Область технического применения
Осуществления согласно изобретению связаны с декодером звукового сигнала для обеспечения декодированного представления звукового сигнала на основе кодированного представления звукового сигнала.
Дальнейшие осуществления согласно изобретению связаны с кодирующим устройством звукового сигнала для обеспечения кодированного представления входного звукового сигнала.
Дальнейшие осуществления согласно изобретению связаны со способом обеспечения декодированного представления звукового сигнала на основе кодированного представления звукового сигнала.
Дальнейшие осуществления согласно изобретению связаны со способом обеспечения кодированного представления входного звукового сигнала.
Дальнейшие осуществления согласно изобретению связаны с компьютерными программами.
Некоторые осуществления согласно изобретению связаны с концепцией адаптации контекста арифметического кодирующего устройства, использующего информацию о деформации, которая может использоваться в комбинации с модифицированным дискретным косинусным преобразованием с деформацией времени (с измененной шкалой времени) (кратко определяемое как TW-MDCT).
Предшествующий уровень техники
В дальнейшем будет дано краткое введение в область звукового кодирования с деформацией времени, концепция которого может применяться в соединении с некоторыми из осуществлений изобретения.
В последние годы были разработаны методы преобразования звукового сигнала в представление частотной области и эффективного кодирования представления частотной области, например, принимая во внимание перцепционные пороги маскирования. Эта концепция кодирования звукового сигнала особенно эффективна, если длина блока, для которого передается набор кодированных спектральных коэффициентов, длинная, и если только сравнительно небольшое число спектральных коэффициентов находится намного выше глобального порога маскирования, в то время как большое число спектральных коэффициентов находится около или ниже глобального порога маскирования и ими можно, таким образом, пренебречь (или закодированы с минимальной длиной кода). Спектр, в котором указанное условие сохраняется, иногда называется разреженным спектром.
Например, основанные на косинусе или основанные на синусе смодулированные перекрывающие преобразования часто используются для кодирования источника, ввиду их свойств сжатия энергии. Таким образом, для гармонических тонов с постоянными основными частотами (высота звука) они концентрируют энергию сигнала до низкого числа спектральных компонентов (поддиапазоны), что приводит к эффективному представлению сигнала.
Основная высота сигнала должна пониматься как самая низкая преобладающая частота, различимая в спектре сигнала. В обычной речевой модели высота-это частота инициирующего сигнала, смодулированного человеческим горлом. Если бы присутствовала только одна единственная основная частота, спектр был бы чрезвычайно простым, включающим только основную частоту и обертоны. Такой спектр может быть закодирован высокоэффективно. Для сигналов с переменной высотой, однако энергия, соответствующая каждому гармоническому компоненту, распространяется по нескольким коэффициентам преобразования, таким образом, приводя к снижению эффективности кодирования.
Чтобы преодолеть снижение эффективности кодирования, звуковой сигнал, подлежащий кодированию, фактически, подвергается повторной выборке по неоднородной временной сетке. При последующей обработке обрабатываются положения выборки, полученные посредством неоднородной повторной выборки, как если бы они представляли значения на однородной временной сетке. Эта операция обычно обозначается фразой «деформация времени». Время выборки может быть преимущественно выбрано в зависимости от временного колебания высоты, таким образом, что колебание высоты в версии с деформацией времени звукового сигнала меньше, чем колебание высоты в оригинальной версии звукового сигнала (до деформации времени). После деформации времени звукового сигнала версия с деформацией времени звукового сигнала преобразуется в частотную область. Зависящая от высоты (звука) деформация времени имеет тот эффект, что представление частотной области звукового сигнала с деформацией времени обычно проявляет сжатие энергии в значительно меньшее число спектральных компонентов, чем представление частотной области оригинала (звукового сигнала без деформации времени).
На стороне декодера представление частотной области звукового сигнала с деформацией времени преобразуется во временную область, таким образом, что представление временной области звукового сигнала с деформацией времени доступно на стороне декодера. Однако в представлении временной области, восстановленного на стороне декодера звукового сигнала с деформацией времени, исходные колебания высоты входного звукового сигнала на стороне кодирующего устройства не включены. Соответственно, применяется еще одна деформация времени посредством повторной выборки представления временной области, восстановленного на стороне декодера звукового сигнала с деформацией времени.
Чтобы получить хорошее восстановление в декодере входного звукового сигнала со стороны кодирующего устройства, желательно, чтобы деформация времени на стороне декодера была, по крайней мере, приблизительно, обратной операцией относительно деформации времени на стороне кодирующего устройства. Чтобы получить соответствующую деформацию времени, желательно иметь доступную информацию в декодере, которая обеспечивает регулирование деформации времени на стороне декодера.
Поскольку обычно требуется передавать такую информацию от кодирующего устройства звукового сигнала декодеру звукового сигнала, желательно сохранять скорость передачи битов, требуемую для этой передачи, небольшой, в тоже время, обеспечивая надежное восстановление требуемой информации о деформации времени на стороне декодера.
Кроме того, эффективность кодирования при кодировании или декодировании спектральных значений иногда увеличивается при использовании зависящего от контекста кодирующего устройства или зависящего от контекста декодера.
Однако было обнаружено, что эффективность кодирования звукового кодирующего устройства или звукового декодера часто сравнительно низка при наличии колебания основной частоты или высоты, даже при применении концепции деформации времени.
Ввиду этой ситуации существует потребность иметь концепцию, которая позволяет получить высокую эффективность кодирования даже при наличии колебания основной частоты.
Краткая сущность изобретения
Осуществление согласно изобретению создает декодер звукового сигнала для обеспечения декодированного представления звукового сигнала на основе кодированного представления звукового сигнала, включающего кодированное представление спектра и кодированную информацию о деформации времени. Декодер звукового сигнала включает декодер контекст-ориентированных спектральных величин, формируемый, чтобы декодировать кодовое слово, описывающее одно или более спектральных значений или, по крайней мере, часть представления чисел одного или более спектральных значений в зависимости от состояния контекста, чтобы получить декодированные спектральные значения. Декодер звукового сигнала также включает определитель состояния контекста, формируемый, чтобы определить текущее состояние контекста в зависимости от одного или более ранее декодированных спектральных значений. Декодер звукового сигнала также включает преобразователь частотной области во временную область с деформацией времени, формируемый, чтобы обеспечить представление временной области с деформацией времени звукового фрейма на основе набора декодированных спектральных значений, связанных с данным звуковым фреймом, и предоставленных определителем контекст-ориентированных спектральных значений и в зависимости от информации о деформации времени. Опеределитель состояния контекста сконфигурирован, чтобы адаптировать определение состояния контекста к изменению основной частоты между последующими фреймами.
Данное осуществление согласно изобретению основывается на обнаружении того, что эффективность кодирования, которая достигается посредством декодера контекст-ориентированных спектральных значений в присутствии звукового сигнала, имеющего изменяемую во времени основную частоту, улучшается, если состояние контекста адаптируется к изменению основной частоты между последующими фреймами, потому что изменение основной частоты с течением времени (которое эквивалентно колебанию высоты во многих случаях) имеет тот эффект, что спектр данного звукового фрейма обычно подобен частотно-масштабированной версии спектра предыдущего звукового фрейма (предшествующего данному звуковому фрейму), таким образом, что адаптация определения контекста в зависимости от изменения основной частоты позволяет использовать указанное подобие для повышения эффективности кодирования.
Другими словами, было обнаружено, что эффективность кодирования (или эффективность декодирования) контекст-ориентированного кодирования спектральных значений сравнительно низкая в присутствии существенного изменения основной частоты между двумя последующими фреймами, и что эффективность кодирования может быть повышена посредством адаптации определения состояния контекста в такой ситуации. Адаптация определения состояния контекста позволяет использовать общие черты между спектрами предыдущего звукового фрейма и текущего звукового фрейма, в то же время, учитывая систематические различия между спектрами предыдущего звукового фрейма и текущего звукового фрейма, такие как, например, масштабирование частоты спектра, которое типично появляется при наличии изменения основной частоты с течением времени (то есть между двумя звуковыми фреймами).
Суммируя вышесказанное, осуществление согласно изобретению помогает повысить эффективность кодирования, не запрашивая добавочную дополнительную информацию или скорость передачи битов (предполагая, что информация, описывающая изменение основной частоты между последующими фреймами, доступна, так или иначе, в звуковом битовом потоке при использовании свойства деформации времени кодирующего устройства или декодера звукового сигнала).
В предпочтительном осуществлении преобразователь частотной области во временную область с деформацией времени включает стандартный (без временной деформации) преобразователь частотной области во временную область, формируемый, чтобы обеспечить представление временной области данного звукового фрейма на основе набора декодированных спектральных значений, связанное с данным звуковым фреймом и предоставленное декодером контекст-ориентированных спектральных значений и ресэмплером (синтезатором повторной выборки) деформации времени, формируемым, чтобы осуществлять повторную выборку представления временной области данного звукового фрейма, или его обработанной версии, в зависимости от информации о деформации времени, чтобы получить повторно выбранное (с деформацией времени) представление временной области данного звукового фрейма. Такое выполнение преобразователя частотной области во временную область с деформацией времени легко осуществить, потому что оно основано на «стандартном» преобразователе частотной области во временную область и включает, как функциональное расширение, ресэмплер (синтезатор повторной выборки) с деформацией времени, функция которого может быть независимой от функции преобразователя частотной области во временную область. Соответственно, преобразователь частотной области во временную область может быть снова использован как в режиме работы, в котором деформация времени (или устранение деформации времени) является неактивной, так и в режиме работы, в котором деформация времени (или устранение деформации времени) является активной.
В предпочтительном осуществлении информация о деформации времени описывает колебание высоты с течением времени. В этом осуществлении определитель состояния контекста сконфигурирован, чтобы получить информацию о растяжении частоты (то есть информацию о масштабировании частоты) из информации о деформации времени. Кроме того, определитель состояния контекста предпочтительно сконфигурирован, чтобы растянуть или сжать прошлый контекст, связанный с предыдущим звуковым фреймом, вдоль оси частоты в зависимости от информации о растяжении частоты, чтобы получить адаптированный контекст для контекст-ориентированного декодирования одного или более спектральных значений текущего звукового фрейма. Было обнаружено, что информация о деформации времени, которая описывает колебание высоты звука с течением времени, является подходящей для получения информации о растяжении частоты. Кроме того, было обнаружено, что растяжение или сжатие прошлого контекста, связанного с предыдущим звуковым фреймом вдоль оси частоты, обычно приводит к растянутому или сжатому контексту, который позволяет получить значащую информацию о состоянии контекста, которая хорошо адаптируется к спектру текущего звукового фрейма и, следовательно, способствует повышению эффективности кодирования.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы получить первую информацию о средней частоте первого звукового фрейма из информации о деформации времени, и получить вторую информацию о средней частоте по второму звуковому фрейму, следующему за первым звуковым фреймом, из информации о деформации времени. В этом случае определитель состояния контекста сконфигурирован, чтобы вычислить соотношение между второй информацией о средней частоте по второму звуковому фрейму и первой информацией о средней частоте по первому звуковому фрейму, чтобы определить информацию о растяжении частоты. Было обнаружено, что обычно не представляет трудности получить информацию о средней частоте из информации о деформации времени, и было также обнаружено, что соотношение между первой и второй информацией о средней частоте обеспечивает эффективное, в вычислительном отношении, получение информации о растяжении частоты.
В другом предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы получить первую информацию о среднем контуре деформации времени по первому звуковому фрейму из информации о деформации времени, и чтобы получить вторую информацию о среднем контуре деформации времени по второму звуковому фрейму, следующему за первым звуковым фреймом, из информации о деформации времени. В этом случае определитель состояния контекста сконфигурирован, чтобы вычислить соотношение между первой информацией о среднем контуре деформации времени по первому звуковому фрейму и второй информацией о среднем контуре деформации времени по второму звуковому фрейму, чтобы определить информацию о растяжении частоты. Было обнаружено, что особенно эффективное вычислительном отношении, вычислить информацию о средних величинах контура деформации времени по первому и второму звуковому фрейму (которые могут перекрываться), и что соотношение между указанной первой информацией о среднем контуре деформации времени и указанной второй информацией о среднем контуре деформации времени предоставляет достаточно точную информацию о растяжении частоты.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы получить первую и вторую информацию о средней частоте или первую и вторую информацию о среднем контуре деформации времени из общего контура деформации времени, простирающегося по множеству последовательных звуковых фреймов. Было обнаружено, что концепция установления общего контура деформации времени, простирающегося по множеству последовательных звуковых фреймов, не только облегчает точное и без искажений вычисление времени повторной выборки, а также обеспечивает очень хорошую основу для оценки изменения основной частоты между двумя последующими звуковыми фреймами. Соответственно, общий контур деформации времени был определен как очень хорошее средство распознавания изменения относительной частоты с течением времени между различными звуковыми фреймами.
В предпочтительном осуществлении декодер звукового сигнала включает вычислитель контура деформации времени, формируемый, чтобы вычислить информацию о контуре деформации времени, описывающую временную эволюцию относительной высоты по множеству последовательных звуковых фреймов на основе информации о деформации времени. В этом случае определитель состояния контекста сконфигурирован, чтобы использовать информацию о контуре деформации времени для получения информации о растяжении частоты. Было обнаружено, что информация о контуре деформации времени, которая может, например, быть определена для каждой выборки звукового фрейма, составляет очень хорошую основу для адаптации определения состояния контекста.
В предпочтительном осуществлении декодер звукового сигнала включает вычислитель положения повторной выборки. Вычислитель положения повторной выборки сконфигурирован, чтобы вычислить положения повторной выборки для использования ресэмплером (синтезатором повторной выборки)с деформацией времени на основе информации о контуре деформации времени, таким образом, что временное изменение положений повторной выборки определяется информацией о контуре деформации времени. Было обнаружено, что обычное использование информации о контура деформации времени для определения информации о растяжении частоты и для определения положений повторной выборки имеет тот эффект, что растянутый контекст, который получается посредством применения информации о растяжении частоты, хорошо адаптируется к характеристикам спектра текущего звукового фрейма, где звуковой сигнал текущего звукового фрейма является, по крайней мере приблизительно, продолжением звукового сигнала предыдущего звукового сигнала, восстановленного посредством операции повторной выборки с использованием вычисленных положений повторной выборки.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы получить числовое значение текущего контекста в зависимости от множества ранее декодированных спектральных значений (которые могут быть включены в или описаны структурой памяти контекста), и чтобы выбрать правило отображения, описывающее отображение кодового значения на коде символа, представляющем одно или более спектральных значений, или часть представления чисел одного или более спектральных значений, в зависимости от числового значения текущего контекста. В этом случае декодер контекст-ориентированных спектральных значений сконфигурирован, чтобы декодировать кодовое значение, описывающее одно или более спектральных значений, или, по крайней мере, часть представления чисел одного или более спектральных значений, используя правило отображения, выбранное определителем состояния контекста. Было обнаружено, что адаптация контекста, при которой числовое значение текущего контекста получается из множества ранее декодированных спектральных значений, и при которой правило отображения выбирается в соответствии с указанным числовым (текущим) значением контекста, получает значительное преимущество от адаптации определения состояния контекста, например, числового (текущего)значения контекста, потому что можно избежать выбора в значительной степени несоответствующего правила отображения при использовании этой концепции. Напротив, если получение состояния контекста, то есть числового текущего значения контекста, не будет адаптировано в зависимости от изменения основной частоты между последующими фреймами, неправильный выбор правила отображения будет часто происходить при наличии изменения основной частоты, таким образом, что эффективность кодирования будет понижена. Такого понижения эффективности кодирования можно избежать посредством описанного механизма.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы настроить и обновить предварительную структуру памяти контекста, таким образом, чтобы входы предварительной структуры памяти контекста описывали одно или более спектральных значений первого звукового фрейма, где входные коэффициенты входов предварительной структуры памяти контекста указывают на элемент разрешения по частоте или на набор смежных элементов разрешения по частоте преобразователя частотной области во временную область, с которым связаны соответствующие входы (например, для обеспечения представления временной области первого звукового фрейма). Определитель состояния контекста далее сконфигурирован, чтобы получить частотно-масштабированную структуру памяти контекста на основе предварительной структуры памяти контекста таким образом, что данный вход или под вход предварительной структуры памяти контекста, имеющей первый коэффициент частотности, отображается на соответствующем входе или под входе частотно-масштабированной структуры памяти контекста, имеющей второй коэффициент частотности. Второй коэффициент частотности связывается с другим элементом или другим набором смежных элементов разрешения по частоте преобразователя частотной области во временную область, чем первый коэффициент частотности.
Другими словами, вход предварительной структуры памяти контекста, которая получается на основе одного или более спектральных значений, которые соответствуют i-му спектральному элементу преобразователя частотной области во временную область (или набор i-х спектральных элементов преобазователя частотной области во временную область), отображается на входе частотно-масштабированной структуры памяти контекста, которая связывается с j-м элементом разрешения по частоте (или набор j-х элементов разрешения по частоте) преобразователя частотной области во временную область, где j отличается от i. Было обнаружено, что эта концепция отображения входов предварительной структуры памяти контекста на входах частотно-масштабированной структуры памяти контекста предоставляет особо эффективный, в вычислительном отношении, способ адаптации определения состояния контекста к изменению основной частоты. Масштабирование частоты контекста может быть осуществлено с незначительным усилием, используя эту концепцию. Соответственно, получение числового значения текущего контекста из частотно-масштабированной структуры памяти контекста может быть идентичным получению числового значения текущего контекста из обычной (например, предварительной) структуры памяти контекста в отсутствие существенного колебания высоты (звука). Таким образом, описанная концепция обеспечивает выполнение адаптации контекста в имеющемся звуковом декодере с минимальным усилием.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы получить значение состояния контекста, описывающее текущее состояние контекста для декодирования кодового слова, описывающего одно или более спектральных значений второго звукового фрейма или, по крайней мере, часть представления чисел одного или более спектральных значений второго звукового фрейма, связывавшего третий коэффициент частотности, используя значения частотно-масштабированной структуры памяти контекста, коэффициенты частотности значений частотно-масштабированной структуры памяти контекста которой находятся в предварительно определенных отношениях с третьим коэффициентом частотности. В этом случае третий коэффициент частотности обозначает элемент разрешения по частоте или набор смежных элементов разрешения по частоте декодера частотной области во временную область, с которым связано одно или более спектральных значений звукового фрейма, который будет декодирован посредством использования текущего значения состояния контекста.
Было обнаружено, что использование предварительно определенного (и, предпочтительно, фиксированного) относительного окружения (в переводе на элементы разрешения по частоте) одного или более спектральных значений, которые будут декодированы для получения значения состояния контекста (например, числовое значение текущего контекста), поддерживает вычисление указанного значения состояния контекста разумно простым. При использовании частотно-масштабированной структуры памяти контекста в качестве входа для получения значения состояния контекста, колебание основной частоты может считаться эффективным.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы установить каждое множество входов частотно-масштабированной структуры памяти контекста, имеющей соответствующий целевой (объектный) коэффициент частотности, на значение соответствующего входа предварительной структуры памяти контекста, имеющей соответствующий исходный коэффициент частотности. Определитель состояния контекста сконфигурирован, чтобы определить соответствующие коэффициенты частотности входа частотно-масштабированной структуры памяти контекста и соответствующего входа предварительной структуры памяти контекста таким образом, что соотношение между соответствующими коэффициентами частотности определяется изменением основной частоты между текущим звуковым фреймом, с которым связаны входы предварительной структуры памяти контекста, и последующим звуковым фреймом, контекст декодирования которого определяется входам и частотно-масштабированной структуры памяти контекста. При использовании такой концепции для получения входов частотно-масштабированной структуры памяти контекста сложность может оставаться небольшой, в то же время имеется возможность адаптировать частотно-масштабированную структуру памяти контекста к изменению основной частоты.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы настроить предварительную структуру памяти контекста таким образом, что каждое множество входов предварительной структуры памяти контекста основывается на множестве спектральных значений первого звукового фрейма, где входные коэффициенты входов предварительной структуры памяти контекста указывают на набор смежных элементов разрешения по частоте преобразователя частотной области во временную область, с которым связаны соответствующие входы (относительно первого звукового фрейма). Определитель состояния контекста сконфигурирован, чтобы извлечь предварительные индивидуальные значения элементов разрешения по частоте контекста, связанные с индивидуальными коэффициентами элементов разрешения по частоте, из входов предварительной структуры памяти контекста. Кроме того, определитель состояния контекста сконфигурирован, чтобы получить частотно-масштабированные индивидуальные значения элементов разрешения по частоте контекста, связанные с индивидуальными коэффициентами элементов разрешения по частоте, таким образом, что данное предварительное индивидуальное значение элементов разрешения по частоте контекста, имеющее первый коэффициент элементов разрешения по частоте, отображается на соответствующем значении частотно-масштабированного индивидуального элемента разрешения по частоте контекста, имеющем второй коэффициент элементов разрешения по частоте, таким образом, что получается отображение индивидуального элемента разрешения по частоте предварительных индивидуальных значений элементов разрешения по частоте контекста. Определитель состояния контекста далее сконфигурирован, чтобы объединить множество частотно-масштабированных индивидуальных значений элементов разрешения по частоте контекста в объединенный вход частотно-масштабированной структуры памяти контекста. Соответственно, можно адаптировать частотно-масштабированную структуру памяти контекста к изменению основной частоты на уровне мелких структурных единиц, даже если множество элементов разрешения по частоте суммировано в единственном входе структуры памяти контекста. Таким образом, может быть достигнута особо точная адаптация контекста к изменению основной частоты.
Другое осуществление согласно изобретению создает кодирующее устройство звукового сигнала для обеспечения кодированного представления входного звукового сигнала, включающего кодированное представление спектра и кодированную информацию о деформации времени. Кодирующее устройство звукового сигнала включает поставщик представления частотной области, формируемый, чтобы обеспечить представление частотной области, представляющее версию входного звукового сигнала с деформацией времени; деформация времени в соответствии с информацией о деформации времени. Кодирующее устройство звукового сигнала далее включает кодирующее устройство контекст-ориентированного спектрального значения, формируемое, чтобы кодировать кодовое слово, описывающее одно или более спектральных значений представления частотной области, или, по крайней мере, часть представления чисел одного или более спектральных значений представления частотной области, в зависимости от состояния контекста, чтобы получить кодированные спектральные значения кодированного спектрального представления. Декодер звукового сигнала также включает определитель состояния контекста, формируемый, чтобы определить текущее состояние контекста в зависимости от одного, или более ранее закодированных спектральных значений. Определитель состояния контекста сконфигурирован, чтобы адаптировать определение контекста к изменению основной частоты между последующими фреймами.
Это кодирующее устройство звукового сигнала основывается на тех же самых идеях и полученных данных, что и вышеописанный декодер звукового сигнала. Кроме того, кодирующее устройство звукового сигнала может быть дополнено любой из характеристик и функциональных возможностей, рассмотренных относительно декодера звукового сигнала, где ранее закодированные спектральные значения играют роль ранее декодированных спектральных значений при вычислении состояния контекста.
В предпочтительном осуществлении определитель состояния контекста сконфигурирован, чтобы получить числовое значение текущего контекста в зависимости от множества ранее закодированных спектральных значений и выбрать правило отображения, описывающее отображение одного или более спектральных значений, или части представления чисел одного или более спектральных значений, на кодовое значение в зависимости от числового значения текущего контекста. В этом случае кодирующее устройство контекст-ориентированного спектрального значения сконфигурировано, чтобы обеспечить кодовое значение, описывающее одно или более спектральных значений, или, по крайней мере, часть представления чисел одного или более спектральных значений, используя правило отображения, выбранное определителем состояния контекста.
Другое осуществление согласно изобретению создает способ обеспечения декодированного представления звукового сигнала на основе кодированного представления звукового сигнала.
Другое осуществление согласно изобретению создает способ обеспечения кодированного представления входного звукового сигнала.
Другое осуществление согласно изобретению создает компьютерную программу для выполнения одного из указанных способов.
Способы и компьютерная программа основываются на тех же самых соображениях, что и выше обсуждавшийся декодер звукового сигнала и кодирующее устройство звукового сигнала.
Кроме того, кодирующее устройство звукового сигнала, способы и компьютерные программы могут быть дополнены любой из характеристик и функциональных возможностей, обсуждавшихся выше, и описаны ниже относительно декодера звукового сигнала.
Краткое описание чертежей
Осуществления согласно данному изобретению будут впоследствии описаны со ссылкой на приложенные чертежи, где:
фиг.1а показывает блок-схему кодирующего устройства звукового сигнала согласно осуществлению изобретения;
фиг.1b показывает блок-схему декодера звукового сигнала согласно осуществлению изобретения;
фиг.2а показывает блок-схему кодирующего устройства звукового сигнала согласно другому осуществлению изобретения;
фиг.2b показывает блок-схему декодера звукового сигнала согласно другому осуществлению изобретения;
фиг.2с показывает блок-схему арифметического кодирующего устройства для использования в звуковых кодирующих устройствах согласно осуществлениям изобретения;
фиг.2d показывает блок-схему арифметического декодера для использования в декодерах звукового сигнала согласно осуществлениям изобретения;
фиг.3а показывает графическое представление контекст-адаптивного арифметического кодирования (кодирование/декодирование);
фиг.3b показывает графическое представление контуров относительной высоты (звука);
фиг.3с показывает графическое представление растягивающего эффекта измененного дискретного косинусного преобразования с деформацией времени (ТВТ-MDCT);
фиг.4а показывает блок-схему определителя состояния контекста для использования в кодирующих устройствах звукового сигнала и декодерах звукового сигнала согласно осуществлениям данного изобретения;
фиг.4b показывает графическое представление сжатия частоты контекста, которое может выполняться определителем состояния контекста согласно фиг.4а;
фиг.4с показывает представление псевдоуправляющей программы алгоритма для растяжения или сжатия контекста, который может применяться в осуществлениях согласно изобретению;
фиг.4d и 4е показывают представление псевдоуправляющей программы алгоритма для растяжения или сжатия контекста, который может использоваться в осуществлениях согласно изобретению;
фиг.5а, 5b показывают детальный фрагмент блок-схемы декодера звукового сигнала, согласно осуществлению изобретения;
фиг.6а, 6b показывают детальный фрагмент блок-схемы устройства отображения для обеспечения декодированного представления звукового сигнала согласно осуществлению изобретения;
фиг.7а показывает легенду определений элементов данных и справочных элементов, которые используются в звуковом декодере согласно осуществлению изобретения;
фиг.7b показывает легенду определений констант, которые используются в звуковом декодере согласно осуществлению изобретения;
фиг.8 показывает табличное представление отображения коэффициента кодового слова на соответствующее декодированное значение деформации времени;
фиг.9 показывает представление псевдоуправляющей программы алгоритма для линейного интерполирования между равномерно распределенными узлами деформации;
фиг.10а показывает представление псевдоуправляющей программы вспомогательной функции "warp_time_inv";
фиг.10b показывает представление псевдоуправляющей программы вспомогательной функции "warp_inv_vec";
фиг.11 показывает представление псевдоуправляющей программы алгоритма для вычисления вектора положения выборки и длины перехода;
фиг.12 показывает табличное представление значений длины окна синтеза N в зависимости от последовательности окон и длины фрейма основного кодирующего устройства;
фиг.13 показывает матричное представление допустимых последовательностей окон;
фиг.14 показывает представление псевдоуправляющей программы алгоритма для управления окнами и для внутреннего наложения - добавления последовательности окон типа "EIGHT_SHORT_SEQUENCE" (последовательность восьми коротких);
фиг.15 показывает представление псевдоуправляющей программы алгоритма для управления окнами и внутреннего наложения - добавления других последовательностей окон, которые не являются последовательностями окон типа "EIGHT_SHORT_SEQUENCE" (последовательность восьми коротких);
фиг.16 показывает представление псевдоуправляющей программы алгоритма для повторной выборки; и
фиг.17 показывает графическое представление контекста для вычисления состояния, которое может использоваться в некоторых осуществлениях согласно изобретению;
фиг.18 показывает легенду определений;
фиг.19 показывает представление псевдоуправляющей программы алгоритма "arith_map_context ()";
фиг.20 показывает представление псевдоуправляющей программы алгоритма "arith_get_context ()";
фиг.21 показывает представление псевдоуправляющей программы алгоритма "arith_get_pk()";
фиг.22 показывает представление псевдоуправляющей программы алгоритма "arith_decode ()";
фиг.23 показывает представление псевдоуправляющей программы алгоритма для декодирования одной или нескольких битовых плоскостей младшего разряда;
фиг.24 показывает представление псевдоуправляющей программы алгоритма для установки входов массива арифметически декодированных спектральных значений;
фиг.25 показывает представление псевдоуправляющей программы функции "arith_update_context ()";
фиг.26 показывает представление псевдоуправляющей программы алгоритма "arith_finish ()";
фиг.27a-27f показывают представления элементов синтаксиса звукового потока согласно осуществлению изобретения.
Детальное описание осуществлений
1. Кодирующее устройство звукового сигнала согласно фиг.1а
Фиг.1а показывает блок-схему кодирующего устройства звукового сигнала 100 согласно осуществлению изобретения.
Кодирующее устройство звукового сигнала 100 сконфигурировано, чтобы получить входной звуковой сигнал 110 и обеспечить кодированное представление 112 входного звукового сигнала. Кодированное представление 112 входного звукового сигнала включает кодированное представление спектра и кодированную информацию о деформации времени.
Кодирующее устройство звукового сигнала 100 включает поставщик представления частотной области 120, который сконфигурировано, чтобы получить входной звуковой сигнал 110 и информацию о деформации времени 122. Поставщик представления частотной области 120 (который может рассматриваться как поставщик представления частотной области с деформацией времени) сконфигурирован, чтобы обеспечить представление частотной области 124, представляющей версию входного звукового сигнала с деформацией времени 110; деформация времени в соответствии с информацией о деформации времени 122. Кодирующее устройство звукового сигнала 100 также включает кодирующее устройство контекст-ориентированного спектрального значения 130, формируемое, чтобы обеспечить кодовое слово 132, описывающее одно или более спектральных значений представления частотной области 124, или, по крайней мере, часть представления чисел одного или более спектральных значений представления частотной области 124, в зависимости от состояния контекста, чтобы получить кодированные спектральные значения кодированного спектрального представления. Состояние контекста может, например, описываться информацией о состоянии контекста 134. Кодирующее устройство звукового сигнала 100 также включает определитель состояния контекста 140, который сконфигурировано, чтобы определить состояние текущего контекста в зависимости от еще одного из ранее закодированных спектральных значений 124. Определитель состояния контекста 140 может, следовательно, предоставить информацию о состоянии контекста 134 кодирующему устройству контекст-ориентированного спектрального значения 130, где информация о состоянии контекста может, например, принять форму числового значения текущего контекста (для выбора правила отображения или таблицы отображения) или ссылки на выбранное правило отображения или таблицу отображения. Определитель состояния контекста 140 сконфигурирован, чтобы адаптировать определение состояния контекста к изменению основной частоты между последующими фреймами. Соответственно, определитель состояния контекста может оценить информацию об изменении основной частоты между последующими звуковыми фреймами. Эта информация об изменении основной частоты между последующими фреймами может, например, основываться на информации о деформации времени 122, которая используется поставщиком представления частотной области 120.
Соответственно, кодирующее устройство звукового сигнала может обеспечить особо высокую эффективность кодирования в случае частей звукового сигнала, включающих изменение основной частоты с течением времени, или изменение высоты (звука) с течением времени, потому что получение информации о состоянии контекста 134 адаптируется к изменению основной частоты между двумя звуковыми фреймами. Соответственно, контекст, который используется кодирующим устройством контекст-ориентированного спектрального значения 130, хорошо адаптируется к спектральному сжатию (относительно частоты) или спектральному расширению (относительно частоты) представления частотной области 124, которое происходит, если основная частота изменяется от одного звукового фрейма до следующего звукового фрейма (то есть между двумя звуковыми фреймами). Следовательно, информация о состоянии контекста 134 хорошо адаптируется, в среднем, к представлению частотной области 124 даже в случае изменения основной частоты, которое, в свою очередь, приводит к хорошей эффективности кодирования кодирующего устройства контекст-ориентированного спектрального значения. Было обнаружено, что, если, напротив, состояние контекста не будет адаптировано к изменению основной частоты, контекст будет неподходящим в ситуациях, в которых основная частота изменяется, таким образом, приводя к существенной деградации эффективности кодирования.
Соответственно, можно сказать, что кодирующее устройство звукового сигнала 100 обычно превосходит обычные кодирующие устройства звукового сигнала, используя кодирование контекст-ориентированного спектрального значения в ситуациях, в которых изменяется основная частота.
Здесь следует заметить, что существует много различных способов адаптации определения состояния контекста к изменению основной частоты между последующими фреймами (то есть от первого фрейма до второго, последующего фрейма). Например, структура памяти контекста, входы которой определяются или получаются из спектральных значений представления частотной области 124 (или, более точно, их содержания), может быть растянута или сжата по частоте прежде, чем будет получено числовое значение текущего контекста, описывающее состояние контекста. Далее такие концепции будут обсуждены более подробно. Альтернативно, однако, также можно изменить (или адаптировать) алгоритм к получению информации о состоянии контекста 134 из входов структуры памяти контекста, входы которой основываются на представлении частотной области 124. Например, может быть отрегулировано, какой вход (входы) такой нечастотно-масштабированной структуры памяти контекста рассматривается, даже при том, что такое решение здесь подробно не обсуждается.
2. Декодер звукового сигнала согласно фиг.1b
Фиг.1b показывает блок-схему декодера звукового сигнала 150.
Декодер звукового сигнала 150 сконфигурирован, чтобы получить кодированное представление звукового сигнала 152, которое может включать кодированное представление спектра и кодированную информацию о деформации времени. Декодер звукового сигнала 150 сконфигурирован, чтобы обеспечить декодированное представление звукового сигнала 154 на основе кодированного представления звукового сигнала 152.
Декодер звукового сигнала 150 включает декодер контекст-ориентированного спектрального значения 160, который сконфигурирован, чтобы получить кодовые слова кодированного представления спектра и обеспечить, на их основе, декодированные спектральные значения 162. Кроме того, декодер контекст-ориентированного спектрального значения 160 сконфигурирован, чтобы получить информацию о состоянии контекста 164, которая может, например, принять форму числового значения текущего контекста, выбранного правила отображения или ссылки на выбранное правило отображения. Декодер контекст-ориентированного спектрального значения 160 сконфигурирован, чтобы декодировать кодовое слово, описывающее одно или более спектральных значений, или, по крайней мере, часть представления чисел одного или более спектральных значений, в зависимости от состояния контекста (которое может быть описано информацией о состоянии контекста 164), чтобы получить декодированные спектральные значения 162. Декодер звукового сигнала 150 также включает определитель состояния контекста 170, который сконфигурирован, чтобы определить состояние текущего контекста в зависимости от одного или более ранее декодированных спектральных значений 162. Декодер звукового сигнала 150 также включает преобразователь (конвертер) частотной области во временную область с деформацией времени 180, который сконфигурирован, чтобы обеспечить представление временной области с деформацией времени 182 на основе набора декодированных спектральных значений 162, связанных с данным звуковым фреймом и предоставленных декодером контекст-ориентированных спектральных значений. Преобразователь (конвертер) частотной области во временную область с деформацией времени 180 сконфигурирован, чтобы получить информацию о деформации времени 184 для адаптации обеспечения представления временной области с деформацией времени 182 к желательной деформации времени, описанной кодированной информацией о деформации времени кодированного представления звукового сигнала 152, таким образом, что представление временной области с деформацией времени 182 составляет декодированное представление звукового сигнала 154 (или, эквивалентно, формирует основание декодированного представления звукового сигнала, если используется постобработка).
Преобразователь частотной области во временную область с деформацией времени 180 может, например, включать преобразователь частотной области во временную область, формируемый, чтобы обеспечить представление временной области данного звукового фрейма на основе набора декодированных спектральных значений 162, связанных с данным звуковым фреймом и предоставленных декодером контекст-ориентированных спектральных значений 160. Преобразователь (конвертер) частотной области во временную область может также включать ресэмплер (синтезатор повторных выборок) деформации времени, формируемый, чтобы произвести повторную выборку представления временной области данного звукового фоейма или его обработанной версии, в зависимости от информации о деформации времени 184, чтобы получить повторно выбранное представление временной области 182 из данного звукового фрейма.
Кроме того, определитель состояния контекста 170 сконфигурирован, чтобы адаптировать определение состояния контекста (который описывается информацией о состоянии контекста 164) к изменению основной частоты между последующими звуковыми фреймами (то есть от первого звукового фрейма до второго, последующего звукового фрейма).
Декодер звукового сигнала 150 основывается на результатах, которые уже были обсуждены относительно кодирующего устройства звукового сигнала 100. В частности, декодер звукового сигнала сконфигурирован, чтобы адаптировать определение состояния контекста к изменению основной частоты между последующими звуковыми фреймами, таким образом, что состояние контекста (и, следовательно, предположения, используемые декодером контекст-ориентированных спектральных значений 160 относительно статистической вероятности возникновения различных спектральных значений) хорошо адаптируется, по крайней мере, в среднем, к спектру текущего звукового фрейма, который будет декодирован посредством использования указанной информации о контексте. Соответственно, кодовые слова, кодирующие спектральные значения указанного текущего звукового фрейма, могут быть особенно короткими, потому что хорошее соответствие между выбранным контекстом, выбранным в соответствии с информацией о состоянии контекста, предоставленной определителем состояния контекста 170, и спектральными значениями, которые будут декодированы, обычно приводит к сравнительно коротким кодовым словам, что способствует хорошей эффективности в отношении скорости передачи битов.
Кроме того, определитель состояния контекста 170 может быть осуществлен эффективно, потому что информация о деформации времени 184, которая включается в кодированное представление звукового сигнала 152, в любом случае, для использования преобразователем частотной области во временную область с деформацией времени, может быть повторно использована определителем состояния контекста 170 как информация об изменении основной частоты между последующими звуковыми фреймами, или для получения информации об изменении основной частоты между последующими звуковыми фреймами.
Соответственно, адаптация определения состояния контекста к изменению основной частоты между последующими фреймами не требует даже добавочной дополнительной информации. Соответственно, декодер звукового сигнала 150 способствует улучшенной кодирующей эффективности декодирования контекст-ориентированных спектральных значений (и позволяет улучшить эффективность кодирования на стороне кодирующего устройства 100), не требуя добавочной дополнительной информации, которая в значительной мере способствует совершенствованию эффективности в отношении скорости передачи битов.
Кроме того, следует заметить, что различные концепции могут использоваться, чтобы адаптировать определение состояния контекста к изменению основной частоты между последующими фреймами (то есть от первого звукового фрейма до второго, последующего звукового фрейма). Например, структура памяти контекста, входы которой основываются на декодированных спектральных значениях 162, может адаптироваться, например, посредством масштабирования частоты (например, растяжение частоты или сжатие частоты) до получения информация о состоянии контекста 164 из частотно-масштабированной структуры памяти контекста определителем состояния контекста 170. Альтернативно, однако, другой алгоритм может использоваться определителем состояния контекста 170, чтобы получить информацию о состоянии контекста 164. Например, она может адаптироваться к тому, какие входы структуры памяти контекста используются, чтобы определить состояние контекста для декодирования кодового слова, имеющего данный коэффициент частотности кодового слова. Даже притом, что последняя концепция не была описана здесь подробно, она может, конечно, быть применена в некоторых осуществлениях согласно изобретению. Кроме того, могут применяться другие концепции для определения изменения основной частоты.
3. Кодирующее устройство звукового сигнала согласно фиг.2а
Фиг.2а показывает блок-схему кодирующего устройства звукового сигнала 200 согласно осуществлению изобретения. Следует заметить, что кодирующее устройство звукового сигнала 200 согласно фиг.2 очень похоже на кодирующее устройство звукового сигнала 100 согласно фиг.1а, так что идентичные средства и сигналы будут обозначаться идентичными ссылочными номерами и не будут снова подробно объясняться.
Кодирующее устройство звукового сигнала 200 сконфигурировано, чтобы получить входной звуковой сигнал 110 и обеспечить, на его основе, кодированное представление звукового сигнала 112. Факультативно, кодирующее устройство звукового сигнала 200 также сконфигурировано, чтобы получить внешне произведенную информацию о деформации времени 214.
Кодирующее устройство звукового сигнала 200 включает поставщик представления частотной области 120, функциональные возможности которого могут быть идентичными функциональным возможностям поставщика представления частотной области 120 кодирующего устройства звукового сигнала 100. Поставщик представления частотной области 120 обеспечивает представление частотной области, представляющее версию с деформацией времени входного звукового сигнала 110, представление частотной области которого обозначается цифрой 124. Кодирующее устройство звукового сигнала 200 также включает кодирующее устройство контекст-ориентированного спектрального значения 130, и определитель состояния контекст 140, которые работают, как описывалось относительно кодирующего устройства звукового сигнала 100. Соответственно, кодирующее устройство контекст-ориентированного спектрального значения 130 обеспечивает кодовые слова (например, acod_m); каждое кодовое слово, представляющее одно или более спектральных значений кодированного представления спектра, или, по крайней мере, часть представления чисел одного или более спектральных значений.
Кодирующее устройство звукового сигнала факультативно включает анализатор деформации времени или анализатор основной частоты 220, который сконфигурирован, чтобы получить входной звуковой сигнал 110 и обеспечить, на его основе, информацию о контуре деформации времени 222, которая описывает, например, деформацию времени, которая будет применена поставщиком представления частотной области 120 к входному звуковому сигналу 110, чтобы компенсировать изменение основной частоты на протяжении звукового фрейма, и/или временную эволюцию основной частоты входного звукового сигнала 110, и/или временную эволюцию высоты (звука) входного звукового сигнала 110. Кодирующее устройство звукового сигнала 200 также включает кодирующее устройство контура деформации времени 224, которое сконфигурировано, чтобы предоставить кодированную информацию о деформации времени 226 на основе информации о контуре деформации времени 222. Кодированная информация о деформации времени 226 предпочтительно включается в кодированное представление звукового сигнала 112, и может, например, принять форму (кодированных) значений отношения деформации времени "tw_ratio [i]".
Кроме того, следует заметить, что информация о контуре деформации времени 222 может быть предоставлена поставщику представления частотной области 120, а также определителю состояния контекста 140.
Кодирующее устройство звукового сигнала 200 может, дополнительно, включать психоакустический процессор для опознавания по эталонной модели 228, который сконфигурирован, чтобы получить входной звуковой сигнал 110, или его предварительно обработанную версию, и выполнить психоакустический анализ, чтобы определить, например, временные эффекты маскировки и/или частотные эффекты маскировки. Соответственно, психоакустический процессор для опознавания по эталонной модели 228 может предоставить управляющую информацию 230, которая представляет, например, психоакустическую релевантность (важность) различных диапазонов частот входного звукового сигнала, поскольку она известна кодирующим устройствам частотной области звука.
В дальнейшем будет кратко описан путь сигнала поставщика представления частотной области 120. Поставщик представления частотной области 120 включает дополнительную предварительную обработку 120а, которая может, факультативно, предварительно обрабатывать входной звуковой сигнал 110, чтобы обеспечить предварительно обработанную версию 120b входного звукового сигнала 110. Поставщик представления частотной области 120 также включает сэмплер (синтезатор выборки) / ресэмплер (синтезатор повторной выборки), формируемый, чтобы произвести выборку или произвести повторную выборку входного звукового сигнала 110, или его предварительно обработанную версию 120b, в зависимости от информации о положении осуществления выборки 120d, полученной от вычислителя положения осуществления выборки 120е. Соответственно, сэмплер (синтезатор выборки) / ресэмплер (синтезатор повторной выборки) 120 с может применять изменяемую во времени выборку или повторную выборку к входному звуковому сигналу 110 (или его предварительно обработанной версии 120b). При применении такой изменяемой во времени выборки (с изменяющимися во времени временными расстояниями между эффективными точками выборки) получается дискретизированное или повторно дискретизированное представление временной области 120f, в котором изменение во времени высоты (звука) или основной частоты уменьшается по сравнению с входным звуковым сигналом 110. Положения осуществления выборки вычисляются посредством вычисления положения осуществления выборки, 120е в зависимости от информации о контуре деформации времени 222. Поставщик представления частотной области 120 также включает устройство управления окнами 120 g, где устройство управления окнами 120g формируются, чтобы управлять окном дискретизированного или повторно дискретизированного представления временной области 120f, предоставленного сэмплером (синтезатором выборки) или ресэмплером (синтезатором повторной выборки) 120 с.Управление окнами выполняется, чтобы уменьшить или устранить артефакты блокирования, чтобы, таким образом, обеспечить гладкую операцию наложения-и-добавления в декодере звукового сигнала. Поставщик представления частотной области 120 также включает преобразователь временной области в частотную область 120i, который сконфигурирован, чтобы получить реализуемое посредством организации окна и дискретизированное / повторно дискретизированное представление временной области 120b, и обеспечить, на его основе, представление частотной области 120j, которое может, например, включать один набор спектральных коэффициентов на звуковой фрейм входного звукового сигнала 110 (где звуковые фреймы входного звукового сигнала могут, например, перекрываться или не перекрываться, где предпочтительное наложение составляет 50% в некоторых осуществлениях для перекрывающихся звуковых фреймов). Однако следует заметить, что в некоторых осуществлениях может быть предоставлено множество наборов спектральных коэффициентов для единственного звукового фрейма.
Поставщик представления частотной области 120, факультативно, включает спектральный процессор 120k, который сконфигурирован, чтобы выполнить временное ограничение шума, и/или долгосрочное предсказание, и/или любую другую форму спектральной постобработки, чтобы, таким образом, получить постобработанное представление частотной области 120l.
Поставщик представления частотной области 120, факультативно, включает счетчик (делитель частоты) / квантователь 120m, где счетчик (делитель частоты) / квантователь 120m может, например, формироваться, чтобы масштабировать различные элементы разрешения по частоте (или диапазоны частот) представления частотной области 120j или их постобработанную версию 120l, в соответствии с управляющей информацией 230 предоставленный психоакустическим процессором опознавания по эталонной модели 228. Соответственно, элементы разрешения по частоте (или диапазоны частот, которые включают множество элементов разрешения по частоте) могут, например, масштабироваться в соответствии с психоакустической релевантностью (важностью) так, что элементы разрешения по частоте (или диапазоны частот), имеющие высокую психоакустическую релевантность (важность), эффективно кодируются с высокой точностью кодирующим устройством контекст-ориентированных спектральных значений, в то время как элементы разрешения по частоте (или диапазоны частот), имеющие низкую психоакустическую релевантность (важность), кодируются с низкой точностью. Кроме того, следует заметить, что управляющая информация 230 может, факультативно, отрегулировать параметры управления окнами преобразователя временной области в частотную область и/или спектральной постобработки. Кроме того, управляющая информация 230 может быть включена, в кодированной форме, в кодированное представление звукового сигнала 112, как известно специалисту, квалифицированному в этой области.
Относительно функциональных возможностей кодирующего устройства звукового сигнала 200, можно сказать, что деформация времени (в смысле изменяющейся во времени неоднородной выборки или повторной выборки) применяется сэмплером (синтезатором выборки) / ресэмплером (синтезатором повторной выборки) 120с в соответствии с информацией о контуре деформации времени 220. Соответственно, можно получить представление частотной области 120j, имеющее отчетливые пики и провалы спектра даже в присутствии входного звукового сигнала, имеющего временное изменение высоты (звука), которое, в отсутствие изменяющейся во времени выборки / повторной выборки, привело бы к смазанному спектру. Кроме того, получение состояния контекста для использования кодирующим устройством контекст-ориентированного спектрального значения 130 адаптируется в зависимости от изменения основной частоты между последующими звуковыми фреймами, что приводит к особенно высокой эффективности кодирования, как обсуждалось выше. Кроме того, информация о контуре деформации времени 222, которая служит основанием как для вычисления положения выборки для сэмплера (синтезатора выборки) / ресэмплера (синтезатора повторной выборки) 120с, так и для адаптации определения состояния контекста, кодируется посредством использования кодирующего устройства контура деформации времени 224, таким образом, что кодированная информация о деформации времени 226, описывающая информацию о контуре деформации времени 222, включается в кодированное представление звукового сигнала 112. Соответственно, кодированное представление звукового сигнала 112 предоставляет необходимую информацию для эффективного декодирования кодированного входного звукового сигнала 110 на стороне декодера звукового сигнала.
Кроме того, следует заметить, что индивидуальные компоненты кодирующего устройства звукового сигнала 200 могут выполнять, по существу, обратные функциональные возможности индивидуальных компонентов декодера звукового сигнала 240, который будет описан ниже со ссылкой на фиг.2b. Кроме того, ссылка также делается на детальное обсуждение относительно функциональных возможностей декодера звукового сигнала повсеместно в данном описании, что также позволяет лучше понять декодер звукового сигнала.
Следует также заметить, что существенные изменения могут быть внесены в декодер звукового сигнала и его индивидуальные компоненты. Например, некоторые функциональные возможности могут быть объединены, например, такие как выборка / повторная выборка, управление окнами и преобразование временной области в частотную область. Кроме того, дополнительные шаги обработки могут быть введены, где необходимо.
Кроме того, кодированное представление звукового сигнала может, естественно, включать добавочную дополнительную информацию, как желательно или необходимо.
4. Декодер звукового сигнала согласно фиг.2b
Фиг.2b показывает блок-схему декодера звукового сигнала 240 согласно осуществлению изобретения. Декодер звукового сигнала 240 может быть подобен декодеру звукового сигнала 150 согласно фиг.1b, так что идентичные средства и сигналы обозначаются идентичными ссылочными номерами и не будут еще раз подробно обсуждаться.
Декодер звукового сигнала 240 сконфигурирован, чтобы получить кодированное представление звукового сигнала 152, например, в форме битового потока. Кодированное представление звукового сигнала 152 включает кодированное представление спектра, например, в форме кодовых слов (например, acod_m), представляющих одно или более спектральных значений, или, по крайней мере, часть представления чисел одного или более спектральных значений. Кодированное представление звукового сигнала 152 также включает кодированную информацию о деформации времени. Кроме того, декодер звукового сигнала 240 сконфигурирован, чтобы обеспечить декодированное представление звукового сигнала 154, например, представление временной области звукового содержания.
Декодер звукового сигнала 240 включает декодер контекст-ориентированных спектральных значений 160, который сконфигурирован, чтобы получить кодовые слова, представляющие спектральные значения из кодированного представления звукового сигнала 152 и обеспечить, на их основе, декодированные спектральные значения 162. Кроме того, декодер звукового сигнала 240 также включает определитель состояния контекста 170, который сконфигурирован, чтобы предоставить информацию о состояния контекста 164 декодеру контекст-ориентированных спектральных значений 160. Декодер звукового сигнала 240 также включает преобразователь (конвертер) частотной области во временную область с деформацией времени 180, который получает декодированные спектральные значения 162 и который обеспечивает декодированное представление звукового сигнала 154.
Декодер звукового сигнала 240 также включает вычислитель деформации времени (или декодер деформации времени) 250, который сконфигурирован, чтобы получить кодированную информацию о деформации времени, которая включается в кодированное представление звукового сигнала 152, и чтобы обеспечить, на ее основе, декодированную информацию о деформации времени 254. Кодированная информация о деформации времени может, например, включать кодовые слова "tw_ratio [i]", описывающие временное изменение основной частоты или высоты (звука). Декодированная информация о деформации времени 254 может, например, принять форму информации о контуре деформации. Например, декодированная информация о деформации времени 254 может включать значения "warp_value_tbl [tw_ratio [i]]" или значения prel[n], как будет подробно обсуждено далее. Факультативно, декодер звукового сигнала 240 также включает вычислитель контура деформации времени 256, который сконфигурирован, чтобы получить информацию о контуре деформации времени 258 из декодированной информации о деформации времени 254. Информация о контуре деформации времени 258 может, например, служить входной информацией для определителя состояния контекста 170, а также для преобразователя (конвертера) частотной области во временную область с деформацией времени 180.
В дальнейшем будут описаны некоторые детали относительно преобразователя (конвертера) частотной области во временную область с деформацией времени. Преобразователь (конвертер) 180 может, факультативно, включать инверсивный квантователь / повторный счетчик (повторный делитель частоты) 180а, который может формироваться, чтобы получить декодированные спектральные значения 162 от декодера контекст-ориентированных спектральных значений 160, и чтобы обеспечить обратно пропорционально квантованную и/или повторно масштабированную версию 180b декодированных спектральных значений 162. Например, инверсный квантователь / повторный счетчик (повторный делитель частоты) 180а может формироваться, чтобы выполнить операцию, которая является, по крайней мере приблизительно, инверсной по отношению к работе дополнительного счетчика (делителя частоты) / квантователь 120m кодирующего устройства звукового сигнала 200. Соответственно, факультативный инверсный квантователь / повторный счетчик (повторный делитель частоты) 180а может получить управляющую информацию, которая может соответствовать управляющей информации 230.
Преобразователь(конвертер) частотной области во временную область с деформацией времени 180 факультативно включает спектральный препроцессор 180с, который сконфигурирован, чтобы получить декодированные спектральные значения 162, или обратно пропорциональные квантованные / повторно масштабированые спектральные значения 180b, и чтобы обеспечить, на их основе, спектрально предварительно обработанные спектральные значения 180d. Например, спектральный препроцессор 180с может выполнять обратную операцию по сравнению со спектральным постпроцессором 120k кодирующего устройства звукового сигнала 200.
Преобразователь частотной области во временную область с деформацией времени 180 также включает Преобразователь частотной области во временную область 180е, который сконфигурирован, чтобы получить декодированные спектральные значения 162, обратно пропорционально квантованные / повторно масштабированные спектральные значения 180b или спектрально предварительно обработанные спектральные значения 180d, и чтобы обеспечить, на их основе, представление временной области 180f. Например, преобразователь частотной области во временную область может формироваться, чтобы выполнить инверсное преобразование спектральной области во временную область, например, инверсное измененное дискретное косинусное преобразование (IMDCT). Преобразователь (конвертер)частотной области во временную область 180е может, например, обеспечить представление временной области звукового фрейма кодированного звукового сигнала на основе одного набора кодированных спектральных значений или, альтернативно, на основе множества наборов декодированных спектральных значений. Однако звуковые фреймы кодированного звукового сигнала могут, например, перекрываться во времени в некоторых случаях. Однако звуковые фреймы могут не перекрываться в некоторых других случаях.
Преобразователь (конвертер) частотной области во временную область с деформацией времени 180 также включает устройство управления окнами 180g, которое сконфигурировано, чтобы управлять окном представления временной области 180f, и чтобы обеспечить реализуемое посредством организации окна представление временной области, 180h на основе представления временной области 180f, предоставленного преобразователем частотной области во временную область 180е.
Преобразователь частотной области во временную область с деформацией времени 180 также включает ресэмплер (синтезатор повторной выборки) 1801, который сконфигурирован для повторной выборки реализуемого посредством организации окна представления временной области 180h, и чтобы обеспечить, на его основе, реализуемое посредством организации окна и повторно дискретизированное представление временной области 180j. Ресэмплер 180i сконфигурирован, чтобы получить информацию о положении выборки 180k от вычислителя положения выборки 180l. Соответственно, ресэмплер 180i обеспечивает реализуемое посредством организации окна и повторно дискретизированное представление временной области 180j для каждого фрейма кодированного представления звукового сигнала, где последующие фреймы могут перекрываться.
Соответственно, перекрыватель / сумматор 180m получает реализуемое посредством организации окна и повторно дискретизированное представление временной области 180j последующих звуковых фреймов кодированного представления звукового сигнала 152 и перекрывает и добавляет указанное реализуемое посредством организации окна и повторно дискретизированное представлении временной области 180j, чтобы получить гладкие переходы между последующими звуковыми фреймами.
Преобразователь частотной области во временную область факультативно включает постобработку временной области 180о, формируемую, чтобы выполнить постобработку на основе объединенного звукового сигнала 180n, предоставленного перекрывателем / сумматором 180m.
Информация о контуре деформации времени 258 служит входной информацией для определителя состояния контекста 170, который сконфигурирован, чтобы адаптировать получение информации о состоянии контекста 164 в зависимости от информации о контуре деформации времени 258. Кроме того, вычислитель положения выборки 180l преобразователя (конвертера)частотной области во временную область с деформацией времени 180 также получает информацию о контуре деформации времени и предоставляет информацию о положении выборки 180k на основе указанной информации о контуре деформации времени 258, чтобы, таким образом, адаптировать изменяющуюся во времени повторную выборку посредством ресэмплера (синтезатора повторной выборки) 180i в зависимости от контура деформации времени, описанного информацией о контуре деформации времени. Соответственно, изменение высоты (звука) вводится в сигнал временной области, описанной представлением временной области 180f в соответствии с контуром деформации времени, описанным информацией о контуре деформации времени 258. Таким образом, можно обеспечить представление временной области 180j звукового сигнала, имеющего существенное изменение высоты (звука) с течением времени (или существенное изменение основной частоты с течением времени) на основе разреженного спектра 180d, имеющего пики и впадины. Такой спектр может быть закодирован с высокой эффективностью относительно скорости передачи битов и, следовательно, приводит к сравнительно низкому требованию к скорости передачи битов кодированного представления звукового сигнала 152.
Кроме того, контекст (или, более широко, получение информации о состоянии контекста 164) также адаптируется в зависимости от информации о контуре деформации времени 258 посредством определителя состояния контекста 170. Соответственно, кодированная информация о деформации времени 252 повторно используется два раза и способствует усовершенствованию эффективности кодирования посредством кодирования разреженного спектра и адаптации информации о состоянии контекста к определенным характеристикам спектра в присутствии деформации времени или изменения основной частоты стечением времени.
Ниже будут описаны дальнейшие детали относительно функциональных возможностей индивидуальных компонентов кодирующего устройства звукового сигнала 240.
5. Арифметическое кодирующее устройство согласно фиг.2с
В дальнейшем будет описано арифметическое кодирующее устройство 290, которое может занять место кодирующего устройства контекст-ориентированного спектрального значения 130 в комбинации с определителем состояния контекста 140 в кодирующем устройстве звукового сигнала 100 или в кодирующем устройстве звукового сигнала 200. Арифметическое кодирующее устройство 290 сконфигурирован, чтобы получить спектральные значения 291 (например, спектральные значения представления частотной области 124), и чтобы обеспечить кодовые слова 292а, 292b на основе этих спектральных значений 291.
Другими словами, арифметическое кодирующее устройство 290 может, например, формироваться, чтобы получить множество постобработанных и масштабированных и квантованных спектральных значений 291 из представления звуковой частотной области 124. Арифметическое кодирующее устройство включает экстрактор битовой плоскости самого старшего разряда 290а, который сконфигурирован, чтобы извлечь битовую плоскость самого старшего разряда из спектрального значения. Здесь следует заметить, что битовая плоскость самого старшего разряда может включать один или даже больше битов (например, два или три бита), которые являются битами самого старшего разряда спектрального значения.
Таким образом, экстрактор битовой плоскости самого старшего разряда 290а обеспечивает значение битовой плоскости самого старшего разряда 290b спектрального значения. Арифметическое кодирующее устройство 290 также включает определитель первого кодового слова 290 с, который сконфигурирован, чтобы определить арифметическое кодовое слово acod_m [pki] [m], представляющее значение битовой плоскости самого старшего разряда m.
Факультативно, определитель первого кодового слова 290с может также обеспечить одно или более кодовых слов смены алфавита (также обозначается здесь как "ARITH_ESCAPE"), показывающих, например, сколько битовых плоскостей младшего разряда доступны (и, следовательно, показывающие числовой вес (весовой коэффициент) битовой плоскости самого старшего разряда). Определитель первого кодового слова 290с может формироваться, чтобы предоставить кодовое слово, связанное со значением битовой плоскости самого старшего разряда m посредством использования выбранной таблицы накопленных частот, имеющих (или на который ссылается) индекс (указатель) таблицы накопленных частот pki.
Чтобы определить, относительно какой таблицы накопленных частот должно быть выбрано арифметическое кодирующее устройство, предпочтительно включающее устройство отслеживания состояния 290d, которое может, например, брать на себя функцию определителя состояния контекста 140. Устройство отслеживания состояния 290d сконфигурировано, чтобы отслеживать состояние арифметического кодирующего устройства, например, отслеживая, какие спектральные значения были закодированы ранее. Устройство отслеживания состояния 290d, следовательно, предоставляет информацию о состоянии 290е, которая может быть эквивалентной информации о состояния контекста 134, например, в форме значения переменной состояния, обозначаемого "s" или иногда "t" (где значение переменной состояния 8 не должно быть перепутано с коэффициентом растяжения частоты s).
Арифметическое кодирующее устройство 290 также включает селектор таблицы накопленных частот 290f, который сконфигурирован, чтобы получить информацию о состоянии 290е и предоставить информацию 290g, описывающую выбранную таблицу накопленных частот определителю кодового слова 290с. Например, селектор таблицы накопленных частот 290f может обеспечить индекс таблицы накопленных частот "pki", описывающий, какая таблица накопленных частот из набора, например, 64 таблиц накопленных частот выбирается для использования определителем кодового слова 290с. Альтернативно, селектор таблицы накопленных частот 290f может предоставить полную выбранную таблицу накопленных частот определителю кодового слова 290с. Таким образом, определитель кодового слова 290с может использовать выбранную таблицу накопленных частот для обеспечения кодового слова acod_m [pki] [m] значения битовой плоскости самого старшего разряда m, таким образом, что фактическое кодовое слово acod_m [pki] [m], кодирующее значения битовой плоскости самого старшего разряда m, зависит от значения m и индекса таблицы накопленных частот pki, и, следовательно, от информации о текущем состоянии 290е. Ниже будут описаны дальнейшие детали относительно процесса кодирования и полученного формата кодового слова. Кроме того, детали относительно работы устройства отслеживания состояния 290d, которое эквивалентно определителю состояния контекста 140, будут обсуждены ниже.
Арифметическое кодирующее устройство 290 далее включает экстрактор битовой плоскости младшего разряда 290h, который сконфигурирован, чтобы извлечь одну или более битовых плоскостей младшего разряда из масштабированного и квантованного представления звуковой частотной области 291, если одно или более спектральных значений, подлежащих кодированию, превышают диапазон кодируемых значений, использующий только битовую плоскость самого старшего разряда. Битовые плоскости младшего разряда могут включать один или более битов, по желанию. Соответственно, экстрактор битовой плоскости младшего разряда 290h предоставляет информацию о битовой плоскости младшего разряда 290i.
Арифметическое кодирующее устройство 290 также включает определитель второго кодового слова 290j, который сконфигурирован, чтобы получить информацию о битовой плоскости младшего разряда 290i и обеспечить, на ее основе, ноль, одно или даже больше кодовых слов "acod_r", представляющих содержание ноля, одной или большего количества битовых плоскостей младшего разряда. Определитель второго кодового слова 290j может формироваться, чтобы применить алгоритм арифметического кодирования или любой другой алгоритм кодирования, чтобы получить кодовое слово "acod_r" битовой плоскости младшего разряда из информации о битовой плоскости младшего разряда 290i.
Здесь следует заметить, что число битовых плоскостей младшего разряда может изменяться в зависимости от значения масштабированных и квантованных спектральных значений 291, так что может вообще не быть битовых плоскостей младшего разряда, если масштабированное и квантованное спектральное значение, подлежащее кодированию, сравнительно маленькое, и что может быть одна битовая плоскость младшего разряда, если текущее масштабированное и квантованное спектральное значение, подлежащее кодированию, имеет средний диапазон, и что может быть больше одной битовой плоскости младшего разряда, если масштабированное и квантованное спектральное значение, подлежащее кодированию, принимает сравнительно большое значение.
Чтобы суммировать вышесказанное, арифметическое кодирующее устройство 290 сконфигурировано, чтобы кодировать масштабированные и квантованные спектральные значения, которые описываются информацией 291, использующей иерархический процесс кодирования. Битовая плоскость самого старшего разряда (включающая, например, один, два или три бита на спектральное значение) кодируется, чтобы получить арифметическое кодовое слово "acod_m [pki] [m]" значения битовой плоскости самого старшего разряда. Одна или больше битовых плоскостей младшего разряда (каждая из битовых плоскостей младшего разряда включает, например, один, два или три бита) кодируются, чтобы получить одно или более кодовых слов "acod_r". При кодировании битовой плоскости самого старшего разряда значение m битовой плоскости самого старшего разряда отображается на кодовом слове acod_m [pki] [m]. 64 различные таблицы накопительных частот доступны для кодирования значения m в зависимости от состояния арифметического кодирующего устройства 170, то есть в зависимости от ранее закодированных спектральных значений. Соответственно, получается кодовое лово "acod_m [pki] [m]". Кроме того, одно или более кодовых слов "acod_r" предоставляются и включаются в битовый поток, если присутствует одна или больше битовых плоскостей младшего разряда.
Однако в соответствии с данным изобретением, получение информации о состоянии 290е, которая эквивалентна информации о состоянии контекста 134, адаптируется к изменениям основной частоты от первого звукового фрейма к последующему второму звуковому фрейму (то есть между двумя последующими звуковыми фреймами). Детали относительно этой адаптации, которые могут быть выполнены устройством отслеживания состояния 290d, будут описаны ниже.
6. Арифметический декодер согласно фиг.2d
Фиг.2d показывает блок-схему арифметического декодера 295, который может занимать место декодера контекст-ориентированного спектрального значения 160 и определителя состояния контекста 170 в декодере звукового сигнала 150 согласно фиг.1d и декодере звукового сигнала 240 согласно фиг.2b.
Арифметический декодер 295 сконфигурирован, чтобы получить кодированное представление частотной области 296, которое может включать, например, арифметически кодированные спектральные данные в форме кодовых слов "acod_m" и "acod_r". Кодированное представление частотной области 296 может быть эквивалентным входу кодовых слов в декодер контекст-ориентированного спектрального значения 160. Кроме того, арифметический декодер сконфигурирован, чтобы обеспечить декодированное представление звуковой частотной области 297, которое может быть эквивалентным декодированным спектральным значениям 162, предоставленным декодером контекст-ориентированныого спектрального значения 160.
Арифметический декодер 295 включает определитель битовой плоскости самого старшего разряда 295а, который сконфигурирован, чтобы получить арифметическое кодовое слово acod_m [pki] [m], описывающее значение битовой плоскости самого старшего разряда m. Определитель битовой плоскости самого старшего разряда 295а может формироваться, чтобы использовать таблицу накопленных частот из набора, включающего множество, например, 64 таблиц накопленных частот для получения значения битовой плоскости самого старшего разряда m из арифметического кодового слова "acod_m [pki] [m]".
Определитель битовой плоскости самого старшего разряда 295а сконфигурирован, чтобы получить значения 295b битовой плоскости самого старшего разряда спектральных значений на основе кодового слова "acod_m". Арифметический декодер 295 далее включает определитель битовой плоскости младшего разряда 295с, который сконфигурирован, чтобы получить одно или более кодовых слов "acod_r", представляющих одну или большего битовых плоскостей младшего разряда спектрального значения. Соответственно, определитель битовой плоскости младшего разряда 295с сконфигурирован, чтобы обеспечить декодированные значения 295d одной или более битовых плоскостей младшего разряда. Арифметический декодер 295 также включает объединитель битовой плоскости 295е, который сконфигурирован, чтобы получить декодированные значения 295b битовой плоскости самого старшего разряда спектральных значений и декодированные значения 295b одной или более битовых плоскостей младшего разряда спектральных значений, если такие битовые плоскости младшего разряда доступны для текущих спектральных значений. Соответственно, объединитель битовой плоскости 295е обеспечивает кодированные спектральные значения, которые являются частью декодированного представления звуковой частотной области 297. Естественно, арифметический декодер 295 обычно сконфигурирован, чтобы обеспечить множество спектральных значений, чтобы получить полный набор декодированных спектральных значений, связанных с текущим фреймом звукового содержания.
Арифметический декодер 295 далее включает селектор таблицы накопленных частот 295f, который сконфигурирован, чтобы выбрать, например, одну из 64 таблиц накопленных частот в зависимости от показателя (индекса) состояния 295g, описывающего состояние арифметического декодера 295. Арифметический декодер 295 далее включает устройство отслеживания состояния 295h, которое сконфигурировано, чтобы отследить состояние арифметического декодера в зависимости от ранее декодированных спектральных значений. Устройство отслеживания состояния 295h может соответствовать определителю состояния контекста 170. Детали относительно устройства отслеживания состояния 295h будут описаны ниже.
Соответственно, селектор таблиц накопленных частот 295f сконфигурирован, чтобы обеспечить индекс (например, pki) выбранной таблицы накопленных частот, или саму выбранную таблицу накопленных частот для применения при декодировании значения битовой плоскости самого старшего разряда m в зависимости от кодового слова "acod_m'.
Соответственно, арифметический декодер 295 использует различные возможности различных комбинаций значений битовой плоскости самого старшего разряда смежных спектральных значений. Различные таблицы накопленных частот выбираются и применяются в зависимости от контекста. Другими словами, статистические зависимости между спектральными значениям используются посредством выбора различных таблиц накопленных частот из набора, включающего, например, 64 различные таблицы накопленных частот, в зависимости от показателя состояния 295g (который может быть эквивалентным информации о состоянии контекста 164), который получается при рассмотрении ранее декодированных спектральных значений. Спектральное масштабирование рассматривается посредством адаптации получения показателя состояния 295g (или информации о состоянии контекста 164) в зависимости от информации об изменении основной частоты (или высоты (звука)) между последующими звуковыми фреймами.
7. Краткий обзор концепции адаптации контекста
В дальнейшем будет дан краткий обзор концепции адаптации контекста арифметического кодирующего устройства, использующего информацию о деформации времени.
7.1 Вспомогательная информация
В дальнейшем будет предоставлена некоторая вспомогательная информация, позволяющая облегчить понимание данного изобретения. Следует заметить, что в Ссылке [3] контекст-адаптивное арифметическое кодирующее устройство (см., например, Ссылку [5]) используется, чтобы без потерь закодировать квантованные спектральные элементы разрешения по частоте.
Используемый контекст описывается на фиг.3а, который показывает графическое представление такого контекст-адаптивного арифметического кодирования. На фиг.3а можно заметить, что уже декодированные элементы разрешения по частоте из предыдущего фрейма используются, чтобы определить контекст для элементов разрешения по частоте, которые подлежат декодированию. Здесь следует заметить, что для описываемого изобретения не имеет значения, организуется ли контекст и кодирование в виде кортежей из четырех элементов или в виде линии (строки) или других кортежей из n элементов, где n может изменяться.
Снова со ссылкой на фиг.3а, который показывает контекст-адаптивное арифметическое кодирование или декодирование, следует заметить, что абсцисса 310 описывает время, и что ордината 312 описывает частоту. Здесь следует заметить, что кортежи из четырех элементов спектральных значений декодируются посредством использования общего состояния контекста в соответствии с контекстом, показанным на фиг.3а. Например, контекст для декодирования кортежа из четырех элементов 320 спектральных значений, связанный со звуковым фреймом, имеющим коэффициент времени k и коэффициент частотности i, основывается на спектральных значениях первого кортежа из четырех элементов 322, имеющего коэффициент времени k и коэффициент частоты i-1, второго кортежа из четырех элементов 324, имеющего коэффициент времени k-1 и коэффициент частоты i-1, третьего кортежа из четырех элементов 326, имеющего коэффициент времени k-1 и коэффициент частоты i и четвертого кортежа из четырех элементов 328, имеющего коэффициент времени k-1 и коэффициент частоты i+1. Следует заметить, что каждый из коэффициентов частоты i-1, i, i+1 обозначает (или, более точно, связан с) четыре элемента разрешения по частоте преобразования временной области в частотную область или преобразования частотной области во временную область. Соответственно, контекст для декодирования кортежа из четырех элементов 320 основывается на спектральных значениях кортежей из четырех элементов 322, 324, 326, 328 спектральных значений. Соответственно, спектральные значения, имеющие коэффициенты частоты i-1, i и i+1 кортежа предыдущего звукового фрейма, имеющего коэффициент времени k-1, используются для получения контекста для декодирования спектральных значений, имеющих коэффициент частоты i кортежа текущего звукового фрейма, имеющего коэффициент времени k (обычно в комбинации со спектральными значениями, имеющими коэффициент частоты i-1 кортежа текущего декодированного звукового фрейма, имеющего коэффициент временив.
Было обнаружено, что преобразование с деформацией времени обычно приводит к лучшему сжатию энергии для гармонических сигналов с изменениями в основных частотах, приводящими к спектрам, которые проявляют очевидную гармоническую структуру вместо более или менее смазанных обертонов, которые возникли бы, если бы не применялась деформация времени. Другой эффект деформации времени вызывается возможными другими средними локально выбранными частотами последовательных фреймов. Было обнаружено, что этот эффект является причиной последовательных спектров сигнала с другой постоянной гармонической структурой, но меняющейся основной частотой, подлежащей растяжению вдоль оси частоты.
Нижний график 390 на фиг.3с показывает такой пример. Он содержит графики (например, величина в децибелах как функция коэффициента элемента разрешения по частоте) двух последовательных фреймов (например, фреймы, обозначенные как "последний фрейм" и "этот фрейм", где гармонический сигнал с изменяющейся основной частотой кодируется кодирующим устройством измененного дискретного косинусного преобразования с деформацией времени (TW-MDCT кодирующее устройство).
Соответствующее изменение относительной высоты (звука) может быть обнаружено на графике 370 фиг.3b, который показывает уменьшающуюся относительную высоту (звука) и, поэтому, увеличивающуюся относительную частоту гармонических линий.
Это приводит к повышенной частоте гармонических линий после применения алгоритма деформации времени (например, выборка или повторная выборка с деформацией времени). Очевидно, что этот спектр текущего фрейма (также обозначаемый как "этот фрейм") является приблизительной копией спектра последнего фрейма, но растянутого вдоль оси частоты 392 (маркированный на основе элементов разрешения по частоте измененного дискретного косинусного преобразования). Это также может означать, что, если бы мы использовали прошлый фрейм (также обозначаемый как "последний фрейм") в качестве контекста для арифметического кодирующего устройства (например, для декодирования спектральных значений текущего фрейма (который также обозначается как "этот фрейм")), контекст был бы под оптимален, так как согласующиеся частичные тоны теперь возникали бы в других элементах разрешения по частоте.
Верхний график 380 на фиг.3с показывает это (например, потребность в битах для спектральных значений кодирования, использующих зависящее от контекста арифметическое кодирование) по сравнению со схемой кодирования Хаффмана, которая обычно считается менее эффективной, чем арифметическая схема кодирования. Вследствие подоптимального прошлого контекста (который может, например, определяться спектральными значениям "последнего фрейма", которые представлены на графике 390 фиг.3с) арифметическая схема кодирования тратит больше битов, где частичные тоны текущего фрейма располагаются в областях с низкой энергией в прошлом фрейме и наоборот. С другой стороны, график 380 фиг.3с показывает, что, если контекст хороший, что, по крайней мере, имеет место в случае основного частичного тона, распределение битов ниже (например, когда используется контекст-зависимое арифметическое кодирование), по сравнению с кодированием по способу Хаффмана.
Чтобы суммировать вышесказанное, график 370 фиг.3b показывает пример эволюции во времени контура относительной высоты (звука). Абсцисса 372 описывает время, и ордината 374 описывает как относительную высоту prel, так и относительную частоту frel. Первая кривая 376 описывает эволюцию во времени относительной высоты, а вторая кривая 377 описывает эволюцию во времени относительной частоты. Как можно видеть, относительная высота уменьшается с течением времени, в то время как относительная частота увеличивается с течением времени. Кроме того, следует заметить, что временное расширение 378а предыдущего фрейма (также обозначаемого как "последний фрейм") и временное расширение 378b текущего фрейма (также обозначаемого как "этот фрейм") не перекрываются на графике 370 фиг.3b. Однако обычно временные расширения 378а, 378b последующих звуковых фреймов могут перекрываться. Например, перекрывание может составить приблизительно 50%.
Теперь со ссылкой на фиг.3с, следует заметить, что график 390 показывает спектры MDCT для двух последующих фреймов. Абсцисса 392 описывает частоту на основе элементов разрешения по частоте измененного дискретного косинусного преобразования. Ордината 394 описывает относительную величину (в децибелах) индивидуальных спектральных элементов. Как можно видеть, спектральные пики спектра текущего фрейма ("этот фрейм") сдвинуты по частоте (способом, зависящим от частоты) относительно соответствующих спектральных пиков спектра предыдущего фрейма ("последний фрейм"). Соответственно, было обнаружено, что контекст для контекст-ориентированного кодирования спектральных значений текущего фрейма плохо адаптируется, если указанный контекст сконфигурирован на основе оригинальной версии спектральных значений предыдущего звукового фрейма, потому что спектральные пики спектра текущего фрейма не совпадают (по частоте) со спектральными пиками спектра предыдущего звукового фрейма. Таким образом, требование к скорости передачи битов для контекст-ориентированного кодирования спектральных значений сравнительно высоко, и может быть даже выше, чем в случае не контекст-ориентированного кодирования Хаффмана. Это видно на графике 380 фиг.3с, где абсцисса описывает частоту (исходя из столбцов диаграммы измененного дискретного косинусного преобразования), и где ордината 384 описывает число битов, требуемых для кодирования спектральных значений.
7.2. Обсуждение решения
Однако осуществления согласно данному изобретению обеспечивают решение обсуждавшейся выше проблемы. Было обнаружено, что информация об изменении высоты (звука) может использоваться, чтобы получить приближение коэффициента растяжения частоты между последовательными спектрами кодирующего устройства измененного дискретного косинусного преобразования с деформацией времени (например, между спектрами последовательных звуковых фреймов). Было обнаружено, что этот коэффициент растяжения может тогда использоваться, чтобы растянуть прошлый контекст вдоль оси частоты, чтобы получить лучший контекст, и поэтому сократить количество битов, необходимых для кодирования одной частотной линии и для увеличения эффективности кодирования.
Было обнаружено, что хорошие результаты могут быть достигнуты, если этот коэффициент растяжения является, приблизительно, отношением средних частот последнего фрейма и текущего фрейма. Кроме того, было обнаружено, что это может быть сделано в виде линии, или, если арифметическое кодирующее устройство кодирует кортежи из n элементов линий как один элемент в виде кортежа.
Другими словами, растяжение контекста может быть сделано в виде линии (строки) (то есть индивидуально на элемент разрешения по частоте измененного дискретного косинусного преобразования) или в виде кортежа (то есть на кортеж или набор множества спектральных элементов измененного дискретного косинусного преобразования).
Кроме того, решение для вычисления коэффициента растяжения может также изменяться в зависимости от требований осуществлений.
7.3 Примеры получения коэффициента растяжение
В дальнейшем некоторые концепции получения коэффициента растяжения будут описаны подробно. Способ измененного дискретного косинусного преобразования с деформацией времени, описанный со ссылкой [3], и, альтернативно, способ измененного дискретного косинусного преобразования с деформацией времени, описанный здесь, обеспечивает так называемый гладкий контур высоты (звука) в качестве промежуточной информации. Этот гладкий контур высоты (звука) (который может, например, описываться входами массива "warp_contour []", или входами массивов "new_warp_contour []" и "past_warp_contour []") содержит информацию об эволюции относительной высоты (звука) на протяжении нескольких последовательных фреймов, так, что для каждой выборки в пределах одного фрейма известна оценка относительной высоты. Относительная частота для этой выборки является тогда просто инверсией этой относительной высоты. Например, могут поддерживаться следующие соотношения:

В вышеприведенном уравнении prel[n] обозначает относительную высоту (звука) для данного коэффициента времени n, который может быть краткосрочной относительной высотой, (где коэффициент времени n может, например, обозначать индивидуальную выборку). Кроме того, frel[n] может обозначать относительную частоту для коэффициента времени n, и может быть значением краткосрочной относительной частоты.
7.3.1 Первая альтернатива
Средняя относительная частота на протяжении одного фрейма k (где k - показатель фрейма) может тогда описываться как среднее арифметическое по всем относительным частотам в пределах этого фрейма k:
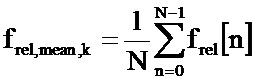
В вышеприведенном уравнении frel, mean k обозначает среднюю относительную частоту на протяжении звукового фрейма, имеющего временной показатель фрейма k. N обозначает число выборок временной области для звукового фрейма, имеющего временной показатель фрейма k. Переменная n, выходящая за пределы коэффициентов выборки временной области n=0-n=N-1 выборок временной области текущего звукового фрейма, имеющего показатель звукового фрейма k. frel[n] обозначает значение местной относительной частоты, связанной с выборкой временной области, имеющим временной коэффициент выборки временной области n.
Из этого (то есть из вычисления frel, mean, k для текущего звукового фрейма, и из вычисления frel, mean, k-1 для предыдущего звукового фрейма), коэффициент растяжения s для текущего звукового фрейма k может тогда быть получен как:

7.3.2 Вторая альтернатива
В дальнейшем будет описана другая альтернатива вычисления коэффициента растяжения s. Может быть найдено более простое и менее точное приближение коэффициента растяжения s (например, при сравнении с первой альтернативой), если учитывать, что, в среднем, относительная высота (звука) близка к единице, так что отношение относительной высоты (звука) и относительной частоты является приблизительно линейным, и так что этап инвертирования относительной высоты (звука) для получения относительной частоты может быть опущен, а используется средняя относительная высота:

В вышеприведенном уравнении, prel, meank обозначает среднюю относительную высоту для звукового фрейма, имеющего временной коэффициент звукового фрейма k. Обозначает число выборок временной области звукового фрейма, имеющего временной коэффициент звукового фрейма k. Текущая переменная n принимает значения между 0 и N-1 и, таким образом, выходит за пределы выборки временной области, имеющие временные коэффициенты n текущего звукового фрейма. prel[n] обозначает значение (локальной) относительной высоты для выборки временной области, имеющей коэффициент временной области n. Например, значение относительной высоты prel[n] может быть равным входу warp_contour [n] массива контуров деформации "warp_contour []".
В этом случае коэффициент растяжения s для звукового фрейма, имеющего временной фрейм k, может быть приближен как:
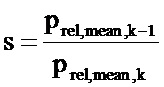
В вышеприведенном уравнении prel,mean,k-1 обозначает среднее значение высоты (звука) для звукового фрейма, имеющего временной коэффициент звукового фрейма k-1, и переменная Prel,mean,k описывает среднее значение относительной высоты (звука) для звукового фрейма, имеющего временной звуковой фрейм k.
7.3.3 Дальнейшие альтернативы
Однако следует заметить, что могут использоваться существенно различные концепции вычисления, или оценки, коэффициента растяжения s, где коэффициент растяжения s обычно также описывает изменение основной частоты между первым звуковым фреймом и последующим вторым звуковым фреймом. Например, спектры первого звукового фрейма и последующего второго звукового фрейма могут сравниваться посредством концепции сравнения выборок, чтобы, таким образом, получить коэффициент растяжения. Однако оказывается, что вычисление коэффициента растяжения частоты s, использующего информацию о контуре деформации, как обсуждалось выше, в вычислительном отношении особенно эффективно, настолько, что оно является предпочтительным выбором.
8. Детали относительно определения состояния контекста
8.1. Пример согласно Фиг.4а и 4b
В дальнейшем будут описаны детали относительно определения состояния контекста. С этой целью будут описаны функциональные возможности определителя состояния контекста 400, блок-схема которого показана на фиг.4а.
Определитель состояния контекста 400 может, например, занять место определителя состояния контекста 140, или определителя состояния контекста 170. Хотя детали относительно определителя состояния контекста будут описаны в дальнейшем для случая декодера звукового сигнала, определитель состояния контекста 400 может также использоваться в контексте кодирующего устройства звукового сигнала.
Определитель состояния контекста 400 сконфигурирован, чтобы получить информацию 410 о ранее декодированных спектральных значениях или о ранее закодированных спектральных значениях. Кроме того, определитель состояния контекста 400 получает информацию о деформации времени или информацию о контуре деформации времени 412. Информация о деформации времени или информация о контуре деформации времени 412 могут, например, быть равными информации о деформации времени 122 и могут, следовательно, описывать (по крайней мере, неявно) изменение основной частоты между последующими звуковыми фреймами. Информация о деформации времени или информация о контуре деформации времени 412 может, альтернативно, быть эквивалентной информации о деформации времени 184 и может, следовательно, описывать изменение основной частоты между последующими фреймами. Однако информация о деформации времени / информации о контуре деформации времени 412 может, альтернативно, быть эквивалентной информации о контуре деформации времени 222 или информации о контуре деформации времени 258. В общем, можно сказать, что информация о деформации времени / информация о контуре деформации времени 412 может описывать изменение частоты между последующими звуковыми фреймами прямо или косвенно. Например, информация о деформации времени / информации о контуре деформации времени 212 может описывать контур деформации и может, следовательно, включать входы массива "warp_contour []", или может описывать контур времени, и может, следовательно, включать входы массива "time_contour []".
Определитель состояния контекста 400 обеспечивает значение состояния контекста 420, которое описывает контекст, который будет использоваться для кодирования или декодирования спектральных значений текущего фрейма, и которое может использоваться кодирующим устройством контекст-ориентированных спектральных значений или декодером контекст-ориентированнных спектральных значений для выбора подходящего правила отображения для кодирования или декодирования спектральных значений текущего звукового фрейма. Значение состояния контекста 420, может, например, быть эквивалентным информации о состоянии контекста 134 или информации о состоянии контекста 164.
Определитель состояния контекста 400 включает поставщик предварительной структуры памяти контекста 430, который сконфигурирован, чтобы обеспечить предварительную структуру памяти контекста 432 как, например, массив q [1] []. Например, поставщик предварительной структуры памяти контекста 430 может формироваться, чтобы выполнять функциональные возможности алгоритмов согласно Фиг.25 и 26, таким образом, чтобы обеспечить набор, например, N/4 входов q [1] [i] массива q [1] [] (для i=0 до i=М/4-1).
Вообще говоря, поставщик предварительной структуры памяти контекста 430 может формироваться, чтобы обеспечить входы предварительной структуры памяти контекста 432 таким образом, что вход, имеющий коэффициент частотности входа i, основанный на (единственном) спектральном значении, имеющем частотный коэффициент i, или на наборе спектральных значений, имеющих общий частотный коэффициент i. Однако поставщик предварительной структуры памяти контекста 430 предпочтительно сконфигурирован, чтобы обеспечить предварительную структуру памяти контекста 432 таким образом, что имеется фиксированное соотношение коэффициента частотности между коэффициентом частотности входа предварительной структуры памяти контекста 432 и коэффициентами частотности одного или более кодированных спектральных значений или декодированных спектральных значений, на которых основывается вход предварительной структуры памяти контекста 432. Например, указанное предварительно определенное соотношение коэффициентов может быть такими, что вход q [1] [i] предварительной структуры памяти контекста основывается на спектральном значении элементов разрешения по частоте, имеющем коэффициент i элемента разрешения по частоте (или i-const, где const - константа) преобразователя временной области в частотную область или преобразователя частотной области во временную область. Альтернативно, вход q [1] [i] предварительной структуры памяти контекста 432 может основываться на спектральных значениях элементов разрешения по частоте, имеющих коэффициенты элементов разрешения по частоте 2i-1 и 2i преобразователя временной области в частотную область или преобразователя частотной области во временную область (или смещенный диапазон коэффициентов элементов разрешения по частоте). Альтернативно, однако, коэффициент q [1] [i] предварительной структуры памяти контекста 432 может основываться на спектральных значениях элементов разрешения по частоте, имеющих коэффициенты элементов разрешения по частоте 4i-3, 4i-2, 4i-1 и 4i преобразователя временной области в частотную область или преобразователя частотной области во временную область (или смещенный диапазон коэффициентов элементов разрешения по частоте). Таким образом, каждый вход предварительной структуры памяти контекста 432 может быть связан со спектральным значением предварительно определенного коэффициента частотности или набора спектральных значений предварительно определенных коэффициентов частотности звуковых фреймов, на основе которых настраивается предварительная структура памяти контекста 432.
Определитель состояния контекста 400 также включает вычислитель коэффициента растяжения частоты 434, который сконфигурирован, чтобы получить информацию о деформации времени / информацию о контуре деформации времени 412 и обеспечить, на их основе, информацию о коэффициенте растяжения частоты 436. Например, вычислитель коэффициента растяжения частоты 434 может формироваться, чтобы получить информацию об относительной высоте (звука)prel[n] от входов массива warp_contour [] (где информация об относительной высоте (звука)prel[n] может, например, быть равной соответствующему входу массива warp_contour []). Кроме того, вычислитель коэффициента растяжения частоты 434 может формироваться, чтобы применить одно из вышеприведенных уравнений, чтобы получить информацию о коэффициенте растяжения частоты s из указанной информации об относительной высоте (звука) prel двух последующих звуковых фреймов. Вообще говоря, вычислитель коэффициента растяжения частоты 434 может формироваться, чтобы предоставить информацию о коэффициенте растяжения частоты (например, значение s или, эквивалентно, значение m_ContextUpdateRatio) таким образом, что информация о коэффициенте растяжения частоты описывает изменение основной частоты между ранее закодированным или декодированным звуковым фреймом и текущим звуковым фреймом, подлежащим кодированию, или декодированию, используя значение текущего состояния контекста 420.
Определитель состояния контекста 400 также включает поставщик частотно-масштабированной структуры памяти контекста, который сконфигурирован, чтобы получить предварительную структуру памяти контекста 432 и обеспечить, на ее основе, частотно-масштабированную структуру памяти контекста. Например, частотно-масштабированная структура памяти контекста может быть представлена обновленной версией массива q [1] [], который может быть обновленной версией массива, несущего предварительную структуру памяти контекста 432.
Поставщик частотно-масштабированной структуры памяти контекста может формироваться, чтобы получить частотно-масштабированную структуру памяти контекста из предварительной структуры памяти контекста 432, используя масштабирование частоты. При масштабировании частоты значение входа, имеющего коэффициент входа i предварительной структуры памяти контекста 432, может быть скопировано или смещено к входу, имеющему коэффициент входа j частотно-масштабированной структуры памяти контекста 440, где коэффициент частотности i может отличаться от коэффициента частотности j. Например, если выполняется растяжение частоты содержания предварительной структуры памяти контекста 432, вход, имеющий коэффициент входа j1 частотно-масштабированной структуры памяти контекста 440, может быть установлен назначение входа, имеющего коэффициент входа i1 предварительной структуры памяти контекста 432, и вход, имеющий коэффициент входа j2 частотно-масштабированной структуры памяти контекста 440, может быть установлен назначение входа, имеющего коэффициент входа i2 предварительной структуры памяти контекста 432, где j2 больше, чем i2, и где j1 больше, чем i1. Соотношение между соответствующими коэффициентами частотности (например, j1 и i1, или j2 и i2) может принимать предварительно определенное значение (за исключением ошибок округления). Аналогично, если сжатие частоты содержания, описанное предварительной структурой памяти контекста 432, должно выполняться поставщиком частотно-масштабированной структуры памяти контекста 438, вход, имеющий коэффициент входа j3 частотно-масштабированной структуры памяти контекста 440, может быть установлен назначение входа, имеющего коэффициент входа i3 предварительной структуры памяти контекста 432, и вход, имеющий коэффициент входа j4 частотно-масштабированной структуры памяти контекста 440, может быть установлен назначение входа, имеющего коэффициент входа i4 предварительной структуры памяти контекста 432. В этом случае коэффициент входа j3 может быть меньше, чем коэффициент входа i3, и коэффициент входа j4 может быть меньше, чем коэффициент входа i4. Кроме того, соотношение между соответствующими коэффициентами входа (например, между коэффициентами входа j3 и i3, или между коэффициентами входа j4 и i4), может быть постоянным (за исключением ошибок округления), и может определяться информацией о коэффициенте растяжения частоты 436. Дальнейшие детали относительно работы частотно-масштабированного поставщика структуры памяти контекста 440 будут описаны ниже.
Определитель состояния контекста 400 также включает поставщик значения состояния контекста 442, который сконфигурирован, чтобы обеспечить значение состояния контекста 420 на основе частотно-масштабированной структуры памяти контекста 440. Например, поставщик значения состояния контекста 442 может формироваться, чтобы обеспечить значение состояния контекста 420, описывающее контекст для декодирования спектрального значения, имеющего коэффициент частотности l0 на основе входов частотно-масштабированной структуры памяти контекста 440, коэффициенты частотности входов которого находятся в предварительно определенных отношениях с коэффициентом частотности l0. Например, поставщик значения состояния контекста 442 может формироваться, чтобы обеспечить значение состояния контекста 420 для декодирования спектрального значения (или кортежа спектральных значений), имеющего коэффициент частотности l0, на основе входов частотно-масштабированной структуры памяти контекста 440, имеющей коэффициенты частотности l0-1, l0 и l0+1.
Соответственно, определитель состояния контекста 400 может эффективно обеспечить значение состояния контекста 420 для декодирования спектрального значения (или кортежа спектральных значений), имеющего коэффициент частотности l0, на основе входов предварительной структуры памяти контекста 432, имеющей соответствующие коэффициенты частотности меньшие, чем l0-1, меньшие, чем l0 и меньшие, чем l0+1, если растяжение частоты выполняется частотно-масштабированным поставщиком структуры памяти контекста 438, и на основе входов предварительной структуры памяти контекста 432, имеющих соответствующие коэффициенты частотности большие, чем l0-1, большие, чем l0 и большие, чем l0+1, соответственно, в случае, если сжатие частоты выполняется частотно-масштабированным поставщиком структуры памяти контекста 438.
Таким образом, определитель состояния контекста 400 сконфигурирован, чтобы адаптировать определение контекста к изменению основной частоты между последующими фреймами посредством обеспечения значения состояния контекста 420 на основе частотно-масштабированной структуры памяти контекста, которая является частотно-масштабированной версией предварительной структуры памяти контекста 432, частотно-масштабированной в зависимости от коэффициента растяжения частоты 436, который, в свою очередь, описывает изменение основной частоты с течением времени.
Фиг.4b показывает графическое представление определения состояния контекста согласно осуществлению изобретения. Фиг.4b показывает схематическое представление входов предварительной структуры памяти контекста 432, которое предоставляется поставщиком предварительной структуры памяти контекста 430, под номером ссылки 450. Например, отмечен вход 450а, имеющий коэффициент частотности i1+1, вход 450b и вход 450 с, имеющий коэффициент частотности i2+2. Однако при обеспечении частотно-масштабированной структуры памяти контекста 440, которая показана под номером ссылки 452, вход 452а, имеющий коэффициент частотности i1, устанавливается так, чтобы принять значение входа 450а, имеющего коэффициент частотности i1+1, а вход 452с, имеющий коэффициент частотности i2-1, устанавливается так, чтобы принять значение входа 450с, имеющего коэффициент частотности i2+2. Аналогично, другие входы частотно-масштабированной структуры памяти контекста 440 могут быть установлены в зависимости от входов предварительной структуры памяти контекста 430, где, обычно, некоторые из входов предварительной структуры памяти контекста отбрасываются в случае сжатия частоты, и где, обычно, некоторые из входов предварительной структуры памяти контекста 432 копируются для более, чем одного входа частотно-масштабированной структуры памяти контекста 440 в случае растяжения частоты.
Кроме того, фиг.4b показывает, как состояние контекста определяется для декодирования спектральных значений звукового фрейма, имеющего временной коэффициент k на основе входов частотно-масштабированной структуры памяти контекста 440 (которые представлены номером ссылки 452). Например, при определении состояния контекста (представленного, например, значением состояния контекста 420) для декодирования спектрального значения (или кортежа спектральных значений), имеющего коэффициент частотности i1 звукового фрейма, имеющего временной коэффициент k, оценивается значение контекста, имеющего коэффициент частотности i1-1 звукового фрейма, имеющего временный коэффициент k, и входы частотно-масштабированной структуры памяти контекста звукового фрейма, имеющего временной коэффициент k-1 и коэффициенты частотности i1-1, i1 и i1+1. Соответственно, входы предварительной структуры памяти контекста звукового фрейма, имеющего временной коэффициент k-1 и коэффициенты частотности i1-1, i1+1 и i1+2, эффективно оцениваются для определения контекста для декодирования спектрального значения (или кортежа спектральных значений) звукового фрейма, имеющего временной коэффициент k и коэффициент частотности i1. Таким образом, окружение спектральных значений, которые используются для определения состояния контекста, эффективно изменяется растяжением частоты или сжатием частоты предварительной структуры памяти контекста (или его содержания).
8.2. Выполнение согласно фиг.4с
В дальнейшем пример отображения контекста арифметического кодирующего устройства, использующего кортежи из 4 элементов, будет описан со ссылкой на Фиг.4с, который показывает покортежную (кортежеобразную) обработку.
Фиг.4с показывает представление псевдоуправляющей программы алгоритма для получения частотно-масштабированной структуры памяти контекста (например, частотно-масштабированной структуры памяти контекста 440) на основе предварительной структуры памяти контекста (например, предварительной структуры памяти контекста 432).
Алгоритм 460, согласно фиг.4с, предполагает, что предварительная структура памяти контекста 432 сохраняется в массиве "self->base.m_qbuf". Кроме того, алгоритм 460 предполагает, что информация о коэффициенте растяжения частоты 436 сохраняется в переменной "self->base.m_ContextUpdateRatio".
На первом этапе 460а калибруются(инициализируются) многие переменные. В частности, переменная коэффициента целевого (объектного) кортежа "nLinTupleIdx" и переменная коэффициента исходного кортежа "nWarpTupleIdx" калибруются (инициализируются) на ноль. Кроме того, калибруется (инициализируется) массив буфера восстановления последовательности"Tqi4".
На этапе 460b входы предварительной структуры памяти контекста "self->base.m_qbuf" копируются в массив буфера восстановления последовательности.
В последствии, алгоритм копирования 460с повторяется до тех пор, пока и переменная коэффициента целевого (объектного) кортежа, и переменная коэффициента и сходного кортежа меньше, чем переменная nTuples, описывающая максимальное число кортежей.
На этапе 460са четыре входа буфера восстановления последовательности, коэффициент частотности (кортежа) которого определяется текущим значением переменной коэффициента исходного кортежа (в комбинации с первым коэффициентом постоянной "firstIdx"), копируются для входов структуры памяти контекста (self->base.m_qbuf[][]), коэффициенты частотности входов которого определяются переменной коэффициента целевого(объектного) кортежа (nLinTupleIdx) (в комбинации с первым коэффициентом постоянной "firstIdx").
На этапе 460cb переменная коэффициента целевого (объектного) кортежа увеличивается на единицу.
На этапе 460сс, переменная коэффициента исходного кортежа устанавливается назначение, которое является произведением текущего значения переменной коэффициента целевого (объектного) кортежа (nLinTupleIdx) и информации о коэффициенте растяжения частоты (self->base.m_ContextUpdateRatio), округленное до ближайшего значения целого числа. Соответственно, значение переменной коэффициента исходного кортежа может быть больше, чем значение переменной коэффициента целевого (объектного) кортежа, если переменная коэффициента растяжения частоты больше единицы, и меньше, чем переменная коэффициента целевого (объектного) кортежа, если переменная коэффициента растяжения частоты меньше единицы.
Соответственно, значение переменной исходного кортежа связывается с каждым значением переменной коэффициента целевого (объектного) кортежа (до тех пор пока и значение переменной коэффициента целевого (объектного) кортежа и значение переменной исходного кортежа меньше, чем постоянная Tuples). Вслед за выполнением этапов 460cb и 460сс, копирование входов из буфера восстановления последовательности для структуры памяти контекста повторяется на этапе 460са посредством использования обновленной связи между исходным кортежем и целевым (объектным) кортежем.
Таким образом, алгоритм 460 согласно фиг.4с выполняет функциональные возможности поставщика частотно-масштабированной структуры памяти контекста 430а, где предварительная структура памяти контекста представляется начальными входами массива "self->base.m_qbuf и где частотно-масштабированная структура памяти контекста 440 представляется обновленными входами массива "self->base.m_qbuf".
8.3. Выполнение согласно Фиг.4d и 4е
В дальнейшем будет описан пример отображения контекста арифметического кодирующего устройства, использующего кортеж из 4 элементов, со ссылкой на Фиг.4 с, который показывает (по-)линейную обработку.
Фиг.4d и 4е показывают представление псевдоуправляющей программы алгоритма выполнения масштабирования частоты (то есть растяжение частоты или сжатие частоты) контекста.
Алгоритм 470 согласно Фиг.4d и 4е получает, в качестве входной информации, массив "self->base.m_qbuf[][]" (или, по крайней мере, ссылку на указанный массив) и информацию о коэффициенте растяжения частоты "selfself->base.m_ContextUpdateRatio". Кроме того, алгоритм 470 получает, в качестве входной информации, переменную "self->base.m_IcsInfo->m_ScaleFactorBandsTransmitted", которая описывает число активных линий (строк). Кроме того, алгоритм 470 изменяет массив self->base.m_qbuf[][] таким образом, что входы указанного массива представляют частотно-масштабированную структуру памяти контекста.
Алгоритм 470 включает, на этапе 470а, калибровку (инициализацию) множества переменных. В частности, переменная коэффициента целевой линии (строки) (linLineIdx) и переменная коэффициента исходной линии (строки) (warpLineIdx) калибруются (инициализируются) на ноль.
На этапе 470b вычисляется ряд активных кортежей и ряд активных линий.
В дальнейшем обрабатываются два набора контекстов, которые включают различные коэффициенты контекста (обозначаемые переменной "contextIdx"). Однако в других осуществлениях бывает достаточно обработать только один контекст.
На этапе 470с, массив построчного кратковременного буфера "lineTmpBuf", и массив построчного буфера восстановления последовательности "lineReorderBuf" калибруются (инициализируются) с нулевыми входами.
На этапе 470d, входы предварительной структуры памяти контекста, связанной с различными элементами разрешения по частоте множества кортежей спектральных значений, копируются для массива построчного буфера восстановления последовательности. Соответственно, входы массива построчного буфера восстановления последовательности, имеющего последующие коэффициенты частотности, устанавливаются на входы предварительной структуры памяти контекста, которые связываются с различными элементами разрешения по частоте. Другими словами, предварительная структура памяти контекста включает вход "self->base.m_qbuf[CurTuple][contextIdx]" на кортеж спектральных значений, где вход, связанный с кортежем спектральных значений, включает под входы а, b, с, d, связанные с индивидуальными спектральными линиями (или спектральными элементами разрешения по частоте). Каждый из под входов а, b, с, d копируется в индивидуальный вход массива построчного буфера восстановления последовательности "lineReorderBuf []" на этапе 470d.
Следовательно, содержание массива построчного буфера восстановления последовательности копируется в массив построчного кратковременного буфера "lineTmpBuf[]" Ha этапе 470е.
Впоследствии переменная коэффициента целевой линии (строки) и переменная коэффициента исходной линии (строки) калибруется (инициализируется), чтобы принять значение ноля на этапе 470f.
Впоследствии входы "lineReorderBuf [warpLineIdx]" массива построчного буфера восстановления последовательности копируются для массива построчного кратковременного буфера для множества значений переменной коэффициента целевой линии (строки) "linLineIdx" Ha этапе 470g. Этап 470g повторяется до тех пор, пока и переменная коэффициента целевой линии (строки) и переменная коэффициента исходной линии (строки) меньше, чем переменная "activeLines", которая обозначает общее количество активных (отличных от нуля) спектральных линий. Вход массива построчного кратковременного буфера, обозначаемого текущим значением переменной коэффициента целевой линии (строки) "linLineIdx", устанавливается назначение массива построчного буфера восстановления последовательности, обозначаемого текущим значением переменной коэффициента исходной линии (строки). Впоследствии переменная коэффициента целевой линии (строки) увеличивается на единицу. Переменная коэффициента исходной линии (строки) "warpLineIdx" устанавливается так, чтобы принять значение, которое определяется произведением текущего значения переменной коэффициента целевой линии (строки) и информации о коэффициенте растяжения частоты (представленной переменной "self->base.m_ContextUpdateRatio").
После обновления переменной коэффициента целевой линии (строки) и исходной переменной коэффициента исходной линии (строки), стадия 470g повторяется, предусматривая, что и переменная коэффициента целевой линии (строки) и переменная коэффициента исходной линии (строки)были меньше, чем значение переменной "activeLines".
Соответственно, контекстные входы предварительной структуры памяти контекста являются частотно-масштабированными линейно-образным способом, а не покортежным (кортежеобразным) способом.
На заключительном этапе 470h представление кортежа восстанавливается на основе линейно-образных входов массива построчного кратковременного буфера. Входы а, b, с, d представления кортежа "self->base.m_qbuf[curTuple][contextIdx]" контекста устанавливаются в соответствии с четырьмя входами "lineTmpBuf [(curTuple-1) *4+0]" для "lineTmpBuf [(curTuple-1) *4+3]" массива построчного кратковременного буфера, входы которого являются смежными по частоте. Кроме того, энергетическое поле кортежа "е", факультативно, устанавливается, чтобы представить энергию спектральных значений, связанных с соответствующим кортежем. Кроме того, дополнительное поле "v" представления кортежа устанавливается, факультативно, если величина спектральных значений, связанных с указанным кортежем, сравнительно мала.
Однако следует заметить, что детали относительно вычисления новых кортежей, которое выполняется на этапе 470h, в значительной степени зависит от фактического представления контекста и может, поэтому, значительно изменяться. Однако, в общем, можно сказать, что кортеж-ориентированное представление создается на основе ориентированного на индивидуальную линию (строку) представления частотоно-масштабированного контекста на этапе 470h.
Чтобы суммировать, в соответствии с алгоритмом 470, покортежное (кортежеобразное) представление контекста (входы массива "self->base.m_qbuf[curTuple][contextIdx]") сначала расщепляется на линейно-образное частотное представление контекста (или поэлементно-разрешенное по частоте представление контекста) (этап 470d). Впоследствии масштабирование частоты выполняется линейно-образным способом (этап 470g). Наконец, покортежное (кортежеобразное) представление контекста (обновленные входы массива "self->base.m_qbuf[curTuple][contextIdx]") восстанавливается (этап 470h) на основе линейно-образной частотно-масштабированной информации.
9. Детальное описание алгоритма декодирования частотной области во временную область
9.1. Краткий обзор
В дальнейшем будут подробно описаны некоторые из алгоритмов, выполняемых звуковым декодером согласно осуществлению изобретения. С этой целью, ссылка делается на фиг.5а, 5b, 6а, 6b, 7а, 7b, 8, 9, 10а, 10b, 11, 12, 13, 14, 15 и 16.
Прежде всего, ссылка делается на фиг.7а, которая показывает легенду определений элементов данных и легенду определений справочных элементов. Кроме того, ссылка делается на фиг.7b, которая показывает легенду определений констант.
В общем, можно сказать, что способы, описанные здесь, могут использоваться для декодирования звукового потока, закодированного согласно измененному дискретному косинусному преобразованию с деформацией времени. Таким образом, когда TW-MDCT задействован для звукового потока (который может быть обозначен флагом (флажком), например, называемым "twMDCT" флагом (флажком), который может включаться в информацию об определенной конфигурации), гребенка фильтров с деформацией времени и переключение блоков могут заменить стандартную гребенку фильтров и переключение блоков в звуковом декодере. Дополнительно к инверсному измененному дискретному косинусному преобразованию (IMCT), гребенка фильтров с деформацией времени и переключение блоков включает отображение временной области на временную область от произвольно расположенной временной сетки до нормальной регулярно расположенной или линейно расположенной сетки времени и соответствующую адаптацию форм окна.
Здесь следует заметить, что алгоритм декодирования, описанный здесь, может выполняться, например, преобразователем частотной области во временную область с деформацией деформированного времени 180 на основе кодированного представления спектра и также на основе кодированной информации о деформации времени 184, 252.
9.2. Определения:
Относительно определения элементов данных, справочных элементов и констант, ссылка делается на фиг.7а и 7b.
9.3. Процесс декодирования- контур деформации Индексы шифровальной книги узлов контура деформации декодируются следующим образом, чтобы деформировать значения для индивидуальных узлов:
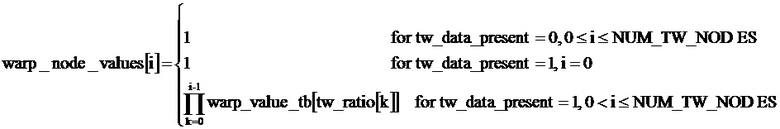
Однако отображение кодовых слов деформации времени "tw_ratio [k]" на декодированные значения деформации времени, обозначенные здесь как "warp_value_tbl [tw_ratio [k]]", может, факультативно, зависеть от частоты выборки в осуществлениях согласно изобретению. Соответственно, в некоторых осуществлениях согласно изобретению нет ни одной таблицы отображения, но есть индивидуальные таблицы отображения для различных частот выборки.
Чтобы получить данные нового контура деформации "new_warp_contour []" по выборкам (n_longsamples), значения узлов деформации "warp_node_values []" теперь интерполируются линейно между одинаково расположенными (interp_distapart) узлами, используя алгоритм, представление псевдоуправляющей программы которого показано на фиг.9.
Прежде, чем получить полный контур деформации для этого фрейма (например, для текущего фрейма), масштаб буферизованных значений от прошлого может быть измерен так, чтобы значение последней деформации прошлого контура деформации "past_warp_contour []"=1.

past_warp_contour[i]=past_warp_contour[i]⋅norm_fac for 0≤i<2⋅n_long
last_warp_sum=last_warp_sum⋅norm_fac
cur_warp_sum=cur_warp_sum⋅norm_fac
Полный контур деформации "warp_contour []" получается посредством соединения прошлого контура деформации "past_warp_contour" и нового контура деформация "new_warp_contour", и новая сумма деформации "new_warp_sum" вычисляется как сумма по всем новым значениям контура деформации "new_warp_contour []":

9.4. Процесс декодирования - положение выборки и регулирование длины окна
Из контура деформации "warp_contour []" вычисляется вектор положений выборки деформированных выборок на линейной шкале времени. Для этого контур деформации времени получается в соответствии со следующими уравнениями:

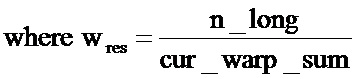
При помощи вспомогательных функций "warp_inv_vec ()" и "warp_time_inv ()", представления псевдоуправляющей программы которых показаны на фиг.10а и 10b, соответственно, вычисляется вектор положения выборки и длина перехода в соответствии с алгоритмом, представление псевдоуправляющей программы которого показано на фиг.11.
9.5. Процесс декодирования - инверсное измененное дискретное косинусное преобразование (IMDCT)
В дальнейшем будет кратко описано инверсное измененное дискретное косинусное преобразование.
Аналитическое выражение инверсного измененного дискретного косинусного преобразования выглядит следующим образом:

где n = индекс выборки,
i = индекс окна,
k = индекс спектрального коэффициента,
N = длина окна, основанная на значении последовательности окон,
n0=(N/2+1)/2.
Длина окна синтеза для инверсного преобразования является функцией элемента синтаксиса "window_sequence" (который может быть включен в битовый поток) и алгоритмического контекста. Длина окна синтеза может, например, определяться в соответствии с таблицей фиг.12.
Значимые блочные переходы перечислены в таблице фиг.13. Штриховая метка в данной ячейке таблицы показывает, что за последовательностью окон, представленной в этом конкретном ряду, может следовать последовательность окон, представленная в этой конкретной колонке.
Относительно разрешенных последовательностей окон следует заметить, что звуковой декодер может, например, быть переключаемым между окнами различной длины. Однако переключение длин окна не имеет особого значения для данного изобретения. Скорее, данное изобретение может пониматься на основе предположения о том, что имеется последовательность окон типа "only_long_sequence", и что длина фрейма основного кодирующего устройства равна 1024.
Кроме того, следует заметить, что декодер звукового сигнала может быть переключаемым между режимом кодирования частотной области и режимом кодирования временной области. Однако эта возможность не имеет особого значения для данного изобретения. Скорее, данное изобретение применимо в декодерах звукового сигнала, которые способны управлять только режимом кодирования частотной области, как обсуждалось, например, в отношении фиг.1b и 2b.
9.6. Процесс декодирования - управление окнами и переключение блока
В дальнейшем будет описано управление окнами и переключение блока, которое может выполняться конвертером частотной области во временную область с деформацией времени 180 и, в частности, его устройством для управления окнами 180g.
В зависимости от элемента "window_shape" (который может быть включен в битовый поток, представляющий звуковой сигнал) используются различные супердискретизированные прототипы окна преобразования, а длина супердискретизированных окон -
NOS=2⋅n_long⋅OS_FACTOR_WIN
Для window_shape (длина окна) = 1, коэффициенты окна представлены полученным окном Кайзера-Бесселя (KBD) следующим образом:
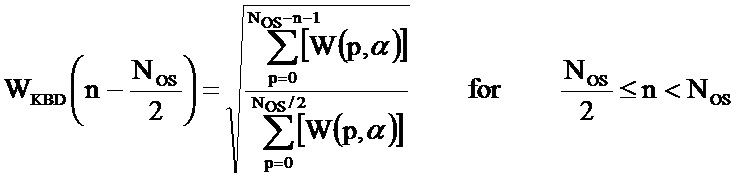
где W', кернфункция Кайзера-Бесселя определяется следующим образом:
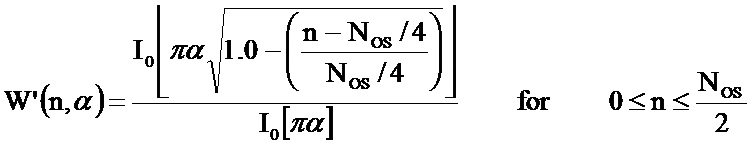
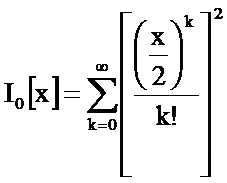
α = альфа фактор базового окна, α=4.
Иначе, для window_shape=0, синусоидальное окно используется следующим образом:

Для всех видов последовательностей окон используемый прототип для левой части окна определяется формой окна предыдущего блока. Следующая формула выражает этот факт:
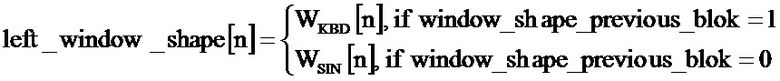
Аналогично, прототип для правой формы окна определяется следующей формулой:
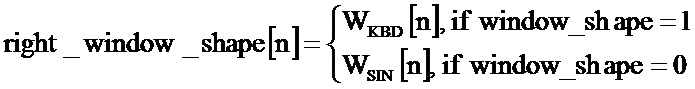
Так как длины перехода уже определены, следует только дифференцировать между последовательностью окна типа "EIGHT_SHORT_SEQUENCE" и всеми другими последовательностями окна.
В случае если текущий фрейм является фреймом типа "EIGHT_SHORT_SEQUENCE", выполняется управление окнами и внутреннее (внутри фрейма) наложение-и-добавление. Часть, подобная С-коду фиг.14, описывает управление окнами и внутреннее наложение - добавление фрейма, имеющего тип окна "EIGHT_SHORT_SEQUENCE".
Для фреймов любых других типов может использоваться алгоритм, представление псевдоуправляющей программы которого показано на фиг.15.
9.7. Процесс декодирования - зависящая от времени повторная выборка
В дальнейшем будет описана зависящая от времени повторная выборка, которая может выполняться преобразователем частотной области во временную область с деформацией времени 180 и, в частности, ресэмплером (синтезатором повторной выборки) 180i.
Реализуемый посредством организации окна блок z [] подвергается повторной выборке согласно положениям выборки (которые предоставляются вычислителем положения выборки 180l на основе декодированной информации о контуре деформации времени 258) посредством использования следующей импульсной характеристики:

α=8
Перед повторной выборкой реализуемый посредством организации окна блок заполняется нолями на обоих концах:

Сама повторная выборка описывается в части псевдоуправляющей программы, показанной на фиг.16.
9.8. Процесс декодирования - наложение и добавление с предыдущими последовательностями окна
Наложение и добавление, которое выполняется устройством наложения / сумматором 180 m преобразователя частотной области во временную область с деформацией времени 180, является тем же самым для всех последовательностей и может описываться математически следующим образом:

9.9. Процесс декодирования - обновление памяти
В дальнейшем будет описано обновление памяти. Хотя никакие характерные возможности на фиг.2b не показаны, следует заметить, что обновление памяти может выполняться преобразователем частотной области во временную область с деформацией времени 180.
Буферы памяти, необходимые для декодирования следующего фрейма, обновляются следующим образом:
past_warp_contour[n]=warp_contour[n+n_long}, for 0≤n<2⋅n_long
cur_warp_sum=new_warp_sum
last_warp_sum=cur_warp_sum
Прежде, чем декодировать первый фрейм или, если последний фрейм был закодирован оптическим кодирующим устройством области LPC (кодирование с линейным предсказанием), состояния памяти устанавливаются следующим образом:
past_warp_contour[n]=1, for 0≤n<2⋅n_long
cur_warp_sum=n_long
last_warp_sum=n_long
9.10. Процесс декодирования - Заключение
Чтобы суммировать вышесказанное, был описан процесс декодирования, который может выполняться преобразователем частотной области во временную область с деформацией времени 180. Как можно видеть, представление временной области предоставляется для звукового фрейма, например, 2048 выборок временной области и последующие звуковые фреймы могут, например, перекрываться приблизительно на 50%, так что обеспечивается гладкий переход между представлениями временной области последующих звуковых фреймов.
Набор, например, NUM_TW_NODES=16 декодированных значений с деформацией времени, может быть связан с каждым из звуковых фреймов (при условии, что деформация времени является активной в указанном звуковом фрейме), независимо от фактической частоты выборки временной области звукового фрейма.
10. Спектральное бесшумное кодирование
В дальнейшем будут описаны некоторые детали относительно спектрального бесшумного кодирования, которое может выполняться декодером контекст-ориентировнного спектрального значения 160 в комбинации с определителем состояния контекста 170. Следует заметить, что соответствующее кодирование может выполняться кодирующим устройством контекстного спектрального значения в комбинации с определителем состояния контекста 140, при этом человек, квалифицированный в этой области, поймет соответствующие этапы кодирования благодаря детальному обсуждению этапов декодирования.
10.1. Спектральное бесшумное кодирование - Описание инструмента
Спектральное бесшумное кодирование используется, чтобы далее уменьшить избыточность квантованного спектра. Схема спектрального бесшумного кодирования основывается на арифметическом кодировании в соединении с динамически адаптированным контекстом. Схема спектрального бесшумного кодирования, обсуждаемая ниже, основывается на кортежах из 2-х элементов, то есть объединяются два соседних спектральных коэффициента. Каждый кортеж из 2-х элементов расщепляется на символ (знак), 2-битовую плоскость самого старшего порядка, и остающиеся битовые плоскости младшего порядка. Бесшумное кодирование для 2-битовой плоскости самого старшего порядка, m, использует контекст-зависимые таблицы накопленных частот, полученные из четырех ранее декодированных кортежей из 2-х элементов. Бесшумное кодирование обеспечивается квантованными спектральными значениями и использует контекст-зависимые таблицы накопленных частот, полученные из (например, выбранный в соответствии с) четырех ранее декодированных соседних кортежей из 2-х элементов. Здесь, соседство, и по времени, и по частоте, принимается во внимание, как иллюстрировано на фиг.16, который показывает графическое представление контекста для вычисления состояния. Таблицы накопленных частот затем используются арифметическим кодером (кодирующее устройство или декодер), чтобы произвести двоичный код переменной длины.
Однако следует заметить, что может быть выбран другой размер контекста. Например, меньшее или большее число кортежей, которые находятся в окружении кортежа, подлежащего декодированию, могут использоваться для определения контекста. Кроме того, кортеж может включать меньшее или большее число спектральных значений. Альтернативно, индивидуальные спектральные значения могут использоваться, чтобы получить контекст, а не кортежи.
Арифметический кодер производит двоичный код для данного набора символов и их соответствующих вероятностей. Двоичный код производится посредством отображения интервала вероятности, где лежит набор символов, на кодовое слово.
10.2 Спектральное бесшумное кодирование - Определения
Относительно определений переменных, констант, и так далее, ссылка делается на фиг.18, который показывает легенду определений.
10.3 Процесс декодирования
Квантованные спектральные коэффициенты "x_ac_dec[]" бесшумно декодируются, начиная от коэффициента самой низкой частоты и продвигаясь до коэффициента самой высокой частоты. Они декодируются, например, группами из двух последовательных коэффициентов а и b, объединенных в так называемый кортеж с 2-мя элементами (а, b).
Декодированные коэффициенты x_ac_dec [] для режима частотной области (как описано выше) затем сохраняются в массиве "x_ac_quant[g][win][sfb][bin]". Порядок передачи кодовых слов бесшумного кодирования таков, что когда они декодируются в порядке, полученном и сохраненном в массиве, bin является самым быстро увеличивающимся (прирастающим) коэффициентом, и g является самым медленно увеличивающимся (прирастающим) коэффициентом. В пределах кодового слова порядок декодирования таков: а и затем b.
Факультативно, коэффициенты для режима преобразование-кодирование-активизация (возбуждение), также могут оцениваться. Хотя вышеприведенные примеры связаны только с кодированием звуковой частотной области и декодированием звуковой частотной области, концепции, раскрытые здесь, могут, фактически, использоваться для звуковых кодирующих устройств и звуковых декодеров, работающих в области преобразование-кодирование-активизация (возбуждение). Декодированные коэффициенты x_ac_dec [] для преобразования-кодирования-возбуждения (ТСХ) сохраняются непосредственно в массиве x_tcx_invquant[win][bin], и порядок передачи кодовых слов бесшумного кодирования таков, что, когда они декодируются в порядке, полученном и сохраненном в массиве, bin является самым быстро увеличивающимся (прирастающим) коэффициентом, и win является самым медленно увеличивающимся (прирастающим) коэффициентом. В пределах кодового слова порядок декодирования таков: а, и затем b.
Во-первых, (факультативный) флаг (флажок) "arith_reset_flag" определяет, должен ли контекст быть восстановлен (или желательно, чтобы он был восстановлен). Если флаг (флажок) - TRUE (истинный), выполняется инициализация.
Процесс декодирования начинается с фазы инициализации, где вектор элемента контекста q обновляется посредством копирования и отображения элементов контекста предыдущего фрейма, сохраненных в массивах (или подмассивах) q [1] [] в q [0] []. Элементы контекста в пределах q сохраняются, например, на 4 битах на кортеж из 2-х элементов. Для получения деталей относительно инициализации делается ссылка на алгоритм, представление псевдоуправляющей программы которого показано на фиг.19.
Вслед за инициализацией, которая может выполняться в соответствии с алгоритмом фиг.19, может выполняться частотное масштабирование контекста, которое обсуждалось выше. Например, массив (или подмассив) q [0] [] может рассматриваться как предварительная структура памяти контекста 432 (или может быть эквивалентным массиву self->base.m_qbuf[][], за исключением деталей относительно размеров и относительно входов е и v). Кроме того, частотно-масштабированный контекст может сохраняться назад в массив q [0] [] (или в массив "self->base.m_qbuf[][]"). Однако альтернативно или в дополнение, содержание массива (или подмассива) q [1] [] может частотно-масштабироваться устройством 438.
Чтобы суммировать, бесшумный декодер производит кортежи из 2-х элементов квантованных спектральных коэффициентов без знака. Сначала (или, обычно, после частотного масштабирования), состояние c контекста вычисляется, основываясь на ранее декодированных спектральных коэффициентах, окружающих кортеж из 2-х элементов, подлежащий декодированию. Поэтому, состояние обновляется инкрементно, используя состояние контекста последнего декодированного кортежа из 2-х элементов, учитывая только два новых кортежа из 2-х элементов. Состояние кодируется, например, на 17 битах и возвращается функцией "arith_get_context []", представление псевдоуправляющей программы которой показано на фиг.20.
Состояние контекста с, которое получается как возвращаемое значение функции "arith_get_context []", определяет таблицу накопленных частот, используемую для декодирования 2-битовой плоскости самого старшего разряда m. Отображение от с на соответствующий индекс pki таблицы накопленных частот выполняется функцией "arith_get_pk []", представление псевдоуправляющей программы которой показано на фиг.21.
Значение m декодируется посредством использования функции "arith_decode []", вызываемой таблицей накопленных частот "arith_cf_m [pki] []", mepki соответствует коэффициенту, возвращенному функцией "arith_get_pk[]". Арифметический кодер - целочисленное выполнение, использующее способ производства тега (управляющего кода) с масштабированием. Псевдо С-код согласно фиг.22 описывает используемый алгоритм.
Когда декодированное значение m является символом смены алфавита "ARITH_ESCAPE", переменные "lev" и "esc_nb" увеличиваются (прирастают) на единицу, и другое значение m декодируется. В этом случае функция "get_pk []" вызывают снова значением с&esc_nb<<17 как входной аргумент, где esc_nb - число символов смены алфавита, ранее декодированных для того же самого кортежа из 2-х элементов, и ограничивающихся 7.
Если значение m не является символом смены алфавита "ARITH_ESCAPE", декодер проверяет, формирует ли следующий m символ "ARITH_STOP". Если условие (esc_nb>0 &&m=0) верно, "ARITH_STOP" обнаруживается, и процесс декодирования заканчивается. Декодер переходит непосредственно к декодированию знака (признака), описываемого позже. Условие означает, что остальная часть фрейма состоит из нулевых значений.
Если символ "ARITH_STOP" не встречается, тогда остающиеся битовые плоскости декодируются, если таковые существует для текущего кортежа из 2-х элементов. Остающиеся битовые плоскости декодируются от уровня самого старшего разряда до уровня самого младшего разряда, вызывая функцию "arith_decode []" lev несколько раз. Декодированные битовые плоскости r позволяют детализировать ранее декодированные значения a, b в соответствии с алгоритмом, псевдоуправляющая программа которого показана на фиг.23.
В этом точке значение без знака кортежа из 2-х элементов (а, b) полностью декодируется. Оно сохраняется в массиве "x_ac_dec []", хранящем спектральные коэффициенты, как показано в псевдоуправляющей программе фиг.24.
Контекст q также обновляется для следующего кортежа из 2-х элементов. Следует заметить, что это обновление контекста может также выполняться для последнего кортежа из 2-х элементов. Обновление контекста выполняется функцией "artih_update_context []", псевдоуправляющая программа которой показана на фиг.25.
Затем следующий кортеж из 2-х элементов фрейма декодируется посредством увеличения (приращения) i на единицу и повторного выполнения того же самого процесса, как описано выше. В частности, может выполняться частотное масштабирование контекста, и впоследствии вышеописанный процесс может быть перезапущен от функции "arith_get_context []". Когда lg/2 кортежи из 2-х элементов декодируется в пределах фрейма, или когда встречается символ остановки "ARITH_STOP", процесс декодирования спектральной амплитуды заканчивается, адекодирование знаков (признаков) начинается.
Как только все квантованные спектральные коэффициенты без знака декодированы, добавляется гармоничный знак(признак). Для каждого ненулевого квантованного значения "х_ас_dec" считывается бит (двоичный разряд). Если считанный бит равен единице, квантованное значение положительное, ничего не сделано, и значение со знаком равно ранее декодированному значению без знака. В противном случае декодированный коэффициент отрицательный, и дополнение двух берется от значения без знака. Знаковые разряды читаются от низких до высоких частот.
Декодирование заканчивается посредством вызова функции "arith_finish []", псевдоуправляющая программа которой показана на фиг.26. Остающиеся спектральные коэффициенты устанавливаются на ноль. Соответствующие состояния контекста соответственно обновляются.
Чтобы суммировать вышесказанное, выполняется контекст-ориентированное (или контекст-зависимое) декодирование спектральных значений, где индивидуальные спектральные значения могут декодироваться, или где спектральные значения могут декодироваться покортежно (как показано выше). Контекст может частотно масштабироваться, как здесь обсуждалось, чтобы получить хорошее исполнение кодирования / декодирования в случае временного изменения основной частоты (или, эквивалентно, высоты (звука)).
11. Звуковой поток согласно фиг.27a-27f
В дальнейшем будет описан звуковой поток, который включает кодированное представление одного или более каналов звукового сигнала и одного или более контуров деформации времени. Звуковой поток, описанный в дальнейшем, может, например, нести кодированное представление звукового сигнала 112 или кодированное представление звукового сигнала 152.
Фиг.27а показывает графическое представление так называемого "USAC_raw_data_block" элемента потока данных, который может включать элемент одиночного канала (SCE), элемент пары каналов (СРЕ) или комбинацию одного или более элементов одиночного канала и/или одного или более элементов пары каналов.
"USAC_raw_data_block" обычно может включать блок кодированных звуковых данных, в то время как дополнительная информация о контуре деформации времени может быть предоставлена в отдельном элементе потока данных. Однако, естественно, можно закодировать некоторые данные контура деформации времени в "USAC_raw_data_block".
Как можно видеть по фиг.27b, элемент одиночного канала обычно включает поток канала частотной области ("fd_channel_stream"), что будет подробно объяснено со ссылкой на фиг.27d.
Как можно видеть по фиг.27 с, элемент пары каналов ("channel_pair_element") обычно включает множество потоков канала частотной области. Кроме того, элемент пары каналов может включать информацию о деформации времени, как, например, флаг (флажок) активации деформации времени ("tw_MDCT"), который может быть передан в элементе конфигурации потока данных или в "USAC_raw_data_block", и который определяет, включена ли информация о деформации времени в элемент пары каналов. Например, если "tw_MDCT" флаг (флажок) показывает, что деформация времени активна, элемент пары каналов может включать флаг (флажок) ("common_tw"), который показывает, есть ли общая деформация времени для звуковых каналов элемента пары каналов. Если указанный флаг (флажок) ("common_tw") показывает, что есть общая деформация времени для многократных звуковых каналов, то общая информация о деформации времени ("tw_data") включается в элемент пары каналов, например, отдельно от потоков канала частотной области.
Теперь со ссылкой на фиг.27d, описывается поток канала частотной области. Как можно видеть по фиг.27d, поток канала частотной области, например, включает информацию о глобальном усилении. Кроме того, поток канала частотной области включает данные деформации времени, если деформация времени активна (флаг (флажок) "tw_MDCT" активный), и если нет общей информации о деформации времени для многократных каналов звукового сигнала (флаг (флажок) "common_tw" неактивный).
Далее, поток канала частотной области также включает данные масштабного коэффициента ("scale_factor_data") и кодированные спектральные данные (например, арифметически закодированные спектральные данные "ac_spectral_data").
Теперь со ссылкой на фиг.27е, кратко обсуждается синтаксис данных деформации времени. Данные деформации времени могут, например, факультативно, включать флаг (флажок) (например, "tw_data_present" или "active_pitch_data"), показывающий, присутствуют ли данные деформации времени. Если данные деформации времени присутствуют (то есть контур деформации времени не является плоским), данные деформации времени могут включать последовательность множества кодированных значений соотношения деформации времени (например, "tw_ratio[i]" или "pitchIdx[i]"), которые могут, например, быть закодированы согласно таблице шифровальной книги, зависящей от частоты выборки, как было описано выше.
Таким образом, данные деформации времени могут включать флаг (флажок), показывающий, что нет доступных данных деформации времени, которые могут быть установлены кодирующим устройством звукового сигнала, если контур деформации времени является постоянным (соотношения деформации времени приблизительно равны 1.000). Наоборот, если контур деформации времени изменяется, соотношения между последующими узлами контура деформации времени могут кодироваться посредством использования коэффициентов шифровальной книги, создавая "tw_ratio" информацию.
Фиг.27f показывает графическое представление синтаксиса арифметически закодированных спектральных данных "ac_spectral_data ()". Арифметически закодированные спектральные данные кодируются в зависимости от статуса флага (флажка) независимости(здесь: "indepFlag"), который показывает, если активен, что арифметически закодированные данные не зависят от арифметически закодированных данных предыдущего фрейма. Если флаг (флажок) независимости "indepFlag" активен, арифметический флаг (флажок) восстановления "arith_reset_flag" устанавливается в активное состояние. В противном случае значение арифметического флага (флажка) восстановления определяется битом (двоичным разрядом) в арифметически закодированных спектральных данных.
Кроме того, арифметически закодированный спектральный блок данных "ac_spectral_data ()" включает одну или более единиц арифметически закодированных данных, где число единиц арифметически закодированных данных "arith_data ()" зависит от числа блоков (или окон) в текущем фрейме. В режиме длинного блока есть только одно окно на звуковой фрейм. Однако в режиме короткого блока может быть, например, восемь окон на звуковой фрейм. Каждая единица арифметически закодированных спектральных данных "arith_data" включает набор спектральных коэффициентов, которые могут служить входом для преобразования частотной области во временную область, которое может выполняться, например, посредством инверсного преобразования 180е.
Число спектральных коэффициентов на единицу арифметически закодированных данных "arith_data" может, например, быть независимым от частоты выборки, но может зависеть от режима длины блока (режим короткого блока "EIGHT_SHORT_SEQUENCE" или режим длинного блока "ONLY_LONG_SEQUENCE").
12. Заключения
Чтобы суммировать вышесказанное, были обсуждены улучшения контекста измененного дискретного косинусного преобразования с деформацией времени. Изобретение, описанное здесь, находится в контексте кодера измененного дискретного преобразования с деформацией времени (см., например, ссылки [1] и [2]), и включает способы улучшения работы кодера MDCT преобразования с деформацией. Одно выполнение такого кодера измененного дискретного косинусного преобразования с деформацией времени реализуется в действующей MPEGUSAC стандартизации звукового кодирования (см., например, ссылку [3]). Детали относительно используемого выполнения TW-MDCT могут быть найдены, например, в ссылке [4].
Однако здесь предложены усовершенствования упомянутой концепции.
13. Альтернативы выполнения
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или характеристике этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или пункта или характеристики соответствующего устройства. Некоторые или все этапы способа могут выполняться (или использоваться) аппаратными средствами, как например, микропроцессор, программируемый компьютер или электронная схема. В некоторых осуществлениях один или более самых важных этапов способа могут быть выполнены таким устройством.
Закодированный звуковой сигнал согласно изобретению может быть сохранен на цифровом носителе данных или может быть передан на передающую среду, такую как беспроводная передающая среда или проводная передающая среда, такая как Интернет.
В зависимости от определенных требований к выполнению осуществления изобретения могут выполняться в аппаратных средствах или в программном обеспечении. Выполнение может реализовываться посредством использования цифрового носителя данных, например, дискета, DVD, Blue-Ray, CD, ROM (постоянное запоминающее устройство, ПЗУ), PROM (программируемое постоянное запоминающее устройство, ППЗУ), EPROM (стираемое программируемое постоянное запоминающее устройство, СППЗУ), EEPROM (электрически стираемое программируемое постоянное запоминающее устройство, ЭСППЗУ) или флэш-память, с хранящимися на них электронно-считываемыми управляющими сигналами, которые взаимодействуют (или могут взаимодействовать) с программируемой компьютерной системой таким образом, что выполняется соответствующий способ. Поэтому, цифровой носитель данных может быть читаемым посредством компьютера.
Некоторые осуществления согласно изобретению включают носитель данных с электронносчитываемыми управляющими сигналами, которые могут взаимодействовать с программируемой компьютерной системой таким образом, чтобы выполнялся один из описанных здесь способов.
В общем, осуществления данного изобретения могут реализовываться как компьютерный программный продукт с управляющей программой; управляющая программа служит для выполнения одного из способов, когда компьютерный программный продукт запущен на компьютере. Управляющая программа может, например, храниться на машиночитаемом носителе.
Другие осуществления включают хранящуюся на машиночитаемом носителе компьютерную программу для выполнения одного из описанных здесь способов.
Другими словами, осуществление способа согласно изобретению, поэтому. представляет собой компьютерную программу, имеющую управляющую программу для выполнения одного из описанных здесь способов, когда компьютерная программа запущена на компьютере.
Дальнейшее осуществление способов согласно изобретению, поэтому, представляет собой носитель данных (или цифровую запоминающую среду, или читаемую компьютером среду), включающий записанную на нем компьютерную программу для выполнения одного из описанных здесь способов. Носитель данных, цифровая запоминающая среда или записанная среда обычно реальные и/или непереходные.
Дальнейшее осуществление способа согласно изобретению, поэтому, представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из описанных здесь способов. Поток данных или последовательность сигналов могут, например, формироваться, чтобы быть переданными через канал передачи данных, например, через Интернет.
Дальнейшее осуществление включает средство обработки, например, компьютер, или программируемое логическое устройство, формируемое для или приспособленное к выполнению одного из описанных здесь способов.
Дальнейшее осуществление включает компьютер с установленной на нем компьютерной программой для выполнения одного из описанных здесь способов.
Дальнейшее осуществление согласно изобретению включает устройство или систему, формируемую, чтобы передавать (например, электронно или оптически) приемнику компьютерную программу для выполнения одного из описанных здесь способов. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством и т.д. Устройство или система может, например, включать файловый сервер для передачи компьютерной программы приемнику.
В некоторых осуществлениях программируемое логическое устройство (например, логическая матрица с эксплуатационным программированием) может использоваться для выполнения некоторых или всех функциональных возможностей описанных здесь способов. В некоторых осуществлениях логическая матрица с эксплуатационным программированием может взаимодействовать с микропроцессором для выполнения одного из описанных здесь способов. В общем, способы предпочтительно выполняются любыми аппаратными средствами устройства.
Описанные выше осуществления просто иллюстрируют принципы данного изобретения. Следует понимать, что модификации и изменения схем и деталей, описанных здесь, будут очевидны для специалистов, сведущих в этой области техники. Поэтому, цель состоит в том, чтобы ограничиться только областью патентной формулы, а не определенными деталями, представленными здесь посредством описания и объяснения осуществлений.
Ссылки
[1] Бернд Эдлер и др. "MDCT с деформацией времени", US 61/042314, Предварительная заявка на патент.
[2] Л. Виллемоус. "Кодирование с преобразованием с деформацией времени звуковых сигналов", РСТ 7 ЕР 2006/010246, Международная заявка на патент, ноябрь 2005 г.
[3] "WD6 USAC", ISO/IEC JTC1/SC29/WG11 N11213, 2010 г.
[4] Бернд Эдлер и др. "Подход MDCTc деформацией времени к кодированию с преобразованием речи", 126-ое Соглашение AES, Мюнхен, май 2009 г., препринт 7710.
[5] Николаус Майне. "Векторное квантование и контекст-зависимое арифметическое кодирование для MPEG-4 AAC", VDI, Ганновер, 2007 г.

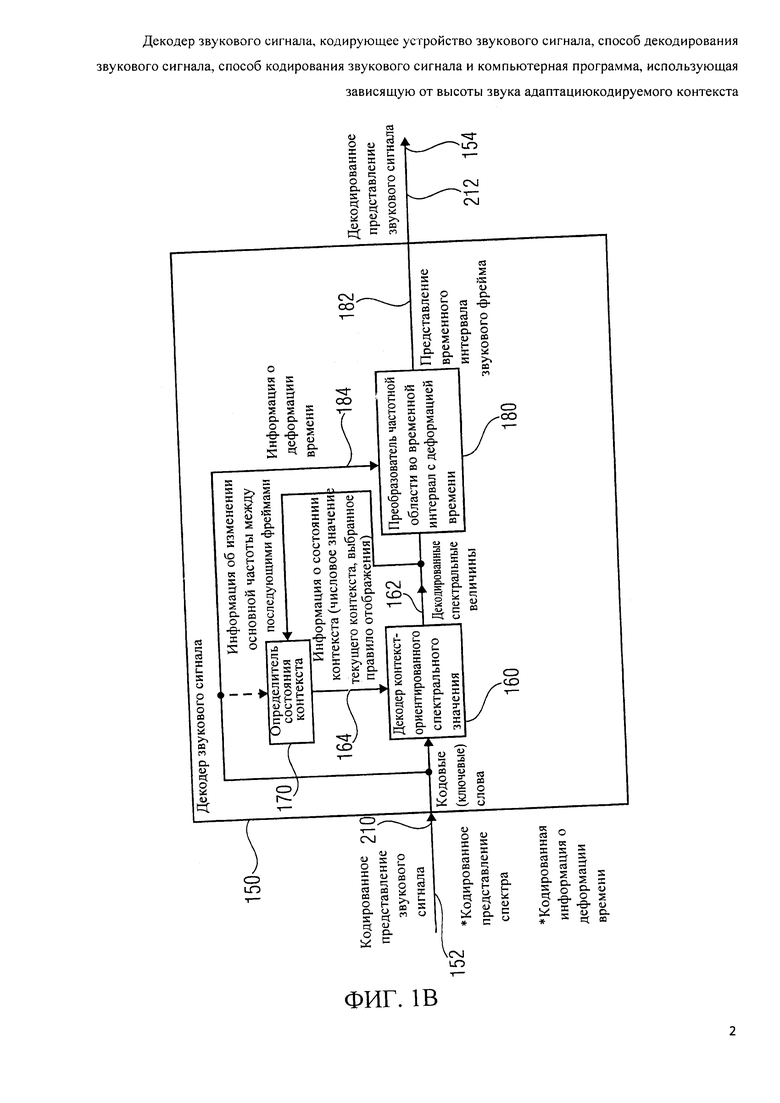


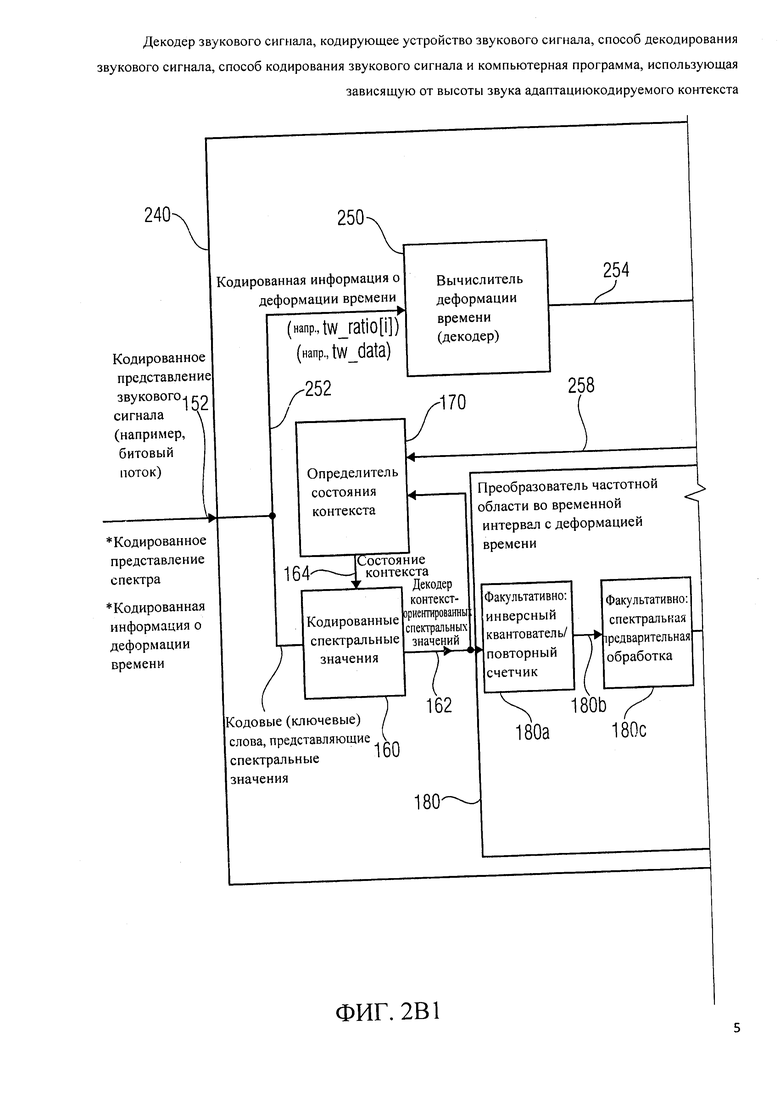

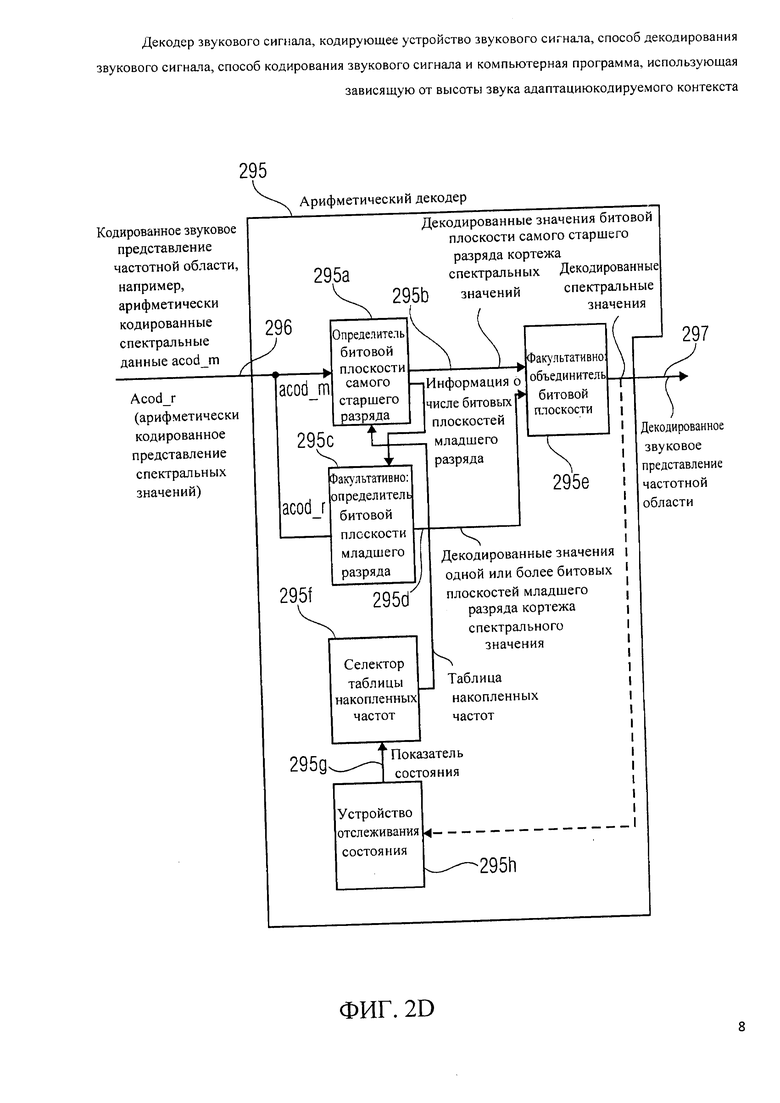

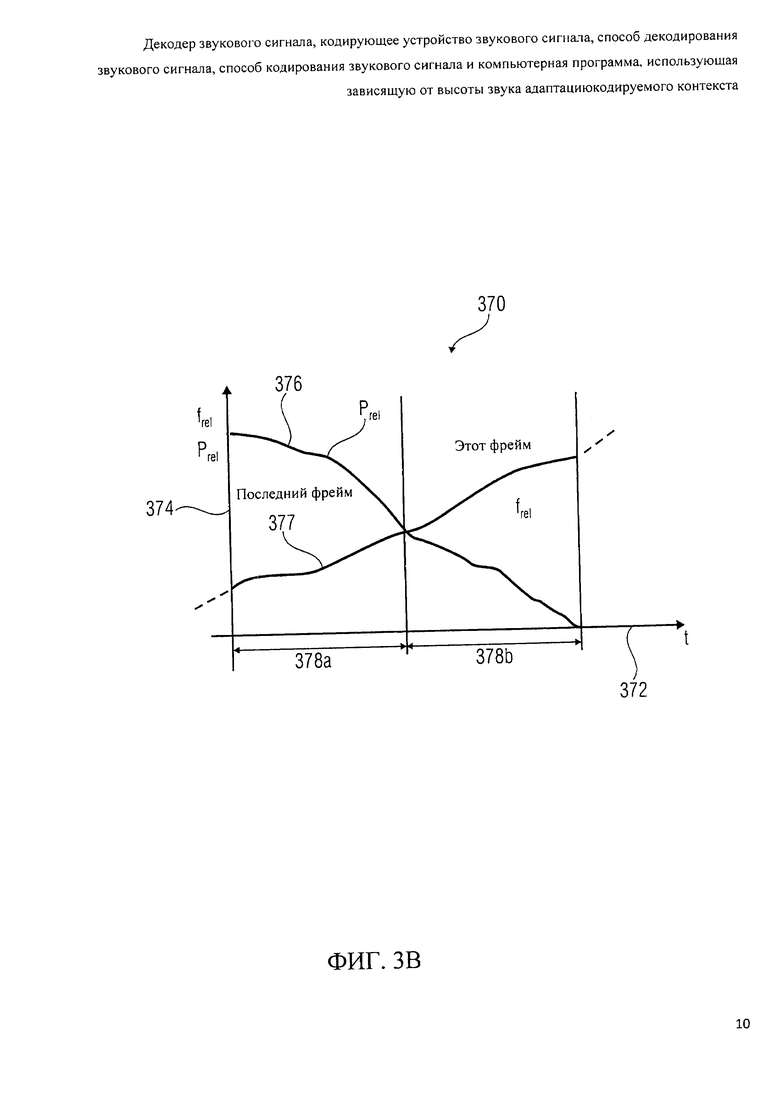
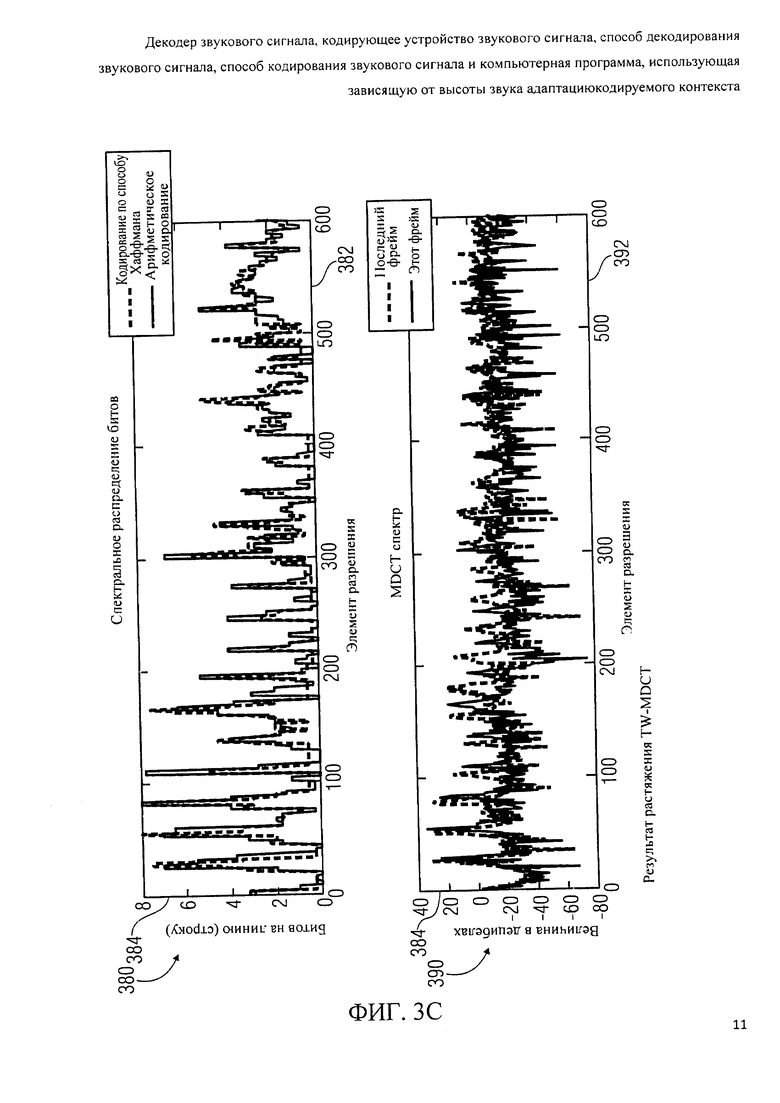






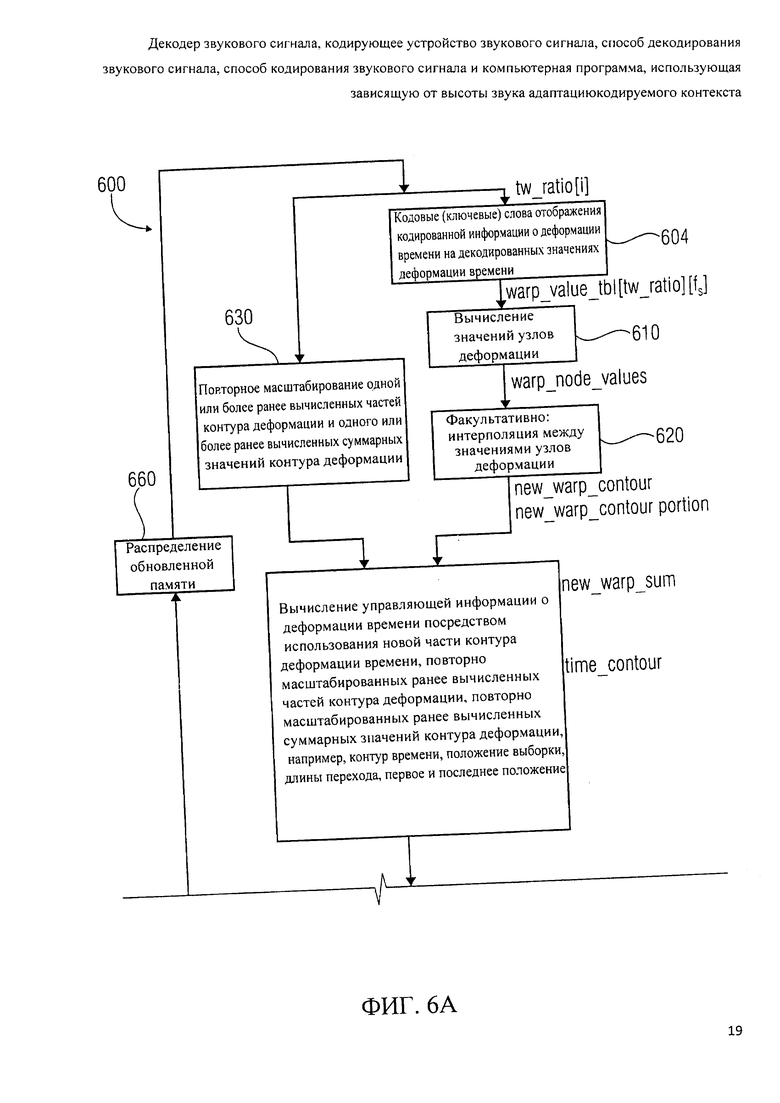
























Изобретение относится к средствам кодирования и декодирования звукового сигнала. Технический результат заключается в повышении эффективности кодирования при наличии колебаний основной частоты. Декодер звукового сигнала включает декодер контекст-ориентированного спектрального значения, сконфигурированный, чтобы декодировать кодовое слово, описывающее одно или более спектральных значений или часть представления чисел одного или более спектральных значений в зависимости от состояния контекста, чтобы получить декодированные спектральные значения. Декодер звукового сигнала также включает определитель состояния контекста, сконфигурированный, чтобы определить текущее состояние контекста в зависимости от одного или более ранних декодированных спектральных значений. Декодер звукового сигнала также включает преобразователь частотной области во временную область с деформацией времени, формируемый, чтобы обеспечить представление временной области с деформацией времени данного звукового фрейма на основе набора декодированных спектральных значений, связанных с данным звуковым фреймом, и предоставленных декодером контекст-ориентированных спектральных значений. 6 н. и 12 з.п. ф-лы, 51 ил.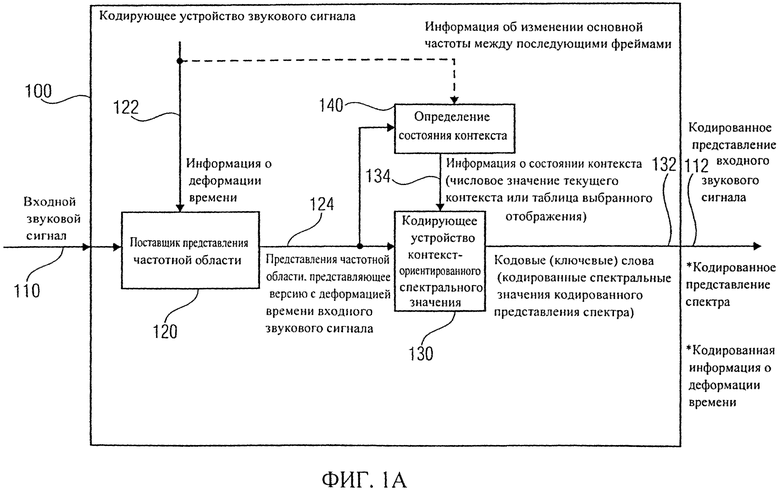
1. Декодер звукового сигнала (150, 240) для обеспечения декодированного представления звукового сигнала (154) на основе кодированного представления звукового сигнала (152), включающего кодированное представление спектра (ac_spectral_data []) и кодированную информацию о деформации времени (tw_data []); декодер звукового сигнала включает:
декодер контекст-ориентированного спектрального значения (160), сконфигурированный, чтобы декодировать кодовое слово (acod_m), описывающее одно или более спектральных значений или, по крайней мере, часть (m) представления чисел одного или более спектральных значений в зависимости от состояния контекста, чтобы получить декодированные спектральные значения (162, 297, x_ac_dec []);
определитель состояния контекста (170, 400), сконфигурированный, чтобы определить текущее состояние контекста (164, с) в зависимости от одного или более ранее декодированных спектральных значений (162, 297);
преобразователь частотной области во временную область с деформацией времени (180), сконфигурированный, чтобы обеспечить представление временной области с деформацией времени (182) данного звукового фрейма на основе набора декодированных спектральных значений (162, 297), связанных с данным звуковым фреймом и предоставленных декодером контекст-ориентированных спектральных значений и в зависимости от информации о деформации времени;
где определитель состояния контекста (170, 400) сконфигурирован, чтобы адаптировать определение состояния контекста к изменению основной частоты между последующими звуковыми фреймами.
2. Декодер звукового сигнала по п. 1, в котором информация о деформации времени (tw_data) описывает изменение (prel) высоты (звука) с течением времени; и
где определитель состояния контекста (170, 400) сконфигурирован, чтобы получить информацию о растяжении частоты (s, m_ContextUpdateRatio) из информации о деформации времени (tw_data); и
где определитель состояния контекста сконфигурирован, чтобы растянуть или сжать прошлый контекст (432, q [0] [], 450), связанный с предыдущим звуковым фреймом, вдоль оси частоты в зависимости от информации о растяжении частоты (s, m_ContextUpdateRatio), чтобы получить адаптированный контекст (440, q [0] [], 452) для декодирования контекст-ориентированного одного или более спектральных значений текущего звукового фрейма.
3. Декодер звукового сигнала по п. 2, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы получить информацию о первой средней частоте (frel, mean, k-1) в первом звуковом фрейме из информации о деформации времени (tw_data, prel, warp_contour []) и чтобы получить информацию о второй средней частоте (frel, mean, k) во втором звуковом фрейме, следующем за первым звуковым фреймом, из информации о деформации времени; и
где определитель состояния контекста сконфигурирован, чтобы вычислить соотношение между информацией о второй средней частоте (frel, mean, k) во втором звуковом фрейме и информацией о первой средней частоте (frel, mean, k-1) в первом звуковом фрейме, чтобы определить информацию о растяжении частоты (s, m_ContextUpdateRatio).
4. Декодер звукового сигнала по п. 2, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы определить информацию о первом среднем контуре с деформацией времени (prel, mean, k-1) в первом звуковом фрейме из информации о деформации времени (tw_data, prel, warp_contour []), и
где определитель состояния контекста сконфигурирован, чтобы получить информацию о втором среднем контуре деформации времени (prel, mean, k) во втором звуковом фрейме, следующем за первым звуковым фреймом, из информации о деформации времени (252, tw_data, prel, warp_contour []), и
где определитель состояния контекста сконфигурирован, чтобы вычислить соотношение между информацией о первом среднем контуре деформации времени (prel, mean, k-1) в первом звуковом фрейме и информацией о втором среднем контуре деформации времени (prel, mean, k) во втором звуковом фрейме для определения информации о растяжении частоты (s, m_ContextUpdateRatio).
5. Декодер звукового сигнала по п. 3, где определитель состояния контекста (170, 400) сконфигурирован, чтобы получить информацию о первой и второй средней частоте или информацию о первом и втором среднем контуре деформации времени из общего контура деформации времени (warp_contour []), простирающегося по множеству последовательных звуковых фреймов.
6. Декодер звукового сигнала по п. 3, где декодер звукового сигнала включает вычислитель деформации времени (250), сконфигурированный, чтобы вычислить информацию о контуре деформации времени (prel[], warp_contour [], 258), описывающую временную эволюцию относительной высоты (звука) по множеству последовательных звуковых фреймов на основе информации о деформации времени (tw_data, 252), и
где определитель состояния контекста (170, 400) сконфигурирован, чтобы использовать информацию о контуре деформации времени для получения информации о растяжении частоты.
7. Декодер звукового сигнала по п. 6, где декодер звукового сигнала включает вычислитель положения повторной выборки (180l),
где вычислитель положения повторной выборки (180l) сконфигурирован, чтобы вычислить положения выборки для использования устройством восстановления дискретизированного сигнала с деформацией времени (180i) на основе информации о контуре деформации времени (prel[], warp_contour [], 258), таким образом, что временное изменение положений повторной выборки определяется информацией о контуре деформации времени.
8. Декодер звукового сигнала по одному из п. 1, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы получить числовое значение текущего контекста (164, с), которое описывает состояние контекста в зависимости от множества ранее декодированных спектральных значений, и чтобы выбрать правило отображения (cum_freq []), описывающее отображение кодового значения (acod_m) на коде символа, представляющем одно или более спектральных значений, или часть (m) представления чисел одного или более спектральных значений в зависимости от числового значения текущего контекста,
где декодер контекст-ориентированного спектрального значения (160) сконфигурирован, чтобы декодировать кодовое значение (acod_m), описывающее одно или более спектральных значений, или, по крайней мере, часть (m) представления чисел одного или более спектральных значений посредством использования правила отображения (cum_freq []), выбранного определителем состояния контекста.
9. Декодер звукового сигнала по п. 8, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы настроить и обновить предварительную структуру памяти контекста (432, m_qbuf) таким образом, чтобы входы предварительной структуры памяти контекста описывали одно или более спектральных значений (162, 297) первого звукового фрейма, где коэффициенты входа входов предварительной структуры памяти контекста указывают на элемент разрешения по частоте или набор смежных элементов разрешения по частоте преобразователя частотной области во временную область (180е), с которым связаны соответствующие входы;
где определитель состояния контекста сконфигурирован, чтобы получить частотно-масштабированную структуру памяти контекста (440, m_qbuf) для декодирования второго звукового фрейма, следующего за первым звуковым фреймом, на основе предварительной структуры памяти контекста таким образом, что данный вход (450а, 450с, self->base.m_qbuf[nWarpTupleIdx]) или элемент данных (self->base.m_qbuf[nWarpTupleIdx].a) предварительной структуры памяти контекста, имеющей первый коэффициент частотности (i1+1, i2+2, nWarpTupleIdx), отображаются на соответствующем входе (452а, 452с, self->base.m_qbuf[nLinTupleIdx]) или элементе данных (self->base.m_qbuf[nLinTupleIdx].a) частотно-масштабированной структуры памяти контекста (440, m_qbuf, 452), имеющей второй коэффициент частотности (i1, i2-1, nLinTupleIdx), где второй коэффициент частотности связывается с иным элементом разрешения по частоте или набором смежных элементов разрешения по частоте преобразователя частотной области во временную область (180е), чем первый коэффициент частотности.
10. Декодер звукового сигнала по п. 9, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы получить значение состояния контекста (164 420), описывающее текущее состояние контекста для декодирования кодового слова (acod_m), описывающего одно или более спектральных значений второго звукового фрейма, или, по крайней мере, часть (m) представления чисел одного или более спектральных значений второго звукового фрейма, имеющую третий коэффициент частотности (i1), посредством использования значений частотно-масштабированной структуры памяти контекста (440, m_qbuf, 452), коэффициенты частотности (i1-1, i1, i1+1) значений частотно-масштабированной структуры памяти контекста которых находятся в предварительно определенных отношениях с третьим коэффициентом частотности (i1),
где третий коэффициент частотности (i1) обозначает элемент разрешения по частоте или набор смежных элементов разрешения по частоте преобразователя частотной области во временную область (180е), с которым связано одно или более спектральных значений второго звукового фрейма, подлежащих декодированию, посредством использования текущего состояния контекста.
11. Декодер звукового сигнала по п. 9, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы установить каждое множество входов (452а, 452с, self->base.m_qbuf[nLinTupleIdx]) частотно-масштабированной структуры памяти контекста (440 452, m_qbuf), имеющей соответствующий целевой коэффициент частотности (i1, i2-1, nLinTupleIdx), назначение соответствующего входа (450а, 450с, self->base.m_qbuf[nWarpTupleIdx]) предварительной структуры памяти контекста (432 450, m_qbuf), имеющего соответствующий исходный коэффициент частотности (i1+1, i2+2, nWarpTupleIdx),
где определитель состояния контекста сконфигурирован, чтобы определить соответствующие коэффициенты частотности (i1, i1+1; i2-1, i2+2; nLinTupleIdx, nWarpTupleIdx) входа частотно-масштабированной структуры памяти контекста и соответствующего входа предварительной структуры памяти контекста таким образом, что соотношение между указанными соответствующими коэффициентами частотности (nLinTupleIdx, nWarpTupleIdx) определяется изменением основной частоты между текущим звуковым фреймом, с которым связаны входы предварительной структуры памяти контекста, и последующим звуковым фреймом, декодируемый контекст которого определяется входами частотно-масштабированной структуры памяти контекста.
12. Декодер звукового сигнала по п. 9, в котором определитель состояния контекста (170, 400) сконфигурирован, чтобы настроить предварительную структуру памяти контекста (432, m_qbuf, 450) таким образом, что каждое множество входов (450а, 450с, self->base.m_qbuf[nWarpTupleIdx]) предварительной структуры памяти контекста основывается на множестве спектральных значений (а, b, с, d) первого звукового фрейма, где коэффициенты входа (i1+1, i2+2, nWarpTupleIdx) входов предварительной структуры памяти контекста (432 450, m_qbuf) указывают на набор смежных элементов разрешения по частоте преобразователя частотной области во временную область (180е), с которым связаны соответствующие входы;
где определитель состояния контекста сконфигурирован, чтобы извлечь предварительные значения индивидуальных элементов разрешения по частоте контекста (lineReorderBuf [(curTuple-1) *4+0], …, lineReorderBuf [(curTuple-1) *4+3]), имеющие связанные индивидуальные коэффициенты элементов разрешения по частоте, из входов (self->base.m_qbuf[curTuple[][]) предварительной структуры памяти контекста;
где определитель состояния контекста сконфигурирован, чтобы получить частотно-масштабированные значения индивидуальных элементов разрешения по частоте контекста (lineTmpBuf [linLineIdx]), имеющие связанные индивидуальные коэффициенты разрешения по частоте (linLineIdx), таким образом, что данное предварительное значение индивидуального элемента разрешения по частоте контекста (lineReorderBuf [warpLineIdx]), имеющее первый коэффициент элемента разрешения по частоте (warpLineIdx), отображается на соответствующем значении частотно-масштабированного индивидуального элемента разрешения по частоте контекста (lineTmpBuf [linLineIdx]), имеющем второй коэффициент элемента разрешения по частоте (linLineIdx), таким образом, что получается отображение индивидуального элемента разрешения по частоте предварительного значения индивидуального элемента разрешения по частоте контекста; и
где определитель состояния контекста сконфигурирован, чтобы объединить множество частотно-масштабированных значений индивидуальных элементов разрешения по частоте контекста (lineTmpBuf [(curTuple-1) *4+0, …, lineTmpBuf [(curTuple-1) *4+3] в объединенный вход (self->base.m_qbuf[curTuple][]) частотно-масштабированной структуры памяти контекста.
13. Кодирующее устройство звукового сигнала (100, 200) для обеспечения кодированного представления (112) входного звукового сигнала (110), включающего кодированное представление спектра (132) и кодированную информацию о деформации времени (226); кодирующее устройство звукового сигнала включает:
поставщик представления частотной области (120), сконфигурированный для обеспечения представления частотной области (124), представляющего версию входного звукового сигнала с деформацией времени; деформация времени в соответствии с информацией о деформации времени (122);
кодирующее устройство контекст-ориентированного спектрального значения (130), сконфигурированное, чтобы обеспечить кодовое слово (acod_m), описывающее одно или более спектральных значений представления частотной области (124), или, по крайней мере, часть (m) представления чисел одного или более спектральных значений представления частотной области (124), в зависимости от состояния контекста (134), чтобы получить кодированные спектральные значения (acod m) кодированного представления спектра (132); и
определитель состояния контекста (140), сконфигурированный, чтобы определить текущее состояние контекста (134) в зависимости от одного или более ранее закодированных спектральных значений, где определитель состояния контекста (140) сконфигурирован, чтобы адаптировать определение состояния контекста к изменению основной частоты между последующими звуковыми фреймами.
14. Кодирующее устройство звукового сигнала по п. 13, в котором определитель состояния контекста сконфигурирован, чтобы получить числовое значение текущего контекста (134, с) в зависимости от множества ранее закодированных спектральных значений и выбрать правило отображения, описывающее отображение одного или более спектральных значений, или части (m) представления чисел одного или более спектральных значений, на кодовое значение (acod_m) в зависимости от числового значения текущего контекста,
где кодирующее устройство контекст-ориентированного спектрального значения сконфигурировано, чтобы обеспечить кодовое значение, описывающее одно или более спектральных значений, или, по крайней мере, часть представления чисел одного или более спектральных значений посредством использования правила отображения, выбранного определителем состояния контекста.
15. Способ обеспечения декодированного представления звукового сигнала (154) на основе кодированного представления звукового сигнала (152), включающего кодированное представление спектра (ac_spectral_data []) и кодированную информацию о деформации времени (tw_data []); способ включает:
декодирование кодового слова (acod_m), описывающего одно или более спектральных значений или, по крайней мере, часть (m) представления чисел одного или более спектральных значений в зависимости от состояния контекста, чтобы получить декодированные спектральные значения (162, 297, x_ac_dec []);
определение текущего состояния контекста (164, с) в зависимости от одного или более ранних декодированных спектральных значений (162, 297);
обеспечение представления временной области с деформацией времени (182) данного звукового фрейма на основе набора декодированных спектральных значений (162, 297), связанных с данным звуковым фреймом и предоставленных декодером контекст-ориентированных спектральных значений и в зависимости от информации о деформации времени;
где определение состояния контекста адаптируется к изменению основной частоты между последующими звуковыми фреймами.
16. Способ обеспечения кодированного представления (112) входного звукового сигнала (110), включающего кодированное представление спектра (132) и кодированную информацию о деформации времени (226); способ включает:
обеспечение представления частотной области (124), представляющего версию входного звукового сигнала с деформацией времени; деформация времени в соответствии с информацией о деформации времени (122);
обеспечение кодового слова (acod_m), описывающего одно или более спектральных значений представления частотной области (124) или, по крайней мере, часть (m) представления чисел одного или более спектральных значений представления частотной области (124), в зависимости от состояния контекста (134), чтобы получить кодированные спектральные значения (acod m) кодированного представления спектра (132); и
определение текущего состояния контекста (134) в зависимости от одного или более ранних закодированных спектральных значений,
где определение состояния контекста адаптируется к изменению основной частоты между последующими звуковыми фреймами.
17. Машиночитаемый носитель информации с сохраненной на нем компьютерной программой, имеющей код программы, для осуществления способа по п. 15.
18. Машиночитаемый носитель информации с сохраненной на нем компьютерной программой, имеющей код программы, для осуществления способа по п. 16.
| US 2007100607 A1, 03.05.2007 | |||
| WO 2010003583 A1, 14.01.2010 | |||
| JP 2004309893 A, 04.11.2004 | |||
| US 2004156397 A1, 12.08.2004 | |||
| СИСТЕМЫ, СПОСОБЫ И УСТРОЙСТВА ДЛЯ ВЫСОКОПОЛОСНОГО ПРЕДЫСКАЖЕНИЯ ШКАЛЫ ВРЕМЕНИ | 2006 |
|
RU2376657C2 |

