ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Данная заявка утверждает приоритет и преимущество предварительной заявки на патент США № 61/481825, озаглавленной "Система и способ управления зашифрованными данными", поданной 3 мая 2011 г.; заявки на патент США на полезную модель № 13/461462, озаглавленной "Система и способ управления зашифрованными данными", поданной 1 мая 2012 г.; и чьи техническое описание и формула включены в настоящую заявку посредством ссылки.
ЗАЯВЛЕНИЕ ОТНОСИТЕЛЬНО ИССЛЕДОВАНИЯ ИЛИ РАЗВИТИЯ, СПОНСИРУЕМЫХ ИЗ ФЕДЕРАЛЬНОГО БЮДЖЕТА
[0002] Не применимо.
ВКЛЮЧЕНИЕ ПОСРЕДСТВОМ ССЫЛКИ МАТЕРИАЛА, ПОДАННОГО НА КОМПАКТ-ДИСКЕ
[0003] Не применимо.
МАТЕРИАЛ, ОХРАНЯЕМЫЙ АВТОРСКИМ ПРАВОМ
[0004] Не применимо.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Область техники, к которой относится изобретение (Область технического применения):
[0005] Настоящее изобретение относится к области баз данных или доступа к файлу и, в частности, к эффективному выполнению сортировки или поиска в зашифрованной базе данных, тогда как она остается зашифрованной.
Описание известного уровня техники:
[0006] Сохраненные данные часто требуют конфиденциальности либо в результате регулятивных обязательств, либо в деловых целях. Законы, такие как Закон США «О преемственности страхования и отчетности в области здравоохранения» (HIPAA), и нормативные акты, регулирующие деятельность банков, требуют сохранения конфиденциальности личной информации. Деловую информацию, такую как секреты фирмы, обычно необходимо сохранять в тайне от конкурентов.
[0007] Доступные в настоящее время системы баз данных не способны обеспечить достаточную защиту, поскольку большинство этих систем хранят базу данных на диске в незашифрованной форме. Кражу конфиденциальной личной или деловой информации обычно осуществляют из незашифрованных баз данных, часто сохраненных в портативном компьютере, который легко похитить, или на сервере, подверженном электронному взлому. Это приводит владельца похищенных данных к ответственности, а также раскрывает личную информацию в базе данных похитителю, что часто приводит к "краже личности".
[0008] Шифрование баз данных может предоставить более надежный способ предотвращения потери данных даже в случае похищения системы хранения данных или электронного взлома сервера при условии, что данные остаются в зашифрованной форме. Тем не менее, данный процесс обычно приводит к проблемам в эксплуатации, в основном связанным с выполнением сортировки и поиска в базе данных.
[0009] Выполнение сортировки и поиска в зашифрованной базе данных обычно требует выполнения расшифрования данных либо путем расшифрования всей базы данных, либо расшифрования некоторой части или всех данных "на лету". Это требует значительных вычислительных затрат и раскрывает по меньшей мере часть данных в незашифрованной форме.
[0010] Те несколько систем, которые действительно шифруют базу данных, обычно расшифровывают ее на диск, когда первый пользователь открывает базу данных, и зашифровывают ее снова, когда последний пользователь закрывает базу данных. Из-за этого данные остаются в файловой системе в незашифрованной форме, пока используется система. Во многих онлайновых приложениях для финансовой обработки и банковских операций это может привести к тому, что данные будут постоянно раскрытыми, находясь в незашифрованном состоянии на внешнем носителе данных, 24 часа в сутки, 7 дней в неделю. В зависимости от системы хранения данных фрагменты временных файлов, содержащих незашифрованные данные, также могут оставаться раскрытыми, находясь на внешнем носителе, до тех пор, пока эти фрагменты для хранения данных не будут перераспределены операционной системой и перезаписаны.
[0011] Если незашифрованные данные хранятся на диске, их легко может "прочитать" похититель. При "падении" системы, переводе ее в "спящий" режим или неправильном выключении данные на диске останутся в незашифрованной форме и, таким образом, будут уязвимы для похищения. Операционные системы, использующие виртуальную память, представляют собой проблему, поскольку файлы страницы памяти записываются на диск. Это подвергает любые незашифрованные данные, сохраненные в ОЗУ, риску обнаружения умелым похитителем. Это подразумевает, что система базы данных должна сохранять минимальное количество незашифрованных данных в защищенной рабочей памяти (т.е. в ОЗУ или внутренних регистрах).
[0012] Настоящее изобретение разработано для минимизации раскрытия незашифрованных данных при сохранении минимальных требований к вычислительным затратам. Применяемая стратегия заключается в том, чтобы максимально долго поддерживать данные в зашифрованном состоянии, минимизировать раскрытие данных в незашифрованной форме и никогда не хранить незашифрованные данные на внешнем носителе, т.е. на диске.
[0013] Другие подходы обладают значительными ограничениями, делающими их не такими универсальными, как настоящее изобретение. Сохраняющий порядок криптографический алгоритм сложно, или невозможно, внедрить из-за разрушающих порядок требований криптографической системы. Хотя был достигнут некоторый прогресс в создании подобного алгоритма (см., например, патентную публикацию США №2005/0147240), в настоящее время его не считают достаточно универсальным или достаточно надежным для применений, требующих высокой степени безопасности.
[0014] Настоящее изобретение не обладает подобным криптографическим недостатком, поскольку изобретение реализовано с использованием криптографического модуля, который может быть оптимизирован в целях безопасности.
[0015] Шифрование "на лету" (OTFE) представляет собой процесс шифрования и расшифровывания всех данных на диске, или с помощью аппаратного обеспечения, или программно-аппаратного обеспечения (в дисковой подсистеме), или с помощью программного обеспечения (в драйвере дискового устройства) во время чтения или записи данных.
[0016] Затраты или в аппаратных, или в программных реализациях OTFE значительно превышают затраты, присутствующие в настоящем изобретении. Кроме того, аппаратное решение обычно является более дорогостоящим, чем программное решение, и его часто тяжелее реализовать в существующей системе.
КРАТКОЕ ИЗЛОЖЕНИЕ СУТИ ИЗОБРЕТЕНИЯ
[0017] Настоящее изобретение представляет собой способ применения синхронизированного поиска и упорядоченных структур данных для доступа к собранию данных, сохраненных на постоянном машиночитаемом носителе, включающий этапы, на которых: организуют структуру результатов поиска с помощью значения зашифрованного ключа, при этом структура результатов поиска содержит лишь ссылки на элементы в собрании и их соответствующие зашифрованные ключи; организуют упорядоченную структуру данных с помощью значения незашифрованного ключа, при этом упорядоченная структура данных содержит лишь ссылки на элементы в собрании и их соответствующие зашифрованные ключи; раскрывают максимум два элемента данных, представляющих собой незашифрованный текст, в ходе операций с собранием; выполняют операции вставки или удаления путем выполнения поиска и обновления структуры результатов поиска и упорядоченной структуры данных для вставки или удаления соответствующих элементов собрания; выполняют операции обновления путем осуществления поиска в структуре результатов поиска на предмет желательных элементов собрания и обновления их соответствующих значений; выполняют операции поиска путем поиска в структуре результатов поиска в соответствии с ключом поиска; выполняют операции сортировки путем поиска в упорядоченной структуре данных для обнаружения диапазона значений и последующего обхода упорядоченной структуры данных в желаемом направлении; выполняют операции слияния путем обхода и выбора введенных элементов из двух или более упорядоченных структур данных; и предоставляют пользователю отчет о результатах этих операций. В предпочтительном варианте осуществления использованы интерфейс прикладных программ и модульная архитектура для структуры данных и криптографических операций для минимизации зависимости от определенных реализаций. Данный способ не зависит от реализации в отношении выбора аппаратного и/или программного обеспечения. Структуру результатов поиска и упорядоченную структуру данных можно комбинировать для создания структуры сводных данных. Организация упорядоченной структуры данных использует обфускацию ключа, наиболее предпочтительно одно или несколько из: соления ключа, переупорядочивания битов ключа или распределения битов ключа. Настоящее изобретение может дополнительно включать этап очистки рабочей памяти компьютера, выполняющего данный способ, после завершения операции над структурой данных, выполнение данного способа на компьютере, использующем защищенную рабочую память, и/или выполнение данного способа на компьютере, использующем защищенные процессы. Собрание данных может представлять собой собрание зашифрованных данных и/или собрание незашифрованных данных. Выполнение операций сортировки может включать выполнение операций многоколоночной сортировки, выполнение операций вставки может включать использование вставляемых значений местоположения, и выполнение операций сортировки может включать выполнение внутренней или внешней сортировки, а выполнение операций слияния включает выполнение внутреннего или внешнего слияния.
[0018] Дальнейший диапазон применения настоящего изобретения будет частично изложен в подробном описании, представленном ниже, совместно с сопроводительными графическими материалами и будет частично понятен специалистам в данной области при рассмотрении следующего или может стать известен путем практического осуществления настоящего изобретения. Цели и преимущества настоящего изобретения могут быть реализованы и достигнуты с помощью инструментов и комбинаций, отдельно указанных в приложенной формуле изобретения.
КРАТКОЕ ОПИСАНИЕ НЕКОТОРЫХ ВИДОВ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0019] Сопроводительные графические материалы, являющиеся частью данного описания, изображают один или несколько вариантов осуществления настоящего изобретения и, вместе с описанием, служат для объяснения принципов изобретения. Графические материалы служат лишь для изображения одного или нескольких предпочтительных вариантов осуществления настоящего изобретения и не должны расцениваться как ограничивающие изобретение.
На графических материалах:
[0020] На фиг. 1 показан обзор предпочтительных структур данных согласно настоящему изобретению;
[0021] На фиг. 2 показана структура 122 результатов поиска;
[0022] На фиг. 3 показана упорядоченная структура 128 данных;
[0023] На фиг. 4 показана блок-схема операции CREATE ("Создать");
[0024] На фиг. 5 показана блок-схема операции INSERT ("Вставить"); и
[0025] На фиг. 6 показана блок-схема операции DELETE ("Удалить").
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0026] Настоящее изобретение разработано для минимизации раскрытия незашифрованных данных и одновременно для сохранения минимальных требований к вычислительным затратам. Применяемая стратегия заключается в том, чтобы максимально долго поддерживать данные в зашифрованном состоянии для минимизации раскрытия данных в незашифрованной форме и в том, чтобы никогда не хранить незашифрованные данные на внешнем носителе, например на диске.
[0027] Изобретение, описанное здесь, обеспечивает эффективное и надежное хранение и извлечение зашифрованных данных, выполняемые соответствующей системой управления базой данных, и содержит структуры данных и способы выполнения операций, разработанные для поддержки поисков и сортировок зашифрованных данных в то время как эти данные остаются в зашифрованной форме. Изобретение не зависит ни от формы соответствующей базы данных, ни от способа шифрования. Оно разработано для интеграции в соответствующую систему управления базой данных.
Определения, сокращения и аббревиатуры
[0028] Термины, используемые в данном описании, являются такими, как определено в American National Standard Dictionary of Information Technology (ANSDIT), ANSI/ISO/IEC 9075:1999 и NIST IR-7298, если особым образом не указано иное.
[0029] В системе управления базой данных (DBMS) данные хранятся в одном или нескольких контейнерах данных. Каждый контейнер данных содержит записи. Данные в каждой записи организованы в одно или несколько полей. В реляционной системе управления базой данных (RDBMS) контейнеры данных обозначены термином "таблицы", записи обозначены термином "строки", а поля обозначены термином "колонки".
[0030] Системы, реализующие настоящее изобретение, не ограничены какими-либо конкретными типами структур данных. Тем не менее, с целью пояснения примеры и терминология, используемые здесь, будут такими примерами и терминологией, которые обычно связаны с реляционными базами данных. Таким образом, термины "таблица", "строка" и "колонка" будут использованы здесь для ссылки соответственно на структуру 110 хранения данных, запись в данной структуре и поле в данной записи. Может быть использована любая структура данных, в которой группы связанных полей ассоциированы в записи.
[0031] Термин "запись" является эквивалентом термина "строка", и каждый термин может использоваться взаимозаменяемо.
[0032] Термин "поле" является эквивалентом термина "колонка", и каждый термин может использоваться взаимозаменяемо.
Сокращения и аббревиатуры
Ссылки
"American National Standard Dictionary of Information Technology (ANSDIT)"
Доступен онлайн по адресу: http://www.incits.org/ANSDIT/Ansdit.htm
Информация о доступе от 10.01.2011 г.
"Database Language SQL"
Международный стандарт ANSI/ISO/IEC 9075:1999
"Glossary of Key Information Security Terms
NIST IR-7298; Kissel, Richard, editor; 25 апреля 2006 г.
"The Art of Computer Programming, Vol.3: Sorting and Searching, Second Edition"
Knuth, Donald; Reading, Massachusetts: Addison-Wesley, 1998
"Algorithms And Theory Of Computation Handbook"
Edited by Mikhail J. Atallah; CRC Press LLC - 1999
"Literary Machines"
Nelson, Ted; Mindful Press - 1988
"System and Method for Order-preserving Encryption of Numeric Data"
Публикация заявки на патент США 2005/0147240 A1, 7 июля 2005 г.
Эксплуатационные требования
[0033] Операции с базами данных, поддерживаемые настоящим изобретением, описанные в соответствии с SQL стандартов ANSI/ISO/IEC, должны включать в себя:
Операции, выполняемые оператором CREATE ("Создать"),
Операции, выполняемые оператором INSERT ("Вставить"),
Операции, выполняемые оператором DELETE ("Удалить"),
Операции, выполняемые оператором UPDATE ("Обновить"),
Операции, выполняемые оператором SELECT ("Выбрать"), и
Операции, выполняемые разделом ORDER BY ("Упорядочить по") оператора SELECT ("Выбрать").
[0034] Следует отметить, что хотя эти операторы описаны в соответствии с SQL, эти описания не подразумевают какой-либо конкретной реализации базы данных, и их следует расценивать лишь в качестве общих примеров типичных операций с базами данных. Подобные операции могут быть образованы для не-SQL систем управления базами данных и т.д.
[0035] Сортировка и поиск, примером которых является оператор SQL SELECT и его раздел ORDER BY, являются наиболее частыми и часто наиболее сложными операциями с базами данных. Данные операции усложняются шифрованием, поскольку процесс шифрования предназначен для сокрытия порядка и значения элементов данных.
Производительность и эффективность
[0036] Минимизация операций шифрования и расшифровывания и обновления индекса являются ключевыми для эффективной работы данного способа.
[0037] При использовании настоящего изобретения большую часть данных лишь необходимо расшифровать для вычисления, для отображения на экране или для печати отчетов. Затраты, добавленные настоящим изобретением, являются минимальными и работа изобретения разработана таким образом, чтобы быть прозрачной для пользователя.
[0038] Настоящее изобретение разработано для интеграции в систему управления базой данных и не является отдельной системой.
[0039] Настоящее изобретение разработано таким образом, чтобы быть независимым от способа хранения данных. Его реализация будет зависеть от деталей системы, в которую оно интегрировано.
Уязвимости
[0040] Уязвимости существуют в любой системе независимо от того, насколько хорошо она разработана. Настоящее изобретение разработано таким образом, чтобы содержать как можно меньше уязвимостей, и здесь мы обсуждаем некоторые из наиболее распространенных характеристик поверхности атаки.
[0041] Атака с использованием виртуальной машины может исходить или от аппаратного обеспечения, или от программного обеспечения. Это включает в себя запуск настоящего изобретения на виртуальной машине и анализ его работы. Это наиболее сложная форма атаки, и отразить ее очень тяжело.
[0042] Техники трассировки и зондирования с использованием логического анализатора, эмулятора аппаратного обеспечения, поддержки средствами аппаратной отладки или поддержки средствами JTAG также тяжело отразить, поскольку обычно они не могут быть обнаружены системой, в отношении которой проводят трассировку или зондирование.
[0043] Атаки "человек посередине" с использованием внедрения кода, перехватчиков операционной системы и руткитов являются другими распространенными направлениями атаки.
Минимизация поверхности атаки
[0044] Целью защиты системы является минимизация "поверхности атаки", подверженной воздействию потенциальных похитителей.
[0045] Чем больше действий доступно пользователю или чем больше ресурсов доступно посредством данных действий, тем больше поверхность атаки. Чем больше поверхность атаки, тем больше шанс успешной атаки на систему и, следовательно, тем меньше ее защищенность. Уменьшение поверхности атаки уменьшит шанс успешной атаки и, следовательно, сделает систему более защищенной.
[0046] Основной способ минимизации поверхности атаки заключается в ограничении доступа к данным в незашифрованной форме. Это можно осуществить путем ограничения физического доступа к системе и путем ограничения практической пользы электронного доступа к системе. Здесь не обсуждается управление доступом с использованием физических средств, поскольку оно не является частью данного изобретения. Потенциальную полезность данных, полученных с помощью электронного доступа, ограничивают с помощью шифрования и путем минимизации подвергания незашифрованных данных какому-либо воздействию.
[0047] Незашифрованные данные в настоящем изобретении ограничены следующим: криптографический ключ шифрования/расшифрования, значение данных, предназначенное для записи, или считанное значение и текущее сравнительное значение поиска. Кроме этого, настоящее изобретение никогда не хранит незашифрованные данные на внешних носителях (например, на диске).
[0048] Настоящее изобретение использует защищенное ОЗУ, где это применимо. Защищенное ОЗУ никогда не записывают на диск - оно зафиксировано во внутренней памяти. Управление памятью с использованием аппаратных средств, включая управление доступом, если является доступным, может быть дополнительно использовано для защиты ОЗУ от доступа со стороны других программ.
[0049] Техники обфускации ключа, такие как "соление" ключа, переупорядочивание битов ключа, распределение битов ключа и т.д., могут быть использованы для сокрытия записей в упорядоченной структуре данных. Следует отметить, что обфускация ключа не подходит для записей в структуре результатов поиска и не должна использоваться там.
[0050] Способы управления памятью с использованием аппаратных средств также могут быть использованы для дальнейшей защиты ключа и процесса шифрования/расшифрования.
[0051] Шифрование/расшифрование могут выполняться в виде защищенного процесса, выполняемого до завершения. Это подразумевает отсутствие переключения на другую задачу, т.е. запрет на прерывания.
[0052] Помимо этого, желательно очищать рабочее ОЗУ и регистры на выходе из процесса шифрования, с тем чтобы не оставлять в памяти чего-либо, способного помочь злоумышленной попытке расшифрования данных.
[0053] Процесс шифрования/расшифрования также может быть запущен в качестве службы операционной системы, что предоставит дополнительную защиту в некоторых операционных системах.
Возможные решения
[0054] Были рассмотрены два возможных решения данной проблемы:
1. Математическая функция шифрования, сохраняющая порядок.
Для работы подобная функция, f(k, d), должна отвечать следующим требованиям:
Уникальность:
f(k, d) уникальна для всех {k, d}
Симметричные ключи (это также может быть сформулировано для асимметричных ключей):
f(k, f(k, d))=d для всех {k, d}
Упорядочение:
f(k, d)=f(k, e) iff d=e для всех {k, d, e}
f(k, d)>f(k, e) iff d>e для всех {k, d, e}
f(k, d)<f(k, e) iff d<e для всех {k, d, e}
где:
k=ключ шифрования/расшифрования,
d=значение данных,
e=значение данных.
[0055] Функцию, отвечающую всем этим требованиям, может быть тяжело или невозможно создать, поскольку часть принципа работы шифрования заключается в разупорядочивании с тем, чтобы уменьшить шанс обнаружения незашифрованных значений данных с помощью криптоанализа.
[0056] Поскольку первое решение не может быть осуществимо, был разработан второй подход:
2. Структура данных, сохраняющая порядок для сортировок и поисков, но не содержащая незашифрованных данных.
Структуры данных обычно используются для сортировки и поиска (см. Donald Knuth Кнут "The Art of Computer Programming, Vol.3: Sorting and Searching").
[0057] Может быть разработано несколько возможных архитектур, реализующих настоящее изобретение. Все эти архитектуры зависят от сохранения двух синхронизированных структур данных для индексации зашифрованных колонок в структуре 110 хранения данных: структуры 122 результатов поиска для быстрого нахождения определенной части данных и упорядоченная структура 128 данных для сортировки данных, каждая из которых оптимизирована для данной цели. Использование двух структур данных для индексации данных способствует как шифрованию, так и простоте сортировки и поиска.
[0058] При создании таблицы базы данных (которая может быть любой адресуемой структурой данных со строками и колонками или записями и полями - неструктурированный файл, RDBMS и т.д.) создают две структуры данных для каждой зашифрованной колонки - упорядоченная структура 128 данных и структура 122 результатов поиска.
[0059] Путем сохранения этих структур данных для каждой колонки зашифрованных данных и поддержания шифрования данных возможно выполнять сортировку и поиск с небольшой расшифровкой или без нее.
[0060] Как упорядоченная структура данных, так и структура результатов поиска лишь хранят указатели и зашифрованные данные.
[0061] Упорядоченная структура 128 данных организована с помощью незашифрованного значения, тогда как структура 122 результатов поиска организована с помощью зашифрованного значения.
[0062] Эти структуры данных используются в качестве индексов для доступа к структуре 110 хранения данных, которая может быть реализована в локальной памяти или реализована на внешнем устройстве хранения данных. Структура 110 хранения данных должна быть адресуемой по строке и колонке. Единственное значение хранится на пересечении каждого адреса строки и колонки.
[0063] При создании или обновлении упорядоченной структуры 128 данных необходимо расшифровывать лишь два элемента данных: новый введенный элемент и один введенный элемент из упорядоченной структуры 128 данных. Те же условия применяются для структуры 122 результатов поиска. Массив данных лишь необходимо расшифровать для отображения на экране для вычисления или для печати отчетов. Во всех других случаях эксплуатации данные остаются зашифрованными.
[0064] Структуры данных должны поддерживать лишь минимальный API, и точные формы реализации будут зависеть от требований применения.
[0065] Например, упорядоченная структура 128 данных может быть реализована с помощью структуры списка пропусков, тогда как структура 122 результатов поиска может представлять собой форму сбалансированного двоичного дерева или даже еще одного списка пропусков. Различные реализации этих структур данных хорошо описаны в литературе и не будут описаны здесь более подробно.
[0066] Другие структуры данных являются возможными и предлагают различную эксплуатационную эффективность. Их выбор будет зависеть от потребностей применения. Требуется лишь функциональная эквивалентность на уровне API.
[0067] Путем сохранения этих структур данных для каждой колонки зашифрованных данных и поддержания шифрования данных возможно выполнять сортировку и поиск с небольшой расшифровкой или без нее.
[0068] При создании или обновлении упорядоченной структуры 128 данных необходимо расшифровывать лишь два элемента данных: новый введенный элемент и один введенный элемент из упорядоченной структуры 128 данных.
[0069] Массив данных лишь необходимо расшифровать для отображения на экране для вычисления или для печати отчетов. Во всех других случаях эксплуатации данные остаются зашифрованными.
Рассмотрение эффективности
[0070] Минимизация операций шифрования/расшифровывания и обновления индекса важны для эффективной работы данного изобретения.
[0071] Операции вставки имеют наибольшие вычислительные затраты, поскольку необходимо обновлять как упорядоченную структуру 128 данных, так и структуру 122 результатов поиска. Операциям удаления свойственны подобные большие вычислительные затраты.
[0072] Операции обновления будут включать в себя внесения изменений в упорядоченную структуру 128 данных и структуру 122 результатов поиска, а также внесение изменений в структуру 110 хранения данных.
[0073] Операции слияния также могут быть выполнены с данными, индексированными с помощью настоящего изобретения, при этом будет раскрываться минимальное количество незашифрованных данных. На любой заданной стадии слияния необходимо расшифровать лишь поля ключа в двух текущих записях в процессе слияния.
[0074] Выбор реализуемых структур данных определяет эксплуатационные характеристики этой системы. То, какие структуры данных выбираются, будут зависеть от потребностей применения.
Масштабируемость
[0075] Настоящее изобретение является легко масштабируемым и может быть реализовано в качестве или внутреннего, или внешнего типа. Тщательность реализации приведет к устойчивости сортировки, требуемой для многоколоночной сортировки.
Преимущества
[0076] Настоящее изобретение предоставляет следующие преимущества по сравнению с другими возможными решениями:
1. Оно обладает низкими затратами. Операции шифрования и расшифровывания поддерживаются на минимальном уровне, необходимом для обработки данных.
2. Оно может представлять собой исключительно программное решение. Все алгоритмы могут быть реализованы исключительно в программном обеспечении.
3. Оно может быть реализовано в программном обеспечении с аппаратной поддержкой. Специализированное аппаратное обеспечение для шифрования и расшифровывания, а также аппаратное обеспечение для работы со структурой данных при желании может быть использовано для ускорения критических частей алгоритма.
4. Оно представляет собой модульное решение. Настоящее изобретение использует модульную архитектуру для предоставления максимальной гибкости в реализации. Части алгоритма могут быть заменены без нарушения функциональности остальных частей алгоритма.
5. Подобные структуры индекса, используемые для индексации колонок зашифрованных данных, также могут быть использованы для индексации колонок незашифрованных данных, что приведет к увеличению скорости сортировок этих колонок.
6. Настоящее изобретение является легко масштабируемым и может быть реализовано в качестве или внутреннего, или внешнего типа.
7. Настоящее изобретение не зависит от архитектуры операционной системы, лежащей в основе, и в некоторых реализациях даже может не взаимодействовать непосредственно с ней.
8. Настоящее изобретение не зависит от архитектуры аппаратного обеспечения, лежащей в основе, но может быть реализовано таким образом, чтобы воспользоваться преимуществами, предоставляемыми доступными элементами аппаратного обеспечения.
9. Настоящее изобретение не зависит от языка, использованного при его реализации. Оно может быть реализовано на языке ассемблера, интерпретированном коде или высокоуровневом языке компилирования в соответствии с определенным способом реализации.
10. Настоящее изобретение не зависит от формы соответствующей структуры хранения, с которой оно используется.
Независимое от системы определение функциональности
[0077] Как является обычной практикой в теории вычислительных машин, описана модель системы, основанная на API. Подробно описаны лишь детали интерфейса и функциональность, которую она представляет. Этот подход предоставляет гибкость в выборе реализации. Множество реализаций является возможным, и предполагается, что конструктор будет выбирать оптимизацию согласно потребностям применения.
[0078] Следующее описание основано на использовании абстрактной модели, состоит из не зависящих от системы описаний структур данных и операций, выполняемых с ними. Хотя это описание является объектно-ориентированным, оно не подразумевает или требует объектно-ориентированной реализации.
[0079] Структура настоящего изобретения соответствует структуре, свойственной проблеме. Предпочтительная реализация настоящего изобретения использует модульную архитектуру, позволяющую основной структуре оставаться неизменной, в то время как детали реализации могут изменяться по мере необходимости.
Структуры данных
[0080] Предпочтительная реализация настоящего изобретения основана на следующих объектах абстрактной структуры данных.
Структура хранения данных
[0081] Структура 110 хранения данных, реализованная структурой данных StorageSystem, представляет собой хранилище для данных, сохраненных в базе данных.
[0082] Структура 110 хранения данных является адресуемой по строке и колонке. Единственное значение хранится на пересечении каждого адреса строки и колонки. Величина этого значения не указана в данном описании, поскольку она зависит от реализации.
[0083] Структура 110 хранения данных может быть реализована в локальной памяти или реализована на внешнем устройстве хранения данных. Реализация структуры 110 хранения данных не должна включать в себя поддержку шифрования, поскольку все способы шифрования предоставлены с помощью модульной архитектуры настоящего изобретения.
Упорядоченная структура данных
[0084] Упорядоченная структура 128 данных, реализованная структурой данных OrderStructure, позволяет сравнивать диапазоны зашифрованных значений и облегчает выполнение сортировки.
[0085] Порядок упорядоченной структуры 128 данных задан незашифрованным значением ключа поиска.
[0086] При создании или обновлении упорядоченной структуры 128 данных лишь два элемента данных должны быть в незашифрованной форме: новый введенный элемент и один введенный элемент из упорядоченной структуры 128 данных. Во всех других случаях данные остаются в зашифрованной форме.
[0087] Результатом поиска определенного искомого значения в упорядоченной структуре 128 данных будет либо указатель на введенный элемент в структуре данных, содержащий список записей, имеющих искомое значение, либо указатель на введенный элемент структуры данных, предшествующий местонахождению искомого значения (место вставки нового введенного элемента структуры данных).
[0088] Поиски диапазона значений выполняются с упорядоченной структурой 128 данных. Это требует, чтобы исследуемый в настоящий момент введенный элемент в упорядоченной структуре 128 данных был временно расшифрован в ОЗУ для сравнения с устанавливаемой границей.
[0089] При обнаружении относительных положений A и B в упорядоченной структуре 128 данных записи, находящиеся между ними, могут быть извлечены путем простого обхода упорядоченной структуры 128 данных от A к B.
[0090] Сортировки являются простейшими благодаря поддержанию упорядоченной структуры в 128 данных в отсортированном порядке согласно незашифрованному значению данных. Сортировка требует лишь обхода упорядоченной структуры 128 данных в соответствующем восходящем или нисходящем направлении.
Структура результатов поиска
[0091] Поиски определенного значения выполняют со структурой 122 результатов поиска, реализованной структурой данных SearchStructure, используя зашифрованное значение искомых данных в качестве ключа поиска.
[0092] Порядок структуры 122 результатов поиска задан зашифрованным значением ключа поиска.
[0093] Результатом поиска определенного искомого значения в структуре 122 результатов поиска будет либо указатель на введенный элемент в структуре данных, содержащий список записей, имеющих искомое значение, либо указатель на введенный элемент структуры данных, предшествующий местонахождению искомого значения (место вставки нового введенного элемента структуры данных).
Типы данных
[0094] Следующие типы абстрактных данных использованы в работе предпочтительной реализации настоящего изобретения. Каждый тип зависит от реализации. Эти определения предназначены для руководства в выборе подходящей реализации и должны расцениваться в качестве минимальных требований, необходимых для этой реализации.
RecordStructure
[0095] Этот тип данных определяет структуру записи, существующей в структуре 110 хранения данных, реализованной объектом StorageStructure. Он содержит введенный элемент для каждой колонки в записи.
[0096] Каждый введенный элемент колонки может относиться к зависимому от реализации типу данных, определенному потребностями применения и доступными типами данных в реализации. Эти введенные элементы могут представлять собой простое значение, структуру значений или указатель на простое значение или структуру значений.
RecordID
[0097] Этот тип данных определяет уникальный идентификатор для записи. Обычно он будет реализован как относительный числовой показатель, который может представлять собой целое значение с основанием 0 или с основанием 1, размер которого зависит от реализации.
StorageAddress
[0098] Этот тип данных представляет собой зависимый от реализации уникальный адрес записи в объекте StorageSystem. Он может представлять собой простое значение (например, относительный индекс единицы памяти) или структуру значения (например, устройство, дорожку, сектор, смещение, длину).
OrderEntry
[0099] Этот тип данных определяет структуру введенного элемента, содержащего узел, в объекте OrderStructure. Этот тип данных зависит от реализации, но, предположив реализацию списка пропусков, каждый узел обычно будет требовать введенного элемента, содержащего ключ, введенного элемента, содержащего данные, 1 или нескольких прямых указателей и 1, или нескольких обратных указателей.
SearchEntry
[00100] Этот тип данных определяет структуру введенного элемента, содержащего узел, в SearchStructure. Этот тип данных зависит от реализации, но, предположив реализацию сбалансированного двоичного дерева, каждый узел обычно будет требовать введенного элемента, содержащего ключ, левого указателя, правого указателя и списка или указателя на список введенных элементов, содержащих RecordID и указывающих на введенные элементы, содержащие RecordStructure и обладающие тем же ключом.
ClearValueType
[00101] Этот тип данных определяет структуру незашифрованного значения. Этот тип данных зависит от реализации и может представлять собой простое значение или указатель на структуру значения.
EncryptedValueType
[00102] Этот тип данных определяет структуру зашифрованного значения. Этот тип данных зависит от реализации и может представлять собой простое значение или указатель на структуру значения.
KeyType
[00103] Этот тип данных определяет структуру значения ключа. Этот тип данных зависит от реализации и может представлять собой простое значение или указатель на структуру значения.
AlgType
[00104] Этот тип данных представляет собой указатель на алгоритм шифрования или алгоритм расшифрования. Указатель должен уточнять адрес соответствующего модульного криптографического алгоритма. Уточненный алгоритм зависит от реализации.
ErrorCode
[00105] Этот тип данных определяет форму кода ошибки. Этот тип данных зависит от реализации и может представлять собой простое значение или указатель на структуру значения.
Интеграция с системой управления базой данных
[00106] Существуют четыре области эксплуатации базисной системы управления базой данных, в которую должно быть интегрировано настоящее изобретение:
Установка (операция DBMS CREATE)
[00107] В ходе начального создания базы данных должны быть созданы вспомогательные структуры данных для настоящего изобретения. Это будет сделано на основании информации, предоставленной базисной системе управления базой данных относительно того, какие колонки должны быть зашифрованы.
Запуск
[00108] В ходе запуска базисной системы управления базой данных необходимо получить колюч (ключи) шифрования у пользователя. Это должно быть сделано безопасным образом, который не будет дополнительно описан здесь.
Выполнение (операции DBMS INSERT, DELETE и SELECT)
[00109] В ходе эксплуатации базисной системы управления базой данных будет необходимо запрашивать и, возможно, обновлять структуры данных, поддерживаемые настоящим изобретением.
[00110] Эти операции дополнительно описаны в разделе "Подробности API", следующим за данным разделом.
Выключение
[00111] Выключение согласно настоящему изобретению состоит из очистки всей информации о криптографическом ключе, а также очистки рабочей памяти из системной памяти. Поскольку вся информация, за исключением информации о криптографическом ключе и, возможно, рабочая память, находится в зашифрованной форме, их очистка является необходимой и достаточной для завершения эксплуатации настоящего изобретения.
Подробности API
Способы StorageSystem
[00112] Эти способы используются для доступа к объекту StorageSystem, который может быть реализован в локальной памяти или реализован на внешнем устройстве хранения данных.
[00113] Этот способ добавляет параметр recordValue типа данных RecordStructure в объект StorageSystem. Он возвращает RecordID, предоставляющий уникальный адрес в объекте StorageSystem для только что добавленного RecordStructure.
[00114] Если объект StorageSystem не может удовлетворить запрос, будет возвращено нулевое значение (NULL). Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00115] Этот способ возвращает указатель на RecordStructure, сохраненный в заданном RecordID в объекте StorageSystem. Если RecordID является недействительным, будет возвращен указатель NULL. Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00116] Данный способ заменяет тип RecordStructure, адресованный параметром whichRecord, типом RecordStructure, уточненным параметром recordValue.
[00117] Если обновление выполнено успешно, возвращается логическое значение "истина". Если обновление не выполнено, возвращается логическое значение "ложь". Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00118] Этот способ возвращает значение, зависимое от реализации, для StorageAddress, соответствующего RecordID, уточненному с помощью whichRecord.
[00119] Этот способ возвращает значение, зависимое от реализации, для RecordID, соответствующего StorageAddress, уточненному с помощью whichAddress.
[00120] Этот способ возвращает значение, обозначающее причину неудачи последнего способа, инициированного на StorageSystem. Значение является свойственным реализации и не будет дополнительно описано здесь.
Способы OrderStructure
[00121] Эти способы определяют API для связи с объектом OrderStructure.
[00122] Этот метод добавляет запись, уточненную с помощью whichRecord, в объект OrderStructure со значением ключа, уточненным с помощью clearKeyValue, используя ключ шифрования, уточненный с помощью columnKey.
[00123] Если запись с уточненным значением ключа уже существует, новая запись будет добавлена к концу списка записей с этим значением ключа. Возвращается указатель на добавленный введенный элемент. Указатель NULL может быть возвращен, если способ не может добавить запись. Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00124] Этот способ удаляет первую запись, уточненную с помощью whichRecord, из объекта OrderStructure с значением ключа, уточненным с помощью clearKeyValue, используя ключ шифрования, уточненный с помощью columnKey.
[00125] Если удаление выполнено успешно, возвращается логическое значение "истина". Если удаление не выполнено, возвращается логическое значение "ложь". Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00126] Данный способ удаляет OrderEntry, уточненный с помощью whichEntry, из объекта OrderStructure, используя ключ шифрования, уточненный с помощью columnKey.
[00127] Если удаление выполнено успешно, возвращается логическое значение "истина". Если удаление не выполнено, возвращается логическое значение "ложь". Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00128] Данный способ обнаруживает OrderEntry в объекте OrderStructure, уточненном с помощью clearKeyValue, используя ключ шифрования, уточненный с помощью columnKey.
[00129] При обнаружении возвращается указатель на первый OrderEntry, соответствующий clearKeyValue. Если подобной записи не существует, будет возвращен указатель NULL.
[00130] Данный способ обнаруживает следующий OrderEntry в объекте OrderStructure, используя ключ шифрования, уточненный с помощью columnKey.
[00131] Если find() возвратил NULL, т.е. если в списке больше нет введенных элементов, то возвращается указатель NULL.
[00132] Этот способ возвращает значение, обозначающее причину неудачи последнего способа, инициированного на объекте OrderStructure. Значение является свойственным реализации и не будет дополнительно описано здесь.
Способы SearchStructure
[00133] Эти способы определяют API для связи с объектом SearchStructure.
[00134] Этот метод добавляет запись, уточненную с помощью whichRecord, в объект SearchStructure со значением ключа, уточненным с помощью clearKeyValue, используя ключ шифрования, уточненный с помощью columnKey.
[00135] Если запись с уточненным значением ключа уже существует, новая запись будет добавлена к концу списка записей с этим значением ключа. Возвращается указатель на добавленный введенный элемент. Указатель NULL может быть возвращен, если способ не может добавить запись. Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00136] Этот метод удаляет запись, уточненную с помощью whichRecord, из объекта SearchStructure со значением ключа, уточненным с помощью clearKeyValue, используя ключ шифрования, уточненный с помощью columnKey.
[00137] Если удаление выполнено успешно, возвращается логическое значение "истина". Если удаление не выполнено, возвращается логическое значение "ложь". Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00138] Данный способ удаляет SearchEntry, уточненный с помощью whichEntry, из объекта SearchStructure, используя ключ шифрования, уточненный с помощью columnKey.
[00139] Если удаление выполнено успешно, возвращается логическое значение "истина". Если удаление не выполнено, возвращается логическое значение "ложь". Причину неудачного выполнения запроса можно исследовать, используя способ getLastError(), описанный ниже.
[00140] Данный способ обнаруживает SearchEntry в объекте SearchStructure, уточненном с помощью clearKeyValue, используя ключ шифрования, уточненный с помощью columnKey.
[00141] При обнаружении возвращается указатель на первый SearchEntry, соответствующий clearKeyValue. Если подобной записи не существует, может быть возвращен указатель NULL.
[00142] Данный способ обнаруживает следующий SearchEntry в объекте SearchStructure, используя ключ шифрования, уточненный с помощью columnKey.
[00143] Если в списке больше нет введенных элементов, то возвращается указатель NULL.
[00144] Этот способ возвращает значение, обозначающее причину неудачи последнего способа, инициированного на объекте SearchStructure.
[00145] Возвращенное значение является свойственным реализации и не будет дополнительно описано здесь.
Способы алгоритма шифрования
[00146] Эти способы уточняют API для алгоритма (алгоритмов), используемого для шифрования и расшифровывания данных.
[00147] Этот способ возвращает зашифрованное значение, соответствующее clearValue, используя ключ шифрования keyValue и модульный алгоритм шифрования, уточненный устройством шифрования.
[00148] Этот способ возвращает незашифрованное значение, соответствующее encryptedValue, используя ключ расшифрования keyValue и модульный алгоритм расшифрования, уточненный устройством расшифрования.
[00149] Далее будут рассмотрены фигуры и следует уточнить, что в следующем описании с целью пояснения многочисленные конкретные детали изложены для предоставления полного понимания настоящего изобретения. Тем не менее, специалисту в данной области будет очевидно, что настоящее изобретение может быть реализовано на практике без этих конкретных деталей. В других случаях хорошо известные структуры и устройства изображены в форме блок-схемы во избежание ненужного усложнения настоящего изобретения. Например, в списке структуры данных изображены лишь прямые указатели, тогда как конкретная реализация может использовать как прямые, так и обратные указатели.
[00150] Приведены ссылки на сопроводительные графические материалы, составляющие часть описания и на которых наглядно изображен конкретный вариант осуществления, в котором изобретение может быть реализовано на практике. Следует понимать, что другие варианты осуществления могут применяться, не выходя за пределы объема настоящего изобретения.
[00151] Системы, реализующие настоящее изобретение, не ограничены каким-либо определенным типом структуры 110 хранения данных, структуры 122 результатов поиска или упорядоченной структуры 128 данных. Тем не менее, с целью пояснения примеры и терминология, используемые здесь, будут такими примерами и терминологией, которые обычно связаны с реляционными базами данных. Таким образом, термины "таблица", "строка" и "колонка" будут использованы здесь для ссылки соответственно на структуру 110 хранения данных, запись в данной структуре и поле в данной записи. Может быть использована любая структура данных, в которой группы связанных полей ассоциированы в записи.
[00152] В дальнейшем термин "структура 110 хранения данных" относится к StorageStructure, определенной в описаниях API, термин "структура 122 результатов поиска" относится к SearchStructure, определенной в описаниях API, и термин "упорядоченная структура 128 данных" относится к OrderStructure, определенной в описаниях API.
[00153] Суть этого изобретения, как изображено в общем виде на фиг. 1, заключается в применении пары синхронизированных индексов 120 для выполнения поисков и сортировок зашифрованных данных в структуре 110 хранения данных и одновременно для минимизации количества криптографических операций и сохранении минимального количества незашифрованных данных во внутренней памяти процессора.
[00154] Содержание значений ключей поиска в структуре 124 ключа структуры результатов поиска и указателя и в структуре 130 ключа упорядоченной структуры данных и указателя сохраняются в зашифрованной форме.
[00155] Структура 110 хранения данных хранит данные, адресованные как строки и колонки, в таблице 112 базы данных, содержащей как зашифрованные, так и незашифрованные (открытый текст) колонки.
[00156] Таблица 112 базы данных содержит по меньшей мере одну зашифрованную колонку 116 и может содержать ноль или более незашифрованных колонок 114, 118 открытого текста.
[00157] Каждая зашифрованная колонка 116 индексирована парой индексов 120, состоящих из структуры 122 результатов поиска и упорядоченной структуры 128 данных.
[00158] Структура 122 результатов поиска используется для нахождения определенной записи или записей, содержащих уточненное значение ключа поиска.
[00159] В структуре 122 результатов поиска находится структура 124 ключа структуры результатов поиска и указателя и связанный с ней список 126 записей структуры результатов поиска.
[00160] Порядок структуры 124 ключа структуры результатов поиска и указателя поддерживается с помощью зашифрованных значений, сохраненных в ней.
[00161] Структура 124 ключа структуры результатов поиска и указателя применяется для определения местонахождения списка 126 записей структуры результатов поиска, содержащего идентификатор записи первой или единственной записи, содержащей желаемое значение.
[00162] На фиг. 2, где в качестве примерной реализации структуры 122 результатов поиска применяется двоичное дерево, поиск начинается в корневом узле 212, на который ссылается указатель 210 корня структуры результатов поиска, и продолжается двоичным поиском в узлах дерева до тех пор, пока не будет найден узел с желаемым значением данных или пока поиск не завершится неудачей.
[00163] Если желаемое значение существует в структуре 122 результатов поиска, то возвращается указатель на список 214 записей упорядоченной структуры данных, ссылающийся на записи, содержащие это значение.
[00164] Если подходящей записи не найдено, будет возвращен код ошибки.
[00165] Если имеется несколько записей, содержащих желаемое значение, на них будут ссылаться последующие введенные элементы в списке 126 записей структуры результатов поиска.
[00166] Упорядоченную структуру 128 данных применяют для выбора диапазона записей в структуре 110 хранения данных.
[00167] В пределах упорядоченной структуры 128 данных находится структура 130 ключа упорядоченной структуры данных и указателя и список 132 записей упорядоченной структуры данных, содержащий пару связанных с ним введенных элементов 134, 136 списка записей упорядоченной структуры данных.
[00168] Порядок структуры 130 ключа упорядоченной структуры данных и указателя поддерживается с помощью зашифрованных значений, сохраненных в ней.
[00169] Структуру 130 ключа упорядоченной структуры данных и указателя применяют для определения местонахождения введенного элемента 134 списка записей упорядоченной структуры данных, содержащего идентификатор записи первой или единственной записи, содержащей наименьшее желаемое значение, и местонахождения введенного элемента 136 списка записей упорядоченной структуры данных, содержащего идентификатор записи первой или единственной записи, содержащей наибольшее желаемое значение.
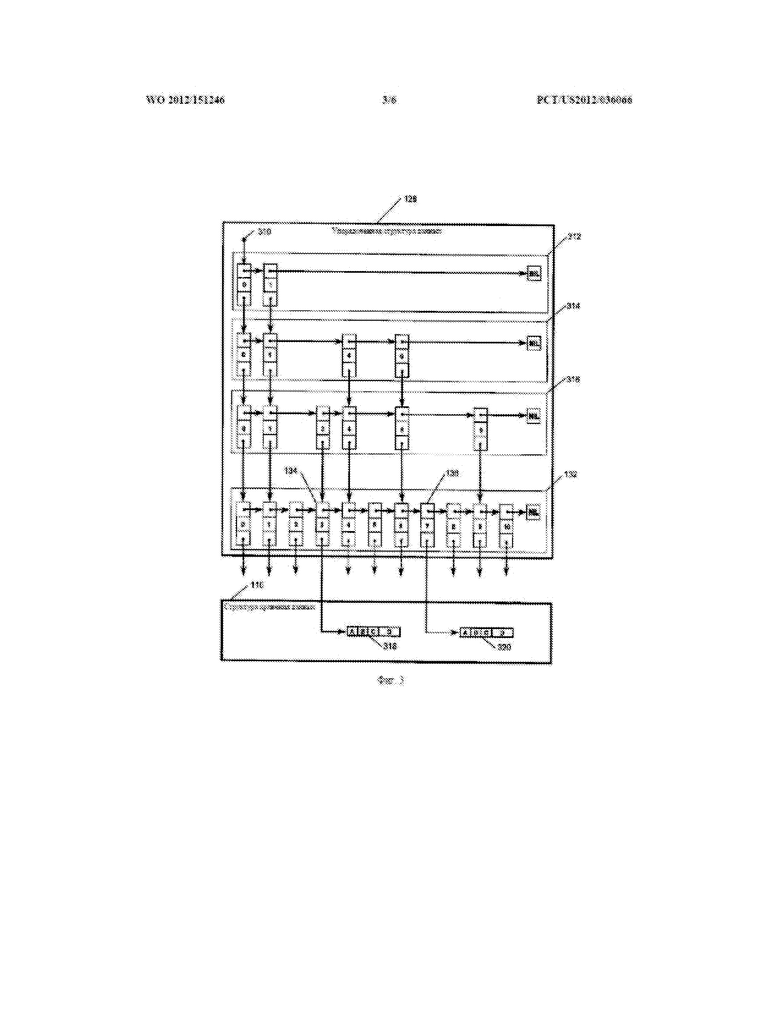
[00170] На фиг. 3, где в качестве примерной реализации упорядоченной структуры 128 данных применяется список пропусков, поиск начинается в указателе 310 корневого узла и продолжается в индексах 314, 315, 316 пропуска до тех пор, пока не будут найдены два введенных элемента 318, 320, чьи значения ключей начинают 318 и заканчивают 320 желаемый диапазон.
[00171] Список 132 записей упорядоченной структуры данных затем обходят или в восходящем, или в нисходящем порядке для извлечения записей, содержащихся в желаемом диапазоне.
[00172] Если имеется несколько записей, содержащих наименьшее желаемое значение, на них будут ссылаться последующие введенные элементы во введенном элементе 134 списка записей упорядоченной структуры данных.
[00173] Если имеется несколько записей, содержащих наибольшее желаемое значение, на них будут ссылаться последующие введенные элементы во введенном элементе 136 списка записей упорядоченной структуры данных.
[00174] Обход записей, начиная с записи или записей во введенном элементе 134 списка записей упорядоченной структуры данных и заканчивая записью или записями во введенном элементе 136 списка записей упорядоченной структуры данных, дает в результате набор записей в восходящем порядке.
[00175] Обход записей, начиная с записи или записей во введенном элементе 136 списка записей упорядоченной структуры данных и заканчивая записью или записями во введенном элементе 134 списка записей упорядоченной структуры данных, дает в результате набор записей в нисходящем порядке.
[00176] Когда необходимо добавить новые записи к одному из введенных элементов 134, 136 списка записей, их добавляют к концу того введенного элемента списка с тем, чтобы сохранять устойчивость сортировки.
[00177] Многоколоночные сортировки могут быть выполнены путем построения временных копий упорядоченной структуры 128 данных.
[00178] Эти временные копии построены из обходов каждой из предыдущих временных копий, первая из которых построена из обхода упорядоченной структуры 128 данных наименее значимой сортируемой колонки.
[00179] На фиг. 4 изображены этапы, выполняемые при создании таблицы базы данных.
[00180] На этапе 410 создают пустую упорядоченную структуру 128 данных, а на этапе 412 создают пустую структуру 122 результатов поиска для каждой новой зашифрованной колонки 116.
[00181] Следует отметить, что при желании для незашифрованных колонок может быть установлена дополнительная структура индексных данных для увеличения производительности сортировок и поисков в этих колонках. Эта структура индекса данных не описана здесь, поскольку не является частью данного изобретения.
[00182] На фиг. 5 изображены этапы, выполняемые при добавлении новой записи в таблицу базы данных.
[00183] Для каждой новой записи выполняют следующее:
1.0. Для каждого зашифрованного поля:
На этапе 510 проверяют структуру 122 результатов поиска на наличие значения колонки, которое будет вставлено:
На этапе 512, существует ли значение колонки в структуре 122 результатов поиска?
1.1. Да, оно существует:
1.1a. На этапе 514 структуру 122 результатов поиска обновляют для соединения с новой записью
1.1b. На этапе 516 упорядоченную структуру 128 данных обновляют для соединения с новой записью.
1.2. Нет, оно не существует:
1.2a. На этапе 518 обнаруживают его положение в упорядоченной структуре 128 данных.
1.2b. На этапе 520 упорядоченную структуру 128 данных обновляют, чтобы она содержала введенный элемент с зашифрованным значением колонки и местонахождением его записи в структуре 110 хранения данных.
1.2c. На этапе 522 структуру 122 результатов поиска обновляют, чтобы она содержала введенный элемент для нового зашифрованного значения колонки, включая местонахождение записи в структуре 110 хранения данных.
2.0. На этапе 524 вставляют новую запись в таблицу 112 базы данных в структуре 110 хранения данных.
[00184] Этот этап включает в себя выделение места для хранения в структуре 110 хранения данных, создание карты преобразования данных из RecordID в StorageAddress и вставку записи в структуру 110 хранения данных.
[00185] Следует отметить, что вставляемое значение местоположения, такое как "переключатели" ("Tumblers") Теда Нельсона, может быть использовано для уменьшения потребности в реорганизации упорядоченной структуры 128 данных, когда операция вставки приведет к конфликту значения местонахождения со значением местонахождения существующей записи.
[00186] На фиг. 6 изображены этапы, выполняемые при удалении записи.
[00187] На этапе 610 введенный элемент индекса записи удаляют из структуры 110 результатов поиска.
[00188] На этапе 612 введенный элемент индекса записи удаляют из упорядоченной структуры 514 данных.
[00189] На этапе 614 запись удаляют из структуры 110 хранения данных.
[00190] Как очевидно специалисту в данной области техники, определенные детали будут зависеть от конкретного применения изобретения. Далее описаны некоторые из подобных деталей.
[00191] При использовании настоящего изобретения большую часть данных лишь необходимо расшифровать для вычисления, для отображения на экране или для печати отчетов. Затраты, добавленные настоящим изобретением, являются минимальными и работа изобретения разработана таким образом, чтобы быть прозрачной для пользователя.
[00192] Настоящее изобретение разработано таким образом, чтобы быть независимым от способа хранения данных. Его реализация будет зависеть от деталей системы, в которую оно интегрировано.
[00193] Настоящее изобретение использует защищенное ОЗУ, где это применимо. Защищенное ОЗУ никогда не записывают на диск - оно зафиксировано во внутренней памяти. Управление памятью с использованием аппаратных средств, включая управление доступом, если является доступным, может быть дополнительно использовано для защиты ОЗУ от доступа со стороны других программ.
[00194] Техники обфускации ключа, такие как "соление" ключа, переупорядочивание битов ключа, распределение битов ключа и т.д., могут быть использованы для сокрытия записей в упорядоченной структуре данных. Следует отметить, что обфускация ключа не подходит для записей в структуре результатов поиска и не должна использоваться там.
[00195] Способы управления памятью с использованием аппаратных средств также могут быть использованы для дальнейшей защиты ключа и процесса шифрования/расшифрования.
[00196] Шифрование/расшифрование могут выполняться в виде защищенного процесса, выполняемого до своего завершения. Это подразумевает отсутствие переключения на другую задачу, например запрет на прерывания.
[00197] Помимо этого, желательно очищать рабочее ОЗУ и регистры на выходе из процесса шифрования, с тем чтобы не оставлять в памяти чего-либо, способного помочь злоумышленной попытке расшифрования данных.
[00198] Процесс шифрования/расшифрования также может быть запущен в качестве службы операционной системы, что предоставит дополнительную защиту в некоторых операционных системах.
[00199] Структуры данных должны поддерживать лишь минимальный API, и точные формы реализации будут зависеть от требований применения.
[00200] Например, упорядоченная структура 128 данных может быть реализована с помощью структуры списка пропусков, тогда как структура 122 результатов поиска может представлять собой форму сбалансированного двоичного дерева или даже еще одного списка пропусков.
[00201] Другие структуры данных являются возможными и предлагают различную эксплуатационную эффективность. Их выбор будет зависеть от потребностей применения. Требуется лишь функциональная эквивалентность на уровне API.
[00202] Путем сохранения этих структур данных для каждой колонки зашифрованных данных и поддержания шифрования данных возможно выполнять сортировку и поиск с небольшой расшифровкой или без нее.
[00203] При создании или обновлении упорядоченной структуры 128 данных необходимо расшифровывать лишь два элемента данных: новый введенный элемент и один введенный элемент из упорядоченной структуры 128 данных.
[00204] Массив данных лишь необходимо расшифровать для отображения на экране, для вычисления или для печати отчетов. Во всех других случаях эксплуатации данные остаются зашифрованными.
[00205] Выбор реализуемых структур данных определяет эксплуатационные характеристики этой системы. То, какие структуры данных выбираются, будет зависеть от потребностей применения.
[00206] В предпочтительном варианте осуществления и как совершенно очевидно специалисту в данной области техники, устройство согласно изобретению будет содержать универсальный или специализированный компьютер или распределенную систему, запрограммированную с помощью компьютерного программного обеспечения, реализующие вышеописанные этапы, при этом указанное компьютерное программное обеспечение может быть написано любым подходящим языком программирования, включая C++, FORTRAN, BASIC, Java, язык ассемблера, микрокод, языки распределенного программирования и т.д. Устройство также может содержать несколько подобных компьютеров/распределенных систем (например, соединенных посредством сети Интернет и/или одной или нескольких корпоративных сетей) в разнообразных аппаратных реализациях. Например, обработку данных может выполнять соответствующим образом запрограммированный микропроцессор, вычислительное облако, интегральная схема специального назначения (ASIC), программируемая пользователем вентильная матрица (FPGA) и т.п., в сочетании с соответствующей памятью, сетью и элементами шины.
[00207] Следует отметить, что в техническом описании и формуле изобретения термины “около” или “приблизительно” обозначают диапазон, равный двадцати процентам (20%) от упомянутой числовой величины. Все компьютерное программное обеспечение, раскрытое здесь, может быть осуществлено на любом постоянном машиночитаемом носителе (включая комбинации носителей), включая, но этим не ограничиваясь, следующее: диски CD-ROM, DVD-ROM, жесткие диски (локальное или сетевое устройство хранения данных), USB-накопители, другие съемные устройства, ПЗУ и программно-аппаратное обеспечение.
[00208] Хотя изобретение было подробно описано с конкретной ссылкой на эти предпочтительные варианты осуществления, другие варианты осуществления могут достичь тех же результатов. Изменения и модификации настоящего изобретения будут очевидны специалистам в данной области техники, и предполагается, что прилагаемая формула изобретения охватывает все подобные модификации и эквиваленты. Полные описания всех ссылок, заявок, патентов и публикаций, приведенных выше, настоящим включены в это описание посредством ссылки.





Изобретение относится к области баз данных или доступа к файлу и, в частности, к выполнению сортировки или поиска в зашифрованной базе данных. Технический результат заключается в повышении уровня защиты данных. Технический результат достигается за счет организации структуры результатов поиска с помощью значения зашифрованного ключа, организации упорядоченной структуры данных с помощью значения незашифрованного ключа, выполнения операции вставки или удаления путем выполнения поиска и обновления структуры результатов поиска и упорядоченной структуры данных для вставки или удаления соответствующих элементов собрания, выполнения операции поиска путем поиска в структуре результатов поиска в соответствии с ключом поиска, выполнения операции сортировки путем поиска в упорядоченной структуре данных для обнаружения диапазона значений и последующего обхода упорядоченной структуры данных в желаемом направлении, выполнения операции слияния путем обхода и выбора введенных элементов из двух или более упорядоченных структур данных и предоставления пользователю отчета о результатах данных операций. 13 з.п. ф-лы, 6 ил.
1. Способ применения синхронизированного поиска и упорядоченных структур данных для доступа к собранию данных, сохраненных на постоянном машиночитаемом носителе, при этом способ включает этапы, на которых:
организуют структуру результатов поиска с помощью значения зашифрованного ключа, при этом структура результатов поиска содержит лишь ссылки на элементы в собрании и их соответствующие зашифрованные ключи;
организуют упорядоченную структуру данных с помощью значения незашифрованного ключа, при этом упорядоченная структура данных содержит лишь ссылки на элементы в собрании и их соответствующие зашифрованные ключи;
раскрывают максимум два элемента данных, представляющих собой незашифрованный текст, в ходе операций с собранием;
выполняют операции вставки или удаления путем выполнения поиска и обновления структуры результатов поиска и упорядоченной структуры данных для вставки или удаления соответствующих элементов собрания;
выполняют операции обновления путем осуществления поиска в структуре результатов поиска на предмет желательных элементов собрания и обновления их соответствующих значений;
выполняют операции поиска путем поиска в структуре результатов поиска в соответствии с ключом поиска;
выполняют операции сортировки путем поиска в упорядоченной структуре данных для обнаружения диапазона значений и последующего обхода упорядоченной структуры данных в желаемом направлении;
выполняют операции слияния путем обхода и выбора введенных элементов из двух или более упорядоченных структур данных; и
предоставляют пользователю отчет о результатах таких операций.
2. Способ по п. 1, отличающийся тем, что применяют интерфейс прикладных программ и модульную архитектуру для структуры данных и криптографических операций для минимизации зависимости от определенных реализаций.
3. Способ по п. 1, отличающийся тем, что способ не зависит от реализации в отношении выбора аппаратного и/или программного обеспечения.
4. Способ по п. 1, отличающийся тем, что структура результатов поиска и упорядоченная структура данных составляют структуру сводных данных.
5. Способ по п. 1, отличающийся тем, что при организации упорядоченной структуры данных используют обфускацию ключа.
6. Способ по п. 5, отличающийся тем, что обфускация ключа включает одно или несколько из: соления ключа, переупорядочивания битов ключа или распределения битов ключа.
7. Способ по п. 1, отличающийся тем, что дополнительно включает этап очистки рабочей памяти компьютера, выполняющего способ, после завершения операции над структурой данных.
8. Способ по п. 1, отличающийся тем, что дополнительно включает выполнение способа на компьютере, использующем защищенную рабочую память.
9. Способ по п. 1, отличающийся тем, что дополнительно включает выполнение способа на компьютере, использующем защищенные процессы.
10. Способ по п. 1, отличающийся тем, что собрание данных представляет собой собрание зашифрованных данных.
11. Способ по п. 1, отличающийся тем, что собрание данных представляет собой собрание незашифрованных данных.
12. Способ по п. 1, отличающийся тем, что выполнение операций сортировки включает выполнение операций многоколоночной сортировки.
13. Способ по п. 1, отличающийся тем, что выполнение операций вставки включает использование вставляемых значений местоположения.
14. Способ по п. 1, отличающийся тем, что выполнение операций сортировки включает выполнение внутренней или внешней сортировки, а выполнение операций слияния включает выполнение внутреннего или внешнего слияния.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ АГРЕГИРОВАННЫХ ПРЕДСТАВЛЕНИЙ ДАННЫХ В КОМПЬЮТЕРНОЙ СЕТИ | 2004 |
|
RU2367010C2 |
| СПОСОБ ИНТЕРАКТИВНОГО ПОИСКА В РАСПРЕДЕЛЕННЫХ ВЫЧИСЛИТЕЛЬНЫХ СЕТЯХ И ИНФОРМАЦИОННО-ПОИСКОВАЯ СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2006 |
|
RU2329533C2 |

