованы. Таким образом, первый абзац в документе, открытом на клиенте 102, перенумеровывается с 1000 на 2000. Диапазон абзацев включает в себя абзацы с 1000 до 1005. Таким образом, абзац 1001 перенумеровывается на 2001, абзац 1002 перенумеровывается на 2002, абзац 1004 перенумеровывается на 2004, и абзац 1005 перенумеровывается на 2005. Как уже рассматривалось выше, абзац 1003 был удален.
Модуль 206 слияния метаданных на клиенте 102 также определяет все идентификаторы абзаца документа, открытого на клиенте 102, которые не включены в этот диапазон абзацев. Это охватывает абзацы с идентификаторами 2002, 8123 и 9123 абзаца, которые были добавлены в примерную копию 304 документа. Так как добавленный абзац 2002 конфликтует с перенумерованным абзацем 2002 (исходным абзацем 1002), примерный модуль 206 слияния метаданных перенумеровывает добавленный абзац 2002 на 1002. Примерный модуль 206 слияния метаданных перенумеровывает добавленный абзац 2002 на 1002, поскольку идентификатор 1002 абзаца больше не используется в документе и, следовательно, нет конфликта, если используется абзац 1002. Примерный модуль 206 слияния метаданных не изменяет идентификаторы 8123 и 9123 абзаца, поскольку нет конфликтов, вызванных этими идентификаторами абзаца.
Когда слияние метаданных завершено, абзацы с общим контентом для документа, открытого на клиенте 102, и для документа, открытого на клиенте 104, имеют одинаковые идентификаторы абзаца. Например, если перед слиянием абзацев, имеющих идентификаторы 1000, 1001, 1002, 1004 и 1005 для документа, открытого на клиенте 102, имеют общий контент с абзацами, имеющими идентификаторы 2000, 2001, 2002, 2004 и 2005, соответственно, для документа, открытого на клиенте 104, после слияния эти абзацы на клиенте 102 и клиенте 104 имеют идентификаторы 2000, 2001, 2002, 2004 и 2005 абзаца. Это позволяет назначить блокировки абзаца этим абзацам. Например, когда автор на клиенте 102 редактирует абзац 2004, блокировка абзаца передается документу на клиенте 104, не давая клиенту 104 редактировать абзац 2004. Блокировка абзаца гарантирует, что несколько авторов не смогут редактировать один и тот же абзац одновременно.
Когда автор на клиенте 102 выполняет операцию сохранения, изменения контента для документа, открытого на клиенте 102, отправляются на сервер 106 по каналу 113 данных. В дополнение к передаче изменений контента, операция сохранения также удаляет любые блокировки абзаца, связанные с абзацами, ранее редактированными на клиенте 102. Изменение в блокировках передается по каналу 111 метаданных.
Сохраненный контент и удаление блокировок абзаца распространяются всем авторам, которые в настоящее время осуществляют авторскую разработку документа. Это позволяет авторам редактировать абзацы, которые ранее были заблокированы. Однако, как только автор начинает редактировать абзац, новая блокировка абзаца создается и распространяется по каналу 111 метаданных всем другим авторам, которые в настоящее время редактируют документ.
Как только идентификаторы абзаца синхронизированы, дополнительные изменения в документе со стороны либо клиента 102, либо клиента 104 могут быть синхронизированы с помощью идентификаторов абзаца образом, описанном в патентной заявке США №11/951973, поданной 6 декабря 2007 года, которая целиком включена сюда посредством ссылки.
Вышеуказанное обсуждение слияния метаданных описывает двух авторов. В других вариантах воплощения, например, более двух авторов могут редактировать один и тот же документ. Те же самые операции слияния метаданных применяются для примерных вариантов воплощения, имеющих более двух авторов.
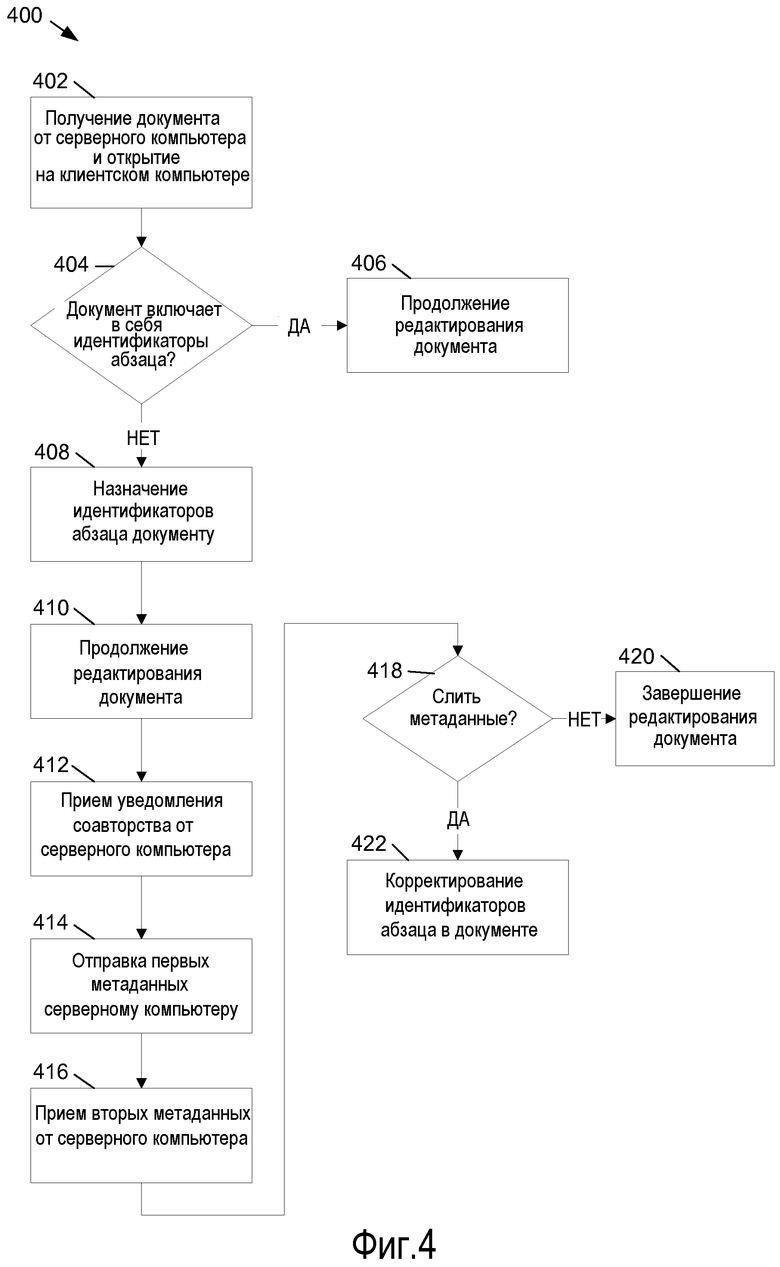
Фиг. 4 показывает примерную логическую блок-схему способа 400 слияния метаданных документа на клиентском компьютере. При операции 402 автор на примерном клиенте 102 получает документ от примерного сервера 106 и открывает этот документ на клиенте 102. Сервер 106 является сервером, таким как Microsoft SharePoint Server 2007, используемым с основанной на интернет-технологиях системой обеспечения совместной работы с документами, такой как Microsoft SharePoint. Клиент 102 открывает документ с помощью программы обработки текстов, такой как Microsoft Word. Примерный способ 400 предполагает, что в то время, когда автор на клиенте 102 открывает документ, другие авторы не открывают документ.
В операции 404 клиент 102 определяет, включает ли в себя документ идентификаторы абзаца. Как правило, устаревшие документы, хранящиеся на сервере 106, не включают в себя идентификаторы абзаца, поскольку устаревшие документы созданы приложениями обработки текстов, которые не поддерживают соавторство или включение идентификаторов абзаца. Если документ не включает в себя идентификаторы абзаца, клиент 102 может начать редактирование документа на операции 406.
Если документ не включает в себя идентификаторы абзаца, идентификаторы абзаца назначаются документу на операции 408. Примерный модуль 204 операций с метаданными случайным образом генерирует идентификатор документа для документа. Идентификатор документа, обычно 32-разрядное число в диапазоне от 1 до Ox7fffffff, затем назначается первому абзацу документа. Затем, остальные абзацы последовательно нумеруются с идентификатора документа.
На операции 410 автор на клиенте 102 продолжает редактировать документ. Поскольку автор на клиенте 102 является единственным автором, который открыл документ, автор на клиенте 102 может редактировать любой абзац документа, а также может добавлять и удалять абзацы.
На операции 412 клиент 102 принимает сообщение от сервера 106, которым обеспечивается уведомление клиента 102 о том, что, по меньшей мере, один другой автор, например, автор на клиенте 104, открыл документ. Когда клиент принимает уведомление 102 о том, что, по меньшей мере, один другой автор открыл документ, на операции 414 примерный модуль 204 операций с метаданными на клиенте 102 посылает первые метаданные на сервер 106. Первые метаданные включают в себя начальное значение метаданных для документа, открытого на клиенте 102, в том числе идентификатор документа, идентификатор следующего абзаца и идентификатор версии.
На операции 416 клиент 102 принимает сообщение от сервера 106, которое включает в себя вторые метаданные. Вторые метаданные исходят от одного из других авторов, осуществляющих авторскую разработку документа, например, автора на клиенте 104. Вторые метаданные представляют выигрышное начальное значение метаданных, принятое на сервер 106. Выигрышное начальное значение метаданных является первым начальным значением метаданных, принятым на сервере 106 от, по меньшей мере, одного из других авторов, которые осуществляют авторскую разработку документа. Вторые метаданные включают в себя идентификатор документа, идентификатор следующего абзаца и идентификатор версии от клиента, который отправляет выигрышное начальное значение метаданных на сервер 106, например, от клиента 104.
На операции 418 клиент 102 определяет, должны ли первые метаданные и вторые метаданные быть слиты вместе. Этапы, задействуемые при определении того, должны ли быть первые метаданные и вторые метаданные слиты вместе, показаны на Фиг. 5 и будут рассмотрены позже в этом раскрытии. Если определено, что первые метаданные и вторые метаданные не должны быть слиты, на операции 420 автор на клиенте 102 продолжает редактировать документ.
Если определено, что первые метаданные и вторые метаданные должны быть слиты вместе, на операции 422 примерный модуль 206 слияния метаданных на клиенте 102 сливает первые метаданные и вторые метаданные вместе. Метаданные объединяются посредством корректировки идентификаторов абзаца в документе, открытом автором на клиенте 102. Операция корректировки идентификаторов абзаца включает в себя изменение идентификаторов абзаца для всех абзацев в документе, открытом на клиенте 102, которые имеют общий контент с соответствующими абзацами в документе, открытом на клиенте 104. Идентификаторы абзаца в документе, открытом на клиенте 102, заменяются на соответствующие идентификаторы абзаца, указываемые идентификатором документа и идентификатором следующего абзаца, включенными во вторые метаданные. Например, если абзацы 1-3 в документе, открытом на клиенте 102, имеют общий контент с абзацами 1-3 в документе, открытом на клиенте 104, и если идентификатор документа для документа на клиенте 102 является 1000 и идентификатор документа во вторых метаданных является 2000, то первые три абзаца в документе на клиенте 104 перенумеруются на 2000, 2001 и 2002.
Кроме того, если определено, что абзацы, добавленные в документ, открытый на клиенте 102, но не сохраненные, имеют идентификаторы абзаца в диапазоне абзацев, указываемом вторыми метаданными, примерный модуль 206 слияния метаданных изменяет эти идентификаторы абзаца, так чтобы они являлись уникальными в документе.
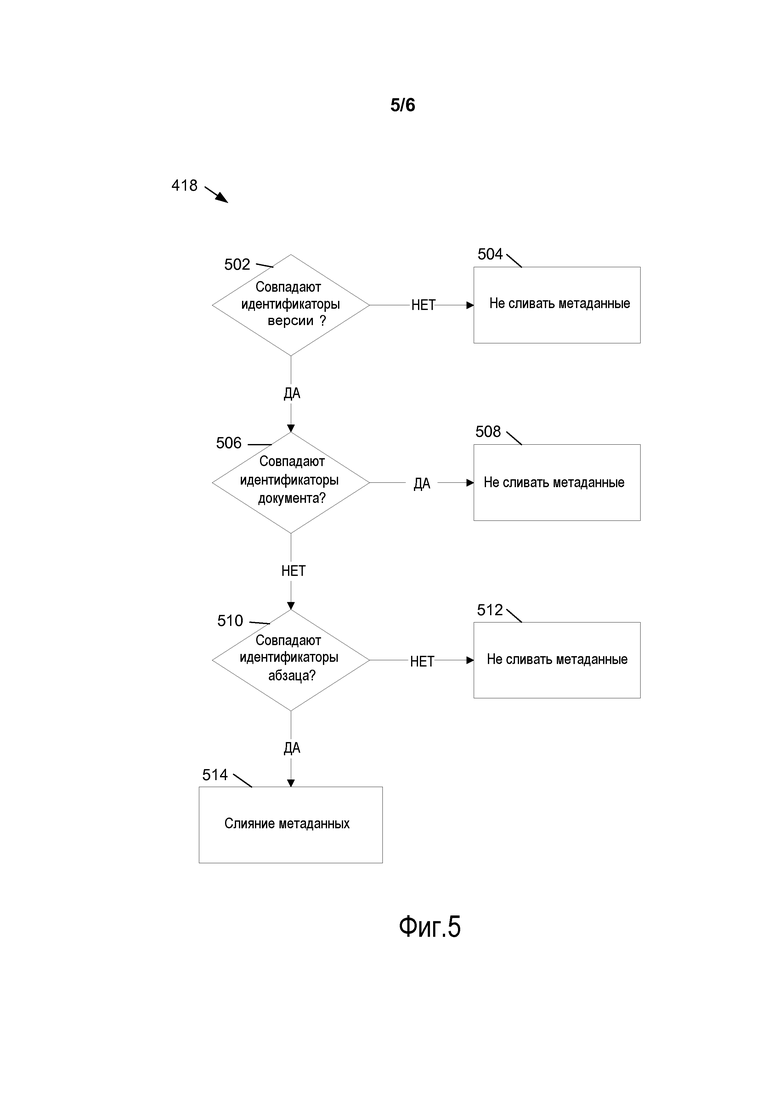
Фиг. 5 показывает пример логической блок-схемы способа 418 определения того, должны ли быть слиты метаданные на клиентском компьютере. Способ реализуется, когда автор на клиентском компьютере, например, клиентском компьютере 102, редактирует документ, который включает в себя первое начальное значение метаданных, и клиентский компьютер принимает второе начальное значение метаданных от серверного компьютера. Второе начальное значение метаданных представляет собой метаданные второго автора, который открыл этот документ. Второе начальное значение метаданных представляет собой первое начальное значение метаданных, принятое на серверном компьютере от одного или более авторов, которые открыли и осуществляют авторскую разработку этого документа. Начальные значения метаданных включают в себя идентификатор документа, идентификатор следующей страницы и идентификатор версии.
На операции 502 выполняется определение того, совпадает ли идентификатор версии из первого начального значения метаданных с идентификатором версии из второго начального значения метаданных. Идентификатор версии указывает версию документа. Для того чтобы слить метаданные вместе, документы должны быть на одном и том же уровне просмотра. Это потому, что, когда каждый автор первоначально открывает документ, контент обоих документов должен быть одинаковым. Если определено, что идентификатор версии из первого начального значения метаданных не соответствует идентификатору версии из второго начального значения метаданных, на операции 504 метаданные не сливаются вместе, и автор на клиенте 102 продолжает редактирование.
Когда определено, что идентификатор версии из первого начального значения метаданных совпадает с идентификатором версии из второго начального значения метаданных, на операции 506 выполняется определение того, совпадает ли идентификатор документа из первого начального значения метаданных идентификатору документа из второго начального значения метаданных. Когда идентификаторы документа совпадают, это указывает на то, что документы уже были синхронизированы и что слияние метаданных не нужно. В этом случае на операции 508 метаданные не сливаются, и автор на клиенте 102 продолжает редактирование.
Когда определено, что идентификатор документа из первого начального значения метаданных не совпадает с идентификатором версии из второго начального значения метаданных, на операции 510 выполняется определение того, совпадает ли размер диапазона абзацев, определенный из первого начального значения метаданных, с размером диапазона абзацев, определенным из второго начального значения метаданных. Когда определено, что диапазоны абзацев не одинаковы, на операции 512 метаданные не сливаются, и автор на клиенте 102 продолжает редактирование.
Когда определено, что диапазоны абзацев одинаковы, на операции 514 первое начальное значение метаданных и второе начальное значение метаданных сливаются вместе. Слияние первого начального значения метаданных и второго начального значения метаданных содержит корректировку идентификаторов абзаца в документе, открытом на клиенте 102, на операции 422, как уже обсуждалось.
Со ссылкой на Фиг. 6 показаны примерные компоненты клиента 102. В примерных вариантах воплощения клиент 102 является вычислительным устройством, таким как настольный компьютер, портативный компьютер, персональное цифровое информационное устройство или устройство сотовой связи. Клиент 102 может включать в себя устройства ввода/вывода, центральный процессор ("CPU"), устройство хранения данных и сетевое устройство.
В базовой конфигурации вычислительное устройство 102 обычно включает в себя, по меньшей мере, одно процессорное устройство 602 и системную память 604. В зависимости от точной конфигурации и типа вычислительного устройства, системная память 604 может быть энергозависимой (например, RAM), энергонезависимой (например, ROM, флэш-память и т.д.) или какой-либо комбинацией того и другого. Системная память 704 обычно включает в себя операционную систему 606, подходящую для управления работой сетевого персонального компьютера, такую как операционная система Windows (R) от MICROSOFT CORPORATION, Redmond, штат Вашингтон, или сервер, такой как Windows SharePoint Server 2007, также от MICROSOFT CORPORATION, Redmond, штат Вашингтон. Системная память 604 также может включать в себя одно или более программных приложений 608 и может включать в себя данные программ.
Вычислительное устройство 102 может иметь дополнительные функции или функциональность. Например, вычислительное устройство 102 может также включать в себя дополнительные устройства хранения данных (съемные и/или несъемные), такие как, например, магнитные диски, оптические диски или пленка. Такой дополнительный накопитель показан на Фиг. 6 в виде съемного носителя 610 и несъемного носителя 612. Компьютерные носители данных могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Системная память 604, съемный носитель 610 и несъемный носитель 612 являются примерами компьютерных носителей данных. Компьютерные носители данных включают, но не ограничиваются этим, RAM, ROM, EEPROM, флэш-память или память другой технологии, CD-ROM, цифровые универсальные диски (DVD) или другие оптические накопители, магнитные кассеты, магнитные ленты, магнитные диски или другие магнитные устройства хранения данных, либо любые другие носители, которые могут быть использованы для хранения необходимой информации и к которым может быть осуществлен доступ вычислительным устройством 102. Любые такие компьютерные носители данных могут быть частью устройства 102. Вычислительное устройство 102 может также иметь устройства 614 ввода, такие как клавиатура, мышь, перо, устройства голосового ввода, устройства тактильного ввода и т.д. Устройства 616 вывода, такие как дисплей, колонки, принтер и т.д., также могут быть включены. Эти устройства широко известны в технике и не должны быть подробно рассмотрены здесь.
Вычислительное устройство 102 может также содержать соединения 618 связи, что позволяет устройству обмениваться данными с другими вычислительными устройствами 620, например, по сети в распределенной вычислительной среде, например интранет или Интернет. Соединение 618 связи является одним из примеров коммуникационных сред. Коммуникационные среды, как правило, могут быть воплощены машиночитаемыми инструкциями, структурами данных, программными модулями или другими данными в модулированном сигнале данных, таком как несущая волна или другой транспортный механизм, и включают в себя любые среды доставки информации. Термин "модулированный сигнал данных" означает сигнал, одна или несколько характеристик которого устанавливаются или изменяются таким образом, чтобы закодировать информацию в этом сигнале. В качестве примера, а не ограничения, коммуникационные среды включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Термин «машиночитаемый носитель», используемый здесь, охватывает как носители данных, так и коммуникационные среды.
Различные варианты воплощения, рассмотренные выше, предоставляются только в качестве иллюстрации и не должны толковаться как ограничивающие. Различные модификации и изменения могут быть сделаны в вариантах воплощения, рассмотренных выше, не отступая от истинной сущности и объема раскрытия.
| название | год | авторы | номер документа |
|---|---|---|---|
| СОГЛАСОВАННОСТЬ КОЛЛЕКТИВНОЙ РАБОТЫ ПО ПЕРЕКРЕСТНЫМ КАНАЛАМ | 2010 |
|
RU2544754C2 |
| ПОДДЕРЖАНИЕ ВОЗМОЖНОСТИ ОТМЕНЫ И ВОЗВРАТА ПРИ ОБЪЕДИНЕНИЯХ МЕТАДАННЫХ | 2010 |
|
RU2554785C2 |
| ИНТЕРФЕЙСЫ ДЛЯ ПРИКЛАДНОГО ПРОГРАММИРОВАНИЯ ДЛЯ КУРИРОВАНИЯ КОНТЕНТА | 2014 |
|
RU2666302C2 |
| СИНХРОНИЗАЦИЯ СТРУКТУРИРОВАННОГО СОДЕРЖИМОГО ВЕБ-УЗЛОВ | 2007 |
|
RU2432608C2 |
| ВЫСОКОТОЧНОЕ ОТОБРАЖЕНИЕ ДОКУМЕНТОВ В КЛИЕНТАХ ПРОСМОТРА | 2009 |
|
RU2487400C2 |
| МНОГОПОЛЬЗОВАТЕЛЬСКОЕ СЕТЕВОЕ СОТРУДНИЧЕСТВО | 2009 |
|
RU2507567C2 |
| СОВМЕСТНАЯ РАБОТА МНОЖЕСТВЕННЫХ КЛИЕНТОВ ДЛЯ ОСУЩЕСТВЛЕНИЯ ДОСТУПА И ОБНОВЛЕНИЯ СТРУКТУРИРОВАННЫХ ЭЛЕМЕНТОВ ДАННЫХ | 2008 |
|
RU2504001C2 |
| УПРАВЛЕНИЕ ДОСТУПОМ К ДОКУМЕНТАМ С ИСПОЛЬЗОВАНИЕМ БЛОКИРОВОК ФАЙЛА | 2009 |
|
RU2501082C2 |
| ПРОЗРАЧНОЕ ВОССТАНОВЛЕНИЕ ПОСЛЕ ОТКАЗА | 2012 |
|
RU2595903C2 |
| ПРОГРАММНЫЙ ИНТЕРФЕЙС ПРИЛОЖЕНИЙ ДЛЯ АДМИНИСТРИРОВАНИЯ РАСПРЕДЕЛЕНИЕМ ОБНОВЛЕНИЙ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ В СИСТЕМЕ РАСПРЕДЕЛЕНИЯ ОБНОВЛЕНИЙ | 2005 |
|
RU2386218C2 |

Изобретение относится к области совместной работы с документами на сетевой основе. Техническим результатом является обеспечение слияния метаданных документа на клиентском компьютере. Документ, полученный от серверного компьютера, открывается пользователем на клиентском компьютере. Если документ не включает в себя идентификаторы абзаца, идентификатор абзаца назначается каждому абзацу в документе. Когда документ открывается вторым пользователем на втором клиентском компьютере, метаданные для документа принимаются от серверного компьютера. Выполняется определение того, сливать ли вместе метаданные, принятые от серверного компьютера, с текущими метаданными для этого документа. Если определено, что текущие метаданные и метаданные, принятые от серверного компьютера, должны быть слиты, идентификаторы абзаца корректируются в документе на основе метаданных, принятых от серверного компьютера. 3 н. и 12 з.п. ф-лы, 6 ил.
1. Способ (400) слияния метаданных документа на клиентском компьютере (102), содержащий этапы, на которых:
получают документ от серверного компьютера (106) на клиентском компьютере (102), причем документ запрошен пользователем на клиентском компьютере (102);
открывают документ на клиентском компьютере (102);
в ответ на открытие документа на клиентском компьютере (102) определяют, включает ли в себя документ идентификаторы блока;
если определено, что документ не включает в себя идентификаторы блока, присваивают идентификатор блока каждому блоку в документе;
принимают первое сообщение от серверного компьютера (106), обеспечивающее уведомление о том, что по меньшей мере один другой пользователь осуществляет авторскую разработку этого документа;
в ответ на прием первого сообщения от серверного компьютера (106) о том, что по меньшей мере один другой пользователь осуществляет авторскую разработку этого документа, отправляют второе сообщение на серверный компьютер (106), причем второе сообщение включает в себя первые метаданные для документа;
в ответ на отправку второго сообщения на серверный компьютер (106) принимают третье сообщение от серверного компьютера (106), причем третье сообщение включает в себя вторые метаданные для документа;
в ответ на прием третьего сообщения от серверного компьютера (106) определяют, должны ли быть слиты первые метаданные и вторые метаданные; и
если определено, что первые метаданные и вторые метаданные должны быть слиты, корректируют идентификаторы блока в документе на основе вторых метаданных.
2. Способ по п.1, в котором первые метаданные включают в себя первый идентификатор документа, первый идентификатор следующего блока и первый идентификатор версии, а вторые метаданные включают в себя второй идентификатор документа, второй идентификатор следующего блока и второй идентификатор версии.
3. Способ по п.2, в котором из первого идентификатора документа определяют первый диапазон идентификаторов блока, и из вторых метаданных определяют второй диапазон идентификаторов блока, причем первый диапазон идентификаторов блока включает в себя первый идентификатор и последний идентификатор, и второй диапазон идентификаторов блока включает в себя первый идентификатор и последний идентификатор, при этом первый идентификатор в первом диапазоне идентификаторов блока имеет исходное значение, равное первому идентификатору документа, и последний идентификатор в первом диапазоне идентификаторов блока имеет значение, на единицу меньшее первого идентификатора следующего блока, причем первый идентификатор во втором диапазоне идентификаторов блока имеет исходное значение, равное второму идентификатору документа, и последний идентификатор во втором диапазоне идентификаторов блока имеет значение, на единицу меньшее второго идентификатора следующего блока.
4. Способ по п.3, в котором при определении того, должны ли быть слиты первые метаданные и вторые метаданные, определяют, совпадает ли первый идентификатор версии со вторым идентификатором версии.
5. Способ по п.4, дополнительно содержащий этап на котором, если определено, что второй идентификатор версии совпадает с первым идентификатором версии, определяют, совпадает ли первый идентификатор документа со вторым идентификатором документа.
6. Способ по п.5, дополнительно содержащий этап, на котором, если первый идентификатор документа не совпадает со вторым идентификатором документа, определяют, совпадает ли размер первого диапазона идентификаторов блока с размером второго диапазона идентификаторов блока.
7. Способ по п.6, дополнительно содержащий этап, на котором, если размер первого диапазона идентификаторов блока совпадает с размером второго диапазона идентификаторов блока, определяют, что первые метаданные и вторые метаданные должны быть слиты.
8. Способ по п.3, в котором первый идентификатор документа генерируется случайным образом, причем каждый блок в первом диапазоне идентификаторов блока последовательно пронумерован, начиная с первого идентификатора документа, и каждый блок во втором диапазоне идентификаторов блока последовательно пронумерован, начиная со второго идентификатора документа.
9. Способ по п.8, в котором при корректировке идентификаторов блока в документе на основе вторых метаданных изменяют первый идентификатор в первом диапазоне идентификаторов блока на второй идентификатор документа.
10. Способ по п.9, дополнительно содержащий этап, на котором изменяют идентификаторы блока для блоков, включенных в первый диапазон идентификаторов блока, на соответствующие идентификаторы блока, включенные во второй диапазон идентификаторов блока.
11. Способ по п.10, дополнительно содержащий этап, на котором определяют, включены ли во второй диапазон идентификаторов блока один или более идентификаторов блока из блоков, не включенных в первый диапазон идентификаторов блока.
12. Способ по п.10, дополнительно содержащий этап, на котором, если определено, что один или более идентификаторов блока из блоков, не включенных в первый диапазон идентификаторов блока, включены во второй диапазон идентификаторов блока, изменяют эти один или более идентификаторов блока из блоков, не включенных в первый диапазон идентификаторов блока, на идентификатор блока, включенный в первый диапазон идентификаторов блока.
13. Компьютерное устройство (102), содержащее:
процессорное устройство (602); системную память (604), соединенную с процессорным устройством (602), причем системная память (604) содержит инструкции, которые при их исполнении процессорным устройством (602) предписывают процессорному устройству (602) реализовывать:
модуль (204) обработки метаданных, который генерирует, отслеживает и сохраняет метаданные для документа в компьютерном устройстве (102), причем метаданные включают в себя идентификатор документа, идентификатор следующего абзаца и идентификатор версии, при этом модуль (204) обработки метаданных генерирует диапазон идентификаторов абзаца из идентификатора документа и из идентификатора следующего абзаца, причем диапазон идентификаторов абзаца включает в себя первый идентификатор абзаца и последний идентификатор абзаца, причем первый идентификатор абзаца имеет значение, равное идентификатору документа, а последний идентификатор абзаца имеет значение, на единицу меньшее идентификатора следующего абзаца, при этом модуль (204) обработки метаданных генерирует идентификаторы абзаца для каждого абзаца в диапазоне идентификаторов абзаца, причем каждый идентификатор абзаца в диапазоне идентификаторов абзаца последовательно пронумерован; и
модуль (206) слияния метаданных, который объединяет метаданные для документа с метаданными, принятыми от серверного компьютера (106), при этом модуль (206) слияния метаданных изменяет идентификатор документа на идентификатор документа, включенный в метаданные, принятые от серверного компьютера (106), причем модуль (206) слияния метаданных изменяет идентификаторы абзаца в диапазоне идентификаторов абзаца на идентификаторы абзаца, включенные в метаданные, принятые от серверного компьютера (106).
14. Компьютерное устройство по п.13, в котором модуль обработки метаданных сохраняет метаданные в файле на серверном компьютере (106), который отделен от документа.
15. Машиночитаемый носитель информации, содержащий инструкции, которые при их исполнении процессорным устройством (602) из состава электронного вычислительного устройства (102) предписывают процессорному устройству (602):
получать документ от серверного компьютера (106), причем документ запрошен пользователем на электронном вычислительном устройстве (102);
открывать документ;
в ответ на открытие документа определять, включает ли документ в себя идентификаторы абзаца;
если определено, что документ не включает в себя идентификаторы абзаца, присваивать идентификатор абзаца каждому абзацу в документе посредством этапов, на которых:
генерируют случайным образом идентификатор для первого абзаца документа;
назначают этот идентификатор для первого абзаца документа в качестве первого идентификатора документа;
последовательно присваивают идентификаторы остальным абзацам в документе; и
назначают первый идентификатор следующего абзаца, имеющий значение, на единицу большее идентификатора, присвоенного последнему абзацу в документе;
принимать первое сообщение от серверного компьютера (106) о том, что по меньшей мере один пользователь осуществляет авторскую разработку этого документа;
в ответ на прием первого сообщения от серверного компьютера (106) о том, что по меньшей мере один другой пользователь осуществляет авторскую разработку этого документа, отправлять второе сообщение на серверный компьютер (106), причем второе сообщение включает в себя первые метаданные для документа, при этом первые метаданные включают в себя первый идентификатор документа, первый идентификатор следующего абзаца и первый идентификатор версии;
определять первый диапазон идентификаторов абзаца из первого идентификатора документа и из первого идентификатора следующего абзаца, причем первый идентификатор в первом диапазоне идентификаторов абзаца является первым идентификатором документа, а последний идентификатор в первом диапазоне идентификаторов абзаца на единицу меньше первого идентификатора следующего абзаца;
в ответ на отправку второго сообщения на серверный компьютер (106) принимать третье сообщение от серверного компьютера (106), причем третье сообщение включает в себя вторые метаданные для документа, при этом вторые метаданные включают в себя второй идентификатор документа, второй диапазон идентификаторов абзаца и второй идентификатор версии;
определять второй диапазон идентификаторов абзаца из второго идентификатора документа и из второго идентификатора следующего абзаца, причем первый идентификатор во втором диапазоне идентификаторов абзаца является вторым идентификатором документа, а последний идентификатор во втором диапазоне идентификаторов абзаца на единицу меньше второго идентификатора следующего абзаца;
в ответ на прием третьего сообщения от серверного компьютера (106) определять, должны ли первые метаданные и вторые метаданные быть слиты посредством этапов, на которых:
определяют, совпадает ли первый идентификатор версии со вторым идентификатором версии;
если определено, что первый идентификатор версии совпадает со вторым идентификатором версии, определяют, совпадает ли первый идентификатор документа со вторым идентификатором документа,
если определено, что первый идентификатор версии совпадает со вторым идентификатором версии, и если определено, что первый идентификатор документа не совпадает со вторым идентификатором документа, определяют, совпадает ли размер первого диапазона идентификаторов абзаца с размером второго диапазона идентификаторов абзаца,
если определено, что первый идентификатор версии совпадает со вторым идентификатором версии, если определено, что первый идентификатор документа не совпадает со вторым идентификатором документа, и если определено, что размер первого диапазона идентификаторов абзаца совпадает с размером второго диапазона идентификаторов абзаца, определяют, что первые метаданные и вторые метаданные должны быть слиты, и,
если определено, что первые метаданные и вторые метаданные должны быть слиты, корректируют идентификаторы абзаца в документе на основе вторых метаданных посредством этапов, на которых:
назначают второй идентификатор документа в качестве первого идентификатора документа, при этом второй идентификатор документа также назначается как идентификатор абзаца для первого абзаца в первом диапазоне идентификаторов абзаца;
присваивают идентификаторы абзаца во втором диапазоне идентификаторов абзаца соответствующим абзацам в первом диапазоне идентификаторов абзаца;
определяют, совпадает ли с идентификатором абзаца во втором диапазоне идентификаторов абзаца идентификатор абзаца в документе из абзаца, не включенного в первый диапазон идентификаторов абзаца,
если определено, что идентификатор абзаца в документе из абзаца, не включенного в первый диапазон идентификаторов абзаца, совпадает с идентификатором абзаца во втором диапазоне идентификатора абзаца, присваивают идентификатор абзаца в документе, который совпадает с идентификатором абзаца во втором диапазоне идентификаторов абзаца, идентификатору абзаца в первом диапазоне идентификаторов абзаца.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6925476 B1, 02.08.2005 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СПОСОБ УПРАВЛЕНИЯ МНОЖЕСТВОМ СОСТОЯНИЙ ФАЙЛА ДЛЯ ДУБЛИРОВАННЫХ ФАЙЛОВ | 2004 |
|
RU2344468C2 |

