2420-185243RU/015
УЛУЧШЕННАЯ ПОТОКОВАЯ ПЕРЕДАЧА ПО ЗАПРОСУ БЛОКОВ С ИСПОЛЬЗОВАНИЕМ ШАБЛОНОВ И ПРАВИЛ КОНСТРУИРОВАНИЯ URL
ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Данная заявка является заявкой на патент, притязающей на преимущество нижеследующих предварительных заявок, причем каждая имеет авторство Michael G. Luby (Майкл Дж. Луби) и др. и каждая озаглавлена "Enhanced Block-Request Streaming System":
[0002] Предварительная патентная заявка США № 61/244767, поданная 22 сентября 2009 г.,
[0003] Предварительная патентная заявка США № 61/257719, поданная 3 ноября 2009 г.,
[0004] Предварительная патентная заявка США № 61/258088, поданная 4 ноября 2009 г.,
[0005] Предварительная патентная заявка США № 61/285779, поданная 11 декабря 2009 г., и
[0006] Предварительная патентная заявка США № 61/296725, поданная 20 января 2010 г.
[0007] Данная заявка также притязает на преимущество Предварительной патентной заявки США № 61/372399, поданной 10 августа 2010 под авторством Ying Chen (Ин Чэнь) и др. и озаглавленной "HTTP Streaming Extensions".
[0008] Каждая предварительная заявка, упомянутая выше, настоящим включается в этот документ путем отсылки во всех смыслах. Настоящее раскрытие изобретения также включает в себя путем отсылки, как если бы они были полностью изложены в этом документе во всех смыслах, следующие принадлежащие тому же правообладателю заявки/патенты:
[0009] Патент США № 6307487, выданный Luby (в дальнейшем "Luby I");
[0010] Патент США № 7068729, выданный Shokrollahi и др. (в дальнейшем "Shokrollahi I");
[0011] Заявка на патент США № 11/423391, поданная 9 июня 2006 г. и озаглавленная "Forward Error-Correcting (FEC) Coding and Streaming" под авторством Luby и др. (в дальнейшем "Luby II");
[0012] Заявка на патент США № 12/103605, поданная 15 апреля 2008 г., озаглавленная "Dynamic Stream Interleaving and Sub-Stream Based Delivery" под авторством Luby и др. (в дальнейшем "Luby III");
[0013] Заявка на патент США № 12/705202, поданная 12 февраля 2010 г., озаглавленная "Block Partitioning for a Data Stream" под авторством Pakzad и др. (в дальнейшем "Pakzad"); и
[0014] Заявка на патент США № 12/859161, поданная 18 августа 2010 г., озаглавленная "Methods and Apparatus Employing FEC Codes with Permanent Inactivation of Symbols for Encoding and Decoding Processes" под авторством Luby и др. (в дальнейшем "Luby IV").
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0015] Настоящее изобретение относится к улучшенным системам и способам мультимедийной потоковой передачи, а конкретнее к системам и способам, которые приспосабливаются к условиям сети и буфера, чтобы оптимизировать представление потокового мультимедиа и позволить эффективную одновременную, или распределенную во времени, доставку потоковых мультимедийных данных.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
[0016] Доставка потоковых мультимедийных данных может стать все более и более важной, так как она становится общепринятой для высококачественного звука и видеоизображения, которые нужно доставить по сетям на основе пакетов, например Интернету, сотовым и беспроводным сетям, сетям в линиях электропередач и другим типам сетей. Качество, с которым можно представить доставленное потоковое мультимедиа, может зависеть от некоторого количества факторов, включая разрешение (или другие атрибуты) исходного контента, качество кодирования исходного контента, возможности приемных устройств по декодированию и представлению мультимедиа, своевременность и качество сигнала, принятого в приемниках, и т.д. Чтобы создать хорошее воспринимаемое впечатление от потокового мультимедиа, могут быть особенно важны транспорт и своевременность сигнала, принятого в приемниках. Хороший транспорт может обеспечить точность принятого в приемнике потока относительно того, что отправляет отправитель, тогда как своевременность может представлять то, как быстро приемник может начать воспроизведение контента после начального запроса того контента.
[0017] Систему доставки мультимедиа можно охарактеризовать как систему, имеющую источники мультимедиа, назначения мультимедиа и каналы (во времени и/или в пространстве), разделяющие источники и назначения. Обычно источник включает в себя передатчик с доступом к мультимедиа с управлением в электронном виде, а приемник имеет возможность электронного управления приемом мультимедиа (или ее приближение) и предоставления его потребителю мультимедиа (например, пользователю, имеющему устройство отображения, соединенное некоторым способом с приемником, запоминающим устройством или элементом, другим каналом и т.д.).
[0018] Хотя возможно много вариантов, в общем примере система доставки мультимедиа содержит один или несколько серверов, которые имеют доступ к мультимедийному контенту в электронном виде, и одна или несколько клиентских систем или устройств создают запросы мультимедиа к серверам, а серверы передают мультимедиа с использованием передатчика как части сервера, передающей к приемнику у клиента, чтобы клиент мог употребить принятое мультимедиа некоторым способом. В простом примере имеется один сервер и один клиент для заданного запроса и ответа, но это не обязательно так.
[0019] Традиционно системы доставки мультимедиа можно описать либо моделью "загрузки", либо моделью "потоковой передачи". Модель "загрузки" могла бы отличаться временной независимостью между доставкой мультимедийных данных и воспроизведением мультимедиа пользователю или устройству-получателю.
[0020] В качестве примера мультимедиа загружается в достаточном количестве заранее, когда оно нужно или будет использоваться, а когда оно используется, оно уже доступно как раз в нужном количестве у получателя. Доставка в контексте загрузки часто выполняется с использованием протокола транспортировки файлов, например HTTP, FTP или Доставки файлов однонаправленным транспортом (FLUTE), и скорость доставки можно было бы определить по лежащему в основе потоку и/или протоколу отслеживания перегрузок, например TCP/IP. Работа потока или протокола отслеживания перегрузок может не зависеть от воспроизведения мультимедиа пользователю или устройству назначения, которое может происходить одновременно с загрузкой или в какое-нибудь другое время.
[0021] Режим "потоковой передачи" мог бы отличаться сильной связью между моментом доставки мультимедийных данных и воспроизведением мультимедиа пользователю или устройству- получателю. Доставка в этом контексте часто выполняется с использованием протокола потоковой передачи, например Потокового протокола реального времени (RTSP) для управления и Транспортного протокола в режиме реального времени (RTP) для мультимедийных данных. Скорость доставки можно было бы определить с помощью сервера потоковой передачи, часто она совпадает со скоростью воспроизведения данных.
[0022] Некоторые недостатки модели "загрузки" могут состоять в том, что из-за временной независимости доставки и воспроизведения мультимедийные данные могут быть либо не доступны, когда они нужны для воспроизведения (например, из-за того, что доступная полоса пропускания меньше скорости передачи мультимедийных данных), вызывая прекращение воспроизведения на мгновение ("остановка"), что приводит к плохому взаимодействию с пользователем, либо мультимедийные данные может потребоваться загрузить гораздо раньше воспроизведения (например, из-за того, что доступная полоса пропускания больше скорости передачи мультимедийных данных), потребляя ресурсы хранения на приемном устройстве, которые могут быть дефицитными, и потребляя ценные сетевые ресурсы для доставки, которые могут растрачиваться напрасно, если контент в конечном счете не воспроизводится или используется иным образом.
[0023] Преимущество модели "загрузки" может состоять в том, что технология, необходимая для выполнения таких загрузок, например HTTP, очень зрелая, широко используется и применима к широкому диапазону приложений. Серверы загрузки и решения для широкой масштабируемости таких загрузок файлов (например, Веб-серверы HTTP и Сети доставки контента) могут быть легко доступны, делая развертывание услуг на основе этой технологии простым и недорогим.
[0024] Некоторые недостатки модели "потоковой передачи" могут состоять в том, что обычно скорость доставки мультимедийных данных не адаптируется к доступной полосе пропускания в соединении от сервера к клиенту, и что необходимы специализированные потоковые серверы или более сложная сетевая архитектура, обеспечивающая полосу пропускания и гарантии задержки. Хотя существуют системы потоковой передачи, которые поддерживают изменение скорости доставки данных в соответствии с доступной полосой пропускания (например, Adobe Flash Adaptive Streaming), они обычно не так эффективны, как протоколы управления транспортными потоками загрузки, например TCP, при использовании всей доступной полосы пропускания.
[0025] В последнее время разработаны и развернуты новые системы доставки мультимедиа на основе сочетания моделей "потоковой передачи" и "загрузки". Пример такой модели в этом документе называется моделью "потоковой передачи по запросу блоков", в которой клиент мультимедиа запрашивает блоки мультимедийных данных у обслуживающей инфраструктуры с использованием протокола загрузки, например HTTP. Вопросом в таких системах может быть возможность начать воспроизведение потока, например декодирование и визуализацию принятых аудио- и видеопотоков с использованием персонального компьютера и отображение видеоизображения на экране компьютера и воспроизведение звука через встроенные динамики, либо, в качестве другого примера, декодирование и визуализацию принятых аудио- и видеопотоков с использованием телевизионной приставки и отображение видеоизображения на телевизионном устройстве отображения и воспроизведение звука через стереосистему.
[0026] Другие вопросы, например способность, декодировать исходные блоки достаточно быстро, чтобы не отставать от скорости потоковой передачи источника, минимизировать задержку декодирования и уменьшить использование доступных ресурсов CPU, являются проблемами. Другим вопросом является предоставление устойчивого и масштабируемого решения по потоковой доставке, которое позволяет выходить из строя компонентам системы без неблагоприятного влияния на качество потоков, доставленных приемникам. Другие проблемы могли бы возникнуть на основе быстро меняющейся информации о представлении, когда она распространяется. Таким образом, желательно иметь усовершенствованные процессы и устройство.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0027] Система потоковой передачи по запросу блоков обеспечивает улучшения во взаимодействии с пользователем и в эффективности полосы пропускания в таких системах, обычно используя систему захвата, которая формирует данные в виде для использования традиционным файловым сервером (HTTP, FTP или т.п.), причем система захвата принимает контент и готовит его в виде файлов или элементов данных для использования файловым сервером, который мог бы включать в себя или не включать кэш. Клиентское устройство можно приспособить для получения выгоды от процесса захвата, также включая улучшения, которые способствуют лучшему представлению независимо от процесса захвата. В одной особенности клиентские устройства и система захвата согласованы в том, что имеется заранее определенное преобразование и шаблон для выполнения запросов блоков к файловым именам HTTP, которые традиционный файловый сервер может принимать посредством использования правил конструирования URL. В некоторых вариантах осуществления предоставляются новые улучшения к способам для задания размера сегмента приблизительным образом для более эффективной организации.
[0028] Нижеследующее подробное описание изобретения вместе с прилагаемыми чертежами обеспечит более полное понимание предмета и преимуществ настоящего изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0029] Фиг. 1 изображает элементы системы потоковой передачи по запросу блоков в соответствии с вариантами осуществления настоящего изобретения.
[0030] Фиг. 2 иллюстрирует систему потоковой передачи по запросу блоков из фиг. 1, показывая больше подробностей в элементах клиентской системы, которая соединяется с обслуживающей инфраструктурой блоков ("BSI") для приема данных, которые обрабатываются системой захвата контента.
[0031] Фиг. 3 иллюстрирует аппаратную/программную реализацию системы захвата.
[0032] Фиг. 4 иллюстрирует аппаратную/программную реализацию клиентской системы.
[0033] Фиг. 5 иллюстрирует возможные структуры хранилища контента, показанного на фиг. 1, включая сегменты и файлы дескриптора представления мультимедиа ("MPD"), и расшифровку сегментов, распределение во времени и другую структуру в файле MPD.
[0034] Фиг. 6 иллюстрирует подробности типичного исходного сегмента, который мог бы храниться в хранилище контента, проиллюстрированном на фиг. 1 и 5.
[0035] Фиг. 7a и 7b иллюстрируют простое и иерархическое индексирование в файлах.
[0036] Фиг. 8(а) иллюстрирует задание переменных размеров блока с выровненными точками поиска на множестве версий мультимедийного потока.
[0037] Фиг. 8(b) иллюстрирует задание переменных размеров блока с невыровненными точками поиска на множестве версий мультимедийного потока.
[0038] Фиг. 9(а) иллюстрирует Таблицу метаданных.
[0039] Фиг. 9(b) иллюстрирует передачу Блоков и Таблицы метаданных от сервера к клиенту.
[0040] Фиг. 10 иллюстрирует блоки, которые не зависят от границ RAP.
[0041] Фиг. 11 иллюстрирует непрерывный и прерывистый тайминг по сегментам.
[0042] Фиг. 12 - фигура, показывающая особенность масштабируемых блоков.
[0043] Фиг. 13 изображает графическое отображение развития со временем некоторых переменных в системе потоковой передачи по запросу блоков.
[0044] Фиг. 14 изображает другое графическое отображение развития со временем некоторых переменных в системе потоковой передачи по запросу блоков.
[0045] Фиг. 15 изображает сетку состояний в зависимости от пороговых значений.
[0046] Фиг. 16 - блок-схема алгоритма процесса, который мог бы выполняться в приемнике, который может запрашивать одиночные блоки и несколько блоков в запросе.
[0047] Фиг. 17 - блок-схема алгоритма гибкого конвейерного процесса.
[0048] Фиг. 18 иллюстрирует пример в некоторый момент возможного набора запросов, их приоритетов, и по каким соединениям они могут быть выданы.
[0049] Фиг. 19 иллюстрирует пример возможного набора запросов, их приоритетов, и по каким соединениям они могут быть выданы, который [пример] прошел от одного момента к другому.
[0050] Фиг. 20 - блок-схема алгоритма совместимого выбора кэширующего прокси-сервера на основе идентификатора файла.
[0051] Фиг. 21 иллюстрирует определение синтаксиса для подходящего языка выражений.
[0052] Фиг. 22 иллюстрирует пример подходящей хэш-функции.
[0053] Фиг. 23 иллюстрирует примеры правил конструирования идентификатора файла.
[0054] Фиг. 24(a) - (e) иллюстрируют колебания полосы пропускания у соединений TCP.
[0055] Фиг. 25 иллюстрирует несколько запросов HTTP исходных данных и данных восстановления.
[0056] Фиг. 26 иллюстрирует примерное время переключения каналов с FEC и без него.
[0057] Фиг. 27 иллюстрирует подробности генератора сегментов восстановления, который, как часть показанной на фиг. 1 системы захвата, формирует сегменты восстановления из исходных сегментов и управляющих параметров.
[0058] Фиг. 28 иллюстрирует отношения между исходными блоками и блоками восстановления.
[0059] Фиг. 29 иллюстрирует процедуру для интерактивных услуг в разные моменты на клиенте.
[0060] На фигурах на одинаковые элементы ссылаются с помощью одинаковых номеров, и субиндексы предоставляются в круглых скобках для указания нескольких экземпляров сходных или идентичных элементов. Пока не указано иное, конечный субиндекс (например, "N" или "M") не предназначен быть ограничивающим до какого-либо конкретного значения, и количество экземпляров одного элемента может отличаться от количества экземпляров другого элемента, даже когда иллюстрируется одинаковый номер и повторно используется субиндекс.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0061] Как описано в этом документе, цель системы потоковой передачи - переместить мультимедиа из места хранения (или места, где оно формируется) в место, где оно потребляется, то есть представляется пользователю или иным образом "используется" человеком или электронным потребителем. В идеале система потоковой передачи может обеспечивать непрерывное воспроизведение (или, в более общем смысле, непрерывное "потребление") на принимающей стороне и может начать воспроизведение потока или совокупности потоков вскоре после того, как пользователь запросил поток или потоки. По причинам эффективности также желательно, чтобы каждый поток останавливался, как только пользователь указывает, что поток уже не нужен, например, когда пользователь переключается с одного потока на другой поток или он следует представлению потока, например потока "субтитров". Если мультимедийный компонент, например видеоизображение, продолжает представляться, но другой поток выбирается для представления этого мультимедийного компонента, часто предпочтительно занять ограниченную полосу пропускания новым потоком и остановить старый поток.
[0062] Система потоковой передачи по запросу блоков в соответствии с вариантами осуществления, описанными в этом документе, обеспечивает много преимуществ. Следует понимать, что жизнеспособная система не должна включать в себя все описанные в этом документе признаки, так как некоторые применения могли бы обеспечить соответственно удовлетворительное впечатление не со всеми признаками, описанными в этом документе.
ПОТОКОВАЯ ПЕРЕДАЧА HTTP
[0063] Потоковая передача HTTP является специальным типом потоковой передачи. При потоковой передаче HTTP источники могли бы быть стандартными веб-серверами и сетями доставки контента (CDN) и могли бы использовать стандартный HTTP. Эта методика может затрагивать сегментацию потока и использование нескольких потоков, все в рамках стандартизованных запросов HTTP. Мультимедиа, например видеоизображение, может кодироваться с несколькими скоростями передачи битов, чтобы сформировать разные версии, или отображения. Термин "версия" и "отображение" в этом документе используются синонимично. Каждую версию или отображение можно разбить на более мелкие фрагменты, возможно порядка нескольких секунд каждый, чтобы образовать сегменты. Каждый сегмент тогда можно сохранить на веб-сервере или CDN в виде отдельного файла.
[0064] На стороне клиента затем можно выполнять запросы с использованием HTTP к отдельным сегментам, которые бесшовно стыкуются вместе с помощью клиента. Клиент может переключаться на разные скорости данных на основе доступной полосы пропускания. Клиент также может запрашивать несколько отображений, причем каждое представляет разный мультимедийный компонент, и может воспроизводить мультимедиа в этих отображениях одновременно и синхронно. Триггеры для переключения могут включать в себя, например, занятость буфера и сетевые замеры. При работе в устойчивом состоянии клиент может задать темп запросов к серверу, чтобы поддерживать целевую занятость буфера.
[0065] Преимущества потоковой передачи HTTP могут включать в себя адаптацию скорости передачи битов, быстрый запуск и поиск, и минимальную ненужную доставку. Эти преимущества происходят из управления доставкой, чтобы она только немного опережала воспроизведение, используя по максимуму доступную полосу пропускания (посредством мультимедиа с переменной скоростью) и оптимизируя сегментацию потока и интеллектуальные процедуры на клиенте.
[0066] Описание представления мультимедиа может предоставляться клиенту потоковой передачи HTTP, так что клиент может использовать совокупность файлов (например, в форматах, заданных 3GPP, в этом документе называется сегментами 3gp) для предоставления пользователю услуги потоковой передачи. Описание представления мультимедиа, и по возможности обновления этого описания представления мультимедиа, описывают представление мультимедиа, которое является структурированной совокупностью сегментов, причем каждый содержит мультимедийные компоненты, так что клиент может представлять включенное мультимедиа синхронизированным способом и может обеспечить расширенные функциональные возможности, например поиск, переключение скоростей передачи битов и совместное представление мультимедийных компонентов в разных отображениях. Клиент может использовать информацию описания представления мультимедиа разными способами для предоставления услуги. В частности, из описания представления мультимедиа клиент потоковой передачи HTTP может определить, к каким сегментам в совокупности можно обращаться, чтобы данные были применимы к возможности клиента и пользователю в рамках услуги потоковой передачи.
[0067] В некоторых вариантах осуществления описание представления мультимедиа может быть статическим, хотя сегменты могли бы создаваться динамически. Описание представления мультимедиа может быть как можно более компактным, чтобы минимизировать время доступа и загрузки для услуги. Остальную соединяемость с выделенным сервером можно минимизировать, например, регулярную или частую временную синхронизацию между клиентом и сервером.
[0068] Представление мультимедиа может создаваться для разрешения доступа терминалам с разными возможностями, например доступом к разным типам сетей доступа, с разными текущими сетевыми условиями, размерами дисплеев, скоростями доступа и поддержкой кодеков. Клиент тогда может извлекать подходящую информацию для предоставления пользователю услуги потоковой передачи.
[0069] Описание представления мультимедиа также может обеспечить гибкость развертывания и компактность в соответствии с требованиями.
[0070] В самом простом случае каждое Альтернативное отображение может храниться в одиночном файле 3GP, то есть в файле, соответствующем 3GPP TS26.244, или в любом другом файле, который соответствует базовому формату мультимедийного файла ISO, который задан в ISO/IEC 14496-12 или производных спецификациях (например, формат файла 3GP, описанный в Техническом описании 3GPP 26.244). В оставшейся части этого документа при ссылке на файл 3GP следует понимать, что ISO/IEC 14496-12 и производные спецификации могут отобразить все описанные признаки в более общий базовый формат мультимедийного файла ISO, который задан в ISO/IEC 14496-12 или любых производных спецификациях. Клиент тогда может запросить начальную часть файла, чтобы узнать метаданные мультимедиа (которые обычно хранятся в блоке Заголовка фильма, также называемом блоком "moov"), вместе с моментами фрагментов фильма и байтовыми смещениями. Клиент затем может выдавать частичные запросы GET HTTP для получения фрагментов фильма при необходимости.
[0071] В некоторых вариантах осуществления может быть желательно, разделить каждое отображение на несколько сегментов. Если формат сегмента основывается на формате файла 3GP, то сегменты содержат неперекрывающиеся временные секции фрагментов фильма, называемые "разделением по времени". Каждый из этих сегментов может содержать несколько фрагментов фильма, и каждый может быть допустимым самостоятельным файлом 3GP. В другом варианте осуществления отображение разделяется на начальный сегмент, содержащий метаданные (обычно это блок Заголовка фильма "moov"), и набор мультимедийных сегментов, содержащих мультимедийные данные, и объединение начального сегмента и любого мультимедийного сегмента образует файл 3GP, а также объединение начального сегмента и всех мультимедийных сегментов одного отображения образует допустимый файл 3GP. Все представление может быть образовано путем воспроизведения каждого сегмента по очереди, преобразуя локальные временные отметки внутри файла в глобальное время представления в соответствии со временем начала каждого отображения.
[0072] Следует отметить, что по всему данному описанию ссылки на "сегмент" следует понимать как включающие в себя любой объект данных, который полностью или частично создан или считан с носителя информации или иным образом получен в результате запроса по протоколу загрузки файла, включая, например, запрос HTTP. Например, в случае HTTP объекты данных могут храниться в фактических файлах, находящихся на диске или другом носителе информации, подключенном или образующем часть сервера HTTP, либо объекты данных могут создаваться с помощью сценария CGI или другой динамически исполняемой программы, которая исполняется в ответ на запрос HTTP. Термин "файл" и "сегмент" в этом документе используются синонимично, пока не указано иное. В случае HTTP сегмент может рассматриваться в виде главной части ответа на запрос HTTP.
[0073] Термин "представление" и "элемент содержимого" в этом документе используются синонимично. Во многих примерах представление является звуком, видеоизображением или другим мультимедийным представлением, которое обладает заданным временем "воспроизведения", однако возможны другие варианты.
[0074] Термин "блок" и "фрагмент" в этом документе используются синонимично, пока не указано иное, и обычно относятся к наименьшему комплексу данных, который индексируется. На основе доступного индексирования клиент может запрашивать разные части фрагмента в разных запросах HTTP либо может запрашивать один или несколько последовательных фрагментов или частей фрагментов в одном запросе HTTP. В случае, когда используются сегменты на основе базового формата мультимедийного файла ISO или сегменты на основе формата файла 3GP, фрагмент обычно относится к фрагменту фильма, заданному в виде сочетания блока заголовка фрагмента фильма ("moof") и блока мультимедийных данных ("mdat").
[0075] В этом документе сеть, переносящая данные, предполагается пакетной сетью, чтобы упростить описания в этом документе, с пониманием того, что после прочтения этого раскрытия изобретения специалист в данной области техники может применить варианты осуществления настоящего изобретения, описанные в этом документе, к другим типам сетей передачи, например сетям с непрерывным битовым потоком.
[0076] В этом документе коды FEC предполагаются обеспечивающими защиту от длительного и переменного времени доставки данных, чтобы упростить описания в этом документе, с пониманием того, что после прочтения этого раскрытия изобретения специалист в данной области техники может применить варианты осуществления настоящего изобретения к другим типам проблем передачи данных, например, искажению при инвертировании разрядов данных. Например, в отсутствии FEC, если последняя часть запрошенного фрагмента поступает гораздо позже или имеет большой разброс во времени поступления, нежели предыдущие части фрагмента, то время переключения контента может быть большим и переменным, тогда как с использованием FEC и параллельных запросов только большинство данных, запрошенных для фрагмента, должно поступить до того, как их можно восстановить, посредством этого уменьшая время переключения контента и нестабильность времени переключения контента. В этом описании можно было бы предположить, что данные, которые нужно кодировать (то есть исходные данные), разбиты на "символы" равной длины, которые могут иметь любую длину (вплоть до одного разряда), но символы могли бы иметь разные длины для разных частей данных, например, разные размеры символов могли бы использоваться для разных блоков данных.
[0077] В этом описании, чтобы упростить описания в этом документе, предполагается, что FEC применяется к "блоку" или "фрагменту" данных за раз, то есть "блок" является "исходным блоком" для целей кодирования и декодирования FEC. Клиентское устройство может использовать индексирование сегмента, описанное в этом документе, чтобы помочь в определении структуры исходного блока в сегменте. Специалист в данной области техники может применить варианты осуществления настоящего изобретения к другим типам структур исходного блока, например, исходный блок может быть частью фрагмента или включать в себя один или несколько фрагментов либо частей фрагментов.
[0078] Коды FEC, рассмотренные для использования с потоковой передачей по запросу блоков, обычно являются систематическими кодами FEC, то есть исходные символы исходного блока могут включаться как часть кодирования исходного блока, и таким образом передаются исходные символы. Как признает специалист в данной области техники, варианты осуществления, описанные в этом документе, в равной степени применяются к кодам FEC, которые не являются систематическими. Систематический кодер FEC формирует из исходного блока исходных символов некоторое количество символов восстановления, и сочетание, по меньшей мере, некоторых из исходных символов и символов восстановления является кодированными символами, которые отправляются по каналу, представляющему исходный блок. Некоторые коды FEC могут быть полезны для эффективного формирования такого количества символов восстановления, которое необходимо, например "информационные аддитивные коды" или "фонтанные коды", и примеры этих кодов включают в себя "коды цепной реакции" и "коды многоэтапной цепной реакции". Другие коды FEC, например коды Рида-Соломона, практически могут формировать только ограниченное количество символов восстановления для каждого исходного блока.
[0079] Во многих этих примерах предполагается, что клиент соединяется с сервером мультимедиа или множеством серверов мультимедиа, и клиент запрашивает потоковое мультимедиа по каналу или множеству каналов от сервера мультимедиа или множества серверов мультимедиа. Однако также возможны более сложные компоновки.
ПРИМЕРЫ ПРЕИМУЩЕСТВ
[0080] При потоковой передаче по запросу блоков клиент мультимедиа поддерживает связь между синхронизацией этих запросов блоков и синхронизацией воспроизведения мультимедиа для пользователя. Эта модель может сохранять преимущества модели "загрузки", описанной выше, наряду с предотвращением некоторых недостатков, которые происходят от обычного разрыва воспроизведения мультимедиа и доставки данных. Модель потоковой передачи по запросу блоков делает доступным использование механизмов контроля скорости и отслеживания перегрузок в транспортных протоколах, например TCP, чтобы гарантировать, что максимальная доступная полоса пропускания используется для мультимедийных данных. Более того, разделение представления мультимедиа на блоки позволяет выбирать каждый блок кодированных мультимедийных данных из набора нескольких доступных кодирований.
[0081] Этот выбор может основываться на любом количестве критериев, включая согласование скорости мультимедийных данных с доступной полосой пропускания, даже когда доступная полоса пропускания меняется со временем, согласование разрешения мультимедиа или сложности декодирования с возможностями или конфигурацией клиента, или согласование с пользовательскими предпочтениями, например языками. Выбор также может включать в себя загрузку и представление вспомогательных компонентов, например компонентов доступности, скрытых субтитров, субтитров, видеоизображения на языке глухонемых и т.д. Примеры существующих систем, использующих модель потоковой передачи по запросу блоков, включают в себя Move Networks™, Microsoft Smooth Streaming и Протокол поточной передачи в Apple iPhone™.
[0082] Обычно каждый блок мультимедийных данных может храниться на сервере в качестве отдельного файла, а затем протокол, например HTTP, в сочетании с программным обеспечением сервера HTTP, выполняемым на сервере, используется для запроса файла как некой единицы. Обычно клиенту предоставляются файлы метаданных, которые могут иметь, например, формат Расширяемого языка разметки (XML) или текстовый формат списка воспроизведения или двоичный формат, которые описывают особенности представления мультимедиа, например доступные кодирования (например, необходимую полосу пропускания, разрешения, параметры кодирования, тип мультимедиа, язык), обычно называемые "отображениями" в этом документе, и способ, которым кодирования разделены на блоки. Например, метаданные могут включать в себя Унифицированный указатель ресурса (URL) для каждого блока. Сами URL могут предоставлять схему, например предваряемую строкой "http://" для указания, что протоколом, который нужно использовать для доступа к документированному ресурсу, является HTTP. Другим примером является "ftp://" для указания, что протоколом, который нужно использовать, является FTP.
[0083] В других системах, например, блоки мультимедиа могут создаваться сервером "на ходу" в ответ на запрос от клиента, который указывает часть представления мультимедиа, в момент, который запрашивается. Например, в случае HTTP со схемой "http://" исполнение запроса с этим URL предоставляет ответ на запрос, который содержит некоторые характерные данные в главной части этого ответа на запрос. Реализация в сети того, как формировать этот ответ на запрос, может быть довольно разной, в зависимости от реализации сервера, обслуживающего такие запросы.
[0084] Обычно каждый блок может быть декодируемым независимо. Например, в случае видеоизображения каждый блок может начинаться с "точки поиска". В некоторых схемах кодирования точка поиска называется "Точками произвольного доступа" или "RAP", хотя не все RAP могут назначаться точкой поиска. Аналогичным образом в других схемах кодирования точка поиска начинается в кадре "Независимого обновления данных", или "IDR", в случае кодирования видеоизображения H.264, хотя не все IDR могут назначаться точкой поиска. Точка поиска является положением в видеоизображении (или другом), где декодер может начать декодирование без необходимости каких-либо данных о предшествующих кадрах или данных или выборок, что могло бы быть случаем, когда кадр или выборка, которая декодируется, кодировалась не автономно, а, например, как разность между текущим кадром и предшествующим кадром.
[0085] Вопросом в таких системах может быть возможность начать воспроизведение потока, например декодирование и визуализацию принятых аудио - и видеопотоков с использованием персонального компьютера и отображение видеоизображения на экране компьютера и воспроизведение звука через встроенные динамики, либо, в качестве другого примера, декодирование и визуализацию принятых аудио - и видеопотоков с использованием телевизионной приставки и отображение видеоизображения на телевизионном устройстве отображения и воспроизведение звука через стереосистему. Первоочередной задачей может быть минимизация задержки между тем, когда пользователь решает посмотреть новый контент, доставленный в виде потока, и выполняет действие, которое выражает это решение, например, пользователь, нажимает на ссылку в окне обозревателя или на кнопку воспроизведения на устройстве дистанционного управления, и тем, когда контент начинает отображаться на экране пользователя, в дальнейшем называемое "временем переключения контента". Каждая из этих задач может быть решена с помощью элементов улучшенной системы, описанной в этом документе.
[0086] Примером переключения контента является то, когда пользователь смотрит первый контент, доставленный посредством первого потока, и затем пользователь решает посмотреть второй контент, доставленный посредством второго потока, и инициирует действие для начала просмотра второго контента. Второй поток может отправляться с такого же набора или другого набора серверов, что и первый поток. Другим примером переключения контента является то, когда пользователь посещает веб-сайт и решает начать просмотр первого контента, доставленного посредством первого потока, путем нажатия на ссылку в окне обозревателя. Аналогичным образом пользователь может решить начать воспроизведение контенте не с начала, а с некоторого времени в рамках потока. Пользователь указывает своему клиентскому устройству перейти к положению во времени, и пользователь мог предполагать, что выбранное время визуализируется мгновенно. Минимизация времени переключения контента важна для просмотра видеоизображения, чтобы обеспечить пользователям впечатление высококачественного быстрого просмотра контента при поиске и отборе широкого диапазона доступного контента.
[0087] В последнее время стало установившейся практикой рассматривать использование кодов Прямого исправления ошибок (FEC) для защиты потокового мультимедиа во время передачи. При отправке по пакетной сети, примеры которой включают в себя Интернет и беспроводные сети, например стандартизованные группами, такими как 3GPP, 3GPP2 и DVB, исходный поток помещается в пакеты, когда формируется, или становится доступным, и соответственно пакеты могут использоваться для переноса исходного потока или потока контента в порядке, которым он формируется, или становится доступным приемникам.
[0088] В типичном применении кодов FEC к этим типам сценариев кодер может использовать код FEC при создании пакетов восстановления, которые затем отправляются в дополнение к исходным пакетам, содержащим исходный поток. Пакеты восстановления обладают таким свойством, что когда происходит потеря исходных пакетов, принятые пакеты восстановления могут использоваться для восстановления данных, содержащихся в потерянных исходных пакетах. Пакеты восстановления могут использоваться для восстановления содержимого потерянных исходных пакетов, которые утрачены полностью, но также могли бы использоваться для восстановления, когда происходит частичная потеря пакетов, либо полностью принятые пакеты восстановления, либо даже частично принятые пакеты восстановления. Таким образом, полностью или частично принятые пакеты восстановления могут использоваться для восстановления полностью или частично потерянных исходных пакетов.
[0089] В еще одних примерах другие типы искажения могут возникать в отправленных данных, например, значения разрядов могут инвертироваться, и соответственно пакеты восстановления могут использоваться для исправления такого искажения и обеспечения как можно более точного восстановления исходных пакетов. В других примерах исходный поток не обязательно отправляется в дискретных пакетах, а вместо этого может отправляться, например, в виде непрерывного потока двоичных сигналов.
[0090] Есть много примеров кодов FEC, которые могут использоваться для обеспечения защиты исходного потока. Коды Рида-Соломона являются общеизвестными кодами для коррекции со стиранием ошибок в системах связи. Для коррекции со стиранием ошибок, например, в сетях пакетной передачи данных общеизвестная эффективная реализация кодов Рида-Соломона использует матрицы Коши или Вандермонда, которые описаны в L. Rizzo, "Effective Erasure Codes for Reliable Computer Communication Protocols", Computer Communication Review, 27(2):24-36 (апрель 1997) (в дальнейшем - "Rizzo"), и Bloemer и др., "An XOR-Based Erasure-Resilient Coding Scheme", Технический отчет TR-95-48, Международный институт вычислительной техники, Беркли, Калифорния (1995) (в дальнейшем - "XOR-Reed-Solomon") или где-либо еще.
[0091] Другие примеры кодов FEC включают в себя коды LDPC, коды цепной реакции, например описанные в Luby I, и коды многоэтапной цепной реакции, например в Shokrollahi I.
[0092] Примеры процесса декодирования FEC для разновидностей кодов Рида-Соломона описываются в Rizzo и XOR-Reed-Solomon. В тех примерах декодирование может применяться после того, как принято достаточное количество пакетов исходных данных и данных восстановления. Процесс декодирования может иметь большой объем вычислений, и в зависимости от доступных ресурсов CPU может требовать значительного времени для завершения относительно длительности времени, занятого мультимедиа в блоке. Приемник может учитывать эту длительность времени, необходимую для декодирования, при вычислении задержки, необходимой между началом приема мультимедийного потока и воспроизведением мультимедиа. Эта задержка из-за декодирования воспринимается пользователем как задержка между запросом конкретного мультимедийного потока и началом воспроизведения. Соответственно, желательно минимизировать эту задержку.
[0093] Во многих применениях пакеты могут дополнительно подразделяться на символы, к которым применяется процесс FEC. Пакет может содержать один или несколько символов (или менее одного символа, но обычно символы не делятся между группами пакетов, пока состояния ошибки среди групп пакетов известны как сильно взаимосвязанные). Символ может иметь любой размер, но часто размер символа составляет не более размера пакета. Исходные символы являются теми символами, которые кодируют данные, которые нужно передать. Символы восстановления являются символами, сформированным из исходных символов, прямо или косвенно в дополнение к исходным символам (то есть данные, которые нужно передать, можно восстановить полностью, если все исходные символы доступны и никакие символы восстановления не доступны).
[0094] Некоторые коды FEC могут быть блочными, в которых операции кодирования зависят от символа (символов), которые находятся в блоке, и могут не зависеть от символов вне того блока. С помощью блочного кодирования кодер FEC может сформировать символы восстановления для блока из исходных символов в том блоке, затем перейти к следующему блоку и не нуждаться в обращении к исходным символам помимо символов для текущего кодируемого блока. При передаче исходный блок, содержащий исходные символы, можно представить кодированным блоком, содержащим кодированные символы (которые могли бы быть некоторыми исходными символами, некоторыми символами восстановления или теми и другими). При наличии символов восстановления не все исходные символы необходимы в каждом кодированного блоке.
[0095] Для некоторых кодов FEC, в особенности кодов Рида-Соломона, время кодирования и декодирования может непрактично расти с ростом количества кодированных символов на исходный блок. Таким образом, на практике часто существует практическая верхняя граница (255 является приблизительным практическим пределом для некоторых применений) для общего количества кодированных символов, которые могут формироваться в расчете на исходный блок, особенно в типичном случае, когда процесс кодирования или декодирования Рида-Соломона выполняется специальными аппаратными средствами, например, процессы MPE-FEC, которые используют коды Рида-Соломона, включенные как часть стандарта DVB-H для защиты потоков от потери пакетов, реализуются в специализированных аппаратных средствах в сотовом телефоне, которые ограничиваются всего 255 кодированными символами Рида-Соломона на исходный блок. Поскольку символы часто необходимо помещать в отдельные полезные нагрузки пакетов, это устанавливает практическую верхнюю границу на максимальную длину кодируемого исходного блока. Например, если полезная нагрузка пакета ограничивается 1024 байтами или меньше, и каждый пакет несет один кодированный символ, то кодированный исходный блок может составлять не более 255 килобайт, и это, конечно, также является верхней границей размера самого исходного блока.
[0096] Другие вопросы, например способность, декодировать исходные блоки достаточно быстро, чтобы не отставать от скорости потоковой передачи источника, минимизировать задержку декодирования, внесенную декодированием FEC, и использовать только небольшую часть доступного CPU в приемном устройстве в любой момент времени в течение декодирования FEC, решаются с помощью элементов, описанных в этом документе.
[0097] Необходимость предоставления устойчивого и масштабируемого решения по потоковой доставке, которое позволяет выходить из строя компонентам системы без неблагоприятного влияния на качество потоков, доставленных приемникам.
[0098] Система потоковой передачи по запросу блоков должна поддерживать изменения в структуре или метаданных представления, например, изменения количества доступных кодирований мультимедиа или изменения параметров кодирований мультимедиа, например скорости передачи битов, разрешения, соотношения сторон или кодеков видеоизображения либо параметров кодеков, или изменения других метаданных, например URL, ассоциированных с файлами контента. Такие изменения могут быть необходимы по некоторому количеству причин, включая редактирование контента одновременно из разных источников, например рекламы или разных сегментов более крупного представления, модификацию URL или других параметров, которые становятся необходимы в результате изменений в обслуживающей инфраструктуре, например, из-за конфигурационных изменений, сбоев оборудования или восстановления из сбоев оборудования, или по другим причинам.
[0099] Существуют способы, в которых представление может управляться с помощью постоянно обновляемого файла списка воспроизведения. Поскольку этот файл постоянно обновляется, то, по меньшей мере, некоторые изменения, описанные выше, можно произвести в рамках этих обновлений. Недостаток традиционного способа состоит в том, что клиентские устройства обязаны все время отыскивать файл списка воспроизведения, что называется "опросом", создавая нагрузку на обслуживающую инфраструктуру, и что этот файл нельзя кэшировать дольше интервала обновления, делая еще сложнее задачу для обслуживающей инфраструктуры. Это решается с помощью элементов в этом документе, так что обновления описанного выше вида обеспечиваются без необходимости в постоянном опросе файла метаданных клиентами.
[0100] Другой проблемой, особенно в интерактивных услугах, обычно известной из вещательного распространения, является отсутствие возможности у пользователя просматривать контент, который был транслирован раньше времени, когда пользователь присоединился к программе. Обычно локальная персональная запись потребляет лишнее локальное хранилище или не возможна, так как клиент не настроился на программу, либо запрещена правилами защиты контента. Сетевая запись и отложенный просмотр предпочтительны, но требуют отдельных соединений пользователя с сервером и раздельного протокола доставки и инфраструктуры помимо интерактивных услуг, приводя к дублированной инфраструктуре и значительным затратам сервера. Это также решается с помощью элементов, описанных в этом документе.
ОБЗОР СИСТЕМЫ
[0101] Один вариант осуществления изобретения описывается со ссылкой на фиг. 1, которая показывает упрощенную схему системы потоковой передачи по запросу блоков, осуществляющей изобретение.
[0102] На фиг. 1 иллюстрируется система 100 потоковой передачи блоков, содержащая обслуживающую инфраструктуру 101 блоков ("BSI"), в свою очередь содержащую систему 103 захвата для захвата контента 102, подготовки этого контента и его упаковки для услуги от сервера 104 потоковой передачи HTTP путем сохранения его в хранилище 110 контента, которое доступно системе 103 захвата и серверу 104 потоковой передачи HTTP. Как показано, система 100 также могла бы включать в себя кэш 106 HTTP. При работе клиент 108, например клиент потоковой передачи HTTP, отправляет запросы 112 на сервер 104 потоковой передачи HTTP и принимает ответы 114 от сервера 104 потоковой передачи HTTP или из кэша 106 HTTP. В каждом случае элементы, показанные на фиг. 1, могли бы быть реализованы, по меньшей мере, частично, в программном обеспечении, содержащем программный код, который выполняется на процессоре или другой электронике.
[0103] Контент мог бы содержать фильмы, звук, плоское (2D) видеоизображение, объемное видеоизображение (3D), другие типы видеоизображения, изображения, синхронизированный текст, синхронизированные метаданные или т.п. Некоторый контент мог бы включать в себя данные, которые нужно представлять или потреблять спланированными по времени, например данные для представления вспомогательной информации (идентификатор станции, реклама, котировки акций, последовательности Flash™ и т.д.) вместе с другим воспроизводимым мультимедиа. Также могли бы использоваться другие гибридные представления, которые объединяют другое мультимедиа и/или выходят за пределы просто звука и видеоизображения.
[0104] Как проиллюстрировано на фиг. 2, блоки мультимедиа могут храниться в обслуживающей инфраструктуре 101(1) блоков, которая могла бы быть, например, сервером HTTP, устройством Сети доставки контента, посредником HTTP, посредником либо сервером FTP или некоторым другим сервером или системой мультимедиа. Обслуживающая инфраструктура 101(1) блоков подключается к сети 122, которая могла бы быть, например, сетью по Интернет-протоколу ("IP"), такой как Интернет. Клиент системы потоковой передачи по запросу блоков показан содержащим шесть функциональных компонентов, а именно селектор 123 блоков, снабжаемый описанными выше метаданными и выполняющий функцию выбора блоков или частичных блоков, которые нужно запросить, из множества доступных блоков, указанного метаданными, запросчик 124 блоков, который принимает команды запросов от селектора 123 блоков и выполняет операции, необходимые для отправки запроса заданного блока, частей блока или нескольких блоков в обслуживающую инфраструктуру 101(1) блоков по сети 122 и для приема данных, содержащих блок в ответ, а также буфер 125 блоков, монитор 126 буфера, декодер 127 мультимедиа и один или несколько преобразователей 128 мультимедиа, которые облегчают потребление мультимедиа.
[0105] Данные блоков, принятые запросчиком 124 блоков, передаются для временного хранения в буфер 125 блоков, который хранит мультимедийные данные. В качестве альтернативы принятые данные блоков могут сохраняться непосредственно в буфер 125 блоков, как проиллюстрировано на фиг. 1. Декодер 127 мультимедиа снабжается мультимедийными данными с помощью буфера 125 блоков и выполняет такие преобразования над этими данными, которые необходимы для предоставления подходящих входных данных в преобразователи 128 мультимедиа, которые визуализируют мультимедиа в виде, подходящем для пользователя или другого потребления. Примеры преобразователей мультимедиа включают в себя устройства визуального отображения, которые можно встретить в мобильных телефонах, компьютерных системах или телевизорах, а также могли бы включать в себя звуковоспроизводящие устройства, например динамики или наушники.
[0106] Примером декодера мультимедиа была бы функция, которая преобразует данные в формате, описанном в стандарте кодирования видеоизображения H.264, в аналоговые или цифровые отображения видеокадров, например карту элементов изображения YUV-формата с ассоциированными временными отметками представления для каждого кадра или выборки.
[0107] Монитор 126 буфера принимает информацию касательно содержимого буфера 125 блоков и на основе этой информации и, по возможности, другой информации предоставляет входные данные в селектор 123 блоков, который используется для определения отбора блоков для запроса, что описывается в этом документе.
[0108] В используемой в этом документе терминологии каждый блок имеет "время воспроизведения" или "длительность", которая представляет собой количество времени, которое заняло бы у приемника воспроизведение мультимедиа, включенного в блок, с нормальной скоростью. В некоторых случаях воспроизведение мультимедиа в блоке может зависеть от того, приняты ли уже данные из предыдущих блоков. В редких случаях воспроизведение некоторого мультимедиа в блоке может зависеть от последующего блока, и в этом случае время воспроизведения для блока задается относительно мультимедиа, которое можно воспроизвести в блоке без обращения к последующему блоку, а время воспроизведения для последующего блока увеличивается на время воспроизведения мультимедиа в этом блоке, который можно воспроизвести только после приема последующего блока. Поскольку включение мультимедиа в блок, который зависит от последующих блоков, является редким случаем, в оставшейся части этого раскрытия изобретения мы допускаем, что мультимедиа в одном блоке не зависит от последующих блоков, но отметим, что специалисты в данной области техники признают, что эту разновидность можно легко добавить в описанные ниже варианты осуществления.
[0109] Приемник может иметь элементы управления, например "пауза", "быстрая перемотка вперед", "перемотка назад" и т.д., что может привести к потреблению блока при воспроизведении с разной скоростью, но если приемник может получить и декодировать каждую последующую последовательность блоков в совокупное время, меньше либо равное их совокупного времени воспроизведения за исключением последнего блока в последовательности, то приемник может представить пользователю мультимедиа без остановки. В некоторых описаниях в этом документе конкретное положение в мультимедийном потоке называется конкретным "временем" в мультимедиа, соответствующим времени, которое прошло бы между началом воспроизведения мультимедиа и временем, когда достигается конкретное положение в видеопотоке. Время или положение в мультимедийном потоке является традиционным понятием. Например, там, где видеопоток содержит 24 кадра в секунду, про первый кадр можно сказать, что он имеет положение или время t=0,0 секунд, а про 241-ый кадр можно сказать, что он имеет положение или время t=10,0 секунд. Естественно, в видеопотоке на основе кадров положение или время не должны быть непрерывными, так как каждый из разрядов в потоке от первого разряда 241-го кадра до точно перед первым разрядом 242-го кадра могли бы все иметь одинаковое значение времени.
[0110] Принимая вышеприведенную терминологию, система потоковой передачи по запросу блоков (BRSS) содержит один или несколько клиентов, которые создают запросы к одному или нескольким серверам контента (например, серверам HTTP, серверам FTP и т.д.). Система захвата содержит один или несколько процессоров захвата, причем процессор захвата принимает контент (в режиме реального времени или нет), обрабатывает контент для использования посредством BRSS и сохраняет его в хранилище, доступном серверам контента, по возможности также, вместе с метаданными, сформированными процессором захвата.
[0111] BRSS также могла бы содержать кэши контента, которые согласованы с серверами контента. Серверы контента и кэши контента могут быть традиционными серверами HTTP и кэшами HTTP, которые принимают запросы файлов или сегментов в виде запросов HTTP, которые включают в себя URL и также могут включать в себя байтовый диапазон, чтобы запросить не весь файл или сегмент, указанный с помощью URL. Клиенты могли бы включать в себя традиционный клиент HTTP, который запрашивает серверы HTTP и обрабатывает ответы на те запросы, причем клиент HTTP управляется новой клиентской системой, которая формулирует запросы, передает их клиенту HTTP, получает ответы от клиента HTTP и обрабатывает их (или сохраняет, преобразует и т.д.) для того, чтобы предоставить проигрывателю представлений для воспроизведения клиентским устройством. Обычно клиентская система заранее не знает, какое мультимедиа потребуется (так как потребности могли бы зависеть от ввода пользователя, изменений во вводе пользователя и т.д.), поэтому говорят, что это "потоковая" система, в которой мультимедиа "потребляется", как только оно принимается, или вскоре после этого. В результате задержки ответа и ограничения полосы пропускания могут вызывать задержки в представлении, например, вызывая приостановку представления, когда поток догоняет то место, где пользователь потребляет представление.
[0112] Чтобы обеспечить представление, которое воспринимается как обладающее хорошим качеством, некоторое количество подробностей может быть реализовано в BRSS на стороне клиента, на стороне захвата либо на обеих сторонах. В некоторых случаях подробности, которые реализуются, выполняются с учетом и для рассмотрения интерфейса клиент-сервер в сети. В некоторых вариантах осуществления клиентская система и система захвата осведомлены об улучшении, тогда как в других вариантах осуществления только одна сторона осведомлена об улучшении. В таких случаях вся система выигрывает от улучшения, даже если одна сторона не осведомлена об этом, хотя в других случаях выгода возникает, только если обе стороны осведомлены об этом, а когда одна сторона не осведомлена, она по-прежнему работает без сбоя.
[0113] Как проиллюстрировано на фиг. 3, система захвата может быть реализована в виде сочетания аппаратных и программных компонентов в соответствии с различными вариантами осуществления. Система захвата может содержать набор команд, который может исполняться для побуждения системы выполнить любую одну или несколько методологий, рассмотренных в этом документе. Система может быть реализована как специальная машина в виде компьютера. Система может быть серверным компьютером, персональным компьютером (ПК) или любой системой, допускающей исполнение набора команд (последовательно или иным образом), которые задают действия, которые должна выполнить система. Кроме того, хотя иллюстрируется только одна система, термин "система" также следует употреблять как включающий любую совокупность систем, которые по отдельности или одновременно выполняют набор (или несколько наборов) команд для выполнения любой одной или нескольких методологий, рассмотренных в этом документе.
[0114] Система захвата может включать в себя процессор 302 захвата (например, центральный процессор (CPU)), запоминающее устройство 304, которое может хранить программный код во время исполнения, и дисковое хранилище 306, все из которых взаимодействуют друг с другом по шине 300. Система может дополнительно включать в себя дисплей 308 (например, жидкокристаллический дисплей (LCD) или электронно-лучевую трубку (CRT)). Система также может включать в себя устройство 310 буквенно-цифрового ввода (например, клавиатуру) и сетевой интерфейс 312 для приема источника контента и доставки в хранилище контента.
[0115] Дисковое запоминающее устройство 306 может включать в себя машиночитаемый носитель, на котором может храниться один или несколько наборов команд (например, программное обеспечение), воплощающих любую одну или несколько методологий или функций, описанных в этом документе. Команды также могут находиться, полностью или, по меньшей мере, частично, в запоминающем устройстве 304 и/или в процессоре 302 захвата во время их исполнения системой, причем запоминающее устройство 304 и процессор 302 захвата также составляют машиночитаемые носители.
[0116] Как проиллюстрировано на фиг. 4, клиентская система может быть реализована в виде сочетания аппаратных и программных компонентов в соответствии с различными вариантами осуществления. Клиентская система может содержать набор команд, который может исполняться для побуждения системы выполнить любую одну или несколько методологий, рассмотренных в этом документе. Система может быть реализована как специальная машина в виде компьютера. Система может быть серверным компьютером, персональным компьютером (ПК) или любой системой, допускающей исполнение набора команд (последовательно или иным образом), которые задают действия, которые должна выполнить система. Кроме того, хотя иллюстрируется только одна система, термин "система" также следует употреблять как включающий любую совокупность систем, которые по отдельности или одновременно выполняют набор (или несколько наборов) команд для выполнения любой одной или нескольких методологий, рассмотренных в этом документе.
[0117] Клиентская система может включать в себя процессор 402 клиента (например, центральный процессор (CPU)), запоминающее устройство 404, которое может хранить программный код во время исполнения, и дисковое хранилище 406, все из которых взаимодействуют друг с другом по шине 400. Система может дополнительно включать в себя дисплей 408 (например, жидкокристаллический дисплей (LCD) или электронно-лучевую трубку (CRT)). Система также может включать в себя устройство 410 буквенно-цифрового ввода (например, клавиатуру) и сетевой интерфейс 412 для отправки запросов и приема ответов.
[0118] Дисковое запоминающее устройство 406 может включать в себя машиночитаемый носитель, на котором может храниться один или несколько наборов команд (например, программное обеспечение), воплощающих любую одну или несколько методологий или функций, описанных в этом документе. Команды также могут находиться, полностью или, по меньшей мере, частично, в запоминающем устройстве 404 и/или в процессоре 402 клиента во время их исполнения системой, причем запоминающее устройство 404 и процессор 402 клиента также составляют машиночитаемые носители.
ИСПОЛЬЗОВАНИЕ ФОРМАТА ФАЙЛА 3GPP
[0119] Формат файла 3GPP или любой другой файл на основе базового формата мультимедийного файла ISO, например формата файла MP4 или формата файла 3GPP2, может использоваться в качестве контейнерного формата для потоковой передачи HTTP со следующими особенностями. Индекс сегмента может включаться в каждый сегмент, чтобы сигнализировать временные смещения и байтовые диапазоны, так что клиент может загружать подходящие фрагменты файлов или мультимедийные сегменты при необходимости. Хронометраж глобального представления всего представления мультимедиа и локальный хронометраж в каждом файле 3GP или мультимедийном сегменте можно точно выровнять. Дорожки в одном файле 3GP или мультимедийном сегменте можно точно выровнять. Дорожки между отображениями также можно выровнять путем назначения каждой из них глобальной временной шкалы, так что переключение по отображению может быть плавным, и совместное представление мультимедийных компонентов в разных отображениях может быть синхронным.
[0120] Формат файла может содержать профиль для Адаптивной потоковой передачи со следующими свойствами. Все данные фильма могут содержаться во фрагментах фильма - блок "moov" может не содержать никакой выборочной информации. Выборочные данные звука и видеоизображения могут чередоваться, с аналогичными требованиями в отношении профиля прогрессивной загрузки, который задан в TS26.244. Блок "moov" можно поместить в начало файла, с последующими данными смещения фрагмента, также называемыми индексом сегмента, содержащим информацию о смещении во временных и байтовых диапазонах для каждого фрагмента или, по меньшей мере, подмножества фрагментов в содержащем сегменте.
[0121] Описанию представления мультимедиа также можно ссылаться на файлы, которые следуют за существующим профилем Прогрессивной загрузки. В этом случае клиент может использовать Описание представления мультимедиа просто для выбора подходящей альтернативной версии среди нескольких доступных версий. Клиенты также могут использовать частичные запросы get HTTP с файлами, совместимыми с профилем Прогрессивной загрузки, чтобы запрашивать подмножества каждой альтернативной версии и посредством этого реализовать менее эффективную форму адаптивной потоковой передачи. В этом случае разные отображения, содержащие мультимедиа в профиле прогрессивной загрузки, по-прежнему могут придерживаться общей глобальной временной шкалы, чтобы сделать возможным плавное переключение между отображениями.
ОБЗОР ПРОГРЕССИВНЫХ СПОСОБОВ
[0122] В следующих разделах описываются способы для усовершенствованных систем потоковой передачи по запросу блоков. Следует понимать, что некоторые из этих улучшений могут использоваться вместе или без других этих улучшений, в зависимости от потребностей применения. В общем процессе приемник запрашивает у сервера или другого передатчика определенные блоки или части блоков данных. Файлы, также называемые сегментами, могут содержать несколько блоков и ассоциируются с одним отображением мультимедийного представления.
[0123] Предпочтительно, чтобы формировалась информация индексирования, также называемая "индексированием сегмента" или "картой сегмента", которая обеспечивает преобразование из моментов воспроизведения или декодирования в байтовые смещения соответствующих блоков или фрагментов в сегменте. Это индексирование сегмента может включаться в сегмент, обычно в начале сегмента (по меньшей мере, часть карты сегмента находится в начале) и часто является небольшим. Индекс сегмента также может предоставляться в отдельном сегменте или файле индекса. Особенно в случаях, когда индекс сегмента содержится в сегменте, приемник может быстро загрузить часть или всю эту карту сегмента и впоследствии использовать ее для определения преобразования между временными смещениями и соответствующими байтовыми положениями фрагментов, ассоциированных с теми временными смещениями в файле.
[0124] Приемник может использовать байтовое смещение для запроса данных из фрагментов, ассоциированных с конкретными временными смещениями, без необходимости загружать все данные, ассоциированные с другими фрагментами, не ассоциированными с интересующими временными смещениями. Таким образом, карта сегмента или индексирование сегмента может значительно увеличить возможность приемника по непосредственному обращению к частям сегмента, которые подходят для текущих интересующих временных смещений, с выгодами, включающими улучшенное время переключения контента, возможность быстро переключиться с одного отображения на другое, когда меняются сетевые условия, и уменьшенную потерю сетевых ресурсов при загрузке мультимедиа, которое не воспроизводится на приемнике.
[0125] Если рассматривается переключение с одного отображения (в этом документе называемого "исходным" отображением) на другое отображение (в этом документе называемое "целевым" отображением), то индекс сегмента также может использоваться для идентификации времени начала точки произвольного доступа в целевом отображении, чтобы идентифицировать объем данных, который нужно запросить в исходном отображении, чтобы гарантировать, что плавное переключение обеспечивается в том смысле, что мультимедиа в исходном отображении загружается вплоть до времени представления, так что воспроизведение целевого отображения может начаться плавно с точки произвольного доступа.
[0126] Те блоки представляют сегменты видеоизображения или другого мультимедиа, которые нужны запрашивающему приемнику для формирования вывода для пользователя приемника. Приемник мультимедиа может быть клиентским устройством, например, когда приемник принимает контент от сервера, который передает контент. Примеры включают в себя телевизионные приставки, компьютеры, игровые приставки, специально оборудованные телевизоры, карманные устройства, специально оборудованные мобильные телефоны или другие клиентские приемники.
[0127] В этом документе описываются многие способы расширенного управления буфером. Например, способ управления буфером дает возможность клиентам запрашивать блоки мультимедиа наивысшего качества, которые можно непрерывно принять во время для воспроизведения. Свойство переменного размера блока повышает эффективность сжатия. Возможность иметь несколько соединений для передачи блоков запрашивающему устройству наряду с ограничением частоты запросов обеспечивает повышенную эффективность передачи. Частично принятые блоки данных могут использоваться для продолжения представления мультимедиа. Соединение может повторно использоваться для нескольких блоков без необходимости фиксировать соединение в начале для конкретного набора блоков. Согласованность при выборе серверов из числа нескольких возможных серверов несколькими клиентами улучшается, что уменьшает частоту дублированного контента на ближайших серверах и повышает вероятность того, что сервер содержит весь файл. Клиенты могут запрашивать блоки мультимедиа на основе метаданных (например, доступных кодирований мультимедиа), которые встраиваются в URL для файлов, содержащих блоки мультимедиа. Система может предусмотреть вычисление и минимизацию величины времени буферизации, необходимого до того, как можно начинать воспроизведение контента, без последующих пауз при воспроизведении мультимедиа. Доступная полоса пропускания может совместно использоваться несколькими блоками мультимедиа, скорректированная, когда приближается время воспроизведения каждого блока, чтобы при необходимости большую долю доступной полосы пропускания можно было выделить блоку с ближайшим временем воспроизведения.
[0128] Потоковая передача HTTP может применять метаданные. Метаданные уровня представления включают в себя, например, длительность потока, доступные кодирования (скорости передачи битов, кодеки, пространственные разрешения, частоты кадров, язык, типы мультимедиа), указатели на метаданные потока для каждого кодирования и защиту контента (информацию управления цифровыми правами (DRM)). Метаданные потока могут быть URL для файлов сегментов.
[0129] Метаданные сегмента могут включать в себя байтовый диапазон в сравнении с временной информацией для запросов в сегменте и идентификацию Точек произвольного доступа (RAP) или других точек поиска, причем часть или вся эта информация может быть, частью индексирования сегмента или карты сегмента.
[0130] Потоки могут содержать несколько кодирований одного и того же контента. Каждое кодирование затем можно разбить на сегменты, где каждый сегмент соответствует единице хранения или файлу. В случае HTTP сегмент обычно является ресурсом, к которому можно обращаться по URL, и запрос такого URL приводит к возврату сегмента в качестве главной части ответного сообщения на запрос. Сегменты могут содержать несколько групп изображений (GoP). Каждая GoP может дополнительно содержать несколько фрагментов, причем индексирование сегмента предоставляет информацию о временном/байтовом смещении для каждого фрагмента, то есть единицей индексирования является фрагмент.
[0131] Фрагменты или части фрагментов можно запрашивать по параллельным соединениям TCP, чтобы увеличить пропускную способность. Это может смягчить проблемы, которые возникают при совместном использовании соединений в узком канале или когда соединения теряются из-за перегрузки, соответственно увеличивая общую скорость и надежность доставки, что может существенно повысить скорость и надежность времени переключения контента. Полосой пропускания можно пожертвовать ради задержки путем избыточного запроса, но следует соблюдать осторожность, чтобы избежать создания запросов слишком далеко в будущее, что может увеличить риск "информационного голода".
[0132] Несколько запросов сегментов на одном и том же сервере можно организовать в конвейер (выполняя следующий запрос перед тем, как завершается текущий запрос), чтобы избежать повторяющихся задержек запуска TCP. Запросы последовательных фрагментов можно сгруппировать в один запрос.
[0133] Некоторые CDN предпочитают большие файлы и могут инициировать фоновые выборки всего файла из сервера-источника, когда первый раз видят запрос диапазона. Однако большинство CDN будут обслуживать запросы диапазона из кэша, если данные доступны. Поэтому может быть полезным отнести некоторую часть клиентских запросов ко всему файлу сегмента. Эти запросы позже можно отменить при необходимости.
[0134] Допустимые точки переключения могут быть точками поиска, в частности RAP, в целевом потоке. Возможны разные реализации, например фиксированные структуры GoP или выравнивание RAP по потокам (на основе начала мультимедиа или на основе GoP).
[0135] В одном варианте осуществления сегменты и GoP могут быть выровнены по потокам с разной скоростью. В этом варианте осуществления GoP могут иметь переменный размер и могут содержать несколько фрагментов, но фрагменты не выровнены между потоками с разной скоростью.
[0136] В некоторых вариантах осуществления может выгодно применяться избыточность файла. В этих вариантах осуществления код стирания применяется к каждому фрагменту для формирования избыточных версий данных. Предпочтительно форматирование источника не меняется из-за использования FEC, и дополнительные сегменты восстановления, например, в виде зависимого отображения от исходного отображения, содержащие данные восстановления FEC, формируются и становятся доступными в качестве дополнительного этапа в системе захвата. Клиент, который способен восстановить фрагмент с использованием только исходных данных для того фрагмента, может запрашивать от серверов только исходные данные для фрагмента в сегменте. Если серверы недоступны или соединение с серверами медленное, что может определяться либо до, либо после запроса исходных данных, то можно запросить дополнительные данные восстановления для фрагмента из сегмента восстановления, что уменьшает время для надежной доставки достаточных данных для восстановления фрагмента, по возможности используя декодирование FEC, чтобы использовать сочетание принятых исходных данных и данных восстановления для восстановления исходных данных фрагмента. Кроме того, можно запросить дополнительные данные восстановления, чтобы сделать возможным восстановление фрагмента, если фрагмент становится срочным, то есть его время воспроизведения становится близким, что увеличивает долю данных для того фрагмента на линии связи, но эффективнее, нежели закрытие других соединений на линии связи для освобождения полосы пропускания. Это также может уменьшить риск "информационного голода" от использования параллельных соединений.
[0137] Форматом фрагмента может быть сохраненный поток пакетов Транспортного протокола в режиме реального времени (RTP) с синхронизацией звука/видеоизображения, достигаемой по протоколу управления передачей в реальном масштабе времени (RTCP).
[0138] Форматом сегмента также может быть сохраненный поток пакетов MPEG-2 с синхронизацией звука/видеоизображения, достигаемой по внутренней синхронизации транспортного потока (TS) MPEG-2.
ИСПОЛЬЗОВАНИЕ СИГНАЛИЗАЦИИ И/ИЛИ СОЗДАНИЯ БЛОКА, ЧТОБЫ СДЕЛАТЬ ЭФФЕКТИВНЕЕ ПОТОКОВУЮ ПЕРЕДАЧУ
[0139] Некоторое количество свойств может использоваться в системе потоковой передачи по запросу блоков для обеспечения улучшенной производительности. Производительность может относиться к возможности воспроизводить представление без остановки, получению мультимедийных данных в рамках ограничений полосы пропускания и/или выполнению этого в рамках ограниченных ресурсов процессора на клиенте, сервере и/или системе захвата. Некоторые из этих свойств сейчас будут описываться.
ИНДЕКСИРОВАНИЕ В СЕГМЕНТАХ
[0140] Чтобы сформулировать частичные запросы GET для фрагментов фильма, клиента можно информировать о байтовом смещении и времени начала при декодировании или времени представления всех мультимедийных компонентов, содержащихся во фрагментах в файле или сегменте, а также о том, какие фрагменты начинаются или содержат Точки произвольного доступа (и поэтому подходят для использования как точки переключения между альтернативными отображениями), где эта информация часто называется индексированием сегмента или картой сегмента. Время начала при декодировании или время представления могут выражаться непосредственно или могут выражаться как дельты (изменения) относительно начального момента.
[0141] Эта информация индексирования временного и байтового смещения может потребовать, по меньшей мере, 8 байт данных на фрагмент фильма. В качестве примера для двухчасового фильма, содержащегося в одиночном файле, с фрагментами фильма по 500 мс это составило бы в итоге около 112 килобайт данных. Загрузка всех этих данных при запуске представления может привести к значительной дополнительной задержке запуска. Однако данные о временном и байтовом смещении могут кодироваться иерархически, чтобы клиент мог быстро найти небольшую порцию данных о времени и смещении, соответствующую моменту в представлении, в котором он желает начать. Информация также может распространяться в сегменте, так что некоторое уточнение индекса сегмента может располагаться чередованным с мультимедийными данными.
[0142] Отметим, что если отображение разделяется по времени на несколько сегментов, использование этого иерархического кодирования может быть не нужным, так как полные данные о времени и смещении для каждого сегмента уже могут быть достаточно малыми. Например, если сегменты составляют одну минуту вместо двух часов в вышеприведенном примере, то информация индексирования временного-байтового смещения составляет около 1 килобайта данных, что обычно может поместиться в один пакет TCP/IP.
[0143] Разные варианты возможны для добавления данных о временном и байтовом смещении фрагмента в файл 3GPP:
[0144] Во-первых, для этой цели может использоваться Блок произвольного доступа к фрагменту фильма ("MFRA"). MFRA предоставляет таблицу, которая может помогать программам считывания в отыскании точек произвольного доступа в файле, используя фрагменты фильма. В поддержку этой функции MFRA, между прочим, содержит байтовые смещения блоков MFRA, содержащих точки произвольного доступа. MFRA можно поместить в конец файла или рядом с ним, но это не обязательно так. Путем сканирования с конца файла в поисках Блока смещения произвольного доступа к фрагменту фильма и использования информации о размере в нем можно найти начало блока произвольного доступа к фрагменту фильма. Однако помещение MFRA в конец для потоковой передачи HTTP обычно требует, по меньшей мере, 3-4 запросов HTTP для доступа к нужным данным: по меньшей мере, один для запроса MFRA из конца файла, один для получения MFRA и наконец, один для получения нужного фрагмента в файле. Поэтому помещение в начало может быть желательным, поскольку тогда MFRA может быть загружен вместе с первыми мультимедийными данными в одном запросе. Также использование MFRA для потоковой передачи HTTP может быть неэффективным, поскольку не нужна никакая информация в "MFRA", кроме времени и moof_offset, и задание смещений вместо длин может потребовать больше разрядов.
[0145] Во-вторых, может использоваться Блок расположения элементов ("ILOC"). "ILOC" предоставляет каталог ресурсов метаданных в этом или других файлах путем определения местоположения содержащего их файла, их смещения в том файле и их длины. Например, система могла бы объединить все ресурсы метаданных с внешней ссылкой в одном файле, соответственно корректируя смещения файлов и ссылки на файлы. Однако "ILOC" предназначен для задания расположения метаданных, поэтому ему может быть трудно, сосуществовать с реальными метаданными.
[0146] Наконец, и возможно наиболее подходящим является описание нового блока, называемого Блоком указателя времени ("TIDX"), специально выделенного для цели предоставления точных моментов или длительностей фрагментов и байтового смещения эффективным способом. Более подробно это описывается в следующем разделе. Альтернативным блоком с такими же функциональными возможностями может быть Блок индекса сегмента ("SIDX"). В этом документе, пока не указано иное, эти два блока могли бы быть взаимозаменяемыми, так как оба блока обеспечивают возможность предоставить точные моменты или длительности фрагментов и байтовое смещение эффективным способом. Разница между TIDX и SIDX предоставляется ниже. Должно быть, очевидно, как менять блоки TIDX и блоки SIDX, так как оба блока реализуют индекс сегмента.
ИНДЕКСИРОВАНИЕ СЕГМЕНТА
[0147] Сегмент имеет установленное время начала и установленное количество байт. Несколько фрагментов могут быть объединены в одиночный сегмент, и клиенты могут выдавать запросы, которые идентифицируют определенный байтовый диапазон в сегменте, который соответствует необходимому фрагменту или подмножеству фрагмента. Например, когда HTTP используется в качестве протокола запроса, то для этой цели может использоваться Заголовок диапазона HTTP. Этот подход требует, чтобы у клиента был доступ к "индексу сегмента" у сегмента, который задает положение разных фрагментов в сегменте. Этот "индекс сегмента" может предоставляться как часть метаданных. Этот подход имеет результатом то, что нужно создавать и управлять гораздо меньшим количеством файлов по сравнению с подходом, где каждый блок хранится в отдельном файле. Управление созданием, передачей и хранением очень больших количеств файлов (которые могли бы вырасти до многих тысяч для представления длиной, например, в 1 час) может быть сложным и подверженным ошибкам, и поэтому сокращение количества файлов символизирует преимущество.
[0148] Если клиент знает только нужное время начала меньшей части сегмента, то он мог бы запросить весь файл, затем считать файл от начала до конца для определения подходящего места начала воспроизведения. Чтобы улучшить использование полосы пропускания, сегменты могут включать в себя индексный файл в качестве метаданных, причем индексный файл устанавливает соответствие байтовых диапазонов отдельных блоков с временными диапазонами, которым соответствуют блоки, называемое индексированием сегмента или картой сегмента. Эти метаданные могут быть отформатированы в виде XML-данных либо могут быть двоичными, например, соответствуя структуре атома и блока в формате файла 3GPP. Индексирование может быть простым, при котором временные и байтовые диапазоны каждого блока являются абсолютными относительно начала файла, либо они могут быть иерархическими, когда некоторые блоки группируются в родительские блоки (а те в блоки предков и т.д.), и временной и байтовый диапазон для заданного блока выражается относительно временного и/или байтового диапазона родительского блока этого блока.
ПРИМЕР СТРУКТУРЫ КАРТЫ ИНДЕКСИРОВАНИЯ
[0149] В одном варианте осуществления исходные данные для одного отображения мультимедийного потока могут содержаться в одном или нескольких мультимедийных файлах, в этом документе называемых "мультимедийным сегментом", причем каждый мультимедийный сегмент содержит мультимедийные данные, используемые для воспроизведения непрерывного временного сегмента мультимедиа, например, 5 минут воспроизведения мультимедиа.
[0150] Фиг. 6 показывает примерную общую структуру мультимедийного сегмента. В каждом сегменте либо в начале, либо по всему исходному сегменту также может присутствовать информация индексирования, которая содержит карту сегмента с временным/байтовым смещением. Карта сегмента с временным/байтовым смещением в одном варианте осуществления может быть списком пар временного/байтового смещения (T(0), B(0)), (T(1), B(1)), (T(i), B(i)), (T(n),B(n)), где T(i-1) представляет время начала в сегменте для воспроизведения i-ого фрагмента мультимедиа относительно исходного времени начала мультимедиа среди всех мультимедийных сегментов, T(i) представляет время окончания для i-ого фрагмента (и соответственно время начала для следующего фрагмента), а байтовое смещение B(i-1) является соответствующим индексом байта начала данных в этом исходном сегменте, где начинается i-ый фрагмент мультимедиа относительно начала исходного сегмента, и B(i) - соответствующий индекс конечного байта i-го фрагмента (и соответственно индекс первого байта следующего фрагмента). Если сегмент содержит несколько мультимедийных компонентов, то T(i) и B(i) могут предоставляться для каждого компонента в сегменте абсолютным способом, либо они могут выражаться относительно другого мультимедийного компонента, который служит опорным мультимедийным компонентом.
[0151] В этом варианте осуществления количество фрагментов в исходном сегменте равно n, где n может меняться от сегмента к сегменту.
[0152] В другом варианте осуществления временное смещение в индексе сегмента для каждого фрагмента может определяться с помощью абсолютного времени начала первого фрагмента и длительностей каждого фрагмента. В этом случае индекс сегмента может документировать время начала первого фрагмента и длительность всех фрагментов, которые включаются в сегмент. Индекс сегмента также может документировать только подмножество фрагментов. В этом случае индекс сегмента документирует длительность субсегмента, который задается в виде одного или нескольких последовательных фрагментов, заканчивающихся либо в конце содержащего сегмента, либо в начале следующего субсегмента.
[0153] Для каждого фрагмента также может присутствовать значение, которое указывает, начинается ли фрагмент в точке поиска или содержит ее, то есть в точке, в которой никакое мультимедиа после той точки не зависит ни от какого мультимедиа перед той точкой, и соответственно мультимедиа дальше с того фрагмента можно воспроизвести независимо от предыдущих фрагментов. Точки поиска обычно являются точками в мультимедиа, причем воспроизведение может начинаться независимо от всех предыдущих мультимедиа. Фиг. 6 также показывает простой пример возможного индексирования сегмента для исходного сегмента. В том примере значение временного смещения выражается в единицах миллисекунд, и соответственно первый фрагмент этого исходного сегмента начинается через 20 секунд от начала мультимедиа, и первый фрагмент имеет время воспроизведения в 485 миллисекунд. Байтовое смещение начала первого фрагмента равно 0, а байтовое смещение конца первого фрагмента/начала второго фрагмента равно 50245, и соответственно первый фрагмент имеет размер 50245 байт. Если фрагмент или субсегмент не начинается с точки произвольного доступа, но точка произвольного доступа содержится во фрагменте или субсегменте, то может задаваться разница времени декодирования или времени представления между временем начала и фактическим временем RAP. Это дает возможность клиенту в случае переключения на этот мультимедийный сегмент точно узнать время до того, как нужно будет представить переключение с отображения.
[0154] В дополнение или вместо простого или иерархического индексирования могло бы использоваться гирляндное индексирование и/или гибридное индексирование.
[0155] Так как длительности выборок для разных дорожек могут быть не одинаковыми (например, отсчеты видеосигнала могли бы отображаться в течение 33 мс, тогда как звуковой отсчет мог бы длиться 80 мс), то разные дорожки во Фрагменте фильма могли бы не начинаться и заканчиваться точно в одно и то же время, то есть звук может начинаться немного раньше или немного позже видеоизображения, причем обратное верно для предыдущего фрагмента, для компенсации. Чтобы избежать неопределенности, временные отметки, заданные в данных временного и байтового смещения, могут задаваться относительно конкретной дорожки, и это может быть одна и та же дорожка для каждого отображения. Обычно это будет видеодорожка. Это позволяет клиенту идентифицировать точно следующий видеокадр, когда он переключает отображения.
[0156] Можно принимать меры в течение представления, чтобы поддерживать строгое отношение между шкалами времени дорожки и временем представления, чтобы обеспечить плавное воспроизведение и сохранение синхронизации звука/видеоизображения, несмотря на вышеупомянутую проблему.
[0157] Фиг. 7 иллюстрирует некоторые примеры, например, простой индекс 700 и иерархический индекс 702.
[0158] Ниже предоставляются два конкретных примера блока, который содержит карту сегмента, один называется Блоком указателя времени ("TIDX"), а другой называется ("SIDX"). Определение соответствует структуре блока в соответствии с базовым форматом мультимедийного файла ISO. Другие исполнения для таких блоков, чтобы задать аналогичный синтаксис и такую же семантику и функциональные возможности, должны быть очевидны читателю.
БЛОК УКАЗАТЕЛЯ ВРЕМЕНИ
[0159] Определение
[0160] Тип блока: "tidx"
[0161] Контейнер: Файл
[0162] Обязательный: Нет
[0163] Количество: Любое число из нуля или единицы
[0164] Блок указателя времени может предоставить набор индексов временного и байтового смещения, которые ассоциируют некоторые области файла с некоторыми интервалами времени представления. Блок указателя времени может включать в себя поле targettype, которое указывает тип данных, на которые ссылаются. Например, Блок указателя времени с targettype "moof" предоставляет индекс Фрагментов мультимедиа, содержащихся в файле, в показателях временных и байтовых смещений. Блок указателя времени с targettype Блока указателя времени может использоваться для построения иерархического указателя времени, позволяющего пользователям файла быстро перейти в необходимую часть индекса.
[0165] Индекс сегмента может содержать, например, следующий синтаксис:
[0166] aligned(8) class TimeIndexBox
extends FullBox('frai') {
unsigned int(32) targettype;
[0167] unsigned int(32) time_reference_track_ID;
unsigned int(32) number_of_elements;
unsigned int(64) first_element_offset;
unsigned int(64) first_element_time;
for(i=1; i <= number_of_elements; i++)
{
bit (1) random_access_flag;
unsigned int(31) length;
unsigned int(32) deltaT;
}
}
[0168] Семантика
[0169] targettype: тип данных блока, на которые ссылается этот Блок указателя времени. Это может быть либо Заголовок фрагмента фильма ("moof"), либо Блок указателя времени ("TIDX").
[0170] time-reference_track_id: указывает дорожку, по отношению к которой задаются временные смещения в этом индексе.
[0171] number_of_elements: количество элементов, индексированных этим Блоком указателя времени.
[0172] first_element_offset: байтовое смещение от начала файла первого индексированного элемента.
[0173] first_element_time: время начала первого индексированного элемента, использующего шкалу времени, заданную в блоке Заголовка мультимедиа дорожки, идентифицированной с помощью time_reference_track_id.
[0174] random_access_flag: Единица, если время начала элемента является точкой произвольного доступа. Ноль в противном случае.
[0175] length: Длина индексированного элемента в байтах
[0176] deltaT: разность в показателях шкалы времени, заданной в блоке Заголовка мультимедиа дорожки, идентифицированной по time_reference_track_id, между временем начала этого элемента и временем начала следующего элемента.
БЛОК ИНДЕКСА СЕГМЕНТА
[0177] Блок индекса сегмента ("sidx") предоставляет компактный индекс фрагментов фильма и других Блоков индекса сегмента в сегменте. Существует две циклические конструкции в Блоке индекса сегмента. Первый цикл документирует первую выборку субсегмента, то есть выборку в первом фрагменте фильма, на который ссылается второй цикл. Второй цикл предоставляет индекс субсегмента. Контейнером для блока "sidx" является файл или непосредственно сегмент.
[0178] Синтаксис
aligned(8) class SegmentIndexBox extends FullBox('sidx', version, 0) {
unsigned int(32) reference_track_ID;
unsigned int(16) track_count;
unsigned int(16) reference_count;
for (i=1; i<= track_count; i++)
{
unsigned int(32) track_ID;
if (version==0)
{
unsigned int(32) decoding_time;
} else
{
unsigned int(64) decoding_time;
}
}
for(i=1; i <= reference_count; i++)
{
bit (1) reference_type;
unsigned int(31) reference_offset;
unsigned int(32) subsegment_duration;
bit(1) contains_RAP;
unsigned int(31) RAP_delta_time;
}
}
[0179] Семантика:
[0180] reference_track_ID предоставляет track_ID для контрольной дорожки.
[0181] track_count: количество дорожек, индексированных в следующем цикле (1 или больше);
[0182] reference_count: количество элементов, индексированных вторым циклом (1 или больше);
[0183] track_ID: ID дорожки, для которой фрагмент дорожки включается в первый фрагмент фильма, идентифицированный этим индексом; точно один track_ID в этом цикле равен reference_track_ID;
[0184] decoding_time: время декодирования для первой выборки на дорожке, идентифицированной по track_ID во фрагменте фильма, на который ссылается первый элемент во втором цикле, выраженное шкалой времени дорожки (как документировано в поле шкалы времени в блоке Заголовка мультимедиа дорожки);
[0185] reference_type: когда установлен в 0, указывает, что ссылка идет на блок фрагмента фильма ("moof"); когда установлен в 1, указывает, что ссылка идет на блок индекса сегмента ("sidx");
[0186] reference_offset: расстояние в байтах от первого байта, идущего после содержащего Блока индекса сегмента, до первого байта блока, на который ссылаются;
[0187] subsegment_duration: когда ссылка идет на Блок индекса сегмента, это поле несет сумму полей subsegment_duration во втором цикле того блока; когда ссылка идет на фрагмент фильма, это поле несет сумму длительностей выборок в контрольной дорожке, в указанном фрагменте фильма и последующих фрагментах фильма либо вплоть до первого фрагмента фильма, документированного следующим входом в цикле, либо конца субсегмента; длительность выражается на шкале времени дорожки (как документировано в поле шкалы времени в блоке Заголовка мультимедиа дорожки);
[0188] contains_RAP: когда ссылка идет на фрагмент фильма, этот разряд может быть 1, если фрагмент дорожки в том фрагменте фильма для дорожки с track_ID, равном reference_track_ID, содержит, по меньшей мере, одну точку произвольного доступа, в противном случае этот разряд устанавливается в 0; когда ссылка идет на индекс сегмента, то этот разряд устанавливается в 1, только если любая из ссылок в том индексе сегмента имеет этот разряд, установленный в 1, и 0 в противном случае;
[0189] RAP_delta_time: если contains_RAP равно 1, предоставляет время представления (композиции) у точки произвольного доступа (RAP); зарезервировано со значением 0, если contains_RAP равно 0. Время выражается в виде разницы между временем декодирования первой выборки субсегмента, документированного этой записью, и временем представления (композиции) у точки произвольного доступа, на дорожке с track_ID, равном reference_track_ID.
РАЗНИЦА МЕЖДУ TIDX И SIDX
[0190] TIDX и SIDX предоставляют одинаковые функциональные возможности по отношению к индексированию. Первый цикл SIDX к тому же предоставляет глобальную синхронизацию для первого фрагмента фильма, но глобальная синхронизация с тем же успехом может содержаться в самом фрагменте фильма, абсолютно либо относительно контрольной дорожки.
[0191] Второй цикл SIDX реализует функциональные возможности TIDX. В частности, SIDX позволяет иметь смесь целевых объектов для ссылки для каждого индекса, называемую reference_type, тогда как TIDX ссылается либо только на TIDX, либо только на MOOF. Number_of_elements в TIDX соответствует reference_count в SIDX, time-reference_track_id в TIDX соответствует reference_track_ID в SIDX, tfirst_element_offset в TIDX соответствует reference_offset в первом входе второго цикла, first_element_time в TIDX соответствует decoding_time у reference_track в первом цикле, random_access_flag в TIDX соответствует contains_RAP в SIDX с дополнительной свободой в том, что RAP не обязательно может помещаться в начало фрагмента в SIDX, требуя поэтому RAP_delta_time, Length в TIDX соответствует reference_offset в SIDX, и в конечном счете deltaT в TIDX соответствует subsegment_duration в SIDX. Поэтому функциональные возможности двух блоков эквивалентны.
ЗАДАНИЕ ПЕРЕМЕННЫХ РАЗМЕРОВ БЛОКОВ И БЛОКИ ПОДГРУППЫ ИЗОБРАЖЕНИЙ
[0192] Для видеоизображения может быть важно отношение между структурой кодирования видеоизображения и структурой блока для запросов. Например, если каждый блок начинается с точки поиска, например Точки произвольного доступа ("RAP"), и каждый блок представляет равный период времени видеоизображения, то размещение, по меньшей мере, некоторых точек поиска в видеоизображении неизменно, и точки поиска будут возникать с равными интервалами при кодировании видеоизображения. Как хорошо известно, специалистам в области кодирования видеоизображения, эффективность сжатия можно повысить, если точки поиска размещаются в соответствии с отношениями между видеокадрами, и в частности, если они размещаются в кадрах, которые имеют мало общего с предыдущими кадрами. Это требование, что блоки представляют равные количества времени, соответственно накладывает ограничение на кодирование видеоизображения, так что сжатие может быть субоптимальным.
[0193] Желательно позволить системе кодирования видеоизображения выбирать положение точек поиска в видеопредставлении вместо требования точек поиска в неизменных положениях. Разрешение системе кодирования видеоизображения выбирать точки поиска приводит к улучшенному сжатию видеоизображения, и соответственно более высокое качество видеоизображения можно обеспечить с использованием заданной доступной полосы пропускания, получая в результате улучшенное взаимодействие с пользователем. Современные системы потоковой передачи по запросу блоков могут требовать, чтобы все блоки были одинаковой длительности (по времени видеоизображения), и что каждый блок должен начинаться с точки поиска, и это соответственно является недостатком существующих систем.
[0194] Теперь описывается новая система потоковой передачи по запросу блоков, которая обеспечивает преимущества по сравнению с вышеупомянутыми. В одном варианте осуществления процесс кодирования видеоизображения первой версии компонента видеоизображения может конфигурироваться для выбора положений точек поиска, чтобы оптимизировать эффективность сжатия, но с требованием, что существует максимум длительности между точками поиска. Это последнее требование действительно ограничивает выбор точек поиска с помощью процесса кодирования, и соответственно снижает эффективность сжатия. Однако снижение эффективности сжатия является небольшим по сравнению с тем, которое получилось бы, если постоянные неизменные положения требовались для точек поиска, при условии, что максимум длительности между точками поиска не очень маленький (например, примерно больше секунды). Кроме того, если максимум длительности между точками поиска составляет несколько секунд, то снижение эффективности сжатия по сравнению с полностью свободным размещением точек поиска обычно очень небольшое.
[0195] Во многих вариантах осуществления, включая этот вариант осуществления, может быть так, что некоторые RAP не являются точками поиска, то есть, может быть, кадр, который является RAP, которая находится между двумя последовательными точками поиска, которая не выбирается как точка поиска, например, потому что RAP находится слишком близко по времени к окружающим точкам поиска, или потому что объем мультимедийных данных между точкой поиска, предшествующей или следующей за RAP, и этой RAP очень небольшой.
[0196] Положение точек поиска во всех других версиях представления мультимедиа может ограничиваться таким же, как точки поиска в первой версии (например, наивысшей скоростью мультимедийных данных). Это снижает эффективность сжатия для этой другой версии по сравнению с разрешением кодеру свободно выбирать точки поиска.
[0197] Использование точек поиска обычно требует независимо декодируемого кадра, что обычно приводит к низкой эффективности сжатия для того кадра. Кадры, которые не должны быть декодируемыми независимо, могут кодироваться со ссылкой на данные в других кадрах, что обычно увеличивает эффективность сжатия для кадра на величину, которая зависит от степени общности между кадром, который нужно кодировать, и опорными кадрами. Эффективный выбор размещения точки поиска предпочтительно выбирает в качестве точки поиска кадр, который обладает низкой общностью с предыдущими кадрами, и посредством этого минимизирует ухудшение эффективности сжатия, вызванное кодированием кадра способом, который является независимо декодируемым.
[0198] Однако, уровень общность между кадром и возможными опорными кадрами сильно коррелирует между разными отображениями контента, поскольку исходный контент один и тот же. В результате ограничение точек поиска в других вариантах такими же положениями, как у точек поиска в первом варианте, не создает большую разницу в эффективности сжатия.
[0199] Структура точки поиска предпочтительно используется для определения структуры блока. Предпочтительно, чтобы каждая точка поиска определяла начало блока, и может быть один или несколько блоков, которые включают в себя данные между двумя последовательными точками поиска. Поскольку длительность между точками поиска не постоянна для кодирования с хорошим сжатием, не всем блокам нужно иметь одинаковую длительность воспроизведения. В некоторых вариантах осуществления блоки выравниваются между версиями контента - а именно, если имеется блок, охватывающий определенную группу кадров в одной версии контента, то имеется блок, охватывающий такую же группу кадров в другой версии контента. Блоки для заданной версии контента не перекрываются, и каждый кадр контента содержится точно в одном блоке каждой версии.
[0200] Полезным свойством, которое позволяет эффективное использование переменных длительностей между точками поиска и соответственно GoP переменной длительности, является индексирование сегмента или карта сегмента, которая может включаться в сегмент или предоставляться клиенту другим способом, то есть это метаданные, ассоциированные с этим сегментом в этом отображении, которые могут предоставляться содержащими время начала и длительность каждого блока представления. Клиент может использовать эти данные индексирования сегмента при определении блока, в котором начать представление, когда пользователь запросил начало представления в конкретной точке в сегменте. Если такие метаданные не предоставляются, то представление может начинаться только с начала контента или в случайной или приблизительной точке рядом с нужной точкой (например, при выборе начального блока путем разделения запрошенной начальной точки (во времени) на среднюю длительность блока, чтобы задать индекс начального блока).
[0201] В одном варианте осуществления каждый блок может предоставляться в виде отдельного файла. В другом варианте осуществления несколько последовательных блоков могут быть сгруппированы в один файл, чтобы образовать сегмент. В этом втором варианте осуществления могут предоставляться метаданные для каждой версии, содержащие время начала и длительность каждого блока и байтовое смещение в файле, с которого начинается блок. Эти метаданные могут предоставляться в ответ на исходный запрос по протоколу, то есть быть доступными отдельно от сегмента или файла, или могут содержаться в таком же файле или сегменте, как и сами блоки, например, в начале файла. Как будет понятно специалистам в данной области техники, эти метаданные могут кодироваться в сжатом виде, например кодирование gzip или дельта-кодирование, либо в двоичном виде, чтобы уменьшить сетевые ресурсы, необходимые для транспортировки метаданных к клиенту.
[0202] Фиг. 6 показывает пример индексирования сегмента, причем блоки имеют переменный размер и при этом границами блоков является частичная GoP, то есть частичный объем мультимедийных данных между одной RAP и следующей RAP. В этом примере точки поиска указываются индикатором RAP, причем значение индикатора RAP, равное 1, указывает, что блок начинается с RAP или точки поиска либо содержит ее, и, причем индикатор RAP, равный 0, указывает, что блок не содержит RAP или точки поиска. В этом примере первые три блока, то есть байты с 0 по 157033, содержат первую GoP, которая имеет длительность представления в 1,623 секунды, с временем представления от 20 секунд до 21,623 секунды в контенте. В этом примере первый из трех первых блоков содержит 0,485 секунды времени представления и содержит первые 50245 байт мультимедийных данных в сегменте. В этом примере блоки 4, 5 и 6 содержат вторую GoP, блоки 7 и 8 содержат третью GoP, а блоки 9, 10 и 11 содержат четвертую GoP. Отметим, что могут быть другие RAP в мультимедийных данных, которые не обозначены как точки поиска, и они соответственно не сигнализируются как RAP в карте сегмента.
[0203] Ссылаясь снова на фиг. 6, если клиент или приемник хочет обратиться к контенту, начиная с временного смещения приблизительно в 22 секунды в представлении мультимедиа, то клиент мог бы сначала использовать другую информацию, например MPD, подробнее описанное позже, чтобы определить, что соответствующие мультимедийные данные находятся в этом сегменте. Клиент может загрузить первую часть сегмента, чтобы получить индексирование сегмента, которое в этом случае составляет всего несколько байт, например, используя запрос байтового диапазона HTTP. Используя индексирование сегмента, клиент может определить, что первый блок, который ему следует загрузить, является первым блоком с временным смещением, которое составляет не более 22 секунд и начинается с RAP, то есть с точки поиска. В этом примере, хотя блок 5 имеет временное смещение, которое меньше 22 секунд, то есть его временное смещение составляет 21,965 секунды, индексирование сегмента указывает, что блок 5 не начинается с RAP, и соответственно вместо него на основе индексирования сегмента клиент выбирает для загрузки блок 4, поскольку его время начала составляет не более 22 секунд, то есть его временное смещение равно 21,623 секунды, и он начинается с RAP. Таким образом, на основе индексирования сегмента клиент сделает запрос диапазона HTTP, начиная с байтового смещения 157034.
[0204] Если бы индексирование сегмента не было доступно, то клиенту пришлось бы загружать все предыдущие 157034 байта данных перед загрузкой этих данных, приводя к гораздо большему времени запуска, или времени переключения каналов, и к неэкономной загрузке данных, которые не нужны. В качестве альтернативы, если бы индексирование сегмента не было доступно, то клиент мог бы приблизительно определить, когда нужные данные начинаются в сегменте, но приближение могло быть плохим, и он может пропустить подходящее время, и тогда потребуется вернуться назад, что снова увеличивает задержку запуска.
[0205] Как правило, каждый блок включает в себя часть мультимедийных данных, которые вместе с предыдущими блоками могут воспроизводиться проигрывателем мультимедиа. Таким образом, блочная структура и сигнализация клиенту блочной структуры индексирования сегмента, содержащейся в сегменте или предоставляемой клиенту другим способом, может значительно улучшить возможность клиента в предоставлении быстрого переключения канала и плавном воспроизведении, несмотря на колебания и сбои в сети. Поддержка блоков переменной длительности и блоков, которые включают в себя только части GoP, что разрешено индексированием сегмента, может значительно улучшить восприятие потоковой передачи. Например, снова обращаясь к фиг. 6 и примеру, описанному выше, когда клиент хочет начать воспроизведение приблизительно с 22 секунд в представлении, клиент может запросить с помощью одного или нескольких запросов данные в блоке 4, а затем подать их в проигрыватель мультимедиа, как только он доступен для начала воспроизведения. Таким образом, в этом примере воспроизведение начинается, как только 42011 байт блока 4 принимаются на клиенте, соответственно обеспечивая быстрое время переключения каналов. Если вместо этого клиенту нужно запросить всю GoP перед тем, как должно было начаться воспроизведение, то время переключения каналов было бы больше, так как это составляет 144211 байт данных.
[0206] В других вариантах осуществления RAP или точки поиска также могут возникать в середине блока, и могут присутствовать данные в индексировании сегмента, которые указывают, где находится та RAP или точка поиска в блоке или фрагменте. В других вариантах осуществления временное смещение может быть временем декодирования первого кадра в блоке вместо времени представления первого кадра в блоке.
[0207] Фиг. 8(а) и (b) иллюстрируют пример задания переменных размеров блока в выровненной структуре точки поиска на множестве версий или отображений; Фиг. 8(а) иллюстрирует задание переменных размеров блока с выровненными точками поиска на множестве версий мультимедийного потока, тогда как фиг. 8(b) иллюстрирует задание переменных размеров блока с невыровненными точками поиска на множестве версий мультимедийного потока.
[0208] Время показано сверху в секундах, и блоки и точки поиска двух сегментов для двух отображений показаны слева направо в показателях их хронометража относительно этой временной шкалы, и соответственно длина каждого показанного блока пропорциональна времени воспроизведения и не пропорциональна количеству байтов в блоке. В этом примере индексирование сегмента для обоих сегментов двух отображений имело бы одинаковые временные смещения для точек поиска, но теоретически отличающиеся количества блоков или фрагментов между точками поиска, и разные байтовые смещения для блоков из-за разных объемов мультимедийных данных в каждом блоке. В этом примере, если клиент хочет переключиться с отображения 1 на отображение 2 во время представления приблизительно в 23 секунды, то клиент мог бы запросить отображение 1 через блок 1.2 в сегменте и начать запрашивание сегмента для отображения 2, начинающегося с блока 2.2, и соответственно переключение могло бы произойти в представлении, совпадающем с точкой поиска 1.2 в отображении 1, которая находится в том же времени, что и точка поиска 2.2 в отображении 2.
[0209] Как должно быть понятно из вышеупомянутого, описанная система потоковой передачи по запросу блоков не ограничивает кодирование видеоизображения помещением точек поиска в определенные положения в контенте, и это смягчает одну из проблем существующих систем.
[0210] В вариантах осуществления, описанных выше, она организуется так, что выравниваются точки поиска для различных отображений одного представления контента. Однако во многих случаях предпочтительно ослабить это требование к выравниванию. Например, иногда имеет место, что инструменты кодирования использованы для формирования отображений, которые не обладают возможностями сформировать отображения с выровненными точками поиска. В качестве другого примера представление контента может кодироваться в разные отображения независимо, без выравнивания точек поиска между разными отображениями. В качестве другого примера отображение может содержать больше точек поиска, так как оно имеет меньшие скорости и в большинстве случаев его нужно переключать, либо оно содержит точки поиска для поддержки сложных режимов, например, быстрой перемотки вперед или перемотки назад или быстрого поиска. Таким образом, желательно предоставить способы, которые делают систему потоковой передачи по запросу блоков допускающей эффективное и плавное обращение с невыровненными точками поиска по различным отображениям для представления контента.
[0211] В этом варианте осуществления положения точек поиска по отображениям могут быть не выровнены. Блоки создаются так, что новый блок начинается в каждой точке поиска, и соответственно могло бы отсутствовать выравнивание между блоками разных версий представления. Пример такой структуры с невыровненными точками поиска между разными отображениями показан на фиг. 8(b). Время показано сверху в секундах, и блоки и точки поиска двух сегментов для двух отображений показаны слева направо в показателях их хронометража относительно этой временной шкалы, и соответственно длина каждого показанного блока пропорциональна времени воспроизведения и не пропорциональна количеству байтов в блоке. В этом примере индексирование сегмента для обоих сегментов двух отображений имело бы теоретически разные временные смещения для точек поиска, а также теоретически отличающиеся количества блоков или фрагментов между точками поиска, и разные байтовые смещения для блоков из-за разных объемов мультимедийных данных в каждом блоке. В этом примере, если клиент хочет переключиться с отображения 1 на отображение 2 во время представления приблизительно в 25 секунд, то клиент мог бы запросить отображение 1 через блок 1.3 в сегменте и начать запрашивание сегмента для отображения 2, начинающегося с блока 2.3, и соответственно переключение могло бы произойти в представлении, совпадающем с точкой поиска 2.3 в отображении 2, которая находится в середине воспроизведения блока 1.3 в отображении 1, и соответственно часть мультимедиа для блока 1.2 не была бы воспроизведена (хотя может потребоваться загрузить мультимедийные данные для кадров блока 1.3, которые не воспроизводятся, в буфер приемника для декодирования других кадров блока 1.3, которые воспроизводятся).
[0212] В этом варианте осуществления работу селектора 123 блоков можно изменить так, что всякий раз, когда необходимо выбрать блок из отображения, которое отличается от ранее выбранной версии, выбирается последний блок, чей первый кадр идет не позже кадра, следующего за последним кадром последнего выбранного блока.
[0213] Этот последний описанный вариант осуществления может устранить требование ограничить положения точек поиска в версиях, отличных от первой версии, и соответственно увеличивает эффективность сжатия для этих версий, приводя к представлению более высокого качества для заданной доступной полосы пропускания, и соответственно к улучшенному взаимодействию с пользователем. Дополнительное соображение состоит в том, что инструменты кодирования видеоизображения, которые выполняют функцию выравнивания точек поиска по нескольким кодированиям (версиям) контента, могут не быть широко доступными, и поэтому преимуществом этого последнего описанного варианта осуществления является то, что могут использоваться доступные в настоящее время инструменты кодирования видеоизображения. Другое преимущество состоит в том, что кодирование разных версий контента может происходить параллельно без какой-либо необходимости в координации между процессами кодирования для разных версий. Другим преимуществом является то, что дополнительные версии контента могут кодироваться и добавляться к представлению позже, без необходимости предоставлять инструменты кодирования со списками конкретных положений точек поиска.
[0214] Как правило, там, где изображения кодируются в виде групп изображений (GoP), первое изображение в последовательности может быть точкой поиска, но это не всегда должно быть так.
ОПТИМАЛЬНОЕ РАЗДЕЛЕНИЕ БЛОКОВ
[0215] Одним проблемным вопросом в системе потоковой передачи по запросу блоков является взаимодействие между структурой кодированного мультимедиа, например видеоизображения, и структурой блока, используемой для запросов блоков. Как станет известно специалистам в области кодирования видеоизображения, часто имеет место, что меняется количество разрядов, необходимое для кодированного отображения каждого видеокадра, иногда существенно, от кадра к кадру. В результате отношение между объемом принятых данных и длительностью мультимедиа, кодированного этими данными, может быть не прямым. Кроме того, разделение мультимедийных данных на блоки в системе потоковой передачи по запросу блоков добавляет дополнительное измерение сложности. В частности, в некоторых системах мультимедийные данные блока могут не воспроизводиться, пока не принят весь блок, например, размещение мультимедийных данных в блоке или зависимости между выборками мультимедиа в блоке использования кодов стирания могут привести к этому свойству. В результате этих сложных взаимодействий между размером блока и длительностью блока и возможной необходимости принимать весь блок до начала воспроизведения для клиентских систем общепринято выбирать консервативный подход, в котором мультимедийные данные буферизуются до того, как начинается воспроизведение. Такая буферизация приводит к длительному времени переключения каналов и соответственно плохому взаимодействию с пользователем.
[0216] Pakzad описывает "способы разделения блоков", которые являются новыми и эффективными способами для определения того, как разделить поток данных на смежные блоки на основе, лежащей в основе структуры потока данных, и дополнительно описывает несколько преимуществ этих способов применительно к системе потоковой передачи. Теперь описывается дополнительный вариант осуществления изобретения для применения способов разделения блоков по Pakzad к системе потоковой передачи по запросу блоков. Этот способ может содержать размещение мультимедийных данных, которые нужно представить в приблизительном порядке времени представления, так что время воспроизведения любого заданного элемента мультимедийных данных (например, видеокадра или звукового отсчета) отличается от такового у любого соседнего элемента мультимедийных данных меньше чем на предоставленную пороговую величину. Мультимедийные данные, упорядоченные таким образом, можно считать потоком данных на языке Pakzad, и любые из способов Pakzad, примененные к этому потоку данных, отождествляют границы блока с потоком данных. Данные между любой парой соседних границ блока считаются "Блоком" на языке этого раскрытия изобретения, и способы из этого раскрытия изобретения применяются для обеспечения представления мультимедийных данных в системе потоковой передачи по запросу блоков. Как будет понятно специалистам в данной области техники при прочтении этого раскрытия изобретения, несколько преимуществ способов, раскрытых в Pakzad, можно реализовать применительно к системе потоковой передачи по запросу блоков.
[0217] Как описано в Pakzad, определение блочной структуры сегмента, включающего блоки, которые включают в себя частичные GoP или части побольше GoP, может влиять на возможность клиента обеспечить быстрое время переключения канала. В Pakzad предоставлены способы, которые, с учетом целевого времени запуска, предоставили бы блочную структуру и целевую скорость загрузки, которые гарантировали бы, что если клиент начал загрузку отображения в любой точке поиска и начал воспроизведение после того, как истекло целевое время запуска, то воспроизведение продолжилось бы плавно при условии, что в каждый момент времени объем данных, который загрузил клиент, по меньшей мере равен целевой скорости загрузки, умноженной на прошедшее время от начала загрузки. Для клиента выгодно иметь доступ к целевому времени запуска и целевой скорости загрузки, так как это предоставляет клиенту средство для определения, когда начать воспроизведение отображения в самый ранний момент времени, и позволяет клиенту продолжить воспроизводить отображение при условии, что загрузка удовлетворяет условию, описанному выше. Таким образом, описанный позже способ предоставляет средство для включения целевого времени запуска и целевой скорости загрузки в Описание представления мультимедиа, чтобы оно могло использоваться для описанных выше целей.
МОДЕЛЬ ДАННЫХ У ПРЕДСТАВЛЕНИЯ МУЛЬТИМЕДИА
[0218] Фиг. 5 иллюстрирует возможные структуры хранилища контента, показанного на фиг. 1, включая сегменты и файлы описания представления мультимедиа ("MPD"), и расшифровку сегментов, распределение во времени и другую структуру в файле MPD. Сейчас будут описываться подробности возможных реализаций структур MPD или файлов. Во многих примерах MPD описывается в виде файла, но с тем, же успехом могут использоваться нефайловые структуры.
[0219] Как проиллюстрировано, хранилище 110 контента хранит множество исходных сегментов 510, MPD 500 и сегменты 512 восстановления. MPD могло бы содержать записи 501 периода, которые в свою очередь могли бы содержать записи 502 отображения, которые содержат информацию 503 о сегменте, например ссылки на сегменты 504 инициализации и мультимедийные сегменты 505.
[0220] Фиг. 9(а) иллюстрирует примерную таблицу 900 метаданных, тогда как фиг. 9(b) иллюстрирует пример того, как клиент 902 потоковой передачи HTTP получает таблицу 900 метаданных и блоки 904 мультимедиа по соединению с сервером 906 потоковой передачи HTTP.
[0221] В способах, описанных в этом документе, предоставляется "Описание представления мультимедиа", которое содержит информацию об отображениях в представлении мультимедиа, которые доступны клиенту. Отображения могут быть альтернативами в том смысле, что клиент выбирает одну из разных альтернатив, либо они могут быть комплементарными в том смысле, что клиент выбирает несколько отображений, каждое по возможности из набора альтернатив, и представляет их одновременно. Отображения преимущественно могут назначаться группам, причем клиент запрограммирован или сконфигурирован понимать, что для отображений в одной группе они являются альтернативами друг другу, тогда как отображения из разных групп таковы, что более одного отображения нужно представлять одновременно. Другими словами, если имеется более одного отображения в группе, то клиент выбирает одно отображение из той группы, одно отображение из следующей группы и т.д., чтобы сформировать представление.
[0222] Информация, описывающая отображения, преимущественно может включать в себя подробности примененных кодеков мультимедиа, включая профили и уровни кодеков, которые необходимы для декодирования отображения, частоты видеокадров, разрешение видеоизображения и скорости данных. Клиент, принимающий Описание представления мультимедиа, может использовать эту информацию для определения заранее, подходит ли отображение для декодирования или представления. Это представляет преимущество, потому что если дифференцирующая информация содержалась бы только в двоичных данных отображения, то было бы необходимо запрашивать двоичные данные из всех отображений и анализировать и извлекать соответствующую информацию, чтобы обнаружить информацию о пригодности. Эти несколько запросов и анализ в дополнение к извлечению данных могут занимать некоторое время, которое привело бы к длительному времени запуска, и поэтому плохому взаимодействию с пользователем.
[0223] Более того, Описание представления мультимедиа может содержать информацию, ограничивающую запросы клиента на основе времени дня. Например, для интерактивной услуги клиент может быть ограничен запросом частей представления, которые близки к "текущему времени трансляции". Это представляет преимущество, поскольку для прямой трансляции может быть желательно, удалить данные из обслуживающей инфраструктуры для контента, который транслировался раньше текущего времени трансляции более чем на предоставленную пороговую величину. Это может быть желательно для повторного использования ресурсов хранения в обслуживающей инфраструктуре. Это также может быть желательно в зависимости от типа предлагаемой услуги, например, в некоторых случаях представление может быть сделано доступным только напрямую из-за определенной модели подписки у приемных клиентских устройств, тогда как другие представления мультимедиа могут быть сделаны доступными напрямую и по требованию, а другие представления могут быть сделаны доступными только напрямую для первого класса клиентских устройств, только по требованию для второго класса клиентских устройств и в сочетании либо напрямую, либо по требованию для третьего класса клиентских устройств. Способы, описанные в Модели данных у представления мультимедиа (ниже), позволяют информировать клиента о таких политиках, чтобы клиент мог избежать создания запросов и настраивания предложений пользователю для данных, которые могут быть недоступны в обслуживающей инфраструктуре. В качестве альтернативы, например клиент, может представить уведомление пользователю, что эти данные не доступны.
[0224] В дополнительном варианте осуществления изобретения мультимедийные сегменты могут быть совместимы с Базовым форматом мультимедийного файла ISO, описанным в ISO/IEC 14496-12 или производных спецификациях (например, форматом файла 3GP, описанным в Техническом описании 3GPP 26.244). Раздел "Использование формата файла 3GPP" (выше) описывает новые улучшения в Базовом формате мультимедийного файла ISO, допускающие эффективное использование структур данных этого формата файла в системе потоковой передачи по запросу блоков. Как описано в этой отсылке, информация может предоставляться в файле, допуская быстрое и эффективное преобразование между временными сегментами представления мультимедиа и байтовыми диапазонами в файле. Сами мультимедийные данные могут быть структурированы в соответствии с конструкцией Фрагмента фильма, заданной в ISO/IEC 14496-12. Эта информация, предоставляющая временные и байтовые смещения, может быть структурирована иерархически или в виде одиночного блока информации. Эта информация может предоставляться в начале файла. Предоставление этой информации с использованием эффективного кодирования, как описано в разделе "Использование формата файла 3GPP", приводит к способности клиента быстро извлекать эту информацию, например с использованием частичных запросов GET HTTP, если протоколом загрузки файла, используемым системой потоковой передачи по запросу блоков, является HTTP, что приводит к короткому времени запуска, поиска или переключения потока, а поэтому к улучшенному взаимодействию с пользователем.
[0225] Отображения в мультимедийном представлении синхронизируются на глобальной временной шкале, чтобы обеспечить плавное переключение между отображениями, обычно являющимися альтернативами, и обеспечить синхронное представление двух или более отображений. Поэтому время выборки содержащейся в отображениях мультимедиа в рамках представления мультимедиа при адаптивной потоковой передаче HTTP может относиться к непрерывной глобальной временной шкале по нескольким сегментам.
[0226] Блок кодированного мультимедиа, содержащий мультимедиа нескольких типов, например звук и видеоизображение, может иметь разные моменты окончания представления для разных типов мультимедиа. В системе потоковой передачи по запросу блоков такие блоки мультимедиа могут воспроизводиться последовательно таким образом, что каждый тип мультимедиа воспроизводится непрерывно, и соответственно выборки мультимедиа одного типа из одного блока могут воспроизводиться перед выборками мультимедиа другого типа в предыдущем блоке, что называется в этом документе "непрерывной стыковкой блоков". В качестве альтернативы такие блоки мультимедиа могут воспроизводиться таким образом, что самая ранняя выборка любого типа одного блока воспроизводится после последней выборки любого типа предыдущего блока, что в этом документе называется "прерывистой стыковкой блоков". Непрерывная стыковка блоков может быть подходящей, когда оба блока содержат мультимедиа из одинакового элемента содержимого и одинакового отображения, кодированные в последовательности, либо в иных случаях. Как правило, в одном отображении непрерывная стыковка блоков может применяться при стыковке двух блоков. Это выгодно, так как может применяться существующее кодирование, и сегментация может выполняться без необходимости выравнивать дорожки мультимедиа на границах блоков. Это иллюстрируется на фиг. 10, где видеопоток 1000 содержит блок 1202 и другие блоки с RAP, например RAP 1204.
ОПИСАНИЕ ПРЕДСТАВЛЕНИЯ МУЛЬТИМЕДИА
[0227] Представление мультимедиа можно рассматривать как структурированную совокупность файлов на сервере потоковой передачи HTTP. Клиент потоковой передачи HTTP может загрузить достаточно информации для представления пользователю услуги потоковой передачи. Альтернативные отображения могут содержать один или несколько файлов 3GP или частей файлов 3GP, соответствующих формату файла 3GPP или, по меньшей мере, четко определенному набору структур данных, который можно легко преобразовать из файла 3GP или в него.
[0228] Представление мультимедиа может описываться Описанием представления мультимедиа. Описание представления мультимедиа (MPD) может содержать метаданные, которые клиент может использовать для создания подходящих запросов файлов, например запросов GET HTTP, для доступа к данным в подходящее время и предоставления пользователю услуги потоковой передачи. Описание представления мультимедиа может предоставлять достаточно информации, чтобы клиент потоковой передачи HTTP выбрал подходящие файлы 3GPP и фрагменты файлов. Блоки, которые сигнализируются клиенту как доступные, называются сегментами.
[0229] Среди прочего описание представления мультимедиа может содержать элементы и атрибуты следующим образом.
[0230] Элемент MediaPresentationDescription
[0231] Элемент, инкапсулирующий метаданные, используемые Клиентом потоковой передачи HTTP для предоставления услуги потоковой передачи конечному пользователю. Элемент MediaPresentationDescription может содержать один или несколько следующих атрибутов и элементов.
[0232] Version: Номер версии для протокола, чтобы обеспечить расширяемость.
[0233] PresentationIdentifier: Информация о том, что представление может быть однозначно идентифицировано среди других представлений. Также может содержать личные поля или названия.
[0234] UpdateFrequency: Частота обновления описания представления мультимедиа, то есть то, как часто клиент может повторно загружать действительное описание представления мультимедиа. Если отсутствует, то представление мультимедиа может быть статическим. Обновление представления мультимедиа может означать, что представление мультимедиа нельзя кэшировать.
[0235] MediaPresentationDescriptionURI: URI для датирования описания представления мультимедиа.
[0236] Stream: Описывает тип Потока или представления мультимедиа: видеоизображение, звук или текст. Тип видеопотока может содержать звук и может содержать текст.
[0237] Service: Описывает тип услуги с дополнительными атрибутами. Типы услуг могут быть реальными (прямыми) и по требованию. Это может использоваться для информирования клиента, что поиск и доступ после некоторого текущего времени не разрешен.
[0238] MaximumClientPreBufferTime: Максимальное количество времени, которое клиент может предварительно буферизовать мультимедийный поток. Это распределение времени может отличать потоковую передачу от прогрессивной загрузки, если клиент ограничивается загрузкой после этого максимального времени предварительной буферизации. Значение может отсутствовать, указывая, что могут не применяться никакие ограничения в плане предварительной буферизации.
[0239] SafetyGuardIntervalLiveService: Информация о максимальном оборотном времени интерактивной услуги на сервере. Предоставляет указание клиенту, что из информации уже доступно в текущее время. Эта информация может быть необходима, если клиент и сервер предполагаются работающими по времени UTC, и не предоставляется никакой синхронизации времени.
[0240] TimeShiftBufferDepth: Информация о том, насколько далеко назад может переместиться клиент в интерактивной услуге относительно текущего времени. С помощью увеличения этой глубины могут быть разрешены услуги отложенного просмотра и захвата без определенных изменений в предоставлении услуги.
[0241] LocalCachingPermitted: Этот признак указывает, может ли Клиент HTTP кэшировать загруженные данные локально после их воспроизведения.
[0242] LivePresentationInterval: Содержит интервалы времени, в течение которых представление может быть доступно, путем задания StartTime и EndTime. StartTime указывает время начала услуги, а EndTime указывает время окончания услуги. Если EndTime не задано, то время окончания неизвестно в данное время, и UpdateFrequency может гарантировать, что клиенты получают доступ к времени окончания до фактического времени окончания услуги.
[0243] OnDemandAvailabilityInterval: Интервал представления указывает доступность услуги по сети. Может предоставляться несколько интервалов представления. Клиент HTTP может не иметь возможности доступа к услуге вне любого заданного интервала времени. Путем предоставления OnDemand Interval может задаваться дополнительный отложенный просмотр. Этот атрибут также может присутствовать для интерактивной услуги. Если он присутствует для интерактивной услуги, то сервер может гарантировать, что клиент может обращаться к услуге как к Услуге OnDemand (по требованию) в течение всех предоставленных интервалов доступности. Поэтому LivePresentationInterval не может пересекаться ни с каким OnDemandAvailabilityInterval.
[0244] MPDFileInfoDynamic: Описывает динамическое создание файлов по умолчанию в представлении мультимедиа. Больше подробностей предоставляется ниже. Спецификация по умолчанию уровня MPD может сэкономить ненужное повторение, если используются одни и те же правила для нескольких или всех альтернативных отображений.
[0245] MPDCodecDescription: Описывает основные кодеки по умолчанию в представлении мультимедиа. Больше подробностей предоставляется ниже. Спецификация по умолчанию уровня MPD может сэкономить ненужное повторение, если используются одни и те же кодеки для нескольких или всех отображений.
[0246] MPDMoveBoxHeaderSizeDoesNotChange: Признак для указания, меняется ли Заголовок MoveBox по размеру среди отдельных файлов во всем представлении мультимедиа. Этот признак может использоваться для оптимизации загрузки и может присутствовать только в случае определенных форматов сегмента, в особенности тех, для которых сегменты содержат заголовок moov.
[0247] FileURIPattern: Шаблон, используемый Клиентом для формирования Запросов файлов в представлении мультимедиа. Разные атрибуты позволяют формирование уникальных URI для каждого из файлов в представлении мультимедиа. Базовым URI может быть URI HTTP.
[0248] Alternative Representation: Описывает список отображений.
[0249] Элемент AlternativeRepresentation:
[0250] Элемент XML, который инкапсулирует все метаданные для одного отображения. Элемент AlternativeRepresentation может содержать следующие атрибуты и элементы.
[0251] RepresentationID: Уникальный ID для этого конкретного Альтернативного отображения в представлении мультимедиа.
[0252] FilesInfoStatic: Предоставляет явный список начальных моментов и URI всех файлов одного альтернативного представления. Статическое предоставление списка файлов может обеспечить преимущество точного описания хронометража представления мультимедиа, но оно может быть не таким компактным, особенно если альтернативное отображение содержит много файлов. Также имена файлов могут иметь произвольные имена.
[0253] FilesInfoDynamic: Предоставляет неявный способ построения списка начальных моментов и URI одного альтернативного представления. Динамическое предоставление списка файлов может обеспечить преимущество более компактного представления. Если предоставляется только последовательность начальных моментов, то здесь также сохраняются преимущества синхронизации, но имена файлов должны создаваться динамически в FilePatternURI. Если предоставляется только длительность каждого сегмента, то отображение является компактным и может подходить для использования в интерактивных услугах, но формирование файлов может определяться глобальной синхронизацией.
[0254] APMoveBoxHeaderSizeDoesNotChange: Признак, который указывает, меняется ли Заголовок MoveBox по размеру среди отдельных файлов в Альтернативном представлении. Этот признак может использоваться для оптимизации загрузки и может присутствовать только в случае определенных форматов сегмента, в особенности тех, для которых сегменты содержат заголовок moov.
[0255] APCodecDescription: Описывает основные кодеки файлов в альтернативном представлении.
[0256] Элемент Media Description
[0257] MediaDescription: Элемент, который может инкапсулировать все метаданные для мультимедиа, которое содержится в этом отображении. В частности, он может содержать информацию о дорожках в этом альтернативном представлении, а также рекомендованную группировку дорожек, если применима. Атрибут MediaDescription содержит следующие атрибуты:
[0258] TrackDescription: Атрибут XML, который инкапсулирует все метаданные для мультимедиа, которое содержится в этом отображении. Атрибут TrackDescription содержит следующие атрибуты:
[0259] TrackID: Уникальный ID для дорожки в альтернативном отображении. Может использоваться, если дорожка является частью описания группировки.
[0260] Bitrate: Скорость передачи битов у дорожки.
[0261] TrackCodecDescription: Атрибут XML, который содержит все атрибуты кодека, используемого на этой дорожке. Атрибут TrackCodecDescription содержит следующие атрибуты:
[0262] MediaName: Атрибут, задающий тип мультимедиа. Типы мультимедиа включают в себя "звук", "видеоизображение", "текст", "приложение" и "сообщение".
[0263] Codec: CodecType, включающий в себя профиль и уровень.
[0264] LanguageTag: LanguageTag, если применимо.
[0265] MaxWidth, MaxHeight: Для видеоизображения Высота и Ширина содержащегося видеоизображения в пикселях.
[0266] SamplingRate: Для звука - частота дискретизации
[0267] GroupDescription: Атрибут, который предоставляет рекомендацию клиенту для подходящей группировки на основе разных параметров.
[0268] GroupType: Тип, на основе которого клиент может решить, как группировать дорожки.
[0269] Информация в описании представления мультимедиа преимущественно используется клиентом потоковой передачи HTTP для выполнения запросов файлов/сегментов или их частей в подходящие моменты, выбирая сегменты из соразмерных отображений, которые соответствуют их возможностям, например, в показателях полосы пропускания для доступа, возможностей отображения, возможностей кодеков и так далее, а также предпочтений пользователя, например языка и так далее. Кроме того, так как описание Представления мультимедиа описывает отображения, которые выровнены по времени и преобразованы к глобальной временной шкале, клиент также может использовать информацию в MPD во время текущего представления мультимедиа для инициирования подходящих действий, чтобы переключаться между отображениями, чтобы показывать отображения одновременно или искать в представлении мультимедиа.
СИГНАЛИЗАЦИЯ НАЧАЛЬНЫХ МОМЕНТОВ СЕГМЕНТОВ
[0270] Отображение может быть разделено по времени на несколько сегментов. Проблема синхронизации между дорожками существует между последним фрагментом одного сегмента и следующим фрагментом следующего сегмента. К тому же другая проблема синхронизации существует в случае, когда используются сегменты постоянной длительности.
[0271] Использование одинаковой длительности для каждого сегмента может обладать преимуществом в том, что MPD компактное и статическое. Однако каждый сегмент по-прежнему может начинаться в Точке произвольного доступа. Таким образом, либо кодирование видеоизображения может быть ограничено предоставлением Точек произвольного доступа в этих конкретных точках, либо фактические длительности сегмента могут быть не такими точными, как задано в MPD. Может быть желательно, чтобы система потоковой передачи не накладывала ненужных ограничений на процесс кодирования видеоизображения, и поэтому второй вариант может быть предпочтительным.
[0272] В частности, если длительность файла задается в MPD в виде d секунд, то n-ый файл может начинаться с Точки произвольного доступа в момент (n-1)d или непосредственно следующий.
[0273] В этом подходе каждый файл может включать в себя информацию в отношении точного времени начала сегмента в показателях глобального времени представления. Три возможных способа сигнализации этого включают в себя:
[0274] (1) Во-первых, ограничить время начала каждого сегмента точной синхронизацией, которая задана в MPD. Но тогда кодер мультимедиа может не обладать гибкостью в размещении кадров IDR и может требовать специального кодирования для потоковой передачи файлов.
[0275] (2) Во-вторых, добавить точное время начала в MPD для каждого сегмента. Для случая по требованию компактность MPD может быть уменьшена. Для случаев прямой передачи это может потребовать регулярного обновления MPD, что может уменьшить масштабируемость.
[0276] (3) В-третьих, добавить глобальное время или точное время начала относительно объявленного времени начала отображения или объявленного времени начала сегмента в MPD к сегменту в том смысле, что сегмент содержит эту информацию. Это можно было бы добавить к новому блоку, выделенному для адаптивной потоковой передачи. Этот блок также может включать в себя информацию, которая предоставлена блоком "TIDX" или "SIDX". Результат этого третьего подхода состоит в том, что при поиске до конкретного положения около начала одного из сегментов клиент на основе MPD может выбрать следующий сегмент после содержащего необходимую точку поиска. Простым ответом в этом случае может быть перемещение точки поиска вперед к началу извлеченного сегмента (то есть в следующую Точку произвольного доступа после точки поиска). Обычно Точки произвольного доступа предоставляются, по меньшей мере, каждые несколько секунд (и часто существует небольшой выигрыш кодирования, если делать их менее частыми), и поэтому в наихудшем случае точку поиска можно переместить на несколько секунд позже заданного. В качестве альтернативы клиент мог бы определять при извлечении информации заголовка для сегмента, что запрошенная точка поиска фактически находится в предыдущем сегменте, и вместо этого запросить тот сегмент. Это может привести к случайному увеличению времени, необходимого для выполнения операции поиска.
СПИСОК ДОСТУПНЫХ СЕГМЕНТОВ
[0277] Представление мультимедиа содержит набор отображений, предоставляющих некоторую другую версию кодирования для исходного мультимедийного контента. Сами отображения преимущественно содержат информацию об отличающихся параметрах отображения по сравнению с другими параметрами. Они также содержат, явно либо неявно, список доступных сегментов.
[0278] Сегменты можно дифференцировать на вневременные сегменты, содержащие только метаданные, и мультимедийные сегменты, которые в основном содержат мультимедийные данные. Описание представления мультимедиа ("MPD") преимущественно идентифицирует и назначает разные атрибуты каждому из сегментов, неявно либо явно. Атрибуты, преимущественно назначенные каждому сегменту, содержат период, в течение которого доступен сегмент, ресурсы и протоколы, по которым доступны сегменты. К тому же мультимедийным сегментам преимущественно назначаются такие атрибуты, как время начала сегмента в представлении мультимедиа и длительность сегмента в представлении мультимедиа.
[0279] Там, где представление мультимедиа имеет тип "по требованию", что преимущественно указывается атрибутом в описании представления мультимедиа, например OnDemandAvailabilityInterval, описание представления мультимедиа обычно описывает все сегменты и также предоставляет указание, когда сегменты доступны, а когда недоступны. Начальные моменты сегментов преимущественно выражаются относительно начала представления мультимедиа, так что два клиента, начинающие воспроизведение одинаковых представлений мультимедиа, но в разные моменты, могут использовать одно и то же описание представления мультимедиа, а также одинаковые мультимедийные сегменты. Это преимущественно увеличивает возможность кэшировать сегменты.
[0280] Там, где представление мультимедиа имеет тип "прямая передача", что преимущественно указывается атрибутом в описании представления мультимедиа, например атрибутом Service, сегменты, содержащие представление мультимедиа после фактического времени дня, обычно не формируются или, по меньшей мере, не доступны, несмотря на то, что сегменты полностью описаны в MPD. Однако с помощью указания, что услуга представления мультимедиа имеет тип "прямая передача", клиент может создать список доступных сегментов вместе с атрибутами синхронизации для внутреннего времени клиента NOW по реальному времени на основе информации, содержащейся в MPD, и времени загрузки MPD. Сервер преимущественно работает в том смысле, что он делает ресурс доступным так, что эталонный клиент, работающий с экземпляром MPD в реальное время NOW, может обращаться к ресурсам.
[0281] В частности, эталонный клиент создает список доступных сегментов вместе с атрибутами синхронизации для внутреннего времени клиента NOW по реальному времени на основе информации, содержащейся в MPD, и времени загрузки MPD. При опережении времени клиент будет использовать такое же MPD и создаст новый список доступных сегментов, который может использоваться для непрерывного воспроизведения представления мультимедиа. Поэтому сервер может объявлять сегменты в MPD до того, как эти сегменты фактически доступны. Это выгодно, поскольку уменьшает частое обновление и загрузку MPD.
[0282] Предположим, что список сегментов, каждый с временем начала tS, описывается либо явно списком воспроизведения в элементах, например FileInfoStatic, либо неявно с использованием такого элемента, как FileInfoDynamic. Выгодный способ для формирования списка сегментов с использованием FileInfoDynamic описывается ниже. На основе этого правила конструирования клиент имеет доступ к списку URI для каждого отображения r, в этом документе называемому FileURI(r,i), и времени начала tS(r,i) для каждого сегмента с индексом i.
[0283] Использование информации в MPD для создания доступного интервала времени сегментов может выполняться с использованием следующих правил.
[0284] Для услуги типа "по требованию", что преимущественно указывается атрибутом, например Service, если текущее реальное время на клиенте NOW находится в любом диапазоне доступности, преимущественно выраженном элементом MPD, например OnDemandAvailabilityInterval, то доступны все описанные сегменты этого Представления по требованию. Если текущее реальное время на клиенте NOW находится вне любого диапазона доступности, то никакие из описанных сегментов в этом Представлении по требованию не доступны.
[0285] Для услуги типа "прямая передача", что преимущественно указывается атрибутом, например Service, время начала tS(r,i) преимущественно выражает время доступности по реальному времени. Время начала доступности может выводиться как сочетание времени интерактивной услуги у события и некоторого оборотного времени на сервере для захвата, кодирования и публикации. Время для этого процесса может задаваться, например, в MPD, используя защитный интервал tG, заданный, например, как SafetyGuardIntervalLiveService в MPD. Это обеспечило бы минимальную разность между временем UTC и доступностью данных на сервере потоковой передачи HTTP. В другом варианте осуществления MPD явно задает время доступности сегмента в MPD без предоставления оборотного времени в виде разности между фактическим временем события и оборотным временем. В нижеследующем описании предполагается, что любые глобальные моменты задаются как моменты доступности. Обычный специалист в транслировании мультимедиа в прямом эфире может вывести эту информацию из подходящей информации в описании представления мультимедиа после прочтения этого описания.
[0286] Если текущее реальное время на клиенте NOW находится вне любого диапазона интервала прямого представления, преимущественно выраженного элементом MPD, например LivePresentationInterval, то никакие из описанных сегментов этого прямого представления не доступны. Если текущее реальное время на клиенте NOW находится в интервале прямого представления, то могут быть доступны, по меньшей мере, некоторые сегменты в описанных сегментах этого прямого представления.
[0287] Ограничение доступных сегментов регулируется следующими значениями:
[0288] Реальное время NOW (которое доступно клиенту).
[0289] Разрешенная глубина буфера отложенного просмотра tTSB, например, заданная как TimeShiftBufferDepth в описании представления мультимедиа.
[0290] Клиенту в относительном времени события tl можно разрешить только запрашивать сегменты с начальными моментами tS(r, i) в интервале (NOW-tTSB) и NOW или в таком интервале, что время окончания сегмента с длительностью d также включается, приводя к интервалу (NOW-tTSB -d) и NOW.
ОБНОВЛЕНИЕ MPD
[0291] В некоторых вариантах осуществления сервер заранее не знает указатель на файл или сегмент и начальные моменты сегментов, так как, например, положение сервера будет меняться, или представление мультимедиа включает в себя некоторую рекламу от другого сервера, или длительность представления мультимедиа неизвестна, или сервер хочет скрыть указатель для следующих сегментов.
[0292] В таких вариантах осуществления сервер мог бы только описать сегменты, которые уже доступны или становятся доступными вскоре после того, как опубликован этот экземпляр MPD. Кроме того, в некоторых вариантах осуществления клиент преимущественно потребляет мультимедиа вблизи мультимедиа, описанного в MPD, так что пользователь воспринимает содержащуюся мультимедийную программу как максимально близкую к формированию мультимедийного контента. Как только клиент ожидает, что он достигает окончания описанных мультимедийных сегментов в MPD, он преимущественно запрашивает новый экземпляр MPD, чтобы продолжить непрерывно воспроизводить в ожидании, что сервер опубликовал новое MPD, описывающее новые мультимедийные сегменты. Сервер преимущественно формирует новые экземпляры MPD и обновляет MPD так, что клиенты могут опираться на процедуры для непрерывных обновлений. Сервер может приспособить процедуры обновления MPD вместе с формированием и публикацией сегментов к процедурам эталонного клиента, который действует, как может действовать распространенный клиент.
[0293] Если новый экземпляр MPD описывает только короткое упреждение, то клиентам нужно часто запрашивать новые экземпляры MPD. Это может привести к проблемам масштабируемости и ненужному восходящему и нисходящему трафику из-за ненужных частых запросов.
[0294] Поэтому с одной стороны уместно описывать сегменты как можно дальше в будущем, не обязательно делая их доступными, а с другой стороны - разрешить непредвиденные обновления в MPD для выражения новых расположений сервера, позволить вставку нового контента, например рекламы, или обеспечить изменения в параметрах кодеков.
[0295] Кроме того, в некоторых вариантах осуществления длительность мультимедийных сегментов может быть небольшой, например, в диапазоне нескольких секунд. Длительность мультимедийных сегментов преимущественно является гибкой, чтобы подстраиваться к подходящим размерам сегментов, которые можно оптимизировать к свойствам доставки или кэширования, чтобы компенсировать сквозную задержку в интерактивных услугах или другие особенности, которые касаются хранения или доставки сегментов, или по другим причинам. Особенно в случаях, где сегменты небольшие по сравнению с длительностью представления мультимедиа, значительный объем ресурсов мультимедийного сегмента и начальных моментов нужно описать в описании представления мультимедиа. В результате размер описания представления мультимедиа может быть большим, что может неблагоприятно влиять на время загрузки описания представления мультимедиа, и поэтому влиять на задержку запуска представления мультимедиа, а также на использование полосы пропускания на линии доступа. Поэтому полезно не только разрешить описание списка мультимедийных сегментов с использованием списков воспроизведения, но также разрешить описание с использованием шаблонов или правил конструирования URL. Шаблоны и правила конструирования URL используются синонимично в данном описании.
[0296] К тому же шаблоны могут использоваться преимущественно для описания указателей сегментов в случаях прямой передачи после текущего времени. В таких случаях обновления MPD, по сути, не нужны, так как указатели, а также список сегментов описываются шаблонами. Однако по-прежнему могут произойти непредвиденные события, которые требуют изменений в описании отображений или сегментов. Изменения в описании представления мультимедиа при адаптивной потоковой передаче HTTP могут быть нужны, когда контент из нескольких разных источников стыкуется вместе, например, когда вставлена реклама. Контент из разных источников может отличаться различными способами. Другая причина во время прямых представлений состоит в том, что может быть необходимо, изменить URL, используемые для файлов контента, чтобы предусмотреть перехват управления при отказе с одного сервера-источника прямой передачи на другой.
[0297] В некоторых вариантах осуществления полезно, что если MPD обновляется, то обновления в MPD осуществляются так, что обновленное MPD совместимо с предыдущим MPD в том смысле, что эталонный клиент, а поэтому и любой реализованный клиент формирует одинаково функциональный список доступных сегментов из обновленного MPD для любого времени вплоть до времени действия предыдущего MPD, как он сделал бы из предыдущего экземпляра MPD. Это требование гарантирует, что (a) клиенты могут немедленно начать использование нового MPD без синхронизации со старым MPD, поскольку оно совместимо со старым MPD до времени обновления; и (b) время обновления не нужно синхронизировать со временем, в которое происходит фактическое изменение в MPD. Другими словами, обновления MPD могут объявляться заранее, и сервер может заменить старый экземпляр MPD, как только доступна новая информация, без необходимости хранить разные версии MPD.
[0298] Две возможности могут существовать для хронометража мультимедиа по всему обновлению MPD для набора отображений или всех отображений. Либо (а) существующая глобальная временная шкала продолжается по всему обновлению MPD (называемому в этом документе "непрерывным обновлением MPD"), либо (b) текущая временная шкала заканчивается, и начинается новая временная шкала с сегмента, следующего за изменением (в этом документе называется "прерывистое обновление MPD").
[0299] Разница между этими вариантами может быть очевидной, принимая во внимание, что дорожки Фрагмента мультимедиа, а поэтому и Сегмента, обычно не начинаются и заканчиваются одновременно из-за отличающейся степени разбиения по дорожкам. Во время обычного представления выборки одной дорожки во фрагменте могут воспроизводиться перед некоторыми выборками другой дорожки предыдущего фрагмента, то есть имеется некоторый вид перекрытия между фрагментами, хотя перекрытие в одной дорожке может отсутствовать.
[0300] Разница между (a) и (b) состоит в том, что такое перекрытие можно задействовать по всему обновлению MPD. Когда обновление MPD происходит из-за стыковки полностью раздельного контента, такого перекрытия обычно сложно достичь, так как новый контент нуждается в новом кодировании для стыковки с предыдущим контентом. Поэтому полезно предоставить возможность дискретного обновления представления мультимедиа путем возобновления временной шкалы для некоторых сегментов, и по возможности также задать новый набор отображений после обновления. Также, если контент независимо кодирован и сегментирован, то также избегают регулировки временных отметок для подгонки к глобальной временной шкале предыдущей порции контента.
[0301] Когда обновление происходит по менее значимым причинам, например, только добавление новых мультимедийных сегментов в список описанных мультимедийных сегментов или если изменяется расположение URL, то перекрытие и непрерывные обновления можно разрешить.
[0302] В случае прерывистого обновления MPD временная шкала последнего сегмента в предыдущем отображении завершается в последнем времени окончания представления любой выборки в сегменте. Временная шкала следующего отображения (или, точнее, первое время представления первого мультимедийного сегмента новой части представления мультимедиа, также называемой новым периодом) обычно и преимущественно начинается в тот же самый момент, что и окончание представления последнего периода, так что обеспечивается плавное и непрерывное воспроизведение.
[0303] Два случая иллюстрируются на фиг. 11.
[0304] Предпочтительно и выгодно ограничить обновления MPD границами сегментов. Логическое обоснование ограничения таких изменений или обновлений границами сегментов выглядит следующим образом. Во-первых, изменения в двоичных метаданных для каждого отображения, обычно в Заголовке фильма, могут происходить, по меньшей мере, на границах сегментов. Во-вторых, Описание представления мультимедиа может содержать указатели (URL) на сегменты. В определенном смысле MPD является "зонтичной" структурой данных, группирующей все файлы сегментов, ассоциированные с представлением мультимедиа. Чтобы сохранить это отношение включения, на каждый сегмент может ссылаться одно MPD, и когда MPD обновляется, оно преимущественно обновляется только на границе сегмента.
[0305] Границы сегментов обычно не требуется выравнивать, однако для случая контента, стыкованного из разных источников, и для прерывистых обновлений MPD в целом имеет смысл выравнивать границы сегментов (в частности, чтобы последний сегмент каждого отображения мог заканчиваться в том же видеокадре и не мог содержать звуковые отсчеты с временем начала представления позже времени представления того кадра). Прерывистое обновление тогда может начать новый набор отображений в общий момент времени, называемый периодом. Предоставляется время начала действия этого нового набора отображений, например, с помощью времени начала периода. Относительное время начала каждого отображения сбрасывается в ноль, и время начала периода помещает набор отображений в этом новом периоде на глобальную временную шкалу представления мультимедиа.
[0306] Для непрерывных обновлений MPD не требуется выравнивать границы сегментов. Каждый сегмент каждого альтернативного отображения может управляться одним описанием представления мультимедиа, и соответственно запросы обновления для новых экземпляров описания представления мультимедиа, обычно инициируемые ожиданием, что никакие дополнительные мультимедийные сегменты не описываются в действующем MPD, могут происходить в разные моменты в зависимости от потребленного набора отображений, включая набор отображений, которые ожидаются для потребления.
[0307] Чтобы поддерживать обновления в элементах MPD и атрибуты в более общем случае, любые элементы, а не только отображения или набор отображений, могут ассоциироваться с временем действия. Поэтому, если некоторые элементы MPD нужно обновить, например, где изменяется количество отображений или изменяются правила конструирования URL, то эти элементы можно обновить по отдельности в заданные моменты путем предоставления нескольких копий элемента с непересекающимися моментами действия.
[0308] Действие преимущественно ассоциируется с глобальным временем мультимедиа, так что описанный элемент, ассоциированный с временем действия, является допустимым в периоде глобальной временной шкалы представления мультимедиа.
[0309] Как обсуждалось выше, в одном варианте осуществления моменты действия добавляются только к полному набору отображений. Каждый полный набор затем образует период. Время действия тогда образует время начала периода. Другими словами, в конкретном случае использования элемента действия полный набор отображений может быть допустимым в течение периода времени, указанного глобальным временем действия для набора отображений. Время действия набора отображений называется периодом. В начале нового периода действие предыдущего набора отображений заканчивается, и допустимым является новый набор отображений. Снова отметим, что моменты действия периодов предпочтительно не пересекаются.
[0310] Как отмечалось выше, изменения в Описании представления мультимедиа происходят на границах сегментов, и поэтому для каждого отображения изменение элемента фактически происходит на следующей границе сегмента. Клиент может тогда сформировать допустимое MPD, включающее в себя список сегментов для каждого момента времени в рамках времени представления мультимедиа.
[0311] Прерывистая стыковка блоков может быть подходящей в случаях, когда блоки содержат мультимедийные данные из разных отображений или из разного контента, например, из сегмента контента и рекламы, либо в иных случаях. В системе потоковой передачи по запросу блоков может быть необходимо, чтобы изменения в метаданных представления происходили только на границах блоков. Это может быть выгодным по причинам реализации, потому что обновление параметров декодера мультимедиа в блоке может быть сложнее их обновления только между блоками. В этом случае преимущественно может задаваться, что интервалы действия, которые описаны выше, можно интерпретировать как приблизительные, так что элемент считается допустимым от первой границы блока не ранее начала заданного интервала действия до первой границы блока не ранее окончания заданного интервала действия.
[0312] Примерный вариант осуществления вышеизложенного, который описывает новые улучшения в системе потоковой передачи по запросу блоков, описывается в позже представленном разделе, озаглавленном "Изменения в Представлениях мультимедиа".
СИГНАЛИЗАЦИЯ ДЛИТЕЛЬНОСТИ СЕГМЕНТА
[0313] Прерывистые обновления эффективно делят представление на последовательность непересекающихся интервалов, называемых периодом. Каждый период обладает своей временной шкалой для синхронизации выборки мультимедиа. Хронометраж мультимедиа в отображении в рамках периода может указываться преимущественно путем задания отдельного компактного списка длительностей сегментов для каждого периода или для каждого отображения в периоде.
[0314] Атрибут, например называемый временем начала периода, ассоциированный с элементами в MPD, может задавать время действия некоторых элементов в рамках времени представления мультимедиа. Этот атрибут может добавляться к любым элементам MPD (атрибуты, которым может назначаться действие, могут меняться на элементы).
[0315] Для прерывистых обновлений MPD сегменты всех отображений могут заканчиваться в точке разрыва. Это обычно, по меньшей мере, подразумевает, что последний сегмент перед точкой разрыва имеет отличную длительность от предыдущих сегментов. Сигнализация длительности сегмента может включать в себя указание, что либо все сегменты имеют одинаковую длительность, либо указание отдельной длительности для каждого сегмента. Может быть, желательно иметь компактное представление для списка длительностей сегментов, которое эффективно в случае, когда многие из них имеют одинаковую длительность.
[0316] Длительности каждого сегмента в одном отображении или наборе отображений преимущественно могут передаваться одиночной строкой, которая задает все длительности сегментов для одного интервала от начала прерывистого обновления, то есть начала периода, до последнего мультимедийного сегмента, описанного в MPD. В одном варианте осуществления формат этого элемента является текстовой строкой, соответствующей произведению, которая содержит список с записями длительностей сегментов, причем каждая запись содержит атрибут длительности dur и необязательный множитель mult атрибута, указывая, что это отображение содержит <mult> сегментов первой записи с длительностью <dur> первой записи, затем <mult> сегментов второй записи с длительностью <dur> второй записи, и так далее.
[0317] Каждая запись длительности задает длительность одного или нескольких сегментов. Если значение <dur> сопровождается символом "*" и числом, то это число задает количество последовательных сегментов с этой длительностью, в секундах. Если знак множителя "*" отсутствует, то количество сегментов равно одному. Если "*" присутствует без последующего числа, то все последующие сегменты имеют заданную длительность, и в списке не может быть никаких дополнительных записей. Например, строка "30*" означает, что все сегменты имеют длительность 30 секунд. Строка "30*12 10,5" указывает 12 сегментов с длительностью 30 секунд с последующим сегментом длительности 10,5 секунд.
[0318] Если длительности сегментов задаются отдельно для каждого альтернативного отображения, то сумма длительностей сегментов в каждом интервале может быть одинаковой для каждого отображения. В случае дорожек видеоизображения интервал может заканчиваться на одном и том же кадре в каждом альтернативном отображении.
[0319] Обычные специалисты в данной области техники при прочтении этого раскрытия изобретения могут обнаружить аналогичные и эквивалентные способы для выражения длительностей сегментов компактным образом.
[0320] В другом варианте осуществления длительность сегмента сигнализируется постоянной для всех сегментов в отображении за исключением последнего с помощью атрибута длительности сигнала <duration>. Длительность последнего сегмента перед прерывистым обновлением может быть короче при условии, что предоставляется начальная точка следующего прерывистого обновления или начало нового периода, которая тогда подразумевает длительность последнего сегмента достигающей начала следующего периода.
ИЗМЕНЕНИЯ И ОБНОВЛЕНИЯ В МЕТАДАННЫХ ОТОБРАЖЕНИЯ
[0321] Указание изменений двоично кодированных метаданных отображения, например изменений заголовка фильма "moov", может выполняться разными способами: (а) может быть один блок moov для всего отображения в отдельном файле, упоминаемом в MPD, (b) может быть один блок moov для каждого альтернативного отображения в отдельном файле, упоминаемом в каждом Альтернативном отображении, (с) каждый сегмент может содержать блок moov и поэтому является независимым, (d) блок moov может присутствовать для всего отображения в одном файле 3GP вместе с MPD.
[0322] Отметим, что в случае (a) и (b) одиночный "moov" преимущественно может объединяться с понятием действия из вышеизложенного в том смысле, что больше блоков "moov" может упоминаться в MPD при условии, что их действие является непересекающимся. Например, с помощью определения границы периода действие "moov" в старом периоде может истечь с началом нового периода.
[0323] В случае варианта (а) ссылка на одиночный блок moov может назначаться элементу действия. Может быть разрешено несколько заголовков представления, но только один может быть допустимым единовременно. В другом варианте осуществления время действия всего набора отображений в периоде или весь период, как задано выше, может использоваться в качестве времени действия для этих метаданных отображения, обычно предоставленных как заголовок moov.
[0324] В случае варианта (b) ссылка на блок moov каждого отображения может назначаться элементу действия. Может быть разрешено несколько заголовков отображения, но только один может быть допустимым единовременно. В другом варианте осуществления время действия всего отображения или весь период, как задано выше, может использоваться в качестве времени действия для этих метаданных отображения, обычно предоставленных как заголовок moov.
[0325] В случае варианта (с) никакую сигнализацию можно не добавлять в MPD, но дополнительная сигнализация в мультимедийном потоке может добавляться для указания, изменится ли блок moov для любого из предстоящих сегментов. Это дополнительно объясняется ниже применительно к разделу "Сигнализации обновлений в метаданных сегмента".
СИГНАЛИЗАЦИЯ ОБНОВЛЕНИЙ В МЕТАДАННЫХ СЕГМЕНТА
[0326] Чтобы избежать частых обновлений описания представления мультимедиа для получения сведений о возможных обновлениях, полезно сигнализировать любые такие обновления вместе с мультимедийными сегментами. Может предоставляться дополнительный элемент или элементы в самих мультимедийных сегментах, которые могут указывать, что обновленные метаданные, например описание представления мультимедиа, доступны и к ним нужно, обратиться в пределах некоторого количества времени, чтобы успешно продолжить создание списков доступных сегментов. К тому же такие элементы могут предоставлять идентификатор файла, например URL, или информацию, которая может использоваться для создания идентификатора файла для обновленного файла метаданных. Обновленный файл метаданных может включать в себя метаданные, идентичные предоставленным в исходном файле метаданных для измененного представления, чтобы указать интервалы действия вместе с дополнительными метаданными, также сопровождаемыми интервалами действия. Такое указание может предоставляться в мультимедийных сегментах всех доступных отображений для представления мультимедиа. Клиент, обращающийся к системе потоковой передачи по запросу блоков, при обнаружении такого указания в блоке мультимедиа может использовать протокол загрузки файла или другое средство для извлечения обновленного файла метаданных. Клиент посредством этого снабжается информацией об изменениях в описании представления мультимедиа и временем, в которое они возникнут или уже возникли. Преимущественно, чтобы каждый клиент запрашивал обновленное описание представления мультимедиа только один раз, когда такие изменения возникают, вместо "опроса" и приема файла много раз ради возможных обновлений или изменений.
[0327] Примеры изменений включают в себя добавление или удаление отображений, изменения в одном или нескольких отображениях, например изменение в скорости передачи битов, разрешении, соотношении сторон, включенных дорожках или параметрах кодека, и изменения в правилах конструирования URL, например, другой сервер-источник для рекламы. Некоторые изменения могут влиять только на сегмент инициализации, например атом Заголовка фильма ("moov"), ассоциированный с отображением, тогда как другие изменения могут влиять на Описание представления мультимедиа (MPD).
[0328] В случае контента по требованию эти изменения и их синхронизация могут быть известны заранее и могли бы сигнализироваться в Описании представления мультимедиа.
[0329] Для контента прямой передачи изменения могут быть неизвестны до момента, в который они возникают. Одним решением является позволить динамически обновлять описание представления мультимедиа, доступное по определенному URL, и требовать от клиентов регулярно запрашивать это MPD, чтобы обнаружить изменения. Это решение имеет недостаток в плане масштабируемости (нагрузка на сервер-источник и эффективность кэша). В сценарии с большим количеством зрителей кэши могут принимать много запросов MPD после того, как предыдущая версия утратила силу в кэше, и перед тем, как принята новая версия, и все эти запросы могут перенаправляться серверу-источнику. Серверу-источнику может потребоваться постоянно обрабатывать запросы из кэшей для каждой обновленной версии MPD. Также обновления может быть не просто выровнять по времени с изменениями в представлении мультимедиа.
[0330] Поскольку одним из преимуществ потоковой передачи HTTP является возможность использовать стандартную веб-инфраструктуру и услуги для масштабируемости, предпочтительное решение может включать в себя только "статические" (то есть кэшируемые) файлы и не полагаться на клиентов, "опрашивающих" файлы, чтобы увидеть, изменились ли они.
[0331] Обсуждаются и предлагаются решения для разделения обновления метаданных, включающих описание представления мультимедиа, и двоичных метаданных отображения, например атомов "moov", в представлении мультимедиа при адаптивной потоковой передаче HTTP.
[0332] Для случая контента прямой передачи моменты, в которые MPD или "moov" могут меняться, могут быть неизвестны, когда создается MPD. Так как обычно следует избегать частого "опроса" MPD для проверки обновлений по причинам полосы пропускания и масштабируемости, обновления MPD могут указываться "в полосе" в самих файлах сегментов, то есть каждый мультимедийный сегмент может иметь возможность указывать обновления. В зависимости от форматов сегментов с (а) по (с) выше может сигнализироваться разное обновление.
[0333] Как правило, следующее указание преимущественно может предоставляться в сигнале в сегменте: индикатор, что MPD может быть обновлено перед запросом следующего сегмента в этом отображении или любого следующего сегмента, который имеет время начала больше времени начала текущего сегмента. Обновление может объявляться заранее, указывая, что обновление должно происходить только в любом сегменте позже следующего. Это обновление MPD также может использоваться для обновления двоичных метаданных отображения, например Заголовков фильма, если изменяется указатель мультимедийного сегмента. Другой сигнал может указывать, что при завершении этого сегмента не следует запрашивать никакие сегменты, которые опережают время.
[0334] Если сегменты форматируются в соответствии с форматом сегмента (с), то есть каждый мультимедийный сегмент может содержать метаданные самоинициализации, например заголовок фильма, то может добавляться еще один сигнал, указывающий, что последующий сегмент содержит обновленный Заголовок фильма (moov). Это преимущественно позволяет включать заголовок фильма в сегмент, но клиенту нужно запрашивать заголовок фильма, только если предыдущий сегмент указывает Обновление заголовка фильма или в случае поиска, либо произвольного доступа при переключении отображений. В других случаях клиент может выдать запрос байтового диапазона к сегменту, который исключает заголовок фильма из загрузки, поэтому преимущественно экономя полосу пропускания.
[0335] В еще одном варианте осуществления, если сигнализируется указание Обновления MPD, то сигнал также может содержать указатель, например URL, для обновленного Описания представления мультимедиа. Обновленное MPD может описывать представление до и после обновления, используя атрибуты действия, например новый и старый период в случае прерывистых обновлений. Это может использоваться преимущественно для разрешения отложенного просмотра, который дополнительно описывается ниже, но также преимущественно позволяет сигнализировать обновление MPD в любое время перед тем, как вступят в силу изменения, которые оно содержит. Клиент может немедленно загрузить новое MPD и применить его к текущему представлению.
[0336] В конкретной реализации сигнализация любых изменений в описании представления мультимедиа, заголовках moov или окончании представления может содержаться в блоке информации потоковой передачи, который форматируется по правилам формата сегмента, используя структуру блока в базовом формате мультимедийного файла ISO. Этот блок может предоставить отдельный сигнал для любого из разных обновлений.
[0337] Блок информации потоковой передачи
[0338] Определение
[0339] Тип блока: "sinf"
Контейнер: Нет
Обязательный: Нет
Количество: Ноль или один.
[0340] Блок информации потоковой передачи содержит информацию о потоковом представлении, частью которого является файл.
[0341] Синтаксис
[0342]
aligned(8) class StreamingInformationBox
extends FullBox('sinf') {
unsigned int(32) streaming_information_flags;
[0343] /// Следующее является необязательными полями
string mpd_location
}
[0344] Семантика
[0345] streaming_information_flags содержит логическое ИЛИ нуля или нескольких из следующего:
[0346] 0x00000001 Последует обновление Заголовка фильма
[0347] 0x00000002 Обновление Описания представления
[0348] 0x00000004 Окончание представления
[0349] mpd_location присутствует тогда и только тогда, когда признак обновления Описания представления устанавливается и предоставляет Унифицированный указатель ресурса для нового Описания представления мультимедиа.
ПРИМЕРНЫЙ ВАРИАНТ ИСПОЛЬЗОВАНИЯ ДЛЯ ОБНОВЛЕНИЙ MPD ДЛЯ ИНТЕРАКТИВНЫХ УСЛУГ
[0350] Предположим, что поставщик услуг хочет предоставить прямую трансляцию футбольного соревнования с использованием улучшенной потоковой передачи по запросу блоков, описанной в этом документе. Возможно, миллионы пользователей могли бы захотеть получить доступ к представлению этого соревнования. Прямая трансляция время от времени прерывается паузами, когда происходит перерыв или другое временное затишье в действии, во время которого могла бы добавляться реклама. Как правило, отсутствует, или имеется небольшое предварительное предупреждение о точном распределении во времени пауз.
[0351] Поставщику услуг могло бы потребоваться предоставить избыточную инфраструктуру (например, кодеры и серверы), чтобы задействовать плавное переключение, если какие-нибудь компоненты выйдут из строя во время прямой трансляции.
[0352] Предположим, что пользователь Анна обращается к услуге в автобусе с помощью своего мобильного устройства, и услуга становится доступной немедленно. Рядом с ней сидит другой пользователь Пол, который смотрит соревнование на переносном компьютере. Забивают гол, и оба празднуют это событие одновременно. Пол говорит Анне, что первый гол в игре был еще более захватывающим, и Анна использует услугу, так, что она может посмотреть соревнование на 30 минут раньше во времени. Увидев гол, она возвращается к прямой трансляции.
[0353] Чтобы разобраться с этим вариантом использования, поставщик услуг должен иметь возможность обновить MPD, сигнализировать клиентам, что обновленное MPD доступно, и разрешить клиентам обратиться к услуге потоковой передачи, так что он может представить данные близко к реальному масштабу времени.
[0354] Обновление MPD осуществимо асинхронно к доставке сегментов, как объясняется где-то в другом месте в этом документе. Сервер может предоставить гарантии приемнику, что MPD не обновляется в течение некоторого времени. Сервер может опираться на текущее MPD. Однако никакой явной сигнализации не нужно, когда MPD обновляется раньше некоторого минимального периода обновления.
[0355] Полностью синхронное воспроизведение едва ли достижимо, так как клиент может работать с разными экземплярами обновления MPD, и поэтому клиенты могут иметь смещение. Используя обновления MPD, сервер может сообщить изменения, и клиенты могут быть предупреждены об изменениях, даже во время представления. Внутриполосная сигнализация на посегментной основе может использоваться для указания обновления MPD, поэтому обновления могли бы ограничиваться границами сегментов, но это должно быть приемлемо в большинстве применений.
[0356] Может добавляться элемент MPD, который предоставляет время публикации MPD по реальному времени, а также необязательный блок обновления MPD, который добавляется в начало сегментов, чтобы сигнализировать, что необходимо обновление MPD. Обновления могут выполняться иерархически, как и в случае с MPD.
[0357] "Время публикации" MPD предоставляет уникальный идентификатор для MPD и то, когда MPD было выпущено. Оно также обеспечивает привязку для процедур обновления.
[0358] Блок обновления MPD можно обнаружить в MPD после блока "styp", с заданным типом блока = "mupe", не требующим контейнера, не обязательным и имеющим количество, равное нулю или единице. Блок обновления MPD содержит информацию о представлении мультимедиа, частью которого является сегмент.
[0359] Примерный синтаксис выглядит следующим образом:
[0360] aligned(8) class MPDUpdateBox
[0361] extends FullBox('mupe') {
[0362] unsigned int(3) mpd information flags;
[0363] unsigned int(l) new-location flag;
[0364] unsigned int(28) latest_mpd_update time;
[0365] /// Следующее является необязательными полями
[0366] string mpd_location
[0367] }
[0368] Семантика различных объектов класса MPDUpdateBox могла бы выглядеть следующим образом:
[0369] mpd_information_flags: логическое или нуля или нескольких из следующего:
[0370] 0x00 Обновление Описания представления мультимедиа сейчас
[0371] 0x01 Обновление Описания представления мультимедиа впереди
[0372] 0x02 Окончание представления
[0373] 0x03-0x07 Зарезервировано
[0374] new_location_flag: если установлен в 1, то новое Описание представления мультимедиа доступно в новом расположении, заданном mpd_location.
[0375] latest_mpd_update time: задает время (в мс), к которому необходимо обновление MPD, относительно времени выпуска MPD у последнего MPD. Клиент может выбирать обновление MPD в любое время между настоящим моментом.
[0376] mpd_location: присутствует тогда и только тогда, когда устанавливается new_location_flag, и если это так, то mpd_location предоставляет Унифицированный указатель ресурса для нового Описания представления мультимедиа.
[0377] Если полоса пропускания, используемая обновлениями, является проблемой, то сервер может предложить MPD для некоторых возможностей устройства, так что обновляются только эти части.
ОТЛОЖЕННЫЙ ПРОСМОТР И СЕТЕВОЙ PVR
[0378] Когда поддерживается отложенный просмотр, может произойти так, что в течение времени существования сеанса допустимы два или более MPD или Заголовка фильма. В этом случае путем обновления MPD при необходимости, но с добавлением идеи механизма или периода действия допустимое MPD может существовать в течение всего интервала времени. Это означает, что сервер может обеспечить, что любое MPD и Заголовок фильма объявляются в течение любого периода времени, который входит в допустимый интервал времени для отложенного просмотра. Клиент должен обеспечить, что доступное MPD и метаданные для текущего времени представления допустимы. Также может поддерживаться переход сеанса прямой передачи на сеанс сетевого PVR, используя только второстепенные обновления MPD.
Специальные мультимедийные сегменты
[0379] Когда формат файла ISO/IEC 14496-12 используется в системе потоковой передачи по запросу блоков, проблема состоит в том, как описано выше, что может быть выгодно, хранить мультимедийные данные для одной версии представления в нескольких файлах, размещенных в последовательных временных сегментах. Кроме того, может быть выгодно, организовать так, что каждый файл начинается с Точки произвольного доступа. Дополнительно может быть выгодно, выбирать положения точек поиска во время процесса кодирования видеоизображения и сегментировать представление на несколько файлов, начинающихся с точки поиска, на основе выбора точек поиска, который был сделан во время процесса кодирования, при котором каждая Точка произвольного доступа может помещаться или не помещаться в начало файла, но при котором каждый файл начинается с Точки произвольного доступа. В одном варианте осуществления с описанными выше свойствами метаданные представления, или Описание представления мультимедиа, могут содержать точную длительность каждого файла, причем длительность воспринимается означающей, например, разницу между временем начала видеоизображения в файле и временем начала видеоизображения в следующем файле. На основе этой информации в метаданных представления клиент способен создать преобразование между глобальной временной шкалой для представления мультимедиа и локальной временной шкалой для мультимедиа в каждом файле.
[0380] В другом варианте осуществления размер метаданных представления преимущественно можно уменьшить путем задания вместо него, что каждый файл или сегмент имеет одинаковую длительность. Однако в этом случае и там, где мультимедийные файлы создаются в соответствии со способом выше, длительность каждого файла может быть не в точности равна длительности, заданной в описании представления мультимедиа, потому что Точка произвольного доступа может не существовать в точке, которая находится в точно заданной длительности от начала файла.
[0381] Теперь описывается дополнительный вариант осуществления изобретения для обеспечения правильной работы системы потоковой передачи по запросу блоков, несмотря на упомянутое выше расхождение. В этом способе может предоставляться элемент в каждом файле, который задает преобразование локальной временной шкалы мультимедиа в файле (под которой понимается временная шкала, начинающаяся от временной отметки нуля, по отношению к которой временные отметки декодирования и композиции выборок мультимедиа в файле задаются в соответствии с ISO/IEC 14496-12) в глобальную временную шкалу представления. Эта информация преобразования может содержать одиночную временную отметку в глобальном времени представления, которое соответствует нулевой временной отметке на локальной временной шкале файла. Информация преобразования в качестве альтернативы может содержать значение смещения, которое задает разницу между глобальным временем представления, соответствующим нулевой временной отметке на локальной временной шкале файла, и глобальным временем представления, соответствующим началу файла в соответствии с информацией, предоставленной в метаданных представления.
[0382] Примером таких блоков может быть, например, блок времени декодирования фрагмента дорожки ("tfdt") или блок регулировки фрагмента дорожки ("tfad") вместе с блоком регулирования мультимедиа фрагмента дорожки ("tfma").
ПРИМЕРНЫЙ КЛИЕНТ, ВКЛЮЧАЮЩИЙ В СЕБЯ ФОРМИРОВАНИЕ СПИСКА СЕГМЕНТОВ
[0383] Сейчас будет описываться примерный клиент. Он мог бы использоваться в качестве эталонного клиента для сервера, чтобы обеспечивать надлежащее формирование и обновления MPD.
[0384] Клиент потоковой передачи HTTP управляется информацией, предоставленной в MPD. Предполагается, что у клиента есть доступ к MPD, которое он принял в момент T, то есть момент, когда он мог успешно принять MPD. Определение успешного приема может включать в себя клиента, получающего обновленное MPD, или клиента, проверяющего, что MPD не обновлено с предыдущего успешного приема.
[0385] Представляется поведение примерного клиента. Для предоставления пользователю непрерывной услуги потоковой передачи клиент сначала анализирует MPD и создает список доступных сегментов для каждого отображения для локального времени клиента в текущее системное время, учитывая процедуры формирования списка сегментов, которые подробно изложены ниже, по возможности используя списки воспроизведения или правила конструирования URL. Затем клиент выбирает одно или несколько отображений на основе информации в атрибутах отображения и другой информации, например, доступной полосы пропускания и возможностей клиента. В зависимости от группировки отображения могут быть показаны автономно или одновременно с другими отображениями.
[0386] Для каждого отображения клиент получает двоичные метаданные, например заголовок "moov" для отображения, если присутствует, и мультимедийные сегменты выбранных отображений. Клиент обращается к мультимедийному контенту, запрашивая сегменты или байтовые диапазоны сегментов, по возможности с использованием списка сегментов. Клиент может сначала буферизовать мультимедиа перед началом представления, и как только представление началось, клиент продолжает потребление мультимедийного контента, постоянно запрашивая сегменты или части сегментов, принимая во внимание процедуры обновления MPD.
[0387] Клиент может переключать отображения, учитывая информацию обновленного MPD и/или обновленную информацию из своего окружения, например, изменение доступной полосы пропускания. С помощью любого запроса мультимедийного сегмента, содержащего точку произвольного доступа, клиент может переключаться на другое отображение. При перемещении вперед, то есть, опережая текущее системное время (называемое "временем NOW" для представления времени относительно представления), клиент потребляет доступные сегменты. При каждом опережении во времени NOW клиент по возможности расширяет список доступных сегментов для каждого отображения в соответствии с процедурами, заданными в этом документе.
[0388] Если окончание представления мультимедиа еще не достигнуто, и если текущее время воспроизведения попадает в пороговую величину, для которой клиент ожидает окончания мультимедиа в мультимедиа, описанном в MPD для любого потребляемого отображения или отображения, которое будет потребляться, то клиент может запросить обновление MPD с новым временем выборки T. Как только оно принято, клиент по возможности принимает во внимание, обновленное MPD и новое время T при формировании списков доступных сегментов. Фиг. 29 иллюстрирует процедуру для интерактивных услуг в разные моменты на клиенте.
ФОРМИРОВАНИЕ СПИСКА ДОСТУПНЫХ СЕГМЕНТОВ
[0389] Допустим, что клиент потоковой передачи HTTP имеет доступ к MPD и может захотеть сформировать список доступных сегментов для реального времени NOW. Клиент синхронизируется с глобальной привязкой ко времени с некоторой точностью, но преимущественно не требуется прямой синхронизации с сервером потоковой передачи HTTP.
[0390] Список доступных сегментов для каждого отображения предпочтительно задается в виде списка пар из времени начала сегмента и указателя сегмента, причем время начала сегмента может задаваться относительно начала отображения без потери общности. Начало отображения может быть выровнено с началом периода, если эта идея применяется. В противном случае начало отображения может находиться в начале представления мультимедиа.
[0391] Клиент использует правила конструирования URL и синхронизацию, которые, например, дополнительно определяются в этом документе. Как только получается список описанных сегментов, этот список дополнительно ограничивается доступными сегментами, которые могут быть подмножеством сегментов полного представления мультимедиа. Создание управляется текущим значением времени во времени клиента NOW. Как правило, сегменты доступны только в течение любого времени NOW в наборе моментов доступности. Для моментов NOW вне этого интервала не доступны никакие сегменты. К тому же для интерактивных услуг предположим, что некоторое время checktime предоставляет информацию о том, насколько далеко в будущем описывается мультимедиа. Checktime задается на документированной в MPD оси времени мультимедиа; когда время воспроизведения клиента достигает checktime, он преимущественно запрашивает новое MPD.
[0392] когда время воспроизведения клиента достигает checktime, он преимущественно запрашивает новое MPD.
[0393] Затем список сегментов дополнительно ограничивается checktime вместе с атрибутом MPD TimeShiftBufferDepth, так что доступными мультимедийными сегментами являются только те, для которых сумма времени начала мультимедийного сегмента и времени начала отображения попадает в интервал между NOW минус timeShiftBufferDepth минус длительность последнего описанного сегмента, и меньшим значением из checktime либо NOW.
МАСШТАБИРУЕМЫЕ БЛОКИ
[0394] Иногда доступная полоса пропускания снижается так низко, что блок или блоки, принимаемые в настоящее время на приемнике, вряд ли будут полностью приняты вовремя для воспроизведения без остановки представления. Приемник мог бы заранее обнаруживать такие ситуации. Например, приемник мог бы определять, что он принимает блоки, кодируя 5 единиц мультимедиа в каждые 6 единиц времени, и содержит буфер на 4 единицы мультимедиа, так что приемник мог бы предположить необходимость остановки представления, или паузы, примерно через 24 единицы времени. При достаточном уведомлении приемник может среагировать на такую ситуацию, например, путем отказа от текущего потока блоков и начала запроса блока или блоков из другого отображения контента, например того, которое использует меньше полосы пропускания на единицу времени воспроизведения. Например, если приемник переключился на отображение, при котором блоки кодированы по меньшей мере на 20% больше времени видеоизображения для такого же размера блоков, то приемник мог бы устранить необходимость останавливаться до тех пор, пока не улучшится ситуация с полосой пропускания.
[0395] Однако, может быть неэкономно заставлять приемник полностью отбрасывать данные, уже принятые из оставленного отображения. В варианте осуществления системы потоковой передачи блоков, описанном в этом документе, данные в каждом блоке могут кодироваться и размещаться так, что некоторые префиксы данных в блоке могут использоваться для продолжения представления без принятой оставшейся части блока. Например, могут использоваться общеизвестные методики масштабируемого кодирования видеоизображения. Примеры таких способов кодирования видеоизображения включают в себя Масштабируемое кодирование видеоизображения (SVC) H.264 или временную масштабируемость в Улучшенном кодировании видеосигнала (AVC) H.264. Преимущественно этот способ позволяет продолжать представление на основе части блока, которая принята, даже когда прием блока или блоков мог быть оставлен, например, из-за изменений в доступной полосе пропускания. Другое преимущество состоит в том, что один файл данных может использоваться в качестве источника для нескольких разных отображений контента. Это возможно, например, путем использования частичных запросов GET HTTP, которые выбирают подмножество блока, соответствующее необходимому отображению.
[0396] Одним улучшением, подробно изложенным в этом документе, является расширенный сегмент, масштабируемая карта сегмента. Масштабируемая карта сегмента содержит расположения разных уровней в сегменте, так что клиент может обратиться соответственно к частям сегментов и извлечь уровни. В другом варианте осуществления мультимедийные данные в сегменте упорядочиваются так, что качество сегмента увеличивается наряду с загрузкой данных постепенно от начала сегмента. В другом варианте осуществления постепенное увеличение качества применяется для каждого блока или фрагмента, заключенных в сегменте, так что запросы фрагментов могут выполняться для отражения масштабируемого подхода.
[0397] Фиг. 12 - фигура, показывающая особенность масштабируемых блоков. На той фигуре передатчик 1200 выводит метаданные 1202, масштабируемый уровень 1 (1204), масштабируемый уровень 2 (1206) и масштабируемый уровень 3 (1208), причем последний задерживается. Тогда приемник 1210 может использовать метаданные 1202, масштабируемый уровень 1 (1204) и масштабируемый уровень 2 (1206) для показа представления 1212 мультимедиа.
НЕЗАВИСИМЫЕ УРОВНИ МАСШТАБИРУЕМОСТИ
[0398] Как объяснялось выше, системе потоковой передачи по запросу блоков нежелательно останавливаться, когда приемник не способен принимать запрошенные блоки определенного отображения мультимедийных данных во время для их воспроизведения, так как это часто приводит к плохому взаимодействию с пользователем. Остановок можно избежать, уменьшить или смягчить путем ограничения скорости передачи данных выбранных отображений гораздо ниже доступной полосы пропускания, чтобы стало маловероятно, что какая-нибудь заданная часть представления не принялась вовремя, но эта стратегия имеет недостаток в том, что качество мультимедиа обязательно гораздо ниже, чем в принципе могло бы поддерживаться доступной полосой пропускания. Представление более низкого качества, нежели возможно, также можно интерпретировать как плохое взаимодействие с пользователем. Таким образом, проектировщик системы потоковой передачи по запросу блоков сталкивается с выбором при исполнении клиентских процедур, программировании клиента или конфигурировании аппаратных средств: запросить версию контента, которая имеет гораздо меньшую скорость передачи данных, чем доступная полоса пропускания, и в этом случае пользователь может страдать от плохого качества мультимедиа, либо запросить версию контента, которая имеет скорость передачи данных, близкую к доступной полосе пропускания, и в этом случае пользователь может страдать от высокой вероятности пауз во время представления, когда меняется доступная полоса пропускания.
[0399] Чтобы справляться с таким ситуациями, системы потоковой передачи блоков, описанные в этом документе, могли бы конфигурироваться для независимой обработки нескольких уровней масштабируемости, так что приемник может выполнять многоуровневые запросы, а передатчик может отвечать на многоуровневые запросы.
[0400] В таких вариантах осуществления, кодированные мультимедийные данные для каждого блока могут, разделяться на несколько непересекающихся фрагментов, называемых в этом документе "уровнями", так что сочетание уровней содержит все мультимедийные данные для блока, и так что клиент, который принял некоторые подмножества уровней, может выполнять декодирование и представление отображения контента. В этом подходе упорядочение данных в потоке таково, что смежные диапазоны увеличиваются по качеству, и метаданные это отражают.
[0401] Примером методики, которая может использоваться для формирования уровней с вышеупомянутым свойством, является методика Масштабируемого кодирования видеоизображения, например, которая описана в Стандартах H.264/SVC ITU-T. Другим примером методики, которая может использоваться для формирования уровней с вышеупомянутым свойством, является методика уровней с временной масштабируемостью, которая предоставлена в Стандарте H.264/AVC ITU-T.
[0402] В этих вариантах осуществления метаданные могли бы предоставляться в MPD или в самом сегменте, что дает возможность создания запросов отдельных уровней любого заданного блока и/или сочетаний уровней и/или заданного уровня из нескольких блоков и/или сочетания уровней нескольких блоков. Например, уровни, содержащие блок, могли бы храниться в одном файле, и могли бы предоставляться метаданные, задающие байтовые диапазоны в файле, соответствующие отдельным уровням.
[0403] Протокол загрузки файла, допускающий задание байтовых диапазонов, например HTTP 1.1, может использоваться для запроса отдельных уровней или нескольких уровней. Кроме того, как будет понятно специалисту в данной области техники при рассмотрении этого раскрытия изобретения, описанные выше методики в отношении создания, запроса и загрузки блоков переменного размера и переменных сочетаний блоков могут применяться с тем же успехом в этом контексте.
СОЧЕТАНИЯ
[0404] Теперь описывается некоторое количество вариантов осуществления, которые могут применяться преимущественно клиентом потоковой передачи по запросу блоков, чтобы добиться улучшения взаимодействия с пользователем и/или сокращения требований к пропускной способности обслуживающей инфраструктуры по сравнению с существующими методиками, путем использования мультимедийных данных, разделенных на уровни, как описано выше.
[0405] В первом варианте осуществления известные методики в системе потоковой передачи по запросу блоков могут применяться с модификацией, что разные версии контента в некоторых случаях заменяются разными сочетаниями уровней. Другими словами, там, где существующая система могла бы предоставить два отдельных отображения контента, описанная здесь улучшенная система могла бы предоставить два уровня, причем одно отображение контента в существующей системе аналогично по скорости передачи, качеству и, возможно, другим показателям первому уровню в улучшенной системе, а второе отображение контента в существующей системе аналогично по скорости передачи, качеству и, возможно, другим показателям сочетанию двух уровней улучшенной системы. В результате объем памяти, необходимый в улучшенной системе, уменьшается по сравнению с необходимым в существующей системе. Кроме того, тогда как клиенты существующей системы могут запрашивать блоки одного отображения или другого отображения, клиенты улучшенной системы могут запрашивать либо первый, либо оба уровня блока. В результате взаимодействие с пользователем в двух системах аналогично. Кроме того, предоставляется усовершенствованное кэширование, так как даже для разного качества используются общие сегменты, которые затем кэшируются с большим правдоподобием.
[0406] Во втором варианте осуществления клиент в улучшенной системе потоковой передачи по запросу блоков, применяющей описываемый способ уровней, может поддерживать отдельный буфер данных для каждого из нескольких уровней кодирования мультимедиа. Как будет понятно специалистам в области управления данными в клиентских устройствах, эти "отдельные" буферы могут быть реализованы путем выделения физически или логически отдельных областей памяти для отдельных буферов или с помощью других методик, в которых буферизованные данные хранятся в одном или нескольких областях памяти, и разделение данных с разных уровней достигается логически посредством использования структур данных, которые содержат ссылки на ячейки памяти данных с отдельных уровней, и поэтому в дальнейшем термин "отдельные буферы" следует понимать включающим в себя любой способ, по которому данные отдельных уровней могут быть идентифицированы отдельно. Клиент выдает запросы отдельных уровней каждого блока на основе занятости каждого буфера, например, уровни могут быть упорядочены в порядке приоритета, так что запрос данных с одного уровня может не выдаваться, если занятость какого-либо буфера для нижнего уровня в порядке приоритета ниже пороговой величины для того нижнего уровня. В этом способе приоритет отдается приему данных с нижних уровней в порядке приоритета, так что если доступная полоса пропускания опускается ниже необходимой, чтобы принимать также верхние уровни в порядке приоритета, то запрашиваются только нижние уровни. Кроме того, пороговые величины, ассоциированные с разными уровнями, могут отличаться, так что, например, нижние уровни имеют более высокие пороговые величины. В случае если доступная полоса пропускания изменяется, так что данные для верхнего уровня нельзя принять перед временем воспроизведения блока, то данные для нижних уровней обязательно будут уже приняты, и поэтому представление может продолжаться с одними нижними уровнями. Пороговые величины для занятости буфера могут быть заданы в показателях байтов данных, длительности воспроизведения данных, содержащихся в буфере, количества блоков или любой другой подходящей величины.
[0407] В третьем варианте осуществления способы из первого и второго вариантов осуществления могут объединяться, так что предоставляются несколько отображений мультимедиа, содержащих подмножество уровней (как в первом варианте осуществления), и так что второй вариант осуществления применяется к подмножеству уровней в отображении.
[0408] В четвертом варианте осуществления способы из первого, второго и/или третьего вариантов осуществления могут объединяться с вариантом осуществления, в котором предоставляется несколько независимых отображений контента, так что, например, по меньшей мере, одно из независимых отображений содержит несколько уровней, к которым применяются методики из первого, второго и/или третьего вариантов осуществления.
УЛУЧШЕННЫЙ ДИСПЕТЧЕР БУФЕРА
[0409] В сочетании с монитором 126 буфера (см. фиг. 2) улучшенный диспетчер буфера может использоваться для оптимизации буфера на стороне клиента. Системы потоковой передачи по запросу блоков хотят гарантировать, что воспроизведение мультимедиа может начинаться быстро и продолжаться плавно, одновременно предоставляя максимальное качество мультимедиа пользователю или устройству назначения. Это может потребовать, чтобы клиент запрашивал блоки, которые имеют наивысшее качество мультимедиа, но которые также могут быстро начинаться и приниматься вовремя, чтобы воспроизводиться без вынуждения паузы в представлении.
[0410] В вариантах осуществления, которые используют улучшенный диспетчер буфера, диспетчер определяет, какие блоки мультимедийных данных запрашивать и когда делать эти запросы. Улучшенный диспетчер буфера мог бы, например, снабжаться набором метаданных для контента, который нужно представить, причем эти метаданные включают в себя список отображений, доступных для контента, и метаданные для каждого отображения. Метаданные для отображения могут содержать информацию о скорости передачи данных в отображении и других параметрах, например кодеки видеоизображения, звука или другие кодеки и параметры кодеков, разрешение видеоизображения, сложность декодирования, язык звукозаписи и любые другие параметры, которые могли бы повлиять на выбор отображения на клиенте.
[0411] Метаданные для отображения также могут содержать идентификаторы для блоков, на которые сегментировано отображение, причем эти идентификаторы предоставляют информацию, необходимую клиенту для запроса блока. Например, когда протоколом запроса является HTTP, идентификатором мог бы быть URL HTTP, по возможности вместе с дополнительной информацией, идентифицирующей байтовый диапазон или временной диапазон в файле, идентифицированном по URL, причем этот байтовый диапазон или временной диапазон идентифицируют определенный блок в файле, идентифицированном по URL.
[0412] В конкретной реализации улучшенный диспетчер буфера определяет, когда приемник делает запрос новых блоков, и мог бы сам обрабатывать отправку запросов. В новой особенности улучшенный диспетчер буфера запрашивает новые блоки в соответствии со значением отношения уравновешивания, которое уравновешивает использование слишком большой полосы пропускания и окончание мультимедиа во время потокового воспроизведения.
[0413] Информация, принятая монитором 126 буфера от буфера 125 блоков, может включать в себя указания каждого события, когда принимаются мультимедийные данные, сколько принято, когда воспроизведение мультимедийных данных началось или прекратилось, и скорость воспроизведения мультимедиа. На основе этой информации монитор 126 буфера мог бы вычислить переменную, представляющую текущий размер буфера, Bcurrent. В этих примерах Bcurrent представляет объем мультимедиа, содержащийся в буфере или буферах клиента или другого устройства, и мог бы измеряться в единицах времени, так что Bcurrent представляет количество времени, которое заняло бы воспроизведение всего мультимедиа, представленного блоками или частичными блоками, сохраненными в буфере или буферах, если бы не принимались никакие дополнительные блоки или частичные блоки. Таким образом, Bcurrent представляет "длительность воспроизведения" при нормальной скорости воспроизведения мультимедийных данных, доступных на клиенте, но еще не воспроизведенных.
[0414] Когда время проходит, значение Bcurrent будет уменьшаться, так как мультимедиа воспроизводится, и может увеличиваться каждый раз, когда принимаются новые данные для блока. Отметим, что для целей этого объяснения предполагается, что блок принимается, когда все данные того блока доступны в запросчике 124 блоков, но вместо этого могли бы использоваться другие меры, например, чтобы учитывать прием частичных блоков. На практике прием блока может происходить за некий период времени.
[0415] Фиг. 13 иллюстрирует изменение значения Bcurrent со временем, когда воспроизводится мультимедиа и принимаются блоки. Как показано на фиг. 13, значение Bcurrent равно нулю для моментов раньше t0, указывая, что не принято никаких данных. В момент t0 принимается первый блок, и значение Bcurrent увеличивается до равного длительности воспроизведения принятого блока. В то же время воспроизведение еще не началось, и поэтому значение Bcurrent остается постоянным до момента t1, в который поступает второй блок, и Bcurrent увеличивается на размер этого второго блока. В то же время начинается воспроизведение, и значение Bcurrent начинает уменьшаться линейно до момента t2, когда поступает третий блок.
[0416] Прогрессия Bcurrent продолжается в этой "пилообразной" манере, увеличиваясь ступенчато каждый раз, когда принимается блок (в моменты t2, t3, t4, t5 и t6), и плавно уменьшаясь, когда данные воспроизводятся между ними. Отметим, что в этом примере воспроизведение проходит на нормальной скорости воспроизведения для контента, и поэтому наклон кривой между приемом блоков равен точно -1, означая, что одна секунда мультимедийных данных воспроизводится за каждую одну секунду реального времени. При кадровом мультимедиа, воспроизводимым с заданным количеством кадров в секунду, например, 24 кадра в секунду, наклон в -1 будет приближенно выражен малыми ступенчатыми функциями, которые указывают воспроизведение каждого отдельного кадра данных, например, шагами -1/24 секунды, когда воспроизводится каждый кадр.
[0417] Фиг. 14 показывает другой пример развития Bcurrent со временем. В том примере первый блок поступает в t0, и воспроизведение начинается немедленно. Поступление блоков и воспроизведение продолжаются до момента t3, в который значение Bcurrent достигает нуля. Когда это происходит, никакие дополнительные мультимедийные данные не доступны для воспроизведения, вызывая паузу в представлении мультимедиа. В момент t4 принимается четвертый блок, и воспроизведение можно возобновить. Этот пример, поэтому показывает случай, когда прием четвертого блока был позже, чем нужно, приведя к паузе в воспроизведении и соответственно плохому взаимодействию с пользователем. Таким образом, цель улучшенного диспетчера буфера и других особенностей состоит в снижении вероятности этого события, одновременно поддерживая высокое качество мультимедиа.
[0418] Монитор 126 буфера также может вычислять другой показатель, Bratio(t), который является отношением мультимедиа, принятого в заданный период времени, к длине этого периода времени. Точнее говоря, Bratio(t) равно Treceived / (Tnow-t), где Treceived- объем мультимедиа (измеренный по его времени воспроизведения), принятый в период времени от t, некоторого момента раньше текущего времени, до текущего момента Tnow.
[0419] Bratio(t) может использоваться для измерения скорости изменения Bcurrent. Bratio(t)=0 является случаем, при котором никакие данные не приняты с момента t; Bcurrent будет уменьшен на (Tnow-t) с того момента, допуская, что мультимедиа воспроизводится. Bratio(t)=1 является случаем, при котором мультимедиа принимается в таком же объеме, как воспроизводится, за время (Tnow-t); Bcurrent будет иметь такое же значение в момент Tnow, как в момент t. Bratio(t)>1 является случаем, при котором принято больше данных, чем необходимо для воспроизведения за время (Tnow-t); Bcurrent будет увеличен с момента t до момента Tnow.
[0420] Монитор 126 буфера дополнительно вычисляет значение State, которое может принимать дискретное количество значений. Монитор 126 буфера дополнительно оснащается функцией NewState(Bcurrent, Bratio), которая, принимая во внимание текущее значение Bcurrent и значения Bratio для t<Tnow, предоставляет новое значение State в качестве результата. Всякий раз, когда Bcurrent и Bratio заставляют эту функция возвращать значение, отличное от текущего значения State, новое значение присваивается State, и это новое значение State указывается селектору 123 блоков.
[0421] Функция NewState может оцениваться относительно пространства всех возможных значений пары (Bcurrent, Bratio(Tnow-Tx)), где Tx может быть фиксированным (сконфигурированным) значением или может выводиться из Bcurrent, например, с помощью таблицы-конфигуратора, которая преобразует из значений Bcurrent в значения Tx, или может зависеть от предыдущего значения State. Монитор 126 буфера снабжается одним или несколькими разбиениями этого пространства, причем каждое разбиение содержит наборы непересекающихся областей, причем каждая область аннотируется значением State. Оценка функции NewState тогда содержит операцию идентификации разбиения и определения области, в которую попадает пара (Bcurrent, Bratio(Tnow-Tx)). Возвращаемое значение тогда является аннотацией, ассоциированной с той областью. В простом случае предоставляется только одно разбиение. В более сложных случаях разбиение может зависеть от пары (Bcurrent, Bratio(Tnow-Tx)) в предыдущее время оценки функции NewState, или от других факторов.
[0422] В конкретном варианте осуществления описанное выше разбиение может основываться на таблице-конфигураторе, содержащей некоторое количество пороговых значений для Bcurrent и некоторое количество пороговых значений для Bratio. В частности, пусть пороговыми значениями для Bcurrent будут Bthresh(0)=0, Bthresh(1), Bthresh(n1), Bthresh(n1+1)=∞, где n1- количество ненулевых пороговых значений для Bcurrent. Пусть пороговыми значениями для Bratio будут Br-thresh(0)=0, Br-thresh(1), Br-thresh(n2), Br-thresh(n2+1)=∞, где n2- количество пороговых значений для Bratio. Эти пороговые значения задают разбиение, содержащее сетку (n1+1) на (n2+1) ячеек, причем i-ая ячейка j-ой строки соответствует области, в которой Bthresh(i-1)<=Bcurrent<Bthresh(i) и Br-thresh(j-1)<=Bratio<Br-thresh(j). Каждая ячейка описанной выше сетки аннотируется значением State, например, ассоциируемым с конкретными значениями, сохраненными в запоминающем устройстве, и тогда функция NewState возвращает значение State, ассоциированное с ячейкой, указанной значениями Bcurrent и Bratio(Tnow-Tx).
[0423] В дополнительном варианте осуществления значение гистерезиса может ассоциироваться с каждым пороговым значением. В этом улучшенном способе оценка функции NewState может основываться на временном разбиении, созданном с использованием набора временно измененных пороговых значений, следующим образом. Для каждого Bcurrent пороговое значение, которое меньше диапазона Bcurrent, соответствующего выбранной ячейке при последней оценке NewState, пороговое значение уменьшается путем вычитания значения гистерезиса, ассоциированного с той пороговой величиной. Для каждого Bcurrent пороговое значение, которое больше диапазона Bcurrent, соответствующего выбранной ячейке при последней оценке NewState, пороговое значение увеличивается путем прибавления значения гистерезиса, ассоциированного с той пороговой величиной. Для каждого Bratio пороговое значение, которое меньше диапазона Bratio, соответствующего выбранной ячейке при последней оценке NewState, пороговое значение уменьшается путем вычитания значения гистерезиса, ассоциированного с той пороговой величиной. Для каждого Bratio пороговое значение, которое больше диапазона Bratio, соответствующего выбранной ячейке при последней оценке NewState, пороговое значение увеличивается путем прибавления значения гистерезиса, ассоциированного с той пороговой величиной. Измененные пороговые значения используются для оценки значения NewState, а затем пороговые значения возвращаются к исходным значениям.
[0424] Другие способы задания разбиений пространства будут очевидны специалистам в данной области техники при прочтении этого раскрытия изобретения. Например, разбиение может задаваться с использованием неравенств на основе линейных комбинаций Bratio и Bcurrent, например, пороговые величины линейного неравенства вида α1 Bratio+α2• Bcurrent≤α0 для действительнозначных α0, α1 и α2, чтобы задать полупространства в общем пространстве, и задания каждого непересекающегося множества как пересечения некоторого количества таких полупространств.
[0425] Вышеприведенное описание поясняет основной процесс. Как будет понятно специалистам в области программирования для систем реального времени при прочтении этого раскрытия изобретения, возможны эффективные реализации. Например, каждый раз, когда новая информация предоставляется монитору 126 буфера, можно вычислить время в будущем, в которое NewState перейдет в новое значение, если, например, не принимаются никакие дополнительные данные для блоков. Затем устанавливается таймер для этого времени, и при отсутствии дополнительных входных данных истечение этого таймера вызовет отправку нового значения State в селектор 123 блоков. В результате вычисления нужно выполнять, только когда новая информация предоставляется монитору 126 буфера или когда истекает таймер, а не постоянно.
[0426] Подходящими значениями State могли бы быть "Низкое", "Устойчивое" и "Полное". Пример подходящего набора пороговых значений и результирующая сетка показаны на фиг. 15.
[0427] На фиг. 15 пороговые величины Bcurrent показаны на горизонтальной оси в миллисекундах с показанными ниже значениями гистерезиса в виде "+/-значение". Пороговые величины Bratio показаны на вертикальной оси в промилле (то есть умноженными на 1000) с показанными ниже значениями гистерезиса в виде "+/-значение". Значения State аннотируются в ячейках сетки в виде "L", "S" и "F" для "Низкого", "Устойчивого" и "Полного" соответственно.
[0428] Селектор 123 блоков принимает уведомления от запросчика 124 блоков всякий раз, когда имеется возможность запросить новый блок. Как описано выше, селектор 123 блоков снабжается информацией в отношении множества доступных блоков и метаданными для тех блоков, включая, например, информацию о скорости мультимедийных данных в каждом блоке.
[0429] Информация о скорости мультимедийных данных блока может содержать фактическую скорость мультимедийных данных конкретного блока (то есть размер блока в байтах, деленный на время воспроизведения в секундах), среднюю скорость мультимедийных данных отображения, которому принадлежит блок, или величину необходимой доступной полосы пропускания, на длительной основе, чтобы без пауз воспроизвести отображение, которому принадлежит блок, или сочетание вышеупомянутого.
[0430] Селектор 123 блоков выбирает блоки на основе значения State, указанного последний раз монитором 126 буфера. Когда этим значением State является "Устойчивое", селектор 123 блоков выбирает блок из того же отображения, что и предыдущий выбранный блок. Выбранный блок является первым блоком (в порядке воспроизведения), содержащим мультимедийные данные за период времени в представлении, для которого никакие мультимедийные данные не запрошены ранее.
[0431] Когда значением State является "Низкое", селектор 123 блоков выбирает блок из отображения с меньшей скоростью мультимедийных данных, чем у ранее выбранного блока. Некоторое количество факторов может влиять на точный выбор отображения в этом случае. Например, селектор 123 блоков мог бы снабжаться указанием групповой скорости входящих данных и может выбирать отображение со скоростью мультимедийных данных, которая меньше этого значения.
[0432] Когда значением State является "Полное", селектор 123 блоков выбирает блок из отображения с большей скоростью мультимедийных данных, чем у ранее выбранного блока. Некоторое количество факторов может влиять на точный выбор отображения в этом случае. Например, селектор 123 блоков может снабжаться указанием групповой скорости входящих данных и может выбирать отображение со скоростью мультимедийных данных, которая не превышает это значение.
[0433] Некоторое количество дополнительных факторов может дополнительно влиять на работу селектора 123 блоков. В частности, может быть ограничена частота, с которой увеличивается скорость мультимедийных данных у выбранного блока, даже если монитор 126 буфера продолжает указывать состояние "Полное". Кроме того, возможно, что селектор 123 блоков принимает указание состояния "Полное", но отсутствуют блоки с большей доступной скоростью мультимедийных данных (например, потому что последний выбранный блок уже был для наивысшей доступной скорости мультимедийных данных). В этом случае селектор 123 блоков может задержать выбор следующего блока на время, выбранное так, что общий объем мультимедийных данных, буферизованных в буфере 125 блоков, ограничивается сверху.
[0434] Дополнительные факторы могут влиять на набор блоков, которые рассматриваются во время процесса выбора. Например, доступные блоки могут ограничиваться блоками из отображений, чье разрешение кодирования входит в определенный диапазон, предоставленный селектором 123 блоков.
[0435] Селектор 123 блоков также может принимать входные данные от других компонентов, которые следят за другими особенностями системы, например доступностью вычислительных ресурсов для декодирования мультимедиа. Если такие ресурсы становятся дефицитными, то селектор 123 блоков может выбирать блоки, чье декодирование указывается в метаданных как имеющее меньшую вычислительную сложность (например, отображения с меньшим разрешением или частотой кадров обычно имеют меньшую сложность декодирования).
[0436] Вышеописанный вариант осуществления дает существенное преимущество в том, что использование значения Bratio при оценке функции NewState в мониторе 126 буфера позволяет быстрее увеличить качество в начале представления по сравнению со способом, который рассматривает только Bcurrent. Без учета Bratio может накапливаться большой объем буферизованных данных перед тем, как система сможет выбрать блоки с большей скоростью мультимедийных данных, а отсюда и более высоким качеством. Однако, когда значение Bratio большое, это указывает, что доступная полоса пропускания гораздо выше скорости мультимедийных данных у ранее принятых блоков, и что даже при относительно небольших буферизованных данных (то есть низком значении для Bcurrent) остается безопасно запрашивать блоки с большей скоростью мультимедийных данных, а отсюда и более высоким качеством. В равной степени, если значение Bratio низкое (например, <1), то это указывает, что доступная полоса пропускания опустилась ниже скорости мультимедийных данных у ранее запрошенных блоков, и соответственно даже если Bcurrent большой, то система переключится на меньшую скорость мультимедийных данных и более низкое качество, например, чтобы избежать достижения точки, где Bcurrent=0, и воспроизведение мультимедиа останавливается. Этот усовершенствованный режим может быть особенно важным в окружениях, где сетевые условия, а соответственно и скорости доставки, могут меняться быстро и динамически, например, пользователи, осуществляющие потоковую передачу на мобильные устройства.
[0437] Другое преимущество предоставляется при использовании конфигурационных данных для задания разбиения пространства значений (Bcurrent, Bratio). Такие конфигурационные данные могут предоставляться монитору 126 буфера как часть метаданных представления, или с помощью другого динамического средства. Поскольку в практических применениях режим пользовательских сетевых соединений может быть весьма изменчивым среди пользователей и со временем для одного пользователя, может быть сложно, предсказать разбиения, которые будут применимы для всех пользователей. Возможность предоставлять такую конфигурационную информацию пользователям динамически позволяет разработать хорошие конфигурационные настройки со временем в соответствии с накопленным опытом.
ЗАДАНИЕ ПЕРЕМЕННОГО РАЗМЕРА ЗАПРОСА
[0438] Высокая частота запросов может быть необходима, если каждый запрос относится к одиночному блоку и если каждый блок кодирует короткий мультимедийный сегмент. Если блоки мультимедиа короткие, то воспроизведение видеоизображения быстро переходит от блока к блоку, что предоставляет приемнику более частые возможности для регулировки или изменения выбранной скорости передачи данных путем изменения отображения, повышая вероятность того, что воспроизведение может продолжаться без остановки. Однако недостатком высокой частоты запросов является то, что они могли бы быть неустойчивыми в некоторых сетях, в которых доступная полоса пропускания ограничивается в сети от клиента к серверу, например, в беспроводных сетях WAN, например беспроводных WAN 3G и 4G, причем пропускная способность канала передачи данных от клиента к сети ограничивается или может стать ограниченной на короткие или длительные периоды времени из-за изменений в условиях радиосвязи.
[0439] Высокая частота запросов также подразумевает высокую нагрузку на обслуживающую инфраструктуру, что дает ассоциированные затраты в виде требований к пропускной способности. Таким образом, было бы желательно иметь некоторые выгоды от высокой частоты запросов без всех недостатков.
[0440] В некоторых вариантах осуществления системы потоковой передачи блоков гибкость высокой частоты запросов объединяется с менее частыми запросами. В этом варианте осуществления блоки могут создаваться, как описано выше, и группироваться в сегменты, содержащие несколько блоков, как также описано выше. В начале представления применяются описанные выше процессы, в которых каждый запрос обращается к одному блоку, либо выполняется несколько одновременных запросов для запроса частей блока, чтобы обеспечить быстрое время переключения каналов и поэтому хорошее взаимодействие с пользователем в начале представления. Впоследствии, когда выполняется некоторое условие, которое будет описано ниже, клиент может выдавать запросы, которые включают в себя несколько блоков в одном запросе. Это возможно, потому что блоки сгруппированы в более крупные файлы или сегменты и могут запрашиваться с использованием байтовых или временных диапазонов. Последовательные байтовые или временные диапазоны могут группироваться в один более крупный байтовый или временной диапазон, приводя к единственному запросу нескольких блоков, и даже прерывистые блоки могут запрашиваться в одном запросе.
[0441] Одна базовая конфигурация, которая может управляться с помощью принятия решения, запросить ли одиночный блок (или частичный блок) либо несколько последовательных блоков, имеет в своей основе решение о том, будут ли воспроизводиться запрошенные блоки. Например, если вероятно, что скоро возникнет потребность переключиться на другое отображение, то клиенту лучше запрашивать одиночные блоки, то есть небольшие объемы мультимедийных данных. Одна причина для этого состоит в том, что если выполняется запрос нескольких блоков, когда переключение на другое отображение могло быть неизбежным, то переключение можно было бы сделать до того, как воспроизводятся последние несколько блоков запроса. Таким образом, загрузка этих последних нескольких блоков могла бы задержать доставку мультимедийных данных отображения, на которое выполняется переключение, что могло бы вызвать остановки воспроизведения мультимедиа.
[0442] Однако, запросы одиночных блоков приводят к большей частоте запросов. С другой стороны, если маловероятно, что скоро возникнет потребность переключиться на другое отображение, то может быть предпочтительно, создавать запросы нескольких блоков, так как все эти блоки, скорее всего, будут воспроизведены, и это приводит к меньшей частоте запросов, что может существенно снизить служебную нагрузку запросов, особенно если типично, что нет близкого изменения в отображении.
[0443] В традиционных системах объединения блоков количество, запрошенное в каждом запросе, не регулируется динамически, то есть обычно каждый запрос предназначен для всего файла, или каждый запрос предназначен приблизительно для одинакового размера файла отображения (иногда измеряемого по времени, иногда в байтах). Таким образом, если все запросы меньше, то служебная нагрузка запросов высокая, тогда как если все запросы больше, то это увеличивает вероятности событий останова мультимедиа и/или предоставления воспроизведения мультимедиа более низкого качества, если выбираются отображения более низкого качества, чтобы избежать необходимости быстро менять отображения, когда меняются сетевые условия.
[0444] Примером условия, которое при выполнении может заставить последующие запросы обращаться к нескольким блокам, является пороговая величина размера буфера, Bcurrent. Если Bcurrent ниже пороговой величины, то каждый выданный запрос обращается к одиночному блоку. Если Bcurrent больше либо равен пороговой величине, то каждый выданный запрос обращается к нескольким блокам. Если выдается запрос, который обращается к нескольким блокам, то количество запрошенных блоков в каждом одиночном запросе может определяться одним из нескольких возможных способов. Например, количество может быть постоянным, например, два. В качестве альтернативы количество запрошенных блоков в одиночном запросе может зависеть от состояния буфера, и в частности, от Bcurrent. Например, можно задать некоторое количество пороговых величин, при этом количество запрошенных блоков в одиночном запросе выводится из наибольшей среди нескольких пороговых величин, которая меньше Bcurrent.
[0445] Другим примером условия, которое при выполнении может заставить запросы обращаться к нескольким блокам, является переменное значение State, описанное выше. Например, когда State является "Устойчивым" или "Полным", то запросы могут выдаваться для нескольких блоков, но когда State является "Низким", то все запросы могут предназначаться одному блоку.
[0446] Другой вариант осуществления показан на фиг. 16. В этом варианте осуществления, когда нужно выдать следующий запрос (определенный на этапе 1300), текущее значение State и Bcurrent используется для определения размера следующего запроса. Если текущим значением State является "Низкое" или текущим значением State является "Полное", и текущее отображение не является наивысшим доступным (определено на этапе 1310, ответ "Да"), то следующий запрос выбирается коротким, например, точно для следующего блока (блок определен и запрос выполнен на этапе 1320). Логическое обоснование этого состоит в том, что они являются условиями, где вероятно, что довольно скоро будет переключение отображений. Если текущим значением State является "Устойчивое" или текущим значением State является "Полное", и текущее отображение является наивысшим доступным (определено на этапе 1310, ответ "Нет"), то длительность последовательных блоков, запрошенных в следующем запросе, выбирается пропорциональной α-доли Bcurrent для некоторого фиксированного α<1 (блоки определены на этапе 1330, запрос выполнен на этапе 1340), например, для α=0,4, если Bcurrent=5 секундам, то следующий запрос мог бы относиться приблизительно к 2 секундам блоков, тогда как если Bcurrent=10 секундам, то следующий запрос мог бы относиться приблизительно к 4 секундам блоков. Одно логическое обоснование этого состоит в том, что в этих условиях могло быть маловероятно, что переключение на новое отображение будет выполнено за количество времени, которое пропорционально Bcurrent.
ГИБКАЯ КОНВЕЙЕРНАЯ ОБРАБОТКА
[0447] Системы потоковой передачи блоков могли бы использовать протокол запроса файлов, который имеет в основе конкретный транспортный протокол, например TCP/IP. В начале соединения по TCP/IP или другому транспортному протоколу может потребоваться некоторое значительное время для достижения использования полной доступной полосы пропускания. Это может приводить к "потере при запуске соединения" каждый раз, когда запускается новое соединение. Например, в случае TCP/IP потеря при запуске соединения происходит из-за времени, затраченного на начальное квитирование связи TCP для установления соединения, и времени, затраченного на протокол отслеживания перегрузок для достижения полного использования доступной полосы пропускания.
[0448] В этом случае может быть желательно, выдать несколько запросов с использованием одного соединения, чтобы снизить частоту, с которой получается потеря при запуске соединения. Однако некоторые протоколы транспортировки файлов, например HTTP, не предоставляют механизма для отмены запроса кроме закрытия всего соединения транспортного уровня и получения посредством этого потери при запуске соединения, когда новое соединение устанавливается вместо старого. Выданный запрос может потребоваться отменить, если определяется, что доступная полоса пропускания изменилась, и вместо этого необходима другая скорость мультимедийных данных, то есть имеется решение переключиться на другое отображение. Другой причиной для отмены выданного запроса может быть ситуация, если пользователь запросил, чтобы представление мультимедиа закончилось, и началось новое представление (возможно, того же элемента содержимого в другой точке представления либо нового элемента содержимого).
[0449] Как известно, потери при запуске соединения можно избежать, поддерживая соединение открытым и повторно используя то же соединение для последующих запросов, и, как также известно, соединение можно поддерживать используемым полностью, если несколько запросов выдаются одновременно по одному и тому же соединению (методика, известная как "конвейерная обработка" применительно к HTTP). Однако недостатком выдачи нескольких запросов одновременно, или в более общем смысле, таким образом, что несколько запросов выдаются до того, как завершены предыдущие запросы по соединению, может быть то, что соединение тогда предназначается для передачи ответа на те запросы, и поэтому, если становятся желательными изменения, на которые следует выдать запросы, то соединение может быть закрыто, если становится необходимым отменить уже выданные запросы, которые уже не нужны.
[0450] Вероятность того, что выданный запрос нужно отменить, может частично зависеть от длительности интервала времени между выдачей запроса и временем воспроизведения запрошенного блока в том смысле, что когда этот интервал времени большой, высока вероятность того, что выданный запрос нужно отменить (потому что доступная полоса пропускания, скорее всего, изменится в течение интервала).
[0451] Как известно, некоторые протоколы загрузки файлов обладают свойством, что одно лежащее в основе соединение транспортного уровня может использоваться преимущественно для нескольких запросов загрузки. Например, HTTP обладает этим свойством, поскольку повторное использование одного соединения для нескольких запросов устраняет "потерю при запуске соединения", описанную выше для запросов кроме первого. Однако недостаток этого подхода в том, что соединение предназначается для транспортировки запрошенных данных в каждом выданном запросе, и поэтому, если запрос или запросы нужно отменить, то либо соединение может быть закрыто, получая потерю при запуске соединения, когда устанавливается заменяющее соединение, либо клиент может ожидать приема данных, которые уже не нужны, получая задержку при приеме последующих данных.
[0452] Теперь мы опишем вариант осуществления, который сохраняет преимущества повторного использования соединения без этого недостатка и который также дополнительно повышает частоту, с которой соединения могут использоваться повторно.
[0453] Варианты осуществления систем потоковой передачи блоков, описанные в этом документе, конфигурируются для повторного использования соединения для нескольких запросов без необходимости выделять соединение в начале под конкретный набор запросов. По существу, новый запрос выдается по существующему соединению, когда уже выданные запросы по соединению еще не закончены, но близки к завершению. Одной причиной, чтобы не ждать завершения существующих запросов, является то, что если предыдущие запросы завершаются, то скорость соединения могла бы ухудшиться, то есть лежащий в основе сеанс TCP мог бы перейти в нерабочее состояние, или переменная cwnd TCP могла бы существенно уменьшиться, в силу этого значительно снижая исходную скорость загрузки нового запроса, выданного по тому соединению. Одной причиной ожидания почти до завершения перед выдачей дополнительного запроса является то, что если новый запрос выдается сильно раньше завершения предыдущих запросов, то новый выданный запрос может даже не начаться в течение некоторого существенного периода времени, и могло бы быть так, что в течение этого периода времени перед тем, как начнется новый выданный запрос, решение создать новый запрос уже не действительно, например, из-за решения переключить отображения. Таким образом, вариант осуществления клиентов, которые реализуют эту методику, будет выдавать новый запрос по соединению как можно позже без замедления возможностей загрузки у соединения.
[0454] Способ содержит слежение за количеством принятых байтов по соединению в ответ на последний запрос, выданный по этому соединению, и применение проверки к этому количеству. Это может выполняться путем наличия приемника (или передатчика, если применим), сконфигурированного для слежения и проверки.
[0455] Если проверка проходит, то по соединению можно выдать дополнительный запрос. Один пример подходящей проверки состоит в том, больше ли количество принятый байтов фиксированной доли размера запрошенных данных. Например, эта доля могла бы составлять 80%. Другой пример подходящей проверки основывается на нижеследующем вычислении, которое проиллюстрировано на фиг. 17. При вычислении пусть R будет оценкой скорости передачи данных соединения, T- оценкой Периода кругового обращения ("RTT"), а X- числовым коэффициентом, который, например, мог быть постоянной, установленной в значение между 0,5 и 2, где оценки R и T обновляются систематически (обновлены на этапе 1410). Пусть S- размер данных, запрошенных в последнем запросе, B- принятое количество байтов в запрошенных данных (вычислено на этапе 1420).
[0456] Подходящей проверкой было бы заставить приемник (или передатчик, если применим) выполнить процедуру для оценки неравенства (S-B)<X•R•T (проверено на этапе 1430), и если "Да", то выполнить некое действие. Например, проверка могла бы проводиться, чтобы увидеть, есть ли другой запрос, готовый к выдаче по соединению (проверено на этапе 1440), и если "Да", то выдать тот запрос по соединению (этап 1450), а если "Нет", то процесс возвращается к этапу 1410, чтобы продолжить обновление и проверку. Если результатом проверки на этапе 1430 является "Нет", то процесс возвращается к этапу 1410, чтобы продолжить обновление и проверку.
[0457] Проверка неравенства на этапе 1430 (выполненная, например, подходящим образом запрограммированными элементами) заставляет каждый последующий запрос выдаваться, когда объем оставшихся данных, которые нужно принять, равен X-кратному объему данных, который можно принять на текущей предполагаемой скорости приема в одном RTT. В данной области техники известно некоторое количество способов для оценки скорости передачи данных, R, на этапе 1410. Например, скорость передачи данных может оцениваться как Dt/t, где Dt- количество разрядов, принятых в предыдущие t секунд, и где t может быть, например, 1 с или 0,5 с либо некоторым другим интервалом. Другим способом является экспоненциальное среднее взвешенное, или фильтр с Бесконечной импульсной характеристикой (БИХ) первого порядка на входящую скорость передачи данных. В данной области техники известно некоторое количество способов для оценки RTT, T, на этапе 1410.
[0458] Проверка на этапе 1430 может применяться к совокупности всех активных соединений на интерфейсе, как подробнее объясняется ниже.
[0459] Способ дополнительно содержит создание списка возможных запросов, ассоциируя каждый запрос с набором подходящих серверов, к которым можно сделать запрос, и упорядочивая список возможных запросов в порядке приоритета. Некоторые записи в списке возможных запросов могут иметь одинаковый приоритет. Серверы в списке подходящих серверов, ассоциированные с каждым возможным запросом, идентифицируются по именам хостов. Каждое имя хоста соответствует набору адресов по Интернет-протоколу, которые можно получить от Системы доменных имен, которая общеизвестна. Поэтому каждый возможный запрос в списке возможных запросов ассоциируется с набором адресов по Интернет-протоколу, в частности, объединением наборов Адресов по Интернет-протоколу, ассоциированных с именами хостов, ассоциированными с серверами, ассоциированными с возможным запросом. Всякий раз, когда описанная на этапе 1430 проверка проходит для некоторого соединения, и никакой новый запрос еще не выдан по тому соединению, выбирается запрос с наивысшим приоритетом в списках возможных запросов, с которыми ассоциируется адрес по Интернет-протоколу у назначения соединения, и этот запрос выдается по тому соединению. Запрос также удаляется из списка возможных запросов.
[0460] Возможные запросы могут удаляться (отменяться) из списка возможных запросов, новые запросы могут добавляться в список кандидатов с приоритетом, который выше уже существующих запросов в списке кандидатов, и существующие запросы в списке кандидатов могут менять свой приоритет. Динамический характер запросов, которые находятся в списке возможных запросов, и динамический характер их приоритета в списке кандидатов могут изменять то, какие запросы могли бы выдаваться следующими, в зависимости от того, когда проходит проверка типа, описанного на этапе 1430.
[0461] Например, могло быть, возможно, что если ответом на проверку, описанную на этапе 1430, является "Да" в некоторый момент t, то следующим выданным запросом был бы запрос A, тогда как если ответом на проверку, описанную на этапе 1430, не является "Да" до некоторого момента t′>t, то следующим выданным запросом вместо этого был бы запрос B, потому что либо запрос A был удален из списка возможных запросов между моментом t и t′, либо потому что запрос B был добавлен в список возможных запросов с более высоким приоритетом, чем запрос A, между моментом t и t′, или потому что запрос B был в списке кандидатов в момент t, но с меньшим приоритетом, чем запрос A, и между моментом t и t′ приоритет запроса B сделали выше, чем у запроса A.
[0462] Фиг. 18 иллюстрирует пример списка запросов в списке кандидатов запросов. В этом примере имеются три соединения, и имеются шесть запросов в списке кандидатов, обозначенные A, B, C, D, E и F. Каждый из запросов в списке кандидатов может выдаваться по подмножеству соединений, которое указано, например, запрос A может выдаваться по соединению 1, тогда как запрос F может выдаваться по соединению 2 или соединению 3. Приоритет каждого запроса также обозначается на фиг. 18, и меньшее значение приоритета указывает, что запрос имеет больший приоритет. Таким образом, запросы A и B с приоритетом 0 являются запросами наивысшего приоритета, тогда как запрос F со значением приоритета 3 является наименьшим приоритетом среди запросов в списке кандидатов.
[0463] Если в этот момент времени t соединение 1 проходит проверку, описанную на этапе 1430, то либо запрос A, либо запрос B выдается по соединению 1. Если вместо этого соединение 3 проходит проверку, описанную на этапе 1430 в то же время t, то запрос D выдается по соединению 3, поскольку запрос D является запросом с наивысшим приоритетом, который может быть выдан по соединению 3.
[0464] Предположим, что для всех соединений ответом на проверку, описанную на этапе 1430, с момента t до некоторого более позднего момента t′ является "Нет", и между моментом t и t′ запрос A меняет свой приоритет с 0 на 5, запрос B удаляется из списка кандидатов, и новый запрос G с приоритетом 0 добавляется в список кандидатов. Тогда в момент t′ новый список кандидатов мог бы быть таким, как показан на фиг. 19.
[0465] Если в момент t′ соединение 1 проходит проверку, описанную на этапе 1430, то запрос C с приоритетом 4 выдается по соединению 1, поскольку это запрос наивысшего приоритета в списке кандидатов, который может быть выдан по соединению 1 в данный момент времени.
[0466] Предположим в той же самой ситуации, что вместо этого был бы выдан запрос A по соединению 1 в момент t (который был одним из двух вариантов с наивысшим приоритетом для соединения 1 в момент t, как показано на фиг. 18). Поскольку ответом на проверку, описанную на этапе 1430, с момента t до некоторого более позднего момента t′ является "Нет" для всех соединений, соединение 1 по-прежнему доставляет данные, по меньшей мере, до момента t′ для запросов, выданных перед моментом t, и соответственно запрос A не начался бы, по меньшей мере, до момента t′. Выдача запроса C в момент t′ является лучшим решением, нежели выдача запроса A в момент t, поскольку запрос C начинается в тот же момент после t′, когда начинался бы запрос A, и поскольку к тому времени запрос C имеет более высокий приоритет, чем запрос A.
[0467] В качестве другой альтернативы, если проверка типа, описанного на этапе 1430, применяется к совокупности активных соединений, то может быть выбрано соединение, которое имеет назначение, чей адрес по Интернет-протоколу ассоциируется с первым запросом в списке возможных запросов или с другим запросом с таким же приоритетом, как упомянутый первый запрос.
[0468] Некоторое количество способов возможно для создания списка возможных запросов. Например, список кандидатов мог бы содержать n запросов, представляющих запросы следующих n частей данных текущего отображения в представлении в порядке временной последовательности, причем запрос самой ранней части данных имеет наивысший приоритет, а запрос последней части данных имеет наименьший приоритет. В некоторых случаях n может быть единицей. Значение n может зависеть от размера буфера Bcurrent, переменной State или другой меры состояния занятости буфера клиента. Например, можно задать некоторое количество пороговых значений для Bcurrent и значение, ассоциированное с каждой пороговой величиной, и тогда значение n берется как значение, ассоциированное с наибольшей пороговой величиной, которая меньше Bcurrent.
[0469] Описанный выше вариант осуществления обеспечивает гибкое распределение запросов по соединениям, гарантируя, что предпочтение отдается повторному использованию существующего соединения, даже если запрос наивысшего приоритета не подходит для того соединения (потому что IP-адрес назначения соединения не тот, который назначается любому из имен хостов, ассоциированных с запросом). Зависимость n от Bcurrent или State или другой меры занятости буфера клиента гарантирует, что такие запросы "вне порядка приоритета" не выдаются, когда клиенту нужно срочно выдать и завершить запрос, ассоциированный со следующей частью данных, которую нужно воспроизвести во временной последовательности.
[0470] Эти способы преимущественно могут объединяться с совместным HTTP и FEC.
СОГЛАСОВАННЫЙ ВЫБОР СЕРВЕРА
[0471] Как общеизвестно, файлы для загрузки с использованием протокола загрузки файла обычно идентифицируются по идентификатору, содержащему имя хоста и имя файла. Например, это случай для протокола HTTP, и в этом случае идентификатором является Унифицированный идентификатор ресурса (URI). Имя хоста может соответствовать нескольким хостам, идентифицированным адресами по Интернет-протоколу. Например, это общий способ распределения нагрузки от запросов от нескольких клиентов по несколькими физическим станциям. В частности, этот подход обычно применяется Сетями доставки контента (CDN). В этом случае запрос, выданный по соединению любому из физических хостов, предполагается достигшим цели. Известно некоторое количество способов, с помощью которых клиент может выбирать среди адресов по Интернет-протоколу, ассоциированных с именем хоста. Например, эти адреса обычно предоставляются клиенту посредством Системы доменных имен и предоставляются в порядке приоритета. Клиент может тогда выбрать адрес по Интернет-протоколу с наивысшим приоритетом (первый). Однако обычно отсутствует координация между клиентами в отношении того, как осуществляется этот выбор, в результате чего разные клиенты могут запрашивать один и тот же файл у разных серверов. Это может привести к одинаковому файлу, сохраненному в кэше нескольких ближайших серверов, что снижает эффективность инфраструктуры кэша.
[0472] Это может обрабатываться системой, которая преимущественно увеличивает вероятность, что два клиента, запрашивающие один и тот же блок, будут запрашивать этот блок у одного и того же сервера. Описанный здесь новый способ содержит выбор из числа доступных адресов по Интернет-протоколу способом, определенным идентификатором файла, который нужно запросить, и таким образом, что разные клиенты, представленные одинаковыми или аналогичными выборами адресов по Интернет-протоколу и идентификаторов файлов, сделают один и тот же выбор.
[0473] Первый вариант осуществления способа описывается со ссылкой на фиг. 20. Клиент сначала получает набор адресов по Интернет-протоколу IP1, IP2, IPn, как показано на этапе 1710. Если имеется файл, для которого должны быть выданы запросы, как решено на этапе 1720, то клиент определяет адрес по Интернет-протоколу для выдачи запросов файла, как определено на этапах 1730-1770. Учитывая набор адресов по Интернет-протоколу и идентификатор для файла, который нужно запросить, способ содержит упорядочение адресов по Интернет-протоколу способом, определенным идентификатором файла. Например, для каждого адреса по Интернет-протоколу создается байтовая строка, содержащая сцепление адреса по Интернет-протоколу и идентификатора файла, как показано на этапе 1730. К этой байтовой строке применяется хэш-функция, как показано на этапе 1740, и результирующие значения хэш-функции размещаются в соответствии с фиксированным упорядочением, как показано на этапе 1750, например, увеличивающимся нумерационным порядком, создавая упорядочение в адресах по Интернет-протоколу. Одна и та же хэш-функция может использоваться всеми клиентами, посредством этого гарантируя, что одинаковый результат создается хэш-функцией над заданным вводом от всех клиентов. Хэш-функция могла бы статически конфигурироваться во всех клиентах в наборе клиентов, или все клиенты в наборе клиентов могли бы получать частичное или полное описание хэш-функции, когда клиенты получают список адресов по Интернет-протоколу, или все клиенты в наборе клиентов могли бы получать частичное или полное описание хэш-функции, когда клиенты получают идентификатор файла, либо хэш-функция может определяться другим способом. Выбирается адрес по Интернет-протоколу, который является первым в этом упорядочении, и этот адрес затем используется для установления соединения и выдачи запросов всего или частей файла, как показано на этапах 1760 и 1770.
[0474] Вышеприведенный способ может применяться, когда устанавливается новое соединение для запроса файла. Он также может применяться, когда доступно некоторое количество установленных соединений, и одно из этих соединений может быть выбрано для выдачи нового запроса.
[0475] Кроме того, когда доступно установленное соединение и запрос может быть выбран из набора возможных запросов с равным приоритетом, создается упорядочение возможных запросов, например, по такому же способу значений хэш-функции, описанному выше, и выбирается возможный запрос, появляющийся первым в этом упорядочении. Способы могут объединяться для выбора соединения и возможного запроса среди набора соединений и запросов равного приоритета, снова путем вычисления хэша для каждого сочетания соединения и запроса, упорядочения этих значений хэш-функции в соответствии с фиксированным упорядочением и выбора сочетания, которое возникает первым в упорядочении, созданном в наборе сочетаний запросов и соединений.
[0476] Этот способ обладает преимуществом по следующей причине: типичный подход, применяемый обслуживающей инфраструктурой блоков, например, показанной на фиг. 1 (BSI 101) или фиг. 2 (BSI 101), и в особенности подход, обычно применяемый CDN, состоит в предоставлении нескольких кэширующих прокси-серверов, которые принимают запросы клиентов. Кэширующему прокси-серверу может не предоставляться файл, запрошенный в заданном запросе, и в этом случае такие серверы обычно перенаправляют запрос другому серверу, принимают ответ от того сервера, обычно включающий запрошенный файл, и перенаправляют ответ клиенту. Кэширующий прокси-сервер также может хранить (кэшировать) запрошенный файл, так что он может ответить немедленно на последующие запросы файла. Описанный выше общий подход обладает таким свойством, что набор файлов, сохраненный на заданном кэширующем прокси-сервере, в значительной степени определяется набором запросов, который принял кэширующий прокси-сервер.
[0477] Описанный выше способ обладает следующим преимуществом. Если всем клиентам в наборе клиентов предоставляется один и тот же список адресов по Интернет-протоколу, то эти клиенты будут использовать один и тот же адрес по Интернет-протоколу для всех запросов, выданных для одного и того же файла. Если существует два разных списка адресов по Интернет-протоколу, и каждый клиент снабжается одним из этих двух списков, то клиенты будут использовать не более двух разных адресов по Интернет-протоколу для всех запросов, выданных для одного и того же файла. Вообще, если предоставленные клиентам списки адресов по Интернет-протоколу аналогичны, то клиенты будут использовать небольшой набор предоставленных адресов по Интернет-протоколу для всех запросов, выданных для одного и того же файла. Поскольку ближайшие клиенты стремятся получить аналогичные списки адресов по Интернет-протоколу, то ближайшие клиенты, скорее всего, выдают запросы файла только от небольшой части кэширующих прокси-серверов, доступных тем клиентам. Таким образом, будет только небольшая доля кэширующих прокси-серверов, которые кэшируют файл, что преимущественно минимизирует объем ресурсов кэширования, используемый для кэширования файла.
[0478] Предпочтительно, чтобы хэш-функция обладала свойством, что очень малая доля разных входных данных преобразуется в один и тот же результат, и что разные входные данные преобразуются в высшей степени случайные результаты, чтобы гарантировать, что для заданного набора адресов по Интернет-протоколу пропорция файлов, для которых заданный адрес из адресов по Интернет-протоколу является первым в отсортированном списке с помощью этапа 1750, приблизительно одинакова для всех адресов по Интернет-протоколу в списке. С другой стороны, важно, чтобы хэш-функция была детерминированной в том смысле, что для заданного входа результат хэш-функции одинаков для всех клиентов.
[0479] Другим преимуществом описанного выше способа является следующее. Предположим, что все клиенты в наборе клиентов снабжаются одним и тем же списком адресов по Интернет-протоколу. Вследствие только что описанных свойств хэш-функции, вероятно, что запросы разных файлов от этих клиентов будут равномерно распределены по набору адресов по Интернет-протоколу, что в свою очередь означает, что запросы будут распределены равномерно по кэширующим прокси-серверам. Таким образом, ресурсы кэширования, используемые для хранения этих файлов, распределяются равномерно по кэширующим прокси-серверам, и запросы файлов распределяются равномерно по кэширующим прокси-серверам. Таким образом, способ обеспечивает как уравновешивание хранения, так и балансирование нагрузки по всей инфраструктуре кэширования.
[0480] Некоторое количество вариаций к описанному выше подходу известно специалистам в данной области техники, и во многих случаях эти вариации сохраняют свойство, что набор файлов, сохраненный на заданном посреднике, по меньшей мере, частично определяется набором запросов, который принял кэширующий прокси-сервер. В общем случае, в котором заданное имя хоста разделяется на несколько физических кэширующих прокси-серверов, будет обычным явлением, что все эти серверы, в конечном счете, будут хранить копию любого заданного файла, который часто запрашивается. Такое дублирование может быть нежелательным, поскольку ресурсы хранения на кэширующих прокси-серверах ограничены, и в результате файлы могут быть случайно удалены из кэша. Описанный здесь новый способ гарантирует, что запросы заданного файла направляются кэширующим прокси-серверам таким образом, что это дублирование уменьшается, посредством этого уменьшая необходимость удалять файлы из кэша, и посредством этого увеличивая вероятность, что любой заданный файл присутствует в кэше посредника (то есть, не удален из него).
[0481] Когда файл присутствует в кэше посредника, быстрее идет ответ, отправленный клиенту, что обладает преимуществом в снижении вероятности того, что запрошенный файл поступает позже, что может привести к паузе в воспроизведении мультимедиа и поэтому плохому взаимодействию с пользователем. Более того, когда файл не присутствует в кэше посредника, запрос может отправляться другому серверу, вызывая дополнительную нагрузку на обслуживающую инфраструктуру и сетевые соединения между серверами. Во многих случаях сервер, которому отправляется запрос, может находиться в отдаленном расположении, и передача файла от этого сервера обратно на кэширующий прокси-сервер может привести к затратам на передачу. Поэтому описанный здесь новый способ приводит к сокращению этих затрат на передачу.
ВЕРОЯТНОСТНЫЕ ЗАПРОСЫ ВСЕГО ФАЙЛА
[0482] Конкретным вопросом в случае, когда протокол HTTP используется с Запросами диапазона, является поведение кэш-серверов, которые широко применяются для обеспечения масштабируемости в обслуживающей инфраструктуре. Хотя для кэш-серверов HTTP может быть общепринятым поддерживать Заголовок диапазона HTTP, точное поведение разных кэш-серверов HTTP меняется от реализации. Большинство реализаций кэш-серверов обслуживают Запросы диапазона из кэша в случае, когда файл доступен в кэше. Общая реализация кэш-серверов HTTP всегда перенаправляет нисходящие запросы HTTP, содержащие Заголовок диапазона, вышестоящему узлу, пока у кэш-сервера не будет копии файла (кэш-сервера или сервера-источника). В некоторых реализациях восходящим ответом на Запрос диапазона является весь файл, и этот весь файл кэшируется, и ответ на нисходящий Запрос диапазона извлекается из этого файла и отправляется. Однако по меньшей мере в одной реализации восходящим ответом на Запрос диапазона являются всего лишь байты данных в самом Запросе диапазона, и эти байты данных не кэшируются, а вместо этого отправляются в качестве ответа на нисходящий Запрос диапазона. В результате использование Заголовков диапазона клиентами может иметь результатом то, что сам файл никогда не заносится в кэши, и желательные свойства масштабируемости сети будут потеряны.
[0483] Выше описывалась работа кэширующих прокси-серверов, а также описывался способ запроса Блоков из файла, который является объединениями нескольких блоков. Например, этого можно добиться путем использования заголовка Запроса диапазона HTTP. Такие запросы в дальнейшем называются "частичными запросами". Теперь описывается дополнительный вариант осуществления, который обладает преимуществом в случае, когда обслуживающая инфраструктура 101 блоков не предоставляет полной поддержки Заголовка диапазона HTTP. Обычно серверы в обслуживающей инфраструктуре блоков, например в Сети доставки, контента, поддерживают частичные запросы, но могут не хранить ответ на частичные запросы в локальном хранилище (кэше). Такой сервер может выполнять частичный запрос путем перенаправления запроса другому серверу, пока весь файл не сохранится в локальном хранилище, и в этом случае ответ может отправляться без перенаправления запроса другому серверу.
[0484] Система потоковой передачи по запросу блоков, которая применяет новое улучшение объединения блоков, описанное выше, может плохо работать, если обслуживающая инфраструктура блоков демонстрирует это поведение, поскольку все запросы, являющиеся частичными запросами, будут перенаправляться другому серверу, и никакие запросы не будут обслуживаться кэширующими прокси-серверами, препятствуя, прежде всего цели предоставления кэширующих прокси-серверов. Во время процесса потоковой передачи по запросу блоков, который описан выше, клиент может в некоторый момент запросить Блок, который находится в начале файла.
[0485] В соответствии с описанным здесь новым способом всякий раз, когда выполняется некоторое условие, такие запросы могут быть преобразованы из запросов первого Блока в файле в запросы всего файла. Когда запрос всего файла принимается кэширующим прокси-сервером, прокси-сервер обычно сохраняет ответ. Поэтому использование этих запросов вынуждает заносить файл в кэш локальных кэширующих прокси-серверов, так что последующие запросы либо полного файла, либо частичные запросы могут обслуживаться непосредственно кэширующим прокси-сервером. Условие может быть таким, что среди набора запросов, ассоциированного с данным файлом, например, набора запросов, сформированного набором клиентов, просматривающих элемент содержимого, о котором идет речь, условие будет выполняться, по меньшей мере, для предоставленной доли этих запросов.
[0486] Примером подходящего условия является то, что случайно выбранное число больше предоставленной пороговой величины. Эта пороговая величина может задаваться так, что преобразование запроса одиночного Блока в запрос всего файла происходит в среднем для предоставленной доли запросов, например, один раз из десяти (и в этом случае случайное число может выбираться из интервала [0,1], а пороговой величиной может быть 0,9). Другим примером подходящего условия является то, что хэш-функция, вычисленная по некоторой информации, ассоциированной с блоком, и некоторой информации, ассоциированной с клиентом, принимает одно из предоставленного множества значений. Этот способ обладает преимуществом в том, что для файла, который часто запрашивается, файл будет занесен кэш локального прокси-сервера, однако работа системы потоковой передачи по запросу блоков не меняется значительно от стандартной работы, в которой каждый запрос предназначен для одиночного Блока. Во многих случаях, когда происходит преобразование запроса из запроса одиночного Блока в запрос всего файла, процедуры клиента в остальных случаях продолжались бы для запроса других Блоков в файле. Если это так, то такие запросы можно остановить, потому что Блоки, о которых идет речь, будут приняты в любом случае в результате запроса всего файла.
КОНСТРУИРОВАНИЕ URL, ФОРМИРОВАНИЕ СПИСКА СЕГМЕНТОВ И ПОИСК ПО НЕМУ
[0487] Формирование списка сегментов сталкивается с проблемой, как клиент может сформировать список сегментов из MPD в локальное время NOW конкретного клиента для конкретного отображения, которое начинается в некоторое время начала starttime либо относительно начала представления мультимедиа для случаев по требованию, либо выраженное реальным временем. Список сегментов может содержать указатель, например URL, на необязательные исходные метаданные отображения, а также список мультимедийных сегментов. Каждому мультимедийному сегменту могут быть назначены starttime, длительность и указатель. Starttime обычно выражает приближенное значение времени мультимедиа у содержащегося в сегменте мультимедиа, но не обязательно точное время выборки. Starttime используется клиентом потоковой передачи HTTP для выдачи запроса загрузки в подходящее время. Формирование списка сегментов, включающего время начала каждого, может выполняться разными способами. URL могут предоставляться в виде списка воспроизведения, либо правило конструирования URL может использоваться преимущественно для компактного представления списка сегментов.
[0488] Список сегментов на основе конструирования URL может, например, выполняться, если MPD сигнализирует это с помощью определенного атрибута или элемента, например FileDynamicInfo или эквивалентного сигнала. Обобщенный способ создания списка сегментов из конструирования URL предоставляется ниже в разделе "Обзор конструирования URL". Конструирование на основе списка воспроизведения может, например, сигнализироваться с помощью другого сигнала. Поиск в списке сегментов и попадание в точное время мультимедиа также преимущественно реализуется в этом контексте.
ОБЗОР КОНСТРУКТОРА URL
[0489] Как описывалось ранее, в одном варианте осуществления настоящего изобретения может предоставляться файл метаданных, содержащий правила конструирования URL, которые позволяют клиентским устройствам конструировать идентификаторы файлов для Блоков представления. Теперь мы описываем дополнительное новое улучшение в системе потоковой передачи по запросу блоков, которое предусматривает изменения в файле метаданных, включающие в себя изменения в правилах конструирования URL, изменения в количестве доступных кодирований, изменения в метаданных, ассоциированных с доступными кодированиями, например скорость передачи битов, соотношение сторон, разрешение, кодек звука или видеоизображения или параметры кодеков, или другие параметры.
[0490] В этом новом улучшении могут предоставляться дополнительные данные, ассоциированные с каждым элементом файла метаданных, указывающие интервал времени в общем представлении. В этом интервале времени элемент может считаться допустимым, а в противном случае элемент можно игнорировать. Кроме того, синтаксис метаданных можно улучшить, так что элементы, которым ранее разрешено появляться только один раз или не более одного раза, могут появляться несколько раз. В этом случае может применяться дополнительное ограничение, которое предусматривает, что для таких элементов заданные интервалы времени должны быть непересекающимися. В любой заданный момент времени рассмотрение только элементов, чей интервал времени содержит заданный момент времени, приводит к файлу метаданных, который соответствует исходному синтаксису метаданных. Мы называем такие интервалы времени интервалами действия. Поэтому этот способ предусматривает сигнализацию в одиночном файле метаданных изменений описанного выше вида. Преимущественно, чтобы такой способ мог использоваться для предоставления представления мультимедиа, которое поддерживает изменения описанного вида в заданных моментах в представлении.
КОНСТРУКТОР URL
[0491] Как описано в этом документе, общим признаком систем потоковой передачи по запросу блоков является необходимость предоставлять клиенту "метаданные", которые идентифицируют доступные кодирования мультимедиа и предоставляют информацию, необходимую клиенту для запроса блоков из тех кодирований. Например, в случае HTTP эта информация могла бы содержать URL для файлов, содержащих блоки мультимедиа. Может предоставляться файл списка воспроизведения, который перечисляет URL для блоков для заданного кодирования. Предоставляется несколько файлов списков воспроизведения, по одному для каждого кодирования, вместе с главным списком воспроизведения списков воспроизведения, который перечисляет списки воспроизведения, соответствующие разным кодированиям. Недостатком этой системы является то, что метаданные могут стать довольно большими и поэтому потребуют некоторое время для запроса, когда клиент начинает поток. Дополнительный недостаток этой системы очевиден в случае контента прямой передачи, когда файлы, соответствующие блокам мультимедийных данных, формируются "на ходу" из мультимедийного потока, который захватывается в реальном масштабе времени (вживую), например, прямая спортивная трансляция или программа новостей. В этом случае файлы списков воспроизведения могут обновляться каждый раз, когда доступен новый блок (например, каждые несколько секунд). Клиентские устройства могут многократно вызывать файл списка воспроизведения для определения, доступны ли новые блоки, и получения их URL. Это может создавать значительную нагрузку на обслуживающую инфраструктуру и в частности означает, что файлы метаданных нельзя кэшировать дольше интервала обновления, который равен размеру блока, который обычно составляет порядка нескольких секунд.
[0492] Одной важной особенностью системы потоковой передачи по запросу блоков является способ, используемый для информирования клиентов об идентификаторах файлов, например URL, которые следует использовать, вместе с протоколом загрузки файла для запроса Блоков. Например, способ, в котором для каждого отображения в представлении предоставляется файл списка воспроизведения, который перечисляет URL файлов, содержащих Блоки мультимедийных данных. Недостаток этого способа состоит в том, что, по меньшей мере, часть самого файла списка воспроизведения нужно загружать перед тем, как может начаться воспроизведение, увеличивая время переключения каналов и поэтому являясь причиной плохого взаимодействия с пользователем. Для длительного представления мультимедиа с несколькими или многими отображениями список URL файлов может быть большим, и поэтому файл списка воспроизведения может быть большим, дополнительно увеличивая время переключения каналов.
[0493] Другой недостаток этого способа возникает в случае контента прямой передачи. В этом случае полный список URL не становится доступным заранее, а файл списка воспроизведения периодически обновляется, когда новые блоки становятся доступными, и клиенты периодически запрашивают файл списка воспроизведения, чтобы принять обновленную версию. Поскольку этот файл часто обновляется, его нельзя долго хранить на кэширующих прокси-серверах. Это означает, что очень много запросов этого файла будет перенаправлено другим серверам и в конечном счете серверу, который формирует тот файл. В случае популярного представления мультимедиа это может привести к высокой нагрузке на этот сервер и сеть, что в свою очередь может привести к большому времени ответа, а поэтому к большому времени переключения каналов и плохому взаимодействию с пользователем. В худшем случае сервер становится перегруженным, и это приводит к тому, что некоторые пользователи не могут посмотреть представление.
[0494] Желательно при исполнении системы потоковой передачи по запросу блоков избегать наложения ограничений на вид идентификаторов файлов, которые могут использоваться. Причина в том, что некоторое количество соображений может побуждать использование идентификаторов конкретного вида. Например, в случае, когда Обслуживающей инфраструктурой блоков является Сеть доставки контента, могут существовать соглашения по присваиванию имен файлам или хранению, имеющие отношение к желанию распределить нагрузку хранения или обслуживания по всей сети, или другие требования, которые приводят к конкретным видам идентификатора файла, которые нельзя предсказать во время проектирования системы.
[0495] Теперь описывается дополнительный вариант осуществления, который смягчает вышеупомянутые недостатки наряду с сохранением гибкости для выбора подходящих соглашений по идентификации файлов. В этом способе метаданные могут предоставляться для каждого отображения в представлении мультимедиа, содержащие правило конструирования идентификатора файла. Правило конструирования идентификатора файла может содержать, например, текстовую строку. Чтобы определить идентификатор файла для заданного блока представления, может предоставляться способ интерпретации правила конструирования идентификатора файла, причем этот способ содержит определение входных параметров и оценку правила конструирования идентификатора файла, вместе с входными параметрами. Входные параметры могут включать в себя, например, индекс файла, который нужно идентифицировать, когда первый файл имеет индекс нуля, второй имеет индекс единицы, третий имеет индекс двойки и так далее. Например, если каждый файл занимает одну и ту же продолжительность времени (или приблизительно одну и ту же продолжительность времени), то можно легко определить индекс файла, ассоциированного с любым заданным временем в представлении. В качестве альтернативы время в представлении, занятое каждым файлом, может предоставляться в представлении или версии метаданных.
[0496] В одном варианте осуществления правило конструирования идентификатора файла может содержать текстовую строку, которая может содержать некоторые специальные идентификаторы, соответствующие входным параметрам. Способ оценки правила конструирования идентификатора файла содержит определение положений специальных идентификаторов в текстовой строке и замену каждого такого специального идентификатора строковым представлением значения соответствующего входного параметра.
[0497] В другом варианте осуществления правило конструирования идентификатора файла может содержать текстовую строку, соответствующую некоторому языку выражений. Язык выражений содержит определение синтаксиса, которому могут соответствовать выражения на этом языке, и набор правил для оценивания строки, соответствующей синтаксису.
[0498] Сейчас будет описываться конкретный пример со ссылкой на фиг. 21 и следующие. Примером определения синтаксиса для подходящего языка выражений, заданного в дополненной форме Бэкуса-Наура, является показанный на фиг. 21. Пример правил для оценивания строки, соответствующей правилу вывода <expression> на фиг. 21, содержит рекурсивное преобразование строки, подчиняющейся правилу вывода <expression> (<expression>), в строку, подчиняющуюся правилу вывода <literal>, следующим образом:
[0499] <expression>, подчиняющееся правилу вывода <literal>, остается без изменений.
[0500] <expression>, подчиняющееся правилу вывода <variable>, заменяется значением переменной, идентифицированной строкой <token> в правиле вывода <variable>.
[0501] <expression>, подчиняющееся правилу вывода <function>, оценивается путем оценивания каждого из его аргументов в соответствии с этими правилами и применения преобразования к этим аргументам, зависящего от элемента <token> в правиле вывода <function>, как описано ниже.
[0502] <expression>, подчиняющееся последней альтернативе правила вывода <expression>, оценивается путем оценивания двух элементов <expression> и применения операции к этим аргументам, зависящей от элемента <operator> последней альтернативы правила вывода <expression>, как описано ниже.
[0503] В описанном выше способе предполагается, что оценка происходит в контексте, в котором можно задать множество переменных. Переменная является парой (имя, значение), где "имя" является строкой, подчиняющейся правилу вывода <token>, а "значение" является строкой, подчиняющейся правилу вывода <literal>. Некоторые переменные могут задаваться вне процесса оценки перед тем, как начинается оценка. Другие переменные могут задаваться в самом процессе оценки. Все переменные являются "глобальными" в том смысле, что только одна переменная существует с каждым возможным "именем".
[0504] Примером функции является функция "printf". Эта функция принимает один или несколько аргументов. Первый аргумент может подчиняться правилу вывода <string> (в дальнейшем "строка"). Функция printf оценивает преобразованную версию первого аргумента. Примененное преобразование является таким же, как функция "printf" в стандартной библиотеке языка C, с дополнительными аргументами, включенными в правило вывода <function>, поставляющее дополнительные аргументы, ожидаемые функцией printf в стандартной библиотеке языка C.
[0505] Другим примером функции является функция "hash". Эта функция принимает два аргумента, первый из которых может быть строкой, а второй может подчиняться правилу вывода <number> (в дальнейшем "число"). Функция "hash" применяет хэш-алгоритм к первому аргументу и возвращает результаты, которые являются неотрицательным целым числом меньше второго аргумента. Пример подходящей хэш-функции задается в функции на языке C, показанной на фиг. 22, чьими аргументами является входная строка (исключая окружающие кавычки) и числовое входное значение. Другие примеры хэш-функции хорошо известны специалистам в данной области техники.
[0506] Другим примером функции является функция "Subst", которая принимает один, два или три строковых аргумента. В случае, когда поступает один аргумент, результатом функции "Subst" является первый аргумент. В случае, когда поступают два аргумента, результат функции "Subst" вычисляется путем удаления любых вхождений второго аргумента (исключая окружающие кавычки) в первом аргументе и возвращения измененного таким образом первого аргумента. В случае, когда поступают три аргумента, результат функции "Subst" вычисляется путем замены любых вхождений второго аргумента (исключая окружающие кавычки) в первом аргументе третьим аргументом (исключая окружающие кавычки) и возвращения измененного таким образом первого аргумента.
[0507] Некоторыми примерами операторов являются операторы добавления, вычитания, деления, умножения и деления по модулю, идентифицированные правилами вывода <operator> "+", "-", "/", "*", "%" соответственно. Эти операторы требуют, чтобы правила вывода <expression> либо сторона правила вывода <operator> оценивались числами. Оценка оператора содержит применение подходящей арифметической операции (добавление, вычитание, деление, умножение и деление по модулю соответственно) к этим двум числам обычным способом и возвращение результата в виде, соответствующем правилу вывода <number>.
[0508] Другим примером оператора является оператор присваивания, идентифицированный правилом вывода <operator> "=". Этот оператор требует, чтобы левый аргумент оценивался строкой, содержимое которой соответствует правилу вывода <token>. Содержимое строки задается строкой символов в окружающих кавычках. Оператор равенства вызывает присвоение переменной, чьим именем является <token>, равной содержимому левого аргумента, значения, равного результату оценивания правого аргумента. Это значение также является результатом оценивания операторного выражения.
[0509] Другим примером оператора является оператор последовательности, идентифицированный правилом вывода <operator ";". Результатом оценивания этого оператора является правый аргумент. Отметим, что как и в случае всех операторов, оцениваются оба аргумента, и левый аргумент оценивается первым.
[0510] В одном варианте осуществления этого изобретения идентификатор файла может быть получен путем оценивания правила конструирования идентификатора файла в соответствии с вышеприведенным правилом с конкретным набором входных переменных, которые идентифицируют необходимый файл. Примером входной переменной является переменная с именем "index" и значением, равным числовому индексу файла в представлении. Другим примером входной переменной является переменная с именем "bitrate" и значением, равным средней скорости передачи битов у необходимой версии представления.
[0511] Фиг. 23 иллюстрирует некоторые примеры правил конструирования идентификатора файла, когда входными переменными являются "id", задающая идентификатор для отображения в нужном представлении, и "seq", задающая порядковый номер для файла.
[0512] Как будет понятно специалистам в данной области техники при прочтении этого раскрытия изобретения, возможны многочисленные вариации вышеприведенного способа. Например, могут предоставляться не все описанные выше функции и операторы, или могут предоставляться дополнительные функции или операторы.
ПРАВИЛА КОНСТРУИРОВАНИЯ URL И РАСПРЕДЕЛЕНИЕ ВО ВРЕМЕНИ
[0513] Этот раздел предоставляет основные Правила конструирования URI для назначения URI файлу или сегменту, а также времени начала для каждого сегмента в отображении и представлении мультимедиа.
[0514] Для этого пункта предполагается доступность описания представления мультимедиа на клиенте.
[0515] Допустим, что клиент потоковой передачи HTTP воспроизводит мультимедиа, которое загружается в рамках представления мультимедиа. Фактическое время представления клиента HTTP может задаваться относительного того, где находится время представления относительно начала представления. При инициализации может допускаться время представления t=0.
[0516] В любой момент t клиент HTTP может загрузить любые данные с временем воспроизведения tP (также относительно начала представления) не более MaximumClientPreBufferTime впереди фактического времени представления t и любые данные, которые необходимы из-за взаимодействия с пользователем, например поиска, быстрой перемотки вперед и т.д. В некоторых вариантах осуществления MaximumClientPreBufferTime может даже не задаваться в том смысле, что клиент может загружать данные впереди текущего времени воспроизведения tP без ограничений.
[0517] Клиент HTTP может избежать загрузки ненужных данных, например, любые сегменты из отображений, которые не предполагаются для воспроизведения, обычно можно не загружать.
[0518] Основным процессом в предоставлении услуг потоковой передачи может быть загрузка данных путем формирования подходящих запросов для загрузки всех файлов/сегментов или подмножества файлов/сегментов, например, с использованием запросов GET HTTP или частичных запросов GET HTTP. Это описание рассматривает то, как обращаться к данным для определенного времени воспроизведения tP, но обычно клиент может загружать данные для большего временного диапазона времени воспроизведения, чтобы избежать неэффективных запросов. Клиент HTTP может минимизировать число/частоту запросов HTTP при предоставлении услуги потоковой передачи.
[0519] Для обращения к мультимедийным данным во время воспроизведения tP или, по меньшей мере, близко к времени воспроизведения tP в конкретном отображении клиент определяет URL на файл, который содержит это время воспроизведения, и к тому же определяет байтовый диапазон в файле для доступа к этому времени воспроизведения.
[0520] Описание представления мультимедиа может назначать каждому отображению id отображения, r, например, с использованием атрибута RepresentationID. Другими словами, содержимое MPD, когда записывается системой захвата или когда считывается клиентом, будет интерпретироваться так, что существует назначение. Чтобы загрузить данные для определенного времени воспроизведения tP для определенного отображения с id r, клиент может составить подходящий URI для файла.
[0521] Описание представления мультимедиа может назначать каждому файлу или сегменту каждого отображения r следующие атрибуты:
[0522] (a) порядковый номер i файла в отображении r, причем i=1, 2, …, Nr, (b) относительное время начала файла с id отображения r и индексом файла i относительно времени представления, заданное как ts(r,i), (c) URI файла для файла/сегмента с id отображения r и индексом файла i, обозначенный как FileURI(r, i).
[0523] В одном варианте осуществления время начала файла и URI файла могут предоставляться явно для отображения. В другом варианте осуществления список URI файла может предоставляться явно, когда каждый URI файла получает неотъемлемо назначенный индекс i в соответствии с положением в списке, и время начала сегмента выводится как сумма всех длительностей сегментов для сегментов с 1 по i-1. Длительность каждого сегмента может предоставляться в соответствии с любым из рассмотренных выше правил. Например, любой специалист в математике может использовать другие способы для выведения методологии, чтобы легко выводить время начала из одного элемента или атрибута и положения/индекса URI файла в отображении.
[0524] Если динамическое правило конструирования URI предоставляется в MPD, то время начала каждого файла, и каждый URI файла могут создаваться динамически с использованием правила конструирования, индекса запрошенного файла и по возможности некоторых дополнительных параметров, предоставленных в описании представления мультимедиа. Информация может предоставляться, например, в атрибутах и элементах MPD, например FileURIPattern и FileInfoDynamic. FileURIPattern предоставляет информацию о том, как конструировать URI на основе порядкового номера i индекса файла и id отображения r. FileURIFormat конструируется в виде:
[0525] FileURIFormat=sprintf(“%s%s%s%s%s.%s”, BaseURI, BaseFileName,
[0526]
RepresentationIDFormat,
SeparatorFormat,
[0527]
FileSequenceIDFormat,
FileExtension);
[0528] а FileURI(r,i) конструируется в виде
[0529] FileURI(r,i)=sprintf(FileURIFormat, r, i);
[0530] Относительное время начала ts(r,i) для каждого файла/сегмента может выводиться с помощью некоторого атрибута, содержащегося в MPD, описывающего длительность сегментов в этом отображении, например атрибута FileInfoDynamic. MPD также может содержать последовательность атрибутов FileInfoDynamic, которая глобальна для всех отображений в представлении мультимедиа или по меньшей мере для всех отображений в периоде точно так же, как задано выше. Если запрашиваются мультимедийные данные для определенного времени воспроизведения tP в отображении r, то соответствующий индекс i(r, tP) может выводиться в виде i(r, tp), так что время воспроизведения этого индекса находится в интервале времени начала ts(r, i(r, tP)) и ts(r, i(r, tP)+1). Доступ к сегменту может дополнительно ограничиваться вышеупомянутыми случаями, например, сегмент является недоступным.
[0531] Доступ к точному времени воспроизведения tP, как только получается индекс и URI соответствующего сегмента, зависит от фактического формата сегмента. В этом примере предположим, что мультимедийные сегменты имеют локальную временную шкалу, которая начинается в 0 без потери общности. Чтобы обратиться и представить данные во времени воспроизведения tP, клиент может загрузить данные, соответствующие локальному времени, из файла/сегмента, к которому можно обратиться посредством URI FileURI(r,i), причем i=i(r, tp).
[0532] Как правило, клиенты могут загрузить весь файл и могут затем обратиться к времени воспроизведения tP. Однако не обязательно загружать всю информацию файла 3GP, так как файл 3GP предоставляет структуры для преобразования локального хронометража в байтовые диапазоны. Поэтому только определенных байтовых диапазонов для доступа к времени воспроизведения tP может быть достаточно для воспроизведения мультимедиа при условии, что доступна достаточная информация о произвольном доступе. Также достаточная информация о структуре и преобразовании байтового диапазона и локального хронометража мультимедийного сегмента может предоставляться в начальной части сегмента, например, с использованием индекса сегмента. Имея доступ к начальным, например, 1200 байтам сегмента, клиент может получить достаточную информацию для прямого доступа к байтовому диапазону, необходимому для времени воспроизведения tP.
[0533] В дополнительном примере предположим, что индекс сегмента, по возможности заданный как блок "tidx" ниже, может использоваться для идентификации байтовых смещений необходимого Фрагмента или Фрагментов. Частичные запросы GET можно сформировать для необходимого Фрагмента или Фрагментов. Существуют другие альтернативы, например клиент, может выдать стандартный запрос файла и отменить его, когда принят первый блок "TIDX".
ПОИСК
[0534] Клиент может попытаться перейти к определенному времени представления tp в отображении. На основе MPD клиент имеет доступ к времени начала мультимедийного сегмента и URL мультимедийного сегмента у каждого сегмента в отображении. Клиент может получить индекс сегмента segment_index у сегмента, вероятнее всего содержащего выборки мультимедиа для времени представления tp, в виде максимального индекса сегмента i, для которого время начала tS(r,i) меньше либо равно времени представления tp, то есть segment_index=max {i | tS(r,i)<=tp}. URL сегмента получается в виде FileURI(r,i).
[0535] Отметим, что информация о синхронизации в MPD может быть приблизительной из-за проблем, имеющих отношение к размещению Точек произвольного доступа, выравниванию дорожек мультимедиа и ухода синхронизации мультимедиа. В результате сегмент, идентифицированный по вышеупомянутой процедуре, может начинаться в момент немного после tp, и мультимедийные данные для времени представления tp могут находиться в предыдущем мультимедийном сегменте. В случае поиска либо время поиска может обновляться до равного первому времени выборки у извлеченного файла, либо вместо этого можно извлечь предыдущий файл. Однако отметим, что во время непрерывного воспроизведения, включая случаи, когда имеется переключение между альтернативными отображениями/версиями, все же доступны мультимедийные данные для времени между tp и началом извлеченного сегмента.
[0536] Для точного перехода к времени представления tp клиенту потоковой передачи HTTP нужно обратиться к точке произвольного доступа (RAP). Чтобы определить точку произвольного доступа в мультимедийном сегменте в случае Адаптивной потоковой передачи HTTP 3GPP, клиент может использовать, например, информацию в блоке "tidx" или "sidx", если имеется, для нахождения точек произвольного доступа и соответствующего времени представления в представлении мультимедиа. В случаях, когда сегмент является фрагментом фильма 3GPP, клиенту также можно использовать информацию в блоках "moof" и "mdat", например, чтобы найти RAP и получить необходимое время представления из информации во фрагменте фильма и время начала сегмента, выведенное из MPD. Если не доступна RAP с временем представления перед запрошенным временем представления tp, то клиент может либо обратиться к предыдущему сегменту, либо может использовать лишь первую точку произвольного доступа в качестве результата поиска. Когда мультимедийные сегменты начинаются с RAP, эти процедуры простые.
[0537] Также отметим, что не обязательно загружать всю информацию мультимедийного сегмента, чтобы обратиться к времени представления tp. Клиент может, например, сначала запросить блок "tidx" или "sidx" из начала мультимедийного сегмента, используя запросы байтовых диапазонов. При использовании блоков "tidx" или "sidx" хронометраж сегмента можно преобразовать в байтовые диапазоны сегмента. Постоянно используя частичные запросы HTTP, нужно обращаться только к значимым частям мультимедийного сегмента для улучшенного взаимодействия с пользователем и малых задержек запуска.
ФОРМИРОВАНИЕ СПИСКА СЕГМЕНТОВ
[0538] Как описано в этом документе, должно быть, очевидно, как реализовать клиента прямой потоковой передачи HTTP, который использует информацию, предоставленную MPD, для создания списка сегментов для отображения, которое имеет сигнализированную приблизительную длительность сегмента dur. В некоторых вариантах осуществления клиент может назначать мультимедийным сегментам в отображении последовательные индексы i=1, 2, 3, …, то есть первому мультимедийному сегменту назначается индекс i=1, второму мультимедийному сегменту назначается индекс i=2, и так далее. Затем списку мультимедийных сегментов с индексами i сегментов назначается startTime[i], и URL[i] формируется, например, следующим образом. Сначала индекс i устанавливается в 1. Время начала первого мультимедийного сегмента получается как 0, startTime[1]=0. URL мультимедийного сегмента i, URL[i], получается как FileURI(r, i). Процесс продолжается для всех описанных мультимедийных сегментов с индексом i, и startTime[i] мультимедийного сегмента i получается как (i-1)*dur, а URL[i] получается как FileURI(r, i).
ОДНОВРЕМЕННЫЕ ЗАПРОСЫ HTTP/TCP
[0539] Проблемой в системе потоковой передачи по запросу блоков является желание всегда запрашивать блоки наивысшего качества, которые могут быть приняты полностью вовремя для воспроизведения. Однако скорость поступления данных может быть неизвестна заранее, и поэтому может произойти так, что запрошенный блок не поступает вовремя для воспроизведения. Это приводит к необходимости приостановить воспроизведение мультимедиа, что приводит к плохому взаимодействию с пользователем. Эту проблему можно смягчить с помощью клиентских алгоритмов, которые применяют консервативный подход к выбору блоков для запроса, запрашивая блоки более низкого качества (и поэтому меньшего размера), которые с большей вероятностью будут приняты вовремя, даже если скорость поступления данных снижается во время приема блока. Однако этот консервативный подход обладает недостатком возможной доставки пользователю или устройству назначения воспроизведения более низкого качества, что также является плохим взаимодействием с пользователем. Проблема может усиливаться, когда несколько соединений HTTP используются одновременно для загрузки разных блоков, как описано ниже, поскольку доступные сетевые ресурсы совместно используются между соединениями и соответственно используются одновременно для блоков с разными моментами воспроизведения.
[0540] Клиенту может быть выгодно, выдавать запросы нескольких блоков одновременно, когда в этом контексте "одновременно" означает, что ответы на запросы возникают в перекрывающиеся интервалы времени, и не обязательно происходит так, что запросы выполняются точно или даже приблизительно в одно и то же время. В случае протокола HTTP этот подход может улучшить использование доступной полосы пропускания благодаря поведению протокола TCP (которое общеизвестно). Это может быть особенно важно для улучшения времени переключения контента, поскольку, когда сначала запрашивается новый контент, соответствующие соединения HTTP/TCP, по которым запрашиваются данные для блоков, могли бы медленно запускаться, и соответственно использование нескольких соединений HTTP/TCP в этот момент может значительно ускорить время доставки данных у первых блоков. Однако запрашивание разных блоков или фрагментов по разным соединениям HTTP/TCP также может привести к ухудшенной производительности, так как запросы блоков, которые нужно воспроизвести первыми, конкурируют с запросами последующих блоков, конкурирующие загрузки HTTP/TCP значительно меняются по скорости доставки, и соответственно время завершения запроса может быть очень переменным, и обычно невозможно управлять тем, какие загрузки HTTP/TCP будут завершены быстро, а какие медленнее, и соответственно возможно, что, по меньшей мере, часть времени загрузки HTTP/TCP первых нескольких блоков будут закончены последними, соответственно приводя к большому и переменному времени переключения каналов.
[0541] Предположим, что каждый блок или фрагмент сегмента загружается по отдельному соединению HTTP/TCP, и что количество параллельных соединений равно n, а длительность воспроизведения каждого блока равна t секунд, и что скорость потоковой передачи контента, ассоциированного с сегментом, равна S. Когда клиент сначала начинает потоковую передачу контента, могут выдаваться запросы первых n блоков, представляющие n*t секунд мультимедийных данных.
[0542] Как известно специалистам в данной области техники, имеется большое отклонение в скорости передачи данных у соединений TCP. Однако для упрощения этого обсуждения предположим, что в идеале все соединения происходят параллельно, так что первый блок будет принят полностью примерно в то же время, что и остальные n-1 запрошенных блоков. Для дополнительного упрощения обсуждения предположим, что совокупная полоса пропускания, используемая n соединениями загрузки, зафиксирована в значении B для всей продолжительности загрузки, и что скорость потоковой передачи S постоянна во всем отображении. Дополнительно предположим, что структура мультимедийных данных такова, что воспроизведение блока может быть выполнено, когда весь блок доступен на клиенте, то есть воспроизведение блока может начаться только после того, как принимается весь блок, например, из-за структуры лежащего в основе кодирования видеоизображения, или потому что применяется шифрование для шифрования каждого фрагмента или блока отдельно, и соответственно весь фрагмент или блок нужно принять перед тем, как его можно расшифровать. Таким образом, чтобы упростить обсуждение ниже, мы допускаем, что весь блок нужно принять перед тем, как можно воспроизвести любой из блоков. Тогда время, необходимое перед тем, как поступил и может быть воспроизведен первый блок, приблизительно равно n*t*S/B.
[0543] Поскольку желательно минимизировать время переключения контента, желательно минимизировать n*t*S/B. Значение t может определяться такими факторами, как лежащая в основе структура кодирования видеоизображения и какие способы захвата используются, и соответственно t может быть довольно малым, но очень маленькие значения t приводят к чрезмерно усложненной карте сегмента и, возможно, могут быть несовместимы с эффективным кодированием видеоизображения и дешифрованием, если используется. Значение n также может влиять на значение B, то есть B может быть больше для большего числа n соединений, и соответственно сокращение количества соединений n имеет отрицательное побочное действие по возможному уменьшению величины доступной полосы пропускания, которая используется, B, и поэтому может быть неэффективно в достижении цели уменьшения времени переключения контента. Значение S зависит от того, какое отображение выбирается для загрузки и воспроизведения, и в идеале S должно быть как можно ближе к B, чтобы максимизировать качество воспроизведения мультимедиа для заданных сетевых условий. Таким образом, чтобы упростить это обсуждение, предположим, что S приблизительно равно B. Тогда время переключения каналов пропорционально n*t. Таким образом, использование большего количества соединений для загрузки разных фрагментов может ухудшить время переключения каналов, если совокупная полоса пропускания, используемая соединениями, сублинейно пропорциональна количеству соединений, что обычно имеет место.
[0544] В качестве примера предположим t=1 секунде, и при n=1 значение B=500 Кбит/с, при n=2 значение B=700 Кбит/с, а при n=3 значение B=800 Кбит/с. Предположим, что выбирается отображение с S=700 Кбит/с. Тогда при n=1 время загрузки для первого блока равно 1*700/500=1,4 секунды, при n=2 время загрузки для первого блока равно 2*700/700=2 секунды, а n=3 время загрузки для первого блока равно 3*700/800=2,625 секунды. Кроме того, так как количество соединений увеличивается, то, скорее всего, увеличивается изменчивость в отдельных скоростях загрузки у соединений (хотя даже при одном соединении вероятна некоторая значительная изменчивость). Таким образом, в этом примере время переключения каналов и изменчивость времени переключения каналов увеличивается, когда увеличивается количество соединений. Интуитивно блоки, которые доставляются, имеют разные приоритеты, то есть первый блок имеет самый ранний крайний срок доставки, второй блок имеет второй самый ранний крайний срок и т.д., тогда как соединения загрузки, по которым доставляются блоки, конкурируют за сетевые ресурсы в течение доставки, и соответственно блоки с самыми ранними крайними сроками больше задерживаются, когда запрашивается больше конкурирующих блоков. С другой стороны, даже в этом случае использование, в конечном счете, более одного соединения загрузки позволяет поддерживать стабильно более высокую скорость потоковой передачи, например, при трех соединениях может поддерживаться скорость потоковой передачи вплоть до 800 Кбит/с в этом примере, тогда как при одном соединении может поддерживаться только поток в 500 Кбит/с.
[0545] На практике, как отмечалось выше, скорость передачи данных у соединения может быть очень переменной как в пределах одного соединения со временем, так и между соединениями, и в результате n запрошенных блоков обычно не завершаются одновременно, и фактически в большинстве случаев один блок может завершиться в половину времени другого блока. Этот эффект приводит к непредсказуемому поведению, поскольку в некоторых случаях первый блок может завершиться гораздо раньше других блоков, а в других случаях первый блок может завершиться гораздо позже других блоков, и в результате начало воспроизведения в некоторых случаях может возникнуть относительно быстро, а в других случаях может возникать с запозданием. Это непредсказуемое поведение может быть разочаровывающим для пользователя и может, поэтому считаться плохим взаимодействием с пользователем.
[0546] Поэтому нужны способы, в которых несколько соединений TCP могут использоваться для улучшения времени переключения каналов и изменчивости во времени переключения каналов, одновременно поддерживая хорошее качество и возможную скорость потоковой передачи. Также нужны способы, которые допускают регулировку доли доступной полосы пропускания, выделенной каждому блоку, когда приближается время воспроизведения блока, чтобы можно было выделить большую долю доступной полосы пропускания блоку с ближайшим временем воспроизведения, если необходимо.
СОВМЕСТНЫЙ ЗАПРОС HTTP/TCP
[0547] Теперь мы описываем способы для использования одновременных запросов HTTP/TCP совместным способом. Приемник может применять несколько одновременных совместных запросов HTTP/TCP, например, используя множество запросов байтового диапазона HTTP, причем каждый такой запрос предназначен для части фрагмента в исходном сегменте или всего фрагмента в исходном сегменте, либо части или фрагмента восстановления в сегменте восстановления, либо для всех фрагментов восстановления в сегменте восстановления.
[0548] Преимущества совместных запросов HTTP/TCP вместе с использованием данных восстановления FEC могут быть особенно важны для предоставления согласованно быстрых времен переключения каналов. Например, во время переключения каналов, возможно, что соединения TCP либо только что начались, либо остановлены на некоторый период времени, и в этом случае окно перегрузки, cwnd, находится в минимальном значении для соединений, и соответственно скорости доставки у этих соединений TCP потребуется несколько периодов кругового обращения (RTT) для увеличения, и будет иметь место высокая изменчивость в скоростях доставки по разным соединениям TCP в течение этого времени увеличения.
[0549] Теперь описывается обзор способа без FEC, который является способом совместного запроса HTTP/TCP, в котором только мультимедийные данные исходных блоков запрашиваются с использованием нескольких одновременных соединений HTTP/TCP, то есть не запрашиваются никакие данные восстановления FEC. С помощью способа без FEC части одного и того же фрагмента запрашиваются по разным соединениям, например, с использованием запросов байтовых диапазонов HTTP для частей фрагмента, и соответственно каждый запрос байтового диапазона HTTP относится, например, к части байтового диапазона, указанной в карте сегмента для того фрагмента. Может быть так, что отдельный запрос HTTP/TCP увеличивает свою скорость доставки, чтобы полностью использовать доступную полосу пропускания, за несколько RTT (периоды кругового обращения), и соответственно имеется относительно длительный период времени, когда скорость доставки меньше доступной полосы пропускания, и соответственно, если одно соединение HTTP/TCP используется для загрузки, например, первого фрагмента контента, который нужно воспроизвести, то время переключения каналов могло бы быть большим. Используя способ без FEC, загрузка разных частей одного и того же фрагмента по разным соединениям HTTP/TCP может значительно уменьшить время переключения каналов.
[0550] Теперь описывается обзор способа с FEC, который является способом совместного запроса HTTP/TCP, в котором мультимедийные данные исходного сегмента и данные восстановления FEC, сформированные из мультимедийных данных, запрашиваются с использованием нескольких соединений HTTP/TCP. С помощью способа с FEC части одного и того же фрагмента и данные восстановления FEC, сформированные из того фрагмента, запрашиваются по разным соединениям с использованием запросов байтовых диапазонов HTTP для частей фрагмента, и соответственно каждый запрос байтового диапазона HTTP относится, например, к части байтового диапазона, указанной в карте сегмента для того фрагмента. Может быть так, что отдельный запрос HTTP/TCP увеличивает свою скорость доставки, чтобы полностью использовать доступную полосу пропускания, за несколько RTT (периоды кругового обращения), и соответственно имеется относительно длительный период времени, когда скорость доставки меньше доступной полосы пропускания, и соответственно, если одно соединение HTTP/TCP используется для загрузки, например, первого фрагмента контента, который нужно воспроизвести, то время переключения каналов могло бы быть большим. Использование способа с FEC имеет такие же преимущества, как и способ без FEC, и обладает дополнительным преимуществом в том, что не все запрошенные данные должны поступить до того, как можно восстановить фрагмент, соответственно дополнительно уменьшая время переключения каналов и изменчивость времени переключения каналов. Делая запросы по разным соединениям TCP и избыточно запрашивая путем запроса также данных восстановления FEC, по меньшей мере, по одному из соединений, количество времени, которое требуется для доставки достаточного объема данных, например, чтобы восстановить первый запрошенный фрагмент, который дает возможность начать воспроизведение мультимедиа, можно значительно уменьшить и сделать гораздо более согласованным, чем, если бы не использовались совместные соединения TCP и данные восстановления FEC.
[0551] Фиг. 24(а) - (е) показывают пример колебаний скорости доставки у 5 соединений TCP, работающих на одной и той же линии связи к одному и тому же клиенту от одного и того же веб-сервера HTTP в эмулированной сети Развития с оптимизацией для данных (EVDO). На фиг. 24(а) - (е) ось X показывает время в секундах, а ось Y показывает скорость для каждого соединения, с которой разряды принимаются на клиенте по каждому из 5 соединений TCP, измеренную в интервалах по 1 секунде. В этой конкретной имитации было всего 12 соединений TCP, работающих на этой линии связи, и соответственно сеть была относительно загружена в течение показанного времени, что могло быть типично, когда более одного клиента осуществляют потоковую передачу в одной и той же соте в сети подвижной связи. Отметим, что хотя скорости доставки отчасти коррелируют со временем, имеется большая разница в скоростях доставки у 5 соединений во многие моменты времени.
[0552] Фиг. 25 показывает возможную структуру запроса фрагмента, который имеет размер 250000 разрядов (приблизительно 31,25 килобайт), где имеется 4 запроса байтовых диапазонов HTTP, сделанных параллельно для разных частей фрагмента, то есть первое соединение HTTP запрашивает первые 50000 разрядов, второе соединение HTTP запрашивает следующие 50000 разрядов, третье соединение HTTP запрашивает следующие 50000 разрядов, и четвертое соединение HTTP запрашивает следующие 50000 разрядов. Если FEC не используется, то есть это способ без FEC, то в этом примере имеются только 4 запроса фрагмента. Если FEC используется, то есть это способ с FEC, то в этом примере имеется одно дополнительное соединение HTTP, которое запрашивает дополнительные 50000 разрядов данных восстановления FEC в сегменте восстановления, сформированных из фрагмента.
[0553] Фиг. 26 является увеличением первой пары секунд у 5 соединений TCP, показанных на фиг. 24(а) - (е), где на фиг. 26 ось X показывает время в интервалах по 100 миллисекунд, а ось Y показывает скорость, с которой разряды принимаются на клиенте по каждому из 5 соединений TCP, измеренную в интервалах по 100 миллисекунд. Одна линия показывает совокупное количество разрядов, которое принято на клиенте для фрагмента от первых 4 соединений HTTP (исключая соединение HTTP, по которому запрашиваются данные FEC), то есть то, что поступает с использованием способа без FEC. Другая линия показывает совокупное количество разрядов, которое принято на клиенте для фрагмента от всех 5 соединений HTTP (включая соединение HTTP, по которому запрашиваются данные FEC), то есть то, что поступает с использованием способа с FEC. Для способа с FEC предполагается, что фрагмент может декодироваться с FEC от приема любых 200000 разрядов из 250000 запрошенных разрядов, что можно осуществить, если используется, например, код FEC Рида-Соломона, и что можно главным образом осуществить, если используется, например, код RaptorQ, описанный в Luby IV. Для способа с FEC в этом примере принимается достаточно данных для восстановления фрагмента с использованием декодирования FEC после 1 секунды, позволяя время переключения каналов в 1 секунду (предполагая, что данные для последующих фрагментов можно запросить и принять до того, как полностью воспроизводится первый фрагмент). Для способа без FEC в этом примере все данные для 4 запросов нужно принять до того, как можно восстановить фрагмент, что происходит после 1,7 секунды, приводя к времени переключения каналов в 1,7 секунды. Таким образом, в показанном на фиг. 26 примере способ без FEC на 70% хуже в показателях времени переключения каналов, чем способ с FEC. Одной из причин для преимущества, показанного способом с FEC в этом примере, является то, что для способа с FEC прием любых 80% запрошенных данных позволяет восстановить фрагмент, тогда как для способа без FEC необходим прием 100% запрошенных данных. Таким образом, способу без FEC нужно ждать самого медленного соединения TCP для завершения доставки, и вследствие естественных изменений в скорости доставки TCP имеется тенденция к большому расхождению в скорости доставки у самого медленного соединения TCP по сравнению со средним соединением TCP. В способе с FEC в этом примере одно медленное соединение TCP не определяет, когда фрагмент является восстанавливаемым. Вместо этого для способа с FEC доставка достаточного количества данных гораздо больше зависит от средней скорости доставки TCP, чем от наихудшей скорости доставки TCP.
[0554] Существует много разновидностей способа без FEC и способа с FEC, описанных выше. Например, совместные запросы HTTP/TCP могут использоваться только для первых нескольких фрагментов после того, как произошло переключение каналов, и после этого только один запрос HTTP/TCP используется для загрузки дополнительных фрагментов, нескольких фрагментов или полных сегментов. В качестве другого примера количество используемых совместных соединений HTTP/TCP может зависеть как от срочности запрашиваемых фрагментов, то есть насколько близко время воспроизведения у этих фрагментов, так и от текущих сетевых условий.
[0555] В некоторых разновидностях множество соединений HTTP может использоваться для запроса данных восстановления из сегментов восстановления. В других разновидностях разные объемы данных могут запрашиваться по разным соединениям HTTP, например, в зависимости от текущего размера буфера мультимедиа и скорости приема данных на клиенте. В другой разновидности исходные отображения не являются независимыми друг от друга, а вместо этого представляют многоуровневое кодирование мультимедиа, где например, улучшенное исходное отображение может зависеть от базового исходного отображения. В этом случае может существовать отображение восстановления, соответствующие базовому исходному отображению, и другое отображение восстановления, соответствующее сочетанию базового и улучшенного исходных отображений.
[0556] Дополнительные общие элементы добавляются к преимуществам, которые можно реализовать с помощью раскрытых выше способов. Например, количество используемых соединений HTTP может меняться в зависимости от текущего объема мультимедиа в буфере мультимедиа и/или скорости приема в буфер мультимедиа. Совместные запросы HTTP, использующие FEC, то есть описанный выше способ с FEC и разновидности того способа, могут использоваться активно, когда буфер мультимедиа относительно пустой, например, больше совместных запросов HTTP выполняется параллельно для разных частей первого фрагмента, запрашивающих весь исходный фрагмент и относительно большую долю данных восстановления из соответствующего фрагмента восстановления, и затем переходя к уменьшенному количеству одновременных запросов HTTP, запрашивающих более крупные части мультимедийных данных на запрос и запрашивающих меньшую долю данных восстановления, например, переходя на 1, 2 или 3 одновременных запроса HTTP, переходя к запросам полных фрагментов или нескольких последовательных фрагментов на запрос и переходя к отказу от запроса данных восстановления, когда увеличивается буфер мультимедиа.
[0557] В качестве другого примера объем данных восстановления FEC мог бы меняться в зависимости от размера буфера мультимедиа, то есть, когда буфер мультимедиа небольшой, то можно запрашивать больше данных восстановления FEC, а когда буфер мультимедиа увеличивается, то объем запрошенных данных восстановления FEC мог бы уменьшиться, и в некоторый момент, когда буфер мультимедиа достаточно большой, можно не запрашивать никакие данные восстановления FEC, только данные из исходных сегментов исходных отображений. Выгоды таких улучшенных методик в том, что они могут позволить меньшее и более согласованное время переключения каналов и больше гибкости к возможным запинкам или остановам мультимедиа, в то же время минимизируя величину дополнительной полосы пропускания, используемой сверх величины, которая потреблялась бы только доставкой мультимедиа в исходных сегментах, путем уменьшения трафика запросов и данных восстановления FEC, в то же время обеспечивая поддержку наивысших скоростей мультимедиа, возможных для данных сетевых условий.
ДОПОЛНИТЕЛЬНЫЕ УЛУЧШЕНИЯ ПРИ ИСПОЛЬЗОВАНИИ ОДНОВРЕМЕННЫХ СОЕДИНЕНИЙ HTTP
[0558] Запрос HTTP/TCP может быть отменен, если выполняется подходящее условие, и другой запрос HTTP/TCP может быть создан для загрузки данных, которые могут заменить данные, запрошенные в отмененном запросе, где второй запрос HTTP/TCP может запрашивать точно такие же данные, как в исходном запросе, например, исходные данные; или перекрывающиеся данные, например, часть таких же исходных данных и данные восстановления, которые не были запрошены в первом запросе; или полностью непересекающиеся данные, например, данные восстановления, которые не были запрошены в первом запросе. Примером подходящего условия является то, когда запрос терпит неудачу из-за отсутствия ответа от Обслуживающей инфраструктуры блоков (BSI) в предоставленное время, или сбоя в установлении транспортного соединения с BSI, или приема явного сообщения о неисправности от сервера, или другого состояния отказа.
[0559] Другим примером подходящего условия является то, когда прием данных проходит необычно медленно согласно сравнению величины скорости соединения (скорость поступления данных в ответ на запрос, о котором идет речь) с предполагаемой скоростью соединения или с оценкой скорости соединения, необходимой для приема ответа до времени воспроизведения содержащихся мультимедийных данных или другого времени, зависимого от того времени.
[0560] Этот подход обладает преимуществом в случае, когда BSI иногда проявляет сбои или плохую производительность. В этом случае вышеупомянутый подход увеличивает вероятность, что клиент может продолжить надежное воспроизведение мультимедийных данных, несмотря на сбои или плохую производительность в BSI. Отметим, что в некоторых случаях может быть преимущественно, спроектировать BSI таким образом, что она не проявляет такие сбои или плохую производительность случайно, например, такое исполнение может иметь меньшую стоимость, чем альтернативное исполнение, которое не проявляет такие сбои или плохую производительность или которое проявляет их менее часто. В этом случае способ, описанный в этом документе, имеет дополнительное преимущество в том, что он позволяет использование такого менее дорогого исполнения для BSI без закономерного ухудшения взаимодействия с пользователем.
[0561] В другом варианте осуществления количество выданных запросов данных, соответствующих заданному блоку, может зависеть от того, выполняется ли подходящее условие относительно блока. Если условие не выполняется, то клиента можно ограничить от создания дополнительных запросов блока, если успешное завершение всех незавершенных в настоящее время запросов данных к блоку позволило бы восстановление блока с большой вероятностью. Если условие выполняется, то может быть выдано большее количество запросов блока, то есть вышеупомянутое ограничение не применяется. Примером подходящего условия является то, когда время до запланированного времени воспроизведения блока или другого времени, зависимого от того времени, уменьшается ниже предоставленной пороговой величины. Этот способ обладает преимуществом, потому что дополнительные запросы данных для блока выдаются, когда прием блока становится более срочным, потому что приближается время воспроизведения мультимедийных данных, содержащих блок. В случае общепринятых транспортных протоколов, например HTTP/TCP, эти дополнительные запросы обладают эффектом увеличения доли доступной полосы пропускания, выделенной данным, что вносит вклад в прием блока, о котором идет речь. Это уменьшает время, необходимое для приема достаточного количества данных для восстановления блока полностью, и поэтому уменьшает вероятность, что блок нельзя восстановить до запланированного времени воспроизведения мультимедийных данных, содержащих этот блок. Как описано выше, если блок нельзя восстановить до запланированного времени воспроизведения мультимедийных данных, содержащих блок, то воспроизведение может остановиться, приведя к плохому взаимодействию с пользователем, и поэтому описанный здесь способ преимущественно уменьшает вероятность этого плохого взаимодействия с пользователем.
[0562] Следует понимать, что по всему этому описанию изобретения ссылки на запланированное время воспроизведения блока относятся к времени, в которое кодированные мультимедийные данные, содержащие блок, могут быть впервые доступны на клиенте, чтобы добиться воспроизведения представления без остановки. Как будет понятно специалистам в области систем представления мультимедиа, это время на практике находится немного раньше фактического времени появления мультимедиа, содержащего блок, в физических преобразователях, используемых для воспроизведения (экран, динамики и т.д.), поскольку может потребоваться применить несколько функций преобразования к мультимедийным данным, содержащим блок, чтобы осуществить фактическое воспроизведение блока, и эти функции могут потребовать некоторого количества времени для завершения. Например, мультимедийные данные обычно транспортируются в сжатом виде, и может применяться преобразование для распаковки.
СПОСОБЫ ФОРМИРОВАНИЯ ФАЙЛОВЫХ СТРУКТУР, ПОДДЕРЖИВАЮЩИХ СОВМЕСТНЫЕ СПОСОБЫ HTTP/FEC
[0563] Теперь описывается вариант осуществления для формирования файловой структуры, которая может использоваться преимущественно клиентом, применяющим совместные способы HTTP/FEC. В этом варианте осуществления для каждого исходного сегмента имеется соответствующий сегмент восстановления, сформированный следующим образом. Параметр R указывает в среднем, сколько данных восстановления FEC формируется для исходных данных в исходных сегментах. Например, R=0,33 указывает, что если исходный сегмент содержит 1000 килобайт данных, то соответствующий сегмент восстановления содержит приблизительно 330 килобайт данных восстановления. Параметр S указывает размер символа в байтах, используемый для кодирования и декодирования FEC. Например, S=64 указывает, что исходные данные и данные восстановления содержат символы с размером 64 байта каждый для целей кодирования и декодирования FEC.
[0564] Сегмент восстановления может формироваться для исходного сегмента следующим образом. Каждый фрагмент исходного сегмента считается исходным блоком для целей кодирования FEC, и соответственно каждый фрагмент рассматривается как последовательность исходных символов исходного блока, из которых формируются символы восстановления. Количество символов восстановления, сформированных в итоге для первых i фрагментов, вычисляется как TNRS(i)=ceiling(R*B(i)/S), где ceiling(x) - функция, которая выводит наименьшее целое число со значением, которое, по меньшей мере, равно x. Таким образом, количество символов восстановления, сформированных для фрагмента i, равно NRS(i)=TNRS(i)-TNRS(i-1).
[0565] Сегмент восстановления содержит объединение символов восстановления для фрагментов, когда порядок символов восстановления в сегменте восстановления является порядком фрагментов, из которых они формируются, и во фрагменте символы восстановления находятся в порядке их идентификатора символа кодирования (ESI). Структура сегмента восстановления, соответствующая структуре исходного сегмента, показана на фиг. 27, включающая генератор 2700 сегментов восстановления.
[0566] Отметим, что путем задания количества символов восстановления для фрагмента, как описано выше, общее количество символов восстановления для всех предыдущих фрагментов, а соответственно индекс байта в сегменте восстановления, зависит только от R, S, B(i-1) и B(i) и не зависит ни от какой предыдущей или последующей структуры фрагментов в исходном сегменте. Это полезно, потому что это позволяет клиенту быстро вычислить положение начала блока восстановления в сегменте восстановления, а также быстро вычислить количество символов восстановления в том блоке восстановления, используя только локальную информацию о структуре соответствующего фрагмента исходного сегмента, из которого формируется блок восстановления. Таким образом, если клиент решает начать загрузку и воспроизведение фрагмента с середины исходного сегмента, то он также может быстро сформировать и обратиться к соответствующему блоку восстановления из соответствующего сегмента восстановления.
[0567] Количество исходных символов в исходном блоке, соответствующее фрагменту i, вычисляется как NSS(i) = ceiling((B(i)-B(i-1))/S). Последний исходный символ дополняется нулевыми байтами для целей кодирования и декодирования FEC, если B(i)-B(i-1) не является кратным S, то есть последний исходный символ дополняется нулевыми байтами, так что он имеет размер S байт для целей кодирования и декодирования FEC, но эти нулевые байты не сохраняются как часть исходного сегмента. В этом варианте осуществления ESI для исходного символа являются 0, 1, …, NSS(i)-1, а ESI для символов восстановления являются NSS(i), …, NSS(i)+NRS(i)-1.
[0568] URL для сегмента восстановления в этом варианте осуществления может формироваться из URL для соответствующего исходного сегмента просто путем добавления, например, суффикса ".repair" к URL исходного сегмента.
[0569] Информация индексирования восстановления и информация FEC для сегмента восстановления неявно задается информацией индексирования для соответствующего исходного сегмента и из значений R и S, как описано в этом документе. Временные смещения и структура фрагмента, содержащая сегмент восстановления, определяются временными смещениями и структурой соответствующего исходного сегмента. Байтовое смещение до конца символов восстановления в сегменте восстановления, соответствующем фрагменту i, может вычисляться как RB(i)=S*ceiling(R*B(i)/S). Количество байт в сегменте восстановления, соответствующем фрагменту i, тогда равно RB(i)-RB(i-1), и соответственно количество символов восстановления, соответствующих фрагменту i, вычисляется как NRS(i)=(RB(i)-RB(i-1))/S. Количество исходных символов, соответствующих фрагменту i, может вычисляться как NSS(i)=ceiling((B(i)-B(i-1))/S). Таким образом, в этом варианте осуществления информация индексирования восстановления для блока восстановления в сегменте восстановления и соответствующая информация FEC могут неявно выводиться из R, S и информации индексирования для соответствующего фрагмента соответствующего исходного сегмента.
[0570] В качестве примера рассмотрим пример, показанный на фиг. 28, показывающий фрагмент 2, который начинается в байтовом смещении B(1)=6410 и заканчивается в байтовом смещении B(2)=6770. В этом примере размер символа S=64 байтам, и пунктирные вертикальные линии показывают байтовые смещения в исходном сегменте, которые соответствуют кратным числам S. Общий размер сегмента восстановления в качестве доли размера исходного сегмента устанавливается в R=0,5 в этом примере. Количество исходных символов в исходном блоке для фрагмента 2 вычисляется как NSS(2)=ceiling((6770-6410)/64)=ceil(5,625)=6, и эти 6 исходных символов имеют ESI 0, 5 соответственно, где первый исходный символ является первыми 64 байтами фрагмента 2, который начинается в индексе байта 6410 в исходном сегменте, второй исходный символ является следующими 64 байтами фрагмента 2, который начинается в индексе байта 6474 в исходном сегменте, и т.д. Конечное байтовое смещение блока восстановления, соответствующего фрагменту 2, вычисляется как RB(2)=64*ceiling(0,5*6770/64)=64*ceiling(52,89…)=64*53=3392, а начальное байтовое смещение блока восстановления, соответствующего фрагменту 2, вычисляется как RB(1)=64*ceiling(0,5*6410/64)=64*ceiling(50,07…)=64*51=3264, и соответственно в этом примере имеются два символа восстановления в блоке восстановления, соответствующие фрагменту 2 с ESI 6 и 7 соответственно, начинающиеся в байтовом смещении 3264 в сегменте восстановления и заканчивающиеся в байтовом смещении 3392.
[0571] Отметим, что в показанном на фиг. 28 примере, даже если R=0,5 и имеются 6 исходных символов, соответствующих фрагменту 2, количество символов восстановления не равно 3, как можно было бы предположить, если просто использовать количество исходных символов для вычисления количества символов восстановления, а вместо этого получилось равным 2 в соответствии со способами, описанными в этом документе. В отличие от простого использования количества исходных символов фрагмента для определения количества символов восстановления, описанные выше варианты осуществления позволяют, вычислить размещение блока восстановления в сегменте восстановления исключительно из индексной информации, ассоциированной с соответствующим исходным блоком, соответствующим исходному сегменту. Кроме того, когда растет количество K исходных символов в исходном блоке, количество символов восстановления KR у соответствующего блока восстановления приблизительно выражается с помощью K*R, так как обычно KR не превышает ceil(K*R) и KR по меньшей мере равно floor((K-1)*R), где floor(x) - целое число не более x.
[0572] Существует много разновидностей вышеприведенных вариантов осуществления для формирования файловой структуры, которая может использоваться преимущественно клиентом, применяющим совместные способы HTTP/FEC, что признает специалист в данной области техники. В качестве примера дополнительного варианта осуществления исходный сегмент для отображения может быть разделен на N > 1 параллельных сегментов, где для i=1, …, N заданная доля Fi исходного сегмента содержится в i-том параллельном сегменте, и где сумма Fi для i=1, …, N равна 1. В этом варианте осуществления может быть одна главная карта сегмента, которая используется для получения карт сегментов для всех параллельных сегментов аналогичному тому, как карта сегмента восстановления получается из карты исходного сегмента в описанном выше варианте осуществления. Например, главная карта сегмента может указывать структуру фрагмента, если все исходные мультимедийные данные не разделялись на параллельные сегменты, а вместо этого содержались в одном исходном сегменте, и тогда карту сегмента для i-того параллельного сегмента можно получить из главной карты сегмента путем вычисления того, что если объем мультимедийных данных в первом префиксе фрагментов исходного сегмента равен L байт, то общее количество байт этого префикса в совокупности среди первых i параллельных сегментов равно ceil(L*Gi), где Gi- сумма Fj по j=1, …, i. В качестве другого примера дополнительного варианта осуществления сегменты могут состоять из сочетания исходных мультимедийных данных для каждого фрагмента с непосредственно следующими данными восстановления для того фрагмента, получая сегмент, который содержит смесь исходных мультимедийных данных и данных восстановления, сформированных с использованием кода FEC из тех исходных мультимедийных данных. В качестве другого примера дополнительного варианта осуществления сегмент, который содержит смесь исходных мультимедийных данных и данных восстановления, можно разделить на несколько параллельных сегментов, содержащих смесь исходных мультимедийных данных и данных восстановления.
[0573] Дополнительные варианты осуществления может представить обычный специалист в данной области техники после прочтения этого раскрытия изобретения. В других вариантах осуществления могут быть созданы преимущественно сочетания или подкомбинации раскрытого выше изобретения. Примерные размещения компонентов показаны для целей иллюстрации, и следует понимать, что сочетания, добавления, перегруппировки и т.п. рассматриваются в альтернативных вариантах осуществления настоящего изобретения. Таким образом, хотя изобретение описано относительно типовых вариантов осуществления, специалист в данной области техники признает, что возможны многочисленные модификации.
[0574] Например, описанные в этом документе процессы могут быть реализованы с использованием аппаратных компонентов, программных компонентов и/или любого их сочетания. В некоторых случаях программные компоненты могут предоставляться на вещественных, не кратковременных носителях для исполнения на аппаратных средствах, которым предоставляются носители, или они отделены от носителей. Описание изобретения и чертежи соответственно должны рассматриваться в пояснительном, а не ограничивающем значении. Однако станет очевидно, что в них можно внести различные модификации и изменения без отклонения от широкой сущности и объема изобретения, которые изложены в формуле изобретения, и что изобретение предназначено для охвата всех модификаций и эквивалентов в рамках нижеследующей формулы изобретения.
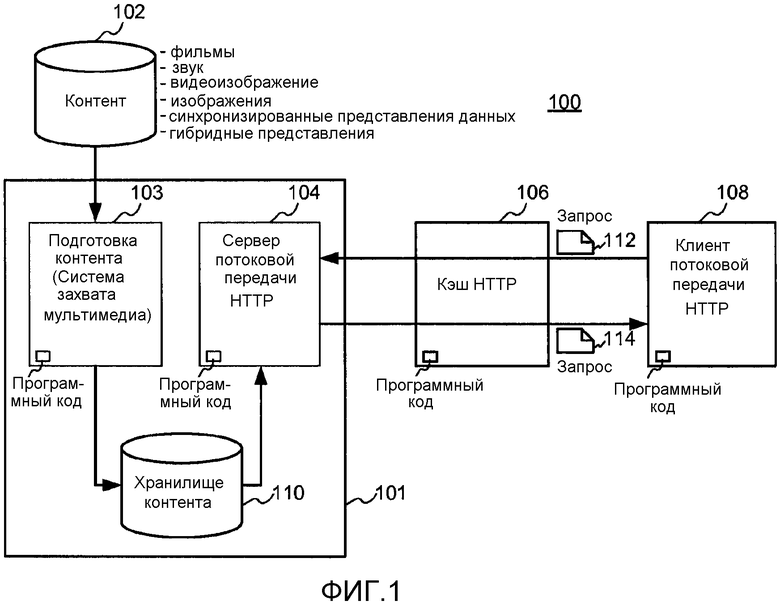
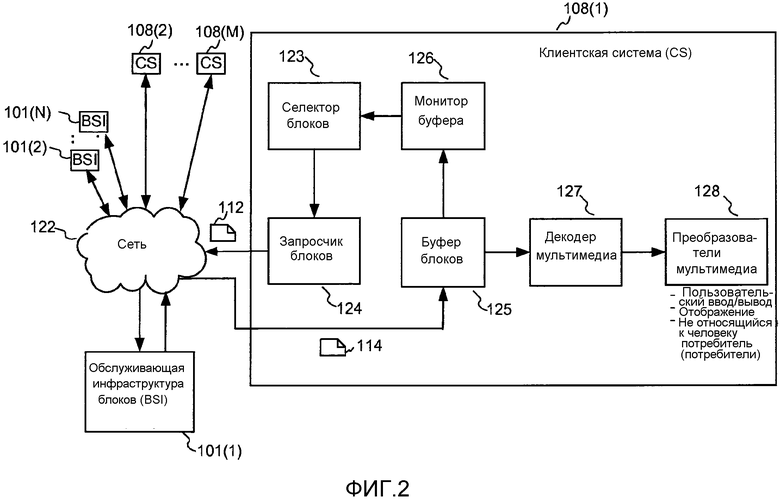
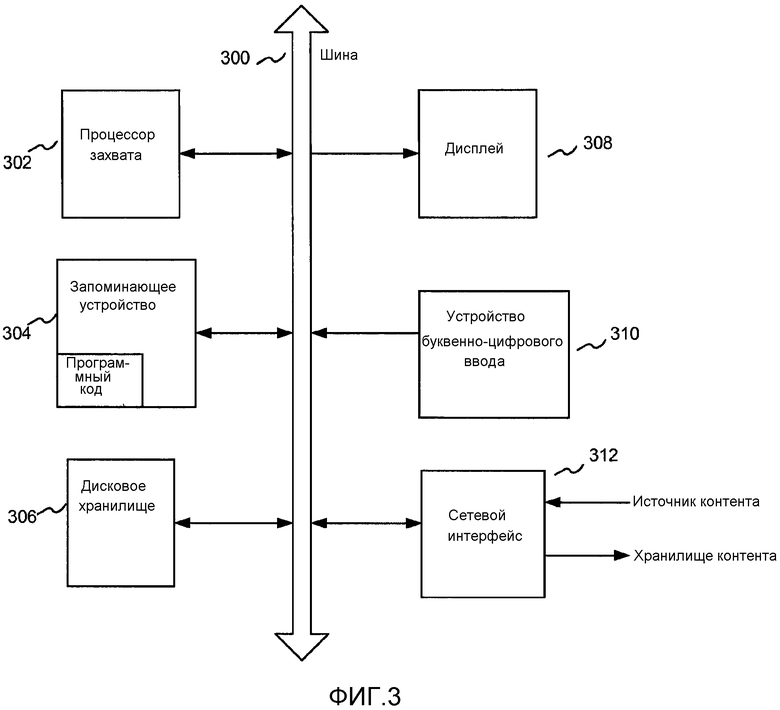
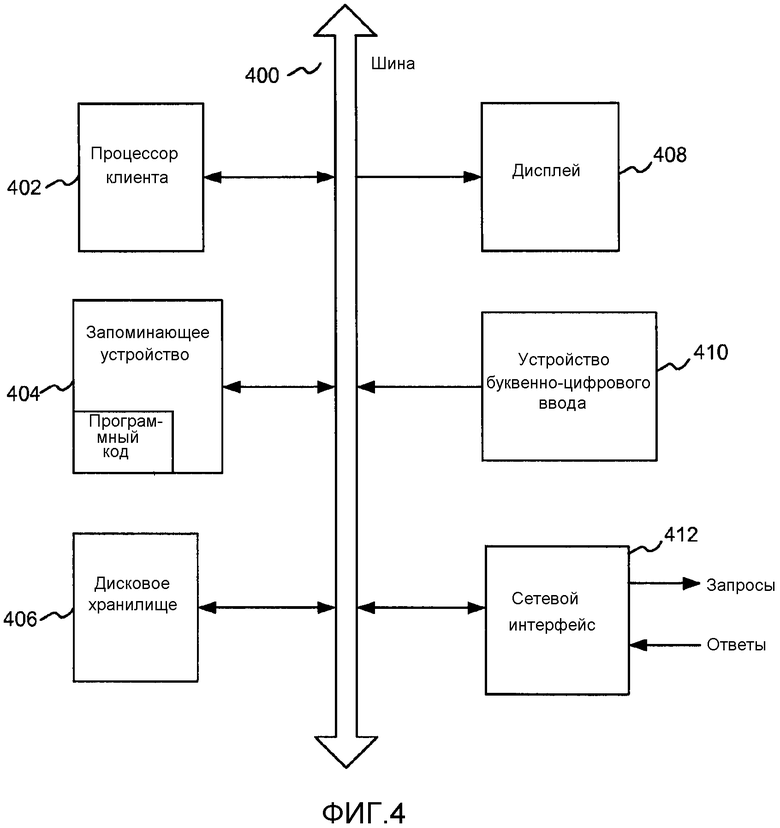
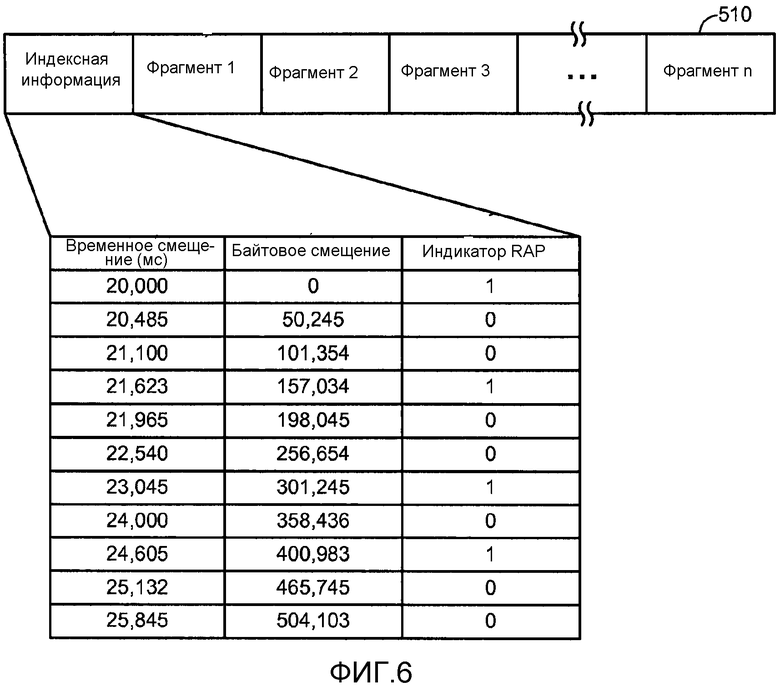
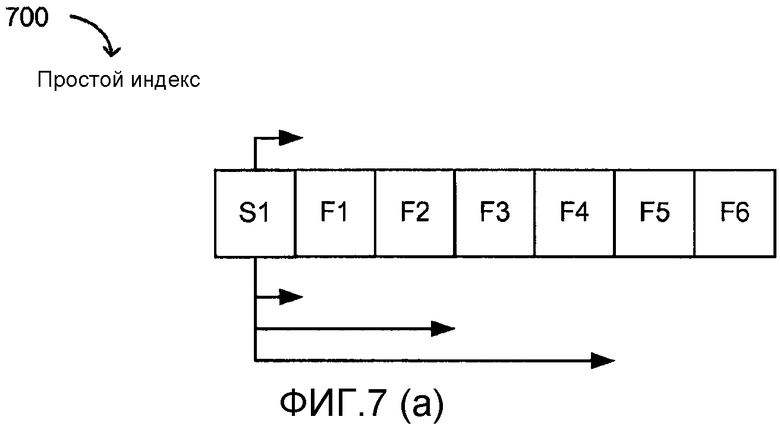
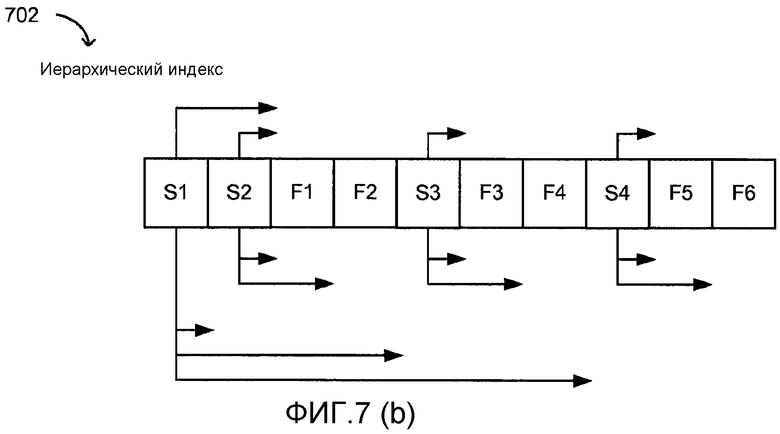
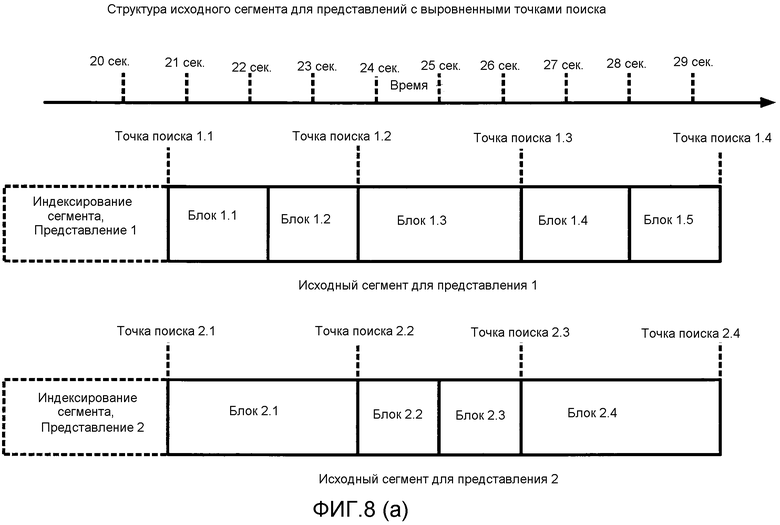
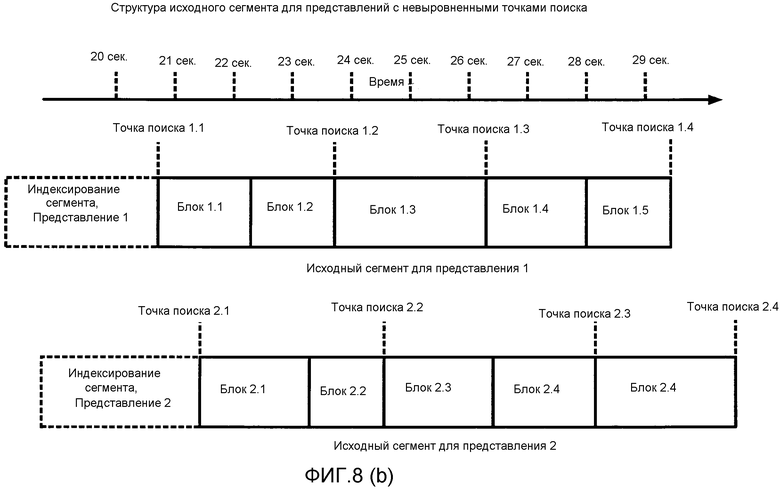

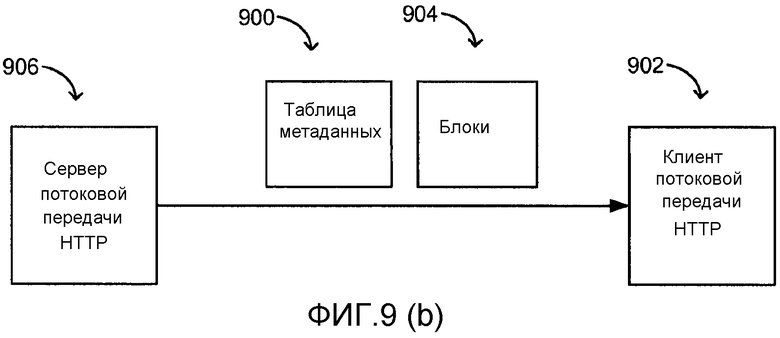
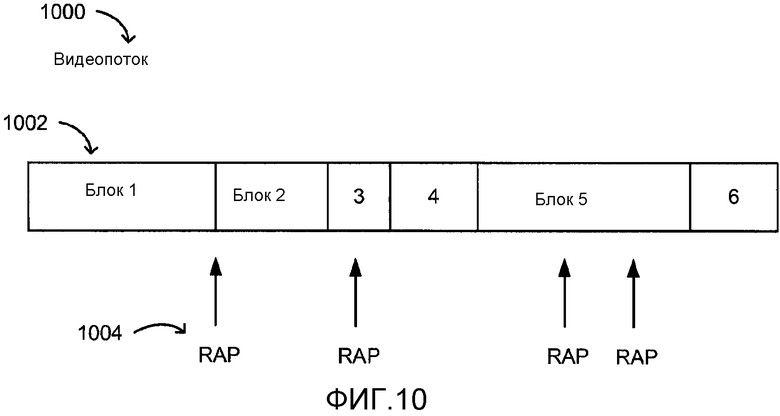
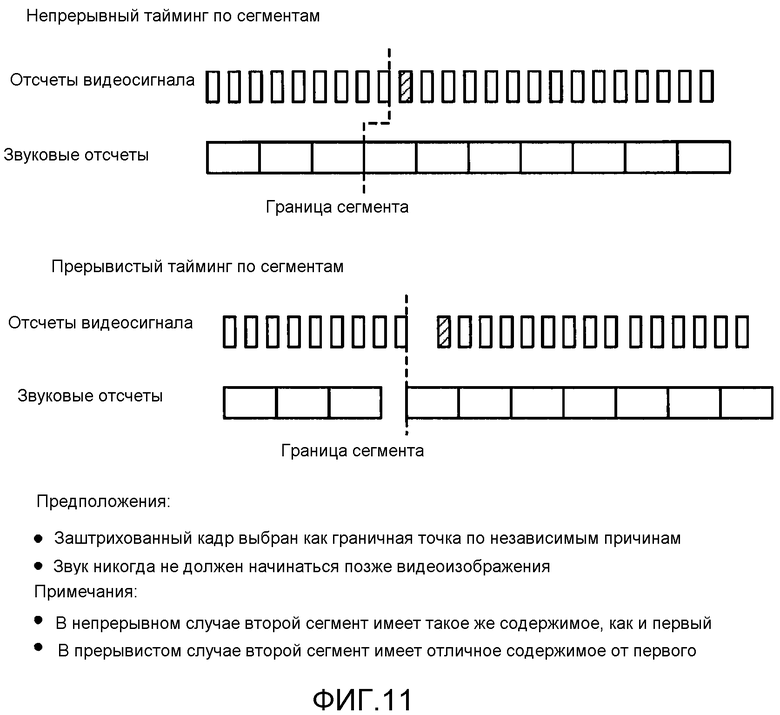
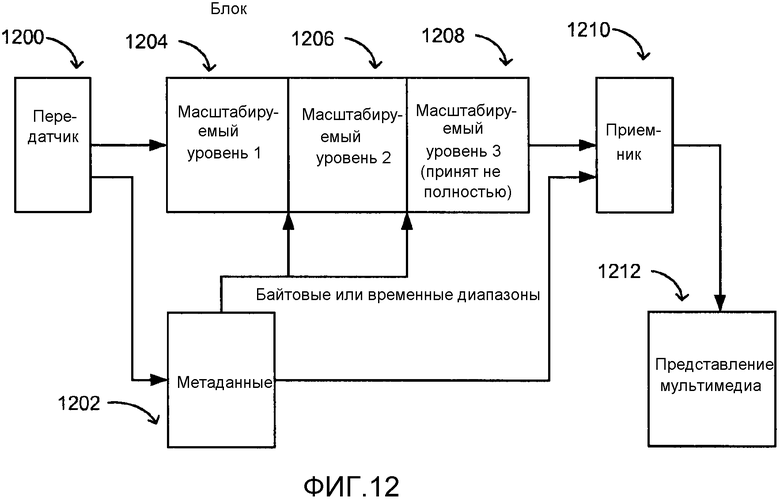
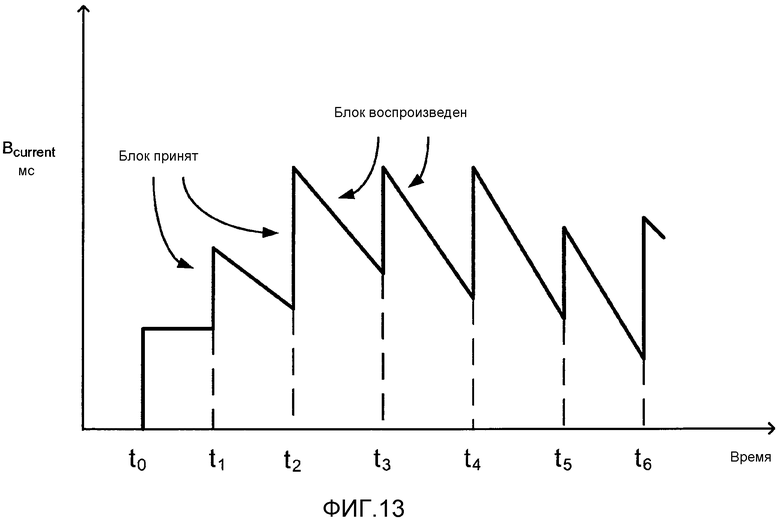
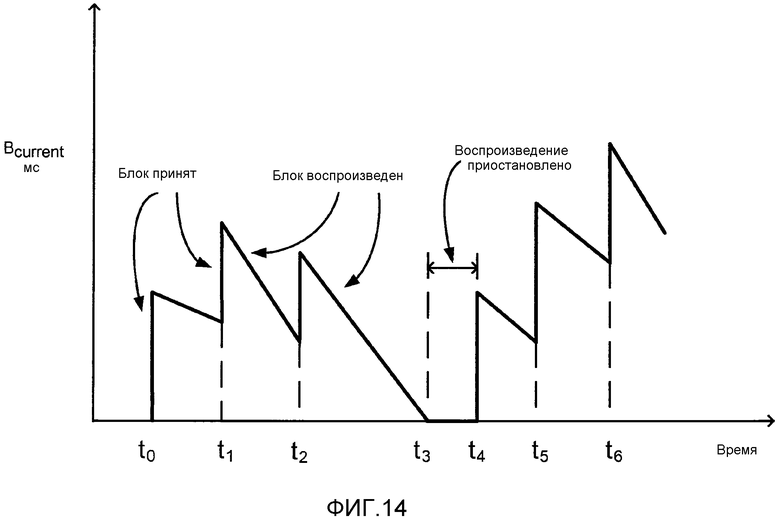
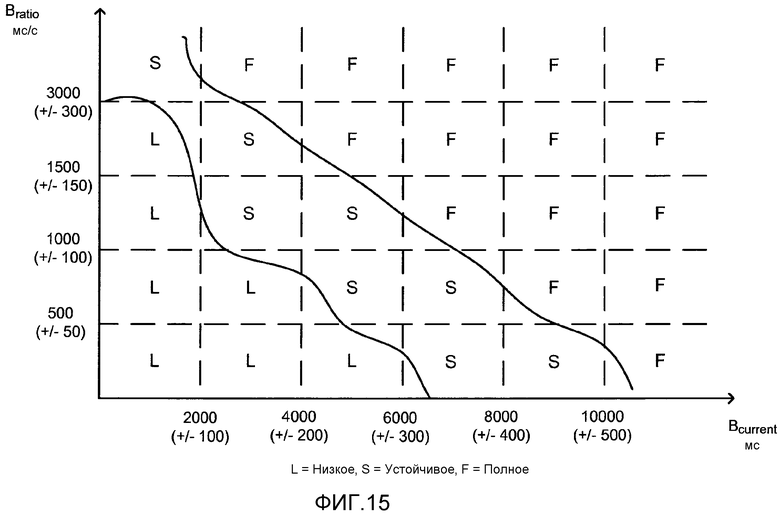
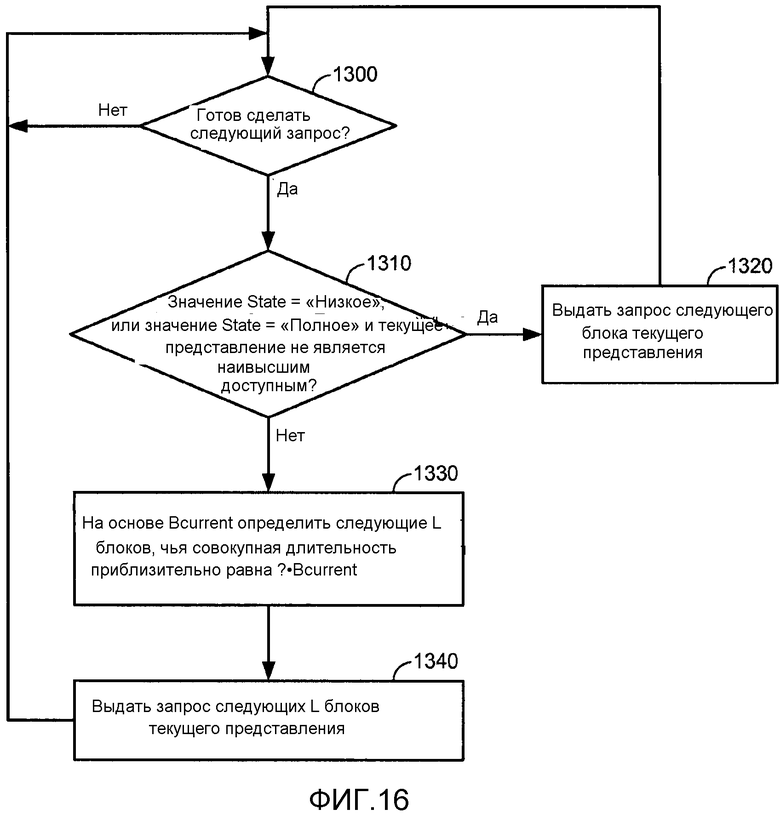
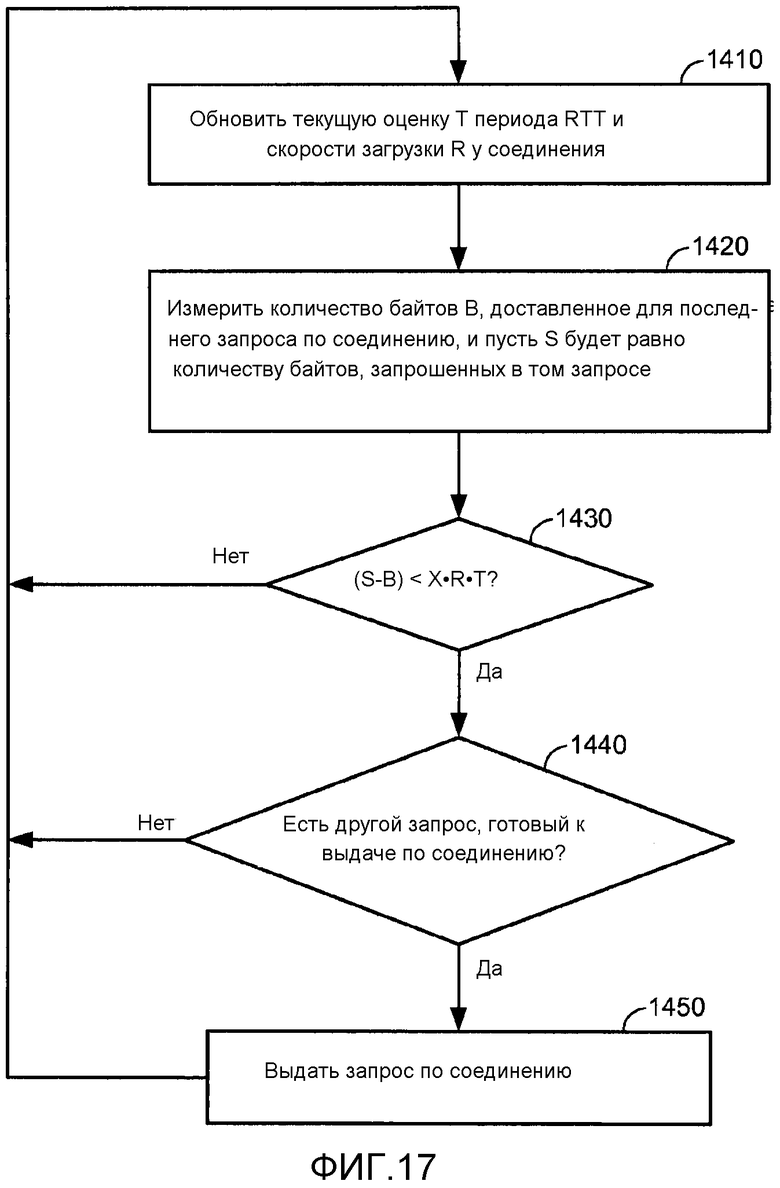
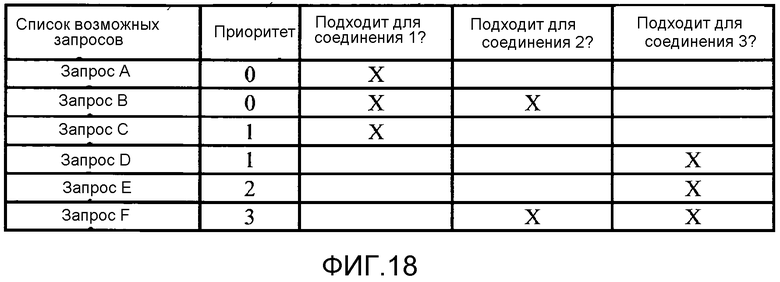
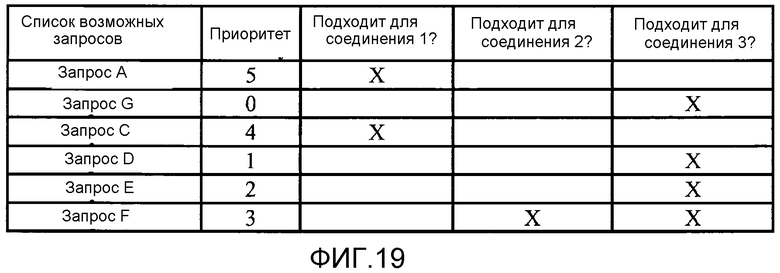
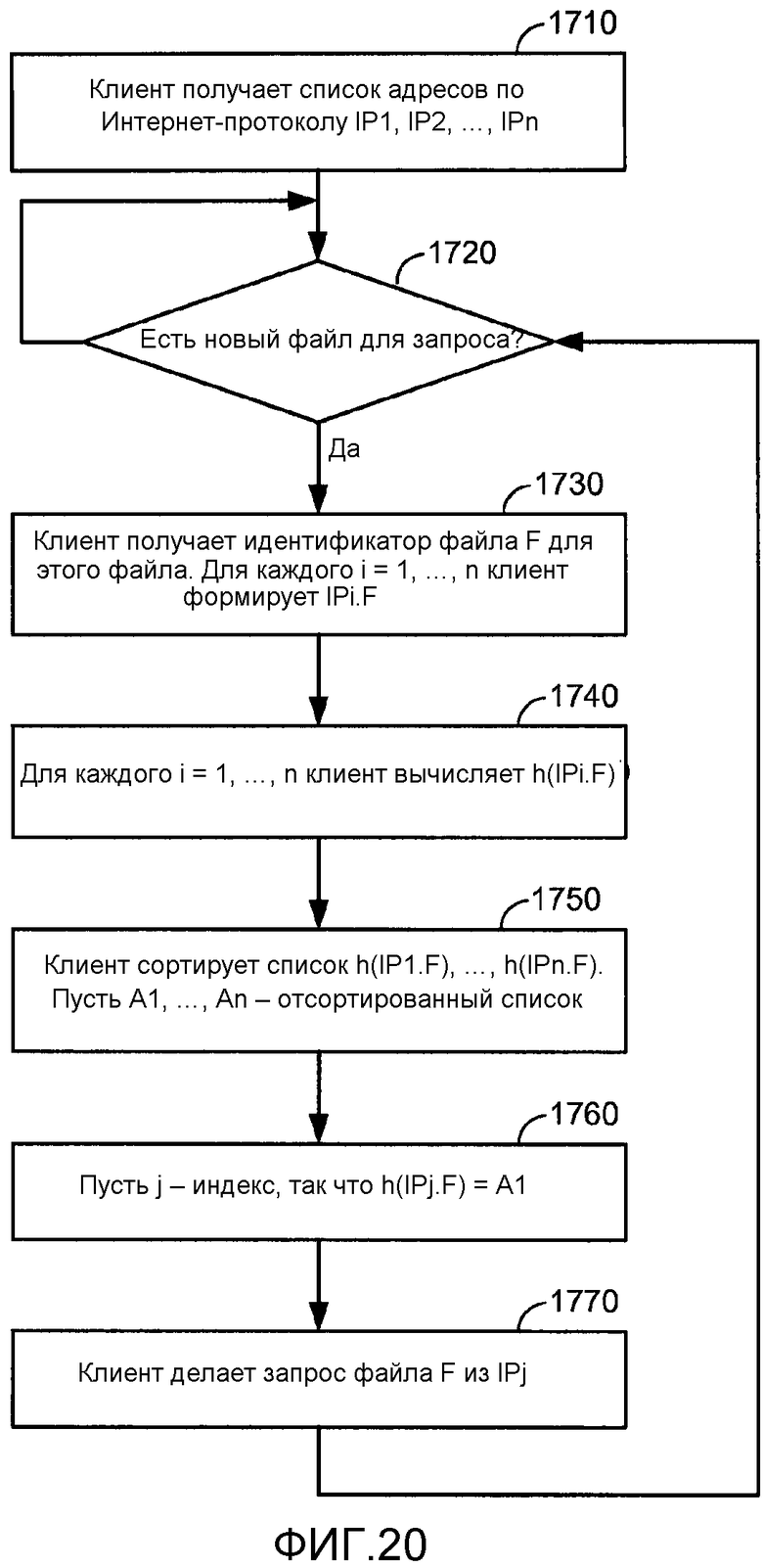

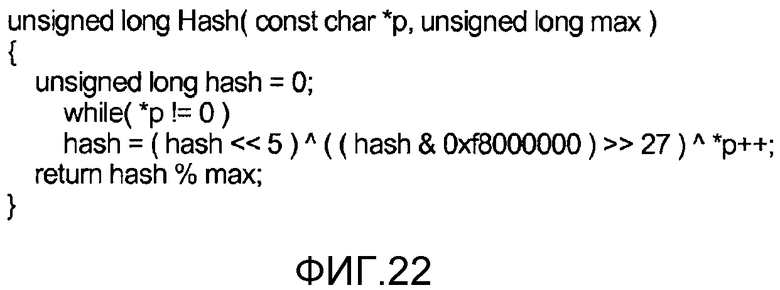
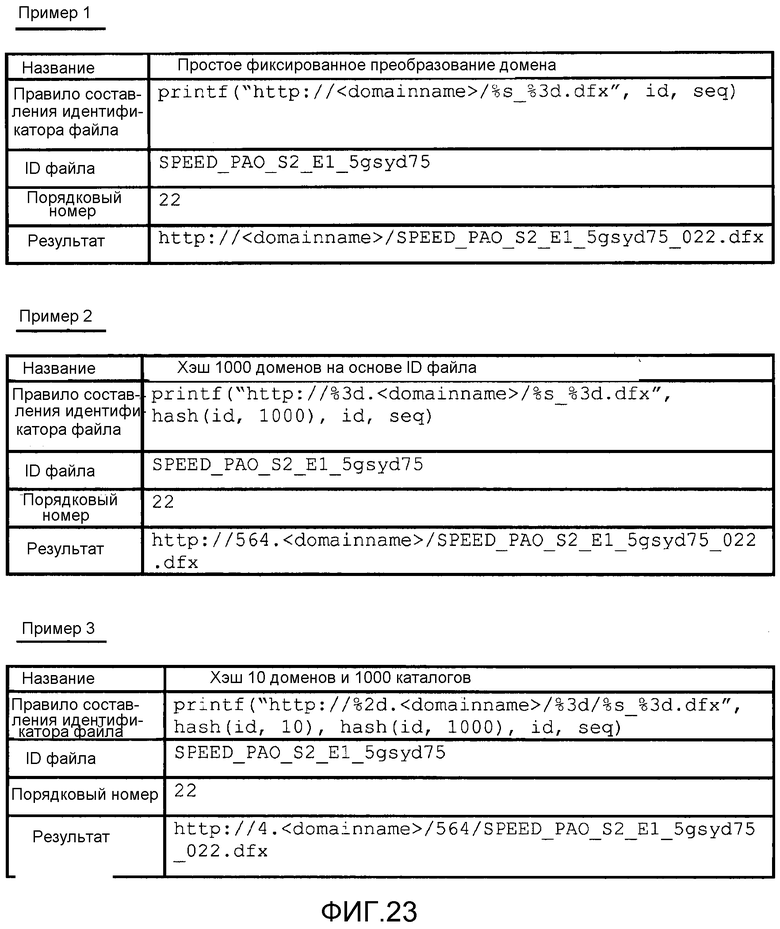
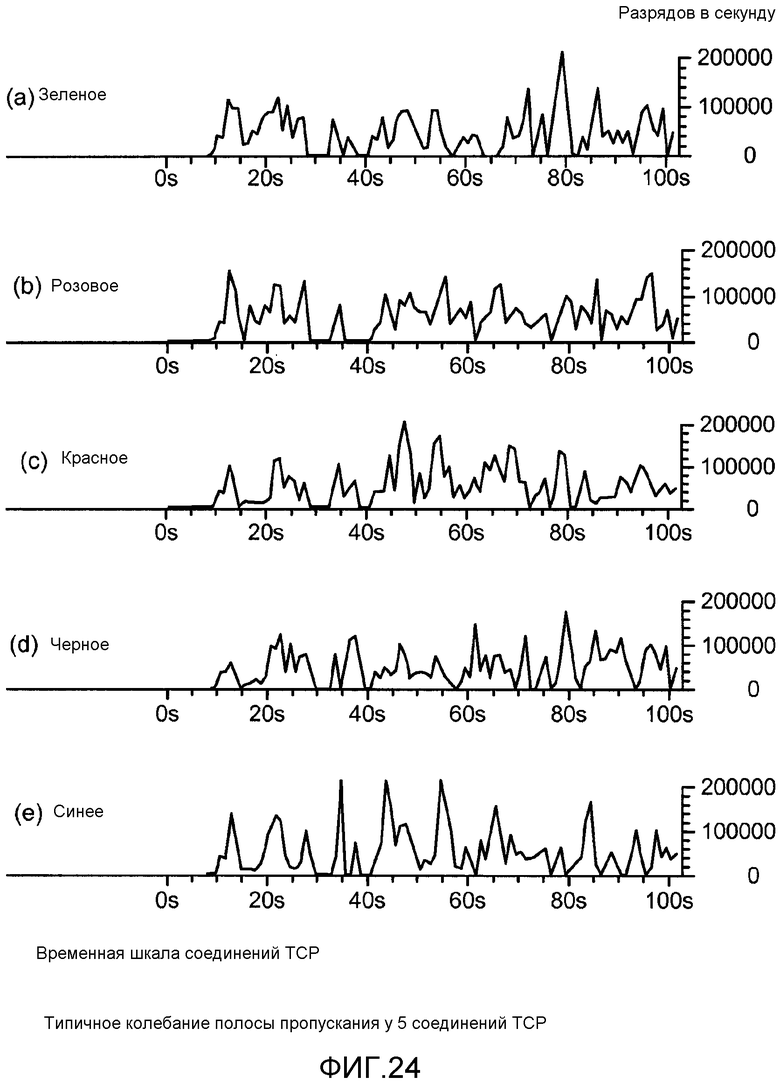
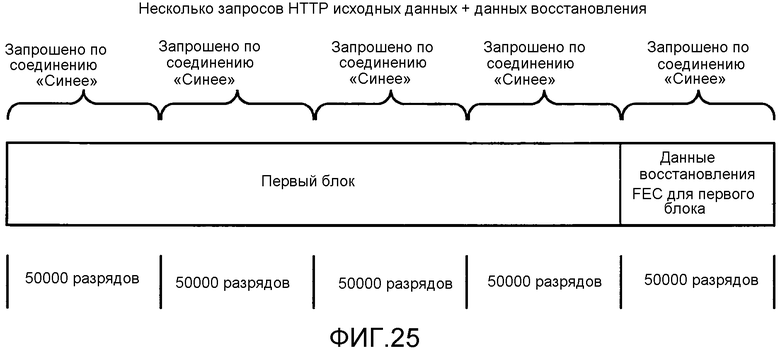
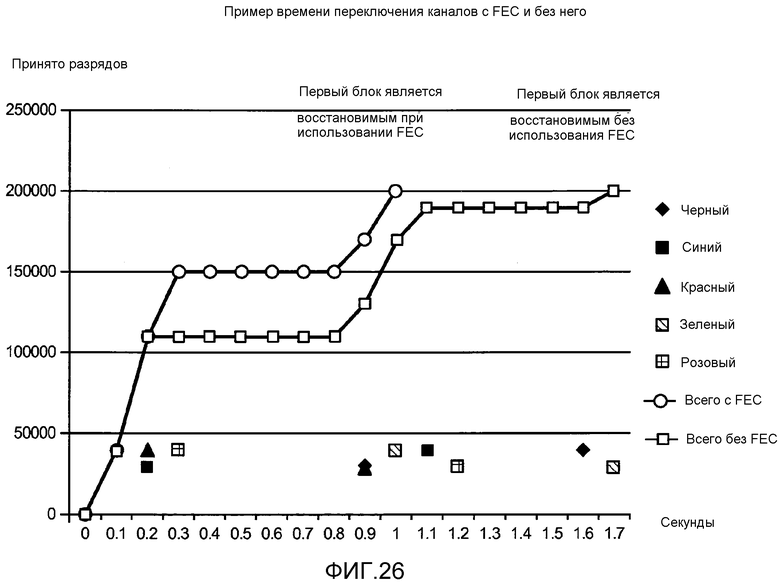
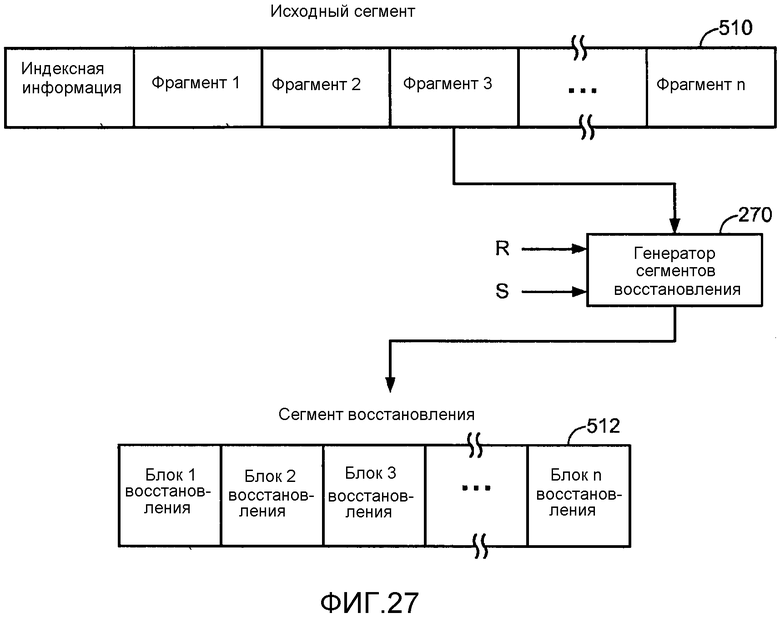
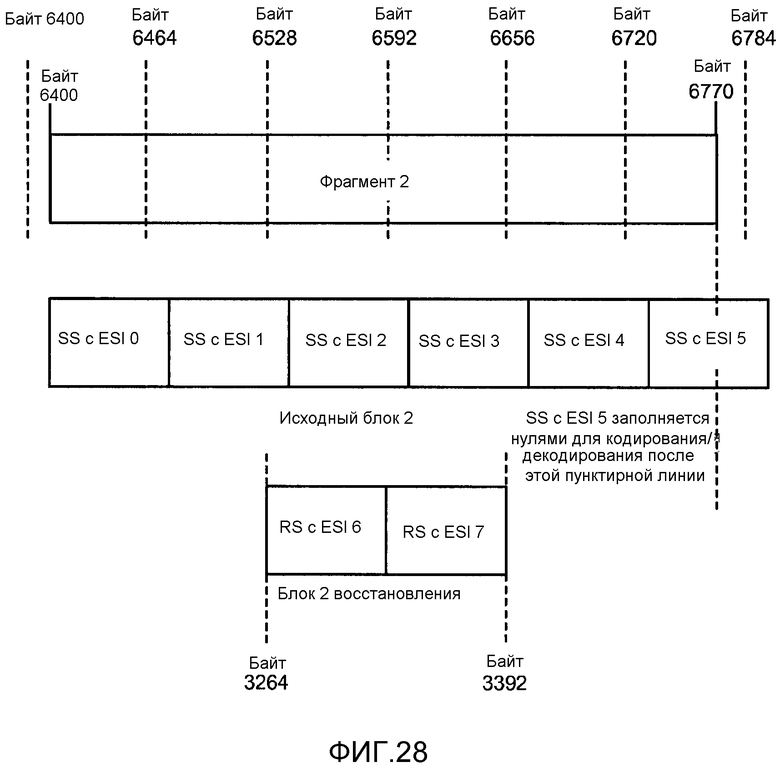
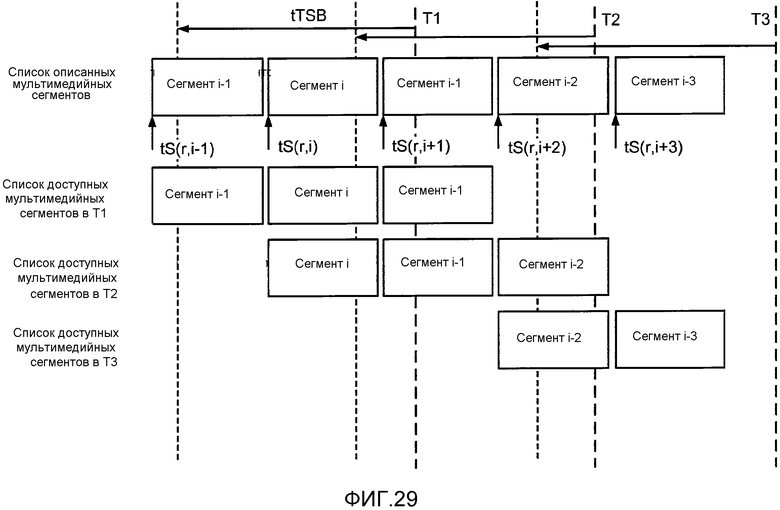
Изобретение относится к средствам запроса и получения сегментов данных. Технический результат заключается в оптимизации представления потовокого мультимедиа. Принимают, в клиентском устройстве, файл для отображения представления мультимедиа, при этом упомянутый файл содержит идентификатор отображения для отображения, индексы файлов и правила конструирования идентификатора файла, причем индекс файла назначен сегменту и включает в себя порядковый номер сегмента в отображении представления мультимедиа. Правила конструирования идентификатора файла предоставляют информацию, которая дает возможность клиентскому устройству динамически конструировать идентификаторы файла с требуемыми медиа и с ассоциированными метаданными с использованием идентификатора отображения и одного или более из индексов файла. Конструируют, посредством клиентского устройства, один или более идентификаторов файла сегментов представления мультимедиа, с использованием одного или более из правил конструирования идентификатора файла, идентификатора отображения и одного или более индексов файла. Отправляют запрос для сегмента представления мультимедиа в систему доставки мультимедиа, причем запрос содержит сконструированный идентификатор файла из одного или более сконструированных идентификаторов файла. 2 н. и 23 з.п. ф-лы, 32 ил.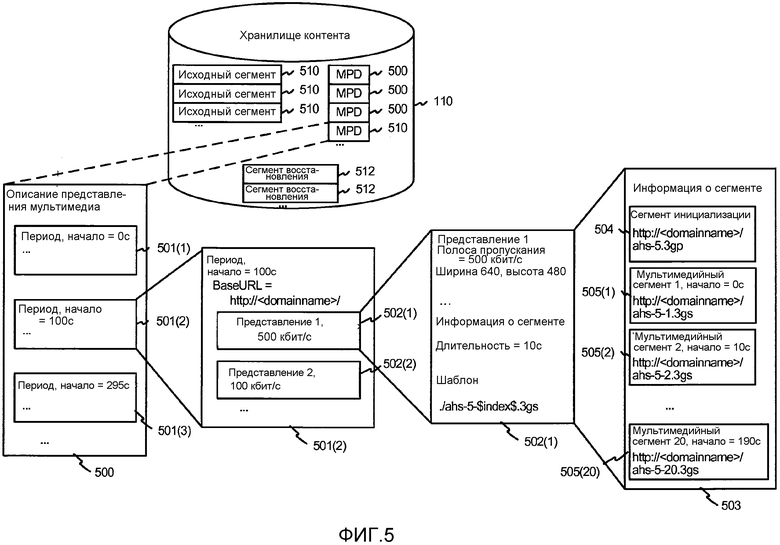
1. Способ запроса сегментов, содержащих мультимедийные данные представления мультимедиа из системы доставки мультимедиа с использованием клиентского устройства, причем способ содержит этапы, на которых:
принимают, в клиентском устройстве, файл для отображения представления мультимедиа, при этом упомянутый файл содержит идентификатор отображения для отображения, индексы файлов и правила конструирования идентификатора файла, причем индекс файла назначен сегменту и включает в себя порядковый номер сегмента в отображении представления мультимедиа, и при этом правила конструирования идентификатора файла предоставляют информацию, которая дает возможность клиентскому устройству динамически конструировать идентификаторы файла с требуемыми медиа и с ассоциированными метаданными с использованием идентификатора отображения и одного или более из индексов файла;
конструируют, посредством клиентского устройства, один или более идентификаторов файла сегментов представления мультимедиа, с использованием одного или более из правил конструирования идентификатора файла, идентификатора отображения и одного или более индексов файла;
отправляют запрос для сегмента представления мультимедиа в систему доставки мультимедиа, причем запрос содержит сконструированный идентификатор файла из одного или более сконструированных идентификаторов файла и причем сконструированный идентификатор файла указывает необходимое мультимедиа и ассоциированные метаданные сегмента; и
принимают запрошенный сегмент представления мультимедиа.
2. Способ по п. 1, в котором правила конструирования идентификатора файла предоставляются на клиентском устройстве заранее перед временем, когда запрошенный сегмент доступен.
3. Способ по п. 2, в котором правила конструирования идентификатора файла включают в себя правила синхронизации будущей доступности сегмента.
4. Способ по п. 1, в котором правила конструирования идентификатора файла включают в себя правила относительно времени воспроизведения сегмента относительно других сегментов.
5. Способ по п. 1, в котором файл содержит файл дескриптора представления мультимедиа (MPD), который описывает правила конструирования идентификатора файла для сегментов.
6. Способ по п. 5, в котором MPD включает в себя правила конструирования для генерирования списка длительностей сегментов для сегментов в отображении представления мультимедиа в периоде, указывающем, когда сегменты должны воспроизводиться относительно друг друга по времени.
7. Способ по п. 6, в котором длительности сигнализируются с использованием последовательности текста, определяющей один или большее число наборов сегментов и длительности для каждого сегмента в наборе сегментов.
8. Способ по п. 1, дополнительно содержащий этап, на котором определяют доступность сегмента, причем доступность сегмента определяется на основе времени клиентского устройства и определенной глубины буфера сдвига по времени.
9. Способ по п. 1, в котором файл включает в себя метаданные, отображающие, для каждого из множества отображений представления мультимедиа, правило конструирования идентификатора файла.
10. Способ по п. 9, в котором метаданные, отображающие правило конструирования идентификатора файла, включают в себя входные параметры, содержащие индекс сегмента, который нужно идентифицировать, причем индекс сегмента определяется исходя из желаемого времени воспроизведения.
11. Способ по п. 1, дополнительно содержащий этап, на котором вычисляют, с использованием правил конструирования идентификатора файла и желаемого времени воспроизведения, идентификатор файла для сегмента для желаемого времени воспроизведения в желаемом отображении представления мультимедиа и байтовый диапазон сегмента, указанного временем воспроизведения.
12. Способ по п. 11, в котором идентификатор файла для сегмента и байтовый диапазон для этого сегмента определяют на основе вычисленных моментов времени начала и конца представления, причем мультимедийные сегменты имеют приблизительные длительности, определенные посредством точек доступа к мультимедиа.
13. Способ по п. 1, в котором один или более идентификаторов файла включает в себя унифицированный указатель ресурса или унифицированный локатор ресурса.
14. Клиентское устройство для получения сегментов, содержащих мультимедийные данные представления мультимедиа из системы доставки мультимедиа, содержащее:
передатчик для отправки запросов файлов, причем запрос файла содержит индикатор файла и байтовый диапазон в указанном файле;
приемник для приема ответов на запросы файлов и файла для отображения представления мультимедиа, при этом упомянутый файл содержит идентификатор отображения для отображения, индексы файлов и правила конструирования идентификатора файла, причем индекс файла назначен сегменту и включает в себя порядковый номер сегмента в отображении представления мультимедиа, и при этом правила конструирования идентификатора файла предоставляют информацию, которая дает возможность клиентскому устройству динамически конструировать идентификаторы файла с требуемыми медиа и с ассоциированными метаданными с использованием идентификатора отображения и одного или более из индексов файла; и
логическую схему для конструирования одного или более идентификаторов файла сегментов представления мультимедиа, с использованием одного или более из правил конструирования идентификатора файла, идентификатора отображения и одного или более индексов файла,
причем передатчик передает запрос для сегмента представления мультимедиа в систему доставки мультимедиа, причем запрос содержит сконструированный идентификатор файла из одного или более сконструированных идентификаторов файла и причем сконструированный идентификатор файла указывает необходимое мультимедиа и ассоциированные метаданные для сегмента, и
при этом приемник принимает запрошенный сегмент представления мультимедиа.
15. Клиентское устройство по п. 14, в котором правила конструирования идентификатора файла предоставляются на клиентском устройстве заранее перед временем, когда запрошенный сегмент доступен.
16. Клиентское устройство по п. 15, в котором правила конструирования идентификатора файла включают в себя правила синхронизации будущей доступности представления мультимедиа.
17. Клиентское устройство по п. 14, в котором правила конструирования идентификатора файла включают в себя правила времени относительно воспроизведения сегмента относительно других сегментов из множества сегментов.
18. Клиентское устройство по п. 14, в котором файл содержит файл дескриптора представления мультимедиа (MPD), который описывает правила конструирования идентификатора файла для сегментов.
19. Клиентское устройство по п. 18, в котором MPD включает в себя список длительностей сегментов для сегментов в отображении представления мультимедиа в периоде, указывающем, когда сегменты должны воспроизводиться относительно друг друга по времени.
20. Клиентское устройство по п. 19, в котором длительности сигнализируются с использованием последовательности текста, определяющей один или большее число наборов сегментов и длительности для каждого сегмента в наборе сегментов.
21. Клиентское устройство по п. 14, дополнительно содержащее логическую схему для определения доступности сегмента, причем доступность сегмента определяется на основе времени клиентского устройства и определенной глубины буфера сдвига по времени.
22. Клиентское устройство по п. 14, в котором файл включает в себя метаданные, отображающие, для каждого из множества отображений представления мультимедиа, правило конструирования идентификатора файла.
23. Клиентское устройство по п. 22, в котором метаданные, отображающие правило конструирования идентификатора файла, включают в себя входные параметры, содержащие индекс сегмента, который нужно идентифицировать, причем индекс сегмента определяется исходя из желаемого времени воспроизведения.
24. Клиентское устройство по п. 14, дополнительно содержащее логическую схему для вычисления, с использованием правил конструирования идентификатора файла и желаемого времени воспроизведения, идентификатора файла для сегмента для желаемого времени воспроизведения в желаемом отображении представления мультимедиа и байтового диапазона сегмента, указанного временем воспроизведения.
25. Клиентское устройство по п. 24, в котором идентификатор файла для сегмента и байтовый диапазон для этого сегмента определяют на основе вычисленных моментов времени начала и конца представления, причем сегменты имеют приблизительные длительности, определенные посредством точек доступа к мультимедиа.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЕЩАТЕЛЬНОЙ ПЕРЕДАЧИ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ | 1999 |
|
RU2222115C2 |

