ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее изобретение относится к способу и устройству для кодирования видеосигналов.
УРОВЕНЬ ТЕХНИКИ
[2] Сжатие относится к способу обработки сигналов для передачи цифровой информации через линию связи или запоминания цифровой информации в подходящем носителе информации. Целевые объекты сжатия включают в себя звуковые сигналы, видеосигналы и текст. Конкретно, способ сжатия изображений называется сжатием видеоизображений. Многовидовое видеоизображение имеет характеристики пространственной избыточности, временнóй избыточности и межвидовой избыточности.
ТЕХНИЧЕСКАЯ ПРОБЛЕМА
[3] Задачей настоящего изобретения является повышение эффективности кодирования видеосигнала.
ТЕХНИЧЕСКОЕ РЕШЕНИЕ
[4] Настоящее изобретение получает межвидовый вектор движения, используя значения глубины из глубинного блока, соответствующего текущему текстурному блоку.
[5] Дополнительно настоящее изобретение получает межвидовый вектор движения, используя часть значений глубины из глубинного блока, соответствующего текущему текстурному блоку.
[6] Кроме того, настоящее изобретение получает коэффициент компенсации, выполняя процедуру компенсации различия в освещенности с использованием соседнего пиксела текущего текстурного блока и соседнего пиксела эталонного блока.
[7] Кроме того, настоящее изобретение получает коэффициент компенсации для компенсации различия в освещенности в соответствии с конкретными условиями.
ПОЛЕЗНЫЕ ЭФФЕКТЫ
[8] Настоящее изобретение может повысить точность предсказания компенсации различия, получая межвидовый вектор движения использованием значений глубины из глубинного блока, соответствующего текущему текстурному блоку.
[9] Дополнительно настоящее изобретение может уменьшить сложность предсказания компенсации различия, получая межвидовый вектор движения использованием части значений глубины из глубинного блока, соответствующего текущему текстурному блоку.
[10] Кроме того, настоящее изобретение может повысить точность предсказания компенсации различия, получая точные значения предсказания для текущего текстурного блока в соответствии с компенсацией различия в освещенности.
[11] Кроме того, настоящее изобретение может уменьшить сложность компенсации различия в освещенности, просто получая коэффициент компенсации в соответствии с конкретными условиями.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[12] ФИГ. 1 – блок-схема широковещательного приемника, в котором применено кодирование по глубине в соответствии с вариантом осуществления настоящего изобретения.
[13] ФИГ. 2 - блок-схема видеодекодера согласно варианту осуществления настоящего изобретения.
[14] ФИГ. 3 - представление концепции глубины согласно варианту осуществления, в котором применено настоящее изобретение.
[15] ФИГ. 4 - пример предсказания компенсации различия согласно варианту осуществления, в котором применено настоящее изобретение.
[16] ФИГ. 5 - блок-схема последовательности операций, иллюстрирующая пример декодирования текущего глубинного блока через предсказание компенсации различия согласно варианту осуществления, в котором применено настоящее изобретение.
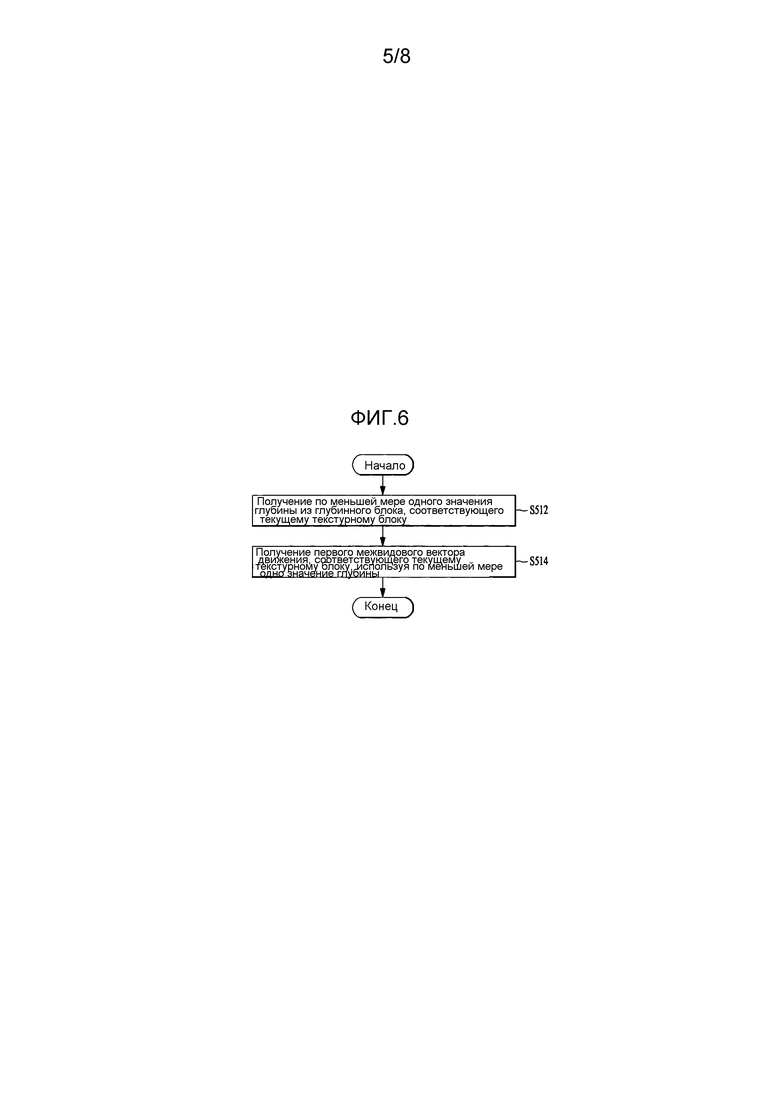
[17] ФИГ. 6 - блок-схема последовательности операций, иллюстрирующая пример получения межвидового вектора движения для текущего текстурного блока путем использования значения глубины из глубинного блока, соответствующего текущему текстурному блоку, согласно варианту осуществления, в котором применено настоящее изобретение.
[18] ФИГ. 7 - пример получения значения глубины в глубинном блоке, соответствующем текущему текстурному блоку, как первого межвидового вектора движения для текущего текстурного блока, согласно варианту осуществления, в котором применено настоящее изобретение.
[19] ФИГ. 8 – пример части пикселов из глубинного блока, соответствующего текущему текстурному блоку, используемых для получения максимального межвидового вектора движения и межвидового вектора движения для наиболее часто встречающейся глубины, согласно варианту осуществления, в котором применено настоящее изобретение.
[20] ФИГ. 9 - блок-схема, иллюстрирующая пример компенсации различия в освещенности, согласно варианту осуществления, в котором применено настоящее изобретение.
[21] ФИГ. 10 – пример текущего текстурного блока, эталонного блока, соседних пикселов текущего текстурного блока и соседних пикселов эталонного блока, которые используются во время процедуры компенсации различия в освещенности, согласно варианту осуществления, в котором применено настоящее изобретение.
НАИЛУЧШИЙ ВАРИАНТ ОСУЩЕСТВЛЕНИЯ
[22] Настоящее изобретение обеспечивает видеодекодер, включающий в себя устройство интерактивного предсказания, выполненное с возможностью получения глубинного блока, соответствующего текущему текстурному блоку, получения первого межвидового вектора движения, используя по меньшей мере одно из значений глубины в глубинном блоке, получения эталонного блока текущего текстурного блока, используя первый межвидовый вектор движения, и получения значений предсказания для текущего текстурного блока, используя эталонный блок, и способ обработки видеосигналов.
[23] По меньшей мере одно значение глубины может по меньшей мере быть одним из значений глубины для левого верхнего пиксела, левого нижнего пиксела, правого верхнего пиксела и правого нижнего пиксела в глубинном блоке.
[24] По меньшей мере одно значение глубины может быть наибольшим значением глубины среди значений глубины для левого верхнего пиксела, левого нижнего пиксела, правого верхнего пиксела и правого нижнего пиксела в глубинном блоке.
[25] Устройство интерактивного предсказания может получать второй межвидовый вектор движения выведенным из соседнего блока текущего текстурного блока, получать текстурный блок в соседнем виде, используя второй межвидовый вектор движения, и получать глубинный блок, используя текстурный блок в соседнем виде.
[26] Глубинный блок может располагаться у соседнего вида текущего текстурного блока.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[27] Способы сжатия или декодирования многовидовых видеосигналов учитывают пространственную избыточность, временную избыточность и межвидовую избыточность. В случае многовидового изображения многовидовое текстурное изображение, снятое при двух или более видах, может быть кодировано для создания трехмерного изображения. Кроме того, относящиеся к глубине данные, соответствующие многовидовому текстурному изображению, могут быть кодированы по мере необходимости. Относящиеся к глубине данные могут быть сжаты с учетом пространственной избыточности, временнóй избыточности или межвидовой избыточности. Относящиеся к глубине данные являются информацией по расстоянию между фотокамерой и соответствующим пикселом. Относящиеся к глубине данные могут гибко интерпретироваться в спецификации как относящаяся к глубине информация, такая как глубинная информация, глубинное изображение, глубинная фотография, глубинная последовательность и связанный с глубиной поток двоичных сигналов. Дополнительно кодирование может по определению включать в себя концепции как кодирования, так и декодирования, и может гибко интерпретироваться в пределах технической сущности и технического объема настоящего изобретения.
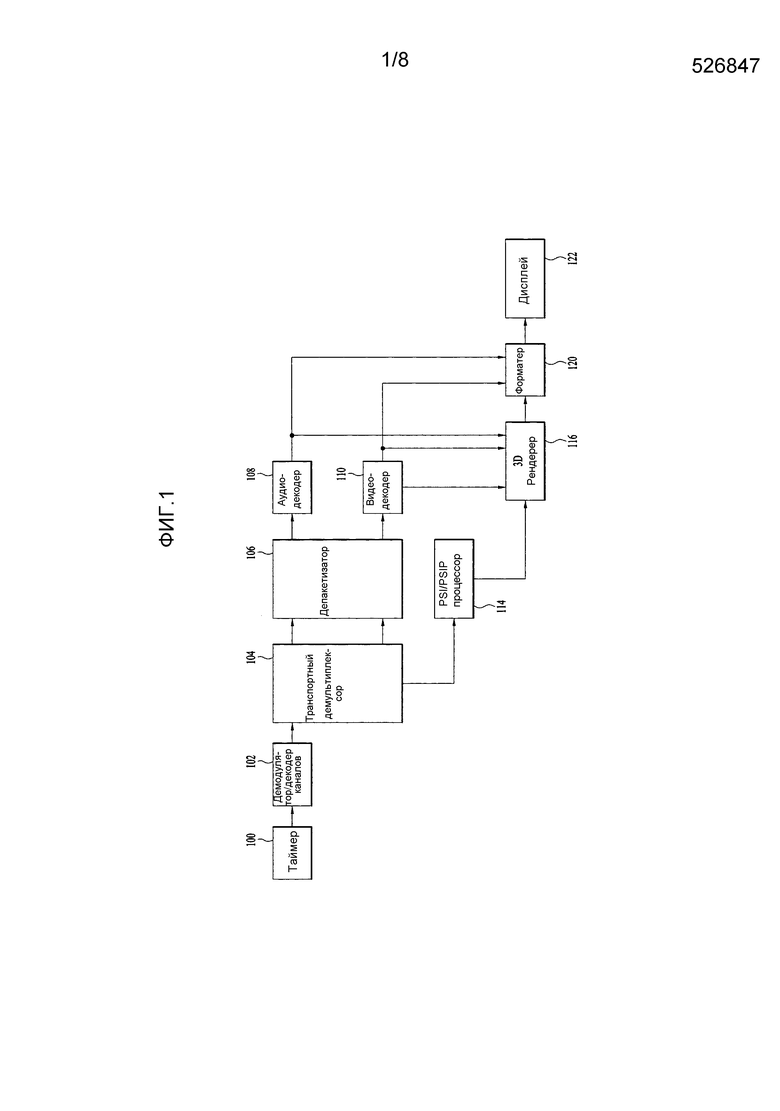
[28] На фиг. 1 представлена блок-схема широковещательного приемника, к которому применимо кодирование по глубине согласно варианту осуществления, в котором используется настоящее изобретение.
[29] Широковещательный приемник, соответствующий настоящему варианту осуществления, принимает широковещательные сигналы наземной станции для воспроизведения изображений. Широковещательный приемник может генерировать трехмерный контент, используя принятую, относящуюся к глубине, информацию. Широковещательный приемник включает в себя тюнер 100, демодулятор/декодер 102 каналов, транспортный демультиплексор 104, депакетизатор 106, аудиодекодер 108, видеодекодер 110, PSI/PSIP процессор 114, 3D рендерер 116, форматер 120 и дисплей 122.
[30] Тюнер 100 выбирает широковещательный сигнал канала, на который настроился пользователь, из множества широковещательных сигналов, вводимых через антенну (не показана), и выводит выбранный широковещательный сигнал. Демодулятор/декодер 102 каналов демодулирует широковещательный сигнал от тюнера 100 и выполняет декодирование с коррекцией ошибок на демодулированном сигнале, чтобы обеспечить на выходе транспортный поток TS. Транспортный демультиплексор 104 демультиплексирует транспортный поток, чтобы разделить транспортный поток на видео PES и аудио PES и извлечь PSI/PSIP информацию. Депакетизатор 106 депакетизирует видео PES и аудио PES, чтобы запомнить видео ES и аудио ES. Аудиодекодер 108 выдает на выходе поток двоичных звуковых сигналов, декодируя аудио ES. Поток двоичных звуковых сигналов преобразуется в аналоговый звуковой сигнал цифро-аналоговым преобразователем (не показан), усиливается усилителем (не показан) и затем выводится через громкоговоритель (не показан). Видеодекодер 110 декодирует видео ES, чтобы запомнить исходное изображение. Процессы декодирования в аудиодекодере 108 и видеожекодере 110 могут выполняться на основе ID пакета (PID), подтвержденного PSI/PSIP процессором 114. Во время процесса декодирования видеодекодер 110 может извлекать глубинную информацию. Кроме того, видеодекодер 110 может извлекать дополнительную информацию, необходимую для генерации изображения виртуального представления фотокамеры, например, информацию о фотокамере или информацию для оценки преграды, скрытой расположенным спереди объектом (например, геометрическую информацию, такую как контур объекта, прозрачность объекта и цветовая информация), и обеспечивать дополнительную информацию для 3D рендерера 116. Однако глубинная информация и/или дополнительная информация могут быть отделены друг от друга транспортным демультиплексором 104 в других вариантах осуществления настоящего изобретения.
[31] PSI/PSIP процессор 114 принимает PSI/PSIP информацию от транспортного демультиплексора 104, подробно анализирует PSI/PSIP информацию и запоминает проанализированную PSI/PSIP информацию в памяти (не показана) или регистрационном журнале, с тем чтобы обеспечить возможность широковещания на основе запомненной информации. 3D рендерер 116 может генерировать цветовую информацию, глубинную информацию, и т.п., в позиции виртуальной фотокамеры, используя восстановленное изображение, глубинную информацию, дополнительную информацию и параметры фотокамеры.
[32] Дополнительно 3D рендерер 116 генерирует виртуальное изображение в позиции виртуальной фотокамеры, выполняя 3D деформирование с использованием восстановленного изображения и глубинной информации применительно к восстановленному изображению. Хотя 3D рендерер 116 в настоящем варианте осуществления выполнен в виде блока, отделенного от видеодекодера 110, это является просто примером, и 3D рендерер может быть включен в с0остав видеодекодера 110.
[33] Форматер 120 форматирует изображение, восстановленное в процессе декодирования, то есть реальное изображение, запечатленное фотокамерой, и виртуальное изображение, созданное 3D рендерером 116 в соответствии с режимом визуального отображения широковещательного приемника, так что 3D изображение воспроизводится на дисплее 122. При этом синтез глубинной информации и виртуального изображения в позиции виртуальной фотокамеры, осуществляемый 3D рендерером 116, и форматирование изображения форматером 120 могут избирательно выполняться в ответ на команду пользователя. То есть пользователь может управлять дистанционным контроллером (не показан), с тем чтобы комбинированное изображение не отображалось на дисплее, и назначать время синтеза изображения.
[34] Как было описано выше, глубинная информация для генерации 3D изображения используется 3D рендерером. Однако в других вариантах осуществления глубинная информация может быть использована видеодекодером 110. Будет дано описание различных вариантов осуществления, в которых видеодекодер 110 использует глубинную информацию.
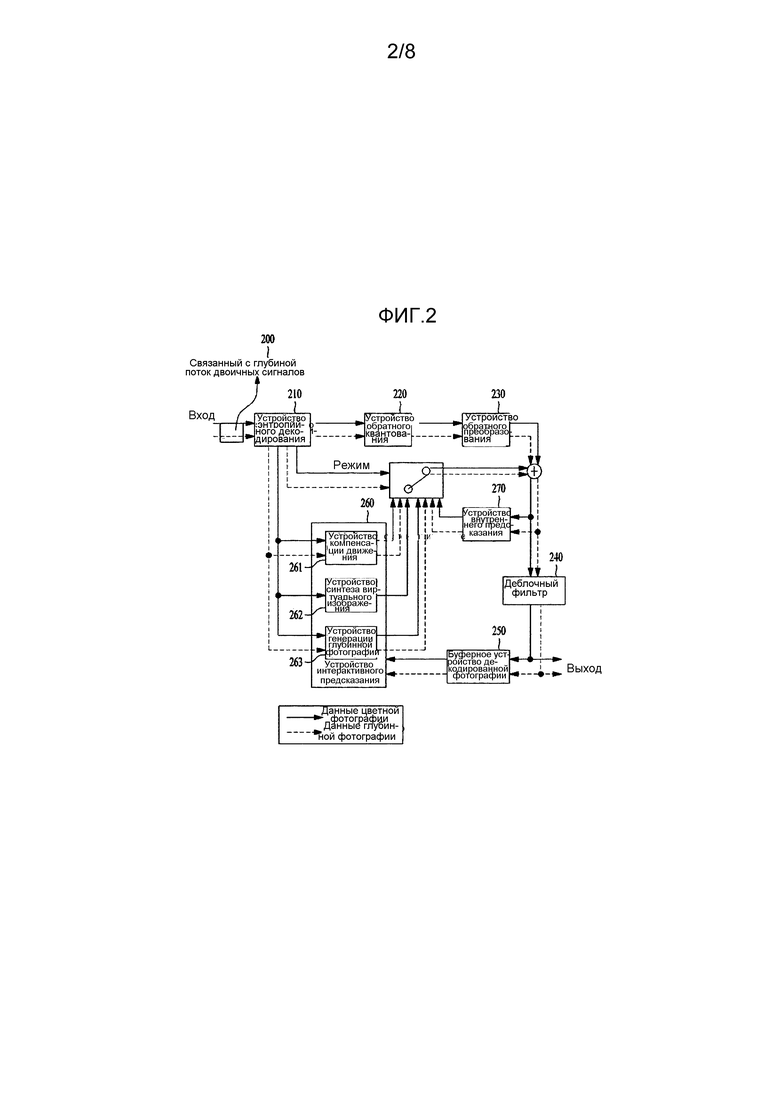
[35] На фиг. 2 представлена блок-схема видеодекодера согласно варианту осуществления, в котором используется настоящее изобретение.
[36] Как показано на фиг. 2, видеодекодер 110 может включать в себя устройство 210 энтропийного декодирования, устройство 220 обратного квантования, устройство 230 обратного преобразования, деблочный фильтр 240, буферное устройство 250 декодированной фотографии, устройство 260 интерактивного предсказания и устройство 270 внутреннего предсказания. На фиг. 2 сплошные линии представляют поток данных цветной фотографии, а пунктирные линии представляют поток данных глубинной фотографии. Хотя данные цветной фотографии и данные глубинной фотографии представлены раздельно на фиг. 2, раздельное представление данных цветной фотографии и данных глубинной фотографии может относиться к раздельным потокам двоичных сигналов или к раздельным потокам данных в одном потоке двоичных сигналов. То есть данные цветной фотографии и данные глубинной фотографии могут передаваться как один поток двоичных сигналов или как раздельные потоки двоичных сигналов. На фиг. 2 показаны только потоки данных, и операции не ограничены операцией, выполняемой в одном декодере.
[37] Прежде всего, для того чтобы декодировать принятый, связанный с глубинной, поток 200 двоичных сигналов, этот связанный с глубиной поток 200 двоичных сигналов анализируется на NAL. При этом различные типы атрибутной информации, относящейся к глубине, могут быть включены в состав зоны заголовка NAL , расширенной зоны заголовка NAL, зоны заголовка последовательности (например, последовательности ряда значений параметров), расширенной зоны заголовка последовательности, зоны заголовка фотографии (например, ряда значений параметров фотографии), расширенной зоны заголовка фотографии, зоны послойного заголовка, расширенной зоны послойного заголовка, зоны послойных данных или зоны макроблока. Хотя кодирование по глубине может выполняться, используя отдельный кодек, может оказаться более эффективным добавление атрибутной информации, относящейся к глубине, только в случае связанного с глубиной потока двоичных сигналов, если обеспечена совместимость с существующими кодеками. Например, глубинная идентификационная информация для идентификации связанного с глубиной потока двоичных сигналов может быть добавлена в зону заголовка последовательности (например, последовательности ряда значений параметров) или в расширенную зону заголовка последовательности. Атрибутная информация, относящаяся к глубинной последовательности, может быть добавлена, только когда входной поток двоичных сигналов является кодированным по глубине потоком двоичных сигналов, соответствующим глубинной идентификационной информации.
[38] Проанализированный связанный с глубиной поток 200 двоичных сигналов энтрпийно декодируется устройством 210 энтропийного декодирования, и извлекаются коэффициент, вектор движения и подобные параметры каждого макроблока. Устройство 220 обратного квантования умножает принятое квантованное значение на заданную константу, чтобы получить преобразованный коэффициент, а устройство 230 обратного преобразования обратно преобразует этот коэффициент, чтобы восстановить глубинную информацию глубинной фотографии. Устройство 270 внутреннего предсказания выполняет внутреннее предсказание, используя восстановленную глубинную информацию для текущей глубинной фотографии. Деблочный фильтр 240 применяет антиблочную фильтрацию к каждому кодированному макроблоку, чтобы уменьшить “блочность” структуры изображения. Деблочный фильтр 240 улучшает текстуру декодированного кадра, сглаживая края блока. Процесс фильтрации выбирается в зависимости от граничной интенсивности и градиента образца изображения вдоль границы. Профильтрованные глубинные фотографии выводятся или запоминаются в буферном устройстве 250 декодированных фотографий, чтобы использоваться в качестве эталонных фотографий.
[39] Буферное устройство 250 декодированных фотографий запоминает или открывает предварительно кодированные глубинные фотографии для интерактивного предсказания. При этом, для того чтобы запомнить кодированные глубинные фотографии в буферном устройстве 250 декодированных фотографий или открыть запомненные кодированные глубинные фотографии, используются frame_num (номер кадра) и POC (Picture Order Count - порядковый номер фотографии) каждой фотографии. Поскольку предварительно кодированные фотографии могут включать в себя глубинные фотографии, соответствующие видам, отличающимся от текущей глубинной фотографии, информация по соотношению между глубиной и видом для идентификации видов глубинных фотографий, а также frame_num и POC могут быть использованы, чтобы применять предварительно кодированные фотографии в качестве эталонных фотографий при кодировании по глубине.
[40] Дополнительно буферное устройство 250 декодированных фотографий может использовать информацию по соотношению между глубиной и видом, для того чтобы создавать перечень эталонных фотографий для межвидового предсказания глубинных фотографий. Например, буферное устройство 250 декодированных фотографий может использовать эталонную информацию глубина-вид. Эталонная информация глубина-вид относится к информации, используемой для указания межвидовой зависимости для глубинных фотографий. Например, эталонная информация глубина-вид может включать в себя ряд глубинных видов, идентификационный номер глубинного вида, ряд эталонных фотографий глубина-вид, идентификационные номера эталонных фотографий глубина-вид, и т.п.
[41] Буферное устройство 250 декодированных фотографий управляет эталонными фотографиями, чтобы обеспечить более гибкое интерактивное предсказание. Например, могут быть использованы способ управления работой памяти и способ скользящего окна. Управление эталонной фотографией объединяет память эталонной фотографии и память не эталонной фотографии в одну память и управляет объединенной памятью, чтобы добиться эффективного управления с памятью малого объема. При кодировании по глубине глубинные фотографии могут маркироваться раздельно, чтобы отличаться от цветных фотографий в буферном устройстве декодированных фотографий, и информация для идентификации каждой глубинной фотографии может быть использована в процессе маркировки. Эталонные фотографии, управляемые посредством описанной выше процедуры, могут быть использованы для кодирования по глубине в устройстве 260 интерактивного предсказания.
[42] Как показано на фиг. 2, устройство 260 интерактивного предсказания может включать в себя устройство 261 компенсации движения, устройство 262 синтеза виртуальных изображений и устройство 263 генерации глубинной фотографии.
[43] Устройство 261 компенсации движения компенсирует движение текущего блока, используя информацию, переданную от устройства 210 энтропийного декодирования. Устройство 261 компенсации движения извлекает векторы движения соседних блоков текущего блока из видеосигнала и получает значение предсказания для вектора движения текущего блока. Устройство 261 компенсации движения компенсирует движение текущего блока, используя значение предсказания для вектора движения и дифференциальный вектор, извлеченный из видеосигнала. Компенсация движения может выполняться, используя одну эталонную фотографию или множество фотографий. При кодировании по глубине компенсация движения может выполняться, используя информацию по перечню эталонных фотографий для межвидового предсказания глубинных фотографий, запомненных в буферном устройстве 250 декодированных фотографий, когда текущая глубинная фотография относится к глубинной фотографии другого вида. Дополнительно компенсация движения может осуществляться, используя информацию по глубинному виду для идентификации вида глубинной фотографии.
[44] Устройство 262 синтеза виртуальных изображений синтезирует цветную фотографию виртуального изображения, используя цветные фотографии соседних видов в представлении текущей цветной фотографии. Для того чтобы использовать цветные фотографии соседних видов или использовать цветные фотографии желаемого конкретного вида, может быть использована информация по идентификации вида, указывающая виды цветных фотографий. Когда генерируется цветная фотография виртуального изображения, может быть определена флаговая информация, указывающая на то, генерируется ли цветная фотография виртуального изображения. Когда флаговая информация указывает на генерацию цветной фотографии виртуального изображения, эта цветная фотография виртуального изображения может генерироваться, используя информацию по идентификации вида. Цветная фотография виртуального изображения, полученная через устройство 262 синтеза виртуального изображения, может быть использована в качестве эталонной фотографии. В этом случае информация по идентификации вида может быть присвоена цветной фотографии виртуального изображения.
[45] В другом варианте осуществления устройство 262 синтеза виртуального изображения может синтезировать глубинную фотографию виртуального изображения, используя глубинные фотографии, соответствующие соседним видам в изображении текущей глубинной фотографии. В этом случае может быть использована информация по идентификации глубинного вида, указывающая вид глубиной фотографии. При этом информация по идентификации глубинного вида может быть выведена из информации по идентификации вида соответствующей цветной фотографии. Например, соответствующая цветная фотография может иметь такую же информацию по команде вывода фотографии и такую же информацию по идентификации вида, как и текущая глубинная фотография.
[46] Устройство 263 генерации глубинной фотографии может генерировать текущую глубинную фотографию, используя информацию по кодированию по глубине. При этом информация по кодированию по глубине может включать в себя относящийся к расстоянию параметр, указывающий расстояние между фотокамерой и объектом (например, значение координаты Z в системе координат фотокамеры, или подобной координаты), информацию о типе макроблока для кодирования по глубине, информацию для идентификации границы в глубинной фотографии, информацию, указывающую на то, включают ли в себя данные в RBSP данные кодирования по глубине, информацию, указывающую на то, являются ли данные этого типа данными для глубинной фотографии, данными для цветной фотографии или данными параллакса, и т.п. Дополнительно текущая глубинная фотография может быть предсказана, используя информацию о кодировании по глубине. То есть может быть выполнено интерактивное предсказание с использованием соседних глубинных фотографий текущей глубиной фотографии, и может быть выполнено внутреннее предсказание с использованием декодированной информации по глубине в текущей глубинной фотографии.
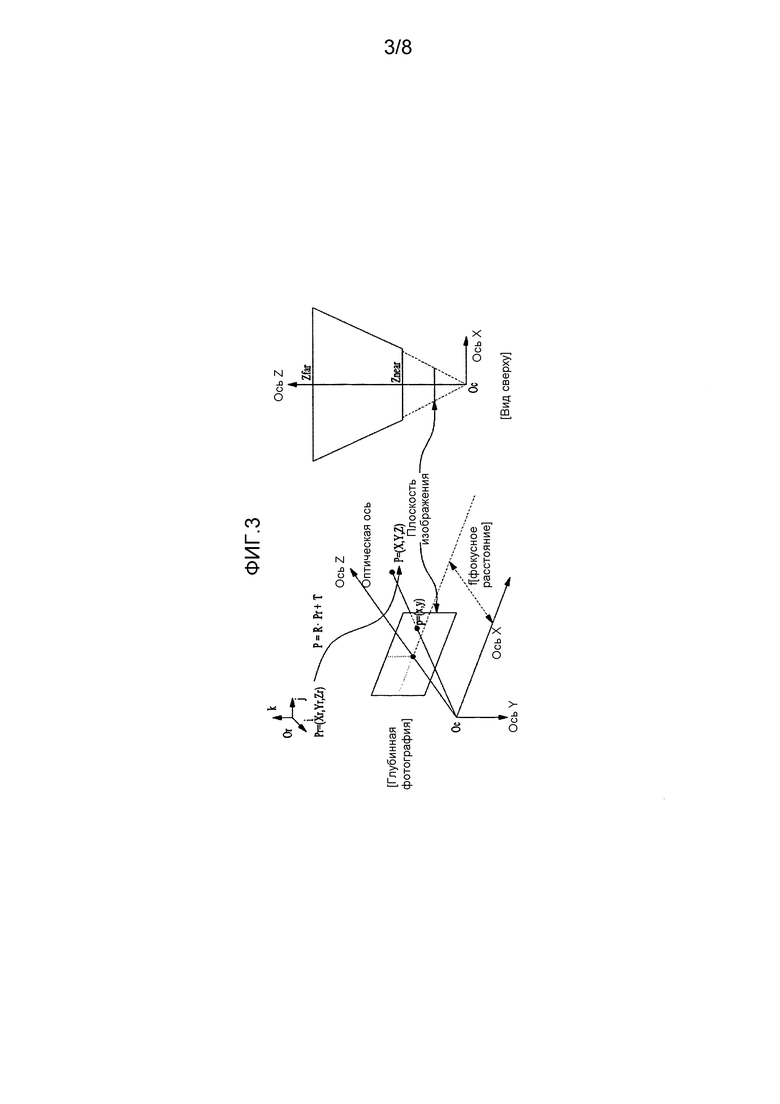
[47] Будет дано подробное описание концепции глубины со ссылкой на фиг. 3.
[48] На фиг. 3 представлена концепция глубины согласно варианту осуществления настоящего изобретения.
[49] На фиг. 3 позиция Oc фотокамеры означает начало координат трехмерной (3D) системы координат фотокамеры, в которой ось Z (оптическая ось) находится на одной линии с направлением взгляда. Произвольная точка P=(X, Y, Z) в системе координат фотокамеры может быть спроецирована в произвольную точку p=(x, y) в плоскости двухмерного (2D) изображения, перпендикулярной оси Z. При этом произвольная точка p=(x, y) в плоскости двухмерного(2D) изображения может быть представлена как значение текстуры или значение цвета для произвольной точки P=(X, Y, Z) в 3D системе координат. В этом случае плоскость 2D изображения может относиться к текстурной фотографии. Точка p=(x, y) в плоскости 2D изображения может быть представлена как значение Z для точки P=(X, Y, Z) в 3D системе координат. В этом случае плоскость 2D изображения может относиться к глубинной фотографии или к глубинной карте.
[50] Дополнительно P=(X, Y, Z) в 3D системе координат означает произвольную точку в системе координат фотокамеры. Однако, когда используется множество фотокамер, может потребоваться общая опорная система координат для фотокамер. На фиг. 3 произвольная точка в опорной системе координат, имеющей точку QW в качестве начала координат, может быть точкой PW=(XW, YW, ZW). Точка PW=(XW, YW, ZW) может быть трансформирована в произвольную точку P=(X, Y, Z) в системе координат фотокамеры, используя 3х3 матрицу поворота R и 3х1 вектор переноса T. Например, P может быть получена из уравнения 1.
[51] [Уравнение 1]

[52] Исходя из приведенного выше описания, глубинная фотография может быть определена как набор цифровой информации с соответствующими значениями расстояний между позицией фотокамеры и объектом на основе позиции фотокамеры. Глубинная информация в глубинной фотографии может быть получена из значения Z в 3D координатах P=(X, Y, Z) в системе координат фотокамеры, которое соответствует произвольному пикселу текстурной фотографии. При этом значение Z лежит в диапазоне действительных чисел и может квантоваться в целочисленное значение, с тем чтобы быть использованным в качестве глубинной информации. Например, глубинная информация может быть квантована, как представлено в уравнении 2 или уравнении 3.
[53] [Уравнение 2]
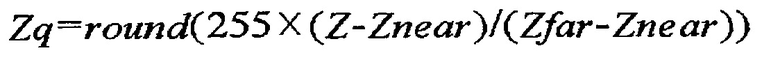
[54] [Уравнение 3]
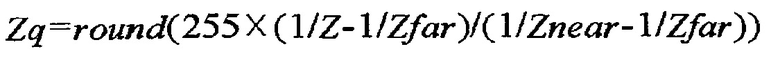
[55] Здесь Zq означает квантованную глубинную информацию. На виде сверху на фиг. 3 Znear может означать нижнее предельное значение координаты Z, а Zfar может означать верхнее предельное значение координаты Z. Глубинная информация, квантованная согласно уравнению 2 или уравнению 3, может иметь целочисленное значение в диапазоне от 0 до 255.
[56] Глубинная фотография может быть кодирована в сочетании с последовательностью текстурного изображения или кодирована в отдельную последовательность. В этом случае могут быть применены различные варианты осуществления для совместимости с обычными кодеками. Например, способ кодирования по глубине может быть применен как дополнительный способ для совместимости с HEVC кодеком, или применен как расширенный способ в H.264/AVC многовидовом видеокодировании.
[57] Настоящее изобретение обеспечивает способ для выполнения точного предсказания компенсации различия, получая вектор межвидового движения для текущего текстурного блока, используя значение глубины из глубинного блока, соответствующего текущему текстурному блоку, и выполняя компенсацию различия в освещенности для значений пикселов эталонного блока, полученных использованием вектора межвидового движения. Описание предсказания компенсации различия будет дано со ссылкой на фиг. 4.
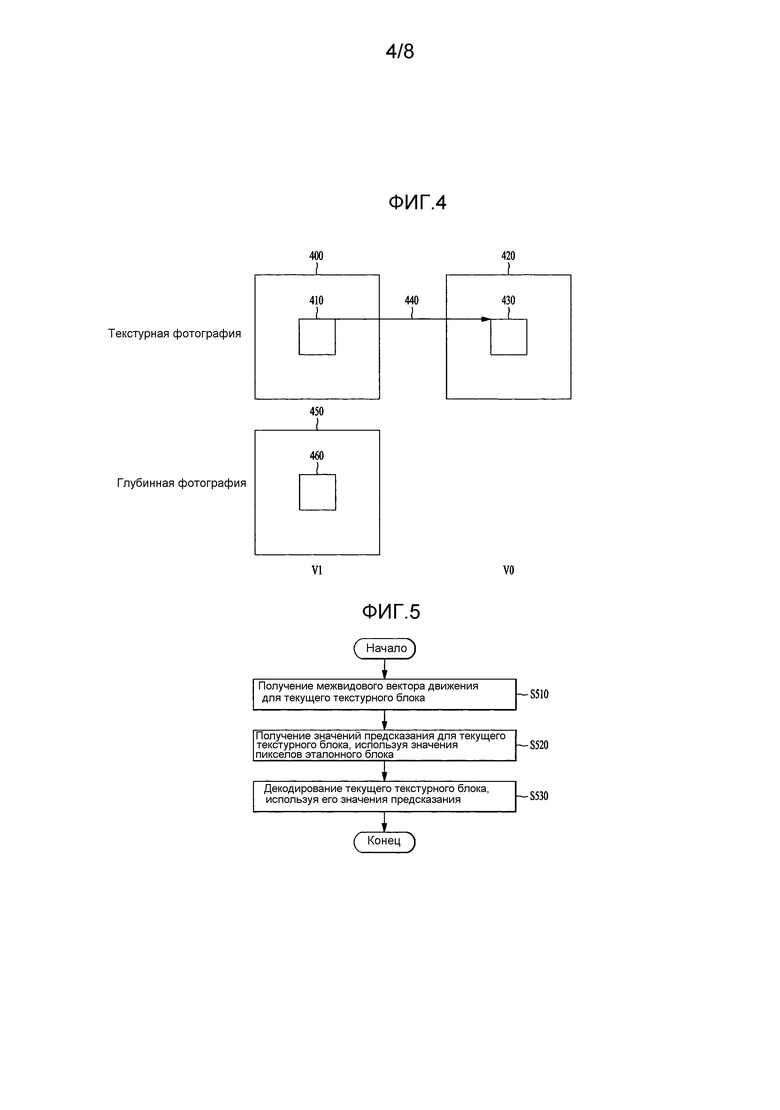
[58] На фиг. 4 приведен пример предсказания компенсации различия согласно варианту осуществления настоящего изобретения.
[59] Предсказание компенсации различия является интерактивным предсказанием, использующим значения пикселов эталонного блока 430 в эталонной фотографии 430, которая расположена в виде, отличающемся от текущего текстурного блока 410 в текущей текстурной фотографии 400, с тем чтобы получать значения предсказания для текущего текстурного блока 410. Точность межвидового интерактивного предсказания близко соотносится с точностью межвидового вектора 440 движения, который указывает эталонный блок 430 текущего текстурного блока 410, и минимизацией различия в освещенности.
[60] В соответствии с этим настоящее изобретение обеспечивает способы для получения правильного межвидового вектора 440 движения, используя глубинный блок 460, соответствующий текущему текстурному блоку в текущей глубинной фотографии 450, или глубинный блок, соответствующий текущему текстурному блоку и получающий правильные значения предсказания для текущего текстурного блока 410 через компенсацию различия в освещенности. Дополнительно настоящее изобретение обеспечивает способ для уменьшения сложности, просто выполняя способ для получения межвидового вектора 440 движения и способ компенсации различия в освещенности. Будет дано описание способа декодирования текущего текстурного блока 410 через предсказание компенсации различия со ссылкой на фиг. 5.
[61] На фиг. 5 представлена блок-схема последовательности операций, иллюстрирующая пример декодирования текущего текстурного блока через предсказание компенсации различия согласно варианту осуществления настоящего изобретения.
[62] Может быть получен межвидовый вектор движения для текущего текстурного блока (этап S510). При этом межвидовый вектор движения может указывать эталонный блок, расположенный в виде, отличающемся от текущего текстурного блока. Межвидовый вектор движения для текущего текстурного блока может быть получен из потока двоичных сигналов, получен от межвидового вектора движения соседнего блока или получен, используя значение глубины из глубинного блока, соответствующего текущему текстурному блоку. Способ для получения межвидового вектора движения от значения глубины будет описан ниже со ссылкой на фиг. 6, 7 и 8.
[63] Значения предсказания для текущего текстурного блока могут быть получены, используя значения пикселов эталонного блока, полученного при использовании межвидового вектора движения (этап S520). Эталонный блок, указанный межвидовым вектором движения, может быть расположен в виде, отличающемся от текущего текстурного блока. Значения пикселов эталонного блока могут быть использованы как значения предсказания для текущего текстурного блока. Может создаваться различие в освещенности, вызываемое различием вида между эталонным блоком эталонного вида и текущим текстурным блоком текущего вида. В соответствии с этим значения пикселов эталонного блока могут быть использован в качестве значений предсказания для текущего текстурного блока за счет компенсации различия в освещенности. Способ для получения значений предсказания для текущего текстурного блока через компенсацию различия в освещенности будет описан ниже со ссылкой на фиг. 9 и 10.
[64] Текущий текстурный блок может быть декодирован, используя его значения предсказания (этап S540).
[65] Будет описан пример получения межвидового вектора движения для текущего текстурного блока, используя значение глубины из глубинного блока, соответствующего текущему текстурному блоку, со ссылкой на фиг. 6. 7 и 8.
[66] На фиг. 6 представлена блок-схема последовательности операций, иллюстрирующая пример получения межвидового вектора движения для текущего текстурного блока с использованием значения глубины из глубинного блока, соответствующего текущему текстурному блоку, согласно варианту осуществления настоящего изобретения.
[67] По меньшей мере одно значение глубины может быть получено из глубинного блока, соответствующего текущему текстурному блоку (этап S512). Глубинный блок может быть глубинным блоком в глубинной фотографии, который распложен в том же самом виде, что и текущий текстурный блок, и имеет такой же POC, что и текущий текстурный блок. Альтернативно глубинный блок может быть глубинным блоком, расположенным в соседнем виде текущего текстурного блока и полученным, используя межвидовый вектор движения (именуемый далее вторым межвидовым вектором движения), выведенный из соседнего блока текущего текстурного блока. Например, можно получить текстурный блок в соседнем виде, указанном вторым межвидовым вектором движения, выведенным из соседнего блока, и получить глубинный блок, соответствующий текущему текстурному блоку, используя текстурный блок в соседнем виде. Глубинный блок располагается в том же виде и в той же позиции, что и текстурный блок в соседнем виде, и находится в позиции у соседнего вида текущего текстурного блока.
[68] Межвидовый вектор движения (именуемый далее первым межвидовым вектором движения) текущего текстурного блока может быть получен, используя по меньшей мере одно значение глубины в глубинном блоке, соответствующем текущему текстурному блоку (этап S514). Способ выведения межвидового вектора движения, используя значение глубины, будет теперь описан на основе уравнений 4 и 5.
[69] [Уравнение 4]
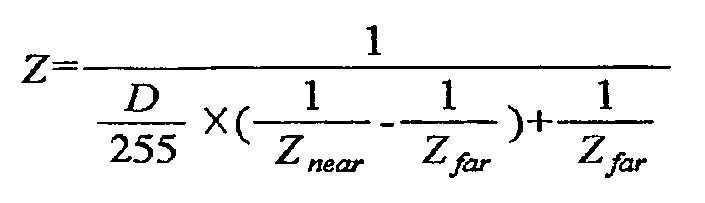
[70] В уравнении 4 Z определяет расстояние между соответствующим пикселом и фотокамерой, D является значением, полученным квантованием Z и соответствует данным глубины по настоящему изобретению, а Znear и Zfar соответственно представляют минимальное значение и максимальное значение Z, определенные для вида, включающего в себя глубинную фотографию. Znear и Zfar могут быть извлечены из потока двоичных данных через ряд параметров последовательности, послойный заголовок, и т.п., и могут быть информацией, заданной в декодере. В соответствии с этим, когда расстояние между соответствующим пикселом и фотокамерой квантуется на уровне 256, координата Z может быть перестроена, используя данные глубины Znear и Zfar, представленные уравнением 5. После этого межвидовый вектор движения по отношению к текущему текстурному блоку может быть выведен, используя перестроенную координату Z, как представлено уравнением 5.
[71] [Уравнение 5]
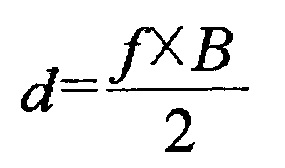
[72] В уравнении 5 f означает фокусное расстояние фотокамеры, а B означает расстояние между фотокамерами. Можно предположить, что все фотокамеры имеют одни и те же f и B, и, таким образом, f и B могут быть информацией, заданной в декодере.
[73] Существуют различные варианты осуществления способов для получения первого межвидового вектора движения, используя значение глубины из глубинного блока, соответствующего текущему текстурному блоку. Например, первый межвидовый вектор движения может быть получен, используя максимальное значение среди значений глубины в глубинном блоке, соответствующем текущему текстурному блоку. Альтернативно первый межвидовый вектор движения может быть получен, используя наиболее часто встречающееся значение среди значений глубины в глубинном блоке, соответствующем текущему текстурному блоку. Альтернативно первый межвидовый вектор движения может быть получен в соответствии с заданным условием. Будет дано описание различных вариантов осуществления для получения первого межвидового вектора движения со ссылкой на фиг. 7 и 8.
[74] На фиг. 7 представлен пример получения первого межвидового вектора движения для текущего текстурного блока, использующий значение глубины в глубинном блоке, соответствующем текущему текстурному блоку, согласно варианту осуществления настоящего изобретения.
[75] Как показано на фиг. 7(a), глубинный блок 460, соответствующий текущему текстурному блоку, может включать в себя значения глубины. Первый межвидовый вектор движения текущего текстурного блока может быть получен, используя по меньшей мере одно значение глубины из глубинного блока, соответствующего текущему текстурному блоку, согласно уравнениям, описанным со ссылкой на фиг. 6. Глубинный блок 460, соответствующий текущему текстурному блоку, может включать в себя множество значений глубины. Когда первый межвидовый вектор движения получается путем использования глубинного блока 460, соответствующего текущему текстурному блоку и включающему в себя множество значений глубины, может быть получено множество первых межвидовых векторов движения, как показано на фиг. 7(b). В соответствии с этим будет дано описание того, какое одно из значений глубины в глубинном блоке, соответствующем текущему текстурному блоку, используется для получения первого межвидового вектора движения текущего текстурного блока.
[76] Способ для получения первого вектора межвидового движения для текущего текстурного блока, используя значение глубины из глубинного блока, соответствующего текущему текстурному блоку, осуществляется описанным ниже образом.
[77] 1) Получение межвидового вектора движения, используя максимальный глубинный блок
[78] Первый межвидовый вектор движения текущего текстурного блока может быть получен, используя наибольшее значение глубины (именуемое далее “максимальным значением глубины”) среди значений глубины в глубинном блоке, соответствующем текущему текстурному блоку. Первый межвидовый вектор движения, полученный с использованием максимального значения глубины, может быть определен как вектор межвидового движения для максимальной глубины, DisMAX. Как показано на фиг. 7(a), межвидовый вектор движения, полученный путем использования пиксела 701, имеющего максимальное значение глубины, может быть получен как межвидовый вектор движения для текущего текстурного блока. Максимальное значение глубины может быть получено сравнением всех пикселов в глубинном блоке. Альтернативно максимальное значение глубины может быть получено через сравнение по меньшей мере одного пиксела в глубинном блоке. Поскольку преграды не возникает в зоне в глубинном блоке, соответствующем текущему текстурному блоку, который имеет максимальное значение глубины, точность предсказания компенсации различия может быть повышена.
[79] 2) Получение межвидового вектора движения, используя наиболее часто встречающееся значение глубины
[80] Первый межвидовый вектор движения для текущего текстурного блока может быть получен, используя наиболее часто встречающееся значение глубины (именуемое далее “наиболее частым значением глубины”) среди значений глубины в глубинном блоке, соответствующем текущему текстурному блоку. Первый межвидовый вектор движения, полученный при использовании наиболее частого значения глубины, может быть определен как вектор межвидового движения для наиболее частого значения глубины, DisMPD. Как показано на фиг. 7(a), межвидовый вектор, полученный с использованием пиксела 702, имеющего наиболее частое значение глубины, может быть получен как первый межвидовый вектор движения для текущего текстурного блока. Наиболее частое значение глубины может быть получено сравнением всех пикселов в глубинном блоке. Альтернативно наиболее частое значение глубины может быть получено через сравнение по меньшей мере одного пиксела в глубинном блоке.
[81] Альтернативно значения глубины в глубинном блоке, соответствующем текущему текстурному блоку, могут трансформироваться в межвидовые векторы движения, и наиболее часто встречающийся межвидовый вектор движения может быть получен как первый межвидовый вектор движения для текущего текстурного блока (наиболее часто встречающийся межвидовый вектор движения должен быть межвидовым вектором движения для наиболее частого значения глубины). Например, наиболее часто встречающийся межвидовый вектор движения на фиг. 7(b) может быть получен как первый межвидовый вектор движения для текущего текстурного блока. Когда используется наиболее частое значение глубины или наиболее часто встречающийся первый межвидовый вектор движения, может быть получен межвидовый вектор движения, соответствующий большинству пикселов глубинного блока, соответствующего текущему текстурному блоку, и, таким образом, может быть повышена точность предсказания компенсации различия.
[82] 3) Получение межвидового вектора движения в соответствии с конкретным условием.
[83] Первый межвидовый вектор движения текущего текстурного блока может быть получен как один из межвидового вектора движения для максимальной глубины и межвидового вектора движения для наиболее частого значения глубины в соответствии с конкретным условием. При таком условии NumDisMAX указывает число пикселов, которые имеют один и тот же межвидовый вектор движения как межвидовый вектор движения для максимальной глубины в глубинном блоке, соответствующем текущему текстурному блоку, или число пикселов, которые имеют межвидовые векторы движения, подобные межвидовому вектору движения для максимальной глубины в пределах заданного диапазона ошибок, в глубинном блоке, соответствующем текущему текстурному блоку. Дополнительно NumDisMAX указывает число пикселов, которые имеют один и тот же межвидовый вектор движения как межвидовый вектор движения для наиболее частого значения глубины в глубинном блоке, соответствующем текущему текстурному блоку, или число пикселов, которые имеют межвидовые векторы движения, подобные межвидовому вектору движения для наиболее частого значения глубины в пределах заданного диапазона ошибок, в глубинном блоке, соответствующем текущему текстурному блоку.
[84] 3-1) Когда сумма NumDisMAX и числа пикселов, соответствующих зоне заграждения, превышает половину числа пикселов текущего текстурного блока, межвидовый вектор движения для максимальной глубины может быть получен как первый межвидовый вектор движении для текущего текстурного блока. В противном случае, когда сумма NumDisMAX и числа пикселов, соответствующих зоне заграждения, не превышает половину числа пикселов текущего текстурного блока, межвидовый вектор движения для наиболее частого значения глубины может быть получен как первый межвидовый вектор движения для текущего текстурного блока. При этом зона заграждения (Occlusion/Area) может быть получена синтезом текущего текстурного блока и глубинного блока, соответствующего текущему текстурному блоку, или через уравнение 6.
[85] [Уравнение 6]
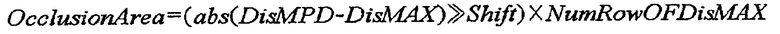
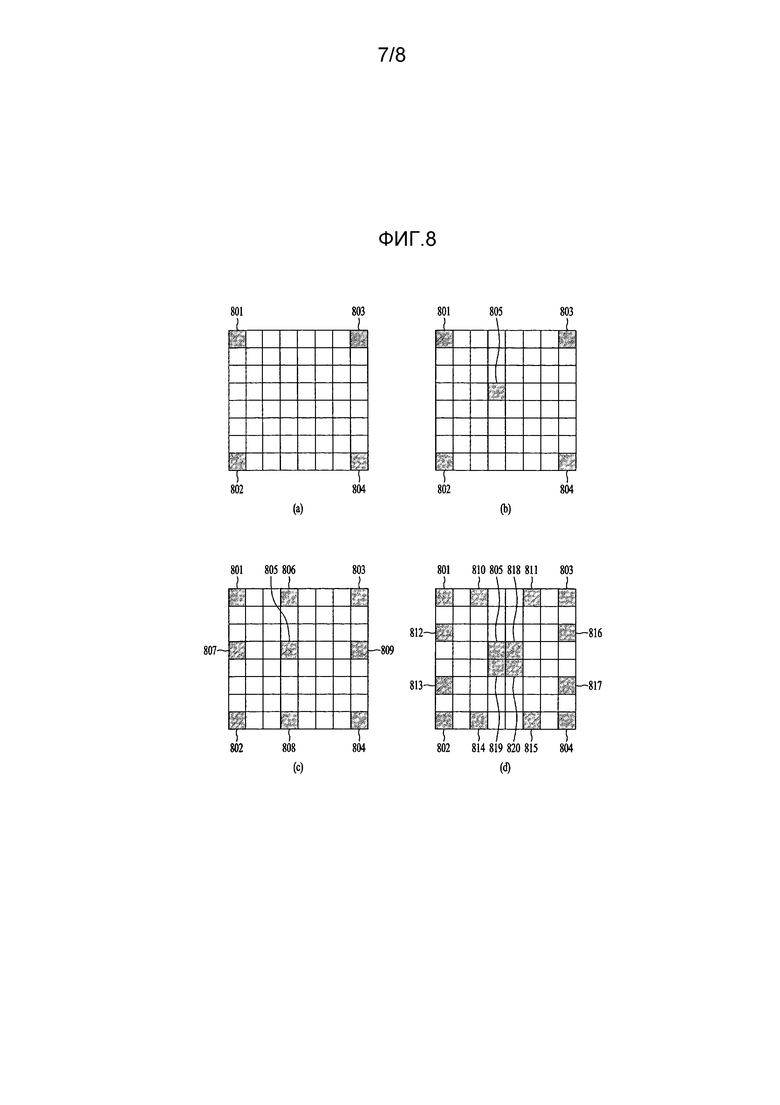
[86] В уравнении 6 NumRowOFDisMAX означает число рядов, в которых присутствуют пикселы, имеющие межвидовые векторы движения, идентичные или подобные DisMAX, а Shift означает преобразование значения межвидового вектора движения в целое число, когда значение межвидового вектора движения не представлено целым числом.
[87] 3-2) Первый межвидовый вектор движения для текущего текстурного блока может быть определен сравнением NumDisMPD и NumDisMAX.
[88] Например, когда abs(NumDisMPD – NumDisMAX) меньше заданной доли числа пикселов текущего текстурного блока, межвидовый вектор движения для максимальной глубины может быть получен как межвидовый вектор движения для текущего текстурного блока. В противном случае межвидовый вектор движения для наиболее частого значения глубины может быть получен как межвидовый вектор движения для текущего текстурного блока.
[89] Альтернативно, когда NumDisMPD/NumDisMAX меньше заданного порогового значения, межвидовый вектор движения для максимальной глубины может быть получен как межвидовый вектор движения для текущего текстурного блока. В противном случае межвидовый вектор движения для наиболее частого значения глубины может быть получен как межвидовый вектор движения для текущего текстурного блока.
[90] 3-3) когда abs(DisMPD – DisMAX) превышает заданное пороговое значение, межвидовый вектор движения для максимальной глубины может быть получен как межвидовый вектор движения для текущего текстурного блока. В противном случае межвидовый вектор движения для наиболее частого значения глубины может быть получен как межвидовый вектор движения для текущего текстурного блока.
[91] Когда используется виртуальное значение глубины, может присутствовать временный межвидовый вектор движения. Либо межвидовый вектор движения для максимальной глубины, либо межвидовый вектор движения для наиболее частого значения глубины, в зависимости от того, какой из них ближе к временному межвидовому вектору движения, может быть получен как первый межвидовый вектор движения для текущего текстурного блока.
[92] Упомянутые выше межвидовый вектор движения для максимальной глубины и межвидовый вектор движения для наиболее частого значения глубины могут быть получены сравнением одного или более пикселов в глубинном блоке, соответствующем текущему текстурному блоку. То есть межвидовый вектор движения для максимальной глубины и межвидовый вектор движения для наиболее частого значения глубины могут быть получены сравнением значений глубины всех пикселов глубинного блока, соответствующего текстурному блоку, или межвидовых векторов движения, соответствующих значениям глубины, или же сравнением значений глубины для части пикселов глубинного блока, соответствующего текущему текстурному блоку, или межвидовых векторов движения, соответствующих им.
[93] На фиг. 8 представлен пример части пикселов глубинного блока, соответствующего текущему текстурному блоку, которые используются для получения межвидового вектора движения для максимальной глубины и межвидового вектора движения для наиболее частого значения глубины.
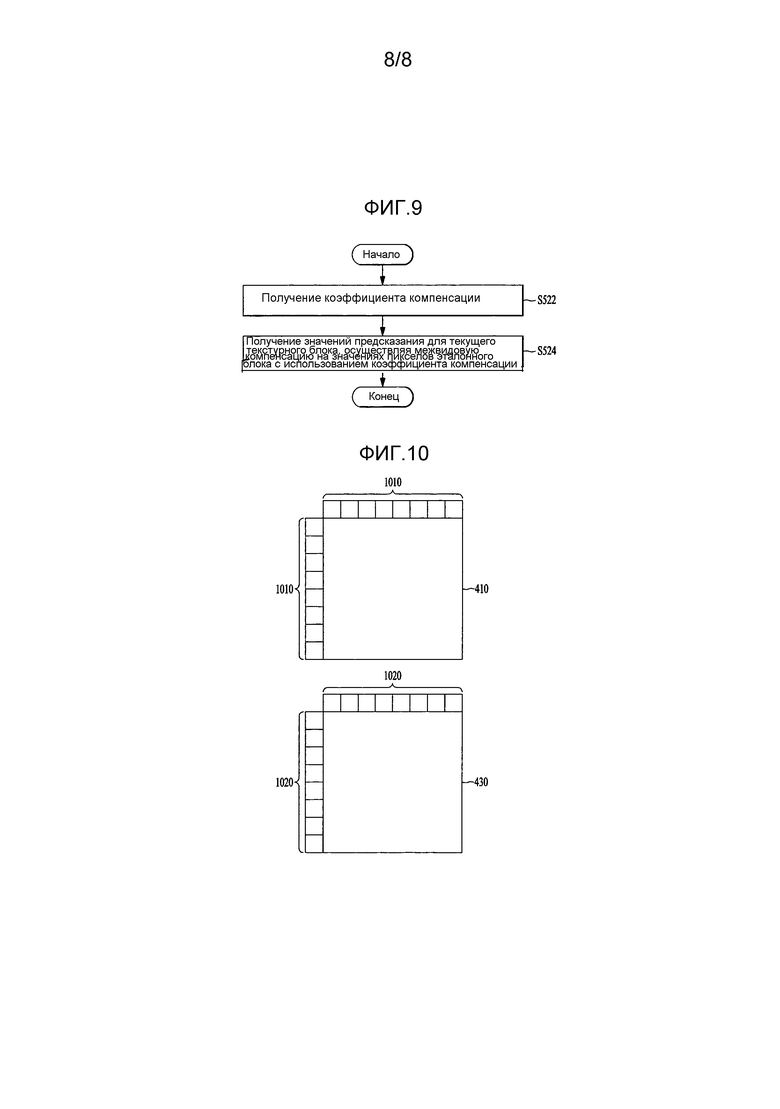
[94] Возможно сравнить значения глубины, соответствующие только части пикселов глубинного блока, соответствующего текущему текстурному блоку, получить наибольшее значение глубины среди значений глубины в качестве максимального значения глубины и получить наиболее часто встречающееся значение глубины среди значений глубины пикселов в качестве наиболее частого значения глубины. Сравниваемые пикселы могут быть изменены согласно конкретному условию.
[95] Например, значения глубины левого верхнего пиксела 801, левого нижнего пиксела 802, правого верхнего пиксела 803 и правого нижнего пиксела 804 глубинного блока, соответствующего текущему текстурному блоку, показанному на фиг. 8(a), могут быть сравнены, и наибольшее значение пиксела среди значений глубины может быть получено как максимальное значение глубины. Дополнительно наиболее часто встречающееся значение глубины среди значений глубины может быть получено как наиболее частое значение глубины. Межвидовый вектор движения для максимальной глубины может быть получен, используя максимальное значение глубины, и межвидовый вектор движения для наиболее частого значения глубины может быть получен, используя наиболее частое значение глубины.
[96] На фиг. 8(b) значения глубины для левого верхнего пиксела 801, левого нижнего пиксела 802, правого верхнего пиксела 803, правого нижнего пиксела 804 и центрального пиксела 805 могут сравниваться, с тем чтобы получить максимальное значение глубины или наиболее частое значение глубины. Дополнительно межвидовый вектор движения для максимальной глубины может быть получен, используя максимальное значение глубины, и межвидовый вектор движения для наиболее частого значения глубины может быть получен, используя наиболее частое значение глубины.
[97] На фиг. 8(c) значения глубины для левого верхнего пиксела 801, левого нижнего пиксела 802, правого верхнего пиксела 803, правого нижнего пиксела 804, центрального пиксела 805, верхнего пиксела 806, левого пиксела 807, нижнего пиксела 808 и правого пиксела 809 могут сравниваться, с тем чтобы получить максимальное значение глубины или наиболее частое значение глубины. Дополнительно межвидовый вектор движения для максимальной глубины может быть получен, используя максимальное значение глубины, и межвидовый вектор движения для наиболее частого значения глубины может быть получен, используя наиболее частое значение глубины.
[98] На фиг. 8(d) значения глубины для левого верхнего пиксела 801, левого нижнего пиксела 802, правого верхнего пиксела 803, правого нижнего пиксела 804, центральных пикселов 805, 818, 819 и 820, верхних пикселов 810 и 811, левых пикселов 812 и 813, нижних пикселов 814 и 815 и правых пикселов 816 и 817 могут сравниваться, с тем, чтобы получить максимальное значение глубины или наиболее частое значение глубины. Дополнительно межвидовый вектор движения для максимальной глубины может быть получен, используя максимальное значение глубины, и межвидовый вектор движения для наиболее частого значения глубины может быть получен, используя наиболее частое значение глубины.
[99] В дополнение к способам, представленным на фиг. 8(a)-8(d), максимальное значение глубины и наиболее частое значение глубины могут быть получены сравнением пикселов, выбранных различным образом.
[100] Эталонный блок текущего текстурного блока может быть получен, используя первый межвидовый вектор движения, полученный, как было описано выше со ссылкой на фиг. 6, 7 и 8. Дополнительно значения предсказания для текущего текстурного блока можно получить, выполняя компенсацию различия в освещенности на значениях предсказания эталонного блока, как описано выше со ссылкой на фиг. 5. Компенсация различия в освещенности необходима, чтобы скомпенсировать межвидовое различие, образуемое вследствие различия в освещенности или характеристик фотокамеры при соответствующих видах, когда записывается многовидовое изображение. Будет дано описание приводимого в качестве примера способа компенсации различия в освещенности со ссылкой на фиг. 9 и 10.
[101] На фиг. 9 представлена блок-схема последовательности операций, иллюстрирующая пример компенсации различия в освещенности согласно варианту осуществления настоящего изобретения.
[102] Может быть получен коэффициент компенсации (этап S522). Коэффициент компенсации является информацией, используемой для компенсации различия в освещенности, и может включать в себя первый коэффициент компенсации и второй коэффициент компенсации. Первый коэффициент компенсации и второй коэффициент компенсации могут быть получены, используя соседний пиксел текущего текстурного блока и соседний пиксел эталонного блока. Способ получения коэффициента компенсации с использованием соседнего пиксела текущего текстурного блока и соседнего пиксела эталонного блока будет описан со ссылкой на фиг. 10.
[103] Значения предсказания для текущего текстурного блока могут быть получены выполнением межвидовой компенсации для значений пикселов эталонного блока, используя коэффициент компенсации (этап S524). Компенсация различия в освещенности может выполняться, используя линейное уравнение, такое как уравнение 7.
[104] [Уравнение 7]
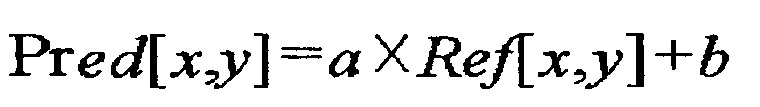
[105] В уравнении 7 pred[x,y] определяет значения предсказания скомпенсированного различия в освещенности для текущего текстурного блока, Ref[x,y] определяет значение пиксела эталонного блока, a представляет первый коэффициент компенсации для компенсации различия в освещенности, и b представляет второй коэффициент компенсации для компенсации различия в освещенности.
[106] На фиг. 10 представлен пример текущего текстурного блока, эталонного блока, соседнего пиксела текущего текстурного блока и соседнего пиксела эталонного блока, которые используются во время процедуры компенсации различия в освещенности.
[107] На фиг. 10(a) показан текущий текстурный блок 410 и соседний пиксел 1010 текущего текстурного блока. Соседний пиксел 1010 текущего текстурного блока может относиться по меньшей мере к одному из левых пикселов или верхних пикселов текущего текстурного блока 410. На фиг. 10(b) показан эталонный блок 430 и соседний пиксел 1020 эталонного блока. Соседний пиксел 1020 эталонного блока может включать в себя по меньшей мере один из левых пикселов или верхних пикселов эталонного блока 430.
[108] Будет дано описание способа для получения коэффициента компенсации с использованием соседнего пиксела 1010 текущего текстурного блока и соседнего пиксела 1020 эталонного блока.
[109] 1) Коэффициент компенсации может быть получен по уравнению 8 согласно линейной оценке по методу наименьших квадратов.
[110] [Уравнение 8]
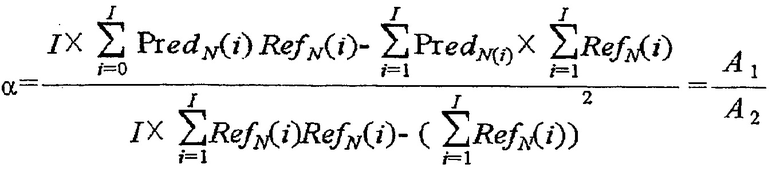
[111]
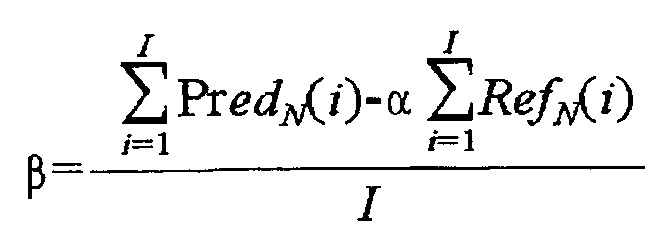
[112] В уравнении 8 α означает первый коэффициент компенсации, и β означает второй коэффициент компенсации. Кроме того, i представляет индексы, присвоенные соседнему пикселу 1010 текущего текстурного блока и соседнему пикселу 1020 эталонного блока. PredN(i) указывает значение соседнего пиксела текущего текстурного блока, а RefN(i) указывает значение соседнего пиксела эталонного блока.
[113] 2) Коэффициент компенсации может быть получен по уравнению 9 с использованием среднего значения и стандартного отклонения соседнего пиксела 1010 текущего текстурного блока и соседнего пиксела 1020 эталонного блока.
[114] [Уравнение 9]
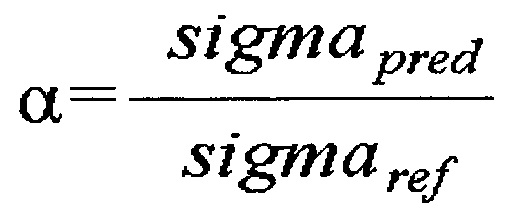
[115]
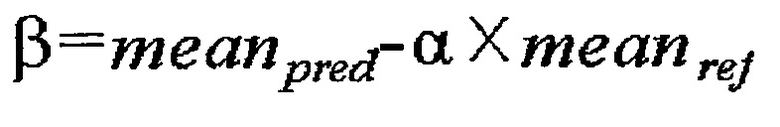
[116] в уравнении 9 sigmapred означает стандартное отклонение соседнего пиксела 1010 текущего текстурного блока, sigmaref означает стандартное отклонение соседнего пиксела 1020 эталонного блока, meanpred означает среднее значение соседних пикселов 1010 текущего текстурного блока, а meanref означает среднее значение соседних пикселов 1020 эталонного блока.
[117] 3) Первый коэффициент компенсации может быть установлен равным 1, и только второй коэффициент компенсации может быть получен по уравнению 10.
[118] [Уравнение 10]
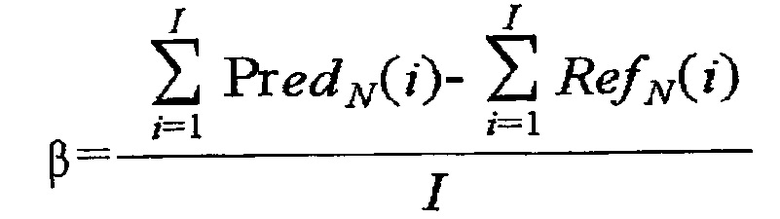
[119] 4) Второй коэффициент компенсации может быть установлен равным 0, и только первый коэффициент компенсации может быть получен по уравнению 11.
[120] [Уравнение 11]
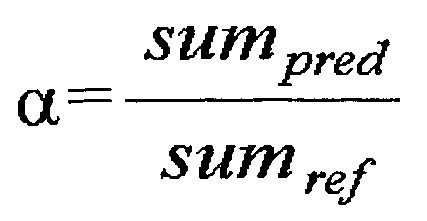
[121] В уравнении 11 sumpred означает сумму соседних пикселов текущего текстурного блока, а sumref означает сумму соседних пикселов эталонного блока.
[122] Коэффициент компенсации, полученный по описанным выше способам, может быть использован в соответствии с конкретными условиями. Например, когда первый и второй коэффициенты компенсации получены по способу 2 и разность между первым коэффициентом компенсации и 1 меньше заданного порогового значения, первый коэффициент компенсации не используется, и первый коэффициент компенсации может быть установлен равным 1, и только второй коэффициент компенсации может быть получен, как в способе 3. Когда первый и второй коэффициенты компенсации получены по способу 2 и разность между вторым коэффициентом компенсации и 0 меньше заданного порогового значения, второй коэффициент компенсации не используется, и второй коэффициент компенсации может быть установлен равным 0, и только первый коэффициент компенсации может быть получен, как в способе 4. Альтернативно, когда первый и второй коэффициенты компенсации получены по способу 2 и как первый, так и второй коэффициенты компенсации могут быть использованы, первый и второй коэффициенты компенсации могут получены, используя способ 1. Такие гибкие способы обеспечивают возможность более эффективной компенсации различия в освещенности.
[123] Как было описано выше, устройство декодирования/кодирования, в котором применено настоящее изобретение, может быть включен в состав мультимедийной широковещательной передающей/приемной аппаратуры, такой как система DMB (цифровое мультимедийное вещание), чтобы использоваться для декодирования видеосигналов, сигналов данных, и т.п. Дополнительно мультимедийная широковещательная передающая/приемная аппаратура может включать в себя мобильный связной терминал.
[124] Способ кодирования/декодирования, в котором применено настоящее изобретение, может быть реализован в виде программы, выполняемой компьютером и запоминаемой в машиночитаемом носителе записи, и мультимедийные данные, имеющие структуру данных согласно настоящему изобретению, могут также запоминаться в машиночитаемом носителе записи. Машиночитаемый носитель записи включает в себя все виды запоминающих устройств, хранящих данные, считываемые компьютерной системой. Примеры машиночитаемых носителей записи включают в себя ROM, RAM, CD-ROM, магнитную ленту, гибкий магнитный диск, оптическое устройство для запоминания данных и среду, использующее несущую волну (например, передача через Internet). Дополнительно поток двоичных сигналов, генерируемый согласно способу кодирования, может запоминаться в машиночитаемом носителе записи или передаваться с использованием проводной/беспроводной сети связи.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
[125] Настоящее изобретение может быть использовано для кодирования видеосигналов.

Изобретение относится к технологиям кодирования/декодирования видеоданных. Техническим результатом является повышение точности предсказания компенсации различия, получая межвидовой вектор движения, с использованием значений глубины из глубинного блока, соответствующего текущему текстурному блоку. Предложен способ обработки видеосигналов. Способ содержит этап, на котором получают глубинный блок, соответствующий текущему текстурному блоку. Далее согласно способу получают первый межвидовой вектор движения, используя одно из значений глубины глубинных пикселей в глубинном блоке. Осуществляют получение эталонного блока текущего текстурного блока, используя первый межвидовый вектор движения. 2 н. и 6 з.п. ф-лы, 10 ил.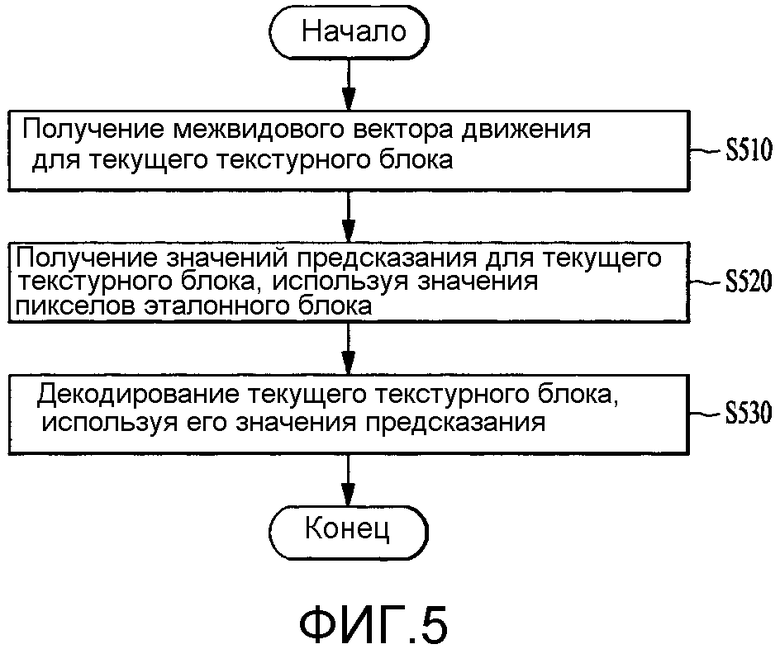
1. Способ обработки видеосигналов, который содержит:
получение глубинного блока, соответствующего текущему текстурному блоку;
получение первого межвидового вектора движения, используя одно из значений глубины глубинных пикселей в глубинном блоке;
получение эталонного блока текущего текстурного блока, используя первый межвидовый вектор движения; и
получение значения предсказания для текущего текстурного блока, используя эталонный блок;
причем глубинные пиксели в глубинном блоке являются левым верхним пикселем, левым нижним пикселем, правым верхним пикселем и правым нижним пикселем.
2. Способ по п. 1, в котором одно из значений глубины является наибольшим значением глубины среди значений глубины глубинных пикселей в глубинном блоке.
3. Способ по п. 1, в котором получение глубинного блока, соответствующего текущему текстурному блоку, содержит:
получение второго межвидового вектора движения, выведенного из соседнего блока текущего текстурного блока;
получение текстурного блока в соседнем виде, используя второй межвидовый вектор движения; и
получение глубинного блока, используя текстурный блок в соседнем виде.
4. Способ по п. 3, в котором глубинный блок расположен у соседнего вида текущего текстурного блока.
5. Видеодекодер, который содержит:
устройство интерактивного предсказания, выполненное с возможностью получения глубинного блока, соответствующего текущему текстурному блоку, получения первого межвидового вектора движения, используя одно из значений глубины глубинных пикселей в глубинном блоке, получения эталонного блока текущего текстурного блока, используя первый межвидовый вектор движения, и получения значений предсказания для текущего текстурного блока, используя эталонный блок;
причем глубинные пиксели в глубинном блоке являются левым верхним пикселем, левым нижним пикселем, правым верхним пикселем и правым нижним пикселем.
6. Видеодекодер по п. 5, в котором одно из значений глубины является наибольшим значением глубины среди значений глубины глубинных пикселей в глубинном блоке.
7. Видеодекодер по п. 5, в котором устройство интерактивного предсказания получает второй межвидовый вектор движения выведенным из соседнего блока текущего текстурного блока, получает текстурный блок в соседнем виде, используя второй межвидовый вектор движения, и получает глубинный блок, используя текстурный блок в соседнем виде.
8. Видеодекодер по п. 7, в котором глубинный блок расположен у соседнего вида текущего текстурного блока.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| KR 20100102493 A, 24.09.2010 | |||
| KR 20090053873 A, 16.06.2008 | |||
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ И ВОСПРОИЗВЕДЕНИЯ ТРЕХМЕРНОГО ВИДЕОИЗОБРАЖЕНИЯ | 2009 |
|
RU2421933C2 |
| RU 2006126660 A, 27.01.2008. | |||

