[0001] ОБЛАСТЬ ТЕХНИКИ
[0002] Группа изобретений относится к решениям в области обработки массивов данных, в частности, к решениям в области обработки структурированных массивов данных, содержащих текст на естественном языке, в частности, лингвистические предложения, и может быть использована для предварительного преобразования структурированного массива данных для обеспечения его последующей обработки.
[0003] УРОВЕНЬ ТЕХНИКИ
[0004] Из патента РФ 2399959 (ЗАО «АВИКОМП СЕРВИСЕЗ»), опубликованного 10.05.2010 (Д1) известен способ автоматической индексации текстов на естественных языках. Известный из Д1 способ заключается в том, что текст сегментируют в электронной форме на элементарные единицы, выявляют устойчивые словосочетания, формируют предложения, выявляют семантически значимые объекты и семантически значимые отношения между ними, формируют для каждого семантически значимого отношения множество триад, в которых единственная триада первого типа соответствует связи, устанавливаемой семантически значимым отношением между двумя семантически значимыми объектами, при этом каждая из триад второго типа соответствует значению конкретного атрибута одного из этих семантически значимых объектов, каждая из триад третьего типа соответствует значению конкретного атрибута самого семантически значимого отношения, затем индексируют на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты по отдельности, запоминают в базе данных сформированные триады и полученные индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады.
[0005] Однако известный из Д1 способ не обладает достаточной точностью индексации элементов текста на естественном языке, что, в свою очередь, сказывается на точности последующей обработки текста на естественном языке и точности поиска в тексте на естественном языке. Главным образом, это происходит из-за недостаточно эффективной предварительной обработки текста на естественном языке, что, соответственно, не позволяет осуществить индексацию с достаточной точностью. Известный из Д1 способ может быть принят в качестве ближайшего аналога.
[0006] РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0007] Технической проблемой, решаемой заявленным изобретением, является создание изобретений, не обладающих недостатками ближайшего аналога и таким образом обладающих повышенной эффективностью обработки текста на естественном языке для его последующей индексации, обработки и поиска.
[0008] Техническим результатом, достигаемым при реализации заявленного изобретения, является устранение недостатков ближайшего аналога и таким образом повышение эффективности обработки текста на естественном языке, а также повышение эффективности его индексации, обработки и поиска в таком тексте. Другим техническим результатом является расширение арсенала технических средств - способов обработки структурированных массивов данных, содержащих текст на естественном языке.
[0009] Технический результат достигается за счет того, что обеспечивается исполняемый процессором или процессорами компьютерного устройства способ преобразования структурированного массива данных (СМД), содержащего простые суждения (ПС), заключающийся в: выполнении этапа 101 формирования первой структуры данных (СД), на котором формируют первую СД СМД, содержащую элементы упомянутой первой СД, причем упомянутые элементы первой СД представляют собой текстовые элементы (ТЭ) лингвистического предложения, а также идентификационные данные ТЭ, представляющие собой в качестве примера, но не ограничения: значения ТЭ и порядковые номера ТЭ в лингвистическом предложении; выполнении этапа 102 формирования базы данных лингво-логических признаков (БДЛЛП), на котором на основании сведений, содержащихся в первой СД, выявляют лингвистические и логические признаки ТЭ лингвистического предложения, из которых формируют базу данных, представляющую собой базу данных лингвистических и логических признаков текстовых элементов лингвистического предложения; выполнении этапа 103 формирования второй СД, на котором на основании сведений, содержащихся в БДЛЛП, первой СД, а также на основании формализованной модели простого суждения, формируют вторую СД СМД, содержащую элементы упомянутой второй СД, причем упомянутые элементы второй СД представляют собой компоненты простых суждений (КПС), а также идентификационные данные КПС, представляющие собой в качестве примера, но не ограничения: значения КПС и порядковые номера ТЭ лингвистического предложения, составляющих КПС; выполнении этапа 104 формирования третьей СД, на котором на основании сведений, содержащихся в БДЛЛП, второй СД, а также на основании формализованной модели простого суждения, формируют третью СД СМД, содержащую элементы упомянутой третьей СД, причем упомянутые элементы третьей СД представляют собой простые суждения (ПС) лингвистического предложения, а также идентификационные данные ПС, представляющие собой в качестве примера, но не ограничения: значения ПС и порядковые номера ТЭ лингвистического предложения, составляющих ПС.
[0010] КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0011] Иллюстративные варианты осуществления настоящего изобретения описываются далее подробно со ссылкой на прилагаемые чертежи, которые включены в данный документ посредством ссылки, и на которых:
[0012] На фиг. 1, в качестве примера, но не ограничения, изображена примерная общая схема выполнения этапов заявленного способа 100.
[0013] На фиг. 2, в качестве примера, но не ограничения, изображена примерная общая схема выполнения этапов этапа 101.
[0014] На фиг. 3, в качестве примера, но не ограничения, изображена общая структура исходной структуры данных, содержащей лингвистические предложения.
[0015] На фиг. 4, в качестве примера, но не ограничения, изображена общая структура сформированной первой структуры данных.
[0016] На фиг. 5, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 102.
[0017] На фиг. 6, в качестве примера, но не ограничения, изображена общая структура сформированной базы данных лингво-логических признаков.
[0018] На фиг. 7, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 103.
[0019] На фиг. 8, в качестве примера, но не ограничения, изображена общая структура сформированной второй структуры данных.
[0020] На фиг. 9, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 104.
[0021] На фиг. 10, в качестве примера, но не ограничения, изображена общая структура сформированной третьей структуры данных.
[0022] На фиг. 11 в качестве примера, но не ограничения, изображена примерная общая схема выполнения этапов заявленного способа 200.
[0023] На фиг. 12, в качестве примера, но не ограничения, изображена общая схема выполнения этапа 201.
[0024] На фиг. 13, в качестве примера, но не ограничения, изображена общая структура первой структуры данных для способа 200, содержащей компоненты простого суждения.
[0025] На фиг. 14, в качестве примера, но не ограничения, изображена общая структура второй структуры данных для способа 200, содержащей простые суждения.
[0026] На фиг. 15, в качестве примера, но не ограничения, изображена общая структура базы данных лингво-логических признаков.
[0027] На фиг. 16, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 105.
[0028] На фиг. 17, в качестве примера, но не ограничения, изображена общая структура сформированной онтологической базы данных системных и семантических связей.
[0029] На фиг. 18, в качестве примера, но не ограничения, изображена примерная общая схема выполнения этапов заявленного способа 300.
[0030] На фиг. 19, в качестве примера, но не ограничения, изображена общая схема выполнения этапа 301.
[0031] На фиг. 20, в качестве примера, но не ограничения, изображена общая структура исходной структуры данных для способа 300, содержащей простые суждения.
[0032] На фиг. 21, в качестве примера, но не ограничения, изображена общая структура онтологической базы данных системных и семантических связей.
[0033] На фиг. 22, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 106.
[0034] На фиг. 23, в качестве примера, но не ограничения, изображена общая структура сформированной карты отношений.
[0035] На фиг. 24, в качестве примера, но не ограничения, изображена общая структура сформированной базы данных отношений.
[0036] На фиг. 25, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 107.
[0037] На фиг. 26, в качестве примера, но не ограничения, изображена общая структура сформированной четвертой структуры данных (итоговой СД).
[0038] На фиг. 27, в качестве примера, но не ограничения, изображена примерная общая схема системы для преобразования структурированного массива данных.
[0039] ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0040] Описанные в данном разделе возможные осуществления вариантов настоящего изобретения представлены на неограничивающих объем правовой охраны примерах, применительно к конкретным вариантам осуществления настоящего изобретения, которые во всех их аспектах предполагаются иллюстративными и не накладывающими ограничения. Альтернативные варианты реализации настоящего изобретения, не выходящие за пределы объема его правовой охраны, являются очевидными специалистам в данной области, имеющим обычную квалификацию, на которых это изобретение рассчитано.
[0041] Варианты осуществления настоящего изобретения относятся к способам, устройствам, системам и машиночитаемым носителям данных для обеспечения повышенной эффективности обработки текста на естественном языке для его последующей индексации, обработки и поиска.
[0042] На фиг. 1, в качестве примера, но не ограничения, изображена примерная общая схема выполнения этапов способа 100 преобразования структурированного массива данных (СМД). В результате реализации тех или иных этапов способа 100 могут быть получены различные структуры данных, пригодные для дальнейшего анализа и использования. Заявленный исполняемый процессором или процессорами компьютерного устройства способ 100 заключается в: выполнении этапа 101 формирования первой структуры данных (СД), на котором формируют первую СД СМД, содержащую элементы упомянутой первой СД, причем упомянутые элементы первой СД представляют собой текстовые элементы (ТЭ) лингвистического предложения (ЛП), а также идентификационные данные ТЭ, представляющие собой в качестве примера, но не ограничения: значения ТЭ и порядковые номера ТЭ в лингвистическом предложении; выполнении этапа 102 формирования базы данных лингво-логических признаков (БДЛЛП), на котором на основании сведений, содержащихся в первой СД, выявляют лингвистические и логические признаки ТЭ лингвистического предложения, из которых формируют базу данных, представляющую собой базу данных лингвистических и логических признаков текстовых элементов лингвистического предложения; выполнении этапа 103 формирования второй СД, на котором на основании сведений, содержащихся в БДЛЛП, первой СД, а также на основании формализованной модели простого суждения, формируют вторую СД СМД, содержащую элементы упомянутой второй СД, причем упомянутые элементы второй СД представляют собой компоненты простых суждений (КПС), а также идентификационные данные КПС, представляющие собой в качестве примера, но не ограничения: значения КПС и порядковые номера ТЭ лингвистического предложения, составляющих КПС; выполнении этапа 104 формирования третьей СД, на котором на основании сведений, содержащихся в БДЛЛП, второй СД, а также на основании формализованной модели простого суждения, формируют третью СД СМД, содержащую элементы упомянутой третьей СД, причем упомянутые элементы третьей СД представляют собой простые суждения (ПС) лингвистического предложения, а также идентификационные данные ПС, представляющие собой в качестве примера, но не ограничения: значения ПС и порядковые номера ТЭ лингвистического предложения, составляющих ПС; выполнении этапа 105 формирования онтологической базы данных системных и семантических связей в третьей СД, на котором на основании сведений, содержащихся в БДЛЛП, второй СД, третьей СД, а также на основании критериев поиска системных и семантических однородностей, выявляют и регистрируют системные и семантические связи между компонентами ПС, из которых формируют онтологическую базу данных системных и семантических связей компонентов ПС в третьей СД (ОБД); выполнении этапа 106 формирования базы данных отношений в третьей СД, на котором на основании сведений, содержащихся в ОБД, а также на основании критериев поиска искомых суждений, сравнивают компоненты ПС, а также классифицируют и регистрируют виды отношений между сравниваемыми компонентами ПС, из которых формируют базу данных отношений компонентов ПС в третьей СД (БДО); выполнении этапа 107 формирования четвертой СД, на котором на основании сведений, содержащихся в БДО, третьей СД, а также на основании упомянутых критериев поиска искомых суждений, формируют четвертую СД, содержащую элементы четвертой СД, причем упомянутые элементы четвертой СД представляют собой искомые суждения (ИС), а также идентификационные данные ИС, представляющие собой в качестве примера, но не ограничения: значения ИС и порядковые номера текстовых элементов (ТЭ) лингвистического предложения, составляющих ИС.
[0043] На фиг. 2, в качестве примера, но не ограничения, изображена примерная общая схема выполнения этапов этапа 101 формирования первой структуры данных. Этап 101 характеризуется: выполнением этапа 1011 идентификации исходной структуры данных СМД на котором идентифицируют элементы 11 исходной структуры данных СМД, являющиеся лингвистическими предложениями 11 (ЛП 11); выполнением этапа 1012 идентификации элементов 21 первой структуры данных СМД, на котором идентифицируют элементы 21 первой структуры данных СМД, являющиеся текстовыми элементами (ТЭ 21) лингвистического предложения 11, а также идентификационные данные ТЭ 21, представляющие собой в качестве примера, но не ограничения значения 211 ТЭ 21 и порядковые номера 212 ТЭ 21 в лингвистическом предложении 11, и формируют первую структуру данных СМД.
[0044] На фиг. 3, в качестве примера, но не ограничения, изображена общая структура исходной структуры данных (ИСД 1), из которой формируется первая структура данных СМД. Исходные данные представляют собой СМД, содержащий элементы 11 исходной структуры данных, представляющие собой лингвистические предложения (ЛП). Такой массив данных представляет собой множество лингвистических предложений 11, относящихся к любой области деятельности и любого назначения, в том числе и тексты правовых актов. У элементов 11 отсутствуют характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных элементы 11 в качестве примера, но не ограничения могут именоваться как «ЛП 1», «ЛП 2», «ЛП n», где n ≥ 1 - порядковый номер элемента в массиве лингвистических предложений. Лингвистическое предложение – это грамматически организованное соединение слов (множество синтаксически связанных слов), обладающее смысловой и логической завершенностью. ЛП содержит следующие объекты: слова, цифры (числа), знаки препинания и индексы (конструкции из букв, цифр и знаков, в том числе формулы (набор букв, цифр и знаков без пробелов, в котором используются специальные символы (например, но не ограничиваясь, звездочка, плюс, минус, равно, больше, меньше, интеграл и тому подобное, характеризующие суть формулы)). Все перечисленные выше объекты, отделены друг от друга в предложении пробелом, за исключением знаков препинания (они присоединены к словам, цифрам и индексам) и формул, и именуются элементами ЛП 11. ЛП 11 в исходной структуре данных представляют собой отдельные элементы, заранее подготовленные и помещенные в исходную структуру данных не в виде лингвистического текста, а в виде структурированного массива (списка, перечня и тому подобного) отдельных ЛП. Такие подготовительные действия могут осуществляться любым известным из уровня техники способом и, соответственно, далее не описываются. Идентификация элементов 11 исходной структуры данных в рамках этапа 1011 сводится к обеспечению классификации элементов, из которых состоит исходная структура данных, и выделению таких элементов как лингвистических предложений (ЛП 11). Исходная структура данных представляет собой таким образом множество элементов 11, идентифицированных на этапе 1011.
[0045] На фиг. 4, в качестве примера, но не ограничения, изображена общая структура сформированной первой структуры данных. Первая структура данных представляет собой СМД, содержащий элементы 21 первой структуры данных, которые представляют собой текстовые элементы (ТЭ 21) лингвистического предложения 11 и идентификационные данные ТЭ 21. У текстовых элементов 21 лингвистического предложения 11 отсутствуют характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных элементы 21 в качестве примера, но не ограничения могут именоваться как «ТЭ 1», «ТЭ 2», «ТЭ 3» «ТЭ n», где n ≥ 1 - порядковый номер элемента в лингвистическом предложении 11. ТЭ 21 лингвистического предложения (ЛП 11) являются текстовыми элементами ЛП, то в качестве примера, но не ограничения текстовыми элементами могут быть ТЭ первичного вида, а именно словами, цифрами (числами), знаками препинания или индексами (конструкциями из букв, цифр и знаков), содержащимися в ЛП и отделенными друг от друга пробелом, за исключением знаков препинания. Текстовыми элементами иного вида могут быть, в качестве примера, но не ограничения, словоформы, то есть группы слов, отличающиеся от первичных ТЭ тем, что представляют собой не формально отдельное слово предложения (то есть букву или набор букв, отделенных пробелом от других слов), а группу слов, которая с лингвистической точки зрения является одним морфологическим и синтаксическим объектом. Такая группа слов именуется «сложной словоформой». Например, слова «в», «соответствие» и «с» представляют собой, как кажется, несколько ТЭ, хотя на самом деле являются одним сложным текстовым элементом «в соответствии с», который и выявляется на этапе 1012 как один ТЭ 21. Текстовые элементы 21 лингвистического предложения 11 имеют идентификационные данные ТЭ 21, в качестве примера, но не ограничения: значение 211 ТЭ и номер 212 ТЭ. Значением 211 ТЭ является набор букв, цифр, знаков, из которых состоит ТЭ 21. Номером 212 ТЭ является порядковый номер ТЭ 21 в лингвистическом предложении 11. Идентификацию и формирование текстовых элементов 21 первой структуры данных в ходе этапа 1012 производят путем анализа текста и выявления (выделения) отдельных текстовых элементов согласно их вида и описания, которое должно быть известно заранее. Например, но не ограничиваясь, такой анализ может производиться путем выделения в предложении слов, чисел или индексов, разделенных друг от друга пробелом, а также знаков препинания, которые присоединены к упомянутым словам, числам и индексам. При этом предпочтительно, чтобы последний знак препинания в предложении не учитывался и не рассматривался в качестве текстового элемента 21 лингвистического предложения 11. Такой анализ может быть выполнен любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такой анализ может быть выполнен традиционно специалистом-лингвистом, или же с помощью программного алгоритма лингвистического (синтаксического) процессора. Более того, при наличии достаточного количества примеров возможно выполнение такого анализа с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. Идентификацию значения 211 текстового элемента 21 первой структуры данных в ходе этапа 1012 производят путём регистрации символов (букв, цифр, знаков), из которых состоит текстовый элемент 21. Идентификацию номера 212 текстового элемента 21 первой структуры данных в ходе этапа 1012 производят путём расчета местоположения ТЭ 21 в лингвистическом предложении 11. При этом первый текстовый элемент 21 в лингвистическом предложении 11 получает номер 1, а все последующие ТЭ получают номер больше на 1, чем номер предыдущего ТЭ 21. Формирование первой структуры данных СМД в ходе этапа 1012 производят путем объединения в одной структуре данных элементов 21 первой структуры данных СМД, а также их идентификационных данных по известным из уровня техники принципам и способам, которые, соответственно далее подробно не описываются.
[0046] На фиг. 5, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 102 формирования базы данных лингво-логических признаков, представляющей собой базу данных лингвистических и логических признаков текстовых элементов 21 предложения 11 после выполнения этапа 102. Этап 102 характеризуется выполнением этапа 1021 формирования первой части лингво-логических признаков ТЭ лингвистического предложения, на котором для лингвистического анализа ТЭ, содержащихся в первой СД и классифицированных как слово, предоставляют идентификационные данные ТЭ и получают лингвистические характеристики ТЭ, а также значения упомянутых лингвистических характеристик; выполнением этапа 1022 формирования второй части лингво-логических признаков ТЭ лингвистического предложения, на котором для логического анализа ТЭ, содержащихся в первой СД и классифицированных как слово, предоставляют идентификационные данные ТЭ, а также лингвистические характеристики ТЭ лингвистического предложения вместе с упомянутыми значениями лингвистических характеристик, и получают логические характеристики ТЭ лингвистического предложения, а также значения упомянутых логических характеристик; выполнением этапа 1023 формирования базы данных лингво-логических признаков (БДЛЛП), на котором формируют БДЛЛП первичных текстовых элементов лингвистического предложения, при этом лингво-логическими признаками ТЭ являются все полученные по соответствующему ТЭ в ходе этапов 1021 и 1022 упомянутые лингвистические характеристики и упомянутые логические характеристики, обладающие соответствующими упомянутыми значениями лингвистических характеристик и упомянутыми значениями логических характеристик.
[0047] На фиг. 6, в качестве примера, но не ограничения, изображена общая структура сформированной базы данных лингво-логических признаков (БДЛЛП), являющейся БДЛЛП текстовых элементов 21 лингвистического предложения 11 после выполнения этапа 102. Первая часть лингво-логических признаков 213 текстовых элементов 21 лингвистического предложения 11 может содержать лингвистические характеристики (морфологические, синтаксические и семантические характеристики). При этом совокупность значений всех лингвистических характеристик текстового элемента является для каждого ТЭ 21 лингвистического предложения 11 его отличительным (уникальным) лингвистическим признаком в лингвистическом предложении 11. Морфологические характеристики предпочтительно указывают на морфологические признаки ТЭ 21 лингвистического предложения 11, которые могут быть классифицированы, в качестве примера, но не ограничения, по уровню вложенности (род-вид-подвид). При этом морфологическими родами ТЭ 21 лингвистического предложения 11 предпочтительно являются слово, цифра, знаки препинания, иные знаки; морфологическими видами – часть речи (для слов), вид цифры (арабская, римская), вид знака препинания (точка, запятая и тому подобное), вид иного знака, вид индекса (формула, сложная нумерация и тому подобное); морфологическими подвидами – род, число, падеж частей речи и тому подобное для слов, а также число, двоичный код, индекс и тому подобное для цифр. Синтаксические характеристики предпочтительно указывают на множество синтаксических признаков ТЭ 21 лингвистического предложения 11, среди которых можно выделить, в качестве примера, но не ограничения, следующие синтаксические признаки ТЭ 21 лингвистического предложения 11: синтаксическая роль (сказуемое, подлежащее и тому подобное); синтаксический родитель (синтаксически главное слово); синтаксические потомки (синтаксически подчиненные слова); синтаксическая сочинительная связь (наличие иного ТЭ, имеющего ту же синтаксическую роль и того же синтаксического родителя). Семантические характеристики предпочтительно указывают на семантические признаки ТЭ 21 лингвистического предложения 11, среди которых можно выделить, в качестве примера, но не ограничения, следующие семантические характеристики ТЭ 21 лингвистического предложения 11: семантическая группа (группа слов, которые можно отнести к одному классу, роду, виду или подвиду предметов или действий окружающего мира при совпадении признаков упомянутых классов, родов, видов или подвидов), семантический статус (смысловое значение слова или группы слов в рамках словосочетания, которым называется некий мыслимый образ (предмет или действие) - например, но не ограничиваясь, мыслимый образ «отсутствие продавца в месте нахождения потребителя» состоит из двух элементов верхнего уровня (терминов): первого - «отсутствие продавца», и второго - «месте нахождения потребителя», у которых имеются следующие семантические статусы: у первого – главный (определяет смысл термина), у второго - дополнительный (уточняет определенный ранее смысл главного термина)). Вторая часть лингво-логических характеристик 214 текстовых элементов 21 лингвистического предложения 11 содержит логические характеристики. При этом совокупность значений всех логических характеристик текстового элемента является для каждого ТЭ 21 лингвистического предложения 11 его отличительным (уникальным) логическим признаком в лингвистическом предложении 11. Логические характеристики предпочтительно указывают на логические признаки ТЭ 21 лингвистического предложения 11, среди которых можно выделить, в качестве примера, но не ограничения, следующие логические характеристики ТЭ 21 лингвистического предложения 11: логические роли каждого слова, являющегося ТЭ 21, в лингвистическом предложении 11. Под логической ролью слова понимается логическая позиция слова в логических сущностях (логических объектах) предложения, среди которых можно выделить, в качестве примера, но не ограничения, следующие логические сущности (логические объекты): понятие, признак понятия, термин (часть образа), образ (элемент простого суждения), простое суждение, сложное суждение. Выявление логической роли слова в самых простых логических объектах (понятие и признак понятия) не зависит от формализованной логической модели предложения, и представляет собой метку (индекс), который указывает на то, чем является данное слово в указанных простых логических объектах. Например, слово «закон» всегда есть логический объект «понятие», а слово «федеральный» есть логический объект «признак понятия». Выявление логической роли слова в более сложных (составных) логических объектах (например, термин и образ) зависит от формализованной логической модели предложения, в привязке к элементам которой и будет установлена логическая роль слова. Формирование первой части лингво-логических характеристик - лингвистических характеристик 213 и их значений 2131 для текстовых элементов 21 лингвистического предложения 11 - предпочтительно производят на этапе 1021 путем первого комплексного лингвистического анализа каждого текстового элемента 21 лингвистического предложения 11, представляющего собой анализ ТЭ 21, в качестве примера, но не ограничения например, анализ на основе местонахождения ТЭ в структуре предложения, его значения, вида, классификации его мыслимого образа и анализа его связей с другими текстовыми элементами в предложении. По результатам первого комплексного анализа предпочтительно производится формирование лингвистических характеристик 213 и их внесение на этапе 1023 в БДЛЛП в виде перечня лингвистических характеристик 213 со значениями этих характеристик 2131. Например, но не ограничиваясь, одной из лингвистических характеристик 213 может быть «синтаксическая роль» ТЭ 21, со значением данной лингвистической характеристики - «подлежащее». Такой анализ может быть выполнен любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такой анализ может быть выполнен традиционно специалистом-лингвистом, или же с помощью программного алгоритма лингвистического (синтаксического) процессора. Более того, при наличии достаточного количества примеров возможно выполнение такого анализа с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. Формирование второй части лингво-логических характеристик - логических характеристик 214 и их значений 2141 для текстовых элементов 21 лингвистического предложения 11 - предпочтительно производят на этапе 1021 путем второго комплексного лингвистического анализа каждого первичного текстового элемента 21 лингвистического предложения 11, представляющего в качестве примера, но не ограничения анализ ТЭ 21 на основе местонахождения ТЭ 21 в структуре предложения, его значения, вида, классификации его мыслимого образа и анализа его связей с другими текстовыми элементами в предложении, а также анализа выявленных лингвистических характеристик 213 и их значений 2131 ТЭ 21. По результатам второго комплексного анализа предпочтительно производится формирование логических характеристик 214 и их внесение на этапе 1023 в БДЛЛП в виде перечня логических характеристик 214 со значениями этих характеристик 2141. Например, но не ограничиваясь, одной из логических характеристик 214 может быть «логическая роль» ТЭ 21, со значением данной логической характеристики - «признак понятия». Такой анализ может быть выполнен любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такой анализ может быть выполнен традиционно специалистом-лингвистом, или же с помощью программного алгоритма лингвистического (синтаксического) процессора. Более того, при наличии достаточного количества примеров возможно выполнение такого анализа с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. На основании выявленных первой части лингво-логических характеристик 213 текстовых элементов 21 лингвистического предложения 11 и их значений 2131, а также второй части лингво-логических характеристик 214 текстовых элементов 21 лингвистического предложения 11 и их значений 2141 в итоге формируют базу данных лингво-логических признаков, являющуюся БДЛЛП текстовых элементов 21 лингвистического предложения 11, созданной после выполнения этапа 102. При этом первая часть лингво-логических характеристик 213 текстовых элементов 21 лингвистического предложения 11 и их значения 2131 формируют уникальные лингвистические признаки ТЭ 21 лингвистического предложения 11, а вторая часть лингво-логических характеристик 214 текстовых элементов 21 лингвистического предложения 11 и их значения 2141 формируют уникальные логические признаки ТЭ 21 лингвистического предложения 11.
[0048] На фиг. 7, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 103 формирования второй структуры данных СМД. Этап 103 характеризуется: выполнением этапа 1031, формирования элементов второй СД, на котором на основании сведений, содержащихся в БДЛЛП, первой СД, а также на основании формализованной модели простого суждения, идентифицируют и формируют элементы второй СД, являющиеся компонентами простого суждения (КПС), а также идентификационные данные КПС; выполнением этапа 1032 формирования второй СД, на котором формируют вторую СД из идентифицированных КПС и их идентификационных данных.
[0049] На фиг. 8, в качестве примера, но не ограничения, изображена общая структура сформированной второй структуры данных СМД. Вторая СД представляет собой СМД, содержащий элементы 31 второй структуры данных, которые представляют собой компоненты простых суждений (КПС 31) лингвистического предложения 11 и идентификационные данные КПС 31. Идентификационные данные КПС представляют собой в качестве примера, но не ограничения значения 311 элементов 31 второй структуры данных СМД и порядковые номера 312 ТЭ 21 лингвистического предложения 11, составляющих элементы 31. Компоненты простых суждений КПС 31 представляют собой различные синтаксические единицы лингвистического предложения 11, например, в качестве примера, но не ограничения: слова (словоформы); различные словосочетания, являющиеся «понятиями с признаком», «группой понятий с признаками» (терминами), «группой терминов» (образом или элементом простого суждения) и тому подобное. Виды компонентов, которые требуется идентифицировать при формировании второй структуры данных СМД зависит от формализованной модели простого суждения и детализации формализованной модели простого суждения, то есть выделения в структуре формализованной модели простого суждения отдельных компонентов. Компоненты простого суждения 31 могут быть как минимум двух видов – первые компоненты КПС 31.1 (самые мелкие компоненты, представляющие собой исходные элементы, из которых формируются все остальные, более крупные компоненты) и вторые компоненты КПС 31.2 (самые крупные компоненты, представляющие собой исходные «блоки», из которых формируются простые суждения, и именуемые «элементами простых суждений»). В связи с этим, КПС 31, как минимум, содержат первый КПС 31.1 и второй КПС 31.2. При этом КПС 31 могут быть и иные виды компонентов 31.х, содержащиеся в формализованной модели простого суждения. При этом индекс x ≥ 3, соответствует порядковому номеру компонента 31 иного вида, находящемуся в формализованной модели простого суждения между компонентами 31.1. и 31.2). Например, но не ограничиваясь, компонентом иного вида для перечисленных первых и вторых КПС 31 может быть компонент «термин». Такие компоненты представляют собой структурные элементы, из которых состоит второй компонент КПС 31 «элемент простого суждения». То есть, в зависимости от текста предложения, второй КПС 31 может состоять из одного, двух или более КПС 31 вида «термин». Например, но не ограничиваясь, при значении 311 второго КПС 31 – «права потребителей в сфере торговли» можно идентифицировать в нем два отдельных КПС 31 иного вида (вида «термин») – «права потребителей» и «в сфере торговли». Первым компонентом (ПК), в качестве примера, но не ограничения, могут являться такие компоненты, которые именуются «понятие» и «признак». Понятием являются объекты или действия, выделенные и обобщенные в рамках некой классификации по их существенным признакам. Признаком является характеристика объекта или действия, указывающая на наличие или отсутствие у него того или иного свойства, состояния или отношения. Понятия и признаки выражаются в словах (словоформах). Вторым компонентом (ВК), в качестве примера, но не ограничения является такой компонент, который именуется «элементом простого суждения». ВК (КПС 31.2) представляет собой то, из чего состоят простые суждения, например, в качестве примера, но не ограничения, можно привести академическую модель простого суждения, в которой существуют два основных элемента «субъект» и «предикат». В такой формализованной модели «субъект» - это предмет о котором идет речь в суждении, предмет о котором что-либо утверждается или опровергается, а «предикат» - это то, что конкретно утверждается или опровергается о предмете суждения. Иным компонентом (ИК), в качестве примера, но не ограничения является такой компонент, который не является ни ПК (КПС 31.1), ни ВК (КПС 31.2), но при этом содержится в формализованной модели простого суждения. В качества примера, но не ограничения, можно привести такой компонент ИК как «понятие с признаком», представляющий собой несколько ПК (КПС 31.1), имеющих прямую синтаксическую подчинительную связь. Такой компонент является структурно более крупным объектом, чем ПК (в качестве примера, но не ограничения - «федеральный закон», состоящий из двух ПК: «федеральный» и «закон»). У ПК (КПС 31.1) лингвистического предложения 11, которые являются отдельными словоформами, отсутствуют характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных КПС 31 в качестве примера, но не ограничения могут именоваться как «КПС 1.1», «КПС 2.1», «КПС 3.1» «ИТЭ n.1», где первое число (1; 2; 3 и так далее) – порядковый номер ПК в лингвистическом предложении 11; второе число «1» (после точки) указывает на то, что это КПС первого вида; n ≥ 1 - порядковый номер элемента в лингвистическом предложении 11. У ВК (КПС 31.2) лингвистического предложения 11, которые являются элементами простого суждения, имеются характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных КПС 31, которые являются элементами простого суждения в качестве примера, но не ограничения, могут именоваться как «КПС 1.2», «КПС 2.2», «КПС 3.2», «КПС n.2»,, где первое число (1; 2; 3 и т.д.) – порядковый номер ВК в лингвистическом предложении 11; второе число «2» (после точки) указывает на то, что это КПС второго вида; n ≥ 1 - порядковый номер элемента в лингвистическом предложении 11. При этом, в качестве примера, но не ограничения элементы ПС 12 могут именоваться так, как установлено в формализованной модели простого суждения, например: «субъект», «объект», «действие», «условие» и тому подобное. У иных компонентов (ИК) простого суждения КПС 31.x лингвистического предложения 11 наличие характеризующих их уникальных наименований (УН), имеющих практическое использование, зависит от принятой формализованной модели простого суждения. В структуре данных такие КПС 31 в качестве примера, но не ограничения могут именоваться как «КПС 1.x», «КПС 2.x», «КПС 3.x» «КПС n.х», где первое число (1; 2; 3 и т.д.) – порядковый номер ИК в лингвистическом предложении 11; второе число «х» (после точки) указывает на порядковый номер КПС иного вида, начиная с 3 и далее; n ≥ 1 - порядковый номер элемента в лингвистическом предложении 11. КПС 31 лингвистического предложения 11, состоящие из компонентов минимум двух видов 31.1 и 31.2 - имеют идентификационные данные КПС: в качестве примера, но не ограничения: значения 311 КПС, состоящие из значений 311.1 и 311.2 компонентов минимум двух видов 31.1 и 31.2, и номера 312 КПС, состоящие из номеров 312.1 и 312.2 компонентов минимум двух видов 31.1 и 31.2. Значениями 311 КПС являются наборы слов (ТЭ 21), из которых состоят как минимум КПС 311.1 и КПС 311.2. Номерами 312 КПС являются порядковые номера КПС 312.1 и КПС 312.2 слов (словоформ) ПК 21, из которых состоят как минимум КПС 31.1 и КПС 31.2 в лингвистическом предложении 11. Идентификация и формирование компонентов простого суждения КПС 31(КПС 31.1, КПС 31.2, КПС 31.х) второй структуры данных в ходе этапа 1031 производят путем комплексного лингво-логического анализа элементов первой структуры данных СМД –текстовых элементов ТЭ 21 и их идентификационных данных. Такой комплексный анализа ТЭ 21 производится с помощью сведений о ТЭ 21 и с помощью сведений из сформированной БДЛЛП первичных текстовых элементов 21, а также на основании представления о формализованной модели простого суждения и с учетом уже сформированных более мелких компонентов простого суждения (то есть КПС 31.1, либо компонентов с меньшим индексом х, чем у формируемого (например, не ограничиваясь, при формировании КПС 31.2 необходимо учитывать сформированные ранее КПС 31.1, а при формировании КПС 31.12 необходимо учитывать сформированные ранее КПС 31.11 и КПС 31.1)). При этом формализованная модель простого суждения содержит минимум два вида компонентов – первый компонент (ПК), как первый вид КПС 31, и второй компонент (ВК), как второй вид КПС 31. Таким образом формализованной моделью простого суждения считается такая система описания простого суждения, которая имеет не менее чем два упомянутых компонента. Целью упомянутого комплексного анализа является выявление в лингвистическом предложении всех компонентов простого суждения, установленных в формализованной модели простого суждения. Идентификация и формирование КПС 31 второй структуры данных в ходе этапа 1031 производится пошагово. Количество шагов этапа 1031 зависит от используемой формализованной модели простого суждения. Модель простого суждения содержит установленное число видов компонентов простого суждения. В соответствии с этим количеством видов компонентов и определяется количество шагов этапа 1031, поскольку на одном шаге возможны идентификация и формирование только одного вида компонента. При этом, поскольку формализованная модель простого суждения минимально может содержать не менее двух компонентов, минимальное число шагов также будет равняться двум. В качестве примера, но не ограничения, приведен пример идентификации и формирования первого (КПС 31.1) и второго (КПС 31.2) компонентов простого суждения КПС 31. Для идентификации первого компонента КПС 31.1 – например, «словоформ», производят лингвистический анализ ТЭ 21 предложения 11. В качестве примера, но не ограничения, рассмотрено следующее предложение: «Товар передается в соответствии с договором». На основании морфологических и синтаксических признаков (характеристик) каждого ТЭ 21, выявленного в ходе формирования первой структуры данных СМД, установлено, что данное предложение содержит следующие первые компоненты (КПС 31.1), являющиеся словоформами (таблица 1):
Таблица 1
[0050] Для идентификации второго компонента КПС 31.2 – например, «элементов простого суждения», производят лингвистический анализ ТЭ 21 предложения 11, а также первых компонентов КПС 31.1, уже сформированных на предыдущем шаге (в данном примере – это ПК, указанные в таблице 1). В качестве примера, но не ограничения рассматривается то же предложение: «Товар передается в соответствии с договором». На основании морфологических и синтаксических признаков (характеристик) каждого первичного текстового элемента (ТЭ 21), выявленного в ходе формирования первой структуры данных СМД, а также с учетом ранее сформированных первых компонентов КПС 31.1 и формализованной модели простого суждения, устанавливается, что данное предложение содержит следующие «элементы простого суждения» (КПС 31.2), являющиеся словоформами, либо словосочетаниями (таблица 2):
Таблица 2
[0051] В качестве примера, но не ограничения, приводится пример идентификации и формирования значений 311.1 для КПС 31.1 вида ПК в том же предложении «Товар передается в соответствии с договором». Значением для КПС 31.1. будут являться полученные в ходе идентификации словоформ. Упомянутый анализ производят путем корреляции текстовых элементов 21 и компонента КПС 31 анализируемого вида (в данном примере - словоформ). В ходе такой корреляции формируется таблица соответствия первичных текстовых элементов ТЭ 21 и словоформ (КПС 31.1). В качестве примера, но не ограничения продемонстрирован пример такой таблицы корреляции (таблица 3):
Таблица 3
[0052] В результате, исходя из данных таблицы корреляции (таблицы 3) ТЭ 21 и КПС 31.1, идентифицируют значение 311.1 КПС 31.1 как слово или набор слов, соответствующие конкретному компоненту КПС 31.1, а также идентифицируют номера 312.1 КПС 31.1 как порядковые номера ТЭ 21, из которых сформированы КПС 31.1. Такая идентификация и формирование могут быть выполнены любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такая идентификация и формирование могут быть выполнены традиционно специалистом-лингвистом, или же с помощью программного алгоритма лингвистического (синтаксического) процессора. Более того, при наличии достаточного количества примеров возможно выполнение такой идентификации и формирование с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. Формирование второй структуры данных СМД в ходе этапа 1032 производят путем объединения в одной структуре данных элементов 31 (КПС) второй структуры данных СМД, а также их идентификационных данных по известным из уровня техники принципам и способам, которые, соответственно далее подробно не описываются.
[0053] На фиг. 9, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 104 формирования третьей структуры данных СМД. Этап 104 характеризуется: выполнением этапа 1041 формирования элементов третьей СД, на котором на основании сведений, содержащихся в БДЛЛП и второй СД, из сформированных КПС в соответствии с формализованной компонентной моделью простого суждения формируют элементы третьей СД, являющиеся простыми суждениями (ПС), а также идентификационные данные ПС, представляющие собой в качестве примера, но не ограничения значения ПС и порядковые номера ТЭ в лингвистическом предложении, составляющих ПС; выполнением этапа 1042 формирования третьей СД, на котором формируют третью СД из сформированных ПС и их идентификационных данных.
[0054] На фиг. 10, в качестве примера, но не ограничения, изображена общая структура сформированной третьей структуры данных СМД. Третья структура данных представляет собой СМД, содержащий элементы 13, которые представляют собой простые суждения (ПС 13) лингвистического предложения 11 и идентификационные данные ПС 12. У элементов 13 лингвистического предложения 11 имеются характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных элементы 13 в качестве примера, но не ограничения могут именоваться как «ПС 1», «ПС 2», «ПС 3», «ПС n», », где n ≥ 1 - порядковый номер элемента в лингвистическом предложении 11. При этом, в качестве примера, но не ограничения, простые суждения ПС 13 могут именоваться как «диспозиция», «санкция», «гипотеза» в юридической предметной области и тому подобное в иных предметных областях. С лингвистической точки зрения ПС 13 это простые предложения. При этом возможны различные варианты простых предложений, которые могут считаться простыми суждениями 13, например, но не ограничиваясь данным примером, можно привести следующие виды простых предложений: 1) простые предложения в изначальном, непреобразованном виде; 2) простые предложения в преобразованном виде, например: а) без причастных или деепричастных оборотов: б) без однородностей (обезоднородненные, без рядов однородных членов); в) без вставок (без текста в скобках); г) без условных именований (без текста в кавычках); д) без обстоятельств (условий); и тому подобные, включая сочетания вышеуказанных и неуказанных видов. Простое суждение ПС 12 с логической точки зрения - это утверждение или опровержение о субъекте суждения. Простое суждение представляет собой первичную логическую конструкцию мышления с помощью которой формируется и передается мысль о том, что нечто (предикат суждения) утверждается или опровергается о предмете суждения (субъект суждения). ПС 13 с точки зрения отдельных предметных областей - это конструкция, описанная формализованной моделью простого суждения. Самыми крупными элементами данной конструкции (формализованной модели простого суждения) являются вторые компоненты простого суждения (КПС 31.2). КПС 31.2 простого суждения 13 с лингвистической точки зрения представляют собой синтаксическую единицу вида «исходный синтаксический объект», либо «синтаксическая конструкция». В зависимости от того, что сообщает простое суждение (насколько отдельные КПС 31.2 являются развернутыми, раскрытыми образами), компоненты простого суждения могут быть выражены как отдельными словами («исходный синтаксический объект»), так и словосочетаниями («синтаксическая конструкция» - набор синтаксически связанных слов). В качестве примера, но не ограничения, можно привести различные варианты значений 311.2 КПС 31.2, с помощью которых передается один и тот же образ: «старый человек» = «старик» = «человек преклонных лет» и тому подобное. Указанные варианты значений 311.2 КПС 31.2 выражаются как одним словом, так и словосочетаниями. В качестве примера, но не ограничения, можно привести пример КПС 31.2, который не может быть передан с помощью одного слова - «права потребителей». С логической точки зрения простое суждение ПС 13 представляет собой утверждение, либо отрицание, в котором что-либо, соответственно, утверждается или опровергается о предмете суждения. С семантической точки зрения КПС 31.2 простого суждения 13 представляет собой обобщенный мыслимый (семантический) образ элемента простого суждения. Например, не ограничиваясь, для предметной области «право» простое суждение может быть соотнесено с частью правовой нормы, а именно в качестве примера, но не ограничения, с «диспозицией» (правило, которое необходимо соблюдать), «санкцией» (правило, которое определяет меру ответственности за нарушение правил) или «гипотезой» (обусловленностью правила, отражающего какое-либо предварительное действие, ситуацию или состояние). Данные правовые сущности содержаться в простых предложениях правовых актов. Для формализации простого суждения в предметной области права необходимо создать формализованную модель правовой нормы. В рамках профессиональной дискуссии может быть сформулировано некоторое количество различных формализованных моделей правовой нормы. При этом специалистам в данной области техники очевидна жесткая связь между логическим «простым суждением» и частью правовой нормы (гипотезой, диспозицией, санкцией), что в качестве примера, но не ограничения продемонстрировано в следующих примерах в рамках некой формализованной модели упомянутых частей правовой нормы (таблица 4):
Таблица 4
[0055] В данном примере формализации простого суждения использованы следующие КПС 31.2. формализованной модели простого суждения: «субъект» - это предмет суждения, то о чем идет речь в суждении, «объект» - это предмет на который направлено действие (часть предиката суждения), «комплемент субъекта» - это иное именование субъекта, выраженное с помощью действия, «действие» - это способ описания сути утверждения о субъекте (либо в рамках его взаимодействия с объектом, его комплементом, либо в отношении него самого), «контр-субъект» - это второй (иной) субъект, с которым взаимодействует субъект в рамках простого суждения, «условие» - некие обстоятельства на фоне которых (при условии наличия которых) утверждение о субъекте является актуальным. Простые суждения 13 лингвистического предложения 11 имеют идентификационные данные, в качестве примера, но не ограничения: значение 131 ПС и номер 132 ПС. Значением 131 ПС является набор значений итоговых текстовых элементов (КПС 31.1), составляющих простое суждение 13 предложения 11. Номером 132 ПС являются порядковые номера ТЭ 21, из которых сформированы все значения 212, составляющие простое суждение 13 предложения 11. Формирование простых суждений ПС 13 третьей структуры данных в ходе этапа 1041 производят на основании сведений о формализованной модели простого суждения, а также с учетом сформированного ранее массива компонентов 31 простого суждения 13 путем объединения компонентов 31 простого суждения согласно формализованной модели простого суждения и с учетом сведений из БДЛЛП текстовых элементов (ТЭ 21) о наличии синтаксических связей между ТЭ 21, входящими в различные компоненты 31 простого суждения 13 лингвистического предложения 11. Идентификацию значения 131 простого суждения 13 третьей структуры данных в ходе этапа 1041 производят путем отождествления значения 121 простого суждения 12 со значениями 311.2 всех компонентов простого суждения 31.2, формирующих данное простое суждение ПС 13. Идентификацию номеров 132 простого суждения 13 третьей структуры данных в ходе этапа 1041 производят путём отождествления номеров 132 простого суждения 13 с номерами 312.2 всех компонентов простого суждения 31.2, формирующих данное простое суждение ПС 13. Такие идентификация и формирование могут быть выполнены любым известным из уровня техники способом и, соответственно, подробно далее не описываются. Например, не ограничиваясь, такие идентификация и формирование могут быть выполнены традиционно специалистом-лингвистом, или же с помощью программного алгоритма лингвистического (синтаксического) процессора. Более того, при наличии достаточного количества примеров возможно выполнение таких идентификации и формирования с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. Формирование третьей структуры данных СМД в ходе этапа 1042 производят путем объединения в одной структуре данных элементов 12 третьей структуры данных СМД и их идентификационных данных по известным из уровня техники принципам и способам, которые, соответственно далее подробно не описываются.
[0056] Далее, после завершения описанного ранее этапа 104, в целях повышения точности последующего поиска в структурированном массиве данных, содержащем, по меньшей мере, простые суждения (ПС) лингвистического предложения и их идентификационные данные, становится возможным осуществить дальнейшее структурирование и классифицирование СД СМД, содержащих, по меньшей мере, компоненты простого суждения (КПС) лингвистического предложения и их идентификационные данные. Специалисту в данной области техники должно быть очевидно, что посредством получаемой в результате реализации этапа 104 третьей СД становится возможным использовать ее для различных необязательных процессов и способов, которые тем не менее, могут иметь практическое значение в контексте рассматриваемого изобретения. Такие необязательные процессы в качестве примера, но не ограничения, описанный далее со ссылками на фиг. 11-26, а также со ссылками на способы 200, 300, как таковые, и со ссылками на этапы 105-107 способа 100.
[0057] На фиг. 11, в качестве примера, но не ограничения, изображена общая схема выполнения этапов заявленного способа 200 формирования онтологической базы данных структурированного массива данных (СМД). Заявленный способ 200 формирования онтологической базы данных структурированного массива данных (СМД) заключается в: выполнении этапа 201 идентификации второй СД (являющейся первой СД для рассматриваемого способа 200), идентификации третьей СД (являющейся второй СД для рассматриваемого способа 200) и идентификации базы данных лингво-логических признаков (БДЛЛП); при этом идентифицированная вторая СД содержит компоненты простых суждений (КПС); при этом идентифицированная третья СД содержит простые суждения (ПС); при этом идентифицированная БДЛЛП, содержит сведения о лингвистических и логических признаках текстовых элементов (ЛЛПТЭ), причем упомянутые ЛЛПТЭ представляют собой лингвистические и логические признаки текстовых элементов (ТЭ) и их значения; выполнении этапа 105 формирования онтологической базы данных системных и семантических связей в третьей СД (являющейся второй СД для рассматриваемого способа 200), на котором на основании сведений, содержащихся в БДЛЛП, второй СД и третьей СД, а также на основании критериев поиска системных и семантических однородностей, выявляют и регистрируют системные и семантические связи между компонентами ПС, из которых формируют онтологическую базу данных системных и семантических связей компонентов ПС в третьей СД (ОБД). При этом, как указано ранее, упомянутой первой СД для рассматриваемого способа 200 (первой СД для способа 200) является любая пригодная для реализации способа 200 СД, содержащая упомянутые компоненты простых суждений. В качестве примера, но не ограничения, такой СД является описанная ранее со ссылкой на способ 100 вторая СД, или любая известная из уровня техники, в том числе в будущем, СД, содержащая упомянутые компоненты простых суждений. При этом, как указано ранее, упомянутой второй СД для рассматриваемого способа 200 (вторая СД для способа 200) является любая пригодная для реализации способа 200 СД, содержащая упомянутые простые суждения. В качестве примера, но не ограничения, такой СД является описанная ранее со ссылкой на способ 100 третья СД, или любая известная из уровня техники, в том числе в будущем, СД, содержащая упомянутые простые суждения. При этом, как указано ранее, упомянутой БДЛЛП является любая база данных, содержащая сведения о ЛЛПТЭ, представляющие собой лингвистические или логические признаки ТЭ и их значения. В качестве примера, но не ограничения, такой базой данных может быть описанная ранее со ссылкой на способ 100 БДЛЛП, или любая известная из уровня техники, в том числе в будущем, база данных, содержащая сведения о ЛЛПТЭ, представляющие собой лингвистические или логические признаки ТЭ и их значения.
[0058] На фиг. 12, в качестве примера, но не ограничения, изображена общая схема выполнения этапа 201 идентификации первой структуры данных (первой СД для способа 200), второй СД для способа 200, и базы данных лингво-логических признаков (БДЛЛП); при этом первая СД для способа 200 содержит компоненты простых суждений (КПС); при этом вторая СД для способа 200 содержит простые суждения (ПС); при этом БДЛЛП, содержит сведения о лингвистических и логических признаках текстовых элементов (ЛЛПТЭ), причем упомянутые ЛЛПТЭ представляют собой лингвистические и логические признаки текстовых элементов (ТЭ) и их значения. Этап 201 характеризуется выполнением идентификации пригодной для формирования ОБД структуры данных, содержащей компоненты простых суждений (КПС), на котором идентифицируют элементы 31 пригодной для формирования ОБД структуры данных, содержащей компоненты простых суждений (КПС), а также идентификационные данные элементов 31, представляющие собой для каждого элемента 31, в качестве примера, но не ограничения, значение 311 элемента 31 пригодной для формирования ОБД структуры данных, и порядковый (порядковые) номер (номера) 312 КПС лингвистического предложения 11, представляющие собой ТЭ 21, составляющие элемент 31, а также выполнением идентификации пригодной для формирования ОБД структуры данных, содержащей простые суждения (ПС), на котором идентифицируют элементы 13 пригодной для формирования ОБД структуры данных, содержащей простые суждений (ПС), а также идентификационные данные элементов 13, представляющие собой для каждого элемента 13, в качестве примера, но не ограничения, значение 131 элемента 13 пригодной для формирования ОБД структуры данных, содержащей ПС и порядковый (порядковые) номер (номера) 132 ПС лингвистического предложения 11, представляющие собой ТЭ 21, составляющие элемент 13, а также выполнением идентификации пригодной для формирования ОБД базы данных, содержащей сведения о лингвистических и логических признаках текстовых элементов (ТЭ), на котором идентифицируют лингво-логические признаки текстовых элементов 21 пригодной для формирования ОБД базы данных, содержащей лингвистические характеристики 213 текстовых элементов 21, пригодной для формирования ОБД базы данных, и значения лингвистических характеристик 2131 ТЭ, а также логические характеристики 214 текстовых элементов 21, пригодной для формирования ОБД базы данных, и значения логических характеристик 2141 ТЭ, а также сами текстовые элементы 21, пригодной для формирования ОБД базы данных, их значения 211 и их порядковые номера 212 в лингвистическом предложении 11. При этом упомянутые процессы идентификации могут происходить в любом пригодном порядке, в том числе, не ограничиваясь, одновременно и/или параллельно, в том числе частично параллельно.
[0059] На фиг. 13, в качестве примера, но не ограничения, изображена первая структура данных для способа 200, являющаяся первой исходной структурой данных для настоящего способа 200, представляющая собой пригодную для формирования ОБД структуру данных, содержащую компоненты простых суждений (КПС). В качестве примера, но не ограничения такой СД является описанная ранее со ссылкой на способ 100 вторая СД, которая таким образом дополнительно не описывается.
[0060] На фиг. 14, в качестве примера, но не ограничения, изображена вторая структура данных для способа 200, являющаяся второй исходной структурой данных для настоящего способа 200, представляющая собой пригодную для формирования ОБД структуру данных, содержащую простые суждения (ПС). В качестве примера, но не ограничения такой СД является описанная ранее со ссылкой на способ 100 третья СД, которая таким образом дополнительно не описывается.
[0061] На фиг. 15, в качестве примера, но не ограничения, изображена база данных лингво-логических признаков ТЭ, представляющая собой пригодную для формирования ОБД базу данных, содержащую лингвистические и логические характеристики и значения этих характеристик. В качестве примера, но не ограничения такой БДЛЛП является описанная ранее со ссылкой на способ 100 БДЛЛП, которая таким образом дополнительно не описывается.
[0062] На фиг. 16, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 105 (202) формирования онтологической базы данных системных и семантических связей в третьей СД (ОБД). Этап 105 (202) характеризуется выполнением этапа 1051 (2021) идентификации системных связей между КПС на основании сведений, содержащихся в БДЛЛП, второй СД и третьей СД (соответственно, первой и второй СД для рассматриваемого способа 200), а также на основании критериев поиска системных однородностей, и регистрации выявленных связей в качестве системных онтологических признаков (СсОП) и значений СсОП; выполнением этапа 1052 (2022) идентификации семантических связей между КПС на основании сведений, содержащихся в БДЛЛП, второй СД и третьей СД (соответственно, первой и второй СД для рассматриваемого способа 200), а также на основании критериев поиска семантических однородностей и регистрации выявленных связей в качестве семантических онтологических признаков (СмОП) и значений СмОП; выполнением этапа 1053 (2023) формирования онтологической базы данных системных и семантических связей в третьей СД (второй СД для способа 200), на котором формируют ОБД путем объединения всех выявленных онтологических признаков (СсОП и СмОП) компонентов простых суждений в третьей СД (второй СД для способа 200), при этом СсОП и СмОП являются всеми идентифицированными и зарегистрированными по каждому соответствующему компоненту простого суждения онтологическими признаками (СсОП и СмОП), обладающие соответствующими значениями СсОП и СмОП.
[0063] На фиг. 17, в качестве примера, но не ограничения, изображена общая структура сформированной онтологической базы данных системных и семантических связей в третьей СД (второй СД для способа 200), являющейся ОБД компонентов 31 простых суждений 13 в третьей структуре данных (второй СД для способа 200) после выполнения этапа 105 (202). Онтологическая база данных системных и семантических связей в третьей СД (второй СД для способа 200) представляет собой организованную структуру, созданную в соответствии с определенными правилами, и предназначенную для хранения, изменения и обработки упомянутых данных. ОБД является такая база данных, в которой элементы базы содержат информацию о различных связях с другими элементами этой базы. При этом элементами ОБД являются все компоненты 31 простых суждений 13 в третьей СД (второй СД для способа 200). Под термином «связь» понимается наличие системной и семантической связи между двумя компонентами 31 или между значениями 311 компонентов 31. Семантическая связь - это наличие каких-либо смысловых однородностей между двумя значениями 311 компонентов 31, указывающих на какое-либо соотношение смысловых объемов этих компонентов (соотношение мыслимых предметов или действий, которые выражают эти компоненты по смыслу). В качестве примера, но не ограничения можно привести следующие смысловые однородности между смысловыми объемами значений 311 компонентов 31: идентичность; эквивалентность; пересечение; поглощение; подчинение; противоречие; противоположность. Идентичность - это полное совпадение слов двух значений 311 компонентов 31 (например, но не ограничиваясь: «закон» и «закон»). Эквивалентность - это равнозначность смысловых объемов двух значений 31 компонентов 31, при условии, что нет полного совпадения слов у этих значений 311 компонентов 31, либо совпадения слов у двух значений 311 компонентов 31 нет вообще (например, но не ограничиваясь: «российский закон» и «закон России»). Пересечение - это такое соотношение смысловых объемов двух значений 311 компонентов 31, при котором смысловые объемы этих значений 311 компонентов 31 совпадают лишь частично (например, но не ограничиваясь: «учащийся» и «студент»). Поглощение - это такое соотношение смысловых объемов двух значений 311 компонентов 31, при котором смысловой объем первого значения 311 компонента 31 полностью поглощает смысловой объем второго значения 311 компонента 31, но при этом смысловой объем второго значения 311 компонента 31 является лишь частью смыслового объема первого значения 311 компонента 31 (например, но не ограничиваясь: «ученик» и «первоклассник»). Подчинение - это такое соотношение смысловых объемов двух значений 311 компонентов 31, при котором смысловой объем первого значения 311 компонента 31 полностью входит в смысловой объем второго значения 311 компонента 31, но не покрывает смысловой объем второго значения 311 компонента 31 полностью (например, но не ограничиваясь: «первоклассник» и «ученик»). Противоречие - это такое соотношение смысловых объемов двух значений 311 компонентов 31, при котором смысловые объемы двух значений 311 компонентов 31 в рамках одного родового понятия содержат признаки этого понятия, взаимоисключающие друг друга (например, но не ограничиваясь: «белый цвет» и «небелый цвет»). Противоположность - это такое соотношение смысловых объемов двух значений 311 компонентов 31, при котором смысловые объемы двух значений 311 компонентов 31 в рамках одного родового понятия содержат несовпадающие признаки этого понятия, указывающие на исключительные свойства этих образов (например, но не ограничиваясь: «федеральный закон» и «региональный закон»). Системная связь - это наличие каких-либо системных однородностей между двумя компонентами 31 или значениями 311 компонентов 31, указывающих на наличие каких-либо соотношений системных признаков этих компонентов 31 или значений 311 компонентов 31. Системной связью двух компонентов 31, либо двух значений 311 компонентов 31 является все то, что не является семантической связью двух значений 311 компонентов 31. Системная связь компонентов 31 - это наличие однородностей (неких характеристик их объединяющих) между двумя компонентами, которые (однородности) имеют системный или классификационный, но не смысловой (семантический) характер. В качестве примера, но не ограничения, можно привести следующие примеры системной связи двух значений 311 компонентов 31 (компонентов, являющихся элементами простого суждения согласно формализованной модели простого суждения) (таблицы 5-8, 9-12):
[0064] Пример 1: компоненты 31 в рамках одного простого суждения 13 (например, но не ограничиваясь: для третьей СД (второй СД для способа 200) из четырех ПС 13)
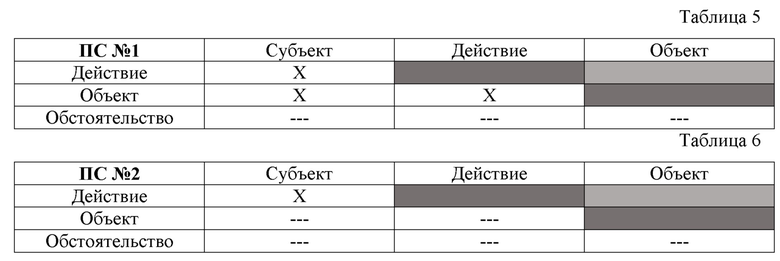
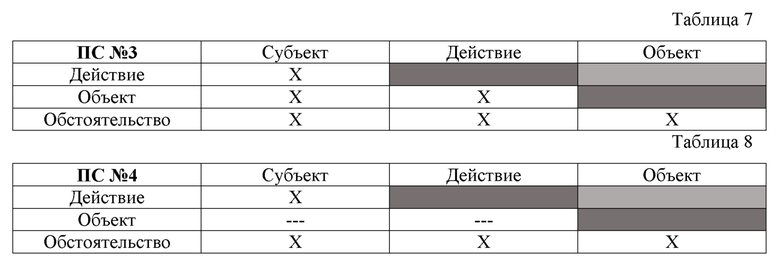
[0065] Пример 1 показывает, что возможна идентификация и регистрация системной связи, основанной на простом факте наличия значений компонентов: в ПС№1 имеется три системные связи (Действие-Субъект; Объект-Субъект и Действие-Объект); в ПС№2 имеется только одна подобная системная связь (Действие-Субъект); в ПС№3 – шесть подобных системных связей (Действие-Субъект; Действие-Объект; Действие-Обстоятельство; Субъект-Объект; Субъект-Обстоятельство; Объект-Обстоятельство), в ПС№4 – четыре подобные системные связи (Действие-Субъект; Действие-Обстоятельство; Субъект-Обстоятельство; Объект-Обстоятельство).
[0066] Пример 2: одинаковые виды компонентов 31 простых суждений 13 в третьей структуре данных (например, но не ограничиваясь: для третьей СД (второй СД для способа 200) из четырех ПС13, указанных в вышеописанном примере):
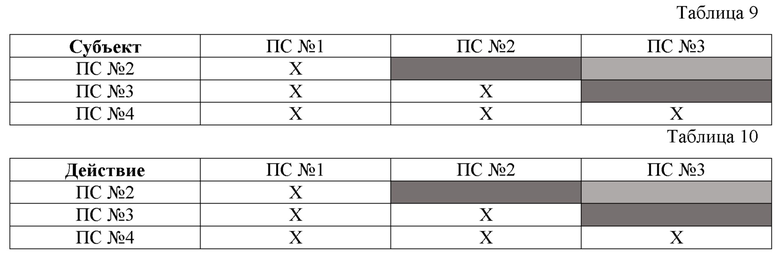
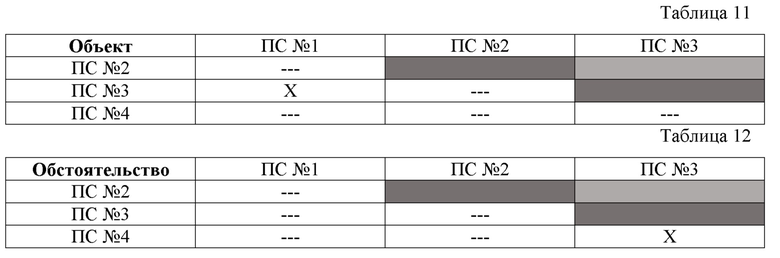
[0067] Пример 2 показывает, что возможна идентификация и регистрация системной связи, основанной на совпадении в четырех анализируемых простых суждениях (ПС) видов компонентов, имеющих значение: по компоненту «субъект» имеется шесть системных связей между четырьмя ПС13 ( ПС№1-ПС№2; ПС№1-ПС№3; ПС№1-ПС№4; ПС№2-ПС№3; ПС№2-ПС№4; ПС№3-ПС№4); по компоненту «действие» имеется шесть системных связей между четырьмя ПС13 ( ПС№1-ПС№2; ПС№1-ПС№3; ПС№1-ПС№4; ПС№2-ПС№3; ПС№2-ПС№4; ПС№3-ПС№4); по компоненту «объект» имеется одна системная связей между двумя ПС12 (ПС№1-ПС№3); по компоненту «обстоятельство» имеется одна системная связь между двумя ПС13 (ПС№3-ПС№4).
[0068] Также, в качестве примера, но не ограничения, можно привести следующие примеры системной связи двух значений 311 компонентов 31 (таблицы 13, 14):
[0069] Пример 3: части речи синтаксически главного слова компонента (элемента простого суждения) значений 311 компонентов 31 в рамках одного простого суждения 13 (например, но не ограничиваясь: для ПС №1 третьей СД (второй СД для способа 200) из указанных ранее примеров:

[0070] Пример 3 показывает, что возможна идентификация и регистрация системной связи, основанной на совпадении частей речи главного слова (синтаксической вершины) в рамках одного простого суждения 13: совпадение части речи главного слова только между следующими компонентами: Субъект-Объект.
[0071] Пример 4: одинаковые части речи значений 311 компонентов 31 в рамках простых суждений 13 третьей СД (например, но не ограничиваясь: для третьей СД (второй СД для способа 200) из четырех ПС 13, указанных приведенных ранее примерах:

[0072] Пример 4 показывает, что возможна идентификация и регистрация системной связи, основанной на совпадении частей речи главного слова (синтаксической вершины) в рамках нескольких (в рамках примера -четырех) простого суждения 13: части речи главного слова только между следующими компонентами: С1-О1; С1-О3; С1-Об3; С1-Об4; О1-О3; О1-Об3; О1-Об4; С2-О1; С2-О3; С2-Об3; С2-Об4; С3-О1; С3-О3; С3-Об3; С3-Об4; О3-О1; О3-Об3; О3-Об4; С4-О1; С4-О3; С4-Об3; С4-Об4; О4-Об4.
[0073] Идентификация системных связей между КПС 31 простых суждений 13 третьей СД предпочтительно производят на этапе 1051 (2021) путем установки критериев поиска системных однородностей между компонентами 31 простых суждений 13 и реализации такого поиска. Для идентификации системных связей между КПС 31 простых суждений 13 третьей СД (второй СД для способа 200) используют сведения из БДЛЛП текстовых элементов, а также сведения о формализованной модели простого суждения, сведения о массиве простых суждений (третьей СД (второй СД для способа 200)) и сведения о массиве компонентов простых суждений (второй СД (первой СД для способа 200)). Виды системных однородностей устанавливаются в зависимости от конкретных целей прикладных задач в предметной области, решаемых с помощью выявления системных связей КПС 31 простых суждений 13. Системные однородности могут быть внутренними и внешними. Внутренние системные однородности относятся к виду однородностей, которые имеют место между компонентами 31 внутри отдельных простых суждений 13, а внешние системные однородности относятся к виду однородностей, которые имеют место между компонентами 31 разных простых суждений 13 третьей СД (второй СД для способа 200). В качестве примера, но не ограничения можно привести способ поиска системной однородности по следующему критерию (аналогичный упомянутому примеру 1): компоненты 31 вида «элементы простого суждения» находятся в одном простом суждении 13. В данном примере идентификация системных связей между КПС 31 вида «элементы простого суждения» простых суждений 13 будет производится в каждом простом суждении 13 на основании формализованной модели простого суждения, которая устанавливает элементы простого суждения, а также по критерию фактического наличия значений 311 у указанных компонентов 31 в рамках отдельных элементов формализованной модели простого суждения. При наличии значений 311 компонента 31 указанного вида у первого и у второго компонентов 31 будет зафиксирована связь между этими компонентами 31 в тех простых суждениях, в которых они будут выявлены в результате поиска системных однородностей по установленному критерию. При наличии значений 311 компонента 31 указанного вида у первого и у второго компонентов 31 будет зафиксирована связь между этими компонентами 31 в тех простых суждениях, в которых они будут выявлены в результате поиска системных однородностей по установленному критерию. Такой анализ может быть выполнен любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такой анализ может быть выполнен традиционно специалистом предметной области, в рамках которой производится поиск системных однородностей или же с помощью программного обеспечения. Более того, при наличии достаточного количества примеров возможно выполнение такого анализа с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. Идентификация семантических связей между КПС 31 простых суждений 13 третьей СД (второй СД для способа 200) предпочтительно производят на этапе 1052 (2022) путем установки критериев поиска семантических однородностей между КПС 31 простых суждений 13 и реализации такого поиска. Виды семантических связей устанавливаются в зависимости от конкретных целей прикладных задач в предметной области, решаемых с помощью выявления семантических связей КПС 31 простых суждений 13. Семантические однородности могут быть внутренними и внешними. Внутренние семантические однородности относятся к виду однородностей, которые имеют место между компонентами 31 внутри отдельных простых суждений 13, а внешние семантические однородности относятся к виду однородностей, которые имеют место между компонентами 31 разных простых суждений 13 третьей СД (второй СД для способа 200). В качестве примера, но не ограничения, можно привести способ поиска семантических однородностей по следующему критерию: значения 311 КПС 31 вида «элемент простого суждения» должны быть эквивалентны. В данном примере идентификация семантических связей между КПС 31 вида «элемент простого суждения» простых суждений 13 будет производится в каждом простом суждении 13 по критерию равнозначности смысловых объемов двух значений 311 компонентов 31 при условии, что нет полного совпадения слов у этих значений 311 компонентов 31, либо совпадения слов у двух значений 311 компонентов 31 нет вообще. При наличии признаков эквивалентности смысловых объемов значений 311 у обоих КПС 31 будет зафиксирована искомая семантическая связь между этими компонентами 31 в тех простых суждениях 13, в которых они будут выявлены в результате поиска семантических однородностей по установленному критерию. Например, но не ограничиваясь, такими компонентами могут быть компоненты 31 со следующими значениями 311: «ученик школы» и «школьник». Такой анализ может быть выполнен любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такой анализ может быть выполнен специалистом-лингвистом с учетом знания специальной терминологии предметной области, в рамках которой производится поиск семантических однородностей или же с помощью программного обеспечения. Более того, при наличии достаточного количества примеров возможно выполнение такого анализа с помощью различных систем машинного обучения, в том числе, статистического процессора или нейросети. На основании идентифицированных системных связей между КПС 31 простых суждений 13 третьей СД (второй СД для способа 200) формируют данные о системных связях между КПС 31 простых суждений ПС 13 третьей СД (второй СД для способа 200), являющихся системными онтологическими признаками 313 КПС 31 простых суждений 13, а также об их значениях 3131, сформированных после выполнения этапа 1051 (2021). На основании идентифицированных семантических связей между КПС 31 простых суждений 13 третьей СД (второй СД для способа 200)формируют данные о семантических связях между КПС 31 простых суждений 13 третьей СД (второй СД для способа 200), являющихся семантическими онтологическими признаками 314 КПС 31 простых суждений 13, а также об их значениях 3141, сформированных после выполнения этапа 1052 (2022). На основании сформированных на этапах 1051 (2021) и 1052 (2022) данных о системных и семантических связях между КПС 31 простых суждений 13 третьей СД (второй СД для способа 200) на этапе 1053 (2023) формируют ОБД.
[0074] Далее, после завершения описанного ранее этапа 105, в целях повышения точности последующего поиска в структурированном массиве данных, содержащем, по меньшей мере, простые суждения (ПС) лингвистического предложения и их идентификационные данные, становится возможным осуществить финальную систематизацию структур данных СМД, содержащих, по меньшей мере, компоненты простого суждения (КПС) лингвистического предложения и их идентификационные данные.
[0075] На фиг. 18, в качестве примера, но не ограничения, изображена общая схема выполнения этапов заявленного способа 300 преобразования структурированного массива данных (СМД), содержащего простые суждения (ПС), заключающегося в: выполнении этапа 301 идентификации исходной структуры данных для способа 300 (далее - исходной СД) и онтологической базы данных (ОБД); при этом исходной СД является СД, содержащая элементы СД, являющиеся простыми суждениями (ПС) лингвистического предложения и идентификационные данные ПС, причем ПС содержат компоненты; при этом ОБД, содержит сведения о системных и семантических связях в исходной СД, причем упомянутые сведения представляют собой системные и семантические связи между компонентами ПС в исходной СД; выполнении этапа 106 формирования базы данных отношений в исходной СД, на котором на основании сведений, содержащихся в ОБД, а также на основании критериев поиска искомых суждений, сравнивают компоненты ПС, а также классифицируют и регистрируют виды отношений между сравниваемыми компонентами ПС, из которых формируют базу данных отношений компонентов ПС в исходной СД (БДО); выполнении этапа 107 формирования четвертой (итоговой) СД, на котором на основании сведений, содержащихся в БДО, исходной СД , а также на основании упомянутых критериев поиска искомых суждений, формируют итоговую СД, содержащую элементы итоговой СД, причем упомянутые элементы итоговой СД представляют собой искомые суждения (ИС), а также идентификационные данные ИС, представляющие собой в качестве примера, но не ограничения: значения ИС и порядковые номера текстовых элементов (ТЭ) лингвистического предложения, составляющих ИС. При этом, как указано ранее, упомянутой исходной СД для рассматриваемого способа 300 является любая пригодная для реализации способа 300 СД, содержащая упомянутые простые суждения. В качестве примера, но не ограничения, такой СД является описанная ранее со ссылкой на способ 100 третья СД, или любая известная из уровня техники, в том числе в будущем, СД, содержащая упомянутые простые суждения. При этом, как указано ранее, упомянутой ОБД является любая онтологическая база данных, пригодная для реализации способа 300, в том числе, не ограничиваясь, описанная ранее со ссылкой на способ 200 ОБД, содержащая упомянутые сведения о системных и семантических связях в третьей СД, являющейся исходной для рассматриваемого способа 300.
[0076] На фиг. 19, в качестве примера, но не ограничения, изображена общая схема выполнения этапа 301 идентификации пригодной для преобразования СМД, содержащего ПС, структуры данных, содержащей простые суждения (например, не ограничиваясь, третьей СД), являющейся исходной структурой данных для рассматриваемого способа 300 (далее – исходная СД), а также базы данных, содержащей сведения о системных и семантических связях в исходной СД (ОБД). Этап 301 характеризуется выполнением идентификации пригодной для преобразования СМД, содержащего ПС, структуры данных, содержащей простые суждения (ПС), на котором идентифицируют элементы 13 пригодной для преобразования СМД, содержащего ПС, структуры данных, содержащей простые суждения (ПС), а также идентификационные данные элементов 13, представляющие собой для каждого элемента 13, в качестве примера, но не ограничения, значение 131 элемента 13 пригодной для преобразования СМД, содержащего ПС, структуры данных, и порядковый (порядковые) номер (номера) 132 ПС лингвистического предложения 11, представляющие собой ТЭ 21, составляющие элемент 13, а также выполнением идентификации пригодной для преобразования СМД, содержащего ПС, базы данных, содержащей сведения о системных и семантических связях в третьей СД, на котором идентифицируют онтологическую базу данных (ОБД), содержащую сведения о системных и семантических связях в третьей СД, пригодной для преобразования СМД, содержащего ПС, базы данных, содержащей данные о системных связях между КПС 31 простых суждений ПС 13 третьей СД (являющейся исходной для рассматриваемого способа 300), являющихся системными онтологическими признаками 313 КПС 31 простых суждений 13, и об их значениях 3131, пригодной для преобразования СМД, содержащего ПС, а также данные о семантических связях между КПС 31 простых суждений ПС 13 третьей СД, являющихся семантическими онтологическими признаками 314 КПС 31 простых суждений 13, и об их значениях 3141, пригодной для преобразования СМД, содержащего ПС, а также сами простые суждения 31, пригодной для преобразования СМД, содержащего ПС, базы данных, их значения 311 и их порядковые номера 312 в лингвистическом предложении 11. При этом упомянутые процессы идентификации могут происходить в любом пригодном порядке, в том числе, не ограничиваясь, одновременно и/или параллельно, в том числе частично параллельно.
[0077] На фиг. 20, в качестве примера, но не ограничения, изображена примерная исходная структура данных для настоящего способа 300, представляющая собой пригодную для преобразования СМД, содержащего ПС, структуру данных, содержащую простые суждения (ПС). В качестве примера, но не ограничения, такой СД может быть описанная ранее со ссылкой на способ 100 третья СД, которая таким образом дополнительно не описывается.
[0078] На фиг. 21, в качестве примера, но не ограничения, изображена примерная онтологическая база данных, представляющая собой пригодную для преобразования СМД, содержащего ПС, базу данных, содержащую сведения о системных и семантических связях в третьей СД. В качестве примера, но не ограничения, такой ОБД может быть описанная ранее со ссылкой на способ 200 ОБД, которая таким образом дополнительно не описывается.
[0079] На фиг. 22, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 106 (302) формирования базы данных отношений в третьей СД (БДО). Этап 106 (302) характеризуется: выполнением этапа 1061 (3021) формирования карты отношений КПС в третьей СД (являющейся исходной для рассматриваемого способа 300) на основании критериев поиска искомых суждений; выполнением этапа 1062 (3022) классификации на основании сведений, содержащихся в ОБД, и регистрации видов отношений между сравниваемыми КПС такой исходной СД и регистрации соответствующих видов отношений в качестве выводов по результатам сопоставления системных и семантических онтологических сведений о сравниваемых КПС; выполнением этапа 1063 (3023) формирования базы данных отношений в такой исходной СД, на котором формируют БДО компонентов простых суждений такой исходной СД путем объединения всех классифицированных и зарегистрированных отношений между сравниваемыми КПС третьей СД.
[0080] На фиг. 23, в качестве примера, но не ограничения, изображена общая структура сформированной карты отношений компонентов 31 простых суждений 13. Под термином «карта отношений» понимается таблица сопоставления системных, а также семантических онтологических сведений о сравниваемых компонентах 31. При этом карта отношений предназначена для сравнения не всех компонентов 31 простых суждений третьей СД, а только тех, которые контролируются (проверяются) в соответствии с критериями поиска искомых суждений, о которых будет упомянуто далее. В качестве примера, но не ограничения, можно привести следующие виды отношений 316 между компонентами 31, установленными в карте отношений: идентичность; эквивалентность; пересечение; поглощение; подчинение. При этом сами виды отношений частично совпадают с упомянутыми в онтологической базе данных видами связей. Это является допустимым, поскольку сами виды отношений установлены в теории логики и применяются для определения соотносимости различных сущностей. При этом, в отличие от видов семантических однородностей компонентов 31 при соотнесении смысловых объемов значений 311 компонентов 31 при формировании семантических онтологических признаков, виды отношений, идентифицируемые для БДО в карте отношений компонентов 31, основаны не только на семантических, но и на системных признаках сравниваемых компонентов 31, т.е. виды отношений представляют собой совокупные гибридные системно-семантические признаки. Причем процесс определения вида отношений, который учитывает одновременно системные и семантические признаки компонентов 31 и определяет вид отношений между сравниваемыми компонентами 31, формируется в зависимости от конкретной прикладной задачи поиска простых суждений 13 в третьей СД в конкретной предметной области. Идентичность - это полное совпадение системно-семантических признаков двух компонентов 31 при условии полной корреляции системно-семантических признаков компонентов 31 и требований к системно-семантическим признакам сравниваемых компонентов 31 в карте отношений. Эквивалентность - это неполное совпадение, но равнозначность системно-семантические признаков двух компонентов 31 при условии игнорирования неполной корреляции системно-семантических признаков компонентов 31 и требований к системно-семантическим признакам сравниваемых компонентов 31 в карте отношений. Пересечение - это неполное совпадение системно-семантических признаков двух компонентов 31 при условии признания неполной корреляции системно-семантических признаков компонентов 31 и требований к системно-семантическим признакам сравниваемых компонентов 31 в карте отношений. Поглощение - это такое соотношение системно-семантических признаков двух компонентов 31, при котором объем системно-семантических признаков первого компонента 31 полностью поглощает объем системно-семантических признаков второго компонента 31, но при этом объем системно-семантических признаков второго компонента 31 является лишь частью объема системно-семантических признаков первого компонента 31 при условии корреляции системно-семантических признаков компонентов 31 и требований к системно-семантических признакам к сравниваемым компонентам 31 в карте отношений. Подчинение - это такое соотношение системно-семантических признаков двух компонентов 31, при котором объем системно-семантических признаков первого компонента 31 полностью входит в объем системно-семантических признаков второго компонента 31, но при этом объем системно-семантических признаков второго компонента 31 не покрывает объем системно-семантических признаков первого компонента 31 при условии корреляции системно-семантических признаков компонентов 31 и требований к системно-семантическим признакам к сравниваемым компонентам 31 в карте отношений.
[0081] На фиг. 24, в качестве примера, но не ограничения, изображена общая структура сформированной базы данных отношений в третьей СД (являющейся исходной для рассматриваемого способа 300), являющейся БДО компонентов 31 простых суждений 13 в третьей СД после выполнения этапа 106 (302). БДО представляет собой организованную структуру, созданную в соответствии с определёнными правилами, и предназначенную для хранения, изменения и обработки упомянутых данных. Данными БДО являются компоненты 31 простых суждений третьей СД, их идентификационные данные (значение 311 и номера 312), а также виды отношений 316 между сравниваемыми компонентами 31 простых суждений 13 третьей СД. БДО фактически является второй частью онтологической базы данных (ОБД), поскольку к уже существующим данным ОБД для компонента 31 просто добавляют новые данные о виде отношений компонента 31 с другим компонентом 31, которые получают путем сопоставления системных, а также семантических онтологических сведений о сравниваемых компонентах 31 (о связях между компонентами 31), содержащихся в ОБД. Таким образом, БДО является такая база данных, в которой элементы БД содержат информацию о различных видах отношений с другими элементами этой базы. При этом элементами БДО являются такие компоненты 31 простых суждений 13 третьей СД, которые установлены в карте отношений компонентов 31 простых суждений 13 в третьей СД. Формирование карты отношений компонентов 31 простых суждений 13 предпочтительно производят на этапе 1061 (3021) путем выполнения анализа критериев поиска искомых суждений. Критерии поиска искомых суждений формируют в связи и в рамках решения конкретной прикладной задачи поиска простых суждений 13 в третьей СД в конкретной предметной области. Эти критерии формируют на этапе поиска простых суждений в соответствии с требованиями поисковой задачи на основании формализованной модели простого суждения (то есть на известном перечне всех компонентов 31 формализованной модели простого суждения) и на указании контролируемых компонентов 31. Критерии поиска искомых суждений должны описывать контролируемые параметры 315 контролируемых компонентов 31 и их контролируемые значения 3151, а также условия (то есть сочетание контролируемых значений 3151 упомянутых параметров 315 у сравниваемых контролируемых компонентов 31), при которых можно сделать вывод о наличии тех или иных видов отношений 316 между сравниваемыми компонентами 31, актуальных для решения прикладной поисковой задачи, в ходе которой производится сравнение простых суждений 13. В результате такого анализа критериев поиска искомых суждений формируют карту отношений, в которой регистрируют выявленные в ходе упомянутого анализа: контролируемые компоненты 31; контролируемые системные и логические признаки (параметры) 315 этих компонентов 31; контролируемые значения 3151 этих параметров 315; виды отношений 316 сравниваемых компонентов 31 при установленных сочетаниях значений 3151 контролируемых параметров 315 сравниваемых компонентов 31. Такой анализ может быть выполнен любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такой анализ может быть выполнен специалистом-лингвистом с учетом знания специальной терминологии предметной области, в рамках которой производится поиск искомых простых суждений или же с помощью программного обеспечения. Более того, при наличии достаточного количества примеров возможно выполнение такого анализа с помощью различных систем машинного обучения, в ом числе статистического процессора или нейросети. Классификацию вида отношений между сравниваемыми компонентами 31 простых суждений 13 третьей СД и регистрацию этого вида предпочтительно производят на этапе 1062 (3022) путем выполнения анализа данных сравниваемых компонентов 31, содержащихся в ОБД с учетом сведений из карты отношений компонентов 31 простых суждений 13. В ходе выполнения классификации последовательно выбирают все сочетания компонентов 31, которые указаны в карте отношений (то есть сочетания контролируемых компонентов 31). В соответствии с контролируемыми параметрами 315 и значениями 3151 указанных параметров, запрашивают в ОБД по выбранным компонентам 31 и получают все актуальные системные онтологические признаки 313 и их значения 3131, а также все актуальные семантические онтологические признаки 314 и из значения 3141. Полученные таким образом значения 3131 признаков 313 и значения 3141 признаков 314 компонентов 31 применяют в упомянутом процессе определения вида отношений для выявления вида отношений сравниваемых компонентов 31 простых суждений 13 третьей СД. Классифицированные таким образом виды отношений между компонентами 31 простых суждений 13 третьей СД регистрируют в качестве результата выполнения этапа 1062 (3022). Идентификационные данные сравниваемых компонентов 31 (значение 311 и номера 312) получают в результате упомянутого запроса в ОБД вместе с системными 313 и семантическими 314 онтологическими признаками. На основании произведенных на этапе 1062 (3022) классификации и регистрации вида отношений 316 между сравниваемыми компонентами 31 простых суждений 13 третьей СД на этапе 1063 (3023) формируют базу данных отношений в третьей СД, содержащей сравниваемые компоненты 31 простого суждения 13, виды отношений 316 сравниваемых компонентов 31 простых суждений 13 третьей СД, которые (компоненты) указаны в карте отношений компонентов 31 и являются актуальными контролируемыми компонентами 31 для решения прикладной поисковой задачи, в ходе которой производится сравнение простых суждений 13, а также идентификационные данные 311 и 312 сравниваемых компонентов 31.
[0082] На фиг. 25, в качестве примера, но не ограничения, изображена общая схема выполнения этапов этапа 107 (303) формирования четвертой структуры данных (являющейся итоговой СД для рассматриваемого способа 300) СМД. Этап 107 (303) характеризуется: выполнением этапа 1071 (3031) формирования последовательности действий для решения поисковой задачи (ПД), в ходе которого на основании предварительно заданных критериев поиска искомых суждений формируют упомянутую ПД; выполнением этапа 1072 (3032) идентификации и формирования первых и вторых элементов итоговой СД, на котором на основании сведений, содержащихся в БДО, идентифицируют и формируют элементы итоговой СД, являющиеся искомыми суждениями (ИС), а также идентификационные данные ИС; выполнением этапа 1073 (3033) формирования итоговой СД, на котором формируют итоговую СД из сформированных ИС и их идентификационных данных.
[0083] На фиг. 26, в качестве примера, но не ограничения, изображена общая структура сформированной четвертой структуры данных, являющейся итоговой СД для рассматриваемого способа 300. Такая четвертая (итоговая) структура данных представляет собой СМД, содержащий элементы 14, которые представляют собой искомые суждения (ИС 14) и их идентификационные данные. Идентификационные данные ИС представляют собой в качестве примера, но не ограничения, значения 141 элементов 14 четвертой структуры данных СМД и порядковые номера 142 ТЭ лингвистического предложения 11, составляющих элементы 14. Элементы 14 четвертой структуры данных подразделяются на первые элементы 14 и вторые элементы 14. В зависимости от конкретной прикладной задачи поиска искомых суждений 14 в третьей СД в конкретной предметной области результатом решения поисковой задачи могут быть: первые элементы 14, либо вторые элементы 14, либо первые элементы 14 и вторые элементы 14 четвертой СД. Например, но не ограничиваясь, при решении прикладной задачи по поиску перечня правил (диспозиций правового акта, регулирующих что-либо), регулирующих поведение субъекта правоотношений, достаточно произвести только одно поисковое действие, чтобы найти первый элемент 14. Таким образом в ходе одной поисковой операции можно получить перечень простых суждений - правил, с помощью которых регулируется поведение данного субъекта. В качестве другого примера, но не ограничения, демонстрируется прикладная задача по поиску всех частей (гипотезы, диспозиции и санкции) норм-предписаний (правил, принципов, определений, содержащихся в тексте положений правовых актов), в рамках которой будут найдены первые элементы 14 и вторые элементы 14 четвертой СД, то есть реализованы два последовательных поисковых действия ПД. Первое поисковое действие ПД может быть реализовано путем поиска первых элементов 14, которые будут простыми суждениями, являющимися диспозициями или санкциями нормы-предписания. Второе поисковое действие ПД может быть реализовано путем поиска вторых элементов 14 которые будут простыми суждениями, являющимися обусловленностями правил (внешними условиями - гипотезами диспозиции или гипотезами санкции, при которых найденные правила считаются действующими), найденных в ходе предшествующей поисковой операции ПД. При этом, никакой связи между найденными диспозициями (с гипотезами) и санкциями (с гипотезами) может не быть, поскольку такая задача по поиску связей между найденными диспозициями и найденными санкциями не была поставлена. В качестве третьего примера, но не ограничения, демонстрируется похожая прикладная задача, в рамках которой будут найдены также первые элементы 14 и вторые элементы 14 четвертой СД. Однако в этом примере, в отличии от предыдущего примера, искомые правила (диспозиции и санкции) будут связаны друг с другом, т.е. отдельной диспозиции будет соответствовать отдельная санкции или санкции. Для такого поиска необходимо использовать три последовательных поисковых действия ПД (например, но не ограничиваясь, задача по поиску регулятивно-охранительных правовых норм). Первое поисковое действие ПД может быть реализовано путем поиска первых элементов 14, которые будут простыми суждениями, являющимися правилами-диспозициями. Второе поисковое действие ПД может быть реализовано путем поиска вторых элементов 14, которые будут простыми суждениями, являющимися правилами-санкциями (правилами, устанавливающими меру ответственности за нарушение уже найденных правил-диспозиций). Третье поисковое действие ПД может быть реализовано путем поиска также вторых элементов 14, которые будут простыми суждениями - гипотезами (обусловленностями для уже найденных диспозиций и обусловленностями для уже найденных санкций). На основании приведенных примеров, но не ограничений, можно представить разницу между первыми элементами 14 и вторыми элементами 14 четвертой СД. Первые элементы 14 четвертой структуры данных - это искомые суждения, полученные в результате первого (по порядку) поискового действия ПД в массиве простых суждений (третьей СД). Особенностью первого поискового действия ПД является то, что первое поисковое действие ПД технически ограничено контролируемыми данными, содержащимися в критериях поиска искомых суждений. Никакие иные контролируемые данные для ПД не присутствуют в ПД при первом поисковом действии. Вторые элементы 14 четвертой структуры данных - это искомые суждения, полученные в результате второго, третьего и всех последующих поисковых действий ПД, из которых состоит ПД, сформированный на основании критериев поиска искомых суждений. Упомянутые вторые, третьи и последующие поисковые действия ПД отличаются от упомянутого первого поискового действия ПД тем, что в таких задачах поиска используются не только контролируемые данные, содержащиеся в критериях поиска искомых суждений, но и дополнительные контролируемые данные (дополнительные данные, содержащихся в уже сформированных массивах искомых суждений четвертой СД). Например, но не ограничиваясь, при реализации второго поискового действия ПД технически возможно в качестве дополнительных контролируемых данных использовать уникальные номера первых элементов 14 и/или уже выявленных вторых элементов 14, то есть уже найденных искомых суждений (например, но не ограничиваясь, уникальные номера простых суждений-диспозиций), чтобы в ходе второго поискового действия ПД в массиве простых суждений (третьей СД) найти простые суждения, связанные с уже найденными простыми суждениями в ходе первого поискового действия ПД (например, но не ограничиваясь, найти простые суждения-гипотезы для уже найденных простых суждений-диспозиций на основании известных уникальных номеров уже найденных простых суждений-диспозиций). При этом, поисковой задачей является любая задача, связанная с анализом текстового материала в формате текста на естественном языке, представленного для анализа в форме текстового документа или текстового массива данных. Результатом такого анализа может быть любой отдельный компонент формализованной модели простого суждения, либо несколько указанных компонентов, либо простые суждения, либо группы простых суждений, что подробно описывается в упомянутых критериях поиска. В юридической предметной области в качестве примера, но не ограничения, можно привести следующие кейсы (ситуации, взятые из практики) поисковых задач: а) поиск норм-предписаний (правовых норм) для известного субъекта/ объекта правоотношений; б) поиск норм-предписаний (правовых норм) для известной (формально описанной) ситуации; в) поиск норм-предписаний (правовых норм) для известного субъекта/ объекта правоотношений в известной ситуации; г) поиск регулятивно-охранительных правовых норм (логических правовых норм) для известного субъекта/ объекта правоотношений; д) поиск регулятивно-охранительных правовых норм (логических правовых норм) для известного субъекта/ объекта правоотношений в известной ситуации; е) поиск норм-предписаний (правовых норм) по отдельному документу, части документа, группе документов; ж) поиск регулятивно-охранительных правовых норм (логических правовых норм) по отдельному документу, части документа, группе документов; з) поиск противоречий между нормами-предписаний (правовыми нормами); и) поиск противоречий в регулятивно-охранительных правовых нормах (логических правовых нормах); к) поиск противоречий между регулятивно-охранительными правовыми нормами (логическими правовыми нормами); л) поиск правовых пробелов для субъектов правоотношений; м) поиск правовых пробелов для объектов правоотношений; н) поиск норм-дефиниций по отдельному документу, части документа, группе документов; о) поиск норм-дефиниций указанного субъекта/объекта правоотношений, и тому подобные кейсы. У отдельных элементов 14 (первый элемент 14 или второй элемент 14) четвертой СД имеются характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных элементы 14 в качестве примера, но не ограничения могут именоваться как «ИС 1», «ИС 2», «ИС 3», «ИС n», где n ≥ 1 - порядковый номер элемента в четвертой СД. При этом, в качестве примера, но не ограничения искомые суждения 13 могут именоваться как «диспозиция», «санкция», «гипотеза» для юридической предметной области, и тому подобное для иных предметных областей. У групп элементов 14 четвертой СД (например, но не ограничиваясь, первый и второй элементы 14) имеются характеризующие их уникальные наименования (УН), имеющие практическое использование. В структуре данных такие группы элементов 14 в качестве примера, но не ограничения могут именоваться как «ГИС 1», «ГИС 2», «ГИС 3», «ГИС n», где «ГИС» - группа искомых суждения, а n ≥ 1 - порядковый номер элемента в четвертой СД. При этом, в качестве примера, но не ограничения искомые суждения 14 (группы ИС 14) могут именоваться как «норма-предписание», «правовая норма» для юридической предметной области, и тому подобное для иных предметных областей. С лингвистической точки зрения элементы 14 (искомое суждение, вне зависимости от вида - первое или второе) это простое предложение. При этом возможны различные варианты простых предложений, которые могут считаться простыми суждениями, например, но не ограничиваясь данным примером, можно привести следующие виды простых предложений: 1) простые предложения в изначальном, непреобразованном виде; 2) простые предложения в преобразованном виде, например: а) без причастных или деепричастных оборотов: б) без однородностей (обезоднородненные, без рядов однородных членов); в) без вставок (без текста в скобках); г) без условных именований (без текста в кавычках); д) без обстоятельств (условий) и тому подобные, включая сочетания вышеуказанных и неуказанных видов. ИС 14 с логической точки зрения (вне зависимости от вида - первое или второе) - это простое суждение, то есть утверждение (простое утверждение) или опровержение о субъекте суждения. Искомое суждение, являясь простым суждением, представляет собой первичную логическую конструкцию мышления с помощью которой формируется и передается мысль о том, что нечто (предикат суждения) утверждается или опровергается о предмете суждения (субъект суждения). ИС 14 (вне зависимости от вида - первое или второе), как простое суждение, с точки зрения отдельных предметных областей - это конструкция, описанная формализованной моделью простого суждения. Искомые суждения 14 четвертой структуры данных имеют идентификационные данные, в качестве примера, но не ограничения: значение 141 ИС и номер 142 ИС. Значением 141 ИС является набор значений итоговых текстовых элементов (компонентов простого суждения), составляющих искомое суждение 14 четвертой СД. Номером 142 ИС являются порядковые номера ТЭ 21, из которых сформированы значения 142, составляющие итоговое суждение 14 четвертой СД. Последовательность действий для решения поисковой задачи (ПД) формируется на основании критериев поиска искомых суждений для решения конкретной прикладной задачи в конкретной предметной области. ПД содержит сведения о поисковых действиях, которые необходимо провести для получения искомых суждений, а также содержит контролируемые данные (показатели и их значения), которые необходимо использовать для поисковых действий ПД. Идентификацию элементов 14 (искомых суждений) четвертой структуры данных СМД производят в ходе этапа 1072 (3032) путем выполнения поисковых действий в соответствии с ПД. При этом выполнение этапа 1072 (3032), на котором идентифицируют первые элементы 14 четвертой структуры данных, является обязательным действием по идентификации, а выполнение этапа 1072 (3032), на котором идентифицируют вторые элементы 14 четвертой структуры данных является дополнительными действиями, наличие и количество которых определяется содержанием ПД. Выполнение идентификации элементов 14 (искомых суждений) четвертой структуры данных СМД производят по двум основным сценариям в зависимости от содержания ПД, а именно от наличия операции сравнения (сопоставления, корреляции) простых суждений. Первый сценарий идентификации элементов 14 (искомых суждений) четвертой структуры данных СМД, не содержащий операции сравнения простых суждений, выполняется на этапе 1072 (3032) путем поиска значений показателей контролируемых данных (заданных в ПД) в массиве простых суждений (третьей СД). При наличии в массиве простых суждений (например, в третьей СД, являющейся исходной для рассматриваемого способа 300) искомых данных, которые соответствуют установленным значениям показателей контролируемых данных, происходит идентификация таких простых суждений как искомых суждений. Второй сценарий идентификации элементов 14 (искомых суждений) четвертой структуры данных СМД, содержащий операции сравнения простых суждений, выполняется на этапе 1072 (3032) путем поиска значений показателей контролируемых данных (заданных в ПД) в массиве простых суждений (третьей СД) и в ОБД с учетом сведений из БДО о наличии отношений определенного вида между компонентами простых суждений. При наличии в массиве простых суждений и в ОБД искомых данных, которые соответствуют установленным значениям показателей контролируемых данных, происходит идентификация таких простых суждений как предварительных искомых суждений. При этом, учитывая сведения полученные из БДО о наличии отношений определенного вида между компонентами простых суждений корректируют результат поиска путем сокращения числа предварительных искомых суждений, либо расширения числа предварительных искомых суждений за счет новых простых суждений, которые в соответствии со сведениями из БДО также могут считаться искомыми суждениями на основании наличия отношений соответствующего вида с предварительными искомыми суждениями. В качестве примера, но не ограничения, в качестве второго сценария идентификации элементов 14 (искомых суждений) четвертой структуры данных СМД можно привести пример интеллектуального поиска диспозиций (правил, устанавливающих права, обязанности, запреты и требования) для такого субъекта правоотношений как «покупатель». Применение второго сценария поиска позволит выявить диспозиции не только для субъекта «покупатель», но и одновременно (в рамках одного поискового действия ПД) также диспозиции для субъектов, поименованных иным образом, но фактически являющимися одним и тем же субъектом, например, но не ограничиваясь: «потребитель», «лицо, покупающее товар», «лицо, покупающее услугу», «услугополучатель», «получатель услуги», «товарополучатель», «получатель услуги», «заказчик». Формирование элементов 14 (искомых суждений) четвертой структуры данных СМД производят путем регистрации идентифицированных элементов 14 четвертой структуры данных, выявленных в ходе анализа элементов 13 (простых суждений) третьей структуры данных на этапе 1072. Идентификацию значения 141 элемента 4(искомого суждения) четвертой структуры данных в ходе этапа 1072 (3032) производят путем отождествления значения 141 элемента 14 (искомого суждения) четвертой структуры данных со значением 131 простого суждения 13 третьей структуры данных, с которым идентифицировано искомое суждение 14. Идентификацию номеров 142 элемента 14 (искомого суждения) четвертой структуры данных в ходе этапа 1072 (3032) производят путём отождествления номеров 142 элемента 14 (искомого суждения) четвертой структуры данных с номерами 132 простого суждения 13 третьей структуры данных, с которым идентифицировано искомое суждение 14. Такие идентификация и формирование могут быть выполнены любым известным из уровня техники способом и, соответственно, подробно далее не описывается. Например, не ограничиваясь, такие идентификация и формирование могут быть выполнены традиционно специалистом-лингвистом, или же с помощью лингвистического (синтаксического) процессора. Более того, при наличии достаточного количества примеров возможно выполнение таких идентификации и формирования с помощью различных систем машинного обучения, в том числе статистического процессора или нейросети. Формирование четвертой структуры данных СМД в ходе этапа 1073 (3033) производят путем объединения в одной структуре данных элементов 14 четвертой структуры данных СМД и их идентификационных данных по известным из уровня техники принципам и способам, которые, соответственно далее подробно не описываются.
[0084] На фиг. 27, в качестве примера, но не ограничения, проиллюстрирована примерная схема системы 400 преобразования структурированного массива данных, которая в предпочтительном варианте реализации содержит, по меньшей мере, одно или более компьютерных устройств 401 преобразования структурированного массива данных, содержащих, по меньшей мере, один или более процессоров 4011 и память 4012. Упомянутые устройства 401 преобразования структурированного массива данных могут представлять собой, но не ограничиваться: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон, фаблет и тому подобное. Память (машиночитаемый носитель данных) 4012 устройства 401 преобразования структурированного массива данных, содержит код программы, который при выполнении побуждает упомянутые один или более процессоры 4011 упомянутого устройства 401 выполнять действия описанных ранее способов преобразования структурированного массива данных. В некоторых случаях компьютерное устройство 401 может представлять собой серверное компьютерное устройство, связанное с пользовательским компьютерным устройством, выполненным с возможностью передачи серверному компьютерному устройству 401 команды или команд, побуждающих процессор или процессоры 4011 серверного компьютерного устройства выполнять код программы, который при выполнении процессором или процессорами серверного компьютерного устройства 4011 побуждает процессор или процессоры 4011 серверного компьютерного устройства выполнять действия какого-либо из описанных ранее способов преобразования структурированного массива данных. Пользовательское компьютерное устройство 402 может представлять собой, но не ограничиваться: персональный компьютер, портативный компьютер, планшетный компьютер, карманный компьютер, смартфон, фаблет, тонкий клиент и тому подобное. Пользовательское компьютерное устройство 402 может быть связано с серверным компьютерным устройством 401 посредством проводного или беспроводного соединения. Упомянутая память 4012 компьютерного устройства 401 (серверного компьютерного устройства 401) содержит подлежащие преобразованию один или несколько структурированных массивов данных, содержащих, по меньшей мере, лингвистическое предложение, а также может содержать любую из описанных ранее структур данных для какого-либо из описанных ранее способов преобразования структурированного массива данных. Более того, подлежащие преобразованию один или несколько структурированных массивов данных могут являться загружаемыми и храниться, в частности, в базе данных 403 системы преобразования структурированного массива данных. В качестве примера, но не ограничения, машиночитаемый носитель данных (память 4012) может включать в себя оперативную память (RAM); постоянное запоминающее устройство (ROM); электрически-стираемое программируемое постоянное запоминающее устройство (EEPROM); флэш-память или другие технологии памяти; CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для кодирования требуемой информации, и к которому может быть осуществлен доступ посредством устройства 401. Память включает в себя носитель данных на основе запоминающего устройства компьютера в форме энергозависимой или энергонезависимой памяти, или их комбинации. Примерные аппаратные устройства включают в себя твердотельную память, накопители на жестких дисках, накопители на оптических дисках и так далее. В памяти хранится примерная среда, в которой при помощи компьютерных команд или кодов, хранящихся в памяти устройства, может быть осуществлена процедура преобразования структурированного массива данных. Устройство содержит один или более процессоров 4011, которые предназначены для выполнения компьютерных команд или кодов, хранящихся в памяти устройства с целью обеспечения выполнения процедуры преобразования структурированного массива данных. Компьютерные команды или коды, хранящиеся в памяти, предназначены для выполнения преобразования структурированного массива данных. Система 400 также может включать в себя базу данных (БД) 403. БД 403 может представлять собой, но не ограничиваясь: иерархическую БД, сетевую БД, реляционную БД, объектную БД, объектно-ориентированную БД, объектно-реляционную БД, пространственную БД, комбинацию перечисленных двух и более БД, и тому подобное. БД 403 хранит данные в памяти, которая может представлять собой, но не ограничиваясь: постоянное запоминающее устройство (ROM), электрически-стираемое программируемое постоянное запоминающее устройство (EEPROM), флэш-память, CDROM, цифровой универсальный диск (DVD) или другие оптические или голографические носители данных; магнитные кассеты, магнитную пленку, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, несущие волны или другой носитель данных, который может быть использован для хранения требуемой информации, и к которому может быть осуществлен доступ посредством устройства 401 преобразования структурированного массива данных. БД 403 служит для хранения данных, представляющих собой, по меньшей мере, команды для выполнения этапов описанных ранее способов преобразования структурированного массива данных; подлежащие преобразованию один или несколько структурированных массивов данных, содержащих, по меньшей мере, лингвистическое предложение, или одну из описанных ранее исходных для какого-либо способа преобразования структур данных, которые могут быть загружены в память 4012 устройства 401 преобразования структурированного массива данных; и других данных, необходимых для функционирования системы. Примерная система 400 преобразования структурированного массива данных дополнительно может содержать серверное компьютерное устройство 401, которое помимо описанных ранее функций, сохраняет и содействует манипуляции компьютерными командами или кодами, ранее описанными в данном документе, которые, соответственно, дополнительно не описываются. Серверное компьютерное устройство 401, помимо описанных ранее функций, может обеспечивает регулирование обменом данных в системе 400 преобразования структурированного массива данных, а также обеспечивает обработку данных при условии подключения к нему одного или более чем одного пользовательских компьютерных устройств 402. В этом случае все вычислительные мощности, необходимые для обеспечения выполнения процедуры преобразования структурированного массива данных, расположены на серверном компьютерном устройстве 401. Система 400 так же может содержать одну или более сетей 404 передачи данных. Сети 404 передачи данных могут включать в себя, но не ограничиваться, одну или более локальных сетей (LAN) и/или глобальных сетей (WAN), или могут представлять собой информационно-телекоммуникационную сеть Интернет, или Интранет, или виртуальную частную сеть (VPN), или их комбинацию, и тому подобное. Серверное компьютерное устройство 401 также имеет возможность обеспечивать виртуальную вычислительную среду (Virtual Machine) для обеспечения взаимодействия между пользовательским компьютерным устройством 402 и БД 403. Сеть 404 служит для обеспечения взаимодействия между компьютерным устройством 401, базой данных 403 и пользовательским компьютерным устройством 402 системы 400 преобразования структурированного массива данных. При этом пользовательское компьютерное устройство 402 может быть связано с серверным компьютерным устройством 401 напрямую, используя известные из уровня техники проводные и беспроводные способы и методы связи, которые, соответственно, далее не подробно не описываются. Упомянутые устройства 401, 402, в качестве примера, но не ограничения, могут быть снабжены устройствами ввода-вывода (i/o), пригодными для предоставления пользователю результатов выполнения тех или иных описанных ранее этапов какого-либо из заявленных способов 100, 200 или 300.
[0085] Настоящее описание осуществления заявленного изобретения демонстрирует лишь частные варианты осуществления и не ограничивает иные варианты реализации заявленного изобретения, поскольку возможные иные альтернативные варианты осуществления заявленного изобретения, не выходящие за пределы объема информации, изложенной в настоящей заявке, должны быть очевидными для специалиста в данной области техники, имеющим обычную квалификацию, на которого рассчитано заявленное изобретение.
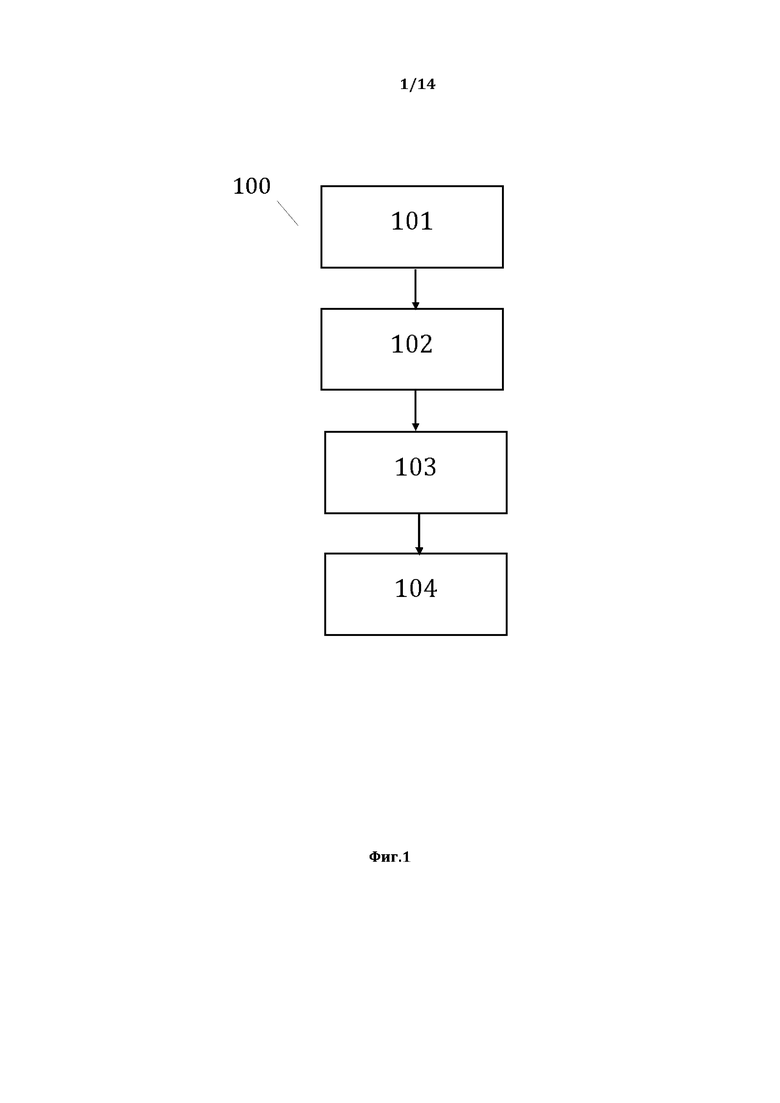
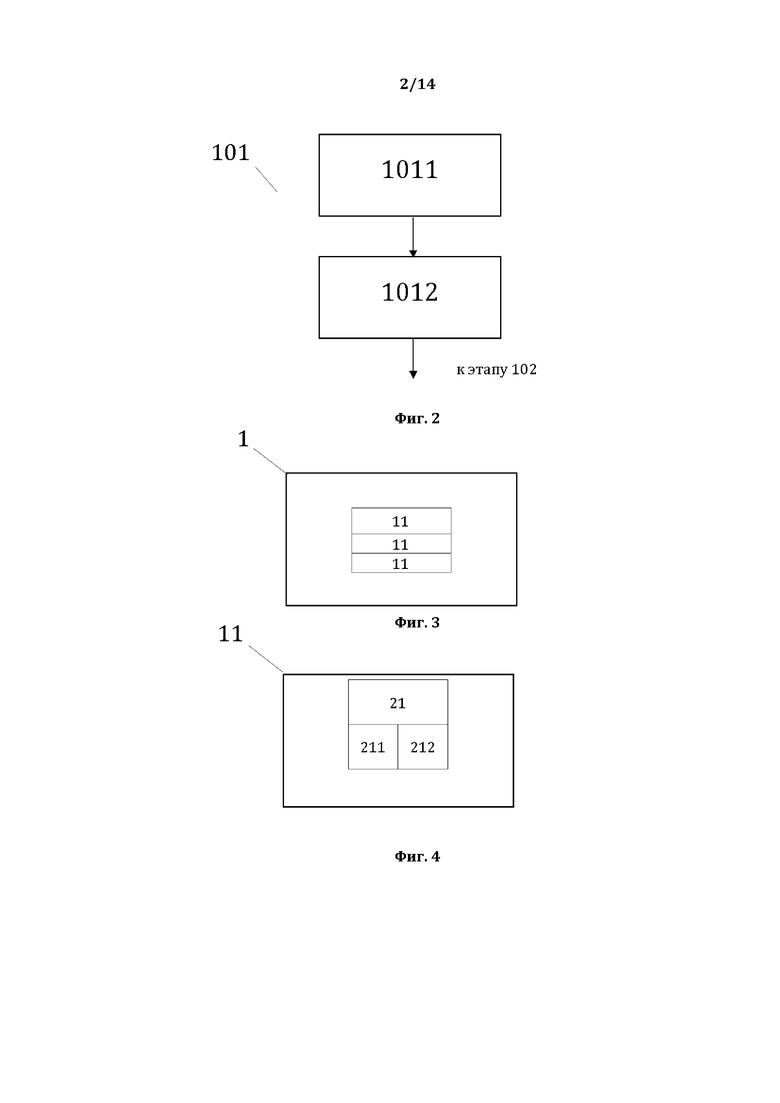
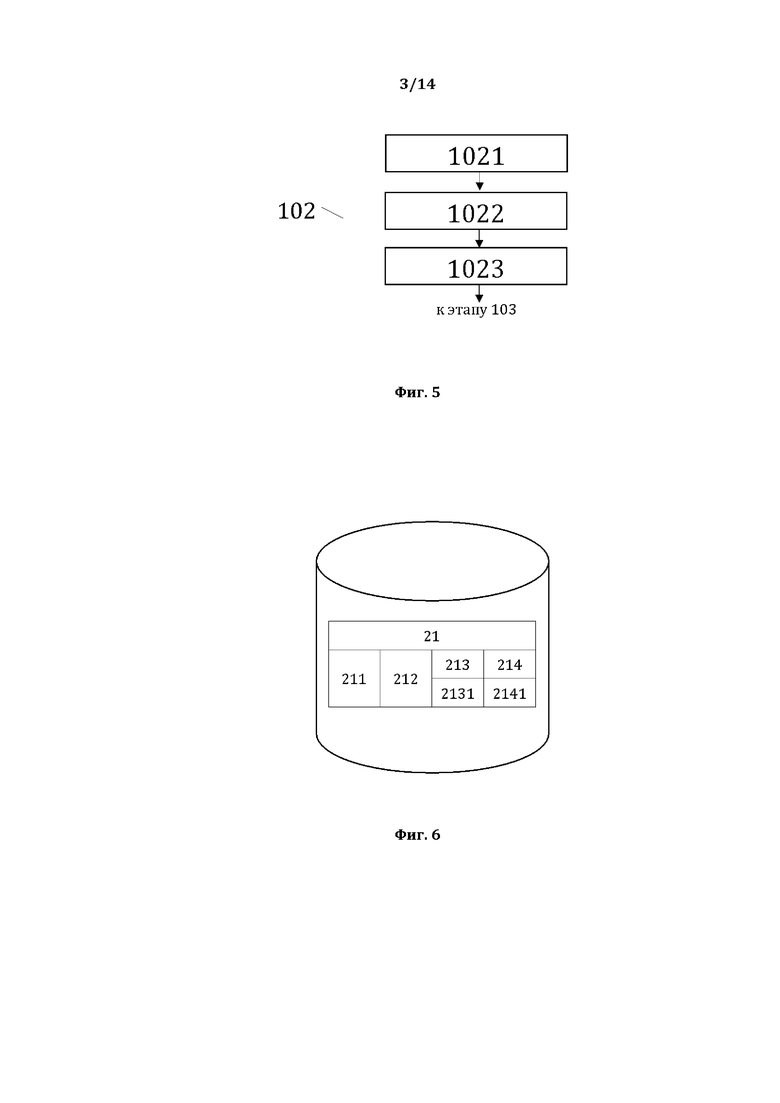
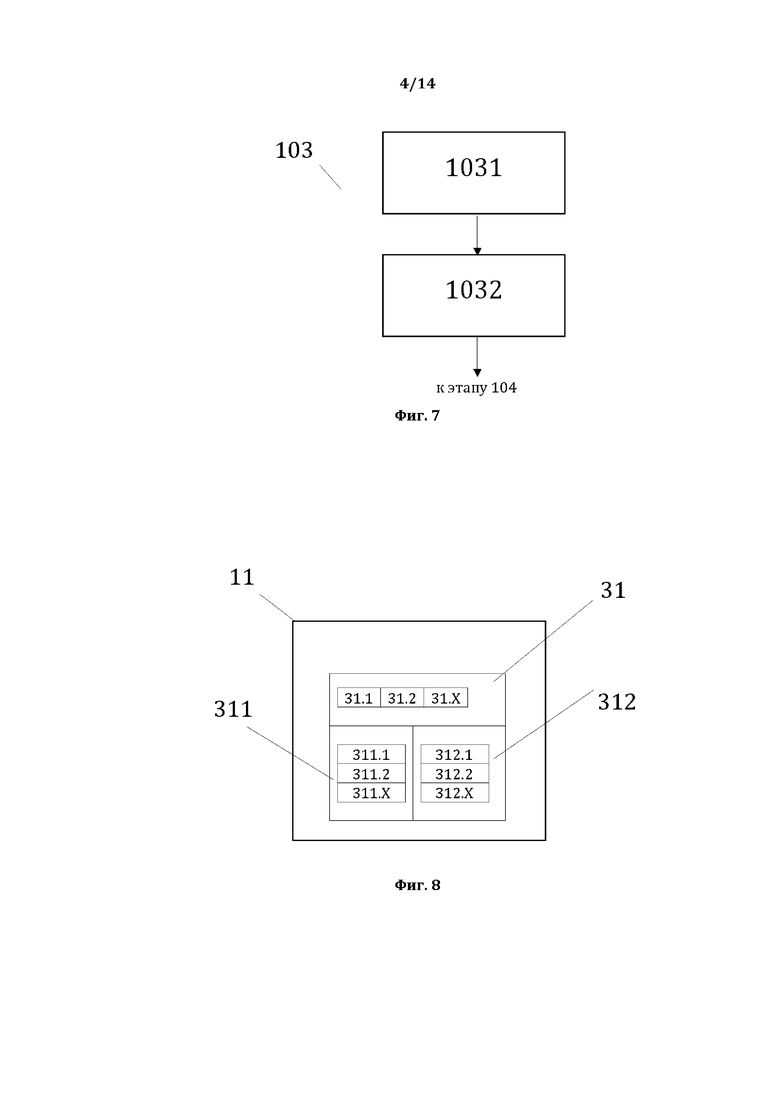
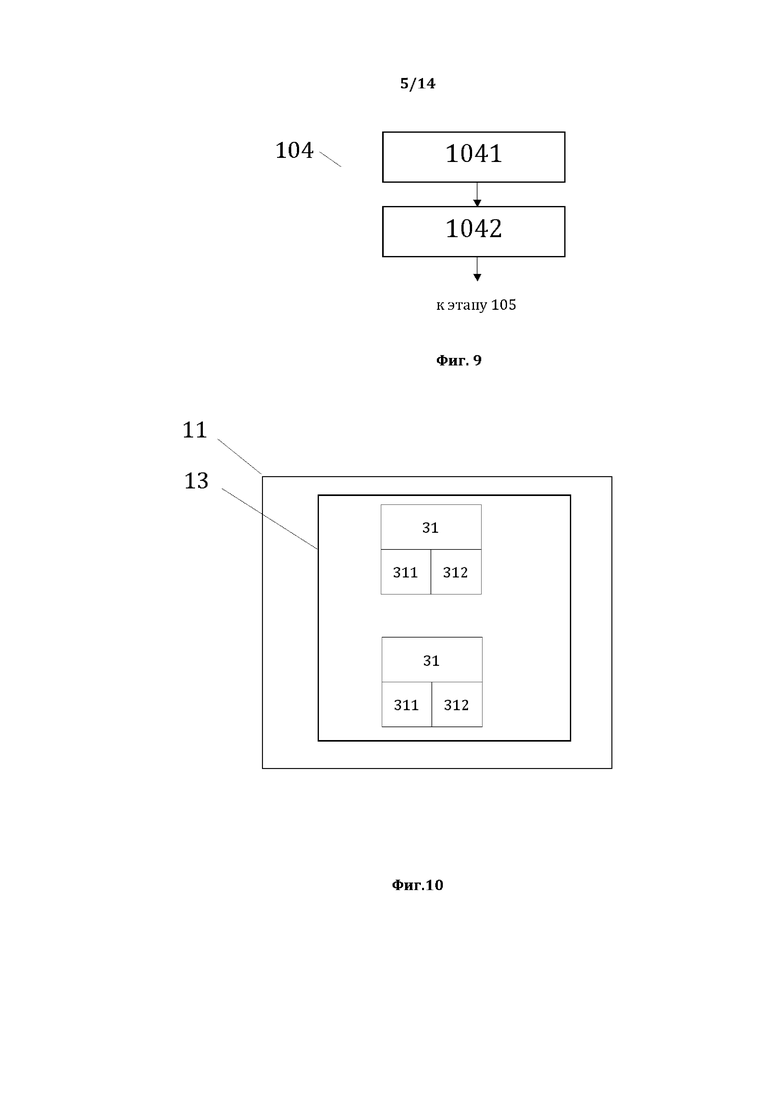
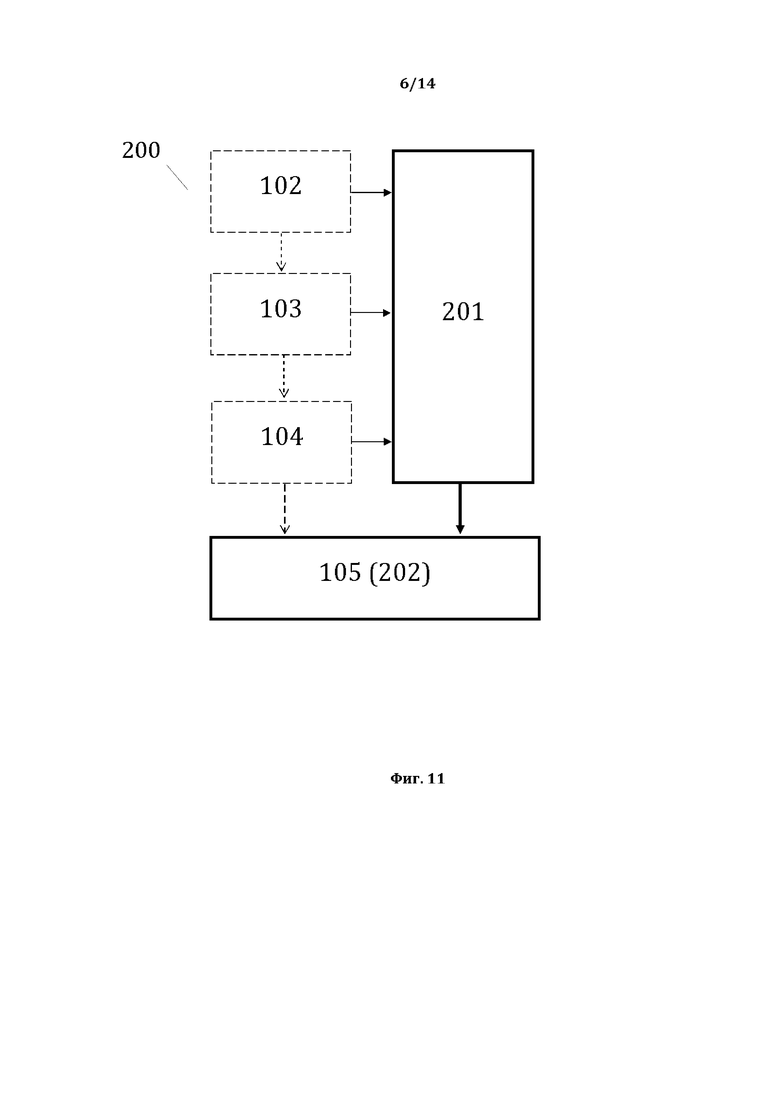
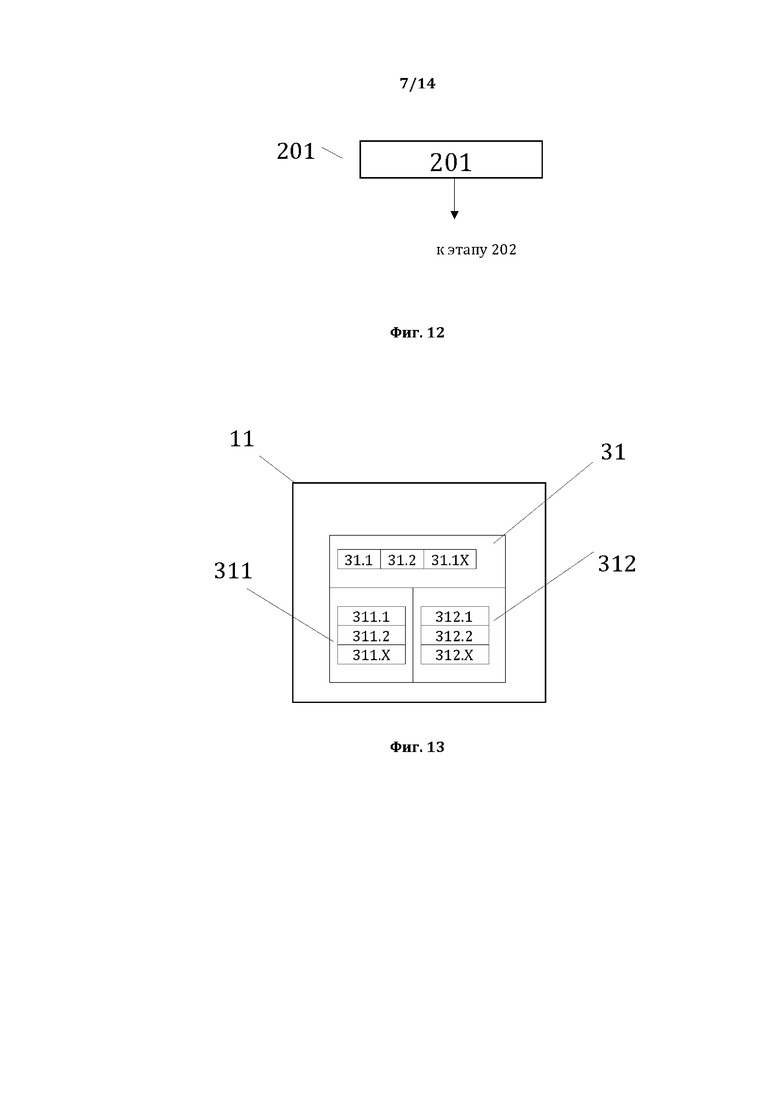
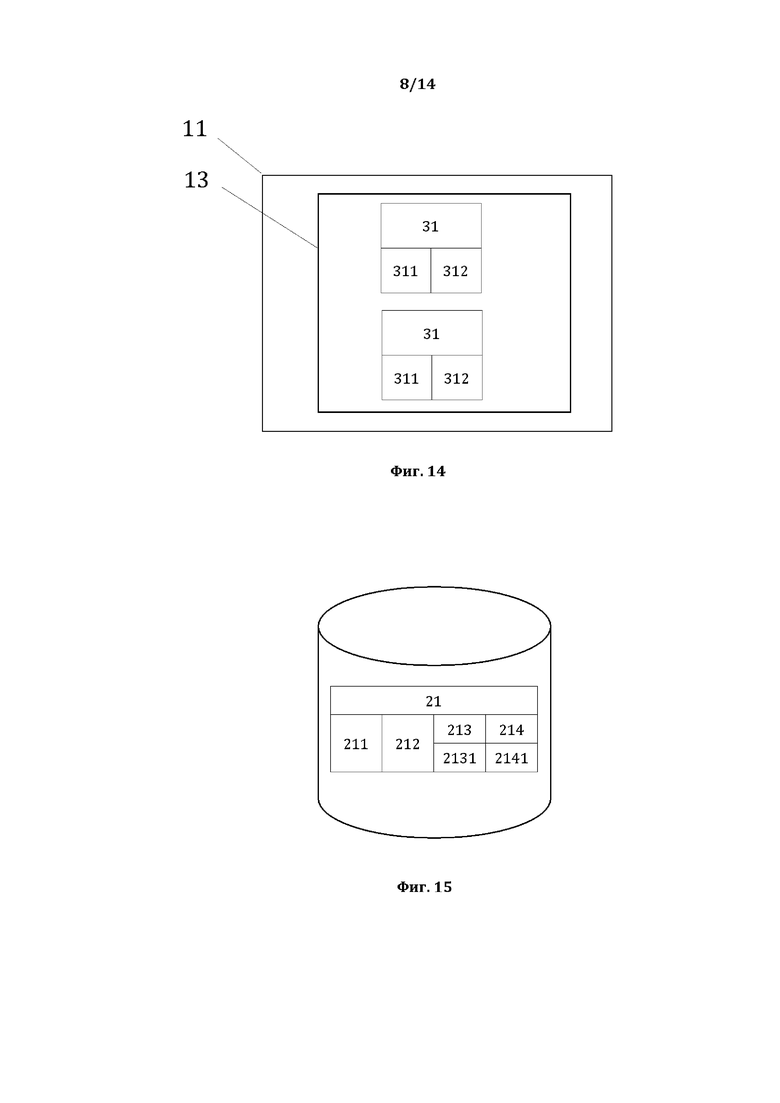
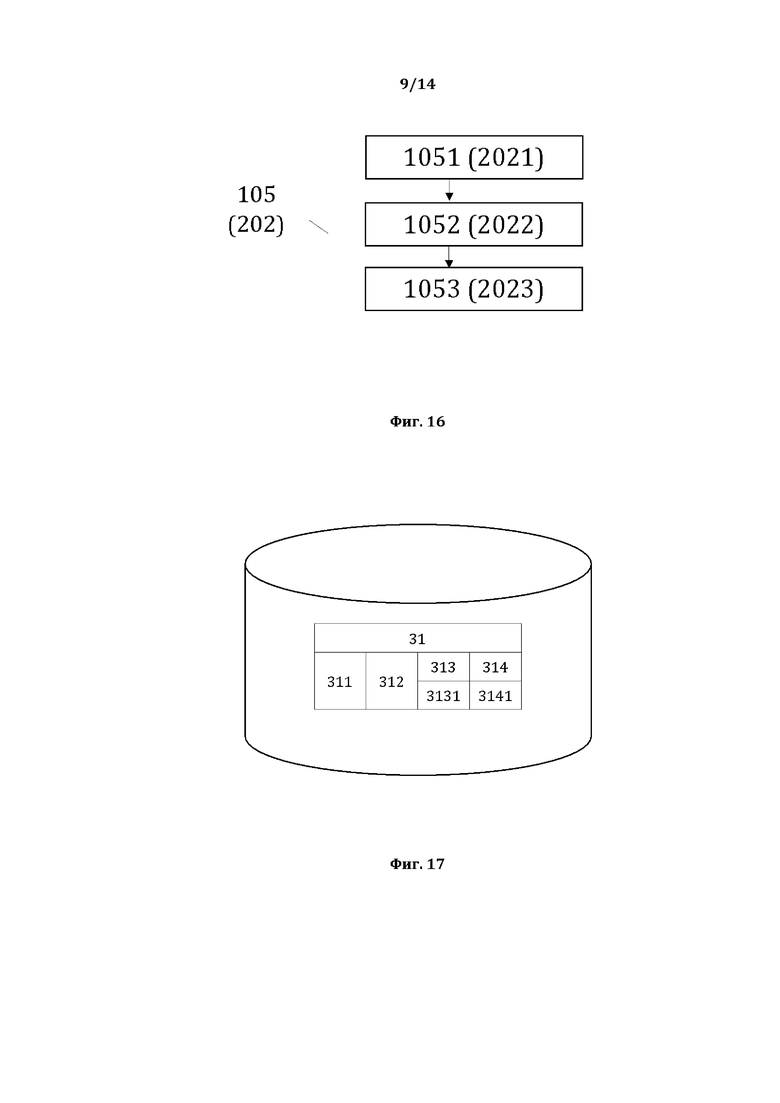
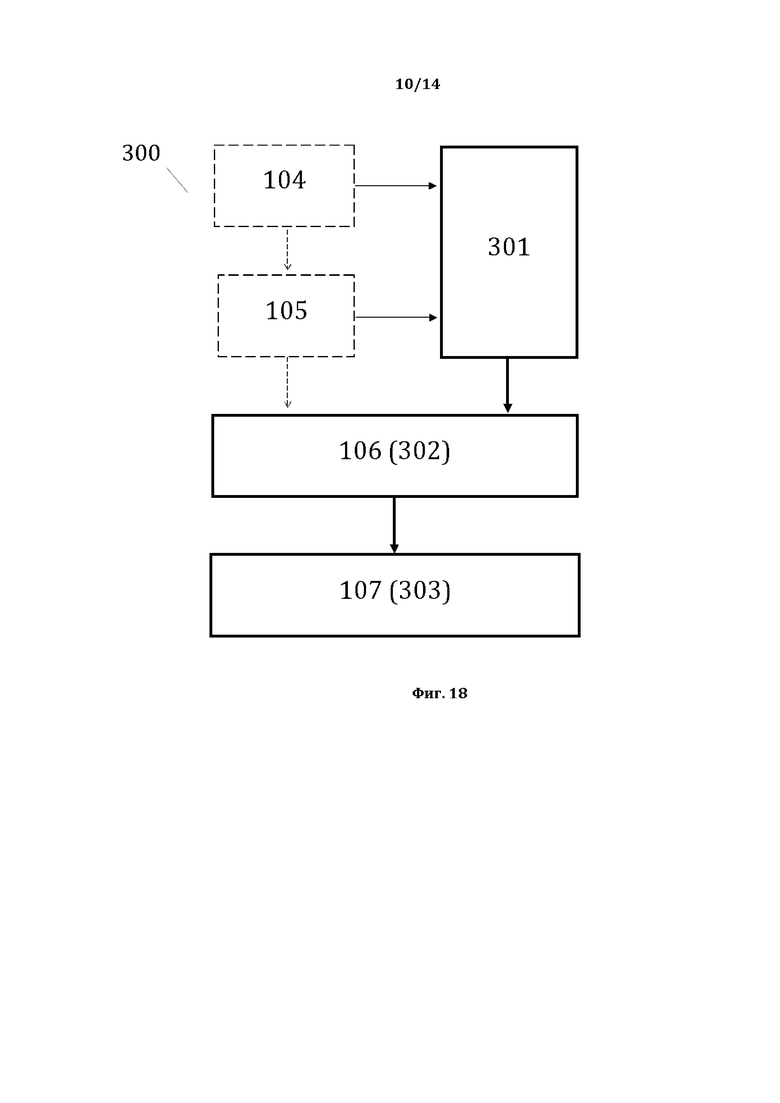
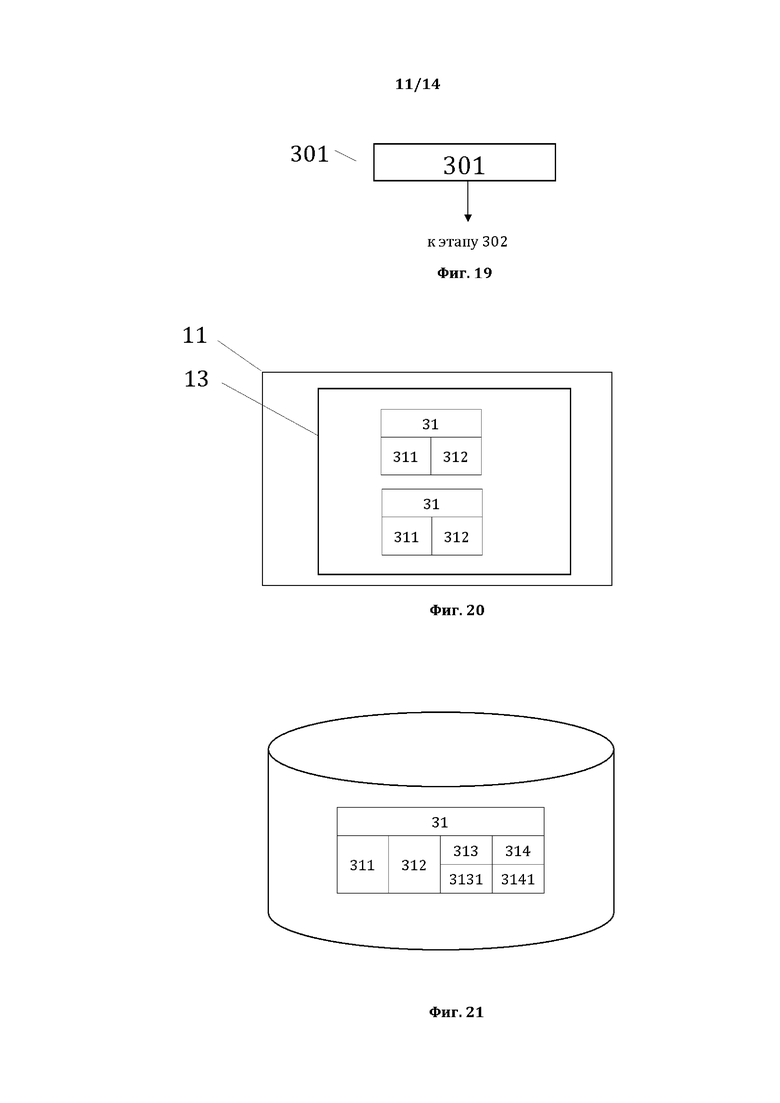
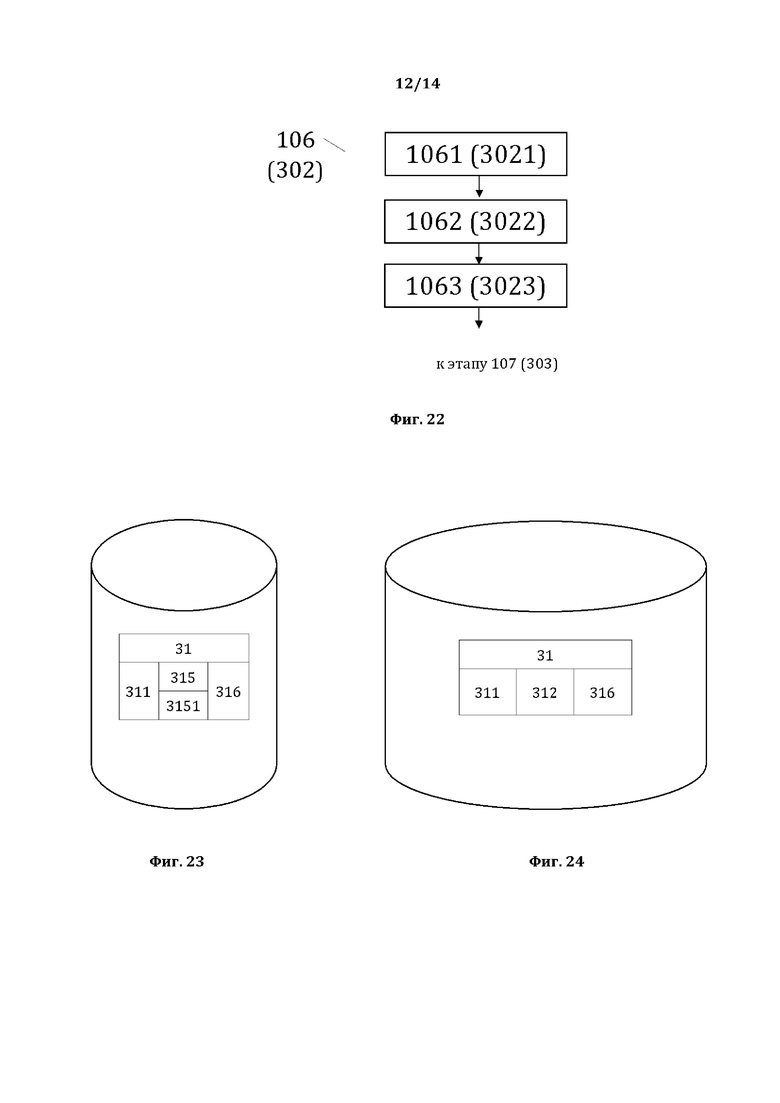
Изобретение относится к области обработки данных. Технический результат заключается в расширении арсенала средств. Способ преобразования структурированного массива данных (СМД), содержащего простые суждения (ПС), заключающийся в выполнении этапов формирования первой структуры данных (СД), на котором формируют первую СД СМД, содержащую элементы упомянутой первой СД, причем упомянутые элементы первой СД представляют собой текстовые элементы (ТЭ) лингвистического предложения (ЛП), а также идентификационные данные ТЭ, формирования базы данных лингво-логических признаков (БДЛЛП), на котором на основании сведений, содержащихся в первой СД, выявляют лингвистические и логические признаки ТЭ ЛП, из которых формируют базу данных, представляющую собой базу данных лингвистических и логических признаков ТЭ ЛП, формирования второй СД, на котором на основании сведений, содержащихся в БДЛЛП, первой СД, формируют вторую СД СМД, формирования третьей СД, на котором на основании сведений, содержащихся в БДЛЛП, второй СД, а также на основании формализованной модели простого суждения формируют третью СД СМД. 4 н. и 4 з.п. ф-лы, 14 табл., 27 ил.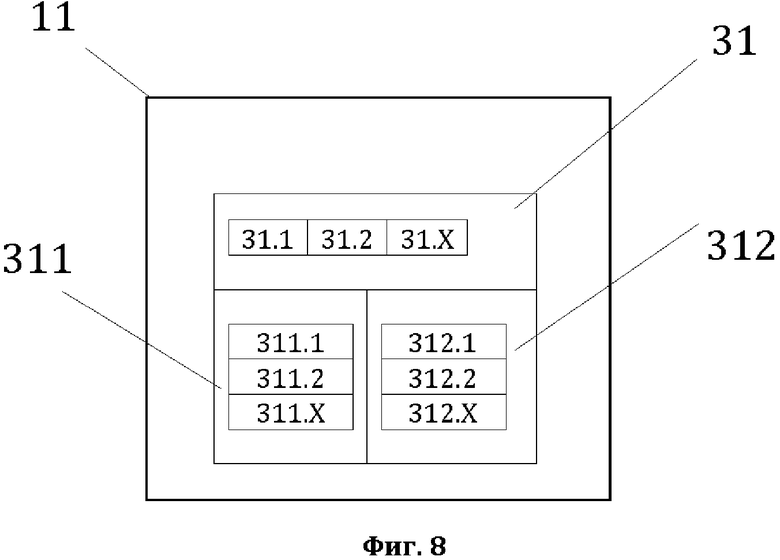
1. Исполняемый процессором или процессорами компьютерного устройства способ формирования структуры данных, содержащей простые суждения, заключающийся в:
выполнении этапа 101 формирования первой структуры данных (СД), на котором формируют первую СД СМД, содержащую элементы упомянутой первой СД, причем упомянутые элементы первой СД представляют собой текстовые элементы (ТЭ) лингвистического предложения, а также идентификационные данные ТЭ, представляющие собой в качестве примера, но не ограничения: значения ТЭ и порядковые номера ТЭ в лингвистическом предложении;
выполнении этапа 102 формирования базы данных лингво-логических признаков (БДЛЛП), на котором на основании сведений, содержащихся в первой СД, выявляют лингвистические и логические признаки ТЭ лингвистического предложения, из которых формируют базу данных, представляющую собой базу данных лингвистических и логических признаков текстовых элементов лингвистического предложения;
выполнении этапа 103 формирования второй СД, на котором на основании сведений, содержащихся в БДЛЛП, первой СД, а также на основании формализованной модели простого суждения, формируют вторую СД СМД, содержащую элементы упомянутой второй СД, причем упомянутые элементы второй СД представляют собой компоненты простых суждений (КПС), а также идентификационные данные КПС, представляющие собой в качестве примера, но не ограничения: значения КПС и порядковые номера ТЭ лингвистического предложения, составляющих КПС;
выполнении этапа 104 формирования третьей СД, на котором на основании сведений, содержащихся в БДЛЛП, второй СД, а также на основании формализованной модели простого суждения, формируют третью СД СМД, содержащую элементы упомянутой третьей СД, причем упомянутые элементы третьей СД представляют собой простые суждения (ПС) лингвистического предложения, а также идентификационные данные ПС, представляющие собой в качестве примера, но не ограничения: значения ПС и порядковые номера ТЭ лингвистического предложения, составляющих ПС.
2. Способ по п. 1, характеризующийся тем, что этап 101 характеризуется:
выполнением этапа 1011 идентификации исходной структуры данных СМД, на котором идентифицируют элементы исходной структуры данных СМД, являющиеся лингвистическими предложениями (ЛП);
выполнением этапа 1012 идентификации элементов первой структуры данных СМД, на котором идентифицируют элементы первой структуры данных СМД, являющиеся первичными текстовыми элементами (ПТЭ) лингвистического предложения, а также идентификационные данные ПТЭ, представляющие собой в качестве примера, но не ограничения значения ПТЭ и порядковые номера ПТЭ в лингвистическом предложении, и формируют первую структуру данных СМД.
3. Способ по п. 1, характеризующийся тем, что этап 102 характеризуется:
выполнением этапа 1021 формирования первой части лингво-логических признаков ПТЭ лингвистического предложения, на котором для лингвистического анализа ПТЭ, содержащихся в первой СД и классифицированных как слово, предоставляют идентификационные данные ПТЭ и получают лингвистические характеристики ПТЭ, а также значения упомянутых лингвистических характеристик;
выполнением этапа 1022 формирования второй части лингво-логических признаков ПТЭ лингвистического предложения, на котором для логического анализа ПТЭ, содержащихся в первой СД и классифицированных как слово, предоставляют идентификационные данные ПТЭ, а также лингвистические характеристики ПТЭ лингвистического предложения вместе с упомянутыми значениями лингвистических характеристик, и получают логические характеристики ПТЭ лингвистического предложения, а также значения упомянутых логических характеристик;
выполнением этапа 1023 формирования базы данных лингво-логических признаков (БДЛЛП), на котором формируют БДЛЛП первичных текстовых элементов лингвистического предложения, при этом лингво-логическими признаками ПТЭ являются все полученные по соответствующему ПТЭ в ходе этапов 1021 и 1022 упомянутые лингвистические характеристики и упомянутые логические характеристики, обладающие соответствующими упомянутыми значениями лингвистических характеристик и упомянутыми значениями логических характеристик.
4. Способ по п. 1, характеризующийся тем, что этап 103 характеризуется:
выполнением этапа 1031, формирования элементов второй СД, на котором на основании сведений, содержащихся в БДЛЛП, первой СД, а также на основании формализованной модели простого суждения, идентифицируют и формируют элементы второй СД, являющиеся КПС, а также идентификационные данные КПС, представляющие собой в качестве примера, но не ограничения значения КПС и порядковые номера ПТЭ в лингвистическом предложении, составляющих КПС;
выполнением этапа 1032 формирования второй СД, на котором формируют вторую СД из идентифицированных КПС и их идентификационных данных.
5. Способ по п. 1, характеризующийся тем, что этап 104 характеризуется:
выполнением этапа 1041 формирования элементов третьей СД, на котором на основании сведений, содержащихся в БДЛЛП и второй СД, из сформированных КПС в соответствии с формализованной компонентной моделью простого суждения формируют элементы третьей СД, являющиеся простыми суждениями (ПС), а также идентификационные данные ПС, представляющие собой в качестве примера, но не ограничения значения ПС и порядковые номера ПТЭ в лингвистическом предложении, составляющих ПС;
выполнением этапа 1042 формирования третьей СД, на котором формируют третью СД из сформированных ПС и их идентификационных данных.
6. Компьютерное устройство для преобразования структурированного массива данных (СМД), содержащего лингвистические предложения (ЛП), содержащее, по меньшей мере:
процессор компьютерного устройства, и
память, содержащую код программы, который при выполнении процессором компьютерного устройства побуждает процессор компьютерного устройства выполнять действия способа по любому из пп. 1-5.
7. Система для преобразования структурированного массива данных (СМД), содержащего лингвистические предложения (ЛП), содержащая, по меньшей мере:
серверное компьютерное устройство, являющееся компьютерным устройством по п. 6, и
пользовательское компьютерное устройство, выполненное с возможностью передачи серверному компьютерному устройству команды или команд, побуждающих процессор серверного компьютерного устройства выполнять код программы, который при выполнении процессором серверного компьютерного устройства побуждает процессор серверного компьютерного устройства выполнять действия способа по любому из пп. 1-5.
8. Машиночитаемый носитель данных, содержащий код программы, который при выполнении процессором компьютерного устройства побуждает процессор компьютерного устройства выполнять действия способа по любому из пп. 1-5.
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ЕГО СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ, СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ КОЛЛЕКЦИИ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ИХ СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2008 |
|
RU2399959C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |

