ОБЛАСТЬ ТЕХНИКИ
Варианты осуществления в соответствии с изобретением относятся к аудиодекодеру для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации, аудиокодеру для предоставления кодированной аудиоинформации на основе входной аудиоинформации, способу для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации, способу для предоставления кодированной аудиоинформации на основе входной аудиоинформации и к компьютерной программе.
Варианты осуществления в соответствии с изобретением относятся к улучшенному спектральному помехоустойчивому кодированию, которое может использоваться в аудиокодере или декодере, например, в так называемом унифицированном кодере речи и звука (аудио) (USAC).
Вариант осуществления в соответствии с изобретением относится к обновлению таблиц спектрального кодирования для применения в текущей спецификации USAC.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Ниже будет кратко объясняться уровень техники изобретения, чтобы упростить понимание изобретения и его преимуществ. За последнее десятилетие приложены большие усилия к созданию возможности цифрового хранения и распространения аудиоконтента с хорошей эффективностью передачи битов (частота следования битов). Одним важным достижением в этом направлении является определение Международного стандарта ISO/IEC 14496-3. Часть 3 этого Стандарта имеет отношение к кодированию и декодированию аудиоконтента, а подраздел 4 части 3 имеет отношение к общему аудиокодированию. Подраздел 4 части 3 ISO/IEC 14496 задает идею для кодирования и декодирования общего аудиоконтента. К тому же предложены дополнительные улучшения для повышения качества и/или снижения необходимой скорости передачи битов.
В соответствии с идеей, описанной в упомянутом Стандарте, аудиосигнал временной области преобразуется в частотно-временное представление. Преобразование из временной области в частотно-временную область обычно выполняется с использованием блоков преобразования, которые также называются "кадрами", выборок временной области. Обнаружено, что полезно использовать перекрывающиеся кадры, которые сдвигаются, например, на половину кадра, потому что перекрытие позволяет эффективно избежать артефактов (или по меньшей мере уменьшить их). К тому же обнаружено, что следует выполнять обработку вырезки окном, чтобы избежать артефактов, происходящих от этой обработки ограниченных по времени кадров.
Путем преобразования обработанной методом окна части входного аудиосигнала из временной области в частотно-временную область во многих случаях получается уплотнение энергии, так что некоторые из спектральных значений содержат значительно большую величину, нежели множество других спектральных значений. Соответственно, во многих случаях имеется сравнительно небольшое количество спектральных значений, обладающих величиной, которая значительно выше средней величины спектральных значений. Типичным примером преобразования из временной области в частотно-временную область, приводящего к уплотнению энергии, является так называемое измененное дискретное косинусное преобразование (MDCT).
Спектральные значения часто масштабируются и квантуются в соответствии с психоакустической моделью, так что ошибки квантования сравнительно меньше для более важных с точки зрения психоакустики спектральных значений и сравнительно больше для менее важных с точки зрения психоакустики спектральных значений. Масштабированные и квантованные спектральные значения кодируются, чтобы предоставить их эффективное по скорости передачи битов представление.
Например, использование так называемого кодирования Хаффмана квантованных спектральных коэффициентов описывается в Международном стандарте ISO/IEC 14496-3:2005(E), часть 3, подраздел 4.
Однако обнаружено, что качество кодирования спектральных значений обладает значительным влиянием на необходимую скорость передачи битов. Также обнаружено, что сложность аудиодекодера, который часто реализуется в портативном бытовом приборе и который поэтому должен быть недорогим и иметь низкое энергопотребление, зависит от кодирования, используемого для кодирования спектральных значений.
В связи с этой ситуацией имеется потребность в идее для кодирования и декодирования аудиоконтента, которая обеспечивает улучшенный компромисс между эффективностью в скорости передачи битов и эффективностью в использовании ресурсов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Вариант осуществления в соответствии с изобретением создает аудиодекодер для предоставления множества декодированных спектральных значений на основе арифметически кодированного представления спектральных значений. Аудиодекодер также содержит преобразователь из частотной области во временную область для предоставления аудиопредставления временной области, используя декодированные спектральные значения, чтобы получить декодированную аудиоинформацию. Арифметический декодер сконфигурирован для выбора правила отображения, описывающего отображение кодового значения, представляющего спектральное значение или матрица старших битов спектрального значения, в кодированной форме на символьный код, представляющий спектральное значение или матрица старших битов спектрального значения, в декодированной форме в зависимости от состояния контекста, описанного числовым текущим значением контекста. Арифметический декодер сконфигурирован для определения числового текущего значения контекста в зависимости от множества ранее декодированных спектральных значений. Арифметический декодер сконфигурирован для оценивания хэш-таблицы, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов числовых значений контекста, чтобы выбрать правило отображения. Арифметический декодер сконфигурирован для оценивания хэш-таблицы для поиска индексного значения i хэш-таблицы, для которого значение ari_hash_m[i]>>8 больше либо равно c, тогда как если найденное индексное значение i хэш-таблицы больше 0, то значение ari_hash_m[i-1]>>8 меньше c. Кроме того, арифметический декодер сконфигурирован для выбора правила отображения, которое определяется индексом (pki) вероятностной модели, который равен ari_hash_m[i]&&0×FF, когда ari_hash_m[i]>>8 равно c, или равен ari_lookup_m[i] в противном случае. В настоящем варианте осуществления хэш-таблица ari_hash_m задается, как приведено на фиг. 22(1), 22(2), 22(3) и 22(4). Кроме того, таблица ari_lookup_m отображения задается, как приведено на фиг. 21.
Обнаружено, что сочетание вышеупомянутого алгоритма с хэш-таблицей из фиг. 22(1)-22(4) предусматривает очень эффективный выбор правила отображения, так как хэш-таблица в соответствии с фиг. 22(1)-22(4) весьма подходящим образом задает как значимые значения числового значения контекста, так и интервалы состояний. Кроме того, взаимодействие между упомянутым алгоритмом и хэш-таблицей в соответствии с фиг. 22(1)-22(4) показало, что оно приводит к очень хорошим результатам наряду с сохранением довольно небольшой вычислительной сложности. Кроме того, таблица отображения, заданная на фиг. 21, также хорошо приспособлена к упомянутому алгоритму, когда используется совместно с вышеупомянутой хэш-таблицей. Подводя итог, использование хэш-таблицы, которая приведена на фиг. 22(1)-22(4), и таблицы отображения, которая задана на фиг. 21, применительно к алгоритму, который описан выше, дает хорошую эффективность кодирования/декодирования и низкую вычислительную сложность.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для оценивания хэш-таблицы с использованием алгоритма, который задан на фиг. 5e, где c обозначает переменную, представляющую числовое текущее значение контекста или его масштабированную версию, где i является переменной, описывающей текущее индексное значение хэш-таблицы, где i_min является переменной, инициализируемой для обозначения индексного значения хэш-таблицы первой записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между c и (j >>8). В вышеупомянутом алгоритме условие "c<(j>>8)" задает, что значение состояния, описанное переменной c, меньше значения состояния, описанного записью ari_hash_m[i] таблицы. Также в вышеупомянутом алгоритме "j&0×FF" описывает индексное значение правила отображения, описанное записью ari_hash_m[i] таблицы. Дополнительно i_max является переменной, инициализируемой для обозначения индексного значения хэш-таблицы последней записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между c и (j>>8). Условие "c>(j>>8)" задает, что значение состояния, описанное переменной c, больше значения состояния, описанного записью ari_hash_m[i] таблицы. Возвращаемое значение упомянутого алгоритма обозначает индекс pki вероятностной модели и является индексным значением правила отображения. "ari_hash_m" обозначает хэш-таблицу, а "ari_hash_m[i]" обозначает запись хэш-таблицы ari_hash_m, имеющую индексное значение i хэш-таблицы. "ari_lookup_m" обозначает таблицу отображения, а "ari_lookup_m[i_max]" обозначает запись таблицы ari_lookup_m отображения, имеющую индексное значение i_max отображения.
Обнаружено, что сочетание вышеупомянутого алгоритма, который показан на фиг. 5e, с хэш-таблицей из фиг. 22(1)-22(4) предусматривает очень эффективный выбор правила отображения, так как хэш-таблица в соответствии с фиг. 22(1)-22(4) весьма подходящим образом задает как значимые значения числового значения контекста, так и интервалы состояний. Кроме того, взаимодействие между упомянутым алгоритмом в соответствии с фиг. 5e и хэш-таблицей в соответствии с фиг. 22(1)-22(4) показало, что оно приводит к очень хорошим результатам в сочетании с быстрым алгоритмом для табличного поиска. Кроме того, таблица отображения, заданная на фиг. 21, также хорошо приспособлена к упомянутому алгоритму, когда используется совместно с вышеупомянутой хэш-таблицей. Подводя итог, использование хэш-таблицы, которая приведена на фиг. 22(1)-22(4), и таблицы отображения, которая задана на фиг. 21, применительно к алгоритму, который задан на фиг. 5e, дает хорошую эффективность кодирования/декодирования и низкую вычислительную сложность. Другими словами, обнаружено, что алгоритм двоичного поиска из фиг. 5e хорошо подходит для работы с таблицами ari_hash_m и ari_lookup_m, которые заданы выше.
Однако следует отметить, что можно произвести небольшие изменения (которые легко осуществимы) или даже значительные изменения поискового алгоритма без изменения идеи в соответствии с настоящим изобретением.
Другими словами, способ поиска не ограничивается упомянутыми способами. Даже если бы использование способа двоичного поиска (например, в соответствии с фиг. 5e) дополнительно повышало производительность, также можно было бы выполнять простой исчерпывающий поиск, который, тем не менее, дает некоторое увеличение сложности.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для выбора правила отображения, описывающего отображение кодового значения на символьный код на основе индексного значения pki правила отображения, которое предоставляется, например, как возвращаемое значение показанного на фиг. 5e алгоритма. Использование упомянутого индексного значения pki правила отображения является очень эффективным, потому что взаимодействие вышеупомянутых таблиц и вышеупомянутого алгоритма оптимизируется для предоставления содержательного индексного значения правила отображения.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для использования индексного значения правила отображения в качестве индексного значения таблицы для выбора правила отображения, описывающего отображение кодового значения на символьный код. Использование индексного значения правила отображения в качестве индексного значения таблицы предусматривает эффективный в вычислительном отношении и использовании памяти выбор правила отображения.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для выбора одной из подтаблиц в таблице ari_cf_m[64][17], которая задана на фиг. 23(1), 23(2), 23(3), в качестве выбранного правила отображения. Эта идея основывается на том, что правила отображения, заданные подтаблицами в таблице ari_cf_m[64][17], которая задана на фиг. 23(1), (2), (3), хорошо приспособлены к результатам, которых можно добиться путем исполнения вышеупомянутого алгоритма в соответствии с фиг. 5e совместно с таблицами в соответствии с фиг. 21 и 22(1)-22(4).
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для получения числового значения контекста на основе числового предыдущего значения контекста с использованием алгоритма в соответствии с фиг. 5c, где алгоритм принимает в качестве входных значений значение переменной c, представляющее числовое предыдущее значение контекста, значение переменной i, представляющее индекс кортежа из двух спектральных значений для декодирования в векторе спектральных значений. Значение или переменная N представляет длину окна собственно окна восстановления для преобразователя из частотной области во временную область. Алгоритм в качестве выходного значения предоставляет обновленное значение или переменную c, представляющую числовое текущее значение контекста. В алгоритме операция "c>>4" описывает сдвиг вправо значения или переменной c на 4 бита. Кроме того, q[0][i+1] обозначает значение подобласти контекста, ассоциированное с предыдущим аудиокадром и имеющее ассоциированный больший (на 1) индекс i+1 частоты, чем текущий индекс частоты кортежа из двух спектральных значений, который должен быть декодирован в настоящее время. Аналогичным образом q[1][i-1] обозначает значение подобласти контекста, ассоциированное с текущим аудиокадром и имеющее ассоциированный меньший индекс i-1 частоты, меньший на 1, чем текущий индекс частоты кортежа из двух спектральных значений, который должен быть декодирован в настоящее время. q[1][i-2] обозначает значение подобласти контекста, ассоциированное с текущим аудиокадром и имеющее ассоциированный меньший индекс i-2 частоты, меньший на 2, чем текущий индекс частоты кортежа из двух спектральных значений, который должен быть декодирован в настоящее время. q[1][i-3] обозначает значение подобласти контекста, ассоциированное с текущим аудиокадром и имеющее ассоциированный меньший индекс i-3 частоты, меньший на 3, чем текущий индекс частоты кортежа из двух спектральных значений, который должен быть декодирован в настоящее время. Обнаружено, что алгоритм в соответствии с фиг. 5e при использовании совместно с таблицами из фиг. 21 и 22(1)-22(4) хорошо приспособлен для предоставления индексного значения правила отображения на основе числового текущего значения c контекста, полученного с использованием алгоритма из фиг. 5c, где получение числового текущего значения контекста с использованием алгоритма из фиг. 5c очень эффективно в вычислительном отношении, потому что алгоритм в соответствии с фиг. 5c требует только очень простого вычисления.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для обновления значения q[1][i] подобласти контекста, ассоциированного с текущим аудиокадром и имеющего ассоциированный текущий индекс частоты кортежа из двух спектральных значений, декодируемого в настоящее время с использованием алгоритма в соответствии с фиг. 5l, где a обозначает абсолютное значение первого спектрального значения кортежа из двух спектральных значений, декодируемого в настоящее время, и где b обозначает второе спектральное значение кортежа из двух спектральных значений, декодируемого в настоящее время. Видно, что предпочтительный алгоритм очень подходит для простого обновления значений подобласти контекста.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для предоставления декодированного значения m, представляющего кортеж из двух декодированных спектральных значений, с использованием алгоритма арифметического декодирования в соответствии с фиг. 5g. Обнаружено, что упомянутый алгоритм арифметического декодирования очень подходит для взаимодействия с вышеописанными алгоритмами.
Другой вариант осуществления в соответствии с изобретением создает декодер для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Аудиодекодер содержит арифметический декодер для предоставления множества декодированных спектральных значений на основе арифметически кодированного представления спектральных значений. Аудиодекодер также содержит преобразователь из частотной области во временную область для предоставления аудиопредставления временной области, используя декодированные спектральные значения, чтобы получить декодированную аудиоинформацию. Арифметический декодер сконфигурирован для выбора правила отображения, описывающего отображение кодового значения, представляющего спектральное значение или матрицу старших битов спектрального значения, в кодированной форме на символьный код, представляющий спектральное значение или матрицу старших битов спектрального значения, в декодированной форме в зависимости от состояния контекста, описанного числовым текущим значением контекста. Арифметический декодер сконфигурирован для определения числового текущего значения контекста в зависимости от множества ранее декодированных спектральных значений. Арифметический декодер сконфигурирован для оценивания хэш-таблицы, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов числовых значений контекста, чтобы выбрать правило отображения. Хэш-таблица ari_hash_m задается, как приведено на фиг. 22(1), 22(2), 22(3) и 22(4). Арифметический декодер сконфигурирован для оценивания хэш-таблицы, чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы, или определить интервал, описанный записями хэш-таблицы, в котором находится числовое текущее значение контекста, и вывести индексное значение правила отображения, описывающее выбранное правило отображения, в зависимости от результата оценки. Обнаружено, что хэш-таблица ari_hash_m, которая приводится на фиг. 22(1)-22(4), подходит для разбора на предмет значений контекста таблицы, описанных записями хэш-таблицы, и интервалов, описанных записями хэш-таблицы, чтобы посредством этого вывести индексное значение отображения. Обнаружено, что определение значений контекста таблицы и интервалов с помощью хэш-таблицы в соответствии с фиг. 22(1)-22(4) предоставляет эффективный механизм для выбора правила отображения при использовании совместно с простой идеей для оценки хэш-таблицы, которая использует записи упомянутой хэш-таблицы, чтобы проверить значения контекста таблицы и чтобы определить, в каком интервале, заданном записями хэш-таблицы, находятся значения, не являющиеся значениями контекста таблицы.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для сравнения числового текущего значения контекста, или масштабированной версии числового текущего значения контекста, с последовательностью численно упорядоченных записей или подзаписей хэш-таблицы, чтобы итерационно получить индексное значение хэш-таблицы записи таблицы, так что числовое текущее значение контекста находится в интервале, заданном полученной записью хэш-таблицы, указанной полученным индексным значением хэш-таблицы, и соседней записью хэш-таблицы. В этом случае арифметический декодер сконфигурирован для определения следующей записи последовательности записей хэш-таблицы в зависимости от результата сравнения между числовым текущим значением контекста, или масштабированной версией числового текущего значения контекста, и текущей записью или подзаписью. Очевидно, что этот механизм предусматривает очень эффективную оценку хэш-таблицы в соответствии с фиг. 22(1)-22(4).
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для выбора правила отображения, заданного второй подзаписью хэш-таблицы, обозначенной текущим индексным значением хэш-таблицы, если найдено, что числовое текущее значение контекста (или его масштабированная версия) равно первой подзаписи хэш-таблицы, обозначенной текущим индексным значением хэш-таблицы. Соответственно, записи хэш-таблицы, которая задана в соответствии с фиг. 22(1)-22(4), берут на себя двойную функцию. Первая подзапись (то есть первая часть записи) хэш-таблицы используется для идентификации особенно значимых состояний числового (текущего) значения контекста, тогда как вторая подзапись хэш-таблицы (то есть вторая часть такой записи) задает правило отображения, например, путем задания индексного значения правила отображения. Таким образом, записи хэш-таблицы используются очень эффективно. Также механизм очень эффективен в предоставлении индексных значений правила отображения для особенно важных состояний числовых текущих значений контекста, которые описываются записями хэш-таблицы, точнее говоря, подзаписями хэш-таблицы. Таким образом, полная запись хэш-таблицы, которая задана на фиг. 22(1)-22(4), задает правила отображения особенно важного состояния числового (текущего) значения контекста в правило отображения и границы интервала областей (или интервалов) менее важных состояний числового текущего значения контекста.
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для выбора правила отображения, заданного записью или подзаписью таблицы ari_lookup_m отображения, если не найдено, что числовое текущее значение контекста равно подзаписи хэш-таблицы. В этом случае арифметический декодер сконфигурирован для выбора записи или подзаписи таблицы отображения в зависимости от итерационно полученного индексного значения хэш-таблицы. Таким образом, создается очень эффективный двухтабличный механизм, который позволяет эффективно предоставлять индексное значение правила отображения для особенно важных состояний числового текущего значения контекста и для менее важных состояний числового текущего значения контекста (где менее важные состояния числового текущего значения контекста не описываются явно, то есть отдельно, записями или подзаписями хэш-таблицы).
В предпочтительном варианте осуществления арифметический декодер сконфигурирован для выборочного предоставления индексного значения правила отображения, заданного записью хэш-таблицы, указанной полученным индексным значением хэш-таблицы, если найдено, что числовое текущее значение контекста равно значению, заданному записью хэш-таблицы, обозначенной текущим индексным значением хэш-таблицы. Таким образом, имеется эффективный механизм, который предусматривает двойное использование записей хэш-таблицы.
Дополнительные варианты осуществления изобретения создают способы для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Упомянутые способы выполняют рассмотренные раньше функциональные возможности аудиодекодеров. Соответственно, способы основываются на таких же идеях и полученных данных, что и аудиодекодеры, так что для краткости обсуждение пропускается. Следует отметить, что способы можно дополнять любыми из признаков и функциональных возможностей аудиодекодеров.
Другой вариант осуществления в соответствии с изобретением создает аудиокодер для предоставления кодированной аудиоинформации на основе входной аудиоинформации. Аудиокодер содержит уплотняющий энергию преобразователь из временной области в частотную область для предоставления аудиопредставления частотной области на основе представления временной области входной аудиоинформации, так что аудиопредставление частотной области содержит набор спектральных значений. Аудиокодер также содержит арифметический кодер, сконфигурированный для кодирования спектрального значения или его предварительно обработанной версии с использованием кодового слова переменной длины. Арифметический кодер сконфигурирован для отображения спектрального значения, или значения матрицы старших битов спектрального значения, на кодовое значение. Арифметический кодер также сконфигурирован для выбора правила отображения, описывающего отображение спектрального значения, или матрицы старших битов спектрального значения, на кодовое значение в зависимости от состояния контекста, описанного числовым текущим значением контекста. Арифметический кодер сконфигурирован для определения числового текущего значения контекста в зависимости от множества ранее кодированных спектральных значений. Арифметический кодер также сконфигурирован для оценивания хэш-таблицы, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов числовых значений контекста, чтобы выбрать правило отображения. Хэш-таблица ari_hash_m задается, как приведено на фиг. 22(1)-22(4). Арифметический кодер сконфигурирован для оценивания хэш-таблицы, чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы, или определить интервал, описанный записями хэш-таблицы, в котором находится числовое текущее значение контекста, и вывести индексное значение правила отображения, описывающее выбранное правило отображения, в зависимости от результата упомянутой оценки. Следует отметить, что функциональные возможности аудиокодера находятся параллельно рассмотренным выше функциональным возможностям аудиодекодера. Соответственно, для краткости производится отсылка к вышеприведенному обсуждению основных идей аудиодекодера.
Кроме того, следует отметить, что аудиокодер можно дополнять любыми из признаков и функциональных возможностей аудиодекодера. В частности, любые из признаков касаемо выбора правила отображения могут быть реализованы в аудиокодере с тем же успехом, где кодированные спектральные значения замещают декодированные спектральные значения, и так далее.
Другой вариант осуществления в соответствии с изобретением создает способ для предоставления кодированной аудиоинформации на основе входной аудиоинформации. Способ выполняет функциональные возможности аудиокодера, описанного раньше, и основывается на таких же идеях.
Другой вариант осуществления в соответствии с изобретением создает компьютерную программу для выполнения по меньшей мере одного из описанных раньше способов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления в соответствии с настоящим изобретением будут описываться позднее со ссылкой на приложенные фигуры, на которых:
фиг. 1 показывает блок-схему аудиокодера в соответствии с вариантом осуществления изобретения;
фиг. 2 показывает блок-схему аудиодекодера в соответствии с вариантом осуществления изобретения;
фиг. 3 показывает представление в псевдокоде алгоритма "values_decode()" для декодирования спектральных значений;
фиг. 4 показывает схематическое представление контекста для вычисления состояния;
фиг. 5a показывает представление в псевдокоде алгоритма "arith_map_context()" для отображения контекста;
фиг. 5b показывает представление в псевдокоде другого алгоритма "arith_map_context()" для отображения контекста;
фиг. 5c показывает представление в псевдокоде алгоритма "arith_get_context()" для получения значения состояния контекста;
фиг. 5d показывает представление в псевдокоде другого алгоритма "arith_get_context()" для получения значения состояния контекста;
фиг. 5e показывает представление в псевдокоде алгоритма "arith_get_pk()" для выведения индексного значения "pki" таблицы накопленных частот из значения состояния (или переменной состояния);
фиг. 5f показывает представление в псевдокоде другого алгоритма "arith_get_pk()" для выведения индексного значения "pki" таблицы накопленных частот из значения состояния (или переменной состояния);
фиг. 5g показывает представление в псевдокоде алгоритма "arith_decode()" для арифметического декодирования символа из кодового слова переменной длины;
фиг. 5h показывает первую часть представления в псевдокоде другого алгоритма "arith_decode()" для арифметического декодирования символа из кодового слова переменной длины;
фиг. 5i показывает вторую часть представления в псевдокоде другого алгоритма "arith_decode()" для арифметического декодирования символа из кодового слова переменной длины;
фиг. 5j показывает представление в псевдокоде алгоритма для выведения абсолютных значений a,b спектральных значений из общего значения m;
фиг. 5k показывает представление в псевдокоде алгоритма для внесения декодированных значений a,b в массив декодированных спектральных значений;
фиг. 5l показывает представление в псевдокоде алгоритма "arith_update_context()" для получения значения подобласти контекста на основе абсолютных значений a,b декодированных спектральных значений;
фиг. 5m показывает представление в псевдокоде алгоритма "arith_finish()" для заполнения записей массива декодированных спектральных значений и массива значений подобласти контекста;
фиг. 5n показывает представление в псевдокоде другого алгоритма для выведения абсолютных значений a,b декодированных спектральных значений из общего значения m;
фиг. 5o показывает представление в псевдокоде алгоритма "arith_update_context()" для обновления массива декодированных спектральных значений и массива значений подобласти контекста;
фиг. 5p показывает представление в псевдокоде алгоритма "arith_save_context()" для заполнения записей массива декодированных спектральных значений и записей массива значений подобласти контекста;
фиг. 5q показывает условные обозначения;
фиг. 5r показывает другие условные обозначения;
фиг. 6a показывает синтаксическое представление блока необработанных данных в унифицированном кодировании речи и звука (USAC);
фиг. 6b показывает синтаксическое представление элемента одиночного канала;
фиг. 6c показывает синтаксическое представление элемента канальной пары;
фиг. 6d показывает синтаксическое представление управляющей информации "ICS";
фиг. 6e показывает синтаксическое представление потока канала частотной области;
фиг. 6f показывает синтаксическое представление арифметически кодированных спектральных данных;
фиг. 6g показывает синтаксическое представление для декодирования набора спектральных значений;
фиг. 6h показывает другое синтаксическое представление для декодирования набора спектральных значений;
фиг. 6i показывает условные обозначения элементов данных и переменных;
фиг. 6j показывает другие условные обозначения элементов данных и переменных;
фиг. 6k показывает синтаксическое представление элемента "UsacSingleChannelElement()" одиночного канала USAC;
фиг. 6l показывает синтаксическое представление элемента "UsacChannelPairElement()" канальной пары USAC;
фиг. 6m показывает синтаксическое представление управляющей информации "ICS";
фиг. 6n показывает синтаксическое представление данных базового кодера USAC "UsacCoreCoderData";
фиг. 6o показывает синтаксическое представление потока "fd_channel_stream()" канала частотной области;
фиг. 6p показывает синтаксическое представление арифметически кодированных спектральных данных "ac_spectral_data()";
фиг. 7 показывает блок-схему аудиокодера в соответствии с первым аспектом изобретения;
фиг. 8 показывает блок-схему аудиодекодера в соответствии с первым аспектом изобретения;
фиг. 9 показывает графическое представление отображения числового текущего значения контекста на индексное значение правила отображения в соответствии с первым аспектом изобретения;
фиг. 10 показывает блок-схему аудиокодера в соответствии со вторым аспектом изобретения;
фиг. 11 показывает блок-схему аудиодекодера в соответствии со вторым аспектом изобретения;
фиг. 12 показывает блок-схему аудиокодера в соответствии с третьим аспектом изобретения;
фиг. 13 показывает блок-схему аудиодекодера в соответствии с третьим аспектом изобретения;
фиг. 14a показывает схематическое представление контекста для вычисления состояния, как он используется в соответствии с рабочим вариантом 4 Проекта стандарта USAC;
фиг. 14b показывает обзор таблиц, которые используются в схеме арифметического кодирования в соответствии с рабочим вариантом 4 Проекта стандарта USAC;
фиг. 15a показывает схематическое представление контекста для вычисления состояния, как он используется в вариантах осуществления в соответствии с изобретением;
фиг. 15b показывает обзор таблиц, которые используются в схеме арифметического кодирования в соответствии со сравнительным примером;
фиг. 16a показывает графическое представление потребности в постоянной памяти для схемы помехоустойчивого кодирования в соответствии со сравнительным примером, в соответствии с рабочим вариантом 5 Проекта стандарта USAC и в соответствии с кодированием Хаффмана с AAC (усовершенствованное аудиокодирование);
фиг. 16b показывает графическое представление общей потребности в постоянной памяти для данных декодера USAC в соответствии со сравнительным примером и в соответствии с идеей согласно рабочему варианту 5 Проекта стандарта USAC;
фиг. 17 показывает схематическое представление компоновки для сравнения помехоустойчивого кодирования в соответствии с рабочим вариантом 3 или рабочим вариантом 5 Проекта стандарта USAC со схемой кодирования в соответствии со сравнительным примером;
фиг. 18 показывает табличное представление средних скоростей передачи битов, выданных арифметическим кодером USAC в соответствии с рабочим вариантом 3 Проекта стандарта USAC и в соответствии со сравнительным примером;
фиг. 19 показывает табличное представление минимального и максимального уровней резервуара битов для арифметического декодера в соответствии с рабочим вариантом 3 Проекта стандарта USAC и для арифметического декодера в соответствии со сравнительным примером;
фиг. 20 показывает табличное представление чисел средней сложности для декодирования битового потока 32 кбит/с в соответствии с рабочим вариантом 3 Проекта стандарта USAC для разных версий арифметического кодера;
фиг. 21 показывает табличное представление содержимого таблицы "ari_lookup_m[742]" в соответствии с вариантом осуществления изобретения;
фиг. 22(1)-22(4) показывают табличное представление содержимого таблицы "ari_hash_m[742]" в соответствии с вариантом осуществления изобретения;
фиг. 23(1)-23(3) показывают табличное представление содержимого таблицы "ari_cf_m[64][17]" в соответствии с вариантом осуществления изобретения; и
фиг. 24 показывает табличное представление содержимого таблицы "ari_cf_r[]";
фиг. 25 показывает схематическое представление контекста для вычисления состояния;
фиг. 26 показывает табличное представление усредненной производительности кодирования для транскодирования битовых потоков эталонного качества WD6 для сравнительного примера ("M17558") и для варианта осуществления в соответствии с изобретением ("Новое предложение");
фиг. 27 показывает табличное представление производительности кодирования для транскодирования битовых потоков эталонного качества WD6 в расчете на рабочий режим для сравнительного примера ("M17558") и для варианта осуществления в соответствии с изобретением ("Переподготовленные таблицы");
фиг. 28 показывает табличное представление сравнения Потребности в памяти помехоустойчивого кодера для WD6, для сравнительного примера ("M17588") и для варианта осуществления в соответствии с изобретением ("Новое предложение");
фиг. 29 показывает табличное представление характеристик таблиц, которые использованы в варианте осуществления в соответствии с изобретением ("Переподготовленная схема кодирования");
фиг. 30 показывает табличное представление чисел средней сложности для декодирования битовых потоков эталонного качества WD6 в 32 кбит/с для разных версий арифметического кодера;
фиг. 31 показывает табличное представление чисел средней сложности для декодирования битовых потоков эталонного качества WD6 в 12 кбит/с для разных версий арифметического кодера;
фиг. 32 показывает табличное представление средних скоростей передачи битов, выданных арифметическим кодером в варианте осуществления в соответствии с изобретением и в WD6;
фиг. 33 показывает табличное представление минимальных, максимальных и средних скоростей передачи битов USAC на кадровой основе с использованием предложенной схемы;
фиг. 34 показывает табличное представление средних скоростей передачи битов, выданных кодером USAC, использующим арифметический кодер WD6, и кодером в соответствии с вариантом осуществления изобретения ("Новое предложение");
фиг. 35 показывает табличное представление лучшего и худшего случаев для варианта осуществления в соответствии с изобретением;
фиг. 36 показывает табличное представление предела резервуара битов для варианта осуществления в соответствии с изобретением;
фиг. 37 показывает синтаксическое представление арифметически кодированных данных "arith_data" в соответствии с вариантом осуществления изобретения;
фиг. 38 показывает условные обозначения и справочные элементы;
фиг. 39 показывает другие условные обозначения;
фиг. 40a показывает представление в псевдокоде функции или алгоритма "arith_map_context" в соответствии с вариантом осуществления изобретения;
фиг. 40b показывает представление в псевдокоде функции или алгоритма "arith_get_context" в соответствии с вариантом осуществления изобретения;
фиг. 40c показывает представление в псевдокоде функции или алгоритма "arith_map_pk" в соответствии с вариантом осуществления изобретения;
фиг. 40d показывает представление в псевдокоде первой части функции или алгоритма "arith_decode" в соответствии с вариантом осуществления изобретения;
фиг. 40e показывает представление в псевдокоде второй части функции или алгоритма "arith_decode" в соответствии с вариантом осуществления изобретения;
фиг. 40f показывает представление в псевдокоде функции или алгоритма для декодирования одного или более младших битов в соответствии с вариантом осуществления изобретения;
фиг. 40g показывает представление в псевдокоде функции или алгоритма "arith_update_context" в соответствии с вариантом осуществления изобретения;
фиг. 40h показывает представление в псевдокоде функции или алгоритма "arith_save_context" в соответствии с вариантом осуществления изобретения;
фиг. 41(1) и 41(2) показывают табличное представление содержимого таблицы "ari_lookup_m[742]" в соответствии с вариантом осуществления изобретения;
фиг. 42(1), (2), (3), (4) показывают табличное представление содержимого таблицы "ari_hash_m[742]" в соответствии с вариантом осуществления изобретения;
фиг. 43(1), (2), (3), (4), (5), (6) показывают табличное представление содержимого таблицы "ari_cf_m[96][17]" в соответствии с вариантом осуществления изобретения; и
фиг. 44 показывает табличное представление содержимого таблицы "ari_cf_r[4]" в соответствии с вариантом осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
1. Аудиокодер в соответствии с фиг. 7
Фиг. 7 показывает блок-схему аудиокодера в соответствии с вариантом осуществления изобретения. Аудиокодер 700 сконфигурирован для приема входной аудиоинформации 710 и предоставления на ее основе кодированной аудиоинформации 712.
Аудиокодер содержит уплотняющий энергию преобразователь 720 из временной области в частотную область, который сконфигурирован для предоставления аудиопредставления 722 частотной области на основе представления временной области входной аудиоинформации 710, так что аудиопредставление 722 частотной области содержит набор спектральных значений.
Аудиокодер 700 также содержит арифметический кодер 730, сконфигурированный для кодирования спектрального значения (из набора спектральных значений, образующего аудиопредставление 722 частотной области) или его предварительно обработанной версии с использованием кодового слова переменной длины, чтобы получить кодированную аудиоинформацию 712 (которая может содержать, например, множество кодовых слов переменной длины).
Арифметический кодер 730 сконфигурирован для отображения спектрального значения, или значения матрицы старших битов спектрального значения, на кодовое значение (то есть на кодовое слово переменной длины) в зависимости от состояния контекста.
Арифметический кодер также сконфигурирован для выбора правила отображения, описывающего отображение спектрального значения, или матрицы старших битов спектрального значения, на кодовое значение в зависимости от (текущего) состояния контекста. Арифметический кодер сконфигурирован для определения текущего состояния контекста или числового текущего значения контекста, описывающего текущее состояние контекста, в зависимости от множества ранее кодированных спектральных значений (предпочтительно, но не обязательно, соседних).
С этой целью арифметический кодер сконфигурирован для оценивания хэш-таблицы, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов числовых значений контекста.
Хэш-таблица (также обозначенная ниже как "ari_hash_m") предпочтительно задается, как приведено в табличном представлении из фиг. 22(1), 22(2), 22(3) и 22(4).
Кроме того, арифметический кодер предпочтительно сконфигурирован для оценивания хэш-таблицы (ari_hash_m), чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записями хэш-таблицы (ari_hash_m), и/или определить интервал, описанный записями хэш-таблицы (ari_hash_m), в котором находится числовое текущее значение контекста, и вывести индексное значение правила отображения (например, обозначенное "pki" в этом документе), описывающее выбранное правило отображения, в зависимости от результата оценки.
В некоторых случаях индексное значение правила отображения может отдельно ассоциироваться с числовым (текущим) значением контекста, являющимся значимым значением состояния. Также общее индексное значение правила отображения может ассоциироваться с разными числовыми (текущими) значениями контекста, лежащими в интервале, заданном границами интервала (где границы интервала предпочтительно задаются записями хэш-таблицы).
Как видно, отображение спектрального значения (аудиопредставления 722 частотной области) или матрицы старших битов спектрального значения на кодовое значение (кодированной аудиоинформации 712) может выполняться с помощью кодирования 740 спектрального значения с использованием правила 742 отображения. Средство 750 отслеживания состояния может быть сконфигурировано для отслеживания состояния контекста. Средство 750 отслеживания состояния предоставляет информацию 754, описывающую текущее состояние контекста. Информация 754, описывающая текущее состояние контекста, предпочтительно может принимать форму числового текущего значения контекста. Селектор 760 правила отображения сконфигурирован для выбора правила отображения, например, таблицы накопленных частот, описывающего отображение спектрального значения или матрицы старших битов спектрального значения на кодовое значение. Соответственно, селектор 760 правила отображения предоставляет информацию 742 правила отображения кодированию 740 спектрального значения. Информация 742 правила отображения может принимать форму индексного значения правила отображения или таблицы накопленных частот, выбранной в зависимости от индексного значения правила отображения. Селектор 760 правила отображения содержит (или по меньшей мере оценивает) хэш-таблицу 752, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы и интервалы числовых значений контекста. Предпочтительно, чтобы записи хэш-таблицы 762 (ari_hash_m[742]) задавались, как приведено в табличном представлении из фиг. 22(1)-22(4). Хэш-таблица 762 оценивается для того, чтобы выбрать правило отображения, то есть для того, чтобы предоставить информацию 742 правила отображения.
Предпочтительно, но не обязательно, что индексное значение правила отображения может отдельно ассоциироваться с числовым значением контекста, являющимся значимым значением состояния, и общее индексное значение правила отображения может ассоциироваться с разными числовыми значениями контекста, лежащими в интервале, заданном границами интервала.
Чтобы подвести итог вышесказанному, аудиокодер 700 выполняет арифметическое кодирование аудиопредставления частотной области, предоставленного преобразователем из временной области в частотную область. Арифметическое кодирование является контекстно-зависимым, так что правило отображения (например, таблица накопленных частот) выбирается в зависимости от ранее кодированных спектральных значений. Соответственно, спектральные значения, соседние по времени и/или частоте (или по меньшей мере в предопределенном окружении) друг с другом и/или с кодируемым в настоящее время спектральным значением (то есть спектральные значения в предопределенном окружении кодируемого в настоящее время спектрального значения), учитываются в арифметическом кодировании, чтобы отрегулировать распределение вероятности, оцененное посредством арифметического кодирования. При выборе подходящего правила отображения оцениваются числовые текущие значения 754 контекста, предоставленные средством 750 отслеживания состояния. Поскольку обычно количество разных правил отображения значительно меньше количества возможных значений числовых текущих значений 754 контекста, селектор 760 правила отображения распределяет одинаковые правила отображения (описанные, например, индексным значением правила отображения) сравнительно большому количеству разных числовых значений контекста. Тем не менее, обычно существуют особые спектральные конфигурации (представленные особыми числовыми значениями контекста), с которыми следует ассоциировать конкретное правило отображения, чтобы получить хорошую эффективность кодирования.
Обнаружено, что выбор правила отображения в зависимости от числового текущего значения контекста может выполняться с очень высокой вычислительной эффективностью, если записи одной хэш-таблицы задают значимые значения состояния и границы интервалов числовых (текущих) значений контекста. Кроме того, обнаружено, что использование хэш-таблицы, как задано на фиг. 22(1), 22(2), 22(3), 22(4), способствует очень высокой эффективности кодирования. Обнаружено, что этот механизм совместно с упомянутой хэш-таблицей хорошо приспособлен к требованиям выбора правила отображения, потому что имеется много случаев, в которых одиночное значимое значение состояния (или значимое числовое значение контекста) встраивается между левосторонним интервалом множества незначимых значений состояния (с которыми ассоциируется общее правило отображения) и правосторонним интервалом множества незначимых значений состояния (с которыми ассоциируется общее правило отображения). Также механизм использования одной хэш-таблицы, записи которой задаются в таблицах из фиг. 22(1), 22(2), 22(3), 22(4) и задают значимые значения состояния и границы интервалов числовых (текущих) значений контекста, может эффективно обрабатывать разные случаи, в которых, например, имеется два соседних интервала незначимых значений состояния (также обозначенных как незначимые числовые значения контекста) без значимого значения состояния между ними. Особенно высокая вычислительная эффективность достигается благодаря тому, что остается небольшим количество обращений к таблицам. Например, в большинстве вариантов осуществления достаточно одиночного итеративного табличного поиска, чтобы выяснить, равно ли числовое текущее значение контекста какому-нибудь из значимых значений состояния, заданных записями упомянутой хэш-таблицы, или в каком из интервалов незначимых значений состояния находится числовое текущее значение контекста. Следовательно, может оставаться небольшим количество обращений к таблицам, которые являются длительными и энергоемкими. Таким образом, селектор 760 правила отображения, который использует хэш-таблицу 762, может считаться очень эффективным селектором правила отображения в показателях вычислительной сложности, позволяя при этом получать хорошую эффективность кодирования (в показателях скорости передачи битов).
Ниже будут описываться дополнительные подробности касательно извлечения информации 742 правила отображения из числового текущего значения 754 контекста.
2. Аудиодекодер в соответствии с фиг. 8
Фиг. 8 показывает блок-схему аудиодекодера 800. Аудиодекодер 800 сконфигурирован для приема кодированной аудиоинформации 810 и предоставления на ее основе декодированной аудиоинформации 812.
Аудиодекодер 800 содержит арифметический декодер 820, который сконфигурирован для предоставления множества спектральных значений 822 на основе арифметически кодированного представления 821 спектральных значений.
Аудиодекодер 800 также содержит преобразователь 830 из частотной области во временную область, который сконфигурирован для приема декодированных спектральных значений 822 и предоставления аудиопредставления 812 временной области, которое может составлять декодированную аудиоинформацию, используя декодированные спектральные значения 822, чтобы получить декодированную аудиоинформацию 812.
Арифметический декодер 820 содержит определитель 824 спектрального значения, который сконфигурирован для отображения кодового значения арифметически кодированного представления 821 спектральных значений на символьный код, представляющий одно или более декодированных спектральных значений или по меньшей мере часть (например, матрица старших битов) одного или более декодированных спектральных значений. Определитель 824 спектрального значения может быть сконфигурирован для выполнения отображения в зависимости от правила отображения, которое может описываться информацией 828a правила отображения. Информация 828a правила отображения может принимать форму, например, индексного значения правила отображения или выбранной таблицы накопленных частот (выбранной, например, в зависимости от индексного значения правила отображения).
Арифметический декодер 820 сконфигурирован для выбора правила отображения (например, таблицы накопленных частот), описывающего отображение кодовых значений (описанных арифметически кодированным представлением 821 спектральных значений) на символьный код (описывающий одно или более спектральных значений или их матрица старших битов в декодированной форме) в зависимости от состояния контекста (которое может описываться информацией 826a состояния контекста).
Арифметический декодер 820 сконфигурирован для определения текущего состояния контекста (описанного числовым текущим значением контекста) в зависимости от множества ранее декодированных спектральных значений. С этой целью может использоваться средство 826 отслеживания состояния, которое принимает информацию, описывающую ранее декодированные спектральные значения и которое предоставляет на ее основе числовое текущее значение 826a контекста, описывающее текущее состояние контекста.
Арифметический декодер также сконфигурирован для оценивания хэш-таблицы 829, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов числовых значений контекста, чтобы выбрать правило отображения. Предпочтительно, чтобы записи хэш-таблицы 829 (ari_hash_m[742]) задавались, как приведено в табличном представлении из фиг. 22(1)-22(4). Хэш-таблица 829 оценивается для того, чтобы выбрать правило отображения, то есть для того, чтобы предоставить информацию 829 правила отображения.
Предпочтительно, чтобы индексное значение правила отображения отдельно ассоциировалось с числовым значением контекста, являющимся значимым значением состояния, а общее индексное значение правила отображения ассоциировалось с разными числовыми значениями контекста, лежащими в интервале, заданном границами интервала. Оценка хэш-таблицы 829 может, например, выполняться с использованием средства оценки хэш-таблицы, которое может быть частью селектора 828 правила отображения. Соответственно, информация 828a правила отображения, например, в форме индексного значения правила отображения получается на основе числового текущего значения 826a контекста, описывающего текущее состояние контекста. Селектор 828 правила отображения может, например, определить индексное значение 828a правила отображения в зависимости от результата оценки хэш-таблицы 829. В качестве альтернативы оценка хэш-таблицы 829 может непосредственно предоставлять индексное значение правила отображения.
Касательно функциональных возможностей декодера 800 аудиосигнала следует отметить, что арифметический декодер 820 сконфигурирован для выбора правила отображения (например, таблицы накопленных частот), которое в среднем хорошо приспособлено к спектральным значениям, которые должны быть декодированы, так как правило отображения выбирается в зависимости от текущего состояния контекста (описанного, например, числовым текущим значением контекста), которое в свою очередь определяется в зависимости от множества ранее декодированных спектральных значений. Соответственно, можно использовать статистические зависимости между соседними спектральными значениями, которые должны быть декодированы. Кроме того, арифметический декодер 820 может быть эффективно реализован с хорошим компромиссом между вычислительной сложностью, размером таблицы и эффективностью кодирования, используя селектор 828 правила отображения. С помощью оценивания (одиночной) хэш-таблицы 829, записи которой описывают как значимые значения состояния, так и границы интервала интервалов незначимых значений состояния, одиночного итеративного табличного поиска может быть достаточно, чтобы вывести информацию 828a правила отображения из числового текущего значения 826a контекста. Кроме того, обнаружено, что использование хэш-таблицы, как задано на фиг. 22(1), 22(2), 22(3), 22(4), способствует очень высокой эффективности кодирования. Соответственно, можно отобразить сравнительно большое количество разных возможных числовых (текущих) значений контекста на сравнительно меньшее количество разных индексных значений правила отображения. Путем использования хэш-таблицы 829, которая описана выше и которая задана табличным представлением на фиг. 22(1)-22(4), можно использовать тот вывод, что во многих случаях одиночное отдельное значимое значение состояния (значимое значение контекста) встраивается между левосторонним интервалом незначимых значений состояния (незначимых значений контекста) и правосторонним интервалом незначимых значений состояния (незначимых значений контекста), где разное индексное значение правила отображения ассоциируется со значимым значением состояния (значимым значением контекста) по сравнению со значениями состояния (значениями контекста) левостороннего интервала и значениями состояния (значениями контекста) правостороннего интервала. Однако использование хэш-таблицы 829 также подходит для ситуаций, в которых два интервала числовых значений состояния являются непосредственно соседними, без значимого значения состояния между ними.
В заключение селектор 828 правила отображения, который оценивает хэш-таблицу 829 ari_hash_m[742], приводит к очень хорошей эффективности при выборе правила отображения (или при предоставлении индексного значения правила отображения) в зависимости от текущего состояния контекста (или в зависимости от числового текущего значения контекста, описывающего текущее состояние контекста), потому что механизм хеширования хорошо приспособлен к типичным сценариям контекста в аудиодекодере.
Ниже будут описываться дополнительные подробности.
3. Механизм хеширования значения контекста в соответствии с фиг. 9
Далее будет раскрываться механизм хеширования контекста, который может быть реализован в селекторе 760 правила отображения и/или селекторе 828 правила отображения. Хэш-таблица 762 и/или хэш-таблица 829, которая задана в табличном представлении фиг. 22(1)-22(4), может использоваться, чтобы реализовать упомянутый механизм хеширования значения контекста.
Ссылаясь теперь на фиг. 9, которая показывает сценарий хеширования числового текущего значения контекста, будут описываться дополнительные подробности. В графическом представлении фиг. 9 абсцисса 910 описывает значения числового текущего значения контекста (то есть числовые значения контекста). Ордината 912 описывает индексные значения правила отображения. Отметки 914 описывают индексные значения правила отображения для незначимых числовых значений контекста (описывающих незначимые состояния). Отметки 916 описывают индексные значения правила отображения для "отдельных" (истинных) значимых числовых значений контекста, описывающих отдельные (истинные) значимые состояния. Отметки 916 описывают индексные значения правила отображения для "неправильных" числовых значений контекста, описывающих "неправильные" значимые состояния, где "неправильное" значимое состояние является значимым состоянием, с которым ассоциируется такое же индексное значение правила отображения, как с одним из соседних интервалов незначимых числовых значений контекста.
Как видно, запись "ari_hash_m[i1]" хэш-таблицы описывает отдельное (истинное) значимое состояние, имеющее числовое значение c1 контекста. Как видно, индексное значение mriv1 правила отображения ассоциируется с отдельным (истинным) значимым состоянием, имеющим числовое значение c1 контекста. Соответственно, числовое значение c1 контекста и индексное значение mriv1 правила отображения могут описываться записью "ari_hash_m[i1]" хэш-таблицы. Интервал 932 числовых значений контекста ограничивается числовым значением c1 контекста, где числовое значение c1 контекста не принадлежит интервалу 932, так что наибольшее числовое значение контекста интервала 932 равно c1-1. Индексное значение mriv4 правила отображения (которое отличается от mriv1) ассоциируется с числовыми значениями контекста у интервала 932. Индексное значение mriv4 правила отображения может, например, описываться записью "ari_lookup_m[i1-1]" таблицы в дополнительной таблице "ari_lookup_m".
Кроме того, индексное значение mriv2 правила отображения может ассоциироваться с числовыми значениями контекста, лежащими в интервале 934. Нижняя граница интервала 934 определяется числовым значением c1 контекста, которое является значимым числовым значением контекста, где числовое значение c1 контекста не принадлежит интервалу 932. Соответственно, наименьшее значение интервала 934 равно c1+1 (предполагая целые числовые значения контекста). Другая граница интервала 934 определяется числовым значением c2 контекста, где числовое значение c2 контекста не принадлежит интервалу 934, так что наибольшее значение интервала 934 равно c2-1. Числовое значение c2 контекста является так называемым "неправильным" числовым значением контекста, которое описывается записью "ari_hash_m[i2]" хэш-таблицы. Например, индексное значение mriv2 правила отображения может ассоциироваться с числовым значением c2 контекста, так что числовое значение контекста, ассоциированное с "неправильным" значимым числовым значением c2 контекста, равно индексному значению правила отображения, ассоциированному с интервалом 934, ограниченным числовым значением c2 контекста. Кроме того, интервал 936 числового значения контекста также ограничивается числовым значением c2 контекста, где числовое значение c2 контекста не принадлежит интервалу 936, так что наименьшее числовое значение контекста интервала 936 равно c2+1. Индексное значение mriv3 правила отображения, которое обычно отличается от индексного значения mriv2 правила отображения, ассоциируется с числовыми значениями контекста интервала 936.
Как видно, индексное значение mriv4 правила отображения, которое ассоциируется с интервалом 932 числовых значений контекста, может описываться записью "ari_lookup_m[i1-1]" таблицы "ari_lookup_m", индексное значение mriv2 правила отображения, которое ассоциируется с числовыми значениями контекста интервала 934, может описываться записью "ari_lookup_m[i1]" таблицы "ari_lookup_m", и индексное значение mriv3 правила отображения может описываться записью "ari_lookup_m[i2]" таблицы "ari_lookup_m". В приведенном здесь примере индексное значение i2 хэш-таблицы может быть больше на 1, чем индексное значение i1 хэш-таблицы.
Как видно из фиг. 9, селектор 760 правила отображения или селектор 828 правила отображения может принимать числовое текущее значение 764, 826a контекста и путем оценивания записей таблицы "ari_hash_m" решать, является ли числовое текущее значение контекста значимым значением состояния (независимо от того, является ли оно "отдельным" значимым значением состояния или "неправильным" значимым значением состояния), или находится ли числовое текущее значение контекста в одном из интервалов 932, 934, 936, которые ограничены ("отдельными" или "неправильными") значимыми значениями c1, c2 состояния. Проверка, равно ли числовое текущее значение контекста значимому значению c1, c2 состояния, и оценка, в каком из интервалов 932, 934, 936 находится числовое текущее значение контекста (в случае, когда числовое текущее значение контекста не равно значимому значению состояния), может выполняться с использованием одиночного обычного поиска по хэш-таблице.
Кроме того, оценка хэш-таблицы "ari_hash_m" может использоваться для получения индексного значения хэш-таблицы (например, i1-1, i1 или i2). Таким образом, селектор 760, 828 правила отображения может быть сконфигурирован для получения, путем оценивания одиночной хэш-таблицы 762, 829 (например, хэш-таблицы "ari_hash_m"), индексного значения хэш-таблицы (например, i1-1, i1 или i2), обозначающего значимое значение состояния (например, c1 или c2) и/или интервал (например, 932, 934, 936), и информации о том, является ли числовое текущее значение контекста значимым значением контекста (также обозначенным как значимое значение состояния).
Кроме того, если при оценке хэш-таблицы 762, 829 "ari_hash_m" обнаруживается, что числовое текущее значение контекста не является "значимым" значением контекста (или "значимым" значением состояния), то индексное значение хэш-таблицы (например, i1-1, i1 или i2), полученное из оценки хэш-таблицы ("ari_hash_m"), может использоваться для получения индексного значения правила отображения, ассоциированного с интервалом 932, 934, 936 числовых значений контекста. Например, индексное значение хэш-таблицы (например, i1-1, i1 или i2) может использоваться для обозначения записи дополнительной таблицы отображения (например, "ari_lookup_m"), которая описывает индексные значения правила отображения, ассоциированные с интервалом 932, 934, 936, в котором находится числовое текущее значение контекста.
За дополнительными подробностями обращаются к подробному обсуждению алгоритма "arith_get_pk" (где имеются разные варианты для этого алгоритма "arith_get_pk()", примеры которых показаны на фиг. 5e и 5f).
Кроме того, следует отметить, что размер интервалов может отличаться от одного случая к другому. В некоторых случаях интервал числовых значений контекста содержит одиночное числовое значение контекста. Однако во многих случаях интервал может содержать множество числовых значений контекста.
4. Аудиокодер в соответствии с фиг. 10
Фиг. 10 показывает блок-схему аудиокодера 1000 в соответствии с вариантом осуществления изобретения. Аудиокодер 1000 в соответствии с фиг. 10 аналогичен аудиокодеру 700 в соответствии с фиг. 7, так что идентичные сигналы и средства обозначаются идентичными номерами ссылок на фиг. 7 и 10.
Аудиокодер 1000 сконфигурирован для приема входной аудиоинформации 710 и предоставления на ее основе кодированной аудиоинформации 712. Аудиокодер 1000 содержит уплотняющий энергию преобразователь 720 из временной области в частотную область, который сконфигурирован для предоставления представления 722 частотной области на основе представления временной области входной аудиоинформации 710, так что аудиопредставление 722 частотной области содержит набор спектральных значений. Аудиокодер 1000 также содержит арифметический кодер 1030, сконфигурированный для кодирования спектрального значения (из набора спектральных значений, образующего аудиопредставление 722 частотной области) или его предварительно обработанной версии с использованием кодового слова переменной длины, чтобы получить кодированную аудиоинформацию 712 (которая может содержать, например, множество кодовых слов переменной длины).
Арифметический кодер 1030 сконфигурирован для отображения спектрального значения либо множества спектральных значений, или значения матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение (то есть на кодовое слово переменной длины) в зависимости от состояния контекста. Арифметический кодер 1030 сконфигурирован для выбора правила отображения, описывающего отображение спектрального значения либо множества спектральных значений, или матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение в зависимости от состояния контекста. Арифметический кодер сконфигурирован для определения текущего состояния контекста в зависимости от множества ранее кодированных (предпочтительно, но не обязательно, соседних) спектральных значений. С этой целью арифметический кодер сконфигурирован для изменения цифрового представления числового предыдущего значения контекста, описывающего состояние контекста, ассоциированное с одним или несколькими ранее кодированными спектральными значениями (например, чтобы выбрать соответствующее правило отображения), в зависимости от значения подобласти контекста, чтобы получить цифровое представление числового текущего значения контекста, описывающего состояние контекста, ассоциированное с одним или несколькими спектральными значениями, которые должны быть кодированы (например, чтобы выбрать соответствующее правило отображения).
Как видно, отображение спектрального значения либо множества спектральных значений, или матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение может выполняться с помощью кодирования 740 спектрального значения, используя правило отображения, описанное информацией 742 правила отображения. Средство 750 отслеживания состояния может быть сконфигурировано для отслеживания состояния контекста. Средство 750 отслеживания состояния может быть сконфигурировано для изменения цифрового представления числового предыдущего значения контекста, описывающего состояние контекста, ассоциированное с кодированием одного или более ранее кодированных спектральных значений, в зависимости от значения подобласти контекста, чтобы получить цифровое представление числового текущего значения контекста, описывающего состояние контекста, ассоциированное с кодированием одного или более спектральных значений, которые должны быть кодированы. Изменение цифрового представления числового предыдущего значения контекста может, например, выполняться модификатором 1052 цифрового представления, который принимает числовое предыдущее значение контекста и одно или более значений подобласти контекста и предоставляет числовое текущее значение контекста. Соответственно, средство 1050 отслеживания состояния предоставляет информацию 754, описывающую текущее состояние контекста, например, в форме числового текущего значения контекста. Селектор 1060 правила отображения может выбирать правило отображения, например таблицу накопленных частот, описывающее отображение спектрального значения либо множества спектральных значений, или матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение. Соответственно, селектор 1060 правила отображения предоставляет информацию 742 правила отображения спектральному кодированию 740.
Следует отметить, что в некоторых вариантах осуществления средство 1050 отслеживания состояния может быть идентично средству 750 отслеживания состояния или средству 826 отслеживания состояния. Также следует отметить, что селектор 1060 правила отображения в некоторых вариантах осуществления может быть идентичен селектору 760 правила отображения или селектору 828 правила отображения. Предпочтительно, что селектор 828 правила отображения может быть сконфигурирован для использования хэш-таблицы "ari_hash_m[742]", которая задана в табличном представлении фиг. 22(1)-22(4), для выбора правила отображения. Например, селектор правила отображения может выполнять функциональные возможности, которые описаны выше со ссылкой на фиг. 7 и 8.
Чтобы подвести итог вышесказанному, аудиокодер 1000 выполняет арифметическое кодирование аудиопредставления частотной области, предоставленного преобразователем из временной области в частотную область. Арифметическое кодирование является контекстно-зависимым, так что правило отображения (например, таблица накопленных частот) выбирается в зависимости от ранее кодированных спектральных значений. Соответственно, спектральные значения, соседние по времени и/или частоте (или по меньшей мере в предопределенном окружении) друг с другом и/или с кодируемым в настоящее время спектральным значением (то есть спектральные значения в предопределенном окружении кодируемого в настоящее время спектрального значения), учитываются в арифметическом кодировании, чтобы отрегулировать распределение вероятности, оцененное посредством арифметического кодирования.
При определении числового текущего значения контекста цифровое представление числового предыдущего значения контекста, описывающего состояние контекста, ассоциированное с одним или несколькими ранее кодированными спектральными значениями, изменяется в зависимости от значения подобласти контекста, чтобы получить цифровое представление числового текущего значения контекста, описывающего состояние контекста, ассоциированное с одним или несколькими спектральными значениями, которые должны быть кодированы. Этот подход позволяет избежать полного пересчета числового текущего значения контекста, причем полный пересчет потребляет значительную величину ресурсов в традиционных подходах. Существует целый ряд возможностей для модификации цифрового представления числового предыдущего значения контекста, включая сочетание перемасштабирования цифрового представления числового предыдущего значения контекста, добавления значения подобласти контекста или выведенного из него значения к цифровому представлению числового предыдущего значения контекста или к обработанному цифровому представлению числового предыдущего значения контекста, замены части цифрового представления (а не всего цифрового представления) числового предыдущего значения контекста в зависимости от значения подобласти контекста, и так далее. Таким образом, обычно числовое представление числового текущего значения контекста получается на основе цифрового представления числового предыдущего значения контекста, а также на основе по меньшей мере одного значения подобласти контекста, где обычно выполняется сочетание операций для объединения числового предыдущего значения контекста со значением подобласти контекста, например, две или более операции из операции сложения, операции вычитания, операции умножения, операции деления, операции логического И, операции логического ИЛИ, операции логического НЕ-И, операции логического ИЛИ-НЕ, операции логического отрицания, операции дополнения или операции сдвига. Соответственно, по меньшей мере часть цифрового представления числового предыдущего значения контекста обычно остается без изменений (за исключением необязательного сдвига в отличную позицию) при выведении числового текущего значения контекста из числового предыдущего значения контекста. В отличие от этого другие части цифрового представления числового предыдущего значения контекста изменяются в зависимости от одного или более значений подобласти контекста. Таким образом, числовое текущее значение контекста можно получить при сравнительно небольшой вычислительной работе, избегая при этом полного пересчета числового текущего значения контекста.
Таким образом, можно получить содержательное числовое текущее значение контекста, которое подходит для использования селектором 1060 правила отображения и которое особенно подходит для использования совместно с хэш-таблицей ari_hash_m, которая задана в табличном представлении фиг. 22(1), 22(2), 22(3), 22(4).
Следовательно, можно добиться эффективного кодирования путем поддержания вычисления контекста достаточно простым.
5. Аудиодекодер в соответствии с фиг. 11
Фиг. 11 показывает блок-схему аудиодекодера 1100. Аудиодекодер 1100 аналогичен аудиодекодеру 800 в соответствии с фиг. 8, так что идентичные сигналы, средства и функциональные возможности обозначаются идентичными номерами ссылок.
Аудиодекодер 1100 сконфигурирован для приема кодированной аудиоинформации 810 и предоставления на ее основе декодированной аудиоинформации 812. Аудиодекодер 1100 содержит арифметический декодер 1120, который сконфигурирован для предоставления множества декодированных спектральных значений 822 на основе арифметически кодированного представления 821 спектральных значений. Аудиодекодер 1100 также содержит преобразователь 830 из частотной области во временную область, который сконфигурирован для приема декодированных спектральных значений 822 и предоставления аудиопредставления 812 временной области, которое может составлять декодированную аудиоинформацию, используя декодированные спектральные значения 822, чтобы получить декодированную аудиоинформацию 812.
Арифметический декодер 1120 содержит определитель 824 спектрального значения, который сконфигурирован для отображения кодового значения арифметически кодированного представления 821 спектральных значений на символьный код, представляющий одно или более декодированных спектральных значений или по меньшей мере часть (например, матрица старших битов) одного или более декодированных спектральных значений. Определитель 824 спектрального значения может быть сконфигурирован для выполнения отображения в зависимости от правила отображения, которое может описываться информацией 828a правила отображения. Информация 828a правила отображения может, например, содержать индексное значение правила отображения или может содержать выбранный набор записей таблицы накопленных частот.
Арифметический декодер 1120 сконфигурирован для выбора правила отображения (например, таблицы накопленных частот), описывающего отображение кодового значения (описанного арифметически кодированным представлением 821 спектральных значений) на символьный код (описывающий одно или более спектральных значений) в зависимости от состояния контекста, которое может описываться информацией 1126a состояния контекста. Информация 1126a состояния контекста может принимать форму числового текущего значения контекста. Арифметический декодер 1120 сконфигурирован для определения текущего состояния контекста в зависимости от множества ранее декодированных спектральных значений 822. С этой целью может использоваться средство 1126 отслеживания состояния, которое принимает информацию, описывающую ранее декодированные спектральные значения. Арифметический декодер сконфигурирован для изменения цифрового представления числового предыдущего значения контекста, описывающего состояние контекста, ассоциированное с одним или несколькими ранее декодированными спектральными значениями, в зависимости от значения подобласти контекста, чтобы получить цифровое представление числового текущего значения контекста, описывающего состояние контекста, ассоциированное с одним или несколькими спектральными значениями, которые должны быть декодированы. Изменение цифрового представления числового предыдущего значения контекста может, например, выполняться модификатором 1127 цифрового представления, который является частью средства 1126 отслеживания состояния. Соответственно, информация 1126a текущего состояния контекста получается, например, в форме числового текущего значения контекста. Выбор правила отображения может выполняться селектором 1128 правила отображения, который выводит информацию 828a правила отображения из информации 1126a текущего состояния контекста и который предоставляет информацию 828a правила отображения определителю 824 спектрального значения. Предпочтительно, что селектор 1128 правила отображения может быть сконфигурирован для использования хэш-таблицы "ari_hash_m[742]", которая задана в табличном представлении фиг. 22(1)-22(4), для выбора правила отображения. Например, селектор правила отображения может выполнять функциональные возможности, которые описаны выше со ссылкой на фиг. 7 и 8.
Касательно функциональных возможностей декодера 1100 аудиосигнала следует отметить, что арифметический декодер 1120 сконфигурирован для выбора правила отображения (например, таблицы накопленных частот), которое в среднем хорошо приспособлено к спектральному значению, которое должно быть декодировано, так как правило отображения выбирается в зависимости от текущего состояния контекста, которое в свою очередь определяется в зависимости от множества ранее декодированных спектральных значений. Соответственно, можно использовать статистические зависимости между соседними спектральными значениями, которые должны быть декодированы.
Кроме того, путем изменения цифрового представления числового предыдущего значения контекста, описывающего состояние контекста, ассоциированное с декодированием одного или более ранее декодированных спектральных значений, в зависимости от значения подобласти контекста, чтобы получить цифровое представление числового текущего значения контекста, описывающего состояние контекста, ассоциированное с декодированием одного или более спектральных значений, которые должны быть декодированы, можно получить содержательную информацию о текущем состоянии контекста, которая подходит для отображения на индексное значение правила отображения и которая особенно подходит для использования совместно с хэш-таблицей ari_hash_m, которая задана в табличном представлении фиг. 22(1), 22(2), 22(3), 22(4), при сравнительно небольшой вычислительной работе. Путем сохранения по меньшей мере части цифрового представления числового предыдущего значения контекста (по возможности в сдвинутой по битам или масштабированной версии) наряду с обновлением другой части цифрового представления числового предыдущего значения контекста в зависимости от значений подобласти контекста, которые не учтены в числовом предыдущем значении контекста, но которые следует учесть в числовом текущем значении контекста, количество операций для выведения числового текущего значения контекста можно сохранить довольно небольшим. Также можно использовать тот факт, что контексты, используемые для декодирования соседних спектральных значений, обычно аналогичны или коррелированны. Например, контекст для декодирования первого спектрального значения (или первого множества спектральных значений) зависит от первого набора ранее декодированных спектральных значений. Контекст для декодирования второго спектрального значения (или второго набора спектральных значений), которое находится рядом с первым спектральным значением (или первым набором спектральных значений), может содержать второй набор ранее декодированных спектральных значений. Поскольку предполагается, что первое спектральное значение и второе спектральное значение являются соседними (например, по отношению к ассоциированным частотам), первый набор спектральных значений, которые определяют контекст для кодирования первого спектрального значения, может содержать некоторое перекрытие со вторым набором спектральных значений, которые определяют контекст для декодирования второго спектрального значения. Соответственно, можно без труда понять, что состояние контекста для декодирования второго спектрального значения содержит некоторую корреляцию с состоянием контекста для декодирования первого спектрального значения. Вычислительной эффективности извлечения контекста, то есть извлечения числового текущего значения контекста, можно добиться путем использования таких корреляций. Обнаружено, что корреляцию между состояниями контекста для декодирования соседних спектральных значений (например, между состоянием контекста, описанным числовым предыдущим значением контекста, и состоянием контекста, описанным числовым текущим значением контекста) можно эффективно использовать путем изменения только тех частей числового предыдущего значения контекста, которые зависят от значений подобласти контекста, не учтенных для извлечения числового предыдущего состояния контекста, и путем выведения числового текущего значения контекста из числового предыдущего значения контекста.
В заключение описанные в этом документе идеи предусматривают очень хорошую вычислительную эффективность при выведении числового текущего значения контекста.
Ниже будут описываться дополнительные подробности.
6. Аудиокодер в соответствии с фиг. 12
Фиг. 12 показывает блок-схему аудиокодера в соответствии с вариантом осуществления изобретения. Аудиокодер 1200 в соответствии с фиг. 12 аналогичен аудиокодеру 700 в соответствии с фиг. 7, так что идентичные средства, сигналы и функциональные возможности обозначаются идентичными номерами ссылок.
Аудиокодер 1200 сконфигурирован для приема входной аудиоинформации 710 и предоставления на ее основе кодированной аудиоинформации 712. Аудиокодер 1200 содержит уплотняющий энергию преобразователь 720 из временной области в частотную область, который сконфигурирован для предоставления аудиопредставления 722 частотной области на основе аудиопредставления временной области входной аудиоинформации 710, так что аудиопредставление 722 частотной области содержит набор спектральных значений. Аудиокодер 1200 также содержит арифметический кодер 1230, сконфигурированный для кодирования спектрального значения (из набора спектральных значений, образующего аудиопредставление 722 частотной области) либо множества спектральных значений, или его предварительно обработанной версии, с использованием кодового слова переменной длины, чтобы получить кодированную аудиоинформацию 712 (которая может содержать, например, множество кодовых слов переменной длины).
Арифметический кодер 1230 сконфигурирован для отображения спектрального значения либо множества спектральных значений, или значения матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение (то есть на кодовое слово переменной длины) в зависимости от состояния контекста. Арифметический кодер 1230 сконфигурирован для выбора правила отображения, описывающего отображение спектрального значения либо множества спектральных значений, или матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение в зависимости от состояния контекста. Арифметический кодер сконфигурирован для определения текущего состояния контекста в зависимости от множества ранее кодированных (предпочтительно, но не обязательно, соседних) спектральных значений. С этой целью арифметический кодер сконфигурирован для получения множества значений подобласти контекста на основе ранее кодированных спектральных значений, сохранения упомянутых значений подобласти контекста и выведения числового текущего значения контекста, ассоциированного с одним или несколькими спектральными значениями, которые должны быть кодированы, в зависимости от сохраненных значений подобласти контекста. Кроме того, арифметический кодер сконфигурирован для вычисления нормы вектора, образованного множеством ранее кодированных спектральных значений, чтобы получить общее значение подобласти контекста, ассоциированное с множеством ранее кодированных спектральных значений.
Как видно, отображение спектрального значения либо множества спектральных значений, или матрицы старших битов спектрального значения либо множества спектральных значений, на кодовое значение может выполняться с помощью кодирования 740 спектрального значения, используя правило отображения, описанное информацией 742 правила отображения. Средство 1250 отслеживания состояния может быть сконфигурировано для отслеживания состояния контекста и может содержать вычислитель 1252 значения подобласти контекста, для вычисления нормы вектора, образованного множеством ранее кодированных спектральных значений, чтобы получить общие значения подобласти контекста, ассоциированные с множеством ранее кодированных спектральных значений. Средство 1250 отслеживания состояния также предпочтительно сконфигурировано для определения текущего состояния контекста в зависимости от результата упомянутого вычисления значения подобласти контекста, выполненного вычислителем 1252 значения подобласти контекста. Соответственно, средство 1250 отслеживания состояния предоставляет информацию 1254, описывающую текущее состояние контекста. Селектор 1260 правила отображения может выбирать правило отображения, например таблицу накопленных частот, описывающее отображение спектрального значения или матрицы старших битов спектрального значения на кодовое значение. Соответственно, селектор 1260 правила отображения предоставляет информацию 742 правила отображения спектральному кодированию 740. Предпочтительно, что селектор 1260 правила отображения может быть сконфигурирован для использования хэш-таблицы "ari_hash_m[742]", которая задана в табличном представлении фиг. 22(1)-22(4), для выбора правила отображения. Например, селектор правила отображения может выполнять функциональные возможности, которые описаны выше со ссылкой на фиг. 7 и 8.
Чтобы подвести итог вышесказанному, аудиокодер 1200 выполняет арифметическое кодирование аудиопредставления частотной области, предоставленного преобразователем 720 из временной области в частотную область. Арифметическое кодирование является контекстно-зависимым, так что правило отображения (например, таблица накопленных частот) выбирается в зависимости от ранее кодированных спектральных значений. Соответственно, спектральные значения, соседние по времени и/или частоте (или по меньшей мере в предопределенном окружении) друг с другом и/или с кодируемым в настоящее время спектральным значением (то есть спектральные значения в предопределенном окружении кодируемого в настоящее время спектрального значения), учитываются в арифметическом кодировании, чтобы отрегулировать распределение вероятности, оцененное посредством арифметического кодирования.
Чтобы предоставить числовое текущее значение контекста, значение подобласти контекста, ассоциированное с множеством ранее кодированных спектральных значений, получается на основе вычисления нормы вектора, образованного множеством ранее кодированных спектральных значений. Результат определения числового текущего значения контекста применяется при выборе текущего состояния контекста, то есть при выборе правила отображения.
С помощью вычисления нормы вектора, образованного множеством ранее кодированных спектральных значений, можно получить содержательную информацию, описывающую часть контекста одного или более спектральных значений, которые должны быть кодированы, где норму вектора ранее кодированных спектральных значений обычно можно представить с помощью сравнительно небольшого количества битов. Таким образом, величину контекстной информации, которая должна быть сохранена для более позднего использования при выведении числового текущего значения контекста, можно удерживать достаточно небольшой путем применения обсужденного выше подхода для вычисления значений подобласти контекста. Обнаружено, что норма вектора ранее кодированных спектральных значений обычно содержит самую важную информацию состояния контекста. В отличие от этого обнаружено, что знак ранее упомянутых кодированных спектральных значений обычно содержит второстепенное влияние на состояние контекста, так что имеет смысл пренебречь знаком ранее декодированных спектральных значений, чтобы уменьшить количество информации, которое должно быть сохранено для более позднего использования. Также обнаружено, что вычисление нормы вектора ранее кодированных спектральных значений является разумным подходом для выведения значения подобласти контекста, так как эффект усреднения, который обычно получается при вычислении нормы, оставляет практически незатронутой самую важную информацию состояния контекста. Подводя итог, вычисление значения подобласти контекста, выполняемое вычислителем 1252 значения подобласти контекста, предусматривает предоставление компактной информации о подобласти контекста для хранения и последующего повторного использования, где наиболее релевантная информация о состоянии контекста сохраняется несмотря на уменьшение количества информации.
Кроме того, обнаружено, что числовое текущее значение контекста, полученное как обсуждалось выше, очень хорошо подходит для выбора правила отображения с использованием хэш-таблицы "ari_hash_m[742]", которая задана в табличном представлении фиг. 22(1)-22(4). Например, селектор правила отображения может выполнять функциональные возможности, которые описаны выше со ссылкой на фиг. 7 и 8.
Соответственно, можно добиться эффективного кодирования входной аудиоинформации 710 наряду с сохранением вычислительной работы и объема данных, который должен быть сохранен арифметическому кодеру 1230, достаточно небольшими.
7. Аудиодекодер в соответствии с фиг. 13
Фиг. 13 показывает блок-схему аудиодекодера 1300. Так как аудиодекодер 1300 аналогичен аудиодекодеру 800 в соответствии с фиг. 8 и аудиодекодеру 1100 в соответствии с фиг. 11, идентичные средства, сигналы и функциональные возможности обозначаются идентичными цифрами.
Аудиодекодер 1300 сконфигурирован для приема кодированной аудиоинформации 810 и предоставления на ее основе декодированной аудиоинформации 812. Аудиодекодер 1300 содержит арифметический декодер 1320, который сконфигурирован для предоставления множества декодированных спектральных значений 822 на основе арифметически кодированного представления 821 спектральных значений. Аудиодекодер 1300 также содержит преобразователь 830 из частотной области во временную область, который сконфигурирован для приема декодированных спектральных значений 822 и предоставления аудиопредставления 812 временной области, которое может составлять декодированную аудиоинформацию, используя декодированные спектральные значения 822, чтобы получить декодированную аудиоинформацию 812.
Арифметический декодер 1320 содержит определитель 824 спектрального значения, который сконфигурирован для отображения кодового значения арифметически кодированного представления 821 спектральных значений на символьный код, представляющий одно или более декодированных спектральных значений или по меньшей мере часть (например, матрица старших битов) одного или более декодированных спектральных значений. Определитель 824 спектрального значения может быть сконфигурирован для выполнения отображения в зависимости от правила отображения, которое описывается информацией 828a правила отображения. Информация 828a правила отображения может, например, содержать индексное значение правила отображения или выбранный набор записей таблицы накопленных частот.
Арифметический декодер 1320 сконфигурирован для выбора правила отображения (например, таблицы накопленных частот), описывающего отображение кодового значения (описанного арифметически кодированным представлением 821 спектральных значений) на символьный код (описывающий одно или более спектральных значений) в зависимости от состояния контекста (которое может описываться информацией 1326a состояния контекста). Предпочтительно, что арифметический декодер 1320 может быть сконфигурирован для использования хэш-таблицы "ari_hash_m[742]", которая задана в табличном представлении фиг. 22(1)-22(4), для выбора правила отображения. Например, арифметический декодер 1320 может выполнять функциональные возможности, которые описаны выше со ссылкой на фиг. 7 и 8. Арифметический декодер 1320 сконфигурирован для определения текущего состояния контекста в зависимости от множества ранее декодированных спектральных значений 822. С этой целью может использоваться средство 1326 отслеживания состояния, которое принимает информацию, описывающую ранее декодированные спектральные значения. Арифметический декодер также сконфигурирован для получения множества значений подобласти контекста на основе ранее декодированных спектральных значений и сохранения упомянутых значений подобласти контекста. Арифметический декодер сконфигурирован для выведения числового текущего значения контекста, ассоциированного с одним или несколькими спектральными значениями, которые должны быть декодированы в зависимости от сохраненных значений подобласти контекста. Арифметический декодер 1320 сконфигурирован для вычисления нормы вектора, образованного множеством ранее декодированных спектральных значений, чтобы получить общее значение подобласти контекста, ассоциированное с множеством ранее декодированных спектральных значений.
Вычисление нормы вектора, образованного множеством ранее кодированных спектральных значений, чтобы получить общее значение подобласти контекста, ассоциированное с множеством ранее декодированных спектральных значений, может выполняться, например, вычислителем 1327 значения подобласти контекста, который является частью средства 1326 отслеживания состояния. Соответственно, информация 1326a текущего состояния контекста получается на основе значений подобласти контекста, где средство 1326 отслеживания состояния предпочтительно предоставляет числовое текущее значение контекста, ассоциированное с одним или несколькими спектральными значениями, которые должны быть декодированы, в зависимости от сохраненных значений подобласти контекста. Выбор правил отображения может выполняться селектором 1328 правила отображения, который выводит информацию 828a правила отображения из информации 1326a текущего состояния контекста и который предоставляет информацию 828a правила отображения определителю 824 спектрального значения.
Касательно функциональных возможностей декодера 1300 аудиосигнала следует отметить, что арифметический декодер 1320 сконфигурирован для выбора правила отображения (например, таблицы накопленных частот), которое в среднем хорошо приспособлено к спектральному значению, которое должно быть декодировано, так как правило отображения выбирается в зависимости от текущего состояния контекста, которое в свою очередь определяется в зависимости от множества ранее декодированных спектральных значений. Соответственно, можно использовать статистические зависимости между соседними спектральными значениями, которые должны быть декодированы.
Однако обнаружено, что в показателях использования памяти эффективно сохранять значения подобласти контекста, которые основываются на вычислении нормы вектора, образованного множеством ранее декодированных спектральных значений, для более позднего использования при определении числового значения контекста. Также обнаружено, что такие значения подобласти контекста по-прежнему содержат наиболее релевантную контекстную информацию. Соответственно идея, используемая средством 1326 отслеживания состояния, является хорошим компромиссом между эффективностью кодирования, вычислительной эффективностью и эффективностью хранения.
Ниже будут описываться дополнительные подробности.
8. Аудиокодер в соответствии с фиг. 1
Ниже будет описываться аудиокодер в соответствии с вариантом осуществления настоящего изобретения. Фиг. 1 показывает блок-схему такого аудиокодера 100.
Аудиокодер 100 сконфигурирован для приема входной аудиоинформации 110 и предоставления на ее основе битового потока 112, который составляет кодированную аудиоинформацию. Аудиокодер 100 необязательно содержит препроцессор 120, который сконфигурирован для приема входной аудиоинформации 110 и предоставления на ее основе предварительно обработанной входной аудиоинформации 110a. Аудиокодер 100 также содержит уплотняющий энергию преобразователь 130 сигнала из временной области в частотную область, который также обозначается как преобразователь сигнала. Преобразователь 130 сигнала сконфигурирован для приема входной аудиоинформации 110, 110a и предоставления на ее основе аудиоинформации 132 частотной области, которая предпочтительно принимает вид набора спектральных значений. Например, преобразователь 130 сигнала может быть сконфигурирован для приема кадра входной аудиоинформации 110, 110a (например, блока выборок временной области) и предоставления набора спектральных значений, представляющих аудиоконтент соответствующего аудиокадра. К тому же преобразователь 130 сигнала может быть сконфигурирован для приема множества последующих, перекрывающихся или неперекрывающихся, аудиокадров входной аудиоинформации 110, 110a и предоставления на их основе аудиопредставления частотно-временной области, которое содержит последовательность последующих наборов спектральных значений, причем один набор спектральных значений ассоциирован с каждым кадром.
Уплотняющий энергию преобразователь 130 сигнала из временной области в частотную область может содержать уплотняющую энергию гребенку фильтров, которая предоставляет спектральные значения, ассоциированные с разными частотными диапазонами, перекрывающимися или неперекрывающимися. Например, преобразователь 130 сигнала может содержать оконный преобразователь 130a MDCT, который сконфигурирован для оконной обработки входной аудиоинформации 110, 110a (или ее кадра) с использованием окна преобразования и для выполнения измененного дискретного косинусного преобразования обработанной методом окна входной аудиоинформации 110, 110a (или ее взвешенного окном кадра). Соответственно, аудиопредставление 132 частотной области может содержать набор, например, из 1024 спектральных значений в виде коэффициентов MDCT, ассоциированных с кадром входной аудиоинформации.
Аудиокодер 100 необязательно может дополнительно содержать спектральный постпроцессор 140, который сконфигурирован для приема аудиопредставления 132 частотной области и предоставления на его основе пост-обработанного аудиопредставления 142 частотной области. Спектральный постпроцессор 140 может, например, конфигурироваться для выполнения временного формирования шума и/или долгосрочного предсказания и/или любой другой спектральной постобработки, известной в данной области техники. Аудиокодер необязательно дополнительно содержит средство масштабирования/квантователь 150, который сконфигурирован для приема аудиопредставления 132 частотной области или его пост-обработанной версии 142 и предоставления масштабированного и квантованного аудиопредставления 152 частотной области.
Аудиокодер 100 необязательно дополнительно содержит процессор 160 психоакустической модели, который сконфигурирован для приема входной аудиоинформации 110 (или ее пост-обработанной версии 110a) и предоставления на ее основе необязательной управляющей информации, которая может использоваться для управления уплотняющим энергию преобразователем 130 сигнала из временной области в частотную область, для управления необязательным спектральным постпроцессором 140 и/или для управления необязательным средством масштабирования/квантователем 150. Например, процессор 160 психоакустической модели может быть сконфигурирован для анализа входной аудиоинформации, для определения, какие составляющие входной аудиоинформации 110, 110a особенно важны для человеческого восприятия аудиоконтента, а какие составляющие входной аудиоинформации 110, 110a менее важны для восприятия аудиоконтента. Соответственно, процессор 160 психоакустической модели может предоставить управляющую информацию, которая используется аудиокодером 100, чтобы регулировать масштабирование аудиопредставления 132, 142 частотной области посредством средства масштабирования/квантователя 150 и/или разрешение квантования, применяемое средством масштабирования/квантователем 150. Следовательно, важные для восприятия диапазоны масштабного коэффициента (то есть группы соседних спектральных значений, которые особенно важны для человеческого восприятия аудиоконтента) масштабируются с большим масштабным коэффициентом и квантуются со сравнительно высоким разрешением, тогда как менее важные для восприятия диапазоны масштабного коэффициента (то есть группы соседних спектральных значений) масштабируются со сравнительно меньшим масштабным коэффициентом и квантуются со сравнительно низким разрешением квантования. Соответственно, масштабированные спектральные значения более важных для восприятия частот обычно значительно больше спектральных значений менее важных для восприятия частот.
Аудиокодер также содержит арифметический кодер 170, который сконфигурирован для приема масштабированной и квантованной версии 152 аудиопредставления 132 частотной области (или, в качестве альтернативы, пост-обработанной версии 142 аудиопредставления 132 частотной области или даже самого аудиопредставления 132 частотной области) и предоставления на ее основе информации 172a арифметического кодового слова, так что информация арифметического кодового слова представляет аудиопредставление 152 частотной области.
Аудиокодер 100 также содержит средство 190 форматирования полезной нагрузки битового потока, которое сконфигурировано для приема информации 172a арифметического кодового слова. Средство 190 форматирования полезной нагрузки битового потока также обычно сконфигурировано для приема дополнительной информации, например информации масштабного коэффициента, описывающей, какие масштабные коэффициенты применены средством масштабирования/квантователем 150. К тому же средство 190 форматирования полезной нагрузки битового потока может быть сконфигурировано для приема другой управляющей информации. Средство 190 форматирования полезной нагрузки битового потока сконфигурировано для предоставления битового потока 112 на основе принятой информации путем компоновки битового потока в соответствии с нужным синтаксисом битового потока, который будет обсуждаться ниже.
Ниже будут описываться подробности касательно арифметического кодера 170. Арифметический кодер 170 сконфигурирован для приема множества пост-обработанных и масштабированных и квантованных спектральных значений аудиопредставления 132 частотной области. Арифметический кодер содержит средство 174 извлечения матрицы старших битов, которое сконфигурировано для извлечения матрицы m старших битов из спектрального значения или даже из двух спектральных значений. Здесь следует отметить, что матрица старших битов может содержать один или даже больше битов (например, два или три бита), которые являются старшими битами спектрального значения. Таким образом, средство 174 извлечения матрицы старших битов предоставляет значение 176 матрицы старших битов спектрального значения.
Однако в качестве альтернативы средство 174 извлечения матрицы старших битов может предоставить объединенное значение m матрицы старших битов, объединяющее матрицы старших битов множества спектральных значений (например, спектральных значений a и b). Матрица старших битов спектрального значения a обозначается с помощью m. В качестве альтернативы объединенное значение матрицы старших битов множества спектральных значений a,b обозначается с помощью m.
Арифметический кодер 170 также содержит первый определитель 180 кодового слова, который сконфигурирован для определения арифметического кодового слова acod_m [pki][m], представляющего значение m матрицы старших битов. Необязательно определитель 180 кодового слова также может предоставить одно или более кодовых слов перехода (также обозначенных в этом документе с помощью "ARITH_ESCAPE"), указывающих, например, сколько доступно матриц менее значащих битов (и следовательно, указывающих численный вес матрицы старших битов). Первый определитель 180 кодового слова может быть сконфигурирован для предоставления кодового слова, ассоциированного со значением m матрицы старших битов, используя выбранную таблицу накопленных частот, содержащую индекс pki таблицы накопленных частот (или указанную тем индексом).
Чтобы определить, какую таблицу накопленных частот следует выбрать, арифметический кодер предпочтительно содержит средство 182 отслеживания состояния, которое сконфигурировано для отслеживания состояния арифметического кодера, например, путем наблюдения за тем, какие спектральные значения кодированы ранее. Средство 182 отслеживания состояния поэтому предоставляет информацию 184 состояния, например, значение состояния, обозначенное "s" или "t" или "c". Арифметический кодер 170 также содержит селектор 186 таблицы накопленных частот, который сконфигурирован для приема информации 184 состояния и предоставления информации 188, описывающей выбранную таблицу накопленных частот, определителю 180 кодового слова. Например, селектор 186 таблицы накопленных частот может предоставить индекс "pki" таблицы накопленных частот, описывающий, какая таблица накопленных частот из набора 64 таблиц накопленных частот выбирается для использования определителем кодового слова. В качестве альтернативы селектор 186 таблицы накопленных частот может предоставить определителю кодового слова всю выбранную таблицу накопленных частот или подтаблицу. Таким образом определитель 180 кодового слова может использовать выбранную таблицу накопленных частот или подтаблицу для предоставления кодового слова acod_m[pki][m] значения m матрицы старших битов, так что фактическое кодовое слово acod_m[pki][m], кодирующее значение m матрицы старших битов, зависит от значения m и индекса pki таблицы накопленных частот, и следовательно, от информации 184 текущего состояния. Дополнительные подробности касательно процесса кодирования и формата полученного кодового слова будут описываться ниже.
Однако следует отметить, что в некоторых вариантах осуществления средство 182 отслеживания состояния может быть идентичным или выполнять функциональные возможности средства 750 отслеживания состояния, средства 1050 отслеживания состояния или средства 1250 отслеживания состояния. Также следует отметить, что селектор 186 таблицы накопленных частот в некоторых вариантах осуществления может быть идентичным или выполнять функциональные возможности селектора 760 правила отображения, селектора 1060 правила отображения или селектора 1260 правила отображения. Кроме того, первый определитель 180 кодового слова в некоторых вариантах осуществления может быть идентичным или выполнять функциональные возможности кодирования 740 спектрального значения.
Арифметический кодер 170 дополнительно содержит средство 189a извлечения матрицы менее значащих битов, которое сконфигурировано для извлечения одной или более матриц менее значащих битов из масштабированного и квантованного аудиопредставления 152 частотной области, если одно или более спектральных значений, которые должны быть кодированы, превышают диапазон значений, кодируемых с использованием только матрицы старших битов. Матрицы менее значащих битов по желанию могут содержать один или более битов. Соответственно, средство 189a извлечения матрицы менее значащих битов предоставляет информацию 189b матрицы менее значащих битов. Арифметический кодер 170 также содержит второй определитель 189c кодового слова, который сконфигурирован для приема информации 189d матрицы менее значащих битов и предоставления на ее основе 0, 1 или более кодовых слов "acod_r", представляющих содержимое 0, 1 или более матриц менее значащих битов. Второй определитель 189c кодового слова может быть сконфигурирован для применения алгоритма арифметического кодирования или любого другого алгоритма кодирования, чтобы вывести кодовые слова "acod_r" матрицы менее значащих битов из информации 189b матрицы менее значащих битов.
Здесь следует отметить, что количество матриц менее значащих битов может меняться в зависимости от значения масштабированных и квантованных спектральных значений 152, так что матрица менее значащих битов может вообще отсутствовать, если масштабированное и квантованное спектральное значение, которое должно быть кодировано, сравнительно небольшое, так что может быть одна матрица менее значащих битов, если текущее масштабированное и квантованное спектральное значение, которое должно быть кодировано, относится к среднему диапазону, и так что может быть более одной матрицы менее значащих битов, если масштабированное и квантованное спектральное значение, которое должно быть кодировано, принимает сравнительно большое значение.
Чтобы подвести итог вышесказанному, арифметический кодер 170 сконфигурирован для кодирования масштабированных и квантованных спектральных значений, которые описываются информацией 152, используя процесс иерархического кодирования. Матрица старших битов (содержащая, например, один, два или три бита на спектральное значение) одного или более спектральных значений кодируется для получения арифметического кодового слова "acod_m[pki][m]" значения m матрицы старших битов. Одна или более матриц менее значащих битов (каждая из матриц менее значащих битов содержит, например, один, два или три бита) одного или более спектральных значений кодируются для получения одного или более кодовых слов "acod_r". При кодировании матрицы старших битов значение m матрицы старших битов отображается на кодовое слово acod_m[pki][m]. С этой целью 64 разные таблицы накопленных частот доступны для кодирования значения m в зависимости от состояния арифметического кодера 170, то есть в зависимости от ранее кодированных спектральных значений. Соответственно получается кодовое слово "acod_m[pki][m]". К тому же одно или более кодовых слов "acod_r" предоставляются и включаются в битовый поток, если присутствует одна или более матриц менее значащих битов.
Описание сброса
Аудиокодер 100 необязательно может быть сконфигурирован для принятия решения, можно ли получить повышение скорости передачи битов путем сброса контекста, например, путем установки индекса состояния в значение по умолчанию. Соответственно, аудиокодер 100 может быть сконфигурирован для предоставления информации сброса (например, названной "arith_reset_flag"), указывающей, сбрасывается ли контекст для арифметического кодирования, и также указывающей, следует ли сбросить контекст для арифметического декодирования в соответствующем декодере.
Подробности касательно формата битового потока и примененных таблиц накопленных частот будут обсуждаться ниже.
9. Аудиодекодер в соответствии с фиг. 2
Ниже будет описываться аудиодекодер в соответствии с вариантом осуществления изобретения. Фиг. 2 показывает блок-схему такого аудиодекодера 200.
Аудиодекодер 200 сконфигурирован для приема битового потока 210, который представляет кодированную аудиоинформацию и который может быть идентичен битовому потоку 112, предоставленному аудиокодером 100. Аудиодекодер 200 предоставляет декодированную аудиоинформацию 212 на основе битового потока 210.
Аудиодекодер 200 содержит необязательное средство 220 расформатирования полезной нагрузки битового потока, которое сконфигурировано для приема битового потока 210 и извлечения из битового потока 210 кодированного аудиопредставления 222 частотной области. Например, средство 220 расформатирования полезной нагрузки битового потока может быть сконфигурировано для извлечения из битового потока 210 арифметически кодированных спектральных данных, например, арифметического кодового слова "acod_m [pki][m]", представляющего значение m матрицы старших битов спектрального значения a либо множества спектральных значений a, b, и кодового слова "acod_r", представляющего содержимое матрицы менее значащих битов спектрального значения a либо множества спектральных значений a, b в аудиопредставлении частотной области. Таким образом, кодированное аудиопредставление 222 частотной области составляет (или содержит) арифметически кодированное представление спектральных значений. Средство 220 расформатирования полезной нагрузки битового потока дополнительно сконфигурировано для извлечения из битового потока дополнительной управляющей информации, которая не показана на фиг. 2. К тому же средство расформатирования полезной нагрузки битового потока необязательно сконфигурировано для извлечения из битового потока 210 информации 224 сброса состояния, которая также обозначается как арифметический флаг сброса или "arith_reset_flag".
Аудиодекодер 200 содержит арифметический декодер 230, который также обозначается как "спектральный помехоустойчивый декодер". Арифметический декодер 230 сконфигурирован для приема кодированного аудиопредставления 220 частотной области и, необязательно, информации 224 сброса состояния. Арифметический декодер 230 также сконфигурирован для предоставления декодированного аудиопредставления 232 частотной области, которое может содержать декодированное представление спектральных значений. Например, декодированное аудиопредставление 232 частотной области может содержать декодированное представление спектральных значений, которые описываются кодированным аудиопредставлением 220 частотной области.
Аудиодекодер 200 также содержит необязательный обратный квантователь/средство 240 перемасштабирования, которое сконфигурировано для приема декодированного аудиопредставления 232 частотной области и предоставления на его основе обратно квантованного и перемасштабированного аудиопредставления 242 частотной области.
Аудиодекодер 200 дополнительно содержит необязательный спектральный препроцессор 250, который сконфигурирован для приема обратно квантованного и перемасштабированного аудиопредставления 242 частотной области и предоставления на его основе предварительно обработанной версии 252 обратно квантованного и перемасштабированного аудиопредставления 242 частотной области. Аудиодекодер 200 также содержит преобразователь 260 сигнала частотной области во временную область, который также обозначается как "преобразователь сигнала". Преобразователь 260 сигнала сконфигурирован для приема предварительно обработанной версии 252 обратно квантованного и перемасштабированного аудиопредставления 242 частотной области (или, в качестве альтернативы, обратно квантованного и перемасштабированного аудиопредставления 242 частотной области или декодированного аудиопредставления 232 частотной области) и предоставления на его основе представления 262 аудиоинформации временной области. Преобразователь 260 сигнала частотной области во временную область может, например, содержать преобразователь для выполнения обратного измененного дискретного косинусного преобразования (IMDCT) и подходящей оконной обработки (а также других вспомогательных функциональных возможностей, например перекрытие и суммирование).
Аудиодекодер 200 может дополнительно содержать необязательный постпроцессор 270 временной области, который сконфигурирован для приема представления 262 аудиоинформации временной области и получения декодированной аудиоинформации 212 с использованием постобработки временной области. Однако, если постобработка пропускается, то представление 262 временной области может быть идентично декодированной аудиоинформации 212.
Здесь следует отметить, что обратный квантователь/средство 240 перемасштабирования, спектральный препроцессор 250, преобразователь 260 сигнала частотной области во временную область и постпроцессор 270 временной области могут управляться в зависимости от управляющей информации, которая извлекается из битового потока 210 средством 220 расформатирования полезной нагрузки битового потока.
Подводя итог всем функциональным возможностям аудиодекодера 200, декодированное аудиопредставление 232 частотной области, например, набор спектральных значений, ассоциированный с аудиокадром кодированной аудиоинформации, можно получить на основе кодированного представления 222 частотной области с использованием арифметического декодера 230. Впоследствии набор, например, из 1024 спектральных значений, которые могут быть коэффициентами MDCT, обратно квантуется, перемасштабируется и предварительно обрабатывается. Соответственно, получается обратно квантованный, перемасштабированный и спектрально предварительно обработанный набор спектральных значений (например, 1024 коэффициента MDCT). Потом представление временной области аудиокадра выводится из обратно квантованного, перемасштабированного и спектрально предварительно обработанного набора значений частотной области (например, коэффициентов MDCT). Соответственно, получается представление аудиокадра временной области. Представление заданного аудиокадра временной области может объединяться с представлениями временной области предыдущего и/или последующего аудиокадров. Например, может выполняться перекрытие и суммирование между представлениями временной области последующих аудиокадров, чтобы сгладить переходы между представлениями временной области соседних аудиокадров и чтобы добиться устранения наложения спектров. За подробностями касательно восстановления декодированной аудиоинформации 212 на основе декодированного аудиопредставления 232 частотно-временной области обращаются, например, к Международному стандарту ISO/IEC 14496-3, часть 3, подраздел 4, где приводится подробное обсуждение. Однако могут использоваться другие более сложные схемы перекрытия и устранения наложения спектров.
Ниже будут описываться некоторые подробности касательно арифметического декодера 230. Арифметический декодер 230 содержит определитель 284 матрицы старших битов, который сконфигурирован для приема арифметического кодового слова acod_m [pki][m], описывающего значение m матрицы старших битов. Определитель 284 матрицы старших битов может быть сконфигурирован для использования таблицы накопленных частот из набора, содержащего 64 таблицы накопленных частот, для выведения значения m матрицы старших битов из арифметического кодового слова "acod_m [pki][m]".
Определитель 284 матрицы старших битов сконфигурирован для выведения значений 286 матрицы старших битов одного или более спектральных значений на основе кодового слова acod_m. Арифметический декодер 230 дополнительно содержит определитель 288 матрицы менее значащих битов, который сконфигурирован для приема одного или более кодовых слов "acod_r", представляющих одну или более матриц менее значащих битов спектрального значения. Соответственно, определитель 288 матрицы менее значащих битов сконфигурирован для предоставления декодированных значений 290 одной или более матриц менее значащих битов. Аудиодекодер 200 также содержит объединитель 292 матрицы битов, который сконфигурирован для приема декодированных значений 286 матрицы старших битов одного или более спектральных значений и декодированных значений 290 одной или более матриц менее значащих битов спектральных значений, если такие матрицы менее значащих битов доступны для текущих спектральных значений. Соответственно, объединитель 292 матрицы битов предоставляет декодированные спектральные значения, которые являются частью декодированного аудиопредставления 232 частотной области. Естественно, арифметический декодер 230 обычно сконфигурирован для предоставления множества спектральных значений, чтобы получить полный набор декодированных спектральных значений, ассоциированный с текущим кадром аудиоконтента.
Арифметический декодер 230 дополнительно содержит селектор 296 таблицы накопленных частот, который сконфигурирован для выбора одной из 64 таблиц ari_cf_m[64][17] накопленных частот (причем каждая таблица ari_cf_m[pki][17] при 0≤pki≤63 имеет 17 записей) в зависимости от индекса 298 состояния, описывающего состояние арифметического декодера. Для выбора одной из таблиц накопленных частот селектор таблицы накопленных частот предпочтительно оценивает хэш-таблицу ari_hash_m[742], которая задана табличным представлением фиг. 22(1), 22(2), 22(3), 22(4). Подробности касательно этой оценки хэш-таблицы ari_hash_m[742] будут описываться ниже. Арифметический декодер 230 дополнительно содержит средство 299 отслеживания состояния, которое сконфигурировано для отслеживания состояния арифметического декодера в зависимости от ранее декодированных спектральных значений. Информацию состояния необязательно можно сбросить до инфомарции состояния по умолчанию в ответ на информацию 224 сброса состояния. Соответственно, селектор 296 таблицы накопленных частот сконфигурирован для предоставления индекса (например, pki) выбранной таблицы накопленных частот, или самой выбранной таблицы накопленных частот либо подтаблицы, для применения в декодировании значения m матрицы старших битов в зависимости от кодового слова "acod_m".
Подводя итог функциональным возможностям аудиодекодера 200, аудиодекодер 200 сконфигурирован для приема аудиопредставления 222 частотной области, эффективно кодированного с точки зрения скорости передачи битов, и получения декодированного аудиопредставления частотной области на его основе. В арифметическом декодере 230, который используется для получения декодированного аудиопредставления 232 частотной области на основе кодированного аудиопредставления 222 частотной области, вероятность разных сочетаний значений матрицы старших битов соседних спектральных значений применяется при использовании арифметического декодера 280, который сконфигурирован для применения таблицы накопленных частот. Другими словами, статистические зависимости между спектральными значениями применяются путем выбора разных таблиц накопленных частот из набора, содержащего 64 разные таблицы накопленных частот, в зависимости от индекса 298 состояния, который получается путем наблюдения ранее вычисленных декодированных спектральных значений.
Следует отметить, что средство 299 отслеживания состояния может быть идентичным или может выполнять функциональные возможности средства 826 отслеживания состояния, средства 1126 отслеживания состояния или средства 1326 отслеживания состояния. Селектор 296 таблицы накопленных частот может быть идентичным или может выполнять функциональные возможности селектора 828 правила отображения, селектора 1128 правила отображения или селектора 1328 правила отображения. Определитель 284 матрицы старших битов может быть идентичным или может выполнять функциональные возможности определителя 824 спектрального значения.
10. Обзор инструмента спектрального помехоустойчивого кодирования
Далее будут объясняться подробности касательно алгоритма кодирования и декодирования, который выполняется, например, арифметическим кодером 170 и арифметическим декодером 230.
Внимание сконцентрировано на описании алгоритма декодирования. Однако следует отметить, что соответствующий алгоритм кодирования может выполняться в соответствии с идеями алгоритма декодирования, где отображения между кодированными и декодированными спектральными значениями меняются на противоположные, и где вычисление индексного значения правила отображения практически идентично. В кодере кодированные спектральные значения замещают декодированные спектральные значения. Также спектральные значения, которые должны быть кодированы, замещают спектральные значения, которые должны быть декодированы.
Следует отметить, что декодирование, которое будет обсуждаться ниже, используется для того, чтобы предусмотреть так называемое "спектральное помехоустойчивое кодирование" обычно пост-обработанных, масштабированных и квантованных спектральных значений. Спектральное помехоустойчивое кодирование используется в идее кодирования/декодирования звука (или в любой другой идее кодирования/декодирования) для дополнительного уменьшения избыточности квантованного спектра, которая получается, например, посредством уплотняющего энергию преобразователя из временной области в частотную область. Схема спектрального помехоустойчивого кодирования, которая используется в вариантах осуществления изобретения, основывается на арифметическом кодировании в сочетании с динамически адаптируемым контекстом.
В некоторых вариантах осуществления согласно изобретению схема спектрального помехоустойчивого кодирования основывается на кортежах из 2-х элементов, то есть объединяются два соседних спектральных коэффициента. Каждый кортеж из 2-х элементов делится на знак, 2-битную матрицу старших битов и оставшиеся матрицы менее значащих битов. Помехоустойчивое кодирование для 2-битной матрицы m старших битов использует контекстно-зависимые таблицы накопленных частот, выведенные из четырех ранее декодированных кортежей из 2-х элементов. Помехоустойчивое кодирование снабжается, например, квантованными спектральными значениями и использует контекстно-зависимые таблицы накопленных частот, выведенные из четырех ранее декодированных соседних кортежей из 2-х элементов. Здесь предпочтительно учитывается соседство и по времени и по частоте, как проиллюстрировано на фиг. 4. Таблицы накопленных частот (которые будут объясняться ниже) затем используются арифметическим кодером для формирования двоичного кода переменной длины (и арифметическим декодером для выведения декодированных значений из двоичного кода переменной длины).
Например, арифметический кодер 170 создает двоичный код для заданного набора символов и их соответствующих вероятностей (то есть в зависимости от соответствующих вероятностей). Двоичный код формируется путем отображения интервала вероятности, где находится набор символов, на кодовое слово.
Помехоустойчивое кодирование для оставшейся матрицы менее значащих битов или матриц r битов использует, например, одиночную таблицу накопленных частот. Накопленные частоты соответствуют, например, равномерному распределению символов, возникающих в матрицах менее значащих битов, то есть предполагается, что существует одинаковая вероятность того, что 0 или 1 возникает в матрицах менее значащих битов. Однако могут использоваться другие решения для кодирования оставшейся матрицы старших битов или матриц битов.
Ниже будет приведен другой краткий обзор инструмента спектрального помехоустойчивого кодирования. Спектральное помехоустойчивое кодирование используется для дополнительного уменьшения избыточности квантованного спектра. Схема спектрального помехоустойчивого кодирования основывается на арифметическом кодировании в сочетании с динамически адаптируемым контекстом. Помехоустойчивое кодирование снабжается квантованными спектральными значениями и использует контекстно-зависимые таблицы накопленных частот, выведенные, например, из четырех ранее декодированных соседних кортежей из 2-х спектральных значений. Здесь учитывается соседство и по времени и по частоте, как проиллюстрировано на фиг. 4. Таблицы накопленных частот затем используются арифметическим кодером для формирования двоичного кода переменной длины.
Арифметический кодер создает двоичный код для заданного набора символов и их соответствующих вероятностей. Двоичный код формируется путем отображения интервала вероятности, где находится набор символов, на кодовое слово.
11. Процесс декодирования
11.1 Обзор процесса декодирования
Ниже будет приведен обзор процесса кодирования спектрального значения со ссылкой на фиг. 3, который показывает представление в псевдокоде процесса декодирования множества спектральных значений.
Процесс декодирования множества спектральных значений содержит инициализацию 310 контекста. Инициализация 310 контекста содержит извлечение текущего контекста из предыдущего контекста с использованием функции "arith_map_context(N, arith_reset_flag)". Извлечение текущего контекста из предыдущего контекста может выборочно содержать сброс контекста. Сброс контекста и извлечение текущего контекста из предыдущего контекста будут обсуждаться ниже. Предпочтительно, что может использоваться функция "arith_map_context(N, arith_reset_flag)" в соответствии с фиг. 5a, но в качестве альтернативы может использоваться функция в соответствии с фиг. 5b.
Декодирование множества спектральных значений также содержит итерацию декодирования 312 спектрального значения и обновления 313 контекста, и это обновление 313 контекста выполняется с помощью функции "arith_update_context(i,a,b)", которая описывается ниже. Декодирование 312 спектрального значения и обновление 313 контекста повторяются lg/2 раз, где lg/2 указывает количество кортежей из 2-х спектральных значений, которые должны быть декодированы (например, для аудиокадра), пока не обнаружится так называемый символ "ARITH_STOP". Кроме того, декодирование набора из lg спектральных значений также содержит декодирование 314 знаков и завершающий этап 315.
Декодирование 312 кортежа спектральных значений содержит вычисление 312a значения контекста, декодирование 312b матрицы старших битов, обнаружение 312c арифметического стоп-символа, добавление 312d матрицы менее значащих битов и обновление 312e массива.
Вычисление 312a значения состояния содержит вызов функции "arith_get_context(c,i,N)", как показано, например, на фиг. 5c или 5d. Предпочтительно, чтобы использовалась функция "arith_get_context(c,i,N)" в соответствии с фиг. 5c. Соответственно, числовое текущее значение (состояние) c контекста предоставляется в виде возвращаемого значения вызова функции "arith_get_context(c,i,N)". Как видно, числовое предыдущее значение контекста (также обозначенное с помощью "c"), которое служит в качестве входной переменной в функцию "arith_get_context(c,i,N)", обновляется для получения числового текущего значения c контекста в качестве возвращаемого значения.
Декодирование 312b матрицы старших битов содержит итеративное исполнение алгоритма 312ba декодирования и извлечение 312bb значений a,b из результирующего значения m алгоритма 312ba. При подготовке алгоритма 312ba переменная lev инициализируется нулем. Алгоритм 312ba повторяется, пока не достигнута инструкция (или условие) "break". Алгоритм 312ba содержит вычисление индекса "pki" состояния (который также служит в качестве индекса таблицы накопленных частот) в зависимости от числового текущего значения c контекста, а также в зависимости от значения "esc_nb" уровня с использованием функции "arith_get_pk()", которая обсуждается ниже (и варианты осуществления которой показаны, например, на фиг. 5e и 5f). Предпочтительно, чтобы использовалась функция "arith_get_pk(c)" в соответствии с фиг. 5e. Алгоритм 312ba также содержит выбор таблицы накопленных частот в зависимости от индекса "pki" состояния, который возвращается с помощью вызова функции "arith_get_pk", где переменная "cum_freq" может устанавливаться в начальный адрес одной из 64 таблиц накопленных частот (или подтаблиц) в зависимости от индекса "pki" состояния. Переменная "cfl" также может инициализироваться длиной выбранной таблицы накопленных частот (или подтаблицы), которая равна, например, количеству символов в алфавите, то есть количеству разных значений, которые можно декодировать. Длина всех таблиц накопленных частот (или подтаблиц) от "ari_cf_m[pki=0][17]" до "ari_cf_m[pki=63][17]", доступных для декодирования значения m матрицы старших битов, равна 17, так как можно декодировать 16 разных значений матрицы старших битов и символ перехода ("ARITH_ESCAPE"). Предпочтительно, чтобы оценивалась таблица ari_cf_m[64][17] накопленных частот, которая задана в табличном представлении в соответствии с фиг. 23(1), 23(2), 23(3), которое задает таблицы накопленных частот (или подтаблицы) от "ari_cf_m[pki=0][17]" до "ari_cf_m[pki=63][17]", чтобы получить выбранную таблицу накопленных частот (или подтаблицу).
Потом значение m матрицы старших битов можно получить путем выполнения функции "arith_decode()", учитывая выбранную таблицу накопленных частот (описанную переменной "cum_freq" и переменной "cfl"). При выведении значения m матрицы старших битов могут оцениваться биты в битовом потоке 210, названные "acod_m" (см., например, фиг. 6g или фиг. 6h). Предпочтительно, чтобы использовалась функция "arith_decode(cum_freq,cfl)" в соответствии с фиг. 5g, но в качестве альтернативы может использоваться функция "arith_decode(cum_freq,cfl)" в соответствии с фиг. 5h и 5i.
Алгоритм 312ba также содержит проверку, равно ли значение m матрицы старших битов символу "ARITH_ESCAPE" перехода. Если значение m матрицы старших битов не равно арифметическому символу перехода, то алгоритм 312ba завершается (условие "break"), а оставшиеся инструкции алгоритма 312ba пропускаются. Соответственно, выполнение процесса продолжается с установкой значения b и значения a на этапе 312bb. В отличие от этого, если декодированное значение m матрицы старших битов идентично арифметическому символу перехода, или "ARITH_ESCAPE", то значение "lev" уровня увеличивается на единицу. Значение "esc_nb" уровня устанавливается равным значению "lev" уровня, пока переменная "lev" не больше семи, и в этом случае переменная "esc_nb" устанавливается равной семи. Как упоминалось, алгоритм 312ba затем повторяется, пока декодированное значение m матрицы старших битов не отличается от арифметического символа перехода, где используется измененный контекст (потому что входной параметр функции "arith_get_pk()" адаптируется в зависимости от значения переменной "esc_nb").
Как только матрица старших битов декодируется с использованием однократного выполнения или итеративного выполнения алгоритма 312ba, то есть декодировано значение m матрицы старших битов, отличное от арифметического символа перехода, переменная "b" спектрального значения устанавливается равной множеству (например, 2) более значащих битов значения m матрицы старших битов, а переменная "a" спектрального значения устанавливается в (например, 2) самых младших битах значения m матрицы старших битов. Подробности касаемо этих функциональных возможностей можно увидеть, например, по номеру 312bb ссылки.
Потом на этапе 312c проверяется, присутствует ли арифметический стоп-символ. Это имеет место, если значение m матрицы старших битов равно нулю, а переменная "lev" больше нуля. Соответственно, условие арифметического прерывания сигнализируется с помощью "необычного" условия, в котором значение m матрицы старших битов равно нулю, хотя переменная "lev" указывает, что увеличенный численный вес ассоциируется со значением m матрицы старших битов. Другими словами, условие арифметического прерывания обнаруживается, если битовый поток указывает, что увеличенный численный вес, больше минимального численного веса, следует назначить значению матрицы старших битов, которое равно нулю, что является условием, которое не возникает в обычной ситуации кодирования. Другими словами, условие арифметического прерывания сигнализируется, если за кодированным арифметическим символом перехода следует кодированное значение матрицы старших битов, равное 0.
После оценки, имеется ли условие арифметического прерывания, которая выполняется на этапе 212c, получаются матрицы менее значащих битов, например, которые показаны номером 212d ссылки на фиг. 3. Для каждой матрицы менее значащих битов декодируются два двоичных значения. Одно из двоичных значений ассоциируется с переменной a (или первым спектральным значением кортежа спектральных значений), и одно из двоичных значений ассоциируется с переменной b (или вторым спектральным значением кортежа спектральных значений). Количество матриц менее значащих битов обозначается переменной lev.
При декодировании одной или более матриц наименее значащих битов (если есть) алгоритм 212da выполняется итерационно, где количество исполнений алгоритма 212da определяется переменной "lev". Здесь следует отметить, что первая итерация алгоритма 212da выполняется на основе значений переменных a, b, которые заданы на этапе 212bb. Дальнейшие итерации алгоритма 212da выполняются на основе обновленных значений переменных a, b.
В начале итерации выбирается таблица накопленных частот. Потом арифметическое декодирование выполняется для получения значения переменной r, где значение переменной r описывает множество менее значащих битов, например, один менее значащий бит, ассоциированный с переменной a, и один менее значащий бит, ассоциированный с переменной b. Функция "ARITH_DECODE" (например, которая задана на фиг. 5g) используется для получения значения r, где таблица "arith_cf_r" накопленных частот используется для арифметического декодирования.
Потом значения переменных a и b обновляются. С этой целью переменная a сдвигается влево на один бит, и наименее значащий бит сдвинутой переменной a устанавливается в значение, заданное наименее значащим битом значения r. Переменная b сдвигается влево на один бит, и наименее значащий бит сдвинутой переменной b устанавливается в значение, заданное битом 1 переменной r, где бит 1 переменной r имеет численный вес 2 в двоичном представлении переменной r. Алгоритм 412ba затем повторяется, пока не декодируются все наименее значащие биты.
После декодирования матриц менее значащих битов массив "x_ac_dec" обновляется в том, что значения переменных a, b сохраняются в записях упомянутого массива, имеющих индексы массива 2*i и 2*i+1.
Потом состояние контекста обновляется путем вызова функции "arith_update_context(i,a,b)", подробности которой будут объясняться ниже со ссылкой на фиг. 5g. Предпочтительно, что может использоваться функция "arith_update_context(i,a,b)", которая задана на фиг. 5l.
После обновления состояния контекста, которое выполняется на этапе 313, алгоритмы 312 и 313 повторяются, пока текущая переменная i не достигнет значения lg/2, или пока не обнаружится условие арифметического прерывания.
Потом выполняется завершающий алгоритм "arith_finish()", как видно по номеру 315 ссылки. Подробности завершающего алгоритма "arith_finish()" будут описываться ниже со ссылкой на фиг. 5m.
После завершающего алгоритма 315 знаки спектральных значений декодируются с использованием алгоритма 314. Как видно, знаки спектральных значений, которые отличаются от нуля, кодируются отдельно. В алгоритме 314 знаки считываются для всех спектральных значений, имеющих индексы i между i=0 и i=lg-1, которые не равны нулю. Для каждого ненулевого спектрального значения, имеющего индекс i спектрального значения между i=0 и i=lg-1, значение s (обычно одиночный бит) считывается из битового потока. Если значение s, которое считывается из битового потока, равно 1, то знак упомянутого спектрального значения инвертируется. С этой целью выполняется обращение к массиву "x_ac_dec", чтобы определить, равно ли нулю спектральное значение, имеющее индекс i, и для обновления знака декодированных спектральных значений. Однако следует отметить, что знаки переменных a, b остаются без изменений при декодировании 314 знаков.
С помощью выполнения завершающего алгоритма 315 перед декодированием 314 знаков можно сбросить все необходимые биты после символа ARITH_STOP.
Здесь следует отметить, что идея для получения значений матриц менее значащих битов не имеет особой важности в некоторых вариантах осуществления в соответствии с настоящим изобретением. В некоторых вариантах осуществления даже может пропускаться декодирование любых матриц менее значащих битов. В качестве альтернативы могут использоваться разные алгоритмы декодирования с этой целью.
11.2 Порядок декодирования в соответствии с фиг. 4
Ниже будет описываться порядок декодирования спектральных значений.
Квантованные спектральные коэффициенты "x_ac_dec[]" помехоустойчиво кодируются и передаются (например, в битовом потоке), начиная с коэффициента наименьшей частоты и продвигаясь к коэффициенту наибольшей частоты.
Следовательно, квантованные спектральные коэффициенты "x_ac_dec[]" помехоустойчиво декодируются, начиная с коэффициента наименьшей частоты и продвигаясь к коэффициенту наибольшей частоты. Квантованные спектральные коэффициенты декодируются группами из двух последовательных (например, соседних по частоте) коэффициентов a и b, собирающихся в так называемый кортеж из 2-х элементов (a,b) (также обозначенный с помощью {a,b}). Здесь следует отметить, что квантованные спектральные коэффициенты также иногда обозначаются с помощью "qdec".
Декодированные коэффициенты "x_ac_dec[]" для режима частотной области (например, декодированные коэффициенты для усовершенствованного аудиокодирования, полученные с использованием измененного дискретного косинусного преобразования, как обсуждалось в ISO/IEC 14496, часть 3, подраздел 4) затем сохраняются в массиве "x_ac_quant[g][win][sfb][bin]". Порядок передачи кодовых слов помехоустойчивого кодирования является таким, что когда они декодируются в порядке принятых и сохраненных в массиве, "bin" является самым быстро увеличивающимся индексом, а "g" является самым медленно увеличивающимся индексом. В рамках кодового слова порядком декодирования является a,b (то есть a, затем b).
Декодированные коэффициенты "x_ac_dec[]" для кодированного возбуждения с преобразованием (TCX) сохраняются, например, непосредственно в массиве "x_tcx_invquant[win][bin]", и порядок передачи кодового слова помехоустойчивого кодирования является таким, что когда они декодируются в порядке принятых и сохраненных в массиве, "bin" является самым быстро увеличивающимся индексом, а "win" является самым медленно увеличивающимся индексом. В рамках кодового слова порядком декодирования является a,b (то есть a, затем b). Другими словами, если спектральные значения описывают кодированное возбуждение с преобразованием фильтра линейного предсказания речевого кодера, то спектральные значения a, b ассоциируются с соседними и увеличивающимися частотами кодированного возбуждения с преобразованием. Спектральные коэффициенты, ассоциированные с меньшей частотой, обычно кодируются и декодируются до спектрального коэффициента, ассоциированного с большей частотой.
В частности, аудиодекодер 200 может быть сконфигурирован для применения декодированного представления 232 частотной области, которое предоставляется арифметическим декодером 230, как для "прямого" формирования представления аудиосигнала временной области с использованием преобразования сигнала частотной области во временную область, так и для "косвенного" предоставления представления аудиосигнала временной области с использованием декодера из частотной области во временную область и фильтра линейного предсказания, возбуждаемого выводом преобразователя сигнала частотной области во временную область.
Другими словами, арифметический декодер, функциональные возможности которого здесь подробно обсуждаются, подходит для декодирования спектральных значений представления частотно-временной области аудиоконтента, кодированного в частотной области, и для предоставления представления частотно-временной области сигнала входного воздействия для фильтра линейного предсказания, приспособленного для декодирования (или синтеза) речевого сигнала, кодированного в области линейного предсказания. Таким образом, арифметический декодер подходит для использования в аудиодекодере, который допускает обработку как кодированного аудиоконтента в частотной области, так и кодированного аудиоконтента в частотной области с линейным предсказанием (режим кодированного возбуждения с преобразованием в области линейного предсказания).
11.3 Инициализация контекста в соответствии с фиг. 5a и 5b
Ниже будет описываться инициализация контекста (также обозначенная как "отображение контекста"), которая выполняется на этапе 310.
Инициализация контекста содержит отображение между прошлым контекстом и текущим контекстом в соответствии с алгоритмом "arith_map_context()", первый пример которого показан на фиг. 5a, а второй пример которого показан на фиг. 5b.
Как видно, текущий контекст хранится в глобальной переменной "q[2][n_context]", которая принимает вид массива, имеющего первую размерность, равную 2, и вторую размерность, равную "n_context". Прошлый контекст необязательно (но в этом нет необходимости) может храниться в переменной "qs[n_context]", которая принимает вид таблицы, имеющей размерность "n_context" (если используется).
Ссылаясь на примерный алгоритм "arith_map_context" на фиг. 5a, входная переменная N описывает длину текущего окна, а входная переменная "arith_reset_flag" указывает, следует ли сбросить контекст. Кроме того, глобальная переменная "previous_N" описывает длину предыдущего окна. Здесь следует отметить, что обычно количество спектральных значений, ассоциированных с окном, по меньшей мере приблизительно равно половине длины упомянутого окна в показателях выборок временной области. Кроме того, следует отметить, что количество кортежей из 2-х спектральных значений поэтому равно, по меньшей мере приблизительно, четверти длины упомянутого окна в показателях выборок временной области.
Сначала следует отметить, что флаг "arith_reset_flag" определяет, нужно ли сбросить контекст.
Ссылаясь на пример из фиг. 5a, отображение контекста может выполняться в соответствии с алгоритмом "arith_map_context()". Здесь следует отметить, что функция "arith_map_context()" устанавливает записи "q[0][j]" массива q текущего контекста в ноль для j от 0 до N/4-1, если флаг "arith_reset_flag" активен и, следовательно, указывает, что контекст следует сбросить. В противном случае, то есть если флаг "arith_reset_flag" неактивен, то записи "q[0][j]" массива q текущего контекста выводятся из записей "q[1][k]" массива q текущего контекста. Следует отметить, что функция "arith_map_context()" в соответствии с фиг. 5a устанавливает записи "q[0][j]" массива q текущего контекста в значения "q[1][k]" массива q текущего контекста, если количество спектральных значений, ассоциированных с текущим аудиокадром (например, кодированным в частотной области), идентично количеству спектральных значений, ассоциированных с предыдущим аудиокадром для j=k=0 до j=k=N/4-1.
Более сложное отображение выполняется, если количество спектральных значений, ассоциированных с текущим аудиокадром, отличается от количества спектральных значений, ассоциированных с предыдущим аудиокадром. Однако подробности касательно отображения в этом случае не очень существенны для основной идеи настоящего изобретения, так что за подробностями дается ссылка на программный псевдокод из фиг. 5a.
Кроме того, значение инициализации для числового текущего значения c контекста возвращается функцией "arith_map_context()". Это значение инициализации равно, например, значению записи "q[0][0]", сдвинутому влево на 12 битов. Соответственно, числовое (текущее) значение c контекста должным образом инициализируется для итеративного обновления.
Кроме того, фиг. 5b показывает другой пример алгоритма "arith_map_context()", который может использовать в качестве альтернативы. За подробностями приводится ссылка на программный псевдокод на фиг. 5b.
Чтобы подвести итог вышесказанному, флаг "arith_reset_flag" определяет, нужно ли сбросить контекст. Если флаг является истиной, то вызывается субалгоритм 500a сброса в алгоритме "arith_map_context()". Однако в качестве альтернативы, если флаг "arith_reset_flag" неактивен (что указывает, что не следует выполнять никакой сброс контекста), то процесс декодирования начинается с фазы инициализации, где вектор q элементов контекста (или массив) обновляется путем копирования и отображения на q[0][] элементов контекста предыдущего кадра, сохраненного в q[1][]. Элементы контекста в q сохраняются в 4 битах на кортеж из 2-х элементов. Копирование и/или отображение элемента контекста выполняются, например, в субалгоритме 500b.
Кроме того, следует отметить, что если контекст нельзя определить надежно, например, если не доступны данные предыдущего кадра, и если "arith_reset_flag" не установлен, то декодирование спектральных данных нельзя продолжить, и считывание текущего элемента "arith_data()" следует пропустить.
В примере из фиг. 5b процесс декодирования начинается с фазы инициализации, где отображение выполняется между записанным прошлым контекстом, сохраненным в qs, и контекстом q текущего кадра. Прошлый контекст qs сохраняется в 2 битах на линию частоты.
11.4 Вычисление значения состояния в соответствии с фиг. 5c и 5d
Ниже будет подробнее описываться вычисление 312a значения состояния.
Первый предпочтительный алгоритм будет описываться со ссылкой на фиг. 5c, а второй альтернативный примерный алгоритм будет описываться со ссылкой на фиг. 5d.
Следует отметить, что числовое текущее значение c контекста (как показано на фиг. 3) можно получить в виде возвращаемого значения функции "arith_get_context(c,i,N)", представление в псевдокоде которой показано на фиг. 5c. Однако в качестве альтернативы числовое текущее значение c контекста можно получить в виде возвращаемого значения функции "arith_get_context(c,i)", представление в псевдокоде которой показано на фиг. 5d.
Касательно вычисления значения состояния также приведена ссылка на фиг. 4, которая показывает контекст, используемый для оценки состояния, то есть для вычисления числового текущего значения c контекста. Фиг. 4 показывает двумерное представление спектральных значений по времени и по частоте. Абсцисса 410 описывает время, а ордината 412 описывает частоту. Как видно на фиг. 4, кортеж 420 спектральных значений для декодирования (предпочтительно с использованием числового текущего значения контекста) ассоциируется с индексом t0 времени и индексом i частоты. Как видно, для индекса t0 времени кортежи, имеющие индексы i-1, i-2 и i-3 частоты, уже декодируются в момент, в который должны быть декодированы спектральные значения кортежа 120, имеющего индекс i частоты. Как видно из фиг. 4, спектральное значение 430, имеющее индекс t0 времени и индекс i-1 частоты, уже декодируется перед тем, как декодируется кортеж 420 спектральных значений, и кортеж 430 спектральных значений учитывается для контекста, который используется для декодирования кортежа 420 спектральных значений. Аналогичным образом кортеж 440 спектральных значений, имеющий индекс t0-1 времени и индекс i-1 частоты, кортеж 450 спектральных значений, имеющий индекс t0-1 времени и индекс i частоты, и кортеж 460 спектральных значений, имеющий индекс t0-1 времени и индекс i+1 частоты, уже декодируются перед тем, как декодируется кортеж 420 спектральных значений, и учитываются для определения контекста, который используется для декодирования кортежа 420 спектральных значений. Спектральные значения (коэффициенты), уже декодированные в момент, когда декодируются спектральные значения кортежа 420, и учтенные для контекста, показаны заштрихованным квадратом. В отличие от этого некоторые другие спектральные значения, уже декодированные (в момент, когда декодируются спектральные значения кортежа 420), но не учтенные для контекста (для декодирования спектральных значений кортежа 420), представлены квадратами из пунктирных линий, а остальные спектральные значения (которые еще не декодируются в момент, когда декодируются спектральные значения кортежа 420) показаны окружностями из пунктирных линий. Кортежи, представленные квадратами с пунктирными линиями, и кортежи, представленные окружностями с пунктирными линиями, не используются для определения контекста для декодирования спектральных значений кортежа 420.
Однако следует отметить, что некоторые из этих спектральных значений, которые не используются для "обычного" или "нормального" вычисления контекста для декодирования спектральных значений кортежа 420, тем не менее могут оцениваться для обнаружения множества ранее декодированных соседних спектральных значений, которые по отдельности или в совокупности удовлетворяют предопределенному условию касательно их величин. Подробности касательно этой проблемы будут обсуждаться ниже.
Ссылаясь теперь на фиг. 5c, будут описываться подробности алгоритма "arith_get_context(c,i,N)". Фиг. 5c показывает функциональные возможности упомянутой функции "arith_get_context(c,i,N)" в виде программного псевдокода, который использует соглашения известного языка C и/или языка C++. Таким образом, будут описываться некоторые подробности касательно вычисления числового текущего значения "c" контекста, которое выполняется функцией "arith_get_context(c,i,N)".
Следует отметить, что функция "arith_get_context(c,i,N)" в качестве входных переменных принимает "контекст старого состояния", который может описываться числовым предыдущим значением c контекста. Функция "arith_get_context(c,i,N)" в качестве входной переменной также принимает индекс i кортежа из 2-х спектральных значений для декодирования. Индекс i обычно является индексом частоты. Входная переменная N описывает длину окна, для которого декодируются спектральные значения.
Функция "arith_get_context(c,i,N)" в качестве выходного значения предоставляет обновленную версию входной переменной c, которая описывает контекст обновленного состояния и которая может считаться числовым текущим значением контекста. Подводя итог, функция "arith_get_context(c,i,N)" принимает числовое предыдущее значение c контекста в качестве входной переменной и предоставляет его обновленную версию, которая считается числовым текущим значением контекста. К тому же функция "arith_get_context" учитывает переменные i, N, а также обращается к "глобальному" массиву q[][].
Касательно подробностей функции "arith_get_context(c,i,N)" следует отметить, что переменная c, которая исходно представляет числовое предыдущее значение контекста в двоичном виде, сдвигается вправо на 4 бита на этапе 504a. Соответственно, отбрасываются четыре младших бита числового предыдущего значения контекста (представленного входной переменной c). Также уменьшаются численные веса остальных битов в числовых предыдущих значениях контекста, например, с коэффициентом 16.
Кроме того, если индекс i кортежа из 2-х элементов меньше N/4-1, то есть не принимает максимальное значение, то числовое текущее значение контекста изменяется в том, что значение записи q[0][i+1] добавляется к битам с 12 по 15 (то есть к битам, имеющим численный вес 212, 213, 214 и 215) сдвинутого значения контекста, которое получается на этапе 504a. С этой целью запись q[0][i+1] массива q[][] (или точнее, двоичное представление значения, представленного упомянутой записью) сдвигается влево на 12 битов. Сдвинутая версия значения, представленного записью q[0][i+1], затем прибавляется к значению c контекста, которое выводится на этапе 504a, то есть к сдвинутому по битам (сдвинутому вправо на 4 бита) цифровому представлению числового предыдущего значения контекста. Здесь следует отметить, что запись q[0][i+1] массива q[][] представляет собой значение подобласти, ассоциированное с предыдущей частью аудиоконтента (например, частью аудиоконтента, имеющей индекс t0-1 времени, как задано со ссылкой на фиг. 4), и с большей частотой (например, частотой, имеющей индекс i+1 частоты, как задано со ссылкой на фиг. 4), чем кортеж спектральных значений, который должен быть декодирован в настоящее время (используя числовое текущее значение c контекста, выведенное функцией "arith_get_context(c,i,N)"). Другими словами, если кортеж 420 спектральных значений должен быть декодирован с использованием числового текущего значения контекста, то запись q[0][i+1] может основываться на кортеже 460 ранее декодированных спектральных значений.
Выборочное добавление записи q[0][i+1] массива q[][] (сдвинутой влево на 12 битов) показано по номеру 504b ссылки. Как видно, добавление значения, представленного записью q[0][i+1], конечно же выполняется, только если индекс i частоты не обозначает кортеж спектральных значений, имеющий наибольший индекс i=N/4-1 частоты.
Потом на этапе 504c выполняется операция логического И, в которой значение переменной c объединяется логическим "И" с шестнадцатеричным значением 0×FFF0, чтобы получить обновленное значение переменной c. Путем выполнения такой И-операции четыре младших бита переменной c фактически устанавливаются в ноль.
На этапе 504d значение записи q[1][i-1] добавляется к значению переменной c, которое получается с помощью этапа 504c, чтобы посредством этого обновить значение переменной c. Однако упомянутое обновление переменной c на этапе 504d выполняется, только если индекс i частоты кортежа из 2-х элементов для декодирования больше нуля. Следует отметить, что запись q[1][i-1] является значением подобласти контекста на основе кортежа ранее декодированных спектральных значений текущей части аудиоконтента для частот меньше частот спектральных значений, которые должны быть декодированы с использованием числового текущего значения контекста. Например, запись q[1][i-1] массива q[][] может ассоциироваться с кортежем 430, имеющим индекс t0 времени и индекс i-1 частоты, если предполагается, что кортеж 420 спектральных значений должен быть декодирован с использованием числового текущего значения контекста, возвращаемого данным выполнением функции "arith_get_context(c,i,N)".
Подводя итог, биты 0, 1, 2 и 3 (то есть часть четырех младших битов) числового предыдущего значения контекста отбрасываются на этапе 504a путем их сдвига из двоичного цифрового представления числового предыдущего значения контекста. Кроме того, биты 12, 13, 14 и 15 сдвинутой переменной c (то есть сдвинутого числового предыдущего значения контекста) устанавливаются в значения, заданные значением q[0][i+1] подобласти контекста на этапе 504b. Биты 0, 1, 2 и 3 сдвинутого числового предыдущего значения контекста (то есть биты 4, 5, 6 и 7 исходного числового предыдущего значения контекста) перезаписываются значением q[1][i-1] подобласти контекста на этапах 504c и 504d.
Следовательно, можно сказать, что биты с 0 по 3 числового предыдущего значения контекста представляют значение подобласти контекста, ассоциированное с кортежем 432 спектральных значений, биты с 4 по 7 числового предыдущего значения контекста представляют значение подобласти контекста, ассоциированное с кортежем 434 ранее декодированных спектральных значений, биты с 8 по 11 числового предыдущего значения контекста представляют значение подобласти контекста, ассоциированное с кортежем 440 ранее декодированных спектральных значений, и биты с 12 по 15 числового предыдущего значения контекста представляют значение подобласти контекста, ассоциированное с кортежем 450 ранее декодированных спектральных значений. Числовое предыдущее значение контекста, которое вводится в функцию "arith_get_context(c,i,N)", ассоциируется с декодированием кортежа 430 спектральных значений.
Числовое текущее значение контекста, которое получается в качестве выходной переменной функции "arith_get_context(c,i,N)", ассоциируется с декодированием кортежа 420 спектральных значений. Соответственно, биты с 0 по 3 числовых текущих значений контекста описывают значение подобласти контекста, ассоциированное с кортежем 430 спектральных значений, биты с 4 по 7 числового текущего значения контекста описывают значение подобласти контекста, ассоциированное с кортежем 440 спектральных значений, биты с 8 по 11 числового текущего значения контекста описывают числовое значение подобласти, ассоциированное с кортежем 450 спектральных значений, и биты с 12 по 15 числового текущего значения контекста описывают значение подобласти контекста, ассоциированное с кортежем 460 спектральных значений. Таким образом, видно, что часть числового предыдущего значения контекста, а именно биты с 8 по 15 числового предыдущего значения контекста, также включается в числовое текущее значение контекста, как и биты с 4 по 11 числового текущего значения контекста. В отличие от этого биты с 0 по 7 числового предыдущего значения контекста отбрасываются при выведении цифрового представления числового текущего значения контекста из цифрового представления числового предыдущего значения контекста.
На этапе 504e переменная c, которая представляет числовое текущее значение контекста, выборочно обновляется, если индекс i частоты кортежа из 2-х элементов для декодирования больше заранее установленного числа, например, 3. В этом случае, то есть если i больше 3, то определяется, является ли сумма значений q[1][i-3], q[1][i-2] и q[1][i-1] подобласти контекста меньшей (либо равной) заранее установленного значения, например, 5. Если обнаруживается, что сумма упомянутых значений подобласти контекста меньше упомянутого заранее установленного значения, то шестнадцатеричное значение, например 0×10000, добавляется к переменной c. Соответственно, переменная c устанавливается так, что переменная c указывает, имеется ли состояние, в котором значения q[1][i-3], q[1][i-2] и q[1][i-1] подобласти контекста содержат очень малое значение суммы. Например, бит 16 числового текущего значения контекста может действовать в качестве флага для указания такого состояния.
В заключение возвращаемое значение функции "arith_get_context(c,i,N)" определяется этапами 504a, 504b, 504c, 504d и 504e, где числовое текущее значение контекста выводится из числового предыдущего значения контекста на этапах 504a, 504b, 504c и 504d, и где флаг, указывающий окружение ранее декодированных спектральных значений, имеющих в среднем очень небольшие абсолютные значения, выводится на этапе 504e и добавляется к переменной c. Соответственно, значение переменной c, полученное на этапах 504a, 504b, 504c, 504d, возвращается на этапе 504f в качестве возвращаемого значения функции "arith_get_context(c,i,N)", если не выполняется условие, оцененное на этапе 504e. В отличие от этого, значение переменной c, которое выводится на этапах 504a, 504b, 504c и 504d, увеличивается на шестнадцатеричное значение 0×10000, и результат этой операции увеличения возвращается на этапе 504e, если выполняется условие, оцененное на этапе 540e.
Чтобы подвести итог вышесказанному, следует отметить, что помехоустойчивый декодер выводит кортежи из 2-х беззнаковых квантованных спектральных коэффициентов (которые будут подробнее описываться ниже). Сначала состояние c контекста вычисляется на основе ранее декодированных спектральных коэффициентов, "окружающих" кортеж из 2-х элементов для декодирования. В предпочтительном варианте осуществления состояние (которое, например, представлено числовым значением c контекста) обновляется шагами, используя состояние контекста последнего декодированного кортежа из 2-х элементов (которое обозначается как числовое предыдущее значение контекста), учитывая только два новых кортежа из 2-х элементов (например, кортежи 430 и 460 из 2-х элементов). Состояние кодируется в 17 битах (например, используя цифровое представление числового текущего значения контекста) и возвращается функцией "arith_get_context()". За подробностями приводится ссылка на представление в программном коде из фиг. 5c.
Кроме того, следует отметить, что на фиг. 5d показан программный псевдокод альтернативного варианта осуществления функции "arith_get_context()". Функция "arith_get_context(c,i)" в соответствии с фиг. 5d аналогична функции "arith_get_context(c,i,N)" в соответствии с фиг. 5c. Однако функция "arith_get_context(c,i)" в соответствии с фиг. 5d не содержит специальную обработку или декодирование кортежей спектральных значений, содержащих минимальный индекс i=0 частоты или максимальный индекс i=N/4-1 частоты.
11.5 Выбор правила отображения
Ниже будет описываться выбор правила отображения, например таблицы накопленных частот, которая описывает отображение значения кодового слова на символьный код. Выбор правила отображения осуществляется в зависимости от состояния контекста, которое описывается числовым текущим значением c контекста.
11.5.1 Выбор правила отображения с использованием алгоритма в соответствии с фиг. 5e
Ниже будет описываться выбор правила отображения с использованием функции "arith_get_pk(c)". Следует отметить, что функция "arith_get_pk()" вызывается в начале субалгоритма 312ba при декодировании кодового значения "acod_m" для предоставления кортежа спектральных значений. Следует отметить, что функция "arith_get_pk(c)" вызывается с разными аргументами в разных итерациях алгоритма 312b. Например, в первой итерации алгоритма 312b функция "arith_get_pk(c)" вызывается с аргументом, который равен числовому текущему значению c контекста, предоставленному предыдущим выполнением функции "arith_get_context(c,i,N)" на этапе 312a. В отличие от этого в дальнейших итерациях субалгоритма 312ba функция "arith_get_pk(c)" вызывается с аргументом, который является суммой числового текущего значения c контекста, предоставленного функцией "arith_get_context(c,i,N)" на этапе 312a, и сдвинутой по битам версии значения переменной "esc_nb", где значение переменной "esc_nb" сдвигается влево на 17 битов. Таким образом, числовое текущее значение c контекста, предоставленное функцией "arith_get_context(c,i,N)", используется в качестве входного значения функции "arith_get_pk()" в первой итерации алгоритма 312ba, то есть при декодировании сравнительно небольших спектральных значений. В отличие от этого при декодировании сравнительно больших спектральных значений входная переменная функции "arith_get_pk()" изменяется в том, что учитывается значение переменной "esc_nb", как показано на фиг. 3.
Ссылаясь теперь на фиг. 5e, которая показывает представление в псевдокоде первого, предпочтительного варианта осуществления функции "arith_get_pk(c)", следует отметить, что функция "arith_get_pk()" принимает переменную c в качестве входного значения, где переменная c описывает состояние контекста, и где входная переменная c функции "arith_get_pk()" равна числовому текущему значению контекста, предоставленному функцией "arith_get_context()" в виде возвращаемой переменной, по меньшей мере в некоторых ситуациях. Кроме того, следует отметить, что функция "arith_get_pk()" в качестве выходной переменной предоставляет переменную "pki", которая описывает индекс вероятностной модели и которая может считаться индексным значением правила отображения.
Ссылаясь на фиг. 5e, видно, что функция "arith_get_pk()" содержит инициализацию 506a переменной, где переменная "i_min" инициализируется значением -1. Аналогичным образом переменная i устанавливается равной переменной "i_min", так что переменная i также инициализируется значением -1. Переменная "i_max" инициализируется значением, которое на 1 меньше количества записей таблицы "ari_lookup_m[]" (подробности которой будут описываться со ссылкой на фиг. 21). Соответственно, переменные "i_min" и "i_max" задают интервал. Например, i_max может инициализироваться значением 741.
Потом выполняется поиск 506b, чтобы идентифицировать индексное значение, которое указывает запись таблицы "ari_hash_m", которая выбирается, как задано в табличном представлении фиг. 22(1), 22(2), 22(3), 22(4), так что значение входной переменной c у функции "arith_get_pk()" находится в интервале, заданном упомянутой записью и соседней записью.
В поиске 506b субалгоритм 506ba повторяется, пока разность между переменными "i_max" и "i_min" больше 1. В субалгоритме 506ba переменная i устанавливается равной среднему арифметическому значений переменных "i_min" и "i_max". Следовательно, переменная i указывает запись таблицы "ari_hash_m[]" (которая задана в табличных представлениях фиг. 22(1), 22(2), 22(3) и 22(4)) в середине интервала таблицы, заданного значениями переменных "i_min" и "i_max". Потом переменная j устанавливается равной значению записи "ari_hash_m[i]" таблицы "ari_hash_m[]". Таким образом, переменная j принимает значение, заданное записью таблицы "ari_hash_m[]", и эта запись находится в середине интервала таблицы, заданного переменными "i_min" и "i_max". Потом обновляется интервал, заданный переменными "i_min" и "i_max", если значение входной переменной c у функции "arith_get_pk()" отличается от значения состояния, заданного старшими битами записи "j=ari_hash_m[i]" таблицы "ari_hash_m[]". Например, "старшие биты" (биты 8-ой и выше) записей таблицы "ari_hash_m[]" описывают значимые значения состояния. Соответственно, значение "j>>8" описывает значимое значение состояния, представленное записью "j=ari_hash_m[i]" таблицы "ari_hash_m[]", указанной индексным значением i хэш-таблицы. Соответственно, если значение переменной c меньше значения "j>>8", то это означает, что значение состояния, описанное переменной c, меньше значимого значения состояния, описанного записью "ari_hash_m[i]" таблицы "ari_hash_m[]". В этом случае значение переменной "i_max" устанавливается равным значению переменной i, что в свою очередь имеет результатом уменьшение размера интервала, заданного "i_min" и "i_max", где новый интервал равен приблизительно половине предыдущего интервала. Если обнаруживается, что входная переменная c у функции "arith_get_pk()" больше значения "j>>8", что означает, что значение контекста, описанное переменной c, больше значимого значения состояния, описанного записью "ari_hash_m[i]" массива "ari_hash_m[]", то значение переменной "i_min" устанавливается равным значению переменной i. Соответственно, размер интервала, заданного значениями переменных "i_min" и "i_max", уменьшается приблизительно до половины размера предыдущего интервала, заданного предыдущими значениями переменных "i_min" и "i_max". Точнее говоря, интервал, заданный обновленным значением переменной "i_min" и предыдущим (неизменившимся) значением переменной "i_max", приблизительно равен верхней половине предыдущего интервала в случае, где значение переменной c больше значимого значения состояния, заданного записью "ari_hash_m[i]".
Однако если обнаруживается, что значение контекста, описанное входной переменной c у алгоритма "arith_get_pk()", равно значимому значению состояния, заданному записью "ari_hash_m[i]" (то есть c==(j>>8)), то индексное значение правила отображения, заданное младшими 8 битами записи "ari_hash_m[i]", возвращается в качестве возвращаемого значения функции "arith_get_pk()" (команда "return (j&0×FF)").
Чтобы подвести итог вышесказанному, запись "ari_hash_m[i]", старшие биты которой (биты 8-ой и выше) описывают значимое значение состояния, оценивается в каждой итерации 506ba, и значение контекста (или числовое текущее значение контекста), описанное входной переменной c у функции "arith_get_pk()", сравнивается со значимым значением состояния, описанным упомянутой записью "ari_hash_m[i]" таблицы. Если значение контекста, представленное входной переменной c, меньше значимого значения состояния, представленного записью "ari_hash_m[i]" таблицы, то уменьшается верхняя граница интервала таблицы (описанная значением "i_max"), а если значение контекста, описанное входной переменной c, больше значимого значения состояния, описанного записью "ari_hash_m[i]" таблицы, то увеличивается нижняя граница интервала таблицы (которая описывается значением переменной "i_min"). В обоих упомянутых случаях субалгоритм 506ba повторяется, пока размер интервала (заданный разностью между "i_max" и "i_min") не меньше либо равен 1. В отличие от этого, если значение контекста, описанное переменной c, равно значимому значению состояния, описанному записью "ari_hash_m[i]" таблицы, то функция "arith_get_pk()" завершается, в которой возвращаемое значение задается младшими 8 битами записи "ari_hash_m[i]" таблицы.
Однако если поиск 506b завершается, потому что размер интервала достигает минимального значения ("i_max"-"i_min" меньше либо равно 1), то возвращаемое значение функции "arith_get_pk()" определяется записью "ari_lookup_m[i_max]" таблицы "ari_lookup_m[]", что можно увидеть по номеру 506c ссылки. Таблица ari_lookup_m[] предпочтительно выбирается, как задано в табличном представлении фиг. 21, и поэтому может быть равной таблице ari_lookup_m[742]. Соответственно, записи таблицы "ari_hash_m[]" (которая предпочтительно равна таблице ari_hash_m[742], которая задана на фиг. 22(1), 22(2), 22(3), 22(4)) задают значимые значения состояния и границы интервалов. В субалгоритме 506ba границы интервала поиска "i_min" и "i_max" итерационно адаптируются, так что запись "ari_hash_m[i]" таблицы "ari_hash_m[]", индекс i хэш-таблицы которой находится, по меньшей мере приблизительно, в центре интервала поиска, заданного значениями границы интервала "i_min" и "i_max", по меньшей мере приблизительно равна значению контекста, описанному входной переменной c. Соответственно получается, что значение контекста, описанное входной переменной c, находится в интервале, заданном "ari_hash_m[i_min]" и "ari_hash_m[i_max]" после завершения итераций субалгоритма 506ba, пока значение контекста, описанное входной переменной c, не равно значимому значению состояния, описанному записью "ari_hash_m[]" таблицы.
Однако если итеративное повторение субалгоритма 506ba завершается, потому что размер интервала (заданный с помощью "i_max-i_min") достигает или превышает минимальное значение, то предполагается, что значение контекста, описанное входной переменной c, не является значимым значением состояния. В этом случае все-таки используется индекс "i_max", который обозначает верхнюю границу интервала. Верхнее значение "i_max" интервала, которое достигается в последней итерации субалгоритма 506ba, повторно используется в качестве индексного значения таблицы для обращения к таблице "ari_lookup_m" (которая может быть равна таблице ari_lookup_m[742] из фиг. 21). Таблица "ari_lookup_m[]" описывает индексные значения правила отображения, ассоциированные с интервалами множества соседних числовых значений контекста. Интервалы, с которыми ассоциируются индексные значения правила отображения, описанные записями таблицы "ari_lookup_m[]", задаются значимыми значениями состояния, описанными записями таблицы "ari_hash_m[]". Записи таблицы "ari_hash_m" задают как значимые значения состояния, так и границы интервала интервалов соседних числовых значений контекста. При выполнении алгоритма 506b определяется, равно ли числовое значение контекста, описанное входной переменной c, значимому значению состояния, и если это не так, в каком интервале числовых значений контекста (из множества интервалов, границы которых задаются значимыми значениями состояния) находится значение контекста, описанное входной переменной c. Таким образом, алгоритм 506b выполняет двойные функциональные возможности для определения, описывает ли входная переменная c значимое значение состояния, и если это не так, для идентификации интервала, ограниченного значимыми значениями состояния, в котором находится значение контекста, представленное входной переменной c. Соответственно, алгоритм 506e очень эффективен и требует только сравнительно небольшого количества обращений к таблицам.
Чтобы подвести итог вышесказанному, состояние c контекста определяет таблицу накопленных частот, используемую для декодирования 2-битной матрицы m старших битов. Отображение из c в соответствующий индекс "pki" таблицы накопленных частот выполняется функцией "arith_get_pk()". Представление в псевдокоде упомянутой функции "arith_get_pk()" объяснено со ссылкой на фиг. 5e.
Чтобы дополнительно резюмировать вышесказанное, значение m декодируется с использованием функции "arith_decode()" (которая подробнее описывается ниже), вызываемой с таблицей "arith_cf_m[pki][]" накопленных частот, где "pki" соответствует индексу (также обозначенному как индексное значение правила отображения), возвращаемому функцией "arith_get_pk()", которая описывается со ссылкой на фиг. 5e в виде псевдокода на языке C.
11.5.2 Выбор правила отображения с использованием алгоритма в соответствии с фиг. 5f
Ниже другой вариант осуществления алгоритма выбора правила отображения "arith_get_pk()" будет описываться со ссылкой на фиг. 5f, которая показывает представление такого алгоритма в псевдокоде, который может использоваться при декодировании кортежа спектральных значений. Алгоритм в соответствии с фиг. 5f может считаться оптимизированной версией (например, оптимизированной по скорости версией) алгоритма "get_pk()" или алгоритма "arith_get_pk()".
Алгоритм "arith_get_pk()" в соответствии с фиг. 5f в качестве входной переменной принимает переменную c, которая описывает состояние контекста. Входная переменная c может представлять, например, числовое текущее значение контекста.
Алгоритм "arith_get_pk()" в качестве выходной переменной предоставляет переменную "pki", которая описывает индекс распределения вероятности (или вероятностной модели), ассоциированный с состоянием контекста, описанным входной переменной c. Переменная "pki" может быть, например, индексным значением правила отображения.
Алгоритм в соответствии с фиг. 5f содержит определение содержимого массива "i_diff[]". Как видно, первая запись массива "i_diff[]" (имеющая индекс 0 массива) равна 299, а дальнейшие записи массива (имеющие индексы массива от 1 до 8) принимают значения 149, 74, 37, 18, 9, 4, 2 и 1. Соответственно, размер шага для выбора индексного значения "i_min" хэш-таблицы уменьшается с каждой итерацией, так как записи массивов "i_diff[]" задают упомянутые размеры шагов. За подробностями обратимся к обсуждению ниже.
Однако фактически могут выбираться разные размеры шагов, например разное содержимое массива "i_diff[]", где содержимое массива "i_diff[]" можно легко приспособить к размеру хэш-таблицы "ari_hash_m[i]".
Следует отметить, что переменная "i_min" инициализируется значением 0 как раз в начале алгоритма "arith_get_pk()".
На этапе 508a инициализации переменная s инициализируется в зависимости от входной переменной c, где цифровое представление переменной c сдвигается влево на 8 битов, чтобы получить цифровое представление переменной s.
Потом выполняется табличный поиск 508b, чтобы идентифицировать индексное значение "i_min" хэш-таблицы у записи хэш-таблицы "ari_hash_m[]", так что значение контекста, описанное значением c контекста, находится в интервале, который ограничивается значением контекста, описанным записью "ari_hash_m[i_min]" хэш-таблицы, и значением контекста, описанным другой записью "ari_hash_m" хэш-таблицы, и эта другая запись "ari_hash_m" находится рядом (в показателях индексного значения хэш-таблицы) с записью "ari_hash_m[i_min]" хэш-таблицы. Таким образом, алгоритм 508b предусматривает определение индексного значения "i_min" хэш-таблицы, обозначающего запись "j=ari_hash_m[i_min]" хэш-таблицы "ari_hash_m[]", так что запись "ari_hash_m[i_min]" хэш-таблицы по меньшей мере приблизительно равна значению контекста, описанному входной переменной c.
Табличный поиск 508b содержит итеративное выполнение субалгоритма 508ba, где субалгоритм 508ba выполняется в течение заранее установленного количества итераций, например девяти. На первом этапе субалгоритма 508ba переменная i устанавливается в значение, которое равно сумме значения переменной "i_min" и значения записи "i_diff[k]" таблицы. Здесь следует отметить, что k является текущей переменной, которая увеличивается от начального значения k=0 с каждой итерацией субалгоритма 508ba. Массив "i_diff[]" задает заранее установленные значения приращения, где значения приращения уменьшаются с увеличением индекса k таблицы, то есть с увеличением номеров итераций.
На втором этапе субалгоритма 508ba значение записи таблицы "ari_hash_m[]" копируется в переменную j. Предпочтительно, чтобы старшие биты записей таблицы "ari_hash_m[]" описывали значимые значения состояния у числового значения контекста, а наименее значащие биты (биты от 0 до 7) записей таблицы "ari_hash_m[]" описывали индексные значения правила отображения, ассоциированные с соответствующими значимыми значениями состояния.
На третьем этапе субалгоритма 508ba значение переменной S сравнивается со значением переменной j, и переменная "i_min" выборочно устанавливается в значение "i+1", если значение переменной s больше значения переменной j. Потом первый этап, второй этап и третий этап субалгоритма 508ba повторяются в течение заранее установленного количества раз, например девять раз. Таким образом, при каждом выполнении субалгоритма 508ba значение переменной "i_min" увеличивается на i_diff[]+1 лишь тогда, когда значение контекста, описанное допустимым в настоящее время индексом i_min + i_diff[] хэш-таблицы, меньше значения контекста, описанного входной переменной c. Соответственно, индексное значение "i_min" хэш-таблицы (итерационно) увеличивается при каждом выполнении субалгоритма 508ba, если (и только если) значение контекста, описанное входной переменной c, и следовательно переменной s, больше значения контекста, описанного записью "ari_hash_m[i=i_min + diff[k]]".
Кроме того, следует отметить, что только однократное сравнение, а именно сравнение в отношении того, больше ли значение переменной s значения переменной j, выполняется при каждом выполнении субалгоритма 508ba. Соответственно, алгоритм 508ba очень эффективен в вычислительном отношении. Кроме того, следует отметить, что имеются разные возможные исходы относительно окончательного значения переменной "i_min". Например, возможно, что значение переменной "i_min" после последнего выполнения субалгоритма 512ba является таким, что значение контекста, описанное записью "ari_hash_m[i_min]" таблицы, меньше значения контекста, описанного входной переменной c, и что значение контекста, описанное записью "ari_hash_m[i_min +1]" таблицы, больше значения контекста, описанного входной переменной c. В качестве альтернативы не исключено, что после последнего выполнения субалгоритма 508ba значение контекста, описанное записью "ari_hash_m[i_min -1]" хэш-таблицы, меньше значения контекста, описанного входной переменной c, и что значение контекста, описанное записью "ari_hash_m[i_min]", больше значения контекста, описанного входной переменной c. Однако в качестве альтернативы не исключено, что значение контекста, описанное записью "ari_hash_m[i_min]" хэш-таблицы, идентично значению контекста, описанному входной переменной c.
По этой причине выполняется предоставление 508c возвращаемого значения на основе решения. Переменная j устанавливается в значение записи "ari_hash_m[i_min]" хэш-таблицы. Потом определяется, больше ли значение контекста, описанное входной переменной c (а также переменной s), значения контекста, описанного записью "ari_hash_m[i_min]" (первый случай, заданный условием "s>j"), или меньше ли значение контекста, описанное входной переменной c, значения контекста, описанного записью "ari_hash_m[i_min]" хэш-таблицы (второй случай, заданный условием "c<j>>8"), или равно ли значение контекста, описанное входной переменной c, значению контекста, описанному записью "ari_hash_m[i_min]" (третий случай).
В первом случае (s>j) запись "ari_lookup_m[i_min +1]" таблицы "ari_lookup_m[]", указанная индексным значением "i_min+1" таблицы, возвращается в качестве выходного значения функции "arith_get_pk()". Во втором случае (c<(j>>8)) запись "ari_lookup_m[i_min]" таблицы "ari_lookup_m[]", указанная индексным значением "i_min" таблицы, возвращается в качестве возвращаемого значения функции "arith_get_pk()". В третьем случае (то есть если значение контекста, описанное входной переменной c, равно значимому значению состояния, описанному записью "ari_hash_m[i_min]" таблицы) индексное значение правила отображения, описанное младшими 8 битами записи "ari_hash_m[i_min]" хэш-таблицы, возвращается в качестве возвращаемого значения функции "arith_get_pk()".
Чтобы подвести итог вышесказанному, очень простой табличный поиск выполняется на этапе 508b, где табличный поиск предоставляет значение переменной "i_min" без различения, равно ли значение контекста, описанное входной переменной c, значимому значению состояния, заданному одной из записей о состоянии в таблице "ari_hash_m[]". На этапе 508c, который выполняется после табличного поиска 508b, оценивается количественное отношение между значением контекста, описанным входной переменной c, и значимым значением состояния, описанным записью "ari_hash_m[i_min]" хэш-таблицы, и возвращаемое значение функции "arith_get_pk()" выбирается в зависимости от результата упомянутой оценки, где значение переменной "i_min", которое определяется в табличном поиске 508b, учитывается для выбора индексного значения правила отображения, даже если значение контекста, описанное входной переменной c, отличается от значимого значения состояния, описанного записью "ari_hash_m[i_min]" хэш-таблицы.
Дополнительно следует отметить, что сравнение в алгоритме предпочтительно (или в качестве альтернативы) следует проводить между индексом c контекста (числовым значением контекста) и j=ari_hash_m[i]>>8. Действительно, каждая запись таблицы "ari_hash_m[]" представляет индекс контекста, кодированный за пределами 8-ми битов, и его соответствующую вероятностную модель, кодированную в 8 первых битах (младших битах). В текущей реализации мы преимущественно заинтересованы в понимании, больше ли настоящий контекст c, чем ari_hash_m[i]>>8, что эквивалентно обнаружению, также ли s=c<<8 больше ari_hash_m[i].
Чтобы подвести итог вышесказанному, как только вычисляется состояние контекста (что может достигаться, например, с использованием алгоритма "arith_get_context(c,i,N)" в соответствии с фиг. 5c или алгоритма "arith_get_context(c,i)" в соответствии с фиг. 5d), 2-битная матрица старших битов декодируется с использованием алгоритма "arith_decode" (который будет описываться ниже), вызываемого с подходящей таблицей накопленных частот, соответствующей вероятностной модели, соответствующей состоянию контекста. Соответствие устанавливается функцией "arith_get_pk()", например, функцией "arith_get_pk()", которая рассмотрена со ссылкой на фиг. 5f.
11.6 Арифметическое декодирование
11.6.1 Арифметическое декодирование с использованием алгоритма в соответствии с фиг. 5g
Ниже функциональные возможности предпочтительной реализации функции "arith_decode()" будут подробно обсуждаться со ссылкой на фиг. 5g. Фиг. 5g показывает псевдокод на C, описывающий используемый алгоритм.
Следует отметить, что функция "arith_decode()" использует вспомогательную функцию "arith_first_symbol (void)", которая возвращает ИСТИНУ, если это первый символ последовательности, и ЛОЖЬ в противном случае. Функция "arith_decode()" также использует вспомогательную функцию "arith_get_next_bit(void)", которая получает и предоставляет следующий бит в битовом потоке.
К тому же функция "arith_decode()" использует глобальные переменные "low", "high" и "value". Кроме того, функция "arith_decode()" в качестве входной переменной принимает переменную "cum_freq[]", которая указывает на первую запись или элемент (имеющий индекс элемента или индекс записи, равный 0) выбранной таблицы накопленных частот или подтаблицы накопленных частот (предпочтительно, одной из подтаблиц от ari_cf_m[pki=0][17] до ari_cf_m[pki=63][17] в таблице ari_cf_m[64][17], которая задана табличным представлением фиг. 23(1), 23(2), 23(3)). Также функция "arith_decode()" использует входную переменную "cfl", которая указывает длину выбранной таблицы накопленных частот или подтаблицы накопленных частот, указанной переменной "cum_freq[]".
Функция "arith_decode()" в качестве первого этапа содержит инициализацию 570a переменной, которая выполняется, если вспомогательная функция "arith_first_symbol()" указывает, что декодируется первый символ в последовательности символов. Инициализация 550a значения инициализирует переменную "value" в зависимости от множества, например, из 16 битов, которые получаются из битового потока с использованием вспомогательной функции "arith_get_next_bit", так что переменная "value" принимает значение, представленное упомянутыми битами. Также переменная "low" инициализируется значением 0, а переменная "high" инициализируется значением 65535.
На втором этапе 570b переменная "range" устанавливается в значение, которое на 1 больше разности между значениями переменных "high" и "low". Переменная "cum" устанавливается в значение, которое представляет относительное положение значения переменной "value" между значением переменной "low" и значением переменной "high". Соответственно, переменная "cum" принимает, например, значение между 0 и 216 в зависимости от значения переменной "value".
Указатель p инициализируется значением, которое на 1 меньше начального адреса выбранной таблицы или подтаблицы накопленных частот.
Алгоритм "arith_decode()" также содержит итеративный поиск 570c по таблице накопленных частот. Итеративный поиск по таблице накопленных частот повторяется, пока переменная cfl не меньше либо равна 1. В итеративном поиске 570c по таблице накопленных частот переменная-указатель q устанавливается в значение, которое равно сумме текущего значения переменной-указателя p и половине значения переменной "cfl". Если значение записи *q выбранной таблицы накопленных частот, которая (запись) адресуется переменной-указателем q, больше значения переменной "cum", то переменная-указатель p устанавливается в значение переменной-указателя q, а переменная "cfl" увеличивается. В конечном счете переменная "cfl" сдвигается вправо на один бит, посредством этого фактически разделяя значение переменной "cfl" на 2 и отбрасывая часть по модулю.
Соответственно, итеративный поиск 570c по таблице накопленных частот фактически сравнивает значение переменной "cum" с множеством записей выбранной таблицы накопленных частот, чтобы идентифицировать интервал в выбранной таблице накопленных частот, который ограничивается записями таблицы накопленных частот, так что значение cum находится в идентифицированном интервале. Соответственно, записи выбранной таблицы накопленных частот задают интервалы, где соответствующее значение символа ассоциируется с каждым из интервалов выбранной таблицы накопленных частот. Также ширины интервалов между двумя соседними значениями таблицы накопленных частот задают вероятности символов, ассоциированных с упомянутыми интервалами, так что выбранная таблица накопленных частот полностью задает распределение вероятности у разных символов (или значений символов). Подробности касательно доступных таблиц накопленных частот или подтаблиц накопленных частот будут обсуждаться ниже со ссылкой на фиг. 23.
Ссылаясь снова на фиг. 5g, значение символа выводится из значения переменной-указателя p, где значение символа выводится, как показано по номеру 570d ссылки. Таким образом, оценивается разность между значением переменной-указателя p и начальным адресом "cum_freq", чтобы получить значение символа, которое представляется переменной "symbol".
Алгоритм "arith_decode" также содержит адаптацию 570e переменных "high" и "low". Если значение символа, представленное переменной "symbol", отличается от 0, то переменная "high" обновляется, как показано по номеру 570e ссылки. Также значение переменной "low" обновляется, как показано по номеру 570e ссылки. Переменная "high" устанавливается в значение, которое определяется значением переменной "low", переменной "range" и записью, имеющей индекс "symbol -1" в выбранной таблице накопленных частот или подтаблице накопленных частот. Переменная "low" увеличивается, где величина увеличения определяется переменной "range" и записью выбранной таблицы накопленных частот, имеющей индекс "symbol". Соответственно, разность между значениями переменных "low" и "high" регулируется в зависимости от числовой разности между двумя соседними записями выбранной таблицы накопленных частот.
Соответственно, если обнаруживается значение символа, обладающее низкой вероятностью, то интервал между значениями переменных "low" и "high" уменьшается до узкого. В отличие от этого, если обнаруженное значение символа содержит относительно большую вероятность, то ширина интервала между значениями переменных "low" и "high" устанавливается в сравнительно большое значение. К тому же ширина интервала между значениями переменных "low" и "high" зависит от обнаруженного символа и соответствующих записей таблицы накопленных частот.
Алгоритм "arith_decode()" также содержит перенормировку 570f интервала, в которой определенный на этапе 570e интервал итерационно сдвигается и масштабируется, пока не достигается условие "break". При перенормировке 570f интервала выполняется операция 570fa выборочного сдвига вниз (к младшим битам). Если переменная "high" меньше 32768, то ничего не происходит, и перенормировка интервала переходит к операции 570fb увеличения размера интервала. Однако если переменная "high" не меньше 32768, а переменная "low" больше либо равна 32768, то все переменные "value", "low" и "high" уменьшаются на 32768, так что интервал, заданный переменными "low" и "high", сдвигается вниз, и так что значение переменной "value" также сдвигается вниз. Однако если обнаруживается, что значение переменной "high" не меньше 32768, а переменная "low" не больше либо равна 32768, и что переменная "low" больше либо равна 16384, а переменная "high" меньше 49152, то переменные "value", "low" и "high" все уменьшаются на 16384, посредством этого сдвигая вниз интервал между значениями переменных "high" и "low", а также значение переменной "value". Однако если никакое из вышеупомянутых условий не выполняется, то перенормировка интервала завершается.
Однако если выполняется какое-нибудь из вышеупомянутых условий, которые оцениваются на этапе 570fa, то выполняется операция 570fb увеличения интервала. В операции 570fb увеличения интервала значение переменной "low" удваивается. Также удваивается значение переменной "high", и результат удвоения увеличивается на 1. Также удваивается значение переменной "value" (сдвигается влево на один бит), и бит битового потока, который получается с помощью вспомогательной функции "arith_get_next_bit", используется в качестве младшего бита. Соответственно, размер интервала между значениями переменных "low" и "high" приблизительно удваивается, и точность переменной "value" увеличивается с использованием нового бита битового потока. Как упоминалось выше, этапы 570fa и 570fb повторяются, пока не достигается условие "break", то есть пока интервал между значениями переменных "low" и "high" не достаточно большой.
Касательно функциональных возможностей алгоритма "arith_decode()" следует отметить, что интервал между значениями переменных "low" и "high" уменьшается на этапе 570e в зависимости от двух соседних записей таблицы накопленных частот, указанной переменной "cum_freq". Если интервал между двумя соседними значениями выбранной таблицы накопленных частот небольшой, то есть если соседние значения находятся сравнительно близко друг к другу, то интервал между значениями переменных "low" и "high", который получается на этапе 570e, будет сравнительно небольшим. В отличие от этого, если две соседних записи таблицы накопленных частот разнесены, то интервал между значениями переменных "low" и "high", который получается на этапе 570e, будет сравнительно большим.
Следовательно, если интервал между значениями переменных "low" и "high", который получается на этапе 570e, сравнительно небольшой, то будет выполняться большое количество этапов перенормировки интервала, чтобы перемасштабировать интервал в "достаточный" размер (так что не выполняется никакое из условий в оценке 570fa условий). Соответственно, будет использоваться сравнительно большое количество битов из битового потока, чтобы увеличить точность переменной "value". В отличие от этого, если размер интервала, полученный на этапе 570e, сравнительно большой, то только небольшое количество повторений этапов 570fa и 570fb нормировки интервала потребуется, чтобы перенормировать интервал между значениями переменных "low" и "high" в "достаточный" размер. Соответственно, будет использоваться только сравнительно небольшое количество битов из битового потока, чтобы увеличить точность переменной "value" и подготовить декодирование следующего символа.
Чтобы подвести итог вышесказанному, если декодируется символ, который содержит сравнительно высокую вероятность и с которым ассоциируется большой интервал с помощью записей выбранной таблицы накопленных частот, то будет считано только сравнительно небольшое количество битов из битового потока, чтобы позволить декодирование последующего символа. В отличие от этого, если декодируется символ, который содержит сравнительно небольшую вероятность и с которым ассоциируется небольшой интервал с помощью записей выбранной таблицы накопленных частот, то сравнительно большое количество битов будет выбрано из битового потока, чтобы подготовить декодирование следующего символа.
Соответственно, записи таблиц накопленных частот отражают вероятности разных символов, а также отражают количество битов, необходимое для декодирования последовательности символов. С помощью изменения таблицы накопленных частот в зависимости от контекста, то есть в зависимости от ранее декодированных символов (или спектральных значений), например, с помощью выбора разных таблиц накопленных частот в зависимости от контекста можно использовать стохастические зависимости между разными символами, что дает возможность особенно эффективного по скорости передачи битов кодирования последующих (или соседних) символов.
Чтобы подвести итог вышесказанному, функция "arith_decode()", которая описана со ссылкой на фиг. 5g, вызывается с таблицей "arith_cf_m[pki][]" накопленных частот, соответствующей индексу "pki", возвращаемому функцией "arith_get_pk()", чтобы определить значение m матрицы старших битов (которое может быть установлено в значение символа, представленное возвращаемой переменной "symbol").
Чтобы подвести итог вышесказанному, арифметический декодер является целочисленной реализацией, использующей способ формирования метки с масштабированием. За подробностями приводится ссылка на книгу "Introduction to Data Compression" под авторством K. Sayood, Third Edition, 2006, Elsevier Inc.
Код компьютерной программы в соответствии с фиг. 5g описывает используемый алгоритм в соответствии с вариантом осуществления изобретения.
11.6.2 Арифметическое декодирование с использованием алгоритма в соответствии с фиг. 5h и 5i
Фиг. 5h и 5i показывают представление в псевдокоде другого варианта осуществления алгоритма "arith_decode()", который может использоваться в качестве альтернативы алгоритму "arith_decode", описанному со ссылкой на фиг. 5g.
Следует отметить, что алгоритмы в соответствии с фиг. 5g, так и в соответствии с фиг. 5h и 5i, могут использоваться в алгоритме "values_decode()" в соответствии с фиг. 3.
Подводя итог, значение m декодируется с использованием функции "arith_decode()", вызываемой с таблицей "arith_cf_m[pki][]" накопленных частот (которая предпочтительно является подтаблицей таблицы ari_cf_m[67][17], заданной в табличных представлениях фиг. 23(1), 23(2), 23(3)), где "pki" соответствует индексу, возвращаемому функцией "arith_get_pk()". Арифметический кодер (или декодер) является целочисленной реализацией, использующей способ формирования метки с масштабированием. За подробностями приводится ссылка на книгу "Introduction to Data Compression" под авторством K. Sayood, Third Edition, 2006, Elsevier Inc. Код компьютерной программы в соответствии с фиг. 5h и 5i описывает используемый алгоритм.
11.7 Механизм перехода
Ниже будет кратко обсуждаться механизм перехода, который используется в алгоритме декодирования "values_decode()" в соответствии с фиг. 3.
Когда декодированное значение m (которое предоставляется в качестве возвращаемого значения функции "arith_decode()") является символом "ARITH_ESCAPE" перехода, переменные "lev" и "esc_nb" увеличиваются на 1, и декодируется другое значение m. В этом случае функция "arith_get_pk()" (или "get_pk()") вызывается еще раз со значением "c+ esc_nb<<17" в качестве входного аргумента, где переменная "esc_nb" описывает количество символов перехода, ранее декодированных для того же кортежа из 2-х элементов и ограниченных 7.
Подводя итог, если идентифицируется символ перехода, то предполагается, что значение m матрицы старших битов содержит увеличенный численный вес. Кроме того, повторяется текущее числовое декодирование, в котором измененное числовое текущее значение "c+ esc_nb<<17" контекста используется в качестве входной переменной функции "arith_get_pk()". Соответственно, в разных итерациях субалгоритма 312ba обычно получается разное индексное значение "pki" правила отображения.
11.8 Механизм арифметического прерывания
Ниже будет описываться механизм арифметического прерывания. Механизм арифметического прерывания предусматривает сокращение количества необходимых битов в случае, где верхняя часть частоты полностью квантуется в 0 в аудиокодере.
В варианте осуществления механизм арифметического прерывания может быть реализован следующим образом: Как только значение m не является символом перехода, "ARITH_ESCAPE", декодер проверяет, образует ли последующая m символ "ARITH_STOP". Если условие "(esc_nb >0&&m==0)" является верным, то обнаруживается символ "ARITH_STOP", и процесс декодирования завершается. В этом случае декодер переходит непосредственно к описанному ниже декодированию знаков или к функции "arith_finish()", которая будет описываться ниже. Условие означает, что оставшаяся часть кадра состоит из нулевых значений.
11.9 Декодирование матрицы менее значащих битов
Ниже будет описываться декодирование одной или более матриц менее значащих битов. Декодирование матрицы менее значащих битов выполняется, например, на этапе 312d, показанном на фиг. 3. Однако в качестве альтернативы могут использоваться алгоритмы, которые показаны на фиг. 5j и 5n, где алгоритм из фиг. 5j является предпочтительным алгоритмом.
11.9.1 Декодирование матрицы менее значащих битов в соответствии с фиг. 5j
Ссылаясь теперь на фиг. 5j, видно, что значения переменных a и b выводятся из значения m. Например, цифровое представление значения m сдвигается вправо на 2 бита, чтобы получить цифровое представление переменной b. Кроме того, значение переменной a получается путем вычитания сдвинутой по битам версии значения переменной b, сдвинутой влево на 2 бита, из значения переменной m.
Потом повторяется арифметическое декодирование значений r матрицы младших битов, где количество повторений определяется значением переменной "lev". Значение r матрицы младших битов получается с использованием функции "arith_decode", где используется таблица накопленных частот, приспособленная к декодированию матрицы младших битов (таблица "arith_cf_r" накопленных частот). Младший бит (имеющий численный вес 1) переменной r описывает матрица менее значащих битов спектрального значения, представленного переменной a, а бит, имеющий численный вес 2, переменной r описывает менее значащий бит спектрального значения, представленного переменной b. Соответственно, переменная a обновляется путем сдвига переменной a влево на 1 бит и добавления бита переменной r, имеющего численный вес 1, в качестве младшего бита. Аналогичным образом переменная b обновляется путем сдвига переменной b влево на один бит и добавления бита переменной r, имеющего численный вес 2.
Соответственно, два переносящих информацию старших бита переменных a,b определяются значением m матрицы старших битов, а один или более младших битов (если есть) значений a и b определяются одним или несколькими значениями r матрицы младших битов.
Чтобы подвести итог вышесказанному, если не встречается символ "ARITH_STOP", то оставшиеся матрицы битов, если они существуют, декодируются для данного кортежа из 2-х элементов. Оставшиеся матрицы битов декодируются с старшего на младший уровень путем вызова функции "arith_decode()" lev раз с таблицей "arith_cf_r[]" накопленных частот. Декодированные матрицы r битов позволяют уточнить ранее декодированное значение m в соответствии с алгоритмом, программный псевдокод которого показан на фиг. 5j.
11.9.2 Декодирование диапазона менее значащих битов в соответствии с фиг. 5n
Однако в качестве альтернативы алгоритм, представление псевдо-программного кода которого показано на фиг. 5n, также может использоваться для декодирования матрицы менее значащих битов. В этом случае, если не встречается символ "ARITH_STOP", то оставшиеся матрицы битов, если они существуют, декодируются для данного кортежа из 2-х элементов. Оставшиеся матрицы битов декодируются со старшего на младший уровень путем вызова "arith_decode()" "lev" раз с таблицей "arith_cf_r[]" накопленных частот. Декодированные матрицы r битов дают возможность уточнения ранее декодированного значения m в соответствии с алгоритмом, показанным на фиг. 5n.
11.10 Обновление контекста
11.10.1 Обновление контекста в соответствии с фиг. 5k, 5l и 5m
Ниже операции, используемые для завершения декодирования кортежа спектральных значений, будут описываться со ссылкой на фиг. 5k и 5l. Кроме того, будет описываться операция, которая используется для завершения декодирования набора кортежей спектральных значений, ассоциированных с текущей частью аудиоконтента (например, текущим кадром).
Следует отметить, что алгоритмы в соответствии с фиг. 5k, 5l и 5m являются предпочтительными, даже если могут использоваться альтернативные алгоритмы.
Ссылаясь теперь на фиг. 5k, видно, что запись, имеющая индекс 2*i записи массива "x_ac_dec[]", устанавливается равной a, и что запись, имеющая индекс "2*i+1" записи массива "x_ac_dec[]", устанавливается равной b после декодирования 312d менее значащих битов. Другими словами, в момент после декодирования 312d менее значащих битов полностью декодируется беззнаковое значение кортежа из 2-х элементов {a,b}. Оно записывается в массив (например, массив "x_ac_dec[]"), хранящий спектральные коэффициенты, в соответствии с алгоритмом, показанным на фиг. 5k.
Потом контекст "q" также обновляется для следующего кортежа из 2-х элементов. Следует отметить, что это обновление контекста также должно быть выполнено для последнего кортежа из 2-х элементов. Это обновление контекста выполняется функцией "arith_update_context()", представление в псевдокоде которой показано на фиг. 5l.
Ссылаясь теперь на фиг. 5l, видно, что функция "arith_update_context(i,a,b)" в качестве входных переменных принимает декодированные беззнаковые квантованные спектральные коэффициенты a, b (или спектральные значения) кортежа из 2-х элементов. К тому же функция "arith_update_context" в качестве входной переменной также принимает индекс i (например, индекс частоты) квантованного спектрального коэффициента для декодирования. Другими словами, входная переменная i может быть, например, индексом кортежа спектральных значений, абсолютные значения которых задаются входными переменными a, b. Как видно, запись "q[1][i]" массива "q[][]" можно установить в значение, которое равно a+b+1. К тому же значение записи "q[1][i]" массива "q[][]" можно ограничить шестнадцатеричным значением "0×F". Таким образом, запись "q[1][i]" массива "q[][]" получается путем вычисления суммы абсолютных значений декодируемого в настоящее время кортежа {a,b} спектральных значений, имеющего индекс i частоты, и добавления 1 к результату упомянутой суммы.
Здесь следует отметить, что запись "q[1][i]" массива "q[][]" может считаться значением подобласти контекста, потому что она описывает подобласть контекста, которая используется для последующего декодирования дополнительных спектральных значений (или кортежей спектральных значений).
Здесь следует отметить, что суммирование абсолютных значений a и b двух декодируемых в настоящее время спектральных значений (версии со знаком которых хранятся в записях "x_ac_dec[2*i]" и "x_ac_dec[2*i+1]" массива "x_ac_dec[]") может считаться вычислением нормы (например, нормы L1) декодированных спектральных значений.
Обнаружено, что значения подобласти контекста (то есть записи массива "q[][]"), которые описывают норму вектора, образованного множеством ранее декодированных спектральных значений, особенно содержательны и эффективны по использованию памяти. Обнаружено, что такая норма, которая вычисляется на основе множества ранее декодированных спектральных значений, содержит значимую контекстную информацию в компактном виде. Обнаружено, что знак спектральных значений обычно не особенно важен для выбора контекста. Также обнаружено, что создание нормы по всему множеству ранее декодированных спектральных значений обычно сохраняет самую важную информацию, даже если отбрасываются некоторые подробности. Кроме того, обнаружено, что ограничение числового текущего значения контекста неким максимальным значением обычно не приводит к серьезной потере информации. Точнее, обнаружено, что эффективнее использовать одно и то же состояние контекста для значимых спектральных значений, которые больше заранее установленного порогового значения. Таким образом, ограничение значений подобласти контекста способствует дальнейшему повышению эффективности использования памяти. Кроме того, обнаружено, что ограничение значений подобласти контекста некоторым максимальным значением дает возможность очень простого и эффективного в вычислительном отношении обновления числового текущего значения контекста, которое описано, например, со ссылкой на фиг. 5c и 5d. С помощью ограничения значений подобласти контекста сравнительно небольшим значением (например, значением 15) можно представить состояние контекста, которое основывается на множестве значений подобласти контекста, в эффективном виде, который рассмотрен со ссылкой на фиг. 5c и 5d.
Кроме того, обнаружено, что ограничение значений подобласти контекста значениями между 1 и 15 способствует очень хорошему компромиссу между точностью и эффективностью использования памяти, потому что 4 битов достаточно для хранения такого значения подобласти контекста.
Однако следует отметить, что в некоторых других вариантах осуществления значение подобласти контекста может основываться только на одном декодированном спектральном значении. В этом случае создание нормы можно пропустить необязательно.
Следующий кортеж из 2-х элементов кадра декодируется после завершения функции "arith_update_context" путем увеличения i на 1 и путем повторения такого же процесса, как описан выше, начиная с функции "arith_get_context()".
Когда в кадре декодируются lg/2 кортежей их 2-х элементов или возникает стоп-символ "ARITH_STOP", процесс декодирования спектральной амплитуды завершается, и начинается декодирование знаков.
Подробности касательно декодирования знаков рассмотрены со ссылкой на фиг. 3, где декодирование знаков показано по номеру 314 ссылки.
Как только декодируются все беззнаковые квантованные спектральные коэффициенты, добавляется соответственный знак. Для каждого непустого квантованного значения "x_ac_dec" считывается бит. Если значение считанного бита равно 1, то квантованное значение является положительным, ничего не выполняется, и значение со знаком равно ранее декодированному беззнаковому значению. В противном случае (то есть если значение считанного бита равно 0) декодированный коэффициент (или спектральное значение) является отрицательным, и дополнительный код берется из беззнакового значения. Знаковые биты считываются от низких к более высоким частотам. За подробностями приводится ссылка на фиг. 3 и на объяснения касательно декодирования 314 знаков.
Декодирование завершается путем вызова функции "arith_finish()". Оставшиеся спектральные коэффициенты устанавливаются в 0. Соответствующие состояния контекста обновляются соответствующим образом.
За подробностями приводится ссылка на фиг. 5m, которая показывает представление в псевдокоде функции "arith_finish()". Как видно, функция "arith_finish()" принимает входную переменную lg, которая описывает декодированные квантованные спектральные коэффициенты. Предпочтительно, чтобы входная переменная lg функции "arith_finish" описывала количество фактически декодированных спектральных коэффициентов, оставляя нерассмотренными спектральные коэффициенты, которым назначено значение 0 в ответ на обнаружение символа "ARITH_STOP". Входная переменная N функции "arith_finish" описывает длину окна у текущего окна (то есть окна, ассоциированного с текущей частью аудиоконтента). Обычно количество спектральных значений, ассоциированных с окном длины N, равно N/2, а количество кортежей из 2-х спектральных значений, ассоциированных с окном длины N, равно N/4.
Функция "arith_finish" в качестве входного значения также принимает вектор "x_ac_dec" декодированных спектральных значений, или по меньшей мере ссылку на такой вектор декодированных спектральных коэффициентов.
Функция "arith_finish" сконфигурирована для установки в 0 записей массива (или вектора) "x_ac_dec", для которых никакие спектральные значения не декодированы из-за наличия условия арифметического прерывания. Кроме того, функция "arith_finish" устанавливает значения подобласти контекста "q[1][i]", которые ассоциируются со спектральными значениями, для которых никакое значение не декодировано из-за наличия условия арифметического прерывания, в заранее установленное значение 1. Заранее установленное значение 1 соответствует кортежу спектральных значений, в котором оба спектральных значения равны 0.
Соответственно, функция "arith_finish()" позволяет обновлять весь массив (или вектор) "x_ac_dec[]" спектральных значений, а также весь массив значений "q[1][i]" подобласти контекста даже при наличии условия арифметического прерывания.
11.10.2 Обновление контекста в соответствии с фиг. 5o и 5p
Ниже другой вариант осуществления обновления контекста будет описываться со ссылкой на фиг. 5o и 5p. В момент, в который полностью декодируется беззнаковое значение кортежа из 2-х элементов (a,b), контекст q обновляется для следующего кортежа из 2-х элементов. Обновление также выполняется, если настоящий кортеж из 2-х элементов является последним кортежем из 2-х элементов. Оба обновления выполняются функцией "arith_update_context()", представление в псевдокоде которой показано на фиг. 5o.
Следующий кортеж из 2-х элементов кадра затем декодируется путем увеличения i на 1 и вызова функции arith_decode(). Если lg/2 кортежей уже декодированы в кадре, или если возник стоп-символ "ARITH_STOP", то вызывается функция "arith_finish()". Контекст записывается и сохраняется в массиве (или векторе) "qs" для следующего кадра. Программный псевдокод функции "arith_save_context()" показан на фиг. 5p.
Как только декодируются все беззнаковые квантованные спектральные коэффициенты, добавляется знак. Для каждого неквантованного значения "qdec" считывается бит. Если значение считанного бита равно 0, то квантованное значение является положительным, ничего не выполняется, и значение со знаком равно ранее декодированному беззнаковому значению. В противном случае декодированный коэффициент является отрицательным, и дополнительный код берется из беззнакового значения. Биты со знаком считываются от низких к высоким частотам.
11.11 Сущность процесса декодирования
Ниже будет кратко подведен итог процесса декодирования. За подробностями приводится ссылка на вышеприведенное обсуждение, а также на фиг. 3, 4, 5a, 5c, 5e, 5g, 5j, 5k, 5l и 5m. Квантованные спектральные коэффициенты "x_ac_dec[]" помехоустойчиво декодируются, начиная с коэффициента наименьшей частоты и продвигаясь к коэффициенту наибольшей частоты. Они декодируются группами из двух последовательных коэффициентов a,b, собирающихся в так называемый кортеж из 2-х элементов (a,b) (также обозначенный с помощью {a,b}).
Декодированные коэффициенты "x_ac_dec[]" для частотной области (то есть для режима частотной области) затем сохраняются в массиве "x_ac_quant[g][win][sfb][bin]". Порядок передачи кодовых слов помехоустойчивого кодирования является таким, что когда они декодируются в порядке принятых и сохраненных в массиве, "bin" является самым быстро увеличивающимся индексом, а "g" является самым медленно увеличивающимся индексом. В рамках кодового слова порядком декодирования является "a, затем b". Декодированные коэффициенты "x_ac_dec[]" для "TCX" (то есть для аудиодекодирования, использующего кодированное возбуждение с преобразованием) сохраняются (например, непосредственно) в массиве "x_tcx_invquant[win][bin]", и порядок передачи кодовых слов помехоустойчивого кодирования является таким, что когда они декодируются в порядке принятых и сохраненных в массиве, "bin" является самым быстро увеличивающимся индексом, а "win" является самым медленно увеличивающимся индексом. В рамках кодового слова порядком декодирования является "a, затем b".
Сначала флаг "arith_reset_flag" определяет, нужно ли сбросить контекст. Если флаг является истиной, то это учитывается в функции "arith_map_context".
Процесс декодирования начинается с фазы инициализации, где вектор "q" элементов контекста обновляется путем копирования и отображения в "q[0][]" элементов контекста предыдущего кадра, сохраненного в "q[1][]". Элементы контекста в "q" сохраняются в 4 битах на кортеж из 2-х элементов. За подробностями приводится ссылка на программный псевдокод из фиг. 5a.
Помехоустойчивый декодер выводит кортежи из 2-х беззнаковых квантованных спектральных коэффициентов. Сначала состояние c контекста вычисляется на основе ранее декодированных спектральных коэффициентов, окружающих кортеж из 2-х элементов для декодирования. Поэтому состояние обновляется шагами с использованием состояния контекста последнего декодированного кортежа из 2-х элементов, учитывая только два новых кортежа из 2-х элементов. Состояние декодируется в 17 битов и возвращается функцией "arith_get_context". Представление в псевдокоде функции "arith_get_context" множества показано на фиг. 5c.
Состояние c контекста определяет таблицу накопленных частот, используемую для декодирования 2-битной матрицы m старших битов. Отображение из c в соответствующий индекс "pki" таблицы накопленных частот выполняется функцией "arith_get_pk()". Представление в псевдокоде функции "arith_get_pk()" показано на фиг. 5e.
Значение m декодируется с использованием функции "arith_decode()", вызываемой с таблицей накопленных частот, "arith_cf_m[pki][]", где "pki" соответствует индексу, возвращаемому "arith_get_pk()". Арифметический кодер (и декодер) является целочисленной реализацией, использующей способ формирования метки с масштабированием. Программный псевдокод в соответствии с фиг. 5g описывает используемый алгоритм.
Когда декодированное значение m является символом "ARITH_ESCAPE" перехода, переменные "lev" и "esc_nb" увеличиваются на 1, и декодируется другое значение m. В этом случае функция "get_pk()" вызывается еще раз со значением "c+ esc_nb<<17" в качестве входного аргумента, где "esc_nb" является количеством символов перехода, ранее декодированных для того же кортежа из 2-х элементов и ограниченных 7.
Как только значение m не является символом "ARITH_ESCAPE" перехода, декодер проверяет, образует ли последующая m символ "ARITH_STOP". Если условие "(esc_nb>0&&m==0)" является верным, то обнаруживается символ "ARITH_STOP", и процесс декодирования завершается. Декодер переходит непосредственно к декодированию знаков, описанному позже. Условие означает, что оставшаяся часть кадра состоит из значений 0.
Если не встречается символ "ARITH_STOP", то оставшиеся матрицы битов, если они существуют, декодируются для данного кортежа из 2-х элементов. Оставшиеся матрицы битов декодируются со старшего на младший уровень путем вызова "arith_decode()" lev раз с таблицей "arith_cf_r[]" накопленных частот. Декодированные матрицы r битов дают возможность уточнения ранее декодированного значения m в соответствии с алгоритмом, программный псевдокод которого показан на фиг. 5j. В этот момент полностью декодируется беззнаковое значение кортежа из 2-х элементов (a,b). Оно записывается в элемент, хранящий спектральные коэффициенты, в соответствии с алгоритмом, представление в псевдокоде которого показано на фиг. 5k.
Контекст "q" также обновляется для следующего кортежа из 2-х элементов. Следует отметить, что это обновление контекста также нужно выполнить для последнего кортежа из 2-х элементов. Это обновление контекста выполняется функцией "arith_update_context()", представление в псевдокоде которой показано на фиг. 5l.
Затем следующий кортеж из 2-х элементов кадра декодируется путем увеличения i на 1 и повторения такого же процесса, как описан выше, начиная с функции "arith_get_context()". Когда в кадре декодируются lg/2 кортежей их 2-х элементов или когда возникает стоп-символ "ARITH_STOP", процесс декодирования спектральной амплитуды завершается, и начинается декодирование знаков.
Декодирование завершается путем вызова функции "arith_finish()". Оставшиеся спектральные коэффициенты устанавливаются в 0. Соответствующие состояния контекста обновляются соответствующим образом. Представление в псевдокоде функции "arith_finish" показано на фиг. 5m.
Как только декодируются все беззнаковые квантованные спектральные коэффициенты, добавляется соответственный знак. Для каждого непустого квантованного значения "x_ac_dec" считывается бит. Если значение считанного бита равно 1, то квантованное значение является положительным, и ничего не выполняется, и значение со знаком равно ранее декодированному беззнаковому значению. В противном случае декодированный коэффициент является отрицательным, и дополнительный код берется из беззнакового значения. Биты со знаком считываются от низких к высоким частотам.
11.12 Условные обозначения
Фиг. 5q показывает условные обозначения, которые имеют отношение к алгоритмами в соответствии с фиг. 5a, 5c, 5e, 5f, 5g, 5j, 5k, 5l и 5m.
Фиг. 5r показывает условные обозначения, которые имеют отношение к алгоритмам в соответствии с фиг. 5b, 5d, 5f, 5h, 5i, 5n, 5o и 5p.
12. Таблицы отображения
В варианте осуществления в соответствии с изобретением особенно полезные таблицы "ari_lookup_m", "ari_hash_m" и "ari_cf_m" используются для выполнения функции "arith_get_pk()" в соответствии с фиг. 5e или фиг. 5f и для выполнения функции "arith_decode()", которая обсуждалась со ссылкой на фиг. 5g, 5h и 5i. Однако следует отметить, что в некоторых альтернативных вариантах осуществления могут использоваться другие таблицы.
12.1 Таблица "ari_hash_m[742]" в соответствии с фиг. 22(1), 22(2), 22(3) и 22(4)
Содержимое особенно полезной реализации таблицы "ari_hash_m", которая используется функцией "arith_get_pk", первый предпочтительный вариант осуществления которой описывался со ссылкой на фиг. 5e и второй вариант осуществления которой описывался со ссылкой на фиг. 5f, показано в таблице из фиг. 22(1)-22(4). Следует отметить, что таблица из фиг. 22(1)-22(4) перечисляет 742 записи таблицы (или массива) "ari_hash_m[742]". Также следует отметить, что табличное представление из фиг. 22(1)-22(4) показывает элементы в порядке индексов элементов, так что первое значение "0×00000104UL" соответствует записи "ari_hash_m[0]" таблицы, имеющей индекс элемента (или индекс таблицы), равный 0, и так что последнее значение "0×FFFFFF00UL" соответствует записи "ari_hash_m[741]" таблицы, имеющей индекс элемента или индекс таблицы, равный 741. Здесь дополнительно следует отметить, что "0×" указывает, что записи таблицы "ari_hash_m[]" представлены в шестнадцатеричном формате. Кроме того, здесь следует отметить, что "UL" указывает, что записи таблицы "ari_hash_m[]" представлены как беззнаковые "длинные" целые значения (имеющие точность 32 бита).
Кроме того, следует отметить, что записи таблицы "ari_hash_m[]" в соответствии с фиг. 22(1)-22(4) размещаются в числовом порядке, чтобы предусмотреть выполнение табличного поиска 506b, 508b, 510b в функции "arith_get_pk()".
Дополнительно следует отметить, что старшие 24 бита записей таблицы "ari_hash_m" представляют некоторые значимые значения состояния (и могут считаться первой подзаписью), тогда как младшие 8 битов представляют индексные значения "pki" правила отображения (и могут считаться второй подзаписью). Таким образом, записи таблицы "ari_hash_m[]" описывают "прямое" отображение значения контекста в индексное значение "pki" правила отображения.
Однако старшие 24 бита записей таблицы "ari_hash_m[]" вместе с тем представляют границы интервала интервалов числовых значений контекста, с которыми ассоциируется одно и то же индексное значение правила отображения. Подробности касательно этой идеи уже рассмотрены выше.
12.2 Таблица "ari_lookup_m" в соответствии с фиг. 21
Содержимое особенно преимущественного варианта осуществления таблицы "ari_lookup_m" показано в таблице из фиг. 21. Здесь следует отметить, что таблица из фиг. 21 перечисляет записи таблицы "ari_lookup_m". На записи ссылается одномерный индекс записи целочисленного типа (также обозначенный как "индекс элемента", "индекс массива" или "индекс таблицы"), который, например, обозначен с помощью "i_max", "i_min" или "i". Следует отметить, что таблица "ari_lookup_m", которая содержит всего 742 записи, подходит для использования функцией "arith_get_pk" в соответствии с фиг. 5e или фиг. 5f. Также следует отметить, что таблица "ari_lookup_m" в соответствии с фиг. 21 приспособлена для взаимодействия с таблицей "ari_hash_m" в соответствии с фиг. 22.
Следует отметить, что записи таблицы "ari_lookup_m[742]" перечисляются в возрастающем порядке индекса "i" таблицы (например "i_min", "i_max" или "i") между 0 и 741. Член "0×" указывает, что записи таблицы описываются в шестнадцатеричном формате. Соответственно, первая запись "0×01" таблицы соответствует записи "ari_lookup_m[0]" таблицы, имеющей индекс 0 таблицы, а последняя запись "0×27" таблицы соответствует записи "ari_lookup_m[741]" таблицы, имеющей индекс 741 таблицы.
Также следует отметить, что записи таблицы "ari_lookup_m[]" ассоциируются с интервалами, заданными соседними записями таблицы "arith_hash_m[]". Таким образом, записи таблицы "ari_lookup_m" описывают индексные значения правила отображения, ассоциированные с интервалами числовых значений контекста, где интервалы задаются записями таблицы "arith_hash_m".
12.3 Таблица "ari_cf_m[64][17]" в соответствии с фиг. 23(1), 23(2) и 23(3)
Фиг. 23 показывает набор из 64 таблиц "ari_cf_m[pki][17]" накопленных частот (или подтаблиц), одна из которых выбирается аудиокодером 100, 700 или аудиодекодером 200, 800, например, для выполнения функции "arith_decode()", то есть для декодирования значения матрицы старших битов. Выбранная одна из 64 таблиц накопленных частот (или подтаблиц), показанная на фиг. 23(1)-23(3), принимает функцию таблицы "cum_freq[]" при выполнении функции "arith_decode()".
Как видно из фиг. 23(1)-23(3), каждый субблок или строка представляет таблицу накопленных частот, имеющую 17 записей. Например, первый субблок или строка 2310 представляет 17 записей таблицы накопленных частот для "pki=0". Второй субблок или строка 2312 представляет 17 записей таблицы накопленных частот для "pki=1". В конечном счете 64-ый субблок или строка 2364 представляет 17 записей таблицы накопленных частот для "pki=63". Таким образом, фиг. 23(1)-23(3) практически представляют 64 разных таблицы накопленных частот (или подтаблицы) для "pki=0"-"pki=95", где каждая из 64 таблиц накопленных частот представляется субблоком или строкой (окруженной фигурными скобками), и где каждая из упомянутых таблиц накопленных частот содержит 17 записей.
В субблоке или строке (например, субблоке или строке 2310 или 2312, или субблоке или строке 2396) первое значение (например, первое значение 708 первого субблока 2310) описывает первую запись таблицы накопленных частот (имеющую индекс массива или индекс таблицы, равный 0), представленной субблоком или строкой, а последнее значение (например, последнее значение 0 первого субблока или строки 2310) описывает последнюю запись таблицы накопленных частот (имеющую индекс массива или индекс таблицы, равный 16), представленной субблоком или строкой.
Соответственно, каждый субблок или строка 2310, 2312, 2364 табличного представления фиг. 23 представляет записи таблицы накопленных частот для использования функцией "arith_decode" в соответствии с фиг. 5g или в соответствии с фиг. 5h и 5i. Входная переменная "cum_freq[]" функции "arith_decode" описывает, какую из 64 таблиц накопленных частот (представленных отдельными субблоками из 17 записей таблицы "arith_cf_m") следует использовать для декодирования текущих спектральных коэффициентов.
12.4 Таблица "ari_cf_r[]" в соответствии с фиг. 24
Фиг. 24 показывает содержимое таблицы "ari_cf_r[]".
Четыре записи упомянутой таблицы показаны на фиг. 24. Однако следует отметить, что таблица "ari_cf_r" в итоге может отличаться в других вариантах осуществления.
13. Обзор, оценка производительности и преимущества
Варианты осуществления в соответствии с изобретением используют обновленные функции (или алгоритмы) и обновленный набор таблиц, которые обсуждались выше, чтобы получить улучшенный компромисс между вычислительной сложностью, требованием к памяти и эффективностью кодирования.
Вообще говоря, варианты осуществления в соответствии с изобретением создают улучшенное спектральное помехоустойчивое кодирование. Варианты осуществления в соответствии с настоящим изобретением описывают улучшение спектрального помехоустойчивого кодирования в USAC (унифицированное кодирование речи и звука).
Варианты осуществления в соответствии с изобретением создают обновленное предложение для CE по улучшенному спектральному помехоустойчивому кодированию спектральных коэффициентов на основе схем, которые представлены во входных документах m16912 и m17002 MPEG. Оба предложения оценивались, возможные недостатки устранялись, а достоинства объединялись. К тому же варианты осуществления изобретения содержат обновление таблиц помехоустойчивого спектрального кодирования для применения в текущей спецификации USAC.
13.1 Обзор
Ниже будет приведен краткий обзор. В ходе продолжающейся стандартизации USAC (унифицированное кодирование речи и звука) предложена усовершенствованная схема спектрального помехоустойчивого кодирования (также известная как схема энтропийного кодирования) в USAC. Эта усовершенствованная схема спектрального помехоустойчивого кодирования помогает эффективнее кодировать квантованные спектральные коэффициенты без потерь. Поэтому спектральные коэффициенты отображаются в соответствующие кодовые слова переменной длины. Эта схема энтропийного кодирования основывается на схеме контекстного арифметического кодирования. Контекст (то есть соседние спектральные коэффициенты) спектрального коэффициента определяет распределение вероятности (таблицу накопленных частот), которое используется для арифметического кодирования спектрального коэффициента.
Варианты осуществления в соответствии с настоящим изобретением используют обновленный набор таблиц для схемы спектрального кодирования, которая предложена ранее применительно к USAC. Чтобы дать историческую справку, следует отметить, что традиционная технология спектрального помехоустойчивого кодирования состоит, во-первых, из алгоритма, а во-вторых, из набора подготовленных таблиц (или по меньшей мере содержит алгоритм и набор подготовленных таблиц). Этот традиционный набор подготовленных таблиц основывается на потоках двоичных сигналов WD4 USAC. Поскольку USAC теперь развился до WD7, и в то же время значительные изменения применены к спецификации USAC, новый набор переподготовленных таблиц используется в вариантах осуществления в соответствии с изобретением, которое основывается на новом USAC версии WD7. Сам алгоритм остается без изменений. В качестве побочного эффекта переподготовленные таблицы обеспечивают производительность сжатия лучше любой из ранее представленных схем.
В соответствии с настоящим изобретением предлагается заменить традиционные подготовленные таблицы переподготовленными таблицами, которые здесь представлены, что приведет к увеличенной производительности кодирования.
13.2 Введение
Ниже будет предоставлено введение.
Для рабочего элемента USAC во время последних заседаний коллегиально выдвигалось несколько предложений по обновлению схемы помехоустойчивого кодирования. Однако эта работа в основном началась на 89-ом заседании. С того времени для всех предложений по кодированию спектральных коэффициентов стало установившейся практикой показывать результаты деятельности на основе битовых потоков эталонного качества WD4 USAC и подготовки на учебной базе данных WD4.
В то же время на сегодняшний день в спецификацию USAC включены значительные улучшения по другим областям USAC, в частности, по стереообработке и оконной обработке. Обнаружилось, что эти улучшения также немного влияют на статистику для спектрального помехоустойчивого кодирования. Поэтому результаты, показанные для CE помехоустойчивого кодирования, можно рассматривать как субоптимальные, поскольку они не соответствуют последней редакции WD.
Соответственно, предлагаются таблицы спектрального помехоустойчивого кодирования, которые лучше приспосабливаются к обновленным алгоритмам и к статистике спектральных значений, которые должны быть кодированы и декодированы.
13.3 Краткое описание алгоритма
Ниже будет предоставлено краткое описание алгоритма.
Чтобы преодолеть проблему занимаемого объема памяти и вычислительной сложности, предлагалась улучшенная схема помехоустойчивого кодирования для замены схемы как в рабочем варианте 6/7 (WD6/7). Основное внимание при разработке было уделено уменьшению потребности в памяти наряду с поддержанием эффективности сжатия и отсутствием увеличения вычислительной сложности. Точнее говоря, целью было достичь наилучшего компромисса в многомерном сложном пространстве производительности сжатия, сложности и требований к памяти.
Предложенная схема кодирования заимствует основной флаг помехоустойчивого кодера WD6/7, а именно адаптацию контекста. Контекст выводится с использованием ранее декодированных спектральных коэффициентов, которые поступают, как и в WD6/7, из прошлого и настоящего кадра. Однако спектральные коэффициенты теперь кодируются путем объединения 2 коэффициентов для образования кортежа из 2-х элементов. Другое отличие состоит в том, что спектральные коэффициенты теперь разделены на три части: знак, MSB и LSB. Знак кодируется независимо от величины, которая дополнительно делится на две части, два старших бита и оставшиеся биты, если они существуют. Кортежи из 2-х элементов, для которых величина двух элементов меньше либо равна 3, кодируются непосредственно с помощью кодирования MSB. В противном случае кодовое слово перехода передается первым для сигнализации любой дополнительной матрицы битов. В базовой версии отсутствующая информация, LSB и знак кодируются с использованием равномерного распределения вероятности.
По-прежнему возможно сокращение размера таблицы, поскольку:
- Нужно хранить только вероятности для 17 символов: {[0;+3], [0;+3]} + символ ESC;
- Не нужно хранить группирующую таблицу (egroups, dgroups, dgvectors); и
- Размер хэш-таблицы можно было бы уменьшить с помощью подходящей подготовки
13.3.1 Кодирование MSB
Ниже будет описываться кодирование MSB.
Как уже упоминалось, основным отличием между WD6/7, предыдущими предложениями и текущим предложением, является размерность символов. В WD6/7 рассматривались кортежи из 4-х элементов для формирования контекста и помехоустойчивого кодирования. В предыдущих представлениях вместо них использовались кортежи из 1 элемента для уменьшения требований к ROM. В ходе нашей разработки обнаружилось, что кортежи из 2-х элементов являются наилучшим компромиссом для уменьшения требований к ROM без увеличения вычислительной сложности. Вместо рассмотрения четырех кортежей из 4-х элементов для извлечения контекста теперь рассматриваются четыре кортежа из 2-х элементов. Как показано на фиг. 25, три кортежа из 2-х элементов поступают из прошлого кадра, а один из настоящего кадра.
Сокращение размера таблицы обусловлено тремя основными факторами. Во-первых, нужно хранить только вероятности для 17 символов (то есть {[0;+3], [0;+3]} + символ ESC). Больше не нужны группирующие таблицы (то есть egroups, dgroups, dgvectors). Кроме того, размер хэш-таблицы уменьшился путем выполнения подходящей подготовки.
Хотя размерность снизилась с 4 до 2, сложность осталась в диапазоне, как в WD6/7. Это было достигнуто путем упрощения формирования контекста и обращения к хэш-таблице.
Разные упрощения и оптимизации производились так, что производительность кодирования не затрагивалась и даже немного улучшалась.
13.3.2 Кодирование LSB
LSB кодируются с помощью равномерного распределения вероятности. По сравнению с WD6/7 LSB теперь рассматриваются в кортежах из 2-х элементов вместо кортежей из 4-х элементов. Однако возможно разное кодирование младших битов.
13.3.3 Кодирование знаков
Знак кодируется без использования арифметического базового кодера ради снижения сложности. Знак передается в 1 бите, только когда соответствующая величина является непустой. 0 означает положительное значение, а 1-отрицательное значение.
13.4 Предложенное обновление таблиц
Это дополнение предоставляет обновленный набор таблиц для схемы спектрального помехоустойчивого кодирования USAC. Таблицы были переподготовлены на основе текущих битовых потоков WD6/7 USAC. Не считая фактических таблиц, которые получаются из процесса подготовки, алгоритм остается без изменений.
Чтобы изучить результат переподготовки, эффективность кодирования и требование к памяти у новых таблиц сравнивается с предыдущим предложением (M17558) и WD6. WD6 выбирается в качестве ориентира, поскольку a) результаты 92-го заседания выносились по отношению к этому эталону, и b) отличия между WD6 и WD7 являются очень незначительными (только исправление ошибок без влияния на энтропийное кодирование или распределение спектральных коэффициентов).
13.4.1 Эффективность кодирования
Во-первых, эффективность кодирования у предложенного нового набора таблиц сравнивается с WD6 USAC и CE, которое предложено в M17558. Как видно в табличном представлении из фиг. 26, путем правильной переподготовки усредненное увеличение эффективности кодирования (по сравнению с WD6) можно было бы повысить с 1,74% (M17558) до 2,45% (новое предложение в соответствии с вариантом осуществления изобретения). По сравнению с M17558 выигрыш от сжатия можно было бы соответственно увеличить приблизительно на 0,7% в вариантах осуществления в соответствии с изобретением.
Фиг. 27 визуализирует выигрыш от сжатия для всех рабочих режимов. Как видно, минимальный выигрыш от сжатия по меньшей мере в 2% по сравнению с WD6 можно достичь с использованием вариантов осуществления в соответствии с изобретением. Для низких скоростей, например 12 кбит/с и 16 кбит/с, выигрыш от сжатия даже немного увеличивается. Хорошая производительность также сохраняется на более высоких скоростях передачи битов, например 64 кбит/с, где можно наблюдать значительное увеличение эффективности кодирования (более 3%).
Следует отметить, что доказано возможным транскодирование без потерь всех битовых потоков эталонного качества WD6 без нарушения ограничений резервуара битов. Более подробные результаты будут приведены в разделе 13.6.
13.4.2 Потребность в памяти и сложность
Во-вторых, потребность в памяти и сложность сравниваются с WD6 USAC и CE, которое предложено в M17558. Таблица из фиг. 28 сравнивает потребность в памяти для помехоустойчивого кодера, как в WD6, предложенном в M17558, и нового предложения в соответствии с вариантом осуществления изобретения. Как очевидно, потребность в памяти значительно снижается в результате выбора нового алгоритма, который предложен в M17558. Дальше видно, что для нового предложения общий размер таблицы можно было бы даже немного уменьшить почти на 80 слов (32 бита), приводя к общей потребности ROM в 1441 слов и общей потребности RAM в 64 слова (32 бита) на звуковой канал. Небольшая экономия в потребности ROM является результатом компромисса между количеством вероятностных моделей и размером хэш-таблицы, найденного алгоритмом автоматической подготовки на основе нового набора учебных битовых потоков WD6. За подробностями приводится ссылка на таблицу из фиг. 29.
В плане сложности вычислительная сложность у недавно предложенных схем сравнивалась с оптимизированной версией текущего помехоустойчивого кодирования в USAC. Способом "карандаша и бумаги" и путем изучения кода обнаружено, что новая схема кодирования имеет такой же порядок сложности, как и текущая схема. Как сообщалось для рабочих режимов 32 кбит/с стерео в таблице из фиг. 30 и 12 кбит/с моно в таблице из фиг. 31, предполагаемая сложность демонстрирует увеличение в 0,006 взвешенных МОПС и 0,024 взвешенных МОПС соответственно на оптимизированной реализации помехоустойчивого декодера WD6. По сравнению с общей сложностью в 11,7 PCU [2] эти отличия можно считать незначительными.
13.5 Заключение
Ниже будут предоставлены некоторые выводы.
Представлен новый набор таблиц для схемы спектрального помехоустойчивого кодирования USAC. В отличие от предыдущего предложения, которое является результатом подготовки на основе старых битовых потоков, предложенные новые таблицы теперь готовятся на текущих потоках двоичных сигналов WD USAC, в которых использована усовершенствованная идея подготовки. С помощью этой переподготовки можно было бы повысить эффективность кодирования на текущих потоках двоичных сигналов USAC без принесения в жертву низкой потребности в памяти или увеличения сложности по сравнению с предыдущими предложениями. По сравнению с WD6 USAC можно было бы значительно уменьшить потребность в памяти.
13.6 Подробная информация о транскодировании битовых потоков WD6
Подробную информацию транскодирования битовых потоков Рабочего варианта 6 (WD6) можно увидеть в табличных представлениях из фиг. 32, 33, 34, 35 и 36.
Фиг. 32 показывает табличное представление средних скоростей передачи битов, выданных арифметическим кодером в варианте осуществления в соответствии с изобретением и в WD6.
Фиг. 33 показывает табличное представление минимальных, максимальных и средних скоростей передачи битов USAC на кадровой основе с использованием предложенной схемы.
Фиг. 34 показывает табличное представление средних скоростей передачи битов, выданных кодером USAC, использующим арифметический кодер WD6, и кодером в соответствии с вариантом осуществления изобретения ("Новое предложение").
Фиг. 35 показывает табличное представление лучшего и худшего случаев для варианта осуществления в соответствии с изобретением.
Фиг. 36 показывает табличное представление предела резервуара битов для варианта осуществления в соответствии с изобретением.
14. Изменения по сравнению с рабочим вариантом 6 или рабочим вариантом 7
Ниже будут описываться изменения помехоустойчивого кодирования по сравнению с традиционным помехоустойчивым кодированием. Соответственно, вариант осуществления задается в виде модификаций по сравнению с рабочим вариантом 6 или рабочим вариантом 7 проекта стандарта USAC.
В частности, будут описываться изменения к тексту WD. Другими словами, этот раздел перечисляет полный набор изменений в спецификации WD7 USAC.
14.1 Изменения в Техническом описании
Предложенное новое помехоустойчивое кодирование порождает модификации в WD USAC MPEG, которые будут описываться ниже. Основные отличия помечаются.
14.1.1. Изменения синтаксиса и полезной нагрузки
Фиг. 7 показывает представление синтаксиса арифметически кодированных данных "arith_data()". Основные отличия помечаются.
Ниже будут описываться изменения относительно полезных нагрузок спектрального помехоустойчивого кодера.
Спектральные коэффициенты из кодированного сигнала "области линейного предсказания" и кодированного сигнала "частотной области" скалярно квантуются, и затем помехоустойчиво кодируются с помощью адаптивного контекстно-зависимого арифметического кодирования. Квантованные коэффициенты собираются в кортежи из 2-х элементов перед передачей из наименьшей частоты в наибольшую частоту. Следует отметить, что использование кортежей из 2-х элементов составляет изменение по сравнению с предыдущими версиями спектрального помехоустойчивого кодирования.
Однако дополнительным изменением является то, что каждый кортеж из 2-х элементов разделяется на знак s, 2-битную матрицу m старших битов и оставшиеся матрицы r младших битов. Также изменением является то, что значение m кодируется в соответствии с окружением коэффициента, и что оставшиеся матрицы r младших битов энтропийно кодируются без учета контекста. Также изменением по отношению к некоторым предыдущим версиям является то, что значения m и r образуют символы арифметического кодера. В конечном счете изменением по отношению к некоторым предыдущим версиям является то, что знаки s кодируются вне арифметического кодера, используя 1 бит на непустой квантованный коэффициент.
Подробная процедура арифметического декодирования описывается ниже в разделе 14.2.3.
14.1.2 Изменения определений и справочных элементов
Изменения определений и справочных элементов показаны в представлении определений и справочных элементов на фиг. 38.
14.2 Спектральное помехоустойчивое кодирование
Ниже будет обобщено спектральное помехоустойчивое кодирование в соответствии с вариантом осуществления.
14.2.1 Описание инструмента
Спектральное помехоустойчивое кодирование используется для дополнительного уменьшения избыточности квантованного спектра.
Схема спектрального помехоустойчивого кодирования основывается на арифметическом кодировании в сочетании с динамически адаптируемым контекстом. Помехоустойчивое кодирование снабжается квантованными спектральными значениями и использует контекстно-зависимые таблицы накопленных частот, выведенные из четырех ранее декодированных соседних кортежей. Здесь учитывается соседство по времени и частоте, как проиллюстрировано на фиг. 25. Таблицы накопленных частот затем используются арифметическим кодером для формирования двоичного кода переменной длины.
Арифметический кодер создает двоичный код для заданного набора символов и их соответствующих вероятностей. Двоичный код формируется путем отображения интервала вероятности, где находится набор символов, на кодовое слово.
14.2.2 Определения
Определения и справочные элементы описываются на фиг. 39. Изменения по сравнению с предыдущими версиями арифметического кодирования помечаются.
14.2.3 Процесс декодирования
Квантованные спектральные коэффициенты qdec помехоустойчиво декодируются, начиная с коэффициента наименьшей частоты и продвигаясь к коэффициенту наибольшей частоты. Они декодируются группами из двух последовательных коэффициентов a и b, собирающихся в так называемый кортеж из 2-х элементов {a,b}.
Декодированные коэффициенты для AAC затем сохраняются в массиве x_ac_quant[g][win][sfb][bin]. Порядок передачи кодовых слов помехоустойчивого кодирования является таким, что когда они декодируются в порядке принятых и сохраненных в массиве, bin является самым быстро увеличивающимся индексом, а g является самым медленно увеличивающимся индексом. В рамках кодового слова порядком декодирования является "a, затем b".
Декодированные коэффициенты для TCX сохраняются в массиве x_tcx_invquant[win][bin], и порядок передачи кодовых слов помехоустойчивого кодирования является таким, что когда они декодируются в порядке принятых и сохраненных в массиве, bin является самым быстро увеличивающимся индексом, а win является самым медленно увеличивающимся индексом. В рамках кодового слова порядком декодирования является "a, затем b".
Процесс декодирования начинается с фазы инициализации, где отображение выполняется между записанным прошлым контекстом, сохраненным в qs, и контекстом q текущего кадра. Прошлый контекст qs сохраняется в 2 битах на строку частоты.
За подробностями приводится ссылка на представление в псевдокоде алгоритма "arith_map_context" на фиг. 40a.
Помехоустойчивый декодер выводит кортежи из 2-х беззнаковых квантованных спектральных коэффициентов. Сначала состояние c контекста вычисляется на основе ранее декодированных спектральных коэффициентов, окружающих кортеж из 2-х элементов для декодирования. Состояние обновляется шагами с использованием состояния контекста последнего декодированного кортежа из 2-х элементов, учитывая только два новых кортежа из 2-х элементов. Состояние кодируется в 17 битах и возвращается функцией arith_get_context().
Представление в псевдокоде функции "arith_get_context()" показано на фиг. 40b.
Как только вычисляется состояние c контекста, 2-битная матрица m старших битов декодируется с использованием arith_decode(), снабжаемого подходящей таблицей накопленных частот, соответствующей вероятностной модели, соответствующей состоянию контекста. Соответствие устанавливается функцией arith_get_pk().
Представление в псевдокоде функции arith_get_pk() показано на фиг. 40c.
Значение m декодируется с использованием функции arith_decode(), вызываемой с таблицей накопленных частот, arith_cf_m[pki][], где pki соответствует индексу, возвращаемому arith_get_pk(). Арифметический кодер является целочисленной реализацией, использующей способ формирования метки с масштабированием. Псевдокод на C, показанный на фиг. 40d и 40e, описывает используемый алгоритм.
Когда декодированное значение m является символом перехода, ARITH_ESCAPE, переменные lev и esc_nb увеличиваются на единицу, и декодируется другое значение m. В этом случае функция get_pk() вызывается еще раз со значением c&esc_nb<<17 в качестве входного аргумента, где esc_nb является количеством символов перехода, ранее декодированных для того же кортежа из 2-х элементов и ограниченных 7.
Как только значение m не является символом перехода, ARITH_ESCAPE, декодер проверяет, образуют ли последующие m символ ARITH_STOP. Если условие (esc_nb>0 && m==0) является верным, то обнаруживается символ ARITH_STOP, и процесс декодирования завершается. Декодер переходит непосредственно к функции arith_save_context(). Условие означает, что оставшаяся часть кадра состоит из нулевых значений.
Если не встречается символ ARITH_STOP, то оставшиеся матрицы битов, если они существуют, декодируются для данного кортежа из 2-х элементов. Оставшиеся матрицы битов декодируются со старшего на младший уровень путем вызова arith_decode() lev раз с таблицей arith_cf_r[] накопленных частот. Декодированные матрицы r битов позволяют уточнить ранее декодированное значение m с помощью функции или алгоритма, представление в псевдокоде которых показано на фиг. 40f.
В этот момент полностью декодируется беззнаковое значение кортежа из 2-х элементов {a,b}. Контекст q затем обновляется для следующего кортежа из 2-х элементов. Точно так же происходит, если это последний кортеж из 2-х элементов. Оба обновления выполняются функцией arith_update_context(), представление в псевдокоде которой показано на фиг. 40g.
Следующий кортеж из 2-х элементов кадра затем декодируется путем увеличения i на единицу и вызова функции. Если lg/2 кортежей уже декодированы в кадре, или если возник стоп-символ ARITH_STOP, то вызывается функция arith_save_context(). Контекст записывается и сохраняется в qs для следующего кадра. Представление в псевдокоде функции или алгоритма arith_save_context() показано на фиг. 40h.
Как только декодируются все беззнаковые квантованные спектральные коэффициенты, добавляется знак. Для каждого непустого квантованного значения qdec считывается бит. Если значение считанного бита равно нулю, то квантованное значение является положительным, ничего не выполняется, и значение со знаком равно ранее декодированному беззнаковому значению. В противном случае декодированный коэффициент является отрицательным, и дополнительный код берется из беззнакового значения. Знаковые биты считываются от низких к высоким частотам.
14.2.4 Обновленные таблицы
Набор переподготовленных таблиц для использования с описанными выше алгоритмами показан на фиг. 41(1), 41(2), 42(1), 42(2), 42(3), 42(4), 43(1), 43(2), 43(3), 43(4), 43(5), 43(6) и 44.
Фиг. 41(1) и 41(2) показывают табличное представление содержимого таблицы "ari_lookup_m[742]" в соответствии с вариантом осуществления изобретения;
Фиг. 42(1), (2), (3), (4) показывают табличное представление содержимого таблицы "ari_hash_m[742]" в соответствии с вариантом осуществления изобретения;
Фиг. 43(1), (2), (3), (4), (5), (6) показывают табличное представление содержимого таблицы "ari_cf_m[96][17]" в соответствии с вариантом осуществления изобретения; и
Фиг. 44 показывает табличное представление содержимого таблицы "ari_cf_r[4]" в соответствии с вариантом осуществления изобретения.
Чтобы подвести итог вышесказанному, видно, что варианты осуществления в соответствии с настоящим изобретением предоставляют очень хороший компромисс между вычислительной сложностью, требованиям к памяти и эффективностью кодирования.
15. Синтаксис битового потока
15.1 Полезные нагрузки спектрального помехоустойчивого кодера
Ниже будут описываться некоторые подробности касательно полезных нагрузок спектрального помехоустойчивого кодера. В некоторых вариантах осуществления имеется множество разных режимов кодирования, например, так называемый режим кодирования "области линейного предсказания" и режим кодирования "частотной области". В режиме кодирования области линейного предсказания формирование шума выполняется на основе анализа аудиосигнала с линейным предсказанием, и шумоподобный сигнал кодируется в частотной области. В режиме кодирования частотной области формирование шума выполняется на основе психоакустического анализа, и шумоподобная версия аудиоконтента кодируется в частотной области.
Спектральные коэффициенты из кодированного сигнала "области линейного предсказания" и кодированного сигнала "частотной области" скалярно квантуются, и затем помехоустойчиво кодируются с помощью адаптивного контекстно-зависимого арифметического кодирования. Квантованные коэффициенты собираются в кортежи из 2-х элементов перед передачей из наименьшей частоты в наибольшую частоту. Каждый кортеж из 2-х элементов разделяется на знак s, матрицу m 2 старших битов и оставшуюся одну или более матриц r менее значащих битов (если есть). Значение m кодируется в соответствии с контекстом, заданным соседними спектральными коэффициентами. Другими словами, m кодируется в соответствии с окружением коэффициентов. Оставшиеся матрицы r менее значащих битов энтропийно кодируются без учета контекста. Посредством m и r можно восстановить амплитуду этих спектральных коэффициентов на стороне декодера. Для всех непустых символов знаки s кодируются вне арифметического кодера с использованием 1 бита. Другими словами, значения m и r образуют символы арифметического кодера. В конечном счете знаки s кодируются вне арифметического кодера с использованием 1 бита на непустой квантованный коэффициент.
Подробная процедура арифметического кодирования описывается в этом документе.
15.2 Синтаксические элементы в соответствии с фиг. 6a-6j
Ниже синтаксис битового потока, переносящего арифметически кодированную спектральную информацию, будет описываться со ссылкой на фиг. 6a-6j.
Фиг. 6a показывает синтаксическое представление так называемого блока необработанных данных USAC ("usac_raw_data_block()").
Блок необработанных данных USAC содержит один или более элементов одиночного канала ("single_channel_element()") и/или один или более элементов канальной пары ("channel_pair_element()").
Ссылаясь теперь на фиг. 6b, описывается синтаксис элемента одиночного канала. Элемент одиночного канала содержит поток канала области линейного предсказания ("lpd_channel_stream ()") или поток канала частотной области ("fd_channel_stream ()") в зависимости от базового режима.
Фиг. 6c показывает синтаксическое представление элемента канальной пары. Элемент канальной пары содержит информацию о базовом режиме ("core_mode0", "core_mode1"). К тому же элемент канальной пары может содержать информацию о конфигурации "ics_info()". Более того, в зависимости от информации о базовом режиме элемент канальной пары содержит поток канала области линейного предсказания или поток канала частотной области, ассоциированный с первым из каналов, и элемент канальной пары также содержит поток канала области линейного предсказания или поток канала частотной области, ассоциированный со вторым из каналов.
Информация о конфигурации "ics_info()", синтаксическое представление которой показано на фиг. 6d, содержит множество разных информационных элементов конфигурации, которые не имеют особой важности для настоящего изобретения.
Поток канала частотной области ("fd_channel_stream ()"), синтаксическое представление которого показано на фиг. 6e, содержит информацию об усилении ("global_gain") и информацию о конфигурации ("ics_info ()"). К тому же поток канала частотной области содержит данные масштабного коэффициента ("scale_factor_data ()"), которые описывают масштабные коэффициенты, используемые для масштабирования спектральных значений разных диапазонов масштабного коэффициента, и которые применяются, например, средством 150 масштабирования и средством 240 перемасштабирования. Поток канала частотной области также содержит арифметически кодированные спектральные данные ("ac_spectral_data ()"), которые представляют арифметически кодированные спектральные значения.
Арифметически кодированные спектральные данные ("ac_spectral_data()"), синтаксическое представление которых показано на фиг. 6f, содержит необязательный арифметический флаг сброса ("arith_reset_flag"), который используется для выборочного сброса контекста, как описано выше. К тому же арифметически кодированные спектральные данные содержат множество блоков арифметических данных ("arith_data"), которые переносят арифметически кодированные спектральные значения. Структура арифметически кодированных блоков данных зависит от количества полос частот (представленных переменной "num_bands"), а также от состояния арифметического флага сброса, который будет обсуждаться ниже.
Ниже структура арифметически кодированного блока данных будет описываться со ссылкой на фиг. 6g, которая показывает синтаксическое представление упомянутых арифметически кодированных блоков данных. Представление данных в арифметически кодированном блоке данных зависит от количества lg спектральных значений, которые должны быть кодированы, состояния арифметического флага сброса, а также от контекста, то есть ранее кодированных спектральных значений.
Контекст для кодирования текущего набора спектральных значений (например, кортежа из 2-х элементов) определяется в соответствии с алгоритмом определения контекста, показанным по номеру 660 ссылки. Подробности относительно алгоритма определения контекста объяснены выше, ссылаясь на фиг. 5a и 5b. Арифметически кодированный блок данных содержит lg/2 наборов кодовых слов, причем каждый набор кодовых слов представляет собой множество (например, кортеж из 2-х элементов) спектральных значений. Набор кодовых слов содержит арифметическое кодовое слово "acod_m[pki][m]", представляющее значение m матрицы старших битов кортежа спектральных значений, использующее от 1 до 20 битов. К тому же набор кодовых слов содержит одно или более кодовых слов "acod_r[r]", если кортеж спектральных значений для правильного представления требует больше матриц битов, чем матрица старших битов. Кодовое слово "acod_r[r]" представляет матрицу менее значащих битов, использующую от 1 до 14 битов.
Однако если необходима одна или более матриц менее значащих битов (в дополнение к матрицы старших битов) для надлежащего представления спектральных значений, то это сигнализируется с использованием одного или более арифметических кодовых слов перехода ("ARITH_ESCAPE"). Таким образом, в целом можно сказать, что для спектрального значения определяется, сколько необходимо матриц битов (матрица старших битов и, по возможности, одна или более дополнительных матриц менее значащих битов). Если необходима одна или более матриц менее значащих битов, то это сигнализируется с помощью одного или более арифметических кодовых слов "acod_m[pki][ARITH_ESCAPE]" перехода, которые кодируются в соответствии с выбранной в настоящее время таблицей накопленных частот, индекс таблицы накопленных частот у которой имеет вид переменной "pki". К тому же контекст адаптируется, как видно по номерам 664, 662 ссылок, если одно или более арифметических кодовых слов перехода включаются в битовый поток. После одного или более арифметических кодовых слов перехода арифметическое кодовое слово "acod_m[pki][m]" включается в битовый поток, как показано по номеру 663 ссылки, где "pki" обозначает допустимый в настоящее время индекс вероятностной модели (учитывая адаптацию контекста, вызванную включением арифметических кодовых слов перехода), и где m обозначает значение матрицы старших битов спектрального значения, которое должно быть кодировано и декодировано (где m отличается от кодового слова "ARITH_ESCAPE").
Как обсуждалось выше, наличие любой матрицы менее значащих битов приводит к наличию одного или более кодовых слов "acod_r[r]", каждое из которых представляет 1 бит матрицы старших битов первого спектрального значения, и каждое из которых также представляет 1 бит матрицы старших битов второго спектрального значения. Одно или более кодовых слов "acod_r[r]" кодируются в соответствии с соответствующей таблицей накопленных частот, которая может быть, например, постоянной и контекстно-независимой. Однако возможны разные механизмы для выбора таблицы накопленных частот для декодирования одного или более кодовых слов "acod_r[r]".
К тому же следует отметить, что контекст обновляется после кодирования каждого кортежа спектральных значений, как показано по номеру 668 ссылки, так что контекст обычно отличается для кодирования и декодирования двух последующих кортежей спектральных значений.
Фиг. 6i показывает условные обозначения и справочные элементы, задающие синтаксис арифметически кодированного блока данных.
Кроме того, альтернативный синтаксис арифметических данных "arith_data()" показан на фиг. 6h с помощью соответствующих условных обозначений и справочных элементов, показанных на фиг. 6j.
Чтобы подвести итог вышесказанному, описан формат битового потока, который может предоставляться аудиокодером 100 и который может оцениваться аудиодекодером 200. Битовый поток из арифметически кодированных спектральных значений кодируется так, что он соответствует рассмотренному выше алгоритму декодирования.
К тому же в целом следует отметить, что кодирование является обратной операцией декодирования, так что в целом можно предположить, что кодер выполняет табличный поиск с использованием рассмотренных выше таблиц, который является почти обратным табличному поиску, выполняемому декодером. В целом можно сказать, что специалист в данной области техники, который знает алгоритм декодирования и/или нужный синтаксис битового потока, сможет без труда спроектировать арифметический кодер, который предоставляет данные, заданные в синтаксисе битового потока и необходимые арифметическому декодеру.
Кроме того, следует отметить, что механизмы для определения числового текущего значения контекста и для выведения индексного значения правила отображения могут быть идентичны в аудиокодере и аудиодекодере, потому что обычно желательно, чтобы аудиодекодер использовал такой же контекст, как и аудиокодер, так что декодирование приспосабливается к кодированию.
15.3 Синтаксические элементы в соответствии с фиг. 6k, 6l, 6m, 6n, 6o и 6p
Ниже выдержка из альтернативного синтаксиса битового потока будет описываться со ссылкой на фиг. 6k, 6l, 6m, 6n, 6o и 6p.
Фиг. 6k показывает синтаксическое представление элемента "UsacSingleChannelElement(indepFlag)" битового потока. Упомянутый синтаксический элемент "UsacSingleChannelElement(indepFlag)" содержит синтаксический элемент "UsacCoreCoderData", описывающий один канал базового кодера.
Фиг. 6l показывает синтаксическое представление элемента "UsacChannelPairElement(indepFlag)" битового потока. Упомянутый синтаксический элемент "UsacChannelPairElement(indepFlag)" содержит синтаксический элемент "UsacCoreCoderData", описывающий один или два канала базового кодера в зависимости от стереофонической конфигурации.
Фиг. 6m показывает синтаксическое представление элемента "ics_info()" битового потока, который содержит определения некоторого количества параметров, как видно на фиг. 6m.
Фиг. 6n показывает синтаксическое представление элемента "UsacCoreCoderData()" битового потока. Элемент "UsacCoreCoderData()" битового потока содержит один или более потоков "lpd_channel_stream()" канала области линейного предсказания и/или один или более потоков "fd_channel_stream()" канала частотной области. Необязательно некоторая другая управляющая информация также может включаться в элемент "UsacCoreCoderData()" битового потока, как видно на фиг. 6n.
Фиг. 6o показывает синтаксическое представление элемента "fd_channel_stream()" битового потока. Элемент "fd_channel_stream()" битового потока среди прочих необязательных элементов битового потока содержит элемент "scale_factor_data()" битового потока и элемент "ac_spectral_data()" битового потока.
Фиг. 6p показывает синтаксическое представление элемента "ac_spectral_data()" битового потока. Элемент "ac_spectral_data()" битового потока необязательно содержит элемент "arith_reset_flag" битового потока. Кроме того, этот элемент битового потока также содержит некоторое количество арифметически кодированных данных "arith_data()". Арифметически кодированные данные могут, например, придерживаться синтаксиса битового потока, описанного со ссылкой на фиг. 6g.
16. Альтернативы реализации
Хотя некоторые особенности описаны применительно к устройству, понято, что эти особенности также представляют собой описание соответствующего способа, где блок или устройство соответствует этапу способа или флагу этапа способа. По аналогии особенности, описанные применительно к этапу способа, также представляют собой описание соответствующего блока или элемента либо флага соответствующего устройства. Некоторые или все этапы способа могут выполняться аппаратным устройством (или с его использованием), например микропроцессором, программируемым компьютером или электронной схемой. В некоторых вариантах осуществления какой-нибудь один или более самых важных этапов способа могут выполняться таким устройством.
Патентоспособный кодированный аудиосигнал может храниться на цифровом носителе информации или может передаваться по передающей среде, например беспроводной передающей среде или проводной передающей среде, такой как Интернет.
В зависимости от некоторых требований к реализации, варианты осуществления изобретения можно реализовать в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя информации, например дискеты, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем электронно-считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой так, что выполняется соответствующий способ. Поэтому цифровой носитель информации может быть считываемым компьютером (носителем).
Некоторые варианты осуществления в соответствии с изобретением содержат носитель информации, имеющий электронно-считываемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой так, что выполняется один из способов, описанных в этом документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на считываемом компьютером носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в этом документе способов, сохраненную на считываемом компьютером носителе.
Другими словами, вариант осуществления патентоспособного способа поэтому является компьютерной программой, имеющей программный код для выполнения одного из описанных в этом документе способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления патентоспособных способов поэтому является носителем информации (или цифровым носителем информации, или считываемым компьютером носителем), содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе. Носитель информации, цифровой носитель информации или записанный носитель обычно являются материальными и/или неизменяемыми со временем.
Дополнительный вариант осуществления патентоспособного способа поэтому является потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в этом документе. Поток данных или последовательность сигналов могут конфигурироваться, например, для передачи по соединению передачи данных, например по Интернету.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированные или приспособленные для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, сконфигурированные для передачи приемнику (например, электронно или оптически) компьютерной программы для выполнения одного из способов, описанных в этом документе. Приемник может быть, например, компьютером, мобильным устройством, запоминающим устройством или т.п. Устройство или система могут, например, содержать файл-сервер для передачи компьютерной программы приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в этом документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнить один из способов, описанных в этом документе. Как правило, способы предпочтительно выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются всего лишь пояснительными для принципов настоящего изобретения. Подразумевается, что модификации и изменения компоновок и подробностей, описанных в этом документе, будут очевидны другим специалистам в данной области техники. Поэтому есть намерение ограничиться только объемом предстоящей формулы изобретения, а не определенными подробностями, представленными посредством описания и объяснения вариантов осуществления в этом документе.
17. Выводы
В заключение варианты осуществления в соответствии с изобретением содержат одну или более следующих особенностей, где особенности могут использоваться отдельно или в сочетании.
a) Механизм хеширования состояния контекста
В соответствии с особенностью изобретения, состояния в хэш-таблице считаются значимыми состояниями и границами группы. Это позволяет значительно уменьшить размер необходимых таблиц.
b) Инкрементное обновление контекста
В соответствии с особенностью некоторые варианты осуществления в соответствии с изобретением содержат эффективный в вычислительном отношении способ для обновления контекста. Некоторые варианты осуществления используют инкрементное обновление контекста, в котором числовое текущее значение контекста выводится из числового предыдущего значения контекста.
с) Извлечение контекста
В соответствии с особенностью изобретения, использование суммы двух спектральных абсолютных значений является ассоциацией отбрасывания. Это некий вид векторного квантования усиления спектральных коэффициентов (в противоположность традиционному векторному квантованию формы-усиления). Оно направлено на ограничение порядка контекста наряду с передачей самой важной информации из окружения.
d) Обновленные таблицы
В соответствии с особенностью изобретения применяются оптимизированные таблицы ari_hash_m[742], ari_lookup_m[742] и ari_cf_m[64][17], которые обеспечивают очень хороший компромисс между эффективностью кодирования и вычислительной сложностью.
Некоторые другие технологии, которые применяются в вариантах осуществления в соответствии с изобретением, описываются в заявках на патент PCT EP2010/065725, PCT EP2010/065726 и PCT EP 2010/065727. Кроме того, в некоторых вариантах осуществления в соответствии с изобретением используется стоп-символ. Кроме того, в некоторых вариантах осуществления для контекста учитываются только беззнаковые значения.
Однако вышеупомянутые международные заявки на патент раскрывают особенности, которые по-прежнему используются в некоторых вариантах осуществления в соответствии с изобретением.
Например, идентификация нулевой области используется в некоторых вариантах осуществления изобретения. Соответственно, устанавливается так называемый "флаг малого значения" (например, бит 16 числового текущего значения c контекста).
В некоторых вариантах осуществления может использоваться зависимое от области вычисление контекста. Однако в других вариантах осуществления зависимое от области вычисление контекста может пропускаться, чтобы сохранить сложность и размер таблиц достаточно небольшим.
Кроме того, хеширование контекста с использованием хэш-функции является важной особенностью изобретения. Хеширование контекста может основываться на двухтабличной идее, которая описывается в вышеуказанных предварительно неопубликованных международных заявках на патент. Однако определенные адаптации хеширования контекста могут использоваться в некоторых вариантах осуществления, чтобы увеличить вычислительную эффективность. Тем не менее, в некоторых других вариантах осуществления в соответствии с изобретением может использоваться хеширование контекста, которое описывается в вышеуказанных международных заявках на патент.
Кроме того, следует отметить, что инкрементное хеширование контекста является довольно простым и эффективным в вычислительном отношении. Также независимость контекста от знака значений, которая используется в некоторых вариантах осуществления изобретения, помогает упростить контекст, посредством этого поддерживая требования к памяти достаточно низкими.
В некоторых вариантах осуществления изобретения используется извлечение контекста с использованием суммы двух спектральных значений и ограничения контекста. Эти две особенности можно объединить. Они обе направлены на ограничение порядка контекста путем передачи самой важной информации из окружения.
В некоторых вариантах осуществления используется флаг малого значения, который может быть аналогичен идентификации группы из нулевых значений.
В некоторых вариантах осуществления в соответствии с изобретением используется механизм арифметического прерывания. Идея аналогична использованию символа "конец блока" в JPEG, который обладает сопоставимой функцией. Однако в некоторых вариантах осуществления изобретения символ ("ARITH_STOP") явно не включается в энтропийный кодер. Вместо этого используется сочетание уже существующих символов, которое не могло бы возникнуть ранее, то есть "ESC+0". Другими словами, аудиодекодер сконфигурирован для обнаружения сочетания существующих символов, которые обычно не используются для представления числового значения, и для интерпретации возникновения такого сочетания уже существующих символов в качестве условия арифметического прерывания.
Вариант осуществления в соответствии с изобретением использует двухтабличный механизм хеширования контекста.
Чтобы дополнительно подвести итог, некоторые варианты осуществления в соответствии с изобретением могут содержать одну или более из следующих пяти основных особенностей.
- улучшенные таблицы;
- расширенный контекст для обнаружения либо нулевых областей, либо областей с малой амплитудой в окружении;
- хеширование контекста;
- формирование состояния контекста: инкрементное обновление состояния контекста; и
- извлечение контекста: специальное квантование значений контекста, включающее суммирование амплитуд и ограничение.
Чтобы дополнительно подвести итог, одна особенность вариантов осуществления в соответствии с настоящим изобретением состоит в инкрементном обновлении контекста. Варианты осуществления в соответствии с изобретением содержат эффективную идею для обновления контекста, которая избегает обширных вычислений рабочего варианта (например, рабочего варианта 5). Точнее, в некоторых вариантах осуществления используются простые операции сдвига и логические операции. Простое обновление контекста значительно облегчает вычисление контекста.
В некоторых вариантах осуществления контекст не зависит от знака значений (например, декодированных спектральных значений). Эта независимость контекста от знака значений способствует уменьшенной сложности переменной контекста. Эта идея основывается на выводе, что пренебрежение знаком в контексте не способствует серьезному ухудшению эффективности кодирования.
В соответствии с особенностью изобретения, контекст выводится с использованием суммы двух спектральных значений. Соответственно, требования к памяти для хранения контекста значительно снижаются. Соответственно, использование значения контекста, которое представляет сумму двух спектральных значений, в некоторых случаях может считаться полезным.
Также ограничение контекста в некоторых случаях способствует значительному улучшению. В дополнение к извлечению контекста с использованием суммы двух спектральных значений в некоторых вариантах осуществления записи массива "q" контекста ограничиваются максимальным значением "0×F", что в свою очередь приводит к ограничению требований к памяти. Это ограничение значений массива "q" контекста способствует некоторым преимуществам.
В некоторых вариантах осуществления используется так называемый "флаг малого значения". При получении переменной c контекста (которая также обозначается как числовое текущее значение контекста) устанавливается флаг, если значения некоторых записей от "q[1][i-3]" до "q[1][i-1]" очень малы. Соответственно, вычисление контекста может выполняться с высокой эффективностью. Можно получить очень важное значение контекста (например, числовое текущее значение контекста).
В некоторых вариантах осуществления используется механизм арифметического прерывания. Механизм "ARITH_STOP" предусматривает эффективное прерывание арифметического кодирования или декодирования, если остались только нулевые значения. Соответственно, эффективность кодирования можно повысить при умеренных затратах в плане сложности.
В соответствии с особенностью изобретения, используется двухтабличный механизм хеширования контекста. Отображение контекста выполняется с использованием алгоритма разделения интервала, оценивающего таблицу "ari_hash_m" совместно с последующей оценкой таблицы "ari_lookup_m". Этот алгоритм эффективнее алгоритма WD3.
Ниже будут обсуждаться некоторые дополнительные подробности.
Здесь следует отметить, что таблицы "arith_hash_m[742]" и "arith_lookup_m[742]" являются двумя отдельными таблицами. Первая используется для отображения одиночного индекса контекста (например, числового значения контекста) в индекс вероятностной модели (например, индексное значение правила отображения), а вторая используется для отображения группы последовательных контекстов, разделенных индексами контекста в "arith_hash_m[]", в одиночную вероятностную модель.
Дополнительно следует отметить, что таблица "arith_cf_m sb[64][16]" может использоваться в качестве альтернативы таблице "ari_cf_m[64][17]", даже если размерности немного отличаются. "ari_cf_m[][]" и "ari_cf_msb[][]" могут ссылаться на одну и ту же таблицу, так как 17ые коэффициенты вероятностных моделей всегда равны нулю. Это иногда не учитывается при подсчете необходимого пространства для хранения таблиц.
Чтобы подвести итог вышесказанному, некоторые варианты осуществления в соответствии с изобретением предоставляют новое помехоустойчивое кодирование (кодирование или декодирование), которое порождает модификации в рабочем варианте USAC MPEG (например, в рабочем варианте 5 USAC MPEG). Упомянутые модификации можно увидеть на приложенных фигурах, а также в связанном описании.
В качестве заключительного примечания следует отметить, что префикс "ari" и префикс "arith" используются взаимозаменяемо в названиях переменных, массивов, функций и так далее.
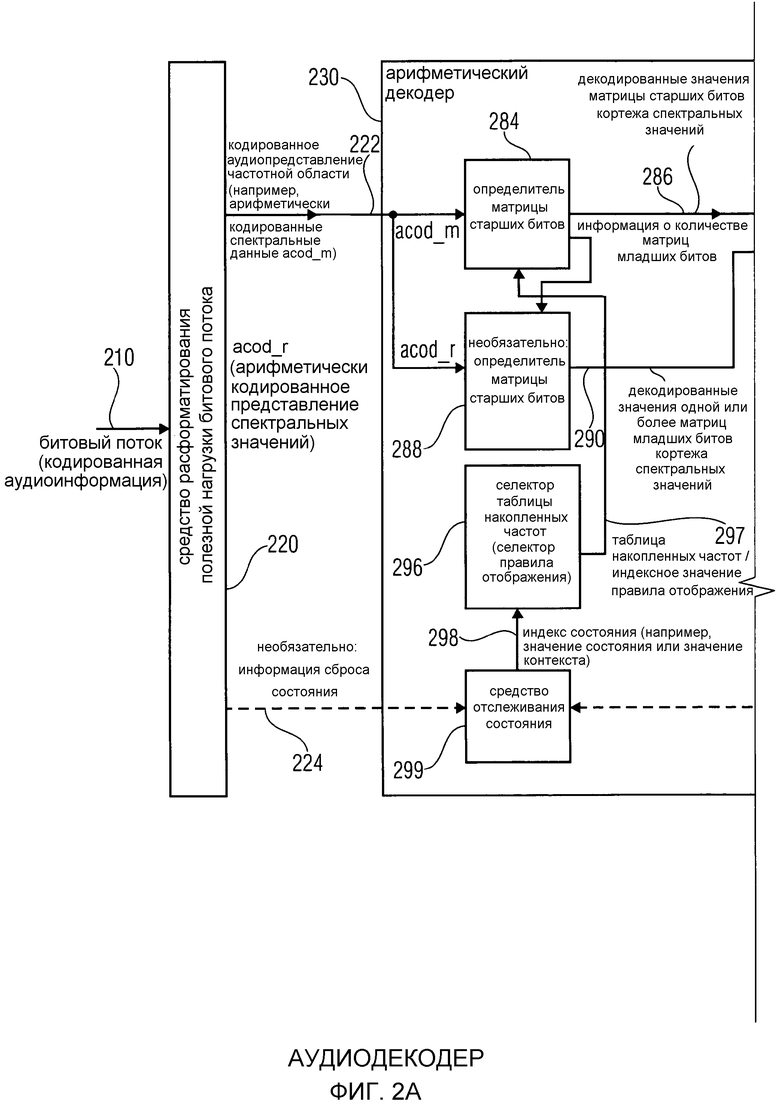
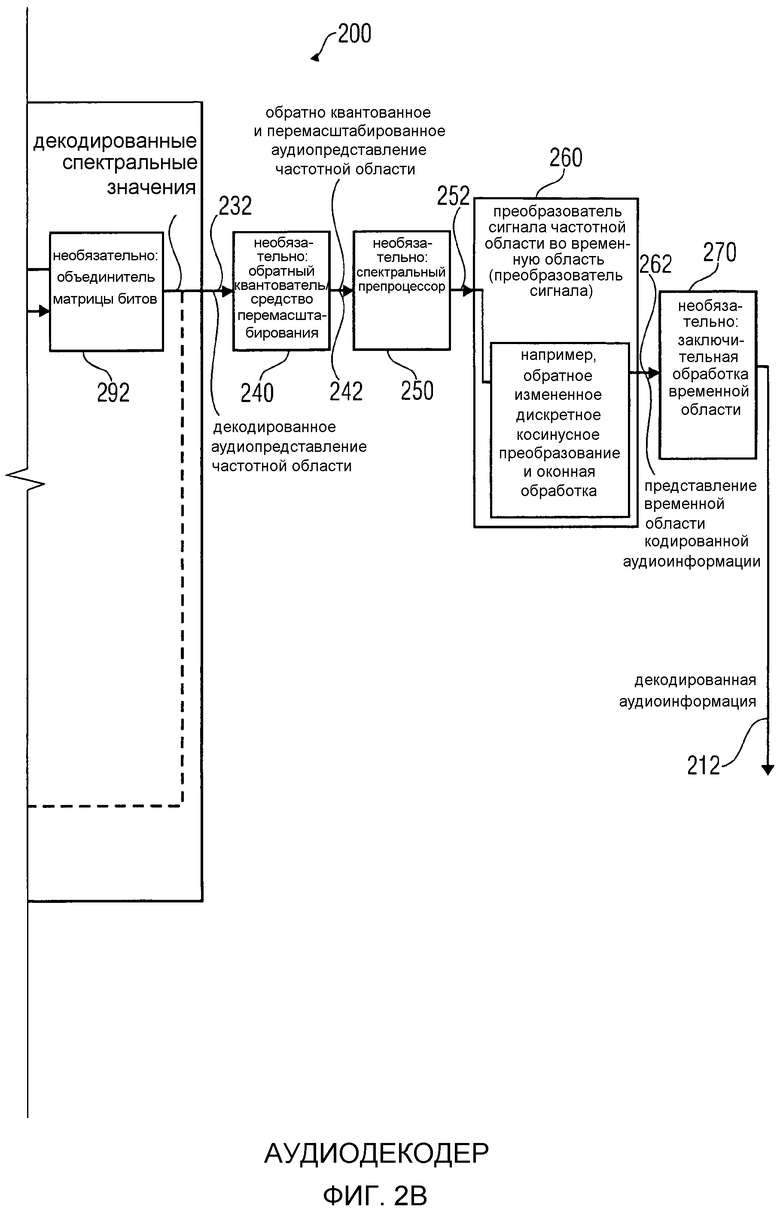
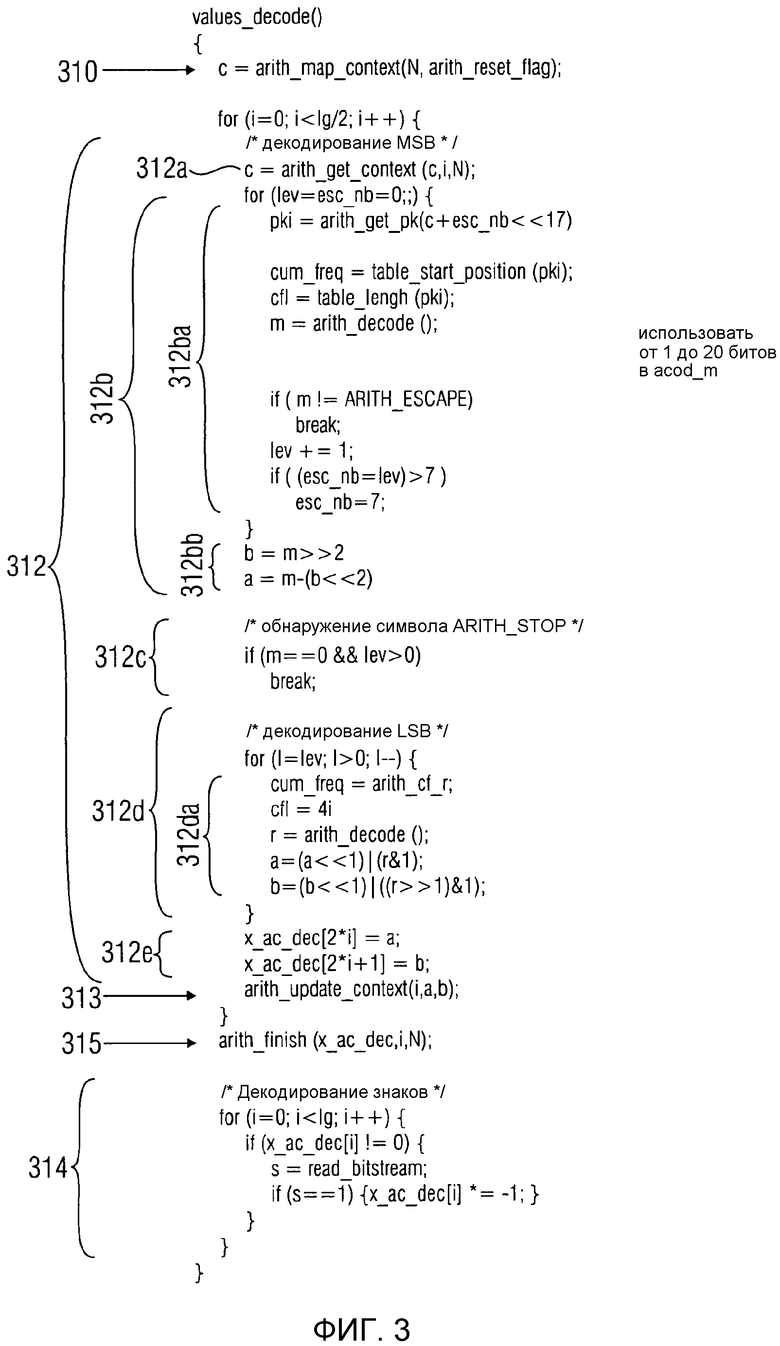
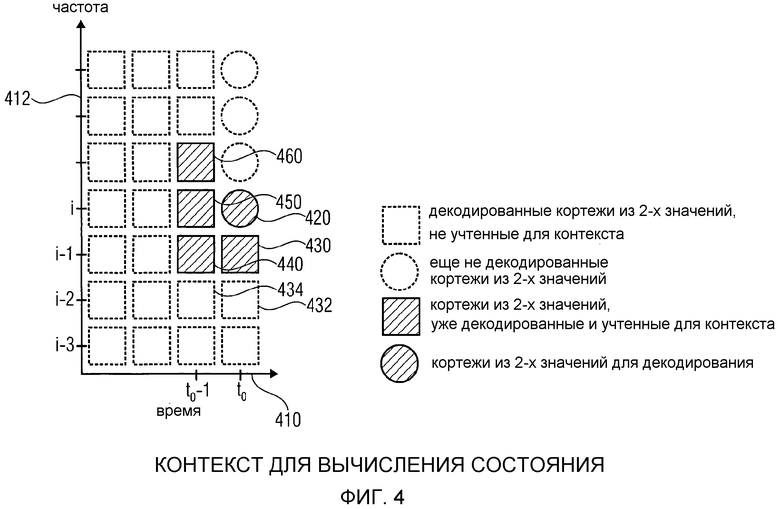





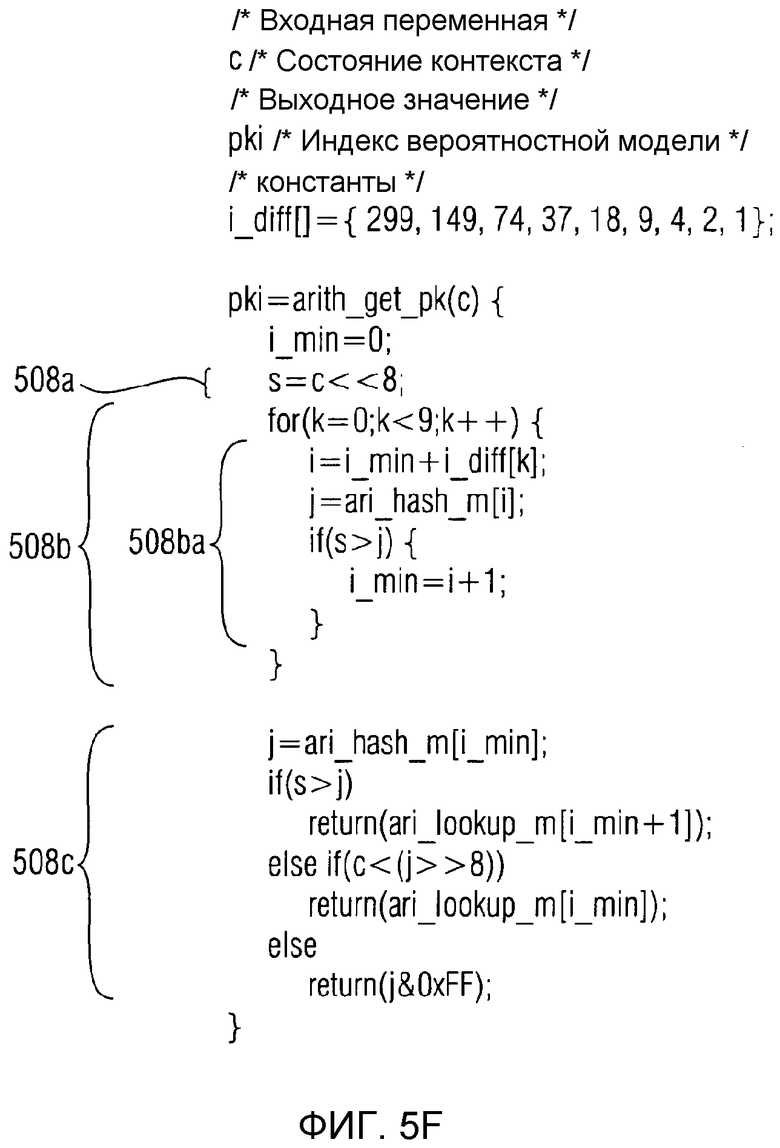

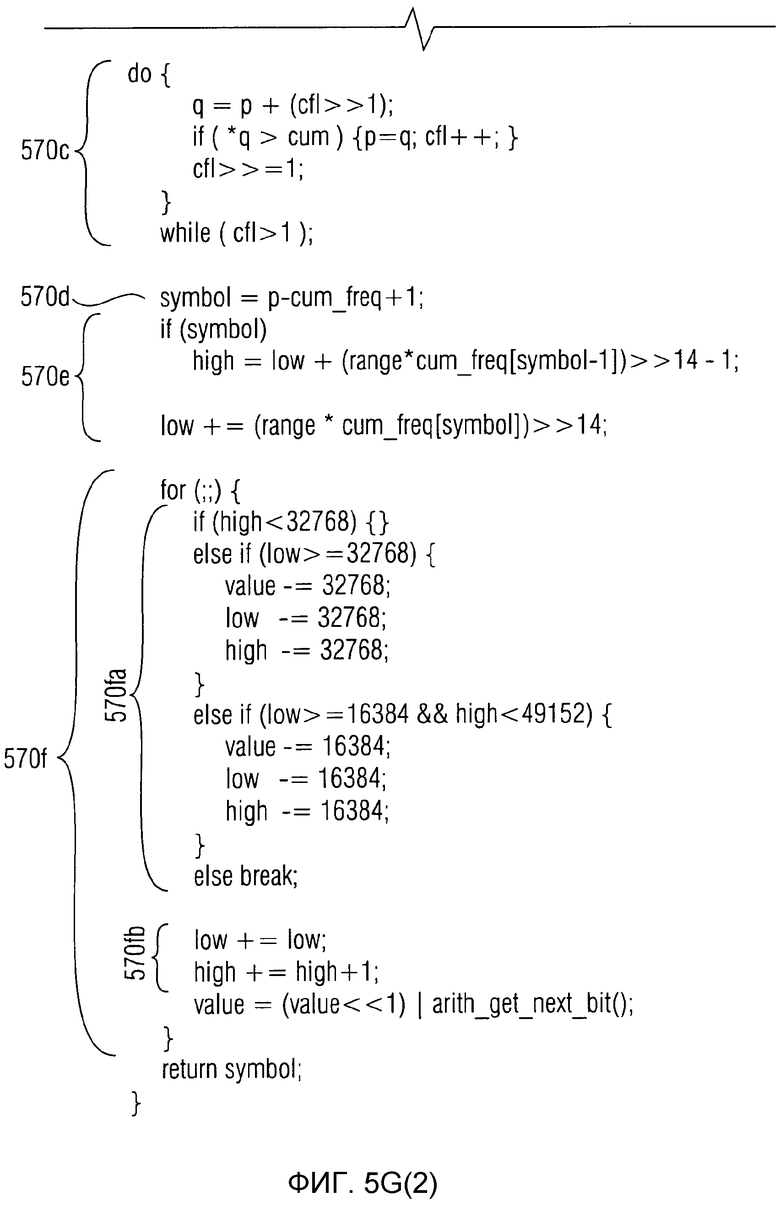



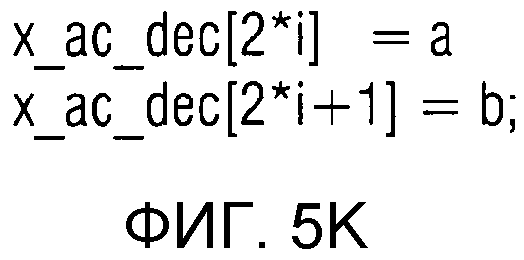







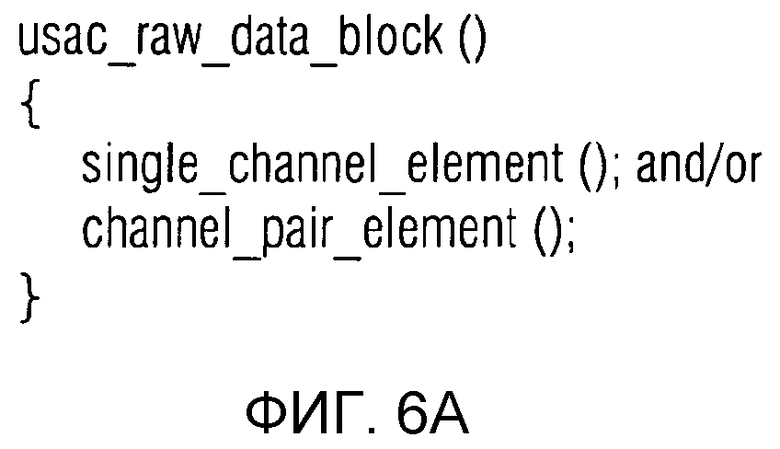
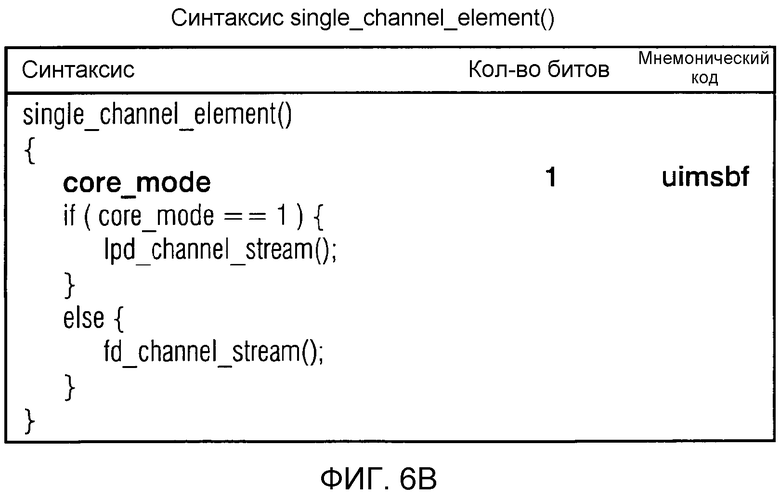

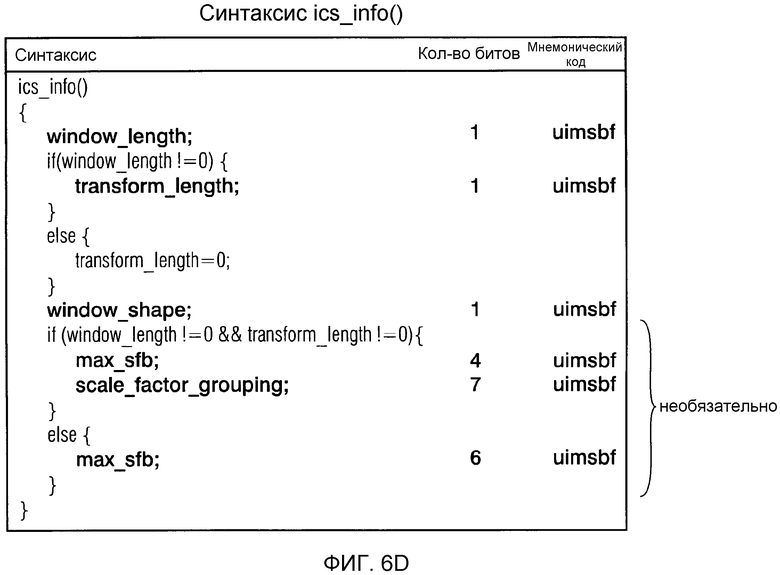
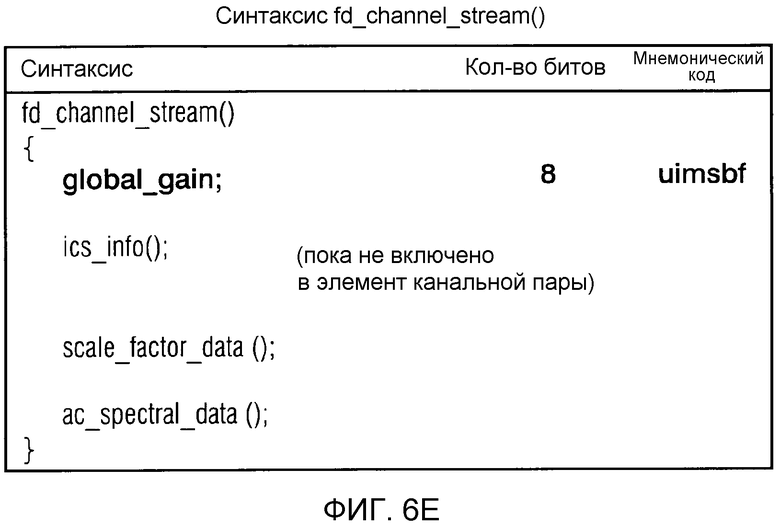





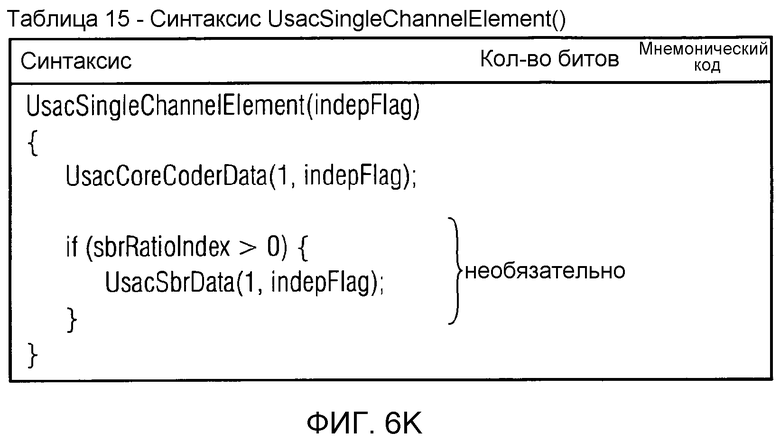
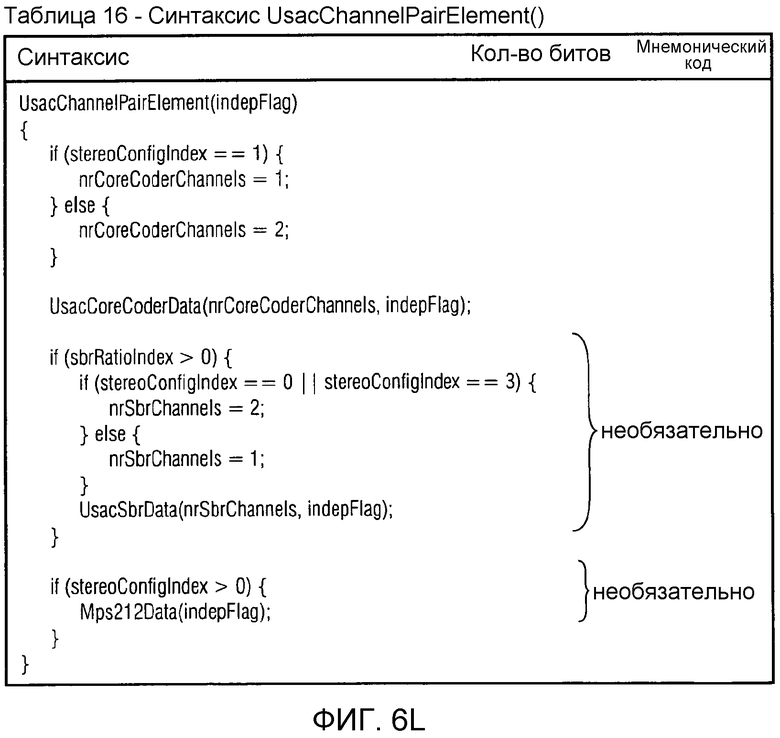

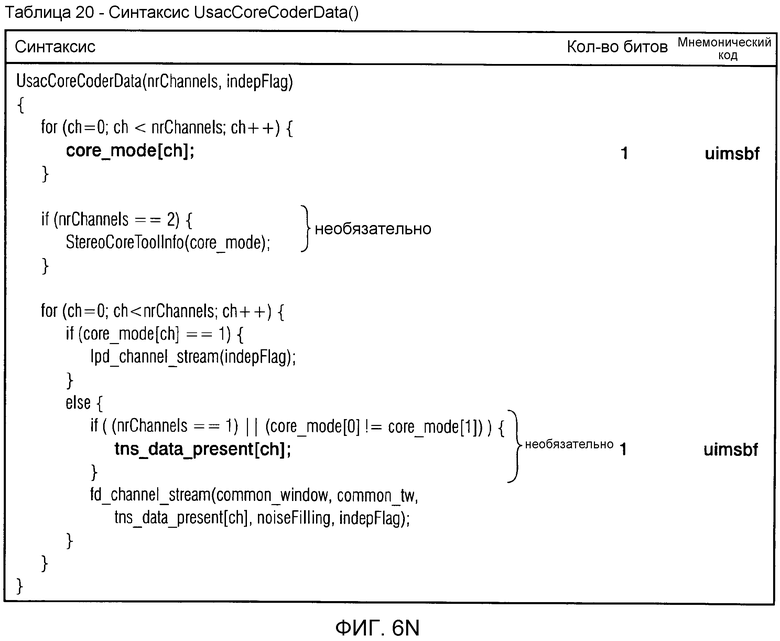
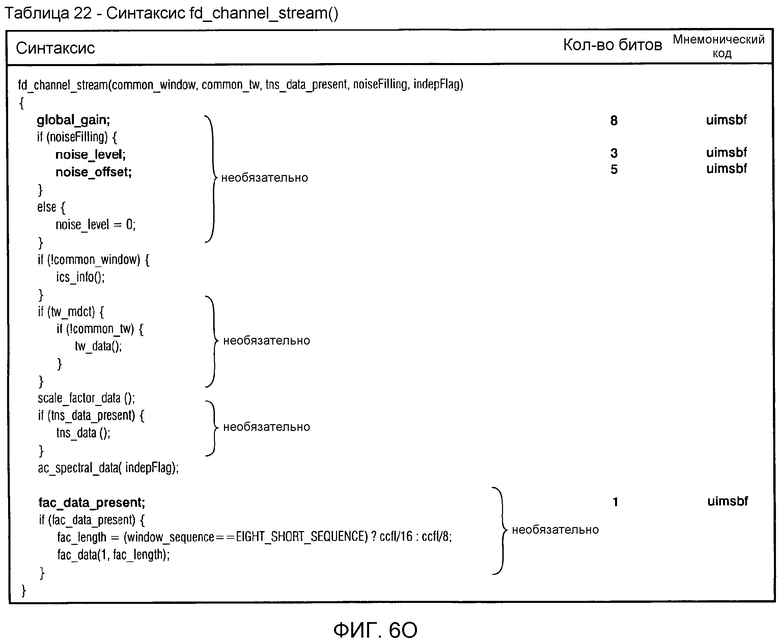

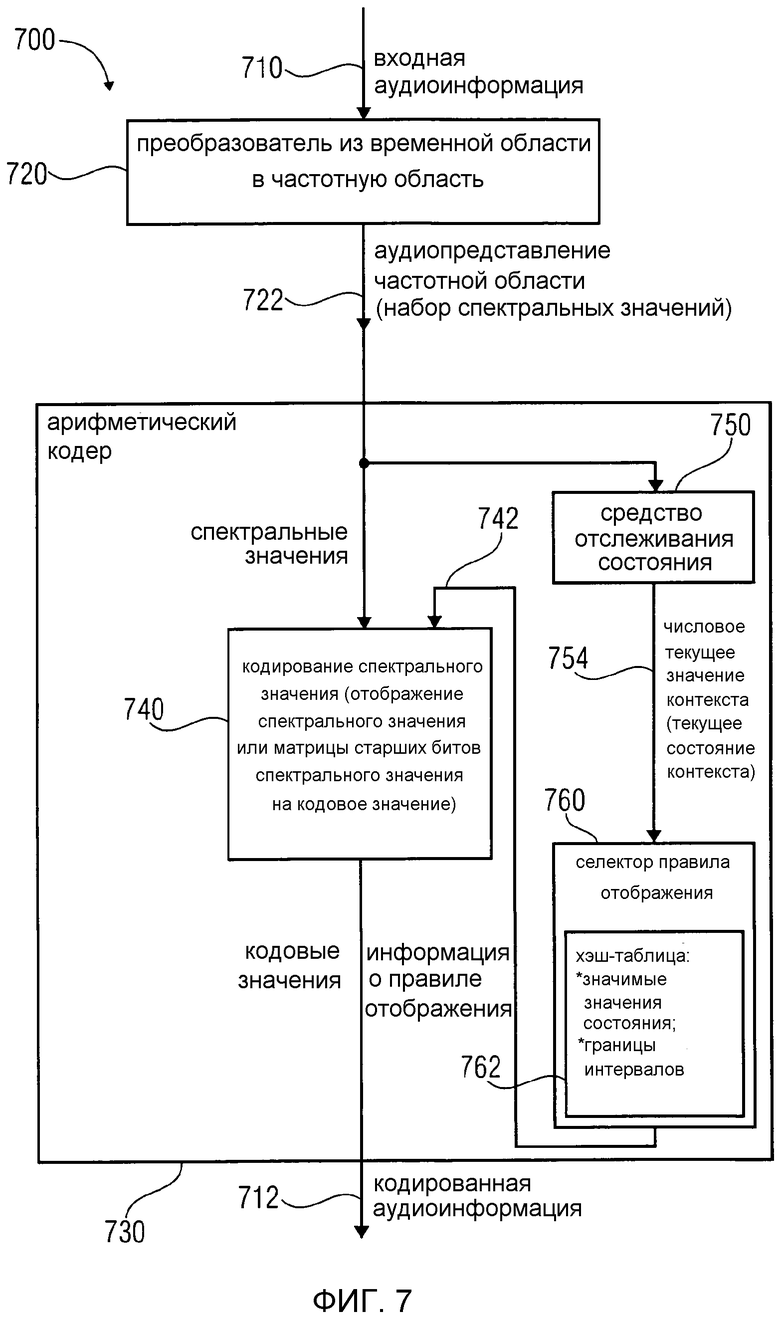
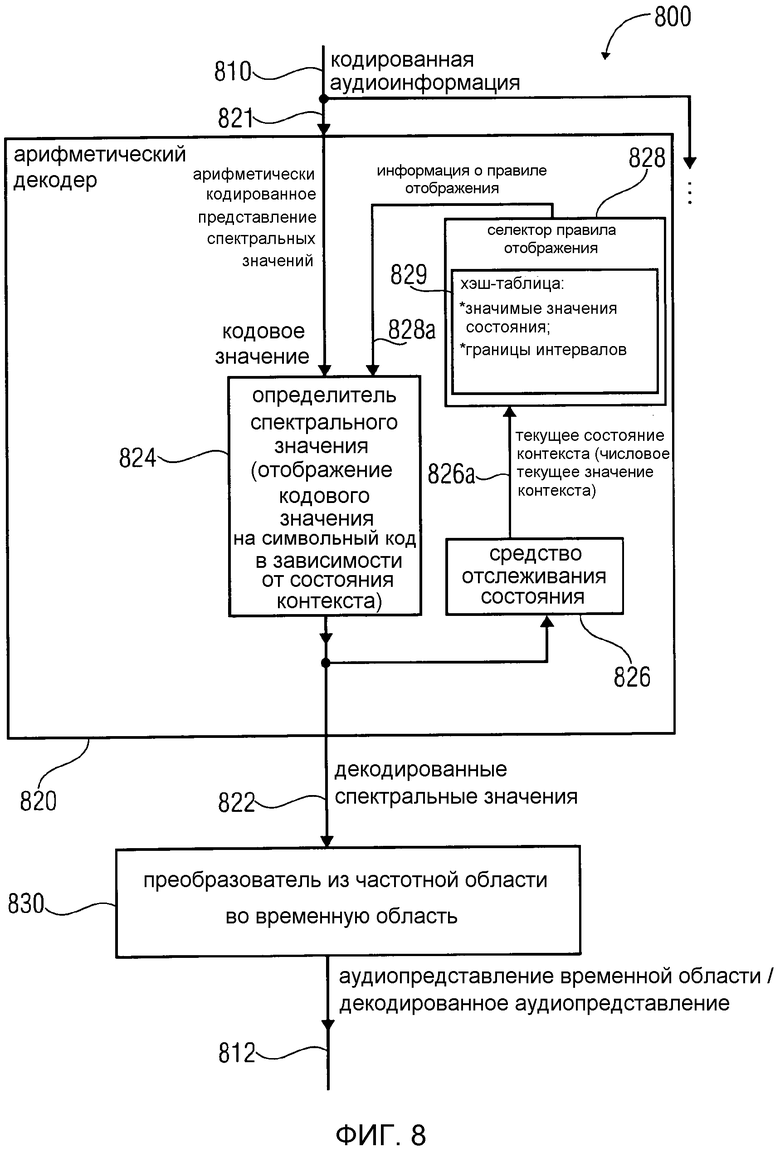
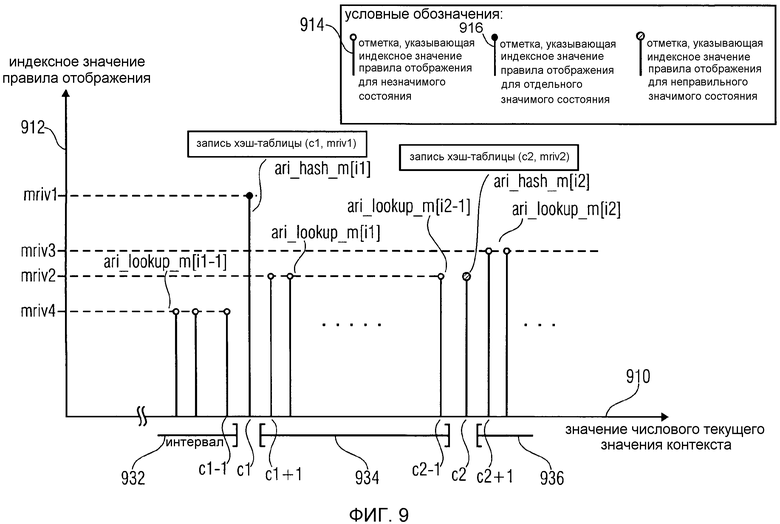
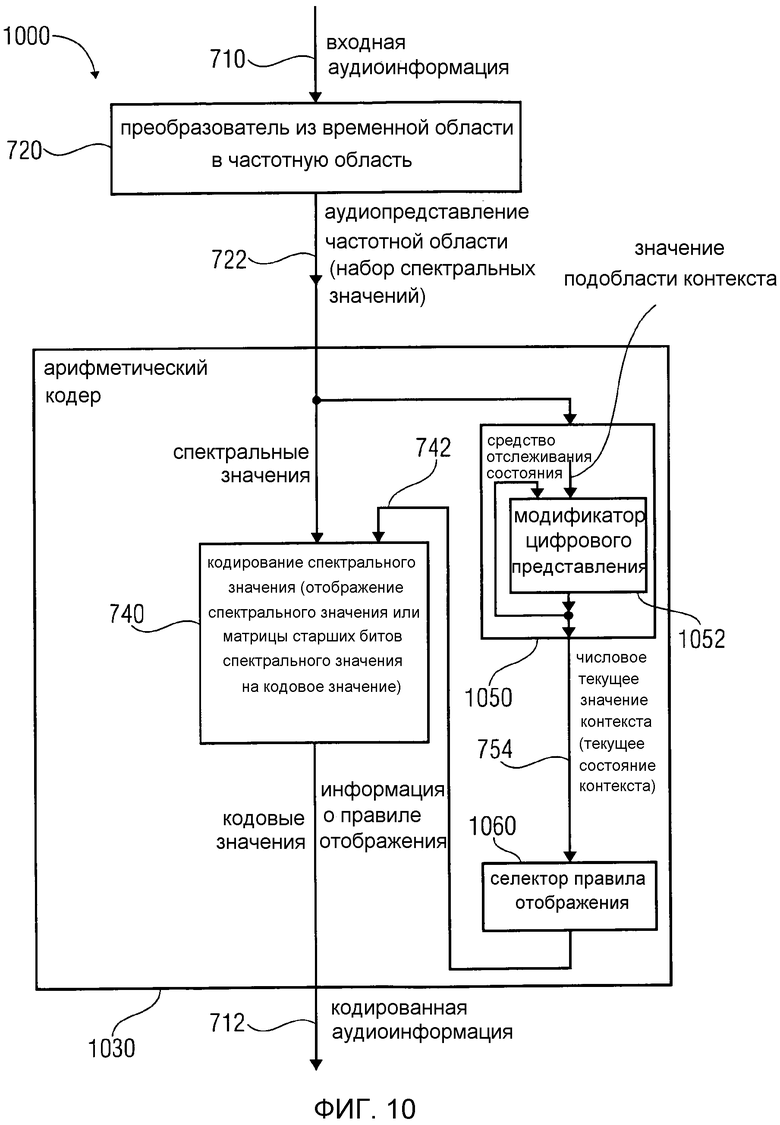
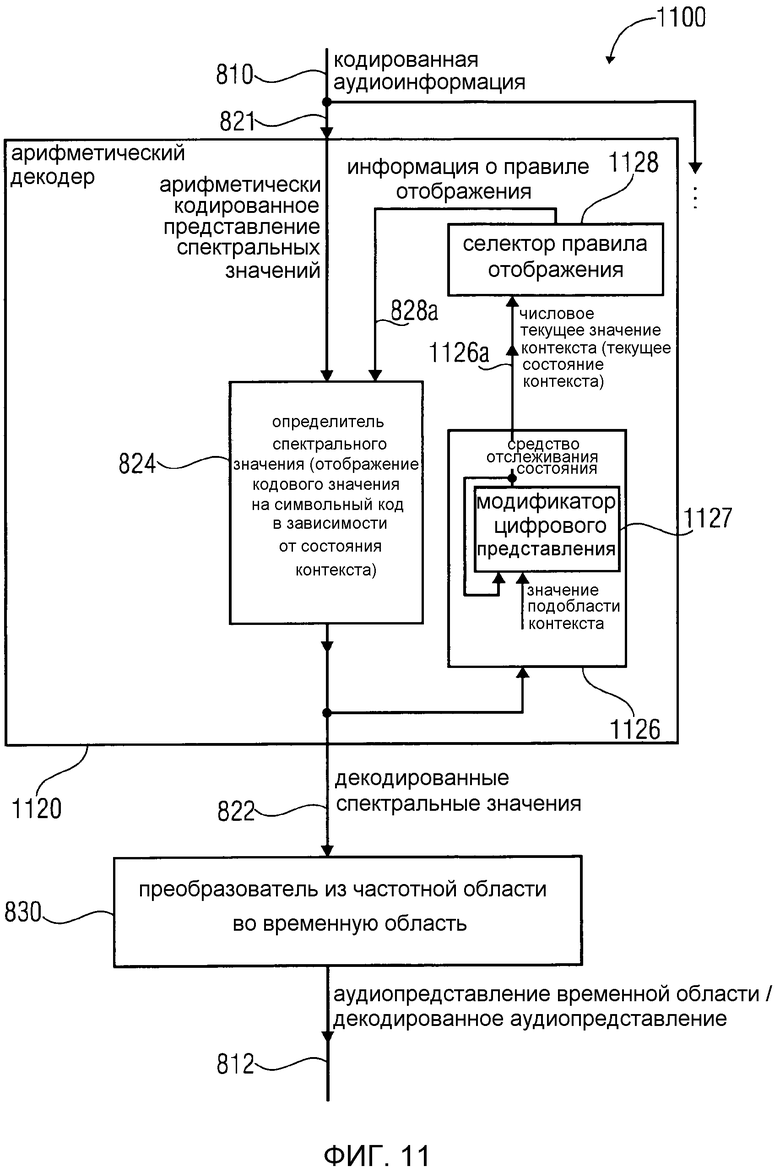
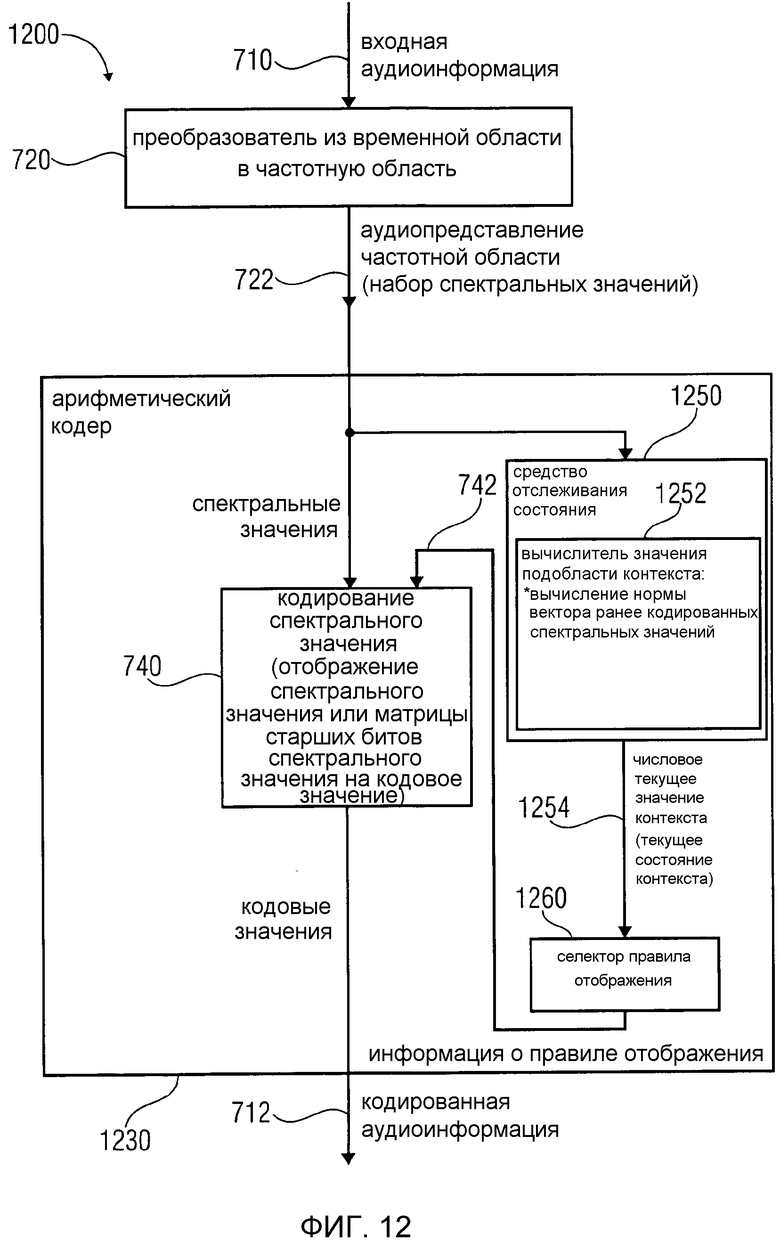
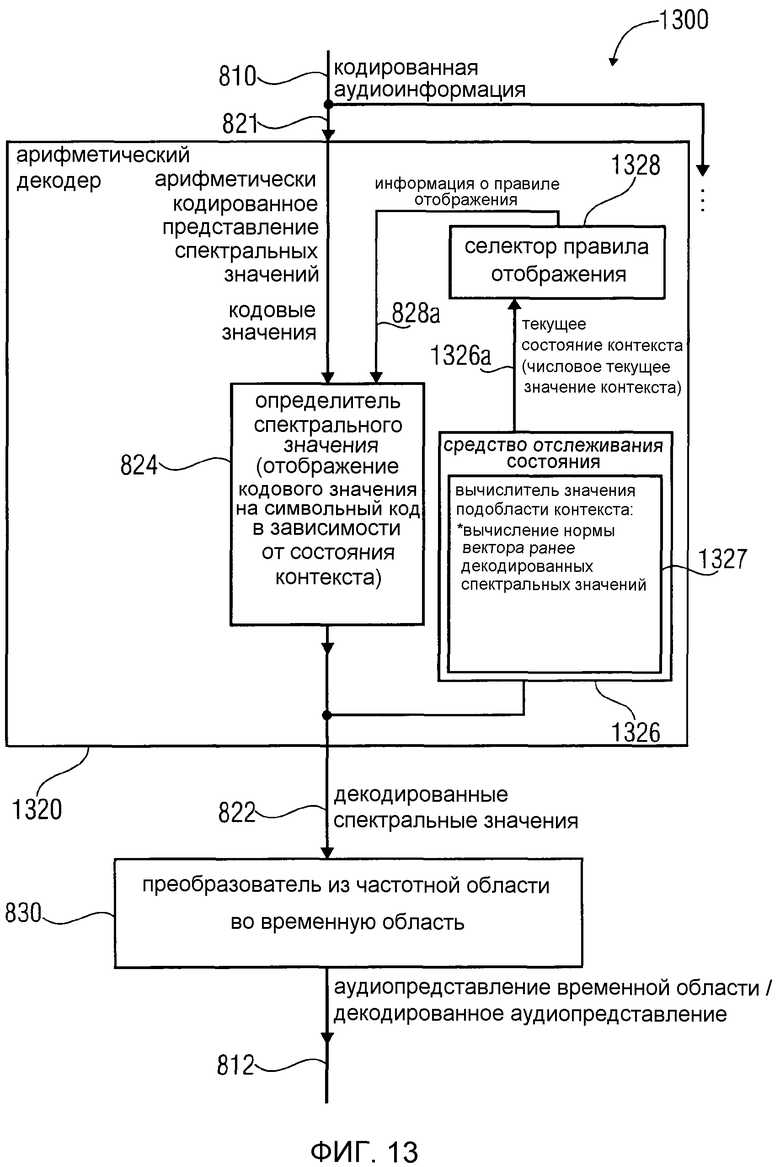
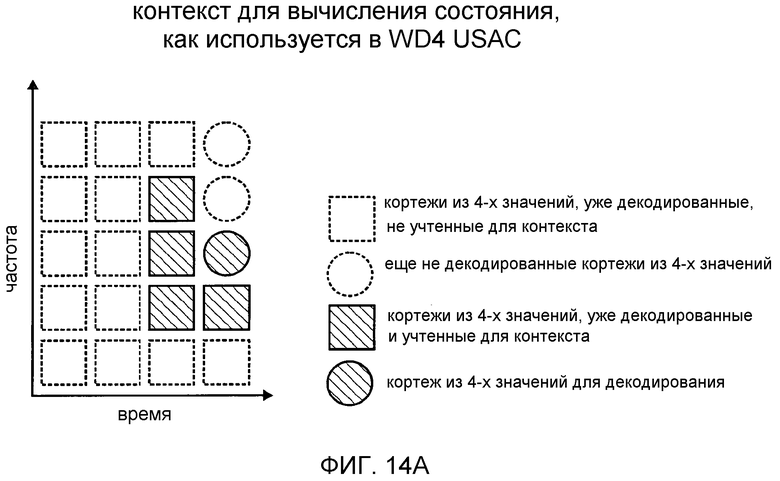

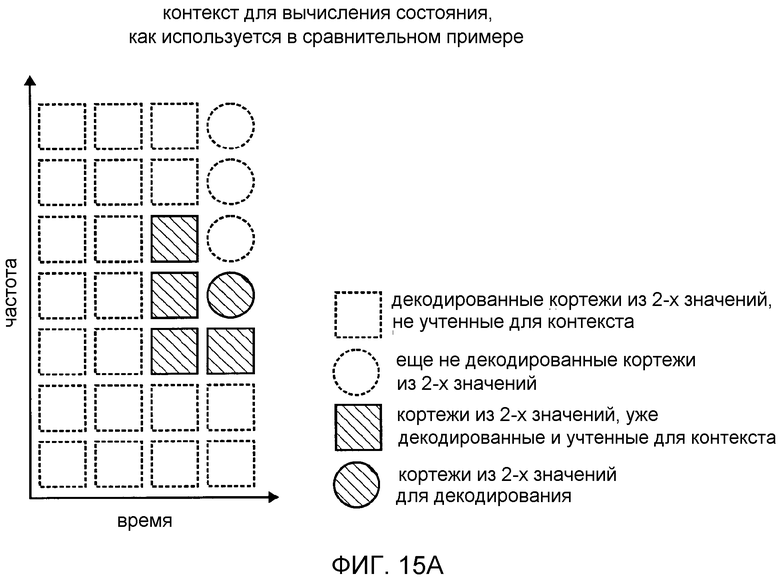
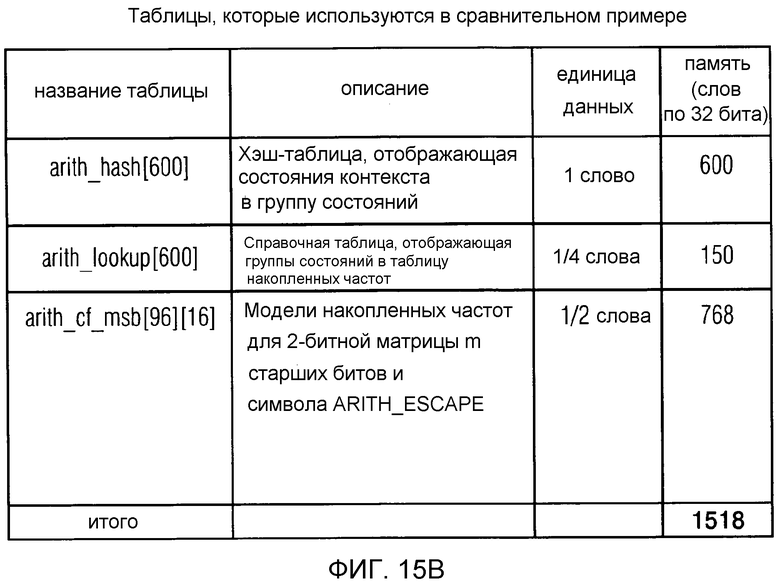
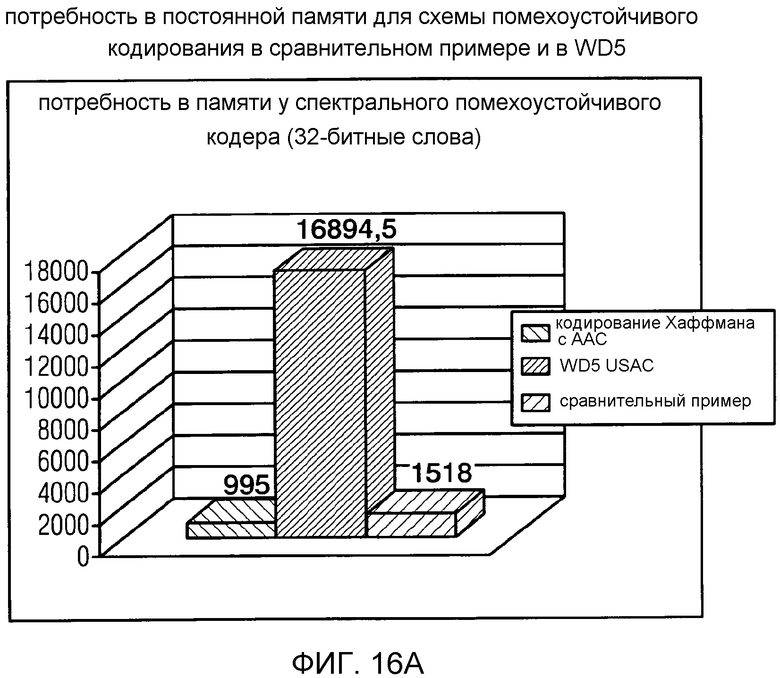
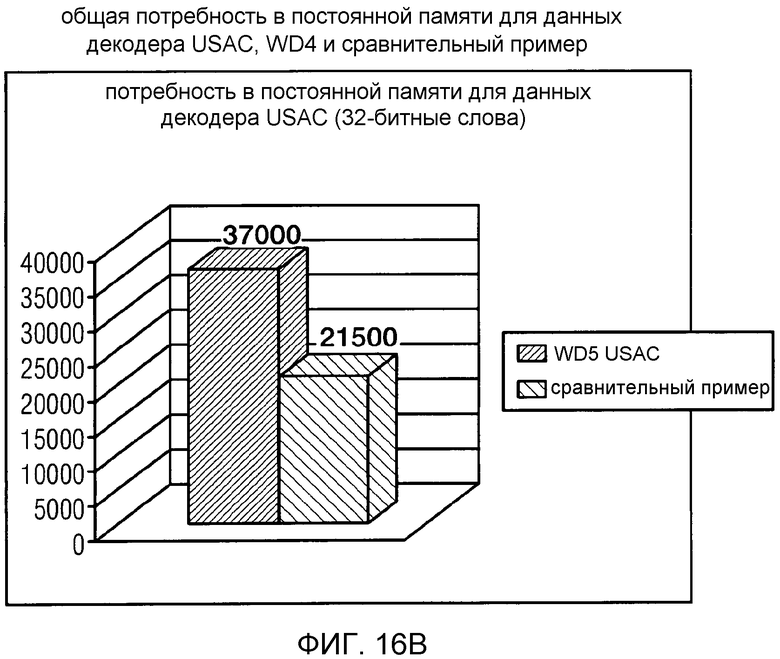
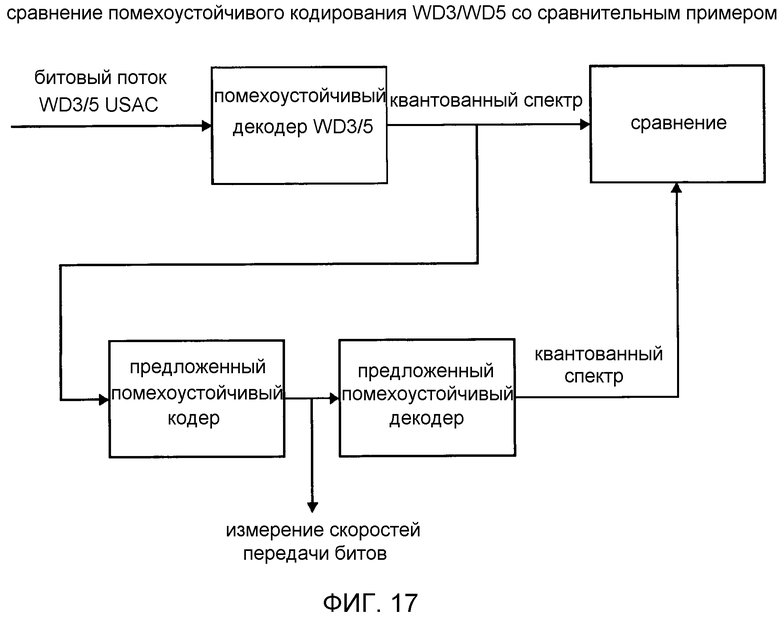
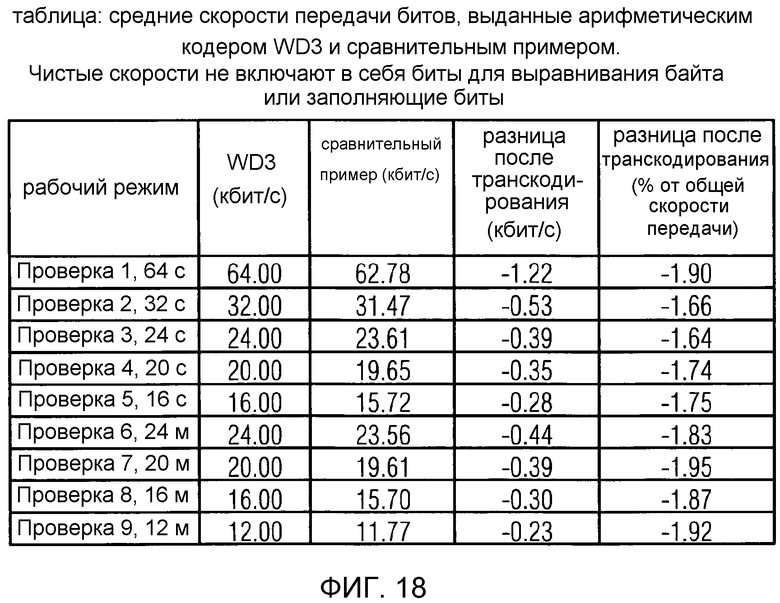
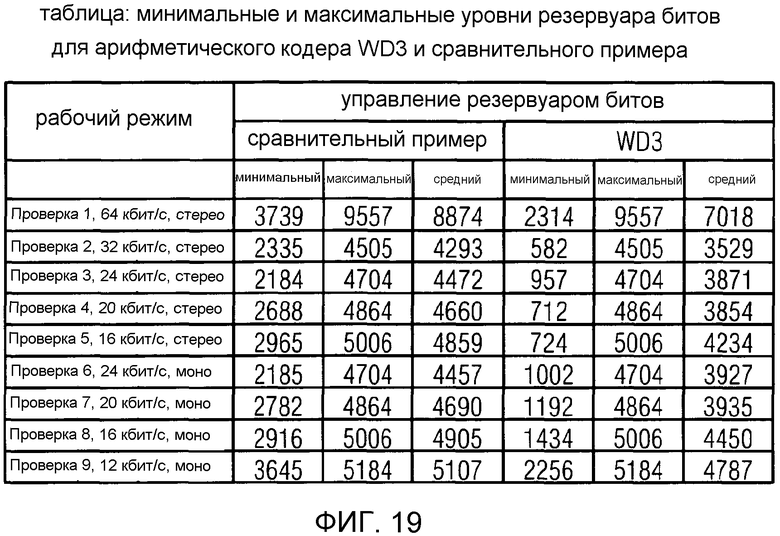
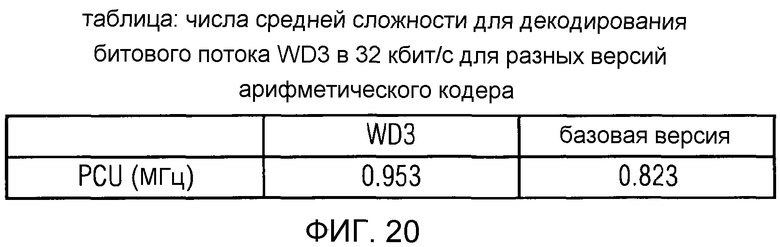








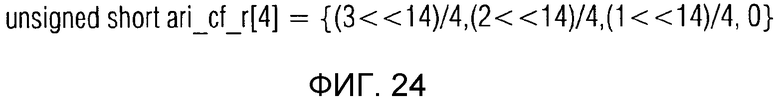
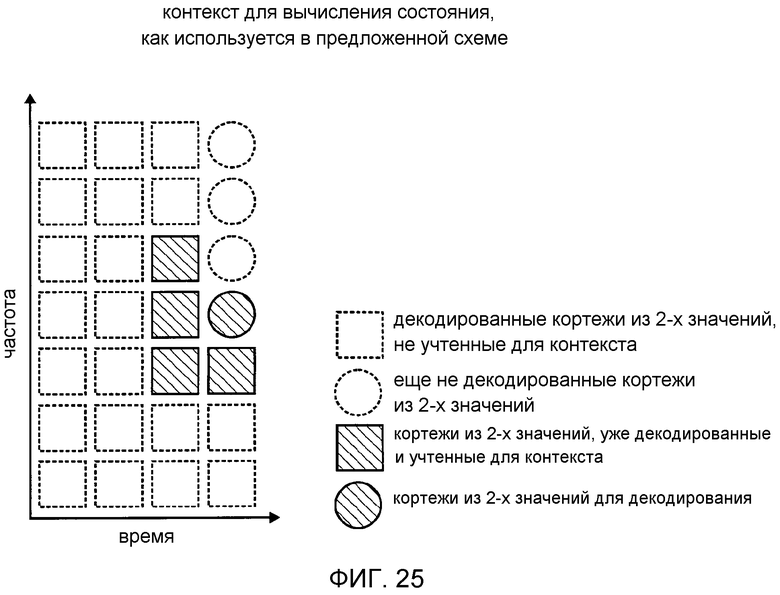

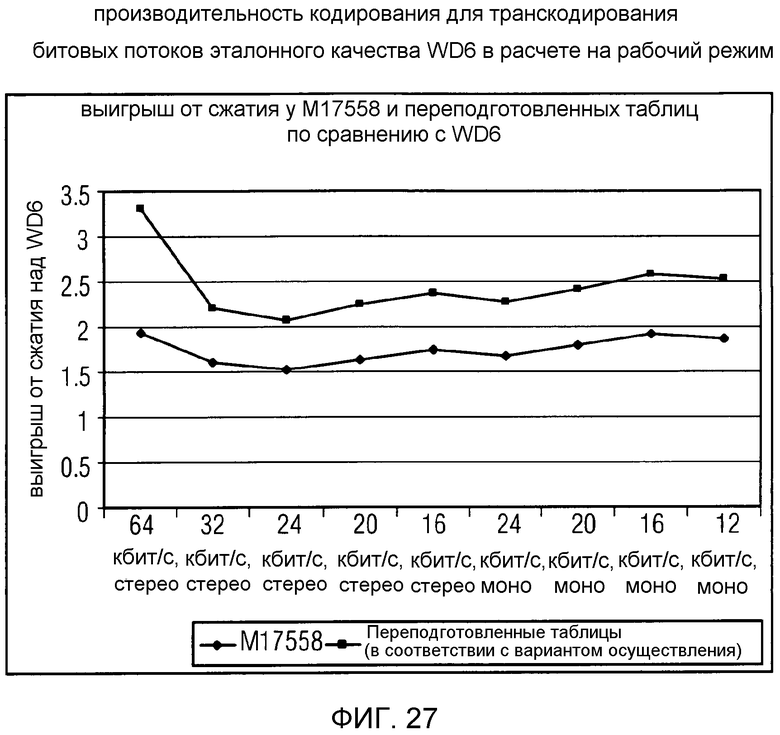
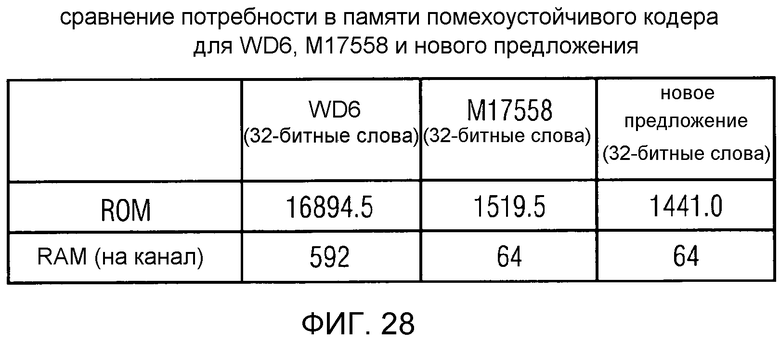
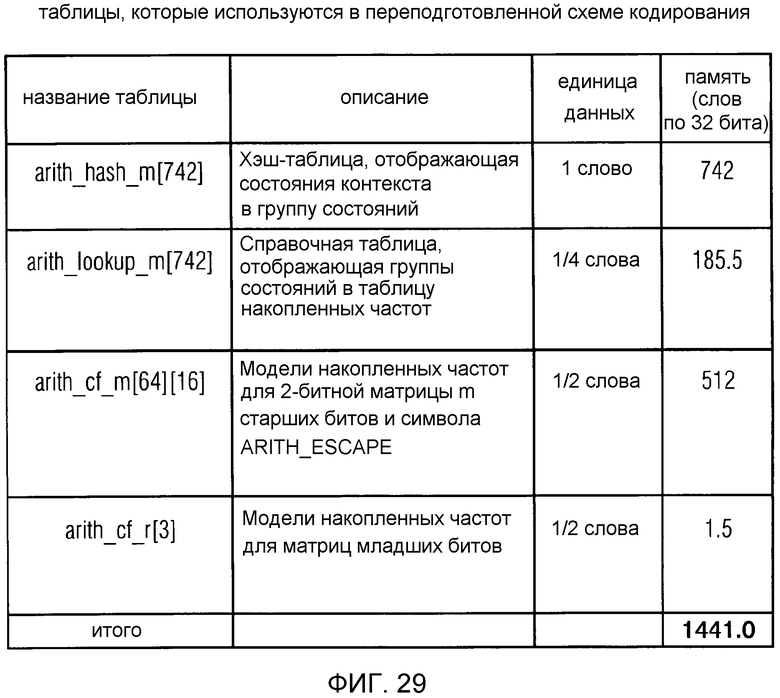



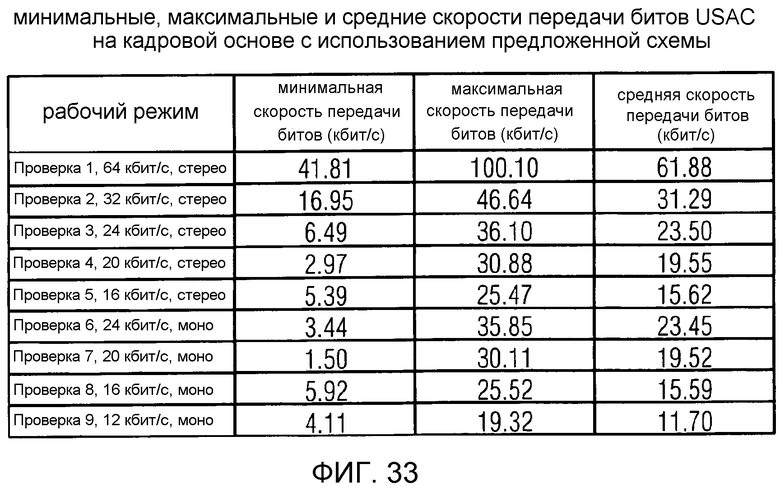
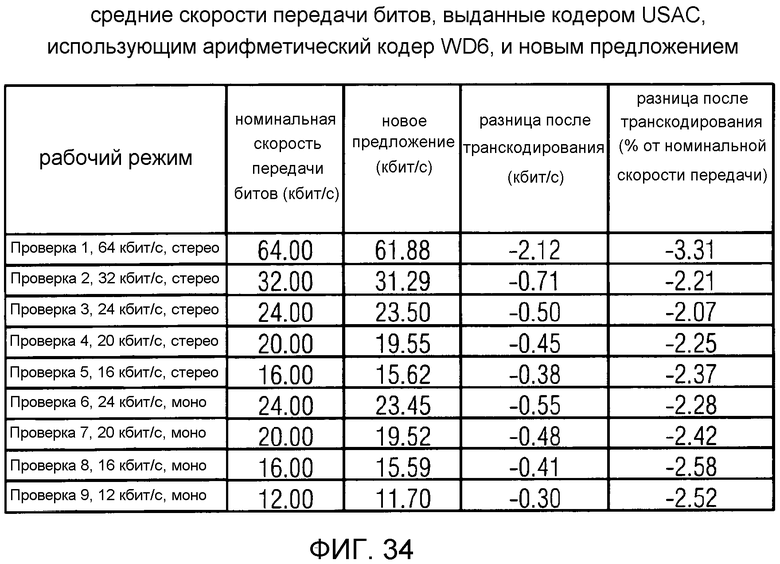
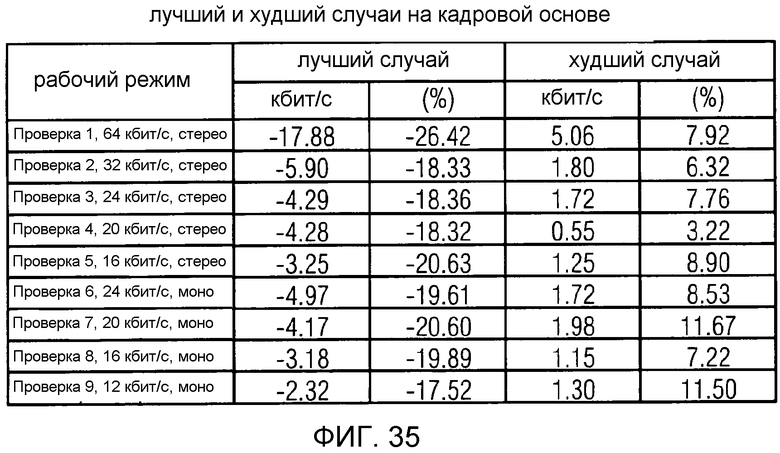
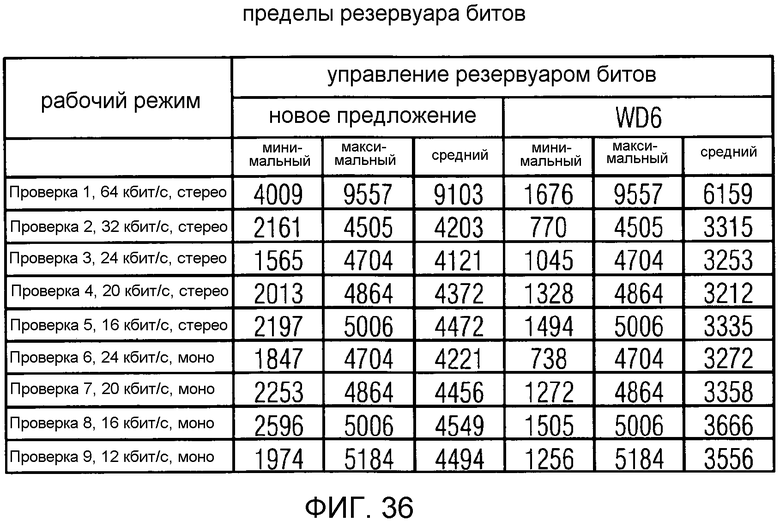
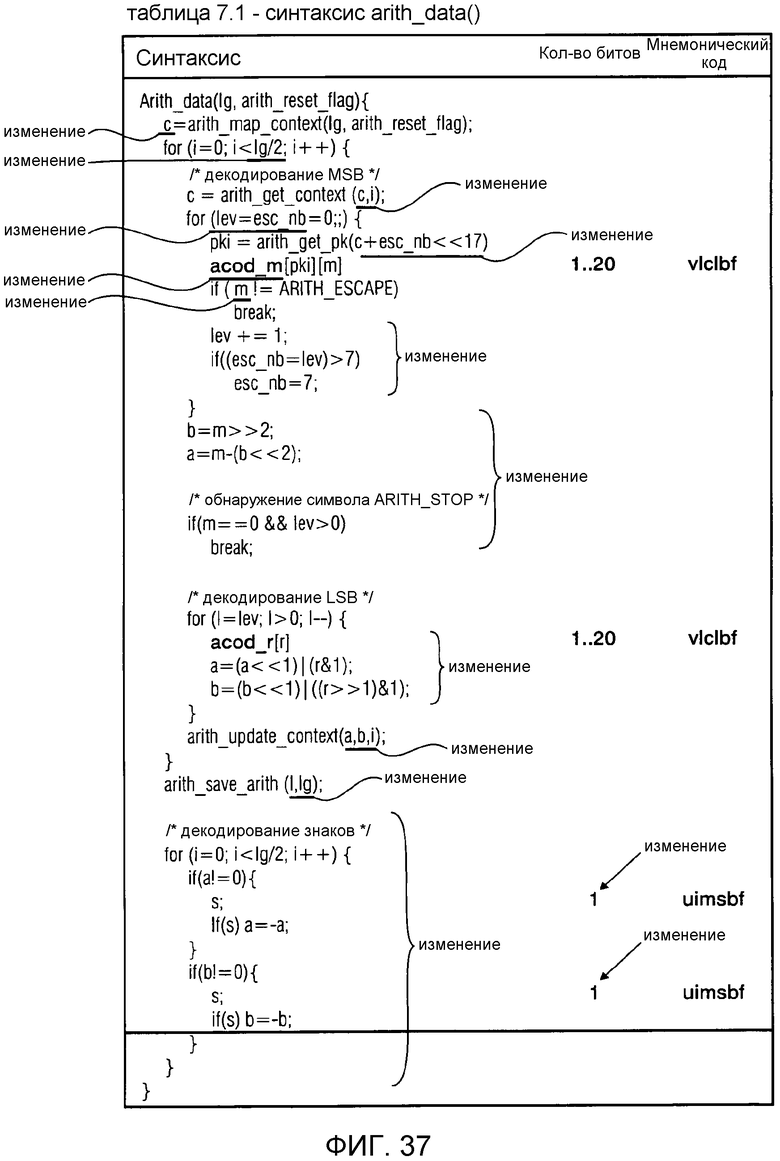

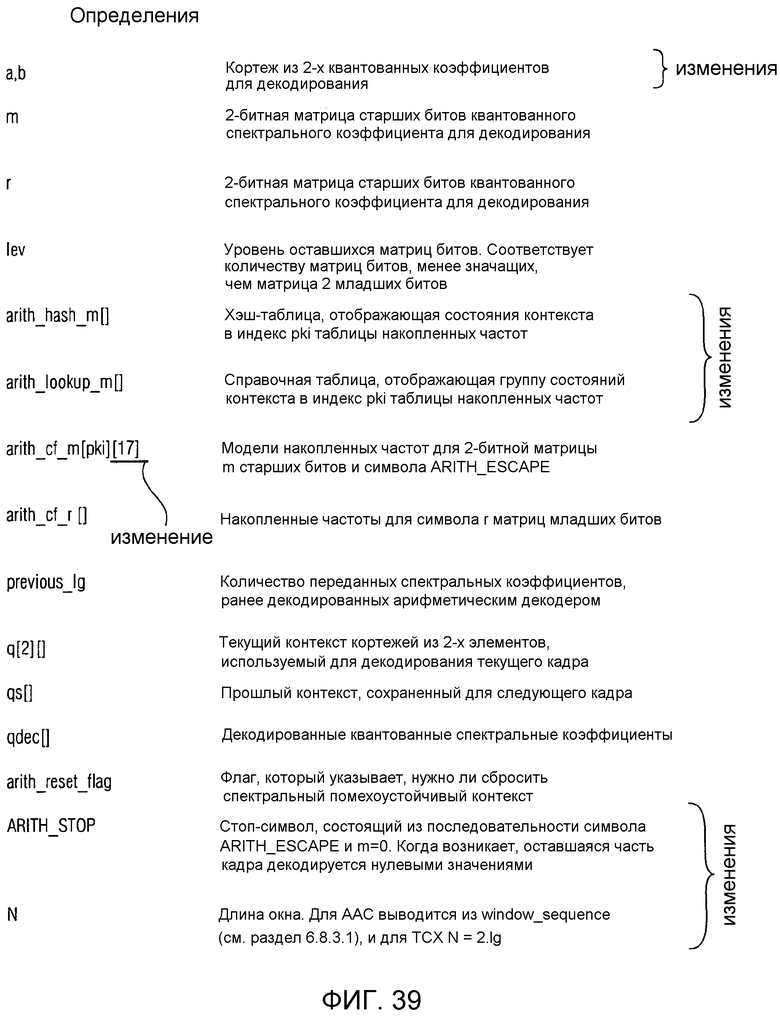




















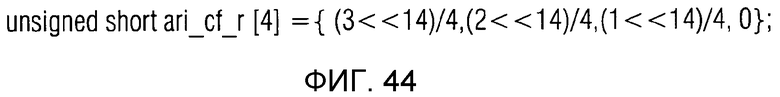
Изобретение относится к средствам кодирования и декодирования аудиоинформации, использующим оптимизированную кэш-таблицу. Технический результат заключается в повышении скорости передачи информации. Преобразовывают информацию из частотной области во временную область для предоставления аудиопредставления временной области используя декодированные спектральные значения, чтобы получить декодированную аудиоинформацию. Выбирают правило отображения, описывающее отображение кодового значения, представляющего спектральное значение или матрицу старших битов спектрального значения, в кодированной форме на символьный код, представляющий спектральное значение или матрицу старших битов спектрального значения, в декодированной форме в зависимости от состояния контекста, описанного числовым текущим значением контекста. Определяют числовое текущее значение контекста в зависимости от множества ранее декодированных спектральных значений. Оценивают кэш-таблицу, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов числовых значений контекста. 7 н. и 12 з.п. ф-лы, 101 ил.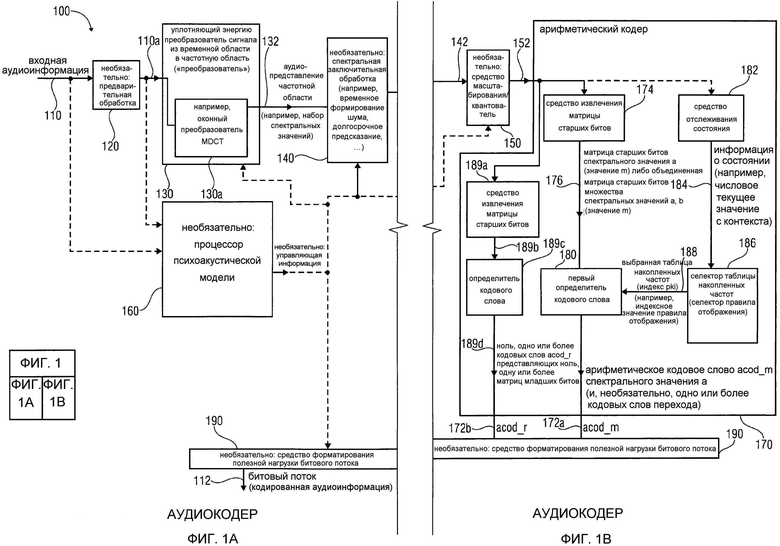
1. Аудиодекодер (200; 800) для предоставления декодированной аудиоинформации (212; 812) на основе закодированной аудиоинформации (210; 810), причем аудиодекодер содержит:
арифметический декодер (230; 820) для предоставления множества декодированных спектральных значений (232; 822) на основе арифметически закодированного представления (222; 821) спектральных значений, содержащихся в закодированной аудиоинформации (210; 810); и
преобразователь (260; 830) из частотной области во временную область для предоставления аудиопредставления (262; 812) временной области с использованием декодированных спектральных значений (232; 822), чтобы получить декодированную аудиоинформацию (212; 812);
при этом арифметический декодер (230; 820) сконфигурирован для выбора правила (297; 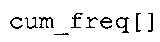 ) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (c) контекста;
) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (c) контекста;
при этом арифметический декодер (230; 820) сконфигурирован
для определения числового текущего значения (c) контекста в зависимости от множества ранее декодированных спектральных значений;
при этом арифметический декодер сконфигурирован для оценки хэш-таблицы 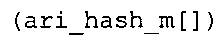 , записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, чтобы выбрать правило отображения,
, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, чтобы выбрать правило отображения,
при этом арифметический декодер сконфигурирован для оценки хэш-таблицы для поиска индексного значения i хэш-таблицы, для которого значение 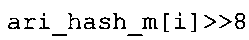 больше либо равно с, при этом если найденное индексное значение i хэш-таблицы больше 0, то значение
больше либо равно с, при этом если найденное индексное значение i хэш-таблицы больше 0, то значение 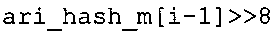 меньше с;
меньше с;
при этом арифметический декодер сконфигурирован для выбора правила отображения, которое определяется индексом (pki) вероятностной модели, который равен 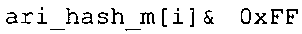 , когда
, когда 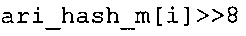 равно с, или равен
равно с, или равен 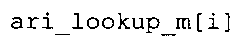 в противном случае;
в противном случае;
при этом хэш-таблица 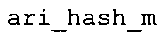 задается, как приведено ниже
задается, как приведено ниже




и
при этом таблица  отображения задается, как приведено ниже
отображения задается, как приведено ниже

при этом индексное значение правила отображения отдельно ассоциируется с числовым значением контекста, являющимся значимым значением состояния; и
при этом 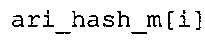 обозначает запись хэш-таблицы
обозначает запись хэш-таблицы 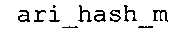 , имеющую индексное значение i хэш-таблицы.
, имеющую индексное значение i хэш-таблицы.
2. Аудиодекодер по п. 1, в котором арифметический декодер сконфигурирован для оценки хэш-таблицы с использованием алгоритма:

при этом с обозначает переменную, представляющую числовое текущее значение контекста или его масштабированную версию;
при этом i является переменной, описывающей текущее индексное значение хэш-таблицы;
при этом 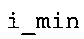 является переменной, инициализируемой для обозначения индексного значения хэш-таблицы первой записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
является переменной, инициализируемой для обозначения индексного значения хэш-таблицы первой записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
при этом условие "c<(j>>8)" задает, что значение состояния, описанное переменной с, меньше значения состояния, описанного записью 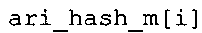 таблицы;
таблицы;
при этом 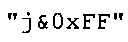 описывает индексное значение правила отображения, описанное записью
описывает индексное значение правила отображения, описанное записью 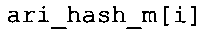 таблицы;
таблицы;
при этом 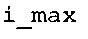 является переменной, инициализируемой для обозначения индексного значения хэш-таблицы последней записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
является переменной, инициализируемой для обозначения индексного значения хэш-таблицы последней записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
при этом условие "c>(j>>8)" задает, что значение состояния, описанное переменной с, больше значения состояния, описанного записью  таблицы;
таблицы;
при этом j является переменной;
при этом возвращаемое значение обозначает индекс pki вероятностной модели и является индексным значением правила отображения;
при этом 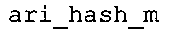 обозначает хэш-таблицу;
обозначает хэш-таблицу;
при этом 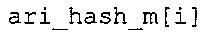 обозначает запись хэш-таблицы
обозначает запись хэш-таблицы 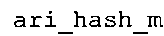 , имеющую индексное значение i хэш-таблицы; при этом
, имеющую индексное значение i хэш-таблицы; при этом 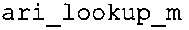 обозначает таблицу отображения; и
обозначает таблицу отображения; и
при этом 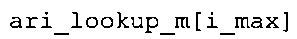 обозначает запись таблицы
обозначает запись таблицы 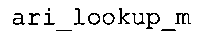 отображения, имеющую индексное значение
отображения, имеющую индексное значение 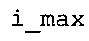 таблицы отображения.
таблицы отображения.
3. Аудиодекодер (200; 800) по п. 1,
в котором арифметический декодер сконфигурирован для выбора правила (297; 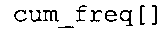 ) отображения, описывающего отображение кодового значения (значения) на символьный код (символ) на основе индексного значения pki правила отображения.
) отображения, описывающего отображение кодового значения (значения) на символьный код (символ) на основе индексного значения pki правила отображения.
4. Аудиодекодер (200; 800) по п. 3,
в котором арифметический декодер сконфигурирован для использования индексного значения правила отображения в качестве индексного значения таблицы для выбора правила (297; 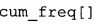 ) отображения, описывающего отображение кодового значения (значения) на символьный код (символ).
) отображения, описывающего отображение кодового значения (значения) на символьный код (символ).
5. Аудиодекодер (200; 800) по п. 1, в котором арифметический декодер сконфигурирован для выбора одной из подтаблиц 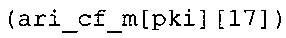 таблицы
таблицы 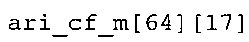 , которая приведена ниже, в качестве выбранного правила отображения
, которая приведена ниже, в качестве выбранного правила отображения


6. Аудиодекодер по п. 1,
в котором арифметический декодер сконфигурирован для получения числового текущего значения контекста на основе числового предыдущего значения контекста с использованием алгоритма:

при этом алгоритм в качестве входных значений принимает значение или переменную с, представляющую числовое предыдущее значение контекста, и значение или переменную i, представляющую индекс кортежа из 2-х спектральных значений для декодирования в векторе спектральных значений;
при этом значение или переменная N представляет длину окна собственно окна восстановления преобразователя из частотной области во временную область; и
при этом алгоритм в качестве выходного значения предоставляет обновленное значение или переменную с, представляющую числовое текущее значение контекста;
при этом операция "c>>4" описывает сдвиг вправо значения или переменной с на 4 бита,
при этом q[0][i+1] обозначает значение подобласти контекста, ассоциированное с предыдущим аудиокадром и имеющее ассоциированный больший индекс i+1 частоты, больший на единицу, чем текущий индекс частоты кортежа из 2-х спектральных значений, которые должны быть декодированы в настоящее время; и
при этом q[1][i-1] обозначает значение подобласти контекста, ассоциированное с текущим аудиокадром и имеющее ассоциированный меньший индекс i-1 частоты, меньший на единицу, чем текущий индекс частоты кортежа из 2-х спектральных значений, которые должны быть декодированы в настоящее время;
при этом q[1][i-2] обозначает значение подобласти контекста, ассоциированное с текущим аудиокадром и имеющее ассоциированный меньший индекс i-2 частоты, меньший на два, чем текущий индекс частоты кортежа из 2-х спектральных значений, которые должны быть декодированы в настоящее время;
при этом q[1][i-3] обозначает значение подобласти контекста, ассоциированное с текущим аудиокадром и имеющее ассоциированный меньший индекс i-3 частоты, меньший на три, чем текущий индекс частоты кортежа из 2-х спектральных значений, которые должны быть декодированы в настоящее время.
7. Аудиодекодер по п. 6,
в котором арифметический декодер сконфигурирован для обновления значения q[1][i] подобласти контекста, ассоциированного с текущим аудиокадром и имеющего ассоциированный текущий индекс частоты кортежа из 2-х спектральных значений, декодируемых в настоящее время, используя сочетание множества спектральных значений, декодируемых в настоящее время.
8. Аудиодекодер по п. 6,
в котором арифметический декодер сконфигурирован для обновления значения q[1][i] подобласти контекста, ассоциированного с текущим аудиокадром и имеющего ассоциированный индекс частоты кортежа из 2-х спектральных значений, декодируемых в настоящее время, используя алгоритм:

при этом a и b являются декодированными беззнаковыми квантованными спектральными коэффициентами кортежа из 2-х элементов, декодируемых в настоящее время; и
при этом i является индексом частоты кортежа из 2-х спектральных значений, декодируемых в настоящее время.
9. Аудиодекодер по п. 1,
в котором арифметический декодер сконфигурирован для предоставления декодированного значения m, представляющего кортеж из 2-х декодированных спектральных значений, используя алгоритм арифметического декодирования:


при этом  является переменной, описывающей начало выбранной таблицы или подтаблицы
является переменной, описывающей начало выбранной таблицы или подтаблицы 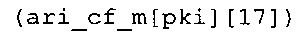 , описывающей отображение кодового значения (значения) на символьный код (символ);
, описывающей отображение кодового значения (значения) на символьный код (символ);
при этом "cfl" является значением или переменной, описывающей длину выбранной таблицы или подтаблицы 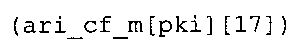 , описывающей отображение кодового значения (значения) на символьный код (символ);
, описывающей отображение кодового значения (значения) на символьный код (символ);
при этом вспомогательная функция 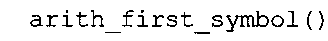 возвращает истину, если символ, который должен быть декодирован, является первым символом последовательности символов, и возвращает ложь в противном случае;
возвращает истину, если символ, который должен быть декодирован, является первым символом последовательности символов, и возвращает ложь в противном случае;
при этом вспомогательная функция 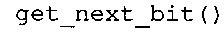 предоставляет следующий бит битового потока;
предоставляет следующий бит битового потока;
при этом переменная "low" является глобальной переменной;
при этом переменная "high" является глобальной переменной;
при этом переменная "value" является глобальной переменной;
при этом "range" является переменной;
при этом "cum" является переменной;
при этом "p" является переменной, указывающей на элемент выбранной таблицы или подтаблицы 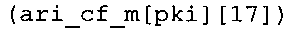 , описывающей отображение кодового значения (значения) на символьный код (символ);
, описывающей отображение кодового значения (значения) на символьный код (символ);
при этом "q" является переменной, указывающей на элемент выбранной таблицы или подтаблицы 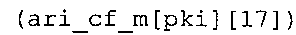 , описывающей отображение кодового значения (значения) на символьный код (символ);
, описывающей отображение кодового значения (значения) на символьный код (символ);
при этом "*q" является элементом таблицы или элементом подтаблицы выбранной таблицы или подтаблицы 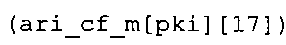 , описывающей отображение кодового значения (значения) на символьный код (символ), на который указывает переменная q;
, описывающей отображение кодового значения (значения) на символьный код (символ), на который указывает переменная q;
при этом переменная "symbol" возвращается алгоритмом арифметического декодирования; и
в котором арифметический декодер сконфигурирован для получения значений матрицы старших битов декодируемого в настоящее время кортежа из 2-х спектральных значений из возвращаемого значения алгоритма арифметического декодирования.
10. Аудиодекодер (200; 800) для предоставления декодированной аудиоинформации (212; 812) на основе закодированной аудиоинформации (210; 810), причем аудиодекодер содержит:
арифметический декодер (230; 820) для предоставления множества декодированных спектральных значений (232; 822) на основе арифметически закодированного представления (222; 821) спектральных значений, содержащихся в закодированной аудиоинформации (210; 810); и
преобразователь (260; 830) из частотной области во временную область для предоставления аудиопредставления (262; 812) временной области с использованием декодированных спектральных значений (232; 822), чтобы получить декодированную аудиоинформацию (212; 812);
при этом арифметический декодер (232; 820) сконфигурирован для выбора правила (297;  ) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (c) контекста;
) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (c) контекста;
при этом арифметический декодер (230; 820) сконфигурирован для определения числового текущего значения (c) контекста в зависимости от множества ранее декодированных спектральных значений;
при этом арифметический декодер сконфигурирован для оценки хэш-таблицы 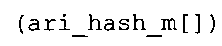 , записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, чтобы выбрать правило отображения,
, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, чтобы выбрать правило отображения,
при этом хэш-таблица 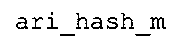 задается, как приведено ниже
задается, как приведено ниже




при этом арифметический декодер сконфигурирован для оценки хэш-таблицы 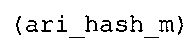 , чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы
, чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы 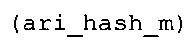 , или определить интервал, описанный записями хэш-таблицы
, или определить интервал, описанный записями хэш-таблицы 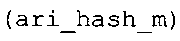 , в котором лежит числовое текущее значение контекста, и получить индексное значение (pki) правила отображения, описывающее выбранное правило отображения, в зависимости от результата оценки;
, в котором лежит числовое текущее значение контекста, и получить индексное значение (pki) правила отображения, описывающее выбранное правило отображения, в зависимости от результата оценки;
при этом индексное значение правила отображения отдельно ассоциируется с числовым значением контекста, являющимся значимым значением состояния.
11. Аудиодекодер по п. 10,
в котором арифметический декодер сконфигурирован для сравнения числового текущего значения (с) контекста или масштабированной версии (s) числового текущего значения контекста с последовательностью численно упорядоченных записей 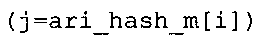 или подзаписей хэш-таблицы
или подзаписей хэш-таблицы 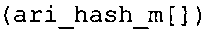 , для итерационного получения индексного значения
, для итерационного получения индексного значения 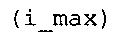 хэш-таблицы записи
хэш-таблицы записи 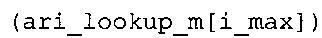 таблицы, так что числовое текущее значение (с) контекста лежит в интервале, заданном полученной записью
таблицы, так что числовое текущее значение (с) контекста лежит в интервале, заданном полученной записью 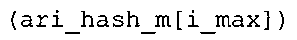 хэш-таблицы, обозначенной полученным индексным значением хэш-таблицы, и соседней записью
хэш-таблицы, обозначенной полученным индексным значением хэш-таблицы, и соседней записью 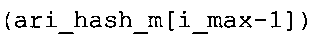 хэш-таблицы, и
хэш-таблицы, и
в котором арифметический декодер сконфигурирован для определения следующей записи последовательности записей хэш-таблицы 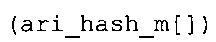 в зависимости от результата сравнения между числовым текущим значением (с) контекста, или масштабированной версией (s) числового текущего значения контекста, и текущей записью или подзаписью
в зависимости от результата сравнения между числовым текущим значением (с) контекста, или масштабированной версией (s) числового текущего значения контекста, и текущей записью или подзаписью 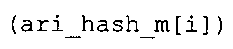 хэш-таблицы.
хэш-таблицы.
12. Аудиодекодер по п. 11,
в котором арифметический декодер сконфигурирован для выбора правила отображения, заданного второй подзаписью 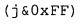 хэш-таблицы
хэш-таблицы 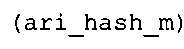 , обозначенной текущим индексным значением i хэш-таблицы, если найдено, что числовое текущее значение (c) контекста или его масштабированная версия (s) равно первой подзаписи (j>>8) хэш-таблицы
, обозначенной текущим индексным значением i хэш-таблицы, если найдено, что числовое текущее значение (c) контекста или его масштабированная версия (s) равно первой подзаписи (j>>8) хэш-таблицы 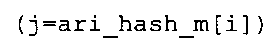 , обозначенной текущим индексным значением i хэш-таблицы.
, обозначенной текущим индексным значением i хэш-таблицы.
13. Аудиодекодер по п. 11,
в котором арифметический декодер сконфигурирован для выбора правила отображения, заданного записью или подзаписью  таблицы
таблицы 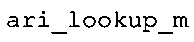 отображения, если не найдено, что числовое текущее значение контекста равно подзаписи хэш-таблицы
отображения, если не найдено, что числовое текущее значение контекста равно подзаписи хэш-таблицы 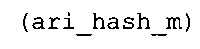 , в котором арифметический декодер сконфигурирован для выбора записи или подзаписи таблицы отображения в зависимости от итерационно полученного индексного значения
, в котором арифметический декодер сконфигурирован для выбора записи или подзаписи таблицы отображения в зависимости от итерационно полученного индексного значения 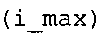 хэш-таблицы.
хэш-таблицы.
14. Аудиодекодер по п. 10, в котором арифметический декодер сконфигурирован для выборочного предоставления индексного значения правила отображения, заданного записью хэш-таблицы, обозначенной текущим индексным значением хэш-таблицы, если найдено, что числовое текущее значение (c) контекста равно значению (j>>8), заданному записью 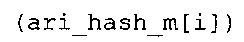 хэш-таблицы, обозначенной текущим индексным значением i хэш-таблицы.
хэш-таблицы, обозначенной текущим индексным значением i хэш-таблицы.
15. Способ для предоставления декодированной аудиоинформации (212; 812) на основе закодированной аудиоинформации (210; 810), причем способ содержит этапы, на которых:
предоставляют множество декодированных спектральных значений (232; 822) на основе арифметически закодированного представления (222; 821) спектральных значений, содержащихся в закодированной аудиоинформации (210; 810); и
предоставляют аудиопредставление (262; 812) временной области с использованием декодированных спектральных значений (232; 822), чтобы получить декодированную аудиоинформацию (212; 812);
при этом предоставление упомянутого множества декодированных спектральных значений содержит выбор правила (297;  ) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (c) контекста;
) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (c) контекста;
при этом числовое текущее значение (с) контекста определяется в зависимости от множества ранее декодированных спектральных значений;
при этом хэш-таблица  , записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, оценивается для того, чтобы выбрать правило отображения,
, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, оценивается для того, чтобы выбрать правило отображения,
при этом хэш-таблица оценивается с использованием алгоритма:

при этом с обозначает переменную, представляющую числовое текущее значение контекста или его масштабированную версию;
при этом i является переменной, описывающей текущее индексное значение хэш-таблицы;
при этом 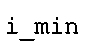 является переменной, инициализируемой для обозначения индексного значения хэш-таблицы первой записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
является переменной, инициализируемой для обозначения индексного значения хэш-таблицы первой записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
при этом условие "c<(j>>8)" задает, что значение состояния, описанное переменной с, меньше значения состояния, описанного записью 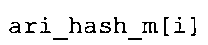 таблицы;
таблицы;
при этом  описывает индексное значение правила отображения, описанное записью
описывает индексное значение правила отображения, описанное записью 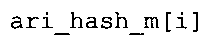 таблицы;
таблицы;
при этом является переменной, инициализируемой для обозначения индексного значения хэш-таблицы последней записи хэш-таблицы и выборочно обновляемой в зависимости от сравнения между с и (j>>8);
при этом условие "c>(j>>8)" задает, что значение состояния, описанное переменной с, больше значения состояния, описанного записью 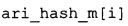 таблицы;
таблицы;
при этом j является переменной;
при этом возвращаемое значение обозначает индекс pki вероятностной модели и является индексным значением правила отображения;
при этом 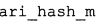 обозначает хэш-таблицу;
обозначает хэш-таблицу;
при этом  обозначает запись хэш-таблицы , имеющую индексное значение i хэш-таблицы;
обозначает запись хэш-таблицы , имеющую индексное значение i хэш-таблицы;
при этом 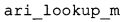 обозначает таблицу отображения;
обозначает таблицу отображения;
при этом  обозначает запись таблицы отображения, имеющую индексное значение
обозначает запись таблицы отображения, имеющую индексное значение 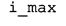 таблицы отображения;
таблицы отображения;
при этом хэш-таблица  задается, как приведено ниже
задается, как приведено ниже




и
при этом таблица 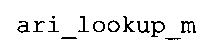 отображения задается, как приведено ниже
отображения задается, как приведено ниже

и
при этом индексное значение правила отображения отдельно ассоциируется с числовым значением контекста, являющимся значимым значением состояния.
16. Способ для предоставления декодированной аудиоинформации (212; 812) на основе закодированной аудиоинформации (210; 810), причем способ содержит этапы, на которых:
предоставляют множество декодированных спектральных значений (232; 822) на основе арифметически закодированного представления (222; 821) спектральных значений, содержащихся в закодированной аудиоинформации (210; 810); и
предоставляют аудиопредставление (262; 812) временной области с использованием декодированных спектральных значений (232; 822), чтобы получить декодированную аудиоинформацию (212; 812);
при этом предоставление множества декодированных спектральных значений содержит выбор правила (297; 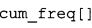 ) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (с) контекста;
) отображения, описывающего отображение кодового значения (значения) арифметически закодированного представления спектральных значений, представляющего одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в закодированной форме, на символьный код (символ), представляющий одно или более спектральных значений или матрицу старших битов одного или более спектральных значений в декодированной форме, в зависимости от состояния (s) контекста, описанного числовым текущим значением (с) контекста;
при этом числовое текущее значение (с) контекста определяется в зависимости от множества ранее декодированных спектральных значений;
при этом хэш-таблица 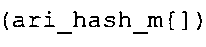 , записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, оценивается для того, чтобы выбрать правило отображения,
, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, оценивается для того, чтобы выбрать правило отображения,
при этом хэш-таблица  задается, как приведено ниже
задается, как приведено ниже




при этом хэш-таблица 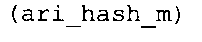 оценивается для определения, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы
оценивается для определения, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы 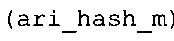 , или для определения интервала, описанного записями хэш-таблицы
, или для определения интервала, описанного записями хэш-таблицы 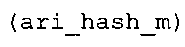 , в котором лежит числовое текущее значение контекста, и
, в котором лежит числовое текущее значение контекста, и
при этом индексное значение (pki) правила отображения, описывающее выбранное правило отображения, получается в зависимости от результата оценки;
при этом индексное значение правила отображения отдельно ассоциируется с числовым значением контекста, являющимся значимым значением состояния.
17. Аудиокодер (100; 700) для предоставления закодированной аудиоинформации (112; 712) на основе входной аудиоинформации (110; 710), причем аудиокодер содержит:
уплотняющий энергию преобразователь (130; 720) из временной области в частотную область для предоставления аудиопредставления (132; 722) частотной области на основе представления (110; 710) временной области входной аудиоинформации, так что аудиопредставление (132; 722) частотной области содержит набор спектральных значений; и
арифметический кодер (170; 730), сконфигурированный для кодирования одного или более спектральных значений (а) или его предварительно обработанной версии с использованием кодового слова 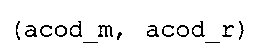 переменной длины, при этом арифметический кодер (170) сконфигурирован для отображения одного или более спектральных значений (а), или значения (m) матрицы старших битов одного или более спектральных значений (а), на кодовое значение
переменной длины, при этом арифметический кодер (170) сконфигурирован для отображения одного или более спектральных значений (а), или значения (m) матрицы старших битов одного или более спектральных значений (а), на кодовое значение 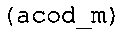 ,
,
при этом арифметический кодер сконфигурирован для выбора правила отображения, описывающего отображение упомянутого одного или более спектральных значений, или матрицы старших битов упомянутого одного или более спектральных значений, на кодовое значение в зависимости от состояния (s) контекста, описанного числовым текущим значением (с) контекста; и
при этом арифметический кодер сконфигурирован для определения числового текущего значения (с) контекста в зависимости от множества ранее закодированных спектральных значений; и
при этом арифметический кодер сконфигурирован для оценки хэш-таблицы, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, чтобы выбрать правило отображения,
при этом хэш-таблица 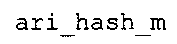 задается, как приведено ниже
задается, как приведено ниже




при этом арифметический кодер сконфигурирован для оценки хэш-таблицы 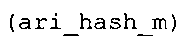 , чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы
, чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы 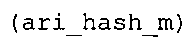 , или определить интервал, описанный записями хэш-таблицы
, или определить интервал, описанный записями хэш-таблицы 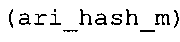 , в котором лежит числовое текущее значение контекста, и получить индексное значение (pki) правила отображения, описывающее выбранное правило отображения, в зависимости от результата оценки;
, в котором лежит числовое текущее значение контекста, и получить индексное значение (pki) правила отображения, описывающее выбранное правило отображения, в зависимости от результата оценки;
при этом индексное значение правила отображения отдельно ассоциируется с числовым значением контекста, являющимся значимым значением состояния.
18. Способ для предоставления закодированной аудиоинформации (112; 712) на основе входной аудиоинформации (110; 710), причем способ содержит этапы, на которых:
предоставляют аудиопредставление (132; 722) частотной области на основе представления (110; 710) временной области входной аудиоинформации с использованием уплотняющего энергию преобразования из временной области в частотную область, так что аудиопредставление (132; 722) частотной области содержит набор спектральных значений; и
арифметически кодируют одно или более спектральных значений (а) или его предварительно обработанную версию с использованием кодового слова 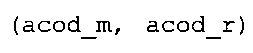 переменной длины, при этом одно или более спектральных значений (а) или значение (m) матрицы старших битов одного или более спектральных значений (а) отображается на кодовое значение
переменной длины, при этом одно или более спектральных значений (а) или значение (m) матрицы старших битов одного или более спектральных значений (а) отображается на кодовое значение 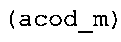 ,
,
при этом правило отображения, описывающее отображение одного или более спектральных значений или матрицы старших битов одного или более спектральных значений на кодовое значение, выбирается в зависимости от состояния (s) контекста, описанного числовым текущим значением (с) контекста; и
при этом числовое текущее значение (с) контекста определяется в зависимости от множества ранее закодированных спектральных значений; и
при этом хэш-таблица, записи которой задают как значимые значения состояния среди числовых значений контекста, так и границы интервалов незначимых значений состояния среди числовых значений контекста, оценивается для того, чтобы выбрать правило отображения,
при этом хэш-таблица 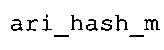 задается, как приведено ниже
задается, как приведено ниже




и
при этом хэш-таблица 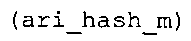 оценивается, чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы
оценивается, чтобы определить, идентично ли числовое текущее значение контекста значению контекста таблицы, описанному записью хэш-таблицы 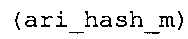 , или определить интервал, описанный записями хэш-таблицы
, или определить интервал, описанный записями хэш-таблицы 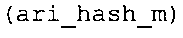 , в котором лежит числовое текущее значение контекста, и при этом индексное значение (pki) правила отображения, описывающее выбранное правило отображения, получается в зависимости от результата оценки;
, в котором лежит числовое текущее значение контекста, и при этом индексное значение (pki) правила отображения, описывающее выбранное правило отображения, получается в зависимости от результата оценки;
при этом индексное значение правила отображения отдельно ассоциируется с числовым значением контекста, являющимся значимым значением состояния.
19. Считываемый компьютером носитель, содержащий компьютерную программу для выполнения способа по п. 16 или 18, когда компьютерная программа выполняется на компьютере.
| БЕСПЛАМЕННЫЙ НАГРЕВАТЕЛЬ УГЛЕВОДОРОДНОГО ГАЗА | 2017 |
|
RU2739736C2 |
| СЖАТИЕ И РАСШИРЕНИЕ ДАННЫХ ЗВУКОВОГО СИГНАЛА | 1997 |
|
RU2178618C2 |
| WO 2009086918 A1, 16.07.2009 | |||
| КВАНТОВАНИЕ ОСНОВНОГО ТОНА ДЛЯ РАСПРЕДЕЛЕННОГО РАСПОЗНАВАНИЯ РЕЧИ | 2004 |
|
RU2331932C2 |
| US 2010082717 A1, 01.04.2010 | |||
| US 2007112565 A1, 17.05.2008 | |||
| WO 2009133856 A1, 05.11.2009 | |||
| US 2007192087 A1, 16.08.2007. | |||

