Группа изобретений относится к решениям в области обработки массивов данных, в частности, к решениям в области обработки структурированных массивов данных, содержащих текст на естественном языке, и может быть использовано для предварительного преобразования структурированного массива данных, содержащего текст на естественном языке, для удобства его последующей обработки.
УРОВЕНЬ ТЕХНИКИ
Из патента ЕА 002016 B1, G06F 17/30, 22.10.2001 (МАТВЕЕВ ЛЕВ ЛАЗАРЕВИЧ И ДР.) известен способ поиска похожих по текстовому и/или смысловому содержимому фрагментов в электронных документах, хранимых на устройствах хранения данных, заключающийся в индексировании каждого сохраняемого в архиве документа, разбиении упомянутых документов на фрагменты и формировании тематик из одного и более фрагмента, определении параметров поиска, проведении поиска, ранжировании полученного в результате поиска списка фрагментов документов, причем в качестве параметров поиска определяют множество входящих в выбранный фрагмент документа уникальных блоков информации, и расширяют его посредством предварительной обработки каждого из упомянутых уникальных блоков информации, где под уникальным блоком информации понимают блок информации, встретившийся в выбранном фрагменте документа один и более раз, где в качестве предварительной обработки используют операцию получения, по меньшей мере, из одного уникального блока информации, одного или нескольких блоков информации, связанных с уникальным блоком информации заданным соотношением.
Из патента RU 2476927 С2, G06F 17/30, 27.02.2013 (АНШУКОВ СЕРГЕЙ АЛЕКСАНДРОВИЧ И ДР.) известен способ позиционирования текстов в пространстве знаний, заключающийся в том, что из входных данных выделяют элементы, соответствующие паттернам, входящим в таксоны, образующие таксономии, объединенные в онтологии; определяют значимые таксоны, которые взвешивают с учетом условий, приписанных паттернам; составляют набор взвешенных векторов, позиционирующих входной документ в пространстве знаний, отличающийся тем, что в нем для позиционирования используют множество онтологии, а также тем, что при составлении наборов векторов рассматривают только те элементы, которые соответствуют паттернам, входящим в один таксой или в таксоны, имеющие общие родительские таксоны.
Из патента RU 2210809 С2, G06F 17/28, 20.08.2003 (ОТКРЫТОЕ АКЦИОНЕРНОЕ ОБЩЕСТВО «МОСКОВСКАЯ ТЕЛЕКОММУНИКАЦИОННАЯ КОРПОРАЦИЯ») известен способ автоматического преобразования исходного текста в совокупность взаимосвязанных объектов на основе таблицы настроек, содержащей знания о структуре исследуемой системы в виде совокупности образующих ее классов, включающих определенный набор атрибутов (в том числе взаимосвязи и отношения между объектами заданных классов) и установленные для каждого атрибута правила распознавания атрибута в тексте. Предусматривается возможность определения формата исходного текста и автоматического перевода его фрагментов в ходе формирования объектов.
Из патента RU 2292078 С1, G06F 17/30, 20.01.2007 (ЗАКРЫТОЕ АКЦИОНЕРНОЕ ОБЩЕСТВО «МЕДИАЛИНГВА») известен способ поиска, разметки и отображения информации, включающий ввод искомых объектов данных исходных электронных документов, подлежащих поиску по информационным сетям с терминала абонента сети, осуществляющего функцию источника запроса искомых объектов данных, сравнение искомых объектов данных исходных электронных документов с контрольными объектами данных ассоциированной информации в информационной сети, а при совпадении искомых объектов с контрольными преобразование объектов данных исходных электронных документов посредством разметки объектов данных исходных электронных документов гиперссылками, визуализацию на терминале абонента сети электронных документов с гиперссылками и вызов на терминал абонента сети данных ассоциированной информации информационной сети, отличающийся тем, что перед разметкой создают, по меньшей мере, две области данных, по меньшей мере, одна из которых является резидентной областью для источника запроса искомых объектов данных и обеспечивает привязку к объектам данных первичных гиперссылок, содержащих дополнительные параметры, для адресации, по меньшей мере, к одной другой области, а, по меньшей мере, одна другая область является нерезидентной для источника запроса искомых объектов данных и обеспечивает привязку к объектам данных вторичных гиперссылок для адресации, по меньшей мере, к одному ресурсу данных ассоциированной информации для доступа к ней с терминалов абонентов, по меньшей мере, одной резидентной области являющейся источником первичной гиперссылки, при этом в резидентной области создают массив контрольных объектов данных с соответствующими каждому указанному объекту первичными гиперссылками в качестве связанных данных, а в нерезидентной области создают массив контрольных объектов данных ассоциированной информации с соответствующей каждому указанному объекту, по меньшей мере, одной вторичной гиперссылкой в качестве связанных данных ассоциированной информации информационной сети.
Из патента RU 2386166 С2, G06F 17/30, 10.04.2010 (ОТКРЫТОЕ АКЦИОНЕРНОЕ ОБЩЕСТВО ТАГАНРОГСКИЙ АВИАЦИОННЫЙ НАУЧНО-ТЕХНИЧЕСКИЙ КОМПЛЕКС ИМ. Г.М. БЕРИЕВА) известен способ формирования базы знаний, которую формируют в виде трехмерного информационного пространства, в котором данные о документе или его части определяют в кластер или кластеры, образованные единичными отрезками (ортами) характеристических признаков. Полный идентификационный номер документа формируют из кодов орт составляющих характеристических признаков и идентификационного номера документа. Производят анализ каждого кластера на полноту определения ограниченной им сферы деятельности содержащимися в кластере документами. Результат анализа заносят в этот же кластер. Поиск и анализ данных производят как с помощью формирования и обработки запроса, так и в обратном направлении с помощью подготовки базы данных для ожидаемого пользователя. В системе также предусмотрены средства для работы с базой данных, для поиска, контроля и анализа информации, документов, областей деятельности, для создания и корректировки документов системными администраторами, экспертами и пользователями в соответствии с правами доступа.
Из патента RU 2253893 С2, G06F 17/27, 10.06.2005 (ЧЕРНИКОВ БОРИС ВАСИЛЬЕВИЧ) известен способ автоматизированного лексикологического синтеза документов, включающий создание и сохранение унифицированной формы документа, классификацию содержания документа путем выделения унифицированной постоянной информации и переменной информации, сохранения постоянной информации в базах данных, внесения постоянной информации в унифицированную форму документа и введения переменной информации в документ, при котором в переменной информации выделяют переменную унифицированную информацию, связанную с устойчивыми формулировками, переменную вводимую информацию, представляющую собой конкретизирующие сведения, и переменную неунифицированную информацию, содержащую свободные формулировки, причем переменную унифицированную информацию выделяют путем формирования совокупности опорных слов, однозначно определяющих конкретные формулировки в документе и составляющих лексикологический скелет документа, и сохраняют в машинной базе данных с избытком по отношению к отдельно взятому экземпляру документа, формируют лексикологическое дерево документа путем определения взаимозависимости отдельных опорных слов и затем формируют информационный контур управления документом путем установления способа внедрения формулировок переменной унифицированной и неунифицированной информации в зависимости от характера связи опорного слова с фрагментом документа.
Из заявки WO 2013043160 A1, G06F 17/21, 28.03.2013 (HEWLETT PACKARD DEVELOPMENT CO ET AL.) известен способ обработки текстового массива данных, который заключается в построении графа, представляющему микромодель сущностей, образующих тело обрабатываемого документа. Разбиение такого текста на узлы графа, причем каждый узел относится к своей особенности выделенного фрагмента из текста, причем упомянутые узлы графа связываются между собой отношениями, аналогично связи фрагментов текста, соответствующего упомянутым узлам. В дальнейшем выстроенные узлы графа ранжируются для определения релевантных данных относительно запроса пользователя.
Из заявки WO 2001001289 A1, G06F 17/27, 04.01.2001 (INV MACHINE CORP INC) известен способ, который заключается в семантической обработке данных, представленных на естественном языке, причем способ включает ввод и хранение пользовательских условий, которые в дальнейшем используются для поиска в массивах данных, содержащих данные на естественном языке, представлений текста, содержащих релевантную пользовательскому вводу информацию, форматирование упомянутых представлений, извлечение из отформатированных представлений текста отношений типа субъект-действие-объект (СДО) и их сохранение в удаленном месте хранения, например, базе данных, реструктуризация выявленных СДО в нормализованный вид, назначение частей СДО, таких как действие-объект (ДО) в качестве наименования папок, в которых содержаться части СДО и назначение с указанными папками одного или более идентичных ассоциированных частей субъекта (S1, S2 … Sn), которые ассоциированы с соответствующими ДО частями. Способ позволяет также ассоциировать предложения, содержащие соответствующие элементы субъектов S1, S2 … Sn, и выделять в них релевантные СДО с их последующей маркировкой на фоне общего массива данных.
Из патента US 8229730 В2, G06F 17/30, 24.07.2012 (MICROSOFT CORP ET AL.) известен способ поиска данных по запросу пользователя, представленного на естественном языке, причем способ заключается в том, что производят парсинг текстового массива данных с назначением грамматических ролей терминам и их последующей индексацией, которые находятся в семантической связи с терминами поискового запроса, причем упомянутые роли содержат доминантную и второстепенные роли, которые выявляются при анализе пользовательского запроса. Данный способ позволяет определять релевантные части документа, содержащие термины с ролями, совпадающими с ролями текста запроса пользователя.
Из заявки ЕР 2400400 A1, G06F 17/27, 28.12.2011 (INBENTA PROFESSIONAL SERVICES S L) известен способ семантического поиска релевантной информации, заключающийся в том, что с помощью лексических функций и критерия значения текста в массиве данных, представленных на естественном языке, формируют фразы или выражения, полученные из базы данных содержания, и выбирают ответ, обладающий нависшим показателем семантического соответствия, причем способ заключается в трансформации контентов и запроса самостоятельных слов или групп слов с присвоенными им токенами, которые преобразовываются в семантические представления, тем самым применяя правила критерия значения текста посредством лексических функций, причем каждое из таких семантических представлений состоит из леммы и семантической категории.
Из заявки WO 2010105216 А2, G06F 17/20, 16.09.2010 (INVENTION MACHINE CORP) известен способ маркировки текстовых данных документа, заключающийся в том, что осуществляют лингвистический анализ документа, сравнивают документ после его анализа с шаблоном требуемых семантических отношений между объектами, формируют семантически размеченный текст с помощью применения семантических связей основанный на лингвистическом анализе текста и сравнения с шаблоном семантических связей, причем семантические метки ассоциированы со словами или фразами предложений текста, и идентифицируют компоненты определенных семантических отношений с последующим сохранением в базе данных семантически размеченного текста для последующего поиска релевантной информации по полученной структуре данных.
Из заявки ЕР 2105847 A1, G06F 17/30, 30.09.2009 (ALCATEL LUCENT) известен способ автоматического формирования онтологии, заключающийся в том, что принимают термин, для которого необходимо сформировать онтологию, определяют значение упомянутого термина с помощью словаря, извлекают подходящие определения для упомянутого термина, определяют значение каждого из извлеченных определений с помощью упомянутого словаря, выполняют построение для каждого из определенных значений термина и каждого подходящего термина для термина начального запроса на создание онтологии, по меньшей мере, один логический пункт, описывающий взаимоотношение между парой упомянутых подходящих терминов, причем упомянутые логические пункты определяют онтологию термина ввода.
Все указанные выше решения не позволяют формировать семантически и логически верно структурированный массив данных из исходного массива данных, содержащего текст, представленный на естественном языке, путем разбиения упомянутого массива на логические разделы, которые подвергаются семантическому разбиению конструкций самих разделов и элементов, входящих в упомянутые разделы, последующий их орфографический и грамматический анализ, и последующую оценку их взаимосвязанности в исходном массиве данных.
Ближайшим аналогом (прототипом) заявленного решения принят способ автоматизированной обработки текста на естественном языке путем его семантической индексации, описанный в патенте RU 2399959 С2, G09B 19/00, 20.09.2010 (ЗАКРЫТОЕ АКЦИОНЕРНОЕ ОБЩЕСТВО «АВИКОМП СЕРВИСЕЗ»). Известный способ представляет собой способ, при котором текст сегментируют в электронной форме на элементарные единицы, выявляют устойчивые словосочетания, формируют предложения, выявляют семантически значимые объекты и семантически значимые отношения между ними, формируют для каждого семантически значимого отношения множество триад, в которых единственная триада первого типа соответствует связи, устанавливаемой семантически значимым отношением между двумя семантически значимыми объектами, причем каждая из триад второго типа соответствует значению конкретного атрибута одного из этих семантически значимых объектов, каждая из триад третьего типа соответствует значению конкретного атрибута самого семантически значимого отношения, индексируют на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты по отдельности, запоминают в базе данных сформированные триады и полученные индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады.
Недостатком данного способа является то, что при формировании упомянутых триад, текст сегментируется непосредственно на элементарные единицы, т.е. слова, а не на логические разделы, при этом данный способ не предусматривает формирования промежуточной структуры исходного текстового массива для ее последующего грамматического и орфографического анализа и не обеспечивает формирование конечной логически, грамматически и орфографически верной структуры данных, пригодной для быстрой и удобной навигации по элементам структуры.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Исходя из этого, задачей, на решение которой направлено заявленное изобретение, является обеспечение такой предварительной обработки структурированного массива данных, содержащего текст на естественном языке, которая позволяла бы в дальнейшем осуществлять последующие преобразования и генерировать логически, грамматически и орфографически верную результирующую структуру, содержащую логические конструкции элементов массива и обеспечивающую быструю и удобную навигацию по элементам массива.
Техническим результатом является обеспечение предварительного преобразования структурированного массива данных, пригодного для дальнейшего формирования логически, грамматически и орфографически верной структуры данных.
Заявленный технический результат достигается за счет того, что выполняют способ преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, причем упомянутый способ содержит, по меньшей мере, этапы, на которых:
А) формируют исходную структуру данных структурированного исходного массива данных, содержащую исходные элементы исходной структуры данных, причем упомянутые исходные элементы представляют собой:
структурно-сложные языковые конструкции, представляющие собой структурно-сложные языковые конструкции, содержащие контекстные термины и структурно-сложные языковые конструкции, не содержащие контекстные термины; и
структурно-простые языковые конструкции, представляющие собой структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Б) идентифицируют в упомянутых исходных элементах контекстные термины и формируют базу данных контекстных терминов, содержащую упомянутые идентифицированные контекстные термины;
В) используя информацию, содержащуюся в упомянутой сформированной базе данных контекстных терминов, в упомянутой исходной структуре данных идентифицируют структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Г) осуществляют преобразование первого типа над упомянутыми структурно-сложными языковыми конструкциями, не содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Д) осуществляют преобразование второго типа над упомянутыми структурно-простыми языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Е) осуществляют преобразование третьего типа над упомянутыми структурно-сложными языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Ж) формируют итоговую структуру данных структурированного исходного массива данных, содержащую элементы итоговой структуры данных, причем элементы итоговой структуры данных представляют собой структурно-простые языковые конструкции, не содержащие контекстные термины и полученные за счет преобразований первого, второго и третьего типов грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины.
Варианты осуществления настоящего изобретения относятся к, способу, устройству, системе и машиночитаемому носителю для обеспечения эффективного преобразования структурированного массива данных, содержащего, по меньшей мере, текст на естественном языке.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Иллюстративные варианты осуществления настоящего изобретения описываются далее подробно со ссылкой на прилагаемые чертежи, которые включены в данный документ посредством ссылки, и на которых:
На фиг. 1 изображена общая схема выполнения этапов заявленного способа преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, в соответствии с первым вариантом осуществления настоящего изобретения.
На фиг. 2 изображена общая схема выполнения этапов заявленного способа преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, в соответствии с третьим вариантом осуществления настоящего изобретения.
На фиг. 3 изображена общая схема этапа формирования первой структуры данных.
На фиг. 4 изображена общая структура исходной структуры данных, из которой сформирована первая структура данных.
На фиг. 5 изображена общая схема этапа формирования базы данных логических связей логических разделов.
На фиг. 6 изображен общий принцип формирования базы данных логических связей логических разделов.
На фиг. 7 изображена общая схема этапа формирования второй структуры данных.
На фиг. 8 изображена общая структура второй структуры данных.
На фиг. 9 изображена общая схема этапа формирования базы данных семантических частей.
На фиг. 10 изображен общий принцип формирования базы данных семантических частей.
На фиг. 11 изображена общая схема этапа формирования грамматически и орфографически верных семантических частей.
На фиг. 12 изображена общая схема второй структуры данных, полученной после выполнения этапа формирования грамматически и орфографически верных семантических частей.
На фиг. 13 изображена общая схема этапа формирования результирующей структуры данных.
На фиг. 14 изображена общая схема результирующей структуры данных.
На фиг. 15 изображена общая структура элементов результирующей структуры данных.
На фиг. 16 изображена общая схема выполнения этапов заявленного способа формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных.
На фиг. 17-18 изображена общая схема выполнения этапов заявленного способа поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций.
На фиг. 19 изображена общая схема системы, содержащей устройство, предназначенной для реализации заявленных способов преобразования структурированного исходного массива данных, способов формирования карты связей компонентов преобразованного структурированного исходного массива данных и способов поиска релевантной информации в преобразованном структурированном исходном массиве данных.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Далее приводятся варианты осуществления настоящего изобретения, раскрывающие примеры его реализации в частных исполнениях. Тем не менее, само описание не предназначено для ограничения объема прав, предоставляемых данным патентом. Скорее, следует исходить из того, что заявленное изобретение также может быть осуществлено другими способами таким образом, что будет включать в себя отличающиеся этапы или комбинации этапов, аналогичных этапам, описанным в данном документе, в сочетании с другими существующими и будущими технологиями.
Заявленный способ будет рассмотрен на примере обработки структурированного массива данных, содержащего текст на естественном языке, представляющего собой, не ограничиваясь, нормативные правовые акты (НПА). Для специалиста должно быть очевидно, что, несмотря на то, что в данном конкретном примере реализации настоящего изобретения, осуществляется преобразование НПА, такой способ преобразования может быть применен в отношении любого структурированного массива данных, схожего с НПА.
НПА - это документ, характеризующийся следующими признаками:
1) НПА имеют правотворческий характер: в них нормы права либо устанавливаются, либо изменяются, либо отменяются. Нормативные правовые акты - это носители правовых норм;
2) НПА содержит правовые инструменты, с помощью которых осуществляется правовое регулирующее воздействие.
3) НПА издается только в пределах компетенции правотворческого органа;
4) НПА облекается в документальную форму и имеет следующие реквизиты: вид нормативного акта, его наименование, орган, его принявший, дату, место принятия акта, номер;
5) НПА не является хаотичным набором положений (предложений), а имеет определенную структуру;
6) НПА должен соответствовать конституции или иному вышестоящему НПА, имеющему большую юридическую силу.
7) НПА обязательно подлежит доведению до сведения граждан и организаций, т.е. опубликованию, и лишь только после этого государство имеет право требовать его неукоснительного исполнения, исходя из презумпции знания закона, и налагать санкции за его неисполнение.
Необходимо отметить, что под термином «структурированный массив данных» в рамках заявленного изобретения может рассматриваться не только совокупность НПА, но и отдельный самостоятельный НПА, представляющий собой, например: Конституцию, закон, указ, постановление и т.п. Отдельный НПА может состоять, например, из частей, глав, разделов, статей. При этом инструментом правового регулирующего воздействия НПА является юридическое правило, обличенное в структуру нормативного предписания, которое в свою очередь является элементом (частью) нормы права (правовой нормы).
Структурированным исходным массивом данных, содержащем, по меньшей мере, текст на естественном языке является, в частности, НПА, который представляет собой текст, состоящий из структурно-простых и структурно-сложных языковых конструкций.
Под языковой конструкцией для целей настоящего изобретения понимается синтаксически связанное сочетание слов, словесное построение.
Для целей настоящего изобретения под структурно-простой языковой конструкцией понимаются завершенные фрагменты текста - грамматически организованные соединения слов, т.е. предложения. При этом каждое предложение обязательно характеризуется смысловой законченностью.
Для целей настоящего изобретения под структурно-сложной языковой конструкцией понимаются конструкции типа «рубрики перечисления».
Примером языковой конструкции, относящейся к «рубрикам перечисления» является следующая языковая конструкция:
«Потребитель в случае обнаружения в товаре недостатков, если они не были оговорены продавцом, по своему выбору вправе:
- потребовать замены на товар этой же марки (этих же модели и (или) артикула);
- потребовать замены на такой же товар другой марки (модели, артикула) с соответствующим перерасчетом покупной цены;
- потребовать соразмерного уменьшения покупной цены;
- потребовать незамедлительного безвозмездного устранения недостатков товара или возмещения расходов на их исправление потребителем или третьим лицом;
- отказаться от исполнения договора купли-продажи и потребовать возврата уплаченной за товар суммы.».
Главной целью предварительного преобразования структурированного исходного массива данных является формирование структурированного массива данных, состоящего только из предложений. Эта цель реализуется за счет преобразования структурно-сложных языковых конструкций в структурно-простые языковые конструкции - предложения.
Другой целью предварительного преобразования является прояснение контекстных терминов и упрощение предложений, содержащих контекстные термины.
Для целей настоящего изобретения под контекстными терминами понимаются условные именования таких терминов, которые либо не имеют самостоятельного смыслового значения вне контекста, либо имеют множество смысловых значений в контексте.
При этом для целей настоящего изобретения под контекстом понимается относительно законченный по смыслу отрывок текста, в пределах которого наиболее точно и ясно выявлен смысл и значение отдельного входящего в него слова, словосочетания или совокупности словосочетаний, а также группа из минимум двух предложений, в двух различных отрывках текста, при условии наличия в одном из предложений ссылки на другое предложение.
В первом варианте осуществления настоящего изобретения обеспечивается способ преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, причем упомянутый способ содержит, по меньшей мере, этапы, на которых:
А) формируют исходную структуру данных структурированного исходного массива данных, содержащую исходные элементы исходной структуры данных, причем упомянутые исходные элементы представляют собой:
структурно-сложные языковые конструкции, представляющие собой структурно-сложные языковые конструкции, содержащие контекстные термины и структурно-сложные языковые конструкции, не содержащие контекстные термины; и
структурно-простые языковые конструкции, представляющие собой структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Б) идентифицируют в упомянутых исходных элементах контекстные термины и формируют базу данных контекстных терминов, содержащую упомянутые идентифицированные контекстные термины;
В) используя информацию, содержащуюся в упомянутой сформированной базе данных контекстных терминов, в упомянутой исходной структуре данных идентифицируют структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Г) осуществляют преобразование первого типа над упомянутыми структурно-сложными языковыми конструкциями, не содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Д) осуществляют преобразование второго типа над упомянутыми структурно-простыми языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Е) осуществляют преобразование третьего типа над упомянутыми структурно-сложными языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Ж) формируют итоговую структуру данных структурированного исходного массива данных, содержащую элементы итоговой структуры данных, причем элементы итоговой структуры данных представляют собой структурно-простые языковые конструкции, не содержащие контекстные термины и полученные за счет преобразований первого, второго и третьего типов грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины.
Во втором варианте осуществления настоящего изобретения обеспечивается способ преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, причем упомянутый способ содержит, по меньшей мере, этапы, на которых:
А) формируют исходную структуру данных структурированного исходного массива данных, содержащую исходные элементы исходной структуры данных, причем упомянутые исходные элементы представляют собой:
структурно-сложные языковые конструкции, представляющие собой структурно-сложные языковые конструкции, содержащие контекстные термины и структурно-сложные языковые конструкции, не содержащие контекстные термины; и
структурно-простые языковые конструкции, представляющие собой структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Б) идентифицируют в упомянутых исходных элементах контекстные термины и формируют базу данных контекстных терминов, содержащую упомянутые идентифицированные контекстные термины;
В) используя информацию, содержащуюся в упомянутой сформированной базе данных контекстных терминов, в упомянутой исходной структуре данных идентифицируют структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Г) осуществляют преобразование первого типа над упомянутыми структурно-сложными языковыми конструкциями, не содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Д) осуществляют преобразование второго типа над упомянутыми структурно-простыми языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Е) осуществляют преобразование третьего типа над упомянутыми структурно-сложными языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины;
Ж) формируют итоговую структуру данных структурированного исходного массива данных, содержащую элементы итоговой структуры данных, причем элементы итоговой структуры данных представляют собой структурно-простые языковые конструкции, не содержащие контекстные термины и полученные за счет преобразований первого, второго и третьего типов грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины; причем
преобразование первого типа включает форматное преобразование и лингвистическое преобразование;
преобразование второго типа включает контекстное преобразование и лингвистическое преобразование;
преобразование третьего типа включает форматное преобразование, контекстное преобразование и лингвистическое преобразование.
В третьем варианте осуществления настоящего изобретения, обеспечивается способ по любому из первого или второго вариантов осуществления настоящего изобретения, дополнительно содержащий, по меньшей мере, этапы на которых:
З) на основании полученной итоговой структуры данных формируют первую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных содержат первые логические разделы и вторые логические разделы;
И) формируют базу данных логических связей логических разделов упомянутых элементов первой структуры данных;
К) формируют вторую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой второй структуры данных, причем упомянутые элементы второй структуры данных содержат логические конструкции логических разделов упомянутых элементов первой структуры данных, сформированные с использованием информации из упомянутой базы данных логических связей логических разделов, причем упомянутые логические разделы содержат первые семантические части и вторые семантические части;
Л) формируют базу данных семантических частей логических разделов из упомянутых вторых семантических частей, причем упомянутые вторые семантические части исключаются из соответствующих упомянутых логических разделов;
М) формируют грамматически и орфографически верные семантические части упомянутых логических разделов путем лингвистических преобразований над упомянутыми семантическими частями;
Н) формируют результирующую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой результирующей структуры данных, причем упомянутые элементы результирующей структуры данных содержат логические конструкции, содержащие, по меньшей мере, упомянутые грамматически и орфографически верные семантические части логических разделов.
В четвертом варианте осуществления настоящего изобретения обеспечивается способ по третьему варианту осуществления настоящего изобретения, характеризующийся тем, что на этапе 3) осуществляют, по меньшей мере, этапы, на которых:
идентифицируют итоговую структуру данных структурированного исходного массива данных;
идентифицируют элементы итоговой структуры данных;
идентифицируют первые логические разделы упомянутых элементов итоговой структуры данных и вторые логические разделы упомянутых элементов итоговой структуры данных; и
формируют первую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных содержат первые логические разделы и вторые логические разделы.
В пятом варианте осуществления настоящего изобретения обеспечивается способ по третьему варианту осуществления настоящего изобретения, характеризующийся тем, что на этапе И) осуществляют, по меньшей мере, этапы, на которых:
идентифицируют элементы первой структуры данных, содержащие один упомянутый первый логический раздел, и элементы первой структуры данных, содержащие один упомянутый второй логический раздел;
идентифицируют элементы первой структуры данных, содержащие более одного упомянутого первого логического раздела, и элементы первой структуры данных, содержащие более одного упомянутого второго логического раздела;
среди элементов первой структуры данных, содержащих более одного упомянутого первого логического раздела и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела, идентифицируют логические связи между упомянутыми первыми логическими разделами или между упомянутыми вторыми логическими разделами;
среди элементов первой структуры данных, содержащих более одного упомянутого первого логического раздела и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела идентифицируют элементы первой структуры данных, не имеющие логической связи между логическими разделами; и
формируют базу данных логических связей логических разделов элементов первой структуры данных.
В шестом варианте осуществления настоящего изобретения обеспечивается способ по третьему варианту осуществления настоящего изобретения, характеризующийся тем, что на этапе К) осуществляют, по меньшей мере, этапы, на которых:
формируют логические конструкции логических разделов элементов первой структуры данных, используя информацию из базы данных логических связей логических разделов элементов первой структуры данных и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый первый логический раздел, и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый второй логический раздел; и
формируют вторую структуру данных структурированного исходного массива данных, содержащую элементы второй структуры данных, причем упомянутые элементы второй структуры данных представляют собой сформированные логические конструкции логических разделов первой структуры данных.
В седьмом варианте осуществления настоящего изобретения обеспечивается способ по третьему варианту осуществления настоящего изобретения, характеризующийся тем, что на этапе Л) осуществляют, по меньшей мере, этапы, на которых:
идентифицируют первые логические разделы элементов второй структуры данных и вторые логические разделы элементов второй структуры данных;
в упомянутых первых логических разделах и вторых логических разделах элементов второй структуры данных идентифицируют первые семантические части и вторые семантические части; и
в упомянутых первых и вторых логических разделах элементов второй структуры данных идентифицируют, по меньшей мере, особые семантические части первых логических разделов элементов второй структуры данных и особые семантические части вторых логических разделов элементов второй структуры данных и формируют базу данных особых семантических частей логических разделов элементов второй структуры данных путем перемещения упомянутых особых семантических частей в упомянутую формируемую базу данных особых семантических частей логических разделов элементов второй структуры данных.
В восьмом варианте осуществления настоящего изобретения обеспечивается способ по третьему варианту осуществления настоящего изобретения, характеризующийся тем, что на этапе М) осуществляют, по меньшей мере, этапы, на которых:
в упомянутых вторых семантических частях, упомянутых вторых логических разделов элементов второй структуры данных идентифицируют, по меньшей мере, уточняющие структуры вторых семантических частей вторых логических разделов; и
осуществляют лингвистические преобразования над всеми семантическими частями, за исключением упомянутых особых семантических частей упомянутых первых и вторых логических разделов, для формирования грамматически и орфографически верных семантических частей логических разделов элементов второй структуры данных.
В девятом варианте осуществления настоящего изобретения обеспечивается способ по третьему варианту осуществления настоящего изобретения, характеризующийся тем, что на этапе Н) осуществляют, по меньшей мере, этапы, на которых:
формируют из первых грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных и упомянутых грамматически и орфографически верных уточняющих структур вторых семантических частей вторых логических разделов элементов второй структуры данных смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных; и
формируют результирующую структуру данных структурированного исходного массива данных, содержащую элементы результирующей структуры данных, причем упомянутые элементы результирующей структуры данных представляют собой логические конструкции, содержащие упомянутые грамматически и орфографически верные семантические части логических разделов элементов второй структуры данных.
В десятом варианте осуществления настоящего изобретения обеспечивается способ по девятому варианту осуществления настоящего изобретения, характеризующийся тем, что упомянутые логические конструкции из упомянутой результирующей структуры данных дополнительно могут содержать упомянутые сформированные смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных.
В одиннадцатом варианте осуществления настоящего изобретения обеспечивается способ по любому из первого или второго вариантов осуществления настоящего изобретения, характеризующийся тем, что дополнительно содержит, по меньшей мере, этапы, на которых:
З) идентифицируют исходную структуру данных исходного структурированного массива данных; идентифицируют элементы исходной структуры данных; идентифицируют первые логические разделы упомянутых элементов исходной структуры данных и вторые логические разделы упомянутых элементов исходной структуры данных; и формируют первую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных содержат первые логические разделы и вторые логические разделы;
И) идентифицируют элементы первой структуры данных, содержащие один упомянутый первый логический раздел, и элементы первой структуры данных, содержащие один упомянутый второй логический раздел; идентифицируют элементы первой структуры данных, содержащие более одного упомянутого первого логического раздела, и элементы первой структуры данных, содержащие более одного упомянутого второго логического раздела; в элементах первой структуры данных, содержащих более одного упомянутого первого логического раздела и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела, идентифицируют логические связи между упомянутыми первыми логическими разделами или между упомянутыми вторыми логическими разделами; в элементах первой структуры данных, содержащих более одного упомянутого первого логического раздела и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела идентифицируют элементы первой структуры данных, не имеющие логической связи между логическими разделами; и формируют базу данных логических связей логических разделов элементов первой структуры данных;
К) формируют логические конструкции логических разделов элементов первой структуры данных, используя информацию из базы данных логических связей логических разделов элементов первой структуры данных и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый первый логический раздел, и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый второй логический раздел; и формируют вторую структуру данных структурированного исходного массива данных, содержащую элементы второй структуры данных, причем упомянутые элементы второй структуры данных представляют собой сформированные логические конструкции логических разделов первой структуры данных;
Л) идентифицируют первые логические разделы элементов второй структуры данных и вторые логические разделы элементов второй структуры данных; в упомянутых первых логических разделах и вторых логических разделах элементов второй структуры данных идентифицируют первые семантические части и вторые семантические части; и в упомянутых первых и вторых логических разделах элементов второй структуры данных идентифицируют, по меньшей мере, особые семантические части первых логических разделов элементов второй структуры данных и особые семантические части вторых логических разделов элементов второй структуры данных и формируют базу данных особых семантических частей логических разделов элементов второй структуры данных путем перемещения упомянутых особых семантических частей в упомянутую формируемую базу данных особых семантических частей логических разделов элементов второй структуры данных;
М) в упомянутых вторых семантических частях упомянутых вторых логических разделов элементов второй структуры данных идентифицируют, по меньшей мере, уточняющие структуры вторых семантических частей вторых логических разделов; и осуществляют лингвистические преобразования над всеми семантическими частями, за исключением упомянутых особых семантических частей упомянутых первых и вторых логических разделов, для формирования грамматически и орфографически верных семантических частей логических разделов элементов второй структуры данных;
Н) формируют из первых грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных и упомянутых грамматически и орфографически верных уточняющих структур вторых семантических частей вторых логических разделов элементов второй структуры данных смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов третьей структуры данных; и формируют результирующую структуру данных структурированного исходного массива данных, содержащую элементы результирующей структуры данных, причем упомянутые элементы результирующей структуры данных представляют собой логические конструкции, содержащие упомянутые грамматически и орфографически верные семантические части логических разделов элементов второй структуры данных.
В двенадцатом варианте осуществления настоящего изобретения обеспечивается способ по одиннадцатому варианту осуществления настоящего изобретения, характеризующийся тем, что упомянутые логические конструкции из упомянутой результирующей структуры данных дополнительно могут содержать упомянутые сформированные смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных.
При этом для специалиста в области техники, к которой относится настоящее изобретение, должно быть очевидным, что варианты осуществления изобретения со второго по двенадцатый характеризуют уточненные этапы способа, охарактеризованного первым вариантом осуществления изобретения, и иные варианты осуществления изобретения могут быть реализованы, причем такие иные варианты осуществления изобретения будут включать различные комбинации уточненных этапов способа.
В тринадцатом варианте осуществления настоящего изобретения обеспечивается устройство преобразования структурированного исходного массива данных, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с первого по двенадцатый, и содержащую подлежащие преобразованию один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке.
В четырнадцатом варианте осуществления настоящего изобретения обеспечивается устройство преобразования исходного структурированного массива данных, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с первого по двенадцатый, и содержащую подлежащие преобразованию один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке, причем упомянутые подлежащие преобразованию один или несколько структурированных исходных массивов данных являются загружаемыми, а упомянутое устройство выполнено с возможностью соединения с базой данных, в которой хранятся упомянутые загружаемые подлежащие преобразованию один или несколько структурированных исходных массивов данных, для осуществления загрузки в упомянутую память устройства, по меньшей мере, одного загружаемого подлежащего преобразованию структурированного исходного массива данных.
В пятнадцатом варианте осуществления настоящего изобретения обеспечивается система преобразования структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с тринадцатого по четырнадцатый;
один или несколько серверов, обеспечивающих регулирование обменом данных в упомянутой системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных.
В шестнадцатом варианте осуществления настоящего изобретения обеспечивается система преобразования структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из тринадцатого или четырнадцатого вариантов осуществления настоящего изобретения;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных; причем
способ по любому из вариантов осуществления настоящего изобретения с первого по двенадцатый осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент.
В семнадцатом варианте осуществления настоящего изобретения обеспечивается система преобразования структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из тринадцатого или четырнадцатого вариантов осуществления настоящего изобретения;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных; причем
способ по любому из вариантов осуществления настоящего изобретения с первого по двенадцатый осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент; причем
упомянутая база данных служит для хранения данных, представляющих собой, по меньшей мере, одно из: код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с первого по двенадцатый, подлежащие преобразованию один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке.
В восемнадцатом варианте осуществления настоящего изобретения обеспечивается система по любому из вариантов осуществления настоящего изобретения с пятнадцатого по семнадцатый, причем упомянутая сеть передачи данных представляет собой одно из локальная сеть (LAN), глобальная сеть (WAN), информационно-телекоммуникационная сеть Интернет, виртуальная частная сеть (VPN).
В девятнадцатом варианте осуществления настоящего изобретения обеспечивается машиночитаемый носитель данных, содержащий код программы, который при выполнении побуждает процессор или процессоры устройства, с которым взаимодействует машиночитаемый носитель данных, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с первого по двенадцатый.
В двадцатом варианте осуществления настоящего изобретения обеспечивается способ формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, причем упомянутый способ включает, по меньшей мере, этапы, на которых:
идентифицируют компоненты грамматически и орфографически верных семантических частей логических разделов логических конструкций из упомянутого преобразованного структурированного исходного массива данных, причем каждая упомянутая грамматически и орфографически верная семантическая часть, содержащая упомянутые компоненты, содержит, по меньшей мере, один упомянутый компонент, причем упомянутый компонент содержит не более одного значения компонента, и формируют таблицу компонентов, содержащую, по меньшей мере, упомянутые идентифицированные компоненты и их значения;
идентифицируют грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащие упомянутые идентифицированные компоненты, и грамматически и орфографически верные семантические части логических разделов логических конструкций, не содержащие упомянутые идентифицированные компоненты;
идентифицируют компоненты, содержащиеся в количестве более одного в упомянутых грамматически и орфографически верных семантических частях, и идентифицируют сочетания компонентов, содержащихся в количестве более одного в каждой отдельной упомянутой грамматически и орфографически верной семантической части, и формируют карту сочетаний компонентов, содержащую, по меньшей мере, упомянутые компоненты, содержащиеся в количестве более одного в каждой отдельной упомянутой грамматически и орфографически верной семантической части, и их сочетания;
идентифицируют значения компонентов, содержащихся в упомянутой карте сочетаний компонентов;
в грамматически и орфографически верных семантических частях логических разделов логических конструкций, не содержащих упомянутых идентифицированных компонентов, идентифицируют понятия, семантически совпадающие с упомянутыми значениями компонентов, содержащихся в упомянутой карте сочетаний компонентов, и формируют таблицу семантически совпадающих понятий, содержащую, по меньшей мере, значения компонентов, содержащихся в упомянутой карте сочетаний компонентов, и семантически совпадающие с ними понятия;
идентифицируют, по меньшей мере, одну грамматически и орфографически верную семантическую часть логического раздела логической конструкции, не содержащую упомянутые идентифицированные компоненты, и содержащую более одного упомянутого понятия;
идентифицируют грамматически и орфографически верную семантическую часть логического раздела логической конструкции, содержащую более одного упомянутого идентифицированного компонента, значения которых семантически совпадают с упомянутыми понятиями, содержащимися в одной грамматически и орфографически верной семантической части логического раздела логической конструкции, не содержащей упомянутых идентифицированных компонентов и содержащей более одного упомянутого понятия;
формируют карту сочетаний семантически совпадающих понятий, содержащую, по меньшей мере, упомянутые понятия, содержащиеся в количестве более одного в одной грамматически и орфографически верной семантической части логического раздела логической конструкции, не содержащей упомянутых идентифицированных компонентов, семантически совпадающие со значениями упомянутых идентифицированных компонентов, содержащихся в одной грамматически и орфографически верной семантической части логического раздела логической конструкции, содержащей более одного упомянутого идентифицированного компонента;
формируют карту связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутую карту сочетаний компонентов и упомянутую карту сочетаний семантически совпадающих понятий.
В двадцать первом варианте осуществления настоящего изобретения обеспечивается способ формирования карты связей компонентов по двадцатому варианту осуществления настоящего изобретения, дополнительно содержащий этап, на котором формируют отчет, демонстрирующий, по меньшей мере, количество связей и значения упомянутых компонентов, содержащихся в карте сочетаний компонентов.
В двадцать втором варианте осуществления настоящего изобретения обеспечивается устройство формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцатого по двадцать первый, и содержащую один или несколько преобразованных структурированных исходных массивов данных.
В двадцать третьем варианте осуществления настоящего изобретения обеспечивается устройство формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцатого по двадцать первый, и содержащую один или несколько преобразованных структурированных исходных массивов данных, причем упомянутые один или несколько преобразованных структурированных исходных массивов данных являются загружаемыми, а упомянутое устройство выполнено с возможностью соединения с базой данных, в которой хранятся упомянутые загружаемые один или несколько преобразованных структурированных исходных массивов данных, для осуществления загрузки в упомянутую память устройства, по меньшей мере, одного загружаемого преобразованного структурированного исходного массива данных.
В двадцать четвертом варианте осуществления настоящего изобретения обеспечивается система формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с двадцать второго по двадцать третий;
один или несколько серверов, обеспечивающих регулирование обменом данных в упомянутой системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных.
В двадцать пятом варианте осуществления настоящего изобретения обеспечивается система формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с двадцать второго по двадцать третий;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных; причем
способ по любому из вариантов осуществления настоящего изобретения с двадцатого по двадцать первый осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент.
В двадцать шестом варианте осуществления настоящего изобретения обеспечивается система формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с двадцать второго по двадцать третий;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных; причем
способ по любому из вариантов осуществления настоящего изобретения с двадцатого по двадцать первый осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент; причем
упомянутая база данных служит для хранения данных, представляющих собой, по меньшей мере, одно из: код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцатого по двадцать первый, один или несколько преобразованных структурированных исходных массивов данных.
В двадцать седьмом варианте осуществления настоящего изобретения обеспечивается система по любому из вариантов осуществления настоящего изобретения с двадцать четвертого по двадцать шестой, причем упомянутая сеть передачи данных представляет собой одно из локальная сеть (LAN), глобальная сеть (WAN), информационно-телекоммуникационная сеть, Интернет, виртуальная частная сеть (VPN).
В двадцать восьмом варианте осуществления настоящего изобретения обеспечивается машиночитаемый носитель данных, содержащий код программы, который при выполнении побуждает процессор или процессоры устройства, с которым взаимодействует машиночитаемый носитель данных, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцатого по двадцать первый.
В двадцать девятом варианте осуществления настоящего изобретения обеспечивается способ поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций, причем упомянутый способ включает, по меньшей мере, этапы, на которых:
формируют поисковый запрос, содержащий, по меньшей мере, один поисковый термин;
идентифицируют массив данных в упомянутом преобразованном структурированном исходном массиве данных, соответствующий упомянутому поисковому термину;
идентифицируют, по меньшей мере, одну грамматически и орфографически верную семантическую часть логических разделов логических конструкций упомянутого преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутый поисковый термин;
идентифицируют, по меньшей мере, одну логическую конструкцию упомянутого преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутую идентифицированную грамматически и орфографически верную семантическую часть;
демонстрируют, по меньшей мере, упомянутую идентифицированную логическую конструкцию упомянутого преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутую идентифицированную грамматически и орфографически верную семантическую часть.
В тридцатом варианте осуществления настоящего изобретения обеспечивается способ поиска по двадцать девятому варианту осуществления настоящего изобретения, дополнительно содержащий этап назначения, по меньшей мере, одного критерия поиска.
В тридцать первом варианте осуществления настоящего изобретения обеспечивается способ поиска по тридцатому варианту осуществления настоящего изобретения, характеризующийся тем, что критерием поиска является, по меньшей мере, одно из: поиск по первым и вторым семантическим частям первых логических разделов логических конструкций и вторым семантическим частям вторых логических разделов логических конструкций; поиск по первым семантическим частям вторых логических разделов логических конструкций и вторым семантическим частям вторых логических разделов логических конструкций.
В тридцать втором варианте осуществления настоящего изобретения обеспечивается способ поиска по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать первый, характеризующийся тем, что формируемый поисковый запрос представляет собой, по меньшей мере, одно из: терминологический поисковый запрос; компонентный поисковый запрос; компонентно-терминологический поисковый запрос.
В тридцать третьем варианте осуществления настоящего изобретения обеспечивается способ поиска по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать первый, дополнительно содержащий, по меньшей мере, этапы, на которых:
выбирают, по меньшей мере, одну из упомянутых идентифицированных логических конструкций, содержащую, по меньшей мере, упомянутую идентифицированную грамматически и орфографически верную семантическую часть;
идентифицируют, по меньшей мере, связанные с упомянутой грамматически и орфографически верной семантической частью грамматически и орфографически верные семантические части, содержащиеся в других логических конструкциях преобразованного структурированного массива данных, причем упомянутая идентификация осуществляется на основании сведений из карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций;
идентифицируют, по меньшей мере, одну или более логические конструкции, содержащие упомянутые идентифицированные связанные грамматически и орфографически верные семантические части или идентифицируют отсутствие логических конструкций, содержащих упомянутые идентифицированные связанные грамматически и орфографически верные семантические части;
демонстрируют, по меньшей мере, одну или более логические конструкции, содержащие упомянутые идентифицированные связанные грамматически и орфографически верные семантические части или демонстрируют отсутствие логических конструкций, содержащих упомянутые идентифицированные связанные грамматически и орфографически верные семантические части.
В тридцать четвертом варианте осуществления настоящего изобретения обеспечивается способ поиска по тридцать третьему варианту осуществления настоящего изобретения, характеризующийся тем, что формируемый поисковый запрос представляет собой, по меньшей мере, одно из: терминологический поисковый запрос; компонентный поисковый запрос; компонентно-терминологический поисковый запрос.
В тридцать пятом варианте осуществления настоящего изобретения обеспечивается устройство поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать четвертый, и содержащую один или несколько преобразованных структурированных исходных массивов данных.
В тридцать шестом варианте осуществления настоящего изобретения обеспечивается устройство поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать четвертый, и содержащую один или несколько преобразованных структурированных исходных массивов данных, причем упомянутые один или несколько преобразованных структурированных исходных массивов данных являются загружаемыми, а упомянутое устройство выполнено с возможностью соединения с базой данных, в которой хранятся упомянутые загружаемые один или несколько преобразованных структурированных исходных массивов данных, для осуществления загрузки в упомянутую память устройства, по меньшей мере, одного загружаемого преобразованного структурированного исходного массива данных.
В тридцать седьмом варианте осуществления настоящего изобретения обеспечивается система поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с тридцать пятого по тридцать шестой;
один или несколько серверов, обеспечивающих регулирование обменом данных в упомянутой системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных.
В тридцать восьмом варианте осуществления настоящего изобретения обеспечивается система поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с тридцать пятого по тридцать шестой;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных; причем
способ по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать четвертый осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент.
В тридцать девятом варианте осуществления настоящего изобретения обеспечивается система поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из вариантов осуществления настоящего изобретения с тридцать пятого по тридцать шестой;
один или несколько серверов, обеспечивающих регулирование обменом данных в системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных; причем
способ по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать четвертый осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент; причем
упомянутая база данных служит для хранения данных, представляющих собой, по меньшей мере, одно из: код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать четвертый, один или несколько преобразованных структурированных исходных массивов данных.
В сороковом варианте осуществления настоящего изобретения обеспечивается система по любому из вариантов осуществления настоящего изобретения с тридцать седьмого по тридцать девятый, причем упомянутая сеть передачи данных представляет собой одно из локальная сеть (LAN), глобальная сеть (WAN), информационно-телекоммуникационная сеть Интернет, виртуальная частная сеть (VPN).
В сорок первом варианте осуществления настоящего изобретения обеспечивается машиночитаемый носитель данных, содержащий код программы, который при выполнении побуждает процессор или процессоры устройства, с которым взаимодействует машиночитаемый носитель данных, выполнять действия способа по любому из вариантов осуществления настоящего изобретения с двадцать девятого по тридцать четвертый.
ДЕТАЛЬНОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Описанные в данном разделе возможные осуществления вариантов настоящего изобретения представлены на неограничивающих объем правовой охраны примерах, применительно к конкретным вариантам осуществления настоящего изобретения, которые во всех их аспектах предполагаются иллюстративными и не накладывающими ограничения. Альтернативные варианты реализации настоящего изобретения, не выходящие за пределы объема его правовой охраны, являются очевидными специалистам в данной области, имеющим обычную квалификацию, на которых это изобретение рассчитано.
На фиг. 1 в качестве примера, но не ограничения, изображена общая схема выполнения этапов заявленного способа 100 преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке. Заявленный способ 100 преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке характеризуется выполнением этапа 101 формирования исходной структуры данных структурированного исходного массива данных, на котором формируют исходную структуру данных структурированного исходного массива данных, содержащую исходные элементы исходной структуры данных, причем упомянутые исходные элементы представляют собой структурно-сложные языковые конструкции, состоящие из структурно-сложных языковых конструкций, содержащих контекстные термины, и структурно-сложных языковых конструкций, не содержащих контекстные термины, и структурно-простые языковые конструкции, содержащие структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины. На этапе 101 формирования исходной структуры данных структурированного исходного массива данных осуществляют анализ элементов структурированного исходного массива данных для выявления наличия в нем исходных элементов исходной структуры данных структурированного исходного массива данных. В результате проведенного анализа осуществляется формирование исходной структуры данных структурированного исходного массива данных, состоящей из структурно-сложных и структурно-простых языковых конструкций - предложений и рубрик перечисления. Идентификация структурно-сложных языковых конструкций осуществляется в соответствии с первым критерием идентификации, который представляет собой критерий идентификации по первому типу комбинации знаков препинания. Первый тип комбинации знаков препинания характеризуется наличием следующих признаков структурно-сложной языковой конструкции:
а) структурно-сложная языковая конструкция состоит из нескольких текстовых фрагментов;
б) в первом текстовом фрагменте имеется последний символ первого текстового фрагмента - знак пунктуации «:» («двоеточие»);
в) после знака пунктуации «:» расположен знак форматирования (знак типографики) - «¶» («абзац»);
г) после знака пунктуации «:» первого текстового фрагмента расположены вторые текстовые фрагменты, каждый из которых расположен на новой строке - красной строке абзаца;
д) каждый из вторых текстовых фрагментов начинается с прописной буквы;
ж) каждый из вторых текстовых фрагментов может начинаться с маркера списка - знака форматирования (знака типографики), используемого для выделения элементов списка (рубрик перечисления);
з) каждый из вторых текстовых фрагментов может начинаться с маркера нумерации - цифры или буквы, с круглой скобкой или точкой;
и) количество вторых текстовых фрагментов, располагающихся на красных строках абзацев, должно быть не менее двух.
При этом структурно-простыми языковыми конструкциями являются такие элементы исходной структуры данных, в которых комбинация знаков препинания не соответствует первому критерию, т.е. такие элементы исходной структуры данных удовлетворяют критерию идентификации по второму типу комбинации знаков препинания, причем второй тип комбинации знаков препинания представляет собой все комбинации знаков препинания, за исключением комбинаций знаков препинания первого типа. Идентификация структурно-простых языковых конструкций производится путем выявления в тексте на естественном языке признаков окончания предложения - знаков препинания «.» («точка»), «…» («многоточие») и т.п., - в совокупности с признаками начала следующего предложения - заглавной буквы, цифры и т.п., учитывая также наличие и определенные сочетания знаков препинаний, а именно - знаков пунктуации («.» («точка»), «;» («точка с запятой»), «…» («многоточие»), «,» («запятая»), «(» («открывающая скобка»), «)» («закрывающая скобка»), «:» («двоеточие») и т.п.), словоразделителей (« » («пробел»), «-» («тире»), и т.п.) и типографики («¶» («абзац»), номер, «°» («градус») и т.п.).
Так же способ 100 преобразования структурированного исходного массива данных характеризуется выполнением этапа 102 идентификации контекстных терминов и формирования базы данных контекстных терминов, на котором идентифицируют в упомянутых исходных элементах контекстные термины и формируют базу данных контекстных терминов, содержащую упомянутые идентифицированные контекстные термины. На данном этапе идентифицируется комбинации контекстных терминов первого типа, контекстных терминов второго типа, контекстных терминов третьего типа, которые в результате идентифицируются как контекстные понятия, контекстно-обобщенные понятия и контекстные ссылки. Идентификация по критерию комбинации контекстных терминов первого типа позволяет идентифицировать контекстные понятия. Контекстные понятия - это однословный или многословный термин, не имеющий самостоятельного смыслового значения, истинный смысл которого проясняется с помощью другого, синонимичного или ассоциативного термина (группы терминов), находящегося в том же предложении, что и контекстное понятие, или в предыдущих предложениях. Идентификация по критерию комбинации контекстных терминов второго типа позволяет идентифицировать контекстно-обобщенные понятия. Контекстно-обобщенные понятия - это однословные или многословные термины, один из которых является обобщающим словом, а другие - обобщенными словами, - при этом термин, являющийся обобщающим словом, включает в себя лексическое значение ряда однородных членов (обобщенных слов) и отвечающих на тот же вопрос, что и однородные члены. Идентификация по критерию комбинации контекстных терминов третьего типа позволяет идентифицировать контекстные ссылки. Контекстные ссылки - это многословный термин, не имеющий самостоятельного смыслового значения, который явно или неявно ссылается на другие предложения, в которых содержатся смысловое значение данного термина. При этом явной контекстной ссылкой считается ссылка, в которой указано точное местонахождение смыслового значения (например - требования, указанные в Статье 12 п. 2 Закона РФ от 07.02.1992 г. N 2300-1 «О защите прав потребителей» - «Продавец (исполнитель), не предоставивший покупателю полной и достоверной информации о товаре (работе, услуге), несет ответственность, предусмотренную пунктами 1-4 статьи 18 или пунктом 1 статьи 29 настоящего Закона, за недостатки товара (работы, услуги), возникшие после его передачи потребителю вследствие отсутствия у него такой информации.»). Если в контекстной ссылке нет точного указания места нахождения смыслового значения, то такая ссылка является неявной контекстной ссылкой, причем «степень неявности» неявной контекстной ссылки является величиной обратно пропорциональной величине «степени точности» указания на место нахождения смыслового значения. Примером неявной контекстной ссылки, обладающей «максимальной степенью неявности» может служить контекстная ссылка вида «указанные требования». В результате идентификации контекстных терминов выявляются, собственно, контекстные термины и термины, проясняющие их смысловое значение. Между контекстными терминами и терминами, проясняющими их смысловое значение, регистрируется контекстная связь, которая является причиной формирования соответствующих записей в базе данных контекстных терминов. На основании информации, содержащейся в базе данных контекстных терминов, становится возможным осуществление специальных преобразований (лингвистических и иных преобразований) над предложениями, содержащими контекстные термины, с целью обеспечения ясности и однозначности понимания контекстных терминов. Контекстные термины, идентифицированные в предложениях, при этом не обязательно удаляются из предложений и могут остаться в них, но при этом их смысловое значение будет ясным и однозначным, т.к. это значение будет прояснено в соответствующих контекстных справочниках (справочнике контекстных понятий, справочнике контекстно-обобщенных понятий, справочнике контекстных ссылок).
Так же способ 100 преобразования структурированного исходного массива данных характеризуется выполнением этапа 103 идентификации элементов исходной структуры данных, на котором, используя информацию, содержащуюся в упомянутой сформированной базе данных контекстных терминов, в упомянутой исходной структуре данных идентифицируют структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины и структурно-простые языковые конструкции, не содержащие контекстные термины. На основании информации, содержащейся в базе данных контекстных терминов, идентифицируются исходные элементы исходной структуры данных структурированного исходного массива данных. На данном этапе, осуществляется однозначная идентификация исходных элементов и их группировка по признакам наличия или отсутствия в них контекстных терминов и типу исходного элемента. Таким образом, однозначно идентифицируются структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины.
Так же способ 100 преобразования структурированного исходного массива данных характеризуется выполнением этапа 104 преобразования первого типа, на котором осуществляют преобразование первого типа над упомянутыми структурно-сложными языковыми конструкциями, не содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины. Структурно-сложные языковые конструкции, не содержащие контекстные термины, подвергаются преобразованиям с целью преобразования рубрик перечисления в предложения. В процессе таких преобразований осуществляется преобразование структурно-сложных языковых конструкций, не содержащих контекстные термины, в структурно-простые языковые конструкции, являющиеся предложениями в обычном понимании этого термина. Данное преобразование носит изначально форматный характер, т.е. неформатный текст структурно-сложной языковой конструкции преобразуется в форматный, т.е. соответствующий грамматическому понятию предложения. Для устранения грамматических и орфографических ошибок, связанных с преобразованием структурно-сложных языковых конструкций, не содержащих контекстные термины, в структурно-простые языковые конструкции, осуществляются лингвистические преобразования. Лингвистические преобразования над созданными структурно-простыми языковыми конструкциями связаны с восстановлением правильной грамматики и орфографии. Под указанными лингвистическими преобразованиями понимается: а) согласование родов, чисел, падежей; б) правка (замена и удаление) несоответствующих знаков препинания. Все вышеуказанные преобразования, производимые над структурно-сложными языковыми конструкциями, не содержащими контекстные термины, являются преобразованиями первого типа.
Так же способ 100 преобразования структурированного исходного массива данных характеризуется выполнением этапа 105 преобразования второго типа, на котором осуществляют преобразование второго типа над упомянутыми структурно-простыми языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины. Структурно-простые языковые конструкции, содержащие контекстные термины, подвергаются преобразованиям с целью структурирования и прояснения смыслового содержания контекстных терминов. В процессе таких преобразований осуществляется преобразование структурно-простых языковых конструкций, содержащих контекстные термины, в грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины. Данное преобразование носит структурно-лингвистический характер, т.е. оно связано с фактической заменой или удалением из текста структурно-простой языковой конструкции, содержащей контекстные термины, всех или части контекстных терминов и фактической заменой удаленных терминов другими терминами, которые являются смысловым содержанием контекстных терминов. Кроме этого упомянутое преобразование может быть связано с дополнением текста структурно-простой языковой конструкции, содержащей контекстные термины, формированием новой записи в соответствующем контекстном справочнике. Для каждого типа контекстных терминов применяется свой тип преобразования. Так для контекстных понятий применяется первое преобразование второго типа, для контекстно-обобщенных понятий - второе преобразование второго типа, для контекстных ссылок - третье преобразование второго типа. По результатам преобразований контекстных терминов осуществляется лингвистическое преобразование для устранения грамматических и орфографических ошибок, связанных с преобразованием структурно-простых языковых конструкций, содержащих контекстные термины, в структурно-простые языковые конструкции, не содержащие контекстных терминов. Лингвистические преобразования над созданными структурно-простыми языковыми конструкциями, не содержащими контекстные термины, связаны с восстановлением правильной грамматики и орфографии. Под указанными лингвистическими преобразованиями понимается: а) согласование родов, чисел, падежей; б) правка (замена и удаление) несоответствующих знаков препинания. Все вышеуказанные преобразования являются преобразованиями второго типа. Первые преобразования второго типа осуществляются над контекстными понятиями и выявленными терминами, проясняющими смысловое значение контекстных понятий. Указанные выявленные термины могут являться либо контекстными синонимами, либо контекстными ассоциациями. Контекстный синоним - это синоним, который может употребляться как синоним только в данном контексте. Например, в предложении: «Изготовитель - это организация независимо от ее организационно-правовой формы», - контекстный термин «ее» является, собственно, контекстным понятием, а выявленный термин «организация» является его контекстным синонимом. Первое преобразование второго типа обеспечивает формирование справочника контекстных понятий, который, в свою очередь, обеспечивает ясность смыслового значения контекстных понятий. Так же за счет первого преобразования второго типа обеспечивается лингвистическая корректировка текста путем замещения контекстных понятий контекстным синонимом или контекстной ассоциацией. Например, предложение: «Изготовитель - это организация независимо от ее организационно-правовой формы», - посредством осуществления над ним первого преобразования второго типа будет преобразовано в предложение: «Изготовитель - это организация независимо от организационно-правовой формы организации». Контекстные ассоциации отличаются от контекстных синонимов тем, что они, как правило, представляют собой более сложную текстовую конструкцию, состоят из нескольких терминов и редко встречаются в одном предложении с контекстным понятием, но чаще в других предложениях. Вторые преобразования второго типа осуществляются над контекстно-обобщенными понятиями. При этом под контекстно-обобщенными понятиями понимают обобщающее слово (обобщающий термин) и однородные слова (однородные термины), а также группу однородных слов (группу слов без обобщающего слова). Обобщающее слово - это слово или словосочетание, которое является общим для расположенных вблизи обобщающего слова однородных слов или словосочетаний. При этом однородными словами (словосочетаниями) в контексте настоящего изобретения называются такие члены предложения, которые зависят от одного и того же слова и отвечают на один и тот же вопрос (т.е. являются однородными членами предложения). При этом обобщающее слово является тем же типом членов предложения, что и однородные с ним слова или словосочетания. Значительная часть предложений, осложненных однородными членами, может быть представлена как результат «сочинительного сокращения» ряда самостоятельных предложений. Второе преобразование второго типа обеспечивает удаление всех однородных с обобщающим словом терминов из анализируемого предложения, за счет чего в предложении остается только тот термин, который является обобщающим термином. При этом формируется справочник контекстно-обобщенных понятий, который содержит выявленный обобщающий термин и все соответствующие ему однородные слова - обобщенные слова (обобщенные понятия). Помимо этого, второе преобразование второго типа обеспечивает лингвистическую корректировку предложения путем создания новых предложений, в которых используются обобщенные понятия вместо обобщающего термина. Например, в предложении: «Исполнитель - это организация, выполняющая работы или оказывающая услуги потребителям по возмездному договору», - присутствуют однородные слова (однородные термины) - термин «выполняющая работы» и термин «оказывающая услуги». В данном примере, за счет второго преобразования второго типа обеспечится формирование записи в справочнике контекстно-обобщенных понятий, содержащей указание на то, что термин «выполняющая работы» является обобщающим термином, и термин «оказывающая услуги» является «обобщенным понятием». При этом из предложения будет удалено обобщенное понятие, т.е. термин «оказывающая услуги». Таким образом, преобразуемое предложение будет упрощено и преобразовано в предложение: «Исполнитель - это организация, выполняющая работы потребителям по возмездному договору». Посредством второго преобразования второго типа формируется дополнительное предложение, в котором вместо термина «выполняющая работы» присутствует термин «оказывающая услуги». Таким образом, вместо одного предложения с контекстно-обобщенными терминами формируется два предложения без контекстных терминов, а именно - предложение «Исполнитель - это организация, выполняющая работы потребителям по возмездному договору» и предложение «Исполнитель - это организация, оказывающая услуги потребителям по возмездному договору». Третье преобразование второго типа осуществляется над контекстными ссылками. Методологически третье преобразование второго типа аналогично первому преобразованию второго типа, осуществляемому над контекстными понятиями. Однако при этом, смысловое значение контекстной ссылки определяется иным образом. Принципиальная разница между первым преобразованием второго типа и третьим преобразованием второго типа заключается в том, что в предложении, в котором содержится контекстная ссылка, как правило, очевидно, что именно является предметом контекстной ссылки. Например, для предложения с неявной контекстной ссылкой - «указанные требования», - очевидно, что предметом контекстной ссылки являются, некоторые «требования». При этом зачастую предложения содержат и более подробную информацию о предмете контекстной ссылки (смысловом значении). Посредством третьего преобразования второго типа, как и в случае с первым преобразованием второго типа, обеспечивается формирование справочника контекстных ссылок, который позволяет уяснить смысловое значение контекстной ссылки. Однако в отличие от первого преобразования второго типа посредством третьего преобразования второго типа не может быть осуществлена лингвистическая корректировка предложения путем замещения контекстной ссылки ее смысловым значением главным образом по причине того, что смысловое значение по объему символов существенно превышает контекстную ссылку.
Так же способ 100 преобразования структурированного исходного массива данных характеризуется выполнением этапа 106 преобразования третьего типа, на котором осуществляют преобразование третьего типа над упомянутыми структурно-сложными языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины. Преобразование третьего типа - это совокупность преобразований первого типа и преобразований второго типа, применяемая к структурно-сложным языковым конструкциям, содержащим контекстные термины. Преобразование третьего типа при этом является двухэтапным преобразованием. На первом этапе над структурно-сложными языковыми конструкциями, содержащими контекстные термины, осуществляется преобразование первого типа, за счет которого осуществляется преобразование структурно-сложной языковой конструкции, содержащей контекстные термины, в структурно-простую языковую конструкцию, содержащую контекстные термины. На втором этапе над структурно-простыми языковыми конструкциями, содержащими контекстные термины, осуществляется соответствующее преобразование второго типа. В результате двухэтапного преобразования структурно-сложные языковые конструкции, содержащие контекстные термины, преобразуются в грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины.
Так же способ 100 преобразования структурированного исходного массива данных характеризуется выполнением этапа 107 формирования итоговой структуры данных структурированного исходного массива данных, на котором формируют итоговую структуру данных структурированного исходного массива данных, содержащую элементы итоговой структуры данных, причем элементы итоговой структуры данных представляют собой структурно-простые языковые конструкции, не содержащие контекстные термины и полученные за счет преобразований первого, второго и третьего типов грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины. Итоговая структура данных формируется из: структурно-простых языковых конструкций, не содержащих контекстные термины; структурно-простых языковых конструкций, не содержащих контекстные термины, полученных путем преобразования структурно-сложных языковых конструкций, не содержащих контекстные термины; структурно-простых языковых конструкций, не содержащих контекстные термины, полученных путем преобразования структурно-простых языковых конструкций, содержащих контекстные термины; структурно-простых языковых конструкций, не содержащих контекстные термины, полученных путем преобразования структурно-сложных языковых конструкций, содержащих контекстные термины. Фактически итоговая структура данных состоит из элементов - грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины, которые с лингвистической точки зрения являются предложениями, не содержащими контекстные термины.
На фиг. 2 в качестве примера, но не ограничения, изображена общая схема выполнения этапов заявленного способа 200 преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке. Заявленный способ 200 преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, в отличие от способа 100 преобразования структурированного исходного массива данных, дополнительно характеризуется выполнением этапа 201 формирования первой структуры данных, на котором на основании полученной на этапе 107 формирования итоговой структуры данных структурированного исходного массива данных формируют первую структуру данных структурированного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных, представляющие собой элементы итоговой структуры данных структурированного исходного массива данных, содержат первые логические разделы и вторые логические разделы; выполнением этапа 202 формирования базы данных логических связей логических разделов, на котором формируют базу данных логических связей логических разделов упомянутых элементов первой структуры данных; выполнением этапа 203 формирования второй структуры данных, на котором формируют вторую структуру данных структурированного массива данных, содержащую элементы упомянутой второй структуры данных, причем упомянутые элементы второй структуры данных содержат логические конструкции логических разделов упомянутых элементов первой структуры данных, сформированные с использованием информации из упомянутой базы данных логических связей логических разделов, причем упомянутые логические разделы содержат первые семантические части и вторые семантические части; выполнением этапа 204 формирования базы данных семантических частей логических разделов, на котором формируют базу данных семантических частей логических разделов из упомянутых вторых семантических частей, причем упомянутые вторые семантические части исключаются из соответствующих упомянутых логических разделов; выполнением этапа 205 формирования грамматически и орфографически верных семантических частей, на котором формируют грамматически и орфографически верные семантические части упомянутых логических разделов путем лингвистических преобразований над упомянутыми семантическими частями; и выполнением этапа 206 формирования результирующей структуры данных, на котором формируют результирующую структуру данных структурированного массива данных, содержащую элементы упомянутой результирующей структуры данных, причем упомянутые элементы результирующей структуры данных содержат логические конструкции, содержащие, по меньшей мере, упомянутые грамматически и орфографически верные семантические части логических разделов.
На фиг. 3 в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 201 формирования первой структуры данных. Этап 201 характеризуется выполнением этапа 2011 идентификации исходной структуры, на котором идентифицируют итоговую структуру данных 1 структурированного массива данных; выполнением этапа 2012 идентификации элементов, на котором идентифицируют элементы 11 итоговой структуры данных 1; выполнением этапа 2013 идентификации логических разделов, на котором идентифицируют первые логические разделы 111 элементов 11 итоговой структуры данных 1 и вторые логические разделы 112 элементов 11 итоговой структуры данных 1; и выполнением этапа 2013 формирования первой структуры данных, на котором формируют первую структуру данных 2 структурированного исходного массива данных, содержащую элементы 21 первой структуры данных, которые являются элементами 11 итоговой структуры данных 1, причем элементы 21 первой структуры данных 2 содержат первые логические разделы 111 элементов 11 итоговой структуры данных 1, и содержащую элементы 22 первой структуры данных, причем элементы 22 первой структуры данных 2 содержат вторые логические разделы 112, элементов 11 итоговой структуры данных 1.
На фиг. 4 в качестве примера, но не ограничения, изображена общая структура итоговой структуры данных 1, из которой формируется первая структура данных 2. Итоговая структура данных 1 представляет собой полученную на этапе 107 итоговую структуру данных, которая, в свою очередь, представляет собой структуру данных структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке. Как уже упоминалось выше, такой массив данных может представлять собой, в частности, нормативный правовой акт (НПА). Итоговая структура данных 1 содержит элементы 11, которые представляют собой положения, являющиеся предложениями - грамматически организованными соединениями слов. При этом каждое предложение характеризуется смысловой законченностью, т.к. является элементом итоговой структуры данных, полученной на этапе 107. Идентификация предложений на этапе 2012 идентификации элементов производится путем выявления в тексте на естественном языке признаков окончания предложения. Признаками окончания предложения при этом являются: точка, точка с запятой, многоточие и т.п.Идентификация предложений осуществляется в совокупности с выявлением признаков начала предложения. Признаками начала предложения являются: заглавная буква, цифра, цифра с закрывающей скобкой, цифра с точкой и т.п. При этом при идентификации также учитывается наличие определенных сочетаний знаков препинаний, а именно знаков пунктуации - точки, запятой, скобки, двоеточия и т.п., - словоразделителей, а именно - пробела и т.п., - и типографики - абзаца, номера, градуса и т.п. На этапе 2012 идентификации элементов осуществляется выявление элементарных смысловых единиц -предложений, являющихся суждениями. Простое суждение - это суждение, никакая часть которого не является суждением. Языковой формой выражения суждения являются повествовательные предложения. Идентификация элементов 11 итоговой структуры данных 1 осуществляется путем выявления и дефрагментации предложения на первичные составляющие предложения, а именно - на слова, частицы, союзы, предлоги и т.п., и знаки препинания. После чего из первичных элементов формируются понятия, выраженные в отдельных словах и/или словосочетаниях на основании различных справочников и словарей. Затем из сформированных понятий формируются простые суждения, которые представляют собой группы взаимосвязанных понятий, при этом взаимосвязанность понятий определяется на основании синтаксических или иных связей между понятиями. Для формирования простых суждений осуществляется лингвистическо-семантический анализ элементов 11 итоговой структуры данных 1, посредством чего в элементах 11 осуществляется выявление структурных элементов простых суждений. Под структурными элементами простых суждений понимаются субъект суждения, предикат суждения, связка и кванторное слово. Субъектом суждения (S) является понятие, выражающее предмет суждения, т.е. то, о чем говорится в данном суждении. Предикатом суждения (Р) является понятие, выражающее ту или иную информацию о предмете суждения. Субъект суждения и предикат суждения - основные структурные элементы суждения, являющиеся терминами суждения. Связь между субъектом суждения и предикатом суждения, отражающая реальные отношения между мыслимыми в понятиях объектами, раскрывается посредством логической связки. В русском языке связка выражается словами: «есть» («не есть»), «является» («не является»), «имеется» («не имеется») и т.д., обозначается тире, двоеточием, а также может подразумеваться, выражаясь согласованием слов («Идет дождь», «Собака лает»). Связка - это логическая постоянная, поскольку в ней заключено неизменное содержание - она всякий раз служит показателем наличия или отсутствия чего-либо у предмета мысли. Кванторное слово (например, «каждый», «все», «ни один», «некоторый» и т.д.) указывает, относится ли информация о предикате суждения ко всему объему понятия, выражающему субъект суждения, или к его части. Например, в суждении «Всякое преступление - противоправное деяние» субъектом суждения является понятие «преступление», предикатом суждения - «противоправное деяние», - связка выражена знаком тире, а кванторное слово «всякое» указывает, на то, что характеристика «противоправное деяние» относится ко всему объему (к каждому элементу) понятия «преступление». В самом общем виде простое суждение можно выразить формулой: «S есть (не есть) Р». Таким образом, в результате идентификации итоговой структуры данных 1 элементы 11 разделяются на то количество суждений, которое в них заложено, т.е. число суждений равно количеству логических разделов в предложении. Далее осуществляется идентификация первых логических разделов 111 и вторых логических разделов 112 элементов 11 итоговой структуры данных 1. Идентификация осуществляется на основании результатов идентификации выявленных суждений, определенных как сложные суждения. Сложные суждения - это группа простых суждений, в которых присутствует связь между отдельными суждениями, установленная с помощью логических союзов «и», «или», «если…, то…», «тогда и только тогда…, когда», «неверно, что…». Виды связей между отдельными суждениями выражаются соответствующими логическими связками и приведены в Таблице 1.

Характер связи определяется смыслом логических союзов, который состоит в ответе на вопрос: «При каких условиях сложное суждение будет истинно, а при каких - ложно?». Иначе говоря - при каких сочетаниях истинности и ложности простых суждений, из которых состоит сложное суждение, логический союз определяет истинную связь, а при каких - ложную. Суждение рассматривается как истинное, если даваемое им описание соответствует действительности (реальной ситуации), и как ложное, если не соответствует ей. «Истина» и «ложь» называются истинностными значениями суждения и являются основной логической характеристикой суждений. Смысл логических союзов можно определить с помощью истинностной таблицы (Таблица 2), в которой в столбцах 1 и 2 содержатся все возможные комбинации истинностных значений простых суждений, а в столбцах 3-9 содержатся значения сложного суждения, образованного из простых суждений с помощью соответствующего логического союза. При этом исходные простые суждения обозначают буквами «А», «В», а значения истинности символами: «и» - истинно, «л» - ложно.
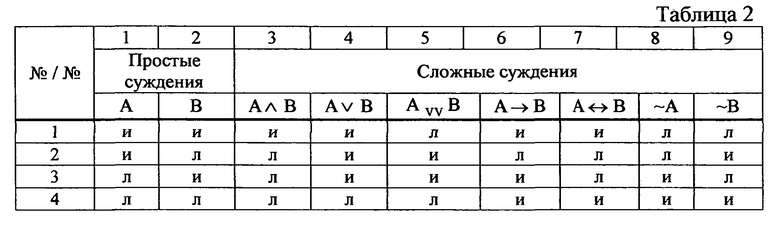
Для выявления первых логических разделов 111 и вторых логических разделов 112 элементов 11 упомянутой итоговой структуры данных 1 необходимо в предложениях текста выявить простые суждения, имеющие между собой импликативную (условную) логическую связь и взаимную (двойную) импликативную (условную) связь. Условное суждение (импликативное суждение) - это сложное суждение, в котором простые суждения объединяются логическим союзом «если…, то…». Например:
«Если гражданин нарушает закон, то это порождает ответственность за нарушение» или «Если число делится на 2 без остатка, то оно четное». Условное суждение состоит из двух составляющих его видов суждений. Суждение, записанное после слова «если» называется основанием (предыдущим). Суждение, записанное после слова «то» называется следствием (последующим). Формула условного суждения может быть представлена как «А→В», где А - основание, В - следствие. При этом, основания и следствия, сами по себе могут быть как простыми суждениями, так и сложными суждениями. Образованное из предыдущего и последующего суждений условное суждение, прежде всего, подразумевает, что не может быть так, чтобы то, о чем говорится в основании, имело место, а то, о чем говорится в следствии - отсутствовало. Иными словами, если основание будет истинным, а следствие - ложным, то такое условное суждение будет ложным. Это условие определяет то, что условное суждение истинно во всех случаях, кроме одного: когда предшествующее есть, а последующего нет, т.е. - суждение по формуле «А→В» - ложно только в одном случае, когда А - истинно, а В - ложно (см. таблицу 2, столбец 6). В форме условных суждений могут быть выражены как объективные зависимости одних объектов от других, так и права и обязанности субъектов правоотношений, связанные с теми или иными условиями. Эквивалентное суждение (двойная импликация) - это сложное суждение, в котором объединяются суждения с взаимной условной зависимостью. Эквивалентные суждения образуются с помощью логического союза «если и только если…, то…», который обозначается символом «↔». Формула эквивалентности: «А↔В», где А, В - суждения, из которых образуется эквивалентное суждение, например: «Человек имеет право на пенсию по возрасту, если и только если он достиг пенсионного возраста». В естественном языке, в том числе, в экономических и юридических текстах, для выражения эквивалентных суждений используются грамматические союзы: «лишь при условии, что…, то…», «только тогда, когда…, то…», «в том и только в том случае, когда…, тогда…». Условия истинности эквивалентных суждений представлены в столбце 7 таблицы 2. Эквивалентное суждение истинно в двух случаях - когда оба составляющих его суждения истинны или, когда оба ложны. Иными словами, связь между элементами эквивалентного суждения можно охарактеризовать как необходимую: «истинность А достаточна для признания истинности В и наоборот» и «ложность А служит показателем ложности В и наоборот». По причине того, что в двойных импликативных суждениях отсутствуют четко выраженные основания и следствия, главным фактором в идентификации первых и вторых логических разделов 111, 112 является наличие в суждениях, находящихся во взаимной импликативной зависимости признаков юридического факта. На примере упомянутого импликативного суждения «Человек имеет право на пенсию по возрасту, если и только если он достиг пенсионного возраста» можно установить, что суждение «Человек имеет право на пенсию по возрасту» не содержит таких признаков, а суждение «если и только если он достиг пенсионного возраста» имеет признак юридического факта, которым является событие - «достижение пенсионного возраста». Таким образом, именно суждение, содержащее признаки юридического факта признается для целей идентификации основанием (А). Другое суждение признается следствием (В). Термин «юридический факт» означает определенное жизненное обстоятельство, с которым норма права связывает возникновение, изменение или прекращение правоотношения или правоотношений. Если предложение содержит одно простое суждение (или несколько простых суждений) или одно сложное суждение (или несколько сложных суждений), которое не идентифицировано как условное суждение, то в результате лингвистическо-семантического анализа текста, «окружающего» такое предложение, может быть выявлен фактический контекстный вид данного простого суждения - первый логический раздел 111 или второй логический раздел 112. Формируемая на этапе 201 первая структура данных 2 содержит такие элементы, как предложения (элемент 11 исходной структуры данных 1) и суждения (логические разделы 111 или 112 элементов 11 исходной структуры данных 1). При этом суждения дополнительно идентифицированы по упомянутой логической связи как основания, т.е. как первый логический раздел 111 элемента исходной структуры данных 11, имеющий логическую связь 1-го типа и являющийся суждением «А», и как следствия, т.е. как второй логический раздел 112 элемента 11 исходной структуры данных 1, имеющий логическую связь 1-го типа и являющийся суждением «В». В первой структуре данных 2 все элементы исходной структуры данных 1 сепарированы по признаку наличия в них упомянутых первых логических разделов 111 или вторых логических разделов 112 исходной структуры данных 1, за счет чего сформированы элементы 21 первой структуры данных 2, имеющие первые логические разделы 111 и элементы 22 первой структуры данных 2, имеющие вторые логические разделы 112.
На фиг. 5 в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 202 формирования базы данных 3 логических связей логических разделов. Этап 202 формирования базы данных 3 логических связей логических разделов характеризуется выполнением этапа 2021 идентификации элементов первой структуры данных 2, на котором идентифицируют элементы 21 первой структуры данных 2, содержащие один упомянутый первый логический раздел 111, представляющие собой элементы 31 первой структуры данных 2, и элементы 22 первой структуры данных 2, содержащие один упомянутый второй логический раздел 112, представляющие собой элементы 32 первой структуры данных 2; выполнением этапа 2022 идентификации элементов первой структуры данных 2, на котором идентифицируют элементы 21 первой структуры данных, содержащие более одного упомянутого первого логического раздела 111, представляющие собой элементы 33 первой структуры данных 2 и элементы 22 первой структуры данных, содержащие более одного упомянутого второго логического раздела, представляющие собой элементы 34 первой структуры данных 2; выполнением этапа 2023 идентификации логических связей, на котором среди элементов 33 первой структуры данных 2, содержащих более одного упомянутого первого логического раздела 111 и элементов 34 первой структуры данных 2, содержащих более одного упомянутого второго логического раздела 112, идентифицируют логические связи между упомянутыми первыми логическими разделами 111 или логические связи между упомянутыми вторыми логическими разделами 112; выполнением этапа 2024 идентификации отсутствия логических связей, на котором среди элементов 33 первой структуры данных 2, содержащих более одного упомянутого первого логического раздела 111 и среди элементов 34 первой структуры данных 2, содержащих более одного упомянутого второго логического раздела 112, идентифицируют элементы 35 первой структуры данных *, не имеющие логических связей между своими логическими разделами; и выполнением этапа 2025 формирования базы данных, на котором формируют базу данных 3 логических связей логических разделов элементов первой структуры данных. Для уточнения всех дополнительных (не только импликативных) имеющихся логических связей между логическими разделами (суждениями) все элементы первой структуры данных 2, а именно массивы элементов 21 предложений, содержащих первые логические разделы 111 и элементов 22 предложений, содержащих вторые логические разделы 112 необходимо сепарировать на группы элементов 31, 33 и 32, 34, содержащих либо только первые логические разделы 111, либо только вторые логические разделы 112, соответственно. При этом каждый элемент, входящий в массивы элементов 31, 33, содержащий первый логический раздел 111 идентифицируется как элемент 31. имеющий только один логический раздел 111, или как элемент 33, имеющий более одного логического раздела 111. При этом в случае наличия в идентифицированных элементах 31, 33 вторых логических разделов 112, вторые логические разделы 112 удаляются из идентифицированных элементов 31, 33. Полученные в итоге массивы элементов 31, 33 по-прежнему связаны с тем элементом, из которого они выделены и по этому основанию идентифицированы как отдельные элементы данного массива элементов. В свою очередь, каждый элемент, входящий в массивы элементов 32. 34, содержащий второй логический раздел 112 идентифицируется как элемент 32, имеющий только один логический раздел 112, или как элемент 34, имеющий более одного логического раздела 112. При этом в случае наличия в идентифицированных элементах 32, 34 первых логических разделов 111, первые логические разделы 111 удаляются из идентифицированных элементов 32, 34. Полученные в итоге массивы элементов 32, 34 так же по-прежнему связаны с тем элементом, из которого они выделены и по этому основанию идентифицированы как отдельные элементы данного массива элементов. Далее устанавливается характер логических связей между однотипными суждениями в элементах двух созданных массивов элементов 31, 33 и элементов 32, 34. В однотипных элементах массивов элементов 33, 34 выявляются логические связи между суждениями, указанные в таблицах 1 и 2, а именно - соединительные связи (конъюнкция), разделительные связи (дизъюнкция, строгая дизъюнкция), эквивалентные связи (эквиваленция). Конъюнктивное (соединительное) суждение - это сложное суждение, образованное из исходных суждений посредством логического союза «и», обозначаемого символом «^». Например, суждение: «Сегодня я пойду на лекцию по логике и в кино», - является «конъюнктивным суждением», состоящим из двух простых суждений (обозначим их А и В, соответственно) - «Сегодня я пойду на лекцию по логике» (А), «Сегодня я пойду в кино» (В). Данное сложное суждение можно представить формулой: «А^B», где А, В - элементы конъюнкции; «^» - символ логического союза - конъюнкция. В русском языке конъюнктивный логический союз выражается многими грамматическими союзами: «и», «а», «но», «да», «хотя», «однако», «а также…». Нередко подобные грамматические союзы заменяются знаками препинания - запятой, двоеточием, точкой с запятой. Дизъюнктивное (разделительное) суждение - это сложное суждение, образованное из «исходных». суждений посредством логического союза «или», обозначаемого символом «V». Например, суждение: «Право может способствовать экономическому развитию или препятствовать ему», - является дизъюнктивным суждением, состоящим из двух простых суждений: «Право может способствовать экономическому развитию» и «Право может препятствовать экономическому развитию». Соответственно, обозначив их через буквы А, В, такое суждение можно представить через формулу: «А V В». Поскольку связка «или» употребляется в двух разных значениях - неисключающем и исключающем, то различают слабую и сильную (строгую) дизъюнкции. Слабая дизъюнкция является истинной в тех случаях, когда истинно, по крайней мере, одно из составляющих ее суждений (или оба вместе) и ложна, когда оба составляющих ее суждения ложны (см. таблицу 2, столбец 4). Сильная дизъюнкция (символ «VV») отличается от слабой дизъюнкции тем, что ее составляющие исключают друг друга. Например, «Преступление может быть умышленным или по неосторожности». Для того, чтобы подчеркнуть строго разделительный, исключающий характер связи, в естественном языке используется усиленная двойная форма разделения: «…либо…, либо…», «…или…, или…», например: «Либо я найду путь, либо я проложу его». Строгая дизъюнкция истинна лишь тогда, когда одно из составляющих ее суждений истинно, а другое - ложно (см. таблицу 2, столбец 5). В результате выявляются все логические связи между элементами (суждениями) массивов элементов 33, 34. При этом допускается, что часть элементов данных массивов может не иметь логических связей друг с другом. Далее для уточнения вида суждений, которые не были до сих пор идентифицированы как сложные суждения, элементы массивов элементов должны быть подвергнуты идентификации на их соответствие отрицаемому суждению. Этому анализу должны быть подвергнуты массивы элементов 31, 32 и, частично, массивы элементов 33, 34, в которых остались суждения, не имеющие логических связей с другими суждениями. Отрицаемое суждение - это сложное суждение, образованное с помощью логического союза «неверно, что…» (или просто «не»), который, как правило, представлен знаком отрицания (символ «~»). В отличие от упомянутых выше бинарных союзов, такой союз относится к одному суждению. Прибавление этого союза к какому-либо суждению означает образование нового суждения, которое находится в определенной зависимости от исходного суждения - отрицаемое суждение истинно, если исходное суждение ложно, и наоборот (см. таблицу 2, столбцы 8, 9). Например, если исходное суждение: «Все свидетели правдивы», - то отрицаемое: «Неверно, что все свидетели правдивы». Если отдельный логический раздел (простое суждение) остается не идентифицированным с точки зрения логического характера суждения, то в результате лингвистическо-семантического анализа текста, окружающего предложения, в котором содержится такой раздел, может быть выявлен фактический контекстный вид данного простого суждения. Таким образом, первая структура данных содержит логические разделы предложений, формирующих исходную структуру данных. По итогам идентификации всех элементов первой структуры данных выявляются все логические разделы предложений (суждения), с точки зрения их наличия и характера связей суждений, формирующих сложные суждения. На основании выявленных характеров связей суждений (в том числе, их отсутствия) формируется база данных 3 логических связей логических разделов (фиг. 6).
На фиг. 7 в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 203 формирования второй структуры данных 4. Этап 203 формирования второй структуры данных 4 характеризуется выполнением этапа 2031 формирования логических конструкций, на котором формируют логические конструкции 41 логических разделов 111, 112 элементов 31, 32, 33, 34 первой структуры данных 2, используя информацию из базы данных 3 логических связей логических разделов элементов 31, 32, 33, 34 первой структуры данных 2 и логические разделы упомянутых элементов 31 первой структуры данных 2, содержащих один упомянутый первый логический раздел 111, и логические разделы упомянутых элементов 32 первой структуры данных 2, содержащих один упомянутый второй логический раздел 112; и выполнением этапа 2032 формирования второй структуры данных 4, на котором формируют вторую структуру данных 4, содержащую элементы 41 второй структуры данных 4, причем упомянутые элементы второй структуры данных 4 представляют собой сформированные логические конструкции 41 логических разделов 111, 112 элементов 31, 32, 33, 34 первой структуры данных 2. Логические конструкции 41 - это результат преобразования данных преобразуемого структурированного массива данных. Логические конструкции 41 формируются в соответствии со спецификой преобразуемого текста на естественном языке, в частности НПА. Специфика НПА состоит в том, что он содержит нормы права (правовые нормы). Так же специфика НПА состоит в том, что в теории нормы права существуют понятия логической нормы права и юридической нормы права. Эти понятия не тождественны. Разница заключается в том, что логическая норма права включает в себя содержание всех элементов нормы права, установленных в юридической науке, включая гипотезу, диспозицию и санкцию, а юридическая норма права отражает конкретные нормативные предписания, содержащиеся в конкретных предложениях конкретных НПА. Фактически разница состоит в том, что одна конкретная логическая норма права может содержаться в конкретном множестве юридических норм права, т.е. в множестве нормативных предписаний. Логическая конструкция - это основа (каркас) основного нормативного предписания, содержащая два основных элемента конструкции, - «ситуацию» и «правило». Основное нормативное предписание (далее - нормативное предписание) является инструментом правового регулирования и включает в себя регулятивные и охранительные нормативные предписания. При этом под ситуацией в нормативных предписаниях понимается любая обусловленность правила, а под правилом понимаются любые правила, включая правила (модель) поведения субъектов правоотношений. Иными словами, ситуация - это суждения, имеющие логическую импликативную связь и являющиеся основаниями, а правила - это суждения, имеющие логическую импликативную связь и являющиеся следствиями. При формировании логических конструкций 41, т.е. нормативных предписаний также необходимо учитывать, что каждый из элементов этой конструкции (и ситуация и правило) могут состоять как из одного суждения, так и из группы суждений. Для формирования логических конструкций необходимо использовать Базу данных логических связей логических разделов. Кроме выявленных логических связей между логическими разделами для формирования логической конструкции необходимо обратиться к правилам формирования логических конструкций. Правила формирования логических конструкций отражают требования юридической науки и юридической практики в отношении состава и структуры нормативного предписания (предписания). Например, условие того, что одно предписание не может содержать двух разных правил, приводит к тому, что в правилах устанавливается, что если в одном предложении содержатся два следствия, которые имеют логически слабую дизъюнктивную связь, то это значит, что эти суждения входят в разные правила и соответственно разные предписания. При этом если эти же два следствия имеют логически сильную дизъюнктивную связь, то это их объединяет в рамках одного сложного правила в рамках одного предписания. По существу, правила формирования логических конструкций 41 сводятся к допустимым сочетаниям логических связей между однотипными суждениями в рамках одного нормативного предписания.
При этом если в предложении имеются несколько ситуаций, объединенных логикой «ИЛИ» (слабая дизъюнктивная связь), то это означает, что каждая из таких ситуаций формирует собственные отдельные предписания с те ми же правилами, которые использовались в первом предписании. Это означает, что несколько ситуаций с такой логикой «ИЛИ» не могут быть в одном предписании. Кроме того, в предложении имеются несколько правил, объединенных логикой «ИЛИ» (слабая дизъюнктивная связь). Это означает, что каждое из таких правил формирует собственные отдельные предписания с те ми же ситуациями, которые использовались в первом предписании. Это означает, что несколько «правил» с такой логикой «ИЛИ» не могут быть в одном предписании. Сформированная вышеуказанным образом вторая структура данных содержит такие элементы как суждения (логический раздел элемента исходной структуры данных) и нормативные предписания (логическая конструкция 41 логических разделов элемента исходной структуры данных) (фиг. 8). При этом суждения идентифицированы по наличию импликативной логической связи на как два основных логических раздела:
1) основания (первый логический раздел элемента исходной структуры данных, содержащий логическую импликативную связь, связь 1-го типа, вида А);
2) следствия (второй логический раздел элемента исходной структуры данных, содержащий логическую импликативную связь, связь 1-го типа, вида В);
При этом основания и следствия дополнительно идентифицированы также по факту выявления иных логических связей между однотипными импликативными суждениями в рамках одного предложения как дополнительные логические разделы:
1) суждения «И» (логический раздел элемента исходной структуры данных, содержащий логическую конъюнктивную (соединительную) связь, связь 2-го типа);
2) суждения «ИЛИ» (логический раздел элемента исходной структуры данных, содержащий логическую слабую дизъюнктивную (разделительную) связь, связь 3-го типа);
3) суждения «ИЛИ*» (логический раздел элемента исходной структуры данных, содержащий логическую сильную дизъюнктивную (разделительную) связь, связь 4-го типа);
Кроме того, вышеуказанные разделы могут быть отдельно идентифицированы как «отрицаемые суждения» (логический раздел элемента исходной структуры данных, содержащий отрицаемую логическую связь, связь 5-го типа).
На фиг. 9 в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 204 формирования базы данных 5 семантических частей. Этап 204 формирования базы данных 5 семантических частей характеризуется выполнением этапа 2041 идентификации логических разделов, на котором идентифицируют первые логические разделы 411 элементов 41 второй структуры данных 4 и вторые логические разделы 412 элементов второй структуры данных 4; выполнением этапа 2042 идентификации семантических частей, на котором в упомянутых первых логических разделах 411 и вторых логических разделах 412 элементов второй структуры данных 4 идентифицируют первые семантические части 4110 и вторые семантические части 4120; и выполнением этапа 2043 идентификации особых семантических частей, на котором в упомянутых первых и вторых логических разделах 411, 412 элементов 41 второй структуры данных 4 идентифицируют, по меньшей мере, особые семантические части 4111 первых логических разделов 411 элементов 41 второй структуры данных 4 и особые семантические части 4121 вторых логических разделов 412 элементов 41 второй структуры данных 4 и формируют базу данных 5 особых семантических частей логических разделов элементов 41 второй структуры данных 4 путем перемещения упомянутых особых семантических частей 4111, 4121 в упомянутую формируемую базу данных 5 особых семантических частей логических разделов элементов 41 второй структуры данных 4 (фиг. 10). Сформированные во второй структуре данных логические конструкции 41 являются каркасом и основой нормативного предписания, но по-прежнему не соответствуют ему полностью. Для достижения максимального соответствия структуры логических конструкций 41 структуре нормативного предписания необходимо провести комплексный семантический анализ логических разделов 411, 412, включающий как минимум синтаксический и логический разборы терминов и понятий, выявление взаимосвязей между понятиями суждения и между терминами сложных понятий. Целью данного семантического анализа является выявление и идентификация в логических разделах 411, 412 логических конструкций 41 второй структуры данных 4 ряда специфических частей (вторых частей) логических разделов, которые приводят к:
1) смешению основных понятий правовой нормы - к смешению ситуаций и правил путем включения в суждение различных обусловленностей;
2) размытию - расфокусированию смысла суждений путем включения в суждение различных качественных и количественных уточнений и детализаций.
На данном этапе осуществляется выявление специфических частей, т.е. выявление в логических разделах 411, 412 логических конструкций 41 второй структуры данных первых и вторых семантических частей 4110, 4120 логических разделов 411, 412. Причем первые семантические части !110 формируются путем удаления из логических разделов 411, 412 вторых семантических частей 4120 (специфических частей). Первая семантическая часть 4110 логического раздела - это смысловое ядро суждения, т.е. суждение, очищенное от специфических частей. Смысловым ядром суждения являются основные элементы суждения такие, как субъект суждения, предикат суждения и связка. Особенность связки состоит в том, что связки является частью смыслового ядра суждения только тогда, когда она не может быть истолкована в «объемном плане», в случаях, когда связка раскрывает включение (или исключение) подкласса в класс объектов или принадлежность (непринадлежность) элемента классу. Например, в суждении: «Преступление есть противоправное деяние», - субъектом суждения является слово «преступление», предикатом суждения словосочетание - «противоправное деяние», а связкой - слово «есть». Вторые семантические части 4120 логического раздела - это понятия суждения, которые идентифицированы как признаки субъекта суждения, предиката суждения, а также термины суждения - связка (когда она может быть истолкована в «объемном плане») и кванторное слово, а также иные, особые части. Например, понятие (субъект суждения) «преступление, предусмотренное Уголовным Кодексом», содержит понятие - слово «преступление» и признак понятия - словосочетание «предусмотренное Уголовным Кодексом». Признаки понятия - это содержание понятия, указывающее на наличие или отсутствие у него того или иного свойства, состояния или отношения. Иначе говоря, признаком понятия является все то, в чем понятия могут быть сходны или отличны друг от друга. Все признаки понятия, образующие содержание понятий идентифицируются как существенные и несущественные по принципу утраты своего качества (невозможности быть самим собой) без данного признака. Например, в суждении: «Преступление есть противоправное деяние», - предикатом суждения является понятие «противоправное деяние» (В), являющееся сложным понятием или «отношением», в котором «деяние» является субъектом суждения (А), а понятие «противоправное» - является признаком А. На примере «отношения» «противоправное деяние» видно, что в нем находятся «понятия», у которых объем одного полностью входит в объем другого, но не исчерпывает его. Иначе говоря, все элементы объема (В) являются элементами объема (А), но не наоборот. Вид таких отношений -«подчинение», т.е. родовидовое отношение, где более общее «понятие» выступает родом, а менее общее - видом. Кванторное слово указывает, относится ли информация о предикате суждения ко всему объему понятия, выражающему субъект суждения, или к его части. Например, в суждении: «Всякое преступление есть противоправное деяние», - кванторное слово «всякое» указывает, что информация о предмете суждения (словосочетание «противоправное деяние») относится ко всему объему (к каждому элементу объема) предмета суждения - слова «преступление». Под иными, особыми частями понимаются такие отдельные понятия и группы понятий суждения, которые также уточняют значение понятий, составляющих первую семантическую часть 4110 логических разделов 41, но формально не относятся к признакам понятия, связке или кванторному слову. Например, в суждении: «Преступление (в т.ч. мошенничество, кража, убийство) есть противоправное деяние», - понятия, указанные в круглых скобках («мошенничество», «кража», «убийство») являются реальными (жизненными) примерами понятия «преступление». Признак понятия «противоправное» является существенным для понятия «деяние», поскольку без него понятие «противоправное деяние» утрачивает свое качество, перестает быть самим собой. Объем понятия - это класс (множество) мыслимых в понятии сущностей. Признаки понятия и объем понятия взаимосвязаны в рамках каждого понятия. Эта взаимосвязь позволяет установить реальный объем понятия, т.е. то, что реально подразумевается в смысловом содержании понятия. Для достижения максимального соответствия структуры логических конструкций 41 структуре нормативного предписания необходимо сепарировать виды вторых семантических частей 4120. С технической точки зрения, идентифицированные в процессе комплексного семантического анализа иные, особые части не являются элементом основного (регулятивного или охранительного) нормативного предписания. В связи с этим они удаляются из логических разделов и формируют базу данных 5 особых семантических частей, представляющую собой нормативный справочник или иной нормативный справочный материал, представляющий собой множество особых нормативных предписаний. Информация из такого справочника является доступной и актуальной, но структурно и методологически она находится за рамками основных (регулятивных и охранительных) нормативных предписаний (фиг. 10). С точки зрения юридической науки особые нормативные предписания представляют собой предписания, устанавливающие основные принципы, механизмы, порядок и цели правового регулирования общественных отношений, закрепляют правовые категории и понятия (например, дефинитивные предписания - предписания, закрепляющие в обобщенном виде признаки того или иного юридического понятия).
На фиг. 11 в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 205 формирования грамматически и орфографически верных семантических частей, на котором формируют грамматически и орфографически верные семантические части упомянутых логических разделов 41 путем лингвистических преобразований над упомянутыми семантическими частями. Этап 205 включает выполнение этапа 2051 идентификации уточняющих структур, на котором в упомянутых вторых семантических частях 4120 упомянутых вторых логических разделов 412 элементов 41 второй структуры данных 4 идентифицируют, по меньшей мере, уточняющие структуры вторых семантических 4122 частей вторых логических разделов 412; и выполнением этапа 2052 лингвистических преобразований, на котором осуществляют лингвистические преобразования над всеми семантическими частями, за исключением упомянутых особых семантических частей 4111, 4121 упомянутых первых и вторых логических разделов 411, 412, для формирования грамматически и орфографически верных семантических частей 4123 и уточняющих структур 4122 логических разделов элементов 41 второй структуры данных 4. Общая схема полученной второй структуры данных 4 представлена на фиг. 12. Для достижения максимального соответствия структуры логических конструкций 41 структуре нормативного предписания необходимо дополнительно идентифицировать оставшиеся виды вторых семантических частей. Дополнительная идентификация также производится в рамках комплексного семантического анализа. Предметом анализа будет являться массив значений, выявленных указанных видов вторых семантических частей 4120, т.е. массив понятий, содержащихся в логических разделах и идентифицированных в качестве соответствующих видов. Каждое понятие данных массивов должно быть идентифицировано с точки зрения его принадлежности к уточнениям 4124 или к зависимостям 4125. При этом уточнением является такая характеристика понятия, которая осуществляет переход от более широкого понятию к более узкому, а зависимости содержат признаки юридического факта, т.е. некого события, при наличие (отсутствии) которого понятие, к которому относится зависимость, актуализируется или наоборот становится неактуальным. Лингвистические преобразования над всеми семантическими частями логических разделов связаны с восстановлением правильной грамматики и орфографии отдельных семантических частей, которое потребуется в связи с фактическим разделением текста предложений на отдельные части - семантические части 4110, 4120 логических разделов, и с учетом удаления особых семантических разделов 4111, 4121 из указанного текста. Под указанными лингвистическими преобразованиями понимается, в частности, согласование родов, чисел, падежей, правка (замена и удаление) несоответствующих знаков препинания.
На фиг. 13 в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 206 формирования итоговой структуры данных 6, на котором формируют результирующую структуру данных 6 структурированного исходного массива данных, содержащую элементы 61 упомянутой результирующей структуры данных 6, причем упомянутые элементы 61 итоговой структуры данных содержат логические конструкции 61, содержащие, по меньшей мере, упомянутые грамматически и орфографически верные семантические части 4123 логических разделов. Этап 206 характеризуется выполнением этапа 2061 формирования смысловых сочетаний, на котором формируют из первых грамматически и орфографически верных семантических частей 4123 вторых логических разделов 412 элементов 41 второй структуры данных 4 и упомянутых грамматически и орфографически верных уточняющих структур 4122 вторых семантических частей 4120 вторых логических разделов 412 элементов 41 второй структуры данных 4 смысловые сочетания 611 грамматически и орфографически верных семантических частей 4122, 4123 вторых логических разделов 412 элементов 41 второй структуры данных 4; и выполнением этапа 2062 формирования результирующей структуры данных 6, на котором формируют результирующую структуру данных 6, содержащую элементы 61 результирующей структуры данных 6, причем упомянутые элементы 61 результирующей структуры данных 6 представляют собой логические конструкции 61, содержащие упомянутые грамматически и орфографически верные семантические части 4122, 4123 логических разделов элементов 41 второй структуры данных 4. Возможна так же ситуация, когда логические конструкции 61 из упомянутой результирующей структуры данных 6 дополнительно содержат упомянутые сформированные смысловые сочетания 611 грамматически и орфографически верных семантических частей 4122, 4123 вторых логических разделов 412 элементов 41 второй структуры данных 4 (фиг. 14). Итоговая общая структура элемента 61 результирующей структуры данных 6 представлена на фиг. 15. Основой нормативного предписания является юридическое правило (правило), которое может быть максимально корректно сформировано в результате проведения комплексного семантического анализа логических разделов логических конструкций. На этапе формирования логических конструкций большая часть обусловленностей была отделена от правила (второго логического раздела 412) и выделена в отдельный раздел - первый логический раздел 411. По результатам комплексного семантического анализа было выявлено смысловое ядро правила (второго логического раздела 412) и остатки обусловленностей были так же выделены во вторые семантические части 4120, в которых некоторые из указанных частей идентифицированы как уточнение 4124. В результате всех преобразований стало возможным в структуре логических конструкций 61 создать смысловые сочетания 611, т.е. сочетания из первых семантических частей 4110 вторых логических разделов 412 и вторых семантических частей 4120 вторых логических разделов 412, идентифицированных как уточнение 4124. Данные смысловые сочетания являются юридическими правилами. Результирующая структура данных представляет собой структурированную конструкцию, элементы которой максимально соответствуют структуре нормативного предписания. Результирующая структура данных сформирована в таком виде с целью упрощения и регламентации профессиональной работы по созданию и корректировке НПА. Результирующая структура данных представляет собой конструкцию, которая позволяет буквально визуализировать нормативные предписания, увидеть все фактические элементы смысловой конструкции, что позволяет проводить их многосторонний полноценный анализ с целью проведения точечных корректировок, как существующих нормативных предписаний, так и проектов предписаний на разных стадиях их создания.
На фиг. 16 в качестве примера, но не ограничения, изображена общая схема выполнения этапов заявленного способа 300 формирования карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных. Заявленный способ 300 формирования карты связей компонентов характеризуется выполнением этапа 301 идентификации компонентов и значений, на котором идентифицируют компоненты грамматически и орфографически верных семантических частей логических разделов логических конструкций из упомянутого преобразованного структурированного исходного массива данных, причем каждая упомянутая грамматически и орфографически верная семантическая часть, содержащая упомянутые компоненты, содержит, по меньшей мере, один упомянутый компонент, причем упомянутый компонент содержит не более одного значения компонента, и формируют таблицу компонентов, содержащую, по меньшей мере, упомянутые идентифицированные компоненты и их значения; этапа 302 идентификации семантических частей, на котором идентифицируют грамматически и орфографически верные семантические части логических разделов логических конструкций, содержащие упомянутые идентифицированные компоненты, и грамматически и орфографически верные семантические части логических разделов логических конструкций, не содержащие упомянутые идентифицированные компоненты; этапа 303 идентификации компонентов, на котором идентифицируют компоненты, содержащиеся в количестве более одного в упомянутых грамматически и орфографически верных семантических частях, и идентифицируют сочетания компонентов, содержащихся в количестве более одного в каждой отдельной упомянутой грамматически и орфографически верной семантической части, и формируют карту сочетаний компонентов, содержащую, по меньшей мере, упомянутые компоненты, содержащиеся в количестве более одного в каждой отдельной упомянутой грамматически и орфографически верной семантической части, и их сочетания; этапа 304 идентификации значений компонентов, на котором идентифицируют значения компонентов, содержащихся в упомянутой карте сочетаний компонентов; этапа 305 идентификации понятий, на котором в грамматически и орфографически верных семантических частях логических разделов логических конструкций, не содержащих упомянутых идентифицированных компонентов, идентифицируют понятия, семантически совпадающие с упомянутыми значениями компонентов, содержащихся в упомянутой карте сочетаний компонентов, и формируют таблицу семантически совпадающих понятий, содержащую, по меньшей мере, значения компонентов, содержащихся в упомянутой карте сочетаний компонентов, и семантически совпадающие с ними понятия; этапа 306 идентификации семантических частей, не содержащих компонентов, и содержащих понятия, на котором идентифицируют, по меньшей мере, одну грамматически и орфографически верную семантическую часть логического раздела логической конструкции, не содержащую упомянутые идентифицированные компоненты, и содержащую более одного упомянутого понятия; этапа 307 идентификации семантических частей, содержащих компоненты, значения которых совпадают с понятиями, идентифицируют грамматически и орфографически верную семантическую часть логического раздела логической конструкции, содержащую более одного упомянутого идентифицированного компонента, значения которых семантически совпадают с упомянутыми понятиями, содержащимися в одной грамматически и орфографически верной семантической части логического раздела логической конструкции, не содержащей упомянутых идентифицированных компонентов и содержащей более одного упомянутого понятия; этапа 308 формирования карты сочетаний семантически совпадающих понятий, на котором формируют карту сочетаний семантически совпадающих понятий, содержащую, по меньшей мере, упомянутые понятия, содержащиеся в количестве более одного в одной грамматически и орфографически верной семантической части логического раздела логической конструкции, не содержащей упомянутых идентифицированных компонентов, семантически совпадающие со значениями упомянутых идентифицированных компонентов, содержащихся в одной грамматически и орфографически верной семантической части логического раздела логической конструкции, содержащей более одного упомянутого идентифицированного компонента; и этапа 309 формирования карты связей компонентов, на котором формируют карту связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутую карту сочетаний компонентов и упомянутую карту сочетаний семантически совпадающих понятий. Дополнительно, способ 300 формирования карты связей компонентов может содержать этап 310 формирования отчета, на котором формируют отчет, демонстрирующий, по меньшей мере, количество связей и значения упомянутых компонентов, содержащихся в карте сочетаний компонентов. Компонент представляет собой атрибут юридического правила. Юридическое правило - это часть нормативного предписания. Целью компонентного структурирования правил является формирование некоего стандарта конструирования и системной технической оценки конструкции юридического правила, а также поиск и выявление связанных предписаний, формирующих конструкцию логической нормы права. Все компоненты правила, упомянутые в настоящем описании являются примерами, используемыми для целей пояснения настоящего изобретения. Иные компоненты без ограничений могут быть выявлены в соответствии с настоящим способом в других юридических правилах. Первым компонентом юридического правила, в качестве примера, но не ограничения, являются субъекты правоотношений -это правомочные лица, установленные в предписании, отношения между которыми регулируются предписанием. Кроме этого в предписании может быть использована одна из сторон, для которой устанавливается определенное правило. Стороны правоотношений именуются как субъект предписания и контрсубъект. При этом субъект предписания является причиной и источником регулирующего воздействия, а контрсубъект - стороной правоотношений, с которой связано это воздействие. Вторым компонентом юридического правила в качестве примера, но не ограничения, является регулирующее воздействие - некое действие, бездействие, требование, принцип и т.п. В случае наличия в предписании субъекта правоотношений, регулирующим воздействием будет являться содержание правоотношения - т.е. возможность определенных действий, необходимость определенных действий или необходимость воздержания от запрещенных действий. В случае если предписание не содержит субъекта правоотношений, то регулирующим воздействием будет являться содержание требований относящихся к объектам правоотношений. Третьим компонентом юридического правила в качестве примера, но не ограничения, является объект правоотношений - это объекты, явления и их производные (далее - объекты), это те предметы окружающего мира, на которые направлено регулирующее воздействие. В случае если правило не содержит субъекта правоотношений, то объектом правоотношений являются те объекты, на которые распространяется регулирующее воздействие в виде содержания требований к данным объектам. Четвертым компонентом юридического правила в качестве примера, но не ограничения, являются связанные объекты - это объекты, явления и их производные, которые присутствуют в правиле, но не являются объектами правоотношений. Связанные объекты используются в правиле либо для детализации и уточнения регулирующего воздействия, либо как объект регулирующего воздействия, либо как объект регулирования.
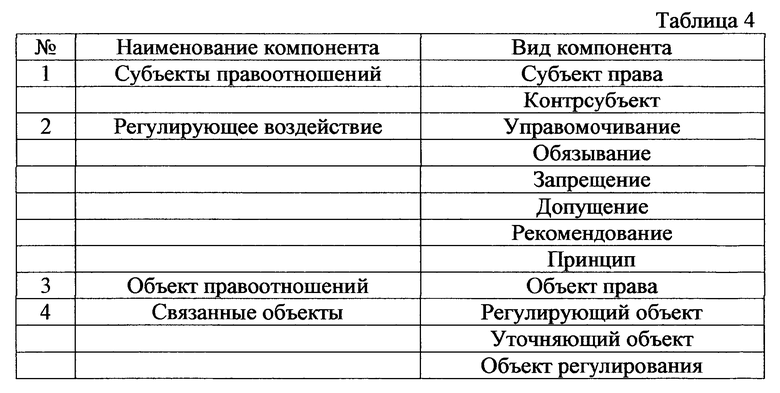
Каждый компонент (вид компонента), установленный в компонентной структуре (см. таблицу 5), описывается с помощью различных лингвистических инструментов, таких как синтаксические функции и связи, части речи, члены предложения и т.п. Лингвистические инструменты описывают отдельные термины (понятия) и группы терминов (понятий), входящие в семантические части. Такие описания формируются в виде логических формул, в которых элементами выступают упомянутые лингвистические инструменты, связанные друг с другом логическими связками - конъюнкцией («и»), дизъюнкцией («или»), строгой дизъюнкцией («либо, …либо»), импликацией («если…, то»). Логические формулы по каждому компоненту (виду компонента) формирует база данных описаний компонентов. База данных описаний компонентов - это набор инструментов для поиска компонентов в грамматически и орфографически верных семантических частях логических разделов логических конструкций преобразованного структурированного исходного массива данных. Карта связей компонентов при этом состоит из внутренних и внешних связей компонентов. Внутренние связи компонентов указывают на сочетания компонентов внутри одного правила (внутри семантической части, содержащей компоненты). Внешние связи компонентов указывают на связь между отдельными нормативными предписаниями, основанными на наличии семантических связей между компонентами и отдельными словами, и словосочетаниями в семантических частях, не содержащих компоненты. Для идентификации компонентов в грамматически и орфографически верных семантических частях логических разделов логических конструкций из упомянутого преобразованного структурированного исходного массива данных необходимо предварительно выявить среди всех семантических частей только те семантически части, которые содержат компоненты. Это первая семантическая часть второго логического раздела логической конструкции. После выявления семантических частей, содержащих компоненты, с помощью инструментов для поиска компонентов, содержащихся в базе данных описаний компонентов, идентифицируются сами компоненты. Под идентификацией компонентов понимается выявление в каждой отдельной семантической части, содержащей компоненты следующей информации: а) наименование компонента; б) вид компонента; в) значение компонента. Наименование компонента - это элемент юридического правила, отражающий признаки правовых отношений в конкретном правиле, являющийся основной частью лингвистической формулы. Вид компонента - это основная и дополнительная части лингвистической формулы, т.е. отдельные подгруппы наименований компонентов, выявленные на основании различий в дополнительной части лингвистической формулы. Значение компонента - это термин или группа терминов, содержащихся в семантической части, которые соответствуют основной и дополнительной частям лингвистической формулы. В качестве примера, но не ограничения, будет произведена идентификация компонентов в юридическом правиле:
«Уполномоченный орган обязан принять меры по отзыву такого товара с внутреннего рынка от потребителя». В данном примере идентифицируются все пять компонентов правила (см. таблицу 6).
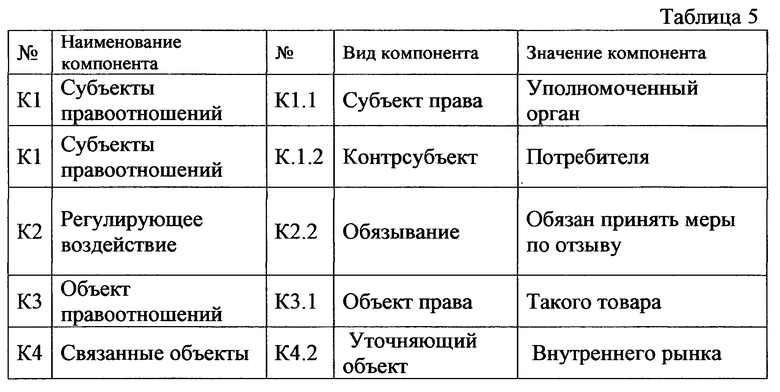
В юридическом правиле, смысловое ядро которого соответствует первой семантической части второго логического раздела, у каждого компонента может быть одно значение. По результатам идентификации компонентов в первых семантических частях второго логического раздела логической конструкции формируется таблица компонентов. Таблица компонентов содержит следующую информацию: наименование компонента; вид компонента; значение компонента; уникальный номер семантической части; уникальный номер логического раздела; уникальный номер логической конструкции. Основываясь на информации, содержащейся в таблице компонентов, из массива семантических частей, содержащих компоненты выявляются семантические части, содержащие более одного компонента и семантические части, содержащие один компонент. Причина такого разделения семантических частей, содержащих компоненты, в том, что карта сочетаний компонентов - это массив фактических сочетаний компонентов в каждом отдельном правиле, т.е. в каждой отдельной семантической части, содержащей компоненты. Поскольку для любого сочетания необходимо минимум два элемента, то карта сочетаний компонентов может быть сформирована на основе семантических частей, содержащих более одного компонента. При этом каждая семантическая часть, содержащая более одного компонента, формирует группу компонентов одного правила. Сочетания компонентов внутри каждой отдельной группы компонентов формируют карту сочетаний компонентов. Карта сочетаний компонентов содержит следующую информацию: наименование сочетаемых компонентов; виды сочетаемых компонентов; значение сочетаемых компонентов; уникальный номер семантической части; уникальный номер логического раздела; уникальный номер логической конструкции. В качестве примера, но не ограничения, будет произведено карты сочетаний компонентов в юридическом правиле:
«Уполномоченный орган обязан принять меры по отзыву такого товара с внутреннего рынка от потребителя».

Указанное в примере сочетание компонентов и их видов позволяет отображать в отчете полностью или частично совпадающие между собой группы предписаний. Полное совпадение подразумевает наличие в выборке предписаний, имеющих один и тот же набор компонентов или видов компонентов, или значений компонентов. Частичное совпадение подразумевает наличие в выборке предписаний совпадающих сочетаний отдельных компонентов, или видов компонентов, или значений компонентов. В качестве примера полного совпадения можно привести выборку предписаний, в которой все предписания содержат, например, такой же состав компонентов, как и состав компонентов, приведенный в таблице 7, а именно К1-К1-К2-К3-К4, или состав указанных там же видов компонентов, или указанных значений. В качестве примера неполного совпадения можно привести выборку предписаний, в которой все предписания содержат часть указанных пользователем компонентов из установленного сочетания - например, только сочетание К1-К3. В такую выборку попадают не только предписания с установленным сочетанием К1-К3, но и с другими сочетаниями компонентов (например К1-К2-К3), в которых наряду с указанными в сочетании К1-К3 компонентами содержатся другие компоненты (например, К2). Карта сочетаний компонентов представляет собой первую часть карты связей компонентов. Внешние связи компонентов, составляющие вторую часть карты связей компонентов, основываются на наличии семантических связей между компонентами и отдельными словами, и словосочетаниями в семантических частях, не содержащих компоненты. Под семантической связью понимается наличие между значениями компонентов и отдельными словами, и словосочетаниями смыслового совпадения, т.е. совпадения значений отдельных компонентов и слов по смыслу. В качестве примера, но не ограничения, может быть рассмотрено одно правило (семантическая часть, содержащая компоненты) - «Продавец обязан передать товар потребителю», - и одна семантическую часть, не содержащая компоненты (ситуация, юридический факт) - «Если товар не передан потребителю». В первую очередь необходимо идентифицировать внешние связи компонентов, т.е. наличие семантической связи между значениями компонентов и понятиями, семантически совпадающими с ними. В результате, для данного примера будет выявлено три связи между следующими значениями компонентов и словами в семантической части «ситуация»: а) товар - товар; б) обязан передать - не передан; в) потребителю - потребителю. Для идентификации второй части карты связей компонентов используются только компоненты, зарегистрированные в карте сочетаний компонентов - т.е. компоненты, содержащиеся в одном юридическом правиле в количестве более одного. При этом в семантической части, не содержащей компоненты (в ситуациях), в которой выявлены понятия, семантически совпадающие со значениями упомянутых компонентов, должно быть выявлено не менее двух таких понятий. При этом семантически совпадающими понятиями могут быть не только полностью совпадающие или однокоренные слова (термины), но и их синонимы и ассоциации, выявленные в специальных подключаемых словарях и справочниках. Все понятия, семантически совпадающие со значениями компонентов, идентифицированные таким образом, регистрируются в специальной таблице - карте сочетаний семантически совпадающих понятий. Карта сочетаний семантически совпадающих понятий устанавливает связи между отдельными семантическими частями, содержащими компоненты и семантическими частями, не содержащими компоненты. Эта связь основана на выявленных связях между компонентами и соответствующими понятиями. В итоге выявляются связанные предписания. Карта сочетаний семантически совпадающих понятий содержит следующую информацию по каждой паре связанных предписаний: наименование компонентов; виды сочетаемых компонентов; значение сочетаемых компонентов; уникальный номер семантической части, содержащей компоненты; уникальный номер логического раздела, содержащего упомянутую семантическую часть; уникальный номер логической конструкции, содержащей упомянутый логический раздел; наименование понятий, семантически совпадающих со значениями упомянутых компонентов; уникальный номер семантической части, содержащей упомянутые понятия; уникальный номер логического раздела, содержащего упомянутую семантическую часть с понятиями; уникальный номер логической конструкции, содержащей упомянутый логический раздел и упомянутую семантическую часть с понятиями. Карта связей компонентов состоит из двух частей - из карты сочетаний компонентов и карты сочетаний семантически совпадающих понятий. Карта сочетаний компонентов может применяться при комплексном правовом анализе некоего правового контента, например, отраслевой или тематической группы НПА, или отдельного НПА или отдельного проекта НПА. По информации, зарегистрированной в Карте сочетаний компонентов можно моментально получить различные «системно-структурные срезы» НПА (проекта НПА или группы НПА) отражающие, по меньшей мере: компонентную структуру правил (как на уровне наименований, использованных в НПА компонентов, так и на уровне видов и значений компонентов); наличие отдельных сочетаний компонентов в правилах НПА (также на трех уровнях - наименование, вид и значение). Первая часть карты связей может быть сформирована и представлена в виде отчета. Этот отчет может быть сформирован по схеме и формату, который будет задан пользователем заранее и будет содержать выборочную и системно подобранную информацию, проясняющую важные для пользователя срезы НПА (проекта НПА, группы НПА). Карта сочетаний семантически совпадающих понятий может применятся как при правовом анализе некоего правового контента, например, отраслевой или тематической группы НПА, или отдельного НПА или отдельного проекта НПА, так и для поиска связанных предписаний в любом правовом контенте. Самым простым практическим результатом идентификации связей между предписаниями является решение задач по автоматическому выявлению предписаний, устанавливающих санкции за нарушение правила, указанного в исходном предписании и наоборот - выявление связи исходного предписания с правилом на основании предписания, содержащего санкции за нарушение данного правила. Выявленные таким образом связанные предписания формируют норму права, в которой присутствует регулятивная и охранительная части.
На фиг. 17 в качестве примера, но не ограничения, изображена общая схема выполнения этапов заявленного способа 400 поиска релевантной информации в преобразованном структурированном исходном массиве данных, содержащем, по меньшей мере, логические конструкции, содержащие грамматически и орфографически верные семантические части логических разделов логических конструкций. Заявленный способ 400 поиска релевантной информации характеризуется выполнением этапа 401 формирования поискового запроса, на котором формируют поисковый запрос, содержащий, по меньшей мере, один поисковый термин и, при необходимости, дополнительно назначают, по меньшей мере, один критерий поиска, который может представлять собой одно из: поиск по первым и вторым семантическим частям первых логических разделов логических конструкций и вторым семантическим частям вторых логических разделов логических конструкций; поиск по первым семантическим частям вторых логических разделов логических конструкций и вторым семантическим частям вторых логических разделов логических конструкций; при этом поисковый запрос может представлять собой одно из: по меньшей мере, одно из: терминологический поисковый запрос; компонентный поисковый запрос; компонентно-терминологический поисковый запрос; этапа 402 идентификации массива поиска, на котором идентифицируют массив данных в упомянутом преобразованном структурированном исходном массиве данных, соответствующий упомянутому поисковому термину; этапа 403 идентификации семантических частей, на котором идентифицируют, по меньшей мере, одну грамматически и орфографически верную семантическую часть логических разделов логических конструкций упомянутого преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутый поисковый термин; этапа 404 идентификации логических конструкций, на котором идентифицируют, по меньшей мере, одну логическую конструкцию упомянутого преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутую идентифицированную грамматически и орфографически верную семантическую часть; и этапа 405 демонстрирования семантических частей, на котором демонстрируют, по меньшей мере, упомянутую идентифицированную логическую конструкцию упомянутого преобразованного структурированного исходного массива данных, содержащую, по меньшей мере, упомянутую идентифицированную грамматически и орфографически верную семантическую часть, которая является искомой релевантной информацией. Дополнительно (фиг. 18) заявленный способ 400 поиска релевантной информации может быть дополнен вторым уровнем поиска, заключающимся в выполнении этапа 406 выбора логической конструкции, на котором выбирают, по меньшей мере, одну из упомянутых идентифицированных логических конструкций, содержащую, по меньшей мере, упомянутую идентифицированную грамматически и орфографически верную семантическую часть; этапа 407 идентификации связанных семантических частей, на котором идентифицируют, по меньшей мере, связанные с упомянутой грамматически и орфографически верной семантической частью грамматически и орфографически верные семантические части, содержащиеся в других логических конструкциях преобразованного структурированного массива данных, причем упомянутая идентификация осуществляется на основании сведений из карты связей компонентов грамматически и орфографически верных семантических частей логических разделов логических конструкций; этапа 408 идентификации логических конструкций, на котором идентифицируют, по меньшей мере, одну или более логические конструкции, содержащие упомянутые идентифицированные связанные грамматически и орфографически верные семантические части или идентифицируют отсутствие логических конструкций, содержащих упомянутые идентифицированные связанные грамматически и орфографически верные семантические части; и этапом 409 демонстрирования логических конструкций, на котором демонстрируют, по меньшей мере, одну или более логические конструкции, содержащие упомянутые идентифицированные связанные грамматически и орфографически верные семантические части или демонстрируют отсутствие логических конструкций, содержащих упомянутые идентифицированные связанные грамматически и орфографически верные семантические части. Изначально, массивом поиска является преобразованный структурированный исходный массив данных - т.е. нормативные правовые акты в виде логических конструкций, состоящих из множества субмассивов данных, в которых взаимозависимости существуют, как на уровне субмассивов, так и между отдельными значениями субмассивов. Субмассивы преобразованного структурированного исходного массива данных - это грамматически и орфографически верные семантические части логических разделов логических конструкций. Релевантность поиска - это выявление в тексте нормативного правового акта логических конструкций, являющихся нормативными предписаниями, соответствующими, по меньшей мере, поисковому запросу. Для достижения требуемого уровня релевантности поиска дополнительно может быть назначен один из возможных критериев поиска, которые предназначены для уточнения области поиска. Для достижения первого уровня релевантности поиска назначают критерий поиска по первым и вторым семантическим частям первых логических разделов логических конструкций и вторым семантическим частям вторых логических разделов логических конструкций. Этот критерий поиска позволяет проводить поиск в массивах, относящихся к разделам ситуаций. Посредством назначения этого критерия поиска обеспечится выбор соответствующего субмассива (субмассива ситуаций), в котором в соответствии с поисковым запросом будет произведен поиск релевантной информации. Поисковый запрос при использовании такого критерия поиска может быть только терминологическим. Терминологический запрос - это запрос на поиск совпадений с установленным в запросе термином (понятием) в соответствующих критерию поиска субмассивах. Для достижения второго уровня релевантности поиска может быть применен критерий поиска по первым семантическим частям вторых логических разделов логических конструкций и вторым семантическим частям вторых логических разделов логических конструкций. Этот критерий поиска позволяет проводить поиск в массивах, относящихся к разделам правил. Посредством назначения этого критерия поиска обеспечится выбор соответствующего субмассива (субмассива правил), в котором в соответствии с поисковым запросом будет произведен поиск релевантной информации. Поисковый запрос при этом может быть простым и сложным. Простыми запросами являются терминологический запрос и компонентный запрос. Компонентный запрос - это запрос на поиск совпадений, как по наличию компонентов юридического правила, так и по их видам, а также по их значениям. Компонентный запрос может быть трехуровневым - поиск по названию компонента юридического правила (первый уровень компонентного запроса), поиск по виду компонента юридического правила (второй уровень компонентного запроса), значение вида компонента (третий уровень компонентного запроса). При этом первые два уровня - это поиск по структуре компонентов юридического правила. Третий уровень - поиск по терминам из текста НПА, индексированным в соответствующих субмассивах как значение вида компонента юридического правила. Сложный поисковый запрос представляет собой объединение двух простых запросов - компонентного и терминологического. Компонентно-терминологический запрос представляет собой компонентный запрос, дополненный четвертым уровнем поиска - поиском по термину или терминам, содержащихся в выявленных по результатам компонентного запроса юридических правилах. Выполнение поискового запроса при этом может быть многоэтапным. В частности, на первом этапе поиска, критерии поиска и поисковый запрос применяются ко всей базе НПА. На втором и последующих этапах при этом может осуществляться применение критериев поиска и поисковых запросов к результатам поиска, полученным при выполнении первого этапа поиска. После назначения критерия поиска и выполнения поискового запроса в соответствующих критерию поиска субмассивах преобразованного структурированного исходного массива данных выявляются совпадения индексов и значений с установленными значениями поискового запроса. Результатом выполнения поискового запроса является идентификация перечня отдельных значений субмассивов, которые соответствуют значениям поискового запроса. Выявленные в результате анализа преобразованного структурированного исходного массива в соответствии с критериями поиска и поисковым запросом значения субмассивов ассоциируются с теми семантическими частями логических разделов логических конструкций, в которых они зарегистрированы. В итоге выявляются те логические конструкции, которые содержат семантические части, в которых выявлены значения, соответствующие поисковому запросу в субмассивах, соответствующих критериям поиска. В результате поиска релевантной информации в преобразованном структурированном исходном массиве данных будут продемонстрированы выявленные логические конструкции - нормативные предписания. Формат логических конструкций соответствует формату элементов преобразованного структурированного исходного массива данных и содержит юридическое правило и обусловленность правила (условно - «ситуации»). При этом юридическое правило состоит из смыслового ядра юридического правила и уточнений понятий смыслового ядра правила, а обусловленность правила состоит из смыслового ядра ситуации, уточнений понятий смыслового ядра ситуации, зависимостей понятий смыслового ядра ситуации и зависимостей понятий смыслового ядра правила. Соответственно, в случае назначения более одного значения поискового запроса (т.е. формирование нескольких запросов одновременно), дополнительно необходимо выявить логическую связь между назначенными значениями. Выявление логической связи необходимо для назначения дополнительного критерия поиска, позволяющего согласовать несколько поисковых запросов и корректной идентификации соответствующих логических конструкций. Несколько поисковых запросов при этом могут быть согласованы по логической связи «и» (конъюнкция) или логической связи или» (дизъюнкция). Назначение конъюнктивной логической связи позволяет выявлять нормативные предписания, полностью соответствующие всем запросам, т.е. нормативные предписания, которые содержат в соответствующих критериям поиска частях текста нормативного предписания, как значение первого запроса, так и значения остальных, связанных с первым запросов. Назначение дизъюнктивной логической связи позволяет выявлять нормативные предписания, полностью соответствующие только отдельным поисковым запросам, т.е. нормативные предписания, которые содержат в соответствующих критериям поиска частях текста нормативного предписания или значение первого запроса, или значения других запросов. Далее способ поиска может быть дополнен вторым уровнем поиска релевантной информации. Для реализации этого способа поиска, результатом которого является выявление логической нормы права, необходимо выбрать одну из выявленных логических конструкций (одно нормативное предписание), которая будет являться исходной для выявления всей связанной с выбранной логической конструкцией совокупности логических конструкций, образующих логическую норму права. Идентификация связей семантической части выбранной логической конструкции с семантическими частями данной и других логических конструкций основана на сведениях из второй части карты связей компонентов (из карты сочетаний семантически совпадающих понятий). Самой минимальной задачей по выявлению логической нормы права является задача идентификации нормативного предписания, устанавливающего санкции за нарушение юридического правила, указанного в исходной логической конструкции (в исходном нормативном предписании) или наоборот - идентификация нормативного предписания на основании исходной логической конструкции, содержащей санкции. В виде поискового запроса могут быть использованы либо значения компонентов, либо понятия (термины), семантически совпадающие со значениями компонентов. Это зависит от того, какая задача ставится при выявлении логической нормы права и этим определяется, в каких массивах будет производиться поиск. При поиске санкций за нарушение юридического правила поисковым запросом являются значения компонентов правила, а поисковым массивом - массивы всех семантических частей, относящиеся к обусловленностям правила. При поиске самого юридического правила по известным, ранее выявленным, санкциям, поисковым запросом являются термины, семантически совпадающие со значениями компонентов правила, а поисковым массивом - массивы всех семантических частей, относящиеся к юридическому правилу. В результате двухуровневого поиска релевантной информации в преобразованном структурированном исходном массиве данных идентифицируются логические конструкции, содержащие семантические части, которые содержат термины или компоненты, соответствующие поисковому запросу второго уровня и которые связаны с исходной логической конструкцией в рамках логической нормы права. Для идентификации таких связей используются внешние связи компонентов, составляющие вторую часть карты связей компонентов (карту сочетаний семантически совпадающих понятий), основывающиеся на наличии семантических связей между компонентами и отдельными словами, и словосочетаниями в семантических частях, не содержащих компоненты. Под семантической связью понимается наличие между значениями компонентов и отдельными словами, и словосочетаниями смыслового (семантического) совпадения, т.е. совпадения значения отдельных компонентов и отдельных слов по смыслу. В качестве примера, но не ограничения, можно рассмотреть одно юридическое правило (семантическую часть, содержащую компоненты) - «Продавец обязан передать товар потребителю» и одну семантическую часть, не содержащую компоненты (обусловленность правила, ситуацию, юридический факт) - «Если товар не передан потребителю». Осуществляется идентификация внешних связей компонентов, т.е. наличия семантической связи между значениями компонентов и понятиями, семантически совпадающими с ними. В результате для данного примера выявлено три связи между следующими значениями компонентов и словами в семантической части «ситуация»: а) товар - товар; б) обязан передать - не передан; в) потребителю - потребителю. Для идентификации связанных семантических частей используются только компоненты, зарегистрированные в карте связей компонентов - т.е. компоненты, содержащиеся в одном юридическом правиле в количестве более одного. При этом в семантической части, не содержащей компоненты («ситуации»), в которой выявлены понятия, семантически совпадающие со значениями упомянутых компонентов, должно быть выявлено не менее двух таких понятий, семантически совпадающих с не менее чем двумя значениями компонентов из одного юридического правила. При этом семантически совпадающими понятиями могут быть не только полностью совпадающие или однокоренные слова (термины), но и их синонимы и ассоциации, выявленные в специальных подключаемых словарях и справочниках. Все понятия, семантически совпадающие со значениями компонентов, идентифицированные таким способом регистрируются в специальной таблице - карте сочетаний семантически совпадающих понятий. Карта сочетаний семантически совпадающих понятий устанавливает связи между отдельными семантическими частями, содержащими компоненты, и семантическими частями, не содержащими компоненты. Эта связь основана на выявленных связях между компонентами и соответствующими понятиями. В итоге выявляются связанные предписания. Карта сочетаний семантически совпадающих понятий содержит следующую информацию по каждой паре связанных предписаний: наименование компонентов; виды сочетаемых компонентов; значение сочетаемых компонентов; уникальный номер семантической части, содержащей компоненты; уникальный номер логического раздела, содержащего упомянутую семантическую часть; уникальный номер логической конструкции, содержащей упомянутый логический раздел; наименование понятий, семантически совпадающих со значениями упомянутых компонентов; уникальный номер семантической части, содержащей упомянутые понятия; уникальный номер логического раздела, содержащего упомянутую семантическую часть с понятиями; уникальный номер логической конструкции, содержащей упомянутый логический раздел и упомянутую семантическую часть с понятиями. Карта сочетаний семантически совпадающих понятий может применятся как при правовом анализе некоего правового контента, например, отраслевой или тематической группы НПА, или отдельного НПА или отдельного проекта НПА, так и для поиска связанных предписаний по требованию пользователя в любом правовом контенте. В результате идентификации пользователю демонстрируются результаты в виде выявленных связанных предписаний (отдельных норм права).
На фиг. 19 в качестве примера, но не ограничения, проиллюстрирована примерная схема заявленной системы 500, которая в предпочтительном варианте реализации содержит, по меньшей мере, одно или более устройств 501, содержащих, по меньшей мере, один или более процессоров 5011, один или более модулей ввода/вывода (I/O) 5012 и память 5013. Упомянутые устройства 501 могут представлять собой, но не ограничиваться: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон, тонкий клиент и тому подобное. Память (машиночитаемый носитель данных) 5013 устройства 501 содержит код программы, который при выполнении побуждает упомянутые один или более процессоры 5011 упомянутого устройства 501 и/или устройства 501, связанного с ним, выполнять действия описанных в вариантах осуществления настоящего изобретения с первого по двенадцатый, в вариантах осуществления настоящего изобретения с двадцатого по двадцать первый, и в вариантах осуществления настоящего изобретения с двадцать девятого по тридцать четвертый, и содержит подлежащие преобразованию или преобразованные один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке. Более того, подлежащие преобразованию или преобразованные один или несколько структурированных исходных массивов данных могут являться загружаемыми и храниться, в частности, в базе данных 502 системы преобразования структурированного массива данных. В качестве примера, но не ограничения, машиночитаемый носитель данных может включать в себя оперативную память (RAM); постоянное запоминающее устройство (ROM); электрически-стираемое программируемое постоянное запоминающее устройство (EEPROM); флэш-память или другие технологии памяти; CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для кодирования требуемой информации, и к которому может быть осуществлен доступ посредством описываемого устройства. Память включает в себя носитель данных на основе запоминающего устройства компьютера в форме энергозависимой или энергонезависимой памяти, или их комбинации. Примерные аппаратные устройства включают в себя твердотельную память, накопители на жестких дисках, накопители на оптических дисках и т.д. В памяти хранится примерная среда, в которой при помощи компьютерных команд или кодов, хранящихся в памяти устройства, могут быть осуществлены процедуры предварительного преобразования структурированного исходного массива данных, процедуры преобразования структурированного исходного массива данных, формирования карты связей компонентов преобразованного структурированного исходного массива данных, и процедуры поиска релевантной информации в преобразованных структурированных исходных массивах данных. Устройство содержит один или более процессоров 5011, которые предназначены для выполнения компьютерных команд или кодов, хранящихся в памяти устройства с целью обеспечения выполнения упомянутых выше процедур. Компьютерные команды или коды, хранящиеся в памяти, предназначены для выполнения предварительных преобразований структурированного исходного массива данных, преобразований структурированного исходного массива данных, формирования карты связей компонентов преобразованных структурированных исходных массивов данных, поиска релевантной информации в преобразованных структурированных исходных массивах данных. Модули I/O 5012 устройства 501 представляют собой, не ограничиваясь, типичные и известные из уровня техники средства управления устройством: манипулятор типа «мышь», клавиатура, джойстик, тачпад, трекбол, электронное перо, стилус, сенсорный дисплей и тому подобное. Так же модули I/O 5012 представляют собой, не ограничиваясь, типичные и известные из уровня техники средства демонстрирования информации: дисплей, монитор, проектор, принтер, графопостроитель и тому подобное. Система 500 также может включать в себя базу данных (БД) 502. БД 502 может представлять собой, не ограничиваясь: иерархическую БД, сетевую БД, реляционную БД, объектную БД, объектно-ориентированную БД, объектно-реляционную БД, пространственную БД, комбинацию перечисленных двух и более БД, и тому подобное. БД 502 хранит данные в памяти, которая может представлять собой, не ограничиваясь: постоянное запоминающее устройство (ROM), электрически-стираемое программируемое постоянное запоминающее устройство (EEPROM), флэш-память, CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для хранения требуемой информации, и к которому может быть осуществлен доступ посредством устройства 501 преобразования структурированного исходного массива данных и сервера 503. БД 502 служит для хранения данных, представляющих собой, по меньшей мере, компьютерные команды или коды, хранящиеся в памяти, предназначенные для выполнения предварительных преобразований структурированного исходного массива данных, преобразований структурированного исходного массива данных, формирования карты связей компонентов преобразованных структурированных исходных массивов данных, поиска релевантной информации в преобразованных структурированных исходных массивах данных; подлежащие преобразованию или преобразованные один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке, которые могут быть загружены в память 5013 устройства 501; и других данных, необходимых для функционирования системы. Примерная система 500 дополнительно содержит серверное вычислительное устройство (сервер) 503, которое сохраняет и содействует манипуляции компьютерными командами или кодами, ранее описанными в данном документе, которые, соответственно, дополнительно не описываются. Сервер 503 может представлять собой: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон, машину баз данных и тому подобное. Сервер 503 обеспечивает регулирование обменом данных в системе 500 преобразования структурированного исходного массива данных, а также обеспечивает обработку данных при условии подключения к нему одного или более чем одного устройств 501 преобразования структурированного массива данных или когда устройство 501 преобразования структурированного массива данных представляет собой тонкий клиент. В этом случае все вычислительные мощности, необходимые для обеспечения выполнения процедуры преобразования структурированного массива данных, расположены на сервере 503. Система 500 так же содержит одну или более сетей 504 передачи данных. Сети 504 передачи данных могут включать в себя, но не ограничиваться, одну или более локальных сетей (LAN) и/или глобальных сетей (WAN), или могут представлять собой информационно-телекоммуникационную сеть Интернет, или Интранет, или виртуальную частную сеть (VPN), или их комбинацию, и тому подобное. Сервер 503 также имеет возможность обеспечивать виртуальную вычислительную среду (Virtual Machine) для обеспечения взаимодействия между устройством 501 преобразования структурированного массива данных и БД 502. Сеть 504 служит для обеспечения взаимодействия между устройством 501, базой данных 502 и сервером 503 системы 500.
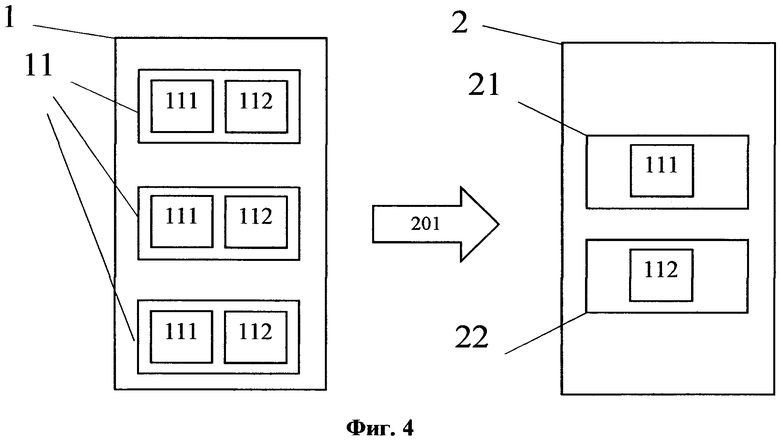
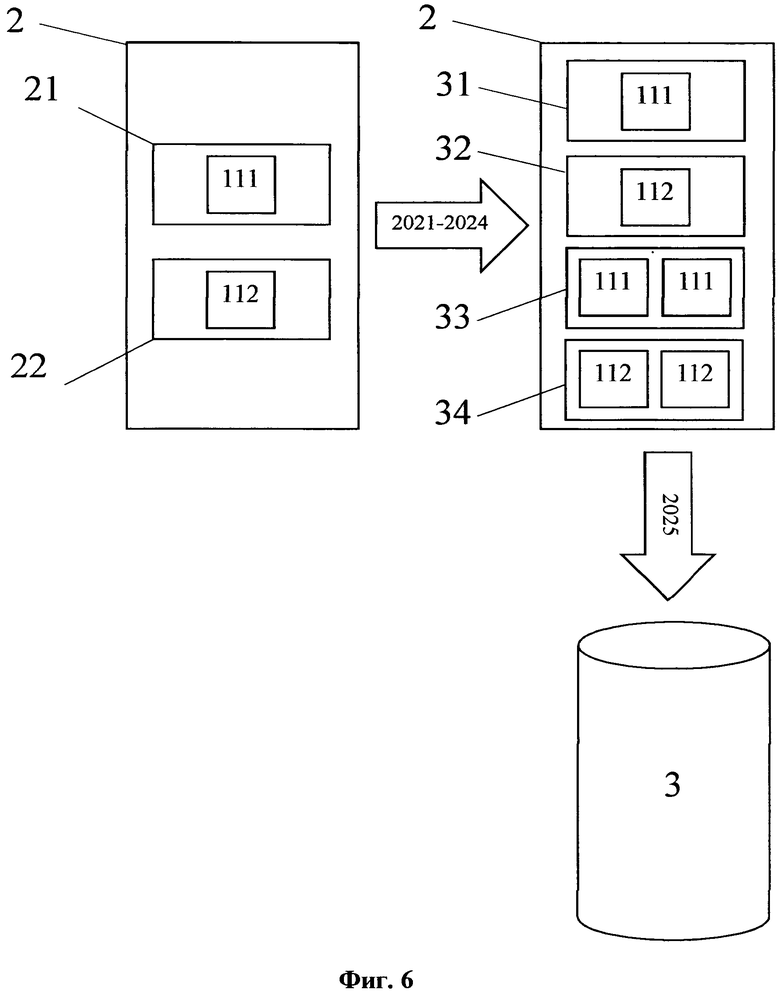
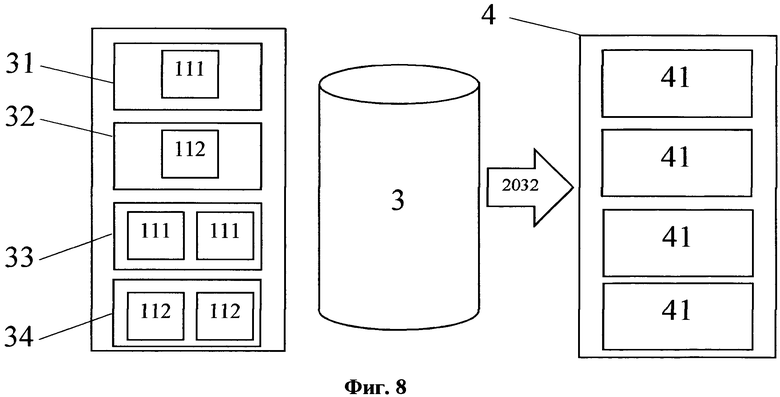
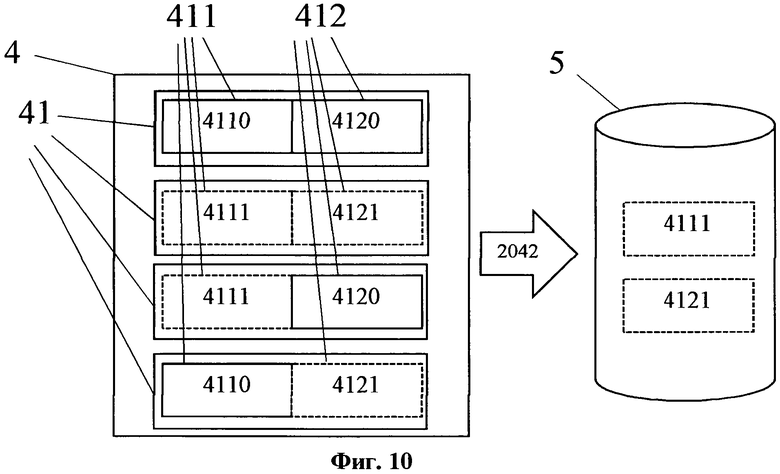
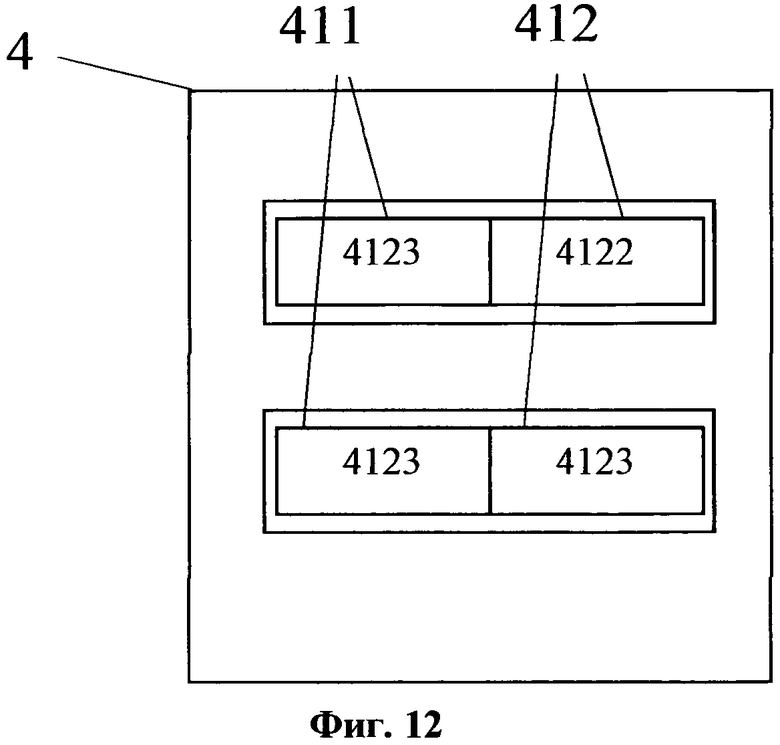
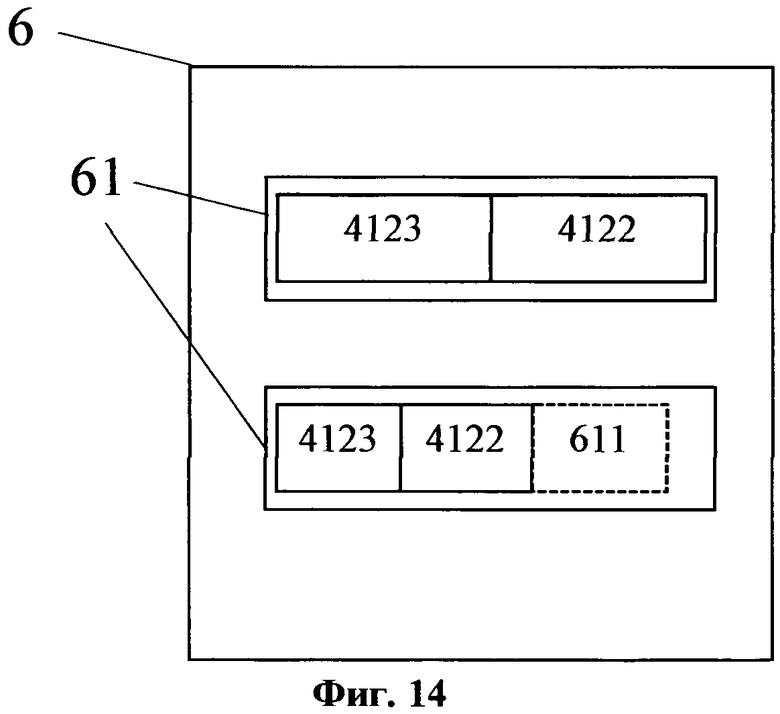
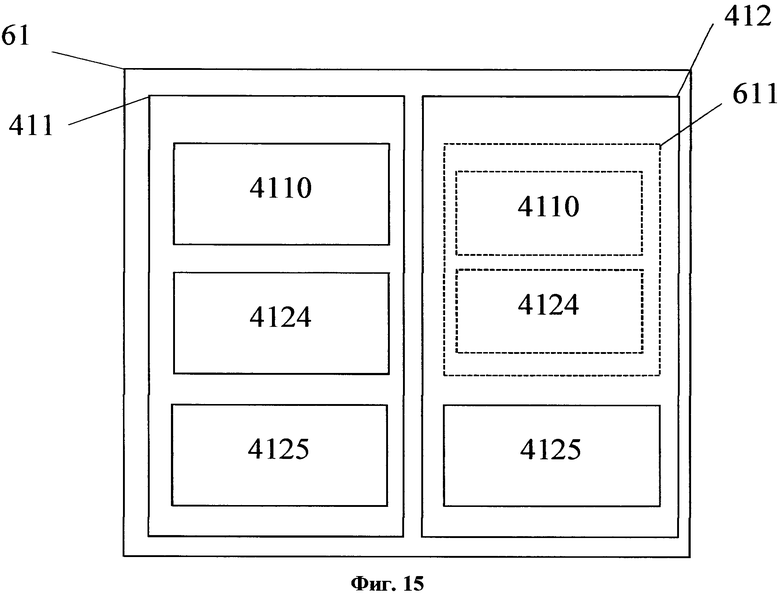

Изобретение относится к обработке массивов данных, содержащих текст на естественном языке. Техническим результатом является повышение точности и скорости навигации по элементам массива данных за счет обеспечения предварительного преобразования структурированного массива данных и дальнейшего формирования логически, грамматически и орфографически верной структуры данных. В способе преобразования структурированного исходного массива данных формируют исходную структуру данных исходного массива данных. Идентифицируют в исходных элементах контекстные термины и формируют базу данных контекстных терминов. Используя информацию, содержащуюся в сформированной базе данных, в исходной структуре данных идентифицируют структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины. Осуществляют преобразования над языковыми конструкциями и формируют итоговую структуру данных структурированного исходного массива данных. 4 н. и 15 з.п. ф-лы, 19 ил., 6 табл.
1. Способ преобразования структурированного исходного массива данных, содержащего, по меньшей мере, текст на естественном языке, причем упомянутый способ содержит, по меньшей мере, этапы, на которых:
A) формируют исходную структуру данных структурированного исходного массива данных, содержащую исходные элементы исходной структуры данных, причем упомянутые исходные элементы представляют собой:
структурно-сложные языковые конструкции, представляющие собой структурно-сложные языковые конструкции, содержащие контекстные термины, и структурно-сложные языковые конструкции, не содержащие контекстные термины; и
структурно-простые языковые конструкции, представляющие собой структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Б) идентифицируют в упомянутых исходных элементах контекстные термины и формируют базу данных контекстных терминов, содержащую упомянутые идентифицированные контекстные термины;
B) используя информацию, содержащуюся в упомянутой сформированной базе данных контекстных терминов, в упомянутой исходной структуре данных идентифицируют структурно-сложные языковые конструкции, содержащие контекстные термины, структурно-сложные языковые конструкции, не содержащие контекстные термины, структурно-простые языковые конструкции, содержащие контекстные термины, и структурно-простые языковые конструкции, не содержащие контекстные термины;
Г) осуществляют преобразование первого типа над упомянутыми структурно-сложными языковыми конструкциями, не содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины, причем преобразование первого типа включает форматное преобразование и лингвистическое преобразование;
Д) осуществляют преобразование второго типа над упомянутыми структурно-простыми языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины, причем преобразование второго типа включает контекстное преобразование и лингвистическое преобразование;
Е) осуществляют преобразование третьего типа над упомянутыми структурно-сложными языковыми конструкциями, содержащими контекстные термины, для получения грамматически и орфографически верных структурно-простых языковых конструкций, не содержащих контекстные термины, причем преобразование третьего типа включает форматное преобразование, контекстное преобразование и лингвистическое преобразование;
Ж) формируют итоговую структуру данных структурированного исходного массива данных, содержащую элементы итоговой структуры данных, причем элементы итоговой структуры данных представляют собой структурно-простые языковые конструкции, не содержащие контекстные термины, и полученные за счет преобразований первого, второго и третьего типов грамматически и орфографически верные структурно-простые языковые конструкции, не содержащие контекстные термины.
2. Способ по п. 1, отличающийся тем, что дополнительно содержит, по меньшей мере, этапы, на которых:
З) на основании полученной итоговой структуры данных формируют первую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных содержат первые логические разделы и вторые логические разделы;
И) формируют базу данных логических связей логических разделов упомянутых элементов первой структуры данных;
К) формируют вторую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой второй структуры данных, причем упомянутые элементы второй структуры данных содержат логические конструкции логических разделов упомянутых элементов первой структуры данных, сформированные с использованием информации из упомянутой базы данных логических связей логических разделов, причем упомянутые логические разделы содержат первые семантические части и вторые семантические части;
Л) формируют базу данных семантических частей логических разделов из упомянутых вторых семантических частей, причем упомянутые вторые семантические части исключаются из соответствующих упомянутых логических разделов;
М) формируют грамматически и орфографически верные семантические части упомянутых логических разделов путем лингвистических преобразований над упомянутыми семантическими частями;
Н) формируют результирующую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой результирующей структуры данных, причем упомянутые элементы результирующей структуры данных содержат логические конструкции, содержащие, по меньшей мере, упомянутые грамматически и орфографически верные семантические части логических разделов.
3. Способ по п. 2, отличающийся тем, что этап З) характеризуется, по меньшей мере, этапами, на которых:
- идентифицируют итоговую структуру данных структурированного исходного массива данных;
- идентифицируют элементы итоговой структуры данных;
- идентифицируют первые логические разделы упомянутых элементов итоговой структуры данных и вторые логические разделы упомянутых элементов итоговой структуры данных; и
- формируют первую структуру данных структурированного исходного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных содержат первые логические разделы и вторые логические разделы.
4. Способ по п. 2, отличающийся тем, что этап И) характеризуется, по меньшей мере, этапами, на которых:
- идентифицируют элементы первой структуры данных, содержащие один упомянутый первый логический раздел, и элементы первой структуры данных, содержащие один упомянутый второй логический раздел;
- идентифицируют элементы первой структуры данных, содержащие более одного упомянутого первого логического раздела, и элементы первой структуры данных, содержащие более одного упомянутого второго логического раздела;
- среди элементов первой структуры данных, содержащих более одного упомянутого первого логического раздела, и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела, идентифицируют логические связи между упомянутыми первыми логическими разделами или между упомянутыми вторыми логическими разделами;
- среди элементов первой структуры данных, содержащих более одного упомянутого первого логического раздела, и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела, идентифицируют элементы первой структуры данных, не имеющие логической связи между логическими разделами; и
- формируют базу данных логических связей логических разделов элементов первой структуры данных.
5. Способ по п. 2, отличающийся тем, что этап К) характеризуется, по меньшей мере, этапами, на которых:
- формируют логические конструкции логических разделов элементов первой структуры данных, используя информацию из базы данных логических связей логических разделов элементов первой структуры данных и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый первый логический раздел, и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый второй логический раздел; и
- формируют вторую структуру данных структурированного исходного массива данных, содержащую элементы второй структуры данных, причем упомянутые элементы второй структуры данных представляют собой сформированные логические конструкции логических разделов первой структуры данных.
6. Способ по п. 2, отличающийся тем, что этап Л) характеризуется, по меньшей мере, этапами, на которых:
- идентифицируют первые логические разделы элементов второй структуры данных и вторые логические разделы элементов второй структуры данных;
- в упомянутых первых логических разделах и вторых логических разделах элементов второй структуры данных идентифицируют первые семантические части и вторые семантические части; и
- в упомянутых первых и вторых логических разделах элементов второй структуры данных идентифицируют, по меньшей мере, особые семантические части первых логических разделов элементов второй структуры данных и особые семантические части вторых логических разделов элементов второй структуры данных и формируют базу данных особых семантических частей логических разделов элементов второй структуры данных путем перемещения упомянутых особых семантических частей в упомянутую формируемую базу данных особых семантических частей логических разделов элементов второй структуры данных.
7. Способ по п. 2, отличающийся тем, что этап М) характеризуется, по меньшей мере, этапами, на которых:
- в упомянутых вторых семантических частях, упомянутых вторых логических разделов элементов второй структуры данных идентифицируют, по меньшей мере, уточняющие структуры вторых семантических частей вторых логических разделов; и
- осуществляют лингвистические преобразования над всеми семантическими частями, за исключением упомянутых особых семантических частей упомянутых первых и вторых логических разделов, для формирования грамматически и орфографически верных семантических частей логических разделов элементов второй структуры данных.
8. Способ по п. 2, отличающийся тем, что этап Н) характеризуется, по меньшей мере, этапами, на которых:
- формируют из первых грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных и упомянутых грамматически и орфографически верных уточняющих структур вторых семантических частей вторых логических разделов элементов второй структуры данных смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных; и
- формируют результирующую структуру данных структурированного исходного массива данных, содержащую элементы результирующей структуры данных, причем упомянутые элементы результирующей структуры данных представляют собой логические конструкции, содержащие упомянутые грамматически и орфографически верные семантические части логических разделов элементов второй структуры данных.
9. Способ по п. 8, отличающийся тем, что упомянутые логические конструкции из упомянутой результирующей структуры данных дополнительно могут содержать упомянутые сформированные смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных.
10. Способ по п. 1, отличающийся тем, что дополнительно содержит, по меньшей мере, этапы, на которых:
З) идентифицируют итоговую структуру данных исходного структурированного массива данных; идентифицируют элементы итоговой структуры данных; идентифицируют первые логические разделы упомянутых элементов итоговой структуры данных и вторые логические разделы упомянутых элементов итоговой структуры данных; и формируют первую структуру данных исходного структурированного массива данных, содержащую элементы упомянутой первой структуры данных, причем упомянутые элементы первой структуры данных содержат первые логические разделы и вторые логические разделы;
И) идентифицируют элементы первой структуры данных, содержащие один упомянутый первый логический раздел, и элементы первой структуры данных, содержащие один упомянутый второй логический раздел; идентифицируют элементы первой структуры данных, содержащие более одного упомянутого первого логического раздела, и элементы первой структуры данных, содержащие более одного упомянутого второго логического раздела; в элементах первой структуры данных, содержащих более одного упомянутого первого логического раздела, и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела, идентифицируют логические связи между упомянутыми первыми логическими разделами или между упомянутыми вторыми логическими разделами; в элементах первой структуры данных, содержащих более одного упомянутого первого логического раздела, и в элементах первой структуры данных, содержащих более одного упомянутого второго логического раздела, идентифицируют элементы первой структуры данных, не имеющие логической связи между логическими разделами; и формируют базу данных логических связей логических разделов элементов первой структуры данных;
К) формируют логические конструкции логических разделов элементов первой структуры данных, используя информацию из базы данных логических связей логических разделов элементов первой структуры данных и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый первый логический раздел, и логические разделы упомянутых элементов первой структуры данных, содержащих один упомянутый второй логический раздел; и формируют вторую структуру данных исходного структурированного массива данных, содержащую элементы второй структуры данных, причем упомянутые элементы второй структуры данных представляют собой сформированные логические конструкции логических разделов первой структуры данных;
Л) идентифицируют первые логические разделы элементов второй структуры данных и вторые логические разделы элементов второй структуры данных; в упомянутых первых логических разделах и вторых логических разделах элементов второй структуры данных идентифицируют первые семантические части и вторые семантические части; и в упомянутых первых и вторых логических разделах элементов второй структуры данных идентифицируют, по меньшей мере, особые семантические части первых логических разделов элементов второй структуры данных и особые семантические части вторых логических разделов элементов второй структуры данных и формируют базу данных особых семантических частей логических разделов элементов второй структуры данных путем перемещения упомянутых особых семантических частей в упомянутую формируемую базу данных особых семантических частей логических разделов элементов второй структуры данных;
М) в упомянутых вторых семантических частях упомянутых вторых логических разделов элементов второй структуры данных идентифицируют, по меньшей мере, уточняющие структуры вторых семантических частей вторых логических разделов и осуществляют лингвистические преобразования над всеми семантическими частями, за исключением упомянутых особых семантических частей упомянутых первых и вторых логических разделов, для формирования грамматически и орфографически верных семантических частей логических разделов элементов второй структуры данных;
Н) формируют из первых грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных и упомянутых грамматически и орфографически верных уточняющих структур вторых семантических частей вторых логических разделов элементов второй структуры данных смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов третьей структуры данных; и формируют результирующую структуру данных исходного структурированного массива данных, содержащую элементы результирующей структуры данных, причем упомянутые элементы результирующей структуры данных представляют собой логические конструкции, содержащие упомянутые грамматически и орфографически верные семантические части логических разделов элементов второй структуры данных.
11. Способ по п. 10, отличающийся тем, что упомянутые логические конструкции из упомянутой результирующей структуры данных дополнительно могут содержать упомянутые сформированные смысловые сочетания грамматически и орфографически верных семантических частей вторых логических разделов элементов второй структуры данных.
12. Устройство преобразования структурированного исходного массива данных, содержащее, по меньшей мере:
один или более процессоров;
один или более модулей ввода/вывода (I/O); и
память, содержащую код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из пп. 1-11, и содержащую подлежащие преобразованию один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке.
13. Устройство по п. 12, отличающееся тем, что упомянутые подлежащие преобразованию один или несколько структурированных исходных массивов данных являются загружаемыми, а упомянутое устройство выполнено с возможностью соединения с базой данных, в которой хранятся упомянутые загружаемые подлежащие преобразованию один или несколько структурированных исходных массивов данных, для осуществления загрузки в упомянутую память устройства, по меньшей мере, одного загружаемого подлежащего преобразованию структурированного исходного массива данных.
14. Система преобразования структурированного исходного массива данных, содержащая, по меньшей мере:
одно или более устройств, выполненных в виде устройств по любому из пп. 12 или 13;
один или несколько серверов, обеспечивающих регулирование обменом данных в упомянутой системе;
одну или несколько баз данных, предназначенных для хранения данных, выполненных с возможностью взаимодействия с упомянутыми одним или более устройствами;
одну или более сетей передачи данных, через которые осуществляется взаимодействие упомянутых устройств, серверов и баз данных.
15. Система по п. 14, отличающаяся тем, что способ по любому из пп. 1-11 осуществляется одним или более упомянутыми серверами, а упомянутые устройства представляют собой тонкий клиент.
16. Система по п. 15, отличающаяся тем, что упомянутая база данных служит для хранения данных, представляющих собой, по меньшей мере, одно из: код программы, который при выполнении побуждает упомянутые один или более процессоры упомянутого устройства и/или устройства, связанного с упомянутым устройством, выполнять действия способа по любому из пп. 1-11, подлежащие преобразованию один или несколько структурированных исходных массивов данных, содержащих, по меньшей мере, текст на естественном языке.
17. Система по любому из пп. 14-16, отличающаяся тем, что упомянутая сеть передачи данных представляет собой одно из: локальная сеть (LAN), глобальная сеть (WAN), информационно-телекоммуникационная сеть Интернет, виртуальная частная сеть (VPN).
18. Машиночитаемый носитель данных, содержащий код программы, который при выполнении побуждает процессор или процессоры устройства, с которым взаимодействует машиночитаемый носитель данных, выполнять действия способа по любому из пп. 1-11.
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

