Изобретение относится к области обработки стереопар (изображений, полученных одновременно с двух камер), а именно к способам и устройствам обработки стереоизображений, в том числе ректификации стереоизображений, вычисления и оптимизации карты диспаратности, реализации видеоаналитических алгоритмов на основе карты диспаратности. Изобретение может применяться в системах видеоаналитики и видеонаблюдения.
Активное развитие технологий позволяет значительно повысить качество вводимого с различных источников видеосигнала за счет увеличения разрешения и частоты кадров видеопотока. Большинство видеоаналитических задач требует обработки видеоданных в реальном масштабе времени. Решение этих задач с использованием универсальных процессоров, обрабатывающих данные из внешней памяти, не позволяет обеспечить требуемую скорость обработки данных, а размещение на кристалле памяти, достаточной для хранения нескольких кадров высокого разрешения, не обеспечивается существующим уровнем технологии СБИС.
Эффективным способом решения вышеупомянутых задач является создание высокопроизводительных кластеров, использующих общую локальную память ограниченного объема для хранения фрагментов изображений и включающих в себя ядра процессоров и специализированные аппаратные ускорители, предназначенные для реализации ряда функций, используемых в алгоритмах видеоаналитики.
Известна система обработки изображений, описанная в заявке US 20120221795 A1, представляющая собой кластер из множества процессоров, таких как центральный процессор (CPU), сигнальные процессоры (DSP), графический процессор (GPU), аппаратные акселераторы. Все процессоры кластера используют локальную память, которая разделяется на кластеры, имеющие различную длину строки. Каждый кластер может разделяться между всеми процессорами, использоваться только одним процессором или группой процессоров. Приоритеты процессоров для доступа к памяти задаются программно.
Использование локальной разделяемой памяти позволяет оптимизировать доступ к внешней памяти, однако объединение в кластер процессоров, выполняющих разные задачи (например, CPU и DSP), снижает ее эффективность для выполнения задач обработки стереоизображений. К тому же аппаратные акселераторы, применяемые для решения таких задач (например, акселератор для вычисления карты диспаратности), требуют очень большого объема данных и большого трафика с локальной памятью, который сложно оптимизировать только длиной строки, более эффективным способом оптимизации трафика и размещения структур данных в локальной памяти является увеличение разрядности шины и использование различных режимов адресации.
В патенте US 7643067 В2 описаны система и способ ректификации стереоизображений, которые принимают с двух камер в реальном масштабе времени, с помощью матрицы, полученной на этапе калибровки. Процесс ректификации представляет собой реализацию проективного преобразования изображения плюс дальнейшую интерполяцию. Таким преобразованием убирают нежелательные повороты камеры и некоторые перспективные искажения.
Используемая при ректификации модель искажений не включает дисторсию. К тому же в системе ректифицируют только одну камеру. Если использовать предложенный алгоритм для ректификации стереопары, то потребуется сначала находить поворот и смещение одной камеры относительно ориентира, а потом поворот и смещение другой камеры относительно ориентира, что увеличивает ошибку алгоритма.
Наиболее близкой к заявленному изобретению является система обработки стереоизображений, описанная в заявке US 20110285701 A1, которая включает в себя генератор карты глубины и генератор multi-view изображений для 3D-дисплея. Генератор карты глубины состоит из процессора для стереоматчинга, который вычисляет значения диспаратности, выполняя стереоматчинг первого и второго изображения по алгоритму belief propagation (BP), и генератора карты глубины, который на основании значений диспаратности вычисляет карту глубины для генератора milti-view изображений. Обмен данными между процессором стереоматчинга, управляющим процессором и внешней памятью осуществляют через 64-битную системную шину.
Процессор стереоматчинга имеет три стадии конвейера: на первой стадии генерируют стоимости данных первого тайла изображения, основываясь на сопоставлении пикселей первого тайла первого изображения с пикселями первого тайла второго изображения; на второй стадии вычисляют значения диспаратности и исходящие сообщения к соседним тайлам, основываясь на значениях стоимостей и входящих сообщений от соседних тайлов; на третьей стадии в локальной памяти сохраняют значения диспаратности и исходящие сообщения, которые затем используют на второй стадии как входящие сообщения. Локальная память процессора состоит из нескольких блоков SRAM, имеющих конкретное назначение (хранение входного и выходного изображения, диспаратностей, исходящих сообщений) и имплементирующих механизм двойной буферизации. Данная система выбрана в качестве прототипа заявленного изобретения.
Недостатки системы-прототипа заключаются в следующем. Использование потайловой обработки с механизмом обмена сообщениями между тайлами позволяет получить хорошее качество карты глубины при небольшом объеме локальной памяти, однако недостатком является необходимость двух-трех итераций пересчета стоимостей, отсутствие постобработки первичной карты. При использовании системы-прототипа для видеоаналитических задач большая вычислительная нагрузка ложится на центральный процессор, это приводит к перекачиванию больших объемов информации через системную шину, что снижает производительность системы.
Задачей заявленного изобретения является создание способа и устройства обработки стереоизображений высокого разрешения с улучшенной эффективностью (производительностью) при использовании ограниченного объема памяти за счет применения аппаратного акселератора вычисления карты диспаратности, использующего алгоритм полуглобального стереоматчинга с трехэтапной постобработкой (детекция пиков, интерполяция и медианная фильтрация), который требует размещения в локальной памяти только нескольких строк (от 4 до 24 на разных этапах вычисления), что позволяет получить высококачественную карту диспаратности в режиме реального времени, а также за счет размещения в устройстве программируемых ядер сигнальных процессоров, выполняющих подготовку данных для вычисления карты диспаратности (ректификацию изображений) и финальную обработку данных с использованием видеоаналитичесих алгоритмов, и аппаратного акселератора, что позволяет минимизировать пересылки между внешней памятью и устройством, поскольку левое и правое изображения только однократно полностью загружают в устройство, а результаты обработки представляют собой структуры данных значительно меньшего объема.
Поставленная задача решена путем создания способа обработки стереоизображений, в котором:
- загружают построчно левое и правое исходные изображения с помощью DMA-контроллера (3) из внешней памяти (2) в буферы локальной памяти (4);
- обрабатывают построчно левое и правое исходные изображения с помощью ядер (5) сигнальных процессоров, при этом выполняют их ректификацию и записывают ректифицированные левое и правое изображения в буферы локальной памяти (4);
- вычисляют карту диспаратности с помощью аппаратного акселератора (8), используя ректифицированные левое и правое изображения, и записывают ее в буфер локальной памяти (4);
- обрабатывают с помощью ядер (5) сигнальных процессоров ректифицированные левое и правое изображения, используя видеоаналитические алгоритмы и карту диспаратности, при этом формируют структуры данных, которые записывают в локальную память (4) и затем выгружают с помощью DMA-контроллера (3) во внешнюю память (2).
В предпочтительном варианте осуществления способа буферы локальной памяти (4), в которых хранятся изображения и карта диспаратности, имеют размер в несколько строк изображения и организованы по принципу двойной буферизации.
В предпочтительном варианте осуществления способа выполняют ректификацию левого и правого исходных изображений, при этом вычисляют координаты прообразов пикселей ректифицированного изображения в исходном изображении и вычисляют яркости прообразов пикселей путем билинейной интерполяции по четырем соседним пикселям.
В предпочтительном варианте осуществления способа вычисляют карту диспаратности по алгоритму полуглобального матчинга (SGBM - Semi-global block matching) в двух направлениях, вычисляя функцию стоимости соответствия и накапливаемую стоимость в каждом направлении, при этом проверяют карту диспаратности левого изображения с помощью карты диспаратности правого изображения и выполняют постфильтрацию карты диспаратности, состоящую из трех этапов: детекции пиков, интерполяции и медианной фильтрации.
В предпочтительном варианте осуществления способа синхронизацию устройств, использующих локальную память (4), осуществляют аппаратно с помощью регистра событий.
В предпочтительном варианте осуществления способа ректификацию левого и правого исходных изображений выполняют параллельно.
В предпочтительном варианте осуществления способа ректификацию левого и правого исходных изображений выполняют одновременно с коррекцией радиальной и тангенциальной дисторсии первого и второго порядка.
В предпочтительном варианте осуществления способа вычисляют карту диспаратности, при этом осуществляют параллельную конвейерную обработку двух строк изображения с сохранением промежуточных результатов в локальной памяти (4) только для нечетных строк.
В предпочтительном варианте осуществления способа детекцию пиков в карте диспаратности осуществляют параллельно для всех пикселей в окне обработки заданного размера.
В предпочтительном варианте осуществления способа осуществляют интерполяцию карты диспаратности после детекции пиков путем медианной фильтрации по ближайшим валидным пикселям из 8-ми направлений с программируемой длиной лучей по алгоритму анизотропной фильтрации или мажоритарной изотропной фильтрации.
В предпочтительном варианте осуществления способа выполняют медианную фильтрацию плотной карты диспаратности в несколько последовательных стадий, на каждой из которых осуществляют параллельную обработку пикселей из нескольких соседних строк изображения с помощью группы медианных фильтров.
Поставленная задача решена также путем создания устройства обработки стереоизображений, содержащего несколько ядер (5) сигнальных процессоров и аппаратный акселератор (8), соединенные через арбитр (9) с локальной памятью (4), DMA-контроллером (3), кэшем программ (6) и кэшем данных (7), при этом ядра (5) сигнальных процессоров и аппаратный акселератор (8) соединены с внешним системным интерфейсом (11) и выполнены с возможностью обмена данными через него под управлением внешнего центрального процессора (10), a DMA-контроллер (3), кэш программ (6) и кэш данных (7) соединены с внешней памятью (4) и выполнены с возможностью обмена данными с ней, причем
- арбитр (9) выполнен с возможностью управления доступом устройства к внешней памяти (4);
- DMA-контроллер (3) выполнен с возможностью передачи данных между устройством и внешней памятью (4), при этом загрузки построчно левого и правого исходных изображений из внешней памяти (2) в буферы локальной памяти (4);
- ядра (5) сигнальных процессоров выполнены с возможностью построчной обработки левого и правого исходных изображений, при этом их ректификации и записи ректифицированных левого и правого изображений в буферы локальной памяти (4);
- аппаратный акселератор (8) выполнен с возможностью вычисления карты диспаратности с использованием ректифицированных левого и правого изображений и записи ее в буфер локальной памяти (4);
- ядра (5) сигнальных процессоров выполнены с возможностью обработки ректифицированных левого и правого изображений с использованием видеоаналитических алгоритмов и карты диспаратности, при этом формирования структуры данных и записи ее в локальную память (4);
- DMA-контроллер (3) выполнен с возможностью выгрузки структуры данных из локальной памяти (4) во внешнюю память (2).
В предпочтительном варианте осуществления устройства локальная память (4) организована в виде банков одинакового объема и разрядности, доступ к которым может производиться как транзакциями к одному банку с разрядностью, равной разрядности банка, так и транзакциями к нескольким банкам одновременно с разрядностью, равной суммарной разрядности нескольких банков, с использованием двух режимов адресации под управлением арбитра (9), выполненного с возможностью осуществления арбитража к каждому банку независимо с фиксированными приоритетами.
В предпочтительном варианте осуществления устройства аппаратный акселератор (8) содержит конвейеры левого и правого изображений, содержащие блок вычисления функции стоимости соответствия и блок вычисления накапливаемой стоимости, которые выполнены с возможностью параллельного вычисления левой и правой карты диспаратности или объединяются в одно устройство для обработки левой карты диспаратности, блок проверки карты диспаратности левого изображения с помощью карты диспаратности правого изображения, блок постобработки карты диспаратности, содержащий блок детекции пиков, блок интерполяции и блок медианной фильтрации, а также блок управления.
В предпочтительном варианте осуществления устройства блок вычисления функции стоимости соответствия выполнен в виде массива однотипных ячеек, которые выполнены с возможностью обработки в конвейере нескольких строк изображения, при этом длительность обработки одного пикселя может изменяться в несколько раз в зависимости от максимального значения диспаратности.
В предпочтительном варианте осуществления устройства вычисление накапливаемой стоимости соответствия в горизонтальном и вертикальном направлениях выполняется одинаковыми блоками, состоящими из массива однотипных ячеек и блока вычисления минимума, количество последовательных этапов обработки изменяется в зависимости от максимального значения диспаратности.
В предпочтительном варианте осуществления устройства блок детекции пиков выполнен в виде вычислительного модуля, представляющего собой матрицу однотипных вычислительных ячеек, управляемых общим потоком инструкций (SIMD), в котором количество ячеек соответствует количеству пикселей в вычислительном окне, каждая ячейка выполнена с возможностью получения значения пикселя, соответствующего положению этой ячейки в вычислительном окне, а также значения соседних пикселей, находящихся слева, справа, снизу и сверху, с возможностью хранения текущего значения, которое изменяется в результате выполнения инструкций и по завершению последовательности инструкций формирования признака инвалидации.
В предпочтительном варианте осуществления устройства блок интерполяции выполнен с возможностью осуществления параллельной обработки N пикселей из N строк, при этом максимальная длина лучей по всем направлениям также равна N.
В предпочтительном варианте осуществления устройства блок медианной фильтрации выполнен в виде нескольких последовательных стадий обработки, каждая из которых осуществляет параллельную обработку пикселей из нескольких строк.
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими графическими материалами.
Фиг. 1. Структурная схема устройства обработки стереоизображений, выполненная согласно изобретению.
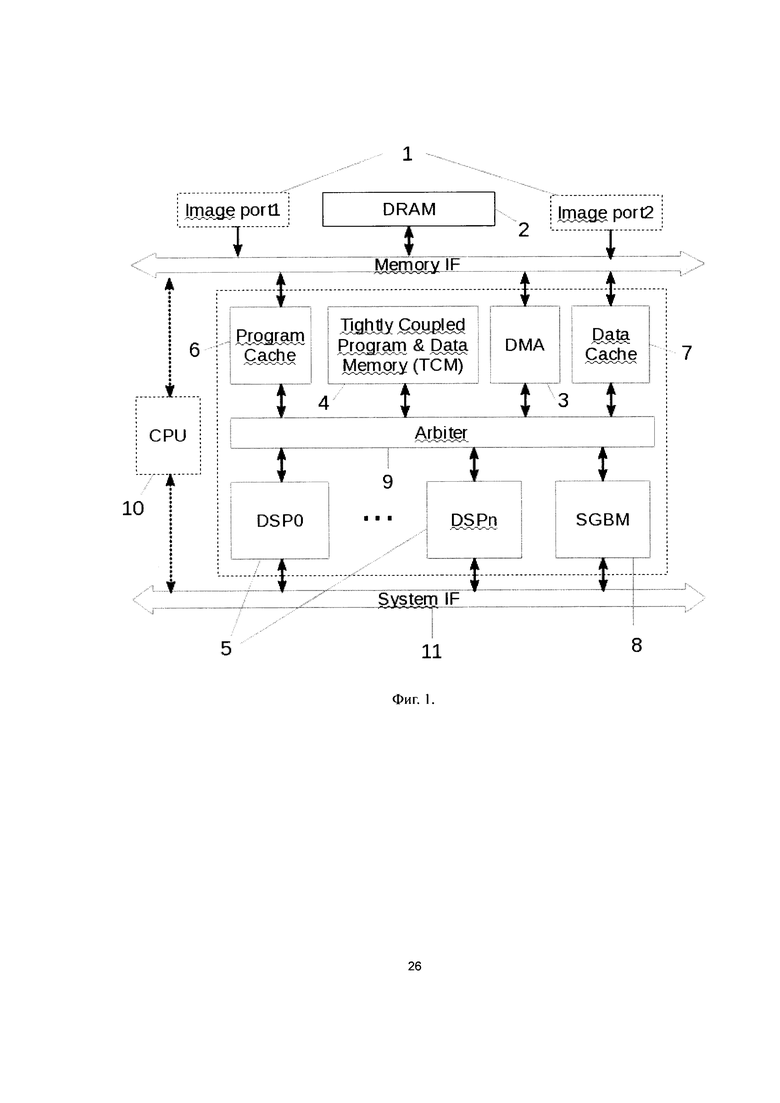
Фиг. 2. Схема прообраза пикселя в исходном изображении, выполненная согласно изобретению.
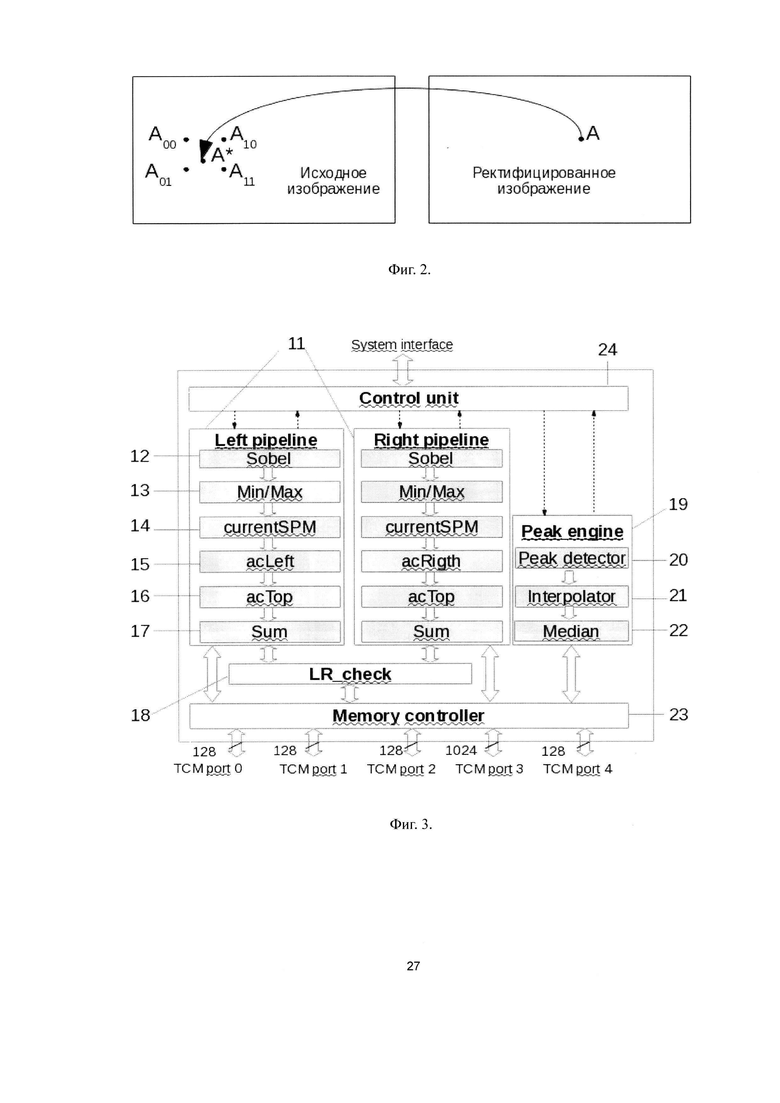
Фиг. 3. Структурная схема аппаратного акселератора SGBM, выполненная согласно изобретению.
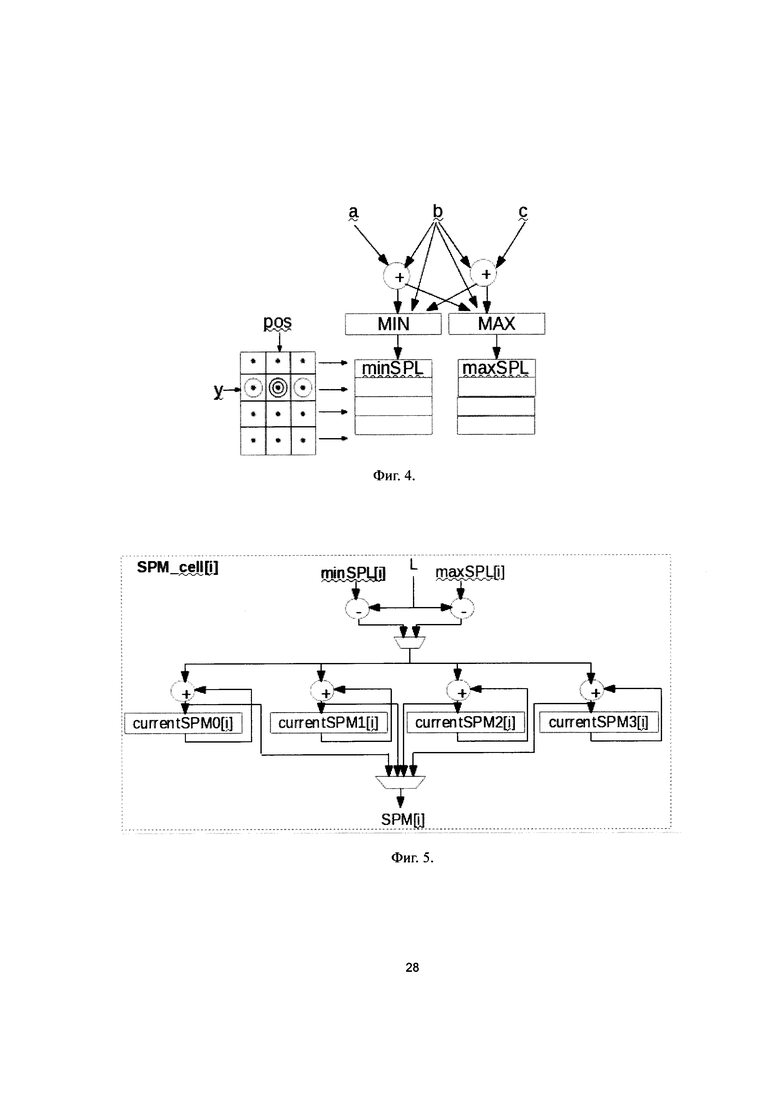
Фиг. 4. Схема алгоритма работы блока Min/Max, выполненная согласно изобретению.
Фиг. 5. Схема ячейки блока currentSPM, выполненная согласно изобретению.
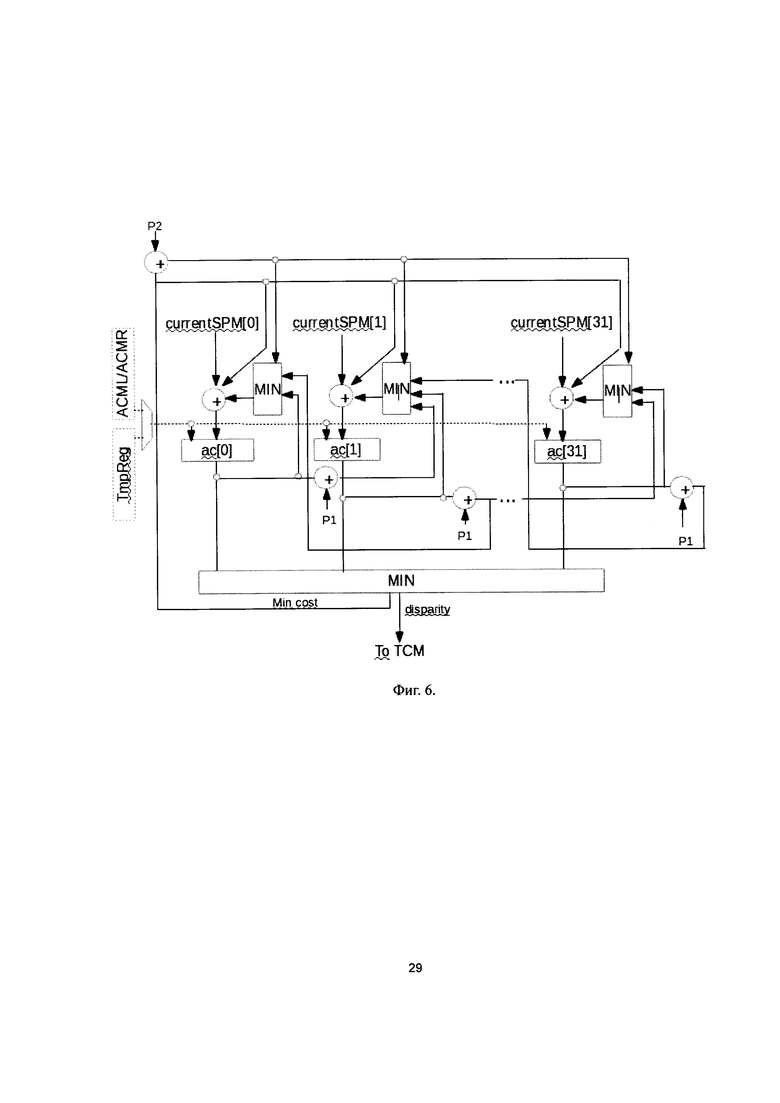
Фиг. 6. Схема блоков acLeft/acRight/acTop, выполненная согласно изобретению.
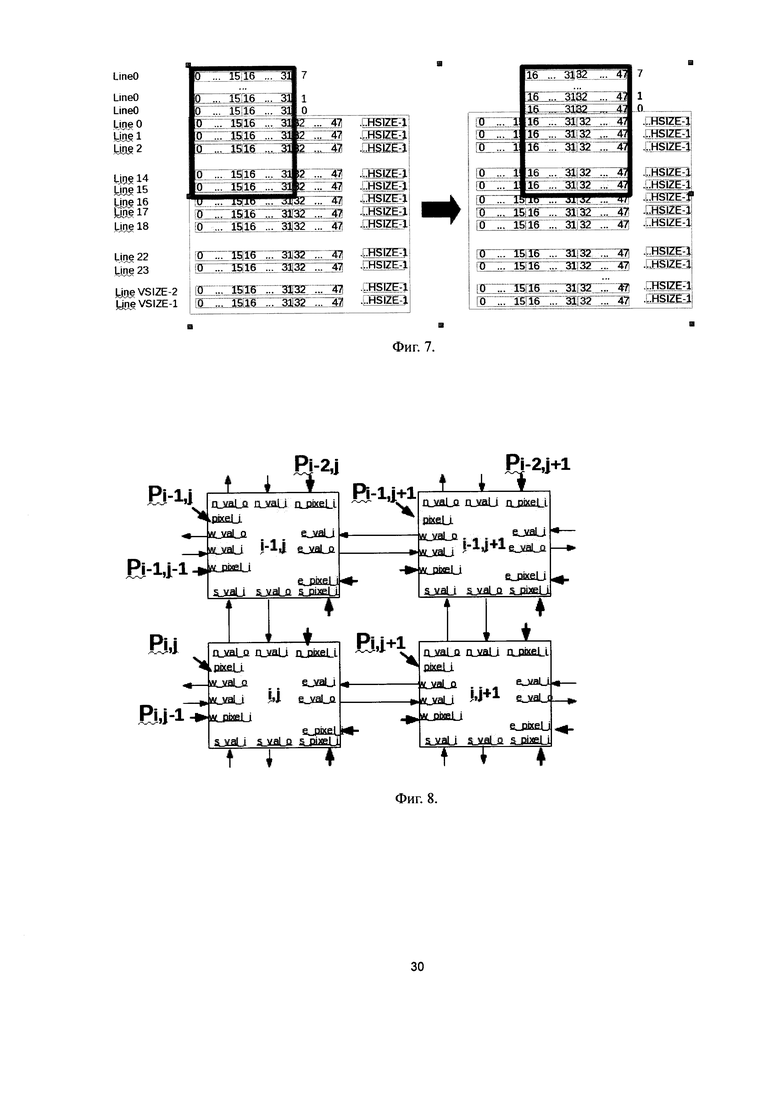
Фиг. 7. Схема перемещения окна обработки при детекции пиков, выполненная согласно изобретению.
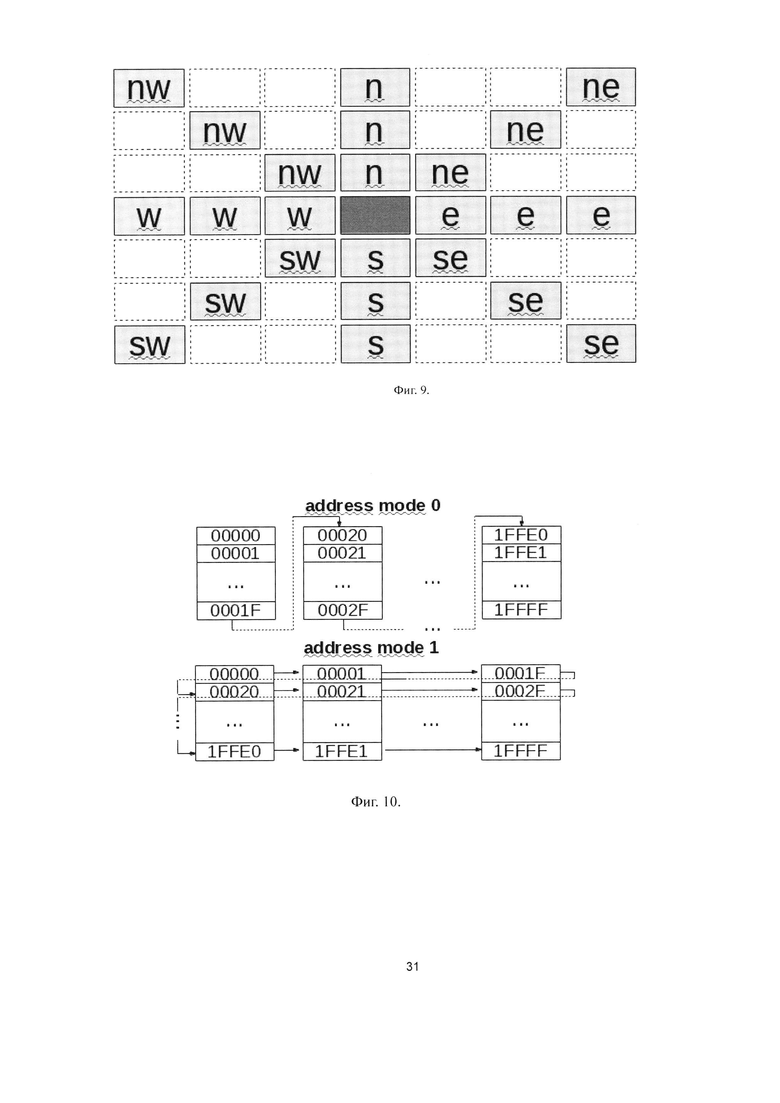
Фиг. 8. Схема фрагменты матрицы вычислительных ячеек блока детекции пиков, выполненная согласно изобретению.
Фиг. 9. Схема ядра блока Interpolator, выполненная согласно изобретению.
Фиг. 10. Схема режимов адресации локальной памяти ТСМ, выполненная согласно изобретению.
Фиг. 11. Схема примера размещения буферов в локальной памяти ТСМ, выполненная согласно изобретению.
Рассмотрим кратко работу заявленных способа и устройства обработки стереоизображений (Фиг. 1).
Заявленное устройство представляет собой вычислительный кластер, имеющий в своем составе несколько (от 4 до 12) ядер (5) сигнальных процессоров и аппаратный акселератор (8) вычисления карты диспаратности. Все ядра (5) сигнальных процессоров и аппаратный акселератор (8) используют общую разделяемую локальную память (4) для хранения программ и промежуточных результатов вычислений. Управление доступом процессорных ядер (5) и аппаратного акселератора (8) к общей локальной памяти (4) осуществляют с помощью арбитра (9).
Обмен данными с внешней памятью (2) осуществляют с помощью DMA-контроллера (3), при этом для временного хранения данных используют кэш программ (6) и кэш данных (7). Доступ к регистрам ядер (5) сигнальных процессоров и аппаратного акселератора (8) осуществляют с помощью центрального процессора (10) через системный интерфейс (11).
Левое и правое исходные изображения, хранящееся во внешней памяти (2), обрабатывают построчно. Несколько строк левого и правого исходных изображений считывают с помощью DMA-контроллера (3) из внешней памяти (2) и сохраняют в локальной памяти (4). Кластер из ядер (5) сигнальных процессоров осуществляет ректификацию изображения, сохраняя результаты в локальной памяти (4). С помощью аппаратного акселератора (8) вычисляют карту диспаратности по алгоритму полуглобального стереоматчинга (SGBM - Semi-global block matching) с постфильтрацией, сохраняя промежуточные и конечные результаты в локальной памяти, а затем с помощью кластера из ядер (5) сигнальных процессоров осуществляют видеоаналитику, используя ректифицированное изображение и карту диспаратности. Полученные результаты записывают с помощью DMA-контроллера во внешнюю память (2).
Рассмотрим более подробно работу варианта выполнения заявленных способа и устройства обработки стереоизображений, показанного на Фиг. 1-11. Левое и правое исходные изображения, получаемые с видеокамер, принимают через порты (1) ввода изображения Image Port1 и Image Port2 и записывают во внешнюю память (2) DRAM (Фиг. 1).
DMA-контроллер (3) пересылает данных между внешней памятью (2), локальной памятью (4) и внутренними памятями программ и данных ядер (5) сигнальных процессоров DSP0-DSPn (5). Программы и данные могут временно размещаться в кэшах программ (6) и данных (7). Пересылки программируют через m (до 16) независимых логических DMA-каналов. Два канала осуществляют пересылку нескольких строк (минимум 4) левого и правого изображения в буферы левого и правого исходного изображения, размещенные в локальной памяти (4). Буферы организованы по принципу двойной буферизации. Минимум один канал осуществляет пересылку результатов обработки во внешнюю память (2). Ядра (5) сигнальных процессоров DSP0-DSPn осуществляют предобработку изображений и выполняют задачи видеоаналитики с использованием карты диспаратности, размещая результаты вычислений в локальной памяти (4). Аппаратный акселератор (8) вычисляет карту диспаратности, размещая ее в буфере в локальной памяти (4). Буферы для хранения промежуточных результатов вычислений также размещаются в локальной памяти (4), все буферы организованы по принципу двойной буферизации. Арбитр (9) осуществляет арбитраж доступа ядер (5) сигнальных процессоров DSP0-DSPn и аппаратного акселератора (8) к локальной памяти (4). Программирование регистров ядер (5) сигнальных процессоров DSP0-DSPn и акселератора (8) осуществляет центральный процессор (10) через системный интерфейс (11).
Для каждого из входных изображений выполняют процедуру ректификации параллельно несколькими из n ядрами (5) сигнальных процессоров DSP0-DSPn. Количество ядер (5) сигнальных процессоров, задействованных для выполнения ректификации, определяют в зависимости от применяемых видеоаналитических алгоритмов. Это количество может составлять от 2 до n. В описываемом варианте заявленного изобретения ректификацию выполняют четырьмя ядрами (5) сигнальных процессоров DSP0-DSP3.
При выполнении ректификации используют внутренние параметры камер, определяемые заранее на этапе калибровки. К ним относятся:
- матрица камеры
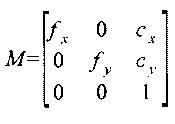
где 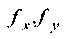 - масштабирующие коэффициенты, обычно равны размеру кадра в пикселах по горизонтали;
- масштабирующие коэффициенты, обычно равны размеру кадра в пикселах по горизонтали;
cx, cy - координаты оптической оси в координатах кадра (левый верхний угол кадра имеет координаты (0, 0));
- матрица дисторсии
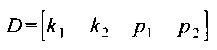 ,
,
где k1, k2 - коэффициенты радиальной дисторсии первого и второго порядка;
p1, p2 - коэффициенты тангенциальной дисторсии первого и второго порядка.
В процессе выполнения ректификации плоскости изображений преобразовывают так, чтобы эпиполярная линия каждого пикселя одного изображения была горизонтальной линией пикселей другого изображения с той же вертикальной координатой. Для этого на основании внутренних и внешних параметров камеры (последние - это матрица R относительного поворота и вектор 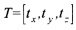 сдвига камер относительно друг друга) определяют матрицы поворота R_left, R_right, на которые необходимо повернуть каждую из камеру, и P_left, P_right, которые должны стать новыми матрицами камер, соответственно для левой и правой камеры. Далее для определенной камеры будем писать R и Р без индексов. Матрица Р имеет вид:
сдвига камер относительно друг друга) определяют матрицы поворота R_left, R_right, на которые необходимо повернуть каждую из камеру, и P_left, P_right, которые должны стать новыми матрицами камер, соответственно для левой и правой камеры. Далее для определенной камеры будем писать R и Р без индексов. Матрица Р имеет вид:
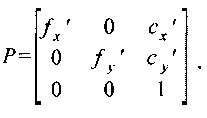
Для фиксированно закрепленных камер описанные выше вычисления выполняют один раз, при выполнении ректификации требуется непосредственно изменить изображения в соответствии с известными М, D, R и Р.
В процессе ректификации левого изображения ядро (5) сигнального процессора DSP0 вычисляет координаты прообразов пикселей ректифицированного изображения в исходном изображении, как показано на Фиг. 2. Вычисления производят согласно следующим формулам:
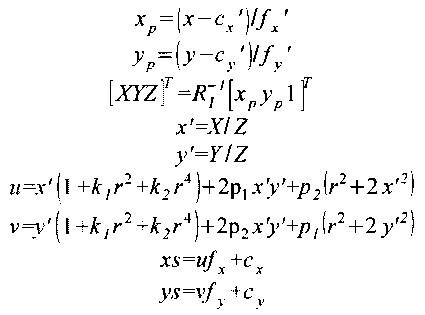
где х, y - координаты пикселя в кадре ректифицированного изображения;
х', y' - координаты пикселя после поворота камеры;
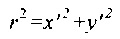 ;
;
u, v - координаты пикселя после применения дисторсии к изображению;
xs, ys - координаты пикселя в исходном кадре.
Ядро (5) сигнального процессора DSP0 записывает в локальную память (4) обратную карту пикселей, в которой каждому пикселю ректифицированного изображения соответствует его прообраз в исходном изображении.
Ядро (5) сигнального процессора DSP1 вычисляет яркости пикселей ректифицированного изображения, используя обратную карту пикселей из локальной памяти (4). Пиксели обрабатывают построчно слева направо. Для каждого пикселя ректифицированного изображения с координатами (х, y) из карты пикселей считывают координаты его прообраза во входном изображении (xs, ys).
Так как координаты xs и ys в общем случае имеют дробное значение (см. Фиг. 2), то, для того чтобы найти значение яркости прообраза, применяют билинейную интерполяцию по четырем соседним пикселям:
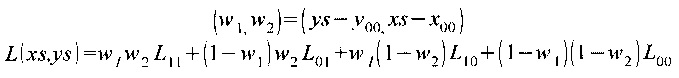 ,
,
где х00, y00 - координаты точки 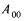 ;
;
А - пиксель ректифицированного изображения;
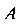 - прообраз пикселя А в исходном изображении;
- прообраз пикселя А в исходном изображении;
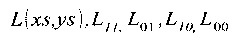 - яркость соответственно в точках
- яркость соответственно в точках 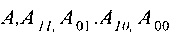 .
.
Ядро (5) сигнального процессора DSP1 считывает из буфера входного изображения значения яркостей пикселей 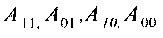 , вычисляет яркость пикселя с координатами (х, y) и записывает ее в буфер ректифицированного изображения.
, вычисляет яркость пикселя с координатами (х, y) и записывает ее в буфер ректифицированного изображения.
Ядра (5) сигнальных процессоров DSP2-DSP3 выполняют процедуру ректификации правого изображения по описанному выше алгоритму. Буферы левого и правого ректифицированного изображения содержат несколько строк (минимум 4) и могут быть организованы по принципу двойной буферизации.
Ректификацию одного изображения может выполнять большее количество ядер (5) сигнальных процессоров DSP, в этом случае первое ядро (5) вычисляет обратную карту пикселей, а яркость пикселей выполняют параллельно остальные ядра (5) сигнального процессора DSP. Строку изображения делят на фрагменты, количество фрагментов соответствует количеству ядер (5) сигнального процессора DSP, каждое ядро (5) обрабатывает свою часть строки ректифицированного изображения.
Аппаратный акселератор (8) вычисляет точную карту диспаратности по известному из уровня техники алгоритму полуглобального стереоматчинга SGBM, проверяет карту диспаратности левого изображения с помощью карты диспаратности правого изображения (Left-Right Check) и улучшает полученную карту путем трехэтапной постобработки (детекция пиков, интерполяция и медианная фильтрация). Вычисление точной карты выполняют с накоплением стоимости по одному или двум направлениям - влево и вниз, это позволяет вычислять диспаратность за один проход по изображению. Тактирование блока осуществляют синхросигналом CLK.
На Фиг. 3 представлена структурная схема аппаратного акселератора (8) SGBM. Обработка данных осуществляют двумя параллельными конвейерами (11) Left pipeline и Right pipeline, каждый из которых может вычислять значения карты диспаратности при максимально возможном значении диспаратности Number_of_Dispatiry (NoD) 127. Если NoD<64, то обработку левого и правого изображения в одном или двух направлениях осуществляют параллельно с максимальной частотой - 2 такта синхросигнала CLK на пиксель. Если 64<=NoD<128, то оба конвейера обрабатывают данные левого и правого изображения вправо и вниз с частотой, вдвое ниже максимальной, - 4 такта на пиксель. В случае NoD>127 осуществляют обработку данных только левого изображения обоими конвейерами в направлениях вправо и вниз с частотой 4 такта на пиксель. Обработку данных в направлении вниз всегда производят при обработке только левого изображения.
Каждый конвейер обработки состоит из шести обрабатывающих блоков: блок фильтрации Sobel (12), блок Min/Max (13), блок currentSPM (14), блок acLeft/acRight (15), блок асТор (16) и блок Sum (17). Проверку карты диспаратности левого изображения с помощью карты диспаратности правого изображения осуществляют блоком Left-Right Check (18). Постобработку первичной карты диспаратности производят блоком Peak Engine (19), и она состоит из трех этапов, осуществляемых блоками Peak Detector (20), Interpolator (21) и Median (22).
Обмен данными между блоками обработки и локальной памятью ТСМ осуществляют под управлением блока Memory Controller (23) через пять независимых Master-портов. Порт 0 предназначен для чтения ректифицированного изображения и записи изображения после фильтрации фильтром Собеля, порт 1 - для чтения отфильтрованного изображения и записи результатов вычисления необработанной карты диспаратности для левого и правого изображений. Порт 2 используют для чтения необработанной карты диспаратности для левого и правого изображений и записи точной карты диспаратности после проверки качества. Разрядность шины данных для портов 0-2 составляет 128 разрядов. Порт 3 используют для чтения и записи накапливаемых стоимостей в вертикальном направлении. Разрядность шины порта 3 определяется значением NoD и может составлять от 256 до 1024 бит. Порт 4 предназначен для чтения точной карты диспаратности (после LR-check'a) и записи плотной карты диспаратности после постобработки. Управление вычислительными конвейерами и портом видеопамяти осуществляют блоком Control unit (24), который содержит регистры, программируемые центральным процессором через системный интерфейс.
Блок фильтрации Sobel (12) выполняет предварительную фильтрацию ректифицированного изображения, считанного из локальной памяти (4), с помощью фильтра Собеля. Промежуточные результаты фильтрации записывают в буфер отфильтрованного изображения, размещенный в локальной памяти (4).
В блоке Min/Max (13) вычисляют концы отрезков [min{L(q'), L(q'+0.5), L(q'-0.5)}; max{L(q'), L(q'+0.5), L(q'-0.5)}] для пикселей q' левого/правого изображения (в зависимости от направления) с горизонтальной координатой pos и вертикальной координатой от y-1 до y+2, где L - яркость пикселя. Левые и правые концы отрезков записывают в циклические по столбцам массивы размером (NoD+1)*4. Для крайних случаев координаты pos (первый и последний столбец региона обработки) отрезки считают вырожденными в точку L(q).
Значения пикселей четырех строк региона обработки, отфильтрованного фильтром Собеля, считывают в регистры из буфера отфильтрованного изображения в локальной памяти (4). Для обработки одного пикселя q требуется 3 пикселя отфильтрованного изображения - сам пиксель q и его окрестность, как показано на Фиг. 4. Пиксель q с координатами (pos, y) обозначен двойной окружностью. Минимум и максимум вычисляют из трех значений a, b и с (а - значение пикселя с горизонтальной координатой pos-1, b - с горизонтальной координатой pos, с - с горизонтальной координатой pos+1). Для получения яркостей точек (q+0.5) и (q-0.5) вычисляют среднеарифметические значения:
L(q+0.5)=(с+b)>>1;
L(q-0.5)=(а+b)>>1.
Вычисления повторяют для пикселей с вертикальными координатами y-1, y, y+1 и y+2. Результатом вычислений являются 4 значения минимума (записываются в массив minSPL/minSPR) и 4 значения максимума (записывают в массив maxSPL/maxSPR).
Блок currentSPM (14) вычисляет текущее 12-разрядное значение функции стоимости соответствия для пикселя p и NoD+1 значений диспаратности. Значения NoD определяют в диапазоне от 15 до 239 с шагом 16. C(p,d) - стоимость соответствия для пикселя p и диспаратности (чем меньше стоимость соответствия C(p,d), тем больше вероятность, что пиксель p имеет диспаратность d) - вычисляют по формуле
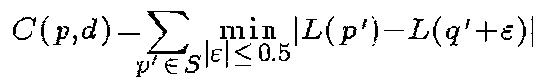
Здесь р' пробегает значения по апертуре S - окрестности левого (правого) изображения вокруг пикселя р, для алгоритма используют окрестность в пять пикселей (сам пиксель и все его соседи по ребру), q' - пиксель правого (левого) изображения, сдвинутый на d относительно р', ε - вещественное число, q'+ε - сдвиг в горизонтальном направлении.
Вычисление 12-разрядных значений массива currentSPM[0:NoD], где currentSPM[d] = C(p,d), осуществляют в конвейере для пикселей двух строк одновременно. Блок состоит из 64-х однотипных ячеек, каждая из которых вычисляет значения currentSPM для одного значения диспаратности. Каждая ячейка обрабатывает в конвейере 4 соседних пикселя из двух строк. Структура ячейки отображена на Фиг. 5. В случае, когда NoD менее 64, на вычисление currentSPM для одного пикселя требуется два такта. Если NoD находится в диапазоне от 64 до 128, блок вычисляет значения диспаратности последовательно в два этапа с частотой четыре такта на пиксель. Если значение NoD>=128, блоки currentSPM конвейеров Left Pipeline и Right Pipeline (11) работают параллельно, конвейер Left Pipeline вычисляет значения currentSPM для NoD<128, конвейер Right Pipeline - для NoD>=128.
В блоках acLeft/acRight (15) вычисляют накапливаемую стоимость соответствия в горизонтальном направлении для левого и правого изображения соответственно, в блоках acDown (16) - накапливаемую стоимость соответствия в направлении вниз.
Накапливаемую стоимость в направлении r для пикселя р и диспаратности d обозначают Cr(p, d) и рекуррентно вычисляют по следующей формуле:
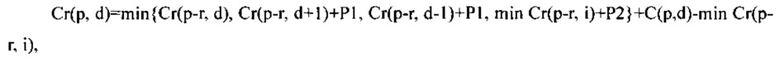
где Р1 и Р2 - штраф за изменение disparity на 1 и на произвольное число соответственно min Cr(p-r, i) - минимум по i (i от 0 до NoD-1).
Структура блоков для всех направлений одинаковая, представлена на Фиг. 6. Блок состоит из 32-х однотипных ячеек и блока вычисления минимума. Блок вычисляет накапливаемую стоимость ac[d]=Cr(p, d) для 32 значений диспаратности за 1 такт. Промежуточные результаты вычислений (накапливаемая стоимость соответствия) для направлений влево-вправо хранят в промежуточных регистрах. Для направления вниз - в зависимости от номера обрабатываемой строки: для четных строк накапливаемая стоимость соответствия хранится в промежуточных регистрах, для нечетных - в буферах ACML/ACMR. Буферы ACML/ACMR размещают в локальной памяти (4). Размер буферов определяется длиной строки карты диспаратности и максимальным значением disparity (NoD).
Скорость обработки данных зависит от NoD и соответствует скорости обработки блоком currentSPM. Накапливаемая стоимость соответствия для одного пикселя при NoD<64 вычисляется за 2, при 64<=NoD<128 - за 4 такта. Если NoD>128, накапливаемые стоимости вычисляют только для левого изображения (без последующего LRcheck'a), при этом блоки acLeft и acRight работают параллельно, acLeft обрабатывает значения диспаратности от 0 до 127, acRight - от 128, вычисления для одного пикселя производятся за 4 такта. Если накопление в направлении вниз не производят, то блоки acLeft/acRight формируют окончательный результат (значение диспаратности, соответствующее минимальному значению накапливаемой стоимости соответствия), который записывают в буферы необработанной карты диспаратности, размещенные в локальной памяти (4).
Блок Sum (17) вычисляет итоговое значение накапливаемой стоимости соответствия в горизонтальном и вертикальном направлениях и осуществляет выбор значений диспаратности, которые записываются в буфера необработанной карты диспаратности, размещенные в локальной памяти (4).
Блок LR-check (18) осуществляет проверку качества необработанной карты диспаратности путем сравнения карт диспаратности, полученных при обработке левого и правого изображения. Значения диспаратности, признанные недостоверными, заменяют на 255 (255 - значение, которое диспаратность не может принимать естественным образом, поскольку максимальная диспаратность строго меньше чем 240). После проверки карту диспаратности для правого изображения не сохраняют. Карту диспаратности для левого изображения записывают в буфер точной карты диспаратности, размещенный в локальной памяти (4).
Конвейер Peak Engine (19) осуществляет постобработку карты диспаратности после LR-check'a. Постобработку производят с целью улучшения полученной точной карты диспаратности, и она включает три этапа: детекция пиков, интерполяция и медианная фильтрация. Могут быть выполнены как все этапы постобработки, так и каждый из них в отдельности. Полученную в результате постобработки плотную карту диспаратности записывают в буфер плотной карты диспаратности в локальной памяти (4).
Блок Peak detector (20) проводит детекцию пиков в точной карте диспаратности. Пиком называется компонента связности ограниченного размера (не более MAX_PEAK_SIZE вершин) в графе, вершинами которого являются пиксели полученной карты диспаратности, ребра между двумя пикселями проводятся, если, во-первых, они имеют общее ребро (то есть являются соседями по горизонтали или по вертикали), а, во-вторых, их диспаратность отличается не больше чем на 1. Значения диспаратности пикселей, принадлежащих пикам, признают недостоверными и заменяют на 254.
Детекцию пиков выполняет вычислительный модуль, реализованный в виде матрицы вычислительных ячеек. Окно обработки размером PD_W по горизонтали и PD_H по вертикали (в описываемом варианте PD_W=32, PD_H=24) перемещают по входной карте диспаратности слева направо с шагом PD_W/2 (16) в горизонтальном направлении до конца строки. Во время первого прохода в горизонтальном направлении в PD_H/3(8) верхних строк окна копируют содержимое первой строки карты, как показано на Фиг. 7. Если длина строки не кратна 16, при перемещении окна в последнюю позицию в горизонтальном направлении недостающие пиксели окна заполняют значениями 0×FF. После обработки первой горизонтальной полосы карты окно возвращают на начало строки, смещают вниз на 8 пикселей и снова перемещают до конца строки. Алгоритм повторяют до конца карты. Последний проход окна в горизонтальном направлении производят, когда при смещении окна по вертикали в окно попадает <= 16 строк. Во время последнего прохода в горизонтальном направлении 8 или более нижних строк окна заполняют значениями 0×FF.
Пиксели входной карты, соответствующие текущему положению окна обработки, передают из входного буфера на вход вычислительного модуля, выполняют детекцию пиков, и на выход вычислительного модуля выдают матрицу invalidate_pixels размером (PD_H-2) x (PD_W-2) бит. Каждому пикселю входной карты из окна обработки (кроме граничной области размером в 1 пиксель) соответствует бит матрицы invalidate_pixels. Если бит установлен в состояние логической единицы, данный пиксель недостоверен, и его значение заменяют на 254.
Вычислительный модуль представляет собой матрицу однотипных вычислительных ячеек, управляемых общим потоком инструкций (SIMD). Количество ячеек соответствует количеству пикселей в вычислительном окне (H×W). Фрагмент матрицы вычислительных ячеек представлен на Фиг. 8. На вход каждой ячейки поступает значение пикселя, соответствующего положению этой ячейки в вычислительном окне (pixel_i), а также значения соседних пикселей, находящихся слева (w_pixel_i), справа (e_pixel_i), снизу (s_pixel_i) и сверху (n_pixel_i). Для ячеек, расположенных на границе матрицы, вместо значения соседних пикселей подают нули.
Каждая ячейка хранит текущее состояние current_value, которое изменяется в результате выполнения инструкций. Исходное значение current_value для всех ячеек, расположенных не на границе матрицы, равно 1. Исходное значение current_value ячеек на верхней границе матрицы задается параметром n_border_constant (в описываемом варианте = 16). Исходное значение current_value ячеек на нижней границе матрицы задается параметром s_border_constant (в описываемом варианте = 16). Исходное значение current_value ячеек на левой границе матрицы (кроме верхней и нижней ячейки) задается параметром w_border_constant (в описываемом варианте = 32). Исходное значение current_value ячеек на левой границе матрицы (кроме верхней и нижней ячейки) задается параметром e_border_constant (в описываемом варианте = 32).
Каждая ячейка имеет горизонтальные и вертикальные связи с соседними ячейками в матрице. В результате выполнения инструкций формируются четыре значения, которые подают на входы соседней верхней ячейки (n_val_o), нижней (s_val_o), левой (w_val_o) и правой ячейки (e_val_o). Выход n_val_o ячейки i, j поступает на вход s_val_i ячейки i-1, j. Выход s_val_o ячейки i, j поступает на вход n_val_i ячейки i+1, j. Выход w_val_o ячейки i, j поступает на вход e_val_i ячейки i, j-1. Выход e_val_o ячейки i, j поступает на вход w_val_i ячейки i, j+1. На входы *_val_i граничных ячеек, не имеющих соседа, подают нули.
При поступлении входных данных ячейка анализирует возможность принадлежности соответствующего ей пикселя к пику и его положение в области пика. Окончательное решение о принадлежности пикселя к пику принимают после вычисления размера области, потенциально являющейся пиком, и сравнения его с параметром MAX_PEAK_SIZE.
Пиксель потенциально принадлежит области пика, если его значение отличается от как минимум одного соседнего пикселя слева, справа, сверху или снизу не более чем на единицу. Ячейка вычисляет признаки принадлежности к пику по всем направлениям:
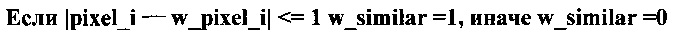
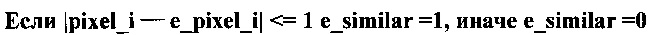
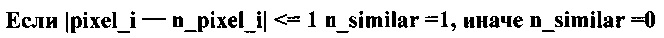
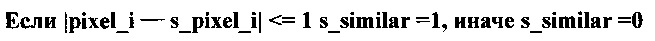
В зависимости от состояния признаков определяют положение пикселя в области потенциального пика: на границе левой (le), правой (re), верхней (te), нижней (be), на горизонтали между левой и правой границами (h), на вертикали между верхней и нижней границами (v). Ячейки, находящиеся в верхнем ряду матрицы, принудительно получают статус верхней границы (te_force). Ячейки, находящиеся в нижнем ряду матрицы, принудительно получают статус верхней границы (be_force). Ячейки, находящиеся в левом ряду матрицы (кроме верхней и нижней), принудительно получают статус левой границы (le_force). Ячейки, находящиеся в правом ряду матрицы (кроме верхней и нижней), принудительно получают статус правой границы (re_force). Каждая ячейка может иметь одновременно статус нескольких границ, одновременно статус вертикали и горизонтали. Ячейка, имеющая статус вертикали и/или горизонтали, не может иметь статуса границ:

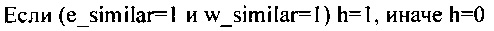
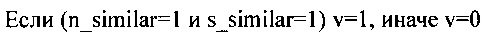
Во время обработки данных ячейки выполняют последовательность инструкций, результат инструкции для каждой ячейки зависит от статуса этой ячейки. По завершению последовательности инструкций каждая ячейка формирует признак invalidate_pixel.
Блок Interpolator (21) вычисляет плотную карту диспаратности путем интерполяции диспаратности на пиксели, диспаратность которых при LR-check'e или детекции пиков была признана недостоверной и заменена на 254 или 255. Ядра блока представляют из себя медианные фильтры по ближайшим валидным пикселям из 8-ми направлений, как показано на Фиг. 9. Длина лучей по каждому направлению может составлять от 1 до 8.
Блок может выполнять следующие виды интерполяции:
- анизотропная фильтрация, когда для выдачи валидного результата должны быть валидные пиксели одновременно в противоположных направлениях в одной из 4 пар противоположных направлений, это препятствует "размазыванию" объектов в области неопределенности. Дополнительно может быть включена эвристика по уменьшению количества генерируемых "островков" в небольших областях невалидности;
- мажоритарная изотропная фильтрация, когда направления не учитывают, а для выдачи валидного результата нужно, чтобы валидных пикселей по направлениям было больше или равно заданного количества NUM_VALID. При NUM_VALID=0 мажоритарная изотропная фильтрация выключена. Значение NUM_VALID, отличное от нуля, задает минимальное число валидных пикселей из "лучей", чтобы результат медианы считать валидным. При включенной мажоритарной изотропной фильтрации анизотропная фильтрация выключена.
Блок интерполяции выполняет параллельную обработку N пикселей из N строк (в описываемом варианте N=8). Максимальная длина лучей по всем направлениям также равна N. Полосу данных размером PD_H=3*N строк с выхода блока детекции пиков передают на вход блока интерполяции. Окно интерполяции размером 3*N×(2*N+1) перемещают по обработанной блоком детекции пиков полосе карты диспаратности слева направо по горизонтали с шагом в 1 пиксель. Недостающие для выполнения интерполяции пиксели слева и справа заменяют значением 0×FF.
На выход блока интерполяции поступает отфильтрованная полоса данных размером N пикселей по вертикали, соответствующая строкам входных данных с N по 2*N-1 плюс одному пикселю строк сверху (2*N) и снизу (N-1) неотфильтрованной карты для выполнения медианной фильтрации.
Блок Median (22) выполняет медианную фильтрацию полученной карты диспаратности. Размер окна медианной фильтрации является фиксированным и составляет 3×3. Фильтрация может иметь от 0 до 8 стадий. Каждая стадия представляет собой 8 медианных фильтров с окном 3×3, которые осуществляют параллельную обработку пикселей из 8 соседних строк.
Плотная карта диспаратности записывается конвейером Peak Engine (19) в буфер плотной карты диспаратности локальной памяти (4).
Локальная память (4) хранит данные, разделяемые DMA-контроллером (3), ядрами (5) сигнальных процессоров DSP0-DSPn и аппаратным акселератором (8). Локальная память (4) состоит из N банков (в описываемом варианте N=32). Все банки имеют одинаковый объем и разрядность (в описываемом варианте 4K 128 разрядных ячеек). При обращении к локальной памяти (4) могут использоваться два режима адресации, которые проиллюстрированы на Фиг. 10. Ядра (5) сигнальных процессоров DSP и DMA-контроллер (3) могут использовать оба режима адресации, аппаратный акселератор (8) - только режим адресации 0. Все устройства, кроме порта 3 аппаратного акселератора (8), во время одной операции чтения/записи обращаются к одному банку локальной памяти (4), разрядность данных в таких операциях равна разрядности банка (128). Порт 3 аппаратного акселератора (8) может осуществлять одновременное чтение/запись из/в несколько банков локальной памяти (4), разрядность данных в таких операциях может составлять от 256 до 1024.
Арбитр (9) декодирует адрес и определяет банк локальной памяти (4), к которому производится обращение. Арбитраж производят независимо для каждого банка. При арбитраже используют фиксированные приоритеты: наивысший приоритет имеет порт 3 аппаратного акселератора (8), затем остальные порты аппаратного акселератора (8) в порядке возрастания нумерации, DMA-контроллер (3), ядра (5) сигнальных процессоров DSP в порядке возрастания нумерации.
Буферы ACML/ACMR размещаются в нескольких банках локальной памяти (4), причем количество ячеек в каждом банке одинаково и определяется длиной строки изображения. Во время одной операции производится одновременное обращение к ячейкам банков с одинаковым номером. Наивысший приоритет порта 3 гарантирует одновременность выполнения операций чтения/записи из всех банков. Поскольку к размещению буферов ACML/ACMR предъявляются жесткие требования, могут возникать проблемы с эффективностью использования памяти. Наличие двух режимов адресации обеспечивает дополнительную гибкость. В примере на Фиг. 11 показаны два варианта размещения буферов. Стрелками показано направление инкрементации адреса. В первом варианте используют только вариант адресации 0, при этом области памяти во второй половине банков, в которых размещаются ACML/ACMR, могут использоваться для хранения только небольших структур данных или останутся неиспользуемыми. Во втором варианте все буфера, используемые аппаратным акселератором (8) или совместно используемые аппаратным акселератором (8) и ядрами (5) сигнальных процессоров DSP, имеют режим адресации 1, а структуры данных, используемые только ядрами (5) сигнальных процессоров DSP, имеют режим адресации 0. При этом вторая половина памяти имеет непрерывное адресное пространство и может использоваться для хранения структур данных достаточно большого объема.
Еще одной функцией арбитра (9) является аппаратная синхронизация данных в буферах между ядрами (5) сигнальных процессоров DSP, аппаратным акселератором (8) и DMA-контролером (3). Синхронизация осуществляют с помощью K-разрядного регистра EVENT, где K - количество синхронизируемых событий.
Например, синхронизацию аппаратного акселератора (8) с ядром (5) сигнального процессора DSP по обмену данными через буфер ректифицированного левого изображения осуществляют с помощью бита SL регистра EVENT в следующей последовательности:
- ядро (5) сигнального процессора DSP анализирует бит SL. Когда SL сбрасывается в 0, начинает ректификацию и записывает данные в буфер ректифицированного левого изображения;
- после завершения записи данных в буфер ректифицированного левого изображения ядро (5) сигнального процессора DSP устанавливает бит SL в 1;
- аппаратный акселератор (8) анализирует бит SL. Когда SL устанавливается в 1, начинает обработку данных из буфера ректифицированного левого изображения;
- после завершения обработки данных из буфера ректифицированного левого изображения акселератор сбрасывает бит SL в 0.
Все синхронизируемые устройства могут считывать содержимое этого регистра по шине EVENT, а также устанавливать и сбрасывать биты этого регистра, используя шину управления. Два старших бита этой шины определяют операцию, которая должная быть выполнена с битом регистра EVENT (0х - нет операции, 10 - сброс бита, 11 - установка бита), младшие биты задают номер бита.
В описываемом варианте 4 из 8 ядер (5) сигнальных процессоров DSP выполняют ректификацию левого и правого изображений. Свободные ресурсы ядер (5) сигнального процессора DSP, используемых для ректификации, и оставшиеся 4 ядра (5) сигнального процессора DSP могут выполнять задачи предобработки входных изображений перед ректификацией и совместной постобработки ректифицированного изображения и карты диспаратности, вычисленной аппаратным акселератором (8). К таким алгоритмам относятся:
- преобразование формата входных изображений;
- преобразование цветов входных изображений;
- масштабирование входных изображений;
- фильтрация входных изображений;
- сегментация карты диспаратности;
- обнаружение особых точек и объектов на карте диспаратности;
- совместная сегментация ректифицированного изображения по яркости, цвету и карте диспаратности;
- совместное обнаружение особых точек и объектов на ректифицированном изображении и карте диспаратности;
- сегментация объектов по ректифицированному изображению с последующей фильтрацией по дальности по карте диспаратности;
- обнаружение особых точек на ректифицированном изображении с последующей фильтрацией по дальности по карте диспаратности;
- оценка расстояния до особых точек и объектов на ректифицированном изображении по карте диспаратности;
- обнаружение объектов, находящихся ближе заданного расстояния по отношению к стереосистеме (пересечение «виртуальной стены»);
- выполнение накопления статистического фона при последовательной обработке изображений на левом канале, правом канале и полученной карте диспаратности, выполнение сегментации изменяющихся областей движения, сопровождение движущихся объектов с повышенным качеством сегментации за счет полученной в аппаратном акселераторе (8) глубины;
- семантическая классификация объектов в поле зрения стереосистемы с помощью алгоритмов машинного обучения, таких как лес случайных деревьев (random forest tree), классификатор Хаара, решающее правило по методу опорных векторов (support vector machine), где на этапе обучения и классификации задействованы признаки, рассчитанные с помощью карты глубины;
- выполнение алгоритмов локализации в пространстве SLAM (simultaneous localization and mapping) в автономных устройствах (например, роботах).
Хотя описанный выше вариант выполнения изобретения был изложен с целью иллюстрации настоящего изобретения, специалистам ясно, что возможны разные модификации, добавления и замены, не выходящие из объема и смысла настоящего изобретения, раскрытого в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ РАССТОЯНИЯ И СКОРОСТЕЙ ОБЪЕКТОВ НА ОСНОВЕ СТЕРЕОПОДХОДА | 2012 |
|
RU2582853C2 |
| Стереоскопическая система обнаружения пешеходов с двухпоточной нейронной сетью с глубоким обучением и способы ее применения | 2019 |
|
RU2730687C1 |
| ЭФФЕКТИВНАЯ РЕАЛИЗАЦИЯ ОБЪЕДИНЕННОГО БИЛАТЕРАЛЬНОГО ФИЛЬТРА | 2018 |
|
RU2767512C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ТРЕХМЕРНОГО ИЗОБРАЖЕНИЯ | 2015 |
|
RU2692432C2 |
| Способ получения ректифицированных изображений документов, сложенных пополам | 2023 |
|
RU2820743C1 |
| УСТРОЙСТВО, СПОСОБ И СИСТЕМА ДЛЯ РЕКОНСТРУКЦИИ 3D-МОДЕЛИ ОБЪЕКТА | 2015 |
|
RU2642167C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ ДВИЖЕНИЯ С АДАПТИВНОЙ К СОДЕРЖИМОМУ ИНФОРМАЦИЕЙ | 2009 |
|
RU2546546C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРЕОБРАЗОВАНИЯ СТЕРЕОКОНТЕНТА | 2009 |
|
RU2423018C2 |
| СПОСОБ ГЕНЕРАЦИИ ПРИМИТИВОВ ИЗОБРАЖЕНИЯ | 2014 |
|
RU2666642C2 |
| ОБНАРУЖЕНИЕ ФОРМАТА ТРЕХМЕРНОГО ВИДЕО | 2011 |
|
RU2568309C2 |

Изобретение относится к области обработки стереоизображений. Техническим результатом является минимизация пересылки данных между памятью и устройством при обработке стереоизображений. В способе загружают построчно левое и правое исходные изображения с помощью DMA-контроллера из внешней памяти в буферы локальной памяти; обрабатывают построчно левое и правое исходные изображения с помощью ядер сигнальных процессоров, при этом выполняют их ректификацию и записывают ректифицированные левое и правое изображения в буферы локальной памяти; вычисляют карту диспаратности с помощью аппаратного акселератора, используя ректифицированные левое и правое изображения, и записывают ее в буфер локальной памяти; обрабатывают с помощью ядер сигнальных процессоров ректифицированные левое и правое изображения, используя видеоаналитические алгоритмы и карту диспаратности, при этом формируют структуры данных, которые записывают в локальную память и затем выгружают с помощью DMA-контроллера во внешнюю память. 2 н. и 17 з.п. ф-лы, 11 ил.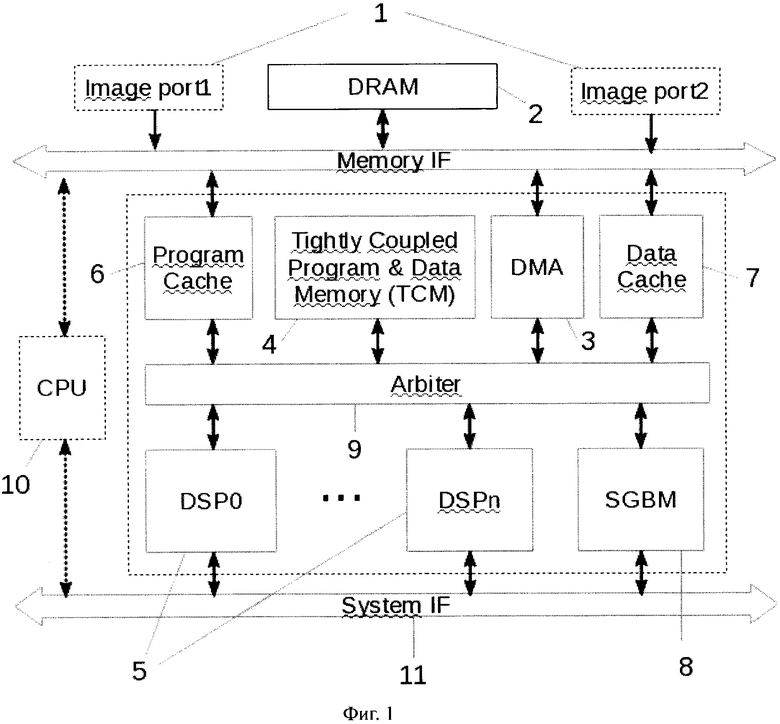
1. Способ обработки стереоизображений, в котором:
- загружают построчно левое и правое исходные изображения с помощью DMA-контроллера (3) из внешней памяти (2) в буферы локальной памяти (4);
- обрабатывают построчно левое и правое исходные изображения с помощью ядер (5) сигнальных процессоров, при этом выполняют их ректификацию и записывают ректифицированные левое и правое изображения в буферы локальной памяти (4);
- вычисляют карту диспаратности с помощью аппаратного акселератора (8), используя ректифицированные левое и правое изображения, и записывают ее в буфер локальной памяти (4);
- обрабатывают с помощью ядер (5) сигнальных процессоров ректифицированные левое и правое изображения, используя видеоаналитические алгоритмы и карту диспаратности, при этом формируют структуры данных, которые записывают в локальную память (4) и затем выгружают с помощью DMA-контроллера (3) во внешнюю память (2).
2. Способ по п. 1, отличающийся тем, что буферы локальной памяти (4), в которых хранятся изображения и карта диспаратности, имеют размер в несколько строк изображения и организованы по принципу двойной буферизации.
3. Способ по п. 1, отличающийся тем, что выполняют ректификацию левого и правого исходных изображений, при этом вычисляют координаты прообразов пикселей ректифицированного изображения в исходном изображении и вычисляют яркости прообразов пикселей путем билинейной интерполяции по четырем соседним пикселям.
4. Способ по п. 1, отличающийся тем, что вычисляют карту диспаратности по алгоритму полуглобального матчинга (SGBM - Semi-global block matching) в двух направлениях, вычисляя функцию стоимости соответствия и накапливаемую стоимость в каждом направлении, при этом проверяют карту диспаратности левого изображения с помощью карты диспаратности правого изображения и выполняют постфильтрацию карты диспаратности, состоящую из трех этапов: детекции пиков, интерполяции и медианной фильтрации.
5. Способ по п. 1, отличающийся тем, что синхронизацию устройств, использующих локальную память (4), осуществляют аппаратно с помощью регистра событий.
6. Способ по п. 1, отличающийся тем, что ректификацию левого и правого исходных изображений выполняют параллельно.
7. Способ по п. 1, отличающийся тем, что ректификацию левого и правого исходных изображений выполняют одновременно с коррекцией радиальной и тангенциальной дисторсии первого и второго порядка.
8. Способ по п. 1, отличающийся тем, что вычисляют карту диспаратности, при этом осуществляют параллельную конвейерную обработку двух строк изображения с сохранением промежуточных результатов в локальной памяти (4) только для нечетных строк.
9. Способ по п. 1, отличающийся тем, что детекцию пиков в карте диспаратности осуществляют параллельно для всех пикселей в окне обработки заданного размера.
10. Способ по п. 9, отличающийся тем, что осуществляют интерполяцию карты диспаратности после детекции пиков путем медианной фильтрации по ближайшим валидным пикселям из восьми направлений с программируемой длиной лучей по алгоритму анизотропной фильтрации или мажоритарной изотропной фильтрации.
11. Способ по п. 10, отличающийся тем, выполняют медианную фильтрацию плотной карты диспаратности в несколько последовательных стадий, на каждой из которых осуществляют параллельную обработку пикселей из нескольких соседних строк изображения с помощью группы медианных фильтров.
12. Устройство обработки стереоизображений, содержащее несколько ядер (5) сигнальных процессоров и аппаратный акселератор (8), соединенные через арбитр (9) с локальной памятью (4), DMA-контроллером (3), кэшем программ (6) и кэшем данных (7), при этом ядра (5) сигнальных процессоров и аппаратный акселератор (8) соединены с внешним системным интерфейсом (11) и выполнены с возможностью обмена данными через него под управлением внешнего центрального процессора (10), a DMA-контроллер (3), кэш программ (6) и кэш данных (7) соединены с внешней памятью (4) и выполнены с возможностью обмена данными с ней, причем
- арбитр (9) выполнен с возможностью управления доступом устройства к внешней памяти (4);
- DMA-контроллер (3) выполнен с возможностью передачи данных между устройством и внешней памятью (4), при этом загрузки построчно левого и правого исходных изображений из внешней памяти (2) в буферы локальной памяти (4);
- ядра (5) сигнальных процессоров выполнены с возможностью построчной обработки левого и правого исходных изображений, при этом их ректификации и записи ректифицированных левого и правого изображений в буферы локальной памяти (4);
- аппаратный акселератор (8) выполнен с возможностью вычисления карты диспаратности с использованием ректифицированных левого и правого изображений и записи ее в буфер локальной памяти (4);
- ядра (5) сигнальных процессоров выполнены с возможностью обработки ректифицированных левого и правого изображений с использованием видеоаналитических алгоритмов и карты диспаратности, при этом формирования структуры данных и записи ее в локальную память (4);
- DMA-контроллер (3) выполнен с возможностью выгрузки структуры данных из локальной памяти (4) во внешнюю память (2).
13. Устройство по п. 12, отличающееся тем, что локальная память (4) организована в виде банков одинакового объема и разрядности, доступ к которым может производиться как транзакциями к одному банку с разрядностью, равной разрядности банка, так и транзакциями к нескольким банкам одновременно с разрядностью, равной суммарной разрядности нескольких банков, с использованием двух режимов адресации под управлением арбитра (9), выполненного с возможностью осуществления арбитража к каждому банку независимо с фиксированными приоритетами.
14. Устройство по п. 12, отличающееся тем, что аппаратный акселератор (8) содержит конвейеры левого и правого изображений, содержащие блок вычисления функции стоимости соответствия и блок вычисления накапливаемой стоимости, которые выполнены с возможностью параллельного вычисления левой и правой карты диспаратности или объединяются в одно устройство для обработки левой карты диспаратности, блок проверки карты диспаратности левого изображения с помощью карты диспаратности правого изображения, блок постобработки карты диспаратности, содержащий блок детекции пиков, блок интерполяции и блок медианной фильтрации, а также блок управления.
15. Устройство по п. 14, отличающееся тем, что блок вычисления функции стоимости соответствия выполнен в виде массива однотипных ячеек, которые выполнены с возможностью обработки в конвейере нескольких строк изображения, при этом длительность обработки одного пикселя может изменяться в несколько раз в зависимости от максимального значения диспаратности.
16. Устройство по п. 14, отличающееся тем, что вычисление накапливаемой стоимости соответствия в горизонтальном и вертикальном направлениях выполняется одинаковыми блоками, состоящими из массива однотипных ячеек и блока вычисления минимума, количество последовательных этапов обработки изменяется в зависимости от максимального значения диспаратности.
17. Устройство по п. 14, отличающееся тем, что блок детекции пиков выполнен в виде вычислительного модуля, представляющего собой матрицу однотипных вычислительных ячеек, управляемых общим потоком инструкций (SIMD), в котором количество ячеек соответствует количеству пикселей в вычислительном окне, каждая ячейка выполнена с возможностью получения значения пикселя, соответствующего положению этой ячейки в вычислительном окне, а также значения соседних пикселей, находящихся слева, справа, снизу и сверху, с возможностью хранения текущего значения, которое изменяется в результате выполнения инструкций, и по завершению последовательности инструкций формирования признака инвалидации.
18. Устройство по п. 14, отличающееся тем, что блок интерполяции выполнен с возможностью осуществления параллельной обработки N пикселей из N строк, при этом максимальная длина лучей по всем направлениям также равна N.
19. Устройство по п. 14, отличающееся тем, что блок медианной фильтрации выполнен в виде нескольких последовательных стадий обработки, каждая из которых осуществляет параллельную обработку пикселей из нескольких строк.
| WO2014152254 A2, 25.09.2014 | |||
| US20070050563 A1, 01.05.2007 | |||
| US20110285701 A1, 24.11.2011 | |||
| RU2012126548 A, 27.12.2013. |

