Изобретение относится к способам считывания и идентификации информации, которые могут использоваться для аутентификации личности по рукописному тексту и могут использоваться в следственной практике и системах безопасности государственных учреждений и банков.
Задача установления исполнителя рукописи называется в почерковедении идентификационной задачей. Решение этой задачи - наиболее распространенный вид криминалистической экспертизы.
Идентификация личности по рукописной подписи (и динамике ее воспроизведения) является одной из старейших. Уже несколько веков назад стали использовать подпись для подтверждения подлинности тех или иных ценных бумаг. Некоторые авторы [1, 2] считают целесообразным разделение проблемы аутентификации личности по факсимильной подписи на две независимые задачи:
- идентификация только по статической подписи, которая поставлена заранее на проверяемом документе;
- идентификация по динамике воспроизведения, то есть в момент подписания, с возможностью наблюдения индивидуальных особенностей процесса.
Обе задачи можно решать параллельно и независимо. Первая задача - статическая, нужно просто сравнивать полученное изображение рисунка письма с тем, которое имеется в базе данных. Для современных информационных технологий она достаточно сложная. И качество ее решения все еще оставляет желать лучшего, хотя и достигнуты некоторые серьезные результаты на сегодняшний день [1].
Во второй задаче обрабатываются данные о динамике воспроизведения рисунка текста (координатах пера, его колебаниях, давлении, временных промежутках и пр.).
Для идентификации исполнителя рукописи по его почерку наибольшее значение имеют особенности графического и технического навыков пишущего. Существующие методики для решения идентификационной задачи основаны на выявлении идентификационно значимых признаков [1, 3]. Поэтому актуальной является задача создания компьютерных методов, позволяющих решать идентификационную задачу, берущих на себя сложную обработку рукописного материала. Основная идея состоит в том, что сложная обработка обширного почеркового материала для выделения немногих идентификационно-значимых признаков для облегчения работы эксперта заменяется обработкой компьютером максимально полного множества признаков без различения идентификационной значимости. Возможность полного перебора, доступная компьютеру, позволяет автоматически выделить значимые признаки. Известно, что почерк человека содержит достаточное число индивидуальных признаков, позволяющих надежно идентифицировать человека по частным особенностям почерка [1, 2, 3]. Однако сравнение образцов почерка, проводимое в следственной практике, присущих только конкретному пользователю, требует достаточно сложных методик и опыта исследователя эксперта-криминалиста. Попытки применить накопленный опыт в области судебного почерковедения и графологии (методики определения характеристик исполнителя рукописных текстов, разработанные специалистами ЭКЦ МВД России) для идентификации подписантов в системах информационной безопасности не позволяют распознавать индивидуумов в реальном масштабе времени, в автоматическом режиме, либо принимать высоконадежное решение о допуске субъекта в охраняемую систему. Поэтому по-прежнему актуальной остается проблема создания быстрой и надежной системы идентификации, позволяющей выбрать набор признаков, надежно разделяющих различных людей, и определить значения этих признаков.
Известен способ распознавания символов текста по информации растрового изображения «Способ распознавания текста с применением настраиваемого классификатора», RU №2234126, G06K 9/66, опубл. 10.08.2004. По этому способу изображение символа распознается при помощи настраиваемого и/или ненастраиваемого классификаторов и контекстного анализа. Данный способ позволяет распознавать лишь качественный печатный текст и не распознает рукописные тексты из-за естественной нестабильности рукописных букв. Этот способ не позволяет осуществлять идентификацию личности по рукописному тексту.
Последний недостаток частично компенсируется "Способом сравнения ручной записи с эталонной записью и применений способа" по патенту Швейцарии №665915, МКИ 4 G06K 9/62, УДК 621.327. Публикация 880615 №11 (ВИНИПИ 117-03-89).
По этому способу эталонный и предъявленный тексты делят на отдельные фрагменты и каждый из этих фрагментов отдельно совмещают с соответствующим эталоном, а также индивидуально масштабируют. Последнее улучшает вероятность правильного решения, но все же не позволяет получить достаточно высокой надежности идентификации.
Наиболее близким по технической сущности прототипом для предлагаемого способа является «Способ биометрической аутентификации по почерку в компьютеризованной системе контроля доступа», патент RU №2469397 от 10.12.12, G06K 9/00, G01L 17/00, заключающийся в том, что преобразованные в цифровую форму колебания пера, воспроизводящего рукописный текст, и его давление вводят в компьютер, формируя матрицу квантованных отсчетов, по значениям ее элементов вычисляют с помощью двумерного дискретного косинусного преобразования матрицу коэффициентов, принимают решение об идентификации личности путем сравнения упомянутых вычисленных коэффициентов с их эталонными значениями, имеющихся в базе данных, при этом вновь вводимого в систему пользователя идентифицируют путем последовательного вычитания по модулю элементов его матрицы коэффициентов двумерного дискретного косинусного преобразования из соответствующих элементов матриц, имеющихся в базе данных, и распознаваемый пользователь считается инцидентным эталонной записи, если эта разница минимальна. Недостатком прототипа является необходимость хранения большого объема данных, а главное - невозможность идентификации личности по «мертвому» рукописному тексту. Общими недостатками аналогов следует также считать необходимость осуществлять сопоставление исследуемого предъявляемого текста с большим числом эталонных, что, в конечном итоге, приводит к большой задержке и снижает надежность распознавания. Указанные недостатки значительно ограничивают возможности использования известных способов в следственной практике для распознавания личности по текстовой рукописной информации.
Задачей, решаемой настоящим изобретением, является повышение достоверности идентификации личности по особенностям почерка за счет создания представления (шаблона) рукописного текста, с помощью которого может производиться предварительный криминалистический анализ более простым, доступным способом на ЭВМ. Созданные таким образом шаблоны могли бы использоваться в следственной практике для отнесения личностей, которым принадлежат эти подписи, к вероятной принадлежности к тому или иному типу, виду, в зависимости от вида исследования. Например, для выявления вероятности подделки подписи.
Поставленная задача решается путем создания способа идентификации личности по рукописному тексту, в котором что после многократного сканирования эталонного рукописного текста осуществляют деление текста на отдельные фрагменты, выделяют на каждом примере фрагмента рукописного текста линии траектории текста, далее дробят рисунок фрагмента текста на элементарные ячейки, так что в пределах элементарной ячейки получают прямой участок траектории текста, далее для всех реализаций эталонного текста по каждому фрагменту для каждой элементарной его ячейки вычисляют среднее значение и среднее квадратическое отклонение угла наклона, по вычисленным значениям формируют идентификационную матрицу, размерность которой равна размерности фрагмента, а ненулевые значения которой, содержат величины средних углов наклона и средних квадратических отклонений, запоминают эти значения средних углов наклонов и средних квадратических отклонений и используют их при идентификации личности по его рукописному тексту; в процессе идентификации предъявленного рукописного текста осуществляют разбиение отсканированного рисунка исследуемого рукописного текста на фрагменты, их масштабирование, выделение на каждом фрагменте рукописного текста линий траектории текста, дробление рисунка фрагмента текста на элементарные ячейки аналогично дроблению фрагмента эталонного текста, вычисление для каждой элементарной ячейки фрагмента значений угла наклона текста, формирование по вычисленным значениям углов наклона матрицы углов наклона, размерность которой равна размерности идентификационной матрицы фрагмента эталона, сравнение этих значений углов наклона текста с соответствующими значениями средних углов наклона фрагмента эталонного текста из базы данных, причем в случае поворота шаблона фрагмента эталонной подписи для полного совмещения значимых ячеек шаблона корректируют углы наклона траектории исследуемого текста по каждой значимой ячейке на величину угла поворота шаблона, при этом в случае совпадения вычисленных значений углов наклона со средними углами наклона фрагмента эталонного текста с заданной вероятностью исследуемый текст считается авторским, а в случае несовпадения вычисленных и эталонных значений процедура идентификации прекращается; причем способ позволяет классифицировать предъявляемый рукописный текст по степени аутентичности с эталонным на классы совпадения с эталонным текстом. Указанная совокупность существенных признаков позволяет сформировать компьютеризированную систему идентификации личности по рукописному почерку.
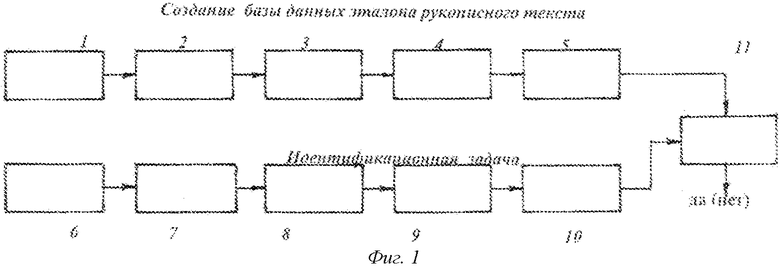
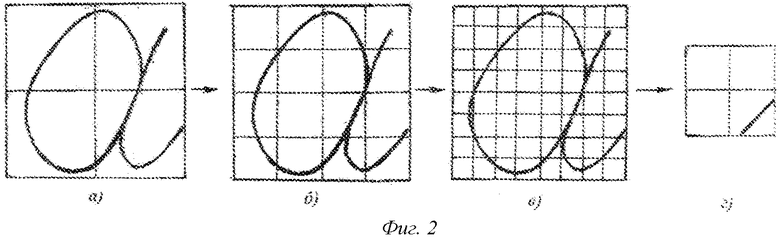
Пример реализации данного способа поясняется чертежами, на которых на фиг.1 показана блок-схема реализации способа, где 1 - сканирование эталона почерка, 2 - фрагментирование эталона, 3 - дробление фрагмента, 4 - вычисление средних углов, 5 - формирование шаблона и идентификационной матрицы, 6 - форматирование исследуемого текста, 7 - навешивание шаблона эталона, 8 - аффинное преобразование шаблона эталона, 9 - вычисление средних углов фрагмента исследуемого текста, 10 - формирование матрицы средних углов фрагмента исследуемого текста, 11 - принятие решения по идентификации фрагмента исследуемого текста; на фиг.2 показан результат дробления рисунка рукописного текста изображения на элементарные ячейки (прямоугольные клетки), в каждой ячейке отображены значения среднего наклона линий текста, на фиг. 3 - образование шаблона эталонного текста и идентификационной матрицы, на фиг. 4 - результаты аффинного преобразования исследуемого текста (на примере одного фрагмента).
Выполнение предлагаемого способа осуществляется в несколько этапов, как это изображено на фиг. 1. Первоначально на этапе предобработки образец авторского текста (фрагмент текста, парольная фраза, подпись) записывается многократно (более 20-30), анонимно, в привычной для пользователя обстановке (могут использоваться росписи в банковских документах, росписи в книгах учета прихода, в библиотечных формулярах и т.п.) для создания базы данных. Этот образец рукописного текста сканируется известными в следственной практике способами (1 на фиг.1). Текст разделяется (фрагментируется) на отдельные фрагменты (знакоместа) (2 на фиг.1), формат фрагмента определяется размерами воспроизводимого символа (высотой и шириной), в отдельных случаях, при идентификации подписи это может быть один формат. При первом предъявлении рукописного текста, при создании базы данных авторского текста - эталонной подписи, его особенности (закругленный, косой, готический и др.) определяют количество шагов дробления текста (3 на фиг.1, при котором линеаризуются элементы траектории текста, проходящие через получаемые элементарные ячейки. В качестве примера реализации этого шага для одного фрагмента текста (прописная буква 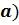 рассмотрим простейшее дробление вводимого рисунка линий, пример которого приведен на фиг. 2. На рисунок фрагмента рукописного текста (подписи), полученный сканированием или другим известным методом, наносится ограничивающая сетка, разделяющая текст на отдельные элементарные ячейки, каждая отдельная элементарная ячейка (клетка) такой сетки содержит криволинейные элементы траектории рукописного текста (фиг. 2а). После этого сетку измельчают до тех пор, пока криволинейные элементы траектории текста в пределах элементарной ячейки станут почти линейными (фиг. 2в). Это дробление ограничивающей сетки создает шаблон фрагмента с числом строк
рассмотрим простейшее дробление вводимого рисунка линий, пример которого приведен на фиг. 2. На рисунок фрагмента рукописного текста (подписи), полученный сканированием или другим известным методом, наносится ограничивающая сетка, разделяющая текст на отдельные элементарные ячейки, каждая отдельная элементарная ячейка (клетка) такой сетки содержит криволинейные элементы траектории рукописного текста (фиг. 2а). После этого сетку измельчают до тех пор, пока криволинейные элементы траектории текста в пределах элементарной ячейки станут почти линейными (фиг. 2в). Это дробление ограничивающей сетки создает шаблон фрагмента с числом строк 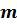 и числом столбцов
и числом столбцов 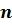 . При создании базы данных фрагмента эталонного текста в зависимости от его особенностей определяют количество шагов дробления и размерность шаблона фрагмента текста (число строк и число столбцов). Шаблон фрагмента в виде совокупности элементарных ячеек, через которые проходит траектория рукописного текста (фиг.3б), может быть представлен в виде матрицы смежности графа, ненулевые элементы которой определяют элементарные ячейки, через которые проходит траектория текста. Активными пикселями, подлежащими анализу, будут точки пересечения границ элементарной ячейки шаблона и траектории текста, проходящей через ячейку шаблона фрагмента. Для каждой элементарной ячейки определяют величины
. При создании базы данных фрагмента эталонного текста в зависимости от его особенностей определяют количество шагов дробления и размерность шаблона фрагмента текста (число строк и число столбцов). Шаблон фрагмента в виде совокупности элементарных ячеек, через которые проходит траектория рукописного текста (фиг.3б), может быть представлен в виде матрицы смежности графа, ненулевые элементы которой определяют элементарные ячейки, через которые проходит траектория текста. Активными пикселями, подлежащими анализу, будут точки пересечения границ элементарной ячейки шаблона и траектории текста, проходящей через ячейку шаблона фрагмента. Для каждой элементарной ячейки определяют величины 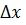 и
и 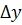 (см. увеличенное изображение ячейки на фиг. 3а), и их отношение
(см. увеличенное изображение ячейки на фиг. 3а), и их отношение 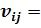
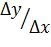 - тангенс угла наклона траектории текста, которое используется в качестве идентификационного параметра. Такой постановкой попиксельное множество точек траектории фрагмента подписи заменяется вполне обозримым, конечным множеством
- тангенс угла наклона траектории текста, которое используется в качестве идентификационного параметра. Такой постановкой попиксельное множество точек траектории фрагмента подписи заменяется вполне обозримым, конечным множеством 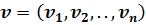 средних углов наклона линий рисунка траекторий текста по выделенному фрагменту рисунка текста. Ограничивающая сетка, в которую вписан текст подписи, заменяется шаблоном (фиг.3б), а каждый фрагмент текста представляет собой множество клеток - элементов шаблона, на границах которых расположены активные пиксели. Парольная фраза (авторская подпись) для базы данных записывается многократно (более 20-30), что позволяет дать интервальную оценку для каждого элемента шаблона в виде
средних углов наклона линий рисунка траекторий текста по выделенному фрагменту рисунка текста. Ограничивающая сетка, в которую вписан текст подписи, заменяется шаблоном (фиг.3б), а каждый фрагмент текста представляет собой множество клеток - элементов шаблона, на границах которых расположены активные пиксели. Парольная фраза (авторская подпись) для базы данных записывается многократно (более 20-30), что позволяет дать интервальную оценку для каждого элемента шаблона в виде 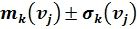 , вычисляя математическое ожидание угла наклона траектории и среднее квадратическое отклонение. Для экономии памяти при создании базы данных для вычисления этих статистик будем использовать следующие формулы:
, вычисляя математическое ожидание угла наклона траектории и среднее квадратическое отклонение. Для экономии памяти при создании базы данных для вычисления этих статистик будем использовать следующие формулы:
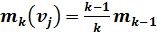
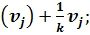
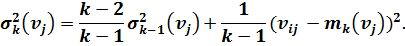
Здесь: 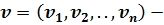 вектор идентификационных параметров;
вектор идентификационных параметров;
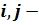 строка, столбец ячейки шаблона;
строка, столбец ячейки шаблона;
 номер реализации записи при создании базы данных.
номер реализации записи при создании базы данных.
Таким образом, вместо попиксельного сравнения, требующего огромное количество времени для создания базы данных, будем иметь ограниченный объем для шаблонов каждого фрагмента в виде идентификационной матрицы (фиг.3в), в ненулевых ячейках которой будут находиться параметры идентификации эталонного текста (характеристики группирования 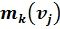 и разброса
и разброса 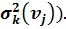 Полученное представление фрагмента рукописного текста позволяет сравнивать подписи между собой.
Полученное представление фрагмента рукописного текста позволяет сравнивать подписи между собой.
На этапе идентификации исследуемая на авторство подпись масштабируется и разбивается на отдельные фрагменты (6 на фиг.1), аналогично разбивке эталонной подписи. На каждый фрагмент исследуемой подписи последовательно один за другим навешивается соответствующий шаблон фрагмента эталонной подписи из базы данных (7 на фиг.1 и фиг.4), который подвергается аффинному преобразованию, причем сжатию (растяжению) в двух координатных направлениях подвергается вначале шаблон в целом, далее сжатию (растяжению) подвергается отдельный элемент шаблона в отдельности, так чтобы в каждый элемент шаблона попал соответствующий фрагмент исследуемой подписи. На фиг.4 показаны варианты преобразования шаблона эталона при анализе исследуемого фрагмента текста. На фиг.4а шаблон эталона текста деформируется с поворотом с целью совмещения с фрагментом исследуемого текста. На фиг.4б с этой же целью для другого фрагмента исследуемого текста проведено неравномерное растяжение (сжатие) по горизонтали. Допустимое растяжение (сжатие) по горизонтали и вертикали для элементарной ячейки шаблона эталона определяется в соответствии с характеристикой разброса 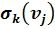 - средним квадратическим отклонением. При этом трансформация шаблона осуществляется за счет соседней пустой (нулевой) ячейки шаблона (при
- средним квадратическим отклонением. При этом трансформация шаблона осуществляется за счет соседней пустой (нулевой) ячейки шаблона (при 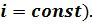
При совмещении шаблона эталона и исследуемого фрагмента вычисляют значения углов наклона траектории текста (9 на фиг.1) и их сравнение со значением средних углов эталонного текста (10 на фиг.1). В случае деформации шаблона эталонной подписи для полного совмещения значимых ячеек (не нулевых) (фиг. 4а) обязательной операцией является операция обратного поворота, который осуществляется с помощью двумерного аффинного преобразования, при которой корректируются углы наклона траектории исследуемого текста по каждой значимой ячейке [4].
При аутентификации личности эксперт-криминалист предъявляет рукописный текст в виде подписи или парольного слова сканеру, данные о рисунке текста отображаются на экране монитора. Введенное изображение разбивается на фрагменты. Эксперт масштабирует подпись, он также может изменить положение исследуемой подписи, ориентируясь на положение изображения на экране монитора. На этапе исследования предъявляемой подписи производятся следующие действия. Из заранее созданной базы данных, в которых хранятся эталоны почерков в виде идентификационных матриц, содержащих средние углы наклона траекторий рукописного текста, загружаются эталоны почерков в виде идентификационных матриц. Исследуемая подпись предъявляется для сравнения последовательно фрагмент за фрагментом.
Здесь определенная важная роль принадлежит эксперту, который на экране монитора выбирает эталон текста, совпадающий (похожий) на исследуемый текст. Введенное изображение разбивается на фрагменты аналогично процедуре создания эталонной записи (6 на фиг.1). Далее происходит навешивание шаблона эталонной подписи (7 на фиг.1), при этом осуществляют аффинное преобразование шаблона эталона (масштабирование и поворот) с целью совмещения шаблона эталона с траекторией исследуемого рукописного текста (8 на фиг.1). Афинное преобразование шаблона позволяет наиболее адекватно совместить его значимые (не нулевые ячейки) с траекторией рисунка исследуемого текста, для дальнейшего сравнения по углам наклона. При совмещении шаблона эталона с предъявленным фрагментом рукописного текста вычисляют углы наклона траектории текста по каждой элементарной ячейки шаблона и формируют матрицу углов (9, 10 на фиг.1). Исследуемая подпись (11 на фиг.1) проверяется на аутентичность в следующей последовательности:
- на совпадение количества шаблонов (идентификационных матриц);
- на совпадение размерности шаблонов (идентификационных матриц).
При несовпадении количества шаблонов, и размерности эталона для хотя бы одного фрагмента исследуемой подписи, сравнение прекращается и из базы данных берется следующий образец эталонной подписи. При выполнении вышеприведенных двух условий на исследуемую подпись навешивается шаблон эталонной подписи. В том случае, когда шаблон эталонной подписи полностью лег на фрагмент предъявленной подписи, на изображении рисунка выделяются линии наклона текста и вычисляют их угол наклона, в соответствии с фрагментацией изображения определяют значение углов наклона линий по каждой из ячеек фрагмента. Далее происходит сравнение значений углов наклонов линий по каждой из ячеек фрагмента, принимаемых в качестве идентификационных параметров (11 на фиг. 1). При этом возможны следующие случаи:
- идентификационный параметр исследуемого текста для каждой элементарной ячейки шаблона эталона попадает в интервал 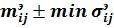 ;
;
- идентификационный параметр исследуемого текста для каждой элементарной ячейки шаблона эталона попадает в интервал 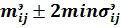 ;
;
- идентификационный параметр исследуемого текста для каждой элементарной ячейки шаблона эталона попадает в интервал 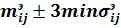 ;
;
- идентификационный параметр исследуемого текста для каждой элементарной ячейки шаблона эталона не попадает в интервал .
При принятии решения сравнивают меру близости параметров предъявленного образца подписи (пароля) с эталонными. При этом возможны три случая сравнения:
1. Если формат шаблона эталонной подписи (размерность идентификационной матрицы, 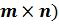 , хотя бы по одному фрагменту не совпадает с форматом исследуемой подписи, то исследуемая подпись не является авторской;
, хотя бы по одному фрагменту не совпадает с форматом исследуемой подписи, то исследуемая подпись не является авторской;
2. Если результаты аффинного преобразования шаблона эталона при масштабировании исследуемой подписи не позволяют приблизить исследуемую подпись к шаблону эталонной подписи, хотя бы по одному фрагменту, то исследуемая подпись не является авторской;
3. Если выполняются условия по п. 1 и 2 и средние углы наклона линий траектории текста по каждой элементарной ячейки шаблона по каждому фрагменту укладываются в интервал разброса эталонной подписи, то исследуемая подпись является авторской.
Если предположить, что средние величины углов наклона траекторий рукописного текста, принадлежащие всему множеству фрагментов (при 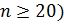 эталонной записи, близки нормальному закону распределения, то с высокой степенью доверительной вероятности можно утверждать, что при выполнении условий п. 1 и 2, исследуемая подпись является авторской. Это же позволяет разделять предъявляемые подписи на три класса по степени достоверности. Полная процедура идентификации может закончиться положительно, если предъявленный рисунок подписи совпадет по расположению его особенностей с эталонными образцами почерка. В противном случае пользователю предлагается повторить образец подписи.
эталонной записи, близки нормальному закону распределения, то с высокой степенью доверительной вероятности можно утверждать, что при выполнении условий п. 1 и 2, исследуемая подпись является авторской. Это же позволяет разделять предъявляемые подписи на три класса по степени достоверности. Полная процедура идентификации может закончиться положительно, если предъявленный рисунок подписи совпадет по расположению его особенностей с эталонными образцами почерка. В противном случае пользователю предлагается повторить образец подписи.
Основное преимущество предлагаемого способа по сравнению с известными биометрическими способами аутентификации заключается в следующем:
- для идентификации по рукописному почерку не требуется дорогостоящих устройств - считывателей биометрической информации;
- способ облегчает создание представления (шаблона) рукописного текста, с помощью которого на ЭВМ может производиться предварительный криминалистический анализ рукописного текста, сокращает время почерковедческой экспертизы и повышает надежность классификации и идентификации;
- способ может предварять и дополнять другие способы идентификации, применяемые в следственной практике.
Литература
1. С.М. Гусакова, А.С. Комаров. Интеллектуальная система для решения идентификационной задачи в почерковедении. Искусственный интеллект и принятие решений, №4/2010, с.49-54.
2. Болл Руд и др. Руководство по биометрии. /Болл Руд, Коннел Джонатан X., Панканти Шарат, Ратха Налини К., Сеньор Эндрю У. //Москва: Техносфера, 2007. - 368 с. (первый абзац на с. 48).
3. МЕРКОВ А.Б. Основные методы, применяемые для распознавания рукописного текста, начальная версия 24.04.2002, найдено 18.02.2008 в Интернет на http://www.recognition.mccme.ru/pub/RecognitionLab.html/methods.html
4. Р. Хартсхорн. Основы проективной геометрии. М.: Мир, 1970. - 161 с.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДИНАМИЧЕСКОЙ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ОСОБЕННОСТЯМ ПОЧЕРКА | 2013 |
|
RU2541131C2 |
| СИСТЕМА И СПОСОБ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЕЙ ЭВМ (ВАРИАНТЫ) | 2011 |
|
RU2459252C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА ПО ЕГО УНИКАЛЬНОЙ ПОДПИСИ | 2012 |
|
RU2483355C1 |
| СПОСОБ ОЦЕНКИ СХОДСТВА ОБРАЗЦОВ ПОЧЕРКА И СПОСОБЫ ВЕРИФИКАЦИИ ЛИЧНОСТИ И ИДЕНТИФИКАЦИИ ПОЧЕРКА С ИСПОЛЬЗОВАНИЕМ ДАННОГО СПОСОБА ОЦЕНКИ | 2006 |
|
RU2340941C2 |
| СПОСОБ КОНТРОЛЯ ИСПОЛНЕНИЯ ДОМАШНЕГО АРЕСТА С БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИЕЙ КОНТРОЛИРУЕМОГО | 2013 |
|
RU2543958C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ЗНАКОВ | 2008 |
|
RU2390843C2 |
| СПОСОБ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ ПО ПОЧЕРКУ В КОМПЬЮТЕРИЗИРОВАННОЙ СИСТЕМЕ КОНТРОЛЯ ДОСТУПА | 2011 |
|
RU2469397C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ОСОБЕННОСТЯМ ПОДПИСИ | 1998 |
|
RU2148274C1 |
| СПОСОБ КОМПЛЕКСНОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ЧЕЛОВЕКА, ПАСПОРТНОГО КОНТРОЛЯ И ДИАГНОСТИКИ ТЕКУЩЕГО ПСИХОФИЗИОЛОГИЧЕСКОГО СОСТОЯНИЯ ЛИЧНОСТИ И КОМПЬЮТЕРНАЯ СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2003 |
|
RU2256223C2 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННОГО БИОМЕТРИЧЕСКОГО УДОСТОВЕРЕНИЯ ЛИЧНОСТИ | 2008 |
|
RU2391704C1 |
Изобретение относится к области идентификации личности по рукописному тексту. Техническим результатом является повышение достоверности идентификации личности. Способ идентификации личности по рукописному тексту заключается в том, что предварительно формируют базу данных из преобразованных в цифровую форму эталонных рукописных текстов в виде шаблонов и матриц, содержащих идентификационные параметры в виде средних значений углов наклона траектории текста, полученных делением текста на отдельные фрагменты, дроблением рисунка текста на элементарные составляющие и их линеаризацией. А при исследовании нового предъявленного образца рукописного почерка формируют шаблон и идентификационную матрицу аналогичным эталонным образцам образом. Сравнивают и принимают решение об отнесении предъявленного рукописного текста к одной из эталонных. 1 з.п. ф-лы, 3 ил.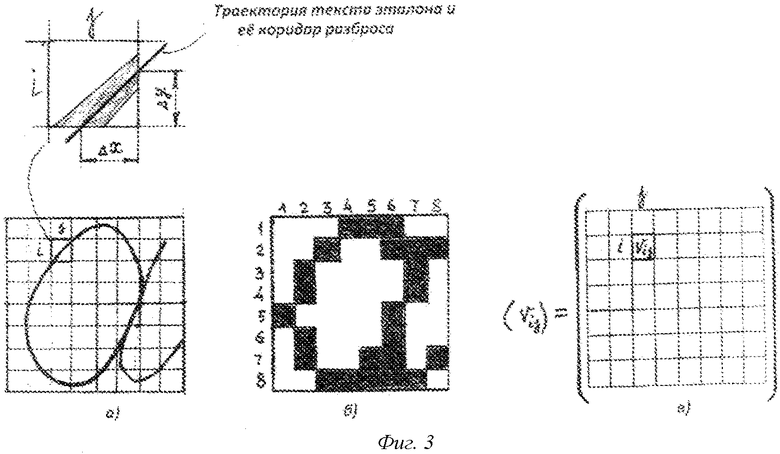
1. Способ идентификации личности по рукописному тексту, включающий преобразование в цифровую форму распознаваемого и эталонного текстов, их деление на отдельные фрагменты и совмещение каждого из исследуемых фрагментов с соответствующим эталонным, сравнение и определение совпадения распознаваемого и эталонного образцов текста, отличающийся тем, что после многократного сканирования эталонного рукописного текста осуществляют деление текста на отдельные фрагменты, выделяют на каждом примере фрагмента рукописного текста линии траектории текста, далее дробят рисунок фрагмента текста на элементарные ячейки так, что в пределах элементарной ячейки получают прямой участок траектории текста, далее для всех реализаций эталонного текста по каждому фрагменту для каждой элементарной его ячейки вычисляют среднее значение и среднее квадратическое отклонение угла наклона, по вычисленным значениям формируют идентификационную матрицу, размерность которой равна размерности фрагмента, а ненулевые значения которой содержат величины средних углов наклона и средних квадратических отклонений, запоминают эти значения средних углов наклонов и средних квадратических отклонений и используют их при идентификации личности по ее рукописному тексту; в процессе идентификации предъявленного рукописного текста осуществляют разбиение отсканированного рисунка исследуемого рукописного текста на фрагменты, их масштабирование, выделение на каждом примере фрагмента рукописного текста линии траектории текста, дробление рисунка фрагмента текста на элементарные ячейки аналогично дроблению фрагмента эталонного текста, вычисление для каждой элементарной ячейки фрагмента значений угла наклона текста, формирование по вычисленным значениям углов наклона матрицы углов наклона, размерность которой равна размерности идентификационной матрицы фрагмента эталона, сравнение этих значений углов наклона текста с соответствующими значениями средних углов наклона фрагмента эталонного текста из базы данных, причем в случае поворота шаблона фрагмента эталонной подписи для полного совмещения значимых ячеек шаблона корректируют углы наклона траектории исследуемого текста по каждой значимой ячейке на величину угла поворота шаблона, при этом в случае совпадения вычисленных значений углов наклона со средними углами наклона фрагмента эталонного текста с заданной вероятностью исследуемый текст считается авторским, а в случае несовпадения вычисленных и эталонных значений процедура идентификации прекращается.
2. Способ по п.1, отличающийся тем, что позволяет классифицировать предъявляемый рукописный текст по степени аутентичности с эталонным на классы совпадения с эталонным текстом.
| СПОСОБ ОЦЕНКИ СХОДСТВА ОБРАЗЦОВ ПОЧЕРКА И СПОСОБЫ ВЕРИФИКАЦИИ ЛИЧНОСТИ И ИДЕНТИФИКАЦИИ ПОЧЕРКА С ИСПОЛЬЗОВАНИЕМ ДАННОГО СПОСОБА ОЦЕНКИ | 2006 |
|
RU2340941C2 |
| СПОСОБ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ ПО ПОЧЕРКУ В КОМПЬЮТЕРИЗИРОВАННОЙ СИСТЕМЕ КОНТРОЛЯ ДОСТУПА | 2011 |
|
RU2469397C1 |
| СИСТЕМА И СПОСОБ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЕЙ ЭВМ (ВАРИАНТЫ) | 2011 |
|
RU2459252C1 |
| JP 2002140709 A, 17.05.2002 | |||
| US 7620244 B1, 17.11.2009 | |||

