Изобретение относится к обработке аудиосигналов, в частности к устройству и способу для маскирования ошибок при стандартизированном кодировании речи и аудио с низкой задержкой (LD-USAC).
Обработка аудиосигналов совершенствуется во множестве аспектов и становится все более и более важной. При обработке аудиосигналов стандартизированное кодирование речи и аудио с низкой задержкой нацелено на предоставление технологий кодирования, подходящих для речи, аудио и любого сочетания речи и аудио. Кроме того, LD-USAC нацелено на обеспечение высокого качества для кодированных аудиосигналов. По сравнению с USAC (стандартизированным кодированием речи и аудио) уменьшается задержка в LD-USAC.
При кодировании аудиоданных LD-USAC-кодер анализирует аудиосигнал, который должен кодироваться. LD-USAC-кодер кодирует аудиосигнал посредством кодирования коэффициентов линейной прогнозирующей фильтрации прогнозного фильтра. В зависимости от аудиоданных, которые должны быть кодированы посредством конкретного аудиокадра, LD-USAC-кодер определяет то, используется или нет ACELP (усовершенствованное линейное прогнозирование с возбуждением по коду) для кодирования, либо то, должны аудиоданные быть кодированы или нет с использованием TCX (возбуждения по кодированию с преобразованием). Тогда как ACELP использует коэффициенты LP-фильтрации (коэффициенты линейной прогнозирующей фильтрации), индексы адаптивных таблиц кодирования и индексы алгебраических таблиц кодирования и усиления адаптивных и алгебраических таблиц кодирования, TCX использует коэффициенты LP-фильтрации, энергетические параметры и индексы квантования, связанные с модифицированным дискретным косинусным преобразованием (MDCT).
На стороне декодера LD-USAC-декодер определяет то, использовано ACELP или TCX для того, чтобы кодировать аудиоданные кадра текущего аудиосигнала. Декодер затем декодирует кадр аудиосигнала соответствующим образом.
Время от времени передача данных завершается неудачно. Например, кадр аудиосигнала, передаваемый посредством отправляющего устройства, поступает с ошибками в приемное устройство либо вообще не поступает, либо кадр поступает поздно.
В этих случаях, может требоваться маскирование ошибок для того, чтобы обеспечивать, что пропущенные или ошибочные аудиоданные могут быть заменены. Это является, в частности, истинным для приложений, имеющих требования для работы в реальном времени, поскольку запрос повторной передачи ошибочного или пропущенного кадра может нарушать требования по низкой задержке.
Тем не менее, существующие технологии маскирования, используемые для других аудиоприложений, зачастую создают искусственный звук, вызываемый посредством синтетических артефактов.
Следовательно, цель настоящего изобретения заключается в том, чтобы предоставлять усовершенствованные принципы для маскирования ошибок для кадра аудиосигнала. Цель настоящего изобретения достигается посредством устройства, посредством способа и посредством компьютерной программы.
Предоставляется устройство для формирования спектральных замещающих значений для аудиосигнала. Устройство содержит буферный блок для сохранения предыдущих спектральных значений, связанных с ранее принимаемым безошибочным аудиокадром. Кроме того, устройство содержит формирователь кадров маскирования для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным. Ранее принимаемый безошибочный аудиокадр содержит информацию фильтра, причем информация фильтра имеет ассоциированное значение стабильности фильтра, указывающее стабильность прогнозного фильтра. Формирователь кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений и на основе значения стабильности фильтра.
Настоящее изобретение основано на том факте, что, в то время как предыдущие спектральные значения ранее принимаемого безошибочного кадра могут использоваться для маскирования ошибок, затухание должно осуществляться для этих значений, и затухание должно зависеть от стабильности сигнала. Чем менее стабильным является сигнал, тем быстрее должно осуществляться затухание.
В варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения посредством произвольной смены знака предыдущих спектральных значений.
Согласно дополнительному варианту осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения посредством умножения каждого из предыдущих спектральных значений на первый коэффициент усиления, когда значение стабильности фильтра имеет первое значение, и посредством умножения каждого из предыдущих спектральных значений на второй коэффициент усиления, меньший первого коэффициента усиления, когда значение стабильности фильтра имеет второе значение, меньшее первого значения.
В другом варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения на основе значения стабильности фильтра, при этом ранее принимаемый безошибочный аудиокадр содержит первые коэффициенты прогнозирующей фильтрации прогнозного фильтра, при этом предшествующий кадр относительно ранее принимаемого безошибочного аудиокадра содержит вторые коэффициенты прогнозирующей фильтрации, и при этом значение стабильности фильтра зависит от первых коэффициентов прогнозирующей фильтрации и от вторых коэффициентов прогнозирующей фильтрации.
Согласно варианту осуществления, формирователь кадров маскирования может быть выполнен с возможностью определять значение стабильности фильтра на основе первых коэффициентов прогнозирующей фильтрации ранее принимаемого безошибочного аудиокадра и на основе вторых коэффициентов прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого безошибочного аудиокадра.
В другом варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения на основе значения стабильности фильтра, при этом значение стабильности фильтра зависит от показателя 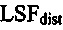 расстояния, и при этом показатель
расстояния, и при этом показатель 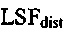 расстояния задается посредством формулы:
расстояния задается посредством формулы:
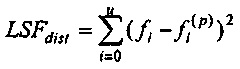 ,
,
где u+1 указывает общее число первых коэффициентов прогнозирующей фильтрации ранее принимаемого безошибочного аудиокадра, и где u+1 также указывает общее число вторых коэффициентов прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого безошибочного аудиокадра, где 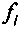 указывает i-й коэффициент фильтрации из первых коэффициентов прогнозирующей фильтрации, и где
указывает i-й коэффициент фильтрации из первых коэффициентов прогнозирующей фильтрации, и где 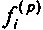 указывает i-й коэффициент фильтрации вторых коэффициентов прогнозирующей фильтрации.
указывает i-й коэффициент фильтрации вторых коэффициентов прогнозирующей фильтрации.
Согласно варианту осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения дополнительно на основе информации класса кадров, связанной с ранее принимаемым безошибочным аудиокадром. Например, информация класса кадров указывает, что ранее принимаемый безошибочный аудиокадр классифицируется как "искусственное вступление", "вступление", "вокализованный переход", "невокализованный переход", "невокализованный" или "вокализованный".
В другом варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения дополнительно на основе числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными с момента, когда последний безошибочный аудиокадр поступает в приемное устройство, при этом другие безошибочные аудиокадры не поступают в приемное устройство с момента, когда последний безошибочный аудиокадр поступает в приемное устройство.
Согласно другому варианту осуществления, формирователь кадров маскирования может быть выполнен с возможностью вычислять коэффициент затухания как на основе значения стабильности фильтра, так и на основе числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными. Кроме того, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения посредством умножения коэффициента затухания, по меньшей мере, на некоторые предыдущие спектральные значения или, по меньшей мере, на некоторые значения из группы промежуточных значений, при этом каждое из промежуточных значений зависит, по меньшей мере, от одного из предыдущих спектральных значений.
В дополнительном варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений, на основе значения стабильности фильтра, а также на основе усиления для прогнозирования временного формирования шума.
Согласно дополнительному варианту осуществления, предоставляется декодер аудиосигналов. Декодер аудиосигналов может содержать устройство для декодирования спектральных значений аудиосигналов и устройство для формирования спектральных замещающих значений согласно одному из вышеописанных вариантов осуществления. Устройство для декодирования спектральных значений аудиосигналов может быть выполнено с возможностью декодировать спектральные значения аудиосигнала на основе ранее принимаемого безошибочного аудиокадра. Кроме того, устройство для декодирования спектральных значений аудиосигналов может быть дополнительно выполнено с возможностью сохранять спектральные значения аудиосигнала в буферном блоке устройства для формирования спектральных замещающих значений. Устройство для формирования спектральных замещающих значений может быть выполнено с возможностью формировать спектральные замещающие значения на основе спектральных значений, сохраненных в буферном блоке, когда текущий аудиокадр не принят или является ошибочным.
Кроме того, предоставляется декодер аудиосигналов согласно другому варианту осуществления. Декодер аудиосигналов содержит блок декодирования для формирования первых промежуточных спектральных значений на основе принимаемого безошибочного аудиокадра, блок временного формирования шума для осуществления временного формирования шума для первых промежуточных спектральных значений, чтобы получать вторые промежуточные спектральные значения, блок вычисления усилений для прогнозирования для вычисления усиления для прогнозирования временного формирования шума в зависимости от первых промежуточных спектральных значений и в зависимости от вторых промежуточных спектральных значений, устройство согласно одному из вышеописанных вариантов осуществления для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным, и блок выбора значений для сохранения первых промежуточных спектральных значений в буферном блоке устройства для формирования спектральных замещающих значений, если усиление для прогнозирования превышает или равно пороговому значению, или для сохранения вторых промежуточных спектральных значений в буферном блоке устройства для формирования спектральных замещающих значений, если усиление для прогнозирования меньше порогового значения.
Кроме того, предоставляется другой декодер аудиосигналов согласно другому варианту осуществления. Декодер аудиосигналов содержит первый модуль декодирования для формирования сформированных спектральных значений на основе принимаемого безошибочного аудиокадра, устройство для формирования спектральных замещающих значений согласно одному из вышеописанных вариантов осуществления, процессор для обработки сформированных спектральных значений посредством осуществления временного формирования шума, применения заполнения шумом и/или применения глобального усиления, чтобы получать спектральные аудиозначения декодированного аудиосигнала. Устройство для формирования спектральных замещающих значений может быть выполнено с возможностью формировать спектральные замещающие значения и подавать их в процессор, когда текущий кадр не принят или является ошибочным.
Предпочтительные варианты осуществления предоставляются в зависимых пунктах формулы изобретения.
Далее описываются предпочтительные варианты осуществления настоящего изобретения со ссылкой на чертежи, на которых:
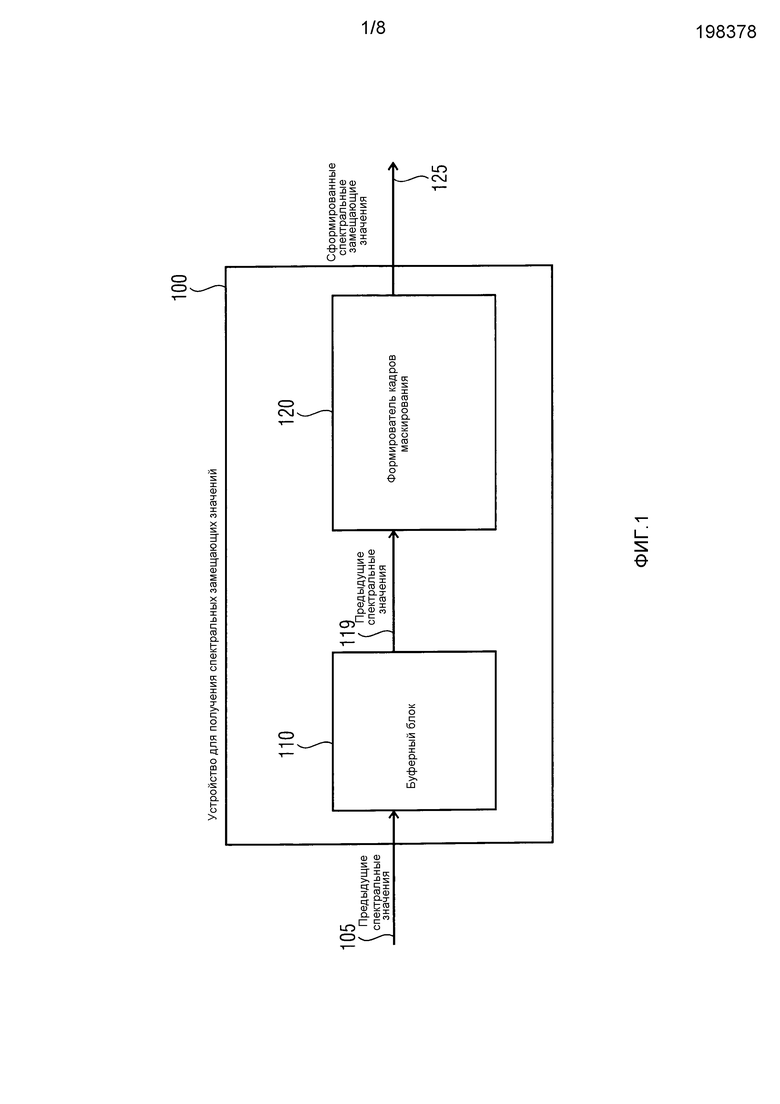
фиг. 1 иллюстрирует устройство для получения спектральных замещающих значений для аудиосигнала согласно варианту осуществления,
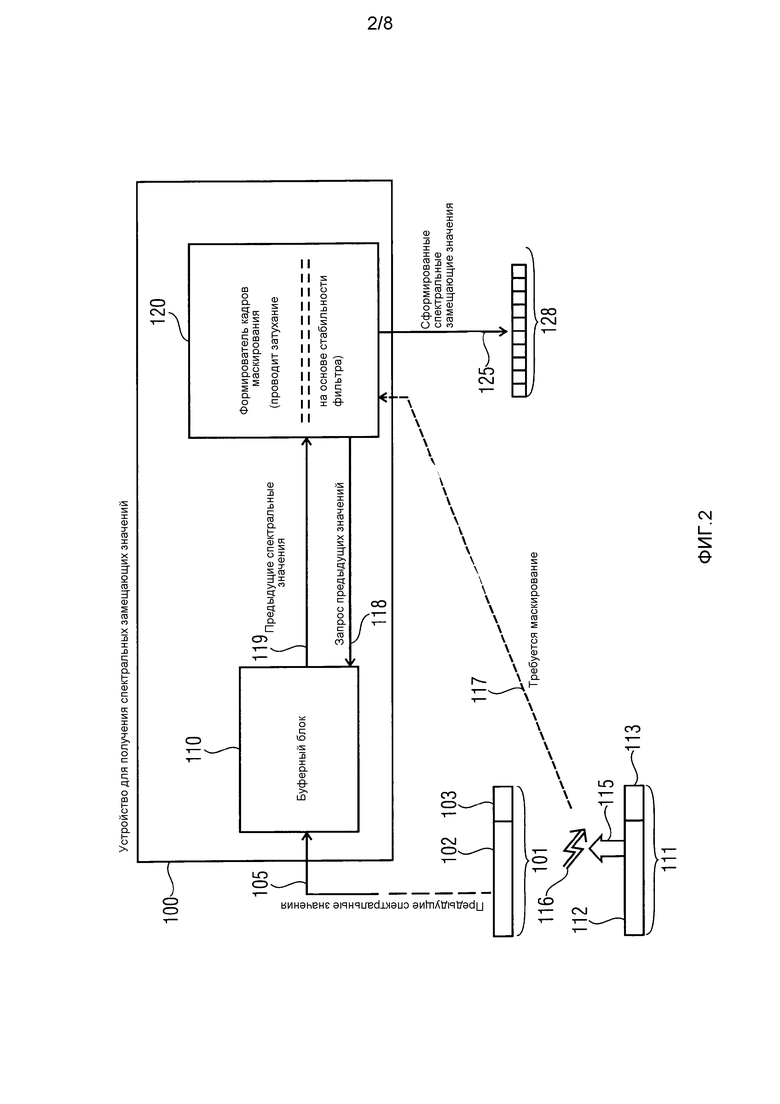
фиг. 2 иллюстрирует устройство для получения спектральных замещающих значений для аудиосигнала согласно другому варианту осуществления,
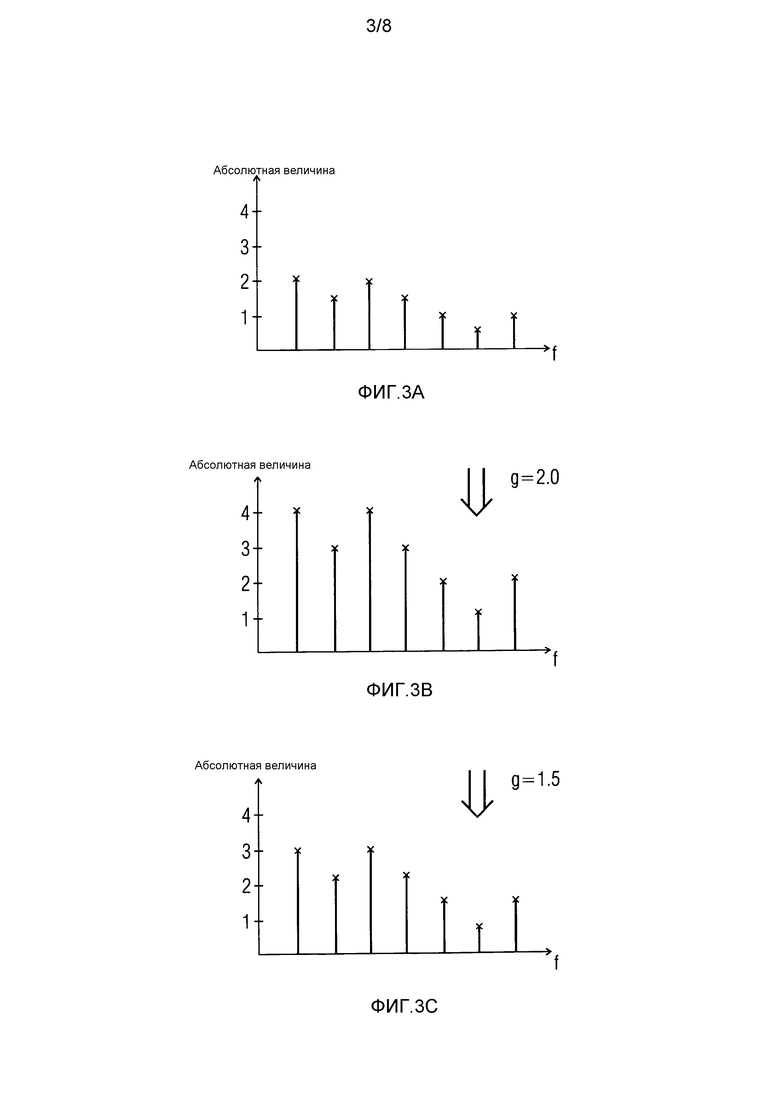
фиг. 3A-3C иллюстрируют умножение коэффициента усиления и предыдущих спектральных значений согласно варианту осуществления,
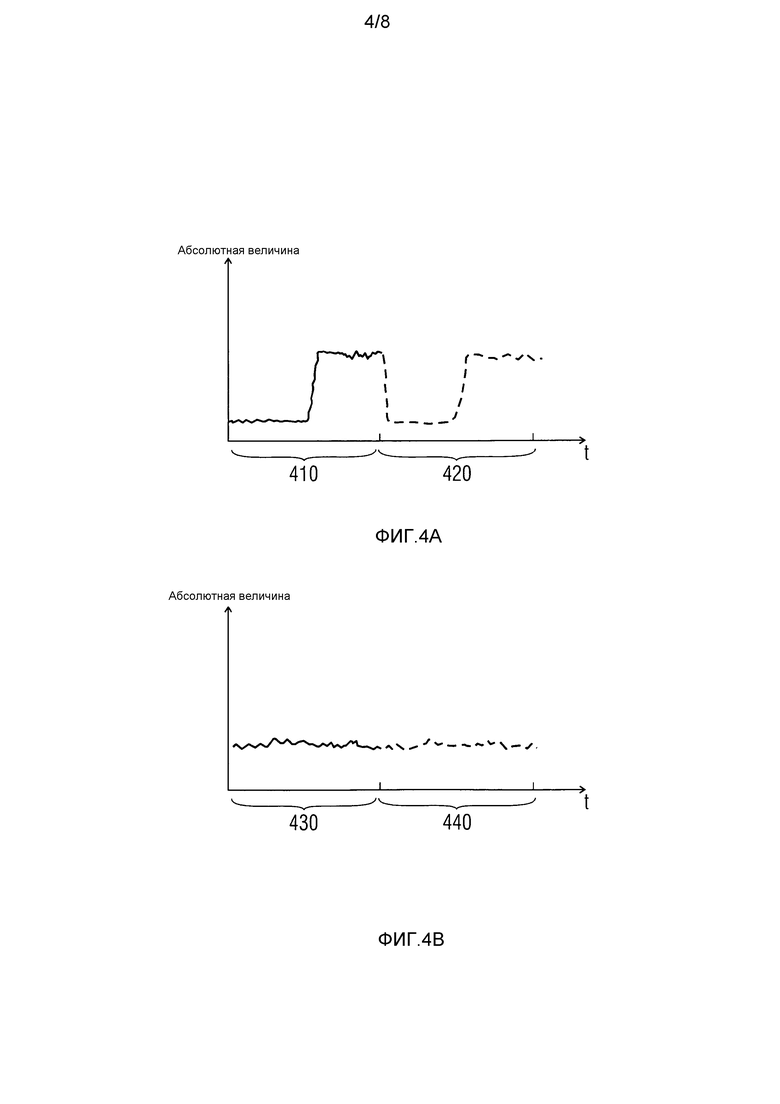
фиг. 4A иллюстрирует повторение части сигнала, которая содержит вступление во временной области,
фиг. 4B иллюстрирует повторение стабильной части сигнала во временной области,
фиг. 5A-5B иллюстрируют примеры, в которых сформированные коэффициенты усиления применяются к спектральным значениям по фиг. 3A, согласно варианту осуществления,
фиг. 6 иллюстрирует декодер аудиосигналов согласно варианту осуществления,
фиг. 7 иллюстрирует декодер аудиосигналов согласно другому варианту осуществления, и
фиг. 8 иллюстрирует декодер аудиосигналов согласно дополнительному варианту осуществления.
Фиг. 1 иллюстрирует устройство 100 для формирования спектральных замещающих значений для аудиосигнала. Устройство 100 содержит буферный блок 110 для сохранения предыдущих спектральных значений, связанных с ранее принимаемым безошибочным аудиокадром. Кроме того, устройство 100 содержит формирователь 120 кадров маскирования для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным. Ранее принимаемый безошибочный аудиокадр содержит информацию фильтра, причем информация фильтра имеет ассоциированное значение стабильности фильтра, указывающее стабильность прогнозного фильтра. Формирователь 120 кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений и на основе значения стабильности фильтра.
Ранее принимаемый безошибочный аудиокадр, например, может содержать предыдущие спектральные значения. Например, предыдущие спектральные значения могут содержаться в ранее принимаемом безошибочном аудиокадре в кодированной форме.
Альтернативно, предыдущие спектральные значения, например, могут быть значениями, которые, возможно, сформированы посредством модификации значений, содержащихся в ранее принимаемом безошибочном аудиокадре, например, спектральных значений аудиосигнала. Например, значения, содержащиеся в ранее принимаемом безошибочном аудиокадре, возможно, модифицированы посредством умножения каждого из них на коэффициент усиления, чтобы получать предыдущие спектральные значения.
Альтернативно, предыдущие спектральные значения, например, могут быть значениями, которые, возможно, сформированы на основе значений, содержащихся в ранее принимаемом безошибочном аудиокадре. Например, каждое из предыдущих спектральных значений, возможно, сформировано посредством использования, по меньшей мере, некоторых значений, содержащихся в ранее принимаемом безошибочном аудиокадре, так что каждое из предыдущих спектральных значений зависит, по меньшей мере, от некоторых значений, содержащихся в ранее принимаемом безошибочном аудиокадре. Например, значения, содержащиеся в ранее принимаемом безошибочном аудиокадре, возможно, использованы для того, чтобы формировать промежуточный сигнал. Например, спектральные значения сформированного промежуточного сигнала затем могут считаться предыдущими спектральными значениями, связанными с ранее принимаемым безошибочным аудиокадром.
Стрелка 105 указывает, что предыдущие спектральные значения сохраняются в буферном блоке 110.
Формирователь 120 кадров маскирования может формировать спектральные замещающие значения, когда текущий аудиокадр не принят вовремя или является ошибочным. Например, передающее устройство может передавать текущий аудиокадр в приемное устройство, в котором, например, может располагаться устройство 100 для получения спектральных замещающих значений. Тем не менее, текущий аудиокадр не поступает в приемное устройство, например, вследствие какого-либо типа ошибки при передаче. Альтернативно, передаваемый текущий аудиокадр принимается посредством приемного устройства, но, например, вследствие нарушений, например, в ходе передачи текущий аудиокадр является ошибочным. В этом или в других случаях, требуется формирователь 120 кадров маскирования для маскирования ошибок.
Для этого формирователь 120 кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе, по меньшей мере, некоторых предыдущих спектральных значений, когда текущий аудиокадр не принят или является ошибочным. Согласно вариантам осуществления, предполагается, что ранее принимаемый безошибочный аудиокадр содержит информацию фильтра, причем информация фильтра имеет ассоциированное значение стабильности фильтра, указывающее стабильность прогнозного фильтра, заданного посредством информации фильтра. Например, аудиокадр может содержать коэффициенты прогнозирующей фильтрации, к примеру, коэффициенты линейной прогнозирующей фильтрации, в качестве информации фильтра.
Формирователь 120 кадров маскирования дополнительно выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений и на основе значения стабильности фильтра.
Например, спектральные замещающие значения могут быть сформированы на основе предыдущих спектральных значений и на основе значения стабильности фильтра так, что каждое из предыдущих спектральных значений умножается на коэффициент усиления, при этом значение коэффициента усиления зависит от значения стабильности фильтра. Например, коэффициент усиления может быть меньшим во втором случае, чем в первом случае, когда значение стабильности фильтра во втором случае меньше, чем в первом случае.
Согласно другому варианту осуществления, спектральные замещающие значения могут быть сформированы на основе предыдущих спектральных значений и на основе значения стабильности фильтра. Промежуточные значения могут быть сформированы посредством модификации предыдущих спектральных значений, например, посредством произвольной смены знака предыдущих спектральных значений и посредством умножения каждого из промежуточных значений на коэффициент усиления, при этом значение коэффициента усиления зависит от значения стабильности фильтра. Например, коэффициент усиления может быть меньшим во втором случае, чем в первом случае, когда значение стабильности фильтра во втором случае меньше, чем в первом случае.
Согласно дополнительному варианту осуществления, предыдущие спектральные значения могут использоваться для того, чтобы формировать промежуточный сигнал, и синтезированный сигнал спектральной области может быть сформирован посредством применения линейного прогнозного фильтра к промежуточному сигналу. Затем каждое спектральное значение сформированного синтезированного сигнала может быть умножено на коэффициент усиления, при этом значение коэффициента усиления зависит от значения стабильности фильтра. Как описано выше, коэффициент усиления, например, может быть меньшим во втором случае, чем в первом случае, если значение стабильности фильтра во втором случае меньше, чем в первом случае.
Далее подробно поясняется конкретный вариант осуществления, проиллюстрированный на фиг. 2. Первый кадр 101 поступает на сторону приемного устройства, на которой может располагаться устройство 100 для получения спектральных замещающих значений. На стороне приемного устройства проверяется то, является аудиокадр безошибочным или нет. Например, безошибочный аудиокадр является аудиокадром, в котором все аудиоданные, содержащиеся в аудиокадре, являются безошибочными. С этой целью, на стороне приемного устройства может использоваться средство (не показано), которое определяет то, является принимаемый кадр безошибочным или нет. С этой целью, могут использоваться технологии распознавания ошибок предшествующего уровня техники, такие как средство, которое тестирует то, являются или нет принятые аудиоданные согласованными с принимаемым контрольным битом или принимаемой контрольной суммой. Альтернативно, средство с обнаружением ошибок может использовать контроль циклическим избыточным кодом (CRC), чтобы тестировать то, являются или нет принятые аудиоданные согласованными с принимаемым CRC-значением. Также может использоваться любая другая технология для тестирования того, является принимаемый аудиокадр безошибочным или нет.
Первый аудиокадр 101 содержит аудиоданные 102. Кроме того, первый аудиокадр содержит контрольные данные 103. Например, контрольные данные могут быть контрольным битом, контрольной суммой или CRC-значением, которое может использоваться на стороне приемного устройства для того, чтобы тестировать то, является принимаемый аудиокадр 101 безошибочным (безошибочным кадром) или нет.
Если определено, что аудиокадр 101 является безошибочным, то значения, связанные с безошибочным аудиокадром, например, с аудиоданными 102, должны быть сохранены в буферном блоке 110 в качестве "предыдущих спектральных значений". Эти значения, например, могут быть спектральными значениями аудиосигнала, кодированного в аудиокадре. Альтернативно, значения, которые сохраняются в буферном блоке, например, могут быть промежуточными значениями, получающимися в результате обработки и/или модификации кодированных значений, сохраненных в аудиокадре. Альтернативно, сигнал, например, синтезированный сигнал в спектральной области, может быть сформирован на основе кодированных значений аудиокадра, и спектральные значения сформированного сигнала могут быть сохранены в буферном блоке 110. Сохранение предыдущих спектральных значений в буферном блоке 110 указывается посредством стрелки 105.
Кроме того, аудиоданные 102 аудиокадра 101 используются на стороне приемного устройства для того, чтобы декодировать кодированный аудиосигнал (не показан). Часть аудиосигнала, который декодирован, затем может быть воспроизведена на стороне приемного устройства.
Далее, после обработки аудиокадра 101, сторона приемного устройства ожидает поступления следующего аудиокадра 111 (также содержащего аудиоданные 112 и контрольные данные 113) на сторону приемного устройства. Тем не менее, например, в то время как передается аудиокадр 111 (как показано в 115), происходит неожиданное событие. Это проиллюстрировано посредством 116. Например, соединение может быть нарушено, так что биты аудиокадра 111 могут быть непреднамеренно модифицированы в ходе передачи, или, к примеру, аудиокадр 111 может вообще не поступать на сторону приемного устройства.
В таком случае требуется маскирование. Когда, например, на стороне приемного устройства воспроизводится аудиосигнал, который формируется на основе принимаемого аудиокадра, должны использоваться технологии, которые скрывают пропущенный кадр. Например, принципы должны задавать то, что следует делать, когда текущий аудиокадр аудиосигнала, который требуется для воспроизведения, не поступает на сторону приемного устройства или является ошибочным.
Формирователь 120 кадров маскирования выполнен с возможностью предоставлять маскирование ошибок. На фиг. 2, в формирователь 120 кадров маскирования сообщается, что текущий кадр не принят или является ошибочным. На стороне приемного устройства может использоваться средство (не показано), чтобы указывать формирователю 120 кадров маскирования, что требуется маскирование (это показывается посредством пунктирной стрелки 117).
Чтобы осуществлять маскирование ошибок, формирователь 120 кадров маскирования может запрашивать некоторые или все предыдущие спектральные значения, например, предыдущие аудиозначения, связанные с ранее принимаемым безошибочным кадром 101, из буферного блока 110. Этот запрос проиллюстрирован посредством стрелки 118. Аналогично примеру по фиг. 2, ранее принимаемый безошибочный кадр, например, может быть последним принимаемым безошибочным кадром, к примеру, аудиокадром 101. Тем не менее, другой безошибочный кадр также может использоваться на стороне приемного устройства в качестве ранее принимаемого безошибочного кадра.
Формирователь кадров маскирования затем принимает (некоторые или все) предыдущие спектральные значения, связанные с ранее принимаемым безошибочным аудиокадром (например, аудиокадром 101), из буферного блока 110, как показано в 119. Например, в случае потерь множества кадров буфер обновляется полностью или частично. В варианте осуществления могут быть реализованы этапы, проиллюстрированные посредством стрелок 118 и 119, на которых формирователь 120 кадров маскирования загружает предыдущие спектральные значения из буферного блока 110.
Формирователь 120 кадров маскирования затем формирует спектральные замещающие значения на основе, по меньшей мере, некоторых предыдущих спектральных значений. В силу этого, слушатель не должен знать, что один или более аудиокадров пропущены, так что не нарушается звуковое возмущение, созданное посредством воспроизведения.
Простой способ достигать маскирования заключается в том, чтобы просто использовать значения, например, спектральные значения последнего безошибочного кадра в качестве спектральных замещающих значений для пропущенного или ошибочного текущего кадра.
Тем не менее, конкретные проблемы существуют, в частности, в случае вступлений, например, когда громкость звука внезапно существенно изменяется. Например, в случае всплеска шумов, посредством простого повторения предыдущих спектральных значений последнего кадра всплеск шумов также повторяется.
Напротив, если аудиосигнал является довольно стабильным, например, его громкость существенно не изменяется, или, например, его спектральные значения существенно не изменяются, то эффект искусственного формирования части текущего аудиосигнала на основе ранее принимаемых аудиоданных, такой как повторение части ранее принимаемого аудиосигнала, является менее раздражающим для слушателя.
Варианты осуществления основаны на этом факте. Формирователь 120 кадров маскирования формирует спектральные замещающие значения на основе, по меньшей мере, некоторых предыдущих спектральных значений и на основе значения стабильности фильтра, указывающего стабильность прогнозного фильтра, связанного с аудиосигналом. Таким образом, формирователь 120 кадров маскирования учитывает стабильность аудиосигнала, например, стабильность аудиосигнала, связанного с ранее принимаемым безошибочным кадром.
Для этого формирователь 120 кадров маскирования может изменять значение коэффициента усиления, который применяется к предыдущим спектральным значениям. Например, каждое из предыдущих спектральных значений умножается на коэффициент усиления. Это проиллюстрировано относительно фиг. 3A-3C.
На фиг. 3A, некоторые спектральные линии аудиосигнала, связанного с ранее принимаемым безошибочным кадром, проиллюстрированы до того, как применяется исходный коэффициент усиления. Например, исходный коэффициент усиления может быть коэффициентом усиления, который передается в аудиокадре. На стороне приемного устройства, если принимаемый кадр является безошибочным, декодер, например, может быть выполнен с возможностью умножать каждое из спектральных значений аудиосигнала на исходный коэффициент g усиления, чтобы получать модифицированный спектр. Это показано на фиг. 3B.
На фиг. 3B проиллюстрированы спектральные линии, которые получаются в результате умножения спектральных линий по фиг. 3A на исходный коэффициент усиления. Для простоты предполагается, что исходный коэффициент g усиления равен 2,0 (g=2,0). Фиг. 3A и 3B иллюстрируют сценарий, в котором маскирование не требуется.
На фиг. 3C предполагается сценарий, в котором текущий кадр не принят или является ошибочным. В таком случае должны быть сформированы замещающие векторы. Для этого предыдущие спектральные значения, связанные с ранее принимаемым безошибочным кадром, которые сохранены в буферном блоке, могут использоваться для формирования спектральных замещающих значений.
В примере по фиг. 3C предполагается, что спектральные замещающие значения формируются на основе принимаемых значений, но исходный коэффициент усиления модифицируется.
Другой, меньший, коэффициент усиления используется для того, чтобы формировать спектральные замещающие значения, чем коэффициент усиления, который используется для того, чтобы усиливать принятые значения в случае фиг. 3B. За счет этого достигается затухание.
Например, модифицированный коэффициент усиления, используемый в сценарии, проиллюстрированном посредством фиг. 3C, может составлять 75% от исходного коэффициента усиления, например, 0,75⋅2,0=1,5. Посредством умножения каждого из спектральных значений на (уменьшенный) модифицированный коэффициент усиления выполняется затухание, поскольку модифицированный коэффициент 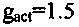 усиления, который используется для умножения каждого из спектральных значений, меньше исходного коэффициента усиления (коэффициента
усиления, который используется для умножения каждого из спектральных значений, меньше исходного коэффициента усиления (коэффициента 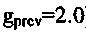 усиления), используемого для умножения спектральных значений в безошибочном случае.
усиления), используемого для умножения спектральных значений в безошибочном случае.
Настоящее изобретение, в числе прочего, основано на том факте, что повторение значений ранее принимаемого безошибочного кадра воспринимается как более раздражающее, когда соответствующая часть аудиосигнала является нестабильной, т.е. в том случае, когда соответствующая часть аудиосигнала является стабильной. Это проиллюстрировано на фиг. 4A и 4B.
Например, если ранее принимаемый безошибочный кадр содержит вступление, то с большой вероятностью воспроизводится вступление. Фиг. 4A иллюстрирует часть аудиосигнала, при этом переходный процесс осуществляется в части аудиосигнала, ассоциированной с последним принимаемым безошибочным кадром. На фиг. 4A и 4B, абсцисса указывает время, ордината указывает значение амплитуды аудиосигнала.
Часть сигнала, указываемая посредством 410, связана с частью аудиосигнала, связанной с последним принимаемым безошибочным кадром. Пунктирная линия в области 420 указывает возможное продолжение кривой во временной области, если значения, связанные с ранее принимаемым безошибочным кадром, просто копируются и используются в качестве спектральных замещающих значений замещающего кадра. Как можно видеть, переходный процесс с большой вероятностью повторяется, что может восприниматься слушателем как раздражающее.
Напротив, фиг. 4B иллюстрирует пример, в котором сигнал является довольно стабильным. На фиг. 4B, проиллюстрирована часть аудиосигнала, связанная с последним принимаемым безошибочным кадром. В части сигнала по фиг. 4B, переходный процесс не осуществлен. Кроме того, абсцисса указывает время, ордината указывает амплитуду аудиосигнала. Область 430 связана с частью сигнала, ассоциированной с последним принимаемым безошибочным кадром. Пунктирная линия в области 440 указывает возможное продолжение кривой во временной области, если значения ранее принимаемого безошибочного кадра копируются и используются в качестве спектральных замещающих значений замещающего кадра. В таких случаях, когда аудиосигнал является довольно стабильным, повторение последней части сигнала оказывается более приемлемым для слушателя, чем в случае, если повторяется вступление, как проиллюстрировано на фиг. 4A.
Настоящее изобретение основано на том факте, что спектральные замещающие значения могут быть сформированы на основе ранее принимаемых значений предыдущего аудиокадра, но также должна рассматриваться и стабильность прогнозного фильтра в зависимости от стабильности части аудиосигнала. Для этого должно учитываться значение стабильности фильтра. Значение стабильности фильтра, например, может указывать стабильность прогнозного фильтра.
В LD-USAC, коэффициенты прогнозной фильтрации, например, коэффициенты линейной прогнозной фильтрации, могут быть определены на стороне кодера и могут быть переданы в приемное устройство в аудиокадре.
На стороне декодера декодер затем принимает коэффициенты прогнозирующей фильтрации, например, коэффициенты прогнозирующей фильтрации ранее принимаемого безошибочного кадра. Кроме того, декодер, возможно, уже принял коэффициенты прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого кадра и, возможно, например, сохранил эти коэффициенты прогнозирующей фильтрации. Предшествующий кадр относительно ранее принимаемого безошибочного кадра является кадром, который непосредственно предшествует ранее принимаемому безошибочному кадру. Формирователь кадров маскирования затем может определять значение стабильности фильтра на основе коэффициентов прогнозирующей фильтрации ранее принимаемого безошибочного кадра и на основе коэффициентов прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого безошибочного кадра.
Далее представлено определение значения стабильности фильтра согласно варианту осуществления, которое является, в частности, подходящим для LD-USAC. Рассматриваемое значение стабильности зависит от коэффициентов прогнозирующей фильтрации, например, 10 коэффициентов 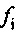 прогнозирующей фильтрации в случае узкой полосы частот или, например, 16 коэффициентов
прогнозирующей фильтрации в случае узкой полосы частот или, например, 16 коэффициентов 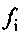 прогнозирующей фильтрации в случае широкой полосы частот, которые, возможно, переданы в ранее принимаемом безошибочном кадре.
прогнозирующей фильтрации в случае широкой полосы частот, которые, возможно, переданы в ранее принимаемом безошибочном кадре.
Кроме того, также рассматриваются коэффициенты прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого безошибочного кадра, например, 10 дополнительных коэффициентов 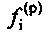 прогнозирующей фильтрации в случае узкой полосы частот (или, например, 16 дополнительных коэффициентов
прогнозирующей фильтрации в случае узкой полосы частот (или, например, 16 дополнительных коэффициентов 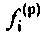 прогнозирующей фильтрации в случае широкой полосы частот).
прогнозирующей фильтрации в случае широкой полосы частот).
Например, k-й прогнозный фильтр 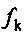 , возможно, вычислен на стороне кодера посредством вычисления автокорреляции, так что:
, возможно, вычислен на стороне кодера посредством вычисления автокорреляции, так что:
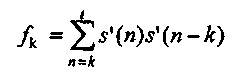 ,
,
где s' является кодированным со взвешиванием речевым сигналом, например, речевым сигналом, который должен кодироваться после того, как окно кодирования применено для речевого сигнала; t может составлять, например, 383. Альтернативно, t может иметь другие значения, к примеру, 191 или 95.
В других вариантах осуществления, вместо вычисления автокорреляции альтернативно может использоваться алгоритм Левинсона-Дурбина, известный из предшествующего уровня техники; см., например, материал:
[3]: 3GPP. "Speech codec speech processing functions; Adaptive Multi-Rate – Wideband (AMR-WB) speech codec; Transcoding functions", 2009 год, V9.0.0, 3GPP TS 26.190.
Как уже указано, коэффициенты 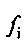 и
и 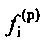 прогнозирующей фильтрации, возможно, переданы в приемное устройство в ранее принимаемом безошибочном кадре и предшествующем элементе ранее принимаемого безошибочного кадра, соответственно.
прогнозирующей фильтрации, возможно, переданы в приемное устройство в ранее принимаемом безошибочном кадре и предшествующем элементе ранее принимаемого безошибочного кадра, соответственно.
На стороне декодера показатель расстояния на основе частоты спектральной линии (показатель LSF-расстояния) 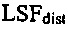 затем может быть вычислен с использованием формулы:
затем может быть вычислен с использованием формулы:
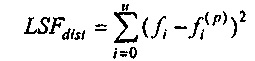 ,
,
u может быть числом прогнозных фильтров в ранее принимаемом безошибочном кадре минус 1. Например, если ранее принимаемый безошибочный кадр имеет 10 коэффициентов прогнозирующей фильтрации, то, например, u=9. Число коэффициентов прогнозирующей фильтрации в ранее принимаемом безошибочном кадре типично является идентичным числу коэффициентов прогнозирующей фильтрации в предшествующем кадре относительно ранее принимаемого безошибочного кадра.
Значение стабильности затем может быть вычислено согласно следующей формуле:
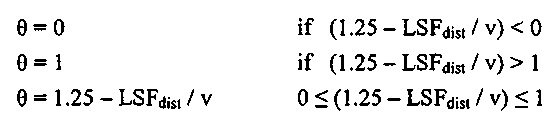 ,
,
v может быть целым числом. Например, v может быть 156250 в случае узкой полосы частот. В другом варианте осуществления, v может быть 400000 в случае широкой полосы частот.
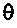 считается указывающим очень стабильный прогнозный фильтр, если
считается указывающим очень стабильный прогнозный фильтр, если 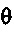 равняется 1 или близко к 1.
равняется 1 или близко к 1.
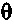 считается указывающим очень нестабильный прогнозный фильтр, если
считается указывающим очень нестабильный прогнозный фильтр, если 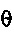 0 или близко к 0.
0 или близко к 0.
Формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений ранее принимаемого безошибочного кадра, когда текущий аудиокадр не принят или является ошибочным. Кроме того, формирователь кадров маскирования может быть выполнен с возможностью вычислять значение 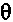 стабильности на основе коэффициентов
стабильности на основе коэффициентов 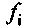 прогнозирующей фильтрации ранее принимаемого безошибочного кадра, а также на основе коэффициентов
прогнозирующей фильтрации ранее принимаемого безошибочного кадра, а также на основе коэффициентов 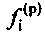 прогнозирующей фильтрации ранее принимаемого безошибочного кадра, как описано выше.
прогнозирующей фильтрации ранее принимаемого безошибочного кадра, как описано выше.
В варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью использовать значение стабильности фильтра для того, чтобы формировать сформированный коэффициент усиления, например, посредством модификации исходного коэффициента усиления и применять сформированный коэффициент усиления к предыдущим спектральным значениям, связанным с аудиокадром, чтобы получать спектральные замещающие значения. В других вариантах осуществления, формирователь кадров маскирования выполнен с возможностью применять сформированный коэффициент усиления к значением, извлеченным из предыдущих спектральных значений.
Например, формирователь кадров маскирования может формировать модифицированный коэффициент усиления посредством умножения принимаемого коэффициента усиления на коэффициент затухания, при этом коэффициент затухания зависит от значения стабильности фильтра.
Допустим, например, что коэффициент усиления, принимаемый в кадре аудиосигнала, имеет, например, значение 2,0. Коэффициент усиления типично используется для умножения предыдущих спектральных значений, чтобы получать модифицированные спектральные значения. Чтобы применять затухание, формируется модифицированный коэффициент усиления, который зависит от значения стабильности в 0.
Например, если значение стабильности 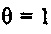 , то прогнозный фильтр считается очень стабильным. Коэффициент затухания затем может задаваться равным 0,85, если кадр, который должен быть восстановлен, является первым пропущенным кадром. Таким образом, модифицированный коэффициент усиления составляет 0,85⋅2,0=1,7. Каждое из принимаемых спектральных значений ранее принимаемого кадра затем умножается на модифицированный коэффициент усиления 1,7 вместо 2,0 (принимаемый коэффициент усиления), чтобы формировать спектральные замещающие значения.
, то прогнозный фильтр считается очень стабильным. Коэффициент затухания затем может задаваться равным 0,85, если кадр, который должен быть восстановлен, является первым пропущенным кадром. Таким образом, модифицированный коэффициент усиления составляет 0,85⋅2,0=1,7. Каждое из принимаемых спектральных значений ранее принимаемого кадра затем умножается на модифицированный коэффициент усиления 1,7 вместо 2,0 (принимаемый коэффициент усиления), чтобы формировать спектральные замещающие значения.
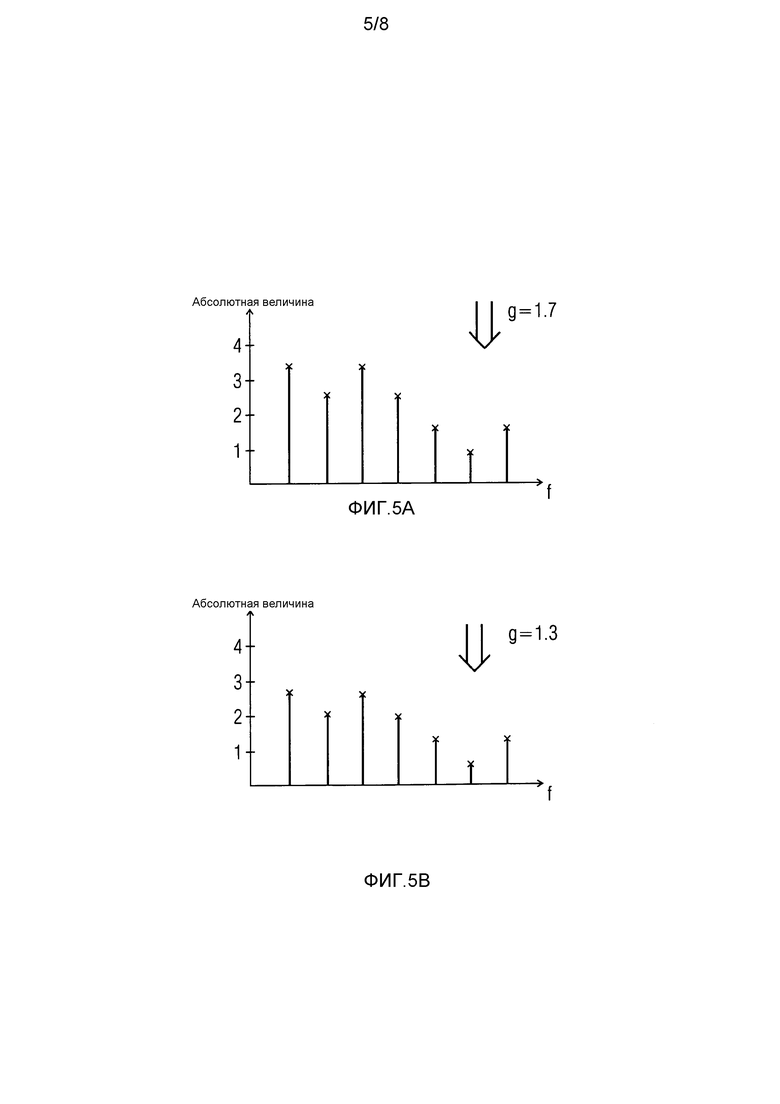
Фиг. 5A иллюстрирует пример, в котором сформированный коэффициент усиления в 1,7 применяется к спектральным значениям по фиг. 3A.
Тем не менее, если, например, значение стабильности 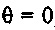 , то прогнозный фильтр считается очень нестабильным. Коэффициент затухания затем может задаваться равным 0,65, если кадр, который должен быть восстановлен, является первым пропущенным кадром. Таким образом, модифицированный коэффициент усиления составляет 0,65⋅2,0=1,3. Каждое из принимаемых спектральных значений ранее принимаемого кадра затем умножается на модифицированный коэффициент усиления 1,3 вместо 2,0 (принимаемый коэффициент усиления), чтобы формировать спектральные замещающие значения.
, то прогнозный фильтр считается очень нестабильным. Коэффициент затухания затем может задаваться равным 0,65, если кадр, который должен быть восстановлен, является первым пропущенным кадром. Таким образом, модифицированный коэффициент усиления составляет 0,65⋅2,0=1,3. Каждое из принимаемых спектральных значений ранее принимаемого кадра затем умножается на модифицированный коэффициент усиления 1,3 вместо 2,0 (принимаемый коэффициент усиления), чтобы формировать спектральные замещающие значения.
Фиг. 5B иллюстрирует пример, в котором сформированный коэффициент усиления 1,3 применяется к спектральным значениям по фиг. 3A. Поскольку коэффициент усиления в примере по фиг. 5B меньше, чем в примере по фиг. 5A, абсолютные величины на фиг. 5B также меньше, чем в примере по фиг. 5A.
Различные стратегии могут применяться в зависимости от значения 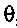 , где
, где 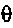 может быть любым значением между 0 и 1.
может быть любым значением между 0 и 1.
Например, значение 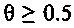 может быть интерпретировано как 1, так что коэффициент затухания имеет такое значение, как если
может быть интерпретировано как 1, так что коэффициент затухания имеет такое значение, как если 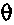 составляет 1, например, коэффициент затухания равен 0,85. Значение
составляет 1, например, коэффициент затухания равен 0,85. Значение 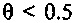 может быть интерпретировано в качестве 0, так что коэффициент затухания имеет такое значение, как если
может быть интерпретировано в качестве 0, так что коэффициент затухания имеет такое значение, как если 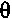 составляет 0, например, коэффициент затухания равен 0,65.
составляет 0, например, коэффициент затухания равен 0,65.
Согласно другому варианту осуществления, альтернативно может быть интерполировано значение коэффициента затухания, если значение 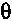 находится между 0 и 1. Например, при условии, что значение коэффициента затухания составляет 0,85, если
находится между 0 и 1. Например, при условии, что значение коэффициента затухания составляет 0,85, если 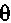 равняется 1, и составляет 0,65, если
равняется 1, и составляет 0,65, если 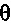 равняется 0, коэффициент затухания может быть вычислен согласно формуле:
равняется 0, коэффициент затухания может быть вычислен согласно формуле:
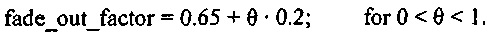
В другом варианте осуществления, формирователь кадров маскирования выполнен с возможностью формировать спектральные замещающие значения дополнительно на основе информации класса кадров, связанной с ранее принимаемым безошибочным кадром. Информация относительно класса может быть определена посредством кодера. Кодер затем может кодировать информацию класса кадров в аудиокадре. Декодер затем может декодировать информацию класса кадров при декодировании ранее принимаемого безошибочного кадра.
Альтернативно, декодер может самостоятельно определять информацию класса кадров посредством анализа аудиокадра.
Кроме того, декодер может быть выполнен с возможностью определять информацию класса кадров на основе информации из кодера и на основе анализа принимаемых аудиоданных, причем анализ осуществляется посредством самого декодера.
Класс кадров может, например, указывать то, классифицируется кадр как "искусственное вступление", "вступление", "вокализованный переход", "невокализованный переход", "невокализованный" и "вокализованный".
Например, "вступление" может указывать то, что ранее принимаемый аудиокадр содержит вступление. Например, "вокализованный" может указывать то, что ранее принимаемый аудиокадр содержит вокализованные данные. Например, "невокализованный" может указывать то, что ранее принимаемый аудиокадр содержит невокализованные данные. Например, "вокализованный переход" может указывать то, что ранее принимаемый аудиокадр содержит вокализованные данные, но при этом, по сравнению с предшествующим элементом относительно предыдущего принимаемого аудиокадра, основной тон изменен. Например, "искусственное вступление" может указывать то, что энергия ранее принимаемого аудиокадра повышена (в силу этого, например, создавая искусственное вступление). Например, "невокализованный переход" может указывать то, что ранее принимаемый аудиокадр содержит невокализованные данные, но при этом невокализованный звук должен быть изменен.
В зависимости от ранее принимаемого аудиокадра, значения стабильности в 9 и числа последовательных стертых кадров, усиление при ослаблении, к примеру, коэффициент затухания, например, может задаваться следующим образом:
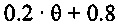
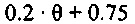
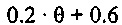
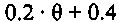
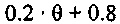
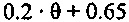
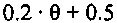
Согласно варианту осуществления, формирователь кадров маскирования может формировать модифицированный коэффициент усиления посредством умножения принимаемого коэффициента усиления на коэффициент затухания, определенный на основе значения стабильности фильтра и класса кадров. Затем предыдущие спектральные значения, например, могут быть умножены на модифицированный коэффициент усиления, чтобы получать спектральные замещающие значения.
Корме того, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения дополнительно также на основе информации класса кадров.
Согласно варианту осуществления, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения дополнительно в зависимости от числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными.
В варианте осуществления, формирователь кадров маскирования может быть выполнен с возможностью вычислять коэффициент затухания на основе значения стабильности фильтра и на основе числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными.
Кроме того, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения посредством умножения коэффициента затухания, по меньшей мере, на некоторые предыдущие спектральные значения.
Альтернативно, формирователь кадров маскирования может быть выполнен с возможностью формировать спектральные замещающие значения посредством умножения коэффициента затухания, по меньшей мере, на некоторые значения из группы промежуточных значений. Каждое из промежуточных значений зависит, по меньшей мере, от одного из предыдущих спектральных значений. Например, группа промежуточных значений, возможно, сформирована посредством модификации предыдущих спектральных значений. Альтернативно, синтезированный сигнал в спектральной области, возможно, сформирован на основе предыдущих спектральных значений, и спектральные значения синтезированного сигнала могут формировать группу промежуточных значений.
В другом варианте осуществления, коэффициент затухания может быть умножен на исходный коэффициент усиления, чтобы получать сформированный коэффициент усиления. Сформированный коэффициент усиления затем умножается, по меньшей мере, на некоторые предыдущие спектральные значения или, по меньшей мере, на некоторые значения из группы промежуточных значений, упомянутых выше, чтобы получать спектральные замещающие значения.
Значение коэффициента затухания зависит от значения стабильности фильтра и от числа последовательных пропущенных или ошибочных кадров и, например, может иметь значения:
Здесь "Число последовательных пропущенных/ошибочных кадров=1" указывает, что непосредственно предшествующий элемент относительно пропущенного/ошибочного кадра является безошибочным.
Как можно видеть в вышеприведенном примере, коэффициент затухания может быть обновлен каждый раз, когда кадр не поступает или является ошибочным на основе последнего коэффициента затухания. Например, если непосредственно предшествующий элемент относительно пропущенного/ошибочного кадра является безошибочным, то, в вышеприведенном примере, коэффициент затухания равен 0,8. Если последующий кадр также пропущен или является ошибочным, коэффициент затухания обновляется на основе предыдущего коэффициента затухания посредством умножения предыдущего коэффициента затухания на коэффициент обновления 0,65: коэффициент затухания=0,8⋅0,65=0,52 и т.д.
Некоторые или все предыдущие спектральные значения могут быть непосредственно умножены на коэффициент затухания.
Альтернативно, коэффициент затухания может быть умножен на исходный коэффициент усиления, чтобы получать сформированный коэффициент усиления. Сформированный коэффициент усиления затем может быть умножен на каждое (или некоторые) из предыдущих спектральных значений (или промежуточных значений, извлекаемых из предыдущих спектральных значений), чтобы получать спектральные замещающие значения.
Следует отметить, что коэффициент затухания также может зависеть от значения стабильности фильтра. Например, вышеуказанная таблица также может содержать задания для коэффициента затухания, если значение стабильности фильтра составляет 1,0, 0,5 или какое-либо другое значение, например:
Значения коэффициента затухания для промежуточных значений стабильности фильтра могут аппроксимироваться.
В другом варианте осуществления, коэффициент затухания может быть определен посредством использования формулы, которая вычисляет коэффициент затухания на основе значения стабильности фильтра и на основе числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными.
Как описано выше, предыдущие спектральные значения, сохраненные в буферном блоке, могут быть спектральными значениями. Чтобы не допускать возникновения раздражающих артефактов, формирователь кадров маскирования, как пояснено выше, может формировать спектральные замещающие значения на основе значения стабильности фильтра.
Тем не менее, такая замена части сформированного сигнала при этом может иметь повторяющийся символ. Следовательно, согласно варианту осуществления, кроме того, предлагается модифицировать предыдущие спектральные значения, например спектральные значения ранее принимаемого кадра, посредством произвольной смены знака спектральных значений. Например, формирователь кадров маскирования определяет произвольно для каждого из предыдущих спектральных значений то, инвертируется или нет знак спектрального значения, например, умножается спектральное значение на -1 или нет. За счет этого уменьшается повторяющийся символ замененного кадра аудиосигнала относительно его предшествующего кадра.
Далее описывается маскирование в LD-USAC-декодере согласно варианту осуществления. В этом варианте осуществления, маскирование обрабатывает спектральные данные непосредственно перед тем, как LD-USAC-декодер осуществляет конечное частотно-временное преобразование.
В этом варианте осуществления, значения поступающего аудиокадра используются для того, чтобы декодировать кодированный аудиосигнал посредством формирования синтезированного сигнала в спектральной области. Для этого промежуточный сигнал в спектральной области формируется на основе значений поступающего аудиокадра. Заполнение шумом осуществляется для значений, квантованных до нуля.
Кодированные коэффициенты прогнозирующей фильтрации задают прогнозный фильтр, который затем применяется к промежуточному сигналу, чтобы формировать синтезированный сигнал, представляющий декодированный/восстановленный аудиосигнал в частотной области.
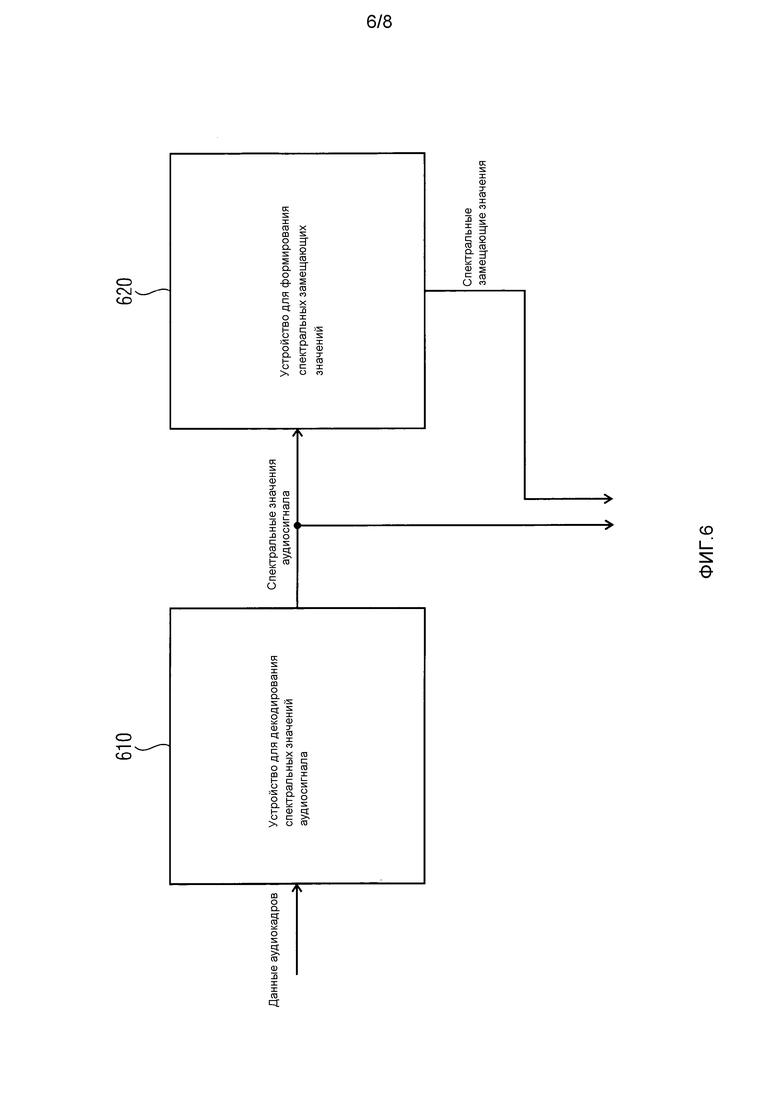
Фиг. 6 иллюстрирует декодер аудиосигналов согласно варианту осуществления. Декодер аудиосигналов содержит устройство 610 для декодирования спектральных значений аудиосигнала и устройство 620 для формирования спектральных замещающих значений согласно одному из вышеописанных вариантов осуществления.
Устройство 610 для декодирования спектральных значений аудиосигнала формирует спектральные значения декодированного аудиосигнала, как описано выше, когда поступает безошибочный аудиокадр.
В варианте осуществления по фиг. 6, спектральные значения синтезированного сигнала затем могут быть сохранены в буферном блоке устройства 620 для формирования спектральных замещающих значений. Эти спектральные значения декодированного аудиосигнала декодированы на основе принимаемого безошибочного аудиокадра и, таким образом, связаны с ранее принимаемым безошибочным аудиокадром.
Когда текущий кадр пропущен или является ошибочным, в устройство 620 для формирования спектральных замещающих значений сообщается, что требуются спектральные замещающие значения. Формирователь кадров маскирования устройства 620 для формирования спектральных замещающих значений затем формирует спектральные замещающие значения согласно одному из вышеописанных вариантов осуществления.
Например, спектральные значения из последнего хорошего кадра немного модифицируются посредством формирователя кадров маскирования посредством произвольной смены их знака. Затем затухание применяется к этим спектральным значениям. Затухание может зависеть от стабильности предыдущего прогнозного фильтра и от числа последовательных потерянных кадров. Сформированные спектральные замещающие значения затем используются в качестве спектральных замещающих значений для аудиосигнала, и после этого осуществляется частотно-временное преобразование для того, чтобы получать аудиосигнал временной области.
В LD-USAC, а также в USAC и MPEG-4 (MPEG – Экспертная группа по киноизображению), может использоваться временное формирование шума (TNS). Посредством временного формирования шума управляется точная временная структура шума. На стороне декодера операция фильтра применяется для спектральных данных на основе информации формирования шума. Дополнительные сведения относительно временного формирования шума можно найти, например, в работе:
[4]: ISO/IEC 14496-3:2005: Information technology – Coding of audio-visual objects –Part 3: Audio, 2005 год.
Варианты осуществления основаны на том факте, что в случае вступления/переходного процесса, TNS является высокоактивным. Таким образом, посредством определения того, является TNS высокоактивным или нет, можно оценивать то, присутствует или нет вступление/переходный процесс.
Согласно варианту осуществления, усиление для прогнозирования, которое имеет TNS, вычисляется на стороне приемного устройства. На стороне приемного устройства, сначала обрабатываются принятые спектральные значения принимаемого безошибочного аудиокадра для того, чтобы получать первые промежуточные спектральные значения ai. Затем осуществляется TNS, и за счет этого получаются вторые промежуточные спектральные значения bi. Первое значение E1 энергии вычисляется для первых промежуточных спектральных значений, а второе значение E2 энергии вычисляется для вторых промежуточных спектральных значений. Чтобы получать усиление 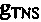 для прогнозирования TNS, второе значение энергии может быть разделено на первое значение энергии.
для прогнозирования TNS, второе значение энергии может быть разделено на первое значение энергии.
Например, может задаваться следующим образом:
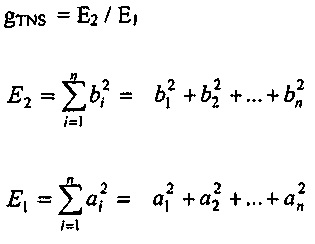
(n – число рассматриваемых спектральных значений)
Согласно варианту осуществления, формирователь кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений, на основе значения стабильности фильтра, а также на основе усиления для прогнозирования временного формирования шума, когда временное формирование шума осуществляется для ранее принимаемого безошибочного кадра. Согласно другому варианту осуществления, формирователь кадров маскирования выполнен с возможностью формировать спектральные замещающие значения дополнительно на основе числа последовательных пропущенных или ошибочных кадров.
Чем выше усиление для прогнозирования, тем быстрее должно быть затухание. Например, рассмотрим значение стабильности фильтра в 0,5, и допустим, что усиление для прогнозирования является высоким, например, =6; в таком случае коэффициент затухания, может составлять, например, 0,65 (=быстрое затухание). Напротив, снова рассмотрим значение стабильности фильтра в 0,5, но допустим, что усиление для прогнозирования является низким, например, 1,5; в таком случае коэффициент затухания может составлять, например, 0,95 (=медленное затухание).
Усиление для прогнозирования TNS также может влиять на то, какие значения должны быть сохранены в буферном блоке устройства для формирования спектральных замещающих значений.
Если усиление 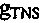 для прогнозирования ниже определенного порогового значения (например, порогового значения =5,0), то спектральные значения после того, как примерено TNS, сохраняются в буферном блоке в качестве предыдущих спектральных значений. В случае пропущенного или ошибочного кадра спектральные замещающие значения формируются на основе этих предыдущих спектральных значений.
для прогнозирования ниже определенного порогового значения (например, порогового значения =5,0), то спектральные значения после того, как примерено TNS, сохраняются в буферном блоке в качестве предыдущих спектральных значений. В случае пропущенного или ошибочного кадра спектральные замещающие значения формируются на основе этих предыдущих спектральных значений.
В противном случае, если усиление 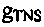 для прогнозирования превышает или равно пороговому значению, спектральные значения до того, как применено TNS, сохраняются в буферном блоке в качестве предыдущих спектральных значений. В случае пропущенного или ошибочного кадра спектральные замещающие значения формируются на основе этих предыдущих спектральных значений.
для прогнозирования превышает или равно пороговому значению, спектральные значения до того, как применено TNS, сохраняются в буферном блоке в качестве предыдущих спектральных значений. В случае пропущенного или ошибочного кадра спектральные замещающие значения формируются на основе этих предыдущих спектральных значений.
TNS не применяется в любом случае к этим предыдущим спектральным значениям.
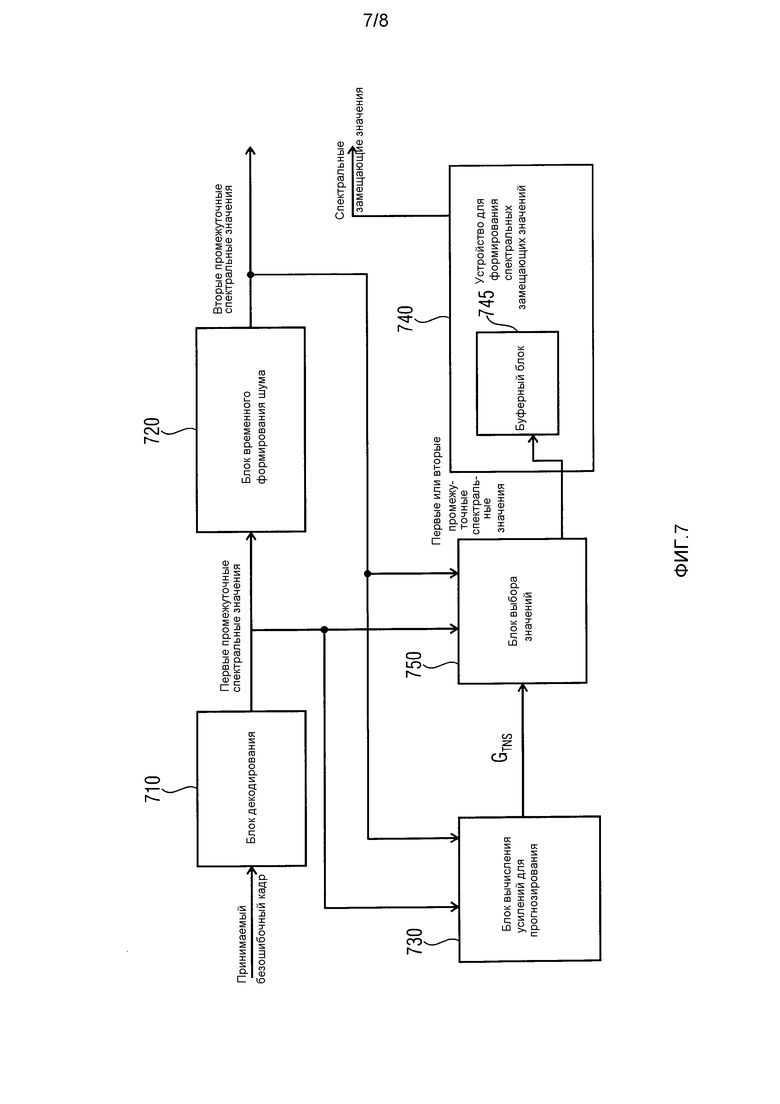
Соответственно, фиг. 7 иллюстрирует декодер аудиосигналов согласно соответствующему варианту осуществления. Декодер аудиосигналов содержит блок 710 декодирования для формирования первых промежуточных спектральных значений на основе принимаемого безошибочного кадра. Кроме того, декодер аудиосигналов содержит блок 720 временного формирования шума для осуществления временного формирования шума для первых промежуточных спектральных значений, чтобы получать вторые промежуточные спектральные значения. Кроме того, декодер аудиосигналов содержит блок 730 вычисления усилений для прогнозирования для вычисления усиления для прогнозирования временного формирования шума в зависимости от первых промежуточных спектральных значений и вторых промежуточных спектральных значений. Кроме того, декодер аудиосигналов содержит устройство 740 согласно одному из вышеописанных вариантов осуществления для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным. Кроме того, декодер аудиосигналов содержит блок 750 выбора значений для сохранения первых промежуточных спектральных значений в буферном блоке 745 устройства 740 для формирования спектральных замещающих значений, если усиление для прогнозирования превышает или равно пороговому значению, или для сохранения вторых промежуточных спектральных значений в буферном блоке 745 устройства 740 для формирования спектральных замещающих значений, если усиление для прогнозирования меньше порогового значения.
Пороговое значение, например, может быть предварительно заданным значением. Например, пороговое значение может предварительно задаваться в декодере аудиосигналов.
Согласно другому варианту осуществления, маскирование осуществляется для спектральных данных сразу после первого этапа декодирования и до того, как осуществляется заполнение шумом, глобальное усиление и/или TNS.
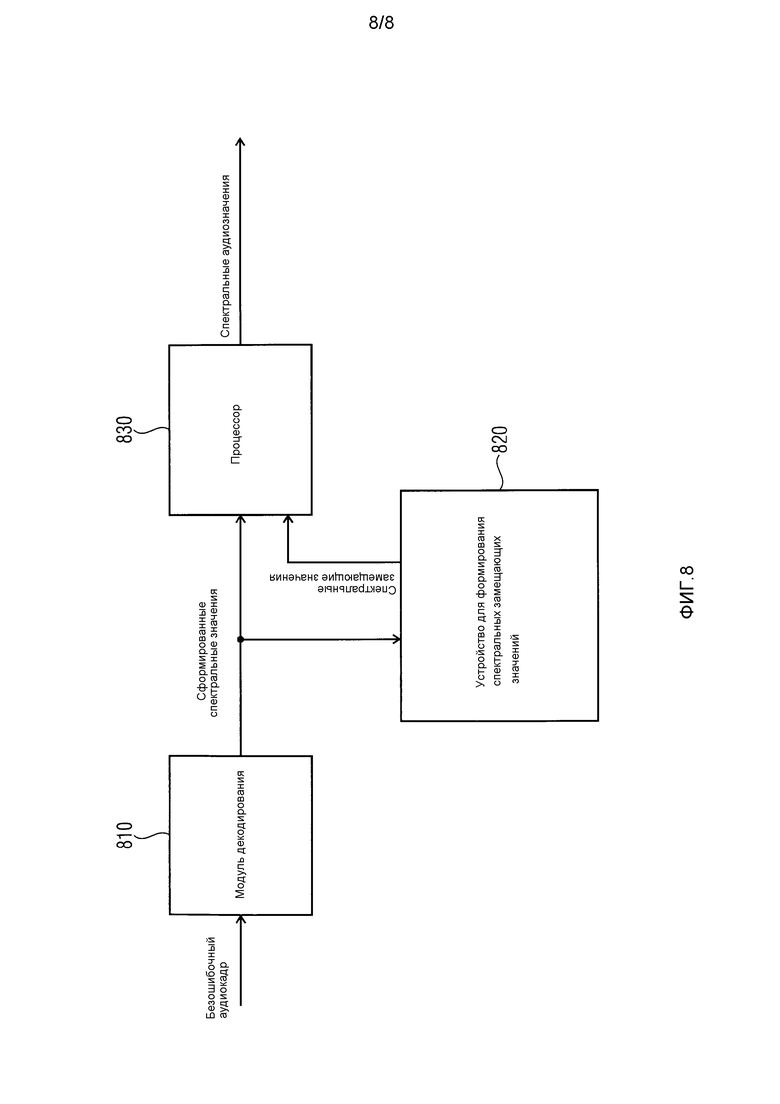
Этот вариант осуществления проиллюстрирован на фиг. 8. Фиг. 8 иллюстрирует декодер согласно дополнительному варианту осуществления. Декодер содержит первый модуль 810 декодирования. Первый модуль 810 декодирования выполнен с возможностью формировать сформированные спектральные значения на основе принимаемого безошибочного аудиокадра. Сформированные спектральные значения затем сохраняются в буферном блоке устройства 820 для формирования спектральных замещающих значений. Кроме того, сформированные спектральные значения вводятся в процессор 830, который обрабатывает сформированные спектральные значения посредством осуществления TNS, применения заполнения шумом и/или посредством применения глобального усиления, чтобы получать спектральные аудиозначения декодированного аудиосигнала. Если текущий кадр пропущен или является ошибочным, устройство 820 для формирования спектральных замещающих значений формирует спектральные замещающие значения и подает их в процессор 830.
Согласно варианту осуществления, проиллюстрированному на фиг. 8, модуль декодирования или процессор осуществляет некоторые или все следующие этапы в случае маскирования.
Спектральные значения, например, от последнего хорошего кадра немного модифицируются посредством произвольной смены их знака. На дополнительном этапе, заполнение шумом осуществляется на основе случайного шума для спектральных элементов выборки, квантованных до нуля. На другом этапе, коэффициент шума немного адаптируется по сравнению с ранее принимаемым безошибочным кадром.
На дополнительном этапе спектральное формирование шума выполняется посредством применения LPC-кодированной (LPC – кодирование с линейным прогнозированием) взвешенной спектральной огибающей в частотной области. Например, могут быть использованы LPC-коэффициенты последнего принимаемого безошибочного кадра. В другом варианте осуществления, могут быть использованы усредненные LPC-коэффициенты. Например, среднее последних трех значений рассматриваемого LPC-коэффициента последних трех принимаемых безошибочных кадров может быть сформировано для каждого LPC-коэффициента фильтра, и усредненные LPC-коэффициенты могут применяться.
На следующем этапе затухание может применяться к этим спектральным значениям. Затухание может зависеть от числа последовательных пропущенных или ошибочных кадров и от стабильности предыдущего LP-фильтра. Кроме того, информация усиления для прогнозирования может быть использована для того, чтобы влиять на затухание. Чем выше усиление для прогнозирования, тем быстрее может быть затухание. Вариант осуществления по фиг. 8 является немного более сложным, чем вариант осуществления по фиг. 6, но предоставляет лучшее качество звука.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на энергонезависимом носителе хранения данных.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет или по радиоканалу.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Литература
1. 3GPP. "Audio codec processing functions; Extended Adaptive Multi-Rate – Wideband (AMR-WB+) codec; Transcoding functions", 2009 год, 3GPP TS 26.290.
2. USAC codec (Unified Speech and Audio Codec), ISO/IEC CD 23003-3, 24 сентября 2010 года.
3. 3GPP. "Speech codec speech processing functions; Adaptive Multi-Rate – Wideband (AMR-WB) speech codec; Transcoding functions", 2009 год, V9.0.0, 3GPP TS 26.190.
4. ISO/IEC 14496-3:2005: Information technology – Coding of audio-visual objects –Part 3: Audio, 2005 год.
5. ITU-T G.718 (06-2008) specification.
Изобретение относится к средствам для маскирования ошибок при кодировании речи с низкой задержкой. Технический результат заключается в обеспечении возможности маскирования ошибок для кадров аудиосигнала без возникновения искусственных артефактов. Устройство для формирования спектральных замещающих значений содержит буферный блок для сохранения предыдущих спектральных значений, связанных с ранее принимаемым безошибочным аудиокадром. Кроме того, устройство содержит формирователь кадров маскирования для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным. Ранее принимаемый безошибочный аудиокадр содержит информацию фильтра, причем информация фильтра имеет ассоциированное значение стабильности фильтра, указывающее стабильность прогнозного фильтра. Формирователь кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений и на основе значения стабильности фильтра. 6 н. и 10 з.п. ф-лы, 12 ил.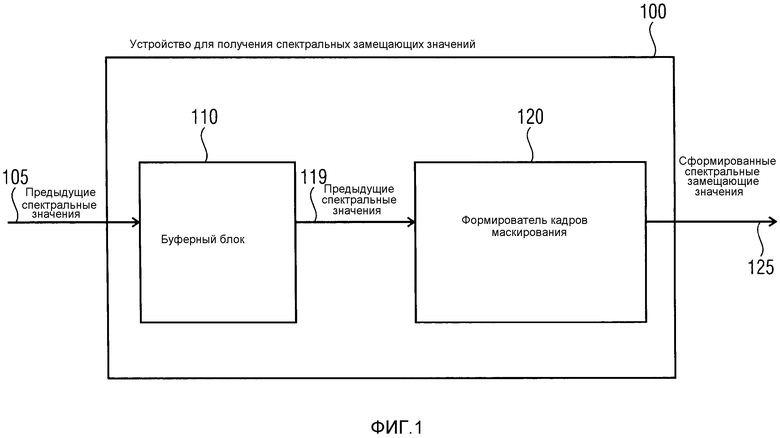
1. Устройство (100) для формирования спектральных замещающих значений для аудиосигнала, содержащее:
- буферный блок (110) для сохранения предыдущих спектральных значений, связанных с ранее принимаемым безошибочным аудиокадром, и
- формирователь (120) кадров маскирования для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным, при этом ранее принимаемый безошибочный аудиокадр содержит информацию фильтра, при этом формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения, в зависимости от значения стабильности фильтра, основываясь на предыдущих спектральных значениях, при этом значение стабильности фильтра указывает стабильность прогнозного фильтра, и при этом значение стабильности фильтра зависит от информации фильтра.
2. Устройство (100) по п. 1, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения посредством произвольной смены знака предыдущих спектральных значений.
3. Устройство (100) по п. 1, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения посредством умножения каждого из предыдущих спектральных значений на первый коэффициент усиления, когда значение стабильности фильтра имеет первое значение, и посредством умножения каждого из предыдущих спектральных значений на второй коэффициент усиления, меньший первого коэффициента усиления, когда значение стабильности фильтра имеет второе значение, меньшее первого значения.
4. Устройство (100) по п. 1, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе значения стабильности фильтра, при этом ранее принимаемый безошибочный аудиокадр содержит первые коэффициенты прогнозирующей фильтрации прогнозного фильтра, при этом предшествующий кадр относительно ранее принимаемого безошибочного аудиокадра содержит вторые коэффициенты прогнозирующей фильтрации, и при этом значение стабильности фильтра зависит от первых коэффициентов прогнозирующей фильтрации и от вторых коэффициентов прогнозирующей фильтрации.
5. Устройство (100) по п. 4, в котором формирователь (120) кадров маскирования выполнен с возможностью определять значение стабильности фильтра на основе первых коэффициентов прогнозирующей фильтрации ранее принимаемого безошибочного аудиокадра и на основе вторых коэффициентов прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого безошибочного аудиокадра.
6. Устройство (100) по п. 4, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе значения стабильности фильтра, при этом значение стабильности фильтра зависит от показателя LSFdist, расстояния, и при этом показатель LSFdist расстояния задается посредством формулы:
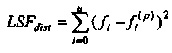 ,
,
где u+1 указывает общее число первых коэффициентов прогнозирующей фильтрации ранее принимаемого безошибочного аудиокадра и где u+1 также указывает общее число вторых коэффициентов прогнозирующей фильтрации предшествующего кадра относительно ранее принимаемого безошибочного аудиокадра, где ƒi указывает i-й коэффициент фильтрации из первых коэффициентов прогнозирующей фильтрации и где ƒi(p) указывает i-й коэффициент фильтрации вторых коэффициентов прогнозирующей фильтрации.
7. Устройство (100) по п. 1, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения дополнительно на основе информации класса кадров, связанной с ранее принимаемым безошибочным аудиокадром.
8. Устройство (100) по п. 7, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе информации класса кадров, при этом информация класса кадров указывает, что ранее принимаемый безошибочный аудиокадр классифицируется как "искусственное вступление", "вступление", "вокализованный переход", "невокализованный переход", "невокализованный" или "вокализованный".
9. Устройство (100) по п. 1, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения дополнительно на основе числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными с момента, когда последний безошибочный аудиокадр поступает в приемное устройство, при этом другие безошибочные аудиокадры не поступают в приемное устройство с момента, когда последний безошибочный аудиокадр поступает в приемное устройство.
10. Устройство (100) по п. 9,
- в котором формирователь (120) кадров маскирования выполнен с возможностью вычислять коэффициент затухания на основе значения стабильности фильтра и на основе числа последовательных кадров, которые не поступают в приемное устройство или которые являются ошибочными, и
- в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения посредством умножения коэффициента затухания, по меньшей мере, на некоторые предыдущие спектральные значения или, по меньшей мере, на некоторые значения из группы промежуточных значений, при этом каждое из промежуточных значений зависит по меньшей мере от одного из предыдущих спектральных значений.
11. Устройство (100) по п. 1, в котором формирователь (120) кадров маскирования выполнен с возможностью формировать спектральные замещающие значения на основе предыдущих спектральных значений, на основе значения стабильности фильтра, а также на основе усиления для прогнозирования временного формирования шума.
12. Декодер аудиосигналов, содержащий:
- устройство (610) для декодирования спектральных значений аудиосигналов и
- устройство (620) для формирования спектральных замещающих значений по п. 1,
- при этом устройство (610) для декодирования спектральных значений аудиосигналов выполнено с возможностью декодировать спектральные значения аудиосигнала на основе ранее принимаемого безошибочного аудиокадра, причем устройство (610) для декодирования спектральных значений аудиосигналов дополнительно выполнено с возможностью сохранять спектральные значения аудиосигнала в буферном блоке устройства (620) для формирования спектральных замещающих значений, и
- при этом устройство (620) для формирования спектральных замещающих значений выполнено с возможностью формировать спектральные замещающие значения на основе спектральных значений, сохраненных в буферном блоке, когда текущий аудиокадр не принят или является ошибочным.
13. Декодер аудиосигналов, содержащий:
- блок (710) декодирования для формирования первых промежуточных спектральных значений на основе принимаемого безошибочного аудиокадра,
- блок (720) временного формирования шума для осуществления временного формирования шума для первых промежуточных спектральных значений, чтобы получать вторые промежуточные спектральные значения,
- блок (730) вычисления усилений для прогнозирования для вычисления усиления для прогнозирования временного формирования шума в зависимости от первых промежуточных спектральных значений и в зависимости от вторых промежуточных спектральных значений,
- устройство (740) по п. 1 для формирования спектральных замещающих значений, когда текущий аудиокадр не принят или является ошибочным, и
- блок (750) выбора значений для сохранения первых промежуточных спектральных значений в буферном блоке (745) устройства (740) для формирования спектральных замещающих значений, если усиление для прогнозирования превышает или равно пороговому значению, или для сохранения вторых промежуточных спектральных значений в буферном блоке устройства для формирования спектральных замещающих значений, если усиление для прогнозирования меньше порогового значения.
14. Декодер аудиосигналов, содержащий:
- первый модуль (810) декодирования для формирования сформированных спектральных значений на основе принимаемого безошибочного аудиокадра,
- устройство (820) для формирования спектральных замещающих значений по п. 1 и
- процессор (830) для обработки сформированных спектральных значений посредством осуществления временного формирования шума, применения заполнения шумом или применения глобального усиления, чтобы получать спектральные аудиозначения декодированного аудиосигнала,
- при этом устройство (820) для формирования спектральных замещающих значений выполнено с возможностью формировать спектральные замещающие значения и подавать их в процессор (830), когда текущий кадр не принят или является ошибочным.
15. Способ для формирования спектральных замещающих значений для аудиосигнала, содержащий этапы, на которых:
- сохраняют предыдущие спектральные значения, связанные с ранее принимаемым безошибочным аудиокадром, и
- формируют спектральные замещающие значения, когда текущий аудиокадр не принят или является ошибочным, при этом ранее принимаемый безошибочный аудиокадр содержит информацию фильтра, при этом спектральные замещающие значения формируются в зависимости от значения стабильности фильтра, основываясь на предыдущих спектральных значениях, при этом значение стабильности фильтра указывает стабильность прогнозного фильтра, заданного посредством информации фильтра, и при этом значение стабильности фильтра зависит от информации фильтра.
16. Машиночитаемый носитель данных, содержащий компьютерную программу для осуществления способа по п. 15, когда компьютерная программа выполняется посредством компьютера или процессора сигналов.
| WO 2007073604 A1, 05.07.2007 | |||
| WO 03102921 A1, 11.12.2003 | |||
| WO 2008056775 A1, 15.05.2008 | |||
| US 2007238415 A1, 11.10.2007 | |||
| US 2011007827 A1, 13.01.2011 | |||
| JP 2007514977 A, 07.06.2007 | |||
| EP 0655159 A1, 31.05.1995 | |||
| АУДИОКОДИРОВАНИЕ | 2005 |
|
RU2335809C2 |

