[0001] Данная заявка основана и притязает на приоритет китайской патентной заявки номер 2013310485775.8, поданной 16 октября 2013 года, содержимое которой полностью содержится в данном документе по ссылке.
Область техники, к которой относится изобретение
[0002] Настоящее раскрытие относится к области техники обработки данных, а более конкретно, к способу, терминалу и электронному устройству для обработки документа электронной книги.
Уровень техники
[0003] С растущей популярностью мобильных терминалов чтение и редактирование электронных книг на мобильных терминалах также становится все более популярным. В некоторых случаях, некоторые электронные книги заменили бумажные книги и стали предпочитаемыми средствами ежедневного чтения. Мобильные терминалы для чтения электронных книг являются универсальными, такие как смартфоны, планшетные компьютеры или электронные устройства чтения.
[0004] В настоящее время, документы электронной книги редактируются в основном посредством использования HTML (языка разметки гипертекста), и документы электронной книги, отредактированные посредством использования HTML, могут считаться HTML-документами. После того, как пользователь открывает электронную книгу через мобильный терминал, мобильный терминал может считать HTML-документ электронной книги в запоминающее устройство и преобразовывать электронную книгу в изображения страниц, которые могут просматриваться пользователем через мобильный терминал посредством интерпретации HTML-документа. Вышеуказанный процесс интерпретации в основном включает в себя этап синтаксического анализа, этап полной разбивки на страницы, этап формирования объектов страницы и этап формирования изображений страниц и т.д.
[0005] В ходе исследований и практической деятельности, автор изобретения выявил, что способ обработки электронных книг так, как описано выше, имеет, по меньшей мере, следующие проблемы.
[0006] Обычно, характеристики хранения и вычисления мобильного терминала ограничены. Если электронная книга имеет относительно большой объем, данные, которые должны обрабатываться при чтении электронной книги посредством мобильного терминала, могут занимать огромные ресурсы хранения, в силу этого приводя к снижению функциональной эффективности этапа синтаксического анализа и этапа полной разбивки на страницы при чтении документа электронной книги и увеличивая время для мобильного терминала, чтобы читать электронную книгу. Кроме того, чем больше объем электронной книги, тем более чрезмерные ресурсы запоминающего устройства потребляются на этапе синтаксического анализа и на этапе полной разбивки на страницы, так что снижается функциональная эффективность мобильного терминала. В серьезной ситуации, в мобильном терминале могут возникать явления нарушений в работе или сбоев.
[0007] Следовательно, то, как предоставлять высокоэффективный способ для обработки электронных книг с небольшим временем считывания и незначительным использованием запоминающего устройства, внезапно стало проблемой, которая должна быть разрешена.
Сущность изобретения
[0008] Соответственно, настоящее раскрытие спроектировано с возможностью иметь цель в предоставлении способа, терминала и электронного устройства для обработки документов электронной книги, так что мобильный терминал, при чтении электронной книги, может иметь меньшее время чтения и сокращенное использование запоминающего устройства.
[0009] Согласно первому аспекту вариантов осуществления настоящего раскрытия, предусмотрен способ для обработки документа электронной книги, включающий в себя:
[0010] получение документа электронной книги;
[0011] разделение контента документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
[0012] компоновку множества сегментов в группу упорядоченных сегментов;
[0013] выбор одного сегмента из группы сегментов в качестве текущего сегмента;
[0014] синтаксический анализ контента текущего сегмента для формирования данных макета; и
[0015] формирование изображения страницы в соответствии с данными макета.
[0016] В вариантах осуществления настоящего раскрытия, документ электронной книги разделяется на множество сегментов. При каждой операции обработки электронной книги только один сегмент документа электронной книги синтаксически анализируется, и данные макета, сформированные из сегмента, используются для того, чтобы формировать изображение страницы, следовательно, объем данных, которые должны обрабатываться каждый раз в ходе работы, представляет собой только объем данных одного сегмента. Таким образом, когда мобильный терминал читает документ электронной книги, может повышаться эффективность обработки данных, за счет этого сокращая время на считывание электронной книги. Кроме того, операция сегментации может обеспечивать обработку документа электронной книги в пакетном режиме, когда мобильный терминал обрабатывает один сегмент документа электронной книги, объем данных, которые должны обрабатываться либо при операции синтаксического анализа, либо при последующей операции формирования изображений страниц, является относительно небольшим, за счет этого сокращая объем памяти мобильного терминала, занимаемый электронной книгой.
[0017] В одном варианте осуществления, после формирования данных макета, способ дополнительно включает в себя:
[0018] запись информации позиции текущего сегмента в группе сегментов; и
[0019] определение того, меньше или нет объем данных для данных макета предварительно установленного значения, если объем данных меньше предварительно установленного значения, выбор следующего сегмента относительно текущего сегмента согласно информации позиции, использование следующего сегмента в качестве текущего сегмента и возвращение к синтаксическому анализу контента текущего сегмента.
[0020] Настоящее решение обеспечивает то, что объем данных для данных макета является достаточным для формирования изображения страницы.
[0021] В одном варианте осуществления, разделение контента документа электронной книги на множество сегментов включает в себя следующие подэтапы:
[0022] определение размера сегмента; и
[0023] разделение контента документа электронной книги на множество сегментов, имеющих размер, идентичный размеру сегмента.
[0024] Настоящее решение осуществляет конкретные способы сегментации.
[0025] В одном варианте осуществления, способ дополнительно включает в себя:
[0026] определение того, является или нет информация начальной точки сегмента полной, и если она не является полной, перемещение из начальной точки сегмента в последний сегмент для того, чтобы определять начальную точку информации, и использование начальной точки информации в качестве начальной точки сегмента и конечной точки последнего сегмента.
[0027] Настоящее решение не допускает разделения одного фрагмента полной информации на два сегмента и дополнительно точно разделяет начальную точку и конечную точку сегмента.
[0028] В одном варианте осуществления, способ дополнительно включает в себя:
[0029] определение того, является или нет информация начальной точки сегмента полной, и если она не является полной, перемещение из начальной точки сегмента в конечную точку сегмента для того, чтобы определять конечную точку информации, и использование конечной точки информации в качестве начальной точки сегмента и конечной точки последнего сегмента.
[0030] Настоящее решение не допускает разделения одного фрагмента полной информации на два сегмента и дополнительно точно разделяет начальную точку и конечную точку сегмента.
[0031] В одном варианте осуществления, способ дополнительно включает в себя:
[0032] определение того, является или нет информация конечной точки сегмента полной, и если она не является полной, перемещение из конечной точки сегмента в следующий сегмент для того, чтобы определять конечную точку информации, и использование конечной точки информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
[0033] Настоящее решение не допускает разделения одного фрагмента полной информации на два сегмента и дополнительно точно разделяет начальную точку и конечную точку сегмента.
[0034] В одном варианте осуществления, способ дополнительно включает в себя:
[0035] определение того, является или нет информация конечной точки сегмента полной, и если она не является полной, перемещение из конечной точки сегмента в начальную точку сегмента для того, чтобы определять начальную точку информации, и использование начальной точки информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
[0036] Настоящее решение не допускает разделения одного фрагмента полной информации на два сегмента и дополнительно точно разделяет начальную точку и конечную точку сегмента.
[0037] В одном варианте осуществления, способ дополнительно включает в себя:
[0038] определение того, используются или нет данные мгновенного макета, содержащиеся в данных макета, в пределах предварительно установленного периода времени, и если они не используются, удаление данных мгновенного макета.
[0039] Настоящее решение позволяет экономить память мобильного терминала.
[0040] В одном варианте осуществления, способ дополнительно включает в себя:
[0041] определение того, превышает или нет объем памяти занимаемый данными мгновенного макета, содержащимися в данных макета, предварительно установленное значение, и если он превышает предварительно установленное значение, удаление данных мгновенного макета.
[0042] Настоящее решение позволяет экономить память мобильного терминала.
[0043] Согласно второму аспекту вариантов осуществления настоящего раскрытия, предусмотрен терминал, включающий в себя:
[0044] модуль получения, выполненный с возможностью получать документ электронной книги;
[0045] модуль сегментации, выполненный с возможностью разделять контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
[0046] модуль компоновки, выполненный с возможностью компоновать множество сегментов в группу упорядоченных сегментов;
[0047] модуль выбора, выполненный с возможностью выбирать один сегмент из группы сегментов в качестве текущего сегмента;
[0048] модуль синтаксического анализа, выполненный с возможностью синтаксически анализировать контент текущего сегмента для того, чтобы формировать данные макета; и
[0049] модуль формирования, выполненный с возможностью формировать изображение страницы в соответствии с данными макета.
[0050] В одном варианте осуществления, терминал дополнительно включает в себя:
[0051] модуль записи, выполненный с возможностью записывать информацию позиции текущего сегмента в группе сегментов;
[0052] первый модуль определения, выполненный с возможностью определять, меньше или нет объем данных для данных макета предварительно установленного значения; и
[0053] первый модуль выполнения, выполненный с возможностью, когда объем данных меньше предварительно установленного значения, выбирать следующий сегмент относительно текущего сегмента согласно информации позиции, использовать следующий сегмент в качестве текущего сегмента, затем возвращаться к выполнению модуля синтаксического анализа.
[0054] В одном варианте осуществления, модуль сегментации включает в себя:
[0055] блок определения размеров сегментов, выполненный с возможностью определять размер сегмента; и
[0056] блок разделения, выполненный с возможностью разделять контент документа электронной книги на множество сегментов, имеющих размер, равный размеру сегмента.
[0057] В одном варианте осуществления, терминал дополнительно включает в себя:
[0058] второй модуль определения, выполненный с возможностью определять то, является или нет информация начальной точки сегмента полной; и
[0059] второй модуль выполнения, выполненный с возможностью, когда информация начальной точки сегмента не является полной, перемещаться вперед из начальной точки сегмента для определения начальной точки данной информации, и использовать эту начальную точку информации в качестве начальной точки сегмента.
[0060] В одном варианте осуществления, терминал дополнительно включает в себя:
[0061] третий модуль определения, выполненный с возможностью определять то, является или нет информация начальной точки сегмента полной; и
[0062] третий модуль выполнения, выполненный с возможностью, при определении того, что информация начальной точки сегмента не является полной, перемещаться из начальной точки сегмента в конечную точку сегмента для определения конечной точки информации и использовать эту конечную точку информации в качестве начальной точки сегмента и конечной точки последнего сегмента.
[0063] В одном варианте осуществления, терминал дополнительно включает в себя:
[0064] четвертый модуль определения, выполненный с возможностью определять, является или нет информация конечной точки сегмента полной; и
[0065] четвертый модуль выполнения, выполненный с возможностью, когда информация конечной точки сегмента не является полной, перемещаться из конечной точки сегмента в следующий сегмент для определения конечной точки данной информации и использовать эту конечную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
[0066] В одном варианте осуществления, терминал дополнительно включает в себя:
[0067] пятый модуль определения, выполненный с возможностью определять то, является или нет информация конечной точки сегмента полной; и
[0068] пятый модуль выполнения, выполненный с возможностью, когда информация конечной точки сегмента не является полной, перемещаться из конечной точки сегмента в начальную точку сегмента для определения начальной точки данной информации и использовать эту начальную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
[0069] В одном варианте осуществления, терминал дополнительно включает в себя:
[0070] шестой модуль определения, выполненный с возможностью определять, используются или нет данные мгновенного макета, содержащиеся в данных макета, в пределах предварительно установленного периода времени; и
[0071] шестой модуль выполнения, выполненный с возможностью удалять данные мгновенного макета, когда данные мгновенного макета не используются в пределах предварительно установленного периода времени.
[0072] В одном варианте осуществления, терминал дополнительно включает в себя:
[0073] седьмой модуль определения, выполненный с возможностью определять, превышает или нет объем памяти, занимаемый данными мгновенного макета, содержащимися в данных макета, предварительно установленное значение; и
[0074] седьмой модуль выполнения, выполненный с возможностью удалять данные мгновенного макета, когда объем памяти, занимаемый данными мгновенного макета, превышает предварительно установленное значение.
[0075] Согласно третьему аспекту вариантов осуществления настоящего раскрытия, также предусмотрено электронное устройство, включающее в себя запоминающее устройство и одну или более программ, при этом одна или более программ хранятся в запоминающем устройстве и выполнены с возможностью их исполнения посредством одного или более процессоров, при этом одна или более программ содержат инструкции для выполнения операций:
[0076] получения документа электронной книги;
[0077] разделения контента документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
[0078] компоновки множества сегментов в группу упорядоченных сегментов;
[0079] выбора одного сегмента из группы сегментов в качестве текущего сегмента;
[0080] синтаксического анализа контента текущего сегмента для формирования данных макета; и
[0081] формирования изображения страницы в соответствии с данными макета.
[0082] Вышеуказанные и другие признаки и преимущества вариантов осуществления настоящего раскрытия описываются в нижеприведенном пояснении и частично должны становиться более очевидными из него или пониматься посредством реализации вариантов осуществления настоящего раскрытия. Признаки и преимущества вариантов осуществления настоящего раскрытия могут реализовываться и получаться посредством структур, установленных в письменном описании, в формуле изобретения и на прилагаемых чертежах.
[0083] Следует понимать, что как вышеприведенное общее описание, так и нижеприведенное подробное описание являются только примерными, а не ограничивающими настоящее раскрытие.
[0084] В дальнейшем в этом документе, подробнее описываются технические решения настоящего раскрытия посредством прилагаемых чертежей и вариантов осуществления.
Краткое описание чертежей
[0085] Прилагаемые чертежи, которые содержатся и составляют часть этого подробного описания, иллюстрируют варианты осуществления в соответствии с изобретением и наряду с описанием служат для того, чтобы пояснять принципы раскрытия изобретения.
[0086] Фиг. 1 является примерной блок-схемой последовательности операций, показывающей способ для обработки документа электронной книги, предоставленный посредством варианта осуществления настоящего раскрытия;
[0087] Фиг. 2 является примерной блок-схемой последовательности операций, показывающей другой способ для обработки документа электронной книги, предоставленный посредством варианта осуществления настоящего раскрытия;
[0088] Фиг. 3 является примерной блок-схемой последовательности операций, показывающей еще один другой способ для обработки документа электронной книги, предоставленный посредством варианта осуществления настоящего раскрытия;
[0089] Фиг. 4 является примерной блок-схемой последовательности операций, показывающей способ для обработки HTML-документа, предоставленный посредством варианта осуществления настоящего раскрытия;
[0090] Фиг. 5 является блок-схемой, показывающей терминал, предоставленный посредством варианта осуществления настоящего раскрытия;
[0091] Фиг. 6 является блок-схемой, показывающей модуль сегментации, предоставленный посредством варианта осуществления настоящего раскрытия;
[0092] Фиг. 7 является блок-схемой, показывающей другой терминал, предоставленный посредством варианта осуществления настоящего раскрытия;
[0093] Фиг. 8 является блок-схемой, показывающей еще один другой терминал, предоставленный посредством варианта осуществления настоящего раскрытия;
[0094] Фиг. 9 является блок-схемой, показывающей еще один другой терминал, предоставленный посредством варианта осуществления настоящего раскрытия;
[0095] Фиг. 10 является структурной блок-схемой, показывающей электронное устройство, предоставленное посредством варианта осуществления настоящего раскрытия.
Подробное описание изобретения
[0096] В настоящее время, процесс, при котором мобильный терминал читает документ электронной книги, может включать в себя следующие этапы: этап синтаксического анализа для синтаксического анализа документа электронной книги в данные макета посредством мобильного терминала; этап полной разбивки на страницы для выполнения процесса полной разбивки на страницы для вышеуказанных данных макета, чтобы получать рамку страницы; этап формирования объектов страницы для формирования соответствующего объекта страницы посредством использования рамки страницы и данных макета; и этап формирования изображений страниц для формирования изображения страницы посредством рендеринга объекта страницы. После обработки вышеуказанных этапов, пользователь может просматривать изображение страницы электронной книги посредством мобильного терминала.
[0097] Чтобы реализовывать лучшее чтение документов электронной книги посредством мобильного терминала, варианты осуществления настоящего раскрытия предоставляют способ, терминал и электронное устройство для обработки документа электронной книги, так что мобильный терминал, при чтении электронной книги, может иметь небольшое время чтения и сокращенное использование запоминающего устройства. Вышеописанные способ, терминал и электронное устройство для обработки документа электронной книги могут иметь множество конкретных реализаций, и их подробное описание приводится через конкретные варианты осуществления, как пояснено ниже.
[0098] Ссылаясь на фиг. 1, которая иллюстрирует способ для обработки документа электронной книги, способ включает в себя следующие этапы.
[0099] На этапе 101 получают документ электронной книги.
[00100] После открытия пользователем электронной книги через мобильный терминал, мобильный терминал может считать документ электронной книги во внутреннее запоминающее устройство, и в это время мобильный терминал получает документ электронной книги.
[00101] В вариантах осуществления настоящего раскрытия, документ электронной книги может представлять собой потоковый документ электронной книги. Потоковый документ электронной книги, описанный здесь, означает, что описанная информация, к примеру, символы и изображения, не имеет фиксированной позиции макета, и когда параметры макета (такие как, ширина макета, размер шрифта и межстрочный интервал) изменяются, макет должен быть перекомпонован, чтобы адаптировать документ электронной книги с новыми параметрами макета. Потоковый документ электронной книги включает в себя документ, содержащий HTML-документ, при этом HTML-документ состоит из меток, в силу чего мобильный терминал также может получать метки, составляющие HTML-документ, при получении HTML-документа электронной книги.
[00102] На этапе 102 контент документа электронной книги разделяют на множество сегментов в соответствии с предварительно установленным способом сегментации.
[00103] Предварительно установленный способ сегментации может иметь множество форм реализации, например, определение размера сегмента и разделение контента документа электронной книги на множество сегментов, имеющих размер, идентичный размеру сегмента. В частности, размер сегмента представляет размер каждого сегмента после того, как документ электронной книги разделен, так что размер сегмента может задаваться заранее либо может задаваться пользователем мобильного терминала, либо может вычисляться согласно экспериментам.
[00104] На этапе 103 множество сегментов компонуют в группу упорядоченных сегментов.
[00105] После разделения документа электронной книги посредством вышеуказанных этапов, документ электронной книги разделен на множество сегментов. Чтобы обеспечивать обработку данных согласно порядку контента исходного документа электронной книги, должно устанавливаться соединение между сегментами, с тем чтобы компоновать сегменты в одну группу сегментов согласно исходному порядку.
[00106] На этапе 104 один сегмент выбирается из группы сегментов в качестве текущего сегмента.
[00107] Любой сегмент в группе сегментов может выбираться согласно требованиям пользователя, с тем чтобы обеспечивать выполнение следующих этапов для обработки выбранного сегмента.
[00108] На этапе 105 контент в текущем сегменте синтаксически анализируется, чтобы сформировать данные макета.
[00109] Контент в определенном сегменте является только частью контента всего документа электронной книги, данные, которые должны синтаксически анализироваться, намного меньше контента всего документа электронной книги, в силу чего скорость синтаксического анализа намного выше. Кроме того, поскольку объем данных уменьшается, занимаемое запоминающее устройство существенно сокращается.
[00110] Помимо этого, после формирования данных макета, для того чтобы экономить объем памяти мобильного терминала, способ может включать в себя следующие этапы: определение того, используются или нет данные мгновенного макета, содержащиеся в данных макета, в пределах предварительно установленного периода времени, и если они не используются, удаление данных мгновенного макета. Если данные макета не используются в течение длительного времени, для того чтобы экономить объем памяти, занимаемый данными макета, данные мгновенного макета могут удаляться и могут повторно формироваться при необходимости позднее.
[00111] Помимо этого, после формирования данных макета, для того чтобы экономить объем памяти мобильного терминала, способ может включать в себя следующие этапы: определение того, превышает или нет объем памяти, занимаемый данными мгновенного макета, содержащимися в данных макета, предварительно установленное значение, и если оно превышает предварительно установленное значение, удаление данных мгновенного макета. Если данных макета слишком много, что может приводить к слишком низкой скорости обработки на следующих этапах, то могут удаляться все данные макета, либо может удаляться предварительно установленный объем данных макета.
[00112] На этапе 106 изображение страницы формируется в соответствии с данными макета.
[00113] Объем данных для данных макета формируется посредством одного сегмента, так что объем данных для данных макета является относительно небольшим. Следовательно, в процессе формирования изображения страницы, отнимаемое время и занимаемое запоминающее устройство значительно сокращаются.
[00114] На этапе 106 способ дополнительно может включать в себя три этапа: 1) выполнение процесса разбивки на страницы для данных макета, чтобы формировать рамку макета страницы; 2) формирование объекта страницы согласно рамке макета страницы и данным макета; и 3) подготовка посредством рендеринга объекта страницы для формирования изображения страницы.
[00115] В варианте осуществления, показанном на фиг. 1, документ электронной книги разделен на множество сегментов. При каждой операции обработки электронной книги только один сегмент документа электронной книги синтаксически анализируется, и данные макета, сформированные из сегмента, используются для формирования изображения страницы, следовательно, объем данных, которые должны обрабатываться каждый раз в ходе работы, представляет собой только объем данных одного сегмента. Таким образом, когда мобильный терминал читает документ электронной книги, может повышаться эффективность обработки данных, за счет этого сокращая время на то, чтобы читать электронную книгу. Кроме того, операция сегментации может обеспечивать выполнение обработки документа электронной книги в пакетном режиме, когда мобильный терминал обрабатывает один сегмент документа электронной книги, объем данных, которые должны обрабатываться либо при операции синтаксического анализа, либо при последующей операции формирования изображений страниц, является относительно небольшим, за счет этого сокращая объем памяти мобильного терминала, занимаемый электронной книгой.
[00116] Ссылаясь на фиг. 2, которая показывает другой способ для обработки документа электронной книги, способ включает в себя следующие этапы.
[00117] На этапе 201 получают документ электронной книги.
[00118] После открытия пользователем электронной книги через мобильный терминал, мобильный терминал может считать документ электронной книги во внутреннее запоминающее устройство, и в это время, мобильный терминал получает документ электронной книги. В вариантах осуществления настоящего раскрытия, документ электронной книги может представлять собой HTML-документ. HTML-документ состоит из меток, в силу чего мобильный терминал также может получать метки, составляющие HTML-документ, при получении HTML-документа электронной книги.
[00119] На этапе 202 контент документа электронной книги разделяют на множество сегментов в соответствии с предварительно установленным способом сегментации.
[00120] Предварительно установленный способ сегментации может иметь множество форм реализации. В дальнейшем в этом документе вводится один способ сегментации, который представляет собой: определение размера сегмента и разделение контента документа электронной книги на множество сегментов, имеющих размер, идентичный размеру сегмента. В частности, размер сегмента представляет размер каждого сегмента после того, как документ электронной книги разделен, так что размер сегмента может задаваться заранее либо может задаваться пользователем мобильного терминала, либо может вычисляться согласно экспериментам.
[00121] На этапе 203 множество сегментов компонуется в группу упорядоченных сегментов.
[00122] После разделения документа электронной книги посредством вышеуказанных этапов, документ электронной книги разделен на множество сегментов. Чтобы обеспечивать обработку данных согласно порядку контента исходного документа электронной книги, должно устанавливаться соединение между сегментами, с тем чтобы компоновать сегменты в одну группу сегментов согласно исходному порядку.
[00123] На этапе 204 один сегмент выбирается из группы сегментов в качестве текущего сегмента.
[00124] Любой сегмент в группе сегментов может выбираться согласно требованиям пользователя, с тем чтобы обеспечить выполнение следующих этапов для обработки выбранного сегмента.
[00125] На этапе 205 контент в текущем сегменте синтаксически анализируется для формирования данных макета.
[00126] Контент в определенном сегменте является только частью контента всего документа электронной книги, данные, которые должны синтаксически анализироваться, намного меньше контента всего документа электронной книги, в силу чего скорость синтаксического анализа намного выше. Кроме того, поскольку объем данных уменьшается, занимаемое пространство памяти существенно сокращается.
[00127] На этапе 206, записывается информация позиции текущего сегмента в группе сегментов.
[00128] Предусмотрено множество способов для реализации информации позиции, например, с использованием байтов, чтобы записывать информацию позиции, или с использованием меток, чтобы записывать информацию позиции. Для документа электронной книги, который представляет собой HTML-документ, информация позиции сегмента может записываться посредством использования байтового смещения. Единицей байтового смещения является байт. Настоящее раскрытие конкретно не ограничивает информацию позиции при условии, что оно может записывать позицию сегмента в группе сегментов, что может быть в пределах объема решения настоящего раскрытия.
[00129] На этапе 207 определяется то, меньше или нет объем данных для данных макета предварительно установленного значения, если "Да", выполняется этап 208; а если "Нет", выполняется этап 209.
[00130] Данные макета формируются посредством синтаксического анализа текущего сегмента, и объем данных для данных макета, сформированных посредством синтаксического анализа каждого сегмента, составляет определенный объем. Если объем данных для сформированных данных макета является достаточным для формирования изображения страницы, то данные макета используются для того, чтобы формировать изображение страницы; а если объем данных для сформированных данных макета является недостаточным для формирования изображения страницы, требуется синтаксически анализировать следующий сегмент для того, чтобы формировать данные макета и комбинировать существующие данные макета и данные макета, сформированные посредством следующего сегмента, между собой для того, чтобы формировать изображение страницы.
[00131] На этапе 208 следующий сегмент относительно текущего сегмента выбирается согласно информации позиции, следующий сегмент используется в качестве текущего сегмента, и процедура возвращается к этапу 205.
[00132] На этапе 206, записана информация позиции текущего сегмента, в силу чего информация позиции следующего сегмента может определяться на основе информации позиции текущего сегмента, и за счет этого можно выбирать контент в следующем сегменте. Затем следующий сегмент используется в качестве сегмента, который должен обрабатываться в данный момент, и процедура возвращается к этапу 205.
[00133] На этапе 209 изображение страницы формируется в соответствии с данными макета.
[00134] Объем данных для данных макета формируется посредством одного сегмента, так что объем данных для данных макета является относительно небольшим. Следовательно, в процессе формирования изображения страницы, отнимаемое время или занимаемое запоминающее устройство значительно сокращаются.
[00135] В варианте осуществления, показанном на фиг. 2, который отличается от варианта осуществления, показанного на фиг. 1, следующим: определение того, является или нет объем данных для сформированных данных макета достаточным для формирования изображения страницы, если "Да", то формирование изображения страницы согласно существующим данным макета; а если "Нет", синтаксический анализ следующего сегмента и формирование изображения страницы посредством комбинирования существующих данных макета и данных макета, сформированных посредством следующего сегмента.
[00136] На основе вышеописанных вариантов осуществления, после этапа формирования множества сегментов, можно точно разделять начальную точку и конечную точку сегмента. Например, когда документ электронной книги конкретно представляет собой HTML-документ, начальная точка сегмента представляет собой начальную позицию сегмента, и конечная точка сегмента представляет собой конечную позицию сегмента. HTML-документ состоит из меток. Метка состоит из двух угловых скобок, а именно, метка состоит из открывающей угловой скобки "<" и закрывающей угловой скобки ">", при этом контент метки размещается между этими двумя угловыми скобками. Согласно синтаксическим предписаниям HTML, метка должна включать в себя открывающую угловую скобку "<" и закрывающую угловую скобку ">", так что метка является полной. Следовательно, после сегментации, не допускается такая нестандартная ситуация, при которой определенный сегмент содержит только открывающую угловую скобку или содержит только закрывающую угловую скобку. Если это происходит, это означает то, что одна метка разделена на два сегмента, что приводит к тому, что метка не может синтаксически анализироваться в дальнейшем. Чтобы дополнительно разделять начальную точку и конечную точку сегмента, см. вариант осуществления на фиг. 3.
[00137] Ссылаясь на фиг. 3, которая показывает еще один другой способ для обработки документа электронной книги, способ включает в себя следующие этапы.
[00138] На этапе 301 получают документ электронной книги.
[00139] После открытия пользователем электронной книги через мобильный терминал, мобильный терминал может читать документ электронной книги во внутреннее запоминающее устройство, и в это время, мобильный терминал получает документ электронной книги. В вариантах осуществления настоящего раскрытия, документ электронной книги может представлять собой HTML-документ. HTML-документ состоит из меток, в силу чего мобильный терминал также может получать метки, составляющие HTML-документ, при получении HTML-документа электронной книги.
[00140] На этапе 302, контент документа электронной книги разделяют на множество сегментов в соответствии с предварительно установленным способом сегментации.
[00141] Предварительно установленный способ сегментации может иметь множество форм реализации. В дальнейшем в этом документе вводится один способ сегментации, который представляет собой: определение размера сегмента и разделение контента документа электронной книги на множество сегментов, имеющих размер, идентичный размеру сегмента. В частности, размер сегмента представляет размер каждого сегмента после того, как документ электронной книги разделен, так что размер сегмента может задаваться заранее либо может задаваться пользователем мобильного терминала, либо может вычисляться согласно экспериментам.
[00142] На этапе 303 определяется то, является или нет информация начальной точки сегмента полной, если "Да", то выполняется этап 305; а если "Нет", выполняется этап 304.
[00143] После сегментации, для того, чтобы не допускать разделения одного фрагмента полной информации на два сегмента, требуется определять то, является или нет информация начальной точки сегмента полной, и если она не является полной, требуется выполнять небольшое регулирование начальной точки и конечной точки сегмента, с тем чтобы обеспечивать то, что информация в каждом сегменте является полной.
[00144] На этапе 304 начальная точка информации определяется посредством перемещения из начальной точки сегмента в последний сегмент, и начальная точка информации используется в качестве начальной точки сегмента и конечной точки последнего сегмента.
[00145] Если информация начальной точки сегмента не является полной, это означает то, что первая половина информации назначается в последнем сегменте, в то время как последняя половина информации остается в начальной точке сегмента. Чтобы обеспечивать то, что информация является полной, предусмотрено множество способов реализации, при этом один способ реализации является способом регулирования этапа 304, который заключается в том, чтобы удалять первую половину информации в последнем сегменте и дополнять первую половину информации до начальной точки сегмента, при этом начальная точка сегмента и конечная точка последнего сегмента являются идентичной точкой. В частности, второй способ реализации заключается в перемещении из начальной точки сегмента в конечную точку сегмента для того, чтобы определять конечную точку информации, и использовании конечной точки информации в качестве начальной точки сегмента и конечной точки последнего сегмента. Второй способ заключается в том, чтобы удалять последнюю половину информации в сегменте и дополнять последнюю половину информации до конечной точки последнего сегмента. Вышеуказанные два способа могут выполнять небольшое регулирование начальной точки и конечной точки каждого сегмента, так что информация в каждом сегменте является полной.
[00146] Безусловно, чтобы гарантировать то, что информация в сегменте является полной, помимо применения способа этапа 304, также может быть возможным определять начальную точку другой информации в качестве начальной точки сегмента и конечной точки последнего сегмента. Хотя при этом способе, смещение начальной точки или конечной точки сегмента может быть слишком большим, он по-прежнему позволяет разрешать проблему неполной информации. Следовательно, вариант осуществления, предоставленный посредством настоящего раскрытия, не ограничен способом этапа 304. Другие способы, имеющие принципы, идентичные принципу этапа 304, при условии способности достижения цели полной информации также могут быть применимыми, на что не накладывается конкретных ограничений в данном документе.
[00147] На этапе 305, множество сегментов компонуется в группу упорядоченных сегментов.
[00148] После разделения документа электронной книги посредством вышеуказанных этапов, документ электронной книги разделен на множество сегментов. Чтобы обеспечивать обработку данных согласно порядку контента исходного документа электронной книги, должно устанавливаться соединение между сегментами, с тем чтобы компоновать сегменты в одну группу сегментов согласно исходному порядку.
[00149] На этапе 306 один сегмент выбирается из группы сегментов в качестве текущего сегмента.
[00150] Любой сегмент в группе сегментов может выбираться согласно требованиям пользователя, с тем чтобы упрощать следующие этапы для того, чтобы обрабатывать выбранный сегмент.
[00151] На этапе 307 контент в текущем сегменте синтаксически анализируется для того, чтобы формировать данные макета.
[00152] Контент в определенном сегменте является только частью контента всего документа электронной книги, данные, которые должны синтаксически анализироваться, намного меньше контента всех документов электронной книги, в силу чего скорость синтаксического анализа намного выше. Кроме того, поскольку объем данных уменьшается, занимаемое запоминающее устройство существенно сокращается.
[00153] На этапе 308 изображение страницы формируется в соответствии с данными макета.
[00154] Объем данных для данных макета формируется посредством одного сегмента, в силу чего объем данных для данных макета является относительно небольшим. Следовательно, в процессе формирования изображения страницы, отнимаемое время и занимаемое запоминающее устройство значительно сокращаются.
[00155] В варианте осуществления, показанном на фиг. 3, для того, чтобы не допускать разделения одного фрагмента полной информации на два сегмента, также можно определять то, является или нет информация конечной точки сегмента полной. В частности, предусмотрено два способа реализации. Первый способ включает в себя: определение того, является или нет информация конечной точки сегмента полной, и если она не является полной, перемещение из конечной точки сегмента в следующий сегмент для того, чтобы определять конечную точку информации, и использование конечной точки информации в качестве конечной точки сегмента и начальной точки следующего сегмента. Второй способ включает в себя: определение того, является или нет информация конечной точки сегмента полной, и если она не является полной, перемещение из конечной точки сегмента в начальную точку сегмента для того, чтобы определять начальную точку информации, и использование начальной точки информации в качестве конечной точки сегмента и начальной точки следующего сегмента. Принцип этих способов является аналогичным принципу этапов 303 и 304, на предмет подробностей см. пояснение для этапов 303 и 304, которые повторно не описываются.
[00156] В варианте осуществления, показанном на фиг. 3, который отличается от варианта осуществления, показанного на фиг. 1 тем, что для того, чтобы не допускать разделения одного фрагмента полной информации на два сегмента, начальная точка и конечная точка сегмента дополнительно точно разделяются.
[00157] Ссылаясь на фиг. 4, которая показывает пример конкретного варианта применения, предоставленный посредством настоящего раскрытия, этот пример варианта применения вводит конкретный способ обработки в случае, если документ электронной книги представляет собой HTML-документ 1, при этом способ для обработки HTML-документа 1 включает в себя следующие этапы.
[00158] На первом этапе получают HTML-документ 1.
[00159] На втором этапе контент HTML-документа 1 разделяют на множество HTML-сегментов согласно предварительно установленному способу сегментации.
[00160] На втором этапе, самый значимый признак процесса синтаксического анализа HTML-документа 1 заключается в том, чтобы синтаксически анализировать HTML-сегмент, и время, расходуемое на синтаксический анализ небольшого HTML-сегмента, является приемлемым. Если только один небольшой HTML-сегмент обрабатывается в ходе каждого процесса синтаксического анализа, время одного синтаксического анализа может сокращаться. Следовательно, HTML-документ синтаксически анализируется в сегментах в данном документе.
[00161] Требуется, во-первых, определять значение m размера сегмента (единица: Б (байт)); затем равномерно разделять HTML-документ 1 с размером n (единица: Б (байт)) на n/m фрагментов согласно значению m, за счет этого получая (n/m-1) точек останова. Поскольку полнота меток в HTML-документе 1 должна быть обеспечена при синтаксическом анализе HTML-документа 1 от неначальной точки, с тем чтобы не допускать появления половины метки в HTML-сегменте, требуется поочередно анализировать то, удовлетворяет или нет каждая точка останова из вышеуказанных (n/m-1) точек останова требованию ненахождения внутри HTML-метки. Согласно синтаксическим предписаниям HTML, метка должна быть заключена в скобки посредством открывающей угловой скобки "<" и закрывающей угловой скобки ">", с длиной, в общем, в пределах 1024 Б. Согласно вышеуказанному ограничению, можно запрашивать вперед или назад на определенное число байтов для каждой точки в вышеуказанных (n/m-1) точек останова, чтобы удовлетворять требованию ненахождения внутри HTML-метки.
[00162] В частности, предусмотрено множество способов для определения значения m размера сегмента, например, способ искусственного задания или способ вычисления. Ниже приведено введение с акцентом на способе вычисления для определения значения m размера сегмента.
[00163] 1. Теоретический анализ
[00164] Поскольку время синтаксического анализа HTML-документа 1 определяется непосредственно посредством числа HTML-узлов, по мере того, как HTML-документ 1 постепенно увеличивается, число HTML-узлов также увеличивается, и время, расходуемое на глубокий обход узлов, должно постепенно увеличиваться. Следовательно, кривая времени синтаксического анализа HTML-документа 1, варьирующегося с размером HTML-документа 1, является возрастающей вперед кривой. Обычно, когда HTML-документ 1 является небольшим, число HTML-узлов меньше. Для современных компьютеров, синтаксический анализ HTML-документа 1 может реализовывать глубокий обход за очень короткое время (например, для HTML-документа 1 в 10 КБ и 50 КБ, времена синтаксического анализа обоих из них могут иметь несущественную разность); и когда размер HTML-документа достигает определенного уровня, число HTML-узлов может иметь нелинейный значительный рост, в силу этого приводя к нелинейному увеличению времени синтаксического анализа HTML-документа 1. В кратком изложении вышеприведенного анализа, можно видеть, что время синтаксического анализа HTML-документа 1, варьирующееся с размером HTML-документа 1, сначала имеет направление уменьшения, а затем увеличения, так что на кривой имеется точка перегиба. Когда размер HTML-документа 1 достигает точки перегиба, эффективность синтаксического анализа HTML-документа 1 резко падает.
[00165] 2. Теоретическая верификация
[00166] Тест производительности синтаксического анализа выполняется для нескольких групп физических HTML-пространств, которые подготовлены ранее посредством использования некоторых стандартных средств анализа производительности, результаты тестирования каждой группы записываются, и затем кривая времени синтаксического анализа HTML-документа, варьирующегося с размером HTML-документа 1, рисуется в виде графика посредством использования инструментального средства визуализации, за счет чего верифицируется вышеуказанный теоретический анализ.
[00167] 3. Поиск точки перегиба производительности синтаксического анализа HTML-документа 1
[00168] Через кривую времени синтаксического анализа HTML-документа 1, варьирующегося с размером HTML-документа 1, после вышеуказанной теоретической верификации, можно определять то, что когда размер HTML-документа 1 меньше определенного значения M, времена синтаксического анализа HTML-документа фактически имеют несущественное варьирование, тогда как когда физическое пространство HTML превышает определенное значение N, время синтаксического анализа HTML-документа может резко увеличиваться. Соответственно, размер HTML-документа 1, соответствующего точке перегиба производительности синтаксического анализа HTML-документа 1, может определяться в интервале [M, N]. Затем выполняется анализ в интервале [M, N]; и в это время, должны рассматриваться два критерия: a) нецелесообразно разделять HTML-документ 1 на слишком большое число сегментов, иначе сложность управления сегментом может увеличиваться, т.е. значение m размера сегмента не может быть слишком маленьким; b) нецелесообразно, чтобы время синтаксического анализа для одного HTML-сегмента было слишком большим, иначе могут возникать такие недостатки, что пользователь ожидает слишком долго, т.е. значение m размера сегмента не может быть слишком большим. Минимальное значение M и максимальное значение N в интервале [M, N] может удаляться согласно вышеуказанным двум критериям, чтобы получать новый интервал, затем минимальное значение и максимальное значение в новом интервале могут удаляться снова согласно вышеуказанным двум критериям. Посредством повторения вышеуказанной операции поочередно, если в завершение остается одно значение, это значение используется в качестве размера HTML-документа 1, соответствующего точке перегиба производительности (т.е. значения m размера сегмента); и если в завершение остаются два значения, то среднее значение между двумя значениями используется в качестве размера HTML-документа 1, соответствующего точке перегиба производительности (т.е. значения m размера сегмента).
[00169] На третьем этапе, множество сегментов компонуются в группу упорядоченных сегментов.
[00170] Наиболее существенный недостаток процесса синтаксического анализа состоит в том, что невозможно осуществлять его в обратном порядке, т.е. синтаксический анализ должен выполняться согласно физическому порядку HTML-документа 1. При начале синтаксического анализа от неначальной точки HTML-документа 1 HTML-документ 1 может иметь неполные контексты, что вызывает такие проблемы, как потеря узлов меток. Следовательно, синтаксический анализ интервала 2 состояний HTML-документа 1 используется в данном документе для того, чтобы преодолевать проблему.
[00171] 1. Синтаксический анализатор для HTML-документа 1 заново создается. В это время, состояние синтаксического анализатора синтаксически не анализируется посредством HTML-документов 1, что называется "начальным состоянием синтаксического анализа". Начальное состояние синтаксического анализа не является релевантным для конкретного HTML-документа 1, и любой новый созданный синтаксический анализатор для HTML-документа 1 может быть в начальном состоянии синтаксического анализа.
[00172] 2. Поскольку состояние синтаксического анализа HTML-документа 1 может записывать байтовое смещение в HTML-документ 1, в то время как результат сегментации HTML-документа 1 также описан посредством использования байтового смещения, соответствие "один-к-одному" между HTML-сегментом и интервалом синтаксического анализа может устанавливаться согласно этой соответствующей взаимосвязи байтового смещения. Следовательно, первый HTML-сегмент соответствует первому интервалу синтаксического анализа, его начальное состояние синтаксического анализа (байтовое смещение находится там, где первый сегмент начинается) применяется в качестве начального состояния синтаксического анализа, и его конечное состояние синтаксического анализа представляет собой состояние после того, как завершен синтаксический анализ первого HTML-сегмента (байтовое смещение находится там, где первый сегмент завершается).
[00173] 3. Для интервала синтаксического анализа, соответствующего каждому HTML-сегменту после первого HTML-сегмента, начальное состояние синтаксического анализа наследует конечное состояние синтаксического анализа последнего интервала синтаксического анализа, и конечное состояние синтаксического анализа представляет собой состояние после того, как завершен синтаксический анализ этого HTML-сегмента. Наследование состояния синтаксического анализа представляет собой процесс клонирования состояния синтаксического анализа, а именно, копирования в неизменном виде байтового смещения HTML-документа 1, в котором расположено одно состояние синтаксического анализа (для записи текущей позиции состояния синтаксического анализа в HTML-документе 1), информации стека родительского узла HTML-метки (для записи тракта, который состояние синтаксического анализа проходит в HTML-документе 1), взаимосвязи контекстов при синтаксическом анализе (для записи взаимосвязи контекстов, что состояние синтаксического анализа в текстовых узлах HTML-документа 1) и т.п. в другое состояние синтаксического анализа.
[00174] Согласно этой схеме, каждый HTML-сегмент, при участии в процессе синтаксического анализа HTML-документа 1, наследует состояние синтаксического анализа последнего HTML-сегмента, т.е. наследует взаимосвязь контекстов последнего HTML-сегмента, за счет чего преодолевается проблема, вызываемая посредством взаимосвязи неполных контекстов.
[00175] На четвертом этапе, один сегмент выбирается из группы сегментов в качестве текущего сегмента.
[00176] На пятом этапе, контент текущего сегмента синтаксически анализируется для того, чтобы формировать данные 3 макета.
[00177] Процесс управления макетом заключается в следующем:
[00178] 1. Механизм формирования макетов запускается. Когда обнаружено, что данные 31 мгновенного макета, соответствующие текущему HTML-сегменту, являются нулевыми, выполняется поиск HTML-сегмента, в котором находится точка в текущем макете, согласно смещению HTML-документа 1, соответствующему точке, интервал синтаксического анализа соответствующего HTML-документа 1 активируется, и соответствующий HTML-сегмент интерпретируется, за счет этого формируя соответствующие данные 32 узла метки и данные 31 мгновенного макета. Для данных 32 узла метки, поскольку данные 31 мгновенного макета зависят от информации вида данных 32 узла метки, наряду с синтаксическим анализом данных 31 мгновенного макета, данные 32 узла метки синтаксически анализируются, соответственно. Данные 32 узла метки должны сохраняться только для одной копии, и если обнаружено, что данные 32 узла метки, соответствующие HTML-сегменту, уже существуют, соответствующие данные 32 узла метки не добавляются в процесс синтаксического анализа.
[00179] 2. Макет выполняется для того, чтобы завершать разбивку на страницы или формирование объектов страницы. Между тем, ситуация использования текущих ресурсов хранения отслеживается, при превышении указанного порогового значения (например, запоминающее устройство для хранения приложений на платформе Android, в общем, ограничивается 24 МБ, а приложение на платформе iOS, в общем, ограничивается 20 МБ), данные 31 мгновенного макета, соответствующие временно неиспользуемому HTML-сегменту, удаляются.
[00180] На шестом этапе, изображение страницы формируется согласно данным 3 макета.
[00181] Процесс полной HTML-разбивки на страницы заключается в следующем:
[00182] Процесс полной разбивки на страницы выполняется с самого начала физического HTML-пространства, с вызовом процесса управления макетом для каждого HTML-сегмента последовательно от начала до конца. Для каждого HTML-сегмента, когда процесс разбивки на страницы достигает последней страницы сегмента, может возникать случай половины страницы. Чтобы обеспечивать то, что последняя страница текущего сегмента является последовательной по отношению к следующему сегменту, в это время HTML-данные следующего сегмента сразу синтаксически анализируются, после чего разбивка на страницы выполняется от начальной точки последней страницы текущего сегмента. Если обнаружено, что мгновенный макет является ненадлежащим, то мгновенный макет следующего сегмента используется для того, чтобы не допускать проблем излома между сегментами.
[00183] Процесс формирования объектов страницы заключается в следующем:
[00184] 1. Посредством байтового смещения HTML-документа 1 (в дальнейшем называемого "запрашиваемой точкой"), определяется номер страницы в пространстве 4 HTML-страницы, соответствующем ей (начальная точка и конечная точка HTML-страницы могут записывать байтовое смещение в физическом HTML). В это время, могут возникать две ситуации: номер страницы получается, и номер страницы не получается. Если номер страницы получается, это означает то, что процесс полной разбивки на страницы достигает запрашиваемой точки, далее используется результат полной разбивки на страницы, соответствующий номеру страницы; а если номер страницы не получается, это означает то, что процесс полной разбивки на страницы еще не достигает запрашиваемой точки, в это время начинается процесс временного синтаксического анализа, чтобы получать результат разбивки на страницы, соответствующий запрашиваемой точке.
[00185] 2. Согласно вышеуказанному полученному результату разбивки на страницы, вызывается процесс управления макетом, и завершается формирование объектов страницы.
[00186] Процесс временного синтаксического анализа заключается в следующем:
[00187] 1. HTML-сегмент, в котором расположена запрашиваемая точка (в дальнейшем называемый "запрашиваемым сегментом"), определяется согласно запрашиваемой точке; интервал 2 состояния синтаксического анализа HTML-документа 1 заново создается, начальное состояние синтаксического анализа применяется в качестве начального состояния синтаксического анализа, и конечное состояние синтаксического анализа применяется в качестве состояния запрашиваемого сегмента после синтаксического анализа посредством использования начального состояния синтаксического анализа.
[00188] 2. Процесс управления макетом вызывается, интервал 2 состояния синтаксического анализа на вышеуказанном этапе принудительно должен использоваться для того, чтобы выполнять разбивку на страницы для запрашиваемого сегмента, и формируется пространство 4 для временного синтаксического анализа страницы.
[00189] 3. Номер страницы запрашиваемой точки в пространстве 4 для временного синтаксического анализа страницы определяется согласно запрашиваемой точке, и результат временного синтаксического анализа страницы получается согласно номеру страницы.
[00190] Отметим, что когда процесс полной разбивки на страницы еще не достигает интервала, в котором расположена требуемая страница, процесс временного синтаксического анализа используется для того, чтобы получать требуемую страницу. В это время, хотя взаимосвязь полных HTML-контекстов не используется, после того, как процесс полной разбивки на страницы достигает требуемой страницы, он обращается к результату полной разбивки на страницы для того, чтобы корректировать проблему синтаксического анализа HTML от неначальной точки. Когда процесс полной разбивки на страницы HTML еще не завершен, запрещено переходить к следующей странице посредством использования номера страницы по причине того, что номер страницы может превышать номер, до которого дошла разбивка в процессе полной разбивки на страницы. В это время, есть возможность переходить к следующей странице согласно процентному отношению от размера физического HTML-пространства. После того, как завершена полная разбивка на страницы, можно переходить к следующей странице посредством использования номера страницы.
[00191] Решение, предоставленное посредством настоящего раскрытия, приводит к тому, что HTML-документ 1 с большим размером занимает меньшее пространство в запоминающем устройстве в ходе процесса полной разбивки на страницы и уменьшает время получения результата полной разбивки на страницы в начальной части HTML-документа 1. Временный синтаксический анализ используется до достижения пространства посредством полной разбивки на страницы, за счет чего повышается производительность HTML-перехода, и проблема, вероятно, существующая во временном синтаксическом анализе, корректируется после того, как полная разбивка на страницы достигает пространства.
[00192] Это позволяет обеспечивать следующие преимущества для возможностей работы пользователей:
[00193] 1. Время синтаксического анализа и время полной разбивки на страницы HTML-документа распределяются для каждого HTML-сегмента, время ожидания первой страницы явно сокращается, когда пользователь открывает электронную книгу в основном с HTML-документом 1, имеющим большой размер;
[00194] 2. После того, как полная разбивка на страницы достигает запрашиваемой точки, результат полной разбивки на страницы используется, с тем чтобы обеспечивать то, что структура вида книги не нарушена, когда пользователь читает электронную книгу в основном с HTML-документом 1, имеющим большой размер, и контент представляется пользователю в форме, наиболее напоминающей исходную книгу;
[00195] 3. Меньшее пространство в запоминающем устройстве занимается, в силу чего явно уменьшается вероятность сбоя, когда пользователь открывает электронную книгу в основном с HTML-документом 1, имеющим большой размер, на устройстве, имеющем меньше ресурсов хранения, к примеру, на мобильном устройстве;
[00196] 4. Меньшее пространство в запоминающем устройстве занимается, в силу чего программное обеспечение для чтения работает быстрее, когда пользователь читает электронную книгу в основном с HTML-документом 1, имеющим большой размер, и повышается скорость работы пользователя;
[00197] 5. Процесс временного синтаксического анализа приспосабливается, в силу чего время ожидания для синхронизации хода чтения явно сокращается, когда пользователь читает электронную книгу в основном с HTML-документом 1, имеющим большой размер;
[00198] 6. Процесс временного синтаксического анализа приспосабливается, в силу чего время ожидания для перехода по каталогу явно сокращается, когда пользователь читает электронную книгу в основном с HTML-документом 1, имеющим большой размер;
[00199] 7. Процесс временного синтаксического анализа приспосабливается, в силу чего время ожидания для ускоренной перемотки вперед или ускоренной перемотки назад явно сокращается, когда пользователь читает электронную книгу в основном с HTML-документом 1, имеющим большой размер.
[00200] Фиг. 5 показывает терминал, включающий в себя: модуль 11 получения, выполненный с возможностью получать документ электронной книги; модуль 12 сегментации, выполненный с возможностью разделять контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации; модуль 13 компоновки, выполненный с возможностью компоновать множество сегментов в группу упорядоченных сегментов; модуль 14 выбора, выполненный с возможностью выбирать один сегмент из группы сегментов в качестве текущего сегмента; модуль 15 синтаксического анализа, выполненный с возможностью синтаксически анализировать контент текущего сегмента для того, чтобы формировать данные макета; и модуль 16 формирования, выполненный с возможностью формировать изображение страницы в соответствии с данными макета. Фиг. 6 показывает подробную структуру модуля 12 сегментации, включающего в себя блок 121 определения размеров сегментов и блок 122 разделения, при этом блок 121 определения размеров сегментов выполнен с возможностью определять размер сегмента; и блок 122 разделения выполнен с возможностью разделять контент документа электронной книги на множество сегментов, имеющих размер, идентичный размеру сегмента.
[00201] В варианте осуществления, показанном на фиг. 5, модуль 12 сегментации используется для того, чтобы разделять документ электронной книги на множество сегментов. При каждой операции обработки электронной книги модуль 15 синтаксического анализа только синтаксически анализирует один сегмент документа электронной книги, и модуль 16 формирования формирует изображение страницы посредством использования данных макета, сформированных из сегмента, следовательно, объем данных, которые должны обрабатываться каждый раз в ходе работы, представляет собой только объем данных одного сегмента. Таким образом, когда мобильный терминал читает документ электронной книги, может повышаться эффективность обработки данных, за счет этого сокращая время на то, чтобы читать электронную книгу. Кроме того, операция сегментации может инструктировать документу электронной книги обрабатываться в пакетном режиме, и когда мобильный терминал обрабатывает один сегмент документа электронной книги, объем данных, которые должны обрабатываться либо при операции синтаксического анализа, либо при последующей операции формирования изображений страниц, является относительно небольшим, за счет этого сокращая запоминающее устройство мобильного терминала, занимаемое посредством электронной книги.
[00202] В варианте осуществления, показанном на фиг. 6, размер сегмента, полученный посредством блока 121 определения размеров сегментов, используется для того, чтобы представлять размер каждого сегмента, после того как разделяется документ электронной книги. Размер сегмента может задаваться заранее либо может задаваться пользователем мобильного терминала, либо может вычисляться согласно экспериментам. Затем блок 122 разделения используется для того, чтобы разделять документ электронной книги согласно полученному размеру сегмента.
[00203] Ссылаясь на фиг. 7, которая показывает другой терминал, терминал включает в себя: модуль 21 получения, выполненный с возможностью получать документ электронной книги; модуль 22 сегментации, выполненный с возможностью разделять контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации; модуль 23 компоновки, выполненный с возможностью компоновать множество сегментов в группу упорядоченных сегментов; модуль 24 выбора, выполненный с возможностью выбирать один сегмент из группы сегментов в качестве текущего сегмента; модуль 25 синтаксического анализа, выполненный с возможностью синтаксически анализировать контент текущего сегмента для того, чтобы формировать данные макета; модуль 26 записи, выполненный с возможностью записи информации позиции текущего сегмента в группе сегментов; первый модуль 27 определения, выполненный с возможностью определять то, меньше или нет объем данных для данных макета предварительно установленного значения; первый модуль 28 выполнения, выполненный с возможностью, когда объем данных меньше предварительно установленного значения, выбирать следующий сегмент относительно текущего сегмента согласно информации позиции в качестве текущего сегмента, затем возвращаться к выполнению модуля 25 синтаксического анализа; и модуль 29 формирования, выполненный с возможностью формировать изображение страницы в соответствии с данными макета.
[00204] В варианте осуществления, показанном на фиг. 7, который отличается от варианта осуществления, показанного на фиг. 6 следующим: является или нет объем данных для сформированных данных макета достаточным для того, чтобы формировать изображение страницы, определяется посредством первого модуля 27 определения, если "Да", изображение страницы формируется согласно существующим данным макета; а если "Нет", следующий сегмент синтаксически анализируется, и существующие данные макета и данные макета, сформированные посредством следующего сегмента, комбинируются друг с другом таким образом, что формируется изображение страницы.
[00205] Ссылаясь на фиг. 8, которая показывает еще один другой терминал, терминал включает в себя: модуль 31 получения, выполненный с возможностью получать документ электронной книги; модуль 32 сегментации, выполненный с возможностью разделять контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации; второй модуль 33 определения, выполненный с возможностью определять то, является или нет информация начальной точки сегмента полной; второй модуль 34 выполнения, выполненный с возможностью перемещаться вперед из начальной точки сегмента для того, чтобы определять начальную точку метки, когда информация начальной точки сегмента не является полной, и использовать начальную точку метки в качестве начальной точки сегмента; модуль 35 компоновки, выполненный с возможностью компоновать множество сегментов в группу упорядоченных сегментов; модуль 36 выбора, выполненный с возможностью выбирать один сегмент из группы сегментов в качестве текущего сегмента; модуль 37 синтаксического анализа, выполненный с возможностью синтаксически анализировать контент текущего сегмента для того, чтобы формировать данные макета; и модуль 38 формирования, выполненный с возможностью формировать изображение страницы в соответствии с данными макета.
[00206] В варианте осуществления, показанном на фиг. 8, который отличается от варианта осуществления, показанного на фиг. 5 тем, что для того, чтобы не допускать разделения одного фрагмента полной информации на два сегмента, начальная точка и конечная точка сегмента дополнительно точно разделяются.
[00207] В варианте осуществления, показанном на фиг. 8, предусмотрено три способа реализации, которые могут эквивалентно заменять функции второго модуля 33 определения и второго модуля 34 выполнения, как описано выше. Три способа реализации кратко вводятся, как пояснено ниже. Первый способ замены заключается в замене второго модуля 33 определения посредством использования третьего модуля определения и в замене второго модуля 34 выполнения посредством использования третьего модуля выполнения. В частности, третий модуль определения выполнен с возможностью определять то, является или нет информация начальной точки сегмента полной; и третий модуль выполнения выполнен с возможностью, при определении того, что информация начальной точки сегмента не является полной, перемещаться из начальной точки сегмента в конечную точку сегмента для того, чтобы определять конечную точку информации, и использовать конечную точку информации в качестве начальной точки сегмента и конечной точки последнего сегмента. Второй способ замены заключается в замене второго модуля 33 определения посредством использования четвертого модуля определения и в замене второго модуля 34 выполнения посредством использования четвертого модуля выполнения. В частности, четвертый модуль определения выполнен с возможностью определять то, является или нет информация конечной точки сегмента полной; и четвертый модуль выполнения выполнен с возможностью, когда информация конечной точки сегмента не является полной, перемещаться из конечной точки сегмента в следующий сегмент для того, чтобы определять конечную точку информации, и использовать конечную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента. Третий способ замены заключается в замене второго модуля 33 определения посредством использования пятого модуля определения и в замене второго модуля 34 выполнения посредством использования пятого модуля выполнения. В частности, пятый модуль определения выполнен с возможностью определять то, является или нет информация конечной точки сегмента полной; и пятый модуль выполнения выполнен с возможностью, когда информация конечной точки сегмента не является полной, перемещаться из конечной точки сегмента в начальную точку сегмента для того, чтобы определять начальную точку информации, и использовать начальную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
[00208] В варианте осуществления, показанном на фиг. 8, чтобы обеспечивать то, что информация в сегменте является полной, можно не только применять функции второго модуля 33 определения и второго модуля 34 выполнения, но также и определять начальную точку другой информации в качестве начальной точки сегмента и конечной точки последнего сегмента. Хотя при этом способе, смещение начальной точки или конечной точки сегмента может быть слишком большим, он по-прежнему позволяет разрешать проблему неполной информации. Следовательно, вариант осуществления, предоставленный посредством настоящего раскрытия, не ограничен способом, показанным на фиг. 8. Другие модули, имеющие функции и принципы, идентичные функциям и принципам второго модуля 33 определения и второго модуля 34 выполнения, при условии способности реализации заполнения информации, также могут быть применимыми, на что не накладывается конкретных ограничений в данном документе.
[00209] Ссылаясь на фиг. 9, которая показывает еще один другой терминал, терминал включает в себя: модуль 41 получения, выполненный с возможностью получать документ электронной книги; модуль 42 сегментации, выполненный с возможностью разделять контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации; модуль 43 компоновки, выполненный с возможностью компоновать множество сегментов в группу упорядоченных сегментов; модуль 44 выбора, выполненный с возможностью выбирать один сегмент из группы сегментов в качестве текущего сегмента; модуль 45 синтаксического анализа, выполненный с возможностью синтаксически анализировать контент текущего сегмента для того, чтобы формировать данные макета; шестой модуль 46 определения, выполненный с возможностью определять то, используются или нет данные мгновенного макета, содержащиеся в данных макета, в пределах предварительно установленного периода времени; шестой модуль 47 выполнения, выполненный с возможностью удалять данные мгновенного макета, когда данные мгновенного макета не используются в пределах предварительно установленного периода времени; и модуль 48 формирования, выполненный с возможностью формировать изображение страницы в соответствии с данными макета.
[00210] В варианте осуществления, показанном на фиг. 9, после формирования данных макета посредством модуля 45 синтаксического анализа, чтобы экономить пространство запоминающего устройства мобильного терминала, он может реализовываться посредством использования шестого модуля 46 определения и шестого модуля 47 выполнения. Если данные макета не используются в течение длительного времени, для того чтобы экономить пространство запоминающего устройства, занимаемое данными макета, данные мгновенного макета могут удаляться и могут повторно формироваться при необходимости позднее.
[00211] В варианте осуществления, показанном на фиг. 9, после формирования данных макета посредством модуля 45 синтаксического анализа, чтобы экономить запоминающее устройство мобильного терминала, он может реализовываться посредством использования седьмого модуля определения для того, чтобы заменять шестой модуль 46 определения, и использования седьмого модуля выполнения для того, чтобы заменять шестой модуль 47 выполнения. В частности, седьмой модуль определения выполнен с возможностью определять то, превышает или нет объем памяти, занимаемый данными мгновенного макета, содержащимися в данных макета, предварительно установленное значение; и седьмой модуль выполнения выполнен с возможностью удалять данные мгновенного макета, когда объем памяти, занимаемый данными мгновенного макета, превышает предварительно установленное значение. Если данных макета слишком много, скорость обработки следующих этапов может быть слишком низкой. Могут удаляться все данные макета, либо может удаляться предварительно установленный объем данных макета, в силу чего достигается цель экономии запоминающего устройства мобильного терминала.
[00212] Как показано на фиг. 10, электронное устройство дополнительно предоставляется посредством варианта осуществления настоящего раскрытия. Электронное устройство используется для того, чтобы реализовывать способ для обработки документа электронной книги, предоставленный в вышеописанных вариантах осуществления. Ниже подробно описывается электронное устройство.
[00213] Электронное устройство 1300 может включать в себя RF (радиочастотную) схему 1310, запоминающее устройство 1320, включающее в себя один или более машиночитаемых носителей хранения данных, блок 1330 ввода, блок 1340 отображения, датчик 1350, аудиосхему 1360, модуль 1370 ближней беспроводной связи, процессор 1380, включающий в себя одно или более ядер обработки, и источник 1390 питания и т.п. Специалисты в данной области техники могут понимать, что структура электронного устройства, показанного на фиг. 13, не ограничивает электронное устройство, и электронное устройство может включать в себя большее или меньшее число частей относительно частей на фиг. 13 либо может комбинировать определенные части, либо может иметь другие компоновки частей.
[00214] RF-схема 1310 может использоваться для того, чтобы принимать и отправлять информацию или принимать и отправлять сигналы в процессе вызова. В частности, после того, как информация нисходящей линии связи принимается из базовой станции, информация нисходящей линии связи обрабатывается посредством одного или более процессоров 1380; и данные восходящей линии связи отправляются в базовую станцию. Обычно, RF-схема 1310 включает в себя антенну, по меньшей мере, один усилитель, тюнер, один или более осцилляторов, карту с модулем идентификации абонента (SIM), приемо-передающее устройство, разветвитель, LNA (малошумящий усилитель) и дуплексер и т.д., но ограничения на это нет. Кроме того, RF-схема 1310 также может обмениваться данными с сетью и другими устройствами посредством беспроводной связи. Беспроводная связь может использовать любой стандарт или протокол связи, включающий в себя GSM (глобальную систему мобильной связи), GPRS (общую службу пакетной радиопередачи), CDMA (множественный доступ с кодовым разделением каналов), WCDMA (широкополосный множественный доступ с кодовым разделением каналов), LTE (стандарт долгосрочного развития), протокол электронной почты, SMS (службу коротких сообщений) и т.п., но ограничения на это нет.
[00215] Запоминающее устройство 1320 может использоваться для того, чтобы сохранять программы и модули. Процессор 1380 выполняет различные виды функциональных приложений и обработки данных посредством управления программами и модулями, сохраненными в запоминающем устройстве 1320. Запоминающее устройство 1320 может в основном включать в себя область хранения программ и область хранения данных, при этом область хранения программ может сохранять операционную систему, по меньшей мере, одну прикладную программу, требуемую для таких функций, как функция воспроизведения звука и функция воспроизведения изображения; и область хранения данных может сохранять данные, такие как аудиоданные и телефонная книга, созданные в соответствии с использованием электронного устройства 1300. Кроме того, запоминающее устройство 1320 может включать в себя высокоскоростное оперативное запоминающее устройство или энергонезависимое запоминающее устройство, или, например, по меньшей мере, одно устройство хранения данных на магнитных дисках, устройство флэш-памяти, или другие энергонезависимые полупроводниковые запоминающие устройства. Соответственно, запоминающее устройство 1320 также может включать в себя контроллер хранения данных, чтобы предоставлять для процессора 1380 и блока 1330 ввода доступ к запоминающему устройству 1320.
[00216] Блок 1330 ввода может использоваться для того, чтобы принимать вводимые цифры или символьную информацию и формировать сигнал, вводимый из клавиатуры, мыши, джойстика, оптического устройства или шарового манипулятора, относящийся к пользовательским настройкам и функциональному управлению. Например, блок 1330 ввода может включать в себя сенсорную поверхность 1331 и другое устройство 1332 ввода. Сенсорная поверхность 1331, которая также упоминается как экран сенсорного дисплея или сенсорная панель, может собирать операции касания от пользователя вслед на ней или около (например, операции на сенсорной поверхности 1331 или около сенсорной поверхности 1331 пользователем с использованием любого надлежащего объекта или вспомогательного устройства, такого как палец или сенсорное перо) и может активировать соответствующее соединительное устройство согласно предварительно установленной программе. Альтернативно, сенсорная поверхность 1331 может включать в себя две части, включающие в себя устройство обнаружения касаний и сенсорный контроллер, при этом устройство обнаружения касаний обнаруживает ориентации касания пользователя и обнаруживает сигналы, активируемые посредством операций касания, затем передает сигналы в сенсорный контроллер; сенсорный контроллер принимает сенсорную информацию из устройства обнаружения касаний и преобразует сенсорную информацию в координаты точек касания, которые должны отправляться в процессор 1380, и сенсорный контроллер принимает команды, отправленные из процессора 1380, и выполняет команды. Кроме того, сенсорная поверхность 1331 может быть реализована посредством использования различных типов способов, к примеру, как резистивная, емкостная, инфракрасная и на основе поверхностных акустических волн. В дополнение к сенсорной поверхности 1331 блок 1330 ввода также может включать в себя другое устройство 1332 ввода. Например, другое устройство 1332 ввода может включать в себя одну или более физических клавиатур, функциональную клавишу (к примеру, клавишу регулирования громкости или клавишу переключения и т.д.), шаровой манипулятор, мышь и джойстик, но ограничения на это нет.
[00217] Блок 1340 отображения может использоваться для того, чтобы отображать информацию, вводимую пользователем, или информацию, предоставленную пользователю, и различные виды графических пользовательских интерфейсов электронного устройства 1300, и эти графические пользовательские интерфейсы могут состоять из графика, текста, значка, видео или любой комбинации вышеозначенного. Блок 1340 отображения может включать в себя панель 1341 отображения, и альтернативно, панель 1341 отображения может быть сконфигурирована посредством использования ЖК-дисплея (жидкокристаллического дисплея), OLED (дисплея на органических светоизлучающих диодах) и т.п. Дополнительно, сенсорная поверхность 1331 может покрывать панель 1341 отображения, и после того, как сенсорная поверхность 1331 обнаруживает операции касания на ней или около, сенсорная поверхность 1331 передает операции касания в процессор 1380, чтобы определять типы событий касания, после чего процессор 1380 предоставляет соответствующий видеовывод на панели 1341 отображения согласно типам событий касания. На фиг. 13, хотя сенсорная поверхность 1331 и панель 1341 отображения являются двумя отдельными частями для того, чтобы реализовывать функции ввода и вывода, в некоторых конкретных вариантах осуществления, сенсорная поверхность 1331 и панель 1341 отображения могут быть интегрированы для того, чтобы реализовывать функции ввода и вывода.
[00218] Электронное устройство 1300 также может включать в себя, по меньшей мере, один вид датчика 1350, к примеру, светочувствительный датчик, датчик движения и другие датчики. Например, светочувствительный датчик может включать в себя датчик окружающего света и бесконтактный датчик, при этом датчик внешнего освещения может регулировать яркость панели 1341 отображения согласно яркости окружающего света, бесконтактный датчик может выключать панель 1341 отображения и/или ее заднюю подсветку, когда электронное устройство 1300 перемещается к уху. В качестве одного из датчиков движения датчик гравитационного ускорения может обнаруживать значения ускорений в соответствующих направлениях (обычно, трехосных направлениях) и может обнаруживать значение и направление гравитации в стационарном состоянии и может использоваться в приложениях для идентификации ориентации телефона в пространстве (к примеру, переключение между горизонтальным и вертикальным экранами, соответствующие игры, калибровка ориентаций в пространстве с помощью магнитометра), соответствующие функции идентификации вибраций (к примеру, шагомер, измеритель ударного воздействия) и т.д.; электронное устройство 1300 также может быть сконфигурировано с другими датчиками, такими как гироскоп, барометр, гигрометр, термометр и инфракрасный датчик, которые повторно не описываются.
[00219] Аудиосхема 1360, динамик 1361 и микрофон 1362 могут предоставлять аудиоинтерфейс между пользователем и электронным устройством 1300. Аудиосхема 1360 может преобразовывать принятые аудиоданные в электрические сигналы и передавать электрические сигналы в динамик 1361, затем динамик 1361 преобразует электрические сигналы в звуковые сигналы, которые должны выводиться; с другой стороны, микрофон 1362 преобразует собранные звуковые сигналы в электрические сигналы, аудиосхема 1360 принимает электрические сигналы и преобразует электрические сигналы в аудиоданные, аудиоданные выводятся в процессор 1380 для обработки, затем аудиоданные отправляются в другое терминальное устройство через RF-схему 1310, или аудиоданные выводятся в запоминающее устройство 1320 для дополнительной обработки. Аудиосхема 1360 может включать в себя гнездо для наушников, чтобы предоставлять связь между периферийной гарнитурой и электронным устройством 1300.
[00220] Модуль 1370 беспроводной связи может представлять собой модуль Wi-Fi (по стандарту высококачественной беспроводной связи) или Bluetooth-модуль и т.п., через который электронное устройство 1300 может помогать пользователю принимать и отправлять электронные письма, просматривать веб-страницы и осуществлять доступ к потоковому мультимедиа. Модуль 1370 беспроводной связи предоставляет пользователю беспроводной широкополосный доступ в Интернет. Хотя фиг. 13 показывает модуль 1370 беспроводной связи, следует понимать, что электронное устройство 1300 не должно обязательно включать в себя модуль 1370 беспроводной связи, и модуль 1370 беспроводной связи может полностью опускаться при необходимости в пределах объема, который не изменяет природу настоящего раскрытия.
[00221] Процессор 1380 представляет собой центр управления электронного устройства 1300, соединяется с соответствующими частями всего электронного устройства посредством использования различных видов интерфейсов и схем и выполняет различные виды функций электронного устройства 1300 и обрабатывает данные посредством управления или выполнения программ и/или модулей, сохраненных в запоминающем устройстве 1320, и обращения к данным, сохраненным в запоминающем устройстве 1320, чтобы за счет этого отслеживать все электронное устройство. Альтернативно, процессор 1380 может включать в себя одно или более ядер обработки; например, процессор 1380 может интегрировать процессор приложений и процессор модуляции-демодуляции, при этом процессор приложений в основном обрабатывает операционную систему, пользовательский интерфейс и прикладную программу, а процессор модуляции-демодуляции в основном обрабатывает беспроводную связь. Очевидно, что процессор модуляции-демодуляции не может быть интегрирован в процессор 1380.
[00222] Электронное устройство 1300 также включает в себя источник 1390 питания (к примеру, аккумулятор), который подает питание в соответствующие части. Предпочтительно, источник питания может быть логически соединен с процессором 1380 посредством системы управления электропитанием, за счет этого реализуя такие функции, как управление зарядом, разрядом и потреблением мощности, посредством системы управления электропитанием. Источник 1390 питания также может включать в себя любой компонент, к примеру, один или более источников питания постоянного тока или переменного тока, систему перезаряда, схему обнаружения сбоев питания, преобразователь питания или инвертор, индикатор состояния источника питания.
[00223] Хотя не показано, электронное устройство 1300 также может включать в себя камеру или Bluetooth-модуль и т.д., которые повторно не описываются. В частности, в настоящем варианте осуществления, блок отображения терминального устройства представляет собой сенсорный дисплей.
[00224] Электронное устройство 1300 дополнительно включает в себя запоминающее устройство и одну или более программ, при этом одна или более программ сохраняются в запоминающем устройстве и выполнены с возможностью осуществления посредством одного или более процессоров, и одна или более программ включает в себя инструкции для осуществления способа обработки документа электронной книги, инструкции включают в себя:
[00225] получение документа электронной книги;
[00226] разделение контента документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
[00227] компоновку множества сегментов в группу упорядоченных сегментов;
[00228] выбор одного сегмента из группы сегментов в качестве текущего сегмента;
[00229] синтаксический анализ контента текущего сегмента для того, чтобы формировать данные макета; и
[00230] формирование изображения страницы в соответствии с данными макета.
[00231] Реализация вышеописанного способа может обращаться к вышеописанным вариантам осуществления способа, который повторно не описывается.
[00232] Следует отметить, что варианты осуществления, показанные на фиг. 1-10, представляют собой только предпочтительные варианты осуществления, описанные в настоящем раскрытии, специалисты в данной области техники могут разрабатывать дополнительные варианты осуществления на этой основе, которые повторно не описываются.
[00233] Соответствующие варианты осуществления в этом описании описываются по восходящей. Для каждого варианта осуществления, его отличия от других вариантов осуществления проиллюстрированы для акцента, и идентичные или аналогичные части между соответствующими вариантами осуществления ссылаются друг на друга. Что касается вышеприведенных соответствующих вариантов осуществления устройства, поскольку они являются практически аналогичными вариантам осуществления способа, их описание является относительно простым, и их коррелированные части могут обращаться к описаниям для соответствующих частей в вариантах осуществления способа.
[00234] Специалисты в данной области техники должны принимать во внимание, что информация, сообщения и сигналы могут быть представлены посредством любого из множества различных процессов и технологий. Например, вышеуказанные сообщения и информация могут представляться как напряжения, токи, электромагнитные волны, магнитные поля или частицы с магнитными полями, оптические поля либо любая комбинация вышеозначенного.
[00235] Специалисты в данной области техники дополнительно могут осознавать, что блоки и этапы алгоритма, описанные в комбинации вариантов осуществления, раскрытых в данном документе, могут реализовываться в электронных аппаратных средствах, в компьютерном программном обеспечении или в комбинации означенного. Чтобы ясно иллюстрировать взаимозаменяемость аппаратных средств и программного обеспечения, структура и этапы в различных примерах, в общем, описаны в соответствии с функциями в вышеприведенных описаниях. То, выполняются эти функции посредством аппаратных средств или программного обеспечения, может зависеть от конкретного варианта применения и проектных ограничений технических решений. Специалисты в данной области техники могут применять различный способ для каждого конкретного варианта применения, чтобы осуществлять описанные функции, без отступления от объема этого раскрытия.
[00236] Этапы способов или алгоритма, описанного в сочетании с вариантами осуществления, раскрытыми в данном документе, могут реализовываться непосредственно в аппаратных средствах, в программных модулях, исполняемых посредством процессора, или в комбинации означенного. Программные модули могут быть помещены в оперативное запоминающее устройство (RAM), запоминающее устройство, постоянное запоминающее устройство (ROM), электрически программируемое ROM, электрически стираемое программируемое ROM, регистры, жесткий диск, съемный диск, CD-ROM или любой другой известный в области техники носитель хранения данных. Вышеприведенное описание раскрытых вариантов осуществления может предоставлять возможность специалистам в данной области техники реализовывать или применять настоящее раскрытие.
[00237] Специалистам в данной области техники должно быть очевидным, что настоящее раскрытие может иметь различные модификации. Общие принципы, заданные в данном документе, могут реализовываться в других вариантах осуществления без отступления от сущности или объема настоящего изобретения. Следовательно, настоящее раскрытие ограничено не этими вариантами осуществления, проиллюстрированными в данном документе, а самым широким объемом в соответствии с принципами и новыми признаками, раскрытыми в данном документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ, СИСТЕМА И УСТРОЙСТВО ДЛЯ ФИЛЬТРАЦИИ РЕКЛАМНЫХ ОБЪЯВЛЕНИЙ ВЕБ-СТРАНИЦ НА МОБИЛЬНОМ ТЕРМИНАЛЕ | 2013 |
|
RU2614572C2 |
| Способ, устройство и терминал для загрузки файлов | 2017 |
|
RU2736857C2 |
| СПОСОБ, УСТРОЙСТВО, ТЕРМИНАЛ И СЕРВЕР ДЛЯ ОТВЕТА НА ВЫЗОВ | 2015 |
|
RU2628480C2 |
| УСТРОЙСТВО ДЛЯ ПЕРЕДАЧИ ПОТОКА БИТОВ ДЛЯ ЕГО ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ СЕГМЕНТАЦИИ НА БЛОКИ | 2023 |
|
RU2830794C1 |
| КОДЕР, ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ И ПРОГРАММА СЖАТИЯ КАДРОВ | 2019 |
|
RU2784381C2 |
| СЕНСОРНАЯ ПЛАНКА И УСТРОЙСТВО МОБИЛЬНОГО ТЕРМИНАЛА | 2013 |
|
RU2580474C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СОКРЫТИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2014 |
|
RU2602985C2 |
| СПОСОБ, УСТРОЙСТВО И ТЕРМИНАЛЬНОЕ УСТРОЙСТВО ДЛЯ ОТОБРАЖЕНИЯ СООБЩЕНИЙ | 2014 |
|
RU2616536C2 |
| СПОСОБ ДЕКОДИРОВАНИЯ ВИДЕО И ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ СЕГМЕНТАЦИИ НА БЛОКИ | 2019 |
|
RU2808103C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБНОВЛЕНИЯ ПОЛЬЗОВАТЕЛЬСКИХ ДАННЫХ | 2014 |
|
RU2608470C2 |
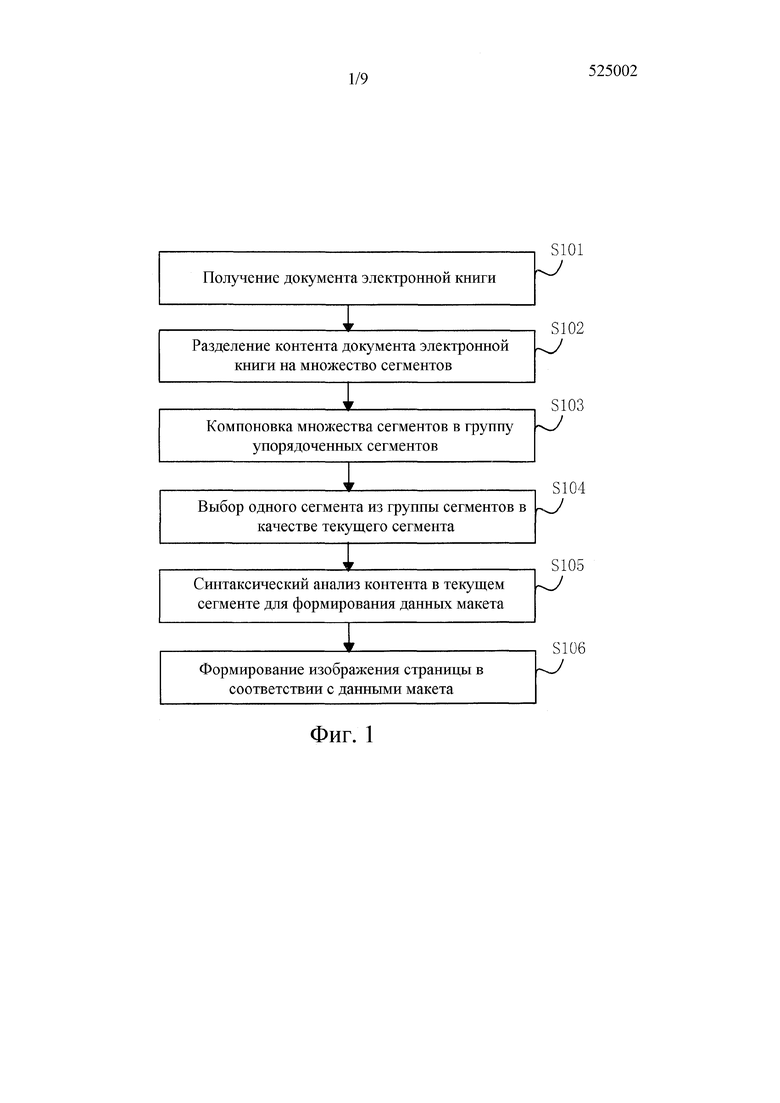
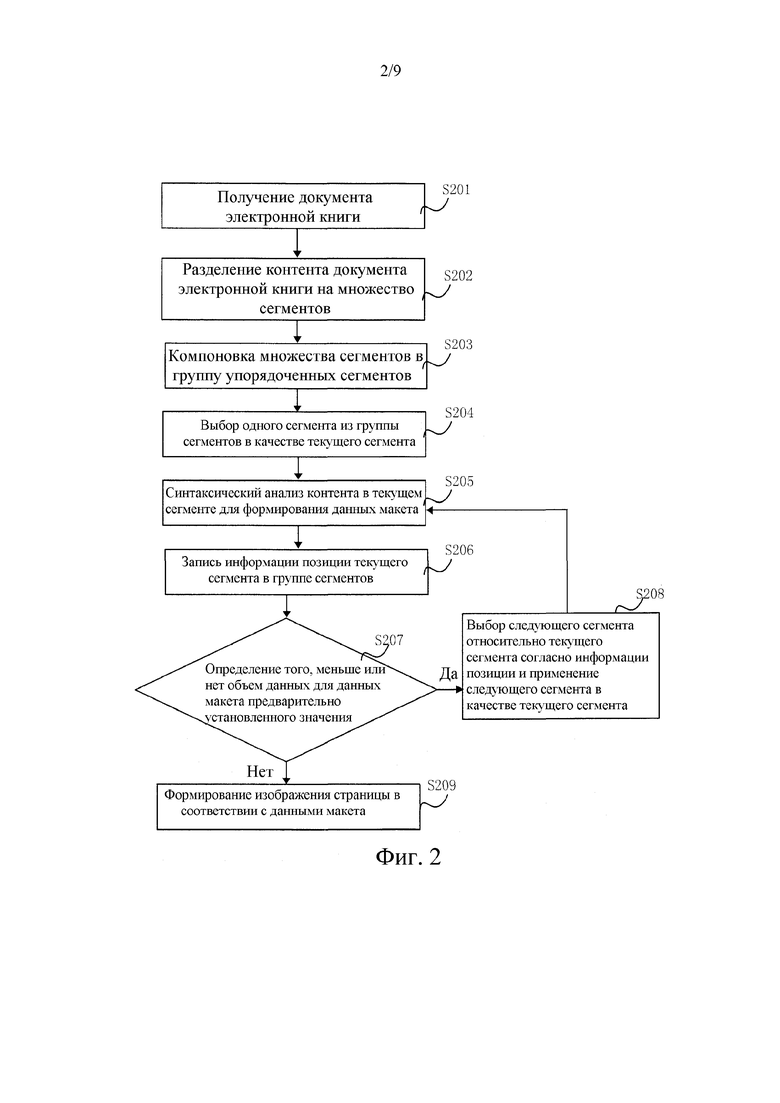
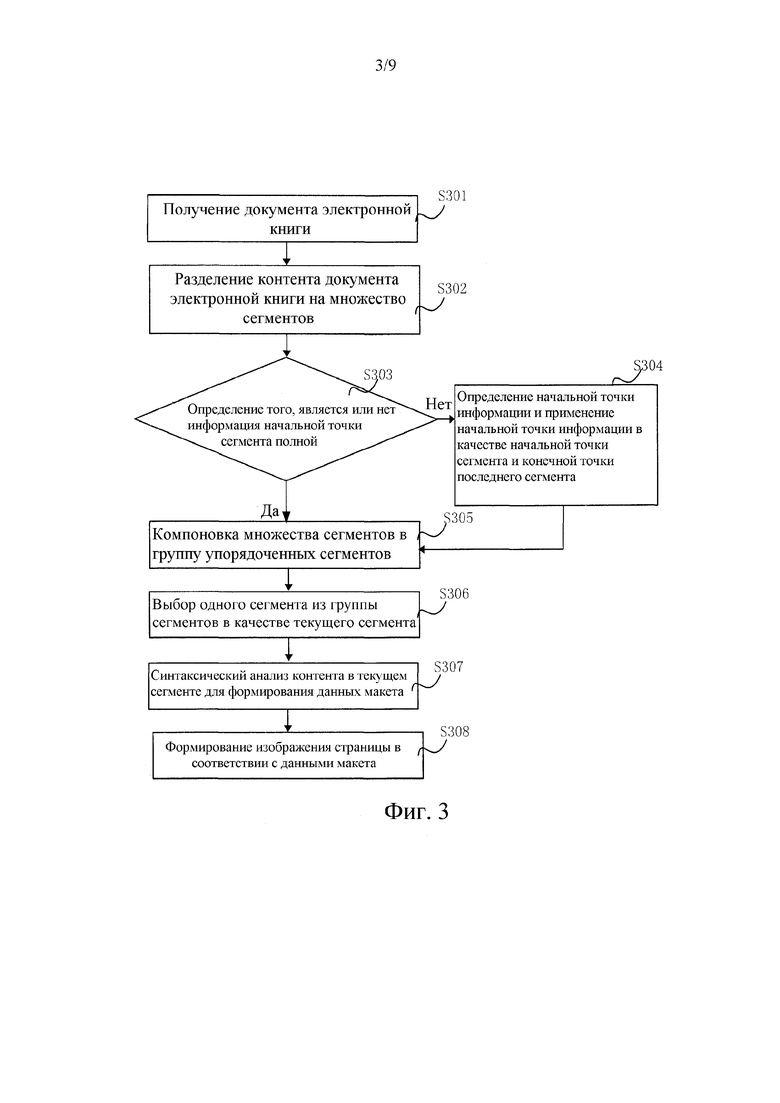

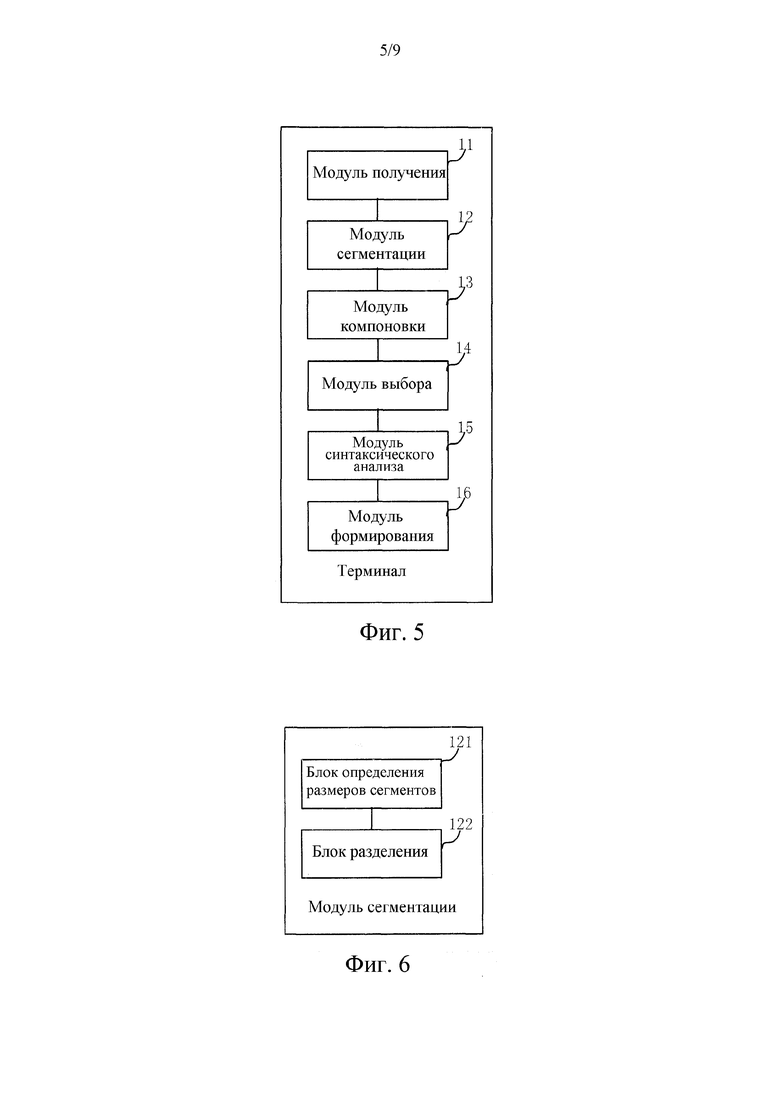


Изобретение относится к области техники обработки данных документов электронной книги. Технический результат заключается в повышении эффективности обработки данных, посредством чего сокращается время на считывание электронной книги. Технический результат достигается за счет получения документа электронной книги, разделения контента документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации, компоновки множества сегментов в группу упорядоченных сегментов, выбора одного сегмента из группы сегментов в качестве текущего сегмента, синтаксического анализа контента текущего сегмента для формирования данных макета и формирования изображения страницы в соответствии с данными макета. При каждой операции обработки электронной книги только один сегмент документа электронной книги синтаксически анализируется и объем данных, которые должны обрабатываться каждый раз в ходе работы, представляет собой только объем данных одного сегмента. 3 н. и 16 з.п. ф-лы, 10 ил.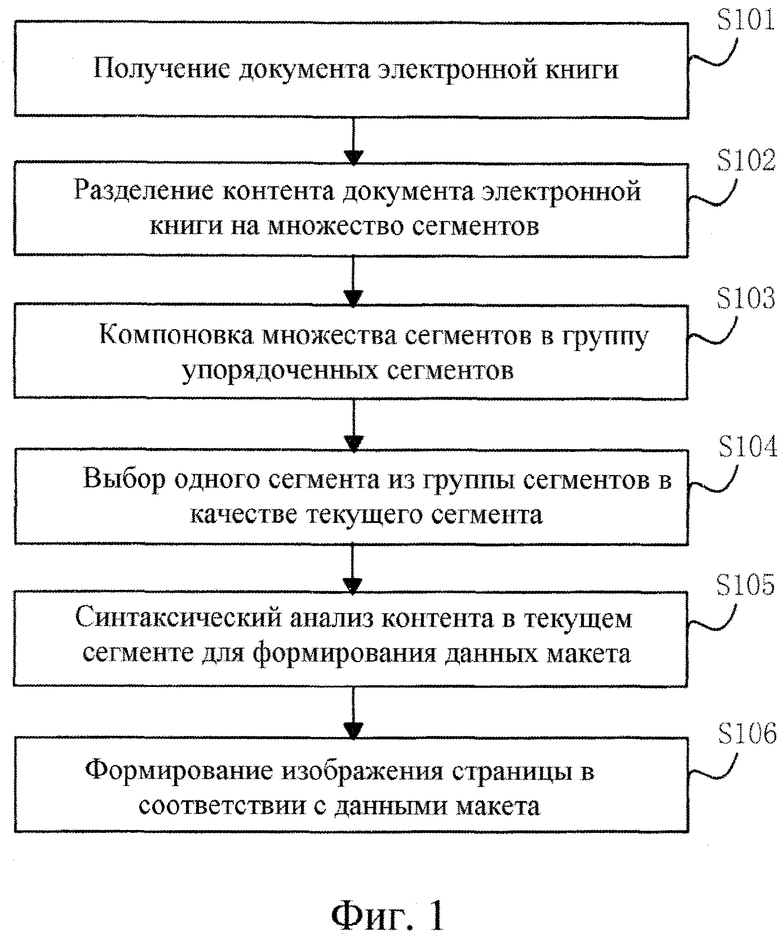
1. Способ обработки документа электронной книги, содержащий этапы, на которых:
получают документ электронной книги;
разделяют контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
компонуют множество сегментов в группу упорядоченных сегментов;
выбирают один сегмент из этой группы сегментов в качестве текущего сегмента;
выполняют синтаксический анализ контента текущего сегмента для формирования данных макета и
формируют изображение страницы в соответствии с данными макета.
2. Способ по п. 1, который после формирования данных макета дополнительно содержит этапы, на которых
записывают информацию позиции текущего сегмента в упомянутой группе сегментов и
определяют, меньше или нет объем данных для данных макета предварительно установленного значения, и, если объем данных меньше предварительно установленного значения, выбирают следующий сегмент относительно текущего сегмента согласно информации позиции, используют следующий сегмент в качестве текущего сегмента и возвращаются к синтаксическому анализу контента текущего сегмента.
3. Способ по п. 1, в котором разделение контента документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации содержит подэтапы, на которых
определяют размер сегмента и
разделяют контент документа электронной книги на сегменты, имеющие размер, равный размеру сегмента.
4. Способ по п. 1, дополнительно содержащий этап, на котором
определяют, является или нет информация начальной точки сегмента полной, и, если она не является полной, перемещаются из начальной точки сегмента в последний сегмент, чтобы определить начальную точку данной информации, и используют эту начальную точку информации в качестве начальной точки сегмента и конечной точки последнего сегмента.
5. Способ по п. 1, дополнительно содержащий этап, на котором
определяют, является или нет информация начальной точки сегмента полной, и, если она не является полной, перемещаются из начальной точки сегмента в конечную точку сегмента, чтобы определить конечную точку данной информации, и используют эту конечную точку информации в качестве начальной точки сегмента и конечной точки последнего сегмента.
6. Способ по п. 1, дополнительно содержащий этап, на котором
определяют, является или нет информация конечной точки сегмента полной, и, если она не является полной, перемещаются из конечной точки сегмента в следующий сегмент, чтобы определить конечную точку данной информации, и используют эту конечную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
7. Способ по п. 1, дополнительно содержащий этап, на котором
определяют, является или нет информация конечной точки сегмента полной, и, если она не является полной, перемещаются из конечной точки сегмента в начальную точку сегмента, чтобы определить начальную точку данной информации, и используют эту начальную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
8. Способ по п. 1, дополнительно содержащий этап, на котором
определяют, используются или нет данные мгновенного макета, содержащиеся в данных макета, в пределах предварительно установленного периода времени, и, если они не используются, удаляют данные мгновенного макета.
9. Способ по п. 1, дополнительно содержащий этап, на котором
определяют, превышает или нет объем памяти, занимаемый данными мгновенного макета, содержащимися в данных макета, предварительно установленное значение, и, если он превышает предварительно установленное значение, удаляют данные мгновенного макета.
10. Терминал, выполненный с возможностью обработки документа электронной книги, при этом терминал содержит:
модуль получения, выполненный с возможностью получать документ электронной книги;
модуль сегментации, выполненный с возможностью разделять контент документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
модуль компоновки, выполненный с возможностью компоновать множество сегментов в группу упорядоченных сегментов;
модуль выбора, выполненный с возможностью выбирать один сегмент из этой группы сегментов в качестве текущего сегмента;
модуль синтаксического анализа, выполненный с возможностью синтаксического анализа контента сегмента для формирования данных макета, и
модуль формирования, выполненный с возможностью формировать изображение страницы в соответствии с данными макета.
11. Терминал по п. 10, дополнительно содержащий:
модуль записи, выполненный с возможностью записывать информацию позиции текущего сегмента в упомянутой группе сегментов;
первый модуль определения, выполненный с возможностью определять, меньше или нет объем данных для данных макета предварительно установленного значения, и
первый модуль выполнения, выполненный с возможностью, когда объем данных меньше предварительно установленного значения, выбирать следующий сегмент относительно текущего сегмента согласно информации позиции, использовать следующий сегмент в качестве текущего сегмента и затем возвращаться к выполнению модуля синтаксического анализа.
12. Терминал по п. 10, в котором модуль сегментации содержит
блок определения размеров сегментов, выполненный с возможностью определять размер сегмента, и
блок разделения, выполненный с возможностью разделять контент документа электронной книги на сегменты, имеющие размер, равный размеру сегмента.
13. Терминал по п. 10, дополнительно содержащий
второй модуль определения, выполненный с возможностью определять, является или нет информация начальной точки сегмента полной, и
второй модуль выполнения, выполненный с возможностью, когда информация начальной точки сегмента не является полной, перемещаться вперед из начальной точки сегмента для определения начальной точки данной информации и использовать эту начальную точку информации в качестве начальной точки сегмента.
14. Терминал по п. 10, дополнительно содержащий
третий модуль определения, выполненный с возможностью определять, является или нет информация начальной точки сегмента полной, и
третий модуль выполнения, выполненный с возможностью, при определении того, что информация начальной точки сегмента не является полной, перемещаться из начальной точки сегмента в конечную точку сегмента для определения конечной точки данной информации и использовать эту конечную точку информации в качестве начальной точки сегмента и конечной точки последнего сегмента.
15. Терминал по п. 10, дополнительно содержащий
четвертый модуль определения, выполненный с возможностью определять, является или нет информация конечной точки сегмента полной, и
четвертый модуль выполнения, выполненный с возможностью, когда информация конечной точки сегмента не является полной, перемещаться из конечной точки сегмента в следующий сегмент для определения конечной точки данной информации и использовать эту конечную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
16. Терминал по п. 10, дополнительно содержащий
пятый модуль определения, выполненный с возможностью определять, является или нет информация конечной точки сегмента полной, и
пятый модуль выполнения, выполненный с возможностью, когда информация конечной точки сегмента не является полной, перемещаться из конечной точки сегмента в начальную точку сегмента для определения начальной точки данной информации и использовать эту начальную точку информации в качестве конечной точки сегмента и начальной точки следующего сегмента.
17. Терминал по п. 10, дополнительно содержащий
шестой модуль определения, выполненный с возможностью определять, используются или нет данные мгновенного макета, содержащиеся в данных макета, в пределах предварительно установленного периода времени, и
шестой модуль выполнения, выполненный с возможностью удалять данные мгновенного макета, когда данные мгновенного макета не используются в пределах предварительно установленного периода времени.
18. Терминал по п. 10, дополнительно содержащий
седьмой модуль определения, выполненный с возможностью определять, превышает или нет объем памяти, занимаемый данными мгновенного макета, содержащимися в данных макета, предварительно установленное значение, и
седьмой модуль выполнения, выполненный с возможностью удалять данные мгновенного макета, когда объем памяти, занимаемый данными мгновенного макета, превышает предварительно установленное значение.
19. Электронное устройство для обработки документа электронной книги, содержащее память и одну или более программу, причем одна или более программа хранится в памяти и приспособлена для исполнения одним или более процессором, при этом одна или более программа содержит инструкции для выполнения операций:
получения документа электронной книги;
разделения контента документа электронной книги на множество сегментов в соответствии с предварительно установленным способом сегментации;
компоновки множества сегментов в группу упорядоченных сегментов;
выбора одного сегмента из этой группы сегментов в качестве текущего сегмента;
синтаксического анализа контента текущего сегмента для формирования данных макета и
формирования изображения страницы в соответствии с данными макета.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 5950214 A, 07.09.1999 | |||
| Электробур для бурения скважин | 1956 |
|
SU118085A1 |

