ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к устройству арифметического декодирования, которое декодирует арифметически закодированные данные, и устройству декодирования изображения, включающему в себя такое устройство арифметического декодирования. Настоящее изобретение также относится к устройству арифметического кодирования, которое генерирует арифметически закодированные данные.
УРОВЕНЬ ТЕХНИКИ
[0002] Чтобы эффективно передать или записать видео, используются устройство кодирования видео (устройство кодирования изображения), которое генерирует закодированные данные посредством кодирования видео, и устройство декодирования видео (устройство декодирования изображения), которое генерирует декодированное изображение посредством декодирования закодированных данных.
[0003] Конкретные примеры схемы кодирования видео включают в себя H.264/MPEG-4.AVC, схему, принятую для программного обеспечения KTA, которое является кодеком для совместного развития в VCEG (группа экспертов по кодированию видео), схему, принятую для программного обеспечения TMuC (тестовая модель на рассмотрении), и схему, предложенная в HEVC (высокоэффективное кодирование видео), которое является последующим кодеком для предшествующих схем (NPL 1).
[0004] В этих схемах кодирования видео изображения (картинки), которые формируют видео, управляются, используя иерархическую структуру, которая составлена из вырезок, полученных посредством деления изображения, единиц кодирования, полученных посредством деления вырезки, и блоков и разделений, полученных посредством деления единицы кодирования, и являются обычно закодированными/декодированными в единицах блоков.
[0005] В этих схемах кодирования в обычных случаях изображение предсказания генерируется на основе локально декодированного изображения, полученного посредством кодирования и декодирования входного изображения, коэффициенты преобразования получают посредством выполнения частотного преобразования, такого как DCT (дискретное косинусное преобразование), в отношении разностного изображения (также называемого "остаточное изображение" или "остаток предсказания"), представляющем разность между изображением предсказания и входным изображением в единицах блоков, и коэффициенты преобразования кодируют.
[0006] В качестве конкретных примеров схемы кодирования коэффициентов преобразования, известны основанное на контексте адаптивное кодирование с переменной длиной кода (CAVLC) и основанное на контексте адаптивное двоичное арифметическое кодирование (CABAC).
[0007] В CALVC индивидуальные коэффициенты преобразования последовательно сканируются, чтобы генерировать одномерные векторы, и затем элементы синтаксиса, представляющие значения этих индивидуальных коэффициентов преобразования, элемент синтаксиса, представляющий длину последовательных нолей (также называемый "длина серии"), и т.д. кодируют.
[0008] В CABAC процесс бинаризации выполняют в отношении различных элементов синтаксиса, представляющих коэффициенты преобразования, и двоичные данные, полученные с помощью процесса бинаризации, арифметически кодируют. Здесь, различные элементы синтаксиса включают в себя флаг, указывающий, равен ли коэффициент преобразования 0, то есть, флаг significant_coeff_flag, указывающий присутствие/отсутствие ненулевого коэффициента преобразования (также называемого флаг присутствия/отсутствия коэффициента преобразования), и элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y, указывающие позицию последнего ненулевого коэффициента преобразования в порядке обработки.
[0009] В CABAC в случае кодирования одного символа (1 бит двоичных данных, также называемого как бин), ссылаются на индекс контекста, назначенный на целевой частотный компонент, который должен быть обработан, и арифметическое кодирование выполняют в соответствии с вероятностью появления, обозначенной индексом состояния вероятности, включенным в переменную контекста, обозначенную индексом контекста. Кроме того, вероятность появления, обозначенная индексом состояния вероятности, обновляется каждый раз, когда символ кодируется.
[0010] NPL 1 описывает, например, метод (1) деления частотной области, относящейся к целевому блоку, который должен быть обработан, на множество частичных областей, (2) назначения частотным компонентам, включенным в частичную область на стороне низких частот, индексов контекста (также называемых контекстами позиции), которые определены в соответствии с позициями частотных компонентов в частотной области, и (3) назначения частотным компонентам, включенным в частичную область на стороне высоких частот, индексов контекста (также называемых соседними опорными контекстами), которые определены в соответствии с количеством ненулевых коэффициентов преобразования в частотных компонентах вокруг каждого из частотных компонентов.
[0011] Источники NPL 2 и 3 предлагают сокращение количества индексов контекста.
[0012] NPL 4 предлагает усовершенствование для порядка сканирования различных элементов синтаксиса.
[0013] NPL 5 предлагает разделение частотной области, относящейся к целевому блоку, который должен быть обработан, на множество суб-блоков, и декодирование флага, указывающего, включает ли каждый суб-блок в себя ненулевой коэффициент преобразования.
[0014] NPL 6 описывает метод, например, в случае, когда размер целевого блока, который должен быть обработан, является некоторым размером или большим, выполнения следующих этапов (1)-(5), чтобы получить индексы контекста, на которые нужно ссылаться, когда флаг присутствия/отсутствия коэффициента преобразования (significant_coeff_flag) декодируется (кодируется).
[0015] (1) Делят частотную область целевого блока, который должен быть обработан, на множество частичных областей. Кроме того, выполняют следующие этапы (2)-(4) в соответствии с тем, находится ли каждое множество частичных областей, полученных с помощью разделения, на любой из стороны низких частот до стороны высоких частот.
(2) Для частотных компонентов, включенных в частичную область на стороне низких частот, выведение индексов контекста (также называемых контекстами позиции), которые определяют в соответствии с позициями частотных компонентов в частотной области.
(3) Для частотных компонентов, включенных в частичную область в области промежуточных частот, выведение индексов контекста (также называемых соседними опорными контекстами), которые определяют в соответствии с количеством ненулевых коэффициентов в частотных компонентах вокруг каждого из частотных компонентов.
(4) Для частотных компонентов, включенных в частичную область на стороне высоких частот, получение фиксированных индексов контекста.
(5) В случае, когда размер целевого блока, который должен быть обработан, является некоторым размером или меньшим, выведение индексов контекста (также называемых контекстами позиции), которые определяют в соответствии с позициями частотных компонентов в частотной области.
Список цитат
Непатентная литература
[0016] NPL 1: " "WD4: Working Draft 4 of High-Efficiency Video Coding (JCTVC-F803_d2)", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11 6th Meeting: Torino, IT, 14-22 July, 2011 (опубликовано 8 октября 2011)
NPL 2: "A combined proposal from JCTVC-G366, JCTVC-G657, and JCTVC-G768 on context reduction of significance map coding with CABAC (JCTVC-G1015)", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG117th Meeting: Geneva, CH, 21-30 November, 2011 (опубликовано 25 ноября 2011)
NPL 3: "JCT-VC break-out report: Harmonization of NSQT with residual coding (JCTVC-G1038)", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG117th Meeting: Geneva, CH, 21-30 November, 2011 (опубликовано 28 ноября 2011)
NPL 4: "CE11: Scanning Passes of Residual Data in HE (JCTVC-G320)", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG117th Meeting: Geneva, CH, 21-30 November, 2011 (опубликовано 9 ноября 2011)
NPL 5: "Multi level significance maps for Large Transform Units (JCTVC-G644)", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG117th Meeting: Geneva, 21-30 November, 2011 (опубликовано 9 ноября 2011)
NPL 6: "High Efficiency Video Coding (HEVC) text specification draft 6 (JCTVC-H1003_dk)", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29 WG11 6th Meeting: San Jose, US, 1-10 February, 2012 (опубликовано 17 февраля 2012).
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Техническая проблема
[0017] Однако, согласно вышеописанному уровню техники, существует проблема, заключающаяся в том, что величина обработки, связанной с кодированием и декодированием коэффициентов преобразования, не является достаточно уменьшенной.
[0018] Настоящее изобретение было сделано ввиду вышеописанной проблемы, и задача изобретения состоит в том, чтобы обеспечить устройство арифметического декодирования и устройство арифметического кодирования, которые способны к сокращению величины обработки, связанной с кодированием и декодированием коэффициентов преобразования, по сравнению с конфигурацией согласно уровню техники.
Решение проблемы
[0019] Чтобы решить вышеописанную проблему, устройство декодирования изображения согласно варианту осуществления настоящего изобретения включает в себя, в устройстве арифметического декодирования, которое декодирует закодированные данные для каждой из единичных областей целевого изображения, средство декодирования флага присутствия/отсутствия коэффициента суб-блока для декодирования, для каждого из двух или более суб-блоков, полученных посредством деления единичной области, флага присутствия/отсутствия коэффициента суб-блока, указывающего, включен ли по меньшей мере один ненулевой коэффициент преобразования, и средство выведения индекса контекста для выведения индекса контекста целевого суб-блока на основе флагов присутствия/отсутствия коэффициента преобразования, каждый указывает, равен ли коэффициент преобразования 0. Средство выведения индекса контекста выводит индекс контекста целевого суб-блока в соответствии с флагами присутствия/отсутствия коэффициента суб-блока смежных суб-блоков, которые являются смежными с целевым суб-блоком.
[0020] Чтобы решить вышеописанную проблему, устройство декодирования изображения согласно варианту осуществления настоящего изобретения включает в себя вышеописанное устройство арифметического декодирования, средство обратного частотного преобразования для выполнения обратного частотного преобразования в отношении коэффициента преобразования, декодированного устройством арифметического декодирования, чтобы сгенерировать остаточное изображение, и средство генерирования декодированного изображения для суммирования остаточного изображения и изображения предсказания, предсказанного из декодированного изображения, которое было сгенерировано, чтобы генерировать декодированное изображение.
[0021] Чтобы решить вышеописанную проблему, устройство арифметического кодирования согласно варианту осуществления настоящего изобретения включает в себя, в устройстве арифметического кодирования, которое генерирует закодированные данные для каждой из единичных областей целевого изображения, средство кодирования флага присутствия/отсутствия коэффициента суб-блока для кодирования, для каждого из двух или более суб-блоков, полученных посредством деления единичной области, флага присутствия/отсутствия коэффициента суб-блока, указывающего, включен ли по меньшей мере один ненулевой коэффициент преобразования, и средство выведения индекса контекста для выведения индекса контекста целевого суб-блока на основе флагов присутствия/отсутствия коэффициента преобразования, причем каждый указывает, равен ли коэффициент преобразования 0. Средство выведения индекса контекста выводит индекс контекста в соответствии с флагами присутствия/отсутствия коэффициента суб-блока смежных суб-блоков, которые являются смежными с целевым суб-блоком.
[0022] Чтобы решить вышеописанную проблему, устройство арифметического декодирования согласно варианту осуществления настоящего изобретения включает в себя, в устройстве арифметического декодирования, которое декодирует закодированные данные для каждой из единичных областей целевого изображения, средство выведения индекса контекста для выведения индексов контекста единичных областей на основе флагов присутствия/отсутствия коэффициента преобразования, каждый указывает, равен ли коэффициент преобразования 0, и средство декодирования синтаксиса для того, чтобы арифметически декодировать флаги присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, обозначенного выведенными индексами контекста. Средство выведения индекса контекста выводит общий индекс контекста для флагов присутствия/отсутствия коэффициента преобразования, которые принадлежат стороне низких частот по меньшей мере двух единичных областей, имеющих различные размеры среди единичных областей.
[0023] Чтобы решить вышеописанную проблему, устройство декодирования изображения согласно варианту осуществления настоящего изобретения включает в себя вышеописанное устройство арифметического декодирования, средство обратного частотного преобразования для выполнения обратного частотного преобразования в отношении коэффициента преобразования, декодированного устройством арифметического декодирования, чтобы генерировать остаточное изображение, и средство генерирования декодированного изображения для суммирования остаточного изображения и изображения предсказания, предсказанного из декодированного изображения, которое было сгенерировано, чтобы генерировать декодированное изображение.
[0024] Чтобы решить вышеописанную проблему, устройство кодирования изображения согласно варианту осуществления настоящего изобретения включает в себя, в устройстве арифметического кодирования, которое генерирует закодированные данные для каждой из единичных областей целевого изображения, средство выведения индекса контекста для выведения индексов контекста единичных областей на основе флагов присутствия/отсутствия коэффициента преобразования, каждый указывает, равен ли коэффициент преобразования 0, и средство кодирования синтаксиса для того, чтобы арифметически кодировать флаги присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, обозначенного выведенными индексами контекста. Средство выведения индекса контекста выводит общий индекс контекста для флагов присутствия/отсутствия коэффициента преобразования, которые принадлежат стороне низких частот по меньшей мере двух единичных областей, имеющих различные размеры среди единичных областей.
Выгодные эффекты изобретения
[0025] Согласно устройству арифметического декодирования, имеющему вышеописанную конфигурацию, может быть уменьшена величина кодов целевых флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть декодированы, и величина обработки, связанная с декодированием коэффициентов преобразования, уменьшается.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0026] [Фиг. 1] Фиг. 1 является блок-схемой, иллюстрирующей конфигурацию декодера квантованной остаточной информации, включенного в устройство декодирования видео согласно варианту осуществления настоящего изобретения.
[Фиг. 2] Фиг. 2 включает в себя диаграммы, иллюстрирующие структуру данных закодированных данных, которые генерируются устройством кодирования видео согласно варианту осуществления настоящего изобретения и декодируются устройством декодирования видео, и части (a)-(d) являются диаграммами, иллюстрирующими уровень картинки, уровень вырезки, уровень блока дерева, и уровень CU, соответственно.
[Фиг. 3] Части (a)-(h) являются диаграммами, иллюстрирующими шаблоны типа разделения единицы PU, соответственно иллюстрирующими формы разделений в случаях, когда типами разделения PU являются 2N×2N, 2N×N, 2N×nU, 2N×nD, N×2N, nL×2N, nR×2N и N×N.
Части (i)-(o) являются диаграммами, иллюстрирующими схемы разделения для разделения квадродерева разделения квадратного узла на квадраты или неквадраты. (i) иллюстрирует разделение на квадраты, (j) иллюстрирует разделение на горизонтально длинные прямоугольники, (k) иллюстрирует разделение на вертикально длинные прямоугольники, (l) иллюстрирует разделение горизонтально длинного узла на горизонтально длинные прямоугольники, (m) иллюстрирует разделение горизонтально длинного узла на квадраты, (n) иллюстрирует разделение вертикально длинного узла на вертикально длинные прямоугольники, и (o) иллюстрирует разделение вертикально длинного узла на квадраты.
[Фиг. 4] Фиг. 4 является диаграммой, иллюстрирующей первую половинную часть таблицы синтаксиса, показывающей элементы синтаксиса, включенные в квантованную остаточную информацию закодированных данных согласно варианту осуществления.
[Фиг. 5] Фиг. 5 является диаграммой, иллюстрирующей последнюю половинную часть таблицы синтаксиса, показывающей элементы синтаксиса, включенные в квантованную остаточную информацию закодированных данных согласно варианту осуществления.
[Фиг. 6] Фиг. 6 включает в себя диаграммы, описывающие работу декодера квантованной остаточной информации согласно варианту осуществления, в которой часть (a) иллюстрирует порядок обработки в случае прямого сканирования, часть (b) иллюстрирует порядок обработки в случае обратного сканирования, часть (c) иллюстрирует ненулевые коэффициенты преобразования в частотной области, которая должна быть обработана, часть (d) иллюстрирует значения элементов синтаксиса significant_coeff_flag в целевой частотной области, часть (e) иллюстрирует значения, полученные посредством декодирования элементов синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, и coeff_abs_level_minus3 в целевой частотной области, и часть (f) иллюстрирует значения элементов синтаксиса coeff_sign_flag в целевой частотной области.
[Фиг. 7] Фиг. 7 включает в себя диаграммы, описывающие порядок сканирования процесса декодирования и процесса кодирования согласно варианту осуществления, в котором часть (a) иллюстрирует случай, в котором сканирование суб-блока является прямым сканированием, (b) иллюстрирует случай, в котором сканирование в суб-блоке является прямым сканированием, (c) иллюстрирует случай, в котором сканирование суб-блока является обратным сканированием, и (d) иллюстрирует случай, в котором сканирование в суб-блоке является обратным сканированием.
[Фиг. 8] Фиг. 8 включает в себя диаграммы, описывающие процесс декодирования ненулевых коэффициентов преобразования в варианте осуществления, в котором часть (a) иллюстрирует порядок сканирования в случае, когда индивидуальные частотные компоненты сканируются прямым сканированием в случае, когда блок, имеющий размер 8×8, разделен на суб-блоки, каждый имеющий размер 4×4, часть (b) иллюстрирует коэффициенты преобразования, которые не являются нулем (ненулевые коэффициенты преобразования) в частотной области, составленной из 8×8 частотных компонентов, часть (c) иллюстрирует индивидуальные значения флагов присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag, которые были декодированы для индивидуальных суб-блоков в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b), часть (d) иллюстрирует индивидуальные значения элементов синтаксиса significant_coeff_flag, указывающих присутствие/отсутствие ненулевого коэффициента преобразования в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b) на Фиг. 8, часть (e) иллюстрирует абсолютные значения индивидуальных коэффициентов преобразования, полученных посредством декодирования элементов синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, и coeff_abs_level_minus3 в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b), и часть (f) иллюстрирует элементы синтаксиса coeff_sign_flag в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b).
[Фиг. 9] Фиг. 9 является блок-схемой, иллюстрирующей конфигурацию устройства декодирования видео согласно варианту осуществления.
[Фиг. 10] Фиг. 10 является блок-схемой, иллюстрирующей конфигурацию декодера кода с переменной длиной слова, включенного в устройство декодирования видео согласно варианту осуществления.
[Фиг. 11] Фиг. 11 является диаграммой, иллюстрирующей направления внутреннего предсказания, которые могут использоваться в устройстве декодирования видео согласно варианту осуществления.
[Фиг. 12] Фиг. 12 является диаграммой, иллюстрирующей режимы внутреннего предсказания, и имена, ассоциированные с режимами внутреннего предсказания.
[Фиг. 13] Фиг. 13 является диаграммой, иллюстрирующей соотношения между значениями логарифма (log2TrafoSize) размеров целевых блоков и номеров режимов предсказания (intraPredModeNum).
[Фиг. 14] Фиг. 14 является таблицей, показывающей примеры индексов scanIndex сканирования, которые указаны индексами IntraPredMode режима внутреннего предсказания и индивидуальных значений log2TrafoSize-2.
[Фиг. 15] Фиг. 15 включает в себя диаграммы, описывающие индексы сканирования, в которых часть (a) иллюстрирует типы ScanType сканирования, указанные индивидуальными значениями индексов scanIndex сканирования, и часть (b) иллюстрирует порядки сканирования приоритетного сканирования в горизонтальном направлении (горизонтальное быстрое сканирование), приоритетное сканирование в вертикальном направлении (вертикальное быстрое сканирование), и сканирование в диагональном направлении (верхнее-правое диагональное сканирование) в случае, когда размер блока соответствует 4×4 компонентам.
[Фиг. 16] Фиг. 16 является таблицей, иллюстрирующей пример индексов scanIndex сканирования суб-блоков, которые обозначаются индексами IntraPredMode режима внутреннего предсказания, и индивидуальные значения log2TrafoSize-2.
[Фиг. 17] Фиг. 17 включает в себя диаграммы, описывающие индексы сканирования суб-блоков, в которых часть (a) иллюстрирует типы ScanType сканирования суб-блоков, указанные индивидуальными значениями индексов scanIndex сканирования суб-блоков, и часть (b) иллюстрирует порядки сканирования приоритетного сканирования в горизонтальном направлении (горизонтальное быстрое сканирование), приоритетное сканирование в вертикальном направлении (вертикальное быстрое сканирование), и сканирование в диагональном направлении (верхнее-правое диагональное сканирование) в случае, когда размер блока соответствует 4×4 компонентам.
[Фиг. 18] Фиг. 18 является таблицей, иллюстрирующей другой пример индексов scanIndex сканирования суб-блоков, которые обозначаются индексами IntraPredMode режима внутреннего предсказания, и индивидуальные значения log2TrafoSize-2.
[Фиг. 19] Фиг. 19 является блок-схемой, иллюстрирующей конфигурацию декодера флага присутствия/отсутствия коэффициента суб-блока согласно варианту осуществления.
[Фиг. 20] Фиг. 20 включает в себя диаграммы, описывающие процесс декодирования, выполняемый декодером флага присутствия/отсутствия коэффициента суб-блока согласно варианту осуществления, в котором часть (a) иллюстрирует целевой суб-блок (xCG, yCG) и смежный суб-блок (xCG, yCG+1), который является смежным с целевым суб-блоком с нижней стороны, часть (b) иллюстрирует целевой суб-блок (xCG, yCG) и смежный суб-блок (xCG+1, yCG), который является смежным с целевым суб-блоком с правой стороны, и часть (c) иллюстрирует целевой суб-блок (xCG, yCG), смежный суб-блок (xCG, yCG+1), который является смежным с целевым суб-блоком с нижней стороны, и смежный суб-блок (xCG+1, yCG), который является смежным с целевым суб-блоком с правой стороны.
[Фиг. 21] Фиг. 21 включает в себя диаграммы, описывающие процесс кодирования и декодирования флагов присутствия/отсутствия коэффициента суб-блока согласно сравнительному примеру, в котором часть (a) иллюстрирует коэффициенты преобразования, которые существуют в частотной области 16×16 компонентов, и часть (b) иллюстрирует флаги присутствия/отсутствия коэффициента суб-блока, назначенные на индивидуальные суб-блоки.
[Фиг. 22] Фиг. 22 включает в себя диаграммы, описывающие процесс кодирования и декодирования флагов присутствия/отсутствия коэффициента суб-блока согласно варианту осуществления, в котором часть (a) иллюстрирует коэффициенты преобразования, которые существуют в частотной области 16×16 компонентов, и часть (b) иллюстрирует флаги присутствия/отсутствия коэффициента суб-блока, назначенные на индивидуальные суб-блоки.
[Фиг. 23] Фиг. 23 является блок-схемой, иллюстрирующей конфигурацию декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 24] Фиг. 24 является диаграммой, иллюстрирующей пример частотной области, которая была разделена на частичные области R0, R1, и R2 с помощью процесса классификации, выполненного модулем частотной классификации, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 25] Фиг. 25 включает в себя диаграммы, описывающие опорные частотные компоненты, на которые ссылаются модулем выведения опорного контекста от соседнего элемента, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления в случае, когда процесс декодирования выполняется в обратном порядке сканирования, в котором часть (a) иллюстрирует относительные позиции между целевым частотным компонентом x и опорными частотными компонентами c1, c2, c3, c4 и c5, и часть (b) иллюстрирует относительные позиции между целевым частотным компонентом x и опорными частотными компонентами c1, c2, c4 и c5.
[Фиг. 26] Фиг. 26 включает в себя диаграммы, описывающие процесс классификации, выполняемый модулем частотной классификации, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует разделение на частичные области, которое предпочтительно придется, чтобы декодировать коэффициенты преобразования, относящиеся к значению яркости, и часть (b) иллюстрирует разделение на частичные области, которое предпочтительно придется, чтобы декодировать коэффициенты преобразования, относящиеся к значению цветности.
[Фиг. 27] Фиг. 27 является диаграммой, описывающей процесс выведения индекса контекста, выполняемый декодером флага присутствия/отсутствия коэффициента согласно варианту осуществления, и иллюстрирует псевдокод, показывающий процесс выведения для выведения индексов контекста, которые должны быть назначены на частотную область, включенную в частичные области R0 к R2, иллюстрированные в части (a) на Фиг. 26.
[Фиг. 28] Фиг. 28 является диаграммой, описывающей процесс выведения индекса контекста, выполняемый декодером флага присутствия/отсутствия коэффициента согласно варианту осуществления, и иллюстрирует псевдокод, показывающий процесс выведения для выведения индексов контекста, которые должны быть назначены на частотную область, включенную в частичные области R0 и R1, иллюстрированные в части (b) на Фиг. 26.
[Фиг. 29] Фиг. 29 включает в себя диаграммы, описывающие процесс выведения индекса контекста, выполняемый модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R9, которые формируют частотную область, имеющую размер 8×8 компонентов.
[Фиг. 30] Фиг. 30 включает в себя диаграммы, описывающие процесс выведения индекса контекста согласно сравнительному примеру, в котором часть (a) иллюстрирует индексы контекста, которые были выведены для индивидуальных частотных компонентов, включенных в частотную область, имеющую размер 4×4 компонентов, и на которые ссылаются, когда significant_coeff_flag, относящийся к яркости Y, декодируется, часть (b) иллюстрирует индексы контекста, которые были выведены для индивидуальных частотных компонентов, включенных в частотную область, имеющую размер 4×4 компонентов, с помощью процесса выведения индекса контекста согласно сравнительному примеру, и на которые ссылаются, когда significant_coeff_flag, относящийся к цветности U и V, декодируется, и часть (c) иллюстрирует индексы контекста, которые были выведены для индивидуальных частотных компонентов, включенных в частотную область, имеющую размер 8×8 компонентов, с помощью процесса выведения индекса контекста согласно сравнительному примеру, и на которые ссылаются, когда significant_coeff_flag, относящийся к яркости Y и цветности U и V, декодируется.
[Фиг. 31] Фиг. 31 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 32] Фиг. 32 включает в себя диаграммы, описывающие процесс выведения индекса контекста, выполняемый модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует пример CTX_IND_MAP_4×4to8×8 [index] в псевдокоде, проиллюстрированном на Фиг. 31, и часть (b) иллюстрирует значения индивидуальных индексов контекста, которые получены в случае использования CTX_IND_MAP_4×4to8×8 [index] в части (a) для псевдокода, иллюстрированного на Фиг. 31.
[Фиг. 33] Фиг. 33 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R9, которые формируют частотную область, имеющую размер 8×8 компонентов.
[Фиг. 34] Фиг. 34 иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 35] Фиг. 35 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует пример CTX_IND_MAP_4×4to8×8 [index] в псевдокоде, проиллюстрированном на Фиг. 34, и часть (b) иллюстрирует значения индивидуальных индексов контекста, которые получены в случае использования CTX_IND_MAP_4×4to8×8 [index] в части (a) для псевдокода, иллюстрированного на Фиг. 34.
[Фиг. 36] Фиг. 36 иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 37] Фиг. 37 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует пример CTX_IND_MAP_4×4to8×8 [index] в псевдокоде, проиллюстрированном на Фиг. 36, и часть (b) иллюстрирует значения индивидуальных индексов контекста, которые получены в случае использования CTX_IND_MAP_4×4to8×8 [index] в части (a) для псевдокода, иллюстрированного на Фиг. 36.
[Фиг. 38] Фиг. 38 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует пример CTX_IND_MAP_4×4to8×8 [index] в псевдокоде, проиллюстрированном на Фиг. 36, и часть (b) иллюстрирует значения индивидуальных индексов контекста, которые получены в случае использования CTX_IND_MAP_4×4to8×8 [index] в части (a) для псевдокода, иллюстрированного на Фиг. 36.
[Фиг. 39] Фиг. 39 является блок-схемой, иллюстрирующей конфигурацию первого примера модификации флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 40] Фиг. 40 иллюстрирует смежный суб-блок (xCG+1, yCG) и смежный блок (xCG, yCG+1), на которые ссылаются модулем выведения опорного контекста соседнего суб-блока, включенным в декодер флага присутствия/отсутствия коэффициента согласно первому примеру модификации.
[Фиг. 41] Фиг. 41 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем выведения опорного контекста соседнего суб-блока, включенным в декодер флага присутствия/отсутствия коэффициента согласно первому примеру модификации, который является псевдокодом, показывающим процесс выведения индексов контекста, на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к яркости Y.
[Фиг. 42] Фиг. 42 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем выведения опорного контекста соседнего суб-блока, включенным в декодер флага присутствия/отсутствия коэффициента согласно первому примеру модификации, который является псевдокодом, показывающим процесс выведения индексов контекста, на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к цветности U и V.
[Фиг. 43] Фиг. 43 является блок-схемой, иллюстрирующей конфигурацию второго примера модификации флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 44] Фиг. 44 иллюстрирует псевдокод, показывающий процесс декодирования коэффициента преобразования, выполняемый декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области является некоторым размером или меньшим (например, 4×4 компонентов или 8×8 компонентов).
[Фиг. 45] Фиг. 45 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования коэффициента преобразования, выполняемого декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области является некоторым размером или меньшим.
[Фиг. 46] Фиг. 46 является последовательностью операций, иллюстрирующей последовательность операций процесса выбора типа сканирования, выполняемого декодером коэффициента преобразования согласно варианту осуществления.
[Фиг. 47] Фиг. 47 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования ненулевых флагов significant_coeff_flag присутствия/отсутствия коэффициента преобразования, выполняемого декодером коэффициента преобразования согласно варианту осуществления.
[Фиг. 48] Фиг. 48 иллюстрирует псевдокод, показывающий процесс декодирования коэффициента преобразования, выполняемый декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области больше, чем некоторый размер (например, 16×16 компонентов или 32×32 компонентов).
[Фиг. 49] Фиг. 49 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования коэффициента преобразования, выполняемого декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области больше, чем некоторый размер.
[Фиг. 50] Фиг. 50 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования флагов присутствия/отсутствия коэффициента суб-блока, выполняемого декодером коэффициента преобразования согласно варианту осуществления.
[Фиг. 51] Фиг. 51 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования индивидуальных ненулевых флагов significant_coeff_flag присутствия/отсутствия коэффициента преобразования в суб-блоке, выполняемого декодером коэффициента преобразования согласно варианту осуществления.
[Фиг. 52] Фиг. 52 является блок-схемой, иллюстрирующей конфигурацию устройства кодирования видео согласно варианту осуществления.
[Фиг. 53] Фиг. 53 является блок-схемой, иллюстрирующей конфигурацию кодировщика кода с переменной длиной слова, включенного в устройство кодирования видео согласно варианту осуществления.
[Фиг. 54] Фиг. 54 является блок-схемой, иллюстрирующей конфигурацию кодировщика квантованной остаточной информации, включенного в устройство кодирования видео согласно варианту осуществления настоящего изобретения.
[Фиг. 55] Фиг. 55 является блок-схемой, иллюстрирующей конфигурацию кодировщика флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 56] Фиг. 56 является блок-схемой, иллюстрирующей конфигурацию кодировщика флага присутствия/отсутствия коэффициента суб-блока согласно варианту осуществления.
[Фиг. 57] Фиг. 57 включает в себя диаграммы, иллюстрирующие конфигурации устройства передачи, включающего в себя вышеописанное устройство кодирования видео, и устройства приема, включающего в себя вышеописанное устройство декодирования видео. Часть (a) иллюстрирует устройство передачи, включающее в себя устройство кодирования видео, и часть (b) иллюстрирует устройство приема, включающее в себя устройство декодирования видео.
[Фиг. 58] Фиг. 58 включает в себя диаграммы, иллюстрирующие конфигурации устройства записи, включающего в себя вышеописанное устройство кодирования видео, и устройства воспроизведения, включающего в себя вышеописанное устройство декодирования видео. Часть (a) иллюстрирует устройство записи, включающее в себя устройство кодирования видео, и часть (b) иллюстрирует устройство воспроизведения, включающее в себя устройство декодирования видео.
[Фиг. 59] Фиг. 59 является таблицей, показывающей другой пример индексов scanIndex сканирования суб-блоков, указанных индексами IntraPredMode режима внутреннего предсказания, и индивидуальные значения log2TrafoSize-2.
[Фиг. 60] Фиг. 60 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 8×8 компонентов.
[Фиг. 61] Фиг. 61 иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 62] Фиг. 62 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном на Фиг. 61, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) для псевдокода, иллюстрированного на Фиг. 61, и часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) для псевдокода, иллюстрированного на Фиг. 61.
[Фиг. 63] Фиг. 63 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61, и часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61.
[Фиг. 64] Фиг. 64 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует другой пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном на Фиг. 61, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) для псевдокода, иллюстрированного на Фиг. 61, и часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) для псевдокода, иллюстрированного на Фиг. 61.
[Фиг. 65] Фиг. 65 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 64 для псевдокода, иллюстрированного на Фиг. 61, и часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 64 для псевдокода, иллюстрированного на Фиг. 61.
[Фиг. 66] Фиг. 66 иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 67] Фиг. 67 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует пример CTX_IND_MAP_L [index] в псевдокоде, проиллюстрированном на Фиг. 66, и часть (b) иллюстрирует пример CTX_IND_MAP_C [index] в псевдокоде, проиллюстрированном на Фиг. 66.
[Фиг. 68] Фиг. 68 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования CTX_IND_MAP_L [index] в части (a) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66, и часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 8×8 компонентов, которые получены в случае использования CTX_IND_MAP_L [index] в части (a) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66.
[Фиг. 69] Фиг. 69 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×4 компонентов, которые получены в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66, и часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 8×8 компонентов, которые получены в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66.
[Фиг. 70] Фиг. 70 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R7, которые формируют частотную область, имеющую размер 8×8 компонентов.
[Фиг. 71] Фиг. 71 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R7, которые формируют частотную область, имеющую размер 8×8 компонентов. Кроме того, часть (a) иллюстрирует пример, в котором общий индекс контекста назначен на области R3 и R5 в 4×4 компонентов, и часть (b) иллюстрирует пример, в котором общий индекс контекста назначен на области R3 и R5 в 8×8 компонентов.
[Фиг. 72] Фиг. 72 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R7, которые формируют частотную область, имеющую размер 8×8 компонентов. Кроме того, иллюстрируется пример, в котором общий индекс контекста назначен на область R0 (компонент DC) в 4×4 компонентов в части (a) и область R7 (компонент DC) в 8×8 компонентов в части (b).
[Фиг. 73] Фиг. 73 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R7, которые формируют частотную область, имеющую размер 8×8 компонентов. Кроме того, иллюстрируется пример, в котором общий индекс контекста назначен на область R0 (компонент DC) в 4×4 компонентов в части (a) и область R7 (компонент DC) в 8×8 компонентов в части (b). Кроме того, часть (a) иллюстрирует пример, в котором общий индекс контекста назначен на области R3 и R5 в 4×4 компонентов, и часть (b) иллюстрирует пример, в котором общий индекс контекста назначен на области R3 и R5 в 8×8 компонентов.
[Фиг. 74] Фиг. 74 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем выведения опорного контекста соседнего суб-блока, включенным в декодер флага присутствия/отсутствия коэффициента согласно первому примеру модификации, который является псевдокодом, показывающим процесс выведения индексов контекста, на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к яркости Y.
[Фиг. 75] Фиг. 75 является последовательностью операций, иллюстрирующей другой пример процесса декодирования коэффициента преобразования, выполняемого декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области больше, чем некоторый размер, и иллюстрирует пример, в котором декодирование флагов присутствия/отсутствия коэффициента суб-блока и декодирование знаков и уровней ненулевых флагов присутствия/отсутствия коэффициента и индивидуальных ненулевых коэффициентов выполняются в одном и том же цикле.
[Фиг. 76] Фиг. 76 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования флагов присутствия/отсутствия коэффициента суб-блока, выполняемого декодером коэффициента преобразования согласно варианту осуществления на Фиг. 75.
[Фиг. 77] Фиг. 77 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования индивидуальных ненулевых флагов significant_coeff_flag присутствия/отсутствия коэффициента преобразования в суб-блоке, выполняемого декодером коэффициента преобразования согласно варианту осуществления на Фиг. 75.
[Фиг. 78] Фиг. 78 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области A0-A6, которые формируют частотную область, имеющую размер 16×4 компонентов, и часть (b) иллюстрирует области A0-A6, которые формируют частотный компонент, имеющий размер 4×6 компонентов.
[Фиг. 79] Фиг. 79 является диаграммой, описывающей, что шаблон разделения блока преобразования 16×4 (16×4 компонентов), и шаблон разделения блока преобразования 4×16 (4×16 компонентов), аналогичны друг другу.
[Фиг. 80] Фиг. 80 иллюстрирует псевдокод, показывающий процесс декодирования коэффициента преобразования, выполняемый декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области является некоторым размером или меньшим (например, 4×4 компонентов, 8×8 компонентов, 16×4 компонентов, или 4×16 компонентов).
[Фиг. 81] Фиг. 81 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 16×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 80, и часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×16 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 80.
[Фиг. 82] Фиг. 82 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 16×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 80, и часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×16 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 80.
[Фиг. 83] Фиг. 83 иллюстрирует псевдокод, показывающий другой пример процесса декодирования коэффициента преобразования, выполняемого декодером коэффициента преобразования согласно варианту осуществления в случае, когда размер частотной области является некоторым размером или меньшим (например, 4×4 компонентов, 8×8 компонентов, 16×4 компонентов, или 4×16 компонентов).
[Фиг. 84] Фиг. 84 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 16×4 компонентов, которые получены в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 80, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×16 компонентов, которые получены в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 80, и часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 8×8 компонентов, которые получены в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 80.
[Фиг. 85] Фиг. 85 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует области R0-R8, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) иллюстрирует области R0-R8, которые формируют частотную область, имеющую размер 8×8 компонентов.
[Фиг. 86] Фиг. 86 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87, часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87, и часть (d) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87.
[Фиг. 87] Фиг. 87 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, и часть (b) иллюстрирует пример CTX_IND_MAP [index] в псевдокоде.
[Фиг. 88] Фиг. 88 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89, часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 4×4 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89, и часть (d) иллюстрирует значения индивидуальных индексов контекста, относящихся к цветности 8×8 компонентов, которые получены в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89.
[Фиг. 89] Фиг. 89 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, и часть (b) иллюстрирует пример CTX_IND_MAP [index] в псевдокоде.
[Фиг. 90] Фиг. 90 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, часть (b) иллюстрирует пример CTX_IND_MAP [index] в псевдокоде, и часть (c) иллюстрирует другой пример CTX_IND_MAP [index] в псевдокоде.
[Фиг. 91] Фиг. 91 включает в себя диаграммы, описывающие пример процесса выведения индекса контекста, относящегося к светимости/цветности 4×4 компонентов, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно уровню техники, в котором часть (a) иллюстрирует псевдокод, показывающий пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно уровню техники, и часть (b) иллюстрирует пример CTX_IND_MAP4×4 [index] в псевдокоде.
[Фиг. 92] Фиг. 92 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования уравнения (Ур.e1) в описании, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда a=1 и b=1 в уравнении (Ур.e2) в описании, часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда a 0 и b=1 в уравнении (Ур.e2) в описании, и часть (d) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=3 и b=4 в уравнении (Ур.e3) в описании.
[Фиг. 93] Фиг. 93 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования уравнения (Ур.f1) в описании, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=3 и a=4 в уравнении (Ур.f2) в описании, часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=4 и a=4 в уравнении (Ур.f2) в описании, часть (d) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, то, которые получены в случае, когда th=1 и a=4 в уравнении (Ур.f3) в описании, часть (e) иллюстрирует значения индивидуальных индексов контекста,, относящейся к яркости 4×4 компонентов, которые получены в случае, когда th=1, a=6, b=2, и высота = 4 в уравнении (Ур.f4) в описании, и часть (f) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=1, a=6, и b=2 в уравнении (Ур.f5) в описании.
[Фиг. 94] Фиг. 94 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда a=1, b=1, и c=3 в уравнении (Ур.g1) в описании, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=3, a=1, b=1, c=3, и d=3 в уравнении (Ур.g2) в описании, часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=4, a=1, b=1, c=3, и d=3 в уравнении (Ур.g2) в описании, и часть (d) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае применения уравнения (Ур.g3) в описании.
[Фиг. 95] Фиг. 95 включает в себя диаграммы, описывающие другой пример процесса выведения индекса контекста, выполняемого модулем выведения контекста позиции, включенным в декодер флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда a=1, b=1, и c=3 в уравнении (Ур.h1) в описании, часть (b) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=3, a=1, b=1, c=3, и d=3 в уравнении (Ур.h2) в описании, часть (c) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае, когда th=4, a=1, b=1, c=3, и d=3 в уравнении (Ур.h2) в описании, и часть (d) иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые получены в случае использования уравнения (Ур.h3) в описании.
[Фиг. 96] Фиг. 96 является блок-схемой, иллюстрирующей примерную конфигурацию третьего примера модификации декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 97] Фиг. 97 является блок-схемой, иллюстрирующей примерную конфигурацию второго примера модификации кодировщика флага присутствия/отсутствия коэффициента согласно варианту осуществления.
[Фиг. 98] Фиг. 98 включает в себя диаграммы, описывающие процесс классификации, выполняемый контроллером способа выведения, включенным в третий пример модификации декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует разделение на частичные области, которые предпочтительно применяются в случае определения частичной области R0 (низкочастотный компонент) посредством использования позиции (xC, yC) коэффициента, когда коэффициенты преобразования, относящиеся к яркости и цветности, декодируются, и часть (b) иллюстрирует разделение на частичные области, которые предпочтительно применяются в случае определения частичной области R0 (низкочастотный компонент) посредством использования позиции (xCG, yCG) суб-блока, когда коэффициенты преобразования, относящиеся к яркости и цветности, декодируются.
[Фиг. 99] Фиг. 99 включает в себя диаграммы, описывающие опорные частотные компоненты, на которые ссылаются в случае, когда процесс декодирования выполняется в обратном порядке сканирования модулем выведения опорного контекста от соседнего элемента, включенным в третий пример модификации декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует отношения между позицией в частотном компоненте и шаблоном, который должен быть выбран, часть (b) иллюстрирует относительные позиции между целевым частотным компонентом x и опорными частотными компонентами c1, c2, c3, c4 и c5, часть (c) иллюстрирует относительные позиции между целевым частотным компонентом x и опорными частотными компонентами c1, c2, c4 и c5, часть и часть (d) иллюстрирует порядок сканирования (обратный порядок сканирования) в диагональном направлении в 4×4 суб-блоках.
[Фиг. 100] Фиг. 100 включает в себя диаграммы, описывающие процесс выведения индекса контекста, выполняемый модулем выведения контекста позиции, включенным в третий пример модификации декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления, в котором часть (a) иллюстрирует таблицу CTX_GRP_TBL [X] [Y] соответствия индивидуальных позиций (X, Y) коэффициента в 4×4 TU и 8×8 TU и группы контекстов, часть (b) иллюстрирует битовое выражение индивидуальных значений таблицы соответствия в части (a), и часть (c) иллюстрирует значения одного младшего бита групп контекстов соответствия в части (a).
[Фиг. 101] Фиг. 101 является диаграммой, описывающей процесс выведения индекса контекста, выполняемый модулем выведения контекста позиции, включенным в третий пример модификации декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления, и иллюстрирует пример комбинации параметров настройки групп контекстов индивидуальными битами x0, x1, y0, и y1 позиции (X, Y) коэффициента.
[Фиг. 102] Фиг. 102 включает в себя диаграммы, описывающие другой пример таблицы CTX_GRP_TBL [X][Y] соответствия индивидуальных позиций (X, Y) коэффициента в 4×4 TU и 8×8 TU и группы контекстов, в которых часть (a) иллюстрирует индивидуальные значения групп контекстов, полученных в случае применения логического вычисления, выраженного уравнением (Ур. A2-10) к шаблону 0 на Фиг. 101, часть (b) иллюстрирует индивидуальные значения групп контекстов, полученных в случае применения логического вычисления, выраженного уравнением (Ур. A2-11) к шаблону 0 на Фиг. 101, и часть (c) иллюстрирует индивидуальные значения групп контекстов, полученных в случае применения логического вычисления, выраженного уравнением (Ур. A2-12), к шаблону 0 на Фиг. 101.
[Фиг. 103] Фиг. 103 является последовательностью операций, иллюстрирующей работу модуля 124z получения контекста, включенного в третий пример модификации декодера флага присутствия/отсутствия коэффициента согласно варианту осуществления.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0027] Вариант осуществления устройства декодирования и устройства кодирования согласно настоящему изобретению описан ниже со ссылками на чертежи. Устройство декодирования согласно этому варианту осуществления декодирует закодированные данные, чтобы генерировать видео. Таким образом, устройство декодирования в дальнейшем упоминается как "устройство декодирования видео". Устройство кодирования согласно этому варианту осуществления кодирует видео, чтобы генерировать закодированные данные. Таким образом, устройство кодирования в дальнейшем упоминается как "устройство кодирования видео".
[0028] Однако диапазон применения настоящего изобретения этим не ограничен. Таким образом, как ясно из нижеследующего описания, особенности настоящего изобретения реализуются без предположения о множестве кадров. Таким образом, настоящее изобретение применимо к общим устройствам декодирования и общим устройствам кодирования независимо от того, является ли целевое изображение видео или неподвижным изображением.
[0029] (Конфигурация закодированных данных #1)
Со ссылками на Фиг. 2, описание будет дано примерной конфигурации закодированных данных #1, которые генерируются устройством 2 кодирования видео и декодируются устройством 1 декодирования видео. Закодированные данные #1 включают в себя, например, последовательность и множество картинок, которые формируют последовательность.
[0030] На уровне последовательности набор данных, к которым обращается устройство 1 декодирования видео, задается, чтобы декодировать целевую последовательность, которая должна быть обработана. Уровень последовательности включает в себя набор SPS параметров последовательности, набор PPS параметров картинки, и картинку PICT.
[0031] Структура уровня картинки и более низких уровней в закодированных данных #1 иллюстрируется на Фиг. 2. Части (a)-(d) на Фиг. 2 являются диаграммами, иллюстрирующими уровень картинки, задающий картинку PICT, уровень вырезки, задающий вырезку S, уровень блока дерева, задающий блок TBLK дерева, и уровень CU, задающий единицу кодирования (CU), включенную в блок TBLK дерева, соответственно.
[0032] (Уровень картинки)
На уровне картинки задается набор данных, на который устройство 1 декодирования видео ссылается, чтобы декодировать целевую картинку PICT, которая должна быть обработана (в дальнейшем также называемую целевой картинкой). Как иллюстрировано в части (a) на Фиг. 2, картинка PICT включает в себя заголовок PH картинки, и вырезки S1-SNS (NS представляет общее количество вырезок, включенных в картинку PICT).
[0033] В случае, когда не является необходимым различать вырезки S1-SNS друг от друга, могут быть опущены нижние индексы опорных символов. То же самое относится к данным, которые включены в закодированные данные #1, описанные ниже, и это описано с нижним индексом.
[0034] Заголовок PH картинки включает в себя группу параметров кодирования, на которую устройство 1 декодирования видео ссылается, чтобы определить способ для декодирования целевой картинки. Например, информация режима кодирования (entropy_coding_mode_flag), представляющая режим кодирования с переменной длиной кода, которое использовалось устройством 2 кодирования видео, чтобы выполнить кодирование, является примером параметров кодирования, включенных в заголовок PH картинки. _co
[0035] В случае, когда entropy ding_mode_flag равен 0, картинку PICT кодируют, используя CAVLC (основанное на контексте адаптивное кодирование с переменной длиной кода). В случае, когда entropy_coding_mode_flag равен 1, картинку PICT кодируют, используя CABAC (основанное на контексте адаптивное двоичное арифметическое кодирование).
[0036] (Уровень вырезки)
На уровне вырезки задается набор данных, на который устройство 1 декодирования видео ссылается, чтобы декодировать целевую вырезку S, которая должна быть обработана (в дальнейшем также называется как целевая вырезка). Как иллюстрировано в части (b) на Фиг. 2, вырезка S включает в себя заголовок SH вырезки и блоки TBLK1-TBLKNC дерева (NC представляет общее количество блоков дерева, включенных в вырезку S).
[0037] Заголовок SH вырезки включает в себя группу параметров кодирования, на которую устройство 1 декодирования движущегося изображения ссылается, чтобы определить способ для декодирования целевой вырезки. Информация обозначения типа вырезки (slice_type), обозначающая тип вырезки, является примером параметров кодирования, включенных в заголовок SH вырезки.
[0038] Типы вырезки, которые могут обозначаться информацией обозначения типа вырезки, включают в себя (1) вырезку I, которая использует только внутреннее предсказание для кодирования, (2) вырезку P, которая использует однонаправленное предсказание или внутреннее предсказание для кодирования, и (3) вырезку B, которая использует однонаправленное предсказание, двунаправленное предсказание, или внутреннее предсказание для кодирования.
[0039] Кроме того, заголовок SH вырезки включает в себя параметр FP фильтра, на который ссылается контурный фильтр, включенный в устройство 1 декодирования видео. Параметр FP фильтра включает в себя группу коэффициентов фильтра. Группа коэффициентов фильтра включает в себя (1) информацию обозначения количества сигналов, обозначающая количество выводов фильтра, (2) коэффициенты фильтра a0-aNT1 (NT представляет общее количество коэффициентов фильтра, включенных в группу коэффициентов фильтра), и (3) смещение.
[0040] (Уровень блока дерева)
На уровне блока дерева задается набор данных, на которые устройство 1 декодирования видео ссылается, чтобы декодировать целевой блок TBLK дерева, который должен быть обработан, (в дальнейшем также именуется как целевой блок дерева).
[0041] Блок TBLK дерева включает в себя заголовок TBLKH блока дерева и части информации единицы кодирования CU1-CUNL (NL представляет общее количество частей информации единицы кодирования, включенной в блок TBLK дерева). Теперь, соотношения между блоком TBLK дерева и информацией CU единицы кодирования будет описано ниже.
[0042] Блок TBLK дерева разделяется на блоки для того, чтобы задать размер блока для индивидуальных процессов внутреннего предсказания или внешнего предсказания, и преобразования.
[0043] Блок Блок TBLK дерева разделяется, используя рекурсивное разделение квадродерева. Структура дерева, полученная посредством рекурсивного разделения квадродерева, в дальнейшем упоминается как дерево кодирования.
[0044] В дальнейшем, блок, соответствующий листу, который является концевым узлом дерева кодирования, упоминается как узел кодирования. Узел кодирования служит основной единицей процесса кодирования, и таким образом узел кодирования также упоминается как единица кодирования (CU) в дальнейшем.
[0045] Таким образом, части информации CU1-CUNL единицы кодирования являются частями информации, соответствующей индивидуальным узлам кодирования (единицам кодирования), которые получены посредством деления блока TBLK дерева, используя рекурсивное разделение квадродерева.
[0046] Корень дерева кодирования ассоциирован с блоком TBLK дерева. Другими словами, блок TBLK дерева ассоциирован с верхним узлом структуры дерева разделения квадродерева, которое рекурсивно включает в себя множество узлов кодирования.
[0047] Размер каждого узла кодирования является половиной размера узла кодирования, которому непосредственно принадлежит этот узел кодирования (то есть, единицы узла, который находится выше на один уровень, чем этот узел кодирования) в горизонтальном и вертикальном направлениях.
[0048] Возможный размер каждого узла кодирования зависит от информации обозначения размера и максимальной иерархической глубины узла кодирования, которые включены в набор SPS параметров последовательности закодированных данных #1. Например, в случае, когда размер блока TBLK дерева соответствует 64×64 пикселям и максимальная иерархическая глубина равна 3, узел кодирования на уровне ниже, чем этот блок TBLK дерева, может быть любого из четырех размеров: 64×64 пикселей, 32×32 пикселей, 16×16 пикселей и 8×8 пикселей.
[0049] (Заголовок блока дерева)
Заголовок TBLKH блока дерева включает в себя параметры кодирования, на которые устройство 1 декодирования видео ссылается, чтобы определить способ для декодирования целевого блока дерева. В частности, как иллюстрировано в части (c) на Фиг. 2, заголовок TBLKH блока дерева включает в себя информацию SP_TBLK разделения блока дерева, которая обозначает шаблон разделения для деления целевого блока дерева на индивидуальные CU, и разность Δqp параметров квантования (qp_delta), который обозначает величину шага квантования.
[0050] Информация SP_TBLK разделения блока дерева является информацией, представляющей дерево кодирования для деления блока дерева, и является в частности информацией, обозначающей формы и размеры индивидуальных CU, включенных в целевой блок дерева и позиции этих CU в целевом блоке дерева.
[0051] Информация разделения блока дерева SP_TBLK не обязательно включает в себя формы и размеры единиц CU явным образом. Например, информация SP_TBLK разделения блока дерева может быть набором флагов (split_coding_unit_flag), указывающих, должен ли весь целевой блок дерева или частичная область блока дерева быть разделен на четыре области. В этом случае форма и размер блока дерева могут также быть использованы для задания формы и размеров индивидуальных CU.
[0052] Разность Δqp параметров квантования является разностью qp-qpʹ между параметром qp квантования в целевом блоке дерева и параметром qpʹ квантования в блоке дерева, который был закодирован непосредственно перед целевым блоком дерева.
[0053] (уровень CU)
На уровне CU задается набор данных, на которые устройство 1 декодирования видео ссылается, чтобы декодировать целевую CU, которая должна быть обработана (в дальнейшем также называемую целевая CU).
[0054] Прежде чем описать подробности данных, включенных в информацию единицы кодирования CU, структура дерева данных, включенных в CU, описывается. Узел кодирования служит узлом корня дерева предсказания (PT) и дерева преобразования (TT). Дерево предсказания и дерево преобразования будут описаны ниже.
[0055] В дереве предсказания узел кодирования разделен на один или множественные блоки предсказания, и позиции и размеры индивидуальных блоков предсказания заданы. В другом выражении блоки предсказания являются одной или множественными областями, которые формируют узел кодирования, и которые не накладывается друг с другом. Дерево предсказания включает в себя один или множественные блоки предсказания, полученные с помощью предшествующего разделения.
[0056] Процесс предсказания выполняется в отношении каждого блока предсказания. В дальнейшем, блок предсказания, который также служит единицей предсказания, также упоминается как единица предсказания (PU).
[0057] Грубо, имеются два типа разделения в дереве предсказания, то есть, случай внутреннего предсказания и случай внешнего предсказания. В случае внутреннего предсказания может использоваться способ разделения 2N×2N (тот же размер как узел кодирования) или N×N. В случае внешнего предсказания может использоваться способ разделения 2N×2N (тот же размер как узел кодирования), 2N×N, N×2N, или N×N.
[0058] В дереве преобразования узел кодирования разделен на один или множественное число блоков преобразования, и позиции и размеры индивидуальных блоков преобразования заданы. В другом выражении, блоки преобразования являются одной или множественными областями, которые формируют узел кодирования, и которые не накладывается друг с другом. Дерево преобразования включает в себя один или множественные блоки преобразования, полученные с помощью предшествующего разделения.
[0059] Процесс преобразования выполняется для каждого блока преобразования. В дальнейшем блок преобразования, который является единицей преобразования, также упоминается как единица преобразования (TU).
[0060] (Структура данных информации единицы кодирования)
Ниже, подробности данных, включенных в информацию CU единицы кодирования, будут описаны в отношении части (d) на Фиг. 2. Как иллюстрировано в части (d) на Фиг. 2, информация единицы кодирования CU в частности включает в себя флаг SKIP режима пропуска, информацию Pred_type типа предсказания CU, информацию PTI PT, и информацию TTI TT.
[0061][Флаг SKIP]
Флаг SKIP пропуска является флагом, указывающим, применен ли режим пропуска к целевой CU. В случае, когда значение флага SKIP пропуска равно 1, то есть, в случае, когда режим пропуска применен к целевой CU, информация PTI PT в информации CU единицы кодирования опущен. Следует отметить, что флаг SKIP пропуска опущен в вырезке I.
[0062][Информация типа предсказания CU]
Информация Pred_type типа предсказания CU включает в себя информацию PredMode схемы предсказания CU и информацию PartMode типа разделения PU. Информация типа предсказания CU может просто упоминаться как информация типа предсказания.
[0063] Информация PredMode схемы предсказания CU обозначает любое из внутреннего предсказания (внутренняя CU), и внешнее предсказание (внешняя CU), которые должны использоваться как способ генерирования изображения предсказания для каждой PU, включенной в целевую CU. Ниже классификация пропуска, внутреннего предсказания и внешнего предсказания в целевой CU упоминается как режим предсказания CU.
[0064] Информация PartMode типа разделения PU обозначает тип разделения PU, который является шаблоном деления целевой единицы кодирования (CU) в индивидуальные PU. Ниже разделение целевой единицы кодирования (CU) в индивидуальные PU в соответствии с типом разделения PU упоминается как разделение PU.
[0065] Информация PartMode типа разделения PU может быть, например, индексом, указывающим тип шаблона разделения PU, и формы и размеры индивидуальных PU, включенных в целевое дерево предсказания и позиции индивидуальных PU в целевом дереве предсказания, может быть обозначена.
[0066] Выбираемый тип разделения PU изменяется в соответствии со схемой предсказания CU и размером CU. Кроме того, выбираемый тип разделения PU изменяется в каждом случае из внешнего предсказания и внутреннего предсказания. Подробности типов разделения PU будут описаны подробно ниже.
[0067] В случае вырезки, отличной от вырезки I, значение информации PartMode типа разделения PU и значение информации PartMode типа разделения PU может быть задано индексом (cu_split_pred_part_mode), который обозначает комбинацию способов для разделения блока дерева, схемы предсказания, и разделение CU.
[0068][Информация PT]
Информация PTI PT является информацией относительно PT, включенного в целевую CU. Другими словами, информация PTI PT является набором частей информации относительно одной или множественных PU, включенных в PT. Как описано выше, изображение предсказания генерируется в единицах PU, и таким образом на информацию PTI PT ссылаются, когда предсказывающее изображение генерируется устройством 1 декодирования видео. Как иллюстрировано в части (d) на Фиг. 2, информация PTI PT включает в себя части информации PU PUI1-PUINP (NP представляет общее количество PU, включенных в целевое PT), включая информацию предсказания и т.д. в каждой PU.
[0069] Информация предсказания PUI включает в себя, в соответствии со способом предсказания, обозначенным информацией Pred_mode типа предсказания, параметр PP_Intra внутреннего предсказания или параметр PP_Inter внешнего предсказания. В дальнейшем, PU, к которой применено внутреннее предсказание, также называется как внутренняя PU, и PU, к которой применено внешнее предсказание, также упоминается как внешняя PU.
[0070] Параметр PP_Inter внешнего предсказания включает в себя параметры кодирования, к которым обращается устройство 1 декодирования видео при генерировании изображения внешнего предсказания, посредством выполнения внешнего предсказания
[0071] Параметр PP_Inter внешнего предсказания включает в себя, например, флаг (merge_flag) слияния, индекс (merge_idx) слияния, индекс (mvp_idx) оцененного вектора движения, опорный индекс (ref_idx) изображения, флаг внешнего предсказания (inter_pred_flag), и остаток вектора движения (mvd).
[0072] Параметр PP_Intra внутреннего предсказания включает в себя параметры кодирования, к которым обращается устройство 1 декодирования видео при генерировании изображения внутреннего предсказания, посредством выполнения внутреннего предсказания.
[0073] Параметр PP_Intra внутреннего предсказания включает в себя, например, флаг оцененного режима предсказания, индекс оцененного режима предсказания, и индекс режима остаточного предсказания.
[0074] Параметр внутреннего предсказания может включать в себя флаг режима PCM, указывающий, должен ли использоваться режим PCM. В случае, когда флаг режима PCM закодирован и флаг режима PCM указывает, что режим PCM должен использоваться, процесс предсказания (внутренний), процесс преобразования, и энтропийное кодирование опущены.
[0075][Информация TT]
Информация TTI TT является информацией относительно TT, включенного в CU. Другими словами, информация TTI TT является набором частей информации относительно одной или множественных TU, включенных в TT, и на который ссылаются, когда устройство 1 декодирования видео декодирует остаточные данные. В дальнейшем, TU может упоминаться как блок.
[0076] Как иллюстрировано в части (d) на Фиг. 2, информация TTI TT включает в себя информацию SP_TU разделения TT, обозначающую шаблон разделения целевой CU в индивидуальные блоки преобразования, и части информации TU TUI1-TUINT (NT представляет общее количество блоков, включенных в целевую CU).
[0077] В частности, информация SP_TU разделения TT является информацией для того, чтобы определить формы и размеры индивидуальных TU, включенных в целевую CU и позиции индивидуальных TU в целевой CU. Например, информация SP_TU TT_split может быть составлена из информации, указывающей, должен ли целевой узел быть разделен (split_transform_flag) и информации, представляющей глубину разделения (trafo_Depth).
[0078] Например, в случае, когда размер CU равен 64×64, каждая TU, полученная посредством разделения, может иметь размер 32×32 пикселей - 4×4 пикселей.
[0079] Части информации TU TUI1-TUINT являются индивидуальными частями информации относительно одной или множественных TU, включенных в TT. Например, информация TUI TU включает в себя квантованный остаток предсказания (также называемый квантованный остаток).
[0080] Каждый квантованный остаток предсказания является закодированными данными, которые генерируются посредством выполнения устройством 2 кодирования видео следующие процессов 1-3 в отношении целевого блока, который должен быть обработан.
[0081] Процесс 1: Выполняют частотное преобразование (например, DCT (дискретное косинусное преобразование)) в отношении остатка предсказания, полученного посредством вычитания изображения предсказания из целевого изображения, которое должно быть закодировано;
Процесс 2: Квантут коэффициент преобразования, полученный в процессе 1; и
Процесс 3: Выполняют кодирование с переменной длиной кода в отношении коэффициента преобразования, квантованного в процессе 2,
в котором вышеописанный параметр qp квантования представляет величину шага квантования QP, который используется, когда устройство 2 кодирования видео квантует коэффициент преобразования (QP=2qp/6).
[0082] (Тип разделения PU)
Тип разделения PU имеет следующие восемь шаблонов, в случае, когда размер целевой CU соответствует 2N×2N пикселям: четыре шаблона симметричного разделения, включая 2N×2N пикселей, 2N×N пикселей, N×2N пикселей, и N×N пикселей, и четыре шаблона асимметричного разделения, включая 2N×nU пикселей, 2N×nD пикселей, nL×2N пикселей, и nR×2N пикселей. Следует отметить, что N=2m (m является некоторым целым числом 1 или более). В дальнейшем, области, полученные посредством разделения целевой CU, также упоминаются как разделения.
[0083] Части (a)-(h) на Фиг. 3 конкретно иллюстрируют позицию границы разделения PU в CU для индивидуальных типов разделения.
[0084] Часть (a) на Фиг. 3 иллюстрирует тип разделения PU 2N×2N, в котором CU не разделяется. Части (b), (c) и (d) на Фиг. 3 иллюстрируют формы разделения в случаях, когда типами разделения PU являются 2N×N, 2N×nU, и 2N×nD, соответственно. Части (e), (f), и (g) на Фиг. 3 иллюстрируют формы разделения в случаях, когда типами разделения PU являются N×2N, nL×2N, и nR×2N, соответственно. Часть (h) на Фиг. 3 иллюстрирует формы разделения в случае, когда типом разделения PU является N×N.
[0085] Типы разделения PU, иллюстрированные в частях (a), и (h) на Фиг. 3, также упоминаются как квадратное разделение, на основе форм разделения. Типы разделения PU, иллюстрированные в частях (b)-(g) на Фиг. 3, также упоминаются как неквадратное разделение.
[0086] В частях (a)-(h) на Фиг. 3, числа, заданные в индивидуальных областях, представляют идентификационные номера областей. Процесс выполняется в отношении областей в порядке, указанном идентификационными номерами. Таким образом, идентификационные номера представляют порядок сканирования областей.
[0087][Тип разделения во внешнем предсказании]
Во внешнем PU семь типов разделения среди вышеописанных восьми типов (кроме N×N (часть (h) на Фиг. 3)) определены. Вышеописанные шесть типов асимметричного разделения могут упоминаться как AMP (Асимметричное Разделение Движения).
[0088] Конкретное значение N задается размером CU, которой принадлежит PU, и конкретные значения nD, nD, nL, и nR определяются в соответствии со значением N. Например, внешняя CU из 128×128 пикселей может быть разделена на внешние PU из 128×128 пикселей, 128×64 пикселей, 64×128 пикселей, 64×64 пикселей, 128×32 пикселей, 128×96 пикселей, 32×128 пикселей, и 96×128 пикселей.
[0089][Тип разделения во внутреннем предсказании]
Во внутренней PU следующие два типа шаблонов разделения определены: шаблон разделения 2N×2N, в котором целевая CU не разделена, то есть, целевая CU расценивается как единственная PU; и шаблон N×N, в котором целевая CU симметрично разделена на четыре PU. Таким образом, во внутренней PU в примере, проиллюстрированном на Фиг. 3, шаблоны разделения, иллюстрированные в частях (a) и (h), могут использоваться. Например, внутренняя CU из 128×128 пикселей может быть разделена во внутренние PU из 128×128 пикселей и 64×64 пикселей.
[0090] (Тип разделения TU)
Затем, типы разделения TU будут описаны в отношении частей (i)-(o) на Фиг. 3. Шаблон разделения TU определяется размером CU, глубиной разделения (trafoDepth), и типом разделения PU целевой PU.
[0091] Шаблоны разделения TU включают в себя квадратное разделение квадродерева и неквадратное разделение квадродерева.
[0092] Части (i)-(k) на Фиг. 3 иллюстрируют схемы разделения для выполнения квадратного разделения квадродерева или неквадратного разделения квадродерева в отношении квадратного узла. Более конкретно, часть (i) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении квадратного узла, чтобы сформировать квадраты. Часть (j) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении квадратного узла, чтобы сформировать горизонтально длинные прямоугольники. Часть (k) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении квадратного узла, чтобы сформировать вертикально длинные прямоугольники.
[0093] Части (l)-(o) на Фиг. 3 иллюстрируют схемы разделения для выполнения разделения квадродерева в отношении неквадратного узла, чтобы сформировать квадраты или неквадраты. Более конкретно, часть (l) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении горизонтально длинного прямоугольного узла, чтобы сформировать горизонтально длинные прямоугольники. Часть (m) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении горизонтально длинного прямоугольного узла, чтобы сформировать квадраты. Часть (n) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении вертикально длинного прямоугольного узла, чтобы сформировать вертикально длинные прямоугольники. Часть (o) на Фиг. 3 иллюстрирует схему разделения для выполнения разделения квадродерева в отношении вертикально длинного прямоугольного узла, чтобы сформировать квадраты.
[0094] (Конфигурация квантованной остаточной информации QD)
Фиг. 4 и 5 иллюстрируют индивидуальные элементы синтаксиса, включенные в квантованную остаточную информацию QD (иллюстрированную как residual_coding_cabac () на Фиг. 4).
[0095] Фиг. 4 является диаграммой, иллюстрирующей первую половинную часть таблицы синтаксиса, показывающей элементы синтаксиса, включенные в квантованную остаточную информацию QD. Фиг. 5 является диаграммой, иллюстрирующей последнюю половинную часть таблицы синтаксиса, показывающей элементы синтаксиса, включенные в квантованную остаточную информацию QD.
[0096] Как иллюстрировано на Фиг. 4 и 5, квантованная остаточная информация QD включает в себя элементы синтаксиса last_significant_coeff_x, last_significant_coeff_y, significant_coeffgroup_flag, significant_coeff_flag, coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, coeff_sign_flag, и coeff_abs_level_minus3.
[0097] Индивидуальные элементы синтаксиса, включенные в квантованную остаточную информацию QD, были закодированы, используя основанное на контексте адаптивное двоичное арифметическое кодирование (CABAC).
[0098] (Процесс декодирования в случае, когда размер блока является некоторым размером или меньшим)
В дальнейшем, описание будет дано процедуры декодирования индивидуальных элементов синтаксиса в случае, когда размер блока является некоторым размером или меньшим со ссылками на Фиг. 4-6. Здесь, предполагается, что размер блока соответствует 8×8 пикселям. Размер блока, который является некоторым размером или меньшим, означает, например, 8×8 пикселей или 4×4 пикселей, но это не ограничивает вариант осуществления (то же самое относится к нижеследующему описанию).
[0099] В частях (a)-(g) на Фиг. 6, горизонтальная ось представляет частоту xC горизонтального направления (0≤xC≤7), и вертикальная ось представляет частоту yC вертикального направления (0≤yC≤7). В следующем описании, среди частичных областей, включенных в частотную область, частичная область, обозначенная частотой xC горизонтального направления и частотой yC вертикального направления, также упоминается как частотный компонент (xC, yC). Коэффициент преобразования для частотного компонента (xC, yC) также упоминается как Coeff (xC, yC). Коэффициент преобразования Coeff (0, 0) представляет компонент DC, и другие коэффициенты преобразования представляют компоненты, отличные от компонента DC. В этом описании (xC, yC) может упоминаться как (u, v).
[0100] Части (a) и (b) являются диаграммами, иллюстрирующими примеры порядка сканирования в частотной области FR, составленной из 8×8 частотных компонентов.
[0101] В примере, проиллюстрированном в части (a) на Фиг. 6, сканирование последовательно выполняется от стороны низких частот (сверху слева в части (a) на Фиг. 6) к стороне высоких частот (снизу справа в части (a) на Фиг. 6). В примере, проиллюстрированном в части (a) на Фиг. 6, сканирование выполняется вдоль стрелок, показанных в частотной области FR. Порядок сканирования, иллюстрированный в части (a) на Фиг. 6, может упоминаться как прямое сканирование.
[0102] С другой стороны, в примере, проиллюстрированном в части (b) на Фиг. 6, сканирование последовательно выполняется от стороны высоких частот (снизу справа в части (b) на Фиг. 6) к стороне низких частот (сверху слева в части (b) на Фиг. 6). В примере, проиллюстрированном в части (b) на Фиг. 6, сканирование выполняется вдоль стрелок, показанных в частотной области FR. Порядок сканирования, иллюстрированный в части (b) на Фиг. 6, может упоминаться как обратное сканирование.
[0103] Часть (c) на Фиг. 6 является диаграммой, иллюстрирующей пример коэффициентов преобразования, которые не являются нулем (ненулевые коэффициенты преобразования) в частотной области, составленной из 8×8 частотных компонентов.
[0104] Элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y являются элементами синтаксиса, указывающими позицию последнего ненулевого коэффициента преобразования вдоль прямого направления сканирования. В примере, проиллюстрированном в части (c) на Фиг. 6, last_significant_coeff_x = 6, и last_significant_coeff_y=0.
[0105] Элемент синтаксиса significant_coeff_flag является элементом синтаксиса, который указывает, для каждого частотного компонента вдоль обратного направления сканирования с ненулевым коэффициентом преобразования, являющимся исходным, присутствием/отсутствием ненулевого коэффициента преобразования. Часть (d) на Фиг. 6 иллюстрирует значения элемента синтаксиса significant_coeff_flag в случае, когда коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (c) на Фиг. 6. Как иллюстрировано в части (d) на Фиг. 6, элемент синтаксиса significant_coeff_flag является флагом, который указывает, для каждого xC и yC, 0, если коэффициент преобразования равен 0, и 1, если коэффициент преобразования не равен 0. Элемент синтаксиса significant_coeff_flag также упоминается как флаг присутствия/отсутствия коэффициента преобразования.
[0106] Элемент синтаксиса coeff_abs_level_greater1_flag является флагом, который указывает, превышает ли абсолютное значение коэффициента преобразования 1, и закодировано для частотного компонента, в котором значение элемента синтаксиса significant_coeff_flag равно 1. В случае, когда абсолютное значение коэффициента преобразования превышает 1, значение coeff_abs_level_greater1_flag равно 1, и иначе значение coeff_abs_level_greater1_flag равно 0.
[0107] Элемент синтаксиса coeff_abs_level_greater2_flag является флагом, который указывает, превышает ли абсолютное значение коэффициента преобразования 2, и кодируется, когда значение coeff_abs_level_greater1_flag равно 1. В случае, когда абсолютное значение коэффициента преобразования превышает 2, значение coeff_abs_level_greater2_flag равно 1, и иначе значение coeff_abs_level_greater2_flag равно 0.
[0108] Элемент синтаксиса coeff_abs_level_minus3 является элементом синтаксиса для, в случае, когда абсолютное значение коэффициента преобразования равно или больше, чем 3, определения абсолютного значения коэффициента преобразования, и кодируется, когда значение coeff_abs_level_greater2_flag равно 1. Значение элемента синтаксиса coeff_abs_level_minus3 равно значению, полученному посредством вычитания 3 из абсолютного значения коэффициента преобразования. Например, coeff_abs_level_minus3 = 1 указывает, что абсолютное значение коэффициента преобразования равно 4.
[0109] Часть (e) на Фиг. 6 иллюстрирует абсолютные значения индивидуальных коэффициентов преобразования, которые были выведены посредством декодирования элементов синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, и coeff_abs_level_minus3.
[0110] Элемент синтаксиса coeff_sign_flag является флагом, который указывает знак коэффициента преобразования (положительный или отрицательный), и кодируется для частотного компонента, в котором значение элемента синтаксиса significant_coeff_flag равно 1.
[0111] Часть (f) на Фиг. 6 является диаграммой, иллюстрирующей элемент синтаксиса coeff_sign_flag в случае, когда коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (c) на Фиг. 6. Как иллюстрировано в части (f) на Фиг. 6, элемент синтаксиса coeff_sign_flag является флагом, который указывает 1 в случае, когда знак коэффициента преобразования положителен, и указывает 0 в случае, когда знак коэффициента преобразования отрицателен.
[0112] Декодер 11 кода с переменной длиной слова, включенный в устройство 1 декодирования видео, декодирует элементы синтаксиса last_significant_coeff_x, last_significant_coeff_y, significant_coeff_flag, coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, coeff_sign_flag, и coeff_abs_level_minus3, и таким образом способен к генерированию коэффициентов преобразования Coeff (xC, yC) для индивидуальных частотных компонентов.
[0113] Набор ненулевых коэффициентов преобразования в конкретной области (например, TU) может упоминаться "как карта значимости".
[0114] Предпочтительно, декодирование элементов синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, coeff_sign_flag, и coeff_abs_level_minus3 последовательно выполняется после того, как частотные компоненты в частотной области были разделены на одну или множественные частичные области или подгруппы (подобласти), из частичной области или подгруппы на стороне высоких частот независимо от размера блока. Часть (g) на Фиг. 6 иллюстрирует пример, в котором частотная область, составленная из 8×8 частотных компонентов, разделена на частичные области. В примере, проиллюстрированном в части (g) на Фиг. 6, декодирование выполняется в отношении индивидуальных частичных областей в порядке третья группа, вторая группа, первая группа и нулевая группа.
[0115] (Процесс декодирования в случае, когда размер блока больше, чем некоторый размер)
В случае, когда размер блока целевого блока, который должен быть обработан, больше, чем некоторый размер, декодер 11 кода с переменной длиной слова, включенный в устройство 1 декодирования видео, делит частотную область на множество суб-блоков, и декодирует significant_coeff_flag, с каждым из суб-блоков, являющихся единицей процесса. Квантованная остаточная информация QD включает в себя, в единицах суб-блоков, флаг, указывающий, существует ли по меньшей мере один ненулевой коэффициент преобразования в суб-блоке (флаг присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag). Размер блока, больший чем некоторый размер, означает, например, 16×16 пикселей, 32×32 пикселей, 4×16 пикселей, 16×4 пикселей, 8×32 пикселей и 32×8 пикселей, но этот вариант осуществления не ограничен этим (то же самое относится к нижеследующему описанию).
[0116] В дальнейшем описание будет дано процесса декодирования в случае, когда размер блока больше, чем некоторый размер, со ссылками на фиг. 7 и 8.
[0117] Часть (a) на Фиг. 7 является диаграммой, иллюстрирующей порядок сканирования относительно множества из (4×4=16 в части (a) на Фиг. 7) суб-блоков, которые получены посредством деления блока. В дальнейшем сканирование, которое выполняется в единицах суб-блоков, также упоминается как сканирование суб-блока. В случае, когда сканирование выполняется в отношении суб-блоков, как иллюстрировано в части (a) на Фиг. 7, сканирование выполняется в отношении индивидуальных частотных областей в суб-блоках в порядке сканирования, проиллюстрированном в части (b) на Фиг. 7. Порядок сканирования, иллюстрированный в частях (a) и (b) на Фиг. 7, также упоминается "как прямое сканирование".
[0118] Часть (c) на Фиг. 7 является диаграммой, иллюстрирующей порядок сканирования относительно множества из (4×4=16 в части (c) на Фиг. 7) суб-блоков, полученные посредством деления блока. В случае, когда сканирование выполняется в отношении суб-блоков способом, проиллюстрированным в части (c) на Фиг. 7, сканирование выполняется в отношении индивидуальных частотных областей в суб-блоках в порядке сканирования, проиллюстрированном в части (d) на Фиг. 7. Порядок сканирования, иллюстрированный в частях (c) и (d) на Фиг. 7, также упоминается "как обратное сканирование".
[0119] Часть (a) на Фиг. 8 является диаграммой, иллюстрирующей порядок сканирования в случае, когда блок, имеющий размер 8×8, разделен на суб-блоки каждый имеющий размер 4×4, и индивидуальные частотные компоненты сканируются прямым сканированием. Части (a)-(f) на Фиг. 8 являются диаграммами, описывающими процесс декодирования в случае, когда размер блока больше, чем некоторый размер. Для удобства описания блоки, имеющие размер 8×8, иллюстрированы в качестве примера.
[0120] Часть (b) на Фиг. 8 является диаграммой, иллюстрирующей пример коэффициентов преобразования, которые не являются нулем (ненулевые коэффициенты преобразования) в частотной области, составленной из 8×8 частотных компонентов. В примере, проиллюстрированном в части (b) на Фиг. 8, last_significant_coeff_x=6, и last_significant_coeff_y=0.
[0121] Часть (c) на Фиг. 8 является диаграммой, иллюстрирующей индивидуальные значения флагов присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag, которые были декодированы для индивидуальных суб-блоков в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b) на Фиг. 8. Значение significant_coeffgroup_flag для суб-блока, включающего в себя по меньшей мере один ненулевой коэффициент преобразования, равно 1, тогда как значение significant_coeffgroup_flag для суб-блока не включающего в себя ненулевые коэффициенты преобразования, равно 0.
[0122] Часть (d) на Фиг. 8 является диаграммой, иллюстрирующей индивидуальные значения элементов синтаксиса significant_coeff_flag указывающих присутствие/отсутствие ненулевого коэффициента преобразования в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b) на Фиг. 8. Для суб-блока, в котором significant_coeffgroup_flag=1, significant_coeff_flag декодируется в обратном порядке сканирования. Для суб-блока, в котором significant_coeffgroup_flag=0, significant_coeff_flag для суб-блока не декодируется, и significant_coeff_flag для всех частотных компонентов, включенных в суб-блок, установлен в 0 (нижний левый суб-блок в части (d) на Фиг. 8).
[0123] Часть (e) на Фиг. 8 иллюстрирует абсолютные значения индивидуальных коэффициентов преобразования, которые были выведены посредством декодирования элементов синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, и coeff_abs_level_minus3 в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b) на Фиг. 8.
[0124] Часть (f) на Фиг. 8 является диаграммой, иллюстрирующей элементы синтаксиса coeff_sign_flag в случае, когда целевые коэффициенты преобразования, которые должны быть декодированы, являются теми, что проиллюстрированы в части (b) на Фиг. 8.
[0125] Подробности процесса декодирования различных элементов синтаксиса будут описаны ниже. Ниже описана конфигурация устройства 1 декодирования видео.
[0126] (Устройство 1 декодирования видео)
В дальнейшем, устройство 1 декодирования видео согласно этому варианту осуществления будет описано со ссылками на Фиг. 1 и 9-51. Устройство 1 декодирования видео является устройством декодирования, которое совместимо с технологией, принятой для стандарта H.264/MPEG-4 AVC, технологией, принятой для программного обеспечения KTA, которое является кодеком для объединенного развития в VCEG (Группа Эксперта по Кодированию видео), технологией, принятой для программного обеспечения TMuC (Тестовая Модель на рассмотрении), и технологией, предложенной HEVC (Высокоэффективное кодирование видео), которое является последующим кодеком для предшествующих технологий.
[0127] Фиг. 9 является блок-схемой, иллюстрирующей конфигурацию устройства 1 декодирования видео. Как иллюстрировано на Фиг. 9, устройство 1 декодирования видео включает в себя декодер 11 кода с переменной длиной слова, генератор 12 изображения предсказания, блок 13 деквантования/обратного преобразования, сумматор 14, память 15 кадров, и контурный фильтр 16. Кроме того, как иллюстрировано на Фиг. 9, генератор 12 изображения предсказания включает в себя блок 12a восстановления вектора движения, генератор 12b изображения внешнего предсказания, генератор 12c изображения внутреннего предсказания, и блок 12d определения схемы предсказания. Устройство 1 декодирования видео является устройством для декодирования закодированных данных #1, чтобы генерировать видео #2.
[0128] (Декодер 11 кода с переменной длиной слова)
Фиг. 10 является блок-схемой, иллюстрирующей конфигурацию главной части декодера 11 кода с переменной длиной слова. Как иллюстрировано на Фиг. 10, декодер 11 кода с переменной длиной слова включает в себя декодер 111 квантованной остаточной информации, декодер 112 параметров предсказания, декодер 113 информации типа предсказания и декодер 114 параметров фильтра.
[0129] Декодер 11 кода с переменной длиной слова декодирует в декодере 112 параметров предсказания закодированные данные #1, чтобы получить PP параметров предсказания, относящихся к индивидуальному разделению, и подает их генератору 12 изображения предсказания. В частности, декодер 112 параметров предсказания декодирует, относительно разделения внешнего предсказания, закодированные данные #1, чтобы получить параметр PP_Inter внешнего предсказания, включающий индекс опорного изображения, индекс оцененного вектора движения, и остаток вектора движения, и подает их к блоку 12a восстановления вектора движения. С другой стороны, относительно разделения внутреннего предсказания, декодер 112 параметров предсказания декодирует закодированные данные #1, чтобы получить параметр PP_Intra внутреннего предсказания, включая флаг оцененного режима предсказания, индекс оцененного режима предсказания, и индекс режима остаточного предсказания, и подает их генератору 12c изображения внутреннего предсказания.
[0130] Декодер 11 кода с переменной длиной слова декодирует, в декодере 113 информации типа предсказания, закодированные данные #1, чтобы получить информацию Pred_type типа предсказания относительно каждого разделения, и подает ее к блоку 12d определения схемы предсказания. Далее, декодер 11 кода с переменной длиной слова декодирует, в декодере 111 квантованной остаточной информации, закодированные данные #1, чтобы получить квантованную остаточную информацию QD, относящуюся к блоку, и квантованную разность Δqp параметров, относящуюся к TU, включающую в себя этот блок, и подает их на блок 13 деквантования/обратного преобразования. Кроме того, декодер 11 кода с переменной длиной слова декодирует, в декодере 114 параметров фильтра, закодированные данные #1, чтобы получить параметр FP фильтра, и подает его к контурному фильтру 16. Конкретная конфигурация декодера 111 квантованной остаточной информации будет описана ниже, и таким образом его описание здесь опущено.
[0131] (Генератор 12 изображения предсказания)
Генератор 12 изображения предсказания идентифицирует, на основе информации Pred_type типа предсказания относительно каждого разделения, является ли разделение разделением внешнего предсказания, в отношении которого внешнее предсказание должно быть выполнено или разделение внутреннего предсказания, в отношении которого должно быть выполнено внутреннее предсказание. В первом случае генератор 12 изображения предсказания генерирует изображение Pred_Inter внешнего предсказания, и подает сгенерированное изображение Pred_Inter внешнего предсказания, которое является изображением Pred предсказания, к сумматору 14. В последнем случае генератор 12 изображения предсказания генерирует изображение Pred_Intra внутреннего предсказания, и подает сгенерированное изображение Pred_Intra внутреннего предсказания к сумматору 14. В случае, когда режим пропуска применен к целевой PU, который должен быть обработан, генератор 12 изображения предсказания пропускает декодирование других параметров, принадлежащих PU.
[0132] (Блок 12a восстановления вектора движения)
Блок 12a восстановления вектора движения восстанавливает вектор mv движения, относящийся к каждому разделению внешнего предсказания посредством использования остатка вектора движения, относящегося к разделению, и восстановленные вектора mvʹ движения, относящегося к другому разделению. В частности, блок 12a восстановления вектора движения получает вектор mv движения посредством (1) выведения оцененного вектора движения из восстановленных векторов mvʹ движения в соответствии со способом оценки, указанным индексом оцененного вектора движения, и (2) суммирования полученного оцененного вектора движения и остатка вектора движения. Восстановленные вектора mvʹ движения, относящиеся к другому разделению, могут быть считаны из памяти 15 кадров. Блок 12a восстановления вектора движения подает восстановленный вектор mv движения к генератору 12b изображения внешнего предсказания вместе с соответствующим индексом RI опорного изображения.
[0133] (Генератор 12b изображения внешнего предсказания)
Генератор 12b изображения внешнего предсказания генерирует изображение mc компенсации движения, относящееся к каждому разделению внешнего предсказания, посредством использования внешнего предсказания. В частности, генератор 12b изображения внешнего предсказания генерирует изображение mc компенсации движения из адаптивного фильтрованного декодированного изображения P_ALFʹ, указанного индексом RI опорного изображения, подаваемым от блока 12a восстановления вектора движения, посредством использования вектора mv движения, подаваемого от блока 12a восстановления вектора движения. Здесь, адаптивное фильтрованное декодированное изображение P_ALFʹ является изображением, полученным посредством выполнения процесса фильтрации контурным фильтром 16 в отношении декодированного изображения, в отношении которого было закончено декодирование по всему кадру. Генератор 12b изображения внешнего предсказания может считывать пиксельные значения индивидуальных пикселей, составляющих адаптивное фильтрованное декодированное изображение P_ALFʹ из памяти 15 кадров. Изображение mc компенсации движения, сгенерированное генератором 12b изображения внешнего предсказания, подается как изображение Pred_Inter внешнего предсказания к блоку 12d определения схемы предсказания.
[0134] (Генератор 12c изображения внутреннего предсказания)
Генератор 12c изображения внутреннего предсказания генерирует изображение Pred_Intra предсказания, относящееся к каждому разделению внутреннего предсказания. В частности, генератор 12c изображения внутреннего предсказания сначала определяет режим предсказания на основе параметра PP_Intra внутреннего предсказания, подаваемого от декодера 11 переменной длины, и назначает заданный режим предсказания на целевое разделение, например, в порядке сканирования растра.
[0135] Здесь, задание режима предсказания на основании параметра PP_Intra внутреннего предсказания может быть выполнена следующим образом. (1) Флаг оцененного режима предсказания декодируется. В случае, когда флаг оцененного режима предсказания указывает, что режим предсказания для целевого разделения, которое должно быть обработано, является тем же самым как режим предсказания, назначенный на разделение вокруг целевого разделения, режим предсказания, назначенный на разделение вокруг целевого разделения, назначается на целевое разделение. (2) С другой стороны, в случае, когда флаг оцененного режима предсказания указывает, что режим предсказания для целевого разделения, которое должно быть обработано, не является тем же самым как режим предсказания, назначенный на разделение вокруг целевого разделения, индекс режима остаточного предсказания декодируется, и режим предсказания, указанный индексом режима остаточного предсказания, назначен на целевое разделение.
[0136] Генератор 12c изображения внутреннего предсказания генерирует изображение Pred_Intra предсказания из (локально) декодированного изображения P с использованием внутреннего предсказания в соответствии со способом предсказания, указанным режимом предсказания, назначенным на целевое разделение. Изображение Pred_Intra внутреннего предсказания, сгенерированное генератором 12c изображения внутреннего предсказания, подается к блоку 12d определения схемы предсказания. Генератор 12c изображения внутреннего предсказания может быть сконфигурирован, чтобы генерировать изображение Pred_Intra предсказания из адаптивного фильтрованного декодированного изображения P_ALF посредством использования внутреннего предсказания.
[0137] Определение режимов предсказания будет описано со ссылками на Фиг. 11. Фиг. 11 иллюстрирует определение режимов предсказания. Как иллюстрировано на Фиг. 11, 36 типов режимов предсказания определены, и индивидуальные режимы предсказания определены числами "0"-"35" (индекс режима внутреннего предсказания). Кроме того, как иллюстрировано на Фиг. 12, следующие названия назначены на индивидуальные режимы предсказания. Таким образом, "0" соответствует "Intra_Planar (плоский режим предсказания)", "1" соответствует "Intra_Vertical (внутренний вертикальный режим предсказания)", "2" соответствует "Intra_Horisontal (внутренний горизонтальный режим предсказания)", "3" соответствует "Intra_DC (внутренний DC режим предсказания)", "4"-"34" соответствуют "Intra Angular (предсказание направления)", и "35" соответствует "Intra_From_Luma". "35" является специфичным для режима предсказания цветности, и является режимом для предсказания цветности на основе предсказания яркости. Другими словами, режим "35" предсказания цветности является режимом предсказания, в котором используется корреляция между пиксельным значением яркости и пиксельным значением цветности. Режим "35" предсказания цветности также упоминается как режим LM.
[0138] Количество режимов предсказания задается в зависимости от размера целевого блока. Фиг. 13 иллюстрирует соотношения между значениями логарифма размера целевого блока (log2TrafoSize) и номерами (intraPredModeNum) режима предсказания.
[0139] Как иллюстрировано на фиг. 13, в случае, когда log2TrafoSize равно "2", intraPredModeNum равно "18". В случаях, когда log2TrafoSize равно "3", "4", "5", и "6", intraPredModeNum равно "35".
[0140] (блок 12d определения схемы предсказания)
Блок 12d определения схемы предсказания определяет, на основе информации Pred_type типа предсказания относительно PU, которой принадлежит каждое разделение, является ли каждое разделение разделением внешнего предсказания, в отношении которого внешнее предсказание должно быть выполнено или разделением внутреннего предсказания, в отношении которого должно быть выполнено внутреннее предсказание. В первом случае, блок 12d определения схемы предсказания подает изображение Pred_Inter внешнего предсказания, сгенерированное генератором 12b изображения внешнего предсказания как изображение Pred предсказания к сумматору 14. В последнем случае блок 12d определения схемы предсказания подает изображение Pred_Intra внутреннего предсказания, сгенерированное генератором 12c изображения внутреннего предсказания как изображение Pred предсказания к сумматору 14.
[0141] (Блок 13 деквантования/обратного преобразования)
Блок 13 деквантования/обратного преобразования (1) деквантует коэффициент Coeff преобразования, который был выводят посредством декодирования квантованной остаточной информации QD закодированных данных #1, (2) выполняет обратное частотное преобразование, такое как обратное DCT (дискретное косинусное преобразование) в отношении коэффициента преобразования Coeff_IQ, полученного посредством деквантования, и (3) подает остаток D предсказания, полученный с помощью обратного частотного преобразования, к сумматору 14. В случае деквантования коэффициента Coeff преобразования, который был выводят посредством декодирования квантованной остаточной информации QD, блок 13 деквантования/обратного преобразования получает шаг qp квантования из разности Δqp параметров квантования, подаваемой от декодера 11 кода с переменной длиной слова. Параметр qp квантования может быть выводят посредством суммирования разности Δqp параметров квантования к параметру qpʹ квантования, относящегося к TU, в отношении которого деквантование и обратное частотное преобразование были выполнены непосредственно ранее, и шаг QP квантования может быть получен из параметра qp квантования посредством использования, например, QP=2qp/6. Генерирование остатка D предсказания с помощью блока 13 деквантования/обратного преобразования, выполнен в единицах TU или в единицах блоков, полученных посредством деления TU.
[0142] В случае, когда размер целевого блока соответствует 8×8 пикселям, например, обратное DCT, выполненное блоком 13 деквантования/обратного преобразования, задается, например, следующим уравнением (1), когда предполагается, что позиция пикселя в целевом блоке (i, j) (0≤i≤7, 0≤j≤7), значение остатка D предсказания в позиции (i, j) представлено посредством D (i, j), и деквантованный коэффициент преобразования в частотном компоненте (u, v) (0≤u≤7, 0≤v≤7) представлен Coeff_IQ (u, v).
[0143][Математическое уравнение 1]
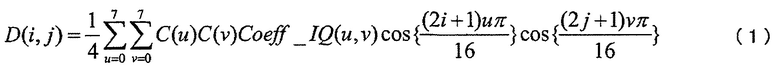
[0144] Здесь, (u, v) является переменной, соответствующей вышеописанному (xC, yC). C (u) и C (v) заданы следующим образом.
C (u)=1/
C (u)=1 (u≠0)
C (v)=1/
C (v)=1 (v≠0)
[0145] (Сумматор 14)
Сумматор 14 суммирует изображение Pred предсказания, подаваемое от генератора 12 изображения предсказания и остаток D предсказания, подаваемый от блока 13 деквантования/обратного преобразования, и таким образом генерирует декодированное изображение P. Сгенерированное декодированное изображение P сохраняется в памяти 15 кадров.
[0146] (Контурный фильтр 16)
Контурный фильтр 16 имеет (1) функцию как фильтра удаления блочности (DF), который выполняет сглаживание (процесс удаления блочности) в отношении изображения около границы блока или границы разделения в декодированном изображении P, и (2) функцию как адаптивный контурный фильтр (ALF), который выполняет адаптивный процесс фильтрации, используя параметр FP фильтра в отношении изображения, обработанного посредством использования фильтра удаления блочности.
[0147] (Декодер 111 квантованной остаточной информации )
Декодер 111 квантованной остаточной информации конфигурируется, чтобы декодировать квантованную остаточную информацию QD, включенную в закодированные данные #1, чтобы получить квантованный коэффициент преобразования Coeff (xC, yC) для каждого частотного компонента (xC, yC). Здесь, xC и yC являются индексами, указывающими позицию каждого частотного компонента в частотной области, и являются индексами, соответствующими вышеописанной частоте u горизонтального направления и частоте v вертикального направления, соответственно. Различные элементы синтаксиса, включенные в квантованную остаточную информацию QD, были закодированы, используя основанное на контексте адаптивное двоичное арифметическое кодирование (CABAC). В дальнейшем, квантованный коэффициент преобразования Coeff может просто упоминаться как коэффициент Coeff преобразования.
[0148] Фиг. 1 является блок-схемой, иллюстрирующей конфигурацию декодера 111 квантованной остаточной информации. Как иллюстрировано на Фиг. 1, декодер 111 квантованной остаточной информации включает в себя декодер 120 коэффициента преобразования и декодер 130 арифметического кода.
[0149] (Декодер 130 арифметического кода)
Декодер 130 арифметического кода конфигурируется, чтобы декодировать каждый бит, включенный в квантованную остаточную информацию QD, обращаясь к контексту, и включает в себя модуль 131 записи/обновления контекста и битовый декодер 132, как иллюстрировано на Фиг. 1.
[0150] (Модуль 131 записи/обновления контекста)
Модуль 131 записи/обновления контекста конфигурируется, чтобы записать и обновить переменную CV контекста, которой управляет каждый индекс ctxIdx контекста. Здесь, переменная CV контекста включает в себя (1) наиболее вероятный символ (MPS), имеющий высокую вероятность появления, и (2) индекс pStateIdx состояния вероятности, указывающий вероятность возникновения самого вероятного символа MPS.
[0151] Модуль 131 записи/обновления контекста обновляет переменную CV контекста посредством обращения к индексу ctxIdx контекста, подаваемому от каждой единицы декодера 120 коэффициента преобразования, и значение бина, декодированного битовым декодером 132, и записывает обновленную переменную CV контекста, до тех пор пока она не будет обновлена в следующий раз. Наиболее вероятный символ MPS равен 0 или 1. Наиболее вероятный символ MPS и индекс pStateIdx состояния вероятности обновляются каждый раз, когда битовый декодер 132 декодирует один бин.
[0152] Индекс ctxIdx контекста может непосредственно указывать контекст для каждого частотного компонента, или может быть значением приращения от смещения индекса контекста, который установлен для каждой целевой TU, которая должна быть обработана (то же самое относится к следующему описанию).
[0153] (Битовый декодер 132)
Битовый декодер 132 обращается к переменной CV контекста, которая записана блоком 131 записи/обновления контекста, и декодирует каждый бит (также называемый как бин), включенный в квантованную остаточную информацию QD. Кроме того, битовый декодер 132 подает значение бина, полученное с помощью декодирования, к каждой единице, включенной в декодер 120 коэффициента преобразования. Значение бина, полученного с помощью декодирования, также подается к модулю 131 записи/обновления контекста, и к нему выполняют обращение для того, чтобы обновить переменную CV контекста.
[0154] (Декодер 120 коэффициента преобразования)
Как иллюстрировано на Фиг. 1, декодер 120 коэффициента преобразования включает в себя декодер 121 позиции последнего коэффициента, память 122 таблицы порядка сканирования, контроллер 123 декодирования коэффициента, декодер флага присутствия/отсутствия коэффициента, декодер 125 значений коэффициентов, память 126 декодированных коэффициентов, и декодер 127 флага присутствия/отсутствия коэффициента суб-блока.
[0155] (Декодер 121 позиции последнего коэффициента)
Декодер 121 позиции последнего коэффициента интерпретирует декодированный бит (бин), подаваемый от битового декодера 132, и декодирует элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y. Декодированные элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y подаются на контроллер 123 декодирования коэффициента. Кроме того, декодер 121 позиции последнего коэффициента вычисляет индекс ctxIdx контекста для того, чтобы определить контекст, который должен использоваться для декодирования бина элементов синтаксиса last_significant_coeff_x и last_significant_coeff_y в арифметическом кодовом декодере 130. Вычисленный индекс ctxIdx контекста подается к модулю 131 записи/обновления контекста.
[0156] (Память 122 таблицы порядка сканирования)
Память 122 таблицы порядка сканирования хранит таблицу, которая дает позицию целевого частотного компонента, который должен быть обработан, в частотной области, с размером целевой TU (блок), которая должна быть обработана, индексом сканирования, представляющим тип направления сканирования, и индексом идентификационной информации частотного компонента, заданным вдоль порядка сканирования, являющихся аргументами.
[0157] Примером такой таблицы порядка сканирования является ScanOrder, иллюстрированная на Фиг. 4 и 5. В ScanOrder, проиллюстрированной на Фиг. 4 и 5, log2TrafoSize-2 представляет размер целевой TU, которая должна быть обработана, scanIdx представляет индекс сканирования, и n представляет индекс идентификационной информации частотного компонента, заданный вдоль порядка сканирования. На Фиг. 4 и 5 xC и yC представляют позицию целевого частотного компонента, который должен быть обработан, в частотной области.
[0158] Таблица, сохраненная в памяти 122 таблицы порядка сканирования, обозначена индексом scanIndex сканирования, ассоциированным с размером целевой TU (блок), которая должна быть обработана, и индексом режима предсказания режима внутреннего предсказания. В случае, когда способ предсказания использовал для целевой TU, которая должна быть обработана, является внутренним предсказанием, контроллер 123 декодирования коэффициента определяет порядок сканирования частотных компонентов посредством обращения к таблице, обозначенной индексом scanIndex сканирования, ассоциированным с размером TU и режимом предсказания TU.
[0159] Фиг. 14 иллюстрирует пример индексов scanIndex сканирования, обозначенных индексом IntraPredMode режима внутреннего предсказания и индивидуальные значения элемента синтаксиса log2TrafoSize-2, который определяет размер блока. На Фиг. 14 log2TrafoSize-2=0 указывает, что размер блока соответствует 4×4 компонентам (4×4 пикселей), тогда как log2TrafoSize-2=1 указывает, что размер блока соответствует 8×8 компонентом (8×8 пикселей). Как иллюстрировано на Фиг. 14, например, в случае, когда размер блока соответствует 4×4 компонентам и индекс режима внутреннего предсказания равен 1, используется индекс сканирования = 1, и в случае, когда размер блока соответствует 4×4 компонентам и индекс режима внутреннего предсказания равен 2, используется индекс сканирования = 2.
[0160] Часть (a) на Фиг. 15 иллюстрирует типы ScanType сканирования, обозначенные индивидуальными значениями индекса scanIndex сканирования. Как иллюстрировано в части (a) на Фиг. 15, в случае, когда индекс сканирования равен 0, сканирование в диагональном направлении (Верхнее-правое диагональное сканирование) определяется, в случае, когда индекс сканирования равен 1, приоритетное сканирование в горизонтальном направлении (горизонтальное быстрое сканирование) определяется, и в случае, когда индекс сканирования равен 2, приоритетное сканирование в вертикальном направлении (вертикальное быстрое сканирование) определяется.
[0161] Часть (b) на Фиг. 15 иллюстрирует порядки сканирования приоритетного сканирования в горизонтальном направлении (горизонтальное быстрое сканирование), приоритетного сканирования в вертикальном направлении (вертикальное быстрое сканирование), и сканирование в диагональном направлении (Верхнее-правое диагональное сканирование) в случае, когда размер блока соответствует 4×4 компонентам. В части (b) на Фиг. 15 числа, назначенные на индивидуальные частотные компоненты, представляют порядок, в котором сканируются частотные компоненты. Индивидуальные примеры, иллюстрированные в части (b) на Фиг. 15, показывают прямые направления сканирования.
[0162] (Таблица порядка сканирования суб-блоков)
Память 122 таблицы порядка сканирования хранит таблицу порядка сканирования суб-блоков для определения порядка сканирования суб-блоков. Таблица порядка сканирования суб-блоков определяется индексом scanIndex сканирования, ассоциированным с размером целевой TU (блок), которая должна быть обработана, и индексом режима предсказания (направлением предсказания) режима внутреннего предсказания. В случае, когда способ предсказания, использованный для целевой TU (блок), которая должна быть обработана, является внутренним предсказанием, контроллер 123 декодирования коэффициента определяет порядок сканирования суб-блоков посредством обращения к таблице, обозначенной индексом scanIndex сканирования, ассоциированным с размером TU и режимом предсказания TU.
[0163] Фиг. 16 иллюстрирует пример индексов scanIndex сканирования суб-блоков, которые обозначаются индексом IntraPredMode режима внутреннего предсказания и индивидуальными значениями элемента синтаксиса log2TrafoSize-2, который определяет размер блока. На фиг. 16 log2TrafoSize-2=2 указывает, что размер блока соответствует 16×16 компонентам (16×16 пикселей), log2TrafoSize-2=3 указывает, что размер блока соответствует 32×32 компонентам (32×32 пикселей), и log2TrafoSize-2=4 указывает, что размер блока соответствует 64×64 компонентам (64×64 пикселей). Как иллюстрировано на фиг. 16, например, в случае, когда размер блока соответствует 16×16 компонентам, и индекс режима внутреннего предсказания равен 1, используется индекс сканирования суб-блоков = 1, и в случае, когда размер блока соответствует 32×32 компонентам, и индекс режима внутреннего предсказания равен 2, используется индекс сканирования суб-блоков = 2.
[0164] В случае, когда размер блока соответствует 4×16 компонентая или 16×4 компонентам, может использоваться индекс сканирования суб-блоков, который определяется в случае, когда размер блока соответствует 16×16 компонентам. В случае, когда размер блока соответствует 8×32 компонентам или 32×8 компонентам, может использоваться индекс сканирования суб-блоков, который определяется в случае, когда размер блока соответствует 32×32 компонентам (то же самое относится к следующему описанию).
[0165] Часть (a) на Фиг. 17 иллюстрирует типы ScanType сканирования суб-блоков, которые обозначены индивидуальными значениями индексов scanIndex сканирования суб-блоков. Как иллюстрировано в части (a) на Фиг. 17, в случае, когда индекс сканирования суб-блоков равен 0, сканирование в диагональном направлении (верхнее-правое диагональное сканирование) определяется, в случае, когда индекс сканирования суб-блоков равен 1, приоритетное сканирование в горизонтальном направлении (горизонтальное быстрое сканирование) определяется, и в случае, когда индекс сканирования суб-блоков равен 2, приоритетное сканирование в вертикальном направлении (вертикальное быстрое сканирование) определяется.
[0166] Часть (b) на Фиг. 17 иллюстрирует порядки сканирования приоритетного сканирования в горизонтальном направлении (горизонтальное быстрое сканирование), приоритетного сканирования в вертикальном направлении (вертикальное быстрое сканирование), и сканирования в диагональном направлении (верхнее-правое диагональное сканирование) для индивидуальных суб-блоков 4×4 компонентов в случае, когда размер блока соответствует 16×16 компонентам. В части (b) на Фиг. 17 числа, назначенные на индивидуальные суб-блоки, представляют порядок, в котором сканируются эти суб-блоки. Индивидуальные примеры, иллюстрированные в части (b) на Фиг. 17, показывают прямые направления сканирования.
[0167] Пример индексов порядка сканирования для определения порядка сканирования суб-блоков не ограничен иллюстрированным на Фиг. 16. Например, индексы порядка сканирования, иллюстрированные на Фиг. 18 или Фиг. 59, могут использоваться. Типы сканирования, обозначенные индивидуальными значениями индексов порядка сканирования, иллюстрированных на Фиг. 18 или Фиг. 59, являются теми же самыми, как проиллюстрированы в частях (a) и (b) на Фиг. 17.
[0168] В примерах, иллюстрированных на Фиг. 16, 18, и 59, один и тот же индекс сканирования определяется для случая, в котором размер блока соответствует 16×16 компонентам, случая, в котором размер блока соответствует 32×32 компонентам, и случая, в котором размер блока соответствует 64×64 компонентам. Это не ограничивает этот вариант осуществления. Даже если режим внутреннего предсказания является одним и тем же, различные индексы сканирования могут быть обозначены в соответствии с размером блока.
[0169] (Контроллер 123 декодирования коэффициента)
Контроллер 123 декодирования коэффициента конфигурируется, чтобы управлять порядком процесса декодирования в каждой единице, включенной в декодер 111 квантованной остаточной информации.
[0170] (В случае, когда размер блока является некоторым размером или меньшим)
В случае, когда размер блока является некоторым размером или меньшим, контроллер 123 декодирования коэффициента обращается к элементам синтаксиса last_significant_coeff_x и last_significant_coeff_y, подаваемым от декодера 121 позиции последнего коэффициента, задает позицию последнего ненулевого коэффициента преобразования вдоль прямого сканирования, и подает позиции (xC, yC) индивидуальных частотных компонентов к декодеру 124 флага присутствия/отсутствия коэффициента и память 126 коэффициентов декодирования в обратном порядке порядку сканирования, в котором заданная позиция последнего ненулевого коэффициента преобразования является исходной, и который задан таблицей порядка сканирования, сохраненной в памяти 122 таблицы порядка сканирования.
[0171] Кроме того, контроллер 123 декодирования коэффициента подает sz, который является параметром, указывающим размер целевой TU (блок), которая должна быть обработана, то есть, размер целевой частотной области, к каждому модулю, включенному в декодер 120 коэффициента преобразования (не проиллюстрировано). Здесь, sz является в частности параметром, представляющим количество пикселей вдоль одной стороны целевой TU (блок), которая должна быть обработана, то есть, количество частотных компонентов вдоль одной стороны целевой частотной области.
[0172] Контроллер 123 декодирования коэффициента может быть сконфигурирован, чтобы подавать позиции (xC, yC) индивидуальных частотных компонентов к декодеру флага присутствия/отсутствия коэффициента в прямом порядке сканирования порядка сканирования, заданного таблицей порядка сканирования, сохраненной в памяти 122 таблицы порядка сканирования.
[0173] (В случае, когда размер блока больше, чем некоторый размер)
В случае, когда размер блока больше, чем некоторый размер, контроллер 123 декодирования коэффициента обращается к элементам синтаксиса last_significant_coeff_x и last_significant_coeff_y, подаваемым от декодера 121 позиции последнего коэффициента, задает позицию последнего ненулевого коэффициента преобразования вдоль прямого сканирования, и подает позиции (xCG, yCG) индивидуальных суб-блоков к декодеру 127 флага присутствия/отсутствия коэффициента суб-блока в обратном порядке сканирования к порядку сканирования, в котором позиция суб-блока, включающая указанный последний ненулевой коэффициент преобразования, является исходной, и который задан таблицей порядка сканирования суб-блоков, сохраненной в памяти 122 таблицы порядка сканирования.
[0174] Кроме того, контроллер 123 декодирования коэффициента подает, относительно целевого суб-блока, который должен быть обработан, позиции (xC, yC) индивидуальных частотных компонентов, включенных в целевой суб-блок, который должен быть обработан, к декодеру 124 флага присутствия/отсутствия коэффициента и память 126 коэффициентов декодирования в обратном порядке сканирования порядку сканирования, заданному таблицей порядка сканирования, сохраненной в памяти 122 таблицы порядка сканирования. Здесь, в качестве порядка сканирования индивидуальных частотных компонентов, включенных в целевой суб-блок, который должен быть обработан, может специально использоваться сканирование в диагональном направлении (верхнее-правое диагональное сканирование).
[0175] Таким образом, контроллер 123 декодирования коэффициента конфигурируется, чтобы в случае, когда схема предсказания, примененная к целевой области единицы, которая должна быть обработана (блок, TU), является внутренним предсказанием, устанавливать порядок сканирования суб-блоков в соответствии с направлением предсказания внутреннего предсказания.
[0176] Вообще, имеется корреляция между режимом внутреннего предсказания и смещением коэффициентов преобразования. Таким образом, сканирование суб-блоков, которое является подходящим для смещения флагов присутствия/отсутствия коэффициента суб-блока, может быть выполнено посредством переключения порядка сканирования в соответствии с режимом внутреннего предсказания. Соответственно, величина кодов флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть закодированы и декодированы, может быть уменьшена, и таким образом величина обработки уменьшается, и эффективность кодирования увеличена.
[0177] (Декодер 127 флага присутствия/отсутствия коэффициента суб-блока)
Декодер 127 флага присутствия/отсутствия коэффициента суб-блока интерпретирует каждый бин, подаваемый от битового декодера 132, и декодирует элемент синтаксиса significant_coeffgroup_flag [xCG][yCG] обозначенный каждой позицией (xCG, yCG) суб-блока. Кроме того, декодер 127 флага присутствия/отсутствия коэффициента суб-блока вычисляет индекс ctxIdx контекста для того, чтобы определить контекст, который должен использоваться арифметическим кодовым декодером 130, чтобы декодировать бин элемента синтаксиса significant_coeffgroup_flag [xCG][yCG]. Вычисленный индекс ctxIdx контекста подается к модулю 131 записи/обновления контекста. Здесь, элемент синтаксиса significant_coeffgroup_flag [xCG][yCG] является элементом синтаксиса, который принимает значение 1 в случае, когда суб-блок, обозначенный позицией (xCG, yCG) суб-блока, включает в себя по меньшей мере один ненулевой коэффициент преобразования, и принимает значение 0 в случае, когда суб-блок, обозначенный позицией (xCG, yCG) суб-блока, не включает в себя ненулевых коэффициентов преобразования. Значение декодированного элемента синтаксиса significant_coeffgroup_flag [xCG][yCG] сохранено в памяти 126 декодированных коэффициентов.
[0178] Более конкретная конфигурация декодера 127 флага присутствия/отсутствия коэффициента суб-блока будет описана ниже.
[0179] (Декодер 124 флага присутствия/отсутствия коэффициента)
Декодер 124 флага присутствия/отсутствия коэффициента согласно этому варианту осуществления декодирует элемент синтаксиса significant_coeff_flag [xC][yC], обозначенный каждой позицией (xC, yC) коэффициента. Значение декодированного элемента синтаксиса significant_coeff_flag [xC][yC] сохранено в памяти 126 коэффициентов декодирования. Кроме того, декодер 124 флага присутствия/отсутствия коэффициента вычисляет индекс ctxIdx контекста для того, чтобы определить контекст, который должен использоваться арифметическим кодовым декодером 130, чтобы декодировать бин элемента синтаксиса significant_coeff_flag [xC][yC]. Вычисленный индекс ctxIdx контекста подается к модулю 131 записи/обновления контекста. Конкретная конфигурация декодера 124 флага присутствия/отсутствия коэффициента будет описана ниже.
[0180] (Декодер 125 значений коэффициентов)
Декодер 125 значений коэффициентов интерпретирует каждый бин, подаваемый от битового декодера 132, декодирует элементы синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, coeff_sign_flag, и coeff_abs_level_minus3, и выводит значение коэффициента преобразования (более конкретно, ненулевого коэффициента преобразования) в целевом частотном компоненте, который должен быть обработан, на основе результата декодирования этих элементов синтаксиса. Индекс ctxIdx контекста, использованный для декодирования различных элементов синтаксиса, подается к модулю 131 записи/обновления контекста. Выведенное значение коэффициента преобразования сохраняется в памяти 126 декодированных коэффициентов.
[0181] (Память 126 декодированных коэффициентов)
Память 126 декодированных коэффициентов конфигурируется, чтобы сохранить индивидуальные значения коэффициентов преобразования, декодированных декодером 125 значений коэффициентов. Кроме того, память 126 декодированных коэффициентов значений хранит индивидуальные элементы синтаксиса significant_coeff_flag, декодированные декодером 124 флага присутствия/отсутствия коэффициента. Индивидуальные значения коэффициентов преобразования, сохраненные памятью 126 декодированных коэффициентов, подаются на блок 13 деквантования/обратного преобразования.
[0182] (Примерная конфигурация декодера 127 флага присутствия/отсутствия коэффициента суб-блока)
В дальнейшем конкретная примерная конфигурация декодера 127 флага присутствия/отсутствия коэффициента суб-блока будет описана со ссылками на Фиг. 19.
[0183] Фиг. 19 является блок-схемой, иллюстрирующей примерную конфигурацию декодера 127 флага присутствия/отсутствия коэффициента суб-блока. Как иллюстрировано на Фиг. 19, декодер 127 флага присутствия/отсутствия коэффициента суб-блока включает в себя модуль 127a выведения контекста, память 127b флага присутствия/отсутствия коэффициента суб-блока, и модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока.
[0184] В дальнейшем описание будет приведено для случая, в котором позиции (xCG, yCG) суб-блока подаются на в обратном порядке сканирования от контроллера 123 декодирования коэффициентов к декодеру 127 флага присутствия/отсутствия коэффициента суб-блока. В этом случае в конфигурации на стороне устройства кодирования, соответствующей декодеру 127 флага присутствия/отсутствия коэффициента суб-блока, позиции (xCG, yCG) суб-блока подаются в прямом порядке сканирования.
[0185] (Модуль 127a выведения контекста)
Модуль 127a выведения контекста, включенный в декодер 127 флага присутствия/отсутствия коэффициента суб-блока, выводит индексы контекста, которые должны быть назначены на суб-блоки, обозначенные индивидуальными позициями суб-блока (xCG, yCG). Индекс контекста, назначенный на суб-блок, используется для декодирования бина, который указывает элемент синтаксиса significant_coeffgroup_flag для суб-блока. В случае выведения индекса контекста, обращаются к значению декодированного флага присутствия/отсутствия коэффициента суб-блока, сохраненному в памяти 127b флага присутствия/отсутствия коэффициента суб-блока. Модуль 127a выведения контекста подает выведенные индексы контекста к модулю 131 записи/обновления контекста.
[0186] В частности, индекс контекста, который должен быть назначен на суб-блок, выводится следующим образом посредством использования позиции (xCG, yCG) суб-блока и значения декодированного флага присутствия/отсутствия коэффициента суб-блока, сохраненного в памяти 127b флага присутствия/отсутствия коэффициента суб-блока.
[0187] (1) В случае, когда xCG == 3, и xCG == 3
Для этого индекса контекста некоторое начальное значение (ctxIdxOffset), которое определяется посредством cIdx, представляющего цветовое пространство, и log2TrafoSize, представляющего размер TU, устанавливается.
ctxIdx = ctxIdxOffset
(2) В случае, когда xCG<3, и yCG == 3
Индекс контекста устанавливается следующим образом в отношении значения декодированного флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG+1][yCG+1], расположенного справа позиции (xCG, yCG) суб-блока.
ctxIdx=ctxIdxOffset+significant_coeffgroup_flag [xCG+1][yCG]
(3) В случае, когда xCG == 3, и yCG<3
Индекс контекста устанавливается следующим образом в отношении значения декодированного флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG][yCG+1], расположенного ниже позиции (xCG, yCG) суб-блока.
ctxIdx=ctxIdxOffset+significant_coeffgroup_flag [xCG][yCG+1]
(4) В случае, когда xCG<3, и yCG<3
Индекс контекста устанавливается следующим образом в отношении значения декодированного флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG+1][yCG], расположенного справа к позиции (xCG, yCG) суб-блока, и значения декодированного флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG][yCG+1], расположенного ниже позиции (xCG, yCG) суб-блока.
ctxIdx=ctxIdxOffset+Max (significant_coeffgroup_flag [xCG+1][yCG], significant_coeffgroup_flag [xCG][yCG+1])
Начальное значение ctxIdxOffset устанавливается следующим образом в соответствии с cIdx, представляющим цветовое пространство, и log2TrafoSize, представляющего размер TU.
ctxIdxOffset = cIdx == 0 ? ((5-log2TrafoSize)* 16)+44:((4- log2TrafoSize)* 16)+44+64
[0188] (Память 127b флага присутствия/отсутствия коэффициента суб-блока)
Память 127b флага присутствия/отсутствия коэффициента суб-блока хранит индивидуальные значения элементов синтаксиса significant_coeffgroup_flag, которые декодированы или установлены модулем 127c установления флага присутствия/отсутствия коэффициента суб-блока. Модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока способен считывать элемент синтаксиса significant_coeffgroup_flag, который был назначен на смежный суб-блок, из памяти 127b флага присутствия/отсутствия коэффициента суб-блока.
[0189] (Модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока)
Модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока интерпретирует каждый бин, подаваемый от битового декодера 132, и декодирует или устанавливает элемент синтаксиса significant_coeffgroup_flag [xCG][yCG]. Более конкретно, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока обращается к позиции (xCG, yCG) суб-блока, и элемент синтаксиса significant_coeffgroup_flag назначенный на суб-блок, смежный с суб-блоком, обозначенным позицией (xCG, yCG) суб-блока (также называемый как «смежный суб-блок»), и декодирует или устанавливает элемент синтаксиса significant_coeffgroup_flag [xCG][yCG]. Значение декодированного или установленного элемента синтаксиса significant_coeffgroup_flag [xCG][yCG] подается к декодеру 124 флага присутствия/отсутствия коэффициента.
[0190] (В случае, когда типом сканирования является приоритетное сканирование в вертикальном направлении)
В случае, когда типом сканирования, обозначающим порядок сканирования суб-блоков, является приоритетное сканирование в вертикальном направлении, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока обращается к значению significant_coeffgroup_flag [xCG][yCG+1] флага присутствия/отсутствия коэффициента суб-блока, назначенному на суб-блок (xCG, yCG+1), смежный с суб-блоком (xCG, yCG), как иллюстрировано в части (a) на Фиг. 20. В случае, когда significant_coeffgroup_flag [xCG][yCG+1]=1, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока устанавливает significant_coeffgroup_flag [xCG][yCG]=1. В этом случае процесс декодирования significant_coeffgroup_flag [xCG][yCG] может быть опущен. Установка значения флага присутствия/отсутствия коэффициента суб-блока, назначенного на смежный суб-блок, в значение флага присутствия/отсутствия коэффициента суб-блока, назначенного на суб-блок, может быть выражено как "оценка флага присутствия/отсутствия коэффициента суб-блока". Для оцененного флага присутствия/отсутствия коэффициента суб-блока могут быть опущены процессы кодирования и декодирования.
[0191] (В случае, когда типом сканирования является приоритетное сканирование в горизонтальном направлении)
В случае, когда типом сканирования, обозначающим порядок сканирования суб-блоков, является приоритетное сканирование в горизонтальном направлении, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока обращается к значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG+1][yCG], назначенному на суб-блок (xCG+1, yCG), смежный с суб-блоком (xCG, yCG), как иллюстрировано в части (b) на Фиг. 20. В случае, когда significant_coeffgroup_flag [xCG+1][yCG]=1, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока устанавливает significant_coeffgroup_flag [xCG][yCG]=1. В этом случае процесс декодирования significant_coeffgroup_flag [xCG][yCG] может быть опущен.
[0192] (В случае, когда типом сканирования является сканирование в диагональном направлении)
В случае, когда типом сканирования, обозначающим порядок сканирования суб-блоков, является сканирование в диагональном направлении, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока обращается к значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG+1][yCG], назначенному на суб-блок (xCG+1, yCG), смежный с суб-блоком (xCG, yCG), и значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG][yCG+1], назначенному на суб-блок (xCG, yCG+1), смежный с суб-блоком (xCG, yCG), как иллюстрировано в части (c) на Фиг. 20.
[0193] В случае, когда significant_coeffgroup_flag [xCG+1][yCG]=1 и significant_coeffgroup_flag [xCG][yCG+1]=1, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока устанавливает significant_coeffgroup_flag [xCG][yCG]=1. В этом случае процесс декодирования significant_coeffgroup_flag [xCG][yCG] может быть опущен.
[0194] Как описано выше, модуль 127c установления флага присутствия/отсутствия коэффициента суб-блока конфигурируется, чтобы переключать смежный суб-блок, к которому нужно обращаться, в соответствии со смещением флагов присутствия/отсутствия коэффициента суб-блока. Соответственно, величина кодов флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть закодированы и декодированы, может быть уменьшена.
[0195] Эффект сокращения величины кодов флагов присутствия/отсутствия коэффициента суб-блока, который получается посредством использования модуля 127c установления флага присутствия/отсутствия коэффициента суб-блока и соответствующей конфигурации на стороне устройства кодирования, будет описан подробно ниже в отношении частей (a) и (b) на Фиг. 21.
[0196] (Процесс кодирования и декодирования флага присутствия/отсутствия коэффициента суб-блока согласно сравнительному примеру)
В процессе кодирования и декодирования флага присутствия/отсутствия коэффициента суб-блока согласно сравнительному примеру сканирование в диагональном направлении выбирается независимо от смещения коэффициентов преобразования. Относительно суб-блока, включающего в себя компонент DC, и суб-блока, включающего в себя последний коэффициент, significant_coeffgroup_flag устанавливается (оценивается) в 1, и не кодируется.
[0197] Например, предполагается, что коэффициенты преобразования существуют в частотной области 16×16 компонентов как иллюстрировано в части (a) на Фиг. 21. В этом случае флаги присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag, иллюстрированные в части (b) на Фиг. 21, назначаются на индивидуальные суб-блоки, составленные из 4×4 компонентов. В этом случае одномерная последовательность сканирования целевых флагов присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag, которые должны быть обработаны, в прямом направлении сканирования равна "1010010001". В процессе декодирования флага присутствия/отсутствия коэффициента суб-блоке согласно сравнительному примеру, "01001000", которая получена посредством удаления significant_coeffgroup_flag для суб-блока, включающего в себя компонент DC, и суб-блока, включающего в себя последний коэффициент, из одномерной последовательности кодируется и декодируется. В частях (a) и (b) на Фиг. 21 коэффициенты преобразования и суб-блоки, выраженные со светлым цветом, не кодируются и не декодируются.
[0198] (Процесс кодирования флага присутствия/отсутствия коэффициента суб-блока согласно этому варианту осуществления)
С другой стороны, в процессе кодирования флага присутствия/отсутствия коэффициента суб-блока согласно этому варианту осуществления, направление сканирования определяется в соответствии с режимом внутреннего предсказания, и таким образом, выбирается порядок сканирования, подходящий для формы смещения коэффициентов преобразования. Относительно суб-блока, включающего в себя компонент DC, и суб-блока, включающего в себя последний коэффициент, significant_coeffgroup_flag устанавливается (оценивается) в 1, и не кодируется.
[0199] Как в части (a) на Фиг. 21, в случае, когда коэффициенты преобразования существуют в частотной области 16×16 компонентов, как иллюстрировано в части (a) на Фиг. 22, имеется высокая вероятность, что вертикальное направление будет выбрано как направление внутреннего предсказания. Таким образом, имеется высокая вероятность, что приоритетное сканирование в горизонтальном направлении будет выбрано в качестве порядка сканирования суб-блоков. В этом случае коэффициенты преобразования, которые должны быть закодированы и декодированы, являются коэффициентами преобразования, иллюстрированными в части (a) на Фиг. 22, кроме выраженных светлым цветом, и их количество явно меньше,
чем таковое в части (a) на Фиг. 21.
[0200] Флаги присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag, которые назначены на индивидуальные суб-блоки, составленные из 4×4 компонентов, иллюстрированы в части (b) на Фиг. 22. В этом случае одномерная последовательность сканирования целевых флагов присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag, которые должны быть обработаны, в прямом направлении сканирования равны "1111". Однако, с вышеописанной "оценкой флагов присутствия/отсутствия коэффициента суб-блока", количество флагов присутствия/отсутствия коэффициента суб-блока, которые фактически кодируются и декодируются, равно 0.
[0201] Как описано выше, с модулем 127c установления флага присутствия/отсутствия коэффициента суб-блока и соответствующей конфигурацией на стороне устройства кодирования согласно этому варианту осуществления, величина кодов флагов присутствия/отсутствия коэффициента суб-блока уменьшена.
[0202] (Примерная конфигурация декодера 124 флага присутствия/отсутствия коэффициента)
В дальнейшем конкретная примерная конфигурация декодера 124 флага присутствия/отсутствия коэффициента будет описана со ссылками на Фиг. 23.
Фиг. 23 является блок-схемой, иллюстрирующей примерную конфигурацию декодера 124 флага присутствия/отсутствия коэффициента. Как иллюстрировано на Фиг. 23, декодер 124 флага присутствия/отсутствия коэффициента включает в себя модуль 124a классификации частоты, модуль 124b выведения контекста позиции, модуль 124c выведения опорного контекста от соседнего элемента, память 124d флага присутствия/отсутствия коэффициента, и модуль 124e установления флага присутствия/отсутствия коэффициента.
[0203] (Модуль 124a классификации частоты)
В случае, когда размер целевой частотной области является некоторым размером или меньшим (например, в случае 4×4 компонентов или 8×8 компонентов), модуль 124a классификации частоты классифицирует каждый из частотных компонентов в частотной области некоторого размера или меньшей в любую из множества частичных областей в соответствии с позицией частотного компонента, и также назначает индекс ctxIdx контекста, полученный модулем 124b выведения контекста позиции.
[0204] С другой стороны, в случае, когда размер целевой частотной области больше, чем некоторый размер (например, в случае 16×16 компонентов или 32×32 компонентов), модуль 124a классификации частоты классифицирует каждый из целевых частотных компонентов, которые должны быть декодированы, в любое из множества частичных областей в соответствии с позицией частотного компонента в частотной области, и также назначает индекс ctxIdx контекста, выведенный любым из модуля 124b выведения контекста позиции и модуля 124c выведения опорного контекста от соседнего элемента, в целевой частотный компонент, который должен быть декодирован.
[0205] Модуль 124a классификации частоты классифицирует каждый из частотных компонентов, включенных в частотную область, в любую из множества частичных областей R0-R2 посредством использования позиции (xC, yC) частотного компонента в частотной области. Здесь предполагается, что xC=0, 1, …, и sz-1, и yC=0, 1, …, и sz-1 (sz представляет количество пикселей вдоль одной стороны целевой TU, которая должна быть обработана, то есть количество частотных компонентов вдоль одной стороны целевой частотной области, например, sz=16, 32, и т.д.).
[0206] С другой стороны, в случае, когда частотная область, составленная из блоков sz×sz, разделена на 4×4 суб-блоков, позиция (xCG, yCG) суб-блока, которому принадлежит частотный компонент (xC, yC), вывится посредством использования следующих уравнений (Ур. A1) и (Ур. A2).
[0207] xCG=xC>>2 (Ур. A1)
yCG=yC>>2 (Ур. A2)
Здесь, предполагается, что xCG=0, 1, …, (sz-1)>>2, и yCG=0, 1, …, (sz-1)>>2.
[0208] Модуль 124a классификации частоты выполняет, например, следующие процессы классификации.
(1) Классифицировать частотный компонент, который удовлетворяет xCG+yCG<THA и xC+yC<THZ, как частичная область R0.
(2) Классифицировать частотный компонент, который удовлетворяет xCG+yCG <THA и THZ≤xC+yC, как частичная область R1.
(3) Классифицировать частотный компонент, который удовлетворяет THA≤xCG+yCG, как частичная область R2.
[0209] Псевдокод, соответствующий вышеописанным процессам классификации, является следующим.

если (xCG+yCG<THA) {
если (xC+yC<THZ) {
Классифицировать в R0
}
иначе {//, если (xC+yC≥THZ)
Классифицировать в R1
}
}
еще {//, если (xCG+yCG≥THA) {
Классифицировать в R2
}
Здесь, 2 используется как порог THZ. THA представляет порог, который удовлетворяет THA≥THZ/4. Конкретным значением может быть, например, THA=1 независимо от размера частотной области (размер целевой TU, которая должна быть обработана). Альтернативно, THA=1<<(log2TrafoSize-2), посредством использования размера log2trafoSize частотной области. Таким образом, в случае, когда размер частотной области равен 16×16, THA=1 может быть удовлетворен, и в случае, когда размер частотной области равен 32×32, THA=2 может быть удовлетворен. Таким образом, различные пороги могут использоваться в соответствии с размером частотной области. Порог THZ может быть равен 1.
[0210] Фиг. 24 иллюстрирует пример частотной области, которая была разделена на частичные области R0, R1, и R2 с помощью процесса классификации, выполненного модулем 124a классификации частоты.
[0211] Модуль 124a классификации частоты назначает индексы контекста, выведенные модулем 124b выведения контекста позиции, индивидуальным частотным компонентам, которые принадлежат частичной области R0, и назначает индексы контекста, выведенные модулем 124c выведения опорного контекста от соседнего элемента, индивидуальным частотным компонентам, которые принадлежат частичным областям R1 и R2. Описание было дано согласно предположению, что размер суб-блоков равен 4×4, но размер не ограничен этим, и суб-блоки (sz>>n) × (sz>>n) может использоваться. Следует отметить, что относительно n, n=1, …, log2TrafoSize >>1 удовлетворено.
[0212] Модуль 124a классификации частоты подает индексы контекста, назначенные на индивидуальные частотные компоненты, к модулю 131 записи/обновления контекста. Эти индексы контекста используются для определения контекста, который должен использоваться арифметическим кодовым декодером 130, чтобы декодировать элемент синтаксиса significant_coeff_flag.
[0213] (Модуль 124b выведения контекста позиции)
Модуль 124b выведения контекста позиции выводит индекс ctxIdx контекста для целевого частотного компонента на основе позиции целевого частотного компонента в частотной области.
[0214] В случае, когда целевая частотная область, которая должна быть обработана, больше, чем некоторый размер, модуль 124b выведения контекста позиции выводит, например, индексы ctxIdx контекста для частотных компонентов, которые принадлежат частичной области R0, иллюстрированной на Фиг. 24, посредством использования следующего уравнения (Ур. A3), и подает результат выведения ctxIdx к модулю 124a классификации частоты.
[0215] ctxIdx=NX+2 х xC+yC (Ур. A3)
NX является константой, которая представляет начальную точку индекса контекста. В случае, когда номера контекстов, используемых для размера 4×4 и 8×8 частотной области, являются N4 и N8, соответственно, начальная точка равна NX=N4+N8 в случае, когда размер частотной области 16×16 и 32×32.
[0216] Конкретный пример процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, описан ниже.
[0217] (Модуль 124c выведения опорного контекста от соседнего элемента)
Модуль 124c выведения опорного контекста от соседнего элемента выводит индекс ctxIdx контекста для целевого частотного компонента, который должен быть декодирован, на основе количества cnt декодированных ненулевых коэффициентов преобразования относительно частотных компонентов вокруг целевого частотного компонента.
[0218] Модуль 124c выведения опорного контекста от соседнего элемента выводит, например, индексы ctxIdx контекста для частотных компонентов, которые принадлежат частичной области R1, иллюстрированной на Фиг. 24, посредством использования следующего уравнения (Ур. A4), и подает результат выведения ctxIdx к модулю 124a классификации частоты.
[0219] ctxIdx=NX+3+min (2, temp) (Ур. A4)
Здесь, temp определен как temp=(cnt+1)>>1.
[0220] Кроме того, модуль 124c выведения опорного контекста от соседнего элемента выводит, например, индексы ctxIdx контекста для частотных компонентов, которые принадлежат частичной области R2, иллюстрированной на Фиг. 24, посредством использования следующего уравнения (Ур. A5), и подает результат выведения ctxIdx к модулю 124a классификации частоты.
[0221] ctxIdx=NX+6+min (2, temp) (Ур. A5)
Здесь, temp определен посредством temp=(cnt+1)>>1, как в вышеописанном случае.
[0222] В уравнениях (Ур. A4) и (Ур. A5) значение подсчета cnt ненулевых коэффициентов преобразования может быть сдвинуто вправо на 1 бит, и таким образом количество контекстов может быть сокращено.
[0223] Далее, модуль 124c выведения опорного контекста от соседнего элемента выводит значение подсчета cnt ненулевых коэффициентов преобразования в частичной области R1, иллюстрированной на фиг. 24, в соответствии со следующим уравнением (Ур. A6) посредством использования опорных частотных компонентов c1-c5, проиллюстрированного в части (a) на Фиг. 25.
[0224] cnt=(c1!=0)+(c2!=0)+(c3!=0)+(c4!=0)+(c5!= 0) (Ур. A6)
Здесь, каждый член в (Ур. A6) принимает значение 1 в случае, когда сравнение в () верно, и принимает значение 0 в случае, когда сравнение в () ложно.
[0225] Количество cnt ненулевых коэффициентов преобразования может быть вычислено, используя уравнение (Ур. A7) вместо уравнения (Ур.A6). В уравнении (Ур. A7) используются опорные частотные компоненты (c1, c2, c4 и c5), иллюстрированные в части (b) на Фиг. 25, и на коэффициент преобразования в координате (c3), расположенной непосредственно перед позицией целевого коэффициента преобразования в порядке обработки (в случае, когда порядком обработки является обратный порядок сканирования, расположенный ниже позиции целевого коэффициента преобразования) не ссылаются. В таком процессе контекст, который должен использоваться для декодирования флага присутствия/отсутствия коэффициента в некоторой позиции, может быть выведен, не обращаясь к значению предыдущего флага присутствия/отсутствия коэффициента, и таким образом процесс выведения контекста и процесс декодирования могут быть выполнены параллельно.
[0226] cnt=(c1!=0)+(c2!=0)+(c4!=0)+(c5!=0) (Ур. A7)
Альтернативно, коэффициент преобразования может быть выведен посредством использования любого из уравнения (Ур. A6) и уравнения (Ур. A7) в соответствии с позицией целевого коэффициента преобразования в суб-блоке. Таким образом, опорные компоненты, которые должны быть использоваться для выведения коэффициента преобразования, могут быть изменены в соответствии с позицией целевого коэффициента преобразования в суб-блоке.
[0227] Более конкретно, в любом из случая, в котором целевой коэффициент преобразования расположен вверхну слева в суб-блоке, и случая, в котором целевой коэффициент преобразования расположен в снизу справа в суб-блоке, опорные частотные компоненты уравнения (Ур. A7) могут использоваться, чтобы не зависеть от значения коэффициента преобразования в позиции (нижней стороне) непосредственно перед целевым коэффициентом преобразования в суб-блоке в порядке обработки, и опорные частотные компоненты уравнения (Ур. A6) могут использоваться в другом случае.
[0228] (Модуль 124e установления флага присутствия/отсутствия коэффициента)
Модуль 124e установления флага присутствия/отсутствия коэффициента интерпретирует каждый бин, подаваемый от битового декодера 132, и декодирует или устанавливает элемент синтаксиса significant_coeff_flag [xC][yC]. Декодированный или установленный элемент синтаксиса significant_coeff_flag [xC][yC] подается к памяти 126 декодированных коэффициентов.
[0229] В случае, когда целевая частотная область разделена на суб-блоки, модуль 124e установления флага присутствия/отсутствия коэффициента обращается к элементу синтаксиса significant_coeffgroup_flag [xCG][yCG], назначенному на целевой суб-блок, и в случае, когда значение significant_coeffgroup_flag [xCG][yCG] равно 0, устанавливает significant_coeff_flag [xC][yC] для всех частотных компонентов, включенных в целевой суб-блок, в 0. С этой конфигурацией процесс декодирования для significant_coeff_flag [xC][yC] в целевом суб-блоке может быть опущен, и таким образом скорость обработки увеличивается.
[0230] (Память 124d флага присутствия/отсутствия коэффициента)
Память 124d флага присутствия/отсутствия коэффициента хранит индивидуальные значения элементов синтаксиса significant_coeff_flag [xC][yC]. На индивидуальные значения элементов синтаксиса significant_coeff_flag [xC][yC], сохраненные в памяти 124d флага присутствия/отсутствия коэффициента, ссылаются посредством модуля 124c выведения опорного контекста от соседнего элемента.
[0231] (Другой пример процесса, выполняемого декодером 124 флага присутствия/отсутствия коэффициента)
В дальнейшем, другой пример процесса, выполняемого декодером 124 флага присутствия/отсутствия коэффициента, будет описан со ссылками на Фиг. 26-28.
[0232] Части (a) и (b) на Фиг. 26 являются диаграммами, иллюстрирующими частичные области, которые получены посредством разделения, выполненного модулем 124a классификации частоты в этом примерном процессе. Часть (a) на Фиг. 26 предпочтительно применяется в случае декодирования коэффициента преобразования, относящегося к значениям яркости, тогда как часть (b) на Фиг. 26 предпочтительно применяется в основе декодирования коэффициента преобразования, относящегося к цветности. В частях (a) и (b) на Фиг. 26, порог TH определен посредством TH=Max (ширина, высота)>>2. Здесь, "ширина" представляет ширинe целевой частотной области, выраженной, используя частотный компонент в качестве единицы, и "высота" представляет высоту целевой частотной области, выраженной, используя частотный компонент в качестве единицы. Например, в случае, когда ширина целевой частотной области соответствует 16 компонентам (16 пикселей) и высота соответствует 4 компонентам (4 пикселя), ширина = 16 и высота = 4.
[0233] Фиг. 27 иллюстрирует псевдокод, показывающий процесс выведения для выведения индексов ctxIdx контекста, которые должны быть назначены на частотные области, включенные в частичные области R0-R2, проиллюстрированные в части (a) на Фиг. 26, и которые относятся к яркости. На Фиг. 27 выведение контекста в области R0 выполняется модулем 124b выведения контекста позиции, и выведение контекста в области R1 и выведение контекста в области R2 выполняются модулем 124c выведения опорного контекста от соседнего элемента.
[0234] Фиг. 28 иллюстрирует псевдокод, показывающий процесс выведения для выведения индексов ctxIdx контекста, которые должны быть назначены на частотные области, включенные в частичные области R0 и R1, иллюстрированные в части (b) на Фиг. 26, и которые относятся к цветности. На Фиг. 28 выведение контекста в области R0 выполняется модулем 124b выведения контекста позиции, и выведение контекста в области R1 выполняется модулем 124c выведения опорного контекста от соседнего элемента.
[0235] (Конкретный пример 1 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны, на подгруппы (подобласти) R0-R6 в случае 4×4 компонентов, и на подгруппы R0-R9 в случае 8×8 компонентов, на основе позиций (xC, yC) целевых частотных компонентов, которые должны быть обработаны.
[0236] (В случае 4×4 компонентов)
(1) В случае, когда xC=0 и yC=0, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда xC=1 и yC=0, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC=0 и yC=1, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC=1 и yC=1, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда 1<xC<4 и yC<2, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC<2 и 1<yC<4, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда 2≤xC<4 и 2≤yC<4, частотный компонент классифицируется в подгруппу R6.
[0237] (В случае 8×8 компонентов)
(1) В случае, когда xC=0 и yC=0, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда xC=1 и yC=0, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC=0 и yC=1, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC=1 и yC=1, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда 1<xC<4 и yC<2, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC<2 и 1<yC<4, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда 2≤xC<4 и 2≤yC<4, частотный компонент классифицируется в подгруппу R6.
(8) В случае, когда xC≥4 и yC<4, частотный компонент классифицируется в подгруппу R7.
(9) В случае, когда xC<4 и yC≥4, частотный компонент классифицируется в подгруппу R8.
(10) В случае, когда xC≥4 и yC≥4, частотный компонент классифицируется в подгруппу R9.
[0238] Пример, в котором вышеописанный процесс классификации применяется к 4×4 компонентам и 8×8 компонентам, иллюстрирован в частях (a) и (b) на Фиг. 29. Часть (a) на Фиг. 29 является диаграммой, иллюстрирующей области (подгруппы) R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) на Фиг. 29 является диаграммой, иллюстрирующей области (подгруппы) R0-R9, которые формируют частотный компонент, имеющий размер 8×8 компонентов.
[0239] В случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции выполняет следующий процесс в отношении подгрупп, классифицированных модулем 124a классификации частоты.
[0240] Таким образом, модуль 124b выведения контекста позиции выводит общие индексы контекста для одного или множественных частотных компонентов, которые принадлежат частотной области, имеющей некоторый размер или меньший (например, 4×4 компонентов или 8×8 компонентов) и имеющей первый размер (например, 4×4 компонентов), и для одного или множественных частотных компонентов, которые принадлежат частотной области, имеющей некоторый размер или меньший и имеющей второй размер, больший, чем первый размер (например, 8×8 компонентов), и назначает общие индексы контекста на эти один или множественные частотные компоненты.
[0241] Например, модуль 124b выведения контекста позиции выводит и назначает общие индексы контекста ctxIdx (i) областям Ri (i=0, 1, 2, 3, 4, 5 и 6), иллюстрированным в части (a) на Фиг. 29, и областям Ri (i=0, 1, 2, 3, 4, 5 и 6), иллюстрированным в части (b) на Фиг. 29.
[0242] Например, предполагается, что ctxIdx=0, 1, 2, 3, 4, 5 и 6 выводятся для областей R0, R1, R2, R3, R4, R5 и R6, иллюстрированных в части (a) на Фиг. 29, соответственно. В этом случае ctxIdx=0, 1, 2, 3, 4, 5 и 6 назначены на области R0, R1, R2, R3, R4, R5 и R6, иллюстрированные в части (b) на Фиг. 29. Кроме того, ctxIdx=7, 8, и 9 назначены на области R7, R8, и R9, иллюстрированные в части (b) на Фиг. 29, соответственно.
[0243] Предпочтительно, модуль 124b выведения контекста позиции устанавливает общие индексы контекста для индексов контекста, на которые ссылаются в случае декодирования индивидуальных коэффициентов преобразования, относящихся к цветности U, и для индексов контекста, на которые ссылаются в случае декодирования индивидуальных коэффициентов преобразования, относящихся к цветности V.
[0244] В частности, индексы ctxIdx контекста_U (i), которые назначены на области Ri (i=0, 1, 2, 3, 4, 5 и 6), иллюстрированные в части (a) на Фиг. 29, и на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к цветности U, являются общими для индексов ctxIdx контекста_V (i), которые назначены на области Ri (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированные в части (b) на Фиг. 29, и на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к цветности V.
[0245] Модуль 124b выведения контекста позиции может быть сконфигурирован, чтобы выполнить установку так, чтобы все индексы контекста, на которые ссылаются в случае декодирования индивидуальных коэффициентов преобразования, относящихся к яркости Y, отличались от индексов контекста, на которые ссылаются в случае декодирования индивидуальных коэффициентов преобразования, относящихся к цветности V и U, или так, чтобы некоторые из индексов контекста были общими друг для друга.
[0246] Эффект, полученный модулем 124b выведения контекста позиции, выводящим индексы контекста в вышеописанном способе, будет описан ниже в отношении частей (a)-(c) на Фиг. 30 согласно сравнительному примеру.
[0247] Часть (a) на Фиг. 30 является диаграммой, иллюстрирующей индексы контекста, которые были выведены с помощью процесса выведения индекса контекста согласно сравнительному примеру для индивидуальных частотных компонентов, включенных в частотную область, имеющую размер 4×4 компонентов, и на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к яркости Y. В примере, проиллюстрированном в части (a) на Фиг. 30, выведены девять индексов контекста. В примере, проиллюстрированном в части (a) на Фиг. 30, индекс контекста не выводится для частотного компонента, расположенного на стороне самого высокочастотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 30). То же самое относится к частям (b) и (c) на Фиг. 30.
[0248] Часть (b) на Фиг. 30 является диаграммой, иллюстрирующей индексы контекста, которые были выведены с помощью процесса выведения индекса контекста согласно сравнительному примеру для индивидуальных частотных компонентов, включенных в частотную область, имеющую размер 4×4 компонентов, и на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к цветности U и V. В примере, проиллюстрированном в части (b) на Фиг. 30, шесть общих индексов контекста выведены для цветности U и V.
[0249] Часть (c) на Фиг. 30 является диаграммой, иллюстрирующей индексы контекста, которые были выведены с помощью процесса выведения индекса контекста согласно сравнительному примеру для индивидуальных частотных компонентов, включенных в частотную область, имеющую размер 8×8 компонентов, и на которые ссылаются в случае декодирования significant_coeff_flag, относящегося к яркости Y и цветности U и V. В примере, проиллюстрированном в части (c) на Фиг. 30, одиннадцать индексов контекста для яркости и одиннадцать общих индексов контекста для цветности U и V выводят, то есть, в целом двадцать два индекса контекста.
[0250] В процессе выведения индекса контекста согласно сравнительному примеру, выводят всего 9+6+22=37 индексов контекста.
[0251] С другой стороны, согласно модулю 124b получения контекста позиции в примере, проиллюстрированном в части (a) на Фиг. 29, выводят семь индексов контекста для яркости и семь индексов контекста для цветности, то есть четырнадцать индексов контекста всего. В областях R7, R8 и R9, иллюстрированных в части (b) на Фиг. 29, выводят три индекса контекста для яркости и три индекса контекста для цветности, то есть, шесть индексов контекста всего.
[0252] Поэтому в процессе выведения индекса контекста, выполненном модулем 124b выведения контекста позиции, достаточно вывести 14+6=20 индексов контекста.
[0253] Как описано выше, в примерах, иллюстрированных на Фиг. 29 и 30, модуль 124b выведения контекста позиции может опустить выведение 37-20=17 индексов контекста.
[0254] Фиг. 31 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем 124b выведения контекста позиции. Часть (a) на Фиг. 32 является диаграммой, иллюстрирующей пример CTX_IND_MAP_4×4to8×8 [index] в псевдокоде, проиллюстрированном на Фиг. 31, тогда как часть (b) на Фиг. 32 иллюстрирует значения индивидуальных индексов контекста, которые выводят в случае использования CTX_IND_MAP_4×4to8×8 [index], иллюстрированной в части (a) на Фиг. 32 для псевдокода, иллюстрированного на Фиг. 31.
[0255] Процесс выведения индекса контекста, выполняемый модулем 124b выведения контекста позиции, не ограничен вышеописанным примером. Как иллюстрировано в частях (a) и (b) на Фиг. 33, процесс выведения общих индексов контекста может быть выполнен только для частотных компонентов R0-R3.
[0256] Фиг. 34 иллюстрирует псевдокод, показывающий такой процесс выведения индекса контекста, выполняемый модулем 124b выведения контекста позиции. Часть (a) на Фиг. 35 является диаграммой, иллюстрирующей пример CTX_IND_MAP_4×4to8×8 [index] в псевдокоде, проиллюстрированном на Фиг. 34, тогда как часть (b) на Фиг. 35 иллюстрирует значения индивидуальных индексов контекста, которые выводят в случае использования CTX_IND_MAP_4×4to8×8 [index], иллюстрированной в части (a) на Фиг. 35 для псевдокода, иллюстрированного на Фиг. 34, и это относится к размеру 4×4 компонентов. Часть (c) на Фиг. 35 иллюстрирует значения индивидуальных индексов контекста, которые выводят в случае использования CTX_IND_MAP_4×4to8×8 [index], иллюстрированной в части (a) на Фиг. 35 для псевдокода, иллюстрированного на Фиг. 34, и это относится к размеру 8×8 компонентов.
[0257] Фиг. 36 иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции. Часть (a) на Фиг. 37 является диаграммой, иллюстрирующей пример CTX_IND_MAP_4×4to8×8_L [index] в псевдокоде, проиллюстрированном на Фиг. 36, тогда как часть (b) на Фиг. 37 иллюстрирует значения индивидуальных индексов контекста, которые выводят в случае использования CTX_IND_MAP_4×4to8×8_L [index], проиллюстрированный в части (a) на Фиг. 37 для псевдокода, иллюстрированного на Фиг. 36, и это относится к яркости.
[0258] В частотной области из 8×8 компонентов, иллюстрированных в части (b) на Фиг. 37, индексы контекста, выведенные для частотных компонентов, которые принадлежат области из 4×4 компонентов на стороне низких частот, также используются в качестве индексов контекста, относящихся к яркости в случае, когда размер целевой частотной области соответствует 4×4 компонентам.
[0259] Часть (a) на Фиг. 38 является диаграммой, иллюстрирующей пример CTX_IND_MAP_4×4to8×8_C [index] в псевдокоде, проиллюстрированном на Фиг. 36, тогда как часть (b) на Фиг. 38 иллюстрирует значения индивидуальных индексов контекста, которые выводят в случае использования CTX_IND_MAP_4×4to8×8_C [index], проиллюстрированного в части (a) на Фиг. 38 для псевдокода, иллюстрированного на Фиг. 37, и это относится к цветности.
[0260] В частотной области из 8×8 компонентов, иллюстрированных в части (b) на Фиг. 38, индексы контекста, выведенные для частотных компонентов, которые принадлежат области из 4×4 компонентов на стороне низких частот, также используются в качестве индексов контекста, относящихся к цветности в случае, когда размер целевой частотной области соответствует 4×4 компонентам.
[0261] В примере, проиллюстрированном в части (b) на Фиг. 37, пятнадцать индексов контекста выведены для яркости. В примере, проиллюстрированном в части (b) на Фиг. 38, тринадцать индексов контекста выведены для цветности. Таким образом, в примере, проиллюстрированном в части (b) на Фиг. 37 и части (b) на Фиг. 38, выводят 15+13=28 индексов контекста.
[0262] Количество этих индексов контекста меньше на девять, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0263] Как описано выше, согласно модулю 124b получения контекста позиции, количество индексов контекста, которые должны быть выведены, может быть сокращено. Соответственно, процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0264] (Конкретный пример 2 из процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
Описание выше было дано для случая выведения общих индексов контекста среди различных блоков преобразования в случае, когда частотная область имеет некоторый размер или меньший, но процесс выведения индекса контекста не ограничен этим. В дальнейшем, описание будет дано случая не выведения общих индексов контекста среди различных блоков преобразования.
[0265] Описание будет дано конкретного примера 2 для процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, со ссылками на Фиг. 60-63.
[0266] Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны, на подгруппы R0-R6 на основе позиций (xC, yC) частотных компонентов.
[0267] (В случае 4×4 компонентов)
(1) В случае, когда xC=0 и yC=0, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда (xC=0 и yC=0) не удовлетворено, xC<2, и yC<2, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC=2 и yC<2, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC=3 и yC<2, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда xC<2 и yC=2, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC<2 и yC=3, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда xC≥2 и yC≥2, частотный компонент классифицируется в подгруппу R6.
[0268] Предшествующие (1) и (2) могут быть заменены следующими (1ʹ) и (2ʹ).
(1ʹ) В случае, когда xC<1 и yC<1, частотный компонент классифицируется в подгруппу R0.
(2ʹ) В случае, когда (xC<1 и yC<1) не удовлетворено, xC<2, и yC<2, частотный компонент классифицируется в подгруппу R1.
[0269] (В случае 8×8 компонентов)
(1) В случае, когда xC<2 и yC<2, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда (xC<2 и yC<2) не удовлетворено, xC<4, и yC<4, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC≥4, xC<6, и yC<4, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC≥6 и yC<4, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда xC<4, yC≥4, и yC<6, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC<4 и yC≥6, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда xC≥4 и yC≥4, частотный компонент классифицируется в подгруппу R6.
[0270] Пример, в котором вышеописанный процесс классификации применяется к 4×4 компонентам и 8×8 компонентам, иллюстрирован в частях (a) и (b) на Фиг. 60. Часть (a) на Фиг. 60 является диаграммой, иллюстрирующей области (подгруппы) R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) на Фиг. 60 является диаграммой, иллюстрирующей области (подгруппы) R0-R6, которые формируют частотный компонент, имеющий размер 8×8 компонентов. Как иллюстрировано в части (a) на Фиг. 60, три компонента AC, которые являются смежными с DC и которые имеют самый низкий порядок, назначены на одну подобласть, и для яркости и для цветности. Так как области AC дерева назначены на одну подобласть, контексты могут быть уменьшены на два в этой части. Изобретатели установили с помощью экспериментов, что ухудшение эффективности кодирования, вызванное таким назначением, является незначительным. Такое назначение может также быть применено к конфигурации, отличной от существующей конфигурации.
[0271] Альтернативно, следующий процесс может быть выполнен посредством использования общего процесса классификации подгруппы для 4×4 компонентов и 8×8 компонентов. Сначала модуль 124a классификации частоты вычисляет переменные X и Y на основе позиции (xC, yC) целевого частотного компонента, который должен быть обработан, и log2TrafoSize, представляющего размер преобразованного блока, посредством использования следующих уравнений.
[0272] X=log2TrafoSize == 2 ? xC:xC>>1
Y=log2TrafoSize == 2 ? yC:yC>>1
Затем на основе выведенных переменных X и Y целевые частотные компоненты (xC, yC), которые должны быть обработаны, классифицируются на подгруппы R0-R6.
[0273] (1) В случае, когда X=0 и Y=0, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда (X=0 и Y=0) не удовлетворено, X<2, и Y<2, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда X=2 и Y<2, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда X=3 и Y<2, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда X<2 и Y=2, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда X<2 и Y=3, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда X≥2 и Y≥2, частотный компонент классифицируется в подгруппу R6.
[0274] Таким образом, шаблон разделения частотной области, которая имеет размер 4×4 компонентов (первый размер), и которая разделена посредством модуля 124a классификации частоты, и шаблон разделения частотной области, которая имеет размер 8×8 компонентов (второй размер), и которая разделена посредством модуля 124a классификации частоты, являются аналогичными друг другу.
[0275] Альтернативно, общий процесс классификации 4×4 компонентов и 8×8 компонентов на подгруппы может быть выполнен следующим образом.
[0276] (1) В случае, когда xC < ширина/4 и yC < ширина/4, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда xC < ширина/2 и yC< ширина/2, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC ≥ ширина/2, x C< ширина ×3/4, и yC< ширина/2, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC ≥ ширина × 3/4 и yC< ширина/2, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда xC < ширина/2, yC ≥ ширина/2, и yC< ширина ×3/4, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC < ширина/2 и yC ≥ ширина ×3/4, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда xC ≥ ширина/2 и yC ≥ ширина/2, частотный компонент классифицируется в подгруппу R6.
Здесь, "ширина" явяляется шириной целевой частотной области (4 для 4×4 компонентов, и 8 для 8×8 компонентов).
[0277] Затем в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции назначает индивидуальные индексы контекста на индивидуальные подгруппы, классифицированные посредством модуля 124a классификации частоты.
[0278] В частности, индекс контекста ctxIdx (i) для яркости выводят, используя следующее уравнение:
[0279] offsetBlk = log2TrafoWidth == 2 ? 0:7
ctxIdx (i)=i+offsetBlk
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetBlk представляет смещение, для того чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов. Некоторое значение установлено в offsetBlk в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока. Таким образом, индексы контекста ctxIdx (i) индивидуальных подгрупп Ri для 4×4 компонентов для яркости установлены способом, поиллюстрированным в части (b) на Фиг. 62, и индексы контекста ctxIdx (i) индивидуальных подгрупп Ri для 8×8 компонентов для яркости установлены способом, поиллюстрированным в части (c) на Фиг. 62.
[0280] Таким образом, когда предполагается, что модуль 124b выведения контекста позиции выводит индексы контекста ctxIdx = 0, 1, 2, 3, 4, 5 и 6 для областей Ri (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированных в части (a) на Фиг. 60 для яркости в случае 4×4 компонентов, модуль 124b выведения контекста позиции выводит индексы контекста ctxIdx=7, 8, 9, 10, 11, 12 и 13 для областей Ri (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированных в части (b) на Фиг. 60 в случае 8×8 компонентов.
[0281] Индекс контекста ctxIdx (i) для цветности выводят, используя следующие уравнения:
[0282] offsetBlk = log2TrafoWidth == 2 ? 0:7
ctxIdx (i)=i+offsetClr+offsetBlk
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetBlk представляет смещение для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов. Некоторое значение установлено в offsetBlk в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока. offsetClr является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности. Например, в случае, когда offsetClr=14, индексы контекста ctxIdx (i) индивидуальных подгрупп Ri для 4×4 компонентов для цветности установлены способом, проиллюстрированным в части (a) на Фиг. 63, и индексы контекста ctxIdx (i) индивидуальных подгрупп Ri для 8×8 компонентов для цветности установлены способом, проиллюстрированным в части (b) на Фиг. 63.
[0283] Таким образом, когда предполагается, что модуль 124b выведения контекста позиции выводит индексы контекста ctxIdx=14, 15, 16, 17, 18, 19, и 20 для областей Ri (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированных в части (a) на Фиг. 60 для цветности в случае 4×4 компонентов, модуль 124b выведения контекста позиции выводит индексы контекста ctxIdx=21, 22, 23, 24, 25, 26, 27, и 28 для областей Ri (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированных в части (b) на Фиг. 60 для цветности 8×8 компонентов. Для удобства описания индексы контекста для цветности проиллюстрированы в частях (a) и (b) на Фиг. 63, со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, равным offsetClr=14, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости блока преобразования 4×4 - блока преобразования 32×32.
[0284] Вышеописанный процесс классификации частоты, выполняемый модулем 124a классификации частоты, и вышеописанный процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, иллюстрированным на Фиг. 61.
[0285] Таким образом, в псевдокоде, иллюстрированным на Фиг. 61, некоторое значение смещения добавляется к опорному значению таблицы поиска CTX_IND_MAP [index], соответствующему индексу значения индекса, который определяется позицией (X, Y) суб-блока, и таким образом вычисляется индекс ctxIdx контекста целевого частотного компонента (xC, yC), который должен быть обработан. В случае блока преобразования 4×4 и блока преобразования 8×8 индекс значения индекса, который определен позицией (X, Y) каждого суб-блока (суб-блока 1×1 в случае 4×4, и суб-блока 2×2 в случае 8×8) представляет порядок сканирования (начальное значение равно 0) суб-блока в горизонтальном направлении, и вычисляется посредством использования следующего уравнения:
[0286] Index=(Y<<2)+X
Индекс ctxIdx контекста для яркости каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP [index]
(В случае 8×8 компонентов)
ctxIdx=CTX_IND_MAP [index]+sigCtxOffset
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов.
[0287] Индекс ctxIdx контекста для цветности каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP [index]+SigCtxOffsetLuma
(В случае 8×8 компонентов)
ctxIdx=CTX_IND_MAP [index]+sigCtxOffset+SigCtxOffsetLuma
Здесь, sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов, тогда как SigCtxOffsetLuma является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0288] В этом случае значение смещения в "sigCtx=log2TrafoSize == 2 ? 0: смещение" на Фиг. 61 установлено равным 7.
[0289] Часть (a) на Фиг. 62 является диаграммой, иллюстрирующей пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном на Фиг. 61. Часть (b) на Фиг. 62 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61. Часть (c) на Фиг. 62 иллюстрирует значения индивидуальных индексов контекста для яркости 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61. Часть (a) на Фиг. 63 иллюстрирует значения индивидуальных индексов контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61. Часть (b) на Фиг. 63 иллюстрирует значения индивидуальных индексов контекста для цветности 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61. В примере, проиллюстрированном в части (b) на Фиг. 62, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (b) на Фиг. 62). То же самое относится к части (c) на Фиг. 62 и части (a) и (b) на Фиг. 63. Для удобства описания индексы контекста для цветности иллюстрированы в частях (a) и (b) на Фиг. 63 со смещением SigCtxOffsetLuma для того, чтобы идентифицировать индексы контекста для яркости и цветности, равным SigCtxOffsetLuma=14, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости блока преобразования 4×4 - блока преобразования 32×32.
[0290] Индексы контекста, назначенные на индивидуальные позиции коэффициента, проиллюстрированные в частях (a) и (b) на Фиг. 60 и частях (a) и (b) на Фиг. 68, описанной ниже, могут также быть выведены с помощью вычисления битов, как иллюстрировано на Фиг. 100, 101, и 102, как описано ниже.
[0291] В примере, проиллюстрированном в частях (b) и (c) на Фиг. 62, четырнадцать индексов контекста выведены для яркости. В примере, проиллюстрированном в частях (a) и (b) на Фиг. 63, четырнадцать индексов контекста выведены для цветности. Таким образом, в примерах, иллюстрированных в частях (b) и (c) на Фиг. 62 и частях (a) и (b) на Фиг. 63, выводят 14+14=28 индексов контекста. Это количество индексов контекста меньше на девять чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0292] Как описано выше, в этом процессе способ выведения индекса контекста, проиллюстрированный на Фиг. 60, использован для выполнения общего процесса классификации для того, чтобы классифицировать 4×4 компонентов и 8×8 компонентов для яркости и цветности на подгруппы. Соответственно, процесс выведения индекса контекста может быть упрощен, в то же время поддерживая эффективность кодирования. Далее, согласно этому процессу, количество индексов контекста, которые должны быть выведены, может быть сокращено, и таким образом процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0293] (Конкретный пример 3 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
Описание будет дано конкретного примера 3 для процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, вновь ссылаясь на Фиг. 64 и 65.
[0294] Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты выполняет процесс, подобный таковому, выполняемому модулем 124a классификации частоты в вышеописанном конкретном примере 2 на основе позиций (xC, yC) целевых частотных компонентов, которые должны быть обработаны, чтобы классифицировать частотные компоненты на подгруппы R0-R6.
[0295] Затем в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции, может назначить индексы контекста на индивидуальные подгруппы, классифицированные посредством модуля 124a классификации частоты, посредством использования характеристики, что частота появления ненулевых коэффициентов является симметричной относительно границы, в которой удовлетворяется u=v, u представляет частотные компоненты горизонтального направления (Фиг. 60) и v представляет частотные компоненты вертикального направления.
[0296] В части (a) на Фиг. 60, относительно 4×4 компонентов, модуль 124b выведения контекста позиции выводит и назначает общий индекс контекста ctxIdx (i) области R3 на стороне высоких частот среди частотных компонентов горизонтального направления и области R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении. В части (b) на Фиг. 60 относительно 8×8 компонентов, модуль 124b выведения контекста позиции выводит и назначает общий индекс контекста ctxIdx (i) области R3 на стороне высоких частот среди частотных компонентов горизонтального направления и области R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении.
[0297] Например, принимается, что, относительно яркости, индексы контекста ctxIdx=0, 1, 2, 3, 4, 3, и 5 соответственно выводятся для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (a) на Фиг. 60 в случае 4×4 компонентов. В этом случае индексы контекста ctxIdx=6, 7, 8, 9, 10, 9, и 11 соответственно выводятся для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (b) на Фиг. 60 в случае 8×8 компонентов.
[0298] Аналогично, принимается, что, относительно цветности, индексы контекста ctxIdx=12, 13, 14, 15, 16, 15, и 17 соответственно выводятся для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (a) на Фиг. 60 в случае 4×4 компонентов. В этом случае индексы контекста ctxIdx=18, 19, 20, 21, 22, 21, и 23 соответственно выводятся для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (b) на Фиг. 60 в случае 8×8 компонентов.
[0299] Вышеописанный процесс классификации частоты, выполняемый модулем 124a классификации частоты, и вышеописанный процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, проиллюстрированным на Фиг. 61.
[0300] Таким образом, в псевдокоде, проиллюстрированном на Фиг. 61, некоторое значение смещения добавляется к опорному значению таблицы поиска CTX_IND_MAP [index], соответствующему индексу значения индекса, который определяется позицией (X, Y) суб-блока, и таким образом вычисляется индекс ctxIdx контекста целевого частотного компонента (xC, yC), который должен быть обработан. В случае 4×4 блока преобразования и 8×8 блока преобразования индекс значения индекса, который определяется позицией (X, Y) каждого суб-блока (суб-блока 1×1 в случае 4×4 и суб-блока 2×2 в случае 8×8), представляет порядок сканирования (начальное значение, равное 0) суб-блока в горизонтальном направлении. Индекс значения индекса вычисляется посредством использования следующего уравнения, на основе позиции (X, Y) суб-блока.
[0301] index =(Y<<2)+X
Индекс ctxIdx контекста для яркости каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP [index] (В случае 8×8 компонентов)
ctxIdx=CTX_IND_MAP [index]+sigCtxOffset
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов.
[0302] Индекс ctxIdx контекста для цветности каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP [index]+SigCtxOffsetLuma
(В случае 8×8 компонентов)
ctxIdx=CTX_IND_MAP [index]+sigCtxOffset+SigCtxOffsetLuma
Здесь, sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов, 16×4 компонентов и 4×16 компонентов, тогда как SigCtxOffsetLuma является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0303] В этом случае значение смещения в "sigCtx=log2TrafoSize == 2 ? 0: смещение" на Фиг. 61 установлено в 6.
[0304] Часть (a) на Фиг. 64 является диаграммой, иллюстрирующей пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном на Фиг. 61. Часть (b) на Фиг. 64 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 64 для псевдокода, иллюстрированного на Фиг. 61. Часть (c) на Фиг. 64 иллюстрирует значения индивидуальных индексов контекста для яркости 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 64 для псевдокода, иллюстрированного на Фиг. 61. Часть (a) на Фиг. 65 иллюстрирует значения индивидуальных индексов контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 64 для псевдокода, иллюстрированного на Фиг. 61. Часть (b) на Фиг. 65 иллюстрирует значения индивидуальных индексов контекста для цветности 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 61. В примере, проиллюстрированном в части (b) на Фиг. 64, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 64). То же самое относится к части (c) на Фиг. 64 и частям (a) и (b) на Фиг. 65. Для удобства описания индексы контекста для цветности иллюстрированы в частях (a) и (b) на Фиг. 65, со смещением SigCtxOffsetLuma для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся SigCtxOffsetLuma = 12, но вариант осуществления не ограничен этим. Предпочтительно, SigCtxOffsetLuma является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0305] В примере, проиллюстрированном в частях (b) и (c) на Фиг. 64, двенадцать индексов контекста выводятся для яркости. В примере, проиллюстрированном в частях (a) и (b) на Фиг. 65, двенадцать индексов контекста выводятся для цветности. Таким образом, в примерах, иллюстрированных в частях (b) и (c) на Фиг. 64 и частях (a) и (b) на Фиг. 65, выводятся 12+12=24 индексов контекста.
[0306] Это количество индексов контекста меньше на тринадцать, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a) - (c) на Фиг. 30.
[0307] Как описано выше, в этом процессе способ выведения индекса контекста, проиллюстрированный на Фиг. 60, используется для выполнения общего процесса классификации для того, чтобы классифицировать 4×4 компонентов и 8×8 компонентов для яркости и цветности на подгруппы. Соответственно, процесс выведения индекса контекста может быть упрощен, в то же время поддерживая эффективность кодирования. Далее, согласно этому процессу, количество индексов контекста, которые должны быть выведены, может быть сокращено, и таким образом процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0308] (Конкретный пример 4 из процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретном примере 3 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, описание было дано примера назначения индексов контекста к индивидуальным подгруппам, классифицированным модулем 124a классификации частоты посредством использования характеристики, что частота появления ненулевых коэффициентов является симметричной относительно границы, на которой удовлетворяется u=v, u представляет частотные компоненты горизонтального направления и v представляет частотные компоненты в вертикальном направлении, и для яркости и для цветности.
[0309] Ниже будет дано описание конкретного примера 4 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, вновь ссылаясь на Фиг. 66-69. В конкретном примере 4, описанном здесь, вышеописанный конкретный пример 2 применяется для яркости, и процесс выведения индекса контекста согласно вышеописанному конкретному примеру 3 применяется для цветности.
[0310] Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты выполняет процесс, подобный выполняемому модулем 124a классификации частоты в вышеописанном конкретном примере 2 на основе позиций (xC, yC) целевых частотных компонентов, которые должны быть обработаны, так, чтобы классифицировать частотные компоненты на подгруппы R0-R6.
[0311] Затем в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции назначает, для яркости, индивидуальные индексы контекста к индивидуальным подгруппам, классифицированным модулем 124a классификации частоты. Для цветности модуль 124b выведения контекста позиции может назначить индексы контекста на индивидуальные подгруппы, классифицированные посредством модуля 124a классификации частоты, посредством использования характеристики, что частота появления ненулевых коэффициентов является симметричной относительно границы, на которой удовлетворяется u=v, u представляет частотные компоненты горизонтального направления и v представляет частотные компоненты в вертикальном направлении. Таким образом, в случае цветности модуль 124b выведения контекста позиции выводит и назначает общий индекс контекста ctxIdx (i) области R3 на стороне высоких частот частотных компонентов горизонтального направления и области R5 на стороне высоких частот частотных компонентов в вертикальном направлении относительно 4×4 компонентов в части (a) на Фиг. 60.
[0312] Например, предположим, что, относительно яркости, индексы контекста ctxIdx=0, 1, 2, 3, 4, 5 и 6 соответственно выводят для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (a) на Фиг. 60 в случае 4×4 компонентов. В этом случае индексы контекста ctxIdx=7, 8, 9, 10, 11, 12 и 13 соответственно выводят для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (b) на Фиг. 60 в случае 8×8 компонентов.
[0313] Предположим, что, относительно цветности, индексы контекста ctxIdx=14, 15, 16, 17, 18, 17 и 19 соответственно выводят для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (a) на Фиг. 60 в случае 4×4 компонентов. В этом случае индексы контекста ctxIdx=20, 21, 22, 23, 24, 23 и 25 соответственно выводят для областей R0, R1, R2, R3, R4, R5 и R6, проиллюстрированных в части (b) на Фиг. 60 в случае 8×8 компонентов.
[0314] Вышеописанный процесс классификации частоты, выполняемый модулем 124a классификации частоты, и вышеописанный процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, проиллюстрированным на Фиг. 66.
[0315] Таким образом, в псевдокоде, проиллюстрированном на Фиг. 66, некоторое значение смещения добавляется к опорному значению таблицы поиска CTX_IND_MAP_L [index] или CTX_IND_MAP_C [index], соответствующему индексу значения индекса, который определен позицией (X, Y) суб-блока, и таким образом вычисляется индекс ctxIdx контекста целевого частотного компонента (xC, yC), который должен быть обработан. В случае 4×4 блока преобразования и 8×8 блока преобразования индекс значения индекса, который определен позицией (X, Y) каждого суб-блока (суб-блока 1×1 в случае 4×4 и суб-блока 2×2 в случае 8×8) представляет порядок сканирования (начальное значение, равное 0) суб-блока в горизонтальном направлении. Индекс значения индекса вычисляют посредством использования следующего уравнения, на основе позиции (X, Y) суб-блока.
[0316] Index = (Y<<2)+X
Индекс ctxIdx контекста для яркости каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP_L [index]
(В случае 8×8 компонентов)
ctxIdx=CTX_IND_MAP_L [index]+sigCtxOffset
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов.
[0317] Индекс ctxIdx контекста для цветности каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP_C [index]+SigCtxOffsetLuma
(В случае 8×8 компонентов)
ctxIdx=CTX_IND_MAP_C [index]+sigCtxOffset+SigCtxOffsetLuma
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов, тогда как SigCtxOffsetLuma является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0318] Часть (a) на Фиг. 67 является диаграммой, иллюстрирующей пример CTX_IND_MAP_L [index] в псевдокоде, проиллюстрированном на Фиг. 66. Часть (a) на Фиг. 68 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP_L [index] в части (a) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66. Часть (b) на Фиг. 68 иллюстрирует значения индивидуальных индексов контекста для яркости 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP_L [index] в части (a) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66.
[0319] Часть (a) на Фиг. 69 иллюстрирует значения индивидуальных индексов контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66. Часть (b) на Фиг. 69 иллюстрирует значения индивидуальных индексов контекста для цветности 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 66. В примере, проиллюстрированном в части (a) на Фиг. 68, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 68). То же самое относится к части (b) на Фиг. 68 и частям (a) и (b) на Фиг. 69. Для удобства описания индексы контекста для цветности иллюстрированы в частях (a) и (b) на Фиг. 69, со смещением SigCtxOffsetLuma для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся SigCtxOffsetLuma=14, но вариант осуществления не ограничен этим. Предпочтительно, SigCtxOffsetLuma является общим количеством индексов контекста для яркости блока преобразования 4×4 - блока преобразования 32×32.
[0320] В примере, проиллюстрированном в частях (a) и (b) на Фиг. 68, четырнадцать индексов контекста выводятся для яркости. В примере, проиллюстрированном в частях (a) и (b) на Фиг. 69, двенадцать индексов контекста выводятся для цветности. Таким образом, в примерах, иллюстрированных в частях (b) и (c) на Фиг. 68 и частях (a) и (b) на Фиг. 69, выводятся 14+12=26 индексов контекста.
[0321] Это количество индексов контекста меньше на одиннадцать, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0322] Как описано выше, в этом процессе процесс выведения индекса контекста, проиллюстрированный на Фиг. 68 и 69, используется для выполнения общего процесса классификации для того, чтобы классифицировать 4×4 компонентов и 8×8 компонентов для яркости и цветности на подгруппы. Соответственно, процесс выведения индекса контекста может быть совместно выполнен, и процесс выведения индекса контекста может быть упрощен. Далее, согласно этому процессу, количество индексов контекста, которые должны быть выведены, может быть сокращено, и таким образом процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0323] (Конкретный пример 5 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретных примерах 2-4 описание было дано случая выполнения общего процесса классификации в отношении частотных компонентов в 4×4 блоке преобразования и 8×8 блоке преобразования. Однако процесс классификации не ограничен этим. Например, в области R0 из 8×8 блока преобразования, проиллюстрированной в части (b) на Фиг. 60, компонент DC может быть классифицирован как другая подгруппа R7. Таким образом, частотная область может быть разделена на подобласти (подгруппы) так, чтобы шаблон разделения частотной области, имеющей размер 4×4 компонентов, и шаблон разделения частотной области, имеющей размер 8×8 компонентов, были аналогичны друг другу в частотной области, кроме компонента DC.
[0324] В частности, в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, целевые частотные компоненты, которые должны быть обработаны, классифицируются на подгруппы R0-R6 в случае 4×4 компонентов, и на подгруппы R0-R7 в случае 8×8 компонентов, на основе позиций (xC, yC) целевых частотных компонентов.
[0325] (В случае 4×4 компонентов)
(1) В случае, когда xC=0 и yC=0, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда (xC=0 и yC=0) не удовлетворено, xC<2, и yC<2, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC=2 и yC<2, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC=3 и yC<2, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда xC<2 и yC=2, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC<2 и yC=3, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда xC≥2 и yC≥2, частотный компонент классифицируется в подгруппу R6.
Предшествующие (1) и (2) могут быть заменены следующими (1ʹ) и (2ʹ).
[0326] (1ʹ) В случае, когда xC<1 и yC<1, частотный компонент классифицируется в подгруппу R0.
(2ʹ) В случае, когда (xC<1 и yC<1) не удовлетворено, xC<2, и yC<2, частотный компонент классифицируется в подгруппу R1.
[0327] (В случае 8×8 компонентов)
(1) В случае, когда xC=0 и yC=0, частотный компонент классифицируется в подгруппу R7.
(2) В случае, когда (xC=0 и yC=0) не удовлетворено, xC<2, и yC<2, частотный компонент классифицируется в подгруппу R0.
(3) В случае, когда (xC<2 и yC<2) не удовлетворено, xC<4, и yC<4, частотный компонент классифицируется в подгруппу R1.
(4) В случае, когда xC≥4, xC<6, и yC<4, частотный компонент классифицируется в подгруппу R2.
(5) В случае, когда xC≥6 и yC<4, частотный компонент классифицируется в подгруппу R3.
(6) В случае, когда xC<4, yC≥4, и yC<6, частотный компонент классифицируется в подгруппу R4.
(7) В случае, когда xC<4 и yC≥6, частотный компонент классифицируется в подгруппу R5.
(8) В случае, когда xC≥4 и yC≥4, частотный компонент классифицируется в подгруппу R6.
[0328] Альтернативно, следующий процесс может быть выполнен посредством использования общего процесса для части процесса классификации подгруппы для 4×4 компонентов и 8×8 компонентов. Сначала модуль 124a классификации частоты вычисляет переменные X и Y на основе позиции (xC, yC) целевого частотного компонента, который должен быть обработан, и log2TrafoSize, представляющего размер преобразованного блока, посредством использования следующих уравнений.
[0329] X=log2TrafoSize == 2 ? xC:xC>>1
Y=log2TrafoSize == 2 ? yC:yC>>1
Затем на основе выведенных переменных X и Y, целевые частотные компоненты (xC, yC), которые должны быть обработаны, классифицируются на подгруппы R0-R6.
[0330] (1) В случае, когда X=0 и Y=0, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда (X=0 и Y=0) не удовлетворено, X<2, и Y<2, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда X=2 и Y<2, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда X=3 и Y<2, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда X<2 и Y=2, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда X<2 и Y=3, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда X≥2 и Y≥2, частотный компонент классифицируется в подгруппу R6.
[0331] После вышеописанного общего процесса компонент DC (xC=0 и yC=0), включенный в подгруппу R0, расположенную в низкочастотных 8×8 компонентах, далее классифицируется как подгруппа R7.
[0332] Альтернативно, общий процесс классификации 4×4 компонентов и 8×8 компонентов на подгруппы может быть выполнен следующим образом.
[0333] (1) В случае, когда xC < ширина/4 и yC < ширина/4, частотный компонент классифицируется в подгруппу R0.
(2) В случае, когда xC < ширина/2 и yC < ширина/2, частотный компонент классифицируется в подгруппу R1.
(3) В случае, когда xC ≥ ширина/2, xC < ширина х 3/4, и yC < ширина/2, частотный компонент классифицируется в подгруппу R2.
(4) В случае, когда xC ≥ ширина × 3/4 и yC < ширина/2, частотный компонент классифицируется в подгруппу R3.
(5) В случае, когда xC < ширина/2, yC ≥ ширина/2, и yC < ширина × 3/4, частотный компонент классифицируется в подгруппу R4.
(6) В случае, когда xC < ширина/2 и yC ≥ ширина × 3/4, частотный компонент классифицируется в подгруппу R5.
(7) В случае, когда xC ≥ ширина/2 и yC ≥ ширина/2, частотный компонент классифицируется в подгруппу R6.
Здесь, "ширина" является шириной целевой частотной области (4 для 4×4 компонентов и 8 для 8×8 компонентов).
[0334] После вышеописанного общего процесса компонент DC (xC=0 и yC=0), включенный в подгруппу R0, расположенную в низкочастотных 8×8 компонентах, далее классифицируется как подгруппа R7.
[0335] Пример, в котором вышеописанный процесс классификации применяется к 4×4 компонентов и 8×8 компонентов, иллюстрирован в частях (a) и (b) на Фиг. 70. Часть (a) на Фиг. 70 является диаграммой, иллюстрирующей области (подгруппы) R0-R6, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) на Фиг. 70 является диаграммой, иллюстрирующей области (подгруппы) R0-R7, которые формируют частотный компонент, имеющий размер 8×8 компонентов.
[0336] Затем модуль 124b выведения контекста позиции может назначить соответствующие индексы контекста ctxIdx (i) индивидуальным подгруппам Ri (i=0, 1, 2, 3, 4, 5, 6, и 7), проиллюстрированным в частях (a) и (b) на Фиг. 70, которые были классифицированы модулем 124a классификации частоты. В частности, индекс контекста ctxIdx (i) для яркости выводят, используя следующие уравнения:
[0337] offsetBlk=log2TrafoWidth == 2 ? 0:7
ctxIdx (i)=i+offsetBlk
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetBlk представляет смещение для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов. Некоторое значение установлено в offsetBlk в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока.
[0338] Относительно яркости индексы контекста ctxIdx (i), соответствующие индивидуальным подгруппам Ri для 4×4 компонентам, выведенным с использованием предшествующих уравнений, проиллюстрированы в части (a) на Фиг. 88, и индексы контекста ctxIdx (i), соответствующие индивидуальным подгруппам Ri для 8×8 компонентов, проиллюстрированы в части (b) на Фиг. 88.
[0339] Индекс контекста ctxIdx (i) для цветности выводят, используя следующие уравнения:
[0340] offsetBlk=log2TrafoWidth == 2 ? 0:7
ctxIdx (i)=i+offsetClr+offsetBlk
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetBlk представляет смещение для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов. Некоторое значение установлено в offsetBlk в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока. offsetClr является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности. Здесь, в случае, когда offsetClr=20, относительно цветности, индексы контекста ctxIdx (i), соответствующие индивидуальным подобластям Ri для 4×4 компонентов, выведенные с использованием предшествующих уравнений, проиллюстрированы в части (c) на Фиг. 88, и индексы контекста ctxIdx (i), соответствующие индивидуальным подобластям Ri для 8×8 компонентов, проиллюстрированы в части (d) на Фиг. 88. Для удобства описания индексы контекста для цветности иллюстрированы в частях (c) и (d) на Фиг. 88, со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся offsetClr=20, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0341] Вышеописанный процесс классификации частоты, выполняемый модулем 124a классификации частоты, и вышеописанный процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, иллюстрированным в части (a) на Фиг. 89. Таким образом, в псевдокоде, проиллюстрированном в части (a) на Фиг. 89, некоторый индекс значения индекса назначается на компонент DC 8×8 блока преобразования, индекс значения индекса, определенный позицией (X, Y) суб-блока, назначается на частотный компонент, кроме DC, 8×8, блока преобразования, и индексы ctxIdx контекста целевых частотных компонентов, которые должны быть обработаны (xC, yC), вычисляют посредством использования индекса значения индекса и таблицы поиска CTX_IND_MAP [index].
[0342] (В случае 4×4 компонентов)
Индекс значения индекса, соответствующий позиции (X, Y) суб-блока (суб-блока 1×1 в случае 4×4), которому принадлежит целевой частотный компонент (xC, yC), который должен быть обработан, вычисляют посредством использования следующего уравнения:
[0343] Index=(Y<<2)+X
Следует отметить, что X=xC и Y=yC. Затем на основе вычисленного индекса значения индекса и таблицы поиска CTX_IND_MAP [index], индекс ctxIdx контекста выводят посредством использования следующего уравнения:
[0344] ctxIdx = CTX_IND_MAP [index]
В случае цветности, посредством использования индекса ctxIdx контекста, вычисленного посредством использования предшествующего уравнения и некоторого смещения offsetClr, индекс контекста выводят посредством использования следующего уравнения:
[0345] ctxIdx=ctxIdx+offsetClr
Следует отметить, что offsetClr является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0346] (В случае 8×8 компонентов)
Индекс значения индекса, соответствующий позиции (X, Y) суб-блока (суб-блока 2×2 в случае 8×8), которому целевой частотный компонент (xC, yC), который должен быть обработан, принадлежит, и компонент DC вычисляют посредством использования следующего уравнения:
[0347] Index = (xC+yC == 0) ? 16:(Y<<2)+X
Следует отметить, что X=xC>>1 и Y=yC>>1. Затем посредством использования вычисленного индекса значения индекса, таблицы поиска CTX_IND_MAP [index], и некоторого смещения offsetBlk для того, чтобы идентифицировать индексы контекста для 4×4 компонентов и 8×8 компонентов, индекс ctxIdx контекста выводят посредством использования следующего уравнения:
[0348] ctxIdx=CTX_IND_MAP [index]+offsetBlk
Здесь, общее количество индексов контекста для яркости 4×4 компонентов равно 7, и таким образом offsetBlk=7. В случае цветности, посредством использования индекса ctxIdx контекста, вычисленного посредством использования предшествующего уравнения и некоторого смещения offsetClr, индекс контекста выводят посредством использования следующего уравнения:
[0349] ctxIdx=ctxIdx+offsetClr
Следует отметить, что offsetClr является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0350] Часть (b) на Фиг. 89 является диаграммой, иллюстрирующей пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном в части (a) на Фиг. 89. Часть (a) на Фиг. 88 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89. Часть (b) на Фиг. 88 иллюстрирует значения индивидуальных индексов контекста для яркости 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89. Часть (c) на Фиг. 88 иллюстрирует значения индивидуальных индексов контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89. Часть (d) на Фиг. 88 иллюстрирует значения индивидуальных индексов контекста для цветности 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 89 для псевдокода, иллюстрированного в части (a) на Фиг. 89. В примере, проиллюстрированном в части (a) на Фиг. 88, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 88). То же самое относится к частям (b), (c) и (d) на Фиг. 88. Для удобства описания индексы контекста для цветности иллюстрированы в частях (c) и (d) на Фиг. 88, со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся offsetClr=20, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
Таким образом, в примере, проиллюстрированном в частях (a) и (b) на Фиг. 70, пятнадцать индексов контекста выводятся для яркости, пятнадцать индексов контекста выводятся для цветности, то есть, выводятся 15+15=30 индексов контекста. Это количество индексов контекста меньше на семь, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0351] Альтернативно, индексы контекста могут быть назначены на подгруппы, иллюстрированные в частях (a) и (b) на Фиг. 70 и классифицированные модулем 124a классификации частоты, посредством использования характеристики, что частота появления ненулевых коэффициентов является симметричной относительно границы, в которой удовлетворяется u=v, u представляет частотные компоненты горизонтального направления и v представляет частотные компоненты в вертикальном направлении. Например, ссылаясь на часть (a) на Фиг. 71 относительно 4×4 компонентов, модуль 124b выведения контекста позиции выводит и назначает общий индекс ctxIdx контекста на область R3 на стороне высоких частот среди частотных компонентов горизонтального направления и область R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении, и выводит и назначает индивидуальные индексы контекста на остаточные R0, R1, R2, R4 и R6. Ссылаясь на часть (b) на Фиг. 71 относительно 8×8 компонентов, модуль 124b выведения контекста позиции выводит и назначает общий индекс ctxIdx контекста на область R3 на стороне высоких частот среди частотных компонентов горизонтального направления и область R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении, и выводит и назначает индивидуальные индексы контекста на остаточные R0, R1, R2, R4, R6 и R7.
[0352] Таким образом, в примере, проиллюстрированном в частях (a) и (b) на Фиг. 71, тринадцать индексов контекста выводятся для яркости, тринадцать индексов контекста выводятся для цветности, то есть, выводятся 13+13=26 индексов контекста. Это количество индексов контекста меньше на одиннадцать, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0353] Альтернативно, для подгрупп, иллюстрированных в частях (a) и (b) на Фиг. 70, которые были классифицированы модулем 124a классификации частоты, индивидуальные индексы контекста могут быть назначены для яркости. Для цветности индексы контекста могут быть назначены посредством использования характеристики, что частота появления ненулевых коэффициентов является симметричной относительно границы, в которой удовлетворяется u=v, u представляет частотные компоненты горизонтального направления и v представляет частотные компоненты в вертикальном направлении. Например, в случае яркости, модуль 124b выведения контекста позиции назначает индивидуальные индексы контекста на R0-R6 4×4 компонентов и R0-R7 8×8 компонентов. В случае цветности, относительно 4×4 компонентов, в части (a) на Фиг. 71, модуль 124b выведения контекста позиции выводит и назначает общий индекс ctxIdx контекста на область R3 на стороне высоких частот среди частотных компонентов горизонтального направления и область R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении, и выводит и назначает индивидуальные индексы контекста на остаточные R0, R1, R2, R4 и R6. Относительно 8×8 компонентов, в части (b) на Фиг. 71, модуль 124b выведения контекста позиции выводит и назначает общий индекс ctxIdx контекста на область R3 на стороне высоких частот среди частотных компонентов горизонтального направления и область R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении, и выводит и назначает индивидуальные индексы контекста на остаточные R0, R1, R2, R4, R6 и R7. То есть, пятнадцать индексов контекста выводятся для яркости, и тринадцать индексов контекста выводятся для цветности, то есть, выводятся 15+13=28 индексов контекста. Это количество индексов контекста меньше на девять, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0354] Альтернативно, для подгрупп, проиллюстрированных в частях (a) и (b) на Фиг. 70, которые были классифицирован модулем 124a классификации частоты, модуль 124b выведения контекста позиции может назначить общий индекс контекста на низкочастотные области различных блоков преобразования. Например, модуль 124b выведения контекста позиции выводит и назначает общий индекс контекста на область R0 (компонент DC) в 4×4 компонентов и область R7 (компонент DC) в 8×8 компонентов, и выводит и назначает индивидуальные индексы контекста на R1, R2, R3, R4, R5 и R6 в 4×4 компонентов и R0, R1, R2, R3, R4, R5 и R6 в 8×8 компонентов. Таким образом, в примере, проиллюстрированном в частях (a) и (b) на Фиг. 72, четырнадцать индексов контекста выводятся для яркости, и четырнадцать индексов контекста выводятся для цветности, то есть, выводятся 14+14=28 индексов контекста. Это количество индексов контекста меньше на девять, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0355] Модуль 124b выведения контекста позиции может быть сконфигурирован, чтобы выводить общий индекс контекста для компонентов DC всех блоков преобразования (4×4, 8×8, 16×4, 4×16, 16×16, 32×8, 8×32, и 32×32), в дополнение к 4×4 компонентам и 8×8 компонентам. С этой конфигурацией может быть далее сокращено количество индексов контекста.
[0356] Альтернативно, для подгрупп, иллюстрированных в частях (a) и (b) на Фиг. 70, которые были классифицирован модулем 124a классификации частоты, модуль 124b выведения контекста позиции может назначить общий индекс контекста на низкочастотные области различных блоков преобразования. Кроме того, высокочастотным областям индивидуальные блоков преобразования модуль 124b выведения контекста позиции может назначить индексы контекста посредством использования характеристики, что частота появления ненулевых коэффициентов является симметричной относительно границы, в которой удовлетворяется u=v, u представляет частотные компоненты горизонтального направления и v представляет частотные компоненты в вертикальном направлении.
[0357] Например, модуль 124b выведения контекста позиции выводит и назначает общий индекс контекста на область R0 (компонент DC) в 4×4 компонентов, проиллюстрированных в части (a) на Фиг. 73, и область R7 (компонент DC) в 8×8 компонентов, проиллюстрированных в части (b) на Фиг. 73. Затем относительно 4×4 компонентов, проиллюстрированных в части (a) на Фиг. 73, модуль 124b выведения контекста позиции выводит и назначает общий индекс ctxIdx контекста на область R3 на стороне высоких частот среди частотных компонентов горизонтального направления и область R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении, и выводит и назначает индивидуальные индексы контекста на остаточные R1, R2, R4 и R6. Кроме того, относительно 8×8 компонентов, проиллюстрированных в части (b) на Фиг. 73, модуль 124b выведения контекста позиции выводит и назначает общий индекс ctxIdx контекста на область R3 на стороне высоких частот среди частотных компонентов горизонтального направления и область R5 на стороне высоких частот среди частотных компонентов в вертикальном направлении, и выводит и назначает индивидуальные индексы контекста на остаточные R0, R1, R2, R4 и R6.
[0358] Таким образом, в примере, проиллюстрированном в частях (a) и (b) на Фиг. 73, двенадцать индексов контекста выводятся для яркости, и двенадцать индексов контекста выводятся для цветности, то есть, выводятся 12+12=24 индексов контекста. Это количество индексов контекста меньше на тринадцать, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0359] Если модуль 124b выведения контекста позиции конфигурируется, чтобы получить общий индекс контекста для компонентов DC всех преобразованных блоков (4×4, 8×8, 16×4, 4×16, 16×16, 32×8, 8×32, и 32×32), количество индексов контекста может быть далее сокращено.
[0360] Как описано выше, согласно этому процессу, количество индексов контекста, которые должны быть выведены, может быть сокращено. Таким образом, процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0361] (Конкретный пример 6 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретном примере 2 описание было дано случая, относительно размеров блока преобразования для 4×4 блоков (4×4 компонентов) и 8×8 блоков (8×8 компонентов), используя общий процесс классификации целевых частотных компонентов, которые должны быть обработаны, на подгруппы, и упрощения процесса выведения индекса контекста. Здесь, описание будет далее дано случая применения 16×4 блоков (16×4 компонентов) с горизонтальной шириной 16 и вертикальной шириной 4, и 4×16 блоков (4×16 компонентов) с горизонтальной шириной 4 и вертикальной шириной 16.
[0362] Сначала в случае, когда целевая частота, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты классифицирует, на основе позиций (xC, yC) целевых частотных компонентов, которые должны быть обработаны, целевые частотные компоненты, которые должны быть обработаны, на подгруппы (подобласти) R0-R6 в случае 4×4 компонентов и 8×8 компонентов, и на подгруппы A0-A6 в случае 4×16 компонентов и 16×4 компонентов. Процесс классификации частот 4×4 компонентов и 8×8 компонентов на подгруппы R0-R6 является аналогичным таковому из конкретного примера 2, и таким образом описание его опущено.
(В случае 16×4 компонентов)
(1) В случае, когда 0≤xC<4 и yC=0, частотный компонент классифицируется в подгруппу A0.
(2) В случае, когда (0≤xC<4 и yC=0) не удовлетворено, 0≤xC<8, и 0≤yC<2, частотный компонент классифицируется в подгруппу A1.
(3) В случае, когда 8≤xC<12 и 0≤yC<2, частотный компонент классифицируется в подгруппу A2.
(4) В случае, когда 12≤xC<16 и 0≤yC<2, частотный компонент классифицируется в подгруппу A3.
(5) В случае, когда 0≤xC<8 и yC=2, частотный компонент классифицируется в подгруппу A4.
(6) В случае, когда 0≤xC<8 и yC=3, частотный компонент классифицируется в подгруппу A5.
(7) В случае, когда 8≤xC<16 и 2≤yC<4, частотный компонент классифицируется в подгруппу A6.
(В случае 4×16 компонентов)
(1) В случае, когда xC=0 и 0≤yC<4, частотный компонент классифицируется в подгруппу A0.
(2) В случае, когда (xC=0 и 0≤yC<4) не удовлетворено, 0≤xC<2, и 0≤yC<8, частотный компонент классифицируется в подгруппу A1.
(3) В случае, когда xC=2 и 0≤yC<8, частотный компонент классифицируется в подгруппу A2.
(4) В случае, когда xC=3 и 0≤yC<8, частотный компонент классифицируется в подгруппу A3.
(5) В случае, когда 0≤xC<2 и 8≤yC<12, частотный компонент классифицируется в подгруппу A4.
(6) В случае, когда 0≤xC<2 и 12≤yC<16, частотный компонент классифицируется в подгруппу A5.
(7) В случае, когда 2≤xC<4 и 8≤yC<16, частотный компонент классифицируется в подгруппу A6.
[0363] Пример, в котором вышеописанный процесс классификации применяется к 16×4 компонентам и 4×16 компонентам, проиллюстрирован в частях (a) и (b) на Фиг. 78. Часть (a) на Фиг. 78 является диаграммой, иллюстрирующей области (подгруппы) A0-A6, которые формируют частотную область, имеющую размер 16×4 компонентов, тогда как часть (b) на Фиг. 78 является диаграммой, иллюстрирующей области (подгруппы) A0-A6, которые формируют частотную область, имеющую размер 4×16 компонентов.
[0364] Общий процесс может быть использован для классификации 16×4 компонентов и 4×16 компонентов на подгруппы, чтобы выполнить процесс следующим образом.
[0365] Сначала модуль 124a классификации частоты делит целевые N×М блоков, которые должны быть обработаны, на суб-блоки некоторого размера, и классифицирует суб-блоки на подгруппы A0 - A6 на основе позиций (X, Y) суб-блоков, которым принадлежат целевые частотные компоненты, которые должны быть обработаны (xC, yC). Например, в случае 16×4 компонентов, 16×4 блоков разделяются на 4×1 суб-блоков, имеющих горизонтальную ширину 4 и вертикальную ширину 1. В случае 4×16 компонентов, 4×16 блоки разделяются на 1×4 суб-блоков, имеющих горизонтальную ширину 1 и вертикальную ширину 4.
[0366] Сначала модуль 124a классификации частоты вычисляет, на основе позиции (xC, yC) целевого частотного компонента, который должен быть обработан, log2TrafoWidth, представляющее значение логарифма горизонтального размера ширины преобразованного блока (2 в 4×16 блоке и 4 в 16×4 блоке), и log2TrafoHeight, представляющее значение логарифма вертикального размера ширины (4 в 4×16 блоке и 2 в 16×4 блоке), позиция (X, Y) суб-блока, которому частотный компонент принадлежит, посредством использования следующих уравнений:
[0367] X=log2TrafoWidth == 2 ? xC:xC>>2
Y=log2TrafoHeight == 2 ? yC:yC>>2
Затем модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны (xC, yC) на подгруппы A0-A6 на основе выведенной позиции (X, Y) суб-блока.
[0368] (1) В случае, когда X=0 и Y=0, частотный компонент классифицируется в подгруппу A0.
(2) В случае, когда (X=0 и Y=0) не удовлетворено, X<2, и Y<2, частотный компонент классифицируется в подгруппу A1.
(3) В случае, когда X=2 и Y<2, частотный компонент классифицируется в подгруппу A2.
(4) В случае, когда X=3 и Y<2, частотный компонент классифицируется в подгруппу A3.
(5) В случае, когда X<2 и Y=2, частотный компонент классифицируется в подгруппу A4.
(6) В случае, когда X<2 и Y=3, частотный компонент классифицируется в подгруппу A5.
(7) В случае, когда X≥2 и Y≥2, частотный компонент классифицируется в подгруппу A6.
[0369] Альтернативно, общий процесс классификации 4×4 компонентов, 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов на подгруппы может быть выполнен следующим образом.
[0370] (1) В случае, когда xC < ширина/4 и yC < высота/4, частотный компонент классифицируется в подгруппу A0.
(2) В случае, когда xC < ширина/2 и yC < высота/2, частотный компонент классифицируется в подгруппу A1.
(3) В случае, когда xC ≥ ширина/2, xC < ширина × 3/4, и yC < высота/2, частотный компонент классифицируется в подгруппу A2.
(4) В случае, когда xC ≥ ширина × 3/4 и yC < высота/2, частотный компонент классифицируется в подгруппу A3.
(5) В случае, когда xC < ширина/2, yC ≥ высота/2, и yC < высота × 3/4, частотный компонент классифицируется в подгруппу A4.
(6) В случае, когда xC < ширина/2 и yC ≥ высота × 3/4, частотный компонент классифицируется в подгруппу A5.
(7) В случае, когда xC ≥ ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подгруппу A6.
[0371] Здесь, "ширина" является горизонтальной ширина целевой частотной области (4 для 4×4 компонентов, 8 для 8×8 компонентов, 16 для 16×4 компонентов, и 4 для 4×16 компонентов). "Высота" является вертикальной шириной целевой частотной области (4 для 4×4 компонентов, 8 для 8×8 компонентов, 4 для 16×4 компонентов, и 16 для 4×16 компонентов).
[0372] Как иллюстрировано на Фиг. 79, шаблон разделения 4×16 компонентов соответствуют шаблону разделения 16×4 компонентов, который симметрично преобразован посредством использования u оси частотных компонентов в горизонтальном направлении u в качестве оси симметрии и затем вращения на 90 градусов по часовой стрелке вокруг начала координат. Таким образом, шаблон разделения частотной области, которая разделена модулем 124a классификации частоты и которая имеет размер 16×4 компонентов (первый размер), и шаблон разделения частотной области, которая разделена модулем 124a классификации частоты и которая имеет размер 4×16 компонентов (второй размер) соответствуют друг другу посредством вращения и преобразования относительно оси симметрии.
[0373] Вообще, форма распределения вероятности возникновения ненулевых коэффициентов компонентов N×M (N!=М., то есть, N≠M) аналогичен форме распределения вероятности возникновения ненулевых коэффициентов компонентов M×N, которое симметрично преобразовано посредством использования оси u частотных компонентов в горизонтальном направлении u в качестве оси симметрии и затем вращения на 90 градусов по часовой стрелке вокруг начала координат.
[0374] Затем модуль 124b выведения контекста позиции назначает общие индексы контекста на подгруппы, соответствующие друг другу, среди подгрупп, иллюстрированных в частях (a) и (b) на Фиг. 78, классифицированных модулем 124a классификации частоты, посредством использования характеристики, что вышеописанные шаблоны разделения и формы распределения ненулевых коэффициентов аналогичны друг другу или соответствуют друг другу через вращение и преобразования относительно оси симметрии. Таким образом, модуль 124b выведения контекста позиции выводит и назначает общие индексы контекста ctxIdx (i) областям Аi (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированным в части (a) на Фиг. 78, и областям Аi (i=0, 1, 4, 5, 2, 3, и 6), проиллюстрированным в части (b) на Фиг. 78. Например, предположим, что, относительно яркости, в случае 16×4 компонентов, модуль 124b выведения контекста позиции выводит ctxIdx=7, 8, 9, 10, 11, 12 и 13 для областей Аi (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированных в части (a) на Фиг. 78, соответственно. В этом случае в случае 4×16 компонентов, модуль 124b выведения контекста позиции выводит ctxIdx=7, 8, 9, 10, 11, 12 и 13 для Аi (i=0, 1, 4, 5, 2, 3, и 6), проиллюстрированных в части (b) на Фиг. 78, соответственно. Аналогично, предположим, что, относительно цветности, в случае 16×4 компонентов, модуль 124b выведения контекста позиции выводит ctxIdx=21, 22, 23, 24, 25, 26, и 27 для областей Аi (i=0, 1, 2, 3, 4, 5 и 6), проиллюстрированных в части (a) на Фиг. 78, соответственно. В случае 4×16 компонентов, модуль 124b выведения контекста позиции выводит ctxIdx=21, 22, 23, 24, 25, 26, и 27 для Аi (i=0, 1, 4, 5, 2, 3, и 6), проиллюстрированных в части (b) на Фиг. 78, соответственно.
[0375] Процесс классификации частоты, выполняемый модулем 124a классификации частоты, и процесс выведения контекста, выполняемый модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, иллюстрированным на Фиг. 80. В частности, в псевдокоде, проиллюстрированном на Фиг. 80, некоторое значение смещения добавлено к опорному значению таблицы поиска CTX_IND_MAP [index], соответствующему индексу значения индекса, определенному позицией (X, Y) суб-блока, и таким образом вычисляется индекс ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC). В случае 4×4 блока преобразования, 8×8 блока преобразования, и 16×4 блока преобразования, индекс значения индекса, определенный позицией (X, Y) каждого суб-блока (суб-блока 1×1 в случае 4×4, суб-блока 2×2 в случае 8×8 и суб-блока 4×1 в случае 16×4), представляет порядок сканирования (начальное значение равное 0) суб-блока в горизонтальном направлении, и вычисляется посредством использования следующего уравнения:
[0376] Index = (Y<<2)+X
В случае 4×16 блока преобразования, индекс значения индекса, определенный позицией (X, Y) суб-блока (4×1 суб-блок), представляет порядок сканирования (начальное значение равное 0) суб-блока в вертикальном направлении, и вычисляется посредством использования следующего уравнения:
[0377] Index=(X<<2)+Y
Индекс ctxIdx контекста для яркости каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP [index]
(В случае 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов)
ctxIdx=CTX_IND_MAP [index]+sigCtxOffset
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов, и индекс контекста 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов.
[0378] Индекс ctxIdx контекста для цветности каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP [index]+SigCtxOffsetLuma
(В случае 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов)
ctxIdx=CTX_IND_MAP [index]+sigCtxOffset+SigCtxOffsetLuma
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов, и индекс контекста 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов, и SigCtxOffsetLuma является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0379] Часть (a) на Фиг. 62 является диаграммой, иллюстрирующей пример таблицы поиска CTX_IND_MAP [index] в псевдокоде, проиллюстрированном на Фиг. 80. Часть (a) на Фиг. 81 иллюстрирует значения индивидуальных индексов контекста для яркости 16×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 80. Кроме того, часть (b) на Фиг. 81 иллюстрирует значения индивидуальных индексов контекста для яркости 4×16 компонентов. Часть (a) на Фиг. 82 иллюстрирует значения индивидуальных индексов контекста для цветности 16×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на Фиг. 80. Кроме того, часть (b) на Фиг. 82 иллюстрирует значения индивидуальных индексов контекста для цветности 4×16 компонентов. В примере, проиллюстрированном в части (a) на Фиг. 81, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 81). То же самое относится к части (b) на Фиг. 81, и частям (a) и (b) на Фиг. 82. Для удобства описания индексы контекста для цветности иллюстрированы в частях (a) и (b) на Фиг. 82, со смещением SigCtxOffsetLuma для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся SigCtxOffsetLuma=14, но вариант осуществления не ограничен этим. Предпочтительно, SigCtxOffsetLuma является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0380] Предпочтительно, модуль 124b выведения контекста позиции устанавливает общие индексы контекста как индексы контекста, которые выводят в случае декодирования индивидуальных коэффициентов преобразования 16×4 блока преобразования, индексы контекста, которые выводят в случае декодирования индивидуальных коэффициентов преобразования 4×16 блока преобразования, и индексы контекста, которые выводят в случае декодирования индивидуальных коэффициентов преобразования 8×8 блока преобразования или 4×4 блока преобразования. В частности, индексы контекста, назначенные на области Аi (i=0, 1, 2, 3, 4, 5 и 6) 16×4 блока преобразования, проиллюстрированные в части (a) на Фиг. 78, и индексы контекста, назначенные на области Аi (i=0, 1, 4, 5, 2, 3, и 6) 4×16 блока преобразования, проиллюстрированные в части (b) на Фиг. 78, являются предпочтительно общими для индексов контекста, назначенных на области Ri (i=0, 1, 2, 3, 4, 5 и 6) 4×4 блока преобразования, проиллюстрированные в части (a) на Фиг. 60, или 8×8 блока преобразования, проиллюстрированные в части (b) на Фиг. 60.
[0381] Как описано выше, в этом процессе, процессы классификации 16×4 компонентов и 4×16 компонентов на подгруппы являются общими друг для друга. Соответственно, процесс выведения индекса контекста может быть выполнен совместно, и процесс выведения индекса контекста может быть упрощен. Кроме того, согласно этому процессу, общие индексы контекста выводят для индивидуальных подгрупп 16×4 компонентов и соответствующих подгрупп 4×16 компонентов, и таким образом количество индексов контекста, которые должны быть выведены, может быть сокращено. Кроме того, общие индексы контекста выводят для индивидуальных подгрупп 16×4 компонентов, 4×16 компонентов и 8×8 компонентов, и таким образом количество индексов контекста, которые должны быть выведены, может быть сокращено. Соответственно, процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0382] Кроме того, модуль 124b выведения контекста позиции может назначить, для цветности, общий индекс контекста областям A3 и A5 16×4 блока преобразования, проиллюстрированным в части (a) на Фиг. 78, областям A3 и A5 4×16 блока преобразования, проиллюстрированным в части (b) на Фиг. 78, и областям R3 и R5 8×8 блока преобразования, проиллюстрированным в части (b) на Фиг. 60. Например, предполагается, что модуль 124b выведения контекста позиции выводит индексы контекста ctxIdx=20, 21, 22, 23, 24, 23 и 25 для областей Аi (i=0, 1, 2, 3, 4, 5 и 6) 16×4 блока преобразования, проиллюстрированных в части (a) на Фиг. 78, соответственно. В этом случае модуль 124b выведения контекста позиции выводит ctxIdx = 20, 21, 22, 23, 24, 23, и 24 для областей Аi (i=0, 1, 4, 5, 2, 3, и 6) 4×16 блока преобразования, проиллюстрированных в части (b) на Фиг. 78, соответственно, и выводит ctxIdx = 20, 21, 22, 23, 24, 23 и 25 для областей Ri (i=0, 1, 2, 3, 4, 5 и 6) 8×8 блока преобразования, проиллюстрированных в части (b) на Фиг. 60, соответственно. В этом случае процесс классификации частоты, выполняемый модулем 124a классификации частоты, и процесс выведения контекста, выполняемый модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, иллюстрированным на Фиг. 83. Таким образом, в псевдокоде, проиллюстрированном на Фиг. 83, некоторое значение смещения добавляется к опорному значению таблицы поиска CTX_IND_MAP_L [index] или CTX_IND_MAP_C [index], соответствующему индексу значения индекса, определенному позицией (X, Y) суб-блока, и таким образом вычисляется индекс ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), для яркости или цветности. В случае 4×4 блока преобразования, 8×8 блока преобразования, и 16×4 блока преобразования, индекс значения индекса, определенный позицией (X, Y) каждого суб-блока (суб-блока 1×1 в случае 4×4, суб-блока 2×2 в случае 8×8, и суб-блока 4×1 в случае 16×4), представляет порядок сканирования (начальное значение равно 0) суб-блока в горизонтальном направлении, и вычисляется посредством использования следующего уравнения:
[0383] Index=(Y<<2)+X
В случае 4×16 блока преобразования, индекс значения индекса, определенный позицией (X, Y) суб-блока (суб-блока 4×1), представляет порядок сканирования (начальное значение равно 0) суб-блока в вертикальном направлении, и вычисляется посредством использования следующего уравнения:
[0384] Index=(X<<2)+Y
Индекс ctxIdx контекста для яркости каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP_L [index]
(В случае 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов)
ctxIdx=CTX_IND_MAP_L [index]+sigCtxOffset
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов, и индекс контекста 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов.
[0385] Индекс ctxIdx контекста для цветности каждого блока преобразования выводят посредством использования следующего уравнения:
(В случае 4×4 компонентов)
ctxIdx=CTX_IND_MAP_C [index]+SigCtxOffsetLuma
(В случае 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов)
ctxIdx=CTX_IND_MAP_C [index]+sigCtxOffset+SigCtxOffsetLuma
Здесь sigCtxOffset является некоторым смещением для того, чтобы идентифицировать индекс контекста 4×4 компонентов, и индекс контекста 8×8 компонентов, 16×4 компонентов, и 4×16 компонентов, и SigCtxOffsetLuma является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0386] Часть (a) на Фиг. 67 является диаграммой, иллюстрирующей пример таблицы поиска CTX_IND_MAP_L [index] в псевдокоде, проиллюстрированном на фиг. 83. Часть (a) на Фиг. 81 иллюстрирует значения индивидуальных индексов контекста для яркости 16×4 компонентов, которые выводят в случае использования CTX_IND_MAP_L [index] в части (a) на Фиг. 62 для псевдокода, иллюстрированного на фиг. 83. Часть (b) на Фиг. 81 иллюстрирует значения индивидуальных индексов контекста для яркости 4×16 компонентов. Часть (b) на Фиг. 62 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, и часть (b) на Фиг. 62 иллюстрирует значения индивидуальных индексов контекста для яркости 8×8 компонентов. Часть (a) на Фиг. 84 иллюстрирует значения индивидуальных индексов контекста для цветности 16×4 компонентов, которые выводят в случае использования CTX_IND_MAP_C [index] в части (b) на Фиг. 67 для псевдокода, иллюстрированного на Фиг. 83. Часть (b) на Фиг. 84 иллюстрирует значения индивидуальных индексов контекста для цветности 4×16 компонентов. Часть (c) на Фиг. 84 иллюстрирует индивидуальные индексы контекста для цветности 8×8 компонентов, и часть (a) на Фиг. 69 иллюстрирует индивидуальные индексы контекста для цветности 4×4 компонентов. В примере, проиллюстрированном в части (a) на Фиг. 84, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 84). То же самое относится к части (b) на Фиг. 84, части (c) на Фиг. 84, и части (a) на Фиг. 69. Для удобства описания индексы контекста для цветности иллюстрированы в частях (a) и (b) на Фиг. 84, со смещением SigCtxOffsetLuma для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся SigCtxOffsetLuma = 14, но вариант осуществления не ограничен этим. Предпочтительно, SigCtxOffsetLuma является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0387] Как описано выше, модуль 124b выведения контекста позиции выводит, для цветности, общий индекс контекста для областей A3 и A5 16×4 блока преобразования, проиллюстрированных в части (a) на Фиг. 78, областей A3 и A5 4×16 блока преобразования, проиллюстрированных в части (b) на Фиг. 78, и областей R3 и R5 8×8 блока преобразования, проиллюстрированных в части (b) на Фиг. 60. Таким образом, количество индексов контекста, которые должны быть выведены, может быть сокращено.
[0388] Согласно уровню техники, в процессе выведения индексов контекста, относящихся к флагам присутствия/отсутствия ненулевых коэффициентов индивидуальных коэффициентов преобразования в 4×16 компонентах и 16×4 компонентах, необходимо посчитать количество смежных ненулевых коэффициентов кроме компонента DC. С другой стороны, согласно вышеописанной конфигурации, индексы контекста, относящихся к флагам присутствия/отсутствия ненулевых коэффициентов индивидуальных коэффициентов преобразования в 4×16 компонентах и 16×4 компонентах, вычисляются в соответствии с позициями флагов присутствия/отсутствия ненулевых коэффициентов, и таким образом объем процесса для выведения индексов контекста может быть уменьшен по сравнению с конфигурацией согласно уровню техники.
[0389] (Конкретный пример 7 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретном примере 7 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, описание будет дано случая деления частотной области на подобласти (подгруппы) так, чтобы шаблон разделения частотной области, имеющей размер 4×4 компонентов, и шаблон разделения частотной области, имеющей размер 8×8 компонентов, был аналогичен друг другу, и выведению индивидуальных индексов контекста для индивидуальных подобластей со ссылками на Фиг. 85-87.
[0390] Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны, на подобласти R0-R8 на основе позиций (xC, yC) целевых частотных компонентов.
[0391] (В случае 4×4 компонентов)
(1) В случае, когда xC<2 и yC<2 удовлетворены, частотный компонент классифицируется в любую из подобластей R0-R3 при следующих условиях (1-a)-(1-d).
(1-a) В случае, когда xC<1 и yC<1, частотный компонент классифицируется в подобласть R0.
(1-b) В случае, когда xC≥1 и yC<1, частотный компонент классифицируется в подобласть R1.
(1-c) В случае, когда xC<1 и yC≥1, частотный компонент классифицируется в подобласть R2.
(1-d) В случае, когда xC≥1 и yC≥1, частотный компонент классифицируется в подобласть R3.
(2) В случае, когда xC≥2 и yC<2, частотный компонент классифицируется в подобласть R4 или R5 при следующих условиях (2-a) и (2-b).
(2-a) В случае, когда xC<3, частотный компонент классифицируется в подобласть R4.
(2-b) В случае, когда xC≥3, частотный компонент классифицируется в подобласть R5.
(3) В случае, когда xC<2 и yC≥2, частотный компонент классифицируется в подобласть R6 или R7 при следующих условиях (3-a) и (3-b).
(3-a) В случае, когда yC<3, частотный компонент классифицируется в подобласть R6.
(3-b) В случае, когда yC≥3, частотный компонент классифицируется в подобласть R7.
(4) В случае, когда xC≥2 и yC≥2, частотный компонент классифицируется в подобласть R8.
[0392] (В случае 8×8 компонентов)
(1) В случае, когда xC<4 и yC<4 удовлетворены, частотный компонент классифицируется в любую из подобластей R0-R3 при следующих условиях (1-a)-(1-d).
(1-a) В случае, когда xC<2 и yC<2, частотный компонент классифицируется в подобласть R0.
(1-b) В случае, когда xC≥2 и yC<2, частотный компонент классифицируется в подобласть R1.
(1-c) В случае, когда xC<2 и yC≥2, частотный компонент классифицируется в подобласть R2.
(1-d) В случае, когда xC≥2 и yC≥2, частотный компонент классифицируется в подобласть R3.
(2) В случае, когда xC≥4 и yC<4, частотный компонент классифицируется в подобласть R4 или R5 при следующих условиях (2-a) и (2-b).
(2-a) В случае, когда xC<6, частотный компонент классифицируется в подобласть R4.
(2-b) В случае, когда xC≥6, частотный компонент классифицируется в подобласть R5.
(3) В случае, когда xC<4 и yC≥4, частотный компонент классифицируется в подобласть R6 или R6 при следующих условиях (3-a) и (3-b).
(3-a) В случае, когда yC<6, частотный компонент классифицируется в подобласть R6.
(3-b) В случае, когда yC≥6, частотный компонент классифицируется в подобласть R7.
(4) В случае, когда xC≥4 и yC≥4, частотный компонент классифицируется в подобласть R8.
[0393] Пример, в котором вышеописанный процесс классификации применяется к 4×4 компонентам и 8×8 компонентам, проиллюстрирован в частях (a) и (b) на Фиг. 85. Часть (a) на Фиг. 85 является диаграммой, иллюстрирующей области (также называемые подобласти или подгруппы) R0-R8, которые формируют частотную область, имеющую размер 4×4 компонентов, и часть (b) на Фиг. 85 является диаграммой, иллюстрирующей области (подобласти) R0-R8, которые формируют частотный компонент, имеющий размер 8×8 компонентов.
[0394] Общий процесс может использоваться для вышеописанных процессов классификации 4×4 компонентов и 8×8 компонентов на подобласти, как описано ниже.
[0395] Сначала модуль 124a классификации частоты вычисляет, на основе позиции (xC, yC) целевого частотного компонента, который должен быть обработан, log2TrafoWidth, представляющее значения логарифма горизонтального размера ширины преобразованного блока (2 в 4×4 блоке и 3 в 8×8 блоке), и log2TrafoHeight, представляющее значение логарифма вертикального размера ширины (2 в 4×4 блоке и 3 в 8×8 блоке), позицию (X, Y) суб-блока, которому частотный компонент, который должен быть обработан, принадлежит, посредством использования следующих уравнений:
[0396] X=log2TrafoWidth == 2 ? xC:xC>>1
Y=log2TrafoHeight == 2 ? yC:yC>>1
Затем модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны (xC, yC) на подобласти R0-R8 на основе выведенной позиции (X, Y) суб-блока.
[0397] (1) В случае, когда X<2 и Y<2 удовлетворены, частотный компонент классифицируется в любую из подобластей R0-R3 при следующих условиях (1-a)-(1-d).
(1-a) В случае, когда X<1 и Y<1, частотный компонент классифицируется в подобласть R0.
(1-b) В случае, когда X≥1 и Y<1, частотный компонент классифицируется в подобласть R1.
(1-c) В случае, когда X<1 и Y≥1, частотный компонент классифицируется в подобласть R2.
(1-d) В случае, когда X≥1 и Y≥1, частотный компонент классифицируется в подобласть R3.
(2) В случае, когда X≥2 и Y<2, частотный компонент классифицируется в подобласть R4 или R5 при следующих условиях (2-a) и (2-b).
(2-a) В случае, когда X<3, частотный компонент классифицируется в подобласть R4.
(2-b) В случае, когда X≥3, частотный компонент классифицируется в подобласть R5.
(3) В случае, когда X<2 и Y≥2, частотный компонент классифицируется в подобласть R6 или R7 при следующих условиях (3-a) и (3-b).
(3-a) В случае, когда Y<3, частотный компонент классифицируется в подобласть R6.
(3-b) В случае, когда Y≥3, частотный компонент классифицируется в подобласть R7.
(4) В случае, когда X≥2 и Y≥2, частотный компонент классифицируется в подобласть R8.
Общий процесс может использоваться для вышеописанных процессов классификации 4×4 компонентов и 8×8 компонентов на подобласти, как описано ниже.
[0398] (1) В случае, когда xC < ширина/2 и yC < высота/2 удовлетворены, частотный компонент классифицируется в любую из подобластей R0 - R3 при следующих условиях (1-a)-(1-d).
(1-a) В случае, когда xC < ширина/4 и yC < высота/4, частотный компонент классифицируется в подобласть R0.
(1-b) В случае, когда xC ≥ ширина/4 и yC < высота/4, частотный компонент классифицируется в подобласть R1.
(1-c) В случае, когда xC < ширина/4 и yC ≥ высота/4, частотный компонент классифицируется в подобласть R2.
(1-d) В случае, когда xC ≥ ширина/4 и yC ≥ высота/4, частотный компонент классифицируется в подобласть R3.
(2) В случае, когда xC ≥ ширина/2 и yC < высота/2, частотный компонент классифицируется в подобласть R4 или R5 при следующих условиях (2-a) и (2-b).
(2-a) В случае, когда xC < ширина × 3/4, частотный компонент классифицируется в подобласть R4.
(2-b) В случае, когда xC ≥ ширина × 3/4, частотный компонент классифицируется в подобласть R5.
(3) В случае, когда xC < ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подобласть R6 или R7 при следующих условиях (3-a) и (3-b).
(3-a) В случае, когда yC < высота × 3/4, частотный компонент классифицируется в подобласть R6.
(3-b) В случае, когда yC ≥ высота × 3/4, частотный компонент классифицируется в подобласть R7.
(4) В случае, когда xC ≥ ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подобласть R8.
Здесь, "ширина" является горизонтальной шириной целевой частотной области (4 для 4×4, и 8 для 8×8). "Высота" является вертикальной шириной целевой частотной области (4 для 4×4, и 8 для 8×8).
[0399] Затем в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции выводит соответствующие индексы контекста ctxIdx (i) для индивидуальных подобластей Ri (i=0, 1, 2, 3, 4, 5, 6, 7, и 8), классифицированных модулем 124a классификации частоты. В частности, индекс контекста ctxIdx (i) для яркости выводят, используя следующие уравнения:
[0400] offsetBlk=log2TrafoWidth == 2 ? 0:9
ctxIdx (i)=i+offsetBlk
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetBlk представляет смещение для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов. Некоторое значение установлено в offsetBlk в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока.
[0401] Индексы контекста 4×4 компонентов и 8×8 компонентов, полученные для яркости посредством использования предшествующих уравнений, иллюстрированы в частях (a) и (b) на Фиг. 86. Часть (a) на Фиг. 86 иллюстрирует индексы контекста ctxIdx (i), соответствующие индивидуальным подобластям Ri для 4×4 компонентов для яркости, и часть (b) на Фиг. 86 иллюстрирует индексы контекста ctxIdx (i), соответствующие индивидуальным подобластям Ri 8×8 компонентов для яркости.
[0402] Индекс контекста ctxIdx (i) для цветности выводят посредством использования следующих уравнений:
[0403] offsetBlk = log2TrafoWidth == 2 ? 0:9
ctxIdx (i)=i+offsetClr+offsetBlk
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetBlk представляет смещение для того, чтобы идентифицировать индекс контекста 4×4 компонентов и индекс контекста 8×8 компонентов. Некоторое значение установлено в offsetBlk в соответствии с log2TrafoWidth, который представляет значение логарифма горизонтального размера ширины преобразованного блока. offsetClr является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности. Здесь, в случае, когда offsetClr=20, индексы контекста 4×4 компонентов и 8×8 компонентов, полученные посредством использования предшествующих уравнений относительно цветности, иллюстрированы в частях (c) и (d) на Фиг. 86. Часть (c) на Фиг. 86 иллюстрирует индексы контекста ctxIdx (i), соответствующие индивидуальным подобластям Ri для 4×4 компонентов для цветности, и часть (d) на Фиг. 86 иллюстрирует индексы контекста ctxIdx (i), соответствующие индивидуальным подобластям Ri 8×8 компонентов для цветности. Для удобства описания индексы контекста для цветности иллюстрированы в частях (c) и (d) на Фиг. 86, со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся offsetClr=20, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0404] Процесс классификации частоты, выполняемый модулем 124a классификации частоты, и процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, иллюстрированным в части (a) на Фиг. 87. Таким образом, в псевдокоде, проиллюстрированном в части (a) на Фиг. 87, индекс ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), вычисляется посредством использования индекса значения индекса, определенного позицией (X, Y) суб-блока и таблицы поиска CTX_IND_MAP [index].
[0405] Сначала позиция (X, Y) суб-блока, которому принадлежит целевой частотный компонент, который должен быть обработан (xC, yC), выводят посредством использования следующих уравнений:
[0406] X=log2TrafoWidth == 2 ? xC:xC>>1
Y=log2TrafoHeight == 2 ? yC: yC>>1
В случае 4×4 компонентов и 8×8 компонентов, индекс значения индекса, который определен позицией (X, Y) каждого суб-блока (суб-блока 1×1 в случае 4×4 и суб-блока 2×2 в случае 8×8) выводят посредством использования следующего уравнения. Индекс значения индекса представляет порядок сканирования (начальное значение равно 0) суб-блока в горизонтальном направлении.
[0407] index=(Y<<2)+X
Индекс ctxIdx контекста для яркости, соответствующей каждому суб-блоку, выводят посредством использования следующего уравнения:
[0408] offsetBlk = log2TrafoWidth == 2 ? 0:9
ctxIdx=CTX_IND_MAP [index]+offsetBlk
Здесь, offsetBlk является смещением для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов, и некоторое значение установлено в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока.
[0409] Индекс ctxIdx контекста для цветности, соответствующей каждому суб-блоку, выводят посредством использования следующего уравнения:
[0410] offsetBlk = log2TrafoWidth == 2 ? 0:9
ctxIdx=CTX_IND_MAP [index]+offsetBlk
ctxIdx=ctxIdx+offsetClr
Здесь, offsetBlk является смещением для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов, и некоторое значение установлено в соответствии с log2TrafoWidth, которое представляет значение логарифма горизонтального размера ширины преобразованного блока. offsetClr является некоторым смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности.
[0411] Часть (b) на Фиг. 87 является диаграммой, иллюстрирующей пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном в части (a) на Фиг. 87. Часть (a) на Фиг. 86 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87. Часть (b) на Фиг. 86 иллюстрирует значения индивидуальных индексов контекста для яркости 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87. Часть (c) на Фиг. 86 иллюстрирует значения индивидуальных индексов контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87. Часть (d) на Фиг. 86 иллюстрирует значения индивидуальных индексов контекста для цветности 8×8 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 87 для псевдокода, иллюстрированного в части (a) на Фиг. 87. В примере, проиллюстрированном в части (a) на Фиг. 86, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 86). То же самое относится к частям (b), (c) и (d) на Фиг. 86. Для удобства описания индексы контекста для цветности иллюстрированы в частях (c) и (d) на Фиг. 86, со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся offsetClr=20, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0412] Индексы контекста, которые назначены на индивидуальные позиции коэффициента, иллюстрированные на Фиг. 85, могут также быть выведены с помощью вычисления битов, описанного ниже.
[0413] В примере, проиллюстрированном в частях (a) и (b) на Фиг. 86, восемнадцать индексов контекста выведены для яркости. В примере, проиллюстрированном в частях (c) и (d) на Фиг. 86, восемнадцать индексов контекста выведены для цветности. Таким образом, в примерах, иллюстрированных в частях (a) и (b) на Фиг. 86 и частях (c) и (d) на Фиг. 86, выводят 18+18=36 индексов контекста. Это количество индексов контекста меньше на единицу, чем тридцать семь индексов контекста, которые выводят в сравнительном примере, проиллюстрированном в частях (a)-(c) на Фиг. 30.
[0414] Как описано выше, в этом процессе общий процесс используется для процессов классификации 4×4 компонентов и 8×8 компонентов для яркости и цветности на подобласти посредством использования способа выведения индекса контекста, иллюстрированного на Фиг. 85. Соответственно, процесс выведения индекса контекста может быть упрощен, в то же время как поддерживая эффективность кодирования. Кроме того, согласно этому процессу, может быть сокращено количество индексов контекста, которые должны быть выведены, и таким образом процесс выведения индекса контекста может быть упрощен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0415] (Конкретный пример 8 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретном примере 8 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, описание будет дано случая деления частотной области на подгруппы так, чтобы шаблон разделения частотной области, имеющей размер M×M (например, 4×4) компонентов, который является наименьшим размером блока преобразования, является общим для яркости и цветности, и выведения индексов контекста, соответствующих индивидуальным подгруппам, со ссылками на Фиг. 90, 91, 30, 60, 62, и 63.
[0416] Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны, на подгруппы R0-R6 на основе позиций (xC, yC) целевых частотных компонентов.
[0417] (1) В случае, когда xC < ширина/2 и yC < высота/2 удовлетворены, частотный компонент классифицируется на подгруппы R0 или R1 при следующих условиях (1-a) и (1-b).
(1-a) В случае, когда xC < ширина/4 и yC < высота/4, частотный компонент классифицируется в подгруппу R0.
(1-b) В случае, когда xC ≥ ширина/4 или yC ≥ высота/4, частотный компонент классифицируется в подгруппу R1.
(2) В случае, когда xC ≥ ширина/2 и yC < высота/2, частотный компонент классифицируется в подгруппу R2 или R3 при следующих условиях (2-a) и (2-b).
(2-a) В случае, когда xC < ширина × 3/4, частотный компонент классифицируется в подгруппу R2.
(2-b) В случае, когда xC ≥ ширина × 3/4, частотный компонент классифицируется в подгруппу R3.
(3) В случае, когда xC < ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подгруппу R4 или R5 при следующих условиях (3-a) и (3-b).
(3-a) В случае, когда yC < высота × 3/4, частотный компонент классифицируется в подгруппу R4.
(3-b) В случае, когда yC ≥ высота × 3/4, частотный компонент классифицируется в подгруппу R5.
(4) В случае, когда xC ≥ ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подгруппу R6.
Здесь, "ширина" является горизонтальной шириной целевой частотной области (4 для 4×4). "Высота" является вертикальной шириной целевой частотной области (4 для 4×4). Пример, в котором вышеописанный процесс классификации применяется к 4×4 компонентам, иллюстрирован в части (a) на Фиг. 60.
[0418] Затем в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции назначает соответствующие индексы контекста на подгруппы, классифицированные модулем 124a классификации частоты.
[0419] В частности, индекс контекста ctxIdx (i) для яркости и цветности выводят посредством использования следующих уравнений:
[0420] ctxIdx (i)=(cIdx == 0) ? i:i+offsetClr
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetClr является смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования. cIdx является переменной для того, чтобы идентифицировать светимость и цветность. В случае яркости, cIdx=0. В случае цветности, cIdx=1.
[0421] Индексы контекста ctxIdx (i), соответствующие индивидуальным подгруппам Ri для 4×4 компонентов, которые выводят для яркости посредством использования предшествующего уравнения, иллюстрированы в части (b) на Фиг. 62. Часть (a) на Фиг. 63 иллюстрирует индексы контекста ctxIdx (i), соответствующие индивидуальным подгруппам Ri для 4×4 компонентов, которые выводят для цветности посредством использования предшествующего уравнения, в случае, когда offsetClr=14.
[0422] Относительно 4×4 компонентов процесс классификации частоты, выполняемый модулем 124a классификации частоты, и процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, иллюстрированным в части (a) на Фиг. 90. Таким образом, в псевдо коде, проиллюстрированном в части (a) на Фиг. 90, индекс ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), вычисляют посредством использования индекса значения индекса, определенного целевым частотным компонентом, который должен быть обработан (xC, yC), и таблицей поиска CTX_IND_MAP [index].
[0423] Сначала индекс значения индекса, определенный целевым частотным компонентом, который должен быть обработан (xC, yC), представляет порядок сканирования (начальное значение равно 0) частотного компонента в горизонтальном направлении, и вычисляется посредством использования следующего уравнения:
[0424] index=(yC<<2)+x
Затем индекс ctxIdx контекста выводят посредством использования следующего уравнения:
[0425] ctxIdx=CTX_IND_MAP [index] В случае цветности, некоторое смещение offsetClr добавляют к индексу ctxIdx контекста, полученному посредством использования предшествующего уравнения, и таким образом выводят индекс контекста. Таким образом,
ctxIdx = ctxIdx + offsetClr.
Часть (b) на Фиг. 90 является диаграммой, иллюстрирующей пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном в части (a) на Фиг. 90. Часть (b) на Фиг. 62 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 90 для псевдокода, иллюстрированного в части (a) на Фиг. 90. Часть (a) на Фиг. 63 иллюстрирует индивидуальные индексы контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (b) на Фиг. 90 для псевдокода, иллюстрированного в части (a) на Фиг. 90. В примере, проиллюстрированном в части (b) на Фиг. 62, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (b) на Фиг. 62). То же самое относится к части (a) на Фиг. 63. Для удобства описания индексы контекста для цветности иллюстрированы в части (a) на Фиг. 63 со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся offsetClr = 14, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0426] Эффект, полученный с помощью выведения индексов контекста, выполненных в вышеописанном способе модулем 124b выведения контекста позиции, будет описан в отношении частей (a) и (b) на Фиг. 91 согласно сравнительному примеру.
[0427] Часть (a) на Фиг. 91 иллюстрирует псевдокод, который выражает процесс выведения индекса контекста, относящийся к 4×4 компонентам согласно сравнительному примеру, тогда как часть (b) на Фиг. 91 иллюстрирует конкретный пример таблицы поиска CTX_IND_MAP4×4 [index] в псевдокоде, проиллюстрированном в части (a) на Фиг. 91. В случае, когда диапазон индекса равен 0≤index≤14 в таблице поиска CTX_IND_MAP4×4 [index], проиллюстрированной в части (b) на Фиг. 91, таблица поиска используется для выведения индекса контекста для яркости, и в случае, когда диапазон индекса равен 15≤index≤30, таблица поиска используется для выведения индекса контекста для цветности. Часть (a) на Фиг. 30 иллюстрирует значения индивидуальных индексов контекста, относящихся к яркости 4×4 компонентов, которые выводят в случае, когда таблица поиска CTX_IND_MAP4×4 [index], (0≤index≤14) проиллюстрированная в части (b) на Фиг. 91 используется для псевдокода, иллюстрированного в части (a) на Фиг. 91. Часть (b) на Фиг. 30 иллюстрирует значения индивидуальных индексов контекста (прежде, чем смещение offsetClr будет добавлено), относящихся к цветности 4×4 компонентов, которые выводят в случае, когда таблица поиска CTX_IND_MAP4×4 [index], (15≤index≤30), проиллюстрированная в части (b) на Фиг. 91, используется для псевдокода, иллюстрированного в части (a) на Фиг. 91. В сравнительном примере, в 4×4 компонентах шаблоны разделения частотной области для яркости и цветности являются различными. Таким образом, в случае выведения индекса контекста посредством использования позиции (xC, yC) целевого частотного компонента, который должен быть обработан, и таблицы поиска необходимо обратиться к различным таблицам поиска для яркости и цветности. Таким образом, количество элементов, включенных в таблицу поиска CTX_IND_MAP4×4 [index], которая необходима, чтобы вывести индекс контекста, равен пятнадцати для яркости и пятнадцати для цветности, то есть, всего тридцати.
[0428] С другой стороны, в этом процессе шаблон разделения частотной области, имеющей размер M×M компонентов (например, 4×4), который является наименьшим размером блока преобразования, является общим для яркости и цветности. Таким образом, в случае вычисления индекса ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), посредством использования целевого частотного компонента, который должен быть обработан (xC, yC), и таблицы поиска CTX_IND_MAP [index], может использоваться таблица поиска, общая для яркости и цветности. Таким образом, по сравнению с тридцатью элементами в сравнительном примере, количество элементов, включенных в таблицу поиска CTX_IND_MAP [index], равно пятнадцати, и размер памяти, который необходим для таблицы поиска, может быть уменьшен.
[0429] (Конкретный пример 9 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретном примере 9 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, описание будет дано случая деления частотной области на подгруппы так, чтобы шаблон разделения частотной области, имеющей размер M×M (например, 4×4) компонентов, который является наименьшим размером блока преобразования, является общим для яркости и цветности, и выведения индексов контекста, соответствующих индивидуальным подгруппам, со ссылками на Фиг. 90, 91, 85, и 86.
[0430] Сначала в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124a классификации частоты классифицирует целевые частотные компоненты, которые должны быть обработаны, на подгруппы R0-R8 на основе позиций (xC, yC) целевых частотных компонентов.
[0431] (1) В случае, когда xC < ширина/2 и yC < высота/2 удовлетворены, частотный компонент классифицируется в любую из подгрупп R0 - R3 при следующих условиях (1-a)-(1-d).
(1-a) В случае, когда xC < ширина/4 и yC < высота/4, частотный компонент классифицируется в подгруппу R0.
(1-b) В случае, когда xC ≥ ширина/4 и yC < высота/4, частотный компонент классифицируется в подгруппу R1.
(1-c) В случае, когда xC < ширина/4 и yC ≥ высота/4, частотный компонент классифицируется в подгруппу R2.
(1-d) В случае, когда xC ≥ ширина/4 и yC ≥ высота/4, частотный компонент классифицируется в подгруппу R3.
(2) В случае, когда xC ≥ ширина/2 и yC < высота/2, частотный компонент классифицируется в подгруппу R4 или R5 при следующих условиях (2-a) и (2-b).
(2-a) В случае, когда xC < ширина × 3/4, частотный компонент классифицируется в подгруппу R4.
(2-b) В случае, когда xC ≥ ширина × 3/4, частотный компонент классифицируется в подгруппу R5.
(3) В случае, когда xC < ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подгруппу R6 или R7 при следующих условиях (3-a) и (3-b).
(3-a) В случае, когда yC < высота × 3/4, частотный компонент классифицируется в подгруппу R6.
(3-b) В случае, когда yC ≥ высота × 3/4, частотный компонент классифицируется в подгруппу R7.
(4) В случае, когда xC ≥ ширина/2 и yC ≥ высота/2, частотный компонент классифицируется в подгруппу R8.
Здесь, "ширина" является горизонтальной шириной целевой частотной области (4 для 4×4). "Высота" является вертикальной шириной целевой частотной области (4 для 4×4).
[0432] Пример, в котором вышеописанный процесс классификации применяется к 4×4 компонентам, проиллюстрирован в части (a) на Фиг. 85. Часть (a) на Фиг. 85 является диаграммой, иллюстрирующей области (также называемые подобласти или подгруппы), R0-R8, которые формируют частотную область, имеющую размер 4×4 компонентов.
[0433] Затем в случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции назначает соответствующие индексы контекста на подгруппы, классифицированные модулем 124a классификации частоты.
[0434] В частности, индекс ctxIdx (i) контекста для яркости и цветности выводят посредством использования следующего уравнения:
[0435] ctxIdx (i)=(cIdx == 0) ? I:i+offsetClr
Следует отметить, что i представляет номер, идентифицирующий подгруппу Ri, и offsetClr является смещением для того, чтобы идентифицировать индексы контекста для яркости и цветности. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования. cIdx является переменной для того, чтобы идентифицировать светимость и цветность. В случае яркости, cIdx=0. В случае цветности, cIdx=1.
[0436] Индексы контекста ctxIdx (i), соответствующие индивидуальным подгруппам Ri для 4×4 компонентов, которые выводятся для яркости посредством использования предшествующего уравнения, проиллюстрированы в части (a) на Фиг. 86. Часть (c) на Фиг. 86 иллюстрирует индексы контекста ctxIdx (i), соответствующие индивидуальным подгруппам Ri для 4×4 компонентов, которые выводят для цветности посредством использования предшествующего уравнения, в случае, когда offsetClr = 20.
[0437] Относительно 4×4 компонентов, процесс классификации частоты, выполняемый модулем 124a классификации частоты, и процесс выведения контекста, выполненный модулем 124b выведения контекста позиции, могут быть выражены псевдокодом, проиллюстрированным в части (a) на Фиг. 90. Таким образом, в псевдокоде, проиллюстрированном в части (a) на Фиг. 90, индекс ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), вычисляется посредством использования индекса значения индекса, определенного целевым частотным компонентом, который должен быть обработан (xC, yC), и таблицей поиска CTX_IND_MAP [index].
[0438] Сначала индекс значения индекса, определенный целевым частотным компонентом, который должен быть обработан (xC, yC), представляет порядок сканирования (начальное значение равно 0) частотного компонента в горизонтальном направлении, и вычисляется посредством использования следующего уравнения:
[0439] index=(yC<<2)+x
Затем индекс ctxIdx контекста выводят посредством использования следующего уравнения.
[0440] ctxIdx = CTX_IND_MAP [index]
В случае цветности, некоторое смещение offsetClr добавляют к индексу ctxIdx контекста, полученного посредством использования предшествующего уравнения, и таким образом выводят индекс контекста. Таким образом,
ctxIdx = ctxIdx + offsetClr.
Часть (c) на Фиг. 90 является диаграммой, иллюстрирующей пример CTX_IND_MAP [index] в псевдокоде, проиллюстрированном в части (a) на Фиг. 90. Часть (a) на Фиг. 86 иллюстрирует значения индивидуальных индексов контекста для яркости 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (c) на Фиг. 90 для псевдокода, иллюстрированного в части (a) на Фиг. 90. Часть (c) на Фиг. 86 иллюстрирует индивидуальные индексы контекста для цветности 4×4 компонентов, которые выводят в случае использования CTX_IND_MAP [index] в части (c) на Фиг. 90 для псевдокода, иллюстрированного в части (a) на Фиг. 90. В примере, проиллюстрированном в части (a) на Фиг. 86, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 86). То же самое относится к части (c) на Фиг. 86. Для удобства описания индексы контекста для цветности проиллюстрированы в части (c) на Фиг. 86 со смещением offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, являющимся offsetClr = 20, но вариант осуществления не ограничен этим. Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0441] Как описано выше, в этом процессе шаблон разделения частотной области, имеющей размер M×M компонентов (например, 4×4), который является наименьшим размером блока преобразования, является общим для яркости и цветности. Таким образом, в случае вычисления индекса ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), посредством использования позиции (xC, yC) целевого частотного компонента, который должен быть обработан, и таблицы поиска CTX_IND_MAP [index], может использоваться таблица поиска, общая для яркости и цветности. Таким образом, по сравнению с тридцатью элементами в сравнительном примере, количество элементов, включенных в таблицу поиска CTX_IND_MAP [index], равно пятнадцать, и размер памяти, который необходим для таблицы поиска, может быть уменьшен.
[0442] (Конкретный пример 10 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший)
В конкретных примерах 9 и 10 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший, описание было дано примера деления частотной области на подгруппы так, чтобы шаблон разделения частотной области, имеющей размер M×M (например, 4×4) компонентов, который является наименьшим размером блока преобразования, является общим для яркости и цветности, и выведения индивидуальных индексов контекста, соответствующих индивидуальным подгруппам, или примера выведения индекса ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), посредством использования позиции (xC, yC) целевого частотного компонента, который должен быть обработан, и таблицы поиска. В дальнейшем описание будет дано примера выведения индекса контекста посредством использования уравнения, используя позицию (xC, yC) целевого частотного компонента, который должен быть обработан, не используя таблицу поиска.
[0443] В случае, когда целевая частотная область, которая должна быть обработана, имеет некоторый размер или меньший, модуль 124b выведения контекста позиции выводит индекс ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), посредством использования следующего уравнения (Ур.e1), и подает результат выведения ctxIdx к модулю 124a классификации частоты.
[0444] ctxIdx = xC+yC (Ур.e1)
В случае цветности некоторое смещение offsetClr для того, чтобы идентифицировать индексы контекста для яркости и цветности, добавлено к ctxIdx, полученному посредством использования уравнения (Ур.e1). Таким образом,
ctxIdx = ctxIdx + offsetClr.
Предпочтительно, offsetClr является общим количеством индексов контекста для яркости 4×4 блока преобразования - 32×32 блока преобразования.
[0445] Относительно яркости пример индексов контекста 4×4 компонентов, которые выводят в случае применения уравнения (Ур.e1), проиллюстрированы в части (a) на Фиг. 92. Как иллюстрировано в части (a) на Фиг. 92, частотная область разделена на подобласти формы волны (формы частотного диапазона) от DC к высокочастотному компоненту, и выводят индексы ctxIdx контекста, соответствующие индивидуальным подобластям. Таким образом, шаблон деления частотной области в форме волны от DC к высокочастотному компоненту является аппроксимацией предпочтительной формой распределения частоты появления ненулевых коэффициентов, и общий индекс контекста может быть назначен на частотные компоненты, в которых частота появления ненулевых коэффициентов эквивалентна. В примере, проиллюстрированном в части (a) на Фиг. 92, индекс контекста не выводят для частотного компонента, расположенного на стороне самого высокого частотного компонента (заштрихованный частотный компонент в части (a) на Фиг. 92). То же самое относится к частям (b)-(d) на Фиг. 92, частям (a)-(f) на Фиг. 93, частям (a)-(d) на Фиг. 94, и частям (a)-(d) на Фиг. 95.
[0446] Затем модуль 124a классификации частоты назначает индексы ctxIdx контекста, полученные модулем 124b выведения контекста позиции, на целевые частотные компоненты, которые должны быть обработаны (xC, yC).
[0447] Как описано выше, в этом процессе уравнение, использующее xC и yC, представляющее позицию целевого частотного компонента, который должен быть обработан, используется, и таким образом частотная область может быть разделена на множество подобластей, и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены. Соответственно, процесс выведения индекса контекста может быть упрощен.
[0448] В модуле 124b выведения контекста позиции, уравнение, использованное для выведения индекса ctxIdx контекста целевого частотного компонента, который должен быть обработан (xC, yC), не ограничен уравнением (Ур.e1). Например, индекс контекста может быть выведен посредством использования следующего уравнения (Ур.e2):
[0449] ctxIdx=(xC+yC+a)>>b (Ур.e2)
Здесь, в уравнении (Ур.e2), в случае, когда a=1 и b=1, индексы контекста для яркости, иллюстрированные в части (b) на Фиг. 92, выводят для 4×4 компонентов.
[0450] В уравнении (Ур.e2), в случае, когда a=0 и b=1, индексы контекста для яркости, иллюстрированные в части (c) на Фиг. 92, выводят для 4×4 компонентов.
[0451] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.e3), вместо уравнения (Ур.e1).
[0452] ctxIdx=(xC+yC>th) ? d:xC+yC (Ур.e3)
Здесь, в уравнении (Ур.e3), в случае, когда th=3 и d=4, индексы контекста для яркости, иллюстрированные в части (d) на Фиг. 92, выводят для 4×4 компонентов.
[0453] Альтернативно, индексы контекста могут быть выведены посредством использования следующего уравнения (Ур.f1), вместо уравнения (Ур.e1).
[0454] ctxIdx=Max (xC, yC) (Ур.f1)
Пример индексов контекста для яркости, которые выводят в случае применения уравнения (Ур.f1) к 4×4 компонентам, проиллюстрирован в части (a) на Фиг. 93. Как иллюстрировано в части (a) на Фиг. 93, частотная область разделена на подобласти в виде перевернутой буквы L от DC к высокочастотному компоненту, и индексы ctxIdx контекста, соответствующие индивидуальным подобластям, выводят. Таким образом, шаблон деления частотной области в виде перевернутой буквы L от DC к высокочастотному компоненту является аппроксимацией предпочтительной формы распределения частоты появления ненулевых коэффициентов, и общий индекс контекста может быть назначен на частотные компоненты, в которых частота появления ненулевых коэффициентов эквивалентна.
[0455] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.f2), вместо уравнения (Ур.f1).
[0456] ctxIdx = (xC+yC>th) ? a: max (xC, yC) (Ур.f2)
Здесь, в уравнении (Ур.f2), в случае, когда th=3 и=4, индексы контекста для яркости, иллюстрированные в части (b) на Фиг. 93, выводят для 4×4 компонентов.
[0457] В уравнении (Ур.f2), в случае, когда th=4 и=4, индексы контекста для яркости, иллюстрированные в части (c) на Фиг. 93, выводят для 4×4 компонентов.
[0458] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.f3) вместо уравнения (Ур.e1).
[0459] ctxIdx=((xC>>1)+(yC>>1)>th) ? a:max (xC, yC) (Ур.f3)
Здесь, в уравнении (Ур.f3), в случае, когда th=1 и=4, индексы контекста для яркости, иллюстрированные в части (d) на Фиг. 93, выводят для 4×4 компонентов.
[0460] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.f4), вместо уравнения (Ур.e1).
[0461] ctxIdx=((xC>>1)+(yC>>1)>th) ?
a: yC<(высота/2) ? max (xC, yC): max (xC, yC)+b (Ур.f4)
Здесь, в уравнении (Ур.f4), в случае, когда th=1, = 6, b=2, и высота = 4, индексы контекста для яркости, иллюстрированные в части (e) на Фиг. 93, выводят для 4×4 компонентов. Шаблон разделения 4×4 компонентов, иллюстрированный в части (e) на Фиг. 93, может выразить шаблон разделения частотных компонентов для 4×4 компонентов, иллюстрированных в части (a) на Фиг. 60.
[0462] Индексы контекста для яркости 4×4 компонентов, иллюстрированные в части (e) на Фиг. 93, могут также быть выражены посредством использования уравнения (Ур.f5).
[0463] X=xC>> (log2TrafoWidth-2)
Y=yC>>(log2TrafoHeight-2)
ctxIdx=((X>>1)+(Y>>1)>th) ?
a: (Y <(1<<(log2TrafoHeight-2))) ? max (X, Y):max (X, Y)+b·(Ур.f5)
В уравнении (Ур.f5), log2TrafoWidth представляет значение логарифма горизонтальной ширины блока преобразования (2 в случае 4×4), и log2TrafoHeight представляет значение логарифма вертикальной ширины блока преобразования (2 в случае 4×4). В случае выведения индексов контекста для яркости, иллюстрированных в части (e) на Фиг. 93 относительно 4×4 компонентов, th=1, a=6, и b=2 в уравнении (Ур.f5). В случае 8×8 компонентов, некоторое смещение offsetBlk для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов, добавлено к индексу ctxIdx контекста, полученному посредством использования уравнения (Ур.f5). Таким образом,
ctxIdx = ctxIdx + offsetBlk.
Здесь, в случае, когда offsetBlk = 7, шаблон разделения и индексы контекста частотных компонентов 8×8 компонентов, иллюстрированные в части (b) на Фиг. 62, могут быть выражены для яркости.
[0464] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.f6) вместо уравнения (Ур.f4).
[0465] ctxIdx=((xC>>1)+(yC>>1)>th) ?
a: (xC < ширина/2)) ? max (xC, yC):max (xC, yC)+b·(Ур.f6)
Здесь, в уравнении (Ур.f6), в случае, когда th=1, a=6, b=2, и ширина = 4, индексы контекста, иллюстрированные в части (f) на Фиг. 93, выводят. Шаблон разделения 4×4 компонентов, иллюстрированный в части (f) на Фиг. 93, может выразить шаблон разделения частотных компонентов 4×4 компонентов, иллюстрированных в части (a) на Фиг. 60.
[0466] Индексы контекста для яркости 4×4 компонентов, иллюстрированные в части (f) на Фиг. 93, могут также быть выражены посредством использования уравнения (Ур.f7).
[0467] X=xC>> (log2TrafoWidth-2)
Y=yC>> (log2TrafoHeight-2)
ctxIdx=((X>>1)+(Y>>1)>th) ?
a: (X <(1<<(log2TrafoWidth-1))) ? max (X, Y):max (X, Y)+b (Ур.f7)
В уравнении (Ур.f7) log2TrafoWidth представляет значение логарифма горизонтальной ширины блока преобразования (2 в случае 4×4), и log2TrafoHeight представляет значение логарифма вертикальной ширины блока преобразования (2 в случае 4×4). В случае выведения индексов контекста, иллюстрированных в части (f) на Фиг. 93 относительно 4×4 компонентов, th=1, a=6, и b=2 в уравнении (Ур.f7). В случае 8×8 компонентов, некоторое смещение offsetBlk для того, чтобы идентифицировать индексы контекста 4×4 компонентов и 8×8 компонентов, добавлено к индексу ctxIdx контекста, полученному посредством использования уравнения (Ур.f7).
[0468] ctxIdx = ctxIdx + offsetBlk
Здесь, в случае, когда offsetBlk=7, шаблон разделения частотных компонентов 8×8 компонентов, иллюстрированные в части (b) на Фиг. 60, может быть выражен.
[0469] В случае, когда частоту появления ненулевых коэффициентов смещено к частотным компонентам горизонтального направления, индексы контекста могут быть выведены посредством использования следующего уравнения (Ур.g1), вместо уравнения (Ур.e1).
[0470] ctxIdx = ((xC+yC+a)>>b)+((yC>xC)* c) (Ур.g1)
Здесь, в уравнении (Ур.g1), в случае, когда a=1, b=1, и c=3, индексы контекста для яркости, иллюстрированные в части (a) на Фиг. 94, выводят для 4×4 компонентов. В уравнении (Ур.g1), (A>B) указывает, что 1 возвращается в случае, когда A больше, чем B, и 0 возвращается в других случаях.
[0471] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.g2), вместо уравнения (Ур.e1).
[0472] ctxIdx=(xC+yC>th) ? d:((xC+yC+a)>>b)+((yC>xC)* c) ·(Ур.g2)
Здесь, в уравнении (Ур.g2), в случае, когда th=3, a=1, b=1, c=3, и d=3, индексы контекста для яркости, иллюстрированные в части (b) на Фиг. 94, выводят для 4×4 компонентов.
[0473] В уравнении (Ур.g2), в случае, когда th=4, a=1, b=1, c=3, и d=3, индексы контекста для яркости, иллюстрированные в части (c) на Фиг. 94, выводят для 4×4 компонентов.
[0474] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.g3), вместо уравнения (Ур.g2).
[0475] ctxIdx=(xC+2*yC+1) >>1 (Ур.g3)
Относительно 4×4 компонентов, в случае применения уравнения (Ур.g3), выводят индексы контекста, иллюстрированные в части (d) на Фиг. 94.
[0476] В случае, когда частота появления ненулевых коэффициентов смещена к частотным компонентам вертикального направления, индексы контекста могут быть выведены посредством использования следующего уравнения (Ур.h1), вместо уравнения (Ур.e1).
[0477] ctxIdx=((xC+yC+a)>>b)+((xC>yC)* c) (Ур.h1)
Здесь, в уравнении (Ур.h1), в случае, когда a=1, b=1, и c=3, индексы контекста для яркости, иллюстрированные в части (a) на Фиг. 95, выводят для 4×4 компонентов.
[0478] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.h2), вместо уравнения (Ур.h1).
[0479] ctxIdx=(xC+yC>th) ? d:((xC+yC+a)>>b)+((xC>yC)* c) (Ур.h2)
Здесь, в уравнении (Ур.h2), в случае, когда th=3, a=1, b=1, c=3, и d=3, индексы контекста для яркости, иллюстрированные в части (b) на Фиг. 95, выводят для 4×4 компонентов.
[0480] В уравнении (Ур.h2), в случае, когда th=4, a=1, b=1, c=3, и d=3, индексы контекста для яркости, иллюстрированные в части (c) на Фиг. 95, выводят для 4×4 компонентов.
[0481] Альтернативно, индексы контекста могут быть выведены посредством использования уравнения (Ур.h3), вместо уравнения (Ур.h1).
[0482] ctxIdx=(2*xC+yC+1)>>1 (Ур.h3)
Относительно 4×4 компонентов, в случае применения уравнения (Ур.g3), выводят индексы контекста, иллюстрированные в части (d) на Фиг. 95.
[0483] Как описано выше, в этом процессе частотная область может быть разделена на множество подобластей, и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены посредством использования уравнения, используя xC и yC, представляющие позиции целевого частотного компонента, который должен быть обработан. Соответственно, процесс выведения индекса контекста и размер памяти для выведения индексов контекста могут быть уменьшены.
[0484] (Пример 1 модификации декодера флага присутствия/отсутствия коэффициента)
Декодер флага присутствия/отсутствия коэффициента согласно этому варианту осуществления не ограничен вышеописанной конфигурацией. В дальнейшем, декодер 124ʹ флага присутствия/отсутствия коэффициента согласно первому примеру модификации будет описан со ссылками на Фиг. 39-42.
[0485] Фиг. 39 является диаграммой, иллюстрирующей конфигурацию декодера 124ʹ флага присутствия/отсутствия коэффициента согласно этому примеру модификации. Как иллюстрировано на Фиг. 39, декодер 124ʹ флага присутствия/отсутствия коэффициента имеет почти ту же самую конфигурацию как декодер 124 флага присутствия/отсутствия коэффициента преобразования, проиллюстрированный на Фиг. 23, но является отличным в следующих деталях:
[0486]
декодер 124ʹ флага присутствия/отсутствия коэффициента не включает в себя модуль 124c выведения опорного контекста от соседнего элемента.
декодер 124ʹ флага присутствия/отсутствия коэффициента включает в себя модуль 124f выведения опорного контекста от соседнего суб-блока.
[0487] Другая часть конфигурации декодера 124ʹ флага присутствия/отсутствия коэффициента является такой же, как у декодера 124 флага присутствия/отсутствия коэффициента, и таким образом описание его опущено. В дальнейшем будет описан модуль 124f выведения опорного контекста от соседнего суб-блока.
[0488] (Модуль 124f выведения опорного контекста от соседнего суб-блока)
Модуль 124f выведения опорного контекста от соседнего суб-блока выводит индексы контекста, которые должны быть назначены на индивидуальные частотные компоненты, включенные в целевой суб-блок, который должен быть обработан, обращаясь к суб-блоку, который является смежным с целевым суб-блоком и в котором был декодирован флаг присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag. Кроме того, модуль 124f выведения опорного контекста от соседнего суб-блока, назначает общий индекс контекста на индивидуальные частотные компоненты, включенные в целевой суб-блок, который должен быть обработан.
[0489] Более конкретно, согласно предположению, что порядок обработки суб-блоков является обратным порядком сканирования, модуль 124f выведения опорного контекста от соседнего суб-блока выводит индекс контекста, который должен использоваться для того, чтобы обратиться к significant_coeff_flag [xC][yC], включенный в суб-блок (xCG, yCG), посредством использования следующего уравнения (Ур. B1), на основе полной суммы ctxCnt значений флагов присутствия/отсутствия коэффициента суб-блока, назначенных на смежный суб-блок (xCG+1, yCG) и смежный суб-блок (xCG, yCG+1).
[0490] ctxCnt=(significant_coeffgroup_flag [xCG+1][yCG]!=0)
+(significant_coeffgroup_flag [xCG][yCG+1]!=0)·· (Ур. B1)
ctxIdx=смещение+ctxCnt
Здесь, предполагается, что каждый член в (Ур. B1) принимает значение 1 в случае, когда сравнение в () верно, и принимает значение 0 в случае, когда сравнение в () ложно. В случае, когда любой из смежного суб-блока (xCG+1, yCG) и смежного суб-блока (xCG, yCG+1), на который нужно ссылаться, расположен вне блока преобразования, значение флага присутствия/отсутствия коэффициента суб-блока в соответствующей позиции обрабатывают как 0.
[0491] Согласно предположению, что значение переменного смещения в уравнении (Ур. B1) равно нулю, ctxIdx, выведенный этим способом принимает следующее значение:
[0492]
ctxIdx=0·ненулевой коэффициент преобразования не существует ни в одном из суб-блока (xCG+1, yCG) и суб-блока (xCG, yCG+1).
ctxIdx=1 ненулевой коэффициент преобразования существует в любом из суб-блока (xCG+1, yCG) и суб-блока (xCG, yCG+1).
ctxIdx=2·· ненулевой коэффициент преобразования существует в обоих из суб-блока (xCG+1, yCG) и суб-блока (xCG, yCG+1).
[0493] ctxIdX, выведенный этим способом, используется совместно, чтобы декодировать весь significant_coeff_flag, включенный в целевой суб-блок (xCG, yCG).
[0494] Фиг. 40 иллюстрирует смежный суб-блок (xCG+1, yCG) и смежный суб-блок (xCG, yCG+1), на которые ссылаются модулем 124f выведения опорного контекста от соседнего суб-блока согласно этому примеру модификации.
[0495] Фиг. 41 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем 124f выведения опорного контекста от соседнего суб-блока. R0, R1, и R2, проиллюстрированные на Фиг. 41, соответствуют иллюстрированным в части (a) на Фиг. 26, например. Псевдокод, проиллюстрированный на Фиг. 41, может быть предпочтительно применен к процессу выведения индексов контекста, на которые ссылаются в случае декодирования significant_coeff_flag для яркости Y.
[0496] Фиг. 42 иллюстрирует псевдокод, показывающий другой пример процесса выведения индекса контекста, выполняемого модулем 124f выведения опорного контекста от соседнего суб-блока. R0 и R1, проиллюстрированные на Фиг. 42, соответствуют иллюстрированным в части (b) на Фиг. 26, например. Псевдокод, проиллюстрированный на Фиг. 42, может быть предпочтительно применен к процессу выведения индексов контекста, на которые ссылаются в случае декодирования significant_coeff_flag для цветности U и V.
[0497] Фиг. 74 иллюстрирует псевдокод, показывающий процесс выведения индекса контекста, выполняемый модулем 124f выведения опорного контекста от соседнего суб-блока. R0, R1 и R2, проиллюстрированные на Фиг. 74, соответствуют иллюстрированным на Фиг. 24, например. Псевдокод, проиллюстрированный на Фиг. 74, может быть предпочтительно применен к процессу выведения индексов контекста, на которые ссылаются в случае декодирования significant_coeff_flag для яркости Y.
[0498] Модуль 124f выведения опорного контекста от соседнего суб-блока согласно этому примеру модификации не выполняет процесс выведения контекста от соседнего суб-блока в блоках частотных компонентов, и назначает общий индекс контекста на индивидуальные частотные компоненты, включенные в суб-блок, и таким образом величина обработки уменьшается. Далее, процесс выведения индекса контекста в единицах суб-блоков выполняется в отношении значений significant_coeffgroup_flag в смежных суб-блоках, и соответственно индекс контекста может быть выведен в соответствии с количеством ненулевых коэффициентов преобразования, которые существуют вокруг целевого суб-блока.
[0499] Поэтому, с модулем 124f выведения опорного контекста от соседнего суб-блока согласно этому примеру модификации, величина обработки для процесса выведения индекса контекста может быть уменьшена, в то же время поддерживая высокую эффективность кодирования.
[0500] (Пример 2 модификации декодера флага присутствия/отсутствия коэффициента)
В дальнейшем второй пример модификации декодера флага присутствия/отсутствия коэффициента будет описан со ссылками на Фиг. 43.
[0501] Фиг. 43 является блок-схемой, иллюстрирующей конфигурацию декодера 124ʹʹ флага присутствия/отсутствия коэффициента согласно этому примеру модификации. Как иллюстрировано на Фиг. 43, декодер 124ʹʹ флага присутствия/отсутствия коэффициента включает в себя модуль 124f выведения опорного контекста от соседнего суб-блока в дополнение к индивидуальным модулям декодера 124 флага присутствия/отсутствия коэффициента преобразования, проиллюстрированного на Фиг. 23.
[0502] Модуль 124f выведения опорного контекста от соседнего суб-блока был описан выше, и таким образом описание его здесь опущено.
[0503] Модуль 124f выведения опорного контекста от соседнего суб-блока согласно этому примеру модификации выполняет процесс, выраженный псевдокодом, иллюстрированным на Фиг. 42 в случае выведения индексов контекста, на которые ссылаются, когда significant_coeff_flag относительно цветности U и V декодируется, и выполняет процесс, выраженный псевдокодом, иллюстрированным на Фиг. 27 в случае выведения индексов контекста, на которые ссылаются, когда significant_coeff_flag относительно яркости Y декодируется.
[0504] С этой конфигурацией величина обработки для процесса выведения индекса контекста может быть уменьшена, в то же время поддерживая высокую эффективность кодирования.
[0505] (Пример 3 модификации из декодера 124 флага присутствия/отсутствия коэффициента)
В дальнейшем третий пример модификации декодера 124 флага присутствия/отсутствия коэффициента будет описан со ссылками на Фиг. 96. Третий пример модификации декодера 124 флага присутствия/отсутствия коэффициента, который должен быть описан ниже, имеет, относительно выведения индексов контекста флагов присутствия/отсутствия коэффициента, следующие характеристики:
(1) в случае, когда размер целевой TU, которая должна быть обработана, имеет некоторый размер или меньший, частотная область разделяется во множество подобластей, посредством использования уравнения, используя xC и yC, которые представляют позицию целевого частотного компонента, который должен быть обработан, и выводят индексы контекста для яркости и цветности, соответствующие индивидуальным подобластям; и
(2) в случае, когда размер целевой TU, которая должна быть обработана, больше, чем некоторый размер, когда позиция целевого частотного компонента, который должен быть обработан, принадлежит низкочастотному компоненту и компоненту промежуточной частоты, индекс контекста выводят на основе количества ненулевых коэффициентов, расположенных вокруг цели, которая должна быть обработана, и когда позиция целевого частотного компонента, который должен быть обработан, принадлежит высокочастотному компоненту, назначают фиксированный индекс контекста.
[0506] Фиг. 96 является блок-схемой, иллюстрирующей примерную конфигурацию третьего примера модификации декодера 124 флага присутствия/отсутствия коэффициента. Как иллюстрировано на Фиг. 96, декодер 124 флага присутствия/отсутствия коэффициента включает в себя модуль 124z выведения контекста, память 124d флага присутствия/отсутствия коэффициента, и модуль 124e установления флага присутствия/отсутствия коэффициента. Далее, модуль 124z выведения контекста включает в себя контроллер 124x способа выведения, модуль 124b выведения контекста позиции, и модуль 124c выведения опорного контекста от соседнего элемента. На Фиг. 96, в контексте, получающем блок 124z, контроллер 124x способа выведения включает в себя модуль 124b выведения контекста позиции и модуль 124c выведения опорного контекста от соседнего элемента, но это является просто примером. Конфигурация модуля 124z получения контекста не ограничена такой конфигурацией.
[0507] (Модуль 124z выведения контекста)
(Контроллер 124x способа выведения)
Контроллер 124x способа выведения принимает позицию (xC, yC) целевого частотного компонента, который должен быть обработан, и значение логарифма блока преобразования (log2TrafoWidth, log2TrafoHeight). С размером значения логарифма, ширина "Width" и высота "Height" частотной области вычисляются посредством использования (1<<log2TrafoWidth) и (1<<log2TraforHeight). Вместо размера значения логарифма могут быть непосредственно введены ширина и высота частотной области.
[0508] Контроллер 124x способа выведения выбирает модуль 124b выведения контекста позиции или модуль 124c выведения опорного контекста от соседнего элемента в соответствии с размером целевой TU и позиции частотного компонента. В выбранном модуле выведения контекста выводят индексы ctxIdx контекста.
[0509] Например, в случае, когда размер TU является некоторым размером или меньшим (например, 4×4 TU или 8×8 TU), контроллер 124x способа выведения выбирает модуль 124b выведения контекста позиции, и назначает индексы ctxIdx контекста, выведенные выбранным модулем 124b выведения контекста позиции к целевым частотным компонентам, которые должны быть декодированы.
[0510] С другой стороны, в случае, когда размер целевой TU больше, чем некоторый размер (например, 16×16 TU или 32×32 TU), контроллер 124x способа выведения классифицирует каждый из частотных компонентов в любую из множества частичных областей в соответствии с позицией целевого частотного компонента, который должен быть декодирован в частотной области, выбирает любой из модуля 124b выведения контекста позиции и модуля 124c выведения опорного контекста от соседнего элемента в соответствии с классифицированными частичными областями, и назначает индексы ctxIdx контекста, полученные выбранным средство выведения контекста для целевых частотных компонентов, которые должны быть декодированы.
[0511] Часть (a) на Фиг. 98 является диаграммой, иллюстрирующей частичные области R0-R2, которые выводят посредством разделения, выполняемого контроллером 124x способа выведения в этом примере обработки. Часть (a) на Фиг. 98 предпочтительно применяется в случае декодирования коэффициентов преобразования, относящихся к яркости и цветности.
[0512] Контроллер 124x способа выведения классифицирует частотные компоненты, включенные в частотную область, на множество частичных областей R0-R2 при следующих условиях, например, посредством использования позиций (xC, yC) частотных компонентов в частотной области. xCG и yCG представляют позицию суб-блока.
[0513] (1) Классифицируют частотный компонент, который удовлетворяет xC+yC<THLo в частичную область R0.
(2) Классифицируют частотный компонент, который удовлетворяет xC+yC≥THLo и xCG+yCG<THHi в частичную область R1.
(3) Классифицируют частотный компонент, который удовлетворяет xCG+yCG≥THHi в частичную область R2.
Здесь, порог THlo предпочтительно устанавливают посредством использования, например, следующего уравнения (Ур. A2-1). Порог THhi предпочтительно устанавливают посредством использования, например, следующего уравнения (Ур. A2-2).
[0514] THlo=2 (Ур. A2-1)
THhi=(3* max (ширина, высота)>>4) (Ур. A2-2)
Изобретатели проверили, что, в результате экспериментов, в случае деления частотной области на частичные области R0-R2 и выведения индексов контекста для частичных областей R0-R1 с помощью ссылки на соседа, предпочтительно устанавливить вышеописанный порог (Ур. A2-1) с точки зрения эффективности кодирования.
[0515] Условия классификации для частичных областей не ограничены описанными выше, и следующие условия (часть (b) на Фиг. 98) могут использоваться.
[0516] (1) Классифицировать частотный компонент, который удовлетворяет xCG+yCG<THLo в частичную область R0.
(2) Классифицировать частотный компонент, который удовлетворяет xCG+yCG≥THLo и xCG+yCG<THHi в частичную область R1.
(3) Классифицировать частотный компонент, который удовлетворяет xCG+yCG≥THHi в частичную область R2.
Здесь, порог THlo предпочтительно равен 1. Порог THhi является тем же самым, как в уравнении (Ур. A2-2).
[0517] В дальнейшем, в качестве примера, частотный компонент, который принадлежит области R0, проиллюстрированной в частях (a) и (b) на Фиг. 98, упоминается как низкочастотный компонент, компонент, который принадлежит области R1, упоминается как промежуточный частотный компонент, и компонент, который принадлежит области R2, упоминается как высокочастотный компонент.
[0518] Вышеописанный процесс выведения индекса контекста сравнивается с процессом выведения, иллюстрированным в части (a) на Фиг. 26. В части (a) на Фиг. 26 в низкочастотном компоненте имеются две ветви, включая ветвь для отделения частичной области контекста позиции и частичной области ссылки на соседний элемент (ветвь для отделения R0 и R1 в части (a) на Фиг. 26), и ветвь для отделения частичных областей ссылки на соседний элемент (ветвь для отделения R1 и R2 в части (a) на Фиг. 26). С другой стороны, на фиг. 98, есть только одна ветвь, то есть, ветвь для отделения частичных областей ссылки на соседний элемент (ветвь для отделения R0 и R1 на Фиг. 98), и процесс выведения контекста выгодно упрощается. В частности, посредством применения ссылку на соседний элемент к индексу контекста компонента DC, может быть с выгодой предотвращено, что процесс, отличающийся от процесса для другого компонента, выполняется в отношении компонента DC. В частности, если позиция ветви для отделения частичных областей ссылки на соседний элемент в низкочастотном компоненте (ветвь для отделения R0 и R1 на Фиг. 98) установлена равной порогу (Ур. A2-1), и если этот процесс применяется, может реализоваться упрощение, в то же время поддерживая эффективность кодирования. Далее, имеется эффект, что эффективность кодирования выше, чем в части (b) на Фиг. 26, который проще.
[0519] Кроме того, используется способ для деления частотной области и выбора средства выведения индекса контекста, который является общим для яркости и цветности, и таким образом не является необходимым обеспечивать различные настройки параметров ветвей для яркости и цветности. Соответственно, процесс выведения индекса контекста, относящийся к флагами присутствия/отсутствия коэффициента, может быть упрощен.
[0520] Альтернативно, контроллер 124x способа выведения может быть сконфигурирован, чтобы выполнять процесс выведения индекса ctxIdx контекста, который является общим для размеров TU 4×4 TU-32×32 TU. Таким образом, контроллер 124x способа выведения может быть сконфигурирован, чтобы выбрать любой из модуля 124b выведения контекста позиции и модуля 124c выведения опорного контекста от соседнего элемента фиксированным способом независимо от размера TU.
[0521] (Модуль 124b выведения контекста позиции)
Модуль 124b выведения контекста позиции выводит индексы ctxIdx контекста для целевых частотных компонентов на основе позиций целевых частотных компонентов в частотной области. Даже в случае выведения индексов ctxIdx контекста, имеющих фиксированные значения независимо от позиций частотных компонентов, процесс выполняется модулем 124b выведения контекста позиции.
[0522] В случае, когда размер TU цели, которая должна быть обработана, больше, чем некоторый размер, и когда xCG+yCG, представленный позицией (xCG, yCG) суб-блока, которому принадлежит целевой частотный компонент (xC, yC), равен или больше, чем некоторый порог THhi, модуль 124b выведения контекста позиции выводит индекс ctxIdx контекста для частотного компонента, который принадлежит частичной области R2, проиллюстрированной в части (a) на Фиг. 98, посредством использования следующего уравнения (Ур. A2-3), и подает результат выведения ctxIdx к контроллеру 124x способа выведения.
[0523] ctxIdx=sigCtxOffsetR2 (Ур. A2-3)
В предшествующем уравнении (Ур. A2-3), sigCtxOffsetR2 является некоторой константой, которая представляет начальную точку индекса контекста, относящегося к частотному компоненту, который принадлежит частичной области R2.
[0524] В случае, когда размер TU цели, которая должна быть обработана, является некоторым размером или меньшим, модуль 124b выведения контекста позиции использует способ назначения индекса контекста, проиллюстрированный на Фиг. 60, на основе позиции (xC, yC) целевого частотного компонента. В дальнейшем способ назначения индекса контекста, проиллюстрированный на Фиг. 60, будет описан подробно со ссылками на Фиг. 100.
[0525] Часть (a) на Фиг. 100 иллюстрирует таблицу CTX_GRP_TBL [X][Y] соответствия индивидуальных позиций коэффициента и относительных индексов контекста (идентификационных номеров подобластей) 4×4 TU и 8×8 TU.
[0526] (Выведение индекса контекста, используя таблицу)
Модуль 124b выведения контекста позиции выводит индекс ctxIdx контекста посредством использования значения назначенного относительного индекса контекста ctxGrpIdx, и некоторого значения смещения baseCtx каждого размера TU. В случае 8×8 TU интерпретация выполняется посредством использования позиции (xC>>1, yC>>1) для 2×2 суб-блока, которому принадлежит позиция (xC, yC) целевого частотного компонента. Таким образом,
X=log2TrafoWidth == 2 ? xC:xC>>1
Y=log2TrafoHeight == 2 ? yC:yC>>1
ctxGrpIdx = CTX_GRP_TBL [X][Y] (Ур. A2-4)
ctxIdx = ctxGrpIdx + baseCtx (Ур. A2-5)
Здесь переменная baseCtx представляет начальную точку индекса контекста каждой TU.
[0527] (Логическое выведение индекса контекста)
Выведение значения относительного индекса контекста ctxGrpIdx не ограничено уравнением (Ур. A2-4) для выведения значения посредством использования таблицы соответствия (таблицы поиска CTX_GRP_TBL [X][Y]) позиций (X, Y) коэффициента и относительных индексов контекста, иллюстрированных в части (a) на Фиг. 100. Альтернативно, может использоваться следующий логический способ выведения. В этом случае модуль 124b выведения контекста позиции выполняет выведение посредством использования следующих значений индивидуальных битов x0, x1, y0, и y1 позиции (X, Y) коэффициента.
[0528] x0=(X & 1) один младший бит X (первый младший бит)
x1=(X & 2)>>1 один старший бит X (второй младший бит)
y0= Y & 1) один младший бит Y (первый младший бит)
y1=(Y & 2)>>1 один старший бит Y (второй младший бит)
В дальнейшем будет дано описание способа для выведения относительных индексов контекста ctxGrpIdx, используя x0, x1, y0, и y1.
[0529] Часть (b) на Фиг. 100 иллюстрирует индивидуальные значения таблицы CTX_GRP_TBL [X][Y] соответствия позиций коэффициента и относительных индексов контекста, иллюстрированных в части (a) на Фиг. 100, посредством использования битов. Позиция коэффициента (X, Y) выражена 2 битами, и значение относительного индекса контекста выражено 3 битами. Здесь первый младший бит (третий старший бит) значения относительного индекса контекста ctxGrpIdx равен ctxGrpIdx0, второй младший бит (второй старший бит) является ctxGrpIdx1, и третий младший бит (первый старший бит) равен ctxGrpIdx2.
[0530] Со ссылками на часть (b) на Фиг. 100, следующее очевидно относительно двух старших битов значения относительного индекса контекста ctxGrpIdx.
значение первого старшего бита (третий младший бит: ctxGrpIdx2) значения относительного индекса контекста ctxGrpIdx равен значению первого старшего бита Y (y1). Таким образом,
ctxGrpIdx2=y1 (Ур. A2-6)
значение второго старшего бита (второй младший бит: ctxGrpIdx1) значения относительного индекса контекста ctxGrpIdx равен значению первого старшего бита X (x1). Таким образом,
ctxGrpIdx1=x1 (Ур. A2-7)
Часть (c) на Фиг. 100 иллюстрирует только один младший бит каждого значения таблицы CTX_GRP_TBL [X][Y] соответствия позиций коэффициента и относительных индексов контекста, иллюстрированных в части (b) на Фиг. 100. Со ссылками на часть (c) на Фиг. 100, первый младший бит (ctxGrpIdx0) значения относительного индекса контекста ctxGrpIdx может быть выражен логическим ИЛИ значения логического И от НЕ x1 и y0, и значения логического И x0 и НЕ y1, посредством использования индивидуальных битов x0, x1, y0, и y1 позиции (X, Y) коэффициента. Таким образом,
ctxGrpIdx0=(!x1 & y0)|(x0 &! y1) (Ур. A2-8)
Здесь, оператор "!" представляет НЕ, и оператор "&" представляет логическое И в единицах битов, и оператор "|" представляет логическое ИЛИ в единицах битов (то же самое относится к следующему описанию).
[0531] Таким образом, индивидуальные значения относительных индексов контекста ctxGrpIdx, соответствующих позициям коэффициента, иллюстрированным в части (a) на Фиг. 100, могут быть выведены с помощью следующего вычисления битов, используя предшествующие уравнения (Ур. A2-6), (Ур. A2-7), и (Ур. A2-8).
[0532] ctxGrpIdx=(ctxGrpIdx2<<2)|(ctxGrpIdx1<<1)|ctxGrpIdx0 (Ур. A2-9)
Установка значений индивидуальных относительных индексов контекста, показанных в таблице соответствия позиций коэффициента и относительных индексов контекста, иллюстрированных в части (a) на Фиг. 100, не ограничено иллюстрированным в части (a) на Фиг. 100. Например, как иллюстрировано на Фиг. 101, шесть шаблонов могут быть установлены, в которых изменяются позиции битов для установки значений x1, y1, и z. В случае, когда z на фиг. 101 выражен следующим образом:
z=(!×1&y0)|(x0&!y1) (Ур. A2-10), индивидуальные значения относительных индексов контекста, соответствующих позициям коэффициента, проиллюстрированным в части (a) на Фиг. 100, выводят посредством использования шаблона 0 проиллюстрированного на фиг. 101.
[0533] Вместо z в уравнении (Ур. A2-10) может использоваться z, которое вычислено с помощью логического вычисления, выраженного уравнением (Ур. A2-10). В этом случае индивидуальные значения относительных индексов контекста, соответствующих позициям коэффициента (X, Y), соответствующим шаблону 0 на фиг. 101, являются теми, что проиллюстрированы в части (a) на Фиг. 102.
[0534] z=((x0^x1) &! y1)|((y0 ^ y1) &! x1) (Ур. A2-11)
Здесь, оператор "^" представляет исключающее логическое ИЛИ в единицах единиц битов (то же самое относится к следующему описанию).
[0535] Вместо z в уравнении (Ур. A2-10) может использоваться z, которое вычислено с помощью логического вычисления, выраженного уравнением (Ур. A2-11). В этом случае индивидуальные значения относительных индексов контекста, соответствующих коэффициенту (X, Y), соответствующему шаблону 0 на Фиг. 101, являются теми, что проиллюстрированы в части (b) на Фиг. 102.
[0536] z=(!(x0|x1|y0|y1))|((y0 & y1) &! x1)|((x0 & x1) &! y1) (Ур. A2-11)
Вместо z в уравнении (Ур. A2-10) может использоваться z, которое вычислено с помощью логического вычисления, выраженного уравнением (Ур. A2-13). В этом случае индивидуальные значения групп относительных контекстов, соответствующих коэффициенту (X, Y), соответствующему шаблону 0 на фиг. 101, являются теми, что проиллюстрированы в части (c) на Фиг. 102.
[0537] z=(! (x0|x1|y0|y1))|((! y0 & y1) &! x1)| (! x0 & x1) &! y1) (Ур. A2-13)
Как описано выше, в этом процессе со способом выведения индекса контекста, проиллюстрированным на Фиг. 60 и 100, используется способ классификации подгрупп, который является общим для 4×4 компонентов и 8×8 компонентов, и для яркости и для цветности. Соответственно, процесс выведения индекса контекста может быть упрощен, в то же время поддерживая эффективность кодирования.
[0538] В способе выведения индекса контекста, проиллюстрированном на Фиг. 60 и 100, с вычислением битов, используя значения индивидуальных битов xC и yC, представляющих позиции целевого частотного компонента, который должен быть обработан, частотная область может быть легко разделена на множество подобластей (относительные индексы контекста), и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены. Соответственно, процесс выведения индекса контекста может быть упрощен. Способ выведения индекса контекста, проиллюстрированный на Фиг. 60 и 100, имеет характеристики, что количество этапов вычисления битов меньше, чем таковое в способе выведения, иллюстрированном на фиг. 85, описанной ниже, потому что выражение может быть выполнено, используя три бита bit0, bit1, и bit2 (диапазоны значений от 0 до 6), и три компонента AC самого низкого порядка, смежного с DC, назначают на один индекс контекста. Поскольку выражение может быть выполнено, используя малое количество битов, то есть три бита, установка может быть легко выполнена, когда аппаратное обеспечение используется.
[0539] Вместо способа выведения индекса контекста, иллюстрированного на фиг. 60, может использоваться способ выведения индекса контекста, проиллюстрированный в частях (a) и (b) на Фиг. 70. В этом случае относительно компонента DC для 8×8 TU, индивидуальные относительные индексы контекста назначают независимо от вышеописанной процедуры. Например, индекс контекста может быть выведен следующим образом вместо того, чтобы использовать уравнение (Ур. A2-9).
[0540] ctxGrpIdx = (xC+yC == 0 & log2TrafoWIdth == 3 && log2TrafoHeight == 3)?7:((ctxGrpIdx2<<2)|(ctxGrpIdx1<<1)| ctxGrpIdx0) (Ур. A2-14)
ctxIdx=ctxGrpIdx+baseCtx (Ур. A2-14)
Этот процесс имеет характеристики, что количество этапов больше, чем в способе выведения индекса контекста, проиллюстрированном на Фиг. 60 и 100, но имеет более высокую эффективность кодирования. Кроме того, этот процесс может быть выполнен в пределах трех битов от 0 до 7 кроме DC, и таким образом установка может быть легко выполнена, когда аппаратное обеспечение используется.
[0541] Как описано выше, в этом процессе способ выведения индекса контекста, проиллюстрированный на Фиг. 70, используется, чтобы использовать процесс классификации подгрупп, который является общим для 4×4 компонентов и 8×8 компонентов и для яркости и для цветности, кроме компонента DC. Соответственно, процесс выведения индекса контекста может быть упрощен, в то же время поддерживая эффективность кодирования.
[0542] В вышеописанном способе частотная область может быть разделена на множество подобластей, как проиллюстрировано в частях (a) и (b) Фиг. 60 и 70, и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены.
[0543] В случае процесса выведения индекса контекста, проиллюстрированного на Фиг. 85, индексы контекста могут быть выведены посредством использования следующих уравнений:
ctxGrpIdx = (bit3<<2)|(bit2<<2)|(bit1<<1)|bit0
bit3=(x1 & y1)
bit2=(x1 &! y1)|(! x1 & y1)
bit1=(! x1 & y1)|(! x1 &! y1 & y0)
bit0=(x0 &! y1)|(y0 & y1 &! x1)
Как описано выше, в этом процессе способ выведения индекса контекста, проиллюстрированный на Фиг. 70, используется, чтобы использовать процесс классификации подгрупп, который общий для 4×4 компонентов и 8×8 компонентов и для яркости и для цветности. Соответственно, процесс выведения индекса контекста может быть упрощен, в то же время поддерживая эффективность кодирования.
[0544] Этот способ выведения использует четыре бита bit0, bit1, bit2, и bit3 для выражения (диапазоны значения от 0 до 8), и имеет характеристики, что эффективность кодирования выше, чем в способе выведения индекса контекста, проиллюстрированном на Фиг. 60 и 100, хотя количество этапов больше из-за необходимости подтверждения большего количества битов на один бит. Способ выведения индекса контекста согласно сравнительному примеру, проиллюстрированному в части (c) на Фиг. 30, очень сложен, потому что позиции 2 и 3 не являются симметричными, позиции 6 и 8 не являются симметричными, и позиции 10 (DC) и 7 являются специальными, и таким образом большее количество этапов, чем в способе выведения, проиллюстрированном на Фиг. 85, необходимо в логическом вычислении, хотя диапазон битов является одним и тем же (4 бита).
[0545] (Модуль 124c выведения опорного контекста от соседнего элемента)
Модуль 124c выведения опорного контекста от соседнего элемента выводит индекс ctxIdx контекста для целевого частотного компонента, который должен быть декодирован, на основе количества cnt ненулевых коэффициентов преобразования, которые были декодированы относительно частотных компонентов вокруг целевого частотного компонента. Более конкретно, в случае, когда позиция (xC, yC) целевого частотного компонента или позиция (xCG, yCG) суб-блока, которому принадлежит целевой частотный компонент, удовлетворяет следующим условиям, модуль 124c выведения опорного контекста от соседнего элемента получает количество cnt декодированных ненулевых коэффициентов преобразования посредством использования опорной позиции (шаблона), который изменяется в соответствии с позицией коэффициента преобразования.
[0546] (1) В случае, когда xC+yC<THLo удовлетворено … частичная область R0, проиллюстрированный в части (a) на Фиг. 98
(2) В случае, когда xC+yC≥THlo и xCG+yCG<THhi удовлетворены … частичная область R1, проиллюстрированный в части (a) на Фиг. 98
Здесь, порог THlo может быть установлен посредством использования предшествующего уравнения (Ур. A2-1), и порог THhi может быть установлен посредством использования предшествующего уравнения (Ур. A2-2), но вариант осуществления не ограничен этим.
[0547] При вышеописанных условиях модуль 124c выведения опорного контекста от соседнего элемента получает количество cnt декодированных ненулевых коэффициентов преобразования посредством использования опорной позиции (шаблона), который изменяется в соответствии с позицией коэффициента преобразования. Кроме того, модуль 124c выведения опорного контекста от соседнего элемента выводит индексы ctxIdx контекста на основе количества cnt декодированных ненулевых коэффициентов преобразования, которые были выведены этим способом.
[0548] В дальнейшем описание будет дано случая, в котором сканирование в суб-блоке является "сканированием в диагональном направлении".
[0549][В случае, когда сканирование в суб-блоке является сканированием в диагональном направлении (часть (d) на Фиг. 99)]
В случае, когда сканирование в суб-блоке является "сканированием в диагональном направлении", модуль 124c выведения опорного контекста от соседнего элемента получает количество cnt декодированных ненулевых коэффициентов преобразования посредством использования опорной позиции (шаблона), который изменяется в соответствии с позицией коэффициента преобразования следующим образом. Часть (a) на Фиг. 99 диаграмма, иллюстрирующая отношения между позициями частотных компонентов в суб-блоке и шаблоном, который должен быть выбран, в случае, когда сканирование в суб-блоке является сканированием в диагональном направлении. В суб-блоке 4×4 компонентов шаблон, проиллюстрированный в части (b) на Фиг. 99, используются в случае, когда символ, заданный в этой позиции, является (b), тогда как шаблон, проиллюстрированный в части (c) на Фиг. 99, используется в случае, когда символ, заданный в этой позиции, является (c). Части (b) и (c) на Фиг. 99 иллюстрируют формы шаблонов, то есть, иллюстрируют относительные позиции опорных частотных компонентов (например, c1, c2, c3, c4 и c5) и целевого частотного компонента x. Часть (d) на Фиг. 99 является диаграммой, иллюстрирующей порядок сканирования (обратный порядок сканирования) сканирования в диагональном направлении в 4×4 суб-блоке.
[0550] Процесс, который выполняется в случае, когда позиция (xC, yC) коэффициента преобразования удовлетворяет следующему уравнению (Ур. A3), то есть, в случае, когда позиция коэффициента преобразования является верхней левой позицией суб-блока или непосредственно выше нижней правой позиции суб-блока, отличается от процесса, который выполняется в других случаях.
[0551] ((xC &3) == 0 && (yC &3) == 0)||((xC &3) == 3 && (yC &3) == 2) (Ур. A3)
В предшествующем уравнении (Ур. A3) оператор "&" является оператором, который принимает логическое ИЛИ в единицах битов, "&&" является оператором, представляющим логический И, и "||" является оператором, представляющим логическое ИЛИ (то же самое относится к следующему описанию).
[0552] Уравнение (Ур. A3) может также быть выражен уравнением (Ур. A3ʹ).
[0553] ((xC %4) == 0 && (yC %4) == 0)||((xC %4) == 3 && (yC %4) == 2) (Ур. A3ʹ)
В предшествующем уравнении (Ур. A3ʹ) "%" является оператором для того, чтобы получить остаток (то же самое относится к следующему описанию).
[0554] (Выведение количества cnt ненулевых коэффициентов преобразования)
(В случае, когда уравнение (Ур. A3) удовлетворено)
В случае, когда позиция (xC, yC) коэффициента преобразования удовлетворяет уравнению (Ур. A3), значение подсчета cnt ненулевых коэффициентов преобразования получают посредством использования следующего уравнения (Ур. A4) посредством использования опорных частотных компонентов (c1, c2, c4 и c5), проиллюстрированных в части (c) на Фиг. 99.
[0555] cnt=(c1!=0)+(c2!=0)+(c4!=0)+(c5!=0)·(Ур. A4)
Здесь, предполагается, что каждый член в уравнении (Ур. A4) принимает значение 1 в случае, когда сравнение в () верно, и принимает значение 0 в случае, когда сравнение в () ложно.
[0556] (В случае, когда уравнение (ep. A3), не удовлетворено)
В случае, когда позиция (xC, yC) коэффициента преобразования не удовлетворяет уравнению (Ур. A3), количество cnt ненулевых коэффициентов преобразования вычисляют посредством использования следующего уравнения (Ур. A5) посредством использования опорных частотных компонентов c1-c5, проиллюстрированных в части (b) на Фиг. 99.
[0557] cnt=(c1!=0)+(c2!=0)+(c3!=0)+(c4!=0)+(c5!=0)·(Ур. A5)
(Выведение индекса ctxIdx контекста)
Затем модуль 124c выведения опорного контекста от соседнего элемента изменяет начальную точку индекса контекста в соответствии с частичной областью R0 или R1, которой принадлежит коэффициент преобразования, выводит индекс ctxIdx контекста посредством использования следующего уравнения (Ур. A6), и подает результат выведения ctxIdx к контроллеру 124x способа выведения.
[0558] ctxIdx=sigCtxOffsetRX+Min (2, ctxCnt) (Ур. A6)
Здесь ctxCnt определяется посредством ctxCnt=(cnt+1)>>1.
[0559] В уравнении (Ур. A6) переменная sigCtxOffsetRX представляет начальную точку некоторого индекса контекста, который определяется в соответствии с частичной областью R0 или R1, которой принадлежит коэффициент преобразования. В случае частичной области R0 переменная sigCtxOffsetRX = sigCtxOffsetR0. В случае частичной области R1 переменная sigCtxOffsetRX= sigCtxOffsetR1. Предпочтительно, значения sigCtxOffsetR0 и sigCtxOffsetR1 отличаются друг от друга.
[0560] В уравнении (Ур. A4) на коэффициент преобразования в координате (c3), расположенной непосредственно до позиции целевого коэффициента преобразования в порядке обработки (в случае, когда порядок обработки является обратным порядком сканирования, более низкая сторона позиции целевого коэффициента преобразования) не ссылаются. В таком процессе выведение контекста, который должен использоваться для декодирования флага присутствия/отсутствия коэффициента в некоторой позиции, может быть выполнено, не обращаясь к значению предыдущего флага присутствия/отсутствия коэффициента, и таким образом процесс выведения контекста и процесс декодирования могут быть выполнены параллельно.
[0561] (Модуль 124e установления флага присутствия/отсутствия коэффициента)
Модуль 124e установления флага присутствия/отсутствия коэффициента интерпретирует каждый бин, подаваемый от битового декодера 132, и устанавливает элемент синтаксиса significant_coeff_flag [xC][yC]. Установленный элемент синтаксиса significant_coeff_flag [xC][yC] подается к памяти 126 коэффициентов декодирования.
[0562] В случае, когда целевая частотная область разделена на суб-блоки, модуль 124e установления флага присутствия/отсутствия коэффициента обращается к элементу синтаксиса significant_coeff_group_flag [xCG][yCG], назначенному на целевой суб-блок. В случае, когда значение significant_coeff_group_flag [xCG][yCG] равно 0, модуль 124e установления флага присутствия/отсутствия коэффициента устанавливает significant_coeff_flag [xC][yC] для всех частотных компонентов, включенных в этот целевой суб-блок, в 0.
[0563] (Память 124d флага присутствия/отсутствия коэффициента)
Память 124d флага присутствия/отсутствия коэффициента хранит индивидуальные значения элементов синтаксиса significant_coeff_flag [xC][yC]. На индивидуальные значения элементов синтаксиса significant_coeff_flag [xC][yC], сохраненные в памяти 124d флага присутствия/отсутствия коэффициента, ссылаются посредством модуля 124c выведения опорного контекста от соседнего элемента. Существует ли ненулевой коэффициент преобразования в позиции (xC, yC) каждого частотного компонента, может быть определено, обращаясь к декодированному значению коэффициента преобразования, без использования памяти, выделенной для флагов присутствия/отсутствия коэффициента. Таким образом, память 126 коэффициентов декодирования может использоваться без обеспечения памяти 124d флага присутствия/отсутствия коэффициента.
[0564] <Работа модуля 124z получения контекста>
Фиг. 103 является последовательностью операций, иллюстрирующей операции контроллера 124x способа выведения, модуля 124b выведения контекста позиции и модуля 124c выведения опорного контекста от соседнего элемента, включенных в модуль 124z выведения контекста.
[0565] (Этап SA101)
Контроллер 124x способа выведения определяет, меньше ли размер TU, чем некоторый размер. Следующее выражение используется для определения, например.
[0566] ширина + высота < THSize
Например, 20 используется как порог THSize. В случае, когда 20 используется как порог THsize, определяется, что 4×4 TU и 8×8 TU меньше чем некоторый размер. Определяется, что 16×4 TU, 4×16 TU, 16×16 TU, 32×4 TU, 4×32 TU, и 32×32 TU равны или более, чем некоторый размер. Порог THSize может быть равным 0. В этом случае определяют, что 4×4 TU-32×32 TU равно или более, чем некоторый размер.
[0567] (Этап SA102)
В случае, когда размер TU цели, которая должна быть обработана, равен или больше, чем некоторый размер (НЕТ на этапе SA101), контроллер 124x способа выведения определяет, соответствует ли позиция суб-блока (xCG, yCG), включающего в себя целевой коэффициент преобразования, высокочастотному компоненту (например, иллюстрировала ли частичная область R2 в части (a) на Фиг. 98).
[0568] (Этап SA103)
В случае, когда позиция суб-блока (xCG, yCG), включающая в себя целевой коэффициент преобразования, не соответствует высокочастотному компоненту (НЕТ на этапе SA102), контроллер 124x способа выведения определяет, соответствуют ли позиция (xC, yC) целевого коэффициента преобразования низкочастотному компоненту (например, иллюстрировала ли частичная область R0 в части (a) на Фиг. 98).
[0569] (Этап SA104)
В случае, когда позиция (xC, yC) целевого коэффициента преобразования не соответствует низкочастотному компоненту (НЕТ на этапе SA103), контроллер 124x способа выведения определяет, что позиция (xC, yC) целевого коэффициента преобразования соответствует промежуточному частотному компоненту, и устанавливает переменную sigCtxOffsetRx в sigCtxOffsetR1. Затем процесс переходит к этапу SA106.
(Этап SA105)
В случае, когда позиция (xC, yC) целевого коэффициента преобразования соответствует низкочастотному компоненту (Да на этапе SA103), контроллер 124x способа выведения устанавливает sifCtxOffsetR0 в переменную sigCtxOffsetRX. Затем процесс переходит к этапу SA106.
(Этап SA106)
Контроллер 124x способа выведения выбирает модуль 124c выведения опорного контекста от соседнего элемента в качестве средства выведения контекста, и выбранный модуль 124c выведения опорного контекста от соседнего элемента выводит индекс контекста целевого коэффициента преобразования.
[0570] (Этап SA107)
В случае, когда размер TU цели, которая должна быть обработана, меньше, чем некоторый размер (Да на этапе SA101), или в случае, когда суб-блок, включающий в себя целевой коэффициент преобразования, соответствует высокочастотному компоненту (ДА на этапе SB103), контроллер 124x способа выведения выбирает модуль 124b выведения контекста позиции в качестве средства выведения контекста, и выбранный модуль 124b выведения контекста позиции выводит индекс контекста целевого коэффициента преобразования.
[0571] Согласно третьему примеру модификации декодера 124 флага присутствия/отсутствия коэффициента в случае, когда размер TU цели, которая должна быть обработана, является некоторым размером или меньшим, частотная область может быть разделена на множество подобластей (относительные индексы контекста) с помощью вычисления битов, используя значения индивидуальных битов xC и yC, представляющих позиции целевого частотного компонента, который должен быть обработан, и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены. Соответственно, процесс выведения индекса контекста может быть упрощен, и размер памяти, относящийся к выведением индексов контекста, может быть уменьшен.
[0572] В случае, когда размер TU цели, которая должна быть обработана, больше, чем некоторый размер, если целевой флаг присутствия/отсутствия коэффициента, который должен быть обработан, расположен в высокочастотной области, модуль выведения контекста позиции выводит индекс контекста, относящийся к целевому флагу присутствия/отсутствия коэффициента, который должен быть обработан. Если целевой флаг присутствия/отсутствия коэффициента, который должен быть обработан, расположен в низкочастотной области и промежуточной частотной области, модуль выведения опорного контекста от соседнего элемента выводит индекс контекста, относящийся к целевому флагу присутствия/отсутствия коэффициента, который должен быть обработан. Таким образом, по сравнению с уровнем техники, индексы контекста могут быть выведены для частотных компонентов, включенных в низкочастотную область с учетом смещения частоты появления ненулевых коэффициентов, объем кодов флагов присутствия/отсутствия коэффициента может быть уменьшен, и величина обработки, связанная с декодированием, может быть уменьшена.
[0573] На основе позиции коэффициента, для позиции целевого коэффициента преобразования, шаблон выбирают так, чтобы не обращаться к коэффициенту преобразования в координате, расположенной непосредственно прежде в порядке обработки (обратный порядок сканирования). В таком процессе выведение контекста, который должен использоваться для декодирования флага присутствия/отсутствия коэффициента в некоторой позиции, может быть выполнено, не обращаясь к значению предыдущего флага присутствия/отсутствия коэффициента, и таким образом процесс выведения контекста и процесс декодирования могут быть выполнены параллельно.
[0574] <Последовательность операций процесса, выполняемого декодером 120 коэффициента преобразования>
В дальнейшем последовательность операций процесса декодирования коэффициента преобразования, выполняемого декодером 120 коэффициента преобразования, будет описана со ссылками на Фиг. 44-51.
[0575] (В случае, когда размер частотной области является некоторым размером или меньшим)
Фиг. 44 иллюстрирует псевдокод, показывающий процесс декодирования коэффициента преобразования, выполняемый декодером 120 коэффициента преобразования, в случае, когда размер частотной области является некоторым размером или меньшим (например, 4×4 компонентов или 8×8 компонентов).
[0576] Фиг. 45 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования коэффициента преобразования, выполняемого декодером 120 коэффициента преобразования, в случае, когда размер частотной области является некоторым размером или меньшим.
[0577] (Этап S11)
Сначала контроллер 123 декодирования коэффициента, включенный в декодер 120 коэффициента преобразования, выбирает тип ScanType сканирования.
(Этап S12)
Затем декодер 121 позиции последнего коэффициента, включенный в декодер 120 коэффициента преобразования, декодирует элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y, которые указывают позицию последнего коэффициента преобразования вдоль прямого сканирования.
(Этап S13)
Затем контроллер 123 декодирования коэффициента начинает цикл в единицах подгрупп. Здесь, подгруппа соответствует одной или множественным областям, полученным посредством деления целевой частотной области. Каждая подгруппа составлена из, например, шестнадцати частотных компонентов.
(Этап S14)
Затем декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, декодирует индивидуальные ненулевые флаги significant_coeff_flag присутствия/отсутствия коэффициента преобразования в целевой подгруппе.
(Этап S15)
Затем декодер 125 значений коэффициентов, включенный в декодер 120 коэффициента преобразования, декодирует знаки и уровни ненулевых коэффициентов преобразования в целевой подгруппе. Это выполняется посредством декодирования индивидуальных элементов синтаксиса coeff_abs_level_greateer1_flag, coeff_abs_level_greateer2_flag, coeff_sign_flag, и coeff_abs_level_minus3.
(Этап S16)
Этот этап является концом цикла, выполняемого в единицах суб-блоков.
[0578] Фиг. 46 является последовательностью операций, описывающей процесс выбора типа сканирования (этап S11) более конкретно.
[0579] (Этап S111)
Сначала контроллер 123 декодирования коэффициента, включенный в декодер 120 коэффициента преобразования, определяет, представляет ли информация схемы предсказания PredMode схему MODE_Intra внутреннего предсказания.
(Этап S112)
В случае, когда схема предсказания является схемой внутреннего предсказания (Да на этапе S111), контроллер 123 декодирования коэффициента, включенный в декодер 120 коэффициента преобразования, устанавливает тип сканирования на основе режима внутреннего предсказания (направления предсказания) и размера TU цели (размера частотной области). Подробности процесса установки типа сканирования были описаны выше, и таким образом его описание здесь опущено.
[0580] С другой стороны, в случае, когда схема предсказания не является схемой внутреннего предсказания (НЕТ на этапе S111), контроллер 123 декодирования коэффициента, включенный в декодер 120 коэффициента преобразования, устанавливает тип сканирования в сканирование в диагональном направлении.
[0581] Фиг. 47 является последовательностью операций, описывающей процесс декодирования ненулевого флага significant_coeff_flag присутствия/отсутствия коэффициента преобразования (этап S14) более конкретно.
[0582] (Этап S141)
Сначала декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, получает позицию подгруппы, включающую в себя последний коэффициент.
(Этап S142)
Затем декодер 124 флага присутствия/отсутствия коэффициента инициализирует значение significant_coeff_flag, включенного в целевую частотную область, в 0.
(Этап S143)
Затем декодер 124 флага присутствия/отсутствия коэффициента начинает цикл в единицах подгрупп. Здесь, цикл является циклом, который начинается с подгруппы, включающей в себя последний коэффициент, в котором подгруппы сканируются в обратном порядке сканирования.
(Этап S144)
Затем декодер 124 флага присутствия/отсутствия коэффициента начинает цикл в целевой подгруппе. Цикл является циклом, выполняемым в единицах частотных компонентов.
(Этап S145)
Затем декодер 124 флага присутствия/отсутствия коэффициента получает позицию коэффициента преобразования.
(Этап S146)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, является ли полученная позиция коэффициента преобразования последней позицией.
(Этап S147)
В случае, когда полученная позиция коэффициента преобразования не является последней позицией (НЕТ на этапе S146), декодер 124 флага присутствия/отсутствия коэффициента декодирует флаг significant_coeff_flag присутствия/отсутствия коэффициента преобразования.
(Этап S148)
Этот этап является концом цикла в подгруппе.
(Этап S149)
Затем декодер 124 флага присутствия/отсутствия коэффициента декодирует знаки и уровни индивидуальных ненулевых коэффициентов преобразования в подгруппе.
(Этап S150)
Этот этап является концом цикла подгруппы.
[0583] (В случае, когда размер частотной области больше, чем некоторый размер)
Фиг. 48 иллюстрирует псевдокод, показывающий процесс декодирования коэффициента преобразования, выполняемый декодером 120 коэффициента преобразования в случае, когда размер частотной области больше, чем некоторый размер (например, 16×16 компонентов или 32×32 компонентов).
[0584] Фиг. 49 является последовательностью операций, иллюстрирующей последовательность операций процесса декодирования коэффициента преобразования, выполняемого декодером 120 коэффициента преобразования в случае, когда размер частотной области больше, чем некоторый размер.
[0585] (Этап S21)
Сначала контроллер 123 декодирования коэффициента, включенный в декодер 120 коэффициента преобразования, выбирает тип ScanType сканирования. Это является таким же, как в вышеописанном этапе S11.
(Этап S22)
Затем декодер 121 позиции последнего коэффициента, включенный в декодер 120 коэффициента преобразования, декодирует элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y, которые указывают позицию последнего коэффициента преобразования вдоль прямого сканирования.
(Этап S23)
Затем контроллер 123 декодирования коэффициента начинает цикл в блоках суб-блоков.
(Этап S24)
Затем декодер 127 флага присутствия/отсутствия коэффициента суб-блока, включенный в декодер 120 коэффициента преобразования, декодирует флаги присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag.
(Этап S25)
Этот цикл является концом цикла, выполняемого в единицах суб-блоков.
(Этап S26)
Затем контроллер 123 декодирования коэффициента начинает цикл в единицах суб-блоков.
(Этап S27)
Затем декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, декодирует индивидуальные ненулевые флаги significant_coeff_flag присутствия/отсутствия коэффициента преобразования в целевом суб-блоке.
(Этап S28)
Затем декодер 125 значений коэффициентов, включенный в декодер 120 коэффициента преобразования, декодирует знаки и уровни ненулевых коэффициентов преобразования в целевой подгруппе. Это выполняется посредством декодирования индивидуальных элементов синтаксиса coeff_abs_level_greateer1_flag, coeff_abs_level_greateer2_flag, coeff_sign_flag, и coeff_abs_level_minus3.
(Этап S29)
Этот этап является концом цикла, выполняемого в единицах суб-блоков (конец цикла, выполняемого в единицах суб-блоков на этапе S26).
[0586] Фиг. 50 является последовательностью операций, описывающей процесс декодирования флагов присутствия/отсутствия коэффициента суб-блока (этап S24) более конкретно.
[0587] (Этап S241)
Сначала декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, получает позицию суб-блока, включающего в себя последний коэффициент.
(Этап S242)
Затем декодер 124 флага присутствия/отсутствия коэффициента инициализирует значения флагов присутствия/отсутствия коэффициента significant_coeffgroup_flag суб-блока, включенного в целевую частотную область. Этот процесс инициализации выполнятся посредством установления флага присутствия/отсутствия коэффициента суб-блока для суб-блока, включающего в себя компонент DC и флаг присутствия/отсутствия коэффициента суб-блока для суб-блока, включающего в себя последний коэффициент, в 1, и установления других флагов присутствия/отсутствия коэффициента суб-блока, в 0.
(Этап S243)
Затем декодер 124 флага присутствия/отсутствия коэффициента начинает цикл в единицах суб-блоков.
(Этап S244)
Затем декодер 124 флага присутствия/отсутствия коэффициента получает позицию суб-блока.
(Этап S245)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, есть ли ненулевой коэффициент преобразования в декодированном суб-блоке, смежном с целевым суб-блоком.
(Этап S246)
В случае, когда результат определения является «Да» на этапе S245, флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока устанавливается в 1.
[0588] Здесь, процесс на этапе S245 и этап S246 зависит от направления сканирования суб-блоков, как описано ниже.
[0589] · В случае, когда сканирование суб-блока является приоритетным сканированием в вертикальном направлении, как иллюстрировано в части (a) на Фиг. 20, в случае, когда ненулевой коэффициент преобразования существует в суб-блоке (xCG, yCG+1) и ненулевой коэффициент преобразования не существует в суб-блоке (xCG+1, yCG), флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока (xCG, yCG) устанавливается в 1.
[0590] В случае, когда сканирование суб-блока является приоритетным сканированием в горизонтальном направлении, как иллюстрировано в части (b) на Фиг. 20, в случае, когда ненулевой коэффициент преобразования существует в суб-блоке (xCG+1, yCG) и ненулевой коэффициент преобразования не существует в суб-блоке (xCG, yCG+1), флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока (xCG, yCG) устанавливается в 1.
В случае, когда сканирование суб-блока является сканированием в диагональном направлении, как иллюстрировано в части (c) на Фиг. 20, в случае, когда ненулевой коэффициент преобразования существует в обоих суб-блоке (xCG+1, yCG) и суб-блоке (xCG, yCG+1), флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока (xCG, yCG) устанавливается в 1.
[0591] (Этап S247)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, является ли целевой суб-блок суб-блоком, включающим в себя последний коэффициент.
(Этап S248)
В случае, когда целевой суб-блок не является суб-блоком, включающим в себя последний коэффициент (НЕТ на этапе S247), декодер 124 флага присутствия/отсутствия коэффициента декодирует флаг присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag.
(Этап S249)
Этот этап является концом цикла суб-блоков.
[0592] Фиг. 51 является последовательностью операций, описывающей процесс декодирования индивидуальных ненулевых флагов significant_coeff_flag присутствия/отсутствия коэффициента преобразования в суб-блоке (этап S27 на Фиг. 49), более конкретно.
[0593] (Этап S271)
Сначала декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, получает позицию суб-блока, включающего в себя последний коэффициент.
(Этап S272)
Затем декодер 124 флага присутствия/отсутствия коэффициента инициализирует значения significant_coeff_flag, включенного в целевую частотную область, в 0.
(Этап S273)
Затем декодер 124 флага присутствия/отсутствия коэффициента начинает цикл в единицах суб-блоков. Здесь, цикл начинается с суб-блока, включающего в себя последний коэффициент. В этом цикле суб-блоки сканируются в обратном порядке сканирования суб-блоков.
(Этап S274)
Затем декодер 124 флага присутствия/отсутствия коэффициента начинает цикл в целевом суб-блоке. Цикл выполняется в единицах частотных компонентов.
(Этап S275)
Затем декодер 124 флага присутствия/отсутствия коэффициента получает позицию коэффициента преобразования.
(Этап S276)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, существует ли ненулевой коэффициент преобразования в целевом суб-блоке.
(Этап S277)
В случае, когда ненулевой коэффициент преобразования существует в целевом суб-блоке (Да на этапе S276), декодер 124 флага присутствия/отсутствия коэффициента определяет, является ли полученная позиция коэффициента преобразования последней позицией.
(Этап S278)
В случае, когда полученная позиция коэффициента преобразования не является последней позицией (НЕТ на этапе S277), декодер 124 флага присутствия/отсутствия коэффициента декодирует флаг significant_coeff_flag присутствия/отсутствия коэффициента преобразования.
(Этап S279)
Этот этап является концом цикла в суб-блоке.
(Этап S280)
Затем декодер 124 флага присутствия/отсутствия коэффициента декодирует знаки и уровни индивидуальных ненулевых коэффициентов преобразования в суб-блоке.
(Этап S281)
Этот этап является концом цикла суб-блоков.
[0594] Со ссылками на Фиг. 48-50, описание было дано примера, в котором декодирование флагов присутствия/отсутствия коэффициента суб-блока, и декодирование ненулевых флагов присутствия/отсутствия коэффициента и знаков и уровней индивидуальных ненулевых коэффициентов выполняются в различных циклах в единицах суб-блоков. Альтернативно, как в последовательности операций, проиллюстрированной на Фиг. 75, эти процессы декодирования могут быть выполнены в одном и том же цикле в единицах суб-блоков.
[0595] В дальнейшем описание будет дано потока (операций) процесса декодирования коэффициента преобразования, выполняемого декодером 120 коэффициента преобразования, в случае, когда размер частотной области больше, чем некоторый размер, со ссылками на Фиг. 75.
[0596] (Этап S31)
Сначала контроллер 123 декодирования коэффициента, включенный в декодер 120 коэффициента преобразования, выбирает тип ScanType сканирования. Это является таким же самым, как вышеописанный этап S11.
(Этап S32)
Затем декодер 121 позиции последнего коэффициента, включенный в декодер 120 коэффициента преобразования, декодирует элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y, которые указывают позицию последнего коэффициента преобразования вдоль прямого сканирования. Кроме того, декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, получает позицию суб-блока, включающего в себя последний коэффициент.
(Этап S33)
Затем контроллер 123 декодирования коэффициента начинает цикл в единицах суб-блоков. В начале цикла декодер 124 флага присутствия/отсутствия коэффициента инициализирует значения флагов присутствия/отсутствия коэффициента significant_coeffgroup_flag суб-блока, включенного в целевую частотную область. Этот процесс инициализации выполняют, устанавливая флаг присутствия/отсутствия коэффициента суб-блока для суб-блока, включающего в себя компонент DC, и флаг присутствия/отсутствия коэффициента суб-блока для суб-блока, включающего в себя последний коэффициент, в 1, и устанавливая другие флаги присутствия/отсутствия коэффициента суб-блока в 0.
(Этап S34)
Затем декодер 127 флага присутствия/отсутствия коэффициента суб-блока, включенный в декодер 120 коэффициента преобразования, декодирует флаги присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag.
(Этап S35)
Затем декодер 124 флага присутствия/отсутствия коэффициента, включенный в декодер 120 коэффициента преобразования, декодирует индивидуальные ненулевые флаги significant_coeff_flag присутствия/отсутствия коэффициента преобразования в целевом суб-блоке.
(Этап S36)
Затем декодер 125 значений коэффициентов, включенный в декодер 120 коэффициента преобразования, декодирует знаки и уровни ненулевых коэффициентов преобразования в целевой подгруппе. Это выполняется посредством декодированя индивидуальных элементов синтаксиса coeff_abs_level_greateer1_flag, coeff_obs_level_greateer2_flag, coeff_sign_flag, и coeff_abs_level_minus3.
(Этап S37)
Этот этап является концом цикла, выполненным в единицах суб-блоков.
[0597] Фиг. 76 является последовательностью операций, описывающей процесс декодирования флагов присутствия/отсутствия коэффициента суб-блока (этап S34) более конкретно.
[0598] (Этап S341)
Затем декодер 124 флага присутствия/отсутствия коэффициента получает позицию суб-блока.
(Этап S342)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, существует ли ненулевой коэффициент преобразования в декодированном суб-блоке, смежном с целевым суб-блоком.
(Этап S343)
В случае, когда результат определения на этапе S342 является «Да», флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока устанавливается в 1.
[0599] Здесь, процесс на этапе S342 и этапе S343 зависит от направления сканирования суб-блоков, как описано ниже.
[0600] · В случае, когда сканирование суб-блока является приоритетным сканированием в вертикальном направлении, как иллюстрировано в части (a) на Фиг. 20, в случае, когда ненулевой коэффициент преобразования существует в суб-блоке (xCG, yCG+1) и ненулевой коэффициент преобразования не существует в суб-блоке (xCG+1, yCG), флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока (xCG, yCG) устанавливается в 1.
В случае, когда сканирование суб-блока является приоритетным сканированием в горизонтальном направлении, как иллюстрировано в части (b) на Фиг. 20, в случае, когда ненулевой коэффициент преобразования существует в суб-блоке (xCG+1, yCG) и ненулевой коэффициент преобразования не существует в суб-блоке (xCG, yCG+1), флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока (xCG, yCG) устанавливается в 1.
В случае, когда сканирование суб-блока является сканированием в диагональном направлении, как иллюстрировано в части (c) на Фиг. 20, в случае, когда ненулевой коэффициент преобразования существует в обоих суб-блоке (xCG+1, yCG) и суб-блоке (xCG, yCG+1), флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока (xCG, yCG) устанавливается в 1.
[0601] (Этап S344)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, является ли целевой суб-блок суб-блоком включающим в себя последний коэффициент.
(Этап S345)
В случае, когда целевой суб-блок не является суб-блоком, включающим в себя последний коэффициент (НЕТ на этапе S344), декодер 124 флага присутствия/отсутствия коэффициента декодирует флаг присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag.
[0602] Фиг. 77 является последовательностью операций, описывающей процесс декодирования индивидуальных ненулевых флагов significant_coeff_flag присутствия/отсутствия коэффициента преобразования в индивидуальных суб-блоках в суб-блоках более конкретно (этап S35 на Фиг. 75).
[0603] (Этап S351)
Сначала декодер 124 флага присутствия/отсутствия коэффициента начинает цикл в целевом суб-блоке. Цикл выполняется в единицах частотных компонентов. В начале цикла декодер 124 флага присутствия/отсутствия коэффициента инициализирует значения significant_coeff_flag, включенных в целевую частотную область, в 0.
(Этап S352)
Затем декодер 124 флага присутствия/отсутствия коэффициента получает позицию коэффициента преобразования.
(Этап S353)
Затем декодер 124 флага присутствия/отсутствия коэффициента определяет, существует ли ненулевой коэффициент преобразования в целевом суб-блоке.
(Этап S354)
В случае, когда ненулевой коэффициент преобразования существует в целевом суб-блоке (Да на этапе S353), декодер 124 флага присутствия/отсутствия коэффициента определяет, является ли полученная позиция коэффициента преобразования последней позицией.
(Этап S355)
В случае, когда полученная позиция коэффициента преобразования не является последней позицией (НЕТ на этапе S354), декодер 124 флага присутствия/отсутствия коэффициента декодирует флаг significant_coeff_flag присутствия/отсутствия коэффициента преобразования.
(Этап S356)
Этот этап является концом цикла в суб-блоке.
[0604] (Устройство 2 кодирования видео)
Конфигурация устройства 2 кодирования видео согласно варианту осуществления будет описана со ссылками на Фиг. 52-56. Устройство 2 кодирования видео является кодирующим устройством, которое совместимо с технологией, принятой для стандарта H.264/MPEG-4 AVC, технологией, принятой для программного обеспечения KTA, которое является кодеком для совместного развития в VCEG (группе экспертов по кодированию видео), технологией, принятой для программного обеспечения TMuC (тестовой модели на рассмотрении), и технологии, предложенной посредством HEVC (высокоэффективное кодирование видео), которое является последующим кодеком предшествующих технологий. В дальнейшем, те же самые части, как те, что описаны выше, обозначены теми же самыми ссылочными позициями, и описание их опущено.
[0605] Фиг. 52 является блок-схемой, иллюстрирующей конфигурацию устройства 2 кодирования видео. Как иллюстрировано на Фиг. 52, устройство 2 кодирования видео включает в себя генератор 21 изображения предсказания, модуль 22 преобразования/квантования, модуль 23 обратного преобразования/деквантования, сумматор 24, память 25 кадров, контурный фильтр 26, кодировщик 27 кода с переменной длиной слова, и вычитатель 28. Кроме того, как иллюстрировано на Фиг. 52, генератор 21 изображения предсказания включает в себя генератор 21a изображения внутреннего предсказания, детектор 21b вектора движения, генератор 21c изображения внешнего предсказания, контроллер 21d схемы предсказания, и модуль 21e удаления избыточности вектора движения. Устройство 2 кодирования видео является устройством для того, чтобы генерировать закодированные данные #1 посредством кодирования видео #10 (изображение, которое должно быть декодировано).
[0606] (Генератор 21 изображения предсказания)
Генератор 21 изображения предсказания рекурсивно делит целевую LCU, которая должна быть обработана, на одну или множественные единицы CU младшего порядка, делит каждую листовую CU на одно или множественные разделения, и генерирует, для каждого разделения, изображение Pred_Inter внешнего предсказания, используя внешнее предсказание, или изображение Pred_Intra внутреннего предсказания, используя внутреннее предсказание. Сгенерированное изображение Pred_Inter внешнего предсказания и изображение Pred_Intra внутреннего предсказания подается как изображение Pred предсказания к сумматору 24 и вычитатель 28.
[0607] Генератор 21 изображения предсказания опускает, для PU, которой режим пропуска применен, кодирование других параметров, которые принадлежат этой PU. Кроме того, (1) форма разделения целевой LCU в единицах CU младшего порядка и разделений, (2), должен ли режим пропуска быть применен, и (3) какое из изображения Pred_Inter внешнего предсказания и изображения Pred_Intra внутреннего предсказания должны генерироваться для каждого разделения, определяются, чтобы оптимизировать эффективность кодирования.
[0608] (Генератор 21a изображения внутреннего предсказания)
Генератор 21a изображения внутреннего предсказания генерирует изображение Pred_Intra предсказания, относящееся к каждому разделению, посредством использования внутреннего предсказания. В частности, генератор 21a изображения внутреннего предсказания (1) выбирает режим предсказания, который должен использоваться для внутреннего предсказания для каждого разделения, и (2) генерирует изображение Pred_Intra предсказания из декодированного изображения P посредством использования выбранного режима предсказания. Генератор 21a изображения внутреннего предсказания подает сгенерированное изображение Pred_Intra внутреннего предсказания к контроллеру 21d схемы предсказания.
[0609] Кроме того, генератор 21a изображения внутреннего предсказания определяет оцененный режим предсказания для целевого разделения из режимов предсказания, назначенных на разделение вокруг целевого разделения, и подает флаг оцененного режима предсказания, который указывает, является ли оцененный режим предсказания тем же самым как режим предсказания, который фактически выбран для целевого разделения, которое является частью параметра PP_Intra внутреннего предсказания, к кодировщику 27 кода с переменной длиной слова через контроллер 21d схемы предсказания. Кодировщик 27 кода с переменной длиной слова включает флаг в закодированные данные #1.
[0610] В случае, когда оцененный режим предсказания для целевого разделения отличается от режима предсказания, который фактически выбран для целевого разделения, генератор 21a изображения внутреннего предсказания подает индекс режима остаточного предсказания, указывающий режим предсказания для целевого разделения, который является частью параметра PP_Intra внутреннего предсказания, к кодировщику 27 кода с переменной длиной слова через контроллер 21d схемы предсказания. Кодировщик 27 кода с переменной длиной слова включает индекс режима остаточного предсказания в закодированные данные #1.
[0611] Генератор 21a изображения внутреннего предсказания выбирает, из числа режимов предсказания, иллюстрированных на Фиг. 11, режим предсказания, который обеспечивает дальнейшее увеличение эффективности кодирования при генерировании изображения Pred_Intra предсказания.
[0612] (Детектор 21b вектора движения)
Детектор 21b вектора движения обнаруживает вектор mv движения относительно каждого разделения. В частности, детектор 21b вектора движения (1) выбирает адаптивное фильтрованное декодированное изображение P_ALFʹ, которое должно использоваться как опорное изображение, и (2) ищет выбранное адаптивное фильтрованное декодированное изображение P_ALFʹ для области, которая лучше всего аппроксимирует целевое разделение, и таким образом обнаруживает вектор mv движения, относящийся к целевому разделению. Здесь, адаптивное фильтрованное декодированное изображение P_ALFʹ является изображением, которое получено посредством выполнения адаптивного процесса фильтрования контурным фильтром 26 в отношении декодированного изображения, в отношении которого декодирование было выполнено на всем кадре, и детектор 21b вектора движения способен считывать пиксельные значения индивидуальных пикселей, которые формируют адаптивное фильтрованное декодированное изображение P_ALFʹ, из памяти 25 кадров. Детектор 21b вектора движения подает обнаруженный вектор mv движения к генератору 21c изображения внешнего предсказания и модулю 21e удаления избыточности вектора движения, вместе с индексом RI опорного изображения, который называет адаптивное фильтрованное декодированное изображение P_ALFʹ, которое используется как опорное изображение.
[0613] (Генератор 21c изображения внешнего предсказания)
Генератор 21c изображения внешнего предсказания генерирует изображение mc компенсации движения, относящееся к каждому разделению внешнего предсказания, посредством использования внешнего предсказания. В частности, генератор 21c изображения внешнего предсказания генерирует изображение mc компенсации движения из адаптивного фильтрованного декодированного изображения P_ALFʹ, обозначенного индексом RI опорного изображения, подаваемым от детектора 21b вектора движения, посредством использования вектора mv движения, подаваемого от детектора 21b вектора движения. Подобно детектору 21b вектора движения, генератор 21c изображения внешнего предсказания способен считывать пиксельные значения индивидуальных пикселей, которые формируют адаптивное фильтрованное декодированное изображение P_ALFʹ, из памяти 25 кадров. Генератор 21c изображения внешнего предсказания подает сгенерированное изображение mc компенсации движения (изображение Pred_Inter внешнего предсказания) к контроллеру 21d схемы предсказания, вместе с индексом RI опорного изображения, подаваемым от детектора 21b вектора движения.
[0614] (Контроллер 21d схемы предсказания)
Контроллер 21d схемы предсказания сравнивает изображение Pred_Intra внутреннего предсказания и изображение Pred_Inter внешнего предсказания с целевым изображением, которое должно быть закодировано, и выбирает, должно ли внутреннее предсказание быть выполнено, или внешнее предсказание должно быть выполнено. В случае, когда внутреннее предсказание выбрано, контроллер 21d схемы предсказания подает изображение Pred_Intra внутреннего предсказания, которое является изображением предсказания Pred, к сумматору 24 и вычитателю 28, и также подает параметр PP_Intra внутреннего предсказания, подаваемый от генератора 21a изображения внутреннего предсказания, к кодировщику 27 кода с переменной длиной слова. С другой стороны, в случае, когда внешнее предсказание выбрано, контроллер 21d схемы предсказания подает изображение Pred_Inter внешнего предсказания, который является изображением Pred предсказания, к сумматору 24 и вычитателю 28, и также подает индекс RI опорного изображения и индекс PMVI оцененного вектора движения и остаток MVD вектора движения, подаваемый от модуля 21e удаления избыточности вектора движения, описанного ниже, которые являются параметрами PP_Inter внешнего предсказания, к кодировщику 27 кода с переменной длиной слова. Кроме того, контроллер 21d схемы предсказания предоставляет информацию Pred_type типа предсказания, которая указывает, какое из изображения Pred_Intra внутреннего предсказания и изображение Pred_Inter внешнего предсказания было выбрано, к кодировщику 27 кода с переменной длиной слова.
[0615] (Модуль 21e удаления избыточности вектора движения)
Модуль 21e удаления избыточности вектора движения удаляет избыточность вектора mv движения, который был обнаружен детектором 21b вектора движения. В частности, модуль 21e удаления избыточности вектора движения (1) выбирает способ оценки, который должен использоваться для того, чтобы оценить вектор mv движения, (2) выводит оцененный вектор pmv движения в соответствии с выбранным способом оценки, и (3) вычитает оцененный вектор pmv движения из вектора mv движения, и таким образом генерирует остаток MVD вектора движения. Модуль 21e удаления избыточности вектора движения подает сгенерированный остаток MVD вектора движения контроллеру 21d схемы предсказания вместе с индексом PMVI оцененного вектора движения указывающий выбранный способ оценки.
[0616] (Модуль 22 преобразования/квантования)
Модуль 22 преобразования/квантования (1) выполняет частотное преобразование, такие как DCT (Дискретное косинусное преобразование), в отношении остатка D предсказания, полученного посредством вычитания изображения Pred предсказания из целевого изображения, которое должно быть закодировано, в единицах блоков (единицах преобразования), (2) квантует коэффициент Coeff_IQ преобразования, полученный посредством частотного преобразования, и (3) подает коэффициент Coeff преобразования, полученный с помощью квантования, к кодировщику 27 кода с переменной длиной слова, и модулю 23 обратного преобразования/деквантования. Модуль 22 преобразования/квантования (1) выбирает, для каждой TU, шаг QP квантования, который используется для квантования, (2) подает разность Δqp параметров квантования, указывающую величину выбранного шага qp квантования, к кодировщику 27 кода с переменной длиной слова, и (3) подает выбранный шаг QP квантования к модулю 23 обратного преобразования/деквантования. Здесь, разность Δqp параметров квантования представляет значение разности, которое получают посредством вычитания значения параметра qpʹ квантования, относящегося к TU, которая была частотно преобразована и квантована непосредственно прежде, из значения параметра qp квантования (например, QP=2qp/6), относящегося к TU, которая должна быть частотно преобразована и квантована.
[0617] DCT, выполненное модулем 22 преобразования/квантования, задается, например, следующим уравнением (2) в случае, когда размер целевого блока равен 8×8 пикселей и где коэффициент преобразования перед квантованием относительно частоты u в горизонтальном направлении и частоте v в вертикальном направлении выражен как Coeff_IQ (u, v) (0≤u≤7, 0≤v≤7).
[0618][Математическое уравнение 2]
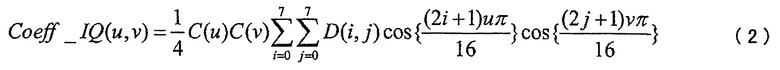
[0619] Здесь, D (i, j) (0≤I≤7, 0≤j≤7) представляет остаток D предсказания в позиции (i, j) в целевом блоке. Кроме того, C (u) и C (v) заданы следующим образом:
[0620] C (u)=1/
C (u)=1 (u≠0)
C (v)=1/
C (v)=1 (v≠0)
(Модуль 23 обратного преобразования/деквантования)
Модуль 23 обратного преобразования/деквантования (1) деквантует квантованный Coeff коэффициента преобразования, (2) выполняет обратное частотное преобразование, такое как обратное DCT (Дискретное косинусное преобразование), в отношении коэффициента Coeff_IQ преобразования, полученного посредством деквантования, и (3) подает остаток D предсказания, полученный посредством обратного частотного преобразования, к сумматору 24. В случае деквантования квантованного коэффициента Coeff преобразования используется шаг QP квантования, подаваемый от модуля 22 преобразования/квантования. Остаток D предсказания, выведенный от модуля 23 обратного преобразования/деквантования, соответствует остатку D предсказания, введенному к модулю 22 преобразования/квантования, к которому добавлена ошибка квантования. Здесь, общее название используется для простоты. Более конкретная работа модуля 23 обратного преобразования/деквантования является почти такой же, как таковая модуля 13 деквантования/обратного преобразования, включенного в устройство 1 декодирования видео.
[0621] (Сумматор 24)
Сумматор 24 суммирует изображение Pred предсказания, выбранное контроллером 21d схемы предсказания, к остатку D предсказания, сгенерированному модулем 23 обратного преобразования/деквантования, и таким образом генерирует (локально) декодированное изображение P. (Локально) декодированное изображение P, сгенерированное сумматором 24, подается к контурному фильтру 26 и также сохраняется в памяти 25 кадров, и используется как опорное изображение во внутреннем предсказании.
[0622] (Кодировщик 27 кода с переменной длиной слова)
Кодировщик 27 кода с переменной длиной слова выполняет кодирование с переменной длиной кода в отношении (1) квантованного коэффициента Coeff преобразования и Δqp, подаваемого от модуля 22 преобразования/квантования, (2) параметров PP квантования, подаваемого от контроллера 21d схемы предсказания (параметр PP_Inter внешнего предсказания и параметр PP_Intra внутреннего предсказания), (3) информации Pred_type типа предсказания, и (4) параметра FP фильтра, подаваемого от контурного фильтра 26, и таким образом генерирует закодированные данные #1.
[0623] Фиг. 53 является блок-схемой, иллюстрирующей конфигурацию кодировщика 27 кода с переменной длиной слова. Как иллюстрировано на Фиг. 53, кодировщик 27 кода с переменной длиной слова включает в себя кодировщик 271 квантованной остаточной информации, который кодирует квантованный коэффициент Coeff преобразования, кодировщик 272 параметра предсказания, который кодирует PP параметра предсказания, кодировщик 273 информации типа предсказания, который кодирует информацию Pred_type типа предсказания, и кодировщик 274 параметра фильтра, который кодирует параметр FP фильтра. Конкретная конфигурация кодировщика 271 квантованной остаточной информации будет описана ниже, и опущена здесь.
[0624] (Вычитатель 28)
Вычитатель 28 вычитает изображение Pred предсказания, выбранное контроллером 21d схемы предсказания, от целевого изображения, которое должно быть закодировано, так чтобы генерировать остаток предсказания D. Остаток D предсказания, сгенерированный вычитателем 28, частотно преобразуется и квантуется модулем 22 преобразования/квантования.
[0625] (Контурный фильтр 26)
Контурный фильтр 26 имеет (1) функцию фильтра удаления блочности (DF), который выполняет сглаживание (процесс удаления блочности) в отношении изображения около границы блока или границы разделения в декодированном изображении P, и (2) функцию адаптивного контурного фильтра (ALF), который выполняет адаптивный процесс фильтра, используя параметр FP фильтра в отношении изображения, обработанном посредством использования фильтра удаления блочности.
[0626] (Кодировщик 271 квантованной остаточной информации)
Кодировщик 271 квантованной остаточной информации выполняет основанное на контексте адаптивное двоичное арифметическое кодирование (CABAC) в отношении квантованного коэффициента Coeff преобразования (xC, yC), чтобы cгенерировать квантованную остаточную информацию QD. Элементы синтаксиса, включенные в сгенерированную квантованную остаточную информацию QD, являются индивидуальными элементами синтаксиса, иллюстрированными на Фиг. 4 и 5, и significant_coeffgroup_flag.
[0627] xC и yC являются индексами, указывающими позицию каждого частотного компонента в частотной области, как описано выше, и соответствуют вышеописанной частоте u в горизонтальном направлении и частоте v в вертикальном направлении, соответственно. В дальнейшем, квантованный коэффициент Coeff преобразования может просто упоминаться как коэффициент Coeff преобразования.
[0628] (Кодировщик 271 квантованной остаточной информации)
Фиг. 54 является блок-схемой, иллюстрирующей конфигурацию кодировщика 271 квантованной остаточной информации. Как иллюстрировано на Фиг. 54, кодировщик 271 квантованной остаточной информации включает в себя кодировщик 220 коэффициента преобразования и арифметический кодовый кодировщик 230.
[0629] (арифметический кодовый кодировщик 230)
Арифметический кодовый кодировщик 230 конфигурируется, чтобы закодировать каждый бин, подаваемый от кодировщика 220 коэффициента преобразования, посредством обращения к контексту, чтобы генерировать квантованную остаточную информацию QD, и включает в себя модуль 231 записи/обновления контекста и кодировщик 232, как иллюстрировано на Фиг. 54.
[0630] (Модуль 231 записи/обновления контекста)
Модуль 231 записи/обновления контекста конфигурируется, чтобы записать и обновить переменную CV контекста, управляемую каждым индексом ctxIdx контекста. Здесь, переменная CV контекста включает в себя (1) наиболее вероятный символ (MPS), имеющий высокую вероятность появления, и (2) индекс pStateIdx состояния вероятности, указывающий вероятность появления самого вероятного символа MPS.
[0631] Модуль 231 записи/обновления контекста обновляет переменную CV контекста, обращаясь к индексу ctxIdx контекста, подаваемому от каждой единицы кодировщика 220 коэффициента преобразования, и значению бина, закодированному битовым кодировщиком 232, и записывает обновленную переменную CV контекста, до тех пор пока она не будет обновлена следующий раз. Наиболее вероятный символ MPS является 0 или 1. Наиболее вероятный символ MPS и индекс pStateIdx состояния вероятности обновляются каждый раз, когда битовый кодировщик 232 кодирует один бин.
[0632] Индекс ctxIdx контекста может непосредственно указывать контекст для каждого частотного компонента, или может быть значением приращения от смещения индекса контекста, который установлен для каждой целевой TU, которая должна быть обработана (то же самое относится к следующему описанию).
[0633] (Битовый кодировщик 232)
Битовый кодировщик 232 обращается к переменной CV контекста, записанной в модуле 231 записи/обновления контекста, и кодирует каждый бин, подаваемый от каждой единицы, включенной в кодировщик 220 коэффициента преобразования, чтобы генерировать квантованную остаточную информацию QD. Значение закодированного бина также подается модулю 231 записи/обновления контекста, и на него ссылаются для того, чтобы обновить переменную CV контекста.
[0634] (Кодировщик 220 коэффициента преобразования)
Как иллюстрировано на Фиг. 54, кодировщик 220 коэффициента преобразования включает в себя кодировщик 221 последней позиции, память 222 таблицы порядка сканирования, контроллер 223 коэффициента кодирования, кодировщик 224 флага присутствия/отсутствия коэффициента, кодировщик 225 значения коэффициента, память 226 коэффициентов кодирования, флаг 227 присутствия/отсутствия коэффициента суб-блока, и модуль 228 выведения синтаксиса.
[0635] (Модуль 228 выведения синтаксиса)
Модуль 228 выведения синтаксиса обращается к каждому значению коэффициента преобразования Coeff (xC, yC), и выводит индивидуальные значения элементов синтаксиса last_significant_coeff_x, last_significant_coeff_y, significant_coeff_flag, coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, coeff_sign_flag, и coeff_abs_level_minus3 для того, чтобы определить эти коэффициенты преобразования в целевой частотной области. Полученные элементы синтаксиса подаются на память 226 коэффициентов кодирования. Среди выведенных элементов синтаксиса, last_significant_coeff_x и last_significant_coeff_y также подаются на контроллер 223 коэффициента кодирования и кодировщик 221 последней позиции. Кроме того, среди выведенных элементов синтаксиса significant_coeff_flag также подается к кодировщику 224 флага присутствия/отсутствия коэффициента. Контент, представленный индивидуальными элементами синтаксиса, был описан выше, и таким образом его описание здесь опущено.
[0636] (Кодировщик 221 последней позиции )
Кодировщик 221 последней позиции генерирует бин, который указывает элементы синтаксиса last_significant_coeff_x и last_significant_coeff_y, подаваемые от модуля 228 выведения синтаксиса. Кроме того, кодировщик 221 последней позиции подает каждый бин, который был сгенерирован, к битовому кодировщику 232. Кроме того, кодировщик 221 последней позиции подает индекс ctxIdx контекста, который указывает контекст, на который ссылаются для кодирования бина элементов синтаксиса last_significant_coeff_x и last_significant_coeff_y, к модулю 231 записи/обновления контекста.
[0637] (Память 222 таблицы порядка сканирования)
Память 222 таблицы порядка сканирования хранит таблицу, которая дает позицию целевого частотного компонента, который должен быть обработан, в частотной области, с размером целевой TU (блока), которая должна быть обработана, индекс сканирования, представляющий тип направления сканирования, и индекс идентификационной информации частотного компонента, заданный вдоль порядка сканирования, являющиеся аргументами. Примером такой таблицы порядка сканирования является ScanOrder, проиллюстрированная на Фиг. 4 и 5.
[0638] Кроме того, память 222 таблицы порядка сканирования хранит таблицу порядка сканирования суб-блоков для обозначения порядка сканирования суб-блоков. Здесь, таблица порядка сканирования суб-блоков обозначается индексом scanIndex сканирования, ассоциированным с размером целевой TU (блока), которая должна быть обработана, и индексом режима предсказания режима внутреннего предсказания.
[0639] Таблица порядка сканирования и таблица порядка сканирования суб-блоков, сохраненные в памяти 222 таблицы порядка сканирования, подобны сохраненным в памяти 122 таблицы порядка сканирования, включенной в устройство 1 декодирования видео, и таким образом ее описание здесь опущено.
[0640] (Контроллер 223 коэффициента кодирования)
Контроллер 223 коэффициента кодирования конфигурируется, чтобы управлять порядком процесса кодирования в каждой единице, включенной в кодировщик 271 квантованной остаточной информации.
[0641] (В случае, когда размер блока является некоторым размером или меньшим)
В случае, когда размер блока является некоторым размером или меньшим (например, 4×4 компонентов или 8×8 компонентов), контроллер 223 коэффициента кодирования обращается к элементам синтаксиса last_significant_coeff_x и last_significant_coeff_y, подаваемым от модуля 228 выведения синтаксиса, определяет позицию последнего ненулевого коэффициента преобразования вдоль прямого сканирования, и подает позиции (xC, yC) индивидуальных частотных компонентов к кодировщику флага присутствия/отсутствия коэффициента в обратном порядке порядка сканирования, в котором указанная позиция последнего ненулевого коэффициента преобразования является началом и которая задана таблицей порядка сканирования, сохраненной в памяти 222 таблицы порядка сканирования.
[0642] Кроме того, контроллер 223 коэффициента кодирования подает sz, который является параметром, указывающим размер целевой TU, которая должна быть обработана, то есть, размер целевой частотной области, к каждому модулю, включенному в кодировщик 220 коэффициента преобразования (не иллюстрировано). Здесь, sz является специальным параметром, представляющим количество пикселей вдоль одной стороны целевой TU, которая должна быть обработана, то есть количество частотных компонентов вдоль одной стороны целевой частотной области.
[0643] Контроллер 223 коэффициента кодирования может быть сконфигурирован, чтобы подавать позиции (xC, yC) индивидуальных частотных компонентов кодировщику 224 флага присутствия/отсутствия коэффициента в прямом порядке сканирования порядка сканирования, заданного таблицей порядка сканирования, сохраненной в памяти 222 таблицы порядка сканирования.
[0644] (В случае, когда размер блока больше, чем некоторый размер)
В случае, когда размер блока больше, чем некоторый размер, контроллер 223 коэффициента кодирования обращается к элементам синтаксиса last_significant_coeff_x и last_significant_coeff_y, подаваемым от модуля 228 выведения синтаксиса, определяет позицию последнего ненулевого коэффициента преобразования вдоль прямого сканирования, и подает позиции (xCG, yCG) индивидуальных суб-блоков к кодировщику 227 флага присутствия/отсутствия коэффициента суб-блока в обратном порядке сканирования порядка сканирования, в котором позиция суб-блока, включающего в себя указанный последний ненулевой коэффициент преобразования, является исходной и которая задана таблицей порядка сканирования суб-блоков, сохраненной в памяти 222 таблицы порядка сканирования.
[0645] Кроме того, контроллер 223 коэффициента кодирования подает, относительно целевого суб-блока, который должен быть обработан, позиции (xC, yC) индивидуальных частотных компонентов, включенных в целевой суб-блок, который должен быть обработан, к кодировщику 224 флага присутствия/отсутствия коэффициента в обратном порядке сканирования порядка сканирования, заданном таблицей порядка сканирования, сохраненной в памяти 222 таблицы порядка сканирования. Здесь, в качестве порядка сканирования индивидуальных частотных компонентов, включенных в целевой суб-блок, который должен быть обработан, может специально использоваться сканирование в диагональном направлении (верхнее-правое диагональное сканирование).
[0646] Таким образом, контроллер 223 коэффициента кодирования конфигурируется, чтобы переключить порядок сканирования относительно каждого режима внутреннего предсказания. Вообще, имеется корреляция между режимом внутреннего предсказания и смещением коэффициентов преобразования. Таким образом, сканирование суб-блока, которое является подходящим для смещения флагов присутствия/отсутствия коэффициента суб-блока, может быть выполнено посредством переключения порядка сканирования в соответствии с режимом внутреннего предсказания. Соответственно, величина кодов флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть закодированы и декодированы, может быть уменьшена, и эффективность кодирования увеличена.
[0647] (Кодировщик 225 значения коэффициента)
Кодировщик 225 значения коэффициента генерирует бин, который указывает элементы синтаксиса coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, coeff_sign_flag, и coeff_abs_level_minus3, подаваемые от модуля 228 выведения синтаксиса. Кроме того, кодировщик 225 значения коэффициента подает каждый бин, который был сгенерирован, к битовому кодировщику 232. Кроме того, кодировщик 225 значения коэффициента подает индекс ctxIdx контекста, указывающий контекст, на который ссылаются для кодирования бина этих элементов синтаксиса, к модулю 231 записи/обновления контекста.
[0648] (Кодировщик 224 флага присутствия/отсутствия коэффициента)
Кодировщик 224 флага присутствия/отсутствия коэффициента согласно этому варианту осуществления кодирует элементы синтаксиса significant_coeff_flag [xC][yC], обозначенные каждой позицией (xC, yC). Более конкретно, кодировщик 224 флага присутствия/отсутствия коэффициента генерирует бин, указывающий элементы синтаксиса significant_coeff_flag [xC][yC], обозначенные каждой позицией (xC, yC). Каждый сгенерированный бин подается к битовому кодировщику 232. Кроме того, кодировщик 224 флага присутствия/отсутствия коэффициента вычисляет индекс ctxIdx контекста для того, чтобы определить контекст, который используется для кодирования бина элементов синтаксиса significant_coeff_flag [xC][yC] арифметическим кодовым кодировщиком 230. Вычисленный индекс ctxIdx контекста подается к модулю 231 записи/обновления контекста.
[0649] Фиг. 55 является блок-схемой, иллюстрирующей конфигурацию кодировщика 224 флага присутствия/отсутствия коэффициента. Как иллюстрировано на Фиг. 55, кодировщик 224 флага присутствия/отсутствия коэффициента включает в себя модуль 224a классификации частоты, модуль 224b выведения контекста позиции, модуль 224c выведения опорного контекста от соседнего элемента, память 224d флага присутствия/отсутствия коэффициента, и модуль 224e установки флага присутствия/отсутствия коэффициента.
[0650] (Модуль 224a классификации частоты)
В случае, когда размер целевой частотной области является некоторым размером или меньшим (например, в случае 4×4 компонентов или 8×8 компонентов), модуль 224a классификации частоты классифицирует каждый из частотных компонентов в частотной области некоторого размера или меньшего в любое из множества частичных областей в соответствии с позицией частотного компонента, и также назначает индекс ctxIdx контекста, выведенный модулем 224b выведения контекста позиции.
[0651] С другой стороны, в случае, когда размер целевой частотной области больше, чем некоторый размер (например, в случае 16×16 компонентов или 32×32 компонентов), модуль 224a классификации частоты классифицирует каждый из целевых частотных компонентов, которые должны быть декодированы в частотной области, в любое из множества частичных областей в соответствии с позицией частотного компонента в частотной области, и также назначает индекс ctxIdx контекста, выведенный любым из модуля 224b выведения контекста позиции и модуля 224c выведения опорного контекста от соседнего элемента к целевому частотному компоненту, который должен быть декодирован.
[0652] Конкретный процесс, выполняемый модулем 224a классификации частоты, является аналогичным выполняемому модулем 124a классификации частоты, включенным в устройство 1 декодирования видео, и таким образом его описание здесь опущено.
[0653] (Модуль 224b выведения контекста позиции)
Модуль 224b выведения контекста позиции выводит индекс ctxIdx контекста для целевого частотного компонента на основе позиции целевого частотного компонента в частотной области.
[0654] Модуль 224b выведения контекста позиции выполняет, например, процесс, подобный процессу, выполняемому модулем 124b выведения контекста позиции, описанным в (конкретном примере 1 процесса классификации частоты, выполняемого модулем 124a классификации частоты, и процесса выведения индекса контекста, выполняемого модулем 124b выведения контекста позиции, в случае, когда частотная область имеет некоторый размер или меньший).
[0655] Таким образом, модуль 224b выведения контекста позиции выводит индекс контекста, общий для одного или множественных частотных компонентов, которые принадлежат частотной области, имеющей некоторый размер или меньший (например, 4×4 компонентов или 8×8 компонентов) и имеющей первый размер (например, 4×4 компонентов), и одного или множественных частотных компонентов, которые принадлежат частотной области, имеющей некоторый размер или меньший и имеющей второй размер, большой, чем первый размер (например, 8×8 компонентов), и назначает индекс контекста на эти один или множественные частотные компоненты.
[0656] Согласно модулю 224b выведения контекста позиции, имеющему вышеописанную конфигурацию, может быть сокращено количество индексов контекста, которые должны быть выведены, и таким образом процесс выведения может быть уменьшен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0657] Другие конкретные процессы, выполненные модулем 224b выведения контекста позиции, подобны выполняемым модулем 124b выведения контекста позиции, включенным в устройство 1 декодирования видео, и таким образом его описание здесь опущено.
[0658] (Модуль 224c выведения опорного контекста от соседнего элемента)
Модуль 224c выведения опорного контекста от соседнего элемента выводит индекс ctxIdx контекста для целевого частотного компонента, который должен быть закодирован, на основе количества cnt закодированных ненулевых коэффициентов преобразования относительно частотных компонентов вокруг целевого частотного компонента.
[0659] Конкретный процесс, выполненный модулем 224c выведения опорного контекста от соседнего элемента, является аналогичным выполняемому модулем 124c выведения опорного контекста от соседнего элемента, включенным в устройство 1 декодирования видео, и таким образом его описание здесь опущено.
[0660] (Модуль 224e установки флага присутствия/отсутствия коэффициента)
Модуль 224e установки флага присутствия/отсутствия коэффициента генерирует бин, который указывает элемент синтаксиса significant_coeff_flag [xC][yC], подаваемый от модуля 228 выведения синтаксиса. Сгенерированный бин подается битовому кодировщику 232. Кроме того, модуль 224e установки флага присутствия/отсутствия коэффициента обращается к значениям significant_coeff_flag [xC][yC], включенным в целевой суб-блок. В случае, когда все значения significant_coeff_flag [xC][yC], включенные в целевой суб-блок, равны 0, то есть, в случае, когда ненулевой коэффициент преобразования не включен в целевой суб-блок, модуль 224e установки флага присутствия/отсутствия коэффициента устанавливает значение significant_coeffgroup_flag [xCG][yCG] относительно целевого суб-блока в 0, и иначе устанавливает значение significant_coeffgroup_flag [xCG][yCG] относительно целевого суб-блока в 1. significant_coeffgroup_flag [xCG][yCG], имеющий такое значение, подается к кодировщику 227 присутствия/отсутствия коэффициента суб-блока.
[0661] (Память 224d флага присутствия/отсутствия коэффициента)
Память 224d флага присутствия/отсутствия коэффициента хранит индивидуальные значения элементов синтаксиса significant_coeff_flag [xC][yC]. К индивидуальным значениям элементов синтаксиса significant_coeff_flag [xC][yC], сохраненным в памяти 224d флага присутствия/отсутствия коэффициента, обращаются посредством модуля 224c выведения опорного контекста от соседнего элемента.
[0662] (Кодировщик 227 флага присутствия/отсутствия коэффициента суб-блока)
Кодировщик 227 флага присутствия/отсутствия коэффициента суб-блока кодирует элементы синтаксиса significant_coeffgroup_flag [xCG][yCG], которые обозначены индивидуальными позициями суб-блока (xCG, yCG). Более конкретно, кодировщик 227 флага присутствия/отсутствия коэффициента суб-блока генерирует бин, представляющий элементы синтаксиса significant_coeffgroup_flag [xCG][yCG], которые обозначены индивидуальными позициями суб-блока (xCG, yCG). Каждый сгенерированный бин подается к битовому кодировщику 232. Кроме того, кодировщик 227 флага присутствия/отсутствия коэффициента суб-блока вычисляет индекс ctxIdx контекста для того, чтобы определить контекст, который используется для кодирования бина элемента синтаксиса significant_coeff_flag [xC][yC] в арифметическом кодовом кодировщике 230. Вычисленный индекс ctxIdx контекста подается к модулю 231 записи/обновления контекста.
[0663] Фиг. 56 является блок-схемой, иллюстрирующей конфигурацию кодировщика 227 флага присутствия/отсутствия коэффициента суб-блока. Как иллюстрировано на Фиг. 56, кодировщик 227 флага присутствия/отсутствия коэффициента суб-блока включает в себя модуль 227a выведения контекста, память 227b флага присутствия/отсутствия коэффициента суб-блока, и модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока.
[0664] В дальнейшем, описание будет дано примера, в котором позиции (xCG, yCG) суб-блока подаются от контроллера 223 кодирования коэффициента к кодировщику 227 флага присутствия/отсутствия коэффициента суб-блока в прямом порядке сканирования. В этом случае в декодере 127 флага присутствия/отсутствия коэффициента суб-блока, включенном в устройство 1 декодирования видео, предпочтительно, чтобы позиции (xCG, yCG) суб-блока подавались в обратном порядке сканирования.
[0665] (Модуль 227a выведения контекста)
Модуль 227a выведения контекста, включенный в кодировщик 227 флага присутствия/отсутствия коэффициента суб-блока, выводит индексы контекста, которые должны быть назначены на суб-блоки, обозначенные индивидуальными позициями суб-блока (xCG, yCG). Индекс контекста, назначенный на суб-блок, используется для декодирования бина, который указывает элемент синтаксиса significant_coeffgroup_flag для суб-блока. В случае выведения индекса контекста, обращаются к значению флага присутствия/отсутствия коэффициента суб-блока, сохраненного в памяти 227b флага присутствия/отсутствия коэффициента суб-блока. Модуль 227a выведения контекста подает выведенные индексы контекста к модулю 231 записи/обновления контекста.
[0666] (Память 227b флага присутствия/отсутствия коэффициента суб-блока)
Память 227b флага присутствия/отсутствия коэффициента суб-блока хранит индивидуальные значения элементов синтаксиса significant_coeffgroup_flag, подаваемых от кодировщика 224 присутствия/отсутствия коэффициента. Модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока способен считывать элемент синтаксиса significant_coeffgroup_flag, который был назначен на смежный суб-блок, из памяти 227b флага присутствия/отсутствия коэффициента суб-блока.
[0667] (Модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока)
Модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока генерирует бин, который указывает элемент синтаксиса significant_coeffgroup_flag [xCG][yCG], подаваемый от кодировщика 224 флага присутствия/отсутствия коэффициента. Сгенерированный бин подается к битовому кодировщику 232.
[0668] Здесь, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока, опускает кодирование элемента синтаксиса significant_coeffgroup_flag [xCG][yCG] следующим образом в соответствии с типом сканирования, определяющим порядок сканирования суб-блоков.
[0669] (В случае, когда типом сканирования является приоритетное сканирование в вертикальном направлении)
В случае, когда тип сканирования, обозначающий порядок сканирования суб-блоков, является приоритетное сканирование в вертикальном направлении, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока обращается к значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG][yCG+1], назначенному на суб-блок (xCG, yCG+1), смежный с суб-блоком (xCG, yCG), как иллюстрировано в части (a) на Фиг. 20. В случае, когда significant_coeffgroup_flag [xCG][yCG+1]=1, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока оценивает, что significant_coeffgroup_flag [xCG][yCG]=1, и опускает кодирование significant_coeffgroup_flag [xCG][yCG].
[0670] (В случае, когда типом сканирования является приоритетное сканирование в горизонтальном направлении)
В случае, когда тип сканирования, обозначающий порядок сканирования суб-блоков, является приоритетное сканирование в горизонтальном направлении, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока обращается к значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG+1][yCG], назначенному на суб-блок (xCG+1, yCG), смежный с суб-блоком (xCG, yCG), как иллюстрировано в части (b) на Фиг. 20. В случае, когда significant_coeffgroup_flag [xCG+1][yCG]=1, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока оценивает, что significant_coeffgroup_flag [xCG][yCG] = 1, и опускает кодирование significant_coeffgroup_flag [xCG][yCG].
[0671] (В случае, когда типом сканирования является сканирование в диагональном направлении)
В случае, когда тип сканирования, обозначающий порядок сканирования суб-блоков, является сканированием в диагональном направлении, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока обращается к значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG+1][yCG], назначенному на суб-блок (xCG+1, yCG), смежный с суб-блоком (xCG, yCG), и значению флага присутствия/отсутствия коэффициента суб-блока significant_coeffgroup_flag [xCG][yCG+1], назначенному на суб-блок (xCG, yCG+1), как иллюстрировано в части (c) на Фиг. 20.
[0672] В случае, когда significant_coeffgroup_flag [xCG+1][yCG]=1 и significant_coeffgroup_flag [xCG][yCG+1]=1, модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока оценивает, что significant_coeffgroup_flag [xCG][yCG]=1, и опускает кодирование significant_coeffgroup_flag [xCG][yCG].
[0673] Модуль 227c установки флага присутствия/отсутствия коэффициента суб-блока конфигурируется, чтобы опустить кодирование significant_coeffgroup_flag [xCG][yCG] в соответствии со смещением флагов присутствия/отсутствия коэффициента суб-блока, как описано выше. Объем кодов флагов присутствия/отсутствия коэффициента суб-блока может быть уменьшен, и таким образом увеличивается эффективность кодирования.
[0674] (Пример 1 модификации кодировщика флага присутствия/отсутствия коэффициента)
Конфигурация кодировщика флага присутствия/отсутствия коэффициента согласно этому варианту осуществления не ограничена вышеописанной конфигурацией. Кодировщик флага присутствия/отсутствия коэффициента согласно этому варианту осуществления может иметь конфигурацию, соответствующую декодеру 124ʹ флага присутствия/отсутствия коэффициента согласно первому примеру модификации.
[0675] То есть, кодировщик 224ʹ флага присутствия/отсутствия коэффициента согласно этому примеру модификации может иметь почти ту же самую конфигурацию как кодировщик 224 флага присутствия/отсутствия коэффициента преобразования, но может быть различным в следующих элементах.
[0676] кодировщик 224ʹ флага присутствия/отсутствия коэффициента не включает в себя модуль 224c выведения опорного контекста от соседнего элемента.
кодировщик 224ʹ флага присутствия/отсутствия коэффициента включает в себя модуль 224f выведения опорного контекста от соседнего суб-блока.
[0677] Здесь, модуль 224f выведения опорного контекста от соседнего суб-блока выводит индексы контекста, которые должны быть назначены на индивидуальные частотные компоненты, включенные в целевой суб-блок, который должен быть обработан, посредством обращения к significant_coeffgroup_flag, назначенному на суб-блок, смежный с целевым суб-блоком, который должен быть обработан.
[0678] Конкретный процесс, выполняемый модулем 224f выведения опорного контекста от соседнего суб-блока, является аналогичным выполняемому модулем 124f выведения опорного контекста от соседнего суб-блока, и таким образом его описание опущено. Однако, следует отметить, что "декодирование" в описании модуля 124f выведения опорного контекста от соседнего суб-блока заменено на "кодирование".
[0679] Модуль 224f выведения опорного контекста от соседнего суб-блока согласно этому примеру модификации не выполняет процесс выведения опорного контекста от соседнего элемента в едницах частотных компонентов, и назначает общие индексы контекста на индивидуальные частотные компоненты, включенные в суб-блок. Соответственно, объем обработки уменьшается. Кроме того, процесс выведения индекса контекста, выполняемый в единицах суб-блоков, выполняют, обращаясь к значению significant_coeffgroup_flag в смежном суб-блоке, и таким образом индексы контекста могут быть выведены в соответствии с количеством ненулевых коэффициентов преобразования, которые существуют вокруг целевого суб-блока.
[0680] Соответственно, с модулем 224f выведения опорного контекста соседнего суб-блока согласно этому примеру модификации объем обработки процесса выведения индекса контекста может быть уменьшен, в то же время поддерживая высокую эффективность кодирования.
[0681] (Пример 2 модификации декодера флага присутствия/отсутствия коэффициента)
Кодировщик флага присутствия/отсутствия коэффициента согласно этому варианту осуществления может иметь конфигурацию, соответствующую декодеру 124ʹʹ флага присутствия/отсутствия коэффициента согласно второму примеру модификации.
[0682] Таким образом, декодер 124ʹʹ флага присутствия/отсутствия коэффициента согласно этому примеру модификации включает в себя модуль 224f выведения опорного контекста от соседнего суб-блока, в дополнение к индивидуальным блокам кодировщика 224 флага присутствия/отсутствия коэффициента преобразования. Здесь, конкретный процесс, выполняемый модулем 224f выведения опорного контекста от соседнего суб-блока согласно этому примеру модификации, является аналогичным выполняемому модулем 124f выведения опорного контекста от соседнего суб-блока согласно второму примеру модификации, и таким образом его описание опущено. Однако, следует отметить, что «декодирование» в описании модуля 124f выведения опорного контекста от соседнего суб-блока согласно второму примеру модификации заменено на "кодирование".
[0683] С этой конфигурацией объем обработки процесса выведения индекса контекста может быть уменьшен, в то же время поддерживая высокую эффективность кодирования.
[0684] (Пример 2 модификации кодировщика 224 флага присутствия/отсутствия коэффициента)
Кодировщик 224 флага присутствия/отсутствия коэффициента согласно этому варианту осуществления может иметь конфигурацию, соответствующую декодеру 124 флага присутствия/отсутствия коэффициента согласно третьему примеру модификации.
[0685] Фиг. 97 является блок-схемой, иллюстрирующей примерную конфигурацию второго примера модификации кодировщика 224 флага присутствия/отсутствия коэффициента согласно этому варианту осуществления. Как иллюстрировано на Фиг. 97, кодировщик 224 флага присутствия/отсутствия коэффициента включает в себя модуль 224z выведения контекста и модуль 224e установки флага присутствия/отсутствия коэффициента. Далее, модуль 224z выведения контекста включает в себя контроллер 224x способа выведения, модуль 224b выведения контекста позиции и модуль 224c выведения опорного контекста от соседнего элемента. На Фиг. 97, в модуле 224z выведения контекста контроллер 224x способа выведения включает в себя модуль 224b выведения контекста позиции и модуль 224c выведения опорного контекста от соседнего элемента, но это является просто примером. Конфигурация модуля 224z выведения контекста не ограничена такой конфигурацией.
[0686] (Контроллер 224x способа выведения)
В случае, когда размер целевой TU является некоторым размером или меньшим (например, 4×4 TU или 8×8 TU), контроллер 224x способа выведения классифицирует каждый из частотных компонентов в частотной области, имеющей некоторый размер или меньший, в любое из множества частичных областей в соответствии с позицией частотного компонента, и также назначает индексы ctxIdx контекста, выведенные модулем 224b выведения контекста позиции.
[0687] С другой стороны, в случае, когда размер целевой TU больше, чем некоторый размер (например, 16×16 TU или 32×32 TU), контроллер 224x способа выведения классифицирует целевой частотный компонент, который должен быть декодирован в частотной области, в любое из множества частичных областей в соответствии с позицией частотного компонента, и также назначает индекс ctxIdx контекста, выведенный любым из модуля 224b выведения контекста позиции и модуля 224c выведения опорного контекста от соседнего элемента, целевому частотному компоненту который должен быть декодирован.
[0688] Конкретный процесс, выполняемый контроллером 224x способа выведения, является аналогичным выполняемому контроллером 124x способа выведения, включенным в устройство 1 декодирования видео, и таким образом его описание здесь опущено.
[0689] (Модуль 224b выведения контекста позиции)
Модуль 224b выведения контекста позиции выводит индекс ctxIdx контекста для целевого частотного компонента на основе позиции целевого частотного компонента в частотной области.
[0690] Конкретный процесс, выполняемый модулем 224b выведения контекста позиции, является аналогичным выполняемому модулем 124b выведения контекста позиции, включенным в пример модификации декодера 124 флага присутствия/отсутствия коэффициента, и таким образом его описание здесь опущено.
[0691] (Модуль 224c выведения опорного контекста от соседнего элемента)
Модуль 224c выведения опорного контекста от соседнего элемента выводит индекс ctxIdx контекста для целевого частотного компонента, который должен быть закодирован, на основе количества cnt закодированных ненулевых коэффициентов преобразования для частотных компонентов вокруг целевого частотного компонента. Более конкретно, в случае, когда позиция (xC, yC) целевого частотного компонента или позиции (xCG, yCG) суб-блока, которому принадлежит целевой частотный компонент, удовлетворяет некоторому условию, модуль 224b выведения опорного контекста от соседнего элемента получает количество cnt закодированных ненулевых коэффициентов преобразования посредством использования опорной позиции (шаблона), который изменяется в соответствии с позицией коэффициента преобразования.
[0692] Конкретный процесс, выполняемый модулем 224c выведения опорного контекста от соседнего элемента, является аналогичным выполняемому модулем 124c выведения опорного контекста от соседнего элемента, включенным в третий пример модификации декодера 124 флага присутствия/отсутствия коэффициента, и таким образом его описание здесь опущено.
[0693] (Модуль 224e установки флага присутствия/отсутствия коэффициента)
Модуль 224e установки флага присутствия/отсутствия коэффициента генерирует бин, который указывает элемент синтаксиса significant_coeff_flag [xC][yC], подаваемый от модуля 228 выведения синтаксиса. Сгенерированный бин подается битовому кодировщику 232. Кроме того, модуль 224e установки флага присутствия/отсутствия коэффициента, обращается к значениям significant_coeff_flag [xC][yC], включенным в целевой суб-блок. В случае, когда все значения significant_coeff_flag [xC][yC], включенные в целевой суб-блок 0, то есть, в случае, когда целевой суб-блок не включает в себя ненулевой коэффициент преобразования, модуль 224e установки флага присутствия/отсутствия коэффициента устанавливает значение significant_coeff_group_flag [xCG][yCG], относящееся к целевому суб-блоку, в 0, и иначе устанавливает значение significant_coeff_group_flag [xCG][yCG], относящееся к целевому суб-блоку, в 1. significant_coeff_group_flag [xCG][yCG], которому значение было дано этим способом, подается к кодировщику 227 флага присутствия/отсутствия коэффициента суб-блока.
[0694] Согласно второму примеру модификации кодировщика 224 флага присутствия/отсутствия коэффициента, в случае, когда размер целевой TU, которая должна быть обработана, является некоторым размером или меньшим, частотная область может быть разделена на множество подобластей (группы контекстов) посредством использования вычисления бита, используя значения индивидуальных битов xC и yC, указывающих позиции целевого частотного компонента, который должен быть обработан, и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены. Соответственно, процесс выведения индекса контекста может быть упрощен, и размер памяти, относящийся к выведением индекса контекста, может быть уменьшен.
[0695] В случае, когда размер целевой TU, которая должна быть обработана, больше, чем некоторый размер, и когда целевой флаг присутствия/отсутствия коэффициента, который должен быть обработан, расположен в высокочастотной области, модуль выведения контекста позиции выводит индекс контекста, относящийся к целевому флагу присутствия/отсутствия коэффициента, который должен быть обработан. В случае, когда целевой флаг присутствия/отсутствия коэффициента, который должен быть обработан, расположен в низкочастотной области и области промежуточных частот, модуль выведения контекста позиции выводит индекс контекста, относящийся к целевому флагу присутствия/отсутствия коэффициента, который должен быть обработан. Соответственно, по сравнению с известным уровнем техники, индексы контекста могут быть выведены для частотных компонентов, включенных в низкочастотную область, с учетом смещения частоты появления ненулевых коэффициентов, и таким образом величина кодов флагов присутствия/отсутствия коэффициента может быть уменьшена, и объем обработки, связанной с кодированием, может быть выгодно уменьшен.
[0696] Шаблон выбирают на основе позиции коэффициента так, чтобы на коэффициент преобразования в координате, расположенной непосредственно перед позицией целевого коэффициента преобразования в порядке обработки (обратный порядок сканирования), не было обращения. В таком процессе контекст, который должен быть использован для декодирования флага присутствия/отсутствия коэффициента в некоторой позиции, может быть выведен, не обращаясь к значению предыдущего флага присутствия/отсутствия коэффициента, и таким образом процесс выведения контекста и процесс декодирования могут быть выполнены параллельно. Поэтому процесс выведения индекса контекста может быть выполнен на высокой скорости, в то же время поддерживая высокую эффективность кодирования.
[0697] (Приложение 1)
Выше описанные устройство 2 кодирования видео и устройство 1 декодирования видео могут быть установлены в и использоваться для различных устройств, которые выполняют передачу, прием, запись, и воспроизведение видео. Видео может быть естественным видео, захваченным камерой или подобным, или может быть искусственным видео (включая CG и GUI), сгенерированным компьютером или подобным.
[0698] Сначала описание будет дано случая, в котором выше описанные устройство 2 кодирования видео и устройство 1 декодирования видео может быть использовано для передачи и приема видео, со ссылками на Фиг. 57.
[0699] Часть (a) на Фиг. 57 является блок-схемой, иллюстрирующей конфигурацию устройства PROD_A передачи, в котором установлено устройство 2 кодирования видео. Как иллюстрировано в части (a) на Фиг. 57, устройство PROD_A передачи включает в себя кодировщик PROD_A1, который кодирует видео, чтобы получить закодированные данные, модулятор PROD_A2, который модулирует несущую посредством использования закодированных данных, полученных кодировщиком PROD_A1, чтобы получить сигнал модуляции, и передатчик PROD_A3, который передает сигнал модуляции, полученный модулятором PROD_A2. Вышеописанное устройство 2 кодирования видео используется как кодировщик PROD_A1.
[0700] Устройство PROD_A передачи может далее включать в себя, в качестве источника видео, которое должно быть введено в кодировщик PROD_A1, камеру PROD_A4, которая захватывает видео, носитель PROD_A5 записи, на котором видео записывается, терминал PROD_A6 ввода, который используется для того, чтобы ввести видео извне, и процессор A7 изображения, который генерирует или обрабатывает изображение. В части (a) на Фиг. 57, устройство PROD_A передачи включает в себя все предшествующие устройства, но некоторые из них могут быть опущены.
[0701] Носитель PROD_A5 записи может быть носителем записи, на котором незакодированное видео записано, или может быть носителем записи, на котором записано видео, которое было закодировано, используя схему кодирования для записи, отличающуюся от схемы кодирования для передачи. В последнем случае декодер (не иллюстрирован), который декодирует закодированные данные, считанные с носителя PROD_A5 записи, в соответствии с схемой кодирования для записи, может быть обеспечен между носителем PROD_A5 записи и кодировщиком PROD_A1.
[0702] Часть (b) на Фиг. 57 является блок-схемой, иллюстрирующей конфигурацию устройства PROD_B приема, в котором установлено устройство 1 декодирования видео. Как иллюстрировано в части (b) на Фиг. 57, устройство PROD_B приема включает в себя приемник PROD_B1, который принимает сигнал модуляции, демодулятор PROD_B2, который демодулирует сигнал модуляции, принятый приемником PROD_B1, чтобы получить закодированные данные, и декодер PROD_B3, который декодирует закодированные данные, полученные демодулятором PROD_B2, чтобы получить видео. Вышеописанное устройство 1 декодирования видео используется как декодер PROD_B3.
[0703] Устройство PROD_B приема может далее включать в себя, как назначение видео вывода от декодера PROD_B3, дисплей PROD_B4, который показывает видео, носитель PROD_B5 записи для того, чтобы записать видео, и терминал PROD_B6 вывода для того, чтобы вывести видео во вне. В части (b) на Фиг. 57, устройство PROD_B приема включает в себя все предшествующие устройства, но некоторые из них могут быть опущены.
[0704] Носитель PROD_B5 записи может быть использован для записи, незакодированного видео, или может быть использован для записи видео, которое было закодировано, используя схему кодирования для записи, отличающуюся от схемы кодирования для передачи. В последнем случае кодировщик (не иллюстрирован), который кодирует видео, полученное из декодера PROD_B3 в соответствии со схемой кодирования для записи, может быть обеспечен между декодером PROD_B3 и носителем PROD_B5 записи.
[0705] Носитель передачи для передачи сигнала модуляции, может быть беспроводной линией связи или проводной линией связи. Форма передачи для передачи сигнала модуляции может быть вещанием (здесь, форма передачи, в которой назначение не задано заранее), или может быть связью (здесь, форма передачи, в которой назначение задано заранее). Таким образом, передача одной модуляции может быть реализована любым из беспроводного вещания, проводного вещания, беспроводной связи и проводной связи.
[0706] Например, станция вещания (устройства вещания или подобное) и принимающая станция (телевизионный приемник или подобное) цифрового наземного вещания соответствует примеру устройства PROD_A передачи и устройства PROD_B приема, которые передают или принимают сигнал модуляции через беспроводное вещание. Станция вещания (устройства вещания или подобное) и принимающая станция (телевизионный приемник или подобное) вещания кабельного телевидения соответствует примеру устройства PROD_A передачи и устройства PROD_B приема, которые передают или принимают сигнал модуляции через проводное радиовещание.
[0707] Сервер (рабочая станция или подобное) для службы VOD (видео по требованию) и службы совместного использования видео, используя Интернет, и клиент (телевизионный приемник, персональный компьютер, смартфон, или подобное) соответствуют примеру устройства PROD_A передачи и устройства PROD_B приема, которые передают или принимают сигнал модуляции с помощью связи (обычно, беспроводная или проводная линия связи используется как носитель передачи в ЛВС, и проводная линия связи используется как носитель передачи в WAN). Здесь, примеры персонального компьютера включают в себя настольный PC, PC-ноутбук, и PC-планшет. Кроме того, примеры смартфона включают в себя многофункциональный терминал мобильного телефона.
[0708] Клиент службы совместного использования видео имеет функцию кодирования видео, захваченного камерой, и выгрузки видео на сервер, в дополнение к функции декодирования закодированных данных, загруженных с сервера, и отображения закодированных данных на дисплее. Таким образом, клиент службы совместного использования видео функционирует и как устройство PROD_A передачи и как устройство PROD_B приема.
[0709] Затем описание будет дано случая, в котором вышеописанное устройство 2 кодирования видео и устройство 1 декодирования видео могут быть использованы для записи и воспроизвести видео, со ссылками на Фиг. 58.
[0710] Часть (a) на Фиг. 58 является блок-схемой, иллюстрирующей конфигурацию устройства PROD_C записи, в котором установлено вышеописанное устройство 2 кодирования видео. Как иллюстрировано в части (a) на Фиг. 58, устройство PROD_C записи включает в себя кодировщик PROD_C1, который кодирует видео, чтобы получить закодированные данные, и модуль PROD_C2 записи, который записывает закодированные данные, полученные кодировщиком PROD_C1, на носитель PROD_M записи. Вышеописанное устройство 2 кодирования видео используется как кодировщик PROD_C1.
[0711] Носитель PROD_M записи может иметь (1) тип, встроенный в устройстве PROD_C записи, такой как HDD (жесткий диск) или SSD (твердотельный накопитель), (2) тип, соединенный с устройством PROD_C записи, такой как карточка с памятью SD или флэш-память с USB (универсальной последовательной шиной), или (3) тип, загруженный на устройство накопителя (не иллюстрирован), встроенное в устройстве PROD_C записи, такой как DVD (цифровой универсальный диск) или BD (Диск Blu-ray: зарегистрированный товарный знак).
[0712] Устройство PROD_C записи может далее включать в себя, в качестве источника видео, которое должно быть введено в кодировщик PROD_C1, камеру PROD_C3, которая захватывает видео, терминал PROD_C4 ввода, который вводит видео извне, приемник PROD_C5, который принимает видео, и процессор C6 изображения, который генерирует или обрабатывает изображение. В части (a) на Фиг. 58, устройство PROD_C записи включает в себя все предшествующие устройства, но некоторые из них могут быть опущены.
[0713] Приемник PROD_C5 может принять незакодированное видео, или может принять закодированные данные, которые были закодированы, используя схему кодирования для передачи, отличающуюся от схемы кодирования для записи. В последнем случае декодер для передачи (не иллюстрирован) для декодирования закодированных данных, которые были закодированы, используя схему кодирования для передачи, может быть обеспечен между приемником PROD_C5 и кодировщиком PROD_C1.
[0714] Примеры устройства PROD_C записи включают в себя устройство записи DVD, устройство записи BD, и устройство записи на HDD (жесткий диск) (в этом случае терминал PROD_C4 ввода или приемник PROD_C5 служит главным источником видео). Примеры устройства PROD_C записи также включают в себя видеокамеру (в этом случае камера PROD_C3 служит главным источником видео), персональный компьютер (в этом случае приемник PROD_C5 или процессор PROD_C6 изображения служит главным источником видео), и смартфон (в этом случае камера PROD_C3 или приемник PROD_C5 служит главным источником видео).
[0715] Часть (b) на Фиг. 58 является блок-схемой, иллюстрирующей конфигурацию устройства PROD_D воспроизведения, в котором установлено вышеописанное устройство 1 декодирования видео. Как иллюстрировано в части (b) на Фиг. 58, устройство PROD_D воспроизведения включает в себя считыватель PROD_D1, который считывает закодированные данные, записанные на носителе PROD_M записи, и декодер PROD_D2, который декодирует закодированные данные, считанные считывателем PROD_D1, чтобы получить видео. Вышеописанное устройство 1 декодирования видео используется как декодер PROD_D2.
[0716] Носитель PROD_M записи может иметь (1) тип, встроенный в устройство PROD_D воспроизведения, такой как HDD или SSD, (2) тип, соединенный с устройством PROD_D воспроизведения, такой как карточка с памятью SD или флэш-память USB, или (3) тип, загруженный в устройство накопителя (не иллюстрирован), встроенное в устройстве PROD_D воспроизведения, такое как DVD или BD.
[0717] Устройство PROD_D воспроизведения может далее включать в себя, в качестве назначения видео, выведенного от декодера PROD_D2, дисплей PROD_D3, который показывает видео, терминал PROD_D4 вывода, который выводит видео во вне, и передатчик PROD_D5, который передает видео. В части (b) на Фиг. 58, устройство PROD_D воспроизведения включает в себя все предшествующие устройства, но некоторые из них могут быть опущены.
[0718] Передатчик PROD_D5 может передать незакодированное видео или может передать закодированные данные, которые были закодированы, используя схему кодирования для передачи, отличающуюся от схемы кодирования для записи. В последнем случае кодировщик (не иллюстрирован), который кодирует видео, используя схему кодирования для передачи, может быть обеспечен между декодером PROD_D2 и передатчиком PROD_D5.
[0719] Примеры устройства PROD_D воспроизведения включают в себя плеер DVD, плеер BD, и плеер HDD (в этом случае терминал PROD_D4 вывода, связанный с телевизионным приемником или подобным, служит главным назначением видео). Примеры устройства PROD_D воспроизведения также включают в себя телевизионный приемник (в этом случае дисплей PROD_D3 служит главным предназначением видео), цифровая сигнатура (также называемая как электронная сигнатура или электронная плата, и дисплей PROD_D3 или передатчик PROD_D5, служат главным назначением видео), настольный PC (в этом случае терминал PROD_D4 вывода или передатчик PROD_D5 служит главным предназначением видео), ноутбук или PC-планшет (в этом случае дисплей PROD_D3 или передатчик PROD_D5 служит главным назначением видео), и смартфон (в этом случае дисплей PROD_D3 или передатчик PROD_D5 служит главным назначением видео).
[0720] (Приложение 2)
Индивидуальные блоки вышеописанных устройства 1 декодирования видео и устройства 2 кодирования видео могут быть составлены в виде аппаратного обеспечения посредством использования логической схемы, сформированной на интегральной схеме (кристалле IC), или могут быть составлены в виде программного обеспечения посредством использования центрального процессора (Центральный процессор).
[0721] В последнем случае каждое из вышеописанных устройств включает в себя центральный процессор, который выполняет инструкцию программы, которая реализует каждую функцию, ROM (постоянное запоминающее устройство), которое хранит программу, RAM (память с произвольным доступом), которому программа передается, запоминающее устройство (носитель записи), которое хранит программу и различные данные, такие как память, и т.д. Задача настоящего изобретения может также быть решена, снабжая каждое из вышеописанных устройств носителем записи, который хранит, считываемом компьютером способом, программный код управляющей программы (программа в выполняемой форме, программа на промежуточном коде, и исходная программа) индивидуальных устройств, который является программным обеспечением, реализующим вышеописанные функции, и посредством считывания и выполнения программного кода, записанного на носителе записи компьютером (или центральным процессором или MPU).
[0722] Примеры носителя записи включают в себя ленты, такие как магнитная лента и лента в кассете; диски (disks) или диски (discs), такие как магнитный диск, например, гибкий диск (зарегистрированный товарный знак) диск или жесткий диск, и оптический диск, например, CD-ROM, MO, MD, DVD, или CD-R; карты, такие как карта IC (включая карточку с памятью) и оптическая карта; полупроводниковые запоминающие устройства, такие как маскирующие ROM, стираемая программируемая постоянная память, EEPROM, и флэш-ROM; и логические схемы, такие как PLD (Программируемое логическое устройство) и FPGA (программируемая пользователем вентильная матрица).
[0723] Альтернативно, каждое из вышеописанных устройств может быть сконфигурировано, чтобы быть подсоединяемым к сети связи, и вышеописанный программный код может поставляться через сеть связи. Сеть связи не ограничена, пока она способна к передаче программного кода. Например, Интернет, интранет, экстранет, LAN, ISDN, VAN, сеть связи кабельного телевидения, виртуальная частная сеть, сеть телефонных линий, сеть мобильной связи, спутниковая сеть связи, и т.п. может использоваться. Носитель передачи, который составляет сеть связи, не ограничен таковой конкретной конфигурации или типа, пока он способен к передаче программного кода. Например, проводные линии связи, такие как IEEE 1394, USB, линии электропередачи, линия кабельного телевидения, телефонная линия, и ADSL (асимметричная цифровая абонентская линия), и беспроводные линии связи, такие как инфракрасная, включая IrDA и удаленное управление, Bluetooth (зарегистрированный товарный знак), IEEE 802.11, HDR (высокоскоростная передача данных), NFC (связь в ближней зоне), DLNA (Альянс цифровых сетей для дома), сеть мобильных телефонов, спутниковая линия, и цифровая наземная сеть, могут использоваться.
[0724] Настоящее изобретение не ограничено вышеописанными вариантами осуществления. Различные изменения могут быть сделаны в рамках формулы изобретения, и вариант осуществления, полученный посредством соответственного комбинирования технических средств, раскрытых в различных вариантах осуществления, также включен в техническую область настоящего изобретения.
[0725] Настоящее изобретение может также быть описано следующим образом. Устройство декодирования изображения согласно варианту осуществления настоящего изобретения является устройством арифметического декодирования, которое декодирует закодированные данные, которые получают посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования, причем коэффициенты преобразования, получаемые для индивидуальных частотных компонентов в результате выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей. Устройство арифметического декодирования включает в себя: средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли коэффициент преобразования равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать флаг присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, которое обозначено индексом контекста, назначенным на флаг присутствия/отсутствия коэффициента преобразования. Средство выведения индекса контекста выводит переменные X и Y посредством использования
X=log2TrafoWidth == 2 ? xC:xC>>1
Y=log2TrafoHeight == 2 ? yC:yC>>1,
на основе позиции (xC, yC) целевого частотного компонента в частотной области (xC - целое число, равное 0 или более, yC - целое число, равное 0 или более), log2TrafoWidth (log2TrafoWidth - натуральное число), который является переменной, представляющей горизонтальную ширину частотной области, и log2TrafoHeight (log2TrafoHeight - натуральное число), который является переменной, представляющей вертикальную ширину частотной области, добавляют некоторое смещение и идентификационный номер (относительный индекс контекста) подобласти, которой целевой частотный компонент принадлежит, причем идентификационный номер определяют на основе значения первого младшего бита (второй старший бит) переменной X, значения второго младшего бита (первый старший бит) переменной X, значения первого младшего бита (второй старший бит) переменной Y, и значения второго младшего бита (первый старший бит) переменной Y, и выводит индекс контекста целевого частотного компонента.
[0726] Согласно вышеописанной конфигурации, частотная область может быть разделена на множество подобластей (относительные индексы контекста) посредством выполнения вычисления битов, используя значения индивидуальных битов xC и yC, указывающих позиции целевого частотного компонента, который должен быть обработан, и индексы контекста, соответствующие индивидуальным подобластям, могут быть выведены. Таким образом, процесс выведения индекса контекста может быть упрощен, и размер памяти, относящийся к выведению индекса контекста, может быть уменьшен.
[0727] В устройстве арифметического декодирования согласно настоящему изобретению значения индивидуальных битов, которые формируют идентификационный номер (относительный индекс контекста) вышеописанной подобласти, могут быть определены комбинацией первого бита, который составлен из значения второго младшего бита переменной X, второго бита, который составлен из значения второго младшего бита переменной Y, и третьего бита, который получен с помощью некоторого логического вычисления значения первого младшего бита переменной X, значения второго младшего бита переменной X, значения первого младшего бита переменной Y, и значения второго младшего бита переменной Y.
[0728] Согласно вышеописанной конфигурации подобласть (относительный индекс контекста), которому принадлежит целевой частотный компонент, может быть идентифицирована с помощью простого вычисление битов на основании позиция (xC, yC) целевого частотного компонента, и таким образом выведение индекса контекста, отнесенное с флагом присутствия/отсутствия коэффициента, может быть упрощено.
[0729] В устройстве арифметического декодирования согласно настоящему изобретению логическое вычисление, использованное для выведения некоторого бита относительного индекса контекста, может быть логическим ИЛИ значения логического И отрицания значения второго младшего бита переменной X и первого младшего бита переменной Y, и значением логического И первого младшего бита переменной X и отрицанием второго младшего бита переменной Y.
[0730] Согласно вышеописанной конфигурации, предпочтительное значение может быть установлено в подобласть (относительный индекс контекста), которому принадлежит целевой частотный компонент.
[0731] Устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство деления на суб-блоки для того, чтобы делить целевую частотную область, соответствующую целевой единичной области, которая должна быть обработана, на суб-блоки, имеющие некоторый размер; средство декодирования флага присутствия/отсутствия коэффициента суб-блока для декодирования, для каждого из суб-блоков, сгенерированных средством деления на суб-блоки, флага присутствия/отсутствия коэффициента суб-блока, указывающего, включает ли упомянутый суб-блок в себя по меньшей мере один ненулевой коэффициент преобразования; средство деления для того, чтобы делить целевую частотную область на множество частичных областей, с по меньшей мере любым из каждого частотного компонента и каждым суб-блоком, являющимся единицей разделения; средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли каждый коэффициент преобразования, принадлежащий каждой частичной области, равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать каждый флаг присутствия/отсутствия коэффициента преобразования, принадлежащий каждой частичной области, на основе состояния вероятности, указанного индексами контекста, назначенными на флаги присутствия/отсутствия коэффициента преобразования. В случае, когда флаг присутствия/отсутствия коэффициента суб-блока, декодированный для целевого суб-блока, указывает, что целевой суб-блок включает в себя по меньшей мере один ненулевой коэффициент преобразования и когда каждый коэффициент преобразования, принадлежащий целевому суб-блоку, принадлежит частичной области низкочастотной области или области промежуточных частот в целевой частотной области, средство выведения индекса контекста может вывести индекс контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, на основе количества декодированных ненулевых коэффициентов преобразования, включенных в опорную область. В случае, когда флаг присутствия/отсутствия коэффициента суб-блока, декодированный для целевого суб-блока, указывает, что целевой суб-блок не включает в себя ненулевой коэффициент преобразования, флаги присутствия/отсутствия коэффициента преобразования, относящиеся ко всем коэффициентам преобразования, принадлежащим целевому суб-блоку, могут быть декодированы, чтобы указать, что коэффициент преобразования равен 0.
[0732] Согласно вышеописанной конфигурации, по сравнению с известным уровнем техники, индексы контекста могут быть выведены для частотных компонентов, включенных в низкочастотную область, с учетом смещения частоты появления ненулевых коэффициентов. Соответственно, объем кодов флагов присутствия/отсутствия коэффициента может быть уменьшен, и объем обработки, связанный с декодированием может быть уменьшен.
[0733] В устройстве арифметического декодирования согласно настоящему изобретению, в случае, когда сумма координаты x и координаты позиции целевого частотного компонента меньше, чем первый порог, частичная область может быть расценена как низкочастотная область. В случае, когда сумма координаты x и координаты позиции целевого частотного компонента равна или больше, чем первый порог, и сумма координаты x и координаты позиции суб-блока, которому принадлежит целевой частотный компонент, меньше чем второй порог, частичная область может быть расценена как промежуточная частотная область. В случае, когда сумма координаты x и координаты позиции целевого частотного компонента равна или больше, чем первый порог, или сумма координаты x и координаты позиции суб-блока, которому принадлежит целевой частотный компонент, больше, чем второй порог, частичная область может быть расценена как высокочастотная область.
[0734] Согласно вышеописанной конфигурации может использоваться процесс определения частичной области, который является общим для яркости и цветности, и таким образом процесс выведения индекса контекста, относящийся к флагом присутствия/отсутствия коэффициента, может быть упрощен.
[0735] В устройстве арифметического декодирования согласно настоящему изобретению первый порог и второй порог, используемые для того, чтобы идентифицировать частичную область, могут быть общими для яркости и цветности.
[0736] Согласно вышеописанной конфигурации может использоваться процесс определения частичной области, который является общим для яркости и цветности, и таким образом процесс выведения индекса контекста, относящийся к флагам присутствия/отсутствия коэффициента, может быть упрощен.
[0737] В устройстве арифметического декодирования согласно настоящему изобретению значение первого порога может быть равно 2.
[0738] Согласно вышеописанной конфигурации предпочтительные пороги используются для идентификации низкочастотной области и промежуточной частотной области, и таким образом величина кодов флагов присутствия/отсутствия коэффициента может быть далее уменьшена, и объем обработки, связанный с декодированием, может быть далее уменьшен.
[0739] Чтобы решить вышеописанную проблему, устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли коэффициент преобразования равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать каждый флаг присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, которое указано индексом контекста, назначенным на флаг присутствия/отсутствия коэффициента преобразования. Средство выведения индекса контекста делит частотную область, имеющую первый размер, и частотную область, имеющую второй размер, больший, чем первый размер, на множество подобластей, и затем выводит индексы контекста для индивидуальных подобластей. Шаблон разделения частотной области, имеющей первый размер, и шаблон разделения частотной области, имеющей второй размер, аналогичны друг другу.
[0740] Согласно устройству арифметического декодирования, имеющему вышеописанную конфигурацию, частотная область, имеющая первый размер, и частотная область, имеющая второй размер, разделяются на множество подобластей посредством использования шаблонов разделения, которые аналогичны друг другу. В результате выполнения процесса разделения посредством использования шаблонов разделения, подобных друг другу, уменьшается объем обработки процесса классификации, и таким образом объем обработки, связанный с декодированием коэффициентов преобразования, может быть уменьшен.
[0741] В вышеописанной конфигурации средство выведения индекса контекста выводит переменные X и Y посредством использования
X=log2TrafoSize == 2 ? xC:xC>>1
Y=log2TrafoSize == 2 ? yC:yC>>1,
на основе позиции (xC, yC) целевого частотного компонента в частотной области (xC - целое число, равное 0 или более, и yC - целое число, равное 0 или более), и log2TrafoSize (log2TrafoSize - натуральное число), которое является переменной, представляющей размер частотной области.
Предпочтительно, в случае, когда X=0 и Y=0, целевой частотный компонент классифицируется в подобласть R0,
в случае, когда (X=0 и Y=0) не удовлетворено, X<2, и Y < 2, целевой частотный компонент классифицируется в подобласть R1,
в случае, когда X=2 и Y<2, целевой частотный компонент классифицируется в подобласть R2,
в случае, когда X=3 и Y<2, целевой частотный компонент классифицируется в подобласть R3,
в случае, когда X<2 и Y=2, целевой частотный компонент классифицируется в подобласть R4,
в случае, когда X<2 и Y=3, целевой частотный компонент классифицируется в подобласть R5, и
в случае, когда X≥2 и Y≥2, целевой частотный компонент классифицируется в подобласть R6.
[0742] Согласно вышеописанной конфигурации, с процессом ветвления, использующим переменные X и Y, которые вычисляют на основе позиции (xC, yC) целевого частотного компонента в частотной области, и log2TrafoSize, который является переменной, представляющей размер частотной области, частотная область разделяется на множество подобластей. Соответственно, объем обработки процесса классификации уменьшается.
[0743] Предпочтительно, в вышеописанной конфигурации, средство выведения индекса контекста выводит общий индекс контекста для подобласти R3 и подобласти R5 среди подобластей R0-R6.
[0744] Согласно вышеописанной конфигурации, общий индекс контекста выводят для по меньшей мере подобласти R3, в которой горизонтальная частота является высокой частотой, и подобласти R5, в которой вертикальная частота является высокой частотой. Таким образом, высокая эффективность кодирования реализуется, в то время как объем обработки уменьшается.
[0745] Чтобы решить вышеописанную проблему, устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство деления на суб-блоки для того, чтобы делить целевую частотную область, соответствующую целевой единичной области, которая должна быть обработана, на суб-блоки, имеющие некоторый размер; средство декодирования флага присутствия/отсутствия коэффициента суб-блока для декодирования, для каждого из суб-блоков, сгенерированных средством деления на суб-блоки, флага присутствия/отсутствия коэффициента суб-блока, указывающего, включает ли суб-блок в себя по меньшей мере один ненулевой коэффициент преобразования; и средство установки порядка сканирования суб-блоков для того, чтобы установить порядок сканирования суб-блоков для средства декодирования флага присутствия/отсутствия коэффициента суб-блока. В случае, когда схема предсказания, примененная к целевой единичной области, которая должна быть обработана, является внутренним предсказанием, средство установки порядка сканирования суб-блоков, устанавливает порядок сканирования суб-блоков в соответствии с направлением предсказания внутреннего предсказания.
[0746] Согласно устройству арифметического декодирования, имеющему вышеописанную конфигурацию, в случае, когда схема предсказания, примененная к целевой единичной области, которая должна быть обработана, является внутренним предсказанием, порядок сканирования суб-блоков устанавливается в соответствии с направлением предсказания внутреннего предсказания. Вообще, имеется корреляция между направлением предсказания внутреннего предсказания и смещением позиций коэффициентов преобразования в частотной области. Таким образом, согласно вышеописанной конфигурации, сканирование суб-блока, подходящее для смещения флагов присутствия/отсутствия коэффициента суб-блока, может быть выполнено посредством установки порядка сканирования суб-блоков в соответствии с направлением предсказания внутреннего предсказания. Соответственно, величина кодов флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть декодированы, может быть уменьшена, и объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0747] В вышеописанной конфигурации предпочтительно, что средство установки порядка сканирования суб-блоков устанавливает порядок сканирования суб-блоков в соответствии с размером целевой единичной области, которая должна быть обработана.
[0748] Согласно вышеописанной конфигурации, порядок сканирования суб-блоков устанавливается в соответствии с размером целевой единичной области, которая должна быть обработана. Таким образом, величина кодов флагов присутствия/отсутствия коэффициента суб-блока может быть уменьшена более эффективно, и объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0749] В вышеописанной конфигурации предпочтительно, что средство декодирования флага присутствия/отсутствия коэффициента суб-блока, оценивает флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока на основе значения флага присутствия/отсутствия коэффициента суб-блока одного или множественных опорных суб-блоков, которые установлены в соответствии с порядком сканирования суб-блоков, среди множества смежных суб-блоков, которые являются смежными с целевым суб-блоком.
[0750] Согласно вышеописанной конфигурации, флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока оценивается на основе значения флага присутствия/отсутствия коэффициента суб-блока одного или множественных опорных суб-блоков, которые установлены в соответствии с порядком сканирования суб-блоков, среди множества смежных суб-блоков, которые являются смежными с целевым суб-блоком. Таким образом, величина кодов флагов присутствия/отсутствия коэффициента суб-блока может быть уменьшена более эффективно, и объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0751] В вышеописанной конфигурации предпочтительно, что, в случае, когда флаг присутствия/отсутствия коэффициента суб-блока каждого опорного суб-блока указывает, что этот опорный суб-блок включает в себя по меньшей мере один ненулевой коэффициент преобразования, средство декодирования флага присутствия/отсутствия коэффициента суб-блока устанавливает флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока равным значению, указывающему, что целевой суб-блок включает в себя по меньшей мере один ненулевой коэффициент преобразования.
[0752] Согласно вышеописанной конфигурации, в случае, когда флаг присутствия/отсутствия коэффициента суб-блока каждого опорного суб-блока указывает, что опорный суб-блок включает в себя по меньшей мере один ненулевой коэффициент преобразования, флаг присутствия/отсутствия коэффициента суб-блока целевого суб-блока устанавливается в значение, указывающее, что целевой суб-блок включает в себя по меньшей мере один ненулевой коэффициент преобразования. Таким образом, величина кодов флагов присутствия/отсутствия коэффициента суб-блока может быть уменьшена более эффективно, и объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0753] Чтобы решить вышеописанную проблему, устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли коэффициент преобразования равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать каждый флаг присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, которое указано индексом контекста, назначенным на флаг присутствия/отсутствия коэффициента преобразования. Средство выведения индекса контекста выводит общий индекс контекста для одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих частотной области, имеющей первый размер, и одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих частотной области, имеющей второй размер, который больше, чем первый размер.
[0754] Согласно устройству арифметического декодирования, имеющему вышеописанную конфигурацию, общий индекс контекста выводят для одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих частотной области, имеющей первый размер, и одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих частотной области, имеющей второй размер, который больше, чем первый размер. Таким образом, объем обработки, связанный с выведением индекса контекста, и размер памяти для хранения индексов контекста могут быть уменьшены.
[0755] В вышеописанной конфигурации предпочтительно, что средство выведения индекса контекста выводит общий индекс контекста для одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих частотной области, имеющей первый размер, и одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих стороне низких частот частотной области, имеющей второй размер.
[0756] Согласно вышеописанной конфигурации, общий индекс контекста выводят для одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих частотной области, имеющей первый размер, и одного или множественных флагов присутствия/отсутствия коэффициента преобразования, принадлежащих стороне низких частот частотной области, имеющей второй размер. Таким образом, объем обработки, связанный с выведением индекса контекста, и размер памяти для хранения индексов контекста могут быть уменьшены более эффективно.
[0757] В вышеописанной конфигурации предпочтительно, что каждый флаг присутствия/отсутствия коэффициента преобразования может быть любым из флага присутствия/отсутствия коэффициента преобразования, относящегося к яркости, и флага присутствия/отсутствия коэффициента преобразования, относящегося к цветности, и что средство выведения индекса контекста выводит индекс контекста независимо для флага присутствия/отсутствия коэффициента преобразования, относящегося к яркости, и флага присутствия/отсутствия коэффициента преобразования, относящегося к цветности.
[0758] Согласно вышеупомянутой описанной конфигурации индекс контекста выводят независимо для флага присутствия/отсутствия коэффициента преобразования, относящегося к яркости, и флага присутствия/отсутствия коэффициента преобразования, относящегося к цветности. Таким образом, объем обработки, связанный с выведением индекса контекста, и размер памяти для хранения индексов контекста, может быть уменьшен, в то же время поддерживая высокую эффективность кодирования.
[0759] Чтобы решить вышеописанную проблему, устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство деления на суб-блоки для того, чтобы делить целевую частотную область, соответствующую целевой единичной области, которая должна быть обработана, на суб-блоки, имеющие некоторый размер; средство декодирования флага присутствия/отсутствия коэффициента суб-блока для декодирования, для каждого из суб-блоков, сгенерированных средством деления на суб-блоки, флага присутствия/отсутствия коэффициента суб-блока, указывающего, включает ли суб-блок в себя по меньшей мере один ненулевой коэффициент преобразования; средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли коэффициент преобразования равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать каждый флаг присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, которое указано индексом контекста, назначенным на флаг присутствия/отсутствия коэффициента преобразования. Средство выведения индекса контекста выводит общий индекс контекста для флагов присутствия/отсутствия коэффициента преобразования, принадлежащих целевому суб-блоку.
[0760] Согласно вышеупомянутой описанной конфигурации общий индекс контекста выводят для флагов присутствия/отсутствия коэффициента преобразования, принадлежащих целевому суб-блоку. Таким образом, объем обработки, связанный с выведением индекса контекста уменьшен.
[0761] В вышеописанной конфигурации предпочтительно, что средство выведения индекса контекста выводит общий индекс контекста для флагов присутствия/отсутствия коэффициента преобразования, принадлежащих целевому суб-блоку на основе того, включают ли в себя смежные суб-блоки, которые являются смежными с целевым суб-блоком, ненулевой коэффициент преобразования.
[0762] Согласно вышеупомянутой описанной конфигурации, общий индекс контекста выводят для флагов присутствия/отсутствия коэффициента преобразования, принадлежащих целевому суб-блоку, на основе того, включают ли в себя смежные суб-блоки, которые являются смежными с целевым суб-блоком, ненулевой коэффициент преобразования. Таким образом, объем обработки, связанный с выведением индекса контекста может быть уменьшен, в то же время поддерживая высокую эффективность кодирования.
[0763] В вышеописанной конфигурации предпочтительно, что каждый флаг присутствия/отсутствия коэффициента преобразования является любым из флага присутствия/отсутствия коэффициента преобразования, относящегося к яркости, и флага присутствия/отсутствия коэффициента преобразования, относящегося к цветности, и что средство выведения индекса контекста выводит общий индекс контекста для флагов присутствия/отсутствия коэффициента преобразования, относящихся к цветности, принадлежащим целевому суб-блоку на основе того, включают ли в себя смежные суб-блоки, которые являются смежными с целевым суб-блоком, ненулевой коэффициент преобразования.
[0764] Согласно вышеупомянутой описанной конфигурации, общий индекс контекста выводят для флагов присутствия/отсутствия коэффициента преобразования, относящихся к цветности, принадлежащих целевому суб-блоку, на основе того, включают ли в себя смежные суб-блоки, которые являются смежными с целевым суб-блоком, ненулевой коэффициент преобразования. Таким образом, объем обработки, связанный с выведением индекса контекста, может быть уменьшен, в то же время поддерживая высокую эффективность кодирования.
[0765] Чтобы решить вышеописанную проблему, устройство декодирования изображения согласно настоящему изобретению включает в себя вышеописанное устройство арифметического декодирования, средство обратного частотного преобразования для выполнения обратного частотного преобразования в отношении коэффициентов преобразования, декодированных устройством арифметического декодирования, чтобы генерировать остаточное изображение, и средство генерирования декодированного изображения для суммирования остаточного изображения, сгенерированного средством обратного частотного преобразования, и изображения предсказания, предсказанного из сгенерированного декодированного изображения, чтобы генерировать декодированное изображение.
[0766] Согласно вышеописанной конфигурации, как в вышеописанном устройстве арифметического декодирования, может быть уменьшена величина кодов целевых флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть декодированы, и объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0767] Чтобы решить вышеописанную проблему, устройство арифметического кодирования согласно настоящему изобретению является устройством арифметического кодирования, которое генерирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированных данных посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического кодирования включает в себя: средство деления на суб-блоки для того, чтобы делить целевую частотную область, соответствующую целевой единичной области, которая должна быть обработана, на суб-блоки, имеющие некоторый размер; средство кодирования флага присутствия/отсутствия коэффициента суб-блока для кодирования, для каждого из суб-блоков, сгенерированных средством деления на суб-блоки, флага присутствия/отсутствия коэффициента суб-блока, указывающего, включает ли в себя суб-блок по меньшей мере один ненулевой коэффициент преобразования; и средство установки порядка сканирования суб-блоков для того, чтобы установить порядок сканирования суб-блоков для средства кодирования флага присутствия/отсутствия коэффициента суб-блока. В случае, когда схема предсказания, примененная к целевой единичной области, которая должна быть обработана, является внутренним предсказанием, средство установки порядка сканирования суб-блоков устанавливает порядок сканирования суб-блоков в соответствии с направлением предсказания внутреннего предсказания.
[0768] Согласно устройству арифметического кодирования, имеющему вышеописанную конфигурацию, в случае, когда схема предсказания, примененная к целевой единичной области, которая должна быть обработана, является внутренним предсказанием, порядок сканирования суб-блоков устанавливается в соответствии с направлением предсказания внутреннего предсказания. Вообще, имеется корреляция между направлением предсказания внутреннего предсказания и смещением позиций коэффициентов преобразования в частотной области. Таким образом, согласно вышеописанной конфигурации, сканирование суб-блоков, подходящее для смещения флагов присутствия/отсутствия коэффициента суб-блока, может быть выполнено посредством установки порядка сканирования суб-блоков в соответствии с направлением предсказания внутреннего предсказания. Соответственно, величина кодов флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть закодированы, может быть уменьшена, и объем обработки, связанный с кодированием коэффициентов преобразования, уменьшается.
[0769] Чтобы решить вышеописанную проблему, устройство кодирования изображения согласно настоящему изобретению включает в себя средство генерирования коэффициентов преобразования для выполнения частотного преобразования в отношении остаточного изображения между целевым изображением, которое должно быть закодировано, и изображением предсказания в единицах единичных областей, так чтобы генерировать коэффициенты преобразования, и вышеописанное устройство арифметического кодирования. Устройство арифметического кодирования арифметически кодирует различные элементы синтаксиса, представляющие коэффициенты преобразования, сгенерированные средством генерирования коэффициентов преобразования, чтобы генерировать закодированные данные.
[0770] Согласно вышеописанной конфигурации, как в вышеописанном устройстве арифметического кодирования, может быть уменьшена величина кодов целевых флагов присутствия/отсутствия коэффициента суб-блока, которые должны быть декодированы, и объем обработки, связанный с кодированием коэффициентов преобразования уменьшается.
[0771] Устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли коэффициент преобразования равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать каждый флаг присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, которое указано индексом контекста, назначенным на флаг присутствия/отсутствия коэффициента преобразования. Средство выведения индекса контекста делит частотную область, имеющую первую форму, и частотную область, имеющую вторую форму, отличную от первой формы, на множество подобластей, и затем выводит индексы контекста для индивидуальных подобластей. Шаблон разделения частотной области, имеющей первую форму, и шаблон разделения частотной области, имеющей вторую форму, соответствует друг другу через вращение, и осесимметричное преобразование.
[0772] Согласно устройству арифметического декодирования, имеющему вышеописанную конфигурацию, шаблон разделения частотной области, имеющей первую форму, и шаблон разделения частотной области, имеющей вторую форму, соответствует друг другу через вращение и осесимметричное преобразование. Таким образом, в результате выполнения процесса разделения, использующего шаблоны разделения, которые соответствуют друг другу через вращение, и осесимметричное преобразование, объем обработки процесса классификации уменьшается, и таким образом объем обработки, связанный с декодированием коэффициентов преобразования может быть уменьшен.
[0773] В вышеописанной конфигурации средство выведения индекса контекста выводит переменные X и Y посредством использования
X=log2TrafoWidth == 2 ? xC:xC>>2
Y=log2TrafoHeight == 2 ? yC:yC>>2,
на основе позиции (xC, yC) целевого частотного компонента в частотной области (xC - целое число, равное 0 или более, и yC - целое число, равное 0 или более), и log2TrafoWidth (log2TrafoWidth - натуральное число), которое является переменной, представляющей горизонтальную ширину частотной области, и log2TrafoHeight (log2TrafoHeight - натуральное число), которое является переменной, представляющей вертикальную ширину частотной области.
Предпочтительно, в случае, когда X=0 и Y=0, целевой частотный компонент классифицируется в подобласть A0,
в случае, когда (X=0 и Y=0) не удовлетворено, X<2, и Y<2, целевой частотный компонент классифицируется в подобласть A1,
в случае, когда X=2 и Y<2, целевой частотный компонент классифицируется в подобласть A2,
в случае, когда X=3 и Y<2, целевой частотный компонент классифицируется в подобласть A3,
в случае, когда X<2 и Y=2, целевой частотный компонент классифицируется в подобласть A4,
в случае, когда X<2 и Y=3, целевой частотный компонент классифицируется в подобласть A5, и
в случае, когда X≥2 и Y≥2, целевой частотный компонент классифицируется в подобласть A6.
[0774] Согласно вышеописанной конфигурации, с процессом ветвления, используя переменные X и Y, которые вычисляются на основе позиции (xC, yC) целевого частотного компонента в частотной области, и log2TrafoWidth, которое является переменной, представляющей горизонтальную ширину частотной области, и log2TrafoHeight, которое является переменной, представляющей вертикальную ширину частотной области, частотная область разделяется на множество подобластей. Соответственно, объем обработки процесса классификации уменьшается.
[0775] В вышеописанном устройстве арифметического декодирования предпочтительно, что шаблон разделения частотной области, имеющей первый размер, является общим для компонентов яркости и компонентов цветности, и что шаблон разделения частотной области, имеющей второй размер, является общим для компонентов яркости и компонентов цветности.
[0776] Согласно вышеописанной конфигурации, шаблон разделения частотного компонента является одинаковым в компонентах яркости и компонентах цветности, и таким образом процесс выведения индекса контекста упрощается. Соответственно, объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0777] Устройство арифметического декодирования согласно настоящему изобретению является устройством арифметического декодирования, которое декодирует, для индивидуальных коэффициентов преобразования, полученных для индивидуальных частотных компонентов посредством выполнения частотного преобразования в отношении целевого изображения для каждой из единичных областей, закодированные данные, полученные посредством арифметического кодирования различных элементов синтаксиса, представляющих коэффициенты преобразования. Устройство арифметического декодирования включает в себя: средство выведения индекса контекста для выведения индекса контекста, который должен быть назначен на каждый флаг присутствия/отсутствия коэффициента преобразования, который является элементом синтаксиса, указывающим, является ли коэффициент преобразования равным 0; и средство декодирования синтаксиса для того, чтобы арифметически декодировать каждый флаг присутствия/отсутствия коэффициента преобразования на основе состояния вероятности, которое указано индексом контекста, назначенным на флаг присутствия/отсутствия коэффициента преобразования. Средство выведения индекса контекста делит целевую частотную область на множество подобластей и выводит индексы контекста для индивидуальных подобластей. Шаблон разделения целевой частотной области является общим для компонентов яркости и компонентов цветности.
[0778] Согласно вышеописанному устройству арифметического декодирования, шаблон разделения частотного компонента является одинаковым в компонентах яркости и компонентах цветности, и таким образом процесс выведения индекса контекста упрощается. Соответственно, объем обработки, связанный с декодированием коэффициентов преобразования, уменьшается.
[0779] Предпочтительно, на основе позиции (xC, yC) целевого частотного компонента в частотной области (xC - целое число, равное 0 или более, и yC - целое число, равное 0 или более), ширины (ширина - натуральное число), которая является переменной, представляющей горизонтальную ширину частотной области, и высоты (высота - натуральное число), которая является переменной, представляющей вертикальную ширину частотной области,
средство выведения индекса контекста классифицирует целевые частотные компоненты на подобласти R0 - R3 при условиях (1-a)-(1-d) в случае, когда xC < ширина/2 и yC < высота/2,
(1-a) в случае, когда xC < ширина/4 и yC < высота/4, целевой частотный компонент классифицируется в подобласть R0,
(1-b) в случае, когда xC ≥ ширина/4 и yC < высота/4, целевой частотный компонент классифицируется в подобласть R1,
(1-c) в случае, когда xC < ширина/4 и yC ≥ высота/4, целевой частотный компонент классифицируется в подобласть R2, и
(1-d) в случае, когда xC ≥ ширина/4 и yC ≥ высота/4, целевой частотный компонент классифицируется в подобласть R3,
средство выведения индекса контекста классифицирует целевые частотные компоненты вподобласти R4 или R5 при условиях (2-a) и (2-b) в случае, когда xC ≥ ширина/2 и yC < высота/2,
(2-a) в случае, когда xC < ширина х 3/4, целевой частотный компонент классифицируется в подобласть R4, и
(2-b) в случае, когда xC ≥ ширина х 3/4, целевой частотный компонент классифицируется в подобласть R5,
средство выведения индекса контекста классифицирует целевые частотные компоненты в подобласти R6 или R7 при условиях (3-a)-(3-b) в случае, когда xC < ширина/2 и yC ≥ высота/2,
(3-a) в случае, когда yC < высота х 3/4, целевой частотный компонент классифицируется в подобласть R6, и
(3-b) в случае, когда yC ≥ высота х 3/4, целевой частотный компонент классифицируется в подобласть R7, и
средство выведения индекса контекста классифицирует целевой частотный компонент к подобласти R8 в случае, когда xC ≥ ширина/2 и yC ≥ высота/2.
[0780] Вышеописанная конфигурация может использоваться как общий процесс классификации для частотных областей, имеющих различные размеры, и таким образом процесс выведения индекса контекста может быть упрощен. Кроме того, согласно вышеописанной конфигурации, по сравнению с конфигурацией известного уровня техники, может быть сокращено количество индексов контекста, которые должны быть выведены, и таким образом процесс выведения индекса контекста может быть уменьшен, и размер памяти для хранения индексов контекста может быть уменьшен.
[0781] Предпочтительно, на основе позиции (xC, yC) целевого частотного компонента в частотной области (xC - целое число, равное 0 или более, и yC - целое число, равное 0 или более), ширины (ширина - натуральное число), которая является переменной, представляющей горизонтальную ширину частотной области, и высоты (высота - натуральное число), которая является переменной, представляющей вертикальную ширину частотной области,
средство выведения индекса контекста классифицирует целевые частотные компоненты на подобласти R0 и R1 при условиях (1-a) и (1-b) в случае, когда xC < ширина/2 и yC < высота/2 удовлетворены,
(1-a) в случае, когда xC < ширина/4 и yC < высота/4, целевой частотный компонент классифицируется в подобласть R0, и
(1-b) в случае, когда xC ≥ ширина/4 или yC ≥ высота/4, целевой частотный компонент классифицируется в подобласть R1,
средство выведения индекса контекста классифицирует целевые частотные компоненты в подобласти R2 или R3 при условиях (2-a) и (2-b) в случае, когда xC ≥ ширина/2 и yC < высота/2,
(2-a) в случае, когда xC < ширина х 3/4, целевой частотный компонент классифицируется в подобласть R2, и
(2-b) в случае, когда xC ≥ ширина х 3/4, целевой частотный компонент классифицируется в подобласть R3,
средство выведения индекса контекста классифицирует целевые частотные компоненты в подобласти R4 или R5 при условиях (3-a) и (3-b) в случае, когда xC < ширина/2 и yC ≥ высота/2,
(3-a) в случае, когда yC < высота х 3/4, целевой частотный компонент классифицируется в подобласть R4, и
(3-b) в случае, когда yC ≥ высота х 3/4, целевой частотный компонент классифицируется в подобласть R5, и
средство выведения индекса контекста классифицирует целевой частотный компонент в подобласть R6 в случае, когда xC ≥ ширина/2 и yC ≥ высота/2.
[0782] Согласно вышеописанной конфигурации, общий процесс классификации может использоваться для частотных областей, имеющих различные размеры, и таким образом процесс выведения индекса контекста может быть упрощен. Кроме того, согласно вышеописанной конфигурации, по сравнению с конфигурацией из известного уровня техники, может быть сокращено количество индексов контекста, которые должны быть выведены, и таким образом процесс выведения индекса контекста может быть уменьшен, и размер памяти для хранения индексов контекста может быть уменьшен.
Промышленная применимость
[0783] Настоящее изобретение может предпочтительно использоваться для устройства арифметического декодирования, которое декодирует арифметически закодированные данные, и устройства арифметического кодирования, которое генерирует арифметически закодированные данные.
Список ссылочных позиций
[0784] 1 - устройство декодирования видео (устройство декодирования изображения)
11 - декодер кода с переменной длиной слова
111 - декодер квантованной остаточной информации (устройство арифметического декодирования)
120 - декодер коэффициента преобразования
123 - контроллер декодирования коэффициентов (средство деления на суб-блоки, средство установки порядка сканирования суб-блоков)
124 - декодер флага присутствия/отсутствия коэффициента (средство выведения индекса контекста)
124a - модуль классификации частоты
124b - модуль выведения контекста позиции
124c - модуль выведения опорного контекста от соседнего элемента
124d - память флагов присутствия/отсутствия коэффициента
124e - модуль установки флага присутствия/отсутствия коэффициента
124x - контроллер способа выведения
124z - модуль выведения контекста
127 - декодер флага присутствия/отсутствия коэффициента суб-блока (средство декодирования флага присутствия/отсутствия коэффициента суб-блока)
127a - модуль выведения контекста
127b - память флагов присутствия/отсутствия коэффициента суб-блока
127c - модуль установки флага флаг присутствия/отсутствия коэффициента суб-блока
130 - арифметический декодер кода
131 - модуль записи /обновления контекста
132 - битовый декодер (средство декодирования синтаксиса)
2 - устройство кодирования видео (устройство кодирования изображения)
27 - кодировщик с переменной длиной кода
271 - кодировщик квантованной остаточной информации (устройство арифметического кодирования)
220 - кодировщик коэффициента преобразования
223 - контроллер кодирования коэффициентов (средство деления на суб-блоки, средство установки порядка сканирования суб-блоков)
224 - кодировщик флага присутствия/отсутствия коэффициента (средство выведения индекса контекста)
224a - модуль классификации частоты
224b - модуль выведения контекста позиции
224c - модуль выведения опорного контекста из соседнего элемента
224d - память флагов присутствия/отсутствия коэффициента
224e - модуль установки флага присутствия/отсутствия коэффициента
224x - контроллер способа выведения
224z - модуль выведения контекста
227 - кодировщик флага присутствия/отсутствия коэффициента суб-блока (средство кодирования флага присутствия/отсутствия коэффициента суб-блока)
227a - модуль выведения контекста
227b - память флагов присутствия/отсутствия коэффициента суб-блока
227c - модуль установки флага присутствия/отсутствия коэффициента суб-блока
228 - модуль выведения синтаксиса
230 - арифметический кодировщик кода
231 - модуль записи/обновления контекста
232 - битовый кодировщик (средство кодирования синтаксиса).
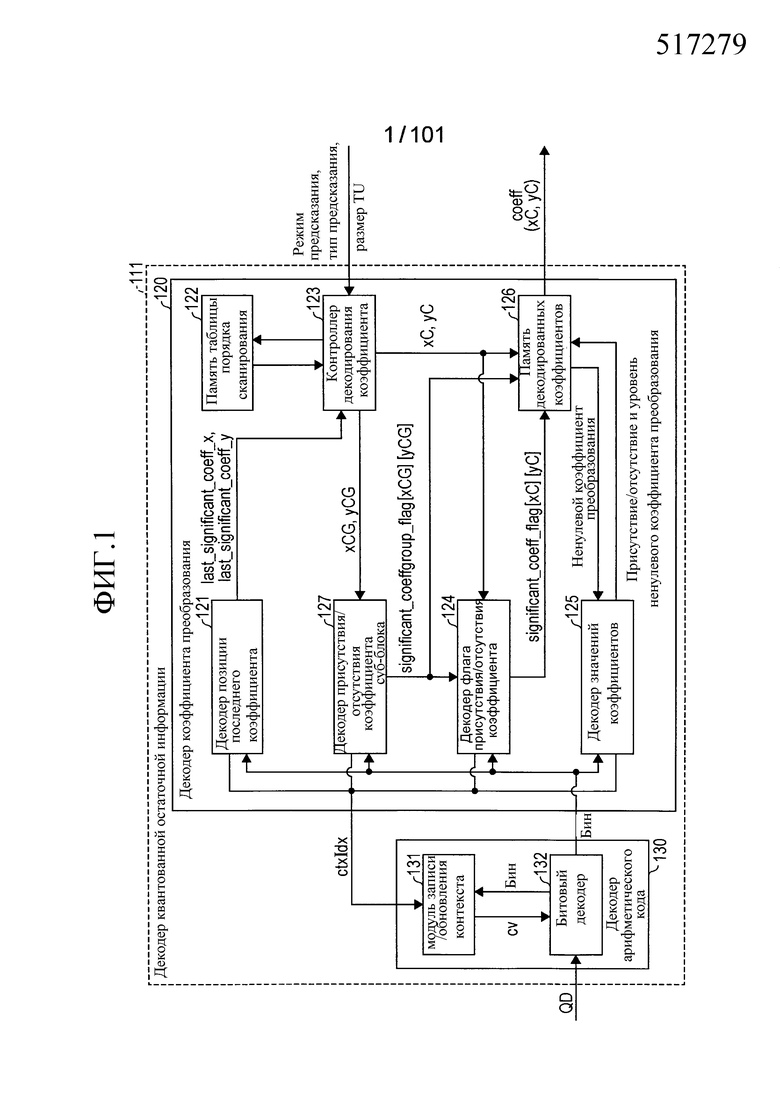
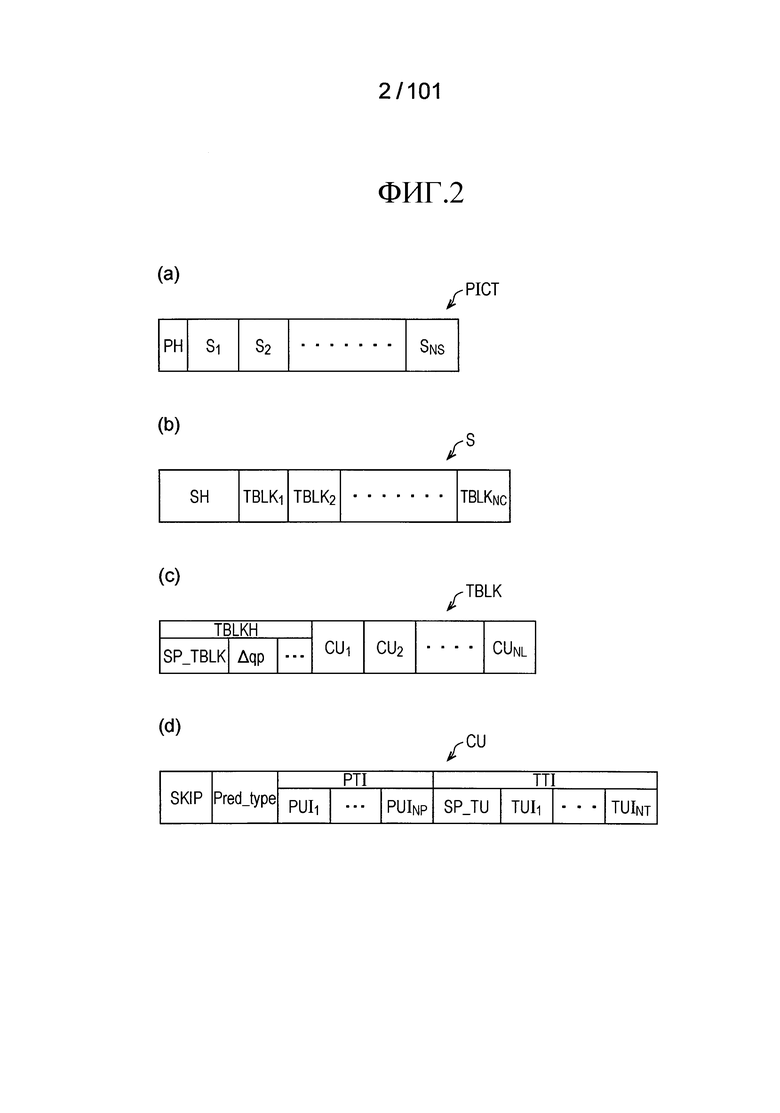
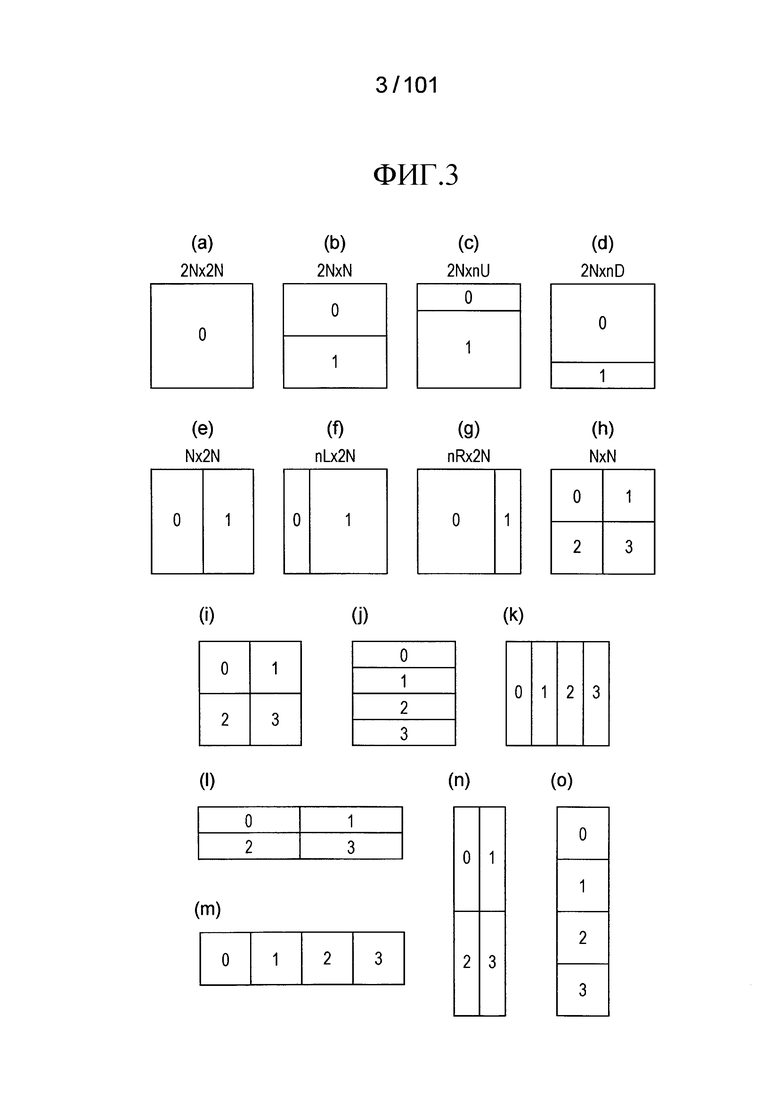


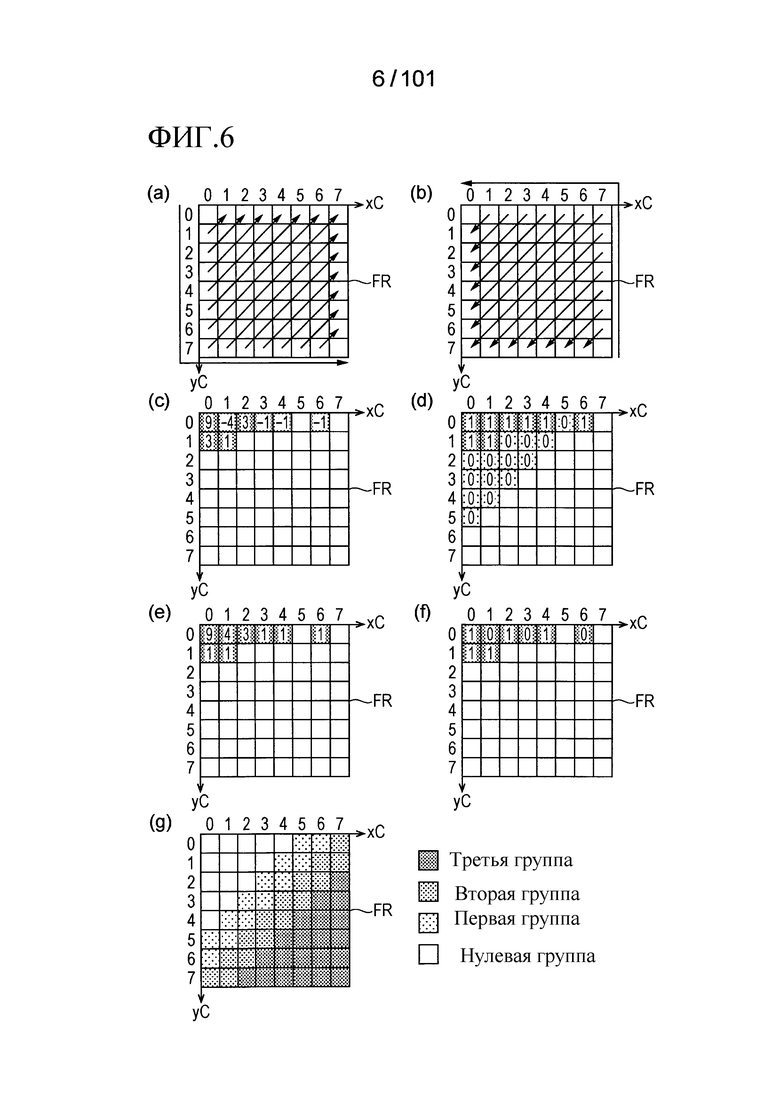
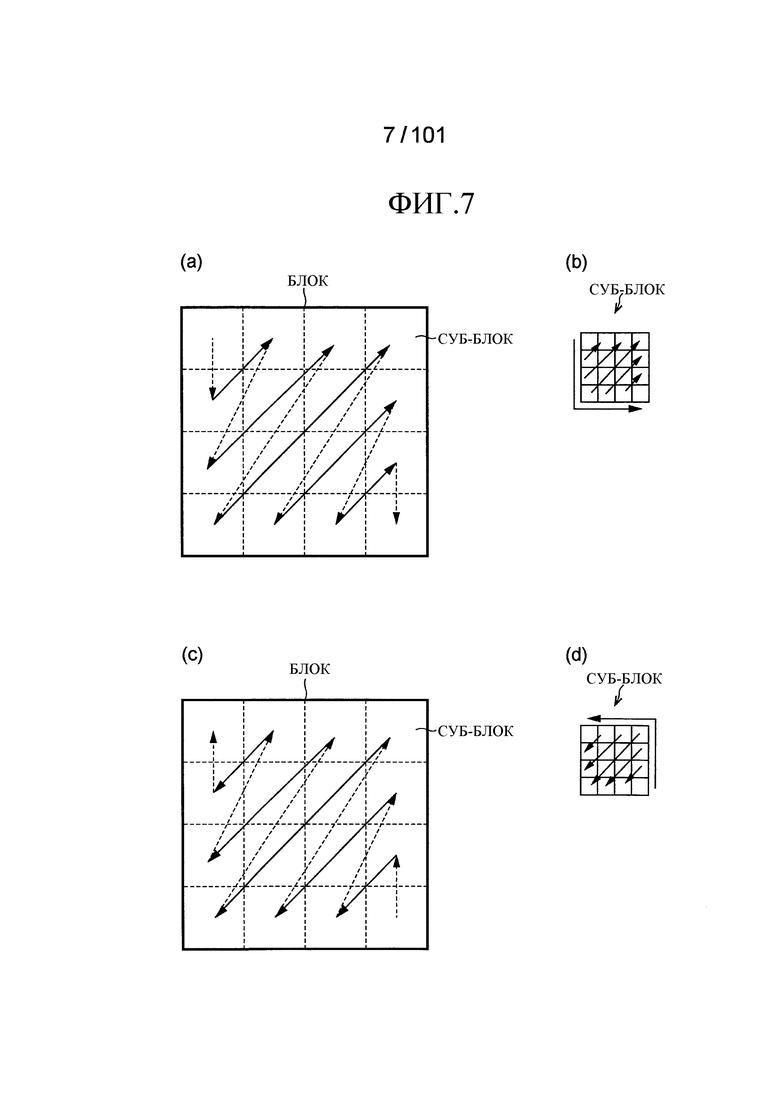
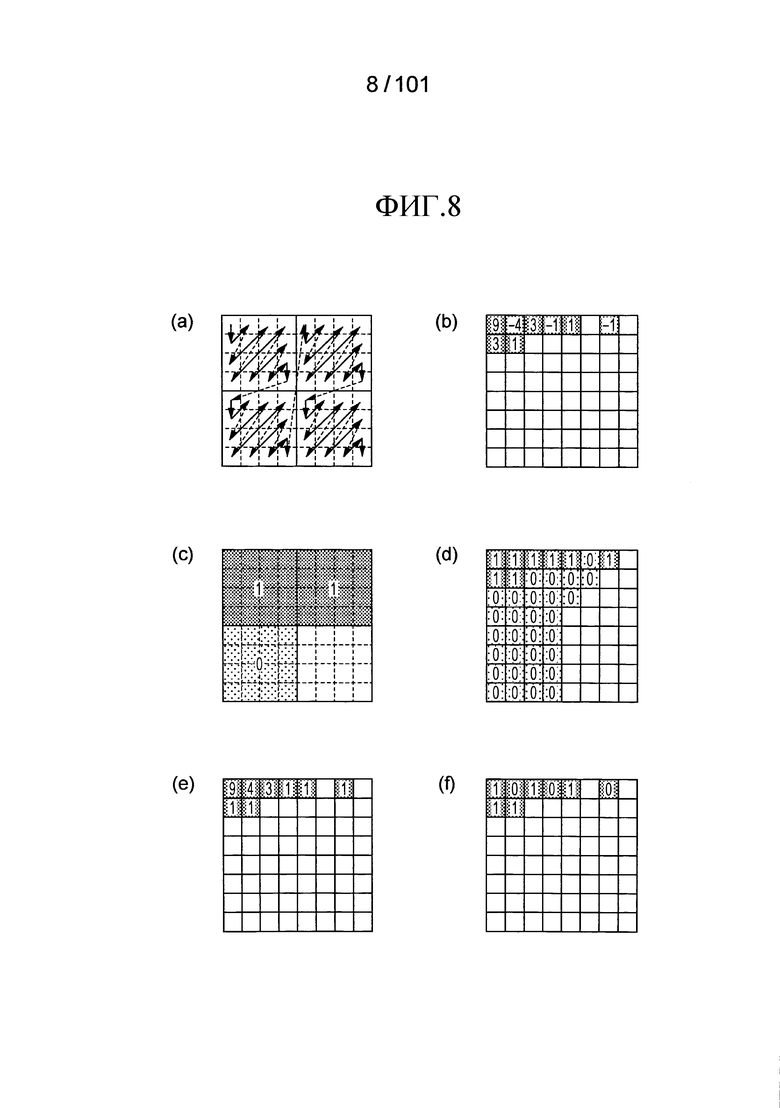
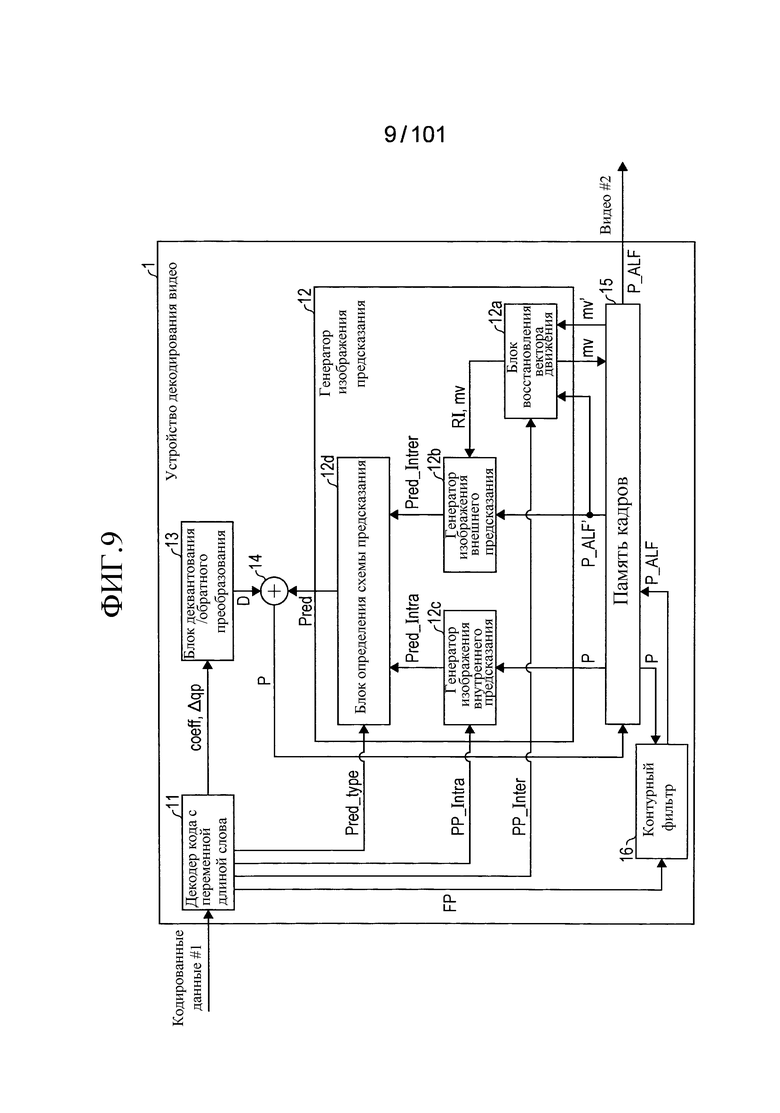
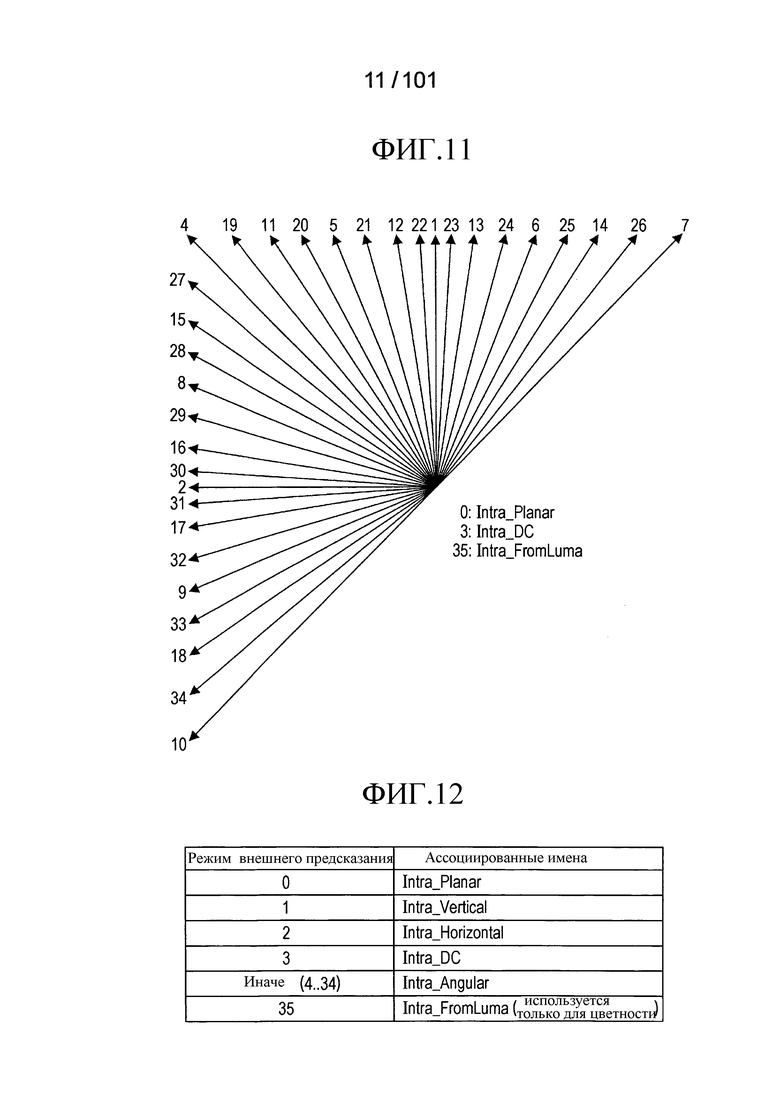

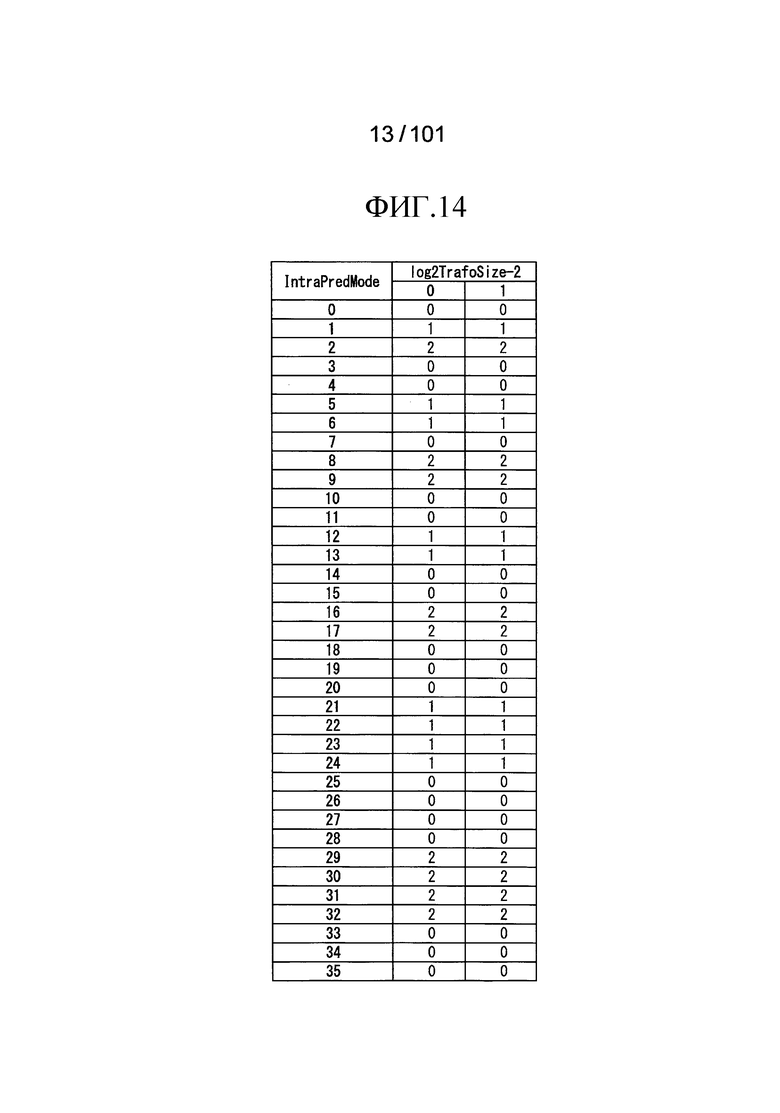
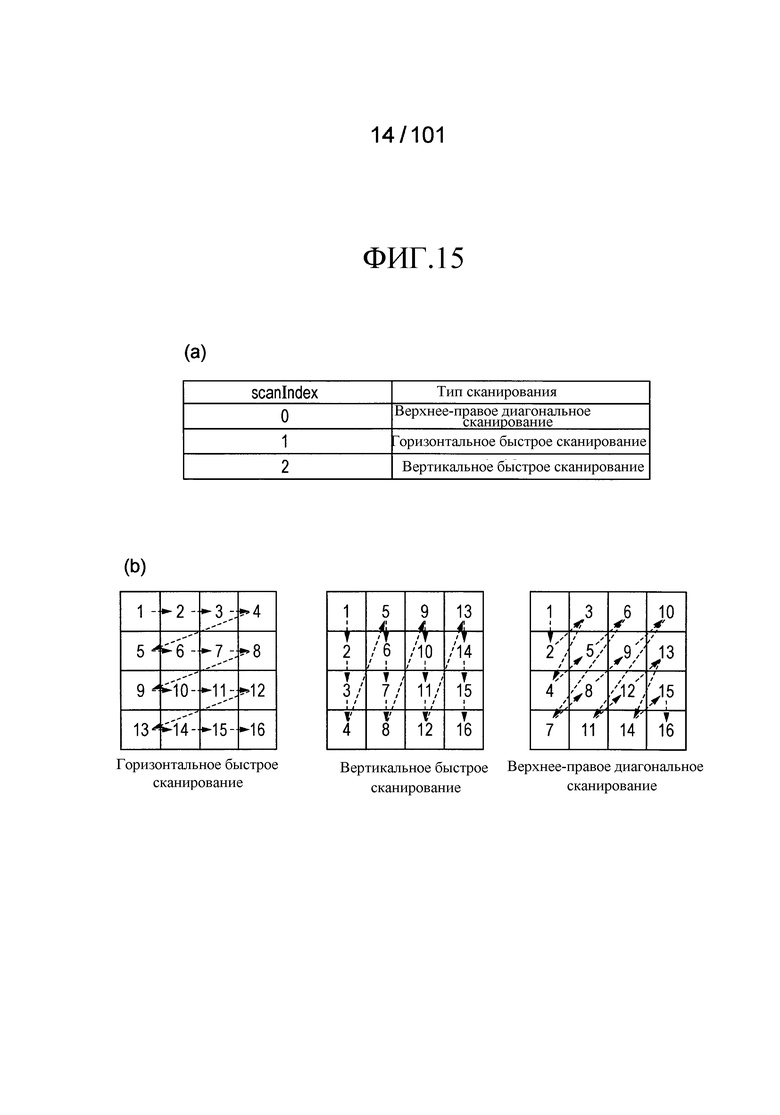
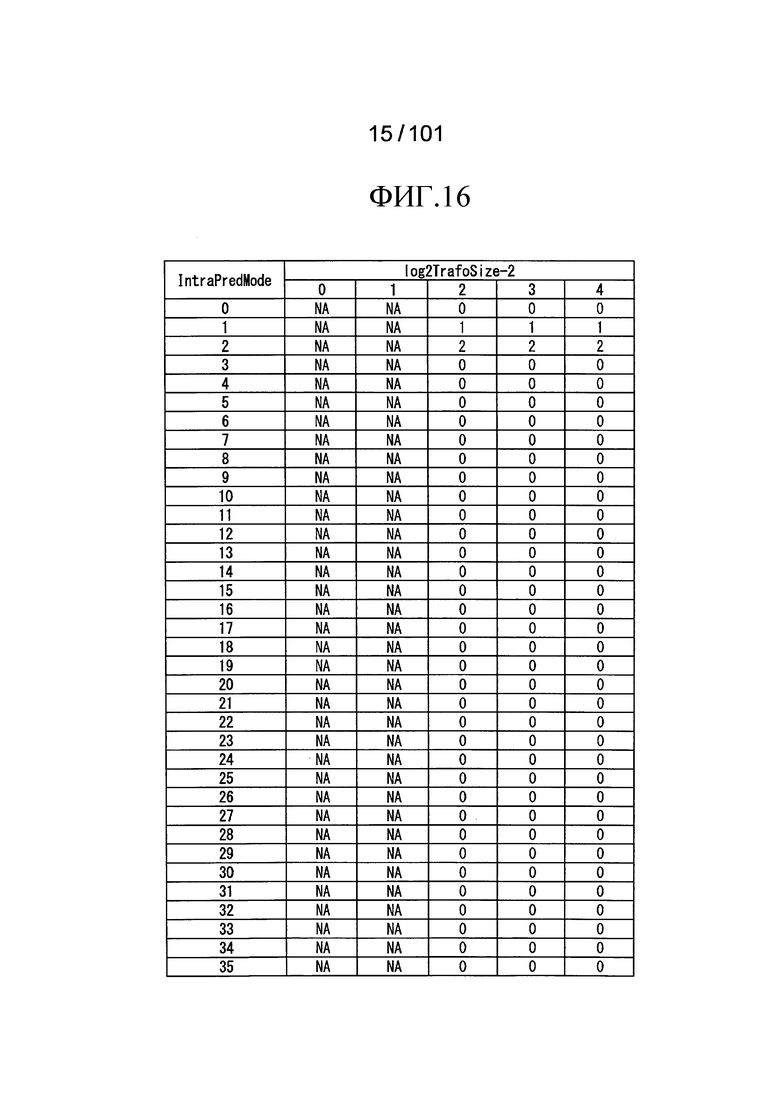
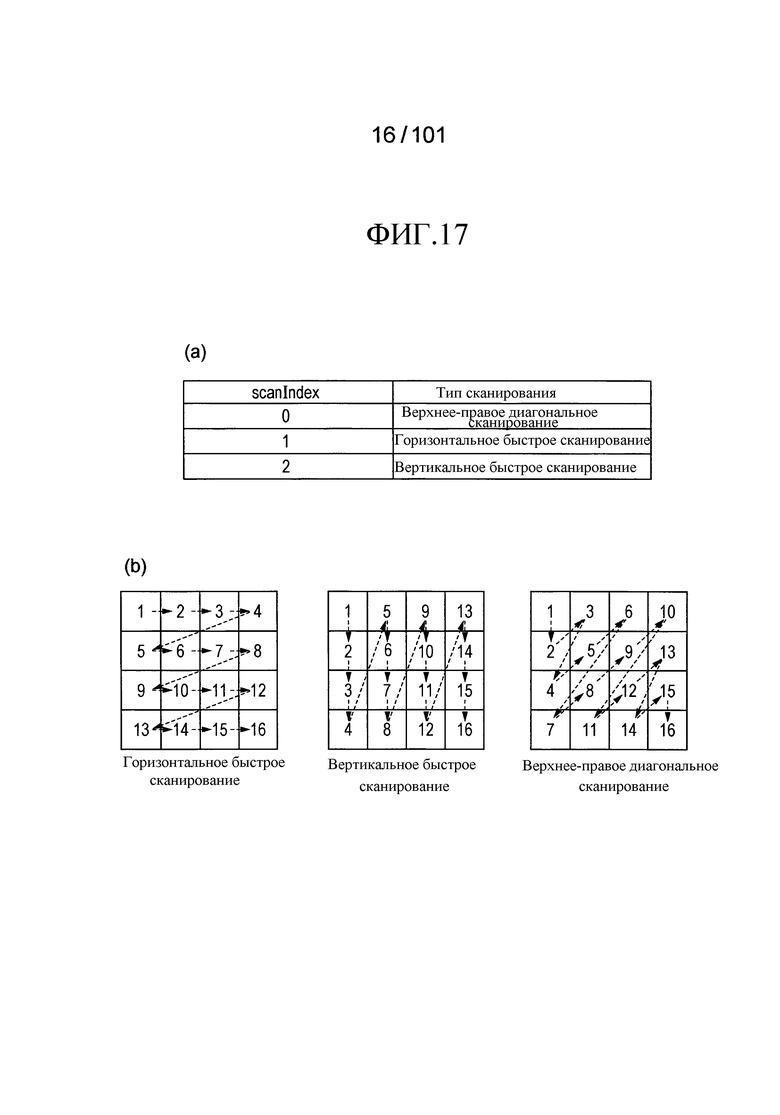
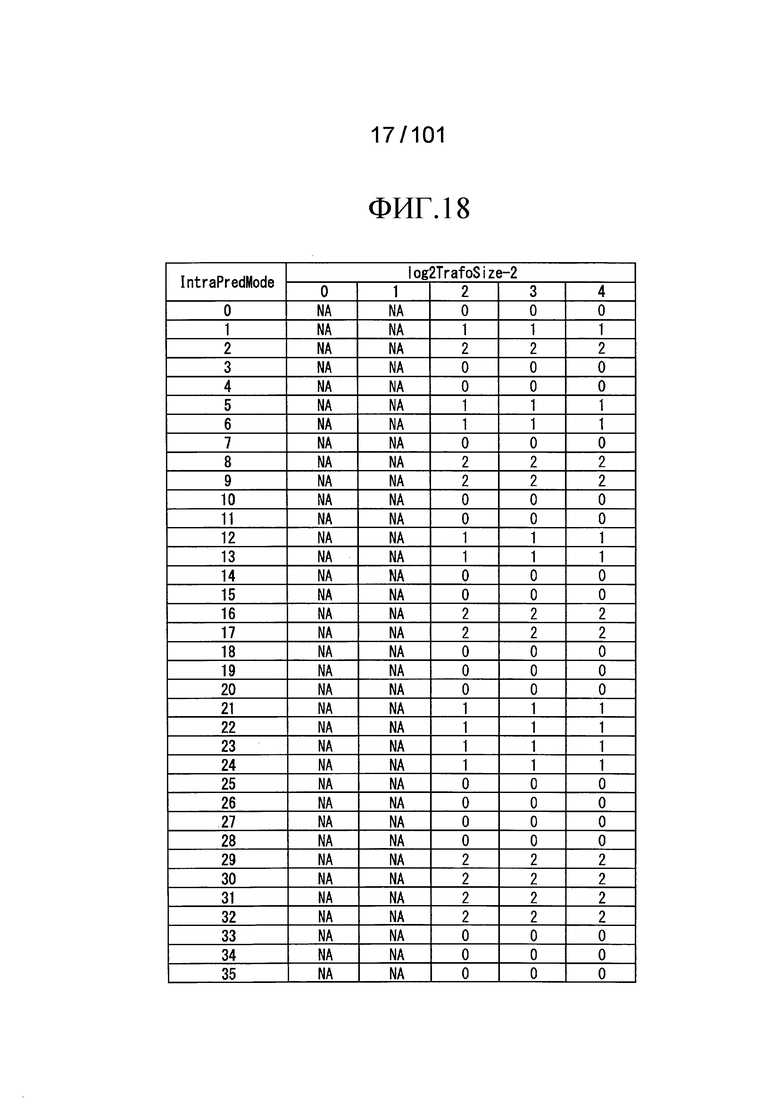
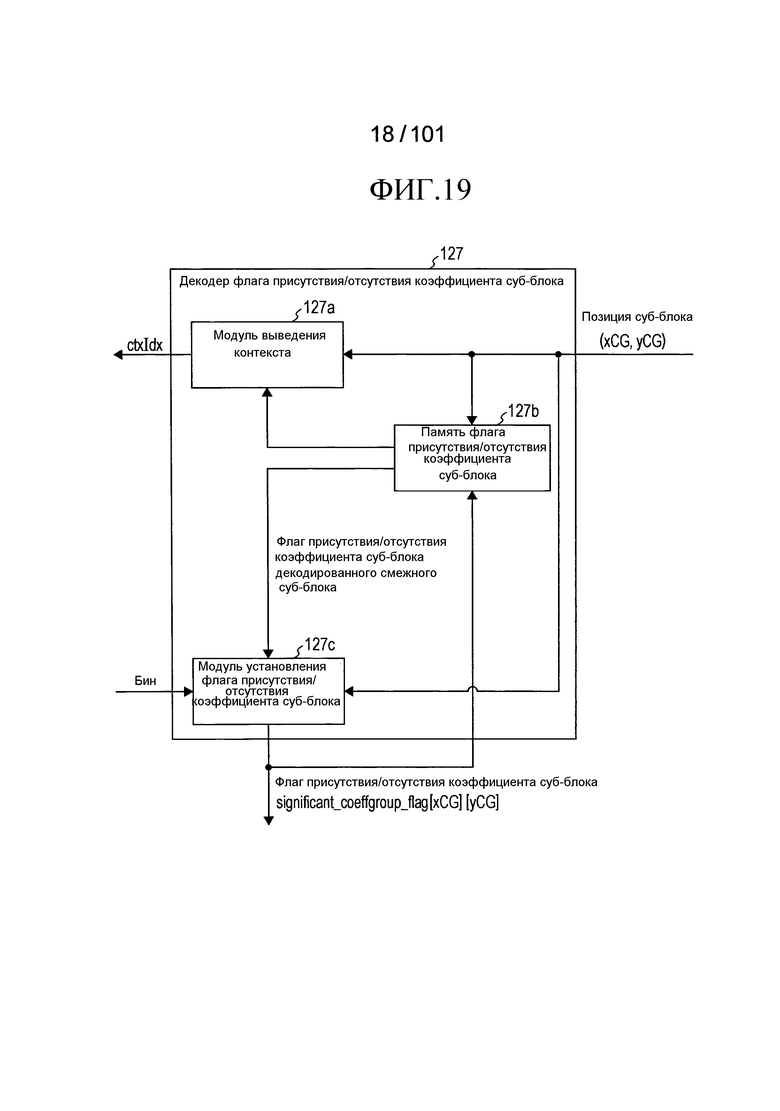
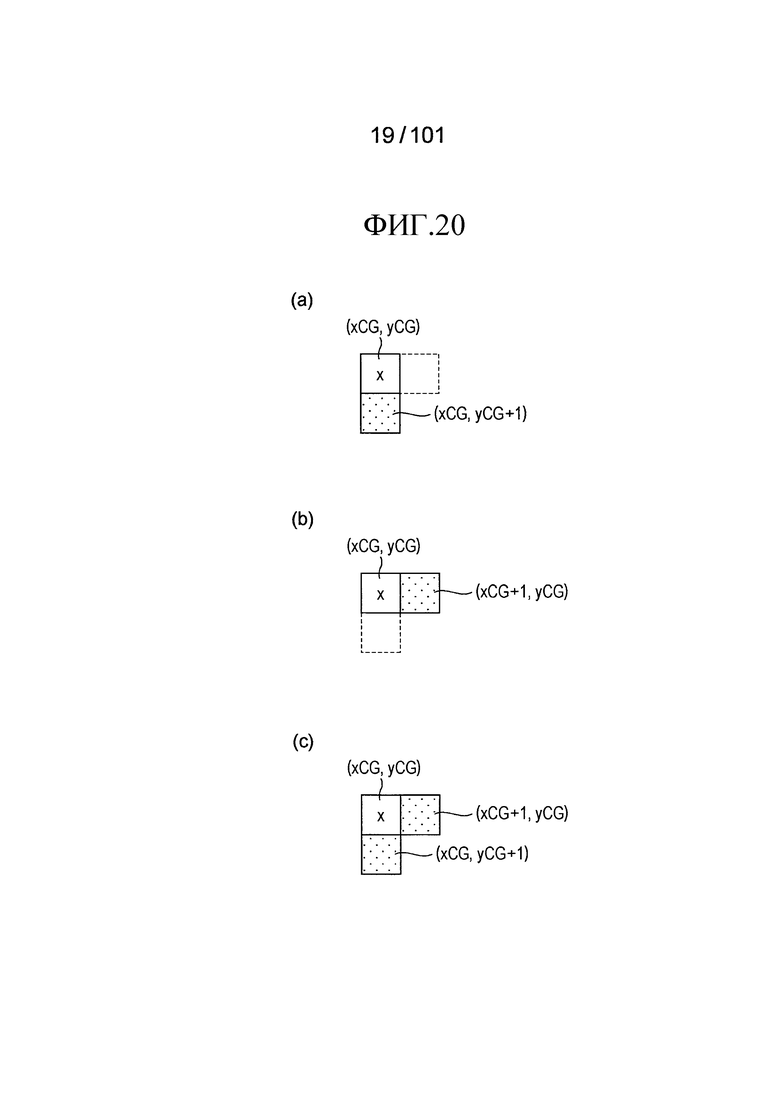


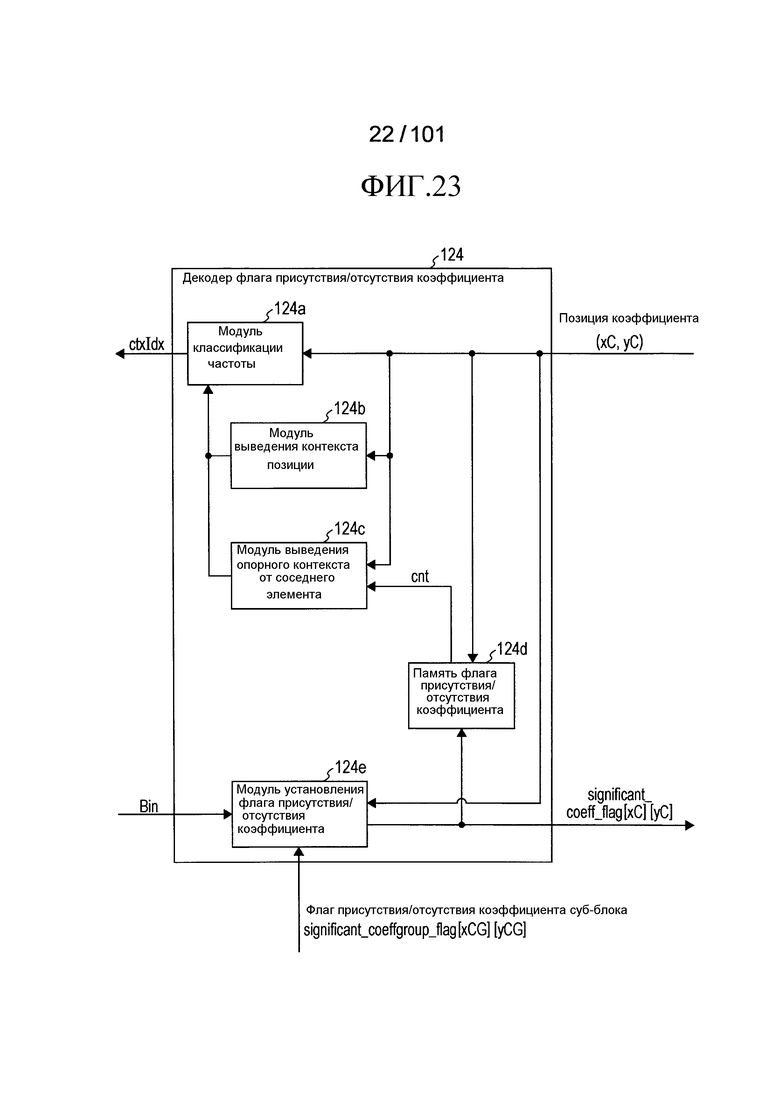
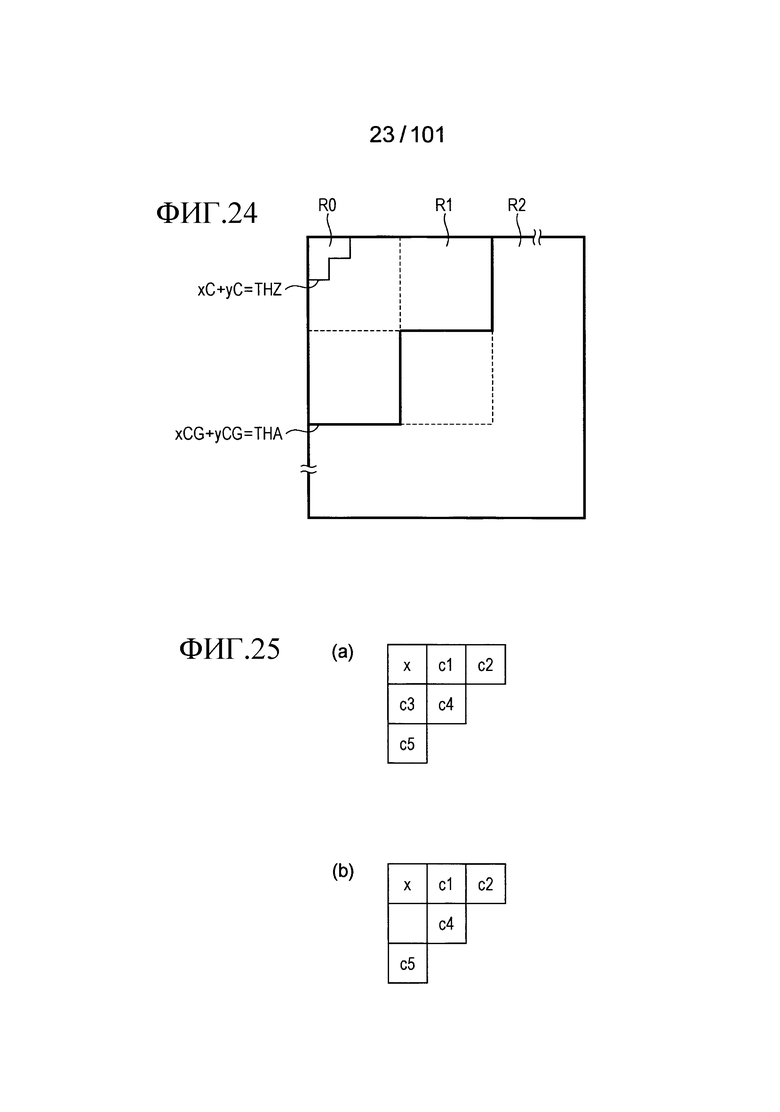
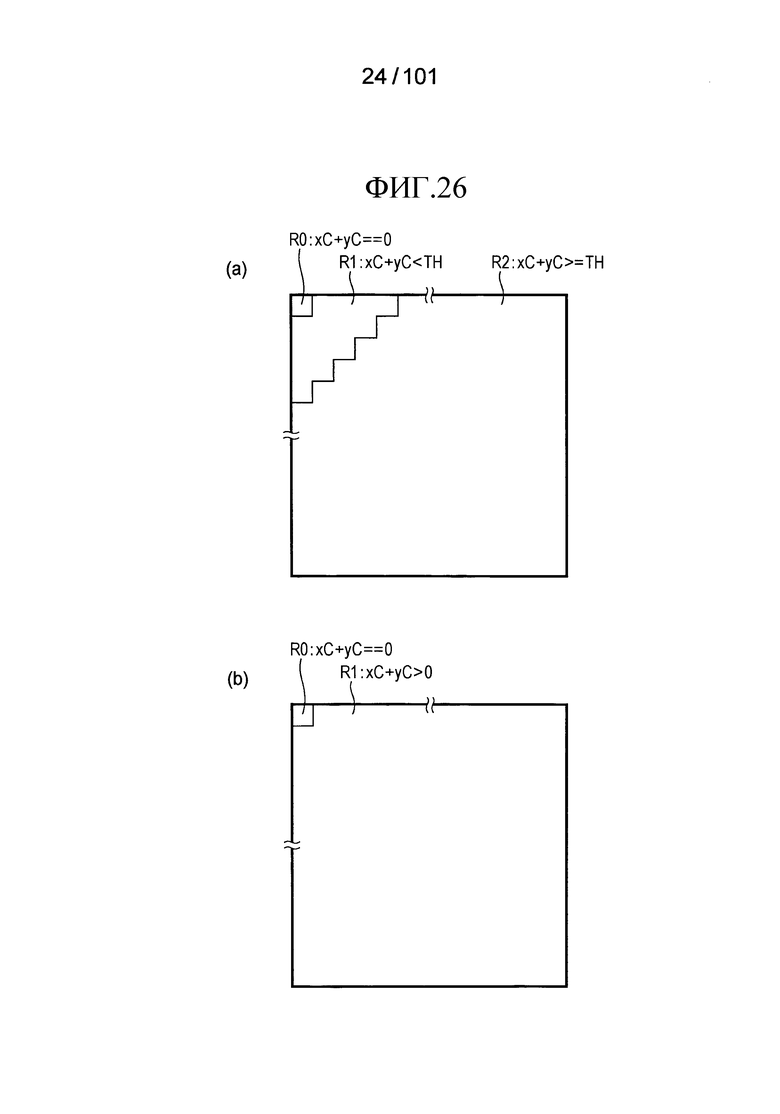


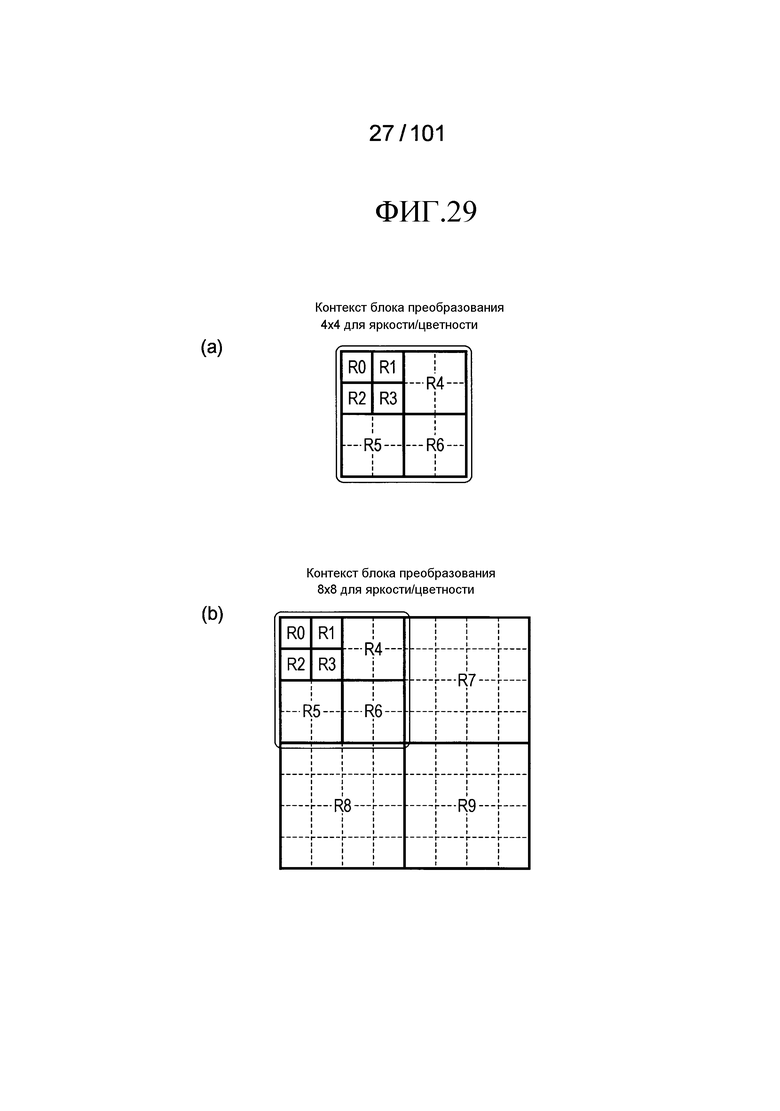


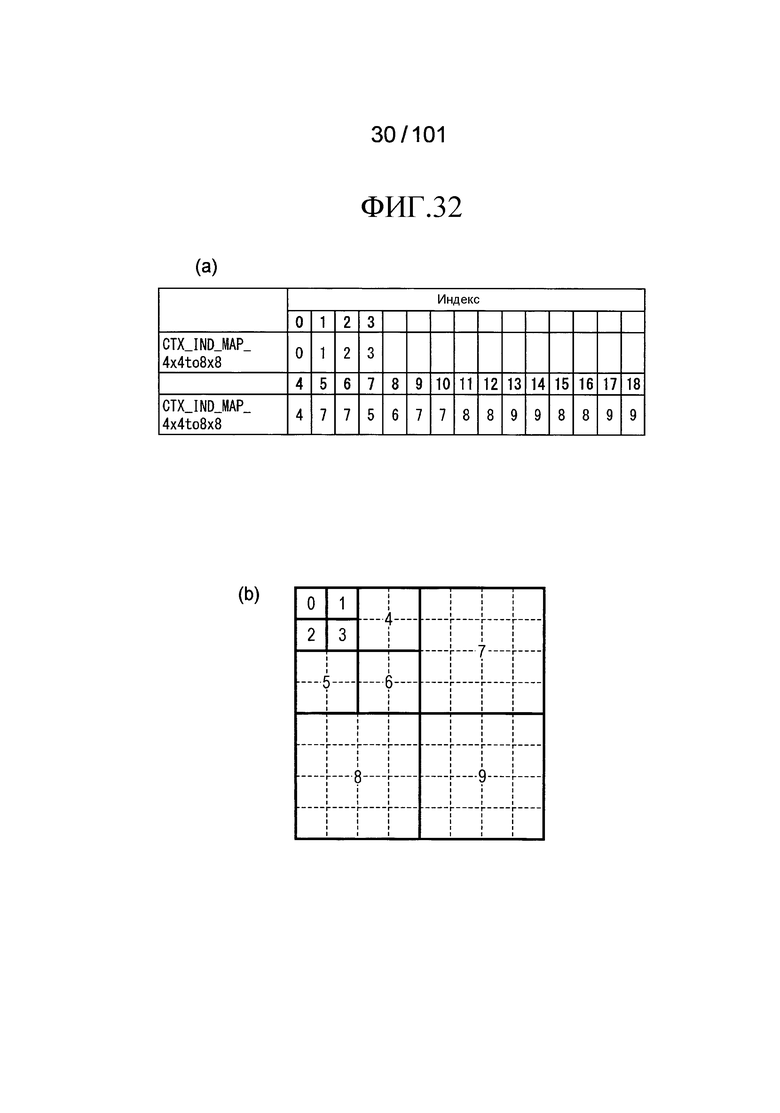
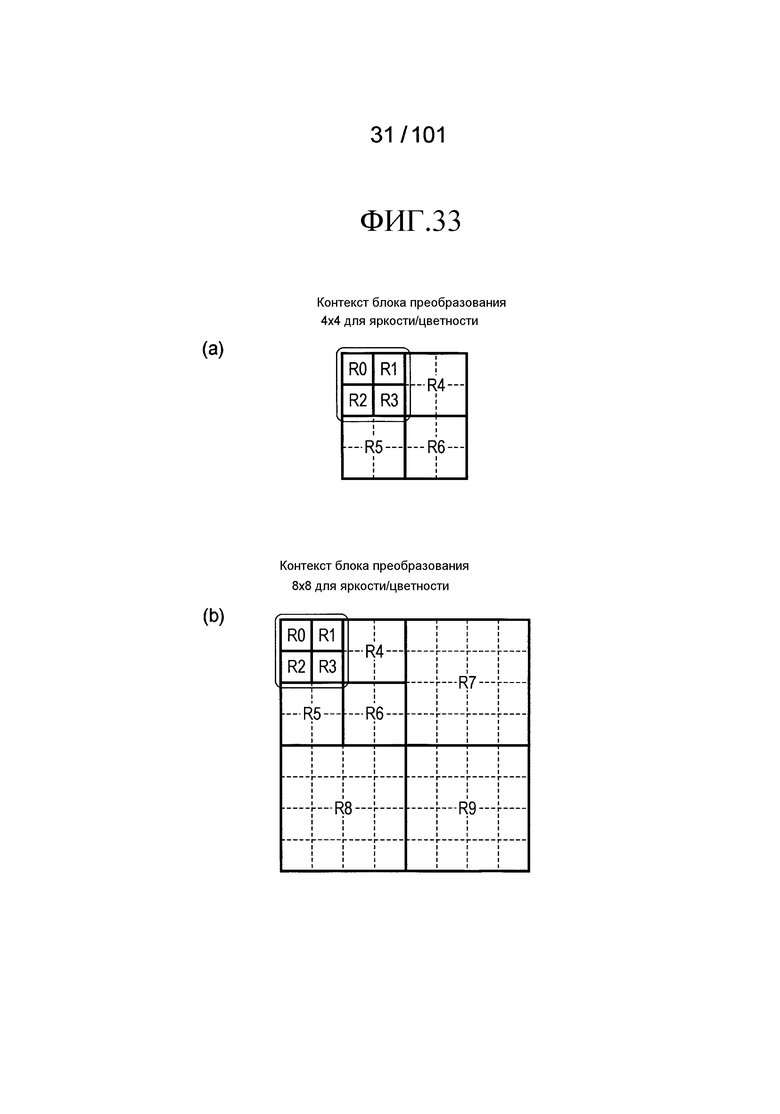

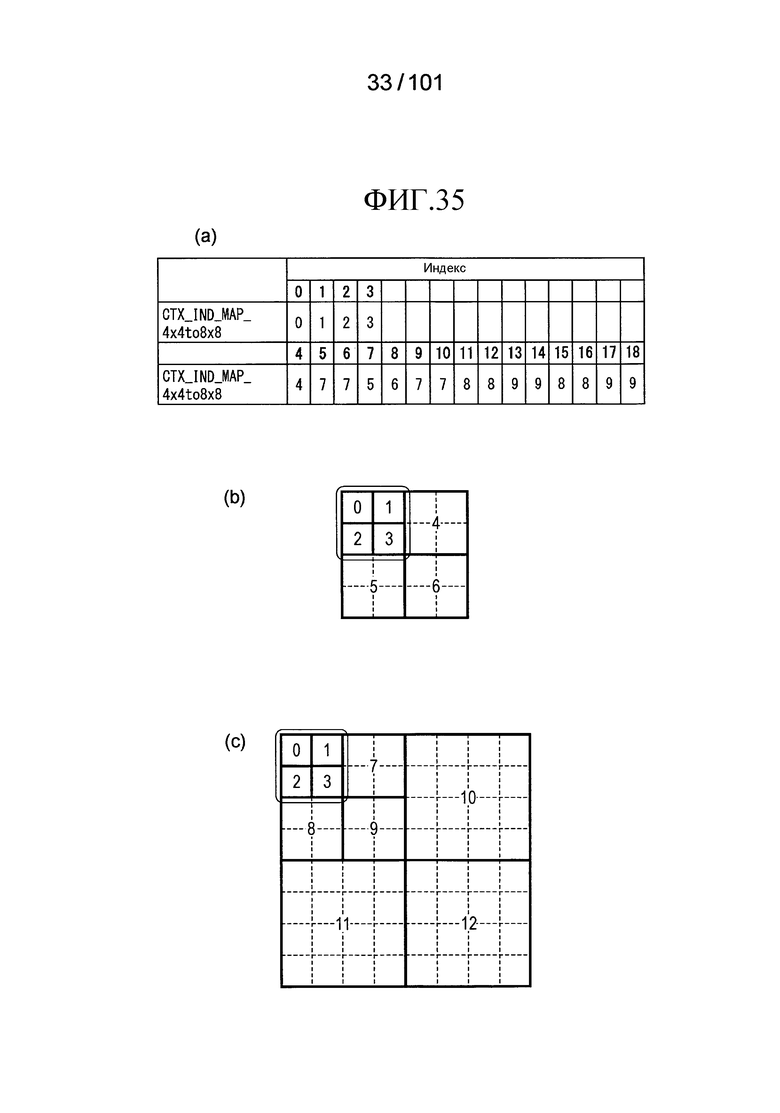

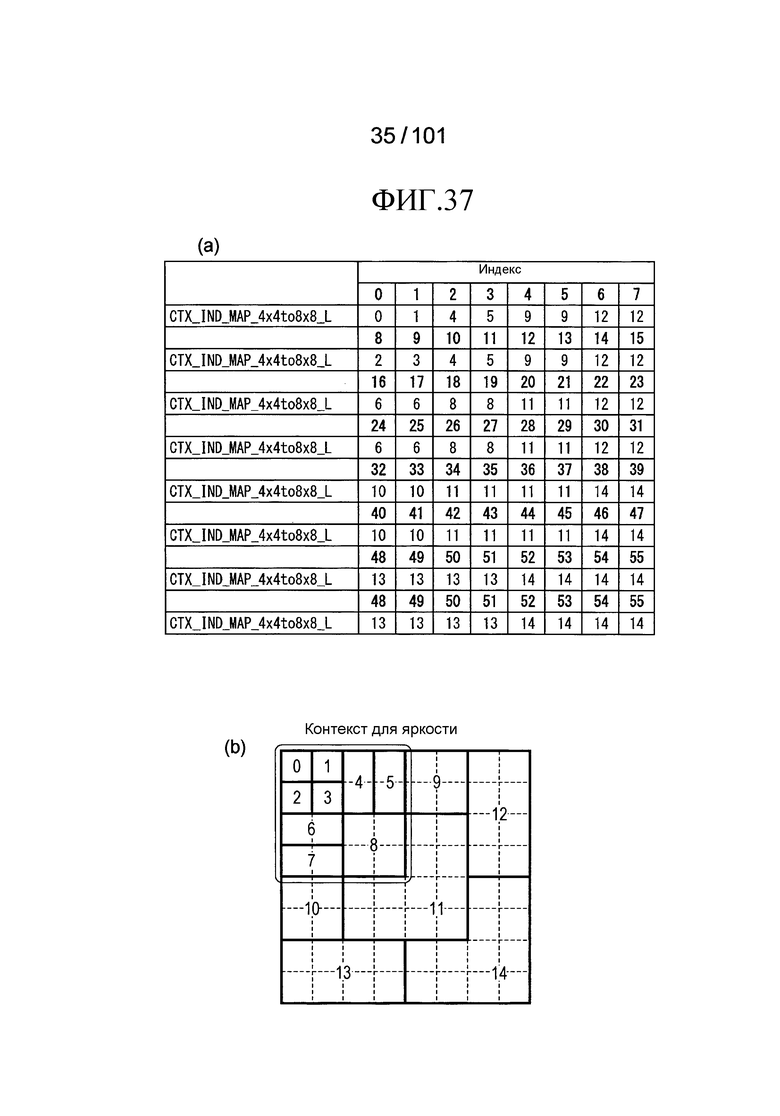
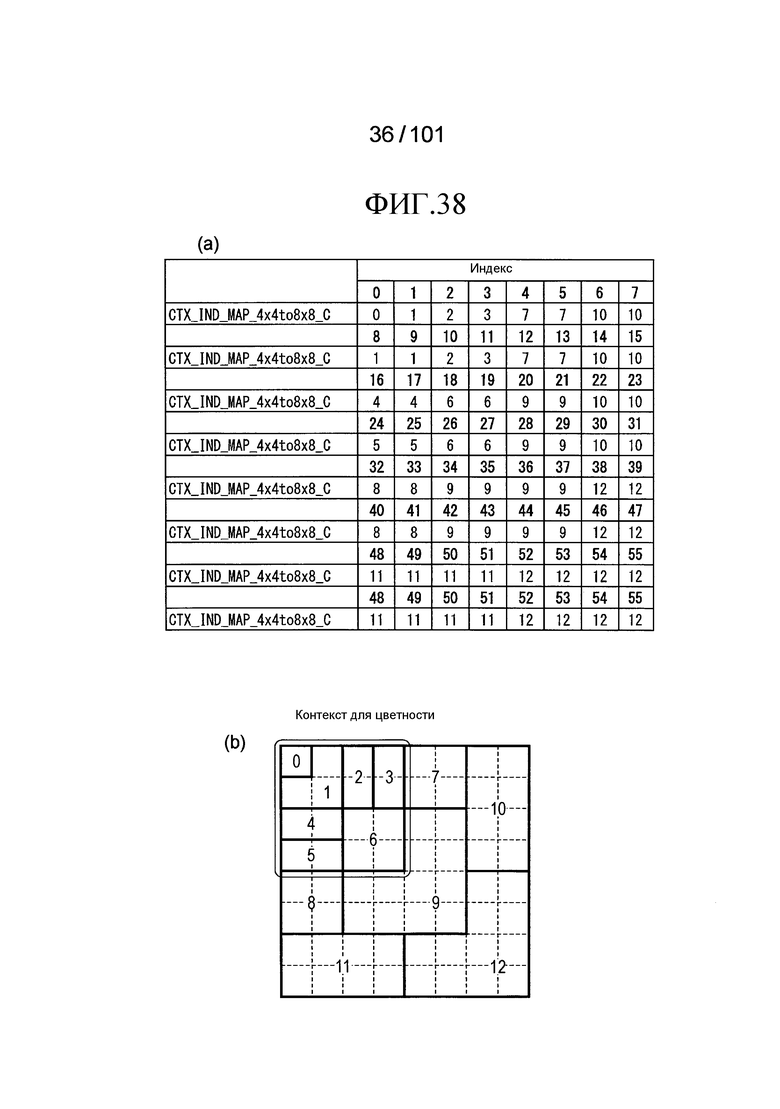
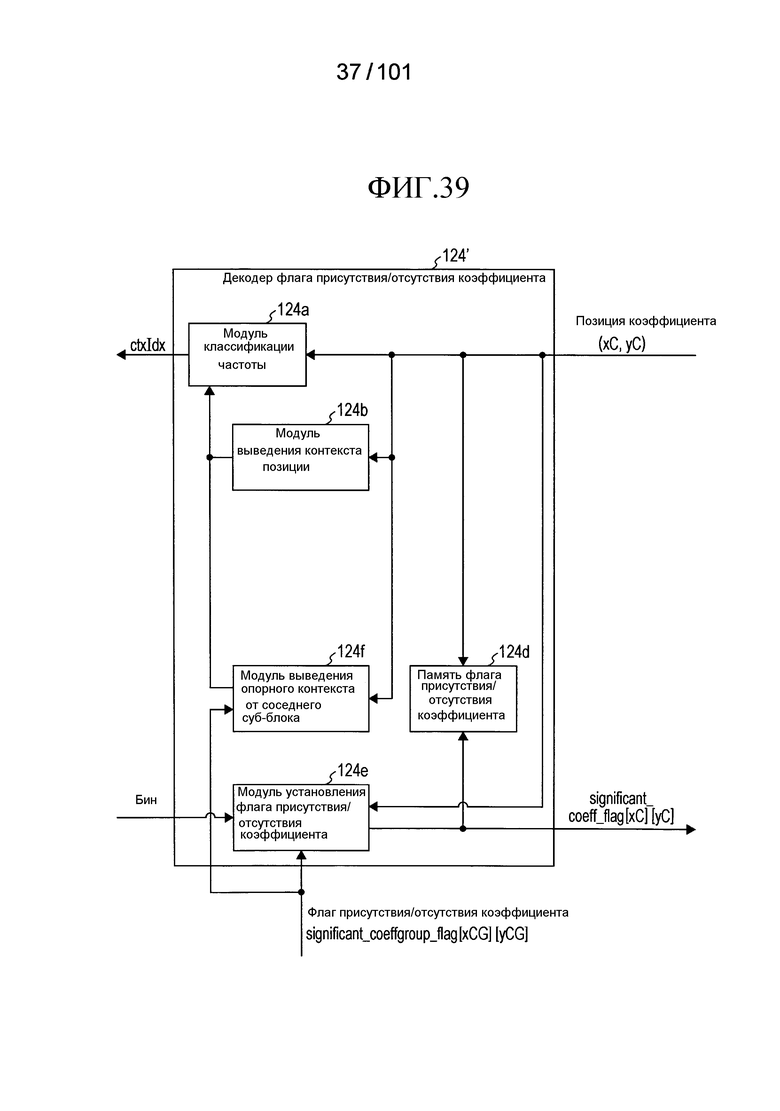
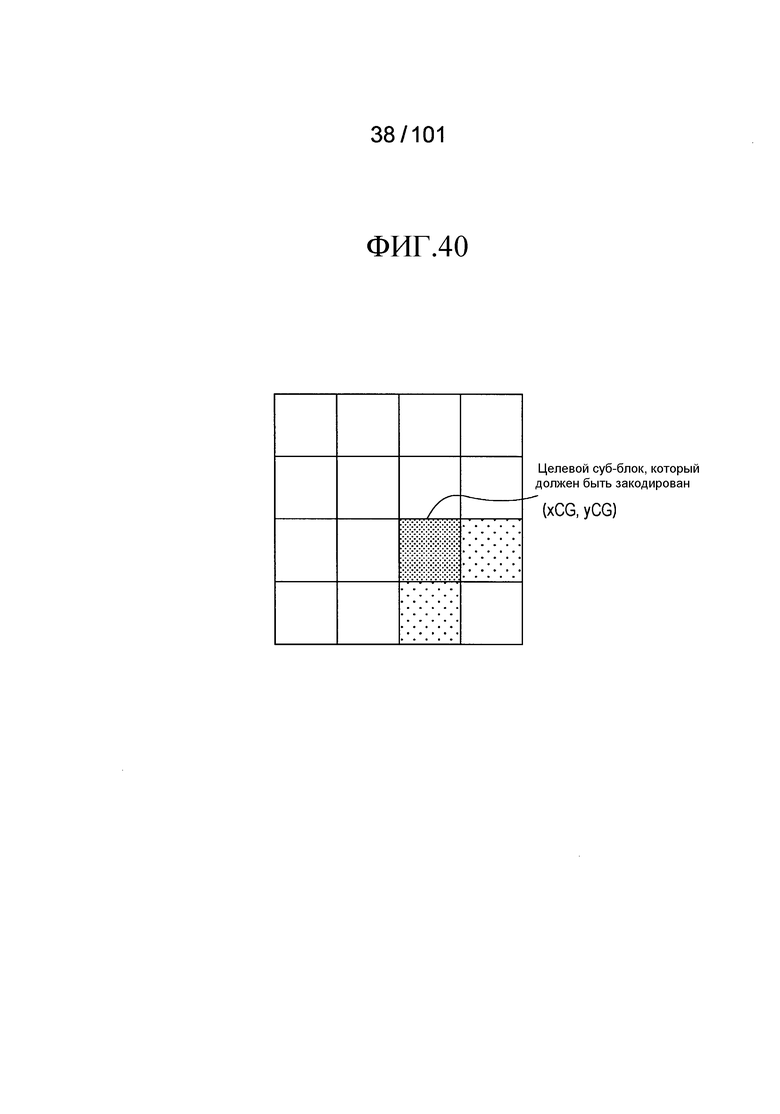


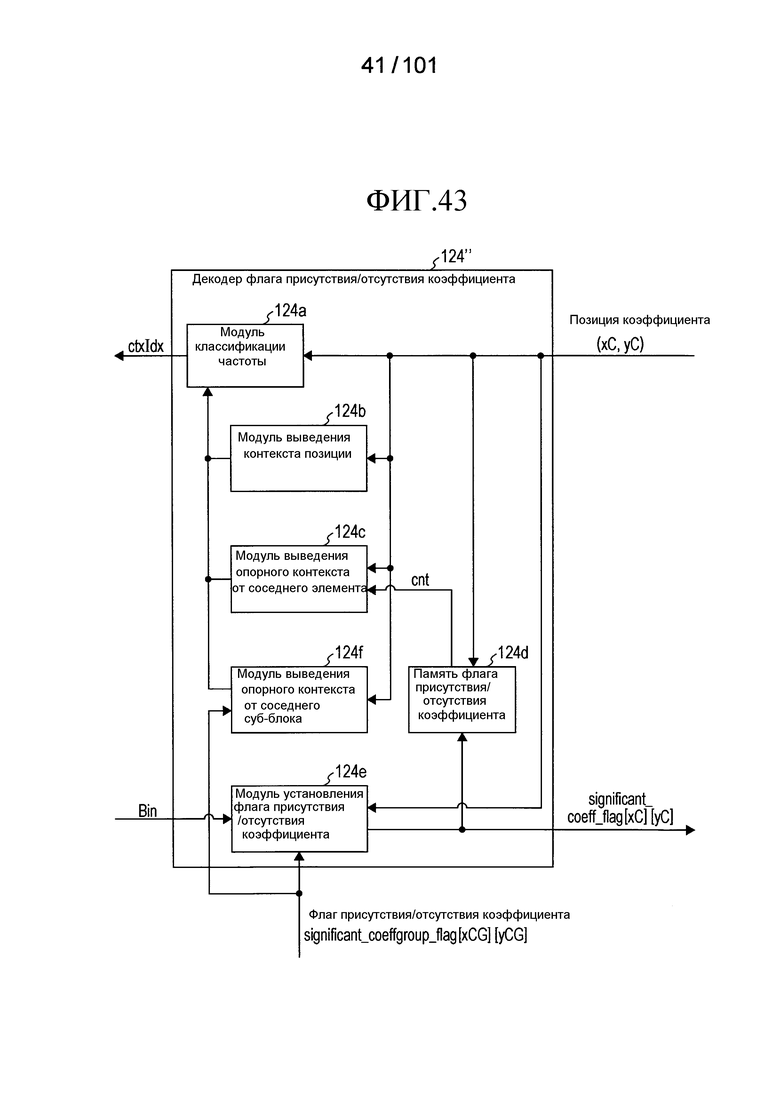

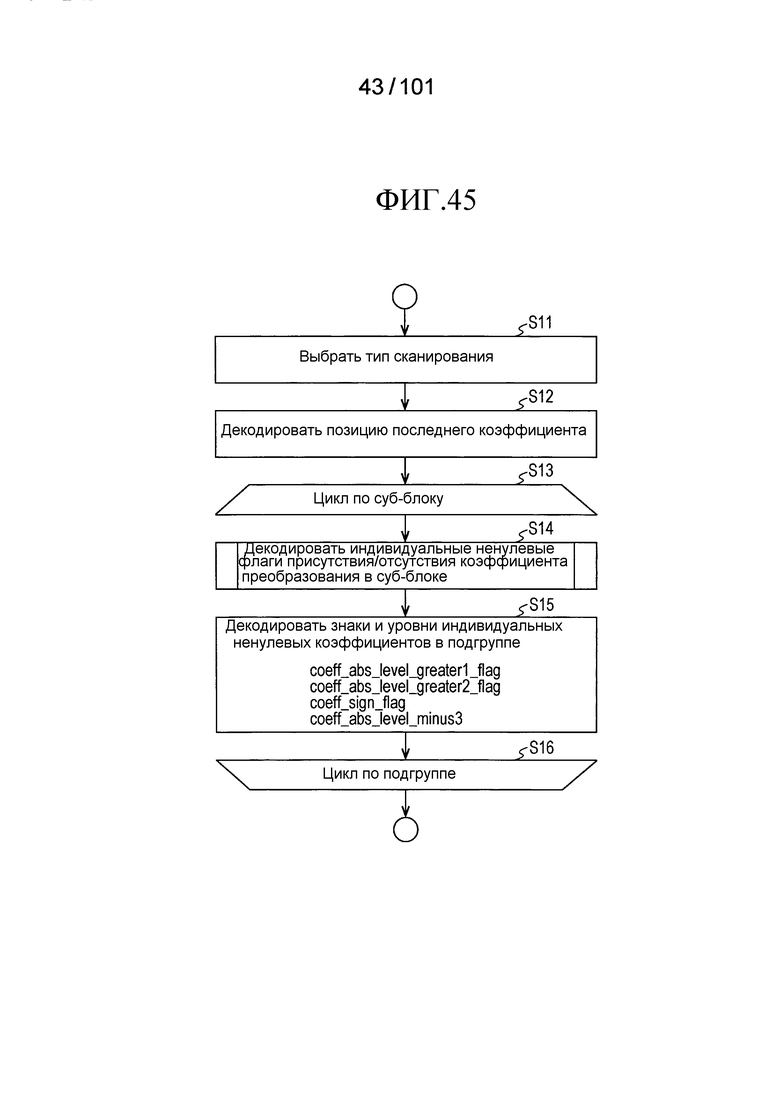
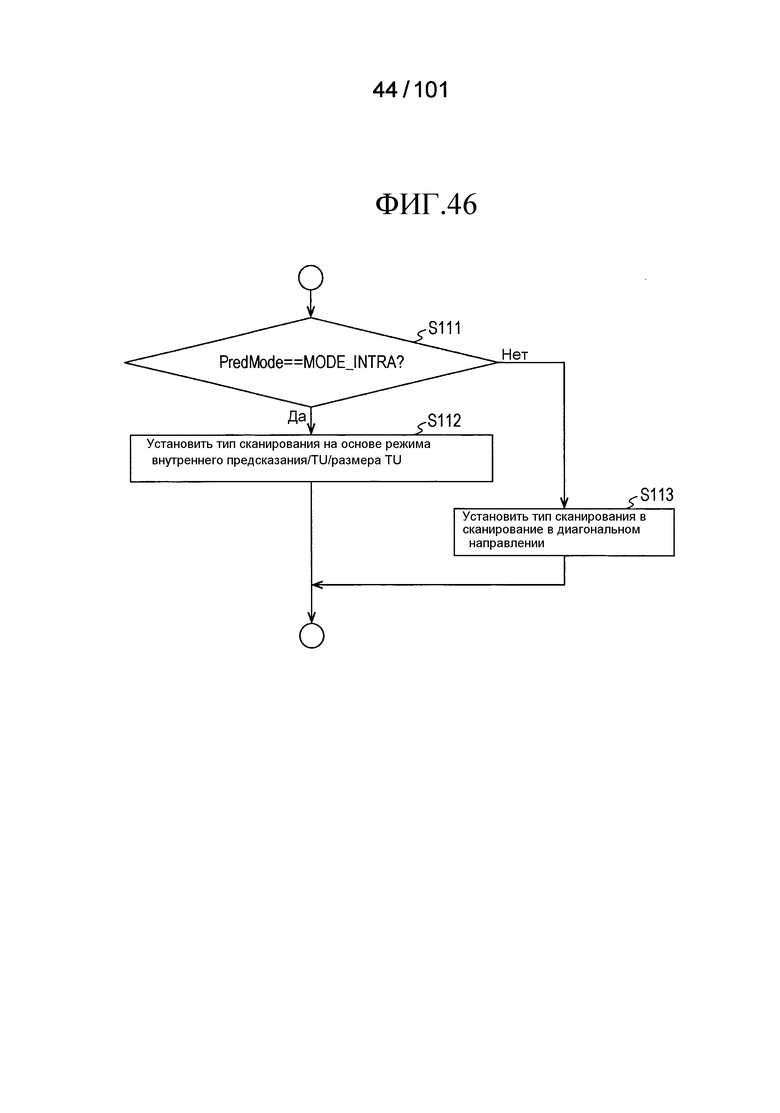
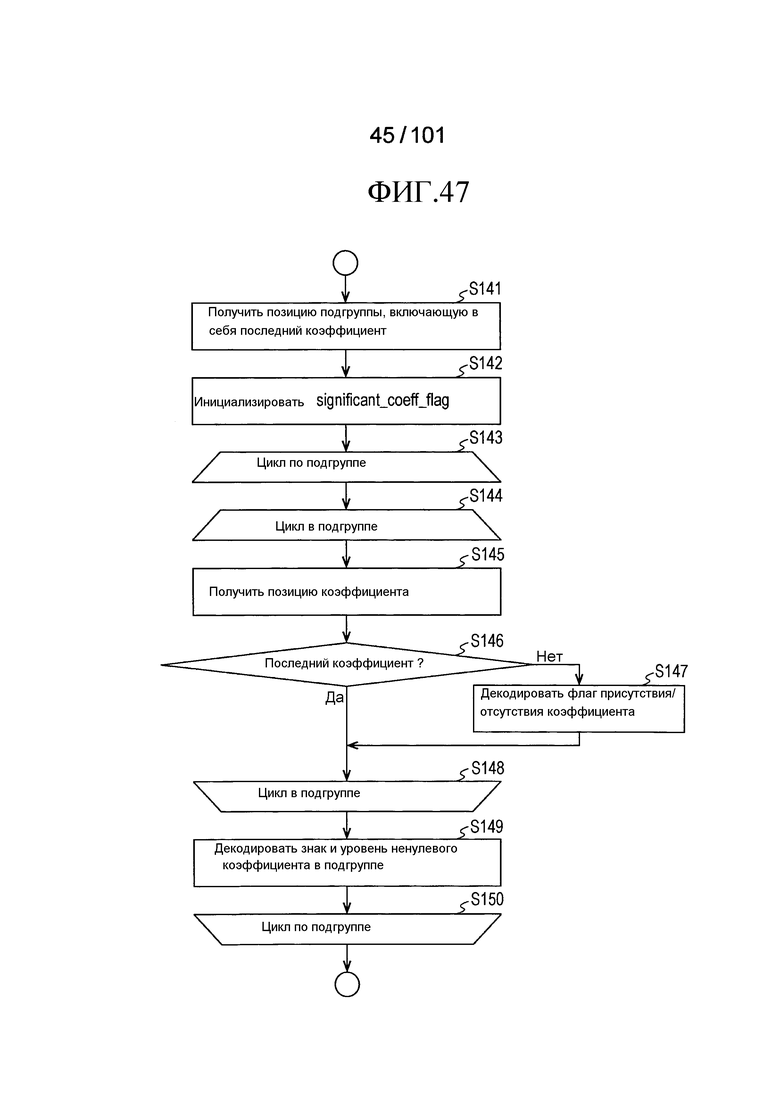

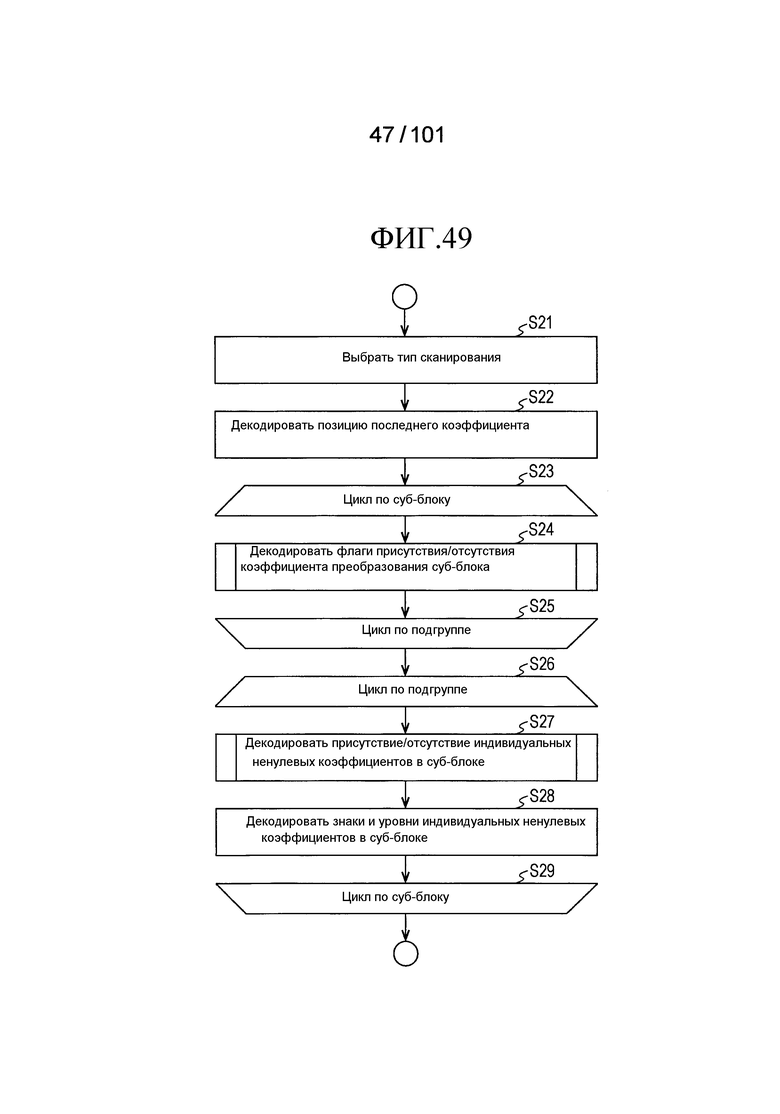
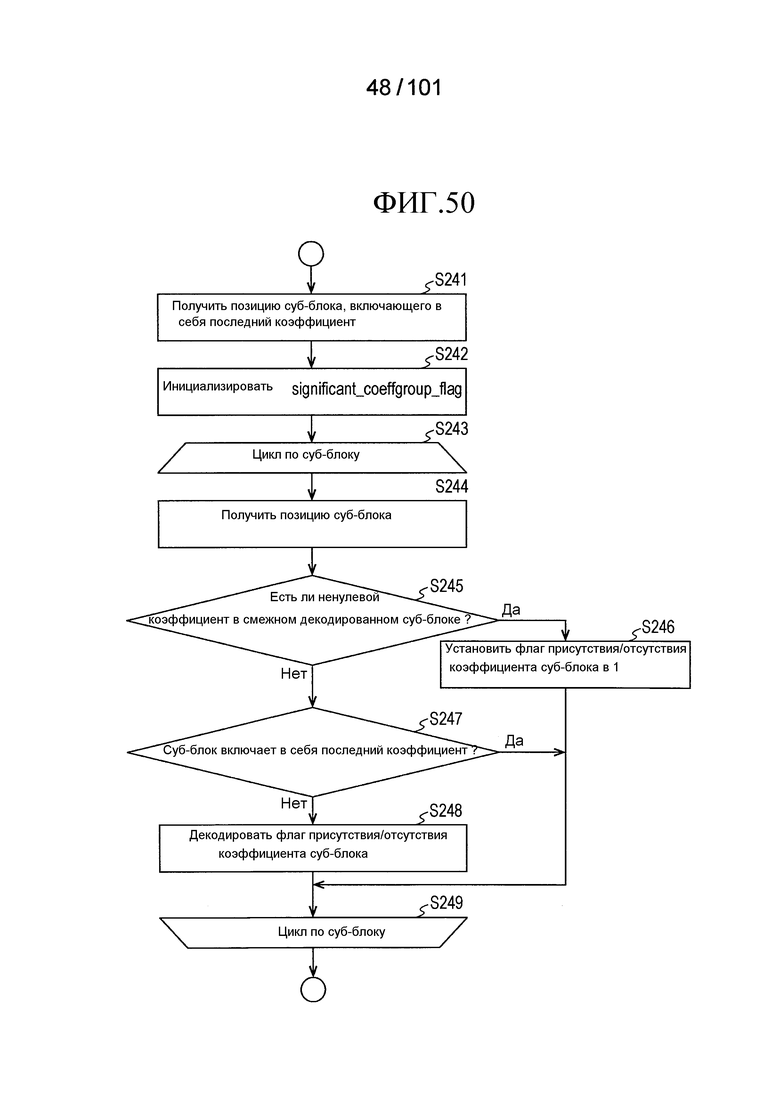
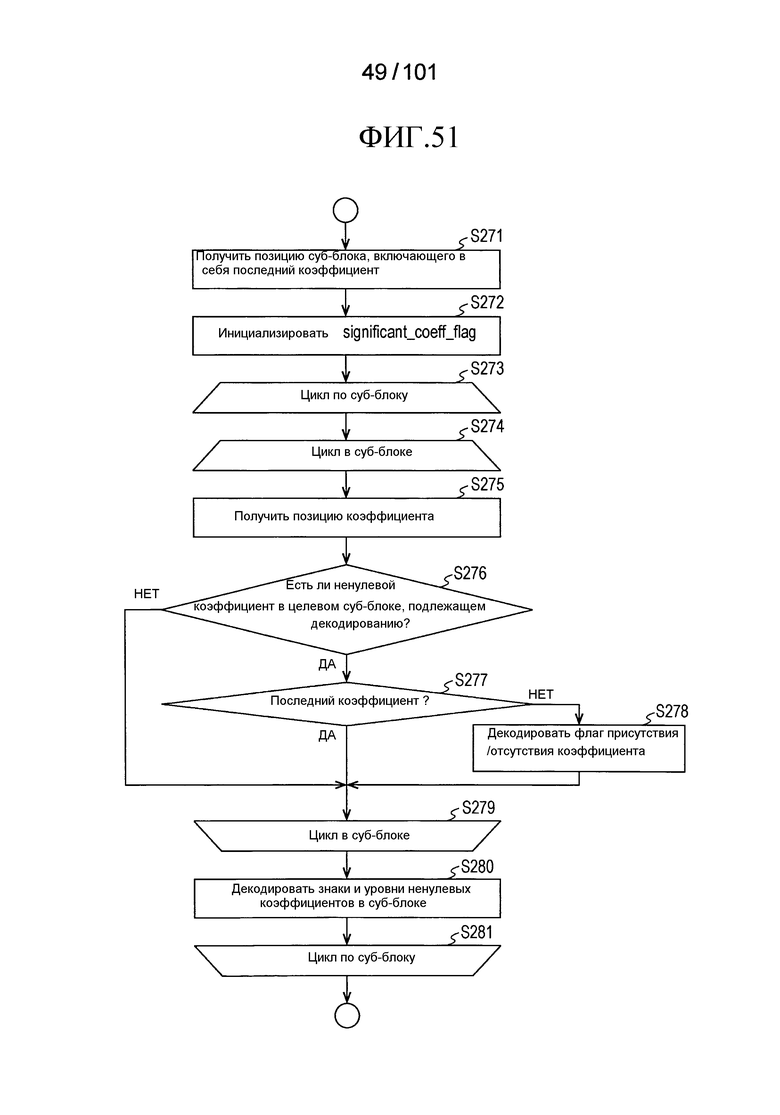
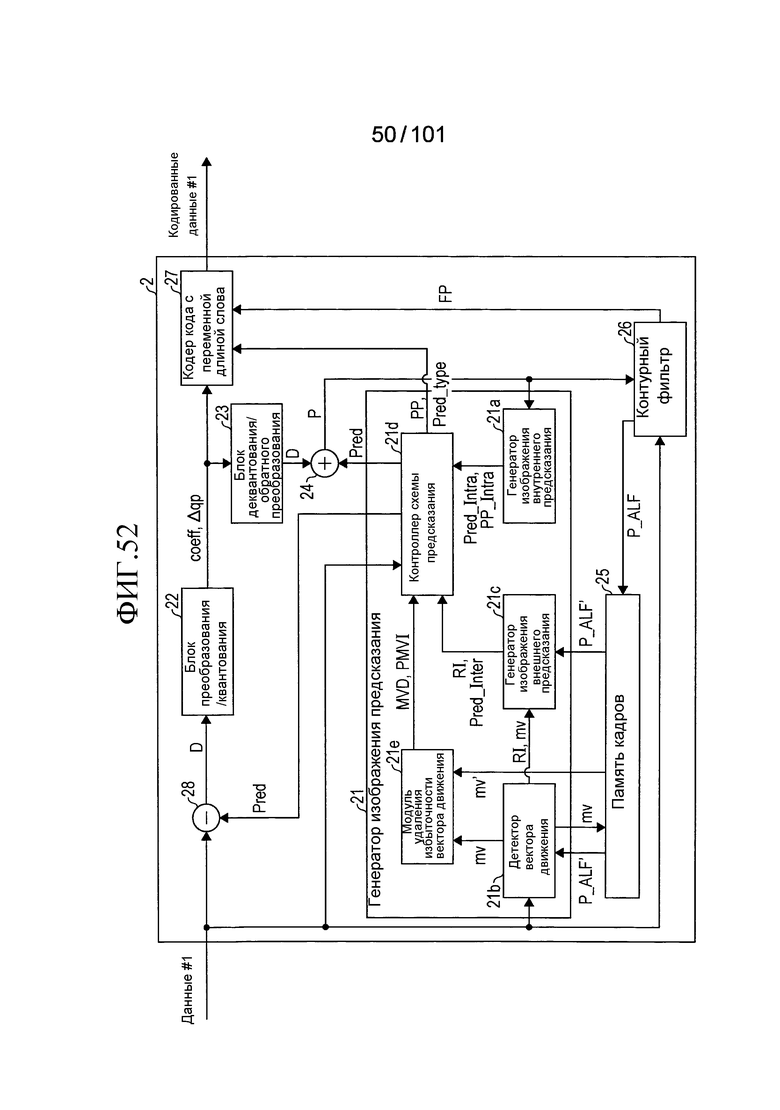
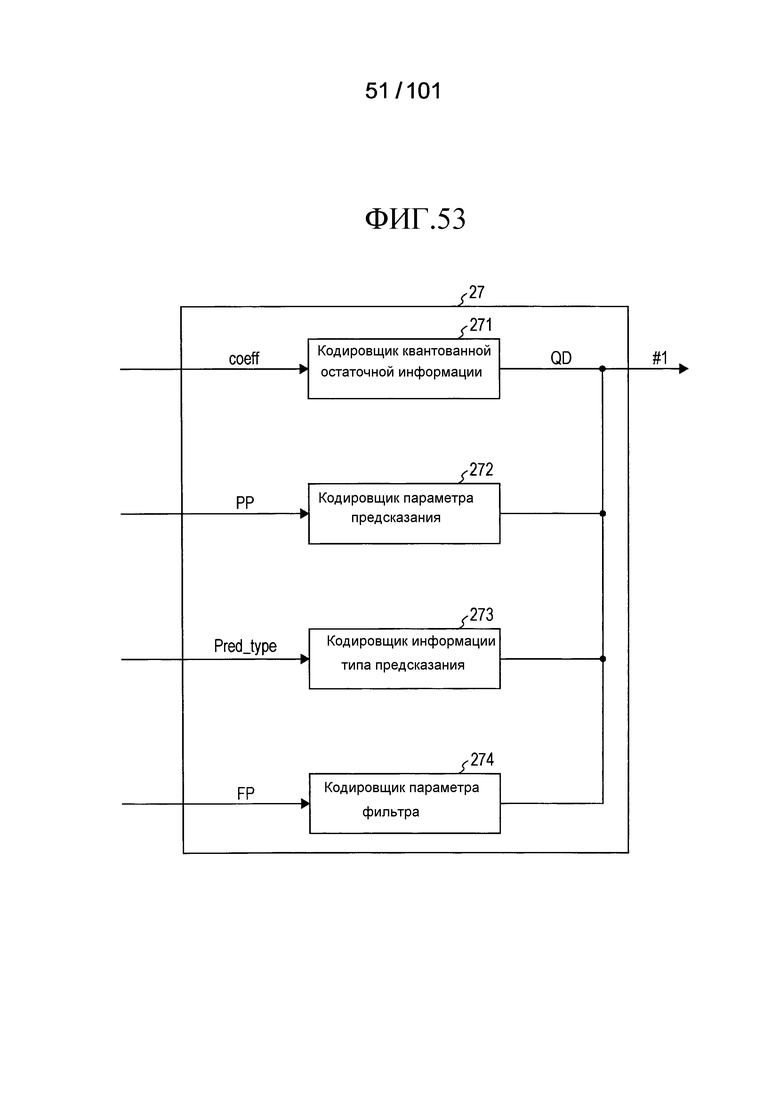
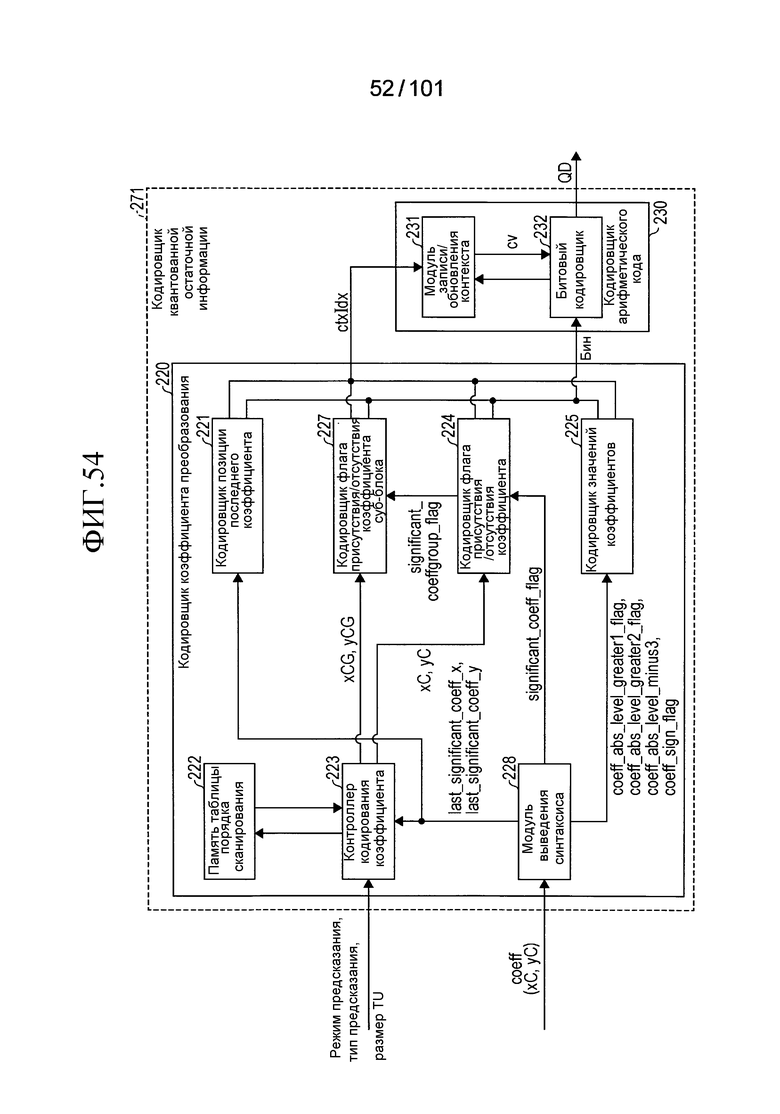
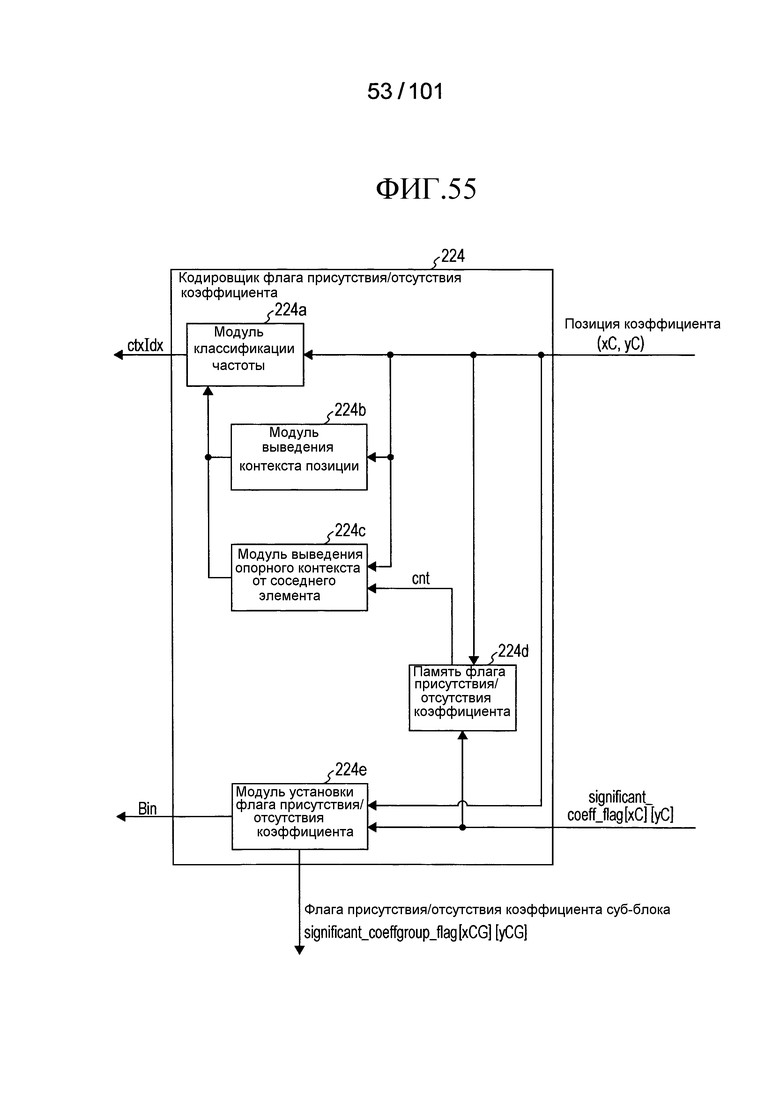
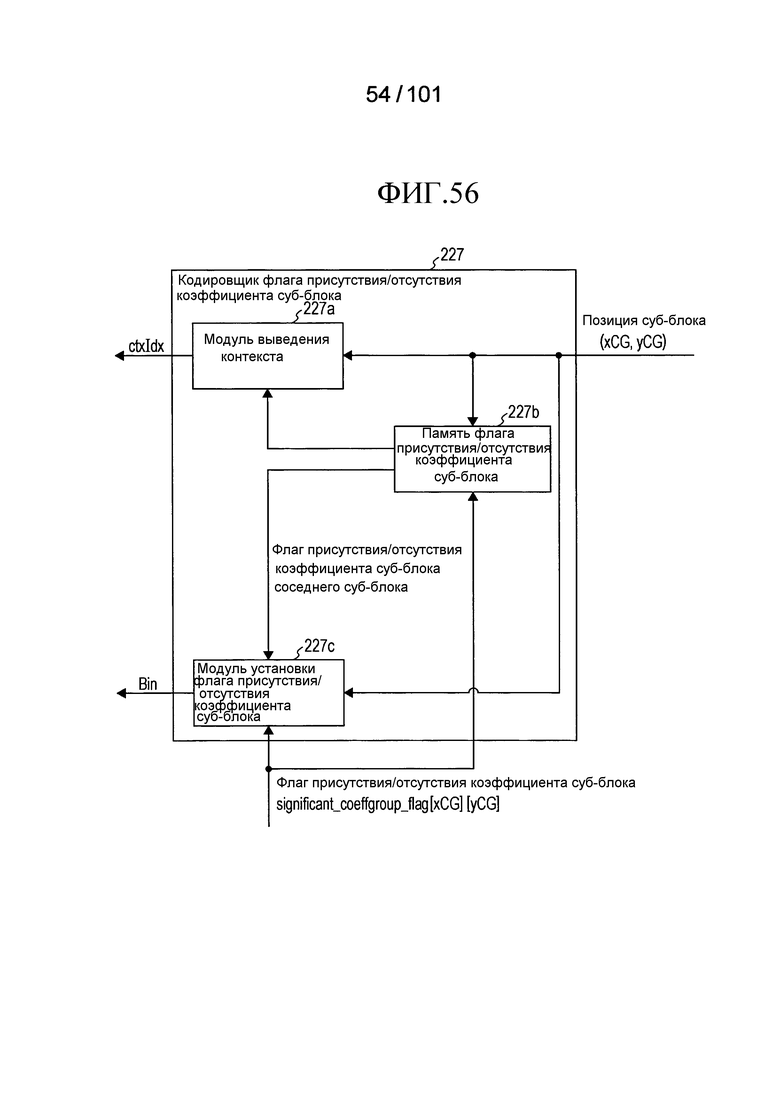
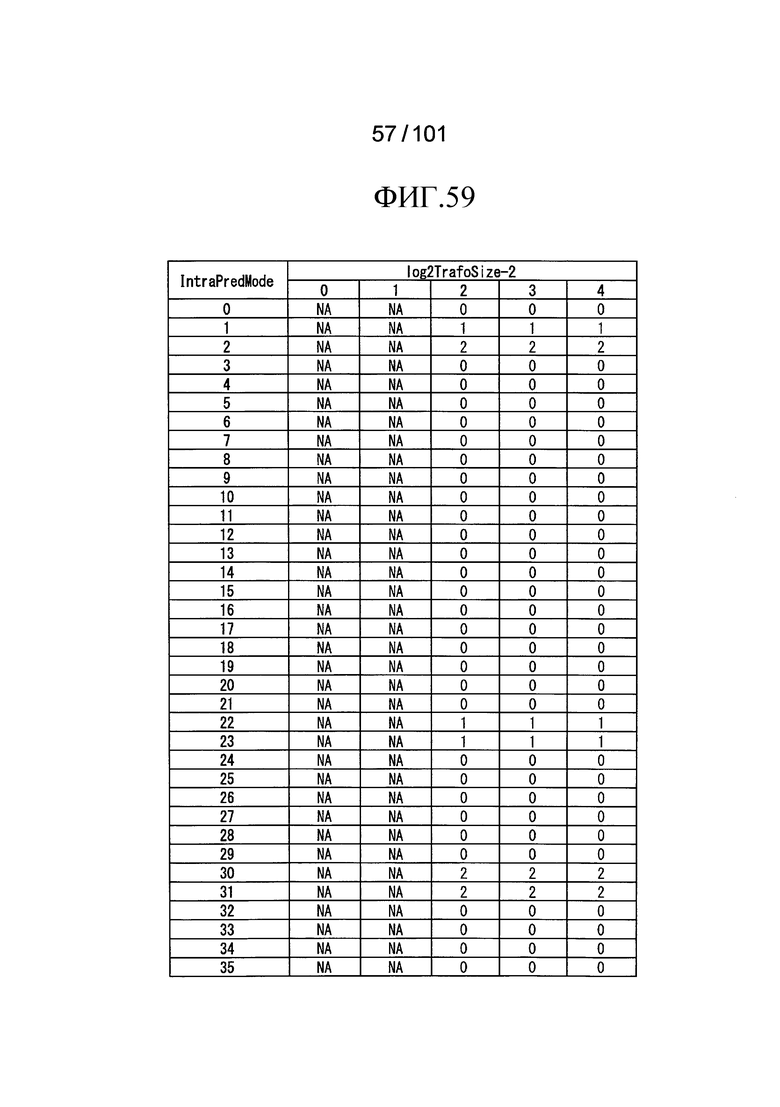

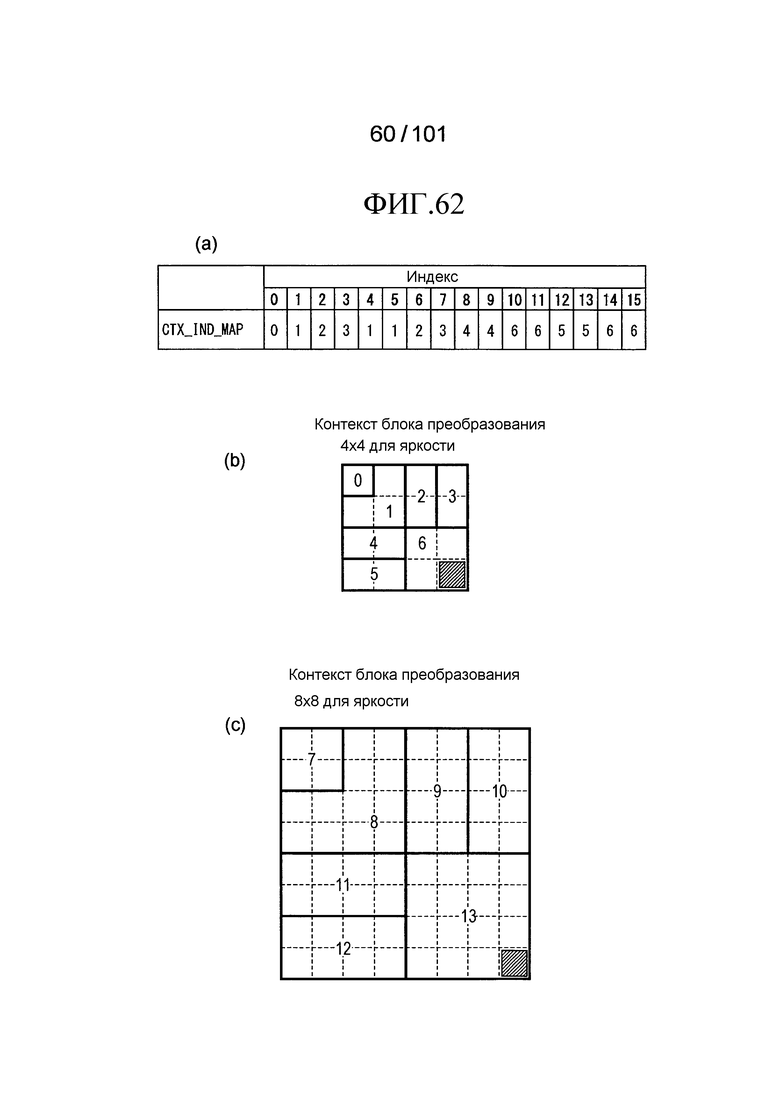
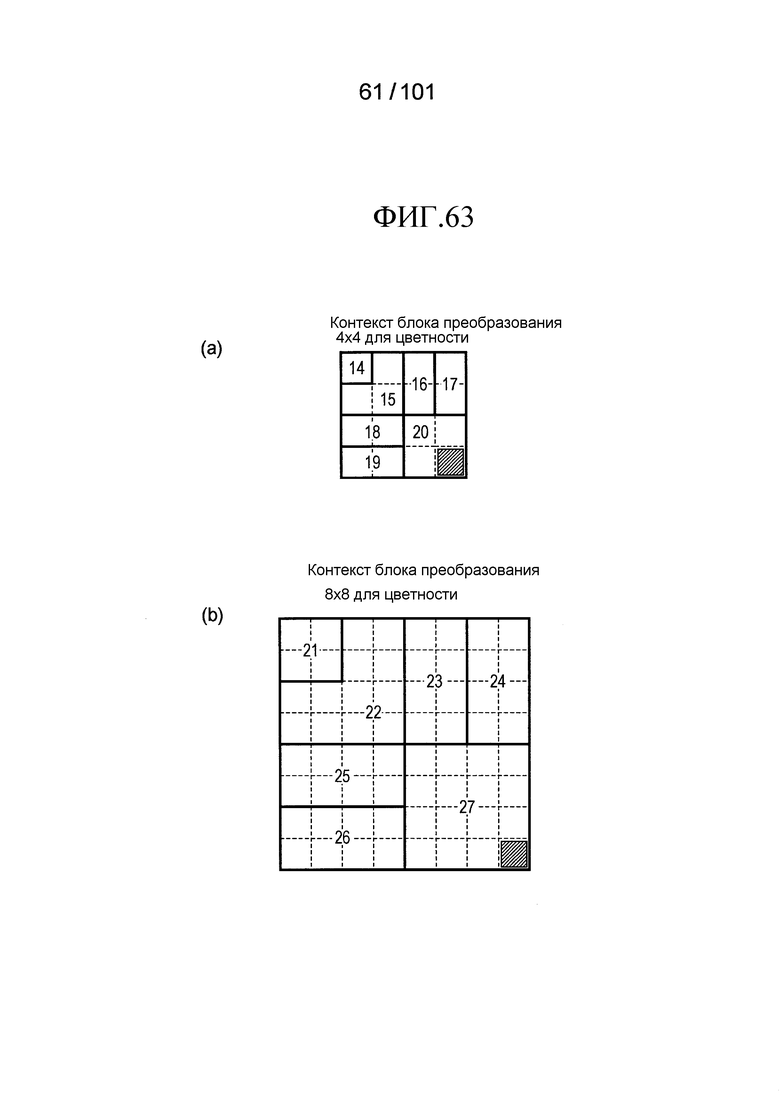
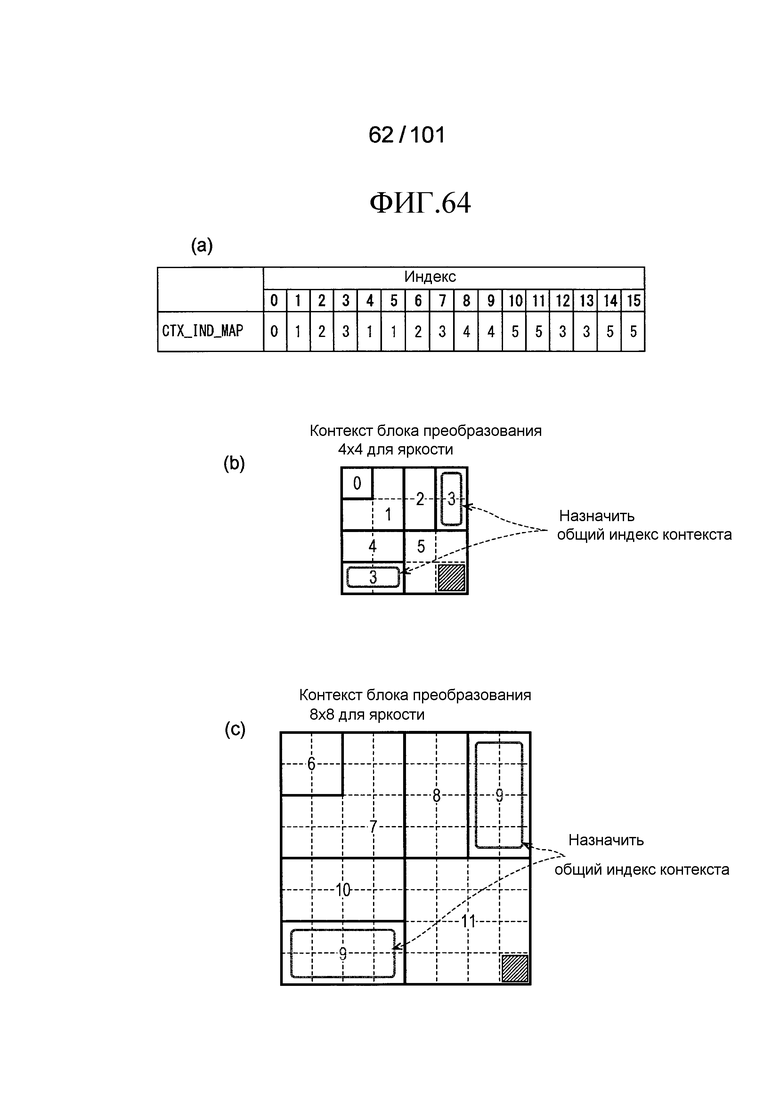
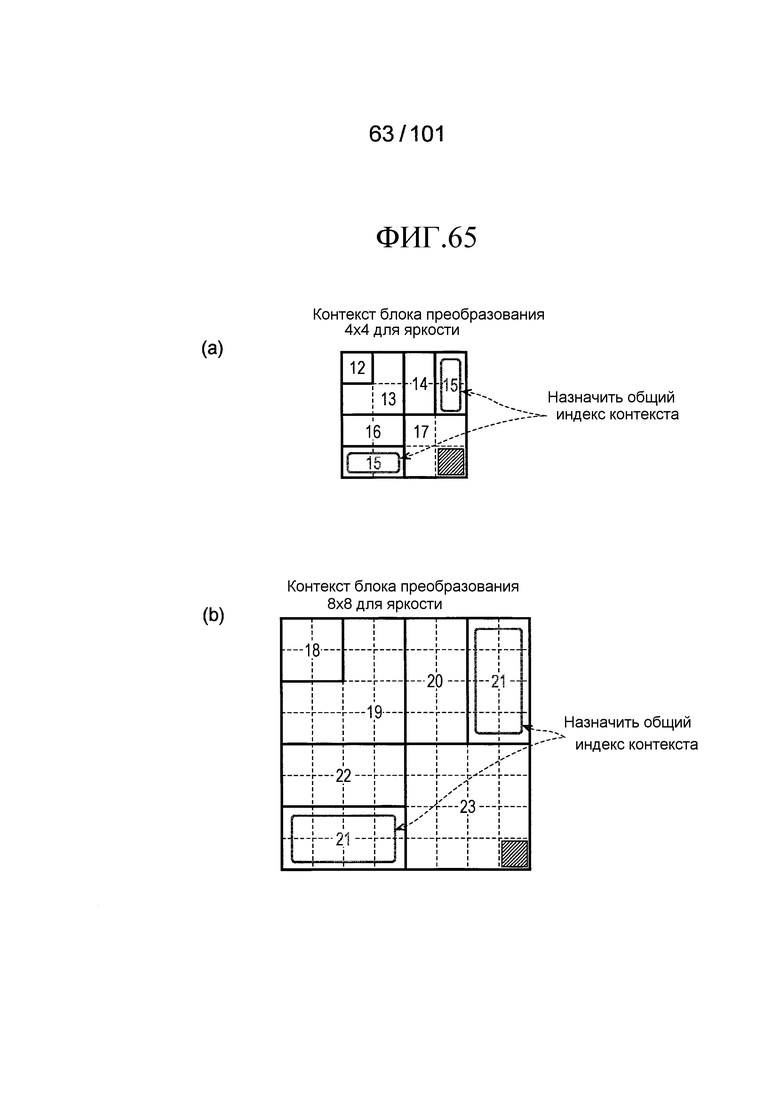

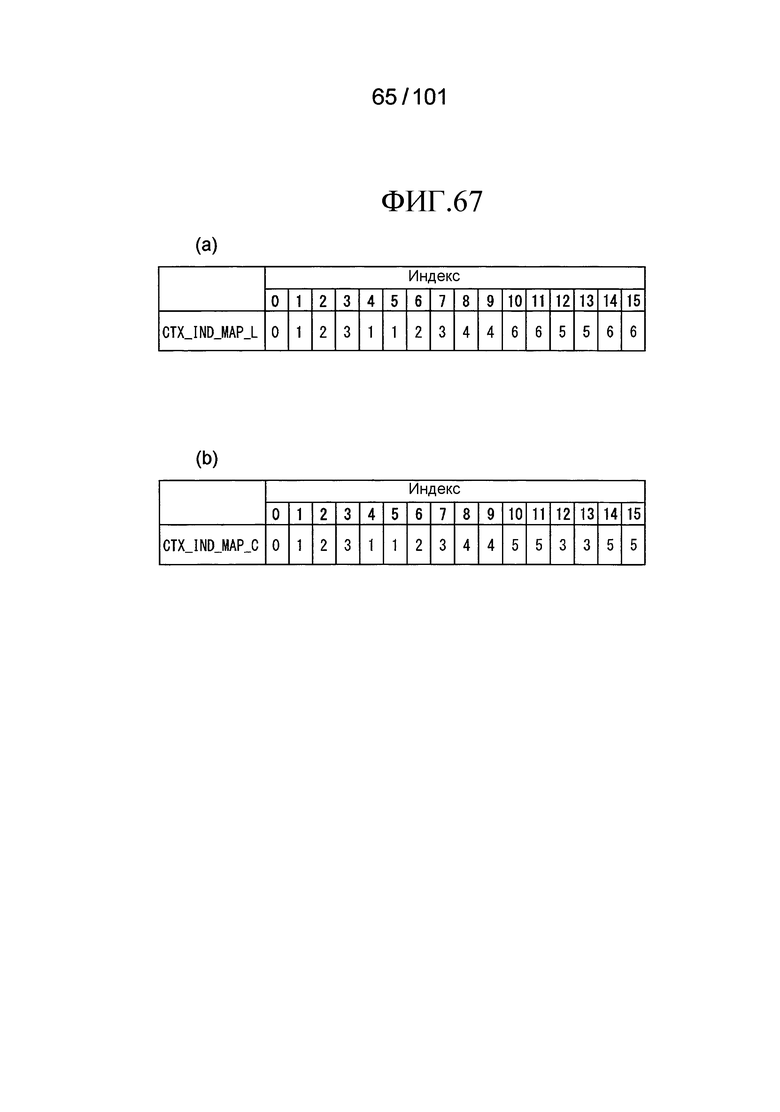
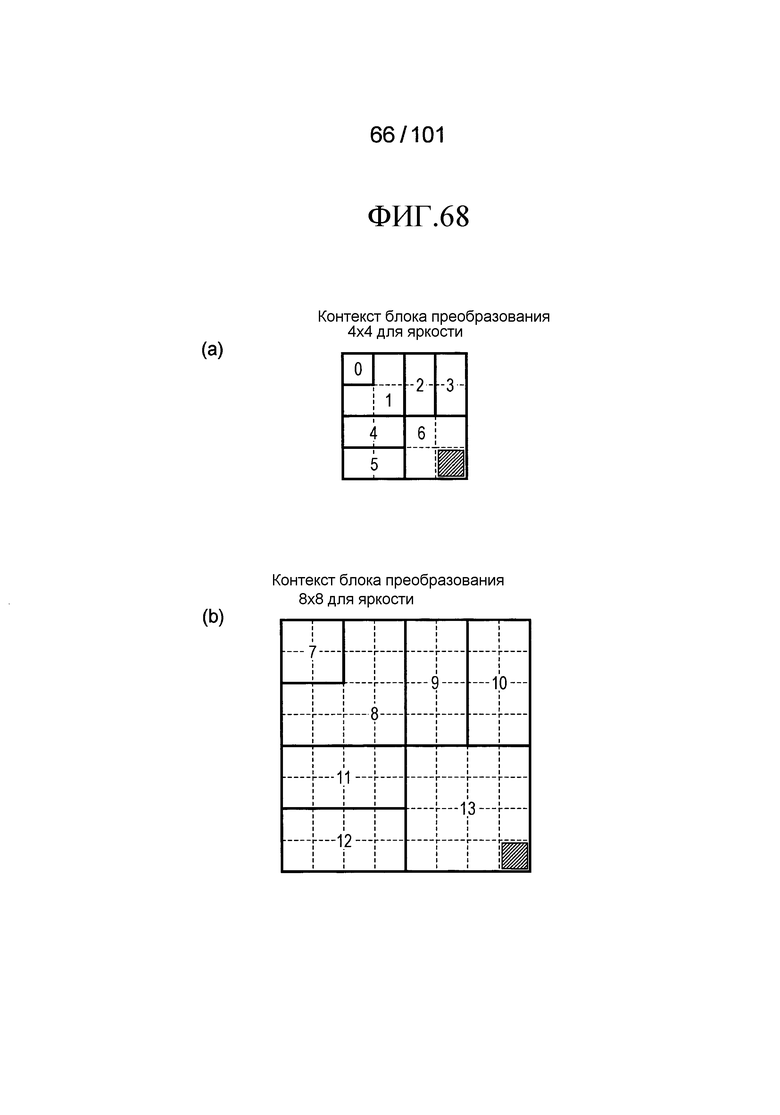
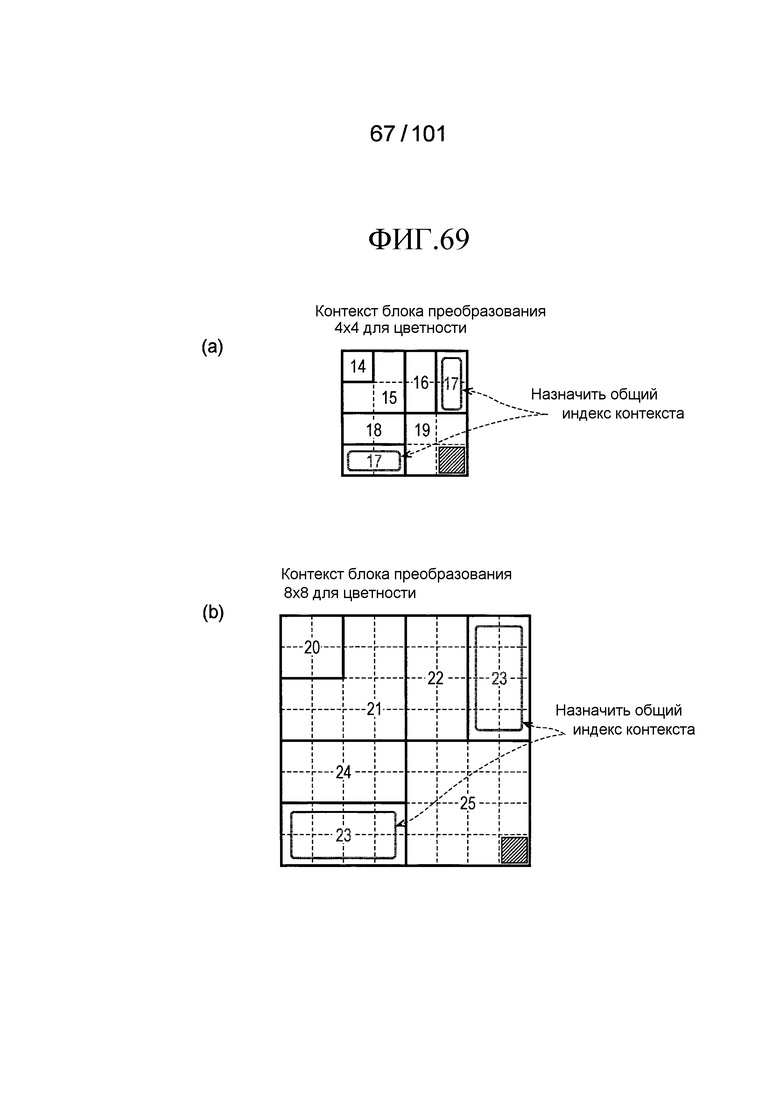
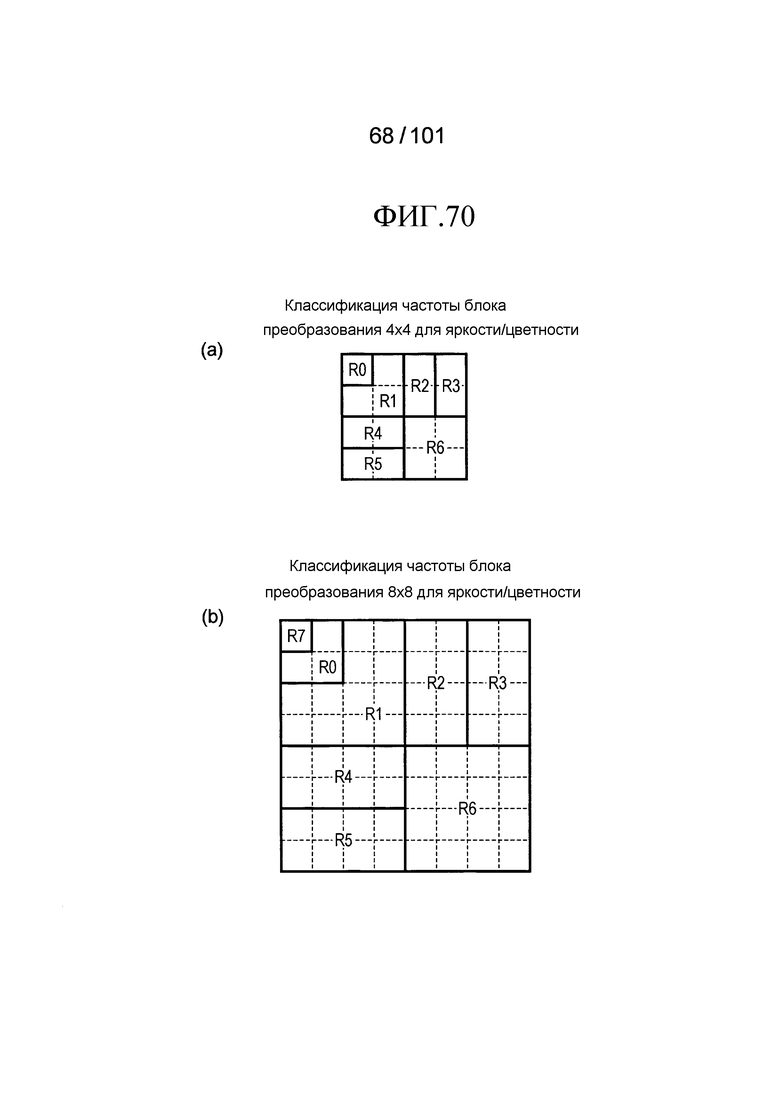
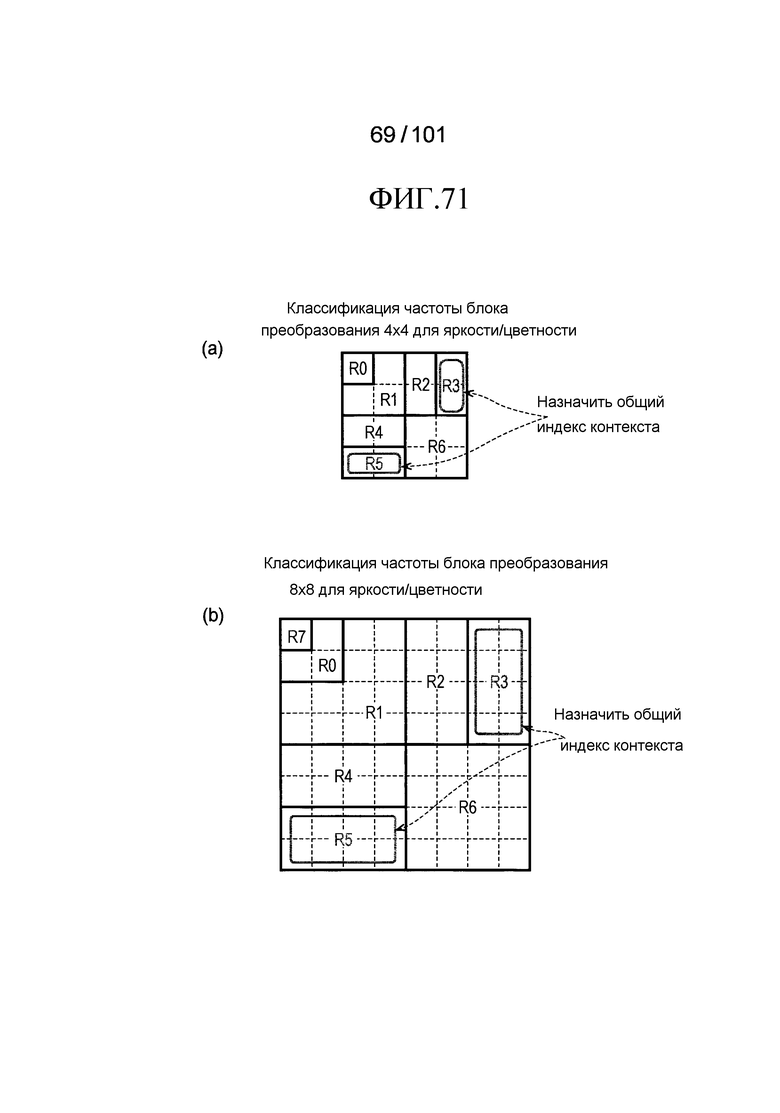
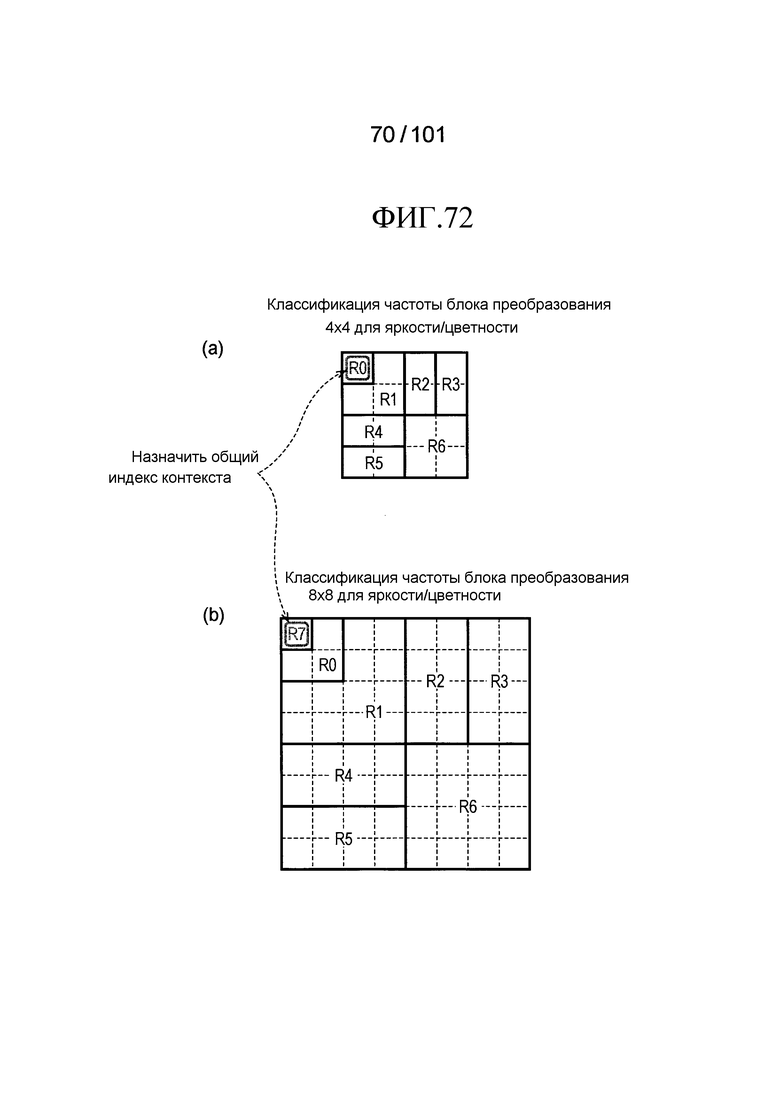
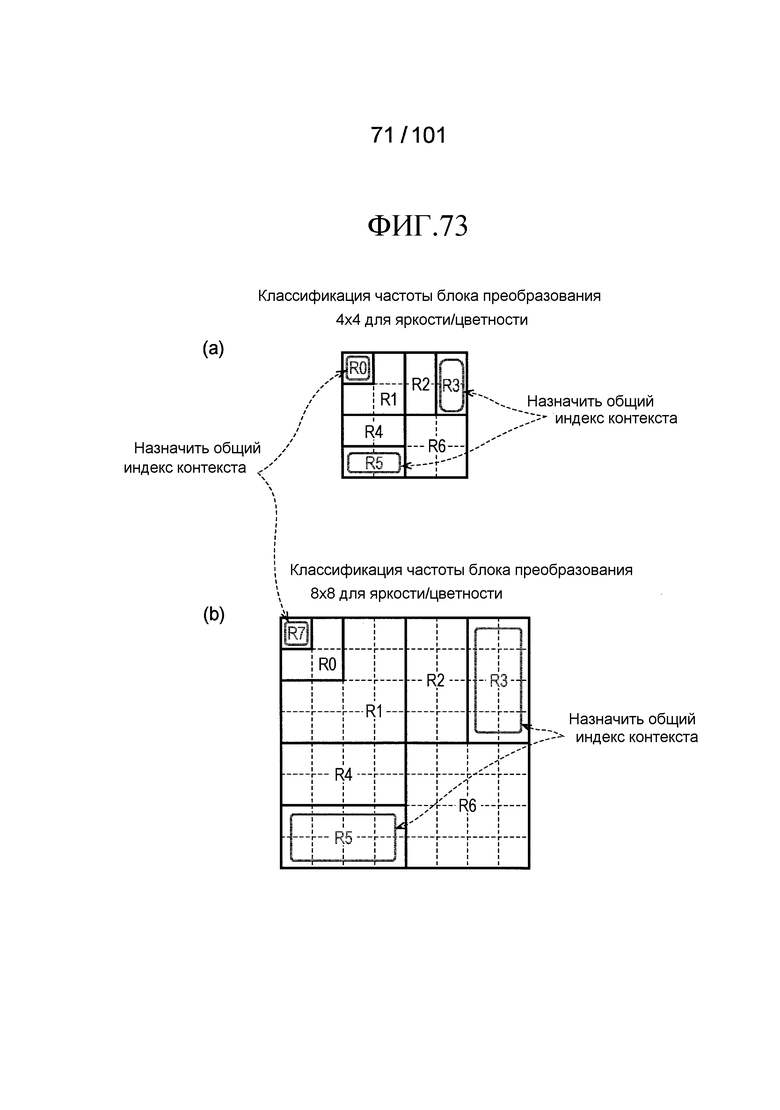

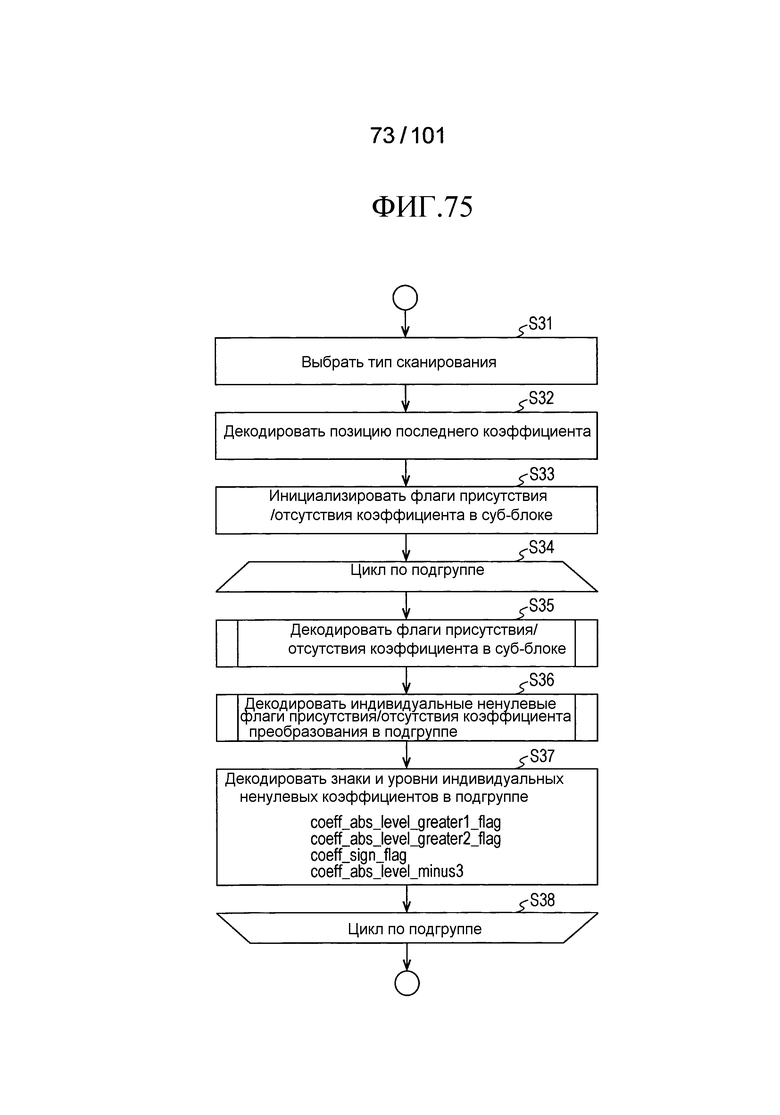
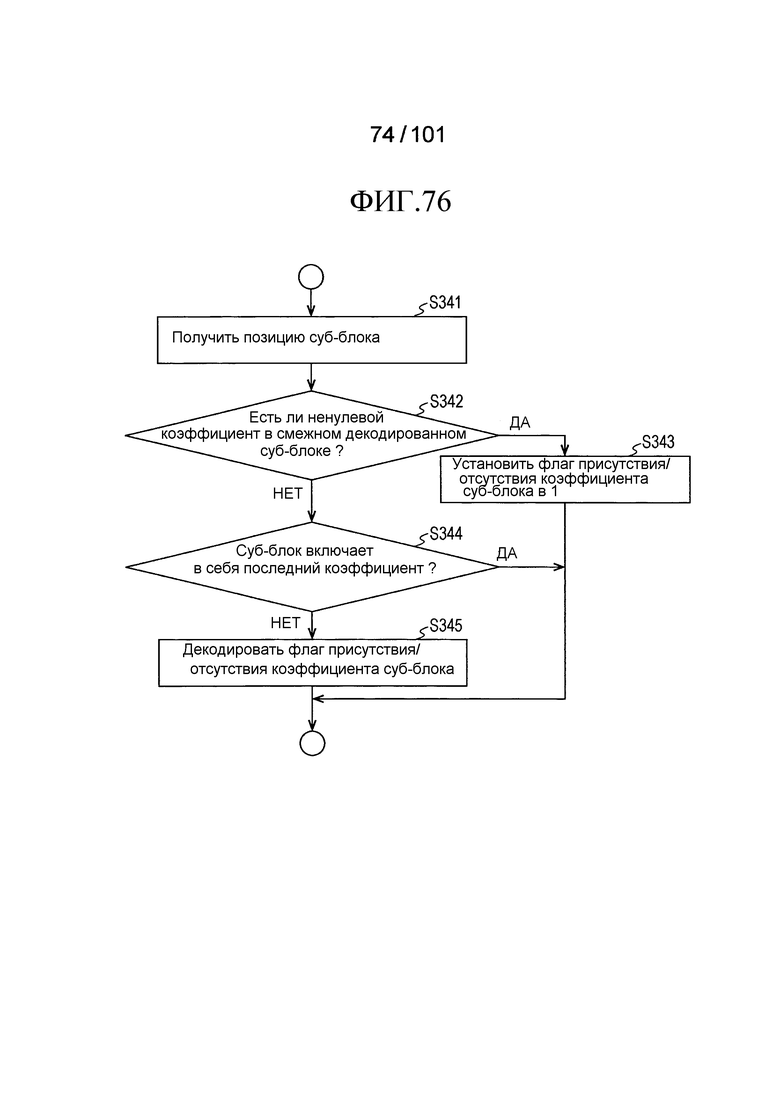
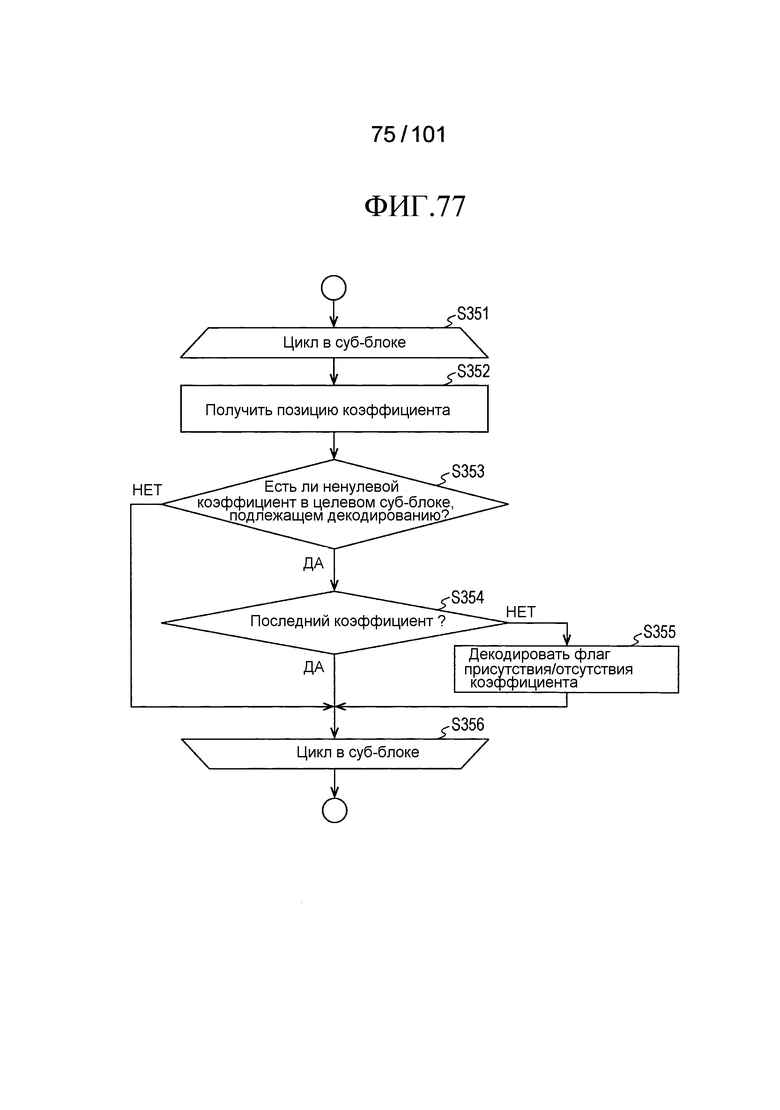
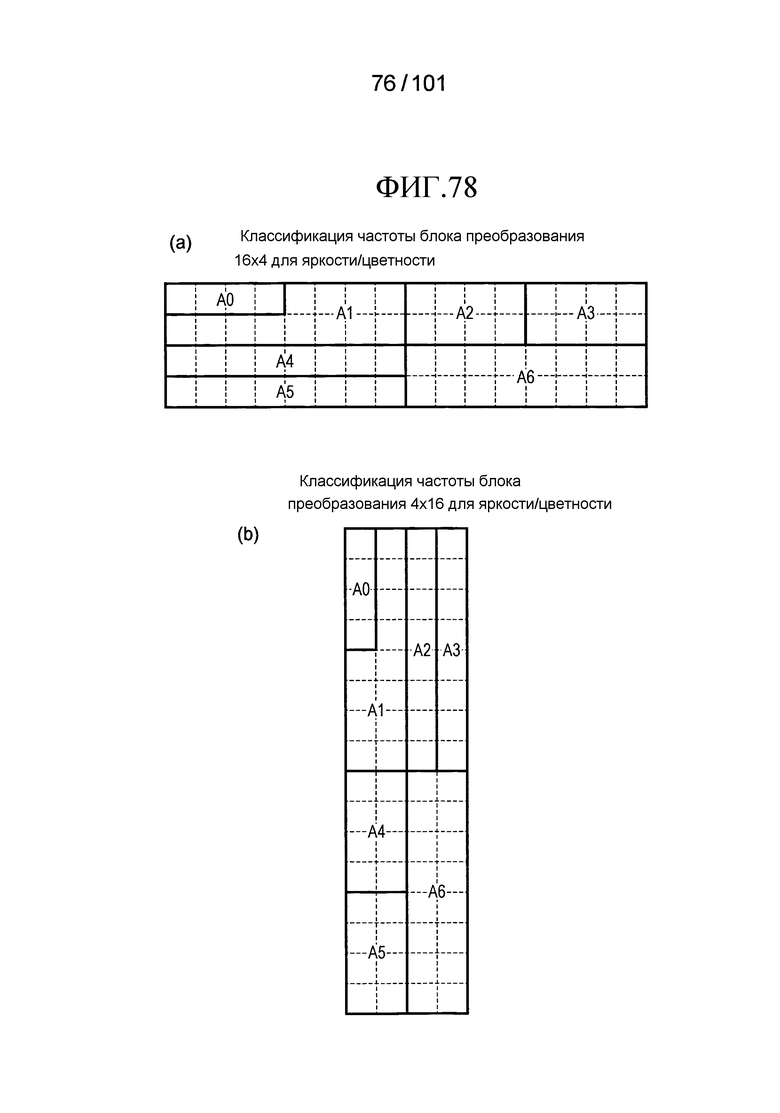
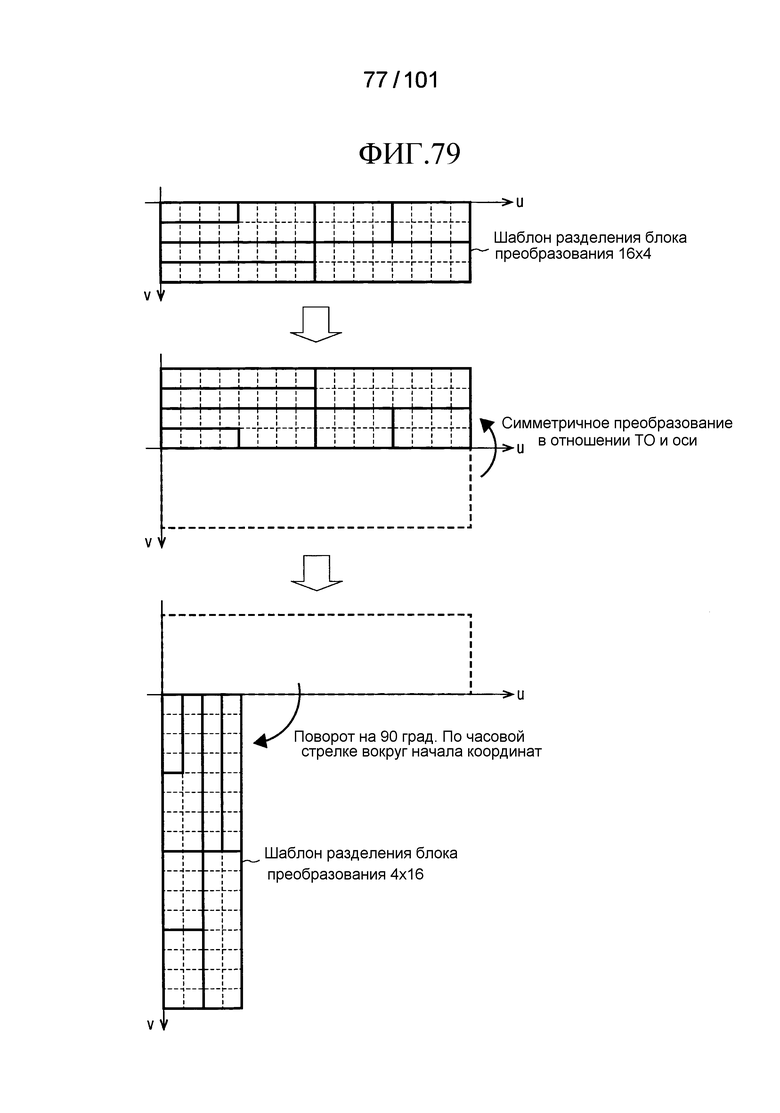

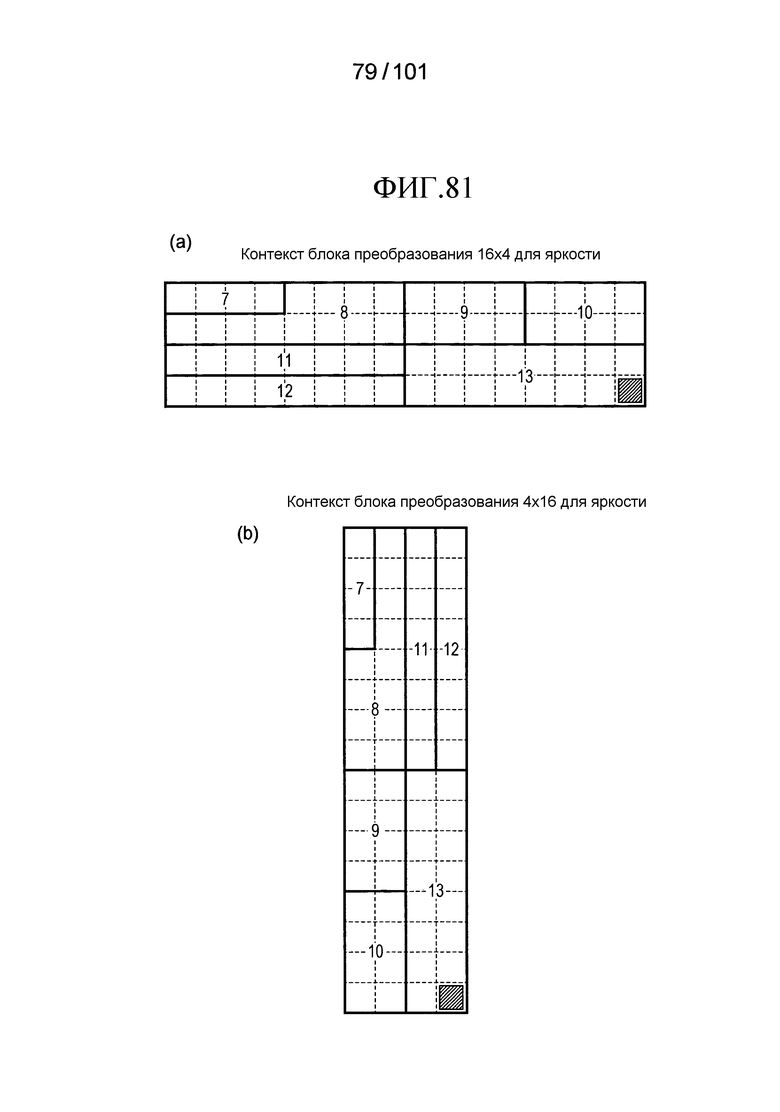
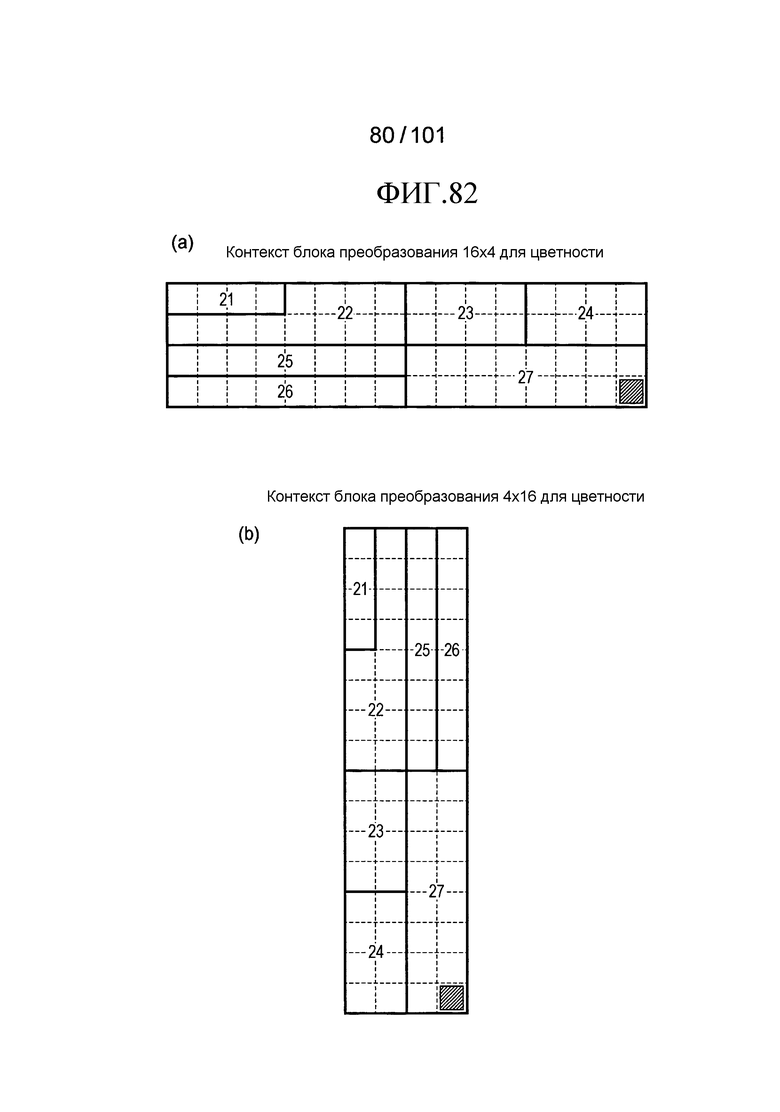

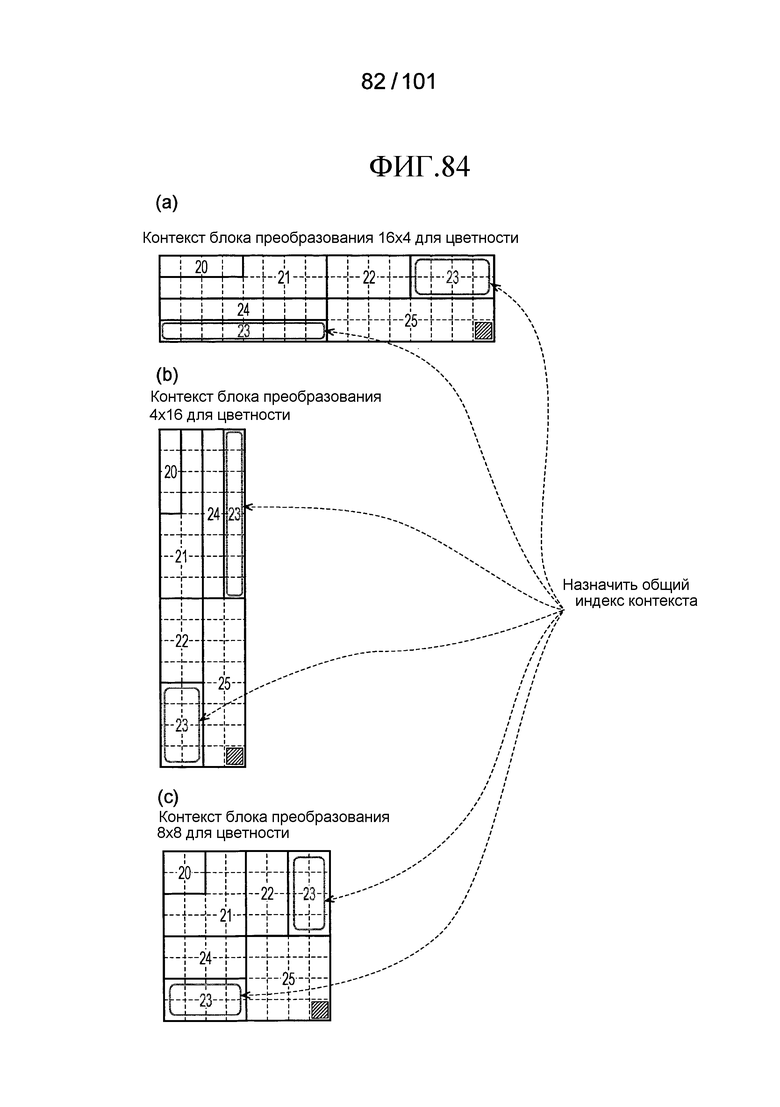

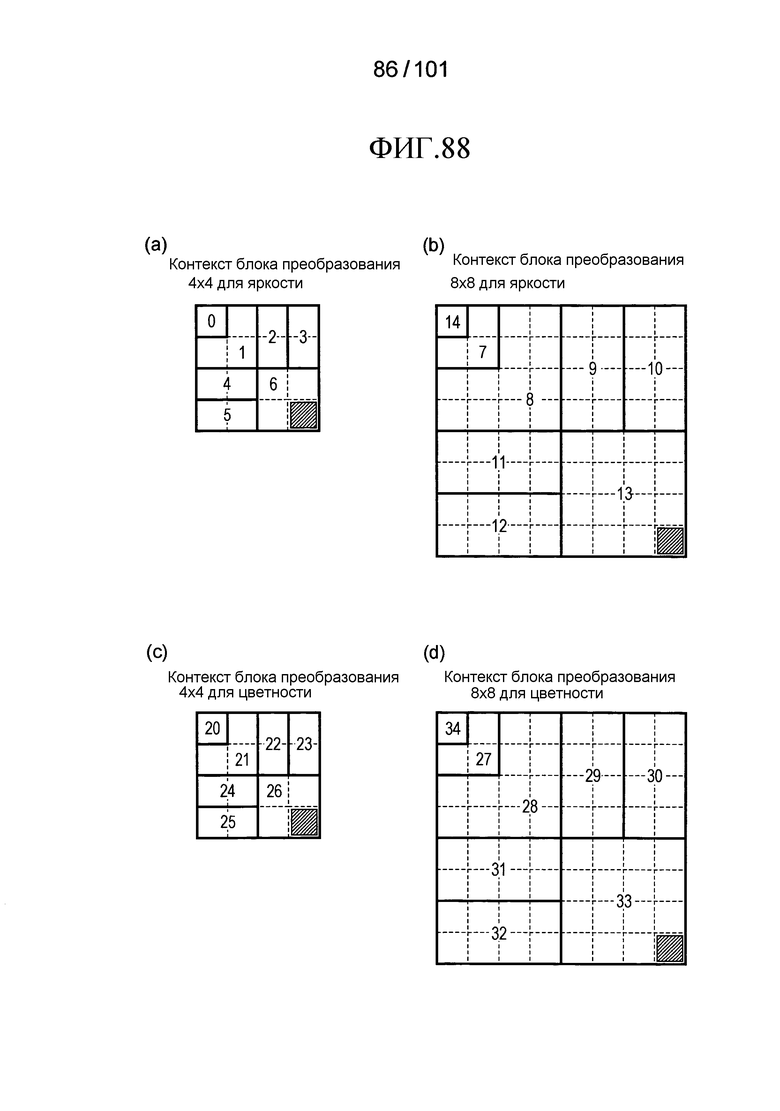

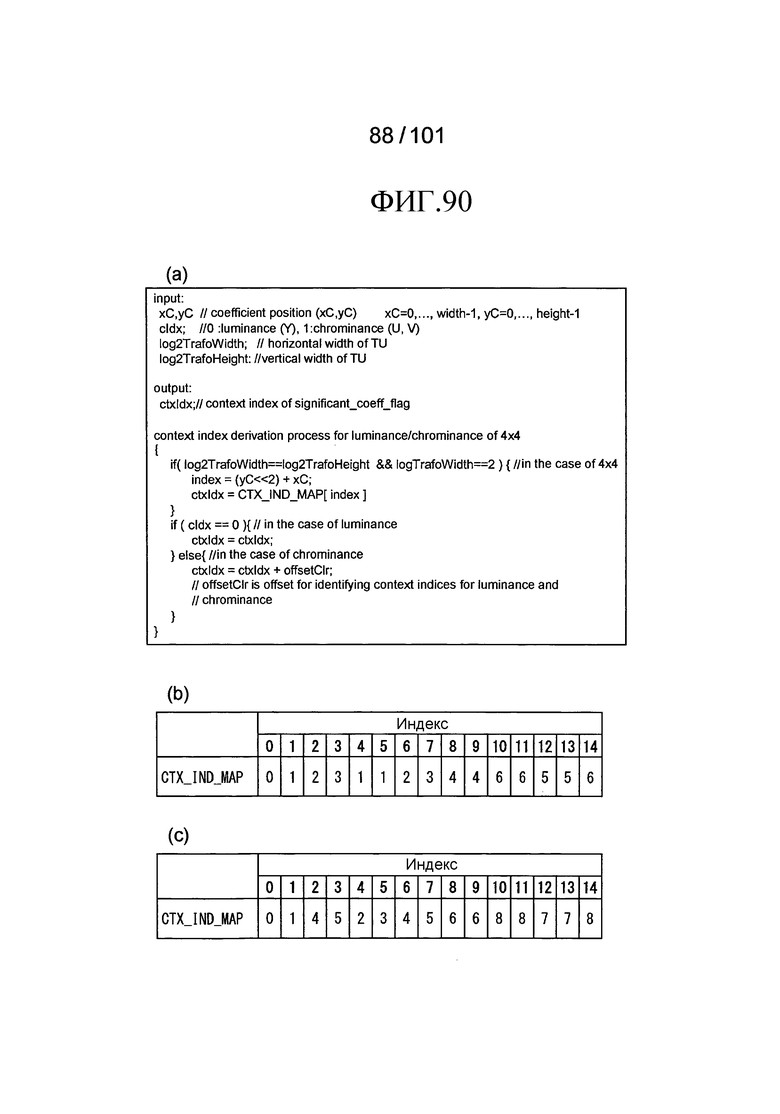

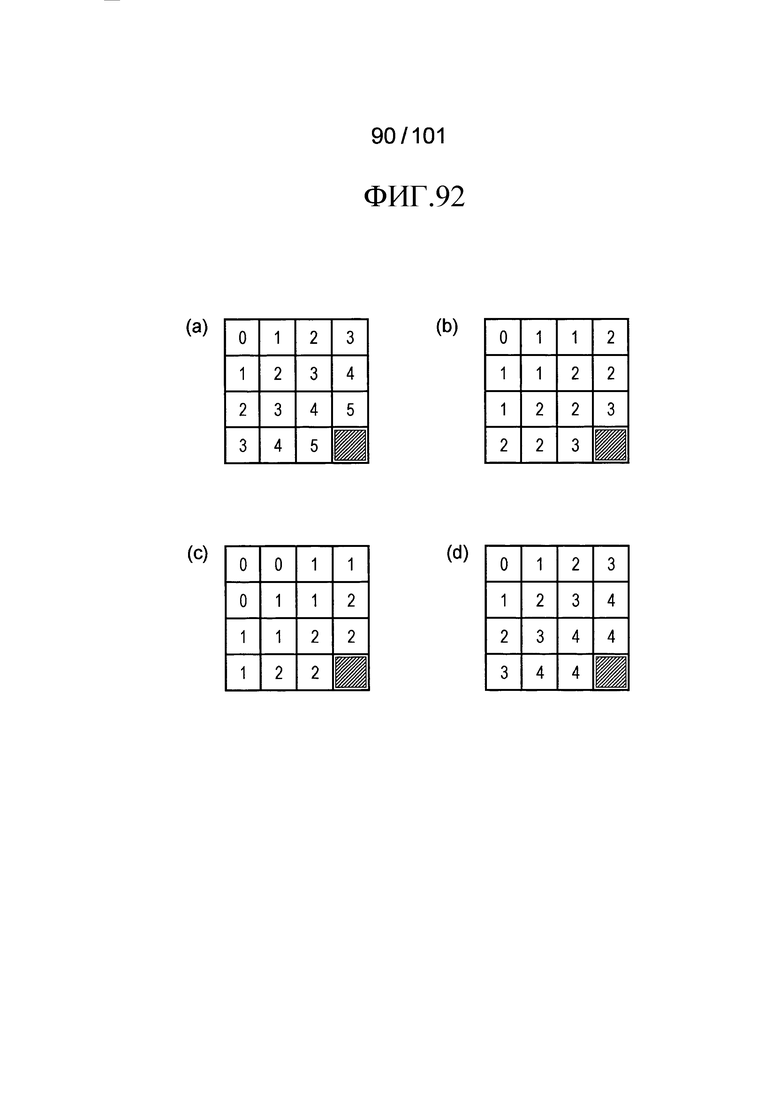
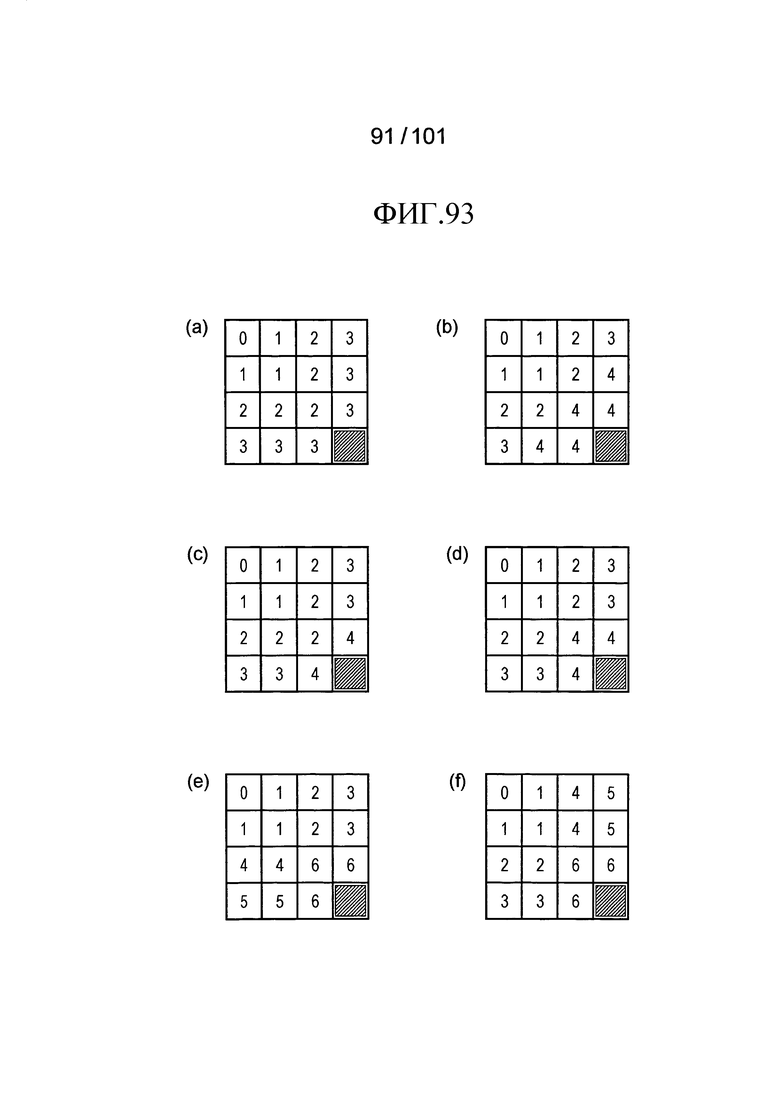
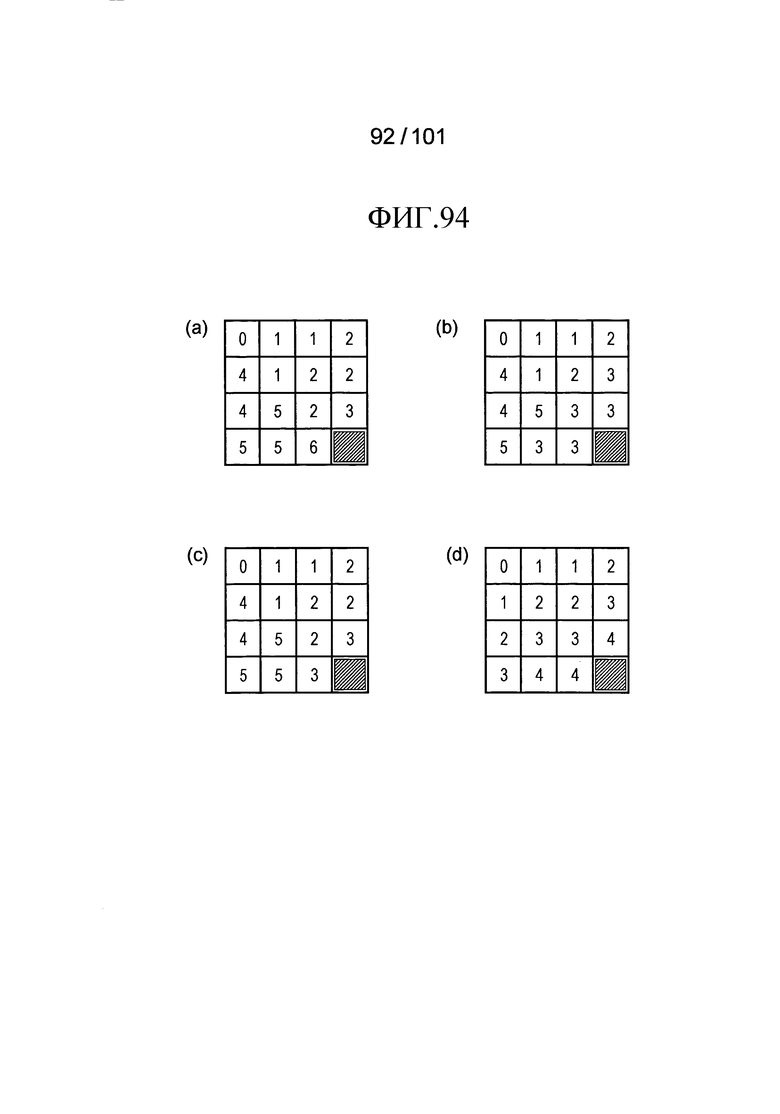
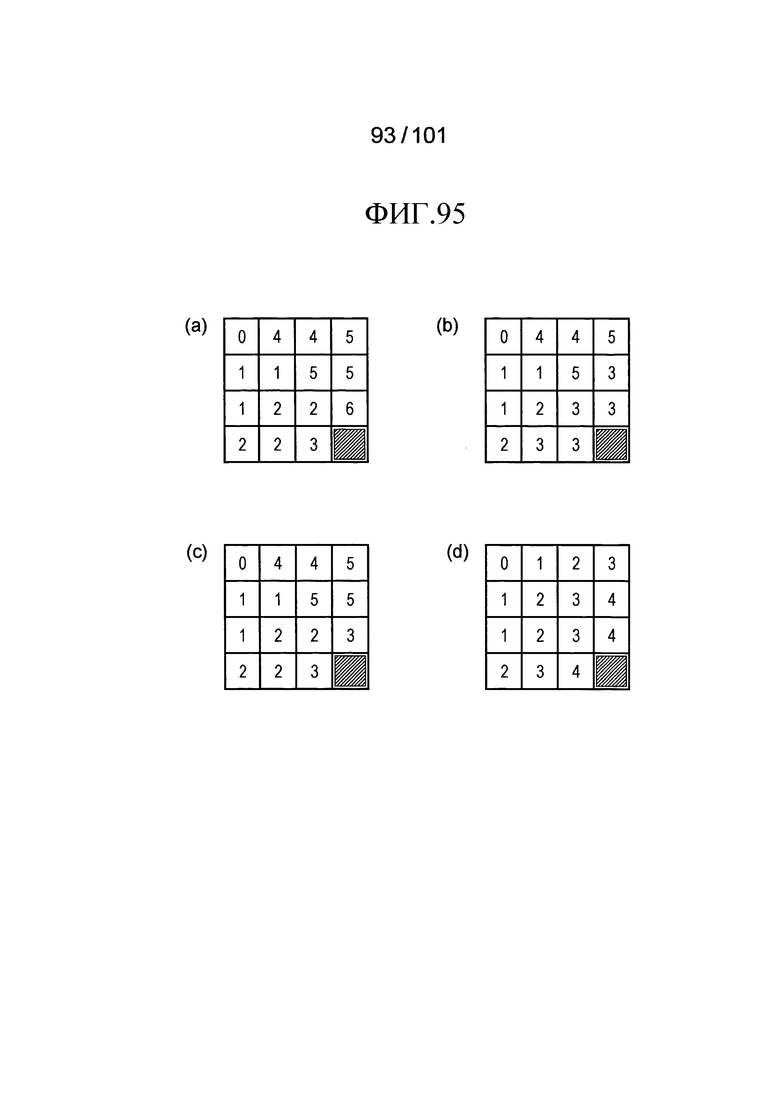
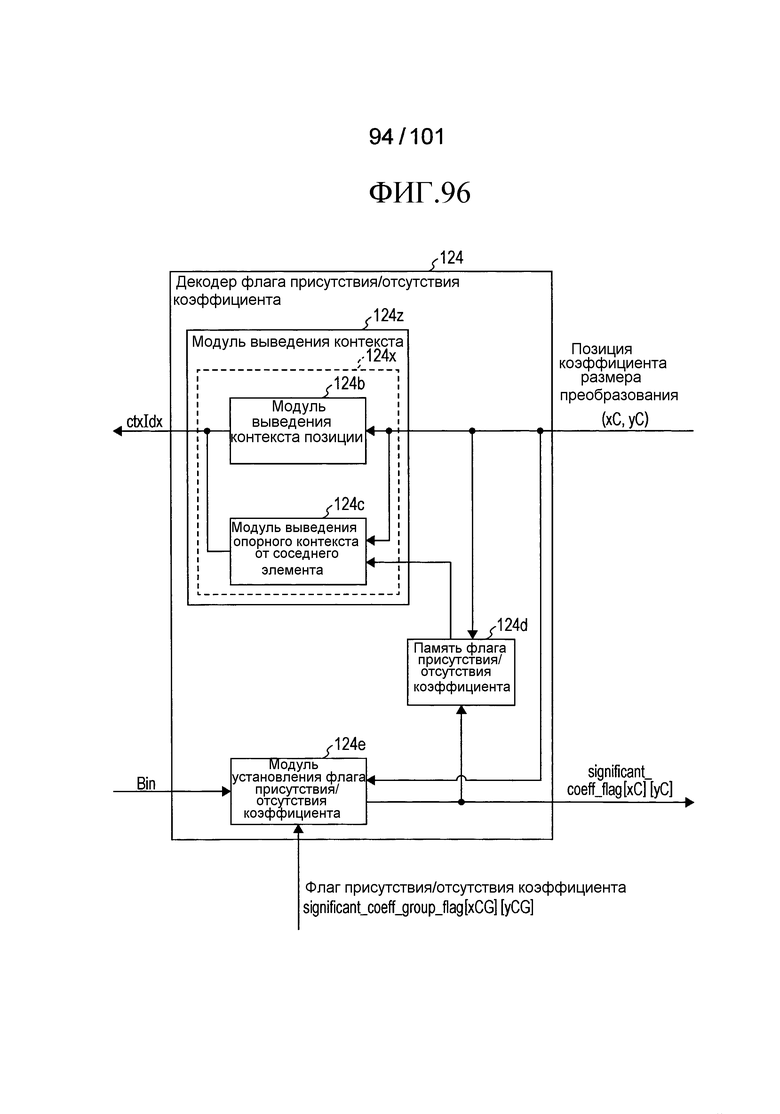
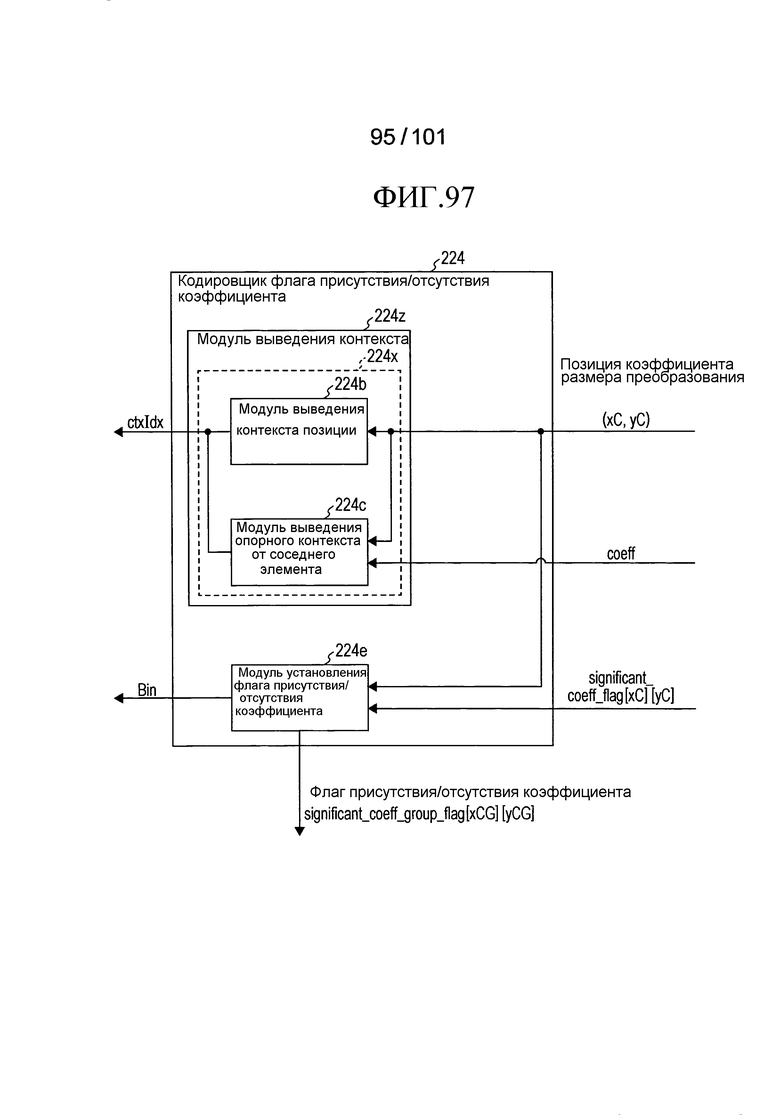
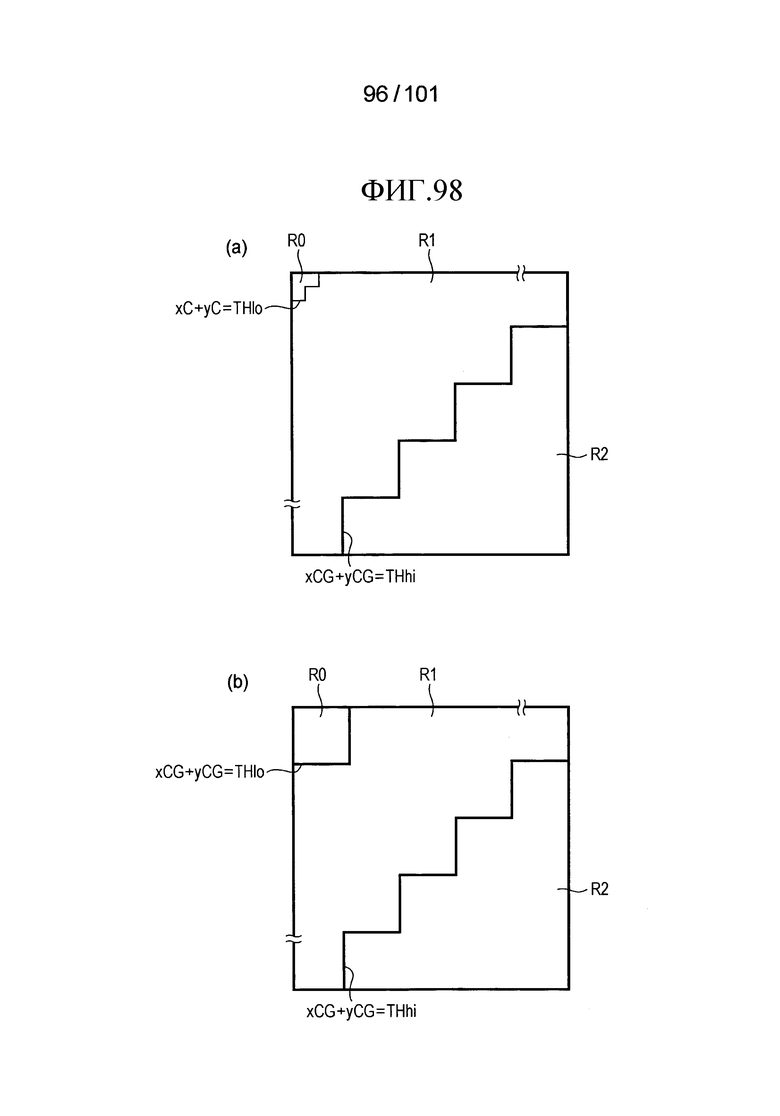
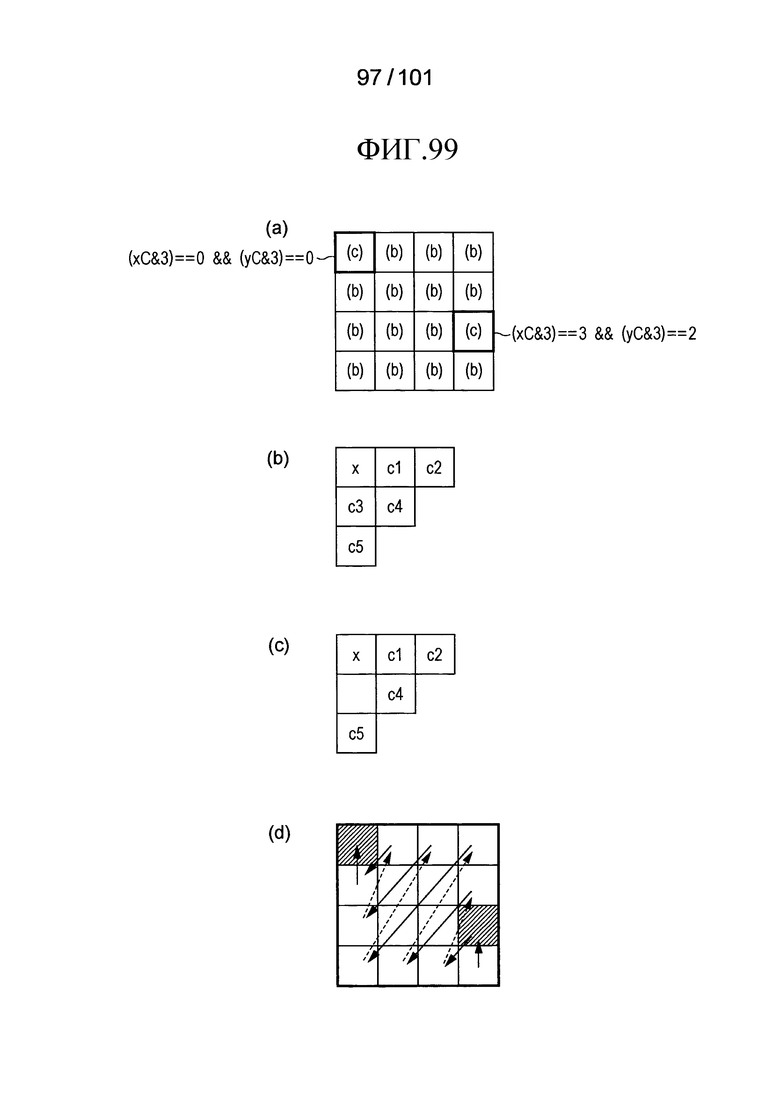

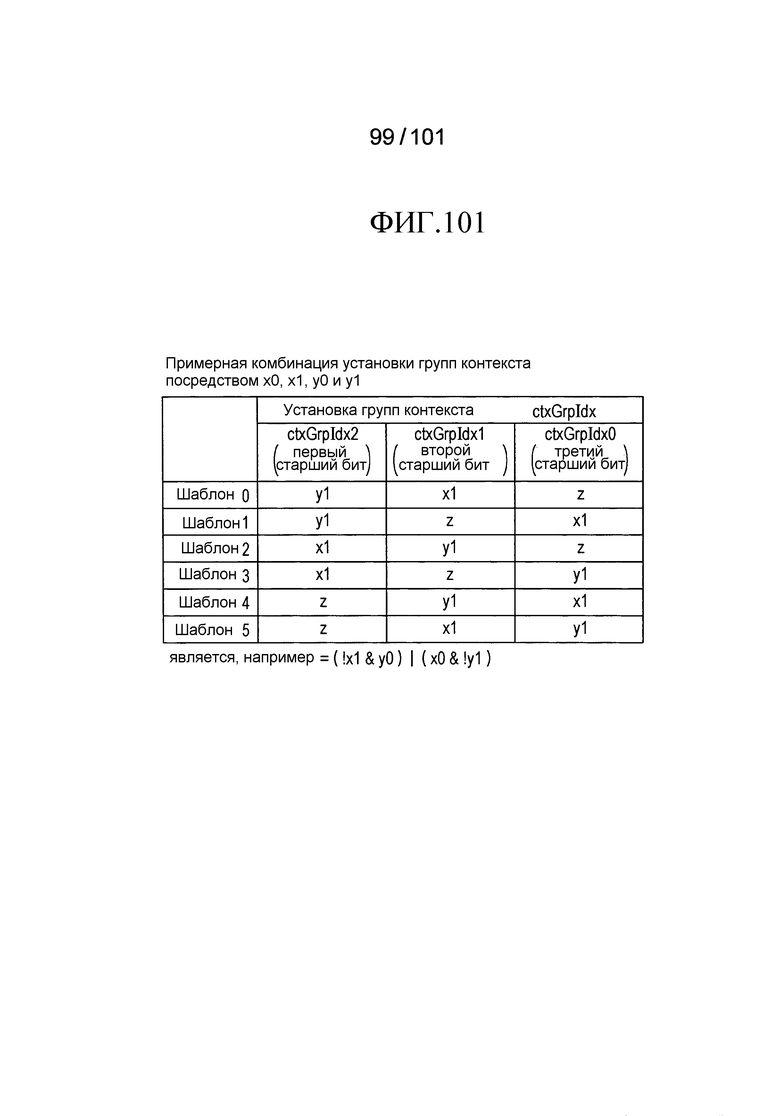
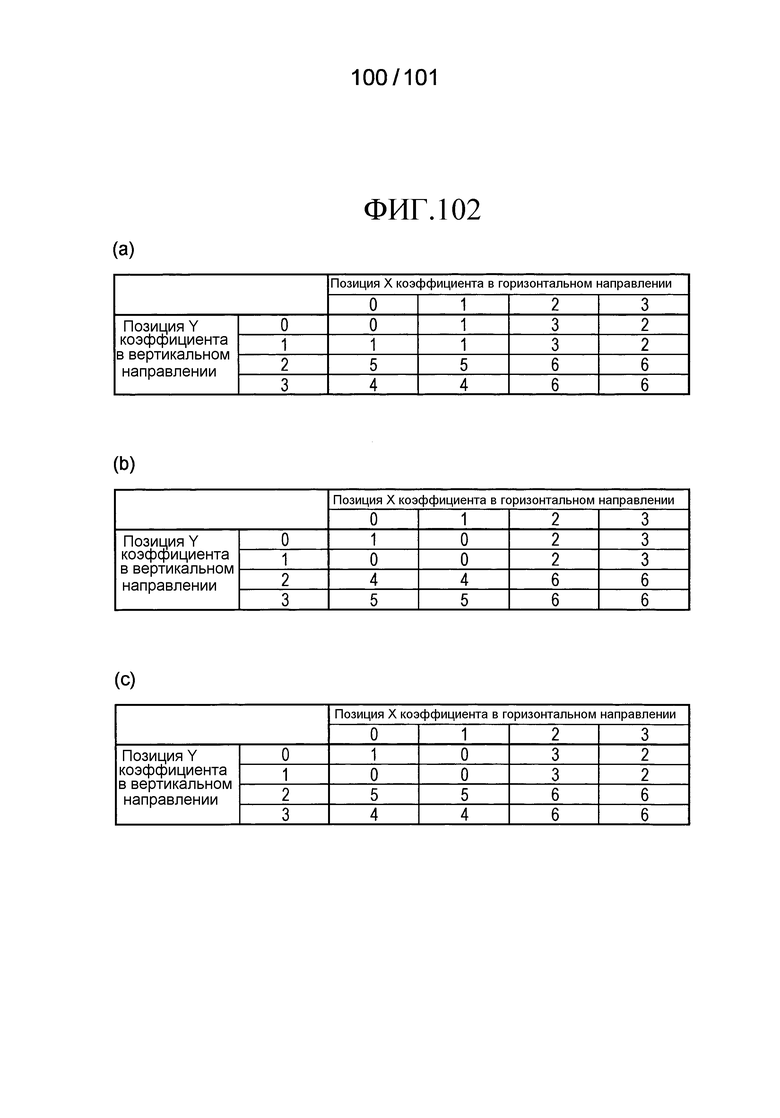
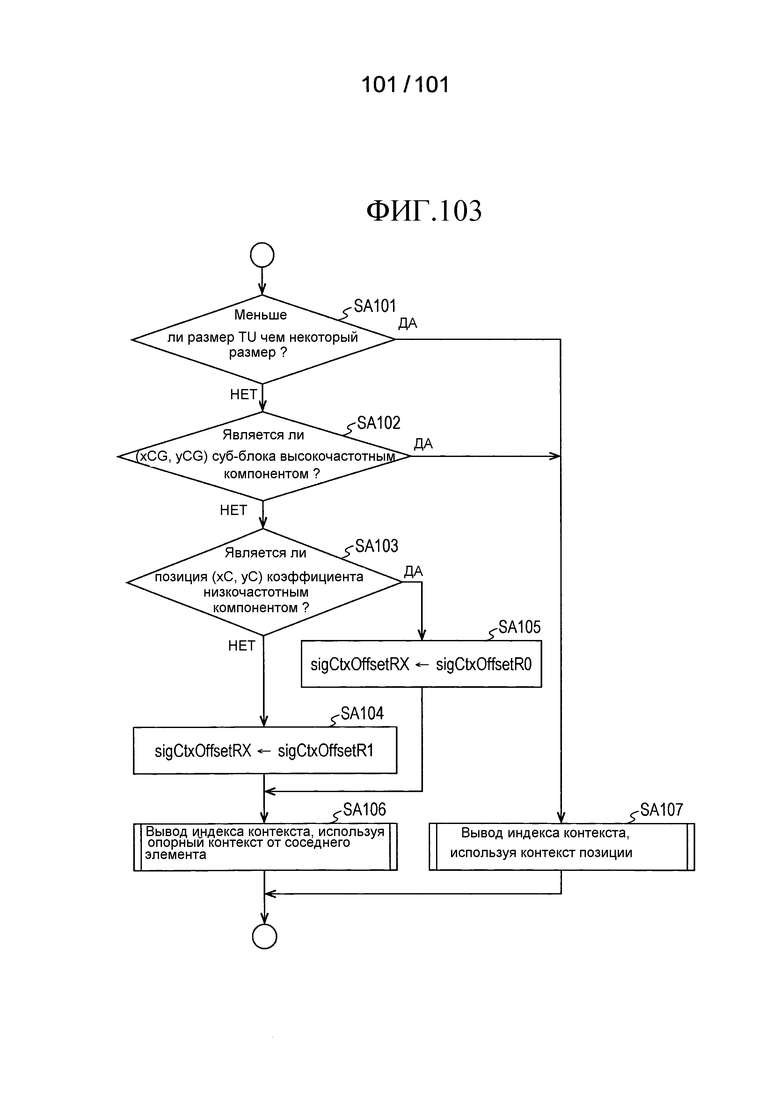
Группа изобретений относится к технологиям арифметического кодирования/декодирования данных. Техническим результатом является повышение эффективности арифметического кодирования/декодирования данных. Предложено устройство арифметического декодирования, которое декодирует закодированные данные для каждой из единичных областей целевого изображения. Устройство содержит модуль выведения индекса контекста, модуль декодирования синтаксиса. Модуль выведения индекса контекста сконфигурирован для вывода индексов контекста флагов присутствия/отсутствия коэффициента преобразования, указывающих, является ли коэффициент преобразования равным 0, для каждой из единичных областей. Модуль декодирования синтаксиса сконфигурирован для арифметического декодирования флагов присутствия/отсутствия коэффициента преобразования на основании состояния вероятности, обозначенного выведенными индексами контекста. 3 н. и 3 з.п. ф-лы, 103 ил.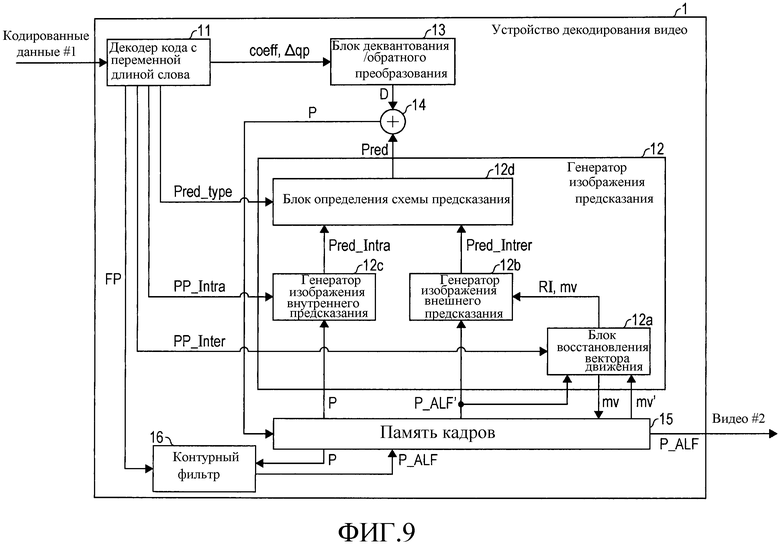
1. Устройство арифметического декодирования, которое декодирует закодированные данные для каждой из единичных областей целевого изображения, содержащее:
модуль выведения индекса контекста, сконфигурированный, чтобы вывести индексы контекста флагов присутствия/отсутствия коэффициента преобразования, указывающих, является ли коэффициент преобразования равным 0, для каждой из единичных областей; и
модуль декодирования синтаксиса, сконфигурированный для арифметического декодирования флагов присутствия/отсутствия коэффициента преобразования на основании состояния вероятности, обозначенного выведенными индексами контекста,
при этом модуль выведения индекса контекста сконфигурирован, чтобы установить:
первое общее значение равным индексу контекста только для флага присутствия/отсутствия коэффициента преобразования, который принадлежит компоненту DC яркости для всех размеров единичных областей; и
второе общее значение равным индексу контекста только для флага присутствия/отсутствия коэффициента преобразования, который принадлежит компоненту DC цветности для всех размеров единичных областей.
2. Устройство арифметического декодирования по п. 1, в котором индекс контекста выводится на основании позиции коэффициента преобразования.
3. Устройство арифметического декодирования по п. 1, в котором модуль выведения индекса контекста сконфигурирован, чтобы вывести индексы контекста для флагов присутствия/отсутствия коэффициента преобразования посредством суммирования заранее определенного смещения с опорным значением таблицы поиска.
4. Устройство арифметического декодирования по п. 1, в котором первое общее значение равно 0 и второе общее значение отличается от упомянутого первого общего значения.
5. Способ арифметического декодирования для декодирования закодированных данных для каждой из единичных областей целевого изображения, содержащий этапы, на которых:
выводят индексы контекста флагов присутствия/отсутствия коэффициента преобразования, указывающих, является ли коэффициент преобразования равным 0, для каждой из единичных областей; и
выполняют арифметическое декодирование флагов присутствия/отсутствия коэффициента преобразования на основании состояния вероятности, обозначенного выведенными индексами контекста,
устанавливают первое общее значение равным индексу контекста только для флага присутствия/отсутствия коэффициента преобразования, который принадлежит компоненту DC яркости для всех размеров единичных областей, и
устанавливают второе общее значение равным индексу контекста только для флага присутствия/отсутствия коэффициента преобразования, который принадлежит компоненту DC цветности для всех размеров единичных областей.
6. Устройство арифметического кодирования, которое генерирует закодированные данные для каждой из единичных областей целевого изображения, содержащее:
модуль выведения индекса контекста, сконфигурированный, чтобы вывести индексы контекста флагов присутствия/отсутствия коэффициента преобразования, указывающих, является ли коэффициент преобразования равным 0 для каждой из единичных областей; и
модуль кодирования синтаксиса, сконфигурированный, чтобы выполнить арифметическое кодирование флагов присутствия/отсутствия коэффициента преобразования на основании состояния вероятности, обозначенного выведенными индексами контекста,
в котором модуль выведения индекса контекста сконфигурирован, чтобы установить:
первое общее значение равным индексу контекста только для флага присутствия/отсутствия коэффициента преобразования, который принадлежит компоненту DC яркости для всех размеров единичных областей; и
второе общее значение равным индексу контекста только для флага присутствия/отсутствия коэффициента преобразования, который принадлежит компоненту DC цветности для всех размеров единичных областей.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 5903676 A, 11.05.1999 | |||
| СПОСОБ И УСТРОЙСТВО АДАПТИВНОГО ВЫБОРА КОНТЕКСТНОЙ МОДЕЛИ ДЛЯ КОДИРОВАНИЯ ПО ЭНТРОПИИ | 2006 |
|
RU2336661C2 |
| АДАПТИВНЫЙ ПОРЯДОК СКАНИРОВАНИЯ КОЭФФИЦИЕНТОВ | 2005 |
|
RU2404534C2 |

