[0001] Настоящее раскрытие испрашивает приоритет предварительной заявке на патент США № 61/512,771 поданной 28 июля 2011, содержимое которой полностью включено посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
[0002] Настоящее раскрытие относится к кодированию видео.
УРОВЕНЬ ТЕХНИКИ
[0003] Цифровые возможности видео могут быть включены в широкий диапазон устройств, включая цифровые телевизоры, цифровые системы прямого вещания, беспроводные системы вещания, персональные цифровые помощники (PDA), портативные или настольные компьютеры, планшетные компьютеры, считыватели электронных книг, цифровые камеры, цифровые устройства регистрации, цифровые медиа плееры, видео игровые устройства, пульты видеоигр, сотовые или спутниковые радиотелефоны, так называемые "смартфоны", устройства организации видео телеконференций, устройства потоковой передачи видео и т.п. Цифровые видео устройства реализуют способы сжатия видео, такие как описанные в стандартах, определенных посредством MPEG-2, MPEG-4, ITU-T H.263 или ITU-T H.264/MPEG-4, Part 10, Advanced Video Coding (AVC), стандарта высокоэффективного кодирования видео (HEVC), развивающегося в настоящее время, и расширениях таких стандартов. Видео устройства могут передавать, принимать, кодировать, декодировать и/или сохранять цифровую видео информацию более эффективно, реализуя такие способы сжатия видео.
[0004] Способы сжатия видео выполняют пространственное (внутри картинки) предсказание и/или временное (между картинками) предсказание, чтобы уменьшить или удалить избыточность, присущую видео последовательностям. Для основанного на блоках кодирования видео вырезка видео (то есть, видео кадр или часть видео кадра) может быть разделена на видео блоки, которые могут также упоминаться как блоки дерева, единицы кодирования (CU) и/или узлы кодирования. Видео блоки во внутренне кодированной (I) вырезке картинки кодируют, используя пространственное предсказание относительно опорных выборок в соседних блоках в той же самой картинке. Видео блоки во внешне кодированной (P или B) вырезке картинки могут использовать пространственное предсказание относительно опорных выборок в соседних блоках в той же самой картинке или временное предсказание относительно опорных выборок в других опорных картинках.
[0005] Пространственное или временное предсказание приводит к предсказывающему блоку для блока, который должен быть закодирован. Остаточные данные представляют пиксельные разности между первоначальным блоком, который должен быть закодирован, и предсказывающим блоком. Внешне кодированный блок кодируют согласно вектору движения, который указывает на блок опорных выборок, формирующих предсказывающий блок, и остаточным данным, указывающим разность между закодированным блоком и предсказывающим блоком. Внутренне кодированный блок кодируют согласно режиму внутреннего кодирования и остаточным данным. Для дальнейшего сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования, приводя к остаточным коэффициентам преобразования, которые затем могут квантоваться. Квантованные коэффициенты преобразования, первоначально размещенные в двумерном массиве, могут быть сканированы, чтобы сформировать одномерный вектор коэффициентов преобразования, и энтропийное кодирование может быть применено, чтобы достигнуть еще большей степени сжатия.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] В целом настоящее раскрытие описывает методы для кодирования видео данных. Например, настоящее раскрытие описывает способы для выполнения кодирования видео множественных видов (MVC), и для MVC-расширения для стандарта кодирования видео HEVC, находящегося в настоящее время в развитии. Таким образом, MVC является методом кодирования видео для инкапсуляции множественных видов видео данных. Каждый вид может соответствовать различной перспективе, или углу, под которым были захвачены соответствующие видео данные общей сцены. Способы настоящего раскрытия в целом касаются формирования единиц уровня абстракции сети (NAL) MVC, наборов параметров MVC, и т.п.
[0007] В одном примере аспекты настоящего раскрытия относятся к способу декодирования видео данных, который включает в себя получение, из закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видео данных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и при этом одна или более единиц NAL инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида и включают в себя информацию, указывающую порядок декодирования соответствующих компонентов вида; получение информации, из закодированного потока битов и отдельной от единиц NAL, указывающую отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида; и декодирование закодированных видео данных из множества компонентов вида в порядке декодирования на основании принятой информации.
[0008] В другом примере аспекты настоящего раскрытия относятся к устройству для декодирования видео данных, которое включает в себя один или более процессоров, сконфигурированных, чтобы получить, из закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видео данных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и в котором одна или более единиц NAL инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида и включают в себя информацию, указывающую порядок декодирования соответствующих компонентов вида; получить информацию, из закодированного потока битов и отдельную от единиц NAL, указывающую отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида; и декодировать закодированные видео данных из множества компонентов вида в порядке декодирования на основании принятой информации.
[0009] В другом примере аспекты настоящего раскрытия относятся к устройству для декодирования видео данных, которое включает в себя средство для получения, из закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видео данных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и в котором одна или более единиц NAL инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида и включают в себя информацию, указывающую порядок декодирования соответствующих компонентов вида; средство для получения информации, из закодированного потока битов и отдельной от единиц NAL, указывающей отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида; и средство для декодирования закодированных видео данных из множества компонентов вида в порядке декодирования на основании принятой информации.
[0010] В другом примере аспекты настоящего раскрытия относятся к невременному считываемому компьютером запоминающему носителю, имеющему инструкции, сохраненные на нем, которые, когда выполняются, вынуждают один или более процессоров получать, из закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видео данных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и при этом одна или более единиц NAL инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида и включают в себя информацию, указывающую порядок декодирования соответствующих компонентов вида; получать информацию, из закодированного потока битов и отдельную от единиц NAL, указывающую отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида; и декодировать закодированные видео данные из множества компонентов вида в порядке декодирования на основании принятой информации.
[0011] В другом примере аспекты настоящего раскрытия относятся к способу кодирования видео данных, который включает в себя кодирование видео данных для множества компонентов вида для соответствующих видов видео данных, в котором каждый из множества компонентов вида соответствует общему временному местоположению; формирование, в качестве части закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для закодированных видео данных каждого из компонентов вида таким образом, что единицы NAL включают в себя информацию, указывающую порядок декодирования видео данных соответствующих компонентов вида, и инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида; и предоставление информации в закодированном потоке битов, отдельной от единиц NAL, указывающей отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида.
[0012] В другом примере аспекты настоящего раскрытия относятся к устройству для кодирования видео данных, причем устройство содержит один или более процессоров, сконфигурированных, чтобы кодировать видео данные для множества компонентов вида для соответствующих видов видео данных, в котором каждый из множества компонентов вида соответствует общему временному местоположению; формировать, в качестве части закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для закодированных видео данных каждого из компонентов вида таким образом, что единицы NAL включают в себя информацию, указывающую порядок декодирования видео данных соответствующих компонентов вида, и инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида; и предоставлять информацию в закодированном потоке битов, отдельную от единиц NAL, указывающую отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида.
[0013] В другом примере аспекты настоящего раскрытия относятся к устройству для кодирования видео данных, которое включает в себя средство для кодирования видео данных для множества компонентов вида для соответствующих видов видео данных, в котором каждый из множества компонентов вида соответствует общему временному местоположению; средство для формирования, в качестве части закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для закодированных видео данных каждого из компонентов вида таким образом, что единицы NAL включают в себя информацию, указывающую порядок декодирования видео данных соответствующих компонентов вида, и инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида; и средство для предоставления информации в закодированном потоке битов, отдельной от единиц NAL, указывающей отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида.
[0014] В другом примере аспекты настоящего раскрытия относятся к невременному считываемому компьютером запоминающему носителю, имеющему инструкции, сохраненные на нем, которые, когда выполняются, вынуждают один или более процессоров кодировать видео данные для множества компонентов вида для соответствующих видов видео данных, в котором каждый из множества компонентов вида соответствует общему временному местоположению; формировать, в качестве части закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для закодированных видео данных каждого из компонентов вида таким образом, что единицы NAL включают в себя информацию, указывающую порядок декодирования видео данных соответствующих компонентов вида, и инкапсулируют по меньшей мере часть закодированных видео данных для соответствующих компонентов вида; и предоставлять информацию в закодированном потоке битов, отдельную от единиц NAL, указывающую отношения между идентификаторами вида для этих видов и порядок декодирования компонентов вида.
[0015] В другом примере аспекты настоящего раскрытия относятся к способу декодирования видео данных, который включает в себя получение, из закодированного потока битов и для любого компонента вида первого вида, информации опорного вида, указывающей один или более опорных видов для предсказания компонентов вида первого вида; включение, для декодирования первого компонента вида в единице доступа и в первом виде, одного или более опорных кандидатов в списке опорных картинок, в котором один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; и декодирование первого компонента вида на основании одного или более опорных кандидатов в списке опорных картинок.
[0016] В другом примере аспекты настоящего раскрытия относятся к устройству для декодирования видео данных, причем устройство содержит один или более процессоров, сконфигурированных, чтобы получить, из закодированного потока битов и для любого компонента вида первого вида, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида; включить, для декодирования первого компонента вида в единице доступа и в первом виде, одного или более опорных кандидатов в список опорных картинок, при этом один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; и декодировать первый компонент вида на основании одного или более опорных кандидатов в списке опорных картинок.
[0017] В другом примере аспекты настоящего раскрытия относятся к устройству для декодирования видео данных, причем устройство содержит средство для получения, из закодированного потока битов и для любого компонента вида первого вида, информации опорного вида, указывающей один или более опорных видов для предсказания компонентов вида первого вида; средство для включения, для декодирования первого компонента вида в единице доступа и в первом виде, одного или более опорных кандидатов в список опорных картинок, в котором один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; и средство для декодирования первого компонента вида на основании одного или более опорных кандидатов в списке опорных картинок.
[0018] В другом примере аспекты настоящего раскрытия относятся к невременному считываемому компьютером запоминающему носителю, имеющему инструкции, сохраненные на нем, которые, когда выполняются, вынуждают один или более процессоров получать, из закодированного потока битов и для любого компонента вида первого вида, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида; включать, для декодирования первого компонента вида в единице доступа и в первом виде, один или более опорных кандидатов в список опорных картинок, при этом один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; и декодировать первый компонент вида на основании одного или более опорных кандидатов в списке опорных картинок.
[0019] В другом примере аспекты настоящего раскрытия относятся к способу кодирования видео данных, содержащий определение, для любого компонента вида первого вида, информации опорного вида, указывающей один или более опорных видов для предсказания компонентов вида первого вида; включение, для кодирования первого компонента вида в единице доступа и в первом виде, одного или более опорных кандидатов в список опорных картинок, при этом один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; кодирование первого компонента вида на основании одного или более опорных кандидатов в списке опорных картинок; и обеспечение закодированного первого компонента вида с определенной информацией опорного вида в закодированном потоке битов.
[0020] В другом примере аспекты настоящего раскрытия относятся к устройству для кодирования видео данных, содержащему один или более процессоров, сконфигурированных, чтобы определить, для любого компонента вида первого вида, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида; включить, для кодирования первого компонента вида в единице доступа и в первом виде, один или более опорных кандидатов в список опорных картинок, в котором один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; кодировать первый компонент вида на основании одного или более опорных кандидатов в списке опорных картинок; и предоставлять кодированный первый компонент вида с определенной опорной информацией вида в закодированный поток битов.
[0021] В другом примере аспекты настоящего раскрытия относятся к устройству для кодирования видео данных, причем устройство содержит средство для определения, для любого компонента вида первого вида, информации опорного вида, указывающей один или более опорных видов для предсказания компонентов вида первого вида; средство для включения, для кодирования первого компонента вида в единице доступа и в первом виде, одного или более опорных кандидатов в списке опорных картинок, в котором один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; средство для кодирования первого компонента вида на основании одного или более опорных кандидатов в списке опорных картинок; и средство для предоставления закодированного первого компонента вида с определенной опорной информацией вида в закодированном потоке битов.
[0022] В другом примере аспекты настоящего раскрытия относятся к невременному считываемому компьютером запоминающему носителю, имеющему инструкции, сохраненные на нем, которые, когда выполняются, вынуждают один или более процессоров определять, для любого компонента вида первого вида, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида; включать, для кодирования первого компонента вида в единице доступа и в первом виде, один или более опорных кандидатов в список опорных картинок, при этом один или более опорных кандидатов содержат компоненты вида в единице доступа и в опорных видах, указанных информацией опорного вида, при этом количество опорных кандидатов равно количеству опорных видов; кодировать первый компонент вида на основании одного или более опорных кандидатов в списке опорных картинок; и предоставлять кодированный первый компонент вида с определенной опорной информацией вида в закодированном потоке битов.
[0023] Детали одного или более аспектов раскрытия сформулированы в прилагаемых чертежах и описании ниже. Другие признаки, объекты, и преимущества способов, описанных в этом раскрытии, будут очевидны из описания и чертежей, и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0024] ФИГ. 1 является блок-схемой, иллюстрирующей примерную систему кодирования и декодирования видео, которая может использовать способы, описанные в настоящем раскрытии.
[0025] ФИГ. 2 является блок-схемой, иллюстрирующей примерный кодер видео, который может реализовать способы, описанные в настоящем раскрытии.
[0026] ФИГ. 3 является блок-схемой, иллюстрирующей примерный декодер видео, который может реализовать способы, описанные в настоящем раскрытии.
[0027] ФИГ. 4 является концептуальной диаграммой, иллюстрирующей примерный шаблон предсказания кодирования видео с множественными видами (MVC).
[0028] ФИГ. 5A является концептуальной диаграммой, иллюстрирующей пример структуры потока битов, которая может использоваться в реализации одного или более способов настоящего раскрытия.
[0029] ФИГ. 5B является концептуальной диаграммой, иллюстрирующей пример вида, который может быть включен в структуру потока битов согласно ФИГ. 5A.
[0030] ФИГ. 5C является концептуальной диаграммой, иллюстрирующей пример единицы уровня абстракции сети (NAL), который может быть включен в структуру потока битов на фиг. 5A.
[0031] ФИГ. 5D является концептуальной диаграммой, иллюстрирующей другой пример единицы NAL, которая может быть включена в структуру потока битов согласно ФИГ. 5A.
[0032] ФИГ. 6 является блок-схемой, иллюстрирующей примерный способ кодирования потока битов множественных видов.
[0033] ФИГ. 7 является блок-схемой, иллюстрирующей примерный способ декодирования потока битов множественных видов.
[0034] ФИГ. 8 является блок-схемой, иллюстрирующей примерный способ кодирования потока битов множественных видов.
[0035] ФИГ. 9 является блок-схемой, иллюстрирующей примерный способ декодирования потока битов множественных видов.
ПОДРОБНОЕ ОПИСАНИЕ
[0036] Согласно некоторым системам кодирования видео, оценка движения и компенсация движения могут быть использованы для уменьшения временной избыточности в видео последовательности, чтобы достигнуть сжатия данных. В этом случае может генерироваться вектор движения, который идентифицирует предсказывающий блок видео данных, например, блок из другой видео картинки или вырезки, которая может быть использована для предсказания значения текущего кодируемого видео блока. Значения предсказывающего видео блока вычитают из значений текущего видео блока, чтобы сформировать блок остаточных данных. Информация движения (например, вектор движения, индексы вектора движения, направления предсказания, или другая информация) передается от видео кодера к видео декодеру, наряду с остаточными данными. Декодер может определить тот же предсказывающий блок (на основании вектора движения) и восстановить закодированный видео блок, комбинируя остаточные данные с данными предсказывающего блока.
[0037] Кодирование видео множественных видов (MVC) является стандартом кодирования видео для инкапсуляции множественных видов видео данных. Обычно каждый вид соответствует различной перспективе, или углу, под которым были захвачены соответствующие видео данные общей сцены. Кодированные виды могут использоваться для трехмерного (3D) отображения видео данных. Например, два вида (например, виды левого и правого глаза человека-зрителя) могут быть отображены одновременно или почти одновременно, используя различные поляризации света, и зритель может носить пассивные поляризованные очки таким образом, что каждый из глаз зрителя принимает соответствующий из видов. Альтернативно, зритель может носить активные очки, которые закрывают каждый глаз независимо, и отображение может быстро чередоваться между изображениями каждого глаза в синхронизации с очками.
[0038] В MVC конкретная картинка конкретного вида упоминается как компонент вида. То есть, компонент вида некоторого вида соответствует конкретному временному экземпляру вида. Видео с множественными видами может содержать относительно большую величину между видами статистических зависимостей, когда все камеры, использованные для захвата данных множественных видов, захватывают одну и ту же сцену с различных точек обзора. Такие зависимости могут использоваться для объединенного временного и/или предсказания между видами, где изображения не только предсказываются от соседних во времени изображений, но также и от соответствующих изображений от других видов. Таким образом, предсказание между видами может быть выполнено среди картинок в одной и той же единице доступа (то есть, в пределах одного и того же момента времени).
[0039] Предсказание между видами обычно реализуется, как если бы компонент вида в другом виде являлся опорной ссылкой внешнего предсказания. Вместо того, чтобы использовать векторы "движения" для предсказания, предсказание между видами использует векторы "смещения", которые концептуально подобны векторам движения, но описывают смещение, а не движение. Потенциальные межвидовые опорные ссылки сигнализируются в расширении MVC набора параметров последовательности (SPS) и могут быть модифицированы процессом построения списка опорных картинок, который разрешает гибкий порядок внешнего предсказания или опорных ссылок предсказания между видами.
[0040] Видео данные, включая данные видео MVC, могут быть организованы в единицы уровня абстракции сети (NAL), которые обеспечивают "дружественное для сети" представление видео, чтобы обеспечить приложения, такие как видео телефония, хранение, вещание или потоковая передача. Например, видео кодер обычно кодирует каждую картинку видео данных как одну или более независимо декодируемых вырезок. Вырезки могут быть упакованы в единицы NAL для передачи через сеть. Единицы NAL, включающие в себя данные уровня кодирования видео (VCL), могут включать в себя данные для картинки или данные для вырезки картинки. Например, единицы NAL могут включать в себя информацию синтаксиса, такую как значения шаблона кодированного блока (CBP), тип блока, режим кодирования, максимальный размер блока для кодированной единицы (такой как кадр, вырезка, блок, или последовательность), или другую информацию.
[0041] Каждая единица NAL включает в себя заголовок, который идентифицирует тип данных, хранящихся в единице NAL. Примерный заголовок единицы NAL MVC может включать в себя элементы синтаксиса, указывающие идентификатор вида для вида, которому принадлежит единица NAL, принадлежит ли единица NAL так называемой картинке с привязкой, которая может использоваться как точка произвольного доступа (для ссылки посредством других компонентов вида), используется ли единица NAL для предсказания между видами для единиц NAL в других видах, и множество другой информации. Как описано здесь, картинка с привязкой может обычно соответствовать картинке произвольного доступа, и такие термины могут быть использованы взаимозаменяемо. Таким образом, "произвольный доступ" обычно относится к акту начала процесса декодирования для потока битов в точке, отличной от начала потока. Картинка произвольного доступа обычно относится к картинке, которая содержит только внутренне кодированные вырезки (I-вырезки). Кодированные картинки, которые следуют за картинкой произвольного доступа как в порядке декодирования так и порядке вывода, не предсказываются из картинок, предшествующих картинке произвольного доступа, или в порядке декодирования или порядке вывода.
[0042] Обычно единица доступа может включать в себя все компоненты вида конкретного момента времени. Конкретный компонент вида включает в себя все единицы NAL конкретного вида в конкретный момент времени. Единица NAL MVC может содержать однобайтовый заголовок единицы NAL (включая тип единицы NAL) и может также включать в себя расширение заголовка единицы NAL MVC.
[0043] В то время как H.264/AVC включает в себя поддержку MVC, текущее расширение MVC к H.264/AVC может содержать некоторые неэффективности относительно других стандартов кодирования видео. Кроме того, как описано более подробно ниже, прямой импорт MVC из H.264/AVC в другие стандарты кодирования, таких как предстоящий стандарт HEVC, может быть не выполним. Способы настоящего раскрытия обычно касаются формирования относящихся к MVC единиц NAL, относящихся к MVC наборов параметров и т.п. Некоторые способы настоящего раскрытия могут обеспечить эффективное MVC кодирование для предстоящего стандарта HEVC.
[0044] ФИГ. 1 является блок-схемой, иллюстрирующей примерную систему 10 кодирования и декодирования видео, которая может использовать способы для предсказания вектора движения при кодировании множественных видов. Как показано на фиг. 1, система 10 включает в себя устройство-источник 12, которое выдает закодированные видео данные, которые должны быть декодированы в более позднее время устройством 14 назначения. В частности устройство-источник 12 выдает видео данные устройству 14 назначения через считываемый компьютером носитель 16. Устройство-источник 12 и устройство 14 назначения могут содержать любое из широкого диапазона устройств, включая настольные компьютеры, портативные компьютеры (то есть, ноутбуки), планшетные компьютеры, телевизионные приставки, телефонные трубки, такие как так называемые "смартфоны”, так называемые "интеллектуальные" клавиатуры, телевизоры, камеры, устройства отображения, цифровые медиа плееры, пульты видеоигр, устройство потоковой передачи видео, или подобные. В некоторых случаях устройство-источник 12 и устройство 14 назначения могут быть оборудованы для беспроводной связи.
[0045] Устройство 14 назначения может принять закодированные видео данные, которые должны быть декодированы, через считываемый компьютером носитель 16. Считываемый компьютером носитель 16 может содержать любой тип носителя или устройства, способного к перемещению закодированных видео данных от устройства-источника 12 к устройству 14 назначения. В одном примере считываемый компьютером носитель 16 может содержать коммуникационный носитель, чтобы позволить исходному устройству 12 передать закодированные видео данные непосредственно к устройству 14 назначения в реальном времени.
[0046] Закодированные видео данные могут быть модулированы согласно стандарту связи, такому как протокол беспроводной связи, и переданы к устройству 14 назначения. Коммуникационный носитель может содержать любой беспроводной или проводной коммуникационный носитель, такой как радиочастотного (RF, РЧ) спектра или одна или более физических линий передачи. Коммуникационный носитель может быть частью основанной на пакетной передаче сети, такой как локальная сеть, региональная сеть, или глобальная сеть, такая как Интернет. Коммуникационный носитель может включать в себя маршрутизаторы, переключатели, базовые станции, или любое другое оборудование, которое может быть полезным, чтобы облегчить связь от устройства-источника 12 к устройству 14 назначения.
[0047] В некоторых примерах закодированные данные могут быть выведены из интерфейса 22 вывода на устройство хранения. Точно так же, к закодированным данным можно получить доступ от устройства хранения посредством интерфейса ввода. Устройство хранения может включать в себя любой из множества распределенных или локально доступных носителей хранения данных, таких как накопитель на жестких дисках, диски Blu-ray, DVD, CD-ROM, флэш-память, энергозависимая или энергонезависимая память, или любые другие подходящие цифровые носители хранения для того, чтобы хранить закодированные видео данные. В дальнейшем примере устройство хранения может соответствовать файловому серверу или другому промежуточному устройству хранения, которое может хранить кодированное видео, генерируемое устройством-источником 12.
[0048] Устройство 14 назначения может получить доступ к сохраненным видео данным от устройства хранения через потоковую передачу или загрузку. Файловый сервер может быть любым типом сервера, способного к тому, чтобы хранить закодированные видео данные и передавать эти кодированные видео данные к устройству 14 назначения. Примерные файловые серверы включают в себя web-сервер (например, для вебсайта), FTP сервер, устройства сетевых хранилищ данных (NAS), или локальный дисковый накопитель. Устройство 14 назначения может получить доступ к кодированным видео данным через любое стандартное соединение данных, включая интернет-соединение. Оно может включать в себя беспроводный канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем, и т.д.), или комбинацию обоих, которое является подходящим для того, чтобы получить доступ к закодированным видео данным, хранящимся на файловом сервере. Передача кодированных видео данных от устройства хранения может быть потоковой передачей, передачей загрузки или комбинацией обоих.
[0049] Способы настоящего раскрытия не обязательно ограничены беспроводными приложениями или параметрами настройки. Эти способы могут быть применены к кодированию видео в поддержку любого из множества мультимедийных приложений, таких как радиовещания телевизионных передач, передач кабельного телевидения, передач спутникового телевидения, потоковых передач видео по Интернет, такие как динамическая адаптивная потоковая передача по HTTP (DASH), цифровое видео, которое закодировано на носитель хранения данных, декодирование цифрового видео, сохраненного на носителе хранения данных, или других приложений. В некоторых примерах система 10 может быть сконфигурирована, чтобы поддерживать одностороннюю или двухстороннюю передачу видео, чтобы поддерживать приложения, такие как потоковая передача видео, воспроизведение видео, вещание видео, и/или видео телефония.
[0050] В примере согласно ФИГ. 1 устройство-источник 12 включает в себя видео источник 18, видео кодер 20 и интерфейс 22 вывода. Устройство 14 назначения включает в себя интерфейс 28 ввода, видео декодер 30, и устройство 32 отображения. В соответствии с настоящим раскрытием видео кодер 20 из устройства-источника 12 может быть сконфигурирован, чтобы применить способы для предсказания вектора движения при кодировании множественных видов. В других примерах устройство-источник и устройство назначения могут включать в себя другие компоненты или компоновки. Например, устройство-источник 12 может принять видео данные из внешнего видео источника 18, такого как внешняя камера. Аналогично, устройство 14 назначения может взаимодействовать с внешним устройством отображения, вместо включения интегрированного устройства отображения.
[0051] Иллюстрированная система 10 согласно ФИГ. 1 является просто одним примером. Способы для предсказания вектора движения при кодировании множественных видов могут быть выполнены любым цифровым устройством кодирования и/или декодирования видео. Хотя обычно способы настоящего раскрытия выполняются устройством кодирования видео, способы могут также быть выполнены видео кодером/декодером, типично называемым как "кодек". Кроме того, способы настоящего раскрытия могут также быть выполнены препроцессором видео. Устройство-источник 12 и устройство 14 назначения является просто примерами таких устройств кодирования, в которых устройство-источник 12 генерирует закодированные видео данные для передачи к устройству 14 назначения. В некоторых примерах устройства 12, 14 могут работать по существу симметричным способом таким образом, что каждое из устройств 12, 14 включают в себя компоненты кодирования и декодирования видео. Следовательно, система 10 может поддерживать одностороннюю или двустороннюю передачу видео между видео устройствами 12, 14, например, для потоковой передачи видео, воспроизведения видео, вещания видео или видео телефонии.
[0052] Видео источник 18 из устройства-источника 12 может включать в себя устройство захвата видео, такое как видео камера, видео архив, содержащий ранее захваченное видео, и/или интерфейс подачи видео, чтобы принимать видео от поставщика видео контента. В качестве дальнейшей альтернативы, видео источник 18 может генерировать основанные на компьютерной графике данные в качестве исходного видео или комбинацию живого видео, заархивированного видео, и генерируемое компьютером видео. В некоторых случаях если видео источник 18 является видео камерой, устройство-источник 12 и устройство 14 назначения могут сформировать так называемые камерофоны или видео телефоны. Как упомянуто выше, однако, способы, описанные в настоящем раскрытии, могут быть применимыми к кодированию видео в целом и могут быть применены к беспроводным и/или проводным приложениям. В каждом случае захваченное, предварительно захваченное, или генерируемое компьютером видео может быть закодировано видео кодером 20. Закодированная видео информация может затем быть выведена интерфейсом 22 вывода на считываемый компьютером носитель 16.
[0053] Считываемый компьютером носитель 16 может включать в себя временные носители, такие как беспроводное вещание или передача по проводной сети, или носители хранения (то есть, невременные носители хранения), такие как жесткий диск, флэш-накопитель, компакт-диск, цифровой видео диск, диск Blu-ray, или другой считываемый компьютером носитель. В некоторых примерах web-сервер (не показан) может принять закодированные видео данные от устройства-источника 12 и выдать закодированные видео данные устройству 14 назначения, например, с помощью сетевой передачи. Точно так же вычислительное устройство средства производства носителей, таких как средство штамповки дисков, может принять закодированные видео данные от устройства-источника 12 и производить диск, содержащий закодированные видео данные. Поэтому, считываемый компьютером носитель 16, как можно понимать, включает в себя один или более считываемых компьютером носителей различных форм, в различных примерах.
[0054] Интерфейс 28 ввода из устройства 14 назначения принимает информацию от считываемого компьютером носителя 16. Информация считываемого компьютером носителя 16 может включать в себя информацию синтаксиса, определенную видео кодером 20, которая также используется видео декодером 30, которая включает в себя элементы синтаксиса, которые описывают характеристики и/или обработку блоков и других закодированных единиц, например, GOP. Устройство 32 отображения отображает декодированные видео данные пользователю, и может содержать любое из множества устройств отображения, таких как электронно-лучевая трубка (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED), или другой тип устройства отображения.
[0055] Видео кодер 20 и видео декодер 30 каждый может быть реализован как любая из множества подходящих схем кодера или декодера, как применимо, таких как один или более микропроцессоров, цифровых сигнальных процессоров (DSPs), специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA), дискретной логики, программного обеспечения, аппаратного обеспечения, программно-аппаратных средств или любых их комбинаций. Каждый из видео кодера 20 и видео декодера 30 может быть включен в один или более кодеров или декодеров, любой из которых может быть интегрированным как часть объединенного кодера/декодера (кодек) видео. Устройство, включающее в себя видео кодер 20 и/или видео декодер 30, может содержать интегральную схему, микропроцессор, и/или устройство беспроводной связи, такое как сотовый телефон.
[0056] Хотя не показано на фиг. 1, в некоторых аспектах видео кодер 20 и видео декодер 30 могут каждый интегрироваться с аудио кодером и декодером, и могут включать в себя соответствующие блоки MUX-DEMUX (мультиплексоров-демультиплексоров), или другое аппаратное обеспечение и программное обеспечение, чтобы выполнять кодирование как аудио так и видео в общем потоке данных или отдельных потоках данных. Если применимо, блоки MUX-DEMUX могут соответствовать протоколу мультиплексора ITU H.223, или другим протоколам, таким как протокол дейтаграмм пользователя (UDP).
[0057] В примере, показанном на фиг. 1, система 10 также включает в себя сервер/сеть 34 доставки контента, имеющую маршрутизатор 36. В некоторых примерах устройство-источник 12 может связываться с сервером/сетью 34 доставки контента через множество беспроводных и/или проводных передач или запоминающих носителей, как описано выше. Кроме того, в то время как показано отдельными в примере на ФИГ. 1, в некоторых примерах, устройство-источник 12 и сервер/сеть 34 доставки контента содержат одно и то же устройство. Сервер/сеть 34 доставки контента может хранить одну или более версий закодированных видео данных (от видео кодера 20 из устройства-источника 12), и может сделать такие закодированные видео данные доступными для доступа для устройства 14 назначения и видео декодера 30. В некоторых примерах маршрутизатор 36 может быть ответственным за выдачу закодированных видео данных устройству 14 назначения в требуемом формате.
[0058] Видео кодер 20 и видео декодер 30 могут работать согласно стандарту сжатия видео, такому как стандарт высокоэффективного кодирования видео (HEVC), находящемся сейчас в развитии, и могут соответствовать Тестовой Модели HEVC (HM). Альтернативно, видео кодер 20 и видео декодер 30 могут работать согласно другим составляющим собственность стандартам или стандартам промышленности, таким как стандарт ITU-T H.264, альтернативно называемый MPEG-4, Part 10, Advanced Video Coding (AVC), или расширениям таких стандартов. Способы настоящего раскрытия, однако, не ограничены никаким конкретным стандартом кодирования. Другие примеры включают в себя MPEG-2 и ITU-T H.263.
[0059] Стандарт ITU-T H.264/MPEG-4 (AVC) был сформулирован Группой Экспертов по Кодированию видео ITU-T (VCEG) вместе с Группой экспертов по движущимся изображениям ISO/IEC (MPEG) как продукт коллективного товарищества, известного как Объединенная Команда Видео (JVT). В некоторых аспектах способы, описанные в настоящем раскрытии, могут быть применены к устройствам, которые обычно соответствуют стандарту H.264. Стандарт H.264 описан в рекомендации H.264 ITU-T, Усовершенствованном видео кодировании для родовых аудиовизуальных услуг, Группой по изучению ITU-T, и датированный мартом 2005, который может быть упомянут здесь как стандарт H.264 или спецификация H.264, или стандарт или спецификация H.264/AVC. Объединенная Видео Команда (JVT) продолжает работать над расширениями к H.264/MPEG-4 AVC.
[0060] JCT-VC работает над развитием стандарта HEVC. Усилия по стандартизации HEVC основаны на развивающейся модели устройства кодирования видео, называемой Тестовая Модель HEVC (HM). HM предполагает несколько дополнительных возможностей устройств кодирования видео перед существующими устройствами согласно, например, ITU-T H.264/AVC. Например, тогда как H.264 обеспечивает девять режимов кодирования с внутренним предсказанием, HM обеспечивает целых тридцать три режима кодирования с внутренним предсказанием.
[0061] Обычно рабочая модель HM описывает, что видео картинка может быть разделена на последовательность блоков дерева или наибольших единиц кодирования (LCU), которые включают в себя выборки как яркости так и цветности. Данные синтаксиса в пределах потока битов могут определить размер для LCU, которая является наибольшей единицей кодирования в терминах количества пикселей. Вырезка включает в себя многие последовательные блоки дерева в порядке кодирования. Картинка может быть разделена на одну или более вырезок. Каждый блок дерева может быть разделен в единицы кодирования (CUs) согласно квадродереву. В целом структура данных квадродерева включает в себя один узел для каждой CU, с корневым узлом, соответствующим блоку дерева. Если CU разделена на четыре суб-CU, узел, соответствующий этой CU, включает в себя четыре листовых узла, каждый из которых соответствует одной из суб-CU.
[0062] Каждый узел структуры данных квадродерева может обеспечить данные синтаксиса для соответствующей CU. Например, узел в квадродереве может включать в себя флаг разделения, указывающий, разделена ли CU, соответствующая узлу, на суб-CU. Элементы синтаксиса для CU могут быть определены рекурсивно, и могут зависеть от того, разделена ли CU на единицы суб-CU. Если CU не разделяется далее, она называется как листовая CU. В настоящем раскрытии четыре суб-CU листовой CU будут также упоминаться как листовые CU, даже если не будет явного разделения первоначальной листовой CU. Например, если CU размером 16x16 не будет разделена далее, то четыре 8x8 суб-CU будут также упоминаться как листовые CU, хотя CU 16x16 никогда не была разделена.
[0063] CU имеет аналогичную цель, что и макроблок стандарта H.264, за исключением того, что CU не имеет различия в размере. Например, блок дерева может быть разделен на четыре дочерних узла (также называемых суб-CU), и каждый дочерний узел может в свою очередь быть родительским узлом и быть разделен еще на четыре дочерних узла. Заключительный, неразделенный дочерний узел, называемый листовым узлом квадродерева, содержит узел кодирования, также называемый листовой CU. Данные синтаксиса, ассоциированные с закодированным потоком битов, могут определить максимальное количество раз, сколько блок дерева может быть разделен, называемое максимальной глубиной этой CU, и может также определить минимальный размер узлов кодирования. Соответственно, поток битов может также определить наименьшую единицу кодирования (SCU). Настоящее раскрытие использует термин "блок", чтобы относится к любой из CU, PU, или TU, в контексте HEVC, или подобным структурам данных в контексте других стандартов (например, макроблоки и его суб-блоки в H.264/AVC).
[0064] CU включает в себя узел кодирования и единицы предсказания (PU) и единицы преобразования (TU), ассоциированные с узлом кодирования. Размер CU соответствует размеру узла кодирования и должен быть квадратным по форме. Размер CU может ранжироваться от 8x8 пикселей вплоть до размера блока дерева с максимум 64x64 пикселей или больше. Каждая CU может содержать одну или более PU и одну или более TU. Данные синтаксиса, ассоциированные с CU, могут описывать, например, разделение CU в одну или более единиц PU. Режимы разделения могут отличаться между тем, является ли CU кодированной в режиме пропуска или прямом режиме, кодированной в режиме внутреннего предсказания или кодированной в режиме внешнего предсказания. PU могут быть разделены, чтобы быть неквадратными по форме. Данные синтаксиса, ассоциированные с CU, могут также описывать, например, разделение CU в одну или более TU согласно квадродереву. TU может быть квадратной или неквадратной (например, прямоугольной) по форме.
[0065] Стандарт HEVC учитывает преобразования согласно единицам TU, которые могут быть различными для различных CU. TU типично имеют размеры на основании размеров PU в пределах заданной CU, определенной для разделенной LCU, хотя это может не всегда иметь место. TU типично имеют тот же размер или меньший, чем PU. В некоторых примерах остаточные выборки, соответствующие CU, могут быть подразделены на меньшие единицы, используя структуру квадродерева, известную как "остаточное квадродерево" (RQT). Листовые узлы RQT могут упоминаться как единицы преобразования (TUs). Значения пиксельных разностей, ассоциированные с TU, могут быть преобразованы, чтобы сформировать коэффициенты преобразования, которые могут быть квантованы.
[0066] Листовая CU может включать в себя одну или более единиц предсказания (PU). В целом PU представляет пространственную область, соответствующую всем или части соответствующей CU, и может включать в себя данные для того, чтобы извлечь опорную выборку для PU. Кроме того, PU включает в себя данные, относящиеся к предсказанию. Например, когда PU является кодированной во внешнем режиме, данные для PU могут быть включены в остаточное квадродерево (RQT), которое может включать в себя данные, описывающие режим внутреннего предсказания для TU, соответствующей этой PU. В качестве другого примера, когда PU является кодированной во внешнем режиме, PU может включать в себя данные, определяющие один или более векторов движения для этой PU. Данные, определяющие вектор движения для PU, могут описывать, например, горизонтальную компоненту вектора движения, вертикальную компоненту вектора движения, разрешение для вектора движения (например, пиксельная точность в одну четверть или пиксельная точность в одну восьмую), опорную картинку, на которую вектор движения указывает, и/или список опорных картинок (например, Список 0, Список 1, или Список C) для вектора движения.
[0067] Листовая CU, имеющая одну или более PU, может также включать в себя одну или более единиц преобразования (TU). Единицы преобразования могут быть определены, используя RQT (также называемую структурой квадродерева TU), как описано выше. Например, флаг разделения может указывать, разделена ли листовая CU в четыре единицы преобразования. Затем, каждая единица преобразования может быть разделена далее в следующие суб-TU. Когда TU не разделена далее, она может упоминаться как листовая TU. В целом для внутреннего кодирования, все листовые TU, принадлежащие листовой CU, совместно использует один и тот же режим внутреннего предсказания. Таким образом, один и тот же режим внутреннего предсказания обычно применяется, чтобы вычислить предсказанные значения для всех TU листовой CU. Для внутреннего кодирования видео кодер 20 может вычислить остаточное значение для каждой листовой TU, используя режим внутреннего предсказания, как разность между частью CU, соответствующей TU, и первоначальным блоком. TU не обязательно ограничена размером PU. Таким образом, TU могут быть большими или меньшими чем PU. Для внутреннего кодирования PU может быть совместно расположена с соответствующей листовой TU для одной и той же CU. В некоторых примерах максимальный размер листовой TU может соответствовать размеру соответствующей листовой CU.
[0068] Кроме того, единицы TU листовых CU могут также быть ассоциированы с соответствующими структурами данных квадродерева, называемых остаточными квадродеревьями (RQT). Таким образом, листовая CU может включать в себя квадродерево, указывающее, как листовая CU разделена на единицы TU. Корневой узел квадродерева TU обычно соответствует листовой CU, в то время как корневой узел квадродерева CU обычно соответствует блок дерева (или LCU). Единицы TU упомянутой RQT, которые не разделены, упоминаются как листовые TU. В целом настоящее раскрытие использует термины CU и TU, чтобы ссылаться на листовые CU и листовые TU, соответственно, если не отмечено иначе.
[0069] Видео последовательность типично включает в себя последовательность картинок. Как описано здесь, "картинка" и "кадр" могут использоваться взаимозаменяемо. Таким образом, картинка, содержащая видео данные, может упоминаться как видео кадр, или просто "кадр". Группа картинок (GOP) обычно содержит последовательность из одной или более видео картинок. GOP может включать в себя данные синтаксиса в заголовке GOP, заголовок одной или более картинок, или в другом месте, которое описывает ряд картинок, включенных в GOP. Каждая вырезка (слайс) картинки может включать в себя данные синтаксиса вырезки, которые описывают режим кодирования для соответствующей вырезки. Видео кодер 20 типично оперирует над видео блоками в пределах индивидуальных видео вырезок, чтобы кодировать видео данные. Видео блок может соответствовать узлу кодирования в пределах CU. Видео блоки могут иметь фиксированные или переменные размеры, и могут отличаться по размеру согласно указанному стандарту кодирования.
[0070] В качестве примера, HM поддерживает предсказание в различных размерах PU. Предполагая, что размер конкретной CU равен 2Nx2N, HM поддерживает внутреннее предсказание в размерах PU 2Nx2N или NxN, и внешнее предсказание в симметричных размерах PU 2Nx2N, 2NxN, Nx2N, или NxN. HM также поддерживает асимметричное разделение для внешнего предсказания в размерах PU 2NxnU, 2NxnD, nLx2N, и nRx2N. При асимметричном разделении одно направление CU не разделяется, в то время как другое направление разделяется в 25% и 75%. Часть CU, соответствующая 25%-ому разделению, указывается посредством "n", сопровождаемым индикацией "Верхняя" (Up), “Нижняя” (Down), "Левая" (Left), или "Правая" (Right). Таким образом, например, "2NxnU" относится к CU размером 2Nx2N, которая разделена горизонтально с PU 2Nx0.5N сверху и PU 2Nx1.5N внизу.
[0071] В настоящем описании "NxN" и "N на N" могут использоваться взаимозаменяемо, чтобы ссылаться на пиксельные размерности блока в терминах вертикального и горизонтального измерений, например, 16x16 пикселей или 16 на 16 пикселей. Обычно блок 16x16 будет иметь 16 пикселей в вертикальном направлении (y=16) и 16 пикселей в горизонтальном направлении (x=16). Аналогично, блок NxN обычно имеет N пикселей в вертикальном направлении и N пикселей в горизонтальном направлении, где N представляет неотрицательное целочисленное значение. Пиксели в блоке могут быть размещены в строках и колонках. Кроме того, блоки не должны обязательно иметь одинаковое количество пикселей в горизонтальном направлении как в вертикальном направлении. Например, блоки могут содержать NxM пикселей, где М не обязательно равно N.
[0072] После кодирования с внутренним предсказанием или с внешним предсказанием, используя единицы PU в CU, видео кодер 20 может вычислить остаточные данные для единиц TU в CU. Единицы PU могут содержать данные синтаксиса, описывающие способ, или режим генерирования предсказывающих пиксельных данных в пространственной области (также называемых пиксельной областью), и единицы TU могут содержать коэффициенты в области преобразования после применения преобразования, например, дискретного косинусного преобразования (DCT), целочисленного преобразования, вейвлет преобразования, или концептуально подобного преобразования к остаточным видео данным. Остаточные данные могут соответствовать пиксельным разностям между пикселями незакодированной картинки и значениями предсказания, соответствующими единицам PU. Видео кодер 20 может сформировать единицы TU, включая остаточные данные для CU, и затем преобразовать единицы TU, чтобы сформировать коэффициенты преобразования для этой CU.
[0073] После любого преобразования, чтобы сформировать коэффициенты преобразования, видео кодер 20 может выполнить квантование коэффициентов преобразования. Квантование обычно относится к процессу, в котором коэффициенты преобразования квантуются, чтобы возможно уменьшить объем данных, используемых, чтобы представить коэффициенты, обеспечивающие дальнейшее сжатие. Процесс квантования может уменьшить глубину в битах, ассоциированную с некоторыми или всеми коэффициентами. Например, n-битовое значение может быть округлено в меньшую сторону до m-битового значения во время квантования, где n больше чем m.
[0074] После квантования видео кодер может сканировать коэффициенты преобразования, формируя одномерный вектор из двумерной матрицы, включающей в себя квантованные коэффициенты преобразования. Сканирование может быть разработан, чтобы поместить коэффициенты с более высокой энергией (и поэтому более низкой частотой) в начале массива и поместить коэффициенты с более низкой энергией (и поэтому более высокой частотой) в конце массива. В некоторых примерах видео кодер 20 может использовать заранее заданный порядок сканирования, чтобы сканировать квантованные коэффициенты преобразования, чтобы сформировать преобразованный в последовательную форму вектор, который может быть энтропийно кодирован. В других примерах видео кодер 20 может выполнить адаптивное сканирование. После сканирования квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, видео кодер 20 может энтропийно кодировать одномерный вектор, например, согласно контекстно адаптивному кодированию с переменной длиной кода (CAVLC), контекстно адаптивному двоичному арифметическому кодированию (CABAC), основанному на синтаксисе контекстно адаптивному двоичному арифметическому кодированию (SBAC), энтропийному кодированию с разделением интервала вероятности (PIPE) или другим методикам энтропийного кодирования. Видео кодер 20 может также энтропийно кодировать элементы синтаксиса, ассоциированные с закодированными видео данными для использования видео декодером 30 при декодировании видео данных.
[0075] Чтобы выполнить CABAC, видео кодер 20 может присвоить контекст в пределах контекстной модели символу, который должен быть передан. Контекст может относиться к тому, например, являются ли соседние значения символа ненулевыми или нет. Чтобы выполнить CAVLC, видео кодер 20 может выбрать код с переменной длиной слова для символа, который должен быть передан. Кодовые слова в VLC могут быть построены таким образом, что относительно более короткие коды соответствуют более вероятным символам, в то время как более длинные коды соответствуют менее вероятным символам. Таким образом, использование VLC может достигать экономии битов, например, при использовании кодовых слов равной длины для каждого символа, который должен быть передан. Определение вероятности может быть основано на контексте, назначенном на символ.
[0076] Видео кодер 20 может также послать данные синтаксиса, такие как основанные на блоке данные синтаксиса, основанные на картинке данные синтаксиса, и основанные на GOP данные синтаксиса, к видео декодеру 30, например, в заголовке картинки, заголовке блока, заголовке вырезки или заголовке GOP. Данные синтаксиса GOP могут описывать ряд картинок в соответствующей GOP, и данные синтаксиса картинки могут указывать режим кодирования/предсказания, использованный для кодирования соответствующей картинки.
[0077] В некоторых примерах видео кодер 20 может генерировать, и видео декодер 30 может принять, некоторые наборы параметров, которые могут использоваться при декодировании видео данных. Например, наборы параметров могут содержать информацию заголовка уровня последовательности (в наборах параметров последовательности (SPS)) и нечасто изменяющуюся информацию заголовка уровня картинки (в наборах параметров картинки (PPS)). С наборами параметров (например, PPS и SPS), нечасто изменяющаяся информация не требуется повторять для каждой последовательности (например, последовательности картинок) или картинки, следовательно эффективность кодирования может быть улучшена. Кроме того, использование наборов параметров может разрешить передачу вне частотного диапазона важной информации заголовка, избегая потребности в избыточных передачах для устойчивости к ошибкам. В примерах передачи вне частотного диапазона единицы NAL набора параметров могут быть переданы по отличному канале, чем другие единицы NAL, такие как единицы NAL информации дополнительного расширения (SEI).
[0078] Единицы NAL SEI (называемые сообщениями SEI) могут содержать информацию, которая не является необходимой для декодирования кодированных выборки картинки из единиц NAL VCL, но может помочь в процессах, относящихся к декодированию, отображению, устойчивости к ошибкам, и другим целям. Сообщения SEI могут содержаться в единицах NAL не-VCL. Сообщения SEI могут быть включены в нормативную часть некоторых спецификаций стандартов, и таким образом не всегда являются обязательными для реализации декодера, совместимого со стандартом. Сообщения SEI могут быть сообщениями SEI уровня последовательности или сообщениями SEI уровня картинки. Некоторая информация уровня последовательности может содержаться в сообщениях SEI, такая как сообщения SEI информации масштабируемости в примере SVC и сообщения SEI информации масштабируемости вида в MVC.
[0079] В некоторых примерах видео кодер 20 может кодировать поток битов MVC, который соответствует расширению MVC к H.264/AVC. Аналогично, видео декодер 30 может декодировать поток битов MVC, который соответствует расширению MVC к H.264/AVC. Последний объединенный проект MVC описан в JVT-AD007, AD007, AD007, “Editors' draft revision to ITU-T Rec. H.264 | ISO/IEC 14496-10 Advanced Video Coding,” 30th JVT meeting, Geneva, Switzerland, Jan.-Feb. 2008, доступной публично по адресу http://wftp3.itu.int/av-arch/jvt-site/2009_01_Geneva/JVT-AD007.
[0080] В масштабируемом расширении H.264/AVC элементы синтаксиса могут быть добавлены в расширение заголовка единицы NAL, чтобы расширить заголовок единицы NAL от одного байта до четырех байтов, чтобы описать характеристики единицы NAL VCL во множественных измерениях. Таким образом, единицы NAL VCL в HEVC может включать в себя более длинный заголовок единицы NAL, чем заголовок единицы NAL в стандарте H.264/AVC. Расширение MVC к H.264/AVC может быть упомянуто в настоящем раскрытии как "MVC/AVC".
[0081] Единица NAL MVC/AVC может содержать однобайтовый заголовок единицы NAL, который включает в себя тип единицы NAL, так же как расширение заголовка единицы NAL MVC/AVC. В качестве примера, расширение заголовка единицы NAL MVC/AVC может включать в себя элементы синтаксиса в следующей Таблицы 1:
[0082] В Таблице 1 выше элемент idr_flag может указывать, принадлежит ли единица NAL к текущему обновлению декодирования (IDR) или картинке IDR вида (V-IDR), которая может использоваться как точка произвольного доступа к закрытой GOP. Например, картинка IDR и все картинки, следующие за картинкой IDR как в порядке отображения так и в порядке потока битов, могут быть должным образом декодированы, не декодируя предыдущие картинки или в порядке потока битов или порядке отображения. Элемент priority_id может использоваться с процессом адаптации потока битов, который изменяет поток битов согласно изменяющимся условиям сети и/или возможностям видео декодера 30 и/или устройства 32 отображения (например, таким как процесс адаптации за единственный проход). Элемент view_id может быть использован для указания идентификатора вида для вида, которому принадлежит единица NAL, который может использоваться в декодере MVC, например, для предсказания между видами и вне декодера, например, для воспроизведения. В некоторых случаях view_id может быть установлен равным заранее заданному id камеры, и может быть относительно большим. Элемент temporal_id может быть использован для указания временного уровня текущей единицы NAL, который может соответствовать конкретной скорости передачи кадра.
[0083] Элемент anchor_pic_flag может быть использован для указания, принадлежит ли единица NAL картинке с привязкой, которая может использоваться как точка произвольного доступа к открытой GOP. Например, картинки с привязкой и все картинки, следующие за картинкой с привязкой в порядке отображения, могут быть должным образом декодированы, не декодируя предыдущие картинки в порядке декодирования (то есть порядке потока битов) и таким образом могут использоваться как случайные точки доступа. Картинки с привязкой и картинки без привязки могут иметь различные зависимости видов, обе из которых могут быть сигнализированы в SPS. Таким образом, как описано здесь, зависимость видов может обычно относиться к виду, от которого зависит в настоящее время кодируемый вид. Другими словами, зависимости видов могут формулировать, от каких видов может быть предсказан в настоящее время кодируемый вид. Согласно некоторым примерам зависимость видов может быть сигнализирована в расширении MVC SPS. В таких примерах все предсказание между видами может быть сделано в пределах области, определенной расширением MVC SPS. Элемент inter_view_flag может быть использован для указания, используется ли единица NAL для предсказания между видами для единиц NAL в других видах.
[0084] Чтобы передать вышеупомянутую 4-байтовую информацию заголовка единицы NAL для основного вида потока битов MVC, единица NAL префикса может быть определена в MVC. В контексте MVC единица доступа базового вида может включать в себя единицы NAL VCL текущего момента времени конкретного вида, а также единицу NAL префикса для единицы доступа базового вида, которая может содержать только заголовок единицы NAL. Если единица NAL префикса не требуется для декодирования (например, такого как декодирование единственного вида), декодер может проигнорировать и/или отказаться от единицы NAL префикса.
[0085] Относительно расширения MVC/AVC SPS, упомянутое MVC SPS может указывать виды, которые могут использоваться в целях предсказания между видами. Например, потенциальные опорные ссылки между видами могут быть сигнализированы в и расширении MVC/AVC SPS, и могут быть изменены процессом конструирования списка опорных картинок, который обеспечивает гибкое упорядочивание внешнего предсказания или опорных ссылок предсказания между видами. Пример MVC/AVC SPS сформулирован в Таблице 2 ниже:
[0086] Согласно некоторым примерам, зависимость видов может быть сигнализирована в расширении MVC SPS. Все предсказание между видами может быть сделано в пределах области, определенной расширением MVC SPS. Таким образом, SPS может формулировать, какие виды могут быть упомянуты в целях предсказания посредством вида, кодируемого в настоящее время. В Таблице 2 выше элемент num_anchor_refs_l0 [i] может задавать количество компонентов вида для предсказания между видами в инициализированном списке опорных картинок для Списка 0 (например, RefPicList0). Кроме того, элемент anchor_ref_l0 [i] [j] может задавать view_id j-го компонента вида для предсказания между видами в инициализированном RefPicList0. Элемент num_anchor_refs_l1 [i] может задавать количество компонентов вида для предсказания между видами в инициализированном списке опорных картинок для списка один (например, RefPicList1). Элемент anchor_ref_l1 [i] [j] может задавать view_id j-го компонента вида для предсказания между видами в инициализированном RefPicList1. Элемент num_non_anchor_refs_l0 [i] может задавать количество компонентов вида для предсказания между видами в инициализированном RefPicList0. Элемент non_anchor_ref_l0 [i] [j] может задавать view_id j-го компонента вида для предсказания между видами в инициализированном RefPicList0. Элемент num_non_anchor_refs_l1 [i] может задавать количество компонентов вида для предсказания между видами в инициализированном RefPicList1. Элемент non_anchor_ref_l1 [i] [j] может задавать view_id j-го компонента вида для предсказания между видами в инициализированном RefPicList.
[0087] Инициализировавший, или "начальный", список опорных картинок может быть одинаковым или отличающимся от окончательного списка опорных картинок, используемого в целях предсказания между видами компонентов вида. Таким образом, некоторые опорные кандидаты (то есть, опорные картинки, которые могут использоваться для предсказания между видами) могут быть удалены из начального списка опорных картинок (например, избыточные картинки). Кроме того, как описано более подробно ниже, опорные кандидаты могут быть переупорядочены из начального списка опорных картинок, чтобы сформировать окончательный список опорных картинок.
[0088] В этом примере, согласно MVC/AVC, зависимости видов для картинок с привязкой и картинок без привязки отдельно поддерживаются и сигнализируются. Таким образом, видео кодер может задавать в общей сложности четыре списка опорных картинок (например, Список 0, картинки без привязки; Список 1, картинки без привязки; Список 0, картинки с привязкой; Список 1, картинки с привязкой). Кроме того, как показано в Таблице 2 выше, отдельная сигнализация требуется для указания зависимости видов видео декодеру 30. Таким образом, SPS должен включать в себя отдельную сигнализацию Списка 0 и Списка 1 и для anchor_refs и для non_anchor_refs.
[0089] Кроме того, согласно Таблице 2, зависимость между видами для компонентов вида без привязки является поднабором его для компонентов вида с привязкой. Таким образом, например, компонент вида для вида с привязкой может быть предсказан из больше чем одного другого вида, такого как вид 3 и 4. Вид без привязки, однако, может только быть предсказан из картинок вида 3 (поднабор вида с привязкой). Таким образом, зависимости видов для и компонентов вида с привязкой без привязки отдельно поддерживаются.
[0090] Кроме того, в Таблице 2, num_level_values_signalled может задавать количество значений уровня, сигнализированных для закодированной видео последовательности. Элемент level_idc [i] может задавать i-е значение уровня, сигнализированное для закодированной видео последовательности. Элемент num_applicable_ops_minus1 [i] плюс 1 может задавать количество рабочих точек, к которым уровень, указанный посредством l_idc1 [i], применяется. Элемент applicable_op_temporal_id [i] [j] может задавать temporal_id j-й рабочей точки, к которой уровень, указанный посредством level_idc [i], применяется. Элемент applicable_op_num_target_views_minus1 [i] [j] может задавать количество целевых видов вывода для j-й рабочей точки, к которой уровень, указанный посредством level_idc [i], применяется. Элемент applicable_op_target_view_id [i] [j] [k] может задавать k-й целевой вид вывода для j-й рабочей точки, к которой уровень, указанный посредством level_idc [i], применяется. Элемент applicable_op_num_views_minus1 [i] [j] может задавать количество видов, включая виды, которые зависят от целевых видов вывода, но которые не принадлежат целевым видам вывода, в j-th рабочей точке, к которой уровень, указанный посредством level_idc [i], применяется.
[0091] Соответственно, в расширении MVC SPS для каждого вида количество видов, которые могут быть использованы для формирования списка 0 опорных картинок и списка 1 опорных картинок, может быть сигнализировано. Кроме того, отношения предсказания для картинки с привязкой, как сигнализировано в расширении MVC SPS, могут отличаться от отношений предсказания для картинки без привязки (сообщенных в расширении MVC SPS) того же вида.
[0092] Как описано более подробно ниже, видео кодер 20 и видео декодер 30 могут гибко компоновать временный и опорные ссылки предсказания видов, при построении списков опорных картинок. Обеспечение гибкой компоновки обеспечивает не только потенциальную выгоду эффективности кодирования, но также и устойчивость к ошибкам, так как секция опорных картинок и механизмы избыточных картинок могут быть расширены до размера вида. Видео кодер 20 и/или видео декодер 30, в одном примере, могут конструировать список опорных картинок согласно следующим этапам:
1) Инициализировать список опорных картинок для временных (то есть, внутри вида) опорных картинок, таким образом что опорные картинки от других видов не рассматриваются.
2) Добавить опорные картинки между видами к концу списка в порядке, в котором картинки имеют место в расширении SPS MVC.
3) Применить процесс переупорядочения списка опорных картинок (RPLR) и для опорных картинок внутри вида и между видами. Опорные картинки между видами могут быть идентифицированы в командах RPLR их значениями индекса, как определено в расширении SPS MVC.
[0093] В то время как H.264/AVC включает в себя поддержку MVC, текущее расширение MVC к H.264/AVC может содержать несколько неэффективностей относительно других стандартов кодирования видео. Кроме того, как описано более подробно ниже, прямой импорт MVC из H.264/AVC в другие стандарты кодирования, таких как предстоящий стандарт HEVC, может не быть выполнимым. Способы настоящего раскрытия в целом касаются формирования относящихся к MVC единиц NAL, относящихся к MVC наборов параметров, и т.п. В то время как способы настоящего раскрытия не ограничены никаким конкретным стандартом кодирования, некоторые способы настоящего раскрытия могут обеспечить эффективное MVC кодирование для предстоящего стандарта HEVC.
[0094] Как пример, стандарт H.264/MVC поддерживает до 1024 видов и использует идентификатор вида (view_id) в заголовке единицы NAL, чтобы идентифицировать вид, которому принадлежит единица NAL. Поскольку view_id имеет длину 10 бит, более чем 1000 различных видов могут быть уникально идентифицированы значениями view_id. Однако, многие приложения трехмерного (3D) видео требуют значительно меньшего количества видов. Кроме того, меньше видов может требоваться для 3D-приложений видео, которые используют синтез видов, чтобы генерировать больше видов (которые не требуют кодирования). Согласно расширению MVC/AVC заголовок единицы NAL включает в себя 10 битовый view_id, который всегда предоставляется. view_id может существенно увеличить число битов для заголовка единицы NAL, которое занимает относительно большую часть потока битов.
[0095] Согласно аспектам настоящего раскрытия порядковый индекс вида (“view_order_index” или “view_idx”) может быть сообщен в качестве части заголовка единицы NAL. Таким образом, видео кодер 20 может кодировать и передавать, и видео декодер 30 может принять и декодировать, порядковый индекс вида в качестве части заголовка единицы NAL. В целях сравнения порядковый индекс вида может заменить view_id, который сообщен в заголовке единицы NAL MVC-расширения к H.264/AVC (в дальнейшем “MVC/AVC”). Таким образом, например, view_idx может заменить view_id в заголовке единицы NAL.
[0096] Как описано выше, MVC обеспечивает предсказание между видами. Соответственно, виды, использованные для ссылки (то есть, виды, которые использованы для предсказания других видов), должны иметь место в порядке кодирования ранее, чем виды, которые ссылаются, как описано выше. Порядок видов обычно описывает порядок видов в единице доступа, и порядковый индекс вида идентифицирует конкретный вид в порядке видов единицы доступа. Таким образом, порядковый индекс вида описывает порядок декодирования соответствующего компонента вида единицы доступа.
[0097] SPS может обеспечить отношения между идентификаторами вида (view_ids) для видов и порядковые индексы вида для упомянутых видов. Согласно аспектам настоящего раскрытия, используя порядковый индекс вида и данные в SPS, видео кодер 20 и видео декодер 30 могут заменить 10 битовый view_id для MVC/AVC в заголовке единицы NAL на порядковый индекс вида. Например, порядковый индекс вида может включать в себя по существу меньше чем 10 битов (например, 2 бита, 3 бита, или подобное). В то время как отношения между порядковым индексом вида и идентификаторами вида могут потребовать некоторой ассоциированной сигнализации, например, в SPS, заголовки единицы NAL типично потребляют намного больше битов, чем такая сигнализация. Соответственно, уменьшая размер заголовков единицы NAL, способы настоящего раскрытия могут достигнуть экономии битов по сравнению со схемой MVC/AVC. Информация, указывающая это отношение, может содержать, например, таблицу отображения, которая отображает значения view_id в значения порядкового индекса вида. В этом способе видео декодер 30 может просто принять значение порядкового индекса вида в заголовке единицы NAL и определить view_id единицы NAL, используя таблицу отображения.
[0098] Согласно некоторым аспектам раскрытия, порядковый индекс вида может иметь динамическую длину, в зависимости от того, является ли он базовым видом HEVC, профилем, или многими видами, поддерживаемыми в потоке битов MVC. Например, дополнительные экономии битов могут быть достигнуты в потоке MVC, который включает в себя только два вида (то есть, для стерео видео). В этом примере порядковый индекс вида может не быть необходимым, поскольку видео декодер 30 может всегда декодировать первый вид (например, вид 0) до декодирования второго вида (например, вида 1). Таким образом, согласно некоторым аспектам настоящего раскрытия базовый вид может быть назначен с порядковым индексом вида, по умолчанию равным 0, и поэтому не должен быть сигнализирован.
[0099] Кроме того, единица NAL префикса, которая включена непосредственно перед единицами NAL базового вида (например, вида 0) базового вида MVC/AVC, может больше не требоваться при использовании порядкового индекса вида, описанного выше. Например, видео декодер 30 может больше не требовать единицы NAL префикса для базового вида, так как порядковый индекс вида может всегда быть нулем для базового вида, и временная позиция базового вида может быть определена, используя temporal_id (включенный в MCV/AVC). Соответственно, видео кодер 20 может сигнализировать temporal_id в заголовке единицы NAL, который может предоставить всю информацию, необходимую для видео декодера 30, чтобы ассоциировать конкретный компонент вида с конкретным видом и с соответствующим временным местоположением.
[0100] Относительно появляющегося стандарта HEVC, согласно аспектам настоящего раскрытия, когда единица NAL префикса не используется для совместимого с HEVC базового вида, флаг может быть добавлен в заголовок единицы NAL базового вида HEVC. Этот флаг может быть использован только для указания, может ли компонент вида (этой конкретной единицы NAL) быть использован для компонентов вида внешнего предсказания других видов потока битов.
[0101] Кроме того, согласно аспектам раскрытия, порядковый индекс вида может быть использован со значением отсчета порядка картинки (POC) (например, которое указывает порядок отображения картинок) или значением кадра (например, которое указывает порядок декодирования картинок), чтобы идентифицировать компонент вида потока битов.
[0102] В качестве другого примера, как отмечено выше, SPS MVC/AVC может указывать зависимые виды (то есть, виды, на которые ссылаются один или более других видов в целях предсказания) отдельно для каждого вида. Например, anchor_pic_flag, включенный в заголовок единицы NAL MVC/AVC, может быть использован для указания, принадлежит ли единица NAL картинке с привязкой, которая может быть использована как точка произвольного доступа открытой GOP. В MVC/AVC, как описано выше, зависимость видов сигнализируется по-разному для картинок с привязкой и картинок без привязки. Соответственно, для зависимых видов, сигнализированных для каждого вида, четыре различных категории рассматриваются, каждая из которых отличается тем, является ли картинка для картинки с привязкой или является ли картинка для Списка 0 или Списка 1. Такая структура не только требует, чтобы относительно большое количество битов поддерживало такие разграничения, но также и может усложнить построение списка опорных картинок (например, каждая категория должна быть поддержана во время построения опорного списка и переупорядочения).
[0103] Согласно аспектам настоящего раскрытия, видео кодер 20 может сигнализировать (и видео декодер 30 может принять такую сигнализацию) зависимость видов для каждого вида потока битов MVC обычно для всех компонентов вида, независимо от того, предназначены ли компоненты вида для картинок с привязкой и картинок без привязки. В некоторых примерах SPS включает в себя индикацию зависимостей вида для компонентов вида, вместо того, чтобы полагаться на информацию в заголовке единицы NAL. В этом способе видео кодер 20 и видео декодер 30 могут не использовать anchor_pic_flag, используемый в заголовке единицы NAL MVC/AVC.
[0104] Компонент вида сигнализированного зависимого вида может быть использован как опорная картинка и в Списке 0 и в Списке 1. Кроме того, построение списка опорных картинок и переупорядочение списка опорных картинок для Списка 0 и Списка 1 могут также быть основаны на общей сигнализации для картинок с привязкой и картинок без привязки. В некоторых примерах уровень последовательности, сообщение информации дополнительного расширения (SEI) могут быть использованы для указания, когда картинка без привязки имеет иную зависимость видов, чем картинка с привязкой.
[0105] Соответственно, некоторые аспекты настоящего раскрытия касаются удаления картинки с привязкой/картинки без привязки и различения сигнализации Списка 0/списка 1 в MVC/AVC, таким образом упрощая поток битов, а также построение списка опорных картинок. Например, согласно аспектам настоящего раскрытия, видео декодер 30 может принять для любого компонента вида первый вид, информацию опорного вида, указывающую один или более опорных видов, для предсказания компонентов вида первого вида. Таким образом, видео декодер 30 может принять опорную информацию вида, указывающую зависимости видов для картинок с привязкой вида и картинок без привязки вида аналогично. Информация опорного вида может включать в себя, например, порядковый индекс вида (указание порядка декодирования вида в единице доступа), ассоциированный с каждым опорным видом, как описано выше.
[0106] Кроме того, при декодировании конкретной картинки (единицы доступа) конкретного вида, видео декодер 30 может включать опорных кандидатов (например, компоненты вида, из которых конкретная картинка может быть предсказана) из той же единицы доступа, что и конкретная картинка, и из опорных видов, указанных информацией опорного вида. В некоторых случаях видео декодер 30 может добавить опорных кандидатов к списку опорных картинок из каждого опорного вида таким образом, что количество опорных кандидатов равно количеству опорных видов. Кроме того, видео декодер 30 может добавить опорных кандидатов к любому из Списка 1, Списка 0, или обоим. Видео декодер 30 может затем декодировать конкретную картинку на основании одной из опорных картинок в списке опорных картинок.
[0107] В качестве еще одного примера, как описано выше, priority_id включен в заголовок единицы NAL совместимого с MVC/AVC потока битов. Этот priority_id обеспечивает индикацию приоритета конкретной единицы NAL. Более подробно, каждой единице NAL обычно назначают значение приоритета. В ответ на запрос о значении P приоритета будут предоставлены все единицы NAL, имеющие значения приоритета, меньше чем или равные P (то есть, единицы NAL, имеющие значения priority_id больше, чем P, отбрасываются). В этом способе более низкие значения приоритета определяют более высокие приоритеты. Нужно подразумевать, что единицы NAL одного и того же вида могут иметь различные приоритеты, например, для временной масштабируемости в пределах вида.
[0108] Этот приоритет может быть использован в целях масштабируемости. Например, чтобы извлечь видео данные, потребляющие наименьшую величину полосы частот (за счет формирования представления относительно низкого качества), видео декодер 30 (или, более широко, устройство 14 назначения) может запросить только единицы NAL с самым высоким приоритетом для передачи из источника, такого как устройство-источник 12/видео кодер 20, и priority_id может быть использован для отфильтровывания единиц NAL более низкого приоритета. В некоторых примерах маршрутизатор 36 из сервера/сети 34 доставки контента могут использовать priority_id, чтобы отделить относительно высокоприоритетные единицы NAL от единиц NAL более низкого приоритета. Чтобы сформировать представление относительно более высокого качества (за счет более высокого потребления полосы частот), видео декодер 30 может запросить единицы NAL, имеющие более низкий приоритет, чтобы дополнить единицы NAL более высокого приоритета, например, посредством задания более высокого значения приоритета.
[0109] Согласно аспектам настоящего раскрытия, вместо того, чтобы сигнализировать priority_id в заголовке единицы NAL, видео кодер 20 может обеспечить значения priority_id в SPS. Таким образом, priority_id для каждого вида с некоторым временным уровнем может быть сигнализирован в уровне последовательности. Кроме того, согласно аспектам настоящего раскрытия, адаптация с единственным проходом может быть разрешена, пока сигнализация контекста, ассоциированного с адаптацией, известна.
[0110] Как описано выше, в некоторых примерах, маршрутизатор 36, который может быть ответственным за направление потока битов устройству 14 назначения, может использовать значения priority_id SPS, чтобы фильтровать некоторые виды. Таким образом, маршрутизатор 36 может принять полный поток битов, но извлечь подпоток битов, включая единицы NAL, имеющие значения priority_id, равные и ниже значения приоритета, определенного устройством 14 назначения, и отправить подпоток битов устройству назначения.
[0111] В другом примере, согласно MVC/AVC, адаптация с единственным проходом требует 6-битового priority_id в заголовке единицы NAL. Например, как отмечено выше, SPS MVC/AVC может включать в себя индикацию уровня вида для масштабируемости вида. Таким образом, каждый вид потока битов MVC может быть кодирован иерархическим способом и ему может быть назначен числовой уровень вида.
[0112] Согласно аспектам настоящего раскрытия, SPS может включать в себя информацию уровня вида. Таким образом, когда устройство 14 назначения запрашивает виды уровня вида V от сервера/сети 34 доставки контента, устройство 14 назначения принимает все виды, имеющие уровни вида, меньше чем или равные V. Подобно использованию значений priority_id, описанных выше, маршрутизатор 36 из сервера/сети 34 доставки контента может использовать уровни вида, чтобы извлечь подпоток битов, включающий в себя данные для видов, имеющих уровни вида, меньше чем или равные запрошенному клиентом уровню вида.
[0113] Другие аспекты настоящего раскрытия относятся к легкому процессу транскодирования, чтобы преобразовать подпоток битов более высокого профиля в поток битов, соответствующий более низкому профилю. Такой процесс транскодирования может быть выполнен, например, сервером/сетью 34 доставки контента. Согласно аспектам настоящего раскрытия, транскодирование может быть выполнено в следующих этапах:
1) Переотображение значений view_idx и view_id в SPS
2) Изменение размеров заголовка единицы NAL с короткой длиной view_idx
[0114] Предположим, например, что поток битов профиля телевизора со свободной точкой обзора (FVT) содержит 32 вида, с view_idx равным view_id для каждого вида. В этом примере поток битов имеет подпоток битов, содержащий 8 видов, с view_idx равным 0, 4, 8, 12, 16, 20, 24, 28. Этот подпоток битов далее содержит подпоток битов, который содержит два вида, со значениями view_id 0 и 4.
[0115] Согласно аспектам настоящего раскрытия, значения view_idx для подпотока битов с 8 видами могут быть переотображены согласно Таблице 3 ниже:
[0116] Согласно аспектам настоящего раскрытия, значения view_idx для подпотока битов с 2 видами могут быть переотображены согласно Таблице 4 ниже:
[0117] Согласно аспектам настоящего раскрытия, view_idx в заголовке единицы NAL может быть переотображен согласно Таблице 5 ниже:
[0118] Альтернативно, легкий процесс транскодирования, описанный выше, может не требовать переотображения view_idx, если соответствовавший поток битов обеспечивает промежуток в порядковом индексе вида.
[0119] ФИГ. 2 является блок-схемой, иллюстрирующей примерный кодер видео 20, который может реализовать способы, описанные в настоящем раскрытии для того, чтобы кодировать поток битов множественных видов. Видео кодер 20 принимает видео данные, которые должны быть закодированы. В примере согласно ФИГ. 2, видео кодер 20 включает в себя модуль 40 выбора режима, сумматор 50, модуль 52 обработки преобразования, модуль 54 квантования, модуль 56 энтропийного кодирования, и память 64 опорных картинок. Модуль 40 выбора режима, в свою очередь, включает в себя модуль 42 оценки движения/диспарантности, модуль 44 компенсации движения, модуль 46 внутреннего предсказания, и модуль 48 разделения.
[0120] Для реконструкции видео блока видео кодер 20 также включает в себя модуль 58 обратного квантования, модуль 60 обработки обратного преобразования и сумматор 62. Фильтр удаления блочности (не показан на фиг. 2) может также быть включен, чтобы фильтровать границы блока, чтобы удалить артефакты блочности из восстановленного видео. Если желательно, фильтр удаления блочности типично может фильтровать выходной сигнал сумматора 62. Дополнительные фильтры контура (в контуре или после контура) могут также использоваться в дополнение к фильтру удаления блочности. Такие фильтры не показаны для краткости, но если желательно, могут фильтровать выходной сигнал сумматора 50 (в качестве фильтра в контуре).
[0121] Модуль 40 выбора режима может принять необработанные видео данные в форме блоков от одного или более видов. Модуль 40 выбора режима может выбрать один из режимов кодирования, внутренний или внешний, например, на основании результатов ошибки, и выдавать результирующий внутри- или внешне- кодированный блок к сумматору 50, чтобы генерировать остаточные данные блока, и к сумматору 62, чтобы восстановить закодированный блок для использования в качестве опорной картинки. Модуль 40 выбора режима также обеспечивает элементы синтаксиса, такие как векторы движения, индикаторы внутреннего режима, информацию разделения, и другую такую информацию синтаксиса, к модулю 56 энтропийного кодирования.
[0122] Модуль 42 оценки движения/диспарантности и модуль 44 компенсации движения могут быть высоко интегрированы, но иллюстрированы отдельно в концептуальных целях. Оценка движения, выполненная модулем 42 оценки движения/диспарантности, является процессом генерирования векторов движения, которые оценивают движение для видео блоков. Вектор движения, например, может указывать смещение PU видео блока в пределах текущей картинки относительно предсказывающего блока в пределах опорной картинки (или другой кодированной единицы) относительно текущего блока, кодированного в пределах текущей картинки (или другой кодированной единицы).
[0123] Предсказывающий блок является блоком, который, как находят, близко соответствует блоку, который должен быть закодирован, в терминах пиксельной разности, которая может быть определена суммой абсолютных разностей (SAD), суммой разностей квадратов (SSD), или другими метриками различия. В некоторых примерах видео кодер 20 может вычислить значения для суб-целочисленных позиций пикселя опорных картинок, сохраненных в памяти 64 опорных картинок, которая может также упоминаться как буфер опорных картинок. Например, видео кодер 20 может интерполировать значения пиксельных позиций в одну четверть, пиксельных позиций в одну восьмую, или других фракционных пиксельных позиций опорной картинки. Поэтому блок 42 оценки движения может выполнять поиск движения относительно полных пиксельных позиций и фракционных пиксельных позиций и вывести вектор движения с фракционной пиксельной точностью.
[0124] Модуль 42 оценки движения/диспарантности вычисляет вектора движения для PU видео блока во внешне кодированной вырезке, посредством сравнения позиции PU с позицией предсказывающего блока опорной картинки. Модуль 42 оценки движения/диспарантности может быть также сконфигурирован, чтобы выполнить предсказание между видами, в этом случае модуль 42 оценки движения/диспарантности может вычислить векторы смещения между блоками картинки одного вида (например, вида 0) и соответствующими блоками картинки опорного вида (например, вида 1). В целом данные для вектора движения/диспарантности могут включать в себя список опорных картинок, индекс в список (ref_idx) опорных картинок, горизонтальную компоненту, и вертикальную компоненту. Опорная картинка может быть выбрана из первого списка опорных картинок (Список 0), второго списка опорных картинок (Список 1), или объединенного списка опорных картинок (Список C), каждый из которых идентифицирует одну или более опорных картинок, сохраненных в памяти 64 опорных картинок. Относительно объединенного списка, видео кодер 20 поочередно выбирает записи из двух списков (то есть, Списка 0 и Списка 1), чтобы вставить (приложить) в объединенный список. Когда запись уже помещена в объединенный список, посредством проверки числа POC, видео кодер 20 может не вставлять запись снова. Для каждого списка (то есть, Списка 0 или Списка 1), видео кодер 20 может выбрать записи на основании возрастающего порядка опорного индекса.
[0125] Модуль 42 оценки движения/диспарантности может генерировать и послать вектор движения/диспарантности, который идентифицирует предсказывающий блок опорной картинки, к модулю 56 энтропийного кодирования и модулю 44 компенсации движения. Таким образом, модуль 42 оценки движения/диспарантности может генерировать и послать данные вектора движения, которые идентифицируют список опорных картинок, содержащий предсказывающий блок, индекс в списке опорных картинок, идентифицирующий картинку предсказывающего блока, и горизонтальную и вертикальную компоненты, чтобы определить местонахождение предсказывающего блока в пределах идентифицированной картинки.
[0126] Компенсация движения, выполненная модулем 44 компенсации движения, может включать в себя извлечение или генерирование предсказывающего блока на основании вектора движения/диспарантности, определенного модулем 42 оценки движения/диспарантности. Снова, модуль 42 оценки движения/диспарантности и модуль 44 компенсации движения могут быть функционально интегрированными, в некоторых примерах. После приема вектора движения для PU текущего видео блока модуль 44 компенсации движения может определять местонахождение предсказывающего блока, на который вектор движения указывает в одном из списков опорных картинок.
[0127] Сумматор 50 формирует остаточный видео блок, вычитая пиксельные значения предсказывающего блока из пиксельных значений текущего закодированного блока видео, формируя значения пиксельной разности, как описано ниже. В целом модуль 42 оценки движения/диспарантности выполняет оценку движения относительно компонентов яркости, и модуль 44 модуль использует вектора движении, вычисленные на основании компонентов яркости как для компонентов насыщенности цвета так и для компонентов яркости. Модуль 40 выбора режима может также генерировать элементы синтаксиса, ассоциированные с видео блоками и видео вырезкой для использования видео декодером 30 при декодировании видео блоков видео вырезки.
[0128] Модуль 46 внутреннего предсказания может внутренне предсказать текущий блок, как альтернатива внешнему предсказанию, выполненному модулем 42 оценки движения/диспарантности и модулем 44 компенсации движения, как описано выше. В частности, модуль 46 внутреннего предсказания может определять режим внутреннего предсказания, чтобы использовать при кодировании текущего блока. В некоторых примерах модуль 46 внутреннего предсказания может кодировать текущий блок, используя различные режимы внутреннего предсказания, например, во время отдельных проходов кодирования, и модуль 46 внутреннего предсказания (или модуль 40 выбора режима в некоторых примерах) может выбрать соответствующий режим внутреннего предсказания для использования из проверенных режимов.
[0129] Например, модуль 46 внутреннего предсказания может вычислить значения «искажение - скорость передачи», используя анализ «искажение - скорость передачи» для различных проверенных режимов внутреннего предсказания, и выбрать режим внутреннего предсказания, имеющий наилучшие характеристики «искажение - скорость передачи»среди проверенных режимов. Анализ «искажение - скорость передачи» обычно определяет величину искажения (или ошибку) между кодированным блоком и первоначальным незакодированным блоком, который был закодирован, чтобы сформировать закодированный блок, а также скорость передачи в битах (то есть, количество битов), использованных для получения кодированного блока. Модуль 46 внутреннего предсказания может вычислить отношения из искажений и скоростей передачи для различных кодированных блоков, чтобы определить, какой режим внутреннего предсказания показывает наилучшее значение «искажение - скорость передачи» для блока.
[0130] После выбора режима внутреннего предсказания для блока модуль 46 внутреннего предсказания может предоставить информацию, указывающую выбранный режим внутреннего предсказания для блока, к модулю 56 энтропийного кодирования. Модуль 56 энтропийного кодирования может кодировать информацию, указывающую выбранный режим внутреннего предсказания. Видео кодер 20 может включать в переданный поток битов данные конфигурации, которые могут включать в себя множество таблиц индекса режима внутреннего предсказания, и множество таблиц модифицированного индекса режима внутреннего предсказания (также называемых таблицы отображения кодовых слов), определения контекстов кодирования для различных блоков, и индикации наиболее вероятного режима внутреннего предсказания, таблицы индекса режима внутреннего предсказания, и таблицы модифицированного индекса режима внутреннего предсказания, чтобы использовать для каждого из контекстов.
[0131] Видео кодер 20 формирует остаточный видео блок, вычитая данные предсказания от модуля 40 выбора режима из первоначального кодируемого видео блока. Сумматор 50 представляет компонент или компоненты, которые выполняют эту операцию вычитания. Модуль 52 обработки преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT) или концептуально подобное преобразование, к остаточному блоку, формируя видео блок, содержащий остаточные значения коэффициента преобразования. Модуль 52 обработки преобразования может выполнить другие преобразования, которые концептуально подобны DCT. Вейвлет преобразования, целочисленные преобразования, преобразования частотных поддиапазонов или другие типы преобразования также могут использоваться. В любом случае модуль 52 обработки преобразования применяет преобразование к остаточному блоку, формируя блок остаточных коэффициентов преобразования. Преобразование может преобразовать остаточную информацию из области пиксельных значений к области преобразования, такой как частотная область.
[0132] Модуль 52 обработки преобразования может послать результирующие коэффициенты преобразования в модуль 54 квантования. Модуль 54 квантования квантует коэффициенты преобразования, чтобы далее уменьшить частоту следования битов. Процесс квантования может уменьшить битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Степень квантования может быть модифицирована посредством настройки параметра квантования. В некоторых примерах модуль 54 квантования может затем выполнить сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. Альтернативно, модуль 56 энтропийного кодирования может выполнить сканирование.
[0133] После квантования модуль 56 энтропийного кодирования энтропийно кодируют квантованные коэффициенты преобразования. Например, модуль 56 энтропийного кодирования может выполнить контекстно-адаптивное кодирование с переменной длиной кода (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), основанное на синтаксисе контекстно-адаптивное двоичное арифметическое кодирование (SBAC), энтропийное кодирование с разделением интервала вероятности (PIPE) или другие методики энтропийного кодирования. В случае основанного на контексте энтропийного кодирования контекст может быть основан на соседних блоках. После энтропийного кодирования модулем 56 энтропийного кодирования закодированный поток битов может быть передан на другое устройство (например, видео декодер 30) или заархивирован для более поздней передачи или поиска.
[0134] Модуль 58 обратного квантования и блок обработки обратного преобразования 60 применяет обратное квантование и обратное преобразование, соответственно, чтобы восстановить остаточный блок в пиксельной области, например, для более позднего использования в качестве опорного блока. Модуль 44 компенсации движения может вычислить опорный блок, добавляя остаточный блок к предсказывающему блоку одной из картинок из памяти 64 опорных картинок. Модуль 44 компенсации движения может также применить один или более фильтров интерполяции к восстановленному остаточному блоку, чтобы вычислить суб-целочисленные пиксельные значения для использования при оценке движения. Сумматор 62 добавляет восстановленный остаточный блок к блоку предсказания со скомпенсированным движением, произведенному модулем 44 компенсации движения, чтобы сформировать восстановленный видео блок для сохранения в памяти 64 опорных картинок. Восстановленный видео блок может быть использован модулем 42 оценки движения/диспарантности и модулем 44 компенсации движения как опорный блок, чтобы внешне кодировать блок в последующей картинке.
[0135] Видео кодер 20 может генерировать ряд элементов синтаксиса, как описано выше, который может быть закодирован блоком 56 энтропийного кодирования или другим блоком кодирования видео кодера 20. В некоторых примерах видео кодер 20 может генерировать и кодировать элементы синтаксиса для потока битов MVC, как описано выше.
[0136] Как отмечено выше, идентификатор вида может быть включен в заголовок единицы NAL, чтобы идентифицировать вид, которому принадлежит единица NAL. Id вида может по существу увеличить число битов для заголовка единицы NAL, который занимает относительно большую часть потока битов. Согласно аспектам настоящего раскрытия, видео кодер 20 может сигнализировать порядковый индекс вида в качестве части заголовка единицы NAL. Таким образом, видео кодер 20 может заменить id вида, который обычно может быть сигнализирован в заголовке единицы NAL, порядковым индексом вида. Порядковый индекс вида может описать порядок декодирования соответствующего компонента вида единицы доступа. Порядковый индекс вида может быть использован со значением POC или значением кадра, чтобы идентифицировать компонент вида потока битов. Видео кодер 20 может также генерировать SPS, который обеспечивает индикацию отношений между id видов для видов и порядковых индексов вида для упомянутых видов. Например, видео кодер 20 может генерировать таблицу отображения, которая отображает значения view_id в значения порядкового индекса вида, и включать такую таблицу отображения в SPS. В других примерах видео кодер 20 может указывать отношения между id видов и порядковые индексы вида в альтернативном способе.
[0137] Видео кодер 20 может также избежать кодирования единицы NAL префикса, которая может типично быть включена непосредственно перед базовым видом. Вместо этого видео кодер 20 может сигнализировать temporal_id в заголовке единицы NAL, который может предоставить всю информацию, необходимую для видео декодера 30, чтобы ассоциировать конкретный компонент вида с конкретным видом и с соответствующим временным местоположением (например, заданным по умолчанию индексом порядка базовых видов, равным нулю). В некоторых примерах видео кодер 20 может добавить флаг к заголовку единицы NAL базового вида, чтобы указать, может ли компонент вида (этой конкретной единицы NAL) быть использован для внешнего предсказания компоненты вида других видов потока битов.
[0138] Согласно аспектам настоящего раскрытия, видео кодер 20 может сигнализировать зависимости видов для каждого вида обычно для всех компонентов вида, независимо от того, предназначены ли компоненты вида для картинок с привязкой и картинок без привязки и принадлежат ли компоненты вида Списку 0 или Списку 1. В некоторых примерах видео кодер 20 может включать индикацию в SPS, которая идентифицирует различные зависимости видов для картинок с привязкой и картинок без привязки.
[0139] Согласно другим аспектам настоящего раскрытия, вместо того, чтобы сигнализировать priority_id в заголовке единицы NAL, видео кодер 20 может обеспечить значения priority_id в SPS. Таким образом, priority_id для каждого вида с некоторым временным уровнем может быть сигнализирован в уровне последовательности. Кроме того, согласно аспектам настоящего раскрытия, адаптация с единственным проходом может быть разрешена, пока сигнализация контекста, ассоциированного с адаптацией, известна. Кроме того, видео кодер 20 может сигнализировать информацию уровня вида в SPS.
[0140] ФИГ. 3 является блок-схемой, иллюстрирующей примерный декодер видео 30, который может реализовать способы, описанные в настоящем раскрытии для декодирования потока битов множественных видов. В примере согласно ФИГ. 3, видео декодер 30 включает в себя модуль 80 энтропийного декодирования, модуль 81 предсказания, имеющий модуль 82 компенсации движения и модуль 84 внутреннего предсказания, модуль 86 обратного квантования, модуль 88 обратного преобразования, сумматор 90, и память 92 опорных картинок.
[0141] Во время процесса декодирования видео декодер 30 принимает закодированный видео поток битов, который представляет видео блоки закодированной видео вырезки и ассоциированные элементы синтаксиса, от видео кодера 20. Модуль 80 энтропийного декодирования из видео декодера 30 энтропийно декодирует поток битов, чтобы генерировать квантованные коэффициенты, вектора движения, и другие элементы синтаксиса. Модуль 80 энтропийного декодирования направляет вектора движения и другие элементы синтаксиса к модулю 81 предсказания. Видео декодер 30 может принять элементы синтаксиса на уровне вырезки видео и/или уровне блока видео.
[0142] Например, видео декодер 30 может принять ряд единиц NAL, имеющих заголовок единицы NAL, который идентифицирует тип данных, сохраненных в единице NAL (например, данных VCL и не-VCL данных). Наборы параметров могут содержать информацию заголовка уровня последовательности, такую как SPS, PPS, или другой набор параметров, описанный выше.
[0143] Согласно аспектам настоящего раскрытия, видео декодер 30 может принять порядковый индекс вида в качестве части заголовка единицы NAL. Таким образом, видео декодер 30 может принять порядковый индекс вида, а не id вида, который может обычно быть сигнализирован в заголовке единицы NAL. Порядковый индекс вида может описать порядок декодирования соответствующего компонента вида единицы доступа. Кроме того, видео декодер 30 может принять информацию, указывающую отношения между принятым порядковым индексом вида и соответствующим id вида. Эта информация может включать в себя, например, таблицу отображения, которая отображает значения view_id, на значения порядкового индекса вида. В этом способе видео декодер 30 может просто принять значение порядкового индекса вида в заголовке единицы NAL и определить view_id единицы NAL, используя таблицу отображения. В некоторых примерах информация отношений может быть принята в SPS. Видео декодер 30 может также использовать порядковый индекс вида со значением POC или значением кадра (номер кадра или frame_num), чтобы идентифицировать компонент вида потока битов.
[0144] В некоторых примерах, согласно аспектам настоящего раскрытия, видео декодер 30 может не принимать единицы NAL префикса, который может типично быть включен непосредственно перед базовым видом. Вместо этого видео декодер 30 может принять temporal_id в заголовке единицы NAL, который может предоставить всю информацию, необходимую для видео декодера 30, чтобы ассоциировать конкретный компонент вида с конкретным видом и с соответствующим временным местоположением (например, заданный по умолчанию индекс порядка базовых видов равный нулю). В некоторых примерах видео декодер 30 может принять флаг в заголовке единицы NAL базового вида, чтобы указать, может ли компонент вида (этой конкретной единицы NAL) быть использован для внешнего предсказания компонентов вида других видов потока битов.
[0145] Согласно аспектам настоящего раскрытия, видео декодер 30 может также принять зависимости видов для каждого вида обычно для всех компонентов вида, независимо от того, предназначены ли компоненты вида для картинок с привязкой и картинок без привязки, и независимо от того, будет ли компонент вида включен в Список 0 или Список 1. В некоторых примерах видео декодер 30 может принять индикацию в SPS, который идентифицирует различные зависимости видов для картинок с привязкой и картинок без привязки.
[0146] Согласно другим аспектам настоящего раскрытия, вместо того, чтобы сигнализировать priority_id в заголовке единицы NAL, видео кодер 20 может обеспечить значения priority_id в SPS. Кроме того, согласно аспектам настоящего раскрытия, адаптация с единственным проходом может быть разрешена, пока сигнальный контекст, ассоциированный с адаптацией, известен. Видео декодер 30 может также принять некоторую информацию уровня вида в SPS.
[0147] Когда видео вырезка закодирована как внутренне кодированная (I) вырезка, модуль 84 внутреннего предсказания из модуля 81 предсказания может генерировать данные предсказания для видео блока текущей видео вырезки на основании сигнализированного режима внутреннего предсказания и данных от ранее декодированных блоков текущей картинки. Когда картинка закодирована как внешне кодированная (то есть, B, P или GPB) вырезка, модуль 84 внутреннего предсказания из модуля 81 предсказания формирует предсказывающие блоки для видео блока текущей видео вырезки на основании вектора движения и других элементов синтаксиса, принятых от модуля 80 энтропийного декодирования. Предсказывающие блоки могут быть произведены из одной из опорных картинок в пределах одного из списков опорных картинок. Видео декодер 30 может конструировать списки опорных картинок, Список 0 и Список 1 (или объединенный список, Список c) используя способы построения по умолчанию, на основании опорных картинок, сохраненных в памяти 92 опорных картинок.
[0148] Модуль 82 компенсации движения определяет информацию предсказания для видео блока текущей видео вырезки, синтаксически разбирая вектора движения и другие элементы синтаксиса, и использует информацию предсказания, чтобы сформировать предсказывающие блоки для текущего видео декодируемого блока. Например, модуль 82 компенсации движения использует некоторые из принятых элементов синтаксиса, чтобы определить режим предсказания (например, внутреннее или внешнее предсказание), использованный для кодирования видео блоков видео вырезки, тип вырезки внешнего предсказания (например, B вырезка, P вырезка, или вырезка GPB), информацию построения для одного или более списков опорных картинок для вырезки, векторы движения для каждого внешне кодированного видео блока вырезки, статус внешнего предсказания для каждого внешне кодированного видео блока вырезки, и другую информацию, чтобы декодировать видео блоки в текущей видео вырезке.
[0149] Модуль 86 обратного квантования обратно квантует, то есть, деквантует, квантованные коэффициенты преобразования, предоставленные в потоке битов и декодированные модулем 80 энтропийного декодирования. Процесс обратного квантования может включать в себя использование параметра квантования, вычисленного видео кодером 20 для каждого видео блока в видео вырезке, чтобы определить степень квантования и, аналогично, степень обратного квантования, которое должно быть применено.
[0150] Модуль 88 обработки обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование, или концептуально подобный процесс обратного преобразования, к коэффициентам преобразования, чтобы сформировать остаточные блоки в пиксельной области. Согласно аспектам настоящего раскрытия, модуль 88 обработки обратного преобразования может задавать способ, в котором преобразования были применены к остаточным данным. Таким образом, например, модуль 88 обработки обратного преобразования может задавать RQT, который представляет способ, в котором преобразования (например, DCT, целочисленное преобразование, вейвлет преобразование, или одно или более других преобразований), были применены к остаточным выборкам яркости и остаточным выборкам насыщенности цвета, ассоциированных с блоком принятых видео данных.
[0151] После того, как модуль 82 компенсации движения сгенерировал предсказывающий блок для текущего блока видео на основании вектора движения и других элементов синтаксиса, видео декодер 30 формирует декодированный видео блок, суммируя остаточные блоки от модуля 88 обработки обратного преобразования с соответствующими предсказывающими блоками, генерируемыми модулем 82 компенсации движения. Сумматор 90 представляет компонент или компоненты, которые выполняют эту операцию суммирования. Если желательно, фильтр удаления блочности может также быть применен, чтобы фильтровать декодированные блоки, чтобы удалить артефакты блочности. Другие контурные фильтры (или в контуре кодирования или после контура кодирования) также могут быть использованы для сглаживания пиксельных переходов, или иначе улучшить качество видео. Декодированные видео блоки в заданной картинке затем сохраняют в памяти 92 опорных картинок, которая хранит опорные картинки, используемые для последующей компенсации движения. Память 92 опорных картинок также хранит декодированное видео для более позднего представления на устройстве отображения, таком как устройство 32 отображения согласно ФИГ. 1.
[0152] ФИГ. 4 является концептуальной диаграммой, иллюстрирующей пример шаблона предсказания MVC. В примере согласно ФИГ. 4 иллюстрированы восемь видов, и двенадцать временных местоположений иллюстрированы для каждого вида. В целом каждая строка на фиг. 4 соответствует виду, в то время как каждая колонка указывает временное местоположение. Каждый из видов может быть идентифицирован, используя идентификатор вида ("view_id"), который может быть использован для указания относительного местоположения камеры относительно других видов. В примере, показанном на фиг. 4, идентификаторы вида обозначены как “S0”-“S7”, хотя могут также использоваться числовые идентификаторы вида. Кроме того, каждое из временных местоположений может быть идентифицировано, используя значение отсчет порядка картинки (POC), которое указывает порядок отображения картинок. В примере, показанном на фиг. 4, значения POC обозначены как “T0”-"T11".
[0153] Хотя MVC имеет так называемый базовый вид, который является декодируемым декодерами H.264/AVC, и пара стерео видов может быть поддержана посредством MVC, MVC может поддерживать больше чем два вида в качестве ввода 3D видео. Соответственно, модуль воспроизведения клиента, имеющего декодер MVC, может ожидать контент видео 3D со множественными видами.
[0154] Картинки на фиг. 4 обозначены, используя заштрихованный блок, включающий в себя символ, обозначающий, является ли кодированной соответствующая картинка внутренне (то есть, I-кадр), или внешне кодированной в одном направлении (то есть, как P-кадр) или во множественных направлениях (то есть, как B-кадр). В целом предсказания обозначены стрелками, где указываемая картинка использует указание от объекта для ссылки предсказания. Например, P-кадр вида S2 во временном местоположении T0 предсказывается из I-кадра вида S0 во временном местоположении T0. Каждая из картинок, показанных на фиг. 4, может упоминаться как компонент вида. Таким образом, компонент вида для вида соответствует конкретному временному экземпляру вида.
[0155] Как и с кодированием единственного вида видео, картинки последовательности видео с множественными видами могут быть закодированы с предсказанием относительно картинок в различных временных местоположениях. Например, b-кадр вида S0 во временном местоположении T1 имеет стрелку, указывающую на нее от I-кадра вида S0 во временном местоположении T0, указывая, что b-кадр предсказан из I-кадра. Дополнительно, однако, в контексте кодирования видео с множественными видами картинки могут быть предсказаны между видами. Таким образом, компонент вида может использовать компоненты вида в других видах для ссылки. В MVC, например, реализуется предсказание между видами, как если компонент вида в другом виде является ссылкой внешнего предсказания. Потенциальные ссылки между видами могут быть сигнализированы в расширении MVC SPS и могут быть изменены процессом конструирования списка опорных картинок, который обеспечивает гибкий порядок внешнего предсказания или ссылок предсказания между видами.
[0156] ФИГ. 4 обеспечивает различные примеры предсказания между видами. Картинки вида S1, в примере согласно ФИГ. 4, иллюстрированы как предсказываемые из картинок в различных временных местоположениях вида S1, так же как предсказываемые между видами из картинок для картинок видов S0 и S2 в одних и тех же временных местоположениях. Например, b-кадр вида S1 во временном местоположении T1 предсказан из каждого из B-кадров вида S1 во временных местоположениях T0 и T2, так же как b-кадры видов S0 и S2 во временном местоположении T1.
[0157] В примере согласно ФИГ. 4, заглавная буква “B” и строчные буквы “b” предназначены, чтобы указывать различные иерархические отношения между картинками, а не различные методологии кодирования. В целом кадры с заглавной буквой “B” являются относительно выше в иерархии предсказания чем кадры со строчными буквами “b”. ФИГ. 4 также иллюстрирует изменения в иерархии предсказания, используя различные уровни штриховки, где большая степень штриховки (то есть, относительно более темные) картинки является более высокой в иерархии предсказания, чем картинки, имеющие меньше штриховки (то есть, относительно светлее). Например, все I-кадры на фиг. 4 иллюстрированы с заполняющей штриховкой, в то время как P-кадры имеют несколько более светлую штриховку, и B-кадры (и b-кадры со строчными буквами) имеют различные уровни штриховки друг относительно друга, но всегда светлее, чем штриховка P-кадров и I-кадров.
[0158] В целом иерархия предсказания относится к порядковым индексам вида, в котором картинки относительно более высокие в иерархии предсказания должны быть декодированы прежде, чем декодированы картинки, которые являются относительно более низкими в иерархии, таким образом что эти картинки относительно более высокие в иерархии могут использоваться в качестве опорных картинок во время декодирования картинок относительно более низких в иерархии. Порядковый индекс вида является индексом, который указывает порядок декодирования компонентов вида в единице доступа. Порядковые индексы вида могут подразумеваться в наборе параметров, таком как SPS.
[0159] В этом способе картинки, используемые в качестве опорных картинок, могут быть декодированы прежде, чем декодированы картинки, которые закодированы со ссылками на опорные картинки. Порядковый индекс вида является индексом, который указывает порядок декодирования компонентов вида в единице доступа. Согласно MVC/AVC, для каждого порядкового индекса i видов, сигнализируется соответствующий view_id. Декодирование компонентов вида следует возрастающему порядку порядковых индексов вида. Если все виды представлены, то набор порядковых индексов вида содержит последовательно упорядоченный набор от нуля до менее, чем полное количество видов.
[0160] В некоторых случаях поднабор всего потока битов может быть извлечен, чтобы сформировать подпоток битов, который все еще соответствует MVC. Существует много возможных подпотоков битов, которые конкретные приложения могут требовать, на основании, например, услуги, обеспеченной сервером, емкости, поддержки, и возможностями декодеров одного или более клиентов, и/или предпочтением одного или более клиентов. Например, клиент может требовать только три вида, и могут быть два сценария. В одном примере один клиент может требовать восприятия гладкого просмотра и может предпочесть виды со значениями view_id S0, S1, и S2, в то время как другой клиент может требовать масштабируемости вида и предпочесть виды со значениями view_id S0, S2, и S4. Оба из этих подпотоков битов могут быть декодированы как независимые потоки битов MVC и могут поддерживаться одновременно.
[0161] В целом позиция камеры, ориентация и геометрическое отношение между различными видами могут быть логически выведены из ID Вида или Порядкового индекса вида. С этой целью и присущие и внешние параметры камеры могут быть включены в поток битов, используя сообщение SEI информации получения множественных видов.
[0162] В то время как ФИГ. 4 показывает восемь видов (S0-S7), как отмечено выше, расширение MVC/AVC поддерживает до 1024 видов и использует view_id в заголовке единицы NAL, чтобы идентифицировать вид, которому принадлежит единица NAL. Согласно аспектам настоящего раскрытия, порядковый индекс вида может быть сигнализирован в качестве части заголовка единицы NAL. Таким образом, в целях сравнения порядковый индекс вида может заменить view_id, который сигнализирован в заголовке единицы NAL расширения MVC/AVC. Порядок видов обычно описывает порядок видов в единице доступа, и порядковый индекс вида идентифицирует конкретный вид в порядке видов единицы доступа. Таким образом, порядковый индекс вида описывает порядок декодирования соответствующего компонента вида единицы доступа.
[0163] Соответственно, согласно аспектам настоящего раскрытия, SPS может обеспечить отношения между view_ids для видов и порядковые индексы вида для упомянутых видов. Используя порядковый индекс вида и данные в SPS, видео кодер 20 и видео декодер 30 могут заменить 10-битовый view_id в MVC/AVC в заголовке единицы NAL порядковым индексом вида, который может привести к экономии битов по сравнению со схемой MVC/AVC.
[0164] Пример SPS, который обеспечивает соотношения между view_ids для видов и порядковыми индексами вида, предоставлен в Таблице 6 ниже:
[0165] В примере, показанном в Таблице 6, выделенные жирным шрифтом и курсивом элементы синтаксиса указывают отступления от синтаксиса SPS MVC/AVC, то есть, модификации относительно синтаксиса SPS MVC/AVC. Например, SPS, показанный в Таблице 6, задает отношения зависимости между видами для закодированной видео последовательности. SPS также задает значения уровня для поднабора рабочих точек для закодированной видео последовательности. Все SPS, на которые ссылаются посредством кодированной видео последовательности, должны быть идентичными. Однако, некоторые виды, идентифицированные посредством view_id [i], могут не присутствовать в этой кодированной видео последовательности. Кроме того, некоторые виды или временные поднаборы, описанные посредством SPS, могут быть удалены из первоначальной закодированной видео последовательности, и таким образом, могут не присутствовать в кодированной видео последовательности. Информация в SPS, однако, может всегда применяться к оставшимся видам и временным поднаборам.
[0166] В Таблице 6 выше, элемент num_views_minus1 плюс 1 может задавать максимальное количество закодированных видов в закодированной видео последовательности. Значение num_view_minus1 может быть в диапазоне от 0 до 31, включительно. В некоторых случаях фактическое количество видов в закодированной видео последовательности может быть меньше чем num_views_minus1 плюс 1. Элемент view_id [i] может задавать идентификатор вида для вида с порядковым индексом вида, равным i. Элемент view_level [i] может задавать view_level вида с порядковым индексом вида, равным i. В некоторых примерах все компоненты вида с view_level вплоть до заранее заданного значения (VL) могут быть декодируемыми без декодирования компонента вида с view_level большим чем VL.
[0167] Согласно аспектам настоящего раскрытия, элемент num_ref_views [i] может задавать количество компонентов вида для предсказания между видами в начальном списке опорных картинок RefPicList0 и RefPicList1 при декодировании компонентов вида с порядковым индексом вида, равным i. Значение элемента num_ref_views [i] может быть не больше чем Min(15, num_views_minus1). Значение num_ref_views [0] может быть равным 0. Кроме того, согласно аспектам настоящего раскрытия, элемент ref_view_idx [i] [j] может задать порядковый индекс вида j-го компонента вида для предсказания между видами в начальном списке опорных картинок RefPicList0 и RefPicList1 при декодировании компонента вида с порядковым индексом вида, равным i. Значение ref_view_idx [i] [j] может быть в диапазоне от 0 до 31, включительно.
[0168] Соответственно, в различных аспектах настоящего раскрытия зависимости видов для картинок с привязкой и картинок без привязки могут больше не требоваться быть отдельно поддерживаемыми и сигнализированными. Таким образом, видео кодер 20 и/или видео кодер 30 могут использовать единственный список опорных картинок (или поддерживать два списка опорных картинок, Список 0 и Список 1) для картинок с привязкой и картинок без привязки аналогично. Таким образом, как показано в Таблице 6 выше, отдельная сигнализация не требуется для указания зависимости видов для видео декодера 30. Вместо этого SPS включает в себя ref_view_idx, который может быть использован для построения и Списка 0 и Списка 1 для компонентов вида.
[0169] Согласно таким аспектам настоящего раскрытия, например, видео декодер 30 может принять для любого компонента вида первый вид, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида. Таким образом, видео декодер 30 может принять опорную информацию вида, указывающую зависимости видов для картинок с привязкой вида и картинок без привязки вида аналогично. При декодировании конкретной картинки (единицы доступа) конкретного вида затем видео декодер 30 может включать опорные кандидаты (например, компоненты вида, из которых конкретная картинка может быть предсказана) из одной и той же единицы доступа в качестве конкретной картинки и от опорных видов, указанных информацией опорного вида. В некоторых случаях видео декодер 30 может добавить опорных кандидатов к списку опорных картинок из каждого опорного вида, так что количество опорных кандидатов равно количеству опорных видов. Кроме того, видео декодер 30 может добавить опорных кандидатов к или Списку 1, Списку 0, или обоим. Видео декодер 30 может затем декодировать конкретную картинку на основании одной из опорных картинок в списке опорных картинок.
[0170] Кроме того, согласно Таблице 6 зависимость между видами для компонентов вида без привязки может быть больше не сигнализирована в SPS как поднабор зависимости между видами для компонентов вида с привязкой. Вместо этого компонент вида для вида с привязкой может быть предсказан от больше чем одного другого вида, такого как вид 3 и 4, и вид без привязки может также быть предсказан из картинок вида 3 и вида 4. Если дополнительное ограничение ограничения зависимости видов желательно для картинок без привязки, такое ограничение может быть предоставлено в дополнительной сигнализации, такой как сообщение SEI.
[0171] Элемент num_level_values_signalled_minus1 плюс 1 может задавать количество значений уровня, сигнализированных для закодированной видео последовательности. Значение num_level_values_signalled_minus1 может быть в диапазоне от 0 до 63, включительно. Элемент level_idc [i] может задавать i-е значение уровня, сигнализированное для закодированной видео последовательности. Элемент num_applicable_ops_minus1 [i] плюс 1 может задавать количество рабочих точек, к которым уровень, указанный посредством level_idc [i], применяется. Значение элемента num_applicable_ops_minus1 [i] может быть в диапазоне от 0 до 1023, включительно. Элемент applicable_op_temporal_id [i] [j] может задавать temporal_id для j-й рабочей точки, к которому уровень, указанный посредством level_idc [i], применяется. Элемент applicable_op_num_target_views_minus1 [i] [j] плюс 1 может задавать количество целевых видов вывода для j-й рабочей точки, к которому уровень, указанный посредством level_idc [i], применяется. Значение элемента applicable_op_num_target_views_minus1 [i] [j] может быть в диапазоне от 0 до 1023, включительно.
[0172] Элемент applicable_op_target_view_idx [i] [j] [k] может задавать порядковый индекс вида k-го целевого вида вывода для j-й рабочей точки, к которому уровень, указанный посредством level_idc [i], применяется. Значение элемента applicable_op_target_view_idx [i] [j] [k] может быть в диапазоне от 0 до 31, включительно. applicable_op_num_views_minus1 [i] [j] плюс 1 может задавать количество видов, требуемых для декодирования целевых видов вывода, соответствующие j-й рабочей точке, к которому уровень, указанный посредством level_idc [i], применяется. Количество видов, определенных посредством applicable_op_num_views_minus1, может включать в себя целевые виды вывода и виды, от которых целевые виды вывода зависят, как определено процессом извлечения подпотока битов.
[0173] В другом примере, согласно аспектам настоящего раскрытия, значение ref_view_idx [i] [j] может требоваться быть меньшим чем i, на основании порядка декодирования компонентов вида в одном и том же моменте времени.
[0174] ref_view_idx [i] [j] может быть далее уменьшен в размере (для дополнительных экономий битов по сравнению с MVC/AVC). Например, дополнительные экономии битов могут быть достигнуты в потоке MVC, который включает в себя только два вида (то есть, для стерео видео). В этом примере порядковый индекс вида может не быть необходимым, поскольку видео декодер 30 может всегда декодировать первый вид (например, вид 0) до декодирования второго вида (например, вид 1). Пример, уменьшенный SPS, предоставлен в Таблице 7 ниже:
[0175] В примере, показанном в Таблице 7, элемент ref_view_idx_diff_minus1 [i] [j] плюс i+1 может задавать порядковый индекс вида j-го компонента вида для предсказания между видами в начальном списке опорных картинок RefPicList0 и RefPicList1 при декодировании компонента вида с порядковым индексом вида, равным i. Значение элемента ref_view_idx_diff_minus1 [i] [j] может быть в диапазоне 0 до 30-i, включительно.
[0176] Другие примеры также возможны. Например, вместо того, чтобы сигнализировать зависимость видов в SPS (как в примерах, показанных в Таблицах 6 и 7 выше), зависимость видов может быть сигнализирована в PPS. В другом примере зависимость видов может быть сигнализирована в SPS, и зависимость видов может быть далее сигнализирована в PPS, который находится в области зависимости вида, сообщенного в наборе параметров последовательности. Например, в SPS, зависимый вид (например, вид 2) может быть сигнализирован как являющийся зависимым от вида 0 и вида 1, в то время как в PPS зависимый вид (например, вид 2) может быть сигнализирован как только являющийся зависимым от вида 0.
[0177] Согласно некоторым аспектам настоящего раскрытия построение списка опорных картинок и переупорядочение могут быть изменены по сравнению с MVC/AVC. Например, согласно аспектам настоящего раскрытия, индекс (view_idx) вида, описанный выше, может быть использован во время построения списка опорных картинок и/или переупорядочения. Примерный синтаксис модификации MVC списка опорных картинок предоставлен в Таблицах 8 и 9 ниже:
[0178] В Таблицах 8 и 9 элемент modification_of_pic_nums_idc вместе с abs_diff_pic_num_minus1, long_term_pic_num, или abs_diff_view_idx_minus1 может задавать, какая из опорных картинок или опорных компонентов только между видами являются переотображенными. Например, элемент abs_diff_view_idx_minus1 плюс 1 может задавать абсолютную разность между опорным индексом между видами, чтобы поместить в текущий индекс в списке опорных картинок и значением предсказания опорного индекса между видами.
[0179] В другом примере, согласно аспектам настоящего раскрытия, inter_view_index опорной ссылки между видами может быть непосредственно сигнализирован. Такой синтаксис модификации MVC списка опорных картинок предоставлен в Таблицах 10 и 11 ниже:
[0180] В Таблицах 10 и 11 опорная картинка между видами может быть идентифицирована посредством inter_view_index следующим образом:
VOIdx=ref_view_idx[CurrVOIdx][inter_view_index]
где CurrVOIdx является порядковым индексом вида текущего компонента вида. Учитывая значение POC текущей картинки, POC и VOIdx могут быть использованы для идентификации опорной картинки между видами.
[0181] В некоторых примерах MVC процесс декодирования для построения списков опорных картинок может быть вызван в начале процесса декодирования для каждой P, SP или B вырезки. Во время вызова этого процесса только опорные картинки, имеющие одно и то же значение view_idx в качестве текущей вырезки могут быть рассмотрены. Декодированные опорные картинки могут быть помечены как "используется для краткосрочной ссылки", или " используется для долгосрочной ссылки." Краткосрочные опорные картинки могут быть идентифицированы значениями frame_num и view_idx, и, для опорных картинок между видами - дополнительно PicOrderCnt (). Долгосрочным опорным картинкам можно назначить долгосрочный индекс кадра и идентифицированы значениями долгосрочного индекса кадра, view_idx, и, для опорных картинок между видами, дополнительно - PicOrderCnt ().
[0182] В дополнение к опорным картинкам опорные компоненты только между видами (который может быть неопорными картинками, и могут быть не отмечены во время процесса маркировки опорной картинки), могут также быть включены в список опорных картинок. Только опорные компоненты между видами могут быть идентифицированы значением view_idx и PicOrderCnt ().
[0183] Во время вызова процесса построения списка опорных картинок следующий процесс, идентифицированный в MVC/AVC как подпункт 8.2.4.1, может быть вызван, чтобы задать:
* назначение переменных FrameNum, FrameNumWrap, и PicNum каждой из краткосрочных опорных картинок, и
* назначение переменной LongTermPicNum каждой из долгосрочных опорных картинок.
[0184] Опорные картинки и, когда присутствуют, только опорные компоненты между видами, адресуются с помощью опорные индексы. Опорный индекс является индексом в список опорных картинок. При декодировании P или SP вырезки имеется единственный список опорных картинок RefPicList0. При декодировании вырезки B, имеется второй независимый список опорных картинок RefPicList1 в дополнение к RefPicList0.
[0185] В начале процесса декодирования для каждой вырезки список опорных картинок RefPicList0, и для вырезок B - RefPicList1, может быть получен как определено следующими упорядоченными этапами:
1. Начальный список опорных картинок RefPicList0 и для вырезок B - RefPicList1 получают как определено в подпункте 8.2.4.2 MVC/AVC.
2. Опорные картинки между видами или только опорные компоненты между видами присоединяют к начальному списку опорных картинок RefPicList0 и для вырезок B RefPicList1, как определено в подпункте 6.4.1 (сформулированный ниже).
3. Когда ref_pic_list_modification_flag_l0 равен 1 или при декодировании вырезки B, ref_pic_list_modification_flag_l1 равен 1, список опорных картинок RefPicList0 и для вырезок B RefPicList1 модифицируют как определено в подпункте 6.4.2 (сформулировано ниже).
[0186] Кроме того, количество записей в модифицированном списке опорных картинок RefPicList0 равно num_ref_idx_l0_active_minus1 + 1, и для вырезок B количество записей в модифицированном списке опорных картинок, RefPicList1, равно num_ref_idx_l1_active_minus1 + 1. Опорная картинка или только опорный компонент между видами может появиться в более чем одном индексе в модифицированных списках опорных картинок RefPicList0 или RefPicList1.
[0187] Во время вызова процесса, определенного в подпункте 6.4.1, может не существовать ссылка предсказания между видами, присоединенная к RefPicListX (с X равным 0 или 1). Однако, ссылка предсказания между видами, которая не существует, может не быть в модифицированном RefPicListX после вызова процесса, определенного в подпункте 6.4.2 (сформулировано ниже).
[0188] В одном примере подпункт 6.4.1 сформулирован ниже, который включает в себя процесс инициализации для списка опорных картинок для ссылок предсказания между видами:
* Входными данными к этому процессу являются список опорных картинок RefPicListX (с X равным 0 или 1), inter_view_flag и информация зависимости видов, которая была декодирована из seq_parameter_set_mvc_extension ().
* Выходными данными этого процесса является возможно модифицированный список опорных картинок RefPicListX, который все еще упоминается как intial список опорных картинок RefPicListX.
* При i, являющимся значением view_idx для текущей вырезки, опорные картинки между видами и только опорные компоненты между видами присоединяются к списку опорных картинок, как определено ниже:
* Для каждого значения опорного индекса между видами j от 0 до num_ref_views [i] − 1, включительно, в порядке возрастания j, ссылки предсказания между видами с view_idx равным ref_view_idx [i] [j] из той же единицы доступа, как и текущая вырезка, присоединяется к RefPicListX.
[0189] В одном примере подпункт 6.4.2 сформулирован ниже, который включает в себя процесс модификации для списков опорных картинок:
* Входными данными к этому процессу является список опорных картинок RefPicList0 и при декодировании вырезки B, также список опорных картинок RefPicList1.
* Выходными данными этого процесса являются возможно модифицированный список опорных картинок RefPicList0 и при декодировании вырезки B, также возможно модифицированный список опорных картинок RefPicList1.
* Когда ref_pic_list_modification_flag_l0 равен 1, задаются следующие упорядоченные этапы:
1. Пусть refIdxL0 является индексом для списка опорных картинок RefPicList0. Он первоначально установлен равным 0.
2. Соответствующие элементы modification_of_pic_nums_idc синтаксиса обрабатывают в порядке, в котором они имеют место в потоке битов. Для каждого из этих элементов синтаксиса применяется следующее:
- Если modification_of_pic_nums_idc равен 0 или равен 1, процесс, определенный в подпункте 6.4.2.1 (сформулирован ниже), вызывается с RefPicList0 и refIdxL0, заданными как введено, и вывод назначается в RefPicList0 и refIdxL0.
- Иначе, если modification_of_pic_nums_idc равен 2, процесс, определенный в подпункте 6.4.2.2 (сформулирован ниже), вызывается с RefPicList0 и refIdxL0, заданными как введено, и вывод назначается в RefPicList0 и refIdxL0.
- Иначе, если modification_of_pic_nums_idc равен 4 или равен 5, процесс, определенный в подпункте 6.4.2.3 (сформулирован ниже), вызывается с RefPicList0 и refIdxL0, заданными как введено, и вывод назначается в RefPicList0 и refIdxL0.
- Иначе (modification_of_pic_nums_idc равно 3), процесс модификации для списка опорных картинок RefPicList0 заканчивается.
* Когда ref_pic_list_modification_flag_l1 равен 1, следующие упорядоченные этапы задаются:
1. Пусть refIdxL1 является индексом для списка опорных картинок RefPicList1. Он первоначально установлен равным 0.
2. Соответствующие элементы синтаксиса modification_of_pic_nums_idc обрабатывают в порядке, в котором они имеют место в потоке битов. Для каждого из этих элементов синтаксиса применяется следующее.
- Если modification_of_pic_nums_idc равен 0 или равен 1, процесс, определенный в подпункте 6.4.2.1 (сформулирован ниже), вызывается с RefPicList1 и refIdxL1, заданными как введено, и вывод назначается на RefPicList1 и refIdxL1.
- Иначе, если modification_of_pic_nums_idc равен 2, процесс, определенный в подпункте 6.4.2.2 (сформулирован ниже), вызывается с RefPicList1 и refIdxL1, заданными как введено, и вывод назначается на RefPicList1 и refIdxL1.
- Иначе, если modification_of_pic_nums_idc равен 4 или равен 5, процесс, определенный в подпункте 6.4.2.3 (сформулирован ниже), вызывается с RefPicList1 и refIdxL1, заданными как введено, и вывод назначается на RefPicList1 и refIdxL1.
- Иначе (modification_of_pic_nums_idc равно 3), процесс модификации для списка опорных картинок RefPicList1 заканчивается.
[0190] В примере подпункт 6.4.2.1 сформулирован ниже, который включает в себя процесс модификации списка опорных картинок для краткосрочных опорных картинок для внешнего предсказания:
* Входными данными к этому процессу являются индекс refIdxLX и список опорных картинок RefPicListX (с X равным 0 или 1).
* Выходными данными этого процесса являются увеличенный индекс refIdxLX и модифицированный список опорных картинок RefPicListX.
- переменная picNumLXNoWrap получается следующим образом:
- Если modification_of_pic_nums_idc равен 0,
if (picNumLXPred−(abs_diff_pic_num_minus1+1)<0)
picNumLXNoWrap=picNumLXPred−(abs_diff_pic_num_minus1+1) +MaxPicNum (h-1)
else
picNumLXNoWrap=picNumLXPred−(abs_diff_pic_num_minus1+1)
- Иначе (modification_of_pic_nums_idc равно 1),
if (picNumLXPred+(abs_diff_pic_num_minus1+1)>=MaxPicNum)
picNumLXNoWrap=picNumLXPred+(abs_diff_pic_num_minus1+1)− MaxPicNum (h-2)
else
picNumLXNoWrap=picNumLXPred+(abs_diff_pic_num_minus1+1)
где picNumLXPred является значением предсказания для переменной picNumLXNoWrap. Когда процесс, определенный в этом подпункте, вызывается первый раз для вырезки (то есть, для первого появления modification_of_pic_nums_idc равным 0 или 1 в синтаксисе ref_pic_list_modification ()), picNumL0Pred и picNumL1Pred первоначально устанавливаются равными CurrPicNum. После каждого присваивания значения picNumLXNoWrap значение picNumLXNoWrap назначается на picNumLXPred.
[0191] В некоторых примерах переменная picNumLX получается, как определено следующим псевдокодом:
if (picNumLXNoWrap>CurrPicNum)
picNumLX=picNumLXNoWrap-MaxPicNum (h-3)
else
picNumLX=picNumLXNoWrap
где picNumLX может быть равным PicNum опорной картинки, которая помечена как "используется для краткосрочной ссылки" и может быть не равным PicNum краткосрочной опорной картинки, которая отмечена как "несуществующая". Следующий процесс может быть выполнен, чтобы поместить картинку с номером picNumLX краткосрочной картинки в позицию refIdxLX индекса, сдвинуть позицию любых других остающихся картинок к позже в списке, и увеличить значение refIdxLX:
for(cIdx=num_ref_idx_lX_active_minus1+1; cIdx>refIdxLX; cIdx − −)
RefPicListX[cIdx]=RefPicListX [cIdx−1]
RefPicListX[refIdxLX ++]=краткосрочная опорная картинка с PicNum, равным picNumLX
nIdx=refIdxLX
for(cIdx=refIdxLX; cIdx<= num_ref_idx_lX_active_minus1+1; cIdx ++) (h-4)
if(PicNumF (RefPicListX [cIdx])!=picNumLX | | viewIDX (RefPicListX [cIdx])! = currViewIDX)
RefPicListX [nIdx ++]=RefPicListX [cIdx]
где функция viewIDX (refpic) возвращает view_idx опорной картинки refpic, переменная currViewIDX равна view_idx текущей вырезки, и функция PicNumF (RefPicListX [cIdx]) получается следующим образом:
- Если опорная картинка RefPicListX [cIdx] помечена как "используется для краткосрочной ссылки", PicNumF (RefPicListX [cIdx]) равно PicNum картинки RefPicListX [cIdx].
- Иначе (опорная картинка RefPicListX [cIdx] не помечена как "используется для краткосрочной ссылки"), PicNumF (RefPicListX [cIdx]) равен MaxPicNum.
[0192] В одном примере подпункт 6.4.2.2 сформулирован ниже, который включает в себя процесс модификации списка опорных картинок для долгосрочных опорных картинок для внешнего предсказания:
* Входными данными к этому процессу являются индекс refIdxLX (с X равным 0 или 1) и список опорных картинок RefPicListX.
* Выходными данными этого процесса являются увеличенный индекс refIdxLX и модифицированный список опорных картинок RefPicListX.
* Следующая процедура проводится, чтобы поместить картинку с номером долгосрочной картинки long_term_pic_num в позицию refIdxLX индекса, сдвинуть позицию любых других остающихся картинок к позже в списке, и увеличить значение refIdxLX:
for(cIdx=num_ref_idx_lX_active_minus1+1; cIdx>refIdxLX; cIdx − −)
RefPicListX [cIdx]=RefPicListX [cIdx−1]
RefPicListX [refIdxLX ++]=долгосрочная опорная картинка с LongTermPicNum, равным long_term_pic_num
nIdx=refIdxLX
for(cIdx=refIdxLX; cIdx<= num_ref_idx_lX_active_minus1+1; cIdx ++) (h-5)
if(LongTermPicNumF (RefPicListX [cIdx])! = long_term_pic_num | |
viewIDX (RefPicListX [cIdx])! = currViewIDX)
RefPicListX [nIdx ++]=RefPicListX [cIdx]
где функция viewIDX (refpic) возвращает view_idx опорной картинки refpic, переменная currViewIDX равна view_idx текущей вырезки, и функция LongTermPicNumF (RefPicListX [cIdx]) может быть получена следующим образом:
* Если опорная картинка RefPicListX [cIdx] отмечена как "используется для долгосрочной ссылки", LongTermPicNumF (RefPicListX [cIdx]) равно LongTermPicNum картинки RefPicListX [cIdx].
* Иначе (опорная картинка RefPicListX [cIdx] не помечена как "используется для долгосрочной ссылки"), LongTermPicNumF (RefPicListX [cIdx]) равен 2 * (MaxLongTermFrameIdx + 1).
[0193] В примере подпункт 6.4.2.3 сформулирован ниже, который включает в себя процесс модификации списка опорных картинок для опорных ссылок предсказания между видами:
* Входными данными к этому процессу являются список опорных картинок RefPicListX (с X равным 0 или 1) и индекс refIdxLX в этом списке.
* Выходными данными этого процесса модифицированный список опорных картинок RefPicListX (с X равным 0 или 1) и увеличенный индекс refIdxLX.
* Пусть currVOIdx является переменной VOIdx текущей вырезки. Переменная maxViewIdx установлена равной num_ref_views [currVOIdx].
* Переменная picInterViewIdxLX получается следующим образом:
* Если modification_of_pic_nums_idc равен 4,
if (picInterViewIdxLXPred − (abs_diff_inter_view_minus1 + 1) <0) picInterViewIdxLX=picInterViewIdxLXPred − (abs_diff_inter_view_ minus1+1) + maxViewIdx (h-6)
else
picInterViewIdxLX=picInterViewIdxLXPred − (abs_diff_inter_view_minus1 +1)
* Иначе (modification_of_pic_nums_idc равно 5),
if (picInterViewIdxLXPred+(abs_diff_inter_view_minus1 + 1)> = maxViewIdx)
picInterViewIdxLX=picInterViewIdxLXPred+(abs_diff_inter_view_ minus1 + 1) − maxViewIdx (h-7)
else
picInterViewIdxLX=picInterViewIdxLXPred+(abs_diff_inter_view_minus1 + 1)
где picInterViewIdxLXPred - значение предсказания для переменной picInterViewIdxLX. Когда процесс, определенный в этом подпункте, вызывается первый раз для RefPicList0 или RefPicList1 вырезки (то есть, для первого появления modification_of_pic_nums_idc, равного 4 или 5 в синтаксисе ref_pic_list_modification ()), picInterViewIdxL0Pred и picInterViewIdxL1Pred могут быть первоначально установлены равными −1. После каждого присваивания значения picInterViewIdxLX значение picInterViewIdxLX присваивается к picInterViewIdxLXPred.
[0194] Поток битов может не содержать данные, которые приводят к picInterViewIdxLX, равного меньше чем 0, или picInterViewIdxLX, большего чем maxViewIdx. Переменная targetViewIDX может быть получена следующим образом:
targetViewIDX=ref_view_idx [currVOIdx] [picInterViewIdxLX] (h-8)
[0195] Следующая процедура может быть проведена, чтобы поместить ссылку предсказания между видами с опорным индексом между видами, равным picInterViewIdxLX, в позицию индекса refIdxLX и сдвинуть позицию любых других остающихся картинок к более поздней в списке:
for (cIdx=num_ref_idx_lX_active_minus1+1; cIdx> refIdxLX; cIdx − −)
RefPicListX [cIdx]=RefPicListX [cIdx − 1]
RefPicListX [refIdxLX ++] = ссылка предсказания между видами с view_idx, равным targetViewIDX
nIdx=refIdxLX
for (cIdx=refIdxLX; cIdx <= num_ref_idx_lX_active_minus1 + 1; cIdx ++) (H-10)
if (viewIDX (RefPicListX [cIdx])! = targetViewIDX | | PictureOrderCnt (RefPicListX [cIdx])! = currPOC)
RefPicListX [nIdx ++] = RefPicListX [cIdx]
где функция viewIDX (refpic) возвращает view_idx опорной картинки refpic, переменная currViewIDX равна view_idx текущей вырезки, и переменная currPOC равна PicOrderCnt () текущей вырезки.
[0196] В некоторых примерах процесс по умолчанию может быть использован для комбинирования списков опорных картинок. Например, процесс комбинирования списка опорных картинок по умолчанию может включать в себя проверку, если опорная картинка (или из RefPicList0 или из RefPicList1) является первым появлением опорной картинки, которая добавляется в комбинированный список. Чтобы выполнить такую проверку, видео кодер (такой как видео кодер 20 или видео декодер 30) может сравнить текущую картинку CurrPic и любую картинку PicA в списке, включая опорные картинки между видами и временные опорные картинки. Сравнение может быть сделано следующим образом.
if (ViewIDX (CurrPic)== ViewIDX (PicA) && POC (CurrPic)== POC (PicA))
return true;
else
return false;
[0197] ФИГ. 5A является концептуальной диаграммой, иллюстрирующей пример структуры потока битов 100, который может быть использован в реализации одного или более способов настоящего раскрытия. Поток битов 100 может соответствовать стандарту кодирования видео, такому как стандарт HEVC. Кроме того, в некоторых примерах, поток битов 100 может соответствовать расширению MVC к стандарту кодирования видео.
[0198] В примере, показанном на фиг. 5A, поток 100 битов включает в себя множество единиц доступа 102-1 - 102-N (все вместе, единицы доступа 102). Как отмечено выше, единицы доступа 102 могут включать в себя последовательность компонентов вида (называемые как «виды»), такие как виды 104-1 - 104m (все вместе, виды 104). В целом единицы доступа 102 включают в себя все данные для общего временного момента, например, данные для одного компонента вида для каждого вида. В некоторых примерах каждая единица доступа из единиц доступа 102 включает в себя одинаковое количество видов 104. Декодирование каждой единицы доступа из единиц доступа 102 может привести к одной декодированной картинке для каждого вида. Единицы доступа 102 могут содержать закодированные видео данные, которые могут быть использованы для воспроизведения трехмерного воспроизведения видео.
[0199] ФИГ. 5B является концептуальной диаграммой, иллюстрирующей пример вида 104-N, который может быть включен в структуру потока 100 битов из ФИГ. 5A. В целом каждый компонент вида в единице доступа (таком как виды 104 в единице доступа 102-N) содержит набор единиц NAL уровня видео кодера/декодера (кодека) (VCL). Таким образом, в примере, показанном на фиг. 5B, вид 104-N включает в себя единицы NAL 106-1 до 106-3 в конкретной форме и порядке. Как правило, компоненты вида размещены в одном и том же порядке в каждой единице доступа таким образом, что k-й компонент вида в каждой единице доступа соответствует одному и тому же виду. В других примерах вид 104-N, может включать в себя другие количества единиц NAL.
[0200] ФИГ. 5C является концептуальной диаграммой, иллюстрирующей пример единицы NAL 108, которая может быть подобной по структуре единицам NAL 106, показанным на фиг. 5B. Единица NAL 108 обычно включает в себя заголовок 110 единицы NAL и полезные данные 112. Кроме того, заголовок 110 единицы NAL включает в себя первую часть 114 и расширение 116 заголовка единицы NAL, которые могут соответствовать расширению MVC/AVC.
[0201] Например, первая часть 114 включает в себя элемент ref_idc и элемент типа единицы NAL. Элемент ref_idc может указывать, используется ли единица NAL как ссылка для других единиц NAL. Например, значение ref_idc 00 может указывать, что контент NALU не используется для восстановления сохраненных картинок (которые могут быть использованы для будущей ссылки). Такие NALU могут быть отклонены, не рискуя целостностью опорных картинок. Значения выше 00 могут указывать, что требуется декодирование NALU, чтобы поддерживать целостность опорных картинок. Элемент типа единицы NAL может указывать тип пакетов единицы NAL 108.
[0202] Расширение 116 заголовка единицы NAL обычно включает в себя флаг IDR (IDR), приоритет ID (priority_id), id вида (view_id), временный ID (temporal_id), флаг картинки с привязкой (APF), и флаг между видами (IVF). Как описано со ссылками на фиг. 1 выше, флаг IDR может указывать, принадлежит ли единица NAL 108 картинке текущего обновления декодирования (IDR) или картинке IDR вида (V-IDR), которая может быть использована как точка произвольного доступа закрытой GOP. priority_id может быть использован с процессом адаптации потока битов, который изменяет поток битов согласно изменяющимся условиям сети и/или возможностям видео декодера 30 и/или устройства 32 отображения (например, таким как процесс адаптации с единственным проходом). view_id может быть использован для указания идентификатора вида для вида, которому принадлежит единица NAL. temporal_id может быть использован для указания временного уровня текущей единицы NAL, которая может соответствовать конкретной частоте кадров. APF может быть использован для указания, принадлежит ли единица NAL картинке с привязкой, которая может быть использована как точка произвольного доступа открытой GOP. IVF может быть использован для указания, используется ли единица NAL для предсказания между видами для единиц NAL в других видах.
[0203] Как описано выше, view_id MVC/AVC имеет длину 10 битов, и может быть использован для уникальной идентификации более чем 1000 различных видов. В целом однако, количество видов, фактически кодированных, типично является на несколько порядков величины меньше чем 1000 видов. Например, ФИГ. 4 включает в себя восемь видов для заданного мультимедийного контента MVC. Так как заголовок 110 единицы NAL включен для каждой единицы NAL, view_id может потреблять существенную величину потока битов. Аспекты настоящего раскрытия, как описано относительно примера, показанного на фиг. 5D, могут удалить view_id из заголовка единицы NAL, таким образом сокращая количество битов, требуемых для кодирования видео данных MVC.
[0204] ФИГ. 5D является концептуальной диаграммой, иллюстрирующей примерную единицу NAL 120, которая может быть подобной по структуре единицам NAL 106, показанным на фиг. 5B. Пример, показанный на фиг. 5D, иллюстрирует пример единицы NAL согласно аспектам настоящего раскрытия. Например, единица NAL 120 включает в себя заголовок 122 единицы NAL и полезные данные 124. Кроме того, заголовок единицы NAL включает в себя первую часть 126 и расширение 128 заголовка единицы NAL.
[0205] Как в примере, показанном на фиг. 5C, первая часть 126 включает в себя элемент ref_idc и элемент типа единицы NAL. Элемент ref_idc может указывать, используется ли единица NAL как ссылка для других единиц NAL. Элемент типа единицы NAL может указывать тип пакетов единицы NAL 120.
[0206] Как показано в примере согласно ФИГ. 5D, однако, вместо включения view_id в расширение 128 заголовка единицы NAL, порядковый индекс вида сигнализируется в качестве части заголовка 122 единицы NAL. Таким образом, согласно аспектам настоящего раскрытия, порядковый индекс вида заголовка 122 единицы NAL может заменить view_id, который сигнализирован в заголовке 110 единицы NAL (ФИГ. 5C). Как отмечено выше, порядок видов обычно описывает упорядочение видов в единице доступа, таких как порядок единиц доступа 102 (ФИГ. 5A). Порядковый индекс вида может указывать конкретный вид, такой как один из видов 104, в порядке видов единицы доступа. Таким образом, порядковый индекс вида может описать порядок декодирования соответствующего компонента вида единицы доступа.
[0207] Пример таблица синтаксиса заголовка единицы NAL для расширения 128 представлен в Таблице 12 ниже:
[0208] В примере, показанном на фиг. 13, non_idr_flag, который равен 0, может указывать, что текущая единица доступа является единицей доступа IDR. Значение non_idr_flag может быть одинаковым для всех единиц NAL VCL единицы доступа. В некоторых случаях non_idr_flag может быть логически выведен, чтобы быть равным 0 для единицы NAL базового вида, который имеет nal_unit_type равный 5. Кроме того, non_idr_flag может быть логически выведен, чтобы быть равным 1 для единицы NAL базового вида, который имеет nal_unit_type равный 1. Для единиц NAL, в которых присутствует non_idr_flag, переменная IdrPicFlag может быть изменена посредством установки флага равным 1, когда non_idr_flag равен 0, и установки равным 0, когда non_idr_flag равен 1.
[0209] Кроме того, anchor_pic_flag, который равен 1, может задавать, что текущая единица доступа является единицей доступа с привязкой. В некоторых случаях anchor_pic_flag может быть логически выведена, чтобы быть равным 0 для единицы NAL базового вида, которая имеет nal_unit_type равный 1, и может быть логически выведен, чтобы быть равным 1 для единицы NAL базового вида, которая имеет nal_unit_type равный 4 (Очистить Обновление Декодирования).
[0210] view_idx может задавать порядковый индекс вида для единицы NAL. В целом единицы NAL с одним и тем же значением view_idx принадлежат одному и тому же виду. Тип единицы NAL равный 20, может быть использован для указания типа единицы NAL для компонентов вида не в базовом виде.
[0211] Как показано в примере Таблицы 12, в отличие от примера, показанного на фиг. 5C, priority_id, temporal_id, и inter_view_flag были удалены, и view_id был заменен посредством view_idx. В некоторых примерах inter_view_flag может быть перемещен из расширения 128, как показано в примере заголовок единицы NAL Таблицы 13 ниже:
[0212] В примере, показанном в Таблице 13, элемент inter_view_flag, который равен 0, может указывать, что текущий компонент вида не используется для предсказания между видами никаким другим компонентом вида в текущей единице доступа. inter_view_flag, который равен 1, может указывать, что текущий компонент вида может быть использован для предсказания между видами другими компонентами вида в текущей единице доступа. Значение inter_view_flag может быть одним и тем же для всех единиц NAL VCL компонента вида.
[0213] Кроме того, в примере, показанном в Таблице 13, когда nal_unit_type равен 1 или 5, порядковый индекс вида может быть логически выведен равным 0, и view_id этого компонента вида равен view_id [0]. В таком примере расширение заголовка единицы NAL может не быть необходимым. Таким образом, в потоке MVC, который включает в себя только два вида (то есть, для стерео видео), может не быть необходимым порядковый индекс вида, поскольку декодер (такой как видео декодер 30) может всегда декодировать первый вид (например, вид 0) до декодирования второго вида (например, вида 1).
[0214] В некоторых примерах единица NAL префикса может быть больше не требоваться для базового вида (например, вида 0). Например, единица NAL префикса для базового вида больше может не быть необходимой, так как порядковый индекс вида всегда равен нулю для базового вида, и временная позиция базового вида может быть определена, используя temporal_id. Соответственно, temporal_id в заголовке единицы NAL обеспечивает всю информацию, чтобы ассоциировать конкретный компонент вида с конкретным видом и с соответствующим временным местоположением.
[0215] Таблица 14 включает в себя другой заголовок единицы NAL, который ссылается на расширение заголовка единицы NAL:
|| nal_unit_type= = 4 || nal_unit_type = = 20) {
[0216] В примере, показанном в Таблице 14, inter_view_flag, который равен 0, может указывать, что текущий компонент вида не используется для предсказания между видами никаким другим компонентом вида в текущей единице доступа. inter_view_flag, который равен 1, может указывать, что текущий компонент вида может быть использован для предсказания между видами другими компонентами вида в текущей единице доступа. Значение inter_view_flag может быть одним и тем же для всех единиц NAL VCL компонента вида. Кроме того, nal_unit_header_mvc_extension ссылается на расширение, такое как то, что показано в Таблице 12 выше.
[0217] Согласно другим аспектам настоящего раскрытия, заголовок единицы NAL для потока битов MVC может быть разработан согласно Таблице 15 ниже:
|| nal_unit_type= = 20){
[0218] В примере, показанном в Таблице 15, формирование заголовка единицы NAL может зависеть, например, от nal_unit_type. Таким образом, например, когда nal_unit_type равен 20, и единица NAL MVC, единица NAL может включать в себя non_idr_flag, anchor_pic_flag, и view_idx, описанные выше. Соответственно, для профиля стерео, заголовок единицы NAL может быть разработан согласно Таблице 16 ниже:
|| nal_unit_type= = 20){
[0219] В еще другом примере, согласно другим аспектам настоящего раскрытия, заголовок единицы NAL для потока битов MVC может быть разработан согласно Таблице 17 ниже:
|| nal_unit_type= = 20){
[0220] Независимо от конкретной конфигурации заголовка единицы NAL, как описано выше со ссылками на фиг. 4, набор параметров последовательности (SPS) может обеспечить отношения между view_ids для видов и порядковыми индексами вида для упомянутых видов. Соответственно, используя порядковый индекс вида и данные в SPS, 10-битовый view_id MVC/AVC может быть заменен в заголовке единицы NAL порядковым индексом вида, который может привести к экономии битов по сравнению со схемой MVC/AVC. Порядковый индекс вида может быть использован со значением POC или значением кадра (номер кадра), чтобы идентифицировать компонент вида потока битов. Например, привязывая сетку компонентов вида, показанных на фиг. 4 к Декартовской сетке, порядковый индекс вида может обеспечить y-координату (например, S0, S1, S2 …) конкретного компонента вида, в то время как значение POC или значение кадра может обеспечить x-координату (например, T0, T1, T2 …) конкретного компонента вида. Идентификация компонентов вида таким образом может быть реализована, например, в списке опорных картинок.
[0221] Согласно другим аспектам настоящего раскрытия, зависимость видов для каждого вида потока битов MVC может обычно быть сигнализирована для всех компонентов вида, независимо от того, являются ли компоненты вида для картинок с привязкой и картинок без привязки. В некоторых примерах SPS может включать в себя зависимости видов для компонентов вида, вместо того, чтобы полагаться на информацию в заголовке единицы NAL. Таким образом может быть удален anchor_pic_flag, используемый в расширении 128 заголовка единицы NAL.
[0222] В этом примере компонент вида сигнализированного зависимого вида может быть использован как опорная картинка и в Списке 0 и в Списке 1, как описано выше со ссылками на фиг. 4. Кроме того, построение списка опорных картинок и переупорядочение списка опорных картинок для Списка 0 и Списка 1 могут также быть основаны на общей сигнализации для картинок с привязкой и картинок без привязки. В некоторых примерах, уровень последовательности, сообщение дополнительной информации расширения (SEI) могут быть использованы для указания, когда картинка без привязки имеет отличную зависимость видов, чем картинка с привязкой.
[0223] Согласно другим аспектам настоящего раскрытия, вместо того, чтобы сигнализировать priority_id в заголовке единицы NAL, видео кодер 20 может обеспечить значения priority_id в SPS. Как описано выше, в некоторых примерах маршрутизатор 36 может использовать значения priority_id SPS, чтобы отфильтровать некоторые виды. Таким образом, маршрутизатор 36 может принять полный поток битов, но извлечь подпоток битов, включая единицы NAL, имеющие значения priority_id равные и ниже значения приоритета, определенного устройством 14 назначения, и отправить подпоток битов устройству назначения.
[0224] Кроме того, согласно аспектам настоящего раскрытия, сообщение адаптации приоритета может быть использовано для выполнения адаптации. Например, Таблица 18 ниже показывает примерное сообщение SEI адаптации приоритета:
[0225] В примере, показанном в Таблице 18, num_temporal_id_minus1 плюс 1 может указывать самый высокий temporal_id для единиц NAL потока битов MVC. same_priority_id_flag [i] [j] равный 1 может указать, что priority_id единиц NAL с temporal_id равным i и порядковым индексом вида j равны ранее сообщенному priority_id, который может быть priority_id [i] [j-1], когда j>0, или priority_id [i-1] [j] когда j=0 и i>0. Элемент priority_id [i] [j] может задавать идентификатор приоритета для единиц NAL с temporal_id равным i и порядковым индексом вида, равным j. Более низкое значение priority_id может указывать более высокий приоритет.
[0226] Адаптация может быть основана на заголовке единицы NAL и сообщении SEI, таком как то, которое показано в Таблице 18. Например, процесс адаптации может предположить, что temporal_id и view_idx единицы NAL равны TID и VIDX, и целевой priority_id равен PID. В этом примере, если priority_id [TID] [VIDX] не больше чем PID, единица NAL поддерживается, иначе, единица NAL отфильтровывается.
[0227] В то время как этот пример описывает информацию приоритета в сообщении SEI, в других примерах информация, описанная как сообщаемая в сообщении SEI, может быть сигнализирована как необязательная часть набора параметров, такого как SPS MVC.
[0228] ФИГ. 6 является блок-схемой, иллюстрирующей примерный способ кодирования потока битов множественных видов. Пример, показанный на фиг. 6, обычно описан как выполняемый видео кодером 20 (ФИГ. 1 и 2). Однако, нужно подразумевать, что процесс, описанный со ссылками на фиг. 6, может быть выполнен множеством других процессоров, блоков обработки, основанных на аппаратном обеспечении блоков кодирования, таких как кодер/декодеры (кодеки), и т.п.
[0229] В примере согласно ФИГ. 6, видео кодер 20 может кодировать видео данные для множества компонентов вида (140). Например, видео кодер 20 может кодировать множество из множества различных видов, с каждым видом, соответствующим различной перспективе, или углу, под которым были захвачены соответствующие видео данные общей сцены. Как отмечено выше, конкретная картинка конкретного вида упоминается как компонент вида. Таким образом, компонент вида для вида соответствует конкретному временному экземпляру вида.
[0230] Видео кодер 20 может также формировать единицы NAL, которые включают в себя индикацию порядка декодирования компонентов вида (142). Например, как описано со ссылками на фиг. 5A-5D, согласно аспектам настоящего раскрытия, видео кодер 20 может обеспечить индикацию порядкового индекса (view_idx) видов в заголовках единицы NAL, которая обеспечивает индикацию порядка декодирования компонентов вида. В целом единицы NAL с одним и тем же значением view_idx принадлежат одному и тому же виду.
[0231] Видео кодер 20 может также предоставить информацию, отдельную от единиц NAL, которая обеспечивает индикацию отношений между идентификаторами вида и порядком (144) декодирования. В некоторых примерах видео кодер 20 может генерировать набор параметров, такой как SPS, который указывает отношения между идентификаторами вида для этих видов и порядковыми индексами вида для этих видов. В других примерах видео кодер 20 может указывать отношения между порядковыми индексами вида и идентификаторами вида иным способом.
[0232] Используя порядковый индекс вида и упомянутую отдельную информацию, видео кодер 20 может заменить 10-битовый идентификатор вида, типично включенный в заголовок единицы NAL на порядковый индекс вида, который может обеспечить экономию битов. Например, порядковый индекс вида может включать в себя по существу меньше битов чем идентификатор вида. В то время как видео кодер 20 должен сигнализировать отношения между порядковым индексом вида и идентификаторами вида, например, в SPS, заголовки единицы NAL типично потребляют намного больше битов, чем такая сигнализация. Замена идентификатора вида в заголовке единицы NAL порядковым индексом вида может уменьшить размер заголовков единицы NAL, таким образом достигая экономии битов по сравнению с кодированием идентификатора вида в заголовке единицы NAL.
[0233] Нужно также подразумевать, что этапы, показанные и описанные со ссылками на фиг. 6, предоставлены как просто один пример. Таким образом, этапы способа ФИГ. 6 не обязательно должны быть выполнены в порядке, показанном на фиг. 6, и меньше, дополнительные, или альтернативные этапы могут быть выполнены.
[0234] ФИГ. 7 является блок-схемой, иллюстрирующей примерный способ декодирования потока битов множественных видов. Пример, показанный на фиг. 7, в целом описан как выполняемый видео декодером 30 (ФИГ. 1 и 3). Однако, нужно подразумевать, что процесс, описанный со ссылками на фиг. 7, может быть выполнен множеством других процессоров, блоков обработки, основанных на аппаратном обеспечении блоков кодирования, таких как кодер/декодеры (кодеки), и т.п.
[0235] В примере согласно ФИГ. 7, видео декодер 30 может принять одну или более единицы NAL для каждого компонента вида, которые включают в себя информацию, указывающую порядок декодирования соответствующих компонентов вида (150). Согласно аспектам настоящего раскрытия, как описано со ссылками на фиг. 6, порядок декодирования соответствующих компонентов вида может быть обозначен, используя порядковый индекс вида. Соответственно, видео декодер 30 может принять индикацию порядкового индекса (view_idx) видов в заголовках единиц NAL, которая обеспечивает индикацию порядка декодирования компонентов вида. В целом единицы NAL с одним и тем же значением view_idx принадлежат одному и тому же виду.
[0236] Видео декодер 30 может также принять информацию, указывающую отношения между идентификаторами вида и порядком декодирования компонентов вида (152). В некоторых примерах видео декодер 30 может принять набор параметров, такой как SPS, который указывает отношения между идентификаторами вида для этих видов и порядковыми индексами вида для этих видов. В других примерах видео декодер 30 может принять иную индикацию отношений между порядковыми индексами вида и идентификаторами вида.
[0237] Видео декодер 30 может также декодировать данные видео с множественными видами, используя принятую информацию. Таким образом, например, видео декодер может декодировать каждый из видов, и определить соответствующий идентификатор вида, используя принятую отдельную информацию. Видео декодер 30 может затем обеспечить 3D представление, используя эти виды, например, на устройстве 32 отображения.
[0238] Нужно также подразумевать, что этапы, показанные и описанные со ссылками на фиг. 7, предоставлены как просто один пример. Таким образом, этапы способа ФИГ. 7 не обязательно должны быть выполнены в порядке, показанном на фиг. 7, и меньше, дополнительные, или альтернативные этапы могут быть выполнены.
[0239] ФИГ. 8 является блок-схемой, иллюстрирующей примерный способ кодирования потока битов множественных видов. Пример, показанный на фиг. 8, в целом описан как выполняемый видео кодером 20 (ФИГ. 1 и 2). В других примерах процесс, описанный со ссылками на фиг. 8, может быть выполнен множеством других процессоров, блоков обработки, основанных на аппаратном обеспечении блоков кодирования, таких как кодер/декодеры (кодеки), и т.п. В примере согласно ФИГ. 8 видео кодер 20 может определить, для любого компонента вида первого вида, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида (160). Например, как отмечено выше, зависимости видов могут быть сигнализированы одним и тем же способом для всех компонентов вида для некоторого вида, независимо от того, является ли конкретный компонент вида конкретной единицей доступа картинки с привязкой (точкой произвольного доступа), или является ли конкретный компонент вида конкретной единицы доступа картинкой без привязки. В некоторых случаях информация опорного вида может указывать зависимости вида, используя значения индекса опорного вида (значения порядкового индекса вида для опорных видов). Таким образом, информация опорного вида может содержать значения индекса опорного вида для каждого опорного вида, который может указывать порядок декодирования опорного вида в единице доступа. В других примерах информация опорного вида может содержать значения разности индексов опорных видов, которые могут указать разность между порядковым индексом вида конкретного опорного вида и порядковым индексом вида компонента вида, кодируемого в настоящее время. В примерах, в которых значения порядкового индекса вида используются, как описано выше, видео кодер 20 может также предоставить дополнительную информацию, которая указывает отношения между значениями порядкового индекса вида и идентификаторами вида видов.
[0240] Видео кодер 20 может также, при кодировании первого компонента вида в единице доступа в первом виде, включать один или более опорных кандидатов в список опорных картинок на основании единицы доступа, которой первый компонент вида принадлежит, информации опорного вида и количества опорных видов, указанных информацией (162) опорного вида. Например, как описано выше, видео кодер 20 может конструировать список опорных картинок, который включает в себя опорные картинки - кандидаты для того, чтобы предсказать первый компонент вида (опорные картинки "кандидаты", так как опорные картинки могут быть удалены из окончательного списка опорных картинок). Видео кодер 20 может идентифицировать опорные картинки - кандидаты между видами в каждом из опорных видов, указанных информацией опорного вида, которые принадлежат одной и той же единице доступа (например, имеют один и тот же момент времени) как первый компонент вида. Видео кодер 20 может добавить все идентифицированные компоненты вида к списку опорных картинок.
[0241] Соответственно, в примере, показанном на фиг. 8, видео кодер 20 может конструировать список опорных картинок без отношения к тому, является ли компонент вида, кодируемый в настоящее время, картинкой с привязкой или картинкой без привязки. Кроме того, видео кодер 20 может конструировать список опорных картинок, не принимая во внимание то, включены ли опорные картинки - кандидаты в Список 0 или Список 1. Таким образом, видео кодер 20 может конструировать список опорных картинок 0 или список опорных картинок 1, используя одну и ту же информацию опорного вида. Кроме того, видео кодер 20 может добавить идентифицированные опорные кандидаты к обоим Спискам 0 или Списку 1 аналогично.
[0242] Видео кодер 20 может также кодировать первый компонент вида на основании одного или более опорных кандидатов в списке (164) опорных картинок. Например, видео кодер 20 может идентифицировать компонент вида в списке опорных картинок, генерировать остаточные данные, используя идентифицированный компонент вида, и кодировать остаточные данные, как описано со ссылками на фиг. 2. Видео кодер 20 может также снабдить кодированный первый компонент вида определенной информацией опорного вида в закодированном потоке битов (166).
[0243] Нужно подразумевать, что этапы, показанные и описанные со ссылками на фиг. 8, предоставлены как просто один пример. Таким образом, этапы способа согласно ФИГ. 8 не обязательно должны быть выполнены в порядке, показанном на фиг. 8, и меньше, дополнительные, или альтернативные этапы могут быть выполнены.
[0244] ФИГ. 9 является блок-схемой, иллюстрирующей примерный способ декодирования потока битов множественных видов. Пример, показанный на фиг. 9, в целом описан как выполняемый видео декодером 30 (ФИГ. 1 и 3). В других примерах процесс, описанный со ссылками на фиг. 9, может быть выполнен множеством других процессоров, блоков обработки, основанных на аппаратном обеспечении блоков кодирования, таких как кодер/декодеры (кодеки), и т.п.
[0245] В примере, показанном на фиг. 9, видео декодер 30 может получить, из кодированного потока битов и для любого компонента вида первого вида, информацию опорного вида, указывающую один или более опорных видов для предсказания компонентов вида первого вида (170). Например, как отмечено выше со ссылками на фиг. 8, зависимости видов могут быть сигнализированы одним и тем же способом для всех компонентов вида для некоторого вида, независимо от того, является ли конкретный компонент вида конкретной единицы доступа картинкой с привязкой (точкой произвольного доступа), или является ли конкретный компонент вида конкретной единицы доступа картинкой без привязки. В некоторых случаях информация опорного вида может указывать зависимости вида, используя значения индекса опорного вида (значения порядкового индекса вида для опорных видов). Таким образом, информация опорного вида может содержать значения индекса опорного вида для каждого опорного вида, который может указывать порядок декодирования опорного вида в единице доступа. В других примерах информация опорного вида может содержать значения разности индексов опорных видов, которые могут указать разность между порядковым индексом вида конкретного опорного вида и порядковым индексом вида компонента вида, кодируемого в настоящее время. В примерах, в которых значения порядкового индекса вида используются, как описано выше, видео декодер 30 может также получить дополнительную информацию из закодированного потока битов, которая указывает отношения между значениями порядкового индекса вида и идентификаторами вида видов. Такая информация может быть получена из уровня последовательности.
[0246] Видео декодер 30 может также при декодировании первого компонента вида в единице доступа в первом виде включать один или более опорных кандидатов в список опорных картинок на основании единицы доступа, которой принадлежит первый компонент вида, информации опорного вида, и количества опорных видов, указанных информацией опорного вида (172). Например, как описано выше, видео декодер 30 может конструировать список опорных картинок, который включает в себя опорные картинки - кандидаты для того, чтобы предсказать первый компонент вида. Видео декодер 30 может идентифицировать опорные картинки - кандидаты между видами в каждом из опорных видов, указанных информацией опорного вида, которые принадлежат одной и той же единице доступа (например, имеют один и тот же момент времени), что и первый компонент вида. Видео декодер 30 может добавить все идентифицированные компоненты вида к списку опорных картинок.
[0247] Соответственно, в примере, показанном на фиг. 9, видео декодер 30 может конструировать список опорных картинок без относительно к тому, является ли компонент вида, кодируемый в настоящее время, картинкой с привязкой или картинкой без привязки. Кроме того, видео декодер 30 может конструировать список опорных картинок, не принимая во внимание то, включены ли опорные картинки - кандидаты в Список 0 или Список 1. Таким образом, видео декодер 30 может конструировать список опорных картинок 0 или список опорных картинок 1 с использованием той же информации опорного вида, которая может только быть получена из закодированного потока битов однажды. Кроме того, видео декодер 30 может добавить идентифицированные опорные кандидаты к обоим Спискам 0 или Списку 1 аналогично.
[0248] Видео декодер 30 может также декодировать первый компонент вида на основании одного или более опорных кандидатов в списке опорных картинок (174). Например, видео декодер 20 может идентифицировать компонент вида в списке опорных картинок, объединить идентифицированный компонент вида с декодированными остаточными данными (из закодированного потока битов), чтобы генерировать компонент вида, как описано со ссылками на фиг. 3 выше.
[0249] Нужно подразумевать, что этапы, показанные и описанные со ссылками на фиг. 9, предоставлены как просто один пример. Таким образом, этапы способа ФИГ. 9 не обязательно должны быть выполнены в порядке, показанном на фиг. 9, и меньше, дополнительные, или альтернативные этапы могут быть выполнены.
[0250] В то время как некоторые элементы синтаксиса, описанные относительно настоящего раскрытия, снабжены примерными названиями в целях объяснения, нужно подразумевать, что понятия, описанные в настоящем раскрытии, более широко применимы к любым элементам синтаксиса, независимо от названия. Например, в то время как некоторые аспекты относятся к “порядковому индексу вида,” “view_order_index” или “view_idx,” нужно подразумевать, что такому элементу синтаксиса можно дать альтернативное название в будущем стандарте кодирования.
[0251] В то время как некоторые способы настоящего раскрытия описаны относительно предстоящего стандарта HEVC, нужно подразумевать, что способы не ограничены никаким конкретным стандартом кодирования. Таким образом, способы более широко относятся к достижению эффективности кодирования при кодировании видео с множественными видами, например, с помощью более коротких и/или менее сложных единиц NAL и наборов параметров, как описано выше.
[0252] Нужно подразумевать, что в зависимости от примера некоторые действия или события любого из способов, описанных здесь, могут быть выполнены в различной последовательности, могут быть добавлены, слиты, или не использованы совместно (например, не все описанные действия или события необходимы для практической реализации способа). Кроме того, в некоторых примерах, действия или события могут быть выполнены одновременно, например, с помощью многопотоковой обработки, обработки прерывания, или множественных процессоров, а не последовательно. Кроме того, в то время как некоторые аспекты настоящего раскрытия описаны как выполняемые единственным модулем или блоком в целях ясности, нужно подразумевать, что способы настоящего раскрытия могут быть выполнены комбинацией блоков или модулей, ассоциированных с видео кодером.
[0253] В одном или более примерах описанные функции могут быть реализованы в аппаратном обеспечении, программном обеспечении, программно-аппаратных средствах, или любой их комбинации. Если реализованы в программном обеспечении, функции могут быть сохранены на или переданы как одна или более инструкций или код по считываемому компьютером носителю и выполнены основанным на аппаратном обеспечении блоком обработки. Считываемый компьютером носитель может включать в себя считываемые компьютером носители данных, которые соответствуют материальному носителю, такому как запоминающие носители данных, или коммуникационные носители, включающие в себя любой носитель, который облегчает передачу компьютерной программы от одного места к другому, например, согласно протоколу связи.
[0254] Таким образом считываемый компьютером носитель в целом может соответствовать (1) материальному считываемому компьютером носителю данных, который является невременным, или (2) коммуникационному носителю, такой как сигнал или несущая. Запоминающие носители данных могут быть любым доступным носителем, к которому могут получить доступ один или более компьютеров или один или более процессоров, чтобы извлечь инструкции, код и/или структуры данных для реализации способов, описанных в настоящем раскрытии. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
[0255] Посредством примера, а не ограничения, такие считываемые компьютером носители данных могут содержать RAM, ROM, EEPROM, CD-ROM или другое оптическое дисковое запоминающее устройство, магнитное дисковое запоминающее устройство, или другие магнитные устройства хранения, флэш-память, или любой другой носитель, который может использоваться, чтобы сохранить желательный программный код в форме инструкций или структур данных и к которому может получить доступ компьютер. Также, любое соединение должным образом называют считываемым компьютером носителем. Например, если инструкции переданы от вебсайта, сервера, или другого удаленного источника, используя коаксиальный кабель, волокно-оптический кабель, витую пару, цифровую абонентскую линию (DSL), или беспроводные технологии такой как инфракрасная, радио- и микроволновая, то эти коаксиальный кабель, волокно-оптический кабель, витая пара, DSL, или беспроводные технологии такие как инфракрасная, радио- и микроволновая, включены в определение носителя.
[0256] Нужно подразумевать, однако, что считываемые компьютером носители данных и запоминающие носители данных не включают в себя соединения, несущие, сигналы, или другие временные носители, но вместо этого направлены на невременные материальные носители данных. Диск и диск, как используется здесь, включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), дискета и диск blu-ray, где диски (disks) обычно воспроизводят данные магнитным образом, в то время как диски (discs) воспроизводят данные оптически с помощью лазеров. Комбинации вышеупомянутого должны также быть включены в рамки считываемого компьютером носителя.
[0257] Инструкции могут быть выполнены одним или более процессорами, такими как один или более цифровых сигнальных процессоров (DSPs), микропроцессоры общего назначения, специализированные интегральные схемы (ASIC), программируемые пользователем логические матрицы (FPGA), или другие эквивалентные интегральные или дискретные логические схемы. Соответственно, термин "процессор", как используется здесь, может относиться к любой известной структуре или любой другой структуре, подходящей для реализации способов, описанных здесь. Также, в некоторых аспектах функциональные возможности, описанные здесь, могут быть предоставлены в пределах специализированного аппаратного обеспечения и/или программных модулей, сконфигурированных для кодирования и декодирования, или встроенных в объединенный кодек. Также, способы могли быть полностью реализованы в одной или более схемах или логических элементах.
[0258] Способы настоящего раскрытия могут быть реализованы в широком разнообразии устройств или аппаратов, включая беспроводную телефонную трубку, интегральную схему (IC) или набор IC (например, микропроцессорный набор). Различные компоненты, модули, или блоки описаны в настоящем описании, чтобы подчеркнуть функциональные аспекты устройств, конфигурируемых, чтобы выполнять раскрытые способы, но не обязательно требовать реализации различными блоками аппаратного обеспечения. Вместо этого, как описано выше, различные блоки могут быть объединены в блоке аппаратного обеспечения кодека или предоставлены коллекцией взаимодействующих блоков аппаратного обеспечения, включая один или более процессоров, как описано выше, в соединении с подходящим программным обеспечением и/или программно-аппаратными средствами.
[0259] Были описаны различные примеры. Эти и другие примеры находятся в рамках ниже следующей формулы изобретения.
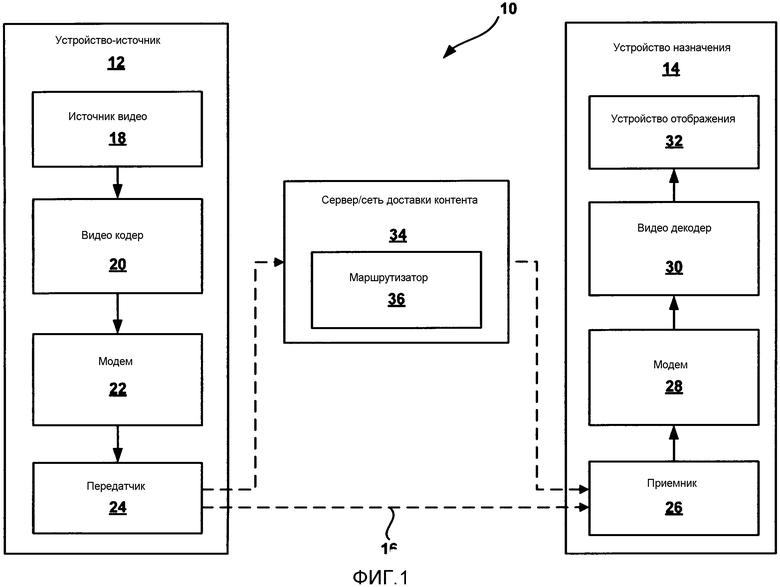
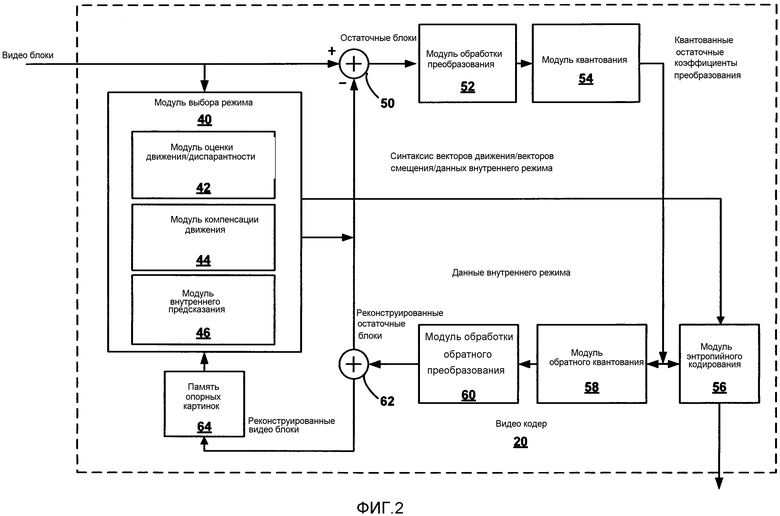
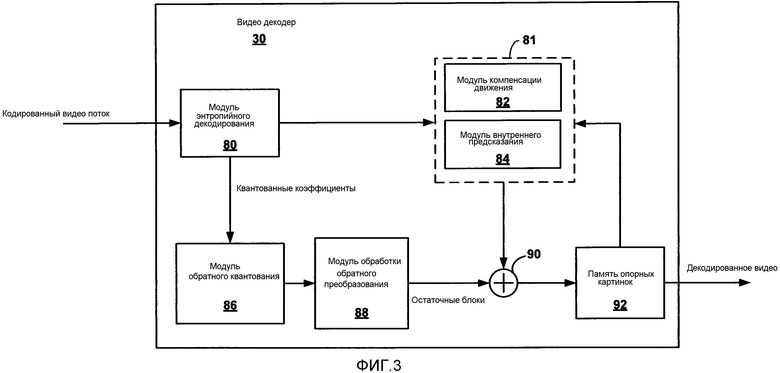
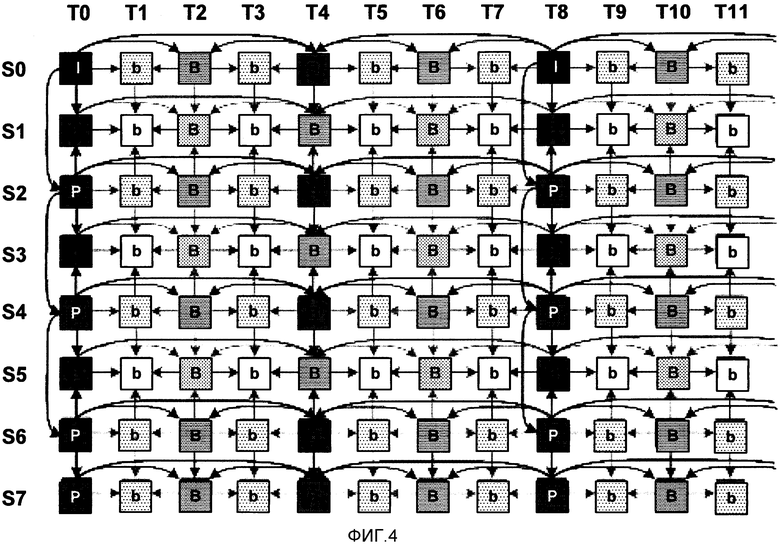
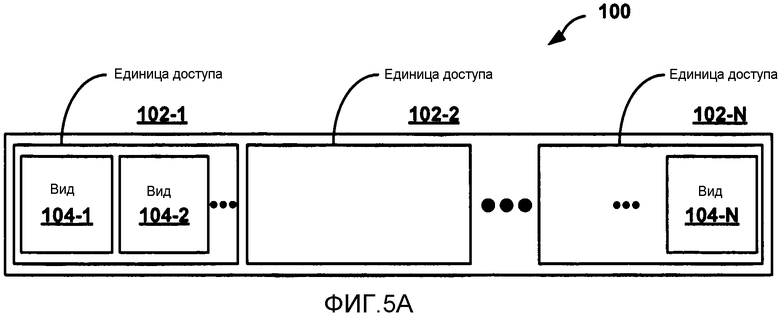
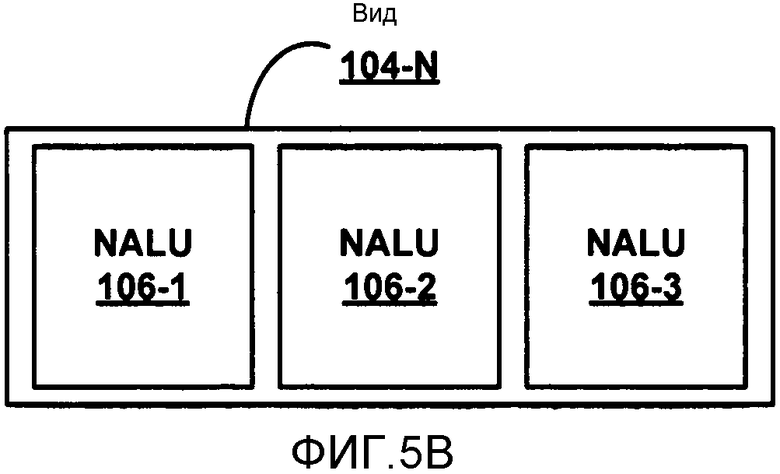
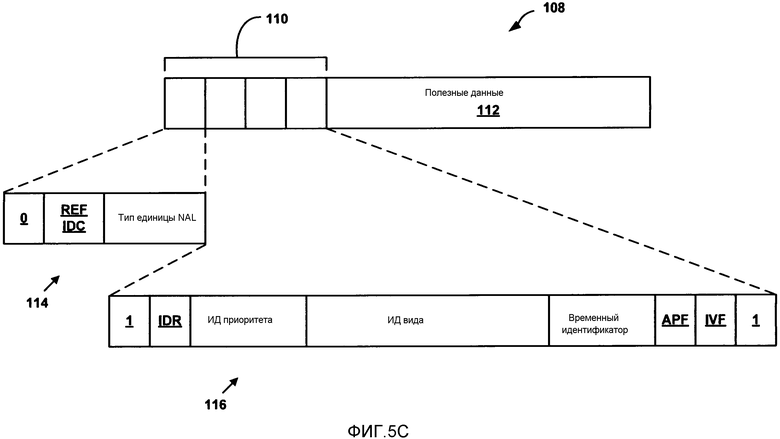
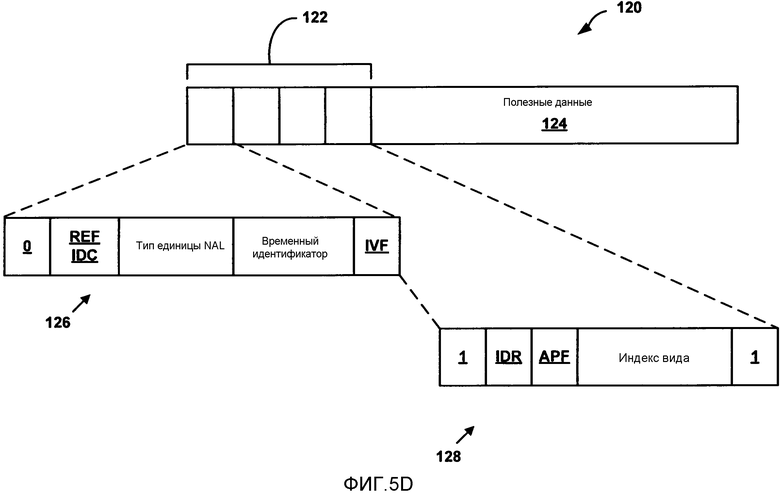
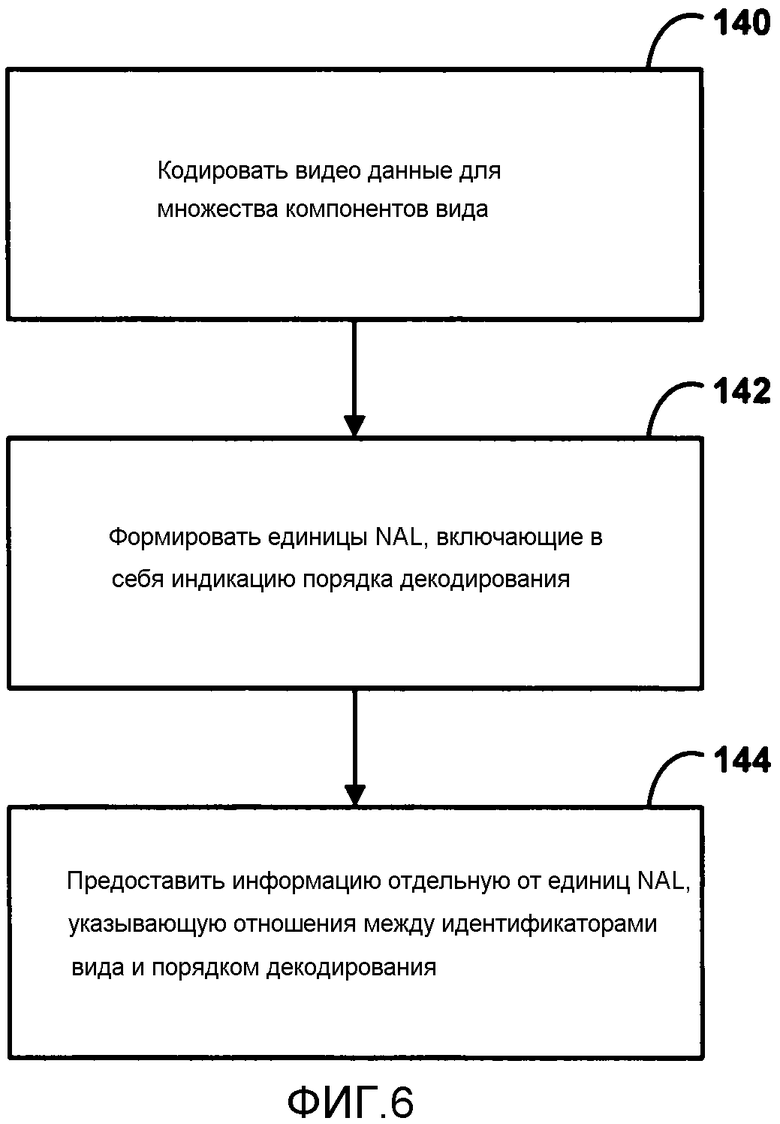

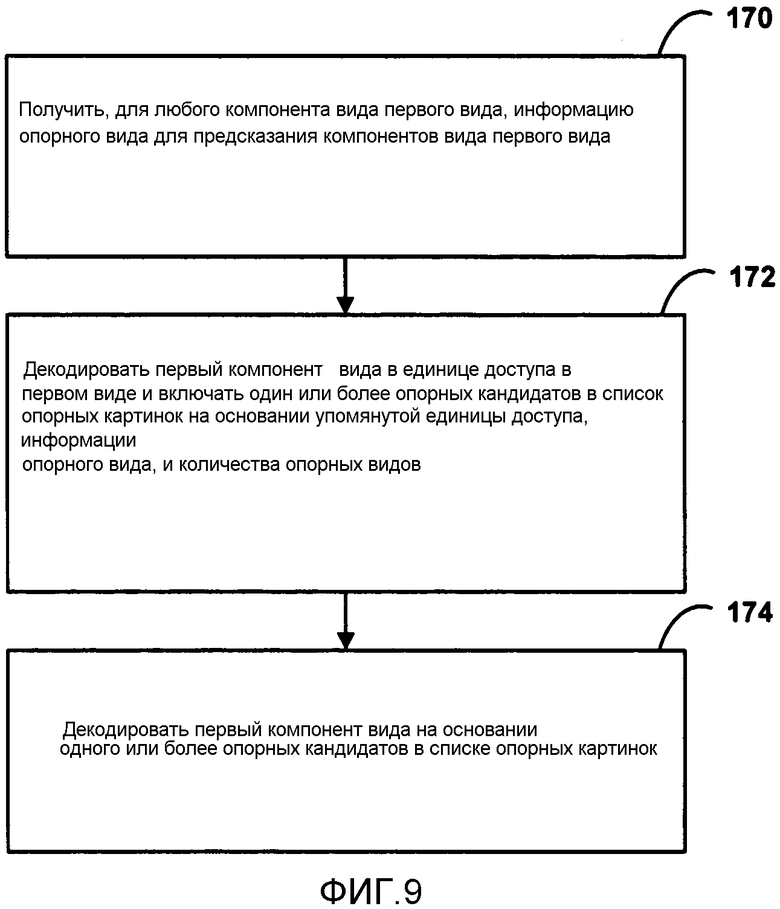
Изобретение относится к кодированию видео множественных видов (MVC). Техническим результатом является повышение эффективности кодирования. Предложен способ кодирования видеоданных, включающий получение из закодированного потока битов одной или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видеоданных, где каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и где одна или более единиц NAL инкапсулируют по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида и включают в себя информацию, указывающую порядок декодирования соответствующих компонентов вида. Способ также включает в себя информацию получения, отдельную от единиц NAL, указывающую отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида. Одна или более единиц NAL также включают в себя информацию, указывающую, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида для второго отличного вида. 8 н. и 60 з.п. ф-лы, 18 табл., 12 ил.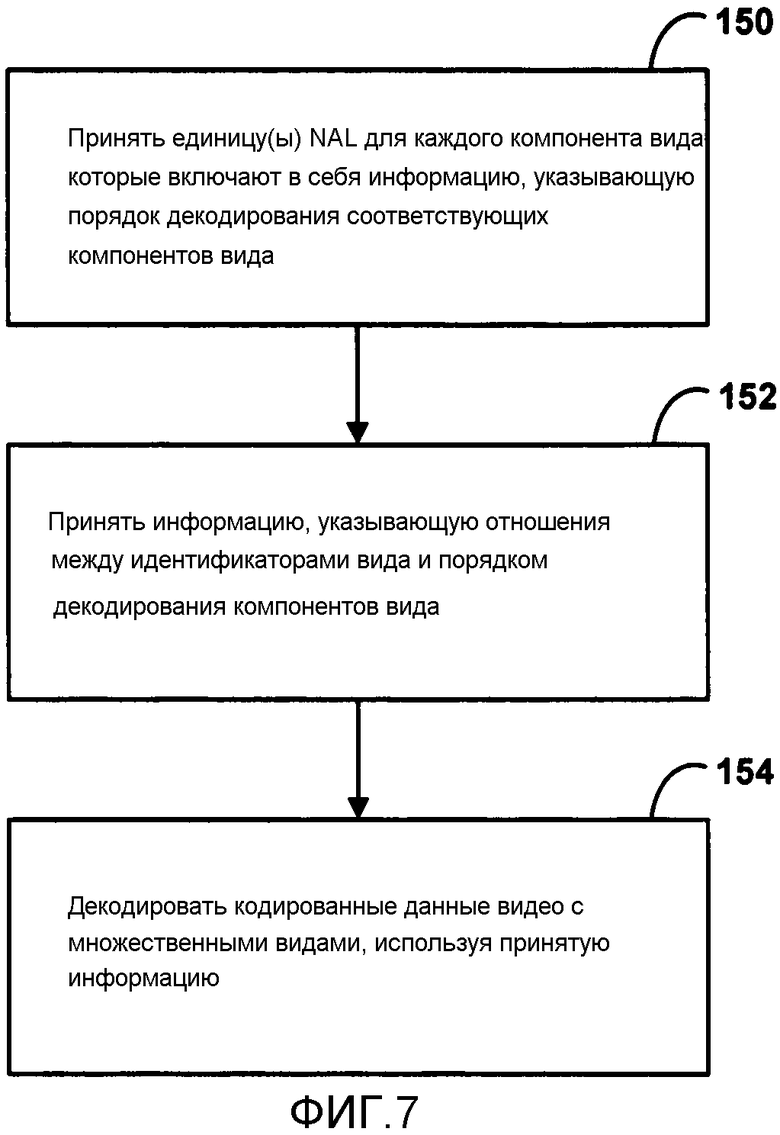
1. Способ декодирования видеоданных, причем способ содержит:
получение, из закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видеоданных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и в котором каждая единица NAL из одной или более единиц NAL инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида и включает в себя информацию, описывающую порядок декодирования соответствующих компонентов вида, и которая является отдельной от идентификатора вида соответствующих компонентов вида;
получение информации, из закодированного потока битов и отдельной от упомянутых одной или более единиц NAL, указывающей отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида; и
декодирование закодированных видеоданных из множества компонентов вида в порядке декодирования на основании полученной информации.
2. Способ по п.1, в котором получение информации, указывающей отношения между идентификаторами вида и порядком декодирования компонентов вида, содержит получение информации из информации уровня последовательности закодированных видеоданных, которая указывает отношения между идентификаторами вида и порядок декодирования упомянутого вида.
3. Способ по п.1, в котором получение информации, указывающей порядок декодирования соответствующих компонентов вида, содержит получение значения по умолчанию порядкового индекса вида, равного нулю, для базового вида из множества компонентов вида.
4. Способ по п.1, в котором одна или более единиц NAL также включают в себя информацию, указывающую, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида для второго отличного вида.
5. Способ по п.4, в котором информация, указывающая, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида, содержит однобитовый флаг заголовка единицы NAL.
6. Способ по п.1, дополнительно содержащий получение из закодированного потока битов значений отсчета порядка картинки (РОС) для множества компонентов вида, и в котором декодирование содержит декодирование кодированных видеоданных на основании информации, указывающей порядок декодирования и значения РОС.
7. Способ по п.1, дополнительно содержащий получение, из закодированного потока битов, значений кадра для множества компонентов вида, и в котором декодирование содержит декодирование кодированных видеоданных на основании информации, указывающей порядок декодирования и значения кадра.
8. Способ по п.1, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит количество элементов синтаксиса, определенных на основании по меньшей мере одного из базового вида, профиля, и количества видов, поддерживаемых в потоке битов.
9. Способ по п.1, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
10. Способ по п.1, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
11. Способ по п.1, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
12. Способ по п.11, в котором компоненты видов множественных временных местоположений общего вида совместно используют общий порядковый индекс вида.
13. Устройство для декодирования видеоданных, причем устройство содержит один или более процессоров, сконфигурированных, чтобы:
получать, из закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видеоданных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и в котором каждая единица NAL из одной или более единиц NAL инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида и включает в себя информацию, описывающую порядок декодирования соответствующих компонентов вида, и которая является отдельной от идентификатора вида соответствующих компонентов вида;
получать информацию, из закодированного потока битов и отдельную от упомянутых одной или более единиц NAL, указывающую отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида; и
декодировать кодированные видеоданные из множества компонентов вида в порядке декодирования на основании полученной информации.
14. Устройство по п.13, в котором, чтобы получить информацию, указывающую отношения между идентификаторами вида и порядком декодирования компонентов вида, упомянутые один или более процессоров конфигурируются, чтобы получить информацию из информации уровня последовательности закодированных видеоданных, которая указывает отношения между идентификаторами вида и порядком декодирования упомянутого вида.
15. Устройство по п.13, в котором чтобы получить информацию, указывающую порядок декодирования соответствующих компонентов вида, упомянутые один или более процессоров конфигурируются, чтобы получить значение по умолчанию порядкового индекса вида, равное нулю, для базового вида из множества компонентов вида.
16. Устройство по п.13, в котором одна или более единиц NAL также включают в себя информацию, указывающую, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида второго, отличного вида.
17. Устройство по п.16, в котором информация, указывающая, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида, содержит однобитовый флаг заголовка единицы NAL.
18. Устройство по п.13, в котором упомянутые один или более процессоров далее конфигурируются, чтобы получить, из закодированного потока битов, значения отсчета порядка картинки (РОС) для множества компонентов вида, и в котором для декодирования упомянутые один или более процессоров конфигурируются, чтобы декодировать закодированные видеоданные на основании информации, указывающей порядок декодирования и значения РОС.
19. Устройство по п.13, в котором упомянутые один или более процессоров также конфигурируются, чтобы получить, из закодированного потока битов, значения кадра для множества компонентов вида, и в котором для декодирования упомянутые один или более процессоров конфигурируются, чтобы декодировать закодированные видеоданные на основании информации, указывающей порядок декодирования и значения кадра.
20. Устройство по п.13, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит количество элементов синтаксиса, определенных на основании по меньшей мере одного из базового вида, профиля, и количества видов, поддерживаемых в потоке битов.
21. Устройство по п.13, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
22. Устройство по п.13, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
23. Устройство по п.13, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
24. Устройство по п.23, в котором компоненты видов множественных временных местоположений общего вида совместно используют общий порядковый индекс вида.
25. Устройство для декодирования видеоданных, причем устройство содержит:
средство для получения, из закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видеоданных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и в котором каждая единица NAL из одной или более единиц NAL инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида и включает в себя информацию, описывающую порядок декодирования соответствующих компонентов вида, и которая является отдельной от идентификатора вида соответствующих компонентов вида;
средство для получения информации, из закодированного потока битов и отдельной от упомянутых одной или более единиц NAL, указывающей отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида; и
средство для декодирования закодированных видеоданных из множества компонентов вида в порядке декодирования на основании полученной информации.
26. Устройство по п.25, в котором средство для получения информации, указывающей отношения между идентификаторами вида и порядком декодирования компонентов вида, содержит средство для получения информации из информации уровня последовательности закодированных видеоданных, которая указывает отношения между идентификаторами вида и порядком декодирования упомянутого вида.
27. Устройство по п.25, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит количество элементов синтаксиса, определенных на основании по меньшей мере одного из базового вида, профиля, и количества видов, поддерживаемых в потоке битов.
28. Устройство по п.25, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
29. Устройство по п.25, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
30. Устройство по п.25, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
31. Считываемый компьютером запоминающий носитель, имеющий сохраненные на нем инструкции, которые, когда выполняются, вынуждают один или более процессоров:
получать, из закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для каждого компонента вида из множества компонентов вида закодированных видеоданных, при этом каждый компонент вида из множества компонентов вида соответствует общему временному местоположению, и в котором каждая единица NAL из одной или более единиц NAL инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида и включает в себя информацию, описывающую порядок декодирования соответствующих компонентов вида, и которая является отдельной от идентификатора вида соответствующих компонентов вида;
получать информацию, из закодированного потока битов и отдельную от упомянутых одной или более единиц NAL, указывающую отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида; и
декодировать закодированные видеоданные из множества компонентов вида в порядке декодирования на основании полученной информации.
32. Считываемый компьютером запоминающий носитель по п.31, в котором, чтобы получить информацию, указывающую отношения между идентификаторами вида и порядком декодирования компонентов вида, инструкции заставляют один или более процессоров получать информацию из информации уровня последовательности закодированных видеоданных, которая указывает отношения между идентификаторами вида и порядком декодирования упомянутого вида.
33. Считываемый компьютером запоминающий носитель по п.31, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит количество элементов синтаксиса, определенных на основании по меньшей мере одного из базового вида, профиля, и количества видов, поддерживаемых в потоке битов.
34. Считываемый компьютером запоминающий носитель по п.31, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
35. Считываемый компьютером запоминающий носитель по п.31, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
36. Считываемый компьютером запоминающий носитель по п.31, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
37. Способ кодирования видеоданных, причем способ содержит:
кодирование видеоданных для множества компонентов вида для соответствующих видов видеоданных, причем каждый из множества компонентов вида соответствует общему временному местоположению;
формирование, в качестве части закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для закодированных видеоданных каждого из компонентов вида таким образом, что каждая из единиц NAL включает в себя информацию, описывающую порядок декодирования видеоданных соответствующих компонентов вида, которая является отдельной от идентификатора вида соответствующих компонентов вида, и инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида; и
предоставление информации в закодированном потоке битов, отдельной от единиц NAL, указывающей отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида.
38. Способ по п.37, в котором предоставление информации, указывающей отношения между идентификаторами вида и порядком декодирования компонентов вида, содержит предоставление информации в уровне последовательности закодированных видеоданных.
39. Способ по п.37, в котором предоставление информации, указывающей порядок декодирования соответствующих компонентов вида, содержит предоставление значения по умолчанию порядкового индекса вида, равное нулю, для базового вида из множества компонентов вида.
40. Способ по п.37, в котором одна или более единиц NAL также включают в себя информацию, указывающую, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида второго, отличного вида.
41. Способ по п.40, в котором информация, указывающая, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида, содержит однобитовый флаг заголовка единицы NAL.
42. Способ по п.37, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит количество элементов синтаксиса, определенных на основании по меньшей мере одного из базового вида, профиля, и количества видов, поддерживаемых в потоке битов.
43. Способ по п.37, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
44. Способ по п.37, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
45. Способ по п.37, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
46. Способ по п.45, в котором компоненты вида множественных временных местоположений общего вида совместно используют общий порядковый индекс вида.
47. Устройство для кодирования видеоданных, причем устройство содержит один или более процессоров, сконфигурированных для того, чтобы:
кодировать видеоданные для множества компонентов вида для соответствующих видов видеоданных, при этом каждый из множества компонентов вида соответствует общему временному местоположению;
формировать, в качестве части закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для закодированных видеоданных каждого из компонентов вида таким образом, что каждая из единиц NAL включает в себя информацию, описывающую порядок декодирования видеоданных соответствующих компонентов вида, которая является отдельной от идентификатора вида соответствующих компонентов вида, и инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида; и
предоставлять информацию в закодированном потоке битов, отдельную от единиц NAL, указывающую отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида.
48. Устройство по п.47, в котором, чтобы предоставить информацию, указывающую отношения между идентификаторами вида и порядком декодирования компонентов вида, упомянутые один или более процессоров конфигурируются, чтобы предоставить информацию в уровне последовательности закодированных видеоданных.
49. Устройство по п.47, в котором, чтобы предоставить информацию, указывающую порядок декодирования соответствующих компонентов вида, упомянутые один или более процессоров конфигурируются, чтобы обеспечить значение по умолчанию порядкового индекса вида, равное нулю, для базового вида из множества компонентов вида.
50. Устройство по п.47, в котором одна или более единиц NAL также включают в себя информацию, указывающую, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида второго, отличного вида.
51. Устройство по п.50, в котором информация, указывающая, используется ли первый компонент вида первого вида как ссылка для предсказания между видами второго компонента вида, содержит однобитовый флаг заголовка единицы NAL.
52. Устройство по п.47, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит количество элементов синтаксиса, определенных на основании по меньшей мере одного из базового вида, профиля, и количества видов, поддерживаемых в потоке битов.
53. Устройство по п.47, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
54. Устройство по п.47, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
55. Устройство по п.47, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
56. Устройство по п.55, в котором компоненты видов множественных временных местоположений общего вида совместно используют общий порядковый индекс вида.
57. Устройство для кодирования видеоданных, причем устройство содержит:
средство для кодирования видеоданных для множества компонентов вида для соответствующих видов видеоданных, при этом каждый из множества компонентов вида соответствует общему временному местоположению;
средство для формирования, в качестве части закодированного потока битов, одной или более единиц уровня абстракции сети (NAL) для закодированных видеоданных каждого из компонентов вида таким образом, что каждая из единиц NAL включает в себя информацию, описывающую порядок декодирования видеоданных соответствующих компонентов вида, которая является отдельной от идентификатора вида соответствующих компонентов вида, и инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида; и
средство для предоставления информации в закодированном потоке битов, отдельной от единиц NAL, указывающей отношения между упомянутыми идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида.
58. Устройство по п.57, в котором средство для предоставления информации, указывающей отношения между идентификаторами вида и порядком декодирования компонентов вида, содержит средство для предоставления информации в уровне последовательности закодированных видеоданных.
59. Устройство по п.57, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
60. Устройство по п.57, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
61. Устройство по п.57, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
62. Устройство по п.61, в котором компоненты видов множественных временных местоположений общего вида совместно используют общий порядковый индекс вида.
63. Считываемый компьютером запоминающий носитель, имеющий сохраненные на нем инструкции, которые, когда выполняются, вынуждают один или более процессоров:
кодировать видеоданные для множества компонентов вида для соответствующих видов видеоданных, при этом каждый из множества компонентов вида соответствует общему временному местоположению;
формировать, в качестве части закодированного потока битов, одну или более единиц уровня абстракции сети (NAL) для закодированных видеоданных каждого из компонентов вида таким образом, что каждая из единиц NAL включает в себя информацию, описывающую порядок декодирования видеоданных соответствующих компонентов вида, которая является отдельной от идентификатора вида соответствующих компонентов вида, и инкапсулирует по меньшей мере часть закодированных видеоданных для соответствующих компонентов вида; и
предоставлять информацию в закодированном потоке битов, отдельную от единиц NAL, указывающую отношения между идентификаторами вида для видов, ассоциированных с упомянутыми компонентами вида, и порядком декодирования компонентов вида.
64. Считываемый компьютером запоминающий носитель по п.63, в котором, чтобы предоставить информацию, указывающую отношения между идентификаторами вида и порядком декодирования компонентов вида, упомянутые инструкции заставляют один или более процессоров предоставлять информацию в уровне последовательности закодированных видеоданных.
65. Считываемый компьютером запоминающий носитель по п.63, в котором информация, указывающая отношения между идентификаторами вида для этих видов и порядком декодирования компонентов вида, содержит таблицу отображения, которая отображает порядок декодирования компонентов вида в идентификаторы вида для упомянутых видов.
66. Считываемый компьютером запоминающий носитель по п.63, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержится в части заголовка единиц NAL.
67. Считываемый компьютером запоминающий носитель по п.63, в котором информация, указывающая порядок декодирования соответствующих компонентов вида, содержит порядковый индекс вида.
68. Считываемый компьютером запоминающий носитель по п.63, в котором компоненты видов множественных временных местоположений общего вида совместно используют общий порядковый индекс вида.
| WO 2008088497 A2 , 2008-07-24 | |||
| US 2010027654 A1, 2010-02-04 | |||
| RU 2008142771 A, 2010-05-10 | |||
| US 2010316134 A1, 2010-12-16 | |||
| RU 2009103915 A, 2010-08-20 | |||
| US 2010316122 A1, 2010-12-16 | |||
| PANDIT P | |||
| ET AL, H.264/AVC extension for MVC using SEI message, JOINT VIDEO TEAM (JVT) OF ISO/IEC MPEG & ITU-T VCEG, JVT-X061, 29 June 2007 | |||
| Information |

