Настоящая заявка основана и испрашивает приоритет по патентной заявке Китая № 201410260916.0, поданной 12 июня 2014 г., полное содержание которой включается в настоящий документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к области электронной публикации и, в частности, к способу и устройству для обновления пользовательских данных.
УРОВЕНЬ ТЕХНИКИ
Электронные публикации имеют все больший спрос ввиду их короткого цикла редактирования и низких затрат на редактирование. При чтении электронных публикаций пользователи могут генерировать пользовательские данные, такое как закладки, примечания и резюме (дайджесты). Пользовательские данные могут включать в себя: цитируемое содержимое и пользовательскую информацию чтения, касающуюся цитируемого содержимого.
Цитируемое содержимое в пользовательских данных в общем случае представлено путем физического смещения. Иначе говоря, одно цитируемое содержимое может быть представлено в виде (позиция, длина), причем "позиция" представляет смещенную позицию текста цитируемого содержимого во всей электронной публикации, а "длина" представляет длину текста цитируемого содержимого. Например, примечание может быть выражено как "цитируемое содержимое (120 305-й символ, всего 32 символа), содержимое примечания (этот абзац так хорошо написан)". Однако, поскольку электронные публикации могут редактироваться множество раз, цитируемое содержимое, представленное путем физического смещения, имеет склонность изменяться после добавления и удаления содержимого в электронных публикациях. Таким образом, родственная технология обеспечивает способ обновления пользовательских данных: когда электронная публикация редактируется, подробное редактирование записей каждой версии записывается способами, подобными файлам коррекции, и цитируемое содержимое в пользовательских данных повторно вычисляется путем записей редактирования.
Однако в течение разработки настоящего изобретения было обнаружено, что вышеупомянутый способ имеет по меньшей мере следующие недостатки: поскольку генерирование файлов коррекции влечет очень высокие вычислительные затраты и должно обслуживаться отдельно, вышеупомянутый способ обновления пользовательских данных неприменим для широкого использования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Для решения той проблемы, что генерирование файлов коррекции влечет очень высокие вычислительные затраты и должно обслуживаться отдельно, и вышеупомянутый способ обновления пользовательских данных неприменим для широкого использования, варианты осуществления настоящего изобретения обеспечивают способ обновления пользовательских данных, причем технические решения следующие.
Согласно первому аспекту вариантов осуществления настоящего изобретения, представлен способ обновления пользовательских данных. Способ включает в себя:
получение исходной строки символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования;
поиск совпадения исходной строки символов в электронной публикации после редактирования; и
когда поиск совпадения успешен, обновление цитируемого содержимого в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
В одном варианте осуществления поиск совпадения исходной строки символов в электронной публикации после редактирования включает в себя:
непосредственный поиск совпадения исходной строки символов в электронной публикации после редактирования;
или,
сегментацию исходной строки символов на n предложений, расположенных по порядку, причем n является положительным целым числом; и последовательный поиск совпадения n предложений в электронной публикации после редактирования;
или,
непосредственный поиск совпадения исходной строки символов в электронной публикации после редактирования; когда поиск совпадения неуспешен, сегментацию исходной строки символов на n предложений, расположенных по порядку, причем n является положительным целым числом; и последовательный поиск совпадения n предложений в электронной публикации после редактирования.
В одном варианте осуществления последовательный поиск совпадения n предложений в электронной публикации после редактирования включает в себя:
поиск совпадения i-го предложения от начальной позиции поиска, 1≤i≤n; когда i=1, начальная позиция поиска является начальной позицией секции, где расположена исходная строка символов;
когда поиск совпадения i-го предложения успешен, обновление начальной позиции поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения, и поиск совпадения (i+1)-го предложения от обновленной начальной позиции поиска, i+1≤n;
когда поиск совпадения i-го предложения неуспешен, поиск совпадения (i+1)-го предложения из позиции поиска, соответствующей i-му предложению; и
после завершения поиска совпадения всех n предложений, если существует совпавшее содержимое, которое полностью совпадает с n предложениями, или если существует совпавшее содержимое, которое совпадает с n предложениями частично, но степень совпадения которого находится в рамках предварительно определенного диапазона совпадения, определение, что поиск совпадения сегментированных предложений успешен.
В одном варианте осуществления способ дополнительно включает в себя:
если самое раннее успешно совпавшее предложение из n предложений не является 1-м предложением, сегментацию всех предложений от 1-го предложения до предложения непосредственно перед самым ранним успешно совпавшим предложением на m сегментаций слов, расположенных по порядку, причем m является положительным целым числом;
от начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения, поиск совпадения m сегментаций слов в обратном порядке; и
принятие начальной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей начальной позиции исходной строки символов в электронной публикации после редактирования.
В одном варианте осуществления способ дополнительно включает в себя:
если последнее успешно совпавшее предложение из n предложений не является n-м предложением, сегментацию всех предложений от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения на q сегментаций слов, расположенных по порядку, причем q является положительным целым числом;
от конечной позиции совпавшего содержимого последнего успешно совпавшего предложения, последовательный поиск совпадения q сегментаций слов; и
принятие конечной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования.
Согласно второму аспекту вариантов осуществления настоящего изобретения, представлено устройство для обновления пользовательских данных. Устройство включает в себя:
модуль получения, сконфигурированный для получения исходной строки символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования;
модуль поиска совпадения, сконфигурированный для поиска совпадения исходной строки символов в электронной публикации после редактирования; и
модуль обновления, сконфигурированный, чтобы, когда поиск совпадения успешен, обновлять цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
В одном варианте осуществления модуль поиска совпадения сконфигурирован для непосредственного поиска совпадения исходной строки символов в электронной публикации после редактирования;
или,
модуль поиска совпадения сконфигурирован для сегментации исходной строки символов на n предложений, расположенных по порядку, причем n является положительным целым числом; и последовательного поиска совпадения n предложений в электронной публикации после редактирования;
или,
модуль поиска совпадения сконфигурирован для непосредственного поиска совпадения исходной строки символов в электронной публикации после редактирования; когда поиск совпадения неуспешен, сегментирования исходной строки символов на n предложений, расположенных по порядку, причем n является положительным целым числом; и последовательного поиска совпадения n предложений в электронной публикации после редактирования.
В одном варианте осуществления модуль поиска совпадения включает в себя:
блок поиска совпадения, сконфигурированный для поиска совпадения i-го предложения от начальной позиции поиска, 1≤i≤n; когда i=1, начальная позиция поиска является начальной позицией секции, где расположена исходная строка символов;
блок обновления позиции, сконфигурированный, чтобы, когда поиск совпадения i-го предложения успешен, обновить начальную позицию поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения, и осуществлять поиск совпадения (i+1)-го предложения от обновленной начальной позиции поиска, i+1≤n;
блок продолжения поиска совпадения, сконфигурированный, чтобы, когда поиск совпадения i-го предложения неуспешен, осуществлять поиск совпадения (i+1)-го предложения от позиции поиска, соответствующей i-му предложению; и
блок определения, сконфигурированный, чтобы, после завершения поиска совпадения всех n предложений, если существует совпавшее содержимое, которое полностью совпадает с n предложениями, или если существует совпавшее содержимое, которое совпадает с n предложениями частично, но степень совпадения которого находится в рамках предварительно определенного диапазона совпадения, определять, что поиск совпадения сегментированных предложений успешен.
В одном варианте осуществления устройство дополнительно включает в себя:
первый блок сегментации слов, сконфигурированный, чтобы, если самое раннее успешно совпавшее предложение из n предложений не является 1-м предложением, сегментировать все предложения от 1-го предложения до предложения непосредственно перед самым ранним успешно совпавшим предложением на m сегментаций слов, расположенных по порядку, причем m является положительным целым числом;
блок поиска совпадения сегментации слов, сконфигурированный, чтобы от начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения осуществлять поиск совпадения m сегментаций слов в обратном порядке; и
блок определения начала, сконфигурированный для принятия начальной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей начальной позиции исходной строки символов в электронной публикации после редактирования.
В одном варианте осуществления устройство включает в себя:
второй блок сегментации слов, сконфигурированный, чтобы, если последнее успешно совпавшее предложение из n предложений не является n-м предложением, сегментировать все предложения от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения на q сегментаций слов, расположенных по порядку, причем q является положительным целым числом;
блок поиска совпадения сегментаций слов, сконфигурированный, чтобы от конечной позиции совпавшего содержимого последнего успешно совпавшего предложения последовательно осуществлять поиск совпадения q сегментаций слов; и
блок определения конца, сконфигурированный для принятия конечной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования.
Согласно третьему аспекту вариантов осуществления настоящего изобретения, представлено устройство для обновления пользовательских данных. Устройство включает в себя:
процессор;
память для хранения инструкций, исполняемых процессором;
причем процессор сконфигурирован, чтобы:
получать исходную строку символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования;
осуществлять поиск совпадения исходной строки символов в электронной публикации после редактирования; и
когда поиск совпадения успешен, обновить цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
Технические решения, представленные вариантами осуществления настоящего изобретения, могут включать в себя следующие полезные эффекты:
Получается исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования, для исходной строки символов ищется совпадение в электронной публикации после редактирования; и когда поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных. С использованием способа обновления пользовательских данных, представленного вариантами осуществления настоящего изобретения, вычислительные затраты для генерирования файлов коррекции сберегаются, и способ обновления пользовательских данных, представленный вариантами осуществления настоящего изобретения, не требует отдельного обслуживания и, таким образом, может применяться широкомасштабно.
Следует понимать, что и вышеприведенное общее описание, и последующее подробное описание являются только примерными и пояснительными и не ограничивают заявленное изобретение.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Сопроводительные чертежи, которые включены в настоящее описание и составляют его часть, иллюстрируют варианты осуществления, соответствующие изобретению, и вместе с описанием служат для объяснения принципов изобретения.
Фиг. 1 изображает структурную схему среды осуществления, используемой в способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения.
Фиг. 2 изображает блок-схему способа обновления пользовательских данных согласно примерному варианту осуществления.
Фиг. 3a изображает блок-схему способа обновления пользовательских данных согласно другому примерному варианту осуществления.
Фиг. 3b изображает схематичное представление, показывающее заданную секцию в электронной публикации до редактирования и соответствующую секцию в электронной публикации после редактирования согласно одному варианту осуществления настоящего изобретения.
Фиг. 4a изображает блок-схему способа обновления пользовательских данных согласно другому примерному варианту осуществления.
Фиг. 4b изображает схематичное представление, показывающее заданную секцию в электронной публикации до редактирования и соответствующую секцию в электронной публикации после редактирования согласно одному варианту осуществления настоящего изобретения.
Фиг. 5a изображает блок-схему способа обновления пользовательских данных согласно другому примерному варианту осуществления.
Фиг. 5b изображает схематичное представление, показывающее заданную секцию в электронной публикации до редактирования и соответствующую секцию в электронной публикации после редактирования согласно одному варианту осуществления настоящего изобретения.
Фиг. 6 изображает структурную схему устройства для обновления пользовательских данных согласно примерному варианту осуществления.
Фиг. 7 изображает структурную схему устройства для обновления пользовательских данных согласно примерному варианту осуществления.
Фиг. 8 изображает структурную схему устройства для обновления пользовательских данных согласно примерному варианту осуществления.
Конкретные варианты осуществления в этом раскрытии были показаны в качестве примера на вышеупомянутых чертежах и далее описываются подробно. Чертежи и письменное описание не предназначены для ограничения объема изобретательских концепций каким-либо образом. В действительности они представлены для иллюстрации изобретательских концепций специалисту в данной области техники со ссылками на конкретные варианты осуществления.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Далее будет подробно сделано обращение к примерным вариантам осуществления, примеры которых иллюстрируются на сопроводительных чертежах. Последующее описание ссылается на сопроводительные чертежи, на которых одни и те же номера на различных чертежах представляют одни и те же или подобные элементы, если обратное не указано. Осуществления, изложенные в последующем описании примерных вариантов осуществления, не представляют всех осуществлений, согласующихся с изобретением. Вместо этого они являются лишь примерами устройств и способов, согласующихся с аспектами, ассоциированными с изобретением, изложенным в прилагаемой формуле изобретения.
Перед подробным объяснением и описанием вариантов осуществления настоящего изобретения сначала будут пояснены пользовательские данные, относящиеся к настоящему изобретению. В вариантах осуществления настоящего изобретения пользовательские данные включают в себя цитируемое содержимое и пользовательскую информацию чтения, относящуюся к цитируемому содержимому. Пользовательские данные могут быть любым из закладки, резюме и примечания.
Например, закладкой может быть "120 305-й символ, 3-я закладка", цитируемое содержимое "120 305-й символ" используется для указания, что чтение пользователя в прошлый раз подошло к позиции 120 305-го символа, и пользовательская информация чтения "3-я закладка" используется для указания, что это 3-я закладка в книге.
В качестве другого примера, резюме может быть "120 305-й символ, всего 32 символа, 1-е резюме", цитируемое содержимое "120 305-й символ, всего 32 символа" используется для указания, что пользовательские данные начинаются с позиции 120 305-го символа и имеют длину 32 символа, и пользовательская информация чтения "1-е резюме" используется для указания, что это 1-е резюме в книге; или цитируемым содержимым также может быть "120 305-й символ, 120 337-й символ", что указывает, что пользовательские данные начинаются от позиции 120 305-го символа и заканчивается в позиции 120 337-го символа.
В качестве еще одного примера, примечанием может быть "120 305-й символ, всего 32 символа, этот абзац так хорошо написан". Цитируемое содержимое "120 305-й символ, всего 32 символа" используется для указания, что цитируемое содержимое, для которого создается это примечание, начинается от позиции 120 305-го символа и имеет длину 32 символа, и информация чтения пользователя "этот абзац так хорошо написан" является содержимым примечания, созданным пользователем для цитируемого содержимого; или цитируемым содержимым также может быть "120 305-й символ, 120 337-й символ", что указывает, что цитируемое содержимое, для которого создается примечание, начинается от позиции 120 305-го символа и заканчивается в позиции 120 337-го символа.
Фиг. 1 изображает структурную схему среды осуществления, задействованной в способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения. Среда осуществления включает в себя по меньшей мере один терминал 120 и по меньшей мере один сервер 140.
Терминалом 120 может быть электронное оборудование, имеющее функцию чтения. Электронное оборудование может быть интеллектуальными телефонами, планшетными PC, интеллектуальными телевизорами или устройствами чтения электронных книг и так далее.
Терминал 120 может быть соединен с сервером 140 беспроводной сетью.
Сервером 140 может быть сервер или серверный кластер, состоящий из некоторого количества серверов, или центр службы облачного вычисления. Сервером 140 может быть сервер, который обеспечивает услугу обновления пользовательских данных терминалу 120.
Фиг. 2 изображает блок-схему способа обновления пользовательских данных согласно примерному варианту осуществления. Со ссылкой на фиг. 2, настоящий вариант осуществления описан посредством примера, где способ применяется в терминале, показанном на фиг. 1. Процесс способа включает в себя следующие этапы.
На этапе 201 исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается.
На этапе 202 для исходной строки символов ищется совпадение в электронной публикации после редактирования.
На этапе 203, когда поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных.
В способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается, для исходной строки символов ищется совпадение в электронной публикации после редактирования; и когда поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных. С использованием способа обновления пользовательских данных, представленного вариантами осуществления настоящего изобретения, вычислительные затраты для генерирования файлов коррекции сберегаются, и способ обновления пользовательских данных, представленный вариантами осуществления настоящего изобретения, не требует отдельного обслуживания и, таким образом, может применяться широкомасштабно.
Вышеупомянутый этап 202 имеет три способа осуществления.
Во-первых, непосредственный поиск совпадения:
Для исходной строки символов непосредственно ищется совпадение в электронной публикации после редактирования.
Во-вторых, поиск совпадения с сегментацией предложения:
Исходная строка символов сегментируется на n предложений, расположенных по порядку, n является положительным целым числом, и для n предложений последовательно ищется совпадение в электронной публикации после редактирования.
В-третьих, комбинация непосредственного поиска совпадения и поиска совпадения с сегментацией предложения:
Для исходной строки символов непосредственно ищется совпадение в электронной публикации после редактирования; когда поиск совпадения неуспешен, исходная строка символов сегментируется на n предложений, расположенных по порядку, n является положительным целым числом; и для n предложений последовательно ищется совпадение в электронной публикации после редактирования.
Вышеупомянутые три способа осуществления будут объяснены в трех различных вариантах осуществления ниже.
Фиг. 3a изображает блок-схему способа обновления пользовательских данных согласно другому примерному варианту осуществления. Со ссылкой на фиг. 3a, настоящий вариант осуществления описан посредством примера, где способ применяется в терминале, показанном на фиг. 1, и терминал задействует непосредственный поиск совпадения. Процесс способа включает в себя следующие этапы.
На этапе 3a01 исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается.
В настоящем варианте осуществления исходная строка символов, соответствующая цитируемому содержимому в пользовательских данных, полученных терминалом, может быть исходной строкой символов, соответствующей любому одному из закладки, резюме или примечания.
В настоящем варианте осуществления есть следующие два способа получения для терминала для получения исходной строки символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования:
Первый способ: терминал получает исходную строку символов согласно начальной позиции и длине цитируемого содержимого.
Например, когда цитируемым содержимым является "120 305-й символ, всего 32 символа", терминал получает, от позиции 120 305-го символа в текущей секции, строку символов с длиной 32 символа после 120 305-го символа, тем самым осуществляя получение исходной строки символов, соответствующей цитируемому содержимому.
Второй способ: терминал получает исходную строку символов согласно начальной позиции и конечной позиции цитируемого содержимого.
Например, когда цитируемым содержимым является "120 305-й символ, 120 337-й символ", терминал получает строку символов от позиции 120 305-го символа до позиции 120 337-го символа в текущей секции, тем самым осуществляя получение исходной строки символов, соответствующей цитируемому содержимому.
Фиг. 3b изображает схематичное представление, показывающее заданную секцию в электронной публикации до редактирования и соответствующую секцию в электронной публикации после редактирования согласно одному варианту осуществления настоящего изобретения. Со ссылкой на фиг. 3b, исходная строка китайских символов, соответствующая цитируемому содержимому в пользовательских данных, полученных терминалом, является 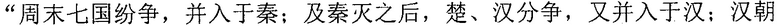
 ("Когда правление династии Чжоу ослабло, возникло семь враждующих царств, воюющих друг с другом, пока царство Цинь не взяло верх и не завладело империей; но когда судьба Цинь была воплощена, появилось два противоборствующих царства, Чу и Хань, чтобы бороться за господство, и Хань вышло победителем; рост успеха Хань начался, когда Лю Бан, великий родоначальник, сразил белого змея, чтобы поднять флаги восстания, которое закончилось, только когда вся империя принадлежала Хань").
("Когда правление династии Чжоу ослабло, возникло семь враждующих царств, воюющих друг с другом, пока царство Цинь не взяло верх и не завладело империей; но когда судьба Цинь была воплощена, появилось два противоборствующих царства, Чу и Хань, чтобы бороться за господство, и Хань вышло победителем; рост успеха Хань начался, когда Лю Бан, великий родоначальник, сразил белого змея, чтобы поднять флаги восстания, которое закончилось, только когда вся империя принадлежала Хань").
На этапе 3a02 для исходной строки символов непосредственно ищется совпадение в электронной публикации после редактирования.
Когда терминал получает исходную строку китайских символов в электронной публикации после редактирования, терминал выполняет поиск, от начальной позиции секции, соответствующей заданной секции электронной публикации до редактирования, исходной строки символов в секции, соответствующей заданной секции, с длиной полученной исходной строки символов в качестве поисковой длины, и, таким образом, поиск совпадения исходной строки символов достигается.
Со ссылкой на фиг. 3b, от начальной позиции 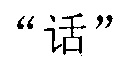 соответствующей секции после редактирования с длиной полученной исходной строки китайских символов в качестве поисковой длины терминал выполняет поиск исходной строки китайских символов в соответствующей секции. Терминал может найти строку китайских символов
соответствующей секции после редактирования с длиной полученной исходной строки китайских символов в качестве поисковой длины терминал выполняет поиск исходной строки китайских символов в соответствующей секции. Терминал может найти строку китайских символов 
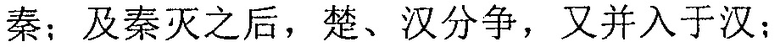
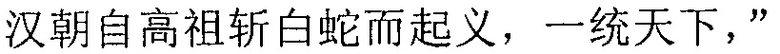 и, таким образом, терминал успешно осуществляет поиск совпадения исходной строки китайских символов.
и, таким образом, терминал успешно осуществляет поиск совпадения исходной строки китайских символов.
На этапе 3a03, когда поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных.
Когда терминал успешно осуществляет поиск совпадения исходной строки символов, терминал обновляет цитируемое содержимое пользовательских данных, соответствующих строке символов, согласно информации позиции совпавшей строки символов для получения обновленных пользовательских данных. Информацией позиции может быть начальная позиция совпавшей строки символов в электронной публикации после редактирования и конечная позиция совпавшей строки символов в электронной публикации после редактирования, или информацией позиции может также быть начальная позиция совпавшей строки символов в электронной публикации после редактирования и длина текста совпавшей строки символов в электронной публикации после редактирования.
Например, когда пользовательскими данными является закладка, терминал добавляет закладку в соответствующей позиции в электронной публикации после редактирования согласно позиции закладки; когда пользовательскими данными является резюме, терминал добавляет резюме в соответствующей позиции в электронной публикации после редактирования согласно начальной позиции резюме и цитируемому содержимому, соответствующему резюме; когда пользовательскими данными является примечание, терминал добавляет примечание в соответствующей позиции в электронной публикации после редактирования согласно начальной позиции примечания, цитируемому содержимому и содержимому примечания.
Со ссылкой на пример на этапе 3a02 в качестве примера, когда терминал успешно осуществляет поиск совпадения исходной строки китайских символов 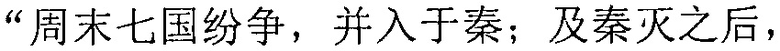
 и пользовательскими данными, соответствующими исходной строке китайских символов, является "120 305-й символ, всего 32 символа, 1-е резюме", терминал обновляет цитируемое содержимое пользовательских данных, соответствующих строке китайских символов в электронной публикации после редактирования, согласно начальной позиции строки китайских символов и содержимому строки китайских символов, и полученными обновленными пользовательскими данными является "120 305-й символ, всего 32 символа, 1-е резюме".
и пользовательскими данными, соответствующими исходной строке китайских символов, является "120 305-й символ, всего 32 символа, 1-е резюме", терминал обновляет цитируемое содержимое пользовательских данных, соответствующих строке китайских символов в электронной публикации после редактирования, согласно начальной позиции строки китайских символов и содержимому строки китайских символов, и полученными обновленными пользовательскими данными является "120 305-й символ, всего 32 символа, 1-е резюме".
В способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается, для исходной строки символов ищется совпадение в электронной публикации после редактирования; и когда поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных. С использованием способа обновления пользовательских данных, представленного вариантами осуществления настоящего изобретения, вычислительные затраты для генерирования файлов коррекции сберегаются, и способ обновления пользовательских данных, представленный вариантами осуществления настоящего изобретения, не требует отдельного обслуживания и, таким образом, может применяться широкомасштабно.
Поскольку непосредственный поиск совпадения применим только в ситуации, когда исходная строка символов не редактируется, для ситуации, когда исходная строка символов редактируется, поиск совпадения не будет успешным. По этой причине предлагается следующий вариант осуществления.
Фиг. 4a изображает блок-схему способа обновления пользовательских данных согласно другому примерному варианту осуществления. Со ссылкой на фиг. 4a описан настоящий вариант осуществления, задействующий пример, где способ применяется в терминале, показанном на фиг. 1, и терминал задействует поиск совпадения с сегментацией предложения. Процесс способа включает в себя следующие этапы.
На этапе 4a01 терминал получает исходную строку символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования.
Этап 4a01 аналогичен или подобен этапу 3a01 из варианта осуществления, показанного на фиг. 3a, и, таким образом, подробное описание этого этапа не будет представлено в этом варианте осуществления.
На этапе 4a02 терминал сегментирует исходную строку символов на n предложений, расположенных по порядку; n является положительным целым числом.
Со ссылкой на исходную строку символов заданной секции до редактирования на фиг. 4b в качестве примера, исходная строка китайских символов, полученная терминалом, является 
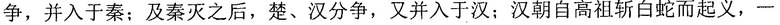
 , и терминал сегментирует исходную строку китайских символов на следующие семь предложений:
, и терминал сегментирует исходную строку китайских символов на следующие семь предложений: 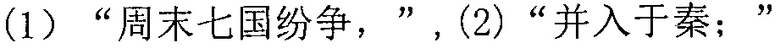 ,
, 
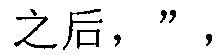

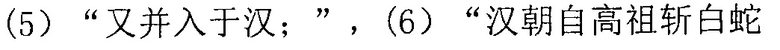
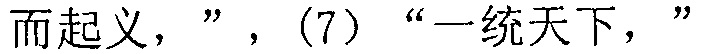 .
.
На этапе 4a03 терминал последовательно осуществляет поиск совпадения n предложений в электронной публикации после редактирования.
Терминал осуществляет поиск совпадения i-го предложения из начальной позиции поиска в электронной публикации после редактирования, 1≤i≤n; когда i=1, начальной позицией поиска является начальная позиция секции, где расположена исходная строка символов; когда поиск совпадения i-го предложения успешен, терминал обновляет начальную позицию поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения, и осуществляет поиск совпадения (i+1)-го предложения от обновленной начальной позиции поиска, i+1≤n; когда поиск совпадения i-го предложения неуспешен, терминал осуществляет поиск совпадения (i+1)-го предложения из позиции поиска, соответствующей i-му предложению.
Следует заметить, что после завершения поиска совпадения всех n предложений, если существует совпавшее содержимое, которое полностью совпадает с n предложениями, или если существует совпавшее содержимое, которое совпадает с n предложениями частично, но степень совпадения которого находится в рамках предварительно определенного диапазона совпадения, определяется, что поиск совпадения сегментированных предложений успешен. Предварительно определенный диапазон совпадения измеряет точность совпавших предложений в целях предотвращения того, чтобы подобная, но не полная строка символов считалась совпадением, и в то же время предотвращения того, чтобы слишком длинная подобная строка символов считалась совпадением. Предварительно определенный диапазон совпадения может быть выражен формулой: 80%Len1≤Len2≤120%Len1, где Len1 - длина текста исходной строки символов, Len2 - длина текста совпавшей строки символов.
Будет сделано описание с использованием семи предложений, полученных на вышеупомянутом этапе 4a02, и соответствующей секции после редактирования, показанной на фиг.4b, в качестве примера. Терминал принимает начальную позицию 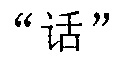 проверенной соответствующей секции в качестве начальной позиции поиска и последовательно осуществляет поиск совпадения вышеупомянутых семи предложений в соответствующей секции после редактирования. От начальной позиции
проверенной соответствующей секции в качестве начальной позиции поиска и последовательно осуществляет поиск совпадения вышеупомянутых семи предложений в соответствующей секции после редактирования. От начальной позиции  с длиной 1-го предложения в качестве поисковой длины терминал выполняет поиск 1-го предложения в секции, и затем терминал может найти 1-е предложение, и, таким образом, терминал осуществляет поиск совпадения 1-го предложения успешно. Терминал обновляет начальную позицию поиска для ее установки в конечную позицию "," 1-го предложения. От конечной позиции "," 1-го предложения с длиной 2-го предложения в качестве поисковой длины терминал выполняет поиск 2-го предложения в секции, и затем терминал может также найти 2-е предложение, и, таким образом, терминал также осуществляет поиск совпадения 2-го предложения успешно. Терминал обновляет начальную позицию поиска для ее установки в конечную позицию ";" 2-го предложения. И затем от конечной позиции ";" 2-го предложения терминал осуществляет поиск совпадения 3-го предложения, и терминал может также осуществлять поиск совпадения успешно. Терминал обновляет начальную позицию поиска для ее установки в конечную позицию "," 3-го предложения. От конечной позиции "," 3-го предложения с длиной 4-го предложения в качестве поисковой длины терминал выполняет поиск 4-го предложения в секции вплоть до конечной позиции
с длиной 1-го предложения в качестве поисковой длины терминал выполняет поиск 1-го предложения в секции, и затем терминал может найти 1-е предложение, и, таким образом, терминал осуществляет поиск совпадения 1-го предложения успешно. Терминал обновляет начальную позицию поиска для ее установки в конечную позицию "," 1-го предложения. От конечной позиции "," 1-го предложения с длиной 2-го предложения в качестве поисковой длины терминал выполняет поиск 2-го предложения в секции, и затем терминал может также найти 2-е предложение, и, таким образом, терминал также осуществляет поиск совпадения 2-го предложения успешно. Терминал обновляет начальную позицию поиска для ее установки в конечную позицию ";" 2-го предложения. И затем от конечной позиции ";" 2-го предложения терминал осуществляет поиск совпадения 3-го предложения, и терминал может также осуществлять поиск совпадения успешно. Терминал обновляет начальную позицию поиска для ее установки в конечную позицию "," 3-го предложения. От конечной позиции "," 3-го предложения с длиной 4-го предложения в качестве поисковой длины терминал выполняет поиск 4-го предложения в секции вплоть до конечной позиции  секции. Но терминал не находит 4-го предложения. Таким образом, терминал осуществляет поиск совпадения 4-го предложения неуспешно; терминал не обновляет начальную позицию поиска, но продолжает осуществлять поиск 5-го предложения в секции от конечной позиции "," 3-го предложения с длиной 5-го предложения в качестве поисковой длины. Затем терминал может найти 5-е предложение, и, таким образом, терминал осуществляет поиск совпадения 5-го предложения успешно. Подобным образом, терминал осуществляет поиск совпадения 6-го и 7-го предложений успешно. Когда поиск совпадения 7-го предложения завершается, поиск совпадения предложений в исходной строке символов терминалом заканчивается.
секции. Но терминал не находит 4-го предложения. Таким образом, терминал осуществляет поиск совпадения 4-го предложения неуспешно; терминал не обновляет начальную позицию поиска, но продолжает осуществлять поиск 5-го предложения в секции от конечной позиции "," 3-го предложения с длиной 5-го предложения в качестве поисковой длины. Затем терминал может найти 5-е предложение, и, таким образом, терминал осуществляет поиск совпадения 5-го предложения успешно. Подобным образом, терминал осуществляет поиск совпадения 6-го и 7-го предложений успешно. Когда поиск совпадения 7-го предложения завершается, поиск совпадения предложений в исходной строке символов терминалом заканчивается.
В вышеупомянутом поиске совпадения семи предложений терминал осуществляет поиск совпадения 4-го предложения неуспешно, поиск совпадения исходной строки символов принадлежит к частичному совпадению. Затем, терминал вычисляет отношение между длиной совпавшей строки китайских символов 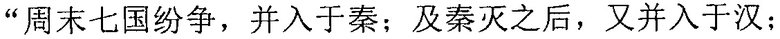
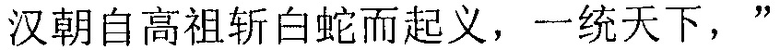 и длиной исходной строки китайских символов
и длиной исходной строки китайских символов 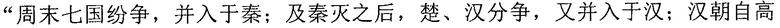
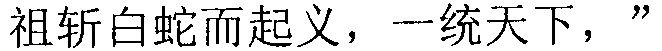 . Терминал может вычислить, что длина текста исходной строки китайских символов равна 47 и длина текста совпавшей строки китайских символов равна 41. Поскольку 80% длины текста исходной строки китайских символов равно 37,5, а 120% длины текста исходной строки китайских символов равно 56,4, и 37,5<47<56,4, то поиск совпадения исходной строки китайских символов терминалом успешен.
. Терминал может вычислить, что длина текста исходной строки китайских символов равна 47 и длина текста совпавшей строки китайских символов равна 41. Поскольку 80% длины текста исходной строки китайских символов равно 37,5, а 120% длины текста исходной строки китайских символов равно 56,4, и 37,5<47<56,4, то поиск совпадения исходной строки китайских символов терминалом успешен.
Следует заметить, что в вышеупомянутом примере, если длина текста совпавшей строки китайских символов терминалом больше 56,4 или меньше 37,5, то поиск совпадения не успешен. Конкретный процесс поиска совпадения подобен вышеупомянутому примеру, и его подробные описания не будут здесь представлены.
На этапе 4a04, когда поиск совпадения успешен, терминал обновляет цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
Этап 4a04 аналогичен или подобен этапу 3a03 из варианта осуществления, показанного на фиг. 3a, и его подробные описания не представлены здесь.
В способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается, исходная строка символов сегментируется на n предложений, расположенных по порядку, причем n является положительным целым числом; и для n предложений последовательно ищется совпадение в электронной публикации после редактирования, и после того как поиск совпадения оказывается успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных. С использованием способа обновления пользовательских данных, представленного вариантами осуществления настоящего изобретения, вычислительные затраты для генерирования файлов коррекции сберегаются, и способ обновления пользовательских данных, представленный вариантами осуществления настоящего изобретения, не требует отдельного обслуживания и, таким образом, может применяться широкомасштабно.
В способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, путем предложения поиска совпадения с сегментацией, достигается тот эффект, что процедура поиска совпадения может быть выполнена, даже если исходная строка символов изменяется на уровне предложения.
В способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, путем оценки отношения между степенью совпадения и предварительно определенным диапазоном совпадения и обновления цитируемого содержимого в пользовательских данных согласно результату оценки, увеличивается точность обновленных пользовательских данных.
Поскольку сегментация предложения применима только в ситуации, когда редактирование происходит на уровне предложения в исходной строке символов, для ситуации, когда редактирование происходит на уровне символов в исходной строке символов, поиск совпадения не будет успешным. По этой причине предлагается следующий вариант осуществления.
Фиг. 5a изображает блок-схему способа обновления пользовательских данных согласно другому примерному варианту осуществления. Со ссылкой на фиг. 5a описан настоящий вариант осуществления, задействующий пример, где способ применяется в терминале, показанном на фиг. 1, и терминал задействует комбинацию непосредственного поиска совпадения и поиска совпадения с сегментацией предложения, и когда поиск совпадения с сегментацией предложения неуспешен, сегментация слов также задействуется. Процесс способа включает в себя следующие этапы.
На этапе 5a01 исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается.
Этап 5a01 аналогичен или подобен этапу 3a01 из варианта осуществления, показанного на фиг. 3a, и его подробные описания здесь не представлены.
На этапе 5a02 для исходной строки символов непосредственно ищется совпадение в электронной публикации после редактирования.
Фиг. 5b изображает схематичное представление, показывающее заданную секцию в электронной публикации до редактирования и соответствующую секцию в электронной публикации после редактирования согласно одному варианту осуществления настоящего изобретения. Со ссылкой на фиг. 5b, исходная строка китайских символов, соответствующая цитируемому содержимому в пользовательских данных, полученных терминалом, является 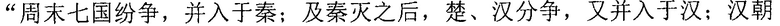
 . Подобно этапу 3a02 в варианте осуществления, показанном на фиг. 3a, от начальной позиции
. Подобно этапу 3a02 в варианте осуществления, показанном на фиг. 3a, от начальной позиции  соответствующей секции после редактирования с длиной полученной исходной строки китайских символов в качестве поисковой длины терминал выполняет поиск исходной строки китайских символов в соответствующей секции после редактирования вплоть до конечной позиции
соответствующей секции после редактирования с длиной полученной исходной строки китайских символов в качестве поисковой длины терминал выполняет поиск исходной строки китайских символов в соответствующей секции после редактирования вплоть до конечной позиции 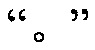 секции. Но терминал не находит исходной строки китайских символов. Следовательно, непосредственный поиск совпадения исходной строки китайских символов терминалом терпит неудачу.
секции. Но терминал не находит исходной строки китайских символов. Следовательно, непосредственный поиск совпадения исходной строки китайских символов терминалом терпит неудачу.
На этапе 5a03, когда непосредственный поиск совпадения неуспешен, исходная строка символов сегментируется на n предложений, расположенных по порядку, и n является положительным целым числом.
Взяв исходную строку символов в заданной секции до редактирования на фиг. 5b в качестве примера, терминал сегментирует исходную строку китайских символов на следующие семь предложений: 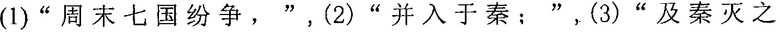
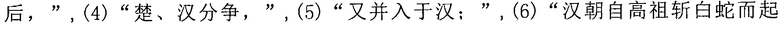
 .
.
На этапе 5a04 для n предложений последовательно ищется совпадение в электронной публикации после редактирования.
Терминал осуществляет поиск совпадения i-го предложения от начальной позиции поиска, 1≤i≤n; когда i=1, начальной позицией поиска является начальная позиция секции, где расположена исходная строка символов; когда поиск совпадения i-го предложения успешен, терминал обновляет начальную позицию поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения, и осуществляет поиск совпадения (i+1)-го предложения от обновленной начальной позиции поиска, i+1≤n; когда поиск совпадения i-го предложения неуспешен, терминал осуществляет поиск совпадения (i+1)-го предложения из позиции поиска, соответствующей i-му предложению.
Будет сделано описание с использованием семи предложений, полученных на этапе 5a03, и соответствующей секции после редактирования, показанной на фиг. 5b, в качестве примера. Терминал принимает начальную позицию  соответствующей секции в качестве начальной позиции поиска и последовательно осуществляет поиск совпадения вышеупомянутым семи предложениям в соответствующей секции. От начальной позиции
соответствующей секции в качестве начальной позиции поиска и последовательно осуществляет поиск совпадения вышеупомянутым семи предложениям в соответствующей секции. От начальной позиции 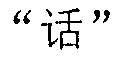 с длиной 1-го предложения в качестве поисковой длины терминал выполняет поиск 1-го предложения в секции вплоть до конечной позиции соответствующей секции. Но терминал не находит 1-е предложение. Таким образом, поиск совпадения 1-го предложения терминалом терпит неудачу. Терминал не обновляет начальную позицию поиска, но продолжает выполнять поиск 2-го предложения в секции путем принятия начальной позиции
с длиной 1-го предложения в качестве поисковой длины терминал выполняет поиск 1-го предложения в секции вплоть до конечной позиции соответствующей секции. Но терминал не находит 1-е предложение. Таким образом, поиск совпадения 1-го предложения терминалом терпит неудачу. Терминал не обновляет начальную позицию поиска, но продолжает выполнять поиск 2-го предложения в секции путем принятия начальной позиции 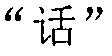 соответствующей секции в качестве начальной позиции поиска с длиной 2-го предложения в качестве поисковой длины вплоть до конечной позиции соответствующей секции. Но терминал не находит 2-е предложение. Таким образом, поиск совпадения 2-го предложения терминалом также терпит неудачу. Терминал не обновляет поисковую начальную позицию, но продолжает выполнять поиск 3-го предложения в соответствующей секции путем принятия начальной позиции соответствующей секции в качестве начальной позиции поиска с длиной 3-го предложения в качестве поисковой длины. Терминал может найти 3-е предложение, и, таким образом, поиск совпадения 3-го предложения терминалом оказывается успешным. Терминал обновляет начальную позиция поиска для ее установки в конечную позицию "," 3-го предложения. И затем от конечной позиции "," 3-го предложения, терминал выполняет поиск 4-го предложения в секции и достигает успешного поиска совпадения 4-го предложения. Подобным образом, терминал осуществляет поиск совпадения 5-го и 6-го предложений успешно. Когда терминал осуществляет поиск совпадения 6-го предложения успешно, терминал обновляет поисковую начальную позицию для ее установки в конечную позицию ", " 6-го предложения, и от конечной позиции ", " 6-го предложения с длиной 7-го предложения в качестве поисковой длины терминал выполняет поиск 7-го предложение в соответствующей секции вплоть до конечной позиции соответствующей секции. Но терминал не находит 7-го предложения. Таким образом, поиск совпадения 7-го предложения терминалом также терпит неудачу. В этот момент поиск совпадения предложений исходной строки символов терминалом завершается.
соответствующей секции в качестве начальной позиции поиска с длиной 2-го предложения в качестве поисковой длины вплоть до конечной позиции соответствующей секции. Но терминал не находит 2-е предложение. Таким образом, поиск совпадения 2-го предложения терминалом также терпит неудачу. Терминал не обновляет поисковую начальную позицию, но продолжает выполнять поиск 3-го предложения в соответствующей секции путем принятия начальной позиции соответствующей секции в качестве начальной позиции поиска с длиной 3-го предложения в качестве поисковой длины. Терминал может найти 3-е предложение, и, таким образом, поиск совпадения 3-го предложения терминалом оказывается успешным. Терминал обновляет начальную позиция поиска для ее установки в конечную позицию "," 3-го предложения. И затем от конечной позиции "," 3-го предложения, терминал выполняет поиск 4-го предложения в секции и достигает успешного поиска совпадения 4-го предложения. Подобным образом, терминал осуществляет поиск совпадения 5-го и 6-го предложений успешно. Когда терминал осуществляет поиск совпадения 6-го предложения успешно, терминал обновляет поисковую начальную позицию для ее установки в конечную позицию ", " 6-го предложения, и от конечной позиции ", " 6-го предложения с длиной 7-го предложения в качестве поисковой длины терминал выполняет поиск 7-го предложение в соответствующей секции вплоть до конечной позиции соответствующей секции. Но терминал не находит 7-го предложения. Таким образом, поиск совпадения 7-го предложения терминалом также терпит неудачу. В этот момент поиск совпадения предложений исходной строки символов терминалом завершается.
На этапе 5a05, если самое раннее успешно совпавшее предложение из n предложений не является 1-м предложением, все предложения от 1-го предложения до предложения непосредственно перед самым ранним успешно совпавшим предложением сегментируются на m сегментаций слов, расположенных по порядку, и m является положительным целым числом.
Когда терминал осуществляет поиск совпадения предложений в исходной строке символов, если поиск совпадения 1-го предложения в исходной строке символов неуспешен, то терминал сегментирует все предложения от предложения непосредственно перед самым ранним успешно совпавшим предложением до 1-го предложения исходной строки символов на m сегментаций слов, и m является положительным целым числом.
Будет сделано описание дополнительно с использованием семи предложений, полученных на вышеупомянутом этапе 5a03, и результата поиска совпадения каждого предложения на этапе 5a04 в качестве примера. На вышеупомянутом этапе 5a04, когда терминал осуществляет поиск совпадения каждого предложения, самым ранним успешно совпавшим предложением является 3-е предложение в исходной строке символов. Иначе говоря, предложением, для которого первым найдено совпадение терминалом, является: 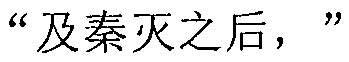 , т.е. терминал осуществляет поиск совпадения 1-го и 2-го предложений в исходной строке китайских символов неуспешно. Тогда терминал сегментирует все предложения от предложения непосредственно перед самым ранним успешно совпавшим предложением
, т.е. терминал осуществляет поиск совпадения 1-го и 2-го предложений в исходной строке китайских символов неуспешно. Тогда терминал сегментирует все предложения от предложения непосредственно перед самым ранним успешно совпавшим предложением  до 1-го предложения в исходной строке китайских символов
до 1-го предложения в исходной строке китайских символов  на сегментации слов. Иначе говоря, терминал сегментирует 1-е и 2-е предложения в исходной строке китайских символов на сегментации слов.
на сегментации слов. Иначе говоря, терминал сегментирует 1-е и 2-е предложения в исходной строке китайских символов на сегментации слов.
1-е и 2-е предложения в исходной строке китайских символов являются: 
 и
и 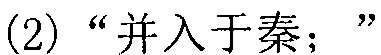 . Терминал сегментирует эти два предложения на сегментации слов для получения шести сегментаций слов, расположенных по порядку:
. Терминал сегментирует эти два предложения на сегментации слов для получения шести сегментаций слов, расположенных по порядку: 
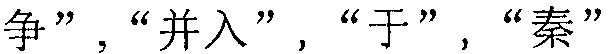 .
.
На этапе 5a06, от начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения, для m сегментаций слов ищется совпадение в обратном порядке; и начальная позиция совпавшего содержимого последней успешно совпавшей сегментации слов принимается в качестве соответствующей начальной позиции исходной строки символов в электронной публикации после редактирования.
От начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения терминал осуществляет поиск совпадения m сегментаций слов в обратном порядке, т.е. терминал сначала осуществляет поиск совпадения последней сегментации слов и затем осуществляет поиск совпадения предпоследней сегментации слов, и так далее, и наконец терминал осуществляет поиск совпадения первой сегментации слов.
Следует заметить, что, когда терминал осуществляет поиск совпадения m сегментаций слов, терминал осуществляет поиск совпадения m сегментаций слов в содержимом перед самым ранним успешно совпавшим предложением в секции.
Следует дополнительно заметить, что после завершения поиска совпадения всех m предложений, если существует совпавшее содержимое, которое полностью соответствует m сегментациям слов, или если существует совпавшее содержимое, которое соответствует m предложениям частично, но степень совпадения которого находится в первом предварительно определенном диапазоне совпадения, определяется, что поиск совпадения сегментаций слов успешен. Терминал принимает позицию последней успешно совпавшей сегментации слов в качестве соответствующей начальной позиции исходной строки символов в электронной публикации после редактирования. Когда степень совпадения находится в первом предварительно определенном диапазоне совпадения, определяется, что поиск совпадения сегментаций слов терпит неудачу. Терминал принимает позицию первого успешно совпавшего предложения в качестве соответствующей начальной позиции исходной строки символов в электронной публикации после редактирования. Первая предварительно определенная степень совпадения может быть: m1≥50%m, m то же самое, что и m на этапе 5a05, т.е. m представляет количество полученных сегментаций слов путем сегментации всех предложений от предложения непосредственно перед самым ранним успешно совпавшим предложением до 1-го предложения исходной строки символов, и m1 представляет количество совпавших сегментаций слов.
Будет сделано описание с использованием шести сегментаций слов, полученных на вышеупомянутом этапе 5a05, и соответствующей секции после редактирования, показанной на фиг. 5b, в качестве примера. При выполнении поиска совпадения сегментированных предложений самое раннее успешно совпавшее предложение терминалом является  , терминал берет начальную позицию
, терминал берет начальную позицию  из
из 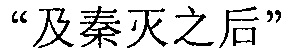 в качестве начальной позиции поиска и осуществляет поиск совпадения шести сегментаций слов в обратном порядке в содержимом перед самым ранним успешно совпавшим предложением в секции.
в качестве начальной позиции поиска и осуществляет поиск совпадения шести сегментаций слов в обратном порядке в содержимом перед самым ранним успешно совпавшим предложением в секции.
Принимая  в качестве начальной позиции поиска, терминал выполняет поиск последней сегментации слов
в качестве начальной позиции поиска, терминал выполняет поиск последней сегментации слов  в обратном порядке в содержимом перед
в обратном порядке в содержимом перед  в соответствующей секции вплоть до позиции
в соответствующей секции вплоть до позиции 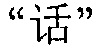 . Но терминал не находит сегментацию слов
. Но терминал не находит сегментацию слов  . Таким образом, поиск совпадения сегментации слов
. Таким образом, поиск совпадения сегментации слов  терминалом терпит неудачу. Терминал не обновляет начальную позицию поиска и продолжает принимать
терминалом терпит неудачу. Терминал не обновляет начальную позицию поиска и продолжает принимать 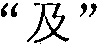 в качестве начальной позиции поиска для поиска предпоследней сегментации слов
в качестве начальной позиции поиска для поиска предпоследней сегментации слов 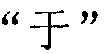 в обратном порядке в содержимом перед в соответствующей секции. Терминал находит, что поиск совпадения сегментации слов также терпит неудачу, и затем терминал продолжает поиск совпадения сегментации слов
в обратном порядке в содержимом перед в соответствующей секции. Терминал находит, что поиск совпадения сегментации слов также терпит неудачу, и затем терминал продолжает поиск совпадения сегментации слов 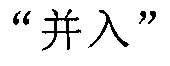 в обратном порядке от позиции . Результат поиска совпадения также является неудачей. Терминал не обновляет начальную позицию поиска и выполняет поиск сегментации слов
в обратном порядке от позиции . Результат поиска совпадения также является неудачей. Терминал не обновляет начальную позицию поиска и выполняет поиск сегментации слов  в обратном порядке от позиции . Терминал может находить в текущей поисковой позиции, и, таким образом, терминал успешно осуществляет поиск совпадения . И затем терминал обновляет начальную позицию поиска как
в обратном порядке от позиции . Терминал может находить в текущей поисковой позиции, и, таким образом, терминал успешно осуществляет поиск совпадения . И затем терминал обновляет начальную позицию поиска как  и выполняет поиск сегментации слов
и выполняет поиск сегментации слов 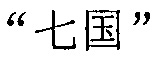 в обратном порядке от позиции . Результат поиска совпадения успешен. Терминал обновляет начальную позицию поиска как
в обратном порядке от позиции . Результат поиска совпадения успешен. Терминал обновляет начальную позицию поиска как 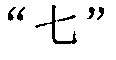 и выполняет поиск сегментации слов
и выполняет поиск сегментации слов  в обратном порядке от позиции . Результат поиска совпадения является неудачей. Поиск совпадения заканчивается.
в обратном порядке от позиции . Результат поиска совпадения является неудачей. Поиск совпадения заканчивается.
В течение поиска совпадения шести сегментаций слов для части сегментаций слов успешно осуществляется поиск совпадения, и, таким образом, это принадлежит к частичному совпадению. Терминал вычисляет отношение между степенью совпадения и первым предварительно определенным диапазоном совпадения. Терминал может вычислить, что существует шесть сегментаций слов, участвующих в поиске совпадения, и существует две сегментации слов, для которых поиск совпадения успешен. 50% сегментаций слов, участвующих в поиске совпадения, равно 3, и 2<3, и, таким образом, поиск совпадения с сегментацией слов терпит неудачу. Терминал не обновляет соответствующую начальную позицию исходной строки символов в электронной публикации после редактирования, иначе говоря, терминал берет в качестве соответствующей начальной позиции исходной строки китайских символов в электронной публикации после редактирования.
Следует заметить, что, если вычисленное количество сегментаций слов, для которых успешно найдено совпадение, больше или равно 3, поиск совпадения с сегментацией слов успешен. При таком условии терминалу необходимо обновить начальную позицию исходной строки символов в электронной публикации для ее установки в позицию последней успешно совпавшей сегментации слов.
На этапе 5a07, если последнее успешно совпавшее предложение из n предложений не является n-м предложением, все предложения от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения сегментируются на q сегментаций слов, расположенных по порядку, и q является положительным целым числом.
Когда терминал выполняет поиск совпадения предложений в исходной строке символов, если последнее успешно совпавшее предложение в исходной строке символов не является n-м предложением, то терминал сегментирует все предложения от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения на q сегментаций слов, расположенных по порядку, и q является положительным целым числом.
Будет сделано описание дополнительно с использованием семи предложений, полученных на этапе 5a03, и результата поиска совпадения каждой сегментации предложений на этапе 5a04 в качестве примера. На вышеупомянутом этапе 5a04, когда терминал выполняет поиск совпадения каждого предложения, последним успешно совпавшим предложением является 6-е предложение в исходной строке символов. Иначе говоря, последнее успешно совпавшее предложение терминалом является: 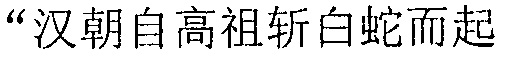
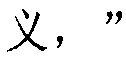 , т.е. терминал осуществляет поиск совпадения 7-го предложения в исходной строке китайских символов неуспешно. Тогда терминал сегментирует все предложения от предложения непосредственно после последнего успешно совпавшего предложения
, т.е. терминал осуществляет поиск совпадения 7-го предложения в исходной строке китайских символов неуспешно. Тогда терминал сегментирует все предложения от предложения непосредственно после последнего успешно совпавшего предложения  до последнего предложения в исходной строке китайских символов
до последнего предложения в исходной строке китайских символов  . Иначе говоря, терминал сегментирует 7-е предложение в исходной строке китайских символов.
. Иначе говоря, терминал сегментирует 7-е предложение в исходной строке китайских символов.
7-е предложение в исходной строке китайских символов является:  . Терминал сегментирует предложение для получения трех сегментаций слов, расположенных по порядку:
. Терминал сегментирует предложение для получения трех сегментаций слов, расположенных по порядку:  .
.
На этапе 5a08, от конечной позиции совпавшего содержимого последнего успешно совпавшего предложения, для q сегментаций слов последовательно ищется совпадение; и конечная позиция совпавшего содержимого последней успешно совпавшей сегментации слов берется в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования.
От конечной позиции совпавшего содержимого последнего успешно совпавшего предложения терминал последовательно осуществляет поиск совпадения q сегментаций слов.
Следует заметить, что, когда терминал выполняет поиск совпадения q сегментаций слов, терминал осуществляет поиск совпадения q сегментаций слов в содержимом после последнего успешно совпавшего предложения в секции.
Следует дополнительно заметить, что после завершения поиска совпадения всех q сегментаций слов, если существует совпавшее содержимое, которое полностью соответствует q сегментациям слов, или если существует совпавшее содержимое, которое соответствует q предложениям частично, но степень совпадения которого находится в первом предварительно определенном диапазоне совпадения, определяется, что поиск совпадения сегментаций слов успешен. Терминал принимает позицию последней успешно совпавшей сегментации слов в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования. Когда степень совпадения не находится в первом определенном диапазоне совпадения, определяется, что поиск совпадения сегментаций слов терпит неудачу. Терминал принимает позицию последнего успешно совпавшего предложения в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования. Первый предварительно определенный диапазон совпадения может быть: q1≥50%q, где q то же самое, что и q на этапе 5a07, т.е. q представляет количество полученных сегментаций слов путем сегментации всех предложений от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения, и q1 представляет количество совпавших сегментаций слов.
Будет сделано описание с использованием трех сегментаций слов, полученных из вышеупомянутого этапа 5a07, и соответствующей секции после редактирования, показанной на фиг. 5b. При выполнении поиска совпадения сегментаций предложений последнее успешно совпавшее предложение терминалом является 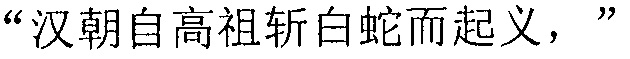 , терминал берет конечную позицию "," из
, терминал берет конечную позицию "," из 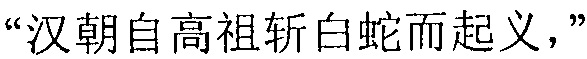 в качестве начальной позиции поиска и последовательно осуществляет поиск совпадения трех сегментаций слов в содержимом после последнего успешно совпавшего предложения в секции.
в качестве начальной позиции поиска и последовательно осуществляет поиск совпадения трех сегментаций слов в содержимом после последнего успешно совпавшего предложения в секции.
Принимая "," в качестве начальной позиции поиска, терминал выполняет поиск первой сегментации слов "-" в содержимом после "," в соответствующей секции вплоть до позиции ".". Но терминал не находит сегментацию слов "-". Таким образом, поиск совпадения сегментации слов "-" терминалом терпит неудачу. Терминал не обновляет начальную позицию поиска и продолжает брать "," в качестве начальной позиции поиска, чтобы последовательно искать вторую сегментацию слов  в содержимом после "," в соответствующей секции. Терминал может найти в текущей позиции поиска. Таким образом, поиск совпадения терминалом успешен. И затем терминал обновляет начальную позицию поиска как и последовательно выполняет поиск совпадения сегментации слов
в содержимом после "," в соответствующей секции. Терминал может найти в текущей позиции поиска. Таким образом, поиск совпадения терминалом успешен. И затем терминал обновляет начальную позицию поиска как и последовательно выполняет поиск совпадения сегментации слов  от позиции . Поиск совпадения оказывается успешен. Тогда поиск совпадения заканчивается.
от позиции . Поиск совпадения оказывается успешен. Тогда поиск совпадения заканчивается.
В течение поиска совпадения трех сегментаций слов для части сегментаций слов поиск совпадения осуществляется неуспешно, и, таким образом, это принадлежит к частичному совпадению. Терминал вычисляет отношение между степенью совпадения и первым предварительно определенным диапазоном совпадения. Терминал может вычислять, что существует три сегментации слов, участвующих в поиске совпадения, и существует 2 сегментации слов, для которых успешно осуществляется поиск совпадения. 50% сегментаций слов, участвующих в поиске совпадения, равно 1,5, и 2>1,5, и, таким образом, поиск совпадения с сегментацией слов успешен. Терминал берет конечную позицию в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования.
Следует заметить, что, если вычисленное количество сегментаций слов, для которых успешно найдено совпадение, меньше 1,5, поиск совпадения с сегментацией слов терпит неудачу. При таком условии терминал не обновляет соответствующую конечную позицию исходной строки символов в электронной публикации после редактирования, т.е. терминал берет "," в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования.
На этапе 5a09, вычисляется отношение между степенью совпадения и предварительно определенным диапазоном совпадения. Когда степень совпадения находится в предварительно определенном диапазоне совпадения, определяется, что поиск совпадения успешен.
После завершения вышеупомянутых этапов 5a01-5a08 терминал вычисляет соответствующее отношение между степенью совпадения и предварительно определенным диапазоном совпадения. Когда диапазон совпадения находится в предварительно определенном диапазоне совпадения, определяется, что поиск совпадения исходной строки символов успешен. Предварительно определенный диапазон совпадения может быть выражен формулой: 80%Len1≤Len2≤120%Len1, где Len1 - длина текста исходной строки символов, и Len2 - длина текста совпавшей строки символов.
Будет сделано описание с использованием исходной строки китайских символов на вышеупомянутом этапах 5a01-5a08 и результата поиска совпадения исходной строки китайских символов в качестве примера. Исходная строка китайских символов является 
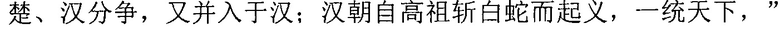 и совпавшая строка китайских символов является
и совпавшая строка китайских символов является 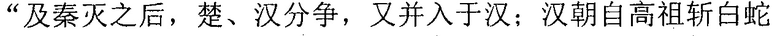
 . Терминал может вычислять, что длина текста исходной строки китайских символов равна 47 и длина текста совпавшей строки китайских символов равна 41. Поскольку 80% длины текста исходной строки китайских символов равно 37,5 и 120% длины текста исходной строки символов равно 56,4 и 34<37,5<56,4, поиск совпадения исходной строки символов терминалом терпит неудачу.
. Терминал может вычислять, что длина текста исходной строки китайских символов равна 47 и длина текста совпавшей строки китайских символов равна 41. Поскольку 80% длины текста исходной строки китайских символов равно 37,5 и 120% длины текста исходной строки символов равно 56,4 и 34<37,5<56,4, поиск совпадения исходной строки символов терминалом терпит неудачу.
Следует заметить, что в вышеупомянутом примере, если длина текста совпавшей строки символов терминалом находится между 37,5 и 56,4, то поиск совпадения успешен при таком условии. Конкретный процесс поиска совпадения подобен вышеупомянутому примеру, и, таким образом, его подробные описания здесь не представлены.
На этапе 5a10, если поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных.
Этап 5a10 аналогичен или подобен этапу 3a03 из варианта осуществления, показанного на фиг. 3a, и, таким образом, подробные описания не представлены в этом варианте осуществления.
В способе обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается, для исходной строки символов ищется совпадение в электронной публикации после редактирования; и когда поиск совпадения неуспешен, исходная строка символов сегментируется для получения n предложений, расположенных по порядку, и для n предложений последовательно ищется совпадение в электронной публикации после редактирования; и когда самое раннее успешно совпавшее предложение не является 1-м предложением и/или последнее успешно совпавшее предложение не является последним предложением в исходной строке символов, предложения от предложения непосредственно перед самым ранним успешно совпавшим предложением до 1-го предложения и предложения от предложения непосредственно после последнего успешно совпавшего предложения до последнего предложения в исходной строке символов сегментируются. Для каждой сегментации слов ищется совпадение в соответствующей секции после редактирования. Пользовательские данные, соответствующие исходной строке символов, обновляются согласно результату поиска совпадения. Таким образом, вычислительные затраты для генерирования файлов коррекции сберегаются, и способ обновления пользовательских данных может применяться широкомасштабно. Кроме того, путем определения отношения между степенью совпадения сегментации слов и предварительно определенным диапазоном совпадения, точность обновленных пользовательских данных улучшается, и может быть обеспечено улучшение способа обновления пользовательских данных.
Следует заметить, что в вариантах осуществления на вышеупомянутых фиг. 2-5 объектом исполнения для обновления цитируемого содержимого пользовательских данных является терминал. Однако фактически в других вариантах осуществления, представленных настоящим раскрытием, объектом исполнения для обновления цитируемого содержимого пользовательских данных может также быть сервер, и терминал может загружать обновленное цитируемое содержимое пользовательских данных с сервера.
Фиг. 6 изображает структурную схему устройства для обновления пользовательских данных согласно примерному варианту осуществления. Устройство для обновления пользовательских данных может достигаться программными средствами, аппаратными средствами или их комбинацией, быть частью или целым DLAN-сервером. Устройство для обновления пользовательских данных может включать в себя модуль 601 получения, модуль 602 поиска совпадения и модуль 603 обновления.
Модуль 601 получения сконфигурирован для получения исходной строки символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования; модуль 601 получения подключен к модулю 602 поиска совпадения. Модуль 602 поиска совпадения сконфигурирован для поиска совпадения исходной строки символов в электронной публикации после редактирования; модуль 602 поиска совпадения подключен к модулю 603 обновления, и модуль 603 обновления сконфигурирован, чтобы, когда поиск совпадения успешен, обновить цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
В одном варианте осуществления модуль 603 поиска совпадения сконфигурирован для непосредственного поиска совпадения исходной строки символов в электронной публикации после редактирования;
или,
модуль 603 поиска совпадения сконфигурирован для сегментации исходной строки символов на n предложений, расположенных по порядку, причем n является положительным целым числом; и последовательного поиска совпадения n предложений в электронной публикации после редактирования;
или,
модуль 603 поиска совпадения сконфигурирован для непосредственного поиска совпадения исходной строки символов в электронной публикации после редактирования; когда поиск совпадения неуспешен, сегментирования исходной строки символов на n предложений, расположенных по порядку, причем n является положительным целым числом; и последовательного поиска совпадения n предложений в электронной публикации после редактирования.
В одном варианте осуществления модуль 603 поиска совпадения включает в себя:
блок поиска совпадения, сконфигурированный для поиска совпадения i-го предложения от начальной позиции поиска, 1≤i≤n; когда i=1, начальной позицией поиска является начальная позиция секции, где расположена исходная строка символов;
блок обновления позиции, сконфигурированный, чтобы, когда поиск совпадения i-го предложения успешен, обновить начальную позицию поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения, и осуществлять поиск совпадения (i+1)-го предложения от обновленной начальной позиции поиска, i+1≤n;
блок продолжения поиска совпадения, сконфигурированный, чтобы, когда поиск совпадения i-го предложения неуспешен, осуществлять поиск совпадения (i+1)-го предложения из позиции поиска, соответствующей i-му предложению; и
блок определения, сконфигурированный, чтобы, после завершения поиска совпадения всех n предложений, если существует совпавшее содержимое, которое полностью совпадает с n предложениями, или если существует совпавшее содержимое, которое совпадает с n предложениями частично, но степень совпадения которого находится в рамках предварительно определенного диапазона совпадения, определить, что поиск совпадения сегментированного предложения успешен.
В одном варианте осуществления устройство дополнительно включает в себя:
первый блок сегментации слов, сконфигурированный, чтобы, если самое раннее успешно совпавшее предложение из n предложений не является 1-м предложением, сегментировать все предложения от 1-го предложения до предложения непосредственно перед самым ранним успешно совпавшим предложением на m сегментаций слов, расположенных по порядку, причем m является положительным целым числом;
блок поиска совпадения с сегментацией слов, сконфигурированный, чтобы от начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения осуществлять поиск совпадения m сегментаций слов в обратном порядке; и
блок определения начала, сконфигурированный для принятия начальной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей начальной позиции исходной строки символов в электронной публикации после редактирования.
В одном варианте осуществления устройство дополнительно включает в себя:
второй блок сегментации слов, сконфигурированный, чтобы, если последнее успешно совпавшее предложение из n предложений не является n-м предложением, сегментировать все предложения от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения на q сегментаций слов, расположенных по порядку, причем q является положительным целым числом;
блок поиска совпадения сегментаций слов, сконфигурированный, чтобы, от конечной позиции совпавшего содержимого последнего успешно совпавшего предложения, последовательно осуществлять поиск совпадения q сегментаций слов; и
блок определения конца, сконфигурированный для принятия конечной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей конечной позиции исходной строки символов в электронной публикации после редактирования.
В устройстве для обновления пользовательских данных, представленном вариантами осуществления настоящего изобретения, исходная строка символов, которая соответствует цитируемому содержимому в пользовательских данных, в электронной публикации до редактирования получается, для исходной строки символов ищется совпадение в электронной публикации после редактирования; и когда поиск совпадения успешен, цитируемое содержимое в пользовательских данных обновляется согласно результату поиска совпадения для получения обновленных пользовательских данных. С использованием устройства для обновления пользовательских данных, представленного вариантами осуществления настоящего изобретения, вычислительные затраты для генерирования файлов коррекции сберегаются, и устройство для обновления пользовательских данных, представленное вариантами осуществления настоящего изобретения, не требует отдельного обслуживания и, таким образом, может применяться широкомасштабно.
В отношении устройства в вышеупомянутых вариантах осуществления, конкретные осуществления для соответственных модулей для выполнения операций были описаны подробно в вариантах осуществления, касающихся способов, и, таким образом, их подробные описания не будут представлены здесь.
Фиг. 7 изображает структурную схему устройства 700 для обновления пользовательских данных согласно примерному варианту осуществления. Например, устройством 700 может быть мобильный телефон, компьютер, терминал цифрового широковещания, устройство приема/передачи сообщений, игровая приставка, планшет, медицинское устройство, тренажерная установка, "электронный помощник" и т.п.
Со ссылкой на фиг. 7, устройство 700 может включать в себя один или несколько из следующих компонентов: обрабатывающий компонент 702, память 704, компонент 706 питания, компонент 708 мультимедиа, аудиокомпонент 710, интерфейс 712 ввода/вывода (I/O), компонент 714 датчиков и компонент 716 связи.
Обрабатывающий компонент 702 обычно управляет общими операциями устройства 700, такими как операции, ассоциированные с отображением, телефонные вызовы, передачи данных, операции камеры и операции записи. Обрабатывающий компонент 702 может включать в себя один или несколько процессоров 720 для исполнения инструкций для выполнения всех или части этапов в вышеописанных способах. Кроме того, обрабатывающий компонент 702 может включать в себя один или несколько модулей, которые обеспечивают взаимодействие между обрабатывающим компонентом 702 и другими компонентами. Например, обрабатывающий компонент 702 может включать в себя модуль мультимедиа для обеспечения взаимодействия между компонентом 708 мультимедиа и обрабатывающим компонентом 702.
Память 704 сконфигурирована для сохранения различных типов данных для поддержки работы устройства 700. Примеры таких данных включают в себя инструкции для любых приложений или способов, управляемых на устройстве 700, контактных данных, данных телефонной книги, сообщений, картинок, видео и т.д. Память 704 может осуществляться с использованием любого типа энергозависимых или энергонезависимых устройств памяти или их комбинации, таких как статическая оперативная память (SRAM), электрически стираемая программируемая постоянная память (EEPROM), стираемая программируемая постоянная память (EPROM), программируемая постоянная память (PROM), постоянная память (ROM), магнитная память, флэш-память, магнитный или оптический диск.
Компонент 706 питания обеспечивает питание различным компонентам устройства 700. Компонент 706 питания может включать в себя систему управления питания, один или несколько источников питания и любые другие компоненты, ассоциированные с генерированием, управлением и распределением питания в устройстве 700.
Компонент 708 мультимедиа включает в себя экран, обеспечивающий выходной интерфейс между устройством 700 и пользователем. В некоторых вариантах осуществления экран может включать в себя жидкокристаллический дисплей (LCD) и сенсорную панель (TP). Если экран включает в себя сенсорную панель, экран может осуществляться в качестве сенсорного экрана для приема входных сигналов от пользователя. Сенсорная панель включает в себя один или несколько датчиков касания для обнаружения прикосновений, скольжений и жестов на сенсорной панели. Датчики касания могут не только обнаруживать границу действия прикосновения или скольжения, но также обнаруживать период времени и давление, ассоциированные с действием прикосновения или скольжения. В некоторых вариантах осуществления компонент 708 мультимедиа включает в себя переднюю камеру и/или заднюю камеру. Передняя камера и задняя камера может принимать внешние данные мультимедиа, в то время как устройство 700 находится в рабочем режиме, таком как режим фотосъемки или режим видеосъемки. Каждая из передней камеры и задней камеры может быть системой фиксированных оптических линз или иметь возможности фокусирования и оптического изменения масштаба.
Аудиокомпонент 710 сконфигурирован для вывода и/или ввода аудиосигналов. Например, аудиокомпонент 710 включает в себя микрофон (MIC), сконфигурированный для приема внешнего аудиосигнала, когда устройство 700 находится в рабочем режиме, таком как режим вызова, режим записи и режим распознавания речи. Принятый аудиосигнал может дополнительно сохраняться в памяти 704 или передаваться через компонент 716 связи. В некоторых вариантах осуществления аудиокомпонент 710 дополнительно включает в себя динамик для вывода аудиосигналов.
I/O-интерфейс 712 обеспечивает интерфейс между обрабатывающим компонентом 702 и периферийными интерфейсными модулями, такими как клавиатура, колесо прокрутки, кнопки и т.д. Кнопки могут включать в себя, но не ограничиваться, кнопку "Домой", кнопку громкости, кнопку запуска и кнопку блокирования.
Компонент 714 датчиков включает в себя один или несколько датчиков для обеспечения оценок состояния различных аспектов устройства 700. Например, компонент 714 датчиков может обнаруживать открытое/закрытое состояние устройства 700, относительное расположение компонентов, например, дисплея и клавиатуры, устройства 700, изменение в позиции устройства 700 или компонента устройства 700, присутствие или отсутствие пользовательского контакта с устройством 700, направление или ускорение/замедление устройства 700 и изменение в температуре устройства 700. Компонент 714 датчиков может включать в себя датчик близости, сконфигурированный для обнаружения присутствия близких объектов без какого-либо физического контакта. Компонент 714 датчиков может также включать в себя датчик света, такой как датчик изображений CMOS или CCD, для использования в приложениях получения изображения. В некоторых вариантах осуществления компонент 714 датчиков может также включать в себя датчик акселерометра, датчик гироскопа, магнитный датчик, датчик давления или датчик температуры.
Компонент 716 связи сконфигурирован для обеспечения связи проводным или беспроводным образом между устройством 700 и другими устройствами. Устройство 700 может осуществлять доступ к беспроводной сети на основе стандарта связи, такого как WiFi, 2G или 3G или их комбинации. В одном примерном варианте осуществления компонент 716 связи принимает широковещательный сигнал или ассоциированную широковещательную информацию от внешней широковещательной системы управления через широковещательный канал. В одном примерном варианте осуществления компонент 716 связи дополнительно включает в себя модуль связи в ближнем поле (NFC) для обеспечения связи малой дальности. Например, модуль NFC может осуществляться на основе технологии радиочастотной идентификации (RFID), технологии ассоциации передачи данных в инфракрасном диапазоне (IrDA), технологии сверхширокополосной связи (UWB), технологии Bluetooth (BT) и других технологий.
В примерных вариантах осуществления устройство 700 может осуществляться с одной или несколькими специализированными интегральными схемами (ASIC), процессорами цифровых сигналов (DSP), устройствами обработки цифровых сигналов (DSPD), программируемыми логическими устройствами (PLD), программируемыми пользователем вентильными матрицами (FPGA), контроллерами, микроконтроллерами, микропроцессорами или другими электронными компонентами для выполнения вышеописанных способов.
В примерных вариантах осуществления также представлен некратковременный компьютерно-читаемый носитель данных, включающий в себя инструкции, такие как включенные в память 704, исполняемые процессором 720 в устройстве 700, для выполнения вышеописанных способов. Например, некратковременным компьютерно-читаемым носителем данных может быть ROM, RAM, CD-ROM, магнитная лента, гибкий диск, оптическое устройство хранения данных и т.п.
Некратковременный компьютерно-читаемый носитель данных содержит сохраненные на нем инструкции, которые при исполнении процессором устройства 700 предписывают устройству 700 выполнять вышеупомянутый способ обновления пользовательских данных.
Фиг. 8 изображает структурную схему устройства 800 для обновления пользовательских данных согласно примерному варианту осуществления. Например, устройство 800 может быть представлено в качестве сервера. Со ссылкой на фиг. 8, устройство 800 включает в себя обрабатывающий компонент 822, который дополнительно включает в себя один или несколько процессоров, и ресурсы памяти, представленные памятью 832, для хранения инструкций, исполняемых обрабатывающим компонентом 822, таких как прикладные программы. Прикладные программы, сохраненные в памяти 832, могут включать в себя один или несколько модулей, каждый из которых соответствует набору инструкций. Кроме того, обрабатывающий компонент 822 сконфигурирован для исполнения инструкций для выполнения вышеописанного способа обновления пользовательских данных.
Устройство 800 может также включать в себя компонент 826 питания, сконфигурированный для выполнения управления питания устройства 800, проводной или беспроводной сетевой интерфейс(ы) 850, сконфигурированный для соединения устройства 800 с сетью, и интерфейс 858 ввода/вывода (I/O). Устройство 800 может оперировать на основе операционной системы, сохраненной в памяти 832, такой как Windows Server™, Mac OS X™, Unix™, Linux™, FreeBSD™ или подобное.
Другие варианты осуществления изобретения будут очевидны специалистам в данной области техники благодаря рассмотрению технического описания и применения на практике изобретения, раскрываемого здесь. Эта заявка предназначена для охвата любых вариаций, использований или конфигураций изобретения, следующих его общим принципам и включающих в себя такие отступления от настоящего раскрытия, которые происходят в рамках известного или обычного применения на практике в данной области техники. Предполагается, что техническое описание и примеры рассматриваются только в качестве примерных, причем истинный объем и сущность изобретения указаны следующей формулой.
Следует понимать, что настоящее изобретение не ограничивается точной структурой, которая была описана выше и проиллюстрирована на сопроводительных чертежах, и что различные модификации и изменения могут быть сделаны без выхода за пределы его объема. Предполагается, что объем изобретения ограничивается только прилагаемой формулой изобретения.
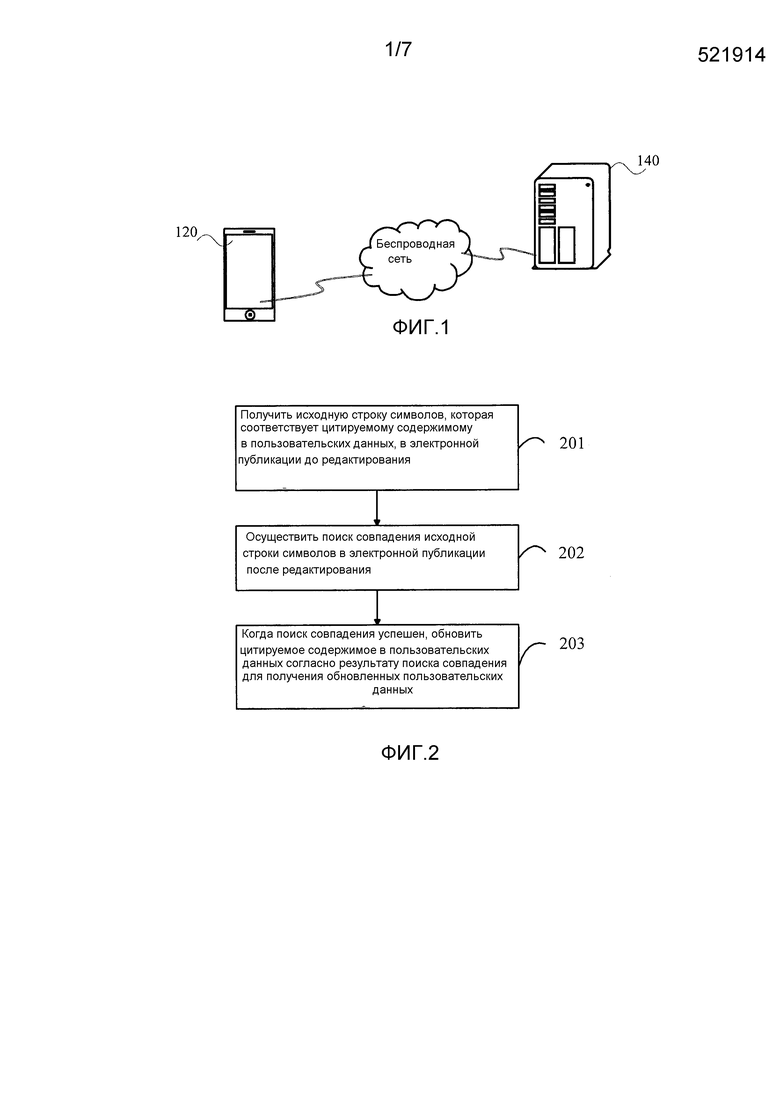
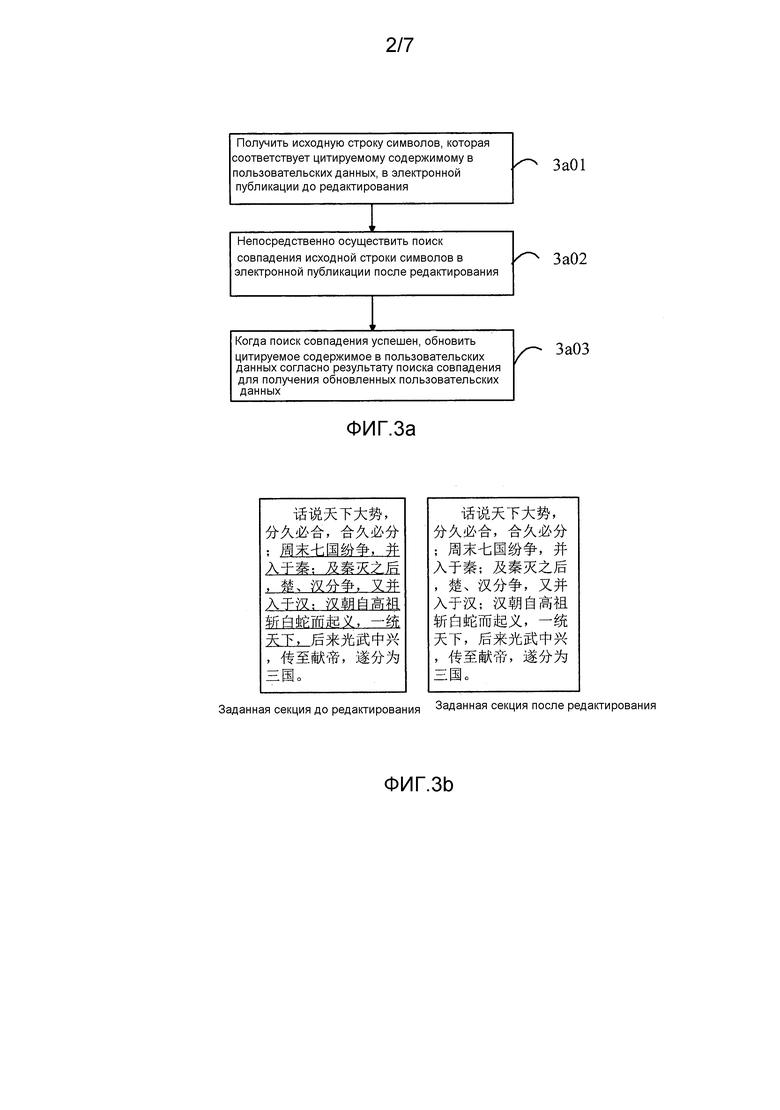
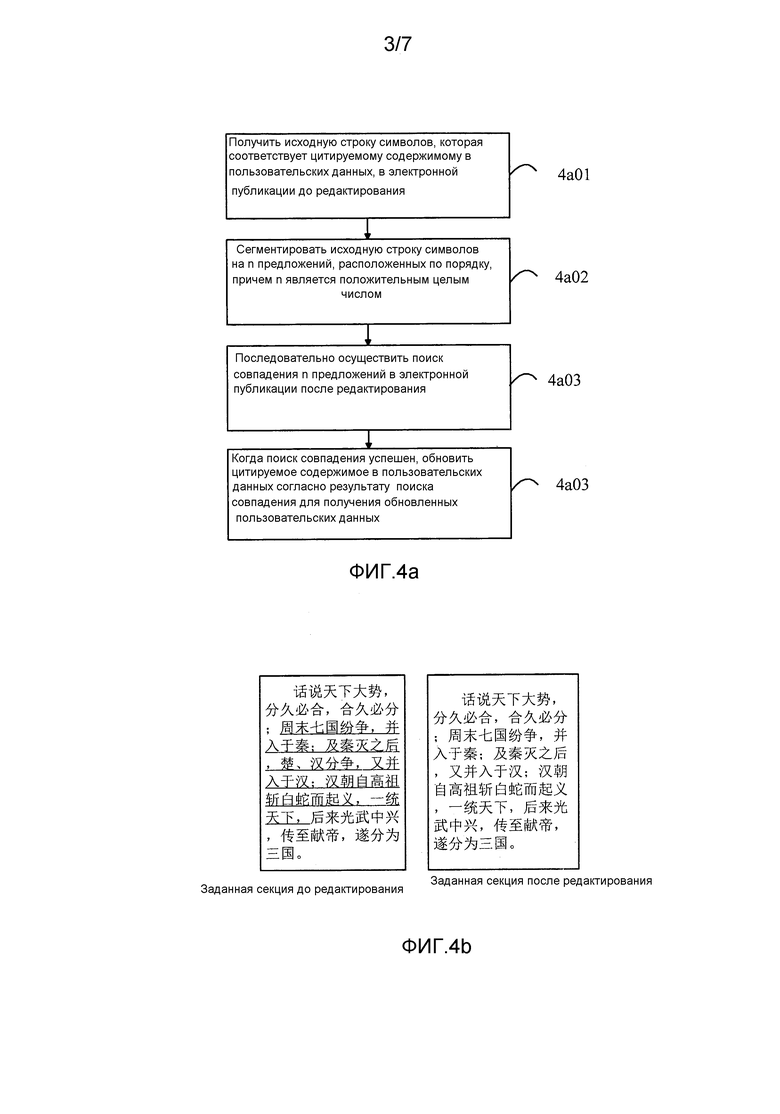

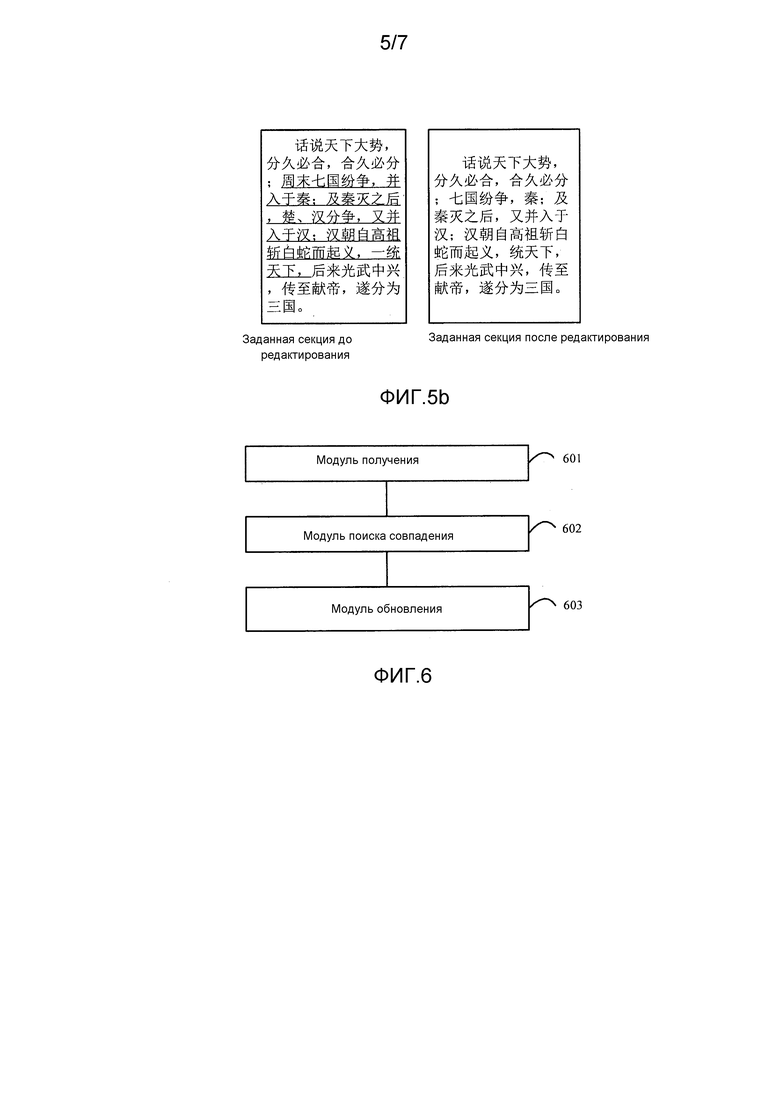
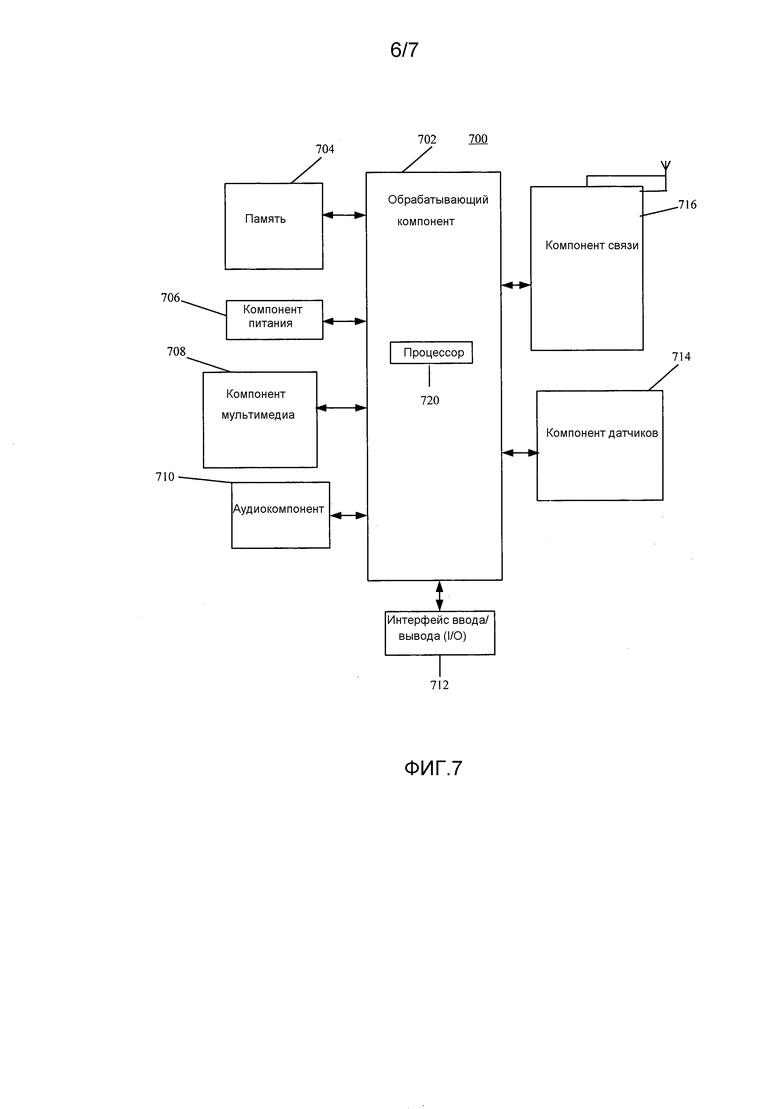
Изобретение относится к области электронной публикации и, в частности, к способу и устройству для обновления пользовательских данных. Техническим результатом является снижение вычислительных затрат при обновлении данных. В способе обновления пользовательских данных получают исходную строку символов, которая соответствует цитируемому содержимому в пользовательских данных, в нередактированной электронной публикации. Выполняют поиск совпадения исходной строки символов в редактированной электронной публикации. Когда поиск совпадения успешен, обновляют цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных. 3 н. и 6 з.п. ф-лы, 11 ил.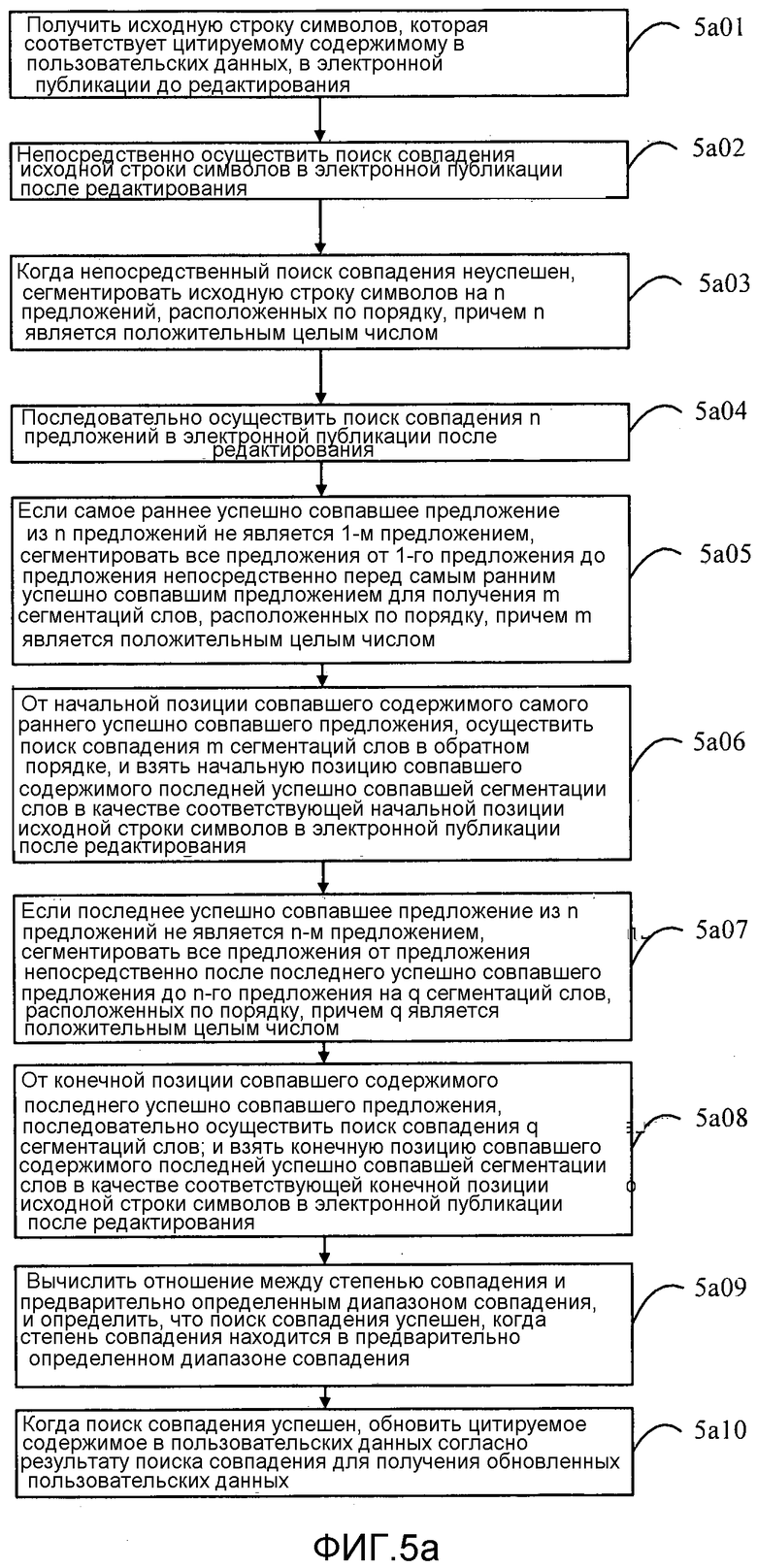
1. Способ обновления пользовательских данных, характеризующийся тем, что способ содержит этапы, на которых:
получают исходную строку символов, которая соответствует цитируемому содержимому в пользовательских данных, в нередактированной электронной публикации;
когда исходная строка символов не редактируется, осуществляют непосредственный поиск совпадения исходной строки символов;
когда исходная строка символов редактируется, сегментируют исходную строку символов на n предложений, расположенных по порядку, где n является положительным целым числом, и последовательно осуществляют поиск совпадения n предложений в редактированной электронной публикации; и
сегментируют все из n предложений на m сегментаций слов, расположенных по порядку, где m является положительным целым числом, и осуществляют поиск совпадения в редактированной электронной публикации;
когда поиск совпадения успешен, обновляют цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
2. Способ по п. 1, отличающийся тем, что последовательный поиск совпадения n предложений в редактированной электронной публикации содержит этапы, на которых:
осуществляют поиск совпадения i-го предложения от начальной позиции поиска, причем 1≤i≤n; когда i=1, начальная позиция поиска является начальной позицией секции, где расположена исходная строка символов;
когда поиск совпадения i-го предложения успешен, обновляют начальную позицию поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения и осуществляют поиск совпадения (i+1)-го предложения из обновленной начальной позиции поиска, i+1≤n;
когда поиск совпадения i-го предложения неуспешен, осуществляют поиск совпадения (i+1)-го предложения из позиции поиска, соответствующей i-му предложению; и
после завершения поиска совпадения всех n предложений, если существует совпавшее содержимое, которое полностью совпадает с n предложениями, или если существует совпавшее содержимое, которое совпадает с n предложениями частично, но степень совпадения которого находится в рамках предварительно определенного диапазона совпадения, определяют, что поиск совпадения сегментированных предложений успешен.
3. Способ по п. 2, отличающийся тем, что способ дополнительно содержит этапы, на которых:
если самое раннее успешно совпавшее предложение из n предложений не является 1-м предложением, сегментируют все предложения от 1-го предложения до предложения непосредственно перед самым ранним успешно совпавшим предложением на m сегментаций слов, расположенных по порядку, причем m является положительным целым числом;
от начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения осуществляют поиск совпадения m сегментаций слов в обратном порядке; и
принимают начальную позицию совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей начальной позиции исходной строки символов в редактированной электронной публикации.
4. Способ по п. 2, отличающийся тем, что способ дополнительно содержит этапы, на которых:
если последнее успешно совпавшее предложение из n предложений не является n-м предложением, сегментируют все предложения от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения на q сегментаций слов, расположенных по порядку, причем q является положительным целым числом;
от конечной позиции совпавшего содержимого последнего успешно совпавшего предложения последовательно осуществляют поиск совпадения q сегментаций слов; и
принимают конечную позицию совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей конечной позиции исходной строки символов в редактированной электронной публикации.
5. Устройство для обновления пользовательских данных, характеризующееся тем, что устройство содержит:
модуль получения, сконфигурированный для получения исходной строки символов, которая соответствует цитируемому содержимому в пользовательских данных, в нередактированной электронной публикации;
модуль поиска совпадения, сконфигурированный для осуществления непосредственного поиска совпадения исходной строки символов, когда исходная строка символов не редактируется;
когда исходная строка символов редактируется, модуль поиска совпадения сконфигурирован для сегментирования исходной строки символов на n предложений, расположенных по порядку, где n является положительным целым числом, и последовательного осуществления поиска совпадения n предложений в редактированной электронной публикации; и
сегментирования всех из n предложений на m сегментаций слов, расположенных по порядку, где m является положительным целым числом, и осуществления поиска совпадения в редактированной электронной публикации;
модуль обновления, сконфигурированный, чтобы, когда поиск совпадения успешен, обновлять цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
6. Устройство по п. 5, отличающееся тем, что модуль поиска совпадения содержит:
блок поиска совпадения, сконфигурированный для поиска совпадения i-го предложения от начальной позиции поиска, 1≤i≤n; когда i=1, начальная позиция поиска является начальной позицией секции, где расположена исходная строка символов;
блок обновления позиции, сконфигурированный, чтобы, когда поиск совпадения i-го предложения успешен, обновить начальную позицию поиска для ее установки в конечную позицию совпавшего содержимого i-го предложения, и осуществлять поиск совпадения (i+1)-го предложения из обновленной начальной позиции поиска, i+1≤n;
блок продолжения поиска совпадения, сконфигурированный, чтобы, когда поиск совпадения i-го предложения неуспешен, осуществлять поиск совпадения (i+1)-го предложения из позиции поиска, соответствующей i-му предложению; и
блок определения, сконфигурированный, чтобы после завершения поиска совпадения всех n предложений, если существует совпавшее содержимое, которое полностью совпадает с n предложениями, или если существует совпавшее содержимое, которое совпадает с n предложениями частично, но степень совпадения которого находится в рамках предварительно определенного диапазона совпадения, определять, что поиск совпадения сегментированных предложений успешен.
7. Устройство по п. 6, отличающееся тем, что устройство дополнительно содержит:
первый блок сегментации слов, сконфигурированный, чтобы, если самое раннее успешно совпавшее предложение из n предложений не является 1-м предложением, сегментировать все предложения от 1-го предложения до предложения непосредственно перед самым ранним успешно совпавшим предложением на m сегментаций слов, расположенных по порядку, причем m является положительным целым числом;
блок поиска совпадения сегментации слов, сконфигурированный, чтобы от начальной позиции совпавшего содержимого самого раннего успешно совпавшего предложения осуществлять поиск совпадения m сегментаций слов в обратном порядке; и
блок определения начала, сконфигурированный для принятия начальной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей начальной позиции исходной строки символов в редактированной электронной публикации.
8. Устройство по п. 6, отличающееся тем, что устройство содержит:
второй блок сегментации слов, сконфигурированный, чтобы, если последнее успешно совпавшее предложение из n предложений не является n-м предложением, сегментировать все предложения от предложения непосредственно после последнего успешно совпавшего предложения до n-го предложения на q сегментаций слов, расположенных по порядку, причем q является положительным целым числом;
блок поиска совпадения сегментаций слов, сконфигурированный, чтобы, от конечной позиции совпавшего содержимого последнего успешно совпавшего предложения, последовательно искать совпадение q сегментаций слов; и
блок определения конца, сконфигурированный для принятия конечной позиции совпавшего содержимого последней успешно совпавшей сегментации слов в качестве соответствующей конечной позиции исходной строки символов в редактированной электронной публикации.
9. Устройство для обновления пользовательских данных, характеризующееся тем, что устройство содержит:
процессор;
память для хранения инструкций, исполняемых процессором;
причем процессор сконфигурирован для того, чтобы:
получать исходную строку символов, которая соответствует цитируемому содержимому в пользовательских данных, в нередактированной электронной публикации;
осуществлять непосредственный поиск совпадения исходной строки символов, когда исходная строка символов не редактируется;
когда исходная строка символов редактируется, сегментировать исходную строку символов на n предложений, расположенных по порядку, где n является положительным целым числом, и последовательно осуществлять поиск совпадения n предложений в редактированной электронной публикации; и
сегментировать все из n предложений на m сегментаций слов, расположенных по порядку, где m является положительным целым числом, и осуществлять поиск совпадения в редактированной электронной публикации; и
когда поиск совпадения успешен, обновлять цитируемое содержимое в пользовательских данных согласно результату поиска совпадения для получения обновленных пользовательских данных.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| CN 102339275 A, 01.02.2012 | |||
| CN 103257956 A, 21.08.2013 | |||
| СПОСОБ И СИСТЕМА ДЛЯ СИНХРОНИЗАЦИИ ИДЕНТИФИЦИРУЮЩЕЙ ИНФОРМАЦИИ | 2004 |
|
RU2364928C2 |
| РАЗРЕШЕНИЕ КОНФЛИКТОВ | 2009 |
|
RU2491621C2 |

