ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Настоящее изобретение относится к устройствам, системам, способам и компьютерным программам в области автоматической обработки текстовых данных, представленных на естественных языках (Natural Language Processing).
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время в области автоматической обработки текстовой информации, представленной на естественных языках, одной из важных задач является синтез текста на основе извлеченных из текстовых данных информационных объектов. Одной из прикладных задач синтеза текста на основе извлеченной информации является автоматическое аннотирование текста.
[0003] Автоматическое аннотирование - это процедура обработки текстовых данных для последующего извлечения из них основной информации и ее дальнейшей обработки. На сегодняшний день существующие методы автоматического аннотирования можно разделить на два типа. Отличительным признаком аннотирования первого типа является то, что текст аннотации состоит из предложений исходного текста, это так называемый метод «extraction-based summarization)). Методы аннотирования второго типа «abstraction-based summarization)) - представляют текст аннотации, который синтезируется на основе содержания исходного текста. Ввиду технической сложности реализации автоматического синтеза текста и извлечения информации из него, основными методами аннотирования являются методы типа «extraction-based summarization)). Примерами автоматического аннотирования типа «extraction-based summarization)) являются методы: TextRank, метод аннотирования на основе терминологии и семантики, метод аннотирования на основе латентного семантического анализа.
[0004] Метод аннотирования TextRank является простейшим алгоритмом автоматического аннотирования, который представляет исходный текст в виде графа, вершинами которого являются предложения, а ребрами - "связь" между двумя предложениями. Связь определяется по числу одинаковых слов в данных предложениях. В графе у каждого ребра имеется вес. Каждой вершине же сопоставляется рейтинг, высчитанный на основе 2-х критериев:
- Количество ребер, которые идут из других вершин,
- Рейтинг этих ребер.
[0005] Вершины с наибольшим рейтингом содержат предложения, которые будут использоваться в тексте аннотации. Основным минусом данного метода аннотирования является то, что он практически не учитывает семантику текста, в результате чего аннотация не всегда точна и верна.
[0006] Алгоритм аннотирования на основе терминологии и семантики ранжирует предложения исходного текста, используя метрики, основанные на извлеченных из текста терминах. С помощью онтологии устанавливается корреляция каждого термина из текста с терминами из заголовка, на основе чего вычисляется вес каждого термина. Вес предложения вычисляется как сумма весов всех терминов, употребляющихся в нем.
[0007] Метод на основе латентного семантического анализа тоже основан на ранжировании предложений с помощью терминов. В основе метода лежит принцип выбора предложений, чья важность по какой-либо теме максимальна. Однако и у данного метода существуют недостатки. Поскольку предложения выбираются по принципу, согласно которому важность предложения хотя бы по одной теме максимальна, это приводит к тому, что предложение, чья важность хороша по всем темам, но не максимальна ни по одному, не попадет в аннотацию. Помимо этого не фильтруются маловажные темы, из-за чего размер аннотации может быть больше, чем нужно.
[0008] В описании предлагаемого изобретения представлен метод автоматического аннотирования текстовых данных типа «abstraction-based summarization)), который покрывает недостатки существующих методов и позволяет с высокой точностью синтезировать текст на основе извлеченных данных - информационных объектов - из текста.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0009] В настоящем описании представлены системы, методы и компьютерные программы для синтеза текста на естественном языке.
[0010] В одном из аспектов типовой способ синтеза текста на естественном языке включает: получение аппаратным процессором множества полученных информационных объектов; выбор аппаратным процессором среди множества полученных информационных объектов по крайней мере одного выбранного информационного объекта и, для каждого выбранного информационного объекта ассоциированный шаблон синтеза в библиотеке шаблонов, при этом библиотека включает по крайне мере один шаблон синтеза, и при этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона; создание аппаратным процессором для каждого выбранного информационного объекта семантико-синтаксическое дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза, выбранного для выбранного информационного объекта; и создание аппаратным процессором текста на естественном языке на основе каждого созданного семантико-синтаксического дерева.
[0011] В другом аспекте типовая система синтеза текста на естественном языке включает: модуль получения информационных объектов, настроенный на получение множества полученных информационных объектов; модуль выбора информационного объекта, настроенный на выбор среди множества полученных информационных объектов по крайней мере одного выбранного информационного объекта и, для каждого выбранного информационного объекта ассоциированный шаблон синтеза в библиотеке шаблонов, при этом библиотека включает по крайне мере один шаблон синтеза, и при этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона; модуль создания семантико-синтаксического дерева синтеза, настроенный на создание для каждого выбранного информационного объекта семантико-синтаксическое дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза, выбранного для выбранного информационного объекта; и модуль создания текста на естественном языке, настроенный на создание текста на естественном языке на основе каждого созданного семантико-синтаксического дерева.
[0012] Еще в одном аспекте типовой программный продукт, который хранится в памяти постоянного машиночитаемого носителя данных, содержит исполняемые компьютером команды на синтеза текста на естественном языке, в том числе команды на: получение аппаратным процессором множества полученных информационных объектов; выбор аппаратным процессором среди множества полученных информационных объектов по крайней мере одного выбранного информационного объекта и, для каждого выбранного информационного объекта ассоциированный шаблон синтеза в библиотеке шаблонов, при этом библиотека включает по крайне мере один шаблон синтеза, и при этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона; создание аппаратным процессором для каждого выбранного информационного объекта семантико-синтаксическое дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза, выбранного для выбранного информационного объекта; и создание аппаратным процессором текста на естественном языке на основе каждого созданного семантико-синтаксического дерева.
[0013] В некоторых аспектах что каждый полученный информационный объект ассоциирован с онтологическим объектом и имеет множество заполненных свойств, каждое заполненное свойство имеет значение; каждый шаблон синтеза ассоциирован с онтологическим объектом, при этом каждый шаблон синтеза включает множество необходимых свойств; каждый шаблон синтеза включает множество необязательных свойств; каждый шаблон синтеза включает скрипт-валидатор; выбор по крайней мере одного информационного объекта и ассоциированного шаблона синтеза включает, для каждого полученного информационного объекта, выбор шаблонов синтеза в библиотеке шаблонов, ассоциированных с тем же онтологическим объектом, что и полученный информационный объект; далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых множество необходимых свойств содержится во множестве заполненных свойств полученного информационного объекта; далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим множеством необходимых свойств; далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых скрипт-валидатор проверяет полученный информационный объект; далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим пересечением множества необязательных свойств со множеством заполненных свойств полученного информационного объекта; и далее, если выбран шаблон синтеза, выбор полученного информационного объекта и нахождение соответствия одного из выбранных шаблонов синтеза с выбранным информационным объектом. В некоторых аспектах выбранный информационный объект имеет множество заполненных свойств, каждое заполненное свойство, имеющее строковое значение на естественном языке; каждое семантико-синтаксическое дерево шаблона включает узлы шаблона; каждый шаблон синтеза включает для каждого из по крайней мере некоторых узлов шаблона, образующие множество замен узлов, соответствующее заполненное свойство; создание для каждого выбранного информационного объекта семантико-синтаксического дерева синтеза включает, для каждого узла шаблона ассоциированного шаблона синтеза, начиная с корневого узла семантико-синтаксического дерева шаблона: если узел шаблона не входит в множество замен узлов, создание в семантико-синтаксическом дереве идентичного узла; если узел шаблона входит в множество замен узлов и если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта, создание в семантико-синтаксическом дереве синтеза узла или поддерева на основе анализа строкового значения на естественном языке заполненного свойства выбранного информационного объекта, соответствующего узлу шаблона; и повторение предыдущих двух шагов для каждого дочернего узла семантико-синтаксического дерева шаблона. В некоторых аспектах создание для каждого выбранного информационного объекта семантико-синтаксического дерева синтеза дополнительно включает, если узел шаблона находится в множестве замен узлов, если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта, и если заполненное свойство выбранного информационного объекта имеет более чем одно строковое значение на естественном языке, для каждого строкового значения на естественном языке, создание в семантико-синтаксическом дереве синтеза узла или поддерева на основе строкового значения на естественном языке соответствующего узлу шаблона; и связывание созданных узлов сочинительной связью. В некоторых аспектах множество полученных информационных объектов формирует RDF граф. В некоторых аспектах формирование по крайней мере одной группы выбранных информационных объектов, ассоциированных с тем же шаблоном синтеза; и создание для по крайней мере одной группы семантико-синтаксического дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза. [0014] Вышеприведенные упрощенное раскрытие типовых аспектов изобретения дает базовое представление о настоящем изобретении. Настоящее раскрытие изобретения не является широким обзором всех подразумеваемых аспектов изобретения и не предназначено ни для определения ключевых или критических элементов всех аспектов, ни для общего описания объема всех или некоторых аспектов настоящего изобретения. Его единственная цель заключается в том, чтобы описать один или более аспектов в упрощенной форме в качестве вводной части к более подробному описанию настоящего изобретения, представленному ниже. Для выполнения вышеуказанных задач один или несколько аспектов настоящего изобретения включают характеристики, описанные и особенным образом отмеченные в пунктах формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0015] Фиг. 1 иллюстрирует последовательность шагов в соответствие с иллюстративным примером.
[0016] Фиг. 1А иллюстрирует блок-схему иллюстративного примера.
[0017] Фиг. 1В иллюстрирует блок-схему альтернативного ого иллюстративного примера.
[0018] Фиг. 1С иллюстрирует последовательность шагов в соответствие с альтернативным иллюстративным примером.
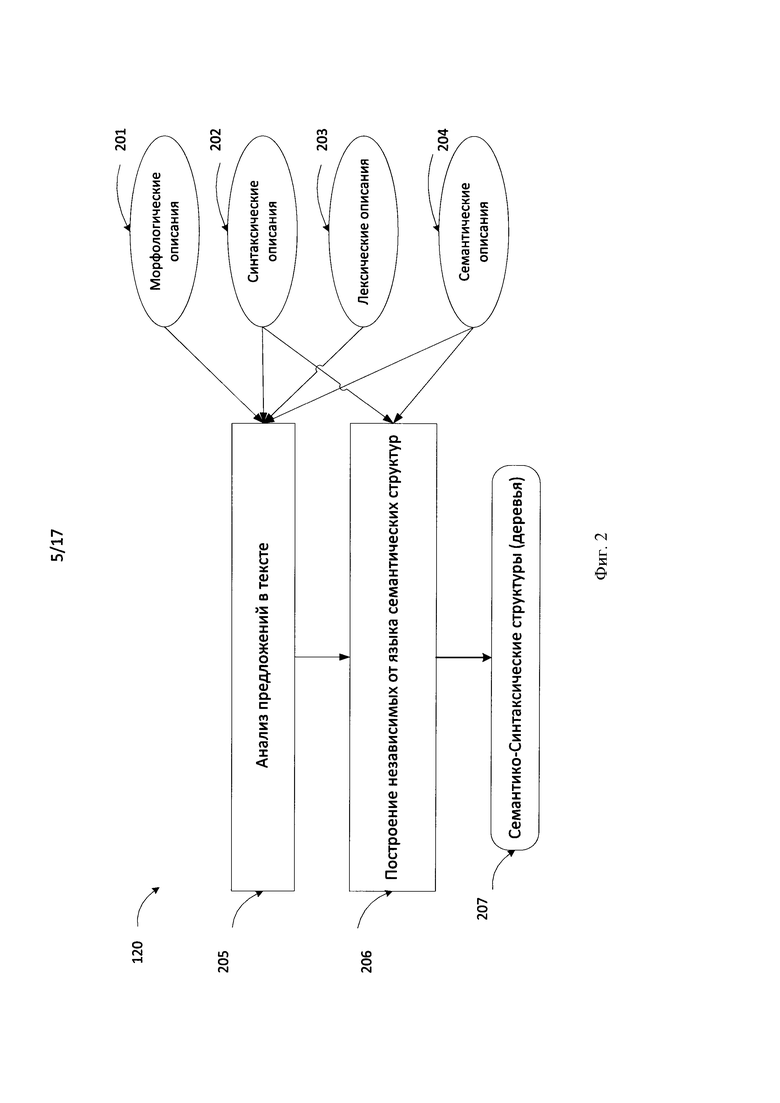
[0019] Фиг. 2 иллюстрирует последовательность шагов семантико-синтаксического анализа в соответствие с иллюстративным примером.
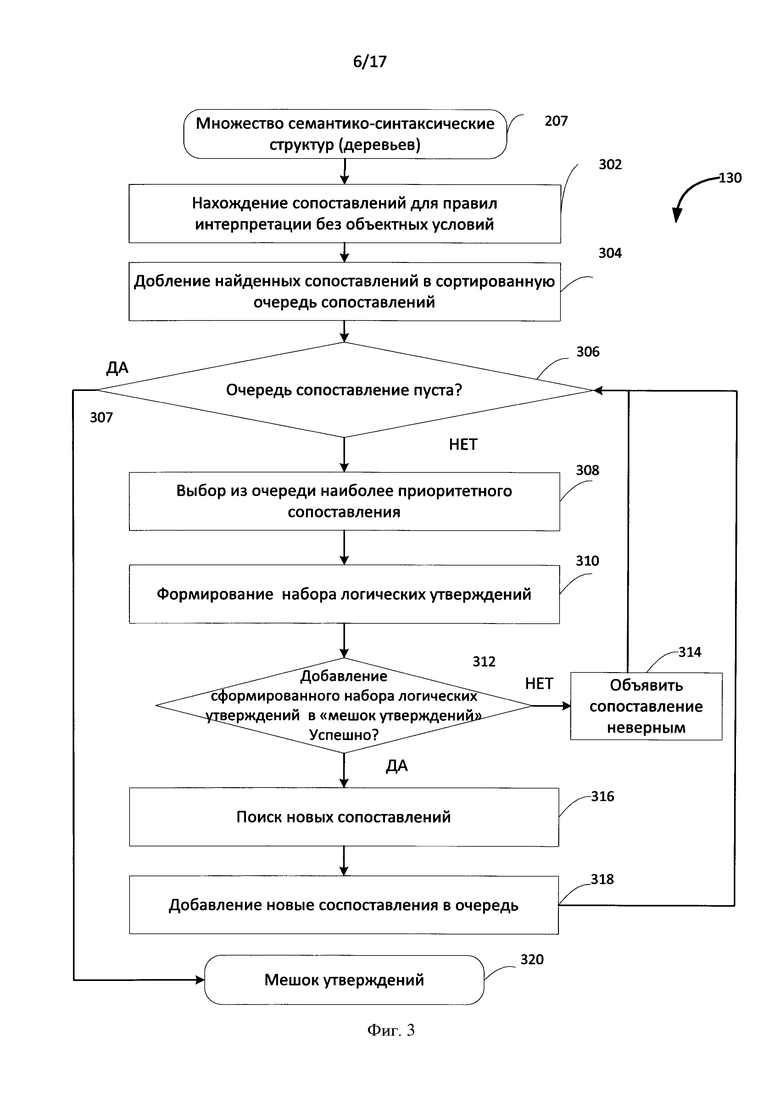
[0020] Фиг. 3 иллюстрирует последовательность шагов метода извлечения информации в соответствие с иллюстративным примером.
[0021] Фиг. 4А иллюстрирует последовательность выбора шаблона в соответствие с одной из реализаций в описании.
[0022] Фиг. 4В иллюстрирует интерфейс для создания шаблона в соответствие с альтернативным иллюстративным примером.
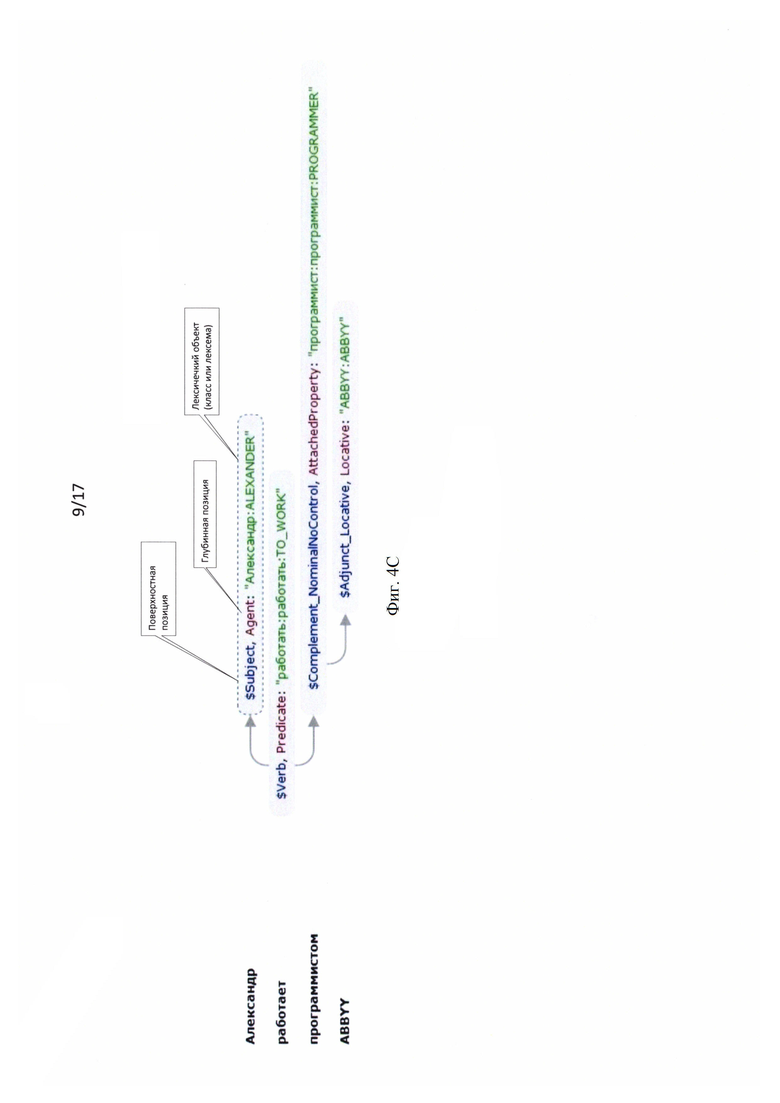
[0023] Фиг. 4С иллюстрирует семантико-синтаксическое дерево иллюстративного предложения из шаблона.
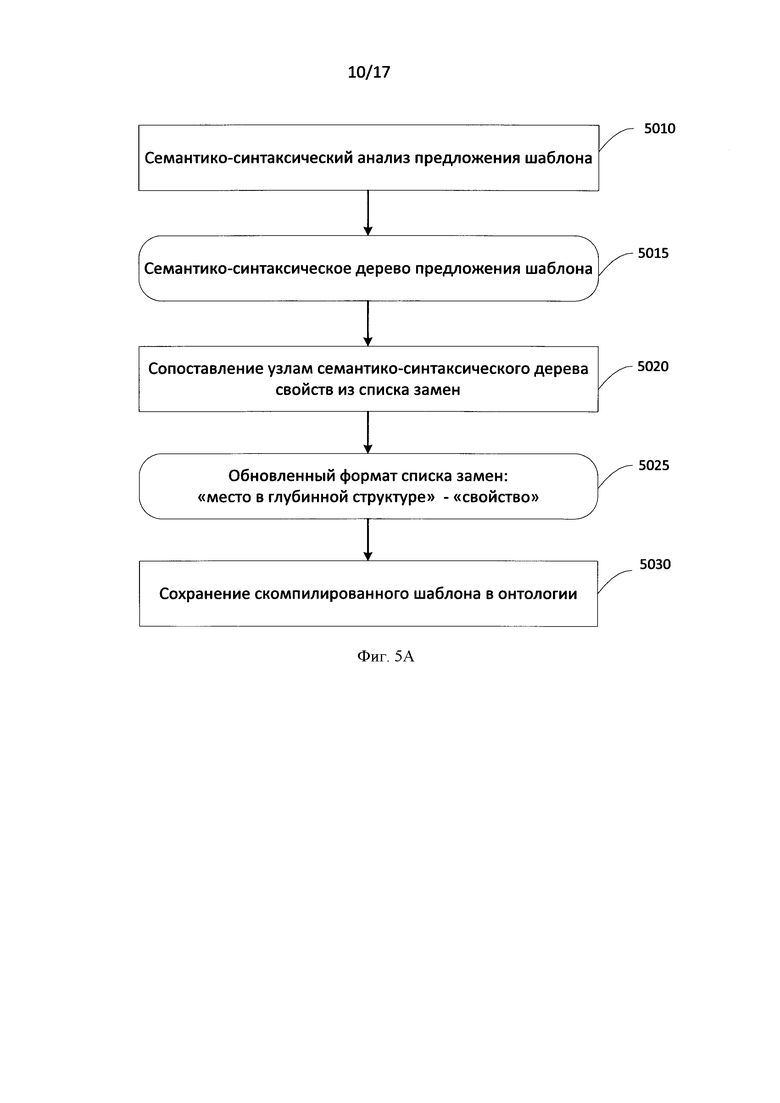
[0024] Фиг. 5А иллюстрирует процедуру компиляции шаблона.
[0025] Фиг. 5В иллюстрирует последовательность метода заполнения глубинной структуры предложения для синтеза в соответствие с иллюстративным примером.
[0026] Фиг. 6А иллюстрирует дерево для случая, когда узла нет в списке замен, в соответствие с иллюстративным примером.
[0027] Фиг. 6В иллюстрирует дерево для случая, когда узел есть в списке замен, однако нет свойства для соответствующего узла в соответствие с иллюстративным примером.
[0028] Фиг. 6C-6D иллюстрируют деревья для случая, когда узел есть в списке и у него два значения свойства, в соответствие с иллюстративным примером.
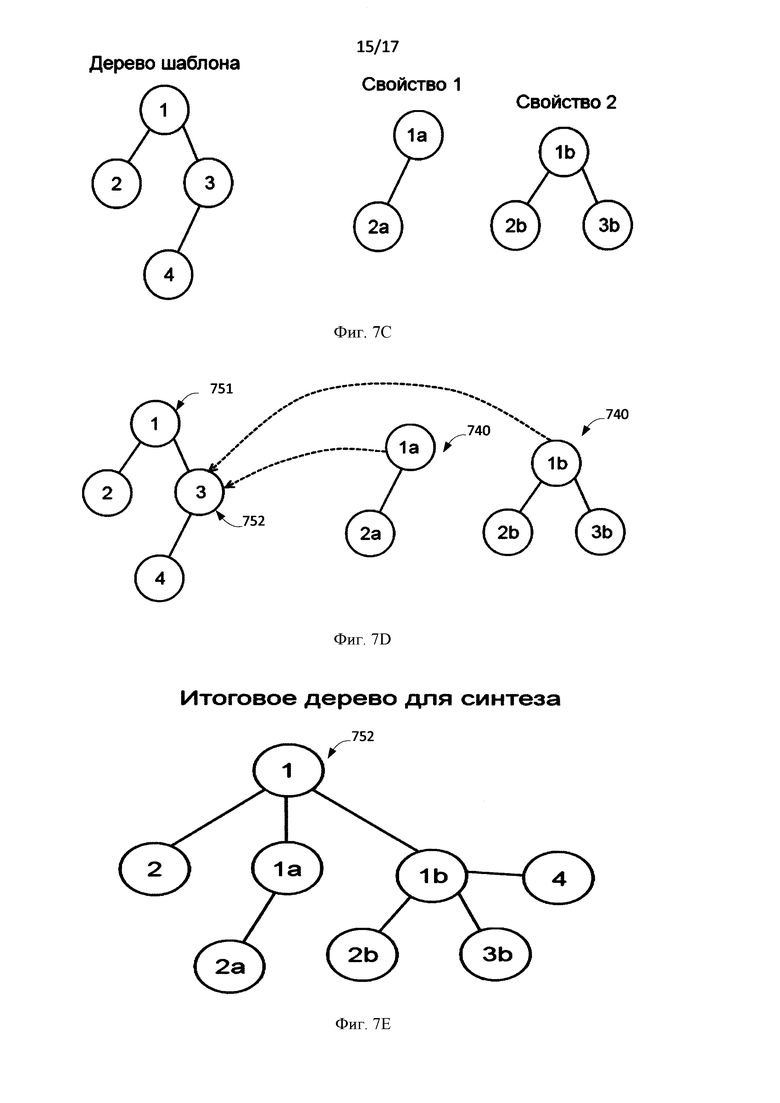
[0029] Фиг. 7А-Е иллюстрирует деревья предложений шаблонов, на основе которых воссоздаются соответствующие деревья синтеза.
[0030] Фиг. 8 иллюстрирует последовательность шагов при синтезе однородных фактов в соответствие с иллюстративным примером.
[0031] Фиг. 9 иллюстрирует пример схемы аппаратного обеспечения, которое может быть использовано в соответствие с иллюстративным примером.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0032] Типовые аспекты описываются в настоящем раскрытии в контексте системы, способа и компьютерной программы для синтеза текста на основе RDF графа с использованием шаблонов. Однако специалисты в этой области техники поймут, что нижеследующее описание носит исключительно иллюстративный, а не ограничивающий в каком-либо отношении характер. Другие аспекты настоящего раскрытия будут очевидны для специалистов в данной области на основании настоящего раскрытия. Далее будут подробно описаны варианты осуществления типовых аспектов, проиллюстрированных на приложенных чертежах. При упоминании в чертежах и нижеследующем описании тех же или аналогичных объектов будут по мере возможности использованы те же исходные индикаторы.
[0033] Настоящее описание представляет способ и систему, позволяющие осуществлять синтез текста на основе RDF графа с использованием шаблонов. Предлагаемый способ синтеза текста позволяет создавать аннотации, которые включают в себя краткое информацию о наиболее важных фактах, упомянутых в тексте. Однако синтез текста на основе RDF графа с использованием шаблонов не ограничивается применением только в области аннотирования.
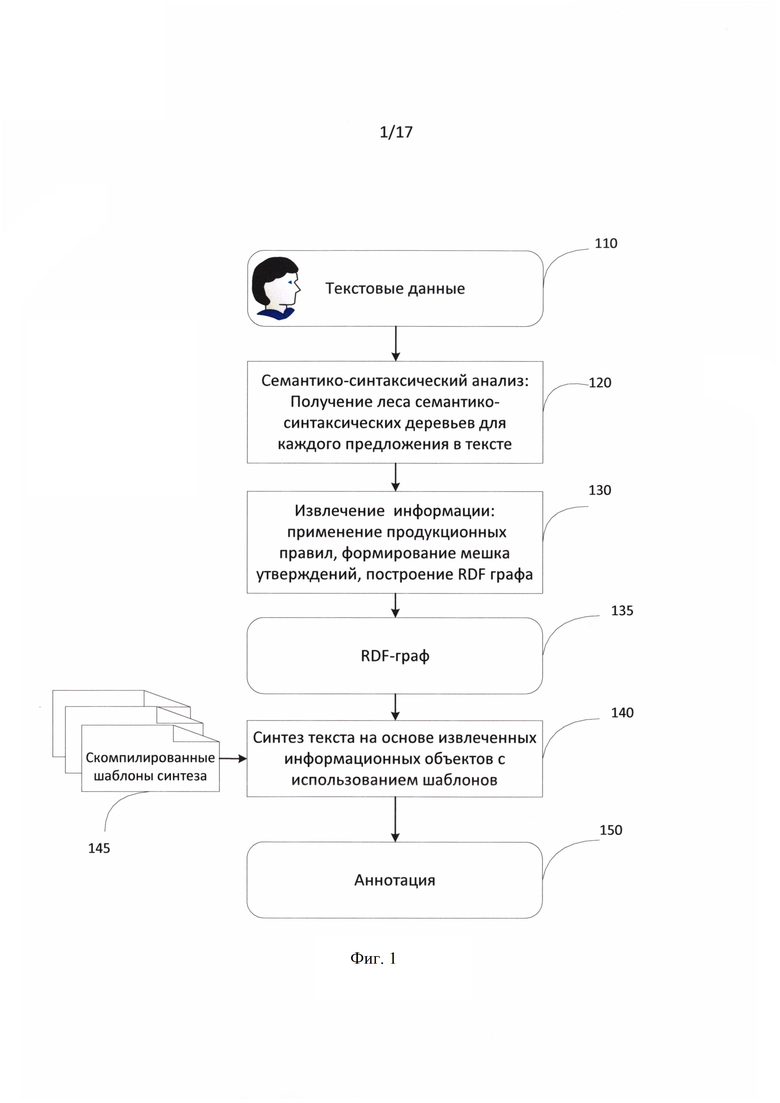
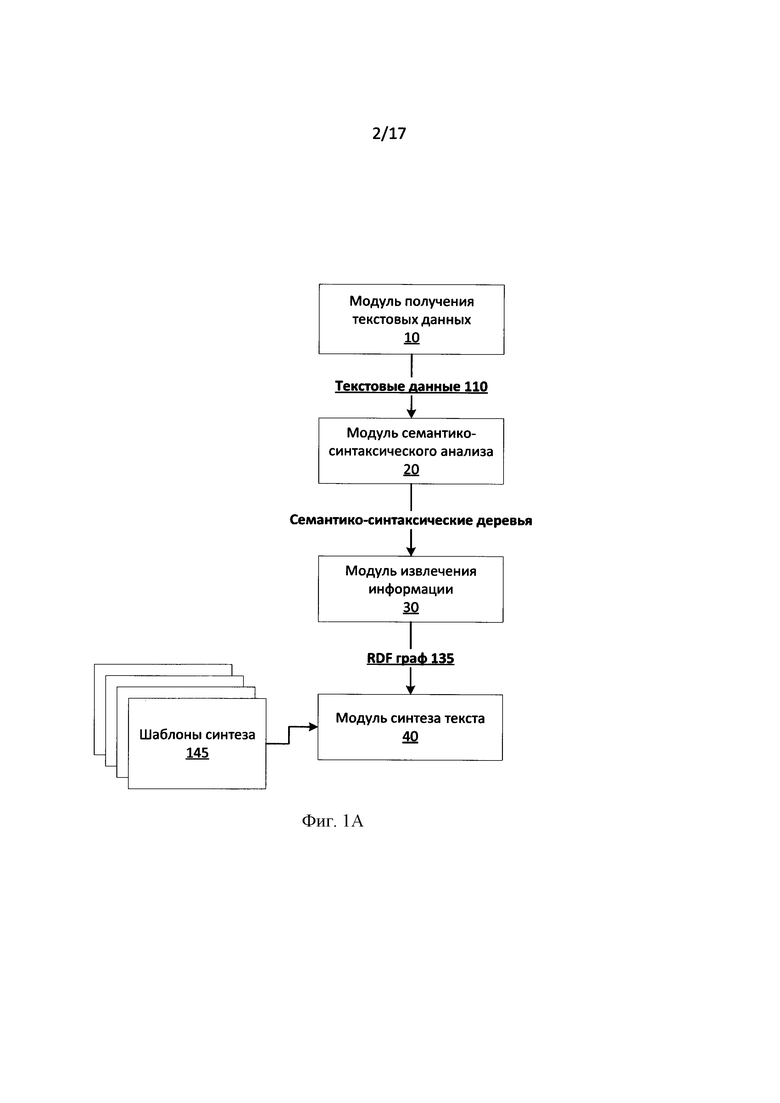
[0034] Фиг. 1 иллюстрирует схему последовательности шагов в соответствии с типовым аспектом. Фиг. 1А иллюстрирует систему в соответствии с типовым аспектом.
[0035] На этапе 110 на вход системе подаются текстовые данные от модуля ввода тестовых данных 10. Данные текстовые данные могут быть как заранее подготовлены, т.е. размечены, так и не подготовлены (не размечены). Далее текстовые данные на этапе 120 подвергаются семантико-синтаксическому анализу модулем семантико-синтаксического анализа 20. Основные принципы семантико-синтаксического анализа на базе лингвистических описаний описаны в патенте США 8,078,450, и данные принципы лежат в основе данного изобретения. Так как семантико-синтаксический анализ основан на использовании независимых от языка смысловых единиц, то данное изобретение также не зависит от языка и позволяет работать с одним или несколькими естественными языками.
[0036] Семантико-синтаксический анализатор текста - модуль, позволяющий проанализировать текстовые данные: отдельное предложение, текст или набор текстов; и получить для текстовых данных лес семантико-синтаксических структур, каждая из которых представляет собой граф, в частности дерево. Узлы и ребра графа дополняются грамматической и семантической информацией, используемой впоследствии для выделения объектов, их свойств и отношений, а также для синтеза предложений.
Семантико-синтаксический анализ:
[0037] Фиг. 2 иллюстрирует общую схему метода глубинного синтаксического и семантического анализа 120, основанного на лингвистических описаниях текстовых данных, представленных на естественных языках 110. Метод подробно представлен в патенте США 8,078,450. Метод использует широкий спектр лингвистических описаний, как универсальных семантических механизмов. Данные способы анализа основаны на принципах целостного и целенаправленного распознавания, т.е. гипотезы о структуре части предложения верифицируются в рамках проверки гипотезы о структуре всего предложения. Это позволяет избежать анализа большого количества вариантов.
[0038] Глубинный анализ включает лексико-морфологический, синтаксический и семантический анализ каждого предложения текста (корпуса текстов), в результате которого строятся семантические структуры для предложений, независимые от языка (language-independent semantic structures), в которых каждому слову сопоставляется соответствующий лексический и/или семантический класс (СК) из универсальной Семантической Иерархии (СИ).
[0039] Семантическая иерархия (СИ) представляет собой лексико-семантический словарь, в котором содержится вся лексика языка, необходимая для анализа и синтеза текста. Семантическая Иерархия организована в виде дерева родо-видовых отношений, в узлах которого находятся Семантические Классы (СК) - универсальные (единые для всех языков), отражающие некоторое понятийное содержание; и лексические классы (ЛК) - конкретноязыковые, являющиеся потомками некоторого семантического класса. Совокупность лексических классов одного Семантического Класса определяет семантическое поле - лексическое выражение понятийного содержания Семантического Класса. Наиболее распространенные понятия находятся на верхних уровнях иерархии.
[0040] Дочерний семантический класс в Семантической Иерархии наследует большинство свойств своего прямого родителя и всех семантических классов - предков. Например, семантический класс SUBSTANCE (Вещество) является дочерним семантическим классом класса ENTITY (Сущность) и материнским семантическим классом для классов GAS (Газ), LIQUID (Жидкость), METAL (Металл), WOOD_MATERIAL (Древесина) и т.д.
[0041] Вернемся к Фиг. 2. Исходные предложения в тексте/коллекции текстов (110) подвергаются семантико-синтаксическому анализу 205 с использованием лингвистических описаний, как исходного языка, так и универсальных семантических описаний, что позволяет анализировать не только поверхностную синтаксическую структуру, но и распознавать глубинную, семантическую структуру, выражающую смысл высказывания, содержащегося в каждом предложении, а также связи между предложениями или фрагментами текста. Лингвистические описания могут включать лексические описания 203, морфологические описания 201, синтаксические описания 202 и семантические описания 204. Анализ 205 включает синтаксический анализ, реализованный в виде двухэтапного алгоритма (грубого синтаксического анализа и точного синтаксического анализа), использующий лингвистические модели и информацию различных уровней для вычисления вероятностей и генерации множества синтаксических структур. В результате чего строится на этапе 206 семантико-синтаксическая структура (207), или другими словами семантико-синтаксическое дерево, которое по некоторой используемой в процессе анализа системе оценок, является лучшей семантико-синтаксической структурой из множества семантико-синтаксических структур.
[0042] Морфологическая модель семантико-синтаксического анализатора существует вне семантической иерархии. Для каждого языка существует список лексем и их парадигмы. Внутри семантической иерархии каждая лексема может прикрепляться к одному или нескольким лексическим классам. Лексический класс обычно связывает вместе несколько лексем.
[0043] Каждый узел полученного семантико-синтаксического дерева прикрепляется к какому-то лексическому классу семантической иерархии, что подразумевает устранение двузначности слов в процессе анализа. Каждый узел также хранит в себе грамматическую и семантическую информацию, которая определяет его роль в тексте, а именно набор граммем и семантем.
[0044] Каждая дуга семантико-синтаксического дерева хранит поверхностную позицию (т.е. синтаксическую функцию зависимого узла, например, $Subject или $Object_Direct) и глубинную позицию (т.е. семантическую роль зависимого узла, например, Agent или Experiencer). Набор глубинных позиций универсален и не зависит от языка, в отличие от набора поверхностных позиций, который отличается от языка к языку.
[0045] В представленном изобретении семантико-синтаксический анализатор используется как для глубинного анализа предложений в тексте, предоставленном системе, например, пользователем, так и в процессе создания шаблонов, по которым потом будет происходить синтез текста. Данная процедура будет описана ниже.
Извлечение информации:
[0046] Вернемся к Фиг. 1. После того текстовые данные, предоставленные пользователем, прошли этап глубинного семантико-синтаксического анализа 120, в результате чего был получен лес семантико-синтаксических деревьев для каждого предложения в тексте, запускается процесс извлечения информации 130, который осуществляется модулем извлечения информации 30. Модуль извлечения информации использует полученные на предыдущем этапе семантико-синтаксические деревья.
[0047] Процесс извлечения информации управляется системой продукционных правил. Существует два типа продукционных правил: правила интерпретации фрагментов семантико-синтаксических деревьев и правила идентификации информационных объектов.
[0048] Правила интерпретации позволяют описывать фрагменты семантико-синтаксических деревьев, при обнаружении которых вступают в силу определенные наборы логических утверждений. Одно правило представляет собой продукцию, левой частью которой является эталонный фрагмент семантико-синтаксического дерева, а правой - набор выражений, описывающих логические утверждения.
[0049] Эталон семантико-синтаксического дерева (или древесные эталон) представляют собой формулу, атомарными элементами которой являются проверки различных свойств узлов семантико-синтаксических деревьев (наличия той или иной граммемы/семантемы, принадлежности к лексическому/семантическому классу, нахождения в некоторой поверхностной/глубинной позиции и многое другое).
[0050] Правила идентификации применяются в тех ситуациях, когда требуется сливать (объединять) уже извлеченные информационные объекты. Правило идентификации представляет собой продукцию, в левой части которой описываются накладываемые на два информационных объекта ограничения, при выполнении которых информационные объекты считаются совпадающими. Правая часть всех правил идентификации считается одинаковой (это одно утверждение об идентичности двух объектов) и не записывается.
[0051] Способ извлечения информации с использованием продукционных правил проиллюстрирован на Фиг. 3. Как уже было упомянуто выше, на вход модулю извлечения информации поступают семантико-синтаксические деревья для каждого предложения, анализируемого системой текста, предоставленного пользователем. На шаге 302 детектируются все сопоставления для правил интерпретации без объектных условий (условий, накладываемых на информационные объекты). Здесь термин сопоставление означает сопоставление древесного эталона правила интерпретации с фрагментом семантико-синтаксического дерева. Далее найденные сопоставления добавляются 304 в сортированную очередь сопоставлений. На этапе 306 проверяется, пуста ли очередь сопоставлений. Если очередь сопоставлений пуста 307, то работа завершается (320). Если очередь не пустая, то из очереди выбирается 308 наиболее приоритетное сопоставление. Далее формируется 310 набор логических утверждений по правой части соответствующего правила. Далее сформированный набор логических утверждений добавляется в «мешок утверждений» 312. «Мешком утверждений» называется множество не противоречащих друг другу логических утверждений об информационных объектах и их свойствах. Логические утверждения не произвольны. Существует ограниченное число типов логических утверждений. В случае неудачи, сопоставление объявляется неверным 314, после чего снова проверяется очередь сопоставления на пустоту. Иначе в случае успеха, производится поиск новых сопоставлений 316. Новые сопоставления, если они найдены, добавляются в очередь. Далее снова переходим к шагу 306. Таким образом, происходит формирование (320) «Мешка утверждений», который представлен в некотором внутреннем формате. Далее формируется RDF граф.
[0052] В соответствии с концепцией RDF (Resource Definition Framework), которая является моделью представления данных, каждому информационному объекту, извлеченному из текстовых данных в процессе извлечения информации, описанном выше, приписывается уникальный идентификатор. А именно, вся извлеченная информация представляется в виде множества триплетов <s,p,o>, где s - идентификатор информационного объекта, р - идентификатор его свойства (предикат), о - значение данного свойства.
[0053] Пример реального RDF графа выглядит следующим образом:



Онтология
[0054] Все извлеченные из текстов RDF данные согласованы с моделью предметной области (онтологией), в рамках которой функционирует модуль извлечения информации. В рамках онтологии специфицируется то, какими свойствами (атрибутами) могут обладать информационные объекты, и то, какие объектные связи могут существовать между ними. Онтология представляет собой формальное явное описание некой предметной области. Основными компонентами онтологии являются концепты (или другими словами, классы), экземпляры, отношения, атрибуты. Концепты онтологии представляют собой формально описанное именованное множество экземпляров, обобщенных по какому-либо признаку. Примером концепта может быть множество всех людей, объединенных в концепт «Person» («Персона»). Концепты в онтологии объединены в таксономию, т.е. в иерархическую структуру. Экземпляр представляет собой конкретный объект или явление предметной области, которое входит в концепт. Например, экземпляр Yury Gagarin («Юрий Гагарин») входит в концепт «Person» («Персона»). Отношения - это формальные описания между концептами, которые фиксируют, какие связи могут быть установлены между экземплярами данных концептов.
[0055] Согласованность данных, порождаемых модулем извлечения информации, с моделью предметной области обеспечивается автоматически. С одной стороны, этому способствует синтаксис языка правил извлечения информации. С другой стороны, в систему встроены специальные механизмы валидации, не допускающие появления онтологически некорректных данных.
[0056] Кроме самого RDF-графа, согласованного с OWL-онтологией, сохраняется информация о связи выделенных информационных объектов с исходным текстом (аннотации или "подсветка" объектов). RDF-граф вместе с информацией об аннотациях информационных объектов мы будем в дальнейшем называть аннотированным RDF-графом.
[0057] Вернемся к Фиг. 1. После того, как RDF граф получен, запускается процесс синтеза текста. Можно отметить, что RDF граф может быть получен любым другим способом, отличным от описанного выше. Для полученного RDF графа генерируется текст, передающий смысл, заложенный в выделенных в процессе работы модуля извлечения информации фактах.
Структура модуля синтеза:
[0058] За создание текста на основе извлеченной информации, представленной в виде RDF графов, ответственен модуль синтеза текста.
[0059] Архитектура модуля синтеза текста позволяет использовать его универсально. А именно в модуле не кодируется явная зависимость от какого-либо естественного языка или факта, что позволяет при расширении онтологии, например, путем добавления пользовательской онтологии, или добавлении нового языка синтезировать текст без модификаций самого модуля синтеза текста.
[0060] Более того в модуль синтеза текста встроен фильтр синтезируемых фактов, что позволяет не синтезировать текст по некоторым извлеченным фактам, например, по некачественно извлеченным фактам. Кроме этого в модуле осуществляется ранжирование выдачи, благодаря которой более важные сгенерированные факты располагаются выше, а менее важные - ниже.
[0061] Для этого используемые онтологии пополняются для каждого информационного объекта (факта), по которому необходимо получить синтезированное предложение, новыми онтологическими объектами - шаблонами синтеза 145 (Фиг. 1). Шаблоны синтеза создаются заранее, до этапа анализа входных текстовых данных, предоставленных пользователем. Шаблоны создаются вручную для каждого типа информационных объектов (в рамках данного описания для каждого типа фактов, которые могут быть обнаружены в текстовых данных, предоставленных пользователем). Подробное описание создания шаблонов приведено ниже.
Создание шаблона
[0062] Синтез текста на основе извлеченных на этапе 130 информационных объектов (в конкретном примере, именно на основе извлеченных фактов) производится с использованием шаблонов 145. Шаблоны создаются вручную для каждого типа факта. Причем для каждого факта можно создать несколько шаблонов. Ниже приведено иллюстративное описание шаблона. Приведенное ниже иллюстративное описание шаблона не ограничивает область применения раскрываемого изобретения. [0063] В одной из реализаций описываемого изобретения шаблон включает в себя следующие компоненты:
- предложение на одном из естественных языков;
- указание на язык, на котором написано данное предложение;
- список замен, который имеет вид «часть предложения (в описываемом изобретении частью является слово предложения) из шаблона» - соответствующее ей «свойство». Чем больше список замен, тем более точным является шаблон.
- список необходимых свойств информационного объекта (согласно реализации описываемого изобретения - факта);
- скрипт-валидатор;
- указание на библиотеку, в которой хранится данный шаблон;
[0064] Предложение (далее, «предложение шаблона») на одном из естественных языков является основой шаблона. Именно на предложение шаблона ссылается список замен. Предложение шаблона далее используется при построении дерева синтеза текста.
[0065] Рассмотрим факт "Occupation" («Занятость»), который был извлечен из текста при помощи модуля извлечении информации. Данный факт отвечает за род занятий. В большинстве случаев факт "Occupation" («Занятость») можно формулировать в общем случае как: «Кто-то работает где-то кем-то». Например, предложением шаблоном для факта "Occupation" («Занятость») может служить предложение "Alexander works as а programmer at ABBYY" («Александр работает программистом в ABBYY»). Список замен для данного шаблона следующий:
- "Alexander" («Александр») - employee (работник);
- "programmer" («программистом») - position (должность);
- «ABBYY» - employer (работодатель),
где "Alexander" («Александр»), "programmer" («программистом»), «ABBYY» являются словами из предложения шаблона; «employee» (работник), «position» (должность), «employer» (работодатель) - соответствующие им свойства. Список замен для шаблона создается пользователем вручную. Чем больше список замен, тем точнее шаблон.
[0066] Помимо этого в шаблоне должны быть указаны те свойства из списка замен, которые являются необходимыми для заполнения извлеченного информационного объекта. Необходимые свойства накладывают следующее условие на использование шаблона: если одно из обязательных свойств шаблона не будет заполнено для извлеченного информационного объекта (факта), то данный шаблон использоваться при синтезе текста не будет. В список необходимых свойств шаблона из вышеупомянутого примера входят два свойства из трех возможных, а именно свойства «position» и «employee». Данные свойства должны быть заполнены у извлеченного факта, для того чтобы использовать вышеупомянутый шаблон "Alexander works as a programmer at ABBYY" («Александр работает программистом в ABBYY»). Необязательное свойство у извлеченного факта может оставаться незаполненным, при этом шаблон использоваться будет. Например, если в извлеченном факте не будет заполнено свойство «работодатель» (это свойство не входит в список обязательных свойств вышеупомянутого примера), то этот шаблон по-прежнему может быть использован при синтезе текста.
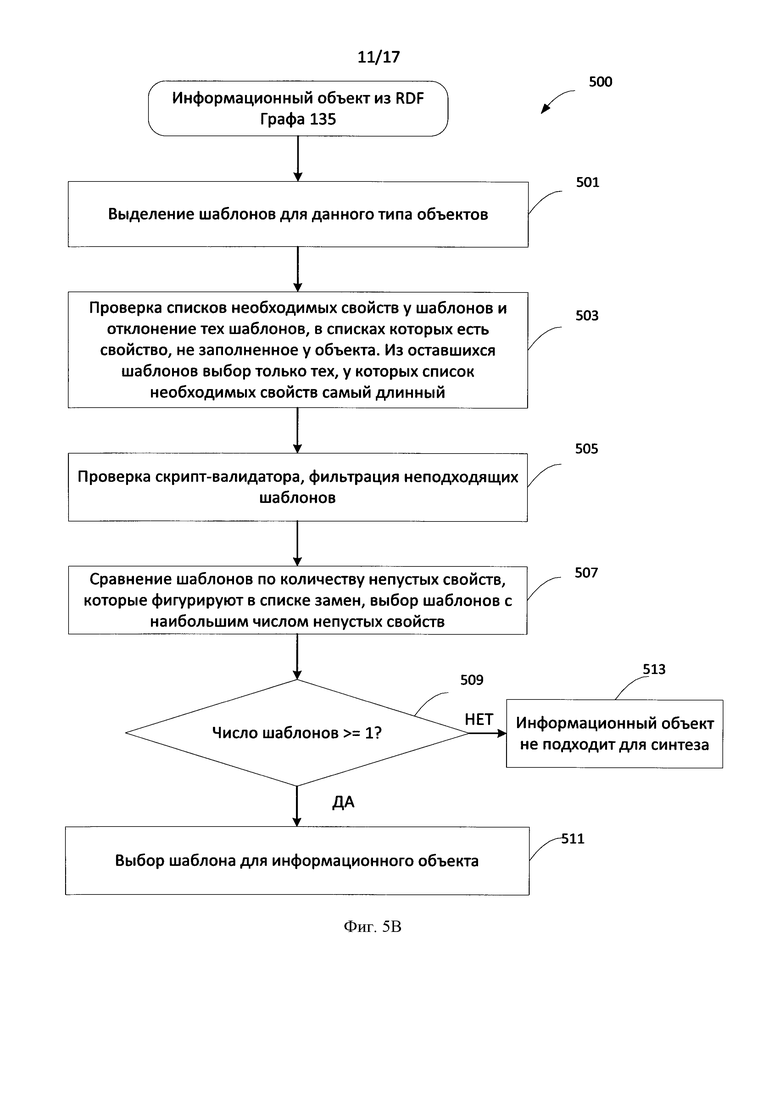
[0067] Скрипт-валидатор накладывает определенные ограничения, которые служат проверкой свойств у извлеченных фактов. Скрипт-валидатор в некой степени участвует в фильтрации фактов, на основе которых может производиться синтез. В качестве скрипта-валидатора здесь может быть использован скрипт (условия) проверки того, что свойство «employee» (работник) у извлеченного факта является именованным, т.е. именем собственным. Это позволяет фильтровать «мусорные» (ошибочно выделенные из текста) факты. Например, если скрипт-валидатором не будет наложено условие, что свойство «employee» (работник) у извлеченного факта является именованным, то при синтезе текста может быть получено следующее предложение - "Programmer works as a programmer", («Программист работает программистом»), которое является бессмысленным.
Компиляция шаблона:
[0068] Для того чтобы в качестве шаблона использовать предложение на естественном языке запускается процесс компиляции шаблона. Фиг. 5А иллюстрирует процедуру компиляции шаблона. Частью компиляции шаблона является семантико-синтаксический анализ 5010, в результате которого создается семантико-синтаксическое дерево 5015, на основе которого будет проводиться в дальнейшем синтез текста. Семантико-синтаксический анализ описан на Фиг. 2. Узлами семантико-синтаксического дерева являются слова из предложения, узлы привязаны к некоторому лексическому классу из Семантической Иерархии (СИ). Помимо этого узлы содержат грамматическую и семантическую информацию о языке (наборы граммем и семантем), характеризующую конкретное употребление соответствующего слова в контексте предложения. Дуги семантико-синтаксических деревьев отражают глубинные позиции (т.е. семантической роли зависимого слова, например Agent) и поверхностные позиции (т.е. синтаксической функции зависимого слова, например $Subject). На Фиг. 4А_ проиллюстрировано семантико-синтаксическое дерево предложения шаблона "Alexander works as a programmer at ABBYY" («Александр работает программистом в ABBYY»). Узлами дерева являются слова из предложения.
[0069] После того как семантико-синтаксическое дерево для предложения из шаблона построено, происходит сопоставление узлам семантико-синтаксического дерева свойств из списка замен шаблона 5020. Сопоставление происходит автоматически. В семантико-синтаксическом дереве ищутся составляющие (узлы), соответствующие словам, указанным в списке замен для шаблона. К данным составляющим (узлам) семантико-синтаксического дерева привязываются указанные в списке замен свойства. Например, узлу Alexander («Александр») в семантико-синтаксическом дереве на Фиг. 4А привязывается свойство «employee» (работник), узлу "programmer" («программистом») - свойство «position» (должность), узлу «ABBYY» - свойство «employer» (работодатель). Формат списка замен теперь изменяется, свойства привязываются не к словам из предложения шаблона, а к месту в глубинной структуре (к узлу семантико-синтаксического дерева) данного предложения. Формат списка замен теперь имеет вид: «место в глубинной структуре» предложения шаблона - соответствующее ему «свойство» 5025.
[0070] Результаты компиляции созданного шаблона, а именно семантико-синтаксическое дерево, список замен, в котором свойства привязаны к месту в глубинной структуре предложения шаблона, список необходимых свойств шаблона, язык предложения шаблона и скрипт-валидатор, сохраняются 5030 в основную онтологическую модель в качестве объекта отдельного типа - «скомпилированный шаблон» или шаблон синтеза.
[0071] Некоторый массив скомпилированных шаблонов прикрепляется к существующему концепту онтологии, например, к концепту «BasicFactOccupation». Таким образом, концепт в онтологии, к которому прикреплены шаблоны, хранит указание на существующий для него массив шаблонов, которые могут быть использованы для данного концепта при синтезе текста. Это полезно для того, чтобы иметь возможность определить множество шаблонов, относящихся к информационному объекту (в данном описании, к факту), которые можно использовать для синтеза текста на основе этого факта. Далее из этого множества шаблонов выбирается единственно подходящий шаблон для синтеза текста.
Структура информационных объектов модуля извлечения информации
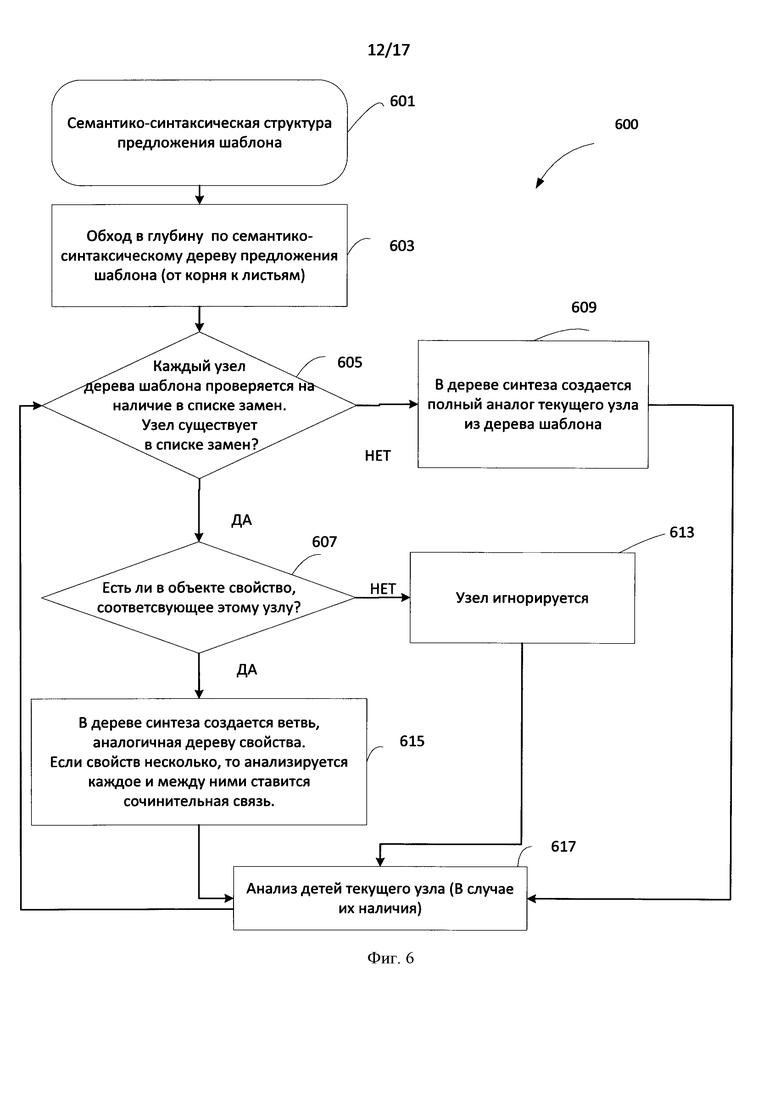
[0072] Информационные объекты могут быть различных типов, например, информационный объект может быть фактом, персоной или локаций. Тип информационных объектов ссылается на соответствующий концепт из онтологии: «BasicFact»; «Person»; «Location». В процессе извлечения информации создается «мешок утверждений» - множество не противоречащих друг другу логических утверждений об информационных объектах и их свойствах. Конечным результатом работы модуля извлечения информации может являться RDF граф. В соответствии с концепцией RDF (Resource Definition Framework), которая является моделью представления данных, каждому информационному объекту приписывается уникальный идентификатор. А именно, вся извлеченная информация представляется в виде множества триплетов <s,p,o>, где s - идентификатор информационного объекта, р - идентификатор его свойства (предикат), о - значение данного свойства.
[0073] Как уже было упомянуто выше, внутри модуля извлечения информации у каждого извлеченного в ходе анализа текста информационного объекта существует набор свойств и значения данных свойств. В рамках задачи синтеза текста с использованием RDF-графа рассматриваются значения свойств извлеченного информационного объекта(факта), которые используются в шаблоне(ах) для данного факта.
[0074] Свойства можно условно поделить на два типа. К первому типу относятся свойства, которые могут быть явно представлены в шаблоне. Примерами таких свойств могут служить: имя персоны, название должности, название организации, дата и т.д. Так, значение свойства "position" («должность») всегда представлено текстовой строкой, поэтому в шаблоне оно может фигурировать явно.
[0075] Ко второму типу относятся свойства, которые явно в шаблоне не фигурируют. Такими свойствами являются: степень доверия к извлеченному объекту (факту), степень завершенности действия и т.д.
[0076] Во время синтеза текста обрабатываются оба типа свойств. Значения свойств первого типа приводятся к строковому типу. Если свойство является информационным объектом, то у всех таких объектов существует свойство «label». Например, у извлеченного факта «Occupation» («Занятость») существует свойство «работодатель», значением этого свойства является информационный объект с концептом «Organization» («Организация»), у которого в имени (и по совместительству в лейбле) указано «ABBYY».
[0077] В это свойство система помещает краткую читаемую информацию об информационном объекте в виде строки, которой достаточно при синтезе. Примерами таких информационных объектов будут: "Pavel Durov" («Павел Дуров») для персоны, «ABBYY» для организации и т.п.
[0078] После приведения значения свойств к строковому типу, строка подвергается семантико-синтаксическому анализу, и встраивается в глубинную структуру (или другими словами, в семантико-синтаксическое дерево) синтезируемого предложения. Чтобы понять, в какое место глубинной структуры синтезируемого предложения необходимо помещать проанализированную строку (значения) свойства используется список замен. Формат списка замен: «место в глубинной структуре» - «свойство».
[0079] В иллюстративном примере предложения шаблона "Alexander works as а programmer at ABBYY" («Александр работает программистом в ABBYY»), приведенном выше, узел "Alexander" («Александр») будет заменено на свойство "employee" («работник»), узел "programmer" («программистом») - на свойство "position" («должность»), а узел «ABBYY» - на свойство "employer" («работодатель»). В результате чего при синтезе текста на основе нового извлеченного факта «Occupation» («Занятость») данного шаблона шаблон заполнится значениями свойств уже извлеченного факта и будет синтезировано нужное предложение. Подробнее процедура синтеза на основе шаблон описана ниже.
[0080] Если же значения для свойства из списка замен шаблона у извлеченного объекта (факта) отсутствует, т.е. указанное свойство остается пустым, то соответствующее данному свойству слово удаляется из дерева синтезируемого предложения. Однако если ни одно свойство не заполнено, то синтезируется бессмысленная фраза "works" («работает»). Чтобы не допустить такого, в шаблонах, как было упомянуто выше, существуют списки необходимых свойств. Если хотя бы одно свойство из списка необходимых свойств отсутствует, то этот шаблон для синтеза текста использовать нельзя.
[0081] Свойства второго типа явно не вставляются в само предложение при синтезе, а зачастую меняют его структуру или отдельное слово. У них отсутствует читаемый параметр «label». Одним из возможных вариантов обработки является написание отдельного шаблона на каждое значение свойства и их совокупности, т.к. свойств второй категории у факта немного (1-5), как и значений таких свойств (не более 4-х). Примером такого предложения может служить "Alexander finished working at ABBYY in 2010" («Александр закончил работать в ABBYY в 2010 году»), в свойстве "degree of completion of the action" («степень завершенности действия») стоит "finished" («закончено»). Однако встает проблема выбора подходящего под факт шаблона, т.к. число необходимых и заполненных для шаблона свойств может быть одинаковым, и единственным отличием станет значение конкретного свойства. Именно для решения этой проблемы и используются скрипты-валидаторы.
[0082] Скрипты-валидаторы - мощный инструмент, позволяющий задавать условия для проверки извлеченных фактов, тем самым создавать сколь угодно точные шаблоны. Они наследуют синтаксис правил извлечения из модуля извлечения информации и имеют доступ ко всем свойствам поступившего на вход информационного объекта, извлеченного из текста. Они могут определить тип и значение свойства, и в случае, если свойство также является информационным объектом, получить доступ к свойствам данного объекта. После запуска скрипт-валидатор указывает, подходит ли шаблон для синтеза, или нет.
Проверка информационного объекта (факта) на возможность его участия в синтезе текста и последующий выбор для него шаблона:
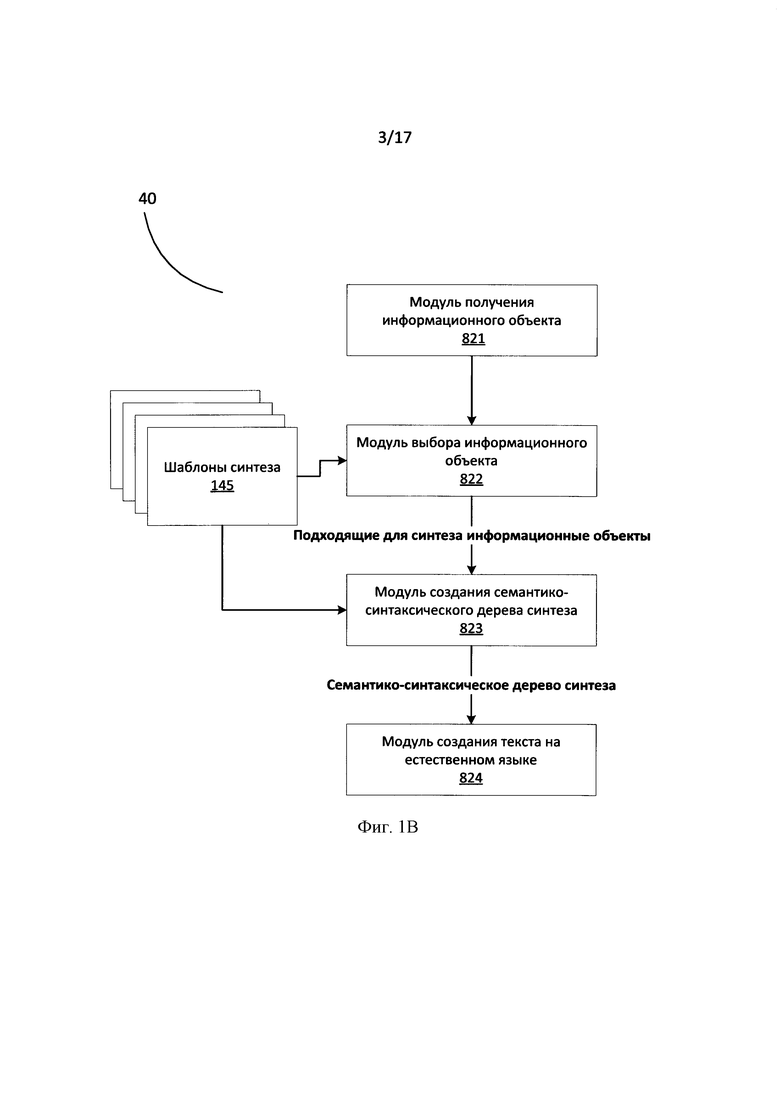
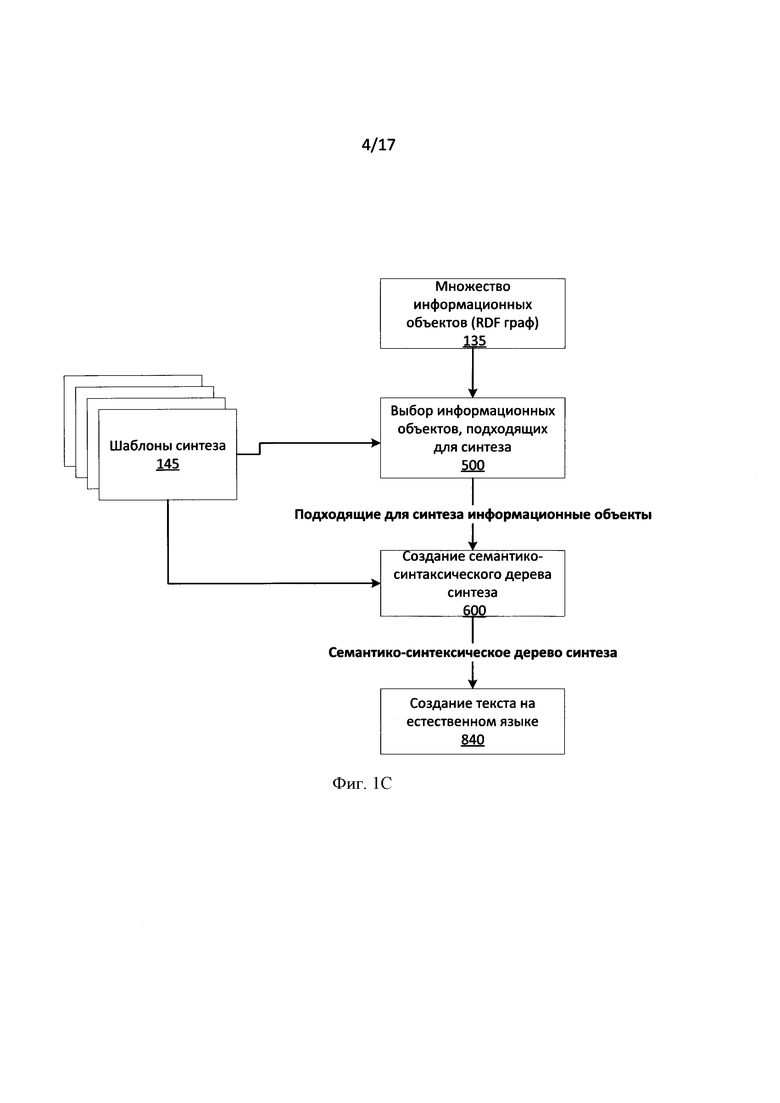
[0083] После проведения семантико-синтаксического анализа текста (120, Фиг. 1) и работы модуля извлечения информации (130, Фиг. 1), на вход модулю синтеза (140, Фиг. 1) подается RDF-граф (135, Фиг. 1), с помощью которого далее производится синтез текста. [0084] Модуль синтеза текста 40, как показано на Фиг. 1В, действующий, как показано на Фиг. 1С, может включать модуль 821 получения информационного объекта, получающий информационные объекты, образующие RDF граф 135. Модуль 40 синтеза текста может дополнительно включать модуль 822 выбора информационного объекта, выбирая среди информационных объектов те, которые могут быть использованы для синтеза текста с использованием шаблонов синтеза 145 на шаге 500 (далее детально представлено на Фиг. 5В). После того, как подходящие объекты для синтеза текста выбраны, на шаге 600 (далее детально представлено на Фиг. 6), модуль генерации 823 семантико-синтаксического дерева синтеза создает семантико-синтаксическое дерево синтеза используя шаблоны синтеза 145. На шаге 840 созданное семантико-синтаксическое дерево синтеза используется для создания текста на естественном языке модулем 824 генерации текста на естественном языке.
[0085] Из полученного RDF-графа выделяются те информационные объекты, для которых возможно производить синтез, т.е. те информационные объекты, извлеченные из текста, для которых существует хотя бы один подходящий для синтеза шаблон. Создание и компиляция шаблонов для каждого типа фактов описано выше. На Фиг. 4С приведен пример RDF графа, построенного в результате работы модуля извлечения информации на основе семантико-синтаксической структуры предложения "Alexander works as а programmer at ABBYY" («Александр работает программистом в ABBYY»), проиллюстрированной на Фиг. 4С.
[0086] Фиг. 5 иллюстрирует последовательность процедуры проверки информационного объекта из RDF графа (135, Фиг. 1) на возможность его участия в синтезе текста, а также выбор подходящего для данного информационного объекта шаблона в соответствии с одной из реализаций изобретения. Если в процессе выбора ни один шаблон не будет удовлетворять условиям проверки, то текущий извлеченный информационный объект (факт) не подходит для синтеза текста.
[0087] Так, на этапе 501 формируется множество шаблонов, которые были созданы для данного типа извлеченного информационного объекта (факта). Так как извлеченный информационный объект является концептом или экземпляром онтологии, данные шаблоны могут быть сохранены (5030, Фиг. 5А) в онтологии в качестве онтологического объекта отдельного типа. У концепта из онтологии, как уже было описано выше, имеется указание на некоторый массив шаблонов, который может быть использован при синтезе текста. Например, для концепта BasicFactOccupation «Occupation» («Занятость») может существовать несколько скомпилированных шаблонов: "Vasya has found a job as a programmer in the USA" («Вася устроился работать программистом в США»); "Vasya is а former programmer" («Вася является бывшим программистом»); "Vasya is a programmer" («Вася является программистом»); "Vasya was a programmer" («Вася являлся программистом »).
[0088] Далее на шаге 503 для каждого шаблона из сформированного на этапе 501 множества шаблонов проверяются списки свойств, которые были указаны как необходимые свойства. А именно проверяется тот факт, являются ли необходимые свойства в шаблоне заполненными у данного извлеченного объекта - факта. На данном этапе исключаются из дальнейшего рассмотрения те шаблоны, в списках необходимых свойств которых есть хотя бы одно свойство, не заполненное у извлеченного из текста информационного объекта.
[0089] Из оставшихся шаблонов выбираются только те шаблоны, у которых список заполненных необходимых свойств самый длинный. Этот этап нужен для выбора наиболее точных шаблонов для извлеченного информационного объекта (факта), т.е. чем больше свойств в шаблоне помечены как необходимые, тем точнее шаблон синтезирует факт.
[0090] На этапе 505 запускаются дополнительные этапы проверки шаблонов при помощи скрипт-валидатора, и те шаблоны, которые не прошли этот этап проверки, исключаются из дальнейшего рассмотрения. Как уже было описано выше скрипт-валидатор накладывает некоторые условия проверки извлеченного информационного объекта (факта), свойств данного факта и т.д.
[0091] Оставшиеся шаблоны сравниваются (507) по количеству непустых свойств, которые фигурируют в списке замен, и среди таких шаблонов выбираются те шаблоны, у которых список непустых свойств наибольший. Если в результате проведенного анализа остается более одного шаблона, то среди них выбирается случайный шаблон (511). Если шаблонов не осталось, то информационный объект, извлеченный из текста, не подходит для синтеза (513).
[0092] Описанная на Фиг. 5 процедура позволяет проверить все извлеченные из текста информационные объекты на возможность участия их в синтезе текста.
Построение (семантико-синтаксического) дерева синтеза:
[0093] После определения всех извлеченных информационных объектов (фактов), пригодных для синтеза текста, а также выбора для каждого информационного объекта подходящего шаблона, происходит генерирование отдельного дерева синтеза на основе (семантико-синтаксического) дерева шаблона. Процедура проиллюстрирована на Фиг. 6. [0094] Согласно одной из реализации, на шаге 601 поступает семантико-синтаксическое дерево, которое было построено для предложения из шаблона. Оно является основой для глубинной структуры синтезируемого предложения, и поступит в модуль синтеза.
[0095] На шаге 603 совершается обход в глубину по семантико-синтаксическому дереву (от корня к листьям) для предложения шаблона. Параллельно обходу семантико-синтаксического дерева (от корня к листьям) предложения шаблона создается семантико-синтаксическое дерево синтеза. Каждый узел семантико-синтаксического дерева предложения шаблона проверяется на наличие его в списке замен 605 для данного шаблона. А именно на этапе 605 проверяется, существует ли узел семантико-синтаксического дерева предложения шаблона в списке замен.
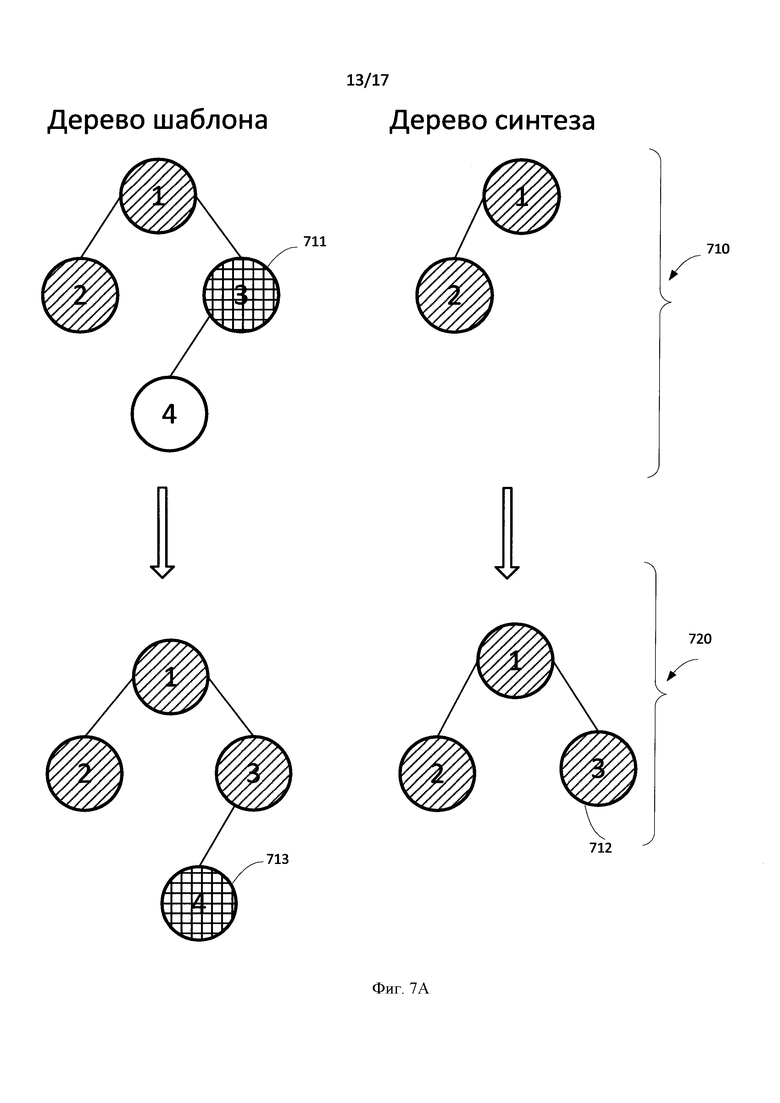
[0096] Если узла в семантико-синтаксическом дерева шаблона, соответствующего слову в предложении, нет в списке замен, то в дереве синтеза создается полный аналог данного узла в семантико-синтаксическом дерева шаблона (609). Далее анализируются его дочерние узлы в семантико-синтаксическом дерева шаблона (617).
[0097] Фиг. 7А иллюстрируют вышеописанный случай (609). На Фиг. 7А-7Е схематично проиллюстрированы деревья предложений шаблонов, на основе которых воссоздаются соответствующие деревья синтеза. Так на этапе 710, после того как были обработаны узлы 1 и 2 в дереве предложения шаблона рассматривается узел 3 (711). Данный узел не включен в список замен для шаблона. Поэтому согласно блох-схеме на Фиг. 6 на этапе 720, в дереве синтеза создается полный аналог текущего узла из дерева шаблона (712), при этом сохраняется наследственность от 1-го узла. Далее анализируется дочерний узел 713 в дереве шаблона. Примером вышеописанного случая может служить следующее предложение: "Yevgeni has been working as a designer at Yandex since 2011" (Евгений работает дизайнером в Яндексе с 2011). В данном предложении узла, обозначающего дату (2011), нет в списке замен для примера шаблона, упомянутого выше.
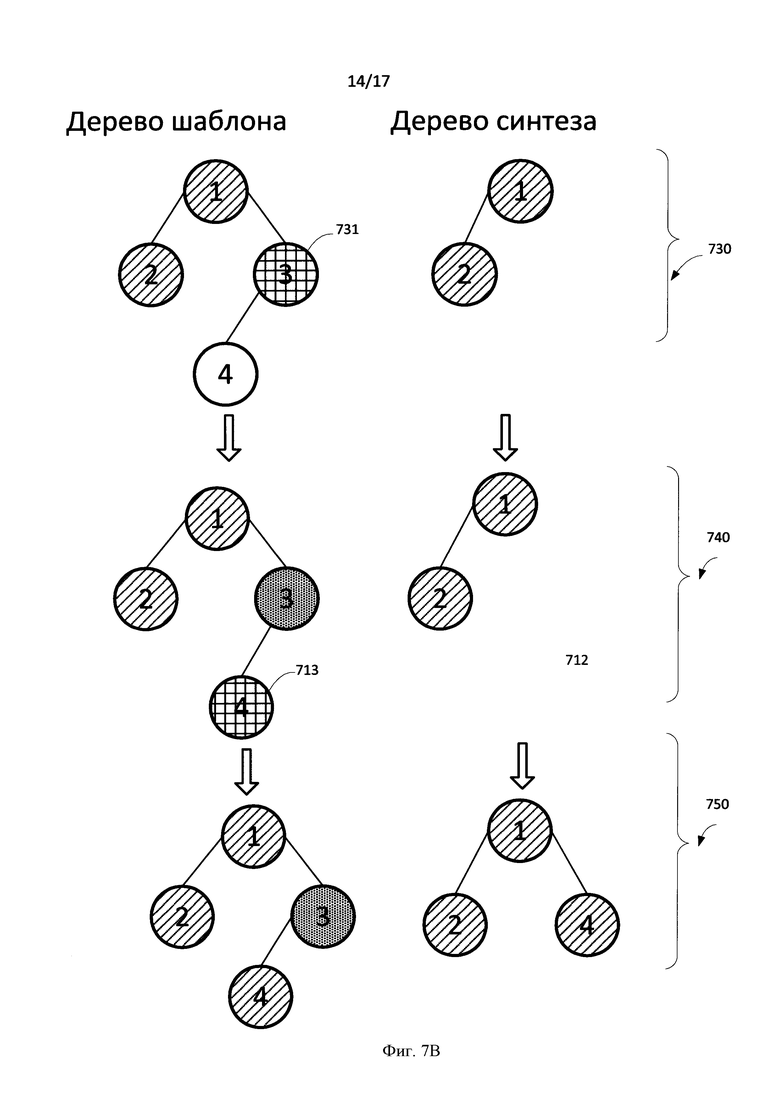
[0098] Вернемся к Фиг. 6. Если узел в списке замен есть, проверяется 607, существует ли свойство, соответствующее данному узлу. Так если узел в списке замен есть, но в информационном объекте отсутствует свойство (то есть оно не заполнено для данного извлеченного факта), соответствующее этому узлу, то этот узел игнорируется 613, и анализируются его дети 617. Пример: "Anna is working at ABBYY" («Анна работает в АББИИ») - тут не будет заполнено свойство «position» (должность), однако в шаблоне это свойство фигурирует.
[0099] Фиг. 7В иллюстрируют данный случай. В момент 730 в дереве синтеза анализируется узел 3 (731). Этот узел существует в списке замен, но в информационном объекте отсутствует свойство, соответствующее этому узлу. Этот узел игнорируется, и в дереве синтеза на этапе 740 он не построен. Далее анализируется дочерний узел 4 в дереве шаблона (742), полный аналог которого прикрепляется в дерево синтеза.
[00100] Вернемся к Фиг. 6. Если узел есть в списке замен и в объекте есть свойство, соответствующее этому узлу, то этом случае 615 в дереве синтеза создается ветвь, аналогичная «поддереву» свойства в дереве шаблона. Данное поддерево свойства строится на основе анализа строкового значения свойства объекта с помощью семантико-синтаксического анализатора. Если свойств несколько, то анализируется каждое свойство и между ними ставится сочинительная связь. После возвращаемся к анализу детей текущего узла. Фиг. 7С-7Е иллюстрируют данный случай. На Фиг. 1С изображено дерево шаблона. Так узел 3 (751) есть в списке замен и в объекте есть свойства «свойства 1» и «свойства 2», соответствующее этому узлу. Причем для свойства 1 и свойства 2 существуют свои «поддеревья» разбора, которые были получены в результате семантико-синтаксического анализа строкового значения этих свойств. В дереве синтеза 752 создается ветви, аналогичные «поддеревьям» свойства (740) и (742), которые замещают узел 3 (752). Данные поддеревья образуют сочинительную связь между собой. Фиг. 7Е иллюстрирует итоговое дерево для синтеза. Например, "Mikhail works at IBM and MIPT." («Михаил работает в IBM и МФТИ.»)
[00101] После того как построено семантико-синтаксического дерево синтеза на основе семантико-синтаксического дерева шаблона, происходит генерирование текста, процедура которого подробно представлена в заявках, описывающих машинный перевод, одна из которых опубликована как заявка на патент США No. US 2008/0091405, включенная в данное описание посредством ссылки, другая заявка на патент США опубликована под номером No. US 2008/0086298, включенная в данное описание посредством ссылки, а также патент США 8,214,199, включенный в данное описание посредством ссылки. На вход данного модуля подается информация о языке (конечный язык), на котором необходимо проводить синтез текста, семантико-синтаксическое дерево, где у каждого узла заполнены его семантический класс, лексема, семантемы, проформа и синтаксическая парадигма, а на ребрах указаны поверхностная и глубинная позиции. Помимо семантико-синтаксического дерева может быть использован любой древовидный результат анализа предложения. Как уже было сказано выше, каждому узлу семантико-синтаксического дерева приписан семантический класс, лексема, семантемы, проформа и синтаксическая парадигма, а на ребрах дерева указаны поверхностная и глубинная позиции. После синтезатор на основе знаний о конкретном языке, которые содержатся в словарях морфологии, строит предложение по заданному дереву.
Синтез однородных фактов
[00102] Зачастую при анализе текста встречаются однородные факты. Если для каждого извлеченного из текста факта синтезировать отдельное предложение, то в синтезированном тексте будет сгенерировано большое число предложений по одинаковым фактам. Например, таким образом, могут быть синтезированы следующие предложения "Alexander works as a programmer at ABBYY" («Александр работает программистом в ABBYY») и "Nikolai works as a programmer at ABBYY" («Николай работает программистом в ABBYY»). Эти предложения оптимально объединить и синтезировать одно предложение, которое будет включать в себя оба факта. Это уменьшает размер синтезированного текста и повышает его качество.
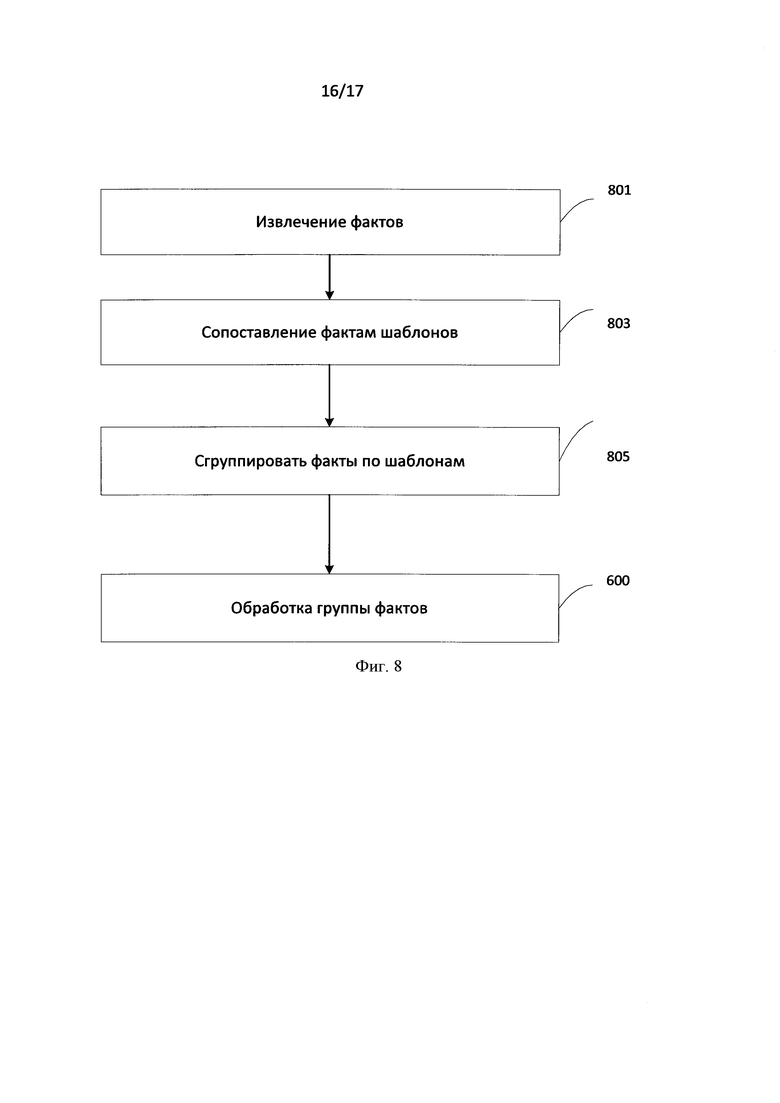
[00103] На Фиг. 8 проиллюстрирована схема синтеза однородных фактов. Вначале необходимо определить, какие факты стоит объединять. Для этого должны быть учтены следующие ограничения.
[00104] Во-первых, факты должны быть однородными. Однородными являются факты, принадлежащие к одному и тому же концепту в онтологии, и у которых, с точки зрения шаблона, должны быть заполнены одинаковые свойства. Если факты будут не однородными, то после синтеза произойдет искажение какого-либо из этих фактов, либо случится потеря информации.
[00105] Во-вторых, нельзя объединять слишком много фактов, иначе предложение получится перегруженным. Для этого устанавливается некоторый порог при объединении однородных фактов.
[00106] В-третьих, у объединяемых объектов не должно отличаться больше одного свойства. Если отличающихся свойств будет два или больше, то в полученном предложении будет тяжело определить, к которому объекту какое свойство относится. Иначе при синтезе текста может быть получено следующее предложение: "Alexander and Nikolai work as programmer and designer at ABBYY and Yandex" («Александр и Николай работают программистом и дизайнером в ABBYY и Яндексе»).
[00107] На шаге 803 происходит сопоставление извлеченным фактам шаблонов.
[00108] Для того чтобы осуществлять синтез однородных фактов, необходимо после получения шаблонов на все объекты (факты) их сгруппировать (805) так, чтобы одинаковые факты и одинаковые шаблоны находились в одной группе. На этапе 805 факты группируются по шаблонам.
[00109] Далее (807) происходит обработка группы фактов, данная обработка проиллюстрирована на Фиг. 6. А именно во время синтеза рассматривается не отдельный информационный объект (факт), а вся группа объектов (фактов) 600. Если строковые значения свойств одинаковы у разных объектов (то есть будут одинаковыми поддеревья разбора), то в дерево синтеза попадает только одно свойство, а если разные свойства разные - то в дерево синтеза попадут все свойства, и между образуется проставится сочинительная связь. Пример синтезированного предложения на основе однородных фактов: "Alexander and Nikolai work as programmers at ABBYY" («Александр и Николай работают программистами в АББИИ.»). В синтезированном предложении проставлена сочинительная связь (союз «и») между "Alexander" («Александр») и "Nikolai" («Николай»).
[00110] После выполнения этих модификаций алгоритма, происходит синтез с объединением однородных фактов.
[00111] Рассмотрим пример синтеза однородных фактов. Проведем семантико-синтаксический анализ следующих предложений: "Nikolai works as a designer at ABBYY. Vasily has found a job at ABBYY in the position of designer" («Николай работает дизайнером в АББИИ. Василий устроился на работу в ABBYY на должность дизайнера»). В каждом из предложений выделим факты при помощи модуля извлечения информации. Для каждых фактов найдем шаблон, и на основе его построим шаблон синтеза.
[00112] Модуль синтеза выдаст такое предложение в качестве ответа: "Nikolai and Vasily are designers at ABBYY" («Николай и Василий являются дизайнерами в АББИИ»).
[00113] Как можно увидеть, здесь произошло объединение двух фактов в одном предложении, не смотря на то, что отличающихся свойств два, а именно свойство "employer" (работодатель) и "employee" (работник).
[00114] На Фиг. 9 приведена схема аппаратного обеспечения (900), которая может быть использована для внедрения настоящего изобретения. Аппаратное средство (900) должно включать в себя, по крайней мере, один процессор (902) соединенный с памятью (904). Слово "процессор" на схеме (902) может обозначать один или несколько процессоров с одним или несколькими вычислительными ядрами, вычислительное устройство или любой иной имеющийся на рынке ЦП. Цифрами 904 обозначается устройство оперативной памяти (RAM), являющееся основным хранилищем (900), а также дополнительные уровни памяти - кэш, энергонезависимая, резервная память (например, программируемая или флэш-память), ПЗУ и т.д. Кроме того, обозначение памяти (904) может подразумевать также и хранилище, расположенное в другой части системы (например, кэш процессора (902) или иное хранилище, используемое в качестве виртуальной памяти, такое как внутреннее или внешнее ПЗУ (910).
[00115] Аппаратное средство (900), как правило, располагает некоторым количеством входов и выходов для передачи и получения информации извне. В качестве пользовательского или операторского интерфейса аппаратного средства (900) может применяться одно или несколько устройств пользовательского ввода (906), таких как клавиатура, мышь, формирователь изображений и пр., а также одно или несколько устройств вывода (жидкокристаллический дисплей или иное (908)) и устройства воспроизведения звука (динамик).
[00116] Для получения дополнительного объема для хранения данных используются накопители данных (910), такие как дискеты или иные съемные диски, жесткие диски, ЗУ прямого доступа (DASD), оптические приводы (компакт-диски и пр.), DVD-приводы, магнитные ленточные накопители и пр. Аппаратное средство (900) может также включать в себя интерфейс сетевого подключения (912) - LAN, WAN, Wi-Fi, Интернет и пр. - для связи с другими компьютерами, находящимися в сети. В частности, можно использовать локальную сеть (LAN) или беспроводную сеть Wi-Fi, не подключенную ко всемирной сети Интернет. Необходимо учесть, что аппаратное средство (900) также включает в себя различные аналоговые и цифровые интерфейсы соединения процессора (902) и других компонентов системы (904, 906, 908, 910 и 912).
[00117] Аппаратное средство (900) работает под управлением Операционной Системы (ОС) (914), которая запускает различные приложения, компоненты, программы, объекты, модули, и пр. с целью осуществления описанного здесь процесса. В состав прикладного ПО должно быть включено приложение по выявлению семантической неоднозначности языка. Также могут быть включены клиентский словарь, приложение для автоматизированного перевода и прочие установленные приложения для отображения тестового и графического содержимого (текстовый процессор и пр). Помимо этого приложения, компоненты, программы и иные объекты, собирательно обозначенные числом 916 на Фиг. 9, могут также запускаться на процессорах других компьютеров, соединенных с аппаратным обеспечением (900) по сети (912). В частности, задачи и функции компьютерной программы могут распределяться между компьютерами в распределенной вычислительной среде.
[00118] Все рутинные операции по применению осуществлений могут выполняться операционной системой или отдельными приложениями, компонентами, программами, объектами, модулями или последовательными инструкциями, обобщенно именуемыми "компьютерными программами". Обычно компьютерные программы представляют собой ряд инструкций, выполняемых в разное время разными устройствами памяти и хранения данных на компьютере. После прочтения и выполнения инструкций процессоры выполняют операции необходимые для запуска элементов описанного осуществления. Несколько вариантов осуществлений было описано в контексте полностью функционирующих компьютеров и компьютерных систем. Специалисты отрасли по достоинству оценят возможности распространения некоторых модификаций в форме различных программных продуктов на любых типах информационных носителей. Примерами таких носителей являются как энергозависимые, так и энергонезависимые устройства памяти, такие как дискеты и другие съемные диски, жесткие диски, оптические диски (напр., CD-ROM, DVD, флэш-диски) и многое другое. Также программный пакет может быть загружен через Интернет.
[00119] В вышеизложенном описании множество конкретных деталей изложено исключительно для пояснения. Специалистам в данной области техники очевидно, что эти конкретные детали являются лишь примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание неоднозначности толкований.
[00120] Приводимые в данном описании ссылки на «один вариант осуществления/ реализации» или «вариант осуществления/реализации» означают, что конкретный признак, структура или характеристика, описанные для варианта реализации, являются компонентом по меньшей мере одного варианта реализации. Использование фразы «в одном варианте реализации» в различных фрагментах описания не означает, что описания относятся к одному и тому же варианту реализации либо что эти описания относятся к различным или альтернативным, взаимно исключающим вариантам реализации. Кроме того, различные описания характеристик могут относиться к некоторым вариантам реализации, но не относиться к другим вариантам реализации. Различные описания требований могут относиться к некоторым вариантам реализации и не относиться к другим вариантам реализации.
[00121] Некоторые образцы вариантов реализации были описаны и показаны на прилагаемых иллюстрациях. Однако необходимо понимать, что такие варианты реализации являются просто примерами, но не ограничениями описываемых вариантов реализации, и что эти варианты реализации не ограничиваются конкретными показанными и описанными конструкциями и устройствами, поскольку специалисты в данной области техники на основе приведенных материалов могут создать собственные варианты реализации. В области технологии, к которой относится настоящее изобретение, быстрое развитие и дальнейшие достижения сложно прогнозировать, поэтому описываемые варианты реализации могут быть с легкостью изменены в устройстве и деталях благодаря развитию технологии, с соблюдением при этом принципов настоящего описываемого изобретения.
[00122] В различных примерах системы и способы, описанные в этом документе, могут быть реализованы в оборудовании, программах, встроенном программном обеспечении или различных комбинациях этих средств. При реализации в программном обеспечении способы могут храниться в виде одной или нескольких комнад или кода на энергонезависимом машинно-читаемом носителе. К машинно-читаемым носителям относятся и накопители данных. В качестве примера, но не для введения ограничений, подобные машинно-читаемые носители могут включать RAM, ROM, EEPROM, CD-ROM, флэш-память или другие типы электрических, магнитных или оптических носителей информации, или другие носители, которые могут использоваться для переноса или хранения требуемого программного кода в виде инструкций или структур данных, и доступ к которым может осуществляться процессором компьютера общего назначения.
[00123] Для наглядности в этом документе не приводятся все обычные свойства описываемых примеров. Следует понимать, что при разработке любых реальных реализаций настоящего изобретения для достижения конкретных целей разработчиков необходимо будет предпринимать множество решений по реализации, и что эти конкретные цели могут быть различными для разных реализаций и разных разработчиков. Следует понимать, что разработка может быть сложной и ресурсоемкой задачей, но при этом останется обычной инженерной работой для специалистов среднего уровня, использующих преимущества этого изобретения.
[00124] Кроме того, следует понимать, что используемая в этом документе фразеология или терминология предназначена для описания, но не ограничения, так что терминология или фразеология настоящего описания может быть интерпретирована специалистом среднего уровня с учетом имеющихся в этом документе принципов и инструкций в сочетании со знаниями специалиста соответствующего профиля. Кроме того, не предполагается назначение терминам, используемым в описании или пунктах формулы изобретения, необычного или особого значения, если об этом не сказано особо.
[00125] Различные примеры, приводимые в этом документе, охватывают существующие и будущие известные эквиваленты известных модулей, упомянутых в настоящем документе в качестве иллюстрации. Кроме того, несмотря на приведенные и описываемые примеры и варианты применения, для специалистов данной области техники, использующих преимущества этого изобретения, ясно, что многие модификации, не описанные выше, можно осуществить, не отходя от описанных здесь принципов изобретения.


Изобретение относится к области автоматической обработки текстовых данных, представленных на естественных языках. Техническим результатом является повышение точности синтезирования текста на основе извлеченных данных - информационных объектов - из текста. В способе синтеза текста на естественном языке получают информационные объекта и производят выбор среди полученных информационных объектов информационных объектов и ассоциированных шаблонов синтеза в библиотеке шаблонов. При этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона. Создают для каждого выбранного информационного объекта семантико-синтаксическое дерево синтеза на основе семантико-синтаксического дерева шаблона. Создают текст на естественном языке на основе каждого созданного семантико-синтаксического дерева. 3 н. и 15 з.п. ф-лы, 19 ил.
1. Способ синтеза текста на естественном языке, включающий:
получение аппаратным процессором множества полученных информационных объектов;
выбор аппаратным процессором среди множества полученных информационных объектов по крайней мере одного выбранного информационного объекта и, для каждого выбранного информационного объекта ассоциированный шаблон синтеза в библиотеке шаблонов,
при этом библиотека включает по крайне мере один шаблон синтеза, и
при этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона;
создание аппаратным процессором для каждого выбранного информационного объекта семантико-синтаксическое дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза, выбранного для выбранного информационного объекта; и
создание аппаратным процессором текста на естественном языке на основе каждого созданного семантико-синтаксического дерева.
2. Способ по п. 1,
отличающийся тем, что каждый полученный информационный объект ассоциирован с онтологическим объектом и имеет множество заполненных свойств, каждое заполненное свойство имеет значение;
отличающийся тем, что каждый шаблон синтеза ассоциирован с онтологическим объектом, при этом каждый шаблон синтеза включает множество необходимых свойств;
отличающийся тем, что каждый шаблон синтеза включает множество необязательных свойств;
отличающийся тем, что каждый шаблон синтеза включает скрипт-валидатор;
отличающийся тем, что выбор по крайней мере одного информационного объекта и ассоциированного шаблона синтеза включает, для каждого полученного информационного объекта,
выбор шаблонов синтеза в библиотеке шаблонов, ассоциированных с тем же онтологическим объектом, что и полученный информационный объект;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых множество необходимых свойств содержится во множестве заполненных свойств полученного информационного объекта;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим множеством необходимых свойств;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых скрипт-валидатор проверяет полученный информационный объект;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим пересечением множества необязательных свойств со множеством заполненных свойств полученного информационного объекта; и
далее, если выбран шаблон синтеза, выбор полученного информационного объекта и нахождение соответствия одного из выбранных шаблонов синтеза с выбранным информационным объектом.
3. Способ по п. 1,
отличающийся тем, что выбранный информационный объект имеет множество заполненных свойств, каждое заполненное свойство, имеющее строковое значение на естественном языке;
отличающийся тем, что каждое семантико-синтаксическое дерево шаблона включает узлы шаблона;
отличающийся тем, что каждый шаблон синтеза включает для каждого из по крайней мере некоторых узлов шаблона, образующих множество замен узлов, соответствующее заполненное свойство;
отличающийся тем, что создание для каждого выбранного информационного объекта семантико-синтаксического дерева синтеза включает, для каждого узла шаблона ассоциированного шаблона синтеза, начиная с корневого узла семантико-синтаксического дерева шаблона:
если узел шаблона не входит в множество замен узлов,
создание в семантико-синтаксическом дереве идентичного узла;
если узел шаблона входит в множество замен узлов и если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта,
создание в семантико-синтаксическом дереве синтеза узла или поддерева на основе анализа строкового значения на естественном языке заполненного свойства выбранного информационного объекта, соответствующего узлу шаблона; и
повторение предыдущих двух шагов для каждого дочернего узла семантико-синтаксического дерева шаблона.
4. Способ по п. 3, отличающийся тем, что создание для каждого выбранного информационного объекта семантико-синтаксического дерева синтеза дополнительно включает, если узел шаблона находится в множестве замен узлов, если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта, и если заполненное свойство выбранного информационного объекта имеет более чем одно строковое значение на естественном языке,
для каждого строкового значения на естественном языке создание в семантико-синтаксическом дереве синтеза узла или поддерева на основе строкового значения на естественном языке соответствующего узлу шаблона; и
связывание созданных узлов сочинительной связью.
5. Способ по п. 1, отличающийся тем, что множество полученных информационных объектов формирует RDF граф.
6. Способ по п. 1 дополнительно включает:
формирование по крайней мере одной группы выбранных информационных объектов, ассоциированных с тем же шаблоном синтеза; и
создание для по крайней мере одной группы семантико-синтаксического дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза.
7. Система синтеза текста на естественном языке, включающая:
модуль получения информационных объектов, настроенный на получение множества полученных информационных объектов;
модуль выбора информационного объекта, настроенный на выбор среди множества полученных информационных объектов по крайней мере одного выбранного информационного объекта и для каждого выбранного информационного объекта ассоциированного шаблона синтеза в библиотеке шаблонов,
при этом библиотека включает по крайне мере один шаблон синтеза, и
при этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона;
модуль создания семантико-синтаксического дерева синтеза, настроенный на создание для каждого выбранного информационного объекта семантико-синтаксическое дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза, выбранного для выбранного информационного объекта; и
модуль создания текста на естественном языке, настроенный на создание текста на естественном языке на основе каждого созданного семантико-синтаксического дерева.
8. Система по п. 7,
отличающаяся тем, что каждый полученный информационный объект ассоциирован с онтологическим объектом и имеет множество заполненных свойств, каждое заполненное свойство имеет значение;
отличающаяся тем, что каждый шаблон синтеза ассоциирован с онтологическим объектом, при этом каждый шаблон синтеза включает множество необходимых свойств;
отличающаяся тем, что каждый шаблон синтеза включает множество необязательных свойств;
отличающаяся тем, что каждый шаблон синтеза включает скрипт-валидатор;
отличающаяся тем, что модуль выбора информационного объекта настроен для каждого полученного информационного объекта
осуществлять выбор шаблонов синтеза в библиотеке шаблонов, ассоциированных с тем же онтологическим объектом, что и полученный информационный объект;
далее, если выбран шаблон синтеза, осуществлять выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых множество необходимых свойств содержится во множестве заполненных свойств полученного информационного объекта;
далее, если выбран шаблон синтеза, осуществлять выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим множеством необходимых свойств;
далее, если выбран шаблон синтеза, осуществлять выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых скрипт-валидатор проверяет полученный информационный объект;
далее, если выбран шаблон синтеза, осуществлять выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим пересечением множества необязательных свойств со множеством заполненных свойств полученного информационного объекта; и
далее, если выбран шаблон синтеза, осуществлять выбор полученного информационного объекта и нахождение соответствия одного из выбранных шаблонов синтеза с выбранным информационным объектом.
9. Система по п. 7,
отличающаяся тем, что выбранный информационный объект имеет множество заполненных свойств, каждое заполненное свойство имеет строковое значение на естественном языке;
отличающаяся тем, что каждое семантико-синтаксическое дерево шаблона включает узлы шаблона;
отличающаяся тем, что каждый шаблон синтеза включает для каждого из по крайней мере некоторых узлов шаблона, образующих множество замен узлов, соответствующее заполненное свойство;
отличающаяся тем, что модуль семантико-синтаксического дерева настроен для каждого узла шаблона ассоциированного шаблона синтеза, начиная с корневого узла семантико-синтаксического дерева шаблона:
если узел шаблона не входит в множестве замен узлов,
создавать в семантико-синтаксическом дереве идентичного узла;
если узел шаблона входит в множество замен узлов и если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта,
создавать в семантико-синтаксическом дереве синтеза узел или поддерево на основе анализа строкового значения на естественном языке заполненного свойства выбранного информационного объекта, соответствующего узлу шаблона; и
повторять предыдущие два шага для каждого дочернего узла семантико-синтаксического дерева шаблона.
10. Система по п. 9, отличающаяся тем, что модуль создания семантико-синтаксического дерева синтеза дополнительно настроен так что, если узел шаблона находится в множестве замен узлов, если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта, и если заполненное свойство выбранного информационного объекта имеет более чем одно строковое значение на естественном языке,
для каждого строкового значения на естественном языке создавать в семантико-синтаксическом дереве синтеза узел или поддерево на основе строкового значения на естественном языке соответствующего узлам шаблона; и
соединять созданные узлы сочинительной связью.
11. Система по п. 7, отличающаяся тем, что множество полученных информационных объектов формирует RDF граф.
12. Система по п. 7, отличающаяся тем, что модуль создания семантико-синтаксического дерева синтеза дополнительно настроен:
формировать по крайней мере одну группу выбранных информационных объектов, ассоциированных с тем же шаблоном синтеза; и
создавать для по крайней мере одной группы семантико-синтаксическое дерево синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза.
13. Машиночитаемый носитель данных, содержащий исполняемые процессором команды для синтеза текста на естественном языке, включающий команды, нацеленные на:
получение аппаратным процессором множества полученных информационных объектов;
выбор аппаратным процессором среди множества полученных информационных объектов по крайней мере одного выбранного информационного объекта и, для каждого выбранного информационного объекта ассоциированный шаблон синтеза в библиотеке шаблонов,
при этом библиотека включает по крайне мере один шаблон синтеза, и
при этом каждый шаблон синтеза включает семантико-синтаксическое дерево шаблона;
создание аппаратным процессором для каждого выбранного информационного объекта семантико-синтаксическое дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза, выбранного для выбранного информационного объекта; и
создание аппаратным процессором текста на естественном языке на основе каждого созданного семантико-синтаксического дерева.
14. Машиночитаемый носитель данных по п. 13,
отличающийся тем, что каждый полученный информационный объект ассоциирован с онтологическим объектом и имеет множество заполненных свойств, каждое заполненное свойство имеет значение;
отличающийся тем, что каждый шаблон синтеза ассоциирован с онтологическим объектом, при этом каждый шаблон синтеза включает множество необходимых свойств;
отличающийся тем, что каждый шаблон синтеза включает множество необязательных свойств;
отличающийся тем, что каждый шаблон синтеза включает скрипт-валидатор;
отличающийся тем, что выбор по крайней мере одного информационного объекта и ассоциированного шаблона синтеза включает, для каждого полученного информационного объекта,
выбор шаблонов синтеза в библиотеке шаблонов, ассоциированных с тем же онтологическим объектом, что и полученный информационный объект;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых множество необходимых свойств содержится во множестве заполненных свойств полученного информационного объекта;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим множеством необходимых свойств;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза тех шаблонов синтеза, для каждого из которых скрипт-валидатор проверяет полученный информационный объект;
далее, если выбран шаблон синтеза, выбор среди выбранных шаблонов синтеза шаблонов синтеза с наибольшим пересечением множества необязательных свойств со множеством заполненных свойств полученного информационного объекта; и
далее, если выбран шаблон синтеза, выбор полученного информационного объекта и нахождение соответствия одного из выбранных шаблонов синтеза с выбранным информационным объектом.
15. Машиночитаемый носитель данных по п. 13,
отличающийся тем, что выбранный информационный объект имеет множество заполненных свойств, каждое заполненное свойство, имеющее строковое значение на естественном языке;
отличающийся тем, что каждое семантико-синтаксическое дерево шаблона включает узлы шаблона;
отличающийся тем, что каждый шаблон синтеза включает для каждого из по крайней мере некоторых узлов шаблона, образующих множество замен узлов, соответствующее заполненное свойство;
отличающийся тем, что создание для каждого выбранного информационного объекта семантико-синтаксического синтеза шаблона включает, для каждого узла шаблона ассоциированного шаблона синтеза, начиная с корневого узла семантико-синтаксического дерева шаблона:
если узел шаблона не входит в множестве замен узлов,
создание в семантико-синтаксическом дереве идентичного узла;
если узел шаблона входит в множество замен узлов и если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта,
создание в семантико-синтаксическом дереве синтеза узла или поддерева на основе анализа строкового значения на естественном языке заполненного свойства выбранного информационного объекта, соответствующего узлу шаблона; и
повторение предыдущих двух шагов для каждого дочернего узла семантико-синтаксического дерева шаблона.
16. Машиночитаемый носитель данных по п. 15, отличающийся тем, что создание для каждого выбранного информационного объекта семантико-синтаксического дерева синтеза дополнительно включает, если узел шаблона находится в множестве замен узлов, если свойство, соответствующее узлу шаблона, является заполненным свойством выбранного информационного объекта, и если заполненное свойство выбранного информационного объекта имеет более чем одно строковое значение на естественном языке,
для каждого строкового значения на естественном языке создание в семантико-синтаксическом дереве синтезе узла или поддерева на основе строкового значения на естественном языке соответствующего узлу шаблона; и
соединение созданных узлов сочинительной связью.
17. Машиночитаемый носитель данных по п. 13, отличающийся тем, что множество полученных информационных объектов формирует RDF граф.
18. Машиночитаемый носитель данных по п. 13, дополнительно включающий:
формирование по крайней мере одной группы выбранных информационных объектов, ассоциированных с тем же шаблоном синтеза; и
создание для по крайней мере одной группы семантико-синтаксического дерева синтеза на основе семантико-синтаксического дерева шаблона ассоциированного шаблона синтеза.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6493663 B1, 10.12.2002 | |||
| US 8078450 B2, 13.12.2011 | |||
| РАЗЛИЧНЫЕ ВИДЫ ОФОРМЛЕНИЯ С ГАРМОНИЧНОЙ ВЕРСТКОЙ ДЛЯ ДИНАМИЧЕСКИ АГРЕГИРОВАННЫХ ДОКУМЕНТОВ | 2006 |
|
RU2419856C2 |
| МОДУЛЬНЫЙ ФОРМАТ ДОКУМЕНТОВ | 2004 |
|
RU2368943C2 |
| СИСТЕМА ДЛЯ ИДЕНТИФИКАЦИИ ПЕРЕФРАЗИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ МАШИННОГО ПЕРЕВОДА | 2004 |
|
RU2368946C2 |

