ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится в целом к вычислительным системам, а точнее к системам и способам обработки естественного языка.
УРОВЕНЬ ТЕХНИКИ
[0002] Различные задачи обработки естественного языка могут включать классификацию текстов на естественном языке. К примерам таких задач относятся выявление семантического сходства, ранжирование результатов поиска, определение авторства текста, фильтрация спама, выбор текстов для контекстной рекламы и т.д.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более аспектами настоящего изобретения пример способа классификации текстов на естественном языке может включать выполнение с помощью вычислительной системы семантико-синтаксического анализа текста на естественном языке для создания семантической структуры, включающей набор семантических классов; связывание первого семантического класса из набора семантических классов с первым значением, отражающим значение некоторого атрибута семантического класса; выявление второго семантического класса, связанного с первым семантическим классом заданными семантическими отношениями; связывание второго семантического класса со вторым значением, отражающим указанный атрибут семантического класса, при этом второе значение определяется применением заданной трансформации к первому значению; вычисление признака текста на естественном языке на основе первого значения и второго значения; и определение с помощью модели классификатора с помощью вычисленного признака текста степени соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий.
[0004] В соответствии с одним или более аспектами настоящего изобретения пример системы классификации текстов на естественном языке может включать память и оперативно связанный с памятью процессор, настроенный на выполнение с помощью вычислительной системы семантико-синтаксического анализа текста на естественном языке для создания семантической структуры, включающей набор семантических классов; связывание первого семантического класса из набора семантических классов с первым значением, отражающим значение некоторого атрибута семантического класса; выявление второго семантического класса, связанного с первым семантическим классом заданными семантическими отношениями; связывание второго семантического класса со вторым значением, отражающим указанный атрибут семантического класса, при этом второе значение определяется применением заданной трансформации к первому значению; вычисление признака текста на естественном языке на основе первого значения и второго значения; и определение с помощью модели классификатора с помощью вычисленного признака текста степени соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий. В соответствии с одним или более аспектами настоящего изобретения пример постоянного машиночитаемого носителя для классификации текстов на естественном языке может содержать исполняемые команды, которые при выполнении их вычислительной системой заставляют эту вычислительную систему выполнять семантико-синтаксического анализ текста на естественном языке для создания семантической структуры, включающей набор семантических классов; связывание первого семантического класса из набора семантических классов с первым значением, отражающим значение некоторого атрибута семантического класса; выявление второго семантического класса, связанного с первым семантическим классом заданными семантическими отношениями; связывание второго семантического класса со вторым значением, отражающим указанный атрибут семантического класса, при этом второе значение определяется применением заданной трансформации к первому значению; вычисление признака текста на естественном языке на основе первого значения и второго значения; и определение с помощью модели классификатора с помощью вычисленного признака текста степени соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий.
[0005] Технический результат от внедрения изобретения состоит в получении системы классификации текстов на естественном языке, позволяющей выполнять классификацию текстов, в том числе, на различных языках, с наибольшей точностью, что обусловлено использованием для классификации не только лексических признаков, но и глубинных семантических признаков.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, но не ограничивается только ими, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
[0007] на Фиг. 1 показана блок-схема примера способа классификации текста на естественном языке на основе семантических признаков в соответствии с одним или более аспектами настоящего изобретения;
[0008] на Фиг. 2 показана блок-схема примера способа для определения значений параметров извлечения признаков и (или) гиперпараметров модели классификатора текста в соответствии с одним или более аспектами настоящего изобретения;
[0009] на Фиг. 3 показана блок-схема примера оптимизации методом дифференциальной эволюции для оптимизации выбранной целевой функции с целью определения значений параметров извлечения признаков и (или) гиперпараметров модели классификатора текста в соответствии с одним или более аспектами настоящего изобретения;
[00010] на Фиг. 4 показана блок-схема примера способа выполнения семантико-синтаксического анализа предложения на естественном языке 212 в соответствии с одним или более аспектами настоящего изобретения.
[00011] на Фиг. 5 схематически показан пример лексико-морфологической структуры предложения в соответствии с одним или более аспектами настоящего изобретения;
[00012] на Фиг. 6 схематически показаны языковые описания, представляющие модель естественного языка в соответствии с одним или более аспектами настоящего изобретения;
[00013] на Фиг. 7 схематически показаны примеры морфологических описаний в соответствии с одним или более аспектами настоящего изобретения;
[00014] на Фиг. 8 схематически показаны примеры синтаксических описаний в соответствии с одним или более аспектами настоящего изобретения;
[00015] на Фиг. 9 схематически показаны примеры семантических описаний в соответствии с одним или более аспектами настоящего изобретения;
[00016] на Фиг. 10 схематически показаны примеры лексических описаний в соответствии с одним или более аспектами настоящего изобретения;
[00017] на Фиг. 11 схематически показаны примеры структур данных, которые могут использоваться одним или более способами, реализованными в соответствии с одним или несколькими аспектами настоящего изобретения;
[00018] на Фиг. 12 схематически показан пример графа обобщенных составляющих в соответствии с одним или более аспектами настоящего изобретения;
[00019] на Фиг. 13 показан пример синтаксической структуры, соответствующей предложению, приведенному на Фиг. 12;
[00020] на Фиг. 14 показана синтаксическая структура, соответствующая синтаксической структуре на Фиг. 13; а также
[00021] на Фиг. 15 показана схема примера вычислительной системы, реализующей способы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00022] В настоящем документе описаны способы и системы классификации текстов на естественном языке с помощью вычислительной системы на основе семантических признаков. В настоящем документе термин «вычислительная система» означает устройство обработки данных, оснащенное универсальным процессором, памятью и по меньшей мере одним интерфейсом связи. Примеры вычислительных систем, которые могут реализовать системы и способы настоящего изобретения, включают, помимо прочего, настольные компьютеры, ноутбуки, планшеты и смартфоны.
[00023] Классификация текстов на естественном языке может подразумевать связывание заданного текста на естественном языке, который может быть представлен, например, по меньшей мере частью документа, с одной или более категориями из определенного набора категорий. В определенных вариантах реализации набор категорий может быть определен заранее (например, получен через графический интерфейс пользователя (GUI) или интерфейс прикладного программирования (API)). Как вариант, набор категорий может быть выявлен в реальном времени в процессе выполнения классификации путем выполнения анализа текстового корпуса, в который входят тексты, подлежащие классификации (например, множество элементов из ленты новостей).
[00024] Тексты на естественном языке могут быть классифицированы на основе одного или более лексических, семантических или синтаксических признаков. Процедура оценки признаков, также называемая извлечением признаков, может включать выполнение семантико-синтаксического анализа текста на естественном языке для создания по меньшей мере одной независимой от конкретного языка семантической структуры, которая может содержать множество семантических классов, как описано более подробно ниже. Любая ссылка на «семантическую структуру» должна считаться ссылкой на одну или более семантических структур.
[00025] Например, текстовый признак может быть представлен частотой встречаемости экземпляров определенного семантического класса в представляющих текст независимых от языка семантических структурах. Независимость семантических структур от конкретного естественного языка позволяет выполнять независимую от языка классификацию текста (например, классификацию текстов, представленных на нескольких естественных языках).
[00026] Независимые от языка семантические классы составляют неотъемлемую часть используемых в данном изобретении лингвистических семантических описаний, что более подробно описано ниже. Семантические классы могут быть организованы в иерархическую структуру, которая в настоящем документе также называется «семантическая иерархия». В определенных вариантах реализации извлечение признаков может обеспечить более точные результаты за счет учета иерархии семантических классов с целью эффективного рассмотрения цепочек семантических классов, представляющих множество уровней абстракции определенного семантического понятия. Например, если признак текста представлен частотой появления экземпляров определенного семантического класса в представляющих текст независимых от языка семантических структурах, то при вычислении значения признака может учитываться встречаемость предков и (или) потомков семантического класса в семантической иерархии. Иерархия семантических классов может учитываться путем связывания определенных значений атрибутов (которые могут сопровождаться весовыми коэффициентами, отражающими связь определенного семантического класса с определенным признаком текста) с каждым семантическим классом в определенной линии наследования. В иллюстративном примере значения атрибута могут быть представлены геометрической прогрессией, состоящей из действительных чисел, которые могут увеличиваться или уменьшаться по линии наследования.
[00027] Таким образом, семантический класс может быть связан с вектором значений атрибутов, отражающих отношение семантического класса к соответствующим текстовым признакам. Значение определенного атрибута потомка или предка определенного базового семантического класса может определяться заданным изменением значения атрибута для базового семантического класса. Такая трансформация может включать умножение значения признака базового семантического класса на некоторый множитель. Трансформация может повторно применяться к значениям атрибутов, связанных с двумя или более поколениями предков и (или) потомков базового семантического класса. В иллюстративном примере последовательные трансформации могут включать умножение значения признака текущего семантического класса на заданный множитель, при этом множители, применяемые к предкам или потомкам заданного базового класса, формируют геометрическую прогрессию, состоящую из действительных чисел.
[00028] В иллюстративном примере каждый текст на естественном языке может быть представлен точкой в многомерном пространстве выбранных текстовых признаков, при этом координаты точки соответствуют значениям признаков. Поэтому выполнение классификации текстов может включать определение параметров одной или более разделительных гиперплоскостей, которые разделяют многомерное пространство на сектора, представляющие категории классификации.
[00029] Классификация текста может выполняться путем вычисления значения функции классификации, отражающей степень связи классифицируемого текста с определенной категорией из множества категорий классификации (например, вероятность связи текста с определенной категорией). Классификация текста может включать вычисление значения выбранной функции классификации для каждой категории из множества категорий классификации, а также связывание текста на естественном языке с категорией, соответствующей оптимальному (максимальному или минимальному) значению функции классификации.
[00030] В определенных вариантах реализации описанная выше процедура извлечения признаков может применяться для анализа корпуса текстов на естественном языке и создания обучающего набора данных, связывающего значения признаков и категории текстов. В иллюстративном примере набор подтверждающих данных может создаваться и (или) обновляться путем обработки множества примеров текстов на естественном языке с известной классификацией. Для каждого примера текста на естественном языке могут быть оценены выбранные признаки, а значения признаков могут быть сохранены в связи с идентификатором категории, к которой относится пример текста на естественном языке.
[00031] Как указано выше, семантическому классу может быть сопоставлен вектор значений атрибутов, отражающих отношение семантического класса к соответствующим текстовым признакам. В определенных вариантах реализации значения различных параметров процесса извлечения признаков (далее «параметры извлечения признаков») могут быть определены путем оптимизации определенной целевой функции (например, функции соответствия, отражающей количество текстов на естественном языке из набора подтверждающих данных, которые могут быть правильно классифицированы с использованием указанных значений параметров извлечения признаков). Примеры параметров извлечения признаков могут включать количество анализируемых уровней семантической иерархии, экземпляры семантических классов которой должны быть учтены в анализируемом тексте на естественном языке, значение определенного атрибута семантического класса, который должен быть соотнесен с экземпляром семантического класса в ответ на выявление такого экземпляра в анализируемом тексте на естественном языке и т.д.
[00032] Как указано выше, классификация текста может выполняться путем вычисления функции классификации, отражающей степень связи классифицируемого текста с определенной категорией из множества категорий классификации (например, вероятность связи текста с определенной категорией). В определенных вариантах реализации в системах и способах настоящего изобретения может использоваться набор обучающих данных для определения значений одного или более гиперпараметров выбранной модели классификации текста. «Гиперпараметр» в настоящем документе означает изменяемое значение, которое определяется до применения машинного обучения для точной настройки параметров модели классификации. Поэтому гиперпараметр может быть выбран априори (например, разработчиком модели классификации) или изменен в автоматическом или ручном режиме в соответствии с одним или более аспектами настоящего изобретения. В определенных вариантах реализации значения различных гиперпараметров модели классификации текста могут быть определены путем оптимизации определенной целевой функции (например, функции соответствия, отражающей количество текстов на естественном языке из набора подтверждающих данных, которые могут быть правильно классифицированы с использованием указанных значений гиперпараметров). Примеры параметров извлечения признаков включают параметр упорядочения модели классификации, которая задействует классификатор на основе метода опорных векторов (англ. SVM, support vector machine), количество ближайших соседей, анализируемых моделью классификации, которая задействует метод k ближайших соседей и т.д.
[00033] В определенных вариантах реализации набор обучающих данных может быть разделен на обучающую выборку данных и тестовую выборку с использованием различных способов перекрестной проверки, что более подробно описано ниже. К обучающим выборкам и к тестовым выборкам затем могут быть применены способы оптимизации для определения значений одного или более параметров извлечения признаков и (или) одного или более гиперпараметров выбранной модели классификации текста.
[00034] В иллюстративном примере используется метод дифференциальной эволюции для определения значений одного или более параметров извлечения признаков и (или) одного или более гиперпараметров выбранной модели классификации текста. В иллюстративном примере итерация метода дифференциальной эволюции может включать определение значений параметров извлечения признаков и (или) гиперпараметров путем оптимизации выбранной целевой функции с помощью обучающей выборки данных с последующим созданием следующего поколения моделей классификации текста на основе текущего поколения и выбранных параметров метода дифференциальной эволюции. После выявления (путем проверки нового поколения моделей классификации текста с использованием тестового набора данных) модели классификации, превосходящей по качеству модель текущего поколения, выявленная модель текущего поколения может быть заменена моделью с более высоким качеством. Итерации метода дифференциальной эволюции могут повторяться до тех пор, пока не будет выполнено прекращающее условие, что более подробно описано ниже.
[00035] В определенных вариантах реализации один или более параметров выбранной модели классификации текста затем могут быть точно настроены способом машинного обучения (например, путем оптимизации выбранной целевой функции, которая может быть представлена функцией соответствия, отражающей количество текстов на естественном языке из набора подтверждающих данных, которые могут быть правильно классифицированы с использованием указанных значений параметров модели классификации текста).
[00036] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
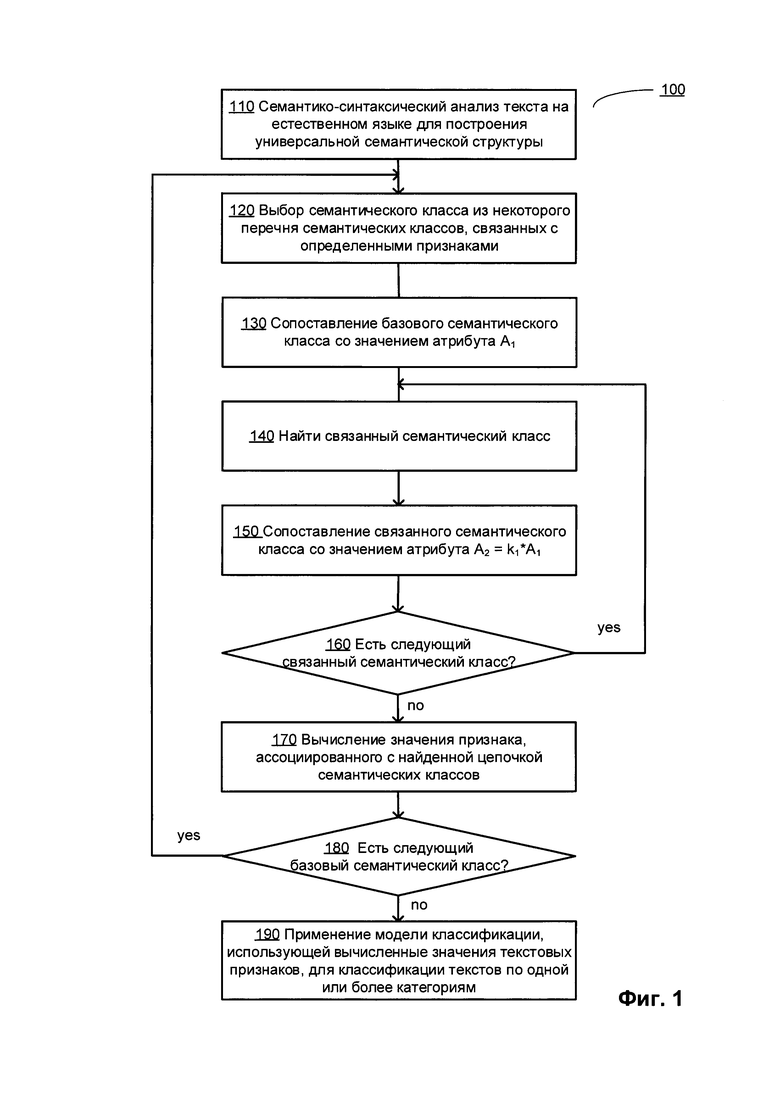
[00037] На Фиг. 1 показана блок-схема примера реализации способа 100 классификации текста на естественном языке на основе семантических признаков в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 100 и (или) каждая из его отдельных функций, стандартных программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, вычислительная система 1000 на Фиг. 15), реализующей этот способ. В некоторых вариантах реализации способ 100 может выполняться в одном потоке обработки. При альтернативном подходе способ 100 может быть реализован с помощью двух или более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций данного способа. В иллюстративном примере потоки обработки, в которых реализован способ 100, могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, реализующие способ (100), могут выполняться асинхронно по отношению друг к другу.
[00038] В блоке 110 реализующая способ вычислительная система может выполнять семантико-синтаксический анализ исходного текста на естественном языке. При семантико-синтаксическом анализе может создаваться одна или более независимых от языка семантических структур, представляющих некоторое множество семантических классов. Каждая семантическая структура может быть представлена графом, включающим множество вершин, соответствующих семантическим классам, и множество дуг, соответствующих множеству семантических отношений, как описано более подробно ниже со ссылками на Фиг. 4-14. Независимые от языка семантические структуры могут быть использованы как источник одного или более лексических, семантических или синтаксических признаков текста на естественном языке. Например, текстовый признак может быть представлен частотностью появления в представляющих текст независимых от языка семантических структурах экземпляров указанного семантического класса и (или) экземпляров других семантических классов, связанных с указанным семантическим классом определенными семантическими отношениями (например, предок указанного семантического класса, потомок указанного семантического класса или одноуровневые родственники указанного семантического класса).
[00039] В блоке 120 вычислительная система может выбрать среди семантических классов, представленных в семантических структурах, представляющих анализируемый текст, некоторый семантический класс (далее «базовый семантический класс»). В определенных вариантах реализации на семантический класс может быть связан с предварительно определенным перечнем семантических классов, связанных с определенными признаками, извлекаемыми из анализируемого текста.
[00040] В блоке 130 вычислительная система может сопоставить базовый семантический класс с некоторым значением, отражающим некоторый атрибут этого семантического класса. В определенных вариантах реализации указанный атрибут может представлять весовой коэффициент, выражающий отношение семантического класса к определенному признаку текста. В иллюстративном примере, если частота появления некоторой лексемы в анализируемом тексте превышает некоторое пороговое значение, текст может быть связан с заданным признаком с помощью определенного весового коэффициента (например, если частота возникновения слова «договор» в анализируемом тексте превышает 1%, текст может быть связан с признаком «юридический» с весовым коэффициентом 0,5).
[00041] В блоке 140 вычислительная система может выявить семантический класс, связанный с указанным семантическим классом через заданные семантические отношения (например, предок указанного семантического класса, потомок указанного семантического класса или одноуровневый родственник указанного семантического класса). Выявленный семантический класс далее называется связанным семантическим классом относительно базового семантического класса.
[00042] В блоке 150 вычислительная система может сопоставить выявленный связанный семантический класс со значением, отражающим указанный атрибут. Значение атрибута, который должен быть сопоставлен со связанным семантическим классом, может определяться заданной трансформацией значения атрибута для базового семантического класса. Трансформация может, например, представлять собой умножение значения признака базового семантического класса на заданный множитель.
[00043] В иллюстративном примере, если частота возникновения указанной лексемы в анализируемом тексте превышает первое пороговое значение, текст может быть связан с заданным признаком с помощью первого весового коэффициента; если частота возникновения гиперонима указанной лексемы в тексте превышает второе пороговое значение, текст также может быть связан с заданным признаком с помощью второго весового коэффициента, который может составлять часть от первого весового коэффициента. «Гипероним» означает семантический класс более высокого порядка, т.е. семантический класс, конкретные экземпляры которого формируют набор, включающий экземпляры дочернего класса.
[00044] После подтверждения в блоке 160 того, что существует, по крайней мере, еще один семантический класс, связанный с основным семантическим классом указанными семантическими отношениями, ранее выявленный семантический класс может быть объявлен новым базовым классом, может быть осуществлен возврат в блок 140 для повтора операций, описанных выше со ссылками на блоки 140-150, для двух или более семантических классов, связанных с базовым семантическим классом и (или) друг с другом заранее определенными семантическими отношениями. В иллюстративном примере может быть выявлена цепочка, включающая два и более предков или потомков базового семантического класса. В другом иллюстративном примере могут быть выявлены два или более потомков базового семантического класса первого поколения, являющихся одноуровневыми "братьями" по отношению друг к другу.
[00045] Если выявлено два или более семантических классов базового класса, значения атрибутов, которые должны быть связаны с выявленными связанными семантическими классами, могут быть выявлены последовательным применением заранее определенной трансформации к значениям атрибутов предшествующего семантического класса в цепочке семантических классов. Как указано выше, последовательные трансформации могут включать, например, умножение значения признака для текущего семантического класса на заданный множитель, при этом множители, применяемые к предкам или потомкам заданного базового класса, формируют прогрессию, состоящую из действительных чисел.
[00046] В блоке 170 вычислительная система может вычислить значение текстового признака, связанный с выявленной цепочкой семантических классов, используя выявленные значения атрибутов, сопоставленных с каждым семантическим классом.
[00047] После подтверждения в блоке 180 того, что в перечне анализируемых семантических классов имеется, по крайней мере, еще один другой базовый семантический класс, способ может вернуться назад к блоку 120; в ином случае обработка может продолжиться в блоке 190.
[00048] В блоке 190 вычислительная система может применить модель классификации с использованием вычисленных признаков текста на естественном языке для определения степени соотнесения текста на естественном языке с одной или более категориями из заранее определенного набора категорий.
[00049] Как указано выше, классификация текстов на естественном языке может подразумевать связывание заданного текста на естественном языке, который может быть представлен, например, по меньшей мере частью документа, с одной или несколькими категориями из определенного набора категорий. В определенных вариантах реализации набор категорий может быть определен заранее (например, получен через графический интерфейс пользователя (GUI) или интерфейс прикладного программирования (API)). Как вариант, набор категорий может сформироваться в процессе выполнения классификации путем выполнения анализа текстового корпуса, в который входят тексты, подлежащие классификации.
[00050] Для каждой категории из набора категорий, к которым в результате классификации может быть отнесен текст, вычислительная система может вычислить значение, выражающее вероятность того, что текст относится к соответствующей категории. Затем вычислительная система может выбрать оптимальное (например, максимальное или минимальное) значение из рассчитанных значений и связать документ с категорией, соответствующей выбранному оптимальному значению модели классификации текста. После завершения операций по классификации, указанных в блоке 190, выполнение способа может быть завершено.
[00051] Хотя в иллюстративном примере, подробно описанном ниже, функция классификации представлена наивным байесовским классификатором, способы, описанные в настоящем документе, могут использовать другие вероятностные или детерминированные функции.
[00052] В иллюстративном примере функция классификации представлена наивным байесовским классификатором:
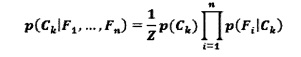
[00053] где 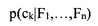 - условная вероятность того, что объект, имеющий значение параметра F1,…,Fn, относится к категории Ck;
- условная вероятность того, что объект, имеющий значение параметра F1,…,Fn, относится к категории Ck;
P(ck) - априорная вероятность того, что объект относится к категории Ск;
Z - нормализующая константа;
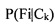 - вероятность того, что объект, имеющий значение параметра Fi, относится к категории Ck.
- вероятность того, что объект, имеющий значение параметра Fi, относится к категории Ck.
[00054] В другом иллюстративном примере функция классификации может быть представлена классификатором на основе метода опорных векторов (SVM). В еще одном иллюстративном примере функция классификации представлена классификатором по методу ближайших соседей.
[00055] В определенных вариантах реализации для каждой категории из множества категорий классификации текста вычислительная система, реализующая способы, описанные в настоящем документе, может вычислять значение выбранной функции классификации, выражающее вероятность того, что текст относится к соответствующей категории. Затем вычислительная система может выбрать оптимальное (например, максимальное или минимальное) значение из рассчитанных значений и связать документ с категорией, соответствующей выбранному оптимальному значению функции классификации.
[00056] Как указано выше, семантический класс может быть связан с вектором значений атрибутов, отражающих отношение семантического класса к соответствующим текстовым признакам. В определенных вариантах реализации значения различных параметров извлечения признаков и (или) гиперпараметров модели классификации текста могут быть определены путем оптимизации определенной целевой функции (например, функция соответствия, отражающая количество текстов на естественном языке из тестового набора х данных, которые могут быть правильно классифицированы с использованием указанных значений параметров извлечения признаков).
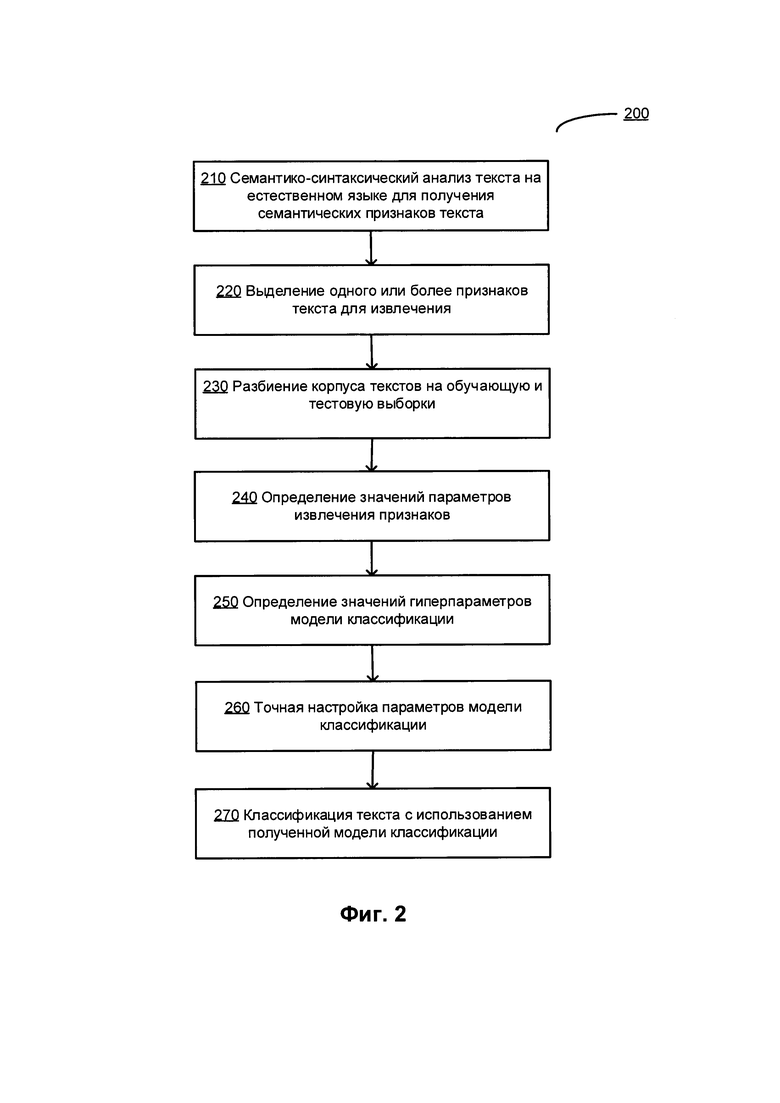
[00057] На Фиг. 2 показана блок-схема примера способа 200 определения значений параметров извлечения признаков и (или) гиперпараметров модели текстового классификатора в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 200 и (или) каждая из его отдельных функций, стандартных программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, вычислительная система 1000 на Фиг. 15), реализующей этот способ. В некоторых вариантах реализации способ 200 может выполняться в одном потоке обработки. При альтернативном подходе способ 200 может быть реализован с помощью двух или более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций данного способа. В иллюстративном примере потоки обработки, в которых реализован способ 200, могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, реализующие способ (200), могут выполняться асинхронно по отношению друг к другу.
[00058] В блоке 210 вычислительная система, реализующая способ, может выполнять семантико-синтаксический анализ одного или более текстов на естественном языке из набора обучающих данных. При анализе может создаваться одна или более независимых от языка семантических структур, представляющих некоторое множество семантических классов. Каждая семантическая структура может быть представлена графом, включающим узлы, соответствующие семантическим классам, и множество дуг, соответствующих семантическим отношениям, как более подробно описано ниже со ссылками на Фиг. 4-14.
[00059] В блоке 220 вычислительная система может установить один или более признаков текста, извлекаемых из семантических структур, созданных при семантико-синтаксическом анализе, как более подробно описано выше. Например, признак текста может быть представлен частотой появления в представляющих текст семантических структурах экземпляров указанного семантического класса и (или) экземпляров других семантических классов, связанных с указанным семантическим классом определенными семантическими отношениями (например, предок указанного семантического класса, потомок указанного семантического класса или одноранговые родственники указанного семантического класса, как более подробно описано выше со ссылками на Фиг. 1).
[00060] В блоке 230 вычислительная система может выполнить разбиение корпуса текстов на естественном языке на обучающую выборку, включающую первое множество текстов на естественном языке, и тестовую выборку, включающий второе множество текстов на естественном языке. В определенных вариантах реализации разделение текстового корпуса может включать перекрестную проверку (метод cross-validating) обучающей выборки и тестовой выборки. Для улучшения результата может выполняться несколько раундов перекрестной проверки с применением различных разбиений, а результаты проверки модели могут быть агрегированы по раундам (например, усреднены).
[00061] В иллюстративном примере k корпусу текстов на естественном языке может применяться способ k-кратной перекрестной проверки (cross-validating). Способ может включать случайное разделение исходного корпуса текстов на k наборов данных одинакового размера, один из которых затем используется в качестве тестовой выборки, а оставшиеся k-l дополнительных наборов затем используются как обучающие выборки данных. Затем процесс перекрестной проверки может быть повторен k раз таким образом, чтобы каждый из к наборов данных использовался один раз в качестве тестовой выборки. После этого k результатов могут быть агрегированы для получения единого значения.
[00062] В блоке 240 вычислительная система может итеративно выявить значения указанных параметров извлечения признаков для модели классификации текста, оптимизирующей определенную целевую функцию (например, максимальное увеличение функции соответствия, отражающей количество текстов на естественном языке из тестовой выборки, которые могут быть правильно классифицированы с использованием указанных значений параметров извлечения признаков). В иллюстративном примере параметры извлечения признаков, значения которых должны быть определены, могут быть выявлены через GUI или API. При альтернативном подходе для оценки может быть выбран предварительно заданный набор параметров извлечения признаков.
[00063] В блоке 250 вычислительная система может итерационно выявить значения указанных гиперпараметров для модели классификации текста, оптимизирующей определенную целевую функцию (например, максимальное увеличение функции соответствия, отражающей количество текстов на естественном языке из набора подтверждающих данных, которые могут быть правильно классифицированы с использованием указанных значений гиперпараметров классификации текста). В иллюстративном примере параметры извлечения признаков, значения которых должны быть определены, могут быть выявлены через GUI или API. При альтернативном подходе для оценки может быть выбран предварительно заданный набор параметров извлечения признаков.
[00064] Поскольку целевая функция, применяемая для оценки параметров извлечения признаков и (или) гиперпараметров классификации текста, является недифференцируемой, способ, выбранный для оптимизации целевой функции, не должен требовать вычисления градиента целевой функции. В определенных вариантах реализации вычислительной системой может использоваться оптимизация методом дифференциальной эволюции, пример которого подробно описан ниже со ссылками на Фиг. 3. Способ оптимизации может включать итеративное выявление набора значений параметров извлечения признаков и (или) гиперпараметров классификации текста путем обработки множества обучающих текстов на естественном языке с известной классификацией. Для каждого обучающего текста вычислительной системой могут быть оценены признаки текста и сохранены определенные значения признаков в связи с идентификатором категории, к которой относится пример текста. Выявленные значения параметров извлечения признаков и (или) гиперпараметров классификации текстов затем могут быть оценены с помощью тестовой выборки.
[00065] В блоке 260 вычислительная система может точно настроить один или более параметров выбранной модели классификации текста способом машинного обучения (например, путем оптимизации выбранной целевой функции, которая может быть представлена функцией соответствия, отражающей количество текстов на естественном языке из тестовой выборки, которые могут быть правильно классифицированы с использованием указанных значений параметров модели классификации текста).
[00066] В блоке 270 вычислительная система может классифицировать текст на естественном языке, подлежащий классификации, за счет применения модели классификации текстов, как более подробно описано выше. Для каждой категории из множества категорий классификации текста вычислительная система может вычислять значение параметров модели классификации текста, выражающей вероятность того, что текст относится к соответствующей категории. Затем вычислительная система может выбрать оптимальное (например, максимальное или минимальное) значение параметров из рассчитанных значений и связать документ с категорией, соответствующей выбранной оптимальной модели классификации текста, как более подробно описано выше. После завершения операций по классификации, указанных в блоке 270, выполнение способа может быть завершено.
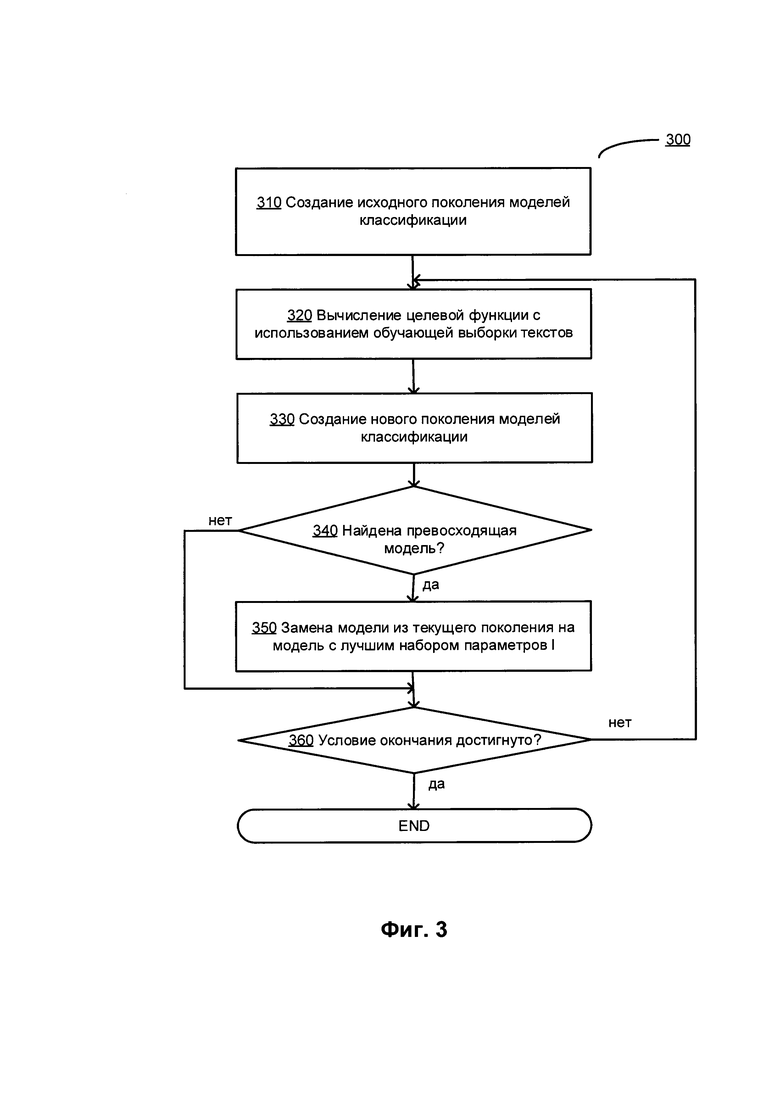
[00067] На Фиг. 3 показана блок-схема примера оптимизации методом дифференциальной эволюции 300 для оптимизации выбранной целевой функции с целью определения значений параметров извлечения признаков и (или) гиперпараметров модели классификатора текста в соответствии с одним или более аспектами настоящего изобретения. Способ 300 и (или) каждая из его отдельных функций, стандартных программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, вычислительная система 1000 на Фиг. 15), реализующей этот способ. В некоторых вариантах реализации способ 300 может выполняться в одном потоке обработки. При альтернативном подходе способ 300 может быть реализован с помощью двух или более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций данного способа. В иллюстративном примере потоки обработки, в которых реализован способ 300, могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, реализующие способ (300), могут выполняться асинхронно по отношению друг к другу.
[00068] В блоке 310 реализующая способ вычислительная система может создать исходное поколение, включающее одну или более моделей классификации текстов, связанных с соответствующими наборами параметров извлечения признаков и (или) гиперпараметров.
[00069] В блоке 320 вычислительная система может использовать один или несколько текстов на естественном языке из обучающей выборки данных для вычисления целевой функции, что в иллюстративном примере может быть представлено функцией соответствия, отражающей количество текстов на естественном языке из обучающей выборки данных, и (или) обучающей выборкой данных, которая будет правильно классифицирована с использованием значений параметров извлечения признаков и (или) гиперпараметров текущего поколения моделей классификации текста.
[00070] В блоке 330 вычислительная система может создать новое поколение моделей классификации, связанных с соответствующими наборами параметров извлечения признаков и (или) гиперпараметров. Создание нового поколения моделей классификации текстов может включать изменение значений одного или более параметров извлечения признаков и (или) гиперпараметров, выбираемых случайным образом с использованием заранее заданной линейной трансформации.
[00071] После определения в блоке 340 модели нового поколения, у которой значение выбранной целевой функции выше, чем у какой-то модели текущего поколения, вычислительная система в блоке 350 может заменить эту модель текущего поколения на модель с более высоким качеством из нового поколения.
[00072] После подтверждения в блоке 360 того, что условие прекращения удовлетворено, выполнение способа может завершиться; в ином случае способ может вернуться к блоку 330. В иллюстративном примере условие прекращения может состоять в достижении значения некоторой метрики качества (например, отношением количества текстов из обучающей выборки данных и (или) обучающей выборки данных, которые были правильно классифицированы, к общему количеству текстов в соответствующих наборах данных), превышающей определенный порог. В другом иллюстративном примере условие прекращения может быть представлено количеством выполненных итераций.
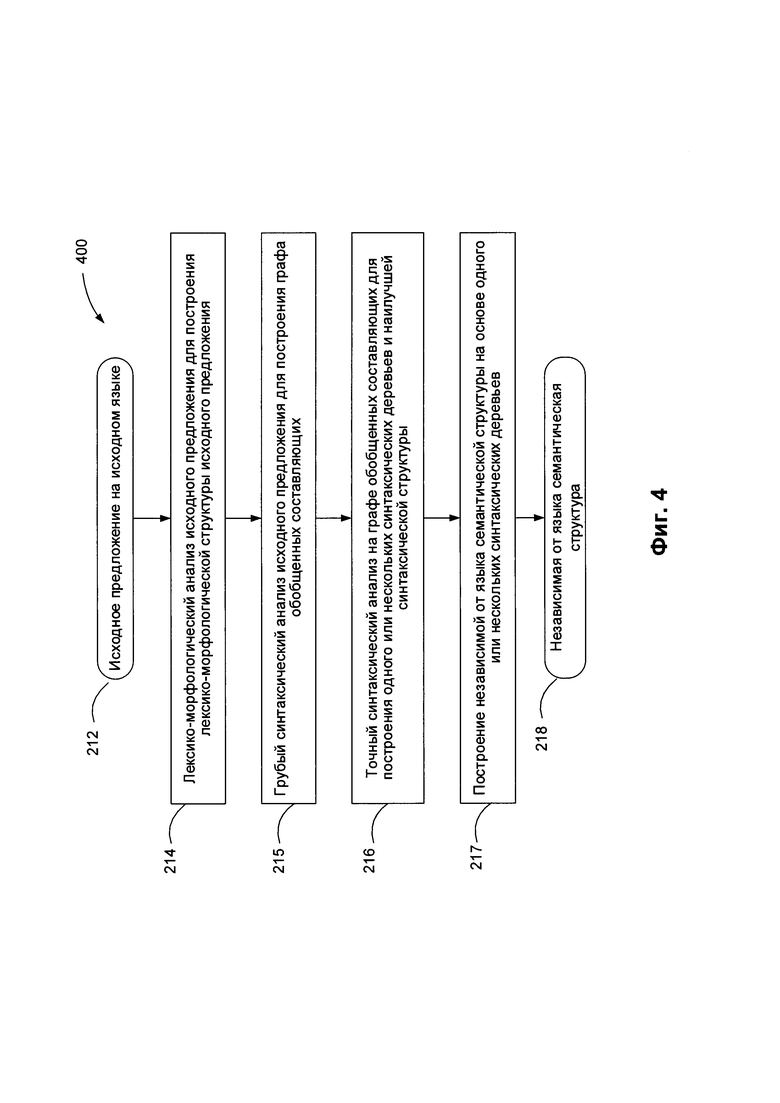
[00073] На Фиг. 4 приведена блок-схема одного иллюстративного примера реализации способа 400 для выполнения семантико-синтаксического анализа предложения на естественном языке 412 в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 400 может быть применен к одной или более синтаксическим единицам (например, предложениям), включенным в определенный текстовый корпус, для формирования множества семантико-синтаксических деревьев, соответствующих синтаксическим единицам. В различных иллюстративных примерах подлежащие обработке способом 400 предложения на естественном языке могут извлекаться из одного или нескольких электронных документов, которые могут создаваться путем сканирования (или другим способом получения изображений бумажных документов) и оптического распознавания символов (OCR) для получения текстов, соответствующих этим документам. Предложения на естественном языке также могут извлекаться из других различных источников, включая сообщения, отправляемые по электронной почте, тексты из социальных сетей, файлы с цифровым содержимым, обработанные с использованием способов распознавания речи и т.д.
[00074] В блоке 214 вычислительное устройство, реализующее данный способ, может проводить лексико-морфологический анализ предложения 212 для установления морфологических значений слов, входящих в состав предложения. В настоящем документе "морфологическое значение" слова означает одну или несколько лемм (т.е. канонических или словарных форм), соответствующих слову, и соответствующий набор значений грамматических признаков, которые определяют грамматическое значение слова. В число таких грамматических признаков могут входить лексическая категория (часть речи) слова и один или более морфологических и грамматических признаков (например, падеж, род, число, спряжение и т.д.). Ввиду омонимии и (или) совпадающих грамматических форм, соответствующих разным лексико-морфологическим значениям определенного слова, для данного слова может быть установлено два или более морфологических значений. Более подробное описание иллюстративного примера проведения лексико-морфологического анализа предложения приведено ниже в настоящем документе со ссылкой на Фиг. 5.
[00075] В блоке 215 вычислительное устройство может проводить грубый синтаксический анализ предложения 212. Грубый синтаксический анализ может включать применение одной или нескольких синтаксических моделей, которые могут быть соотнесены с элементами предложения 212, с последующим установлением поверхностных (т.е. синтаксических) связей в рамках предложения 212 для получения графа обобщенных составляющих. В настоящем документе "составляющая" означает группу соседних слов исходного предложения, функционирующую как одна грамматическая сущность. Составляющая включает в себя ядро в виде одного или более слов и может также включать одну или несколько дочерних составляющих на более низких уровнях. Дочерняя составляющая является зависимой составляющей, которая может быть соотнесена с одной или несколькими родительскими составляющими.
[00076] В блоке 216 вычислительное устройство может проводить точный синтаксический анализ предложения 212 для формирования одного или более синтаксических деревьев предложения. Среди различных синтаксических деревьев на основе определенной функции оценки с учетом совместимости лексических значений слов исходного предложения, поверхностных отношений, глубинных отношений и т.д. может быть отобрано одно или несколько лучших синтаксических деревьев, соответствующих предложению 212.
[00077] В блоке 217 вычислительное устройство может обрабатывать синтаксические деревья для формирования семантической структуры 218, соответствующей предложению 212. Семантическая структура 218 может включать множество узлов, соответствующих семантическим классам и также может включать множество дуг, соответствующих семантическим отношениям (более подробное описание см. ниже в настоящем документе).
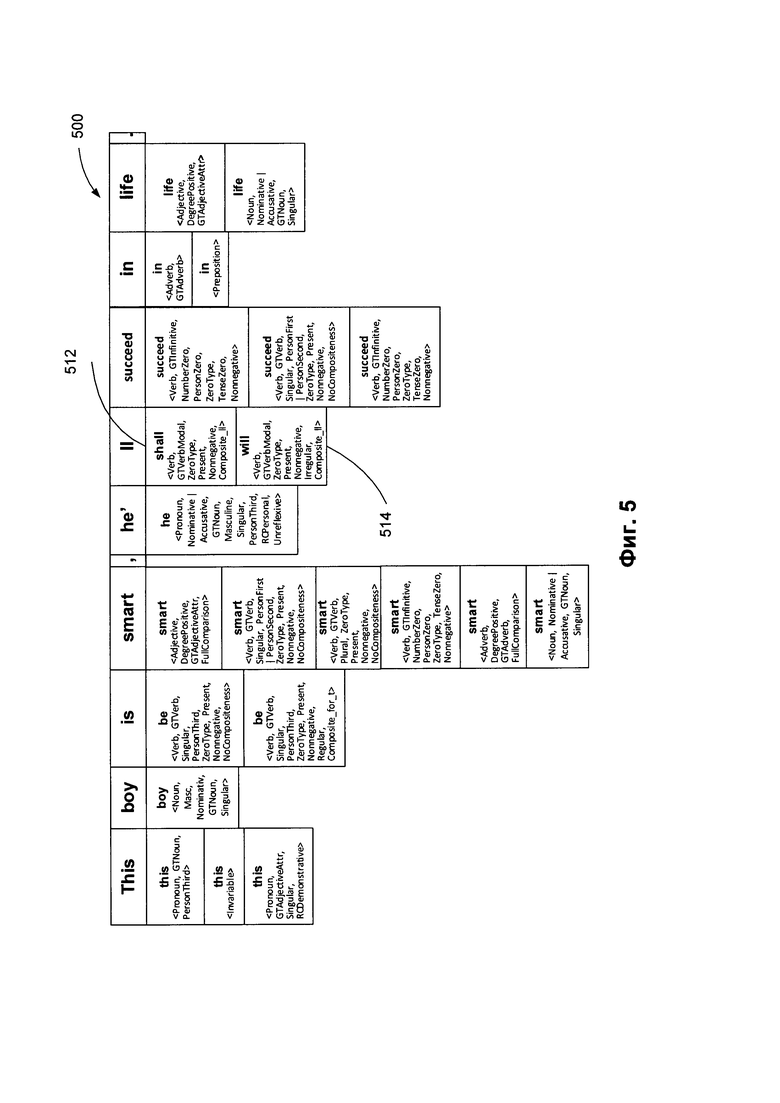
[00078] Фиг. 5 схематически иллюстрирует пример лексико-морфологической структуры предложения в соответствии с одним или более аспектами настоящего изобретения. Пример лексико-морфологической структуры 500 может включать множество пар "лексическое значение - грамматическое значение" для примера предложения. В качестве иллюстративного примера, "ll" может быть соотнесено с лексическим значением "shall" 512 и "will" 514. Грамматическим значением, соотнесенным с лексическим значением 512, является <Verb, GTVerbModal, ZeroType, Present, Nonnegative, Composite II>. Грамматическим значением, соотнесенным с лексическим значением 514, является <Verb, GTVerbModal, ZeroType, Present, Nonnegative, Irregular, Composite II>.
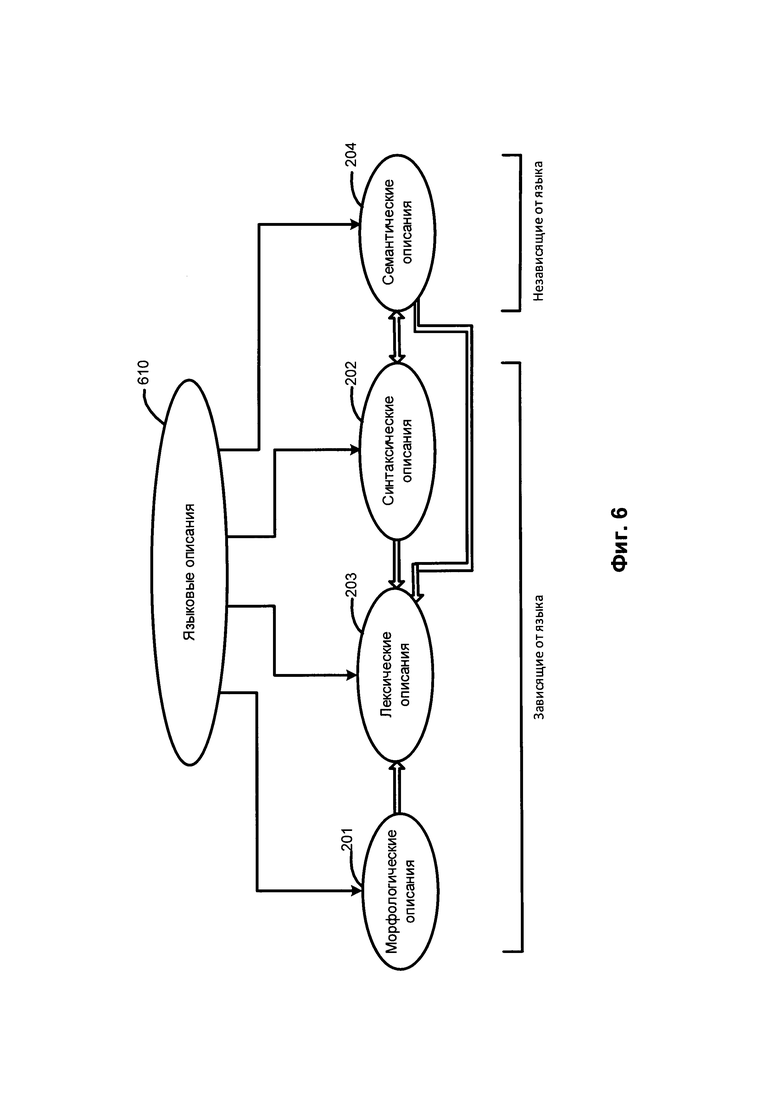
[00079] Фиг. 6 схематически иллюстрирует используемые языковые описания 610, в том числе морфологические описания 201, лексические описания 203, синтаксические описания 202 и семантические описания 204, а также отношения между ними. Среди них морфологические описания 201, лексические описания 203 и синтаксические описания 02 зависят от языка. Набор языковых описаний 610 представляет собой модель определенного естественного языка.
[00080] В качестве иллюстративного примера определенное лексическое значение в лексических описаниях 203 может быть соотнесено с одной или несколькими поверхностными моделями синтаксических описаний 202, соответствующих данному лексическому значению. Определенная поверхностная модель синтаксических описаний 202 может быть соотнесена с глубинной моделью семантических описаний 204.
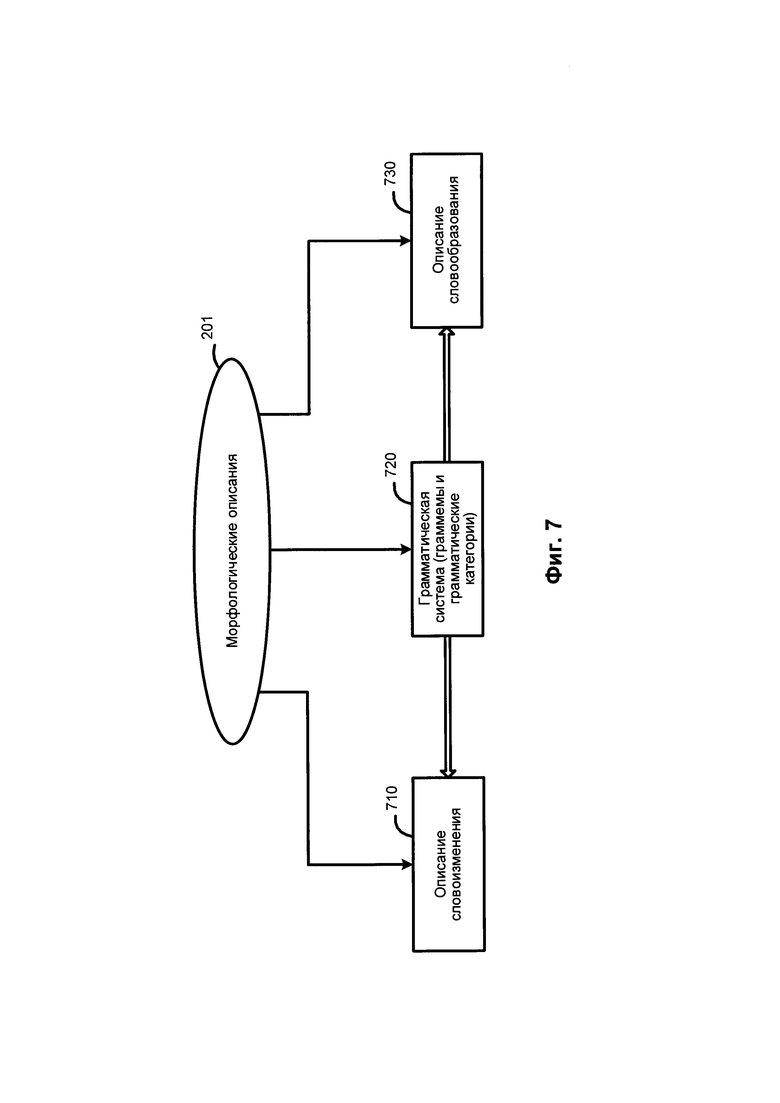
[00081] На Фиг. 7 схематически иллюстрируются несколько примеров морфологических описаний. В число компонентов морфологических описаний 201 могут входить: описания словоизменения 710, грамматическая система 720, описания словообразования 730 и другие. Грамматическая система 720 включает набор грамматических категорий, таких как часть речи, падеж, род, число, лицо, возвратность, время, вид и их значения (так называемые "граммемы"), в том числе, например, прилагательное, существительное или глагол; именительный, винительный или родительный падеж; женский, мужской или средний род и т.д. Соответствующие граммемы могут использоваться для составления описания словоизменения 710 и описания словообразования 730.
[00082] Описание словоизменения 710 определяет формы данного слова в зависимости от его грамматических категорий (например, падеж, род, число, время и т.д.) и в широком смысле включает в себя или описывает различные возможные формы слова. Описание словообразования 730 определяет, какие новые слова могут быть образованы от данного слова (например, сложные слова).
[00083] В соответствии с одним из аспектов настоящего изобретения при установлении синтаксических отношений между элементами исходного предложения могут использоваться модели составляющих. Составляющая представляет собой группу соседних слов в предложении, ведущих себя как единое целое. Ядром составляющей является слово, она также может содержать дочерние составляющие более низких уровней. Дочерняя составляющая является зависимой составляющей и может быть прикреплена к другим составляющим (родительским) для построения синтаксических описаний 202 исходного предложения.
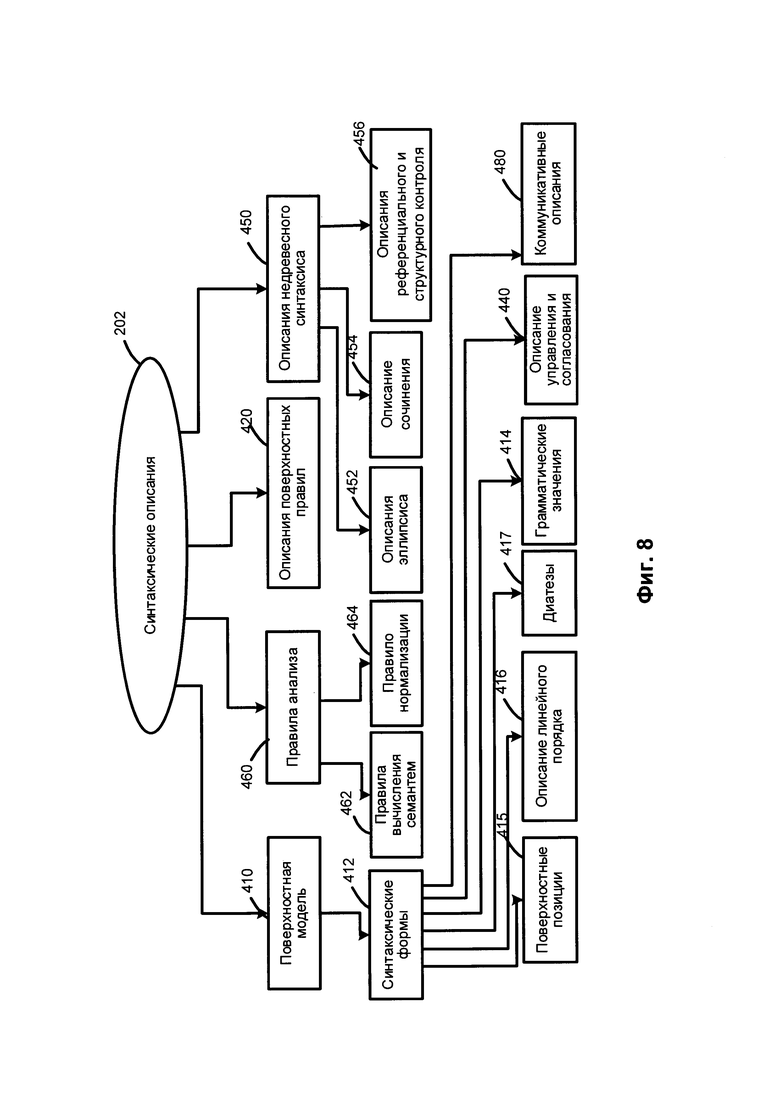
[00084] На Фиг. 8 приведены примеры синтаксических описаний. В число компонентов синтаксических описаний 202 могут входить, среди прочего, поверхностные модели 410, описания поверхностных позиций 420, описание референциального и структурного контроля 456, описание управления и согласования 440, описание недревесного синтаксиса 450 и правила анализа 460. Синтаксические описания 202 могут использоваться для построения возможных синтаксических структур исходного предложения на заданном естественном языке с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, согласование, эллипсис и т.д.), референциальных отношений и других факторов.
[00085] Поверхностные модели 410 могут быть представлены в виде совокупностей одной или нескольких синтаксических форм («синтформ» 412) для описания возможных синтаксических структур предложений, входящих в состав синтаксического описания 202. В целом, лексическое значение слова на естественном языке может быть связано с поверхностными (синтаксическими) моделями 410. Поверхностная модель может представлять собой составляющие, которые возможны, если лексическое значение выступает в роли "ядра". Поверхностная модель может включать набор поверхностных позиций дочерних элементов, описание линейного порядка и (или) диатезу. В настоящем документе "диатеза" означает определенное отношение между поверхностными и глубинными позициями и их семантическими ролями, выражаемыми посредством глубинных позиций. Например, диатеза может быть выражаться залогом глагола: если субъект является агентом действия, глагол в активном залоге, а когда субъект является направлением действия, это выражается пассивным залогом глагола.
[00086] В модели составляющих может использоваться множество поверхностных позиций 415 дочерних составляющих и описаний их линейного порядка 416 для описания грамматических значений 414 возможных заполнителей этих поверхностных позиций. Диатезы 417 представляют собой соответствия между поверхностными позициями 415 и глубинными позициями 514 (как показано на Фиг. 9). Коммуникативные описания 480 описывают коммуникативный порядок в предложении.
[00087] Описание линейного порядка (416) может быть представлено в виде выражений линейного порядка, отражающих последовательность, в которой различные поверхностные позиции (415) могут встречаться в предложении. В число выражений линейного порядка могут входить наименования переменных, имена поверхностных позиций, круглые скобки, граммемы, оператор «or» (или) и т.д. В качестве иллюстративного примера описание линейного порядка простого предложения "Boys play football" можно представить в виде "Subject Core Object_Direct" (Подлежащее - Ядро - Прямое дополнение), где Subject (Подлежащее), Core (Ядро) и Object_Direct (Прямое дополнение) представляют собой имена поверхностных позиций 415, соответствующих порядку слов.
[00088] Коммуникативные описания 480 могут описывать порядок слов в синтформе 412 с точки зрения коммуникативных актов, представленных в виде коммуникативных выражений порядка, которые похожи на выражения линейного порядка. Описания управления и согласования 440 может включать правила и ограничения на грамматические значения присоединяемых составляющих, которые используются во время синтаксического анализа.
[00089] Описания недревесного синтаксиса 450 могут создаваться для отражения различных языковых явлений, таких как эллипсис и согласование, они используются при трансформациях синтаксических структур, которые создаются на различных этапах анализа в различных вариантах реализации изобретения. Описания недревесного синтаксиса 450 могут, среди прочего, включать описание эллипсиса 452, описания согласования 454, а также описания референциального и структурного контроля 430.
[00090] Правила анализа 460 могут описывать свойства конкретного языка и использоваться в рамках семантического анализа. Правила анализа 460 могут включать правила вычисления семантем 462 и правила нормализации 464. Правила нормализации 464 могут использоваться для описания трансформаций семантических структур, которые могут отличаться в разных языках.
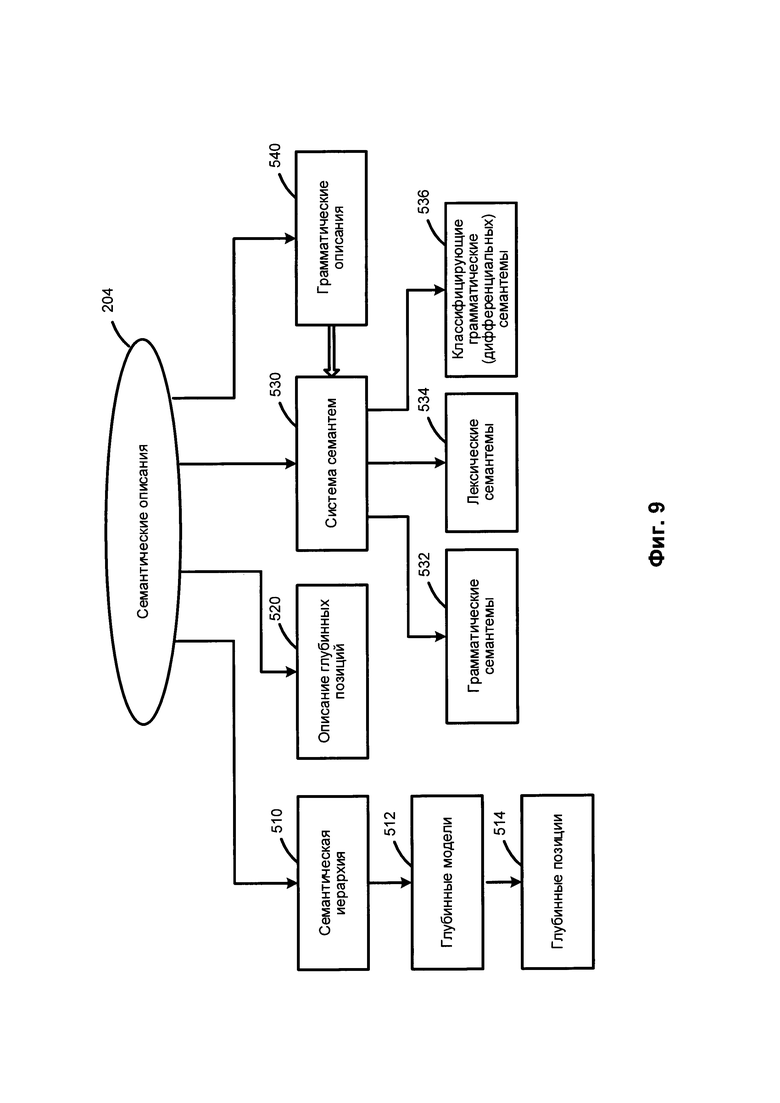
[00091] На Фиг. 9 приведен пример семантических описаний. Компоненты семантических описаний 204 не зависят от языка и могут, среди прочего, включать семантическую иерархию 510, описания глубинных позиций 520, систему семантем 530 и прагматические описания 540.
[00092] Ядро семантических описаний может быть представлено семантической иерархией 510, в которую могут входить семантические понятия (семантические сущности), также называемые семантическими классами. Последние могут быть упорядочены в иерархическую структуру, отражающую отношения "родитель-потомок". В целом, дочерний семантический класс может унаследовать одно или более свойств своего прямого родителя и других семантических классов-предков. В качестве иллюстративного примера семантический класс SUBSTANCE (Вещество) является дочерним семантическим классом класса ENTITY (Сущность) и родительским семантическим классом для классов GAS, (Газ), LIQUID (Жидкость), METAL (Металл), WOOD MATERIAL (Древесина) и т.д.
[00093] Каждый семантический класс в семантической иерархии 510 может сопровождаться глубинной моделью 512. Глубинная модель 512 семантического класса может включать множество глубинных позиций 514, которые могут отражать семантические роли дочерних составляющих в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей. Глубинная модель 512 также может включать возможные семантические классы, выступающие в роли заполнителей глубинных позиций. Глубинные позиции (514) могут выражать семантические отношения, в том числе, например, "agent" (агент), "addressee" (адресат), "instrument" (инструмент), "quantity" (количество) и т.д. Дочерний семантический класс может наследовать и уточнять глубинную модель своего непосредственного родительского семантического класса.
[00094] Описания глубинных позиций 520 отражают семантические роли дочерних составляющих в глубинных моделях 512 и могут использоваться для описания общих свойств глубинных позиций 514. Описания глубинных позиций 520 также могут содержать грамматические и семантические ограничения в отношении заполнителей глубинных позиций 514. Свойства и ограничения, связанные с глубинными позициями 514 и их возможными заполнителями в различных языках, могут быть в значительной степени подобными и зачастую идентичными. Таким образом, глубинные позиции 514 не зависят от языка.
[00095] Система семантем 530 может представлять собой множество семантических категорий и семантем, которые представляют значения семантических категорий. В качестве иллюстративного примера семантическая категория "DegreeOfComparison" (Степень сравнения) может использоваться для описания степени сравнения прилагательных и включать следующие семантемы: "Positive" (Положительная), "ComparativeHigherDegree" (Сравнительная степень сравнения), "SuperlativeHighestDegree" (Превосходная степень сравнения) и другие. В качестве еще одного иллюстративного примера семантическая категория "RelationToReferencePoint" (Отношение к точке) может использоваться для описания порядка (пространственного или временного в широком смысле анализируемых слов), как, например, до или после точки или события, и включать семантемы "Previous" (Предыдущий) и "Subsequent" (Последующий). В качестве еще одного иллюстративного примера семантическая категория "EvaluationObjective" (Оценка) может использоваться для описания объективной оценки, как, например, "Bad" (Плохой), "Good" (Хороший) и т.д.
[00096] Система семантем 530 может включать независимые от языка семантические атрибуты, которые могут выражать не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы могут использоваться для выражения атомарного значения, которое находит регулярное грамматическое и (или) лексическое выражение в естественном языке. По своему целевому назначению и использованию системы семантем могут разделяться на категории, например, грамматические семантемы 532, лексические семантемы 534 и классифицирующие грамматические (дифференцирующие) семантемы 536.
[00097] Грамматические семантемы 532 могут использоваться для описания грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы 534 могут описывать конкретные свойства объектов (например, "being flat" (быть плоским) или "being liquid" (являться жидкостью)) и использоваться в описаниях глубинных позиций 520 как ограничение заполнителей глубинных позиций (например, для глаголов "face (with)" (облицовывать) и "flood" (заливать), соответственно). Классифицирующие грамматические (дифференцирующие) семантемы 536 могут выражать дифференциальные свойства объектов внутри одного семантического класса. В качестве иллюстративного примера в семантическом классе HAIRDRESSER (ПАРИКМАХЕР) семантема «RelatedToMen» (Относится к мужчинам) присваивается лексическому значению "barber" в отличие от других лексических значений, которые также относятся к этому классу, например, «hairdresser», «hairstylist» и т.д. Используя данные независимые от языка семантические свойства, которые могут быть выражены в виде элементов семантического описания, в том числе семантических классов, глубинных позиций и семантем, можно извлекать семантическую информацию в соответствии с одним или более аспектами настоящего изобретения.
[00098] Прагматические описания 540 позволяют назначать определенную тему, стиль или жанр текстам и объектам семантической иерархии 510 (например, «Экономическая политика», «Внешняя политика», «Юриспруденция», «Законодательство», «Торговля», «Финансы» и т.д.). Прагматические свойства также могут выражаться семантемами. В качестве иллюстративного примера прагматический контекст может приниматься во внимание при семантическом анализе.
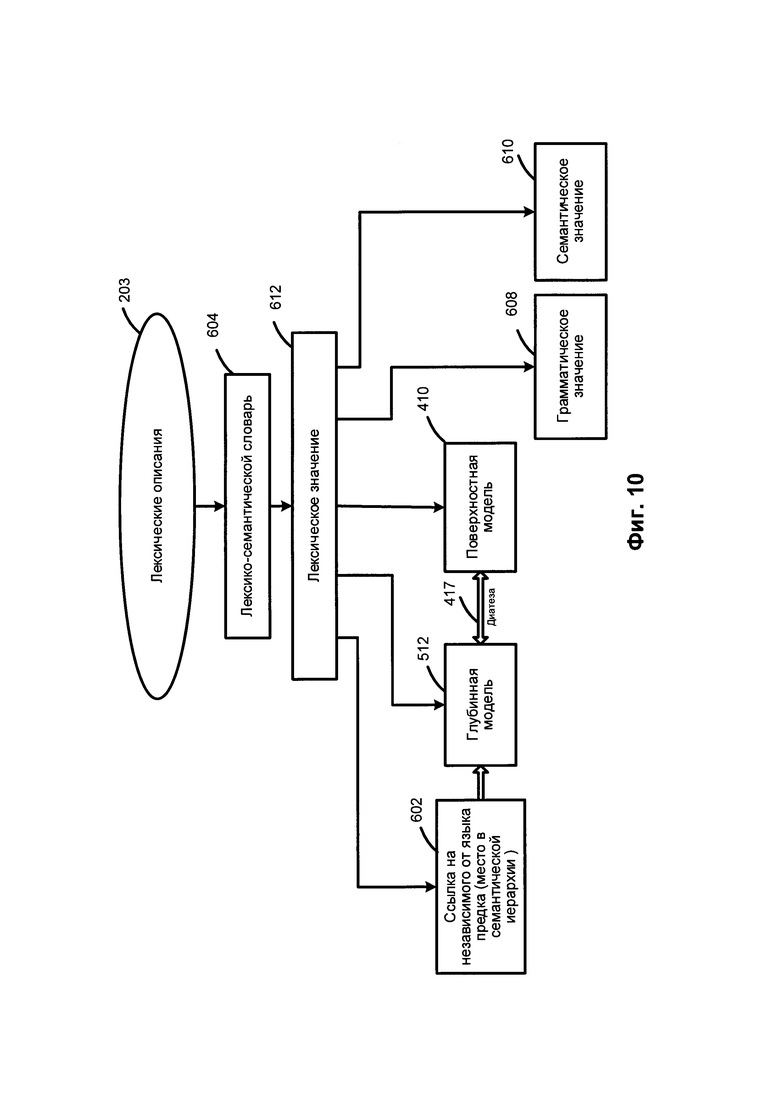
[00099] На Фиг. 10 приведен пример лексических описаний. Лексические описания (203) представляют собой множество лексических значений 612 конкретного естественного языка. Для каждого лексического значения 612 имеется связь 602 с его независимым от языка семантическим родителем для того, чтобы указать положение какого-либо заданного лексического значения в семантической иерархии 510.
[000100] Лексическое значение 612 в лексико-семантической иерархии 510 может быть соотнесено с поверхностной моделью 410, которая в свою очередь через одну или несколько диатез 417 может быть соотнесена с соответствующей глубинной моделью 512. Лексическое значение 612 может наследовать семантический класс своего родителя и уточнять свою глубинную модель 512.
[000101] Поверхностная модель 410 лексического значения может включать одну или несколько синтаксических форм 412. Синтформа 412 поверхностной модели 410 может включать одну или несколько поверхностных позиций 415, в том числе соответствующие описания их линейного порядка 416, одно или несколько грамматических значений 414, выраженных в виде набора грамматических категорий (граммем), одно или несколько семантических ограничений, соотнесенных с заполнителями поверхностных позиций, и одну или несколько диатез 417. Семантические ограничения, соотнесенные с определенным заполнителем поверхностной позиции, могут быть представлены в виде одного или более семантических классов, объекты которых могут заполнить эту поверхностную позицию.
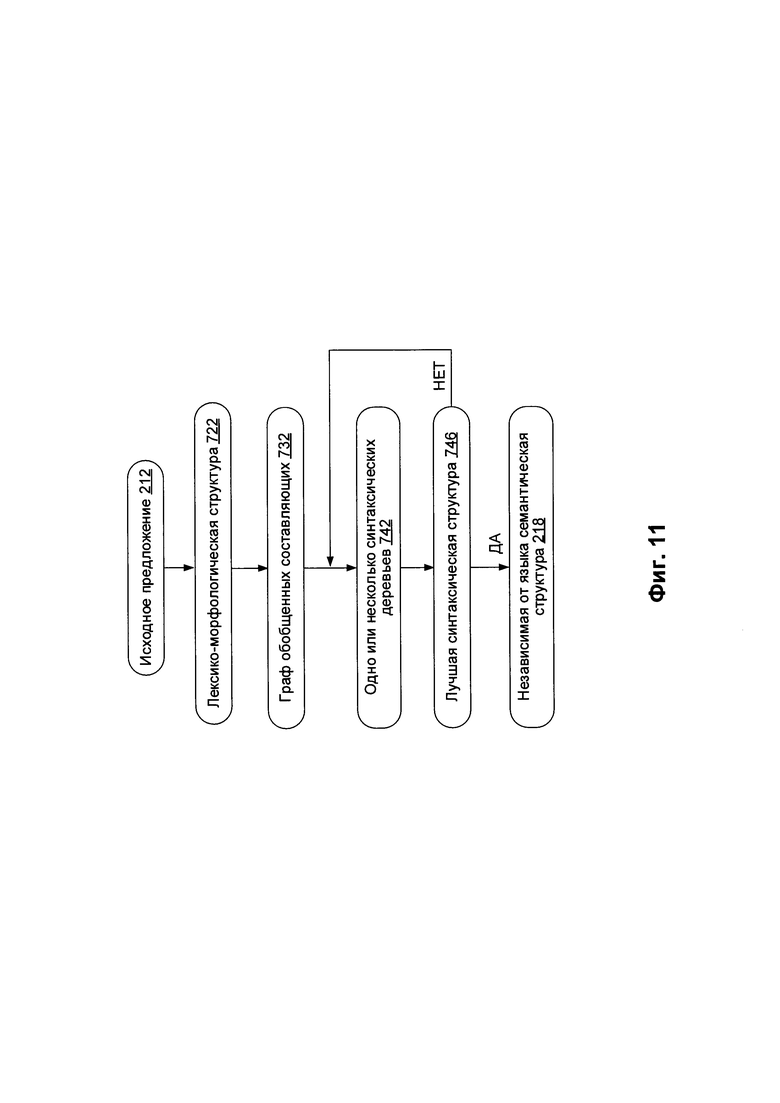
[000102] На Фиг. 11 схематически иллюстрируются примеры структур данных, которые могут быть использованы в рамках одного или более методов настоящего изобретения. Снова ссылаясь на Фиг. 4, в блоке 214 вычислительное устройство, реализующее данный способ, может проводить лексико-морфологический анализ предложения 212 для построения лексико-морфологической структуры 722 согласно Фиг. 11. Лексико-морфологическая структура 722 может включать множество соответствий лексического и грамматического значений для каждой лексической единицы (например, слова) исходного предложения. Фиг. 5 схематически иллюстрирует пример лексико-морфологической структуры.
[000103] В блоке 215 вычислительное устройство может проводить грубый синтаксический анализ исходного предложения 212 для построения графа обобщенных составляющих 732 согласно Фиг. 11. Грубый синтаксический анализ предполагает применение одной или нескольких возможных синтаксических моделей возможных лексических значений к каждому элементу множества элементов лексико-морфологической структуры 722 с тем, чтобы установить множество потенциальных синтаксических отношений в составе исходного предложения 212, представленных графом обобщенных составляющих 732.
[000104] Граф обобщенных составляющих 732 может быть представлен ациклическим графом, включающим множество узлов, соответствующих обобщенным составляющим исходного предложения 212 и включающим множество дуг, соответствующих поверхностным (синтаксическим) позициям, которые могут выражать различные типы отношений между обобщенными лексическими значениями. В рамках данного способа может применяться множество потенциально применимых синтаксических моделей для каждого элемента множества элементов лексико-морфологических структур исходного предложения 212 для формирования набора составляющих исходного предложения 212. Затем в рамках способа может рассматриваться множество возможных составляющих исходного предложения 212 для построения графа обобщенных составляющих 732 на основе набора составляющих. Граф обобщенных составляющих 732 на уровне поверхностной модели может отражать множество потенциальных связей между словами исходного предложения 212. Поскольку количество возможных синтаксических структур может быть относительно большим, граф обобщенных составляющих 732 может, в общем случае, включать избыточную информацию, в том числе относительно большое число лексических значений по определенным узлам и (или) поверхностных позиций по определенным дугам графа.
[000105] Граф обобщенных составляющих 732 может изначально строиться в виде дерева, начиная с концевых узлов (листьев) и двигаясь далее к корню, путем добавления дочерних составляющих, заполняющих поверхностные позиции 415 множества родительских составляющих, с тем, чтобы были охвачены все лексические единицы исходного предложения 212.
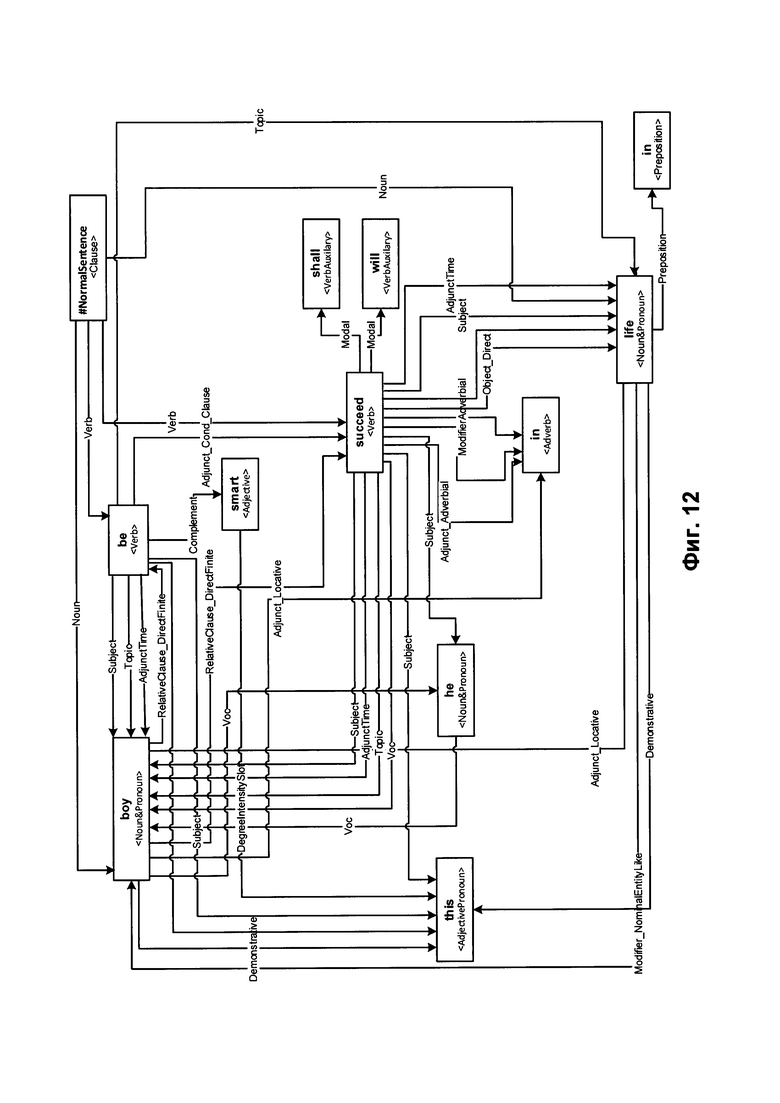
[000106] В некоторых вариантах осуществления корень графа обобщенных составляющих 732 представляет собой предикат. В ходе описанного выше процесса дерево может стать графом, так как определенные составляющие более низкого уровня могут быть включены в одну или несколько составляющих верхнего уровня. Множество составляющих, которые представляют определенные элементы лексико-морфологической структуры, затем может быть обобщено для получения обобщенных составляющих. Составляющие могут быть обобщены на основе их лексических значений или грамматических значений 414, например, на основе частей речи и отношений между ними. На Фиг. 12 схематически иллюстрируется пример графа обобщенных составляющих.
[000107] В блоке 216 вычислительное устройство может проводить точный синтаксический анализ предложения 212 для формирования одного или более синтаксических деревьев 742 согласно Фиг. 9 на основе графа обобщенных составляющих 732. Для каждого синтаксического дерева вычислительное устройство может определить интегральную оценку на основе априорных и вычисляемых оценок. Дерево с наилучшей оценкой может быть выбрано для построения наилучшей синтаксической структуры 746 исходного предложения 212.
[000108] В ходе построения синтаксической структуры 746 на основе выбранного синтаксического дерева вычислительное устройство может установить одну или несколько недревесных связей (например, путем создания дополнительной связи среди как минимум двух узлов графа). Если этот процесс заканчивается неудачей, вычислительное устройство может выбрать синтаксическое дерево с условно оптимальной оценкой, наиболее близкой к оптимальной, и производится попытка установить одну или несколько недревесных связей в дереве. Наконец, в результате точного синтаксического анализа создается синтаксическая структура 746, которая представляет собой лучшую синтаксическую структуру, соответствующую исходному предложению 212. Фактически в результате отбора лучшей синтаксической структуры 746 определяются лучшие лексические значения 240 для элементов исходного предложения 212.
[000109] В блоке 217 вычислительное устройство может обрабатывать синтаксические деревья для формирования семантической структуры 218, соответствующей предложению 212. Семантическая структура 218 может отражать передаваемую исходным предложением семантику в независимых от языка терминах. Семантическая структура 218 может быть представлена в виде ациклического графа, например, дерево, возможно, дополненное одной или более недревесной связью (дугой графа). Слова исходного предложения представлены узлами с соответствующими независимыми от языка семантическими классами семантической иерархии 510. Дуги графа представляют глубинные (семантические) отношения между элементами предложения. Переход к семантической структуре 218 может осуществляться с помощью правил анализа 460 и предполагает соотнесение одного или более атрибутов (отражающих лексические, синтаксические и (или) семантические свойства слов исходного предложения 212) с каждым семантическим классом.
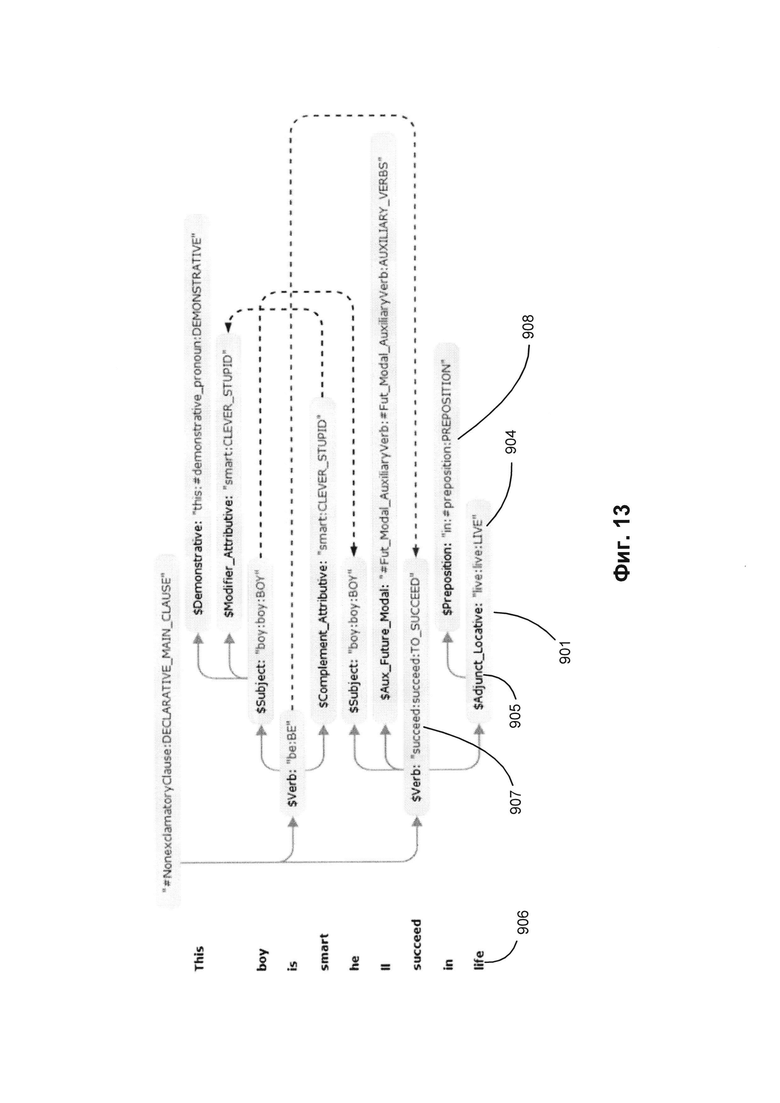
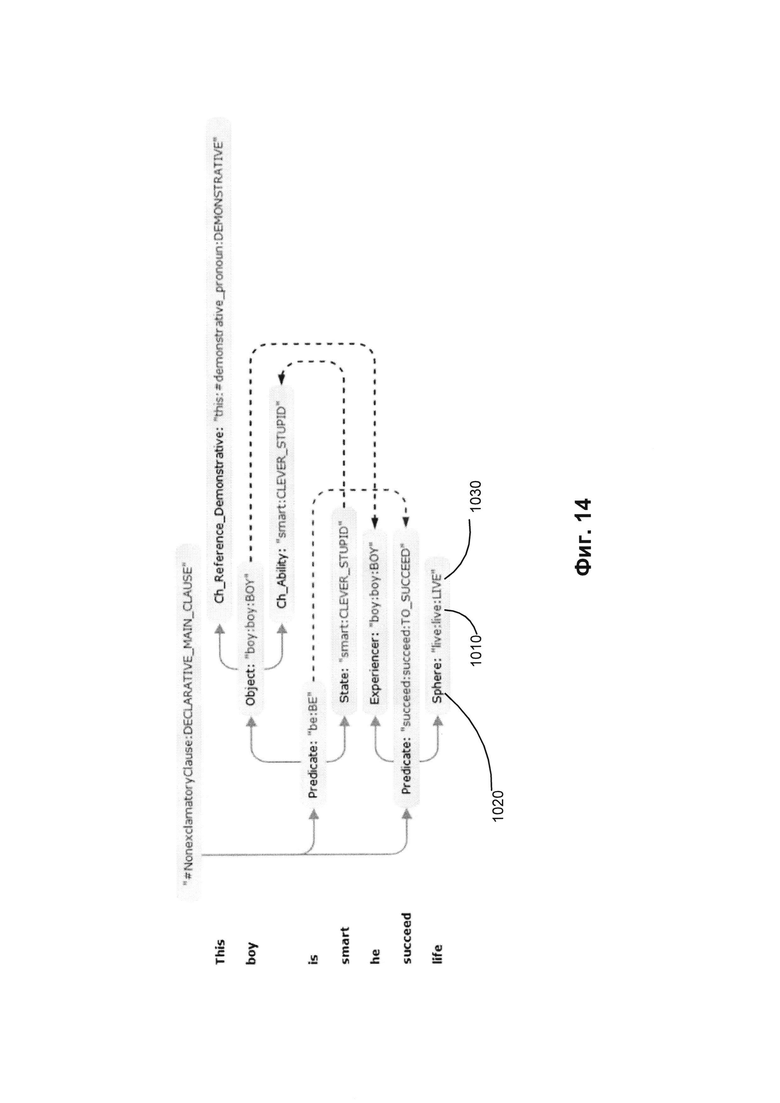
[000110] На Фиг. 13 приводятся примеры синтаксической структуры предложения, сгенерированной из графа обобщенных составляющих, показанного на Фиг. 12. Узел 901 соответствует лексическому элементу "life" (жизнь) 906. Применяя способ описанного в настоящем документе синтактико-семантического анализа, вычислительное устройство может установить, что лексический элемент "life" (жизнь) 906 представляет одну из форм лексического значения, соотнесенного с семантическим классом "LIVE" (ЖИТЬ) 904 и заполняет поверхностную позицию $Adjunct_Locative 905) в родительской составляющей, представленной управляющим узлом Verb:succeed:succeed:TO_SUCCEED (907).
[000111] На Фиг. 14 приводится семантическая структура, соответствующая синтаксической структуре на Фиг. 13. В отношении вышеупомянутого лексического элемента "life" (жизнь) (906) на Фиг. 13 семантическая структура включает лексический класс 1010 и семантический класс 1030, соответствующие представленным на Фиг. 13, однако вместо поверхностной позиции (905) семантическая структура включает глубинную позицию "Sphere" (сфера_деятельности) 1020.
[000112] В соответствии с одним или несколькими аспектами настоящего изобретения вычислительное устройство, в котором реализованы описанные в настоящем описании способы, может индексировать один или несколько параметров, полученных в результате семантико-синтаксического анализа. Таким образом, способы настоящего изобретения позволяют рассматривать не только множество слов в составе исходного текстового корпуса, но и множество лексических значений этих слов, сохраняя и индексируя всю синтаксическую и семантическую информацию, полученную в ходе синтаксического и семантического анализа каждого предложения исходного текстового корпуса. Такая информация может дополнительно включать данные, полученные в ходе промежуточных этапов анализа, а также результаты лексического выбора, в том числе результаты, полученные в ходе разрешения неоднозначностей, вызванных омонимией и (или) совпадающими грамматическими формами, соответствующими различным лексико-морфологическим значениям некоторых слов исходного языка.
[000113] Для каждой семантической структуры можно создать один или несколько индексов. Индекс можно представить в виде структуры данных в памяти, например, в виде таблицы, состоящей из нескольких записей. Каждая запись может представлять собой установление соответствия между определенным элементом семантической структуры (например, одно слово или несколько слов, синтаксическое отношение, морфологическое, синтаксическое или семантическое свойство или синтаксическая или семантическая структура) и одним или несколькими идентификаторами (или адресами) случаев употребления данного элемента семантической структуры в исходном тексте.
[000114] В некоторых вариантах осуществления индекс может включать одно или несколько значений морфологических, синтаксических, лексических и (или) семантических параметров. Эти значения могут создаваться в процессе двухэтапного семантического анализа (более подробное описание см. в настоящем документе). Индекс можно использовать для выполнения различных задач обработки естественного языка, в том числе для выполнения семантического поиска.
[000115] Вычислительное устройство, реализующее данный способ, может извлекать широкий спектр лексических, грамматических, синтаксических, прагматических и (или) семантических характеристик в ходе проведения синтактико-семантического анализа и создания семантических структур. В иллюстративном примере система может извлекать и сохранять определенную лексическую информацию, данные о принадлежности определенных лексических единиц семантическим классам, информацию о грамматических формах и линейном порядке, информацию об использовании определенных форм, аспектов, тональности (например, положительной или отрицательной), глубинных позиций, недревесных связей, семантем и т.д.
[000116] Вычислительное устройство, в котором реализованы описанные здесь способы, может производить анализ, используя один или несколько описанных в этом документе способов анализа текста, и индексировать любой один или несколько параметров описаний языка, включая лексические значения, семантические классы, граммемы, семантемы и т.д. Индексацию семантического класса можно использовать в различных задачах обработки естественного языка, включая семантический поиск, классификацию, кластеризацию, фильтрацию текста и т.д. Индексация лексических значений (вместо индексации слов) позволяет искать не только слова и формы слов, но и лексические значения, т.е. слова, имеющие определенные лексические значения. Вычислительное устройство, реализующее способы настоящего изобретения, также может хранить и индексировать синтаксические и семантические структуры, созданные одним или несколькими описанными в настоящем документе способами анализа текста, для использования данных структур и (или) индексов при проведении семантического поиска, классификации, кластеризации и фильтрации документов.
[000117] На Фиг. 15 показан иллюстративный приме вычислительного устройства (1000), которое может исполнять набор команд, которые вызывают выполнение вычислительным устройством любого отдельно взятого или нескольких способов настоящего изобретения. Вычислительное устройство может подключаться к другому вычислительному устройству по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительное устройство может работать в качестве сервера или клиентского вычислительного устройства в сетевой среде "клиент/сервер" либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительное устройство может быть представлено персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любым вычислительным устройством, способным выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этим вычислительным устройством. Кроме того, в то время как показано только одно вычислительное устройство, следует принять, что термин «вычислительное устройство» также может включать любую совокупность вычислительных устройств, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или нескольких методик, описанных в настоящем документе.
[000118] Пример вычислительного устройства (1000) включает процессор (502), основную память (504) (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных (518), которые взаимодействуют друг с другом по шине (530).
[000119] Процессор (502) может быть представлен одним или более универсальными вычислительными устройствами, например, микропроцессором, центральным процессором и т.д. В частности, процессор (502) может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор (502) также может представлять собой одно или несколько вычислительных устройств специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор (502) настроен на выполнение команд (526) для осуществления рассмотренных в настоящем документе операций и функций.
[000120] Вычислительное устройство (1000) может дополнительно включать устройство сетевого интерфейса (522), устройство визуального отображения (510), устройство ввода символов (512) (например, клавиатуру), и устройство ввода - сенсорный экран (514).
[000121] Устройство хранения данных (518) может содержать машиночитаемый носитель данных (524), в котором хранится один или более наборов команд (526), и в котором реализован один или более из методов или функций настоящего изобретения. Команды (526) также могут находиться полностью или по меньшей мере частично в основной памяти (504) и/или в процессоре (502) во время выполнения их в вычислительном устройстве (1000), при этом оперативная память (504) и процессор (502) также составляют машиночитаемый носитель данных. Команды (526) дополнительно могут передаваться или приниматься по сети (516) через устройство сетевого интерфейса (522).
[000122] В некоторых вариантах осуществления команды (526) могут включать в себя команды способа (100) классификации текстов на естественном языке yf на основе семантических признаков и/или способа вычисления параметров модели классификации. В то время как машиночитаемый носитель данных (524), показанный на примере на Фиг. 15, является единым носителем, термин «машиночитаемый носитель» должен включать один носитель или несколько носителей (например, централизованную или распределенную базу данных, и/или соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин "машиночитаемый носитель данных" также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять любую одну или несколько из методик, описанных в настоящем раскрытии изобретения. Таким образом, термин «машиночитаемый носитель данных», помимо прочего, также относится к твердотельной памяти и оптическим и магнитным носителям.
[000123] Описанные в документе способы, компоненты и функции могут быть реализованы дискретными аппаратными компонентами, либо они могут быть интегрированы в функции других аппаратных компонентов, таких как ASICS, FPGA, DSP или подобных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратных устройств. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации вычислительных средств и программных компонентов, либо исключительно с помощью программного обеспечения.
[000124] В приведенном выше описании изложены многочисленные детали. Однако специалисту в этой области техники, благодаря этому описанию, очевидно, что настоящее изобретение может быть реализовано на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схемы, а не детально, чтобы не усложнять описание настоящего изобретения.
[000125] Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. В настоящем документе и в целом алгоритмом называется самосогласованная последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и подвергать другим манипуляциям. Оказалось, что прежде всего для обычного использования удобно описывать эти сигналы в виде битов, значений, элементов, символов, членов, цифр и т.д.
[000126] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они представляют собой просто удобные метки, применяемые к этим величинам. Если иное специально и недвусмысленно не указано в нижеследующем обсуждении, следует принимать, что везде по тексту такие термины как "определение", "вычисление", "расчет", "вычисление", "получение", "установление", "изменение" и т.п., относятся к действиям и процессам вычислительного устройства или аналогичного электронного вычислительного устройства, которое работает с данными и преобразует данные, представленные в виде физических (например, электронных) величин в регистрах и памяти вычислительного устройства, в другие данные, аналогичным образом представленные в виде физических величин в памяти или регистрах вычислительного устройства, либо других подобных устройствах хранения, передачи или отображения информации.
[000127] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей или оно может содержать универсальный компьютер, который избирательно активируется или реконфигурируется с помощью компьютерной программы, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, таком как, в числе прочих, диск любого рода, в том числе дискеты, оптические диски, компакт-диски, магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и другие виды носителей данных, подходящие для хранения электронных команд.
[000128] Следует понимать, что вышеприведенное описание носит иллюстративный, а не ограничительный характер. Различные другие варианты осуществления станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому объем раскрытия должен определяться со ссылкой на прилагаемую формулу изобретения наряду с полным объемом эквивалентов, на которые такие требования предоставляют право.
Изобретение относится к системам и способам обработки естественного языка. Техническим результатом является повышение точности выполнения классификации текстов, в том числе на различных языках. В способе классификации текстов на естественном языке семантико-синтаксический анализ текста на естественном языке для создания семантической структуры, включающей набор семантических классов. Связывают первый семантический класс с первым значением, отражающим значение некоторого атрибута семантического класса. Выявляют второй семантический класс, связанный с первым семантическим классом заданными семантическими отношениями, и связывают его со вторым значением, отражающим указанный атрибут семантического класса. При этом второе значение определяется применением заданной трансформации к первому значению. Вычисляют признак текста на естественном языке на основе первого значения и второго значения и определяют с помощью модели классификатора с помощью вычисленного признака текста степени соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий. 3 н. и 17 з.п. ф-лы, 15 ил.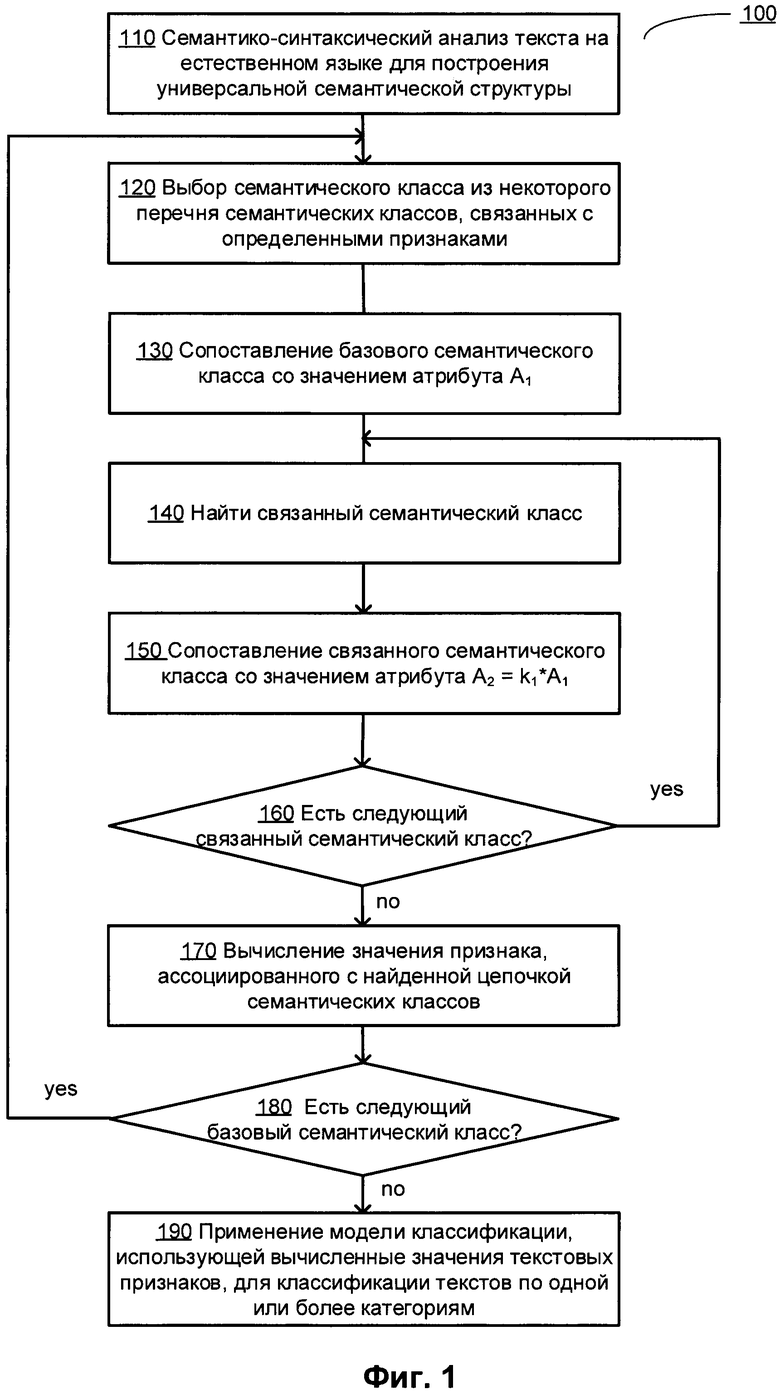
1. Способ классификации текстов на естественном языке для компьютерной системы, включающий:
выполнение с помощью вычислительной системы семантико-синтаксического анализа текста на естественном языке для создания семантической структуры, включающей набор семантических классов;
связывание первого семантического класса из набора семантических классов с первым значением, отражающим значение некоторого атрибута семантического класса;
выявление второго семантического класса, связанного с первым семантическим классом заданными семантическими отношениями;
связывание второго семантического класса со вторым значением, отражающим указанный атрибут семантического класса, при этом второе значение определяется применением заданной трансформации к первому значению;
вычисление признака текста на естественном языке на основе первого значения и второго значения; и
определение с помощью модели классификатора с помощью вычисленного признака текста степени соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий.
2. Способ по п. 1, отличающийся тем, что признак текста на естественном языке отражает частоту встречаемости экземпляров первого семантического класса в семантической структуре.
3. Способ по п. 1, отличающийся тем, что семантическая структура представлена графом, содержащим множество узлов, соответствующих семантическим классам, и множество дуг, соответствующих семантическим отношениям.
4. Способ по п. 1, отличающийся тем, что указанный атрибут первого семантического класса включает по меньшей мере один из множества: лексических атрибутов, синтаксических атрибутов или семантических атрибутов.
5. Способ по п. 1, отличающийся тем, что экземпляр второго семантического класса является предком первого семантического класса в семантической иерархии, представляющей множество семантических классов.
6. Способ по п. 1, отличающийся тем, что применение предопределенной трансформации подразумевает умножение первого значения на заданный множитель.
7. Способ по п. 6, дополнительно включающий:
последовательное применение ко множеству атрибутов цепочки заданных трансформаций для связанных семантических классов с использованием множителей, которые формируют геометрическую прогрессию, состоящую из действительных чисел.
8. Способ по п. 1, дополнительно включающий:
выявление третьего семантического класса, связанного со вторым семантическим классом заданными семантическими отношениями; а также
связывание третьего семантического класса с третьим значением, отражающим указанный атрибут третьего семантического класса, при этом третье значение определяется применением заданной трансформации ко второму значению.
9. Система для классификации текстов на естественном языке, включающая:
память;
процессор, связанный с этой памятью, причем этот процессор настроен на:
выполнение семантико-синтаксического анализа текста на естественном языке для создания семантической структуры, включающей набор семантических классов;
связывание первого семантического класса из набора семантических классов с первым значением, отражающим значение некоторого атрибута семантического класса;
выявление второго семантического класса, связанного с первым семантическим классом заданными семантическими отношениями;
связывание второго семантического класса со вторым значением, отражающим указанный атрибут семантического класса, при этом второе значение определяется применением заданной трансформации к первому значению;
вычисление признака текста на естественном языке на основе первого значения и второго значения; и
определение с помощью модели классификатора с помощью вычисленного признака текста степени соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий.
10. Система по п. 9, отличающаяся тем, что признак текста на естественном языке отражает частоту встречаемости экземпляров первого семантического класса в семантической структуре.
11. Система по п. 9, отличающаяся тем, что семантическая структура представлена графом, содержащим множество узлов, соответствующих набору семантических классов, и множество дуг, соответствующих множеству семантических отношений.
12. Система по п. 9, отличающаяся тем, что указанный атрибут первого семантического класса включает по меньшей мере один из множества: лексических атрибутов, синтаксических атрибутов или семантических атрибутов.
13. Система по п. 9, отличающаяся тем, что экземпляр второго семантического класса является предком первого семантического класса в семантической иерархии, представляющей множество семантических классов.
14. Система по п. 9, отличающаяся тем, что применение предопределенной трансформации подразумевает умножение первого значения на заданный множитель.
15. Постоянный машиночитаемый носитель, включающий исполняемые команды для классификации текстов на естественном языке, которые при выполнении вычислительной системой заставляют эту вычислительную систему:
выполнять семантико-синтаксический анализ текста на естественном языке для создания семантической структуры, включающей набор семантических классов;
связывать первый семантический класс из набора семантических классов с первым значением, отражающим значение некоторого атрибута семантического класса;
выявлять второй семантический класс, связанный с первым семантическим классом заданными семантическими отношениями;
связывать второй семантический класс со вторым значением, отражающим указанный атрибут семантического класса, при этом второе значение определяется применением заданной трансформации к первому значению;
вычислять признак текста на естественном языке на основе первого значения и второго значения; и
определять с помощью модели классификатора с помощью вычисленного признака текста степень соотнесения текста на естественном языке с конкретной категорией из заданного набора категорий.
16. Постоянный машиночитаемый носитель по п. 15, отличающийся тем, что признак текста на естественном языке отражает частоту встречаемости экземпляров первого семантического класса в семантической структуре.
17. Постоянный машиночитаемый носитель по п. 15, отличающийся тем, что семантическая структура представлена графом, содержащим множество узлов, соответствующих набору семантических классов, и множество дуг, соответствующих множеству семантических отношений.
18. Постоянный машиночитаемый носитель по п. 15, отличающийся тем, что указанный атрибут первого семантического класса включает по меньшей мере один из множества: лексических атрибутов, синтаксических атрибутов или семантических атрибутов.
19. Постоянный машиночитаемый носитель по п. 15, отличающийся тем, что экземпляр второго семантического класса является предком первого семантического класса в семантической иерархии, представляющей множество семантических классов.
20. Постоянный машиночитаемый носитель по п. 15, отличающийся тем, что применение предопределенной трансформации подразумевает умножение первого значения на заданный множитель.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |

