Перекрестная ссылка на родственные заявки
[1] Данная заявка представляет собой национальную фазу международной заявки № PCT/KR2014/000093, поданной 6 января 2014 г., претендующей на приоритет предварительной заявки США № 61/748 964, поданной 4 января 2013 г., содержимое которой включено в данный документ по ссылке во всей своей полноте.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[2] Способы и устройства, совместимые с примерными вариантами осуществления, относятся к энтропийному кодированию и энтропийному декодированию для видеокодирования и видеодекодирования.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[3] Так как были разработаны и поставляются аппаратные средства для воспроизведения и хранения видеоконтента с высоким разрешением или высоким качеством, увеличилась потребность в видеокодеке, который эффективно кодирует или декодирует видеоконтент с высоким разрешением или высоким качеством. Обычно, видео кодируется в соответствии со способом ограниченного кодирования, основанным на макроблоке, имеющим заданный размер.
[4] Данные изображения пространственной области преобразуются в коэффициенты частотной области посредством использования преобразования частоты. Видеокодек разбивает изображение на блоки, причем каждый имеет заранее заданный размер, чтобы быстро выполнять преобразование частоты, выполняет преобразование DCT (дискретное косинусное преобразование) каждого блока и кодирует частотные коэффициенты в единицах блоков. Коэффициенты частотной области могут сжиматься легче, чем данные изображения пространственной области. В частности, так как значение пикселя изображения пространственной области выражается в виде ошибки предсказания посредством внешнего предсказания или внутреннего предсказания видеокодека, то когда выполняется преобразование частоты ошибки предсказания, большие количества данных могут преобразовываться в нуль (0). Видеокодек уменьшает количество данных посредством замены данных, которые постоянно и повторно генерируются, на данные, имеющие меньший размер.
[5] Выполняется энтропийное кодирование, чтобы сжать строку битов символа, генерируемого видеокодированием. Недавно широко использовалось энтропийное кодирование на основе арифметического кодирования. Чтобы выполнять энтропийное кодирование на основе арифметического кодирования, символы оцифровываются в строку битов, и выполняется контекстное арифметическое кодирование строки битов.
Сущность изобретения
[6] Примерные варианты осуществления обеспечивают способы энтропийного кодирования и декодирования, использующие контекстную информацию близлежащих данных, учитывая атрибут сегмента слайса, для видеокодирования и видеодекодирования.
[7] Согласно аспекту примерного варианта осуществления способ энтропийного видеодекодирования включает в себя: определение строки бинов («контейнеров») и индекса бина для максимальной единицы кодирования, которая получается из битового потока; определение значения синтаксического элемента посредством сравнения определенной строки бинов со строками бинов, которые могут быть назначены синтаксическому элементу в индексе бина; когда синтаксический элемент является последним синтаксическим элементом в максимальной единице кодирования, зависимый сегмент слайса может быть включен в видеокадр, в который включена максимальная единица кодирования, и максимальной единицей кодирования является последняя максимальная единица кодирования в сегменте слайса, сохранение контекстных переменных для максимальной единицы кодирования; и восстановление символов максимальной единицы кодирования посредством использования определенного значения синтаксического элемента.
[8] Согласно аспекту примерного варианта осуществления способ энтропийного видеодекодирования включает в себя: определение строки бинов и индекса бина для максимальной единицы кодирования, которая получается из битового потока; определение значения синтаксического элемента посредством сравнения определенной строки бинов со строками бинов, которые являются назначаемыми синтаксическому элементу в индексе бина; сохранение контекстных переменных для максимальной единицы кодирования, когда синтаксический элемент является последним синтаксическим элементом в максимальной единице кодирования, зависимый сегмент слайса является включаемым в видеокадр, в который включена максимальная единица кодирования, и максимальная единица кодирования является последней максимальной единицей кодирования в сегменте слайса; и восстановление символов максимальной единицы кодирования посредством использования определенного значения синтаксического элемента.
[9] Сохранение контекстных переменных согласно различным примерным вариантам осуществления может включать в себя сохранение контекстных переменных для максимальной единицы кодирования, когда зависимый сегмент слайса является включаемым в видеокадр, независимо от того, является ли сегмент слайса независимым сегментом слайса или зависимым сегментом слайса.
[10] Способ энтропийного видеодекодирования согласно различным примерным вариантам осуществления может дополнительно включать в себя использование сохраненных контекстных переменных для энтропийного декодирования контекстной переменной первой максимальной единицы кодирования зависимого сегмента слайса, причем зависимый сегмент слайса находится среди сегментов слайса, включенных в видеокадр, и располагается после сегмента слайса.
[11] Способ энтропийного видеодекодирования согласно различным примерным вариантам осуществления может дополнительно включать в себя: определение, является ли зависимый сегмент слайса включаемым в видеокадр, основываясь на первой информации, которая получается из набора параметров видеокадра битового потока; определение, является ли максимальная единица кодирования последней максимальной единицей кодирования в сегменте слайса, основываясь на второй информации, которая получается из данных о максимальной единице кодирования, причем данные о максимальной единице кодирования включены в число данных, соответствующих сегментам слайса битового потока; и получение строки бинов из данных о максимальной единице кодирования.
[12] Способ энтропийного видеодекодирования согласно различным примерным вариантам осуществления может дополнительно включать в себя: определение числа точек входа поднаборов, которые включены в сегмент слайса, основываясь на третьей информации, которая получается из заголовка сегмента слайса битового потока; определение положения каждой точки входа посредством использования смещения и числа, указанного четвертой информацией, причем смещение представляет собой число, которое больше числа, указанного четвертой информацией на 1, и четвертая информация получается из заголовка сегмента слайса битового потока и указывает смещение в соответствии с каждой точкой входа; и число точек входа и положения точек входа определяются тогда, когда тайл является включаемым в сегмент слайса, который включен в видеокадр, или операция синхронизации является выполняемой для контекстных переменных максимальной единицы кодирования, которая включена в видеокадр.
[13] Согласно аспекту примерного варианта осуществления способ энтропийного видеокодирования включает в себя: генерирование строки битов символов, которые определяются посредством кодирования максимальной единицы кодирования; определение контекстной переменной в соответствии с каждым индексом бина значения синтаксического элемента, соответствующего символам; определение строки бинов, указывающей значение синтаксического элемента, основываясь на контекстном значении синтаксического элемента; и сохранение контекстных переменных для максимальной единицы кодирования, когда синтаксический элемент является последним синтаксическим элементом в максимальной единице кодирования, зависимый сегмент слайса является включаемым в видеокадр, в который включена максимальная единица кодирования, и максимальная единица кодирования является последней максимальной единицей кодирования в сегменте слайса.
[14] Сохранение контекстных переменных согласно различным примерным вариантам осуществления может включать в себя сохранение контекстных переменных для максимальной единицы кодирования, когда зависимый сегмент слайса является включаемым в видеокадр, независимо от того, является ли сегмент слайса независимым сегментом слайса или зависимым сегментом слайса.
[15] Согласно аспекту примерного варианта осуществления устройство энтропийного видеодекодирования включает в себя: инициализатор контекста, который определяет строку бинов и индекс бина для максимальной единицы кодирования, которая получается из битового потока, и определяет значение синтаксического элемента посредством сравнения определенной строки бинов со строками бинов, которые являются назначаемыми синтаксическому элементу в индексе бина; блок сохранения контекста, который сохраняет контекстные переменные для максимальной единицы кодирования, когда синтаксический элемент является последним синтаксическим элементом в максимальной единице кодирования, зависимый сегмент слайса является включаемым в видеокадр, в который включена максимальная единица кодирования, и максимальная единица кодирования является последней максимальной единицей кодирования в сегменте слайса; и блок восстановления символа, который восстанавливает символы максимальной единицы кодирования посредством использования определенного значения синтаксического элемента.
[16] Согласно аспекту примерного варианта осуществления устройство энтропийного видеокодирования включает в себя: бинаризатор, который генерирует строку битов символов, которые определяются посредством выполнения кодирования максимальной единицы кодирования; определитель строки бинов, который определяет значение контекста в соответствии с каждым индексом бина значения синтаксического элемента, соответствующего символам, и определяет строку бинов, указывающую значение синтаксического элемента, основываясь на контекстной переменной синтаксического элемента; и блок сохранения контекста, который сохраняет контекстные переменные для максимальной единицы кодирования, когда синтаксический элемент является последним синтаксическим элементом в максимальной единице кодирования, зависимый сегмент слайса является включаемым в видеокадр, в который включена максимальная единица кодирования, и максимальная единица кодирования является последней максимальной единицей кодирования в сегменте слайса.
[17] Согласно аспекту примерного варианта осуществления обеспечивается считываемая компьютером среда записи, имеющая внедренную на ней инструкциями программу, которая при исполнении компьютером выполняет способ энтропийного видеодекодирования.
[18] Согласно аспекту примерного варианта осуществления обеспечивается считываемая компьютером среда записи, имеющая внедренную на ней инструкциями программу, которая при исполнении компьютером выполняет способ энтропийного видеокодирования.
[19] Таким образом, если зависимый сегмент слайса может использоваться в текущем видеокадре, основанном на энтропийном кодировании/декодировании, контекстная переменная может сохраняться после того, как будет завершено энтропийное кодирование (декодирование) последней максимальной единицы кодирования (LCU) каждого сегмента слайса. Следовательно, хотя предыдущий сегмент слайса является независимым сегментом слайса, начальная переменная контекстной переменной, которая необходима для следующего зависимого сегмента слайса, может быть получена из контекстной переменной последней LCU независимого сегмента слайса, который кодировался ранее.
[20] Так как информация, указывающая число, которое меньше на 1 смещения поднабора, обеспечивается посредством сегмента слайса, чтобы эффективно информировать о точке синхронизации контекстной переменной для энтропийного кодирования/декодирования, может быть уменьшен размер данных сегмента слайса.
Краткое описание чертежей
[21] Фиг.1A представляет собой блок-схему, иллюстрирующую устройство энтропийного видеокодирования согласно одному или нескольким примерным вариантам осуществления.
[22] Фиг.1B представляет собой блок-схему последовательности операций способа энтропийного видеокодирования согласно одному или нескольким примерным вариантам осуществления.
[23] Фиг.2A представляет собой блок-схему, иллюстрирующую устройство энтропийного видеодекодирования согласно одному или нескольким примерным вариантам осуществления.
[24] Фиг.2B представляет собой блок-схему последовательности операций способа энтропийного видеодекодирования согласно одному или нескольким примерным вариантам осуществления.
[25] Фиг.3 представляет собой чертеж, иллюстрирующий тайлы и максимальные единицы кодирования (LCU) в видеокадре.
[26] Фиг.4 представляет собой чертеж, иллюстрирующий сегмент слайса и LCU в видеокадре.
[27] Фиг.5 представляет собой блок-схему последовательности действий операции синтаксического анализа контекстно-адаптивного двоичного арифметического кодирования (CABAC) согласно примерному варианту осуществления.
[28] Фиг.6A представляет собой чертеж для объяснения энтропийного декодирования с использованием сохраненной контекстной переменной.
[29] Фиг.6B представляет собой подробную блок-схему последовательности действий операции сохранения контекстной переменной в операции синтаксического анализа CABAC согласно примерному варианту осуществления.
[30] Фиг.7 представляет собой чертеж, иллюстрирующий синтаксис заголовка сегмента слайса согласно примерному варианту осуществления.
[31] Фиг.8 представляет собой блок-схему устройства видеокодирования, основанного на единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления.
[32] Фиг.9 представляет собой блок-схему устройства видеодекодирования, основанного на единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления.
[33] Фиг.10 представляет собой чертеж для объяснения понятия единиц кодирования согласно примерному варианту осуществления.
[34] Фиг.11 представляет собой блок-схему кодера изображений, основанного на единицах кодирования, согласно примерному варианту осуществления.
[35] Фиг.12 представляет собой блок-схему декодера изображений, основанного на единицах кодирования, согласно примерному варианту осуществления.
[36] Фиг.13 представляет собой чертеж, иллюстрирующий более глубокие единицы кодирования в соответствии с глубинами и разделами согласно примерному варианту осуществления.
[37] Фиг.14 представляет собой чертеж для объяснения взаимосвязи между единицей кодирования и единицами преобразования согласно примерному варианту осуществления.
[38] Фиг.15 представляет собой чертеж для объяснения информации кодирования единиц кодирования, соответствующих кодированной глубине, согласно примерному варианту осуществления.
[39] Фиг.16 представляет собой чертеж, иллюстрирующий более глубокие единицы кодирования в соответствии с глубинами согласно примерному варианту осуществления.
[40] Фиг.17-19 представляют собой чертежи для объяснения взаимосвязи между единицами кодирования, единицами предсказания и единицами преобразования, согласно примерному варианту осуществления.
[41] Фиг.20 представляет собой чертеж для объяснения взаимосвязи между единицей кодирования, единицей предсказания и единицей преобразования в соответствии с информацией о режиме кодирования таблицы 1.
[42] Фиг.21 представляет собой чертеж, иллюстрирующий физическую структуру диска, на котором сохраняется программа согласно примерному варианту осуществления.
[43] Фиг.22 представляет собой чертеж, иллюстрирующий дисковод для записи и считывания программы посредством использования диска.
[44] Фиг.23 представляет собой чертеж, иллюстрирующий общую структуру системы подачи контента для предоставления услуги распределения контента.
[45] Фиг.24 и 25 представляют собой чертежи, иллюстрирующие внешнюю конструкцию и внутреннюю конструкцию мобильного телефона, в котором применяются способ видеокодирования и способ видеодекодирования согласно примерному варианту осуществления, согласно примерному варианту осуществления.
[46] Фиг.26 представляет собой чертеж, иллюстрирующий систему цифрового вещания, в которой применяется система связи согласно примерному варианту осуществления.
[47] Фиг.27 представляет собой чертеж, иллюстрирующий сетевую структуру системы облачных вычислений, использующей устройство видеокодирования и устройство видеодекодирования согласно примерному варианту осуществления.
ПОДРОБНОЕ ОПИСАНИЕ ПРИМЕРНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[48] Способ энтропийного кодирования в сегменте слайса и способ энтропийного декодирования в сегменте слайса согласно различным примерным вариантам осуществления объясняется с ссылкой на фиг.1A-7. Способ видеокодирования и способ видеодекодирования, основанные на единицах кодирования, имеющих древовидную структуру согласно различным примерным вариантам осуществления, в которых может применяться способ энтропийного кодирования и способ энтропийного декодирования, объясняются с ссылкой на фиг.8-20. Кроме того, различные примерные варианты осуществления, в которых может применяться способ видеокодирования и способ видеодекодирования, объясняются с ссылкой на фиг.21-27. Ниже в данном документе термин «изображение» может ссылаться на неподвижное изображение или движущееся изображение, т.е. само видео.
[49] Фиг.1A представляет собой блок-схему устройства 10 энтропийного видеокодирования согласно различным примерным вариантам осуществления.
[50] Устройство 10 энтропийного видеокодирования согласно различным примерным вариантам осуществления включает в себя бинаризатор 12, определитель 14 строки бинов и блок 16 сохранения контекста.
[51] Устройство 10 энтропийного видеокодирования может выполнять энтропийное кодирование символов, которые кодируются в соответствии с максимальными единицами кодирования (LCU). Устройство 10 энтропийного видеокодирования может сохранять видеокодер (не показан), который выполняет кодирование LCU.
[52] Для удобства объяснения ниже подробно объясняется процесс, используемый устройством 10 энтропийного видеокодирования, включающий в себя видеокодер (не показан), для выполнения кодирования LCU и генерирования символов. Однако понятно, что устройство 10 энтропийного видеокодирования не ограничивается конструкцией, непосредственно включающей в себя видеокодер (не показан), и устройство 10 энтропийного видеокодирования может принимать символы, которые кодируются внешним устройством кодирования.
[53] Процесс видеокодирования согласно примерному варианту осуществления может быть разделен на процесс кодирования источника, который минимизирует избыточные данные вследствие пространственно-временного сходства данных изображения, и процесс энтропийного кодирования, который минимизирует избыточность снова в строке битов данных, которые генерируются посредством процесса кодирования источника. Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления выполняет кодирование источника каждого из видеокадров, которые составляют видео, в соответствии с блоками, и генерирует кодированные символы. Кодирование источника включает в себя процесс выполнения внутреннего предсказания/внешнего предсказания, преобразования и квантования видеоданных в пространственной области в единицах блоков. В результате кодирования источника могут генерироваться кодированные символы в соответствии с блоками. Примеры кодированных символов могут включать в себя квантованный коэффициент преобразования составляющей остатка, вектор движения, атрибут внутреннего режима, атрибут внешнего режима и параметр квантования.
[54] Энтропийное кодирование согласно примерному варианту осуществления может быть разделено на процесс бинаризации, который преобразует символы в строку битов, и процесс арифметического кодирования, который выполняет контекстное арифметическое кодирование строки битов. Контекстно-адаптивное двоичное арифметическое кодирование (CABAC) широко используется в качестве способа кодирования, который выполняет контекстное арифметическое кодирование. Согласно контекстному арифметическому кодированию/декодированию каждым битом строки битов символов может быть каждый бин, и положение каждого бита может отображаться на индекс бина. Длина строки битов, т.е. длина бинов, может изменяться в соответствии со значением символа. Для контекстного арифметического кодирования/декодирования является необходимым контекстное моделирование, которое определяет контекст символа.
[55] Для контекстного моделирования контексту необходимо заново обновляться для положения каждого бита строки битов символов, т.е. для каждого индекса бина. Термин «контекстное моделирование» ссылается на процесс анализа вероятности, что каждый бин равен 0 или 1. Процесс обновления контекста посредством отражения результата, полученного посредством анализа вероятности каждого из символов нового блока в соответствии с битами текущего контекста может выполняться неоднократно в единицах блоков. Таблица вероятности, в которой вероятность сопоставляется с каждым бином, может обеспечиваться как информация, содержащая результат такого контекстного моделирования. Информация вероятности энтропийного кодирования согласно примерному варианту осуществления может представлять собой информацию, содержащую результат контекстного моделирования.
[55] Следовательно, если получена информация контекстного моделирования, т.е. информация вероятности энтропийного кодирования, энтропийное кодирование может выполняться посредством назначения кода каждому из битов бинаризованной строки битов блочных символов, основываясь на контексте информации вероятности энтропийного кодирования.
[57] Так как энтропийное кодирование включает в себя контекстное арифметическое кодирование/декодирование, контекстная информация кода символа может обновляться в единицах блоков, и, так как энтропийное кодирование выполняется посредством использования обновленной контекстной информации кода символа, может повышаться коэффициент сжатия.
[58] Способ видеокодирования согласно различным примерным вариантам осуществления не должен толковаться как ограниченный только способом видеокодирования, выполняемым над «блоком», т.е. единицей данных, и может применяться к различным единицам данных.
[59] Для эффективного кодирования изображения изображение разбивается на блоки, причем каждый имеет заданный размер, и затем кодируется. Блок может иметь совершенную квадратную или прямоугольную форму или произвольную геометрическую форму. Настоящий примерный вариант осуществления не ограничивается единицей данных, имеющей заданный размер. Блоком согласно примерному варианту осуществления может быть LCU, единица кодирования, единица предсказания или единица преобразования, из числа единиц кодирования, имеющих древовидную структуру. Способ видеокодирования/видеодекодирования, основанный на единицах кодирования в соответствии с древовидной структурой, объясняются ниже с ссылкой на фиг.8-20.
[60] Блоки видеокадра кодируются в направлении растрового сканирования.
[61] Устройство 10 энтропийного видеокодирования может разбивать видеокадр на один или несколько тайлов, и каждый из тайлов может включать в себя блоки, которые располагаются по направлению растра, из числа блоков видеокадра. Видеокадр может разбиваться на тайлы, которые разбиваются на один или несколько столбцов, тайлы, которые разбиваются на одну или несколько строк, или тайлы, которые разбиваются на один или несколько столбцов и одну или несколько строк. Каждый из тайлов может разбивать пространственную область на подобласти. Чтобы индивидуально кодировать каждую из подобластей, устройство 10 энтропийного видеокодирования может индивидуально выполнять кодирование в единицах тайлов.
[62] Так как каждый сегмент слайса включает в себя блоки, которые располагаются по направлению растра, устройство 10 энтропийного видеокодирования может генерировать сегмент слайса посредством разбиения видеокадра в горизонтальном направлении. Видеокадр может разбиваться на один или несколько сегментов слайса. Данные каждого сегмента слайса могут передаваться посредством одной единицы уровня сетевой абстракции (NAL).
[63] Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может выполнять кодирование сегментов слайса. Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может генерировать кодированные символы согласно блокам посредством последовательного выполнения кодирования блоков, которые включены в каждый сегмент слайса. Кодированные данные блоков в каждом сегменте слайса могут включаться в и могут передаваться посредством одной единицы NAL. Каждый тайл может включать в себя по меньшей мере один сегмент слайса. Если необходимо, каждый сегмент слайса может включать в себя по меньшей мере один тайл.
[64] Сегмент слайса может классифицироваться на зависимый сегмент слайса и независимый сегмент слайса.
[65] Если текущий сегмент слайса является зависимым сегментом слайса, может выполняться предсказание в видеокадре, которое ссылается на кодированные символы предыдущего сегмента слайса, который кодируется раньше текущего сегмента слайса. Когда текущий сегмент слайса является зависимым сегментом слайса, может выполняться зависимое энтропийное кодирование, которое ссылается на энтропийную информацию предыдущего сегмента слайса, который кодируется раньше текущего сегмента слайса.
[66] Если текущий сегмент слайса является независимым сегментом слайса, не выполняется предсказание в видеокадре, которое ссылается на предыдущий сегмент слайса, и не выполняется ссылка на энтропийную информацию предыдущего сегмента слайса.
[67] Один видеокадр согласно примерному варианту осуществления может включать в себя один независимый сегмент слайса и по меньшей мере один зависимый сегмент слайса, который является последующим независимому сегменту слайса в порядке растрового сканирования. Один независимый сегмент слайса может представлять собой один слайс.
[68] Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может индивидуально выполнять кодирование каждого тайла, отдельно от других тайлов. Устройство 10 энтропийного видеокодирования может последовательно кодировать LCU, которые включены в текущий тайл, в соответствии с тайлами.
[69] Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может кодировать LCU текущего сегмента слайса согласно сегментам слайса. LCU, которые включены в заданный тайл из числа LCU, которые включены в текущий сегмент слайса, могут кодироваться в порядке кодирования текущего тайла.
[70] Если все LCU текущего сегмента слайса принадлежат текущему тайлу, устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может кодировать множество LCU, которые включены в текущий сегмент слайса в порядке растрового сканирования в текущем тайле. В данном случае, так как текущий сегмент слайса не располагается через границу текущего тайла, LCU текущего сегмента слайса не пересекают границу текущего тайла. В данном случае, устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может последовательно выполнять кодирование по меньшей мере одного сегмента слайса, который включен в каждый тайл, и может кодировать множество блоков, которые включены в каждый сегмент слайса в порядке растрового сканирования.
[71] Даже когда текущий сегмент слайса включает в себя по меньшей мере один тайл, устройство 10 энтропийного видеокодирования может выполнять кодирование, в порядке растрового сканирования LCU текущего тайла, LCU, которые принадлежат текущему тайлу, из числа LCU, которые включены в текущий сегмент слайса. Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может последовательно выполнять кодирование сегментов слайса. Следовательно, устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может генерировать кодированные символы в соответствии с блоками посредством последовательного выполнения кодирования сегментов слайса и последовательного выполнения кодирования блоков, которые включены в каждый сегмент слайса. Устройство 10 энтропийного видеокодирования может выполнять внутреннее предсказание, внешнее предсказание, преобразование, петлевую фильтрацию, компенсацию адаптивного смещения отсчетов (SAO) и квантование в единицах блоков каждого сегмента слайса.
[72] Чтобы выполнять кодирование с предсказанием кодированных символов, которые генерируются во время процесса кодирования источника, например, внутреннего отсчета, вектора движения и информации о режиме кодирования, может выполняться предсказание в видеокадре. Когда выполняется предсказание в видеокадре, может кодироваться разностное значение между текущим кодированным символом и предыдущим кодированным символом, вместо текущего кодированного символа. Может кодироваться разностное значение между текущим отсчетом и соседним отсчетом, вместо текущего отсчета.
[73] Чтобы выполнить кодирование с предсказанием энтропийной контекстной информации или контекстной информации кода, которая генерируется во время процесса энтропийного кодирования, может выполняться зависимое энтропийное кодирование. Когда выполняется зависимое энтропийное кодирование, и текущая энтропийная информация и предыдущая энтропийная информация одинаковые, может опускаться кодирование текущей энтропийной информации.
[74] Однако, так как устройство 10 энтропийного видеокодирования индивидуально кодирует каждый тайл, может не выполняться предсказание в видеокадре или зависимое энтропийное кодирование между LCU, которые принадлежат к разным тайлам.
[75] Устройство 10 энтропийного видеокодирования может записывать информацию, указывающую доступность сегмента слайса или атрибут сегмента слайса, о заголовках различных единиц кодирования, такую как набор параметров последовательности (SPS), набор параметров видеокадра (PPS) и заголовок сегмента слайса.
[76] Например, устройство 10 энтропийного видеокодирования может генерировать заголовок сегмента слайса, включающий в себя информацию, указывающую, является ли текущий сегмент слайса начальным сегмент слайса в текущем видеокадре.
[77] Различная основная информация о текущем видеокадре, к которому принадлежит текущий сегмент слайса, может содержаться в PPS и может передаваться посредством его. В частности, PPS может включать в себя информацию о том, может ли текущий видеокадр включать в себя зависимый сегмент слайса. Следовательно, когда информация, указывающая, что зависимый сегмент слайса используется в текущем видеокадре, содержится в PPS, устройство 10 энтропийного видеокодирования может включать в себя, в заголовке текущего сегмента слайса, информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, используя информацию заголовка слайса о предыдущем сегменте слайса.
[78] И наоборот, когда информация, указывающая, что зависимый сегмент слайса не используется в текущем видеокадре, включена в PPS текущего видеокадра, информация, указывающая, является ли текущий сегмент слайса зависимым сегментом слайса, не включается в заголовок текущего сегмента слайса.
[79] Когда текущий сегмент слайса не является начальным сегментом слайса, устройство 10 энтропийного видеокодирования может добавлять информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, в заголовок сегмента слайса.
[80] Т.е., когда информация, указывающая, что зависимый сегмент слайса используется в текущем видеокадре, включена в PPS текущего видеокадра, и информация, указывающая, что текущий сегмент слайса не является начальным сегментом слайса, включена в заголовок текущего сегмента слайса, информация, указывающая, является ли текущий сегмент слайса зависимым сегментом слайса, может дополнительно добавляться в заголовок текущего сегмента слайса. Начальный сегмент слайса согласно примерному варианту осуществления должен быть независимым сегментом слайса. Следовательно, когда текущий сегмент слайса является начальным сегментом слайса, может опускаться информация, указывающая, является ли текущий сегмент слайса зависимым сегментом слайса. Следовательно, устройство 10 энтропийного видеокодирования может добавлять информацию, указывающую, является ли текущий сегмент слайса начальным сегментом слайса, в заголовок сегмента слайса для начального сегмента слайса и затем может добавлять основную информацию о текущем сегменте слайса в заголовок сегмента слайса и может передавать результирующую информацию.
[81] Соответственно, когда зависимый сегмент слайса может использоваться в текущем видеокадре, и текущий сегмент слайса не является начальным сегментом слайса, информация, указывающая, является ли текущий сегмент слайса зависимым сегментом слайса, может дополнительно добавляться в заголовок текущего сегмента слайса.
[82] Однако, когда текущий сегмент слайса является зависимым сегментом слайса, а не начальным сегментом слайса, основная информация о сегменте слайса может быть такой же, что и информация заголовка предыдущего сегмента слайса. Следовательно, заголовок текущего сегмента слайса может передаваться, когда включает информацию, указывающую, является ли текущий сегмент слайса начальным сегментом слайса, и информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, но опуская информацию, которая такая же, что и информация заголовка предыдущего сегмента слайса.
[83] Когда текущий сегмент слайса согласно примерному варианту осуществления не является зависимым сегментом слайса, заголовок текущего сегмента слайса может включать в себя информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, и может дополнительно включать в себя различную информацию заголовка для текущего сегмента слайса.
[84] Устройство 10 энтропийного видеокодирования может содержать, в заголовке сегмента слайса, параметр квантования и начальную контекстную информацию контекста для энтропийного кодирования и может передавать результирующую информацию.
[85] Однако, когда текущий сегмент слайса является зависимым сегментом слайса, устройство 10 энтропийного видеокодирования может выполнять предсказание в видеокадре, которое ссылается на кодированные символы предыдущего сегмента слайса, который кодируется раньше текущего сегмента слайса. Когда текущий сегмент слайса является зависимым сегментом слайса, устройство 10 энтропийного видеокодирования может выполнять зависимое энтропийное кодирование, которое ссылается на энтропийную информацию предыдущего сегмента слайса, который кодируется раньше текущего сегмента слайса.
[86] Соответственно, когда текущий сегмент слайса является зависимым сегментом слайса, устройство 10 энтропийного видеокодирования не содержит параметр квантования и начальную контекстную информацию в заголовке сегмента слайса текущего сегмента слайса. Это потому, что параметр квантования и начальная контекстная информация зависимого сегмента слайса могут инициализироваться в параметр квантования и начальную контекстную информацию, которые содержатся в информации заголовка независимого сегмента слайса, который кодируется раньше.
[87] Когда текущий сегмент слайса является независимым сегментом слайса, так как не выполняется предсказание в видеокадре, устройство 10 энтропийного видеокодирования может выводить строку битов кодированных символов текущего сегмента слайса, независимо от предыдущего сегмента слайса. Когда текущий сегмент слайса является независимым сегментом слайса, устройство 10 энтропийного видеокодирования может выводить энтропийную информацию текущего сегмента слайса, независимо от энтропийной информации соседнего сегмента слайса, который кодируется раньше. Например, когда текущий сегмент слайса является независимым сегментом слайса, параметр квантования и начальная контекстная информация должны содержаться в заголовке текущего сегмента слайса.
[88] Устройство 10 энтропийного видеокодирования может передавать заголовок сегмента слайса и символы сегмента слайса в соответствии с сегментами слайса.
[89] Ниже подробно объясняется операция энтропийного видеокодирования, выполняемая каждым элементом устройства 10 энтропийного видеокодирования, с ссылкой на фиг.1B.
[90] Фиг.1B представляет собой блок-схему последовательности действий способа энтропийного видеокодирования согласно различным примерным вариантам осуществления.
[91] Устройство 10 энтропийного видеокодирования может разбивать видеокадр на по меньшей мере один сегмент слайса, может выполнять кодирование каждого сегмента слайса и может последовательно выполнять кодирование LCU, которые включены в каждый сегмент слайса.
[92] В операции 11 бинаризатор 12 может выполнять бинаризацию символов, которые определяются посредством выполнения кодирования LCU для генерирования строки битов символов.
[93] В операции 13 определитель 14 строки бинов может определять контекстную переменную в соответствии с каждым индексом бина значения синтаксического элемента, соответствующего символам LCU. Контекстная переменная для текущей LCU может определяться на основе контекстной переменной в соответствии с каждым индексом бина значения синтаксического элемента, которое используется в другой LCU, которая кодируется раньше.
[94] Каждая контекстная переменная может включать в себя контекстную таблицу и контекстный индекс. Контекстная переменная может определяться в соответствии с синтаксическим элементом.
[95] В операции 15 определитель 14 строки бинов может определять строку бинов, указывающую значение синтаксического элемента, основываясь на определенной контекстной переменной синтаксического элемента. Устройство 10 энтропийного видеокодирования может сохранять данные о контекстной таблице, содержащей корреляцию между строкой бинов и контекстной переменной для каждого синтаксического элемента.
[96] Определитель 14 строки бинов может принимать строку бинов, указанную контекстной переменной, которая определяется в операции 13, в контекстной таблице для значения текущего синтаксического элемента.
[97] Устройство 10 энтропийного видеокодирования может генерировать строку бинов для всех синтаксических элементов для LCU, и затем может определять, сохранять ли контекстные переменные, которые определены в соответствии с LCU.
[98] В операции 17, когда синтаксический элемент является последним синтаксическим элементом в LCU, зависимый сегмент слайса может быть включен в видеокадр, в который включена LCU, и LCU является последней LCU в сегменте слайса, блок 16 сохранения контекста может сохранять контекстные переменные для LCU.
[99] Независимо от того, является ли сегмент слайса независимым сегментом слайса или зависимым сегментом слайса, когда зависимый сегмент слайса может быть включен в видеокадр, блок 16 сохранения контекста может сохранять контекстные переменные для LCU.
[100] Когда множество сегментов слайса включено в видеокадр, для энтропийного кодирования контекстной переменной первой LCU зависимого сегмента слайса, который располагается следующим за текущим сегментом слайса, могут использоваться контекстные переменные, которые сохраняются в текущем сегменте слайса.
[101] Устройство 10 энтропийного видеокодирования может генерировать PPS, содержащий сегмент слайса, который включен в видеокадр, LCU и различную информацию, которая обычно является необходимой для декодирования LCU. Устройство 10 энтропийного видеокодирования может включать, в PPS, первую информацию, указывающую, может ли зависимый сегмент слайса быть включен в видеокадр.
[102] Устройство 10 энтропийного видеокодирования может генерировать данные сегмента слайса, включающие в себя данные, которые генерируются посредством кодирования LCU, которые включены в каждый сегмент слайса. Устройство 10 энтропийного видеокодирования может включать, в данные о LCU из числа данных в соответствии с сегментами слайса, вторую информацию, указывающую, является ли LCU последней LCU в сегменте слайса. Строка бинов, которая генерируется посредством энтропийного кодирования, может быть включена в данные о LCU.
[103] Устройство 10 энтропийного видеокодирования может генерировать заголовок сегмента слайса, включающий в себя LCU, которая включена в сегмент слайса, и различную информацию, которая обычно является необходимой для декодирования LCU. Устройство 10 энтропийного видеокодирования может генерировать битовый поток, включающий в себя PPS, заголовок сегмента слайса и данные в соответствии с сегментами слайса, в результате кодирования, выполняемого над сегментами слайса.
[104] Когда тайл может быть включен в сегмент слайса, который включен в видеокадр, или операция синхронизации может выполняться для контекстных переменных LCU, которая включена в видеокадр, устройство 10 энтропийного видеокодирования может включать, в заголовок сегмента слайса, третью информацию, указывающую число точек входа поднаборов, которые включены в сегмент слайса, и четвертую информацию, указывающую число, которое меньше на 1 смещения в соответствии с каждой точкой входа.
[105] Термин «поднабор, который включен в сегмент слайса», ссылается на группу LCU, которые последовательно кодируются в порядке сканирования, из числа LCU, которые включены в сегмент слайса. Обработка поднаборов может выполняться одновременно.
[106] Первый байт текущего поднабора может определяться суммированием смещений поднабора из предыдущего поднабора с текущим поднабором посредством использования четвертой информации, которая назначается каждому поднабору. Когда существует два или более поднаборов, так как смещение поднабора должно быть больше 0, четвертая информация, указывающая смещение поднабора, может быть получена вычитанием 1 из смещения поднабора. Следовательно, фактическое смещение поднабора может представлять собой значение, которое больше на 1 числа, указанного четвертой информацией.
[107] Индекс байтов, которые составляют каждый поднабор, начинается с 0, и индекс байта, указывающий первый байт, равен 0. Следовательно, последний байт текущего поднабора может определяться суммированием первого байта текущего поднабора с числом, указанным четвертой информацией, которая назначается текущему поднабору.
[108] Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может включать в себя центральный процессор (не показан), который, в основном, управляет бинаризатором 12, определитель 14 строки бинов и блок 16 сохранения контекста. Альтернативно, каждый из бинаризатора 12, определителя 14 строки бинов и блока 16 сохранения контекста может работать благодаря своему собственному процессору (не показан), и устройство 10 энтропийного видеокодирования может, в основном, работать так, как по сути работают процессоры (не показаны). Альтернативно, устройство 10 энтропийного видеокодирования может работать под управлением внешнего процессора (не показан) устройства 10 энтропийного видеокодирования согласно примерному варианту осуществления.
[109] Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может включать в себя один или несколько блоков хранения данных (не показаны), в которых сохраняются вводимые/выводимые данные бинаризатора 12, определителя 14 строки бинов и блока 16 сохранения контекста. Устройство 10 энтропийного видеокодирования может включать в себя контроллер памяти (не показан), который управляет вводом/выводом данных блоков хранения данных (не показаны).
[110] Фиг.2A представляет собой блок-схему устройства 20 энтропийного видеодекодирования согласно различным примерным вариантам осуществления.
[111] Устройство 20 энтропийного видеодекодирования согласно примерному варианту осуществления включает в себя инициализатор 22 контекста, блок 24 восстановления символа (например, модуль восстановления символа и т.д.) и блок 26 сохранения контекста (например, запоминающее устройство контекста и т.д.).
[112] Устройство 20 энтропийного видеодекодирования согласно примерному варианту осуществления может принимать битовый поток, который генерируется в результате того, что видеокадр разбивается на два или более тайла и по меньшей мере один сегмент слайса и затем кодируется. Битовый поток может представлять собой данные, которые генерируются в соответствии с сегментами слайса, и могут представлять собой данные, которые генерируются в соответствии с тайлами.
[113] Затем устройство 20 энтропийного видеодекодирования может синтаксически анализировать заголовок сегмента слайса в соответствии с атрибутом сегмента слайса. Устройство 20 энтропийного видеодекодирования может синтаксически анализировать информацию, указывающую, является ли текущий сегмент слайса начальным сегментом слайса в текущем видеокадре, из заголовка сегмента слайса текущего сегмента слайса.
[114] Когда определяется из синтаксически анализируемой информации, что текущий сегмент слайса не является начальным сегментом слайса, устройство 20 энтропийного видеодекодирования может дополнительно синтаксически анализировать информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, который использует информацию заголовка слайса предыдущего сегмента слайса, из заголовка текущего сегмента слайса.
[115] Однако информация о том, может ли текущий видеокадр включать в себя зависимый сегмент слайса, может синтаксически анализироваться из PPS для текущего видеокадра, к которому принадлежит текущий сегмент слайса. Следовательно, когда информация, указывающая, что зависимый сегмент слайса используется в текущем видеокадре, синтаксически анализируется из PPS текущего видеокадра, устройство 20 энтропийного видеодекодирования может синтаксически анализировать информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, из заголовка текущего сегмента слайса.
[116] С другой стороны, когда информация, указывающая, что зависимый сегмент слайса не используется в текущем видеокадре, синтаксически анализируется из PPS текущего видеокадра, информация, указывающая, является ли текущий сегмент слайса зависимым сегментом слайса, не анализируется синтаксически из заголовка текущего сегмента слайса.
[117] Следовательно, когда информация, указывающая, что зависимый сегмент слайса используется в текущем видеокадре, синтаксически анализируется из PPS текущего видеокадра, и синтаксически анализируется информация, указывающая, что текущий сегмент слайса не является начальным сегментом слайса, устройство 20 энтропийного видеодекодирования может дополнительно синтаксически анализировать информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, из заголовка текущего сегмента слайса. Т.е. когда определяется, что текущий видеокадр использует зависимый сегмент слайса, и текущий зависимый сегмент слайса не является начальным сегментом слайса, устройство 20 энтропийного видеодекодирования может дополнительно синтаксически анализировать информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, из заголовка текущего сегмента слайса.
[118] Когда определяется из синтаксически анализируемой информации, что текущий сегмент слайса является начальным сегментом слайса, устройство 20 энтропийного видеодекодирования не анализирует синтаксически информацию, указывающую, является ли текущий сегмент слайса зависимым сегментом слайса, из заголовка текущего сегмента слайса. Так как начальный сегмент слайса не может быть зависимым сегментом слайса, может определяться, что начальным сегментом слайса является независимый сегмент слайса без синтаксически анализируемой информации. Следовательно, когда текущий сегмент слайса является начальным сегментом слайса, устройство 20 энтропийного видеодекодирования может дополнительно синтаксически анализировать информацию, указывающую, является ли текущий сегмент слайса начальным сегментом слайса и основной информацией о текущем сегменте слайса, из заголовка начального сегмента слайса видеокадра.
[119] Когда определяется из информации, синтаксически анализируемой из заголовка текущего сегмента слайса, что текущий сегмент слайса является зависимым сегментом слайса, устройство 20 энтропийного видеодекодирования может определять некоторую информацию заголовка, которая синтаксически анализируется из заголовка предыдущего сегмента слайса в качестве основной информации текущего сегмента слайса.
[120] Когда определяется из информации, синтаксически анализируемой из заголовка текущего сегмента слайса, что текущий сегмент слайса не является зависимым сегментом слайса, устройство 20 энтропийного видеодекодирования может синтаксически анализировать различную информацию заголовка для текущего сегмента слайса из заголовка текущего сегмента слайса.
[121] Устройство 20 энтропийного видеодекодирования может декодировать текущий сегмент слайса посредством использования информации, синтаксически анализируемой из заголовка текущего сегмента слайса и символов текущего сегмента слайса.
[122] Когда каждый сегмент слайса принимается посредством одной единицы NAL, устройство 20 энтропийного видеодекодирования может принимать кодированные данные блоков в соответствии с сегментами слайса. Каждый тайл может включать в себя по меньшей мере один сегмент слайса. Если необходимо, сегмент слайса может включать в себя по меньшей мере один тайл. Взаимосвязь между сегментом слайса и тайлом является такой же, что и взаимосвязь, описанная с ссылкой на фиг.1A и 1B.
[123] Устройство 20 энтропийного видеодекодирования, включающее восстановленный текущий сегмент слайса, может восстанавливать по меньшей мере один сегмент слайса, который включен в каждый тайл, и может восстанавливать видеокадр посредством объединения восстановленных тайлов.
[124] Устройство 20 энтропийного видеодекодирования может синтаксически анализировать, в порядке растрового сканирования, символы множества блоков, которые включены в текущий сегмент слайса, в соответствии с по меньшей мере одним сегментом слайса, который включен в текущий тайл, в соответствии с тайлами. Кроме того, устройство 20 энтропийного видеодекодирования может декодировать, в порядке растрового сканирования, блоки посредством использования символов, которые синтаксически анализируются в порядке растрового сканирования блоков.
[125] Устройство 20 энтропийного видеодекодирования может синтаксически анализировать кодированные символы в соответствии с LCU посредством выполнения энтропийного декодирования битового потока каждого сегмента слайса. Устройство 20 энтропийного видеодекодирования может синтаксически анализировать кодированные символы в соответствии с LCU посредством последовательного выполнения энтропийного декодирования LCU, которые включены в сегмент слайса. Ниже с ссылкой на фиг.2B подробно объясняется процесс, используемый устройством 20 энтропийного видеодекодирования для выполнения восстановления посредством синтаксического анализа кодированных символов в соответствии с единицами кодирования, которые включены в сегмент слайса.
[126] Фиг.2B представляет собой блок-схему последовательности действий способа энтропийного видеодекодирования согласно различным примерным вариантам осуществления.
[127] В операции 21 инициализатор 22 контекста может определять строку бинов и индекс бина для LCU, которая получается из битового потока.
[128] Инициализатор 22 контекста может сохранять таблицу инициализации для значения инициализации в соответствии с каждым контекстным индексом для каждого синтаксического элемента. В соответствии с операцией инициализации контекстной переменной контекстный индекс текущего синтаксического элемента может определяться равным значению инициализации, основываясь на таблице инициализации.
[129] Инициализатор 22 контекста может сохранять данные о контекстной таблице, содержащей корреляцию между строкой бинов и контекстной переменной для каждого синтаксического элемента.
[130] Инициализатор 22 контекста может определять контекстную переменную для каждого синтаксического элемента. Контекстные переменные текущей LCU могут синхронизироваться посредством использования контекстных переменных близлежащей LCU.
[131] В операции 23 инициализатор 22 контекста может определять значение синтаксического элемента, указанного текущей строкой бинов, посредством сравнения строк бинов, которые могут назначаться синтаксическому элементу в текущей контекстной переменной, основываясь на контекстной таблице, со строй бинов в индексе бина, который определяется в операции 21.
[132] Каждая контекстная переменная может обновляться на основе контекста, который накапливается заново, из начальной контекстной переменной, когда начинается энтропийное декодирование LCU, во время энтропийного декодирования, выполняемого над строками бинов для LCU.
[133] Инициализатор 22 контекста может определять, может ли быть включен зависимый сегмент слайса в видеокадр, основываясь на первой информации, которая получается из PPS битового потока. Инициализатор 22 контекста может определять, является ли LCU последней LCU в сегменте слайса, основываясь на второй информации, которая получается из данных о LCU из числа данных в соответствии с сегментами слайса битового потока. Инициализатор 22 контекста может получать строку бинов из данных о LCU из числа данных в соответствии с сегментами слайса.
[134] В операции 25, когда синтаксический элемент является последним синтаксическим элементом в LCU, зависимый сегмент слайса может включаться в видеокадр, в который включена LCU, и LCU является последней LCU в сегменте слайса, блок 26 сохранения контекста может сохранять контекстные переменны для LCU.
[135] Независимо от того, является ли сегмент слайса независимым сегментом слайса или зависимым сегментом слайса, когда зависимый сегмент слайса может быть включен в видеокадр, могут сохраняться контекстные переменные для LCU.
[136] Когда множество сегментов слайса включено в видеокадр, для энтропийного кодирования контекстной переменной первой LCU зависимого сегмента слайса, который расположен следующим за текущим сегментом слайса, могут использоваться контекстные переменные, которые сохраняются в текущем сегменте слайса.
[137] В операции 27 блок 24 восстановления символа может восстанавливать символы LCU посредством использования значения синтаксического элемента, который определяется в операции 23.
[138] Устройство 20 энтропийного видеодекодирования может определять число точек входа поднаборов, которые включены в сегмент слайса, основываясь на третьей информации, которая получается из заголовка сегмента слайса битового потока.
[139] Устройство 20 энтропийного видеодекодирования может определять положение каждой точки входа посредством использования смещения, которое представляет собой число, которое больше на 1 числа, указываемого четвертой информацией о смещении в соответствии с каждой точкой входа, которая получается из заголовка сегмента слайса битового потока. Следовательно, так как устройство 20 энтропийного видеодекодирования может точно определять точку входа для каждого поднабора, такого как столбец сегментов слайса, тайлов или LCU, может точно определяться точка синхронизации энтропии, в которой должна быть получена контекстная переменная близлежащей LCU.
[140] Устройство 20 энтропийного видеодекодирования может последовательно выполнять декодирование, в порядке растрового сканирования, каждой LCU посредством использования кодированных символов LCU, которые синтаксически анализируются для каждого сегмента слайса в операциях 21-27.
[141] Устройство 20 энтропийного видеодекодирования может индивидуально выполнять декодирование каждого тайла, отдельно от других тайлов. LCU, которые включены в текущий тайл, могут последовательно декодироваться в соответствии с тайлами.
[142] Следовательно, устройство 20 энтропийного видеодекодирования может последовательно выполнять декодирование, в порядке растрового сканирования, каждой LCU посредством использования кодированных символов LCU, которые синтаксически анализируются для каждого сегмента слайса.
[143] LCU, которые включены в заданный тайл, из числа LCU, которые включены в текущий сегмент слайса, могут декодироваться в соответствии с порядком декодирования в текущем тайле.
[144] Когда все LCU текущего сегмента слайса принадлежат текущему тайлу, устройство 20 энтропийного видеодекодирования может декодировать, в порядке растрового сканирования в текущем тайле, множество LCU, которые включены в текущий сегмент слайса. В данном случае, текущий сегмент слайса не располагается через границу текущего тайла. Устройство 20 энтропийного видеодекодирования может последовательно декодировать по меньшей мере один сегмент слайса, который включен в каждый тайл, и может декодировать множество блоков, которые включены в каждый сегмент слайса в порядке растрового сканирования.
[145] Даже когда текущий сегмент слайса включает в себя по меньшей мере один тайл, устройство 20 энтропийного видеодекодирования может выполнять декодирование, в порядке растрового сканирования LCU текущего тайла в текущем тайле, LCU текущего тайла из числа LCU, которые включены в текущий сегмент слайса.
[146] Предсказание в видеокадре может выполняться посредством использования кодированных символов, таких как внутренний отсчет, который синтаксически анализируется в соответствии с LCU, вектором движения и информацией о режиме кодирования. Посредством предсказания в видеокадре значение восстановления текущего кодированного символа может определяться посредством синтезирования значения восстановления предыдущего кодированного символа с разностным значением между текущим кодированным символом и предыдущим кодированным символом. Кроме того, значение восстановления текущего отсчета может определяться посредством синтезирования значения восстановления соседнего отсчета, который восстанавливается раньше текущего отсчета, с разностным значением между текущим отсчетом и предыдущим отсчетом.
[147] Декодирование, использующее кодированные символы LCU, может выполняться посредством обратного квантования, обратного преобразования и внутреннего предсказания/компенсации движения. Например, коэффициенты преобразования единиц преобразования могут восстанавливаться посредством выполнения обратного квантования кодированных символов каждой LCU, и остаточная информация единиц предсказания может восстанавливаться посредством выполнения обратного преобразования коэффициентов преобразования единиц преобразования. Внутреннее предсказание может выполняться посредством использования внутреннего отсчета в остаточной информации. Отсчеты текущей единицы предсказания могут восстанавливаться посредством компенсации движения, которая синтезирует остаточную информацию с другой восстановленной единицей предсказания, указанной вектором движения. Кроме того, над LCU могут выполняться компенсация SAO и петлевая фильтрация.
[148] Следовательно, устройство 20 энтропийного видеодекодирования может последовательно декодировать LCU каждого сегмента слайса и каждого тайла в соответствии с порядком декодирования в тайле.
[149] Когда тайл включает в себя по меньшей мере один сегмент слайса согласно примерному варианту осуществления, один тайл может восстанавливаться посредством декодирования LCU для каждого сегмента слайса и объединения результатов восстановления сегментов слайса.
[150] Когда сегмент слайса включает в себя по меньшей мере один тайл согласно примерному варианту осуществления, один сегмент слайса может восстанавливаться посредством декодирования LCU для каждого тайла и объединения результатов восстановления тайлов.
[151] Устройство 20 энтропийного видеодекодирования может восстанавливать видеокадр, который состоит из восстановленных тайлов или восстановленных сегментов слайса.
[152] Согласно способам энтропийного кодирования/декодирования по фиг.1A, 1B, 2A и 2B, когда зависимый сегмент слайса может использоваться в текущем видеокадре, после того как будет завершено энтропийное кодирование (декодирование) последней LCU каждого сегмента слайса, может сохраняться контекстная переменная. Следовательно, даже когда предыдущий сегмент слайса является независимым сегментом слайса, начальная переменная контекстной переменной, которая необходима для следующего зависимого сегмента слайса, может получаться из контекстной переменной последней LCU независимого сегмента слайса, который кодируется раньше.
[153] Так как информация, указывающая число, которое меньше на 1 смещения поднабора, предоставляется сегменту слайса, чтобы эффективно информировать о точке синхронизации контекстной переменной для энтропийного кодирования/декодирования, может быть уменьшен размер данных сегмента слайса.
[154] Ниже объясняется взаимосвязь между сегментом слайса и тайлом, которые представляют собой подобласти, используемые устройством 10 энтропийного видеокодирования и устройством 20 энтропийного видеодекодирования согласно примерному варианту осуществления, с ссылкой на фиг.3 и 4.
[155] Фиг.3 представляет собой чертеж, иллюстрирующий тайлы и LCU в видеокадре 301.
[156] Когда кодирование и декодирование выполняется независимо в каждой области, которая генерируется разбиением видеокадра 301 по меньшей мере в одном направлении из числа вертикального направления и горизонтального направления, каждая область может упоминаться как тайл. Чтобы выполнять обработку в реальном времени посредством использования большого количества данных видео с высоким разрешением (HD) или ультравысоким разрешением (UHD), тайлы могут формироваться посредством разбиения видеокадров на по меньшей мере один столбец и по меньшей мере строку, и кодирование/декодирование могут выполняться в соответствии с тайлами.
[157] Так как каждый тайл в видеокадре 301 представляет собой пространственную область, где кодирование/декодирование выполняется индивидуально, только тайл, требуемый для кодирования/декодирования, может селективно кодироваться/декодироваться.
[158] На фиг.3 видеокадр 301 может разбиваться на тайлы границами 321 и 323 столбцов и границами 311 и 313 строк. Область, окруженная одной из границ 321 и 323 столбцов и одной из границ 311 и 313 строк, представляет собой тайл.
[159] Когда видеокадр 301 разбивается на тайлы и кодируется, информация о положениях границ 321 и 323 столбцов и границ 311 и 313 строк может содержаться в и может передаваться посредством SPS или PPS. Когда декодируется видеокадр 301, информация о положениях границ 321 и 323 столбцов и границ 311 и 313 строк может синтаксически анализироваться из SPS или PPS, декодирование может выполняться над тайлами, и подобласти видеокадра 301 могут восстанавливаться, и подобласти могут восстанавливаться до одного видеокадра 301 посредством использования информации о границах 321 и 323 столбцов и границах 311 и 313 строк.
[160] Видеокадр 301 разбивается на LCU, и кодирование/декодирование выполняется над блоками. Следовательно, каждый тайл, который образуется разбиением видеокадра 301 посредством использования границ 321 и 323 столбцов и границ 311 и 313 строк, может включать в себя LCU. Так как границы 321 и 323 столбцов и границы 311 и 313 строк, которые разбивают видеокадр 301, проходят через границы между соседними LCU, каждая LCU не разбивается. Следовательно, каждый тайл может включать в себя M (M представляет собой целое число) LCU.
[161] Следовательно, когда выполняется обработка тайлов видеокадра 301, кодирование/декодирование может выполняться над LCU в каждом тайле. Число в каждой LCU на фиг.3 обозначает порядок сканирования LCU в тайле, т.е. порядок, в котором выполняется обработка для кодирования или декодирования.
[162] Тайл может отличаться от сегмента слайса и слайса тем, что кодирование/декодирование выполняется независимо между тайлами. Ниже подробно объясняется сегмент слайса и слайс с ссылкой на фиг.4.
[163] Фиг.4 представляет собой чертеж, иллюстрирующий сегмент слайса и LCU в видеокадре 401.
[164] Видеокадр 401 разбивается на множество LCU. На фиг.4 видеокадр 401 разбивается на 13 LCU в горизонтальном направлении и 9 LCU в вертикальном направлении, т.е. в сумме 117 LCU. Каждая LCU может разбиваться на единицы кодирования, имеющие древовидную структуру, и может кодироваться/декодироваться.
[165] Видеокадр 401 разбивается на верхний слайс и нижний слайс, т.е. два слайса, линией 411 границы. Видеокадр 401 разбивается на сегменты 431, 433, 435 и 441 слайса линиями 421, 423 и 411 границы.
[166] Сегменты 431, 433, 435 и 441 слайса могут классифицироваться на зависимые сегменты слайса и независимые сегменты слайса. В зависимом сегменте слайса на информацию, которая используется или генерируется при кодировании источника и энтропийном кодировании для заданного сегмента слайса, может выполняться ссылка при кодировании источника и энтропийном кодировании другого сегмента слайса. Аналогично, во время декодирования на информацию, которая используется или восстанавливается при декодировании источника, и на синтаксически анализируемую информацию при энтропийном кодировании для заданного сегмента слайса из числа зависимых сегментов слайса может выполняться ссылка для энтропийного декодирования и декодирования источника другого сегмента слайса.
[167] В независимом сегменте слайса на информацию, которая используется или генерируется при кодировании источника и энтропийном кодировании, выполняемым над сегментами слайса, вообще не выполняется ссылка и кодируется независимо. Аналогично, во время декодирования для энтропийного декодирования и декодирования источника независимого сегмента слайса синтаксически анализируемая информация и информация восстановления другого сегмента слайса вообще не используется.
[168] Информация о том, является ли сегмент слайса зависимым сегментом слайса или независимым сегментом слайса, может содержаться в и может передаваться посредством заголовка сегмента слайса. Когда должен декодироваться видеокадр 301, информация о типе сегмента слайса может синтаксически анализироваться из заголовка сегмента слайса, и может определяться, декодируется ли текущий сегмент слайса независимо от другого сегмента слайса или восстанавливается ли с ссылкой на сегмент слайса в соответствии с типом сегмента слайса.
[169] В частности, значение синтаксических элементов заголовка сегмента слайса независимого сегмента слайса, т.е. информация заголовка, может определяться не подразумеваемой из информации заголовка предыдущего сегмента слайса. И наоборот, информация заголовка в заголовке сегмента слайса зависимого сегмента слайса может определяться подразумеваемой из информации заголовка предыдущего сегмента слайса.
[170] Каждый слайс может включать в себя N (N представляет собой целое число) LCU. Один слайс может включать в себя по меньшей мере один сегмент слайса. Когда один слайс включает в себя только один сегмент слайса, слайс может включать в себя независимый сегмент слайса. Один слайс может включать в себя один независимый сегмент слайса и по меньшей мере один зависимый сегмент слайса, который является последующим для независимого сегмента слайса. По меньшей мере один сегмент слайса, который включен в один слайс, может передаваться/приниматься посредством одного и того же блока доступа.
[171] Верхний слайс видеокадра 410 включает в себя сегмент 421 слайса, который представляет собой один независимый сегмент слайса, и сегменты 433 и 435 слайса, которые представляют собой два зависимых сегмента слайса. Нижний слайс видеокадра 410 включает в себя только сегмент 441 слайса, который является независимым сегментом слайса.
[172] Ниже подробно объясняется процесс синтаксического анализа символа посредством энтропийного декодирования с ссылкой на фиг.5-7.
[173] Фиг.5 представляет собой блок-схему последовательности действий операции 50 синтаксического анализа CABAC согласно примерному варианту осуществления.
[174] Когда устройство 20 энтропийного видеодекодирования выполняет декодирование CABAC согласно примерному варианту осуществления, символ для заданного синтаксического элемента может синтаксически анализироваться посредством операции 50 синтаксического анализа CABAC.
[175] В операции 511 устройство 20 энтропийного видеодекодирования определяет, является ли синтаксический элемент, подлежащий синтаксическому анализу в данный момент, первым синтаксическим элементом в поднаборе, таком как столбец сегментов слайса, тайлы или LCU, т.е. синтаксическим элементом, который синтаксически анализируется первым.
[176] Когда в операции 511 определяется, что синтаксический элемент, подлежащий синтаксическому анализу в данный момент, является первым синтаксическим элементом, операция 50 синтаксического анализа CABAC переходит к операции 513. В операции 513 инициализируется контекстная внутренняя переменная. Контекстная внутренняя переменная может быть контекстным индексом и контекстной таблицей для текущего синтаксического элемента. Контекстная внутренняя переменная может определяться равной предварительно установленному значению по умолчанию.
[177] В операции 521 устройство 20 энтропийного видеодекодирования может получать строку бинов, указывающую текущий синтаксический элемент из битового потока. В операциях 523 и 525 первый индекс бина строки бинов может устанавливаться на -1, и индекс бина может увеличиваться на 1 всякий раз, когда один бит добавляется к строке бинов.
[178] В операции 527 устройство 20 энтропийного видеодекодирования может получать контекстную переменную, соответствующую текущему индексу бина синтаксического элемента. Например, контекстная переменная, соответствующая текущему индексу бина, может включать в себя контекстную таблицу, контекстный индекс и флаг обхода. Предварительно установленные данные о контекстной переменной могут предварительно сохраняться в устройстве 20 энтропийного видеодекодирования, чтобы соответствовать каждому индексу бина каждого синтаксического элемента. Контекстная переменная, соответствующая индексу бина текущего синтаксического элемента, может выбираться на основе предварительно сохраненных данных.
[179] В операции 529 устройство 20 энтропийного видеодекодирования может декодировать строку битов, соответствующую контекстной переменной строки бинов. Состояние обхода, которое назначается текущему индексу бина, может определяться на основе данных о флаге обхода, который предварительно устанавливается в соответствии с каждым индексом бина в соответствии с синтаксическими элементами. Контекстный индекс может определяться на основе атрибута (например, индекса сканирования единицы данных, индекса цветовой составляющей или размера единицы данных) или текущего состояния единицы данных (например, единицы кодирования, единицы преобразования или единицы предсказания), которая кодируется в данный момент в соответствии каждым синтаксическим элементом. Строка битов, соответствующая текущему контекстному индексу и состоянию обхода, может определяться в контекстной таблице.
[180] В операции 531 устройство 20 энтропийного видеодекодирования может сравнивать данные, которые содержат строку битов, которая доступна в текущем синтаксическом элементе, с текущей строкой битов, которая определяется в операции 529. Когда текущая строка битов не принадлежит данным строки битов, операция 50 синтаксического анализа CABAC может возвращаться к операции 525 для увеличения индекса бина на 1 и операциям 527 и 529 для определения контекстной переменной для строки бинов, полученной добавлением одного бита и декодирования строки битов.
[181] Когда определяется в операции 531, что текущая строка битов, которая определяется в операции 529, принадлежит данным строки битов для синтаксического элемента, операция 50 синтаксического анализа CABAC переходит к операции 533. В операции 533 может определяться, является ли текущий синтаксический элемент информацией «pcm_flag», указывающий режим PCM, и значение синтаксического элемента указывает режим PCM. Когда определяется в операции 529, что единицей является LCU в режиме PCM, операция 50 синтаксического анализа CABAC переходит к операции 535. В операции 535 может инициализироваться операция 50 синтаксического анализа CABAC.
[182] Когда в операции 533 определяется, что режимом не является режим PCM, операция 50 синтаксического анализа CABAC переходит на операцию 537. В операции 537 может определяться, является ли текущий синтаксический элемент последним синтаксическим элементом в текущем поднаборе (например, LCU или сегмент слайса), т.е. является ли объектом, который будет синтаксически анализироваться последним. Когда определяется в операции 537, что текущий синтаксический элемент является последним синтаксическим элементом, операция 50 синтаксического анализа CABAC переходит к операции 539. В операции 539 может сохраняться контекстная переменная, которая в заключение обновляется в текущей LCU.
[183] Когда сохранение контекстной переменной будет завершено, или когда текущий синтаксический элемент не является последним синтаксическим элементом, может завершаться процесс синтаксического анализа текущего синтаксического элемента.
[184] Контекстная переменная, которая сохраняется в операции 539, может использоваться для энтропийного декодирования другого поднабора. Фиг.6A представляет собой чертеж для объяснения энтропийного декодирования, использующего сохраненную контекстную переменную.
[185] Когда поднабором является каждая строка LCU, начальная контекстная переменная текущей строки LCU может определяться посредством использования конечной контекстной переменной предыдущей строки LCU.
[186] Например, начальная контекстная переменная первой LCU текущей строки LCU в изображении 60 может определяться являющейся, т.е. может синхронизироваться с, конечной контекстной переменной последней LCU строки LCU, которая располагается как раз над текущей строкой LCU. Следовательно, в то время как начальная контекстная переменная первой LCU 61 первой строки LCU может устанавливаться на контекстную переменную по умолчанию, начальная контекстная переменная 631 первой LCU 63 второй строки LCU может определяться являющейся конечной контекстной переменной 629 последней LCU 62 первой строки LCU, и начальная контекстная переменная 651 первой LCU 66 третьей строки LCU может определяться являющейся конечной контекстной переменной 649 последней LCU 64 второй строки LCU.
[187] Если расстоянием синхронизации является 1, для синхронизации контекстной переменной текущей LCU блок 26 сохранения контекста может использовать контекстную переменную второй LCU верхней строки LCU. Следовательно, когда будет завершено обновление второй LCU верхней строки LCU, и будет определена конечная контекстная переменная, может сохраняться конечная контекстная переменная, и контекстная переменная LCU текущей строки LCU может определяться с использованием сохраненной конечной контекстной переменной верхней строки LCU.
[188] Фиг.6B представляет собой подробную блок-схему последовательности действий операции 539 сохранения контекстной переменной в операции 50 синтаксического анализа CABAC согласно примерному варианту осуществления.
[189] В операции 551 блок 16 или 26 сохранения контекста может определять, является ли текущая LCU второй LCU в текущем поднаборе, и должна ли выполняться синхронизация контекстной переменной в текущем видеокадре. Когда определяется в операции 551, что необходима синхронизация контекстной переменной, и текущая LCU является второй LCU, операция 539 переходит на операцию 553. В операции 553 блок 16 или 26 сохранения контекста может сохранять конечную контекстную переменную текущей LCU для волновой параллельной обработки (WPP). При WPP, когда расстоянием синхронизации является 1, как показано на фиг.6A, контекстная переменная первой LCU текущей строки LCU может синхронизироваться с контекстной переменной, которая сохранена во второй LCU верхней строки LCU.
[190] В операции 561 блок 16 или 26 сохранения контекста может определять, является ли текущая LCU последней LCU в текущем сегменте слайса, и может ли существовать зависимый сегмент слайса в текущем видеокадре. Когда определяется в операции 561, что зависимый сегмент слайса может существовать, и текущий сегмент слайса является последним сегментом слайса, операция 539 может переходить на операцию 563. В операции 563 блок 16 или 26 сохранения контекста может сохранять конечную контекстную переменную текущей LCU для зависимого сегмента слайса, который является последующим.
[191] Фиг.7 представляет собой чертеж, иллюстрирующий синтаксис заголовка 71 сегмента слайса согласно примерному варианту осуществления.
[192] Устройство 20 энтропийного видеодекодирования может получать информацию о смещениях точки входа текущего сегмента слайса из заголовка 71 сегмента слайса. Подробно, в информации 72, когда сегмент слайса в видеокадре, в который включен текущий сегмент слайса, удовлетворяет по меньшей мере одному условию из числа условия для возможности «tiles_enabled_flag», что тайл существует, и условия для возможности «entropy_coding_sync_enabled_flag», что контекстная переменная синхронизирована в соответствии с LCU, заголовок 71 сегмента слайса может содержать информацию 73 «num_entry_point_offsets», указывающую число точек входа поднаборов, которые включены в текущий сегмент слайса. Информация «entry_point_offset_minus1[i]» 75, указывающая число, которое меньше на 1 смещения в соответствии с каждой фактической точкой входа для каждой точки 74 входа, может назначаться в соответствии с точками входа.
[193] Когда существуют два или более поднаборов, так как смещение поднабора должно быть больше 0, информация о смещении точки входа «entry_point_offset_minus1[i]» может получаться вычитанием 1 из фактического смещения поднабора. Следовательно, фактическое смещение поднабора может представлять собой значение, которое больше на 1 числа, указанного информацией о смещении точки входа «entry_point_offset_minus1[i]».
[194] Первый байт текущего поднабора может определяться суммированием смещений поднабора из предыдущего поднабора с текущим поднабором посредством использования информации о смещении точки входа «entry_point_offset_minus1[i]», которая назначается каждому поднабору. Следовательно, значение, полученное после суммирования значений, которые больше на 1 числа, указанного информацией о смещении точки входа «entry_point_offset_minus1[i]» поднаборов из предыдущего поднабора, с текущим поднабором, может определяться в качестве первого байта текущего поднабора.
[195] Индекс байтов, которые составляют каждый поднабор, начинается с 0, и индекс байта, указывающий первый байт, равен 0. Следовательно, последний байт текущего поднабора может определяться суммированием первого байта текущего поднабора с числом, указанным информацией о смещении точки входа «entry_point_offset_minus1[i]», которая назначается текущему поднабору.
[196] В устройстве 10 энтропийного видеокодирования согласно примерному варианту осуществления и в устройстве 20 энтропийного видеодекодирования согласно примерному варианту осуществления блоки, на которые разбиваются видеоданные, представляют собой LCU, и каждая из LCU разбивается на единицы кодирования, имеющие древовидную структуру, как описано выше. Ниже объясняются способ и устройство видеокодирования и способ и устройство видеодекодирования, основанные на LCU и единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления с ссылкой на фиг.8-20.
[197] Фиг.8 представляет собой блок-схему устройства 100 видеокодирования, основанного на единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления.
[198] Устройство 100 видеокодирования, включающее предсказание видео, основанное на единицах кодирования, имеющих древовидную структуру, включает в себя модуль 110 разбиения максимальной единицы кодирования (LCU), определитель 120 единицы кодирования и блок 130 вывода (например, выход и т.д.). Ниже в данном документе устройство 100 видеокодирования, включающее предсказание видео, основанное на единицах кодирования, имеющих древовидную структуру согласно примерному варианту осуществления, упоминается как «устройство 100 видеокодирования» для удобства объяснения.
[199] Модуль 110 разбиения единицы кодирования LCU может разбивать текущий видеокадр, основываясь на LCU, которая представляет собой единицу кодирования, имеющую максимальный размер для текущего видеокадра изображения. Если текущий видеокадр больше LCU, данные изображения текущего видеокадра могут разбиваться на по меньшей мере одну LCU. LCU согласно примерному варианту осуществления может представлять собой единицу данных, имеющую размер 32×32, 64×64, 128×128, 256×256 и т.д., причем форма единицы данных представляет собой квадрат, имеющий ширину и длину, равные квадратам числа 2.
[200] Единица кодирования согласно примерному варианту осуществления может характеризоваться максимальным размером и глубиной. Глубина обозначает число раз, на которое пространственно разбивается единица кодирования из LCU, и, когда глубина увеличивается, более глубокие единицы кодирования в соответствии с глубинами могут разбиваться с LCU до минимальной единицы кодирования. Глубина LCU является самой меньшей глубиной, и глубина минимальной единицы кодирования является самой большой глубиной. Так как размер единицы кодирования, соответствующий каждой глубине, уменьшается, когда увеличивается глубина LCU, единица кодирования, соответствующая меньшей глубине, может включать в себя множество единиц кодирования, соответствующих большим глубинам.
[201] Как описано выше, данные изображения текущего видеокадра разбиваются на LCU в соответствии с максимальным размером единицы кодирования, и каждая из LCU может включать в себя более глубокие единицы кодирования, которые разбиваются в соответствием с глубинами. Так как LCU согласно примерному варианту осуществления разбивается в соответствии с глубинами, данные изображения пространственной области, включенные в LCU, могут иерархически классифицироваться в соответствии с глубинами.
[202] Могут задаваться максимальная глубина и максимальный размер единицы кодирования, которые ограничивают общее число раз, на которое иерархически разбивается высота и ширина LCU.
[203] Определитель 120 единицы кодирования кодирует по меньшей мере одну зону разбиения, полученную разбиением зоны LCU в соответствии с глубинами, и определяет глубину для вывода кодированных в конечном счете данных изображения в соответствии с по меньшей мере одной зоной разбиения. Другими словами, определитель 120 единицы кодирования определяет кодированную глубину посредством кодирования данных изображения в более глубоких единицах кодирования в соответствии с глубинами, в соответствии с LCU текущего видеокадра, и выбора глубины, имеющей наименьшую ошибку кодирования. Определенная кодированная глубина и кодированные данные изображения в соответствии с определенной кодированной глубиной выводятся на блок 130 вывода.
[204] Данные изображения в LCU кодируются на основе более глубоких единиц кодирования, соответствующих по меньшей мере одной глубине, которая равна или меньше максимальной глубины, и результаты кодирования данных изображения сравниваются на основе каждой более глубокой единицы кодирования. Глубина, имеющая наименьшую ошибку кодирования, может выбираться после сравнения ошибок кодирования более глубоких единиц кодирования. По меньшей мере одна кодированная глубина может выбираться для каждой LCU.
[205] Размер LCU разбивается так, как иерархически разбивается единица кодирования в соответствии с глубинами, и увеличивается число единиц кодирования. Даже если единицы кодирования соответствуют одной и той же глубине в одной LCU, определяется, разбивать ли каждую единицу кодирования, соответствующую этой же глубине, на большую глубину посредством измерения отдельно ошибки кодирования данных изображения каждой единицы кодирования. Следовательно, даже когда данные изображения включены в одну LCU, ошибки кодирования могут отличаться в соответствии с зонами в одной LCU, и, таким образом, кодированные глубины могут отличаться в соответствии с зонами в данных изображения. Таким образом, одна или несколько кодированных глубин могут определяться в одной LCU, и данные изображения LCU могут разбиваться в соответствии с единицами кодирования по меньшей мере одной кодированной глубины.
[206] Следовательно, определитель 120 единицы кодирования может определять единицы кодирования, имеющие древовидную структуру, включенные в LCU. «Единицы кодирования, имеющие древовидную структуру» согласно примерному варианту осуществления, включают в себя единицы кодирования, соответствующие глубине, определенной равной кодированной глубине, из числа всех более глубоких единиц кодирования, включенных в LCU. Единица кодирования кодированной глубины может иерархически определяться в соответствии с глубинами в одной и той же зоне LCU, и может независимо определяться в разных зонах. Аналогично, кодированная глубина в текущей зоне может независимо определяться из кодированной глубины в другой зоне.
[207] Максимальная глубина согласно примерному варианту осуществления представляет собой индекс, связанный с числом раз разбиений с LCU до минимальной единицы кодирования. Первая максимальная глубина согласно примерному варианту осуществления может обозначать суммарное число раз разбиений с LCU до минимальной единицы кодирования. Вторая максимальная глубина согласно примерному варианту осуществления может обозначать суммарное число уровней глубины с LCU до минимальной единицы кодирования. Например, когда глубина LCU равна 0, глубина единицы кодирования, в которой LCU разбивается один раз, может устанавливаться на 1, и глубина единицы кодирования, в которой LCU разбивается два раза, может устанавливаться на 2. В данном случае, если минимальной единицей кодирования является единица кодирования, в которой LCU разбивается четыре раза, существует 5 уровней глубины для глубин 0, 1, 2, 3 и 4, и, таким образом, первая максимальная глубина может устанавливаться на 4, и вторая максимальная глубина может устанавливаться на 5.
[208] Кодирование с предсказанием и преобразование могут выполняться над LCU. Кодирование с предсказанием и преобразование также выполняются на основе более глубоких единиц кодирования в соответствии с глубиной, равной максимальной глубине, или с глубинами, меньшими максимальной глубины, в соответствии с LCU.
[209] Так как число более глубоких единиц кодирования увеличивается, когда LCU разбивается в соответствии с глубинами, кодирование, включающее в себя кодирование с предсказанием и преобразование, должно выполняться над всеми более глубокими единицами кодирования, генерируемыми тогда, когда увеличивается глубина. Для удобства объяснения кодирование с предсказанием и преобразование ниже описываются на основе единицы кодирования текущей глубины, в по меньшей мере одной LCU.
[210] Устройство 100 видеокодирования согласно примерному варианту осуществления может по-разному выбирать размер или форму единицы данных для кодирования данных изображения. Чтобы кодировать данные изображения, выполняются операции, такие как кодирование с предсказанием, преобразование и энтропийное кодирование, и одновременно одна и та же единица данных может использоваться для всех операций, или разные единицы данных могут использоваться для каждой операции.
[211] Например, устройство 100 видеокодирования может выбирать не только единицу кодирования для кодирования данных изображения, но также единицу данных, отличную от единицы кодирования, чтобы выполнять кодирование с предсказанием данных изображения в единице кодирования.
[212] Чтобы выполнять кодирование с предсказанием в LCU, кодирование с предсказанием может выполняться на основе единицы кодирования, соответствующей кодированной глубине, т.е. на основе единицы кодирования, которая больше не разбивается на единицы кодирования, соответствующие большей глубине. Ниже в данном документе единица кодирования, которая больше не разбивается и становится базовой единицей для кодирования с предсказанием, ниже упоминается как «единица предсказания». Раздел, полученный посредством разбиения единицы предсказания, может включать в себя единицу предсказания или единицу данных, полученную посредством разбиения по меньшей мере одного из высоты и ширины единицы предсказания. Раздел представляет собой единицу данных, где разбивается единица предсказания единицы кодирования, и единица предсказания может представлять собой раздел, имеющий такой же размер, что и единица кодирования.
[213] Например, когда единица кодирования размером 2N×2N (где N представляет собой положительное целое число) больше не разбивается, единица кодирования может стать единицей предсказания размером 2N×2N, и размер раздела может быть равен 2N×2N, 2N×N, N×2N или N×N. Примеры типа раздела включают в себя симметричные разделы, которые получаются симметричным разбиением высоты или ширины единицы предсказания, разделы, полученные асимметричным разбиением высоты или ширины единицы предсказания, таким как 1:n или n:1, разделы, которые получаются геометрическим разбиением единицы предсказания, и разделы, имеющие произвольную форму.
[214] Режим предсказания единицы предсказания может быть по меньшей мере одним из внутреннего режима, внешнего режима или режима пропуска. Например, внутренний режим или внешний режим могут выполняться над разделом размером 2N×2N, 2N×N, N×2N или N×N. Режим пропуска может выполняться только над разделом размером 2N×2N. Кодирование выполняется независимо над одной единицей предсказания в единице кодирования, таким образом выбирая режим предсказания, имеющий наименьшую ошибку кодирования.
[215] Устройство 100 видеокодирования согласно примерному варианту осуществления также может выполнять преобразование данных изображения в единице кодирования, основываясь не только на единице кодирования для кодирования данных изображения, но также основываясь на единице данных, которая отличается от единицы кодирования. Чтобы выполнять преобразование в единице кодирования, преобразование может выполняться на основе единицы данных, имеющей размер, который меньше или равен единице кодирования. Например, единица данных для преобразования может включать в себя единицу данных для внутреннего режима и единицу данных для внешнего режима.
[216] Единица преобразования в единице кодирования может рекурсивно разбиваться на зоны меньшего размера подобно единице кодирования в соответствии с древовидной структурой. Таким образом, остаточные данные в единице кодирования могут разбиваться в соответствии с единицей преобразования в соответствии с древовидной структурой в соответствии с глубинами преобразования.
[217] Глубина преобразования, указывающая число раз разбиений для достижения единицы преобразования посредством разбиения высоты и ширины единицы кодирования, также может устанавливаться в единице преобразования. Например, в текущей единице кодирования размером 2N×2N глубина преобразования может быть равна 0, когда размер единицы преобразования равен 2N×2N, может быть равна 1, когда размер единицы преобразования равен N×N, и может быть равна 2, когда размер единицы преобразования равен N/2×N/2. Другими словами, единица преобразования в соответствии с древовидной структурой может устанавливаться в соответствии с глубинами преобразования.
[218] Информация кодирования в соответствии с единицами кодирования, соответствующими кодированной глубине, требует не только информации о кодированной глубине, но также об информации, относящейся к кодированию с предсказанием и преобразованию. Следовательно, определитель 120 единицы кодирования не только определяет кодированную глубину, имеющую наименьшую ошибку кодирования, но также определяет тип раздела в единице предсказания, режим предсказания в соответствии с единицами предсказания и размер единицы преобразования для преобразования.
[219] Единицы кодирования, имеющие древовидную структуру в LCU, и способы определения единицы предсказания/раздела и единица преобразования, согласно примерному варианту осуществления, подробно описываются ниже с ссылкой на фиг.10-20.
[220] Определитель 120 единицы кодирования может измерять ошибку кодирования более глубоких единиц кодирования в соответствии с глубинами посредством использования оптимизации искажения по скорости, основываясь на множителях Лагранжа.
[221] Блок 130 вывода выводит данные изображения LCU, которая кодируется на основе по меньшей мере одной кодированной глубины, определенной определителем 120 единицы кодирования, и информации о режиме кодирования в соответствии с кодированной глубиной, в битовых потоках.
[222] Кодированные данные изображения могут получаться посредством кодирования остаточных данных изображения.
[223] Информация о режиме кодирования в соответствии с кодированной глубиной может включать в себя информацию о кодированной глубине, о типе раздела в единице предсказания, о режиме предсказания и о размере единицы преобразования.
[224] Информация о кодированной глубине может определяться посредством использования информации о разбиении в соответствии с глубинами, которая указывают, выполняется ли кодирование над единицами кодирования большей глубины вместо текущей глубины. Если текущая глубина текущей единицы кодирования представляет собой кодированную глубину, данные изображения в текущей единице кодирования кодируются и выводятся, и, таким образом, информация о разбиении может определяться, чтобы не разбивать текущую единицу кодирования на большую глубину. Альтернативно, если текущая глубина текущей единицы кодирования не является кодированной глубиной, кодирование выполняется над единицей кодирования большей глубины, и, таким образом, информация о разбиении может определяться для разбиения текущей единицы кодирования для получения единиц кодирования с большей глубиной.
[225] Если текущая глубина не является кодированной глубиной, кодирование выполняется над единицей кодирования, которая разбивается на единицу кодирования с большей глубиной. Так как по меньшей мере одна единица кодирования с большей глубиной существует в одной единице кодирования текущей глубины, кодирование выполняется неоднократно над каждой единицей кодирования с большей глубиной, и, таким образом, кодирование может рекурсивно выполняться для единиц кодирования, имеющих такую же глубину.
[226] Так как единицы кодирования, имеющие древовидную структуру, определяются для одной LCU, и информация о по меньшей мере одном режиме кодирования определяется для единицы кодирования кодированной глубины, информация о по меньшей мере одном режиме кодирования может определяться для одной LCU. Кодированная глубина данных изображения LCU может быть другой в соответствии с расположениями, так как данные изображения иерархически разбиваются в соответствии с глубинами, и, таким образом, информация о кодированной глубине и режиме кодирования может устанавливаться для данных изображения.
[227] Следовательно, блок 130 вывода может назначать информацию кодирования о соответствующей кодированной глубине и режиме кодирования по меньшей мере одной из единицы кодирования, единицы предсказания и минимальной единицы, включенной в LCU.
[228] Минимальная единица согласно примерному варианту осуществления представляет собой квадратную единицу данных, полученную разбиением минимальной единицы кодирования, составляющей самую большую глубину, на 4. Альтернативно, минимальная единица согласно примерному варианту осуществления может представлять собой максимальную квадратную единицу данных, которая может быть включена во все единицы кодирования, единицы предсказания, единицы раздела и единицы преобразования, включенные в LCU.
[229] Например, информация кодирования, выводимая блоком 130 вывода, может классифицироваться на информацию кодирования в соответствии с более глубокими единицами кодирования и информацию кодирования в соответствии с единицами предсказания. Информация кодирования в соответствии с более глубокими единицами кодирования может включать в себя информацию о режиме предсказания и о размере разделов. Информация кодирования в соответствии с единицами предсказания может включать в себя информацию о оцененном направлении внешнего режима, об индексе опорного изображения внешнего режима, о векторе движения, о цветовой составляющей внутреннего режима и о способе интерполяции внутреннего режима.
[230] Информация о максимальном размере единицы кодирования, определенной в соответствии с видеокадрами, слайсами или группами видеокадров (GOP), и информация о максимальной глубине могут вставляться в заголовок битового потока, SPS или PPS.
[231] Информация о максимальном размере единицы преобразования, разрешенном в отношении текущего видео, и информация о минимальном размере единицы преобразования также могут выводиться при помощи заголовка битового потока, SPS или PPS. Блок 130 вывода может кодировать и выводить опорную информацию, относящуюся к предсказанию, информации предсказания и информации о типе слайса.
[232] В устройстве 100 видеокодирования согласно самому простому примерному варианту осуществления более глубокая единица кодирования может представлять собой единицу кодирования, полученную делением высоты или ширины единицы кодирования меньшей глубины, которая находится на один уровень выше, на два. Другими словами, когда размер единицы кодирования текущей глубины равен 2N×2N, размер единицы кодирования большей глубины равен N×N. Единица кодирования с текущей глубиной, имеющая размер 2N×2N, может включать в себя максимум 4 единицы кодирования с большей глубиной.
[233] Следовательно, устройство 100 видеокодирования может формировать единицы кодирования, имеющие древовидную структуру, посредством определения единиц кодирования, имеющих оптимальную форму и оптимальный размер для каждой LCU, основываясь на размере LCU и максимальной глубине, определенной с учетом характеристик текущего видеокадра. Так как кодирование может выполняться над каждой LCU посредством использования любого одного из различных режимов предсказания и преобразований, оптимальный режим кодирования может определяться с учетом характеристик единицы кодирования различных размеров изображения.
[234] Таким образом, если изображение, имеющее высокое разрешение или большое количество данных, кодируется в макроблоке, чрезмерно увеличивается число макроблоков на видеокадр. Следовательно, увеличивается число порций сжатой информации, генерируемой для каждого макроблока, и, таким образом, трудно передавать сжатую информацию, и уменьшается эффективность сжатия данных. Однако посредством использования устройства 100 видеокодирования согласно примерному варианту осуществления эффективность сжатия изображения может повышаться, так как единица кодирования корректируется с учетом характеристик изображения, в то же время увеличивая максимальный размер единицы кодирования с учетом размера изображения.
[235] Устройство 100 видеокодирования согласно примерному варианту осуществления определяет единицы кодирования древовидной структуры для каждой LCU и генерирует символы в результате кодирования, выполняемого для каждой единицы кодирования. Устройство 10 энтропийного видеокодирования согласно примерному варианту осуществления может выполнять энтропийное кодирование символов для каждой LCU. В частности, устройство 10 энтропийного видеокодирования может выполнять энтропийное кодирование каждой LCU в соответствии со строкой LCU, включающих в себя LCU, которые последовательно располагаются по горизонтальному направлению, для каждого тайла или сегмента слайса, генерируемого посредством разбиения видеокадра. Устройство 10 энтропийного видеокодирования может одновременно выполнять параллельное энтропийное кодирование двух или более строк LCU.
[236] Устройство 10 энтропийного видеокодирования может генерировать строку битов символов посредством выполнения бинаризации символов, которые определяются посредством выполнения кодирования LCU. Может определяться контекстная переменная каждого индекса бина значения синтаксического элемента, соответствующего символу LCU, и строка бинов, указывающая значение синтаксического элемента, может определяться на основе контекстной переменной синтаксического элемента. Устройство 10 энтропийного видеокодирования может принимать строку бинов, указанную текущей контекстной переменной, которая определяется в контекстной таблице, для значения текущего синтаксического элемента.
[237] После формирования строки бинов для всех синтаксических элементов для LCU, устройство 10 энтропийного видеокодирования может определять, сохранять ли контекстные переменные, которые определены в LCU. Когда синтаксический элемент является последним синтаксическим элементом в LCU, зависимый сегмент слайса может быть включен в видеокадр, в который включена LCU, и LCU является последней LCU в сегменте слайса, могут сохраняться контекстные переменные для LCU.
[238] Блок 16 сохранения контекста может сохранять контекстные переменные для LCU, когда зависимый сегмент слайса может быть включен в видеокадр, независимо от того, является ли сегмент слайса независимым сегментом слайса или зависимым сегментом слайса.
[239] Когда множество сегментов слайса включено в видеокадр, для энтропийного кодирования контекстной переменной первой LCU зависимого сегмента слайса, который располагается следующим за текущим сегментом слайса, может использоваться контекстная переменная, которая сохраняется в текущем сегменте слайса.
[240] Фиг.9 представляет собой блок-схему устройства 200 видеодекодирования, основанного на единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления.
[241] Устройство 200 видеодекодирования, которое включает в себя предсказание видео, основанное на единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления, включает в себя приемник 210, модуль 220 извлечения данных изображения и информации кодирования и декодер 230 данных изображения. Ниже в данном документе устройство 200 видеодекодирования, включающее в себя предсказание видео, основанное на единицах кодирования, имеющих древовидную структуру, согласно примерному варианту осуществления, упоминается как «устройство 200 видеодекодирования» для удобства объяснения.
[242] Определения различных терминов, таких как единица кодирования, глубина, единица предсказания, единица преобразования и информация о различных режимах кодирования, для операций декодирования устройства 200 видеодекодирования идентичны тем, которые описаны с ссылкой на фиг.8 и устройство 100 видеокодирования.
[243] Приемник 210 принимает и синтаксически анализирует битовый поток кодированного видео. Модуль 220 извлечения данных изображения и информации кодирования извлекает кодированные данные изображения для каждой единицы кодирования из синтаксически анализируемого битового потока, причем единицы кодирования имеют древовидную структуру в соответствии с каждой LCU, и выводит извлеченные данные изображения на декодер 230 данных изображения. Модуль 220 извлечения данных изображения и информации кодирования может извлекать информацию о максимальном размере единицы кодирования текущего видеокадра, из заголовка о текущем видеокадре, SPS или PPS.
[244] Модуль 220 извлечения данных изображения и информации кодирования извлекает информацию о кодированной глубине и режиме кодирования для единиц кодирования, имеющих древовидную структуру, согласно каждой LCU, из синтаксически анализируемого битового потока. Извлеченная информация о кодированной глубине и режиме кодирования выводится на декодер 230 данных изображения. Другими словами, данные изображения в строке битов разбиваются на LCU, так что декодер 230 данных изображения декодирует данные изображения для каждой LCU.
[245] Информация о кодированной глубине и режиме кодирования в соответствии с LCU может устанавливаться для информации о по меньшей мере одной единице кодирования, соответствующей кодированной глубине, и информация о режиме кодирования может включать в себя информацию о типе раздела соответствующей единицы кодирования, соответствующей кодированной глубине, о режиме предсказания и размере единицы преобразования. Информация о разбиении в соответствии с глубинами может извлекаться как информация о кодированной глубине.
[246] Информация о кодированной глубине и режиме кодирования в соответствии с каждой LCU, извлеченная модулем 220 извлечения данных изображения и информации кодирования, представляет собой информацию о кодированной глубине и режиме кодирования, определенную для генерирования минимальной ошибки кодирования, когда кодер, такой как устройство 100 видеокодирования, неоднократно выполняет кодирование для каждой более глубокой единицы кодирования в соответствии с глубинами в соответствии с каждой LCU. Следовательно, устройство 200 видеодекодирования может восстанавливать изображение посредством декодирования данных изображения в соответствии с кодированной глубиной и режимом кодирования, который генерирует минимальную ошибку кодирования.
[247] Так как информация кодирования о кодированной глубине и режиме кодирования может назначаться заданной единице данных из числа соответствующей единицы кодирования, единицы предсказания и минимальной единицы, модуль 220 извлечения данных изображения и информации кодирования может извлекать информацию о кодированной глубине и режиме кодирования в соответствии с заданными единицами данных. Если информация о кодированной глубине и режиме кодирования соответствующей LCU записывается в соответствии с заданными единицами данных, заданные единицы данных, которым назначается одинаковая информация о кодированной глубине и режиме кодирования, как можно предположить, представляют собой единицы данных, включенные в одну и ту же LCU.
[248] Декодер 230 данных изображения восстанавливает текущий видеокадр посредством декодирования данных изображения в каждой LCU на основе информации о кодированной глубине и режиме кодирования в соответствии с LCU. Другими словами, декодер 230 данных изображения может декодировать кодированные данные изображения на основе извлеченной информации о типе раздела, режиме предсказания и единице преобразования для каждой единицы кодирования из числа единиц кодирования, имеющих древовидную структуру, включенных в каждую LCU. Процесс декодирования может включать в себя предсказание, включающее в себя внутреннее предсказание и компенсацию движения, и обратное преобразование.
[249] Декодер 230 данных изображения может выполнять внутреннее предсказание или компенсацию движения в соответствии с разделом и режимом предсказания каждой единицы кодирования на основе информации о типе раздела и режиме предсказания единицы предсказания единицы кодирования в соответствии с кодированными глубинами.
[250] Кроме того, декодер 230 данных изображения может считывать информацию о единице преобразования в соответствии с древовидной структурой для каждой единицы кодирования, чтобы выполнять обратное преобразование на основе единиц преобразования для каждой единицы кодирования, для обратного преобразования для каждой LCU. Посредством обратного преобразования может восстанавливаться значение пикселя пространственной области единицы кодирования.
[251] Декодер 230 данных изображения может определять кодированную глубину текущей LCU посредством использования информации о разбиении в соответствии с глубинами. Если информация о разбиении указывает, что данные изображения больше не разбиваются на текущей глубине, то текущая глубина представляет собой кодированную глубину. Следовательно, декодер 230 данных изображения может декодировать кодированные данные в текущей LCU посредством использования информации о типе раздела единицы предсказания, режиме предсказания и размере единицы преобразования для каждой единицы кодирования, соответствующей кодированной глубине.
[252] Другими словами, единицы данных, содержащие информацию кодирования, включающую в себя одинаковую информацию о разбиении, можно собирать посредством наблюдения за набором информации кодирования, назначенным для заданной единицы данных из числа единицы кодирования, единицы предсказания и минимальной единицы, и собранные единицы данных могут рассматриваться как одна единица данных, подлежащая декодированию декодером 230 данных изображения в одном и том же режиме кодирования. По существу, текущая единица кодирования может декодироваться посредством получения информации о режиме кодирования для каждой единицы кодирования.
[253] Приемник 210 может включать в себя устройство 20 энтропийного видеодекодирования по фиг.2A. Устройство 20 энтропийного видеодекодирования может синтаксически анализировать множество строк LCU из принимаемого битового потока.
[254] Когда приемник 22 извлекает первую строку LCU и вторую строку LCU из битового потока, первый энтропийный декодер 24 может последовательно восстанавливать символы LCU первой строки LCU посредством выполнения энтропийного декодирования первой строки LCU.
[255] Устройство 20 энтропийного видеодекодирования может определять строку бинов и индекс бина для LCU, которая получается из битового потока. Устройство 20 энтропийного видеодекодирования может сохранять данные о контекстной таблице, содержащей корреляцию между строкой бинов и контекстной переменной для каждого синтаксического элемента. Устройство 20 энтропийного видеодекодирования может определять значение синтаксического элемента, указанного текущей строкой бинов, посредством сравнения строк бинов, которые могут назначаться синтаксическому элементу в текущей контекстной переменной, основываясь на контекстной таблице, со строкой бинов в индексе бина, который определяется в настоящий момент.
[256] Когда синтаксический элемент является последним синтаксическим элементом в LCU, зависимый сегмент слайса может быть включен в видеокадр, в который включена LCU, и LCU является последней LCU в сегменте слайса, устройство 20 энтропийного видеодекодирования может сохранять контекстные переменные для LCU. Когда зависимый сегмент слайса может быть включен в видеокадр независимо от того, является ли сегмент слайса независимым сегментом слайса или зависимым сегментом слайса, могут сохраняться контекстные переменные для LCU.
[257] Когда множество сегментов слайса включено в видеокадр, для энтропийного кодирования для контекстной переменной первой LCU зависимого сегмента слайса, который располагается следующим за текущим сегментом слайса, может использоваться контекстная переменная, которая сохраняется в текущем сегменте слайса.
[258] Устройство 20 энтропийного видеодекодирования может восстанавливать символы LCU посредством использования значения каждого синтаксического элемента.
[259] В результате, устройство 200 видеодекодирования может получать информацию об единице кодирования, имеющей минимальную ошибку кодирования, посредством рекурсивного выполнения кодирования каждой LCU во время процесса кодирования и может использовать информацию для декодирования текущего видеокадра. Т.е. могут декодироваться кодированные данные изображения единиц кодирования, имеющих древовидную структуру, определенных в качестве оптимальных единиц кодирования для каждой LCU.
[260] Следовательно, даже когда изображение имеет высокое разрешение или большое количество данных, данные изображения могут эффективно декодироваться и восстанавливаться в соответствии с режимом кодирования и размером единицы кодирования, которые адаптивно определяются в соответствии с характеристиками изображения посредством использования информации об оптимальном режиме кодирования, которая передается от кодера.
[261] Фиг.10 представляет собой чертеж для объяснения понятия единиц кодирования согласно примерному варианту осуществления.
[262] Размер единицы кодирования может выражаться в виде «ширина × высота», и он может составлять 64×64, 32×32, 16×16 и 8×8. Единица кодирования размером 64×64 можно разбиваться на разделы размером 64×64, 64×32, 32×64 или 32×32, и единица кодирования размером 32×32 может разбиваться на разделы размером 32×32, 32×16, 16×32 или 16×16, единица кодирования размером 16×16 может разбиваться на разделы размером 16×16, 16×8, 8×16 или 8×8, и единица кодирования размером 8×8 может разбиваться на разделы размером 8×8, 8×4, 4×8 или 4×4.
[263] В видеоданных 310 разрешение составляет 1920×1080, максимальный размер единицы кодирования составляет 64, и максимальная глубина составляет 2. В видеоданных 320 разрешение составляет 1920×1080, максимальный размер единицы кодирования составляет 64, и максимальная глубина составляет 3. В видеоданных 330 разрешение составляет 352×288, максимальный размер единицы кодирования составляет 16, и максимальная глубина составляет 1. Максимальная глубина, показанная на фиг.10, обозначает суммарное число разбиений с LCU до минимальной единицы декодирования.
[264] Если разрешение является высоким или количество данных является большим, максимальный размер единицы кодирования может быть настолько большим, что не только увеличивается эффективность кодирования, но также точно отражаются характеристики изображения. Следовательно, максимальный размер единицы кодирования видеоданных 310 и 320, имеющих большее разрешение, чем видеоданные 330, может составлять 64.
[265] Так как максимальная глубина видеоданных 310 составляет 2, единицы 315 кодирования видеоданных 310 могут включать в себя LCU, имеющую размер вдоль длинной оси, составляющий 64, и единицы кодирования, имеющие размеры вдоль длинных осей, составляющие 32 и 16, так как глубины увеличиваются до двух уровней посредством двукратного разбиения LCU. Так как максимальная глубина видеоданных 330 составляет 1, единицы 335 кодирования видеоданных 330 могут включать в себя LCU, имеющую размер вдоль длинной оси, составляющий 16, и единицы кодирования, имеющие размер вдоль длинной оси, составляющий 8, так как глубины увеличиваются до одного уровня посредством однократного разбиения LCU.
[266] Так как максимальная глубина видеоданных 320 составляет 3, единицы 325 кодирования видеоданных 320 могут включать в себя LCU, имеющую размер вдоль длинной оси, составляющий 64, и единицы кодирования, имеющие размеры вдоль длинных осей, составляющие 32, 16 и 8, так как глубины увеличиваются до 3 уровней посредством трехкратного разбиения LCU. Так как глубина увеличивается, можно точно выразить подробную информацию.
[267] Фиг.11 представляет собой блок-схему кодера 400 изображения на основе единиц кодирования согласно примерному варианту осуществления.
[268] Кодер 400 изображения согласно примерному варианту осуществления выполняет операции определителя 120 единицы кодирования устройства 100 видеокодирования, чтобы кодировать данные изображения. Другими словами, модуль 410 внутреннего предсказания выполняет внутреннее предсказание единиц кодирования во внутреннем режиме из текущего кадра 405, и модуль 420 оценки движения и модуль 425 компенсации движения выполняют соответственно внешнюю оценку и компенсацию движения над единицами кодирования во внешнем режиме из текущего кадра 405 посредством использования текущего кадра 405, и опорного кадра 495.
[269] Данные, выводимые из модуля 410 внутреннего предсказания, модуля 420 оценки движения и модуля 425 компенсации движения, выводятся в виде квантованного коэффициента преобразования с помощью модуля 430 преобразования и модуля 440 квантования. Квантованный коэффициент преобразования восстанавливается в виде данных в пространственной области с помощью модуля 460 обратного квантования и модуля 470 обратного преобразования, и восстановленные данные в пространственной области выводятся в виде опорного кадра 495 после выполнения постобработки с помощью деблокирующего блока 480 (например, деблокирующего фильтра и т.д.) и блока 490 петлевой фильтрации (например, петлевого фильтра, блока коррекции смещения, корректора смещения и т.д.). Квантованный коэффициент преобразования может выводиться в виде битового потока 455 с помощью энтропийного кодера 450.
[270] Чтобы можно было применить кодер 400 изображения в устройстве 100 видеокодирования, все элементы кодера 400 изображения, т.е. модуль 410 внутреннего предсказания, модуль 420 оценки движения, модуль 425 компенсации движения, модуль 430 преобразования, модуль 440 квантования, энтропийный кодер 450, модуль 460 обратного квантования, модуль 470 обратного преобразования, деблокирующий блок 480 и блок 490 петлевой фильтрации, должны выполнять операции на основе каждой единицы кодирования из числа единиц кодирования, имеющих древовидную структуру, с учетом максимальной глубины каждой LCU.
[271] Конкретно, модуль 410 внутреннего предсказания, модуль 420 оценки движения и модуль 425 компенсации движения определяют разделы и режим предсказания каждой единицы кодирования из числа единиц кодирования, имеющих древовидную структуру, с учетом максимального размера и максимальной глубины текущей LCU, и модуль 430 преобразования определяет размер единицы преобразования в каждой единице кодирования из числа единиц кодирования, имеющих древовидную структуру.
[272] В частности, энтропийный кодер 450 может соответствовать устройству 10 энтропийного видеокодирования согласно примерному варианту осуществления.
[273] Фиг.12 представляет собой блок-схему декодера 500 изображения на основе единиц кодирования согласно примерному варианту осуществления.
[274] Модуль 510 синтаксического анализа синтаксически анализирует кодированные данные изображения, подлежащие декодированию, и информацию о кодировании, требуемую для декодирования, из битового потока 505. Кодированные данные изображения выводятся в виде данных обратного квантования с помощью энтропийного декодера 520 и модуля 530 обратного квантования, и данные обратного квантования восстанавливаются в данные изображения в пространственной области с помощью модуля 540 обратного преобразования.
[275] Модуль 550 внутреннего предсказания выполняет внутреннее предсказание единиц кодирования во внутреннем режиме в отношении данных изображения в пространственной области, и модуль 560 компенсации движения выполняет компенсацию движения над единицами кодирования во внешнем режиме посредством использования опорного кадра 585.
[276] Данные изображения в пространственной области, которые прошли через модуль 550 внутреннего предсказания и модуль 560 компенсации движения, могут выводиться в виде восстановленного кадра 595 после выполнения постобработки с помощью деблокирующего блока 570 (например, деблокирующего фильтра и т.д.) и блока 580 петлевой фильтрации (например, блока коррекции смещения, корректора смещения, петлевого фильтра и т.д.). Данные изображения, над которыми выполняется постобработка посредством деблокирующего блока 570 и блока 580 петлевой фильтрации, могут выводиться в виде опорного кадра 585.
[277] Чтобы декодировать данные изображения в декодере 230 данных изображения устройства 200 видеодекодирования, декодер 500 изображения может выполнять операции, которые выполняются после модуля 510 синтаксического анализа.
[278] Чтобы можно было применить декодер 500 изображения в устройстве 200 видеодекодирования, все элементы декодера 500 изображения, т.е. модуль 510 синтаксического анализа, энтропийный декодер 520, модуль 530 обратного квантования, модуль 540 обратного преобразования, модуль 550 внутреннего предсказания, модуль 560 компенсации движения, деблокирующий блок 570 и блок 580 петлевой фильтрации, должны выполнять операции на основе единиц кодирования, имеющих древовидную структуру, для каждой LCU.
[279] Конкретно, модуль 550 внутреннего предсказания и модуль 560 компенсации движения определяют разделы и режим предсказания для каждой единицы кодирования, имеющей древовидную структуру, и модуль 540 обратного преобразования определяет размер единицы преобразования для каждой единицы кодирования. В частности, энтропийный декодер 520 может соответствовать устройству 20 энтропийного видеодекодирования согласно примерному варианту осуществления.
[280] Фиг.13 представляет чертеж, иллюстрирующий более глубокие единицы кодирования в соответствии с глубинами и разделами согласно примерному варианту осуществления.
[281] Устройство 100 видеокодирования согласно примерному варианту осуществления и устройство 200 видеодекодирования согласно примерному варианту осуществления используют иерархические единицы кодирования, чтобы учитывать характеристики изображения. Максимальная высота, максимальная ширина и максимальная глубина единиц кодирования могут адаптивно определяться в соответствии с характеристиками изображения, или могут иначе устанавливаться пользователем. Размеры более глубоких единиц кодирования в соответствии с глубинами могут определяться в соответствии с заданным максимальным размером единицы кодирования.
[282] В иерархической структуре 600 единиц кодирования согласно примерному варианту осуществления каждая из максимальной высоты и максимальной ширины единиц кодирования составляет 64, и максимальная глубина составляет 4. В данном случае, максимальная глубина ссылается на суммарное число раз, на сколько единица кодирования разбивается с LCU до минимальной единицы кодирования. Так как глубина увеличивается вдоль вертикальной оси иерархической структуры 600, разбивается каждая из высоты и ширины более глубокой единицы кодирования. Единица предсказания и разделы, которые являются базами для кодирования с предсказанием каждой более глубокой единицы кодирования, показаны вдоль горизонтальной оси иерархической структуры 600.
[283] Другими словами, единица 610 кодирования представляет собой LCU в иерархической структуре 600, причем глубина равна 0, и размер, т.е. произведение высоты на ширину, составляет 64×64. Глубина увеличивается вдоль вертикальной оси, и присутствуют единица 620 кодирования, имеющая размер 32×32 и глубину 1, единица 630 кодирования, имеющая размер 16×16 и глубину 2, единица 640 кодирования, имеющая размер 8×8 и глубину 3, и единица 650 кодирования, имеющая размер 4×4 и глубину 4. Единица 640 кодирования, имеющая размер 4×4 и глубину 4, представляет собой минимальную единицу кодирования.
[284] Единица предсказания и разделы единицы кодирования располагаются вдоль горизонтальной оси в соответствии с каждой глубиной. Другими словами, если единица 610 кодирования, имеющая размер 64×64 и глубину 0, представляет собой единицу предсказания, то эта единица предсказания может разбиваться на разделы, включенные в единицу 610 кодирования, т.е. раздел 610, имеющий размер 64×64, разделы 612, имеющие размер 64×32, разделы 614, имеющие размер 32×64, или разделы 616, имеющие размер 32×32.
[285] Аналогично, единица предсказания единицы 620 кодирования, имеющей размер 32×32 и глубину 1, может разбиваться на разделы, включенные в единицу 620 кодирования, т.е. раздел 620, имеющий размер 32×32, разделы 622, имеющие размер 32×16, разделы 624, имеющие размер 16×32, и разделы 626, имеющие размер 16×16.
[286] Аналогично, единица предсказания единицы 630 кодирования, имеющей размер 16×16 и глубину 2, может разбиваться на разделы, включенные в единицу 630 кодирования, т.е. раздел, имеющий размер 16×16, включенный в единицу 630 кодирования, разделы 632, имеющие размер 16×8, разделы 634, имеющие размер 8×16, и разделы 636, имеющие размер 8×8.
[287] Аналогично, единица предсказания единицы 640 кодирования, имеющей размер 8×8 и глубину 3, может разбиваться на разделы, включенные в единицу 640 кодирования, т.е. раздел, имеющий размер 8×8, включенный в единицу 640 кодирования, разделы 642, имеющие размер 8×4, разделы 644, имеющие размер 4×8, и разделы 646, имеющие размер 4×4.
[288] Наконец, единица 650 кодирования, имеющая глубину 4 и размер 4×4, которая является минимальной единицей кодирования, представляет собой единицу кодирования, имеющую набольшую глубину, и соответствующая единица предсказания может устанавливаться только на разделы, имеющие размер 4×4.
[289] Чтобы определить по меньшей мере одну кодированную глубину единиц кодирования, составляющих LCU 610, определитель 120 единицы кодирования устройства 100 видеокодирования согласно примерному варианту осуществления должен выполнять кодирование для единиц кодирования, соответствующих каждой глубине, включенных в LCU 610.
[290] Число более глубоких единиц кодирования в соответствие с глубинами, включающих в себя данные в одном и том же диапазоне и одного и того же размера, увеличивается по мере увеличения глубины. Например, четыре единицы кодирования, соответствующие глубине 2, требуются для того, чтобы охватить данные, которые включены в одну единицу кодирования, соответствующую глубине 1. Следовательно, чтобы сравнить результаты кодирования одних и тех же данных в соответствии с глубинами, должна кодироваться каждая единица кодирования, соответствующая глубине 1, и четыре единицы кодирования, соответствующие глубине 2.
[291] Чтобы выполнить кодирование для текущей глубины из числа глубин, может выбираться наименьшая ошибка кодирования для текущей глубины посредством выполнения кодирования для каждой единицы предсказания в единицах кодирования, соответствующих текущей глубине, вдоль горизонтальной оси иерархической структуры 600. Альтернативно, может выполняться поиск минимальной ошибки кодирования посредством сравнения наименьших ошибок кодирования в соответствии с глубинами посредством выполнения кодирования для каждой глубины по мере увеличения глубины вдоль вертикальной оси иерархической структуры 600. Глубина и раздел, имеющие минимальную ошибку кодирования в единице 610 кодирования, могут выбираться в качестве кодированной глубины и типа раздела единицы 610 кодирования.
[292] Фиг.14 представляет собой чертеж для объяснения взаимосвязи между единицей 710 кодирования и единицами 720 преобразования согласно примерному варианту осуществления.
[293] Устройство 100 видеокодирования согласно примерному варианту осуществления или устройство 200 видеодекодирования согласно примерному варианту осуществления кодирует или декодирует изображение в соответствии с единицами кодирования, имеющими размеры, меньшие LCU, или равные ей, для каждой LCU. Размеры единиц преобразования для преобразования во время кодирования могут выбираться на основе единиц данных, которые не больше соответствующей единицы кодирования.
[294] Например, в устройстве 100 видеокодирования согласно примерному варианту осуществления или в устройстве 200 видеодекодирования согласно примерному варианту осуществления, если размер единицы 710 кодирования составляет 64×64, то преобразование может выполняться посредством использования единиц 720 преобразования, имеющих размер 32×32.
[295] Данные единицы 710 кодирования, имеющей размер 64×64, могут кодироваться посредством выполнения преобразования каждой единицы преобразования, имеющей размер 32×32, 16×16, 8×8 и 4×4, которые меньше размера 64×64, и затем может выбираться единица преобразования, имеющая наименьшую ошибку кодирования.
[296] Фиг.15 представляет собой чертеж для объяснения информации кодирования единиц кодирования, соответствующих кодированной глубине, согласно примерному варианту осуществления.
[297] Блок 130 вывода устройства 100 видеокодирования согласно примерному варианту осуществления может кодировать и передавать информацию 800 о типе раздела, информацию 810 о режиме предсказания и информацию 820 о размере единицы преобразования для каждой единицы кодирования, соответствующей кодированной глубине, в качестве информации о режиме кодирования.
[298] Информация 800 указывает информацию о форме раздела, полученного посредством разбиения единицы предсказания текущей единицы кодирования, причем этот раздел представляет собой единицу данных для кодирования с предсказанием текущей единицы кодирования. Например, текущая единица CU_0 кодирования, имеющая размер 2N×2N, может разбиваться на любой один из раздела 802, имеющего размер 2N×2N, раздела 804, имеющего размер 2N×N, раздела 806, имеющего размер N×2N, и раздела 808, имеющего размер N×N. В данном случае, информация 800 о типе раздела устанавливается так, чтобы указывать один из раздела 804, имеющего размер 2N×N, раздела 806, имеющего размер N×2N, и раздела 808, имеющего размер N×N.
[299] Информация 810 указывает режим предсказания каждого раздела. Например, информация 810 может указывать режим кодирования с предсказанием, выполняемого над разделом, указанным информацией 800, т.е. внутренний режим 812, внешний режим 814, или режим 816 пропуска.
[300] Информация 820 указывает единицу преобразования, на основе которой выполняется преобразование текущей единицы кодирования. Например, единица преобразования может быть первой единицей 822 внутреннего преобразования, второй единицей 824 внутреннего преобразования, первой единицей 826 внешнего преобразования или второй единицей 828 внешнего преобразования.
[301] Модуль 210 извлечения данных изображения и информации кодирования устройства 200 видеодекодирования согласно примерному варианту осуществления может извлекать и использовать информацию 800, 810 и 820 для декодирования в соответствии с каждой более глубокой единицей кодирования.
[302] Фиг.16 представляет собой чертеж, иллюстрирующий более глубокие единицы кодирования в соответствии с глубинами согласно примерному варианту осуществления.
[303] Информация о разбиении может использоваться для указания изменения глубины. Эта информация о разбиении указывает, разбивается ли единица кодирования текущей глубины на единицы кодирования большей глубины.
[304] Единица 910 предсказания для кодирования с предсказанием единицы 900 кодирования, имеющей глубину 0 и размер 2N_0×2N_0, может включать в себя разделы типа 912 раздела, имеющего размер 2N_0×2N_0, типа 914 раздела, имеющего размер 2N_0×N_0, типа 916 раздела, имеющего размер N_0×2N_0, и типа 918 раздела, имеющего размер N_0×N_0. Фиг.16 иллюстрирует только типы 912-918 раздела, которые получаются симметричным разбиением единицы 910 предсказания, но тип раздела ими не ограничивается, и разделы единицы 910 предсказания могут включать в себя асимметричные разделы, разделы, имеющие заданную форму, и разделы, имеющие геометрическую форму.
[305] Кодирование с предсказанием выполняется повторно в одном разделе, имеющем размер 2N_0×2N_0, в двух разделах, имеющих размер 2N_0×N_0, в двух разделах, имеющих размер N_0×2N_0, и в четырех разделах, имеющих размер N_0×N_0, в соответствии с каждым типом раздела. Кодирование с предсказанием во внутреннем режиме и внешнем режиме может выполняться в разделах, имеющих размеры 2N_0×2N_0, N_0×2N_0, 2N_0×N_0 и N_0×N_0. Кодирование с предсказанием в режиме пропуска выполняется только в разделе, имеющем размер 2N_0×2N_0.
[306] Если ошибка кодирования является наименьшей в одном из типов 912-916 раздела, то единица 910 предсказания может не разбиваться на большую глубину.
[307] Если ошибка кодирования является наименьшей в типе 918 раздела, глубина меняется с 0 до 1 для разбиения типа 918 раздела в операции 920, и повторно выполняется кодирование на единицах 930 кодирования, имеющих глубину 2 и размер N_0×N_0, чтобы найти минимальную ошибку кодирования.
[308] Единица 940 предсказания для кодирования с предсказанием единицы 930 кодирования, имеющей глубину 1 и размер 2N_1×2N_1 (=N_0×N_0), может включать в себя разделы типа 942 раздела, имеющего размер 2N_1×2N_1, типа 944 раздела, имеющего размер 2N_1×N_1, типа 946 раздела, имеющего размер N_1×2N_1, и типа 948 раздела, имеющего размер N_1×N_1.
[309] Если ошибка кодирования является наименьшей в типе 948 раздела, то глубина меняется с 1 до 2 для разбиения типа 948 раздела в операции 950, и кодирование повторно выполняется над единицами 960 кодирования, которые имеют глубину 2 и размер N_2×N_2, для поиска минимальной ошибки кодирования.
[310] Когда максимальная глубина равна d, операция разбиения в соответствии с каждой глубиной может выполняться до того момента, когда глубина становится равной d-1, и информация о разбиении может кодироваться до того момента, когда глубина будет равна одному значению от 0 до d-2. Другими словами, когда кодирование выполняется до того момента, когда глубина будет равной d-1, после того как будет выполнено разбиение единицы кодирования, соответствующей глубине d-2, в операции 970, единица 990 предсказания для кодирования с предсказанием единицы 980 кодирования, имеющей глубину d-1 и размер 2N_(d-1)×2N_(d-1), может включать в себя разделы типа 992 раздела, имеющего размер 2N_(d-1)×2N_(d-1), типа 994 раздела, имеющего размер 2N_(d-1)×N_(d-1), типа 996 раздела, имеющего размер N_(d-1)×2N_(d-1), и типа 998 раздела, имеющего размер N_(d-1)×N_(d-1).
[311] Кодирование с предсказанием может повторно выполняться в одном разделе, имеющем размер 2N_(d-1)×2N_(d-1), двух разделах, имеющих размер 2N_(d-1)×N_(d-1), двух разделах, имеющих размер N_(d-1)×2N_(d-1), четырех разделах, имеющих размер N_(d-1)×N_(d-1), из числа типов 992-998 раздела, чтобы найти тип раздела, имеющий минимальную ошибку кодирования.
[312] Даже когда тип 998 раздела имеет минимальную ошибку кодирования, так как максимальная глубина равна d, единица CU_(d-1) кодирования, имеющая глубину d-1, больше не разбивается на большую глубину, и кодированная глубина для единиц кодирования, составляющих текущую LCU 900, определяется равной d-1, и тип раздела текущей LCU 900 может определяться равный N_(d-1)×N_(d-1). Так как максимальная глубина равна d, и минимальная единица 980 кодирования, имеющая наибольшую глубину d-1, больше не разбивается на большую глубину, не устанавливается информация о разбиении для минимальной единицы 980 кодирования.
[313] Единица 999 данных может быть «минимальной единицей» для текущей LCU. Согласно примерному варианту осуществления минимальной единицей может быть квадратная единица данных, полученная посредством разбиения минимальной единицы 980 кодирования на 4. Посредством повторного выполнения кодирования устройство 100 видеокодирования согласно примерному варианту осуществления может выбирать глубину, имеющую наименьшую ошибку кодирования, посредством сравнения ошибок кодирования в соответствии с глубинами единицы 900 кодирования для определения кодированной глубины, и устанавливать соответствующий тип раздела и режим предсказания в качестве режима кодирования кодированной глубины.
[314] По существу, минимальные ошибки кодирования в соответствии с глубинами сравниваются на всех глубинах от 1 до d, и глубина, имеющая наименьшую ошибку кодирования, может быть определена в качестве кодированной глубины. Кодированная глубина, тип раздела единицы предсказания и режим предсказания могут кодироваться и передаваться в виде информации о режиме кодирования. Так как единица кодирования разбивается с глубины 0 до кодированной глубины, только информацию о разбиении кодированной глубины устанавливается на 0, и информация о разбиении глубин, в которые кодированная глубина не входит, устанавливается на 1.
[315] Модуль 220 извлечения данных изображения и информации кодирования устройства 200 видеодекодирования согласно примерному варианту осуществления может извлекать и использовать информацию о кодированной глубине и единицу предсказания единицы 900 кодирования с целью декодирования раздела 912. Устройство 200 видеодекодирования согласно примерному варианту осуществления может определять глубину, на которой информация о разбиении равна 0, в качестве кодированной глубины посредством использования информации о разбиении в соответствии с глубинами, и использовать информацию о режиме кодирования соответствующей глубине для декодирования.
[316] Фиг.17-19 представляют собой чертежи для объяснения взаимосвязи между единицами 1010 кодирования, единицами 1060 предсказания и единицами 1070 преобразования согласно примерному варианту осуществления.
[317] Единицы 1010 кодирования представляют собой единицы кодирования, имеющие древовидную структуру, соответствующую кодированным глубинам, определенным устройством 100 видеокодирования согласно примерному варианту осуществления, в LCU. Единицы 1060 предсказания представляют собой разделы единиц предсказания каждой единицы 1010 кодирования, и единицы 1070 преобразования представляют собой единицы преобразования каждой единицы 1010 кодирования.
[318] Когда глубина LCU равна 0 в единицах 1010 кодирования, глубины единиц 1012 и 1054 кодирования равны 1, глубины единиц 1014, 1016, 1018, 1028, 1050 и 1052 кодирования равны 2, глубины единиц 1020, 1022, 1024, 1026, 1030, 1032 и 1048 кодирования равны 3, и глубины единиц 1040, 1042, 1044 и 1046 кодирования равны 4.
[319] В единицах 1060 предсказания некоторые единицы 1014, 1016, 1022, 1032, 1048, 1050, 1052 и 1054 кодирования получаются посредством разбиения единиц кодирования в единицах 1010 кодирования. Другими словами, типы раздела в единицах 1014, 1022, 1050 и 1054 кодирования имеют размер 2N×N, типы раздела в единицах 1016, 1048 и 1052 кодирования имеют размер N×2N, и тип раздела единицы 1032 кодирования имеет размер N×N. Единицы предсказания и разделы единиц 1010 кодирования меньше или равны каждой единице кодирования.
[320] Преобразование или обратное преобразование выполняется над данными изображения единицы 1052 кодирования в единицах 1070 преобразования в единице данных, которая меньше единицы 1052 кодирования. Единицы 1014, 1016, 1022, 1032, 1048, 1050, 1052 и 1054 кодирования в единицах 1070 преобразования отличаются размерами и формами от единиц кодирования в единицах 1060 предсказания. Другими словами, устройство 100 видеокодирования согласно примерному варианту осуществления и устройство 200 видеодекодирования согласно примерному варианту осуществления могут выполнять внутреннее предсказание, оценку движения, компенсацию движения, преобразование и обратное преобразование отдельно над единицей данных в этой же единице кодирования.
[321] Следовательно, кодирование выполняется рекурсивно над каждой единицей кодирования, имеющей иерархическую структуру, в каждой зоне LCU, для определения оптимальной единицы кодирования, и таким образом могут быть получены единицы кодирования, имеющие рекурсивную древовидную структуру. Информация кодирования может включать в себя информацию о разбиении о единице кодирования, информацию о типе раздела, информацию о режиме предсказания и информацию о размере единицы преобразования. Таблица 1 иллюстрирует информацию кодирования, которая может быть установлена устройством 100 видеокодирования согласно примерному варианту осуществления и устройством 200 видеодекодирования согласно примерному варианту осуществления.
(кодирование единицы кодирования, имеющей размер 2N×2N и текущую глубину d)
пропуска (только 2Nx2N)
2NxN
Nx2N
NxN
2NxnD
nLx2N
nRx2N
(симметричный тип)
N/2xN/2
(асимметричный тип)
[322] Блок 130 вывода устройства 100 видеокодирования согласно примерному варианту осуществления может выводить информацию кодирования об единицах кодирования, имеющих древовидную структуру, и модуль 220 извлечения данных изображения и информации кодирования устройства 200 видеодекодирования согласно примерному варианту осуществления может извлекать информацию кодирования об единицах кодирования, имеющих древовидную структуру, из принимаемого битового потока.
[323] Информация о разбиении указывает, разбивается ли текущая единица кодирования на единицы кодирования большей глубины. Если информация о разбиении текущей глубины d представляет собой 0, глубина, на которой текущая единица кодирования больше не разбивается на большую глубину, является кодированной глубиной, и, таким образом, информация о типе раздела, режим предсказания и размер единицы преобразования могут определяться для кодированной глубины. Если текущая единица кодирования дополнительно разбивается в соответствии с информацией о разбиении, кодирование выполняется независимо на четырех единицах кодирования разбиения большей глубины.
[324] Режим предсказания может быть одним из внутреннего режима, внешнего режима и режима пропуска. Внутренний режим и внешний режим могут определяться во всех типах раздела, и режим пропуска определяется только в типе раздела, имеющем размер 2N×2N.
[325] Информация о типе раздела может указывать симметричные типы раздела, имеющие размеры 2N×2N, 2N×N, N×2N и N×N, которые получаются посредством симметричного разбиения высоты или ширины единицы предсказания, и асимметричные типы раздела, имеющие размеры 2N×nU, 2N×nD, nL×2N и nR×2N, которые получаются посредством асимметричного разбиения высоты или ширины единицы предсказания. Асимметричные типы раздела, имеющие размеры 2N×nU и 2N×nD, могут получаться соответственно разбиением высоты единицы предсказания в отношениях 1:3 и 3:1, и асимметричные типы раздела, имеющие размеры nL×2N и nR×2N, могут получаться соответственно разбиением ширины единицы предсказания в отношениях 1:3 и 3:1.
[326] Размер единицы преобразования может устанавливаться в соответствии с двумя типами во внутреннем режиме и с двумя типами во внешнем режиме. Другими словами, если информация о разбиении единицы преобразования представляет собой 0, размер единицы преобразования может составлять 2N×2N, который является размером текущей единицы кодирования. Если информация о разбиении единицы преобразования представляет собой 1, единицы преобразования могут получаться посредством разбиения текущей единицы кодирования. Кроме того, если тип раздела текущей единицы кодирования, имеющей размер 2N×2N, является симметричным типом раздела, размер единицы преобразования может составлять N×N, и, если тип раздела текущей единицы кодирования является асимметричным типом раздела, размер единицы преобразования может составлять N/2×N/2.
[327] Информация кодирования об единицах кодирования, имеющих древовидную структуру согласно примерному варианту осуществления, может включать в себя по меньшей мере одно из единицы кодирования, соответствующей кодированной глубине, единицы предсказания и минимальной единицы. Единица кодирования, соответствующая кодированной глубине, может включать в себя по меньшей мере одно из единицы предсказания и минимальной единицы, содержащей такую же информацию кодирования.
[328] Следовательно, определяется, включены ли смежные единицы данных в одну и ту же единицу кодирования, соответствующую кодированной глубине, посредством сравнения информации кодирования смежных единиц данных. Соответствующая единица кодирования, которая соответствует кодированной глубине, определяется посредством использования информации кодирования единицы данных, и, таким образом, может определяться распределение кодированных глубин в LCU.
[329] Следовательно, если текущая единица кодирования предсказывается на основе информации кодирования смежных единиц данных, может выполняться непосредственное обращение и использование информации кодирования единиц данных в более глубоких единицах кодирования, смежных с текущей единицей кодирования.
[330] Альтернативно, если текущая единица кодирования предсказывается на основе информации кодирования смежных единиц данных, то выполняется поиск единиц данных, смежных с текущей единицей кодирования, используя кодированную информацию единиц данных, и к найденным смежным единицам кодирования можно обращаться для предсказания текущей единицы кодирования.
[331] Фиг.20 представляет собой чертеж для объяснения взаимосвязи между единицей кодирования, единицей предсказания и единицей преобразования в соответствии с информацией о режиме кодирования из таблицы 1.
[332] LCU 1300 включает в себя единицы 1302, 1304, 1306, 1312, 1314, 1316 и 1318 кодирования кодированных глубин. В данном случае, так как единица 1318 кодирования представляет собой единицу кодирования кодированной глубины, информация о разбиении может устанавливаться на 0. Информация о типе раздела единицы 1318 кодирования, имеющей размер 2N×2N, может устанавливаться равной единице типа 1322 раздела, имеющего размер 2N×2N, типа 1324 раздела, имеющего размер 2N×N, типа 1326 раздела, имеющего размер N×2N, типа 1328 раздела, имеющего размер N×N, типа 1332 раздела, имеющего размер 2N×nU, типа 1334 раздела, имеющего размер 2N×nD, типа 1336 раздела, имеющего размер nL×2N, и типа 1338 раздела, имеющего размер nR×2N.
[333] Информация о разбиении (флаг размера TU) единицы преобразования представляет собой тип индекса преобразования. Размер единицы преобразования, соответствующий индексу преобразования, может меняться в соответствии с типом единицы предсказания или типом раздела единицы кодирования.
[334] Например, когда тип раздела устанавливается равный симметричному, т.е. типу 1322, 1324, 1326 или 1328 раздела, устанавливается единица 1342 преобразования, имеющая размер 2N×2N, если флаг размера TU единицы преобразования равен 0, и устанавливается единица 1344 преобразования, имеющая размер N×N, если флаг размера TU равен 1.
[335] Когда тип раздела устанавливается равный асимметричному, т.е. типу 1332, 1334, 1336 или 1338 раздела, устанавливается единица 1352 преобразования, имеющая размер 2N×2N, если флаг размера TU равен 0, и устанавливается единица 1354 преобразования, имеющая размер N/2×N/2, если флаг размера TU равен 1.
[336] Как показано на фиг.20, флаг размера TU представляет собой флаг, имеющий значение или 0, или 1, но флаг размера TU не ограничивается одним битом, и единица преобразования может иерархически разбиваться, имея древовидную структуру, когда флаг размера TU увеличивается с 0. Информация о разбиении (флаг размера TU) единицы преобразования может представлять собой пример индекса преобразования.
[337] В этом случае, размер единицы преобразования, которая фактически использовалась, может выражаться посредством использования флага размера TU единицы преобразования согласно примерному варианту осуществления вместе с максимальным размером и минимальным размером единицы преобразования. Устройство 100 видеокодирования согласно примерному варианту осуществления выполнено с возможностью кодирования информации о максимальном размере единицы преобразования, информации о минимальном размере единицы преобразования и флага максимального размера TU. Результат кодирования информации о максимальном размере единицы преобразования, информации о минимальном размере единицы преобразования и флага максимального размера TU, может вставляться в SPS. Устройство 200 видеодекодирования согласно примерному варианту осуществления может декодировать видео посредством использования информации о максимальном размере единицы преобразования, информации о минимальном размере единицы преобразования и флага максимального размера TU.
[338] Например, (a) если текущий размер единицы кодирования составляет 64×64 и максимальный размер единицы преобразования составляет 32×32, (a-1) тогда размер единицы преобразования может составлять 32×32, когда флаг размера TU равен 0, (a-2) может составлять 16×16, когда флаг размера TU равен 1, и (a-3) может составлять 8×8, когда флаг размера TU равен 2.
[339] В качестве другого примера, (b), если текущий размер единицы кодирования составляет 32×32, и минимальный размер единицы преобразования составляет 32×32, (b-1) тогда размер единицы преобразования может составлять 32×32, когда флаг размера TU равен 0. В данном случае, флаг размера TU не может устанавливаться на значение, отличное от 0, так как размер единицы преобразования не может быть меньше 32×32.
[340] В качестве другого примера, (с), если текущий размер единицы кодирования составляет 64×64, и флаг максимального размера TU равен 1, тогда флаг размера TU может быть равен 0 или 1. В данном случае, флаг размера TU не может устанавливаться на значение, отличное от 0 или 1.
[341] Таким образом, если определяется, что флагом максимального размера TU является «MaxTransformSizeIndex» (индекс максимального размера преобразования), минимальным размером единицы преобразования является «MinTransformSize» (минимальный размер преобразования), и размером единицы преобразования является «RootTuSize» (корневой размер TU), когда флаг размера TU равен 0, тогда размер текущей минимальной единицы преобразования «CurrMinTuSize» (размер текущей минимальной TU), который может определяться в текущей единице кодирования, может определяться по уравнению (1):
CurrMinTuSize
= max (MinTransformSize, RootTuSize/(2^MaxTransformSizeIndex)) (1)
[342] По сравнению с размером текущей минимальной единицы преобразования «CurrMinTuSize», который может быть определен в текущей единице кодирования, размер единицы преобразования «RootTuSize», когда флаг размера TU равен 0, может обозначать максимальный размер единицы преобразования, который может выбираться в системе. В уравнении (1), «RootTuSize/(2^MaxTransformSizeIndex)» обозначает размер единицы преобразования, когда размер единицы преобразования «RootTuSize», когда флаг размера TU равен 0, подвергается разбиению некоторое число раз, которое соответствует флагу максимального размера TU, и «MinTransformSize» обозначает минимальный размер преобразования. Таким образом, меньшее из значений «RootTuSize/(2^MaxTransformSizeIndex)» и «MinTransformSize» может быть размером текущей минимальной единицы преобразования «CurrMinTuSize», который может определяться в текущей единице кодирования.
[343] Согласно примерному варианту осуществления максимальный размер единицы преобразования «RootTuSize» может изменяться в соответствии с типом режима предсказания.
[344] Например, если текущим режимом предсказания является внешний режим, тогда «RootTuSize» может определяться с помощью уравнения (2) ниже. В уравнении (2), «MaxTransformSize» обозначает максимальный размер единицы преобразования, и «PUSize» обозначает размер текущей единицы предсказания.
RootTuSize = min(MaxTransformSize, PUSize) (2)
[345] То есть, если текущим режимом предсказания является внешний режим, то размер единицы преобразования «RootTuSize», когда флаг размера TU равен 0, может быть меньшим значением из максимального размера единицы преобразования и размера текущей единицы предсказания.
[346] Если режимом предсказания текущей единицы раздела является внутренний режим, то «RootTuSize» может определяться по уравнению (3) ниже. В уравнении (3), выражение «PartitionSize» обозначает размер текущей единицы раздела.
RootTuSize = min(MaxTransformSize, PartitionSize) (3)
[347] То есть, если текущим режимом предсказания является внутренний режим, то размер единицы преобразования «RootTuSize», когда флаг размера TU равен 0, может быть меньшим значением из максимального размера единицы преобразования и размера текущей единицы раздела.
[348] Однако размер текущей максимальной единицы преобразования «RootTuSize», который изменяется в соответствии с типом режима предсказания в единице раздела, является просто примером, и примерный вариант осуществления не ограничивается им.
[349] Согласно способу видеокодирования, основанному на единицах кодирования, имеющих древовидную структуру, как описано в ссылкой на фиг.8-20, данные изображения пространственной области кодируются для каждой единицы кодирования, имеющей древовидную структуру. Согласно способу видеодекодирования, основанному на единицах кодирования, имеющих древовидную структуру, декодирование выполняется для каждой LCU для восстановления данных изображения пространственной области. Таким образом, могут восстанавливаться видеокадр и видео, которое представляет собой последовательность видеокадров. Восстановленное видео может воспроизводиться воспроизводящим устройством, может сохраняться на запоминающей среде или может передаваться по сети.
[350] Примерные варианты осуществления могут быть написаны в виде компьютерных программ и могут быть реализованы в цифровых компьютерах общего пользования, которые исполняют программы, используя считываемую компьютером среду записи. Примеры считываемой компьютером среды записи включают в себя магнитные запоминающие среды (например, постоянное запоминающее устройство (ROM), дискеты, жесткие диски и т.д.) и среды оптической записи (например, компакт-диск (CD-ROM) или цифровые многофункциональные диски (DVD)).
[351] Для удобства объяснения способ видеокодирования, включающий способ энтропийного кодирования, описанный в ссылкой на фиг.1A-20, упоминается вместе как «способ видеокодирования согласно примерному варианту осуществления». Кроме того, способ видеодекодирования, включающий способ энтропийного декодирования, описанный с ссылкой на фиг.1A-20, вместе упоминается как «способ видеодекодирования согласно примерному варианту осуществления».
[352] Устройство 100 видеокодирования, включающее в себя устройство 10 энтропийного кодирования, и устройство видеокодирования, включающее в себя кодер 400 изображения, описанное с ссылкой на фиг.1A-20, упоминается как «устройство видеокодирования согласно примерному варианту осуществления». Кроме того, устройство 200 видеодекодирования, включающее в себя устройство 20 энтропийного декодирования и декодер 500 изображения, описанное с ссылкой на фиг.1A-20, упоминается как «устройство видеодекодирования согласно примерному варианту осуществления».
[353] Ниже подробно описывается считываемая компьютером среда записи, хранящая программу, например, диск 26000, согласно примерному варианту осуществления.
[354] Фиг.21 представляет собой чертеж, иллюстрирующий физическую конструкцию диска 26000, на котором сохраняется программа, согласно примерному варианту осуществления. Диском 26000, который представляет собой запоминающую среду, может быть жесткий диск, диск компакт-диска постоянной памяти (CD-ROM), диск Blu-ray или цифровой многофункциональный диск (DVD). Диск 26000 включает в себя множество концентрических дорожек Tr, каждая из которых разделена на конкретное число секторов Se в круговом направлении диска 26000. Конкретной области диска 26000 выделяется и в ней сохраняется программа, которая выполняет способ определения параметров квантования, способ видеокодирования и способ видеодекодирования, описанные выше.
[355] Ниже с ссылкой на фиг.22 описывается воплощенная компьютерная система, использующая запоминающую среду, которая хранит программу для выполнения способа видеокодирования и способа видеодекодирования, описанных выше.
[356] Фиг.22 представляет собой чертеж, иллюстрирующий дисковод 26800 для записи и считывания программы посредством использования диска 26000. Компьютерная система 27000 может сохранять программу, которая выполняет по меньшей мере один из способа видеокодирования и способа видеодекодирования согласно примерному варианту осуществления, на диске 26000 при помощи дисковода 26800. Для выполнения программы, хранимой на диске 26000 в компьютерной системе 27000, программа может считываться с диска 26000 и передаваться на компьютерную систему 26700 посредством использования дисковода 26800.
[357] Программа, которая исполняет по меньшей мере один из способа видеокодирования и способа видеодекодирования согласно примерному варианту осуществления, может сохраняться не только на диске 26000, показанном на фиг.21 или 22, но также на карте памяти, кассете ROM или на твердотельном диске (SSD).
[358] Ниже описывается система, в которой применяется способ видеокодирования и способ видеодекодирования, описанные выше.
[359] Фиг.23 представляет собой чертеж, иллюстрирующий общую структуру системы 11000 подачи контента для предоставления услуги распределения контента. Зона обслуживания системы связи разделяется на соты заданного размера, и беспроводные базовые станции 11700, 11800, 11900 и 12000 соответственно устанавливаются в этих сотах.
[360] Система 11000 подачи контента включает в себя множество независимых устройств. Например, множество независимых устройств, таких как компьютер 12100, персональный цифровой помощник (PDA) 12200, видеокамера 12300 и мобильный телефон 12500, подключены к Интернету 11100 посредством провайдера 11200 услуг Интернета, сети 11400 связи и беспроводных базовых станций 11700, 11800, 11900 и 12000.
[361] Однако система 11000 подачи контента не ограничивается системой, изображенной на фиг.24, и устройства могут подключаться селективно к ней. Множество независимых устройств может непосредственно подключаться к сети 11400 связи, не при помощи беспроводных базовых станций 11700, 11800, 11900 и 12000.
[362] Видеокамера 12300 представляет собой устройство формирования изображения, например, цифровую видеокамеру, которая способна захватывать видеоизображения. Мобильный телефон 12500 может применять по меньшей мере один способ связи из числа различных протоколов, например, персональную цифровую связь (PDC), множественный доступ с кодовым разделением каналов (CDMA), широкополосный множественный доступ с кодовым разделением каналов (W-CDMA), глобальную систему мобильной связи (GSM) и систему персональных портативных телефонов (PHS).
[363] Видеокамера 12300 может быть подключена к потоковому серверу 11300 посредством беспроводной базовой станции 11900 и сети 11400 связи. Потоковый сервер 11300 позволяет выполнять потоковую передачу контента, принятого от пользователя посредством видеокамеры 12300, посредством широковещания в реальном времени. Контент, принятый от видеокамеры 12300, может кодироваться с использованием видеокамеры 12300 или потокового сервера 11300. Видеоданные, захваченные видеокамерой 12300, могут передаваться на потоковый сервер 11300 посредством компьютера 12100.
[364] Видеоданные, захваченные камерой 12600, также могут передаваться на потоковый сервер 11300 посредством компьютера 12100. Камера 12600 представляет собой устройство формирования изображения, способное захватывать как неподвижные изображения, так и видеоизображения, подобные цифровой камере. Видеоданные, захваченные камерой 12600, могут кодироваться с использованием камеры 12600 или компьютера 12100. Программное обеспечение, которые выполняет кодирование и декодирование видео, может храниться на считываемой компьютером среде записи, например, компакт-диске, дискете, накопителе на жестком диске, SSD или карте памяти, к которым может выполнять доступ компьютер 12100.
[365] Если видеоданные захватываются камерой, встроенной в мобильный телефон 12500, видеоданные могут приниматься от мобильного телефона 12500.
[366] Видеоданные также могут кодироваться системой на большой интегральной схеме (LSI), установленной в видеокамере 12300, мобильном телефоне 12500 или камере 12600.
[367] Система 1100 подачи контента может кодировать данные контента, записанные пользователем с использованием видеокамеры 12300, камеры 12600, мобильного телефона 12500 или другого устройства формирования изображения, например, контента, записанного во время концерта, и передавать кодированные данные контента на потоковый сервер 11300. Потоковый сервер 11300 может передавать кодированные данные контента в виде потокового контента другим клиентам, которые запрашивают данные контента.
[368] Клиентами являются устройства, способные декодировать кодированные данные контента, например, компьютер 12100, PDA 12200, видеокамера 12300 или мобильный телефон 12500. Таким образом, система 11000 подачи контента позволяет клиентам принимать и воспроизводить кодированные данные контента. Система 11000 подачи контента позволяет клиентам принимать кодированные данные контента и декодировать и воспроизводить кодированные данные контента в реальном времени, таким образом позволяя выполнять персональное вещание.
[369] Операции кодирования и декодирования множества независимых устройств, включенных в систему 11000 подачи контента, могут быть подобны операциям устройства видеокодирования и устройства видеодекодирования согласно примерному варианту осуществления.
[370] Мобильный телефон 12500, включенный в систему 11000 подачи контента согласно примерному варианту осуществления, ниже подробно описывается с ссылкой на фиг.24 и 25.
[371] Фиг.24 представляет собой чертеж, иллюстрирующий внешнюю конструкцию мобильного телефона 12500, в котором способ видеокодирования и способ видеодекодирования согласно примерному варианту осуществления применяются согласно примерному варианту осуществления. Мобильным телефоном 12500 может быть смартфон, функции которого не ограничены, и большое количество функций которого может быть изменено или расширено.
[372] Мобильный телефон 12500 включает в себя внутреннюю антенну 12510, посредством которой радиочастотный (RF) сигнал может обмениваться с беспроводной базовой станцией 12000, и включает в себя экран 12520 дисплея для отображения изображений, захваченных камерой 12530, или изображений, которые принимаются посредством антенны 12510 и декодируются, например, жидкокристаллический дисплей (LCD) или экран на органических светоизлучающих диодах (OLED). Мобильный телефон 12500 включает в себя панель 12540 управления, включающую в себя кнопку управления и сенсорную панель. Если экран 12520 дисплея представляет собой сенсорный экран, панель 12540 управления дополнительно включает в себя сенсорную панель экрана 12520 дисплея. Мобильный телефон 12500 включает в себя громкоговоритель 12580 для вывода голоса и звука или другой вид блока вывода звука, и микрофон 12550 для ввода голоса и звука или блок ввода звука другого вида. Мобильный телефон 12500 дополнительно включает в себя камеру 12530, такую как камера на приборах с зарядовой связью (CCD), для захвата видеоизображений и неподвижных изображений. Мобильный телефон 12500 может дополнительно включать в себя запоминающую среду 12570 для хранения кодированных/декодированных данных, например, видео или неподвижных изображений, захваченных камерой 12530, принятых по электронной почте, или полученных различными путями; и гнездо 12560, посредством которого запоминающая среда 12570 вставляется в мобильный телефон 12500. Запоминающей средой 12570 может быть флэш-память, например, SD-карта или электрически стираемое и программируемое постоянное запоминающее устройство (EEPROM), заключенное в пластмассовый корпус.
[373] Фиг.25 представляет собой чертеж, иллюстрирующий внутреннюю конструкцию мобильного телефона 12500. Чтобы системно управлять элементами мобильного телефона 12500, включающими экран 12520 дисплея и панель 12540 управления, схема 12700 источника питания, контроллер 12640 ввода управления, блок 12720 кодирования изображения, интерфейс 12630 камеры, контроллер 12620 LCD, блок 12690 декодирования изображения, мультиплексор/демультиплексор 12680, блок 12670 записи/считывания, блок 12660 модуляции/демодуляции и звуковой процессор 12650 подсоединены к центральному контроллеру 12710 по шине 12730 синхронизации.
[374] Если пользователь приводит в действие кнопку включения питания и устанавливает из состояния «питание выключено» в состояние «питание включено», схема 12700 источника питания подает питание на все элементы мобильного телефона 12500 от аккумуляторной батареи, таким образом устанавливая мобильный телефон 12500 в рабочий режим.
[375] Центральный контроллер 12710 включает в себя центральный блок обработки (CPU), ROM и RAM.
[376] Когда мобильный телефон 12500 передает данные связи наружу, цифровой сигнал генерируется мобильным телефоном 12500 под управлением центрального контроллера 12710. Например, звуковой процессор 12650 может генерировать цифровой звуковой сигнал, блок 12720 кодирования изображения может генерировать цифровой сигнал изображения, и текстовые данные сообщения могут генерироваться посредством панели 12540 управления и контроллера 12640 ввода управления. Когда цифровой сигнал передается на блок 12660 модуляции/демодуляции под управлением центрального контроллера 12710, блок 12660 модуляции/демодуляции модулирует частотную полосу цифрового сигнала, и схема 12610 связи выполняет цифро-аналоговое преобразование (DAC) и преобразование частоты цифрового звукового сигнала с модулированной частотной полосой. Сигнал передачи, выводимый со схемы 12610 связи, может передаваться на базовую станцию телефонной связи или беспроводную базовую станцию 12000 при помощи антенны 12510.
[377] Например, когда мобильный телефон 12500 находится в режиме разговора, звуковой сигнал, полученный посредством микрофона 12550, преобразуется в цифровой звуковой сигнал звуковым процессором 12650 под управлением центрального контроллера 12710. Цифровой звуковой сигнал может преобразовываться в сигнал преобразования посредством блока 12660 модуляции/демодуляции и схемы 12610 связи и может передаваться при помощи антенны 12510.
[378] Когда текстовое сообщение, например, электронная почта, передается в режиме передачи данных, текстовые данные текстового сообщения вводятся при помощи панели 12540 управления и передаются на центральный контроллер 12610 при помощи контроллера 12640 ввода управления. Под управлением центрального контроллера 12610 текстовые данные преобразуются в сигнал передачи при помощи блока 12660 модуляции/демодуляции и схемы 12610 связи и передаются на беспроводную базовую станцию 12000 при помощи антенны 12510.
[379] Чтобы передавать данные изображения в режиме передачи данных, данные изображения, захваченные камерой 12530, подаются на блок 12720 кодирования изображения при помощи интерфейса 12630 камеры. Захваченные данные изображения могут непосредственно отображаться на экране 12520 дисплея при помощи интерфейса 12630 камеры и контроллера 12620 LCD.
[380] Конструкция блока 12720 кодирования изображения может соответствовать конструкции устройства 100 видеокодирования, описанного выше. Блок 12720 кодирования изображения может преобразовывать данные изображения, принимаемые от камеры 12530, в сжатые и кодированные данные изображения в соответствии со способом видеокодирования, применяемого устройством 100 видеокодирования или кодером 400 изображения, описанным выше, и затем выводить кодированные данные изображения на мультиплексор/демультиплексор 12680. В операции записи камеры 12530 звуковой сигнал, полученный микрофоном 12550 мобильного телефона 12500, может преобразовываться в цифровые звуковые данные при помощи звукового процессора 12650, и цифровые звуковые данные могут передаваться на мультиплексор/демультиплексор 12680.
[381] Мультиплексор/демультиплексор 12680 мультиплексирует кодированные данные изображения, принимаемые от блока 12720 кодирования изображения, вместе со звуковыми данными, принимаемыми от звукового процессора 12650. Результат мультиплексирования данных может преобразовываться в сигнал передачи при помощи блока 12660 модуляции/демодуляции и схемы 12610 связи, и затем может передаваться при помощи антенны 12510.
[382] Когда мобильный телефон 12500 принимает данные связи извне, восстановление частоты и аналого-цифровое преобразование (ADC) выполняются над сигналом, принимаемым при помощи антенны 12510, для преобразования сигнала в цифровой сигнал. Блок 12660 модуляции/демодуляции модулирует полосу частот цифрового сигнала. Цифровой сигнал с модулированной полосой частот передается на блок 12690 видеодекодирования, звуковой процессор 12650 или контроллер 12620 LCD в соответствии с типом цифрового сигнала.
[383] В режиме разговора мобильный телефон 12500 усиливает сигнал, принимаемый при помощи антенны 12510, и получает цифровой звуковой сигнал посредством выполнения преобразования частоты и ADC усиленного сигнала. Принимаемый цифровой звуковой сигнал преобразуется в аналоговый звуковой сигнал при помощи блока 12660 модуляции/демодуляции и звукового процессора 12650, и аналоговый звуковой сигнал выводится при помощи громкоговорителя 12580 под управлением центрального контроллера 12710.
[384] В режиме передачи данных принимаются данные видеофайла, к которому обращаются на веб-сайте Интернета, сигнал, принимаемый от беспроводной базовой станции 12000 при помощи антенны 12510, выводится в виде мультиплексированных данных при помощи блока 12660 модуляции/демодуляции, и мультиплексированные данные передаются на мультиплексор/демультиплексор 12680.
[385] Чтобы декодировать мультиплексированные данные, принимаемые при помощи антенны 12510, мультиплексор/демультиплексор 12680 демультиплексирует мультиплексированные данные в поток кодированных видеоданных и поток кодированных аудиоданных. Посредством шины 12730 синхронизации поток кодированных видеоданных и поток кодированных аудиоданных подаются на блок 12690 видеодекодирования и звуковой процессор 12650 соответственно.
[386] Конструкция блока 12690 декодирования изображения может соответствовать конструкции устройства видеодекодирования согласно примерному варианту осуществления. Блок 12690 декодирования изображения может декодировать кодированные видеоданные для получения восстановленных видеоданных и подачи восстановленных видеоданных на экран 1252 дисплея при помощи контроллера 1262 LCD в соответствии со способом видеодекодирования согласно примерному варианту осуществления.
[387] Таким образом, данные видеофайла, к которому обращаются на веб-сайте Интернета, могут отображаться на экране 1252 дисплея. Одновременно, звуковой процессор 1265 может преобразовывать аудиоданные в аналоговый звуковой сигнал и подавать аналоговый звуковой сигнал на громкоговоритель 1258. Таким образом, аудиоданные, содержащиеся в видеофайле, к которому выполняются обращение на веб-сайте Интернета, также могут воспроизводиться при помощи громкоговорителя 1258.
[388] Мобильный телефон 1250 или терминал связи другого типа может представлять собой приемопередающий терминал, включающий в себя как устройство видеокодирования, так и устройство видеодекодирования согласно примерному варианту осуществления, может представлять собой приемопередающий терминал, включающий в себя только устройство видеокодирования согласно примерному варианту осуществления, или может представлять собой приемопередающий терминал, включающий в себя только устройство видеодекодирования согласно примерному варианту осуществления.
[389] Система связи согласно примерному варианту осуществления не ограничивается системой связи, описанной выше с ссылкой на фиг.24. Например, фиг.26 представляет собой чертеж, иллюстрирующий систему цифрового вещания, применяющую систему связи согласно примерному варианту осуществления. Система цифрового вещания по фиг.26 может принимать цифровое вещание, передаваемое через спутник или наземную сеть посредством использования устройства видеокодирования и устройства видеодекодирования согласно примерному варианту осуществления.
[390] Конкретно, вещательная станция 12890 передает поток видеоданных на спутник связи или вещательный спутник 12900 посредством использования радиоволн. Вещательный спутник 12900 передает вещательный сигнал, и вещательный сигнал передается на спутниковый вещательный приемник при помощи домашней антенны 12860. В каждом доме кодированный видеопоток может декодироваться и воспроизводиться телевизионным (ТВ) приемником 12810, телевизионной приставкой 12870 или другим устройством.
[391] Когда устройство видеодекодирования согласно примерному варианту осуществления реализуется в воспроизводящем устройстве 12830, воспроизводящее устройство 12830 может синтаксически анализировать и декодировать кодированный видеопоток, записанный на запоминающей среде 12820, такой как диск или карта памяти, для восстановления цифровых сигналов. Таким образом, восстановленный видеосигнал может воспроизводиться, например, на мониторе 12840.
[392] В телевизионной приставке 12870, подключенной к антенне 12860 для спутникового/наземного вещания или кабельной антенне 12850 для приема кабельного телевизионного (ТВ) вещания, может быть установлено устройство видеодекодирования согласно примерному варианту осуществления. Данные, выводимые с телевизионной приставки 12870, также могут воспроизводиться на ТВ-мониторе 12880.
[393] В качестве другого примера, устройство видеодекодирования согласно примерному варианту осуществления может быть установлено в ТВ-приемнике 12810 вместо телевизионной приставки 12870.
[394] Автомобиль 12920, который имеет соответствующую антенну 12910, может принимать сигнал, передаваемый со спутника 12900 или беспроводной базовой станции 11700. Декодированное видео может воспроизводиться на экране дисплея автомобильной навигационной системы 12930, установленной в автомобиле 12920.
[395] Видеосигнал может кодироваться устройством видеокодирования согласно примерному варианту осуществления и затем может сохраняться на запоминающей среде. Конкретно, сигнал изображения может сохраняться на диске 12960 DVD устройством записи на DVD или может сохраняться на жестком диске устройством 12950 записи на жесткий диск. В качестве другого примера, видеосигнал может сохраняться на SD-карте 12970. Если устройство 12950 записи на жесткий диск включает в себя устройство видеодекодирования согласно примерному варианту осуществления, видеосигнал, записанный на диск 12960 DVD, SD-карту 12970 или другую запоминающую среду, может воспроизводиться на ТВ-мониторе 12880.
[396] Автомобильная навигационная система 12930 может не включать в себя камеру 12530, интерфейс 12630 камеры и блок 12720 видеокодирования по фиг.26. Например, компьютер 12100 и ТВ-приемник 12810 могут быть не включены в камеру 12530, интерфейс 12630 камеры и блок 12720 кодирования изображения по фиг.26.
[397] Фиг.27 представляет собой чертеж, иллюстрирующий сетевую структуру системы облачных вычислений, использующей устройство видеокодирования и устройство видеодекодирования согласно примерному варианту осуществления.
[398] Система облачных вычислений может включать в себя сервер 14100 облачных вычислений, пользовательскую базу 14100 данных (DB), множество вычислительных ресурсов 14200 и пользовательский терминал.
[399] Система облачных вычислений предоставляет услуги по запросам с привлечением внешних ресурсов множества вычислительных ресурсов 14200 посредством сети передачи данных, например, Интернета, в ответ на запрос с пользовательского терминала. В среде облачных вычислений провайдер услуг предоставляет пользователям требуемые услуги посредством объединения вычислительных ресурсов на центрах обработки данных, расположенных в физически разных расположениях посредством использования технологии виртуализации. Пользователю услуги не нужно устанавливать вычислительные ресурсы, например, приложение, запоминающее устройство, операционную систему (OS) и защиту на его/ее собственный терминал, чтобы использовать их, но может выбирать и использовать требуемые услуги из числа услуг в виртуальном пространстве, генерируемом посредством технологии виртуализации, в требуемый момент времени.
[400] Пользовательский терминал пользователя конкретной услуги подключается к серверу 14100 облачных вычислений по сети передачи данных, включающей Интернет и сеть мобильной связи. Пользовательским терминалам могут предоставляться услуги облачных вычислений и, в частности, услуги воспроизведения видео, с сервера 14100 облачных вычислений. Пользовательские терминалы могут представлять собой электронные устройства различных типов, способные подключаться к Интернету, например, настольный персональный компьютер (PC) 14300, интеллектуальный ТВ 14400, смартфон 14500, блокнотный компьютер 14600, портативный мультимедийный плеер (PMP) 14700, планшетный PC 14800 и т.п.
[401] Сервер 14100 облачных вычислений может объединять множество вычислительных ресурсов 14200, распределенных в облачной сети, и предоставлять пользовательским терминалам результат объединения. Множество вычислительных ресурсов 14200 может включать в себя различные услуги передачи данных и может включать в себя данные, загружаемые с пользовательских терминалов. Как описано выше, сервер 14100 облачных вычислений может предоставлять пользовательским терминалам требуемые услуги посредством объединения базы видеоданных, распределенной по разным областям, согласно технологии виртуализации.
[402] Информация о пользователе о пользователях, которые подписались на услугу облачных вычислений, хранится в пользовательской базе 14100 данных (DB). Информация о пользователе может включать в себя информацию регистрации, адреса, имена и персональную кредитную информацию пользователей. Информация о пользователе может дополнительно включать в себя индексы видео. В данном случае, индексы могут включать в себя список видео, которые уже были воспроизведены, список видео, которые воспроизводятся, точку приостановки видео, которое воспроизводилось, и т.п.
[403] Информация о видео, хранимом в пользовательской DB 14100, может совместно использоваться пользовательскими устройствами. Например, когда видеоуслуга предоставляется блокнотному компьютеру 14600 в ответ на запрос с блокнотного компьютера 14600, предыстория воспроизведения видеоуслуги сохраняется в пользовательской DB 14100. Когда запрос на воспроизведение данной видеоуслуги принимается от смартфона 14500, сервер 14000 облачных вычислений выполняет поиск этой видеоуслуги и воспроизводит ее, основываясь на пользовательской DB 14100. Когда смартфон 14500 принимает поток видеоданных от сервера 14100 облачных вычислений, процесс воспроизведения видео посредством декодирования потока видеоданных аналогичен операции мобильного телефона 12500, описанной выше с ссылкой на фиг.24.
[404] Сервер 14100 облачных вычислений может ссылаться на предысторию воспроизведения требуемой видеоуслуги, хранимую в пользовательской DB 14100. Например, сервер 14100 облачных вычислений принимает запрос на воспроизведение видео, хранимое в пользовательской DB 14100, от пользовательского терминала. Если это видео воспроизводилось, тогда способ потоковой передачи этого видео, выполняемый сервером 14100 облачных вычислений, может изменяться в соответствии с запросом от пользовательского терминала, т.е. в соответствии с тем, будет ли видео воспроизводиться, начиная с его начала или точки его приостановки. Например, если пользовательский терминал запрашивает воспроизведение видео, начиная с его начала, сервер 14100 облачных вычислений передает потоковые данные видео, начиная с его первого кадра, на пользовательский терминал. Если пользовательский терминал запрашивает воспроизведение видео, начиная с его точки приостановки, сервер 14100 облачных вычислений передает потоковые данные видео, начиная с кадра, соответствующего точке приостановки, на пользовательский терминал.
[405] В данном случае, пользовательский терминал может включать в себя устройство видеодекодирования, описанное выше с ссылкой на фиг.1A-20. В качестве другого примера, пользовательский терминал может включать в себя устройство видеокодирования, описанное выше с ссылкой на фиг.1A-20. Альтернативно, пользовательский терминал может включать в себя как устройство видеодекодирования, так и устройство видеокодирования, описанные выше с ссылкой на фиг.1A-20.
[406] Различные применения способа видеокодирования, способа видеодекодирования, устройства видеокодирования и устройства видеодекодирования согласно примерному варианту осуществления, описанные выше с ссылкой на фиг.1A-20, были описаны выше с ссылкой на фиг.21-27. Однако способы сохранения способа видеокодирования и способа видеодекодирования на запоминающей среде или способы реализации устройства видеокодирования и устройства видеодекодирования в устройстве согласно различным примерным вариантам осуществления, не ограничиваются вариантами осуществления, описанными выше с ссылкой на фиг.21-27.
[407] Хотя примерные варианты осуществления были конкретно показаны и описаны с ссылкой на чертежи посредством использования конкретных терминов, примерные варианты осуществления и термины были использованы просто для объяснения и не должны истолковываться как ограничивающие объем идеи изобретения, определенной формулой изобретения. Примерные варианты осуществления должны рассматриваться только в описательном смысле и не для целей ограничения. Поэтому, объем идеи изобретения определяется не подробным описанием, но прилагаемой формулой изобретения, и все отличительные признаки в объеме истолковываются как включенные в идею изобретения.
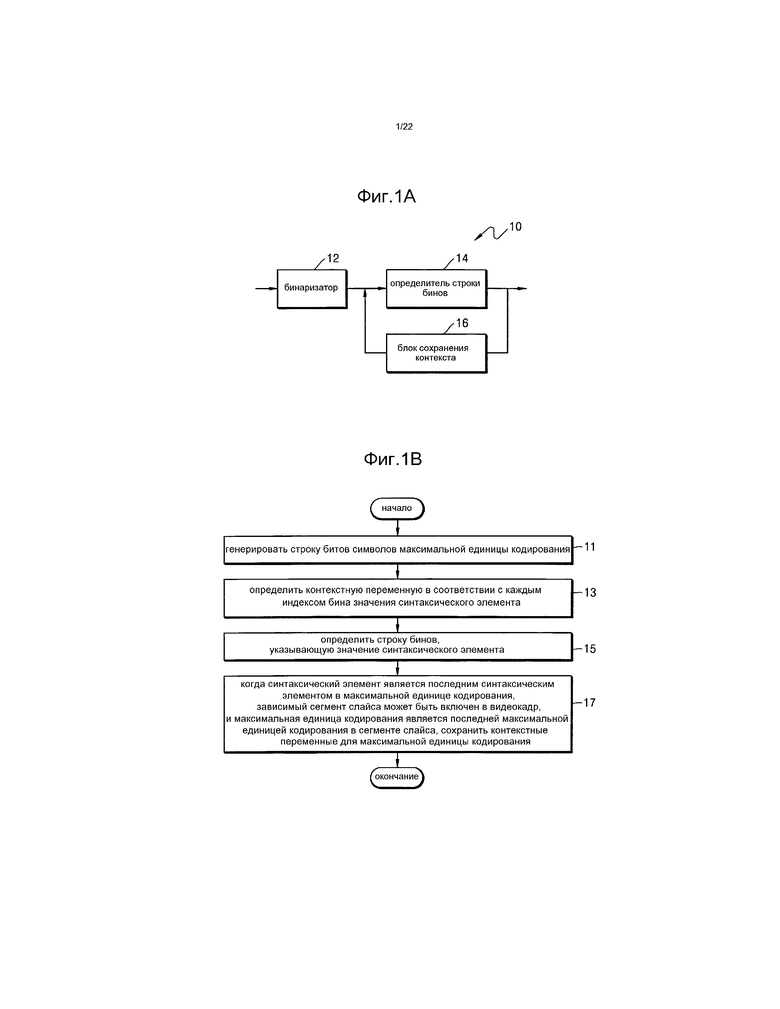
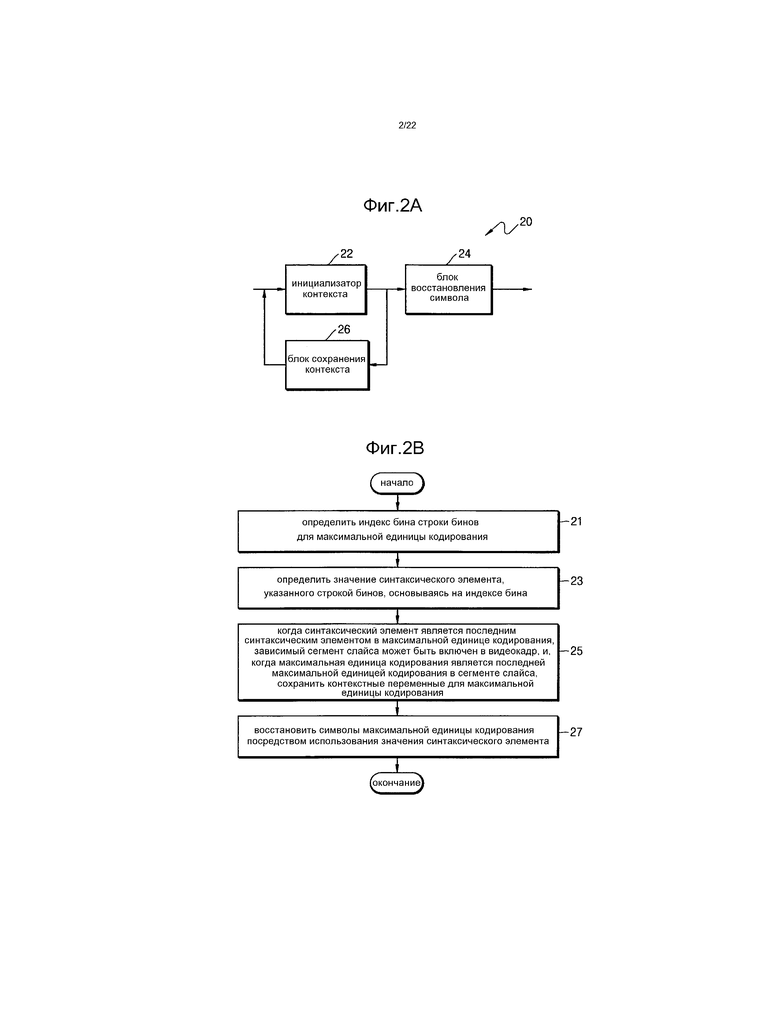
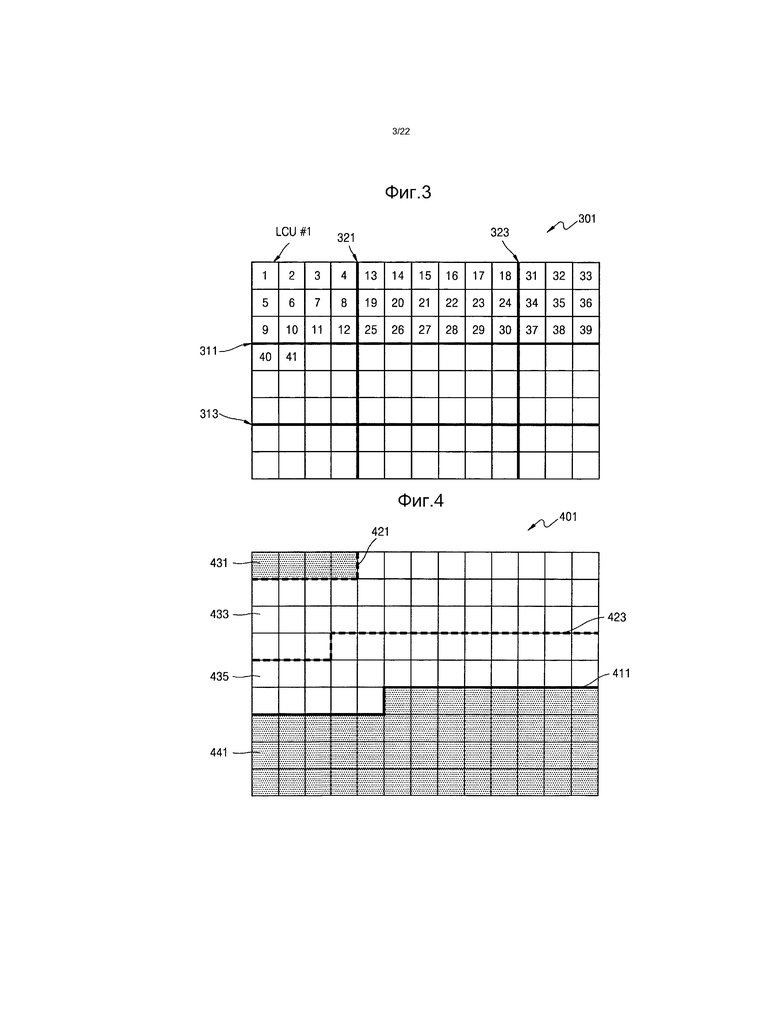
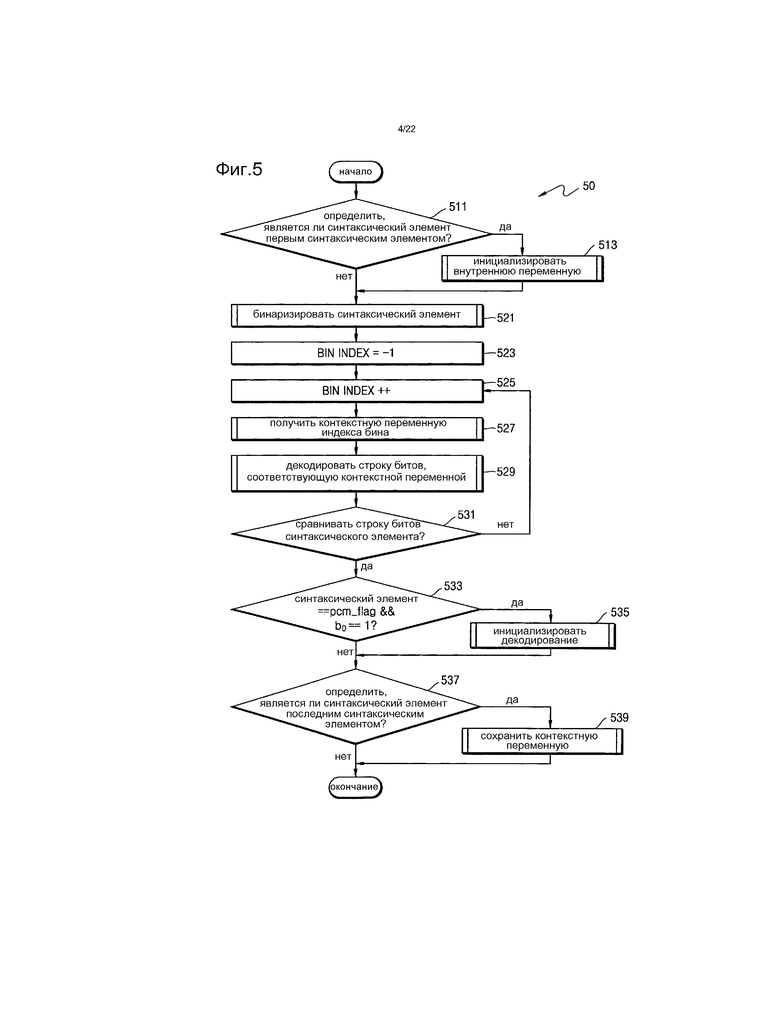
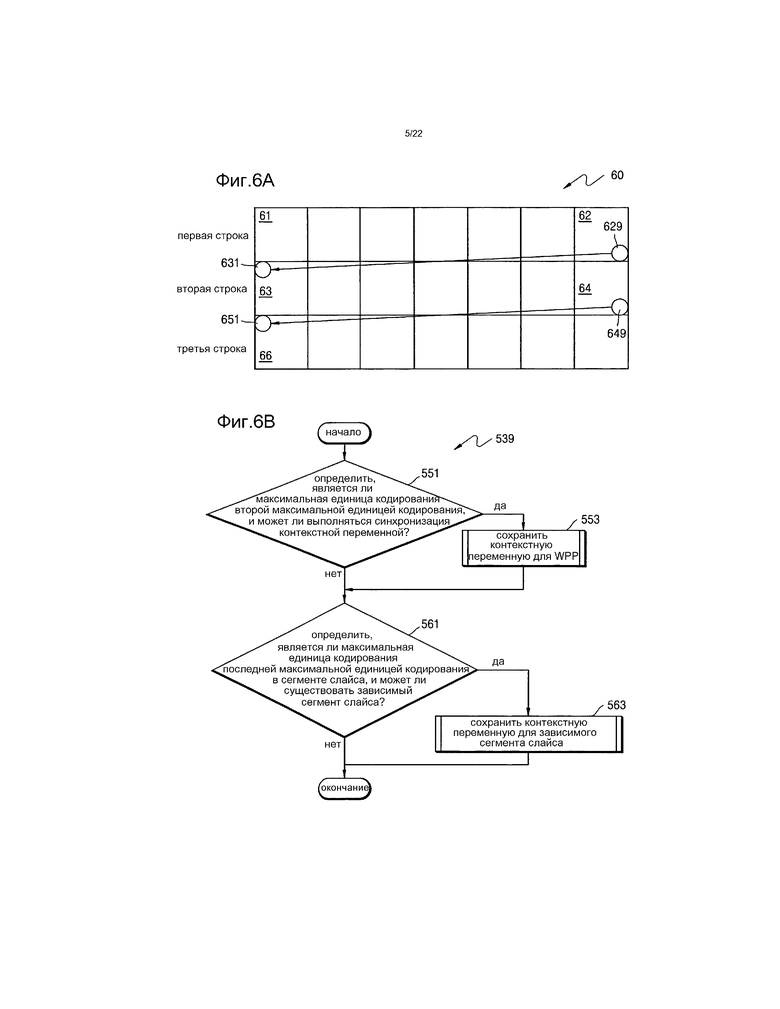

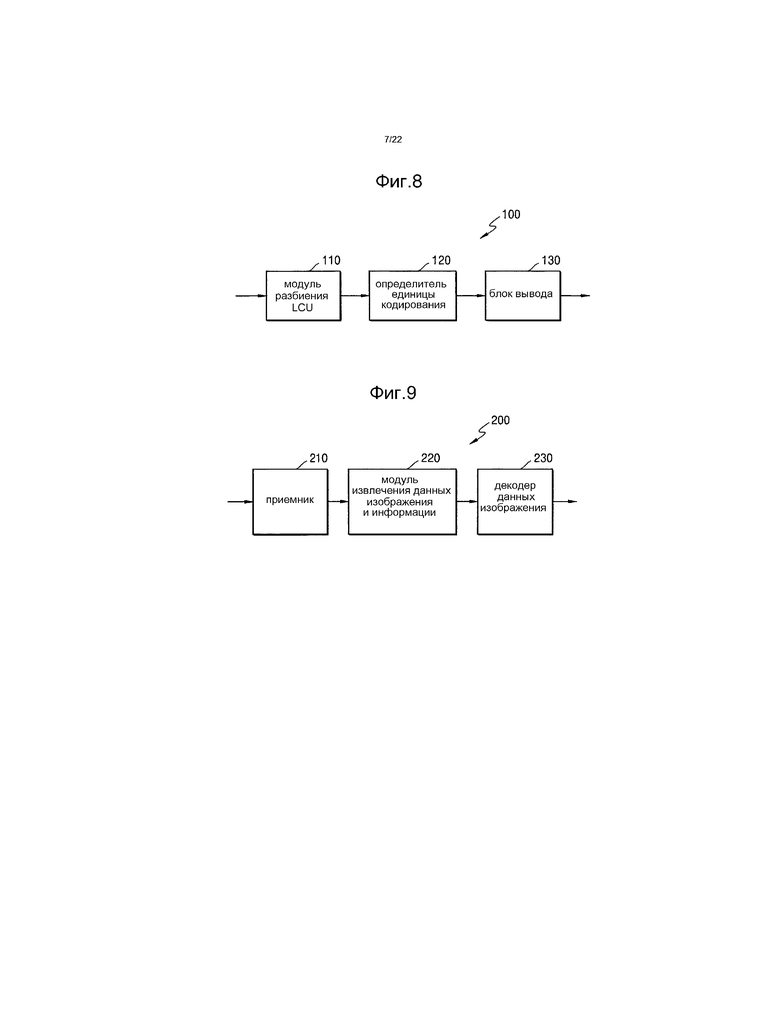
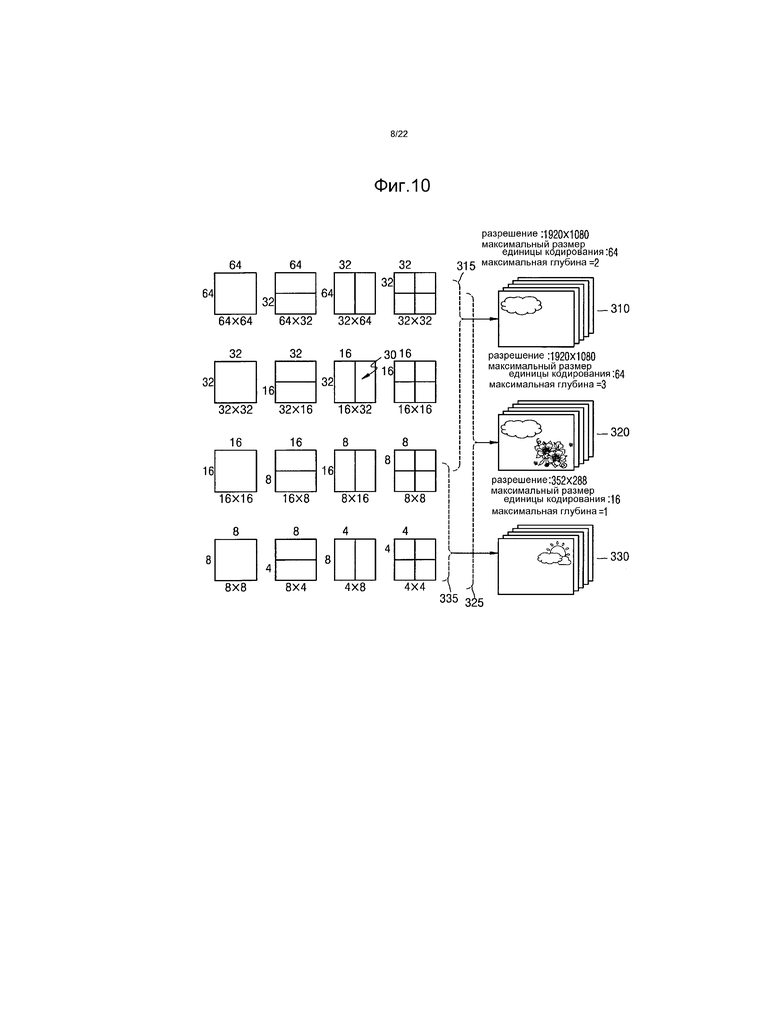
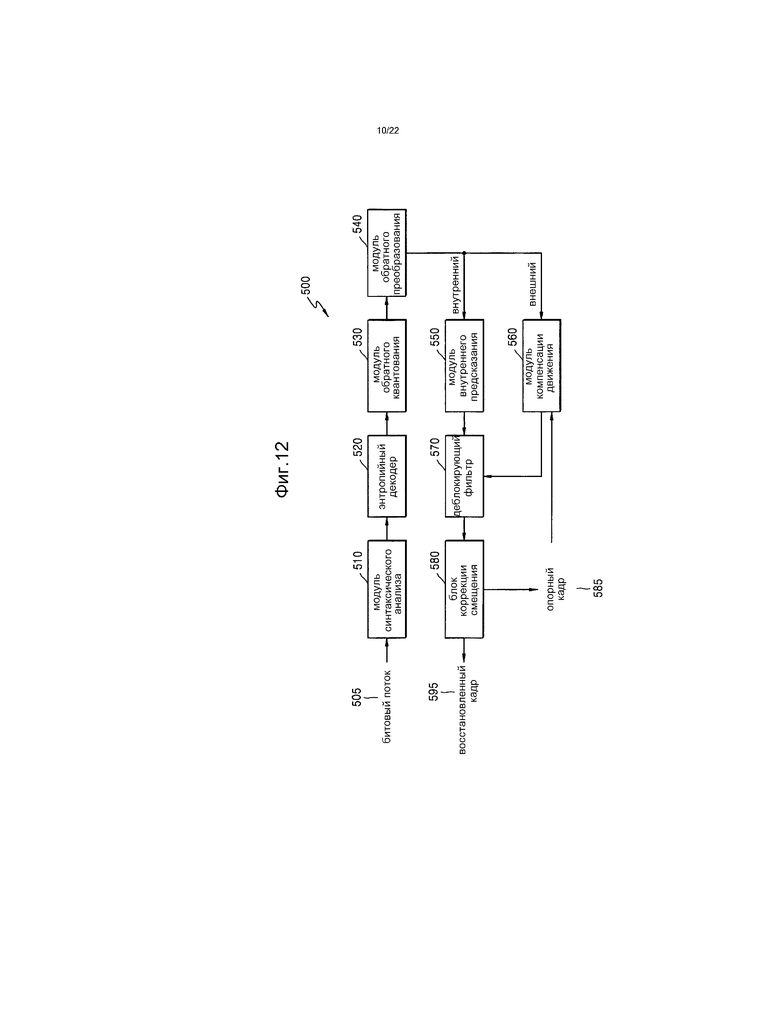
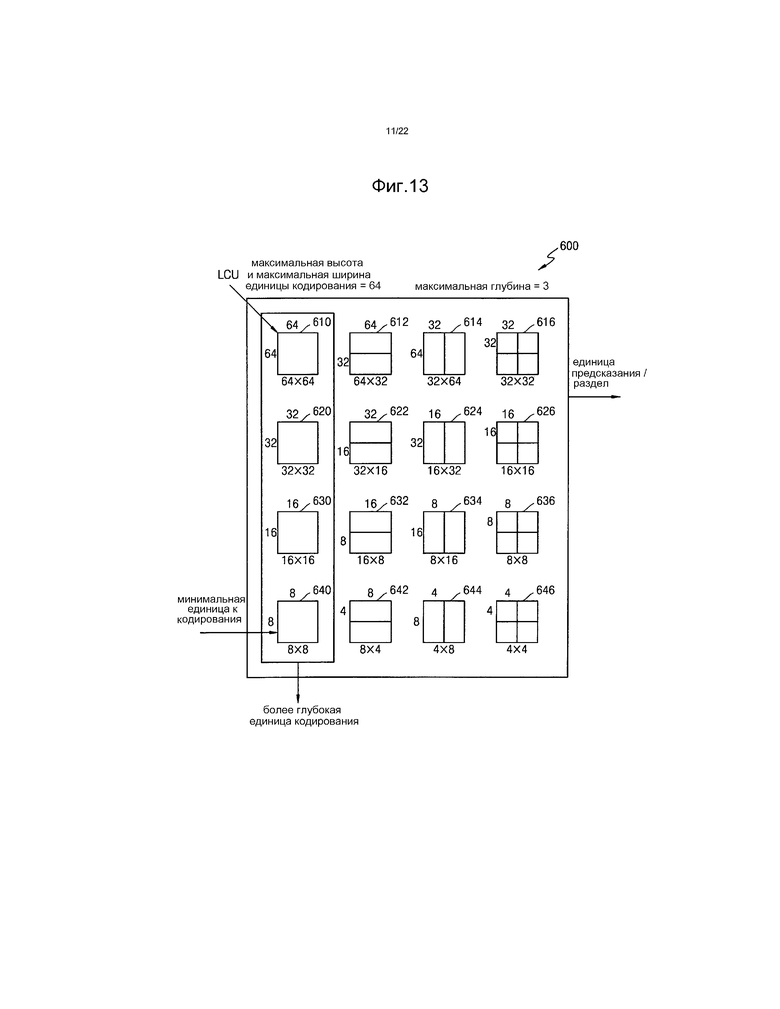
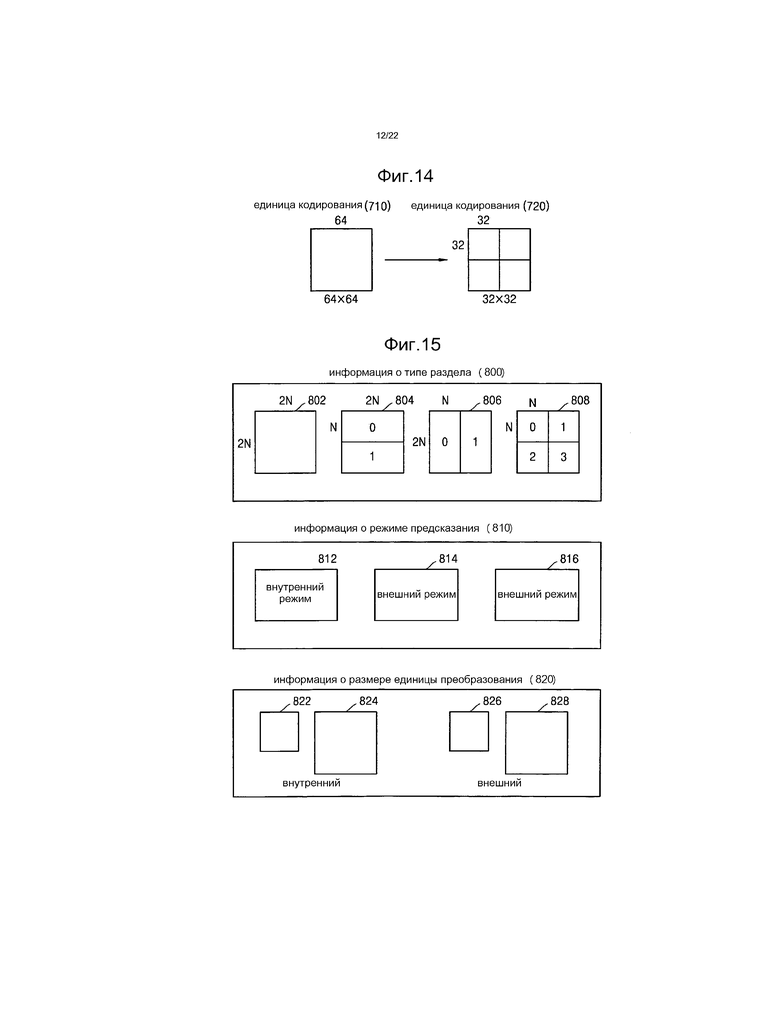
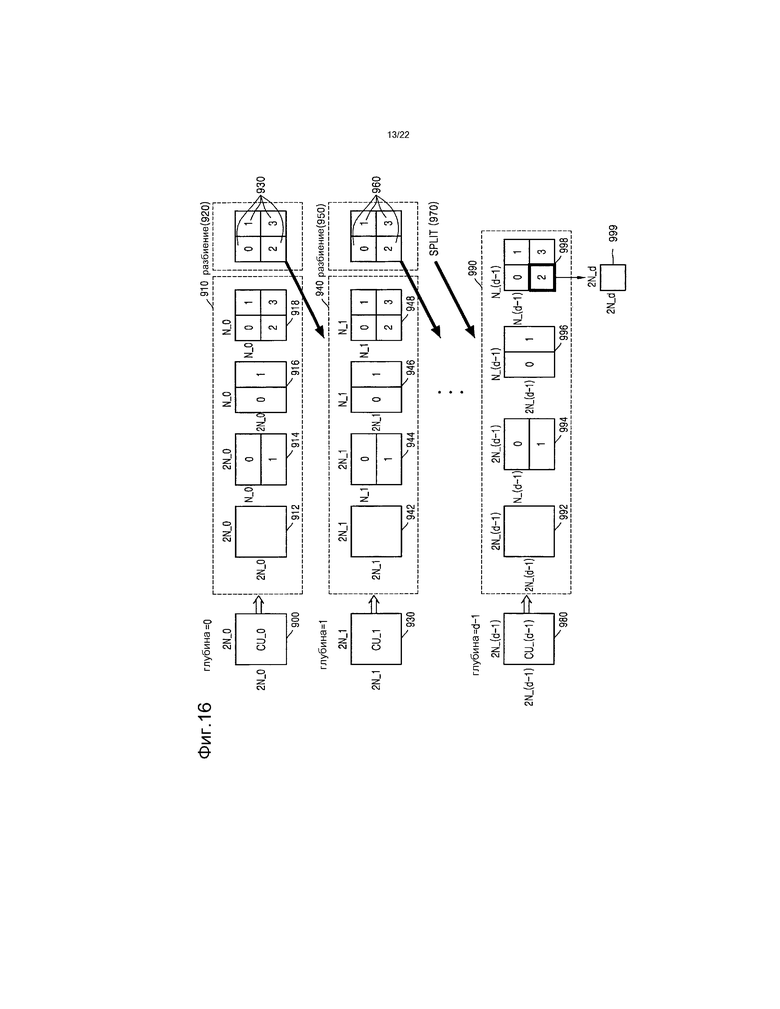
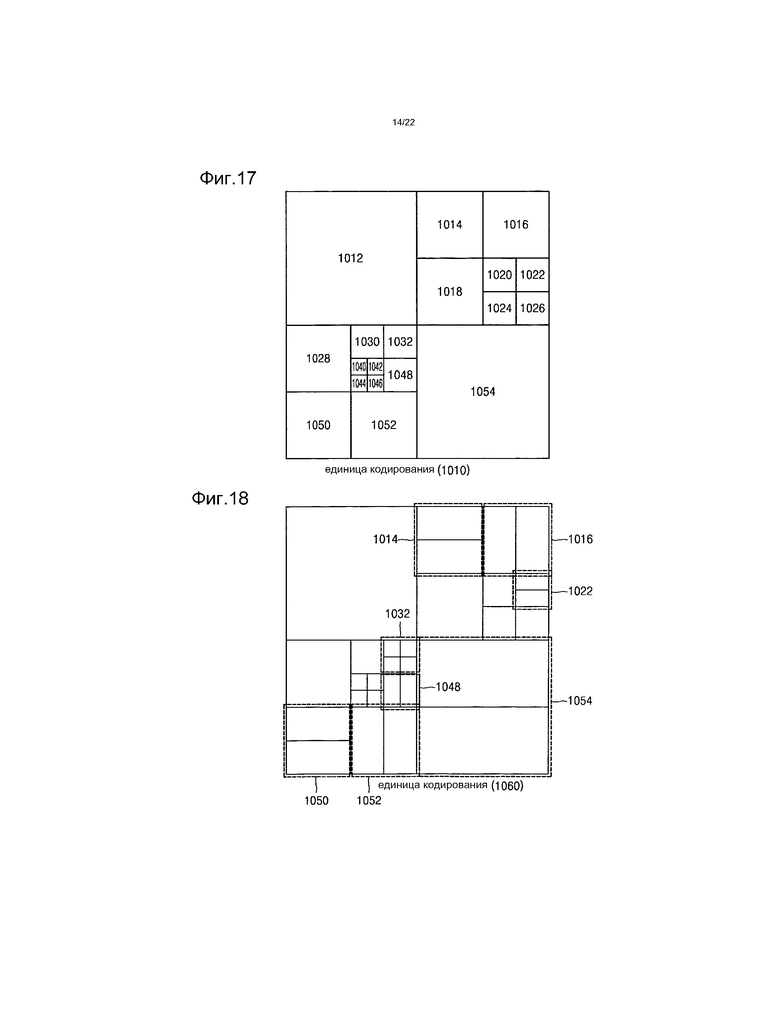

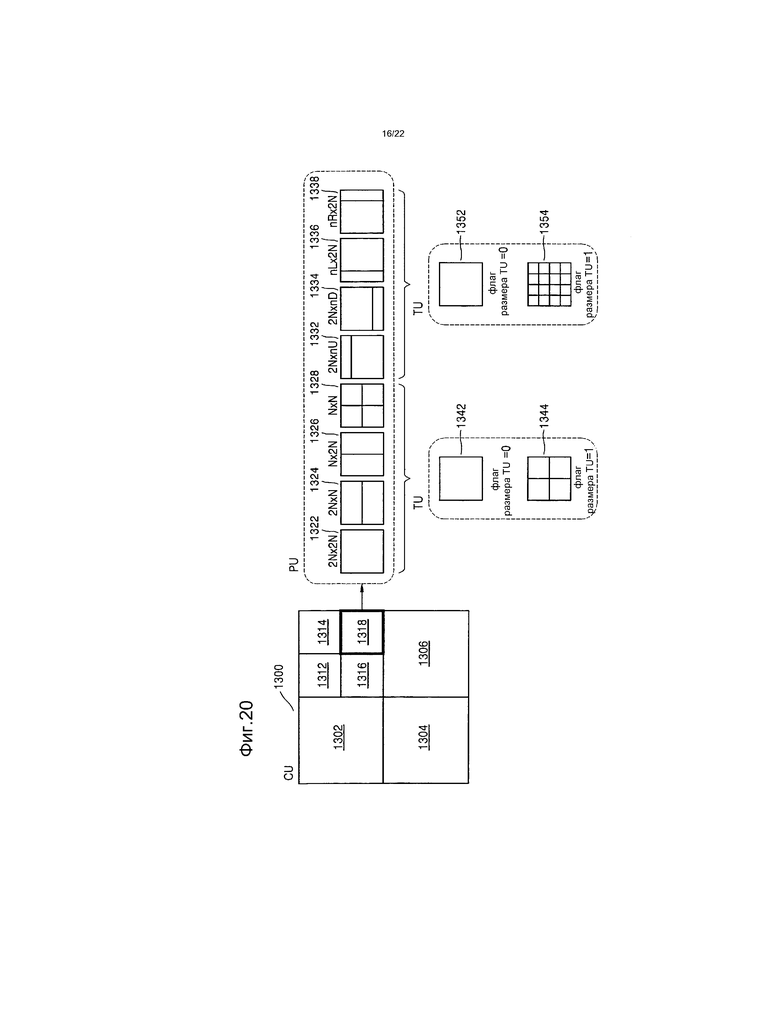
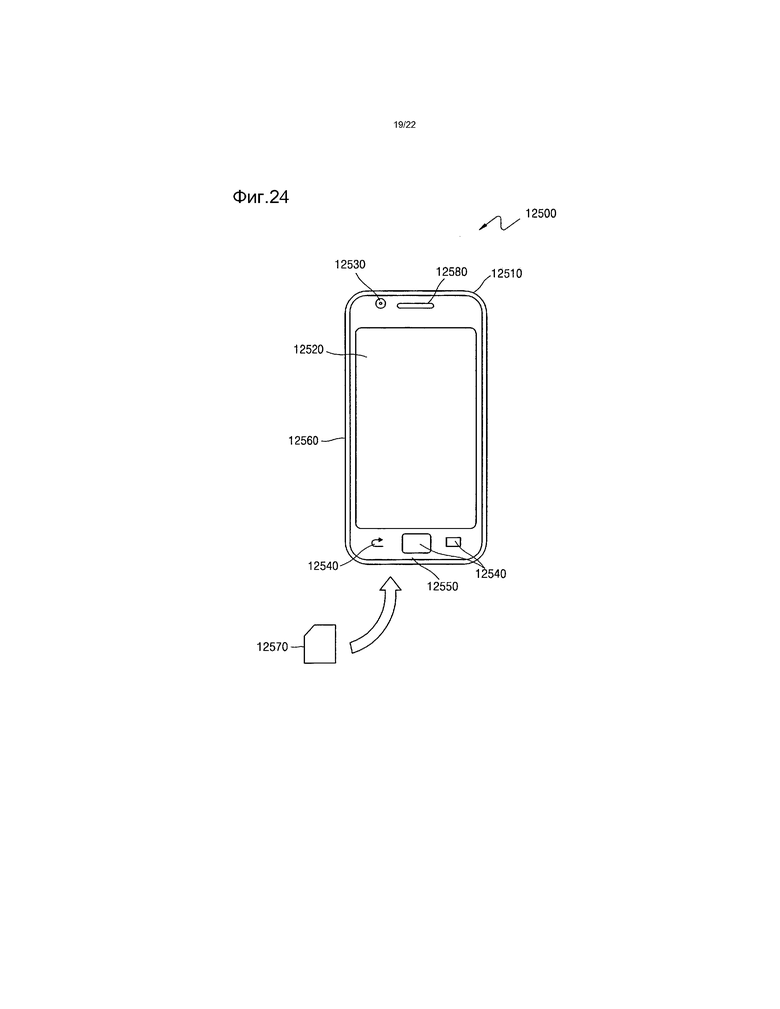
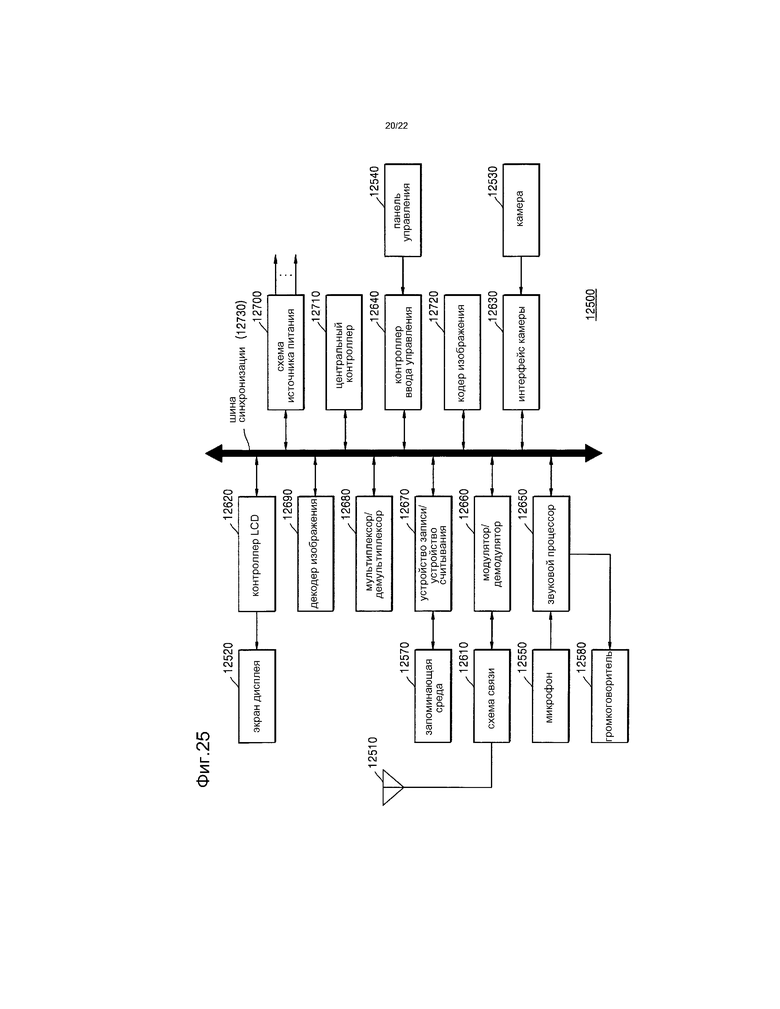
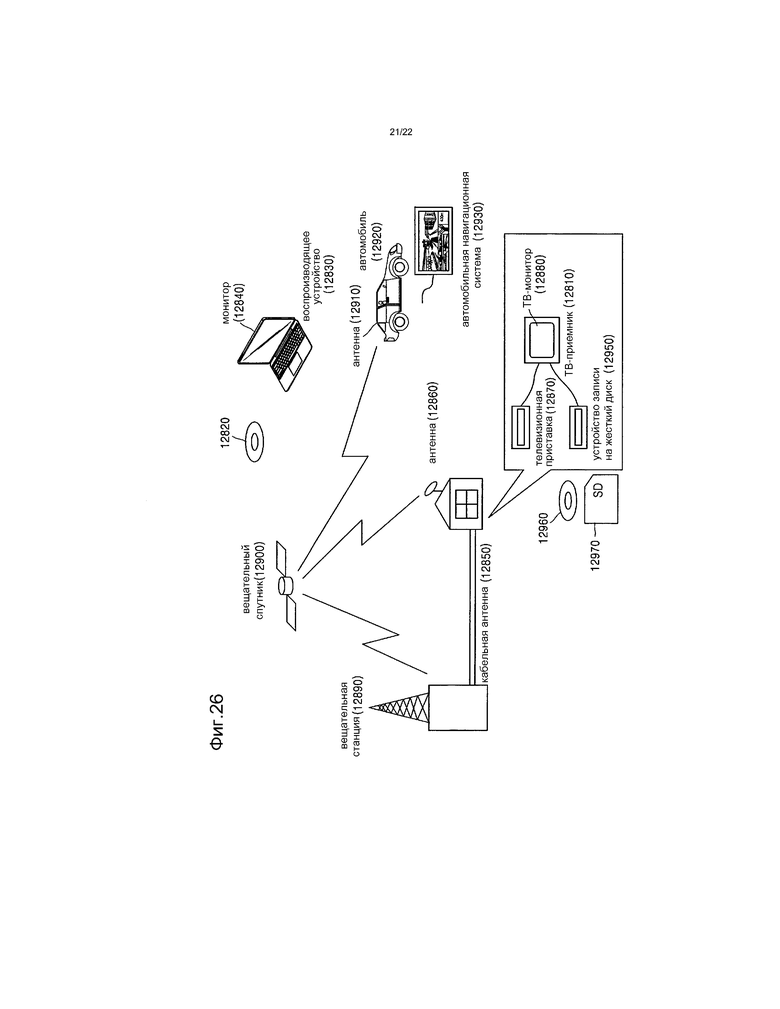
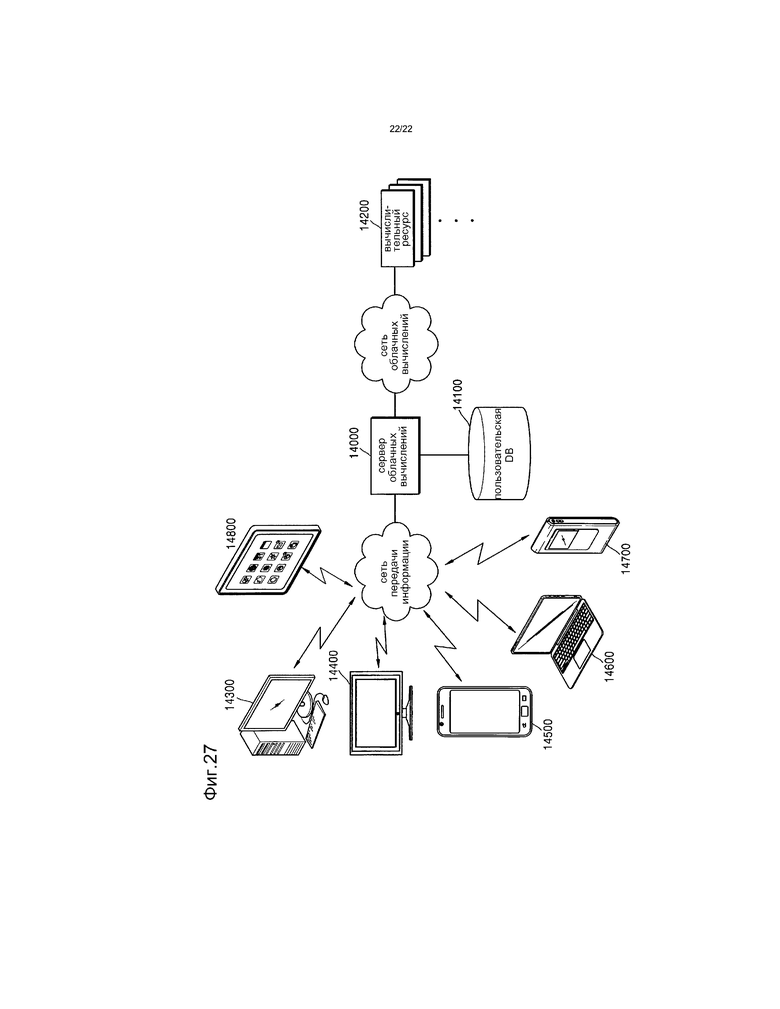
Изобретение относится к технологиям энтропийного кодирования и декодирования для кодирования и декодирования видеосигнала. Техническим результатом является повышение эффективности кодирования/декодирования видеосигнала. Предложен способ видеодекодирования. Способ содержит этап, на котором осуществляют получение из битового потока информации о максимальном размере единицы кодирования. Далее согласно способу получают из битового потока первую информацию, указывающую, разрешено ли включить зависимый сегмент слайса в видеокадр. А также согласно способу определяют число точек входа поднаборов, которые включают в себя одну или более максимальных единиц кодирования первого сегмента слайса, основываясь на третьей информации, получаемой из заголовка сегмента слайса битового потока. 3 з.п. ф-лы, 30 ил., 1 табл.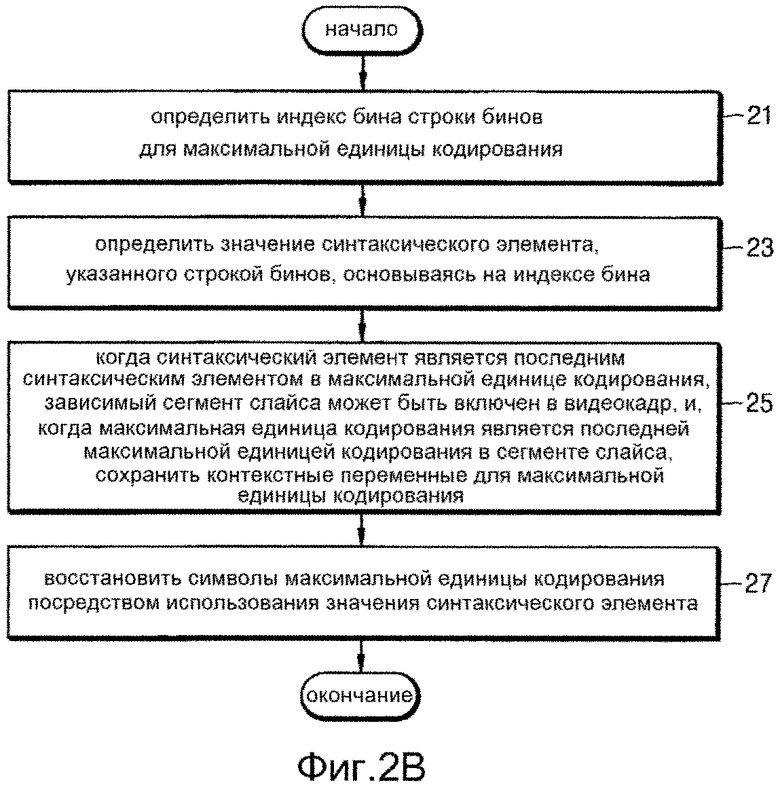
1. Способ видеодекодирования, содержащий:
получение из битового потока информации о максимальном размере единицы кодирования;
получение из битового потока первой информации, указывающей, разрешено ли включить зависимый сегмент слайса в видеокадр или нет;
определение одной или более максимальной единицы кодирования, включенной в первый сегмент слайса, основываясь на максимальном размере единицы кодирования, который определяется посредством использования информации о максимальном размере;
получение из битового потока второй информации, указывающей, находится ли текущая максимальная единица кодирования в конце первого сегмента слайса или нет;
определение числа точек входа поднаборов, которые включают в себя одну или более максимальных единиц кодирования первого сегмента слайса, основываясь на третьей информации, получаемой из заголовка сегмента слайса битового потока;
определение положений точек входа посредством использования смещения, которое на 1 больше числа, указанного четвертой информацией, получаемой из заголовка сегмента слайса;
сохранение контекстной переменной первого сегмента слайса, если первая информация указывает, что разрешено включить зависимый сегмент слайса в видеокадр, и вторая информация указывает, что текущая максимальная единица кодирования находится в конце первого сегмента слайса; и
декодирование зависимого сегмента слайса, который расположен следующим после первого сегмента слайса в видеокадре, посредством использования сохраненной контекстной переменной,
причем число и положения точек входа определяются, если множество тайлов включены в видеокадр, или синхронизация может выполняться для контекстных переменных текущей максимальной единицы кодирования, включенной в видеокадр.
2. Способ видеодекодирования по п.1, в котором сохранение контекстной переменной содержит сохранение контекстных переменных текущей максимальной единицы кодирования, если разрешено зависимый сегмент слайса включить в видеокадр.
3. Способ видеодекодирования по п.1, в котором сохранение контекстной переменной содержит сохранение контекстной переменной текущей максимальной единицы кодирования, декодированной в конечном счете в первом сегменте слайса, если вторая информация указывает, что текущая максимальная единица кодирования находится в конце первого сегмента слайса.
4. Способ видеодекодирования по п.1, дополнительно содержащий:
определение, может ли быть включен зависимый сегмент слайса видеокадра или нет, основываясь на первой информации, получаемой из набора параметров видеокадра битового потока;
определение, является ли текущая максимальная единица кодирования окончательной максимальной единицей кодирования или нет, основываясь на второй информации, получаемой из данных текущей максимальной единицы кодирования из числа данных каждого из сегментов слайса битового потока; и
получение строки бинов из данных текущей максимальной единицы кодирования.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ МАСШТАБИРУЕМОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2004 |
|
RU2329615C2 |

