Изобретение относится к технике распознавания печатного и рукописного текста, представленного в виде векторно-растрового графического изображения, полученного сканированием или цифровым фотографированием. Изобретение может быть использовано при сканировании и переводе в электронный вид бумажной документации, включая печатную и рукописную документацию.
Известен способ распознавания символов по информации растрового изображения [1]. По этому способу изображение символа распознается при помощи настраиваемого и/или ненастраиваемого классификаторов и контекстного анализа. Данный способ позволяет распознавать лишь печатный текст при достаточно низком уровне шума и искажений и не обладает способностью к самообучению. К примеру, если распознавание сканированного текста проходит с минимальными ошибками, то распознавание цифрового сфотографированного текста, либо листов отсканированных старых книг или сшитых печатных документов без их расшивки проходит с достаточно частыми ошибками. Причина этого - то, что при фотографировании или сканировании происходит деформация образов печатных знаков из-за неплотного прилегания бумаги к поверхности сканера по причине изгиба бумаги в начале или конце строк в областях, близких к переплету. Кроме того, этот способ очень плохо распознает рукописные тексты из-за естественной нестабильности рукописных букв.
Известен также способ [2, страница 57, рисунок 3.4], отличающийся использованием для анализа растровых изображений искусственной нейронной сети. При этом значения яркости точек растрового изображения подаются на входы искусственной нейронной сети, в простейшем случае состоящей из одного нейрона. Практика показывает, что при этом приемлемых результатов распознавания символов достигнуть не удается. Однако использование такого способа позволяет создавать самообучающиеся средства распознавания рукописных и печатных символов, корректирующие свое поведение после каждой выявленной ошибки.
Известен способ идентификации личности по особенностям подписи [3]. Этот способ позволяет надежно идентифицировать человека по особенностям его почерка. При этом выполняется разложение кривых рукописного ввода «живой подписи» на ортогональные проекции x(t), у(t), масштабирование и вычисление коэффициентов разложения масштабированных кривых в ортогональный ряд Фурье. Полученные коэффициенты сравнивают с эталонами и на основании результатов сравнения делают вывод о личности автора. Данный способ не предназначен для распознавания одиночных символов, однако позволяет с большой точностью определить отдельно написанный рукописный знак, то есть способ может быть успешно применен и в области распознавания символов.
Известен способ идентификации личности по особенностям подписи [4, страницы 165-172]. Данный способ отличается от способа [3] применением для анализа коэффициентов Фурье обучаемой искусственной нейронной сети. Благодаря использованию большой нейронной сети удается учитывать сотни параметров и снизить вероятность ошибок на несколько порядков. Если по способу [3] удается учитывать не более 32 наиболее информативных параметров, то по способу [4] удается учитывать до 416 параметров, включая менее информативные параметры, которые, тем не менее, в совокупности обладают достаточно большой информативностью. Это позволяет снизить вероятность коллизий на несколько порядков (от миллиона раз или 6 порядков до миллиарда раз или 9 порядков). Применение больших нейронных сетей по способу [4] позволяет решить проблему надежного распознавания непосредственно вводимых («живых») рукописных знаков (знаков, сохраняющих при их вводе динамику написания), однако этот способ не может быть применен для распознавания «мертвых» (написанных на бумаге и утративших динамику воспроизведения) рукописных знаков. Способ [4] также нельзя использовать для распознавания печатных знаков, нанесенных ранее на листы бумаги.
Наиболее близким к предлагаемому является способ распознавания символов, нечувствительный к шуму [5]. По этому способу осуществляют выделение распознаваемого знака. Далее выделяют точку начала обхода знака (например, самую верхнюю точку). Далее осуществляют обход границ изображения символа по внешнему контуру. Далее определяют наличие внутренних контуров у распознаваемого символа, далее находят начальные точки обхода внутренних контуров распознаваемого символа. Далее вычисляют характеристики кривых обхода, которые для распознавания символа сравнивают с эталонными. Данный способ отличается увеличенной устойчивостью к шуму. Однако он не дает возможности дообучать систему на выявленных оператором ее ошибках. Кроме того, способ-прототип [5] имеет недостаточную устойчивость к шумам сканирования и недостаточную устойчивость к нестабильности рукописного почерка человека.
Целью предлагаемого изобретения является повышение качества распознавания символов в условиях высокого уровня помех и деформаций изображений, связанных с вариациями угла зрения сканера по отношению к различным фрагментам сканируемого документа, обусловленными, например, изгибом носителя знаков в местах сшива документов. Кроме того, целью изобретения является расширение функциональных возможностей способа распознавания до возможности распознавания не только печатных, но и рукописных знаков, написанных почерком одного человека, с возможностью дообучения средства распознавания.
Сущность предлагаемого изобретения по п.1 формулы состоит в том, что изображения знаков, находящихся на бумаге, сканируют или фотографируют и полученное цифровое растровое изображение подвергают обработке. Выделяют строки знаков и/или отдельно стоящие знаки. В случае выделения строки печатных знаков ее разбивают на равные по своим параметрам знакоместа. Выделяют границы каждого знакоместа распознаваемого знака. Далее выделяют горизонтальные (верхнюю и нижнюю) и вертикальные (правую и левую) границы одного знакоместа, анализируя значения изменения яркостных характеристик элементов растрового изображения. Затем выделяют точку начала обхода, в качестве которой можно использовать, например, крайнюю верхнюю правую точку изображения символа, точку пересечения линий изображения символа, либо другую точку. Далее выполняют обход внешнего контура изображения знака с постоянной скоростью, например, против часовой стрелки. Далее находят число внутренних полостей изображения знака, анализируя значения изменений яркостных характеристик изображения символа. Затем для каждой найденной полости выделяют точку начала обхода по заранее заданному правилу и затем выполняют с постоянной скоростью обход каждой внутренней полости изображения символа.
Отличие предложенного способа от прототипа состоит в том, что вычисляют ортогональные проекции кривых обхода на оси координат (например, на ортогональные декартовы оси координат, получая кривые X(t) и Y(t)), после чего сглаживают эти кривые. Далее масштабируют сглаженные проекции X(t) и Y(t) по амплитуде и времени, приводя их к заранее заданным значениям амплитуд колебаний и времени обхода. Далее находят коэффициенты разложения функций кривых обхода X(t) и Y(t)) в один из ортогональных рядов (например, в ортогональный ряд Фурье), после чего полученные коэффициенты разложения в ряд сравнивают с заранее запомненными шаблонами. По результатам сравнения вычисленных коэффициентов Фурье с их шаблонами делают вывод о соответствии анализируемого знака тому или иному классу (выбор правила сравнения данных с их шаблонами для п.1 формулы изобретения несущественен, может быть использовано любое из известных классических решающих правил).
Преимуществом предлагаемого способа по отношению к прототипу является повышение точности и помехозащищенности средства распознавания символов, а также возможность распознавания рукописных символов. Технический результат достигается тем, что дополнительно введена операция сглаживания шумов, образуемых дискретизацией изображения знака. Кроме того, случайные ошибки и шумы дополнительно подавляются при разложении проекций X(t) и Y(t) в ортогональный ряд (известно, что представление данных в виде коэффициентов ортогональных рядов устойчивее к шумам по сравнению с иными неортогональными функционалами и, в том числе, функционалами, используемыми у прототипа, - центры, длины, наклоны отрезков кривой обхода).
По предложенному способу удается использовать для сглаживания данных обычные одномерные низкочастотные фильтры. Если пытаться осуществлять сглаживание в способе прототипа, придется использовать двухмерные низкочастотные фильтры, сглаживающие (выравнивающие) границы знака. Очевидно, что двухмерная фильтрация менее эффективна, чем одномерная фильтрация при одинаковых затратах вычислительных ресурсов. По предложенному способу удается реализовывать низкочастотные сглаживающие фильтры с окном сглаживания до 64 точек или порядка 20% общей длины анализируемых кривых. Аналогичный двухмерный фильтр (матрица 8×8 точек) требует тех же ресурсов, но соответствует окну одномерного фильтра только из 8 точек. При переходе к одномерным сглаживаниям шумов по каждой из проекций X(t) и Y(t) удается при одинаковых вычислительных ресурсах примерно в 8 раз увеличить ширину окна сглаживания и тем самым примерно в 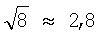 раза увеличить подавление случайных составляющих шума.
раза увеличить подавление случайных составляющих шума.
Недостатком предлагаемого способа по п 1 формулы изобретения является невозможность его дообучения. По п.1 формулы необходимо заранее обучить систему распознавания, снабдив ее шаблонами распознаваемых символов. Это возможно сделать только для типовых шрифтов, отсканированных без искажений. Для рукописных букв людей с разными почерками и для печатных шрифтов с искажениями из-за изгибов бумаги в переплете способ по п.1 формулы дает значительное число ошибок.
Предлагается дополнительный способ по п.2 формулы, отличающийся от вышеописанного тем, что коэффициенты разложения кривых обхода в ортогональный ряд Фурье анализируют при помощи заранее обученной для распознавания типовых символов искусственной нейронной сети. При этом коэффициенты разложения в ряд Фурье подаются на входы нейронов искусственных нейронных сетей, каждая из которых обучена для распознавания определенного символа (класса). В случае обнаружения ошибок системой ее пользователь вводит правильное значение символа. Выявленные ошибки запоминают и далее при накоплении достаточной статистики на выявленных ошибках дообучают уже имеющиеся искусственные нейронные сети. Решение о дообучении той или иной нейронной сети принимает человек-пользователь.
В случае выявления человеком-пользователем нескольких однотипных искажений некоторого символа пользователь принимает решение о введении еще одного класса уже имеющегося символа. В этом случае формируют дополнительную нейронную сеть и обучают ее распознавать новый класс типового искажения заданного символа на имеющихся примерах этого искажения.
Преимуществом способа по п.2 по сравнению с описанным выше способом по п.1 формулы является возможность дообучения средства распознавания, позволяющая за счет адаптации повысить точность распознавания символов в конкретных условиях, а также позволяющая распознавать рукописные символы, воспроизведенные рукописным почерком, характерным для одного человека.
Технический результат, достигаемый предлагаемыми способами по п.1 и п.2 формулы, заключается в создании средства распознавания символов, нечувствительного к высокому уровню помех и деформаций изображений, способного распознавать не только печатные, но и рукописные знаки и обладающего способностью к дообучению средства на типовых искажениях символов, появляющихся вблизи переплета сканируемого документа.
Одной из проблем при использовании способа по п.2. формулы является то, что процедура дообучения в ручном режиме занимает много времени у пользователя и тем неудобна. При распознавании рукописного почерка эта проблема не может быть решена из-за высокой нестабильности рукописного почерка каждого человека. Человек вынужден тратить свое время на дообучение средства распознавания особенностям распознавания псевдодинамики своего рукописного почерка.
При распознавании печатных знаков эта техническая задача может быть решена в соответствии с п.3 формулы изобретения. Предлагается определять наклон каждой строки в ее центре, выравнивать этот наклон для изображений с нарушением параллельности строк элементам всего изображения. Кроме того, предлагается измерять кривизну строк печатных знаков в зонах оптического искажения (обычно находящихся в начале или конце строки знаков) и сортировать создаваемые шаблоны символов и заранее обученные нейронные сети по значениям кривизны строки символов, отражающей величину оптической деформации символов. После выделения строки символов измеряют значения ее кривизны (степени изогнутости) для каждого из распознаваемых символов, далее при распознавании очередного знака обращаются к системе заранее созданных шаблонов или к системе заранее обученных нейронных сетей, имеющих кривизну строки, наиболее близкую к кривизне распознаваемого в текущий момент знака.
Техническим эффектом от использования способа по п.3. формулы является то, что типовые искажения печатных знаков, обусловленные изгибом бумажного носителя печатных знаков в месте сшивки (переплета), учитываются системой распознавания текста. Снижается уровень ошибок при распознавании печатных знаков листов отсканированных (сфотографированных) без расшивки книг и печатных документов, переплетенных для последующего их хранения.
На фигуре 1 представлен пример печатного знака «А» с двумя контурами обхода. В качестве точки начала обхода выбиралась крайняя правая и одновременно крайняя верхняя точка знака на внешней и внутренней линиях обхода.
На фигуре 2 приведен пример деформированных из-за сшивки листов книги строки знаков с изменяющейся по мере деформации кривизной строки.
Практическая реализация предложенного способа по п.п.1, 2, 3 заявленного изобретения ориентируется на преобразование в компактную цифровую форму (текст и рисунок) цифровых изображений листов книг, учебников, газетных и журнальных страниц, а также рукописных конспектов, написанных рукой одного автора.
Средство, реализующее предложенный способ, выделяет из растрового изображения строки букв и измеряет их наклон в центре строки. Далее осуществляется трансформация изображения через его вращение, выравнивающая центры строк распознаваемых символов. Кроме того, осуществляют измерение кривизны строк в зонах начала и конца строк, где обычно возникают оптические искажения печатных символов, как это показано на фигуре 2.
Далее осуществляют разбиение строк символов на отдельные знакоместа. При распознавании печатных знаков знакоместа выбирают стандартных размеров. При распознавании рукописных букв размеры знакоместа зависят от знака и корректируются по результатам распознавания.
После выделения каждого из знакомест находят точку старта обхода внешнего контура распознаваемого символа. Например, может быть использована верхняя правая точка внешнего контура распознаваемого символа, как это показано на фигуре 1. Далее определяют число внутренних контуров распознаваемого знака и осуществляют обход внутренних контуров. Для знака «А», приведенного на фигуре 1, по предложенному способу будет выделен внешний и внутренний контуры. При этом будут получены две кривых обхода Q1(t) и Q2(t).
Эти две кривые раскладываются на соответствующие проекции X1(t), Y1(t) и X2(t), Y2(t). Далее осуществляют сглаживание полученных кривых, применяя один из низкочастотных фильтров. При этом проекции внешнего контура X1(t), Y1(t) будут иметь период времени псевдонаписания T1, а проекции внутреннего контура X2(t), Y2(t) будут иметь период времени псевдонаписания Т2.
Далее раскладывают 4 кривые X1 (t), Y1(t) и X2(t), Y2(t) в 4 ряда Фурье по 4 периодам: Т1 и, соответственно, Т2. При этом для каждой из 4 кривых получают по 16 косинусных и по 16 синусных коэффициента. Полученные коэффициенты масштабируют по амплитуде, приводя их общую энергию к заранее заданному эталонному значению.
Далее осуществляют сравнение полученных 128 контролируемых параметров с эталонными значениями этих параметров по всем распознаваемым знакам. Находят наиболее близкие значения и определяют тем самым класс распознаваемого знака.
В случае, если распознаваемый знак попал в зону оптического искажения, используют систему шаблонов с коэффициентом кривизны, наиболее близким к коэффициенту кривизны строки в месте, где находился распознаваемый знак.
В случае, если средство распознавания делает ошибки, пользователь осуществляет их исправления. При этом пользователь отвечает на вопрос средства распознавания относительно необходимости введения нового дополнительного класса или же корректировки шаблона уже имеющегося класса.
Обычно при распознавании печатных знаков заданного шрифта достаточно иметь шаблоны этого шрифта и шаблоны их типового искажения. Нет необходимости собирать статистику возможных вариантов влияния шумов сканирования.
При распознавании рукописных текстов нет возможности заранее разместить в средство распознавания все возможные варианты рукописных почерков. При распознавании конкретного рукописного текста обычно возникает значительный поток ошибок. Пользователь исправляет эти ошибки, при этом система накапливает статистику примеров написания в конкретном тексте различных букв. При достаточном объеме статистик (по 12-16 примеров написания одного символа) средство запрашивает у пользователя разрешение на процедуру дообучения нейросетевого распознавателя. При этом пользователь отвечает на вопрос средства распознавания относительно необходимости введения нового дополнительного класса (новой дополнительной нейронной сети) или же корректировки нейронных весов нейронной сети уже имеющегося класса.
В случае команды на дообучение средство корректирует весовые коэффициенты нейронов уже имеющейся нейронной сети. В случае обучения новой нейронной сети вводится еще один класс уже имеющегося знака. И в том и в другом случае обучение большой многослойной нейронной сети с:
- 64 входами для одноконтурных знаков;
- 128 входами для двухконтурных знаков;
- 192 входами для трехконтурных знаков;
- 256 входами для четырехконтурных знаков
осуществляется по любому известному алгоритму обучения, однако наиболее выгодными является использование быстрых алгоритмов обучения [4], способных обучать многослойную сеть из нескольких тысяч нейронов всего за несколько секунд машинного времени.
Положительным техническим эффектом предложенного способа распознавания знаков является снижение вероятности ошибок распознавания за счет учета оптических искажений начала и конца строк переплетенных документов. Кроме того, при распознавании рукописных текстов также происходит снижение вероятности появления ошибок из-за возможности дообучения средства распознавания особенностям рукописного почерка конкретного человека.
Источники информации
1. Патент РФ №2234126 «Способ распознавания текста с применением настраиваемого классификатора», МПК G06K 9/66, приоритет 09.09.2002, заявка №2002123859, заявитель - Аби Софтвер ЛТД, авторы: Анисимович К.В., Терещенко В.В., Рыбкин В.Ю.
2. Ф.Уоссерман. Нейрокомпьютерная техника. М.: «Мир», 1992 г.
3. Патент РФ №2148274 «Способ идентификации личности по особенностям подписи», приоритет 17.08.1998, заявка №98115719, заявитель - ФГУП «Пензенский государственный научно-исследовательский электротехнический институт», авторы: Иванов А.И., Сорокин И.А., Бочкарев В.Л., Оськин В.А., Андрианов В.В.
4. В.И.Волчихин, А.И.Иванов, В.А.Фунтиков «Быстрые алгоритмы обучения нейросетевых механизмов биометрико-криптографической защиты информации». Издательство Пензенского государственного университета, 2005 г.
5. United States Patent 5,237,627 «Noise tolerant optical character recognition system»; int. cl. G06K 9/00; appl. no. 772,054, filed Jun. 27, 1991; inventors: Dan S.Johnson, Mark D.Seaman.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ нейросетевого распознавания рукописных текстовых данных на изображениях | 2024 |
|
RU2837308C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| Способ автоматического формирования базы биометрических образов "Свой" для обучения и тестирования средств высоконадежной биометрико-нейросетевой аутентификации личности | 2020 |
|
RU2734846C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО РУКОПИСНОМУ ТЕКСТУ | 2014 |
|
RU2553094C1 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2007 |
|
RU2365047C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СИМВОЛА НА БАНКНОТЕ И СОПРОЦЕССОР ДЛЯ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ УСТРОЙСТВА ДЛЯ ОБРАБОТКИ БАНКНОТ | 2019 |
|
RU2707320C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| СПОСОБ АНОНИМНОЙ БИОМЕТРИЧЕСКОЙ РЕГИСТРАЦИИ ЧЕЛОВЕКА | 2008 |
|
RU2371765C2 |
| СПОСОБ ЗАЩИТЫ ПЕРСОНАЛЬНЫХ ДАННЫХ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ И АУТЕНТИФИКАЦИИ | 2007 |
|
RU2346397C1 |
| СПОСОБ КОНТРОЛЯ ИСПОЛНЕНИЯ ДОМАШНЕГО АРЕСТА С БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИЕЙ КОНТРОЛИРУЕМОГО | 2013 |
|
RU2543958C2 |
Изобретение относится к технике распознавания печатного и рукописного текста. Технический результат заключается в снижении вероятности ошибок при распознавании знаков. Такой результат достигается путем осуществления обхода внешнего и внутренних контуров распознаваемого знака с постоянной скоростью, разложения каждой кривой обхода на две проекции X(t), Y(t) и сглаживания этих функций. При этом в качестве контролируемых параметров используют коэффициенты ряда Фурье или иного ортогонального ряда кривых X(t), Y(t), которые далее масштабируют и сравнивают их с эталонами, принадлежащими шаблонам распознаваемых знаков. 2 з.п. ф-лы, 2 ил.
1. Способ распознавания знаков, состоящий в том, что анализируют растровое изображение, выделяют строки знаков, выделяют горизонтальные и вертикальные границы одного знакоместа, выделяют точку начала обхода границы знака по заранее заданному правилу, далее осуществляют обход внешнего контура знака, после этого определяют число внутренних не заполненных изображением знака полостей, для каждой полости находят по заранее заданному правилу точку обхода и осуществляют обход полости, после чего выделяют из кривых их характерные параметры и сравнивают их с шаблонами, отличающийся тем, что обход знаков осуществляют с постоянной скоростью движения по границе изображения, далее вычисляют ортогональные проекции кривых обхода на оси координат, сглаживают и затем масштабируют их, далее находят коэффициенты разложения кривых обхода в ортогональный ряд и затем сравнивают полученные коэффициенты с их шаблонами.
2. Способ по п.1, отличающийся тем, что коэффициенты разложения кривых обхода в ортогональный ряд анализируют при помощи заранее обученной для распознавания типовых знаков искусственной нейронной сети, в случае обнаружения ошибок пользователь их исправляет, ошибки запоминают и далее при накоплении достаточной статистики на выявленных ошибках дообучают уже имеющиеся искусственные нейронные сети, уточняя типовые образы знаков или вводят новые классы для типовых искажений уже имеющихся классов знаков и обучают их распознаванию дополнительные нейронные сети; решение о дополнении типового знака еще одним классом этого знака с часто встречающимся искажением принимает пользователь.
3. Способ по п.1 или 2, отличающийся тем, что определяют наклон строки знаков в ее центральной части, выравнивают значение наклона строки знаков в ее центре по отношению к элементам цифрового изображения, измеряют кривизну строки знаков в зонах оптического искажения распознаваемых печатных знаков, и в зависимости от значения кривизны строки знаков выбирают ближайшую по значению кривизны систему заранее созданных шаблонов распознаваемых знаков и/или заранее обученных нейронных сетей.
| СПОСОБ МНОГОЭТАПНОГО АНАЛИЗА ИНФОРМАЦИИ РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2002 |
|
RU2234734C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ОСОБЕННОСТЯМ ПОДПИСИ | 1998 |
|
RU2148274C1 |
| RU 2003125815 A, 20.02.2005 | |||
| US 5237627 A, 17.08.1993. | |||

