Уровень техники
Область техники
[1] Настоящее изобретение относится к технологии, ассоциированной с кодированием видео, а более конкретно, к способу и устройству для кодирования изображения с эффектом глубины при кодировании видео.
Описание предшествующего уровня техники
[2] В последние годы, потребности в высококачественном видео высокого разрешения возрастают в различных областях применения. Тем не менее, чем выше становится разрешение и качество видеоданных, тем больше становится объем видеоданных.
[3] Соответственно, когда видеоданные передаются с использованием таких сред, как существующие проводные или беспроводные широкополосные линии, либо видеоданные сохраняются на существующих носителях хранения данных, затраты на их передачу и затраты на хранение увеличиваются. Высокоэффективные технологии сжатия видео могут использоваться для того, чтобы эффективно передавать, сохранять и воспроизводить высококачественные видеоданные высокого разрешения.
[4] С другой стороны, с реализацией возможностей обработки видео высокого разрешения/с высокой пропускной способностью, цифровые широковещательные услуги с использованием трехмерного видео привлекают внимание в качестве широковещательной услуги следующего поколения. Трехмерное видео может предоставлять ощущение реализма и ощущение погружения с использованием многовидовых каналов.
[5] Трехмерное видео может использоваться в различных областях техники, таких как видео со свободной точкой обзора (FVV), телевидение со свободной точкой обзора (FTV), 3DTV, наблюдение и домашние развлечения.
[6] В отличие от одновидового видео, трехмерное видео с использованием мультивидов имеет высокую корреляцию между видами, имеющими идентичный номер в последовательности изображений (POC). Поскольку идентичная сцена снимается с помощью нескольких соседних камер, т.е. с несколькими видами, многовидовые видео имеют почти идентичную информацию за исключением параллакса и небольшой разности освещения, и в силу этого разностные виды имеют высокую корреляцию между собой.
[7] Соответственно, корреляция между различными видами может рассматриваться для кодирования/декодирования многовидового видео, и может получаться информация, требуемая для кодирования и/или декодирования текущего вида. Например, блок, который должен быть декодирован в текущем виде, может предсказываться или декодироваться при обращении к блоку в другом виде.
[8] Дополнительно, поскольку изображение с эффектом глубины и изображение текстуры содержат информацию относительно идентичной сцены, изображение с эффектом глубины и изображение текстуры имеют высокую корреляцию между собой. Соответственно, изображение с эффектом глубины может предсказываться или декодироваться посредством обращения к изображению текстуры.
Сущность изобретения
[9] Настоящее изобретение предоставляет способ и устройство для предсказания текущего блока при кодировании трехмерного видео.
[10] Настоящее изобретение предоставляет способ и устройство для выполнения межвидового предсказания движения (IMVP).
[11] Настоящее изобретение предоставляет способ и устройство для задания доступного опорного вида при выполнении IMVP.
[12] Настоящее изобретение предоставляет способ и устройство для введения диспаратности текущего блока при кодировании изображений с эффектом глубины.
[13] Настоящее изобретение предоставляет способ и устройство для задания индекса опорного вида, используемого для введения диспаратности текущего блока.
[14] В аспекте, предусмотрен способ для декодирования трехмерного видео. Способ декодирования включает в себя: получение значения диспаратности на основе опорного вида и предварительно определенного значения; извлечение информации перемещения текущего блока в изображении с эффектом глубины на основе значения диспаратности; и формирование выборки предсказания текущего блока на основе информации перемещения, при этом опорный вид представляет собой вид опорного изображения в списке опорных изображений.
[15] В другом аспекте, предусмотрено устройство для декодирования трехмерного видео. Устройство декодирования включает в себя: декодер, принимающий поток битов, включающий в себя информацию режима предсказания; и модуль предсказания, получающий значение диспаратности на основе опорного вида и предварительно определенного значения; извлекающий информацию движения текущего блока в изображении с эффектом глубины на основе значения диспаратности и формирующий выборку предсказания текущего блока на основе информации движения, при этом опорный вид представляет собой вид опорного изображения в списке опорных изображений.
[16] Согласно настоящему изобретению, вектор диспаратности текущего блока может быть плавно вызван при кодировании трехмерного видео.
[17] Согласно настоящему изобретению, даже когда к базовому виду не может осуществляться доступ, вектор диспаратности может быть вызван на основе доступного индекса опорного вида в буфере декодированных изображений (DPB), и может повышаться эффективность кодирования.
Краткое описание чертежей
[18] Фиг. 1 кратко иллюстрирует процесс кодирования и декодирования трехмерного видео, к которому является применимым настоящее изобретение.
[19] Фиг. 2 кратко иллюстрирует структуру устройства кодирования видео, к которому является применимым настоящее изобретение.
[20] Фиг. 3 кратко иллюстрирует структуру устройства декодирования видео, к которому является применимым настоящее изобретение.
[21] Фиг. 4 является схемой для схематичного описания одного примера кодирования многовидового видео, к которому является применимым настоящее изобретение.
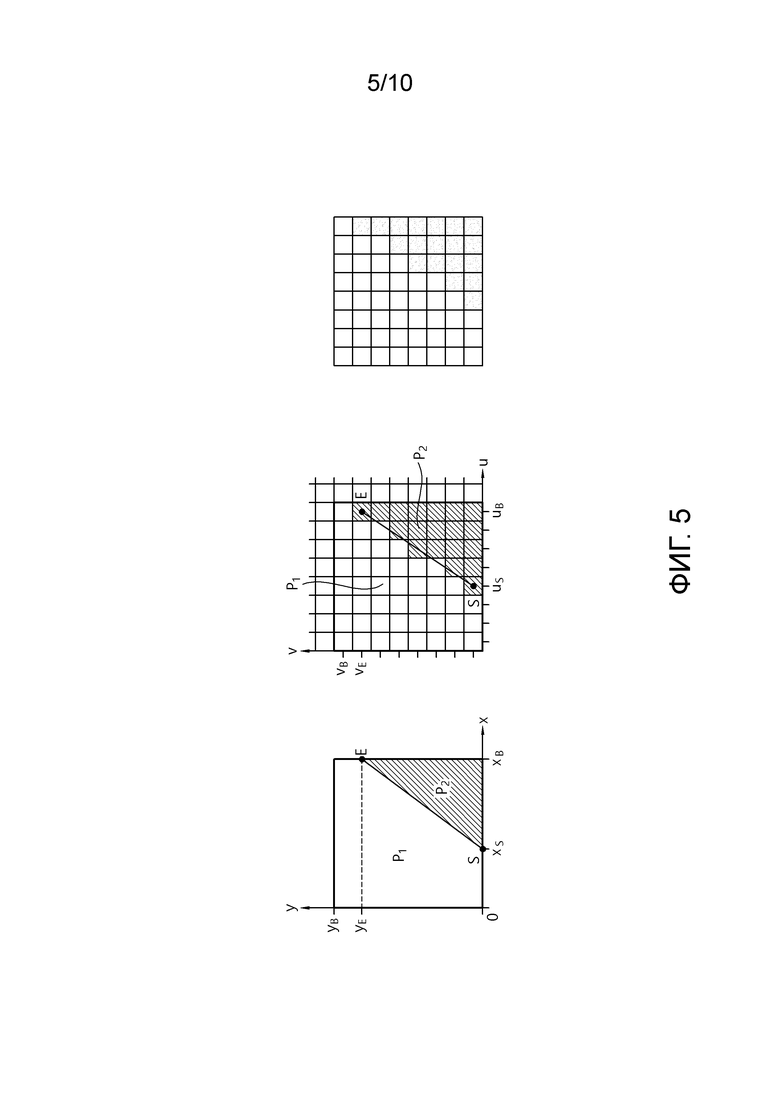
[22] Фиг. 5 является схемой, схематично иллюстрирующей веджлет-режим.
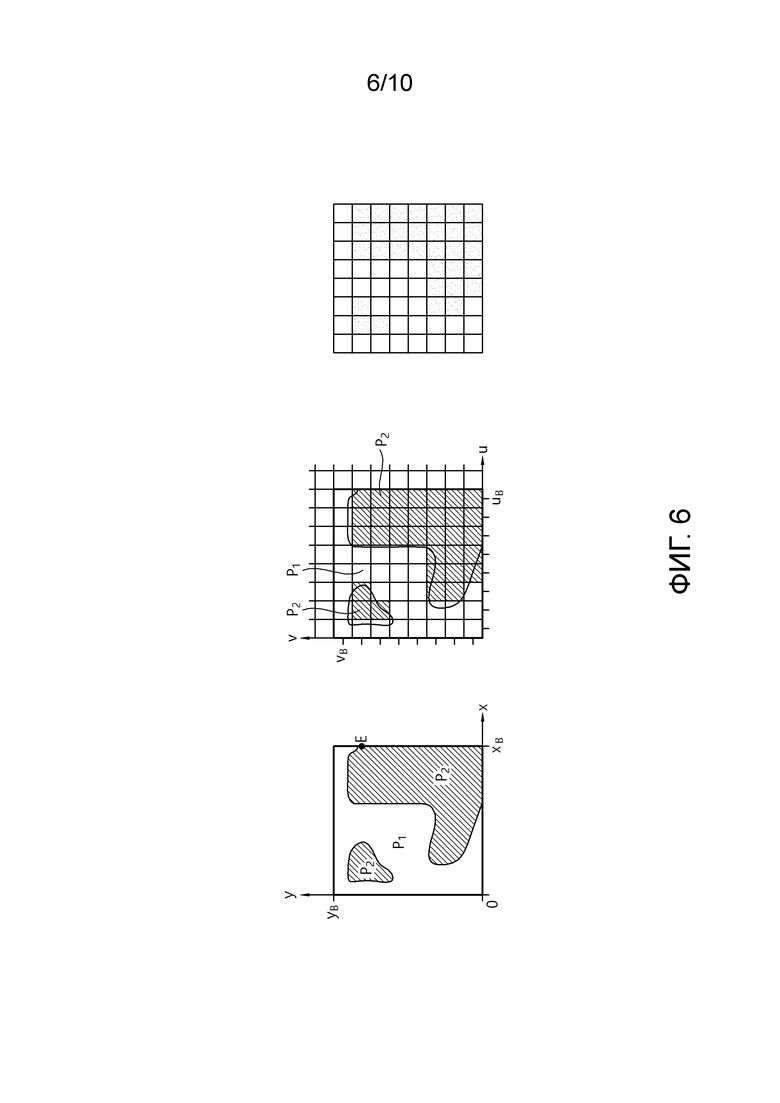
[23] Фиг. 6 является схемой, схематично иллюстрирующей контурный режим.
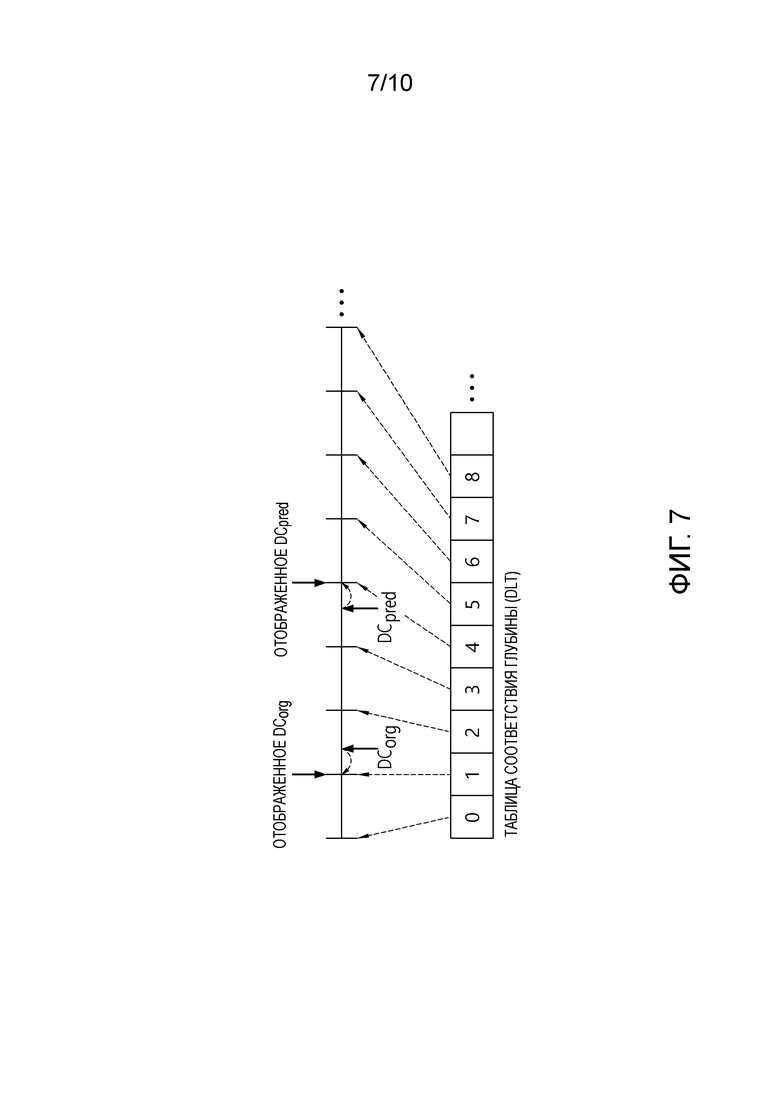
[24] Фиг. 7 является схемой, схематично иллюстрирующей способ SDC-кодирования.
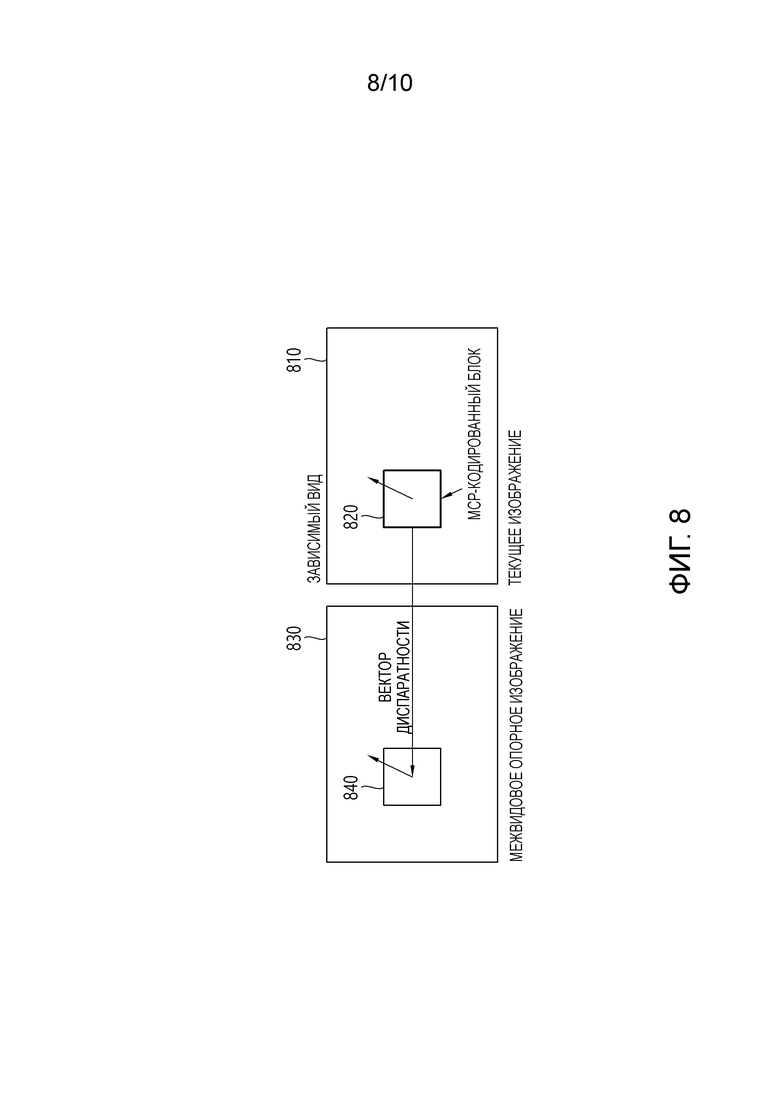
[25] Фиг. 8 является схемой, схематично иллюстрирующей IVMP-способ.
[26] Фиг. 9 является блок-схемой последовательности операций, схематично иллюстрирующей способ для кодирования трехмерного видео согласно варианту осуществления настоящего изобретения.
[27] Фиг. 10 является блок-схемой последовательности операций, схематично иллюстрирующей способ для декодирования трехмерного видео согласно варианту осуществления настоящего изобретения.
Подробное описание вариантов осуществления
[28] Изобретение может различными способами модифицироваться в различных формах и может иметь различные варианты осуществления, и его конкретные варианты осуществления этого проиллюстрированы на чертежах и подробно описаны. Тем не менее, эти варианты осуществления не предназначены для ограничения изобретения. Термины, используемые в нижеприведенном описании, используются для того, чтобы просто описывать конкретные варианты осуществления, но не предназначены для ограничения технической сущности изобретения. Выражение единственного числа включает в себя выражение множественного числа до тех пор, пока они четко трактуются по-разному. Такие термины, как "включать в себя" и "иметь" в этом описании, предназначены для указания того, что существуют признаки, числа, этапы, операции, элементы, компоненты либо комбинации вышеозначенного, используемые в нижеприведенном описании, и в силу этого следует понимать, что не исключается возможность наличия или добавления одного или более других признаков, чисел, этапов, операций, элементов, компонентов либо комбинаций вышеозначенного.
[29] С другой стороны, элементы чертежей, описанных в изобретении, нарисованы независимо для удобства пояснения относительно различных конкретных функций и не означают то, что элементы осуществлены посредством независимых аппаратных средств или независимого программного обеспечения. Например, два или более элемента из элементов могут комбинироваться, чтобы формировать один элемент, или один элемент может разбиваться на несколько элементов. Варианты осуществления, в которых элементы комбинируются и/или разбиваются, принадлежат объему изобретения без отступления из принципа изобретения.
[30] Далее подробно описываются примерные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи. Помимо этого, аналогичные ссылки с номерами используются для того, чтобы указывать аналогичные элементы на всех чертежах, и идентичные описания подобных элементов опускаются.
[31] В настоящем описании изобретения, изображение, в общем, означает единицу, представляющую одно изображение в конкретной временной полосе, и серия последовательных макроблоков представляет собой единицу, составляющую часть изображения при кодировании. Одно изображение может состоять из множества серий последовательных макроблоков, и по мере необходимости изображение и серия последовательных макроблоков могут смешанно использоваться.
[32] Пиксел или пел может означать минимальную единицу, составляющую одно изображение (или изображение). Дополнительно, "выборка" может использоваться в качестве термина, представляющего значение конкретного пиксела. Выборка, в общем, может указывать значение пиксела, может представлять только пикселное значение компонента сигнала яркости и может представлять только пикселное значение компонента сигнала цветности.
[33] Единица указывает базовую единицу обработки изображений. Единица может включать в себя, по меньшей мере, одну из специальной области и информации, связанной с областью. Необязательно, единица может смешиваться с такими терминами, как блок, область и т.п. В типичном случае блок M*N может представлять набор выборок или коэффициентов преобразования, размещаемых в M столбцов и N строк.
[34]
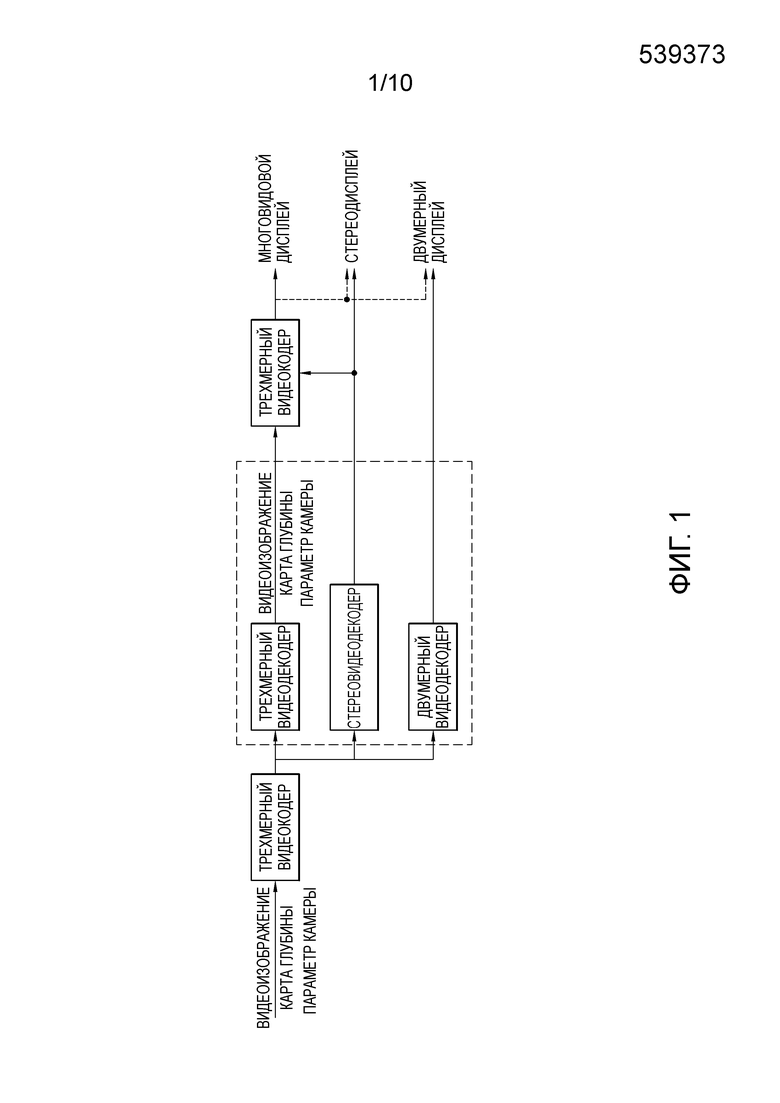
[35] Фиг. 1 кратко иллюстрирует процесс кодирования и декодирования трехмерного видео, к которому является применимым настоящее изобретение.
[36] Ссылаясь на фиг. 1, трехмерный видеокодер может кодировать видеоизображение, карту глубины и параметр камеры, чтобы выводить поток битов.
[37] Карта глубины может состоять из информации расстояния (информации глубины) между камерой и объектом относительно изображения соответствующего видеоизображения (изображения текстуры). Например, карта глубины может представлять собой изображение, полученное посредством нормализации информации глубины согласно битовой глубине. В этом случае, карта глубины может состоять из информации глубины, записываемой без представления цветового различия. Карта глубины может называться изображением с картой глубины или изображением с эффектом глубины.
[38] В общем, расстояние до объекта и диспаратность являются обратно пропорциональными друг другу. Следовательно, информация диспаратности, указывающая межвидовую корреляцию, может извлекаться из информации глубины карты глубины посредством использования параметра камеры.
[39] Поток битов, включающий в себя карту глубины и параметр камеры вместе с типичным цветным изображением, т.е. видеоизображением (изображением текстуры), может передаваться в декодер через сеть или носитель хранения данных.
[40] Со стороны декодера, поток битов может приниматься, чтобы восстанавливать видео. Если трехмерный видеодекодер используется на стороне декодера, трехмерный видеодекодер может декодировать видеоизображение, карту глубины и параметр камеры из потока битов. Виды, требуемые для многовидового дисплея, могут быть синтезированы на основе декодированного видеоизображения, карты глубины и параметра камеры. В этом случае, если используемый дисплей представляет собой стереодисплей, трехмерное изображение может отображаться посредством использования изображений для двух видов из восстановленных мультивидов.
[41] Если используется стереовидеодекодер, стереовидеодекодер может восстанавливать два изображения, которые должны падать в оба глаза, из потока битов. В стереодисплее, стереоскопическое изображение может отображаться посредством использования разности видов или диспаратности левого изображения, которое падает в левый глаз, и правого изображения, которое падает в правый глаз. Когда многовидовой дисплей используется вместе со стереовидеодекодером, мультивид может отображаться посредством формирования различных видов на основе восстановленных двух изображений.
[42] Если используется двумерный декодер, двумерное изображение может восстанавливаться, чтобы выводить изображение в двумерный дисплей. Если используется двумерный дисплей, но трехмерный видеодекодер или стереовидеодекодер используется в качестве декодера, одно из восстановленных изображений может выводиться в двумерный дисплей.
[43] В структуре по фиг. 1, синтез видов может выполняться на стороне декодера или может выполняться на стороне дисплея. Дополнительно, декодер и дисплей могут представлять собой одно устройство или могут представлять собой отдельные устройства.
[44] Хотя на фиг. 1 для удобства описывается то, что трехмерный видеодекодер и стереовидеодекодер и двумерный видеодекодер представляют собой отдельные декодеры, одно устройство декодирования может выполнять все из декодирования трехмерного видео, декодирования стереовидео и декодирования двумерного видео. Дополнительно, устройство декодирования трехмерного видео может выполнять декодирование трехмерного видео, устройство декодирования стереовидео может выполнять декодирование стереовидео, и устройство декодирования двумерного видео может выполнять декодирование двумерного видео. Дополнительно, многовидовой дисплей может выводить двумерное видео или может выводить стереовидео.
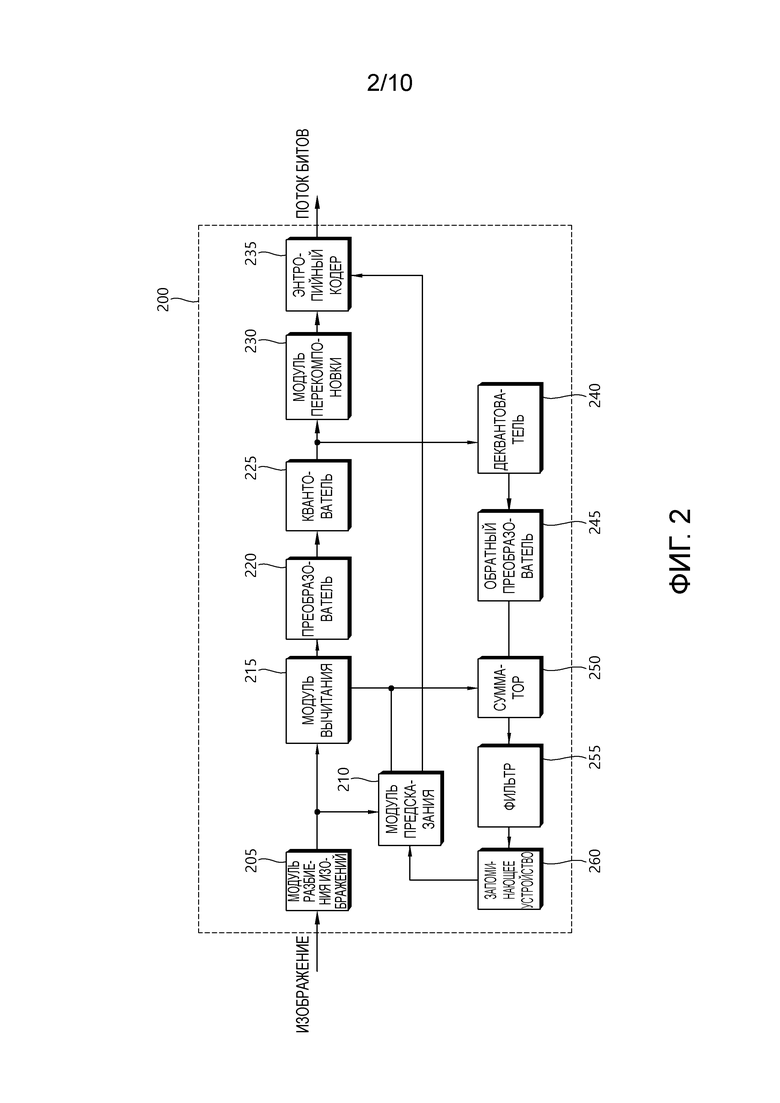
[45] Фиг. 2 кратко иллюстрирует структуру устройства кодирования видео, к которому является применимым настоящее изобретение.
[46] Ссылаясь на фиг. 2, устройство 200 кодирования видео включает в себя модуль 205 разбиения изображений, модуль 210 предсказания, модуль 215 вычитания, преобразователь 220, квантователь 225, модуль 230 перекомпоновки, энтропийный кодер 235, деквантователь 240, обратный преобразователь 245, сумматор 250, фильтр 255 и запоминающее устройство 260.
[47] Модуль 205 разбиения изображений может разбивать входное изображение, по меньшей мере, на один единичный блок обработки. В этом случае, единичный блок обработки может представлять собой единичный блок кодирования, единичный блок предсказания или единичный блок преобразования. В качестве единичного блока кодирования, единичный блок кодирования может разбиваться из наибольшего единичного блока кодирования согласно структуре в виде дерева квадрантов. В качестве блока, сегментированного из единичного блока кодирования, единичный блок предсказания может представлять собой единичный блок выборочного предсказания. В этом случае, единичный блок предсказания может разделяться на субблоки. Единичный блок преобразования может разбиваться из единичного блока кодирования согласно структуре в виде дерева квадрантов и может представлять собой единичный блок для извлечения согласно коэффициенту преобразования либо единичный блок для извлечения остаточного сигнала из коэффициента преобразования.
[48] В дальнейшем в этом документе, единичный блок кодирования может называться блоком кодирования (CB) или единицей кодирования (CU), единичный блок предсказания может называться блоком (PB) предсказания или единицей (PU) предсказания, и единичный блок преобразования может называться блоком (TB) преобразования или единицей (TU) преобразования.
[49] Блок предсказания или единица предсказания может означать специальную область, имеющую форму блока в изображении, и может включать в себя массив выборок предсказания. Дополнительно, блок преобразования или единица преобразования может означать специальную область, имеющую форму блока в изображении, и может включать в себя коэффициент преобразования или массив остаточных выборок.
[50] Модуль 210 предсказания может выполнять предсказание для целевого блока обработки (в дальнейшем в этом документе, текущего блока) и может формировать блок предсказания, включающий в себя выборки предсказания для текущего блока. Единица предсказания, выполняемого в модуле 210 предсказания, может представлять собой блок кодирования либо может представлять собой блок преобразования, либо может представлять собой блок предсказания.
[51] Модуль 210 предсказания может определять то, применяется внутреннее предсказание или применяется взаимное предсказание к текущему блоку. Например, модуль 210 предсказания может определять то, применяется внутреннее предсказание или взаимное предсказание в единице CU.
[52] В случае внутреннего предсказания, модуль 210 предсказания может извлекать выборку предсказания для текущего блока на основе опорной выборки за пределами текущего блока в изображении, которому принадлежит текущий блок (в дальнейшем в этом документе, в текущем изображении). В этом случае, модуль 210 предсказания может извлекать выборку предсказания на основе среднего или интерполяции соседних опорных выборок текущего блока (случай (i)) или может извлекать выборку предсказания на основе опорной выборки, существующей в конкретном направлении (предсказания) в отношении выборки предсказания из соседних опорных выборок текущего блока (случай (ii)). Случай (i) может называться ненаправленным режимом, и случай (ii) может называться направленным режимом. Модуль 210 предсказания может определять режим предсказания, который должен применяться к текущему блоку, посредством использования режима предсказания, применяемого к соседнему блоку.
[53] В случае взаимного предсказания, модуль 210 предсказания может извлекать выборку предсказания для текущего блока на основе выборки, указываемой посредством вектора движения в опорном изображении. Модуль 210 предсказания может извлекать выборку предсказания для текущего блока посредством применения любого из режима пропуска, режима объединения и режима предсказания векторов движения (MVP). В случае режима пропуска и режима объединения, модуль 210 предсказания может использовать информацию движения соседнего блока в качестве информации движения текущего блока. В случае режима пропуска, в отличие от режима объединения, разность (остаток) между выборкой предсказания и исходной выборкой не передается. В случае MVP-режима, вектор движения соседнего блока используется в качестве предиктора вектора движения и за счет этого используется в качестве предиктора вектора движения текущего блока, чтобы извлекать вектор движения текущего блока.
[54] В случае взаимного предсказания, соседний блок включает в себя пространственный соседний блок, существующий в текущем изображении, и временной соседний блок, существующий в опорном изображении. Опорное изображение, включающее в себя временной соседний блок, также может называться совместно размещенным изображением (colPic). Информация движения может включать в себя вектор движения и опорное изображение. Если информация движения временного соседнего блока используется в режиме пропуска и режиме объединения, верхнее изображение в списке опорных изображений может использоваться в качестве опорного изображения.
[55] Мультивид может разделяться на независимый вид и зависимый вид. В случае кодирования для независимого вида, модуль 210 предсказания может выполнять не только взаимное предсказание, но также и межвидовое предсказание.
[56] Модуль 210 предсказания может конфигурировать список опорных изображений посредством включения изображений различных видов. Для межвидового предсказания, модуль 210 предсказания может извлекать вектор диспаратности. В отличие от этого, в векторе движения, который указывает блок, соответствующий текущему блоку в различном изображении в текущем виде, вектор диспаратности может указывать блок, соответствующий текущему блоку в другом виде идентичной единицы доступа (AU), в качестве текущего изображения. В мультивиде, например, AU может включать в себя видеоизображения и карты глубины, соответствующие идентичному моменту времени. В данном документе, AU может означать набор изображений, имеющий идентичный номер в последовательности изображений (POC). POC соответствует порядку отображения и может отличаться от порядка кодирования.
[57] Модуль 210 предсказания может указывать блок глубины в виде глубины на основе вектора диспаратности и может выполнять конфигурирование списков объединения, межвидовое предсказание движения, остаточное предсказание, компенсацию освещения (IC), синтез видов и т.п.
[58] Вектор диспаратности для текущего блока может извлекаться из значения глубины посредством использования параметра камеры либо может извлекаться из вектора движения или вектора диспаратности соседнего блока в текущем или различном виде.
[59] Например, модуль 210 предсказания может добавлять, в список возможных вариантов объединения, возможный вариант межвидового объединения (IvMC), соответствующий временной информации движения опорного вида, возможный вариант межвидового вектора диспаратности (IvDC), соответствующий вектору диспаратности, сдвинутый IvMC, извлекаемый посредством сдвига вектора диспаратности, возможный вариант объединения текстуры (T), извлекаемый из соответствующего изображения текстуры, когда текущий блок представляет собой блок на карте глубины, возможный вариант объединения с извлечением за счет диспаратности (D), извлекаемый посредством использования диспаратности из возможного варианта объединения текстуры, возможный вариант предсказания на основе синтеза видов (VSP), извлекаемый на основе синтеза видов, и т.п.
[60] В этом случае, число возможных вариантов, включенных в список возможных вариантов объединения, которые должны применяться к зависимому виду, может быть ограничено конкретным значением.
[61] Дополнительно, модуль 210 предсказания может предсказывать вектор движения текущего блока на основе вектора диспаратности посредством применения межвидового предсказания векторов движения. В этом случае, модуль 210 предсказания может извлекать вектор диспаратности на основе преобразования наибольшего значения глубины в соответствующем блоке глубины. Когда позиция опорной выборки в опорном виде указывается посредством добавления вектора диспаратности в позицию выборки текущего блока в опорном виде, блок, включающий в себя опорную выборку, может использоваться в качестве опорного блока. Модуль 210 предсказания может использовать вектор движения опорного блока в качестве возможного варианта параметра движения текущего блока или возможного варианта предиктора вектора движения и может использовать вектор диспаратности в качестве возможного варианта вектора диспаратности для предсказания с компенсацией диспаратности (DCP).
[62] Модуль 215 вычитания формирует остаточную выборку, которая является разностью между исходной выборкой и выборкой предсказания. Если применяется режим пропуска, остаточная выборка не может формироваться, как описано выше.
[63] Преобразователь 220 преобразует остаточную выборку в единицу блока преобразования, чтобы формировать коэффициент преобразования. Квантователь 225 может квантовать коэффициенты преобразования, чтобы формировать квантованный коэффициент преобразования.
[64] Модуль 230 перекомпоновки перекомпонует квантованные коэффициенты преобразования. Модуль 230 перекомпоновки может перекомпоновывать квантованные коэффициенты преобразования, имеющие форму блока в форме одномерного вектора, посредством использования способа сканирования.
[65] Энтропийный кодер 235 может выполнять энтропийное кодирование для квантованных коэффициентов преобразования. Энтропийное кодирование может включать в себя способ кодирования, например, экспоненциальный код Голомба, контекстно-адаптивное кодирование переменной длины (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC) и т.п. Энтропийный кодер 235 может выполнять кодирование вместе или отдельно для информации (например, значения синтаксического элемента и т.п.), требуемой для восстановления видео, в дополнение к квантованным коэффициентам преобразования. Энтропийно кодированная информация может передаваться или сохраняться в единице слоя абстрагирования от сети (NAL) в форме потока битов.
[66] Сумматор 250 суммирует остаточную выборку и выборку предсказания, чтобы восстанавливать изображение. Остаточная выборка и выборка предсказания могут суммироваться в единице блоков, чтобы формировать блок восстановления. Хотя в данном документе описывается то, что сумматор 250 сконфигурирован отдельно, сумматор 250 может быть частью модуля 210 предсказания.
[67] Фильтр 255 может применять фильтрацию для удаления блочности и/или дискретизированное адаптивное смещение к восстановленному изображению. Артефакт границы блока в восстановленном изображении или искажения в процессе квантования может корректироваться через фильтрацию для удаления блочности и/или дискретизированное адаптивное смещение. Дискретизированное адаптивное смещение может применяться в единице выборок и может применяться после того, как процесс фильтрации для удаления блочности закончен.
[68] Запоминающее устройство 260 может сохранять восстановленное изображение или информацию, требуемую для кодирования/декодирования. Например, запоминающее устройство 260 может сохранять (опорные) изображения, используемые при взаимном предсказании/межвидовом предсказании. В этом случае, изображения, используемые при взаимном предсказании/межвидовом предсказании, могут быть обозначены посредством набора опорных изображений или списка опорных изображений.
[69] Хотя в данном документе описывается то, что одно устройство кодирования кодирует независимый вид и зависимый вид, это служит для удобства пояснения. Таким образом, отдельное устройство кодирования может быть сконфигурировано для каждого вида, или отдельный внутренний модуль (например, модуль предсказания для каждого вида) может быть сконфигурирован для каждого вида.
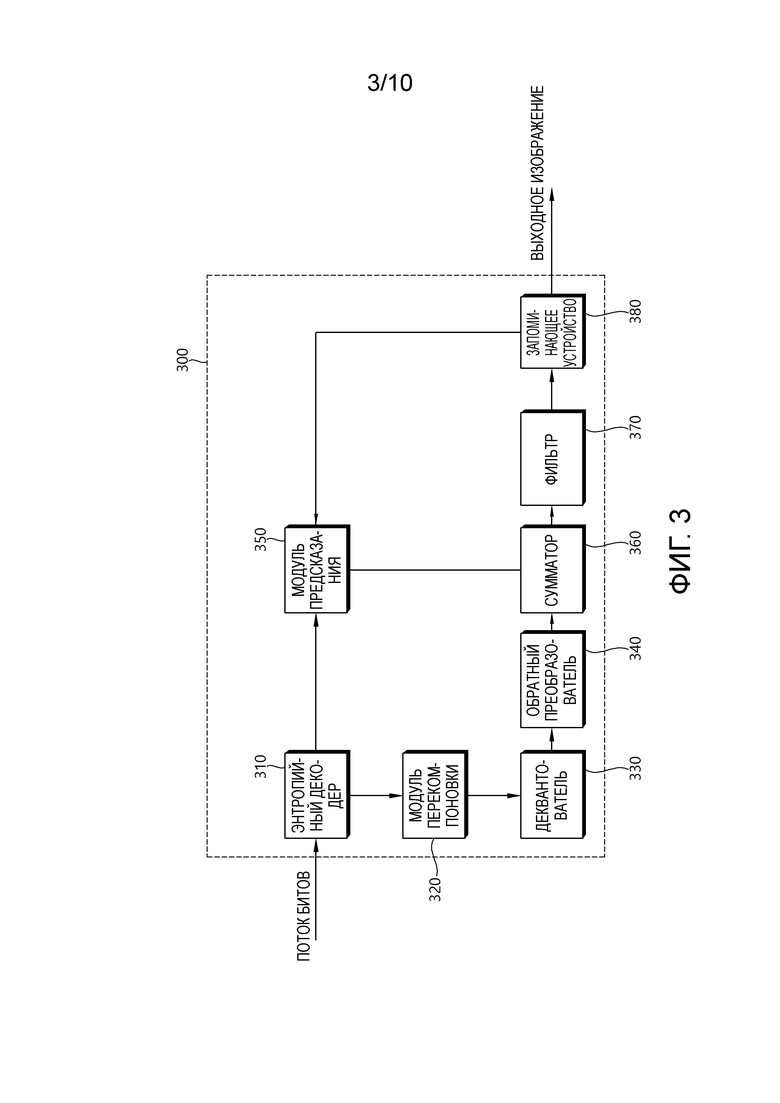
[70] Фиг. 3 кратко иллюстрирует структуру устройства декодирования видео, к которому является применимым настоящее изобретение.
[71] Ссылаясь на фиг. 3, устройство 300 декодирования видео включает в себя энтропийный декодер 310, модуль 320 перекомпоновки, деквантователь 330, обратный преобразователь 340, модуль 350 предсказания, сумматор 360, фильтр 370 и запоминающее устройство 380.
[72] Когда поток битов, включающий в себя видеоинформацию, вводится, устройство 300 декодирования видео может восстанавливать видео в ассоциации с процессом, посредством которого видеоинформация обрабатывается в устройстве кодирования видео.
[73] Например, устройство 300 декодирования видео может выполнять декодирование видео посредством использования единицы обработки, применяемой в устройстве кодирования видео. Следовательно, единичный блок обработки декодирования видео может представлять собой единичный блок кодирования, единичный блок предсказания или единичный блок преобразования. В качестве единичного блока декодирования, единичный блок кодирования может разбиваться согласно структуре дерева квадрантов из наибольшего единичного блока кодирования. В качестве блока, сегментированного из единичного блока кодирования, единичный блок предсказания может представлять собой единичный блок выборочного предсказания. В этом случае, единичный блок предсказания может разделяться на субблоки. В качестве единичного блока кодирования, единичный блок преобразования может разбиваться согласно структуре дерева квадрантов и может представлять собой единичный блок для извлечения коэффициента преобразования или единичный блок для извлечения остаточного сигнала из коэффициента преобразования.
[74] Энтропийный декодер 310 может синтаксически анализировать поток битов, чтобы выводить информацию, требуемую для восстановления видео или восстановления изображений. Например, энтропийный декодер 310 может декодировать информацию в потоке битов на основе способа кодирования, такого как экспоненциальное кодирование кодом Голомба, CAVLC, CABAC и т.п., и может выводить значение синтаксического элемента, требуемого для восстановления видео, и квантованное значение коэффициента преобразования относительно остатка.
[75] Если множество видов обрабатывается, чтобы воспроизводить трехмерное видео, поток битов может вводиться для каждого вида. Альтернативно, информация относительно каждого вида может мультиплексироваться в потоке битов. В этом случае, энтропийный декодер 310 может демультиплексировать поток битов, чтобы синтаксически анализировать его на предмет каждого вида.
[76] Модуль 320 перекомпоновки может перекомпоновывать квантованные коэффициенты преобразования в форме двумерного блока. Модуль 320 перекомпоновки может выполнять перекомпоновку в ассоциации со сканированием коэффициентов, выполняемым в устройстве кодирования.
[77] Деквантователь 330 может деквантовать квантованные коэффициенты преобразования на основе параметра (де)квантования, чтобы выводить коэффициент преобразования. В этом случае, информация для извлечения параметра квантования может передаваться в служебных сигналах из устройства кодирования.
[78] Обратный преобразователь 340 может обратно преобразовывать коэффициенты преобразования, чтобы извлекать остаточные выборки.
[79] Модуль 350 предсказания может выполнять предсказание для текущего блока и может формировать блок предсказания, включающий в себя выборки предсказания для текущего блока. Единица предсказания, выполняемого в модуле 350 предсказания, может представлять собой блок кодирования либо может представлять собой блок преобразования, либо может представлять собой блок предсказания.
[80] Модуль 350 предсказания может определять то, следует применять внутреннее предсказание или взаимное предсказание. В этом случае, единица для определения того, какое из них используется между внутренним предсказанием и взаимным предсказанием, может отличаться от единицы для формирования выборки предсказания. Помимо этого, единица для формирования выборки предсказания также может отличаться при взаимном предсказании и внутреннем предсказании. Например, то, какое из них должно применяться между взаимным предсказанием и внутренним предсказанием, может определяться в единице CU. Дополнительно, например, при взаимном предсказании, выборка предсказания может формироваться посредством определения режима предсказания в единице PU, и при внутреннем предсказании, выборка предсказания может формироваться в единице TU посредством определения режима предсказания в единице PU.
[81] В случае внутреннего предсказания, модуль 350 предсказания может извлекать выборку предсказания для текущего блока на основе соседней опорной выборки в текущем изображении. Модуль 350 предсказания может извлекать выборку предсказания для текущего блока посредством применения направленного режима или ненаправленного режима на основе соседней опорной выборки текущего блока. В этом случае, режим предсказания, который должен применяться к текущему блоку, может определяться посредством использования режима внутреннего предсказания соседнего блока.
[82] В случае взаимного предсказания, модуль 350 предсказания может извлекать выборку предсказания для текущего блока на основе выборки, указываемой в опорном изображении посредством вектора движения в опорном изображении. Модуль 350 предсказания может извлекать выборку предсказания для текущего блока посредством применения любого из режима пропуска, режима объединения и MVP-режима.
[83] В случае режима пропуска и режима объединения, информация движения соседнего блока может использоваться в качестве информации движения текущего блока. В этом случае, соседний блок может включать в себя пространственный соседний блок и временной соседний блок.
[84] Модуль 350 предсказания может составлять список возможных вариантов объединения посредством использования информации движения доступного соседнего блока и может использовать информацию, указываемую посредством индекса объединения в списке возможных вариантов объединения, в качестве вектора движения текущего блока. Индекс объединения может передаваться в служебных сигналах из устройства кодирования. Информация движения может включать в себя вектор движения и опорное изображение. Когда информация движения временного соседнего блока используется в режиме пропуска и режиме объединения, наибольшее изображение в списке опорных изображений может использоваться в качестве опорного изображения.
[85] В случае режима пропуска, в отличие от режима объединения, разность (остаток) между выборкой предсказания и исходной выборкой не передается.
[86] В случае MVP-режима, вектор движения текущего блока может извлекаться посредством использования вектора движения соседнего блока в качестве предиктора вектора движения. В этом случае, соседний блок может включать в себя пространственный соседний блок и временной соседний блок.
[87] В случае зависимого вида, модуль 350 предсказания может выполнять межвидовое предсказание. В этом случае, модуль 350 предсказания может конфигурировать список опорных изображений посредством включения изображений различных видов.
[88] Для межвидового предсказания, модуль 350 предсказания может извлекать вектор диспаратности. Модуль 350 предсказания может указывать блок глубины в виде глубины на основе вектора диспаратности и может выполнять конфигурирование списков объединения, межвидовое предсказание движения, остаточное предсказание, компенсацию освещения (IC), синтез видов и т.п.
[89] Вектор диспаратности для текущего блока может извлекаться из значения глубины посредством использования параметра камеры либо может извлекаться из вектора движения или вектора диспаратности соседнего блока в текущем или различном виде. Параметр камеры может передаваться в служебных сигналах из устройства кодирования.
[90] Когда режим объединения применяется к текущему блоку зависимого вида, модуль 350 предсказания может добавлять, в список возможных вариантов объединения, IvMC, соответствующий временной информации движения опорного вида, IvDC, соответствующий вектору диспаратности, сдвинутый IvMC, извлекаемый посредством сдвига вектора диспаратности, возможный вариант объединения текстуры (T), извлекаемый из соответствующего изображения текстуры, когда текущий блок представляет собой блок на карте глубины, возможный вариант объединения с извлечением за счет диспаратности (D), извлекаемый посредством использования диспаратности из возможного варианта объединения текстуры, возможный вариант предсказания на основе синтеза видов (VSP), извлекаемый на основе синтеза видов, и т.п.
[91] В этом случае, число возможных вариантов, включенных в список возможных вариантов объединения, которые должны применяться к зависимому виду, может быть ограничено конкретным значением.
[92] Дополнительно, модуль 350 предсказания может предсказывать вектор движения текущего блока на основе вектора диспаратности посредством применения межвидового предсказания векторов движения. В этом случае, модуль 350 предсказания может использовать блок в опорном виде, указываемом посредством вектора диспаратности, в качестве опорного блока. Модуль 350 предсказания может использовать вектор движения опорного блока в качестве возможного варианта параметра движения или возможного варианта предиктора вектора движения текущего блока и может использовать вектор диспаратности в качестве возможного варианта вектора для предсказания с компенсацией диспаратности (DCP).
[93] Сумматор 360 может суммировать остаточную выборку и выборку предсказания, чтобы восстанавливать текущий блок или текущее изображение. Сумматор 360 может суммировать остаточную выборку и выборку предсказания в единице блоков, чтобы восстанавливать текущее изображение. Когда применяется режим пропуска, остаток не передается, и в силу этого выборка предсказания может представлять собой восстановительную выборку. Хотя в данном документе описывается то, что сумматор 360 сконфигурирован отдельно, сумматор 360 может быть частью модуля 350 предсказания.
[94] Фильтр 370 может применять фильтрацию для удаления блочности и/или дискретизированное адаптивное смещение к восстановленному изображению. В этом случае, дискретизированное адаптивное смещение может применяться в единице выборок и может применяться после фильтрации для удаления блочности.
[95] Запоминающее устройство 380 может сохранять восстановленное изображение и информацию, требуемую при декодировании. Например, запоминающее устройство 380 может сохранять изображения, используемые при взаимном предсказании/межвидовом предсказании. В этом случае, изображения, используемые при взаимном предсказании/межвидовом предсказании, могут быть обозначены посредством набора опорных изображений или списка опорных изображений. Восстановленное изображение может использоваться в качестве опорного изображения для различного изображения.
[96] Дополнительно, запоминающее устройство 380 может выводить восстановленное изображение согласно порядку вывода. Хотя не показано, модуль вывода может отображать множество различных видов, чтобы воспроизводить трехмерное изображение.
[97] Хотя в примере по фиг. 3 описывается то, что независимый вид и зависимый вид декодируются в одном устройстве декодирования, это служит только для примерных целей, и настоящее изобретение не ограничено этим. Например, каждое устройство декодирования может работать для каждого вида, и внутренний модуль (например, модуль предсказания) может предоставляться в ассоциации с каждым видом в одном устройстве декодирования.
[98] Кодирование многовидового видео может выполнять кодирование для текущего изображения посредством использования декодирования данных другого вида, принадлежащего идентичной единице доступа (AU), в качестве текущего изображения, чтобы повышать эффективность кодирования видео для текущего вида.
[99] При декодировании многовидового видео, виды могут кодироваться в единице AU, и изображения могут кодироваться в единице видов. Кодирование выполняется между видами согласно определенному порядку. Вид, который может кодироваться без обращения к другому виду, может называться базовым видом или независимым видом. Дополнительно, вид, который может кодироваться при обращении к независимому виду или другому виду после того, как независимый вид кодируется, может называться зависимым видом или расширенным видом. Дополнительно, если текущий вид представляет собой зависимый вид, вид, используемый в качестве ссылки при кодировании текущего вида, может называться опорным видом. В данном документе, кодирование вида включает в себя кодирование изображения текстуры, изображения с эффектом глубины и т.п., принадлежащих виду.
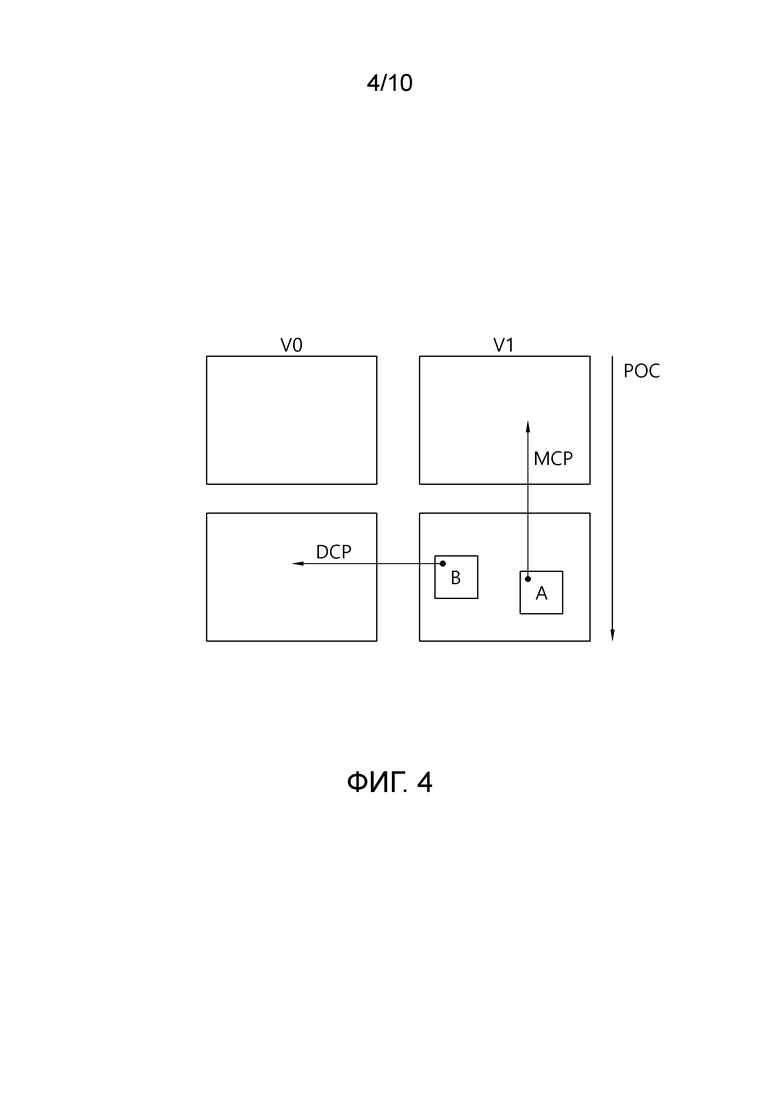
[100] Фиг. 4 является схемой для схематичного описания одного примера кодирования многовидового видео, к которому является применимым настоящее изобретение.
[101] В случае кодирования многовидового видео, изображения, в которых идентификаторы видов в одной AU отличаются друг от друга, и POC являются идентичными друг другу, кодируются согласно предварительно заданному порядку видового кодирования.
[102] Например, как проиллюстрировано на фиг. 4, два вида (виды V0 и V1) кодируются, и порядок видового кодирования предполагается в качестве порядка видов V0 и V1. В этом случае, V0 в качестве вида, который кодируется сначала в AU, может кодироваться без обращения к другому виду, и V0 становится базовым видом или независимым видом, и V1 в качестве вида, который кодируется следующим, становится зависимым видом.
[103] Базовый вид кодируется посредством обращения к изображению, включенному в базовый вид, без обращения к другому виду. Зависимый вид кодируется посредством обращения к другому виду, который уже кодирован при кодировании после базового вида.
[104] При кодировании многовидового видео, CU, которая принадлежит зависимому виду, может выполнять взаимное предсказание посредством обращения к изображению, которое уже кодировано. В этом случае, способ, который выполняет предсказание посредством обращения к изображениям, в которых идентификаторы видов являются идентичными друг другу, упоминается в качестве предсказания с компенсацией движения (MCP) и способ, который выполняет предсказание посредством обращения к изображениям, в которых идентификаторы видов в идентичной AU отличаются друг от друга, упоминается в качестве предсказания с компенсацией диспаратности (DCP).
[105] Например, ссылаясь на фиг. 4, блок A может вызывать выборки предсказания посредством выполнения MCP на основе вектора движения посредством обращения к изображению, которое принадлежит идентичному виду V1. Блок B может вызывать выборки предсказания посредством выполнения DCP на основе вектора диспаратности посредством обращения к изображению другого вида V0 из блока B в идентичной AU. При кодировании многовидового видео, изображение другого вида может использоваться, и изображение с эффектом глубины идентичного вида может использоваться.
[106] Например, когда выборки предсказания вызваны посредством выполнения DCP, вектор диспаратности добавляется в позицию (x, y) соответствующего изображения в опорном виде, соответствующем позиции (x, y) выборки предсказания в текущем блоке, чтобы определять позицию опорной выборки соответствующего изображения в опорном виде. Выборка предсказания может быть вызвана на основе опорной выборки в опорном виде. В качестве одного примера, вектор диспаратности может иметь только компонент по оси X. В этом случае, вектор диспаратности может быть (disp, 0), и позиция (xr, y) опорной выборки может определяться в качестве (x+disp, y). В данном документе, disp представляет значение вектора диспаратности.
[107]
[108] Между тем, трехмерное видео включает в себя изображение текстуры, имеющее общую информацию цветных изображений, и изображение с эффектом глубины, имеющее информацию глубины в изображении текстуры. В трехмерном видео, может существовать множество изображений текстуры, имеющих различные виды в идентичном POC, и изображения с эффектом глубины, соответствующие множеству изображений текстуры, соответственно, могут существовать. Дополнительно, множество изображений текстуры может получаться из множества камер, имеющих различные виды.
[109] Изображение с эффектом глубины сохраняет расстояние, которое каждый пиксел имеет в качестве шкалы полутонов, и существует много случаев, в которых мгновенная разность глубины между соответствующими пикселами не является большой, и карта глубины может выражаться при разделении на два типа переднего плана и фона в одном блоке. Дополнительно, видео на основе карты глубины показывает такую характеристику, что карта глубины имеет сильный край на границе объекта и имеет почти постоянное значение (например, постоянное значение) в позиции, отличной от границы.
[110] Изображение с эффектом глубины может кодироваться и декодироваться посредством использования внутреннего предсказания, компенсации движения, компенсации на основе диспаратности, преобразования и т.п. посредством аналогичного способа для изображения текстуры. Тем не менее, поскольку изображение с эффектом глубины имеет такую характеристику, что изменение пикселного значения не является большим, и изображение с эффектом глубины имеет сильный край, может использоваться новый режим внутреннего предсказания для отражения характеристики изображения с эффектом глубины.
[111] В режиме внутреннего предсказания для изображения с эффектом глубины, блок (альтернативно, блок глубины) может выражаться как модель, которая сегментирует блок на две непрямоугольных области, и каждая сегментированная область может выражаться как постоянное значение.
[112] Как описано выше, режим внутреннего предсказания для того, чтобы предсказывать изображение с эффектом глубины посредством моделирования блока в изображении с эффектом глубины, упоминается в качестве режима моделирования глубины (DMM). В DMM, изображение с эффектом глубины может предсказываться на основе информации сегментов, указывающей то, как сегментируется блок в изображении с эффектом глубины, и информации, указывающей то, каким значением заполняется каждый сегмент.
[113] Например, DMM может разделяться на веджлет-режим и контурный режим.
[114] Фиг. 5 является схемой, схематично иллюстрирующей веджлет-режим.
[115] Ссылаясь на фиг. 5, в веджлет-режиме, две области в блоке (альтернативно, блок глубины и текущий блок) могут быть сегментированы посредством прямой линии. Иными словами, блок может быть сегментирован на область P1 и область P2 посредством прямой линии SE. В каждой из сегментированных областей, значение предсказания может формироваться в качестве одного постоянного значения.
[116] Фиг. 6 является схемой, схематично иллюстрирующей контурный режим.
[117] Ссылаясь на фиг. 6, в контурном режиме, две области в блоке (альтернативно, блок глубины и текущий блок) могут быть сегментированы посредством предварительно определенной формы кривой. В контурном режиме, две области в блоке не могут легко выражаться посредством одной геометрической функции, и две области могут иметь предварительно определенные формы. В данном документе, как проиллюстрировано на фиг. 5, каждая область может представлять собой не один крупный фрагмент, а сегментированную форму. В контурном режиме, области могут быть сегментированы на основе соответствующего блока (блока текстуры) в изображении текстуры, соответствующем текущему блоку (блоку глубины) в изображении с эффектом глубины. В контурном режиме, в каждой из сегментированных областей, значение предсказания может формироваться в качестве одного постоянного значения.
[118] После того, как значение предсказания для блока формируется, остаток, представляющий разность (альтернативно, остаточный сигнал) между исходной выборкой и выборкой предсказания, вычисляется, и остаточный сигнал может передаваться через преобразование и квантование, аналогично режиму внутреннего предсказания в предшествующем уровне техники.
[119] Между тем, способ посегментного DC-кодирования (SDC) может использоваться для изображения с эффектом глубины. В SDC, остаточный сигнал может формироваться посредством использования среднего значений предсказания сегментированных областей. В SDC, остаточные данные могут кодироваться без процедур преобразования и квантования. В общем, выборочные (пикселные) значения изображения с эффектом глубины неравномерно распределяются от минимального значения (например, 0) до максимального значения (например, 255), но концентрированно распределяются в специальной области и имеют такую характеристику, что изменение значения не является большим посредством единицы блока. Таблица соответствия глубины (DLT) формируется посредством рассмотрения такой характеристики, и когда кодирование выполняется посредством преобразования значения глубины изображения с эффектом глубины в значение индекса таблицы соответствия глубины посредством использования таблицы соответствия глубины, число битов, которые должны кодироваться, может уменьшаться. Остаточный блок, сформированный посредством использования таблицы соответствия глубины, может энтропийно кодироваться без процессов преобразования и квантования. Иными словами, SDC может рассматриваться в качестве способа остаточного кодирования, который передает только разность между средним значением яркости исходного изображения и средним значением яркости изображения предсказания.
[120] В дальнейшем в этом документе подробнее описывается SDC-способ.
[121] Значение глубины изображения с эффектом глубины передается в расчете на набор параметров последовательности (SPS) или серию последовательных макроблоков. В этом случае, значение глубины изображения с эффектом глубины может передаваться на основе DLT. В этом случае, предсказание для SDC выполняется посредством единицы CU- или PU-блока.
[122] Например, вычисляются среднее DCpred значений глубины, внутренне предсказанных относительно соответствующих сегментированных областей в текущем блоке (двух областей в случае DMM и одной области в случае более плоского режима), и среднее DCorg исходного значения глубины, и соответствующие вычисленные средние значения отображаются в значение, имеющее наименьшую ошибку в DLT, чтобы находить каждое значение индекса. Помимо этого, вместо кодирования значения разности между исходным значением глубины и значением предсказания глубины, может кодироваться разностное значение SDCresidual между индексом для среднего DCorg исходного значения глубины, отображенного в DLT, и индексом для среднего DCpred значения предсказания глубины. SDC может быть избирательно использовано посредством информации флага посредством единицы CU-блока. Информация режима SDC передается в блок, к которому применяется SDC. После того, как информация режима SDC передается, разностное значение SDCresidual между индексом для среднего DCorg исходного значения глубины и индексом для среднего DCpred значения предсказания глубины передается.
[123] Уравнение 1, приведенное ниже, показывает процесс, который формирует значение индекса разности для текущего блока посредством SDC-способа.
[124] уравнение 1
[125] SDCresidual=Value2Idx(DCorg)-Value2Idx(DCpred)
[126] В уравнении 1, Value2Idx(x) представляет индекс, имеющий значение, ближайшее к значению x, введенному в DLT.
[127] Фиг. 7 является схемой, схематично иллюстрирующей способ SDC-кодирования.
[128] Ссылаясь на фиг. 7, DCorg получается относительно исходного блока, который должен быть кодирован, DCpred получается относительно блока предсказания, сформированного посредством внутреннего предсказания, и после этого, каждое из DCorg и DCpred отображается в индекс, имеющий ближайшее DLT-значение. На фиг. 6, DCorg отображается в DLT-индекс 2, и DCpred отображается в DLT-индекс 4. Соответственно, в ходе процесса кодирования, 2 в качестве значения, соответствующего разности между обоими DLT-индексами, кодируется и передается. Между тем, может часто возникать случай, в котором отсутствует разность индекса после отображения DCorg, и DCpred, и флаг, указывающий то, существует или нет разность индекса, может сначала передаваться для эффективной обработки. В случае если значение флага равно 0, случай означает то, что отсутствует разность между DCorg и DCpred, и декодер может формировать восстановленное изображение посредством использования среднего значения DCpred блока предсказания. В случае если значение флага равно 1, случай означает то, что существует разность между DCorg и DCpred, и в этом случае, разностное значение индекса передается. Поскольку разностное значение индекса может существовать в качестве положительного числа отрицательного числа, может передаваться каждое из знака и абсолютной величины разностного значения индекса.
[129] Между тем, в случае если изображение с эффектом глубины принадлежит зависимому виду, может использоваться межвидовое предсказание движения (IVMP), которое извлекает информацию движения текущего блока на основе информации движения, такой как вектор движения, который существует в соответствующем блоке опорного вида, аналогично изображению текстуры.
[130] Фиг. 8 является схемой, схематично иллюстрирующей IVMP-способ.
[131] Ссылаясь на фиг. 8, предполагается, что текущий блок 820 в текущем изображении 810 кодируется (кодируется/декодируется). В данном документе, текущее изображение 810 может представлять собой изображение с эффектом глубины. Дополнительно, в данном документе, текущий блок 820 может представлять собой блок предсказания и может представлять собой блок, кодированный на основе MCP. В случае если применяется IVMP, информация движения текущего блока 820 может извлекаться на основе информации движения соответствующего блока 840 в межвидовом опорном изображении 830. Соответствующий блок 840 может быть вызван на основе вектора диспаратности.
[132] Согласно настоящему изобретению, предусмотрен способ передачи служебных сигналов для эффективного выполнения внутреннего предсказания, извлечения за счет диспаратности и SDC для изображения с эффектом глубины.
[133] В общем, диапазон единицы PU предсказания, используемой для внутреннего предсказания, может определяться посредством кодера. Тем не менее, размер PU, которая фактически предсказана, может варьироваться в зависимости от размера единицы TU преобразования. Иными словами, информация блоков и режим предсказания передаются посредством единицы PU, но процесс внутреннего предсказания выполняется посредством единицы TU. Начиная с пиксела соседнего блока относительно текущего блока, который должен быть кодирован при внутреннем предсказании, предсказание выполняется согласно TU-размеру, помимо PU-размера. Иными словами, в ходе процесса внутреннего предсказания, внутреннее предсказание выполняется посредством использования восстановленных соседних выборок единичного TU-блока. Это служит для того, чтобы повышать эффективность сжатия и кодирования посредством использования восстановленных соседних пикселов. Соответственно, размер блока, в котором выполняется внутреннее предсказание, ограничен посредством TU-размера. Наоборот, поскольку преобразование и квантование не используются в SDC-способе, предсказание может выполняться относительно PU независимо от TU-размера. Тем не менее, в некоторых случаях, внутреннее предсказание для блока, большего представленного максимального TU-размера, может требоваться в кодере, и с этой целью, даже относительно блока, к которому применяется SDC-способ, оно может ограничиваться таким образом, что PU-предсказание выполняется согласно TU-размеру. Между тем, в случае DMM, предсказание не может выполняться посредством сегментации блока, даже если PU-размер превышает TU-размер вследствие характеристики режима. Соответственно, когда PU-размер превышает TU-размер, он должен ограничиваться таким образом, что DMM не применяется. Процесс предсказания для блока, большего TU-размера, заданного посредством кодера, может исключаться через такое ограничение.
[134] Между тем, как описано выше, вектор диспаратности требуется для выполнения IVMP для текущего блока текущего изображения (с эффектом глубины) зависимого вида. В отличие от случая, когда вектор диспаратности из соседних блоков (NBDV) или извлечение ориентированных на глубину векторов диспаратности (DoNBDV) используются для вида текстуры или изображения текстуры, диспаратность для вида глубины или изображения с эффектом глубины может быть вызвана из соседнего декодированного значения глубины или вызвана из предварительно определенного значения (глубины). Предварительно определенное значение (глубины) может быть средним значением диапазона значений глубины. Дополнительно, предварительно определенное значение может составлять "1<<(битовая глубина-1)". В данном документе, битовая глубина может представлять собой битовую глубину, заданную относительно выборки сигнала яркости.
[135] В IVMP, поскольку вектор движения может обеспечиваться из соответствующего блока опорного вида, опорный вид для обеспечения вектора движения должен рассматриваться при вызывании вектора диспаратности. В качестве одного примера, опорный вид не может фиксироваться как базовый вид, а задается как вид доступного опорного изображения в списке опорных изображений. Дополнительно, опорный вид для введения вектора диспаратности и опорный вид для обеспечения вектора движения могут задаваться идентичными друг другу.
[136] Например, вектор диспаратности может быть вызван, как показано в уравнении 2, приведенном ниже.
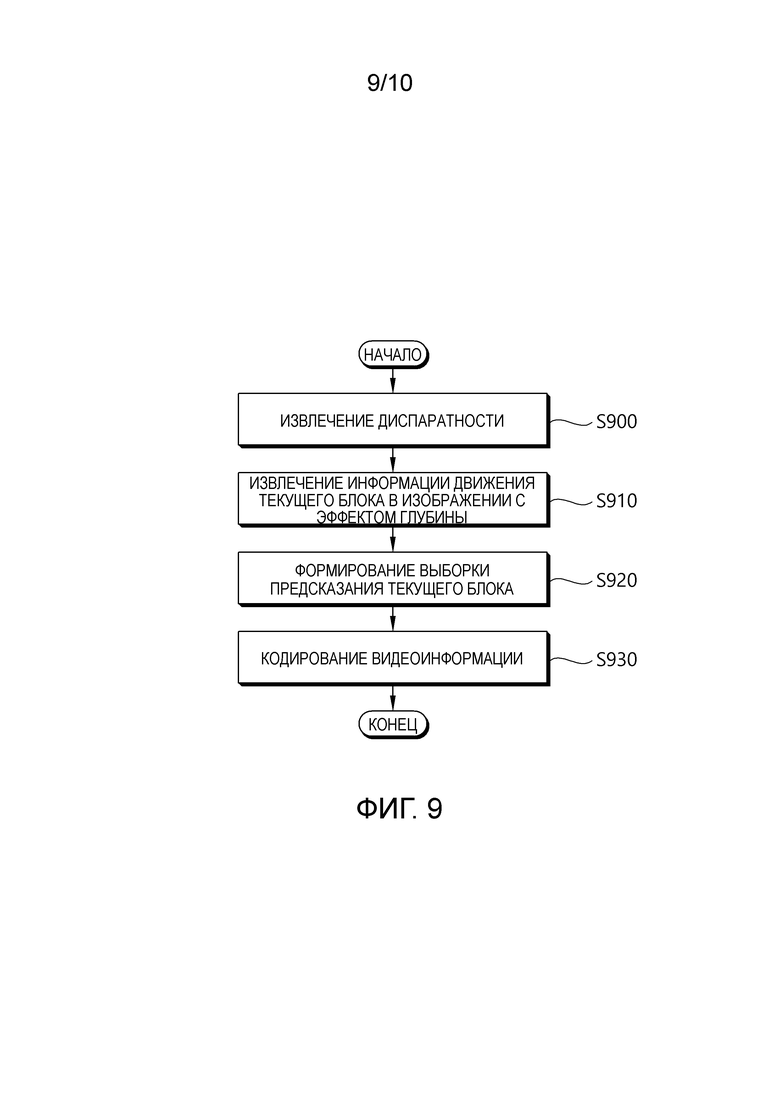
[137] уравнение 2
[138] DispVec[x][y]=(DepthToDisparityB[DefaultRefViewIdx][1<<(BitDepth-1)], 0)
[139] где DepthToDisparityB[j][d] представляет горизонтальный компонент вектора диспаратности между текущим видом и видом с ViewIdx, равным j, соответствующим значению d глубины в виде с ViewIdx, равным j. Иными словами, в данном документе, DefaultRefViewIdx представляет индекс опорного вида для введения вектора диспаратности. В этом случае, индекс в последовательности опорных видов (RefViewIdx) опорного вида для обеспечения вектора движения может быть идентичным DefaultRefViewIdx.
[140] Между тем, как описано выше, согласно SDC, значение индекса разности для текущего блока передается, и в этом случае, значение индекса разности может передаваться посредством двух этапов или немедленно передаваться в качестве разностного значения. В качестве одного примера, сначала может передаваться информация флага, указывающая то, существует или нет разностное значение индекса, и когда значение флага равно 1, может передаваться разностное значение индекса. В этом случае, разностное значение не может иметь 0. Соответственно, в этом случае, знак для разностного значения индекса может непрерывно передаваться. В качестве другого примера, разностное значение индекса может немедленно передаваться без информации флага, указывающей то, существует или нет разностное значение индекса. В этом случае, разностное значение индекса может иметь 0, и знак для разностного значения индекса может передаваться только тогда, когда разностное значение индекса не равно 0.
[141]
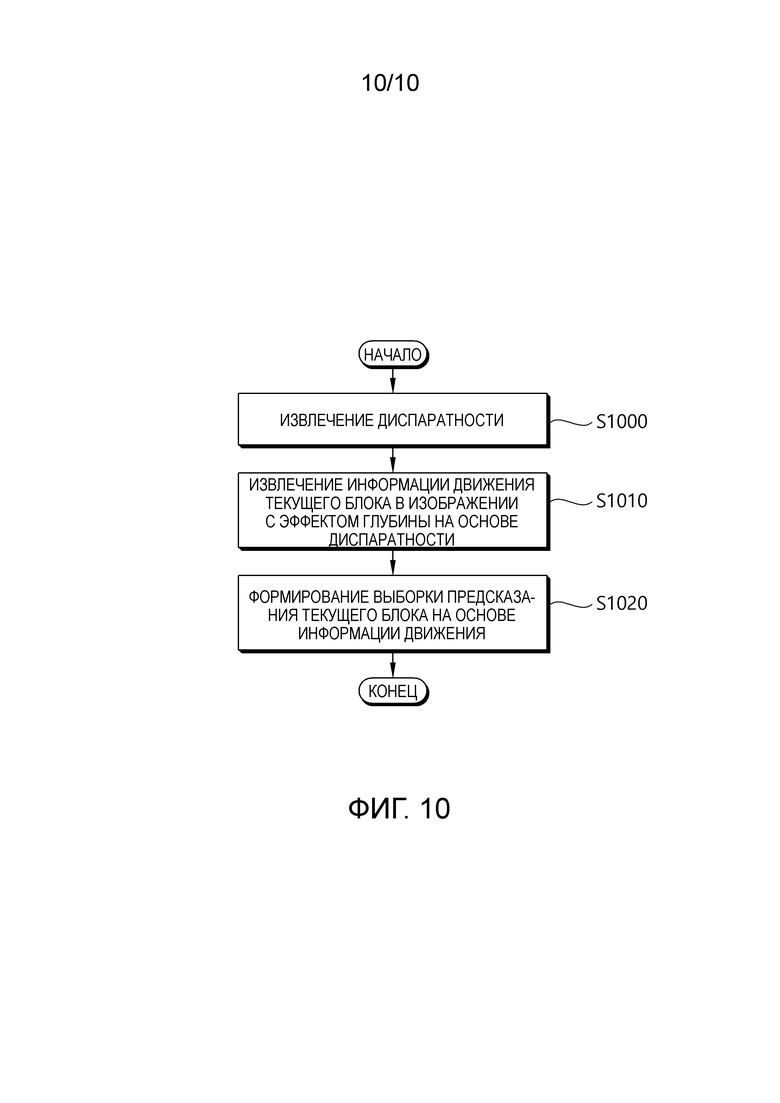
[142] Фиг. 9 является блок-схемой последовательности операций, схематично иллюстрирующей способ для кодирования трехмерного видео согласно варианту осуществления настоящего изобретения. Способ по фиг. 9 может осуществляться посредством устройства кодирования видео по фиг. 2.
[143] Ссылаясь на фиг. 9, устройство кодирования извлекает вектор диспаратности (S900). Вектор диспаратности может представлять собой вектор диспаратности для текущего блока текущего изображения вида глубины. Устройство кодирования может извлекать вектор диспаратности из соседнего декодированного значения глубины или извлекать вектор диспаратности из предварительно определенного значения, как описано выше. Предварительно определенное значение может быть средним значением диапазона значений глубины. Дополнительно, предварительно определенное значение может составлять "1<<(битовая глубина-1)". В данном документе, битовая глубина может представлять собой битовую глубину, заданную относительно выборки сигнала яркости.
[144] Устройство кодирования извлекает информацию движения для текущего блока (S910). Устройство кодирования может выполнять поиск в блоке, аналогичном текущему блоку, согласно процедуре оценки информации движения в предварительно определенной области опорного изображения, и извлекать информацию движения для текущего блока.
[145] Устройство кодирования создает выборку предсказания для текущего блока (S920). Устройство кодирования может восстанавливать текущее изображение на основе выборки предсказания и остаточной выборки (сигнала), и восстановленное изображение может использоваться в качестве опорного изображения для кодирования другого изображения.
[146] Устройство кодирования может кодировать видеоинформацию для декодирования видео (S930). Устройство кодирования может энтропийно кодировать видеоинформацию и выводить энтропийно кодированную видеоинформацию в качестве потока битов. Выходной поток битов может передаваться через сеть или сохраняться на носителе хранения данных. Видеоинформация может включать в себя информацию (например, информацию режима предсказания и остаточный сигнал) для восстановления текущего блока. Видеоинформация может включать в себя значения синтаксических элементов для восстановления текущего блока.
[147] Фиг. 10 является блок-схемой последовательности операций, схематично иллюстрирующей способ для декодирования трехмерного видео согласно варианту осуществления настоящего изобретения. Способ по фиг. 10 может осуществляться посредством устройства декодирования видео по фиг. 3.
[148] Ссылаясь на фиг. 10, устройство декодирования извлекает вектор диспаратности (S700). Устройство декодирования может энтропийно декодировать видеоинформацию, включенную в поток битов, и получать значение диспаратности для текущего блока текущего изображения в виде глубины на основе опорного вида и предварительно определенного значения.
[149] Устройство декодирования может извлекать вектор диспаратности из соседнего декодированного значения глубины или извлекать вектор диспаратности из предварительно определенного значения, как описано выше. Предварительно определенное значение может быть средним значением диапазона значений глубины. Дополнительно, предварительно определенное значение может составлять "1<<(битовая глубина-1)". В данном документе, битовая глубина может представлять собой битовую глубину, заданную относительно выборки сигнала яркости. Устройство декодирования может извлекать вектор диспаратности на основе уравнения 2, приведенного выше.
[150] Опорный вид может представлять собой вид опорного изображения в списке опорных изображений. В качестве одного примера, опорный вид может представлять собой вид первого опорного изображения в списке опорных изображений.
[151] Устройство декодирования извлекает информацию движения текущего блока на основе значения диспаратности (S1010). Устройство декодирования может активировать информацию движения текущего блока на основе IVMP-способа. В этом случае, информация движения текущего блока может извлекаться на основе информации движения соответствующего блока, извлекаемого в межвидовом опорном изображении посредством использования значения диспаратности. В данном документе, информация движения соответствующего блока может использоваться в качестве информации движения текущего блока. Информация движения включает в себя вектор движения. В данном документе, вид, который принадлежит межвидовому опорному изображению, может быть идентичным опорному виду.
[152] Устройство декодирования формирует выборку предсказания текущего блока на основе информации движения (S1020). Устройство декодирования может формировать выборку предсказания текущего блока на основе информации движения и опорного изображения в виде глубины (текущем виде). Иными словами, устройство декодирования может формировать выборку предсказания на основе блока, извлекаемого на основе информации движения для опорного изображения в виде глубины.
[153] Устройство декодирования может формировать остаточную выборку для текущего блока из принимаемого потока битов и восстанавливать текущее изображение посредством введения восстановительной выборки на основе сформированной выборки предсказания и остаточной выборки. Выборка может восстанавливаться посредством единицы блока или изображения.
[154] Хотя настоящее изобретение конкретно показано и описано со ссылкой на его примерные варианты осуществления, специалисты в данной области техники должны понимать, что различные изменения по форме и содержанию могут вноситься без отступления от сущности и объема изобретения, заданных посредством прилагаемой формулы изобретения. Примерные варианты осуществления должны рассматриваться только в описательном смысле, а не в целях ограничения, и не предназначены для того, чтобы ограничивать объемы настоящего изобретения. Следовательно, объем изобретения должен задаваться посредством прилагаемой формулы изобретения.
[155] Когда вышеописанные варианты осуществления реализуются в программном обеспечении в настоящем изобретении, вышеописанная схема может реализовываться с использованием модуля (процесса или функции), который выполняет вышеуказанную функцию. Модуль может сохраняться в запоминающем устройстве и выполняться посредством процессора. Запоминающее устройство может располагаться в процессоре внутренне или внешне и соединяться с процессором с использованием множества известных средств.
Группа изобретений относится к технологиям кодирования/декодирования изображения с эффектом глубины. Техническим результатом является повышение эффективности кодирования/декодирования трехмерного видео. Предложен способ декодирования трехмерного видео. Способ содержит этап, на котором принимают остаточную информацию текущего блока в изображении с эффектом глубины из потока битов. Далее, согласно способу, получают значение диспаратности текущего блока в изображении с эффектом глубины на основе опорного вида. А также извлекают информацию движения текущего блока в изображении с эффектом глубины на основе значения диспаратности и формируют выборку предсказания текущего блока на основе информации движения. 2 н. и 7 з.п. ф-лы, 10 ил.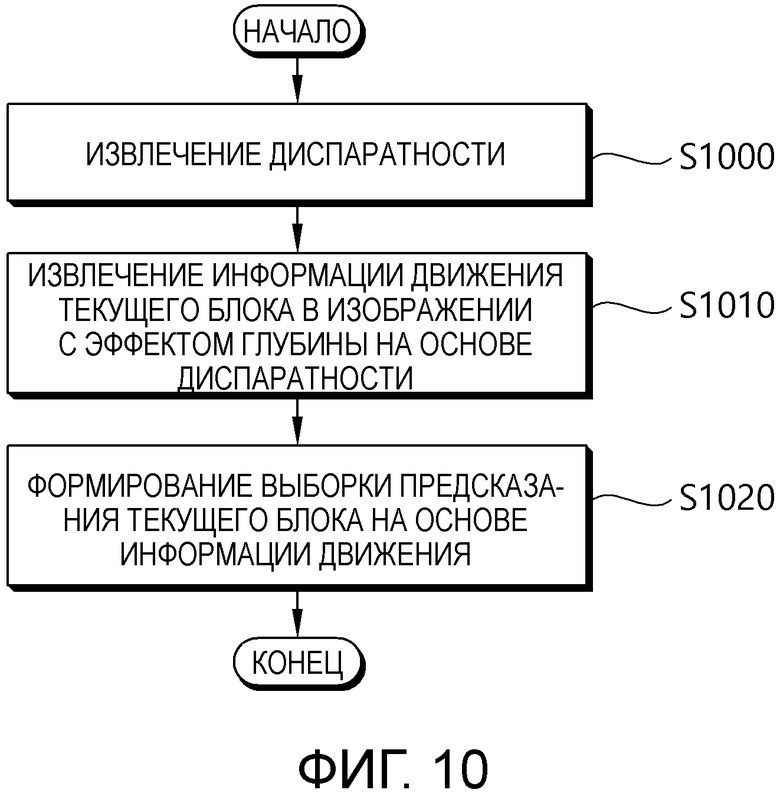
1. Способ декодирования трехмерного видео, при этом упомянутый способ содержит этапы, на которых:
принимают остаточную информацию текущего блока в изображении с эффектом глубины из потока битов;
получают значение диспаратности текущего блока в изображении с эффектом глубины на основе опорного вида;
извлекают информацию движения текущего блока в изображении с эффектом глубины на основе значения диспаратности;
формируют выборку предсказания текущего блока на основе информации движения;
формируют остаточную выборку текущего блока на основе остаточной информации;
восстанавливают текущее изображение посредством извлечения восстановительной выборки текущего блока на основе выборки предсказания и остаточной выборки,
при этом опорный вид представляет собой вид опорного изображения в списке опорных изображений.
2. Способ по п. 1, в котором опорный вид представляет собой вид первого опорного изображения в списке опорных изображений.
3. Способ по п. 1, в котором информация движения текущего блока извлекается на основе информации движения соответствующего блока, извлекаемого в межвидовом опорном изображении посредством использования значения диспаратности.
4. Способ по п. 3, в котором опорный вид является идентичным виду, которому принадлежит межвидовое опорное изображение.
5. Способ по п. 4, в котором выборка предсказания формируется на основе блока, извлекаемого на основе информации движения для опорного изображения в текущем виде.
6. Способ по п. 1, в котором значение диспаратности текущего блока в изображении с эффектом глубины получают дополнительно на основе предварительно определенного значения,
при этом предварительно определенное значение является средним значением диапазона значений глубины.
7. Способ по п. 1, в котором значение диспаратности текущего блока в изображении с эффектом глубины получают дополнительно на основе предварительно определенного значения,
при этом предварительно определенное значение составляет "1<<(битовая глубина-1)".
8. Способ по п. 7, в котором битовая глубина представляет собой битовую глубину, заданную для выборки сигнала яркости.
9. Устройство декодирования трехмерного видео, содержащее:
модуль энтропийного декодирования, выполненный с возможностью приема остаточной информации текущего блока в изображении с эффектом глубины из потока битов, получения значения диспаратности текущего блока в изображении с эффектом глубины на основе опорного вида; и
модуль предсказания, выполненный с возможностью извлечения информации движения текущего блока в изображении с эффектом глубины на основе значения диспаратности, формирования выборки предсказания текущего блока на основе информации движения, формирования остаточной выборки текущего блока на основе остаточной информации и восстановления текущего изображения посредством извлечения восстановительной выборки текущего блока на основе выборки предсказания и остаточной выборки, и
при этом опорный вид представляет собой вид опорного изображения в списке опорных изображений.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| УНИВЕРСАЛЬНЫЙ ФОРМАТ 3-D ИЗОБРАЖЕНИЯ | 2009 |
|
RU2519057C2 |

