Настоящее изобретение относится к рекомендательному модулю для рекомендации элементов контента пользователю, репозиторию контента, способу эксплуатации рекомендательного модуля для рекомендации элементов контента пользователю и к компьютерно-читаемому носителю информации.
Автоматические рекомендательные системы часто используются для помощи пользователям при выборе элементов, которые соответствуют их вкусу. Из большого набора элементов, из которых человек может выбрать, рекомендательная система делает выбор, который соответствует вкусу данного пользователя.
Прежде чем рекомендательная система сможет дать действительно персонализованные рекомендации, она сначала должна изучить вкус пользователя. Для этого, пользователь обычно должен присвоить рейтинг некоторому числу элементов, например, точно определить степень, в которой ему нравится или не нравится некоторое число элементов.
Рекомендательные системы могут быть грубо разделены на две категории, а именно, рекомендательные системы, основанные на контенте, и рекомендатели, основанные на совместной фильтрации. Для первого типа, элементы должны характеризоваться некоторым числом признаков. Например, кинофильм может характеризоваться названием, жанром, режиссером, списком актеров и т.д. История рейтинга пользователя (описание симпатий и антипатий некоторого числа элементов) может быть затем использована для оценки взаимосвязи между парами признак-значение и вероятностью, что пользователю понравится элемент с этими парами признак-значение. И наоборот, рекомендательная система, использующая совместную фильтрацию, использует рейтинги огромного сообщества пользователей, чтобы извлечь из этого сходство между пользователями (так как им нравятся/не нравятся одни и те же элементы) или сходство между элементами (так как они нравятся/не нравятся одним и тем же пользователям). Эта информация затем используется, чтобы либо рекомендовать элементы, которые схожи с элементами, которые пользователь точно определил как нравящиеся, либо рекомендовать элементы, которые нравятся пользователям, которые схожи с данным пользователем (и еще не просмотрены или куплены данным пользователем). Подходы совместной фильтрации не требуют определения характеристик элементов в том, что касается пар признак-значение.
За последние годы значительно увеличилась популярность служб социальных сетей, таких как Facebook и LinkedIn. Эти службы помогают пользователю легко обмениваться идеями, интересами и т.д. с друзьями, семьей и коллегами. Эти службы также предлагают пользователям возможность выражения их интересов, посредством выражения «симпатий» («лайков») к субъектам, таким как кинофильмы, музыка, знаменитости, организации, продукты и т.д. Каждый из этих субъектов точно определяется веб-страницей, которая дает дополнительные подробности о конкретном субъекте. Например, Facebook имеет обширную коллекцию этих субъектов, которые могут искать пользователи.
Предполагается, что пользователь хочет выразить его или ее интересы для данного субъекта. Если веб-страница уже существует для этого субъекта, то пользователь может просто нажать на соответствующую кнопку "нравится", и ссылка на эту веб-страницу будет добавлена в профиль пользователя. Если нет подходящей веб-страницы, которая выражает субъект, представляющий его или ее интерес, пользователь может создать такую веб-страницу посредством дополнительного добавления текстовой информации о субъекте. Для многих субъектов, эта информация извлекается из Wikipedia или других ресурсов, предоставляющих подробную высококачественную информацию.
Для обеих категорий рекомендательных систем, упомянутых выше, пользователь, который является новым для рекомендательной системы, сначала должен присвоить рейтинг некоторому числу элементов, прежде чем рекомендательная система сможет сгенерировать полезные персонализированные рекомендации. Это может помешать широкому распространению использования рекомендательной системы, так как пользователи могут не всегда желать первоначально вкладывать время и силы в "объяснение" системе своего вкуса. Все равно пользователи ожидают незамедлительных рекомендаций. Рекомендательная система будет иметь возможность изучить вкус пользователя со временем, но в этом случае рекомендации изначально не будут оптимально настроены для конкретного пользователя.
Одним путем для решения этой проблемы является позволить рекомендательной системе первоначально рекомендовать элементы, которые понравились многим пользователям. Однако, критически настроенный пользователь может не оценить эти рекомендации как очень значимые, и он или она может прекратить использование рекомендательной системы, пока не будет иметься возможность настройки своих рекомендаций.
Другой подход обнаружен в Chumki Basu ET AL: "Technical paper recommendation: A study in combining multiple information sources", журнал исследования искусственного интеллекта 1, 1 января 2001 (2001-01-01), стр.231-252. В этой статье для извлечения совпадений из множественных источников информации предлагается использование системы WHIRL.
Согласно первому аспекту настоящего изобретения, рекомендательный модуль для рекомендации элементов контента пользователю содержит:
- блок генерирования профиля, имеющий блок ввода предварительного профиля, который выполнен с возможностью приема из базы данных, которая является внешней для рекомендательного модуля, данных предварительного профиля, содержащих текстовые данные предварительного профиля, подходящие для идентификации субъектов, представляющих интерес для данного пользователя, и имеющий блок анализа предварительного профиля, который соединен с блоком ввода предварительного профиля и выполнен с возможностью извлечения из данных предварительного профиля идентификационных данных, идентифицирующих субъекты, представляющие интерес, и генерирования набора данных первоначального профиля пользователя для данного пользователя исходя из извлеченных идентификационных данных;
- блок генерирования запросов, который соединен с блоком генерирования профиля и выполнен с возможностью генерирования, с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя, по меньшей мере двух запросов, семантически отличающихся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента;
- блок извлечения контента, который соединен с блоком генерирования запросов и выполнен с возможностью выдачи сгенерированных запросов по меньшей мере одному репозиторию контента и который выполнен с возможностью приема из по меньшей мере одного репозитория контента, в ответ на запрос, ответных данных, относящихся к контенту, содержащих соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента; и
- блок перемежения, который соединен с блоком извлечения контента и который выполнен с возможностью генерирования из разных списков совпадения единого списка рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из данных списков совпадений.
Блок перемежения объединяет списки совпадений, возникающие в результате по меньшей мере двух явных запросов, которые семантически отличаются друг от друга. Другими словами, по меньшей мере перемежаются два списка совпадений, чтобы сгенерировать списки рекомендаций, в отличие от использования одиночного дизъюнктивного запроса. Явное создание многочисленных, семантически разных запросов, которые приводят к отличным спискам совпадений, создает возможность применения усовершенствованных алгоритмов перемежения в отношении отдельных списков, например, для достижения достаточной степени разнообразия в результирующих списках.
Рекомендательный модуль согласно первому аспекту данного изобретения основан на концепции обеспечения возможности генерирования рекомендаций элементов контента для нового пользователя посредством автоматического создания первоначального профиля пользователя на основании данных, относящихся к пользователю, называемых здесь данными предварительного профиля, которые приняты из внешней базы данных. Новый пользователь рекомендательного модуля может, например, предоставить доступ к данным под ее или его учетной записью в базе данных электронной социальной сети, примеры которых известны под товарными знаками Facebook или LinkedIn. Существуют многие другие такие электронные социальные сети.
Электронная социальная сеть содержит пользовательские данные, в отношении субъектов, таких как люди, артисты, группы людей, города, страны, клубы, политические партии, компании, идеи, теории, наука, всевозможные вещи, игры, произведения искусства, например, фрагменты музыки, кинофильмов, пьес, статей, книг, фотографий, распечаток, картин, стилей искусства, событий, активности, спорта и т.д. Термин "субъект" используется в настоящей заявке для ссылки на любой такой идентифицируемый интерес данного пользователя.
Соответственно, рекомендательный модуль по настоящему изобретению сильно ускоряет процесс изучения вкуса пользователя посредством обеспечения возможности рекомендаций на основании задокументированной активности пользователя в среде, внешней для рекомендательного модуля, такой как электронная социальная сеть. В то же время, данное изобретение распознает и преодолевает другую важную проблему раннего использования рекомендательного модуля пользователем, посредством перемежения рекомендаций из разных списков контента, называемых здесь списками совпадений, извлеченных рекомендательным модулем. Это перемежение повышает разнообразие рекомендаций, которое является важным требованием функциональности рекомендательного модуля, в частности для верхней области списка рекомендаций, как может быть измерено посредством общей частоты использования сгенерированных рекомендаций. Рекомендательному модулю по настоящему изобретению, таким образом, обеспечена возможность представления пользователю рекомендаций в едином списке, не только тех, что пользователю уже известны, но и разнообразного набора рекомендаций, за счет перемежения рекомендаций, возникающих в результате двух семантически разных запросов.
Таким образом, посредством объединения автоматической оценки импортированных данных предварительного профиля и перемежения рекомендаций из разных списков совпадения контента для данного пользователя, рекомендательный модуль по настоящему изобретению достигает тесного сцепления рекомендаций с действительными интересами и ожиданиями пользователя от рекомендательной системы прямо сначала, не требуя редакционного ввода или первоначального взаимодействия с пользователем касательно его или ее вкуса. Обе меры, таким образом, совместно ускоряют зависящий от конкретного пользователя процесс изучения рекомендательного модуля, сразу после первого взаимодействия с конкретным пользователем. Для заинтересованного пользователя, кому предоставлены рекомендации, близкие к ее или его интересам, сразу после начала взаимодействий, более часто и, таким образом, быстрее предоставляется информация, требуемая для корректирования набора данных первоначального профиля пользователя. Это, в свою очередь, повышает общее восприятие качества и адекватности рекомендаций и обеспечивает более высокое качество пользования продуктом для пользователя.
В нижеследующем будут описаны варианты осуществления рекомендательного модуля по первому аспекту данного изобретения. Дополнительные признаки разных вариантов осуществления могут быть объединены друг с другом для образования дополнительных вариантов осуществления, пока не будут явно исключены в настоящем описании.
Предпочтительно, рекомендательный модуль сортирует рекомендации согласно релевантности. Для этого, блок извлечения контента в одном варианте осуществления дополнительно выполнен с возможностью извлечения текстовых данных контента, связанных с соответствующими идентификаторами размещения контента, в ответ на запросы. Таким образом, текстовая связанность между данными предварительного профиля и текстовыми данными контента может быть использована, чтобы автоматически оценивать релевантность. Для этого, один вариант осуществления содержит блок присваивания рейтинга, который соединен с блоком извлечения контента и который выполнен с возможностью
- назначения идентификаторам размещения контента, которые были приняты в ответ на каждый из по меньшей мере двух запросов, показателей релевантности, основанных на критерии сходства, оценивающем текстовую связанность между текстовыми данными предварительного профиля и текстовыми данными контента,
- сортировки списков совпадений согласно релевантности, которая выражена показателями релевантности, и
- предоставления отсортированных списков совпадений блоку перемежения.
Таким образом блок присваивания рейтинга отличается от других подходов присваивания в том, что присваивание рейтинга основано не на профиле пользователя (как в предшествующем уровне техники), а на данных предварительного профиля, например, на основании данных, относящихся к пользователю, которые могут быть извлечены, например, из социальных сетей.
В другом варианте осуществления, блок генерирования профиля содержит классификационную базу данных, которая присваивает соответствующий класс субъектов, согласно по меньшей мере одному критерию классификации, соответствующему набору из по меньшей мере одного ключевого слова, которое должно быть включено в запрос
- при этом блок генерирования профиля выполнен с возможностью присваивания по меньшей мере одного класса извлеченным идентификационным данным, идентифицирующим соответствующий субъект, представляющий интерес, в соответствии с классификационной базой данных, и
- при этом блок генерирования запросов выполнен с возможностью генерирования запросов, с использованием соответствующих идентификационных данных и по меньшей мере одного из ключевых слов, присвоенных соответствующему классу идентификационных данных в соответствии с классификационной базой данных.
Преимущества этого варианта осуществления проиллюстрированы посредством следующего примера применения: знание того, что субъект, идентифицированный в данных предварительного профиля, является человеком, может повлечь за собой, при посредстве рекомендательного модуля настоящего варианта осуществления, запрос, в котором имя человека объединено с ключевым словом "интервью" или "биография". Выданные в репозиторий контента поставщика контента, такого как YouTube или Wikipedia, эти запросы могут повлечь за собой рекомендации видео, содержащего интервью с человеком, или веб-сайта, содержащего биографический материал о данном человеке.
В дополнительном варианте осуществления, блок анализа предварительного профиля дополнительно выполнен с возможностью классификации текстовых данных предварительного профиля по их языку и предоставления на свой выход по меньшей мере одного идентификатора языка, указывающего соответствующий язык, используемый в текстовых данных предварительного профиля. Классификационная база данных рекомендательного модуля согласно этому варианту осуществления содержит ключевые слова на разных языках. Блок генерирования запросов выполнен с возможностью генерирования запросов с использованием ключевых слов на языке, соответствующем идентификатору языка. Например, если субъект имеет отношение к французскому автору, то имя автора объединяется с "écrit par" вместо "written by" в запросе для поиска книг, которые он или она написала. В разновидности этого варианта осуществления, блок генерирования запросов дополнительно выполнен с возможностью генерирования запросов с использованием ключевых слов на заданном по умолчанию языке, если для соответствующего класса в классификационной базе данных не присутствуют ключевые слова на точно определенном другом языке.
Чтобы дополнительно улучшить разнообразие сгенерированного списка рекомендаций, блок генерирования запросов в одном варианте осуществления выполнен с возможностью включения в запросы извлеченных идентификационных данных по меньшей мере двух субъектов, представляющих интерес.
В другом варианте осуществления, блок генерирования профиля выполнен с возможностью детектирования в данных предварительного профиля ссылки ресурса на ресурс контента в сетевом месте в глобальной сети данных, осуществления доступа к ресурсу контента и добавления текстовых данных, доступных из ресурса контента, к текстовым данным предварительного профиля. Такие ссылки обычно ссылаются на субъекты, которые семантически относятся к исходному "понравившемуся" субъекту. Например, если исходным "понравившимся" субъектом является режиссер фильма, то ссылки обычно точно определяют названия фильмов, которые он или она срежиссировала. Для автора, могут точно определить названия книг, которые он или она написала. Ссылки могут также ссылаться на родственных артистов или тип направления искусства, с которым обычно связан "понравившийся" субъект. Следовательно, посредством генерирования конкретных запросов, которые объединяют эти части с возможно разными дополнительными направляющими ключевыми словами, такими как "written by", "influenced by" и т.д., и посредством выдачи этих запросов в конкретные репозитории контента, широкий диапазон возвращенных результатов получается с использованием различных потенциальных ссылок, которые могут быть обнаружены в текстовом описании.
В разновидности этого варианта осуществления, блок генерирования профиля либо в качестве альтернативы, либо дополнительно выполнен с возможностью сканирования данных предварительного профиля на предмет сегментов, выделенных посредством типов тегов разметки, отличных от типов тегов разметки, идентифицирующих ссылку, как, например, внешний вид, соответствующий выделению жирным и т.д., и включения таких сегментов в запросы, как описано ранее.
Для того, чтобы дополнительно усовершенствовать генерирование рекомендаций, блок генерирования профиля по одному варианту осуществления рекомендательного модуля выполнен с возможностью извлечения из данных предварительного профиля разных поднаборов текстовых данных предварительного профиля, которые отличаются друг от друга своей датой генерирования, которая назначена внешней базой данных, и извлечения из поднаборов соответствующих дат генерирования поднаборов. Это обеспечивает возможность фильтрации поднаборов, согласно их дате генерирования. Блок присваивания рейтинга по этому варианту осуществления, в свою очередь, предпочтительно выполнен с возможностью применения взвешивания к показателю релевантности, причем взвешивание увеличивает показатель релевантности тем больше, чем более поздней является дата генерирования соответствующего одного из наборов, относящихся к данному размещению контента, принадлежащему данному субъекту, представляющему интерес.
В дополнительном варианте осуществления, блок анализа предварительного профиля выполнен с возможностью детектирования из текстовых данных предварительного профиля присутствия ключевых слов, указывающих, что данному пользователю или некоторому другому субъекту (обычно человеку), связанному с данным пользователем согласно внешней базе данных, нравится субъект/элемент, и назначения указателя "нравится" этому соответствующему субъекту/элементу в наборе данных первоначального профиля пользователя. Блок присваивания рейтинга по этому варианту осуществления предпочтительно выполнен с возможностью применения взвешивания к показателю релевантности, причем взвешивание увеличивает показатель релевантности, если данный субъект/элемент, представляющий интерес, имеет связанный указатель "нравится".
В дополнительном варианте осуществления рекомендательного модуля, блок присваивания рейтинга выполнен с возможностью оценивания значения текстовой связанности между текстовыми данными предварительного профиля и текстовыми данными контента. Предпочтительно, текстовая связанность оценивается с использованием вычисления веса «частота термина - на - обратную частоту документа, в дальнейшем в этом документе вес tf-idf. Реализация этого варианта осуществления может основывать оценку на наборе слов, содержащихся в текстовых данных предварительного профиля и в текстовых данных контента. Например, слова, превышающие предварительно заданный вес tf-idf, могут быть идентифицированы и сравнены для текстовых данных предварительного профиля с одной стороны и в текстовых данных контента с другой стороны. Дополнительно или в качестве альтернативы, математически предварительно заданный критерий сходства весов td-idf для слов, встречающихся в обоих типах текстовых данных, может быть использован для оценки текстовой связанности.
Дополнительный или альтернативный подход к взвешиванию релевантности совпадений реализован в варианте осуществления, в котором блок присваивания рейтинга выполнен с возможностью взвешивания показателей релевантности на основе критерия сходства, оценивающего текстовую связанность между текстовыми данными контента разных элементов контента, найденными в запросах. В этом варианте осуществления, взвешивание уменьшает показатель релевантности, если элемент контента, который должен быть оценен на предмет релевантности, имеет текстовую связанность с элементом контента, оцененным непосредственно перед ним, причем текстовая связанность превышает предварительно определенное значение. Этот вариант осуществления дополнительно повышает разнообразие сгенерированного списка рекомендаций при том, что результаты запросов, имеющие высокое взаимное сходство согласно их текстовой связанности, оцениваются как релевантные не в равной степени, таким образом автоматически делая избранным только один из взаимно сходных результатов запросов для единого списка рекомендаций, который должен быть сгенерирован.
В дополнительном варианте осуществления, рекомендательный модуль дополнительно содержит блок аутентификации, который выполнен с возможностью приема через интерфейс пользовательского ввода аутентификационных данных пользователя, подходящих для осуществления доступа к внешней базе данных. Блок генерирования профиля выполнен с возможностью осуществления доступа к внешней базе данных для извлечения данных предварительного профиля.
Для того, чтобы продолжить адаптацию профиля пользователя, другой вариант осуществления рекомендательного модуля дополнительно содержит блок обслуживания профиля в дополнение к блоку генерирования профиля. Блок обслуживания профиля выполнен с возможностью извлечения дополнительных идентификационных данных для дополнительного субъекта из извлеченных текстовых данных контента. Блок обслуживания профиля предпочтительно дополнительно выполнен с возможностью добавления извлеченных дополнительных идентификационных данных к набору данных профиля пользователя после детектирования значения текстовой связанности между текстовыми данными предварительного профиля и текстовыми данными контента, которое превышает предварительно определенное пороговое значение. Профиль пользователя в этом варианте осуществления таким образом дополнительно адаптирован посредством дополнительного обслуживания первоначально сгенерированного профиля пользователя.
Второй аспект настоящего изобретения образован репозиторием контента, содержащим
- базу данных контента, содержащую элементы контента в виде файлов данных, хранящихся в размещениях контента;
- рекомендательный модуль согласно первому аспекту настоящего изобретения или согласно одному из вариантов его осуществления, раскрытых в настоящем описании, включая формулу изобретения.
В репозитории контента согласно второму аспекту второго изобретения, блок извлечения контента из состава рекомендательного модуля выполнен с возможностью выдачи сгенерированных запросов базе данных контента. Это делается не для того, чтобы принципиально исключить выдачу сгенерированных запросов другим, внешним базам данных контента, не содержащимся в репозитории контента настоящего аспекта данного изобретения. Однако, в варианте осуществления, выдача запросов фактически ограничена самой базой данных контента репозитория контента.
Варианты осуществления репозитория контента содержат по меньшей мере один из вариантов осуществления рекомендательного модуля согласно первому аспекту данного изобретения. Преимущества репозитория контента по второму аспекту данного изобретения и вариантов его осуществления таким образом соответствуют преимуществам, описанным выше в соответствующем контексте первого аспекта данного изобретения, и не будут повторяться в настоящем контексте.
Согласно третьему аспекту данного изобретения, способ функционирования рекомендательного модуля для рекомендации элементов контента пользователю содержит этапы, на которых
- принимают из базы данных, которая является внешней для рекомендательного модуля, данные предварительного профиля, содержащие текстовые данные предварительного профиля, подходящие для идентификации субъектов, представляющих интерес для конкретного пользователя;
- извлекают из данных предварительного профиля идентификационные данные, идентифицирующие субъекты, представляющие интерес;
- генерируют набор данных первоначального профиля пользователя для этого конкретного пользователя исходя из извлеченных идентификационных данных;
- генерируют, с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя, по меньшей мере два запроса, семантически отличающиеся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента;
- выдают сгенерированные запросы в этот по меньшей мере один репозиторий контента;
- принимают из данного по меньшей мере одного репозитория контента, в ответ на запрос, ответные данные, относящиеся к контенту, содержащие соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента;
- генерируют из разных извлеченных списков совпадения единый список рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из данных списков совпадений.
Способ согласно третьему аспекту непосредственно соответствует функциональности рекомендательного модуля по первому аспекту данного изобретения. Вследствие этого, для описания его преимуществ и вариантов осуществления, делается ссылка на описание рекомендательного модуля по первому аспекту данного изобретения и его различные варианты осуществления в настоящем описании и пунктах формулы изобретения.
Четвертый аспект настоящего изобретения образован компьютерно-читаемым носителем информации, хранящим исполняемый компьютером код, причем компьютерный код реализует способ для управления функционированием рекомендательного модуля для рекомендации элементов контента пользователю, согласно третьему аспекту данного изобретения или одному из его вариантов осуществления.
Предпочтительные варианты осуществления данного изобретения также заданы в зависимых пунктах формулы изобретения. Вышеупомянутые и другие аспекты данного изобретения будут очевидны и разъяснены со ссылкой на варианты осуществления, описанные в дальнейшем. На нижеследующих чертежах:
фиг.1 показывает блок-схему рекомендательного модуля и репозитория контента согласно одному варианту осуществления;
фиг.2 показывает схему последовательности операций способа эксплуатации рекомендательного модуля согласно дополнительному варианту осуществления.
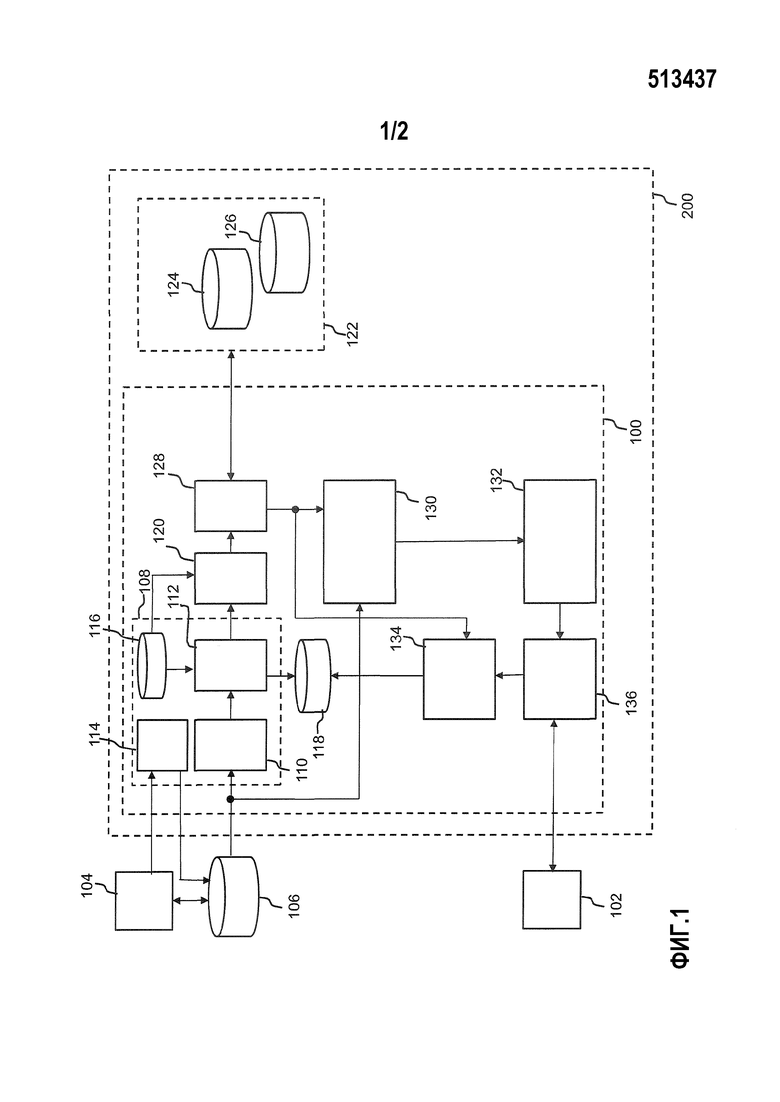
Фиг.1 показывает блок-схему рекомендательного модуля согласно одному варианту осуществления. Фиг.1 будет также использована дополнительно ниже, чтобы разъяснить вариант осуществления репозитория контента.
Рекомендательный модуль 100 по фиг.1 в основном служит для рекомендации элементов контента пользователю. Пользователь эксплуатирует устройство 102 отображения контента. Рекомендательный модуль 100 настоящего варианта осуществления эксплуатируется как устройство, которое физически отделено от устройства 102 отображения. Другими словами, в настоящем варианте осуществления устройство отображения является внешним для рекомендательного модуля 100. В другом полезном варианте осуществления, рекомендательный модуль интегрирован с устройством 102 отображения контента. В любом из этих вариантов осуществления, рекомендательный модуль 100 и устройство 102 отображения контента коммуникативно соединены друг с другом.
Коммуникационное соединение может также быть создано между рекомендательным модулем 100 и устройством 104 пользовательского терминала, который обычно является некоторой формой компьютера, таким как настольный компьютер, мобильный компьютер подобный ноутбуку, или интеллектуальный телефон. Устройство 104 терминала и устройство 102 отображения контента во многих случаях применения интегрированы в единое устройство. Однако, по соображениям ясности по отношению к функциональности при их взаимодействии с рекомендательным модулем 100, фиг.1 показывает их как отдельные блоки, также для указания, что они могут фактически быть реализованы на физически отдельных устройствах.
Устройство 104 терминала выполнено с возможностью обмена информацией с базой данных 106 электронной социальной сети. Как хорошо известно, пользователь может использовать устройство 104 терминала для ввода и таким образом осуществлять передачу в социальную сеть, то есть в целях настоящего описания: в базу данных 106, его персональную информацию, комментарии, избранные элементы ("симпатии"), ссылки на веб-сайты и т.д., и приема аналогичного ввода от других пользователей (его "друзей") социальной сети.
Устройство 104 терминала может также быть использовано для взаимодействия с рекомендательным модулем 100, как будет описано дополнительно ниже.
Рекомендательный модуль 100 содержит блок 108 генерирования профиля. Блок 108 генерирования профиля разделен на блок 110 ввода предварительного профиля, который коммуникационно соединяется с базой данных 106 или (не показано на фиг.1) устройством 104 терминала, или с обоими. Блок ввода предварительного профиля выполнен с возможностью приема данных предварительного профиля, содержащих текстовые данные предварительного профиля, подходящие для идентификации субъектов, представляющих интерес для данного пользователя. Например, данные предварительного профиля могут содержать персональную страницу "симпатий", т.е. код, обычно на языке разметки наподобие html или xml, который точно определяет субъекты, представляющие интерес для пользователя, посредством публикаций, комментариев, других типов текста или текстовых фрагментов, ссылок для отображения с использованием программного обеспечения веб-браузера, и который обслуживается пользователем посредством его вводов в базу данных 106 также с использованием интерфейса веб-браузера, представляемого пользователю поставщиком социальной сети.
Блок 108 генерирования профиля дополнительно содержит блок 112 анализа предварительного профиля, который соединен с блоком 110 ввода предварительного профиля и выполнен с возможностью извлечения из данных предварительного профиля идентификационных данных, идентифицирующих субъекты, представляющие интерес, и генерирования набора данных первоначального профиля пользователя для данного пользователя исходя из идентификационных данных. Например, веб-страница, которая точно определяет субъект, который "понравился" данному пользователю, обычно содержит некоторое число признаков, которые присутствуют почти всегда, такие как категория, изображение субъекта и число пользователей, которым "понравился" субъект. Текст, который точно определяет категорию, обычно является произвольным текстом, т.е. он может быть любым текстовым фрагментом, но могут быть распознаны наиболее встречающиеся категории, такие как, например, "музыкант/группа" или "публичная фигура". В дополнение, извлекаются части страницы "симпатий", которые содержат большие фракции текста. Они обычно обозначены как "описание", "о" и т.д. Эти текстовые фрагменты сканируются на предмет конкретных тегов разметки, указывающих ссылки, выделенные, жирные и т.д. части. Эти части обычно ссылаются на субъекты, которые семантически относятся к исходному "понравившемуся" субъекту. Например, если исходным "понравившимся" субъектом является режиссер фильма, то эти части могут точно определить названия фильмов, которые он или она срежиссировала. Для автора, могут точно определить названия книг, которые он или она написала. Но эти конкретные части могут также ссылаться на родственных артистов или тип направления искусства, с которым обычно связан "понравившийся" субъект. Дополнительно, многие социальные среды, такие как Facebook, YouTube и Twitter, обеспечивают пользователям возможность "публикации" комментариев и информации в социальных средах, также относящихся к элементам, для оповещения друзей об их активности или интересах. Информация, содержащаяся в публикации или комментарии, и "симпатия" (необязательно принадлежащая пользователю, публикующему комментарий, но скорее другу), с которой связаны эти публикации и комментарии, могут также быть использованы как данные предварительного профиля блоком анализа предварительного профиля в процессе генерирования набора данных первоначального профиля пользователя, который должен быть использован для генерирования первых рекомендаций для пользователя.
Чтобы идентифицировать, должен ли комментарий друга в отношении "понравившегося" субъекта быть интерпретирован как положительный или отрицательный, чувство относительно комментария может быть проанализировано в варианте настоящего варианта осуществления, например, посредством блока 112 анализа предварительного профиля, ищущего наличие слов, которые обычно связаны с положительным чувством, и слова, которые обычно связаны с отрицательным чувством.
Опцией для получения данных предварительного профиля является оборудовать рекомендательный модуль блоком аутентификации, который выполнен с возможностью приема через интерфейс пользовательского ввода аутентификационных данных пользователя, подходящих для осуществления доступа к базе данных 106. Таким образом, пользователь раскрывает свою информацию аутентификации пользователя, требуемую для осуществления доступа к базе данных 106, рекомендательному модулю 100 рекомендаций через блок 114 аутентификации. В этом случае, блок 108 генерирования профиля выполнен с возможностью осуществления доступа к внешней базе данных 106 для извлечения данных предварительного профиля, с использованием аутентификационных данных пользователя.
Однако, обеспечение блока 112 аутентификации является необязательным признаком рекомендательного модуля 100. Данные предварительного профиля могут быть предоставлены самим пользователем посредством его или ее устройства 104 терминала. Например, пользователь может сначала скачать копию персональных данных из соответствующей социальной сети и затем предоставить копию в качестве данных предварительного профиля рекомендательному модулю посредством блока 110 ввода предварительного профиля.
Блок 112 анализа профиля блока 108 генерирования профиля рекомендательного модуля 100 дополнительно выполнен с возможностью присвоения по меньшей мере одного класса извлеченным идентификационным данным, идентифицирующим соответствующий субъект, представляющий интерес, в соответствии с классификационной базой данных 116. Классы субъектов могут, например, различать субъекты посредством назначения атрибута, такого как человек, артист, группы людей, город, страна, организация, клуб, политическая партия, компания, идея, теория, наука, вещь (любого вида), игра, произведение искусства, например, фрагмент музыки, кинофильма, пьесы, статьи, книги, фотографии, распечатки, картины, стиля искусства, события, активности, спорта и т.д. Классификационная база данных 116 дополнительно присваивает соответствующий класс субъектов соответствующему набору из по меньшей мере одного ключевого слова, который должен быть включен в запрос.
Классификационная база данных 116 предпочтительно содержит ключевые слова на разных языках. Это обеспечивает возможность снабжения пользователя рекомендациями на его предпочтительном языке, выбранном из числа доступных языков, как будет разъяснено дополнительно ниже. На стороне блока генерирования профиля этот признак поддерживается блоком 112 анализа предварительного профиля, являющегося дополнительно выполненным с возможностью классификации текстовых данных предварительного профиля по их языку и предоставления на свой выход по меньшей мере одного идентификатора языка, указывающего соответствующий язык, используемый в текстовых данных предварительного профиля. Набор данных первоначального профиля пользователя, сгенерированный блоком генерирования профиля, хранится в базе данных 118 профилей пользователей.
Рекомендательный модуль 100 дополнительно содержит блок 120 генерирования запросов. Блок 120 генерирования запросов соединен с блоком 108 генерирования профиля и выполнен с возможностью генерирования, с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя, по меньшей мере двух запросов, семантически отличающихся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента. Два разных репозитория контента, представленные на фиг.1 под ссылочными надписями 124 и 126, и сведены для простоты графического представления под ссылочной надписью 122. В целях описания настоящего варианта осуществления, предполагается, что к репозиториям контента можно осуществить доступ посредством рекомендательного модуля через публичную сеть связи, такую как Интернет. Примерами таких репозиториев контента являются, например, источники контента со свободным доступом, такие как YouTube или Wikipedia, но также могут быть источники контента с ограниченным доступом, такие как базы данных коммерческих кинофильмов.
Посредством генерирования конкретных запросов, которые объединяют части, идентифицированные как субъекты, представляющие интерес, посредством блока 108 генерирования профиля с разными дополнительными направляющими ключевыми словами, такими как "written by" "influenced by" и т.д., и посредством их выдачи конкретным репозиториям 122 контента, широкий диапазон возвращенных результатов получается с использованием различных потенциальных ключей, которые были обнаружены в текстовом описании блоком анализа предварительного профиля. В дополнение, так как язык(и) используемый в текстовых описаниях идентифицирован, как упоминалось ранее, это предпочтительно используется для генерирования запросов с использованием того же языка ключевых слов, как и язык, используемый в тех частях, идентифицирующих субъект, представляющий интерес. Например, если субъект имеет отношение к французскому автору и соответствующей странице "симпатий", то имеет смысл объединить имя автора с "écrit par" вместо "written by", чтобы попытаться найти книги, которые он или она написала. Блок 120 генерирования запросов для этого выполнен с возможностью генерирования запросов с использованием ключевых слов на языке, соответствующем идентификатору языка, или, если ключевые слова на этом языке не присутствуют в классификационной базе данных для соответствующего класса, на заданном по умолчанию языке.
Блок 128 извлечения контента, который соединен с блоком 120 генерирования запросов, выполнен с возможностью выдачи сгенерированных запросов по меньшей мере одному репозиторию 128 контента и приема из по меньшей мере одного репозитория 128 контента, в ответ на запросы, ответные данные, относящиеся к контенту, содержащие соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента.
Следует отметить, что экстенсивность описания "понравившегося" субъекта, которое извлечено блоком 108 генерирования профиля из текстовых данных предварительного профиля, будет влиять на разнообразие выдаваемых запросов и возвращаемых результатов. Например, предполагается, что пользователь Facebook точно определил, что ему или ей "нравится" композитор Моцарт. Страница Facebook в отношении Моцарта содержит многочисленные ссылки, например, на такие города как "Зальцбург" и "Вена", но также на "Реквием" и "Констанцу". Разнообразие этих терминов, которые могут быть объединены в запросы с "Моцартом", дает очень разнообразные результаты. В частности, в этом случае, запросы, содержащие ключевые слова "Вена" и "Зальцбург", могут возвратить результаты, которые не имеют ничего общего с Моцартом. Вследствие этого, дополнительный этап является предпочтительным для отфильтрования нерелевантных результатов, которые не должны быть рекомендованы. Соответственно, рекомендательный модуль настоящего варианта осуществления содержит блок 130 присваивания рейтинга, который соединен с блоком извлечения контента и который выполнен с возможностью назначения идентификаторам размещения контента, которые были приняты в ответ на каждый из по меньшей мере двух запросов, показателей релевантности, основанных на критерии сходства, оценивающем текстовую связанность между текстовыми данными предварительного профиля и текстовыми данными контента, чтобы сортировать списки совпадений согласно релевантности, которая выражена показателями релевантности, и чтобы предоставить на свой выход отсортированные списки совпадений.
На основании результатов, найденных в многочисленных запросах, возможно к разным репозиториям контента, рекомендательный модуль эксплуатирует блок 130 присваивания рейтинга. Цель присваивания рейтинга состоит в том, чтобы верхняя часть конечного списка рекомендаций давала набор релевантных результатов. Релевантность результата создается посредством определения текстовой связанности результата с исходным "понравившимся" субъектом. Есть некоторое число подходов, известных в данной области техники, для идентификации текстовой связанности. Подход, известный как tf-idf, который был уже упомянут ранее в настоящем описании, часто используется на практике. Также принято использовать модель векторного пространства, в которой каждый текст (или документ) представлен многомерным вектором, где каждая размерность соответствует слову, которое встречается в тексте. Запись такого слова-вектора вычисляется посредством умножения относительной частоты термина (tf), т.е. числа раз, которое данное слово встречается в тексте, поделенного на общее число слов в тексте, на обратную частоту документа (idf), которая выражает то, как часто слово встречается в документе из данной совокупности документов. Следует отметить, что совокупность является ориентированной на конкретный язык. Как описано ранее, язык текста, из которого генерируются запросы, идентифицируется и может быть использован для выбора правильной совокупности для вычисления обратной частоты документа. Таким образом, как текст исходного "понравившегося" субъекта, так и текст, который соответствует данному результату, могут быть представлены как векторы в пространстве высокой размерности, и косинус между этими векторами может быть использован в качестве меры их текстовой связанности.
Для реализации присваивания рейтинга можно сделать следующее. Пусть q1, …, qn будет списком запросов, которые были отправлены репозиториям контента, и для каждого qi пусть R(qi) обозначает список результатов, возвращенных в отношении выдачи qi. Теперь, для каждого qi, можно расположить результаты R(qi) в порядке уменьшения текстовой связанности с исходным "понравившимся" субъектом.
Присваивание рейтинга в некоторых вариантах также предусматривает применение веса к оцениваемому показателю релевантности. На основании извлеченных дат генерирования разных записей, сделанных пользователем в базе данных 106, блок 130 присваивания рейтинга может применить взвешивание к показателю релевантности, согласно возраста соответствующей записи пользователя. Другими словами, взвешивание увеличивает показатель релевантности тем больше, чем более поздней является дата генерирования соответствующего одного из наборов, относящихся к данному размещению контента, принадлежащему данному субъекту, представляющему интерес. Например, "понравившиеся" субъекты могут содержать ленты новостей, сообщающие о последних новостях соответствующего субъекта. Также, предпочтения могут быть даны посредством соответствующего взвешивания наиболее поздних добавлений к "понравившемуся" субъекту, для результатов повторного присваивания рейтинга, или даже для предварительного выбора более поздних текстовых фрагментов для генерирования запросов. В другом варианте, блок анализа предварительного профиля выполнен с возможностью детектирования в данных предварительного профиля присутствия ключевых слов, указывающих, что данному пользователю или кому-то, относящемуся к данному пользователю, нравится субъект. Указатель "нравится" может таким образом быть назначен соответствующему субъекту в наборе данных первоначального профиля пользователя, и блок присваивания рейтинга может применить взвешивание к показателю релевантности, причем взвешивание увеличивает показатель релевантности, если данный субъект, представляющих интерес, имеет связанный указатель "нравится".
Обеспечение блока присваивания рейтинга не является обязательным для рекомендательного модуля. Присваивание рейтинга рекомендательным модулем рекомендаций может, например, быть пропущено в процессе генерирования единого списка рекомендаций, если репозитории контента уже применили присваивание рейтинга к их спискам совпадений на основании терминов, используемых для запроса. Также, присваивание рейтинга может быть реализовано как опция, которая может быть включена или выключена пользователем.
Для того, чтобы получить единый список рекомендаций, который обеспечивает разнообразие в своих записях, рекомендательный модуль 100 содержит блок 132 перемежения. Блок 132 перемежения соединен с блоком 128 извлечения контента (в настоящем варианте осуществления посредством блока 130 присваивания рейтинга) и выполнен с возможностью генерирования из разных списков совпадения единого списка рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из данных списков совпадений. Перемежение упорядоченных списков результатов разных запросов может, например, быть выполнено посредством использования подхода циклического обслуживания (round-robin) или посредством использования более усовершенствованного подхода планирования на основе кредита.
Перемежение является одним вариантом осуществления, основанным на оценке текстовой связанности результатов, полученных из разных запросов. Блок перемежения выполнен с возможностью взвешивания показателей релевантности, основанных на критерии сходства, оценивающем текстовую связанность между текстовыми данными контента разных элементов контента, найденных в запросах, при этом взвешивание уменьшает показатель релевантности, если элемент контента, который должен быть оценен на предмет релевантности, имеет текстовую связанность с элементом контента, оцененным непосредственно перед ним, чья текстовая связанность превышает предварительно определенное значение. Также посредством этой реализации гарантируется, что по меньшей мере верхняя часть конечного списка рекомендаций содержит достаточное разнообразие.
В дополнение, чтобы помочь перекрыть первоначальный период, где рекомендательный модуль 100 все еще должен изучать вкус пользователя, ускорение процесса изучения рекомендательной системы может быть достигнуто, как следует ниже. Результаты, которые идентифицированы как достаточно релевантные, например, так как косинусное сходство их описания с описанием "понравившегося" субъекта является достаточно высоким, могут быть интерпретированы рекомендателем как симпатии. Это может напрямую повлечь за собой относительно большой набор симпатий. Для рекомендательного модуля, который использует подход совместной фильтрации, они могли бы быть напрямую добавлены как симпатии в таблицу элементов пользователя. Для рекомендательной системы на основе контента, эти "симпатии" могут быть преобразованы в изменения степени симпатии для пар признак-значение, предоставленных, чтобы эти признаки могли быть идентифицированы из результатов. Это может быть реализовано, если результат распознан как запись в базе данных, которая хранит информацию пары признак-значение об элементах контента. Для обеспечения возможности такого улучшенного процесса, рекомендательный модуль 100 настоящего варианта осуществления также содержит блок 134 обслуживания профиля. Блок обслуживания профиля выполнен с возможностью адаптирования набора данных первоначального профиля пользователя, хранящегося в базе данных 118 профиля пользователя, в дальнейшем процессе использования. Для этого, блок обслуживания профиля выполнен с возможностью извлечения дополнительных идентификационных данных для дополнительного субъекта из извлеченных текстовых данных контента и добавления извлеченных дополнительных идентификационных данных к набору данных профиля пользователя после детектирования значения текстовой связанности между текстовыми данными предварительного профиля и текстовыми данными контента, которое превышает предварительно определенное пороговое значение.
Дальнейшее обслуживание может быть основано на известных алгоритмах, использующих детектированные взаимодействия пользователя. Для обеспечения возможности такого взаимодействия пользователя, предоставлен интерфейс 136 для доставки на устройство 102 отображения сгенерированного единого списка рекомендаций, предоставленного блоком 132 перемежения, обычно в виде данных, обеспечивающих возможность графического представления списка рекомендаций, чтобы обеспечить возможность интуитивного взаимодействия пользователя для осуществления выбора, отмены выбора или другого типа оценки рекомендованных элементов пользователем. Такой пользовательский ввод оценивается блоком 134 обслуживания профиля.
Рекомендательный модуль может быть реализован в аппаратных средствах, с использованием выделенных схем для разных функциональных блоков рекомендательного модуля. В другом варианте осуществления, рекомендательный модуль реализован в компьютерных аппаратных средствах, с использованием одного или более процессоров, управляемых программой, для реализации разных функциональных блоков модуля.
Фиг.1 также подходит для иллюстрации варианта осуществления репозитория 200 контента согласно настоящему изобретению. В репозитории контента, рекомендательный модуль и по меньшей мере одна база данных 122 контента эксплуатируются одним поставщиком. Доступ к базам данных контента за пределами внутренней базы данных 122 контента репозитория 200 контента в соответствии с предыдущим описанием может или не может быть реализован, согласно бизнес-модели поставщика. Таким образом, репозиторий 200 контента может ограничивать рекомендации для элементов контента, содержащихся в базе данных контента поставщика. Посредством использования рекомендательного модуля вместе с базой данных создается привлекательный способ рекламы элементов контента для пользователей репозитория контента.
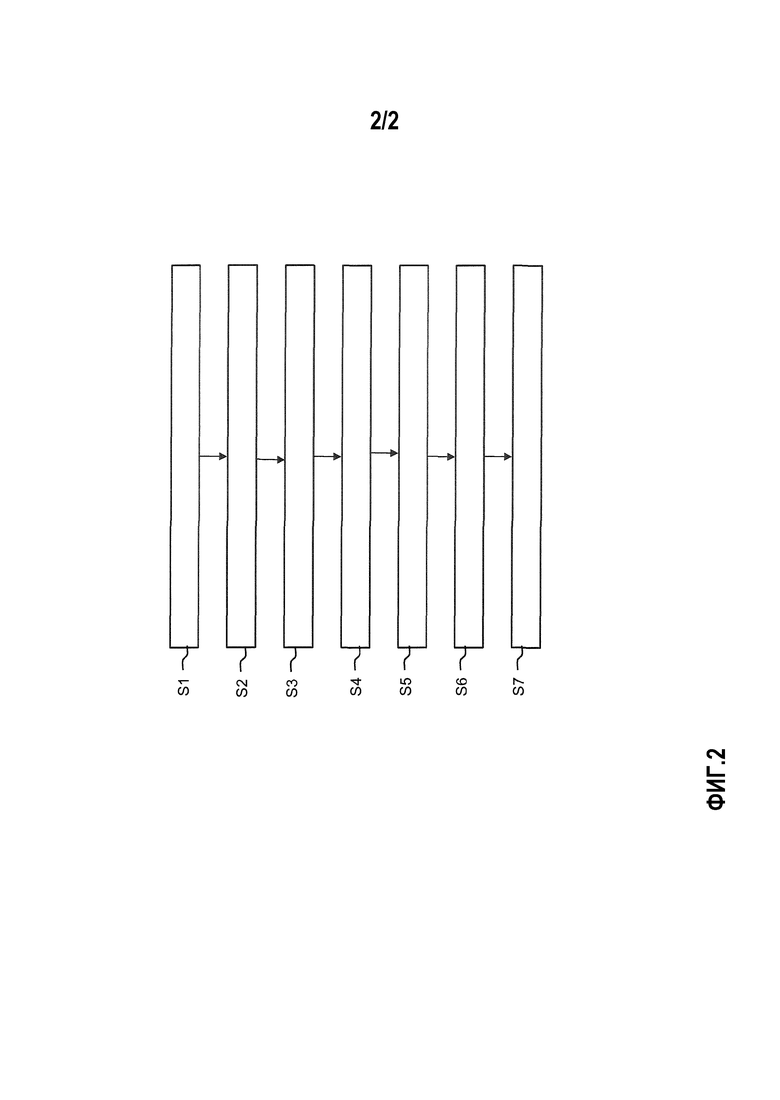
Фиг.2 показывает схему последовательности операций способа эксплуатации рекомендательного модуля для рекомендации элементов контента пользователю согласно варианту осуществления настоящего изобретения. Вариант осуществления содержит следующие этапы, на которых:
этап S1: принимают из базы данных, которая является внешней для рекомендательного модуля, данные предварительного профиля, содержащие текстовые данные предварительного профиля, подходящие для идентификации субъектов, представляющих интерес для данного пользователя;
этап S2: извлекают из данных предварительного профиля идентификационные данные, идентифицирующие субъекты, представляющие интерес;
этап S3: генерируют набор данных первоначального профиля пользователя для данного пользователя исходя из извлеченных идентификационных данных;
этап S4: генерируют, с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя, по меньшей мере два запроса, семантически отличающиеся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента;
этап S5: выдают сгенерированные запросы по меньшей мере одному репозиторию контента;
этап S6: принимают из по меньшей мере одного репозитория контента, в ответ на запрос, ответные данные, относящиеся к контенту, содержащие соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента; и
этап S7: генерируют из разных извлеченных списков совпадения единый список рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из данных списков совпадений.
Другой вариант осуществления процесса генерирования рекомендаций на основании данной страницы "симпатий", такой как веб-страница, которая точно определяет субъекты, представляющие интерес, содержит следующие этапы.
1. Текст веб-страницы анализируют, посредством извлечения категории субъекта и посредством извлечения конкретных текстовых фрагментов из текста.
2. Этот этап реализован посредством нижеследующих этапов либо 2a, либо 2b, либо обоих:
2a. Запросы генерируют с использованием категории понравившегося субъекта и с использованием извлеченных текстовых фрагментов. Эти запросы отправляют в подключенные к сети репозитории контента, такие как YouTube и Amazon, с использованием API, который эти репозитории предлагают для этого типа использования.
2b. Вместо отправки запросов по возможности внешнему репозиторию контента, в качестве альтернативы некоторые могут сопоставлять извлеченные текстовые фрагменты и категорию понравившегося субъекта с записями во внутреннем репозитории контента, где есть полное управление над тем, как реализуется сопоставление.
3. Результаты, которые возвращены подключенными к сети репозиториями, анализируются, чтобы определить для каждого из этих результатов семантическую связанность с исходным "понравившимся" субъектом. В дополнение, в качестве опции, может быть проанализировано взаимное сходство между каждой парой результатов. Оба анализа основаны на сравнении их текстового сходства.
4. Впоследствии, результаты объединяют в единый список рекомендаций, с целью иметь в верхней части списка результаты, которые семантически в высокой степени относятся к исходному "понравившемуся" элементу, но являются взаимно довольно разными.
5. В качестве опции, результаты с достаточно высоким текстовым сходством с исходным "понравившемся" субъектом могут быть непосредственно включены как "симпатии" в рекомендательную систему, так чтобы процесс изучения профиля пользователя был ускорен.
В заключение, данное изобретение обеспечивает возможность генерирования персональных и разнообразных рекомендаций, особенно для новых пользователей, которые начали использовать рекомендательную систему. Вследствие этого, перекрывается период, в котором рекомендатель еще не изучил вкус пользователя из-за отсутствия рейтингов от нового пользователя. Пользователь может входить в рекомендательную систему используя его или ее учетную запись службы социальной сети и давая рекомендательной системе разрешение использовать "симпатии", которые пользователь точно определил ранее. Таким образом, рекомендателю дается достаточно времени для изучения вкуса пользователя, тогда как список рейтингов увеличивается.
Посредством соответствующего использования API разных репозиториев контента, некоторые могут использовать данное изобретение для рекомендации различных типов контента, включающего в себя кинофильмы, ТВ-шоу, книги, статьи, цифровые документы и т.д., таким образом очень разные субъекты, в том числе люди и общие интересы.
В то время как данное изобретение было проиллюстрировано и описано подробно на чертежах и вышеприведенном описании, такую иллюстрацию и описание следует считать иллюстративными и примерными, а не ограничивающими; данное изобретение не ограничено раскрытыми вариантами осуществления.
Другие изменения в раскрытых вариантах осуществления могут быть поняты и осуществлены специалистами в данной области техники при применении на практике заявленного изобретения, исходя из эскизов чертежей, разглашения и прилагаемых пунктах формулы изобретения.
В пунктах формулы изобретения слово "содержащий" не исключает других элементов или этапов и указание единственного числа не исключает множественности. Единый блок может выполнять функции нескольких элементов, перечисленных в пунктах формулы изобретения. Сам факт, что определенные меры перечислены в обоюдно разных зависимых пунктах формулы изобретения, не указывает на то, что сочетания этих мер нельзя использовать с пользой.
Компьютерная программа может храниться/распространяться на подходящем носителе, таком как оптический носитель информации или твердотельный носитель, поставляемый вместе или как часть других аппаратных средств, но также может распространяться в других формах, таких как посредством Интернета или других проводных или беспроводных телекоммуникационных систем.
Любые ссылочные обозначения в пунктах формулы изобретения не следует толковать как ограничивающие объем.
Изобретение относится к средствам создания списков рекомендаций элементов контента пользователю. Технический результат заключается в повышении точности выдачи рекомендаций. Генерируют набор данных первоначального профиля пользователя для этого конкретного пользователя исходя из извлеченных идентификационных данных. Генерируют с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя по меньшей мере два запроса, семантически отличающиеся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента. Выдают сгенерированные запросы в по меньшей мере один репозиторий контента. Принимают из по меньшей мере одного репозитория контента в ответ на запрос относящиеся к контенту ответные данные, содержащие соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента. Генерируют из разных извлеченных списков совпадения единый список рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из упомянутых списков совпадений. 4 н. и 11 з.п. ф-лы, 2 ил.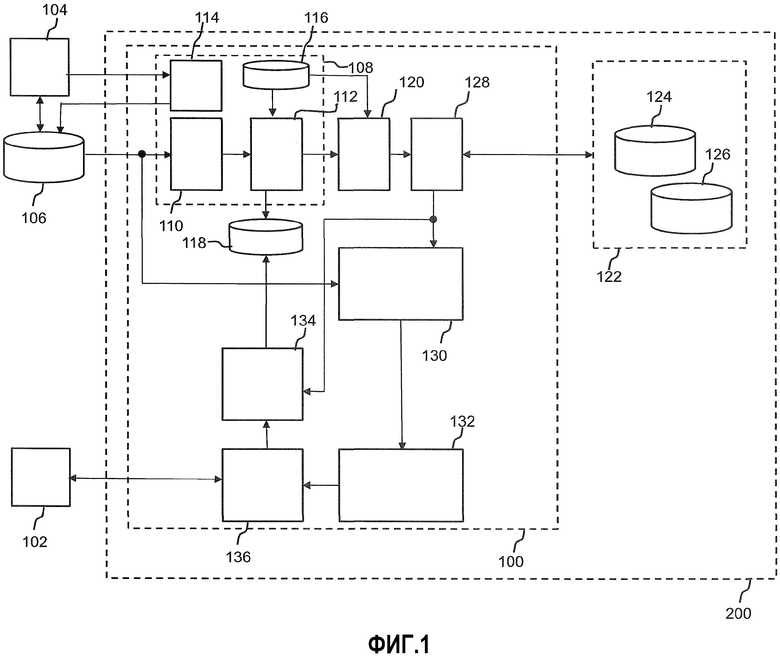
1. Рекомендательный модуль (100) для рекомендации элементов контента пользователю, содержащий
блок генерирования профиля, имеющий блок (110) ввода предварительного профиля, который выполнен с возможностью принимать данные предварительного профиля, содержащие текстовые данные предварительного профиля, подходящие для идентификации субъектов, представляющих интерес для конкретного пользователя, и имеющий блок (112) анализа предварительного профиля, который соединен с блоком (110) ввода предварительного профиля и выполнен с возможностью извлекать из данных предварительного профиля идентификационные данные, идентифицирующие упомянутые субъекты, представляющие интерес, и генерировать набор данных первоначального профиля пользователя для этого конкретного пользователя исходя из извлеченных идентификационных данных;
блок (120) генерирования запросов, который соединен с блоком генерирования профиля и выполнен с возможностью генерировать с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя по меньшей мере два запроса, семантически отличающиеся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента;
блок (128) извлечения контента, который соединен с блоком (120) генерирования запросов и выполнен с возможностью выдавать сгенерированные запросы в по меньшей мере один репозиторий (122) контента и который выполнен с возможностью принимать из по меньшей мере одного репозитория контента в ответ на упомянутые запросы относящиеся к контенту ответные данные, содержащие соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента; и
блок (132) перемежения, который соединен с блоком извлечения контента и который выполнен с возможностью генерировать из разных списков совпадения единый список рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из упомянутых списков совпадений.
2. Рекомендательный модуль по п.1,
в котором блок (128) извлечения контента дополнительно выполнен с возможностью извлекать текстовые данные контента, связанные с соответствующими идентификаторами размещения контента, в ответ на упомянутые запросы;
при этом рекомендательный модуль (100) дополнительно содержит блок (130) присваивания рейтинга, который соединен с блоком (128) извлечения контента и который выполнен с возможностью:
назначать идентификаторам размещения контента, которые были приняты в ответ на каждый из упомянутых по меньшей мере двух запросов, показатели релевантности на основе критерия сходства, которым оценивается текстовая связанность между текстовыми данными предварительного профиля и текстовыми данными контента,
сортировать списки совпадений по релевантности, которая выражена показателями релевантности, и
предоставлять отсортированные списки совпадений в блок перемежения.
3. Рекомендательный модуль по п.1 или 2,
в котором блок (108) генерирования профиля содержит классификационную базу данных (116), которая присваивает соответствующий класс субъектов в соответствии с по меньшей мере одним критерием классификации субъектов соответствующему набору из по меньшей мере одного ключевого слова, которое должно быть включено в запрос,
в котором блок (108) генерирования профиля выполнен с возможностью присваивать по меньшей мере один класс извлеченным идентификационным данным, идентифицирующим соответствующий субъект, представляющий интерес, в соответствии с классификационной базой данных, и
в котором блок (120) генерирования запросов выполнен с возможностью генерировать запросы с использованием соответствующих идентификационных данных и по меньшей мере одного из ключевых слов, присвоенных соответствующему классу идентификационных данных в соответствии с классификационной базой данных.
4. Рекомендательный модуль по п.3,
в котором блок (112) анализа предварительного профиля дополнительно выполнен с возможностью классифицировать текстовые данные предварительного профиля по их языку и подавать на свой выход по меньшей мере один идентификатор языка, указывающий соответствующий язык, используемый в текстовых данных предварительного профиля;
при этом классификационная база данных (116) содержит ключевые слова на разных языках; и
в котором блок (120) генерирования запросов выполнен с возможностью генерировать запросы с использованием ключевых слов на языке, соответствующем идентификатору языка, или, если ключевые слова на этом языке не присутствуют в классификационной базе данных для соответствующего класса, на заданном по умолчанию языке.
5. Рекомендательный модуль по п.1, в котором блок (120) генерирования запросов выполнен с возможностью включать в упомянутые запросы извлеченные идентификационные данные по меньшей мере двух субъектов, представляющих интерес.
6. Рекомендательный модуль по п.1, в котором блок (108) генерирования профиля выполнен с возможностью обнаруживать в данных предварительного профиля ссылку ресурса на ресурс контента в сетевом месте размещения в глобальной сети данных, осуществлять доступ к ресурсу контента и добавлять текстовые данные, доступные из ресурса контента, к текстовым данным предварительного профиля.
7. Рекомендательный модуль по п.2,
в котором блок (108) генерирования профиля выполнен с возможностью извлекать из данных предварительного профиля разные поднаборы текстовых данных предварительного профиля, которые отличаются друг от друга своей датой генерирования, которая назначена внешней базой данных, и извлекать из этих поднаборов соответствующие даты генерирования поднаборов, и
в котором блок (130) присваивания рейтинга выполнен с возможностью применять взвешивание к показателю релевантности, причем взвешивание увеличивает показатель релевантности тем больше, чем более поздней является дата генерирования соответствующего одного из поднаборов, относящихся к конкретному размещению контента, связанному с конкретным субъектом, представляющим интерес.
8. Рекомендательный модуль по п.2, в котором блок (112) анализа предварительного профиля выполнен с возможностью обнаруживать в текстовых данных предварительного профиля наличие ключевых слов, указывающих, что конкретному пользователю или кому-то, связанному с этим конкретным пользователем, нравится субъект, и назначать указатель "нравится" соответствующему субъекту в наборе данных первоначального профиля пользователя, при этом блок (130) присваивания рейтинга выполнен с возможностью применять взвешивание к показателю релевантности, причем взвешивание увеличивает показатель релевантности, если конкретный субъект, представляющий интерес, имеет связанный с ним указатель "нравится".
9. Рекомендательный модуль по п.2, в котором блок (130) присваивания рейтинга или блок (132) перемежения выполнен с возможностью оценивать значение текстовой связанности между текстовыми данными предварительного профиля и текстовыми данными контента.
10. Рекомендательный модуль по п.2, в котором
блок (132) перемежения выполнен с возможностью взвешивания показателей релевантности на основе критерия сходства, которым оценивается текстовая связанность между текстовыми данными контента различных элементов контента, найденных в упомянутых запросах, при этом взвешивание уменьшает показатель релевантности, если элемент контента, который должен быть оценен на предмет релевантности, имеет такую текстовую связанность с элементом контента, оцененным непосредственно перед ним, которая превышает предварительно определенное значение.
11. Рекомендательный модуль по п.1,
дополнительно содержащий блок (114) аутентификации, который выполнен с возможностью принимать через интерфейс пользовательского ввода аутентификационные данные пользователя, подходящие для осуществления доступа к внешней базе данных,
в котором блок (108) генерирования профиля выполнен с возможностью осуществлять доступ к внешней базе данных для извлечения данных предварительного профиля.
12. Рекомендательный модуль по п.9, дополнительно содержащий блок (134) обслуживания профиля, который выполнен с возможностью извлекать дополнительные идентификационные данные для дополнительного субъекта из текстовых данных контента и который выполнен с возможностью добавлять извлеченные дополнительные идентификационные данные к набору данных профиля пользователя после обнаружения того, что значение текстовой связанности между текстовыми данными предварительного профиля и текстовыми данными контента превышает предварительно определенное пороговое значение.
13. Репозиторий (200) контента, содержащий:
базу данных контента, содержащую элементы контента в виде файлов данных, хранящихся в местах размещения контента;
рекомендательный модуль согласно одному из предыдущих пунктов,
при этом блок извлечения контента из состава рекомендательного модуля выполнен с возможностью выдачи сгенерированных запросов в базу данных контента.
14. Способ функционирования рекомендательного модуля для рекомендации элементов контента пользователю, содержащий этапы, на которых
принимают (S1) из базы данных, которая является внешней для рекомендательного модуля, данные предварительного профиля, содержащие текстовые данные предварительного профиля, подходящие для идентификации субъектов, представляющих интерес для конкретного пользователя;
извлекают (S2) из данных предварительного профиля идентификационные данные, идентифицирующие упомянутые субъекты, представляющие интерес;
генерируют (S3) набор данных первоначального профиля пользователя для этого конкретного пользователя исходя из извлеченных идентификационных данных;
генерируют (S4) с использованием извлеченных идентификационных данных из набора данных первоначального профиля пользователя по меньшей мере два запроса, семантически отличающиеся друг от друга, которые должны быть направлены в по меньшей мере один репозиторий контента;
выдают (S5) сгенерированные запросы в по меньшей мере один репозиторий контента;
принимают (S6) из по меньшей мере одного репозитория контента в ответ на запрос относящиеся к контенту ответные данные, содержащие соответствующие списки совпадений, имеющие по меньшей мере один соответствующий идентификатор размещения контента, указывающий место хранения соответствующего элемента контента; и
генерируют (S7) из разных извлеченных списков совпадения единый список рекомендаций посредством перемежения друг с другом идентификаторов размещения контента, содержащихся в разных списках совпадений из упомянутых списков совпадений.
15. Компьютерно-читаемый носитель информации, хранящий исполняемый компьютером код, причем компьютерный код реализует способ управления функционированием рекомендательного модуля для рекомендации элементов контента пользователю согласно п.12.
| Chumki Basu et al, 'Technical paper recommendation: A study in combining multiple information sources', Journal of Artificial Intelligence Research 1 (2001), c | |||
| Машина для удаления камней из почвы | 1922 |
|
SU231A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СПОСОБ И УСТРОЙСТВО ГЕНЕРАЦИИ РЕКОМЕНДАЦИИ ДЛЯ ПО МЕНЬШЕЙ МЕРЕ ОДНОГО ЭЛЕМЕНТА КОНТЕНТА | 2006 |
|
RU2420908C2 |

