Настоящее изобретение относится к принципу энтропийного кодирования для кодирования видеоданных.
В технике известны многие видеокодеки. Как правило, эти кодеки уменьшают необходимое количество данных, чтобы представлять видеоконтент, т.е. они сжимают данные. В контексте видеокодирования известно, что сжатие видеоданных выгодно достигается последовательным применением разных методов кодирования: используется предсказание с компенсацией движения, чтобы предсказывать содержимое изображения. Векторы движения, определенные при предсказании с компенсацией движения, а также остаток предсказания, подвергаются энтропийному кодированию без потерь. Чтобы дополнительно уменьшить количество данных сами векторы движения подвергаются предсказанию, так что только разности векторов движения, представляющие остаток предсказания вектора движения, должны энтропийно кодироваться. В H.264, например, применяется только что кратко изложенная процедура, чтобы передавать информацию о разностях векторов движения. В частности, разности векторов движения бинаризуются в строки бинов (контейнеров), соответствующие комбинации усеченного унарного кода и, от некоторого значения отсечки, экспоненциального кода Голомба. Тогда как бины экспоненциального кода Голомба легко кодируются с использованием режима равновероятного обхода с фиксированной вероятностью 0,5, для первых бинов обеспечиваются несколько контекстов. Значение отсечки выбирается равным девяти. Следовательно, обеспечивается большое количество контекстов для кодирования разностей векторов движения.
Обеспечение большого количества контекстов, однако, не только увеличивает сложность кодирования, но также может оказывать отрицательное влияние на эффективность кодирования: если контекст посещается очень редко, не выполняется эффективно вероятностная адаптация, т.е. адаптация оценки вероятности, ассоциированной с соответствующим контекстом во время причины энтропийного кодирования. Следовательно, примененные не надлежащим образом оценки вероятности оценивают фактическую статистику символов. Кроме того, если для некоторого бина бинаризации обеспечивается несколько контекстов, выбор между ними может потребовать инспектирование значений соседних бинов/синтаксических элементов, необходимость чего может препятствовать выполнению процесса декодирования. С другой стороны, если количество контекстов обеспечивается слишком малым, бины с сильно изменяющейся фактической статистикой символов группируются вместе в одном контексте и, следовательно, оценка вероятности, ассоциированная с этим контекстом, не кодирует эффективно бины, ассоциированные с ним.
Существует текущая потребность в дальнейшем повышении эффективности кодирования энтропийного кодирования разностей векторов движения.
Следовательно, задачей настоящего изобретения является обеспечение такого принципа кодирования.
Данная задача достигается объектом независимых пунктов формулы изобретения, приложенных к данному документу.
Основным решением настоящего изобретения является то, что эффективность кодирования энтропийного кодирования разностей векторов движения может быть дополнительно повышена посредством снижения значения отсечки, до которого используется усеченный унарный код, чтобы бинаризировать разности векторов движения, до двух, так что имеется только две позиции бинов усеченного унарного кода, и, если порядок единицы используется для экспоненциального кода Голомба для бинаризации разностей векторов движения от значения отсечки, и, если, дополнительно, точно один контекст обеспечивается для двух позиций бинов усеченного унарного кода, соответственно, так что не является необходимым выбор контекста, основанный на значениях бина или синтаксического элемента соседних блоков изображения, и исключается слишком мелкая классификация бинов в этих позициях бинов в контексты, так что вероятностная адаптация работает надлежащим образом, и, если одинаковые контексты используются для горизонтальных и вертикальных составляющих, тем самым дополнительно уменьшая отрицательные эффекты слишком мелкого подразделения контекста.
Кроме того, было обнаружено, что только что упомянутые установки в отношении энтропийного кодирования разностей векторов движения являются особенно ценными при объединении их с улучшенными способами предсказания векторов движения и уменьшения необходимого количества разностей векторов движения, подлежащих передаче. Например, могут обеспечиваться многочисленные предикторы вектора движения, чтобы получать упорядоченный список предикторов вектора движения, и индекс этого списка предикторов вектора движения может использоваться, чтобы определять фактический предиктор вектора движения, остаток предсказания которого представляется рассматриваемой разностью вектора движения. Хотя информация об используемом индексе списка должна выводиться из потока данных на декодирующей стороне, общее качество предсказания векторов движения повышается, и, следовательно, величина разностей векторов движения дополнительно уменьшается, так что в целом эффективность кодирования дополнительно повышается, и уменьшение значения отсечки и общее использование контекста для горизонтальных и вертикальных составляющих разностей векторов движения соответствуют такому улучшенному предсказанию вектора движения. С другой стороны, может использоваться слияние, чтобы уменьшить количество разностей векторов движения, подлежащих передаче в потоке данных: с этой целью, информация слияния может передаваться в потоке данных, сигнализируя блокам декодера о подразделении блоков, которые группируются в группу блоков. Разности векторов движения затем могут передаваться в потоке данных в единицах этих объединенных групп вместо индивидуальных блоков, таким образом уменьшая количество разностей векторов движения, которые необходимо передавать. Так как эта кластеризация блоков уменьшает взаимную корреляцию между соседними разностями векторов движения, только что упомянутое исключение обеспечения нескольких контекстов для одной позиции бина предотвращает очень мелкую классификацию схемы энтропийного кодирования в контексты в зависимости от соседних разностей векторов движения. Вместо этого, принцип слияния уже использует взаимную корреляцию между разностями векторов движения соседних блоков, и, следовательно, является достаточным один контекст для одной позиции бина - один и тот же для горизонтальной и вертикальной составляющих.
Предпочтительные варианты осуществления настоящей заявки описываются ниже в отношении чертежей, среди которых:
фиг. 1 изображает блок-схему кодера согласно варианту осуществления;
фиг. 2a-2c схематически изображают разные подразделения массива элементов дискретизации, такого как изображение, на блоки;
фиг. 3 изображает блок-схему декодера согласно варианту осуществления;
фиг. 4 изображает более подробно блок-схему кодера согласно варианту осуществления;
фиг. 5 изображает более подробно блок-схему декодера согласно варианту осуществления;
фиг. 6 схематически иллюстрирует преобразование блока из пространственной области в спектральную область, результирующий блок преобразования и его повторное преобразование;
фиг. 7 изображает блок-схему кодера согласно варианту осуществления;
фиг. 8 изображает блок-схему декодера, пригодного для декодирования битового потока, генерируемого кодером по фиг. 8, согласно варианту осуществления;
фиг. 9 изображает схематическую диаграмму, иллюстрирующую пакет данных с мультиплексированными частичными битовыми потоками согласно варианту осуществления;
фиг. 10 изображает схематическую диаграмму, иллюстрирующую пакет данных с альтернативным сегментированием, использующим сегменты фиксированного размера, согласно другому варианту осуществления;
фиг. 11 изображает декодер, поддерживающий переключение режимов, согласно варианту осуществления;
фиг. 12 изображает декодер, поддерживающий переключение режимов, согласно другому варианту осуществления;
фиг. 13 изображает кодер, соответствующий декодеру по фиг. 11, согласно варианту осуществления;
фиг. 14 изображает кодер, соответствующий декодеру по фиг. 12, согласно варианту осуществления;
фиг. 15 изображает отображение pStateCtx и fullCtxState/256**E**;
фиг. 16 изображает декодер согласно варианту осуществления настоящего изобретения; и
фиг. 17 изображает кодер согласно варианту осуществления настоящего изобретения.
Фиг. 18 схематически изображает бинаризацию разности векторов движения согласно варианту осуществления настоящего изобретения;
фиг. 19 схематически иллюстрирует принцип слияния согласно варианту осуществления; и
фиг. 20 схематически иллюстрирует схему предсказания вектора движения согласно варианту осуществления.
Отмечается, что при описании чертежей элементы, встречающиеся на нескольких из этих чертежей, обозначаются одинаковой ссылочной позицией на каждом из этих чертежей, и исключается повторное описание этих элементов, что касается функциональных возможностей, чтобы исключить необязательные повторения. Тем не менее, функциональные возможности и описания, обеспечиваемые в отношении одного чертежа, также применимы к другим чертежам, если только в явной форме не указано противоположное.
Ниже сначала описываются варианты осуществления общего принципа видеокодирования, в отношении фиг. 1-10. Фиг. 1-6 относятся к части видеокодека, работающей на уровне синтаксиса. Последующие фиг. 8-10 относятся к вариантам осуществления для части кода, относящегося к преобразованию потока синтаксических элементов в поток данных и наоборот. Затем описываются конкретные аспекты и варианты осуществления настоящего изобретения в виде возможных реализаций общего принципа, представительно кратко изложенного в отношении фиг. 1-10.
Фиг. 1 изображает пример кодера 10, в котором могут быть реализованы аспекты настоящей заявки.
Кодер кодирует массив элементов 20 дискретизации информации в поток данных. Массив элементов дискретизации информации может представлять элементы дискретизации информации, соответствующие, например, значениям освещенности, значениям цветности, значениям яркости, значениям насыщенности цвета или т.п. Однако элементы дискретизации информации также могут представлять собой значения глубины в случае массива 20 элементов дискретизации, представляющего собой карту глубины, сгенерированную, например, по времени датчика света или т.п.
Кодер 10 представляет собой кодер на основе блоков. Т.е. кодер 10 кодирует массив 20 элементов дискретизации в поток 30 данных в единицах блоков 40. Кодирование в единицах блоков 40 не обязательно означает, что кодер 10 кодирует эти блоки 40 совершенно независимо один от другого. Вместо этого кодер 10 может использовать восстановления ранее кодированных блоков, чтобы экстраполировать или внутренне предсказывать остальные блоки, и может использовать степень разбиения блоков для установки параметров кодирования, т.е. для установки метода, которым кодируется каждая область массива элементов дискретизации, соответствующая соответствующему блоку.
Кроме того, кодер 10 представляет собой кодер с преобразованием. Т.е. кодер 10 кодирует блоки 40 посредством использования преобразования, чтобы переносить элементы дискретизации информации в каждом блоке 40 из пространственной области в спектральную область. Может использоваться двумерное преобразование, такое как дискретное косинусное преобразование (DCT) быстрого преобразования Фурье (FFT) или т.п. Предпочтительно, что блоки 40 имеют квадратную форму или прямоугольную форму.
Подразделение массива 20 элементов дискретизации на блоки 40, показанное на фиг. 1, служит просто для целей иллюстрации. Фиг. 1 изображает массив 20 элементов дискретизации с подразделением на обычное двумерное расположение квадратных или прямоугольных блоков 40, которые примыкают друг к другу неперекрывающимся образом. Размер блоков 40 может определяться заранее. Т.е. кодер 10 может не переносить информацию о размере блока блоков 40 в потоке 30 данных на декодирующую сторону. Например, декодер может ожидать заданный размер блока.
Однако возможно несколько альтернатив. Например, блоки могут перекрывать друг друга. Перекрытие, однако, может ограничиваться до такой степени, что каждый блок имеет часть, не перекрываемую никаким соседним блоком, или так, что каждый элемент дискретизации блоков перекрывается по максимуму одним блоком из числа соседних блоков, расположенных рядом друг с другом с текущим блоком по заданному направлению. Последнее означает, что левый и правый соседние блоки могут перекрывать текущий блок, чтобы полностью покрывать текущий блок, но они могут не накладываться друг на друга, и это же применимо к соседям в вертикальном и диагональном направлении.
В качестве другой альтернативы, подразделение массива 20 элементов дискретизации на блоки 40 может адаптироваться к содержимому массива 20 элементов дискретизации кодером 10, причем информация подразделения об используемом подразделении пересылается на сторону декодера по битовому потоку 30.
Фиг. 2a-2c изображают разные примеры для подразделения массива 20 элементов дискретизации в блоки 40. Фиг. 2a изображает подразделение на основе квадродерева массива 20 элементов дискретизации в блоки 40 разных размеров, причем типовые блоки обозначаются позициями 40a, 40b, 40c и 40d с увеличивающимся размером. В соответствии с подразделением на фиг. 2a, массив 20 элементов дискретизации сначала делится на обычное двумерное расположение древовидных блоков 40d, которые, в свою очередь, имеют индивидуальную информацию подразделения, ассоциированную с ним, в соответствии с которой некоторый древовидный блок 40d может дополнительно подразделяться или нет в соответствии со структурой квадродерева. Древовидный блок слева от блока 40d, в качестве примера, подразделяется на меньшие блоки в соответствии со структурой квадродерева. Кодер 10 может выполнять одно двумерное преобразование для каждого из блоков, показанных сплошными и пунктирными линиями на фиг. 2a. Другими словами, кодер 10 может преобразовывать массив 20 в единицах подразделения блока.
Вместо подразделения на основе квадродерева может использоваться более общее подразделение на основе нескольких деревьев, и количество дочерних узлов на уровень иерархии может отличаться между разными уровнями иерархии.
Фиг. 2b изображает другой пример для подразделения. В соответствии с фиг. 2b массив 20 элементов дискретизации сначала делится на макроблоки 40b, расположенные в обычном двумерном расположении неперекрывающимся, взаимно примыкающим образом, причем каждый макроблок 40b имеет ассоциированную с ним информацию подразделения, в соответствии с которой макроблок не подразделяется, или, если подразделяется, подразделяется обычным двумерным образом на подблоки равного размера для достижения разных степеней разбиения подразделения для разных макроблоков. Результатом является подразделение массива 20 элементов дискретизации в блоках 40 с разным размером, причем представители разных размеров обозначаются позициями 40a, 40b и 40a’. Как на фиг. 2a, кодер 10 выполняет двумерное преобразование в отношении каждого из блоков, показанных на фиг.2b сплошными и пунктирными линиями. Фиг. 2c описывается ниже.
Фиг. 3 изображает декодер 50, способный декодировать поток 30 данных, сгенерированный кодером 10 для восстановления восстановленной версии 60 массива 20 элементов дискретизации. Декодер 50 извлекает из потока 30 данных блок коэффициентов преобразования для каждого из блоков 40 и восстанавливает восстановленную версию 60 посредством выполнения обратного преобразования в отношении каждого из блоков коэффициентов преобразования.
Кодер 10 и декодер 50 могут быть выполнены с возможностью выполнения энтропийного кодирования/декодирования, чтобы вставлять информацию о блоках коэффициентов преобразования в поток данных и извлекать эту информацию из него соответственно. Ниже описываются подробности в этом отношении в соответствии с разными вариантами осуществления. Необходимо отметить, что поток 30 данных необязательно содержит информацию о блоках коэффициентов преобразования для всех блоков 40 массива 20 элементов дискретизации. Вместо этого, так как подмножество блоков 40 может кодироваться в битовый поток 30 другим образом. Например, кодер 10, вместо этого, может принять решение воздержаться от вставки блока коэффициентов преобразования для некоторого блока из блоков 40 со вставкой в битовый поток 30 параметров альтернативного кодирования, которые позволяют декодеру 50 предсказывать или иным образом наполнять соответствующий блок в восстановленной версии 60. Например, кодер 10 может выполнять анализ текстуры, чтобы определять расположение блоков в массиве 20 элементов дискретизации, который может наполняться на стороне декодера декодером посредством синтеза текстуры, и указывать это в битовом потоке соответствующим образом.
Как описывается в отношении следующих фигур, блоки коэффициентов преобразования необязательно представляют представление спектральной области исходных элементов дискретизации информации соответствующего блока 40 массива 20 элементов дискретизации. Вместо этого, такой блок коэффициентов преобразования может представлять представление спектральной области остатка предсказания соответствующего блока 40. Фиг. 4 изображает вариант осуществления для такого кодера. Кодер по фиг. 4 содержит ступень (каскад) 100 преобразования, энтропийный кодер 102, ступень 104 обратного преобразования, предиктор (предсказатель) 106 и вычитатель 108, а также сумматор 110. Вычитатель 108, ступень 100 преобразования и энтропийный кодер 102 соединены последовательно в упомянутом порядке между входом 112 и выходом 114 кодера на фиг. 4. Ступень 104 обратного преобразования, сумматор 110 и предиктор 106 соединены в упомянутом порядке между выходом ступени 100 преобразования и инвертирующим входом вычитателя 108, причем выход предиктора 106 также соединен с другим входом сумматора 110.
Кодер по фиг. 4 представляет собой блочный кодер на основе преобразования с предсказанием. Т.е. блоки массива 20 элементов дискретизации, поступающие на вход 112, предсказываются из ранее кодированных и восстановленных частей этого же массива 20 элементов дискретизации или ранее кодированных и восстановленных других массивов элементов дискретизации, которые могут предшествовать или следовать за текущим массивом 20 элементов дискретизации во времени представления. Предсказание выполняется предиктором 106. Вычитатель 108 вычитает предсказание из такого исходного блока, и ступень 100 преобразования выполняет двумерное преобразование остатков предсказания. Само двумерное преобразование или последующая мера в ступени 100 преобразования могут приводить к квантованию коэффициентов преобразования в блоках коэффициентов преобразования. Квантованные блоки коэффициентов преобразования кодируются без потерь, например, посредством энтропийного кодирования в энтропийном кодере 102, причем результирующий поток данных выводится на выходе 114. Ступень 104 обратного преобразования восстанавливает квантованный остаток, и сумматор 110, в свою очередь, объединяет восстановленный остаток с соответствующим предсказанием для получения восстановленных элементов дискретизации информации, основываясь на которых предиктор 106 может предсказывать вышеупомянутые кодируемые в настоящий момент блоки предсказания. Предиктор 106 может использовать разные режимы предсказания, такие как режимы внутреннего предсказания и режимы внешнего предсказания, чтобы предсказывать блоки, и параметры предсказания направляются энтропийному кодеру 102 для вставки в поток данных. Для каждого блока предсказания с внешним предсказанием соответствующие данные движения вставляются в битовый поток при помощи энтропийного кодера 114, чтобы предоставить возможность декодирующей стороне повторно выполнить предсказание. Данные движения для блока предсказания изображения могут включать в себя часть синтаксиса, включающую в себя синтаксический элемент, представляющий разность вектора движения, дифференциально кодирующую вектор движения для текущего блока предсказания относительно предиктора вектора движения, полученного, например, посредством заданного способа из векторов движения соседних, уже кодированных блоков предсказания.
Т.е. согласно варианту осуществления по фиг. 4 блоки коэффициентов преобразования представляют спектральное представление остатка массива элементов дискретизации, а не его фактические элементы дискретизации информации. Т.е. согласно варианту осуществления по фиг. 4 последовательность синтаксических элементов может поступать в энтропийный кодер 102 для энтропийного кодирования в поток 114 данных. Последовательность синтаксических элементов может содержать синтаксические элементы разностей векторов движения для блоков внешнего предсказания и синтаксические элементы, касающиеся карты значимостей, указывающей позиции значимых уровней коэффициентов преобразования, а также синтаксические элементы, определяющие сами значимые уровни коэффициентов преобразования, для блоков преобразования.
Необходимо отметить, что несколько альтернатив существует для варианта осуществления по фиг. 4, причем некоторые из них были описаны в вводной части описания изобретения, описание которых включено в описание фиг. 4 настоящего документа.
Фиг. 5 изображает декодер, способный декодировать поток данных, генерируемый кодером по фиг. 4. Декодер по фиг. 5 содержит энтропийный декодер 150, ступень 152 обратного преобразования, сумматор 154 и предиктор 156. Энтропийный декодер 150, ступень 152 обратного преобразования и сумматор 154 последовательно соединены между входом 158 и выходом 160 декодера по фиг. 5 в упомянутом порядке. Другой выход энтропийного декодера 150 соединен с предиктором 156, который, в свою очередь, подсоединен между выходом сумматора 154 и другим его входом. Энтропийный декодер 150 извлекает из потока данных, поступающего в декодер по фиг. 5 на входе 158, блоки коэффициентов преобразования, причем обратное преобразование применяется к блокам коэффициентов преобразования в ступени 152 для получения сигнала остатка. Сигнал остатка объединяется с предсказанием от предиктора 156 в сумматоре 154 для получения восстановленного блока восстановленной версии массива элементов дискретизации на выходе 160. Основываясь на восстановленных версиях, предиктор 156 генерирует предсказания, таким образом восстанавливая предсказания, выполняемые предиктором 106 на стороне кодера. Для получения таких же предсказаний, что и те, которые используются на стороне кодера, предиктор 156 использует параметры предсказания, которые энтропийный декодер 150 также получает из потока данных на входе 158.
Необходимо отметить, что в вышеописанных вариантах осуществления пространственная степень разбиения, с которой выполняется предсказание и преобразование остатка, не должна быть равной друг другу. Это показано на фиг. 2C. Эта фигура изображает подразделение для блоков предсказания степени разбиения предсказания сплошными линиями и степень разбиения остатка - пунктирными линиями. Как можно видеть, подразделения могут выбираться кодером независимо друг от друга. Более точно, синтаксис потока данных может учитывать определение подразделения остатка независимо от подразделения предсказания. Альтернативно, подразделение остатка может представлять собой расширение подразделения предсказания, так что каждый блок остатка или равен блоку предсказания или представляет собой надлежащее подмножество его. Это показано на фиг. 2a и фиг. 2b, например, где снова степень разбиения предсказания показана сплошными линиями и степень разбиения остатка - пунктирными линиями. Т.е. на фиг. 2a-2c все блоки, имеющие ссылочную позицию, ассоциированную с ними, будут блоками остатка, для которых будет выполняться одно двумерное преобразование, тогда как блоки со сплошными линиями большего размера, охватывающие блоки 40a с пунктирными линиями, например, будут блоками предсказания, для которых установка параметров предсказания выполняется индивидуально.
Вышеупомянутые варианты осуществления имеют в общем то, что блок (элементов дискретизации остатка или исходных элементов дискретизации) должен преобразовываться на стороне кодера в блок коэффициентов преобразования, который, в свою очередь, должен обратно преобразовываться в восстановленный блок элементов дискретизации на стороне декодера. Это изображено на фиг. 6. Фиг. 6 изображает блок 200 элементов дискретизации. В случае фиг. 6, этот блок 200 в качестве примера является квадратным и имеет 4×4 элементов 202 дискретизации в размере. Элементы 202 дискретизации регулярно располагаются по горизонтальному направлению x и по вертикальному направлению y. Посредством вышеупомянутого двумерного преобразования T, блок 200 преобразуется в спектральную область, а именно, в блок 204 коэффициентов 206 преобразования, причем блок 204 преобразования имеет такой же размер, что и блок 200. Т.е. блок 204 преобразования имеет столько коэффициентов 206 преобразования, сколько блок 200 имеет элементов дискретизации как в горизонтальном направлении, так и вертикальном направлении. Однако так как преобразование T представляет собой спектральное преобразование, позиции коэффициентов 206 преобразования в блоке 204 преобразования не соответствуют пространственным позициям, но скорее спектральным составляющим содержимого блока 200. В частности, горизонтальная ось блока 204 преобразования соответствует оси, вдоль которой спектральная частота в горизонтальном направлении монотонно увеличивается, в то время как вертикальная ось соответствует оси, вдоль которой пространственная частота в вертикальном направлении монотонно увеличивается, причем коэффициент преобразования составляющей постоянного тока (DC) располагается в углу - здесь, в качестве примера, верхний левый угол - блока 204, так что в нижнем правом углу располагается коэффициент 206 преобразования, соответствующий наибольшей частоте как в горизонтальном, так и в вертикальном направлении. Пренебрегая пространственным направлением, пространственная частота, к которой принадлежит некоторый коэффициент 206 преобразования, как правило увеличивается от верхнего левого угла к нижнему правому углу. Посредством обратного преобразования T-1, блок 204 преобразования переносится из спектральной области в пространственную область, чтобы повторно получить копию 208 блока 200. В случае отсутствия введения потерь квантования при преобразовании, восстановление будет совершенным.
Как уже отмечено выше, можно видеть на фиг. 6, что большие размеры блока у блока 200 увеличивают спектральное разрешение результирующего спектрального представления 204. С другой стороны, шум квантования стремится распространиться по всему блоку 208, и, таким образом, резкие и очень локализованные объекты в блоках 200 стремятся привести к отклонениям повторно преобразованного блока относительно исходного блока 200 из-за шума квантования. Главным преимуществом использования больших блоков является, однако, то, что отношение между количеством значимых, т.е. ненулевых (квантованных) коэффициентов преобразования, т.е. уровней, с одной стороны, и количеством незначимых коэффициентов преобразования, с другой стороны, может уменьшаться в больших блоках по сравнению с меньшими блоками, тем самым позволяя получить лучшую эффективность кодирования. Другими словами, часто значимые уровни коэффициентов преобразования, т.е. коэффициенты преобразования, не квантованные в нуль, редко распределяются по блоку 204 преобразования. Вследствие этого, согласно вариантам осуществления, описанным более подробно ниже, позиции значимых уровней коэффициентов преобразования сигнализируются в потоке данных посредством карты значимостей. Отдельно от нее, значения значимого коэффициента преобразования, т.е. уровней коэффициентов преобразования в случае, когда коэффициенты преобразования квантуются, передаются в потоке данных.
Все кодеры и декодеры, описанные выше, таким образом, выполнены с возможностью работы с некоторым синтаксисом синтаксических элементов. Т.е. вышеупомянутые синтаксические элементы, такие как уровни коэффициентов преобразования, синтаксические элементы, касающиеся карты значимостей блоков преобразования, синтаксические элементы данных движения, касающиеся блоков внешнего предсказания, и т.п., как предполагается, располагаются последовательно в потоке данных заданным образом. Такой заданный образ может представляться в виде псевдокода, как, например, сделано в стандарте H.264 или других видеокодеках.
Другими словами, вышеупомянутое описание, имеющее дело главным образом с преобразованием мультимедийных данных, здесь, в качестве примера, видеоданные, в последовательность синтаксических элементов в соответствии с предварительно определенной синтаксической структурой, задающей некоторые типы синтаксических элементов, его семантикой и порядком среди них. Энтропийный кодер и энтропийный декодер по фиг. 4 и 5 может быть выполнен с возможностью работы, и может быть структурирован, как кратко изложено ниже. Они отвечают за выполнение преобразования между последовательностью синтаксических элементов и потоком данных, т.е. потоком символов или битов.
Энтропийный кодер согласно варианту осуществления изображен на фиг. 7. Кодер без потерь преобразует поток синтаксических элементов 301 в множество из двух или более частичных битовых потоков 312.
В предпочтительном варианте осуществления изобретения каждый синтаксический элемент 301 ассоциируется с категорией множества из одной или нескольких категорий, т.е. типом синтаксического элемента. В качестве примера, категории могут задавать тип синтаксического элемента. В контексте гибридного видеокодирования отдельная категория может ассоциироваться с режимами кодирования макроблоков, режимами кодирования блоков, индексами опорного изображения, разностями векторов движения, флагами подразделения, флагами кодированного блока, параметрами квантования, уровнями коэффициентов преобразования и т.д. В других областях применения, таких как аудио, речь, текст, документ или обычное кодирование данных, возможны разные категоризации синтаксических элементов.
Обычно, каждый синтаксический элемент может принимать значение конечного или счетно-бесконечного множества значений, где множество возможных значений синтаксического элемента может различаться для разных категорий синтаксических элементов. Например, имеются двоичные синтаксические элементы, а также целочисленные.
Для уменьшения сложности алгоритма кодирования и декодирования и для предоставления возможности общей разработки кодирования и декодирования для разных синтаксических элементов и категорий синтаксических элементов, синтаксические элементы 301 преобразуются в упорядоченные множества двоичных решений, и эти двоичные решения затем обрабатываются простыми алгоритмами двоичного кодирования. Поэтому, бинаризатор 302 биективно (взаимно-однозначно) отображает значение каждого синтаксического элемента 301 на последовательность (или строку или слово) бинов 303. Последовательность бинов 303 представляет множество упорядоченных двоичных решений. Каждый бин 303 или двоичное решение может принимать одно значение из множества из двух значений, например, одно из значений 0 и 1. Схема бинаризации может быть разной для разных категорий синтаксических элементов. Схема бинаризации для конкретной категории синтаксических элементов может зависеть от множества возможных значений синтаксических элемента и/или других свойств синтаксического элемента для конкретной категории.
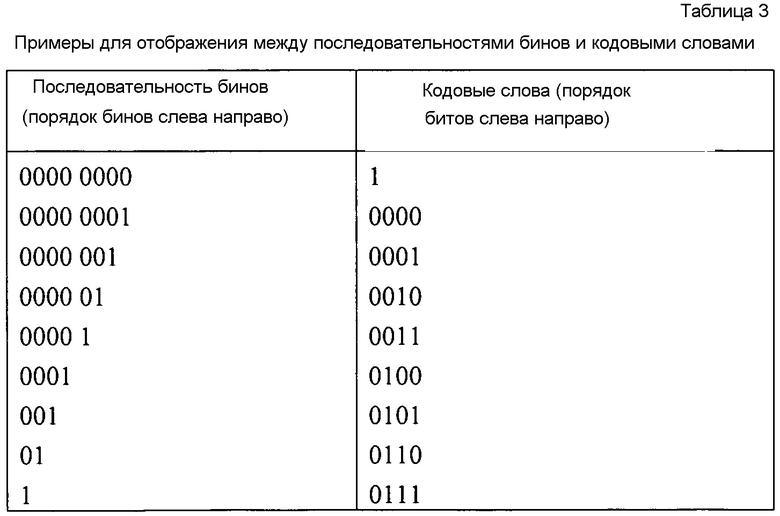
Таблица 1 иллюстрирует три примерные схемы бинаризации для счетно-бесконечных множеств. Схемы бинаризации для счетно-бесконечных множеств также могут быть применимы для конечных множеств значений синтаксических элементов. В частности для больших конечных множеств значений синтаксических элементов может быть незначительной неэффективность (являющаяся результатом неиспользованных последовательностей бинов), но универсальность таких схем бинаризации обеспечивает преимущество в смысле сложности и требований к памяти. Для малых конечных множеств значений синтаксических элементов часто бывает предпочтительным (в смысле эффективности кодирования) адаптировать схему бинаризации к количеству возможных значений символов.
Таблица 2 иллюстрирует три примерные схемы бинаризации для конечных множеств из 8 значений. Схемы бинаризации для конечных множеств могут быть выведены из универсальных схем бинаризации для счетно-бесконечных множеств посредством модифицирования некоторых последовательностей бинов таким образом, что конечные множества последовательностей бинов представляют код без избыточности (и потенциально переупорядочение последовательностей бинов). В качестве примера, схема усеченной унарной бинаризации в таблице 2 была создана посредством модифицирования последовательности бинов для синтаксического элемента 7 универсальной унарной бинаризации (см. таблицу 1). Усеченная и переупорядоченная экспоненциальная бинаризация Голомба порядка 0 в таблице 2 была создана посредством модифицирования последовательности бинов для синтаксического элемента 7 универсальной экспоненциальной бинаризации Голомба порядка 0 (см. таблица 1) и посредством переупорядочения последовательностей бинов (усеченная последовательность бинов для символа 7 была назначена символу 1). Для конечных множеств синтаксических элементов также возможно использование несистематических/неуниверсальных схем бинаризации, как приведено в качестве примера в последнем столбце таблицы 2.



Каждый бин 303 последовательности бинов, создаваемых бинаризатором 302, подается в средство 304 назначения параметра в последовательном порядке. Средство назначения параметра назначает множество из одного или нескольких параметров каждому бину 303 и выводит бин с ассоциированным множеством параметров 305. Множество параметров определяется точно одинаковым образом в кодере и декодере. Множество параметров может состоять из одного или нескольких из следующих параметров:
В частности, средство 304 назначения параметра может быть выполнено с возможностью назначения текущему бину 303 контекстной модели. Например, средство 304 назначения параметра может выбирать один из доступных индексов контекста для текущего бина 303. Доступное множество контекстов для текущего бина 303 может зависеть от типа бина, который, в свою очередь, может определяться типом/категорией синтаксического элемента 301, бинаризация какого текущего бина 303 является частью и позицией текущего бина 303 в последней бинаризации. Выбор контекста из числа доступного множества контекстов может зависеть от предыдущих бинов и синтаксических элементов, ассоциированных с последним. Каждый из этих контекстов имеет вероятностную модель, ассоциированную с ним, т.е. меру для оценки вероятности для одного из двух возможных значений бина для текущего бина. Вероятностная модель, в частности, может представлять собой меру для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина, причем вероятностная модель дополнительно определяется идентификатором, задающим оценку, какое из двух возможных значений бина представляет менее вероятное или более вероятное значение бина для текущего бина 303. В случае, когда доступен только один контекст для текущего бина, может быть исключен выбор контекста. Как более подробно изложено ниже, средство 304 назначения параметра также может выполнять адаптацию вероятностной модели, чтобы адаптировать вероятностные модели, ассоциированные с различными контекстами, с фактической статистикой бинов соответствующих бинов, принадлежащих соответствующим контекстам.
Как также более подробно описано ниже, средство 304 назначения параметра может работать по-разному в зависимости от активизированного режима высокой эффективности (HE) или режима низкой сложности (LC). В обоих режимах вероятностная модель ассоциирует текущий бин 303 с любым из кодеров 310 бина, как изложено ниже, но режим работы средства 304 назначения параметра стремится быть менее сложным в режиме LC, причем, однако, эффективность кодирования повышается в режиме высокой эффективности из-за того, что средство 304 назначения параметра вызывает более точную адаптацию ассоциирования индивидуальных бинов 310 с индивидуальными кодерами 310 со статистикой бинов, тем самым оптимизируя энтропию относительно режима LC.
Каждый бин с ассоциированным множеством параметров 305, который представляет собой выходной результат средства 304 назначения параметра, подается в селектор 306 буфера бинов. Селектор 306 буфера бинов потенциально модифицирует значение введенного бина 305, основываясь на значении введенного бина и ассоциированных параметрах 305, и подает выводимый бин 307 - с потенциально модифицированным значением - в один из двух или более буферов 308 бинов. Буфер 308 бинов, на который посылается выводимый бин 307, определяется на основе значения вводимого бина 305 и/или значения ассоциированных параметров 305.
В предпочтительном варианте осуществления изобретения селектор 306 буфера бинов не модифицирует значение бина, т.е. выводимый бин 307 всегда имеет одно и то же значение, что и вводимый бин 305. В другом предпочтительном варианте осуществления изобретения селектор 306 буфера бинов определяет значение 307 выводимого бина, основываясь на значении 305 вводимого бина и ассоциированной мере для оценки вероятности для одного из двух возможных значений бина для текущего бина. В предпочтительном варианте осуществления изобретения значение 307 выводимого бина устанавливается равным значению 305 вводимого бина, если мера для вероятности для одного из двух возможных значений бина для текущего бина меньше (или меньше или равна) конкретному порогу; если мера для вероятности для одного из двух возможных значений бина для текущего бина больше или равна (или больше) конкретного порога, значение 307 выводимого бина модифицируется (т.е. устанавливается на противоположное значение значению вводимого бина). В другом предпочтительном варианте осуществления изобретения значение 307 выводимого бина устанавливается равным значению 305 вводимого бина, если мера для вероятности для одного из двух возможных значений бина для текущего бина больше (или больше или равна) конкретному порогу; если мера для вероятности для одного из двух возможных значений бина для текущего бина меньше или равна (или меньше) конкретному порогу, значение 307 выводимого бина модифицируется (т.е. устанавливается на противоположное значение значению вводимого бина). В предпочтительном варианте осуществления изобретения значение порога соответствует значению 0,5 для оцененной вероятности для обоих возможных значений бина.
В другом предпочтительном варианте осуществления изобретения селектор 306 буфера бинов определяет значение 307 выводимого бина, основываясь на значении 305 вводимого бина и ассоциированном идентификаторе, задающим оценку, какое из двух возможных значений бина представляет менее вероятное или более вероятное значение бина для текущего бина. В предпочтительном варианте осуществления изобретения значение 307 выводимого бина устанавливается равным значению 305 вводимого бина, если идентификатор задает, что первое из двух возможных значений бина представляет менее вероятное (или более вероятное) значение бина для текущего бина, и значение 307 выводимого бина модифицируется (т.е. устанавливается на противоположное значение значению вводимого бина), если идентификатор задает, что второе из двух возможных значений бина представляет менее вероятное (или более вероятное) значение бина для текущего бина.
В предпочтительном варианте осуществления изобретения селектор 306 буфера бинов определяет буфер 308 бинов, на который посылается выводимый бин 307, основываясь на ассоциированной мере для оценки вероятности для одного из двух возможных значений бина для текущего бина. В предпочтительном варианте осуществления изобретения множество возможных значений для меры для оценки вероятности для одного из двух возможных значений бина является конечным, и селектор 306 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 308 бинов с каждым возможным значением для оценки вероятности для одного из двух возможных значений бина, где разные значения для меры для оценки вероятности для одного из двух возможных значений бина могут ассоциироваться с одним и тем же буфером 308 бинов. В другом предпочтительном варианте осуществления изобретения диапазон возможных значений для меры для оценки вероятности для одного из двух возможных значений бина разделяется на несколько интервалов, селектор 306 буфера бинов определяет индекс интервала для текущей меры для оценки вероятности для одного из двух возможных значений бина, и селектор 306 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 308 бинов с каждым возможным значением для индекса интервала, где разные значения для индекса интервала могут ассоциироваться с одним и тем же буфером 308 бинов. В предпочтительном варианте осуществления изобретения вводимые бины 305 с противоположными мерами для оценки вероятности для одного из двух возможных значений бина (противоположной мерой являются те, которые представляют оценки P и 1-P вероятности) подаются в один и тот же буфер 308 бинов. В другом предпочтительном варианте осуществления изобретения ассоциирование меры для оценки вероятности для одного из двух возможных значений бина для текущего бина с конкретным буфером бинов адаптируется во времени, например, чтобы гарантировать, что созданные частичные битовые потоки имеют подобные скорости передачи битов. Кроме того, индекс интервала также называется индексом pipe (энтропия разделения интервала вероятности), тогда как индекс pipe вместе с индексом уточнения, и флаг, указывающий более вероятное значение бина, индексирует фактическую вероятностную модель, т.е. оценку вероятности.
В другом предпочтительном варианте осуществления изобретения селектор 306 буфера бинов определяет буфер 308 бинов, на который посылается выводимый бин 307, основываясь на ассоциированной мере для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина. В предпочтительном варианте осуществления изобретения множество возможных значений для меры для оценки вероятности для менее вероятного или более вероятного значения бина является конечным, и селектор 306 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 308 бинов с каждым возможным значением оценки вероятности для менее вероятного или более вероятного значения бина, где разные значения для меры для оценки вероятности для менее вероятного или более вероятного значения бина могут ассоциироваться с одним и тем же буфером 308 бинов. В другом предпочтительном варианте осуществления изобретения диапазон возможных значений для меры для оценки вероятности для менее вероятного или более вероятного значения бина разделяется на несколько интервалов, селектор 306 буфера бинов определяет индекс интервала для текущей меры для оценки вероятности для менее вероятного или более вероятного значения бина, и селектор 306 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 308 бинов с каждым возможным значением для индекса интервала, где разные значения для индекса интервала могут ассоциироваться с одним и тем же буфером 308 бинов. В другом предпочтительном варианте осуществления ассоциирование меры для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина с конкретным буфером бинов адаптируется во времени, например, чтобы гарантировать, что создаваемые частичные битовые потоки имеют подобные скорости передачи битов.
Каждый из двух или более буферов 308 бинов соединен с точно одним кодером 310 бинов, и каждый кодер бинов соединен только с одним буфером 308 бинов. Каждый кодер 310 бинов считывает бины из ассоциированного буфера 308 бинов и преобразует последовательность бинов 309 в кодовое слово 311, которое представляет последовательность битов. Буферы 308 бинов представляют буферы «первым пришел - первым обслужен»; бины, которые подаются позже (в последовательном порядке) в буфер 308 бинов, не кодируются перед бинами, которые подаются ранее (в последовательном порядке) в буфер бинов. Кодовые слова 311, которые представляют собой выходной результат конкретного кодера 310 бинов, записываются в конкретный частичный битовый поток 312. Общий алгоритм кодирования преобразует синтаксические элементы 301 в два или более частичных битовых потока 312, где количество частичных битовых потоков равно количеству буферов бинов и кодеров бинов. В предпочтительном варианте осуществления изобретения кодер 310 бинов преобразует изменяемое количество бинов 309 в кодовое слово 311 с изменяемым количеством битов. Одним преимуществом вышеупомянутых и ниже кратко изложенных вариантов осуществления изобретения является то, что кодирование бинов может выполняться параллельно (например, для разных групп мер вероятности), что уменьшает время обработки для нескольких реализаций.
Другим преимуществом вариантов осуществления изобретения является то, что кодирование бинов, которое выполняется кодерами 310 бинов, может быть конкретно разработано для разных множеств параметров 305. В частности, кодирование бинов и кодирование могут быть оптимизированы (в смысле эффективности и/или сложности кодирования) для разных групп оцененных вероятностей. С одной стороны, это предоставляет возможность уменьшить сложность кодирования/декодирования, и, с другой стороны, это позволяет получить повышение эффективности кодирования. В предпочтительном варианте осуществления изобретения кодеры 310 бинов реализуют разные алгоритмы кодирования (т.е. отображение последовательностей бинов в кодовые слова) для разных групп мер для оценки вероятности для одного из двух возможных значений 305 бина для текущего бина. В другом предпочтительном варианте осуществления изобретения кодеры 310 бинов реализуют разные алгоритмы кодирования для разных групп мер для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина.
В предпочтительном варианте осуществления изобретения кодеры 310 бинов - или один или несколько из кодеров бинов - представляют энтропийные кодеры, которые прямо отображают последовательности вводимых бинов 309 в кодовые слова 310. Такое отображение может быть эффективно реализовано и не требует сложного механизма арифметического кодирования. Обратное отображение кодовых слов в последовательности бинов (что выполняется в декодере) должно быть уникальным, чтобы гарантировать совершенное декодирование вводимой последовательности, но отображение последовательностей 309 бинов в кодовые слова 310 необязательно должно быть уникальным, т.е. возможно, что конкретная последовательность бинов может отображаться на более чем одну последовательность кодовых слов. В предпочтительном варианте осуществления изобретения отображение последовательностей вводимых бинов 309 в кодовые слова 310 является биективным. В другом предпочтительном варианте осуществления изобретения кодеры 310 бинов - или один или несколько из кодеров бинов - представляют энтропийные кодеры, которые прямо отображают последовательности переменной длины вводимых бинов 309 в кодовые слова 310 переменной длины. В предпочтительном варианте осуществления изобретения выводимые кодовые слова представляют коды без избыточности, такие как общие коды Хаффмана или канонические коды Хаффмана.
В таблице 3 изображены два примера для биективного отображения последовательностей бинов в коды без избыточности. В другом предпочтительном варианте осуществления изобретения выводимые кодовые слова представляют избыточные коды, пригодные для обнаружения ошибок и восстановления при ошибках. В другом предпочтительном варианте осуществления изобретения выводимые кодовые слова представляют коды шифрования, пригодные для шифрования синтаксических элементов.

В другом предпочтительном варианте осуществления изобретения кодеры 310 бинов - или один или несколько из кодеров бинов - представляют энтропийные кодеры, которые прямо отображают последовательности переменной длины вводимых бинов 309 в кодовые слова 310 фиксированной длины. В другом предпочтительном варианте осуществления изобретения кодеры 310 бинов - или один или несколько из кодеров бинов - представляют энтропийные кодеры, которые прямо отображают последовательности фиксированной длины вводимых бинов 309 в кодовые слова 310 переменной длины.
Декодер согласно варианту осуществления изобретения изображен на фиг. 8. Декодер выполняет, в основном, операции, обратные кодеру, так что (ранее кодированная) последовательность синтаксических элементов 327 декодируется из множества из двух или нескольких частичных битовых потоков 324. Декодер включает в себя два разных потока обработки: поток для запроса данных, который повторяет поток данных кодера, и поток данных, который представляет обратное потока данных кодера. На иллюстрации на фиг. 8 пунктирные стрелки представляют поток запросов данных, тогда как сплошные стрелки представляют поток данных. Стандартные блоки декодера, в основном, повторяют стандартные блоки кодера, но реализуют обратные операции.
Декодирование синтаксического элемента запускается запросом нового декодируемого синтаксического элемента 313, который посылается на бинаризатор 314. В предпочтительном варианте осуществления изобретения каждый запрос нового декодируемого синтаксического элемента 313 ассоциируется с категорией множества из одной или нескольких категорий. Категория, которая ассоциируется с запросом синтаксического элемента, является той же, что и категория, которая была ассоциирована с соответствующим синтаксическим элементом во время кодирования.
Бинаризатор 314 отображает запрос синтаксического элемента 313 на один или несколько запросов бина, которые посылаются на средство 316 назначения параметра. В качестве окончательного ответа на запрос бина, который посылается средству 316 назначения параметра бинаризатором 314, бинаризатор 314 принимает декодируемый бин 326 от селектора 318 буфера бинов. Бинаризатор 314 сравнивает принятую последовательность декодируемых бинов 326 с последовательностями бинов конкретной схемы бинаризации для запрашиваемого синтаксического элемента, и, если принятая последовательность декодируемых бинов 26 совпадает с бинаризацией синтаксического элемента, бинаризатор освобождает свой буфер бинов и выводит декодируемый синтаксический элемент в качестве окончательного ответа на запрос нового декодируемого символа. Если уже принятая последовательность декодируемых бинов не совпадает ни с какой из последовательностей бинов для схемы бинаризации для запрашиваемого синтаксического элемента, бинаризатор посылает другой запрос бина средству назначения параметра до тех пор, пока последовательность декодируемых бинов не будет совпадать с одной из последовательностей бинов схемы бинаризации для запрашиваемого синтаксического элемента. Для каждого запроса синтаксического элемента декодер использует одну и туже схему бинаризации, которая использовалась для кодирования соответствующего синтаксического элемента. Схема бинаризации может быть разной для разных категорий синтаксических элементов. Схема бинаризации для конкретной категории синтаксических элементов может зависеть от множества возможных значений синтаксического элемента и/или других свойств синтаксических элементов для конкретной категории.
Средство 316 назначения параметра назначает множество из одного или нескольких параметров каждому запросу бина и посылает запрос бина с ассоциированным множеством параметров селектору буфера бинов. Множество параметров, которое назначается запрашиваемому бину средством назначения параметра, является тем же, которое было назначено соответствующему бину во время кодирования. Множество параметров может состоять из одного или нескольких параметров, которые упомянуты при описании кодера на фиг. 7.
В предпочтительном варианте осуществления изобретения средство 316 назначения параметра ассоциирует каждый запрос бина с теми же параметрами, что и делало средство 304 назначения, т.е. контекст и его ассоциированная мера для оценки вероятности для одного из двух возможных значений бина для текущего запрашиваемого бина, такую как мера для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина и идентификатор, задающий оценку, какое из двух возможных значений бина представляет менее вероятное или более вероятное значение бина для текущего запрашиваемого бина.
Средство 316 назначения параметра может определять одну или несколько из вышеупомянутых мер вероятности (мера для оценки вероятности для одного из двух возможных значений бина для текущего запрашиваемого бина, мера для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина, идентификатор, задающий оценку, какое из двух возможных значений бина представляет менее вероятное или более вероятное значение бина для текущего запрашиваемого бина), основываясь на множестве из одного или нескольких уже декодированных символов. Определение мер вероятности для конкретного запроса бина повторяет процесс в кодере для соответствующего бина. Декодированные символы, которые используются для определения мер вероятности, могут включать в себя один или несколько уже декодированных символов этой же категории символов, один или несколько уже декодированных символов этой же категории символов, которая соответствует множествам данных (таким как блоки или группы элементов дискретизации) соседних пространственных и/или временных расположений (в отношении множества данных, ассоциированного с текущим запросом синтаксического элемента), или один или несколько уже декодированных символов разных категорий символов, которые соответствуют множествам данных этого же и/или соседних пространственных и/или временных расположений (в отношении к множеству данных, ассоциированному с текущим запросом синтаксического элемента).
Каждый запрос бина с ассоциированным множеством параметров 317, который представляет собой выходной результат средство 316 назначения параметра, подается на селектор 318 буфера бинов. Основываясь на ассоциированном множестве параметров 317, селектор 318 буфера бинов посылает запрос бина 319 одному из двух или более буферов 320 бинов и принимает декодированный бин 325 от выбранного буфера 320 бинов. Декодированный вводимый бин 325 потенциально модифицируется, и декодированный выводимый бин 326 - с потенциально модифицированным значением - посылается на бинаризатор 314 в качестве окончательного ответа на запрос бина с ассоциированным множеством параметров 317.
Буфер 320 бинов, на который направляется запрос бина, выбирается таким же образом, что и буфер бинов, на который был послан выводимый бин селектора буфера бинов на стороне кодера.
В предпочтительном варианте осуществления изобретения селектор 318 буфера бинов определяет буфер 320 бинов, на который посылается запрос бина 319, основываясь на ассоциированной мере для оценки вероятности для одного из двух возможных значений бина для текущего запрашиваемого бина. В предпочтительном варианте осуществления изобретения множество возможных значений для меры для оценки вероятности для одного из двух возможных значений бина является конечным, и селектор 318 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 320 бинов с каждым возможным значением оценки вероятности для одного из двух возможных значений бина, где разные значения для меры для оценки вероятности для одного из двух возможных значений бина могут ассоциироваться с одним и тем же буфером 320 бинов. В другом предпочтительном варианте осуществления изобретения диапазон возможных значений для меры для оценки вероятности для одного из двух возможных значений бина разделяется на несколько интервалов, селектор 318 буфера бинов определяет индекс интервала для текущей меры для оценки вероятности для одного из двух возможных значений бина, и селектор 318 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 320 бинов с каждым возможным значением для индекса интервала, где разные значения для индекса интервала могут ассоциироваться с одним и тем же буфером 320 бинов. В предпочтительном варианте осуществления изобретения запросы бинов 317 с противоположными мерами для оценки вероятности для одного из двух возможных значений бина (противоположной мерой являются те, которые представляют оценки P и 1-P вероятности) направляются одному и тому же буферу 320 бинов. В другом предпочтительном варианте осуществления изобретения ассоциирование меры для оценки вероятности для одного из двух возможных значений бина для текущего запроса бина с конкретным буфером бинов адаптируется во времени.
В другом предпочтительном варианте осуществления изобретения селектор 318 буфера бинов определяет буфер 320 бинов, на который посылается запрос бина 319, основываясь на ассоциированной мере для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина. В предпочтительном варианте осуществления изобретения множество возможных значений для меры для оценки вероятности для менее вероятного или более вероятного значения бина является конечным, и селектор 318 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 320 бинов с каждым возможным значением оценки вероятности для менее вероятного или более вероятного значения бина, где разные значения для меры для оценки вероятности для менее вероятного или более вероятного значения бина могут ассоциироваться с одним и тем же буфером 320 бинов. В другом предпочтительном варианте осуществления изобретения диапазон возможных значений для меры для оценки вероятности для менее вероятного или более вероятного значения бина разделяется на несколько интервалов, селектор 318 буфера бинов определяет индекс интервала для текущей меры для оценки вероятности для менее вероятного или более вероятного значения бина, и селектор 318 буфера бинов содержит таблицу, которая ассоциирует точно один буфер 320 бинов с каждым возможным значением для индекса интервала, где разные значения для индекса интервала могут ассоциироваться с одним и тем же буфером 320 бинов. В другом предпочтительном варианте осуществления изобретения ассоциирование меры для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запроса бина с конкретным буфером бинов адаптируется во времени.
После приема декодированного бина 325 от выбранного буфера 320 бинов селектор 318 буфера бинов потенциально модифицирует вводимый бин 325 и посылает выводимый бин 326 - с потенциально модифицированным значением - бинаризатору 314. Отображение вводимого/выводимого бина селектора 318 буфера бинов представляет собой обратное отображению вводимого/выводимого бина селектора буфера бинов на стороне кодера.
В предпочтительном варианте осуществления изобретения селектор 318 буфера бинов не модифицирует значение бина, т.е. выводимый бин 326 всегда имеет одно и то же значение, что и вводимый бин 325. В другом предпочтительном варианте осуществления изобретения селектор 318 буфера бинов определяет значение 326 выводимого бина, основываясь на значении 325 вводимого бина и мере для оценки вероятности для одного из двух возможных значений бина для текущего запрашиваемого бина, который ассоциируется с запросом бина 317. В предпочтительном варианте осуществления изобретения значение 326 выводимого бина устанавливается равным значению 325 вводимого бина, если мера для вероятности для одного из двух возможных значений бина для текущего запроса бина меньше (или меньше или равна) конкретному порогу; если мера для вероятности для одного из двух возможных значений бина для текущего запроса бина больше или равна (или больше) конкретного порога, значение 326 выводимого бина модифицируется (т.е. устанавливается на значение, противоположное значению вводимого бина). В другом предпочтительном варианте осуществления изобретения значение 326 выводимого бина устанавливается равным значению 325 вводимого бина, если мера для вероятности для одного из двух возможных значений бина для текущего запроса бина больше (или больше или равна) конкретному порогу; если мера для вероятности для одного из двух возможных значений бина для текущего запроса бина меньше или равна (или меньше) конкретного порога, значение 326 выводимого бина модифицируется (т.е. устанавливается на значение, противоположное значению вводимого бина). В предпочтительном варианте осуществления изобретения значение порога соответствует значению 0,5 для оцененной вероятности для обоих возможных значений бина.
В другом предпочтительном варианте осуществления изобретения селектор 318 буфера бинов определяет значение 326 выводимого бина, основываясь на значении 325 вводимого бина и идентификатора, задающего оценку, какое из двух возможных значений бина представляет менее вероятное или более вероятное значение бина для текущего запроса бина, который ассоциируется с запросом бина 317. В предпочтительном варианте осуществления изобретения значение 326 выводимого бина устанавливается равным значению 325 вводимого бина, если идентификатор задает, что первое из двух возможных значений бина представляет менее вероятное (или более вероятное) значение бина для текущего запроса бина, и значение 326 выводимого бина модифицируется (т.е устанавливается на значение, противоположное значению вводимого бина), если идентификатор задает, что второе из двух возможных значений бина представляет менее вероятное (или более вероятное) значение бина для текущего запроса бина.
Как описано выше, селектор буфера бинов посылает запрос бина 319 одному из двух или более буферов 320 бинов. Буферы 20 бинов представляют буфер «первый пришел - первым обслужен», на которые подаются последовательности декодированных бинов 321 от подсоединенных декодеров 322 бинов. В качестве ответа на запрос бина 319, который посылается буферу 320 бинов от селектора 318 буфера бинов, буфер 320 бинов удаляет бин из своего содержимого, который был первым подан в буфер 320 бинов, и посылает его на селектор 318 буфера бинов. Бины, которые ранее были посланы буферу 320 бинов, раньше удаляются и посылаются селектору 318 буфера бинов.
Каждый из двух или более буферов 320 бинов соединен с точно одним декодером 322 бинов, и каждый декодер бинов соединен только с одним буфером 320 бинов. Каждый декодер 322 бинов считывает кодовые слова 323, которые представляют последовательности битов, из отдельного частичного битового потока 324. Декодер бинов преобразует кодовое слово 323 в последовательность бинов 321, которая посылается на подсоединенный буфер 320 бинов. Общий алгоритм декодирования преобразует два или более частичных битовых потока 324 в несколько декодированных синтаксических элементов, где количество частичных битовых потоков равно количеству буферов бинов и декодеров бинов, и декодирование синтаксических элементов запускается запросами новых синтаксических элементов. В предпочтительном варианте осуществления изобретения декодер 322 бинов преобразует кодовые слова 323 с переменным количеством битов в последовательность переменного количества бинов 321. Одним преимуществом вариантов осуществления изобретения является то, что декодирование бинов из двух или более частичных битовых потоков может выполняться параллельно (например, для разных групп мер вероятности), что уменьшает время обработки для нескольких реализаций.
Другим преимуществом вариантов осуществления изобретения является то, что декодирование бинов, которое выполняется декодерами 322 бинов, может быть специально разработано для разных множеств параметров 317. В частности, кодирование и декодирование бинов может оптимизироваться (в смысле эффективности и/или сложности кодирования) для разных групп оцениваемых вероятностей. С одной стороны, это позволяет уменьшить сложность кодирования/декодирования относительно современных алгоритмов энтропийного кодирования с подобной эффективностью кодирования. С другой стороны, это позволяет улучшить эффективность кодирования относительно современных алгоритмов энтропийного кодирования с подобной сложностью кодирования/декодирования. В предпочтительном варианте осуществления изобретения декодеры 322 бинов реализуют разные алгоритмы декодирования (т.е. отображение последовательностей бинов в кодовые слова) для разных групп мер для оценки вероятности для одного из двух возможных значений 317 бина для текущего запроса бина. В другом предпочтительном варианте осуществления изобретения декодеры 322 бинов реализуют разные алгоритмы декодирования для разных групп мер для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина.
Декодеры 322 бинов выполняют отображение, обратное соответствующим кодерам бинов на стороне кодера.
В предпочтительном варианте осуществления изобретения декодеры 322 бинов - или один или несколько из декодеров бинов - представляют энтропийные декодеры, которые прямо отображают кодовые слова 323 в последовательности бинов 321. Такое отображение может быть эффективно реализовано и не требует сложного механизма арифметического кодирования. Отображение кодовых слов в последовательности бинов должно быть уникальным. В предпочтительном варианте осуществления изобретения отображение кодовых слов 323 в последовательности бинов 321 является биективным. В другом предпочтительном варианте осуществления изобретения декодеры 310 бинов - или один или несколько из декодеров бинов - представляют энтропийные декодеры, которые прямо отображают кодовые слова 323 переменной длины в последовательности переменной длины бинов 321. В предпочтительном варианте осуществления изобретения вводимые кодовые слова представляют коды без избыточности, такие как общие коды Хаффмана или канонические коды Хаффмана. Два примера для биективного отображения кодов без избыточности в последовательности бинов приведены в таблице 3.
В другом предпочтительном варианте осуществления изобретения декодеры 322 бинов - или один или несколько из декодеров бинов - представляют энтропийные декодеры, которые прямо отображают кодовые слова 323 фиксированной длины на последовательности переменной длины бинов 321. В другом предпочтительном варианте осуществления изобретения декодеры 322 бинов - или один или несколько из декодеров бинов - представляют энтропийные декодеры, которые прямо отображают кодовые слова 323 переменной длины на последовательности фиксированной длины бинов 321.
Таким образом, фиг. 7 и 8 изображают вариант осуществления для кодера для кодирования последовательности символов 3 и декодера для восстановления их. Кодер содержит средство 304 назначения, выполненное с возможностью назначения нескольких параметров 305 каждому символу последовательности символов. Назначение основывается на информации, содержащейся в предыдущих символах последовательности символов, такой как категория синтаксического элемента 1 для представления - такого как бинаризация - к которой принадлежит текущий символ, и который, в соответствии со структурой синтаксиса синтаксических элементов 1, как ожидается в настоящий момент, которое ожидание, в свою очередь, является выводимым из предыстории предыдущих синтаксических элементов 1 и символов 3. Кроме того, кодер содержит множество энтропийных кодеров 10, каждый из которых выполнен с возможностью преобразования символов 3, направляемых в соответствующий энтропийный кодер, в соответствующий битовый поток 312, и селектор 306, выполненный с возможностью направления каждого символа 3 к выбранному одному из множества энтропийных кодеров 10, причем выбор зависит от количества параметров 305, назначенных соответствующему символу 3. Средство 304 назначения может рассматриваться как интегрируемое в селектор 206, чтобы получить соответствующий селектор 502.
Декодер для восстановления последовательности символов содержит множество энтропийных декодеров 322, каждый из которых выполнен с возможностью преобразования соответствующего битового потока 323 в символы 321; средство 316 назначения, выполненное с возможностью назначения нескольких параметров 317 каждому символу 315 последовательности символов, подлежащей восстановлению, основываясь на информации, содержащейся в ранее восстановленных символах последовательности символов (см. позиции 326 и 327 на фиг. 8); и селектор 318, выполненный для извлечения каждого символа из последовательности символов, подлежащей восстановлению, от выбранного одного из множества энтропийных декодеров 322, причем выбор зависит от количества параметров, определенных для соответствующего символа. Средство 316 назначения может быть выполнено так, что количество параметров, назначаемых каждому символу, содержит или представляет собой, меру для оценки вероятности распределения среди возможных значений символа, которые соответствующий символ может принимать. Снова, средство 316 назначения и селектор 318 могут рассматриваться как интегрируемые в один блок, селектор 402. Последовательность символов, подлежащих восстановлению, может представлять собой двоичный алфавит, и средство 316 назначения может быть выполнено так, что оценка распределения вероятности состоит из меры для оценки вероятности менее вероятного или более вероятного значения бина из двух возможных значений бина двоичного алфавита и идентификатора, задающего оценку, какое из двух возможных значений бина представляет менее вероятное или более вероятное значение бина. Средство 316 назначения может быть дополнительно выполнено с возможностью внутреннего назначения контекста каждому символу последовательности символов 315, подлежащих восстановлении, основываясь на информации, содержащейся в ранее восстановленных символах последовательности символов, подлежащих восстановлению, причем каждый контекст имеет соответствующую оценку распределения вероятности, ассоциированную с ним, и адаптации оценки распределения вероятности для каждого контекста фактической статистике символов, основываясь на значениях символа ранее восстановленных символов, которым назначен соответствующий контекст. Контекст может принимать во внимание пространственную зависимость или соседство позиций, к которым принадлежат синтаксические элементы, такие как при кодировании видео или изображений, или даже в таблицах, в случае финансовых применений. Затем мера для оценки распределения вероятности для каждого символа может определяться на основе оценки распределения вероятности, ассоциированной с контекстом, назначенным соответствующему символу, например, посредством квантования, или использования в качестве индекса в соответствующей таблице, оценки распределения вероятности, ассоциированной с контекстом, назначенным с соответствующим символом (в последующих вариантах осуществления, индексируемых индексом pipe вместе с индексом уточнения), одному из множества представителей оценки распределения вероятности (вырезая индекс уточнения), чтобы получить меру для оценки распределения вероятности (индекс pipe индексирует частичный битовый поток 312). Селектор может быть выполнен так, что определяется биективная ассоциация между множеством энтропийных кодеров и множеством представителей оценки распределения вероятности. Селектор 18 может быть выполнен с возможностью изменения во времени отображения квантования из диапазона оценок распределения вероятности в множество представителей оценки распределения вероятности заданным детерминированным образом в зависимости от ранее восстановленных символов последовательности символов. Т.е. селектор 318 может изменять размеры шага квантования, т.е. интервалы распределений вероятности, отображаемых на индивидуальные индексы вероятности, биективно ассоциированные с индивидуальными энтропийными декодерами. Множество энтропийных декодеров 322, в свою очередь, может быть выполнено с возможностью адаптации их способа преобразования символов в битовые потоки, реагируя на изменение в отображении квантования. Например, каждый энтропийный декодер 322 может быть оптимизирован, т.е. может иметь оптимальный коэффициент сжатия, для некоторой оценки распределения вероятности в пределах соответствующего интервала квантования оценки распределения вероятности, и может изменять отображение своих кодовых слов/последовательности символов, чтобы адаптировать позицию этой некоторой оценки распределения вероятности в пределах соответствующего интервала квантования оценки распределения вероятности при изменении последнего, чтобы она была оптимизирована. Селектор может быть выполнен с возможностью изменения отображения квантования, так что скорости, с которыми символы извлекаются из множества энтропийных декодеров, делаются менее рассредоточенными. Что касается бинаризатора 314, отмечается, что он может быть исключен, если синтаксические элементы уже являются двоичными. Кроме того, в зависимости от типа декодера 322 существование буферов 320 не является необходимым. Кроме того, буферы могут интегрироваться в декодеры.
Завершение конечных последовательностей синтаксических элементов
В предпочтительном варианте осуществления изобретения кодирование и декодирование выполняется для конечного множества синтаксических элементов. Часто кодируется некоторое количество данных, такое как неподвижное изображение, кадр или поле видеопоследовательности, слайс изображения, слайс кадра или поля видеопоследовательности или множество последовательных элементов дискретизации аудио и т.д. Для конечных множеств синтаксических элементов, как правило, частичные битовые потоки, которые создаются на стороне кодера, должны завершаться, т.е. необходимо гарантировать, что все синтаксические элементы могут декодироваться из передаваемых или хранимых частичных битовых потоков. После того как последний бин будет вставлен в соответствующий буфер 308 бинов, кодер 310 бинов должен гарантировать, что полное кодовое слово записывается в частичный битовый поток 312. Если кодер 310 бинов представляет энтропийный кодер, который реализует прямое отображение последовательностей бинов в кодовые слова, последовательность бинов, которая сохраняется в буфере бинов после записи последнего бина в буфер бинов, может не представлять последовательность бинов, которая ассоциируется с кодовым словом (т.е. она может представлять префикс двух или более последовательностей бинов, которые ассоциируются с кодовыми словами). В таком случае, любое из кодовых слов, ассоциированное с последовательностью бинов, которая содержит последовательность бинов в буфере бинов в качестве префикса, должна записываться в частичный битовый поток (буфер бинов должен быть очищен). Это может выполняться посредством вставки бинов с конкретным или произвольным значением в буфер бинов до тех пор, пока не будет записано кодовое слово. В предпочтительном варианте осуществления изобретения кодер бинов выбирает одно из кодовых слов с минимальной длиной (в дополнение к свойству, что ассоциированная последовательность бинов должна содержать последовательность бинов в буфере бинов в качестве префикса). На стороне декодера декодер 322 бинов может декодировать больше бинов, чем требуется для последнего кодового слова в частичном битовом потоке; эти бины не запрашиваются селектором 318 буфера бинов и отбрасываются и игнорируются. Декодирование конечного множества символов управляется запросами декодируемых синтаксических элементов; если не запрашивается дальнейший синтаксический элемент для количества данных, декодирование завершается.
Передача и мультиплексирование частичных битовых потоков
Частичные битовые потоки 312, которые создаются кодером, могут передаваться отдельно, или они могут мультиплексироваться в единственный битовый поток, или кодовые слова частичных битовых потоков могут перемежаться в единственном битовом потоке.
В варианте осуществления изобретения каждый частичный битовый поток для некоторого количества данных записывается в один пакет данных. Количество данных может представлять собой произвольное множество синтаксических элементов, такое как неподвижное изображение, поле или кадр видеопоследовательности, слайс неподвижного изображения, слайс поля или кадра видеопоследовательности, или кадр элементов дискретизации аудио, и т.д.
В другом предпочтительном варианте осуществления изобретения два или более частичных битовых потоков для некоторого количества данных или все частичные битовые потоки для некоторого количества данных мультиплексируются в один пакет данных. Структура пакета данных, который содержит мультиплексированные частичные битовые потоки, изображена на фиг. 9.
Пакет 400 данных состоит из заголовка и одного раздела для данных каждого частичного битового потока (для рассматриваемого количества данных). Заголовок 400 пакета данных содержит указания для разделения (остальной части) пакета данных на сегменты данных 402 битового потока. Кроме указаний для разделения заголовок может содержать дополнительную информацию. В предпочтительном варианте осуществления изобретения указания для разделения пакета данных представляют собой расположения начала сегментов данных в единицах битов или байтов или кратных битам или кратным байтам. В предпочтительном варианте осуществления изобретения расположения начала сегментов данных кодируются в виде абсолютных значений в заголовке пакета данных, или относительно начала пакета данных, или относительно конца заголовка, или относительно начала предыдущего пакета данных. В другом предпочтительном варианте осуществления изобретения расположения начала сегментов данных кодируются дифференцированно, т.е. кодируется только разность между фактическим началом сегмента данных и предсказанием для начала сегмента данных. Предсказание может выводиться на основе уже известной или переданной информации, такой как общий размер пакета данных, размер заголовка, количество сегментов данных в пакете данных, расположение начала предшествующих сегментов данных. В предпочтительном варианте осуществления изобретения расположение начала первого пакета данных не кодируется, но выводится на основе размера заголовка пакета данных. На стороне декодера переданные указания о разделах используются для выведения начала сегментов данных. Сегменты данных затем используются в качестве частичных битовых потоков, и данные, содержащиеся в сегментах данных, подаются в соответствующие декодеры бинов в последовательном порядке.
Существует несколько альтернатив для мультиплексирования частичных битовых потоков в пакет данных. Одна альтернатива, которая может уменьшать требуемую дополнительную информацию, в частности для случаев, в которых размеры частичных потоков являются очень похожими, изображена на фиг. 10. Полезная нагрузка пакета данных, т.е. пакет 410 данных без заголовка 411, разделяется на сегменты 412 заданным образом. В качестве примера, полезная нагрузка пакета данных может разделяться на сегменты одинакового размера. Затем каждый сегмент ассоциируется с частичным битовым потоком или с первой частью частичного битового потока 413. Если частичный битовый поток больше ассоциированного сегмента данных, его оставшаяся часть 414 размещается в неиспользуемое пространство в конце других сегментов данных. Это может выполняться таким образом, что оставшаяся часть битового потока вставляется в обратном порядке (начиная с конца сегмента данных), что уменьшает дополнительную информацию. Ассоциирование остальных частей частичных битовых потоков с сегментами данных, и, когда более одной остальной части добавляется к сегменту данных, начальная точка для одной или нескольких остальных частей должна сигнализироваться внутри битового потока, например, в заголовке пакета данных.
Перемежение кодовых слов переменной длины
Для некоторых применений вышеописанное мультиплексирование частичных битовых потоков (для некоторого количества синтаксических элементов) в одном пакете данных может иметь следующие недостатки: С одной стороны, для малых пакетов данных количество битов для дополнительной информации, которая требуется для сигнализации разделения, может стать существенным относительно фактических данных в частичных битовых потоках, что, в конце концов, уменьшает эффективность кодирования. С другой стороны, мультиплексирование может не быть подходящим для применений, которые требуют низкой задержки (например, для приложений видеоконференции). С описанным мультиплексированием кодер не может начать передачу пакета данных, перед тем как не будут полностью созданы частичные битовые потоки, так как прежде неизвестны расположения начала разделов. Кроме того, как правило, декодеру приходится ожидать до тех пор, пока он не примет начало последнего сегмента данных, перед тем как он сможет начать декодирование пакета данных. Для применений в качестве систем видеоконференции эти задержки могут добавлять к дополнительной общей задержке системы нескольких изображений (в частности, для скоростей передачи битов, которые близки к скорости передачи битов и для кодеров/декодеров, которые требуют чуть ли не временной интервал между двумя изображениями для кодирования/декодирования изображения), что является критичным для таких приложений. Чтобы преодолеть недостатки для некоторых применений, кодер предпочтительного варианта осуществления изобретения может быть выполнен таким образом, что кодовые слова, которые генерируются двумя или более кодерами бинов, перемежаются в единственный битовый поток. Битовый поток с перемежаемыми кодовыми словами может непосредственно посылаться декодеру (при игнорировании малой задержки буфера, см. ниже). На стороне декодера два или более декодеров бинов считывают кодовые слова непосредственно из битового потока в порядке декодирования; декодирование может начинаться с первым принятым битом. Кроме того, не требуется никакая дополнительная информация для сигнализации мультиплексирования (или перемежения) частичных битовых потоков. Другой путь уменьшения сложности декодера может достигаться тогда, когда декодеры 322 бинов не считывают кодовые слова переменной длины из глобального буфера битов, но, вместо этого, они всегда считывают последовательности фиксированной длины битов из глобального буфера битов и добавляют эти последовательности фиксированной длины битов в локальный буфер битов, где каждый декодер 322 бинов соединен с отдельным локальным буфером битов. Кодовые слова переменной длины затем считываются из локального буфера битов. Следовательно, синтаксический анализ кодовых слов переменной длины может выполняться параллельно, только доступ к последовательностям фиксированной длины битов должен выполняться синхронизированным образом, но такой доступ к последовательностям фиксированной длины битов обычно является очень быстрым, так что общая сложность декодирования может быть уменьшена для некоторых архитектур. Фиксированное количество бинов, которые посылаются в конкретный локальный буфер битов, может быть разным для разных локальных буферов битов, и оно также может изменяться во времени в зависимости от некоторых параметров, таких как события в декодере бинов, буфере бинов или буфере битов. Однако количество битов, которые считываются посредством конкретного доступа, не зависит от фактических битов, которые считываются во время конкретного доступа, что представляет собой важное отличие от считывания кодовых слов переменной длины. Считывание последовательностей фиксированной длины битов запускается некоторыми событиями в буферах бинов, декодерах бинов или локальных буферах битов. В качестве примера, возможно выполнять запрос считывания новой последовательности фиксированной длины битов, когда количество битов, которые присутствуют в подсоединенном буфере битов, падает ниже заданного порога, когда разные пороговые значения могут использоваться для разных буферов битов. В кодере необходимо гарантировать, что последовательности фиксированной длины бинов вставляются в том же порядке в битовый поток, в котором они считываются из битового потока на стороне декодера. Также является возможным объединение этого перемежения последовательностей фиксированной длины с управлением с малой задержкой, подобно тем, которые описаны выше. Ниже описывается предпочтительный вариант осуществления для перемежения последовательностей фиксированной длины битов. В отношении дополнительных подробностей, касающихся последних схем перемежения, ссылка делается на WO2011/128268A1.
После описания вариантов осуществления, согласно которым даже ранее кодирование используется для сжатия видеоданных, описывается в качестве еще другого варианта осуществления для реализации вариантов осуществления настоящего изобретения, которое изображает реализацию, особенно эффективную в смысле хорошего компромисса между коэффициентом сжатия, с одной стороны, и таблицей поиска и издержками вычисления, с другой стороны. В частности, нижеследующие варианты осуществления позволяют использовать менее сложные в смысле вычисления коды переменной длины для энтропийного кодирования индивидуальных битовых потоков, и эффективно закрывают части оценки вероятности. В вариантах осуществления, описанных ниже, символы являются двоичной природы, и коды VLC (коды переменной длины), представленные ниже, эффективно закрывают оценку вероятности, представленную, например, посредством RLPS (наименее вероятный символ), проходящего в пределах [0; 0,5].
В частности, варианты осуществления, кратко описанные ниже, описывают возможные реализации для индивидуальных энтропийных кодеров 310 и декодеров 322 на фиг. 7-17 соответственно. Они подходят для кодирования бинов, т.е. двоичных символов, так как они имеют место в приложениях сжатия изображения или видео. Следовательно, эти варианты осуществления также применимы к кодированию изображения или видео, где такие двоичные символы разделяются на один или несколько потоков бинов 307, подлежащих кодированию, и битовые потоки 324, подлежащие декодированию соответственно, где каждый такой поток бинов может рассматриваться как реализация процесса Бернулли. Варианты осуществления, описанные ниже, используют один или несколько из объясняемых ниже различных так называемых переменный-в-переменный кодов (v2v-коды) для кодирования потоков бинов. v2v-код может рассматриваться как два беспрефиксных кода с одинаковым количеством кодовых слов. Первичный и вторичный беспрефиксный код. Каждое кодовое слово первичного беспрефиксного кода ассоциируется с одним кодовым словом вторичного беспрефиксного кода. В соответствии с ниже описанными кратко вариантами осуществления по меньшей мере некоторые из кодеров 310 и декодеров 322 работают следующим образом: Для кодирования конкретной последовательности бинов 307, всякий раз когда кодовое слово первичного беспрефиксного кода считывается из буфера 308, соответствующее кодовое слово вторичного беспрефиксного кода записывается в битовый поток 312. Эта же процедура используется для декодирования такого битового потока 324, но первичный и вторичный беспрефиксный код меняются местами. Т.е. для декодирования битового потока 324 всякий раз, когда кодовое слово вторичного беспрефиксного кода считывается из соответствующего битового потока 324, соответствующее кодовое слово первичного беспрефиксного кода записывается в буфер 320.
Полезно, что коды, описанные ниже, не требуют таблиц поиска. Коды являются реализуемыми в виде конечных автоматов. v2v-коды, представленные здесь, могут генерироваться простыми правилами построения, такими как, что нет необходимости сохранять большие таблицы для кодовых слов. Вместо этого, простой алгоритм может использоваться для выполнения кодирования или декодирования. Ниже описываются три правила построения, где два из них могут параметризоваться. Они закрывают разные или даже непересекающиеся части вышеупомянутого интервала вероятностей и, следовательно, являются особенно полезными, если используются вместе, например, все три кода параллельно (каждый для разных кодеров/декодеров 11 и 22) или два из них. С описанными ниже правилами построения является возможным разрабатывать набор v2v-кодов, так что для процессов Бернулли с произвольной вероятностью p, один из кодов хорошо работает в отношении избыточной длины кода.
Как изложено выше, кодирование и декодирование потоков 312 и 324 соответственно может выполняться или независимо для каждого потока, или перемежаемым образом. Это, однако, не является характерным для представленных классов v2v-кодов, и, поэтому, только кодирование и декодирование конкретного кодового слова описывается для каждого из трех правил построения в нижеследующем. Однако подчеркивается, что все вышеупомянутые варианты осуществления, касающиеся решений с перемежением, также являются пригодными для объединения с описанными в настоящее время кодами или кодерами и декодерами 310 и 322 соответственно.
Правило построения 1: Коды «pipe (энтропия разделения интервала вероятностей) унарных бинов» или кодеры/декодеры 310 и 322
Коды энтропии разделения интервала вероятностей (pipe) унарных бинов представляют собой особую версию так называемых кодов «pipe бинов», т.е. кодов, пригодных для кодирования любого из индивидуальных битовых потоков 12 и 24, причем каждый переносит данные о статистике двоичных символов, принадлежащей некоторому вероятностному подынтервалу вышеупомянутого диапазона вероятности [0; 0,5]. Сначала описывается построение кодов pipe бинов. Код pipe бинов может быть построен из любого беспрефиксного кода с по меньшей мере тремя кодовыми словами. Для образования v2v-кода он использует беспрефиксный код в качестве первичного и вторичного кода, но меняются местами два кодовых слова вторичного беспрефиксного кода. Это означает, что за исключением двух кодовых слов бины записываются в битовый поток неизменными. С этим методом необходимо сохранять только один беспрефиксный код вместе с информацией, какие два кодовых слова меняются местами, и, таким образом, уменьшается потребление памяти. Отметьте, что это имеет смысл только для перестановки кодовых слов разной длины, так как, в противном случае, битовый поток будет иметь такую же длину, что и поток бинов (не учитывая эффекты, которые могут иметь место в конце потока бинов).
Вследствие этого правила построения известным свойством кодов pipe бинов является, что, если первичный и вторичный беспрефиксный код переставляется (тогда как отображение кодовых слов сохраняется), результирующий v2v-код является идентичным исходному v2v-коду. Поэтому, алгоритм кодирования и алгоритм декодирования идентичны для кодов pipe бинов.
Код pipe унарных бинов составляется из специального беспрефиксного кода. Этот специальный беспрефиксный код составляется следующим образом. Сначала беспрефиксный код, состоящий из n унарных кодовых слов, генерируется, начиная с «01», «001», «0001», …, пока не будет получено n кодовых слов. n представляет собой параметр для кода pipe унарных бинов. Из самого длинного кодового слова удаляется конечная 1. Это соответствует усеченному унарному коду (но без кодового слова «0»). Затем n-1 унарных кодовых слов генерируется, начиная с «10», «110», «1110», …, пока не будет получено n-1 кодовых слов. Из самого длинного из этих кодовых слов удаляется конечный 0. Множество объединения из этих двух беспрефиксных кодов используется в качестве ввода для генерирования кода pipe унарных бинов. Два кодовых слова, которые переставляются, представляют собой один, состоящий только из 0, и один, состоящий только из 1.
Пример для n=4:
№ Первичный Вторичный
1 0000 111
2 001 0001
3 001 001
4 01 01
5 10 10
6 110 110
7 111 0000
Правило 2 построения: «Унарный-в-Райс»-коды и унарные-в-Райс-кодеры/декодеры 10 и 22:
Унарный-в-Райс-коды используют усеченный унарный код в качестве первичного кода. Т.е. унарные кодовые слова генерируются, начиная с «1», «01», «001», …, пока не будут сгенерированы 2n+1 кодовых слов и из самого длинного кодового слова удаляется конечная 1. n представляет собой параметр унарного-в-Райс-кода. Вторичный беспрефиксный код составляется из кодовых слов первичного беспрефиксного кода следующим образом. Первичному кодовому слову, состоящему только из 0, назначается кодовое слово «1». Все другие кодовые слова состоят из конкатенации кодового слова «0» с n-битовым двоичным представлением количества 0 соответствующего кодового слова первичного беспрефиксного кода.
Пример для n=3:
№ Первичный Вторичный
1 1 0000
2 01 0001
3 001 0010
4 0001 0011
5 00001 0100
6 000001 0101
7 0000001 0110
8 00000001 0111
9 00000000 1
Отметьте, что это идентично отображению бесконечного унарного кода на код Райса с параметром Райса 2n.
Правило построения 3: «Трехбиновый» код
Трехбиновый код определяется как:
№ Первичный Вторичный
1 000 0
2 001 100
3 010 101
4 100 110
5 110 11100
6 101 11101
7 011 11110
8 111 11111
Он имеет свойство, что первичный код (последовательность символов) имеет фиксированную длину (всегда три бина), и кодовые слова сортируются по возрастающим числам 1.
Ниже описывается эффективная реализация трехбинового кода. Кодер и декодер для трехбинового кода могут быть реализованы без хранения таблиц следующим образом.
В кодере (любой из 10) три бина считываются из потока бинов (т.е. 7). Если эти три бина содержат точно одну 1, кодовое слово «1» записывается в битовый поток, за которыми следует два бина, состоящие из двоичного представления позиции 1 (начиная справа с 00). Если три бина содержат точно один 0, кодовое слово «111» записывается в битовый поток, за которым следует два бина, состоящие из двоичного представления позиции 0 (начиная справа с 00). Остальные кодовые слова «000» и «111» отображаются на «0» и «11111» соответственно.
В декодере (любом из 22) один бин или бит считывается из соответствующего битового потока 24. Если он равен «0», кодовое слово «000» декодируется в поток 21 бинов. Если он равен «1», еще два бина считываются из битового потока 24. Если эти два бита не равны «11», они интерпретируются как двоичное представление числа, и два 0 и одна 1 декодируются в битовый поток, так что позиция 1 определяется числом. Если два бита равны «11», еще два бита считываются и интерпретируются как двоичное представление числа. Если это число меньше 3, две 1 и один 0 декодируются, и число определяет позицию 0. Если оно равно 3, «111» декодируется в поток бинов.
Ниже описывается эффективная реализация кодов pipe унарных бинов. Кодер и декодер для кодов pipe унарных бинов могут эффективно реализоваться посредством использования счетчика. Вследствие структуры кодов pipe бинов, кодирование и декодирование кодов pipe бинов легко реализовать:
В кодере (любом из 10), если первый бин кодового слова равен «0», бины обрабатываются до тех пор, пока не встретится «1», или пока не будут считаны n 0 (включая первый «0» кодового слова). Если встретилась «1», считанные бины записываются в битовый поток неизменными. В противном случае, (т.е. были считаны n 0), n-1 1 записываются в битовый поток. Если первый бин кодового слова равен «1», бины обрабатываются до тех пор, пока не встретится «0», или пока не будут считаны n-1 1 (включая первую «1» кодового слова). Если встречается «0», считанные бины записываются в битовый поток неизменными. В противном случае, (т.е. были считаны n-1 1), n 0 записывается в битовый поток.
В декодере (любом из 322) используется этот же алгоритм, что и для кодера, так как он является одинаковым для кодов pipe бинов, как описано выше.
Ниже описывается эффективная реализация унарных-в-Райс-кодов. Кодер и декодер для унарных-в-Райс-кодов могут быть эффективно реализованы посредством использования счетчика, как описывается ниже.
В кодере (любом из 310) бины считываются из потока бинов (т.е. 7) до тех пор, пока не встретится 1, или пока не будут считаны 2n 0. Количество 0 подсчитывается. Если подсчитанное количество равно 2n, кодовое слово «1» записывается в битовый поток. В противном случае, записывается «0», за которым следует двоичное представление подсчитанного количества, записанное с n битами.
В декодере (любом из 322) считывается один бит. Если он равен «1», 2n 0 декодируется в строку бинов. Если он равен «0», еще n битов считывается и интерпретируется как двоичное представление количества. Это количество 0 декодируется в поток бинов, за которым следует «1».
Другими словами, только что описанные варианты осуществления описывают кодер для кодирования последовательности символов 303, содержащий средство 316 назначения, выполненное с возможностью назначения нескольких параметров 305 каждому символу последовательности символов, основываясь на информации, содержащейся в предыдущих символах последовательности символов; множество энтропийных кодеров 310, каждый из которых выполнен с возможностью преобразования символов 307, направляемых соответствующему энтропийному кодеру 310, в соответствующий битовый поток 312; и селектор 6, выполненный с возможностью направлять каждый символ 303 выбранному одному из множества энтропийных кодеров 10, причем выбор зависит от количества параметров 305, назначенных соответствующему символу 303. Согласно только что описанным вариантам осуществления по меньшей мере первое подмножество энтропийных кодеров может представлять собой кодер переменной длины, выполненный с возможностью отображения последовательностей символов переменной длины в потоке символов 307 на кодовые слова переменной длины, подлежащие вставлению в битовый поток 312 соответственно, причем каждый из энтропийных кодеров 310 первого подмножества использует правило биективного отображения, согласно которому кодовые слова первичного беспрефиксного кода с (2n-1)≥3 кодовыми словами отображаются на кодовые слова вторичного беспрефиксного кода, который идентичен первичному префиксному коду, так что все кроме двух из кодовых слов первичного беспрефиксного кода отображаются на идентичные кодовые слова вторичного беспрефиксного кода, тогда как два кодовых слова первичного и вторичного беспрефиксных кодов имеют разные длины и отображаются друг на друга попеременно, причем энтропийные кодеры могут использовать разные n, чтобы закрывать разные части интервала вышеупомянутого интервала вероятностей. Первый беспрефиксный код может составляться так, что кодовыми словами первого беспрефиксного кода являются (a,b)2, (a,a,b)3, …, (a, …, a,b)n, (a, …, a)n, (b,a)2, (b,b,a)3, …, (b, …, b,a)n-1, (b, …, b)n-1, и двумя кодовыми словами, отображаемыми друг на друга попеременно, являются (a, …, a)n и (b, …, b)n-1 с b≠a и a,b
Другими словами, каждый из первого подмножества энтропийных кодеров может быть выполнен, при преобразовании символов, направляемых соответствующему энтропийному кодеру, в соответствующий битовый поток, с возможностью исследования первого символа, направляемого соответствующему энтропийному кодеру, для определения, (1) равен ли первый символ a
Дополнительно или альтернативно, второе подмножество энтропийных кодеров 10 может представлять собой кодер переменной длины, выполненный с возможностью отображения последовательностей символов переменной длины на кодовые слова фиксированной длины соответственно, причем каждый из энтропийных кодеров второго подмножества использует правило биективного отображения, согласно которому кодовые слова первичного усеченного унарного кода с 2n+1 кодовыми словами типа {(a), (ba), (bba), …, (b…ba), (bb…b)} с b≠a и a,b
Снова, с точки зрения режима работы соответствующего кодера 10, каждый из второго подмножества энтропийных кодеров может быть выполнен, при преобразовании символов, направляемых соответствующему энтропийному кодеру, в соответствующий битовый поток, с возможностью подсчета количества b в последовательности символов, направляемых соответствующему энтропийному кодеру до тех пор, пока не встретится, или пока количество последовательности символов, направляемых соответствующему энтропийному кодеру, не достигнет 2n, причем все 2n символов в последовательности равны b, и (1) если количество b равно 2n, записи c с c
Также дополнительно или альтернативно, предварительно определенным одним из энтропийных кодеров 10 может быть кодер переменной длины, выполненный с возможностью отображения последовательностей символов фиксированной длины на кодовые слова переменной длины соответственно, причем предварительно определенный энтропийный кодер использует правило биективного отображения, согласно которому 23 кодовых слов длиной 3 первичного кода отображаются на кодовые слова вторичного беспрефиксного кода, так что кодовое слово (aaa)3 первичного кода с a
Снова предварительно определенный один из энтропийных кодеров может быть выполнен, при преобразовании символов, направляемых предварительно определенному энтропийному кодеру, в соответствующий битовый поток, с возможностью исследования символов на предварительно определенный энтропийный кодер в тройках, (1) состоит ли тройка из a, в этом случае предварительно определенный энтропийный кодер выполняется с возможностью записи кодового слова (c) в соответствующий битовый поток, (2) содержит ли тройка точно одну b, в этом случае предварительно определенный энтропийный кодер выполняется с возможностью записи кодового слова, имеющего (d) в качестве префикса и 2-битовое представление позиции b в тройке в качестве суффикса, в соответствующий битовый поток; (3) содержит ли тройка точно одно a, в этом случае предварительно определенный энтропийный кодер выполняется с возможностью записи кодового слова, имеющего (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого множества, и 2-битового представления позиции a в тройке в качестве суффикса, в соответствующий битовый поток; или (4) состоит ли тройка из b, в этом случае предварительно определенный энтропийный кодер выполняется с возможностью записи кодового слова, имеющего (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого множества, и первого 2-битового слова, не являющегося элементом второго множества, в качестве суффикса, в соответствующий битовый поток.
Что касается декодирующей стороны, только что описанные варианты осуществления описывают декодер для восстановления последовательности символов 326, содержащий множество энтропийных декодеров 322, каждый из которых выполнен с возможностью преобразования соответствующего битового потока 324 в символы 321; средство 316 назначения, выполненное с возможностью назначения нескольких параметров каждому символу 326 последовательности символов, подлежащих восстановлению, основываясь на информации, содержащейся в ранее восстановленных символах последовательности символов; и селектор 318, выполненный с возможностью извлечения каждого символа 325 последовательности символов, подлежащих восстановлению, из выбранного одного из множества энтропийных декодеров, причем выбор зависит от количества параметров, определенных соответствующему символу. Согласно только что описанным вариантам осуществления по меньшей мере первое подмножество энтропийных декодеров 322 представляет собой декодеры переменной длины, выполненные с возможностью отображения кодовых слов переменной длины на последовательности символов переменной длины соответственно, причем каждый из энтропийных декодеров 22 первого подмножества использует правило биективного отображения, в соответствии с которыми кодовые слова первичного беспрефиксного кода с (2n-1)≥3 кодовыми словами отображаются на кодовые слова вторичного беспрефиксного кода, который идентичен первичному префиксному коду, так что все кроме двух из кодовых слов первичного беспрефиксного кода отображаются на идентичные кодовые слова вторичного беспрефиксного кода, тогда как два кодовых слова первичного и вторичного беспрефиксных кодов имеют разные длины и отображаются друг на друга попеременно, причем энтропийные кодеры используют разные n. Первый беспрефиксный код может быть построен так, что кодовыми словами первого беспрефиксного кода являются (a,b)2, (a,a,b)3, …, (a, …, a,b)n, (a, …, a)n, (b,a)2, (b,b,a)3, …, (b, …, b,a)n-1, (b, …, b)n-1, и двумя кодовыми словами, отображаемыми друг на друга попеременно, могут быть (a, …, a)n и (b, …, b)n-1 с b≠a и a,b
Каждый из первого подмножества энтропийных кодеров может быть выполнен, при преобразовании соответствующего битового потока в символы, с возможностью исследования первого бита соответствующего битового потока, для определения, (1) равен ли первый бит a 0 {0,1}, в этом случае соответствующий энтропийный кодер выполняется с возможностью исследования следующих битов соответствующего битового потока для определения, (1.1) встречается ли b с b≠a и b 0 {0,1} в следующих n-1 битах, следующих за первым битом, в этом случае соответствующий энтропийный декодер выполняется с возможностью восстановления последовательности символов, которая равна первому биту, за которым следуют последующие биты соответствующего битового потока, до бита b; или (1.2) не встречается ли b в следующих n-1 битах, следующих за первым битом, в этом случае соответствующий энтропийный декодер выполняется с возможностью восстановления последовательности символов, которая равна (b, …, b)n-1; или (2) равен ли первый бит b, в этом случае соответствующий энтропийный декодер выполняется с возможностью исследования последующих битов соответствующего битового потока для определения, (2.1) встречается ли a в следующих n-2 битах, следующих за первым битом, в этом случае соответствующий энтропийный декодер выполняется с возможностью восстановления последовательности символов, которая равна первому биту, за которым следуют последующие биты соответствующего битового потока до символа a; или (2.2) не встречается ли a в следующих n-2 битах, следующих за первым битом, в этом случае соответствующий энтропийный декодер выполняется с возможностью восстановления последовательности символов, которая равна (a, …, a)n.
Дополнительно или альтернативно, по меньшей мере второе подмножество энтропийных декодеров 322 может представлять собой декодер переменной длины, выполненный с возможностью отображения кодовых слов фиксированной длины на последовательности символов переменной длины соответственно, причем каждый из энтропийных декодеров второго подмножества использует правило биективного отображения, согласно которому кодовые слова вторичного беспрефиксного кода отображаются на кодовые слова первичного усеченного унарного кода с 2n+1 кодовыми словами типа {(a), (ba), (bba), …, (b…ba), (bb…b)} с b≠a и a,b
Каждый из второго подмножества энтропийных декодеров может представлять собой декодер переменной длины, выполненный с возможностью отображения кодовых слов фиксированной длины на последовательности символов переменной длины соответственно, и выполненный, при преобразовании битового потока соответствующего энтропийного декодера в символы, с возможностью исследования первого бита соответствующего битового потока для определения, (1) равен ли он c с c
Дополнительно или альтернативно, предварительно определенный один из энтропийных декодеров 322 может быть декодером переменной длины, выполненным с возможностью отображения кодовых слов переменной длины на последовательности символов фиксированной длины соответственно, причем предварительно определенный энтропийный декодер использует правило биективного отображения, согласно которому кодовые слова вторичного беспрефиксного кода отображаются на 23 кодовые слова длины 3 первичного кода, так что кодовое слово (c) с c
Предварительно определенный один из энтропийных декодеров может представлять собой декодер переменной длины, выполненный с возможностью отображения кодовых слов переменной длины на последовательности символов из трех символов каждая соответственно, и выполненный, при преобразовании битового потока соответствующего энтропийного декодера в символы, с возможностью исследования первого бита соответствующего битового потока для определения, (1) равен ли первый бит соответствующего битового потока c с c
Теперь после описания общего принципа схемы видеокодирования описываются варианты осуществления настоящего изобретения в отношении вышеупомянутых вариантов осуществления. Другими словами, варианты осуществления, кратко описанные ниже, могут быть реализованы посредством использования вышеупомянутых схем, и наоборот, вышеупомянутые схемы кодирования могут быть реализованы с использованием и применением вариантов осуществления, кратко описанных ниже.
В вышеупомянутых вариантах осуществления, описанных в отношении фиг. 7-9, энтропийный кодер и декодеры по фиг. 1-6, были реализованы в соответствии с принципом PIPE. Один особый вариант осуществления использовал кодеры/декодеры 310 и 322 с арифметическим одновероятностным состоянием. Как описано ниже, согласно альтернативному варианту осуществления объекты 306-310 и соответствующие объекты 318-322 могут быть заменены обычным механизмом энтропийного кодирования. В качестве примера, представим механизм арифметического кодирования, который управляет только одним общим состоянием R и L и кодирует все символы в один общий битовый поток, таким образом отказываясь от полезных аспектов настоящего принципа PIPE, касающегося параллельной обработки, но исключая необходимость перемежения частичных битовых потоков, как дополнительно описано ниже. Делая так, количество вероятностных состояний, посредством которых вероятности контекста оцениваются посредством обновления (такого как табличный поиск), может быть выше, чем количество вероятностных состояний, посредством которых выполняется подразделение интервала вероятностей. Т.е. аналогично квантованию значения ширины интервала вероятностей перед индексированием в таблицу Rtab, также может квантоваться индекс состояния вероятности. Вышеупомянутое описание для возможной реализации для единственных кодеров/декодеров 310 и 322, таким образом, может быть расширено для примера реализации энтропийных кодеров/декодеров 318-322/306-310 в качестве механизмов контекстно-адаптивного двоичного арифметического кодирования/декодирования.
Более точно, согласно варианту осуществления энтропийный кодер, подсоединенный к выходу средства назначения параметра (который служит здесь в качестве средства назначения контекста), может работать следующим образом:
0. Средство 304 назначения направляет значение бина вместе с параметром вероятности. Вероятность равна pState_current[bin].
1. Таким образом, механизм энтропийного кодирования принимает: 1) valLPS, 2) бин и 3) оценку pState_current[bin] распределения вероятности. pState_current[bin] может иметь больше состояний, чем количество индексов различимых вероятностных состояний Rtab. Если это так, pState_current[bin] может квантоваться, так что, например, посредством игнорирования m младших значащих битов (LSB), при этом m больше или равно 1 или предпочтительно 2 или 3 для получения p_state, т.е. индекс, который затем используется для доступа к таблице Rtab. Квантование, однако, может быть исключено, т.е. p_state может быть pState_current[bin].
2. Затем выполняется квантование R (Как упомянуто выше: или один R (и соответствующий L с одним общим битовым потоком) используется/управляется для всех различимых значений p_state, или одно R (и соответствующий L с ассоциированным частичным битовым потоком на пару R/L) на различимое значение p_state, этот последний случай будет соответствовать тому, что имеется один кодер 310 бинов на такое значение)
q_index=Qtab[R>>q] (или некоторый другой вид квантования)
3. Затем выполняется определение RLPS и R:
RLPS=Rtab[p_state][q_index]; Rtab сохранил в нем предварительно вычисленные значения для p[p_state]∙Q[q_index]
R=R-RLPS [т.е. R предварительно предобновляется, как если бы «бином» был MPS (наиболее вероятный символ)]
4. Вычисление нового предварительного интервала:
if (bin=1-valMPS) then
L ¬ L+R
R ¬ RLPS
5. Ренормализация L и R, запись битов
Аналогично, энтропийный декодер, присоединенный к выходу средства назначения параметра (который служит здесь в качестве средства назначения контекста) может работать следующим образом:
0. Средство 304 назначения направляет значение бина вместе с параметром вероятности. Вероятностью является pState_current[bin].
1. Таким образом, механизм энтропийного декодирования принимает запрос бина вместе с: 1) valLPS, и 2) оценкой распределения вероятности pState_current[bin]. pState_current[bin] может иметь больше состояний, чем количество индексов различимых вероятностных состояний Rtab. Если это так, pState_current[bin] может квантоваться так, например, пренебрегая m LSB, причем m больше или равен 1 и предпочтительно 2 или 3 для получения p_state, т.е. индекса, который затем используется для доступа к таблице Rtab. Квантование, однако, может исключаться, т.е. p_state может быть pState_current[bin].
2. Затем выполняется квантование R (Как упомянуто выше: или один R (и соответствующий V с одним общим битовым потоком) используется/управляется для всех различимых значений p_state, или один R (и соответствующий V с ассоциированным частичным битовым потоком на пару R/L) на различимое значение p_state, этот последний случай соответствует тому, что имеется один кодер 310 бинов на такое значение)
q_index=Qtab[R>>q] (или некоторый другой вид квантования)
3. Затем выполняется определение RLPS и R:
RLPS=Rtab[p_state][q_index]; Rtab сохранила в себе предварительно вычисленные значения для p[p_state]∙Q[q_index]
R=R-RLPS [т.е. R предварительно предобновляется, как если бы «бином» был MPS]
4. Определение бина в зависимости от позиции частичного интервала:
if(V3R) then
bin ¬ 1 - valMPS (бин декодируется как LPS; селектор 18 буфера бинов получает фактическое значение бина посредством использования этой информации о бине и valMPS)
V ¬ V-R
R ¬ RLPS
else
bin ¬ valMPS (бин декодируется как MPS; фактическое значение бина получается посредством использования этой информации о бине и valMPS)
5. Ренормализация R, считывание одного бита и обновление V
Как описано выше, средство 4 назначения назначает pState_current[bin] каждому бину. Ассоциирование может выполняться на основе выбора контекста. Т.е. средство 4 назначения может выбирать контекст, используя индекс ctxIdx контекста, который, в свою очередь, имеет соответствующий pState_current, ассоциированный с ним. Обновление вероятности может выполняться каждый раз, когда вероятность pState_current[bin] была применена к текущему бину. Обновление состояния вероятности pState_current[bin] выполняется в зависимости от значения кодированного бита:

Если обеспечивается более одного контекста, адаптация выполняется по контексту, т.е. pState_current[ctxIdx] используется для кодирования и затем обновления, используя текущее значение бина (кодированное или декодированное соответственно).
Как более подробно изложено ниже, согласно вариантам осуществления, описываемым теперь, кодер и декодер могут необязательно быть реализованы для работы в разных режимах, а именно, режиме низкой сложности (LC) и высокой эффективности (HE). Это изображается, главным образом, касательно кодирования PIPE в нижеследующем (упоминая тогда режимы LC и HE PIPE), но описание подробностей масштабируемости сложности легко переносится на другие реализации механизмов энтропийного кодирования/декодирования, такие как вариант осуществления использования одного общего контекстно-адаптивного арифметического кодера/декодера.
Согласно вариантам осуществления, кратко изложенным ниже, оба режима энтропийного кодирования могут совместно использовать
один и тот же синтаксис и семантику (для последовательности 301 и 327 синтаксических элементов соответственно)
одинаковые схемы бинаризации для всех синтаксических элементов (определенные в настоящее время для CABAC (контекстно-адаптивное двоичное арифметическое кодирование)) (т.е. бинаризаторы могут работать независимо от активизированного режима)
применение одинаковых кодов PIPE (т.е. кодеры/декодеры бинов могут работать независимо от активизированного режима)
применение 8-битовых значений инициализации вероятностной модели (вместо 16-битовых значений инициализации, определенных в настоящее время для CABAC)
Вообще говоря, LC-PIPE отличается от HE-PIPE сложностью обработки, такой как сложность выбора тракта 312 PIPE для каждого бина.
Например, режим LC может работать при следующих ограничениях: Для каждого бина (binIdx) может быть точно одна вероятностная модель, т.е. один ctxIdx. Т.е. в LC PIPE не может обеспечиваться выбор/адаптация контекста. Конкретные синтаксические элементы, такие как те, которые используются для кодирования остатка, могут, однако, кодироваться с использованием контекстов, как дополнительно изложено ниже. Кроме того, все вероятностные модели могут быть неадаптивными, т.е. все модели могут инициализироваться в начале каждого слайса с соответствующими вероятностями модели (в зависимости от выбора типа слайса и QP (параметр квантования) слайса) и могут поддерживаться фиксированными во время обработки слайса. Например, может поддерживаться только 8 разных вероятностей модели, соответствующих 8 разным кодам 310/322 PIPE, как для моделирования, так и кодирования контекста. Конкретные синтаксические элементы для кодирования остатка, т.е. significance_coeff_flag и coeff_abs_level_greaterX (с X=1,2), семантика которых более подробно изложена ниже, могут назначаться вероятностным моделям, таким как (по меньшей мере) группы, например, из 4 синтаксических элементов, кодируются/декодируются с одинаковой вероятностью модели. По сравнению с CAVLC (контекстно-адаптивный код переменной длины) режим LC-PIPE достигает грубо таких же рабочих характеристик R-D и такую же производительность.
HE-PIPE может быть выполнен концептуально подобно CABAC в стандарте H.264 со следующими отличиями: Двоичное арифметическое кодирование (BAC) заменяется кодированием PIPE (таким же, что и в случае LC-PIPE). Каждая вероятностная модель, т.е. каждый ctxIdx, может быть представлена посредством pipeIdx и refineIdx, где pipeIdx со значениями в диапазоне 0-7 представляет вероятность модели 8 разных кодов PIPE. Это изменение оказывает влияние только на внутреннее представление состояний, а не на поведение самого конечного автомата (т.е. оценку вероятности). Как более подробно изложено ниже, инициализация вероятностных моделей может использовать 8-битовые значения инициализации, как изложено выше. Обратное сканирование синтаксических элементов coeff_abs_level_greaterX (с X=1,2), coeff_abs_level_minus3 и coeff_sign_flag (семантика которых станет ясной из нижеследующего описания) может выполняться по этому же пути сканирования, что и сканирование вперед (используемое, например, при кодировании карты значимостей). Вывод контекста для кодирования coeff_abs_level_greaterX (с X=1,2) также может быть упрощен. По сравнению с CABAC предложенный HE-PIPE достигает грубо таких рабочих характеристик R-D при лучшей производительности.
Легко видеть, что только что упомянутые режимы легко генерируются посредством рендеринга, например, вышеупомянутого механизма контекстно-адаптивного двоичного арифметического кодирования/декодирования, так как он работает в разных режимах.
Таким образом, согласно варианту осуществления в соответствии с первым аспектом настоящего изобретения декодер для декодирования потока данных может быть выполнен так, как показано на фиг. 11. Декодер предназначен для декодирования потока 401 данных, такого как битовый поток 340 с перемежением, в какие медиаданные, такие как данные видео, кодируется. Декодер содержит переключатель 400 режима, выполненный с возможностью активизирования режима низкой сложности или режима высокой эффективности в зависимости от потока 401 данных. С этой целью, поток 401 данных может содержать синтаксический элемент, такой как двоичный синтаксический элемент, имеющий двоичное значение 1 в случае режима низкой сложности, являющегося тем, который необходимо активизировать, и имеющий двоичное значение 0 в случае режима высокой эффективности, являющегося тем, который необходимо активизировать. Очевидно, что ассоциирование между двоичным значением и режимом кодирования может переключаться, и также может использоваться недвоичный синтаксический элемент, имеющий более двух возможных значений. Так как фактический выбор между двумя режимами еще не ясен перед приемом соответствующего синтаксического элемента, этот синтаксический элемент может содержаться в некотором переднем заголовке потока 401 данных, кодированного, например, с фиксированной оценкой вероятности или вероятностной моделью или записываемого в поток 401 данных как есть, т.е. используя режим обхода.
Кроме того, декодер по фиг. 11 содержит множество энтропийных декодеров 322, каждый из которых выполнен с возможностью преобразования кодовых слов в потоке 401 данных в частичные последовательности 321 символов. Как описано выше, деперемежитель 404 может быть подсоединен между входами энтропийных декодеров 322, с одной стороны, и входом декодера по фиг. 11, где подается поток 401 данных, с другой стороны. Кроме того, как уже описано выше, каждый из энтропийных декодеров 322 может ассоциироваться с соответствующим вероятностным интервалом, причем вероятностные интервалы различных энтропийных декодеров вместе покрывают весь интервал вероятностей от 0 до 1 - или 0-0,5 в случае энтропийных декодеров 322, имеющих дело с MPS и LPS, а не абсолютными значениями символов. Подробности, касающиеся этого вопроса, были описаны выше. Позже предполагается, что количество декодеров 322 равно 8, причем индекс PIPE назначается каждому декодеру, но также возможно любое другое количество. Кроме того, один из этих кодеров, ниже им является, в качестве примера, тот, который имеет pipe_id равный 0, оптимизируется для бинов, имеющих равновероятную статистику, т.е. их значение бина принимают 1 и 0 равновероятно. Этот декодер может просто пропускать бины. Соответствующий кодер 310 работает аналогичным образом. Могут быть исключены даже любые манипулирования бинами в зависимости от значения наиболее вероятного значения бина valMPS селекторами 402 и 502 соответственно. Другими словами, энтропия соответствующего частичного потока уже является оптимальной.
Кроме того, декодер на фиг. 11 содержит селектор 402, выполненный с возможностью извлечения каждого символа последовательности 326 символов из выбранного одного из множества энтропийных декодеров 322. Как упомянуто выше, селектор 402 может быть разделен на средство 316 назначения параметра и селектор 318. Десимволизатор 314 выполнен с возможностью десимволизирования последовательности 326 символов для получения последовательности 327 синтаксических элементов. Восстановитель 404 выполнен с возможностью восстановления медиаданных 405, основываясь на последовательности синтаксических элементов 327. Селектор 402 выполнен с возможностью выполнения выбора в зависимости от активизированного одного из режима низкой сложности и режима высокой эффективности, как указывается стрелкой 406.
Как уже упомянуто выше, восстановитель 404 может быть частью видеодекодера на основе блоков предсказания, работающего с фиксированным синтаксисом и семантикой синтаксических элементов, т.е. фиксированными относительно выбора режима переключателем 400 режима. Т.е. конструкция восстановителя 404 не допускает переключаемости режимов. Более точно, восстановитель 404 не увеличивает издержки реализации из-за переключаемости режимов, предлагаемой переключателем 400 режима, и по меньшей мере функциональная возможность в отношении данных остатка и данных предсказания остается такой же независимо от режима, выбранного переключателем 400. Это также применимо, однако, в отношении энтропийных декодеров 322. Все эти декодеры 322 повторно используются в обоих режимах, и, следовательно, нет дополнительных издержек реализации, хотя декодер по фиг. 11 является совместимым с обоими режимами, режимами низкой сложности и высокой эффективности.
В качестве дополнительного аспекта необходимо отметить, что декодер по фиг. 11 не только способен работать с автономными потоками данных или в одном режиме, или в другом режиме. Вместо этого, декодер по фиг. 11, а также поток 401 данных могут быть выполнены так, что переключение между обоими режимами даже будет возможным в течение одной порции медиаданных, например, во время видео или некоторой порции аудио, чтобы, например, управлять сложностью кодирования на декодирующей стороне в зависимости от внешних или окружающих условий, таких как состояние батареи или т.п. с использованием канала обратной связи от декодера к кодеру, чтобы соответствующим образом управлять с замкнутой петлей выбором режима.
Таким образом, декодер по фиг. 11 работает аналогично в обоих случаях, в случае, когда выбирается режим LC или когда выбирается режим HE. Восстановитель 404 выполняет восстановление с использованием синтаксических элементов и запрашивает текущий синтаксический элемент заданного типа синтаксического элемента посредством обработки или подчинения некоторому предписанию структуры синтаксиса. Десимволизатор 314 запрашивает несколько бинов, чтобы выдать достоверную бинаризацию для синтаксического элемента, запрашиваемого восстановителем 404. Очевидно, что в случае двоичного алфавита бинаризация, выполняемая десимволизатором 314 понижает до простого пропускания соответствующего бина/символа 326 на восстановитель 404 в качестве запрашиваемого в настоящий момент двоичного синтаксического элемента.
Селектор 402, однако, действует независимо от режима, выбранного переключателем 400 режима. Режим работы селектора 402 имеет тенденцию быть более сложным в случае режима высокой эффективности и менее сложным в случае режима низкой сложности. Кроме того, нижеследующее описание показывает, что режим работы селектора 402 в режиме низкой сложности также имеет тенденцию уменьшать частоту, с которой селектор 402 изменяет выбор среди энтропийных декодеров 322 при извлечении последовательных символов из энтропийных декодеров 322. Другими словами, в режиме низкой сложности существует повышенная вероятность, что непосредственно последующие символы извлекаются из одного и того же энтропийного декодера из числа множества энтропийных декодеров 322. Это, в свою очередь, позволяет получить более быстрое извлечение символов из энтропийных декодеров 322. В режиме высокой эффективности, в свою очередь, режим работы селектора 402 стремится привести к выбору из числа энтропийных декодеров 322, где интервал вероятностей, ассоциированный с соответствующим выбранным энтропийным декодером 322, более точно соответствует фактической статистике символов символа, извлекаемого в настоящий момент селектором 402, таким образом получая лучший коэффициент сжатия на кодирующей стороне при генерировании соответствующего потока данных в соответствии с режимом высокой эффективности.
Например, разное поведение селектора 402 в обоих режимах может быть реализовано следующим образом. Например, селектор 402 может быть выполнен с возможностью выполнения для заданного символа выбора из числа множества энтропийных декодеров 322 в зависимости от ранее извлеченных символов последовательности 326 символов в случае активизированного режима высокой эффективности и независимо от любых ранее извлеченных символов последовательности символов в случае активизированного режима низкой сложности. Зависимость от ранее извлеченных символов последовательности 326 символов может происходить из контекстной адаптивности и/или вероятностной адаптивности. Обе адаптивности могут отключаться во время режима низкой сложности в селекторе 402.
Согласно другому варианту осуществления поток 401 данных может быть структурирован в последовательные части, такие как слайсы, кадры, группы изображений, последовательности кадров или т.п., и каждый символ последовательности символов может ассоциироваться с соответствующим одним из множества типов символа. В данном случае, селектор 402 может быть выполнен с возможностью изменения, для символов заданного типа символа в текущей части, выбора в зависимости от ранее извлеченных символов последовательности символов заданного типа символа в текущей части в случае активизированного режима высокой эффективности и оставления выбора постоянным в текущей части в случае активизированного режима низкой сложности. Т.е. селектору 402 может быть предоставлена возможность изменять выбор среди энтропийных декодеров 322 для заданного типа символа, но эти изменения ограничены тем, что происходят между переходами между последовательными частями. Посредством этой меры оценки фактической статистики символов ограничиваются редко встречающимися временными случаями, тогда как сложность кодирования уменьшается в большей части времени.
Кроме того, каждый символ последовательности 326 символов может ассоциироваться с соответствующим одним из множества типов символа, и селектор 402 может быть выполнен, для заданного символа заданного типа символа, с возможностью выбора одного из множества контекстов в зависимости от ранее извлеченных символов последовательности 326 символов и выполнения выбора среди энтропийных декодеров 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом вместе с обновлением вероятностной модели, ассоциированной с выбранным контекстом в зависимости от заданного символа в случае активизированного режима высокой эффективности, и выполнения выбора одного из множества контекстов в зависимости от ранее извлеченных символов последовательности 326 символов и выполнения выбора среди энтропийных декодеров 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом вместе с оставлением вероятностной модели, ассоциированной с выбранным контекстом, постоянной в случае активизированного режима низкой сложности. Т.е. селектор 402 может использовать контекстную адаптивность в отношении некоторого типа синтаксического элемента в обоих режимах, в тоже время подавляя вероятностную адаптацию в случае режима LC.
Альтернативно, вместо полного подавления вероятностной адаптации селектор 402 может просто уменьшить частоту обновления вероятностной адаптации режима LC относительно режима HE.
Кроме того, другими словами, возможные аспекты, характерные для LC-PIPE, т.е. аспекты режима LC, могут быть описаны следующим образом. В частности, неадаптивные вероятностные модели могут использоваться в режиме LC. Неадаптивная вероятностная модель может или иметь жестко закодированную, т.е. полную постоянную вероятность, или ее вероятность поддерживается фиксированной только во время обработки слайса и, таким образом, может устанавливаться в зависимости от типа слайса и QP, т.е. параметра квантования, который, например, сигнализируется в потоке 401 данных для каждого слайса. Предполагая, что последовательные бины, назначенные одному и тому же контексту, придерживаются фиксированной вероятностной модели, возможно декодирование нескольких из этих бинов на одном шаге, когда они кодируются с использованием одного и того же кода pipe, т.е. используя один и тот же энтропийный декодер, и опускается обновление вероятности после каждого декодированного бина. Опускание обновлений вероятности экономит операции во время процесса кодирования и декодирования и, таким образом, также приводит к уменьшению сложности и существенному упрощению аппаратной конструкции.
Неадаптивное ограничение может быть ослаблено для всех или некоторых выбранных вероятностных моделей таким образом, что обновления вероятности разрешаются после того, как некоторое количество бинов будет кодировано/декодировано с использованием этой модели. Соответствующий интервал обновления допускает вероятностную адаптацию, в то же время имея возможность одновременного декодирования нескольких бинов.
Ниже представлено более подробное описание возможных общих и с масштабируемой сложностью аспектов LC-pipe и HE-pipe. В частности, ниже описываются аспекты, которые могут использоваться для режима LC-pipe и режима HE-pipe одинаковым образом или с масштабируемой сложностью. Масштабируемая сложность означает, что случай LC выводится из случая HE посредством удаления конкретных частей или посредством замены их несколько менее сложными. Однако перед продолжением с ними необходимо упомянуть, что вариант осуществления на фиг.11 является легко переносимым на вышеупомянутый вариант осуществления контекстно-адаптивного двоичного арифметического кодирования/декодирования: селектор 402 и энтропийные декодеры 322 сосредотачиваются в контекстно-адаптивный двоичный арифметический декодер, который непосредственно принимает поток 401 данных и выбирает контекст для бина, подлежащего извлечению в настоящий момент из потока данных. Это особенно верно для контекстной адаптивности и/или вероятностной адаптивности. Обе функциональные возможности/адаптивности могут быть отключены, или разработаны более ослабленными, во время режима низкой сложности.
Например, при реализации варианта осуществления по фиг.11 ступень энтропийного кодирования pipe, включающая в себя энтропийные декодеры 322, может использовать восемь систематических переменный-в-переменный-кодов, т.е. каждый энтропийный декодер 322 может быть типа v2v, который был описан выше. Принцип PIPE-кодирования, использующий систематические v2v-коды, упрощается посредством ограничения количества v2v-кодов. В случае контекстно-адаптивного двоичного арифметического декодера он может управлять его вероятностными состояниями для разных контекстов и использовать его - или его квантованную версию - для подразделения вероятности. Отображение состояний CABAC или вероятностной модели, т.е. состояний, используемых для обновления вероятности, в PIPE id или индексы вероятности для поиска в Rtab, может быть таким, какое изображено в таблице A.
Таблица A: Отображение состояний CABAC в индексы PIPE
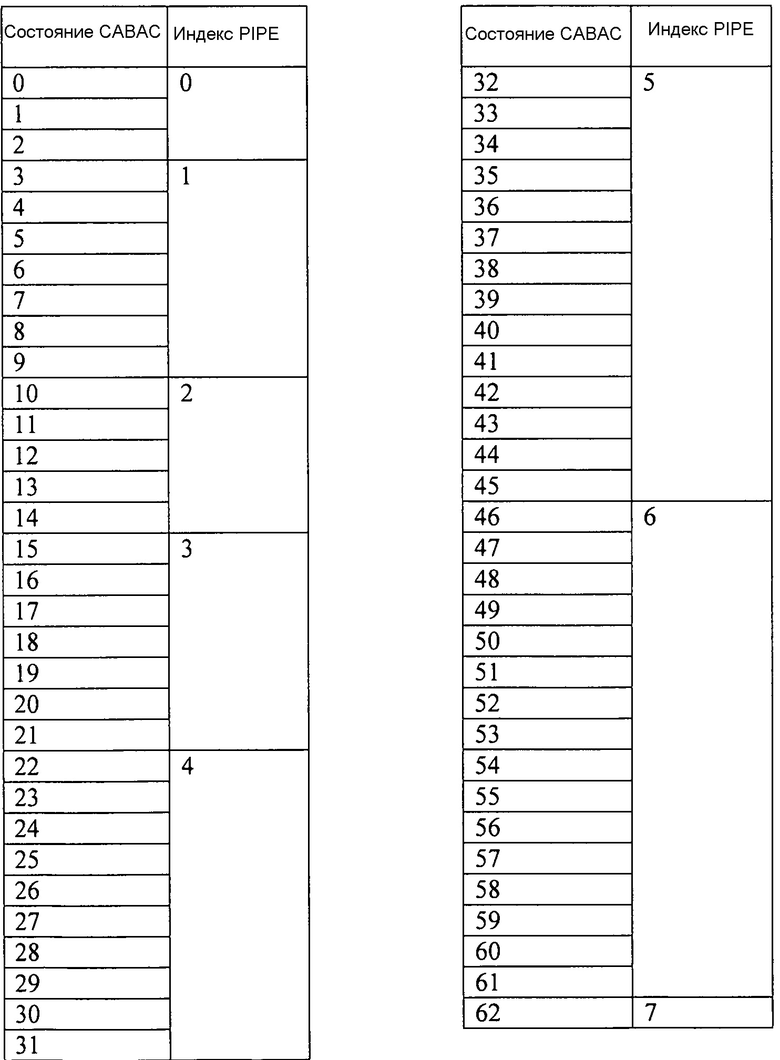
Эта модифицированная схема кодирования может использоваться в качестве основы для подхода видеокодирования с масштабируемой сложностью. При выполнении вероятностной адаптации режима селектор 402 или контекстно-адаптивный двоичный арифметический декодер соответственно выбирают декодер 322 PIPE, т.е. выводят индекс pipe, подлежащий использованию, и индекс вероятности в Rtab, соответственно, основываясь на индексе состояния вероятности - здесь в качестве примера диапазон составляет от 0 до 62 - ассоциированный с подлежащим декодированию текущим символом - например, при помощи контекста - используя отображение, показанное в таблице A, и обновляет этот индекс состояния вероятности в зависимости от декодируемого в настоящий момент символа, используя, например, конкретные значения перехода обхода таблицы, указывающие на следующий индекс состояния вероятности, подлежащий посещению в случае MPS и LPS соответственно. В случае режима LC обновление последнего может быть исключено. Даже отображение может быть исключено в случае глобально фиксированных вероятностных моделей.
Однако может использоваться произвольное установление энтропийного кодирования, и методы в данном документе также могут использоваться с незначительной адаптацией.
Вышеупомянутое описание фиг. 11 скорее в общих чертах ссылалось на синтаксические элементы и типы синтаксических элементов. Ниже описывается кодирование с конфигурируемой сложностью уровней коэффициентов преобразования.
Например, восстановитель 404 может быть выполнен с возможностью восстановления блока 200 преобразования уровней 202 коэффициентов преобразования, основываясь на части последовательности синтаксических элементов независимо от активизированного режима высокой эффективности или режима низкой сложности, причем часть последовательности 327 синтаксических элементов содержит, без перемежения, синтаксические элементы карты значимостей, определяющие карту значимостей, указывающую позиции ненулевых уровней коэффициентов преобразования в блоке 200 преобразования, и затем (за которым следует) определение синтаксических элементов уровня, определяющих ненулевых уровни коэффициентов преобразования. В частности, следующие элементы могут быть включены: синтаксические элементы конечной позиции (last_significant_pos_x, last_significant_pos_y), указывающие позицию последнего ненулевого уровня коэффициентов преобразования в блоке преобразования; первые синтаксические элементы (coeff_significant_flag), определяющие вместе карту значимостей и указывающие, для каждой позиции по одномерному пути (274), ведущему от позиции DC (постоянного тока) в позицию последнего ненулевого уровня коэффициентов преобразования в блоке (200) преобразования, в отношении того, является ли ненулевым или нет уровень коэффициентов преобразования в соответствующей позиции; вторые синтаксические элементы (coeff_abs_greater1), указывающие, для каждой позиции одномерного пути (274), где, согласно первым двоичным синтаксическим элементам, располагается ненулевой уровень коэффициентов преобразования, в отношении того, является ли больше единицы уровень коэффициентов преобразования в соответствующей позиции; и третьи синтаксические элементы (coeff_abs_greater2, coeff_abs_minus3), показывающие, для каждой позиции одномерного пути, где, согласно первым двоичным синтаксическим элементам, располагается уровень коэффициентов преобразования больше единицы, величину, на которую соответствующий уровень коэффициентов преобразования в соответствующей позиции превышает единицу.
Порядок среди синтаксических элементов конечной позиции, первых, вторых и третьих синтаксических элементов может быть одинаковым для режима высокой эффективности и режима низкой сложности, и селектор 402 может быть выполнен с возможностью выполнения выбора из числа энтропийных декодеров 322 для символов, от которого десимволизатор 314 получает синтаксические элементы конечной позиции, первые синтаксические элементы, вторые синтаксические элементы и/или третьи синтаксические элементы, в разной зависимости от активизированного режима низкой сложности или режима высокой эффективности.
В частности, селектор 402 может быть выполнен, для символов заданного типа символа из числа последовательности символов, из которой десимволизатор 314 получает первые синтаксические элементы и вторые синтаксические элементы, с возможностью выбора для каждого символа заданного типа символа одного из множества контекстов в зависимости от ранее извлеченных символов заданного типа символа из числа последовательности символов и выполнения выбора в зависимости от вероятностной модели, ассоциированной с выбранным контекстом в случае активизированного режима высокой эффективности, и выполнения выбора кусочно-постоянным образом, так что выбор является постоянным по последовательным непрерывным подчастям последовательности в случае активизированного режима низкой сложности. Как описано выше, подчасти могут измеряться количеством позиций, по которым простирается соответствующая подчасть при измерении по одномерному пути 274, или количеством синтаксических элементов соответствующего типа, уже кодированных с текущим контекстом. Т.е. двоичные синтаксические элементы coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2, например, кодируются адаптивно к контексту с выбором декодера 322, основываясь на вероятностной модели выбранного контекста в режиме HE. Также используется вероятностная адаптация. В режиме LC также существуют разные контексты, которые используются для каждого из двоичных синтаксических элементов coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2. Однако для каждого из этих синтаксических элементов контекст сохраняется статичным для первой части по пути 274 с изменением контекста только при переходе в следующую, непосредственно последующую часть по пути 274. Например, каждая часть может определяться длиной равной 4, 8, 16 позициям блока 200, независимо от того, присутствует ли или нет для соответствующей позиции соответствующий синтаксический элемент. Например, coeff_abs_greater1 и coeff_abs_greater2 просто присутствуют для значимых позиций, т.е. позиций, где - или для которых - coeff_significant_flag равен 1. Альтернативно, каждая часть может определяться длиной, равной 4, 8, 16 синтаксических элементов, независимо от того, простирается ли результирующая таким образом соответствующая часть по большему количеству позиций блока. Например, coeff_abs_greater1 и coeff_abs_greater2 просто присутствуют для значимых позиций, и, таким образом, части каждых из четырех синтаксических элементов могут проходить по более чем 4 позициям блока вследствие позиций между ними по пути 274, для которых не передается такой синтаксический элемент, такой как ни coeff_abs_greater1, ни coeff_abs_greater2, так как соответствующий уровень в этой позиции равен нулю.
Селектор 402 может быть выполнен, для символов заданного типа символа в последовательности символов, из которой десимволизатор получает первые синтаксические элементы и вторые синтаксические элементы, с возможностью выбора для каждого символа заданного типа символа одного из множества контекстов в зависимости от количества ранее извлеченных символов заданного типа символа в последовательности символов, которые имеют заданное значение символа и принадлежит к этой же подчасти, или количества ранее извлеченных символов заданного типа символа в последовательности символов, которые принадлежат этой же подчасти. Первая альтернатива была верной для coeff_abs_greater1, и вторая альтернатива была верной для coeff_abs_greater2 в соответствии с вышеупомянутыми конкретными вариантами осуществления.
Кроме того, третьи синтаксические элементы, показывающие, для каждой позиции одномерного пути, где, согласно первым двоичным синтаксическим элементам, располагается уровень коэффициентов преобразования больший единицы, величину, на которую соответствующий уровень коэффициентов преобразования в соответствующей позиции превышает единицу, могут содержать целочисленные синтаксические элементы, т.е. coeff_abs_minus3, и десимволизатор 314 может быть выполнен с возможностью использования функции отображения, управляемой параметром управления для отображения области определения слов последовательности символов на область значений целочисленных синтаксических элементов, и установления параметра управления на целочисленный синтаксический элемент в зависимости от целочисленных синтаксических элементов предыдущих третьих синтаксических элементов, если активизирован режим высокой эффективности, и выполнения установления кусочно-постоянным образом, так что установление является постоянным по последовательным непрерывным подчастям последовательности в случае активизированного режима низкой сложности, причем селектор 402 может быть выполнен с возможностью выбора заданного одного из энтропийных декодеров (322) для символов слов последовательности символов, отображаемых на целочисленные синтаксические элементы, которая ассоциируется с равновероятным распределением как в режиме высокой эффективности, так и в режиме низкой сложности. Т.е. даже если десимволизатор может работать в зависимости от режима, выбранного переключателем 400, как изображено пунктирной линией 407. Вместо кусочно-постоянного установления параметра управления десимволизатор 314 может поддерживать параметр управления постоянным во время текущего слайса, например, или постоянным глобально во времени.
Ниже описывается моделирование контекста с масштабируемой сложностью.
Оценка одного и того же синтаксического элемента верхнего и левого соседа для выведения индекса контекстной модели представляет собой общий подход и часто используется в случае HE, например, для синтаксического элемента разностей векторов движения. Однако эта оценка требует большего буферного накопителя и не позволяет выполнять прямое кодирование синтаксического элемента. Также, для достижения более высоких рабочих характеристик кодирования могут оцениваться более доступные соседи.
В предпочтительном варианте осуществления все синтаксические элементы оценки ступени контекстного моделирования соседних квадратных или прямоугольных блоков или единиц предсказания являются фиксированными для одной контекстной модели. Это равнозначно запрещению адаптивности на ступени выбора контекстной модели. Для этого предпочтительного варианта осуществления выбор контекстной модели в зависимости от индекса бина строки бинов после бинаризации не модифицируется по сравнению с текущей разработкой для CABAC. В другом предпочтительном варианте осуществления дополнительно к фиксированной контекстной модели для синтаксических элементов применяют оценку соседей, также является фиксированной контекстная модель для другого индекса бина. Отметьте, что описание не включает бинаризацию и выбор контекстной модели для разностей векторов движения и синтаксических элементов, относящихся к кодированию уровней коэффициентов преобразования.
В предпочтительном варианте осуществления разрешается только оценка левого соседа. Это приводит к уменьшенному буферу в цепочке обработки, так как последний блок или строка единиц кодирования больше не должна сохраняться. В другом предпочтительном варианте осуществления оцениваются только соседи, лежащие в одной и той же единице кодирования.
В предпочтительном варианте осуществления оцениваются все доступные соседи. Например, в дополнение к верхнему и левому соседу верхний левый, верхний правый и нижний левый соседи оцениваются в случае доступности.
Т.е. селектор 402 по фиг. 11 может быть выполнен с возможностью использования, для заданного символа, относящегося к заданному блоку медиаданных, ранее извлеченных символов последовательности символов, относящихся к большему количеству разных соседних блоков медиаданных в случае активизированного режима высокой эффективности, чтобы выбирать один из множества контекстов и выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом. Т.е. соседние блоки могут быть соседями во временной и/или пространственной области. Пространственно соседние блоки являются видимыми, например, на фиг. 1-3. Тогда селектор 402 может реагировать на выбор режима переключателем 400 режима и выполнять адаптацию контакта, основываясь на ранее извлеченных символах или синтаксических элементах, относящихся к большему количеству соседних блоков в случае режима HE по сравнению с режимом LC, таким образом уменьшая издержки хранения как только что описано.
Ниже описывается кодирование с уменьшенной сложностью разностей векторов движения согласно варианту осуществления.
В стандарте видеокодека H.264/AVC вектор движения, ассоциированный с макроблоком, передается посредством сигнализации разности (разность вектора движения - mvd) между вектором движения текущего макроблока и предсказателем среднего вектора движения. Когда используется CABAC в качестве энтропийного кодера, mvd кодируется следующим образом. Целочисленная mvd разделяется на абсолютную и знаковую часть. Абсолютная часть бинаризуется с использованием комбинации усеченного унарного кода и экспоненциального кода Голомба 3-го порядка, упоминаемых как префикс и суффикс результирующей строки бинов. Бины, относящиеся к усеченной унарной бинаризации, кодируются с использованием контекстных моделей, тогда как бины, относящиеся к экспоненциальной бинаризации Голомба, кодируются в режиме обхода, т.е. с фиксированной вероятностью 0,5 с CABAC. Унарная бинаризация работает следующим образом. Пусть абсолютным целочисленным значением mvd является n, тогда результирующая строка бинов состоит из n «1» и одного завершающего «0». В качестве примера, пусть n=4, тогда строкой бинов является «11110». В случае усеченного унарного существует предел, и, если значение превышает этот предел, строка бинов состоит из n+1 «1». Для случая mvd предел равен 9. Это означает, если кодируется абсолютная mvd, равная или больше 9, приводя к 9 «1», строка бинов состоит из префикса и суффикса с экспоненциальной бинаризацией Голомба. Контекстное моделирование для усеченной унарной части выполняется следующим образом. Для первого бина строки бинов берутся абсолютные значения mvd от верхних и левых соседних макроблоков, если доступны (если недоступны, значение подразумевается равным 0). Если сумма для конкретной составляющей (горизонтального или вертикального направления) больше 2, выбирается вторая контекстная модель, если абсолютная сумма больше 32, выбирается третья контекстная модель, в противном случае, (абсолютная сумма меньше 3) выбирается первая контекстная модель. Кроме того, контекстные модели являются разными для каждой составляющей. Для второго бина из строки бинов используется четвертая контекстная модель, и пятая контекстная модель применяется для остальных бинов унарной части. Когда абсолютная mvd равна или больше 9, например, все бины усеченной унарной части равны «1», разность между абсолютным значением mvd и 9 кодируется в режиме обхода при помощи экспоненциальной бинаризации Голомба 3 порядка. На последнем этапе кодируется знак mvd в режиме обхода.
Самым последним методом кодирования для mvd при использовании CABAC в качестве энтропийного кодера задается в текущей тестовой модели (HM) проекта высокоэффективного видеокодирования (HEVC). В HEVC размеры блока являются переменными, и форма, задаваемая вектором движения, упоминается как единица предсказания (PU). Размер PU верхнего и левого соседа может иметь другие формы и размеры, чем текущий PU. Поэтому, где это уместно, определение верхнего и левого соседа упоминается теперь как верхний и левый сосед верхнего-левого угла текущего PU. Для самого кодирования процесс выведения для первого бина может меняться согласно варианту осуществления. Вместо оценки абсолютной суммы MV из соседей, каждый сосед может оцениваться отдельно. Если абсолютный MV соседа является доступным и больше 16, индекс контекстной модели может быть увеличен, приводя к такому же количеству контекстных моделей для первого бина, тогда как кодирование оставшегося абсолютного уровня MVD и знака являются точно таким же, что и в H.264/AVC.
В вышеописанном кратко методе кодирования mvd до 9 бинов должны кодироваться с контекстной моделью, тогда как остальное значение mvd может кодироваться в режиме обхода низкой сложности вместе с информацией о знаке. Данный настоящий вариант осуществления описывает метод уменьшения количества бинов, кодируемых с контекстными моделями, приводя к увеличенному количеству обходов, и уменьшает количество контекстных моделей, требуемых для кодирования mvd. Для этого, значение отсечки уменьшается с 9 до 1 или 2. Это означает, что только первый бин, задающий, является ли абсолютный mvd больше нуля, кодируется с использованием контекстной модели, или первый и второй бин, задающие, является ли абсолютный mvd больше нуля и единицы, кодируется с использованием контекстной модели, тогда как оставшееся значение кодируется в режиме обхода и/или используя код VLC (код переменной длины). Все бины, являющиеся результатом бинаризации с использованием кода VLC - не используя унарный или усеченный унарный код - кодируются с использованием режима обхода низкой сложности. В случае PIPE возможно непосредственное вставление в битовый поток и из него. Кроме того, если есть, может использоваться другое определение верхнего и левого соседа для выведения лучшего выбора контекстной модели для первого бина.
В предпочтительном варианте осуществления экспоненциальные коды Голомба используются для бинаризации остальной части абсолютных составляющих MVD. Для этого, порядок экспоненциального кода Голомба является переменным. Порядок экспоненциального кода Голомба выводится следующим образом. После того как будет выведена и кодирована контекстная модель для первого бина, и, поэтому, индекс этой контекстной модели, индекс используется в качестве порядка для части экспоненциальной бинаризации Голомба. В этом предпочтительном варианте осуществления контекстная модель для первого бина находится в диапазоне 1-3, приводя к индексу 0-2, которые используются в качестве порядка экспоненциального кода Голомба. Этот предпочтительный вариант осуществления может использоваться для случая HE.
В альтернативе вышеописанному кратко методу использования двух, умноженных на пять, контекстов при кодировании абсолютной MVD, чтобы кодировать 9 бинов бинаризации унарным кодом, также может использоваться 14 контекстных моделей (7 для каждой составляющей). Например, в то время как первый и второй бины унарной части могут кодироваться при помощи четырех разных контекстов, как описано ранее, пятый контекст может использоваться для третьего бина, и шестой контекст может использоваться в отношении четвертого бина, тогда как пятый-девятый бины кодируются с использованием седьмого контекста. Таким образом, в данном случае, будет требоваться даже 14 контекстов, и просто оставшееся значение может кодироваться в режиме обхода низкой сложности. Метод для уменьшения количества бинов, кодируемых при помощи контекстных моделей, приводя к увеличенному количеству обходов и уменьшению количества контекстных моделей, требуемых для кодирования MVD, должен уменьшать значение отсечки, например, с 9 до 1 или 2. Это означает, то только первый бин, задающий, является ли абсолютная MVD больше нуля, будет кодироваться с использованием контекстной модели, или первый и второй бины, задающие, является ли абсолютная MVD больше нуля и единицы, будет кодироваться с использованием соответствующей контекстной модели, тогда как оставшееся значение кодируется при помощи кода VLC. Все бины, являющиеся результатом бинаризации с использованием кода VLC, кодируются с использованием режима обхода низкой сложности. В случае PIPE, возможно непосредственное вставление в битовый поток и из него. Кроме того, представленный вариант осуществления использует другое определение верхнего и левого соседа для выведения выбора лучшей контекстной модели для первого бина. В дополнение к этому, контекстное моделирование модифицируется таким образом, что количество контекстных моделей, требуемых для первого или первого и второго бинов, уменьшается, приводя к дальнейшему снижению объема памяти. Также, оценка соседей, таких как вышеприведенный сосед, может запрещаться, приводя к экономии объема памяти/буфера строк, требуемого для хранения значений mvd соседей. Наконец, порядок кодирования составляющих может быть разделен таким образом, который позволяет выполнять кодирование бинов префикса для обоих составляющих (т.е. бинов, кодированных контекстными моделями), за которым следует кодирование бинов обхода.
В предпочтительном варианте осуществления экспоненциальные коды Голомба используются для бинаризации остальной части абсолютных составляющих mvd. Для этого, порядок экспоненциального кода Голомба является переменным. Порядок экспоненциального кода Голомба может выводиться следующим образом. После того как будет получена контекстная модель для первого бина, и, поэтому, индекс этой контекстной модели, индекс используется в качестве порядка для экспоненциальной бинаризации Голомба. В данном предпочтительном варианте осуществления контекстная модель для первого бина находится в диапазоне 1-3, приводя к индексу 0-2, который используется в качестве порядка экспоненциального кода Голомба. Данный предпочтительный вариант осуществления может использоваться для случая HE, и количество контекстных моделей уменьшается до 6. Чтобы еще уменьшить количество контекстных моделей и, поэтому, сэкономить память, горизонтальные и вертикальные составляющие могут совместно использовать одни и те же контекстные модели в другом предпочтительном варианте осуществления. В этом случае, требуется только 3 контекстных модели. Кроме того, может учитываться только левый сосед для оценки в другом предпочтительном варианте осуществления изобретения. В данном предпочтительном варианте осуществления порог может не модифицироваться (например, только единственный порог 16, приводя к параметру экспоненциального кода Голомба 0 или 1, или единственный порог 32, приводя к параметру экспоненциального кода Голомба 0 или 2). Этот предпочтительный вариант осуществления экономит буфер строк, требуемый для хранения mvd. В другом предпочтительном варианте осуществления порог модифицируется и равен 2 и 16. Для этого предпочтительного варианта осуществления в сумме требуется 3 контекстных модели для кодирования mvd, и возможный параметр экспоненциального кода Голомба находится в диапазоне 0-2. В другом предпочтительном варианте осуществления порог равен 16 и 32. Снова, описанный вариант осуществления пригоден для случая HE.
В другом предпочтительном варианте осуществления изобретения значение отсечки уменьшается с 9 до 2. В данном предпочтительном варианте осуществления первый бин и второй бин могут кодироваться с использованием контекстных моделей. Выбор контекстной модели для первого бина может выполняться как в современном состоянии техники или в модифицированном виде таким образом, который описан в предпочтительном варианте осуществления выше. Для второго бина выбирается отдельная контекстная модель как в современном состоянии техники. В другом предпочтительном варианте осуществления контекстная модель для второго бина выбирается посредством оценки mvd левого соседа. Для этого случая, индекс контекстной модели является тем же, что и для первого бина, тогда как доступные контекстные модели являются другими, чем для первого бина. В итоге, требуется 6 контекстных моделей (отметьте, что составляющие совместно используют контекстные модели). Снова, параметр экспоненциального кода Голомба может зависеть от индекса выбранной контекстной модели первого бина. В другом предпочтительном варианте осуществления изобретения параметр экспоненциального кода Голомба зависит от индекса контекстной модели второго бина. Описанные варианты осуществления изобретения могут использоваться для случая HE.
В другом предпочтительном варианте осуществления изобретения контекстные модели для обоих бинов являются фиксированными и не выводятся посредством оценки или левого, или верхнего соседей. Для этого предпочтительного варианта осуществления общее количество контекстных моделей равно 2. В другом предпочтительном варианте осуществления изобретения первый бин и второй бин совместно используют одну и ту же контекстную модель. В результате, только одна контекстная модель требуется для кодирования mvd. В обоих предпочтительных вариантах осуществления изобретения параметр экспоненциального кода Голомба может быть фиксированным и равным 1. Описанный предпочтительный вариант осуществления изобретения пригоден для обоих конфигураций HE и LC.
В другом предпочтительном варианте осуществления порядок экспоненциальной части кода Голомба выводится независимо из индекса контекстной модели первого бина. В данном случае, абсолютная сумма выбора обычной контекстной модели H.264/AVC используется для выведения порядка для экспоненциальной части кода Голомба. Этот предпочтительный вариант осуществления может использоваться для случая HE.
В другом предпочтительном варианте осуществления порядок экспоненциальных кодов Голомба является фиксированным и устанавливается на 0. В другом предпочтительном варианте осуществления порядок экспоненциальных кодов Голомба является фиксированным и устанавливается на 1. В предпочтительном варианте осуществления порядок экспоненциальных кодов Голомба фиксируется на 2. В другом варианте осуществления порядок экспоненциальных кодов Голомба фиксируется на 3. В другом варианте осуществления порядок экспоненциальных кодов Голомба фиксируется в соответствии с формой и размером текущего PU. Представленные предпочтительные варианты осуществления могут использоваться для случая LC. Отметьте, что фиксированный порядок части экспоненциального кода Голомба рассматривается с уменьшенным количеством бинов, кодированных с контекстными моделями.
В предпочтительном варианте осуществления соседи определяются следующим образом. Для вышеупомянутого PU все PU, которые закрывают текущий PU, принимаются во внимание, и используется PU с наибольшим MV. Это также выполняется для левого соседа. Все PU, которые закрывают текущий PU, оцениваются, и используется PU с наибольшим MV. В другом предпочтительном варианте осуществления среднее абсолютное значение вектора движения от всех PU, которые закрывают верхнюю и левую границу текущего PU, используется для выведения первого бина.
Для представленных выше предпочтительных вариантов осуществления является возможным изменять порядок кодирования следующим образом. mvd должен быть задан для горизонтального и вертикального направления один за другим (или наоборот). Таким образом, две строки бинов должны кодироваться. Чтобы минимизировать количество переключений режима для механизма энтропийного кодирования (т.е. переключение между режимом обхода и обычным режимом), является возможным кодировать бины, кодированные с контекстными моделями для обоих составляющих на первом этапе, за которым следует бины, кодированные в режиме обхода на втором этапе. Отметьте, что это представляет собой только переупорядочивание.
Необходимо отметить, что бины, являющиеся результатом унарной или усеченной унарной бинаризации, также могут представляться эквивалентной бинаризацией фиксированной длины одного флага на индекс бина, задающего, является ли значение больше индекса текущего бина. В качестве примера, значение отсечки для усеченной унарной бинаризации mvd устанавливается на 2, приводя к кодовым словам 0, 10, 11 для значений 0, 1, 2. При соответствующей бинаризации фиксированной длины с одним флагом на индекс бина, один флаг для индекса 0 бина (т.е. первого бина) задает, является ли абсолютное значение mvd больше 0 или нет, и один флаг для второго бина с индексом 1 бина задает, является ли абсолютное значение mvd больше 1 или нет. Когда второй флаг только кодируется, когда первый флаг равен 1, это приводит к таким же кодовым словам 0, 10, 11.
Ниже описывается представление с масштабируемой сложностью внутреннего состояния вероятностных моделей согласно варианту осуществления.
При установке HE-PIPE, внутреннее состояние вероятностной модели обновляется после кодирования бина с ним. Обновленное состояние выводится посредством табличного поиска перехода состояния, используя старое состояние и значение кодированного бина. В случае CABAC вероятностная модель может принимать 63 разных состояний, когда каждое состояние соответствует вероятности модели в интервале (0,0, 0,5). Каждое из этих состояний используется для реализации двух вероятностей модели. В дополнение к вероятности, назначенной состоянию, 1,0 минус вероятность также используется, и флаг, названный valMps, хранит информацию, используется ли вероятность или 1,0 минус вероятность. Это приводит к сумме в 126 состояний. Чтобы использовать такую вероятностную модель с принципом кодирования PIPE, каждое из 126 состояний необходимо отображать на один из доступных кодеров PIPE. В текущих реализациях кодеров PIPE это выполняется посредством использования таблицы поиска. Пример такого отображения описывается в таблице A.
Ниже описывается вариант осуществления, как внутреннее состояние вероятностной модели может быть представлено для исключения использования таблицы поиска для преобразования внутреннего состояния в индекс PIPE. Необходимы исключительно некоторые простые операции маскирования битов для извлечения индекса PIPE из переменной внутреннего состояния вероятностной модели. Это новое представление с масштабируемой сложностью внутреннего состояния вероятностной модели разработано двухуровневым образом. Для применений, где операция низкой сложности является обязательной, используется только первый уровень. Он описывает только индекс pipe и флаг valMps, который используется для кодирования или декодирования ассоциированных бинов. В случае описанной схемы энтропийного кодирования PIPE, первый уровень может использоваться для различения между 8 разными вероятностями моделей. Таким образом, первому уровню потребуется 3 бита для pipeIdx, и один дополнительный бит для флага valMps. Со вторым уровнем каждый из диапазонов грубой вероятности первого уровня уточняется в несколько меньшие интервалы, которые поддерживают представление вероятностей при более высоких разрешениях. Это более подробное представление позволяет получить более точную работу устройств оценки вероятности. В общем, оно подходит для применений кодирования, которые стремятся к высоким характеристикам RD. В качестве примера, это представление с масштабируемой сложностью внутреннего состояния вероятностных моделей с использованием PIPE изображается следующим образом:

Первый и второй уровни сохраняются в единственной 8-битовой памяти. 4 бита требуются для хранения первого уровня - индекс, который определяет индекс PIPE со значением MPS на самом старшем бите - и другие 4 бита используются для хранения второго уровня. Для реализации поведения устройства оценки вероятности CABAC, каждый индекс PIPE имеет конкретное количество разрешенных индексов уточнения в зависимости от того, сколько состояний CABAC было отображено на индекс PIPE. Например, для отображения в таблице A количество состояний CABAC на индекс PIPE изображается в таблице B.

Таблица B: Количество состояний CABAC на индекс PIPE для примера таблицы A.
Во время процесса кодирования или декодирования бина к индексу PIPE и valMps можно обращаться непосредственно посредством применения простой битовой маски или операций сдвига бита. Процессы кодирования низкой сложности требуют 4 бита первого уровня, и процессы кодирования высокой эффективности могут дополнительно использовать 4 бита второго уровня для выполнения обновления вероятностной модели устройства оценки вероятности CABAC. Для выполнения этого обновления может быть разработана таблица поиска переходов состояния, которая делает такие же переходы состояния, что и исходная таблица, но используя двухуровневое представление с масштабируемой сложностью состояний. Исходная таблица переходов состояний состоит из двух, умноженных на 63 элементов. Для каждого состояния ввода она содержит два состояния вывода. При использовании представления с масштабируемой сложностью размер таблицы переходов состояний не превышает 2, умноженных на 128 элементов, что представляет собой допустимое увеличение размера таблицы. Это увеличение зависит от того, сколько битов используется для представления индекса уточнения и точного имитирования поведения устройства оценки вероятности CABAC, необходимо четыре бита. Однако могут использоваться другие устройства оценки вероятности, которые могут работать на уменьшенном наборе состояний CABAC, так что для каждого индекса pipe разрешается не более 8 состояний. Поэтому, потребление памяти может сопоставляться с данным уровнем сложности процесса кодирования посредством адаптации количества битов, используемых для представления индекса уточнения. По сравнению с внутренним состоянием вероятностей модели с CABAC - где существует 64 индекса состояния вероятности - исключается использование табличных поисков для отображения вероятностей модели на конкретный код PIPE, и не требуется дополнительного преобразования.
Ниже описывается обновление контекстной модели с масштабируемой сложностью согласно варианту осуществления.
Для обновления контекстной модели ее индекс состояния вероятности может обновляться на основе одного или нескольких ранее кодированных бинов. В установке HE-PIPE это обновление выполняется после кодирования или декодирования каждого бина. И наоборот, в установке LC-PIPE это обновление может никогда не выполняться.
Однако является возможным выполнять обновление контекстных моделей с масштабируемой сложностью. Т.е. решение, обновлять ли контекстную модель или нет может основываться на различных аспектах. Например, установка кодера может не выполнять обновление только для конкретных контекстных моделей, подобно, например, контекстным моделям синтаксического элемента coeff_significant_flag и выполнять всегда обновления для всех других контекстных моделей.
Другими словами, селектор 402 может быть выполнен, для символов каждого из нескольких заданных типов символа, с возможностью выполнения выбора среди энтропийных декодеров 322 в зависимости от соответствующей вероятностной модели, ассоциированной с соответствующим заданным символом, так что количество заданных типов символа меньше в режиме низкой сложности по сравнению с режимом высокой эффективности.
Кроме того, критериями для управления, обновлять ли контекстную модель или нет, могут быть, например, размер пакета битового потока, количество бинов, декодированных до сих пор, или обновление выполняется только после кодирования конкретного фиксированного или переменного количества бинов для контекстной модели.
С данной схемой для принятия решения, обновлять ли контекстные модели или нет, может быть реализовано обновление контекстной модели с масштабируемой сложностью. Это позволяет увеличивать или уменьшать долю бинов в битовом потоке, для которого выполняется обновления контекстной модели. Чем больше количество обновлений контекстной модели, тем лучше эффективность кодирования и выше вычислительная сложность. Таким образом, обновление контекстной модели с масштабируемой сложностью может достигаться с описанной схемой.
В предпочтительном варианте осуществления обновление контекстной модели выполняется для бинов всех синтаксических элементов за исключением синтаксических элементов coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2.
В другом предпочтительном варианте осуществления обновление контекстной модели выполняется только для бинов синтаксических элементов coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2.
В другом предпочтительном варианте осуществления обновление контекстной модели выполняется для всех контекстных моделей, когда начинается кодирование или декодирование слайса. После того как будет обработано конкретное заданное количество блоков преобразования, обновление контекстной модели запрещается для всех контекстных моделей до тех пор, пока не будет достигнут конец слайса.
Например, селектор 402 может быть выполнен, для символов заданного типа символа, с возможностью выполнения выбора из числа энтропийных декодеров 322 в зависимости от вероятностной модели, ассоциированной с заданным типом символа, вместе или без обновления ассоциированной вероятностной модели, так что длительность фазы обучения последовательности символов, по которой выполняется выбор символов заданного типа символа вместе с обновлением, является более короткой в режиме низкой сложности по сравнению с режимом высокой эффективности.
Другой предпочтительный вариант осуществления идентичен ранее описанному предпочтительному варианту осуществления, но он использует представление с масштабируемой сложностью внутреннего состояния контекстных моделей таким образом, что одна таблица хранит «первую часть» (valMps и pipeIdx) всех контекстных моделей, и вторая таблица хранит «вторую часть» (refineIdx) всех контекстных моделей. Тогда, когда обновление контекстной модели запрещается для всех контекстных моделей (как описано в предыдущем предпочтительном варианте осуществления), больше не требуется таблица, хранящая «вторую часть», и она может быть отброшена.
Ниже описывается обновление контекстной модели для последовательности бинов согласно варианту осуществления.
В конфигурации LC-PIPE бины синтаксических элементов типа coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2 группируются в подмножества. Для каждого подмножества используется единственная контекстная модель для кодирования ее бинов. В данном случае, обновление контекстной модели может выполняться после кодирования фиксированного количества бинов данной последовательности. Это обозначается многобиновым обновлением в нижеследующем. Однако это обновление может отличаться от обновления, использующего только последний кодированный бин и внутреннее состояние контекстной модели. Например, для каждого бина, который был кодирован, выполняется один этап обновления контекстной модели.
Ниже приведены примеры для кодирования примерного подмножества, состоящего из 8 бинов. Буква «b» обозначает декодирование бина, и буква «u» обозначает обновление контекстной модели. В случае LC-PIPE выполняется только декодирование бинов без выполнения обновлений контекстной модели:
b b b b b b b b
В случае HE-PIPE после декодирования каждого бина выполняется обновление контекстной модели:
b u b u b u b u b u b u b u b u
Чтобы в некоторой степени уменьшить сложность, обновление контекстной модели может выполняться после последовательности бинов (в данном примере после каждых 4 бинов выполняются обновления этих 4 бинов):
b b b b u u u u b b b b u u u u
Т.е. селектор 402 может быть выполнен, для символов заданного типа символа, с возможностью выполнения выбора из числа энтропийных декодеров 322 в зависимости от вероятностной модели, ассоциированной с заданным типом символа вместе с или без обновления ассоциированной вероятностной модели, так что частота, с которой выполняется выбор символов заданного типа символа вместе с обновлением, меньше в режиме низкой сложности по сравнению с режимом высокой эффективности.
В данном случае, после декодирования 4 бинов следует 4 этапа обновления, основанные на только что декодированных 4 бинах. Отметьте, что эти четыре этапа обновления могут выполняться одним единственным этапом посредством использования специальной таблицы поиска для поиска. Эта таблица поиска хранит для каждой возможной комбинации из 4 бинов и каждого возможного внутреннего состояния контекстной модели результирующее новое состояние после четырех обычных этапов обновления.
В некотором режиме многобиновое обновление используется для синтаксического элемента coeff_significant_flag. Для бинов всех других синтаксических элементов не используется обновление контекстной модели. Количество бинов, которые кодируются перед этапом многобинового обновления, устанавливается на n. Когда количество бинов множества не является кратным n, 1-n-1 бинов остается в конце подмножества после последнего многобинового обновления. Для каждого из этих бинов выполняется обычное однобиновое обновление после кодирования всех этих бинов. Количество n может представлять собой любое положительное число больше 1. Другой режим может быть идентичным предыдущему режиму за исключением того, что многобиновое обновление выполняется для произвольных комбинаций coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2 (только вместо coeff_significant_flag). Таким образом, этот режим будет более сложным, чем другой. Все другие синтаксические элементы (где не используется многобиновое обновление) могут быть разделены на два непересекающихся подмножеств, где для одного из подмножеств используется однобиновое обновление, и для другого подмножества не используется обновление контекстной модели. Любые возможные непересекающиеся подмножества являются действительными (включая пустое подмножество).
В альтернативном варианте осуществления многобиновое обновление может основываться только на последних m бинах, которые кодируются непосредственно перед этапом многобинового обновления. m может представлять собой любое натуральное число меньше n. Таким образом, декодирование может выполняться подобно следующему:
b b b b u u b b b b u u b b b b u u b b b b …
при n=4 и m=2.
Т.е. селектор 402 может быть выполнен, для символов заданного типа символа, с возможностью выполнения выбора из числа энтропийных декодеров 322 в зависимости от вероятностной модели, ассоциированной с заданным типом символа, вместе с обновлением ассоциированной вероятностной модели каждого n-го символа заданного типа, основываясь на m самых последних символах заданного типа символа, так что отношение n/m является более высоким в режиме низкой сложности по сравнению с режимом высокой эффективности.
В другом предпочтительном варианте осуществления для синтаксического элемента coeff_significant_flag может использоваться схема контекстного моделирования, использующая местный шаблон, как описано выше для конфигурации HE-PIPE, для назначения контекстных моделей бинам синтаксического элемента. Однако для этих бинов не используется обновление контекстной модели.
Кроме того, селектор 402 может быть выполнен, для символов заданного типа символа, с возможностью выбора одного из нескольких контекстов в зависимости от количества ранее извлеченных символов последовательности символов и выполнения выбора из числа энтропийных декодеров 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом, так что количество контекстов, и/или количество ранее извлеченных символов, меньше в режиме низкой сложности по сравнению с режимом высокой эффективности.
ИНИЦИАЛИЗАЦИЯ ВЕРОЯТНОСТНОЙ МОДЕЛИ, ИСПОЛЬЗУЮЩАЯ 8-БИТОВЫЕ ЗНАЧЕНИЯ ИНИЦИАЛИЗАЦИИ
Этот раздел описывает процесс инициализации внутреннего состояния с масштабируемой сложностью вероятностных моделей, используя так называемое 8-битовое значение инициализации вместо двух 8-битовых значений, как в случае современного стандарта H.264/AVC видеокодирования. Оно состоит из двух частей, которые являются сравнимыми с парами значений инициализации, используемыми для вероятностных моделей в CABAC в H.264/AVC. Две части представляют два параметра линейного уравнения для вычисления исходного состояния вероятностной модели, представляющей конкретную вероятность (например, в виде индекса PIPE) из QP:
Первая часть описывает наклон, и он использует зависимость внутреннего состояния касательно параметра квантования (QP), который используется во время кодирования или декодирования.
Вторая часть описывает индекс PIPE при данном QP, а также valMps.
Два разных режима являются доступными для инициализации вероятностной модели, используя данное значение инициализации. Первый режим обозначается как независимая от QP инициализация. Он использует только индекс PIPE и valMps, определенные во второй части значения инициализации для всех QP. Это идентично случаю, когда наклон равен 0. Второй режим обозначается как зависимая от QP инициализация, и он дополнительно использует наклон первой части значения инициализации для изменения индекса PIPE и определения индекса уточнения. Две части 8-битового значения инициализации изображаются следующим образом:

Оно состоит из двух 4-битовых частей. Первая часть содержит индекс, который указывает на 1 из 16 разных заданных наклонов, которые хранятся в массиве. Заданные наклоны состоят из 7 отрицательных наклонов (индекс наклона 0-6), одного наклона, который равен нулю (индекс 7 наклона) и 8 положительных наклонов (индекс 8-15 наклона). Наклоны изображены в таблице C.

Таблица C
Все значения масштабируются коэффициентом 256, чтобы избежать использования операций с плавающей запятой. Вторая часть представляет собой индекс PIPE, который изображает восходящую вероятность valMps=1 между интервалом вероятности p=0 и p=1. Другими словами, кодер n PIPE должен работать при более высокой вероятности модели, чем кодер n-1 PIPE. Для каждой вероятностной модели доступен один индекс вероятности PIPE, и он идентифицирует кодер PIPE, интервал вероятностей которого содержит вероятность pvalMPs=1 для QP=26.
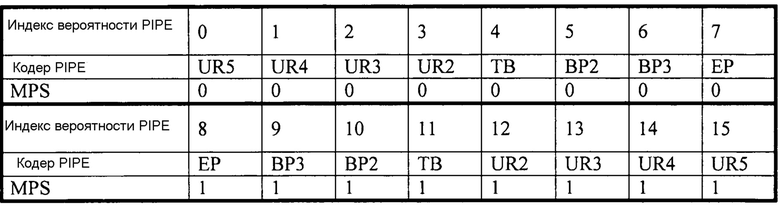
Таблица D: Отображение второй части значения инициализации на кодеры PIPE и valMps: UR - унарный-в-Райс-код; TB - трехбиновый код, BP - бин-pipe-код, EP - равновероятность (не кодируется)
QP и 8-битовое значение инициализации требуются для вычисления инициализации внутреннего состояния вероятностных моделей посредством вычисления простого линейного уравнения в виде y=m*(QP-QPref)+256*b. Отметьте, что m определяет наклон, который берется из таблицы C посредством использования индекса наклона (первая часть 8-битового значения инициализации), и b обозначает кодер PIPE при QPref=26 (вторая часть 8-битового значения инициализации: «Индекс вероятности PIPE»). Тогда valMPS равен 1, и pipeIdx равен (y-2048)>>8, если y больше 2047. В противном случае, valMPS равен 0, и pipeIdx равен (2047-y)>>8. Индекс уточнения равен (((y-2048)&255)*numStates)>>8, если valMPS равен 1. В противном случае, индекс уточнения равен (((2047-y)&255)*numStates)>>8. В обоих случаях, numStates равен количеству состояний CABAC в pipeIdx, как изображено в таблице B.
Вышеупомянутая схема не только может использоваться в комбинации с кодерами PIPE, но также в связи с вышеупомянутыми схемами CABAC. При отсутствии PIPE количество состояний CABAC, т.е. вероятностных состояний, между которыми выполняется переход состояния при обновлении вероятности (pState_current[bin]) на PIPE Idx (т.е. соответствующие самые старшие биты pState_current[bin]) представляют собой тогда только множество параметров, которые реализуют, фактически, кусочно-линейную интерполяцию состояния CABAC в зависимости от QP. Кроме того, эта кусочно-линейная интерполяция также может быть виртуально запрещена в случае, когда параметр numStates использует одинаковое значение для всех PIPE Idx. Например, установка numStates в 8 для всех случаев дает в сумме 16*8 состояний, и вычисление индекса уточнения упрощается до ((y-2048)&255)>>5 для valMPS равного 1 или ((2047-y)&255)>>5 для valMPS равного 0. Для этого случая является очень простым отображение представления, использующего valMPS, PIPE Idx и idx уточнения обратно к представлению, используемому исходным CABAC в H.264/AVC. Состояние CABAC определяется как (PIPE Idx<<3)+Idx уточнения. Этот аспект дополнительно описывается ниже в отношении фиг. 16.
Если наклон 8-битового значения инициализации не равен нулю, или если QP не равно 26, то необходимо вычислять внутреннее состояние применением линейного уравнения с QP процесса кодирования или декодирования. В случае наклона, равного нулю, или что QP текущего процесса кодирования равно 26, вторая часть 8-битового значения инициализации может использоваться непосредственно для инициализации внутреннего состояния вероятностной модели. В противном случае, десятичная часть результирующего внутреннего состояния может дополнительно использоваться для определения индекса уточнения в применениях высокоэффективного кодирования посредством линейной интерполяции между пределами конкретного кодера PIPE. В данном предпочтительном варианте осуществления линейная интерполяция выполняется простым умножением десятичной части на общее количество индексов уточнения, доступных для текущего кодера PIPE и отображением результата на ближайший целочисленный индекс уточнения.
Процесс инициализации внутреннего состояния вероятностных моделей может изменяться относительно количества состояний индекса вероятности PIPE. В частности, двойное присутствие равновероятного режима, использующего кодер E1 PIPE, т.е. использование двух разных индексов PIPE для различения между MPS, равным 1 или 0, можно избежать следующим образом. Снова, процесс может вызываться во время начала синтаксического разбора данных слайса, и вводом данного процесса может быть 8-битовое значение инициализации, как показано в таблице E, которое, например, передается в битовом потоке для каждой контекстной модели, подлежащей инициализации.
Таблица E: Установка 8 битов initValue для вероятностной модели

Первые 4 бита определяют индекс наклона и извлекаются посредством маскирования битов b4-b7. Для каждого индекса наклона slope(m) задается и отображается в таблице F.
Таблица F: Значения переменной m для slopeIdx

Биты b0-b3, последние 4 бита 8-битового значения инициализации, идентифицируют probIdx и описывают вероятность при заданном QP. probIdx 0 указывает наибольшую вероятность для символов со значением 0 и, соответственно, probIdx 14 указывает наибольшую вероятность для символов со значением 1. Таблица G изображает для каждого probIdx соответствующий pipeCoder и его valMps.
Таблица G: Отображение последней 4-битовой части значения инициализации на кодеры PIPE и valMps: UR - унарный-в-Райс-код, TB - трехбиновый код, BP - бин-pipe-код, EP - равновероятность (не кодируется)

С обоими значениями вычисление внутреннего состояния может выполняться посредством использования линейного уравнения, подобного y=m*x+256*b, где m обозначает наклон, x обозначает QP текущего слайса, и b выводится из probIdx, как показано в последующем описании. Все значения в данном процессе масштабируются коэффициентом 256, чтобы избежать использование операций с плавающей запятой. Выходной результат (y) данного процесса представляет внутреннее состояние вероятностной модели при текущем QP и сохраняется в 8-битовой памяти. Как показано в G, внутреннее состояние состоит из valMPs, pipeIdx и refineIdx.
Таблица H: Установка внутреннего состояния вероятностной модели


Назначение refineIdx и pipeIdx подобно внутреннему состоянию вероятностных моделей CABAC (pStateCtx) и представлено в H.
Таблица I: Назначение pipeIdx, refineIdx и pStateCtx

В предпочтительном варианте осуществления probIdx определяется при QP26. Основываясь на 8-битовом значении инициализации, внутреннее состояние (valMps, pipeIdx и refineIdx) вероятностной модели обрабатывается так, как описано в следующем псевдокоде:


Как показано в псевдокоде, refineIdx вычисляется посредством линейной интерполяции между интервалом pipeIdx и квантованием результата в соответствующий refineIdx. Смещение задает общее количество refineIdx для каждого pipeIdx. Интервал [7, 8) fullCtxState/256 делится пополам. Интервал [7, 7,5) отображается на pipeIdx=0 и valMps=0, и интервал [7,5, 8) отображается на pipeIdx=0 и valMps=1. Фиг. 16 изображает процесс выведения внутреннего состояния и отображает отображение fullCtxState/256 на pStateCtx.
Отметьте, что наклон указывает зависимость probIdx и QP. Если slopeIdx 8-битового значения инициализации равно 7, результирующее внутреннее состояние вероятностной модели является одинаковым для всех QP слайса - следовательно процесс инициализации внутреннего состояния является независимым от текущего QP слайса.
Т.е., селектор 402 может инициализировать индексы pipe, подлежащие использованию при декодировании следующей части потока данных, такой как полный поток или следующий слайс, используя синтаксический элемент, указывающий размер QP шага квантования, используемый для квантования данных этой части, таких как уровни коэффициентов преобразования, содержащиеся в нем, используя данный синтаксический элемент в качестве индекса в таблицу, которая может быть общей для обоих режимов, LC и HE. Таблица, такая как таблица D, может содержать индексы pipe для каждого типа символа, для соответствующего опорного значения QPref или других данных для каждого типа символа. В зависимости от фактического QP текущей части селектор может вычислять значение индекса pipe, используя соответствующий элемент a таблицы, индексированный фактическим QP или самим QP, например, умножением a на (QP-QPref). Единственное отличие в режиме LC и HE: Селектор вычисляет результат только при меньшей точности в случае LC по сравнению с режимом HE. Селектор, например, может просто использовать целочисленную часть результата вычисления. В режиме HE используется остаток более высокой точности, такой как дробная часть, для выбора одного из доступных индексов уточнения для соответствующего индекса pipe, как указывается частью с меньшей точностью или целочисленной частью. Индекс уточнения используется в режиме HE (потенциально менее редко также в режиме LC) для выполнения вероятностной адаптации, например, посредством использования вышеупомянутого обхода таблицы. Если оставлять доступные индексы для текущего индекса pipe на более верхней границе, тогда более высокий индекс pipe выбирается следующим с минимизированием индекса уточнения. Если оставлять доступные индексы для текущего индекса pipe при более низкой границе, тогда следующий более низкий индекс pipe выбирается следующим с максимизированием индекса уточнения до максимума, доступного для нового индекса pipe. Индекс pipe вместе с индексом уточнения определяют состояние вероятности, но для выбора из числа частичных потоков, селектор просто использует индекс pipe. Индекс уточнения служит просто для более точного отслеживания вероятности, или для более высокой точности.
Вышеупомянутое описание также показало, однако, что масштабируемость сложности может достигаться независимо от принципа кодирования PIPE по фиг. 7-10 или CABAC, используя декодер, показанный на фиг. 12. Декодер по фиг.12 предназначен для декодирования потока 601 данных, в который кодируются медиаданные, и содержит переключатель 600 режима, выполненный с возможностью активизирования режима низкой сложности или режима высокой эффективности в зависимости от потока 601 данных, а также десимволизатор 602, выполненный с возможностью десимволизирования последовательности 603 символов, полученных - или прямо или посредством энтропийного декодирования, например - из потока 601 данных для получения целочисленных синтаксических элементов 604, используя функцию отображения, управляемую параметром управления, для отображения области определения слов последовательности символов в область значений целочисленных синтаксических элементов. Восстановитель 605 выполнен с возможностью восстановления медиаданных 606, основываясь на целочисленных синтаксических элементах. Десимволизатор 602 выполнен с возможностью выполнения десимволизирования, так что параметр управления изменяется в соответствии с потоком данных с первой скоростью в случае активизированного режима высокой эффективности, и параметр управления является постоянным независимо от потока данных или изменяется в зависимости от потока данных, но со второй скоростью, которая меньше первой скорости, в случае активизированного режима низкой сложности, как показано стрелкой 607. Например, параметр управления может изменяться в соответствии с ранее десимволизированными символами.
Некоторые из вышеупомянутых вариантов осуществления использовали аспект фиг. 12. Синтаксические элементы coeff_abs_minus3 и MVD в последовательности 327, например, бинаризировались в десимволизаторе 314 в зависимости от выбранного режима, как указано позицией 407, и восстановитель 605 использовал эти синтаксические элементы для восстановления. Очевидно, оба аспекта по фиг. 11 и 19 являются легко объединяемыми, но аспект фиг. 12 также может объединяться с другими средами кодирования.
См., например, отмеченное выше кодирование разностей векторов движения. Десимволизатор 602 может быть выполнен так, что функция отображения использует усеченный унарный код для выполнения отображения в первом интервале области определения целочисленных синтаксических элементов ниже значения отсечки и комбинацию префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде кодового слова VLC во втором интервале области определения целочисленных синтаксических элементов, включая и выше значения отсечки, причем декодер может содержать энтропийный декодер 608, выполненный с возможностью выведения количества первых бинов усеченного унарного кода из потока 601 данных, используя энтропийное декодирование с оценкой изменяющейся вероятности, и количества вторых бинов кодового слова VLC, используя режим обхода с постоянной равновероятностью. В режиме HE энтропийное кодирование может быть более сложным, чем при кодировании LC, как показано стрелкой 609. Т.е. контекстная адаптивность и/или вероятностная адаптация могут применяться в режиме HE и подавляться в режиме LC, или сложность может масштабироваться в других показателях, как изложено выше в отношении различных вариантов осуществления.
Кодер, соответствующий декодеру по фиг. 11, для кодирования медиаданных в поток данных показан на фиг. 13. Он может содержать устройство 500 вставки, выполненное с возможностью сигнализации в потоке 501 данных активизирования режима низкой сложности или режима высокой эффективности, конструктор 504, выполненный с возможностью предкодирования медиаданных 505 в последовательность 506 синтаксических элементов, символизатор 507, выполненный с возможностью символизирования последовательности 506 синтаксических элементов в последовательность 508 символов, множество энтропийных кодеров 310, каждый из которых выполнен с возможностью преобразования частичных последовательностей символов в кодовые слова потока данных, и селектор 502, выполненный с возможностью направления каждого символа последовательности 508 символов на выбранный один из множества энтропийных кодеров 310, причем селектор 502 выполнен с возможностью выполнения выбора в зависимости от активизированного одного из режима низкой сложности и режима высокой эффективности, как показано стрелкой 511. Перемежитель 510 может необязательно обеспечиваться для перемежения кодовых слов кодеров 310.
Кодер, соответствующий декодеру по фиг. 12, для кодирования медиаданных в поток данных показан на фиг. 14, содержащий устройство 700 вставки, выполненное с возможностью сигнализации в потоке 701 данных активизирования режима низкой сложности или режима высокой эффективности, конструктор 704, выполненный с возможностью предкодирования медиаданных 705 в последовательность 706 синтаксических элементов, содержащую целочисленный синтаксический элемент, и символизатор 707, выполненный с возможностью символизирования целочисленного синтаксического элемента, используя функцию отображения, управляемую параметром управления, для отображения области определения целочисленных синтаксических элементов в область значений слов последовательности символов, причем символизатор 707 выполнен с возможностью выполнения символизирования, так что параметр управления изменяется в соответствии с потоком данных с первой скоростью в случае активизированного режима высокой эффективности, и параметр управления является постоянным независимо от потока данных или изменяется в зависимости от потока данных, но со второй скоростью, которая меньше первой скорости, в случае активизированного режима низкой сложности, как показано стрелкой 708. Результат символизирования кодируется в поток 701 данных.
Снова, необходимо упомянуть, что вариант осуществления по фиг. 14 легко переносится на вышеупомянутый вариант осуществления контекстно-адаптивного двоичного арифметического кодирования/декодирования: селектор 509 и энтропийные кодеры 310 сводятся вместе в контекстно-адаптивный двоичный арифметический кодер, который будет выводить поток 401 данных непосредственно и выбирать контекст для бина, подлежащего выведению в настоящий момент из потока данных. Это особенно верно для контекстной адаптивности и/или вероятностной адаптивности. Обе функциональные возможности/адаптивности могут отключаться, или могут быть разработаны более ослабленными, во время режима низкой сложности.
Выше было кратко отмечено, что возможность переключения режима, описанная в отношении некоторых вышеупомянутых вариантов осуществления, согласно альтернативным вариантам осуществления, может быть исключена. Чтобы сделать это ясным, ссылка делается на фиг. 16, которая суммирует вышеупомянутое описание в той мере, в какой только исключение возможности переключения режима отличает вариант осуществления по фиг. 16 от вышеупомянутых вариантов осуществления. Кроме того, последующее описание показывает преимущества, являющиеся результатом инициализации оценок вероятности контекстов, используя менее точные параметры для наклона и смещения по сравнению, например, с H.264.
В частности, фиг. 16 изображает декодер для декодирования видео 405 из потока 401 данных, для которого кодируются горизонтальные и вертикальные составляющие разностей векторов движения, используя бинаризации горизонтальных и вертикальных составляющих, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки, и комбинации префикса в виде усеченного унарного кода. Значение отсечки и суффикс в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно 2, и экспоненциальный код Голомба имеет порядок 1. Декодер содержит энтропийный декодер 409, выполненный, для горизонтальных и вертикальных составляющих разностей векторов движения, с возможностью выведения усеченного унарного кода из потока данных, используя контекстно-адаптивное двоичное энтропийное декодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, который является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью для получения бинаризаций разностей векторов движения. Более точно, как описано выше, энтропийный декодер 409 может быть выполнен с возможностью выведения количества бинов 326 бинаризаций из потока 401 данных, используя бинарное энтропийное декодирование, такое как вышеупомянутая схема CABAC, или бинарное декодирование PIPE, т.е. использование конструкции, включающей в себя несколько параллельно работающих энтропийных декодеров 322 вместе с соответствующим селектором/средством назначения. Десимволизатор 314 дебинаризирует бинаризации синтаксических элементов разностей векторов движения для получения целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения, и восстановитель 404 восстанавливает видео, основываясь на целочисленных значениях горизонтальных и вертикальных составляющих разностей векторов движения.
Чтобы объяснить это более подробно, ссылка кратко делается на фиг. 18. Позиция 800 представительно изображает одну разность вектора движения, т.е. вектор, представляющий остаток предсказания между предсказанным вектором движения и фактическим/восстановленным вектором движения. Также показаны горизонтальные и вертикальные составляющие 802x и 802y. Они могут передаваться в единицах позиций пикселя, т.е. шага пикселя, или позиций субпикселя, таких как половина шага пикселя или его четвертая часть или т.п. Горизонтальные и вертикальные составляющие 802x,y являются целочисленными. Их область простирается от нуля до бесконечности. Значение знака может обрабатываться отдельно и здесь больше не рассматривается. Другими словами, описание, кратко изложенное в данном документе, сосредоточено на величине разностей 802x,y вектора движения. Область определения изображена позицией 804. На правой стороне оси 804 области определения фиг. 19 изображает, ассоциированные с положительными значениями составляющей 802x,y, вертикально расположенными друг на друге, бинаризации, в которую отображается (бинаризируется) соответствующее возможное значение. Как можно видеть, ниже значения отсечки, равное 2, имеет место только усеченный унарный код 806, тогда как бинаризация имеют, в качестве суффикса, также экспоненциальный код Голомба порядка 808 из возможных значений, равных или больше значения отсечки 2, чтобы продолжать бинаризацию для остатка целочисленного значения выше значения отсечки минус 1. Для всех бинов обеспечивается только два контекста: один для позиции первого бина бинаризаций горизонтальных и вертикальных составляющих 802x,y, и другой один для позиции второго бина усеченного унарного кода 806 как горизонтальной, так и вертикальной составляющих 802x,y. Для позиции бина экспоненциального кода 808 Голомба режим обхода с равновероятностью используется энтропийным декодером 409. Т.е. оба значения бина, как предполагается, происходят равновероятно. Оценка вероятности для этих бинов является фиксированной. В сравнении с ней, оценка вероятности, ассоциированная с только что упомянутыми двумя контекстами бинов усеченного унарного кода 806, адаптируется непрерывно при декодировании.
Перед описанием более подробно, в отношении того, как может быть реализован энтропийный декодер 409, в соответствии с вышеупомянутым описанием, чтобы выполнять только что упомянутые задачи, описание теперь сосредотачивается на возможной реализации восстановителя 404, который использует разности 800 вектора движения и его целочисленные значения, полученные десимволизатором 314 посредством ребинаризации бинов кодов 106 и 108, причем ребинаризация изображается на фиг. 18, используя стрелки 810. В частности, восстановитель 404, как описано выше, может извлекать из потока 401 данных информацию, касающуюся подразделения восстановленного в настоящий момент изображения в блоки, среди которых по меньшей мере некоторые подвергаются предсказанию с компенсацией движения. Фиг. 19 изображает изображение, подлежащий восстановлению, представительно в позиции 820 и блоки только что упомянутого подразделения изображения 120, для которого предсказание с компенсацией движения используется для предсказания в нем содержимого изображения в позиции 822. Как описано в отношение фиг. 2A-2C, имеются разные возможности для подразделения и размеров блоков 122. Чтобы избежать передачи разности 800 вектора движения для каждого из этих блоков 122, восстановитель 404 может использовать принцип слияния, согласно которому поток данных дополнительно передает информацию о слиянии в дополнение к информации о подразделении или, при отсутствии информации о подразделении, в дополнение к тому факту, что подразделение является фиксированным. Информация слияния сигнализирует восстановителю 404, в отношении какого из блоков 822 сформировать группы слияния. Посредством этой меры, является возможным для восстановителя 404 применить некоторую разность 800 вектора движения ко всей группе слияния блоков 822. Конечно, на кодирующей стороне передача информации о слиянии подвержена компромиссу между издержками передачи подразделения (если присутствует), издержками передачи информации о слиянии и издержками передачи разности векторов движения, которые уменьшаются с увеличением размера групп слияния. С другой стороны, увеличение количества блоков на группу слияния уменьшает адаптацию разности векторов движения для этой группы слияния к фактическим потребностям индивидуальных блоков соответствующей группы слияния, тем самым получая менее точные предсказания с компенсацией движения разностей векторов движения этих блоков и делая необходимым более высокие издержки передачи для передачи остатка предсказания в виде, например, уровня коэффициентов преобразования. Следовательно, находится компромисс на кодирующей стороне соответствующим образом. В любом случае, однако, принцип слияния приводит к разностям вектора движения для групп слияния, изображая меньшую пространственную взаимную корреляцию. См., например, фиг. 19, которая изображает штриховкой членство в некоторой группе слияния. Очевидно, что фактическое движение содержимого изображения в этих блоках было настолько подобным, что кодирующая сторона решила выполнить слияние соответствующих блоков. Однако является малой корреляция с движением содержимого изображения в других группах слияния. Следовательно, ограничение на использование просто одного контекста на бин усеченного унарного кода 806 не оказывает отрицательного влияния на эффективность энтропийного кодирования, так как принцип слияния уже в достаточной степени обеспечивает пространственную взаимную корреляцию между движением содержимого соседних изображений. Контекст может просто выбираться на основе того факта, что бин является частью бинаризации составляющей 802x,y разности векторов движения и позиции бина, которой является или 1 или 2 вследствие того, что значением отсечки является два. Следовательно, другие уже декодированные бины/синтаксические элементы/составляющие 802x,y mvd не оказывают влияние на выбор контекста.
Аналогично, восстановитель 404 может быть выполнен с возможностью дополнительного уменьшения информационного содержимого, подлежащего пересылке, посредством разностей векторов движения (кроме пространственного и/или временного предсказания векторов движения) посредством использования принципа многогипотезного предсказания, согласно которому, сначала, генерируется список предикторов вектора движения для каждого блока или группы слияния, затем явной или неявной передачи в потоке данных информации об индексе предиктора, подлежащего фактическому использованию для предсказания разностей векторов движения. См., например, незаштрихованный блок 122 на фиг. 20. Восстановитель 404 может обеспечивать разные предикторы для вектора движения данного блока, например, посредством предсказания вектора движения пространственно, например, из левого, из верхнего, комбинации обоих и т.п., и временного предсказания вектора движения из вектора движения совместно размещенной части ранее декодированного изображения видео и дополнительных комбинаций вышеупомянутых предикторов. Эти предикторы сортируются восстановителем 404 предсказуемым образом, который является прогнозируемым на кодирующей стороне. Некоторая информация передается с этой целью в потоке данных и используется восстановителем. Т.е. некоторая рекомендация содержится в потоке данных, в отношении того, какой предиктор из данного упорядоченного списка предикторов будет фактически использоваться в качестве предиктора для вектора движения данного блока. Этот индекс может явно передаваться в потоке данных для этого блока. Однако также является возможным, что индекс сначала предсказывается и затем передается только его предсказание. Также существуют другие возможности. В любом случае, только что упомянутая схема предсказания позволяет получить очень точное предсказание вектора движения текущего блока и, следовательно, уменьшается требование к информационному содержимому, накладываемое на разность вектора движения. Следовательно, ограничение контекстно-адаптивного энтропийного кодирования на только два бина усеченного унарного кода и уменьшение значения отсечки до 2, как описано в отношении фиг. 18, а также выбор порядка экспоненциального кода Голомба равным 1, не оказывает отрицательного эффекта на эффективность кодирования, так как разности векторов движения показывают, вследствие высокой эффективности предсказания, частотную гистограмму, согласно которой более высокие значения составляющих 802x,y разности векторов движения посещаются менее часто. Даже пропуск любого отличия между горизонтальной и вертикальной составляющими подходит для эффективного предсказания, так как являются высокими тенденции предсказания работы с одинаковым успехом по обеим направлениям точности предсказания.
Необходимо отметить, что в вышеупомянутом описании все подробности, обеспечиваемые с фиг. 1-15, также являются переносимыми на объекты, показанные на фиг. 16, такие как, например, которые касаются функциональности десимволизатора 314, восстановителя 404 и энтропийного декодера 409. Тем не менее, для полноты, некоторые из этих подробностей снова кратко описываются ниже.
Для лучшего понимания только что кратко изложенной схемы предсказания, см. фиг. 20. Как только что описано, конструктор 404 может получать разные предикторы для текущего блока 822 или текущей группы слияния блоков, причем эти предикторы показаны векторами 824 со сплошными линиями. Предикторы могут быть получены посредством пространственного и/или временного предсказания, причем, кроме того, могут использоваться операции арифметического среднего или т.п., так что индивидуальные предикторы могут быть получены восстановителем 404 таким образом, что они коррелируют друг с другом. Независимо от способа, которым были получены векторы 826, восстановитель 404 представляет последовательно или сортирует эти предикторы 126 в упорядоченный список. Это изображается числами 1-4 на фиг. 21. Предпочтительно, если процесс сортировки является уникально определяемым, так что кодер и декодер могут работать синхронно. Тогда только что упомянутый индекс может быть получен восстановителем 404 для текущего блока, или группы слияния, из потока данных, явно или неявно. Например, второй предиктор «2» может быть выбран, и восстановитель 404 добавляет разность 800 вектора движения к этому выбранному предсказателю 126, таким образом получая окончательно восстановленный вектор 128 движения, который затем используется для предсказания, посредством предсказания с компенсацией движения, содержимого текущего блока/группы слияния. В случае группы слияния будет возможным, что восстановитель 404 содержит дополнительные разности векторов движения, обеспечиваемые для блоков группы слияния, чтобы дополнительно уточнять вектор 128 движения в отношении индивидуальных блоков группы слияния.
Таким образом, продолжая далее с описанием реализаций объектов, показанных на фиг. 16, может быть, что энтропийный декодер 409 выполняется с возможностью выведения усеченного унарного кода 806 из потока 401 данных, используя бинарное арифметическое декодирование или бинарное кодирование PIPE. Оба принципа были описаны выше. Кроме того, энтропийный декодер 409 может быть выполнен с возможностью использования разных контекстов для двух позиций бина усеченного унарного кода 806 или, альтернативно, даже одного и того же контекста для обоих бинов. Энтропийный декодер 409 может быть выполнен с возможностью выполнения обновления состояния вероятности. Энтропийный декодер 409 может это делать, для бина, выведенного на данный момент из усеченного унарного кода 806, посредством перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для выведенного в данный момент бина, в новое состояние вероятности в зависимости от бина, выведенного в данный момент. См. вышеприведенные таблицы Next_State_LPS и Next_State_MPS, табличный поиск в отношении которого выполняется энтропийным декодером в дополнение к другим этапам 0-5, перечисленным выше. В вышеприведенном описании текущее состояние вероятности было упомянуто посредством pState_current. Оно определяется для соответствующего контекста, представляющего интерес. Энтропийный декодер 409 может быть выполнен с возможностью двоичного арифметического декодирования бина, подлежащего в данный момент выведению из усеченного унарного кода 806 посредством квантования значения ширины текущего интервала вероятностей, т.е. R, представляющего текущий интервал вероятностей для получения индекса интервала вероятностей, q_index, и выполнения подразделения интервала посредством индексирования элемента таблицы среди элементов таблицы, используя индекс интервала вероятностей и индекс состояния вероятности, т.е. p_state, который, в свою очередь, зависит от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, подвергаемого выведению в данный момент, для получения подразделения текущего интервала вероятностей на два частичных интервала. В вышеупомянутых кратко описанных вариантах осуществления эти частичные интервалы ассоциировались с наиболее вероятным и наименее вероятным символом. Как описано выше, энтропийный декодер 409 может быть выполнен с возможностью использования восьмибитового представления для значения R ширины текущего интервала вероятностей с захватыванием, например, двух или трех самых старших битов восьмибитового представления и квантованием значения ширины текущего интервала вероятностей. Энтропийный декодер 409 дополнительно может быть выполнен с возможностью выбора из числа двух частичных интервалов, основываясь на значении состояния смещения из внутренней части текущего интервала вероятностей, а именно V, обновления значения R ширины интервала вероятностей и значения состояния смещения и предположения значения бина, подлежащего выводу в данный момент, используя выбранный частичный интервал, и выполнения ренормализации обновленного значения R ширины интервала вероятностей и значения V состояния смещения, включая продолжение считывания битов из потока 401 данных. Энтропийный декодер 409, например, может быть выполнен с возможностью двоичного арифметического декодирования бина из экспоненциального кода Голомба посредством деления пополам значения ширины текущего интервала вероятностей для получения подразделения текущего интервала вероятностей на два частичных интервала. Деление пополам соответствует оценке вероятности, которая является фиксированной и равной 0,5. Оно может быть реализовано простым сдвигом битов. Энтропийный декодер дополнительно может быть выполнен, для каждой разности вектора движения, с возможностью выведения усеченного унарного кода горизонтальной и вертикальной составляющих соответствующей разности векторов движения из потока 401 данных, перед экспоненциальным кодом Голомба горизонтальной и вертикальной составляющих соответствующей разности векторов движения. Посредством этой меры энтропийный декодер 409 может использовать, что большее количество бинов вместе формируют серию бинов, для которых оценка вероятности является фиксированной, а именно 0,5. Это может ускорить процедуру энтропийного декодирования. С другой стороны, энтропийный декодер 409 может предпочитать поддерживать порядок среди разностей векторов движения посредством сначала выведением горизонтальной и вертикальной составляющих одной разности вектора движения, переходя затем просто к выведению горизонтальной и вертикальной составляющих следующей разности вектора векторов движения. Посредством этой меры, снижаются требования к памяти, налагаемые на декодирующий объект, т.е. декодер по фиг. 16, так как десимволизатор 314 может продолжать дебинаризацию разностей векторов движения непосредственно без необходимости ожидания сканирования других разностей векторов движения. Это делается возможным посредством выбора контекста: так как только точно один контекст является доступным на каждую позицию бина кода 806, не нужно инспектировать пространственную взаимосвязь.
Восстановитель 404, как описано выше, может пространственно и/или временно предсказывать горизонтальные и вертикальные составляющие векторов движения, чтобы получать предикторы 126 для горизонтальной и вертикальной составляющих вектора движения и восстанавливать горизонтальные и вертикальные составляющие векторов движения посредством уточнения предикторов 826, используя горизонтальные и вертикальные составляющие разностей векторов движения, например, просто добавлением разности векторов движения к соответствующему предсказателю.
Кроме того, восстановитель 404 может быть выполнен с возможностью предсказания горизонтальных и вертикальных составляющих векторов движения разным образом, чтобы получать упорядоченный список предикторов для горизонтальной и вертикальной составляющей векторов движения, получать индекс списка из потока данных и восстанавливать горизонтальные и вертикальные составляющие векторов движения посредством уточнения предиктора, тем предиктором списка, на который указывает индекс списка, используя горизонтальные и вертикальные составляющие разностей векторов движения.
Кроме того, как уже было описано выше, восстановитель 404 может быть выполнен с возможностью восстановления видео, используя предсказание с компенсацией движения посредством применения горизонтальных и вертикальных составляющих 802x,y векторов движения при пространственной степени разбиения, определяемой подразделением изображений видео в блоки, причем восстановитель 404 может использовать синтаксические элементы слияния, присутствующие в потоке 401 данных, чтобы группировать блоки в группы слияния и применять целочисленные значения горизонтальных и вертикальных составляющих 802x,y разностей векторов движения, полученных бинаризатором 314 в единицах групп слияния.
Восстановитель 404 может выводить подразделение изображений видео в блоки из части потока 401 данных, который исключает синтаксические элементы слияния. Восстановитель 404 также может адаптировать горизонтальную и вертикальную составляющие предопределенного вектора движения для всех блоков ассоциированной группы слияния, или уточнять их посредством горизонтальных и вертикальных составляющих разностей векторов движения, ассоциированных с блоками группы слияния.
Только для полноты, фиг. 17 изображает кодер, соответствующий декодеру по фиг. 16. Кодер по фиг. 17 содержит конструктор 504, символизатор 507 и энтропийный кодер 513. Кодер содержит конструктор 504, выполненный с возможностью кодирования с предсказанием видео 505 посредством предсказания с компенсацией движения, используя векторы движения, и кодирования с предсказанием векторов движения посредством предсказания векторов движения и установки целочисленных значений 506 горизонтальных и вертикальных составляющих разностей векторов движения для представления ошибки предсказания предсказываемых векторов движения; символизатор 507, выполненный с возможностью бинаризации целочисленных значений для получения бинаризаций 508 горизонтальных и вертикальных составляющих разностей векторов движения, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки и комбинации префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно двум, и экспоненциальный код Голомба имеет порядок, равный единице; и энтропийный кодер 513, выполненный, для горизонтальных и вертикальных составляющих разностей векторов движения, с возможностью кодирования усеченного унарного кода в поток данных, используя контекстно-адаптивное двоичное энтропийное кодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, который является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью. Другие возможные подробности реализации являются непосредственно переносимыми из описания, касающегося декодера по фиг. 16, в кодер по фиг. 17.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут выполняться аппаратным устройством (или использовать их), подобных, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления некоторый один или несколько из наиболее важных этапов способа могут выполняться таким устройством.
Обладающий признаками изобретения кодированный сигнал может сохраняться на цифровой запоминающей среде или может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от некоторых требований к реализации варианты осуществления изобретения могут быть реализованы аппаратными средствами или программными средствами. Реализация может выполняться с использованием цифровой запоминающей среды, например, гибкого диска, цифрового многофункционального диска (DVD), диска Blue-Ray, компакт-диска, постоянного запоминающего устройства (ROM), программируемого ROM (PROM), стираемого программируемого ROM (EPROM), электрически стираемого программируемого ROM (EEPROM) или флэш-памяти, имеющих электронно-считываемые сигналы управления, хранимые на них, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так что выполняется соответствующий способ. Поэтому, цифровая запоминающая среда может быть считываемая компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой, так что выполняется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде продукта компьютерной программы с программным кодом, причем программный код действует для выполнения одного из способов, когда продукт компьютерной программы выполняется на компьютере. Программный код, например, может сохраняться на машиносчитываемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в данном документе, хранимых на машиносчитываемом носителе.
Другими словами, вариантом осуществления обладающего признаками изобретения способа, поэтому, является компьютерная программа, имеющая программный код для выполнения одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Другим вариантом осуществления обладающих признаками изобретения способов, поэтому, является носитель данных (или цифровая запоминающая среда или считываемая компьютером среда), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в данном документе. Носитель данных, цифровая запоминающая среда или записанная среда являются обычно материальными и/или непереходными.
Другим вариантом осуществления обладающего признаками изобретения способа, поэтому, является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, могут быть выполнены с возможностью пересылки по соединению передачи данных, например, по Интернету.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, выполненное с возможностью или адаптируемое к выполнению одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью пересылки (например, электронным или оптическим образом) на приемник компьютерной программы для выполнения одного из способов, описанных в данном документе. Приемником, например, может быть компьютер, мобильное устройство, устройство памяти или т.п. Устройство или система, например, может содержать файловый сервер для пересылки компьютерной программы на приемник.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в данном документе. В некоторых вариантах осуществления программируемая вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в данном документе. В общем, способы, предпочтительно, выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Понятно, что модификации и изменения устройств и деталей, описанных в данном документе, очевидны для специалиста в данной области техники. Предполагается, что они, поэтому, ограничиваются только объемом находящейся на рассмотрении формулы изобретения и не конкретными деталями, представленными посредством описания и объяснения вариантов осуществления в данном документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2658883C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2018 |
|
RU2758981C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2021 |
|
RU2776910C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2024 |
|
RU2839971C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2022 |
|
RU2820857C2 |
| ОБХОДНЫЕ БИНЫ ДЛЯ КОДИРОВАНИЯ ОПОРНЫХ ИНДЕКСОВ ПРИ КОДИРОВАНИИ ВИДЕО | 2013 |
|
RU2643655C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |










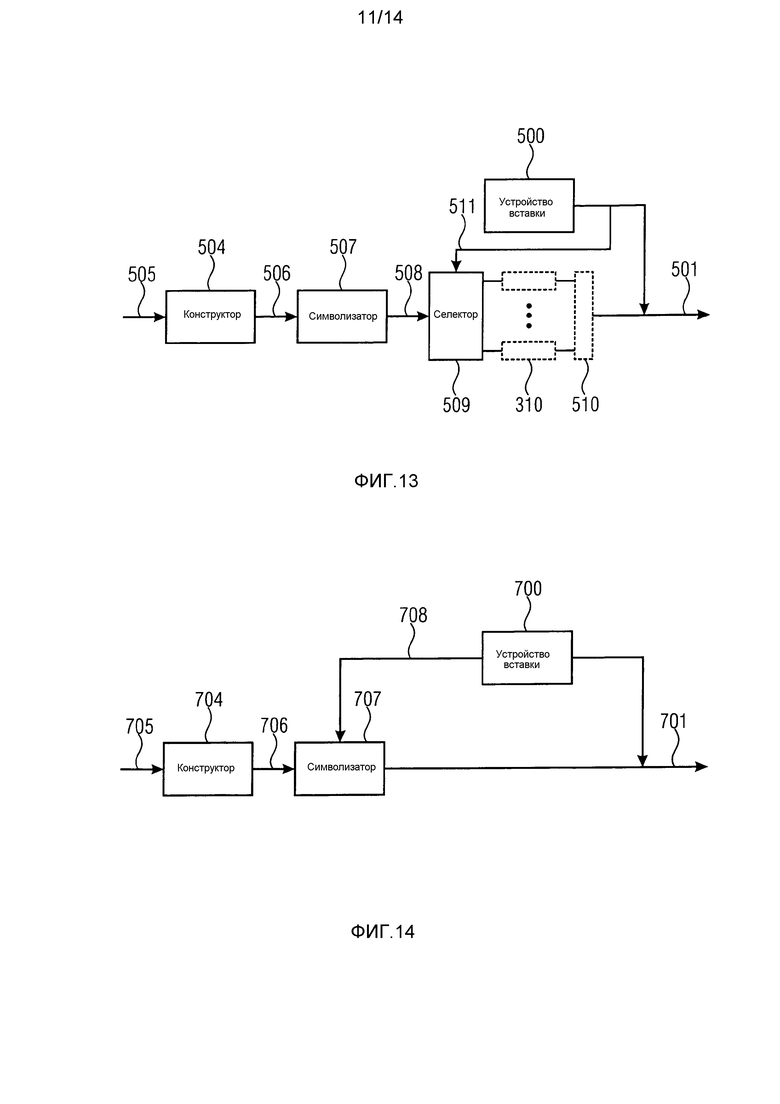



Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности энтропийного кодирования разностей векторов движения. Декодер для декодирования видео из потока данных, в который кодируются горизонтальные и вертикальные составляющие разностей векторов движения, содержит энтропийный декодер, выполненный, для горизонтальных и вертикальных составляющих разностей векторов движения, с возможностью выведения усеченного унарного кода из потока данных, используя контекстно-адаптивное двоичное энтропийное декодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, который является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью для получения бинаризаций разностей векторов движения; десимволизатор для дебинаризации бинаризаций синтаксических элементов разностей векторов движения для получения целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения; восстановитель для восстановления видео, основываясь на целочисленных значениях горизонтальных и вертикальных составляющих разностей векторов движения. 7 н. и 30 з.п. ф-лы, 22 ил., 12 табл.
1. Декодер для декодирования видео из потока данных, в который кодируются горизонтальные и вертикальные составляющие разностей векторов движения, используя бинаризации горизонтальных и вертикальных составляющих, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки и комбинации префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно двум и экспоненциальный код Голомба имеет порядок единицы, содержащий:
энтропийный декодер, выполненный, для горизонтальных и вертикальных составляющих разностей векторов движения, с возможностью выведения усеченного унарного кода из потока данных, используя контекстно-адаптивное двоичное энтропийное декодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, который является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью для получения бинаризаций разностей векторов движения;
десимволизатор, выполненный с возможностью дебинаризации бинаризаций синтаксических элементов разностей векторов движения для получения целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения;
восстановитель, выполненный с возможностью восстановления видео, основываясь на целочисленных значениях горизонтальных и вертикальных составляющих разностей векторов движения.
2. Декодер по п. 1, в котором энтропийный декодер (409) выполнен с возможностью выведения усеченного унарного кода (806) из потока (401) данных, используя двоичное арифметическое декодирование или двоичное энтропийное декодирование с разделением на интервалы вероятности.
3. Декодер по п. 1, в котором энтропийный декодер (409) выполнен с возможностью использования разных контекстов для двух позиций бина усеченного унарного кода 806.
4. Декодер по п. 1, в котором энтропийный декодер (409) выполнен с возможностью выполнения обновления состояния вероятности для бина, выводимого в данный момент из усеченного унарного кода (806), посредством перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, выводимого в данный момент, в новое состояние вероятности в зависимости от бина, выводимого в данный момент.
5. Декодер по п. 1, в котором энтропийный декодер (409) выполнен с возможностью двоичного арифметического декодирования бина, подлежащего выведению в данный момент из усеченного унарного кода (806) посредством квантования значения ширины текущего интервала вероятности, представляющего текущий интервал вероятности, для получения индекса интервала вероятности и выполнения подразделения интервала посредством индексирования элемента таблицы из числа элементов таблицы, используя индекс интервала вероятности и индекс состояния вероятности в зависимости от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, подлежащего выведению в данный момент, для получения подразделения текущего интервала вероятности на два частичных интервала.
6. Декодер по п. 5, в котором энтропийный декодер (409) выполнен с возможностью использования 8-битового представления для значения ширины текущего интервала вероятности и захватывания 2 или 3 самых старших битов 8-битового представления при квантовании значения ширины текущего интервала вероятности.
7. Декодер по п. 5, в котором энтропийный декодер (409) выполнен с возможностью выбора из числа упомянутых двух частичных интервалов, основываясь на значении состояния смещения из внутренней части текущего интервала вероятности, обновления значения ширины интервала вероятности и значения состояния смещения и предположения значения бина, подлежащего выведению в данный момент, используя выбранный частичный интервал, и выполнения ренормализации обновленного значения ширины интервала вероятности и значения состояния смещения, включая продолжение считывания битов из потока (401) данных.
8. Декодер по п. 5, в котором энтропийный декодер (409) выполнен, в режиме обхода с постоянной равновероятностью, с возможностью двоичного арифметического декодирования бина из экспоненциального кода Голомба посредством деления пополам значения ширины текущего интервала вероятности для получения подразделения текущего интервала вероятности на два частичных интервала.
9. Декодер по п. 1, в котором энтропийный декодер (409) выполнен, для каждой разности вектора движения, с возможностью выведения усеченного унарного кода горизонтальной и вертикальной составляющих соответствующей разности векторов движения из потока данных перед экспоненциальным кодом Голомба горизонтальной и вертикальной составляющих соответствующей разности векторов движения.
10. Декодер по п. 1, в котором восстановитель выполнен с возможностью пространственного и/или временного предсказания горизонтальных и вертикальных составляющих векторов движения, чтобы получать предикторы для горизонтальных и вертикальных составляющих векторов движения и восстанавливать горизонтальные и вертикальные составляющие векторов движения посредством уточнения предикторов, используя горизонтальные и вертикальные составляющие разностей векторов движения.
11. Декодер по п. 1, в котором восстановитель выполнен с возможностью предсказания горизонтальных и вертикальных составляющих векторов движения различным образом, чтобы получать упорядоченный список предикторов для горизонтальных и вертикальных составляющих векторов движения, получать индекс списка из потока данных и восстанавливать горизонтальные и вертикальные составляющие векторов движения посредством уточнения предиктора из списка предикторов, на который указывает индекс списка, используя горизонтальные и вертикальные составляющие разностей векторов движения.
12. Декодер по п. 10, в котором восстановитель выполнен с возможностью восстановления видео, используя предсказание с компенсацией движения посредством использования горизонтальных и вертикальных составляющих векторов движения.
13. Декодер по п. 12, в котором восстановитель выполнен с возможностью восстановления видео, используя предсказание с компенсацией движения посредством применения горизонтальных и вертикальных составляющих векторов движения с пространственной степенью разбиения, определяемой подразделением изображений видео в блоки, причем восстановитель использует синтаксические элементы слияния, присутствующие в потоке данных, чтобы группировать блоки в группы слияния и применять целочисленные значения горизонтальных и вертикальных составляющих разностей векторов движения, полученные десимволизатором, в единицах групп слияния.
14. Декодер по п. 13, в котором восстановитель выполнен с возможностью выведения подразделения изображений видео в блоках из части потока данных, исключая синтаксические элементы слияния.
15. Декодер по п. 13, в котором восстановитель выполнен с возможностью принятия горизонтальных и вертикальных составляющих предопределенного вектора движения для всех блоков ассоциированной группы слияния или уточнения их посредством горизонтальных и вертикальных составляющих разностей векторов движения, ассоциированных с блоками группы слияния.
16. Декодер по п. 1, в котором в поток данных закодирована карта глубины.
17. Кодер для кодирования видео в поток данных, содержащий
конструктор, выполненный с возможностью кодирования с предсказанием видео посредством предсказания с компенсацией движения, используя векторы движения и кодируя с предсказанием векторы движения посредством предсказания векторов движения и установки целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения для представления ошибки предсказания предсказанных векторов движения;
символизатор, выполненный с возможностью бинаризации целочисленных значений для получения бинаризаций горизонтальных и вертикальных составляющих разностей векторов движения, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки и комбинации префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно двум и экспоненциальный код Голомба имеет порядок единицы; и
энтропийный кодер, выполненный, для горизонтальных и вертикальных составляющих разностей векторов движения, с возможностью кодирования усеченного унарного кода в поток данных, используя контекстно-адаптивное двоичное энтропийное кодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, который является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью.
18. Кодер по п. 17, в котором энтропийный кодер выполнен с возможностью кодирования усеченного унарного кода в поток данных, используя двоичное арифметическое кодирование или двоичное энтропийное кодирование с разделением на интервалы вероятности.
19. Кодер по п. 17, в котором энтропийный кодер выполнен с возможностью использования разных контекстов для двух позиций бина усеченного унарного кода.
20. Кодер по п. 17, в котором энтропийный кодер выполнен с возможностью выполнения обновления состояния вероятности для бина, подлежащего кодированию в данный момент из усеченного унарного кода, посредством перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, подлежащего кодированию в данный момент, в новое состояние вероятности в зависимости от бина, подлежащего кодированию в данный момент.
21. Кодер по п. 17, в котором энтропийный кодер выполнен с возможностью двоичного арифметического кодирования бина, подлежащего кодированию в данный момент из усеченного унарного кода посредством квантования значения ширины текущего интервала вероятности, представляющего текущий интервал вероятности, для получения индекса интервала вероятности и выполнения подразделения интервала посредством индексирования элемента таблицы из числа элементов таблицы, используя индекс интервала вероятности и индекс состояния вероятности в зависимости от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, подлежащего кодированию в данный момент, для получения подразделения текущего интервала вероятности на два частичных интервала.
22. Кодер по п. 21, в котором энтропийный кодер выполнен с возможностью использования 8-битового представления для значения ширины текущего интервала вероятности и захватывания 2 или 3 самых старших битов 8-битового представления при квантовании значения ширины текущего интервала вероятности.
23. Кодер по п. 21, в котором энтропийный кодер выполнен с возможностью выбора из числа двух частичных интервалов, основываясь на целочисленном значении бина, подлежащего кодированию в данный момент, обновления значения ширины интервала вероятности и смещения интервала вероятности, используя выбранный частичный интервал, и выполнения ренормализации значения ширины интервала вероятности и смещения интервала вероятности, включая продолжение записи битов в поток данных.
24. Кодер по п. 21, в котором энтропийный кодер выполнен с возможностью двоичного арифметического кодирования бина из экспоненциального кода Голомба посредством деления пополам значения ширины текущего интервала вероятности для получения подразделения текущего интервала вероятности на два частичных интервала.
25. Кодер по п. 17, в котором энтропийный кодер выполнен, для каждой разности вектора движения, с возможностью кодирования усеченного унарного кода горизонтальной и вертикальной составляющих соответствующей разности векторов движения в поток данных перед экспоненциальным кодом Голомба горизонтальной и вертикальной составляющих соответствующей разности векторов движения.
26. Кодер по п. 17, в котором конструктор выполнен с возможностью пространственного и/или временного предсказания горизонтальных и вертикальных составляющих векторов движения, чтобы получать предикторы для горизонтальных и вертикальных составляющих векторов движения, и определения горизонтальных и вертикальных составляющих разностей векторов движения, чтобы уточнять предикторы к горизонтальным и вертикальным составляющим векторов движения.
27. Кодер по п. 17, в котором конструктор выполнен с возможностью предсказания горизонтальных и вертикальных составляющих векторов движения разным образом, чтобы получать упорядоченный список предикторов для горизонтальных и вертикальных составляющих векторов движения, определения индекса списка и вставки информации, раскрывающей его, в поток данных и определения горизонтальных и вертикальных составляющих разностей векторов движения, чтобы уточнять предиктор, на который указывает индекс списка, к горизонтальным и вертикальным составляющим векторов движения.
28. Кодер по п. 17, в котором конструктор выполнен с возможностью кодирования видео, используя предсказание с компенсацией движения посредством применения горизонтальных и вертикальных составляющих векторов движения с пространственной степенью разбиения, определяемой подразделением изображений видео в блоки, причем конструктор определяет и вставляет в поток данных синтаксические элементы слияния, чтобы группировать блоки в группы слияния и применять целочисленные значения горизонтальных и вертикальных составляющих разностей векторов движения, подвергаемые бинаризации символизатором, в единицах групп слияния.
29. Кодер по п. 28, в котором конструктор выполнен с возможностью кодирования подразделения изображений видео в блоках в часть потока данных, исключая синтаксические элементы слияния.
30. Кодер по п. 29, в котором конструктор выполнен с возможностью принятия горизонтальных и вертикальных составляющих предопределенного вектора движения для всех блоков ассоциированной группы слияния или уточнения их посредством горизонтальных и вертикальных составляющих разностей векторов движения, ассоциированных с блоками группы слияния.
31. Кодер по п. 17, в котором в поток данных закодирована карта глубины.
32. Способ декодирования видео из потока данных, в который кодируются горизонтальные и вертикальные составляющие разностей векторов движения, используя бинаризации горизонтальных и вертикальных составляющих, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки и комбинации префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно двум и экспоненциальный код Голомба имеет порядок единицы, содержащий:
для горизонтальных и вертикальных составляющих разностей векторов движения, выведение
усеченного унарного кода из потока данных, используя контекстно-адаптивное двоичное энтропийное декодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, причем контекст является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и
экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью, для получения бинаризаций разностей векторов движения;
дебинаризацию бинаризаций синтаксических элементов разностей векторов движения для получения целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения;
восстановление видео, основываясь на целочисленных значениях горизонтальных и вертикальных составляющих разностей векторов движения.
33. Способ кодирования видео в поток данных, содержащий:
кодирование с предсказанием видео посредством предсказания с компенсацией движения, используя векторы движения и кодирование с предсказанием векторов движения посредством предсказания векторов движения и установки целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения для представления ошибки предсказания предсказываемых векторов движения;
бинаризацию целочисленных значений для получения бинаризаций горизонтальных и вертикальных составляющих разностей векторов движения, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки и комбинации префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно двум и экспоненциальный код Голомба имеет порядок единицы; и,
для горизонтальных и вертикальных составляющих разностей векторов движения,
кодирование
усеченного унарного кода в поток данных, используя контекстно-адаптивное двоичное энтропийное кодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, причем контекст является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и
экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью.
34. Считываемый компьютером носитель данных, хранящий компьютерную программу, имеющую программный код для выполнения, при выполнении на компьютере, способа по п. 32.
35. Считываемый компьютером носитель данных, хранящий компьютерную программу, имеющую программный код для выполнения, при выполнении на компьютере, способа по п. 33.
36. Цифровой носитель данных, хранящий поток данных, в который кодируется видео, причем носитель данных содержит
горизонтальные и вертикальные составляющие разностей векторов движения,
при этом горизонтальные и вертикальные составляющие разностей векторов движения кодируются в поток данных с использованием бинаризаций горизонтальных и вертикальных составляющих, причем бинаризации равны усеченному унарному коду горизонтальных и вертикальных составляющих соответственно в первом интервале области определения горизонтальных и вертикальных составляющих ниже значения отсечки и комбинации префикса в виде усеченного унарного кода для значения отсечки и суффикса в виде экспоненциального кода Голомба горизонтальных и вертикальных составляющих соответственно во втором интервале области определения горизонтальных и вертикальных составляющих включительно и выше значения отсечки, причем значение отсечки равно двум и экспоненциальный код Голомба имеет порядок единицы;
причем горизонтальные и вертикальные составляющие разностей векторов движения являются декодируемыми из потока данных посредством:
для горизонтальных и вертикальных составляющих разностей векторов движения, выведения усеченного унарного кода из потока данных, используя контекстно-адаптивное двоичное энтропийное декодирование с точно одним контекстом на каждую позицию бина усеченного унарного кода, который является общим для горизонтальных и вертикальных составляющих разностей векторов движения, и экспоненциального кода Голомба, используя режим обхода с постоянной равновероятностью, для получения бинаризаций разностей векторов движения; и
дебинаризации бинаризаций синтаксических элементов разностей векторов движения для получения целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения; и
при этом видео является восстанавливаемым на основе целочисленных значений горизонтальных и вертикальных составляющих разностей векторов движения.
37. Цифровой носитель данных по п. 36, при этом в поток данных закодирована карта глубины.
| US 6900748 B2, 31.05.2005 | |||
| US 7932843 B2, 26.04.2011 | |||
| US 7221296 B2, 22.05.2007 | |||
| EP 1294193 A1, 19.03.2003 | |||
| RU 2371881 C1, 27.10.2009. |

