Настоящее изобретение относится к кодерам для кодирования аудиосигнала, в частности, речевого аудиосигнала. Настоящее изобретение также относится к декодерам и способам для декодирования кодированного аудиосигнала. Настоящее изобретение дополнительно относится к кодированным аудиосигналам и к усовершенствованному кодированию невокализованной речи на низких скоростях передачи битов.
На низкой скорости передачи битов, кодирование речи может извлекать выгоду из специальной обработки для невокализованных кадров, чтобы поддерживать качество речи при уменьшении скорости передачи битов. Невокализованные кадры могут перцепционно моделироваться в качестве случайного возбуждения, которое формируется в частотной и временной области. Поскольку форма сигнала и возбуждение выглядит и звучит почти идентично с белым гауссовым шумом, его кодирование на основе формы сигналов может ослабляться и заменяться посредством синтетически сформированного белого шума. В таком случае кодирование должно состоять из кодирования форм во временной и частотной области сигнала.
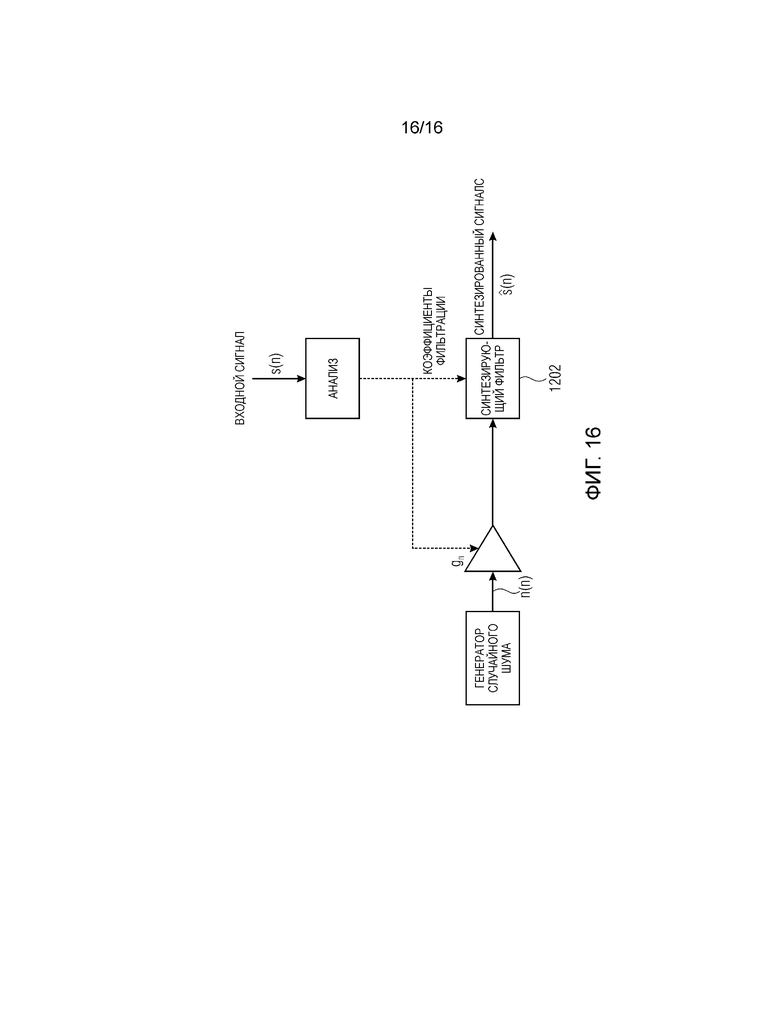
Фиг. 16 показывает принципиальную блок-схему схемы параметрического невокализованного кодирования. Синтезирующий фильтр 1202 выполнен с возможностью моделирования речевого тракта и параметризован посредством параметров LPC (линейного прогнозирующего кодирования). Из извлеченного LPC-фильтра, содержащего функцию A(z) фильтра, перцепционный взвешивающий фильтр может извлекаться посредством взвешивания LPC-коэффициентов. Перцепционный фильтр fw(n) обычно имеет передаточную функцию следующей формы:
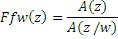 ,
,
где w ниже 1. Параметр gn усиления вычисляется для получения синтезированной энергии, совпадающей с исходной энергией в перцепционной области, согласно следующему:
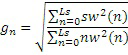 ,
,
где sw(n) и nw(n) являются входным сигналом и сформированным шумом, соответственно, фильтруемыми посредством перцепционного фильтра fw(n). Усиление gn вычисляется для каждого субкадра размера Ls. Например, аудиосигнал может быть разделен на кадры с длиной в 20 мс. Каждый кадр может подразделяться на субкадры, например, на четыре субкадра, каждый из которых имеет длину в 5 мс.
Схема кодирования на основе линейного прогнозирования с возбуждением по коду (CELP) широко используется в речевой связи и представляет собой очень эффективный способ кодирования речи. Она обеспечивает более естественное качество речи, чем параметрическое кодирование, но она также запрашивает более высокие скорости. CELP синтезирует аудиосигнал посредством передачи в линейный прогнозирующий фильтр, называемый синтезирующим LPC-фильтром, который может содержать форму 1/A(z), суммы двух возбуждений. Одно возбуждение исходит из декодированного прошлого, что называется адаптивной таблицей кодирования. Другая доля исходит из изобретаемой таблицы кодирования, заполненной посредством фиксированных кодов. Тем не менее, на низких скоростях передачи битов изобретаемая таблица кодирования недостаточно заполняется для эффективного моделирования точной структуры речи или шумоподобного возбуждения невокализованной речи. Следовательно, перцепционное качество ухудшается, в частности, невокализованные кадры, которые в таком случае звучат трескуче и неестественно.
Для уменьшения артефактов кодирования на низких скоростях передачи битов, уже предложены различные решения. В G.718[1] и в [2], коды изобретаемой таблицы кодирования адаптивно и спектрально формируются посредством улучшения спектральных областей, соответствующих формантам текущего кадра. Позиции и формы формант могут быть выведены непосредственно из LPC-коэффициентов, причем коэффициенты уже доступны на сторонах кодера и декодера. Улучшение формант кодов c(n) выполняется посредством простой фильтрации согласно следующему:
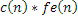 ,
,
где * обозначает оператор свертки, и где fe(n) является импульсной характеристикой фильтра передаточной функции следующим образом:
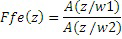 ,
,
где w1 и w2 являются двумя весовыми константами, подчеркивающими более или менее формантную структуру передаточной функции Ffe(z). Результирующие коды определенной формы наследуют характеристику речевого сигнала, и синтезированный сигнал звучит чище.
В CELP, также обычно добавляется спектральный наклон в декодер изобретаемой таблицы кодирования. Это выполняется посредством фильтрации кодов с помощью следующего фильтра:
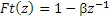 .
.
Коэффициент β обычно связан с вокализацией предыдущего кадра и зависит, т.е. он варьируется. Вокализация может оцениваться из доли энергии из адаптивной таблицы кодирования. Если предыдущий кадр является вокализованным, предполагается, что текущий кадр также является вокализованным, и что коды должны иметь большую энергию на низких частотах, т.е. должны показывать отрицательный наклон. Наоборот, добавленный спектральный наклон является положительным для невокализованных кадров, и большая энергия должна распределяться в направлении высоких частот.
Использование формирования спектра для улучшения речи и уменьшения уровня шума выхода декодера является обычной практикой. Так называемое улучшение формант в качестве постфильтрации состоит из адаптивной постфильтрации, для которой коэффициенты извлекаются из LPC-параметров декодера. Постфильтр похож на постфильтр (fe(n)), используемый для формирования изобретаемого возбуждения в определенных CELP-кодерах, как пояснено выше. Тем не менее, в этом случае, постфильтрация применяется только на конце процесса декодера, а не на стороне кодера.
В традиционном CELP (CELP – линейное прогнозирование с возбуждением по таблицам кодирования), форма частоты моделируется посредством синтезирующего фильтра на основе LP (линейного прогнозирования), в то время как форма во временной области может быть аппроксимирована посредством усиления при возбуждении, отправленного в каждый субкадр, хотя долговременное прогнозирование (LTP) и изобретаемая таблица кодирования обычно не подходят для моделирования шумоподобного возбуждения невокализованных кадров. CELP требует относительно высокой скорости передачи битов для достижения хорошего качества невокализованной речи.
Определение вокализованных или невокализованных характеристик может быть связано с сегментацией речи на части и ассоциированием каждой из них с различной исходной моделью речи. Исходные модели, когда они используются в схеме CELP-кодирования речи, основываются на адаптивном гармоническом возбуждении, моделирующем поток воздуха, выходящий из голосовой щели, и резонансном фильтре, моделирующем речевой тракт, возбужденный посредством сформированного потока воздуха. Такие модели могут предоставлять хорошие результаты для фонем, таких как вокалы, но могут приводить к некорректному моделированию для речевых частей, которые не формируются посредством голосовой щели, в частности, когда голосовые связки не вибрируют, к примеру, невокализованных фонем "s" или "f".
С другой стороны, параметрические речевые кодеры также называются вокодерами и приспосабливают одну исходную модель для невокализованных кадров. Она позволяет достигать очень низких скоростей передачи битов при достижении так называемого синтетического качества, не настолько естественного, насколько качество, обеспечиваемое посредством схем CELP-кодирования на гораздо более высоких скоростях.
Таким образом, имеется потребность в улучшении аудиосигналов.
Цель настоящего изобретения заключается в том, чтобы повышать качество звука на низких скоростях передачи битов и/или уменьшать скорости передачи битов для хорошего качества звука.
Это цель достигается посредством кодера, декодера, кодированного аудиосигнала и способов согласно независимым пунктам формулы изобретения.
Авторы изобретения выяснили, что в первом аспекте, качество декодированного аудиосигнала, связанного с невокализованным кадром аудиосигнала, может увеличиваться, т.е. повышаться, посредством определения информации формирования речевого спектра таким образом, что информация параметров усиления для усиления сигналов может извлекаться из информации формирования речевого спектра. Кроме того информация формирования речевого спектра может использоваться для спектрального формирования декодированного сигнала. Частотные области, содержащие более высокую важность для речи, например, низкие частоты ниже 4 кГц, в силу этого могут обрабатываться таким образом, что они содержат меньше ошибок.
Авторы изобретения дополнительно выяснили, что во втором аспекте, посредством формирования первого сигнала возбуждения из детерминированной таблицы кодирования для кадра или субкадра (части) синтезированного сигнала и посредством формирования второго сигнала возбуждения из шумоподобного сигнала для кадра или субкадра синтезированного сигнала и посредством комбинирования первого сигнала возбуждения и второго сигнала возбуждения для формирования комбинированного сигнала возбуждения качество звука синтезированного сигнала может увеличиваться, т.е. повышаться. В частности, для частей аудиосигнала, содержащего речевой сигнал с фоновым шумом, качество звука может повышаться посредством добавления шумоподобных сигналов. Параметр усиления для необязательного усиления первого сигнала возбуждения может определяться в кодере, и информация, связанная с ним, может передаваться с кодированным аудиосигналом.
Альтернативно или помимо этого, улучшение синтезированного аудиосигнала может быть по меньшей мере частично использовано для уменьшения скоростей передачи битов для кодирования аудиосигнала.
Кодер согласно первому аспекту содержит анализатор, выполненный с возможностью извлечения коэффициентов прогнозирования и остаточного сигнала из кадра аудиосигнала. Кодер дополнительно содержит модуль вычисления информации формант, выполненный с возможностью вычисления информации формирования речевого спектра из коэффициентов прогнозирования. Кодер дополнительно содержит модуль вычисления параметров усиления, выполненный с возможностью вычисления параметра усиления из невокализованного остаточного сигнала и информации формирования спектра, и модуль формирования потоков битов, выполненный с возможностью формирования выходного сигнала на основе информации, связанной с вокализованным кадром сигнала, параметром усиления или параметром квантованного усиления и коэффициентами прогнозирования.
Дополнительные варианты осуществления первого аспекта предоставляют кодированный аудиосигнал, содержащий информацию коэффициентов прогнозирования для вокализованного кадра и невокализованного кадра аудиосигнала, дополнительную информацию, связанную с вокализованным кадром сигнала, и параметр усиления либо параметр квантованного усиления для невокализованного кадра. Это дает возможность эффективной передачи речевой информации, чтобы обеспечивать декодирование кодированного аудиосигнала с тем, чтобы получать синтезированный (восстановленный) сигнал с высоким качеством звука.
Дополнительные варианты осуществления первого аспекта предоставляют декодер для декодирования принимаемого сигнала, содержащего коэффициенты прогнозирования. Декодер содержит модуль вычисления информации формант, генератор шума, формирователь и синтезатор. Модуль вычисления информации формант выполнен с возможностью вычисления информации формирования речевого спектра из коэффициентов прогнозирования. Генератор шума выполнен с возможностью формирования шумоподобного сигнала для декодирования. Формирователь выполнен с возможностью придания определенной формы спектру шумоподобного сигнала для декодирования или его усиленному представлению с использованием информации формирования спектра, чтобы получать шумоподобный сигнал для декодирования определенной формы. Синтезатор выполнен с возможностью синтезирования синтезированного сигнала из усиленного шумоподобного сигнала для кодирования определенной формы и коэффициентов прогнозирования.
Дополнительные варианты осуществления первого аспекта относятся к способу для кодирования аудиосигнала, к способу для декодирования принимаемого аудиосигнала и к компьютерной программе.
Варианты осуществления второго аспекта предоставляют кодер для кодирования аудиосигнала. Кодер содержит анализатор, выполненный с возможностью извлечения коэффициентов прогнозирования и остаточного сигнала из невокализованного кадра аудиосигнала. Кодер дополнительно содержит модуль вычисления параметров усиления, выполненный с возможностью вычисления информации первых параметров усиления для задания первого сигнала возбуждения, связанного с детерминированной таблицей кодирования, и вычисления информации вторых параметров усиления для задания второго сигнала возбуждения, связанного с шумоподобным сигналом для невокализованного кадра. Кодер дополнительно содержит модуль формирования потоков битов, выполненный с возможностью формирования выходного сигнала на основе информации, связанной с вокализованным кадром сигнала, информации первых параметров усиления и информации вторых параметров усиления.
Дополнительные варианты осуществления второго аспекта предоставляют декодер для декодирования принимаемого аудиосигнала, содержащего информацию, связанную с коэффициентами прогнозирования. Декодер содержит генератор первых сигналов, выполненный с возможностью формирования первого сигнала возбуждения из детерминированной таблицы кодирования для части синтезированного сигнала. Декодер дополнительно содержит генератор вторых сигналов, выполненный с возможностью формирования второго сигнала возбуждения из шумоподобного сигнала для части синтезированного сигнала. Декодер дополнительно содержит модуль комбинирования и синтезатор, при этом модуль комбинирования выполнен с возможностью комбинирования первого сигнала возбуждения и второго сигнала возбуждения для формирования комбинированного сигнала возбуждения для части синтезированного сигнала. Синтезатор выполнен с возможностью синтезирования части синтезированного сигнала из комбинированного сигнала возбуждения и коэффициентов прогнозирования.
Дополнительные варианты осуществления второго аспекта предоставляют кодированный аудиосигнал, содержащий информацию, связанную с коэффициентами прогнозирования, информацию, связанную с детерминированной таблицей кодирования, информацию, связанную с первым параметром усиления и вторым параметром усиления, и информацию, связанную с вокализованным и невокализованным кадром сигнала.
Дополнительные варианты осуществления второго аспекта предоставляют способы для кодирования и декодирования аудиосигнала, принимаемого аудиосигнала, соответственно, и компьютерную программу.
Далее описываются предпочтительные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи, на которых:
Фиг. 1 показывает принципиальную блок-схему кодера для кодирования аудиосигнала согласно варианту осуществления первого аспекта;
Фиг. 2 показывает принципиальную блок-схему декодера для декодирования принимаемого входного сигнала согласно варианту осуществления первого аспекта;
Фиг. 3 показывает принципиальную блок-схему дополнительного кодера для кодирования аудиосигнала согласно варианту осуществления первого аспекта;
Фиг. 4 показывает принципиальную блок-схему кодера, содержащего отличающийся модуль вычисления параметров усиления относительно фиг. 3, согласно варианту осуществления первого аспекта;
Фиг. 5 показывает принципиальную блок-схему модуля вычисления параметров усиления, выполненного с возможностью вычисления информации первых параметров усиления и формирования сигнала с возбуждением по коду по согласно варианту осуществления второго аспекта;
Фиг. 6 показывает принципиальную блок-схему кодера для кодирования аудиосигнала, содержащего модуль вычисления параметров усиления, описанного на фиг. 5, согласно варианту осуществления второго аспекта;
Фиг. 7 показывает принципиальную блок-схему модуля вычисления параметров усиления, который содержит дополнительный формирователь, выполненный с возможностью формирования шумоподобного сигнала, относительно фиг. 5, согласно варианту осуществления второго аспекта;
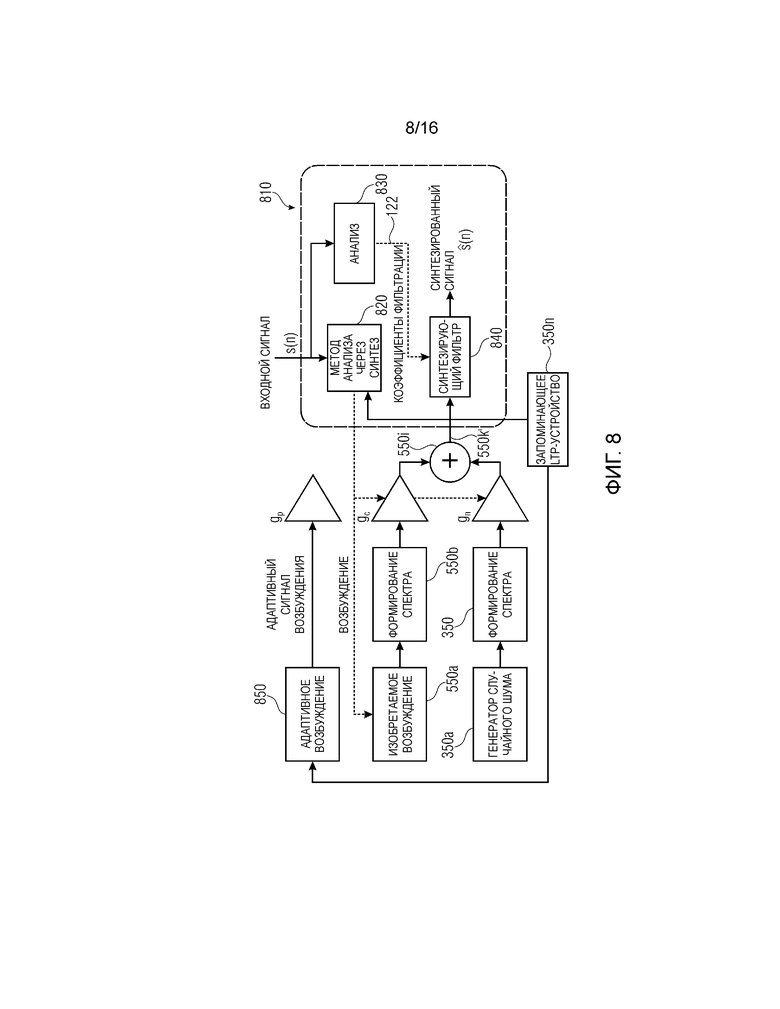
Фиг. 8 показывает принципиальную блок-схему схемы невокализованного кодирования для CELP согласно варианту осуществления второго аспекта;
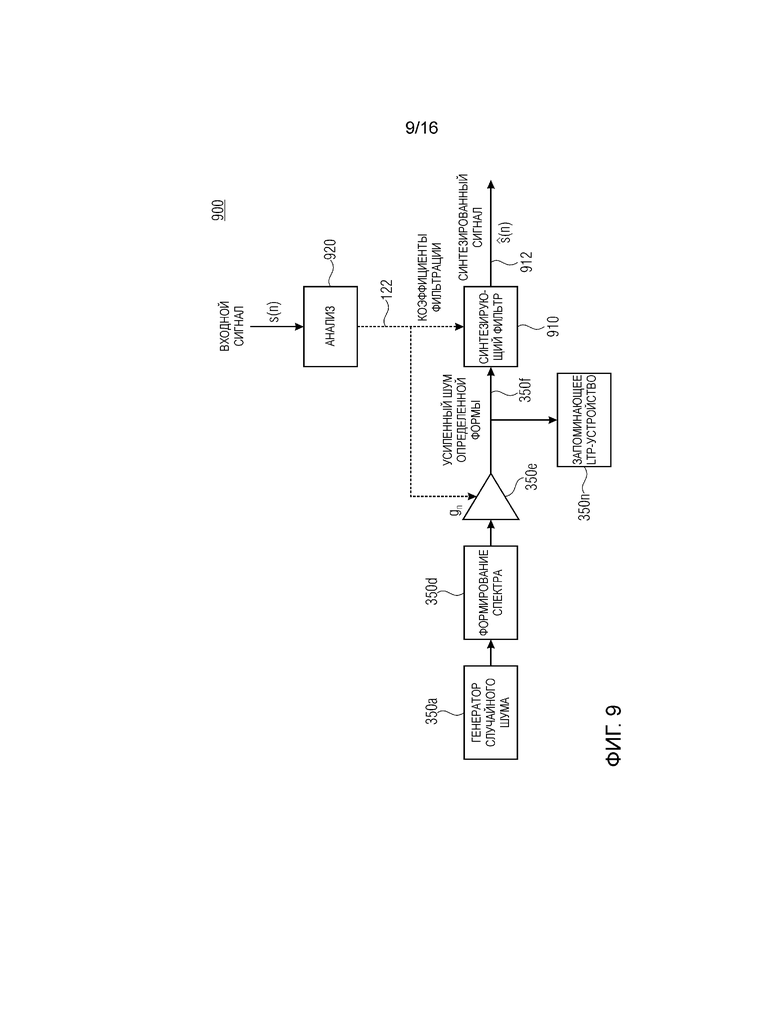
Фиг. 9 показывает принципиальную блок-схему параметрического невокализованного кодирования согласно варианту осуществления первого аспекта;
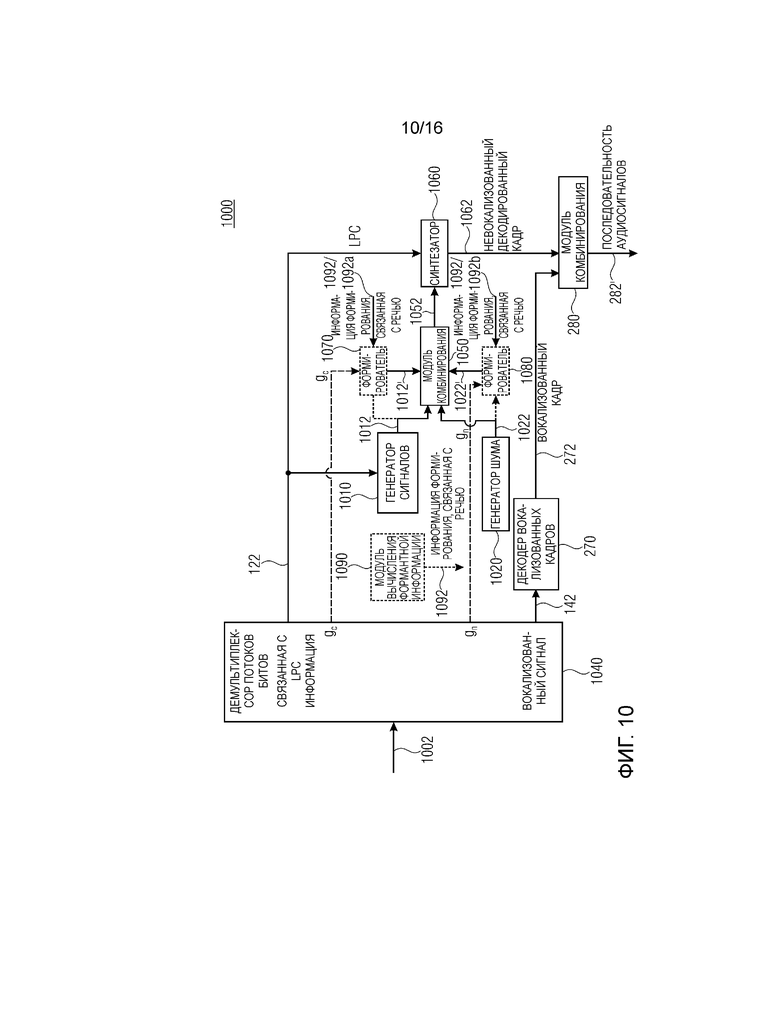
Фиг. 10 показывает принципиальную блок-схему декодера для декодирования кодированного аудиосигнала согласно варианту осуществления второго аспекта;
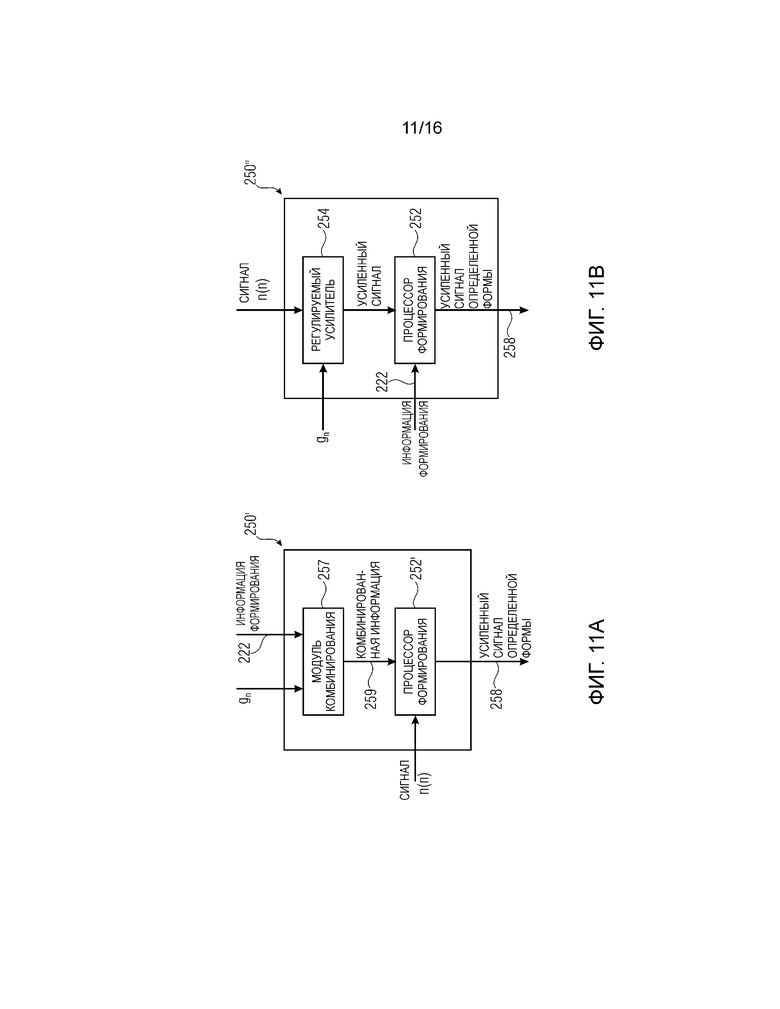
Фиг. 11a показывает принципиальную блок-схему формирователя, реализующую альтернативную структуру относительно формирователя, показанного на фиг. 2, согласно варианту осуществления первого аспекта;
Фиг. 11b показывает принципиальную блок-схему дополнительного формирователя, реализующего дополнительную альтернативу относительно формирователя, показанного на фиг. 2, согласно варианту осуществления первого аспекта;
Фиг. 12 показывает блок-схему последовательности операций способа для кодирования аудиосигнала согласно варианту осуществления первого аспекта;
Фиг. 13 показывает блок-схему последовательности операций способа для декодирования принимаемого аудиосигнала, содержащего коэффициенты прогнозирования и параметр усиления, согласно варианту осуществления первого аспекта;
Фиг. 14 показывает блок-схему последовательности операций способа для кодирования аудиосигнала согласно варианту осуществления второго аспекта; и
Фиг. 15 показывает блок-схему последовательности операций способа для декодирования принимаемого аудиосигнала согласно варианту осуществления второго аспекта.
Идентичные или эквивалентные элементы или элементы с идентичной или эквивалентной функциональностью обозначаются в нижеприведенном описании посредством идентичных или эквивалентных ссылок с номерами даже при возникновении на различных чертежах.
В нижеприведенном описании, множество деталей изложено с тем, чтобы предоставлять более полное пояснение вариантов осуществления настоящего изобретения. Тем не менее, специалистам в данной области техники должно быть очевидным, что варианты осуществления настоящего изобретения могут быть использованы на практике без этих конкретных деталей. В других случаях, известные структуры и устройства показаны в форме блок-схемы, а не подробно, чтобы не затруднять понимание вариантов осуществления настоящего изобретения. Помимо этого, признаки различных вариантов осуществления, описанных далее, могут комбинироваться между собой, если прямо не указано иное.
Далее приводятся сведения по модификации аудиосигнала. Аудиосигнал может модифицироваться посредством усиления и/или ослабления частей аудиосигнала. Часть аудиосигнала, например, может представлять собой последовательность аудиосигнала во временной области и/или его спектра в частотной области. Относительно частотной области, спектр может модифицироваться посредством усиления или ослабления спектральных значений, размещаемых на/в частотах или частотных диапазонах. Модификация спектра аудиосигнала может содержать последовательность операций, таких как усиление и/или ослабление первой частоты или частотного диапазона и впоследствии усиление и/или ослабление второй частоты или частотного диапазона. Модификации в частотной области могут представляться как вычисление, например, умножение, деление, суммирование и т.п., спектральных значений и значений усиления и/или значений ослабления. Модификации могут выполняться последовательно, к примеру, умножение спектральных значений сначала на первое значение умножения, а затем на второе значение умножения. Умножение на второе значение умножения, а затем на первое значение умножения может обеспечивать возможность приема идентичного или почти идентичного результата. Кроме того, первое значение умножения и второе значение умножения могут сначала комбинироваться и затем применяться с точки зрения комбинированного значения умножения к спектральным значениям при приеме идентичного или сравнимого результата операции. Таким образом, этапы модификации, выполненные с возможностью формировать или модифицировать спектр аудиосигнала, описанные ниже, не ограничены описанным порядком, но также могут выполняться в измененном порядке при приеме идентичного результата и/или эффекта.
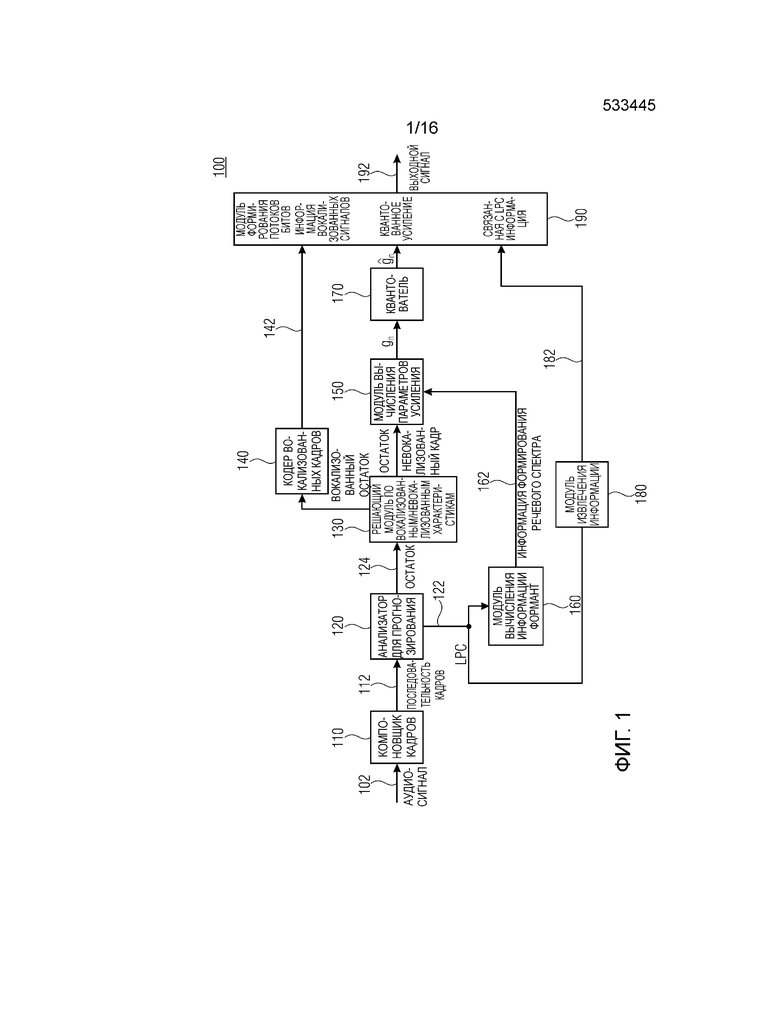
Фиг. 1 показывает принципиальную блок-схему кодера 100 для кодирования аудиосигнала 102. Кодер 100 содержит компоновщик 110 кадров, выполненный с возможностью формировать последовательность 112 кадров на основе аудиосигнала 102. Последовательность 112 содержит множество кадров, при этом каждый кадр аудиосигнала 102 имеет длину (длительность) во временной области. Например, каждый кадр может иметь длину в 10, 20 или 30 мс.
Кодер 100 содержит анализатор 120, выполненный с возможностью извлечения коэффициентов 122 прогнозирования (LPC – коэффициентов линейного прогнозирования) и остаточного сигнала 124 из кадра аудиосигнала. Компоновщик 110 кадров или анализатор 120 выполнен с возможностью определять представление аудиосигнала 102 в частотной области. Альтернативно, аудиосигнал 102 уже может быть представлением в частотной области.
Коэффициенты 122 прогнозирования, например, могут представлять собой коэффициенты линейного прогнозирования. Альтернативно, также нелинейное прогнозирование может применяться таким образом, что модуль 120 прогнозирования выполнен с возможностью определять коэффициенты нелинейного прогнозирования. Преимущество линейного прогнозирования заключается в уменьшенных вычислительных затратах для определения коэффициентов прогнозирования.
Кодер 100 содержит решающий модуль 130 по вокализованным/невокализованным характеристикам, выполненный с возможностью определения того, определен или нет остаточный сигнал 124 из невокализованного аудиокадра. Решающий модуль 130 выполнен с возможностью предоставления остаточного сигнала в кодер 140 вокализованных кадров, если остаточный сигнал 124 определен из вокализованного кадра сигнала, и предоставления остаточного сигнала в модуль 150 вычисления параметров усиления, если остаточный сигнал 124 определен из невокализованного аудиокадра. Для определения того, определен остаточный сигнал 122 из вокализованного или невокализованного кадра сигнала, решающий модуль 130 может использовать разные подходы, такие как автокорреляция выборок остаточного сигнала. Способ для определения того, является кадр сигнала вокализованным или невокализованным, предоставляется, например, в стандарте G.718 ITU (Международного союза по телекоммуникациям) – T (Сектор стандартизации связи). Большая величина энергии, размещаемой на низких частотах, может указывать вокализованную часть сигнала. Альтернативно, невокализованный сигнал может приводить к большим величинам энергии на высоких частотах.
Кодер 100 содержит модуль 160 вычисления информации формант, выполненный с возможностью вычисления информации формирования речевого спектра из коэффициентов 122 прогнозирования.
Информация формирования речевого спектра может рассматривать информацию формант, например, посредством определения частот или частотных диапазонов обработанного аудиокадра, которые содержат большую величину энергии, чем окружение. Информация формирования спектра имеет возможность сегментировать спектр абсолютной величины речи на формантные (т.е. пики) и неформантные (т.е. впадины) частотные области. Области формант спектра, например, могут извлекаться посредством использования представления в форме частот спектральных иммитансов (ISF) или частот спектральных линий (LSF) коэффициентов 122 прогнозирования. Фактически, ISF или LSF представляют частоты, для которых синтезирующий фильтр с использованием коэффициентов 122 прогнозирования резонирует.
Информация 162 формирования речевого спектра и невокализованные остатки перенаправляются в модуль 150 вычисления параметров усиления, который выполнен с возможностью вычислять параметр gn усиления из невокализованного остаточного сигнала и информации 162 формирования спектра. Параметр gn усиления может быть скалярным значением или их множеством, т.е. параметр усиления может содержать множество значений, связанных с усилением или ослаблением спектральных значений во множестве частотных диапазонов спектра сигнала, который должен усиливаться или ослабляться. Декодер может быть выполнен с возможностью применять параметр gn усиления к информации принимаемого кодированного аудиосигнала таким образом, что части принимаемых кодированных аудиосигналов усиливаются или ослабляются на основе параметра усиления в ходе декодирования. Модуль 150 вычисления параметров усиления может быть выполнен с возможностью определять параметр gn усиления посредством одного или более математических выражений или правил определения, приводящих к непрерывному значению. Операции, выполняемые в цифровой форме, например, посредством процессора, выражающие результат в переменной с ограниченным числом битов, могут приводить к квантованному усилению 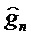
Кодер 100 дополнительно содержит модуль 180 извлечения информации, выполненный с возможностью извлечения связанной с коэффициентами прогнозирования информации 182 из коэффициентов 122 прогнозирования. Коэффициенты прогнозирования, такие как коэффициенты линейного прогнозирования, используемые для возбуждения изобретаемых таблиц кодирования, содержат низкую устойчивость к искажениям или ошибкам. Следовательно, например, известно преобразовывать коэффициенты линейного прогнозирования в межспектральные частоты (ISF) и/или извлекать пары спектральных линий (LSP) и передавать информацию, связанную с ними, вместе с кодированным аудиосигналом. Информация LSP и/или ISF содержит более высокую устойчивость к искажениям в средах передачи, например, к ошибке или ошибкам модуля вычисления. Модуль 180 извлечения информации дополнительно может содержать квантователь, выполненный с возможностью предоставлять квантованную информацию относительно LSF и/или ISP.
Альтернативно, модуль извлечения информации может быть выполнен с возможностью перенаправлять коэффициенты 122 прогнозирования. Альтернативно, кодер 100 может быть реализован без модуля 180 извлечения информации. Альтернативно, квантователь может представлять собой функциональный блок модуля 150 вычисления параметров усиления или модуля 190 формирования потоков битов, так что модуль 190 формирования потоков битов выполнен с возможностью принимать параметр gn усиления и извлекать квантованное усиление
Кодер 100 содержит модуль 190 формирования потоков битов, выполненный с возможностью принимать вокализованный сигнал, вокализованную информацию 142, связанную с вокализованным кадром кодированного аудиосигнала, соответственно, предоставленного посредством кодера 140 вокализованных кадров, принимать квантованное усиление
Кодер 100 может представлять собой часть устройства речевого кодирования, такого как стационарный или мобильный телефон, либо устройства, содержащего микрофон для передачи аудиосигналов, такого как компьютер, планшетный PC и т.п. Выходной сигнал 192 или сигнал, извлекаемый из него, могут передаваться, например, через мобильную связь (беспроводную связь) или через проводную связь, к примеру, сетевой сигнал.
Преимущество кодера 100 состоит в том, что выходной сигнал 192 содержит информацию, извлекаемую из информации формирования спектра, преобразованной в квантованное усиление
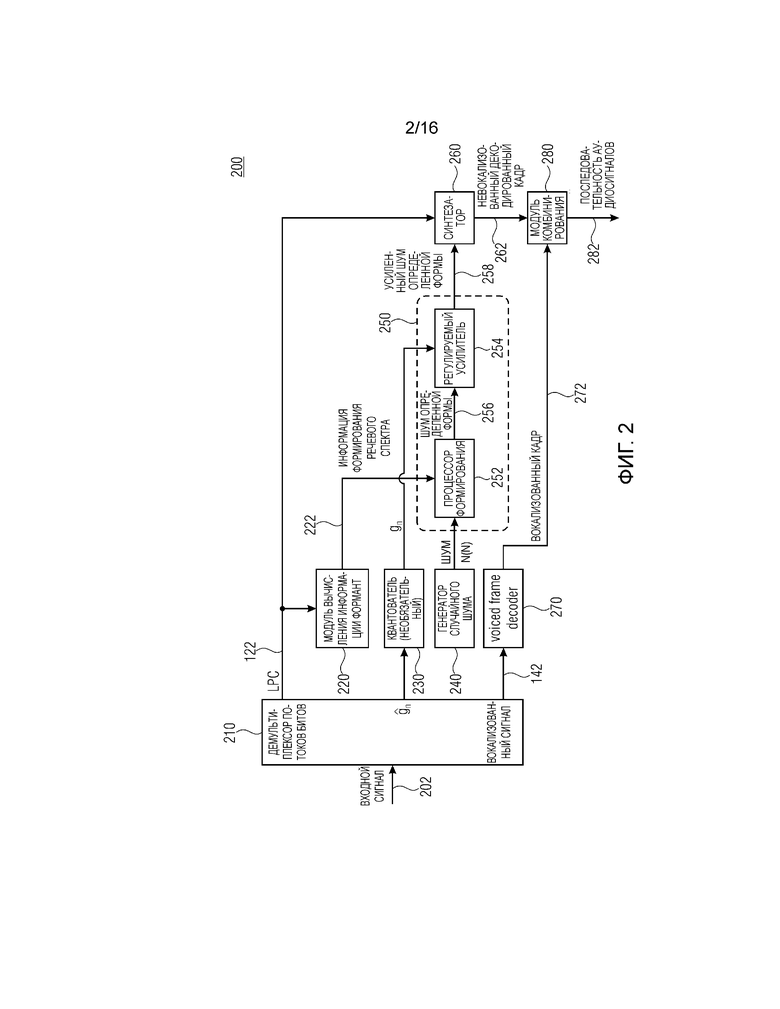
Фиг. 2 показывает принципиальную блок-схему декодера 200 для декодирования принимаемого входного сигнала 202. Принимаемый входной сигнал 202 может соответствовать, например, выходному сигналу 192, предоставленному посредством кодера 100, при этом выходной сигнал 192 может кодироваться посредством высокоуровневых кодеров, передаваться через среду, приниматься посредством приемного устройства, декодироваться на верхних уровнях, приводя к входному сигналу 202 для декодера 200.
Декодер 200 содержит модуль обратного формирования потоков битов (демультиплексор, демультиплексор) для приема входного сигнала 202. Модуль 210 обратного формирования потоков битов выполнен с возможностью предоставлять коэффициенты 122 прогнозирования, квантованное усиление
Декодер 200 содержит модуль 220 вычисления информации формант, выполненный с возможностью вычисления информации формирования речевого спектра из коэффициентов 122 прогнозирования, как описано для модуля 160 вычисления информации формант. Модуль 220 вычисления информации формант выполнен с возможностью предоставлять информацию 222 формирования речевого спектра. Альтернативно, входной сигнал 202 также может содержать информацию 222 формирования речевого спектра, при этом передача коэффициентов прогнозирования или информации, связанной с ними, такой как, например, квантованная LSF и/или ISF, вместо информации 222 формирования речевого спектра обеспечивает более низкую скорость передачи битов входного сигнала 202.
Декодер 200 содержит генератор 240 случайного шума, выполненный с возможностью формирования шумоподобного сигнала, который может упрощенный обозначаться как шумовой сигнал. Генератор 240 случайного шума может быть выполнен с возможностью воспроизводить шумовой сигнал, который получен, например, при измерении и сохранении шумового сигнала. Шумовой сигнал может измеряться и записываться, например, посредством формирования теплового шума в сопротивлении или другом электрическом компоненте и посредством сохранения записанных данных в запоминающем устройстве. Генератор 240 случайного шума выполнен с возможностью предоставлять шумо(подобный) сигнал n(n).
Декодер 200 содержит формирователь 250, содержащий процессор 252 формирования и регулируемый усилитель 254. Формирователь 250 выполнен с возможностью придания определенной формы спектру шумового сигнала n(n). Процессор 252 формирования выполнен с возможностью приема информации формирования речевого спектра и придания определенной формы спектру шумового сигнала n(n), например, посредством умножения спектральных значений спектра шумового сигнала n(n) и значений информации формирования спектра. Операция также может выполняться во временной области посредством свертки шумового сигнала n(n) с помощью фильтра, заданного посредством информации формирования спектра. Процессор 252 формирования выполнен с возможностью предоставления шумового сигнала 256 определенной формы, его спектра, соответственно, в регулируемый усилитель 254. Регулируемый усилитель 254 выполнен с возможностью приема параметра gn усиления и усиления спектра шумового сигнала 256 определенной формы, чтобы получать усиленный шумовой сигнал 258 определенной формы. Усилитель может быть выполнен с возможностью умножать спектральные значения шумового сигнала 256 определенной формы на значения параметра gn усиления. Как указано выше, формирователь 250 может реализовываться таким образом, что регулируемый усилитель 254 выполнен с возможностью принимать шумовой сигнал n(n) и предоставлять усиленный шумовой сигнал в процессор 252 формирования, выполненный с возможностью формирования усиленного шумового сигнала. Альтернативно, процессор 252 формирования может быть выполнен с возможностью принимать информацию 222 формирования речевого спектра и параметр gn усиления и применять последовательно, по одной, оба вида информации к шумовому сигналу n(n) либо комбинировать оба вида информации, например, посредством умножения или других вычислений и применять комбинированный параметр к шумовому сигналу n(n).
Шумоподобный сигнал n(n) или его усиленная версия, сформированная с информацией формирования речевого спектра, обеспечивают декодированный аудиосигнал 282, содержащий более речевое (естественное) качество звука. Это обеспечивает возможность получения высококачественных аудиосигналов и/или уменьшение скоростей передачи битов на стороне кодера при поддержании или улучшении выходного сигнала 282 в декодере с уменьшенным охватом.
Декодер 200 содержит синтезатор 260, выполненный с возможностью приема коэффициентов 122 прогнозирования и усиленного шумового сигнала 258 определенной формы и синтезирования синтезированного сигнала 262 из усиленного шумоподобного сигнала 258 определенной формы и коэффициентов 122 прогнозирования. Синтезатор 260 может содержать фильтр и может быть выполнен с возможностью адаптации фильтра с коэффициентами прогнозирования. Синтезатор может быть выполнен с возможностью фильтровать усиленный шумоподобный сигнал 258 определенной формы с помощью фильтра. Фильтр может реализовываться как программное обеспечение или как аппаратная структура и может содержать структуру с бесконечной импульсной характеристикой (IIR) или с конечной импульсной характеристикой (FIR).
Синтезированный сигнал соответствует невокализованному декодированному кадру выходного сигнала 282 декодера 200. Выходной сигнал 282 содержит последовательность кадров, которые могут преобразовываться в непрерывный аудиосигнал.
Модуль 210 обратного формирования потоков битов выполнен с возможностью разделения и предоставления сигнала 142 вокализованной информации из входного сигнала 202. Декодер 200 содержит декодер 270 вокализованных кадров, выполненный с возможностью предоставления вокализованного кадра на основе вокализованной информации 142. Декодер вокализованных кадров (процессор вокализованных кадров) выполнен с возможностью определять вокализованный сигнал 272 на основе вокализованной информации 142. Вокализованный сигнал 272 может соответствовать вокализованному аудиокадру и/или вокализованному остатку декодера 100.
Декодер 200 содержит модуль 280 комбинирования, выполненный с возможностью комбинирования невокализованного декодированного кадра 262 и вокализованного кадра 272, чтобы получать декодированный аудиосигнал 282.
Альтернативно, формирователь 250 может быть реализован без усилителя таким образом, что формирователь 250 выполнен с возможностью придания определенной формы спектру шумоподобного сигнала n(n) без дополнительного усиления получаемого сигнала. Это может обеспечивать уменьшенный объем информации, передаваемый посредством входного сигнала 222, и в силу этого уменьшенную скорость передачи битов или меньшую длительность последовательности входного сигнала 202. Альтернативно или помимо этого, декодер 200 может быть выполнен с возможностью декодировать только невокализованные кадры или обрабатывать вокализованные и невокализованные кадры посредством как спектрального формирования шумового сигнала n(n), так и посредством синтезирования синтезированного сигнала 262 для вокализованных и невокализованных кадров. Это может обеспечивать возможность реализации декодера 200 без декодера 270 вокализованных кадров и/или без модуля 280 комбинирования и в силу этого приводить к меньшей сложности декодера 200.
Выходной сигнал 192 и/или входной сигнал 202 содержит информацию, связанную с коэффициентами 122 прогнозирования, информацию для вокализованного кадра и невокализованного кадра, такую как флаг, указывающий то, является обработанный кадр вокализованным или невокализованным, и дополнительную информацию, связанную с вокализованным кадром сигнала, такую как кодированный вокализованный сигнал. Выходной сигнал 192 и/или входной сигнал 202 дополнительно содержит параметр усиления или параметр квантованного усиления для невокализованного кадра, так что невокализованный кадр может декодироваться на основе коэффициентов 122 прогнозирования и параметра gn,
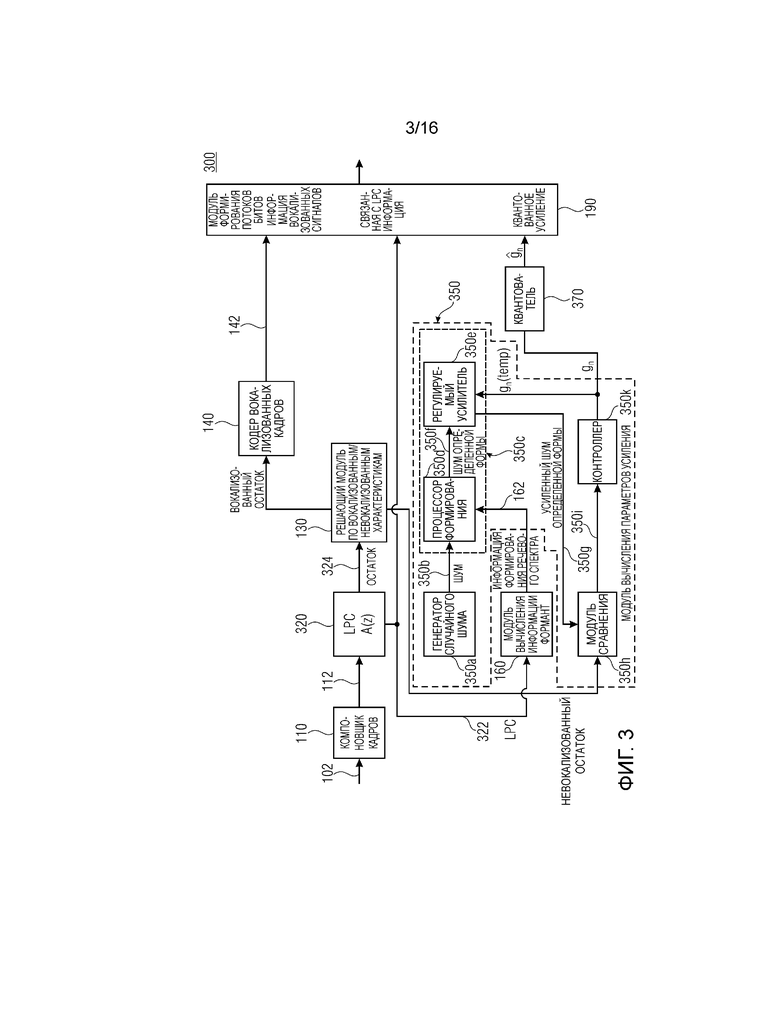
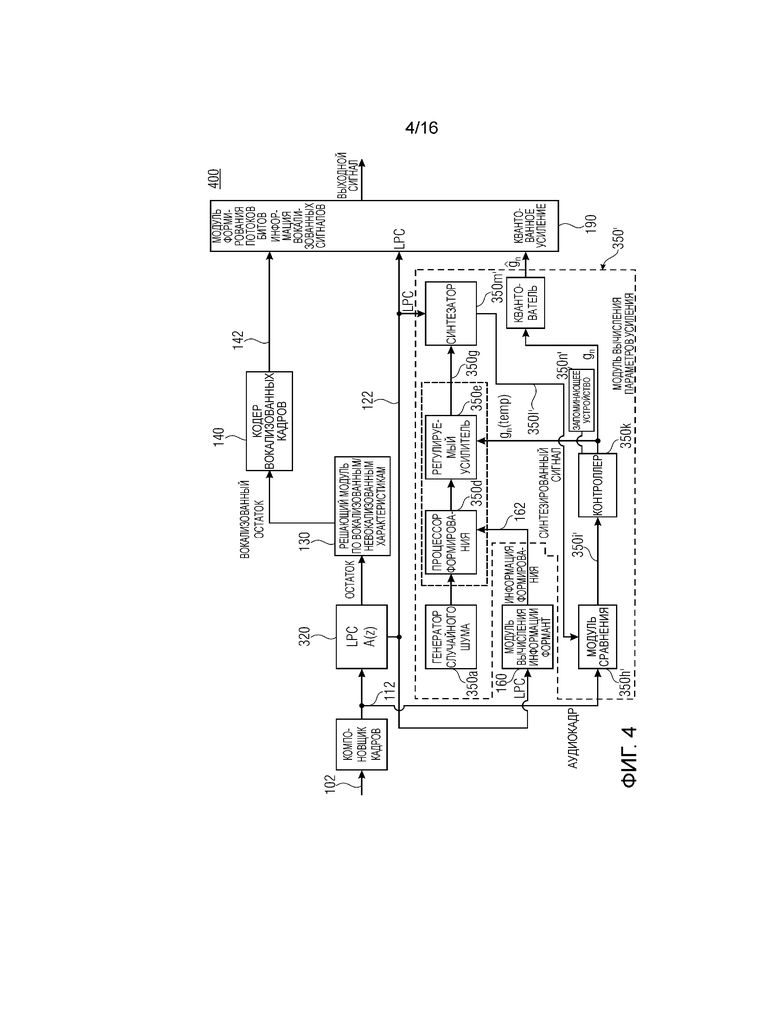
Фиг. 3 показывает принципиальную блок-схему кодера 300 для кодирования аудиосигнала 102. Кодер 300 содержит компоновщик 110 кадров, модуль 320 прогнозирования, выполненный с возможностью определения коэффициентов 322 линейного прогнозирования и остаточного сигнала 324 посредством применения фильтра A(z) к последовательности 112 кадров, предоставленной посредством компоновщика 110 кадров. Кодер 300 содержит решающий модуль 130 и кодер 140 вокализованных кадров, чтобы получать информацию 142 вокализованных сигналов. Кодер 300 дополнительно содержит модуль 160 вычисления информации формант и модуль 350 вычисления параметров усиления.
Модуль 350 вычисления параметров усиления выполнен с возможностью предоставления параметра gn усиления, как описано выше. Модуль 350 вычисления параметров усиления содержит генератор 350a случайного шума для формирования шумоподобного сигнала 350b для кодирования. Модуль 350 вычисления усиления дополнительно содержит формирователь 350c, имеющий процессор 350d формирования и регулируемый усилитель 350e. Процессор 350d формирования выполнен с возможностью приема информации 222 формирования речевого спектра и шумоподобного сигнала 350b и придания определенной формы спектру шумоподобного сигнала 350b с помощью информации 162 формирования речевого спектра, как описано для формирователя 250. Регулируемый усилитель 350e выполнен с возможностью усиления шумоподобного сигнала 350f определенной формы с помощью параметра gn(temp) усиления, который является временным параметром усиления, принимаемым из контроллера 350k. Регулируемый усилитель 350e дополнительно выполнен с возможностью предоставления усиленного шумоподобного сигнала 350g определенной формы, как описано для усиленного шумоподобного сигнала 258. Как описано для формирователя 250, порядок формирования и усиления шумоподобного сигнала может комбинироваться или изменяться относительно фиг. 3.
Модуль 350 вычисления параметров усиления содержит модуль 350h сравнения, выполненный с возможностью сравнения невокализованного остатка, предоставленного посредством решающего модуля 130, и усиленного шумоподобного сигнала 350g определенной формы. Модуль сравнения выполнен с возможностью получать показатель для сходства невокализованного остатка и усиленного шумоподобного сигнала 350g определенной формы. Например, модуль 350h сравнения может быть выполнен с возможностью определения взаимной корреляции обоих сигналов. Альтернативно или помимо этого, модуль 350h сравнения может быть выполнен с возможностью сравнения спектральных значений обоих сигналов в некоторых или всех элементах разрешения по частоте. Модуль 350h сравнения дополнительно выполнен с возможностью получать результат 350i сравнения.
Модуль 350 вычисления параметров усиления содержит контроллер 350k, выполненный с возможностью определения параметра gn(temp) усиления на основе результата 350i сравнения. Например, когда результат 350i сравнения указывает то, что усиленный шумоподобный сигнал определенной формы содержит амплитуду или абсолютную величину, которая ниже соответствующей амплитуды или абсолютной величины невокализованного остатка, контроллер может быть выполнен с возможностью увеличивать одно или более значений параметра gn(temp) усиления для некоторых или всех частот усиленного шумоподобного сигнала 350g. Альтернативно или помимо этого, контроллер может быть выполнен с возможностью уменьшать одно или более значений параметра gn(temp) усиления, когда результат 350i сравнения указывает то, что усиленный шумоподобный сигнал определенной формы содержит слишком высокую абсолютную величину или амплитуду, т.е. то, что усиленный шумоподобный сигнал определенной формы является слишком громким. Генератор 350a случайного шума, формирователь 350c, модуль 350h сравнения и контроллер 350k могут быть выполнены с возможностью реализовывать оптимизацию с замкнутым контуром для определения параметра gn(temp) усиления. Когда показатель для сходства невокализованного остатка с усиленным шумоподобным сигналом 350g определенной формы, например, выражаемого как разность между обоими сигналами, указывает то, что сходство выше порогового значения, контроллер 350k выполнен с возможностью предоставлять определенный параметр gn усиления. Квантователь 370 выполнен с возможностью квантовать параметр gn усиления, чтобы получать параметр
Генератор 350a случайного шума может быть выполнен с возможностью доставлять гауссов шум. Генератор 350a случайного шума может быть выполнен с возможностью выполнения (вызова) генератора случайных чисел с числом n равномерных распределений между нижним пределом (минимальным значением), к примеру, -1 и верхним пределом (максимальным значением), к примеру, +1. Например, генератор случайного шума 350 выполнен с возможностью вызова три раза генератора случайных чисел. Поскольку реализованные в цифровой форме генераторы случайного шума могут выводить псевдослучайные значения, добавление либо наложение нескольких или множества псевдослучайных функций может обеспечивать возможность получения достаточно случайной распределенной функции. Эта процедура подчиняется центральной предельной теореме. Генератор 350a случайного шума может быть выполнен с возможностью вызывать генератор случайных чисел по меньшей мере два, три или более раз, как указано посредством следующего псевдокода:
for(i=0;i<Ls;i++){
n[i]=uniform_random;
n[i]+=uniform_random;
n[i]+=uniform_random;
}
Альтернативно, генератор 350a случайного шума может формировать шумоподобный сигнал из запоминающего устройства, как описано для генератора 240 случайного шума. Альтернативно, генератор 350a случайного шума может содержать, например, электрическое сопротивление или другое средство для формирования шумового сигнала посредством выполнения кода или посредством измерения физических эффектов, таких как тепловой шум.
Процессор 350b формирования может быть выполнен с возможностью добавлять формантную структуру и наклон в шумоподобные сигналы 350b посредством фильтрации шумоподобного сигнала 350b с помощью fe(n), как указано выше. Наклон может добавляться посредством фильтрации сигнала с помощью фильтра t(n), содержащего передаточную функцию, на основе следующего:
,
где коэффициент β может быть выведен из вокализации предыдущего субкадра:
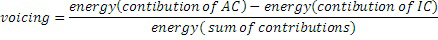 ,
,
где AC является сокращением для адаптивной таблицы кодирования, а IC является сокращением для изобретаемой таблицы кодирования.
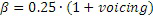 .
.
Параметр gn усиления, параметр
Относительно правила определения:
,
параметр w1 может содержать положительное ненулевое значение самое большее в 1,0, предпочтительно, самое меньшее в 0,7 и самое большее в 0,8, и более предпочтительно содержать значение в 0,75. Параметр w2 может содержать положительное ненулевое скалярное значение самое большее в 1,0, предпочтительно, самое меньшее в 0,8 и самое большее в 0,93, и более предпочтительно содержать значение в 0,9. Параметр w2 предпочтительно превышает w1.
Фиг. 4 показывает принципиальную блок-схему кодера 400. Кодер 400 выполнен с возможностью предоставлять информацию 142 вокализованных сигналов, как описано для кодеров 100 и 300. По сравнению с кодером 300, кодер 400 содержит отличающийся модуль 350' вычисления параметров усиления. Модуль 350h' сравнения выполнен с возможностью сравнивать аудиокадр 112 и синтезированный сигнал 350l', чтобы получать результат 350i' сравнения. Модуль 350' вычисления параметров усиления содержит синтезатор 350m', выполненный с возможностью синтезирования синтезированного сигнала 350l' на основе усиленного шумоподобного сигнала 350g определенной формы и коэффициентов 122 прогнозирования.
По существу, модуль 350' вычисления параметров усиления реализует по меньшей мере частично декодер посредством синтезирования синтезированного сигнала 350l'. По сравнению с кодером 300, содержащим модуль 350h сравнения, выполненный с возможностью сравнения невокализованного остатка и усиленного шумоподобного сигнала определенной формы, кодер 400 содержит модуль 350h' сравнения, который выполнен с возможностью сравнивать (вероятно, полный) аудиокадр и синтезированный сигнал. Это позволяет обеспечивать более высокую точность, поскольку кадры сигнала, а не только их параметры, сравниваются между собой. Более высокая точность может требовать увеличенных вычислительных затрат, поскольку аудиокадр 122 и синтезированный сигнал 350l' могут содержать более высокую сложность по сравнению с остаточным сигналом и с усиленной шумоподобной информацией определенной формы, так что сравнение обоих сигналов также является более сложным. Помимо этого, должен вычисляться синтез, что требует вычислительных затрат посредством синтезатора 350m'.
Модуль 350' вычисления параметров усиления содержит запоминающее устройство 350n', выполненное с возможностью записи информации кодирования, содержащей параметр gn усиления при кодировании или его квантованную версию
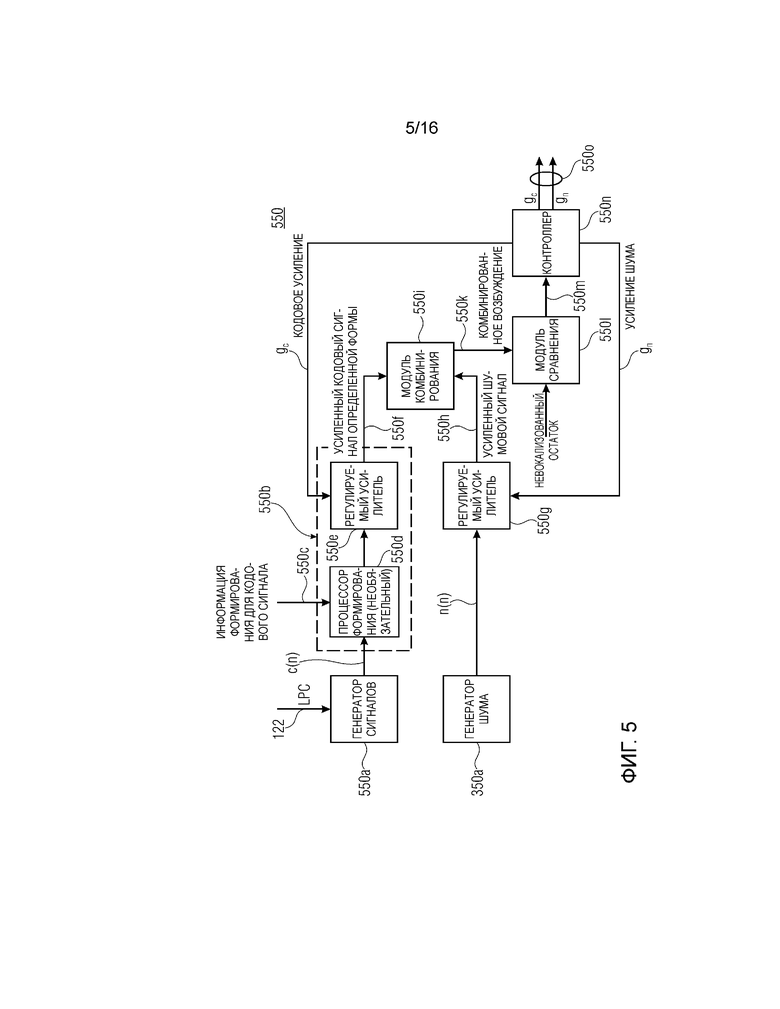
Фиг. 5 показывает принципиальную блок-схему модуля 550 вычисления параметров усиления, выполненного с возможностью вычисления информации gn первых параметров усиления согласно второму аспекту. Модуль 550 вычисления параметров усиления содержит генератор 550a сигналов, выполненный с возможностью формирования сигнала c(n) возбуждения. Генератор 550a сигналов содержит детерминированную таблицу кодирования и индекс в таблице кодирования, чтобы формировать сигнал c(n). Иными словами, входная информация, такая как коэффициенты 122 прогнозирования, приводит к детерминированному сигналу c(n) возбуждения. Генератор 550a сигналов может быть выполнен с возможностью формировать сигнал c(n) возбуждения согласно изобретаемой таблице кодирования схемы CELP-кодирования. Таблица кодирования может определяться или обучаться согласно измеренным речевым данным на предыдущих этапах калибровки. Модуль вычисления параметров усиления содержит формирователь 550b, выполненный с возможностью придания определенной формы спектру кодового сигнала c(n) на основе информации 550c формирования речевого спектра для кодового сигнала c(n). Информация 550c формирования речевого спектра может получаться из контроллера 160 информации формант. Формирователь 550b содержит процессор 550d формирования, выполненный с возможностью приема информации 550c формирования для формирования кодового сигнала. Формирователь 550b дополнительно содержит регулируемый усилитель 550e, выполненный с возможностью усиления кодового сигнала c(n) определенной формы, чтобы получать усиленный кодовый сигнал 550f определенной формы. Таким образом, параметр кодового усиления выполнен с возможностью задания кодового сигнала c(n), который связан с детерминированной таблицей кодирования.
Модуль 550 вычисления параметров усиления содержит генератор 350a шума, выполненный с возможностью предоставления шумо(подобного) сигнала n(n), и усилитель 550g, выполненный с возможностью усиления шумового сигнала n(n) на основе параметра gn усиления шума, чтобы получать усиленный шумовой сигнал 550h. Модуль вычисления параметров усиления содержит модуль 550i комбинирования, выполненный с возможностью комбинирования усиленного кодового сигнала 550f определенной формы и усиленного шумового сигнала 550h, чтобы получать комбинированный сигнал 550k возбуждения. Модуль 550i комбинирования, например, может быть выполнен с возможностью спектрального суммирования или умножения спектральных значений усиленного кодового сигнала определенной формы и усиленного шумового сигнала 550f и 550h. Альтернативно, модуль 550i комбинирования может быть выполнен с возможностью свертывать оба сигнала 550f и 550h.
Как описано выше для формирователя 350c, формирователь 550b может реализовываться таким образом, что кодовый сигнал c(n) сначала усиливается посредством регулируемого усилителя 550e и далее формируется посредством процессора 550d формирования. Альтернативно, информация 550c формирования для кодового сигнала c(n) может комбинироваться с информацией gc параметров кодового усиления таким образом, что комбинированная информация применяется к кодовому сигналу c(n).
Модуль 550 вычисления параметров усиления содержит модуль 550l сравнения, выполненный с возможностью сравнения комбинированного сигнала 550k возбуждения и невокализованного остаточного сигнала, полученного для решающего модуля 130 по вокализованным/невокализованным характеристикам. Модуль 550l сравнения может представлять собой модуль 550h сравнения и может быть выполнен с возможностью предоставления результата сравнения, т.е. показателя 550m для сходства комбинированного сигнала 550k возбуждения и невокализованного остаточного сигнала. Модуль вычисления кодового усиления содержит контроллер 550n, выполненный с возможностью управления информацией gc параметров кодового усиления и информацией gn параметров усиления шума. Параметр gc кодового усиления и информация gn параметров усиления шума могут содержать несколько или множество скалярных или мнимых значений, которые могут быть связаны с частотным диапазоном шумового сигнала n(n) или сигнала, извлекаемого из него, либо со спектром кодового сигнала c(n) или сигнала, извлекаемого из него.
Альтернативно, модуль 550 вычисления параметров усиления может реализовываться без процессора 550d формирования. Альтернативно, процессор 550d формирования может быть выполнен с возможностью формировать шумовой сигнал n(n) и предоставлять шумовой сигнал определенной формы в регулируемый усилитель 550g.
Таким образом, посредством управления обеими видами информации gc и gn параметров усиления, сходство комбинированного сигнала 550k возбуждения относительно невокализованного остатка может повышаться, так что декодер, принимающий информацию в информацию gc параметров кодового усиления и информацию gn параметров усиления шума, может воспроизводить аудиосигнал, который содержит хорошее качество звука. Контроллер 550n выполнен с возможностью предоставлять выходной сигнал 550o, содержащий информацию, связанную с информацией gc параметров кодового усиления и информацией gn параметров усиления шума. Например, сигнал 550o может содержать оба вида информации gn и gc параметров усиления в качестве скалярных или квантованных значений либо в качестве значений, извлеченных из них, например, кодированных значений.
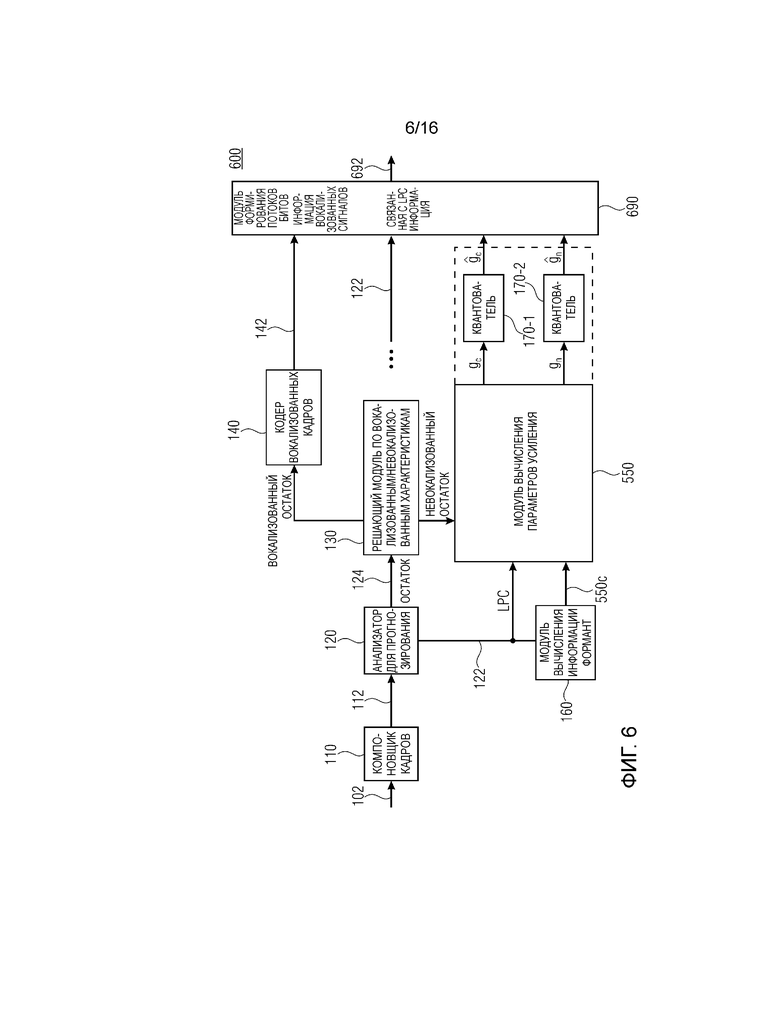
Фиг. 6 показывает принципиальную блок-схему кодера 600 для кодирования аудиосигнала 102, содержащего модуль 550 вычисления параметров усиления, описанный на фиг. 5. Кодер 600 может получаться, например, посредством модификации кодера 100 или 300. Кодер 600 содержит первый квантователь 170-1 и второй квантователь 170-2. Первый квантователь 170-1 выполнен с возможностью квантования информации gc параметров усиления для получения информации 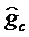
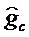
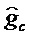
Альтернативно, кодер 600 может быть выполнен с возможностью содержать один квантователь, выполненный с возможностью квантования информации gc параметров кодового усиления и параметра gn усиления шума для получения информации
Модуль 160 вычисления информации формант выполнен с возможностью вычислять информацию 550c формирования речевого спектра из коэффициентов 122 прогнозирования.
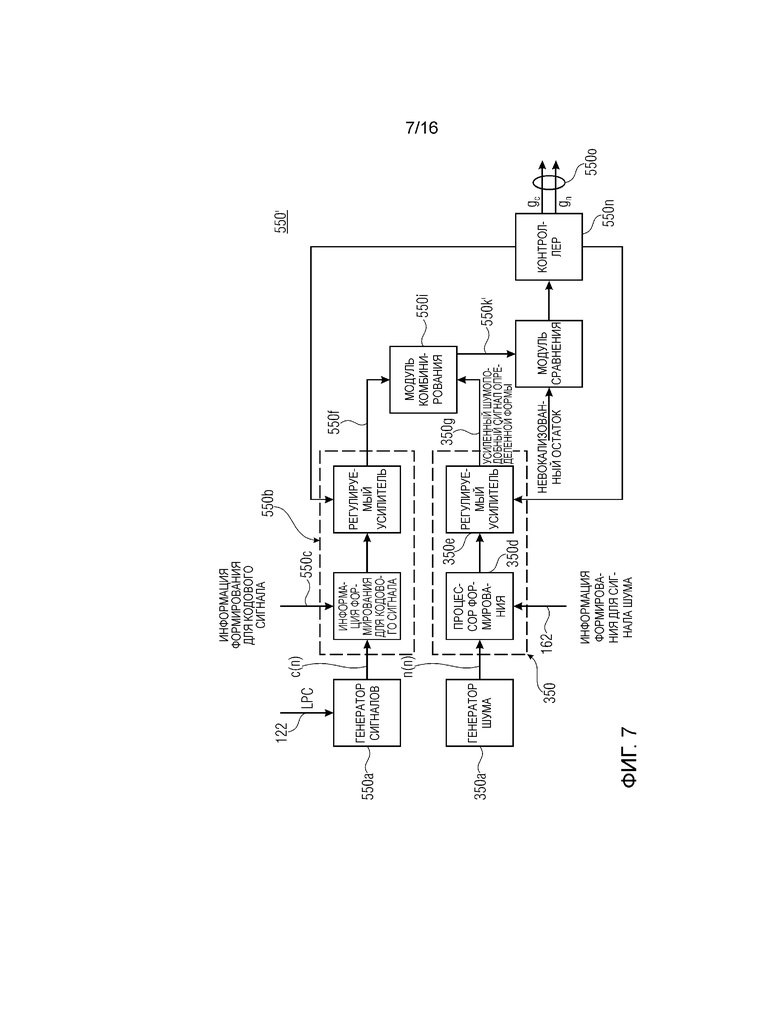
Фиг. 7 показывает принципиальную блок-схему модуля 550' вычисления параметров усиления, который модифицируется относительно модуля 550 вычисления параметров усиления. Модуль 550' вычисления параметров усиления содержит формирователь 350, описанный на фиг. 3, вместо усилителя 550g. Формирователь 350 выполнен с возможностью предоставлять усиленный шумовой сигнал 350g определенной формы. Модуль 550i комбинирования выполнен с возможностью комбинировать усиленный кодовый сигнал 550f определенной формы и усиленный шумовой сигнал 350g определенной формы, чтобы предоставлять комбинированный сигнал 550k' возбуждения. Модуль 160 вычисления информации формант выполнен с возможностью предоставлять оба вида информации 162 и 550c речевых формант. Информация 550c и 162 речевых формант может быть одинаковой. Альтернативно, оба вида информации 550c и 162 могут отличаться друг от друга. Это обеспечивает возможность отдельного моделирования, т.е. формирования сигнала c(n) и n(n) с формированием на основе кода.
Контроллер 550n может быть выполнен с возможностью определения информации gc и gn параметров усиления для каждого субкадра обработанного аудиокадра. Контроллер может быть выполнен с возможностью определять, т.е. вычислять, информацию gc и gn параметров усиления на основе подробностей, изложенных ниже.
Во-первых, средняя энергия субкадра может вычисляться для исходного сигнала остатка кратковременного прогнозирования, доступного во время LPC-анализа, т.е. для невокализованного остаточного сигнала. Энергия усредняется по четырем субкадрам текущего кадра в логарифмической области следующим образом:
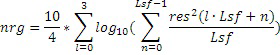 ,
,
где Lsf является размером субкадра в выборках. В этом случае, кадр разделен на 4 субкадра. Усредненная энергия затем может кодироваться в определенном числе битов, например, в трех, четырех или пяти, посредством использования предварительно обученной стохастической таблицы кодирования. Стохастическая таблица кодирования может содержать число записей (размер) согласно числу различных значений, которые могут быть представлены посредством числа битов, например, размер 8 для числа 3 битов, размер 16 для числа 4 битов или число 32 для числа 5 битов. Квантованное усиление 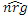 может определяться из выбранного кодового слова таблицы кодирования. Для каждого субкадра вычисляются два вида информации gc и gn усиления. Усиление gc кода может вычисляться, например, на основе следующего:
может определяться из выбранного кодового слова таблицы кодирования. Для каждого субкадра вычисляются два вида информации gc и gn усиления. Усиление gc кода может вычисляться, например, на основе следующего:
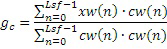 ,
,
где cw(n), например, является фиксированным новшеством, выбранным из фиксированной таблицы кодирования, состоящей из генератора 550a сигналов, фильтруемого посредством перцепционного взвешивающего фильтра. Выражение xw(n) соответствует традиционному целевому перцепционному возбуждению, вычисленному в CELP-кодерах. Информация gc кодового усиления затем может быть нормализована для получения нормализованного усиления gnc на основе следующего:
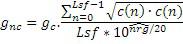 .
.
Нормализованное усиление gnc может квантоваться, например, посредством квантователя 170-1. Квантование может выполняться согласно линейной или логарифмической шкале. Логарифмическая шкала может содержать шкалу размера в 4, 5 или более битов. Например, логарифмическая шкала содержит размер в 5 битов. Квантование может выполняться на основе следующего:
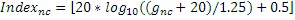 ,
,
где Indexnc может быть ограничен между 0 и 31, если логарифмическая шкала содержит 5 битов. Indexnc может быть информацией квантованных параметров усиления. Квантованное усиление кода
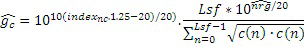 .
.
Усиление кода может вычисляться для того, чтобы минимизировать среднеквадратичную ошибку или среднеквадратическую ошибку (MSE):
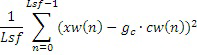 ,
,
где Lsf соответствует частотам спектральных линий, определенным из коэффициентов 122 прогнозирования.
Информация параметров усиления шума может определяться с точки зрения несовпадения энергии посредством минимизации ошибки на основе следующего:
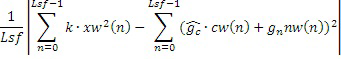 .
.
Переменная k является коэффициентом ослабления, который может варьироваться в зависимости или на основе коэффициентов прогнозирования, при этом коэффициенты прогнозирования могут обеспечивать определение того, содержит или нет речь низкую часть фонового шума или даже вообще не содержит фоновый шум (чистая речь). Альтернативно, сигнал также может определяться в качестве зашумленной речи, например, когда аудиосигнал или его кадр содержит изменения между невокализованными и неневокализованными кадрами. Переменная k может задаваться равной значению самое меньшее в 0,85, самое меньшее в 0,95 или даже значению в 1 для чистой речи, когда высокая динамика энергии является перцепционно важной. Переменная k может задаваться равной значению самое меньшее в 0,6 и самое большее в 0,9, предпочтительно значению самое меньшее в 0,7 и самое большее в 0,85, и более предпочтительно, значению в 0,8 для зашумленной речи, когда шумовое возбуждение задается более умеренным для недопущения флуктуации в выходной энергии между невокализованными и неневокализованными кадрами. Ошибка (несовпадение энергии) может вычисляться для каждого из этих возможных вариантов
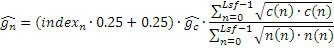 ,
,
где Indexn ограничен между 0 и 3 согласно четырем возможным вариантам. Результирующий комбинированный сигнал возбуждения, к примеру, сигнал 550k или 550k' возбуждения может получаться на основе следующего:
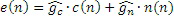 ,
,
где e(n) является комбинированным сигналом 550k или 550k' возбуждения.
Кодер 600 или модифицированный кодер 600, содержащий модуль 550 или 550' вычисления параметров усиления, может обеспечивать возможность невокализованного кодирования на основе схемы CELP-кодирования. Схема CELP-кодирования может модифицироваться на основе следующих примерных подробностей для обработки невокализованных кадров.
Параметры LTP не передаются, поскольку фактически отсутствует периодичность в невокализованных кадрах, и результирующее усиление при кодировании является очень низким. Адаптивное возбуждение задается равным нулю.
Сэкономленные биты сообщаются в фиксированную таблицу кодирования. Большее число импульсов может кодироваться для идентичной скорости передачи битов, и в таком случае может повышаться качество.
На низких скоростях, т.е. для скоростей между 6 и 12 Кбит/с, импульсное кодирование не является достаточным для моделирования надлежащим образом целевого шумоподобного возбуждения невокализованного кадра. Гауссова таблица кодирования добавляется в фиксированную таблицу кодирования для компоновки конечного возбуждения.
Фиг. 8 показывает принципиальную блок-схему схемы невокализованного кодирования для CELP согласно второму аспекту. Модифицированный контроллер 810 содержит функции как модуля 550l сравнения, так и контроллера 550n. Контроллер 810 выполнен с возможностью определения информации gc параметров кодового усиления и информации gn параметров усиления шума на основе анализа через синтез, т.е. посредством сравнения синтезированного сигнала с входным сигналом, указываемым в качестве s(n), который, например, представляет собой невокализованный остаток. Контроллер 810 содержит фильтр 820 по методу анализа через синтез, выполненный с возможностью формирования возбуждения для генератора 550a сигналов (изобретаемого возбуждения) и предоставления информации gc и gn параметров усиления. Блок 810 по методу анализа через синтез выполнен с возможностью сравнивать комбинированный сигнал 550k' возбуждения посредством сигнала, внутренне синтезированного посредством адаптации фильтра в соответствии с предоставленными параметрами и информацией.
Контроллер 810 содержит блок анализа, выполненный с возможностью получения коэффициентов прогнозирования, как описано для анализатора 320, чтобы получать коэффициенты 122 прогнозирования. Контроллер дополнительно содержит синтезирующий фильтр 840 для фильтрации комбинированного сигнала 550k возбуждения с помощью синтезирующего фильтра 840, при этом синтезирующий фильтр 840 адаптирован посредством коэффициентов 122 фильтрации. Дополнительный модуль сравнения может быть выполнен с возможностью сравнивать входной сигнал s(n) и синтезированный сигнал ŝ(n), например, декодированный (восстановленный) аудиосигнал. Дополнительно, приспосабливается запоминающее устройство 350n, при этом контроллер 810 выполнен с возможностью сохранять прогнозированный сигнал и/или прогнозные коэффициенты в запоминающем устройстве. Генератор 850 сигналов выполнен с возможностью предоставлять сигнал адаптивного возбуждения на основе сохраненных прогнозирований в запоминающем устройстве 350n, обеспечивая возможность улучшения адаптивного возбуждения на основе первого комбинированного сигнала возбуждения.
Фиг. 9 показывает принципиальную блок-схему параметрического невокализованного кодирования согласно первому аспекту. Усиленный шумовой сигнал определенной формы может представлять собой входной сигнал синтезирующего фильтра 910, который адаптирован посредством определенных коэффициентов 122 фильтрации (коэффициентов прогнозирования). Вывод синтезированного сигнала 912 посредством синтезирующего фильтра может сравниваться с входным сигналом s(n), который, например, может представлять собой аудиосигнал. Синтезированный сигнал 912 содержит ошибку относительно входного сигнала s(n). Посредством модификации параметра gn усиления шума посредством блока 920 анализа, который может соответствовать модулю 150 или 350 вычисления параметров усиления, может уменьшаться или минимизироваться ошибка. Посредством сохранения усиленного шумового сигнала 350f определенной формы в запоминающем устройстве 350n может выполняться обновление адаптивной таблицы кодирования, так что обработка вокализованных аудиокадров также может совершенствоваться на основе улучшенного кодирования невокализованного аудиокадра.
Фиг. 10 показывает принципиальную блок-схему декодера 1000 для декодирования кодированного аудиосигнала, например, кодированного аудиосигнала 692. Декодер 1000 содержит генератор 1010 сигналов и генератор 1020 шума, выполненный с возможностью формирования шумоподобного сигнала 1022. Принимаемый сигнал 1002 содержит связанную с LPC информацию, при этом модуль 1040 обратного формирования потоков битов выполнен с возможностью предоставлять коэффициенты 122 прогнозирования на основе связанной с коэффициентами прогнозирования информации. Например, декодер 1040 выполнен с возможностью извлекать коэффициенты 122 прогнозирования. Генератор 1010 сигналов выполнен с возможностью формировать сигнал 1012 возбуждения с возбуждением по коду, как описано для генератора 558 сигналов. Модуль 1050 комбинирования декодера 1000 выполнен с возможностью комбинирования сигнала 1012 с возбуждением по коду и шумоподобного сигнала 1022, как описано для модуля 550 комбинирования, чтобы получать комбинированный сигнал 1052 возбуждения. Декодер 1000 содержит синтезатор 1060, имеющий фильтр для адаптации с коэффициентами 122 прогнозирования, при этом синтезатор выполнен с возможностью фильтрации комбинированного сигнала 1052 возбуждения с помощью адаптированного фильтра, чтобы получать невокализованный декодированный кадр 1062. Декодер 1000 также содержит модуль 284 комбинирования, комбинирующий невокализованный декодированный кадр и вокализованный кадр 272, чтобы получать последовательность 282 аудиосигналов. По сравнению с декодером 200, декодер 1000 содержит генератор вторых сигналов, выполненный с возможностью предоставлять сигнал 1012 возбуждения с возбуждением по коду. Шумоподобный сигнал 1022 возбуждения, например, может представлять собой шумоподобный сигнал n(n), проиллюстрированный на фиг. 2.
Последовательность 282 аудиосигналов может содержать хорошее качество и сильное сходство относительно кодированного входного сигнала.
Дополнительные варианты осуществления предоставляют декодеры, улучшающие декодер 1000 посредством формирования и/или усиления сигнала 1012 возбуждения с формированием на основе кода (с возбуждением по коду) и/или шумоподобного сигнала 1022. Таким образом, декодер 1000 может содержать процессор формирования и/или регулируемый усилитель, размещаемый между генератором 1010 сигналов и модулем 1050 комбинирования, между генератором 1020 шума и модулем 1050 комбинирования, соответственно. Входной сигнал 1002 может содержать информацию, связанную с информацией gc параметров кодового усиления и/или информацией параметров усиления шума, при этом декодер может быть выполнен с возможностью адаптировать усилитель для усиления сигнала 1012 возбуждения с формированием на основе кода или его версии определенной формы посредством использования информации gc параметров кодового усиления. Альтернативно или помимо этого, декодер 1000 может быть выполнен с возможностью адаптировать, т.е. управлять усилителем для усиления шумоподобного сигнала 1022 или его версии определенной формы с помощью усилителя посредством использования информации параметров усиления шума.
Альтернативно, декодер 1000 может содержать формирователь 1070, выполненный с возможностью формирования сигнала 1012 возбуждения с возбуждением по коду, и/или формирователь 1080, выполненный с возможностью формирования шумоподобного сигнала 1022, как указано посредством пунктирных линий. Формирователи 1070 и/или 1080 могут принимать параметры gc и/или gn усиления и/или информацию формирования речевого спектра. Формирователи 1070 и/или 1080 могут формироваться так, как описано для вышеописанных формирователей 250, 350c и/или 550b.
Декодер 1000 может содержать модуль 1090 вычисления формантной информации, чтобы предоставлять информацию 1092 формирования речевого спектра для формирователей 1070 и/или 1080, как описано для модуля 160 вычисления информации формант. Модуль 1090 вычисления информации формант может быть выполнен с возможностью предоставлять различную информацию (1092a; 1092b) формирования речевого спектра в формирователи 1070 и/или 1080.
Фиг. 11a показывает принципиальную блок-схему формирователя 250', реализующую альтернативную структуру по сравнению с формирователем 250. Формирователь 250' содержит модуль 257 комбинирования для комбинирования информации 222 формирования и связанного с шумом параметра gn усиления, чтобы получать комбинированную информацию 259. Модифицированный процессор 252' формирования выполнен с возможностью формировать шумоподобный сигнал n(n) посредством использования комбинированной информации 259, чтобы получать усиленный шумоподобный сигнал 258 определенной формы. Поскольку как информация 222 формирования, так и параметр gn усиления могут быть интерпретированы в качестве коэффициентов умножения, оба коэффициента умножения могут умножаться посредством использования модуля 257 комбинирования и затем применяться в комбинированной форме к шумоподобному сигналу n(n).
Фиг. 11b показывает принципиальную блок-схему формирователя 250'', реализующую дополнительную альтернативу по сравнению с формирователем 250. По сравнению с формирователем 250, регулируемый усилитель 254 выполнен с возможностью сначала формировать усиленный шумоподобный сигнал посредством усиления шумоподобного сигнала n(n) с использованием параметра gn усиления. Процессор 252 формирования выполнен с возможностью формировать усиленный сигнал с использованием информации 222 формирования, чтобы получать усиленный сигнал 258 определенной формы.
Хотя фиг. 11a и 11b связаны с формирователем 250, иллюстрирующим альтернативные реализации, вышеприведенные описания также применяются к формирователям 350c, 550b, 1070 и/или 1080.
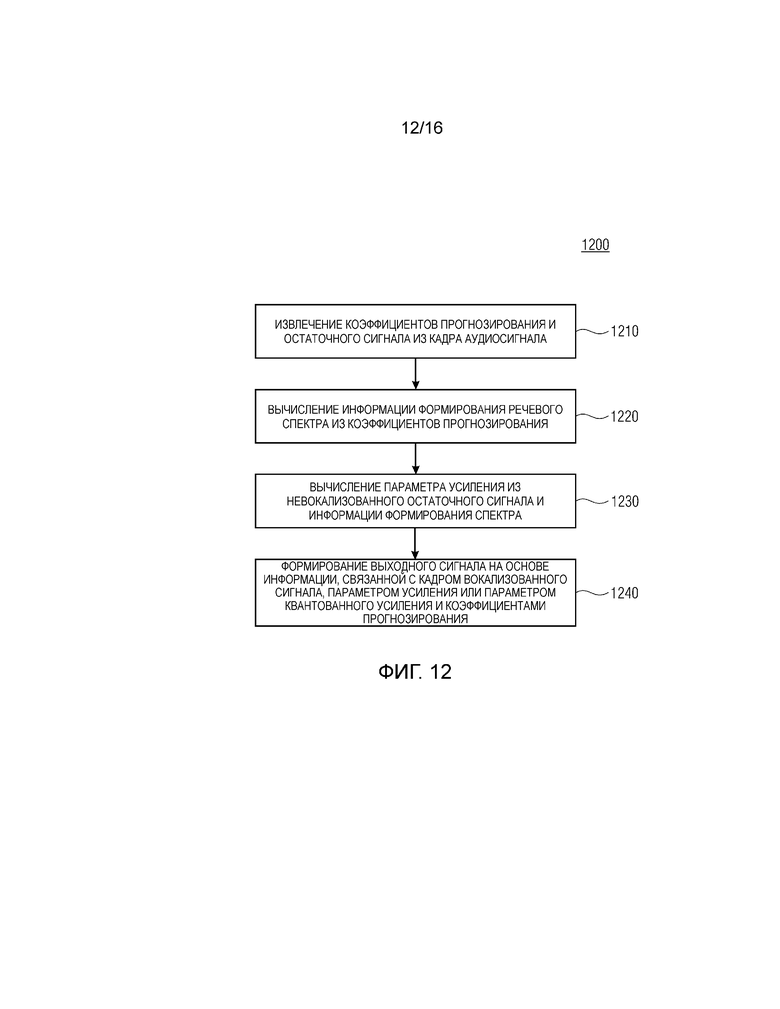
Фиг. 12 показывает блок-схему последовательности операций способа 1200 для кодирования аудиосигнала согласно первому аспекту. Способ 1210 содержит извлечение коэффициентов прогнозирования и остаточного сигнала из кадра аудиосигнала. Способ 1200 содержит этап 1230, на котором параметр усиления вычисляется из невокализованного остаточного сигнала и информации формирования спектра, и этап 1240, на котором выходной сигнал формируется на основе информации, связанной с вокализованным кадром сигнала, параметром усиления или параметром квантованного усиления и коэффициентами прогнозирования.
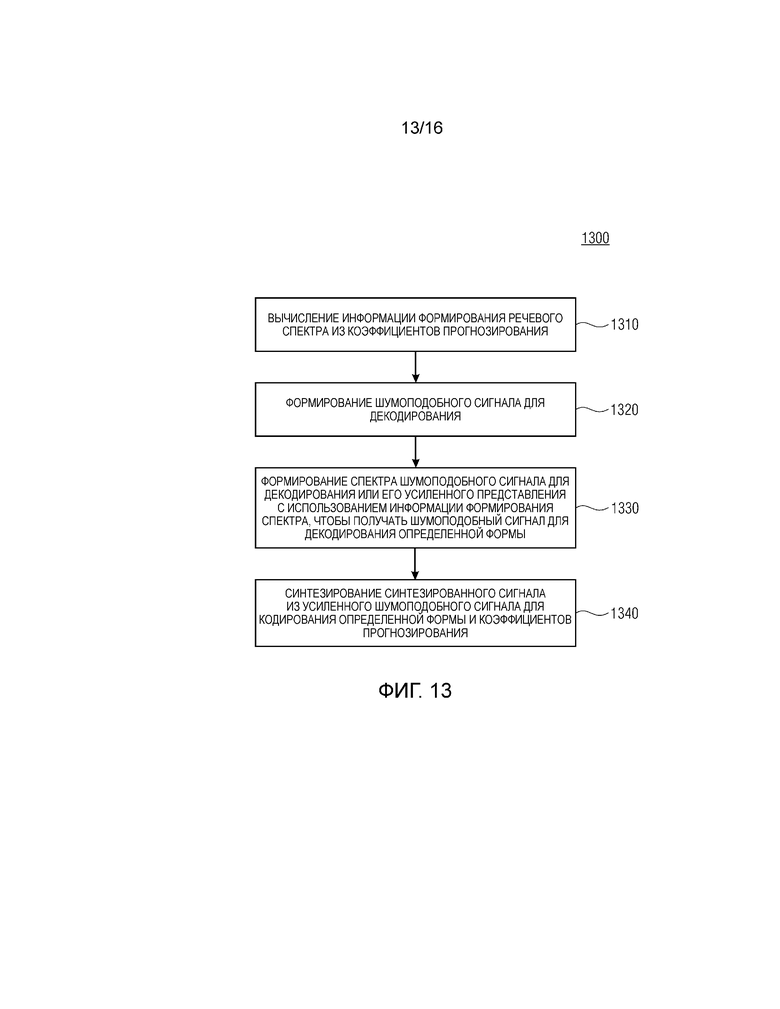
Фиг. 13 показывает блок-схему последовательности операций способа 1300 для декодирования принимаемого аудиосигнала, содержащего коэффициенты прогнозирования и параметр усиления, согласно первому аспекту. Способ 1300 содержит этап 1310, на котором информация формирования речевого спектра вычисляется из коэффициентов прогнозирования. На этапе 1320, формируется шумоподобный сигнал для декодирования. На этапе 1330, спектр шумоподобного сигнала для декодирования или его усиленное представление формируется с использованием информации формирования спектра, чтобы получать шумоподобный сигнал для декодирования определенной формы. На этапе 1340 способа 1300, синтезированный сигнал синтезируется из усиленного шумоподобного сигнала для кодирования определенной формы и коэффициентов прогнозирования.
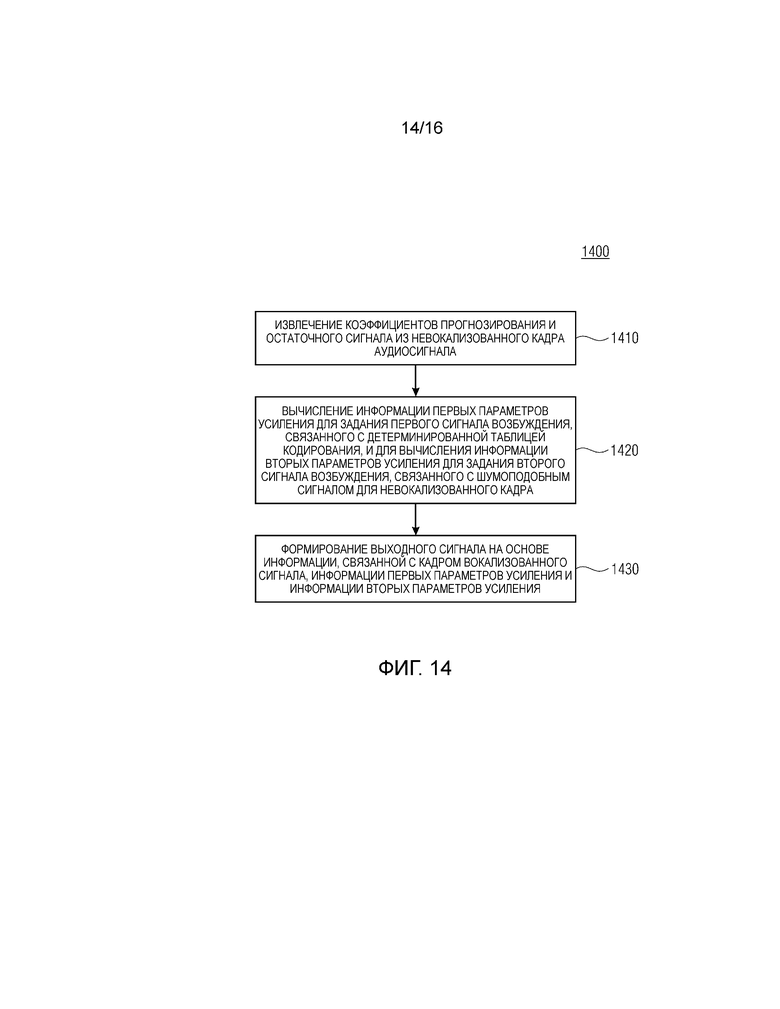
Фиг. 14 показывает блок-схему последовательности операций способа 1400 для кодирования аудиосигнала согласно второму аспекту. Способ 1400 содержит этап 1410, на котором коэффициенты прогнозирования и остаточный сигнал извлекаются из невокализованного кадра аудиосигнала. На этапе 1420 способа 1400, информация первых параметров усиления для задания первого сигнала возбуждения, связанного с детерминированной таблицей кодирования, и информация вторых параметров усиления для задания второго сигнала возбуждения, связанного с шумоподобным сигналом, вычисляется для невокализованного кадра.
На этапе 1430 способа 1400, выходной сигнал формируется на основе информации, связанной с вокализованным кадром сигнала, информации первых параметров усиления и информации вторых параметров усиления.
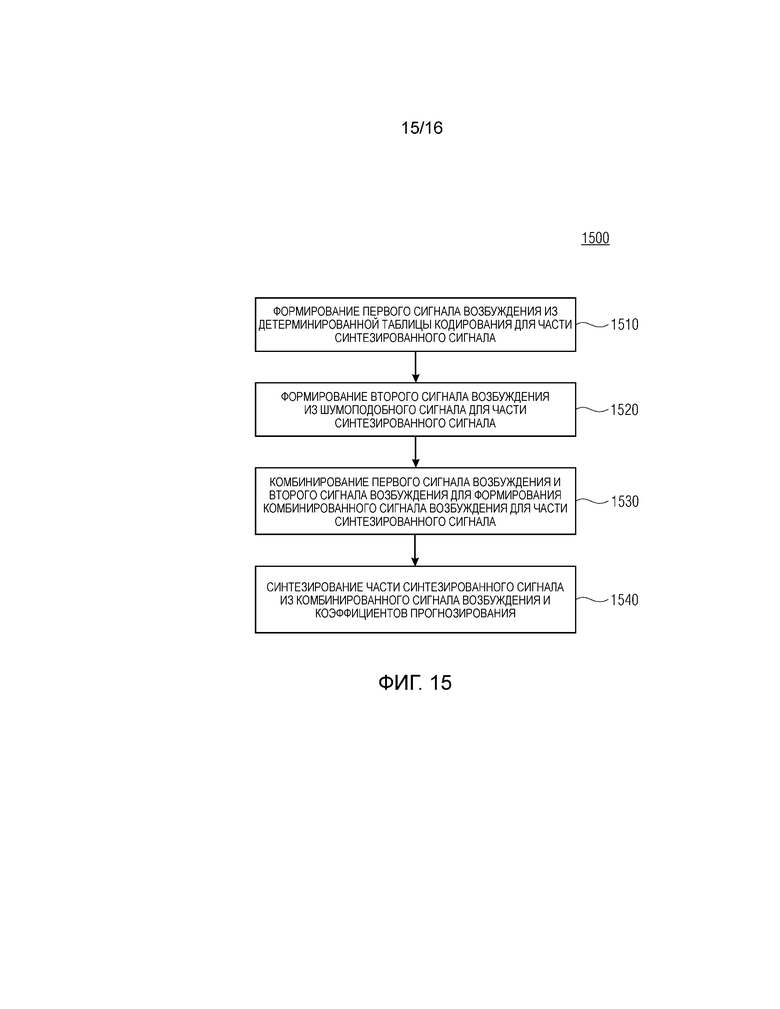
Фиг. 15 показывает блок-схему последовательности операций способа 1500 для декодирования принимаемого аудиосигнала согласно второму аспекту. Принимаемый аудиосигнал содержит информацию, связанную с коэффициентами прогнозирования. Способ 1500 содержит этап 1510, на котором первый сигнал возбуждения формируется из детерминированной таблицы кодирования для части синтезированного сигнала. На этапе 1520 способа 1500, второй сигнал возбуждения формируется из шумоподобного сигнала для части синтезированного сигнала. На этапе 1530 способа 1000, первый сигнал возбуждения и второй сигнал возбуждения комбинируются для формирования комбинированного сигнала возбуждения для части синтезированного сигнала. На этапе 1540 способа 1500, часть синтезированного сигнала синтезируется из комбинированного сигнала возбуждения и коэффициентов прогнозирования.
Другими словами, аспекты настоящего изобретения предлагают новый способ кодирования невокализованных кадров посредством формирования случайно сформированного гауссова шума и придания определенной формы его спектру посредством добавления в него формантной структуры и спектрального наклона. Формирование спектра выполняется в области возбуждения перед возбуждением синтезирующего фильтра. Как следствие, возбуждение определенной формы обновляется в запоминающем устройстве долговременного прогнозирования для формирования последующих адаптивных таблиц кодирования.
Последующие кадры, которые не являются невокализованными, также должны извлекать выгоду из формирования спектра. В отличие от улучшения формант при постфильтрации, предложенное формирование шума выполняется на сторонах кодера и декодера.
Такое возбуждение может использоваться непосредственно в схеме параметрического кодирования для фокусирования на очень низких скоростях передачи битов. Тем не менее, также предлагается ассоциировать такое возбуждение в сочетании с традиционной изобретаемой таблицей кодирования в схеме CELP-кодирования.
Для обоих способов предлагается новое кодирование усиления, в частности, эффективное как для чистой речи, так и для речи с фоновым шумом. Предлагаются некоторые механизмы, чтобы максимально приближаться к исходной энергии при одновременном недопущении слишком резких переходов с неневокализованными кадрами, а также недопущении нежелательной нестабильности вследствие квантования по усилению.
Первый аспект фокусируется на невокализованном кодировании со скоростью 2,8 и 4 килобита в секунду (Кбит/с). Сначала обнаруживаются невокализованные кадры. Это может выполняться посредством обычной классификации речи, которая осуществляется в стандарте многорежимного широкополосного кодирования с переменной скоростью (VMR-WB), как известно из [3].
Предусмотрено два основных преимущества при выполнении формирования спектра на этой стадии. Во-первых, формирование спектра учитывает вычисление усиления возбуждения. Поскольку вычисление усиления представляет собой единственный неслепой модуль во время формирования возбуждения, его наличие в конце цепочки после формирования является большим преимуществом. Во-вторых, оно обеспечивает сохранение усовершенствованного возбуждения в запоминающем устройстве LTP. В таком случае улучшение также подходит для последующих неневокализованных кадров.
Хотя квантователи 170, 170-1 и 170-2 описаны как выполненные с возможностью получения квантованных параметров
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
Изобретаемый кодированный аудиосигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Источники информации
[1] Recommendation ITU-T G.718: "Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s".
[2] Патент US №5444816, "Dynamic codebook for efficient speech coding based on algebraic codes".
[3] Jelinek M., Salami R. "Wideband Speech Coding Advances in VMR-WB Standard", Audio, Speech and Language Processing, IEEE Transactions on, издание 15, №4, с. 1167, 1179, май 2007 г.
Изобретение относится к средствам для кодирования и декодирования аудиосигнала. Технический результат заключается в повышении качества кодируемого звука при низких скоростях передачи битов. Кодер для кодирования аудиосигнала содержит: анализатор, выполненный с возможностью извлечения коэффициентов прогнозирования и остаточного сигнала из невокализованного кадра аудиосигнала; модуль вычисления параметров усиления, выполненный с возможностью вычисления информации первого параметра (gc) усиления для задания первого сигнала (c(n)) возбуждения, связанного с детерминированной таблицей кодирования, и вычисления информации второго параметра (gn) усиления для задания второго сигнала (n(n)) возбуждения, связанного с шумоподобным сигналом для невокализованного кадра; и модуль (690) формирования потоков битов, выполненный с возможностью формирования выходного сигнала на основе информации, связанной с вокализованным кадром сигнала, информации первого параметра (gc) усиления и информации второго параметра (gn) усиления. 6 н. и 14 з.п. ф-лы, 17 ил.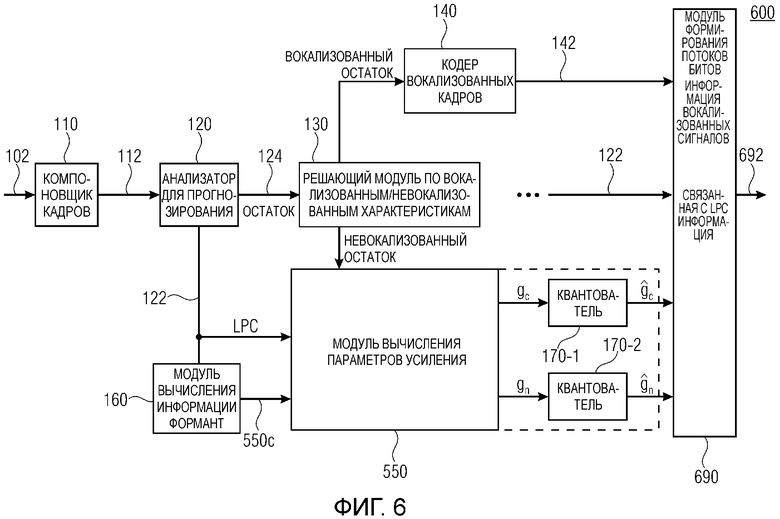
1. Кодер для кодирования аудиосигнала, причем кодер содержит:
- анализатор (120; 320), выполненный с возможностью извлечения коэффициентов (122; 322) прогнозирования и остаточного сигнала из невокализованного кадра аудиосигнала (102);
- модуль (550; 550') вычисления параметров усиления, выполненный с возможностью вычисления информации первого параметра (gc) усиления для задания первого сигнала (c(n)) возбуждения, связанного с детерминированной таблицей кодирования, и вычисления информации второго параметра (gn) усиления для задания второго сигнала (n(n)) возбуждения, связанного с шумоподобным сигналом для невокализованного кадра; и
- модуль (690) формирования потоков битов, выполненный с возможностью формирования выходного сигнала (692) на основе информации (142), связанной с вокализованным кадром сигнала, информации первого параметра (gc) усиления и информации второго параметра (gn) усиления.
2. Кодер по п.1, дополнительно содержащий:
решающий модуль (130), выполненный с возможностью определения того, определен или нет остаточный сигнал из невокализованного аудиокадра сигнала;
причем кодер содержит запоминающее устройство (350n) LTP и генератор (850) сигналов для генерирования сигнала адаптивного возбуждения для вокализированного кадра;
причем когда сравнивается со схемой кодирования для CELP, кодер выполнен с возможностью не передавать параметры LTP для невокализированного кадра, чтобы сэкономить биты, при этом сигнал адаптивного возбуждения задается равным нулю для невокализированного кадра, и при этом детерминированная таблица кодирования выполнена с возможностью кодировать больше импульсов для идентичной скорости передачи битов с использованием сэкономленных битов;
причем модуль формирования потоков битов выполнен с возможностью формирования выходного сигнала (692) на основе информации (142), связанной с вокализированным кадром сигнала, информации (182), связанной с коэффициентом (122; 322) прогнозирования, информации первого параметра (gc) усиления и информации второго параметра (gn) усиления.
3. Кодер по п.1, в котором модуль (550; 550') вычисления параметров усиления выполнен с возможностью вычисления первого параметра (gc) усиления и второго параметра (gn) усиления, при этом модуль (690) формирования потоков битов выполнен с возможностью формирования выходного сигнала (692) на основе первого параметра (gc) усиления и второго параметра (gn) усиления; или
- при этом модуль (550; 550') вычисления параметров усиления содержит квантователь (170-1, 170-2), выполненный с возможностью квантования первого параметра (gc) усиления для получения первого параметра (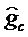
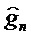
4. Кодер по п.1 -3, дополнительно содержащий модуль (160) вычисления информации формант, выполненный с возможностью вычисления информации (162) формирования речевого спектра из коэффициентов (122; 322) прогнозирования, при этом модуль (550; 550') вычисления параметров усиления выполнен с возможностью вычислять информацию (gc) первых параметров усиления и информацию (gn) вторых параметров усиления на основе информации (162) формирования речевого спектра.
5. Кодер по п.1, в котором модуль (550') вычисления параметров усиления содержит:
- первый усилитель (550e), выполненный с возможностью усиления первого сигнала (c(n)) возбуждения посредством применения первого параметра gc усиления, чтобы получать первый усиленный сигнал (550f) возбуждения;
- второй усилитель (350e; 550g), выполненный с возможностью усиления второго сигнала (n(n)) возбуждения, отличающегося от первого сигнала возбуждения (c(n)), посредством применения второго параметра (gn) усиления, чтобы получать второй усиленный сигнал (350g; 550h) возбуждения;
- модуль (550i) комбинирования, выполненный с возможностью комбинирования первого усиленного сигнала (550f) возбуждения и второго усиленного сигнала (350g; 550h) возбуждения, чтобы получать комбинированный сигнал (550k; 550k') возбуждения;
- контроллер (550n), выполненный с возможностью фильтрации комбинированного сигнала (550k; 550k') возбуждения с помощью синтезирующего фильтра, чтобы получать синтезированный сигнал (350l'), сравнения синтезированного сигнала (350l') и кадра (102) аудиосигнала, чтобы получать результат сравнения, адаптировать первый параметр (gc) усиления или второй параметр (gn) усиления на основе результата сравнения; и
- при этом модуль (690) формирования потоков битов выполнен с возможностью формирования выходного сигнала (692) на основе информации (
6. Кодер по п.1, в котором контроллер (550; 550') параметров усиления дополнительно содержит по меньшей мере один формирователь (350; 550b), выполненный с возможностью придания определенной формы спектру первого сигнала (c(n)) возбуждения или сигнала, извлекаемого из него, или второго сигнала (n(n)) возбуждения или сигнала, извлекаемого из него, на основе информации (162) формирования спектра.
7. Кодер по п.1, который выполнен с возможностью кодирования аудиосигнала (102) покадрово в последовательности кадров, при этом модуль (550; 550') вычисления параметров усиления выполнен с возможностью определения первого параметра (gc) усиления и второго параметра (gn) усиления для каждого из множества субкадров обработанного кадра, при этом контроллер (550; 550') параметров усиления выполнен с возможностью определения среднего значения энергии, ассоциированного с обработанным кадром.
8. Кодер по п.1, дополнительно содержащий:
- модуль (160) вычисления информации формант, выполненный с возможностью вычисления по меньшей мере первой информации формирования речевого спектра из коэффициентов (122; 322) прогнозирования;
- решающий модуль (130), выполненный с возможностью определения того, определен или нет остаточный сигнал из невокализованного аудиокадра сигнала.
9. Кодер по п.1, в котором контроллер (550; 550') параметров усиления содержит контроллер (550n), выполненный с возможностью определения первого параметра (gc) усиления на основе следующего:
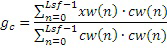 ,
,
- при этом cw(n) является фильтрованным сигналом возбуждения изобретаемой таблицы кодирования и xw(n) является целевым перцепционным возбуждением, вычисленным в CELP-кодере;
- при этом контроллер (550n) выполнен с возможностью определять квантованное усиление (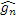 ) шума на основе квантованного значения первого параметра
) шума на основе квантованного значения первого параметра 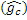 усиления и корневого квадратного энергетического отношения между первым возбуждением и вторым возбуждением:
усиления и корневого квадратного энергетического отношения между первым возбуждением и вторым возбуждением:
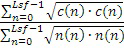 ,
,
- при этом Lsf является размером субкадра в выборках.
10. Кодер по п.1, дополнительно содержащий квантователь (170-1, 170-2), выполненный с возможностью квантования первого параметра (gc) усиления, чтобы получать квантованный первый параметр усиления (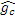 ), при этом контроллер (550n) параметров усиления выполнен с возможностью определения первого параметра (gc) усиления на основе следующего:
), при этом контроллер (550n) параметров усиления выполнен с возможностью определения первого параметра (gc) усиления на основе следующего:
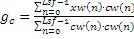 ,
,
- при этом gc является первым параметром усиления, Lsfis является размером субкадра в выборках, cw(n) обозначает первый сигнал возбуждения определенной формы, xw(n) обозначает сигнал кодирования на основе линейного прогнозирования с возбуждением по коду;
- при этом контроллер (550n) параметров усиления или квантователь (170-1, 170-2) дополнительно выполнен с возможностью нормализации первого параметра (gc) усиления, чтобы получать нормализованный первый параметр усиления на основе следующего:
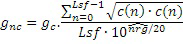 ,
,
- при этом gnc обозначает нормализованный первый параметр усиления и  является показателем для средней энергии невокализованного остаточного сигнала для всего кадра; и
является показателем для средней энергии невокализованного остаточного сигнала для всего кадра; и
- при этом квантователь (170-1, 170-2) выполнен с возможностью квантования нормализованного первого параметра усиления, чтобы получать квантованный первый параметр () усиления.
11. Кодер по п.10, в котором квантователь (170-1, 170-2) выполнен с возможностью квантования второго параметра (gn) усиления, чтобы получать квантованный второй параметр (
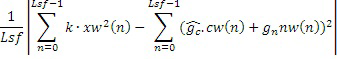 ,
,
- при этом k - это переменный коэффициент ослабления в диапазоне между 0,5 и 1, nw(n) является шумовым сигналом, Lsf соответствует размеру субкадра обработанного аудиокадра, cw(n) обозначает первый сигнал (c(n)) возбуждения определенной формы, xw(n) обозначает сигнал кодирования на основе линейного прогнозирования с возбуждением по коду, gn обозначает второй параметр усиления и обозначает квантованный первый параметр усиления.
12. Кодер по п.11, в котором модуль (550i) комбинирования выполнен с возможностью комбинирования первого параметра (gc) усиления и второго параметра (gn) усиления, чтобы получать комбинированный сигнал (e(n)) возбуждения на основе следующего:
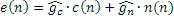 .
.
13. Декодер (1000) для декодирования принимаемого аудиосигнала (1002), содержащего информацию, связанную с коэффициентами (122) прогнозирования, причем декодер (1000) содержит:
- генератор (1010) первых сигналов, выполненный с возможностью формирования первого сигнала (1012) возбуждения из детерминированной таблицы кодирования для части синтезированного сигнала (1062);
- генератор (1020) вторых сигналов, выполненный с возможностью формирования второго сигнала (1022) возбуждения из шумоподобного сигнала для части синтезированного сигнала (1062);
- модуль (1050) комбинирования, выполненный с возможностью комбинирования первого сигнала (1012) возбуждения и второго сигнала (1022) возбуждения для формирования комбинированного сигнала (1052) возбуждения для части синтезированного сигнала (1062); и
- синтезатор (1060), выполненный с возможностью синтезирования части синтезированного сигнала (1062) из комбинированного сигнала (1052) возбуждения и коэффициентов (122) прогнозирования.
14. Декодер по п.13, содержащий запоминающее устройство (350n) LTP и генератор (850) сигналов для генерирования сигнала адаптивного возбуждения для вокализированного кадра, причем принятый аудиосигнал не содержит параметры LTP для невокализированного кадра, при этом декодер выполнен с возможностью задавать равным нулю сигнал адаптивного возбуждения для невокализированного кадра и при этом детерминированная таблица кодирования выполнена с возможностью обеспечивать больше импульсов для идентичной скорости передачи битов ввиду сэкономленных битов из-за отсутствия параметров LTP для невокализированного кадра.
15. Декодер по п.13, в котором принимаемый аудиосигнал (1002) содержит информацию, связанную с первым параметром (gc) усиления и со вторым параметром (gn) усиления, при этом декодер дополнительно содержит:
- первый усилитель (254; 350e; 550e), выполненный с возможностью усиления первого сигнала (1012) возбуждения или сигнала, извлекаемого из него, посредством применения первого параметра (gc) усиления, чтобы получать первый усиленный сигнал (1012') возбуждения;
- второй усилитель (254; 350e; 550e), выполненный с возможностью усиления второго сигнала (1022) возбуждения или извлекаемого сигнала посредством применения второго параметра усиления, чтобы получать второй усиленный сигнал (1022') возбуждения.
16. Декодер по п.13 -15, дополнительно содержащий:
- модуль (160; 1090) вычисления информации формант, выполненный с возможностью вычисления первой информации (1092a) формирования спектра и второй информации (1092b) формирования спектра из коэффициентов (122; 322) прогнозирования;
- первый формирователь (1070) для придания определенной спектральной формы спектру первого сигнала (1012) возбуждения или сигнала, извлекаемого из него, с использованием первой информации (1092a) формирования спектра; и
- второй формирователь (1080) для придания определенной спектральной формы спектру второго сигнала (1022) возбуждения или сигнала, извлекаемого из него, с использованием второй информации (1092b) формирования.
17. Способ (1400) для кодирования аудиосигнала (102), при этом способ содержит этапы, на которых:
- извлекают (1410) коэффициенты (122; 322) прогнозирования и остаточный сигнал из невокализованного кадра аудиосигнала(102);
- вычисляют (1420) информацию () первых параметров усиления для задания первого сигнала (c(n)) возбуждения, связанного с детерминированной таблицей кодирования, и вычисляют информацию (
- формируют (1430) выходной сигнал (692; 1002) на основе информации (142), связанной с вокализованным кадром сигнала, информации () первых параметров усиления и информации (
18. Способ (1500) для декодирования принимаемого аудиосигнала (692; 1002), содержащего информацию, связанную с коэффициентами (122; 322) прогнозирования, причем декодер (1000) содержит:
- формируют (1510) первый сигнал (1012, 1012') возбуждения из детерминированной таблицы кодирования для части синтезированного сигнала (1062);
- формируют (1520) второй сигнал (1022, 1022') возбуждения из шумоподобного сигнала (n(n)) для части синтезированного сигнала (1062);
- комбинируют (1530) первый сигнал (1012, 1012') возбуждения и второй сигнал (1022, 1022') возбуждения для формирования комбинированного сигнала (1052) возбуждения для части синтезированного сигнала (1062); и
- синтезируют (1540) часть синтезированного сигнала (1062) из комбинированного сигнала (1052) возбуждения и коэффициентов (122; 322) прогнозирования.
19. Цифровой носитель хранения данных, содержащий компьютерную программу, имеющую программный код, и которая при выполнении на компьютере осуществляет способ по п.17.
20. Цифровой носитель хранения данных, содержащий компьютерную программу, имеющую программный код, и которая при выполнении на компьютере осуществляет способ по п.18.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6003001 A, 14.12.1999 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБ ФОРМИРОВАНИЯ СИГНАЛА ВОЗБУЖДЕНИЯ В НИЗКОСКОРОСТНЫХ ВОКОДЕРАХ С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ | 2008 |
|
RU2400832C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КВАНТОВАНИЯ УСИЛЕНИЯ В ШИРОКОПОЛОСНОМ РЕЧЕВОМ КОДИРОВАНИИ С ПЕРЕМЕННОЙ БИТОВОЙ СКОРОСТЬЮ ПЕРЕДАЧИ | 2004 |
|
RU2316059C2 |
| АДАПТИВНЫЙ КРИТЕРИЙ КОДИРОВАНИЯ РЕЧИ | 1999 |
|
RU2223555C2 |
| СПОСОБ И УСТРОЙСТВО ВОСПРОИЗВЕДЕНИЯ РЕЧЕВЫХ СИГНАЛОВ И СПОСОБ ИХ ПЕРЕДАЧИ | 1996 |
|
RU2255380C2 |

