Предпосылки создания изобретения
Использование данного изобретения связано с аудио декодером, аудио кодером, методом для декодирования аудио сигнала, методом для кодирования аудио сигнала и соответствующей компьютерной программой. Некоторые варианты использования изобретения связаны с аудио сигналом.
Некоторые воплощения изобретения связаны с концепцией аудио кодирования / декодирования, в котором служебная информация используется для перенастройки контекста энтропии кодирования / декодирования.
Некоторые варианты использования связаны с контролем за настройкой арифметического кодера.
Традиционные концепции кодирования звука включают схемы кодирования энтропии (например, для кодирования спектральных коэффициентов представления сигнала в частотной области) для того, чтобы уменьшить избыточность. Как правило, энтропийное кодирование применяется к квантованным спектральным коэффициентам в схемах кодирования, основанных на частотной области, или к квантованным сэмплам временной области в схемах кодирования, основанных на временной области. Эти схемы энтропийного кодирования обычно используют передачу кодового слова вместе с соответствующим индексом кодовой книги, что позволяет декодеру находить нужную страницу кодовой книги для декодирования кодированного информационного слова, соответствующего переданному кодовому слову на указанной странице кодовой книги.
Подробнее такие способы кодирования звука рассматриваются, например, в международном стандарте ISO / IEC 14496-3:2005 (Е), часть 3: аудио, часть 4: общие способы кодирования звука: (GA)-AAC, Twin VQ, В SAC, в которых описываются так называемые концепции "энтропия / кодирование".
Тем не менее, было установлено, что значительное количество данных в битрейте обусловлено необходимостью регулярной передачи подробной информации о выборе кодовой книги (например, sect_cb).
Соответственно, задачей настоящего изобретения является создание битрейт-эффективной концепции для адаптации правил отображения информации энтропийного декодирования к статистике сигнала.
Краткое описание изобретения
Это достигается с помощью аудио декодера в соответствии с п.1, аудио кодера в соответствии с п.12, метода декодирования аудио сигнала в соответствии с п.11, метода кодирования аудио сигнала в соответствии с п.16, компьютерной программы в соответствии с п.17 и кодированного аудио сигнала в соответствии с п.18.
Примером воплощения изобретения является аудио декодер для получения декодированной аудио информации на основе кодированной аудио информации. Аудио декодер включает в себя контекстно-зависимый энтропийный декодер, который предназначен для декодирования энтропийно-кодированных аудио данных в зависимости от контекста. Декодер основывается на ранее декодированных аудио без перенастройки. Энтропийный декодер предназначен для того, чтобы выбирать отображение информации (например, сводная таблица частот или Huffmann-кодовая книга) для получения декодированной аудио информации из кодированной аудио информации в зависимости от контекста. Кроме того, контекстно-зависимый энтропийный декодер также включает в себя контекстный ресеттер, который предназначен для настройки контекста для выбора отображения информации по умолчанию, которая не зависит от ранее декодированной аудио информации, в зависимости от служебной информации в кодированной аудио информации.
Этот вариант использования изобретения основан на том, что во многих случаях битрейт-эффективным является получение контекста, который определяет отображение энтропийно-кодированной аудио информации в декодированной аудио информации (например, обратившись к кодовой книге, или путем определения распределения вероятностей), в зависимости от контекста, который основан на ранее декодированных элементах аудио информации, а соответственно, могут быть использованы корреляции в пределах энтропийно-кодированных данных. Например, если буфер содержит большую интенсивность в первом звукокадре, тогда существует высокая вероятность того, что тот же буфер снова содержит большую интенсивность в следующем звукокадре после первого звукокадра. Таким образом, становится очевидным, что выбор отображения информации на основе контекста учитывает снижение битрейта по сравнению со случаем, когда передается подробная информация для выбора отображения информации для получения декодированной аудио информации из кодированной аудио информации.
Тем не менее, также было установлено, что вывод контекста из ранее декодированной аудио информации иногда приводит к ситуации, когда выбирается неподходящее отображение информации (для получения декодированной аудио информации из кодированной аудио информации), которое приводит к неоправданно высокому расходу битов для кодирования аудио информации. Эта ситуация будет иметь место, если, например, спектральное распределение энергии последующих звукокадров существенно различается так, что новое спектральное распределение энергии в последующем звукокадре сильно отклоняется от распределения, которое можно было бы ожидать на основании знания о спектральном распределении в предыдущем звукокадре.
В соответствии с основной идеей изобретения, в таких случаях, когда битрейт будет значительно ухудшаться из-за выбора неподходящего отображения информации (для получения декодированной аудио информации из кодированной аудио информации), контекст перенастраивается в соответствии со служебной информацией из кодированной аудио информации, обеспечивая тем самым выбор отображения информации по умолчанию (в связи с контекстом по умолчанию), что в свою очередь приводит к умеренной затрате бит для кодирования / декодирования аудио информации.
Подводя итог сказанному выше, основной идеей изобретения является то, что битрейт-эффективное кодирование аудио информации может быть достигнуто путем совместного использования контекстно-зависимого энтропийного декодера, который в обычном режиме (не в состоянии перенастройки работы) использует ранее кодированную аудио информацию для получения контекста и для выбора соответствующего отображения, с механизмом сброса в зависимости от служебной информации для сброса контекста, потому что такая концепция позволяет с минимальными усилиями поддерживать соответствующий контекст декодирования, который хорошо адаптирован к аудио контенту в обычной ситуации (когда аудио-контент соответствует ожиданиям, на основании которых построен контекстно-зависимый выбор правила отображения информации) и позволяет избежать чрезмерного увеличения битрейта в нестандартной ситуации (когда аудио-контент сильно отличается от ожиданий).
В предпочтительном варианте использования изобретения, контекстный ресеттер настроен выборочно перенастраивать контекстно-зависимый энтропийный декодер при переходе между последовательными временными частями (например, звукокадрами), имеющими сопряженные спектральные данные одного и того же спектрального разрешения (например, количество частот бункеров). Этот вариант использования основан на идее, что сброс контекста может иметь благоприятный эффект (в плане снижения требуемого битрейта), даже если спектральное разрешение остается неизменным. Другими словами, было установлено, что возможно выполнить сброс контекста независимо от изменения спектрального разрешения, так как было установлено, что контекст может быть неподходящим, даже если не нужно менять спектральное разрешение (например, за счет перехода от "длинного окна" в кадре к множеству «коротких окон» в кадре). Другими словами, было установлено, что контекст может быть неподходящим (что повышает желание сбросить контекст) даже в той ситуации, когда нежелательно переходить от низкого временного разрешения (например, длинные окна, в сочетании с высоким спектральным разрешением) к высокому временному разрешению (например, короткие окна, в сочетании с малым спектральным разрешением).
В предпочтительном варианте использования изобретения аудио декодер настроен на получение, в качестве кодированной аудио информации, информации, описывающей спектральные значения в первом звукокадре и во втором звукокадре после первого звукокадра. В этом случае аудио декодер предпочтительно содержит трансформатор спектральной области во временную область, предназначенный для того, чтобы перекрывать и добавлять первый оконный сигнал во временной области, который основан на спектральных значениях первого звукокадра, и второй оконный сигнал во временной области, который основан на спектральных значениях второго звукокадра. Аудио декодер предназначен для того, чтобы отдельно настраивать вид окна для получения первого оконного сигнала во временной области и окна для получения второго оконного сигнала во временной области. Аудио декодер также предпочтительно настроить на выполнение, в зависимости от служебной информации, сброса контекста между декодированием спектральных значений первого звукокадра и декодированием спектральных значений второго звукокадра, даже если вторая форма окна идентична первой форме окна, например, если контекст, используемый для декодирования кодированной аудио информации второго звукокадра, не зависит от декодированной аудио информации первого звукокадра в случае сброса.
Этот вариант использования изобретения позволяет сбросить контекст между декодированием (при помощи отображения информации, выбранной на основе контекста) спектральных значений первого звукокадра и декодированием (при помощи отображения информации, выбранной на основе контекста) спектральных значений второго звукокадра, даже если оконные сигналы во временной области первого и второго звукокадров накладываются друг на друга и расширяются, и даже если одинаковые формы окон выбираются для получения первого оконного сигнала во временной области и второго оконного сигнала во временной области из спектральных значений первого звукокадра и второго звукокадра. Таким образом, сброс контекста может дать дополнительную степень свободы, которую может использовать контекстный ресеттер даже между декодированием спектральных значений тесно связанных звукокадров, оконные сигналы временной области которых получены с использованием идентичных оконных форм и наложены друг на друга и добавлены друг к другу.
Таким образом, предпочтительно, чтобы сброс контекста не зависел от используемых форм окон, а также не зависел от того, что оконные сигналы временной области последующих кадров принадлежат смежному аудио-контенту, т.е. накладываются друг на друга и добавляются.
В предпочтительном варианте использования изобретения энтропийный декодер настроен на сброс, в зависимости от служебной информации, контекста между декодированием аудио информации смежных кадров аудио информации, имеющей одинаковое частотное разрешение. В этом варианте сброс контекста происходит независимо от изменения частотного разрешения.
В еще одном предпочтительном варианте использования изобретения аудио декодер настраивается на получение служебной информации о сбросе контекста для передачи сигнала о сбросе контекста. В этом случае аудио декодер также настроен на дополнительное получение служебной информации о форме окна для корректировки вида окна и для получения первого и второго оконных сигналов временной области независимо от выполнения сброса контекста.
В предпочтительном варианте использования изобретения аудио декодер настроен на прием, в качестве служебной информации о сбросе контекста, однобитового флага контекстного сброса на каждый звукокадр кодированной аудио информации. В этом случае аудио декодер предпочтительно настроен на прием, в дополнение к флагу сброса контекста, служебной информации, описывающей спектральное разрешение спектральных значений, представленных кодированной аудио информацией или длиной временного окна, для управления окнами значений временной области, представленных кодированной аудио информацией. Контекстный ресеттер настроен для выполнения сброса контекста в ответ на однобитовый флаг сброса контекста на переходе между двумя звукокадрами кодированной аудио информации, представляющей спектральные значения идентичных спектральных разрешений. В этом случае однобитовый флаг сброса контекста обычно приводит к одному сбросу контекста между декодированием кодированной аудио информации последующих звукокадров.
В другом предпочтительном варианте использования изобретения аудио декодер настроен на прием, в качестве служебной информации о сбросе контекста, однобитового флага контекстного сброса на каждый звукокадр кодированной аудио информации. Кроме того, аудио декодер настроен на прием кодированной аудио информации, содержащей множество наборов спектральных значений на каждый звукокадр (например, такой, что один звукокадр подразделяется на множество субкадров, с которыми связаны отдельные короткие окна). В этом случае контекстно-зависимый энтропийный декодер настроен на декодирование энтропийно-кодированной аудио информации последующего набора спектральных значений заданного звукокадра в зависимости от контекста, который основывается на ранее декодированной аудио информации из предыдущего набора спектральных значений заданного звукокадра в несброшенном состоянии. Тем не менее, контекстный ресеттер настроен на сброс контекста по умолчанию перед декодированием первого набора спектральных значений заданного звукокадра, а также между декодированием любых двух последующих наборов спектральных значений заданного звукокадра в ответ на однобитовый флаг сброса контекста (то есть только тогда, когда однобитовый флаг сброса контекста активен), так, что активация однобитового флага сброса контекста заданного звукокадра вызывает сброс контекста множество раз при декодировании множества наборов спектральных значений звукокадра.
Этот вариант использования изобретения основан на идее о неэффективности, с точки зрения битрейта, выполнять только один сброс контекста звукокадра, содержащего множество «коротких окон», для которых кодируются отдельные наборы спектральных значений. Звукокадр, включающий в себя множество наборов спектральных значений, обычно содержит разрыв аудио-контента, так, что желательно для уменьшения битрейта сбросить контекст между каждым из последующих наборов спектральных значений. Установлено, что такое решение более эффективно, чем одноразовый сброс контекста (например, только в начале кадра), и отдельная передача сигнала о сбросе контекста (например, с помощью дополнительных однобитовых флагов) множество раз в пределах (нескольких коротких окон) кадра.
В предпочтительном варианте использования изобретения аудио декодер настроен также получать служебную информацию о группировании при использовании так называемых "коротких окон" (то есть при передаче нескольких наборов спектральных значений, которые накладываются друг на друга и добавляются с помощью нескольких окон короче, чем звукокадр). В этом случае аудио декодер предпочтительно настроен группировать два или более набора спектральных значений для комбинации с общей информацией о коэффициенте масштабирования в зависимости от служебной информации о группировании. В этом случае контекстный ресеттер предпочтительно настроен на сброс контекста по умолчанию между декодированием множества спектральных значений, группированных вместе в зависимости от однобитового флага сброса контекста. Этот вариант основан на открытии, что в некоторых случаях может быть широкий разброс между декодированными аудио значениями (например, декодированными спектральными значениями) группированных последовательностей наборов спектральных значений, даже если начальные масштабные коэффициенты применяются к последующим наборам спектральных значений. Например, если есть устойчивое, но значительное изменение частоты между последующими наборами спектральных значений, то коэффициенты масштабирования последующих наборов спектральных значений могут быть равными (например, если изменение частоты не превышает полосы коэффициента масштабирования), при этом, тем не менее, необходимо сбросить контекст при переходе между различными наборами спектральных значений. Таким образом, описанный вариант использования изобретения делает возможным битрейт-эффективное кодирование и декодирование даже при наличии такого изменения частоты переходов аудио сигнала. Кроме того, эта концепция обеспечивает эффективную работу при кодировании быстрых изменений значений в присутствии коррелирующих спектральных значений. В этом случае сброса контекста можно избежать, отключив флаг сброса контекста, даже если различные коэффициенты масштабирования связаны с последующим набором спектральных значений (которые в данном случае не сгруппированы, поскольку коэффициенты масштабирования различаются).
В другом варианте использования изобретения аудио декодер настроен на прием, в качестве служебной информации для сброса контекста, однобитового флага сброса контекста на каждый звукокадр кодированной аудио информации. В этом случае аудио декодер также настроен на прием, в качестве кодированной аудио информации, последовательности кодированных звукокадров, последовательности кодированных кадров, включающих звукокадры в линейно предсказанной области. Звукокадр линейно-предсказанной области содержит, например, выборочное число частей с преобразованием кодированного возбуждения для возбуждения аудио синтезатора в линейно-предсказанной области. Этот контекстно-зависимый энтропийный декодер настроен для декодирования спектральных значений частей с преобразованием кодированного возбуждения в зависимости от контекста, который основывается на ранее декодированной аудио информации в несброшенном состоянии. Контекстный ресеттер настроен на сброс, в зависимости от служебной информации, контекста по умолчанию перед декодированием набора спектральных значений первой части с преобразованием кодированного возбуждения данного звукокадра, пропуская сброс контекста по умолчанию между декодированием наборов спектральных значений различных частей с преобразованием кодированного возбуждения (т.е. в пределах) заданного звукокадра. Этот вариант основан на открытии, что сочетание контекстно-зависимого декодирования и сброса контекста влечет за собой снижение битрейта при кодировании преобразования кодированного возбуждения для линейно-предсказанной области аудио синтезатора. Кроме того, было установлено, что временная детализация сброса контекста при кодировании преобразования кодированного возбуждения обычно может быть выбрана большей, чем временная детализация сброса контекста при наличии перехода (коротких окон) к чистому кодированию частотной области (например, Advanced-Audio-Coding-type audio coding аудио).
В другом предпочтительном варианте использования изобретения, аудио декодер настроен на получение кодированной аудио информации, содержащей множество наборов спектральных значений на каждый звукокадр. В этом случае аудио декодер также предпочтительно настроен на получение служебной информации о группировании. Этот аудио декодер настроен на группирование двух или более наборов спектральных значений для комбинации с общей информацией о коэффициненте масштабирования в зависимости от служебной информации о группировании. В предпочтительном варианте контекстный ресеттер настроен на сброс контекста по умолчанию в ответ на (то есть в зависимости от) служебную информацию о группировании. Контекстный ресеттер настроен на сброс контекста между декодированием наборов спектральных значений последующих групп, и на избежание сброса контекста между декодированием наборов спектральных значений в одной группе (т.е. в пределах одной группы). Этот вариант использования изобретения основан на открытии, что необязательно использовать выделенную служебную информацию о сбросе контекста, если есть сигнализация наборов пространственных значений, обладающих высоким сходством (и сгруппированных на этом основании). В частности, было установлено, что во многих случаях уместен сброс контекста каждый раз, когда коэффициент масштабирования меняется (например, при переходе от одного набора спектральных значений к другому набору спектральных значений в пределах окна, в частности, если наборы спектральных значений не сгруппированы, или при переходе из одного окна в другое окно). Если, однако, желательно сбросить контекст между двумя наборами спектральных значений, с которыми связаны одни и те же коэффициенты масштабирования, по-прежнему имеется возможность принудительно сбросить контекст с помощью сигнала о наличии новой группы. Это можно сделать за счет повторной передачи идентичных коэффициентов масштабирования, но это принесет положительный результат, если пропущенный сброс контекста вызвал бы значительное ухудшение эффективности кодирования. Тем не менее, оценка служебной информации о группировании для сброса контекста может быть эффективной концепцией, чтобы избежать необходимости передачи выделенной служебной информации о сбросе контекста, в то же время позволяя сброс контекста, когда это целесообразно. В тех случаях, когда контекст должен быть сброшен, даже если можно использовать ту же информацию о коэффициенте масштабирования, существуют недостатки с точки зрения битрейта (вызванные необходимостью использования дополнительных групп и ретранслирования информации о коэффициентах масштабирования), эти недостатки в битрейте можно компенсировать сокращением битрейта в других кадрах.
Другой вариант использования изобретения приводит к созданию аудио кодера для получения кодированной аудио информации на основе входной аудио информации. Аудио кодер включает в себя контекстно-зависимый энтропийный кодер, предназначенный для кодирования заданной аудио информации из входной аудио информации в зависимости от контекста, который основывается на смежной аудио информации, временно или пространственно смежной к заданной аудио информации в несброшенном состоянии. Этот контекстно-зависимый энтропийный кодер также настроен на выбор отображения информации для получения кодированной аудио информации из входной аудио информации в зависимости от контекста. Этот контекстно-зависимый энтропийный кодер также включает в себя контекстный ресеттер, настроенный на сброс контекста для выбора отображения информации контекста по умолчанию, который не зависит от ранее декодированной аудио информации, в пределах непрерывной части входной аудио информации в ответ на появление условия для сброса контекста. Этот контекстно-зависимый энтропийный кодер также настроен предоставлять служебную информацию кодированной аудио информации, указывающую на присутствие условий для сброса контекста. Этот вариант использования изобретения основывается на открытии, что сочетание контекстно-зависимого энтропийного кодирования и периодичного сброса контекста, о котором сигнализирует соответствующая служебная информация, делает возможным битрейт-эффективное кодирование входной аудио информации.
В предпочтительном варианте использования изобретения аудио кодер настроен для выполнения регулярного сброса контекста по крайней мере один раз за n кадров входной аудио информации. Было установлено, что регулярный сброс контекста влечет за собой возможность синхронизировать аудио сигнал очень быстро, потому что сброс контекста вводит временные ограничения на межкадровые зависимости (или, по крайней мере, способствует таким ограничениям межкадровых зависимостей).
В другом предпочтительном варианте использования изобретения аудио кодер настроен на переключение между множеством различных режимов кодирования (например, режим кодирования частотной области и режим кодирования линейно-предсказанной области). В этом случае аудио кодер предпочтительно может быть настроен для выполнения сброса контекста в ответ на изменение между двумя режимами кодирования. Этот вариант основан на открытии, что смена между двумя режимами кодирования, как правило, связана с существенным изменением входного аудио сигнала так, что обычно существует только очень ограниченная корреляция между аудио-контентом до переключения режима кодирования и после переключения режима кодирования.
В другом предпочтительном варианте использования изобретения аудио кодер настроен на расчет или оценку первого числа битов, необходимых для кодирования определенной аудио информации (например, конкретного кадра или части входной аудио информации, или, по крайней мере, одного или нескольких конкретных спектральных значений входной аудио информации) входной аудио информации в зависимости от несброшенного контекста, который основывается на смежной аудио информации, временно или спектрально прилегающей к определенной аудио информации, и на расчет или оценку второго числа битов, необходимых для кодирования определенной аудио информации, используя контекст по умолчанию (например, состояние контекста, до которого контекст сбрасывается). Аудио кодер также настроен на сравнение первого числа битов и второго числа битов для решения, нужно ли предоставлять кодированную аудио информацию, соответствующую определенной аудио информации на основе несброшенного контекста или на основе контекста по умолчанию. Кодер также настроен сигнализировать результат указанного решения, используя служебную информацию. Этот вариант использования изобретения основан на открытии, что иногда трудно решить априори, является ли выгодным, с точки зрения битрейта, сброс контекста. Сброс контекста может привести к выбору отображения информации (для получения кодированной аудио информации из определенной входной аудио информации), которое лучше подходит (в плане обеспечения более низким битрейтом) для кодирования определенной аудио информации или подходит хуже (в плане обеспечения более высоким битрейтом) для кодирования определенной аудио информации. В некоторых случаях было установлено, что выгодно решать, следует ли сбросить контекст или нет, путем определения числа битов, необходимых для кодирования, используя оба варианта: со сбросом и без сброса контекста.
Дальнейшие варианты использования изобретения помогают создать метод для получения декодированной аудио информации на основе кодированной аудио информации и метод получения кодированной аудио информации на основе входной аудио информации.
Дальнейшие варианты использования изобретения помогают создать соответствующие компьютерные программы.
Дальнейшие варианты использования изобретения помогают создать аудио сигнал.
Краткое описание чертежей
Использования изобретения будут далее описаны со ссылкой на прилагаемые чертежи, на которых:
Фиг.1 показывает блок-схему аудио декодера в соответствии с одним из вариантов использования изобретения;
Фиг.2 показывает блок-схему аудио декодера в соответствии с другим вариантом использования изобретения;
Фиг.3а показывает графическое представление, в виде синтаксиса информации, входящей в состав потока канала частотной области, который может быть получен изобретенным аудио кодером и который может быть использован изобретенным аудио декодером;
Фиг.3b показывает графическое представление, в виде синтаксиса информации, представляющей арифметически кодированные спектральные данные потока канала частотной области на фиг.3а;
Фиг.4 показывает графическое представление, в виде синтаксиса арифметически кодированных данных, которые могут состоять из арифметически кодированных спектральных данных, представленных на фиг.3b, или данных преобразования кодированного возбуждения, представленных на фиг.11b;
Фиг.5 показывает алгоритм, определяющий элементы информации и справочные элементы, используемые в синтаксисе на фиг.3а, 3b и 4;
Фиг.6 показывает блок-схему последовательности процесса метода обработки звукокадра, который может быть использован в варианте осуществления изобретения;
Фиг.7 показывает графическое представление контекста для расчета состояния для выбора отображения информации;
Фиг.8 показывает алгоритм, определяющий элементы данных и справочные элементы, используемые для арифметического декодирования арифметически кодированной спектральной информации, например, с помощью алгоритма на фиг.9а до 9f;
Фиг.9а показывает псевдокод программы - в форме языка программирования Си - метода сброса контекста арифметического кодирования;
Фиг.9b показывает псевдокод программы метода отображения контекста арифметического декодирования между кадрами или окнами одинакового спектрального разрешения, а также между кадрами или окнами различного спектрального разрешения;
Фиг.9с показывает псевдокод программы метода получения значения переменной состояния из контекста;
Фиг.9d показывает псевдокод программы метода получения индекса сводной таблицы частот из значения, описывающего состояние контекста;
Фиг.9е показывает псевдокод программы метода арифметического декодирования арифметически кодированных спектральных значений;
Фиг.9f показывает псевдокод программы метода обновления контекста после/следующего за декодированием фрагмента спектральных значений;
Фиг.10а показывает графическое представление сброса контекста в присутствии звукокадров, имеющих связанные с ними "длинные окна" (одно длинное окно на звукокадр);
Фиг.10b показывает графическое представление сброса контекста для звукокадров, имеющих связанное с ними множество «коротких окон» (например, восемь коротких окон на звукокадр);
Фиг.10с показывает графическое представление сброса контекста при переходе между первым звукокадром, имеющим связанное с ним "длинное окно запуска", и звукокадром, имеющим связанное с ним множество «коротких окон»;
Фиг.11a показывает графическое представление, в виде синтаксиса информации, содержащейся в потоке канала линейного предсказания области;
Фиг.11b показывает графическое представление информации кодирования преобразования кодированного возбуждения, которое (кодирование) является частью потока канала линейного предсказания области на фиг.11а;
Фиг.11с и 11d показывают алгоритм, определяющий информационные элементы и справочные элементы, используемые в синтаксисе представления на фиг.11а и 11b;
Фиг.12 показывает графическое представление сброса контекста для звукокадров, содержащих кодирование возбуждения линейно-предсказанной области;
Фиг.13 показывает графическое представление сброса контекста на основе информации о группировании;
Фиг.14 показывает блок-схему аудио кодера согласно одному из вариантов использования изобретения;
Фиг.15 показывает блок-схему аудио кодера согласно другому варианту осуществления изобретения;
Фиг.16 показывает блок-схему аудио кодера согласно другому варианту осуществления изобретения;
Фиг.17 показывает блок-схему аудио кодера согласно еще одному варианту использования изобретения;
Фиг.18 показывает блок-схему последовательности процесса метода получения декодированной аудио информации согласно одному из вариантов использования изобретения;
Фиг.19 показывает блок-схему последовательности процесса метода получения кодированной аудио информации согласно одному из вариантов использования изобретения;
Фиг.20 показывает блок-схему последовательности процесса метода контекстно-зависимого арифметического декодирования фрагментов спектральных значений, который может использоваться в изобретенных аудио декодерах;
Фиг.21 показывает блок-схему последовательности процесса метода контекстно-зависимого арифметического кодирования фрагментов спектральных значений, который может использоваться в изобретенных аудио кодерах.
Подробное описание вариантов использования изобретения
1. Аудио декодер
1.1. Аудио декодер - основная реализация
Фиг.1 показывает блок-схему аудио декодера в соответствии с одним из вариантов использования изобретения. Аудио декодер 100 на фиг.1 настроен на получение энтропийно-кодированной аудио информации 110 и на представлении на ее основе декодированной аудио информации 112. Аудио декодер 100 содержит контекстно-зависимый энтропийный декодер 120, который настроен на декодирование энтропийно-кодированной аудио информации 110 в зависимости от контекста 122, который основан на ранее декодированной аудио информации в несброшенном состоянии. Энтропийный декодер 120 также настроен на выбор отображения информации 124 для получения декодированной аудио информации 112 из кодированной аудио информации 110 в зависимости от контекста 122. Контекстно-зависимый энтропийный декодер 120 также включает в себя контекстный ресеттер 130, который настроен на получение/прием служебной информации 132 из энтропийно-кодированной аудио информации 110 и на получение/производство на ее основе сигнала контекстного ресеттера 134. Контекстный ресеттер 130 настроен на сброс контекста 122 для выбора отображения информации 124 до контекста по умолчанию, который не зависит от ранее декодированной аудио информации, в ответ на соответствующую служебную информацию 132 из энтропийно-кодированной аудио информации 110.
Таким образом, в действии контекстный ресеттер 130 сбрасывает контекст 122 всякий раз, когда обнаруживает служебную информацию о контекстном сбросе
(например, флаг контекстного сброса), связанную с энтропийно-кодированной аудио информацией 110. Сброс контекста 122 до контекста по умолчанию может привести к тому, что отображение информации по умолчанию (например, по умолчанию Huffmann-кодовой книги, в случае Huffmann кодирования, и по умолчанию (сводной) частотной информации "cum_freq" в случае арифметического кодирования) выбирается для извлечения декодированной аудио информации 112 (например, декодированных спектральных значений a, b, c, d) из энтропийно-кодированной аудио информации 110 (включающей, например, кодированные спектральные значения a, b, c, d).
Соответственно, в несброшенном состоянии контекст 122 зависит от ранее декодированной аудио информации, например спектральных значений ранее декодированных звукокадров. Следовательно, выбор отображения информации (который осуществляется на основе контекста) для декодирования текущего звукокадра (или для декодирования одного или нескольких спектральных значений текущего звукокадра), как правило, зависит от декодированной аудио информации из ранее декодированного кадра (или ранее декодированного "окна").
Напротив, если контекст сбрасывается, влияние ранее декодированной аудио информации (например, декодированных спектральных значений) из ранее декодированных звукокадров на выбор отображения информации для декодирования текущего звукокадра устраняется. Таким образом, после сброса энтропийное декодирование текущего звукокадра (или по крайней мере некоторых спектральных значений), как правило, больше не зависит от аудио информации (например, спектральных значений) ранее декодированного звукокадра. Тем не менее, декодирование аудио-контента (например, одного или нескольких спектральных значений) текущего звукокадра может (или не может) включать некоторые зависимости от ранее декодированной аудио информации того же звукокадра.
Соответственно, рассмотрение контекста 122 может улучшить отображение информации 124, используемой для извлечения декодированной аудио информации 112 из кодированной аудио информация 110 в отсутствии условия для сброса. Контекст 122 может быть сброшен, если служебная информация 132 указывает на условие сброса для того, чтобы избежать обработки неподходящего контекста, который, как правило, приводит к увеличению битрейта. Соответственно, аудио декодер 100 делает возможным декодирование энтропийно-кодированной аудио информации с высокой эффективностью битрейта.
1.2. Использование изобретения для декодирования единого кодирования звука и речи
1.2.1. Обзор декодера
Далее будет представлен обзор аудио декодера, который делает возможным декодирование как кодированного в частотной области аудио-контента, так и кодированного в линейно-предсказанной области аудио-контента, тем самым делая возможным динамический (например, в отношении кадра) выбор наиболее подходящего режима кодирования. Следует отметить, что аудио декодер, описанный далее, сочетает декодирование в частотной области и декодирование в области линейного предсказания. Тем не менее, следует отметить, что функциональные возможности, которые описываются далее, могут использоваться отдельно в аудио декодере частотной области и аудио декодере области линейного предсказания.
Фиг.2 показывает аудио декодер 200, который настроен на прием кодированного аудио сигнала 210 и получение на его основе декодированного аудио сигнала 212. Аудио декодер 200 настроен на прием битового потока, представляющего кодированный аудио сигнал 210. Аудио декодер 200 состоит из демультиплексора битового потока 220, который настроен на извлечение различных элементов информации из битового потока, представляющего кодированный аудио сигнал 210. Например, мультиплексор битового потока 220 настроен на извлечение данных потока канала частотной области 222, включающих, например, так называемые "arith_data" и так называемый "arith_reset_flag", и на извлечение данных потока канала линейно-предсказанной области 224 (включающих, например, так называемые "arith_data" и так называемый "arith_reset_flag") из битового потока, представляющего кодированный аудио сигнал 200, в зависимости от того, что присутствует в битовом потоке. Кроме того, демультиплексор битового потока настроен на извлечение дополнительной аудио информации и/или служебной информации из битового потока, представляющего кодированный аудио сигнал 200, например управляющей информации о линейном предсказании области 226, управляющей информации о частотной области 228, информации о выборе области 230 и управляющей информации о последующей обработке 232. Аудио декодер 200 также включает в себя энтропийный декодер / контекстный ресеттер 240, который настроен на энтропийное декодирование энтропийно-кодированных спектральных значений частотной области или энтропийно-кодированных спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения. Энтропийный декодер / контекстный ресеттер 240 иногда также называется «бесшумным декодером» или «арифметическим декодером», потому что он обычно выполняет декодирование без потерь. Энтропийный декодер / контекстный ресеттер 240 настроен на получение декодированных спектральных значений в частотной области 242 на основе данных потока канала частотной области 222 или на получение спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения (transform-coded-excitation TCX) 244 на основе данных потока канала области линейного предсказания 224. Таким образом, энтропийный декодер / контекстный ресеттер 240 может быть сконфигурирован для использования как для декодирования спектральных значений в частотной области, так и для декодирования спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения, в зависимости от того, что содержится в битовом потоке текущего кадра.
Аудио декодер 200 также включает в себя реконструкцию сигнала во временной области. В случае кодирования частотной области реконструкция сигнала во временной области может, например, включать обратный квантователь 250, который принимает декодированные спектральные значения в частотной области, полученные энтропийным декодером 240, и может представлять на его основе обратно квантованные в частотной области декодированные спектральные значения к реконструкции аудио сигнала в частотной области к временной области 252. Реконструкция аудио сигнала в частотной области к временной области может быть настроена на прием управляющей информации в частотной области 228 и, по желанию, дополнительной информации (как, например, управляющей информации). Реконструкция аудио сигнала в частотной области к временной области 252 может быть настроена для получения, в качестве выходного сигнала, аудио сигнала частотной области, кодированного во временной области 254. Что касается области линейного предсказания, аудио декодер 200 включает в себя реконструкцию аудио сигнала в линейно-предсказанной области к временной области 262, которая настроена на прием декодированных спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения 244, управляющей информации линейно-предсказанной области 226 и, при необходимости/по выбору, дополнительной информации линейно-предсказанной области (например, коэффициенты линейных моделей прогнозирования или их кодированную версию), и на получение на их основе аудио сигнала линейно-предсказанной области, кодированного во временной области 264.
Аудио декодер 200 также включает в себя селектор 270 для выбора между аудио сигналом частотной области, кодированным во временной области 254, и аудио сигналом линейно-предсказанной области, кодированным во временной области 264 в зависимости от информации о выборе области 230, чтобы определить, является ли декодированный аудио сигнал 212 (или его временная часть) основанным на аудио сигнале частотной области, кодированном во временной области 254, или на аудио сигнале линейно-предсказанной области, кодированном во временной области 264. Переход между областями может осуществляться при помощи селектора 270 для получения выходного сигнала селектора 272. Декодированный аудио сигнал 212 может быть равен аудио сигналу селектора 272, или предпочтительно может быть извлечен из аудио сигнала селектора 272 с помощью постпроцессора аудио сигнала 280. Постпроцессор аудио сигнала 280 может принимать во внимание управляющую информацию о постобработке 232, предоставленную демультиплексором битового потока 220.
Подводя итог сказанному выше, нужно сказать, что аудио декодер 200 может производить декодированный аудио сигнал 212 на основе либо данных потока канала частотной области 222 (в сочетании с возможной дополнительной управляющей информацией), либо на основе данных потока канала линейно-предсказанной области 224 (в сочетании с дополнительной управляющей информацией), причем аудио декодер 200 может переключаться между частотной областью и линейно-предсказанной областью с помощью селектора 270. Аудио сигнал частотной области, кодированный во временной области 254, и аудио сигнал линейно-предсказанной области, кодированный во временной области 264, могут быть созданы независимо друг от друга. Однако тот же самый энтропийный декодер / контекстный ресеттер 240 может быть применен (возможно, в сочетании с различной, зависящей от области информацией отображения, например сводной таблицей частот) для извлечения декодированных спектральных значений в частотной области 242, которые формируют основу аудио сигнала частотной области, кодированного во временной области 254, и для извлечения декодированных спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения 244, которые формируют основу аудио сигнала линейно-предсказанной области, кодированного во временной области 264.
Далее будет представлено подробное описание, касающееся предоставления декодированных спектральных значений в частотной области 242 и предоставления декодированных спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения 244.
Следует отметить, что подробности, касающиеся извлечения аудио сигнала частотной области, кодированного во временной области 254, из декодированных спектральных значений в частотной области 242 можно найти в международном стандарте ISO / IEC 14496-3:2005, часть 3: аудио, часть 4: общее кодирование звука (GA)-ААС, Twin VQ, BSAC, и документов, перечисленных в нем.
Следует также отметить, что подробности, касающиеся вычисления аудио сигнала линейно-предсказанной области, кодированного во временной области 264, на основе декодированных спектральных значений в линейно-предсказанной области со стимулом преобразования кодированного возбуждения 244 можно найти, например, в международных стандартах 3GPP TS 26,090, 3GPP TS 26,190 и 3GPP TS 26,290.
Указанные стандарты также содержат информацию о некоторых символах, используемых далее.
1.2.2. Декодирование потока канала в частотной области
Далее будет описано, как декодированные спектральные значения в частотной области 242 можно извлечь из данных потока канала частотной области, и как изобретенный контекстный ресеттер участвует в этих расчетах.
1.2.2.1. Структуры данных потока канала частотной области
Далее будут описаны соответствующие структуры данных потока канала в частотной области со ссылкой на фиг.3а, 3b, 4 и 5.
Фиг.3а показывает графическое представление в виде таблицы синтаксиса потока канала в частотной области. Как видно, поток канала в частотной области может включать в себя "global_gain" информацию. Кроме того, поток канала в частотной области может включать в себя данные о коэффициенте масштабирования ("scale_factor_data"), которые определяют коэффициенты масштабирования для различных бункеров частоты. Что касается общего коэффициента усиления (global gain) и данных о коэффициенте масштабирования, и их использования, делается ссылка на международный стандарт ISO / IEC 14496-3 (2005), часть 3, подчасть/ подпункт 4, а также документы, перечисленные в нем.
Поток канала частотной области может также включать арифметически кодированные спектральные данные ("ac_spectral_data"), которые будут подробно описаны далее. Следует отметить, что поток канала частотной области может содержать дополнительную необязательную информацию, такую как информацию о шумозаполнении, сведения о конфигурации, информацию о трансформации времени и речи и информацию о временном ограничении шума/ фильтрации и преобразовании шума, которые не имеют отношение к данному изобретению.
Далее будут представлены подробные сведения об арифметически кодированных спектральных данных со ссылкой на фиг.3b и 4. Как видно на фиг.3b, которая показывает графическое представление в виде таблицы синтаксиса арифметически кодированных спектральных данных "ac_spectral_data," арифметически кодированные спектральные данные включают флаг сброса контекста "arith_reset_flag" для сброса контекста для арифметического декодирования. Кроме того, арифметически кодированные спектральные данные включают один или несколько блоков арифметически кодированных данных "arith_data." Следует отметить, что звукокадр, который представлен/обозначен элементом синтаксиса "fd_channel_stream", может включать одно или несколько "окон", где количество окон определяется переменной "num_windows." Следует отметить, что один набор спектральных значений (также именуемых «спектральными коэффициентами») связан с каждым из окон звукокадра, так, что звукокадр, включающий num_windows окон, содержит num_windows наборов спектральных значений. Подробно о концепции с множеством окон (и множеством наборов спектральных значений) в пределах одного звукокадра можно узнать из, например, международного стандарта ISO / IEC 14493-3 (2005), часть 3, подчасть/подпункт 4.
Вновь обращаясь к фиг.3, можно сделать вывод о том, что арифметически кодированные спектральные данные "ac_spectral_data" из звукокадра, которые включены в поток канала частотной области "fd_channel_stream", содержат один флаг сброса контекста "arith_reset_flag" и один блок арифметически кодированных данных "arith_data", если одно окно связано со звукокадром, представленным в текущем потоке канала частотной области. В противоположность этому, арифметически кодированные спектральные данные кадра включают единственный флаг сброса контекста "arith_reset_flag" и множество блоков арифметически кодированных данных "arith_data", если текущий звукокадр (связанный с потоком канала частотной области) состоит из множества окон (т.е. num_windows окон).
Теперь обратимся к фиг.4, структура блока арифметически кодированных данных "arith_data" будет описана со ссылкой на фиг.4, которая показывает графическое представление синтаксиса арифметически кодированных данных "arith_data". Как видно из фиг.4, арифметически кодированные данные включают арифметически кодированные данные, например lg / 4 кодированных фрагмента данных (где lg является числом спектральных значений текущего звукокадра или текущего окна). Для каждого фрагмента данных арифметически кодированный индекс группы "acod_ng" включается в арифметически кодированные данные "arith_data". Индекс группы ng фрагмента квантованных спектральных значений a,b,c,d, к примеру, арифметически кодирован (на стороне кодера) в зависимости от сводной таблицы частот, которая выбирается в зависимости от контекста, о чем будет сказано позже. Индекс группы ng фрагмента данных арифметически кодирован, при этом так называемый «арифметический выход» ("ARITH_ESCAPE") может быть использован для того, чтобы расширить диапазон возможных значений.
Кроме того, для групп из 4 фрагментов данных, имеющих кардинальное число больше одного, арифметическое кодовое слово "acod_ne" для декодирования индекса ne фрагмента данных в группе ng может быть включено в арифметически кодированные данные "arith_data." Кодовое слово "acod_ne" может быть кодировано, например, в зависимых от контекста.
Кроме того, один или несколько арифметически кодированных кодовых слов "acod_r", кодирующих один или более наименее значимых битов значений a, b, c, d во фрагменте данных, может быть включено в арифметически кодированные данные "arith_data".
Подводя итог, арифметически кодированные данные "arith_data" содержат одно (или в присутствии арифметической управляющей последовательности для устройства вывода/escape-последовательности более чем одно) арифметическое кодовое слово "acod_ng" для кодирования индекса группы ng с учетом сводной таблицы частот, имеющих индекс pki. В зависимости от кардинального числа группы, обозначенной индексом группы ng, арифметически кодированные данные могут также включать арифметическое кодовое слово "acod_ne" для кодирования индекса элемента ne. Арифметически кодированные данные могут также содержать одно или несколько арифметических кодовых слов для кодирования одного или более наименее важных битов.
Контекст, который определяет индекс (например, pki) по сводной таблице частот, используемой для кодирования / декодирования арифметических кодовых слов "acod_ng", основан на данных контекста q[0], q[1], qs, не показанных на фиг.4, но описанных ниже. Контекстная информация q[0], q[1], qs либо основывается на значении по умолчанию, если флаг сброса контекста "arith_reset_flag" активен до начала кодирования / декодирования кадра или окна, либо основывается на ранее кодированных / декодированных спектральных значениях (например, значения a, b, c, d) из предыдущего окна (если текущий кадр содержит окно, предшествующее в настоящем рассматриваемому окну) или предыдущего кадра (если текущий кадр содержит только одно окно, или если рассматривается первое в пределах текущего кадра). Подробное описание определения контекста можно увидеть в разделе псевдокода с надписью "получить межоконную контекстную информацию obtain inter-window context information" на фиг.4, также сделана ссылка на определение процедур "arith_reset_context" и "arith_map_context", подробно описанных со ссылкой на фиг.9а и 9d ниже. Следует также отметить, что части псевдокода с надписью "вычислить состояние контекста" и "получить индекс pki сводной таблицы частот" служат для извлечения индекса pki для выбора "отображения информации" в зависимости от контекста, и могут быть заменены другими функциями для выбора "отображения информации" или "правила отображения" в зависимости от контекста. Функции "arith_get_context" и "arith_get_pk" будут описаны более подробно ниже.
Было установлено, что инициализация контекста, которая описана в разделе "получить межоконную контекстную информацию", проводится один раз (и предпочтительно только один раз) на звукокадр (если звукокадр содержит только одно окно) или один раз (и предпочтительно только один раз) на окно (если текущий звукокадр состоит из более чем одного окна).
Соответственно, сброс всей контекстной информации q[0], q[1], qs (или альтернативная инициализация контекстной информации q[0] на основе декодированных спектральных значений предыдущего кадра (или предыдущего окна)) лучше проводить только один раз на блок арифметически кодированных данных (т.е. только один раз на окно, если настоящий кадр содержит только одно окно, или только один раз на окно, если настоящий кадр состоит из более чем одного окна).
В противоположность этому, контекстная информация q[1] (которая основывается на ранее декодированных спектральных значениях текущего кадра или окна) обновляется после завершения декодирования одного фрагмента данных спектральных значений а, b, с, d, например, как это определено в соответствии с процедурой "arith_update_context".
Более подробно о полезных нагрузках "спектрального бесшумного кодера" (то есть для кодирования арифметически кодированных спектральных значений) можно узнать из определений, приведенных в таблицах на фиг.5.
Подводя итог, коэффициенты спектра (например, а, b, с, d) и из "области линейного предсказания" кодированного сигнала 224, и из "частотной области" кодированного сигнала 222 являются скалярными квантованными, а затем бесшумно кодированными с помощью адаптивно контекстно-зависимого арифметического кодирования (например, кодера, предоставляющего энтропийно-кодированный аудио сигнал 210). Квантованные коэффициенты (например, а, b, с, d) собраны во фрагменты, состоящие из 4-х частей, перед передачей (при помощи кодера) от самых низких к самым высоким частотам. Каждый фрагмент разделен на наиболее значимые 3-битные (один бит для знака и 2 для амплитуды) плоскости, и остальные наименее значимые битовые плоскости. Наиболее значимые 3-битные плоскости кодируются в соответствии с их окружением (т.е. с учетом "контекста") с помощью индекса группы ng и индекс элемента ne. Остальные менее значимые битовые плоскости энтропийно-кодируются без учета контекста. Индексы ng и ne и менее значимые битовые плоскости образуют сэмплы арифметического кодера (которые оцениваются энтропийным декодером 240). Подробная информация относительно арифметического кодирования будет дана ниже в разделе 1.2.2.2.
1.2.2.2. Метод декодирования потока канала в частотной области
Далее будут описаны функциональные средства контекстно-зависимого энтропийного декодера 120, 240, включающего контекстный ресеттер 130 со ссылками на фиг.6, 7, 8, 9а-9f и 20.
Следует отметить, что функция контекстно-зависимого энтропийного декодера состоит в восстановлении (декодировании) энтропийно-декодированной (предпочтительно арифметически декодированной) аудио информации (например, спектральных значений а, b, с, d представления аудио сигнала в частотной области, или представления аудио сигнала в линейно-предсказанной области с преобразованием кодированного возбуждения) на основе энтропийно кодированной (предпочтительно арифметически кодированной) аудио информации (например, кодированных спектральных значений). Контекстно-зависимой энтропийный декодер (содержащий контекстный ресеттер), например, может быть настроен для декодирования спектральных значений а, b, с, d, кодированных, как описывает синтаксис, показанный на фиг.4.
Следует также отметить, что синтаксис, показанный на фиг.4, может рассматриваться как правило декодирования, особенно в сочетании с определениями на фиг.5, 7, 8 и 9a-9f и 20, когда декодер настроен на декодирование информации, кодированной в соответствии с фиг.4.
Далее со ссылкой на фиг.6, где представлена блок-схема последовательности процесса упрощенного алгоритма декодирования для обработки звукокадра или окна в звукокадре, будет описано декодирование. Метод 600 на фиг.6 может включать шаг 610 получения межоконной контекстной информации. Для этой цели можно проверить, установлен ли флаг контекстного сброса "arith_reset_flag" для текущего окна (или текущего кадра, если кадр состоит из только одного окна). Если флаг контекстного сброса установлен, контекстная информация может быть сброшена на шаге 612, например, выполняя функцию "arith_reset_context", которая описывается ниже. Часть контекстной информации, описывающей кодированные значения предыдущего окна (или предыдущего кадра), может быть установлена в значение по умолчанию (например, 0 или -1) в шаге 612. Напротив, если будет обнаружено, что флаг контекстного сброса не установлен для окна, контекстная информации из предыдущего кадра может быть скопирована, или отображена для того, чтобы использовать ее для определения контекста для декодирования арифметически кодированных спектральных значений текущего окна. Шаг 614 может соответствовать выполнению функции "arith_map_context". При выполнении указанной функции контекст может быть отображен, даже если текущий кадр и предыдущий кадр содержат разные спектральные разрешения (хотя эта функция не строго обязательна).
Следовательно, множество арифметически кодированных спектральных значений (или фрагментов данных таких значений) может быть декодировано путем выполнения шагов 620, 630, 640 один или несколько раз. На шаге 620 отображение информации (например, кодовой книги Huffmann, или сводной таблицы частот "cum_freq") выбирается на основе контекста, как определено на шаге 610 (и, возможно, обновлено на шаге 640). Шаг 620 может включать в себя одно- или многошаговый метод для определения отображения информации. Например, шаг 620 может включать в себя шаг 622 для вычисления состояния контекста на основе контекстной информации (например, q[0], q[1]). Вычисление состояния контекста, например, может быть выполнено функцией "arith_get_context", которая описывается ниже. Вспомогательное отображение может быть выполнено по желанию (например, как показано на части псевдокода с надписью "вычислить состояние контекста" на фиг.4). Кроме того, шаг 620 может включать содержать подшаг 624 для отображения состояния контекста (например, при помощи переменной t, как показано в синтаксисе на фиг.4) к индексу (например, обозначенному как "pki") в отображении информации (например, указывая строку или столбец в сводной таблице частот). С этой целью, например, возможно оценить функцию "arith_get_pk". Подводя итог, шаг 620 позволяет отобразить текущий контекст (q[0],q[1]) с индексом (например, pki), описывающим, какое отображение информации (из множества дискретных наборов отображения информации) следует использовать для энтропийного декодирования (например, арифметического декодирования). Метод 600 также включает в себя шаг 630 энтропийного декодирования кодированной аудио информации (например, спектральных значений а, b, с, d) с помощью выбранного отображения информации (например, одной сводной таблицы частот из множества сводных таблиц частот) для получения новой декодированной аудио информации (например, спектральных значений а, b, с, d). Для энтропийного декодирования аудио информация может быть использована функция "arith_decode", подробно описанная ниже.
Далее контекст может быть обновлен в шаге 640 с помощью /новой декодированной аудио информации (например, с помощью одного или нескольких спектральных значений а, b, с, d). Например, часть контекста, представляющая ранее кодированную аудио информацию настоящего кадра или окна (например, q[1]), может быть обновлена. Для этой цели может быть использована функция "arith_update_context", подробно описанная ниже.
Как упоминалось выше, шаги 620, 630, 640 могут быть повторены.
Энтропийное декодирование кодированной аудио информации может включать использование одного или более арифметических кодовых слов (например, "acod_ng", "acod_ne" и/или "acod_r"), входящих в состав энтропийно кодированной аудио информации 222, 224, например, как представлено на фиг.4.
Далее описан пример контекста, рассматриваемого для расчета состояния со ссылкой на фиг.7. Можно сказать, что спектральное бесшумное кодирование (и соответствующее спектральное бесшумное декодирование) используется (например, в кодере) для дальнейшего сокращения избыточности квантованного спектра (и используется в декодере для восстановления квантованного спектра). Схема бесшумного кодирования спектра основывается на арифметическом кодировании в сочетании с динамически адаптированным контекстом. Бесшумное кодирование устанавливается квантованными спектральными значениями (например, а, b, с, d) и использует зависимые от контекста сводные таблицы частот (например, cum_freq), полученные из, например, 4-х ранее декодированных смежных фрагментов. Здесь учитывается смежность как во времени, так и по частоте, как показано на фиг.7. Сводные таблицы частот (которые выбираются в зависимости от контекста) потом используются арифметическим кодером для создания двоичного кода переменной длины (а также арифметическим декодером для декодирования двоичного кода переменной длины).
Обратимся к фиг.7, на которой можно увидеть, что контекст для декодирования фрагмента данных для декодирования 710 основывается на фрагменте 720, уже декодированном и смежном по частоте к фрагменту 710, предназначенному для декодирования, и связанном с тем же самым звукокадром или окном, как и фрагмент 710 для декодирования. Кроме того, контекст фрагмента данных для декодирования 710 также основывается на трех дополнительных фрагментах 730а, 730b, 730с, уже декодированных и связанных с звукокадром или окном, предшествующим звукокадру или окном 4-фрагмента данных 710 для декодирования.
Что касается арифметического кодирования и арифметического декодирования, следует отметить, что арифметический кодер производит двоичный код для данного набора символов (например, спектральных значений а, b, с, d) и их соответствующих вероятностей (как определено, например, сводными таблицами частоты). Двоичный код генерируется путем отображения вероятностного интервала, в котором лежит набор символов (например, а, b, с, d), по кодовому слову. И наоборот, набор сэмплов (например, a, b, с, d) извлекается из двоичного кода путем обратного отображения, в котором учитывается вероятность сэмплов (например, а, b, с, d) (например, путем выбора отображения информации, как сводное распределение частот, на основе контекста). Далее, со ссылкой на фиг.9a-9f будет описан процесс декодирования, то есть процесс арифметического декодирования, которое может быть выполнено контекстно-зависимым энтропийным декодером 120, или энтропийным декодером / контекстным ресеттером 240, и которое уже было описано со ссылкой на фиг.6.
Для этой цели делается ссылка на определения, указанные в таблице на фиг.8. В таблице на фиг.8 даются определения данных, переменных и справочных элементов, используемых в псевдопрограммных кодах на фиг.9a-9f. Внимание обращается также к определениям на фиг.5 и в вышеуказанных описаниях.
Что касается процесса декодирования, можно сказать, что фрагменты квантованных спектральных коэффициентов бесшумно кодированы (кодером) и передаются (через канал передачи или запоминающее средство хранения между кодером и декодером), начиная с коэффициентов самых низких частот и, нарастая, до коэффициентов самых высоких частот.
Коэффициенты из перспективного звукового кодирования Advanced Audio Coding (ААС) (т.е. коэффициенты в данных потока канала частотной области) хранятся в массиве "x_ac_quant[g][win][sfb][bin]", а порядок передачи кодового слова бесшумного кодирования такой, что, когда они декодируются в порядке поступления и хранятся в массиве, [bin] является наиболее быстро увеличивающимся индексом и [g] является наиболее медленно увеличивающимся индексом. В кодовом слове порядок декодирования следующий - а, b, с, d.
Коэффициент от преобразования кодированного возбуждения transform-coded-excitation (TCX) (например, данные потока канала линейно-предсказанной области) хранятся непосредственно в массиве "x_tcx_mvquant[wm][bin]", а порядок передачи кодовых слов бесшумного кодирования такой, что, когда они декодируются в порядке поступления и хранятся в массиве, [bin] является наиболее быстро увеличивающимся индексом и [g] является наиболее медленно увеличивающимся индексом. В кодовом слове порядок декодирования следующий: а, b, с, d.
Во-первых, оценивается флаг "arith_reset_flag". Флаг "arith_reset_flag" определяет, должен ли контекст быть сброшен. Если флаг имеет значение ИСТИНА, то вызывается функция "arith_reset_context", которая показана в представлении псевдопрограммного кода на фиг.9а. В противном случае, когда "arith_reset_flag" имеет значение ЛОЖЬ, осуществляется отображение между прошлым контекстом (т.е. контекстом, определяемым декодированной аудио информацией из ранее декодированного окна или кадра) и текущим контекстом. Для этой цели вызывается функция "arith_map_context", которая представлена в псевдопрограммном коде на фиг.9b (тем самым позволяя повторное использование контекста, даже если предыдущий кадр или окно содержат различное спектральное разрешение). Тем не менее, следует отметить, что вызов функции "arith_map_context" следует рассматривать как опциональный.
Бесшумный декодер (или энтропийный декодер) выводит фрагменты данных, состоящие из отмеченных квантованных спектральных коэффициентов. Во-первых, состояние контекста рассчитывается на основе четырех ранее декодированных групп "окружающих" (или, точнее, соседних) фрагментов для декодирования (как показано на фиг.7 при соответствующей цифре 720, 730a, 730b, 730с). Состояние контекста задается функцией "arith_get_context ()", которая представлена в псевдопрограммном коде на фиг.9с. Как видно, функция "arith_get_context" выделяет значение состояния контекста s контексту в зависимости от значений "v" (как определено в псевдопрограммном коде на фиг.9f).
Как только состояние s известно, группа, к которой принадлежит самая значимая 2-битовая плоскость фрагмента данных, декодируется с помощью функции "arith_decode ()", в которую подается сигнал (или которая настроена на использование) соответствующей (выбранной) сводной таблицы частот, соответствующей состоянию контекста. Соответствие устанавливается функцией "arith_get_pk ()", которая представлена в псевдопрограммном коде на фиг.9d.
Функции "arith_get_context" и "arith_get_pk" позволяют получить индекс сводной таблицы частот pki на основе контекста (а именно q[0][1+i], q[1][1+i-1], q[s][1+i-1], q[0][1+i+1]). Таким образом, можно выбрать отображение информации (а именно одну из сводных таблиц частот) в зависимости от контекста.
Тогда (как только сводная таблица частот выбрана) функция "arith_decode ()" вызывается со сводной таблицей частот, соответствующей индексу, полученному с помощью "arith_get_pk ()". Арифметический декодер применяет целые числа и осуществляет масштабирование. Псевдокод Си языка, изображенный на фиг.9е, описывает используемый алгоритм.
Обращаясь к алгоритму "arith_decode", показанному на фиг.9е, следует отметить, что предполагается, что соответствующая сводная таблица частот выбирается на основе контекста. Следует также отметить, что алгоритм "arith_decode" проводит арифметическое декодирование с использованием битов (или битовых последовательностей) "acod_ng", "acod ne" и "acod r", определенных на фиг.4. Кроме того, следует отметить, что алгоритм "arith_decode" может использовать сводную таблицу частот "cum_freq", определенную контекстом, для декодирования первого появления битовой последовательности "acod_ng", связанной с фрагментом данных. Однако дополнительные появления битовых последовательностей "acod_ng" в тот же самый фрагмент (которые могут следовать за ним и arith_escape-последовательности), например, могут быть декодированы с использованием различных сводных таблиц частот или даже сводной таблицы частот по умолчанию. Кроме того, следует отметить, что декодирование битовых последовательностей "acod_ne" и "acod_r" может быть выполнено с использованием соответствующей сводной таблицы частот, которая может не зависеть от контекста. Таким образом, чтобы подвести итог, контекстно-зависимая сводная таблица частот может применяться (если контекст не сбрасывается так, что по достижению состояния сброса контекста используется сводная таблица частот по умолчанию) для декодирования арифметического кодового слова "acod_ng" для декодирования индекса группы (по крайней мере, пока не признается арифметический выход /escape).
Это можно увидеть при рассмотрении графического представления синтаксиса "arith_data", которое представлено на фиг.4, если смотреть в сочетании с псевдопрограммным кодом функции "arith_decode", приведенной на фиг.9е. Понимание декодирования может быть достигнуто на основе понимания синтаксиса "arith_data".
В то время как декодированный индекс группы ng является символом "выхода/бегства" "ARITH_ESCAPE," дополнительный индекс группы ng декодируется и переменная lev увеличивается в два раза. Как только декодированный индекс группы не является символом "выхода/бегства" "ARITH_ESCAPE," количество элементов, mm, в пределах группы и смещение группы, og, выводятся путем поиска в таблице "dgroups []":
mm=dgroups[nq]&255
og=dgroups[nq]>>8
Индекс элемента ne затем декодируется с помощью вызова функции "arith_decode ()" с сводной таблицей частот (arith_cf_ne+((mm*(mm-1))>>1)[]. Как только индекс элемента декодируется, наиболее значимая 2-битовая плоскость фрагмента данных может быть получена из таблицы "dgvector []:"
a=dgvectors [4*(og+ne)]
b=dgvectors [4*(og+ne)+1]
c=dgvectors[4*(og+ne)+2]
d=dgvectors[4*(og+ne)+3]
Остальные битовые плоскости (например, менее значимые биты) затем декодируются от наиболее значимого до наименее значимого уровня вызовом функции "arith_decode ()" lev раз с сводной таблицей частот "arith_cf_r []" (которая является предопределенной сводной таблицей частот для декодирования наименее значимых битов, и которая может указывать равные частоты битовых комбинаций). Декодированная битовая плоскость r позволяет уточнить декодированный фрагмент следующим образом:
а=(а<<1)|(r&1)
b=(b<<l)|((r>>1)&1)
с=(с<<1)|((r>>2)&1)
d=(d<<l)|(r>>3)
Как только фрагмент (а, b, с, d) полностью декодирован, контекстные таблицы q и qs обновляются с помощью вызова функции "arith_update_context ()", которая представлена в псевдопрограммном коде на фиг.9f.
Как видно из фиг.9f, контекст, представляющий ранее декодированные спектральные значения текущего окна или кадра, а именно q[l], обновляется (например, каждый раз, когда новый фрагмент спектральных значений декодируется). Кроме того, функция "arith_update_context" также включает в себя раздел псевдокода для обновления истории контекста qs, которое выполняется только один раз на кадр или окно.
Функция "arith_update_comext" включает в себя две основные функциональности, а именно обновление части контекста (например, q[l]), представляющие ранее декодированные спектральные значения текущего кадра окна, как только новое спектральное значение текущего кадра или окна декодируется, а также обновление истории контекста (например, qs) в ответ на завершение декодирования кадра или окна, так, что история контекста может быть использована для получения части контекста (например, q[0]), которая представляет "старый" контекст при декодировании следующего кадра или окна.
Как можно увидеть на представлении псевдопрограммного кода на фиг.9а и 9b, история контекста (например, qs) либо отбрасывается, а именно в случае сброса контекста, или используется для получения "старой" части контекста (например, q[0]), a именно, если нет сброса контекста при переходе к арифметическому декодированию следующего кадра или окна.
Далее будет кратко изложен метод арифметического декодирования со ссылкой на фиг.20, которая иллюстрирует блок-схему воплощения схемы декодирования. На шаге 2005, соответствующем шагу 2105, контекст извлекается на основе t0, t1, t2 и t3. На шаге 2010 первый уровень снижения lev0 рассчитывается из контекста, и переменная lev устанавливается на lev0. На следующем шаге 2015 группа ng читается из битового потока, и распределение вероятностей для декодирования ng выводится из контекста. На шаге 2015 группа ng может быть декодирована из битового потока далее. На шаге 2020 определяется, равна ли ng группа 544, что соответствует значению выхода/побега. Если это так, переменная lev может быть увеличена на 2, прежде чем вернуться к шагу 2015.
В случае, если эта ветвь используется в первый раз, то есть, если lev=lev0, распределение вероятностей соответственно контексту может быть адаптировано, соответственно, отброшено, если ветвь используется не в первый раз, в соответствии с описанным выше механизмом адаптации контекста. В случае, если индекс группы ng не равен 544 на шаге 2020, в следующем шаге 2025 будет определено, является ли число элементов в группе больше 1, и если да, то на шаге 2030 элемент группы ne читается и декодируется из битового потока, предполагая равномерное распределение вероятностей. Индекс элемента ne извлекается из битового потока с помощью арифметического кодирования и равномерного распределения вероятностей.
На шаге 2035 буквенное кодовое слово (a, b, c, d) извлекается из ng и ne, например, с помощью поиска в таблицах, например, обратимся к dgroups [ng] и acod_ne [ne]. На шаге 2040 для всех lev отсутствующих битовых плоскостей плоскости считываются из битового потока с помощью арифметического кодирования и предполагая равномерное распределение вероятностей. Битовые плоскости затем можно добавить в конец к (a, b, c, d) путем сдвига (a, b, c, d) влево и добавления битовой плоскости bitplane bp: ((a, b, c, d)<<=l)|=bp. Этот процесс может повторяться lev раз. Наконец, на шаге 2045 может быть предоставлен 4-фрагмент q (n, m), т.е. (a, b, c, d).
1.2.2.3 Процесс декодирования
Далее будет кратко изложен ход декодирования в различных сценариях с ссылкой на фиг.10а-10c.
Фиг.10а показывает графическое представление хода декодирования звукокадра, кодированного в частотной области с помощью так называемого "длинного окна." Что касается кодирования, можно обратиться к международному стандарту IOC/IEC 14493-3(2005), часть 3, подраздел 4. Как можно увидеть, аудио-контенты первого кадра 1010 тесно связаны, а сигналы временной области, реконструированные для звукокадров 1010, 1012, перекрываются и накладываются (как определено в указанном стандарте). Один набор спектральных коэффициентов связан с каждым кадром 1010, 1012, как известно из вышеупомянутого стандарта. Кроме того, новый 1-битовый флаг сброса контекста ("arith_reset_flag") связан с каждым кадром 1010, 1012. Если флаг сброса контекста, связанный с первым кадром 1010, включен, контекст сбрасывается (например, по алгоритму, показанному на фиг.9а) до арифметического декодирования набора спектральных значений первого звукокадра 1010. Аналогичным образом, если 1-битный флаг сброса контекста второго звуко кадра 1012 включен, то контекст сбрасывается, чтобы не зависеть от спектральных значений первого звукокадра 1010, до декодирования спектральных значений второго звукокадра 1012. Таким образом, оценивая флаг сброса контекста, можно сбросить контекст для декодирования второго звукокадра 1012, хотя первый звукокадр 1010 и второй звукокадр 1012 тесно связаны между собой в том, что оконные аудио сигналы временной области, извлеченные из спектральных значений указанных звукокадров 1010, 1012, перекрываются и накладываются, хотя одинаковые оконные формы связаны с первым и вторым звукокадрами 1010,1012.
Обратимся к фиг.10b, которая показывает графическое представление декодирования звукокадра 1040, имеющего связанное с ним множество (например, 8) коротких окон, для этого случая будет описан сброс контекста. Опять же здесь есть один 1-битовый флаг сброса контекста, связанный со звукокадром 1040, даже несмотря на множество коротких окон, связанных со звукокадром 1040. Что касается коротких окон, следует отметить, что один набор спектральных значений связан с каждым коротким окном, так, что звукокадр 1040 включает множество из (например, 8) наборов (арифметически кодированных) спектральных значений. Однако, если флаг сброса контекста активен, контекст будет сброшен перед декодированием спектральных значений первого окна 1042а звукокадра 1040 и между декодированием спектральных значений любых последующих кадров 1042b-1042h звукокадра 1040. Таким образом, контекст сбрасывается между декодированием спектральных значений двух последующих окон, аудио-контент которых тесно связан между собой (они накладываются друг на друга и добавляются), и хотя последующие окна (например, окна 1042а, 1042b) содержат идентичные формы окон, связанные с ними. Кроме того, следует отметить, что контекст сбрасывается во время декодирования одного звукокадра (т.е. между декодированием различных спектральных значений одного звукокадра). Кроме того, следует отметить, что однобитовый флаг сброса контекста вызывает несколько сбросов контекста, если кадр 1040 содержит множество коротких окон 1042а-1042h.
Обратимся теперь к фиг.10с, которая показывает графическое представление сброса контекста в присутствии перехода от звукокадров, связанных с длинными окнами (звукокадр 1070 и предыдущие звукокадры), к одному или нескольким звукокадрам, связанным с множеством коротких окон (звукокадр 1072). Следует отметить, что флаг сброса контекста позволяет сигнализировать о необходимости сброса контекста независимо от формы окна. Например, энтропийный декодер может быть настроен для получения спектральных значений первого окна 1074а звукокадра 1072, используя контекст, который основан на спектральных значениях звукокадра 1070, даже если форма окна "окна" (или, точнее, части кадра или "подкадра", связанного с коротким окном) 1074а существенно отличается от формы окна длинного окна звукокадра 1070, и даже не смотря на то, что спектральное разрешение короткого окна 1074а обычно меньше, чем спектральное разрешение (разрешение по частоте) длинного окна звукокадра 1070. Это можно получить отображением контекста между окнами (или кадрами) различного спектрального разрешения, которое описывается псевдопрограммным кодом на фиг.9b. Тем не менее, энтропийный декодер в то же время способен сбрасывать контекст между декодированием спектральных значений длинного окна звукокадра 1070 и спектральных значений первого короткого окна 1074а звукокадра 1072, если обнаружится, что флаг сброса контекста звукокадра 1072 активен. Сброс контекста в этом случае осуществляется по алгоритму, который был описан со ссылкой на псевдопрограммный код на фиг.9а.
Подводя итог сказанному выше, оценка флага сброса контекста придает изобретенному энтропийному декодеру очень большую гибкость. В предпочтительном варианте использования изобретения энтропийный декодер способен:
- использовать контекст, который основан на ранее декодированном кадре или окне различных спектральных разрешений при кодировании (спектральных значений) текущего кадра или окна;
- выборочно сбрасывать контекст, в ответ на флаг сброса контекста, между декодированием (спектральных значений) кадров или окон различной формы окна и/или различных спектральных разрешений;
- выборочно сбрасывать контекст, в ответ на флаг сброса контекста, между декодированием (спектральных значений) кадров или окон, имеющих одинаковую форму окна и/или спектральное разрешение.
Другими словами, энтропийный декодер настроен для выполнения сброса контекста независимо от изменения формы окна и/или спектрального разрешения, оценивая служебную информацию о сбросе контекста отдельно от формы окна / служебной информации о спектральном разрешении.
1.2.1. Декодирование потока канала линейно-предсказанной области
1.2.3.1. Данные потока канала линейно-предсказанной области
Далее будет описан синтаксис потока канала линейно-предсказанной области со ссылкой на фиг.11а, которая показывает графическое представление синтаксиса потока канала линейно-предсказанной области, и со ссылкой на фиг.11b, которая показывает графическое представление синтаксиса кодирования преобразования кодированного возбуждения (tcx_coding), а также на фиг.11с и 11d, которые показывают определения и элементы данных, используемых в синтаксисе потока канала линейно-предсказанной области.
Обратимся теперь к фиг.11а, где будет описана общая структура потока канала линейно-предсказанной области. Поток канала линейно-предсказанной области, показанный на фиг.11а, состоит из нескольких элементов информации о конфигурации, как, например, "acelp_core_mode" и "lpd_mode." Что касается смысла элементов конфигурации, а также общей концепции кодирования линейно-предсказанной области, можно обратиться к международному стандарту 3GPP TS 26.090, 3GPP TS 26.190 и 3GPP TS 26.290.
Кроме того, следует отметить, что поток канала линейно-предсказанной области может включать до четырех "блоков" (с индексами k=0 to k=3), которые содержат либо ACELP-кодированное возбуждение или преобразование кодированного возбуждения (которая само по себе может быть арифметически кодировано). Вновь обращаясь к фиг.11а, можно увидеть, что поток канала линейно-предсказанной области содержит, для каждого из "блоков", кодирование ACELP-стимула или кодирование ТСХ-стимула. Так как кодирование ACELP стимула не имеет отношения к настоящему изобретению, его подробное обсуждение пропущено, но ссылка дана на вышеуказанные международные стандарты по этому вопросу.
Что касается кодирования ТСХ-стимула, следует отметить, что различные кодировки используются для кодирования первого ТСХ "блока" (также именуемого «ТСХ кадр») текущего звукокадра и для кодирования любых последующих ТСХ "блоков" (ТСХ кадров) текущего звукокадра. На это указывает так называемый "first_tcx_flag", который указывает, является ли в настоящее время обрабатываемый ТСХ "блок" (ТСХ кадр) первым в настоящем кадре (также именуемом «супер кадр» в терминологии кодирования линейно-предсказанной области).
Обратившись теперь к фиг.11b, можно заметить, что кодирование "блока" преобразования кодированного возбуждения (ТСХ кадра) содержит кодированный коэффициент шума ("noise_factor") и кодированный общий коэффициент усиления ("global_gain"). Кроме того, если в настоящее время рассматриваемый ТСХ "блок" является первым ТСХ "блоком" в пределах в настоящее время рассматриваемого звукокадра, кодирование в настоящее время рассматриваемого ТСХ включает флаг сброса контекста ("arith_reset_flag"). В противном случае, если в настоящее время рассматриваемый ТСХ "блок" уже не первый ТСХ "блок" текущего звукокадра, то кодирование текущего ТСХ "блока" не содержит такой флаг сброса контекста, какой видно из синтаксиса описания на фиг.11b. Кроме того, кодирование ТСХ-стимула содержит арифметически кодированные спектральные значения (или спектральные коэффициенты) "arith_data", которые кодированы в соответствии с арифметическим кодированием, уже объясненным со ссылкой на фиг.4 выше.
Спектральные значения, представляющие стимул преобразования кодированного возбуждения в линейно-предсказанной области первого ТСХ "блока" из звукокадра, кодируются с помощью сброшенного контекста (контекста по умолчанию), если флаг сброса контекста ("arith_reset_flag") указанного ТСХ "блока" активен. Арифметически кодированные спектральные значения первого ТСХ "блока" звукокадра кодируются с использованием несброшенного контекста, если флаг сброса контекста указанного звукокадра неактивен. Арифметически кодированные значения любых последующих ТСХ "блоков" (после первого ТСХ "блока") из звукокадра кодируются с использованием несброшенного контекста (т.е. с использованием контекста, извлеченного из предыдущего ТСХ блока). Указанные подробности, касающиеся арифметического кодирования спектральных значений (или спектральных коэффициентов) преобразования кодированного возбуждения, можно увидеть на фиг.11b, рассматриваемой в сочетании с фиг.11а.
1.2.3.2. Метод декодирования спектральных значений преобразования кодированного возбуждения
Спектральные значения преобразования кодированного возбуждения, которые являются арифметически кодированными, могут быть декодированы с учетом контекста. Например, если флаг сброса контекста ТСХ "блока" активен, контекст может быть сброшен, например, в соответствии с алгоритмом, показанным на фиг.9а, до декодирования арифметически кодированных спектральных значений ТСХ "блока", используя алгоритм, описанный на фиг.9c-9f. Напротив, если флаг сброса контекста ТСХ "блока" неактивен, контекст для декодирования может быть определен с помощью отображения (истории контекста из ранее декодированного ТСХ блока), описанного со ссылкой на фиг.9b, или с помощью извлечения контекста из ранее декодированных спектральных значений в любой другой форме. Кроме того, контекст для декодирования "последующих" ТСХ "блоков", которые не являются первыми ТСХ "блоками" из звукокадра, может быть извлечен из ранее декодированных спектральных значений предыдущих ТСХ "блоков".
Для декодирования спектральных значений стимула ТСХ возбуждения декодер может, следовательно, использовать алгоритм, который был объяснен, например, со ссылкой на фиг.6, 9a-9f и 20. Тем не менее, установка флага сброса контекста ("arith_reset_flag") не измеряется на каждом ТСХ "блоке" (что соответствует «окну»), а только на первом ТСХ "блоке" из звукокадра. Для последующих ТСХ "блоков" (которые соответствуют «окнам») можно предположить, что контекст не будет сброшен.
Таким образом, декодер спектральных значений стимула ТСХ возбуждения может быть настроен для декодирования спектральных значений, кодированных согласно синтаксису, показанному на фиг.11b и 4.
1.2.3.3. Процесс декодирования
Далее будет описано декодирование аудио информации возбуждения линейно-предсказанной области с ссылкой на фиг.12. Тем не менее, декодирование параметров (например, параметров линейного предиктора, возбужденного стимулом или возбуждением) синтезатора сигнала линейно-предсказанной области не будет здесь описано. В центре внимания последующего описания будет декодирование спектральных значений стимула преобразования кодированного возбуждения.
Фиг.12 показывает графическое представление кодированного возбуждения для возбуждения аудио синтезатора линейно-предсказанной области. Информация о кодированном стимуле показана для последующих звукокадров 1210, 1220, 1230. Например, первый звукокадр 1210 включает в себя первый "блок" 1212а, который содержит ACELP-кодированный стимул. Звукокадр 1210 также включает в себя три "блока" 1212b, 1212с, 1212d, которые содержат стимул преобразования кодированного возбуждения, при этом стимул преобразования кодированного возбуждения каждого из этих ТСХ "блоков" 1212В, 1212С, 1212D включает в себя набор арифметически кодированных спектральных значений. Кроме того, первый ТСХ блок 1212В кадра 1210 содержит флаг сброса контекста «arith_reset_flag». Звукокадр 1220 содержит, например, четыре ТСХ "блока" 1222A-1222D, в которых первый ТСХ блок 1222А кадра 1220 включает в себя флаг сброса контекста. Звукокадр 1230 состоит из одного ТСХ блока 1232, который сам по себе включает флаг сброса контекста. Соответственно, есть один флаг сброса контекста на каждый звукокадр, содержащий один или несколько ТСХ блоков.
Соответственно, при декодировании стимула линейно-предсказанной области, показанном на фиг.12, декодер будет проверять, установлен ли флаг сброса контекста ТСХ блока 1212В и сбрасывать ли контекст до декодирования спектральных значений ТСХ блока 1212В, в зависимости от состояния флага сброса контекста. Тем не менее, не будет сброса контекста между арифметическим декодированием этих спектральных значений ТСХ блоков 1212В и 1212С, независимо от состояния флага сброса контекста звукокадра 1210. Точно так же не будет сброса контекста между декодированием спектральных значений ТСХ блоков 1212С и 1212D. Тем не менее, декодер будет сбрасывать контекст перед декодированием спектральных значений ТСХ блока 1222А в зависимости от статуса флага сброса контекста звукокадра 1222 и не будет проводить сброс контекста между декодированием спектральных значений ТСХ блоков 1222А и 1222В, 1222В и 1222С, 1222С и 1222D. Декодер будет выполнять сброс контекста до декодирования спектральных значений ТСХ блока 1232 в зависимости от статуса флага сброса контекста звукокадра 1230.
Следует также отметить, что аудио поток может содержать сочетание звукокадров в частотной области и звукокадров в линейно-предсказанной области, так, что декодер может быть настроен правильно декодировать такие переменные. На переходе между различными режимами кодирования (частотной области и области линейного предсказания) сброс контекста может быть обеспечен контекстным ресеттером или он может отсутствовать.
1.3. Аудио декодер - третий вариант использования
Далее будет описана другая концепция аудио декодера, которая делает возможным битрейт-эффективный сброс контекста даже в отсутствие служебной информации о сбросе контекста.
Было установлено, что служебная информация, которая сопровождает энтропийно-кодированные спектральные значения, может быть использована для принятия решения о сбросе контекста для энтропийного-декодирования (например, арифметического декодирования) энтропийно-кодированных спектральных значений.
Эффективная концепция сброса контекста для арифметического декодирования была уже найдена для звукокадров, в которых содержатся наборы спектральных значений, связанные со множеством окон. Например, так называемое перспективное звуковое кодирование "Advanced Audio Coding" (также кратко обозначаемое как "ААС"), которое определено в международном стандарте ISO / IEC 14496-3:2005, часть 3, подраздел 4, использует звукокадры, содержащие восемь наборов спектральных коэффициентов, при этом каждый набор спектральных коэффициентов связан с одним «коротким окном». Соответственно, восемь коротких окон связаны с таким звуокадром, в котором восемь коротких окон используются для процедуры перекрытия оконных сигналов временной области, реконструированных на основе наборов спектральных коэффициентов. Для получения дополнительной информации можно обратиться к указанному международному стандарту. Однако в звукокадре, содержащем множество наборов спектральных коэффициентов, два или более наборов спектральных коэффициентов могут быть сгруппированы, так, что общие коэффициенты масштабирования будут связаны со сгруппированными наборами спектральных коэффициентов (и подаются для этой цели в декодер). Группирование наборов спектральных коэффициентов может быть, например, сигнализировано с помощью побочной информации о группировании (например, "scale_factor_grouping" бит). Для получения дополнительной информации можно обратиться, например, к ISO / IEC 14496-3:2005 (Е), часть 3, подраздел 4, таблицы 4.6, 4.44, 4.45, 4.46 и 4.47. Тем не менее, в целях обеспечения полного понимания можно обратиться к вышеупомянутому международному стандарту в полном объеме.
Однако в аудио декодере в соответствии с вариантом осуществления изобретения информация о группировании различных наборов спектральных значений (например, связывая их с общей шкалой спектральных значений) может быть использована для определения того, когда сбрасывать контекст для арифметического кодирования / декодирования спектральных значений. Например, изобретенный аудио декодер в соответствии с третьим вариантом может быть настроен для сброса контекста энтропийного декодирования (например, на основе контекстно-зависимого Huffmarm-декодирования или контекстно-зависимого арифметического декодирования, как описано выше), каждый раз, когда устанавливается, что происходит переход от одной группы наборов кодированных спектральных значений к другой группе наборов спектральных значений (с которыми связана другая группа наборов новых коэффициентов масштабирования). Соответственно, вместо использования флага сброса контекста побочная информация о группировании коэффициентов масштабирования может быть использована для определения того, когда сбрасывать контекст арифметического декодирования.
Далее будет объяснен пример этой концепции с ссылкой на фиг.13, которая показывает графическое представление последовательности звукокадров и соответствующую побочную информацию. Фиг.13 показывает первый звукокадр 1310, второй звукокадр 1320 и третий звукокадр 1330. Первый звукокадр 1310 может быть звукокадром с "длинным окном" в значении ISO / IEC 14493-3, часть 3, подраздел 4 (например, типа "LONG_START_WINDOW"), Флаг сброса контекста может быть связан с звукокадром 1310 для решения, сбрасывать ли контекст для арифметического декодирования спектральных значений звукокадра 1310, этот флаг сброса контекста будет соответственно рассмотрен аудио декодером.
В отличие от этого второй звукокадр является типом "EIGHTJ3HORTJSEQUENCE" и может соответственно содержать восемь наборов кодированных спектральных значений. Тем не менее, первые три набора кодированных спектральных значений могут быть объединены в одну группу (с которой связана информация об общем коэффициенте масштабирования) 1322а. Другая группа 1322b может быть определена единственным набором спектральных значений. Третья группа 1322С может содержать два набора спектральных значений, связанных с ней, а четвертая группа 1322D может включать в себя еще два набора спектральных значений, связанных с ней. Группирование наборов спектральных значений звукокадра 1320 может быть сигнализировано так называемыми "scale_factor_grouping" битами, определенными, например, в таблице 4.6 вышеупомянутого стандарта. Точно так же звукокадр 1340 может содержать четыре группы 1330А, 1330 В, 1330С, 1330D.
Тем не менее, звукокадры 1320, 1330 могут, например, не включать специальный флаг сброса контекста. Для энтропийного декодирования спектральных значений звукокадра 1320 декодер может, например, независимо или в зависимости от флага сброса контекста сбрасывать контекст перед декодированием первого набора спектральных коэффициентов первой группы 1322А. Впоследствии аудио декодер может избежать сброса контекста между декодированием различных наборов спектральных коэффициентов той же группы спектральных коэффициентов. Тем не менее, всякий раз, когда аудио декодер распознает начало новой группы в звукокадре 1320, состоящем из множества групп (наборов спектральных коэффициентов), аудио декодер может сбрасывать контекст для энтропийного декодирования спектральных коэффициентов. Таким образом, аудио кодер может эффективно сбрасывать контексты для декодирования спектральных коэффициентов первой группы 1322А перед декодированием спектральных коэффициентов второй группы 1322В, перед декодированием спектральных коэффициентов третьей группы 1322С, и перед декодирование спектральных коэффициентов четвертой группы 1322D.
Соответственно, отдельную передачу специальных флагов сброса контекста можно избежать в таких звукокадрах, в которых есть множество наборов спектральных коэффициентов. Таким образом, дополнительная битовая нагрузка, вызванная передачей битов группирования, может хотя бы частично компенсироваться отсутствием передачи специального флага сброса контекста, в таком кадре, что может оказаться ненужным в некоторых приложениях.
Таким образом, была описана стратегия сброса, которая может быть реализована декодером (а также функциями кодера). Стратегии, описанной здесь, не требуется передача любой дополнительной информации (например, специальной служебной информации для сброса контекста) для декодера. Он использует служебную информацию, уже отправленную на декодер (например, кодером, предоставляющим ААС кодированный аудио поток, соответствующий вышеуказанному отраслевому стандарту). Как это описано в настоящем документе, изменение содержания в сигнале (аудио сигнале) может произойти от кадра к кадру, например 1024 сэмплов. В этом случае у нас уже есть флаг сброса, который может управлять контекстно-адаптивным кодированием и смягчать влияние на его работу. Однако в кадре из 1024 сэпмлов содержание также может меняться. В таком случае, когда аудио кодер (например, в соответствии с единым кодированием речи и звука unified speech and audio coding "USAC") использует кодирование частотной области (FD), декодер, как правило, переключится на короткие блоки. В коротких блоках передается информация группирования (см. выше), которая сообщает о положении перехода или транзиента (аудио-сигнала). Такая информация может быть повторно использована для сброса контекста, о чем говорится в этом разделе.
С другой стороны, когда аудио кодер (как, например, в соответствии с единым кодированием речи и звука длиной речи и кодирования звука "USAC") использует кодирование линейной области предсказания (LPD), изменение содержания повлияет на выбранные режимы кодирования. Когда различные преобразования кодированного возбуждения происходят в пределах одного кадра из 1024 сэмплов, контекстное отображение может быть использовано, как описано выше. (См., например, контекстное отображение на фиг.9D.) Было установлено, что это решение лучше, чем сброс контекста каждый раз, когда выбирается другое преобразование кодированного возбуждения. Так как кодирование линейно-предсказанной области очень адаптивно, режим кодирования постоянно меняется и систематический сброс будет значительно мешать производительности кодирования. Однако, когда ACELP выбран, будет полезно сбрасывать контекст для следующего преобразования кодированного возбуждения (ТСХ). Выбор ACELP между преобразованием кодированных возбуждений является свидетельством того, что произошло значительное изменение сигнала.
Другими словами, обращаясь, например, к фиг.12, флаг сброса контекста, предшествующего первому ТСХ "блоку" из звукокадра, при использовании кодирования линейно-предсказанной области может быть опущен, полностью или выборочно, если есть хотя бы один ACELP кодированный стимул в звукокадре. Декодер может, в этом случае, быть настроен на сброс контекста, если определен первый ТСХ-блок, следующий за ACELP-блоком, и на пропуск сброса контекста между декодированием спектральных значений последующих ТСХ-блоков.
Кроме того, по желанию, декодер может быть настроен на оценку флага сброса контекста, например один раз на звукокадр, если ТСХ блоку предшествует основной звукокадр, чтобы сделать возможным сброс контекста даже при наличии расширенных сегментов из ТСХ-блоков.
2. Аудио кодер
2.1. Аудио кодер - основные понятия
Далее будет описана основная концепция контекстно-зависимого энтропийного кодера в целях облегчения понимания специальных процедур для сброса контекста, которые будут подробно рассмотрены далее.
Бесшумное кодирование может быть основано на квантованных спектральных значениях и может использовать контекстно-зависимые сводные таблицы частот, извлеченные из, например, четырех ранее декодированных соседних фрагментов данных. Фиг.7 представляет другой вариант. Фиг.7 показывает плоскость временной частоты, в которой по оси времени указываются три временных слота n, n-1 и n-2. Кроме того, фиг.7 показывает четыре частотные или спектральные полосы, которые помечены m-2, m-1, m и m+1. Фиг.7 показывает рамки частотно-временных слотов, которые представляют собой фрагменты сэмплов для кодирования и декодирования. Три различных типа фрагментов данных показаны на фиг.7, в которой круглые сегменты, имеющие штриховую или пунктирную границу, указывают на оставшиеся фрагменты для кодирования или декодирования, прямоугольные сегменты, имеющие пунктирную границу, указывают на ранее кодированные или декодированные фрагменты и серые сегменты со сплошной границей указывают на ранее кодированные/ декодированные фрагменты, которые используются для определения контекста для текущего фрагмента данных при кодировании или декодировании.
Необходимо обратить внимание, что предыдущий и текущий сегменты, упомянутые в вышеописанных вариантах, могут соответствовать фрагменту в данном варианте, иными словами, сегменты могут быть обработаны с точки зрения полосы в частотной или в спектральной области. Как показано на фиг.76, сегменты в окрестности текущего фрагмента данных (то есть в частотно-временной и спектральной областях) могут быть приняты во внимание для получения контекста. Сводные таблицы частот могут затем быть использованы арифметическим кодером для генерации бинарного кода переменной длины. Арифметический кодер может произвести бинарный код для данного набора символов и их вероятностей. Бинарный код может быть получен путем сопоставления вероятностного интервала, в котором лежит набор символов, к кодовому слову.
В настоящем варианте контекстно-зависимое арифметическое кодирование может быть осуществлено на основе 4 фрагментов данных (т.е. на четырех спектральных индексах коэффициентов), которые также помечены q(n,m), и q[m][n], представляя спектральные коэффициенты после квантования, которые граничат в частотной или спектральной области, и которые энтропийно кодированы в один шаг. В соответствии с вышеуказанным описанием, кодирование может осуществляться на основе контекста кодирования. Как показано на фиг.7, дополнительно к 4-м фрагментам данных, которые кодируются (т.е. текущего сегмента), учитываются четыре ранее кодированных 4-фрагмента данных в целях извлечения контекста. Эти 4 фрагмента данных определяют контекст и предшествуют в частотной и/или временной областях.
Фиг.21 показывает блок-схему USAC ((USAC=Universal Speech and Audio Coder) универсального кодера речи и звука) контекстно-зависимого арифметического кодера для кодирования схемы спектральных коэффициентов. Процесс кодирования зависит от текущего фрагмента данных и контекста, где контекст используется для выбора распределения вероятностей арифметического кодера и для прогнозирования амплитуды спектральных коэффициентов. На фиг.21 ящик 2105 представляет определение контекста, которое основано на t0, t1, t2 и t3, соответственно q (n-1, m), q (n, m-1), q (n-1, m-1) и q (n-1, m+1).
Как правило, в вариантах энтропийный кодер может быть адаптирован для кодирования текущего сегмента в единицах спектральных коэффициентов фрагмента данных и для предсказания амплитуды диапазона фрагмента данных - на основе контекста кодирования.
В данном варианте схема кодирования состоит из нескольких этапов. Во-первых, буквенное кодовое слово кодируется с помощью арифметического кодера и определенного распределения вероятностей. Кодовое слово представляет четыре соседних спектральных коэффициента (a, b, c, d), однако каждый из a, b, c, d ограничен в диапазоне:
-5<a, b, c, d<4.
Как правило, в вариантах энтропийный кодер может быть адаптирован для разделения фрагмента данных по заданному фактору так часто, как это необходимо, чтобы подогнать результат разделения в предсказанный диапазон или в заданный диапазон, и для кодирования числа необходимых разделений, остатка разделения и результата разделения, когда фрагмент не лежит в предсказанном диапазоне, и для кодирования остатка разделения и результата разделения в противном случае.
Далее, если элемент (a, b, c, d), т.е. любой элемент a, b, c, d, превышает заданный диапазон в этом варианте, он может быть разделен на коэффициент так часто (например, 2 или 4 раза), как это необходимо, для умещения результирующего кодового слова в заданном диапазоне. Деление на коэффициент 2 соответствует бинарному смещению к правой части, т.е. (a, b, c, d)>>1. Это уменьшение осуществляется до целого числа, то есть информация может быть утрачена. Наименее значимые биты, которые могут потеряться при смещении направо, сохраняются и в дальнейшем кодируются с помощью арифметического кодера и равномерного распределения вероятностей. Процесс смещения вправо осуществляется для всех четырех спектральных коэффициентов (a, b, c, d).
В общих вариантах энтропийный кодер может быть адаптирован для кодирования результата разделения или фрагмента данных с помощью индекса группы ng, индекс группы ng указывает на группу из одного или более кодовых слов, для которых распределение вероятности основывается на контексте кодирования, и индекса элемента ne в случае, если группа состоит из более чем одного кодового слова, индекс элемента ne указывает на кодовое слово в группе, и индекс элемента предположительно равномерно распределен, и для кодирования числа делений числом символов выхода/побега, символ выхода/побега при этом является специальным индексом группы ng, используемым только для обозначения деления и для кодирования остатков разделений на основе равномерного распределения при помощи правила арифметического кодирования. Энтропийный кодер может быть адаптирован для кодирования последовательности символов в кодированный аудио поток с помощью символьного алфавита, включающего символ выхода/побега, управляющий символ и групповые символы, соответствующие набору доступных индексов группы, с помощью символьного алфавита, включающего соответствующие индексы элементов, и символьного алфавита, включающего различные значения остатков.
В варианте на фиг.21 распределение вероятностей для кодирования буквенного кодового слова, а также оценка числа шагов для сужения диапазона могут быть выведены из контекста. Например, все кодовые слова, в общей сложности 84=4096, охватывают в общей сложности 544 групп, которые состоят из одного или нескольких элементов. Кодовое слово может быть представлено в битовом потоке как индекс группы ng и элемент группы ne. Оба значения могут быть кодированы с помощью арифметического кодера, используя определенные вероятностные распределения. В одном из вариантов распределения вероятностей ng может быть извлечено из контекста, тогда как распределение вероятностей для ne можно считать однородным. Сочетание ng и ne может однозначно указывать на кодовое слово. Остаток от деления, т.е. смещенные битовые плоскости, можно также считать равномерно распределенными.
На фиг.21 в шаге 2110 предоставляется фрагмент q (n, m), то есть (a, b, c, d) или текущий сегмент, и инициируется параметр lev, он устанавливается равным 0. На шаге 2115 из контекста оценивается диапазон (a, b, c, d). Согласно этой оценке, (a, b, c, d) могут быть уменьшены на lev0 уровней, т.е. разделены на коэффициент 2lev0. Lev0 наименее значимых битовых плоскостей сохраняются для дальнейшего использования в шаге 2150.
На шаге 2120 проверяется, превышают ли (a, b, c, d) заданный диапазон, и если да, то диапазон (a, b, c, d) уменьшается на коэффициент 4 в шаге 2125. Другими словами, на шаге 2125 (a, b, c, d) смещаются на 2 вправо и удаленные битовые плоскости сохраняются для дальнейшего использования в шаге 2150.
Для того чтобы сообщить о шаге сокращения, ng установлен до 544 в шаге 2130, то есть ng=544 служит как escape/ управляющий код. Это кодовое слово записывается в битовый поток в шаге 2155, где для извлечения кодового слова в шаге 2130 используется арифметический кодер с распределением вероятностей, извлеченный из контекста. В случае, если этот шаг сокращения был применен впервые, то есть если lev=lev0, контекст незначительно адаптируется. В случае, если шаг сокращения применяется более одного раза, контекст отбрасывается, и далее используется распределение по умолчанию. Затем процесс продолжается с шагом 2120.
Если на шаге 2120 обнаруживается совпадение диапазона, в частности, если (a, b, c, d) соответствует условию диапазона, (a, b, c, d) переходит в группу (a, b, c, d), и применяется индекс элемента группы - индекс ne. Это отображение однозначно, т.е. (a, b, c, d) могут быть выведены из ng и ne. Индекс группы ng затем кодируется арифметическим кодером, с использованием вероятностного распределения полученного для адаптированного / отброшенного контекста в шаге 2135. Индекс группы ng затем вставляется в битовый поток в шаге 2155. В следующем шаге 2140 проверяется, является ли количество элементов в группе большим чем 1. Если необходимо, то есть если группа, индексированная ng, состоит из более чем одного элемента, то индекс элемента группы ne кодируется арифметическим кодером на шаге 2145, предполагая равномерное распределение вероятности в данном варианте.
На следующем шаге 2145 индекс элемента группы ne вставляется в битовый поток в шаге 2155. Наконец, на шаге 2150 все сохраненные битовые плоскости кодируются с помощью арифметического кодера, при условии равномерного распределения вероятности. Кодированные сохраненные битовые плоскости затем также вставляются в битовый поток в шаге 2155.
Подводя итог сказанному выше, энтропийный кодер, в котором могут использоваться концепции сброса контекста, описанные далее, принимает одно или несколько спектральных значений и производит кодовое слово, как правило, переменной длины, на основе одного или нескольких полученных спектральных значений. Отображение полученных спектральных значений на кодовом слове зависит от предполагаемого распределения вероятности кодовых слов, таких, как короткие кодовые слова, которые связаны со спектральными значениями (или их комбинациями), имеющими высокую вероятность, и таких, как длинные кодовые слова, которые связаны со спектральными значениями (или их комбинациями), имеющими низкую вероятность. Контекст принимается во внимание в связи с тем, что предполагается, что вероятность спектральных значений (или их комбинаций) зависит от ранее кодированных спектральных значений (или их комбинаций). Соответственно, правило отображения (также обозначаемое "отображение информации", или "кодовая книга", или "сводная таблица частот") выбирается в зависимости от контекста, т.е. ранее кодированных спектральных значений (или их комбинаций). Тем не менее, контекст не всегда принимается во внимание. Более того, контекст иногда сбрасывается при помощи функции «сброс контекста», описанной в данном документе. При сбросе контекста можно считать, что спектральные значения (или их комбинации) для текущего кодирования сильно отличаются от того, что можно было бы ожидать исходя из контекста.
2.2. Аудио кодер - вариант использования согласно фиг.14
Далее аудио кодер будет описан с ссылкой на фиг.14, который базируется на основных концепциях, описанных выше. Аудио кодер 1400 на фиг.14 включает в себя аудио процессор 1410, который настроен на прием звукового сигнала 1412 и выполнение обработки звука, например преобразования аудио сигнала 1410 из временной области в частотную область, и квантование спектральных значений, полученных с помощью преобразования временной области в частотную область. Соответственно, аудио процессор генерирует квантованные спектральные коэффициенты (также обозначаемые как спектральные значения) 1414. Аудио кодер 1400 также включает в себя контекстно-адаптивный арифметический кодер 1420, который настроен на получение/прием спектральных коэффициентов 1414 и контекстной информации 1422, которая может быть использована для выбора правил отображения для отображения спектральных значений (или их комбинаций) на кодовые слова, которые являются кодированным представлением этих спектральных значений (или их комбинаций). Соответственно, контекстно-адаптивный арифметический кодер 1420 производит кодированные спектральные значения (кодированные коэффициенты) 1424. Кодер 1400 также включает в себя буфер 1430 для хранения ранее кодированных спектральных значений 1414, так как ранее кодированные спектральные значения 1432, предоставляемые буфером 1430, влияют на контекст. Кодер 1400 также включает в себя контекстный генератор 1440, который настроен на получение/прием сохраненных, ранее кодированных коэффициентов 1432 и извлечение контекстной информации 1422 (например, значение "PKI" для выбора сводной таблицы частот или отображения информации для контекстно-адаптивного арифметического кодера 1420) на его основе. Тем не менее, аудио кодер 1400 также включает в себя механизм сброса 1450 для сброса контекста. Механизм сброса 1450 настроен для определения момента сброса контекста (или контекстной информации), предоставляемого контекстным генератором 1440. Механизм сброса 1450 может дополнительно воздействовать на буфер 1430, чтобы сбросить коэффициенты, сохраненные или предоставляемые буфером 1430, или на контекстный генератор 1440, чтобы сбросить контекстную информацию, предоставленную контекстным генератором 1440.
Аудио кодер 1400 на фиг.14 содержит стратегию сброса как функцию кодера. Стратегия сброса запускает на стороне кодера "флаг сброса", который можно рассматривать как служебную информацию о сбросе контекста, которая отправляется на каждый кадр из 1024 сэмплов (сэмплов временной области аудио сигнала) на одном бите. Аудио кодер 1400 содержит стратегию «регулярного сброса». В соответствии с этой стратегией флаг сброса регулярно активируется, тем самым сбрасывая контекст, используемый в кодере, а также контекст в соответствующем декодере (который обрабатывает флаг сброса контекста, как описано выше).
Преимущество такого регулярного сброса состоит в ограничении зависимости кодирования настоящего кадра от предыдущих кадров. Сброс контекста каждого из n-кадров (что достигается счетчиком 1460 и генератором флага сброса 1470) позволяет декодеру синхронизировать свои состояния с кодером, даже если происходит ошибка передачи. Декодированный сигнал может быть восстановлен после точки сброса. Кроме того, стратегия "регулярного сброса" позволяет декодеру прямой доступ в любую точку сброса битового потока без учета прошлой информации. Интервал между точками сброса и производительностью кодирования является компромиссом, который сделан со стороны кодера в соответствии с целевым приемником и характеристиками канала передачи.
2.3. Аудио кодер - вариант использования согласно фиг.15
Далее будет описана другая стратегия сброса как функция кодера. Такая стратегия запускает со стороны кодера флаг сброса, который отправляется на каждый кадр из 1024 сэмплов на 1 бит. В варианте на фиг.15 сброс вызывается характеристиками кодирования.
Как видно на фиг.15, аудио кодер 1500 очень похож на аудио кодер 1400, так, что одинаковые средства и сигналы обозначаются одинаковыми номерами в ссылках и не будут объясняться еще раз. Тем не менее, аудио кодер включает другой механизм сброса 1550. Механизм сброса контекста 1550 включает в себя детектор изменения режима кодирования 1560 и генератор флага сброса. Детектор изменения режима кодирования обнаруживает изменение в режиме кодирования и инструктирует генератор флага сброса 1570 предоставить флаг сброса (контекста). Флаг сброса контекста также действует в соответствии с контекстным генератором 1440, в качестве альтернативы или в дополнение к буферу 1430 для сброса контекста. Как упоминалось выше, сброс запускается характеристиками кодирования. В коммутируемом кодере, таком как единый кодер речи и звука (USAC), могут применяться различные режимы кодирования, которые могут следовать друг за другом. В этом случае контекст вывести трудно, потому что временное/ частотное разрешение настоящего кадра может отличаться от разрешения предыдущих кадров. По этой причине в едином кодере речи и звука (USAC) существует механизм отображения контекста, который позволяет восстановить контекст, даже если разрешение меняется между двумя кадрами. Тем не менее, некоторые режимы кодирования настолько отличаются друг от друга, что даже отображение контекста может не быть эффективным. В этом случае требуется сброс.
Например, в едином кодере речи и звука (USAC) такой сброс может быть запущен при переходе из/в кодирование частотной области в/из кодирования линейно-предсказанной области. Другими словами, сброс контекста контекстно-адаптивного арифметического кодера 1420 может быть выполнен и сигнализирован всякий раз, когда режим кодирования меняется между кодированием частотной области и кодированием линейно-предсказанной области. Такой сброс контекста может быть сигнализирован или особым флагом сброса контекста. Как альтернатива, на стороне декодера может быть использована другая служебная информация, чтобы вызвать сброс контекста, например служебная информация, указывающая на режим кодирования.
2.4. Аудио кодер - вариант использования согласно фиг.16
Фиг.16 показывает блок-схему другого аудио кодера, который реализует еще одну стратегию сброса как функцию кодера. Эта стратегия запускает на стороне кодера флаг сброса, который отправляется на каждый кадр из 1024 сэмплов на 1 бит.
Аудио кодер 1600 на фиг.16 похож на аудио кодеры 1400, 1500 на фиг.14 и 15, так, что одинаковые характеристики и сигналы обозначаются одинаковыми номерами в ссылках. Тем не менее, кодер 1600 содержит два контекстно-адаптивных арифметических кодера 1420, 1620 (или, по крайней мере, способен кодировать спектральные значения 1414 для текущего кодирования с помощью двух различных контекстов кодирования). Для этой цели перспективный advanced контекстный генератор 1640 настроен для предоставления контекстной информации 1642, которая получается без сброса контекста, для первого контекстно-адаптивного арифметического кодирования (например, в контекстно-адаптивном арифметическом кодере 1420), а также настроен для предоставления второй контекстной информации 1644, которая получается путем применения сброса контекста, для второго кодирования спектральных значений для текущего кодирования (например, в контекстно-адаптивном арифметическом кодере 1620).
Битовый счетчик / блок сравнения 1660 определяет (или оценивает) число битов, необходимое для кодирования спектрального значения с использованием несброшенного контекста, а также определяет (или оценивает) число битов, необходимых для кодирования спектральных значений для кодирования в настоящее время с использованием сброшенного контекста. Соответственно, битовый счетчик / блок сравнения 1660 решает, что выгоднее, с точки зрения битрейта, - сбрасывать контекст или нет. Соответственно, битовый счетчик / блок сравнения 1660 обеспечивает активацию флага сброса контекста в зависимости от того, является ли выгодным, с точки зрения битрейта, сбрасывать контекст или нет. Кроме того, битовый счетчик / блок сравнение 1660 выборочно предоставляет спектральные значения, кодированные с помощью несброшенного контекста, или спектральные значения, кодированные с помощью сброшенного контекста, как выходную информацию 1424, в зависимости от того, что приводит к меньшему битрейту - несброшенный или сброшенный контекст.
Подводя итог сказанному выше, фиг.16 показывает аудио кодер, который использует замкнутое решение для определения активировать или не активировать флаг сброса. Таким образом, декодер включает стратегию сброса как функцию кодера. Эта стратегия запускает на стороне кодера флаг сброса, который отправляется на каждый кадр из 1024 сэмплов на один бит.
Было установлено, что иногда характеристики сигнала резко меняются от кадра к кадру. Для таких неоднородных частей сигнала контекст из прошлого кадра часто не имеет смысла. Кроме того, было установлено, что учет предыдущих кадров в контекстно-адаптивном кодировании может принести больше вреда, чем пользы. Решением этой проблемы является запуск флага сброса, когда это происходит. Способом обнаружения такого случая является сравнение эффективности декодирования, когда флаг сброса и активирован, и не активирован. Значение флага, соответствующее лучшему кодированию, затем используется (для определения нового состояния контекста кодера) и передается. Этот механизм был применен в едином кодировании речи и звука (USAC), а также было вычислено усиление средней производительности:
12 кбит моно:1.55 бит/кадр (макс:54)
16 кбит моно:1.97 бит/кадр (макс:57)
20 кбит моно:2.85 бит/кадр (макс:69)
24 кбит моно:3.25 бит/кадр (макс:122)
16 кбит стерео:2,27 бит/кадр (макс:70)
20 кбит стерео:2,92 бит/кадр (макс:80)
24 кбит стерео:2,88 бит/кадр (макс:119)
32 кбит стерео:3,01 бит/кадр (макс:121)
2.5. Аудио кодер - вариант использования согласно фиг.17
Далее другой аудио кодер 1700 будет описан с ссылкой на фиг.17. Аудио кодер 1700 похож на аудио кодеры 1400, 1500 и 1600 на фиг.14, 15 и 16, так, что одинаковые номера в ссылках будут использоваться для обозначения одинаковых средств и сигналов.
Тем не менее, аудио кодер 1700 включает в себя другой генератор флага сброса 1770 по сравнению с другими аудио кодерами. Генератор флага сброса 1770 принимает служебную информацию, которая предоставляется аудио процессором 1410, и предоставляет на ее основе флаг сброса 1772, который отправляется в контекстный генератор 1440. Тем не менее, следует отметить, что аудио кодер 1700 избегает включать/ не включать флаг сброса 1772 в кодированный аудио поток. Только побочная информация аудио процессора 1780 включается в кодированный аудио поток.
Генератор флага сброса 1770 может, например, быть настроен на получение флага сброса контекста 1772 из побочной информации аудио процессора 1780. Например, генератор флага сброса 1770 может оценить информацию о группировании (уже описанную выше), чтобы решить, следует ли сбросить контекст. Таким образом, контекст может быть сброшен между кодированием различных групп наборов спектральных коэффициентов, как описано, например, для декодера со ссылкой на фиг.13.
Таким образом, кодер 1700 использует стратегию сброса, которая может быть идентичной стратегии сброса декодера. Тем не менее, эта стратегия сброса может избежать передачу особого флага сброса контекста. Другими словами, стратегия сброса, описанная здесь, не требует передачи какой-либо дополнительной информации декодеру. Она использует служебную информацию, которая уже была направлена декодеру (например, побочную информацию о группировании). Следует отметить, что для данной стратегии одинаковые механизмы для определения того, следует ли сбрасывать контекст или нет, используются в кодере и декодере. Соответственно, можно сослаться на описание для фиг.13.
2.6. Аудио кодер - дальнейшие замечания
Прежде всего, следует отметить, что различные стратегии сброса, упоминаемые в данном документе, например, в разделах 2.1. до 2.5, могут быть объединены. В частности, стратегии сброса как функции кодера, которые обсуждались со ссылкой на фиг.14-16, могут быть объединены. Тем не менее, стратегия сброса, описанная со ссылкой на фиг.17, может быть объединена с другими стратегиями сброса, если это необходимо.
Кроме того, следует отметить, что сброс контекста на стороне кодера должен происходить синхронно со сбросом контекста на стороне декодера. Соответственно, кодер настроен на предоставление флага сброса контекста, описанного выше, во время (или кадры, или окна), описанное выше (например, со ссылкой на фиг.10а-10с, 12 и 13), так, что описание декодера означает соответствующие функциональные возможности кодера (в отношении генерации флага сброса контекста). Точно так же описание функциональных возможностей кодера соответствует соответствующей функциональности декодера в большинстве случаев.
3. Метод декодирования аудио информации
Далее будет кратко описан метод получения декодированной аудио информации на основе кодированной аудио информация с ссылкой на фиг.18. Фиг.18 показывает такой метод 1800. Метод 1800 содержит шаг 1810 декодирования энтропийно-кодированной аудио информации с учетом контекста, который основан на ранее декодированной аудио информации, в несброшенном состоянии работы. Декодирование энтропийно-кодированной аудио информации содержит этап 1812 отображения информации для извлечения декодированной аудио информации из кодированной аудио информации в зависимости от контекста и использование 1814 выбранного отображения информации для извлечения части декодированной аудио информации. Декодирование энтропийно-кодированной аудио информации также включает в себя сброс 1816 контекста для выбора отображения информации до контекста по умолчанию, который не зависит от ранее декодированной аудио информации, в ответ на побочную информацию, и использование 1818 отображения информации, которая основана на контексте по умолчанию, для извлечения второй части декодированной аудио информации.
Метод 1800 может быть дополнен любыми функциональными возможностями, описанными в данном документе, касающимися декодирования аудио информации, а также касающимися изобретенного аппарата.
4. Метод кодирования аудио сигнала
Далее будет описан метод 1900 для получения кодированной аудио информации на основе входной аудио информации с ссылкой на фиг.19.
Метод 1900 включает кодирование 1910 заданной аудио информации из входной аудио информации в зависимости от контекста, который основывается на смежной аудио информации, временно или спектрально прилегающей к данной аудио информации, в несброшенном состоянии работы.
Метод 1900 также содержит этап 1920 отображения информации для извлечения кодированной аудио информации из входной аудио информации в зависимости от контекста.
Кроме того, метод 1900 включает в себя сброс 1930 контекста для выбора отображения информации до контекста по умолчанию, который не зависит от ранее декодированной аудио информации, в рамках непрерывного фрагмента данных входной аудио информации (например, между декодированием двух кадров, сигналы временной области которых накладываются друг на друга и не добавляются) в ответ на возникновение условия сброса контекста.
Метод 1900 также включает в себя предоставление 1940 служебной информации (например, флаг сброса контекста или информация о группировании) кодированной аудио информации, указывающей на наличие такого условия сброса контекста.
Метод 1900 может быть дополнен любой возможностью и функцией, описанной в связи с изобретенной концепцией аудио кодирования.
5. Альтернативные варианты использования
Хотя некоторые аспекты уже были описаны в контексте аппарата, ясно, что эти аспекты также представляют собой описание соответствующего метода, где блок или устройство соответствуют шагу метода или функции шага метода. Аналогично, аспекты, изложенные в контексте шага метода, также представляют собой описание соответствующего блока или элемента или функции соответствующего аппарата.
Согласно настоящему изобретению кодированный аудио сигнал может быть сохранен на цифровом носителе или может быть передан с помощью передающего средства, такого как беспроводное средство передачи или проводное средство передачи, например Интернет.
В зависимости от требований определенных реализаций изобретения варианты использования изобретения могут быть реализованы в виде аппаратного обеспечения или программного обеспечения. Реализация может быть осуществлена с помощью цифрового носителя, например дискеты, DVD, Blue-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем электронно-читаемые управляющие сигналы, которые совместимы с программируемой компьютерной системой так, что выполняется соответствующий метод. Таким образом, цифровой носитель может быть читаемым на компьютере.
Некоторые воплощения в соответствии с изобретением содержат носитель данных, имеющий электронно-читаемые управляющие сигналы, которые совместимы с программируемой компьютерной системой так, что выполняется один из методов, описанных в данном документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы в виде программного продукта с программным кодом, который выполняется для реализации одного из методов, когда компьютерный программный продукт запущен на компьютере. Программный код, например, может быть сохранен на носителе, который читается на компьютере.
Другие варианты включают компьютерную программу для выполнения одного из методов, описанных в данном документе, хранящуюся на носителе, который читается на компьютере.
Иными словами, воплощением изобретенного метода, следовательно, является компьютерная программа, имеющая программный код для выполнения одного из методов, описанных в данном документе, когда компьютерная программа запущена на компьютере.
Еще одним вариантом использования изобретенных методов, таким образом, является носитель информации (или цифровой носитель), включающий записанную на нем компьютерную программу для выполнения одного из методов, описанных в данном документе.
Еще одним вариантом использования изобретенного метода является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из методов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть настроен для передачи через соединение передачи данных, например через Интернет.
Еще один вариант использования включает в себя средства обработки, например компьютер или программируемое логическое устройство, настроенное или адаптированное для выполнения одного из методов, описанных в данном документе.
Еще один вариант использования включает компьютер с установленной на нем компьютерной программой для выполнения одного из методов, описанных в данном документе.
В некоторых вариантах использования программируемое логическое устройство (например, поле-программируемая вентильная матрица) может быть использовано для выполнения некоторых или всех функциональных возможностей, описанных в данном документе. В некоторых вариантах поле-программируемая вентильная матрица может сотрудничать с микропроцессором для выполнения одного из методов, описанных в данном документе. Как правило, методы предпочтительно выполнять с помощью аппаратных средств.
Описанные выше варианты осуществления изобретения являются только иллюстрацией принципов данного изобретения. Подразумевается, что модификации и вариации устройства и деталей, описанных в данном документе, будут очевидны для специалистов в данной области. Таким образом, данный документ ограничивается только сферой предстоящих патентных притязаний, а не конкретными деталями, представленными в виде описания и объяснения использования изобретения в настоящем документе.




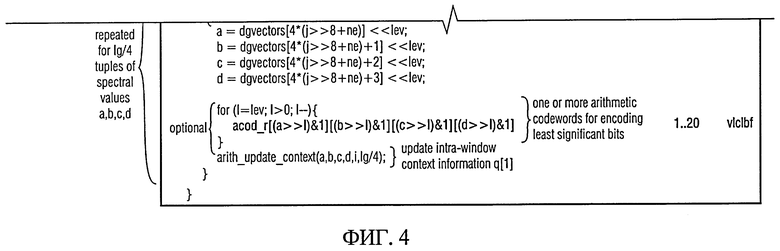

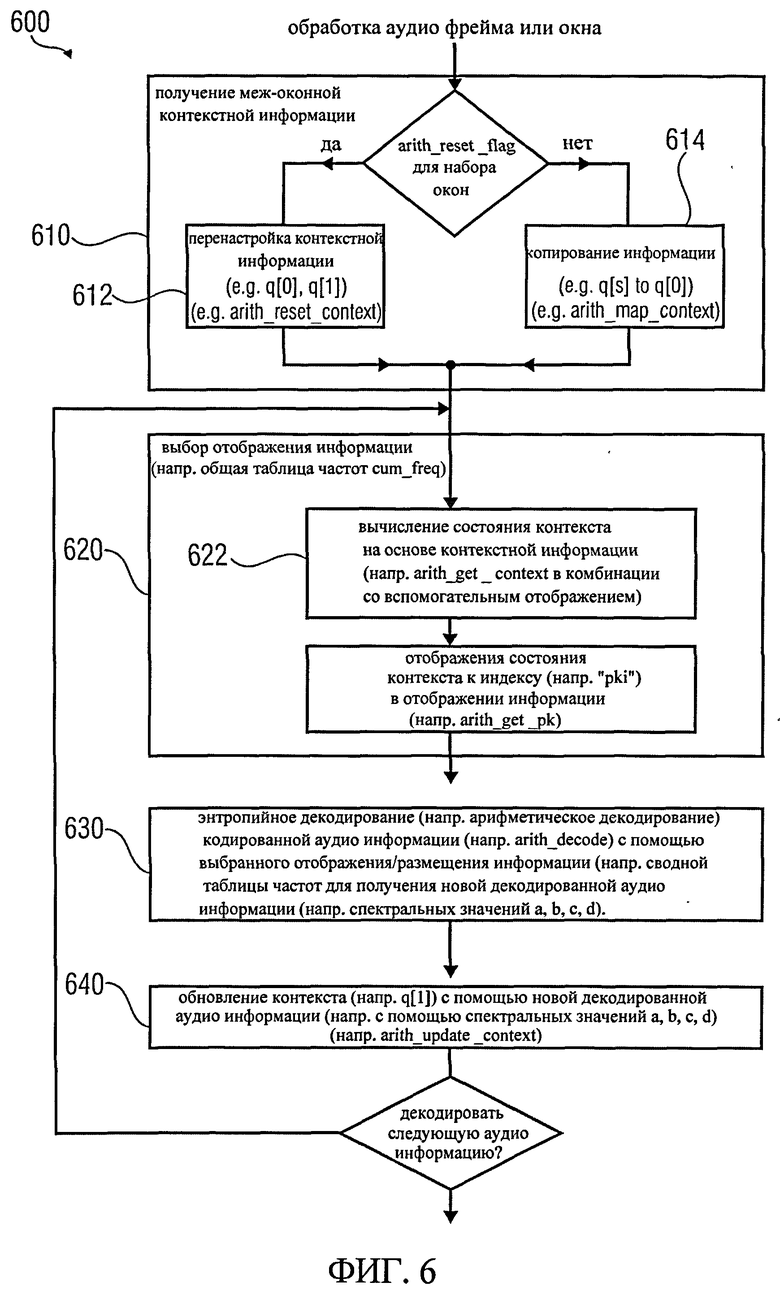









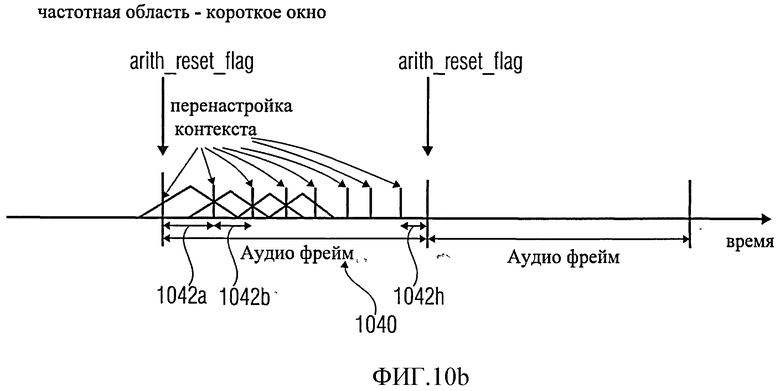


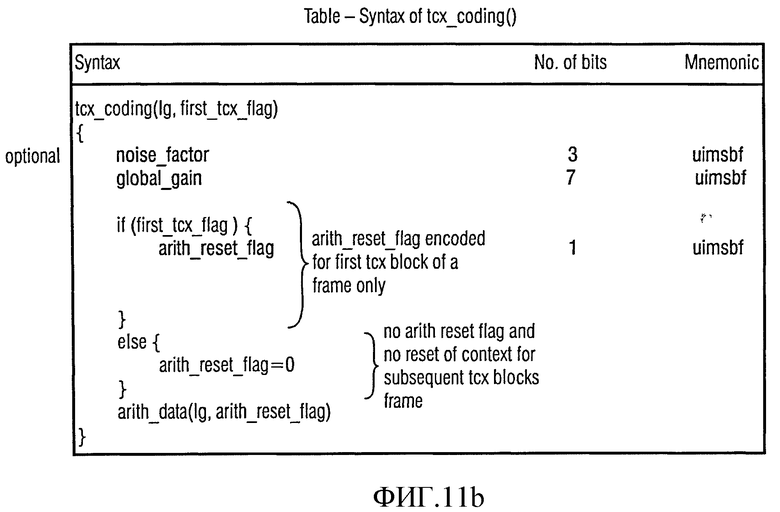
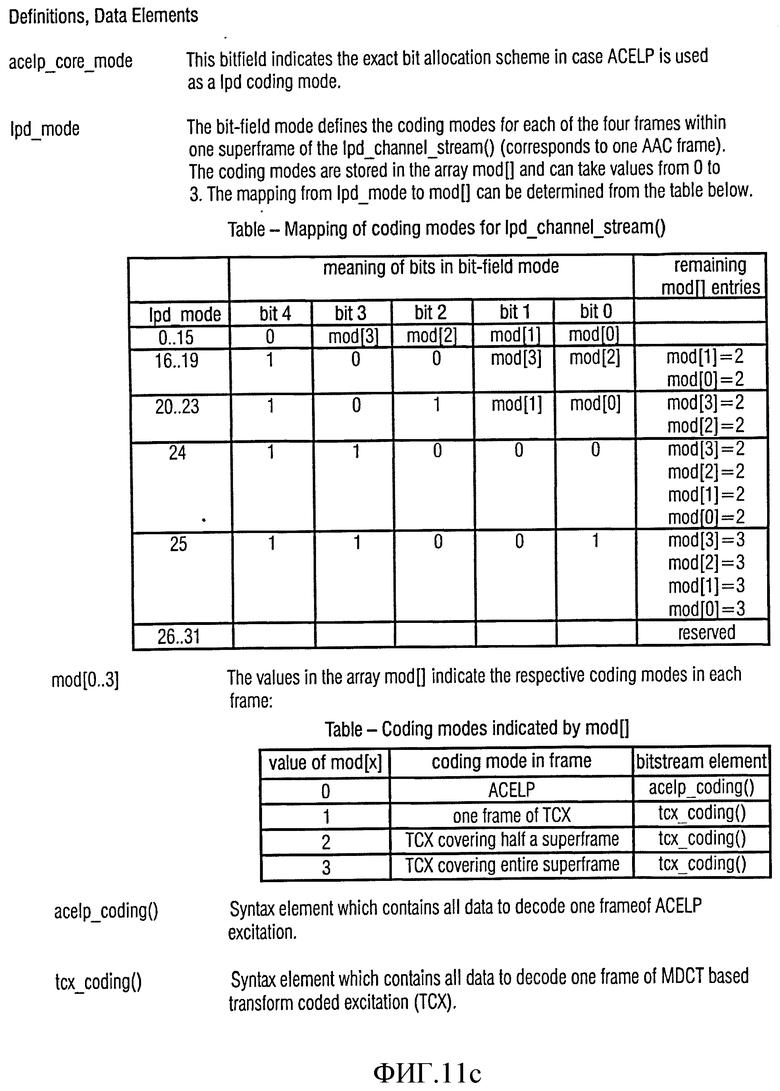



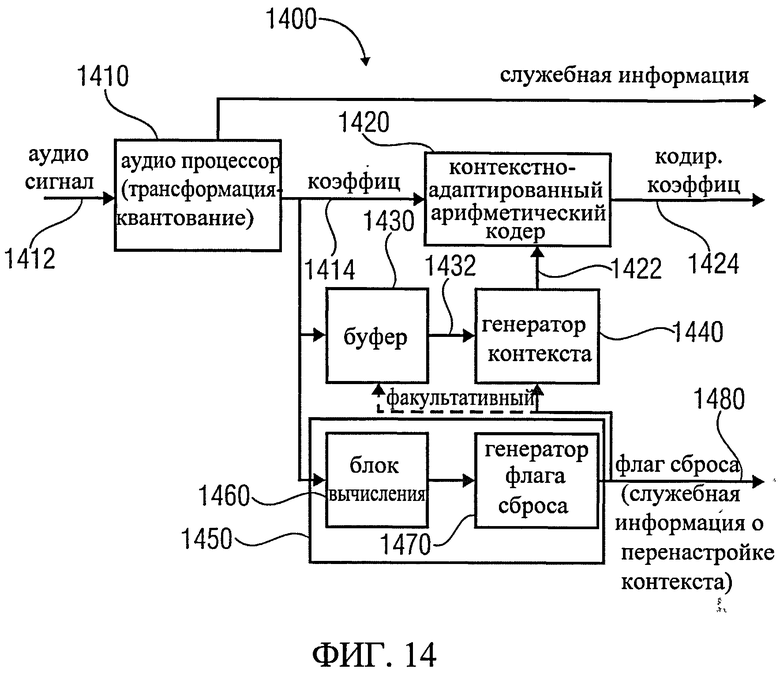



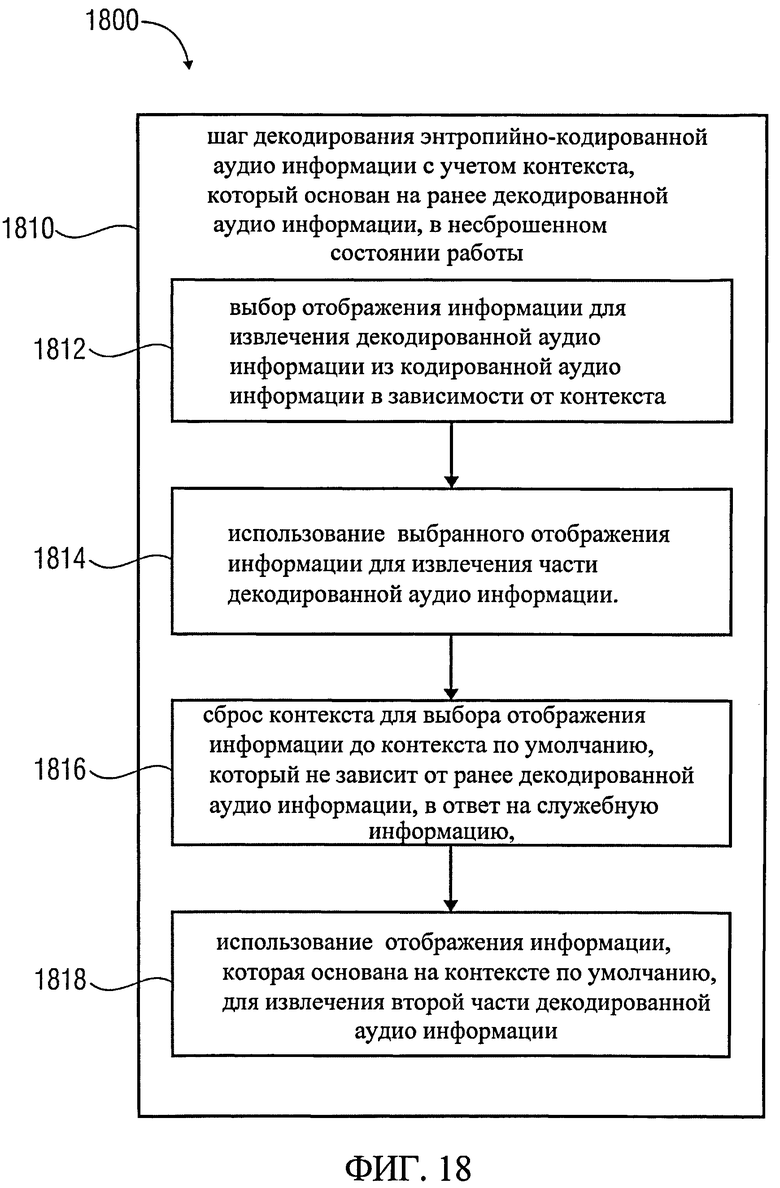
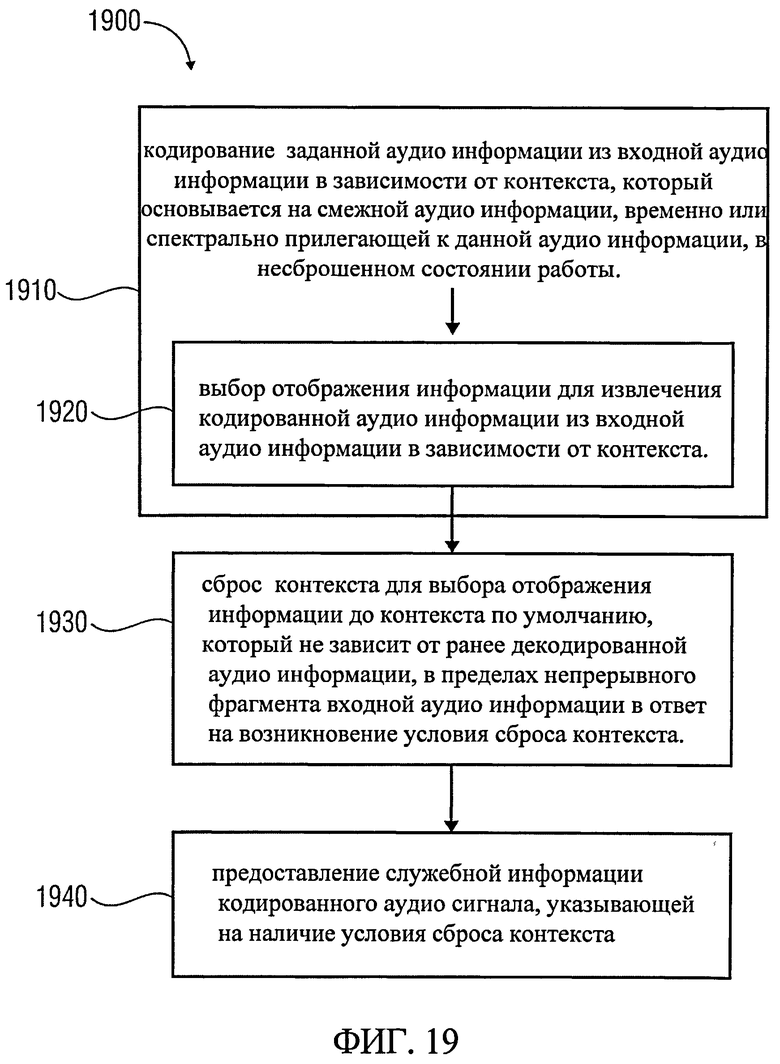

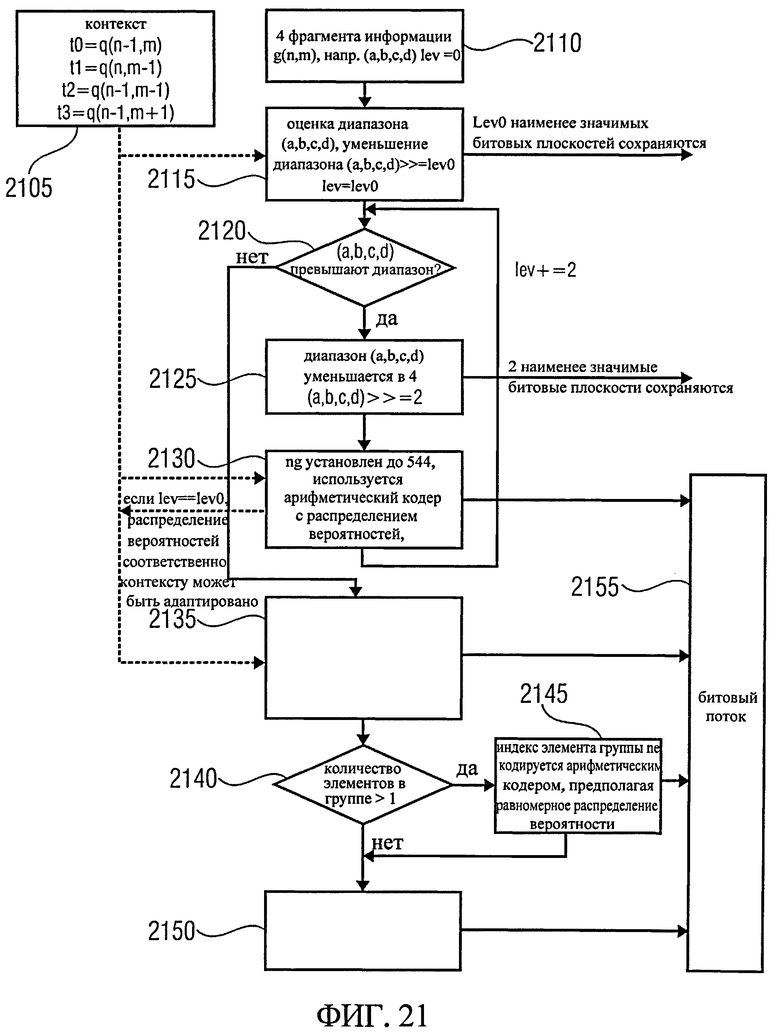
Изобретение относится к области кодирования и декодирования аудио сигналов. Технический результат заключается в обеспечении адаптации правил отображения информации энтропийного декодирования к статике сигнала. Технический результат достигается за счет аудио декодера для получения декодированной аудио информации на основе энтропийно-кодированной аудио информации, который включает в себя контекстно-зависимый энтропийный декодер, предназначенный для декодирования энтропийно-кодированной аудио информации в зависимости от контекста, который основывается на ранее декодированной аудио информации в несброшенном состоянии. Контекстно-зависимый энтропийный декодер предназначен для выбора отображения информации для извлечения декодированной аудио информации из кодированной аудио информации в зависимости от контекста. Контекстно-зависимый энтропийный декодер состоит из контекстного ресеттера, предназначенного для сброса контекста для выбора отображения информации до контекста по умолчанию, который не зависит от ранее декодированной аудио информации, в ответ на служебную информацию в кодированной аудио информации. 7 н. и 12 з.п. ф-лы, 21 ил.
1. Аудио декодер (100; 200) для получения декодированной аудио информации (112; 212) на основе энтропийно-кодированной аудио информации (110; 210, 222, 224), включающий контекстно-зависимый энтропийный декодер (120; 240), настроенный для декодирования энтропийно-кодированной аудио информации (110; 210 222, 224) в зависимости от контекста, который основывается на ранее декодированной аудио информации (112, 212) в несброшенном состоянии; при этом контекстно-зависимый энтропийный декодер (120; 240) настроен для выбора отображения информации для получения декодированной аудио информации (112; 212) из кодированной аудио информации в зависимости от контекста; контекстно-зависимый энтропийный декодер (120; 240) содержит контекстный ресеттер (130), настроенный на сброс контекста для выбора отображения информации до контекста по умолчанию, при этом контекст по умолчанию не зависит от ранее декодированной аудио информации, в ответ на побочную информацию в кодированной аудио информации (110; 210).
2. Аудио декодер (100; 200) по п.1, в котором контекстный ресеттер (130) настроен на выборочный сброс контекстно-зависимого энтропийного декодера (120; 240) между декодированием первого (1010) и второго (1012) звукокадров кодированной аудио информации (110; 210), имеющей связанные с ней спектральные данные одинакового спектрального разрешения.
3. Аудио декодер (100; 200) по п.1, при этом аудио декодер настроен на прием в качестве составной части энтропийно-кодированной аудио информации (110; 210, 222, 224) информации, описывающей спектральные значения в первом звукокадре (1010) и во втором звукокадре (1012), следующем за первым звукокадром; при этом аудио декодер включает преобразователь спектральной области во временной области (252; 262), настроенный перекрывать и добавлять первый оконный сигнал во временной области, который основан на спектральных значениях первого звукокадра (1010), и второй оконный сигнал во временной области, который основан на спектральных значениях второго звукокадра (1012), для получения декодированной аудио информации (112; 212); аудио декодер настроен отдельно регулировать формы окна для получения первого оконного сигнала во временной области и окна для получения второго оконного сигнала во временной области, аудио декодер настроен для выполнения, в ответ на служебную информацию (132), сброса контекста между декодированием спектральных значений первого звукокадра (1010) и декодированием спектральных значений второго звукокадра (1012), даже если вторая форма окна идентична первой форме окна, контекст, используемый для декодирования кодированной аудио информации второго звукокадра (1012), не зависит от декодированной аудио информации первого звукокадра (1010), если служебная информация указывает на то, что нужно сбросить контекст.
4. Аудио декодер (100; 200) по п.3, при этом аудио декодер настроен на получение служебной информации о сбросе контекста (132) для передачи сигнала сброса контекста; аудио декодер настроен на дополнительный прием служебной информации о форме окна, аудио декодер настроен для регулировки форм окон для получения первого и второго оконных сигналов во временной области независимо от выполнения сброса контекста.
5. Аудио декодер (100; 200) по п.1, аудио декодер настроен на прием в качестве служебной информации о сбросе контекста (132) однобитового флага сброса контекста на каждый звукокадр кодированной аудио информации; аудио декодер настроен на прием, в дополнение к флагу сброса контекста, служебной информации, описывающей спектральное разрешение спектральных значений, представленных энтропийно-кодированной аудио информацией (110; 210, 222, 224), или длину временного окна для управления окнами во временной области значений, представленную кодированной аудио информацией; контекстный ресеттер (130) настроен для выполнения сброса контекста, в ответ на однобитовый флаг сброса контекста, между декодированием спектральных значений (242, 244) двух звукокадров кодированной аудио информации, представляющей спектральные значения одинаковых спектральных разрешений или длин окон.
6. Аудио декодер (100; 200) по п.1, при этом аудио декодер настроен на прием в качестве служебной информации для сброса контекста (132) однобитового флага сброса контекста на каждый звукокадр кодированной аудио информации; аудио декодер настроен на прием кодированной аудио информации (110; 210, 222, 224), содержащей множество наборов спектральных значений (1042a, 1042b, … 1042h) на каждый звукокадр (1040); контекстно-зависимый энтропийный декодер (120; 240) настроен для декодирования энтропийно-кодированной аудио информации последующего набора спектральных значений (1042b) данного звукокадра (1040) в зависимости от контекста, который основывается на ранее декодированной аудио информации предыдущего набора (1042а) спектральных значений данного звукокадра (1040), в несброшенном состоянии, при этом контекстный ресеттер (130) настроен на сброс контекста до контекста по умолчанию перед декодированием первого набора (1042а) спектральных значений данного звукокадра (1040) и между декодированием любых двух последующих наборов (1042a-1042h) спектральных значений данного звукокадра (1040) в ответ на однобитовый флаг сброса контекста (132), активация однобитового флага сброса контекста (132) данного звукокадра (1040) вызывает многократный сброс контекста при декодировании нескольких наборов (1042a-1042h) спектральных значений звукокадра (1040).
7. Аудио декодер (100; 200) по п.6, аудио декодер настроен на получение служебной информации о группировании, аудио декодер настроен группировать два или более наборов (1042a-1042h) спектральных значений для объединения с информацией об общем коэффициенте масштабирования в зависимости от служебной информации о группировании, при этом контекстный ресеттер (130) настроен на сброс контекста до контекста по умолчанию между декодированием двух наборов (1042a, 1042b) спектральных значений, группированных вместе, в ответ на однобитовый флаг сброса контекста (132).
8. Аудио декодер (100; 200) по п.1, аудио декодер настроен на получение в качестве служебной информации для сброса контекста однобитового флага сброса контекста (132) на каждый звукокадр; когда аудио декодер настроен на получение в качестве кодированной аудио информации последовательности (1070, 1072) кодированных звукокадров, последовательность кодированных звукокадров, включающая однооконные кадры (1070) и многооконные кадры (1072); при этом энтропийный декодер (120) настроен для декодирования энтропийно-кодированных спектральных значений многооконного звукокадра (1072), следующего за предыдущим однооконным звукокадром (1070), в зависимости от контекста, который основывается на ранее декодированной аудио информации предыдущего однооконного звукокадра (1070) в несброшенном состоянии; энтропийный декодер (120) настроен для декодирования энтропийно-кодированных спектральных значений однооконного звукокадра, следующего за предыдущим многооконным звукокадром (1072), в зависимости от контекста, который основывается на ранее декодированной аудио информации предыдущего многооконного звукокадра (1072) в несброшенном состоянии; энтропийный декодер (120) настроен для декодирования энтропийно-кодированных спектральных значений однооконного звукокадра (1012), следующего за предыдущим однооконным звукокадром (1010), в зависимости от контекста, который основывается на ранее декодированной аудио информации предыдущего однооконного звукокадра (1010) в несброшенном состоянии; при этом энтропийный декодер (120) настроен для декодирования энтропийно-кодированных спектральных значений многооконного звукокадра, следующего за предыдущим многооконным звукокадром (1072), в зависимости от контекста, который основывается на ранее декодированной аудио информации предыдущего многооконного звукокадра (1072) в несброшенном состоянии; при этом контекстный ресеттер (130) настроен на сброс контекста между декодированием энтропийно-кодированных спектральных значений последующих звукокадров в ответ на однобитовый флаг сброса контекста (132), при этом контекстный ресеттер (130) настроен на дополнительный сброс, в случае многооконного звукокадра, контекста между декодированием энтропийно-кодированных спектральных значений, связанных с различными окнами из многооконного звукокадра в ответ на однобитовый флаг сброса контекста.
9. Аудио декодер (100; 200) по п.1, при этом аудио декодер настроен на прием в качестве служебной информации (132) для сброса контексте однобитового флага сброса контекста на каждый звукокадр кодированной аудио информации (110, 210 224) и на прием в качестве кодированной аудио информации последовательности кодированных звукокадров (1210, 1220, 1230), последовательность кодированных звукокадров, которая включает звукокадр в области линейного предсказания (1210, 1220, 1230); при этом звукокадр в линейно-предсказанной области содержит выборочное число частей преобразования кодированного возбуждения (1212b, 1212c, 1212d, 1222a, 1222b, 1222c, 1222d, 1232) для возбуждения синтезатора линейно-предсказанной области (262), при этом контекстно-зависимый энтропийный декодер (120; 240) настроен для декодирования спектральных значений частей преобразования кодированного возбуждения в зависимости от контекста, который основывается на ранее декодированной аудио информации в несброшенном состоянии; контекстный ресеттер (130) настроен на сброс, в ответ на служебную информацию (132), контекста до контекста по умолчанию перед декодированием набора спектральных значений первой части преобразования кодированного возбуждения (1212b, 1222a, 1232) данного звукокадра (1210, 1220, 1230), опуская сброс контекста до контекста по умолчанию между декодированием наборов спектральных значений разных частей преобразования кодированного возбуждения (1212b, 1212c, 1212d; 1222a, 1222b, 1222c, 1222d) данного звукокадра (1210, 1220, 1230).
10. Аудио декодер (100; 200) по п.1, при этом аудио декодер настроен на получение кодированной аудио информации, содержащей множество наборов спектральных значений на каждый звукокадр (1320, 1330), при этом аудио декодер настроен также принимать служебную информацию о группировании, аудио декодер настроен группировать (1322a, 1322c, 1322d, 1330c, 1330d) два или более набора спектральных значений для объединения с информацией об общем коэффициенте масштабирования в зависимости от служебной информации о группировании; при этом контекстный ресеттер (130) настроен на сброс контекста до контекста по умолчанию в ответ на служебную информацию о группировании, при этом контекстный ресеттер (130) настроен на сброс контекста между декодированием наборов спектральных значений последующих групп, и на избежание сброса контекста между декодированием наборов спектральных значений одной группы.
11. Способ (1800) для получения декодированной аудио информации на основе кодированной аудио информации, включающий декодирование (1810) энтропийно-кодированной аудио информации с учетом контекста, который основывается на ранее декодированной аудио информации в несброшенном состоянии, декодирование энтропийно-кодированной аудио информации включает этап (1812) отображения информации для получения декодированной аудио информации из кодированной аудио информации в зависимости от контекста, и при помощи (1814) выбранного отображения информации для извлечения первой части декодированной аудио информации; декодирование энтропийно-кодированной аудио информации также включает в себя сброс (1816) контекста для выбора отображения информации до контекста по умолчанию, который не зависит от ранее декодированной аудио информации, в ответ на служебную информацию, и использование (1818) отображения информации, которая основана на контексте по умолчанию, для декодирования второй части декодированной аудио информации.
12. Аудио кодер (1400; 1500; 1600; 1700) для получения кодированной аудио информации (1424) на основе входной аудио информации (1412), содержащий контекстно-зависимый энтропийный кодер (1420), настроенный для кодирования входной аудио информации (1412) в зависимости от контекста, который основывается на смежной аудио информации, временно или спектрально прилегающей к данной аудио информации, в несброшенном состоянии; контекстно-зависимый энтропийный кодер (1420) настроен на выбор отображения информации для получения кодированной аудио информации (1424) из входной аудио информации (1412) в зависимости от контекста; а также контекстно-зависимый энтропийный кодер содержит контекстный ресеттер (1450; 1550; 1660; 1770), настроенный на сброс контекста для выбора отображения информации до контекста по умолчанию, в пределах непрерывного фрагмента входной аудио информации (1412) в ответ на возникновение условия сброса контекста; кодер настроен на получение служебной информации (1480; 1780) из кодированной аудио информации (1424), указывающей на наличие условия сброса контекста.
13. Аудио кодер (1400) по п.12, при этом аудио кодер настроен для выполнения регулярного сброса контекста хотя бы раз в n кадров входной аудио информации.
14. Аудио кодер (1500) по п.12, при этом аудио настроен на переключение между множеством различных режимов кодирования, аудио кодер настроен для выполнения сброса контекста в ответ на изменение между двумя режимами кодирования.
15. Аудио кодер (1600) по п.12, аудио кодер настроен для расчета или оценки первого числа битов, необходимых для кодирования определенной входной аудио информации (1212) в зависимости от несброшенного контекста (1642), который основывается на смежной аудио информации, временно или спектрально прилегающей к определенной аудио информации, а также для расчета или оценки второго числа битов, необходимых для кодирования определенной аудио информации, используя контекст по умолчанию (1644), при этом аудио кодер настроен на сравнение первого числа битов и второго числа битов для того, чтобы решить, предоставлять ли кодированную аудио информацию (1424), соответствующую определенной аудио информации на основе несброшенного контекста (1642) или контекста по умолчанию (1644), и для сигнализирования результата указанного решения с помощью служебной информации (1480).
16. Способ предоставления кодированной аудио информации (1424) на основе входной аудио информации (1412), включающий кодирование (1910) данной аудио информации из входной аудио информации в зависимости от контекста, который основывается на смежной аудио информации, временно или спектрально прилегающей к данной аудио информации, в несброшенном состоянии, при этом кодирование данной аудио информации в зависимости от контекста включает в себя выбор (1920) отображения информации для получения кодированной аудио информации из входной аудио информации в зависимости от контекста, сброс (1930) контекста для выбора отображения информации до контекста по умолчанию, в рамках непрерывного фрагмента входной аудио информации в ответ на возникновение условия сброса контекста; предоставление (1940) служебной информации кодированной аудио информации, указывающей на наличие условия сброса контекста.
17. Цифровой носитель с записанной на нем компьютерной программой осуществления способа по п.11, когда компьютерная программа запущена на компьютере.
18. Цифровой носитель с записанной на нем компьютерной программой для осуществления способа по п.16, когда компьютерная программа запущена на компьютере.
19. Средство передачи кодированной аудио информации, которая содержит кодированное представление множества наборов спектральных значений, при этом множество наборов спектральных значений, кодированных в зависимости от несброшенного контекста, который зависит от соответствующего предыдущего набора спектральных значений; при этом множество наборов спектральных значений, кодированных в зависимости от контекста по умолчанию, который не зависит от соответствующего предыдущего набора спектральных значений, кодированный аудио сигнал содержит служебную информацию, указывающую, кодирован ли набор спектральных коэффициентов в зависимости от несброшенного контекста или в зависимости от контекста по умолчанию.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 7330812 B2, 12.02.2008 | |||
| Электрическое сопротивление для нагревательных приборов и нагревательный элемент для этих приборов | 1922 |
|
SU1997A1 |
| УЛУЧШЕННОЕ МАСКИРОВАНИЕ ОШИБКИ В ОБЛАСТИ ЧАСТОТ | 2004 |
|
RU2328775C2 |
| УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ СИГНАЛА, ИМЕЮЩЕГО ПОСЛЕДОВАТЕЛЬНОСТЬ ДИСКРЕТНЫХ ЗНАЧЕНИЙ | 2004 |
|
RU2325708C2 |

