ОБЛАСТЬ ТЕХНИКИ
Изобретение в целом относится к способу и устройству для кодирования информации, имеющей отношение к кодированию видео.
УРОВЕНЬ ТЕХНИКИ
Кодирование видео может быть выполнено в режиме интра-кодирования и/или в режиме интер-кодирования. Режим интра-кодирования использует избыточность в пределах видеокадра, и режим интер-кодирования использует избыточность между видеокадрами. В режиме интер-кодирования предсказания яркости/цветности пикселей получаются из уже кодированных/декодированных изображений, называемых опорными изображениями. В зависимости от количества опорных изображений, используемых для предсказания, режим интер-кодирования подразделяется на режим предсказания по одному изображению (или однонаправленный режим), режим предсказания по двум изображениям (режим B) и, возможно, режим предсказания по трем и т.д. изображениям, где, соответственно, используются 1, 2 и 3 опорных изображения. В этом документе эти разные режимы, то есть предсказание по одному, по двум и т.д. изображениям, будут упоминаться как "опорные режимы".
Стандарт усовершенствованного кодирования видео (Advanced Video Coding (AVC)), который также известен как H.264 и MPEG4, часть 10, является современным стандартом для кодирования двухмерного (2D) видео от сектора стандартизации Международного союза по телекоммуникациям (ITU-T) и Группы экспертов по кинематографии (MPEG). Кодек AVC представляет собой гибридный кодек, который использует устранение избыточности между кадрами и в пределах одного кадра.
В стандарте AVC индикаторы релевантных опорных изображений помещены по порядку в два опорных списка. Индикаторы обозначены опорными индексами и пронумерованы от 0 до N, например, (0, 1,..., N). Первый список, список 0 (L0), прежде всего управляет прошлыми опорными изображениями, то есть опорными изображениями, предшествующими текущему изображению во времени, и второй список, список 1 (L1), обычно управляет будущими опорными изображениями, то есть опорными изображениями, последующими за текущим изображением во времени. Для кодирования видео с низкой задержкой список L1 также может управлять прошлыми опорными изображениями. Каждый список может содержать индексы до 15 опорных изображений, то есть N=14.
Кроме того, в стандарте AVC, индикатор или индекс опорного режима, определяющий выбор одного из списков опорных изображений (например, для предсказания по одному изображению) или обоих списков опорных изображений (например, для предсказания по двум изображениям), кодируется вместе со структурой разделов в режиме макроблоков (MB)/режиме субмакроблоков, в то время как индикаторы или индексы опорного режима, определяющие выбранные опорные изображения в соответственных списках, кодируются как отдельные синтаксические элементы. "Структура раздела" относится к разделам, таким как, например, 16×16, 16×8 или 8×16 макроблока 16×16. Раздел, например 16×16, обычно ассоциирован с одним вектором движения (MV) и одним опорным индексом, когда используется предсказание по одному изображению, и двум векторам движения и двум опорным индексам, когда используется предсказание по двум изображениям. Вектор движения имеет горизонтальный компонент MVx и вертикальный компонент MVy, которые описывают, как пиксели текущего раздела получаются из соответствующего опорного изображения, например Ipred (x, y) =Iref(x-MVx, y-MVy).
Количество опорных изображений, ассоциированных с изображением или разделом, зависит от опорного режима, ассоциированного с этим же разделом, то есть является ли режим предсказанием по одному изображению или предсказанием по двум изображениям и т.д. При декодировании опорной информации в декодере и индекс опорного режима, и один или более индексов опорных изображений, ассоциированных с изображением или разделом, должны быть правильно декодированы, чтобы декодер мог правильно декодировать изображение или раздел. Неправильное декодирование либо индекса опорного режима, либо одного или более индексов опорных изображений может привести к ошибочной интерпретации опорной информации.
Текущие способы кодирования опорной информации, такие как способ описанного выше стандарта AVC, требуют относительно большого количества битов, чтобы передать опорную информацию, ассоциированную с каждым блоком. Это неэффективно с точки зрения эффективности кодирования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Было бы желательно сделать возможной улучшенную эффективность кодирования для опорной информации, то есть информации, идентифицирующей одно или более опорных изображений, используемых для предсказания текущего кадра. Задача изобретения состоит в том, чтобы сделать возможной улучшенную эффективность кодирования для опорной информации. Кроме того, задача изобретения состоит в том, чтобы обеспечить способ и устройство для улучшенного кодирования опорной информации. Эти задачи могут быть решены посредством способа и устройства в соответствии с независимыми пунктами приложенной формулы изобретения. Необязательные варианты осуществления определены зависимыми пунктами формулы изобретения. Описанные ниже предсказание, кодирование и декодирование могут быть выполнены в пределах одного объекта или узла или в разных объектах или узлах.
Согласно первому аспекту обеспечен способ в объекте декодирования видео. Способ содержит этап, на котором получают одиночный синтаксический элемент, ассоциированный с закодированным блоком Be. Способ также содержит этапы, на которых идентифицируют опорный режим и одно или более опорных изображений на основе полученного синтаксического элемента и декодируют блок Be на основе идентифицированного опорного режима и одного или более опорных изображений и тем самым предоставляют декодированный блок B пикселей.
Согласно второму аспекту обеспечено устройство в объекте декодирования видео. Устройство содержит функциональный блок, который выполнен с возможностью получать одиночный синтаксический элемент, ассоциированные с закодированным блоком Be. Устройство также содержит функциональный блок, который выполнен с возможностью идентифицировать опорный режим и одно или более опорных изображений на основе полученного синтаксического элемента. Устройство также содержит функциональный блок, который выполнен с возможностью декодировать блок Be на основе идентифицированного опорного режима и одного или более опорных изображений и тем самым предоставлять декодированный блок B пикселей.
Согласно третьему аспекту предоставлен способ в объекте кодирования видео сигнала. Способ содержит этап, на котором кодируют блок B пикселей с использованием опорного режима и одного или более опорных изображений и тем самым предоставляют закодированный блок Be. Способ дополнительно содержит этапы, на которых получают одиночный синтаксический элемент, идентифицирующий опорный режим и одно или более опорных изображений и предоставляют одиночный синтаксический элемент декодеру блока Be.
Согласно четвертому аспекту представлено устройство в объекте кодирования видео. Устройство содержит функциональный блок, который выполнен с возможностью кодировать блок B пикселей с использованием опорного режима и одного или более опорных изображений и тем самым предоставлять закодированный блок Be. Устройство дополнительно содержит функциональный блок, который выполнен с возможностью получать одиночный синтаксический элемент, идентифицирующий опорный режим и одно или более опорных изображений. Устройство также содержит функциональный блок, который выполнен с возможностью предоставлять одиночный синтаксический элемент декодеру блока Be.
Описанные выше способы и устройства могут использоваться для улучшения эффективности кодирования. Эффективность кодирования может быть улучшена благодаря использованию меньшего количества битов для идентификации одного или более опорных изображений, используемых для предсказания текущего кадра. Упомянутые выше способы и устройства также могут улучшить устойчивость к ошибкам. Кроме того, посредством привязки опорной информации для формирования одиночного синтаксического элемента становится выполнимым легкое манипулирование числами опорных индексов. Кроме того, описанное выше использование синтаксического элемента делает возможным использование того, что некоторые комбинации опорного индекса и опорного режима более вероятны, чем другие, и делает возможным эффективное кодирование этих комбинаций. Например, более короткие кодовые слова могут быть назначены более вероятным комбинациям опорного индекса и опорного режима.
Описанные выше способы и устройства могут быть реализованы в различных вариантах осуществления. В некоторых вариантах осуществления идентификация опорного режима и одного или более опорных изображений основана на предопределенном отображении между синтаксическим элементом и опорным режимом и одним или более конкретными опорными изображениями. В некоторых вариантах осуществления одиночный синтаксический элемент представляет запись в первых предопределенных опорных списках, которые могут содержать одну или более записей. Запись может идентифицировать множество опорных изображений или одиночное опорное изображение и также может идентифицировать опорный режим.
Одиночный синтаксический элемент также может представлять опорный режим и запись во втором предопределенном опорном списке, который может содержать одну или более записей, идентифицирующих одиночное опорное изображение, соответственно.
Записи в списках могут быть идентифицированы индексами списка. Кроме того, количество битов, представляющих полученный синтаксический элемент, может быть связано с вероятностью конкретных значений синтаксического элемента.
В некоторых вариантах осуществления предсказание опорной информации может быть выполнено для блока Be (или блока B в объекте кодирования) на основе одиночных синтаксических элементов, ассоциированных с соседними блоками блока Be (или B). Кроме того, в некоторых вариантах осуществления могут быть идентифицированы подобласти блока, ассоциированного с множественным предсказанием, для которых подобласти, соответственные соответствующие области опорных блоков множественного предсказания, имеют относительно низкую корреляцию между собой, и тогда для идентифицированных подобластей может использоваться альтернативное предсказание вместо множественного предсказания.
Описанные выше варианты осуществления главным образом описаны с точки зрения способа. Однако подразумевается, что приведенное выше описание также охватывает варианты осуществления устройств, выполненных с возможностью выполнять описанные выше признаки. Различные функции описанных выше иллюстративных вариантов осуществления могут по-разному сочетаться согласно необходимости, требованиям или предпочтению.
Согласно еще одному аспекту предоставлена компьютерная программа, содержащая машиночитаемые коды, которые при их исполнении в одном или более блоках обработки заставляют любое из описанных выше устройств выполнять соответствующую процедуру в соответствии с одним из описанных выше способов.
Согласно еще одному аспекту предоставлен компьютерный программный продукт, который содержит описанную выше компьютерную программу.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Теперь изобретение будет описано более подробно посредством иллюстративных вариантов осуществления и со ссылкой на сопроводительные чертежи, на которых:
Фигура 1 - схематическое изображение, иллюстрирующее преобразование из представления опорной информации в соответствии с предшествующей областью техники в представление опорной информации в соответствии с примерным вариантом осуществления.
Фигура 2 - таблица, показывающая различия между представлением опорного индекса стандарта AVC и представлением опорного индекса в соответствии с примерным вариантом осуществления.
Фигура 3 - схематическое изображение, иллюстрирующее назначение индикаторов опорной информации в соответствии с примерным вариантом осуществления.
Фигура 4 - блок-схема последовательности операций, иллюстрирующая процедуру декодирования совместно закодированной информации, относящейся к опорному режиму и одному или более опорным изображениям, в объекте декодирования видео в соответствии с примерным вариантом осуществления.
Фигура 5 - блок-схема, иллюстрирующая устройство, выполненное с возможностью декодировать совместно закодированную информацию, относящуюся к опорному режиму и одному или более опорным изображениям, в объекте декодирования видео в соответствии с примерным вариантом осуществления.
Фигура 6 - блок-схема последовательности операций, иллюстрирующая процедуру совместного кодирования информации, относящейся к опорному режиму и одному или более опорным изображениям, в объекте кодирования видео в соответствии с примерным вариантом осуществления.
Фигура 7 - блок-схема, иллюстрирующая устройство, выполненное с возможностью выполнять совместное кодирование информации, относящейся к опорному режиму и одному или более опорным изображениям, в объекте кодирования видео в соответствии с примерным вариантом осуществления.
Фигура 8 - схематическое изображение, иллюстрирующее устройство в объекте кодирования/декодирования видео в соответствии с примерным вариантом осуществления.
Фигуры 9 и 10 - схематические изображения, иллюстрирующие определение частоты возникновения различных комбинаций опорного режима и одного или более опорных изображений, ассоциированных с соседними блоками текущего блока, в соответствии с примерным вариантом осуществления.
Фигура 11 - схематическое изображение, иллюстрирующее назначение индикаторов (кодовых слов) разным индексным символам в соответствии с предшествующей областью техники.
Фигура 12 - схематическое изображение, иллюстрирующее назначение индикаторов (кодовых слов) в соответствии с примерным вариантом осуществления.
Фигура 13 - схематическое изображение, иллюстрирующее разделение на основе неявной информации в соответствии с примерным вариантом осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
В нескольких словах, для интер-кодирования и декодирования с предсказанием обеспечена новая процедура для представления и передачи опорной информации, то есть опорного режима (режимов) и опорного изображения (изображений). Процедура может упоминаться как сигнализация опорного индекса или сигнализация индикатора опорной информации (RIS).
В этом документе термин "соседние блоки блока X" используется для обозначения блоков, которые являются соседями блока X, то есть расположены смежно с блоком X или около блока X. Кроме того, в этом документе термин "блок" используется для обозначения блока пикселей. Термин "опорное изображение" или "опорный блок" используются для обозначения ранее закодированного/декодированного изображения, блока или области изображения, которые используются в качестве опорной информации для предсказания.
При использовании процедуры RIS вместо, например, кодирования индикатора опорного режима в тесной связи с индикатором структуры раздела и кодирования индикаторов опорных изображений отдельно, например, как в стандарте AVC, индикатор опорного режима и индикатор (индикаторы) опорного изображения (изображений), ассоциированные с закодированным блоком, "связаны вместе в одном месте", то есть закодированы совместно. Совместное кодирование индикаторов опорного режима и опорного изображения (изображений), то есть опорной информации, приводит к тому, что одиночный синтаксический элемент или индикатор представляет всю необходимую информацию об опорном режиме (режимах) и опорном изображении (изображениях), чтобы декодировать закодированный блок удовлетворительным образом. Таким образом, когда этот одиночный синтаксический элемент задан для закодированного блока, декодер должен быть в состоянии идентифицировать опорное изображение (изображения), требуемое для декодирования блока. "Синтаксический элемент" также может быть обозначен, например, как "синтаксический блок", "блок совместной индикации" или "блок совместной идентификации".
Один способ описания процедуры RIS состоит в том, чтобы описать "преобразование" или отображение из традиционного представления, такого как, например, представление стандарта AVC опорной информации с использованием двух отдельных списков, в иллюстративное представление опорной информации в соответствии с процедурой RIS. Такое преобразование в представление процедуры RIS в основном может быть сделано в три этапа, как проиллюстрировано на фигуре 1.
Первый этап 102 может формировать один одиночный список опорных индексов из нескольких списков индексов. Например, вместо того, чтобы управлять двумя списками опорных индексов, как в стандарте AVC, все индексы опорных изображений могут быть отсортированы в определенном порядке в одиночном объединенном списке в качестве альтернативы или дополнения к двум спискам стандарта AVC. Это проиллюстрировано на фигуре 1, где списки L0 и L1 индексов опорных изображений объединяются или мультиплексируются в новый список LRIS чередованным образом. Кроме того, на втором этапе 104 номера индексов могут быть переназначены соответствующим образом, чтобы они следовали последовательно, то есть 0-5 в новом списке LRIS.
Номера индексов или записи в списке LRIS после этапа 104 представляют информацию и относительно опорного режима (обратное или прямое предсказание по одному изображению), так и относительно опорного изображения. Индекс для записи в списке LRIS может быть обозначен, например, как "индекс RIS" или "параметр индекса". Номера индексов RIS 0-5 после этапа 104 в этом примере представляют предсказание по одному изображению из четырех прошлых изображений (первоначально в списке L0=(0,1,2,3)) и два будущих изображения (первоначально в списке L1=(0,1)).
Кроме того, одна или более записей списка, представляющих предсказание по двум изображениям, могут быть добавлены в список LRIS, например, посредством вставки или присоединения. Таким образом, индексы RIS, являющиеся показателем записей, представляющих предсказание по двум изображениям, указывают не на одиночное опорное изображение, а на два опорных изображения. Таким образом, индекс RIS может идентифицировать комбинацию опорного режима и одного или более опорных изображений.
Затем на заключительном этапе 106 записи, относящиеся к режиму предсказания по двум изображениям, в котором два опорных изображения используются для предсказания, могут быть последовательно присоединены к списку LRIS и указаны или представлены индексами RIS, пример, запись с индексом RIS 7 может оповещать или подразумевать, что текущее изображение использует изображение с номером номер 0 и изображение с номером номер 1 как опорные для предсказания по двум изображениям. Таким образом, эта информация свойственна для индекса RIS 7. Номер индекса 8 может аналогичным образом подразумевать, что текущее изображение использует изображение с номером 0 и изображение с номером 2 как опорные для предсказания по двум изображениям. Аналогично список LRIS может быть расширен далее с помощью записей, представляющих предсказание по трем изображениям, идентифицирующих три опорных изображения, и т.д.
В качестве альтернативы этапы 104 и 106 могут быть выполнены в обратном порядке таким образом, что сначала добавляются, например вставляются или присоединяются, записи, относящиеся к режиму предсказания по двум изображениям, и затем индексы переназначаются соответствующим образом. Как описано ранее, записи, относящиеся к режиму предсказания по двум изображениям, также могут быть вставлены, например, между записями, относящимися к предсказанию по одному изображению, что потребовало бы, чтобы переназначение индексов выполнялось после вставки, как дополнение или альтернатива для этапа 104. В этом примере отображение представлено одиночным опорным списком, индексы разных записей которого представляют опорный режим и одно или более опорных изображений. Следует отметить, что это лишь пример варианта, и что отображение может включать в себя несколько этапов, и что никакой явный список или запись иллюстрированного типа не являются необходимыми для выполнения отображения.
Пример различия между представлением опорного индекса AVC и представлением индекса RIS в соответствии с примерным вариантом осуществления показан в таблице на фигуре 2. В этом примере предполагается, что имеется четыре опорных изображения, доступных для кодирования текущего изображения, из которых два опорных изображения являются прошлыми опорными изображениями, и два - будущими опорными изображениями. В этом иллюстративном представлении RIS индексы 0, 1, 3 и 4 установлены для указания предсказания по одному изображению относительно соответственного одного из четырех опорных изображений. Индексы 2 и 5 установлены для указания предсказания по двум изображениям относительно соответственной пары из четырех опорных изображений. Следует отметить, что сигнализирование стандарта AVC об опорных индексах также содержит информацию, относящуюся к разделам, поскольку эта информация кодируется вместе с индексом опорного режима, например "INTER_16×16_10". Однако это не показано на фигуре 2.
В примере, показанном в таблице на фигуре 2, некоторые из индексов RIS, указывающих или представляющих предсказание по двум изображениям, помещены непосредственно после "ближайших" индексов RIS предсказания по одному изображению, то есть чередованы с индексами, представляющими предсказание по одному изображению. Это представление индексов RIS далее проиллюстрировано на фигуре 3, которая показывает так называемую иерархическую группу изображений 7B (BGOP). На этой фигуре так называемый "текущий кадр", то есть кадр, который должен быть закодирован, является кадром 3 в группе 7B GOP. Индексы RIS, показанные на фигуре 3, соответствуют индексам RIS 0-7 в таблице на фигуре 2. Альтернативное представление RIS может позволить индексам RIS 0-3 указывать предсказание по одному изображению, а следующим индексам RIS указывать предсказание по двум изображениям, как в примере, проиллюстрированном на фигуре 1.
Способы определения значения индекса RIS или параметра RIS не ограничены примерами, данными в этом документе. Например, может быть определена математическая формула для интерпретации значения индекса RIS, например, функция с 2 переменными f(RIS_index, current_frame_num), который возвращает идентификацию двух индексов опорных изображений для индекса RIS предсказания по двум изображениям и одного индекса опорного изображения для однонаправленного индекса RIS и т.д. В одном примере current_frame_num соответствует номеру кадра в группе BGOP изображений 7B, где 0 - первый кадр в порядке отображения, и 8 - последний кадр в группе BGOP. В другом примере индекс RIS всегда назначается с использованием формулы:
Вперед: refidx0
Диапазон: [0~L0_len-1]
Назад: L0_len+refidx1
Диапазон: [L0_len~L0_len+L1_len-1]
По двум изображениям: (L0_len+L1_len)+refidx0*L1_len+refidx1
Диапазон: [L0_len+L1_len~L0_len+L1_len+L0_len*L1_len-1]
Где refidx0 и refidx1 - индекс в опорных списках L0 и L1, соответственно. L0_len и L1_len - длина списка L0 и L1, соответственно.
В качестве альтернативы может использоваться таблица для установления соответствия индекса RIS с двумя соответствующими однонаправленными индексами в случае предсказания по двум изображениям и одним однонаправленным индексом для случая предсказания по оному изображению. Выбор способа зависит, например, от ограничений аппаратных средств и программного обеспечения.
Однако, независимо от того, какой способ используется для получения синтаксического элемента, способ должен быть известен и кодеру, и декодеру, с тем чтобы кодер мог получить и предоставить корректный синтаксический элемент, и декодер мог правильно интерпретировать синтаксический элемент и тем самым идентифицировать опорную информацию, необходимую для декодирования закодированного блока или рассматриваемого кадра.
Индекс RIS может применяться к разным уровням кодирования видео, например, к уровню кадров, уровню больших макроблоков, уровню макроблоков или уровню субмакроблоков.
ИЛЛЮСТРАТИВНАЯ ПРОЦЕДУРА, ФИГУРА 4, ДЕКОДИРОВАНИЕ
Теперь со ссылкой на фигуру 4 будет описан вариант осуществления части декодирования процедуры передачи опорной информации. Процедура может выполняться в объекте декодирования видео, который может представлять собой видеодекодер или объектом, содержащим дополнительные функциональные блоки в дополнение к видеодекодеру. Первоначально одиночный синтаксический элемент, ассоциированный с закодированным блоком Be, получается на этапе 402. Одиночный синтаксический элемент может представлять собой блок, например символ, в "битовом потоке", то есть в закодированном представлении, например последовательности видеокадров, или представлять собой блок, который декодируется из битового потока. Синтаксический элемент представляет собой один или более битов, представляющих число, которое соответствует опорной информации, такой как, например, индекс RIS. Как правило, для представления индексов RIS, которые встречаются относительно часто, используется меньшее количество битов по сравнению с количеством битов, используемых для представления индексов RIS, которые встречаются менее часто. Синтаксический элемент декодируется из битового потока для получения числа, например индекса RIS, который оно представляет. Декодирование может быть выполнено, например, согласно кодированию с переменной длиной (VIC) или арифметическому кодированию, такому как контекстно-адаптивное двоичное арифметическое кодирование (CABAC).
Затем на этапе 404 опорный режим и одно или более опорных изображений, которые будут использоваться при декодировании блока Be, идентифицируются на основе полученного синтаксического элемента. Идентифицированный опорный режим и одно или более опорных изображений соответствуют режиму и опорным изображениям, используемым при кодировании блока в кодере. Идентификация может включать в себя, например, обратное отображение, дешифрирование или "декодирование" синтаксического элемента с использованием таблицы отображения, опорного списка или другой предопределенной информации или функции, при помощи которых опорный режим и одно или более опорных изображений могут быть идентифицированы по заданному синтаксическому элементу. Далее, когда опорный режим и одно или более необходимых опорных изображений идентифицированы, закодированный блок Be, который, как предполагается, получен с использованием общепринятых способов, декодируется на этапе 406.
Одиночный синтаксический элемент может представлять собой индикатор или индекс, например, обозначенный индекс RIS, записи в опорном списке, который может содержать множество записей, каждая из которых представляет или идентифицирует один или более опорных режимов и одно или более опорных изображений. В качестве альтернативы синтаксический элемент представляет собой кодовое слово, соответствующее записи в таблице поиска. Таблица поиска может привязывать кодовое слово, например, к опорному режиму и одной или более записям в одном или более опорных списках, например, списках L0 и L1 в стандарте AVC. Опорный режим может определять, какой одиночный опорный список или несколько опорных списков должны использоваться при декодировании блока.
ИЛЛЮСТРАТИВНОЕ УСТРОЙСТВО, ФИГУРА 5, ДЕКОДИРОВАНИЕ
Ниже со ссылкой на фигуру 5 будет описано иллюстративное устройство 500, выполненное с возможностью предоставлять возможность выполнения описанной выше процедуры декодирования. Устройство проиллюстрировано как располагаемое в объекте 501 декодирования видео, которое может представлять собой видеодекодер или объект, содержащий дополнительные функциональные блоки в дополнение к видеодекодеру, например компьютер, мобильный терминал или специализированное устройство для работы с видео. Устройство 500 также взаимодействует с другими объектами через блок 502 связи, который может содержать традиционные средства для проводной или беспроводной связи любого типа. Предполагается, что закодированная видеоинформация, которая должна быть декодирована, получена из блока 502 связи или памяти посредством блока 504 получения, и закодированные блоки декодируются в блоке 508 декодирования, причем функциональный блок 508 использует традиционные способы декодирования.
Блок 504 получения выполнен с возможностью получать одиночный синтаксический элемент, ассоциированный с закодированным блоком Be. Устройство 500 также содержит блок 506 идентификации, который выполнен с возможностью идентифицировать опорный режим и одно или более опорных изображений, которые должны использоваться при декодировании блока Be, на основе полученного синтаксического элемента. Как описано ранее, устройство 500 также содержит блок 508 декодирования, который выполнен с возможностью декодировать блок Be на основе определенного опорного режима и опорного изображения (изображений) и, таким образом, предоставляет декодированный блок Be пикселей.
В этом устройстве синтаксический элемент может представлять собой индикатор или индекс записи в опорном списке, который может содержать множество записей, каждая из которых представляет или идентифицирует один или более опорных режимов и одно или более опорных изображений. В качестве альтернативы, устройство может быть адаптировано к другому случаю, когда синтаксический элемент представляет собой кодовое слово, соответствующее записи в таблице поиска. Таблица поиска может привязывать кодовое слово, например, к опорному режиму и одной или более записям в одном или более опорных списках, например списках L0 и L1 в стандарте AVC.
Объект 501 декодирования видео дополнительно может содержать, например, блок 510 отображения, выполненный с возможностью отображать декодированную видеоинформацию.
ИЛЛЮСТРАТИВНАЯ ПРОЦЕДУРА, ФИГУРА 6, КОДИРОВАНИЕ
Теперь со ссылкой на фигуру 6 будет описан вариант осуществления части кодирования процедуры передачи опорной информации. Процедура может выполняться в объекте кодирования видео, который может представлять собой видеокодер, или объекте, содержащем дополнительные функциональные блоки в дополнение к видеокодеру. Первоначально блок B пикселей кодируется на этапе 602 с использованием опорного режима и одного или более опорных изображений и, таким образом, предоставляется закодированный блок Be.
Затем на этапе 604 извлекается одиночный синтаксический элемент на основе опорного режима и одного или более опорных изображений, используемых для кодирования, таким образом, синтаксический элемент прямо или косвенно идентифицирует опорный режим и одно или более опорных изображений, используемых для кодирования блока B. Синтаксический элемент, например, может быть извлечен посредством определения местоположения записи списка, соответствующей режиму опорных изображений и используемому опорному изображению (отображениям) в предопределенном опорном списке, и затем установки номера индекса упомянутой записи, чтобы составить синтаксический элемент. В качестве альтернативы предопределенная таблица отображения или таблица поиска может предоставить отображение между разными комбинациями опорных режимов и опорных изображений и разными синтаксическими элементами. Синтаксический элемент может также являться аргументом предопределенной функции, которая возвращает индикатор опорного режима и один или более индикаторов опорных изображений. Такой синтаксический элемент в виде "аргумента" может быть извлечен, например, посредством предопределенной "реверсивной функции", которая берет индикатор опорного режима и один или более индикаторов опорных изображений в качестве аргумента и возвращает одиночный синтаксический элемент.
Далее полученный синтаксический элемент выдается декодеру блока Be вместе с блоком Be на этапе 606. Таким образом, опорная информация, то есть информация о режиме опорных изображений и об одном или более опорных изображениях, использованных при кодировании блока B, также должна использоваться для декодирования закодированного блока Be, может быть передана декодеру компактным и устойчивым к ошибкам образом. Синтаксический элемент, например, может быть предоставлен, например, посредством его передачи по радиоканалу к объекту или узлу, содержащему декодер. Кроме того, синтаксический элемент, например, может храниться в памяти вместе с ассоциированной закодированной видеоинформацией, и доступ к нему может быть получен объектом декодирования в другой момент времени.
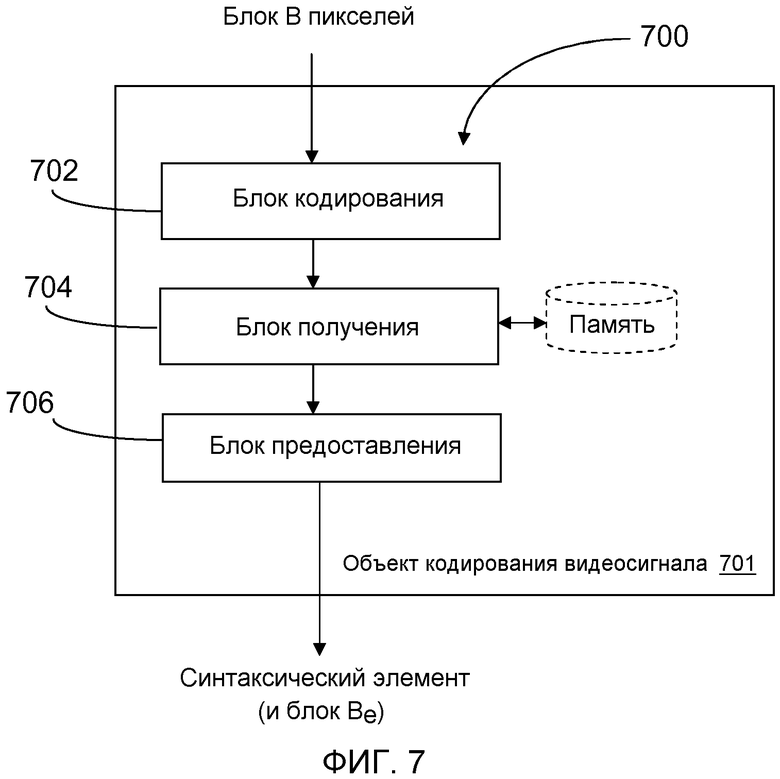
ИЛЛЮСТРАТИВНОЕ УСТРОЙСТВО, ФИГУРА 7, КОДИРОВАНИЕ
Ниже со ссылкой на фигуру 7 будет дано описание иллюстративного устройства 700, выполненного с возможностью предоставлять возможность выполнения описанной выше процедуры, имеющей отношение к кодированию. Устройство проиллюстрировано как расположенное в объекте 701 кодирования видео, которое может представлять собой видеокодер или объект, содержащий дополнительные функциональные блоки в дополнение к видеокодеру, например компьютер, мобильный терминал или специализированное устройство для работы с видео. Устройство 700 может взаимодействовать с другими объектами через блок связи (не показан), который содержит традиционные средства для проводной или беспроводной связи любого типа. Предполагается, что незакодированная видеоинформация, которая должна быть закодирована, получается, например, из блока связи или памяти.
Устройство 700 содержит блок 702 кодирования, который выполнен с возможностью кодировать блок B пикселей с использованием опорного режима и одного или более опорных изображений и, таким образом, предоставляет закодированный блок Be. Устройство 700 также содержит блок 704 получения, который выполнен с возможностью получать одиночный синтаксический элемент, который прямо или косвенно идентифицирует опорный режим и одно или более опорных изображений, используемых при кодировании блока B. Индексный элемент может быть получен по-разному, как описано ранее, и, например, может являться индикатором, таким как, например, индекс или кодовое слово и т.д.
Устройство 700 также содержит блок 706 предоставления, который выполнен с возможностью выдавать одиночный синтаксический элемент декодеру блока Be, возможно, через блок связи. Одиночный синтаксический элемент может быть предоставлен, например, посредством передачи по радиоканалу к объекту или узлу, содержащему декодер.
ИЛЛЮСТРАТИВНОЕ УСТРОЙСТВО, ФИГУРА 8
Фигура 8 схематично показывает вариант осуществления устройства 800 в объекте декодирования видео, который также может представлять собой альтернативный способ раскрытия варианта осуществления устройства для декодирования в объекте декодирования видео, проиллюстрированном на фигуре 5. В устройстве 800 содержится блок 806 обработки, например, с процессором цифровых сигналов (DSP). Блок 806 обработки может представлять собой одиночный блок или множество блоков для выполнения различных этапов процедур, описанных здесь. Устройство 800 также может содержать блок 802 ввода для приема сигналов от других объектов и блок 804 вывода для предоставления сигнала (сигналов) другим объектам. Блок 802 ввода и блок 804 вывода могут быть выполнены как объединенный объект.
Кроме того, устройство 800 содержит по меньшей мере один компьютерный программный продукт 808 в виде энергонезависимой памяти, например, электрически стираемого программируемого постоянного запоминающего устройства (EEPROM), флэш-памяти и накопителя на жестком диске. Компьютерный программный продукт 808 содержит компьютерную программу 810, которая содержит коды, которые при их исполнении в блоке 808 обработки в устройстве 800 заставляют устройство и/или объект декодирования видео выполнять действия процедур, описанных ранее в отношении фигуры 4.
Компьютерная программа 810 может быть выполнена как компьютерный программный код, структурированный в модулях компьютерной программы. Таким образом, в описанных иллюстративных вариантах осуществления коды в компьютерной программе 810 устройства 800 содержат модуль 810a получения для получения одиночного синтаксического элемента, ассоциированного с закодированным блоком видео, например, посредством декодирования его из битового потока, исходящего из объекта передачи данных или из хранилища данных, например, из памяти. Компьютерная программа также содержит модуль 810b идентификации для идентификации опорного режима и одного или более опорных изображений на основе полученного синтаксического элемента. Компьютерная программа 810 также содержит модуль 810c декодирования для декодирования закодированного блока.
Модули 810a-c могут фактически выполнять действия потока выполнения, проиллюстрированного на фигуре 4, для имитирования устройства в объекте декодирования видео, проиллюстрированного на фигуре 5. Другими словами, когда разные модули 810a-c исполняются в блоке 806 обработки, они соответствуют блокам 502-506 на фигуре 5.
Аналогичным образом возможна соответствующая альтернатива устройству, проиллюстрированному на фигуре 7.
Хотя коды в варианте осуществления, раскрытом выше в отношении фигуры 8, реализованы как модули компьютерной программы, которые при их исполнении в блоке обработки заставляют устройство и/или объект обработки, представления видеоинформации выполнять действия, описанные выше в отношении упомянутых выше фигур, по меньшей мере один из кодов в альтернативных вариантах осуществления может быть реализован по меньшей мере частично как аппаратные схемы.
Процессор может представлять собой одиночный центральный процессор (CPU), но также может содержать два или более блоков обработки, Например, процессор может включать в себя микропроцессоры общего назначения; процессоры системы команд и/или соответствующие наборы микросхем, и/или специализированные микропроцессоры, такие как специализированная интегральная схема (ASIC). Процессор также может содержать собственную память для целей кэширования. Компьютерная программа может осуществляться посредством компьютерного программного продукта, присоединенного к процессору. Компьютерный программный продукт содержит машиночитаемый носитель, на котором хранится компьютерная программа, например, компьютерный программный продукт может представлять собой флэш-память, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM) или электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), и описанные выше модули компьютерной программы в альтернативных вариантах осуществления могут быть распространены на разные компьютерные программные продукты в виде памяти в блоке приема данных.
Кроме того, понятно, что одна проблема с существующей технологией кодирования видео состоит в том, что не определены или применены удовлетворяющий опорный режим/схема предсказания опорных изображений. Ниже будет описана такая схема предсказания. Понятно, что, например, в сценарии завершения сцены/затемнения/вспышки довольно часто одна и та же комбинация опорного режима и опорных изображений используется для предсказания соседних или смежных макроблоков. Кроме того, понятно, что текущие способы кодирования не используют преимущество корреляции между опорными режимами/опорными изображениями, используемыми для соседних макроблоков. В предыдущих решениях отдельные компоненты, идентифицирующие опорную информацию макроблока, кодируются независимо и передаются видеодекодеру.
Примерная схема предсказания на уровне макроблока может быть описана следующим образом. Примерная схема предсказания применяется и к кодеру, и к декодеру и может быть применена для любого размера блока.
Совместно с кодированием/декодированием текущего макроблока кодер/декодер выполнен с возможностью анализировать опорные индикаторы закодированных макроблоков в окружении, также названном "контекстом" макроблока. Эти окружающие блоки также могут обозначаться как "соседние блоки" текущего блока. Кодер/декодер подсчитывает количество раз, когда каждый из множества потенциальных индикаторов или индексов появляется среди соседних блоков, и, например, в соответствии с предопределенной схемой, выбирает индекс с самым большим подсчитанным количеством в качестве предсказания или оценки. Выбранный опорный индикатор должен относиться к предсказанию с интер-кодированием. Выбранный опорный индикатор устанавливается в качестве предсказания или оценки того, какое опорное изображение (изображения) (и опорный режим) может быть подходящим для использования при кодировании/декодировании текущего макроблока. Предсказание получается посредством анализа информации, относящейся к кодируемым/декодируемым соседним блокам, а не посредством анализа непосредственно текущего макроблока. В кодере макроблок может быть либо закодирован, либо раскодирован во время этого выбора предсказания, поскольку в этом примере предсказание не должно использоваться для выбора опорного изображения (изображений) (и опорного режима), которые используются при кодировании текущего макроблока. В декодере текущий макроблок кодируется во время предсказания.
Иллюстративный анализ опорного индикатора соседнего блока и выбор оценки проиллюстрированы на фигуре 9. В примере, проиллюстрированном на фигуре 9, рассматриваются четыре соседних блока текущего блока. Однако способ применим также для других множеств или подмножеств рассматриваемых соседних блоков. Одно иллюстративное множество соседних блоков может, например, состоять из левого блока, верхнего левого блока и верхнего блока относительно текущего блока, Другое иллюстративное множество может содержать только левый блок и верхний блок. На фигуре 9 соседние блоки текущего блока ассоциированы с соответственными опорными индикаторами или индексами 1, 1, 2 и 0. Таким образом, опорный индикатор "1" имеет самое большое подсчитанное количество, то есть самую высокую частоту возникновения, появляясь дважды среди соседних блоков. Таким образом, опорный индикатор "1" выбирается для представления предсказания или оценки опорного изображения (изображений) (и режима), которое используется или должно использоваться при кодировании текущего блока, или предсказания опорного изображения (изображений) (и режима), которое должно использоваться для декодирования текущего блока, когда в декодере имеет место предсказание.
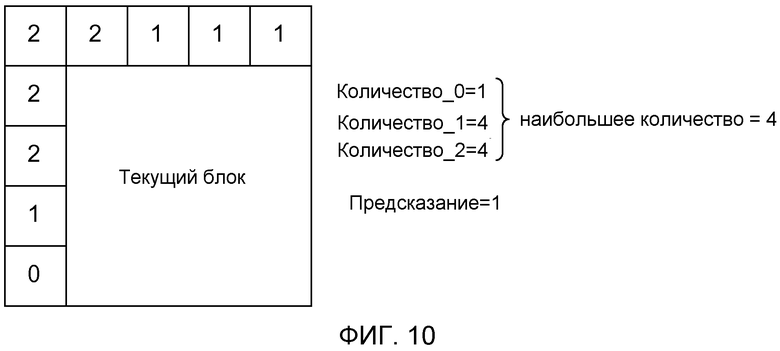
При подсчете числа возникновений некоторого определенного опорного индикатора среди соседних блоков более одного кандидата могут иметь одинаковое наибольшее число подсчетов. Это проиллюстрировано на фигуре 10, где опорные индикаторы "1" и "2" оба появляются четыре раза. Это могло быть разрешено, например, посредством выбора опорных индикаторов в соответствии с предопределенной схемой ранжирования, Например, когда опорные индикаторы представлены номерами 0-2, как проиллюстрировано на фигурах 9 и 10, опорный индикатор, представленный самым большим или самым маленьким числом, может быть выбран в качестве предсказания.
Различие между блоком предсказанных пиксельных значений и первоначальными пиксельными значениями, то есть источником перед кодированием, кодируется посредством кодирования с преобразованием, например посредством дискретного косинусного преобразования (DCT). Выходная информация преобразования содержит коэффициенты преобразования, которые затем квантуются. Количество коэффициентов преобразования, ассоциированных с блоком, отражает, насколько хорошим является соответствие между предсказанным блоком и первоначальным блоком для данного квантования. Относительно небольшое количество коэффициентов преобразования указывает, что имеется хорошее соответствие. Следовательно, опорные индикаторы, ассоциированные с блоками, имеющими небольшое количество коэффициентов преобразования, можно считать более надежными.
Таким образом, подсчет возникновений также может быть взвешен согласно, например, закодированным коэффициентам преобразования, ассоциированным с опорными блоками. Как описано выше, опорный индекс, ассоциированный с соседним блоком с небольшим количеством закодированных коэффициентов преобразования, можно считать более надежным предсказанием, чем опорный индекс, ассоциированный с соседним блоком с большим количеством коэффициентов преобразования, и, таким образом, ему может быть назначен больший весовой коэффициент для предсказания опорного индекса. В другом примере блоки с закодированными коэффициентами могут иметь больший весовой коэффициент, чем блоки без закодированных коэффициентов, то есть пропущенные блоки. В другом примере опорный индекс, ассоциированный с соседним блоком, который имеет большой раздел вектора движения, например большой макроблок, можно считать более надежным, чем соседний блок с меньшим разделом вектора движения, и, таким образом, ему будет назначен больший весовой коэффициент для предсказания опорного индекса. Использование весовых коэффициентов, которые являются кратными двум, является преимущественным с точки зрения сложности. Подсчет с использованием весовых коэффициентов также может быть реализован посредством использования таблицы поиска.
Некоторые опорные индикаторы могут быть более связаны друг с другом, чем другие, например, при использовании совместно закодированной опорной информации опорный индикатор, представляющий предсказание по двум изображениям c использованием опорных кадров ref0 и ref1, будет более связан с опорным индикатором, представляющим предсказание по одному изображению с использованием одного из опорных кадров ref0 и ref1, чем, например, с опорным индикатором, представляющим предсказание по одному изображению с использованием опорного кадра ref2. Таким образом, при подсчете индикатора предсказания по двум изображениям соответствующие индикаторы, представляющие предсказание по одному изображению с использованием тех же самых опорных кадров, могут обновляться на некоторое незначительное значение, то есть ниже, чем значение для "полного соответствия". Аналогичным образом, опорные индикаторы, представляющие предсказание по одному изображению, использующее например, опорные кадры ref0 и ref1, более связаны с соответствующим опорным индикатором, представляющим предсказание по двум изображениям с использованием опорных кадров ref0 и ref1, чем с другими опорными индикаторами предсказания по двум изображениям. Таким образом, при подсчете однонаправленного опорного индикатора количество опорных индикаторов, соответствующих предсказанию по нескольким изображениям, в котором используется рассматриваемый опорный кадр, может также быть обновлено на некоторое незначительное значение.
Фигура 10 иллюстрирует другой иллюстративный вариант осуществления определения частоты возникновения некоторых опорных индикаторов для текущего блока посредством подсчета опорных индикаторов, ассоциированных с соседними блоками текущего блока. При этом текущий блок представляет собой большой макроблок, и соседние блоки меньше по размеру, чем текущий блок. В некоторых случаях может быть интересно иметь одинаковое количество соседних блоков в контексте независимо от размера рассматриваемых блоков.
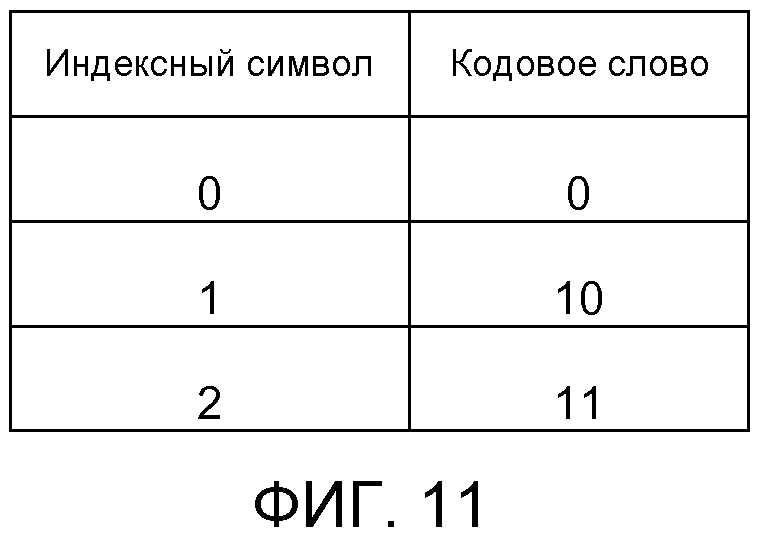
Одно из преимуществ введения предсказания с опорным индикатором или предсказания с опорным индексом состоит в том, чтобы дать возможность более эффективного отображения таблицы кодирования с переменной длиной (VIC). Посредством рассмотрения предсказания и таблицы VIC вместе может быть получено большее сжатие. Например, при кодировании трех индексов (0, 1, 2) без использования предсказания может быть назначена фиксированная таблица VIC, проиллюстрированная на фигуре 11. В предположении, что индекс "2" возникает наиболее часто, таблица, проиллюстрированная на фигуре 11, будет иметь субоптимальную конфигурацию, поскольку индекс "2" кодируется с использованием кодового слова с двумя битами, то есть "11", в то время как менее частый индекс "0" кодируется с использованием одного вида, то есть "0".
Когда предсказание добавляется, делается возможной более хорошая конфигурация таблицы VIC. Пример такой улучшенной конфигурации таблицы VIC проиллюстрирован на фигуре 12. В такой улучшенной конфигурации таблицы VIC биты, израсходованные на кодирование опорного индикатора или индексного символа, могут быть адаптированы на основе предсказания и, таким образом, на основе контекста текущего блока. В таблице, проиллюстрированной на фигуре 12, наиболее часто встречающийся опорный индикатор в контексте текущего блока кодируется с использованием кодового слова с одиночным битом, в этом примере "0". Кодовые слова "10" и "11", содержащие два бита, могут быть определены для идентификации, например, опорного индикатора, имеющего вторую по величине частоту возникновения, и опорного индикатора, имеющего третью по величине частоту возникновения, соответственно. И кодер, и декодер опорных индикаторов должны знать и быть согласованы в том, каким образом выполнять предсказание и как интерпретировать кодовые слова.
Описанный выше пример представляет собой лишь простой пример, и следует отметить, что возможная конфигурация не ограничена этим. Имеются различные способы назначить разные таблицы VIC для ссылки на индикаторы или индексные символы, например, когда используется больше опорных индикаторов или индексных символов. Примерный подход может состоять в том, чтобы изменять индексацию с вероятностью возникновения индексов, с тем чтобы часто возникающему опорному индикатору назначался низкий индекс и наоборот, и чтобы низкому индексу требовалось меньше битов для кодирования, чем высокому индексу. Контекстно-адаптивное двоичное арифметическое кодирование (CABAC) может использоваться для достижения переменного количества битов для представления опорных индикаторов или индексов в соответствии с их вероятностью. Некоторые примеры различных контекстов представляют собой, например, опорные индикаторы, ассоциированные с соседними блоками, подсчитанное количество опорных индикаторов или взвешенное подсчитанное количество опорных индикаторов, как описано выше.
На современном уровне техники, например, при использовании стандарта H.264 формирование блока предсказания по двум изображениям с использованием двух векторов движения/опорных изображений, блоков или областей включает в себя усреднение по двум опорным областям. Когда вектор движения указывает на позицию субпикселя в опорной области, сначала перед усреднением должны быть сформированы пиксельные значения позиции субпикселя. Формирование пиксельных значений позиции субпикселя называется "пространственной фильтрацией", то есть процесс формирования включает в себя пространственную фильтрацию соответственных опорных областей. Таким образом, современный процесс для формирования блока предсказания по двум изображениям с использованием двух опорных областей включает в себя пространственную фильтрацию первой области, пространственную фильтрацию второй области и, наконец, усреднение по отфильтрованным областям. Пространственная фильтрация относительно требовательна с точки зрения вычислительной сложности.
Понятно, что эта вычислительная сложность может быть уменьшена, что будет описано ниже. Чтобы уменьшить сложность, блок может сначала быть создан на основе целочисленного движения, например, посредством добавления двух опорных блоков вместе (без выполнения пространственной фильтрации). Это добавление представляет собой операцию, которая является относительно легкой с точки зрения вычислительной сложности. Затем, получившийся в результате блок может быть отфильтрован, например интерполирован, чтобы получить, например, разрешение в половину или четверть пикселя. Корректировка субпикселей может быть выполнена в соответствии с одним из векторов движения или, например, на основе отдельно закодированной/декодированной дополнительной информации.
Когда блок ассоциирован с более чем одним вектором движения и опорным индексом, что называется здесь "множественным предсказанием", могут быть определены соответственные однонаправленные компоненты предсказания множественного предсказания. Предсказание по одному изображению, а также предсказание с интра-кодированием, может называться "одиночным предсказанием". Понятно, что разделение информации может быть получено на основе абсолютной разности между этими однонаправленными предсказаниями. Информация о разделении может быть получена и в кодере, и в декодере, чтобы избежать дополнительного служебного сигнализирования при передаче информации о мелком разделении.
В областях, в которых абсолютная разность между однонаправленными предсказаниями является относительно большой, может использоваться одиночное однонаправленное предсказание или специальное предсказание по двум изображениям. Одиночное однонаправленное предсказание может быть сделано в соответствии с опорным индексом и вектором движения, указанным в битовом потоке для одного из компонентов с предсказанием по одному изображению предсказания по двум изображениям (или множественного предсказания). В других областях блока, в которых абсолютная разность между однонаправленными предсказаниями является относительно небольшой, предсказание по двум изображениям может использоваться, как указано в битовом потоке для блока. Решение о том, использовать ли для области одиночное предсказание по двум изображениям/специальное предсказание по двум изображениям или использовать предсказание по двум изображениям, указанным в битовом потоке, может быть основано, например, на сравнении абсолютной разности между однонаправленными предсказаниями, ассоциированными с областью, и предопределенным порогом.
Рассмотрим блок предсказания по двум изображениям, ассоциированный с двумя векторами движения и двумя опорными областями. Традиционно на данном этапе этот блок далее не разделяется, а кодируется как есть. Однако понято, что "неявная" информация, полученная из анализа абсолютных разностей или "отображения разности", может использоваться для разделения блока на дополнительные разделы и в кодере, и в декодере.
Когда абсолютная разность двух опорных областей или предсказаний будет вычислена, будет иметься некоторая область (области) в отображении разности с более высоким абсолютным значением (значениями) и некоторая область (области) с более низким абсолютным значением (значениями). Низкое значение абсолютной разности в области обычно представляет, что один и тот же объект изображен в этой области в обеих опорных областях. Если разные объекты изображены в области в соответственных опорных областях, абсолютная разность будет большой. Если один и тот же объект изображен в соответствующей области в соответственных опорных областях, уместно усреднить области. Если соответствующие области изображают разные объекты, не имеет смысла их усреднять.
Например, может быть определен порог, причем значения разности выше порога представляют "области с разными объектами", и значения разности ниже порога представляют "области с одним и тем же объектом". Блок может быть разделен в соответствии с этими областями согласно предопределенной схеме. Как заявлено ранее, разделение может быть выполнено на основе неявной информации, то есть без явного сигнализирования, описывающего разделение. Другое преимущество этого состоит в том, что может поддерживаться "не квадратное разделение", например, когда в одном блоке изображена половина шара, разделение блока может быть сделано очень точно по границе шара.
Кодер может сообщить декодеру, следует ли использовать описанный выше подход разделения. Когда сообщается, что подход разделения должен использоваться, для областей, имеющих относительно высокое значение абсолютной разности, кодер может по выбору сообщить, какое из однонаправленных предсказаний следует использовать или какое специальное предсказание по двум изображениям следует использовать. Например, может использоваться взвешенное предсказание по двум изображениям (отличное от среднего и, возможно, со смещением DC). В некоторых случаях может требоваться кодировать/декодировать некоторую дополнительную информацию для определения локальных параметров, чтобы было возможно получить специальное предсказание по двум изображениям. Полученная информация о разделении также может использоваться для предсказания информации о разделении, и кодер может закодировать изменения по сравнению с предсказанным разделом, который должен быть декодирован и использоваться декодером. Получение информации о разделении на основе разности между опорными областями может дать грубое указание относительно того, как должно быть сделано разделение. Также возможно дополнительное уточнение посредством отправки уточнений предсказанной информации разделения.
Один пример получения информации о разделении состоит в том, чтобы разделить блок на 4 блока одинакового размера. Субблок с самой большой нормализованной суммой абсолютных разностей (SAD) (разделенной на количество пикселей, для которых она была вычислена) итерационно делится на 4 области одинакового размера, если нормализованная сумма SAD субблока, например, равна или больше нормализованной суммы SAD в 4 раза большего "родительского" блока. Нормализованной суммой SAD называется сумма SAD для каждого пикселя или сумма SAD для одного заданного размера субблока. Вместо суммы SAD в качестве альтернативы могут использоваться другие показатели разности пикселей. Одним примером является показатель с большим весовым коэффициентом на сильной локальной структуре изображения, например, на краях/линиях. Остающийся субблок, который далее не разделяется, устанавливается в качестве раздела, который должен использовать, например, некоторую модификацию предсказания по двум изображениям.
Фигура 13 показывает иллюстративный вариант осуществления способа разделения. Блок на левой стороне 1302:a является предсказанным по двум изображениям. Вычисление суммы SAD выполняется над блоком (теперь обозначенном 1302:b), и области с большой суммой SAD идентифицируются и выбираются и обрабатываются соответствующим образом. В этом примере область с большой суммой SAD обрабатывается посредством замены на однонаправленное предсказание только с обратным вектором движения. Таким образом, первоначальный блок может быть разделен на два раздела, из которых один использует предсказание по двум изображениям, указанное в битовом потоке, и один (проиллюстрирован как содержащий круги) использует предсказание по одному изображению (один из компонентов предсказания по двум изображениям). Оптимизация частоты искажений (RDO) может использоваться для выбора наилучшего предсказания по одному изображению (компонента предсказания по двум изображениям).
Другой пример получения информации о разделении состоит в том, чтобы разделить, например, блок предсказания по двум изображениям на несколько субблоков одинакового размера; определить максимальную сумму SAD рассматриваемого размера субблока и выбрать субблоки, имеющие сумму SAD, "близкую" к максимальному значению, например, в пределах некоторого интервала, в качестве части области, которая должна использовать некоторую измененную версию предсказания по двум изображениям или однонаправленное предсказание.
Помимо разделения этот подход может использоваться, например, для определения ранее описанного индекса RIS или традиционных опорных индексов, когда используется режим предсказания по двум изображениям, например гладкое отображение разности для области может предложить и быть интерпретировано таким образом, что область, возможно, ассоциирована с "индексом RIS по двум изображениям". Подход также может использоваться как альтернативное предсказание или в комбинации с ранее описанным предсказанием с опорным индикатором. Выбор может быть сделан и в кодере, и в декодере на основе суммы SAD между возможными кандидатами предсказания по двум изображениям, чтобы выбрать комбинацию с наименьшей суммой SAD.
Следует отметить, что в описанном выше подходе с разделением на основе множественного предсказания вместо того, чтобы получать разделение на основе блоков, другие виды разделения могут быть получены и в кодере, и в декодере. Они включают в себя линейное (например, по горизонтали, вертикали или диагонали) или нелинейное разделение блока на два или более разделов, например, в соответствии со способами нелинейной обработки изображений, такими как обнаружение краев и/или сегментация, например, сигнал разности множественного предсказания может быть сегментирован в соответствии со способом сегментации изображения, таким как обнаружение краев или наращивание областей, и затем раздел блока получается на основе сегментированного сигнала разности.
Количество подразделов может быть либо получено посредством способов обработки изображений, таких как сегментация изображения, либо может быть сообщено от кодера декодеру. В качестве альтернативы линейному или нелинейному разделению также может быть применено разделение на основе пикселей. Один вариант может заключаться в том, чтобы сообщить от кодера декодеру, какой способ разделения используется, другой вариант состоит в том, что способ разделения согласован между кодером и декодером через другие средства оповещения. Преимущество способов на основе множественного предсказания состоит в том, что информация о разделении может быть получена на основе информации, которая уже является доступной в кодере и декодере, то есть она не должна явно сообщаться, и тем самым сокращается количество битов, используемых для кодирования.
Следует отметить, что в соответствии с разделением на основе множественного предсказания вместо того, чтобы переключаться с предсказания по двум изображениям на предсказание по одному изображению с однонаправленными векторами движения, полученными из векторов движения, используемых для предсказания по двум изображениям, также возможно сообщить дополнительные векторы движения и/или режимы предсказания (однонаправленное предсказание между изображениями, двунаправленное предсказание между изображениями или предсказание внутри изображения для подразделов). Другими словами, количество и формы разделов для блока могут быть явно сообщены и/или быть получены из неявной информации, например, на основе способа сегментации. Кроме того, векторы движения и/или режим предсказания могут быть сообщены для некоторых или всех полученных в результате подразделов.
Хотя предложенная выше процедура была описана в отношении конкретных вариантов осуществления, представленных в качестве примеров, описание в общем предназначено только для иллюстрации идеи изобретения и не должно быть воспринято в качестве ограничения объема предложенных способов и устройств, которые определены посредством приложенной формулы изобретения. Хотя способы и устройства описаны в общем, они могут быть применены, например, для систем связи разных типов с использованием общедоступных технологий связи, таких как, например, GSM/EDGE, WCDMA или LTE или технологий спутникового, наземного или кабельного вещания, например DVBS, DVB-T или DVBC, а также и для сохранения видеоинформации в памяти и извлечения из нее.
Также следует понимать, что выбор взаимодействующих блоков или модулей, а также наименование блоков имеют лишь иллюстративную цель, и объекты обработки видеоинформации, подходящие для исполнения любого из описанных выше способов, могут быть выполнены по-разному для исполнения предложенных этапов процесса.
Следует также отметить, что блоки или модули, описанные в этом раскрытии, должны рассматриваться как логические объекты и необязательно как отдельные физические объекты.
СОКРАЩЕНИЯ
AVC Усовершенствованное кодирование видео
CABAC Контекстно-адаптивное двоичное арифметическое кодирование
GOP Группа изображений
MB Макроблок
MV Вектор движения
RIS Оповещение об опорном индексе/оповещение об индикаторе опорной информации
SAD Сумма абсолютных разностей
VIC Кодирование с переменной длиной









Изобретение относится к средствам кодирования и декодирования видео. Техническим результатом является повышение эффективности кодирования опорной информации. В способе получают (402) одиночный синтаксический элемент, ассоциированный с закодированным блоком Be, представляющий запись в первом предопределенном опорном списке, который содержит записи, идентифицирующие опорные изображения и одиночное опорное изображение, идентифицируют (404) опорный режим и опорные изображения на основе полученного синтаксического элемента, декодируют (406) блок Be на основе идентифицированного опорного режима и опорных изображений, предоставляют декодированный блок B пикселей. 6 н. и 22 з.п. ф-лы, 13 ил.
1. Способ декодирования в объекте видео, причем способ содержит этапы, на которых:
получают (402) одиночный синтаксический элемент, ассоциированный с закодированным блоком Be, причем одиночный синтаксический элемент представляет запись в первом предопределенном опорном списке и причем первый список содержит одну или более записей, идентифицирующих по меньшей мере одно из множества опорных изображений и одиночного опорного изображения,
идентифицируют (404) опорный режим и одно или более опорных изображений на основе полученного синтаксического элемента, и
декодируют (406) блок Be на основе идентифицированного опорного режима и одного или более опорных изображений, и тем самым предоставляют декодированный блок B пикселей.
2. Способ по п.1, в котором этап идентификации опорного режима и одного или более опорных изображений основан на предопределенном отображении между полученным синтаксическим элементом и опорным режимом и одним или более конкретными опорными изображениями, которые должны использоваться для декодирования блока Be.
3. Способ по любому из пп.1 и 2, в котором каждая запись в первом списке дополнительно идентифицирует опорный режим.
4. Способ по любому из пп.1 и 2, в котором одиночный синтаксический элемент дополнительно представляет опорный режим и запись во втором предопределенном опорном списке.
5. Устройство (500) декодирования в объекте (501) видео, содержащее:
блок (504) получения, выполненный с возможностью получать одиночный синтаксический элемент, ассоциированный с закодированным блоком Be, причем одиночный синтаксический элемент представляет запись в первом предопределенном опорном списке и причем первый список содержит одну или более записей, идентифицирующих по меньшей мере одно из множества опорных изображений и одиночного опорного изображения, и
блок (506) идентификации, выполненный с возможностью идентифицировать опорный режим и одно или более опорных изображений на основе полученного синтаксического элемента, и
блок (508) декодирования, выполненный с возможностью декодировать блок Be на основе идентифицированного опорного режима и одного или более опорных изображений и тем самым предоставлять декодированный блок B пикселей.
6. Устройство по п.5, дополнительно выполненное с возможностью идентифицировать опорный режим и одно или более опорных изображений на основе предопределенного отображения между полученным синтаксическим элементом и опорным режимом и одним или более конкретными опорными изображениями, которые должны использоваться для декодирования блока Be.
7. Устройство по любому из пп.5 и 6, в котором каждая запись в первом списке дополнительно идентифицирует опорный режим.
8. Устройство по любому из пп.5 и 6, дополнительно выполненное с возможностью интерпретировать одиночный синтаксический элемент как дополнительное представление опорного режима и записи во втором предопределенном опорном списке.
9. Устройство по п.8, в котором второй список содержит одну или более записей, идентифицирующих одиночное опорное изображение.
10. Устройство по любому из пп.5 и 6, в котором одна или более записей списка идентифицируются индексом списка.
11. Устройство по любому из пп.5 и 6, дополнительно выполненное с возможностью интерпретировать количество битов, представляющих полученный синтаксический элемент, как коррелированное с вероятностью конкретных значений синтаксического элемента таким образом, что меньшее количество битов подразумевает вероятные значения и большее количество битов подразумевает менее вероятные значения.
12. Устройство по любому из пп.5 и 6, дополнительно выполненное с возможностью выполнять предсказание опорной информации для блока Be на основе одиночных синтаксических элементов, ассоциированных с соседними блоками.
13. Устройство по любому из пп.5 и 6, дополнительно выполненное с возможностью идентифицировать одну или более подобластей блока, ассоциированного с множественным предсказанием, для упомянутых подобластей соответственные соответствующие области опорных блоков множественного предсказания имеют относительно низкую корреляцию между собой, и
устройство дополнительно выполнено с возможностью использовать альтернативное предсказание вместо множественного предсказания для идентифицированной одной или более подобластей блока.
14. Способ кодирования в объекте видео, причем способ содержит этапы, на которых:
кодируют (602) блок B пикселей с использованием опорного режима и одного или более опорных изображений и тем самым предоставляют закодированный блок Be,
получают (604) одиночный синтаксический элемент, идентифицирующий опорный режим и одно или более опорных изображений, причем одиночный синтаксический элемент представляет запись в первом предопределенном опорном списке и причем первый список содержит одну или более записей, идентифицирующих по меньшей мере одно из множества опорных изображений и одиночного опорного изображения,
предоставляют (606) одиночный синтаксический элемент декодеру блока Be.
15. Способ по п.14, в котором синтаксический элемент получается посредством того, что используемый опорный режим и одно или более опорных изображений отображают на синтаксический элемент в соответствии с предопределенной схеме отображения.
16. Способ по любому из пп.14 и 15, в котором каждая запись в первом списке дополнительно идентифицирует опорный режим.
17. Способ по любому из пп.14 и 15, в котором одиночный синтаксический элемент дополнительно представляет опорный режим и запись во втором предопределенном опорном списке.
18. Устройство (700) кодирования в объекте видео, содержащее:
блок (702) кодирования, выполненный с возможностью кодировать блок B пикселей с использованием опорного режима и одного или более опорных изображений и тем самым предоставляют закодированный блок Be,
блок (704) получения, выполненный с возможностью получать одиночный синтаксический элемент, идентифицирующий опорный режим и одно или больше опорных изображений, причем одиночный синтаксический элемент представляет запись в первом предопределенном опорном списке и причем первый список содержит одну или более записей, идентифицирующих по меньшей мере одно из множества опорных изображений и одиночного опорного изображения,
блок (706) предоставления, выполненный с возможностью предоставлять одиночный синтаксический элемент декодеру блока Be.
19. Устройство по п.18, дополнительно выполненное с возможностью получать синтаксический элемент из предопределенного отображения между опорным режимом и одним или более опорными изображениями и синтаксическим элементом.
20. Устройство по любому из пп.18 и 19, в котором каждая запись в первом списке дополнительно идентифицирует опорный режим.
21. Устройство по любому из пп.18 и 19, дополнительно выполненное с возможностью получать одиночный синтаксический элемент таким образом, что он дополнительно представляет опорный режим и запись во втором предопределенном опорном списке.
22. Устройство по п.21, в котором второй список содержит одну или более записей, идентифицирующих соответственное соответствующее одиночное опорное изображение.
23. Устройство по любому из пп.18 и 19, дополнительно выполненное с возможностью получать одиночный синтаксический элемент посредством выбора индекса списка, идентифицирующего одну или более записей в одном или более предопределенных опорных списках.
24. Устройство по любому из пп.18 и 19, дополнительно выполненное с возможностью выбирать количество битов, представляющих синтаксический элемент таким образом, чтобы оно было коррелировано с вероятностью конкретного режима (режимов) и изображения (изображений), которые синтаксический элемент идентифицирует, с тем чтобы более высокая вероятность соответствовала меньшему количеству битов и более низкая вероятность соответствовала большему количеству битов.
25. Устройство по любому из пп.18 и 19, дополнительно выполненное с возможностью выполнять предсказание опорной информации для блока B или блока Be на основе одиночных синтаксических элементов, ассоциированных с соседними блоками.
26. Устройство по любому из пп.18 и 19, дополнительно выполненное с возможностью идентифицировать одну или более подобластей блока, ассоциированного с множественным предсказанием, для упомянутых подобластей соответственные соответствующие области опорных блоков множественного предсказания имеют относительно низкую корреляцию между собой, и
устройство дополнительно выполнено с возможностью использовать альтернативное предсказание вместо множественного предсказания для идентифицированной одной или более подобластей блока.
27. Читаемый компьютером носитель, хранящий исполняемые компьютером команды, чтобы заставить компьютер осуществлять способ по пп.1-4.
28. Читаемый компьютером носитель, хранящий исполняемые компьютером команды, чтобы заставить компьютер осуществлять способ по пп.14-17.
| US 20090187960 A1, 23.07.2009 | |||
| US 20060093038 A1, 04.05.2006 | |||
| US 20060153297 A1, 13.07.2006 | |||
| US 20080159638 A1, 03.07.2008 | |||
| УСТРОЙСТВО ЗАПИСИ ДАННЫХ, СПОСОБ ЗАПИСИ ДАННЫХ, УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ, СПОСОБ ОБРАБОТКИ ДАННЫХ, ПРОГРАММА, НОСИТЕЛЬ ЗАПИСИ ПРОГРАММЫ, НОСИТЕЛЬ ЗАПИСИ ДАННЫХ И СТРУКТУРА ДАННЫХ | 2005 |
|
RU2335856C1 |
| СПОСОБ ИНТЕРПОЛЯЦИИ ЗНАЧЕНИЙ ПОДПИКСЕЛОВ | 2002 |
|
RU2317654C2 |

