Настоящее изобретение относится к принципу энтропийного кодирования для кодирования видеоданных.
В данной области техники известно множество видеокодеков. В общем, эти кодеки уменьшают объем данных, необходимый для того, чтобы представлять видеоконтент, т.е. они сжимают данные. При энтропийном кодировании важно кодировать символы с использованием оценки вероятности, которая максимально близко соответствует фактической статистике по символам. Оценка вероятности ассоциирует значение вероятности с каждым возможным значением, которое могут допускать символы, чтобы кодировать. В случае двоичного энтропийного кодирования, например, символы имеют двоичную природу, и существуют всего два таких возможных значения. В случае кодирования видео символы, которые должны быть кодированы, принадлежат различным элементам синтаксиса, которые удовлетворяют различным задачам, чтобы описывать видеоконтент: предусмотрены разности векторов движения, режимы кодирования, уровни коэффициентов преобразования, представляющие остаток прогнозирования, и т.д. Прежде всего, все эти элементы синтаксиса имеют различную область возможных значений, и даже те, которые задаются в идентичной области возможных значений, с наибольшей вероятностью демонстрируют различную частотную гистограмму в этой области возможных значений. Соответственно, символы/бины из строк символов/строк бинов для преобразования в символьную форму/бинаризации этих элементов синтаксиса также демонстрируют различную статистику относительно распределения вероятностей в символьном алфавите. Соответственно, используется контекстно-адаптивное энтропийное кодирование: сначала предоставляются различные контексты, причем каждый контекст ассоциирован с различной оценкой вероятности. Соответственно, целесообразно, например, назначать бины различных элементов синтаксиса с различными контекстами. Даже пространственные взаимосвязи между бинами/символами элементов синтаксиса относительно соседних частей изображения видео могут быть использованы для того, чтобы выбирать между различными предоставленными контекстами. Посредством этого показателя можно классифицировать бины/символы на группы, статистика по символам которых изменяется аналогично для различного видеоконтента. Помимо этого, тем не менее, оценки вероятности, ассоциированные с этими контекстами, непрерывно адаптируются к фактической статистике по символам в ходе кодирования.
Из вышеприведенного описания напрямую следует то, что важно тщательно разрабатывать контексты и инициализировать оценки вероятности контекстов надлежащим образом. Например, если число контекстов является слишком высоким, адаптация оценок вероятности завершается неудачно вследствие слишком низкой частоты символов в отдельном контексте. С другой стороны, если число контекстов является слишком низким, символы, собранные в отдельных контекстах, фактически имеют различную статистику, и оценка вероятности не может близко аппроксимировать фактическую статистику по символам всех этих символов в соответствующем контексте. Что касается инициализации оценки вероятности, преимущество для нее может быть получено из выполнения некоторой фазы обучения, в которой репрезентативное смешение видеоконтента подвергается кодированию, чтобы изучать статистику по выборкам (элементам дискретизации) элементов синтаксиса. В этом случае в H.264 используется, например, то, что статистика по символам символов различных контекстов H.264 частично показывает зависимость от параметра QP квантования, который кодер выбирает для отдельных слайсов видео. Соответственно, в H.264 использована зависимая от параметров квантования инициализация оценки вероятности. В частности, кодек H.264 задает пару значений для каждого контекста, а именно, зависимый от параметров линейного квантования фактор, т.е. наклон, а также значение смещения, т.е. значение независимой от параметров квантования инициализации. Оба значения заданы в 8 битах.
Имеется постоянная потребность дополнительно повышать эффективность кодирования при кодировании видео, и, соответственно, должно быть предпочтительным, если вышеуказанное контекстно-адаптивное двоичное энтропийное кодирование может быть дополнительно улучшено с точки зрения эффективности, т.е. с точки зрения компромисса между коэффициентом сжатия, с одной стороны, и сложностью реализации, с другой стороны.
Соответственно, цель настоящего изобретения заключается в том, чтобы предоставлять такой принцип кодирования.
Это цель достигается посредством предмета изобретения в независимых пунктах формулы изобретения, прилагаемой к данному документу.
Базовые новшества настоящего изобретения вытекают из обнаружения авторов изобретения того, что точность, при которой вышеобозначенный наклон и смещение при контекстно-адаптивном двоичном энтропийном кодировании не должны быть слишком высокими, с тем, чтобы не допускать, что любая фаза обучения, в которой анализируется репрезентативное смешение видеоконтента для того, чтобы извлекать пары значений наклона и смещения для отдельного контекста, останавливается на оптимизированных значениях, которые фактически более близко представляют смешение фактически проанализированного видеоконтента, чем репрезентативные значения статистической совокупности видео. Соответственно, авторы настоящего изобретения выявили, что предпочтительно снижать точность для предоставления значений наклона и смещения для инициализации оценки вероятности контекстов. Авторы изобретения выяснили, например, что это уменьшение не только приводит к уменьшению требований к запоминающему устройству, налагаемых на видеокодеры и декодеры для сохранения пар наклона и смещения для каждого контекста, но также и к небольшому повышению эффективности кодирования при тестировании эффективности кодирования в рабочих условиях.
Предпочтительные варианты осуществления настоящей заявки описываются ниже со ссылкой на чертежи, на которых:
фиг.1 показывает блок-схему кодера согласно варианту осуществления;
фиг.2a-2c схематично показывают различные подразделения массива выборок (элементов дискретизации), такого как изображение, на блоки;
фиг.3 показывает блок-схему декодера согласно варианту осуществления;
фиг.4 подробнее показывает блок-схему кодера согласно варианту осуществления;
фиг.5 подробнее показывает блок-схему декодера согласно варианту осуществления;
фиг.6 схематично иллюстрирует преобразование блока из пространственной области в спектральную область, результирующий блок преобразования и его повторное преобразование;
фиг.7 показывает блок-схему кодера согласно варианту осуществления;
фиг.8 показывает блок-схему декодера, подходящего для декодирования потока битов, сформированного посредством кодера по фиг.8, согласно варианту осуществления;
фиг.9 показывает принципиальную схему, иллюстрирующую пакет данных с мультиплексированными частичными потоками битов согласно варианту осуществления;
фиг.10 показывает принципиальную схему, иллюстрирующую пакет данных с альтернативной сегментацией с использованием сегментов фиксированного размера согласно дополнительному варианту осуществления;
фиг.11 показывает декодер, поддерживающий переключение режимов согласно варианту осуществления;
фиг.12 показывает декодер, поддерживающий переключение режимов согласно дополнительному варианту осуществления;
фиг.13 показывает кодер, соответствующий декодеру по фиг.11 согласно варианту осуществления;
фиг.14 показывает кодер, соответствующий декодеру по фиг.12 согласно варианту осуществления;
фиг.15 показывает преобразование pStateCtx и fullCtxState/256;
фиг.16 показывает декодер согласно варианту осуществления настоящего изобретения; и
фиг.17 показывает кодер согласно варианту осуществления настоящего изобретения.
Следует отметить, что в ходе описания чертежей элементы, имеющиеся на нескольких из этих чертежей, указываются с помощью идентичной ссылки с номером на каждом из этих чертежей, и повторное описание этих элементов в отношении функциональности исключается во избежание необязательных повторений. Тем не менее, функциональности и описания, предоставленные в отношении одного чертежа, также должны применяться к другим чертежам, если иное не указано явно.
Далее, сначала описываются варианты осуществления общего принципа кодирования видео относительно фиг.1-17. Фиг.1-6 относятся к части видеокодека, работающей на уровне синтаксиса. Следующие фиг.8-17 относятся к вариантам осуществления для части кода, связанной с преобразованием потока элементов синтаксиса в поток данных, и наоборот. Затем, конкретные аспекты и варианты осуществления настоящего изобретения описываются в форме возможных реализаций общего принципа, приведенных относительно фиг.1-17.
Фиг.1 показывает пример для кодера 10, в котором могут быть реализованы аспекты настоящей заявки.
Кодер кодирует массив информационных выборок 20 в поток данных. Массив информационных выборок может представлять информационные выборки, соответствующие, например, значениям яркости, значениям цвета, значениям яркости, значениям цветности и т.п. Тем не менее, информационные выборки также могут быть значениями глубины в случае, если массив 20 выборок представляет собой карту глубины, сформированную, например, посредством времени светочувствительного датчика и т.п.
Кодер 10 является кодером на основе блоков. Иными словами, кодер 10 кодирует массив 20 выборок в поток 30 данных в единицах блоков 40. Кодирование в единицах блоков 40 не обязательно означает, что кодер 10 кодирует эти блоки 40 полностью независимо друг от друга. Наоборот, кодер 10 может использовать восстановление ранее кодированных блоков, чтобы экстраполировать или внутренне прогнозировать оставшиеся блоки, и может использовать степень разбиения блоков для задания параметров кодирования, т.е. для задания способа, которым кодируется каждая область массива выборок, соответствующая надлежащему блоку.
Дополнительно, кодер 10 является кодером с преобразованием. Иными словами, кодер 10 кодирует блоки 40 посредством использования преобразования, чтобы переводить информационные выборки в каждом блоке 40 из пространственной области в спектральную область. Может использоваться двумерное преобразование, к примеру, DCT FFT и т.п. Предпочтительно, блоки 40 имеют квадратную форму или прямоугольную форму.
Подразделение массива 20 выборок на блоки 40, показанные на фиг.1, служит просто в качестве иллюстрации. Фиг.1 показывает массив 20 выборок как подразделенный на регулярную двумерную компоновку квадратных или прямоугольных блоков 40, которые примыкают друг к другу неперекрывающимся способом. Размер блоков 40 может быть предварительно определен. Иными словами, кодер 10 может не передавать информацию относительно размера блока блоков 40 в потоке 30 данных стороне декодирования. Например, декодер может ожидать предварительно определенный размер блока.
Тем не менее, возможно несколько альтернатив. Например, блоки могут перекрывать друг друга. Тем не менее, перекрытие может ограничиваться до такой степени, что каждый блок имеет часть, не перекрывающуюся посредством соседних блоков, или до такой степени, что каждая выборка блоков перекрывается максимум посредством одного блока из соседних блоков, размещаемых рядом с текущим блоком вдоль предварительно определенного направления. Второе означает, что левый и правый соседние блоки могут перекрывать текущий блок таким образом, что они полностью охватывают текущий блок, но они могут не перекрывать друг друга, и то же применимо к соседним узлам в вертикальном и диагональном направлении.
В качестве дополнительной альтернативы, подразделение массива 20 выборок на блоки 40 может быть адаптировано к контенту массива 20 выборок посредством кодера 10, при этом информация подразделения относительно используемого подразделения передается стороне декодера через поток 30 битов.
Фиг.2a-2c показывают различные примеры для подразделения массива 20 выборок на блоки 40. Фиг.2a показывает подразделение на основе дерева квадрантов массива 20 выборок на блоки 40 различных размеров, при этом репрезентативные блоки указываются в 40a, 40b, 40c и 40d с увеличивающимся размером. В соответствии с подразделением по фиг.2a массив 20 выборок сначала разделяется на регулярную двумерную компоновку древовидных блоков 40d, которые, в свою очередь, имеют ассоциированную отдельную информацию подразделения, согласно которой определенный древовидный блок 40d дополнительно может подразделяться согласно структуре в виде дерева квадрантов или нет. Древовидный блок слева от блока 40d, в качестве примера, подразделяется на меньшие блоки в соответствии со структурой в виде дерева квадрантов. Кодер 10 может выполнять одно двумерное преобразование в отношении каждого из блоков, показанных с помощью сплошных и пунктирных линий на фиг.2a. Другими словами, кодер 10 может преобразовывать массив 20 в единицах подразделения на блоки.
Вместо подразделения на основе дерева квадрантов может быть использовано более общее подразделение на основе множественного дерева, и число дочерних узлов в расчете на уровень иерархии может отличаться между различными уровнями иерархии.
Фиг.2b показывает другой пример для подразделения. В соответствии с фиг.2b массив 20 выборок сначала разделяется на макроблоки 40b, размещаемые в регулярной двумерной компоновке неперекрывающимся взаимно примыкающим способом, при этом каждый макроблок 40b имеет ассоциированную информацию подразделения, согласно которой макроблок не подразделяется, либо если подразделяется, подразделяется регулярным двумерным способом на субблоки одинакового размера таким образом, чтобы достигать различных степеней разбиения подразделения для различных макроблоков. Результатом является подразделение массива 20 выборок на блоки 40 различного размера, при этом репрезентативные элементы различных размеров указываются как 40a, 40b и 40a'. Как показано на фиг.2a, кодер 10 выполняет двумерное преобразование в отношении каждого из блоков, показанных на фиг.2b с помощью сплошных и пунктирных линий. Фиг.2c поясняется ниже.
Фиг.3 показывает возможность декодера 50 декодировать поток 30 данных, сформированный посредством кодера 10, чтобы восстанавливать восстановленную версию 60 массива 20 выборок. Декодер 50 извлекает из потока 30 данных блок коэффициентов преобразования для каждого из блоков 40 и восстанавливает восстановленную версию 60 посредством выполнения обратного преобразования в отношении каждого из блоков коэффициентов преобразования.
Кодер 10 и декодер 50 могут быть сконфигурированы с возможностью осуществлять энтропийное кодирование/декодирование, чтобы вставлять информацию относительно блоков коэффициентов преобразования и извлекать эту информацию из потока данных, соответственно. Ниже описываются подробности в этом отношении в соответствии с различными вариантами осуществления. Следует отметить, что поток 30 данных не обязательно содержит информацию относительно блоков коэффициентов преобразования для всех блоков 40 массива 20 выборок. Наоборот, поднабор блоков 40 может быть кодирован в поток 30 битов другим способом. Например, кодер 10 может решать отказываться от вставки блока коэффициентов преобразования для определенного блока блоков 40 со вставкой, вместо этого, в поток 30 битов альтернативных параметров кодирования, которые позволяют декодеру 50 прогнозировать или иным образом заполнять соответствующий блок в восстановленной версии 60. Например, кодер 10 может выполнять анализ текстуры, чтобы находить блоки в массиве 20 выборок, которые могут быть заполнены на стороне декодера посредством декодера посредством синтеза текстуры, и указывать это в потоке битов, соответственно.
Как пояснено относительно следующих чертежей, блоки коэффициентов преобразования не обязательно представляют представление в спектральной области исходных информационных выборок соответствующего блока 40 массива 20 выборок. Наоборот, такой блок коэффициентов преобразования может представлять представление в спектральной области остатка прогнозирования соответствующего блока 40. Фиг.4 показывает вариант осуществления для такого кодера. Кодер по фиг.4 содержит каскад 100 преобразования, энтропийный кодер 102, каскад 104 обратного преобразования, модуль 106 прогнозирования и модуль 108 вычитания, а также сумматор 110. Модуль 108 вычитания, каскад 100 преобразования и энтропийный кодер 102 последовательно соединяются в упомянутом порядке между входом 112 и выходом 114 кодера по фиг.4. Каскад 104 обратного преобразования, сумматор 110 и модуль 106 прогнозирования соединяются в упомянутом порядке между выходом каскада 100 преобразования и инвертирующим входом модуля 108 вычитания, при этом выход модуля 106 прогнозирования также соединяется с дополнительным входом сумматора 110.
Кодер по фиг.4 представляет собой прогнозирующий блочный кодер на основе преобразования. Иными словами, блоки массива 20 выборок, поступающие на вход 112, прогнозируются из ранее кодированных и восстановленных частей идентичного массива 20 выборок или ранее кодированных и восстановленных других массивов выборок, которые могут предшествовать или следовать после текущего массива 20 выборок во времени представления. Прогнозирование выполняется посредством модуля 106 прогнозирования. Модуль 108 вычитания вычитает прогнозирование из такого исходного блока, и каскад 100 преобразования выполняет двумерное преобразование для остатков прогнозирования. Непосредственно двумерное преобразование или последующий показатель в каскаде 100 преобразования может приводить к квантованию коэффициентов преобразования в блоках коэффициентов преобразования. Блоки квантованных коэффициентов преобразования кодируются без потерь, например, посредством энтропийного кодирования в энтропийном кодере 102, при этом результирующий поток данных выводится на выходе 114. Каскад 104 обратного преобразования восстанавливает квантованный остаток, и сумматор 110, в свою очередь, комбинирует восстановленный остаток с соответствующим прогнозированием, чтобы получать восстановленные информационные выборки, на основе которых модуль 106 прогнозирования может прогнозировать вышеуказанные текущие кодированные прогнозные блоки. Модуль 106 прогнозирования может использовать различные режимы прогнозирования, к примеру, режимы внутреннего прогнозирования и режимы взаимного прогнозирования, чтобы прогнозировать блоки, и параметры прогнозирования перенаправляются в энтропийный кодер 102 для вставки в поток данных. Для каждого взаимно прогнозированного прогнозного блока соответствующие данные движения вставляются в поток битов через энтропийный кодер 114, чтобы позволять стороне декодирования восстанавливать прогнозирование. Данные движения для прогнозного блока изображения могут заключать в себе часть синтаксиса, включающую в себя элемент синтаксиса, представляющий разность векторов движения, дифференциально кодирующую вектор движения для текущего прогнозного блока относительно извлекаемого предиктора вектора движения, например, посредством предписанного способа из векторов движения соседних уже кодированных прогнозных блоков.
Иными словами, в соответствии с вариантом осуществления по фиг.4 блоки коэффициентов преобразования представляют спектральное представление остатка массива выборок, а не его фактические информационные выборки. Иными словами, в соответствии с вариантом осуществления по фиг.4 последовательность элементов синтаксиса может поступать в энтропийный кодер 102 для энтропийного кодирования в поток 114 данных. Последовательность элементов синтаксиса может содержать элементы синтаксиса разности векторов движения для блоков взаимного прогнозирования и элементы синтаксиса относительно карты значимости, указывающей позиции значимых уровней коэффициентов преобразования, а также элементы синтаксиса, задающие сами значимые уровни коэффициентов преобразования для блоков преобразования.
Следует отметить, что предусмотрено несколько альтернатив для варианта осуществления по фиг.4, при этом некоторые из них описаны во вводной части подробного описания, причем данное описание включается в описание фиг.4.
Фиг.5 показывает декодер, который в состоянии декодировать поток данных, сформированный посредством кодера по фиг.4. Декодер по фиг.5 содержит энтропийный декодер 150, каскад 152 обратного преобразования, сумматор 154 и модуль 156 прогнозирования. Энтропийный декодер 150, каскад 152 обратного преобразования и сумматор 154 последовательно соединяются между входом 158 и выходом 160 декодера по фиг.5 в упомянутом порядке. Дополнительный выход энтропийного декодера 150 соединяется с модулем 156 прогнозирования, который, в свою очередь, соединяется между выходом сумматора 154 и его дополнительным входом. Энтропийный декодер 150 извлекает из потока данных, поступающего в декодер по фиг.5 на входе 158, блоки коэффициентов преобразования, при этом обратное преобразование применяется к блокам коэффициентов преобразования в каскаде 152 с тем, чтобы получать остаточный сигнал. Остаточный сигнал комбинируется с прогнозированием из модуля 156 прогнозирования в сумматоре 154 таким образом, чтобы получать восстановленный блок восстановленной версии массива выборок на выходе 160. На основе восстановленных версий модуль 156 прогнозирования формирует прогнозирования, тем самым перекомпоновывая прогнозирования, выполняемые посредством модуля 106 прогнозирования на стороне кодера. Чтобы получать прогнозирования, идентичные прогнозированиям, используемым на стороне кодера, модуль 156 прогнозирования использует параметры прогнозирования, которые энтропийный декодер 150 также получает из потока данных на входе 158.
Следует отметить, что в вышеописанных вариантах осуществления пространственная степень разбиения, с которой выполняются прогнозирование и преобразование остатка, не должна быть равной друг другу. Это показано на фиг.2C. Этот чертеж показывает подразделение для прогнозных блоков степени разбиения прогнозирования с помощью сплошных линий и степени разбиения остатков с помощью пунктирных линий. Как можно видеть, подразделения могут быть выбраны посредством кодера независимо друг от друга. Если точнее, синтаксис потоков данных может обеспечивать возможность задания подразделения остатков независимо от подразделения прогнозирования. Альтернативно, подразделение остатков может быть расширением подразделения прогнозирования таким образом, что каждый остаточный блок либо равен, либо является надлежащим поднабором прогнозного блока. Это показывается на фиг.2a и фиг.2b, например, на которых также степень разбиения прогнозирования показывается с помощью сплошных линий, а степень разбиения остатков - с помощью пунктирных линий. Иными словами, на фиг.2a-2c все блоки, имеющие ассоциированную ссылку с номером, являются остаточными блоками, для которых выполняется одно двумерное преобразование, в то время как большие блоки со сплошными линиями, охватывающие блоки 40a с пунктирными линиями, например, являются прогнозными блоками, для которых задание параметров прогнозирования выполняется по отдельности.
Вышеописанные варианты осуществления имеют общее то, что блок (остаточных или исходных) выборок должен быть преобразован на стороне кодера в блок коэффициентов преобразования, который, в свою очередь, должен быть обратно преобразован в восстановленный блок выборок на стороне декодера. Это проиллюстрировано на фиг.6. Фиг.6 показывает блок выборок 200. В случае фиг.6 этот блок 200 в качестве примера является квадратным и имеет размер в 4×4 выборки 202. Выборки 202 регулярно упорядочены вдоль горизонтального направления x и вертикального направления y. Посредством вышеуказанного двумерного преобразования T блок 200 преобразуется в спектральную область, а именно, в блок 204 коэффициентов 206 преобразования, причем блок 204 преобразования имеет размер, идентичный размеру блока 200. Иными словами, блок 204 преобразования имеет столько коэффициентов 206 преобразования, сколько блок 200 имеет выборок, как в горизонтальном направлении, так и в вертикальном направлении. Тем не менее, поскольку преобразование T является спектральным преобразованием, позиции коэффициентов 206 преобразования в блоке 204 преобразования соответствуют не пространственным позициям, а вместо этого спектральным компонентам контента блока 200. В частности, горизонтальная ось блока 204 преобразования соответствует оси, вдоль которой монотонно увеличивается спектральная частота в горизонтальном направлении, в то время как вертикальная ось соответствует оси, вдоль которой монотонно увеличивается пространственная частота в вертикальном направлении, при этом коэффициент преобразования DC-компоненты размещается в углу (здесь в качестве примера верхнем левом углу) блока 204, так что в нижнем правом углу размещается коэффициент 206 преобразования, соответствующий наибольшей частоте как в горизонтальном, так и в вертикальном направлении. При пренебрежении пространственным направлением пространственная частота, которой принадлежит определенный коэффициент 206 преобразования, в общем, увеличивается от верхнего левого угла к нижнему правому углу. Посредством обратного преобразования T-1 блок 204 преобразования заново переводится из спектральной области в пространственную область с тем, чтобы повторно получать копию 208 блока 200. В случае если квантование/потери не введены во время преобразования, восстановление является идеальным.
Как уже указано выше, на фиг.6 можно отметить, что большие размеры блоков блока 200 увеличивают спектральное разрешение результирующего спектрального представления 204. С другой стороны, шум квантования имеет тенденцию распространяться по всему блоку 208, и в силу этого резкие и очень локализованные объекты в блоках 200 имеют тенденцию приводить к отклонениям повторно преобразованного блока относительно исходного блока 200 вследствие шума квантования. Тем не менее, основное преимущество использования больших блоков заключается в том, что отношение между числом значимых, т.е. ненулевых (квантованных) коэффициентов преобразования, т.е. уровней, с одной стороны, и числом незначимых коэффициентов преобразования, с другой стороны, может быть снижено в больших блоках по сравнению с меньшими блоками, за счет этого обеспечивая более высокую эффективность кодирования. Другими словами, часто, значимые уровни коэффициентов преобразования, т.е. коэффициенты преобразования, не квантованные до нуля, разреженно распределяются по блоку 204 преобразования. Вследствие этого, в соответствии с вариантами осуществления, описанными подробнее ниже, позиции значимых уровней коэффициентов преобразования передаются в служебных сигналах в потоке данных посредством карты значимости. Отдельно от этого, значения значимого коэффициента преобразования, т.е. уровни коэффициентов преобразования в случае квантования коэффициентов преобразования, передаются в потоке данных.
Все кодеры и декодеры, описанные выше, в силу этого сконфигурированы с возможностью рассматривать определенный синтаксис элементов синтаксиса. Иными словами, вышеуказанные элементы синтаксиса, к примеру, уровни коэффициентов преобразования, элементы синтаксиса относительно карты значимости блоков преобразования, элементы синтаксиса данных движения относительно блоков взаимного прогнозирования и т.д., предположительно последовательно размещаются в потоке данных предписанным способом. Такой предписанный способ может быть представлен в форме псевдокода, как это предусмотрено, например, в стандарте H.264 или в других видеокодеках.
Иными словами, вышеприведенное описание главным образом направлено на преобразование мультимедийных данных, здесь в качестве примера видеоданных, в последовательность элементов синтаксиса в соответствии с предварительно заданной синтаксической структурой, предписывающей определенные типы элементов синтаксиса, их семантику и порядок для них. Энтропийный кодер и энтропийный декодер по фиг.4 и 5 могут быть сконфигурированы с возможностью работать и иметь такую структуру, как указано ниже. Они отвечают за выполнение преобразования между последовательностью элементов синтаксиса и потоком данных, т.е. потоком символов или битов.
Энтропийный кодер согласно варианту осуществления проиллюстрирован на фиг.7. Кодер преобразует без потерь поток элементов 301 синтаксиса в набор из двух или более частичных потоков 312 битов.
В предпочтительном варианте осуществления изобретения каждый элемент 301 синтаксиса ассоциирован с категорией набора из одной или более категорий, т.е. с типом элемента синтаксиса. В качестве примера, категории могут указывать тип элемента синтаксиса. В контексте гибридного кодирования видео отдельная категория может быть ассоциирована с режимами макроблочного кодирования, режимами блочного кодирования, индексами опорных изображений, разностями векторов движения, флагами подразделения, флагами кодированных блоков, параметрами квантования, уровнями коэффициентов преобразования и т.д. В других областях применения, таких как кодирование аудио, речи, текста, документов или общих данных, возможны различные классификации элементов синтаксиса.
В общем, каждый элемент синтаксиса может принимать значение из конечного или исчисляемого бесконечного набора значений, причем набор возможных значений элементов синтаксиса может отличаться для различных категорий элементов синтаксиса. Например, предусмотрены двоичные элементы синтаксиса, а также целочисленные элементы синтаксиса.
Для снижения сложности алгоритма кодирования и декодирования и для обеспечения общей схемы кодирования и декодирования для различных элементов синтаксиса и категорий элементов синтаксиса элементы 301 синтаксиса преобразуются в упорядоченные наборы двоичных решений, и эти двоичные решения затем обрабатываются посредством простых алгоритмов двоичного кодирования. Следовательно, модуль 302 бинаризации биективно отображает значение каждого элемента 301 синтаксиса в последовательность (строку или слово) элементов 303 выборки. Последовательность элементов 303 выборки представляет набор упорядоченных двоичных решений. Каждый элемент 303 выборки или двоичное решение может принимать одно значение из набора двух значений, например, одно из значений 0 и 1. Схема бинаризации может отличаться для различных категорий элементов синтаксиса. Схема бинаризации для конкретной категории элементов синтаксиса может зависеть от набора возможных значений элементов синтаксиса и/или других свойств элемента синтаксиса для конкретной категории.
Таблица 1 иллюстрирует три примерных схемы бинаризации для исчисляемых бесконечных наборов. Схемы бинаризации для исчисляемых бесконечных наборов также могут применяться для конечных наборов значений элементов синтаксиса. В частности, для больших конечных наборов значений элементов синтаксиса неэффективность (возникающая в результате неиспользуемых последовательностей бинов) может быть пренебрежимо малой, но универсальность таких схем бинаризации предоставляет преимущество с точки зрения сложности и требований к запоминающему устройству. Для небольших конечных наборов значений элементов синтаксиса зачастую предпочтительно (с точки зрения эффективности кодирования) адаптировать схему бинаризации к числу возможных значений символов.
Таблица 2 иллюстрирует три примерных схемы бинаризации для конечных наборов из 8 значений. Схемы бинаризации для конечных наборов могут извлекаться из универсальных схем бинаризации для исчисляемых бесконечных наборов посредством модификации некоторых последовательностей бинов таким образом, что конечные наборы последовательностей бинов представляют код без избыточности (и потенциально переупорядочение последовательностей бинов). В качестве примера, схема усеченной унарной бинаризации в таблице 2 создана посредством модификации последовательности бинов для элемента 7 синтаксиса универсальной унарной бинаризации (см. таблицу 1). Усеченная и переупорядоченная экспоненциальная бинаризация Голомба порядка 0 в таблице 2 создана посредством модификации последовательности бинов для элемента 7 синтаксиса универсальной экспоненциальной бинаризации Голомба порядка 0 (см. таблицу 1) и посредством переупорядочения последовательностей бинов (усеченная последовательность бинов для символа 7 назначена символу 1). Для конечных наборов элементов синтаксиса также можно использовать схемы несистематической/неуниверсальной бинаризации, как проиллюстрировано в последнем столбце таблицы 2.
Примеры бинаризации для исчисляемых бесконечных наборов (или крупных конечных наборов)
Примеры бинаризации для конечных наборов
Каждый элемент 303 выборки последовательности бинов, созданных посредством модуля 302 бинаризации, подается в модуль 304 назначения параметров в последовательном порядке. Модуль назначения параметров назначает набор из одного или более параметров для каждого элемента 303 выборки и выводит бин с ассоциированным набором параметров 305. Набор параметров определяется совершенно идентично в кодере и декодере. Набор параметров может состоять из одного или более следующих параметров.
В частности, модуль 304 назначения параметров может быть сконфигурирован с возможностью назначать текущему элементу 303 выборки контекстную модель. Например, модуль 304 назначения параметров может выбирать одни из доступных индексов контекстов для текущего элемента 303 выборки. Доступный набор контекстов для текущего элемента 303 выборки может зависеть от типа бина, который, в свою очередь, может быть задан посредством типа/категории элемента 301 синтаксиса, частью бинаризации которого является текущий элемент 303 выборки, и позиции текущего элемента 303 выборки в более поздней бинаризации. Выбор контекста в доступном контекстном наборе может зависеть от предыдущих бинов и элементов синтаксиса, ассоциированных с ними. Каждый из этих контекстов имеет ассоциированную вероятностную модель, т.е. показатель для оценки вероятности для одного из двух возможных значений бинов для текущего бина. Вероятностная модель может, в частности, быть показателем для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина, при этом вероятностная модель дополнительно задается посредством идентификатора, указывающего оценку того, какое из двух возможных значений бинов представляет менее вероятное или более вероятное значение бина для текущего элемента 303 выборки. В случае доступности только одного контекста для текущего бина выбор контекста может не применяться. Как подробнее указано ниже, модуль 304 назначения параметров также может выполнять адаптацию вероятностных моделей для того, чтобы адаптировать вероятностные модели, ассоциированные с различными контекстами, к фактической статистике по бинам соответствующих бинов, принадлежащих соответствующим контекстам.
Как также подробнее описано ниже, модуль 304 назначения параметров может работать по-разному в зависимости от того, активирован режим с высокой эффективностью (HE) или режим с низкой сложностью (LC). В обоих режимах вероятностная модель ассоциирует текущий элемент 303 выборки с любым из кодеров 310 бинов, как указано ниже, но режим работы модуля 304 назначения параметров зачастую является менее сложным в LC-режиме, при том что, тем не менее, эффективность кодирования повышается в режиме с высокой эффективностью вследствие принудительной более точной адаптации ассоциирования посредством модуля 304 назначения параметров отдельных элементов 303 выборки с отдельными кодерами 310 к статистике по бинам, в силу этого оптимизируя энтропию относительно LC-режима.
Каждый бин с ассоциированным набором параметров 305, который выводится из модуля 304 назначения параметров, подается в модуль 306 выбора буфера бинов. Модуль 306 выбора буфера бинов потенциально модифицирует значение входного бина 305 на основе значения входного бина и ассоциированных параметров 305 и подает выходной бин 307 (с потенциально модифицированным значением) в один из двух или более буферов 308 бинов. Буфер 308 бинов, в который отправляется выходной бин 307, определяется на основе значения входного бина 305 и/или значения ассоциированных параметров 305.
В предпочтительном варианте осуществления изобретения модуль 306 выбора буфера бинов не модифицирует значение бина, т.е. выходной бин 307 всегда имеет значение, идентичное значению входного бина 305. В дополнительном предпочтительном варианте осуществления изобретения модуль 306 выбора буфера бинов определяет значение 307 выходного бина на основе значения 305 входного бина и ассоциированного показателя для оценки вероятности для одного из двух возможных значений бинов для текущего бина. В предпочтительном варианте осуществления изобретения значение 307 выходного бина задается равным значению 305 входного бина, если показатель для вероятности для одного из двух возможных значений бинов для текущего бина меньше (либо меньше или равен) конкретного порогового значения; если показатель для вероятности для одного из двух возможных значений бинов для текущего бина превышает или равен (или превышает) конкретному пороговому значению, значение 307 выходного бина модифицируется (т.е. оно задается равным инверсии значения входного бина). В дополнительном предпочтительном варианте осуществления изобретения значение 307 выходного бина задается равным значению 305 входного бина, если показатель для вероятности для одного из двух возможных значений бинов для текущего бина превышает (либо больше или равен) конкретное пороговое значение; если показатель для вероятности для одного из двух возможных значений бинов для текущего бина меньше или равен (или меньше) конкретному пороговому значению, значение 307 выходного бина модифицируется (т.е. оно задается равным инверсии значения входного бина). В предпочтительном варианте осуществления изобретения пороговое значение соответствует значению 0,5 для оцененной вероятности для обоих возможных значений бинов.
В дополнительном предпочтительном варианте осуществления изобретения модуль 306 выбора буфера бинов определяет значение 307 выходного бина на основе значения 305 входного бина и ассоциированного идентификатора, указывающего оценку того, какое из двух возможных значений бинов представляет менее вероятное или более вероятное значение бина для текущего бина. В предпочтительном варианте осуществления изобретения значение 307 выходного бина задается равным значению 305 входного бина, если идентификатор указывает то, что первое из двух возможных значений бинов представляет менее вероятное (или более вероятное) значение бина для текущего бина, и значение 307 выходного бина модифицируется (т.е. оно задается равным инверсии значения входного бина), если идентификатор указывает то, что второе из двух возможных значений бинов представляет менее вероятное (или более вероятное) значение бина для текущего бина.
В предпочтительном варианте осуществления изобретения модуль 306 выбора буфера бинов определяет буфер 308 бинов, в который отправляется выходной бин 307, на основе ассоциированного показателя для оценки вероятности для одного из двух возможных значений бинов для текущего бина. В предпочтительном варианте осуществления изобретения набор возможных значений для показателя для оценки вероятности для одного из двух возможных значений бинов является конечным, и модуль 306 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 308 бинов с каждым возможным значением для оценки вероятности для одного из двух возможных значений бинов, при этом различные значения для показателя для оценки вероятности для одного из двух возможных значений бинов могут быть ассоциированы с идентичным буфером 308 бинов. В дополнительном предпочтительном варианте осуществления изобретения диапазон возможных значений для показателя для оценки вероятности для одного из двух возможных значений бинов сегментируется на некоторое число интервалов, модуль 306 выбора буфера бинов определяет индекс интервала для текущего показателя для оценки вероятности для одного из двух возможных значений бинов, и модуль 306 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 308 бинов с каждым возможным значением для индекса интервала, при этом различные значения для индекса интервала могут быть ассоциированы с идентичным буфером 308 бинов. В предпочтительном варианте осуществления изобретения входные элементы 305 выборки с противоположными показателями для оценки вероятности для одного из двух возможных значений бинов (противоположными показателями являются показатели, которые представляют оценки вероятности P и 1-P) подаются в идентичный буфер 308 бинов. В дополнительном предпочтительном варианте осуществления изобретения ассоциирование показателя для оценки вероятности для одного из двух возможных значений бинов для текущего бина с конкретным буфером бинов адаптируется во времени, например, чтобы обеспечивать то, что созданные частичные потоки битов имеют аналогичные скорости передачи битов. Дополнительно ниже, индекс интервала также называется PIPE-индексом, в то время как PIPE-индекс вместе с индексом уточнения и флагом, указывающим индексы более вероятных значений бинов, - фактической вероятностной моделью, т.е. оценкой вероятности.
В дополнительном предпочтительном варианте осуществления изобретения модуль 306 выбора буфера бинов определяет буфер 308 бинов, в который отправляется выходной бин 307, на основе ассоциированного показателя для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина. В предпочтительном варианте осуществления изобретения набор возможных значений для показателя для оценки вероятности для менее вероятного или более вероятного значения бина является конечным, и модуль 306 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 308 бинов с каждым возможным значением оценки вероятности для менее вероятного или более вероятного значения бина, при этом различные значения для показателя для оценки вероятности для менее вероятного или более вероятного значения бина могут быть ассоциированы с идентичным буфером 308 бинов. В дополнительном предпочтительном варианте осуществления изобретения диапазон возможных значений для показателя для оценки вероятности для менее вероятного или более вероятного значения бина сегментируется на некоторое число интервалов, модуль 306 выбора буфера бинов определяет индекс интервала для текущего показателя для оценки вероятности для менее вероятного или более вероятного значения бина, и модуль 306 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 308 бинов с каждым возможным значением для индекса интервала, при этом различные значения для индекса интервала могут быть ассоциированы с идентичным буфером 308 бинов. В дополнительном предпочтительном варианте осуществления изобретения ассоциирование показателя для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина с конкретным буфером бинов адаптируется во времени, например, чтобы обеспечивать то, что созданные частичные потоки битов имеют аналогичные скорости передачи битов.
Каждый из двух или более буферов 308 бинов соединяется строго с одним кодером 310 бинов, и каждый кодер бинов соединяется только с одним буфером 308 бинов. Каждый кодер 310 бинов считывает бины из ассоциированного буфера 308 бинов и преобразует последовательность бинов 309 в кодовое слово 311, которое представляет последовательность битов. Буферы 308 бинов представляют буферы ʺпервый на входе - первый на выходеʺ; бины, которые подаются позже (в последовательном порядке) в буфер 308 бинов, не кодируются до бинов, которые подаются раньше (в последовательном порядке) в буфер бинов. Кодовые слова 311, которые выводятся из конкретного кодера 310 бинов, записываются в конкретный частичный поток 312 битов. Общий алгоритм кодирования преобразует элементы 301 синтаксиса в два или более частичных потока 312 битов, при этом число частичных потоков битов равно числу буферов бинов и кодеров бинов. В предпочтительном варианте осуществления изобретения кодер 310 бинов преобразует переменное число бинов 309 в кодовое слово 311 переменного числа битов. Одно преимущество выше- и нижеуказанных вариантов осуществления изобретения состоит в том, что кодирование бинов может выполняться параллельно (например, для различных групп показателей вероятности), что уменьшает время обработки для нескольких реализаций.
Другое преимущество вариантов осуществления изобретения состоит в том, что кодирование бинов, которое выполняется посредством кодеров 310 бинов, может быть специально предназначено для различных наборов параметров 305. В частности, кодирование и кодирование бинов может быть оптимизировано (с точки зрения эффективности кодирования и/или сложности) для различных групп оцененных вероятностей. С одной стороны, это дает возможность снижения сложности кодирования/декодирования, а с другой стороны, это дает возможность повышения эффективности кодирования. В предпочтительном варианте осуществления изобретения кодеры 310 бинов реализуют различные алгоритмы кодирования (т.е. отображение последовательностей бинов в кодовые слова) для различных групп показателей для оценки вероятности для одного из двух возможных значений 305 бинов для текущего бина. В дополнительном предпочтительном варианте осуществления изобретения кодеры 310 бинов реализуют различные алгоритмы кодирования для различных групп показателей для оценки вероятности для менее вероятного или более вероятного значения бина для текущего бина.
В предпочтительном варианте осуществления изобретения кодеры 310 бинов (либо один или более кодеров бинов) представляют энтропийные кодеры, которые непосредственно отображают последовательности входных бинов 309 в кодовые слова 310. Такие отображения могут быть эффективно реализованы и не требуют сложного механизма арифметического кодирования. Обратное отображение кодовых слов в последовательности бинов (выполняемое в декодере) должно быть уникальным, чтобы гарантировать идеальное декодирование входной последовательности, но отображение последовательностей 309 бинов в кодовые слова 310 не обязательно должно быть уникальным, т.е. возможно то, что конкретная последовательность бинов может отображаться в несколько последовательностей кодовых слов. В предпочтительном варианте осуществления изобретения отображение последовательностей входных бинов 309 в кодовые слова 310 является биективным. В дополнительном предпочтительном варианте осуществления изобретения кодеры 310 бинов (либо один или более кодеров бинов) представляют энтропийные кодеры, которые непосредственно отображают последовательности переменной длины входных бинов 309 в кодовые слова 310 переменной длины. В предпочтительном варианте осуществления изобретения выходные кодовые слова представляют коды без избыточности, к примеру, общие коды Хаффмана или канонические коды Хаффмана.
Два примера для биективного отображения последовательностей бинов в коды без избыточности проиллюстрированы в таблице 3. В дополнительном предпочтительном варианте осуществления изобретения выходные кодовые слова представляют избыточные коды, подходящие для обнаружения ошибок и восстановления после ошибок. В дополнительном предпочтительном варианте осуществления изобретения выходные кодовые слова представляют коды шифрования, подходящие для шифрования элементов синтаксиса.
Примеры для отображений между последовательностями бинов и кодовыми словами
В дополнительном предпочтительном варианте осуществления изобретения кодеры 310 бинов (или один или более кодеров бинов) представляют энтропийные кодеры, которые непосредственно отображают последовательности переменной длины входных бинов 309 в кодовые слова 310 фиксированной длины. В дополнительном предпочтительном варианте осуществления изобретения, кодеры 310 бинов (или один или более кодеров бинов) представляют энтропийные кодеры, которые непосредственно отображают последовательности фиксированной длины входных бинов 309 в кодовые слова 310 переменной длины.
Декодер согласно варианту осуществления изобретения проиллюстрирован на фиг.8. Декодер выполняет по существу обратные операции относительно кодера, так что (ранее кодированная) последовательность элементов 327 синтаксиса декодируется из набора из двух или более частичных потоков 324 битов. Декодер включает в себя две различных последовательности операций обработки: последовательность операций для запросов на получение данных, которая реплицирует поток данных кодера, и поток данных, который представляет инверсию потока данных кодера. На иллюстрации на фиг.8 пунктирные стрелки представляют последовательность операций запроса на получение данных, в то время как сплошные стрелки представляют поток данных. Стандартные блоки декодера по существу реплицируют стандартные блоки кодера, но реализуют обратные операции.
Декодирование элемента синтаксиса инициируется посредством запроса на новый декодированный элемент 313 синтаксиса, который отправляется в модуль 314 бинаризации. В предпочтительном варианте осуществления изобретения каждый запрос на новый декодированный элемент 313 синтаксиса ассоциирован с категорией набора из одной или более категорий. Категория, которая ассоциирована с запросом на элемент синтаксиса, является идентичной категории, которая ассоциирована с соответствующим элементом синтаксиса в ходе кодирования.
Модуль 314 бинаризации отображает запрос на элемент 313 синтаксиса в один или более запросов на бин, которые отправляются в модуль 316 назначения параметров. В качестве конечного ответа на запрос на бин, который отправляется в модуль 316 назначения параметров посредством модуля 314 бинаризации, модуль 314 бинаризации принимает декодированный бин 326 из модуля 318 выбора буфера бинов. Модуль 314 бинаризации сравнивает принимаемую последовательность декодированных бинов 326 с последовательностями бинов конкретной схемы бинаризации для запрашиваемого элемента синтаксиса, и если принимаемая последовательность декодированных бинов 26 совпадает с бинаризацией элемента синтаксиса, модуль бинаризации освобождает свой буфер бинов и выводит декодированный элемент синтаксиса в качестве конечного ответа на запрос на новый декодированный символ. Если уже принятая последовательность декодированных бинов не совпадает ни с одной из последовательностей бинов для схемы бинаризации для запрашиваемого элемента синтаксиса, модуль бинаризации отправляет другой запрос на бин в модуль назначения параметров до тех пор, пока последовательность декодированных бинов не совпадет с одной из последовательностей бинов схемы бинаризации для запрашиваемого элемента синтаксиса. Для каждого запроса на элемент синтаксиса декодер использует схему бинаризации, идентичную схеме, которая использована для кодирования соответствующего элемента синтаксиса. Схема бинаризации может отличаться для различных категорий элементов синтаксиса. Схема бинаризации для конкретной категории элементов синтаксиса может зависеть от набора возможных значений элементов синтаксиса и/или других свойств элементов синтаксиса для конкретной категории.
Модуль 316 назначения параметров назначает набор из одного или более параметров для каждого запроса на бин и отправляет запрос на бин с ассоциированным набором параметров в модуль выбора буфера бинов. Набор параметров, которые назначаются запрашиваемому бину посредством модуля назначения параметров, является идентичным с набором параметров, который назначен соответствующему бину в ходе кодирования. Набор параметров может состоять из одного или более параметров, которые упоминаются в описании кодера на фиг.7.
В предпочтительном варианте осуществления изобретения модуль 316 назначения параметров ассоциирует каждый запрос на бин с параметрами, идентичными параметрам для модуля 304 назначения, т.е. с контекстом и его ассоциированным показателем для оценки вероятности для одного из двух возможных значений бинов для текущего запрашиваемого бина, таким как показатель для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина и идентификатор, указывающий оценку того, какое из двух возможных значений бинов представляет менее вероятное или более вероятное значение бина для текущего запрашиваемого бина.
Модуль 316 назначения параметров может определять один или более вышеуказанных показателей вероятности (показатель для оценки вероятности для одного из двух возможных значений бинов для текущего запрашиваемого бина, показатель для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина, идентификатор, указывающий оценку того, какое из двух возможных значений бинов представляет менее вероятное или более вероятное значение бина для текущего запрашиваемого бина) на основе набора из одного или более уже декодированных символов. Определение показателей вероятности для конкретного запроса на бин реплицирует процесс в кодере для соответствующего бина. Декодированные символы, которые используются для определения показателей вероятности, могут включать в себя один или более уже декодированных символов идентичной категории символов, один или более уже декодированных символов идентичной категории символов, которые соответствуют наборам данных (таким как блоки или группы выборок) соседних пространственных и/или временных местоположений (относительно набора данных, ассоциированного с текущим запросом на элемент синтаксиса), или один или более уже декодированных символов различных категорий символов, которые соответствуют наборам данных идентичных и/или соседних пространственных и/или временных местоположений (относительно набора данных, ассоциированного с текущим запросом на элемент синтаксиса).
Каждый запрос на бин с ассоциированным набором параметров 317, который выводится из модуля 316 назначения параметров, подается в модуль 318 выбора буфера бинов. На основе ассоциированного набора параметров 317 модуль 318 выбора буфера бинов отправляет запрос на бин 319 в один из двух или более буферов 320 бинов и принимает декодированный бин 325 из выбранного буфера 320 бинов. Декодированный входной бин 325 потенциально модифицируется, и декодированный выходной бин 326 с потенциально модифицированным значением отправляется в модуль 314 бинаризации в качестве конечного ответа на запрос на бин с ассоциированным набором параметров 317.
Буфер 320 бинов, в который перенаправляется запрос на бин, выбирается аналогично буферу бинов, в который отправлен выходной бин из модуля выбора буфера бинов на стороне кодера.
В предпочтительном варианте осуществления изобретения модуль 318 выбора буфера бинов определяет буфер 320 бинов, в который отправляется запрос на бин 319, на основе ассоциированного показателя для оценки вероятности для одного из двух возможных значений бинов для текущего запрашиваемого бина. В предпочтительном варианте осуществления изобретения набор возможных значений для показателя для оценки вероятности для одного из двух возможных значений бинов является конечным, и модуль 318 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 320 бинов с каждым возможным значением оценки вероятности для одного из двух возможных значений бинов, при этом различные значения для показателя для оценки вероятности для одного из двух возможных значений бинов могут быть ассоциированы с идентичным буфером 320 бинов. В дополнительном предпочтительном варианте осуществления изобретения диапазон возможных значений для показателя для оценки вероятности для одного из двух возможных значений бинов сегментируется на некоторое число интервалов, модуль 318 выбора буфера бинов определяет индекс интервала для текущего показателя для оценки вероятности для одного из двух возможных значений бинов, и модуль 318 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 320 бинов с каждым возможным значением для индекса интервала, при этом различные значения для индекса интервала могут быть ассоциированы с идентичным буфером 320 бинов. В предпочтительном варианте осуществления изобретения запросы на бины 317 с противоположными показателями для оценки вероятности для одного из двух возможных значений бинов (противоположными показателями являются показатели, которые представляют оценки вероятности P и 1-P) перенаправляются в идентичный буфер 320 бинов. В дополнительном предпочтительном варианте осуществления изобретения ассоциирование показателя для оценки вероятности для одного из двух возможных значений бинов для запроса на текущий бин с конкретным буфером бинов адаптируется во времени.
В дополнительном предпочтительном варианте осуществления изобретения модуль 318 выбора буфера бинов определяет буфер 320 бинов, в который отправляется запрос на бин 319, на основе ассоциированного показателя для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина. В предпочтительном варианте осуществления изобретения набор возможных значений для показателя для оценки вероятности для менее вероятного или более вероятного значения бина является конечным, и модуль 318 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 320 бинов с каждым возможным значением оценки вероятности для менее вероятного или более вероятного значения бина, при этом различные значения для показателя для оценки вероятности для менее вероятного или более вероятного значения бина могут быть ассоциированы с идентичным буфером 320 бинов. В дополнительном предпочтительном варианте осуществления изобретения диапазон возможных значений для показателя для оценки вероятности для менее вероятного или более вероятного значения бина сегментируется на некоторое число интервалов, модуль 318 выбора буфера бинов определяет индекс интервала для текущего показателя для оценки вероятности для менее вероятного или более вероятного значения бина, и модуль 318 выбора буфера бинов содержит таблицу, которая ассоциирует строго один буфер 320 бинов с каждым возможным значением для индекса интервала, при этом различные значения для индекса интервала могут быть ассоциированы с идентичным буфером 320 бинов. В дополнительном предпочтительном варианте осуществления изобретения ассоциирование показателя для оценки вероятности для менее вероятного или более вероятного значения бина для запроса на текущий бин с конкретным буфером бинов адаптируется во времени.
После приема декодированного бина 325 из выбранного буфера 320 бинов модуль 318 выбора буфера бинов потенциально модифицирует входной бин 325 и отправляет выходной бин 326 с потенциально модифицированным значением в модуль 314 бинаризации. Преобразование входных/выходных бинов из модуля 318 выбора буфера бинов является инверсией преобразования входных/выходных бинов из модуля выбора буфера бинов на стороне кодера.
В предпочтительном варианте осуществления изобретения модуль 318 выбора буфера бинов не модифицирует значение бина, т.е. выходной бин 326 всегда имеет значение, идентичное значению входного бина 325. В дополнительном предпочтительном варианте осуществления изобретения модуль 318 выбора буфера бинов определяет значение 326 выходного бина на основе значения 325 входного бина и показателя для оценки вероятности для одного из двух возможных значений бинов для текущего запрашиваемого бина, который ассоциирован с запросом на бин 317. В предпочтительном варианте осуществления изобретения значение 326 выходного бина задается равным значению 325 входного бина, если показатель для вероятности для одного из двух возможных значений бинов для запроса на текущий бин меньше (либо меньше или равен) конкретного порогового значения; если показатель для вероятности для одного из двух возможных значений бинов для запроса на текущий бин превышает или равен (или превышает) конкретному пороговому значению, значение 326 выходного бина модифицируется (т.е. оно задается равным инверсии значения входного бина). В дополнительном предпочтительном варианте осуществления изобретения значение 326 выходного бина задается равным значению 325 входного бина, если показатель для вероятности для одного из двух возможных значений бинов для запроса на текущий бин превышает (либо больше или равен) конкретное пороговое значение; если показатель для вероятности для одного из двух возможных значений бинов для запроса на текущий бин меньше или равен (или меньше) конкретному пороговому значению, значение 326 выходного бина модифицируется (т.е. оно задается равным инверсии значения входного бина). В предпочтительном варианте осуществления изобретения пороговое значение соответствует значению 0,5 для оцененной вероятности для обоих возможных значений бинов.
В дополнительном предпочтительном варианте осуществления изобретения модуль 318 выбора буфера бинов определяет значение 326 выходного бина на основе значения 325 входного бина и идентификатора, указывающего оценку того, какое из двух возможных значений бинов представляет менее вероятное или более вероятное значение бина для запроса на текущий бин, который ассоциирован с запросом на бин 317. В предпочтительном варианте осуществления изобретения значение 326 выходного бина задается равным значению 325 входного бина, если идентификатор указывает то, что первое из двух возможных значений бинов представляет менее вероятное (или более вероятное) значение бина для запроса на текущий бин, и значение 326 выходного бина модифицируется (т.е. оно задается равным инверсии значения входного бина), если идентификатор указывает то, что второе из двух возможных значений бинов представляет менее вероятное (или более вероятное) значение бина для запроса на текущий бин.
Как описано выше, модуль выбора буфера бинов отправляет запрос на бин 319 в один из двух или более буферов 320 бинов. Буферы бинов 20 представляют буферы ʺпервый на входе - первый на выходеʺ, в которые подаются последовательности декодированных бинов 321 из соединенных декодеров 322 бинов. В качестве ответа на запрос на бин 319, который отправляется в буфер 320 бинов из модуля 318 выбора буфера бинов, буфер 320 бинов удаляет бин своего контента, который первым подан в буфер 320 бинов, и отправляет его в модуль 318 выбора буфера бинов. Бины, которые раньше отправлены в буфер 320 бинов, раньше удаляются и отправляются в модуль 318 выбора буфера бинов.
Каждый из двух или более буферов 320 бинов соединяется строго с одним декодером 322 бинов, и каждый декодер бинов соединяется только с одним буфером 320 бинов. Каждый декодер 322 бинов считывает кодовые слова 323, которые представляют последовательности битов, из отдельного частичного потока 324 битов. Декодер бинов преобразует кодовое слово 323 в последовательность бинов 321, которая отправляется в соединенный буфер 320 бинов. Общий алгоритм декодирования преобразует два или более частичных потока 324 битов в некоторое число декодированных элементов синтаксиса, при этом число частичных потоков битов равно числу буферов бинов и декодеров бинов, и декодирование элементов синтаксиса инициируется посредством запросов на новые элементы синтаксиса. В предпочтительном варианте осуществления изобретения декодер 322 бинов преобразует кодовые слова 323 переменного числа битов в последовательность переменного числа бинов 321. Одно преимущество вариантов осуществления изобретения состоит в том, что декодирование бинов из двух или более частичных потоков битов может выполняться параллельно (например, для различных групп показателей вероятности), что уменьшает время обработки для нескольких реализаций.
Другое преимущество вариантов осуществления изобретения состоит в том, что декодирование бинов, которое выполняется посредством декодеров 322 бинов, может быть специально предназначено для различных наборов параметров 317. В частности, кодирование и декодирование бинов может быть оптимизировано (с точки зрения эффективности кодирования и/или сложности) для различных групп оцененных вероятностей. С одной стороны, это дает возможность снижения сложности кодирования/декодирования относительно алгоритмов энтропийного кодирования предшествующего уровня техники при аналогичной эффективности кодирования. С другой стороны, это дает возможность повышения эффективности кодирования относительно алгоритмов энтропийного кодирования предшествующего уровня техники при аналогичной сложности кодирования/декодирования. В предпочтительном варианте осуществления изобретения декодеры 322 бинов реализуют различные алгоритмы декодирования (т.е. отображение последовательностей бинов в кодовые слова) для различных групп показателей для оценки вероятности для одного из двух возможных значений бинов 317 для запроса на текущий бин. В дополнительном предпочтительном варианте осуществления изобретения декодеры 322 бинов реализуют различные алгоритмы декодирования для различных групп показателей для оценки вероятности для менее вероятного или более вероятного значения бина для текущего запрашиваемого бина.
Декодеры 322 бинов выполняют обратное отображение относительно соответствующих кодеров бинов на стороне кодера.
В предпочтительном варианте осуществления изобретения декодеры 322 бинов (либо один или более декодеров бинов) представляют энтропийные декодеры, которые непосредственно отображают кодовые слова 323 в последовательности бинов 321. Такие отображения могут быть эффективно реализованы и не требуют сложного механизма арифметического кодирования. Отображение кодовых слов в последовательности бинов должно быть уникальным. В предпочтительном варианте осуществления изобретения отображение кодовых слов 323 в последовательности бинов 321 является биективным. В дополнительном предпочтительном варианте осуществления изобретения декодеры бинов 310 (либо один или более декодеров бинов) представляют энтропийные декодеры, которые непосредственно отображают кодовые слова переменной длины 323 в последовательности переменной длины бинов 321. В предпочтительном варианте осуществления изобретения входные кодовые слова представляют коды без избыточности, к примеру, общие коды Хаффмана или канонические коды Хаффмана. Два примера для биективного отображения кодов без избыточности в последовательности бинов проиллюстрированы в таблице 3.
В дополнительном предпочтительном варианте осуществления изобретения декодеры 322 бинов (либо один или более декодеров бинов) представляют энтропийные декодеры, которые непосредственно отображают кодовые слова фиксированной длины 323 в последовательности переменной длины бинов 321. В дополнительном предпочтительном варианте осуществления изобретения декодеры 322 бинов (либо один или более декодеров бинов) представляют энтропийные декодеры, которые непосредственно отображают кодовые слова переменной длины 323 в последовательности фиксированной длины бинов 321.
Таким образом, фиг.7 и 8 показывают вариант осуществления для кодера для кодирования последовательности символов 3 и декодера для ее восстановления. Кодер содержит модуль 304 назначения, сконфигурированный с возможностью назначать некоторое число параметров 305 каждому символу из последовательности символов. Назначение основано на информации, содержащейся в предыдущих символах из последовательности символов, такой как категория элемента 1 синтаксиса для представления (к примеру, бинаризации), которой принадлежит текущий символ и которая, согласно синтаксической структуре элементов 1 синтаксиса, в данный момент ожидается, причем это ожидание, в свою очередь, логически выводится из предыстории предыдущих элементов 1 синтаксиса и символов 3. Дополнительно, кодер содержит множество энтропийных кодеров 10, каждый из которых сконфигурирован с возможностью преобразовывать символы 3, перенаправляемые в соответствующий энтропийный кодер, в соответствующий поток 312 битов, и модуль 306 выбора, сконфигурированный с возможностью перенаправлять каждый символ 3 в выбранный один из множества энтропийных кодеров 10, причем выбор зависит от числа параметров 305, назначаемых соответствующему символу 3. Модуль 304 назначения может рассматриваться как интегрированный в модуль 206 выбора, чтобы в результате получать соответствующий модуль 502 выбора.
Декодер для восстановления последовательности символов содержит множество энтропийных декодеров 322, каждый из которых сконфигурирован с возможностью преобразовывать соответствующий поток битов 323 в символы 321; модуль 316 назначения, сконфигурированный с возможностью назначать некоторое число параметров 317 каждому символу 315 последовательности символов, которая должна быть восстановлена на основе информации, содержащейся в ранее восстановленных символах из последовательности символов (см. 326 и 327 на фиг.8); и модуль 318 выбора, сконфигурированный с возможностью извлекать каждый символ из последовательности символов, которая должна быть восстановлена из выбранного множества энтропийных декодеров 322, причем выбор зависит от числа параметров, заданных для соответствующего символа. Модуль 316 назначения может иметь такую конфигурацию, в которой некоторое число параметров, назначаемых каждому символу, содержит или представляет собой показатель для оценки вероятности распределения возможных значений символов, которые может допускать соответствующий символ. С другой стороны, модуль 316 назначения и модуль 318 выбора могут рассматриваться как интегрированные в один блок, модуль 402 выбора. Последовательность символов, которые должны быть восстановлены, может состоять из двоичного алфавита, и модуль 316 назначения может иметь такую конфигурацию, в которой оценка распределения вероятностей состоит из показателя для оценки вероятности менее вероятного или более вероятного значения бина из двух возможных значений бинов в двоичном алфавите и идентификатора, указывающего оценку того, какое из двух возможных значений бинов представляет менее вероятное или более вероятное значение бина. Модуль 316 назначения дополнительно может быть сконфигурирован с возможностью внутренне назначать контекст каждому символу из последовательности символов 315, которые должны быть восстановлены, на основе информации, содержащейся в ранее восстановленных символах из последовательности символов, которые должны быть восстановлены, при этом каждый контекст имеет ассоциированную соответствующую оценку распределения вероятностей, а также адаптировать оценку распределения вероятностей для каждого контекста к фактической статистике по символам на основе значений символов для ранее восстановленных символов, которым назначается соответствующий контекст. Контекст может принимать во внимание пространственное соотношение или окружение позиций, которым принадлежат элементы синтаксиса, к примеру, при кодировании видео или изображений, или даже таблицы в случае финансовых вариантов применения. Затем, показатель для оценки распределения вероятностей для каждого символа может быть определен на основе оценки распределения вероятностей, ассоциированной с контекстом, назначаемым соответствующему символу, к примеру, посредством квантования или использования в качестве индекса в соответствующей таблице, оценки распределения вероятностей, ассоциированной с контекстом, которому назначен соответствующий символ (в нижеприведенных вариантах осуществления, индексированный посредством PIPE-индекса вместе с индексом уточнения) для одного из множества репрезентативных элементов оценки распределения вероятностей (с отсеканием индекса уточнения), чтобы получать показатель для оценки распределения вероятностей (PIPE-индекс, индексирующий частичный поток 312 битов). Модуль выбора может иметь такую конфигурацию, в которой биективное ассоциирование задается между множеством энтропийных кодеров и множеством репрезентативных элементов оценки распределения вероятностей. Модуль 18 выбора может быть сконфигурирован с возможностью изменять отображение при квантовании из диапазона оценок распределения вероятностей во множество репрезентативных элементов оценки распределения вероятностей предварительно определенным детерминированным способом в зависимости от ранее восстановленных символов из последовательности символов, во времени. Иными словами, модуль 318 выбора может изменять размеры шагов квантования, т.е. интервалы распределений вероятностей, преобразованных в отдельные индексы вероятности, биективно ассоциированные с отдельными энтропийными декодерами. Множество энтропийных декодеров 322, в свою очередь, может быть выполнено с возможностью адаптировать свой способ преобразования символов в потоки битов в ответ на изменение при отображении при квантовании. Например, каждый энтропийный декодер 322 может быть оптимизирован для (т.е. может иметь оптимальный коэффициент сжатия для) некоторой оценки распределения вероятностей в соответствующем интервале квантования оценки распределения вероятностей и может изменять свое отображение последовательности кодовых слов/символов так, чтобы адаптировать позицию этой некоторой оценки распределения вероятностей в соответствующем интервале квантования оценки распределения вероятностей при ее изменении таким образом, что она оптимизируется. Модуль выбора может быть сконфигурирован с возможностью изменять отображение при квантовании таким образом, что скорости, на которых символы извлекаются из множества энтропийных декодеров, становятся менее разбросанными. В отношении модуля 314 бинаризации следует отметить, что он может не применяться, если элементы синтаксиса уже являются двоичными. Дополнительно, в зависимости от типа декодера 322, наличие буферов 320 не является обязательным. Дополнительно, буферы могут быть интегрированы в декодерах.
Завершение конечных последовательностей элементов синтаксиса
В предпочтительном варианте осуществления изобретения кодирование и декодирование выполняется для конечного набора элементов синтаксиса. Зачастую кодируется некоторый объем данных, к примеру, неподвижное изображение, кадр или поле видеопоследовательности, слайс изображения, слайс кадра или поле видеопоследовательности или набор последовательных аудиовыборок и т.д. Для конечных наборов элементов синтаксиса, в общем, частичные потоки битов, которые создаются на стороне кодера, должны завершаться, т.е. необходимо обеспечивать то, что все элементы синтаксиса могут быть декодированы из передаваемых или сохраненных частичных потоков битов. После того как последний бин вставляется в соответствующий буфер 308 бинов, кодер 310 бинов должен обеспечивать то, что полное кодовое слово записывается в частичный поток 312 битов. Если кодер 310 бинов представляет энтропийный кодер, который реализует прямое отображение последовательностей бинов в кодовые слова, последовательность бинов, которая сохраняется в буфере бинов после записи последнего бина в буфер бинов, может не представлять последовательность бинов, которая ассоциирована с кодовым словом (т.е. она может представлять префикс двух или более последовательностей бинов, которые ассоциированы с кодовыми словами). В таком случае любое из кодовых слов, ассоциированных с последовательностью бинов, которая содержит последовательность бинов в буфере бинов в качестве префикса, должно записываться в частичный поток битов (буфер бинов должен очищаться). Это может осуществляться посредством вставки бинов с конкретным или произвольным значением в буфер бинов до тех пор, пока не будет записано кодовое слово. В предпочтительном варианте осуществления изобретения кодер бинов выбирает одно из кодовых слов с минимальной длиной (в дополнение к такому свойству, что ассоциированная последовательность бинов должна содержать последовательность бинов в буфере бинов в качестве префикса). На стороне декодера декодер 322 бинов может декодировать большее число бинов, чем требуется для последнего кодового слова в частичном потоке битов; эти бины не запрашиваются посредством модуля 318 выбора буфера бинов и отбрасываются, и игнорируются. Декодирование конечного набора символов управляется посредством запросов на декодированные элементы синтаксиса; если дополнительные элементы синтаксиса не запрашиваются для данного объема данных, декодирование завершается.
Передача и мультиплексирование частичных потоков битов
Частичные потоки 312 битов, которые создаются посредством кодера, могут быть переданы отдельно, или они могут быть мультиплексированы в один поток битов, или кодовые слова частичных потоков битов могут перемежаться в одном потоке битов.
В варианте осуществления изобретения каждый частичный поток битов для объема данных записывается в один пакет данных. Объем данных может быть произвольным набором элементов синтаксиса, таким как неподвижное изображение, поле или кадр видеопоследовательности, слайс неподвижного изображения, слайс поля или кадра видеопоследовательности либо кадр аудиовыборок и т.д.
В другом предпочтительном варианте осуществления изобретения два или более из частичных потоков битов для объема данных или все частичные потоки битов для объема данных мультиплексируются в один пакет данных. Структура пакета данных, который содержит мультиплексированные частичные потоки битов, проиллюстрирована на фиг.9.
Пакет 400 данных состоит из заголовка и одного сегмента для данных каждого частичного потока битов (для рассматриваемого объема данных). Заголовок 400 пакета данных содержит индикаторы для сегментирования (остатка) пакета данных на сегменты данных 402 потока битов. Помимо индикаторов для сегментирования заголовок может содержать дополнительную информацию. В предпочтительном варианте осуществления изобретения индикаторы для сегментирования пакета данных представляют собой местоположения начала сегментов данных в единицах битов или байтов, либо кратных чисел битов или кратных чисел байтов. В предпочтительном варианте осуществления изобретения местоположения начала сегментов данных кодируются в качестве абсолютных значений в заголовке пакета данных либо относительно начала пакета данных, либо относительно конца заголовка, либо относительно начала пакета предыдущих данных. В дополнительном предпочтительном варианте осуществления изобретения местоположения начала сегментов данных дифференциально кодируются, т.е. кодируется только разность между фактическим началом сегмента данных и прогнозированием в течение начала сегмента данных. Прогнозирование может извлекаться на основе уже известной или передаваемой информации, такой как полный размер пакета данных, размер заголовка, число сегментов данных в пакете данных, местоположения начала предыдущих сегментов данных. В предпочтительном варианте осуществления изобретения местоположение начала первого пакета данных не кодируется, а логически выводится на основе размера заголовка пакета данных. На стороне декодера передаваемые индикаторы сегмента используются для извлечения начала сегментов данных. Сегменты данных затем используются в качестве частичных потоков битов, и данные, содержащиеся в сегментах данных, подаются в соответствующие декодеры бинов в последовательном порядке.
Существует несколько альтернатив для мультиплексирования частичных потоков битов в пакет данных. Одна альтернатива, которая позволяет уменьшать требуемую побочную информацию, в частности, для случаев, в которых размеры частичных потоков битов являются очень близкими, проиллюстрирована на фиг.10. Рабочие данные пакета данных, т.е. пакет 410 данных без заголовка 411, сегментируются на сегменты 412 предварительно заданным способом. В качестве примера, рабочие данные пакета данных могут быть сегментированы на сегменты идентичного размера. Затем каждый сегмент ассоциирован с частичным потоком битов или с первой частью частичного потока 413 битов. Если частичный поток битов превышает ассоциированный сегмент данных, его остаток 414 размещается в неиспользуемом месте в конце других сегментов данных. Это может осуществляться таким образом, что оставшаяся часть потока битов вставляется в обратном порядке (начиная с конца сегмента данных), что уменьшает побочную информацию. Ассоциирование остатков частичных потоков битов с сегментами данных и, когда несколько остатков добавляются в сегмент данных, начальная точка для одного или более остатков должны быть переданы в служебных сигналах в потоке битов, например, в заголовке пакета данных.
Перемежение кодовых слов переменной длины
В некоторых вариантах применения вышеописанное мультиплексирование частичных потоков битов (для числа элементов синтаксиса) в одном пакете данных может иметь следующие недостатки. С одной стороны, для небольших пакетов данных число битов для побочной информации, которая требуется для передачи в служебных сигналах сегментирования, может становиться значимым относительно фактических данных в частичных потоках битов, что в итоге снижает эффективность кодирования. С другой стороны, мультиплексирование может не подходит для вариантов применения, которые требуют низкой задержки (например, для вариантов применения в видеоконференц-связи). При описанном мультиплексировании кодер не может начинать передачу пакета данных до того, как полностью созданы частичные потоки битов, поскольку местоположения начала сегментов не известны до этого. Кроме того, в общем, декодер должен ожидать до тех пор, пока он не примет начало последнего сегмента данных, до того как он может начинать декодирование пакета данных. Для вариантов применения в качестве систем проведения видеоконференций эти задержки могут способствовать дополнительной общей задержке системы из нескольких видеоизображений (в частности, для скоростей передачи битов, которые находятся близко к скорости передачи битов, и для кодеров/декодеров, которые требуют практически временного интервала между двумя изображениями для кодирования/декодирования изображения), что является критическим для таких вариантов применения. Чтобы преодолевать недостатки для некоторых вариантов применения, кодер предпочтительного варианта осуществления изобретения может быть сконфигурирован таким образом, что кодовые слова, которые формируются посредством двух или более кодеров бинов, перемежаются в один поток битов. Поток битов с перемеженными кодовыми словами может непосредственно отправляться в декодер (при пренебрежении небольшой задержкой в буфере, см. ниже). На стороне декодера два или более декодеров бинов считывают кодовые слова непосредственно из потока битов в порядке декодирования; декодирование может начинаться с первого принимаемого бита. Помимо этого, побочная информация не требуется для передачи в служебных сигналах мультиплексирования (или перемежения) частичных потоков битов. Дополнительный способ снижения сложности декодера может достигаться, когда декодеры 322 бинов не считывают кодовые слова переменной длины из глобального битового буфера, а вместо этого они всегда считывают последовательности фиксированной длины битов из глобального битового буфера и добавляют эти последовательности фиксированной длины битов в локальный битовый буфер, при этом каждый декодер 322 бинов соединяется с отдельным локальным битовым буфером. Кодовые слова переменной длины затем считываются из локального битового буфера. Следовательно, синтаксический анализ кодовых слов переменной длины может выполняться параллельно, только доступ последовательностей фиксированной длины битов должен осуществляться синхронизированным способом, но такой доступ последовательностей фиксированной длины битов обычно является очень быстрым, так что общая сложность декодирования может быть уменьшена для некоторых архитектур. Фиксированное число бинов, которые отправляются в конкретный локальный битовый буфер, может отличаться для различного локального битового буфера, и оно также может варьироваться во времени в зависимости от некоторых параметров в качестве событий в декодере бинов, буфере бинов или битовом буфере. Тем не менее, число битов, которые считываются посредством конкретного доступа, не зависит от фактических битов, которые считываются в ходе конкретного доступа, что является важным отличием от считывания кодовых слов переменной длины. Считывание последовательностей фиксированной длины битов инициируется посредством некоторых событий в буферах бинов, декодерах бинов или локальных битовых буферах. В качестве примера, можно запрашивать считывание новой последовательности фиксированной длины битов, когда число битов, которые присутствуют в соединенном битовом буфере, опускается ниже предварительно заданного порогового значения, при этом различные пороговые значения могут использоваться для различных битовых буферов. В кодере необходимо обеспечивать то, что последовательности фиксированной длины бинов вставляются в идентичном порядке в поток битов, в котором они считываются из потока битов на стороне декодера. Также можно комбинировать это перемежение последовательностей фиксированной длины с управлением с низкой задержкой, аналогично последовательностям, поясненным выше. Далее описывается предпочтительный вариант осуществления для перемежения последовательностей фиксированной длины битов. Для получения дальнейшей информации касательно последующих схем перемежения следует обратиться к WO2011/128268A1.
После описания вариантов осуществления, согласно которым даже предшествующее кодирование используется для сжатия видеоданных, описывается еще один дополнительный вариант осуществления для реализации вариантов осуществления настоящего изобретения, который обеспечивает реализацию, в частности, эффективную с точки зрения оптимального компромисса между коэффициентом сжатия, с одной стороны, и таблицей поиска и объемом служебной информации для вычисления, с другой стороны. В частности, следующие варианты осуществления предоставляют использование в вычислительном отношении менее сложных кодов переменной длины, чтобы энтропийно кодировать по отдельности потоки битов и эффективно охватывать части оценки вероятности. В вариантах осуществления, описанных ниже, символы имеют двоичную природу, и VLC-коды, представленные ниже, эффективно охватывают оценку вероятности, представленную, например, посредством RLPS в диапазоне [0; 0,5].
В частности, нижеуказанные варианты осуществления описывают возможные реализации для отдельных энтропийных кодеров 310 и декодеров 322 на фиг.7-17, соответственно. Они являются подходящими для кодирования бинов, т.е. двоичных символов, по мере того, как они возникают в вариантах применения для сжатия изображений или видео. Соответственно, эти варианты осуществления также являются применимыми к кодированию изображений или видео, при котором такие двоичные символы разбиваются на один или более потоков бинов 307, которые должны быть кодированы, и потоков 324 битов, которые должны быть декодированы, соответственно, при этом каждый такой поток бинов может рассматриваться как реализация процесса Бернулли. Варианты осуществления, описанные ниже, используют один или более из нижеописанных различных так называемых переменно-переменных кодов (v2v-кодов) для того, чтобы кодировать потоки бинов. v2v-код может рассматриваться как два кода без префикса с идентичным числом кодовых слов. Первичный и вторичный код без префикса. Каждое кодовое слово первичного кода без префикса ассоциировано с одним кодовым словом вторичного кода без префикса. В соответствии с нижеуказанными вариантами осуществления, по меньшей мере, некоторые кодеры 310 и декодеры 322 работают следующим образом. Чтобы кодировать конкретную последовательность бинов 307, каждый раз, когда кодовое слово первичного кода без префикса считывается из буфера 308, соответствующее кодовое слово вторичного кода без префикса записывается в поток 312 битов. Идентичная процедура используется для того, чтобы декодировать такой поток битов 324, но с перестановкой первичного и вторичного кода без префикса. Иными словами, чтобы декодировать поток 324 битов, каждый раз, когда кодовое слово вторичного кода без префикса считывается из соответствующего потока 324 битов, соответствующее кодовое слово первичного кода без префикса записывается в буфер 320.
Преимущественно, коды, описанные ниже, не требуют таблиц поиска. Коды являются реализуемыми в форме конечных автоматов. v2v-коды, представленные здесь, могут быть сформированы по простым правилам составления так, что нет необходимости сохранять большие таблицы для кодовых слов. Вместо этого, простой алгоритм может быть использован для того, чтобы выполнять кодирование или декодирование. Ниже описываются три правила составления, при этом два из них могут быть параметризованы. Они охватывают различные или даже непересекающиеся части вышеуказанного интервала вероятности и, соответственно, являются, в частности, преимущественными при совместном использовании, к примеру, все три кода параллельно (каждый для различных кодеров/декодеров 11 и 22) или два из них. С помощью правил составления, описанных ниже, можно разрабатывать набор v2v-кодов так, что для процессов Бернулли с произвольной вероятностью p один из кодов работает оптимально с точки зрения избыточной длины кода.
Как указано выше, кодирование и декодирование потоков 312 и 324, соответственно, может выполняться либо независимо для каждого потока, либо перемеженным способом. Тем не менее, это не является конкретным для представленных классов v2v-кодов, и, следовательно, далее описывается только кодирование и декодирование конкретного кодового слова для каждого из трех правил составления. Тем не менее, следует подчеркнуть, что все вышеописанные варианты осуществления относительно решений по перемежению также являются комбинируемыми с текущими описанными кодами либо кодерами и декодерами 310 и 322, соответственно.
Правило 1 составления: унарные PIPE-коды бинов или кодеры/декодеры 310 и 322 на основе унарных PIPE-кодов бинов
Унарные PIPE-коды бинов (PIPE = энтропия сегментирования интервала вероятности) являются специальной версией так называемых PIPE-кодов бинов, т.е. кодов, подходящих для кодирования любого из отдельных потоков 12 и 24 битов, каждый из которых переносит данные статистики по двоичным символам, принадлежащей некоторому под-интервалу вероятности вышеуказанного диапазона вероятностей [0; 0,5]. Сначала описывается составление PIPE-кодов бинов. PIPE-код бина может составляться из любого кода без префикса с по меньшей мере тремя кодовыми словами. Чтобы формировать v2v-код, он использует код без префикса в качестве первичного и вторичного кода, но с перестановкой двух кодовых слов вторичного кода без префикса. Это означает то, что за исключением двух кодовых слов, бины записываются в поток битов неизмененными. При этой технологии только один код без префикса должен быть сохранен вместе с информацией относительно того, какие два кодовых слова переставляются, и за счет этого сокращается потребление запоминающего устройства. Следует отметить, что целесообразно переставлять только кодовые слова различной длины, поскольку в противном случае поток битов имеет длину, идентичную длине потока бинов (при пренебрежении эффектами, которые могут возникать в конце потока бинов).
Вследствие этого правила составления преимущественное свойство PIPE-кодов бинов заключается в том, что если первичный и вторичный код без префикса переставляются (в то время как отображение кодовых слов сохраняется), результирующий v2v-код является идентичным исходному v2v-коду. Следовательно, алгоритм кодирования и алгоритм декодирования являются идентичными для PIPE-кодов бина.
Унарный PIPE-код бина составляется из специального кода без префикса. Этот специальный код без префикса составляется следующим образом. Сначала код без префикса, состоящий из n унарных кодовых слов, формируется, начиная с ʺ01ʺ, ʺ001ʺ, ʺ0001ʺ, ..., до тех пор, пока не будет сформировано n кодовых слов; n является параметром для унарного PIPE-кода бина. Из самого длинного кодового слова удаляется последняя единица. Это соответствует усеченному унарному коду (но без кодового слова ʺ0ʺ). Затем, n-1 унарных кодовых слов формируются, начиная с ʺ10ʺ, ʺ110ʺ, ʺ1110ʺ, ..., до тех пор, пока не будет сформировано n-1 кодовых слов. Из самого длинного из этих кодовых слов удаляется последний нуль. Объединенный набор из этих двух кодов без префикса используется в качестве ввода для того, чтобы формировать унарный PIPE-код бина. Два кодовых слова, которые переставляются, представляют собой кодовое слово, состоящее только из нулей, и кодовое слово, состоящее только из единиц.
Пример для n=4:
Правило 2 составления: коды с преобразованием из унарного кода в код Райса и кодеры/декодеры 10 и 22 на основе преобразования из унарного кода в код Райса
Коды с преобразованием из унарного кода в код Райса используют усеченный унарный код в качестве первичного кода. Иными словами, унарные кодовые слова формируются начиная с ʺ1ʺ, ʺ01ʺ, ʺ001ʺ, ..., до тех пор, пока не будет сформировано 2n+1 кодовых слов, и из самого длинного кодового слова удаляется последняя единица; n является параметром кода с преобразованием из унарного кода в код Райса. Вторичный код без префикса составляется из кодовых слов первичного кода без префикса следующим образом. Первичному кодовому слову, состоящему только из нулей, назначается кодовое слово ʺ1ʺ. Все другие кодовые слова состоят из конкатенации кодового слова ʺ0ʺ с n-битовым двоичным представлением числа нулей соответствующего кодового слова первичного кода без префикса.
Пример для n=3:
Следует отметить, что это является идентичным отображению бесконечного унарного кода в код Райса с параметром Райса 2n.
Правило 3 составления: код с тремя бинами
Код с тремя бинами задается следующим образом:
Это имеет такое свойство, что первичный код (последовательности символов) имеет фиксированную длину (всегда три бина), и кодовые слова сортируются посредством возрастающих чисел единиц.
Далее описывается эффективная реализация кода с тремя бинами. Кодер и декодер для кода с тремя бинами может быть реализован без сохранения таблиц следующим образом.
В кодере (любом из 10) три бина считываются из потока бинов (т.е. 7). Если эти три бина содержат строго одну единицу, кодовое слово ʺ1ʺ записывается в поток битов, а затем два бина, состоящие из двоичного представления позиции единицы (начиная справа с 00). Если три бина содержат строго один нуль, кодовое слово ʺ111ʺ записывается в поток битов, а затем два бина, состоящие из двоичного представления позиции нуля (начиная справа с 00). Оставшиеся кодовые слова ʺ000ʺ и ʺ111ʺ преобразуются в ʺ0ʺ и ʺ11111ʺ, соответственно.
В декодере (любом из 22) один бин или бит считывается из соответствующего потока 24 битов. Если он равен ʺ0ʺ, кодовое слово ʺ000ʺ декодируется в поток 21 бинов. Если он равен ʺ1ʺ, еще два бина считываются из потока 24 битов. Если два бита не равны ʺ11ʺ, они интерпретируются в качестве двоичного представления числа, и два нуля и одна единица декодируются в поток битов, так что позиция единицы определяется посредством числа. Если два бита равны ʺ11ʺ, еще два бита считываются и интерпретируются в качестве двоичного представления числа. Если это число меньше 3, две единицы и один нуль декодируются, и число определяет позицию 0. Если оно равно 3, ʺ111ʺ декодируется в поток бинов.
Далее описывается эффективная реализация унарных PIPE-кодов бинов. Кодер и декодер для унарных PIPE-кодов бинов могут быть эффективно реализованы посредством использования счетчика. Вследствие структуры PIPE-кодов бинов, кодирование и декодирование PIPE-кодов бинов просто реализовывать.
В кодере (любом из 10), если первый бин кодового слова равен ʺ0ʺ, бины обрабатываются до тех пор, пока не возникнет единица, или до тех пор, пока не будет считано n нулей (включающих в себя первый нуль кодового слова). Если возникает единица, бины считывания записываются в поток битов неизмененными. В противном случае (т.е. считано n нулей) n-1 единиц записываются в поток битов. Если первый бин кодового слова равен ʺ1ʺ, бины обрабатываются до тех пор, пока не возникнет нуль, или до тех пор, пока не будет считано n-1 единиц (включающих в себя первую единицу кодового слова). Если возникает нуль, бины считывания записываются в поток битов неизмененными. В противном случае (т.е. считано n-1 единиц) n нулей записываются в поток битов.
В декодере (любом из 322) используется алгоритм, идентичный алгоритму для кодера, поскольку он является идентичным в отношении PIPE-кодов бинов, как описано выше.
Далее описывается эффективная реализация кодов с преобразованием из унарного кода в код Райса. Кодер и декодер для кодов с преобразованием из унарного кода в код Райса могут быть эффективно реализованы посредством использования счетчика, как теперь будет описано.
В кодере (любом из 310) бины считываются из потока бинов (т.е. 7) до тех пор, пока не возникнет единица, или до тех пор, пока не будет считано 2n нулей. Число нулей подсчитывается. Если подсчитанное число равно 2n, кодовое слово ʺ1ʺ записывается в поток битов. В противном случае, записывается ʺ0ʺ, а затем двоичное представление подсчитанного числа, записанное с помощью n битов.
В декодере (любом из 322) считывается один бит. Если он равен ʺ1ʺ, 2n нулей декодируются в строку бинов. Если он равен ʺ0ʺ, еще n битов считываются и интерпретируются в качестве двоичного представления числа. Это число нулей декодируется в поток бинов, а затем декодируется единица.
Другими словами, вышеописанные варианты осуществления описывают кодер для кодирования последовательности символов 303, содержащий модуль 316 назначения, сконфигурированный с возможностью назначать некоторое число параметров 305 каждому символу из последовательности символов на основе информации, содержащейся в предыдущих символах из последовательности символов; множество энтропийных кодеров 310, каждый из которых сконфигурирован с возможностью преобразовывать символы 307, перенаправляемые в соответствующий энтропийный кодер 310, в соответствующий поток 312 битов; и модуль 6 выбора, сконфигурированный с возможностью перенаправлять каждый символ 303 в выбранный один из множества энтропийных кодеров 10, причем выбор зависит от числа параметров 305, назначаемых соответствующему символу 303. Согласно вышеуказанным вариантам осуществления по меньшей мере первый поднабор энтропийных кодеров может быть кодером переменной длины, сконфигурированным с возможностью отображать последовательности символов переменных длин в потоке символов 307 в кодовые слова переменных длин, которые должны быть вставлены в поток 312 битов, соответственно, причем каждый из энтропийных кодеров 310 из первого поднабора использует правило биективного отображения, согласно которому кодовые слова первичного кода без префикса с (2n-1)≥3 кодовых слова отображаются в кодовые слова вторичного кода без префикса, который является идентичным первичному коду с префиксом, так что все за исключением двух из кодовых слов первичного кода без префикса отображаются в идентичные кодовые слова вторичного кода без префикса, в то время как два кодовых слова первичных и вторичных кодов без префикса имеют различные длины и отображаются друг в друга с перестановкой, при этом энтропийные кодеры могут использовать различный n с тем, чтобы охватывать различные части интервала для вышеуказанного интервала вероятности. Первый код без префикса может составляться таким образом, что кодовые слова первого кода без префикса представляют собой (a,b)2, (a,a,b)3, ..., (a,...,a,b)n, (a,...,a)n, (b,a)2, (b,b,a)3, ..., (b,...,b,a)n-1, (b,...,b)n-1, и два кодовых слова, отображенные друг в друга с перестановкой, представляют собой (a,...,a)n и (b,...,b)n-1, где b≠a и a,b∈{0,1}. Тем не менее, альтернативы являются осуществимыми.
Другими словами, каждый из первого поднабора энтропийных кодеров может быть сконфигурирован с возможностью, при преобразовании символов, перенаправляемых в соответствующий энтропийный кодер, в соответствующий поток битов, исследовать первый символ, перенаправляемый в соответствующий энтропийный кодер, чтобы выполнять определение в отношении того: (1) первый символ равен a∈{0,1}, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью анализировать следующие символы, перенаправляемые в соответствующий энтропийный кодер, чтобы выполнять определение в отношении того: (1.1) возникает b, где b≠a и b∈{0,1}, в следующих n-1 символов после первого символа, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью записывать кодовое слово в соответствующий поток битов, который равен первому символу, после чего следуют следующие символы, перенаправляемые в соответствующий энтропийный кодер, вплоть до символа b; или (1.2) не возникает b в следующих n-1 символов после первого символа, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью записывать кодовое слово в соответствующий поток битов, который равен (b,...,b)n-1; или (2) первый символ равен b, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью анализировать следующие символы, перенаправляемые в соответствующий энтропийный кодер, чтобы выполнять определение в отношении того: (2.1) возникает a в следующих n-2 символов после первого символа, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью записывать кодовое слово в соответствующий поток битов, который равен первому символу, после чего следуют следующие символы, перенаправляемые в соответствующий энтропийный кодер, вплоть до символа a; или (2.2) не возникает a в следующих n-2 символов после первого символа, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью записывать кодовое слово в соответствующий поток битов, который равен (a,...,a)n.
Дополнительно или альтернативно, второй поднабор энтропийных кодеров 10 может быть кодером переменной длины, сконфигурированным с возможностью отображать последовательности символов переменных длин в кодовые слова фиксированных длин, соответственно, причем каждый из энтропийных кодеров из второго поднабора использует правило биективного отображения, согласно которому кодовые слова первичного усеченного унарного кода с 2n+1 кодовых слов типа {(a), (ba), (bba), ..., (b...ba), (bb...b)}, где b≠a и a,b∈{0,1} отображаются в кодовые слова вторичного кода без префикса таким образом, что кодовое слово (bb...b) первичного усеченного унарного кода отображается в кодовое слово (c) вторичного кода без префикса, а все остальные кодовые слова {(a), (ba), (bba), ..., (b...ba)} первичного усеченного унарного кода отображаются в кодовые слова, имеющие (d), где c≠d и c,d∈{0,1}, в качестве префикса и n-битовое слово в качестве суффикса, при этом энтропийные кодеры используют различный n. Каждый из второго поднабора энтропийных кодеров может иметь такую конфигурацию, в которой n-битовое слово является n-битовым представлением числа b в соответствующем кодовом слове первичного усеченного унарного кода. Тем не менее, альтернативы являются осуществимыми.
С другой стороны, с точки зрения режима работы соответствующего кодера 10, каждый из второго поднабора энтропийных кодеров может быть сконфигурирован с возможностью, при преобразовании символов, перенаправляемых в соответствующий энтропийный кодер, в соответствующий поток битов, подсчитывать число b в последовательности символов, перенаправляемой в соответствующий энтропийный кодер, до тех пор, пока не возникнет a, или до тех пор, пока номер последовательности символов, перенаправляемой в соответствующий энтропийный кодер, не достигнет 2n, причем все 2n символов последовательности равны b, и (1) если число b равно 2n, записывать c, где c∈{0,1}, в качестве кодового слова вторичного кода без префикса в соответствующий поток битов, и (2) если число b ниже 2n, записывать кодовое слово вторичного кода без префикса в соответствующий поток битов, который имеет (d), где c≠d и d∈{0,1}, в качестве префикса и n-битовое слово, определенное в зависимости от числа b, в качестве суффикса.
Также, дополнительно или альтернативно, предварительно определенный один из энтропийных кодеров 10 может быть кодером переменной длины, сконфигурированным с возможностью отображать последовательности символов фиксированных длин в кодовые слова переменных длин, соответственно, причем предварительно определенный энтропийный кодер использует правило биективного отображения, согласно которому 23 кодовых слова длины 3 первичного кода отображаются в кодовые слова вторичного кода без префикса таким образом, что кодовое слово (aaa)3 первичного кода, где a∈{0,1}, отображается в кодовое слово (c), где c∈{0,1}, все три кодовых слова первичного кода, имеющие строго один b, где b≠a и b∈{0,1}, отображаются в кодовые слова, имеющие (d), где c≠d и d∈{0,1}, в качестве префикса и соответствующее первое 2-битовое слово из первого набора 2-битовых слов в качестве суффикса, все три кодовых слова первичного кода, имеющие строго один a, отображаются в кодовые слова, имеющие (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого набора, и второго 2-битового слова из второго набора 2-битовых слов в качестве суффикса, при этом кодовое слово (bbb)3 отображается в кодовое слово, имеющее (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого набора, и второго 2-битового слова, не являющегося элементом второго набора, в качестве суффикса. Первое 2-битовое слово кодовых слов первичного кода, имеющих строго один b, может быть 2-битовым представлением позиции b в соответствующем кодовом слове первичного кода, а второе 2-битовое слово кодовых слов первичного кода, имеющих строго один a, может быть 2-битовым представлением позиции в соответствующем кодовом слове первичного кода. Тем не менее, альтернативы являются осуществимыми.
С другой стороны, предварительно определенный один из энтропийных кодеров может быть сконфигурирован с возможностью, при преобразовании символов, перенаправляемых в предварительно определенный энтропийный кодер, в соответствующий поток битов, исследовать символы для предварительно определенного энтропийного кодера в триплетах на предмет того: (1) триплет состоит из a, причем в этом случае предварительно определенный энтропийный кодер сконфигурирован с возможностью записывать кодовое слово (c) в соответствующий поток битов, (2) триплет содержит строго один b, причем в этом случае предварительно определенный энтропийный кодер сконфигурирован с возможностью записывать кодовое слово, имеющее (d) в качестве префикса и 2-битовое представление позиции b в триплете в качестве суффикса, в соответствующий поток битов; (3) триплет содержит строго один a, причем в этом случае предварительно определенный энтропийный кодер сконфигурирован с возможностью записывать кодовое слово, имеющее (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого набора, и 2-битового представления позиции в триплете в качестве суффикса, в соответствующий поток битов; или (4) триплет состоит из b, причем в этом случае предварительно определенный энтропийный кодер сконфигурирован с возможностью записывать кодовое слово, имеющее (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого набора, и первого 2-битового слова, не являющегося элементом второго набора, в качестве суффикса, в соответствующий поток битов.
Что касается стороны декодирования, вышеописанные варианты осуществления раскрывают декодер для восстановления последовательности символов 326, содержащий множество энтропийных декодеров 322, каждый из которых сконфигурирован с возможностью преобразовывать соответствующий поток 324 битов в символы 321; модуль 316 назначения, сконфигурированный с возможностью назначать некоторое число параметров для каждого символа 326 последовательности символов, которые должны быть восстановлены на основе информации, содержащейся в ранее восстановленных символах из последовательности символов; и модуль 318 выбора, сконфигурированный с возможностью извлекать каждый символ 325 из последовательности символов, которая должна быть восстановлена из выбранного множества энтропийных декодеров, причем выбор зависит от числа параметров, заданных для соответствующего символа. Согласно вышеописанным вариантам осуществления по меньшей мере первый поднабор энтропийных декодеров 322 представляет собой декодеры переменной длины, сконфигурированные с возможностью отображать кодовые слова переменных длин в последовательности символов переменных длин, соответственно, причем каждый из энтропийных декодеров 22 из первого поднабора использует правило биективного отображения, согласно которому кодовые слова первичного кода без префикса с (2n-1)≥3 кодовых слова отображаются в кодовые слова вторичного кода без префикса, который является идентичным первичному коду с префиксом, так что все за исключением двух из кодовых слов первичного кода без префикса отображаются в идентичные кодовые слова вторичного кода без префикса, в то время как два кодовых слова первичных и вторичных кодов без префикса имеют различные длины и отображаются друг в друга с перестановкой, при этом энтропийные кодеры используют различный n. Первый код без префикса может составляться таким образом, что кодовые слова первого кода без префикса представляют собой (a,b)2, (a,a,b)3, ..., (a,...,a,b)n, (a,...,a)n, (b,a)2, (b,b,a)3, ..., (b,...,b,a)n-1, (b,...,b)n-1, и два кодовых слова, отображенные друг в друга с перестановкой, могут представлять собой (a,...,a)n и (b,...,b)n-1, где b≠a и a,b∈{0,1}. Тем не менее, альтернативы являются осуществимыми.
Каждый из первого поднабора энтропийных кодеров может быть сконфигурирован с возможностью, при преобразовании соответствующего потока битов в символы, исследовать первый бит из соответствующего потока битов, чтобы выполнять определение в отношении того: (1) первый бит равен 0 {0,1}, причем в этом случае соответствующий энтропийный кодер сконфигурирован с возможностью анализировать следующие биты соответствующего потока битов, чтобы выполнять определение в отношении того: (1.1) возникает b, где b≠a и b 0 {0,1}, в следующих n-1 битов после первого бита, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна первому биту, после чего следуют следующие биты соответствующего потока битов вплоть до бита b; или (1.2) не возникает b в следующих n-1 битов после первого бита, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна (b,...,b)n-1; или (2) первый бит равен b, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью анализировать следующие биты соответствующего потока битов, чтобы выполнять определение в отношении того: (2.1) возникает a в следующих n-2 битов после первого бита, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна первому биту, после чего следуют следующие биты соответствующего потока битов вплоть до символа a; или (2.2) не возникает a в следующих n-2 битов после первого бита, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна (a,...,a)n.
Дополнительно или альтернативно, по меньшей мере второй поднабор энтропийных декодеров 322 может быть декодером переменной длины, сконфигурированным с возможностью отображать кодовые слова фиксированных длин в последовательности символов переменных длин, соответственно, причем каждый из энтропийных декодеров из второго поднабора использует правило биективного отображения, согласно которому кодовые слова вторичного кода без префикса отображаются в кодовые слова первичного усеченного унарного кода с 2n+1 кодовых слов типа {(a), (ba), (bba), ..., (b...ba), (bb...b)}, где b≠a и a,b∈{0,1} таким образом, что кодовое слово (c) вторичного кода без префикса отображается в кодовое слово (bb...b) первичного усеченного унарного кода, и кодовые слова, имеющие (d), где c≠d, и c,d∈{0,1}, в качестве префикса и n-битовое слово в качестве суффикса отображаются в соответствующее из других кодовых слов {(a), (ba), (bba), ..., (b...ba)} первичного усеченного унарного кода, при этом энтропийные декодеры используют различный n. Каждый из второго поднабора энтропийных декодеров может иметь такую конфигурацию, в которой n-битовое слово является n-битовым представлением числа b в соответствующем кодовом слове первичного усеченного унарного кода. Тем не менее, альтернативы являются осуществимыми.
Каждый из второго поднабора энтропийных декодеров может быть декодером переменной длины, сконфигурированным с возможностью отображать кодовые слова фиксированных длин в последовательности символов переменных длин, соответственно, и сконфигурированным с возможностью, при преобразовании потока битов соответствующего энтропийного декодера в символы, анализировать первый бит из соответствующего потока битов, чтобы выполнять определение в отношении того: (1) равен первый бит c, где c∈{0,1}, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна (bb...b)2n, где b∈{0,1}; или (2) равен первый бит d, где c≠d и c,d∈{0,1}, причем в этом случае соответствующий энтропийный декодер сконфигурирован с возможностью определять n-битовое слово из n дополнительных битов соответствующего потока битов после первого бита и восстанавливать из него последовательность символов, которая имеет тип {(a), (ba), (bba), ..., (b...ba), (bb...b)}, где b≠a и b∈{0,1} с числом b в зависимости от n-битового слова.
Дополнительно или альтернативно, предварительно определенный один из энтропийных декодеров 322 может быть декодером переменной длины, сконфигурированным с возможностью отображать кодовые слова переменных длин в последовательности символов фиксированных длин, соответственно, причем предварительно определенный энтропийный декодер использует правило биективного отображения, согласно которому кодовые слова вторичного кода без префикса преобразуются в 23 кодовых слова длины 3 из первичного кода таким образом, что кодовое слово (c), где c∈{0,1}, отображается в кодовое слово (aaa)3 первичного кода, где a∈{0,1}, кодовые слова, имеющие (d), где c≠d и d∈{0,1}, в качестве префикса и соответствующее первое 2-битовое слово из первого набора из трех 2-битовых слов в качестве суффикса, отображаются во все три кодовых слова первичного кода, имеющие строго один b, где b≠a и b∈{0,1}, кодовые слова, имеющие (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого набора, и второго 2-битового слова из второго набора из трех 2-битовых слов в качестве суффикса, отображаются во все три кодовых слова первичного кода, имеющие строго один a, и кодовое слово, имеющее (d) в качестве префикса и конкатенацию первого 2-битового слова, не являющегося элементом первого набора, и второго 2-битового слова, не являющегося элементом второго набора, в качестве суффикса, отображается в кодовое слово (bbb)3. Первое 2-битовое слово кодовых слов первичного кода, имеющих строго один b, может быть 2-битовым представлением позиции b в соответствующем кодовом слове первичного кода, а второе 2-битовое слово кодовых слов первичного кода, имеющих строго один a, может быть 2-битовым представлением позиции в соответствующем кодовом слове первичного кода. Тем не менее, альтернативы являются осуществимыми.
Предварительно определенный один из энтропийных декодеров может быть декодером переменной длины, сконфигурированным с возможностью отображать кодовые слова переменных длин в последовательности символов из трех символов, соответственно, и сконфигурированным с возможностью, при преобразовании потока битов соответствующего энтропийного декодера в символы, анализировать первый бит из соответствующего потока битов, чтобы выполнять определение в отношении того: (1) равен первый бит из соответствующего потока битов c, где c∈{0,1}, причем в этом случае предварительно определенный энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна (aaa)3, где a 0 {0,1}, или (2) равен первый бит из соответствующего потока битов d, где c≠d и d∈{0,1}, причем в этом случае предварительно определенный энтропийный декодер сконфигурирован с возможностью определять первое 2-битовое слово из 2 дополнительных битов соответствующего потока битов после первого бита и анализировать первое 2-битовое слово, чтобы выполнять определение в отношении того: (2.1) не является первое 2-битовое слово элементом первого набора из трех 2-битовых слов, причем в этом случае предварительно определенный энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая имеет строго один b, где b≠a и b 0 {0,1}, причем позиция b в соответствующей последовательности символов зависит от первого 2-битового слова, или (2.2) является первое 2-битовое слово элементом первого набора, причем в этом случае предварительно определенный энтропийный декодер сконфигурирован с возможностью определять второе 2-битовое слово из 2 дополнительных битов соответствующего потока битов после двух битов, из которых первое 2-битовое слово определено, и анализировать второе 2-битовое слово, чтобы выполнять определение в отношении того: (3.1) не является второе 2-битовое слово элементом второго набора из трех 2-битовых слов, причем в этом случае предварительно определенный энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая имеет строго один a, причем позиция в соответствующей последовательности символов зависит от второго 2-битового слова, или (3.2) является второе 2-битовое слово элементом второго набора из трех 2-битовых слов, причем в этом случае предварительно определенный энтропийный декодер сконфигурирован с возможностью восстанавливать последовательность символов, которая равна (bbb)3.
Далее, после описания общего принципа схемы кодирования видео, варианты осуществления настоящего изобретения описываются относительно вышеописанных вариантов осуществления. Другими словами, нижеуказанные варианты осуществления могут быть реализованы посредством использования вышеописанных схем, и наоборот, вышеуказанные схемы кодирования могут быть реализованы с применением и использованием нижеуказанных вариантов осуществления.
В вышеописанных вариантах осуществления, описанных относительно фиг.7-9, энтропийный кодер и декодеры по фиг.1-6 реализованы в соответствии с PIPE-принципом. Один специальный вариант осуществления использует арифметические кодеры/декодеры 310 и 322 с одним вероятностным состоянием. Как описано ниже, в соответствии с альтернативным вариантом осуществления, объекты 306-310 и соответствующие объекты 318-322 могут быть заменены посредством общего механизма энтропийного кодирования. Например, механизм арифметического кодирования может управлять только одним общим состоянием R и L и кодировать все символы в один общий поток битов, в силу этого исключая преимущественные аспекты настоящего PIPE-принципа относительно параллельной обработки, но предотвращая необходимость перемежения частичных потоков битов, как дополнительно пояснено ниже. При этом число состояний вероятности, посредством которых вероятности контекста оцениваются посредством обновления (табличного поиска), может быть выше числа состояний вероятности, посредством которых выполняется подразделение на интервалы вероятности. Иными словами, аналогично квантованию значения ширины интервала вероятности до индексации в таблицу Rtab, также может быть квантован индекс состояния вероятности. Таким образом, вышеприведенное описание для возможной реализации для одиночных кодеров/декодеров 310 и 322 может распространяться на пример реализации энтропийных кодеров/декодеров 318-322/306-310 в качестве механизмов контекстно-адаптивного двоичного арифметического кодирования/декодирования.
Если точнее, в соответствии с вариантом осуществления энтропийный кодер, соединенный с выходом модуля назначения параметров (который здесь выступает в качестве модуля назначения контекстов), может работать следующим образом:
0. Модуль 304 назначения перенаправляет значение бина вместе с вероятностным параметром. Вероятность представляет собой pState_current[bin].
1. Таким образом, механизм энтропийного кодирования принимает: 1) valLPS, 2) бин и 3) оценку pState_current[bin] распределения вероятностей; pState_current[bin] может иметь больше состояний, чем число отличимых индексов состояний вероятности Rtab. Если да, pState_current[bin] может быть квантован, например, посредством игнорирования m LSB, при этом m превышает или равно 1 и предпочтительно составляет 2 или 3, с тем, чтобы получать p_state, т.е. индекс, который затем используется для того, чтобы осуществлять доступ к таблице Rtab. Тем не менее, квантование может не применяться, т.е. p_state может представлять собой pState_current[bin].
2. Затем выполняется квантование R (как упомянуто выше: либо один R (и соответствующий L с одним общим потоком битов) используется/управляется для всех отличимых значений p_state, либо один R (и соответствующий L с ассоциированным частичным потоком битов в расчете на R/L-пару) для каждого отличимого значения p_state, причем второй случай должен соответствовать наличию одного кодера 310 бинов для каждого такого значения)
q_index=Qtab[R>>q] (или некоторая другая форма квантования).
3. Затем выполняется определение RLPS и R:
RLPS=Rtab[p_state][q_index]; Rtab имеет сохраненные заранее вычисленные значения для p[p_state]*Q[q_index]
R=R-RLPS (т.е. R заранее предварительно обновляется, как если ʺбинʺ представляет собой MPS).
4. Вычисление нового частичного интервала:
if (bin=1-valMPS) then
L¬L+R
R¬RLPS.
5. Ренормализация L и R, запись битов.
Аналогично, энтропийный декодер, соединенный с выходом модуля назначения параметров (который здесь выступает в качестве модуля назначения контекстов), может работать следующим образом:
0. Модуль 304 назначения перенаправляет значение бина вместе с вероятностным параметром. Вероятность представляет собой pState_current[bin].
1. Таким образом, механизм энтропийного декодирования принимает запрос на бин вместе с: 1) valLPS и 2) оценкой pState_current[bin] распределения вероятностей; pState_current[bin] может иметь больше состояний, чем число отличимых индексов состояний вероятности Rtab. Если да, pState_current[bin] может быть квантован, например, посредством игнорирования m LSB, при этом m превышает или равно 1 и предпочтительно составляет 2 или 3, с тем, чтобы получать p_state, т.е. индекс, который затем используется для того, чтобы осуществлять доступ к таблице Rtab. Тем не менее, квантование может не применяться, т.е. p_state может представлять собой pState_current[bin].
2. Затем выполняется квантование R (как упомянуто выше: либо один R (и соответствующий V с одним общим потоком битов) используется/управляется для всех отличимых значений p_state, либо один R (и соответствующий V с ассоциированным частичным потоком битов в расчете на R/L-пару) для каждого отличимого значения p_state, причем второй случай должен соответствовать наличию одного кодера 310 бинов для каждого такого значения)
q_index=Qtab[R>>q] (или некоторая другая форма квантования).
3. Затем выполняется определение RLPS и R:
RLPS=Rtab[p_state][q_index]; Rtab имеет сохраненные заранее вычисленные значения для p[p_state]*Q[q_index]
R=R-RLPS (т.е. R заранее предварительно обновляется, как если ʺбинʺ представляет собой MPS).
4. Определение бина в зависимости от позиции частичного интервала:
if (V³R) then
bin¬1-valMPS (бин декодируется в качестве LPS; модуль 18 выбора буфера бинов получает фактическое значение бина посредством использования этой информации бина и valMPS)
V¬V-R
R¬RLPS
else
bin¬valMPS (бин декодируется в качестве MPS; фактическое значение бина получается посредством использования этой информации бина и valMPS).
5. Ренормализация R, считывание одного бита и обновление V.
Как описано выше, модуль 4 назначения назначает pState_current[bin] каждому бину. Ассоциирование может выполняться на основе выбора контекста. Иными словами, модуль 4 назначения может выбирать контекст с использованием индекса ctxIdx контекста, который, в свою очередь, имеет соответствующий ассоциированный pState_current. Обновление вероятности может быть выполнено каждый раз, когда вероятность pState_current[bin] применяется к текущему бину. Обновление состояния вероятности pState_current[bin] выполняется в зависимости от значения кодированного бита:
if (bit=1-valMPS) then
pState_current←Next_State_LPS [pState_current]
if (pState_current=0) then valMPS←1-valMPS
else
pState_current←Next_State_MPS [pState_current].
Если предоставляются несколько контекстов, адаптация выполняется контекстно-зависимо, т.е. pState_current[ctxIdx] используется для кодирования и затем обновляется с использованием значения текущего бина (кодированного или декодированного, соответственно).
Как подробнее указано ниже, в соответствии с вариантами осуществления, описанными теперь, кодер и декодер необязательно может быть реализован с возможностью работать в различных режимах, а именно, в режиме с низкой сложностью (LC) и с высокой эффективностью (HE). Далее это проиллюстрировано главным образом в отношении PIPE-кодирования (и со ссылкой на LC- и HE-PIPE-режимы), но описание сведений по масштабируемости сложности легко переносится на другие реализации механизмов энтропийного кодирования/декодирования, такие как вариант осуществления с использованием одного общего контекстно-адаптивного арифметического кодера/декодера.
В соответствии с нижеуказанными вариантами осуществления оба режима энтропийного кодирования могут совместно использовать:
- идентичный синтаксис и семантику (для последовательности 301 и 327 элементов синтаксиса, соответственно),
- идентичные схемы бинаризации для всех элементов синтаксиса (как указано в настоящее время для CABAC) (т.е. модули бинаризации могут работать независимо от активированного режима),
- использование идентичных PIPE-кодов (т.е. кодеры/декодеры бинов могут работать независимо от активированного режима),
- использование 8-битовых значений инициализации вероятностной модели (вместо 16-битовых значений инициализации, как указано в настоящее время для CABAC).
Вообще говоря, LC-PIPE отличается от HE-PIPE по сложности обработки, к примеру, по сложности выбора PIPE-тракта 312 для каждого бина.
Например, LC-режим может работать при следующих ограничениях: для каждого бина (binIdx) может быть строго одна вероятностная модель, т.е. один ctxIdx. Иными словами, выбор/адаптация контекста не может предоставляться в LC-PIPE. Конкретные элементы синтаксиса, к примеру, элементы синтаксиса, используемые для остаточного кодирования, тем не менее, могут кодироваться с использованием контекстов, как дополнительно указано ниже. Кроме того, все вероятностные модели могут быть неадаптивными, т.е. все модели могут быть инициализированы в начале каждого слайса с надлежащими вероятностями моделей (в зависимости от выбора типа слайса и QP слайса) и могут сохраняться фиксированными в течение обработки слайса. Например, только 8 различных вероятностей моделей, соответствующих 8 различным PIPE-кодам 310/322, могут поддерживаться как для контекстного моделирования, так и для кодирования. Конкретные элементы синтаксиса для остаточного кодирования, т.е. significance_coeff_flag и coeff_abs_level_greaterX (где X=1, 2), семантика которых подробнее указана ниже, могут назначаться вероятностным моделям, так что (по меньшей мере) группы, например, из 4 элементов синтаксиса кодируются/декодируются с помощью идентичной вероятности модели. По сравнению с CAVLC, LC-PIPE-режим достигает примерно идентичной R-D-производительности и идентичной пропускной способности.
HE-PIPE может быть сконфигурирована с возможностью быть концептуально аналогичной CABAC H.264 со следующими отличиями. Двоичное арифметическое кодирование (BAC) заменяется посредством PIPE-кодирования (как и в LC-PIPE-случае). Каждая вероятностная модель, т.е. каждый ctxIdx, может быть представлена посредством pipeIdx и refineIdx, где pipeIdx со значениями в диапазоне 0...7 представляет вероятность модели 8 различных PIPE-кодов. Это изменение влияет только на внутреннее представление состояний, а не на сам режим работы конечного автомата (т.е. оценку вероятности). Как подробнее указано ниже, инициализация вероятностных моделей может использовать 8-битовые значения инициализации, как указано выше. Обратное сканирование элементов синтаксиса coeff_abs_level_greaterX (где X=1, 2), coeff_abs_level_minus3 и coeff_sign_flag (семантика которых становится очевидной из нижеприведенного пояснения) может быть выполнено вдоль идентичного пути сканирования с прямым сканированием (используемого, например, при кодировании на основе карты значимости). Извлечение контекста для кодирования coeff_abs_level_greaterX (где X=1, 2) также может быть упрощено. По сравнению с CABAC предложенная HE-PIPE достигает примерно идентичной R-D-производительности при более высокой пропускной способности.
Нетрудно видеть, что вышеуказанные режимы легко формируются посредством рендеринга, например, вышеуказанного механизма контекстно-адаптивного двоичного арифметического кодирования/декодирования таким образом, что он работает в различных режимах.
Таким образом, в соответствии с вариантом осуществления в соответствии с первым аспектом настоящего изобретения, декодер для декодирования потока данных может иметь структуру, показанную на фиг.11. Декодер служит для декодирования потока 401 данных, к примеру, перемеженного потока 340 битов, в который кодируются мультимедийные данные, к примеру, видеоданные. Декодер содержит переключатель 400 режима, сконфигурированный с возможностью активировать режим с низкой сложностью или режим с высокой эффективностью в зависимости от потока 401 данных. С этой целью поток 401 данных может содержать элемент синтаксиса, к примеру, двоичный элемент синтаксиса, имеющий двоичное значение 1 в случае, если режим с низкой сложностью должен быть активирован, и имеющий двоичное значение 0 в случае, если режим с высокой эффективностью должен быть активирован. Очевидно, ассоциирование между двоичным значением и режимом кодирования может переключаться, и также может использоваться недвоичный элемент синтаксиса, имеющий более двух возможных значений. Поскольку фактический выбор между обоими режимами еще не является очевидным до приема соответствующего элемента синтаксиса, этот элемент синтаксиса может содержаться в некотором начальном заголовке потока 401 данных, кодированного, например, с оценкой с фиксированной вероятностью или вероятностной моделью, либо записываемого в поток 401 данных как есть, т.е. с использованием обходного режима.
Дополнительно, декодер по фиг.11 содержит множество энтропийных декодеров 322, каждый из которых сконфигурирован с возможностью преобразовывать кодовые слова в потоке 401 данных в частичные последовательности 321 символов. Как описано выше, модуль 404 обратного перемежения может быть соединен между входами энтропийных декодеров 322, с одной стороны, и входом декодера по фиг.11, в котором применяется поток 401 данных, с другой стороны. Дополнительно, как уже описано выше, каждый из энтропийных декодеров 322 может быть ассоциирован с соответствующим интервалом вероятности, причем интервалы вероятности различных энтропийных декодеров совместно охватывают полный интервал вероятности от 0 до 1 (или от 0 до 0,5 в случае работы энтропийных декодеров 322 с MPS и LPS, а не с абсолютными значениями символов). Подробности в отношении этой проблемы описаны выше. Далее предполагается, что число декодеров 322 составляет 8, при этом PIPE-индекс назначается каждому декодеру, но любое другое число также является осуществимым. Дополнительно, один из этих кодеров, далее он представляет собой в качестве примера кодер, имеющий pipe_id 0, оптимизируется для бинов, имеющих равновероятную статистику, т.е. их значение бина равновероятно допускает 1 и 0. Этот декодер может просто передавать бины. Соответствующий кодер 310 работает идентично. Даже любая обработка бинов в зависимости от значения наиболее вероятного значения бина, valMPS, посредством модулей 402 и 502 выбора, соответственно, может не применяться. Другими словами, энтропия соответствующего частичного потока является уже оптимальной.
Дополнительно, декодер по фиг.11 содержит модуль 402 выбора, сконфигурированный с возможностью извлекать каждый символ из последовательности 326 символов из выбранного множества энтропийных декодеров 322. Как упомянуто выше, модуль 402 выбора может разбиваться на модуль 316 назначения параметров и модуль 318 выбора. Модуль 314 преобразования из символьной формы сконфигурирован с возможностью осуществлять преобразование из символьной формы последовательности 326 символов, чтобы получать последовательность 327 элементов синтаксиса. Модуль 404 восстановления сконфигурирован с возможностью восстанавливать мультимедийные данные 405 на основе последовательности элементов 327 синтаксиса. Модуль 402 выбора сконфигурирован с возможностью осуществлять выбор в зависимости от активированного режима с низкой сложностью и режима с высокой эффективностью, как указано посредством стрелки 406.
Как уже отмечено выше, модуль 404 восстановления может быть частью прогнозирующего видеодекодера на основе блоков, работающего для фиксированного синтаксиса и семантики элементов синтаксиса, т.е. фиксированного относительно выбора режима посредством переключателя 400 режима. Иными словами, структура модуля 404 восстановления не страдает от возможности переключения режимов. Если точнее, модуль 404 восстановления не увеличивает объем служебной информации реализации вследствие возможности переключения режимов, предлагаемой посредством переключателя 400 режима, и по меньшей мере функциональность относительно остаточных данных и прогнозирующих данных остается идентичной независимо от режима, выбранного посредством переключателя 400. Тем не менее, то же применимо относительно энтропийных декодеров 322. Все эти декодеры 322 многократно используются в обоих режимах, и, соответственно, отсутствует дополнительный объем служебной информации для реализации, хотя декодер по фиг.11 является совместимым с обоими режимами, т.е. с режимом с низкой сложностью и с высокой эффективностью.
В качестве вспомогательного аспекта следует отметить, что декодер по фиг.11 не только имеет возможность управлять автономными потоками данных в одном режиме или в другом режиме. Наоборот, декодер по фиг.11, а также поток 401 данных могут иметь такую конфигурацию, в которой переключение между обоими режимами возможно даже в течение одного фрагмента мультимедийных данных, к примеру, в течение видео или некоторого фрагмента аудио, для того, чтобы, например, управлять сложностью кодирования на стороне декодирования в зависимости от внешних или окружающих условий, таких как состояние аккумулятора и т.п., с использованием канала обратной связи из декодера в кодер, чтобы, соответственно, управлять с замкнутым контуром выбором режима.
Таким образом, декодер по фиг.11 работает аналогично в обоих случаях, в случае выбора LC-режима или выбора HE-режима. Модуль 404 восстановления выполняет восстановление с использованием элементов синтаксиса и запрашивает текущий элемент синтаксиса предварительно определенного типа элемента синтаксиса посредством обработки или подчинения определенному предписанию синтаксической структуры. Модуль 314 преобразования из символьной формы запрашивает число бинов, чтобы давать в результате допустимую бинаризацию для элемента синтаксиса, запрашиваемого посредством модуля 404 восстановления. Очевидно, в случае двоичного алфавита, бинаризация, выполняемая посредством модуля 314 преобразования из символьной формы, сокращается до простой передачи соответствующего бина/символа 326 в модуль 404 восстановления в качестве текущего запрошенного двоичного элемента синтаксиса.
Тем не менее, модуль 402 выбора работает независимо от режима, выбранного посредством переключателя 400 режима. Режим работы модуля 402 выбора зачастую является более сложным в случае режима с высокой эффективностью и менее сложным в случае режима с низкой сложностью. Кроме того, нижеприведенное пояснение демонстрирует, что режим работы модуля 402 выбора в менее сложном режиме также зачастую уменьшает скорость, на которой модуль 402 выбора изменяет выбор между энтропийными декодерами 322 при извлечении последовательных символов из энтропийных декодеров 322. Другими словами, в режиме с низкой сложностью имеется повышенная вероятность того, что непосредственно последовательные символы извлекаются из идентичного энтропийного декодера из множества энтропийных декодеров 322. Это, в свою очередь, обеспечивает возможность более быстрого извлечения символов из энтропийных декодеров 322. В режиме с высокой эффективностью, в свою очередь, режим работы модуля 402 выбора зачастую приводит к выбору между энтропийными декодерами 322, при этом интервал вероятности, ассоциированный с соответствующим выбранным энтропийным декодером 322, более близко соответствует фактической статистике по символам символа, в данный момент извлеченного посредством модуля 402 выбора, в силу этого давая в результате лучший коэффициент сжатия на стороне кодирования при формировании соответствующего потока данных в соответствии с режимом с высокой эффективностью.
Например, различный режим работы модуля 402 выбора в обоих режимах может быть реализован следующим образом. Например, модуль 402 выбора может быть сконфигурирован с возможностью осуществлять, для предварительно определенного символа, выбор между множеством энтропийных декодеров 322 в зависимости от ранее извлеченных символов последовательности 326 символов в случае активации режима с высокой эффективностью и независимо от ранее извлеченных символов из последовательности символов в случае активации режима с низкой сложностью. Зависимость от ранее извлеченных символов последовательности 326 символов может следовать из адаптивности контекста и/или адаптивности вероятности. Обе адаптивности могут отключаться в ходе режима с низкой сложностью в модуле 402 выбора.
В соответствии с дополнительным вариантом осуществления поток 401 данных может быть структурирован на последовательные части, к примеру, слайсы, кадры, группу изображений, последовательности кадров и т.п., и каждый символ из последовательности символов может быть ассоциирован с соответствующим одним из множества типов символов. В этом случае модуль 402 выбора может быть сконфигурирован с возможностью варьировать, для символов предварительно определенного типа символа в текущей части, выбор в зависимости от ранее извлеченных символов из последовательности символов предварительно определенного типа символа в текущей части в случае активации режима с высокой эффективностью и оставлять выбор постоянным в текущей части в случае активации режима с низкой сложностью. Иными словами, модулю 402 выбора может разрешаться изменять выбор между энтропийными декодерами 322 для предварительно определенного типа символа, но эти изменения ограничены так, что они осуществляются между переходами между последовательными частями. Посредством этого показателя оценки фактической статистики по символам ограничены редко возникающими моментами времени, в то время как сложность кодирования уменьшается в большой части времени.
Дополнительно, каждый символ из последовательности 326 символов может быть ассоциирован с соответствующим одним из множества типов символов, и модуль 402 выбора может быть сконфигурирован с возможностью, для предварительно определенного символа предварительно определенного типа символа, выбирать один из множества контекстов в зависимости от ранее извлеченных символов последовательности 326 символов и выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом, наряду с обновлением вероятностной модели, ассоциированной с выбранным контекстом, в зависимости от предварительно определенного символа в случае активации режима с высокой эффективностью, и выполнять выбор одного из множества контекстов в зависимости от ранее извлеченных символов последовательности 326 символов, и выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом, наряду с оставлением постоянной вероятностной модели, ассоциированной с выбранным контекстом, в случае активации режима с низкой сложностью. Иными словами, модуль 402 выбора может использовать адаптивность контекста относительно определенного типа элемента синтаксиса в обоих режимах при подавлении адаптации вероятности в случае LC-режима.
Альтернативно, вместо полного подавления адаптации вероятности модуль 402 выбора может просто уменьшать скорость обновления адаптации вероятности LC-режима относительно HE-режима.
Дополнительно, возможные конкретные для LC-PIPE аспекты, т.е. аспекты LC-режима, могут быть описаны следующим образом другими словами. В частности, неадаптивные вероятностные модели могут быть использованы в LC-режиме. Неадаптивная вероятностная модель либо может иметь жесткую, т.е. полную постоянную вероятность, либо ее вероятность сохраняется фиксированной только в течение обработки слайса и в силу этого может задаваться в зависимости от типа слайса и QP, т.е. параметра квантования, который, например, передается в служебных сигналах в потоке 401 данных для каждого слайса. Посредством допущения того, что последовательные бины, назначаемые идентичному контексту, соответствуют фиксированной вероятностной модели, можно декодировать несколько из этих бинов за один шаг, поскольку они кодируются с использованием идентичного PIPE-кода, т.е. с использованием идентичного энтропийного декодера, и обновление вероятности после каждого декодированного бина опускается. Опускание обновлений вероятности сокращает число операций в ходе процесса кодирования и декодирования и, таким образом, также приводит к снижению сложности и существенному упрощению аппаратной конструкции.
Неадаптивное ограничение может быть упрощено для всех или некоторых выбранных вероятностных моделей таким образом, что обновления вероятности разрешаются после того, как некоторое число бинов кодировано/декодировано с использованием этой модели. Надлежащий интервал обновления дает возможность адаптации вероятности при наличии возможности сразу декодировать несколько бинов.
Далее представляется подробное описание возможных общих аспектов и аспектов с масштабируемой сложностью LC-PIPE и HE-PIPE. В частности, далее описываются аспекты, которые могут использоваться для LC-PIPE-режима и HE-PIPE-режима идентично или на основе принципа с масштабируемой сложностью. Масштабируемая сложность означает то, что LC-случай извлекается из HE-случая посредством удаления конкретных частей или посредством их замены на что-либо менее сложное. Тем не менее, перед продолжением следует отметить, что вариант осуществления по фиг.11 легко переносится на вышеуказанный вариант осуществления контекстно-адаптивного двоичного арифметического кодирования/декодирования: модуль 402 выбора и энтропийные декодеры 322 должны сокращаться до контекстно-адаптивного двоичного арифметического декодера, который должен принимать поток 401 данных непосредственно и выбирать контекст для бина, который должен быть извлечен в данный момент из потока данных. Это является, в частности, истинным для адаптивности контекста и/или адаптивности вероятности. Обе функциональности/адаптивности могут отключаться или разрабатываться менее строгими в ходе режима с низкой сложностью.
Например, в реализации варианта осуществления по фиг.11 PIPE-каскад энтропийного кодирования, заключающий в себе энтропийные декодеры 322, может использовать восемь систематических переменно-переменных кодов, т.е. каждый энтропийный декодер 322 может иметь v2v-тип, который описан выше. Принцип PIPE-кодирования с использованием систематических v2v-кодов упрощается посредством ограничения числа v2v-кодов. В случае контекстно-адаптивного двоичного арифметического декодера, он может управлять идентичными состояниями вероятности для различных контекстов и использовать их (или их квантованную версию) для подразделения по вероятности. Отображение CABAC-состояний или состояний вероятностной модели, т.е. состояний, используемых для обновления вероятности, в PIPE-индексы или индексы вероятности для поиска в Rtab может выполняться так, как проиллюстрировано в таблице A.
Отображение CABAC-состояний в PIPE-индексы
Эта модифицированная схема кодирования может быть использована в качестве базиса для подхода к кодированию видео с масштабируемой сложностью. При выполнении адаптации вероятностного режима модуль 402 выбора или контекстно-адаптивный двоичный арифметический декодер, соответственно, должен выбирать PIPE-декодер 322, т.е. извлекать PIPE-индекс, который должен быть использован, и индекс вероятности в Rtab, соответственно, на основе индекса состояния вероятности (здесь в качестве примера в пределах от 0 до 62), ассоциированного с символом, который должен быть в данный момент декодирован (к примеру, через контекст) с использованием отображения, показанного в таблице A, и должен обновлять этот индекс состояния вероятности в зависимости от текущего декодированного символа с использованием, например, конкретных переходных значений при обходе таблицы, указывающих на следующий индекс состояния вероятности, который должен обходиться в случае MPS и LPS, соответственно. В случае LC-режима может не применяться второе обновление. Даже отображение может не применяться в случае глобально фиксированных вероятностных моделей.
Тем не менее, может быть использована произвольная настройка энтропийного кодирования, и технологии в этом документе также могут быть использованы с незначимыми адаптациями.
Вышеприведенное описание по фиг.11 чаще всего упоминает элементы синтаксиса и типы элементов синтаксиса. Далее описывается кодирование с конфигурируемой сложностью уровней коэффициентов преобразования.
Например, модуль 404 восстановления может быть сконфигурирован с возможностью восстанавливать блок 200 преобразования из уровней 202 коэффициентов преобразования на основе части последовательности элементов синтаксиса независимо от того, активирован режим с высокой эффективностью или режим с низкой сложностью, причем часть последовательности 327 элементов синтаксиса содержит, неперемеженным способом, элементы синтаксиса карты значимости, задающие карту значимости, указывающую позиции уровней ненулевых коэффициентов преобразования в блоке 200 преобразования, и затем (после этого) элементы синтаксиса уровня, задающие уровни ненулевых коэффициентов преобразования. В частности, могут включаться следующие элементы: элементы синтаксиса в конечной позиции (last_significant_pos_x, last_significant_pos_y), указывающие позицию последнего уровня ненулевых коэффициентов преобразования в блоке преобразования; первые элементы синтаксиса (coeff_significant_flag), совместно задающие карту значимости и указывающие, для каждой позиции вдоль одномерного тракта (274), идущего от DC-позиции до позиции последнего уровня ненулевых коэффициентов преобразования в блоке (200) преобразования, то, является или нет уровень коэффициентов преобразования в соответствующей позиции ненулевым; вторые элементы синтаксиса (coeff_abs_greater1), указывающие, для каждой позиции одномерного тракта (274), в которой согласно первым двоичным элементам синтаксиса размещается уровень ненулевых коэффициентов преобразования, то, превышает или нет уровень коэффициентов преобразования в соответствующей позиции единицу; и третьи элементы синтаксиса (coeff_abs_greater2, coeff_abs_minus3), раскрывающие для каждой позиции одномерного тракта, в которой согласно первым двоичным элементам синтаксиса размещается уровень коэффициентов преобразования, превышающий единицу, величину, на которую соответствующий уровень коэффициентов преобразования в соответствующей позиции превышает единицу.
Порядок элементов синтаксиса в конечной позиции, первого, второго и третьих элементов синтаксиса, может быть идентичным для режима с высокой эффективностью и режима с низкой сложностью, и модуль 402 выбора может быть сконфигурирован с возможностью осуществлять выбор между энтропийными декодерами 322 для символов, из которых модуль 314 преобразования из символьной формы получает элементы синтаксиса в конечной позиции, первые элементы синтаксиса, вторые элементы синтаксиса и/или третьи элементы синтаксиса, по-разному в зависимости от того, активирован режим с низкой сложностью или режим с высокой эффективностью.
В частности, модуль 402 выбора может быть сконфигурирован с возможностью, для символов предварительно определенного типа символа из подпоследовательности символов, из которых модуль 314 преобразования из символьной формы получает первые элементы синтаксиса и вторые элементы синтаксиса, выбирать для каждого символа предварительно определенного типа символа один из множества контекстов в зависимости от ранее извлеченных символов предварительно определенного типа символа из подпоследовательности символов и выполнять выбор в зависимости от вероятностной модели, ассоциированной с выбранным контекстом, в случае активации режима с высокой эффективностью, и выполнять выбор кусочно-постоянным способом таким образом, что выбор является постоянным для последовательных непрерывных подчастей подпоследовательности, в случае активации режима с низкой сложностью. Как описано выше, подчасти могут измеряться в числе позиций, которые охватывает соответствующая подчасть при измерении вдоль одномерного тракта 274, или в числе элементов синтаксиса соответствующего типа, уже кодированных в текущем контексте. Иными словами, двоичные элементы синтаксиса coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2, например, кодируются контекстно-адаптивно с выбором декодера 322 на основе вероятностной модели выбранного контекста в HE-режиме. Также используется адаптация вероятности. В LC-режиме также предусмотрены различные контексты, которые используются для каждого из двоичных элементов синтаксиса coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2. Тем не менее, для каждого из этих элементов синтаксиса контекст сохраняется статическим для первой части вдоль тракта 274 с изменением контекста только при переходе к следующей, непосредственно последующей части вдоль тракта 274. Например, каждая часть может задаваться с длиной в 4, 8, 16 позиций блока 200 независимо от того, присутствует или нет для соответствующей позиции соответствующий элемент синтаксиса. Например, coeff_abs_greater1 и coeff_abs_greater2 присутствуют только для значимых позиций, т.е. позиций, в которых, или для которых, coeff_significant_flag равен 1. Альтернативно, каждая часть может задаваться с длиной в 4, 8, 16 элементов синтаксиса независимо от того, охватывает или нет такая результирующая соответствующая часть большее число позиций блоков. Например, coeff_abs_greater1 и coeff_abs_greater2 присутствуют только для значимых позиций, и в силу этого части четырех элементов синтаксиса могут охватывать более 4 позиций блоков вследствие позиций между ними вдоль тракта 274, для которых не передается такой элемент синтаксиса, к примеру, coeff_abs_greater1 и coeff_abs_greater2, поскольку соответствующий уровень в этой позиции является нулевым.
Модуль 402 выбора может быть сконфигурирован с возможностью, для символов предварительно определенного типа символа из подпоследовательности символов, из которых модуль преобразования из символьной формы получает первые элементы синтаксиса и вторые элементы синтаксиса, выбирать для каждого символа предварительно определенного типа символа один из множества контекстов в зависимости от числа ранее извлеченных символов предварительно определенного типа символа в подпоследовательности символов, которые имеют предварительно определенное значение символа и принадлежат идентичной подчасти, или числа ранее извлеченных символов предварительно определенного типа символа в последовательности символов, которые принадлежат идентичной подчасти. Первая альтернатива является истинной для coeff_abs_greater1, а вторичная альтернатива должна быть истинной для coeff_abs_greater2 в соответствии с вышеуказанными конкретными вариантами осуществления.
Дополнительно, третьи элементы синтаксиса, раскрывающие для каждой позиции одномерного тракта, в которой согласно первым двоичным элементам синтаксиса размещается уровень коэффициентов преобразования, превышающий единицу, величину, на которую соответствующий уровень коэффициентов преобразования в соответствующей позиции превышает единицу, могут содержать целочисленные элементы синтаксиса, т.е. coeff_abs_minus3, и модуль 314 преобразования из символьной формы может быть сконфигурирован с возможностью использовать функцию отображения, управляемую посредством параметра управления, чтобы отображать область слов последовательности символов в сообласть целочисленных элементов синтаксиса и задавать параметр управления в расчете на целочисленный элемент синтаксиса в зависимости от целочисленных элементов синтаксиса из предыдущих третьих элементов синтаксиса, если режим с высокой эффективностью активируется, и выполнять задание кусочно-постоянным способом таким образом, что задание является постоянным для последовательных непрерывных подчастей подпоследовательности, в случае активации режима с низкой сложностью, при этом модуль 402 выбора может быть сконфигурирован с возможностью выбирать предварительно определенный один из энтропийных декодеров (322) для символов слов последовательности символов, отображенных в целочисленные элементы синтаксиса, который ассоциирован с равным распределением вероятностей как в режиме с высокой эффективностью, так и в режиме с низкой сложностью. Иными словами, даже модуль преобразования из символьной формы может работать в зависимости от режима, выбранного посредством переключателя 400, проиллюстрированного посредством пунктирной линии 407. Вместо кусочно-постоянного задания параметра управления модуль 314 преобразования из символьной формы может поддерживать постоянным параметр управления, например, в течение текущего слайса или постоянным глобально во времени.
Ниже описывается контекстное моделирование с масштабируемой сложностью.
Оценка идентичного элемента синтаксиса верхнего и левого соседнего узла для извлечения индекса контекстной модели является стандартным подходом и зачастую используется в HE-случае, например, для элемента синтаксиса разности векторов движения. Тем не менее, эта оценка требует большего объема буферного запоминающего устройства и запрещает прямое кодирование элемента синтаксиса. Кроме того, чтобы достигать более высокой производительности кодирования, больше доступных соседних узлов может быть оценено.
В предпочтительном варианте осуществления все элементы синтаксиса для оценки каскада контекстного моделирования соседних квадратных или прямоугольных блоков либо единиц прогнозирования являются фиксированными для одной контекстной модели. Это идентично деактивации адаптивности в каскаде выбора контекстной модели. Для этого предпочтительного варианта осуществления выбор контекстной модели в зависимости от индекса бина из строки бинов после бинаризации не модифицируется по сравнению с текущей схемой для CABAC. В другом предпочтительном варианте осуществления помимо фиксированной контекстной модели для элементов синтаксиса используют оценку соседних узлов, также контекстная модель для различного индекса бина является фиксированной. Следует отметить, что описание не включает в себя бинаризацию и выбор контекстной модели для разности векторов движения и элементов синтаксиса, связанных с кодированием уровней коэффициентов преобразования.
В предпочтительном варианте осуществления разрешается только оценка левого соседнего узла. Это приводит к уменьшенному буферу в цепочке обработки, поскольку последняя строка блоков или единиц кодирования более не должна сохраняться. В дополнительном предпочтительном варианте осуществления оцениваются только соседние узлы, расположенные в идентичной единице кодирования.
В предпочтительном варианте осуществления оцениваются все доступные соседние узлы. Например, в дополнение к верхнему и левому соседнему узлу, верхний левый, верхний правый и нижний левый соседний узел оцениваются в случае доступности.
Иными словами, модуль 402 выбора по фиг.11 может быть сконфигурирован с возможностью использовать, для предварительно определенного символа, связанного с предварительно определенным блоком мультимедийных данных, ранее извлеченные символы из последовательности символов, связанные с большим числом различных соседних блоков мультимедийных данных в случае активации режима с высокой эффективностью, чтобы выбирать один из множества контекстов и выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом. Иными словами, соседние блоки могут граничить во временной и/или пространственной области. Пространственно соседние блоки являются видимыми, например, на фиг.1-3. Затем, модуль 402 выбора в ответ на выбор режима посредством переключателя 400 режима может выполнять контактную адаптацию на основе ранее извлеченных символов или элементов синтаксиса, связанных с большим числом соседних блоков в случае HE-режима по сравнению с LC-режимом, в силу этого уменьшая объем служебной информации для хранения, как описано выше.
Ниже описывается кодирование с меньшей сложностью разностей векторов движения в соответствии с вариантом осуществления.
В стандарте видеокодеков H.264/AVC вектор движения, ассоциированный с макроблоком, передается посредством передачи в служебных сигналах разности (разности векторов движения - MVD) между вектором движения текущего макроблока и средним предиктором вектора движения. Когда CABAC используется в качестве энтропийного кодера, MVD кодируется следующим образом. Целочисленная MVD разбивается на абсолютную часть и часть знака. Абсолютная часть бинаризуется с использованием комбинации усеченной унарной (и третьего порядка) экспоненциальной бинаризации Голомба, называемой в качестве префикса, и суффикса результирующей строки бинов. Бины, связанные с усеченной унарной бинаризацией, кодируются с использованием контекстных моделей, в то время как бины, связанные с экспоненциальной бинаризацией Голомба, кодируются в обходном режиме, т.е. с фиксированной вероятностью в 0,5 с помощью CABAC. Унарная бинаризация работает следующим образом. Пусть абсолютное целочисленное значение MVD равно n, в этом случае результирующая строка бинов состоит из n единиц и одного последнего нуля. В качестве примера, пусть n=4, в этом случае строка бинов представляет собой ʺ11110ʺ. В случае усеченного унарного существует предел, и если значение превышает этот предел, строка бинов состоит из n+1 единиц. Для случая MVD предел равен 9. Это означает то, что если кодируется абсолютная MVD, равная или превышающая 9, приводя в результате к 9 единицам, то строка бинов состоит из префикса и суффикса с экспоненциальной бинаризацией Голомба. Контекстное моделирование для усеченной унарной части выполняется следующим образом. Для первого бина из строки бинов значения абсолютной MVD из верхнего и левого соседних макроблоков извлекаются при доступности (если недоступны, значение логически выводится как равное 0). Если сумма для конкретной компоненты (горизонтальное или вертикальное направление) превышает 2, выбирается вторая контекстная модель, если абсолютная сумма превышает 32, выбирается третья контекстная модель, в противном случае (абсолютная сумма меньше 3) выбирается первая контекстная модель. Кроме того, контекстные модели отличаются для каждой компоненты. Для второго бина из строки бинов используется четвертая контекстная модель, и пятая контекстная модель используется для оставшихся бинов унарной части. Когда абсолютная MVD равна или превышает 9, например, все бины усеченной унарной части равны ʺ1ʺ, разность между значением абсолютной MVD и 9 кодируется в обходном режиме с экспоненциальной бинаризацией Голомба третьего порядка. На последнем этапе знак MVD кодируется в обходном режиме.
Самая новая технология кодирования для MVD при использовании CABAC в качестве энтропийного кодера указывается в текущей тестовой модели (HM) проекта стандарта высокоэффективного кодирования видео (HEVC). В HEVC размеры блоков являются переменными, и форма, указываемая посредством вектора движения, упоминается в качестве единицы прогнозирования (PU). PU-размер верхнего и левого соседнего узла может иметь другие формы и размеры по сравнению с текущей PU. Следовательно, если релевантно, верхний и левый соседний узел определяются теперь как верхний и левый соседний узел для верхнего левого угла текущей PU. Для кодирования, только процесс извлечения для первого бина может быть изменен в соответствии с вариантом осуществления. Вместо оценки абсолютной суммы MV из соседних узлов, каждый соседний узел может быть оценен отдельно. Если абсолютный MV соседнего узла доступен и превышает 16, может увеличиваться индекс контекстной модели, что приводит к идентичному числу контекстных моделей для первого бина, при этом кодирование оставшегося уровня абсолютной MVD и знака является совершенно идентичным в H.264/AVC.
В вышеуказанной технологии при кодировании MVD вплоть до 9 бинов должны быть кодированы с помощью контекстной модели, в то время как оставшееся значение MVD может быть кодировано в обходном режиме с низкой сложностью вместе с информацией знака. Этот настоящий вариант осуществления описывает технологию для того, чтобы сокращать число бинов, кодированных с помощью контекстных моделей, приводящих к увеличенному числу обходов, и для того, чтобы сокращать число контекстных моделей, требуемых для кодирования MVD. Для этого значение отсечки снижается с 9 до 1 или 2. Это означает то, что только первый бин, указывающий то, превышает или нет абсолютная MVD нуль, кодируется с использованием контекстной модели, либо первый и второй бин, указывающие то, превышает или нет абсолютная MVD нуль и единицу, кодируются с использованием контекстной модели, в то время как оставшееся значение кодируется в обходном режиме и/или с использованием VLC-кода. Все бины, получающиеся в результате бинаризации с использованием VLC-кода, а не с использованием унарного или усеченного унарного кода, кодируются с использованием обходного режима с низкой сложностью. В случае PIPE возможна прямая вставка в и из потока битов. Кроме того, при возможности может быть использовано различное задание верхнего и левого соседнего узла для того, чтобы извлекать выбор лучшей контекстной модели для первого бина.
В предпочтительном варианте осуществления экспоненциальные коды Голомба используются для того, чтобы осуществлять бинаризацию оставшейся части компонент абсолютной MVD. Для этого порядок экспоненциального кода Голомба является переменным. Порядок экспоненциального кода Голомба извлекается следующим образом. После того как извлекается и кодируется контекстная модель для первого бина и, как следствие, индекс этой контекстной модели, индекс используется в качестве порядка для части экспоненциальной бинаризации Голомба. В этом предпочтительном варианте осуществления контекстная модель для первого бина варьируется в диапазоне 1-3, что приводит к индексу 0-2, который используется в качестве порядка экспоненциального кода Голомба. Этот предпочтительный вариант осуществления может использоваться для HE-случая.
В альтернативе вышеуказанной технологии с использованием два раза по пять контекстов при кодировании абсолютной MVD, для того, чтобы кодировать 9 бинов бинаризации унарного кода, также могут быть использованы 14 контекстных моделей (7 для каждой компоненты). Например, в то время как первый и второй бины унарной части могут быть кодированы с четырьмя различными контекстами, как описано выше, пятый контекст может использоваться для третьего бина, и шестой контекст может быть использован относительно четвертого бина, в то время как пятый-девятый бины кодируются с использованием седьмого контекста. Таким образом, даже в этом случае требуется 14 контекстов, и только оставшееся значение может быть кодировано в обходном режиме с низкой сложностью. Технология для того, чтобы сокращать число бинов, кодированных с помощью контекстных моделей, приводящих к увеличенному числу обходов, и для того, чтобы сокращать число контекстных моделей, требуемых для кодирования MVD, заключается в том, чтобы снижать значение отсечки, к примеру, с 9 до 1 или 2. Это означает то, что только первый бин, указывающий то, превышает или нет абсолютная MVD нуль, должен быть кодирован с использованием контекстной модели, либо первый и второй бин, указывающие то, превышает или нет абсолютная MVD нуль и единицу, должны быть кодированы с использованием соответствующей контекстной модели, в то время как оставшееся значение кодируется с помощью VLC-кода. Все бины, получающиеся в результате бинаризации с использованием VLC-кода, кодируются с использованием обходного режима с низкой сложностью. В случае PIPE возможна прямая вставка в и из потока битов. Кроме того, представленный вариант осуществления использует другое определение верхнего и левого соседнего узла для того, чтобы извлекать выбор лучшей контекстной модели для первого бина. Помимо этого, контекстное моделирование модифицируется таким образом, что число контекстных моделей, требуемых для первого или первого и второго бина, сокращается, приводя к дополнительному уменьшению объема запоминающего устройства. Кроме того, может деактивироваться оценка соседних узлов, таких как вышеуказанный соседний узел, что приводит к экономии объема линейного буфера/запоминающего устройства, требуемого для хранения значений MVD соседних узлов. В завершение, порядок кодирования компонент может разбиваться согласно способу обеспечения возможности кодирования бинов префикса для обоих компонент (т.е. бинов, кодированных с помощью контекстных моделей) и последующего кодирования обходных бинов.
В предпочтительном варианте осуществления экспоненциальные коды Голомба используются для того, чтобы осуществлять бинаризацию оставшейся части компонент абсолютной MVD. Для этого порядок экспоненциального кода Голомба является переменным. Порядок экспоненциального кода Голомба может извлекаться следующим образом. После того как извлекается контекстная модель для первого бина и, как следствие, индекс этой контекстной модели, индекс используется в качестве порядка для экспоненциальной бинаризации Голомба. В этом предпочтительном варианте осуществления контекстная модель для первого бина варьируется в диапазоне 1-3, что приводит к индексу 0-2, который используется в качестве порядка экспоненциального кода Голомба. Этот предпочтительный вариант осуществления может использоваться для HE-случая, и число контекстных моделей сокращается до 6. Чтобы еще сокращать число контекстных моделей и, как следствие, экономить объем запоминающего устройства, горизонтальный и вертикальный компоненты могут совместно использовать идентичные контекстные модели в дополнительном предпочтительном варианте осуществления. В этом случае требуются только 3 контекстных модели. Кроме того, только левый соседний узел может быть принят во внимание для оценки в дополнительном предпочтительном варианте осуществления изобретения. В этом предпочтительном варианте осуществления пороговое значение может быть немодифицированным (например, только одно пороговое значение 16, приводящее к параметру экспоненциальной бинаризации Голомба в 0 или 1, или одно пороговое значение 32, приводящее к параметру экспоненциальной бинаризации Голомба в 0 или 2). Этот предпочтительный вариант осуществления экономит объем линейного буфера, требуемый для хранения MVD. В другом предпочтительном варианте осуществления пороговое значение модифицируется и равно 2 и 16. Для этого предпочтительного варианта осуществления всего 3 контекстных модели требуются для кодирования MVD, и возможный параметр экспоненциальной бинаризации Голомба варьируется в диапазоне 0-2. В дополнительном предпочтительном варианте осуществления пороговое значение равно 16 и 32. С другой стороны, описанный вариант осуществления является подходящим для HE-случая.
В дополнительном предпочтительном варианте осуществления изобретения значение отсечки снижается от 9 до 2. В этом предпочтительном варианте осуществления первый бин и второй бин могут быть кодированы с использованием контекстных моделей. Выбор контекстной модели для первого бина может выполняться аналогично предшествующему уровню техники или модифицирован способом, описанным в предпочтительном варианте осуществления выше. Для второго бина отдельная контекстная модель выбирается аналогично предшествующему уровню техники. В дополнительном предпочтительном варианте осуществления контекстная модель для второго бина выбирается посредством оценки MVD левого соседнего узла. Для этого случая индекс контекстной модели является идентичным для первого бина, в то время как доступные контекстные модели отличаются от контекстных моделей для первого бина. Всего требуются 6 контекстных моделей (следует отметить, что компоненты совместно используют контекстные модели). С другой стороны, параметр экспоненциальной бинаризации Голомба может зависеть от выбранного индекса контекстной модели первого бина. В другом предпочтительном варианте осуществления изобретения параметр экспоненциальной бинаризации Голомба зависит от индекса контекстной модели второго бина. Описанные варианты осуществления изобретения могут использоваться для HE-случая.
В дополнительном предпочтительном варианте осуществления изобретения контекстные модели для обоих бинов являются фиксированными и не извлекаются посредством оценки или левого или вышеуказанных соседних узлов. Для этого предпочтительного варианта осуществления общее число контекстных моделей равно 2. В дополнительном предпочтительном варианте осуществления изобретения первый бин и второй бин совместно используют идентичную контекстную модель. Как результат, только одна контекстная модель требуется для кодирования MVD. В обоих предпочтительных вариантах осуществления изобретения параметр экспоненциальной бинаризации Голомба может быть фиксированным и быть равным 1. Описанный предпочтительный вариант осуществления изобретения является подходящим для HE- и LC-конфигураций.
В другом предпочтительном варианте осуществления порядок части экспоненциальной бинаризации Голомба извлекается независимо от индекса контекстной модели первого бина. В этом случае абсолютная сумма обычного выбора контекстной модели H.264/AVC используется для того, чтобы извлекать порядок относительно части экспоненциальной бинаризации Голомба. Этот предпочтительный вариант осуществления может использоваться для HE-случая.
В дополнительном предпочтительном варианте осуществления порядок экспоненциальных кодов Голомба является фиксированным и задается равным 0. В другом предпочтительном варианте осуществления порядок экспоненциальных кодов Голомба является фиксированным и задается равным 1. В предпочтительном варианте осуществления порядок экспоненциальных кодов Голомба задается фиксированно равным 2. В дополнительном варианте осуществления порядок экспоненциальных кодов Голомба задается фиксированно равным 3. В дополнительном варианте осуществления порядок экспоненциальных кодов Голомба является фиксированным согласно форме и размеру текущей PU. Представленные предпочтительные варианты осуществления могут использоваться для LC-случая. Следует отметить, что фиксированный порядок части экспоненциальной бинаризации Голомба рассматривается с сокращенным числом бинов, кодированных с помощью контекстных моделей.
В предпочтительном варианте осуществления соседние узлы задаются следующим образом. Для вышеуказанной PU учитываются все PU с охватом, в том числе, и текущей PU, и используется PU с наибольшим MV. Это выполняется также для левого соседнего узла. Все PU с охватом, в том числе, и текущей PU оцениваются, и используется PU с наибольшим MV. В другом предпочтительном варианте осуществления среднее абсолютное значение вектора движения из всех PU с охватом верхней и левой границы текущей PU используется для того, чтобы извлекать первый бин.
Для представленных предпочтительных вариантов осуществления выше можно изменять порядок кодирования следующим образом. MVD должна указываться для горизонтального и вертикального направления один за другим (или наоборот). Таким образом, две строки бинов должны быть кодированы. Чтобы минимизировать число переключений режимов для механизма энтропийного кодирования (т.е. переключений между обходным и регулярным режимом), можно кодировать бины, кодированные с помощью контекстных моделей для обоих компонент, на первом этапе, а затем бины, кодированные в обходном режиме, на втором этапе. Следует отметить, что это представляет собой только переупорядочение.
Следует обратить внимание на то, что бины, получающиеся в результате унарной или усеченной унарной бинаризации, также могут быть представлены посредством эквивалентной бинаризации фиксированной длины одного флага в расчете на индекс бина, указывающего то, превышает или нет это значение индекс текущего бина. В качестве примера, значение отсечки для усеченной унарной бинаризации MVD задается равным 2, что приводит к кодовым словам 0, 10, 11 для значений 0, 1, 2. В соответствующей бинаризации фиксированной длины с одним флагом в расчете на индекс бина один флаг для индекса бина в 0 (т.е. первого бина) указывает то, превышает или нет значение абсолютной MVD 0, и один флаг для второго бина с индексом бина в 1 указывает то, превышает или нет значение абсолютной MVD 1. Когда второй флаг кодируется только тогда, когда первый флаг равен 1, это приводит к идентичным кодовым словам 0, 10, 11.
Далее описывается представление с масштабируемой сложностью внутреннего состояния вероятностных моделей в соответствии с вариантом осуществления.
В HE-PIPE-настройке внутреннее состояние вероятностной модели обновляется после кодирования бина с ним. Обновленное состояние извлекается посредством поиска в таблице переходов состояний с использованием старого состояния и значения кодированного бина. В случае CABAC вероятностная модель может принимать 63 различных состояния, при этом каждое состояние соответствует вероятности модели в интервале (0,0, 0,5). Каждое из этих состояний используется для того, чтобы реализовывать две вероятности моделей. В дополнение к вероятности, назначаемой состоянию, также используется 1,0 минус вероятность, и флаг, называемый valMps, сохраняет информацию в отношении того, используется вероятность или 1,0 минус вероятность. Это приводит всего к 126 состояниям. Чтобы использовать такую вероятностную модель с принципом PIPE-кодирования, каждое из 126 состояний должно быть отображено в один из доступных PIPE-кодеров. В текущих реализациях PIPE-кодеров это выполняется посредством использования таблицы поиска. Пример такого отображения проиллюстрирован в таблице A.
Далее описывается вариант осуществления в отношении того, как внутреннее состояние вероятностной модели может быть представлено, чтобы исключать использование таблицы поиска, чтобы преобразовывать внутреннее состояние в PIPE-индекс. Исключительно несколько простых операций побитового маскирования необходимо для того, чтобы извлекать PIPE-индекс из переменной внутреннего состояния вероятностной модели. Это новое представление с масштабируемой сложностью внутреннего состояния вероятностной модели разрабатывается двухуровневым способом. Для вариантов применения, в которых режим работы с низкой сложностью является обязательным, используется только первый уровень. Он описывает только PIPE-индекс и флаг valMps, который используется для того, чтобы кодировать или декодировать ассоциированные бины. В случае описанной схемы энтропийного PIPE-кодирования первый уровень может быть использован для того, чтобы проводить различие между 8 различными вероятностями моделей. Таким образом, первый уровень требует 3 битов для pipeIdx и один дополнительный бит для флага valMps. На втором уровне каждый из приблизительных диапазонов вероятностей первого уровня уточняется до несколько меньших интервалов, которые поддерживают представление вероятностей при более высоких разрешениях. Это более подробное представление обеспечивает более точную работу модулей оценки вероятности. В общем, оно является подходящим для вариантов применения кодирования, которые нацелены на высокую RD-производительность. В качестве примера, это представление с масштабируемой сложностью внутреннего состояния вероятностных моделей с использованием PIPE проиллюстрировано следующим образом:
Первый и второй уровень сохраняются в одном 8-битовом запоминающем устройстве. 4 бита требуются для того, чтобы сохранять первый уровень, т.е. индекс, который задает PIPE-индекс со значением MPS для старшего бита, и еще 4 бита используются для того, чтобы сохранять второй уровень. Чтобы реализовывать режим работы модуля оценки CABAC-вероятности, каждый PIPE-индекс имеет конкретное число разрешенных индексов уточнения в зависимости от того, сколько CABAC-состояний отображено в PIPE-индекс. Например, для отображения в таблице A число CABAC-состояний в расчете на PIPE-индекс проиллюстрировано в таблице B.
Число CABAC-состояний в расчете на PIPE-индекс для примера таблицы A
В ходе процесса кодирования или декодирования бина доступ к PIPE-индексу и valMps может осуществляться непосредственно посредством использования простой операции применения битовой маски или побитового сдвига. Процессы кодирования с низкой сложностью требуют только 4 битов первого уровня, и процессы высокоэффективного кодирования дополнительно могут использовать 4 бита второго уровня для того, чтобы выполнять обновление вероятностной модели модуля оценки CABAC-вероятности. Для выполнения этого обновления может разрабатываться таблица поиска переходов состояний, которая осуществляет переходы состояний, идентичные переходам состояний исходной таблицы, но с использованием двухуровневого представления состояний с масштабируемой сложностью. Исходная таблица переходов состояний состоит из двух раз по 63 элемента. Для каждого входного состояния она содержит два выходных состояния. При использовании представления с масштабируемой сложностью размер таблицы переходов состояний не превышает два раза по 128 элементов, что представляет собой приемлемое увеличение размера таблицы. Это увеличение зависит от того, сколько битов используется для того, чтобы представлять индекс уточнения, и для того, чтобы точно эмулировать режим работы модуля оценки CABAC-вероятности, требуется четыре бита. Тем не менее, может быть использован другой модуль оценки вероятности, который может работать с сокращенным набором CABAC-состояний, так что для каждого PIPE-индекса разрешено не более 8 состояний. Следовательно, потребление запоминающего устройства может согласовываться с данным уровнем сложности процесса кодирования посредством адаптации числа битов, используемого для того, чтобы представлять индекс уточнения. По сравнению с внутренним состоянием вероятностей моделей в CABAC, в котором существует 64 индекса состояний вероятности, не допускается использование табличных поисков для того, чтобы преобразовывать вероятности моделей в конкретный PIPE-код, и дополнительное преобразование не требуется.
Ниже описывается обновление контекстной модели с масштабируемой сложностью в соответствии с вариантом осуществления.
Для обновления контекстной модели ее индекс состояния вероятности может быть обновлен на основе одного или более ранее кодированных бинов. В HE-PIPE-настройке это обновление выполняется после кодирования или декодирования каждого бина. Наоборот, в LC-PIPE-настройке это обновление вообще может не выполняться.
Тем не менее, можно выполнять обновление контекстных моделей на основе принципа с масштабируемой сложностью. Иными словами, решение в отношении того, обновлять или нет контекстную модель, может быть основано на различных аспектах. Например, настройка кодера может не выполнять обновления только для конкретных контекстных моделей, таких как, например, контекстные модели элемента синтаксиса coeff_significant_flag, и всегда выполнять обновления для всех других контекстных моделей.
Другими словами, модуль 402 выбора может быть сконфигурирован с возможностью, для символов каждого из определенного числа предварительно определенных типов символов, выполнять выбор между энтропийными декодерами 322 в зависимости от соответствующей вероятностной модели, ассоциированной с соответствующим предварительно определенным символом, так что число предварительно определенных типов символов является более низким в режиме с низкой сложностью по сравнению с режимом с высокой эффективностью.
Кроме того, критерии для управления тем, обновлять или нет контекстную модель, могут представлять собой, например, размер пакета потока битов, число бинов, декодированных до сих пор, либо обновление выполняется только после кодирования конкретного фиксированного или переменного числа бинов для контекстной модели.
С помощью этой схемы для определения того, обновлять или нет контекстные модели, может быть реализовано обновление контекстной модели с масштабируемой сложностью. Это обеспечивает возможность увеличения или уменьшения части бинов в потоке битов, для которого выполняются обновления контекстной модели. Чем выше число обновлений контекстной модели, тем выше эффективность кодирования и выше вычислительная сложность. Таким образом, обновление контекстной модели с масштабируемой сложностью может достигаться с помощью описанной схемы.
В предпочтительном варианте осуществления обновление контекстной модели выполняется для бинов всех элементов синтаксиса, за исключением элементов синтаксиса coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2.
В дополнительном предпочтительном варианте осуществления обновление контекстной модели выполняется только для бинов элементов синтаксиса coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2.
В дополнительном предпочтительном варианте осуществления обновление контекстной модели выполняется для всех контекстных моделей, когда начинается кодирование или декодирование слайса. После обработки конкретного предварительно заданного числа блоков преобразования обновление контекстной модели деактивируется для всех контекстных моделей до тех пор, пока не будет достигнут конец слайса.
Например, модуль 402 выбора может быть сконфигурирован с возможностью, для символов предварительно определенного типа символа, выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с предварительно определенным типом символа, наряду с или без обновления ассоциированной вероятностной модели, так что длина обучающей фазы последовательности символов, в которой выполняется выбор для символов предварительно определенного типа символа вместе с обновлением, меньше в режиме с низкой сложностью по сравнению с режимом с высокой эффективностью.
Дополнительный предпочтительный вариант осуществления является идентичным вышеописанному предпочтительному варианту осуществления, но он использует представление с масштабируемой сложностью внутреннего состояния контекстных моделей таким образом, что одна таблица сохраняет ʺпервую частьʺ (valMps и pipeIdx) всех контекстных моделей, а вторая таблица сохраняет ʺвторую частьʺ (refineIdx) всех контекстных моделей. В момент, в который обновление контекстной модели деактивируется для всех контекстных моделей (как описано в предыдущем предпочтительном варианте осуществления), таблица, сохраняющая ʺвторую частьʺ, более не является обязательной и может быть отброшена.
Ниже описывается обновление контекстной модели для последовательности бинов в соответствии с вариантом осуществления.
В LC-PIPE-конфигурации бины элементов синтаксиса типа coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2 группируются в поднаборы. Для каждого поднабора одна контекстная модель используется для того, чтобы кодировать ее бины. В этом случае обновление контекстной модели может выполняться после кодирования фиксированного числа бинов этой последовательности. Далее это называется обновлением нескольких бинов. Тем не менее, это обновление может отличаться от обновления с использованием только последнего кодированного бина и внутреннего состояния контекстной модели. Например, для каждого бина, который кодирован, один этап обновления контекстной модели осуществляется.
Далее приводятся примеры для кодирования примерного поднабора, состоящего из 8 бинов. Буква ʺbʺ обозначает декодирование бина, а буква ʺuʺ обозначает обновление контекстной модели. В LC-PIPE-случае выполняется только декодирование бина без выполнения обновлений контекстной модели:
b b b b b b b b.
В HE-PIPE-случае после декодирования каждого бина выполняется обновление контекстной модели:
b u b u b u b u b u b u b u b u.
Чтобы снижать сложность до некоторой степени, обновление контекстной модели может выполняться после последовательности бинов (в этом примере после каждого 4 бина выполняются обновления этих 4 бинов):
b b b b u u u u b b b b u u u u.
Иными словами, модуль 402 выбора может быть сконфигурирован с возможностью, для символов предварительно определенного типа символа, выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с предварительно определенным типом символа, наряду с или без обновления ассоциированной вероятностной модели, так что частота, на которой выполняется выбор для символов предварительно определенного типа символа вместе с обновлением, ниже в режиме с низкой сложностью по сравнению с режимом с высокой эффективностью.
В этом случае, после декодирования 4 бинов, 4 этапа обновления выполняются на основе 4 только что декодированных бинов. Следует отметить, что эти четыре этапа обновления могут осуществляться на одном этапе посредством использования специальной таблицы поиска. Эта таблица поиска сохраняет для каждой возможной комбинации 4 бинов и каждого возможного внутреннего состояния контекстной модели результирующее новое состояние после четырех традиционных этапов обновления.
В определенном режиме обновление нескольких бинов используется для элемента синтаксиса coeff_significant_flag. Для бинов всех других элементов синтаксиса не используется обновление контекстной модели. Число бинов, которые кодируются до того, как выполняется этап обновления нескольких бинов, задается равным n. Когда число бинов набора не делится на n, бины от 1 до n-1 остаются в конце поднабора после последнего обновления нескольких бинов. Для каждого из этих бинов традиционное обновление одного бина выполняется после кодирования всех этих бинов. Число n может быть любым положительным числом, превышающим 1. Другой режим может быть идентичным предыдущему режиму за исключением того, что обновление нескольких бинов выполняется для произвольных комбинаций coeff_significant_flag, coeff_abs_greater1 и coeff_abs_greater2 (вместо только coeff_significant_flag). Таким образом, этот режим сложнее другого. Все другие элементы синтаксиса (в которых обновление нескольких бинов не используется) могут быть разделены на два непересекающихся поднабора, причем для одного из поднаборов используется обновление одного бина, а для другого поднабора не используется обновление контекстной модели. Любые возможные непересекающиеся поднаборы являются допустимыми (включающие в себя пустой поднабор).
В альтернативном варианте осуществления обновление нескольких бинов может быть основано только на последних m бинах, которые кодируются непосредственно перед этапом обновления нескольких бинов; m может быть любым натуральным числом, меньшим n. Таким образом, декодирование может выполняться следующим образом:
b b b b u u b b b b u u b b b b u u b b b b...,
где n=4 и m=2.
Иными словами, модуль 402 выбора может быть сконфигурирован с возможностью, для символов предварительно определенного типа символа, выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с предварительно определенным типом символа, наряду с обновлением ассоциированной вероятностной модели каждый n-ный символ предварительно определенного типа на основе m последних символов предварительно определенного типа символа, так что отношение n/m является более высоким в режиме с низкой сложностью по сравнению с режимом с высокой эффективностью.
В дополнительном предпочтительном варианте осуществления, для элемента синтаксиса coeff_significant_flag, схема контекстного моделирования с использованием локального шаблона, как описано выше для HE-PIPE-конфигурации, может быть использована для того, чтобы назначать контекстные модели бинам элемента синтаксиса. Тем не менее, для этих бинов не используется обновление контекстной модели.
Дополнительно, модуль 402 выбора может быть сконфигурирован с возможностью, для символов предварительно определенного типа символа, выбирать один из определенного числа контекстов в зависимости от числа ранее извлеченных символов из последовательности символов и выполнять выбор между энтропийными декодерами 322 в зависимости от вероятностной модели, ассоциированной с выбранным контекстом, так что число контекстов и/или число ранее извлеченных символов ниже в режиме с низкой сложностью по сравнению с режимом с высокой эффективностью.
Инициализация вероятностной модели с использованием 8-битовых значений инициализации
Этот раздел описывает процесс инициализации внутреннего состояния с масштабируемой сложностью вероятностных моделей с использованием так называемого 8-битного значения инициализации вместо двух 8-битовых значений, как в случае стандарта кодирования видео предшествующего уровня техники H.265/AVC. Оно состоит из двух частей, которые являются сравнимыми с парами значений инициализации, используемыми для вероятностных моделей в CABAC H.264/AVC. Эти две части представляют два параметра линейного уравнения, чтобы вычислять начальное состояние вероятностной модели, представляющее конкретную вероятность (например, в форме PIPE-индекса) из QP:
- Первая часть описывает наклон, и она использует зависимость внутреннего состояния относительно параметра квантования (QP), который используется в ходе кодирования или декодирования.
- Вторая часть задает PIPE-индекс при данном QP, а также valMps.
Два различных режима доступны, чтобы инициализировать вероятностную модель с использованием данного значения инициализации. Первый режим обозначается как независимая от QP инициализация. Он использует только PIPE-индекс и valMps, заданные во второй части значения инициализации, для всех QP. Это является идентичным случаю, в котором наклон равен 0. Второй режим обозначается как зависимая от QP инициализация, и он дополнительно использует наклон первой части значения инициализации для того, чтобы изменять PIPE-индекс и задавать индекс уточнения. Две части 8-битного значения инициализации проиллюстрированы следующим образом:
Оно состоит из двух 4-битовых частей. Первая часть содержит индекс, который указывает на 1 из 16 различных предварительно заданных наклонов, которые сохраняются в массиве. Предварительно заданные наклоны состоят из 7 отрицательных наклонов (индекс 0-6 наклона), одного наклона, который равен нулю (индекс 7 наклона), и 8 положительных наклонов (индекс 8-15 наклона). Наклоны проиллюстрированы в таблице C.
Все значения масштабируются на коэффициент 256, чтобы не допускать использования операций с плавающей запятой. Вторая часть является PIPE-индексом, который осуществляет возрастающую вероятность valMps=1 между интервалом вероятности p=0 и p=1. Другими словами, PIPE-кодер n должен работать при более высокой вероятности модели, чем PIPE-кодер n-1. Для каждой вероятностной модели доступен один PIPE-индекс вероятности, и он идентифицирует PIPE-кодер, интервал вероятности которого содержит вероятность pvalMPs=1 для QP=26.
QP и 8-битное значение инициализации требуются для того, чтобы вычислять инициализацию внутреннего состояния вероятностных моделей посредством вычисления простого линейного уравнения в форме y=m*(QP-QPref)+256*b. Следует отметить, что m задает наклон, который извлекается из таблицы C посредством использования индекса наклона (первая часть 8-битного значения инициализации), и b обозначает PIPE-кодер в QPref=26 (вторая часть 8-битного значения инициализации: ʺPIPE-индекс вероятностиʺ). Затем, valMPS равен 1, и pipeIdx равен (y-2048)>>8, если y превышает 2047. В противном случае, valMPS равен 0, и pipeIdx равен (2047-y)>>8. Индекс уточнения равен (((y-2048) и 255)*numStates)>>8, если valMPS равен 1. В противном случае, индекс уточнения равен (((2047-y) и 255)*numStates)>>8. В обоих случаях numStates равен числу CABAC-состояний pipeIdx, как проиллюстрировано в таблице B.
Вышеописанная схема может быть использована не только в комбинации с PIPE-кодерами, но также и в связи с вышеуказанными CABAC-схемами. В отсутствие PIPE, число CABAC-состояний, т.е. состояний вероятности, между которыми выполняется переход состояния при обновлении вероятности (pState_current[bin]) в расчете на PIPE-индекс (т.е. соответствующих старших битов pState_current[bin]), в таком случае представляет собой только набор параметров, который фактически реализует кусочно-линейную интерполяцию CABAC-состояния в зависимости от QP. Кроме того, эта кусочно-линейная интерполяция также может фактически деактивироваться в случае, если параметр numStates использует идентичное значение для всего PIPE-индекса. Например, задание numStates равным 8 для всех случаев дает в результате всего 16*8 состояний, и вычисление индекса уточнения упрощается до ((y-2048) и 255)>>5 для valMPS, равного 1, или ((2047-y) и 255)>>5 для valMPS, равного 0. Для этого случая отображение представления с использованием valMPS, PIPE-индекса и индекса уточнения обратно в представление, используемое посредством исходного CABAC H.264/AVC, является очень простым. CABAC-состояние задается как (PIPE-индекс<<3) + индекс уточнения. Этот аспект дополнительно описывается ниже относительно фиг.16.
Если наклон 8-битного значения инициализации не равен нулю или если QP не равен 26, необходимо вычислять внутреннее состояние посредством использования линейного уравнения с QP процесса кодирования или декодирования. В случае если наклон равен нулю или если QP текущего процесса кодирования равен 26, вторая часть 8-битного значения инициализации может быть использована непосредственно для инициализации внутреннего состояния вероятностной модели. В противном случае, десятичная часть результирующего внутреннего состояния может быть дополнительно использована для того, чтобы определять индекс уточнения в вариантах применения высокоэффективного кодирования посредством линейной интерполяции между пределами конкретного PIPE-кодера. В этом предпочтительном варианте осуществления линейная интерполяция выполняется посредством простого умножения десятичной части на общее число индексов уточнения, доступных для текущего PIPE-кодера, и отображения результата в ближайший целочисленный индекс уточнения.
Процесс инициализации внутреннего состояния вероятностных моделей может варьироваться относительно числа состояний PIPE-индексов вероятности. В частности, двойное возникновение равновероятного режима с использованием PIPE-кодера E1, т.е. использование двух различных PIPE-индексов для того, чтобы проводить различие между MPS, равным 1 или 0, может не допускаться следующим образом. С другой стороны, процесс может активироваться во время начала синтаксического анализа данных слайса, и вводом этого процесса может быть 8-битное значение инициализации, как проиллюстрировано в таблице E, которое, например, должно быть передано в потоке битов для каждой контекстной модели, которая должна быть инициализирована.
Настройка 8 битов initValue для вероятностной модели
Первые 4 бита задают индекс наклона и извлекаются посредством маскирования битов b4-b7. Для каждого индекса наклона наклон (m) указывается и отображается в таблице F.
Значения переменной m для slopeIdx
Биты b0-b3, последние 4 бита 8-битного значения инициализации, идентифицируют probIdx и описывают вероятность при предварительно заданном QP; probIdx 0 указывает наибольшую вероятность для символов со значением 0, и, соответственно, probIdx 14 указывает наибольшую вероятность для символов со значением 1. Таблица G показывает для каждого probIdx соответствующий pipeCoder и его valMps.
Отображение части последних 4 битов значения инициализации в PIPE-кодеры и valMps: UR=код с преобразованием из унарного кода в код Райса, TB=код с тремя бинами, BP=PIPE-код бина, EP=равная вероятность (не кодируется)
Для обоих значений вычисление внутреннего состояния может выполняться посредством использования линейного уравнения, к примеру, y=m*x+256*b, где m обозначает наклон, x обозначает QP текущего слайса, и b извлекается из probIdx, как показано в нижеприведенном описании. Все значения в этом процессе масштабируются на коэффициент 256, чтобы не допускать использования операций с плавающей запятой. Вывод (y) этого процесса представляет внутреннее состояние вероятностной модели в текущем QP и сохраняется в 8-битовом запоминающем устройстве. Как показано в G, внутреннее состояние состоит из valMPs, pipeIdx и refineIdx.
Настройка внутреннего состояния вероятностной модели
Назначение refineIdx и pipeIdx является аналогичным внутреннему состоянию вероятностных CABAC-моделей (pStateCtx) и представляется в H.
Назначение pipeIdx, refineIdx и pStateCtx
В предпочтительном варианте осуществления probIdx задается в QP26. На основе 8-битного значения инициализации внутреннее состояние (valMps, pipeIdx и refineIdx) вероятностной модели обрабатывается, как описано в следующем псевдокоде:
n=(probIdx<<8)-m*26
fullCtxState=max(0, min(3839, (m*max(0, min(51, SliceQPy))))+n+128)
remCtxState=fullCtxState and 255
preCtxState=fullCtxState>>8
if(preCtxState<8) {
pipeIdx=7-preCtxState
valMPS=0
} else {
pipeIdx=preCtxState-8
valMPS=1
}
offset={3, 7, 5, 7, 10, 14, 16, 1}
if(pipeIdx==0) {
if(remCtxState<=127)
remCtxState=127-remCtxState
else
remCtxState=remCtxState-128
refineIdx=((remCtxState<<1)*offset)>>8
} else {
if(valMPS==0)
remCtxState=255-remCtxState
refineIdx=(remCtxState*offset[pipeIdx])>>8
}
Как показано в псевдокоде, refineIdx вычисляется посредством линейной интерполяции между интервалом pipeIdx и квантования результата в соответствующий refineIdx. Смещение указывает общее число refineIdx для каждого pipeIdx. Интервал [7, 8) fullCtxState/256 разделяется пополам. Интервал [7, 7,5) преобразуется в pipeIdx=0 и valMps=0, а интервал [7,5, 8) преобразуется в pipeIdx=0 и valMps=1. Фиг.15 иллюстрирует процесс извлечения внутреннего состояния и отображает преобразование fullCtxState/256 к pStateCtx.
Следует отметить, что наклон указывает зависимость probIdx и QP. Если slopeIdx 8-битного значения инициализации равен 7, результирующее внутреннее состояние вероятностной модели является идентичными для всех QP слайса, и, следовательно, процесс инициализации внутреннего состояния является независимым от текущего QP слайса.
Иными словами, модуль 402 выбора может инициализировать PIPE-индексы, которые должны быть использованы при декодировании следующей части потока данных, такой как целый поток или следующий слайс, с использованием элемента синтаксиса, указывающего размер QP шага квантования, используемый для того, чтобы квантовать данные этой части, такие как уровни коэффициентов преобразования, содержащиеся в ней, с использованием этого элемента синтаксиса в качестве индекса в таблицу, которая может быть общей для обоих режимов, LC и HE. Таблица, такая как таблица D, может содержать PIPE-индексы для каждого типа символа для соответствующего опорного QPref или другие данные для каждого типа символа. В зависимости от фактического QP текущей части, модуль выбора может вычислять значение PIPE-индекса с использованием соответствующей записи a таблицы, индексированной посредством фактического QP, и самого QP, к примеру, посредством умножения на (QP-QPref). Единственное отличие в LC- и HE-режиме: модуль выбора вычисляет результат просто с меньшей точностью в случае LC по сравнению с HE-режимом. Модуль выбора, например, может использовать только целую часть результата вычисления. В HE-режиме остаток большей точности, к примеру, дробная часть, используется для того, чтобы выбирать один из доступных индексов уточнения для соответствующего PIPE-индекса, как указано посредством меньшей точности или целой части. Индекс уточнения используется в HE-режиме (потенциально реже также в LC-режиме) для того, чтобы выполнять адаптацию вероятности, к примеру, посредством использования вышеуказанного обхода таблицы. Если доступные индексы для текущего PIPE-индекса находятся у верхней границы, то более высокий PIPE-индекс выбирается затем с минимизацией индекса уточнения. Если доступные индексы для текущего PIPE-индекса находятся у нижней границы, то следующий более низкий PIPE-индекс выбирается затем с максимизацией индекса уточнения до максимума, доступного для нового PIPE-индекса. PIPE-индекс вместе с индексом уточнения задает состояние вероятности, но для выбора между частичными потоками модуль выбора использует только PIPE-индекс. Индекс уточнения служит просто для более тщательного или более точного отслеживания вероятности.
Тем не менее, вышеприведенное пояснение также показывает, что масштабируемость сложности может достигаться независимо от принципа PIPE- или CABAC-кодирования по фиг.7-17 с использованием декодера, как показано на фиг.12. Декодер по фиг.12 служит для декодирования потока 601 данных, в который кодируются мультимедийные данные, и содержит переключатель 600 режимов, сконфигурированный с возможностью активировать режим с низкой сложностью или режим с высокой эффективностью в зависимости от потока 601 данных, а также модуль 602 преобразования из символьной формы, сконфигурированный с возможностью осуществлять преобразование из символьной формы последовательности 603 из символов, полученных (например, либо непосредственно, либо посредством энтропийного декодирования) из потока 601 данных, чтобы получать целочисленные элементы синтаксиса 604 с использованием функции отображения, управляемой посредством параметра управления, для преобразования области слов последовательности символов в сообласть целочисленных элементов синтаксиса. Модуль 605 восстановления сконфигурирован с возможностью восстанавливать мультимедийные данные 606 на основе целочисленных элементов синтаксиса. Модуль 602 преобразования из символьной формы сконфигурирован с возможностью осуществлять преобразование из символьной формы таким образом, что параметр управления варьируется в соответствии с потоком данных на первой скорости в случае активации режима с высокой эффективностью, и параметр управления является постоянным независимо от потока данных либо изменяется в зависимости от потока данных, но на второй скорости, ниже первой скорости, в случае активации режима с низкой сложностью, как проиллюстрировано посредством стрелки 607. Например, параметр управления может варьироваться в соответствии с символами, для которых ранее выполнено преобразование из символьной формы.
Некоторые вышеописанные варианты осуществления используют аспект по фиг.12. Элементы синтаксиса coeff_abs_minus3 и MVD в последовательности 327, например, преобразуются в модуле 314 преобразования из символьной формы в зависимости от выбранного режима, как указано посредством 407, и модуль 605 восстановления использует эти элементы синтаксиса для восстановления. Очевидно, что оба аспекта по фиг.11 и 12 являются легко комбинируемыми, но аспект по фиг.12 также может быть комбинирован с другими окружениями кодирования.
См., например, кодирование разности векторов движения, указанное выше. Модуль 602 преобразования из символьной формы может иметь такую конфигурацию, в которой функция преобразования использует усеченный унарный код для того, чтобы выполнять преобразование в первом интервале области целочисленных элементов синтаксиса ниже значения отсечки, и комбинацию префикса в форме усеченного унарного кода для значения отсечки и суффикса в форме кодового VLC-слова во втором интервале области целочисленных элементов синтаксиса включительно и выше значения отсечки, при этом декодер может содержать энтропийный декодер 608, сконфигурированный с возможностью извлекать число первых бинов усеченного унарного кода из потока 601 данных с использованием энтропийного декодирования с варьирующейся оценкой вероятности и число вторых бинов кодового VLC-слова с использованием постоянного равновероятного обходного режима. В HE-режиме энтропийное кодирование может быть более сложным, чем при LC-кодировании, как проиллюстрировано посредством стрелки 609. Иными словами, адаптивность контекста и/или адаптация вероятности могут применяться в HE-режиме и подавляться в LC-режиме, или сложность может масштабироваться в другом отношении, как изложено выше относительно различных вариантов осуществления.
Кодер, соответствующий декодеру по фиг.11, для кодирования мультимедийных данных в поток данных показан на фиг.13. Он может содержать модуль 500 вставки, сконфигурированный с возможностью передавать в служебных сигналах в потоке 501 данных активацию режима с низкой сложностью или режима с высокой эффективностью, модуль 504 составления, сконфигурированный с возможностью предварительно кодировать мультимедийные данные 505 в последовательность 506 элементов синтаксиса, модуль 507 преобразования в символьную форму, сконфигурированный с возможностью преобразовывать в символьную форму последовательность 506 элементов синтаксиса в последовательность 508 символов, множество энтропийных кодеров 310, каждый из которых сконфигурирован с возможностью преобразовывать частичные последовательности символов в кодовые слова потока данных, и модуль 502 выбора, сконфигурированный с возможностью перенаправлять каждый символ из последовательности 508 символов в выбранный один из множества энтропийных кодеров 310, при этом модуль 502 выбора сконфигурирован с возможностью осуществлять выбор в зависимости от активированного режима с низкой сложностью и режима с высокой эффективностью, как проиллюстрировано посредством стрелки 511. Модуль 510 перемежения может быть необязательно предоставлен для перемежения кодовых слов кодеров 310.
Кодер, соответствующий декодеру по фиг.12, для кодирования мультимедийных данных в поток данных показан на фиг.14 как содержащий модуль 700 вставки, сконфигурированный с возможностью передавать в служебных сигналах в потоке 701 данных активацию режима с низкой сложностью или режима с высокой эффективностью, модуль 704 составления, сконфигурированный с возможностью предварительно кодировать мультимедийные данные 705 в последовательность 706 элементов синтаксиса, содержащих целочисленный элемент синтаксиса, и модуль 707 преобразования в символьную форму, сконфигурированный с возможностью преобразовывать в символьную форму целочисленный элемент синтаксиса с использованием функции отображения, управляемой посредством параметра управления, для преобразования области целочисленных элементов синтаксиса в сообласть слов последовательности символов, при этом модуль 707 преобразования в символьную форму сконфигурирован с возможностью осуществлять преобразование в символьную форму таким образом, что параметр управления варьируется в соответствии с потоком данных на первой скорости в случае активации режима с высокой эффективностью, и параметр управления является постоянным независимо от потока данных либо изменяется в зависимости от потока данных, но на второй скорости, ниже первой скорости, в случае активации режима с низкой сложностью, как проиллюстрировано посредством стрелки 708. Результат преобразования в символьную форму кодируется в поток 701 данных.
С другой стороны, следует отметить, что вариант осуществления по фиг.14 легко переносится на вышеуказанный вариант осуществления контекстно-адаптивного двоичного арифметического кодирования/декодирования: модуль 509 выбора и энтропийные кодеры 310 должны сокращаться до контекстно-адаптивного двоичного арифметического кодера, который должен выводить поток 401 данных непосредственно и выбирать контекст для бина, который должен быть извлечен в данный момент из потока данных. Это является, в частности, истинным для адаптивности контекста и/или адаптивности вероятности. Обе функциональности/адаптивности могут отключаться или разрабатываться менее строгими в ходе режима с низкой сложностью.
Выше вкратце отмечено, что возможность переключения режимов, поясненная относительно некоторых вышеописанных вариантов осуществления, в соответствии с альтернативными вариантами осуществления может не применяться. Более конкретно, следует обратиться к фиг.16, которая обобщает вышеприведенное описание в той степени, в которой исключение возможности переключения режимов отличает вариант осуществления по фиг.16 от вышеописанных вариантов осуществления. Кроме того, нижеприведенное описание раскрывает преимущества, получающиеся в результате инициализации оценок вероятности контекстов с использованием менее точных параметров для наклона и смещения по сравнению, например, с H.264.
В частности, фиг.16 показывает декодер для декодирования видео из потока 401 данных, в который элементы 327 синтаксиса кодируются с использованием бинаризаций элементов 327 синтаксиса. Важно отметить, что в вышеприведенном описании общие сведения, содержащиеся на фиг.1-15, также переносятся на объекты, показанные на фиг.16, такие как, например, касательно функциональности модуля 314 преобразования из символьной формы, модуля 404 восстановления и энтропийного декодера 409. Тем не менее, для полноты некоторые из этих сведений снова указываются ниже.
Декодер содержит энтропийный декодер 409, сконфигурированный с возможностью извлекать число бинов 326 бинаризаций из потока 401 данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее декодированных частей потока 401 данных. Если точнее, как описано выше, энтропийный декодер 409 может быть сконфигурирован с возможностью извлекать число бинов 326 бинаризаций из потока 401 данных с использованием двоичного энтропийного декодирования, к примеру, вышеуказанной CABAC-схемы или двоичного PIPE-декодирования, т.е. с использованием структуры, заключающей в себе несколько параллельно работающих энтропийных декодеров 322 вместе с соответствующим модулем выбора/модулем назначения. Что касается выбора контекста, его зависимость от ранее декодированного потока частей данных 401 может быть осуществлена так, как указано выше. Иными словами, энтропийный декодер может быть сконфигурирован с возможностью осуществлять выбор контекста для бина, который должен быть извлечен в данный момент, в зависимости от позиции бина для бина, который должен быть извлечен в данный момент в бинаризации, которой принадлежит бин, который должен быть извлечен в данный момент, типа элемента синтаксиса для элемента синтаксиса, целочисленное значение которого получается посредством дебинаризации, которой принадлежит бин, который должен быть извлечен в данный момент, или одного или более бинов, ранее извлеченных из потока 401 данных или целочисленного значения элемента синтаксиса, дебинаризованного ранее. Например, выбранный контекст может отличаться между первым и вторым бином бинаризации определенного элемента синтаксиса. Кроме того, различные группы контекстов могут предоставляться для различных типов элементов синтаксиса, такие как уровни коэффициентов преобразования, разности векторов движения, параметры режима кодирования и т.п.
Что касается обновления состояния вероятности, энтропийный декодер 409 может быть сконфигурирован с возможностью осуществлять его для извлеченного в настоящий момент бина посредством перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для извлеченного в настоящий момент бина в пределах 126 состояний вероятности, в новое состояние вероятности из 126 состояний вероятности в зависимости от извлеченного в настоящий момент бина. Как описано выше, энтропийный декодер 409, например, может осуществлять доступ к записи таблицы с использованием текущего состояния и значения извлеченного в настоящий момент бина, причем запись таблицы, к которой осуществляют доступ, раскрывает новое состояние вероятности. См. Next_State_LPS и Next_State_MPS в вышеприведенных таблицах, относительно которых выполняется табличный поиск посредством энтропийного декодера в дополнение к другим этапам 0-5, упомянутым выше. В вышеприведенном описании состояние вероятности иногда обозначается как pState_current[bin]. Как также описано выше, энтропийный декодер 409 может быть сконфигурирован с возможностью подвергать двоичному арифметическому декодированию бин, который должен быть извлечен в данный момент посредством квантования битового значения (R) текущего интервала вероятности, представляющего текущий интервал вероятности, чтобы получать индекс q_index интервала вероятности, и выполнения подразделения интервала посредством индексации записи таблицы из записей таблицы (Rtab) с использованием индекса интервала вероятности и индекса p_state состояния вероятности, который зависит от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, который должен быть извлечен в данный момент, чтобы получать подразделение текущего интервала вероятности на два частичных интервала. Как описано выше, энтропийный декодер 409 может использовать 8-битное представление для значения R ширины текущего интервала вероятности. Для квантования текущего значения ширины вероятности энтропийный декодер 409, например, может захватывать два или три старших бита 8-битного представления.
Энтропийный декодер 409 затем может выполнять выбор между двумя частичными интервалами на основе значения состояния смещения от внутренней части текущего интервала вероятности, обновлять значение ширины интервала вероятности и значение состояния смещения и логически выводить значение бина, который должен быть извлечен в данный момент, с использованием выбранного частичного интервала и выполнять ренормализацию обновленного значения ширины вероятности и значения состояния смещения, а именно, V, в вышеприведенном описании, включающую в себя продолжение считывания битов из потока 401 данных. Как описано выше, выбор между двумя частичными интервалами на основе значения V состояния смещения может заключать в себе сравнение между R и V, в то время как обновление значения ширины интервала вероятности и значения состояния смещения может зависеть от значения бина, который должен быть извлечен в данный момент.
Продолжая описание фиг.16, декодер дополнительно описывает модуль 314 преобразования из символьной формы, который сконфигурирован с возможностью осуществлять дебинаризацию элементов 327 синтаксиса, чтобы получать целочисленные значения элементов синтаксиса. Модуль 404 восстановления, который также состоит из декодера по фиг.16, затем восстанавливает видео 405 на основе целочисленных значений элементов синтаксиса с использованием параметра QP квантования. Например, модуль 404 восстановления, как описано выше, может работать в режиме прогнозирования с использованием параметра квантования, чтобы задавать точность для представления остатка прогнозирования, такого как уровни коэффициентов преобразования, представляющие преобразованную версию остатка прогнозирования. Энтропийный декодер 409, как описано выше, сконфигурирован с возможностью проводить различие между 126 состояниями вероятности. Иными словами, pState_current[bin] в комбинации с индикатором относительно valMPS, т.е. индикатором MPS из 0 и 1, т.е. из возможных состояний символа, имеет возможность допускать 126 различных состояний. Энтропийный декодер 409 инициализирует состояния вероятности, ассоциированные с различными контекстами, т.е. pState_current для различных доступных контекстов, согласно линейному уравнению параметра квантования, т.е. уравнению согласно a*QP+d. Следует напомнить, что pState_current фактически просто указывает вероятность LPS. Таким образом, a*QP+d раскрывает оба параметра, а именно, pState_current и valMPS, т.е. индикатор того, какое из двух состояний представляет собой MPS, а какое представляет собой LBS. Хотя a*QP+d указывает вероятность определенного символа, т.е. 1 или 0, тот факт, выше a*QP+d 63 или нет, непосредственно указывает то, 0 или 1 представляет собой MPS. Энтропийный декодер 126 извлекает, для каждого из различных контекстов, наклон и смещение b линейного уравнения из первой и второй 4-битовых частей соответствующего 8-битного значения инициализации, а именно, четырех MPS, с одной стороны, и более младших четырех LPS. В этом отношении, энтропийный декодер 409 может быть сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в качестве начала слайсов видео. Энтропийный декодер, например, может быть сконфигурирован с возможностью по отдельности определять параметр квантования для каждого слайса видео. Иными словами, энтропийный декодер 409 может извлекать из потока 401 данных информацию в отношении того, как задавать параметр квантования для каждого слайса. Затем, с использованием наклона и смещения, оценки вероятности задаются в начале каждого слайса с использованием соответствующего параметра квантования соответствующего слайса. ʺВ начале слайсаʺ, например, может означать ʺперед декодированием первого бина, который должен энтропийно декодироваться с использованием любого контекстаʺ. В частности, энтропийный декодер 409 может быть сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различным контекстом, в началах слайсов видео посредством считывания параметра QP квантования для текущего слайса из потока 401 данных и инициализации состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования для текущего слайса, при этом энтропийный декодер, для каждого из слайсов, может извлекать наклон и смещение линейного уравнения из первой и второй 4-битовых частей того же самого соответствующего 8-битного значения инициализации. Иными словами, тогда как параметр QP квантования варьируется между слайсами видео, пары из наклона и смещения не варьируются.
Модуль 404 восстановления, как описано выше, может работать в режиме прогнозирования. Соответственно, модуль 404 восстановления может, при восстановлении видео 405 на основе целочисленных значений элементов 327 синтаксиса, деквантовать уровни коэффициентов преобразования, состоящие из элементов синтаксиса с использованием параметра QP квантования, выполнять повторное преобразование в деквантованные уровни коэффициентов преобразования, чтобы получать остаток прогнозирования, выполнять пространственное и/или временное прогнозирование, чтобы получать сигнал прогнозирования, и комбинировать остаток прогнозирования и сигнал прогнозирования, чтобы восстанавливать видео 405.
В качестве конкретного примера, энтропийный декодер 409 может быть сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение из первой и второй 4-битовых частей независимо друг от друга, к примеру, посредством табличного поиска, как описано выше, или, альтернативно, с использованием отдельных арифметических операций, к примеру, линейных операций. Иными словами, чтобы пересекать пропуск между 4 битами двух 4-битовых частей 8-битовых значений инициализации, с одной стороны, и 126 различными значениями состояния вероятности, с другой стороны, энтропийный декодер 409 может по отдельности подвергать обе 4-битовых части линейным уравнениям. Например, MSB 8-битного значения инициализации, p, превращаются в наклон посредством вычисления slope=m*p+n, и четыре LSB 8-битного значения инициализации, q, используются для того, чтобы вычислять смещение посредством offset=s*q+t; m, n, t и s являются надлежащим образом выбранными константами. Только для полноты, фиг.17 показывает кодер, соответствующий декодеру по фиг.16, при этом кодер по фиг.17 близко соответствует структуре, например, кодера по фиг.20 и других вариантов осуществления для кодера, аналогично декодеру по фиг.16, соответствующему декодеру по фиг.11, т.е. без учета возможности переключения режимов и реализации энтропийного кодера 513 в более общем отношении как включающего в себя PIPE-принцип или другой принцип, к примеру, вышеуказанный CABAC-принцип. Помимо этого, все описание, предоставленное выше относительно фиг.16, в равной степени переносится на фиг.17.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены посредством (или с использованием) устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства.
Изобретаемый кодированный сигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код сконфигурирован с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на считываемом компьютером носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на считываемом компьютером носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть сконфигурирована с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может быть компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
В одном аспекте настоящего изобретения обеспечен декодер для декодирования видео из потока (401) данных, в который элементы синтаксиса кодируются с использованием бинаризаций элементов (327) синтаксиса, содержащий:
- энтропийный декодер (409), сконфигурированный с возможностью извлекать число бинов (326) бинаризаций из потока (401) данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее декодированных частей потока (401) данных;
- модуль (314) преобразования из символьной формы, сконфигурированный с возможностью осуществлять дебинаризацию элементов (327) синтаксиса, чтобы получать целочисленные значения элементов синтаксиса;
- модуль (404) восстановления, сконфигурированный с возможностью восстанавливать видео на основе целочисленных значений элементов синтаксиса с использованием параметра квантования,
- при этом энтропийный декодер (409) сконфигурирован с возможностью проводить различие между 126 состояниями вероятности и инициализировать состояния вероятности, ассоциированные с различными контекстами, согласно линейному уравнению параметра квантования, при этом энтропийный декодер сконфигурирован с возможностью, для каждого из различных контекстов, извлекать наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации.
При этом энтропийный декодер (409) сконфигурирован с возможностью извлекать число бинов (326) бинаризаций из потока (401) данных с использованием двоичного арифметического декодирования или двоичного PIPE-декодирования.
При этом энтропийный декодер (409) сконфигурирован с возможностью осуществлять выбор контекста для бина, который должен быть извлечен в данный момент, в зависимости от одного или более из:
- позиции бина для бина, который должен быть извлечен в данный момент в бинаризации, которой принадлежит бин, который должен быть извлечен в данный момент,
- типа элемента синтаксиса для элемента синтаксиса, целочисленное значение которого получается посредством дебинаризации, которой принадлежит бин, который должен быть извлечен в данный момент, и
- одного или более бинов, ранее извлеченных из потока (401) данных, или целочисленного значения элемента синтаксиса, дебинаризованного ранее.
При этом энтропийный декодер (409) сконфигурирован с возможностью осуществлять обновление состояния вероятности посредством, для извлеченного в настоящий момент бина, перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для извлеченного в настоящий момент бина в пределах 126 состояний вероятности, в новое состояние вероятности из 126 состояний вероятности в зависимости от извлеченного в настоящий момент бина.
При этом энтропийный декодер (409) сконфигурирован с возможностью подвергать двоичному арифметическому декодированию бин, который должен быть извлечен в данный момент, посредством квантования значения ширины текущего интервала вероятности, представляющего текущий интервал вероятности, чтобы получать индекс интервала вероятности, и выполнения подразделения интервала посредством индексации записи таблицы из записей таблицы с использованием индекса интервала вероятности и индекса состояния вероятности в зависимости от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, который должен быть извлечен в данный момент, чтобы получать подразделение текущего интервала вероятности на два частичных интервала.
При этом энтропийный декодер (409) сконфигурирован с возможностью использовать 8-битное представление для значения ширины текущего интервала вероятности и захватывать 2 или 3 старших бита 8-битного представления при квантовании значения ширины текущего интервала вероятности.
При этом энтропийный декодер (409) сконфигурирован с возможностью выбирать из числа упомянутых двух частичных интервалов на основе значения состояния смещения от внутренней части текущего интервала вероятности, обновлять значение ширины интервала вероятности и значение состояния смещения и логически выводить значение бина, который должен быть извлечен в данный момент, с использованием выбранного частичного интервала и выполнять ренормализацию обновленного значения ширины интервала вероятности и значения состояния смещения, включающую в себя продолжение считывания битов из потока (401) данных.
При этом энтропийный декодер (409) сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео.
При этом энтропийный декодер (409) сконфигурирован с возможностью по отдельности определять параметр квантования для каждого слайса видео.
При этом энтропийный декодер (409) сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео посредством считывания параметра квантования для текущего слайса из потока (401) данных и инициализации состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования для текущего слайса, при этом энтропийный декодер (409) сконфигурирован с возможностью, для каждого из слайсов, извлекать наклон и смещение линейного уравнения из первой и второй четырехбитных частей того же самого соответствующего 8-битного значения инициализации.
При этом модуль (404) восстановления сконфигурирован с возможностью, при восстановлении видео (405) на основе целочисленных значений элементов (327) синтаксиса, деквантовать уровни коэффициентов преобразования, состоящие из элементов синтаксиса, с использованием параметра квантования, выполнять повторное преобразование в деквантованные уровни коэффициентов преобразования таким образом, чтобы получать остаток прогнозирования, выполнять пространственное и/или временное прогнозирование таким образом, чтобы получать сигнал прогнозирования, и комбинировать остаток прогнозирования и сигнал прогнозирования таким образом, чтобы восстанавливать видео (405).
При этом энтропийный декодер (409) сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации независимо друг от друга.
При этом энтропийный декодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации посредством табличного поиска или с использованием арифметической операции.
При этом энтропийный декодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения посредством умножения и смещения первой четырехбитной части посредством первой пары параметров и смещение посредством умножения и смещения второй четырехбитной части посредством второй пары параметров.
В другом аспекте настоящего изобретения обеспечен кодер для кодирования видео в поток данных посредством кодирования элементов синтаксиса в поток данных с использованием бинаризаций элементов синтаксиса, содержащий:
- модуль составления, сконфигурированный с возможностью представлять видео посредством задания целочисленных значений элементов синтаксиса в зависимости от параметра квантования,
- модуль преобразования в символьную форму, сконфигурированный с возможностью осуществлять бинаризацию целочисленных значений элементов синтаксиса, чтобы получать бинаризации элементов синтаксиса;
- энтропийный кодер, сконфигурированный с возможностью кодировать число бинов бинаризаций в поток данных с использованием двоичного энтропийного кодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее кодированных частей потока данных;
- при этом энтропийный кодер сконфигурирован с возможностью проводить различие между 126 состояниями вероятности и инициализировать состояния вероятности, ассоциированные с различными контекстами, согласно линейному уравнению параметра квантования, при этом энтропийный кодер сконфигурирован с возможностью, для каждого из различных контекстов, извлекать наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации.
При этом энтропийный кодер сконфигурирован с возможностью кодировать число бинов бинаризаций в поток данных с использованием двоичного арифметического кодирования или двоичного PIPE-кодирования.
При этом энтропийный кодер сконфигурирован с возможностью осуществлять выбор контекста для бина, который должен быть кодирован в данный момент, в зависимости от одного или более из:
- позиции бина для бина, который должен быть кодирован в данный момент в бинаризации, которой принадлежит бин, который должен быть кодирован в данный момент,
- типа элемента синтаксиса, целочисленное значение которого бинаризуется в бинаризацию, которой принадлежит бин, который должен быть кодирован в данный момент, и
- одного или более бинов, ранее кодированных в поток данных, или целочисленного значения элемента синтаксиса, бинаризация которого была кодирована ранее.
При этом энтропийный декодер сконфигурирован с возможностью осуществлять обновление состояния вероятности посредством, для кодированного в настоящий момент бина, перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для кодированного в настоящий момент бина в пределах 126 состояний вероятности, в новое состояние вероятности из 126 состояний вероятности в зависимости от извлеченного в настоящий момент бина.
При этом энтропийный кодер сконфигурирован с возможностью подвергать двоичному арифметическому кодированию бин, который должен быть кодирован в данный момент, посредством квантования значения ширины текущего интервала вероятности, представляющего текущий интервал вероятности, чтобы получать индекс интервала вероятности, и выполнения подразделения интервала посредством индексации записи таблицы из записей таблицы с использованием индекса интервала вероятности и индекса состояния вероятности, который зависит от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, который должен быть кодирован в данный момент, чтобы получать подразделение текущего интервала вероятности на два частичных интервала.
При этом энтропийный кодер сконфигурирован с возможностью использовать 8-битное представление для значения ширины текущего интервала вероятности и захватывать 2 или 3 старших бита 8-битного представления при квантовании значения ширины текущего интервала вероятности.
При этом энтропийный кодер сконфигурирован с возможностью выбирать из числа упомянутых двух частичных интервалов на основе целочисленного значения бина, который должен быть кодирован в данный момент, обновлять значение ширины интервала вероятности и смещение интервала вероятности с использованием выбранного частичного интервала и выполнять ренормализацию значения ширины интервала вероятности и смещения интервала вероятности, включающую в себя продолжение записи битов в поток данных.
При этом энтропийный декодер сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео.
При этом энтропийный кодер сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео.
При этом энтропийный кодер сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео посредством отдельного задания параметра квантования для текущего слайса из потока данных и инициализации состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования для текущего слайса, при этом энтропийный кодер сконфигурирован с возможностью, для каждого из слайсов, извлекать наклон и смещение линейного уравнения из первой и второй четырехбитных частей того же самого соответствующего 8-битного значения инициализации.
При этом модуль составления сконфигурирован с возможностью, при задании целочисленных значений элементов синтаксиса, выполнять пространственное и/или временное прогнозирование таким образом, чтобы получать сигнал прогнозирования, извлекать остаток прогнозирования из сигнала прогнозирования и видео, выполнять преобразование в остаток прогнозирования таким образом, чтобы получать уровни коэффициентов преобразования, и квантовать уровни коэффициентов преобразования с использованием параметра квантования таким образом, чтобы получать квантованные уровни коэффициентов преобразования, состоящие из элементов синтаксиса.
При этом энтропийный кодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации независимо друг от друга.
При этом энтропийный кодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации посредством табличного поиска или с использованием арифметической операции.
При этом энтропийный кодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения посредством умножения и смещения первой четырехбитной части посредством первой пары параметров и смещение посредством умножения и смещения второй четырехбитной части посредством второй пары параметров.
В другом аспекте настоящего изобретения обеспечен способ для декодирования видео из потока данных, в который элементы синтаксиса кодируются с использованием бинаризаций элементов синтаксиса, содержащий этапы, на которых:
- извлекают число бинов бинаризаций из потока данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее декодированных частей потока данных;
- осуществляют дебинаризацию бинаризаций элементов синтаксиса, чтобы получать целочисленные значения элементов синтаксиса;
- восстанавливают видео на основе целочисленных значений элементов синтаксиса с использованием параметра квантования,
- при этом извлечение числа бинов бинаризаций проводит различие между 126 состояниями вероятности, и способ дополнительно содержит инициализацию состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования и для каждого из различных контекстов извлечение наклона и смещения линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации.
В другом аспекте настоящего изобретения обеспечен способ для кодирования видео в поток данных посредством кодирования элементов синтаксиса в поток данных с использованием бинаризаций элементов синтаксиса, содержащий этапы, на которых:
- представляют видео посредством задания целочисленных значений элементов синтаксиса в зависимости от параметра квантования;
- осуществляют бинаризацию целочисленных значений элементов синтаксиса, чтобы получать бинаризации элементов синтаксиса;
- кодируют число бинов бинаризаций в поток данных с использованием двоичного энтропийного кодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее кодированных частей потока данных;
- при этом представление видео проводит различие между 126 состояниями вероятности, и способ дополнительно содержит инициализацию состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования, и для каждого из различных контекстов извлекают наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации.
В другом аспекте настоящего изобретения обеспечена компьютерная программа, имеющая программный код для осуществления, при выполнении на компьютере, способа по любому из вышеописанных аспектов.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2021 |
|
RU2779898C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2595934C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2615681C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2658883C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2018 |
|
RU2758981C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2021 |
|
RU2776910C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2024 |
|
RU2839971C1 |
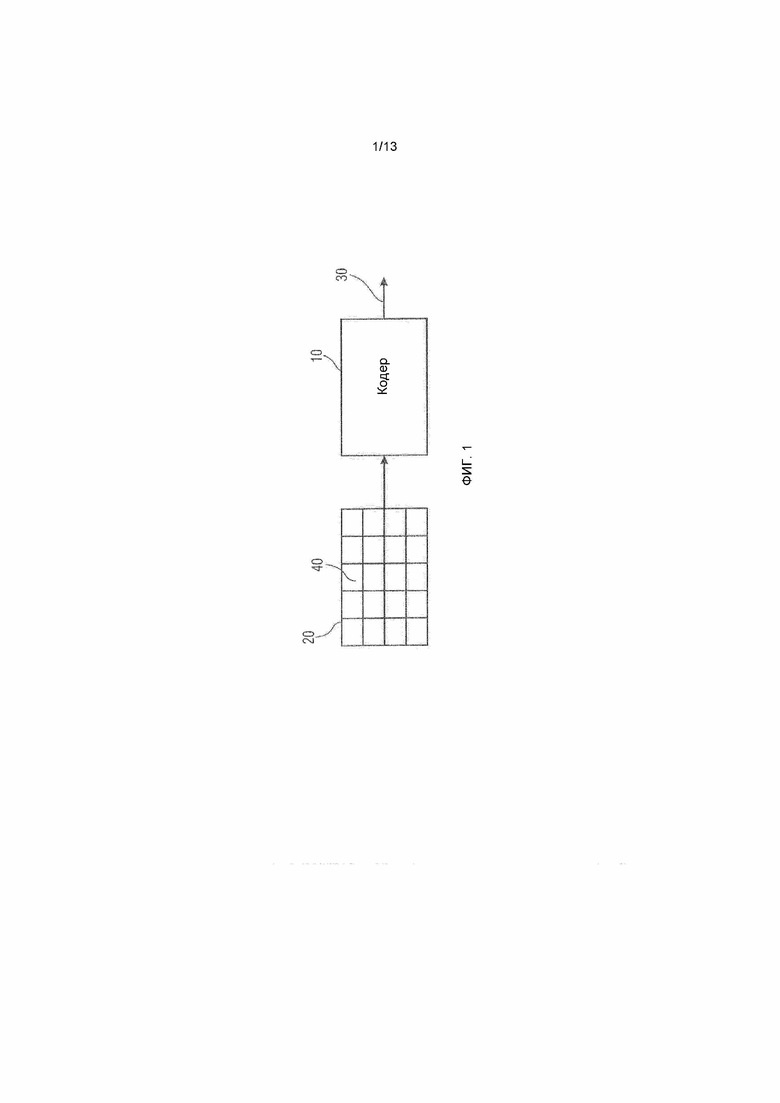
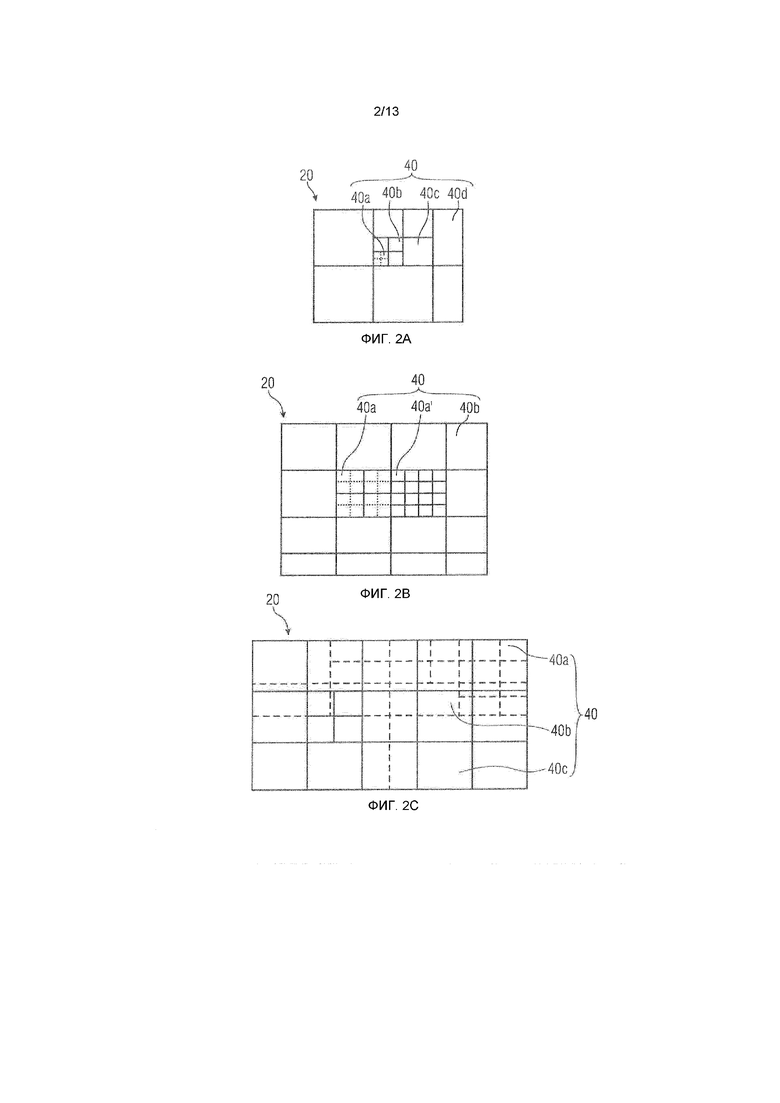
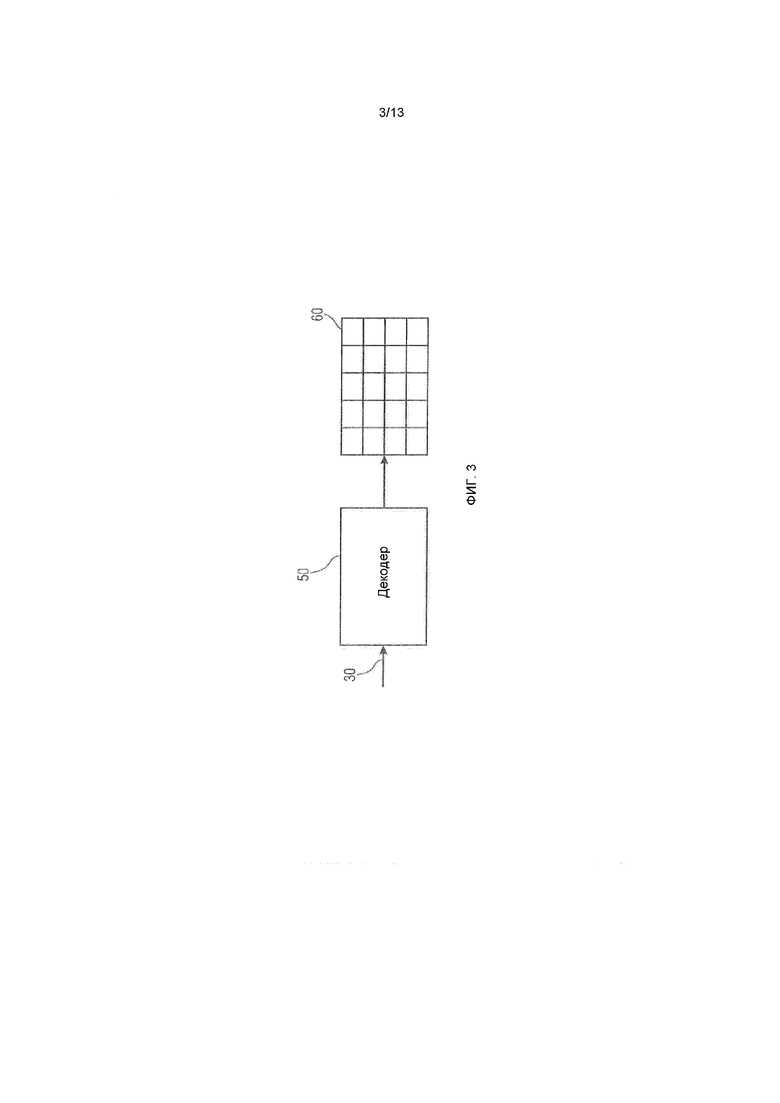
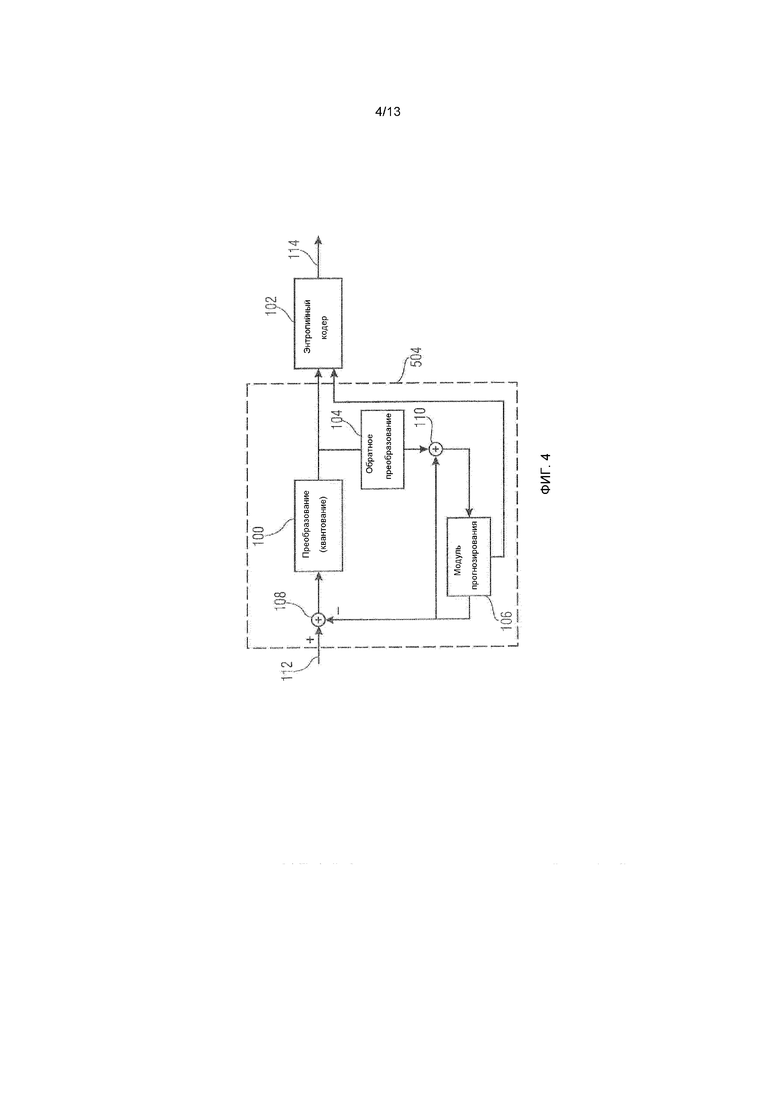

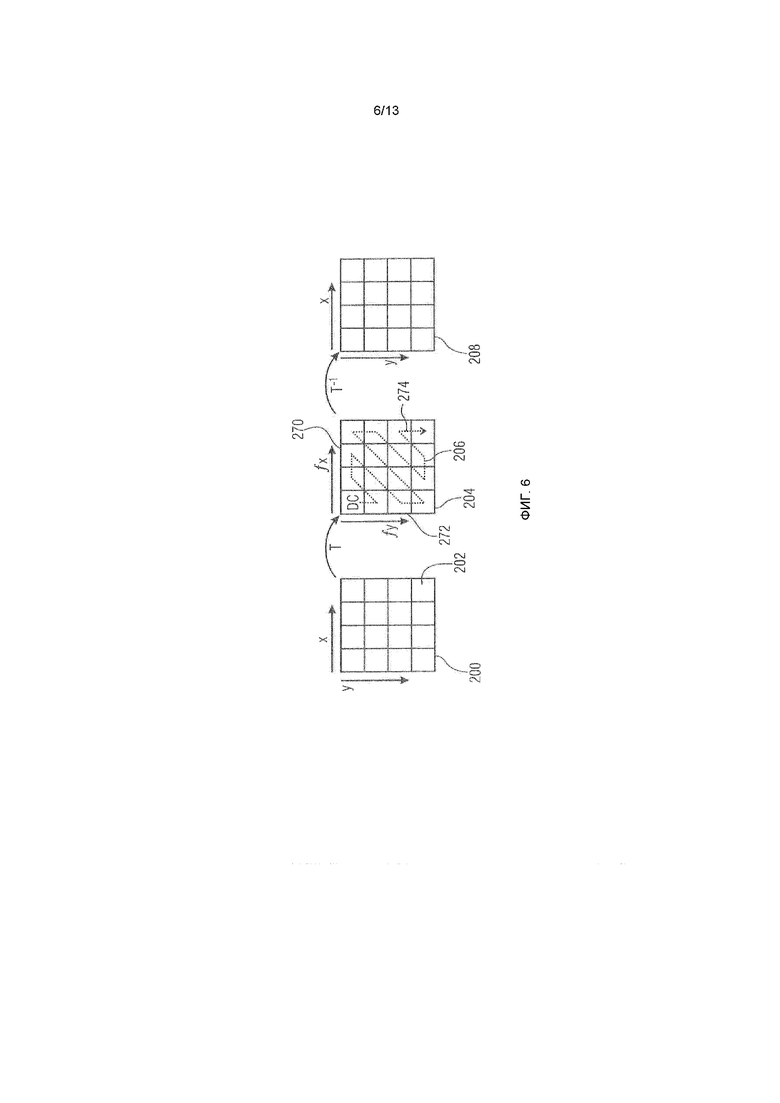
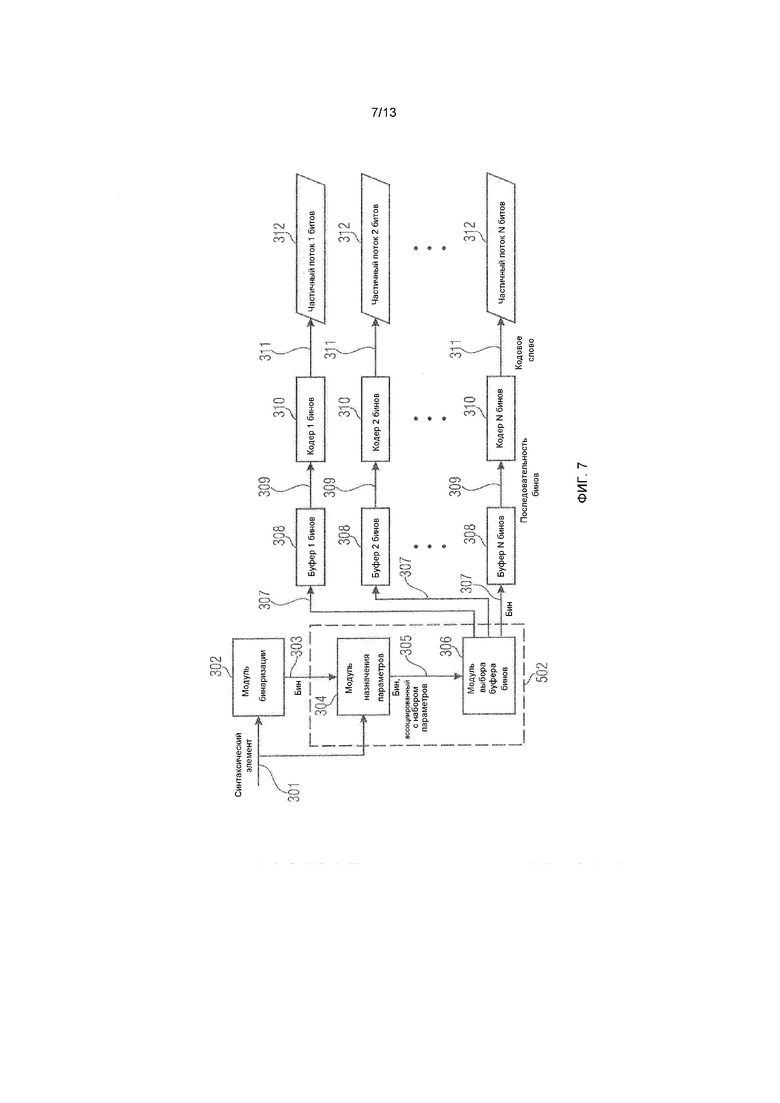


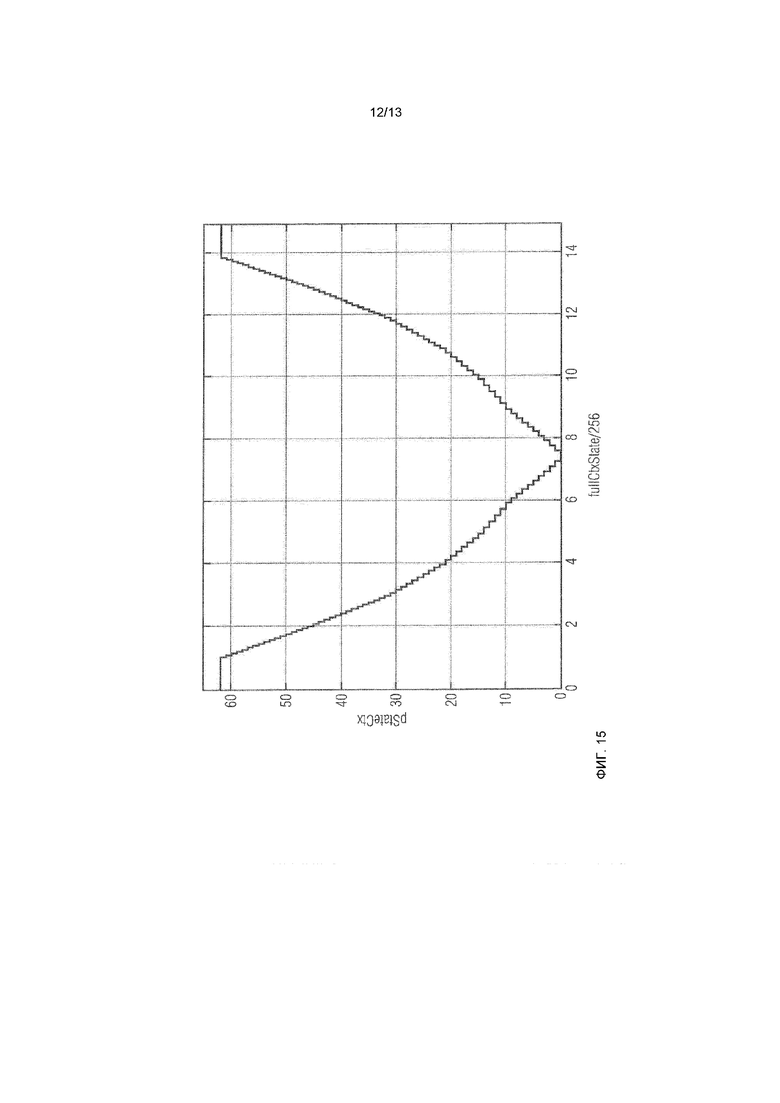
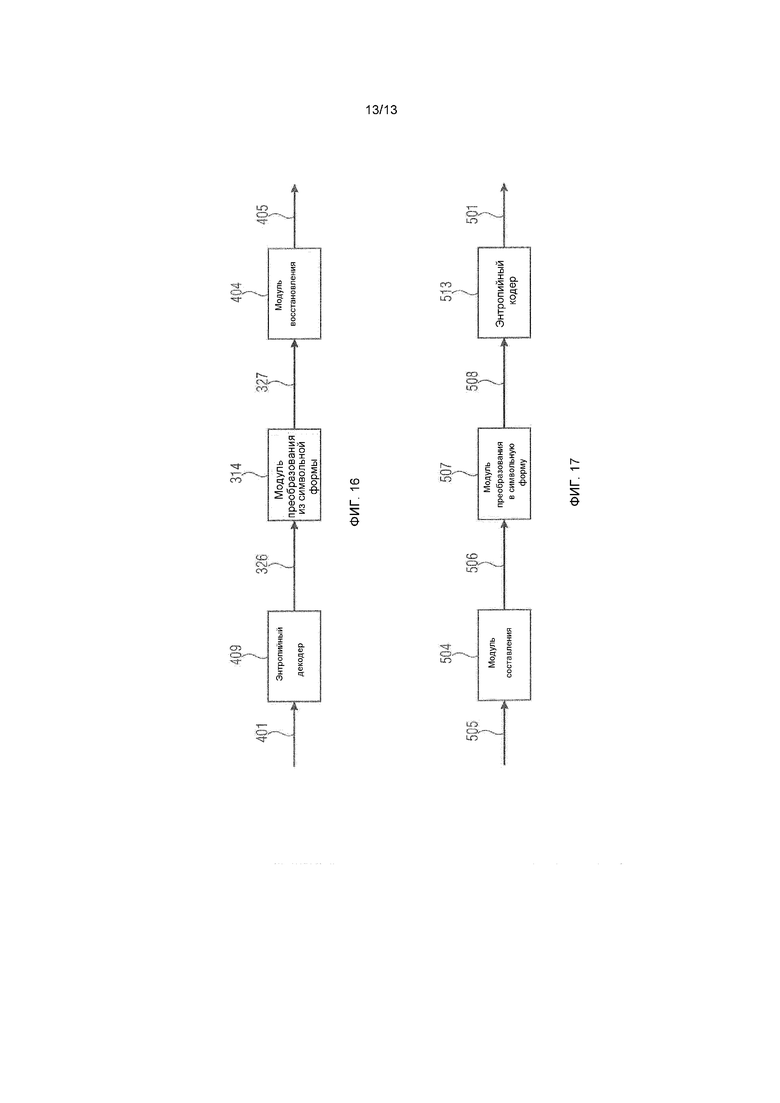
Изобретение относится к технологиям энтропийного декодирования/кодирования видеоданных. Технический результат заключается в улучшении эффективности декодирования/кодирования видеоданных за счет оптимизации инициализированного состояния вероятности для каждого контекста. Декодер содержит: энтропийный декодер, извлекающий число бинов бинаризаций из потока данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности; модуль преобразования из символьной формы, осуществляющий дебинаризацию бинаризаций элементов синтаксиса; модуль восстановления, восстанавливающий видео на основе целочисленных значений элементов синтаксиса с использованием параметра квантования, при этом энтропийный декодер проводит различие между 126 состояниями вероятности и инициализирует состояния вероятности, ассоциированные с различными контекстами, согласно линейному уравнению параметра квантования, также для каждого из различных контекстов, независимо извлекает наклон линейного уравнения из четырех старших битов 8-битного значения инициализации и смещение линейного уравнения из четырех младших битов упомянутого 8-битного значения инициализации. 7 н. и 28 з.п. ф-лы, 19 ил., 12 табл.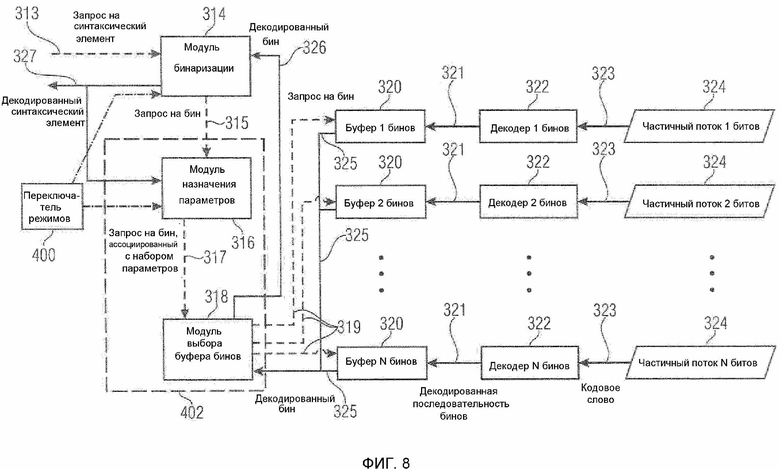
1. Декодер для декодирования видео из потока (401) данных, в который элементы синтаксиса кодированы с использованием бинаризаций элементов (327) синтаксиса, содержащий:
- энтропийный декодер (409), сконфигурированный с возможностью извлекать число бинов (326) бинаризаций из потока (401) данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее декодированных частей потока (401) данных;
- модуль (314) преобразования из символьной формы, сконфигурированный с возможностью осуществлять дебинаризацию бинаризаций элементов (327) синтаксиса, чтобы получать целочисленные значения элементов синтаксиса;
- модуль (404) восстановления, сконфигурированный с возможностью восстанавливать видео на основе целочисленных значений элементов синтаксиса с использованием параметра квантования,
при этом энтропийный декодер (409) сконфигурирован с возможностью проводить различие между 126 состояниями вероятности и инициализировать состояния вероятности, ассоциированные с различными контекстами, согласно линейному уравнению параметра квантования,
при этом энтропийный декодер сконфигурирован с возможностью, для каждого из различных контекстов, независимо извлекать наклон линейного уравнения из четырех старших битов 8-битного значения инициализации и смещение линейного уравнения из четырех младших битов упомянутого 8-битного значения инициализации.
2. Декодер по п. 1, в котором энтропийный декодер (409) сконфигурирован с возможностью извлекать число бинов (326) бинаризаций из потока (401) данных с использованием двоичного арифметического декодирования или двоичного PIPE-декодирования.
3. Декодер по п. 1 или 2, в котором энтропийный декодер (409) сконфигурирован с возможностью осуществлять выбор контекста для бина, который должен быть извлечен в данный момент, в зависимости от одного или более из:
- позиции бина для бина, который должен быть извлечен в данный момент, в бинаризации, которой принадлежит бин, который должен быть извлечен в данный момент,
- типа элемента синтаксиса для элемента синтаксиса, целочисленное значение которого получается посредством дебинаризации бинаризации, которой принадлежит бин, который должен быть извлечен в данный момент, и
- одного или более бинов, ранее извлеченных из потока (401) данных, или целочисленного значения элемента синтаксиса, дебинаризованного ранее.
4. Декодер по любому из пп. 1-3, в котором энтропийный декодер (409) сконфигурирован с возможностью осуществлять обновление состояния вероятности посредством, для бина, который должен быть извлечен в данный момент, перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для извлекаемого в данный момент бина, в пределах (126) состояний вероятности, в новое состояние вероятности из этих 126 состояний вероятности в зависимости от бина, который должен быть извлечен в данный момент.
5. Декодер по любому из пп. 1-4, в котором энтропийный декодер (409) сконфигурирован с возможностью осуществлять двоичное арифметическое декодирование бина, который должен быть извлечен в данный момент, посредством квантования значения ширины текущего интервала вероятности, представляющего текущий интервал вероятности, чтобы получать индекс интервала вероятности, и выполнения подразделения интервала посредством индексации некоторой записи таблицы из числа записей таблицы, используя индекс интервала вероятности и индекс состояния вероятности, в зависимости от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, который должен быть извлечен в данный момент, чтобы получать подразделение текущего интервала вероятности на два частичных интервала.
6. Декодер по п. 5, в котором энтропийный декодер (409) сконфигурирован с возможностью использовать 8-битное представление для значения ширины текущего интервала вероятности и захватывать 2 или 3 старших бита 8-битного представления при квантовании значения ширины текущего интервала вероятности.
7. Декодер по п. 5 или 6, в котором энтропийный декодер (409) сконфигурирован с возможностью выбирать из числа упомянутых двух частичных интервалов на основе значения состояния смещения от внутренней части текущего интервала вероятности, обновлять значение ширины интервала вероятности и значение состояния смещения и логически выводить значение бина, который должен быть извлечен в данный момент, используя выбранный частичный интервал, и выполнять ренормализацию обновленного значения ширины интервала вероятности и значения состояния смещения, в том числе продолжение считывания битов из потока (401) данных.
8. Декодер по любому из пп. 1-7, в котором энтропийный декодер (409) сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео.
9. Декодер по п. 8, в котором энтропийный декодер (409) сконфигурирован с возможностью индивидуального определения параметра квантования для каждого слайса видео.
10. Декодер по любому из пп. 1-9, в котором энтропийный декодер (409) сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео посредством считывания параметра квантования для текущего слайса из потока (401) данных и инициализации состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования для текущего слайса, при этом энтропийный декодер (409) сконфигурирован с возможностью, для каждого из слайсов, извлекать наклон и смещение линейного уравнения из первой и второй четырехбитных частей одного соответствующего 8-битного значения инициализации.
11. Декодер по любому из пп. 1-10, в котором модуль (404) восстановления сконфигурирован с возможностью, при восстановлении видео (405) на основе целочисленных значений элементов (327) синтаксиса, деквантовать уровни коэффициентов преобразования, состоящие из элементов синтаксиса, с использованием параметра квантования, выполнять повторное преобразование в отношении деквантованных уровней коэффициентов преобразования для того, чтобы получать остаток прогнозирования, выполнять пространственное и/или временное прогнозирование для того, чтобы получать сигнал прогнозирования, и комбинировать остаток прогнозирования и сигнал прогнозирования для того, чтобы восстанавливать видео (405).
12. Декодер по любому из пп. 1-11, в котором энтропийный декодер (409) сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации независимо друг от друга.
13. Декодер по любому из пп. 1-12, в котором энтропийный декодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации посредством табличного поиска или с использованием арифметической операции.
14. Декодер по любому из пп. 1-12, в котором энтропийный декодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон линейного уравнения посредством умножения и смещения первой четырехбитной части посредством первой пары параметров и смещение посредством умножения и смещения второй четырехбитной части посредством второй пары параметров.
15. Декодер по п. 1, в котором массив информационных выборок представляет собой карту глубины.
16. Кодер для кодирования видео в поток данных посредством кодирования элементов синтаксиса в поток данных с использованием бинаризаций элементов синтаксиса, содержащий:
- модуль составления, сконфигурированный с возможностью представлять видео посредством задания целочисленных значений элементов синтаксиса в зависимости от параметра квантования,
- модуль преобразования в символьную форму, сконфигурированный с возможностью осуществлять бинаризацию целочисленных значений элементов синтаксиса, чтобы получать бинаризации элементов синтаксиса;
- энтропийный кодер, сконфигурированный с возможностью кодировать число бинов бинаризаций в поток данных с использованием двоичного энтропийного кодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее кодированных частей потока данных;
при этом энтропийный кодер сконфигурирован с возможностью проводить различие между 126 состояниями вероятности и инициализировать состояния вероятности, ассоциированные с различными контекстами, согласно линейному уравнению параметра квантования,
при этом энтропийный кодер сконфигурирован с возможностью, для каждого из различных контекстов, независимо извлекать наклон линейного уравнения из четырех старших битов 8-битного значения инициализации и смещение линейного уравнения из четырех младших битов упомянутого 8-битного значения инициализации.
17. Кодер по п. 16, в котором энтропийный кодер сконфигурирован с возможностью кодировать число бинов бинаризаций в поток данных с использованием двоичного арифметического кодирования или двоичного PIPE-кодирования.
18. Кодер по п. 16 или 17, в котором энтропийный кодер сконфигурирован с возможностью осуществлять выбор контекста для бина, который должен быть кодирован в данный момент, в зависимости от одного или более из:
- позиции бина для бина, который должен быть кодирован в данный момент, в бинаризации, которой принадлежит бин, который должен быть кодирован в данный момент,
- типа элемента синтаксиса, целочисленное значение которого бинаризуется в бинаризацию, которой принадлежит бин, который должен быть кодирован в данный момент, и
- одного или более бинов, ранее кодированных в поток данных, или целочисленного значения элемента синтаксиса, бинаризация которого была кодирована ранее.
19. Кодер по любому из пп. 16-18, в котором энтропийный кодер сконфигурирован с возможностью осуществлять обновление состояния вероятности посредством, для бина, который должен быть кодирован в данный момент, перехода из текущего состояния вероятности, ассоциированного с контекстом, выбранным для кодируемого в данный момент бина, в пределах 126 состояний вероятности, в новое состояние вероятности из числа этих 126 состояний вероятности в зависимости от бина, который должен быть кодирован в данный момент.
20. Кодер по любому из пп. 16-19, в котором энтропийный кодер сконфигурирован с возможностью осуществлять двоичное арифметическое кодирование бина, который должен быть кодирован в данный момент, посредством квантования значения ширины текущего интервала вероятности, представляющего текущий интервал вероятности, чтобы получать индекс интервала вероятности, и выполнения подразделения интервала посредством индексации некоторой записи таблицы из числа записей таблицы, используя индекс интервала вероятности и индекс состояния вероятности, который зависит от текущего состояния вероятности, ассоциированного с контекстом, выбранным для бина, который должен быть кодирован в данный момент, чтобы получать подразделение текущего интервала вероятности на два частичных интервала.
21. Кодер по п. 20, в котором энтропийный кодер сконфигурирован с возможностью использовать 8-битное представление для значения ширины текущего интервала вероятности и захватывать 2 или 3 старших бита 8-битного представления при квантовании значения ширины текущего интервала вероятности.
22. Кодер по п. 20 или 21, в котором энтропийный кодер сконфигурирован с возможностью выбирать из числа упомянутых двух частичных интервалов на основе целочисленного значения бина, который должен быть кодирован в данный момент, обновлять значение ширины интервала вероятности и смещение интервала вероятности с использованием выбранного частичного интервала и выполнять ренормализацию значения ширины интервала вероятности и смещения интервала вероятности, в том числе продолжение записи битов в поток данных.
23. Кодер по любому из пп. 16-22, в котором энтропийный кодер сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео.
24. Кодер по любому из пп. 16-23, в котором энтропийный кодер сконфигурирован с возможностью инициализировать состояния вероятности, ассоциированные с различными контекстами, в началах слайсов видео посредством индивидуального задания параметра квантования для текущего слайса из потока данных и инициализации состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования для текущего слайса, при этом энтропийный кодер сконфигурирован с возможностью, для каждого из слайсов, извлекать наклон и смещение линейного уравнения из первой и второй четырехбитных частей одного соответствующего 8-битного значения инициализации.
25. Кодер по любому из пп. 16-24, в котором модуль составления сконфигурирован с возможностью, при задании целочисленных значений элементов синтаксиса, выполнять пространственное и/или временное прогнозирование для того, чтобы получать сигнал прогнозирования, извлекать остаток прогнозирования из сигнала прогнозирования и видео, выполнять преобразование в отношении остатка прогнозирования для того, чтобы получать уровни коэффициентов преобразования, и квантовать уровни коэффициентов преобразования с использованием параметра квантования для того, чтобы получать квантованные уровни коэффициентов преобразования, состоящие из элементов синтаксиса.
26. Кодер по любому из пп. 16-25, в котором энтропийный кодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации независимо друг от друга.
27. Кодер по любому из пп. 16-26, в котором энтропийный кодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон и смещение линейного уравнения из первой и второй четырехбитных частей соответствующего 8-битного значения инициализации посредством табличного поиска или с использованием арифметической операции.
28. Кодер по любому из пп. 16-27, в котором энтропийный кодер сконфигурирован с возможностью извлекать, для каждого из различных контекстов, наклон линейного уравнения посредством умножения и смещения первой четырехбитной части посредством первой пары параметров и смещение посредством умножения и смещения второй четырехбитной части посредством второй пары параметров.
29. Кодер по п. 16 или 17, в котором массив информационных выборок представляет собой карту глубины.
30. Способ для декодирования видео из потока данных, в который элементы синтаксиса кодированы с использованием бинаризаций элементов синтаксиса, содержащий этапы, на которых:
- извлекают число бинов бинаризаций из потока данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее декодированных частей потока данных;
- осуществляют дебинаризацию бинаризаций элементов синтаксиса, чтобы получать целочисленные значения элементов синтаксиса;
- восстанавливают видео на основе целочисленных значений элементов синтаксиса с использованием параметра квантования,
при этом извлечение числа бинов бинаризаций проводит различие между 126 состояниями вероятности и способ содержит инициализацию состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования, и, для каждого из различных контекстов, независимое извлечение наклона линейного уравнения из четырех старших битов 8-битного значения инициализации и смещения линейного уравнения из четырех младших битов упомянутого 8-битного значения инициализации.
31. Способ для кодирования видео в поток данных посредством кодирования элементов синтаксиса в поток данных с использованием бинаризаций элементов синтаксиса, содержащий этапы, на которых:
- представляют видео посредством задания целочисленных значений элементов синтаксиса в зависимости от параметра квантования;
- осуществляют бинаризацию целочисленных значений элементов синтаксиса, чтобы получать бинаризации элементов синтаксиса;
- кодируют число бинов бинаризаций в поток данных с использованием двоичного энтропийного кодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее кодированных частей потока данных;
при этом представление видео проводит различие между 126 состояниями вероятности и способ дополнительно содержит инициализацию состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования, и, для каждого из различных контекстов, независимое извлечение наклона линейного уравнения из четырех старших битов 8-битного значения инициализации и смещения линейного уравнения из четырех младших битов соответствующего 8-битного значения инициализации.
32. Считываемый компьютером носитель, хранящий компьютерную программу, имеющую программный код для осуществления, при выполнении на компьютере, способа по п. 30.
33. Считываемый компьютером носитель, хранящий компьютерную программу, имеющую программный код для осуществления, при выполнении на компьютере, способа по п. 31.
34. Цифровой носитель данных, хранящий
поток данных, в который элементы синтаксиса кодированы с использованием бинаризаций элементов синтаксиса и из которого видео может быть декодировано посредством способа, содержащего:
- извлечение числа бинов бинаризаций из потока данных с использованием двоичного энтропийного декодирования посредством выбора контекста из числа различных контекстов и обновления состояний вероятности, ассоциированных с различными контекстами, в зависимости от ранее декодированных частей потока данных;
- дебинаризацию бинаризаций элементов синтаксиса, чтобы получать целочисленные значения элементов синтаксиса;
- восстановление видео на основе целочисленных значений элементов синтаксиса с использованием параметра квантования,
при этом извлечение числа бинов бинаризаций проводит различие между 126 состояниями вероятности, и способ содержит инициализацию состояний вероятности, ассоциированных с различными контекстами, согласно линейному уравнению параметра квантования, и, для каждого из различных контекстов, независимое извлечение наклона линейного уравнения из четырех старших битов 8-битного значения инициализации и смещения линейного уравнения из четырех младших битов упомянутого 8-битного значения инициализации.
35. Цифровой носитель данных по п. 34, в котором массив информационных выборок представляет собой карту глубины.
| Cтатья Detlev Marpe et al | |||
| Железнодорожный снегоочиститель | 1920 |
|
SU264A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ И УСТРОЙСТВО АДАПТИВНОГО ВЫБОРА КОНТЕКСТНОЙ МОДЕЛИ ДЛЯ КОДИРОВАНИЯ ПО ЭНТРОПИИ | 2006 |
|
RU2336661C2 |

