Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству кодирования изображений, устройству декодирования изображений, способу кодирования изображений и способу декодирования изображений, которые используются для технологии кодирования со сжатием изображений, технологии передачи сжатых данных изображений и т.д.
Уровень техники
Обычно в способах кодирования видео по международным стандартам, таким как MPEG и ITU-T H.26x, каждый входной видеокадр подвергается процессу сжатия, причем видеокадр разделяется на макроблоки, каждый из которых состоит из блоков пикселов 16×16.
С другой стороны, в последние годы требуется технология кодирования со сжатием высококачественного видео высокой четкости, имеющего такой видеоформат, как видеоформат 4K×2K пикселов, имеющий пространственное разрешение, которое в четыре раза превышает пространственное разрешение HDTV (телевидение высокой четкости, 1920×1080 пикселов), видеоформат 8K×4K пикселов, имеющий пространственное разрешение, которое дополнительно увеличивается до превышения в четыре раза пространственного разрешения видеоформата 4K×2K пикселов, или формат видеосигнала 4:4:4 для увеличения числа дискретизированных сигналов сигнала цветности, тем самым улучшая характер цветовоспроизведения. При кодировании со сжатием такого высококачественного видео высокой четкости невозможно выполнять процесс кодирования посредством использования корреляции сигналов изображения в макроблоке пикселов 16×16 в достаточной степени, и, следовательно, трудно предоставлять высокий коэффициент сжатия. Чтобы разрешить эту проблему, предложена, например, технология увеличения размера каждого обычного макроблока пикселов 16×16 до блока пикселов 32×32, как раскрыто в непатентном источнике 1, и увеличения единицы, в которой вектор движения выделяется, тем самым уменьшая объем кодированных параметров, требуемых для прогнозирования, или технология увеличения размера блока для кодирования с преобразованием сигнала ошибки прогнозирования, тем самым эффективно удаляя корреляцию между пикселами сигнала ошибки прогнозирования.
Фиг. 21 является блок-схемой, показывающей структуру устройства кодирования, раскрытого в непатентном источнике 1. При кодировании, раскрытом в непатентном источнике 1, модуль 1002 разделения на блоки разделяет введенный видеосигнал 1001, который является целью, которая должна быть кодирована, на макроблоки (прямоугольные блоки сигнала яркости, имеющие 32 пиксела × 32 строки каждый), и вводит в модуль 1004 прогнозирования в качестве кодированного видеосигнала 1003.
Модуль 1004 прогнозирования прогнозирует сигнал изображения каждого цветового компонента в каждом макроблоке в рамках каждого кадра и между кадрами, чтобы получить сигнал 1005 ошибки прогнозирования. В частности, при выполнении прогнозирования с компенсацией движения между кадрами, модуль прогнозирования выполняет поиск вектора движения для каждого макроблока непосредственно или для каждого из субблоков, на которые каждый макроблок дополнительно разделяется, создает прогнозируемое изображение с компенсацией движения согласно вектору движения и получает сигнал 1005 ошибки прогнозирования посредством вычисления разности между прогнозируемым изображением с компенсацией движения и кодированным видеосигналом 1003.
После выполнения процесса DCT (дискретного косинусного преобразования) для сигнала 1005 ошибки прогнозирования, чтобы удалять корреляцию сигналов из сигнала 1005 ошибки прогнозирования при изменении размера блока согласно размеру единицы площади, которой выделяется вектор движения, модуль 1006 сжатия квантует сигнал ошибки прогнозирования, чтобы получить сжатые данные 1007. Хотя сжатые данные 1007 энтропийно кодируются и выводятся в качестве потока 1009 битов посредством модуля 1008 кодирования переменной длины, сжатые данные также отправляются в модуль 1010 локального декодирования, и декодированный сигнал 1011 ошибки прогнозирования получают посредством этого модуля локального декодирования.
Этот декодированный сигнал 1011 ошибки прогнозирования добавляется к сигналу 1012 прогнозирования, который используется для того, чтобы создавать сигнал 1005 ошибки прогнозирования, чтобы создавать декодированный сигнал 1013, и этот декодированный сигнал вводится в контурный фильтр 1014. Декодированный сигнал 1013 сохраняется в запоминающем устройстве 1016 в качестве опорного сигнала 1015 изображения для создания последующего сигнала 1012 прогнозирования после того, как декодированный сигнал подвергается процессу удаления искажения в виде блочности посредством контурного фильтра 1014. Параметр 1017, используемый для создания сигнала прогнозирования, который определяется посредством модуля 1004 прогнозирования, чтобы получить сигнал 1012 прогнозирования, отправляется в модуль 1008 кодирования переменной длины и мультиплексируется в поток 1009 битов, и этот поток битов выводится. Информация, такая как информация режима внутреннего прогнозирования, показывающая то, как выполнять пространственное прогнозирование в каждом кадре, и вектор движения, показывающий величину межкадрового перемещения, например, включается в параметр 1017, используемый для создания сигнала прогнозирования.
Хотя обычный способ кодирования видео по международным стандартам, к примеру MPEG или ITU-T H.26x, использует 16×16 пикселов в качестве размера макроблока, устройство кодирования, раскрытое в непатентном источнике 1, использует 32×32 пикселов в качестве размера макроблока (супермакроблока: SMB). Фиг. 22 показывает формы разделенных областей, каждой из которых вектор движения выделяется во время выполнения прогнозирования с компенсацией движения для каждого макроблока пикселов M×M, и фиг. 22(a) показывает каждый SMB, раскрытый в непатентном источнике 1, а фиг. 22(b) показывает каждый макроблок на основе обычного MPEG-4 AVC/H.264 (см. непатентный источник 2). Хотя каждый SMB имеет большую площадь для каждой области прогнозирования движения, которая покрывается посредством одного вектора движения с числом пикселов M=32, каждый традиционный макроблок использует число пикселов M/2=16. Как результат, поскольку в случае SMB объем информации вектора движения, который необходим для всего экрана, снижается по сравнению со случаем традиционных макроблоков, имеющих число пикселов M/2=16, объем кода векторов движения, который должен быть передан в качестве потока битов, может быть уменьшен.
Документы уровня техники
Непатентные источники
Непатентный источник 1. Siwei Ma и C.-C. Jay Kuo, "High-definition Video Coding with Super-macroblocks", Proc. SPIE, издание 6508, 650816 (2007)
Непатентный источник 2. Стандарты MPEG-4 AVC (ISO/IEC 14496-10)/H.ITU-T 264
Раскрытие изобретения
В обычных способах, раскрытых в непатентных источниках 1 и 2, предоставляется специальный режим, называемый режимом чередования, в котором данные, которые должны быть кодированы для вектора движения и сигнала ошибки прогнозирования, вообще отсутствуют, как результат вышеуказанного прогнозирования движения. Например, в непатентном источнике 2 случай, в котором «вектор движения совпадает со своим прогнозированным значением, и все коэффициенты преобразования сигнала ошибки прогнозирования равны нулю», задается как режим чередования. Кроме того, режим чередования может выбираться только тогда, когда область, в которой выделяется вектор движения, имеет размер, идентичный размеру макроблока. Следовательно, когда размер макроблока увеличен, как показано в непатентном источнике 1, режим чередования задается только для блока прогнозирования движения, имеющего максимальный размер. Следовательно, проблема состоит в том, что режим чередования вообще не применяется к блокам прогнозирования движения, имеющим размер, меньший максимального размера, и, следовательно, трудно повышать эффективность кодирования.
Настоящее изобретение реализовано, чтобы решить вышеуказанную проблему, и, следовательно, задача настоящего изобретения заключается в том, чтобы создать устройство кодирования изображений, которое реализует способ кодирования видео, имеющий хорошую балансировку нагрузки, для более эффективного удаления корреляции сигналов согласно статистическим и локальным свойствам видеосигнала, который является целью, которая должна быть кодирована, и выполнения эффективного сжатия информации, тем самым повышая оптимальность для кодирования видеосигнала сверхвысокой четкости, а также способ реализации устройства кодирования изображений и устройства декодирования изображений и способ декодирования изображений.
В соответствии с настоящим изобретением предусмотрено устройство кодирования изображений, включающее в себя: модуль прогнозирования для адаптивного определения размера единичного блока прогнозирования движения в каждом макроблоке согласно заданному условию и для разделения вышеуказанного единичного блока прогнозирования движения на области выделения векторов движения, чтобы выполнять поиск вектора движения; и модуль кодирования для выполнения, когда вектор движения выделяется всему единичному блоку прогнозирования движения, кодирования в первом режиме чередования, если вышеуказанный вектор движения равен оцененному вектору, который определяется из векторов движения в окружающих единичных блоках прогнозирования движения, и данных, которые должны быть кодированы как сигнал ошибки прогнозирования движения, не существует, и для выполнения, когда каждая из областей выделения векторов движения имеет размер, равный или превышающий заданный размер, и вектор движения выделяется полностью для каждой из областей выделения векторов движения, кодирования во втором режиме чередования, если вышеуказанный вектор движения равен оцененному вектору, который определяется из векторов движения в окружающих областях выделения векторов движения, и данных, которые должны быть кодированы как сигнал ошибки прогнозирования движения, не существует.
В соответствии с настоящим изобретением предусмотрено устройство декодирования изображений, включающее в себя: модуль декодирования для декодирования потока битов, чтобы получить данные, показывающие размер единичного блока прогнозирования движения в каждом макроблоке, режим прогнозирования движения для указания формы каждой из областей выделения векторов движения, на которые единичный блок прогнозирования движения разделяется, и вектор движения, соответствующий каждой области выделения векторов движения, и для определения того, находится или нет единичный блок прогнозирования движения в первом режиме чередования и находится или нет одна из областей выделения векторов движения во втором режиме чередования, из вышеуказанного режима прогнозирования движения; и модуль прогнозирования для определения, когда единичный блок прогнозирования движения находится в первом режиме чередования или одна из областей выделения векторов движения находится во втором режиме чередования, оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения, а также задания всех сигналов ошибки прогнозирования движения равными нулю, чтобы создавать прогнозируемое изображение, и для создания, когда единичный блок прогнозирования движения не находится в первом режиме чередования и области выделения векторов движения вышеуказанного единичного блока прогнозирования движения не находятся во втором режиме чередования, прогнозируемого изображения на основе режима прогнозирования движения и вектора движения, которые модуль декодирования получает посредством декодирования потока битов.
В соответствии с настоящим изобретением предусмотрен способ кодирования изображений, включающий в себя: этап прогнозирования для адаптивного определения размера единичного блока прогнозирования движения в каждом макроблоке согласно заданному условию и разделения вышеуказанного единичного блока прогнозирования движения на области выделения векторов движения, чтобы выполнять поиск вектора движения; и этап кодирования для выполнения, когда вектор движения выделяется всему единичному блоку прогнозирования движения, кодирования в первом режиме чередования, если вышеуказанный вектор движения равен оцененному вектору, который определяется из векторов движения в окружающих единичных блоках прогнозирования движения, и данных, которые должны быть кодированы как сигнал ошибки прогнозирования движения, не существует, и когда каждая из областей выделения векторов движения имеет размер, равный или превышающий заданный размер, и вектор движения выделяется полностью для каждой из областей выделения векторов движения, выполнения кодирования во втором режиме чередования, если вышеуказанный вектор движения равен оцененному вектору, который определяется из векторов движения в окружающих областях выделения векторов движения, и данных, которые должны быть кодированы как сигнал ошибки прогнозирования движения, не существует.
В соответствии с настоящим изобретением предусмотрен способ декодирования изображений, включающий в себя: этап декодирования для декодирования потока битов, чтобы получить данные, показывающие размер единичного блока прогнозирования движения в каждом макроблоке, режим прогнозирования движения для указания формы каждой из областей выделения векторов движения, на которые единичный блок прогнозирования движения разделяется, и вектор движения, соответствующий каждой области выделения векторов движения, чтобы определять то, находится или нет единичный блок прогнозирования движения в первом режиме чередования и находится или нет одна из областей выделения векторов движения во втором режиме чередования, из вышеуказанного режима прогнозирования движения; этап прогнозирования режима чередования для определения, когда единичный блок прогнозирования движения находится в первом режиме чередования или одна из областей выделения векторов движения находится во втором режиме чередования, оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения, а также задания всех сигналов ошибки прогнозирования движения равными нулю, чтобы создавать прогнозируемое изображение; и этап прогнозирования для декодирования, когда единичный блок прогнозирования движения не находится в первом режиме чередования и области выделения векторов движения единичного блока прогнозирования движения не находятся во втором режиме чередования, потока битов, чтобы получить данные, показывающие вектор движения, соответствующий каждой области выделения векторов движения, чтобы создавать прогнозируемое изображение на основе вышеуказанного вектора движения и режима прогнозирования движения, которые получают посредством декодирования потока битов на этапе декодирования.
Согласно настоящему изобретению, поскольку первый режим чередования и второй режим чередования задаются для каждого единичного блока прогнозирования движения и его областей выделения векторов движения, соответственно, устройство кодирования изображений и устройство декодирования изображений могут иметь такую структуру, что они имеют возможность выражать иерархию режимов чередования при кодировании и декодировании видеосигнала, имеющего формат 4:4:4, и являются гибкими и адаптивными к характеристикам временного изменения сигнала каждого цветового компонента. Следовательно, устройство кодирования изображений может выполнять оптимальный процесс кодирования для видеосигнала, имеющего формат 4:4:4.
Краткое описание чертежей
Фиг. 1 является видом, показывающим формат 4:4:4, который является целью, которая должна обрабатываться посредством устройства кодирования изображений и устройства декодирования изображений в соответствии с вариантом 1 осуществления;
Фиг. 2 является блок-схемой, показывающей структуру устройства кодирования изображений в соответствии с вариантом 1 осуществления;
Фиг. 3 является пояснительным чертежом, показывающим опорный блок, который модуль разделения на блоки, показанный на фиг. 2, создает;
Фиг. 4 является пояснительным чертежом, показывающим примеры форм, на которые модуль прогнозирования, показанный на фиг. 2, разделяет набор единичных блоков прогнозирования движения, причем каждая из форм состоит из одного или более базисных блоков;
Фиг. 5 является блок-схемой последовательности операций способа, показывающей работу модуля прогнозирования, показанного на фиг. 2;
Фиг. 6 является видом для пояснения способа вычисления затрат J, который выполняется посредством модуля прогнозирования;
Фиг. 7 является видом, показывающим пример определения оцененного вектора PMV в каждом из режимов mc_mode1-mc_mode4 прогнозирования движения, которое выполняется посредством модуля прогнозирования;
Фиг. 8 является видом для пояснения режима чередования;
Фиг. 9 является видом для пояснения способа энтропийного кодирования, который использует модуль кодирования переменной длины;
Фиг. 10 является блок-схемой, показывающей внутреннюю структуру модуля кодирования переменной длины, показанного на фиг. 2;
Фиг. 11 является блок-схемой последовательности операций способа, показывающей работу модуля кодирования переменной длины, показанного на фиг. 2;
Фиг. 12 является пояснительным чертежом, показывающим принцип в отношении контекстной модели (ctx);
Фиг. 13 является пояснительным чертежом, показывающим пример контекстной модели (ctx), связанной с вектором движения;
Фиг. 14 является видом, поясняющим разность в корреляции в режиме прогнозирования движения, и фиг. 14(a) и 14(b) показывают два состояния режима прогнозирования движения, которые выбираются для базисных блоков Ba и Bb соответственно;
Фиг. 15 является видом, показывающим результат преобразования в двоичную форму режима прогнозирования движения, которое выполняется посредством модуля преобразования в двоичную форму, показанного на фиг. 10;
Фиг. 16A является видом, поясняющим преобразование в двоичную форму режима прогнозирования движения, выполняемого посредством модуля преобразования в двоичную форму, показанного на фиг. 10, и показывает способ выбора контекстной модели для bin0;
Фиг. 16B является видом, поясняющим преобразование в двоичную форму режима прогнозирования движения, выполняемого посредством модуля преобразования в двоичную форму, показанного на фиг. 10, и показывает способ выбора контекстной модели для bin1;
Фиг. 16C является видом, поясняющим преобразование в двоичную форму режима прогнозирования движения, выполняемого посредством модуля преобразования в двоичную форму, показанного на фиг. 10, и показывает способ выбора контекстной модели для bin2;
Фиг. 16D является видом, поясняющим преобразование в двоичную форму режима прогнозирования движения, выполняемого посредством модуля преобразования в двоичную форму, показанного на фиг. 10, и показывает способ выбора контекстной модели для bin4;
Фиг. 16E является видом, поясняющим преобразование в двоичную форму режима прогнозирования движения, выполняемого посредством модуля преобразования в двоичную форму, показанного на фиг. 10, и показывает способ выбора контекстной модели для bin5;
Фиг. 17 является пояснительным чертежом, показывающим компоновку данных потока битов;
Фиг. 18 является блок-схемой, показывающей структуру устройства декодирования изображений в соответствии с вариантом 1 осуществления;
Фиг. 19 является блок-схемой, показывающей внутреннюю структуру модуля декодирования переменной длины, показанного на фиг. 18;
Фиг. 20 является блок-схемой последовательности операций способа, показывающей работу модуля декодирования переменной длины, показанного на фиг. 18;
Фиг. 21 является блок-схемой, показывающей структуру устройства кодирования, раскрытого в непатентном источнике 1; и
Фиг. 22 является видом, показывающим появление разделенных форм области выделения векторов движения во время выполнения прогнозирования с компенсацией движения для каждого макроблока в устройстве кодирования, раскрытом в непатентном источнике 1.
Осуществление изобретения
Вариант 1 осуществления
Далее, предпочтительные варианты осуществления настоящего изобретения подробнее поясняются со ссылкой на чертежи.
В этом варианте осуществления описывается устройство кодирования изображений, которое выполняет сжатие цифрового видеосигнала, имеющего формат 4:4:4, вводимого в него, и которое приспособлено для состояния сигнала каждого цветового компонента, чтобы выполнять процесс прогнозирования с компенсацией движения, и устройство декодирования изображений, которое выполняет расширение цифрового видеосигнала, имеющего формат 4:4:4, и которое приспособлено для состояния сигнала каждого цветового компонента, чтобы выполнять процесс прогнозирования с компенсацией движения.
Фиг. 1 показывает формат 4:4:4, который устройство кодирования изображений и устройство декодирования изображений в соответствии с вариантом 1 осуществления используют в качестве формата ввода. Формат 4:4:4 обозначает формат, в котором, как показано на фиг. 1(a), числа пикселов трех компонентов сигнала C0, C1 и C2, которые составляют цветное движущееся изображение, являются идентичными друг другу. Цветовое пространство этих трех компонентов сигнала может быть RGB или XYZ, либо может быть яркостным и цветовым различием (YUV, YCbCr или YPbPr). В отличие от формата 4:4:4, формат 4:2:0, как показано на фиг. 1(b), обозначает формат, в котором цветовое пространство - это YUV, YCbCr или YPbPr, и каждый из элементов цветоразностного сигнала (например, Cb и Cr в случае YCbCr) имеет пикселы в горизонтальном направлении W и в вертикальном направлении H, число которых вдвое меньше числа пикселов яркости Y в горизонтальном направлении и в вертикальном направлении.
Устройство кодирования изображений и устройство декодирования изображений поясняются далее посредством конкретного ограничения примером с использованием способа выполнения процессов посредством условия, что цветовое пространство формата 4:4:4 - это YUV, YCbCr или YPbPr и каждый цветовой компонент является эквивалентным яркостному компоненту. Тем не менее, разумеется, что операции, которые поясняются далее, могут применяться непосредственно к сигналу яркости, даже когда устройство кодирования изображений и устройство декодирования изображений рассматривают видеосигнал, имеющий формат 4:2:0.
1. Устройство кодирования изображений
Фиг. 2 является блок-схемой, показывающей структуру устройства кодирования изображений в соответствии с вариантом 1 осуществления.
Устройство кодирования изображений, показанное на фиг. 2, имеет такую структуру, что оно разделяет каждый введенный видеокадр, имеющий формат 4:4:4, на блоки, имеющие заданный размер, т.е. на блоки, имеющие Mmax×Mmax пикселов (каждый блок далее упоминается как «опорный блок»), и выполняет прогнозирование движения для каждого из опорных блоков, чтобы кодировать со сжатием сигнал ошибки прогнозирования.
Во-первых, введенный видеосигнал 1, который является целью, которая должна быть кодирована, разделяется на опорные блоки посредством модуля 2 разделения на блоки, и эти блоки вводятся в модуль 4 прогнозирования в качестве кодированного сигнала 3. Каждый опорный блок, созданный посредством модуля 2 разделения на блоки, показывается на фиг. 3. Как показано на фиг. 3, каждый опорный блок имеет структуру данных опорного блока, которые являются единицей, в которой собираются прямоугольные блоки, состоящие из Mmax×Mmax пикселов. Хотя подробно упомянуто ниже, размер Mmax опорного блока определяется и кодируется на уровне данных верхнего уровня, к примеру, кадра, последовательности или GOP (группы изображений). Размер Mmax опорного блока может быть изменен в каждом кадре. В этом случае, размер Mmax опорного блока указывается для каждой серии последовательных макроблоков и т.п., в которой множество макроблоков собираются.
Данные каждого опорного блока дополнительно разделяются на один или более «единичных блоков прогнозирования движения», которые являются блоками пикселов Li×Mi (i: идентификатор цветового компонента), и прогнозирование движения и кодирование выполняются посредством задания каждого единичного блока прогнозирования движения в качестве основания. Шаблон единичных блоков прогнозирования движения, показанный на фиг. 3(a), имеет L0=Mmax/2 и M0=Mmax/2, а шаблон единичных блоков прогнозирования движения, показанный на фиг. 3(b), имеет L0=Mmax/2 и M0=Mmax. В обоих из фиг. 3(a) и 3(b), L1=M1=L2=M2=Mmax. В следующем пояснении предполагается, что опорные блоки каждого цветового компонента, имеющего формат 4:4:4, являются идентичными по размеру для трех цветовых компонентов C0, C1 и C2, и когда размер Mmax опорного блока изменяется, размер опорного блока изменяется на идентичный размер для всех трех цветовых компонентов. Помимо этого, каждый из размеров Li и Mi единичных блоков прогнозирования движения может быть по выбору определен для каждых из цветовых компонентов C0, C1 и C2 и может быть изменен в единицах последовательностей, GOP, кадров, опорных блоков и т.п. С использованием этой структуры размеры Li и Mi единичных блоков прогнозирования движения могут быть гибко определены согласно разности в свойствах сигнала каждого цветового компонента без необходимости изменять размер Mmax опорного блока. Эффективная реализация с учетом параллелизации и конвейерной обработки кодирования и декодирования, выполняемой в единицах опорных блоков, может устанавливаться.
Модуль 4 прогнозирования выполняет прогнозирование с компенсацией движения сигнала изображения каждого цветового компонента в каждом опорном блоке, чтобы получить сигнал 5 ошибки прогнозирования (сигнал ошибки прогнозирования движения). Поскольку работа модуля 4 прогнозирования является признаком устройства кодирования изображений в соответствии с этим вариантом 1 осуществления, работа модуля прогнозирования подробно упоминается ниже. После выполнения процесса преобразования, к примеру DCT-процесса, для сигнала 5 ошибки прогнозирования, чтобы удалять корреляцию сигналов из этого сигнала ошибки прогнозирования, модуль 6 сжатия квантует сигнал ошибки прогнозирования, чтобы получить сжатые данные 7 ошибки прогнозирования. В это время, модуль 6 сжатия выполняет ортогональное преобразование и квантование, к примеру, DCT, для сигнала 5 ошибки прогнозирования и выводит сжатые данные 7 ошибки прогнозирования в модуль 8 кодирования переменной длины (модуль кодирования) и модуль 10 локального декодирования.
Модуль 8 кодирования переменной длины энтропийно кодирует сжатые данные 7 ошибки прогнозирования и выводит энтропийно кодированные сжатые данные ошибки прогнозирования в качестве потока 9 битов. Модуль 10 локального декодирования получает декодированный сигнал 11 ошибки прогнозирования из сжатых данных 7 ошибки прогнозирования. Этот декодированный сигнал 11 ошибки прогнозирования добавляется к сигналу 12 прогнозирования (прогнозируемому изображению), который используется для создания сигнала 5 ошибки прогнозирования посредством модуля сумматора, так что декодированный сигнал 13 создается и вводится в контурный фильтр 14. Параметры 17 для создания сигнала прогнозирования, которые определяются посредством модуля 4 прогнозирования, чтобы получить сигнал 12 прогнозирования, отправляются в модуль 8 кодирования переменной длины и выводятся в качестве потока 9 битов. Подробные описания параметров 17 для создания сигнала прогнозирования приводятся ниже вместе с пояснением модуля 4 прогнозирования. Кроме того, поскольку способ кодирования параметров 17 для создания сигнала прогнозирования, который модуль 8 кодирования переменной длины использует, является признаком этого варианта 1 осуществления, способ кодирования подробно поясняется ниже.
Контурный фильтр 14 выполняет процесс фильтрации отклонения искажения в виде блочности для декодированного сигнала 13, в котором искажение в виде блочности, возникающее в результате квантования коэффициента преобразования посредством модуля 6 сжатия, комбинируется посредством использования как параметров 17 для создания сигнала прогнозирования, так и параметров 19 квантования. Декодированный сигнал 13 сохраняется в запоминающем устройстве 16 в качестве опорного сигнала 15 изображения для создания последующего сигнала 12 прогнозирования после того, как декодированный сигнал подвергается процессу удаления шума кодирования посредством контурного фильтра 14.
В способах кодирования видео, раскрытых в непатентных источниках 1 и 2, когда каждый опорный блок задается как макроблок, типично используется способ кодирования каждого кадра при выборе внутрикадрового кодирования или межкадрового прогнозирующего кодирования для каждого макроблока. Это обусловлено тем, что, когда межкадровое прогнозирование движения не является достаточным, использование корреляции между кадрами дополнительно может повышать эффективность кодирования. В дальнейшем в этом документе, в устройстве кодирования изображений в соответствии с этим вариантом 1 осуществления, хотя описание внутрикадрового кодирования и избирательного использования внутрикадрового кодирования явно не указывается в этом подробном описании при пояснении идеи настоящего изобретения, устройство кодирования изображений может иметь такую структуру, что оно имеет возможность избирательно использовать внутрикадровое кодирование для каждого опорного блока, если иное конкретно не указано. В устройстве кодирования изображений в соответствии с этим вариантом 1 осуществления, хотя каждый опорный блок может задаваться как макроблок, термин «опорный блок» используется далее для пояснения прогнозирования движения.
Далее, работа модуля 4 прогнозирования, который является признаком этого варианта 1 осуществления, подробнее поясняется. Модуль 4 прогнозирования в соответствии с этим вариантом 1 осуществления имеет следующие три признака.
(1) Адаптация размера опорного блока и размера единичного блока прогнозирования движения в связи с адаптацией формы каждой разделенной области, используемой для прогнозирования движения,
(2) Определение режима прогнозирования движения и вектора движения согласно свойствам каждого цветового компонента,
(3) Адаптивный выбор режима чередования на основе размера опорного блока и размера единичного блока прогнозирования движения.
Как упомянуто выше (1), модуль 4 прогнозирования разделяет каждый опорный блок на один или более единичных блоков прогнозирования движения, имеющих Li×Mi пикселов, согласно свойствам сигнала каждого цветового компонента, и дополнительно разделяет каждый единичный блок прогнозирования движения на множество форм, каждая из которых состоит из комбинации одного или более блоков, имеющих Li×Mi пикселов. Модуль 4 прогнозирования затем выполняет прогнозирование посредством выделения конкретного вектора движения для каждой разделенной области, выбирает множество форм, которые предоставляют наибольшую эффективность прогнозирования, в качестве режима прогнозирования движения, и затем выполняет прогнозирование движения для каждой разделенной области посредством использования вектора движения, обнаруженного как результат выбора, чтобы получить сигнал 5 ошибки прогнозирования. Каждая из разделенных форм в каждом единичном блоке прогнозирования движения может иметь структуру комбинации одного или более «базисных блоков», каждый из которых состоит из Li×Mi пикселов. В устройстве кодирования изображений в соответствии с этим вариантом 1 осуществления, следующие ограничения: «mi=Mi/2» и «li=Li/2» предоставляются между Mi и mi и между Li и li, соответственно.
Разделенные формы, каждая из которых состоит из одного или более базисных блоков, которые определяются согласно этим требованиям, показаны на фиг. 4. Фиг. 4 является пояснительным чертежом, показывающим примеры форм, в которых модуль 4 прогнозирования разделяет каждый единичный блок прогнозирования движения на единицы, каждая из которых состоит из одного или более базисных блоков. Далее, в устройстве кодирования изображений этого варианта 1 осуществления предполагается, что шаблоны (шаблоны разделения) mc_mode0-mc_mode7 разделенных форм, показанные на фиг. 4, являются общими для этих трех цветовых компонентов. В качестве альтернативы, шаблоны разделения mc_mode0-mc_mode7 могут быть определены независимо для каждого из этих трех цветовых компонентов. Далее, эти шаблоны разделения mc_mode0-mc_mode7 упоминаются как «режимы прогнозирования движения».
В способах кодирования видео, раскрытых в непатентных источниках 1 и 2, форма каждой области применения прогнозирования движения ограничивается прямоугольником, и такое диагональное разделение, как показано на фиг. 4, каждого опорного блока в области, включающей в себя область, отличную от прямоугольной области, не может быть использовано. В отличие от этого, в соответствии с этим вариантом 1 осуществления, поскольку форма каждой разделенной области, как показано на фиг. 4, к которой применяется прогнозирование движения, диверсифицируются, когда сложное перемещение, к примеру контур движущегося объекта, включается в опорный блок, прогнозирование движения может выполняться с меньшим числом векторов движения, чем используется в случае прямоугольного разделения.
Кроме того, работа S. Kondo и H. Sasai, "A Motion Compensation Technique using Sliced Blocks and its Application to Hybrid Video Coding", 2005 VCIP, июль 2005 года раскрывает способ диверсификации форм областей, на которые разделяется обычный макроблок и к каждой из которых применяется прогнозирование движения.
В этом противопоставленном материале разделенные формы выражаются посредством позиций пересечения между сегментом линии, используемым для разделения на макроблоки, и границей блока. Тем не менее, поскольку этот способ увеличивает число шаблонов разделения в каждом опорном блоке при фиксации числа M пикселов, возникают следующие проблемы.
Проблема 1
Объем кода для описания шаблонов разделения каждого опорного блока увеличивается. Когда произвольное mi, удовлетворяющее Mmax mod mi=0, разрешается, число шаблонов разделения в каждом опорном блоке увеличивается, и становится необходимо кодировать информацию для указания каждого из шаблонов разделения в качестве служебной информации. Поскольку вероятность того, что каждый определенный конкретный шаблон разделения возникает, распределяется по мере того, как число шаблонов разделения увеличивается, энтропийное кодирование шаблонов разделения становится неэффективным и становится служебной информацией, поскольку объем кода и общая способность кодирования достигает своего предела.
Проблема 2
По мере того как число шаблонов разделения увеличивается, объем арифметических операций, требуемых, чтобы выбирать разделение, оптимальное во время кодирования, увеличивается. Поскольку прогнозирование движения является процессом с большой нагрузкой, который занимает большой процент нагрузки по обработке кодирования, обычное устройство кодирования изображений не имеет другого варианта, кроме выполнения с возможностью верифицировать и использовать только конкретный шаблон разделения из множества шаблонов разделения, если обычное устройство кодирования изображений использует алгоритм, который увеличивает число шаблонов разделения вслепую. Следовательно, возникает случай, когда обычное устройство кодирования изображений не может полностью использовать исходную способность, которую имеет алгоритм.
В отличие от этого, подход, показанный на фиг. 4, устройства кодирования изображений этого варианта 1 осуществления разрешает вышеуказанные проблемы посредством использования следующих трех способов: первый способ (1) предоставления возможности изменения значения Mmax на верхнем уровне, к примеру, кадра, согласно требованиям по кодированию и разрешению и свойствам видеосигнала; второй способ (2) предоставления возможности разделения каждого опорного блока Mmax×Mmax на один или более единичных блоков прогнозирования движения Li×Mi пикселов согласно характеристикам каждого цветового компонента Ci; и третий способ (3) обеспечения вариантов разделения при ограничении требований по разделению каждого единичного блока прогнозирования движения на базисные блоки к разделению, имеющему разделенные формы, которые удовлетворяют следующим ограничениям: «mi=Mi/2» и «li=Li/2». Значение размера Mmax базисных блоков не изменяется локально в каждом кадре или каждой серии последовательных макроблоков и может быть изменено только на уровне структуры данных высшего порядка, к примеру, уровне кадра или последовательности кадров (последовательности или GOP). Этот механизм предоставляет возможность адаптации к отличию в значении шаблона сигнала изображения, включенного в каждый опорный блок. Например, в видео, имеющем небольшое разрешение (видеографическая матрица: VGA и т.п.), и видео, имеющее большое разрешение (HDTV и т.п.), их шаблоны сигналов в каждом имеющем идентичный размер блоке пикселов Mmax×Mmax выражают различные значения. При прогнозировании идентичного объекта, который должен быть заснят, в то время как шаблон сигнала близко к структуре объекта, который должен быть заснят, захватывается в видео, имеющем небольшое разрешение, шаблон сигнала дополнительной локальной части объекта, который должен быть заснят, просто захватывается в видео, имеющем большое разрешение, даже если используется размер блока, идентичный размеру блока в случае видео, имеющего небольшое разрешение. Следовательно, когда размер опорного блока не изменяется в зависимости от разрешения, шаблон сигнала в каждом опорном блоке имеет больший компонент шума по мере того, как разрешение увеличивается, и, следовательно, становится невозможным повышать способность прогнозирования движения в качестве технологии сопоставления с шаблоном.
Следовательно, посредством предоставления возможности изменения значения размера Mmax опорного блока только на уровне структуры данных высокого порядка, в то время как объем кода, требуемый для сообщения в служебных сигналах значения размера Mmax опорного блока, может быть уменьшен, шаблон сигнала, включенный в каждый опорный блок, может быть оптимизирован согласно условиям, таким как разрешение и смены сцен видео и изменения активности всего экрана с точки зрения прогнозирования движения. В дополнение к этому механизму, посредством предоставления возможности изменения шаблона разделения в каждом единичном блоке прогнозирования движения для каждого цветового компонента, как показано на фиг. 3, единица, которая должна обрабатываться для прогнозирования движения, может быть оптимизирована согласно характеристикам сигналов каждого цветового компонента. Помимо этого, посредством предоставления ограниченной гибкости шаблонов разделения каждому единичному блоку прогнозирования движения, как показано на фиг. 4, в то время как объем кода, требуемый для того, чтобы выражать шаблоны разделения в каждом единичном блоке прогнозирования движения, уменьшается, общая эффективность прогнозирования движения может быть повышена. Кроме того, посредством выполнения эффективного процесса определения значения размера Mmax опорного блока на уровне кадра, варианты шаблона разделения, которые должны проверяться в каждом опорном блоке после этого, могут быть уменьшены по сравнению с обычными технологиями, и нагрузка в процессе кодирования может быть уменьшена.
В качестве способа определения значения размера Mmax опорного блока, например, предусмотрены следующие способы.
Первый способ (1) определения значения размера Mmax опорного блока согласно разрешению видео, которое должно быть кодировано. В случае идентичного значения Mmax видео, имеющее большое разрешение, представляет то, что шаблон сигнала изображения в каждом опорном блоке имеет более значительный компонент шума, и для вектора движения становится трудным захватывать шаблон сигнала изображения. В таком случае, значение Mmax увеличивается, чтобы предоставлять возможность вектору движения захватывать шаблон сигнала изображения.
Второй способ (2) допущения того, что то, является или нет разность между кадрами большой, является активностью, и когда активность является большой, выполнения прогнозирования движения с небольшим значением Mmax, тогда как когда активность является небольшой, выполнения прогнозирования движения с большим значением Mmax. Кроме того, управление размером в это время определяется согласно частоте кадров видео, которое должно быть кодировано. Поскольку по мере того, как частота кадров увеличивается, взаимная кадровая корреляция становится большой, динамический диапазон самого вектора движения становится небольшим, и, следовательно, объем кода становится небольшим, например, может рассматриваться способ задания значения Mmax равным большому значению таким образом, что это значение не становится чрезмерным, даже если активность является достаточно небольшой, чтобы обеспечивать возможность прогнозировать вплоть до точного перемещения.
Третий способ (3) комбинирования способов (1) и (2) посредством взвешивания этих способов, чтобы определять значение размера Mmax опорного блока.
После того, как значение размера Mmax опорного блока определяется, размеры Li и Mi каждого единичного блока прогнозирования движения для каждого цветового компонента определяются. Например, в случае, в котором введенный видеосигнал 1 задается в цветовом пространстве YUV (или YCbCr и т.п.), U/V-компонент, который является сигналом цветности, имеет узкую полосу частот сигнала по сравнению с Y-компонентом сигнала яркости. Следовательно, дисперсия в блоках становится небольшой по сравнению с дисперсией яркости. Может рассматриваться пример критерия определения, посредством которого можно определять размеры Li и Mi U/V-компонента таким образом, что они превышают размеры Li и Mi Y-компонента сигнала яркости, на основе того факта, что дисперсия в блоках становится небольшой по сравнению с дисперсией яркости (см. фиг. 3).
Значения размеров Mmax, Li и Mi блоков, обнаруженные в результате выполнения этих определений, уведомляются в модуль 2 разделения на блоки, модуль 4 прогнозирования и модуль 8 кодирования переменной длины в качестве информации 18 размера опорных блоков. Посредством просто задания Li и Mi в качестве полученных значений относительно Mmax посредством простых арифметических операций, как показано на фиг. 3, необходимо только кодировать идентификаторы вычислительных выражений вместо кодирования Li и Mi в качестве независимых значений. Следовательно, объем кода, требуемый для информации 18 размера опорных блоков, может быть уменьшен.
Хотя не проиллюстрировано, в частности, на фиг. 2, устройство кодирования изображений может иметь такую структуру, что оно включает в себя модуль определения размера опорных блоков для определения значений Mmax, Li и Mi и уведомления этих значений в каждый модуль и определения информации 18 размера опорных блоков.
Модуль 4 прогнозирования выполняет процесс обнаружения движения с использованием шаблонов разделения, показанных на фиг. 3 и 4, согласно размерам Li и Mi единичных блоков прогнозирования движения, которые извлекаются из информации 18 размера опорных блоков. Фиг. 5 является блок-схемой последовательности операций способа, показывающей работу модуля 4 прогнозирования. Модуль 4 прогнозирования выполняет прогнозирование движения Ci-компонента кадра в единицах единичных блоков прогнозирования движения, имеющих Li×Mi пикселов. Фундаментально, в этом процессе модуль прогнозирования получает оптимальный вектор движения в каждой разделенной области в указанном диапазоне поиска перемещения для каждого из шаблонов mc_mode0-mc_mode7 разделения, показанных на фиг. 4, и в завершение определяет то, какой из шаблонов разделения mc_mode0-mc_mode7 должен использоваться для рассматриваемого единичного блока прогнозирования движения, чтобы предоставлять наибольшую эффективность прогнозирования.
Эффективность прогнозирования задается посредством следующих затрат J, которые извлекаются и из общего объема R кода векторов движения в единичном блоке прогнозирования движения, и из величины D ошибки прогнозирования между сигналом 12 прогнозирования, который создается из опорного изображения, сохраненного в запоминающем устройстве 16, посредством применения вышеуказанных векторов движения и введенного видеосигнала 1. Модуль 4 прогнозирования имеет такую структуру, что он выводит режим прогнозирования движения и вектор движения, которые минимизируют эти затраты J.
J=D+λR (λ - константа)
Следовательно, модуль 4 прогнозирования сначала вычисляет затраты Jk для каждого режима mc_modek прогнозирования движения (этап ST1). Со ссылкой на фиг. 6, способ вычисления затрат J поясняется посредством рассмотрения случая mc_mode5 в качестве примера. В это время, единичный блок прогнозирования движения, который является целью, которая должна быть прогнозирована в кадре F(t), состоит из двух разделенных областей B0 и B1. Кроме того, предполагается, что два опорных изображения F'(t-1) и F'(t-2), которые уже кодированы и локально декодированы, сохраняются в запоминающем устройстве 16, и модуль прогнозирования может выполнять прогнозирование движения с использованием этих двух опорных изображений F'(t-1) и F'(t-2) для разделенных областей B0 и B1. В примере по фиг. 6 модуль прогнозирования получает вектор MVt-2(B0) движения с использованием опорного изображения F'(t-2) для разделенной области B0, а также получает вектор MVt-1(B1) движения с использованием опорного изображения F'(t-1) для разделенной области B1. Когда каждая разделенная область выражается как B, пиксельное значение в позиции x=(i, j) на экране n-ого кадра выражается как Sn(x), и вектор движения выражается как v, величина D ошибки прогнозирования разделенной области B может быть вычислена с использованием суммы абсолютных разностей (SAD) согласно уравнению (2), показанному ниже.
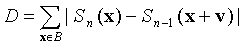
Из величин D0 и D1 ошибки прогнозирования, соответствующей разделенным областям B0 и B1, каждую из которых получают в результате вычисления с использованием вышеуказанного уравнения (2), величина D ошибки прогнозирования определяется в качестве D=D0+D1.
С другой стороны, в отношении общего объема R кода модуль прогнозирования использует оцененные векторы PMV(B0) и PMV(B1), чтобы получить прогнозируемые разности MVD(B0) и MVD(B1) векторов движения согласно уравнению (3), показанному ниже, и затем выполняет преобразование объема кода этих значений, чтобы получить объемы R0 и R1 кода и определять общий объем кода R=R0+R1.
MVD(B0)=MVt-2(B0)-PMV(B0)
MVD(B1)=MVt-1(B1)-PMV(B1)
Как результат, определяются затраты J. Модуль 4 прогнозирования вычисляет затраты J каждого из всех векторов движения, которые являются целями, которые должны быть проанализированы в диапазоне поиска, и определяет решение, которое предоставляет наименьшие затраты J, в качестве шаблона разделения mc_mode5. Пример определения оцененных векторов PMV в mc_mode1-mc_mode4 показывается на фиг. 7. На фиг. 7, каждая стрелка означает вектор MV движения в окружающей или смежной области, которая используется для извлечения оцененного вектора, и медиана трех векторов MV движения, включенных посредством ○, задается как оцененный вектор PMV разделенной области, указываемой посредством медианы.
Когда k=7, т.е. mc_mode7, выбирается для каждого блока пикселов Li×Mi, каждый из режимов прогнозирования движения, соответствующих режимам mc_mode0-mc_mode7, выбирается для каждого из блоков пикселов li×mi. Режимы в это время называются sub_mc_mode0-sub_mc_mode7, соответственно, для удобства. Процесс определения sub_mc_mode для каждого из блоков пикселов li×mi выполняется согласно последовательности операций обработки по фиг. 5, и затраты J7 в mc_mode7 в соответствующем блоке пикселов Li×Mi являются общей суммой затрат, обнаруженных с использованием sub_mc_mode, определенного для каждого из блоков пикселов li×mi.
Затем, модуль 4 прогнозирования верифицирует, меньше или нет затраты Jk в mc_modek, которые модуль прогнозирования определяет таким образом, затрат в mc_modek-1, mc_modek-2 и т.д., которые он верифицирует к настоящему моменту (этап ST2), и когда затраты Jk в mc_modek меньше затрат в mc_modek, которые он верифицирует к настоящему моменту (если «Да» на этапе ST2), сохраняет mc_modek в качестве режима прогнозирования движения, который допускается как оптимальный вплоть до этого времени, а также сохраняет вектор движения и сигнал ошибки прогнозирования, определенный в это время (этап ST3). После окончания верификации всех режимов прогнозирования движения (если «Да» на этапе ST4), модуль 4 прогнозирования выводит режим прогнозирования движения, вектор движения и сигнал 5 ошибки прогнозирования, который модуль прогнозирования сохраняет к настоящему моменту, в качестве окончательного решения (этап ST5). В противном случае (если «Нет» на этапе ST2 или «Нет» на этапе ST4), модуль прогнозирования на этапе ST6 увеличивает переменную k и затем возвращается к этапу ST1 и верифицирует следующий режим прогнозирования движения.
В каждом режиме прогнозирования движения, соответствующем mc_mode0, и режимах прогнозирования движения, соответствующих sub_mc_mode0, случай, в котором вектор движения совпадает с оцененным вектором (прогнозируемая разность, которая должна быть кодирована, равна нулю), и все коэффициенты преобразованного и квантованного сигнала ошибки прогнозирования равны нулю, задается как специальный режим чередования. Далее, режим чередования, соответствующий mc_mode0, называется режимом mc_skip (первым режимом чередования), и режим чередования, соответствующий sub_mc_mode0, называется режимом sub_mc_skip (вторым режимом чередования). Фиг. 8 является видом для пояснения режимов чередования, и фиг. 8(a) показывает пример, в котором каждый прямоугольник, включенный в качестве сплошной линии, обозначает единичный блок прогнозирования движения, и его вектор движения обозначается посредством MV. В это время, модуль прогнозирования вычисляет оцененный вектор PMV в единичном блоке прогнозирования движения посредством использования, например, векторов движения в окружающих или смежных единичных блоках прогнозирования движения, как показано на фиг. 8. Поскольку кодирование вектора движения выполняется посредством кодирования значения прогнозируемой разности между вектором движения и оцененным вектором, этот единичный блок прогнозирования движения допускается как в режиме mc_skip в случае, если прогнозируемая разность равна нулю (MV==PMV) и сигнал 5 ошибки прогнозирования не имеет ненулевых коэффициентов, которые должны кодироваться. Кроме того, фиг. 8(b) является укрупненным отображением части по фиг. 8(a), где заштрихованный базисный блок, показанный на фиг. 8(a), располагается по центру на укрупненном чертеже, и рамка с жирной линией показывает область единичного блока прогнозирования движения. В этом случае sub_mc_mode целевого базисного блока является sub_mc_mode0. Когда вектор движения в это время выражается как MV и оцененный вектор в это время выражается как PMV, режим прогнозирования движения, который применяется к этому базисному блоку, допускается как режим sub_mc_skip в случае, если прогнозируемая разность равна нулю (MV==PMV), и сигнал 5 ошибки прогнозирования не имеет ненулевых коэффициентов, которые должны кодироваться, как в случае определения mc_skip.
В обычных способах кодирования, раскрытых, например, в непатентных источниках 1 и 2, mc_mode0, т.е. режим чередования, соответствующий только наибольшему единичному блоку прогнозирования движения (в непатентных источниках 1 и 2, опорный блок, как показано в этом варианте 1 осуществления, имеет размер, идентичный размеру единичного блока прогнозирования движения, как показано в этом варианте 1 осуществления, и наибольший единичный блок прогнозирования движения соответствует макроблоку), типично предоставляется, и в режиме чередования он выполнен с возможностью вообще не кодировать информацию о макроблоках. Напротив, этот вариант 1 осуществления отличается тем, что этот режим чередования дополнительно задается также на иерархическом уровне sub_mc_mode. В обычных способах кодирования, раскрытых, например, в непатентных источниках 1 и 2, поскольку видеосигнал, который обрабатывается, имеет относительно низкую частоту дискретизации, которая имеет порядок вплоть до разрешения HDTV, единичный блок прогнозирования движения, меньший, чем макроблок, просто означает, что перемещение становится сложным, и, следовательно, трудно эффективно выполнять кодирование, даже если режим чередования учитывается. С другой стороны, при кодировании видеосигнала, имеющего высокую частоту дискретизации, к примеру видео сверхвысокой четкости, имеющего частоту дискретизации, превышающую частоту дискретизации HDTV, или видеосигнала, имеющего формат 4:4:4, простое предоставление режима чередования с учетом только размера каждого единичного блока прогнозирования движения, который состоит из блока пикселов Li×Mi, не позволяет эффективно использовать требования по чередованию при выборе базисного блока (или области выделения векторов движения, которая определяется посредством комбинации базисных блоков), меньшего каждого единичного блока прогнозирования движения, и, следовательно, вектора движения, имеющего коэффициент с нулевым значением, и значения нулевого коэффициента кодируются всегда явно, и эффективность кодирования является плохой. Следовательно, устройство кодирования изображений в соответствии с этим вариантом 1 осуществления имеет такую структуру, что оно, если не только каждый единичный блок прогнозирования движения, который состоит из блока пикселов Li×Mi, который является единицей для выделения mc_mode, имеет размер, превышающий постоянный размер, но также и каждый базисный блок, который состоит из блока пикселов li×mi, который является единицей для выделения sub_mc_mode, имеет размер, превышающий постоянный размер (li>lt, mi>mt), имеет возможность выбирать и использовать режим sub_mc_skip для каждого базисного блока. Пороговые значения lt и mt могут быть уникально определены из значений Mi и Li (например, lt=Li/2 и mt=Mi/2). В качестве альтернативы, пороговые значения могут быть переданы мультиплексированными в поток битов на уровне, к примеру, кадра или последовательности.
Посредством вышеуказанного процесса посредством модуля 4 прогнозирования выводятся сигнал 5 ошибки прогнозирования и параметры 17 (режим прогнозирования движения и вектор движения) для создания сигнала прогнозирования, и они энтропийно кодируются посредством модуля 8 кодирования переменной длины. Далее описывается способ энтропийного кодирования для энтропийного кодирования параметров 17 для создания сигнала прогнозирования, которое является признаком устройства кодирования изображений в соответствии с этим вариантом 1 осуществления.
При кодировании параметра 17 для создания сигнала прогнозирования, которое поясняется далее, два типа параметров, включающих в себя вектор движения и режим прогнозирования движения, являются целью пояснения. Фиг. 9 является видом для пояснения способа энтропийного кодирования, который модуль 8 кодирования переменной длины использует. В устройстве кодирования изображений в соответствии с этим вариантом 1 осуществления, как показано на фиг. 9, при кодировании режима m(Bx) прогнозирования движения базисного блока Bx, который является целью для прогнозирующего кодирования, модуль кодирования переменной длины выполняет энтропийное кодирование посредством избирательного обращения к состоянию режима m(Ba) прогнозирования базисного блока Ba слева от целевого базисного блока в идентичном кадре F(t), состоянию режима m(Bb) прогнозирования базисного блока Bb немного выше целевого базисного блока в идентичном кадре F(t), и состоянию режима m(Bc) прогнозирования движения базисного блока Bc в позиции, идентичной позиции базисного блока Bx в непосредственно предыдущем смежном кадре F'(t-1).
Фиг. 10 показывает внутреннюю структуру модуля 8 кодирования переменной длины, и фиг. 11 показывает последовательность операций модуля кодирования переменной длины. Модуль 8 кодирования переменной длины в соответствии с этим вариантом 1 осуществления состоит из модуля 21 определения контекстных моделей для определения контекстной модели (которая упоминается ниже), заданной для каждого из типов данных, включающих в себя режим прогнозирования движения и вектор движения, которые являются данными, которые должны кодироваться, модуля 22 преобразования в двоичную форму для преобразования многозначных данных в двоичные данные согласно правилу преобразования в двоичную форму, определенному для каждого типа данных для кодирования, модуля 23 создания вероятностей появления для предоставления вероятности появления каждого значения (0/1) каждого преобразованного в двоичную форму элемента выборки, модуля 24 кодирования для выполнения арифметического кодирования согласно созданной вероятности появления, и запоминающего устройства 25 информации вероятности появления для сохранения информации вероятности появления. В дальнейшем в этом документе пояснение приводится посредством ограничения ввода в модуль 21 определения контекстных моделей режимом прогнозирования движения и вектором движения из параметров 17 для создания прогнозируемых изображений.
(A) Процесс определения контекстной модели (этап ST11 на фиг. 11)
Контекстная модель моделирует отношение зависимости с другой информацией, приводящее к варьированию вероятности появления символа источника информации, и она получает возможность выполнять кодирование, которое адаптируется согласно фактической вероятности появления символа посредством изменения состояния вероятности появления в зависимости от этого отношения зависимости. Принцип в отношении контекстной модели ctx показывается на фиг. 12. На этом чертеже, хотя символ источника информации является двоичным, он альтернативно может быть многозначным. Тем не менее, в этом варианте 1 осуществления обрабатывается только двоичное арифметическое кодирование.
Варианты выбора от 0 до 2 контекстной модели ctx, показанной на фиг. 12, задаются при условии, что состояние вероятности появления символа источника информации с использованием этой контекстной модели ctx должно варьироваться согласно условиям. При применении этого определения к устройству кодирования изображений в соответствии с этим вариантом 1 осуществления, значение контекстной модели ctx изменяется согласно отношению зависимости между кодированными данными в определенном опорном блоке и кодированными данными в другом опорном блоке, смежном с опорным блоком.
Например, фиг. 13 показывает пример контекстной модели для вектора движения, которая раскрывается в работе D. Marpe и другие, "Video Compression Using Context-Based Adaptive Arithmetic Coding", International Conference on Image Processing, 2001 год. В примере по фиг. 13 вектор движения блока C является целью, которая должна быть кодирована (точно, значение прогнозируемой разности mvdk(C), которое прогнозируется для вектора движения блока C из смежных блоков, кодируется). Кроме того, ctx_mvd(C, k) показывает контекстную модель, применяемую к вектору движения блока C. Mvdk(A) показывает прогнозируемую разность векторов движения в блоке A, и mvdk(B) показывает прогнозируемую разность векторов движения в блоке B. Эти значения используются для задания оцененного значения ek(C) для изменения контекстной модели. Оцененное значение ek(C) показывает варьирования в смежных векторах движения. В общем, когда эти варьирования являются небольшими, значение mvdk(C) прогнозируемой разности векторов движения является небольшим, тогда как, когда оцененное значение ek(C) является большим, значение прогнозируемой разности векторов движения (C) имеет тенденцию быть большим. Следовательно, желательно то, чтобы вероятность появления символа прогнозируемой разности mvdk(C) векторов движения адаптировалась согласно оцененному значению ek(C). Набором варьирований этой вероятности появления являются контекстные модели, и в этом случае можно сказать, что существует три типа варьирований вероятности появления.
Таким образом, контекстные модели задаются для каждых данных, которые должны кодироваться, заранее и совместно используются устройством кодирования изображений и устройством декодирования изображений. Модуль 21 определения контекстных моделей выполняет процесс выбора одной из моделей, заданных согласно типу таких данных, которые должны кодироваться. То, какое варьирование вероятности появления в контекстной модели выбирается, соответствует процессу создания вероятности появления (C), который показан ниже.
На фиг. 10, модуль 8 кодирования переменной длины отличается тем, что он подготавливает два или более вариантов для контекстной модели 26, которая должна выделяться режиму прогнозирования движения и вектору движения, и затем переключается между этими двумя или более вариантами для контекстной модели 26, которую модуль кодирования переменной длины использует, согласно информации 27 выбора контекстной модели. Как показано на фиг. 9, поскольку можно считать, что режим m(Bx) прогнозирования движения базисного блока Bx, который является целью для прогнозирования и кодирования, имеет высокую корреляцию с состоянием области изображения, которая является пространственно смежной в идентичном кадре, если корреляция состояния перемещения между кадрами является низкой (более конкретно, на значение режима m(Bx) прогнозирования движения оказывают существенное влияние разделенные формы в режимах m(Ba) и m(Bb) прогнозирования движения), и режим m(Ba) прогнозирования движения базисного блока Bb слева от целевого базисного блока в идентичном кадре и режим m(Bb) прогнозирования движения базисного блока Ba немного выше целевого базисного блока в идентичном кадре используются для определения контекстной модели 26. Пример, который лежит в основе для этого принципа, показывается на фиг. 14. Фиг. 14 показывает сравнение между двумя состояниями режимов прогнозирования движения, выбранных для базисных блоков Ba и Bb, в случае режима прогнозирования движения m(Bx)=mc_mode3. В состоянии, показанном на фиг. 14(a), разрывы разделения каждого из базисных блоков Ba и Bb, разумеется, соединяются с разделенными формами в режиме m(Bx) прогнозирования движения соответственно. Напротив, в состоянии, показанном на фиг. 14(b), разрывы разделения каждого из базисных блоков Ba и Bb, разумеется, не соединяются с разделенными формами. В общем, поскольку эти разделенные формы в каждом опорном блоке показывают наличие множества различных областей перемещения, существующих в опорном блоке, они легко отражают структуру видео. Следовательно, можно считать, что состояние, показанное на фиг. 14(a), является «состоянием, которое возникает легко», а не состоянием, показанным на фиг. 14(b). Более конкретно, на вероятность появления режима m(Bx) прогнозирования движения оказывают влияние состояния режимов m(Ba) и m(Bb) прогнозирования движения.
Аналогично, поскольку можно считать, что режим m(Bx) прогнозирования движения базисного блока Bx имеет высокую корреляцию с состоянием области изображения, которая является смежной относительно времени, если корреляция состояния перемещения между кадрами является высокой (более конкретно, вероятность, которую может иметь режим m(Bx) прогнозирования движения, варьируется в зависимости от разделенных форм в режиме m(Bc) прогнозирования движения), модуль 8 кодирования переменной длины использует режим m(Bc) прогнозирования движения базисного блока Bc в позиции, идентичной позиции базисного блока Bx в непосредственно предыдущем смежном кадре, для определения контекстной модели 26.
Аналогично, при определении контекстной модели 26 для вектора движения, если корреляция состояния перемещения между кадрами является низкой, модуль 8 кодирования переменной длины использует как вектор движения блока Ba слева от целевого базисного блока в идентичном кадре, так и вектор движения блока Bb немного выше целевого базисного блока для определения контекстной модели 26. Напротив, если корреляция состояния перемещения между кадрами является высокой, модуль 8 кодирования переменной длины использует вектор движения блока Bc в позиции, идентичной позиции блока Bx в непосредственно предыдущем смежном кадре, для определения контекстной модели 26. Как в случае определения контекстной модели для режима прогнозирования движения, модуль кодирования переменной длины может использовать корреляцию между цветовыми компонентами также для определения контекстной модели 26 для вектора движения.
Устройство кодирования изображений может обнаруживать, является корреляция состояния перемещения между кадрами высокой или низкой, посредством использования заданного способа, и может явно мультиплексировать значение информации 27 выбора контекстной модели с потоком 9 битов, чтобы передавать это значение информации выбора контекстной модели в устройство декодирования изображений. Как устройство кодирования изображений, так и устройство декодирования изображений могут иметь такую структуру, что они определяют значение информации 27 выбора контекстной модели согласно получаемой информации. Поскольку видеосигнал является неустановившимся, эффективность арифметического кодирования может быть повышена посредством предоставления возможности выполнять такое адаптивное управление.
(B) Процесс преобразования в двоичную форму (этап ST12, показанный на фиг. 11)
Модуль 22 преобразования в двоичную форму формирует каждые данные, которые должны кодироваться, в двоичную последовательность и определяет контекстную модель согласно каждому элементу выборки (двоичной позиции) двоичной последовательности. Правило преобразования в двоичную форму следует приблизительному распространению значений, которые каждые кодированные данные могут иметь, и модуль преобразования в двоичную форму выполняет преобразование каждых данных, которые должны кодироваться, в двоичную последовательность переменной длины. Поскольку при преобразовании в двоичную форму данные, которые должны кодироваться, которые первоначально могут быть многозначными, кодируются в расчете на элемент выборки вместо арифметического кодирования как есть, преобразование в двоичную форму имеет преимущество, например, возможности сокращать число разделений числовой оси вероятностей, и, следовательно, упрощать арифметическую операцию и сокращать контекстную модель.
Например, при выполнении кодирования с помощью Li=Mi=32 и li=mi=16 модуль 22 преобразования в двоичную форму выполняет преобразование в двоичную форму режима прогнозирования движения, как показано на фиг. 15(a) и 15(b).
Контекстные модели, как показано на фиг. 16A-16E, применяются к Bin0, Bin1, Bin2, Bin4 и Bin5 соответственно. Как показано на фиг. 16A, Bin0 имеет критерий, посредством которого можно переключаться между вероятностями появления согласно тому, являются или нет состояния единичного блока прогнозирования движения в верхней позиции (блока A) и единичного блока прогнозирования движения в левой позиции (блока B) относительно данных, которые должны кодироваться (блок C), «режимом чередования». Как показано на фиг. 16B, Bin1 имеет критерий, посредством которого можно переключаться между вероятностями появления согласно тому, являются или нет состояния единичного блока прогнозирования движения в верхней позиции (блока A) и единичного блока прогнозирования движения в левой позиции (блока B) такими: «существует или нет разделение на прогнозные блоки движения». Как показано на фиг. 16C, Bin2 имеет критерий, посредством которого можно переключаться между вероятностями появления согласно тому, являются или нет состояния единичного блока прогнозирования движения в верхней позиции (блока A) и единичного блока прогнозирования движения в левой позиции (блока B) такими: «является или нет состояние сложным режимом прогнозирования движения». Для Bin3 контекстная модель не задается, и вероятность появления задается фиксированно равной заданной вероятности появления. Как показано на фиг. 16D, Bin4 имеет критерий, посредством которого можно переключаться между вероятностями появления согласно тому, является или нет состояние единичного блока прогнозирования движения в левой позиции (блока B) таким: «является или нет разделение формы прогнозирования движения горизонтальным разделением». Как показано на фиг. 16E, Bin5 имеет критерий, посредством которого можно переключаться между вероятностями появления согласно тому, является или нет состояние единичного блока прогнозирования движения в верхней позиции (блока A) таким: «является или нет разделение формы прогнозирования движения вертикальным разделением». Посредством определения контекстной модели 26 согласно форме области прогнозирования движения таким образом, выбор вероятности появления, связанной с информацией режима прогнозирования движения, может осуществляться адаптивно в зависимости от свойств локального видеосигнала, и эффективность кодирования арифметического кодирования может быть повышена. Устройство кодирования изображений имеет такую структуру, чтобы, при принятии решения не использовать sub_mc_skip при li=mi=16 (пороговое значение lt16 и пороговое значение mt≥16), не кодировать Bin0, показанный на фиг. 15(b).
(C) Процесс создания вероятности появления (этап ST13, показанный на фиг. 11)
В процессах (этапы ST11 и ST12) вышеуказанных (A) и (B) выполняется преобразование в двоичную форму каждых многозначных данных, которые должны кодироваться, и установление контекстной модели, которая применяется к каждому элементу выборки, и подготовка к кодированию завершается. Модуль 23 создания вероятностей появления затем выполняет процесс создания для создания информации вероятности появления, используемой для арифметического кодирования. Поскольку варьирования вероятности появления, соответствующие каждому из значений 0 и 1, включаются в каждую контекстную модель, модуль создания вероятностей появления выполняет процесс в отношении контекстной модели 26, определенной на этапе ST11. Модуль 23 создания вероятностей появления определяет оцененное значение для выбора вероятности появления, к примеру оцененное значение ek(C), показанное на фиг. 13, и определяет то, какое варьирование вероятности появления модуль создания вероятностей появления использует для текущего кодирования, согласно этому оцененному значению из числа вариантов для выбора контекстной модели, к которым обращается модуль создания вероятностей появления.
Помимо этого, модуль 8 кодирования переменной длины в соответствии с этим вариантом 1 осуществления содержит запоминающее устройство 25 информации вероятности появления и имеет механизм для сохранения информации 28 вероятности появления, которая обновляется, в свою очередь, через процесс кодирования, фрагментов информации вероятности появления, сохраненной как результат обновления, соответствующего варьированиям используемой контекстной модели. Модуль 23 создания вероятностей появления определяет информацию 28 вероятности появления, которая используется для текущего кодирования, согласно значению контекстной модели 26.
(D) Процесс кодирования (этап ST14, показанный на фиг. 11)
В вышеуказанном процессе (C) (этап ST13), поскольку получают вероятность появления каждого из значений 0 и 1 на числовой оси вероятностей, требуемую для процесса арифметического кодирования, модуль 24 кодирования выполняет арифметическое кодирование согласно процессу, упомянутому в качестве обычного примера (этап ST14).
Кроме того, фактическое кодированное значение (0/1) 29 возвращается в модуль 23 создания вероятностей появления, модуль создания вероятностей появления подсчитывает частоту возникновения каждого из значений 0 и 1, чтобы обновлять используемую информацию 28 вероятности появления (этап ST15). Например, предполагается, что, когда процесс кодирования для кодирования 100 элемента(ов) выборки выполняется с использованием определенного фрагмента информации 28 вероятности появления, вероятности появления 0 и 1 в варьировании вероятности появления составляют 0,25 и 0,75 соответственно. В этом случае, когда «1» кодируется с использованием идентичного варьирования вероятности появления, частота возникновения «1» обновляется, и вероятности появления 0 и 1 изменяются на 0,247 и 0,752 соответственно. С использованием этого механизма модуль кодирования получает возможность выполнять эффективное кодирование, которое приспособлено для фактической вероятности появления.
После того как процесс кодирования для всех элементов выборки завершается, результат 30 арифметического кодирования, который создал модуль 24 кодирования, становится выводом из модуля 8 кодирования переменной длины и выводится из устройства кодирования изображений в качестве потока 9 битов (этап ST16).
2. Структура кодированного потока битов
Введенный видеосигнал 1 кодируется посредством устройства кодирования изображений по фиг. 2 согласно вышеуказанным процессам, и кодированный видеосигнал выводится из устройства кодирования изображений в качестве потока 9 битов в единицах, каждая из которых является пакетом, состоящим из множества опорных блоков (каждая единица упоминается как серия последовательных макроблоков с этого места). Компоновка данных потока 9 битов показывается на фиг. 17. Поток 9 битов имеет такую структуру, в которой определенное число кодированных данных, число которых равно числу опорных блоков, включенных в каждый кадр, собирается в каждом кадре, и опорные блоки пакетируются в каждой серии последовательных макроблоков. Заголовок уровня изображения, к которому опорные блоки, принадлежащие идентичному кадру, обращаются в качестве общего параметра, подготавливается, и информация 18 размера опорных блоков сохраняется в этом заголовке уровня изображения. Если размер Mmax опорного блока является фиксированным в расчете на последовательность на более высоком уровне, чем уровень изображения, информация 18 размера опорных блоков может формироваться так, что она мультиплексируется в заголовок уровня последовательности.
Каждая серия последовательных макроблоков начинается с заголовка серии последовательных макроблоков, и кодированные данные каждого опорного блока в серии последовательных макроблоков размещаются непрерывно после заголовка серии последовательных макроблоков. Пример по фиг. 17 показывает, что K опорных блоков включаются во вторую серию последовательных макроблоков. Данные каждого опорного блока состоят из заголовка опорного блока и сжатых данных ошибки прогнозирования. В заголовке опорного блока размещаются режимы mc_mode прогнозирования движения и векторы движения единичных блоков прогнозирования движения в соответствующем опорном блоке (они соответствуют параметрам 17 для создания сигнала прогнозирования), параметры 19 квантования, используемые для создания сжатых данных 7 ошибки прогнозирования, и т.д.
Информация типа режима, в качестве режима mc_mode прогнозирования движения, указывающая mc_skip или один из mc_mode0-mc_mode7, кодируется сначала, и когда режимом mc_mode прогнозирования движения является mc_skip, все последующие фрагменты информации макроблочного кодирования не передаются. Когда режимом mc_mode прогнозирования движения является один из mc_mode0-mc_mode6, фрагменты информации вектора движения областей выделения векторов движения, указываемых посредством режима прогнозирования движения, кодируются. Когда режимом mc_mode прогнозирования движения является mc_mode7, то, включены или нет sub_mc_skip в код sub_mc_mode, определяется согласно информации 18 размера опорных блоков. В дальнейшем в этом документе предполагается, что пороговые значения, используемые для определения того, включены или нет sub_mc_skip в код sub_mc_mode, задаются как lt=Li/2 и mt=Mi/2 из размеров Mi и Li опорных блоков. Кроме того, когда требования «li>lt и mi>mt» удовлетворяются, кодирование sub_mc_mode, включающего в себя sub_mc_skip, выполняется согласно правилу преобразования в двоичную форму, показанному на фиг. 15(b). Напротив, когда требования «li>lt и mi>mt» не удовлетворяются, только кодирование Bin0 исключается из правила преобразования в двоичную форму, показанного на фиг. 15(b). Кроме того, информация 27 выбора контекстной модели, показывающая направление для выбора контекстной модели в арифметическом кодировании режима прогнозирования движения и вектора движения, включается в заголовок опорного блока.
Хотя не проиллюстрировано, модуль определения размера опорных блоков может иметь такую структуру, что он выбирает размеры Li и Mi каждого единичного блока прогнозирования движения, которые используются в каждом опорном блоке для каждого опорного блока, и мультиплексирует размеры Li и Mi единичного блока прогнозирования движения, которые используются в каждом опорном блоке, в заголовок каждого опорного блока вместо мультиплексирования размеров Li и Mi в заголовок уровня последовательности или изображения. Как результат, хотя устройство кодирования изображений должно кодировать размеры Li и Mi каждого единичного блока прогнозирования движения для каждого опорного блока, устройство кодирования изображений может изменять размеры каждого единичного блока прогнозирования движения согласно свойствам локального сигнала изображения и получает возможность выполнять прогнозирование движения с более высокой степенью адаптируемости. Информация, указывающая, следует мультиплексировать размеры Li и Mi каждого единичного блока прогнозирования движения в заголовок каждого опорного блока либо фиксированно мультиплексировать их в заголовок на верхнем уровне, к примеру, последовательности, GOP, изображения или серии последовательных макроблоков, может быть мультиплексирована, в качестве идентификационной информации, в заголовок на верхнем уровне, к примеру, последовательности, GOP, изображения или серии последовательных макроблоков. Как результат, когда влияние, оказываемое на способность прогнозирования движения, является небольшим, даже если размеры каждого единичного блока прогнозирования движения фиксированно мультиплексируются в заголовок верхнего уровня, устройство кодирования изображений может уменьшать объем служебной информации, требуемый для кодирования размеров Li и Mi каждого единичного блока прогнозирования движения для каждого опорного блока, и, следовательно, эффективно выполнять кодирование.
3. Устройство декодирования изображений
Фиг. 18 является блок-схемой, показывающей структуру устройства декодирования изображений в соответствии с этим вариантом 1 осуществления. После приема потока 9 битов, показанного на фиг. 17, и затем декодирования заголовка уровня последовательности, модуль 100 декодирования переменной длины (модуль декодирования) декодирует заголовок уровня изображения, а также декодирует информацию, показывающую размер опорного блока. Как результат, модуль декодирования переменной длины распознает размер Mmax каждого опорного блока и размеры Li и Mi каждого единичного блока прогнозирования движения, которые используются для изображения, и уведомляет эту информацию 18 размера опорных блоков в модуль 101 декодирования ошибок прогнозирования и модуль 102 прогнозирования. Модуль 100 декодирования переменной длины имеет такую структуру, что он, когда поток битов имеет структуру, в которой размеры Li и Mi каждого единичного блока прогнозирования движения могут быть мультиплексированы в заголовок каждого опорного блока, декодирует идентификационную информацию, показывающую то, мультиплексируются или нет размеры Li и Mi каждого единичного блока прогнозирования движения в заголовок каждого опорного блока, и распознает размеры Li и Mi каждого единичного блока прогнозирования движения посредством декодирования заголовка каждого опорного блока согласно идентификационной информации.
Модуль декодирования переменной длины начинает декодирование данных каждого опорного блока с декодирования заголовка опорного блока сначала. В этом процессе, модуль 100 декодирования переменной длины декодирует информацию 27 выбора контекстной модели. Затем, согласно декодированной информации 27 выбора контекстной модели модуль декодирования переменной длины декодирует режим прогнозирования движения, который применяется к каждому единичному блоку прогнозирования движения для каждого цветового компонента. При декодировании режима прогнозирования движения модуль декодирования переменной длины декодирует mc_mode для каждого единичного блока прогнозирования движения сначала и, когда mc_skip показывает mc_mode, определяет оцененный вектор из смежных векторов движения согласно требованиям, показанным на фиг. 8, и выделяет оцененный вектор для текущего вектора движения. Когда mc_mode показывает mc_mode7, модуль декодирования переменной длины декодирует sub_mc_mode для каждого базисного блока согласно требованиям, показанным на фиг. 8. В это время, на основе информации 18 размера опорных блоков, модуль декодирования переменной длины определяет то, использовать или нет sub_mc_skip, согласно критерию определения, идентичному критерию определения, который использует устройство кодирования изображений, и затем выполняет процесс декодирования sub_mc_mode согласно этому определению. При использовании sub_mc_skip, если sub_mc_mode==sub_mc_skip, модуль декодирования переменной длины пропускает декодирование кодированных данных рассматриваемого базисного блока и выделяет оцененный вектор, который модуль декодирования переменной длины определяет посредством использования способа, показанного на фиг. 8, текущему вектору движения. Когда mc_mode показывает другой режим, модуль декодирования переменной длины декодирует вектор движения в каждой из определенного числа областей выделения векторов движения согласно информации 27 выбора контекстной модели и дополнительно декодирует фрагменты информации по параметрам 19 квантования, сжатым данным 7 ошибки прогнозирования и т.д. поочередно для каждого опорного блока.
Сжатые данные 7 ошибки прогнозирования и параметры 19 квантования вводятся в модуль 101 декодирования ошибок прогнозирования и распаковываются в декодированный сигнал 11 ошибки прогнозирования. Этот модуль 101 декодирования ошибок прогнозирования выполняет процесс, эквивалентный процессу, выполняемому посредством модуля 10 локального декодирования в устройстве кодирования изображений, показанном на фиг. 2.
Модуль 102 прогнозирования создает сигнал 12 прогнозирования как из параметров 17 для создания сигнала прогнозирования, декодированных посредством модуля 100 декодирования переменной длины, так и из опорного сигнала 15 изображения, сохраненного в запоминающем устройстве 103. Хотя модуль 102 прогнозирования выполняет процесс, эквивалентный процессу, выполняемому посредством модуля 4 прогнозирования в устройстве кодирования изображений, этот процесс не включает в себя операции обнаружения вектора движения. Режим прогнозирования движения имеет любой из mc_mode0-mc_mode7, показанных на фиг. 4, и модуль 102 прогнозирования создает прогнозируемое изображение 12 посредством использования вектора движения, выделяемого каждому базисному блоку согласно разделенным формам.
Декодированный сигнал 11 ошибки прогнозирования и сигнал 12 прогнозирования суммируются посредством модуля сумматора и вводятся в контурный фильтр 104 в качестве декодированного сигнала 13. Этот декодированный сигнал 13 сохраняется в запоминающем устройстве 103 в качестве опорного сигнала 15 изображения для создания последующего сигнала 12 прогнозирования после того, как декодированный сигнал подвергается процессу удаления шума кодирования в контурном фильтре 104. Хотя не проиллюстрировано на фиг. 18, контурный фильтр 104 выполняет процесс, эквивалентный процессу, выполняемому посредством контурного фильтра 14 в устройстве кодирования изображений, посредством использования информации 20 коэффициентов фильтрации в дополнение к параметрам 17 для создания сигнала прогнозирования и параметрам 19 квантования, которые получают посредством декодирования посредством модуля 100 декодирования переменной длины, чтобы создавать опорный сигнал 15 изображения. Отличие между контурным фильтром 14 устройства кодирования изображений и контурным фильтром 104 устройства декодирования изображений заключается в том, что тогда как первый создает информацию 20 коэффициентов фильтрации в отношении кодированного сигнала 3, который является сигналом исходного изображения, второй выполняет процесс фильтрации в отношении информации 20 коэффициентов фильтрации, обнаруженной посредством декодирования потока 9 битов.
Далее описывается процесс декодирования режима прогнозирования движения и вектора движения каждого опорного блока, который выполняется посредством модуля 100 декодирования переменной длины.
Фиг. 19 показывает внутреннюю структуру, ассоциированную с процессом арифметического декодирования, выполняемым посредством модуля 100 декодирования переменной длины, и фиг. 20 показывает последовательность операций процесса арифметического декодирования.
Модуль 100 декодирования переменной длины в соответствии с этим вариантом 1 осуществления состоит из модуля 21 определения контекстных моделей для определения типа каждых из данных, которые должны быть декодированы, включающих в себя параметры 17 для создания сигнала прогнозирования, включающие в себя режим прогнозирования движения, вектор движения и т.д., сжатые данные 7 ошибки прогнозирования и параметры 19 квантования, чтобы определять контекстную модель, которая задается общей с устройством кодирования изображений, для каждой цели, которая должна быть декодированными данными, модуля 22 преобразования в двоичную форму для создания правила преобразования в двоичную форму, которое задается согласно типу каждых данных, которые должны быть декодированы, модуля 23 создания вероятностей появления для предоставления вероятности появления каждого элемента выборки (0 или 1) согласно правилу преобразования в двоичную форму и контекстной модели, модуля 105 декодирования для выполнения арифметического декодирования согласно созданной вероятности появления и декодирования кодированных данных на основе двоичной последовательности, обнаруженной как результат арифметического декодирования, и вышеуказанного правила преобразования в двоичную форму, и запоминающего устройства 25 информации вероятности появления для сохранения информации 28 вероятности появления. Каждый модуль, который обозначен ссылочной позицией, идентичной ссылочной позиции, обозначающей внутренний компонент модуля 8 кодирования переменной длины, показанного на фиг. 10, из модулей, показанных на фиг. 19, выполняет операцию, идентичную операции, выполняемой посредством внутреннего компонента.
(E) Процесс определения контекстной модели, процесс преобразования в двоичную форму и процесс создания вероятности появления (этапы ST11-ST13, показанные на фиг. 20)
Поскольку эти процессы (этапы ST11-ST13) являются аналогичными процессам (A)-(C) (этапам ST11-ST13, показанным на фиг. 11), выполняемым посредством устройства кодирования изображений, пояснение этапов далее опускается. Для определения контекстной модели, которая используется для декодирования режима прогнозирования движения и вектора движения, обращаются к вышеуказанной декодированной информации 27 выбора контекстной модели.
(F) Процесс арифметического декодирования (этапы ST21, ST15 и ST22, показанные на фиг. 20)
Поскольку вероятность появления элемента выборки, который модуль 105 декодирования должен декодировать с этого времени, определяется в вышеуказанном процессе (E), модуль 105 декодирования восстанавливает значение элемента выборки согласно заданному процессу арифметического декодирования (этап ST21). Восстановленное значение 40 (фиг.19) элемента выборки возвращается в модуль 23 создания вероятностей появления, и частота возникновения каждого из 0 и 1 подсчитывается для обновления используемой информации 28 вероятности появления (этап ST15). Каждый раз, когда восстановленное значение каждого элемента выборки определяется, модуль 105 декодирования проверяет то, совпадает или нет восстановленное значение с шаблоном двоичной последовательности, определенным согласно правилу преобразования в двоичную форму, и выводит значение данных, указываемое посредством шаблона, с которым восстановленное значение совпадает, в качестве значения 106 декодированных данных (этап ST22). Если декодированные данные не определяются, модуль декодирования возвращается к этапу ST11 и продолжает процесс декодирования.
Хотя информация 27 выбора контекстной модели мультиплексируется в единицах опорных блоков в вышеуказанном пояснении, информация выбора контекстной модели может быть альтернативно мультиплексирована в единицах серий последовательных макроблоков, изображений и т.п. В случае, если информация выбора контекстной модели мультиплексируется в качестве флага, размещаемого на более высоком уровне данных, к примеру серии последовательных макроблоков, изображения или последовательности, и соответствующая степень эффективности кодирования может быть обеспечена посредством переключения между верхними уровнями выше серии последовательных макроблоков, объем служебных битов может быть уменьшен без мультиплексирования информации 27 выбора контекстной модели последовательно на уровне опорного блока.
Кроме того, информация 27 выбора контекстной модели может быть информацией, которая определяется в устройстве декодирования изображений согласно связанной информации, отличающейся от информации выбора контекстной модели и включенной в поток битов. Помимо этого, хотя в вышеуказанном пояснении поясняется то, что модуль 8 кодирования переменной длины и модуль 100 декодирования переменной длины выполняют процесс арифметического кодирования и процесс арифметического декодирования, эти процессы могут быть процессом кодирования методом Хаффмана и процессом декодирования методом Хаффмана, и информация 27 выбора контекстной модели может быть использована в качестве средства для адаптивного изменения таблицы кодирования переменной длины.
Устройства кодирования и декодирования изображений, которые имеют такую структуру, как указано выше, могут выражать иерархию режимов чередования и могут адаптивно кодировать информацию, включающую в себя режим прогнозирования движения и вектор движения, согласно внутреннему состоянию каждого опорного блока, который должен быть кодирован, и могут, следовательно, эффективно выполнять кодирование.
Как упомянуто выше, устройство кодирования изображений в соответствии с вариантом 1 осуществления имеет такую структуру, что оно включает в себя модуль 4 прогнозирования для адаптивного определения размера каждого единичного блока прогнозирования движения согласно сигналам цветовых компонентов и для разделения каждого единичного блока прогнозирования движения на области выделения векторов движения, чтобы выполнять поиск вектора движения; и модуль 8 кодирования переменной длины для выполнения, когда вектор движения выделяется полностью каждому единичному блоку прогнозирования движения, кодирования, чтобы создавать поток 9 битов посредством задания режима прогнозирования движения как режима mc_skip, если вектор движения равен оцененному вектору, который определяется из векторов движения в окружающих единичных блоках прогнозирования движения, и данных, которые должны быть кодированы как сигнал 5 ошибки прогнозирования движения, не существует, и для выполнения, когда каждая из областей выделения векторов движения имеет размер, равный или превышающий заданный размер, и вектор движения выделяется полностью для каждой из областей выделения векторов движения, кодирования, чтобы создавать поток 9 битов посредством задания режима прогнозирования движения как режима sub_mc_skip, если вектор движения равен оцененному вектору, который определяется из векторов движения в окружающих областях выделения векторов движения, и данных, которые должны быть кодированы как сигнал 5 ошибки прогнозирования, не существует. Следовательно, чтобы эффективного кодировать цветовой видеосигнал, имеющий формат 4:4:4, устройство кодирования изображений может выражать иерархию режимов чередования и может адаптивно кодировать информацию, включающую в себя режим прогнозирования движения и вектор движения, согласно внутреннему состоянию каждого опорного блока, который должен быть кодирован. Как результат, при выполнении кодирования на низкой скорости передачи в битах, предоставляющего высокий коэффициент сжатия, устройство кодирования изображений может эффективно выполнять кодирование при уменьшении объема кода вектора движения.
Кроме того, устройство декодирования изображений в соответствии с вариантом 1 осуществления имеет такую структуру, что оно включает в себя модуль 100 декодирования переменной длины для декодирования потока 9 битов, введенных в него, чтобы получить параметры 17 для создания сигнала прогнозирования, показывающего размер каждого единичного блока прогнозирования движения, режим прогнозирования движения для указания формы каждой из областей выделения векторов движения, на которые каждый единичный блок прогнозирования движения разделяется, и вектор движения, соответствующий каждой области выделения векторов движения, и для определения того, находится или нет каждый единичный блок прогнозирования движения в режиме mc_skip и находится или нет одна из областей выделения векторов движения в режиме sub_mc_skip, из вышеуказанного режима прогнозирования движения, и модуль 102 прогнозирования для определения, когда единичный блок прогнозирования движения находится в режиме mc_skip, или одна из областей выделения векторов движения находится в режиме sub_mc_skip, оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения, а также задания всех декодированных сигналов 11 ошибки прогнозирования равными нулю, чтобы создавать сигнал 12 прогнозирования, и для создания, когда единичный блок прогнозирования движения не находится в режиме mc_skip и области выделения векторов движения единичного блока прогнозирования движения не находятся в режиме sub_mc_skip, сигнала 12 прогнозирования на основе режима прогнозирования движения и вектора движения, которые модуль 100 декодирования переменной длины получает посредством декодирования потока битов. Соответственно, устройство декодирования видео может иметь такую структуру, что оно соответствует вышеуказанному устройству кодирования изображений.
Хотя в этом варианте 1 осуществления пример, в котором кодируется и декодируется видеосигнал 4:4:4, поясняется, разумеется, что процессы кодирования и декодирования в соответствии с настоящим изобретением могут применяться к случаю, в котором кодирование и декодирование выполняются в единицах опорных блоков, к примеру макроблоков, при кодировании видео, направленного на то, чтобы кодировать видео, имеющее формат 4:2:0 или 4:2:2, в котором операция разбавления цветов выполняется в обычном формате цветоразностного компонента яркости, как упомянуто выше.
Промышленная применимость
Поскольку устройство кодирования изображений, устройство декодирования изображений, способ кодирования изображений и способ декодирования изображений в соответствии с настоящим изобретением позволяют выполнять оптимальный процесс кодирования для видеосигнала, имеющего формат 4:4:4, они являются подходящими для использования в технологии кодирования со сжатием изображений, технологии передачи сжатых данных изображений и т.д.
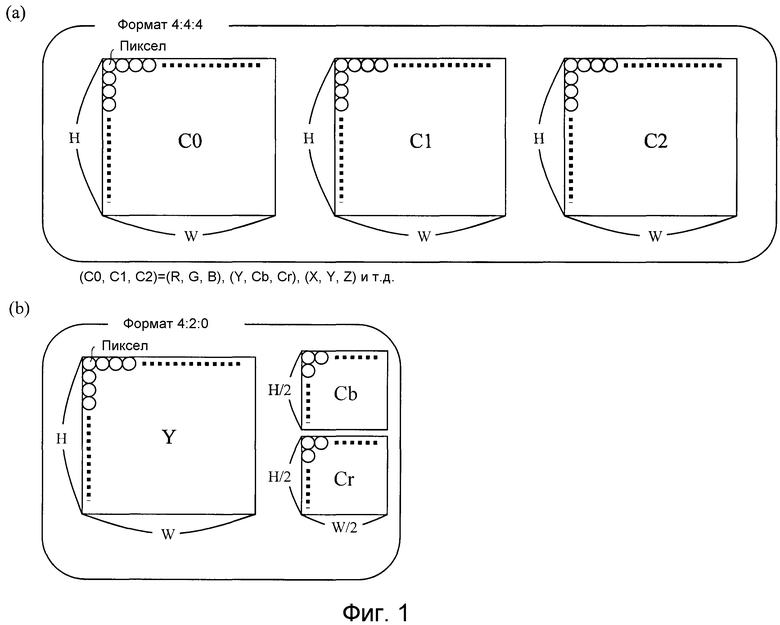
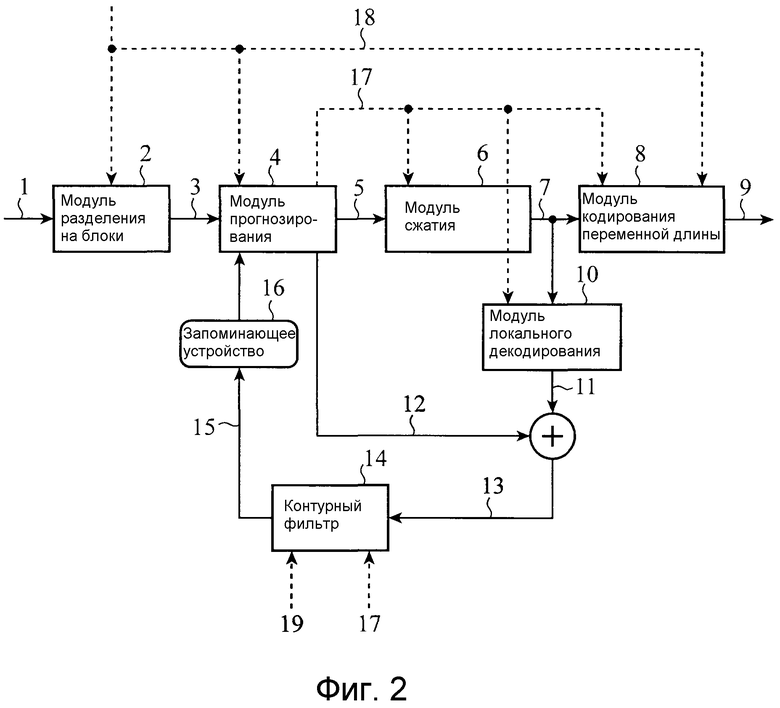
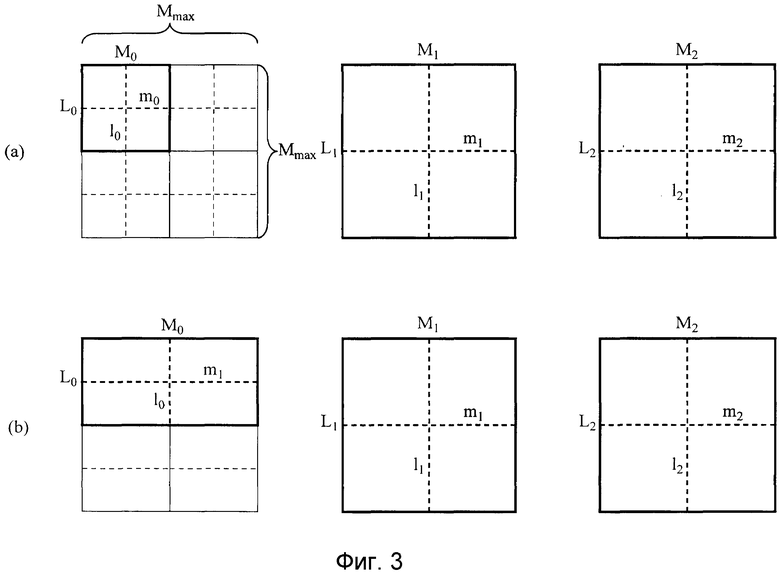
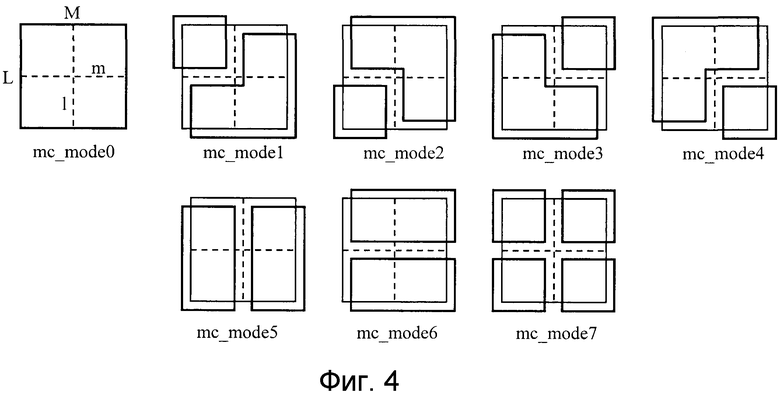
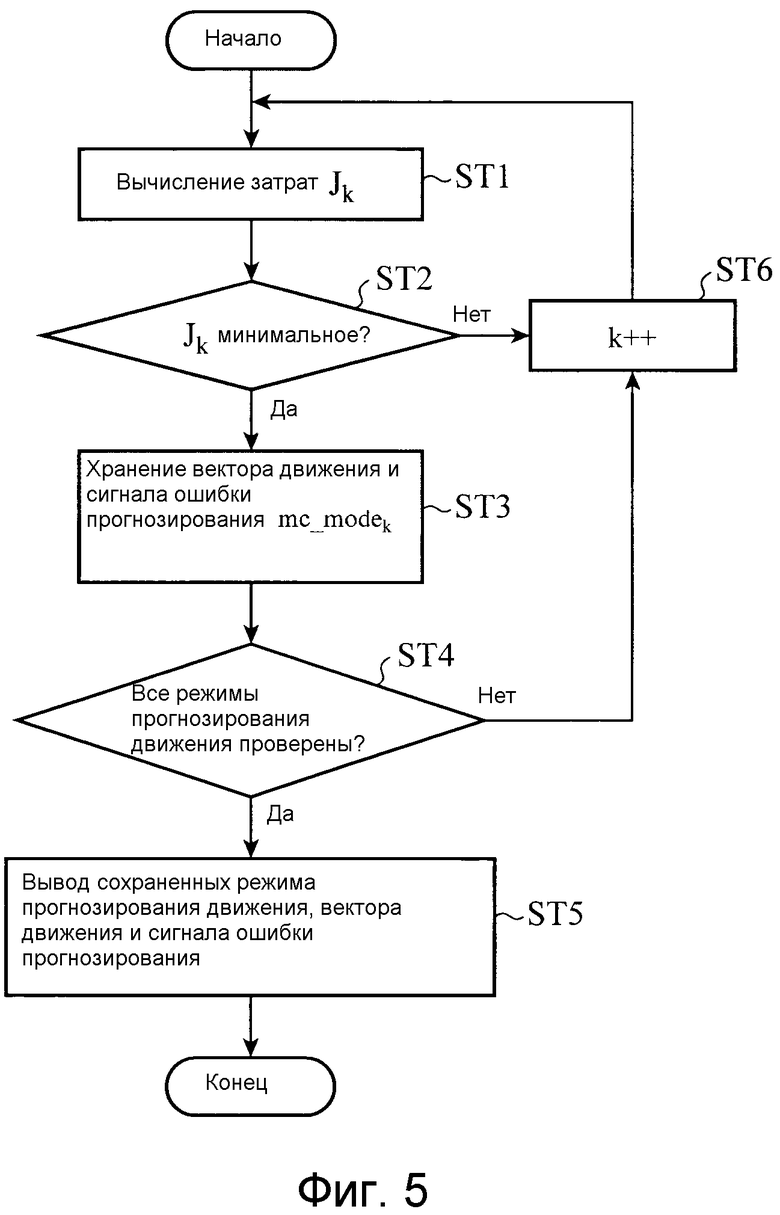
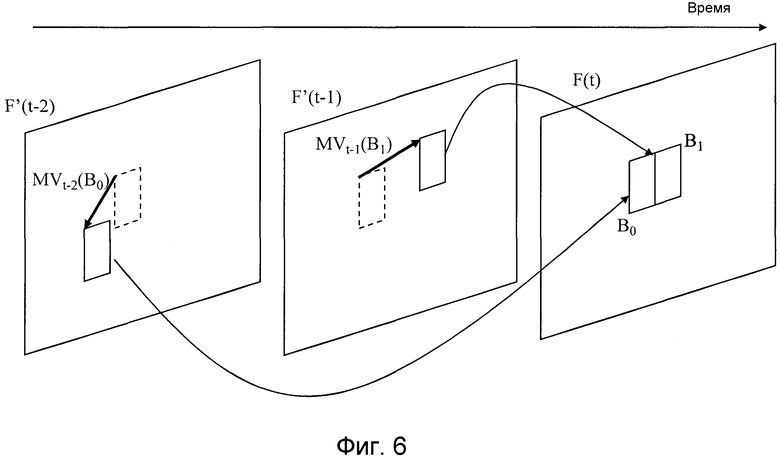
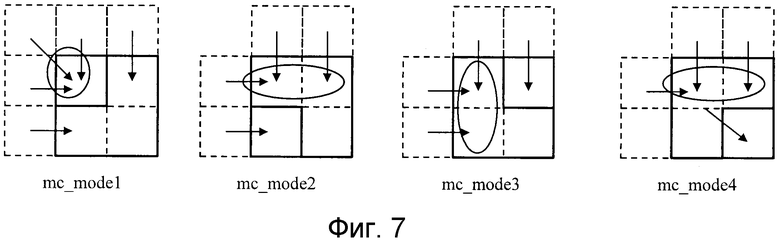
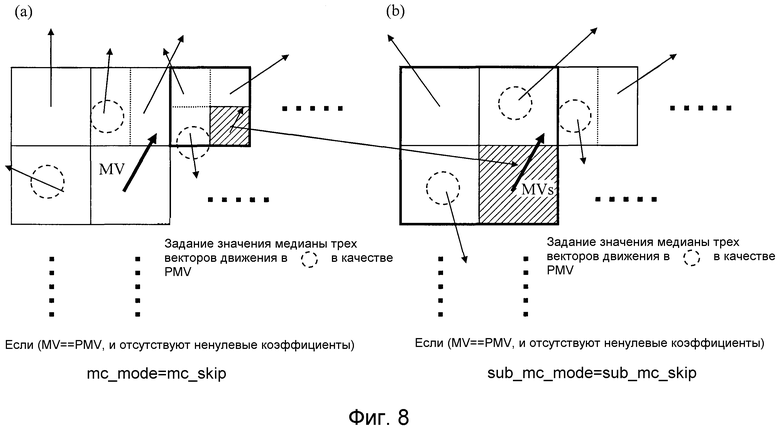
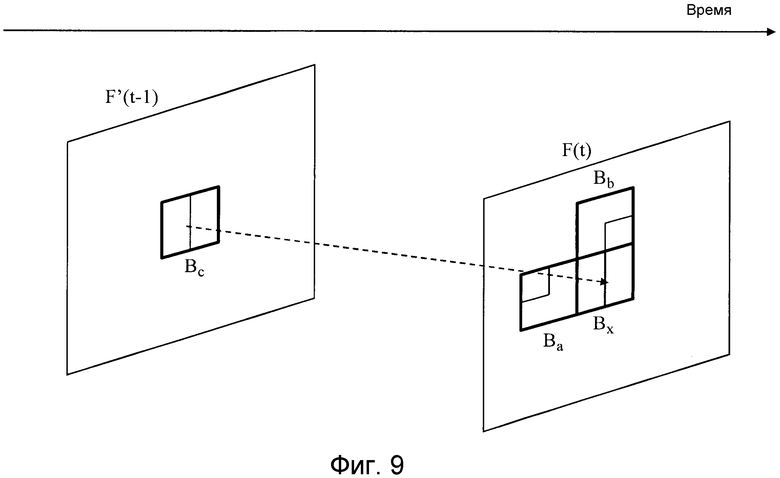
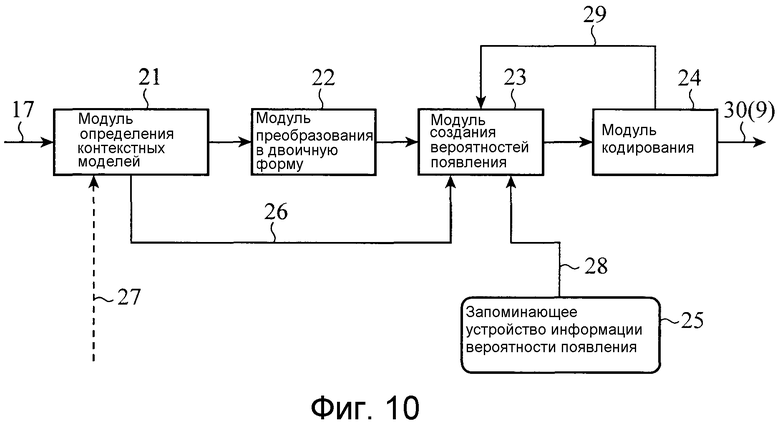
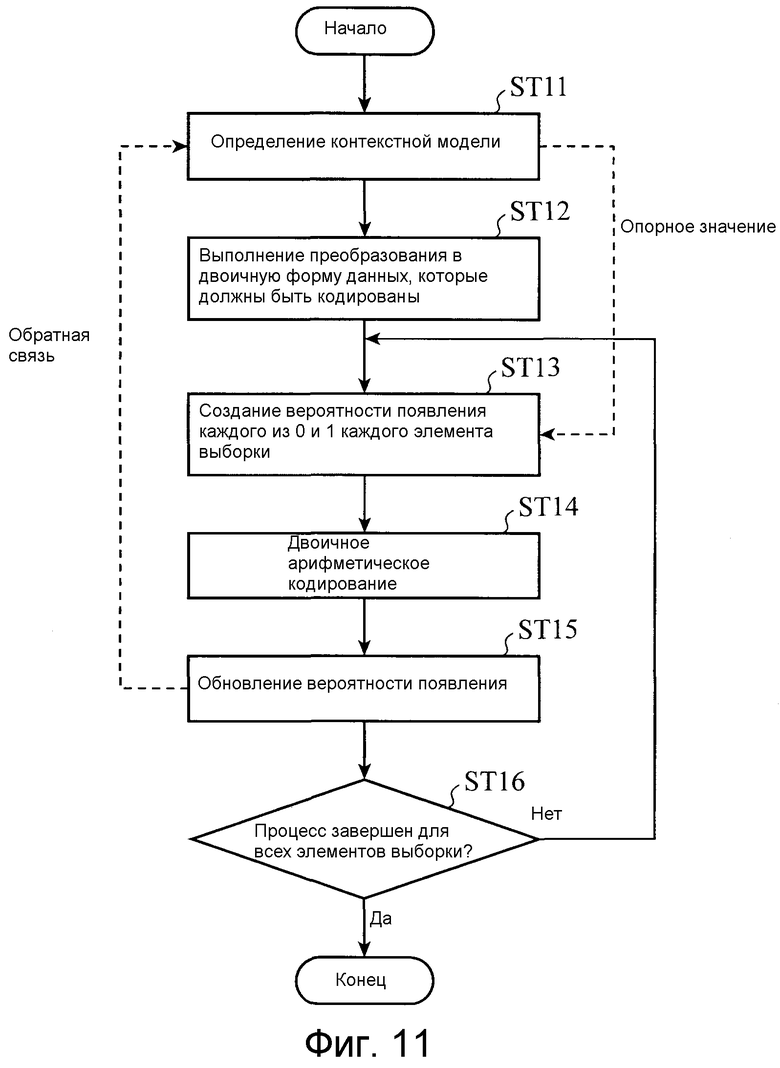
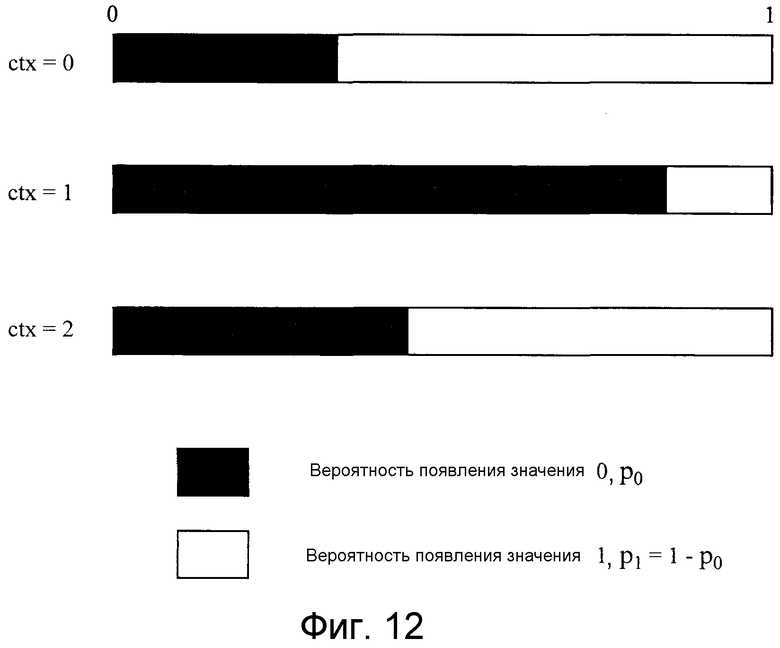
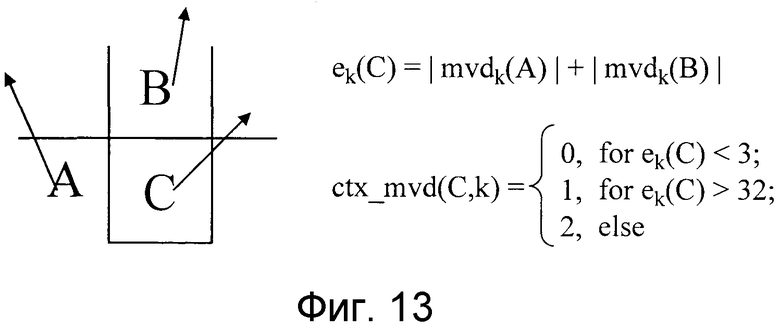
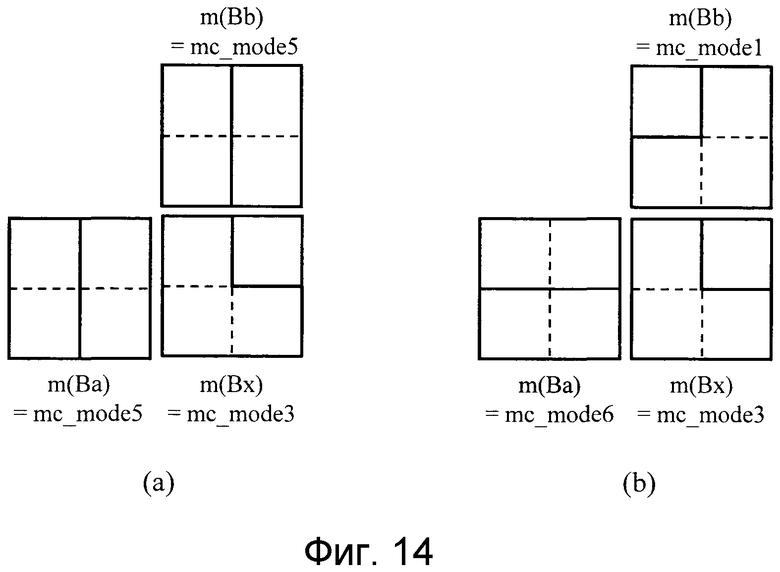
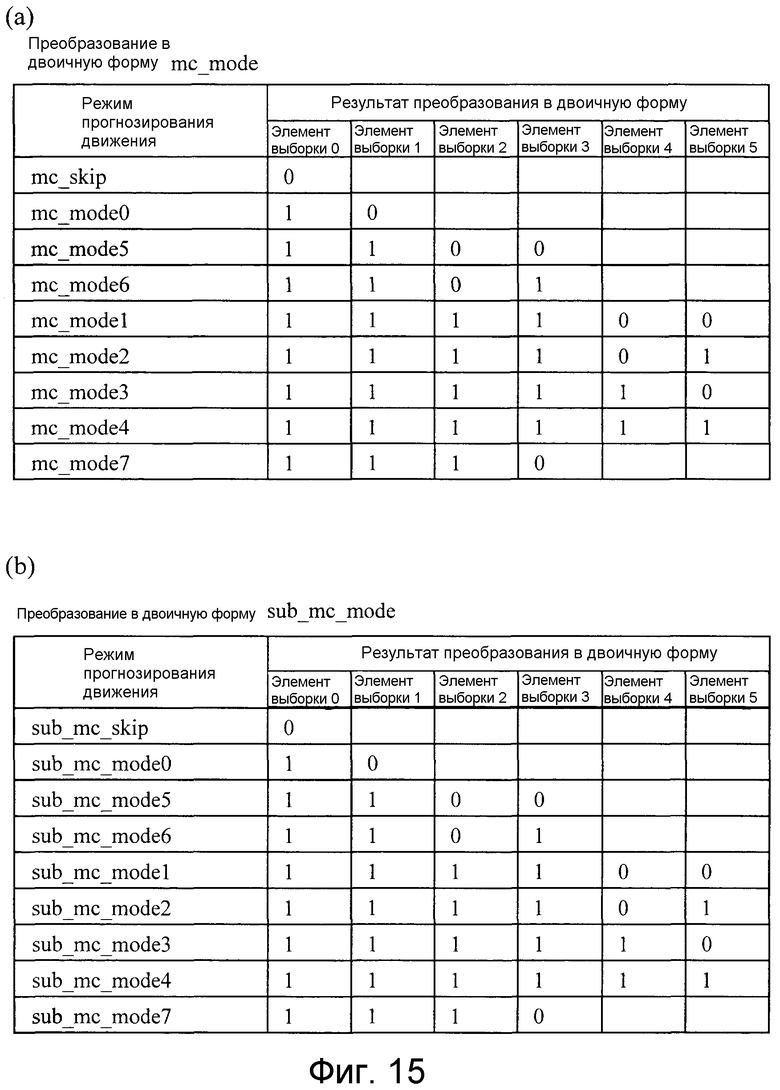
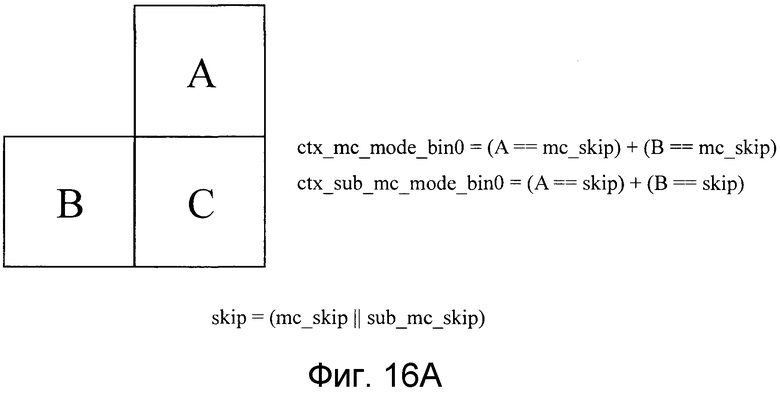
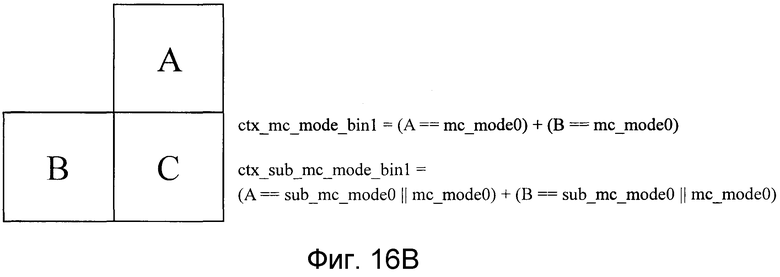
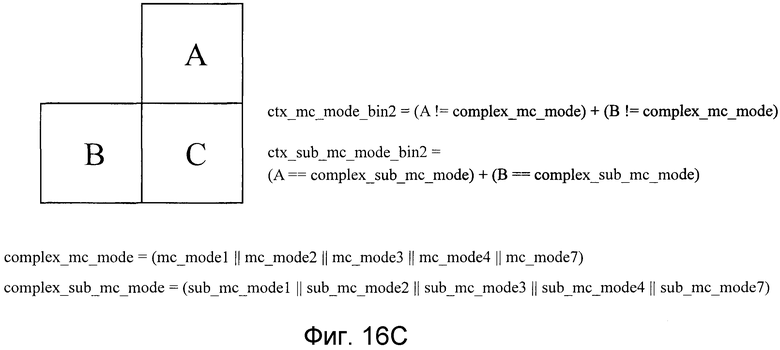
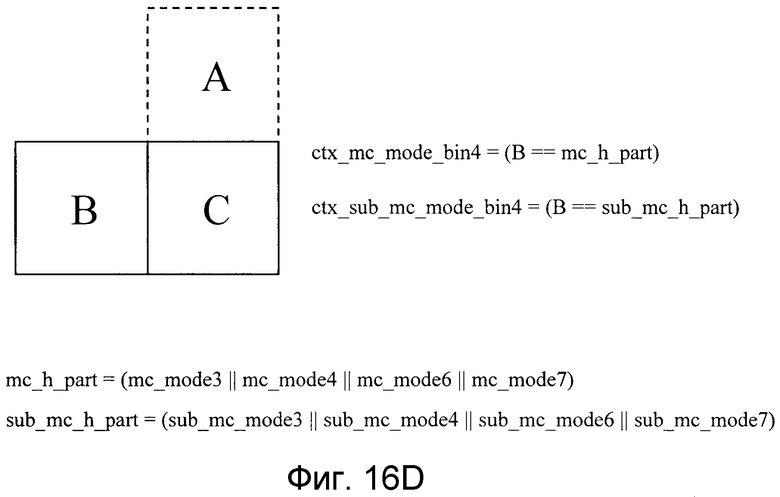
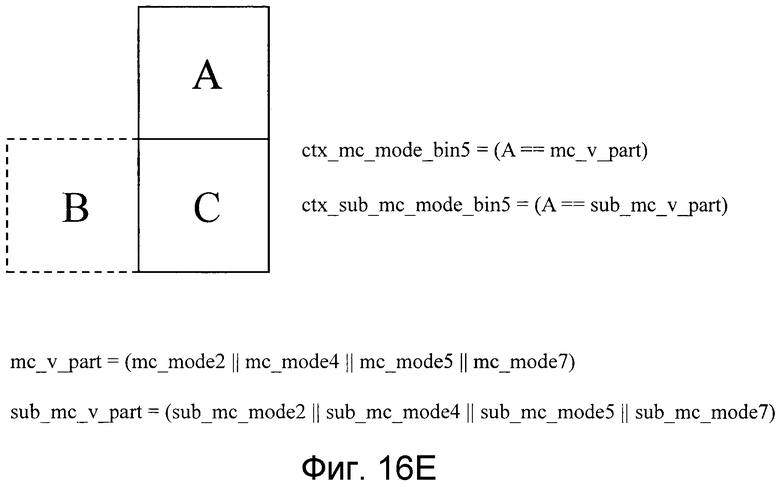
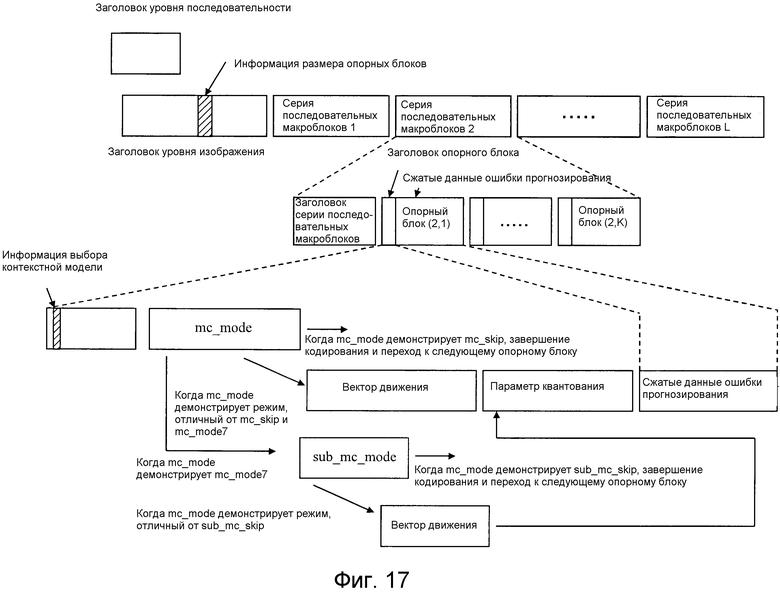
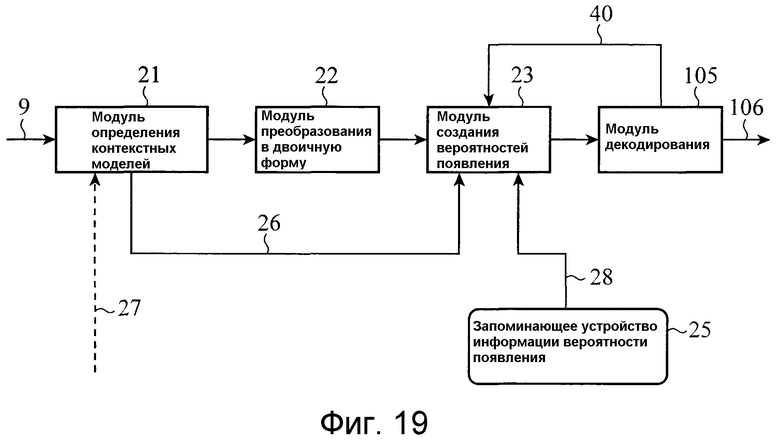
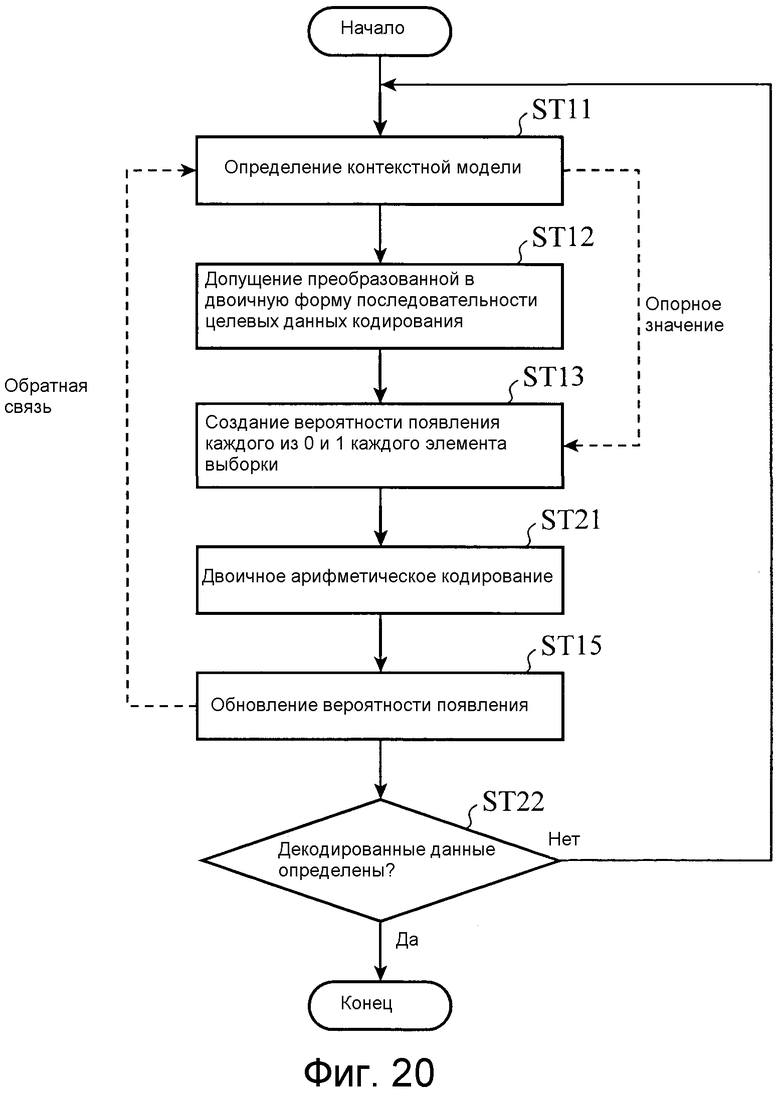
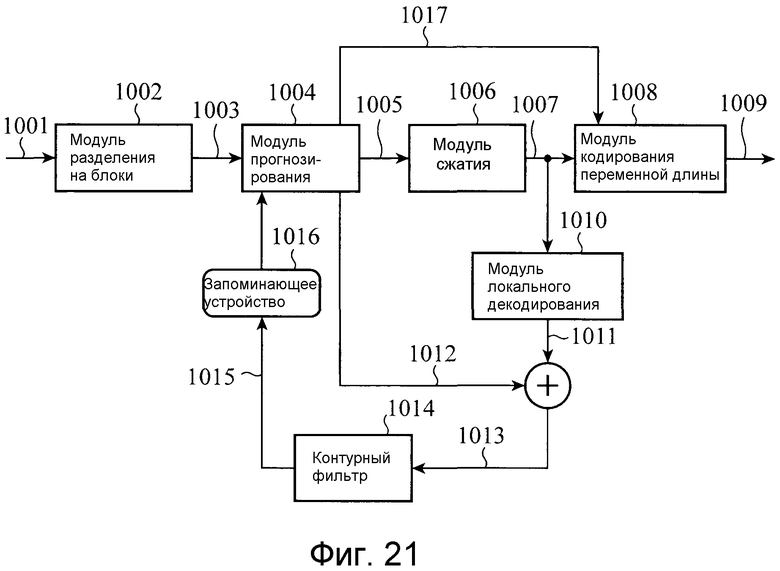
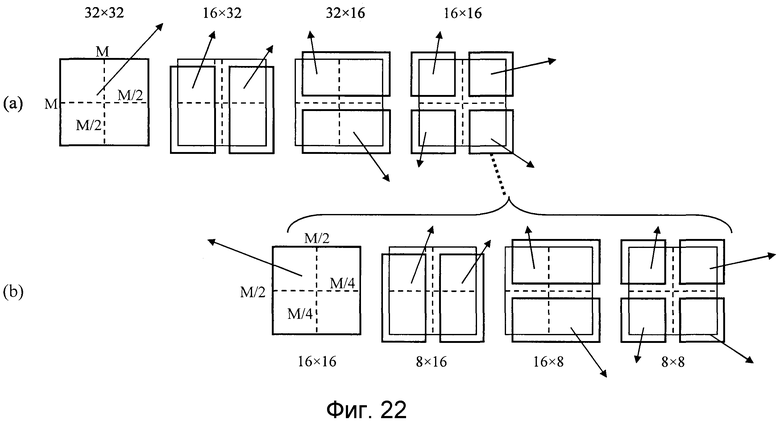
Изобретение относится к технологиям кодирования и декодирования видеоизображений. Техническим результатом является повышение эффективности декодирования информации. Предложены устройство и способ декодирования изображений. Устройство декодирования изображений декодирует кодированный с прогнозированием поток битов для получения сигнала движущегося изображения. При этом указанный поток битов создается посредством разделения каждого кадра сигнала движущегося изображения на множество блоков и посредством выполнения прогнозирования движения для каждого из блоков. Устройство декодирования изображений содержит модуль декодирования и модуль прогнозирования. Модуль декодирования осуществляет декодирование потока битов для получения информации, указывающей размер блока, информации, указывающей пороговое значение размера блока, первого режима прогнозирования движения, который соответствуют указанному блоку. 2 н.п. ф-лы, 26 ил.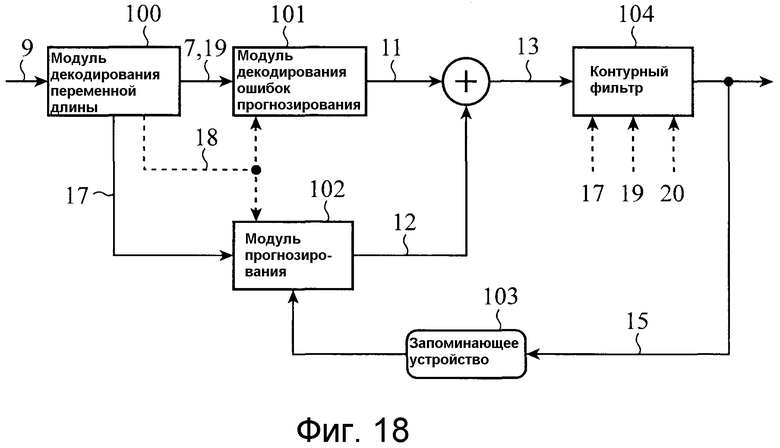
1. Устройство декодирования изображений, которое декодирует кодированный с прогнозированием поток битов для получения сигнала движущегося изображения, при этом указанный поток битов создается посредством разделения каждого кадра сигнала движущегося изображения на множество блоков и посредством выполнения прогнозирования движения для каждого из блоков, причем упомянутое устройство декодирования изображений содержит:
- модуль декодирования для декодирования упомянутого потока битов, чтобы получить информацию, указывающую размер блока, информацию, указывающую пороговое значение размера блока, первый режим прогнозирования движения для первого единичного блока прогнозирования движения, который соответствует указанному блоку, и для декодирования потока битов для получения второго режима прогнозирования движения для второго единичного блока прогнозирования движения, когда первый режим прогнозирования движения не является режимом чередования и размер первого единичного блока прогнозирования движения больше порогового значения, при этом второй единичный блок прогнозирования движения получается путем иерархического разделения первого единичного блока прогнозирования движения; и
- модуль прогнозирования, когда первый режим прогнозирования движения является режимом чередования, для определения оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения первого единичного блока прогнозирования движения, чтобы создать прогнозируемое изображение, и, когда второй режим прогнозирования движения является режимом чередования, для определения оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения для второго единичного блока прогнозирования движения для создания прогнозируемого изображения.
2. Способ декодирования изображений для декодирования кодированного с прогнозированием потока битов для получения сигнала движущегося изображения, при этом указанный поток битов создается посредством разделения каждого кадра сигнала движущегося изображения на множество блоков и посредством выполнения прогнозирования движения для каждого из блоков, способ декодирования изображения содержит:
этап декодирования для декодирования потока битов для получения информации, указывающей размер блока, информации, указывающей пороговое значение размера блока, первого режима прогнозирования движения для первого единичного блока прогнозирования движения, который соответствует указанному блоку, и для декодирования потока битов для получения второго режима прогнозирования движения для второго единичного блока прогнозирования движения, когда первый режим прогнозирования движения не является режимом чередования и размер первого единичного блока прогнозирования движения больше порогового значения, при этом второй единичный блок прогнозирования движения получается путем иерархического разделения первого единичного блока прогнозирования движения; и
этап прогнозирования, когда первый режим прогнозирования движения является режимом чередования, для определения оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения первого единичного блока прогнозирования движения, чтобы создать прогнозируемое изображение, и, когда второй режим прогнозирования движения является режимом чередования, для определения оцененного вектора из окружающих векторов движения и задания этого оцененного вектора в качестве вектора движения для второго единичного блока прогнозирования движения для создания прогнозируемого изображения.
| JP 2003259377 A, 12.09.2003 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Оптическое стекло | 1985 |
|
SU1296525A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 6058212 A, 02.05.2000 | |||
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРЕДСКАЗЫВАЕМОГО ВЕКТОРА ДВИЖЕНИЯ | 2003 |
|
RU2263349C2 |
| УСТРОЙСТВО КОДИРОВАНИЯ ДВИЖУЩИХСЯ ИЗОБРАЖЕНИЙ, СПОСОБ И ПРОГРАММА УПРАВЛЕНИЯ ЭТИМ УСТРОЙСТВОМ | 2004 |
|
RU2335859C2 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ БЕЗ ПОТЕРЬ | 2005 |
|
RU2342804C2 |

