Настоящая заявка испрашивает приоритет заявки на патент США №61/611,959, поданной 16 марта 2012 года, заявки на патент США №61/624,990, поданной 16 апреля 2012 года, заявки на патент США №61/658,344, поданной 11 июня 2012 года, заявки на патент США №61/663,484, поданной 22 июня 2012 года, и заявки на патент США №61/746,476, поданной 27 декабря 2012 года, содержание которых полностью включено в настоящую заявку посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее раскрытие относится к кодированию видео.
УРОВЕНЬ ТЕХНИКИ
Возможности цифрового видео могут быть включены в широкий ряд устройств, включая цифровые телевизоры, цифровые системы прямого вещания, беспроводные системы вещания, персональные цифровые помощники (PDA), портативные или настольные компьютеры, планшеты, устройства для чтения электронных книг, цифровые камеры, цифровые записывающие устройства, цифровые медиапроигрыватели, устройства видеоигр, игровые видеоприставки, сотовые или спутниковые радиотелефоны, так называемые смартфоны, устройства для видеотелеконференции, устройства потокового видео и тому подобное. Цифровые видеоустройства осуществляют способы видеокодирования, как, например, описанные в стандартах, определенных MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, часть 10, Продвинутое кодирование (AVC) видеосигнала, стандарт Высокоэффективного Видеокодирования (HEVC), находящийся в разработке в настоящее время, и расширения этих стандартов. Видеоустройства могут передавать, принимать, кодировать, декодировать и/или хранить цифровую видеоинформацию более эффективно путем осуществления подобных способов видеокодирования.
Способы видеокодирования включают в себя пространственное (с внутренним (intra-) кодированием) прогнозирование и/или временное (с внешним (inter-) кодированием) прогнозирование для сокращения или устранения избыточности, присущей для последовательностей видеокадров. Для кодирования видео на основе блоков, видеослайс (например, видеокадр или часть видеокадра) может быть разделен на видеоблоки, которые также называют древовидными блоками, элементами (единицами) (CU) кодирования и/или узлами кодирования. Видеоблоки во внутренне кодированном (I) слайсе изображения кодируются с использованием пространственного прогнозирования по отношению к опорным отсчетам в соседних блоках в том же изображении. Видеоблоки во внешне-кодированном (Р или В) слайсе могут использовать пространственное прогнозирование по отношению к опорным отсчетам в соседних блоках в том же изображении или временное прогнозирование по отношению к опорным отсчетам в других опорных изображениях. Изображения можно также называть кадрами, а опорные изображения можно называть опорными кадрами.
Пространственное или временное прогнозирование имеет своим результатом прогнозирующий блок для блока, который должен быть кодирован. Остаточные данные представляют собой разницы пикселов между исходным блоком, который должен быть кодирован, и прогнозирующим блоком. Внешне-кодированный блок кодируется в соответствии с вектором движения, который указывает на блок опорных отсчетов, формирующих прогнозирующий блок, и остаточными данными, указывающими разницу между закодированным блоком и прогнозирующим блоком. Внутренне-кодированный блок кодируется в соответствии с режимом внутреннего кодирования и остаточными данными. Для дополнительного сжатия остаточные данные могут быть преобразованы из области пикселов в область преобразования, что приведет к остаточным коэффициентам преобразования, которые затем могут быть квантованы. Квантованные коэффициенты преобразования, изначально размещенные в двумерном массиве, могут быть сканированы для воспроизведения одномерного вектора коэффициентов преобразования, и может быть применено энтропийное кодирование для достижения еще большего сжатия.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
В общем, настоящее раскрытие описывает различные способы поддержки расширений стандартов кодирования, как, например, развивающийся стандарт Высокоэффективного Видеокодирования (HEVC), с изменением только синтаксиса высокого уровня. Например, настоящее раскрытие описывает способы как в базовой спецификации HEVC, так и в расширениях HEVC многовидового видеокодека и/или трехмерного (3D) видеокодека, где базовый вид сравним с базовой спецификацией HEVC. В общем, «базовая спецификация видеокодирования» может соответствовать спецификации видеокодирования, которая используется для кодирования двумерных, одноуровневых видеоданных. Расширения базовой спецификации видеокодирования могут расширять возможности базовой спецификации видеокодирования, чтобы позволить 3D и/или многоуровневое видеокодирование. Базовая спецификация HEVC представляет собой пример базовой спецификации видеокодирования, в то время как расширения MVC и SVC к базовой спецификации HEVC представляют собой примеры расширений базовой спецификации видеокодирования.
В одном примере способ включает в себя декодирование значения счета порядка изображения (POC) для первого изображения видеоданных, декодирование идентификатора изображения второй размерности для первого изображения и декодирование в соответствии с базовой спецификацией видеокодирования второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения. Идентификатор изображения второй размерности может дополнительно быть упрощен до типа изображения, например является ли изображение долгосрочным или краткосрочным изображением, или имеет ли изображение, если оно опорное изображение, то же значение счета порядка изображения (POC), что и изображение, которое ссылается на него. При формировании кандидатов векторов движения из соседних блоков кандидат может считаться недоступным, когда он имеет идентификатор изображения второй размерности, отличный от такового у вектора движения, который должен быть прогнозирован, идентификатор изображения второй размерности которого - это изображение, на которое указывает этот вектор движения, и идентифицированное индексом целевой ссылки.
В другом примере способ включает в себя кодирование значения счета порядка изображения (POC) для первого изображения видеоданных, кодирование идентификатора изображения второй размерности для первого изображения и кодированиев соответствии с базовой спецификацией видеокодирования второго изображения на основании по меньшей мере частично, значения РОС и идентификатора изображения второй размерности первого изображения.
В другом примере устройство включает в себя видеодекодер, выполненный с возможностью декодировать значение счета порядка изображения (POC) для первого изображения видеоданных, декодировать идентификатор изображения второй размерности для первого изображения и декодировать в соответствии с базовой спецификацией видеокодирования второе изображение на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
В другом примере, устройство включает в себя видеокодер, выполненный с возможностью кодировать значение счета порядка изображения (POC) для первого изображения видеоданных, кодировать идентификатор изображения второй размерности для первого изображения и кодировать, в соответствии с базовой спецификацией видеокодирования, второе изображение на основании, по меньшей мере, частично, значения РОС и идентификатора изображения второй размерности первого изображения.
В другом примере устройство включает в себя средство декодирования значения счета порядка изображения (POC) для первого изображения видеоданных, средство декодирования идентификатора изображения второй размерности для первого изображения и средство декодирования в соответствии с базовой спецификацией видеокодирования второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
В другом примере устройство включает в себя средство для кодирования значения счета порядка изображения (POC) для первого изображения видеоданных, средство для кодирования идентификатора изображения второй размерности для первого изображения и средство для кодирования в соответствии с базовой спецификацией видеокодирования, второго изображения на основании по меньшей мере частично, значения РОС и идентификатора изображения второй размерности первого изображения.
В другом примере считываемый компьютером носитель данных, на котором хранятся инструкции, которые, при их исполнении, побуждают процессор декодировать значение счета порядка изображения (POC) для первого изображения видеоданных, декодировать идентификатор изображения второй размерности для первого изображения и декодировать в соответствии с базовой спецификацией видеокодирования второе изображение на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
В другом примере считываемый компьютером носитель данных, на котором хранятся инструкции, которые, при их исполнении, побуждают процессор кодировать значение счета порядка изображения (POC) для первого изображения видеоданных, кодировать идентификатор изображения второй размерности для первого изображения и кодировать в соответствии с базовой спецификацией видеокодирования второе изображение на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
Детали одного или нескольких примеров указаны в сопровождающих чертежах и последующем описании. Другие особенности, цели и преимущества будут очевидны из описания и чертежей, а также из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 является блочной диаграммой, изображающей пример системы кодирования и декодирования видео, которая может использовать способы кодирования видеоданных в соответствии с синтаксическим расширением высокого уровня стандарта видеокодирования.
Фиг. 2 является блочной диаграммой, изображающей пример видеокодера, который может осуществлять способы кодирования видеоданных в соответствии с синтаксическим расширением высокого уровня стандарта видеокодирования.
Фиг. 3 является блочной диаграммой, изображающей пример видеодекодера, который может осуществлять способы кодирования видеоданных в соответствии с синтаксическим расширением высокого уровня стандарта видеокодирования.
Фиг. 4 является концептуальной диаграммой, изображающей пример модели прогнозирования MVC.
Фиг. 5-9 являются концептуальными диаграммами, изображающими потенциальные проблемы, которые должны быть преодолены для достижения только синтаксического расширения высокого уровня HEVC.
Фиг. 10 является концептуальной диаграммой, изображающей пример группы соседних блоков для текущего блока для использования в прогнозировании вектора движения.
Фиг. 11 является блок-схемой, изображающей пример способа кодирования видеоданных, в соответствии со способами настоящего раскрытия.
Фиг. 12 является блок-схемой, изображающей пример способа декодирования видеоданных, в соответствии со способами настоящего раскрытия.
ПОДРОБНОЕ ОПИСАНИЕ
В общем, настоящее раскрытие описывает различные способы поддержки расширений стандартов кодирования, как, например, развивающийся стандарт Высокоэффективного Видеокодирования (HEVC), с изменением только синтаксиса (HLS) высокого уровня. Например, настоящее раскрытие описывает способы как в базовой спецификации HEVC, так и в расширениях HEVC многовидового Видеокодирования (MVC) и/или кодирования трехмерного видеосигнала (3DV), где базовый вид сравним с базовой спецификацией HEVC.
Настоящее раскрытие описывает конкретные способы, обеспечивающие профиль только синтаксиса высокого уровня в спецификации расширения HEVC. Термин «межвидовой» в контексте MVC/3DV может быть заменен на «межуровневый» в контексте Масштабируемого Видеокодирования (SVC). То есть хотя описание этих способов первично фокусируется на «межвидовом» кодировании, те же или подобные идеи можно применить к «межуровневым» опорным изображениям для расширения только HLS SVC HEVC.
Фиг. 1 является блочной диаграммой, изображающей пример системы 10 кодирования и декодирования видео, которая может использовать способы кодирования видеоданных в соответствии только с синтаксическим расширением высокого уровня стандарта видеокодирования. Как изображено на Фиг. 1, система 10 включает в себя устройство-источник 12, которое обеспечивает закодированные видеоданные, которые должны быть декодированы позже устройством-адресатом 14. Более конкретно устройство-источник 12 обеспечивает видеоданные устройству-адресату 14 по считываемому компьютером носителю 16. Устройство-источник 12 и устройство-адресат 14 могут содержать любое из широкого диапазона устройств, включая настольные компьютеры, ноутбуки (то есть портативные компьютеры), планшетные компьютеры, телевизионные приставки, телефонные трубки, как, например, так называемые смартфоны, так называемые смартпады, телевизоры, камеры, устройства отображения, цифровые медиаплееры, игровые видеоприставки, устройство потокового видео или тому подобное. В некоторых случаях устройство-источник 12 и устройство-адресат 14 могут быть оборудованы для беспроводной связи.
Устройство-адресат 14 может принимать закодированные видеоданные, которые должны быть декодированы по считываемому компьютером носителю 16. Считываемый компьютером носитель 16 может содержать любой тип носителя или устройства, способного перемещать закодированные видеоданные от устройства-источника 12 к устройству-адресату 14. В одном примере считываемый компьютером носитель 16 может содержать носитель связи для разрешения устройству-источнику 12 передавать закодированные видеоданные напрямую устройству-адресату 14 в реальном времени. Закодированные видеоданные могут быть модулированы в соответствии со стандартом связи, как, например, протокол беспроводной связи, и переданы устройству-адресату 14. Носитель связи может содержать любой беспроводной или проводной носитель связи, как, например, радиочастотный (RF) спектр или одна или несколько физических линий передачи. Носитель связи может формировать часть пакетной сети, как, например, локальная сеть, региональная сеть или глобальная сеть, как, например, Интернет. Носитель связи может включать в себя роутеры, переключатели, базовые станции или любое другое оборудование, которое может быть использовано для усиления связи от устройства-источника 12 к устройству-адресату 14.
В некоторых примерах закодированные данные могут быть выведены от выходного интерфейса 22 устройству хранения. Подобным образом доступ к закодированным данным может быть осуществлен от устройства хранения с помощью входного интерфейса. Устройство хранения может включать в себя любое из разнообразных распределенных носителей данных или носителей данных локального доступа, как, например, накопитель на жестких дисках, диски Blu-ray, DVD, CD-ROM, флэш-память, энергозависимое или энергонезависимое запоминающее устройство, или любые другие подходящие цифровые носители данных для хранения закодированных видеоданных. В дополнительном примере устройство хранения может соответствовать файловому серверу или другому промежуточному устройству хранения, которое может хранить закодированное видео, сформированное устройством-источником 12. Устройство-адресат 14 может осуществлять доступ к сохраненным видеоданным в устройстве хранения по потоковой передаче или загрузке данных. Файловый сервер может быть любым типом сервера, способным хранить закодированные видеоданные и передавать эти закодированные видеоданные устройству-адресату 14. Примеры файловых серверов включают в себя вебсервер (например, для вебсайта), сервер FTP, устройства сетевого хранилища (NAS) данных или накопитель на локальном диске. Устройство-адресат 14 может осуществлять доступ к закодированным видеоданным по любому стандартному соединению данных, включая интернет-соединение. Это может включать в себя беспроводной канал (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем и так далее) или их комбинацию, подходящую для доступа к закодированных видеоданным, хранящимся на файловом сервере. Передача закодированных видеоданных от устройства хранения может быть потоковой передачей, передачей загрузки или их комбинацией.
Способы настоящего раскрытия необязательно ограничены беспроводными применениями или настройками. Способы могут быть применены к кодированию видео для поддержки любого из разнообразных мультимедийных применений, как, например, эфирные телевизионные широковещательные передачи, кабельные телевизионные передачи, спутниковые телевизионные передачи, потоковые передачи видеосигнала по интернету, как, например, динамическая адаптивная потоковая передача по HTTP (DASH), цифровой видеосигнал, который закодирован на носителе данных, декодирование цифрового видеосигнала, хранящегося на носителе данных, или другие применения. В некоторых примерах система 10 может быть выполнена с возможностью поддерживать одностороннюю или двустороннюю передачу видеосигнала для поддержки таких применений, как потоковая передача видеосигнала, воспроизведение видеосигнала, широковещательная передача видеосигнала и/или видеотелефония.
В примере на Фиг. 1 устройство-источник 12 включает в себя источник 18 видео, видеокодер 20 и выходной интерфейс 22. Устройство-адресат 14 включает в себя входной интерфейс 28, видеодекодер 30 и устройство 32 отображения. В соответствии с настоящим раскрытием видеокодер 20 устройства-источника 12 может быть выполнен с возможностью применять способы кодирования видеоданных в соответствии только с синтаксическим расширением высокого уровня стандарта видеокодирования. В других примерах устройство-источник и устройство-адресат могут включать в себя другие компоненты или установки. Например, устройство-источник 12 может принимать видеоданные от внешнего источника 18 видео, как, например, внешняя камера. Подобным образом устройство-адресат 14 может взаимодействовать с внешним устройством отображения вместо того, чтобы включать в себя интегрированное устройство отображения.
Изображенная система 10 на Фиг. 1 является лишь примером. Способы кодирования видеоданных в соответствии только с синтаксическим расширением высокого уровня стандарта видеокодирования могут быть выполнены любым цифровым устройством кодирования и/или декодирования видео. Хотя, в общем, способы настоящего изобретения выполняются устройством видеокодирования, способы могут также быть выполнены видеокодером/декодером, как правило, называемым «CODEC». Более того, способы настоящего раскрытия могут также быть выполнены устройством предварительной обработки видеосигнала. Устройство-источник 12 и устройство-адресат 14 являются лишь примерами таких устройств кодирования, в которых устройство 12 формирует закодированные видеоданные для передачи устройству-адресату 14. В некоторых примерах устройства 12, 14 могут функционировать по сути симметричным образом, так что каждое из устройств 12, 14 включает в себя компоненты кодирования и декодирования видео. Следовательно, система 10 может поддерживать одностороннюю или двустороннюю передачу между видеоустройствами 12, 14, например, для потокового видео, воспроизведения видеосигнала, широковещательной передачи видеосигнала или видеотелефонии.
Источник 18 видео устройства-источника 12 может включать в себя устройство захвата видеосигнала, как, например, видеокамера, видеоархив, содержащий ранее захваченное видео, и/или интерфейс подачи видео для приема видео от провайдера видеосодержимого. В качестве дополнительной альтернативы источник 18 видео может формировать данные компьютерной графики в качестве исходного видео, либо комбинацию видео в реальном времени, архивированного видео и сформированного компьютером видео. В некоторых случаях, если источником 18 видео является видеокамера, то устройство-источник 12 и устройство-адресат 14 могут формировать так называемые камерофоны или видеофоны. Однако, как упомянуто выше, способы, описанные в настоящем изобретении, могут быть применимы к кодированию видео в общем и могут быть применимы в беспроводных и/или проводных применениях. В любом случае захваченное, заранее захваченное или сформированное компьютером видео может быть закодировано видеокодером 20. Закодированная видеоинформация затем может быть выведена выходным интерфейсом 22 на считываемый компьютером носитель 16.
Считываемый компьютером носитель 16 может включать в себя энергозависимые носители, как, например, беспроводная широковещательная или проводная сетевая передача, либо носители данных (то есть энергонезависимые носители данных), как, например, накопитель на жестких дисках, флэш-память, компакт-диск, цифровой видеодиск, диск Blu-ray или другие считываемые компьютером носители данных. В некоторых примерах сетевой сервер (не изображен) может принимать закодированные видеоданные от устройства-источника 12 и обеспечивать закодированные видеоданные устройству-адресату 14, например, по сетевой передаче. Подобным образом вычислительное устройство блока воспроизведения носителя, как, например, блока маркировки диска, может принимать закодированные видеоданные от устройства-источника 12 и производить диск, содержащий закодированные видеоданные. Следовательно, считываемый компьютером носитель 16 можно понимать как включающий в себя один или несколько считываемых компьютером носителей различных форм, в различных примерах.
Входной интерфейс 28 устройства-адресата 14 принимает информацию от считываемого компьютером носителя 16. Информация считываемого компьютером носителя 16 может включать в себя синтаксическую информацию, определенную видеокодером 20, которая также используется видеодекодером 30, которая включает в себя синтаксические элементы, описывающие характеристики и/или обрабатывающие блоки и другие закодированные элементы, например GOP. Устройство 32 отображения отображает закодированные видеоданные пользователю и может содержать любое из разнообразных устройств, как, например, катодно-лучевая трубка (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED) или другой тип устройства отображения.
Видеокодер 20 и видеодекодер 30 могут функционировать в соответствии со стандартом видеокодирования, как, например, стандарт Высокоэффективного Видеокодирования (HEVC), находящийся в разработке в настоящее время, и могут соответствовать тестовой модели (HM) HEVC. Последняя рабочая версия HEVC, называемая «Рабочая версия 7 HEVC» или «WD7», описана в документе JCTVC-I1003, Бросс и другие, «Рабочая версия 7 текстовой спецификации высокоэффективного Видеокодирования (HEVC)», Совместная экспертная группа (JCT-VC) по кодированию видео ITU-T SG16 WP3 и ISO/IEC JTC1/SC29/WG11, 9-я встреча: Женева, Швейцария, с 27 апреля 2012 года по 7 мая 2012 года, которую по состоянию на 22 июня 2012 года можно загрузить с http://phenix.it-sudparis.eu/jct/doc_end_user/documents/9_Geneva/wg11/JCTVC-I1003-v3.zip. Как отмечено выше, настоящее раскрытие включает в себя способы расширения HEVC с использованием синтаксиса высокого уровня. Соответственно видеокодер 20 и видеодекодер 30 могут функционировать в соответствии с версией HEVC, расширенной с использованием синтаксиса высокого уровня.
Альтернативно видеокодер 20 и видеодекодер 30 могут функционировать в соответствии с другими частными или промышленными стандартами, как, например, стандарт ITU-T H.264, альтернативно называемый MPEG-4, Часть 10, Продвинутое кодирование (AVC) видеосигнала, или расширениями таких стандартов. Опять же эти расширения могут быть достигнуты с использованием синтаксиса высокого уровня. Способы настоящего изобретения, однако, не ограничены любым конкретным стандартом кодирования. Другие примеры стандартов видеокодирования включают в себя MPEG-2 ITU-T и H.263. Хотя это не изображено на Фиг. 1, в некоторых аспектах видеокодер 20 и видеодекодер 30 могут быть интегрированы с аудиокодером и декодером и могут включать в себя соответствующие элементы MUX-DEMUX или другие технические средства или программное обеспечение для управления кодированием аудио и видео в общем потоке данных или отдельных потоках данных. Если это применимо, то элементы MUX-DEMUX могут соответствовать протоколу мультиплексирования ITU H.223 или другим протоколам, как, например, протокол (UDP) пользовательской датаграммы.
Стандарт ITU-T H.264/MPEG-4 (AVC) был сформулирован Экспертной группой (VCEG) кодирования видео ITU-T совместно с Экспертной группой (MPEG) по движущемуся изображению ISO/IEC как продукт коллективного партнерства, известного как Объединенная команда (JVT) по кодированию видео. В некоторых аспектах, способы, описанные в настоящем раскрытии, могут быть применены к устройствам, которые, в общем, соответствуют стандарту Н.264. Стандарт Н.264 описан в Рекомендации Н.264 ITU-T, Продвинутое видеокодирование для общих аудиовизуальных услуг, исследовательской группой ITU-T, от марта 2005 года, и в настоящем документе может называться стандарт Н.264 или спецификация Н.264, или стандарт H.264/AVC, или спецификация. Объединенная команда (JVT) по кодированию видео продолжает работу над расширениями H.264/MPEG-4 AVC.
Видеокодер 20 и видеодекодер 30 могут быть осуществлены в качестве любой из разнообразных подходящих схем устройства кодирования, как, например, один или несколько микропроцессоров, цифровые сигнальные процессоры (DSP), специализированные интегральные схемы (ASIC), программируемые пользователем вентильные матрицы (FPGA), дискретная логика, программное обеспечение, технические средства, программно-аппаратные средства или любая их комбинация. Когда способы осуществлены частично в программном обеспечении, устройство может хранить инструкции для программного обеспечения на подходящем, энергонезависимом считываемом компьютером носителе и выполнять инструкции в технических средствах с использованием одного или нескольких процессоров для выполнения способов настоящего раскрытия. Каждый из видеокодера 20 и видеодекодера 30 может быть включен в один или несколько устройств кодирования или устройств декодирования, любое из которых может быть интегрировано как часть комбинированного кодера/декодера (CODEC) в соответствующем устройстве.
JCT-VC разрабатывает стандарт HEVC. Усилия по стандартизации HEVC основаны на развивающейся модели устройства видеокодирования, называемого Тестовой моделью (НМ) HEVC. НМ предоставляет несколько дополнительных возможностей устройств видеокодирования по отношению к существующим устройствам в соответствии, например, с ITU-T H.264/AVC. Например, в то время как Н.264 обеспечивает девять режимов кодирования с внутренним прогнозированием, НМ может обеспечивать тридцать три режима кодирования с внутренним прогнозированием.
В общем, рабочая модель НМ описывает, что видеокадр или изображение может быть разделен на последовательность древовидных блоков или наибольших элементов (LCU) кодирования, которые включают в себя отсчеты яркости и цветности. Синтаксические данные внутри битового потока могут определять размер LCU, который является наибольшим элементом кодирования в смысле числа пикселов. Слайс включает в себя число последовательных древовидных блоков в порядке кодирования. Видеокадр или изображение может быть разделено на один или несколько слайсов. Каждый древовидный блок может быть разбит на элементы (CU) кодирования в соответствии с деревом квадратов. В общем, структура данных дерева квадратов включает в себя один узел на CU, с корневым узлом, соответствующим древовидному блоку. Если CU разбит на четыре под-CU, то узел, соответствующий CU, включает в себя четыре концевых узла, каждый из которых соответствует одному из под-CU.
Каждый узел структуры данных дерева квадратов может обеспечивать синтаксические данные соответствующему CU. Например, узел в дереве квадратов может включать в себя флаг разделения, указывающий, разделен ли CU, соответствующий узлу, на под-CU. Синтаксические элементы CU могут быть определены рекурсивно и могут зависеть от того, разделен ли CU на под-CU. Если CU не разделен дополнительно, он называется концевым CU. В настоящем раскрытии четыре под-CU концевого CU будут также называться концевыми CU, даже если нет четкого разделения исходного концевого CU. Например, если CU размера 16×16 не разделен дополнительно, четыре под-CU 8×8 будут также называться концевыми CU, хотя CU 16×16 никогда не был разделен.
CU имеет ту же цель, что и макроблок стандарта Н.264, за исключением того, что CU не имеет отличия в размере. Например, древовидный блок может быть разделен на четыре дочерних узла (также называемых под-CU), и каждый дочерний узел, в свою очередь, может быть родительским узлом и быть разделен на другие четыре дочерних узла. Последний, не разделенный дочерний узел, называемый концевым узлом дерева квадратов, содержит узел кодирования, также называемый концевым CU. Синтаксические данные, связанные с закодированным битовым потоком, могут определять число раз, которое дерево квадратов может быть разделено, называемое максимальной глубиной CU, и может также определять минимальный размер узлов кодирования. Соответственно битовый поток может также определять наименьший элемент (SCU) кодирования. Настоящее раскрытие использует термин «блок» для ссылки на любой из CU, PU или TU в контексте HEVC или подобные структуры данных в контексте других стандартов (например, макроблоки и их подблоки в H.264/AVC).
CU включает в себя узел кодирования, элементы (PU) прогнозирования и элементы (TU) преобразования, связанные с узлом кодирования. Размер CU соответствует размеру узла кодирования и должен быть квадратным по форме. Размер CU может варьироваться от 8х8 пикселов до размера дерева квадратов, максимально 64х64 пикселов или больше. Каждый СU может содержать один или несколько PU и один или несколько ТU. Синтаксические данные, связанные с CU, могут описывать, например, разделение CU на один или несколько PU. Режимы разделения могут отличаться в зависимости от того, является ли CU закодированным в режиме пропуска или прямом режиме, закодированным в режиме внутреннего прогнозирования или закодированным в режиме внешнего прогнозирования. PU может быть разделен так, что по форме он неквадратный. Синтаксические данные, связанные с CU, могут также описывать, например, разделение CU на один или несколько TU в соответствии с деревом квадратов. TU может быть квадратной или неквадратной (например, прямоугольной) формы.
Стандарт HEVC допускает преобразования, в соответствии с TU, которые могут отличаться для различных CU. TU, как правило, имеют размер на основании размера PU внутри заданного CU, определенного для разделенного LCU, хотя это не всегда может быть так. TU, как правило, имеют тот же размер или меньше, чем PU. В некоторых примерах остаточные отсчеты, соответствующие CU, могут быть подразделены на меньшие элементы с использованием структуры дерева квадратов, известной как «остаточное дерево (RQT) квадратов». Концевые узлы RQT могут называться элементами (TU) преобразования. Значения разницы пикселов, связанные с TU, могут быть преобразованы для воспроизведения коэффициентов преобразования, которые могут быть квантованы.
Концевой CU может включать в себя один или несколько элементов (PU) прогнозирования. В общем, PU представляет собой пространственную область, соответствующую всем или части соответствующих CU, и может включать в себя данные для извлечения опорного отсчета для PU. Более того, PU включает в себя данные, относящиеся к прогнозированию. Например, когда PU закодирован во внутреннем режиме, данные для PU могут быть включены в остаточное дерево (RQT) квадратов, которое может включать в себя данные, описывающие режим внутреннего прогнозирования для TU, соответствующего PU. В качестве другого примера, когда PU закодирован во внешнем режиме, PU может включать в себя данные, определяющие один или несколько векторов движения для PU. Данные, определяющие вектор движения для PU, могут описывать, например, горизонтальную компоненту вектора движения, вертикальную компоненту вектора движения, разрешение вектора движения (например, с точностью до одной четвертой пиксела или с точностью до одной восьмой пиксела), опорное изображение, на которое указывает вектор движения, и/или список опорных изображений (например, Список 0, Список 1, или Список С) для вектора движения.
Концевой CU, имеющий один или несколько PU, может также включать в себя один или несколько элементов (TU) преобразования. Элементы преобразования могут быть определены с использованием RQT (также называемого структурой дерева квадратов TU), как описано выше. Например, флаг разделения может указывать, разделен ли концевой CU на четыре элемента преобразования. Затем каждый элемент преобразования может быть дополнительно разделен на дополнительные под-TU. Когда TU не разделен дополнительно, он может называться концевым TU. В общем, для внутреннего кодирования все концевые TU, принадлежащие концевому CU, имеют одинаковый режим внутреннего прогнозирования. То есть, одинаковый режим внутреннего прогнозирования, в общем, применяется для вычисления прогнозированных значений для всех TU концевого CU. Для внутреннего кодирования видеокодер может вычислять остаточное значение для каждого концевого TU с использованием режима внутреннего прогнозирования в качестве разницы между частью CU, соответствующего TU, и исходным блоком. TU необязательно ограничен размером PU. Таким образом, TU могут быть больше или меньше, чем PU. Для внутреннего кодирования PU может быть расположен совместно с соответствующим концевым TU для того же CU. В некоторых примерах максимальный размер концевого TU может соответствовать размеру соответствующего концевого CU.
Более того, TU концевых CU могут также быть связаны с соответственными структурами данных дерева квадратов, называемыми остаточные деревья (RQT) квадратов. То есть концевой CU может включать в себя дерево квадратов, указывающее, как концевой CU разделен на TU. Корневой узел дерева квадратов TU, в общем, соответствует концевому CU, в то время как корневой узел дерева квадратов CU, в общем, соответствует древовидному блоку (или LCU). TU RQT, которые не разделены, называются концевыми TU. В общем, настоящее раскрытие использует термины CU и TU для ссылки на концевой CU и концевой TU соответственно, если только не указано иное.
Видеопоследовательность, как правило, включает в себя ряд видеокадров или изображений. Группа (GOP) изображений, в общем, содержит ряд из одного или нескольких изображений. GOP может включать в себя синтаксические данные в заголовке GOP, заголовке одного или нескольких изображений или в другом месте, которое описывает число изображений, включенных в GOP. Каждый слайс изображения может включать в себя синтаксические данные слайса, которые описывают режим кодирования для соответствующего слайса. Видеокодер 20, как правило, функционирует с видеоблоками внутри отдельных видеослайсов, чтобы закодировать видеоданные. Видеоблок может соответствовать узлу кодирования внутри CU. Видеоблоки могут иметь фиксированные или изменяемые размеры и могут отличаться в размерах в соответствии с конкретным стандартом кодирования.
В качестве примера НМ поддерживает прогнозирование в различных размерах PU. Предположим, что размер конкретного CU равен 2N×2N, тогда НМ поддерживает внутреннее прогнозирование в размерах PU 2N×2N или N×N, и внешнее прогнозирование в симметричных размерах PU 2N×2N, 2N×N, N×2N или N×N. НМ также поддерживает асимметричное разделение для внешнего прогнозирования в размерах PU 2N×nU, 2N×nD, nL×2N и nR×2N. При асимметричном разделении одно направление CU не разделяется, в то время как другое направление разделяется на 25% и 75%. Часть CU, соответствующая 25% разделению, указывается «n», за которым следует указание «Сверху», «Снизу», «Слева» или «Справа». Таким образом, например, «2N×nU» относится к 2N×2N CU, который разделен горизонтально с 2N×0,5N PU сверху и 2N×1,5N PU снизу.
В настоящем раскрытии «N×N» и «N на N» могут быть использованы взаимозаменяемо для ссылки на пиксельные размеры видеоблока относительно вертикальных и горизонтальных размеров, например 16×16 пикселов или 16 на 16 пикселов. В общем, блок 16×16 имеет 16 пикселов в вертикальном направлении (у=16) и 16 пикселов в горизонтальном направлении (х=16). Подобным образом блок N×N, в общем, имеет N пикселов в вертикальном направлении и N пикселов в горизонтальном направлении, где N представляет собой неотрицательное целое значение. Пикселы в блоке могут быть упорядочены в ряды и столбцы. Более того, блоки необязательно должны иметь одинаковое число пикселов в горизонтальном направлении, а также в вертикальном направлении. Например, блоки могут содержать N×M пикселов, где М необязательно равно N.
Вслед за кодированием с внутренним прогнозированием или внешним прогнозированием с использованием PU CU видеокодер 20 может вычислять остаточные данные для TU CU. PU могут содержать синтаксические данные, описывающие способ или режим формирования прогнозных пиксельных данных в пространственном домене (также называемом пиксельным доменом), и TU могут содержать коэффициенты в домене преобразования вслед за применением преобразования, например дискретного косинусного преобразования (DCT), целочисленного преобразования, волнового преобразования или концептуально похожего преобразования к остаточным видеоданным. Остаточные данные могут соответствовать разницам пикселов между пикселами незакодированного изображения и значениями прогнозирования, соответствующими PU. Видеокодер 20 может формировать TU, включающие в себя остаточные данные для CU, а затем преобразовывать TU для воспроизведения коэффициентов преобразования для CU.
Вслед за любыми преобразованиями для воспроизведения коэффициентов преобразования видеокодер 20 может выполнять квантование коэффициентов преобразования. Квантование, в общем, относится к процессу, в котором коэффициенты преобразования квантуются для возможного сокращения количества данных, используемых для представления коэффициентов, что обеспечивает дополнительное сжатие. Процесс квантования может сократить глубину битов, связанную с некоторыми или всеми коэффициентами. Например, значение n-бит может быть округлена до значения m-бит во время квантования, где n больше, чем m.
Вслед за квантованием видеокодер может сканировать коэффициенты преобразования, производя одномерный вектор из двумерной матрицы, включающей в себя квантованные коэффициенты преобразования. Сканирование может быть задумано так, чтобы разместить коэффициенты с высокой энергией (и, следовательно, с низкой частотой) в передней части массива и разместить коэффициенты с низкой энергией (и, следовательно, с высокой частотой) в задней части массива. В некоторых примерах видеокодер 20 может использовать заранее заданный порядок сканирования для сканирования квантованных коэффициентов преобразования для воспроизведения упорядоченного вектора, который можно энтропийно закодировать. В других примерах видеокодер 20 может выполнять адаптивное сканирование. После сканирования квантованных коэффициентов преобразования для формирования одномерного вектора видеокодер 20 может энтропийно кодировать одномерный вектор, например, в соответствии с контекстно-зависимым адаптивным кодированием с переменной длиной кодового слова (CAVLC), контекстно-зависимым адаптивным двоичным арифметическим кодированием (CAВАC), синтаксическим контекстно-зависимым адаптивным двоичным арифметическим кодированием (SBAC), энтропийным кодированием (PIPE) с разделением интервалов вероятности или другой методологией энтропийного кодирования. Видеокодер 20 может также энтропийно кодировать синтаксические элементы, связанные с закодированными видеоданными для использования видеодекодером 30 при декодировании видеоданных.
Для выполнения САВАС видеокодер 20 может назначать контекст внутри контекстной модели символу, который должен быть передан. Контекст может относиться, например, к тому, являются ли соседние значения символа ненулевыми или нет. Для выполнения САVLC видеокодер 20 может выбирать переменную длину кодового слова для символа, который должен быть передан. Кодовые слова в VLC могут быть построены так, что относительно более короткие коды соответствуют наиболее вероятным символам, в то время как более длинные коды соответствуют менее вероятным символам. Таким образом, с помощью использования VLC можно добиться сохранения битов по сравнению, например, с использованием кодовых слов равной длины для каждого символа, который должен быть передан. Определение вероятности может быть основано на контексте, назначенном символу.
Видеокодер 20 может дополнительно отправлять синтаксические данные, как, например, синтаксические данные на основании блока, синтаксические данные на основании кадра и синтаксические данные на основании GOP, видеодекодеру 30, например, в заголовке кадра, заголовке блока, заголовке слайса или заголовке GOP. Синтаксические данные GOP могут описывать число кадров в соответствующей GOP, и синтаксические данные кадра могут указывать режим кодирования/прогнозирования, используемый для кодирования соответствующего кадра.
В общем, настоящее раскрытие описывает различные примеры решений для разрешения только синтаксического расширения высокого уровня (HLS) стандарта видеокодирования, как, например, HEVC. Например, эти способы могут быть использованы для разработки расширения только-HLS для профиля HEVC, как, например, MVC или SVC. Различные примеры описаны далее. Необходимо понимать, что различные примеры описаны отдельно, а элементы любых или всех примеров могут быть скомбинированы в любой комбинации.
В первом примере изменений в текущей базовой спецификации HEVC нет. В расширении HEVC изображение (например, компонента вида) может быть идентифицировано по двум качествам: его значению счета порядка изображения (POC) и идентификатору изображения второй размерности, например значению view_id (которое может идентифицировать вид, в котором изображение представлено). Видеокодеру 20 может потребоваться указать компоненту вида, которая должна быть использована для межвидового прогнозирования, в качестве долгосрочного опорного изображения.
Во втором примере изменений в текущей базовой спецификации HEVC нет. В расширении HEVC могут быть применены следующие изменения. Изображение (например, компонента вида) может быть идентифицировано по двум качествам: значению РОС и идентификатору изображения второй размерности, например view_id. Во втором примере,процесс маркировки дополнительного изображения может быть произведен сразу до кодирования текущей компоненты вида, для маркировки всех межвидовых опорных изображений в качестве долгосрочных опорных изображений. Другой процесс маркировки изображения может быть произведен сразу после кодирования текущей компоненты вида для маркировки каждого межвидового опорного изображения в качестве либо долгосрочного, краткосрочного или «неиспользуемого для ссылки», что является тем же, что его предыдущий статус маркировки до того как была закодирована текущая компонента вида.
В третьем примере способы второго примера используются и дополняются, как описано далее. В дополнение к способам второго примера для каждого межвидового опорного изображения, после того, как оно маркировано в качестве долгосрочного опорного изображения, его значение РОС отображается в новое значение POC, которое не эквивалентно значению РОС любого существующего опорного изображения. После декодирования текущей компоненты вида для каждого межвидового опорного изображения его значение РОС отображается обратно в исходное значение РОС, которое равно текущей компоненте вида. Например, текущая компонента вида может принадлежать виду 3 (предположим, что идентификатор вида равен индексу порядка вида) и может иметь значение РОС, равное 5. Два межвидовых опорных изображения могут иметь свои значения РОС (которые равны 5), конвертированные, например, в 1025 и 2053. После декодирования текущей компоненты вида значения РОС межвидовых изображений могут быть обратно конвертированы в 5.
В четвертом примере способы второго либо третьего примеров могут быть использованы и дополнены, как описано далее. В дополнение к способам первого примера или второго примера, как указано выше, в базовой спецификации HEVC дополнительный прием может быть использован для запрета прогнозирования между любым вектором движения, относящимся к краткосрочному изображению, и другим вектором движения, относящимся к долгосрочным изображениям, особенно во время усовершенствованного прогнозирования вектора движения (AMVP).
В пятом примере в расширении HEVC изображение может быть идентифицировано по двум качествам: значению РОС и идентификатору изображения второй размерности, например view_id. В базовой спецификации HEVC одна или несколько следующих привязок могут быть добавлены (по отдельности или в комбинации). В одном примере (называемом пример 5.1) при идентификации опорного изображения во время AMVP и режима слияния идентификация изображения второй размерности, например индекс порядка вида, может быть использована вместе с РОС. В контексте двумерного 2D декодирования видео в базовой спецификации HEVC идентификация изображения второй размерности всегда может полагаться (устанавливаться) равной 0.
В другом примере (пример 5.2) прогнозирование между временным вектором движения и межвидовым вектором движения запрещается во время AMVP (включая временное прогнозирование вектора движения (TMVP)). Качество вектора движения может быть определено с помощью связанного опорного индекса, который идентифицирует опорное изображение, и то, как на опорное изображение ссылается изображение, содержащее вектор движения, например как на долгосрочное опорное изображение, краткосрочное опорное изображение, или межвидовое опорное изображение. В другом примере (пример 5.3) прогнозирование между временным краткосрочным вектором движения и временным долгосрочным вектором движения может быть запрещено (например, явно или неявно). В другом примере (пример 5.4) прогнозирование между временным краткосрочным вектором движения и временным долгосрочным вектором движения может быть разрешено (например, явно или неявно).
В другом примере (пример 5.5) прогнозирование между векторами движения, ссылающимися на два различных межвидовых опорных изображения, может быть запрещено (например, явно или неявно). Два межвидовых опорных изображения можно рассматривать как имеющие различные типы, если значения идентификаторов изображения второй размерности для них являются различными. В другом примере (пример 5.6) прогнозирование между векторами движения, ссылающимися на два различных межвидовых опорных изображения, может быть разрешено (например, явно или неявно). В другом примере (пример 5.7) прогнозирование между векторами движения, ссылающимися на долгосрочное изображение и межвидовое изображение, может быть разрешено (например, явно или неявно). В другом примере (пример 5.8) прогнозирование между векторами движения, ссылающимися на долгосрочное изображение и межвидовое изображение, может быть запрещено (например, явно или неявно).
В любом из вышеуказанных примеров прогнозирование между двумя векторами движения, ссылающимися на два различных временных краткосрочных опорных изображения, может всегда быть разрешено, и масштабирование из одного в другое на основании значений РОС может быть разрешено. Дополнительно или альтернативно в любом из вышеуказанных примеров прогнозирование между векторами движения, ссылающимися на два различных долгосрочных изображения, может быть запрещено. Конкретные детали различных примеров, описанных выше, обсуждаются более подробно далее.
В общем, настоящее раскрытие ссылается на «вектор движения» или «данные вектора движения» как включающие в себя опорный индекс (то есть указатель на опорное изображение) и х- и у-координаты самого вектора движения. Оба вектора движения - диспаратности и временной вектор движения - могут, в общем, называться «векторами движения». Опорное изображение, соответствующее опорному индексу, может называться опорным изображением, на которое ссылается вектор движения. Если вектор движения ссылается на опорное изображение другого вида, он называется вектор движения диспаратности.
Временной вектор движения может быть краткосрочным временным вектором движения («краткосрочный вектор движения») или долгосрочным временным вектором движения («долгосрочный вектор движения»). Например, вектор движения является краткосрочным, если он ссылается на краткосрочное опорное изображение, в то время как вектор движения является долгосрочным, если он ссылается на долгосрочное опорное изображение. Необходимо отметить, что если не указано иное, вектор движения диспаратности и долгосрочный вектор движения, в общем, описывают различные категории векторов движения, например, для межвидового прогнозирования и временного внутривидового прогнозирования соответственно. Краткосрочное и долгосрочное опорные изображения представляют собой примеры временных опорных изображений.
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью идентифицировать опорное изображение из буфера (DPB) декодированных изображений, который может быть осуществлен в качестве памяти опорных изображений. Процесс идентификации опорного изображения из DPB может быть использован в любом из примеров способов, описанных в настоящем раскрытии. Процесс идентификации опорного изображения из DPB может быть использован для следующих целей в спецификации расширения HEVC: создание группы опорных изображений, создание списка опорных изображений и/или маркировка опорных изображений.
Компонента вида, компонента вида текстуры, компонента вида глубины или масштабируемый уровень (например, с конкретной комбинацией dependency_id и quality_id) могут быть идентифицированы с помощью значения счета порядка изображения (POC) и информации идентификации изображения второй размерности. Информация идентификации изображения второй размерности может включать в себя одно или несколько из следующих: ID вида (view_id) в многовидовом контексте; индекс порядка вида в многовидовом контексте; в 3DV (многовидовой с глубиной) контексте, комбинацию индекса порядка вида и depth_flag (указывающий, является ли текущая компонента вида текстурой или глубиной), например, индекс порядка вида, умноженный на два, плюс значение depth_flag; в контексте SVC, ID уровня (в окружении масштабируемого кодирования, например, в SVC на основании AVC, ID уровня может быть равен dependency_id, умноженному на 16, плюс quality_id); или общий ID уровня (layer_id), например, значение reserved_one_5bits минус 1, причем reserved_one_5bits указана в базовой спецификации HEVC. Необходимо отметить, что общий ID уровня может применяться в смешанном 3DV (многовидовой с глубиной) и масштабируемом сценариях. Вышеуказанные примеры могут применяться к любому многоуровневому кодеку, включая масштабируемый видеокодек, с помощью, например, рассмотрения каждого уровня в качестве вида. Другими словами, для многовидового видеокодирования различные виды могут быть рассмотрены как отдельные уровни.
В некоторых сценариях базовый уровень или зависимый вид могут иметь много представлений, например, вследствие использования различных фильтров повышающей дискретизации/сглаживания, или вследствие факта использования изображения с синтезированным видом для прогнозирования; таким образом, в местоположении одного вида могут быть два изображения, готовых для использования, где одно является обычным восстановленным зависимым изображением вида, а другое является изображением с синтезированным видом, оба имеют одинаковый view_id или индекс порядка вида. В таком случае может быть использована идентификация изображения третьей размерности.
Видеокодер 20 и видеодекодер 30 также могут быть выполнены с возможностью идентифицировать опорное изображение из списка опорных изображений. Буфер (DPB) опорных изображений может быть организован в списки опорных изображений, например RefPicList0, который включает в себя потенциальные опорные изображения, имеющие значения РОС меньше, чем значение РОС текущего изображения, и RefPicList1, который включает в себя потенциальные опорные изображения, имеющие значения РОС больше, чем значение РОС текущего изображения. Способы идентификации опорного изображения из списка опорных изображений используются в качестве привязки для текущей базовой спецификации HEVC. Определенные функции могут быть использованы много раз видеокодером или видеодекодером во время AMVP и режима слияния.
Компонента вида, компонента вида текстуры, компонента вида глубины или масштабируемый уровень (например, с конкретной комбинацией dependency_id и quality_id) могут быть идентифицированы с помощью значения РОС и информации идентификации изображения второй размерности, которая может быть одной из следующих: индекс порядка вида в многовидовом или 3DV контексте. Функция viewOldx (pic) возвращает индекс порядка вида для вида, к которому принадлежит изображение, идентифицированное как «pic». Эта функция возвращает 0 для любой компоненты вида, компоненты вида текстуры или компоненты вида глубины базового вида; ID вида (view_id); в контексте 3DV, комбинацию индекса порядка вида и depth_flag (указывающую, является ли текущая компонента вида текстурой или глубиной): индекс порядка вида, умноженный на 2, плюс значение depth_flag; в контексте SVC, ID уровня (в окружении масштабируемого кодирования, например, SVC на основании AVC, ID уровня может быть равен dependency_id, умноженному на 16, плюс quality_id); или общему ID уровня (layer_id), например, значение reserved_one_5bits минус 1, причем reserved_one_5bits указан в базовой спецификации HEVC. Функция layerId (pic) возвращает layer_id изображения pic. LayerId (pic) возвращает 0 для любой компоненты вида (текстуры) базового вида. LayerId (pic) возвращает 0 для любого изображения (или представления уровня) базового уровня SVC. Необходимо отметить, что общий ID уровня может применяться в смешанном 3DV (многовидовой с глубиной) и масштабируемом сценариях.
В некоторых сценариях базовый уровень или зависимый вид могут иметь множество представлений, например, вследствие использования различных фильтров повышающей дискретизации/сглаживания, или вследствие факта использования изображения с синтезированным видом для прогнозирования; таким образом, в местоположении одного вида, могут быть два изображения, готовых для использования: одно является обычным восстановленным зависимым изображением вида, а другое является изображением с синтезированным видом, оба имеют одинаковый view_id или индекс порядка вида. В таком случае может быть использована идентификация изображения третьей размерности.
Одна или несколько из вышеупомянутых идентификаций изображений второй размерности и/или третьей размерности может быть определена с помощью функции AddPicId (pic).
Видеокодер 20 и видеодекодер 30 могут также быть выполнены с возможностью идентифицировать тип записи в списке опорных изображений. Это может быть использовано в качестве привязки для текущей базовой спецификации HEVC. Любая или все функции, определенные ниже, могут быть использованы много раз видеокодером 20 и/или видеодекодером 30 во время AMVP и/или режима слияния. Любой или все из следующих примеров способов могут быть использованы для идентификации типа записи в списке опорных изображений. В одном примере функция «RefPicType (pic)» возвращает 0, если изображение pic является временным опорным изображением, и возвращает 1, если изображение pic не является временным опорным изображением. В другом примере функция RefPicType (pic) возвращает 0, если изображение имеет тот же РОС, что и текущее изображение, и возвращает 1, если изображение имеет РОС, отличный от РОС текущего изображения.
В другом пример, результатов примеров, описанных выше, можно достичь с помощью замещения использования функции RefPicType (pic) просто на проверку того, равен ли РОС «pic» (аргумент функции) РОС текущего изображения. В некоторых примерах межвидовое опорное изображение может быть промаркировано как «неиспользуемое для ссылки». Межвидовое опорное изображение может быть промаркировано как «неиспользуемое для ссылки». Для упрощения такое изображение называется неопорным изображением в базовой спецификации HEVC. В некоторых примерах изображение, маркированное как «используемое для долгосрочной ссылки» или «используемое для краткосрочной ссылки», может называться опорным изображением в базовой спецификации HEVC. В некоторых примерах функция RefPicType (pic) возвращает 0, если изображение маркировано как «используемое для долгосрочной ссылки» или «используемое для краткосрочной ссылки», и возвращает 1, если изображение маркировано как «неиспользуемое для ссылки». Дополнительно в некоторых примерах, в расширении HEVC, компонента вида сразу после ее декодирования, может быть маркирована как «неиспользуемая для ссылки», независимо от значения синтаксического элемента nal_ref_flag.
После того как весь элемент доступа закодирован, компоненты вида элемента доступа могут быть маркированы как «используемые для краткосрочной ссылки» или «используемые для долгосрочной ссылки», если nal_ref_flag истинен. Альтернативно компонента вида может быть промаркирована только как «используемая для краткосрочной ссылки» либо «используемая для долгосрочной ссылки», если это включено в набор опорных изображений (RPS) последующей компоненты вида в порядке декодирования в том же виде, сразу после того, как извлечен RPS для последующей компоненты вида. Дополнительно в базовой спецификации HEVC текущее изображение сразу после его декодирования может быть маркировано как «неиспользуемое для ссылки».
В некоторых примерах RefPicType (picX, refIdx, LX) возвращает значение RefPicType (pic) в то время когда picX является текущим изображением, причем pic является опорным изображением с индексом refIdx из списка LX опорных изображений изображения picX.
По отношению к примеру, упоминаемому выше в качестве «четвертого примера», видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью разрешать прогнозирование между долгосрочными опорными изображениями без масштабирования во время AMVP и TMVP. По отношению к AMVP видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять модифицированный процесс извлечения кандидатов предиктора вектора движения (MVP). Вводы в процесс могут включать в себя местоположение (хР, уР) яркости, указывающее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения, переменные, указывающие ширину и высоту элемента прогнозирования для яркости, nPSW и nPSH, и опорный индекс refIdxLX (где Х равен 0 или 1) разделения текущего элемента прогнозирования. Выводы процесса могут включать в себя (где N замещен либо на А, либо на В, где А соответствует соседним кандидатам слева, а В соответствует соседним кандидатам сверху, как изображено в примере на Фиг. 10) векторы mvLXN движения соседних элементов прогнозирования и флаги availableFlagLXN доступности соседних элементов прогнозирования. Переменная isScaledFlagLX, где Х равен 0 или 1, может полагаться равной 1 или 0.
Видеокодер 20 и видеодекодер 30 могут извлекать вектор mvLXA движения и флаг availableFlagLXA доступности в следующем порядке этапов в одном примере, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Пусть набор из двух местоположений отсчета будет (xAk, yAk), где k=0, 1, указывающий местоположения отсчета, где xAk=xP-1, yAo=yP+nPSH и yA1=yA0 - MinPuSize. Набор местоположений отсчета (xAk, yAk) представляет собой местоположения отсчета непосредственно с левой стороны левой границы разделения и ее продленной линии.
2. Пусть флаг availableFlagLXA доступности будет первоначально полагаться равным 0, и обе компоненты mvLXA полагаться равными 0.
3. Когда одно или несколько из следующих условий истинно, переменная isScaledFlagLX полагается равной 1, в данном примере:
- Элемент прогнозирования, покрывающий местоположение (xA0, yA0) яркости доступен [Ed. (Ред.) (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA.
- Элемент прогнозирования, покрывающий местоположение (xA1, yA1) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA.
4. Для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0-MinPuSize, следующее применяется повторно до тех пор, пока availableFlagLXA не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и опорный индекс refIdxLX[xAk][yAk] равен опорному индексу refIdxLX текущего элемента прогнозирования, то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] (где Y=!X) равен 1, и PicOrderCnt(RefPicListY[refIdxLY[xAk][yAk]]) равен PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY, и mvLXA полагается равным mvLXA.
5. Когда availableFlagLXA равен 0, то для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0 - MinPuSize, следующее применяется повторно, пока availableFlagLXA не равен 1, в данном примере:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и RefPicListX[refIdxLX] и refPicListX[refIdxLX[xAk][yAk]] оба являются долгосрочными опорными изображениями или оба являются краткосрочными опорными изображениями, то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, и RefPicListX[refIdxLX] и RefPicListY[refIdxLY[xAk][yAk]] оба являются долгосрочными опорными изображениями или оба являются краткосрочными опорными изображениями, то availableFlagLXA полагается равным 1, а вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY.
- Когда availableFlagLXA равен 1, и оба RefPicListА[refIdxLА] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXA извлекают, как указано ниже (где обозначение 8-### относится к разделам текущей рабочей версии HEVC, то есть к WD7):
tx=(16384+(Abs(td)>>1))/td (8-126)
DistScaleFactor = Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127)
mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListA[refIdxA])) (8-129)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-130).
Видеокодер 20 и видеодекодер 30 могут выполнены с возможностью извлекать вектор mvLXB движения и флаг availableFlagLXB доступности в следующем порядке этапов в одном примере, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Пусть набор из трех местоположений отсчета будет (xВk, yВk), где k=0, 1, 2, указывающая местоположения отсчета, где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, хВ2=хP-MinPuSize и yВk=yР-1. Набор местоположений отсчета (xВk, yВk) представляет собой местоположения отсчета непосредственно с верхней стороны границы разделения сверху и ее продленной линии. [Ed. (BB): Определить MinPuSize в SPS, но извлечение должно зависеть от использования флага AMP].
2. Когда уР-1 меньше, чем ((yC>>Log2CtbSize)<<Log2CtbSize), то применяется следующее:
xB0=(xB0>>3)<<3)+((xB0>>3)&1)*7 (8-131)
xB1=(xB1>>3)<<3)+((xB1>>3)&1)*7 (8-132)
xB2=(xB2>>3)<<3)+((xB2>>3)&1)*7 (8-133).
3. Пусть флаг availableFlagLXВ доступности будет первоначально полагаться равным 0, и обе компоненты mvLXВ полагаться равными 0.
4. Для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где хВ0=xP+nPSW, xB1=xB0 - MinPuSize и xB2=xP - MinPuSize, то следующее применяется повторно до тех пор, пока availableFlagLXВ не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и опорный индекс refIdxLX[xВk][yВk] равен опорному индексу refIdxLX текущего элемента прогнозирования, то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и PicOrderCnt(RefPicListY[refIdxLY[xВk][yВk]]) равен PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
5. Когда isScaledFlagLX равен 0 и availableFlagLXB равен 1, то mvLXA полагается равным mvLXB, refIdxA полагается равным refIdxB, и availableFlagLXA полагается равным 1.
6. Когда isScaledFlagLX равен 0, то availableFlagLXB полагается равным 0 и для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где xВ0=xP+nPSW, xВ1 = xВ0 - MinPuSize, и xВ2=xP-MinPuSize, следующее применяется повторно, пока availableFlagLXВ не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и RefPicListX[refIdxLX] и RefPicListX[refIdxLX[xВk][yВk]] оба являются долгосрочными опорными изображениями или оба являются краткосрочными опорными изображениями, то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и RefPicListX[refIdxLX] и RefPicListY[refIdxLY[xВk][yВk]] оба являются долгосрочными опорными изображениями или оба являются краткосрочными опорными изображениями, то availableFlagLXВ полагается равным 1, а вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXВ равен 1, PicOrderCnt(RefPicListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]), и RefPicListВ[refIdxLВ] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXВ извлекают, как указано ниже (где обозначение 8-### относится к разделам текущей рабочей версии HEVC):
tx = (16384+(Abs(td)>>1))/td (8-134)
DistScaleFactor = Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135)
mvLXB = Clip3(-8192, 8191.75, Sign(DistScaleFactor * mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicList[refIdxB])) (8-137)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-138).
Видеокодер 20 и видеодекодер 30 могут также быть выполнены с возможностью выполнять модифицированный процесс извлечения для временного прогнозирования вектора движения (TMVP) для кодирования векторов движения блоков сигнала яркости. В одном примере вводы в этот процесс включают в себя местоположение (хР, уР) яркости, указывающее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения, переменные, указывающие ширину и высоту элемента прогнозирования для яркости, nPSW и nPSH, и опорный индекс разделения refIdxLX (где Х равен 0 или 1) текущего элемента прогнозирования. Выводы этого процесса могут включать в себя прогнозирование mvLXCol вектора движения и флаг availableFlagLXCol доступности.
В одном примере видеокодер 20 и видеодекодер 30 могут выполнять функцию RefPicOrderCnt(picX, refIdx, LX), которая возвращает счет PicOrderCntVal порядка изображения опорного изображения с индексом refIdx из списка LX опорных изображений изображения picХ. Эта функция может быть определена, как указано далее, где (8-141) и подобные ссылки в этом описании относятся к разделам HEVC WD7:
RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] изображения PicX) (8-141).
В зависимости от значений slice_type, collocated_from_10_flag и collocated_ref_idx, переменная colPic, определяющая изображение, которое содержит совмещенное разделение, может быть извлечена следующим образом:
- Если slice_type равен В и collocated_from_10_flag равен 0, то переменная colPic определяет изображение, которое содержит совмещенное разделение, как определено RefPicList1[collocated_ref_idx].
- Иначе, (slice_type равен В и collocated_from_10_flag равен 1 либо slice_type равен Р), переменная colPic определяет изображение, которое содержит совмещенное разделение, как указано RefPicList0 [collocated_ref_idx].
Переменная colPu и ее положение (xPCol, yPCol) могут быть извлечены с использованием следующего порядка этапов:
1. Переменная colPu может быть извлечена следующим образом:
yPRb=yP+nPSH (8-139)
- Если (yP>>Log2CtbSize) равна (yPRb>>Log2CtbSize), то горизонтальная компонента правого нижнего положения яркости текущего элемента прогнозирования определяется так:
xPRB=xP+nPSW (8-140)
и переменная colPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPRb>>4) <<4, (yPRb>>4) <<4) внутри colPic.
- Иначе, ((yP>>Log2CtbSize) не равен (yPRB>>Log2CtbSize)), colPu маркируется как «недоступная».
2. Когда colPU кодируется в режиме внутреннего прогнозирования, либо colPu промаркирована как «недоступная», то применяется следующее:
- Центральное положение яркости текущего элемента прогнозирования определяется так:
xPCtr=(xP+(nPSW>>1) (8-141)
yPCtr=(yP+(nPSH>>1) (8-142)
- Переменная ColPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPCtr>>4) <<4), (yPCtr>>4) <<4) внутри colPic.
(xPCol, yPCol) полагается равным верхнему левому отсчету яркости colPu относительно верхнего левого отсчета яркости colPic.
Функция LongTermRefPic (picX, refIdx, LX) может быть определена следующим образом. Если опорное изображение с индексом refIdx из списка LX опорных изображений изображения picX было промаркировано как «используемое для долгосрочной ссылки» в момент, когда picX было текущим изображением, то LongTermRefPic (picX, refIdx, LX) возвращает 1; иначе LongTermRefPic (picX, refIdx, LX) возвращает 0.
Переменные mvLXCol и availableFlagLXCol могут быть извлечены следующим образом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом:
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1 соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее:
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0 соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения.
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN соответственно, где N является значением collocated_from_10_flag.
- Если одно из следующих условий истинно, то переменная availableFlagLXCol полагается равной 0:
- RefPicListX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 0;
- RefPicListX[refIdxLX] является краткосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1;
- Иначе, переменная availableFlagLXCol полагается равной 1 и применяется следующее:
- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal - PicOrderCnt(RefPicListX[refIdxLX]), то
mvLXCol = mvCol (8-143).
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384+(Abs(td)>>1))/td (8-144)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol) * ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148).
В вышеуказанном примере доступность совмещенного блока, используемого во время TMVP, также может зависеть от типа опорного изображения (например, является ли изображение долгосрочным или краткосрочным опорным изображением) для совмещенного блока. То есть даже когда правый нижний блок для TMVP доступен (после этапа 1 в подпункте), то нижний правый блок может дополнительно полагаться недоступным, если вектор движения в блоке ссылается на тип изображения (краткосрочный или долгосрочный), который отличается от типа целевого опорного изображения. Подобным образом центральный блок может дополнительно быть использован для TMVP.
Например, видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать предиктор вектора движения для вектора движения яркости в соответствии со следующим подробным примером. Вводы в этот процесс, осуществляемые видеокодером 20 и видеодекодером 30, могут включать в себя:
- местоположение (xP, yP) яркости, определяющее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения,
- переменные, определяющие ширину и высоту элемента прогнозирования для яркости, nPSW и NPSH,
- опорный индекс разделения refIdxLX (где Х равен 0 или 1) текущего элемента прогнозирования.
Выводы из этого процесса могут включать в себя:
- прогнозирование mvLXCol вектора движения,
- флаг availableFlagLXCol доступности.
Функция RefPicOrderCnt(picX, refIdx, LX), при выполнении ее видеокодером 20 и/или видеодекодером 30 может возвращать счет PicOrderCntVal порядка изображения опорного изображения из списка LX опорных изображений изображения picX. Пример осуществления этой функции определен следующим образом:
RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] изображения picX) (8-141).
В зависимости от значений slice_type, collocated_from_10_flag и collocated_ref_idx, переменная colPic, определяющая изображение, которое содержит совмещенное разделение, может быть извлечена следующим образом:
- Если slice_type равен В и collocated_from_10_flag равен 0, то переменная colPic определяет изображение, которое содержит совмещенное разделение, как определено RefPicList1[collocated_ref_idx].
- Иначе, (slice_type равен В и collocated_from_10_flag равен 1 либо slice_type равен Р), переменная colPic определяет изображение, которое содержит совмещенное разделение, как указано RefPicList0 [collocated_ref_idx].
Видеокодер 20 и видеодекодер 30 могут извлекать переменную colPu и ее положение (xPCol, yPCol) с использованием следующего порядка этапов:
1. Видеокодер 20 и видеодекодер 30 могут извлекать переменную colPu следующим образом:
yPRb = yP + nPSH (8-139)
- Если (yP>>Log2CtbSize) равна (yPRb>>Log2CtbSize), то горизонтальная компонента правого нижнего положения яркости текущего элемента прогнозирования определяется так:
xPRB=xP+nPSW (8-140)
и переменная colPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPRb>>4)<<4, (yPRb>>4)<<4) внутри colPic.
- Иначе, ((yP>>Log2CtbSize) не равен (yPRb>>Log2CtbSize)), то видеокодер 20 и видеодекодер 30 могут маркировать colPu как «недоступная».
2. Когда colPU кодируется в режиме внутреннего прогнозирования, либо colPu промаркирована как «недоступная», то применяется следующее в данном примере:
- Центральное положение яркости текущего элемента прогнозирования определяется так:
xPCtr=(xP+(nPSW>>1) (8-141)
yPCtr=(yP+(nPSH>>1) (8-142)
- Переменная ColPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPCtr>>4)<<4), (yPCtr>>4)<<4) внутри colPic.
3. Видеокодер 20 и видеодекодер 30 могут устанавливать (xPCol, yPCol) равным верхнему левому отсчету яркости colPu относительно верхнего левого отсчета яркости colPic.
Функция LongTermRefPic (picX, refIdx, LX) может быть определена следующим образом:
Если опорное изображение с индексом refIdx из списка LX опорных изображений изображения picX было промаркировано как «используемое для долгосрочной ссылки» в момент, когда picX было текущим изображением, то LongTermRefPic (picX, refIdx, LX) возвращает 1; иначе, LongTermRefPic (picX, refIdx, LX) возвращает 0.
Видеокодер 20 и видеодекодер 30 могут извлекать переменные mvLXCol и availableFlagLXCol следующим образом:
availableFlagLXCol полагается равным 0, numTestBlock равен 0.
Если numTestBlock меньше, чем 2, и availableFlagLXCol равен 0, то выполняется следующий порядок:
xPCtr=(xP+(nPSW>>1)
yPCtr=(yP+(nPSH>>1)
- Если colPu покрывает положение, заданное ((xPCtr>>4)<<4, (yPCtr>>4)<<4) внутри colPic, то numTestBlock полагается равным 1.
- Иначе, если numTestBlock равен 1, то colPu полагается равным элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPCtr>>4)<<4, (yPCtr>>4)<<4) внутри colPic, и (xPCol, yPCol) полагается равным верхнему левому отсчету яркости colPu относительно верхнего левого отсчета яркости colPic.
- numTestBlock++
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом.
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1 соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее:
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0 соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения.
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN, соответственно, где N является значением collocated_from_10_flag.
- Если одно из следующих условий истинно, то переменная availableFlagLXCol полагается равной 0:
- RefPicListX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 0;
- RefPicListX[refIdxLX] является краткосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1;
- Иначе, переменная availableFlafLXCol полагается равной 1, и применяется следующее:- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX]), то
mvLXCol = mvCol (8-143).
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384+(Abs(td)>>1))/td (8-144)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148),
В альтернативном примере долгосрочный вектор движения никогда не прогнозируется из другого долгосрочного вектора движения, если значения РОС опорных изображений неодинаковы. Видеокодер 20 и видеодекодер 30 могут быть выполнены в соответствии со следующим процессом извлечения кандидатов предиктора вектора движения, где подчеркнутый текст представляет собой изменения относительно HEVC WD7.
Переменная isScaledFlagLX, где Х равен 0 или 1, может полагаться равной 0. Вектор mvLXA движения и флаг availableFlagLXA доступности извлекаются в следующем порядке этапов, где многоточия представляют собой тот же текст, что и в текущей рабочей версии HEVC, а подчеркивание представляет собой изменения относительно текущей рабочей версии HEVC:
1. …
2. …
3. …
4. …
5. Когда availableFlagLXA равен 0, для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0 - MinPuSize, следующее применяется повторно до тех пор, пока availableFlagLXA не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и RefPicListX[refIdxLX] и RefPicListX[refIdxLX[xAk][yAk]] оба являются долгосрочными опорными изображениями с различными значениями РОС или оба являются краткосрочными опорными изображениями, то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, и RefPicListX[refIdxLX] и RefPicListY[refIdxLY[xAk][yAk]] оба являются долгосрочными опорными изображениями с различными значениями РОС или оба являются краткосрочными опорными изображениями, то availableFlagLXA полагается равным 1, а вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY.
- Когда availableFlagLXA равен 1, и RefPicListА[refIdxLА] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXA извлекают, как указано ниже:
Тx=(16384+(Abs(td)>>1))/td (8-126)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127)
mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListA[refIdxA])) (8-129)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-130).
Видеокодер 20 и видеодекодер 30 могут извлекать вектор mvLXB движения и флаг availableFlagLXB доступности с использованием следующего порядка этапов, где многоточия представляют собой тот же текст, что и в HEVC WD7:
1. …
2. …
3. …
4. …
5. …
6. Когда isScaledFlagLX равен 0, то availableFlagLXB полагается равным 0 и для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, и xВ2=xP - MinPuSize, следующее применяется повторно, пока availableFlagLXВ не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и RefPicListX[refIdxLX] и RefPicListX[refIdxLX[xВk][yВk]] оба являются долгосрочными опорными изображениями с различными значениями РОС или оба являются краткосрочными опорными изображениями, то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и RefPicListX[refIdxLX] и RefPicListY[refIdxLY[xВk][yВk]] оба являются долгосрочными опорными изображениями с различными значениями РОС или оба являются краткосрочными опорными изображениями, то availableFlagLXВ полагается равным 1, а вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXВ равен 1, PicOrderCnt(RefPicListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]), и RefPicListВ[refIdxLВ] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXВ извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-134)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135)
mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicList[refIdxB])) (8-137)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-138).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать временные предикторы вектора движения яркости в соответствии со следующим процессом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7. Переменные mvLXCol и availableFlagLXCol могут быть извлечены следующим образом:
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом:
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1 соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее:
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0 соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения.
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN соответственно, где N является значением collocated_from_10_flag.
- Если одно из следующих условий истинно, то переменная availableFlagLXCol полагается равной 0:
- RefPicListX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 0.
- RefPicListX[refIdxLX] является краткосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1;
- RefPicListX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1, и RefPicOrderCnt(colPic, refIdxCol, listCol) не равна PicOrderCnt(RefPicListX[refIdxL]_.
- Иначе, переменная availableFlagLXCol полагается равной 1, и применяется следующее.
- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX]), то
mvLXCol=mvCol (8-143).
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384+(Abs(td)>>1))/td (8-144)
- DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148).
В другом примере межвидовое опорное изображение может быть маркировано как «неиспользуемое для ссылки». Для простоты такое изображение можно называть неопорное изображение в базовой спецификации HEVC, и изображение, маркированное как «используемое для долгосрочной ссылки» или «используемое для краткосрочной ссылки», можно называть опорным изображением в базовой спецификации HEVC. Термины «опорное изображение» и «неопорное изображение» можно заменить на «изображение, маркированное как «используемое для ссылки» и «изображение, маркированное как «неиспользуемое для ссылки».
Функцию UnusedRefPic(picX, refIdx, LX) можно определить следующим образом. Если опорное изображение с индексом refIdx из списка LX опорных изображений изображения picX было маркировано как «неиспользуемое для ссылки» в момент, когда picX было текущим изображением, то UnusedRefPic(picX, refIdx, LX) возвращает 1; иначе, UnusedRefPic(picX, refIdx, LX) возвращает 0.
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять процесс извлечения кандидатов предиктора вектора движения следующим образом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7, а многоточия представляют собой тот же текст, что и в HEVC WD7:
Переменная isScaledFlagLX, где Х равен 0 или 1, может полагаться равной 1 или 0.
Вектор mvLXA движения и флаг availableFlagLXA доступности могут быть извлечены в следующем порядке этапов:
1. …
2. …
3. …
4. …
5. Когда availableFlagLXA равен 0, то для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0 - MinPuSize, следующее применяется повторно, пока availableFlagLXA не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и RefPicListX[refIdxLX] и RefPicListX[refIdxLX[xAk][yAk]] оба являются опорными изображениями или оба являются неопорными изображениями, то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, и RefPicListX[refIdxLX] и RefPicListY[refIdxLY[xAk][yAk]] оба являются опорными изображениями или оба являются неопорными изображениями, то availableFlagLXA полагается равным 1, а вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY.
- Когда availableFlagLXA равен 1, и RefPicListА[refIdxLА] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXA извлекают, как указано ниже:
Tx=(16384+(Abs(td)>>1))/td (8-126)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127)
mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListA[refIdxA])) (8-129)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-130).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать вектор mvLXB движения и флаг availableFlagLXB доступности с использованием следующего порядка этапов, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. …
2. …
3. …
4. …
5. …
6. Когда isScaledFlagLX равен 0, то availableFlagLXB полагается равным 0 и для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, и xВ2=xP - MinPuSize, следующее применяется повторно, пока availableFlagLXВ не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и RefPicListX[refIdxLX] и RefPicListX[refIdxLX[xВk][yВk]] оба являются опорными изображениями или оба являются неопорными изображениями, то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и RefPicListX[refIdxLX] и RefPicListY[refIdxLY[xВk][yВk]] оба являются опорными изображениями или оба являются неопорными изображениями, то availableFlagLXВ полагается равным 1, а вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXВ равен 1, PicOrderCnt(RefPicListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]), и RefPicListВ[refIdxLВ] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXВ извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-134)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135)
mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicList[refIdxB])) (8-137)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-138).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать временные предикторы вектора движения яркости следующим образом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
Переменные mvLXCol и availableFlagLXCol могут быть извлечены следующим образом.
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом.
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1 соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее.
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0 соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения:
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений, больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN соответственно, где N является значением collocated_from_10_flag.
- Если одно из следующих условий истинно, то переменная availableFlagLXCol полагается равной 0:
- RefPicListX[refIdxLX] является неопорным изображением, и UnusedRefPic(colPic, refIdxCol, listCol) равна 0;
- RefPicListX[refIdxLX] является опорным изображением, и UnusedRefPic(colPic, refIdxCol, listCol) равна 1;
- Иначе, переменная availableFlagLXCol полагается равной 1, и применяется следующее:
- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX]), то
mvLXCol = mvCol (8-143).
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384+(Abs(td)>>1))/td (8-144)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td = Clip3(-128, 127, PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148).
По отношению к примеру, называемому выше «пятым примером», видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять любой или все из следующих способов. В данном примере прогнозирование между векторами движения, ссылающимися на различные долгосрочные опорные изображения, может быть запрещено, прогнозирование между векторами движения, ссылающимися на различные межвидовые опорные изображения, может быть запрещено, и прогнозирование между векторами движения, ссылающимися на межвидовое опорное изображение и долгосрочное опорное изображение, может быть запрещено.
В данном примере функция AddPicId(pic) возвращает индекс порядка вида или ID уровня вида, или уровень, которому принадлежит изображение pic. Таким образом, для любого изображения «pic», принадлежащего базовому виду или уровню, AddPicId(pic) возвращает 0. В базовой спецификации HEVC может применяться следующее: функция AddPicId(pic) может быть определена следующим образом: AddPicId(pic) возвращает 0 (или reserved_one_5bits минус 1). В данном примере, когда AddPicId(pic) не равна 0, то изображение pic не является временным опорным изображением (то есть ни краткосрочным опорным изображением, ни долгосрочным опорным изображением). AddPicId(picX, refIdx, LX) может возвращать AddPicId(pic), причем pic является опорным изображением с индексом refIdx из списка LX опорных изображений изображения picX.
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять процесс извлечения кандидатов предиктора вектора движения. Вводы в процесс могут включать в себя местоположение (хР, уР) яркости, указывающее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения, переменные, указывающие ширину и высоту элемента прогнозирования для яркости, nPSW и nPSH, и опорный индекс refIdxLX (где Х равен 0 или 1) разделения текущего элемента прогнозирования. Выводы этого процесса могут включать в себя (где N замещен либо на А, либо на В): векторы mvLXN движения соседних элементов прогнозирования и флаги availableFlagLXN доступности соседних элементов прогнозирования.
Переменная isScaledFlagLX, где Х равен 0 или 1, может полагаться равной 1 или 0. Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать вектор mvLXA движения и флаг availableFlagLXA доступности с использованием следующего порядка этапов, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Пусть набор из двух местоположений отсчета будет (xAk, yAk), где k=0, 1, указывающий местоположения отсчета, где xAk=xP-1, yAo=yP+nPSH и yA1=yA0 - MinPuSize. Набор местоположений отсчета (xAk, yAk) представляет собой местоположения отсчета непосредственно с левой стороны левой границы разделения и ее продленной линии.
2. Пусть флаг availableFlagLXA доступности будет первоначально полагаться равным 0, и обе компоненты mvLXA полагаться равными 0.
3. Когда одно или несколько из следующих условий истинно, переменная isScaledFlagLX полагается равной 1.
- элемент прогнозирования, покрывающий местоположение (xA0, yA0) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA.
- элемент прогнозирования, покрывающий местоположение (xA1, yA1) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA.
4. Для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0- MinPuSize, если availableFlagLXA равен 0, то применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и опорный индекс refIdxLX[xAk][yAk] равен опорному индексу refIdxLX текущего элемента прогнозирования, то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, AddPicId(RefPicListX[refIdxLX]) равна AddPicId(RefPicListY[refIdxLY[xAk][yAk]]), и PicOrderCnt(RefPicListY[refIdxLY[xAk][yAk]]) равен PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY, и mvLXA полагается равным mvLXA.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если одно или несколько из следующих истинно:
- Одно и только одно из RefPicListX[refIdxLX] и ListA[refIdxA] является долгосрочным опорным изображением;
- Оба RefPicListX[refIdxLX] и ListA[refIdxA] являются долгосрочными опорными изображениями, и PicOrderCnt(ListA[refIdxA]) не равна PicOrderCnt(RefPicListX[refIdxLX]).
5. Когда availableFlagLXA равен 0, то для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0 - MinPuSize, если availableFlagLXA равен 0, применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и AddPicId(RefPicListLX[refIdxLX]) равен AddPicId(RefPicListLX[refIdxLX[xAk][yAk]]), то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, и AddPicId(RefPicListLX[refIdxLX]) равен AddPicId(RefPicListLY[refIdxLY[xAk][yAk]]), то availableFlagLXA полагается равным 1, а вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если одно или несколько из следующих истинно:
- Одно и только одно из RefPicListX[refIdxLX] и ListA[refIdxA] является долгосрочным опорным изображением;
- Оба RefPicListX[refIdxLX] и ListA[refIdxA] являются долгосрочными опорными изображениями, и PicOrderCnt(ListA[refIdxA]) не равна PicOrderCnt(RefPicListX[refIdxLX]).
- Когда availableFlagLXA равен 1, и оба RefPicListА[refIdxLА] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXA извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-126)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127)
mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListA[refIdxA])) (8-129)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-130).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать вектор mvLXB движения и флаг availableFlagLXB доступности с использованием следующего порядка этапов, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Пусть набор из трех местоположений отсчета будет (xВk, yВk), где k=0, 1, 2, указывающая местоположения отсчета, где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, хВ2=хP - MinPuSize и yВk=yР-1. Набор местоположений отсчета (xВk, yВk) представляет собой местоположения отсчета непосредственно с верхней стороны границы разделения сверху и ее продленной линии. [Ed. (BB): Определить MinPuSize в SPS, но извлечение должно зависеть от использования флага AMP].
2. Когда уР-1 меньше, чем ((yC>>Log2CtbSize)<<Log2CtbSize), то применяется следующее:
xB0=(xB0>>3)<<3)+((xB0>>3)&1)*7 (8-131)
xB1=(xB1>>3)<<3)+((xB1>>3)&1)*7 (8-132)
xB2=(xB2>>3)<<3)+((xB2>>3)&1)*7 (8-133).
3. Пусть флаг availableFlagLXВ доступности будет первоначально полагаться равным 0, и обе компоненты mvLXВ полагаться равными 0.
4. Для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где хВ0=xP+nPSW, xB1=xB0 - MinPuSize и xB2=xP - MinPuSize, если availableFlagLXВ равен 0, то применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и опорный индекс refIdxLX[xВk][yВk] равен опорному индексу refIdxLX текущего элемента прогнозирования, то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, AddPicId(RefPicListX[refIdxLX]) равен AddPicId(RefPicListLY[refIdxY[xВk][yВk]]), и PicOrderCnt(RefPicListY[refIdxLY[xВk][yВk]]) равен PicOrderCnt(RefPicListX[refIdxLX]), то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если одно или несколько из следующих истинно:
- Один и только один из RefPicListX[refIdxLX] и ListB[refIdxB] является долгосрочным опорным изображением.
- AddPicId(RefPicListX[refIdxLX]) не равен AddPicId(ListB[refIdxB]).
- Оба RefPicListX[redIdxLX] и ListB[refIdxB] являются долгосрочными опорными изображениями, и PicOrderCnt(ListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]).
5. Когда isScaledFlagLX равен 0 и availableFalgLXB равен 1, то mvLXA полагается равным mvLXB, refIdxA полагается равным refIdxB, и availableFlagLXA полагается равным 1.
6. Когда isScaledFlagLX равен 0, то availableFlagLXB полагается равным 0 и для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, и xВ2=xP - MinPuSize, если availableFlagLXВ равен 0, то применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и AddPicId(RefPicListX[refIdxLX]) равен AddPicId(RefPicListX[refIdxLX[xВk][yВk]]), то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и AddPicId(RefPicListX[refIdxLX]) равен AddPicId(RefPicListY[refIdxLY[xВk][yВk]]), то availableFlagLXВ полагается равным 1, а вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если одно или несколько из следующих истинно:
- Один и только один из RefPicListX[refIdxLX] и ListB[refIdxB] является долгосрочным опорным изображением.
- Оба RefPicListX[refIdxLX] и ListB[refIdxB] являются долгосрочными опорными изображениями, и PicOrderCnt(ListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]).
- Когда availableFlagLXВ равен 1, PicOrderCnt(RefPicListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]), и RefPicListВ[refIdxLВ] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXВ извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-134)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135)
mvLXB = Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicList[refIdxB])) (8-137)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-138).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать временные предикторы вектора движения. Вводы в этот процесс могут включать в себя местоположение (хР, уР) яркости, указывающее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения, переменные, указывающие ширину и высоту элемента прогнозирования для яркости, nPSW и nPSH, и опорный индекс разделения refIdxLX (где Х равен 0 или 1) текущего элемента прогнозирования. Выводы этого процесса могут включать в себя прогнозирование mvLXCol вектора движения и флаг availableFlagLXCol доступности.
Функция RefPicOrderCnt(picX, refIdx, LX), которая может возвращать счет PicOrderCntVal порядка изображения опорного изображения с индексом refIdx из списка LX опорных изображений изображения picХ, может быть определена следующим образом:
RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] изображения PicX) (8-141).
В зависимости от значений slice_type, collocated_from_10_flag и collocated_ref_idx, видеокодер 20 и видеодекодер 30 могут извлекать переменную colPic, определяющую изображение, которое содержит совмещенное разделение, следующим образом:
- Если slice_type равен В и collocated_from_10_flag равен 0, то переменная colPic определяет изображение, которое содержит совмещенное разделение, как определено RefPicList1[collocated_ref_idx].
- Иначе, (slice_type равен В и collocated_from_10_flag равен 1 либо slice_type равен Р), переменная colPic определяет изображение, которое содержит совмещенное разделение, как указано RefPicList0 [collocated_ref_idx].
Видеокодер 20 и видеодекодер 30 могут извлекать переменную colPu и ее положение (xPCol, yPCol) с использованием следующего порядка этапов, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Переменная colPu может быть извлечена следующим образом
yPRb=yP+nPSH (8-139)
- Если (yP>>Log2CtbSize) равна (yPRb>>Log2CtbSize), то горизонтальная компонента правого нижнего положения яркости текущего элемента прогнозирования определяется так:
xPRB=xP+nPSW (8-140)
и переменная colPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPRb>>4)<<4, (yPRb>>4)<<4) внутри colPic.
- Иначе, ((yP>>Log2CtbSize) не равен (yPRB>>Log2CtbSize)), colPu маркируется как «недоступная».
2. Когда colPU кодируется в режиме внутреннего прогнозирования, либо colPu промаркирована как «недоступная», то применяется следующее:
- Центральное положение яркости текущего элемента прогнозирования определяется так:
xPCtr=(xP+(nPSW>>1) (8-141)
yPCtr=(yP+(nPSH>>1) (8-142)
- Переменная ColPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPCtr>>4)<<4), (yPCtr>>4)<< 4) внутри colPic.
3. (xPCol, yPCol) полагается равным верхнему левому отсчету яркости colPu относительно верхнего левого отсчета яркости colPic.
Функция LongTermRefPic (picX, refIdx, LX) определена следующим образом. Если опорное изображение с индексом refIdx из списка LX опорных изображений изображения picX было промаркировано как «используемое для долгосрочной ссылки» в момент, когда picX было текущим изображением, то LongTermRefPic (picX, refIdx, LX) возвращает 1; иначе, LongTermRefPic (picX, refIdx, LX) возвращает 0.
Функция AddPicId(picX, refIdx, LX) возвращает AddPicId(pic), причем pic является опорным изобржанием с индексом refIdx из списка LX опорных изображений изображения picX.
Переменные mvLXCol и availableFlagLXCol извлечены следующим образом.
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом:
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1 соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее.
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0 соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения.
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений, больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN соответственно, где N является значением collocated_from_10_flag.
- Если одно из следующих условий истинно, то переменная availableFlagLXCol полагается равной 0.
- AddPicId(RefPicListX[refIdxLX]) не равна AddPicId(colPic, refIdxCol, listCol);
- RefPicListX[refIdxLX] является краткосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1;
- RefPicListX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 0;
- RefPicListLX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1, и RefPicOrderCnt(colPic, refIdxCol, listCol) не равен PicOrderCnt(RefPicListX[refIdxLX]).
- Иначе, переменная availableFlagLXCol полагается равной 1, и применяется следующее:
- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX]), то:
mvLXCol = mvCol (8-143)
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384 +(Abs(td)>>1))/td (8-144)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol = Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять следующий процесс извлечения комбинированных би-прогнозирующих кандидатов слияния. Вводы в этот процесс могут включать в себя список mergeCandList кандидатов слияния, опорные индексы refIdxL0N и refIdxL1N каждого кандидата N, находящегося в mergeCandList, флаги predFlagL0N и predFlagL1N использования списка прогнозирования каждого кандидата N, находящегося в mergeCandList, векторы mvL0N и mvL1N движения каждого кандидата N, находящегося в mergeCandList, число элементов numMergeCand внутри mergeCandList, и число элементов numOrigMergeCand внутри mergeCandList после процесса извлечения пространственных и временных кандидатов слияния. Выводы этого процесса могут включать в себя список mergeCandList кандидатов слияния, число элементов numMergeCand внутри mergeCandList, индексы refIdxL0combCandk и refIdxL1combCandk каждого нового кандидата combCandk, добавленного в mergeCandList во время вызова этого процесса, флаги predFlagL0combCandk и predFalgL1combCandk использования списка прогнозирования каждого нового кандидата combCandk, добавляемого в mergeCandList во время вызова этого процесса, и векторы mvL0combCandk и mvL1combCandk движения каждого нового кандидата combCandk, добавляемого в mergeCandList во время вызова этого процесса.
Когда numOrigMergeCand больше, чем 1, и меньше, чем MaxNumMergeCand, то переменная numInputMergeCand может полагаться равной numMergeCand, переменные combIdx и combCnt могут полагаться равными 0, переменная combStop может полагаться равной FALSE (ЛОЖЬ), и последующие этапы могут повторяться до тех пор, пока combStop не равен TRUE (ИСТИНА) (где многоточия представляют собой те же этапы, что и в HEVC WD7, а подчеркнутый текст представляет собой изменения относительно HEVC WD7):
1. Переменные 10CandIdx и 11CandIdx извлекают с использованием combIdx, как указано в Таблице 8-8.
2. Следующие назначения делаются, когда 10Cand является кандидатом в положении 10CandIdx, а 11Cand является кандидатом в положении 11CandIdx в списке mergeCandList кандидатов слияния (10Cand = mergeCandList[10CandIdx], 11Cand = mergeCandList[11CandIdx]).
3. Когда все из следующих условий истинны,
- predFlagL010Cand = = 1
- predFlagL111Cand = = 1
- AddPicId(RefPicListL0[refIdxL010Cand]) != AddPicId(RefPicListL1[refIdxL111Cand]) || PicOrderCnt(RefPicList0[refIdxL010Cand]) != PicOrderCnt(RefPicList) [refIdxL111Cand]) || mvL010Cand != mvL111Cand
то применяется следующее:
- …
4. …
5. …
В качестве альтернативыпрогнозирование между двумя долгосрочными опорными изображениями может быть разрешено без масштабирования, и прогнозирование между двумя межвидовыми опорными изображениями может быть разрешено без масштабирования. Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять процесс извлечения кандидатов предиктора вектора движения следующим образом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7, а многоточия представляют собой тот же текст, что и в HEVC WD7:
Переменная isScaledFlagLX, где Х равен 0 или 1, может полагаться равной 0.
Вектор mvLXA движения и флаг availableFlagLXA доступности могут быть извлечены в следующем порядке этапов:
1. …
2. …
3. …
4. …
5. Когда availableFlagLXA равен 0, то для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0 - MinPuSize, следующее применяется повторно, пока availableFlagLXA не равен 1, в данном примере:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и RefPicType(RefPicListX[refIdxLX]) равен RefPicType(RefPicListX[refIdxLX[xAk][yAk]]), то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, и RefPicType(RefPicListX[refIdxLX]) равен RefPicType(RefPicListY[refIdxLY[xAk][yAk]]), то availableFlagLXA полагается равным 1, а вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY.
- Когда availableFlagLXA равен 1, и RefPicListА[refIdxLА] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXA извлекают, как указано ниже:
Тx=(16384+(Abs(td)>>1))/td (8-126)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127)
mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListA[refIdxA])) (8-129)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-130).
Видеокодер 20 и видеодекодер 30 могут извлекать вектор mvLXB движения и флаг availableFlagLXB доступности с использованием следующего порядка этапов, где подчеркнутый текст представляет собой изменения относительно HEVC WD7, а многоточия представляют собой тот же текст, что в HEVC WD7:
1. …
2. …
3. …
4. …
5. …
6. Когда isScaledFlagLX равен 0, то availableFlagLXB полагается равным 0 и для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, и xВ2=xP - MinPuSize, то следующее применяется повторно, пока availableFlagLXВ не равен 1:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и RefPicType(RefPicListX[refIdxLX]) равен RefPicType(RefPicListX[refIdxLX[xВk][yВk]]), то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и RefPicType(RefPicListX[refIdxLX]) равен RefPicType(RefPicListY[refIdxLY[xВk][yВk]]), то availableFlagLXВ полагается равным 1, а вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXВ равен 1, PicOrderCnt(RefPicListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]), и оба RefPicListВ[refIdxLВ] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXВ извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-134)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135)
mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicList[refIdxB])) (8-137)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-138).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять процесс извлечения временного прогнозирования вектора движения яркости следующим образом.
Переменные mvLXCol и availableFlagLXCol могут быть извлечены следующим образом:
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом:
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1 соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее.
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0 соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения.
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений, больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN соответственно, где N является значением collocated_from_10_flag.
- Если RefPicType(RefPicListX[refIdxLX]) не равен RefPicType(colPic, refIdxCol, listCol), то переменная availableFlagLXCol полагается равной 0.
- Иначе, переменная availableFlagLXCol полагается равной 1, и применяется следующее.
- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX]), то:
mvLXCol=mvCol (8-143).
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384 +(Abs(td)>>1))/td (8-144)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol = Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148).
Раздел 8.5.2.1.3 HEVC WD7 может оставаться тем же для целей данного примера.
В альтернативном примере, прогнозирование между векторами движения, ссылающимися на различные долгосрочные опорные изображения, может быть запрещено, прогнозирование между векторами движения, ссылающимися на межвидовое опорное изображение и долгосрочное опорное изображение, может бытьзапрещено, и прогнозирование между векторами движения, ссылающимися на различные межвидовые опорные изображения, может быть разрешено. В данном примере видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять процесс извлечения кандидатов предиктора вектора движения, как описано ниже. Вводы в процесс могут включать в себя местоположение (хР, уР) яркости, указывающее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения, переменные, указывающие ширину и высоту элемента прогнозирования для яркости, nPSW и nPSH, и опорный индекс refIdxLX (где Х равен 0 или 1) разделения текущего элемента прогнозирования. Выводы процесса могут включать в себя (где N замещен либо на А, либо на В) векторы mvLXN движения соседних элементов прогнозирования и флаги availableFlagLXN доступности соседних элементов прогнозирования.
Переменная isScaledFlagLX, где Х равен 0 или 1, может полагаться равной 1 или 0. Видеокодер 20 и видеодекодер 30 могут извлекать вектор mvLXA движения и флаг availableFlagLXA доступности с использованием следующего порядка, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Пусть набор из двух местоположений отсчета будет (xAk, yAk), где k=0, 1, указывающий местоположения отсчета, где xAk=xP-1, yAo=yP+nPSH и yA1=yA0 - MinPuSize. Набор местоположений отсчета (xAk, yAk) представляет собой местоположения отсчета непосредственно с левой стороны левой границы разделения и ее продленной линии.
2. Пусть флаг availableFlagLXA доступности будет первоначально полагаться равным 0, и обе компоненты mvLXA полагаться равными 0.
3. Когда одно или несколько из следующих условий истинно, переменная isScaledFlagLX полагается равной 1.
- элемент прогнозирования, покрывающий местоположение (xA0, yA0) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA.
- элемент прогнозирования, покрывающий местоположение (xA1, yA1) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA.
4. Для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0-MinPuSize, если availableFlagLXA равен 0, то применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и опорный индекс refIdxLX[xAk][yAk] равен опорному индексу refIdxLX текущего элемента прогнозирования, то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, AddPicId(RefPicListX[refIdxLХ]) равен AddPicId(RefPicListY[refIdxLY[xAk][yAk]]), и PicOrderCnt(RefPicListY[refIdxLY[xAk][yAk]]) равен PicOrderCnt(RefPicListX[refIdxLX]), то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY, и mvLXA полагается равным mvLXA.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если верно следующее:
- Одно и только одно из RefPicListX[refIdxLX] и ListA[refIdxA] является долгосрочным опорным изображением.
5. Когда availableFlagLXA равен 0, то для (xAk, yAk) от (xA0, yA0) до (xA1, yA1), где yA1=yA0 - MinPuSize, если availableFlagLXA равен 0, применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xAk][yAk] равен 1, и AddPicId(RefPicListLX[refIdxLX]) равен AddPicId(RefPicListLX[refIdxLX[xAk][yAk]]), то availableFlagLXA полагается равным 1, вектор mvLXA движения полагается равным вектору mvLX[xAk][yAk] движения, refIdxA полагается равным refIdxLX[xAk][yAk], а ListA полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xAk, yAk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (где Y=!X) равен 1, и AddPicId(RefPicListLX[refIdxLX]) равен AddPicId(RefPicListLY[refIdxLY[xAk][yAk]]), то availableFlagLXA полагается равным 1, а вектор mvLXA движения полагается равным вектору mvLY[xAk][yAk] движения, refIdxA полагается равным refIdxLY[xAk][yAk], а ListA полагается равным ListY.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если верно следующее:
- Одно и только одно из RefPicListX[refIdxLX] и ListA[refIdxA] является долгосрочным опорным изображением.
- Когда availableFlagLXA равен 1, и оба RefPicListА[refIdxLА] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXA извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-126)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127)
mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListA[refIdxA])) (8-129)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-130).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью извлекать вектор mvLXB движения и флаг availableFlagLXB доступности с использованием следующего порядка этапов, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
1. Пусть набор из трех местоположений отсчета будет (xВk, yВk), где k=0, 1, 2, указывающая местоположения отсчета, где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, хВ2=хP-MinPuSize и yВk=yР-1. Набор местоположений отсчета (xВk, yВk) представляет собой местоположения отсчета непосредственно с верхней стороны границы разделения сверху и ее продленной линии. [Ed. (BB): Определить MinPuSize в SPS, но извлечение должно зависеть от использования флага AMP].
2. Когда уР-1 меньше, чем ((yC>>Log2CtbSize)<<Log2CtbSize), то применяется следующее:
xB0=(xB0>>3)<<3)+((xB0>>3)&1)*7 (8-131)
xB1=(xB1>>3)<<3)+((xB1>>3)&1)*7 (8-132)
xB2=(xB2>>3)<<3)+((xB2>>3)&1)*7 (8-133).
3. Пусть флаг availableFlagLXВ доступности будет первоначально полагаться равным 0, и обе компоненты mvLXВ полагаться равными 0.
4. Для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где хВ0=xP+nPSW, xB1=xB0 - MinPuSize и xB2=xP - MinPuSize, если availableFlagLXВ равен 0, то применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и опорный индекс refIdxLX[xВk][yВk] равен опорному индексу refIdxLX текущего элемента прогнозирования, то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, AddPicId(RefPicListX[refIdxLX]) равен AddPicId(RefPicListLY[refIdxY[xВk][yВk]]), и PicOrderCnt(RefPicListY[refIdxLY[xВk][yВk]]) равен PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXB равен 1, то availableFlagLXB полагается равным 0, если верно следующее:
- Одно и только одно из RefPicListX[refIdxLX] и ListB[refIdxB] является долгосрочным опорным изображением.
5. Когда isScaledFlagLX равен 0 и availableFlagLXB равен 1, то mvLXA полагается равным mvLXB, refIdxA полагается равным refIdxB, и availableFlagLXA полагается равным 1.
6. Когда isScaledFlagLX равен 0, то availableFlagLXB полагается равным 0 и для (xВk, yВk) от (xВ0, yВ0) до (xВ2, yВ2), где xВ0=xP+nPSW, xВ1=xВ0 - MinPuSize, и xВ2=xP - MinPuSize, если availableFlagLXВ равен 0, то применяется следующее:
- Если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLX[xВk][yВk] равен 1, и AddPicId(RefPicListX[refIdxLX]) равен AddPicId(RefPicListX[refIdxLX[xВk][yВk]]), то availableFlagLXВ полагается равным 1, вектор mvLXВ движения полагается равным вектору mvLX[xВk][yВk] движения, refIdxВ полагается равным refIdxLX[xВk][yВk], а ListВ полагается равным ListX.
- Иначе, если элемент прогнозирования, покрывающий местоположение (xВk, yВk) яркости доступен [Ed. (BB): Переписать с использованием MinCbAddrZS[][] и процесса доступности для минимальных блоков кодирования], и PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (где Y=!X) равен 1, и AddPicId(RefPicListX[refIdxLX]) равен AddPicId(RefPicListY[refIdxLY[xВk][yВk]]), то availableFlagLXВ полагается равным 1, а вектор mvLXВ движения полагается равным вектору mvLY[xВk][yВk] движения, refIdxВ полагается равным refIdxLY[xВk][yВk], а ListВ полагается равным ListY.
- Когда availableFlagLXA равен 1, то availableFlagLXA полагается равным 0, если верно следующее:
- Одно и только одно из RefPicListX[refIdxLX] и ListB[refIdxB] является долгосрочным опорным изображением.
- Когда availableFlagLXВ равен 1, PicOrderCnt(RefPicListB[refIdxB]) не равен PicOrderCnt(RefPicListX[refIdxLX]), и оба RefPicListВ[refIdxLВ] и RefPicListX[refIdxLX] оба являются краткосрочными опорными изображениями, то mvLXВ извлекают, как указано ниже:
tx=(16384+(Abs(td)>>1))/td (8-134)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135)
mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicList[refIdxB])) (8-137)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-138).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью осуществлять процесс извлечения временного прогнозирования вектора движения яркости, как описано ниже. Вводы в процесс могут включать в себя местоположение (хР, уР) яркости, указывающее верхний левый отсчет яркости текущего элемента прогнозирования относительно верхнего левого отсчета текущего изображения, переменные, указывающие ширину и высоту элемента прогнозирования для яркости, nPSW и nPSH, и опорный индекс refIdxLX (где Х равен 0 или 1) разделения текущего элемента прогнозирования. Выводы процесса могут включать в себя вектор mvLXCol движения и флаг availableFlagLXCol доступности.
Функция RefPicOrderCnt(picX, refIdx, LX), в одном примере, возвращает счет PicOrderCntVal порядка изображения опорного изображения с индексом refIdx из списка LX опорных изображений изображения picХ и может быть определена следующим образом:
RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] изображения PicX) (8-141).
В зависимости от значений slice_type, collocated_from_10_flag и collocated_ref_idx, видеокодер 20 и видеодекодер 30 могут извлекать переменную colPic, определяющую изображение, которое содержит совмещенное разделение, следующим образом:
- Если slice_type равен В и collocated_from_10_flag равен 0, то переменная colPic определяет изображение, которое содержит совмещенное разделение, как определено RefPicList1[collocated_ref_idx].
- Иначе, (slice_type равен В и collocated_from_10_flag равен 1 либо slice_type равен Р), переменная colPic определяет изображение, которое содержит совмещенное разделение, как указано RefPicList0 [collocated_ref_idx].
Видеокодер 20 и видеодекодер 30 могут извлекать переменную colPu и ее положение (xPCol, yPCol) с использованием следующего порядка этапов:
1. Переменная colPu извлекается следующим образом:
yPRb=yP+nPSH (8-139).
- Если (yP>>Log2CtbSize) равна (yPRb>>Log2CtbSize), то горизонтальная компонента правого нижнего положения яркости текущего элемента прогнозирования определяется так:
xPRB=xP+nPSW (8-140)
и переменная colPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPRb>>4)<<4, (yPRb>>4)<<4) внутри colPic.
- Иначе, ((yP>>Log2CtbSize) не равен (yPRB>>Log2CtbSize)), colPu маркируется как «недоступная».
2. Когда colPU кодируется в режиме внутреннего прогнозирования либо colPu промаркирована как «недоступная», то применяется следующее:
- Центральное положение яркости текущего элемента прогнозирования определяется так:
xPCtr=(xP+(nPSW>>1) (8-141)
yPCtr=(yP+(nPSH>>1) (8-142).
- Переменная ColPu полагается равной элементу прогнозирования, покрывающему модифицированное положение, заданное ((xPCtr>>4)<<4), (yPCtr>>4)<<4) внутри colPic.
3. (xPCol, yPCol) полагается равным верхнему левому отсчету яркости colPu относительно верхнего левого отсчета яркости colPic.
Функция LongTermRefPic (picX, refIdx, LX) может быть определена следующим образом: если опорное изображение с индексом refIdx из списка LX опорных изображений изображения picX было промаркировано как «используемое для долгосрочной ссылки» в момент, когда picX было текущим изображением, то LongTermRefPic (picX, refIdx, LX) возвращает 1; иначе, LongTermRefPic (picX, refIdx, LX) возвращает 0.
Видеокодер 20 и видеодекодер 30 могут осуществлять модифицированную версию функции «AddPicId()» HEVC. Например, видеокодер 20 и видеодекодер 30 могут осуществлять AddPicId(picX, refIdx, LX), так что эта функция возвращает AddPicId(pic), причем «pic» является опорным изображением с индексом refIdx из списка LX опорных изображений изображения picX.
Видеокодер 20 и видеодекодер 30 могут извлекать переменные mvLXCol и availableFlagLXCol следующим образом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7:
- Если одно или несколько следующих условий истинно, то обе компоненты mvLXCol полагаются равными 0, и availableFlagLXCol полагается равным 0.
- colPU кодируется в режиме внутреннего прогнозирования.
- colPu промаркирована как «недоступная».
- pic_temporal_mvp_enable_flag равен 0.
- Иначе, вектор mvCol движения, опорный индекс refIdxCol и идентификатор listCol опорного списка извлекаются следующим образом.
- Если PredFlagL0[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] и L1, соответственно.
- Иначе, (PredFlagL0[xPCol][yPCol] равен 1), применяется следующее.
- Если PredFlagL1[xPCol][yPCol] равен 0, то mvCol, refIdxCol и listCol полагаются равными MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] и L0, соответственно.
- Иначе, (PredFlagL1[xPCol][yPCol] равен 1), делаются следующие назначения.
- Если PicOrderCnt(pic) каждого изображения pic в каждом списке опорных изображений меньше или равен PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] и LХ, соответственно, где Х является значением X, для которого вызван этот процесс.
- Иначе, (PicOrderCnt(pic) по меньшей мере одного изображения pic в по меньшей мере одном списке опорных изображений, больше, чем PicOrderCntVal, то mvCol, refIdxCol и listCol полагаются равными MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] и LN, соответственно, где N является значением collocated_from_10_flag.
- Если одно из следующих условий истинно, то переменная availableFlagLXCol полагается равной 0:
- AddPicId(RefPicListX[refIdxLX]) не равна AddPicId(colPic, refIdxCol, listCol);
- RefPicListX[refIdxLX] является краткосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 1;
- RefPicListX[refIdxLX] является долгосрочным опорным изображением, и LongTermRefPic(colPic, refIdxCol, listCol) равна 0;
- Иначе, переменная availableFlagLXCol полагается равной 1, и применяется следующее:
- Если RefPicListX[refIdxLX] является долгосрочным опорным изображением, или LongTermRefPic(colPic, refIdxCol, listCol) равна 1, или PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol) равно PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX]), то
mvLXCol = mvCol (8-143).
- Иначе, mvLXCol извлекается как масштабированная версия вектора mvCol движения, как определено ниже:
tx=(16384+(Abs(td)>>1))/td (8-144)
DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145)
mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146),
где td и tb могут быть извлечены так:
td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147)
tb=Clip3(-128, 127, PicOrderCntVal- PicOrderCnt(RefPicListX[refIdxLX])) (8-148).
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять процесс извлечения комбинированных би-прогнозирующих кандидатов слияния. Вводы в этот процесс могут включать в себя список mergeCandList кандидатов слияния, опорные индексы refIdxL0N и refIdxL1N каждого кандидата N, находящегося в mergeCandList, флаги predFlagL0N и predFlagL1N использования списка прогнозирования каждого кандидата N, находящегося в mergeCandList, векторы mvL0N и mvL1N движения каждого кандидата N, находящегося в mergeCandList, число элементов numMergeCand внутри mergeCandList и число элементов numOrigMergeCand внутри mergeCandList после процесса извлечения пространственных и временных кандидатов слияния. Выводы этого процесса могут включать в себя список mergeCandList кандидатов слияния, число элементов numMergeCand внутри mergeCandList, индексы refIdxL0combCandk и refIdxL1combCandk каждого нового кандидата combCandk, добавленного в mergeCandList во время вызова этого процесса, флаги predFlagL0combCandk и predFalgL1combCandk использования списка прогнозирования каждого нового кандидата combCandk, добавляемого в mergeCandList во время вызова этого процесса, и векторы mvL0combCandk и mvL1combCandk движения каждого нового кандидата combCandk, добавляемого в mergeCandList во время вызова этого процесса.
Этот процесс может быть определен следующим образом, где подчеркнутый текст представляет собой изменения относительно HEVC WD7, а многоточия представляют собой тот же текст, что и в HEVC WD7. Когда numOrigMergeCand больше, чем 1, и меньше, чем MaxNumMergeCand, то переменная numInputMergeCand может полагаться равной numMergeCand, переменные combIdx и combCnt могут полагаться равными 0, переменная combStop может полагаться равной FALSE, и последующие этапы могут повторяться до тех пор, пока combStop не равен TRUE:
1. Переменные 10CandIdx и 11CandIdx извлекают с использованием combIdx, как указано в Таблице 8-8.
2. Следующие назначения делаются, когда 10Cand является кандидатом в положении 10CandIdx, а 11Cand является кандидатом в положении 11CandIdx в списке mergeCandList кандидатов слияния (10Cand = mergeCandList[10CandIdx], 11Cand = mergeCandList[11CandIdx]).
3. Когда все из следующих условий истинны,
- predFlagL010Cand = = 1
- predFlagL111Cand = = 1
- AddPicId(RefPicListL0[refIdxL010Cand]) != AddPicId(RefPicListL1[refIdxL111Cand]) || PicOrderCnt(RefPicList0[refIdxL010Cand]) != PicOrderCnt(RefPicList1 [refIdxL111Cand]) || mvL010Cand != mvL111Cand
то применяется следующее:
- …
4. …
5. …
В некоторых примерах, прогнозирование между двумя векторами движения, ссылающимися на два различных долгосрочных опорных изображения, может быть запрещено. В других примерах, прогнозирование между двумя векторами движения, ссылающимися на два различных межвидовых опорных изображения, может быть запрещено.
Подобным образом, видеокодер 20 и видеодекодер 30 представляют собой примеры видеокодера, выполненного с возможностью кодировать значение счета порядка изображения (POC) для первого изображения видеоданных, кодировать идентификатор изображения второй размерности для первого изображения и кодировать второе изображение на основании, по меньшей мере, частично, значения РОС и идентификатора изображения второй размерности первого изображения. Кодирование второго изображения на основании значения РОС и идентификатора изображения второй размерности первого изображения может включать в себя идентификацию первого изображения с использованием значения РОС первого изображения и идентификатора изображения второй размерности.
Более того, как показано выше, кодирование второго изображения может включать в себя разрешение или запрет прогнозирования вектора движения для вектора движения, который ссылается на первое изображение, на основании значения РОС и идентификатора изображения второй размерности первого изображения, и значения РОС и идентификатора изображения второй размерности опорного изображения, на которое ссылается кандидат предиктора вектора движения. Например, если идентификатор изображения второй размерности первого изображения указывает, что первое изображение является краткосрочным изображением, и идентификатор изображения второй размерности опорного изображения указывает, что опорное изображение является долгосрочным изображением, то видеокодер 20 и видеодекодер 30 могут запрещать прогнозирование вектора движения между вектором движения, ссылающимся на первое изображение, и вектором движения, ссылающимся на опорное изображение.
Дополнительно, как показано выше, кодирование второго изображения может включать в себя кодирование вектора движения блока второго изображения, который ссылается на первое изображение, как отмечено выше. Такое кодирование может быть основано на значении РОС первого изображения в том, что если предиктор вектора движения ссылается на опорное изображение, имеющее другое значение РОС, то видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью масштабировать предиктор вектора движения на основании разниц значений РОС между первым и вторым изображениями и опорным изображением и вторым изображением.
Видеокодер 20 и видеодекодер 30 могут быть выполнены с возможностью выполнять способы любого или всех примеров, описанных выше, по отдельности или в комбинации. Видеокодер 20 и видеодекодер 30 могут быть осуществлены в качестве любой из множества подходящих схем кодера или декодера, в зависимости от ситуации, как, например, один или несколько микропроцессоров, цифровых сигнальных процессоров (DSP), специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA), схемы дискретной логики, программном обеспечении, технических средствах, программно-аппаратных средствах или любой их комбинации. Каждый из видеокодера 20 и видеодекодера 30 может быть включен в один или несколько кодеров или декодеров, любой из которых может быть интегрирован в качестве части комбинированного видеокодера/декодера (CODEC). Устройство, включающее в себя видеокодер 20 и/или видеодекодер 30, может содержать интегральную схему, микропроцессор и/или устройство беспроводной связи, как, например, сотовый телефон или планшетный компьютер.
Фиг. 2 является блочной диаграммой, изображающей пример видеокодера 20, который может осуществлять способы кодирования видеоданных в соответствии только с синтаксическим расширением высокого уровня стандарта видеокодирования. Видеокодер 20 может выполнять внутренне и внешнее кодирование видеоблоков внутри видеослайсов. Внутреннее кодирование полагается на пространственное прогнозирование для сокращения или устранения пространственной избыточности в видеосигнале внутри заданного видеокадра или изображения. Внешнее кодирование полагается на временное прогнозирование для сокращения или устранения временной избыточности в видеосигнале внутри смежных кадров или изображений видеопоследовательности. Внутренний режим (I режим) может относиться к любому или нескольким режимам кодирования на основании пространственного прогнозирования. Внешние режимы, как, например, однонаправленное прогнозирование (Р режим) или двунаправленное прогнозирование (В режим), могут относиться к любому из нескольких режимов кодирования на основании временного прогнозирования.
Как изображено на Фиг. 2, видеокодер 20 принимает текущий видеоблок внутри видеокадра, который должен быть кодирован. В примере на Фиг. 2, видеокодер 20 включает в себя элемент 40 выбора режима, память 64 опорных изображений, сумматор 50, элемент 52 обработки преобразования, элемент 54 квантования и элемент 56 энтропийного кодирования. Элемент 40 выбора режима, в свою очередь, включает в себя элемент 44 компенсации движения, элемент 42 оценки движения, элемент 46 внутреннего прогнозирования и элемент 48 разделения. Для восстановления видеоблока, видеокодер 20 также включает в себя элемент 58 обратного квантования, элемент 60 обратного преобразования и сумматор 62. Деблокирующий фильтр (не изображен на Фиг. 2) может также быть включен для фильтрации границ блока для устранения артефактов блочности из восстановленного видео. Если желательно, то деблокирующий фильтр, как правило, фильтрует вывод сумматора 62. Дополнительные фильтры (в контуре или пост-контуре) могут также быть использованы дополнительно к деблокирующему фильтру. Такие фильтры не изображены для краткости, но, если желательно, то могут фильтровать вывод сумматора 50 (как внутриконтурный фильтр).
Во время процесса кодирования, видеокодер 20 принимает видеокадр или слайс, который должен быть кодирован. Кадр или слайс может быть разделен на множество видеоблоков. Элемент 42 оценки движения и элемент 44 компенсации движения выполняют кодирование с внешним прогнозированием принятого видеоблока по отношению к одному или нескольким блокам в одном или нескольких опорных кадрах для обеспечения временного прогнозирования. Элемент 44 компенсации движения может кодировать вектор движения в соответствии со способами настоящего раскрытия, например, во время усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (TMVP) или кодирования в режиме слияния. Элемент 46 внутреннего прогнозирования может альтернативно выполнять кодирование с внутренним прогнозированием принятого видеоблока по отношению к одному или нескольким соседним блокам в том же кадре или слайсе, что и блок, который должен быть кодирован, для обеспечения пространственного прогнозирования. Видеокодер 20 может выполнять много проходов кодирования, например, для выбора подходящего режима кодирования для каждого блока видеоданных.
Более того, элемент 48 разделения может разделять блоки видеоданных на подблоки на основании оценки предыдущих схем разделения в предыдущих проходах кодирования. Например, элемент 48 разделения может первоначально разделять кадр или слайс на LCU и разделять каждый LCU на под-CU на основании анализа (например, оптимизации скорость передачи - искажение) скорость передачи - искажение. Элемент 40 выбора режима может дополнительно производить структуру данных дерева квадратов, указывающую на разделение LCU на под-CU. Концевой узел CU дерева квадратов может включать в себя один или несколько PU и один или несколько TU.
Элемент 40 выбора режима может выбирать один или несколько режимов кодирования, внутренний или внешний, например, на основании результатов ошибки, и обеспечивает получившийся блок с внутренним или внешним кодированием сумматору 50 для формирования данных остаточного блока и сумматору 62 для восстановления закодированного блока для использования в качестве опорного кадра. Элемент 40 выбора режима также обеспечивает синтаксические элементы, как, например, векторы движения, указатели внутреннего режима, информацию разделения и другую синтаксическую информацию, элементу 56 энтропийного кодирования.
Элемент 42 оценки движения и элемент 44 компенсации движения могут быть высоко интегрированы, но изображены отдельно для концептуальных целей. Оценка движения, выполняемая элементом 42 оценки движения, является процессом формирования векторов движения, которые оценивают движение для видеоблоков. Вектор движения, например, может указывать смещение PU видеоблока внутри текущего видеокадра или изображения относительно прогнозирующего блока внутри опорного кадра (или другого закодированного элемента) относительно текущего блока, который кодируют, внутри текущего кадра (или другого закодированного элемента). Прогнозирующий блок является блоком, который близко совпадает с блоком, который кодируют, в части разницы пикселов, которая может быть определена как сумма (SAD) абсолютной разницы, сумма (SSD) квадратной разницы, или другие метрики разницы. В некоторых примерах, видеокодер 20 может вычислять значения подцелочисленных пиксельных положений опорных изображений, хранящихся в памяти 64 опорных изображений. Например, видеокодер 20 может интерполировать значения одной четвертой пиксельных положений, одной восьмой пиксельных положений или других дробных пиксельных положений опорного изображения. Следовательно, элемент 42 оценки движения может выполнять поиск движения относительно целочисленных пиксельных положений и дробных пиксельных положений и выводить вектор движения с дробной пиксельной точностью.
Элемент 42 оценки движения вычисляет вектор движения для PU видеоблока во внешне кодированном слайсе путем сравнения положения PU с положением прогнозирующего блока опорного изображения. Опорное изображение может быть выбрано из первого списка (Список 0) опорных изображений или из второго списка (Список 1) опорных изображений, каждый из которых идентифицирует одно или несколько опорных изображений, хранящихся в памяти 64 опорных изображений. Элемент 42 оценки движения отправляет вычисленный вектор движения элементу 56 энтропийного кодирования и элементу 44 компенсации движения.
Компенсация движения, выполняемая элементом 44 компенсации движения, может вовлекать выбор или формирование прогнозирующего блока на основании вектора движения, определенного элементом 42 оценки движения. Опять же, элемент 42 оценки движения и элемент 44 компенсации движения могут функционально быть интегрированы, в некоторых примерах. После приема вектора движения для PU текущего видеоблока, элемент 44 компенсации движения может располагать прогнозирующий блок, на который указывает вектор движения, в одном из списков опорных изображений. Сумматор 50 формирует остаточный видеоблок путем вычитания значений пикселов прогнозирующего блока из значений пикселов текущего видеоблока, который кодируют, формируя значения пиксельной разницы, как описано выше. В общем, элемент 42 оценки движения выполняет оценку движения относительно компонент яркости, а элемент 44 компенсации движения использует векторы движения, вычисленные на основании компонент яркости, для компонент цветности и компонент яркости. Элемент 40 выбора режима также может формировать синтаксические элементы, связанные с видеоблоками и видеослайсом, для использования видеодекодером 30 при декодировании видеоблоков видеослайса.
Элемент 46 внутреннего прогнозирования может выполнять внутреннее прогнозирование текущего блока, в качестве альтернативы внешнему прогнозированию, выполняемому элементом 42 оценки движения и элементом 44 компенсации движения, как описано выше. Более конкретно, элемент 46 внутреннего прогнозирования может определять режим внутреннего прогнозирования для использования при кодировании текущего блока. В некоторых примерах, элемент 46 внутреннего прогнозирования может кодировать текущий блок с использованием различных режимов внутреннего прогнозирования, например, во время отдельных проходов кодирования, и элемент 46 внутреннего прогнозирования (или элемент 40 выбора режима, в некоторых примерах) может выбирать подходящий режим внутреннего прогнозирования для использования из протестированных режимов.
Например, элемент 46 внутреннего прогнозирования может вычислять значения скорость передачи - искажение с использованием анализа скорость передачи - искажение для различных протестированных режимов внутреннего прогнозирования, и выбирать режим внутреннего прогнозирования, имеющий лучшие характеристики скорость передачи - искажение среди протестированных режимов. Анализ скорость передачи - искажение, в общем, определяет количество искажений (или ошибку) между закодированным блоком и исходным, незакодированным блоком, который был закодирован для воспроизведения закодированного блока, а также скорость прохождения битов (то есть число битов), используемую для воспроизведения закодированного блока. Элемент 46 внутреннего прогнозирования может вычислять соотношения по искажениям и скоростям передачи для различных закодированных блоков для определения того, какой из режимов внутреннего прогнозирования дает лучшее значение скорость передачи - искажение для блока.
После выбора режима внутреннего прогнозирования для блока, элемент 46 внутреннего прогнозирования может обеспечивать информацию, указывающую выбранный режим внутреннего прогнозирования для блока, элементу 56 энтропийного кодирования. Элемент 56 энтропийного кодирования может кодировать информацию, указывающую выбранный режим внутреннего прогнозирования. Видеокодер 20 может включать в передаваемый битовый поток данные конфигурации, которые могут включать в себя множество индексных таблиц режима внутреннего прогнозирования и множество модифицированных индексных таблиц режима внутреннего прогнозирования (также называемых таблицами отображения кодовых слов), определения контекстов кодирования для различных блоков и указатели наиболее вероятного режима внутреннего прогнозирования, индексной таблицы режима внутреннего прогнозирования и модифицированной индексной таблицы режима внутреннего прогнозирования для использования для каждого из контекстов.
Видеокодер 20 формирует остаточный видеоблок путем вычитания данных прогнозирования от элемента 40 выбора режима из исходного видеоблока, который кодируют. Сумматор 50 представляет собой компонент или компоненты, которые выполняют эту функцию вычитания. Элемент 52 обработки преобразования применяет преобразование, как, например, дискретное косинусное преобразование (DCT) или концептуально похожее преобразование, к остаточному блоку, производя видеоблок, содержащий значения остаточных коэффициентов преобразования. Элемент 52 обработки преобразования может выполнять другие преобразования, которые концептуально похожи на DCT. Вейвлет-преобразования, целочисленные преобразования, преобразования поддиапазона или другие типы преобразований также могут быть использованы. В любом случае, элемент 52 обработки преобразования применяет преобразование к остаточному блоку, производя блок остаточных коэффициентов преобразования. Преобразование может переводить остаточную информацию из области пиксельных значений в область преобразования, как, например, частотная область. Элемент 52 обработки преобразования может отправлять получившиеся коэффициенты преобразования элементу 54 квантования. Элемент 54 квантования квантует коэффициенты преобразования для дополнительного улучшения скорости передачи данных. Процесс квантования может сократить битовую глубину, связанную с некоторыми или всеми коэффициентами. Степень квантования может быть модифицирована путем регулировки параметра квантования. В некоторых примерах, элемент 54 квантования затем может выполнять сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. Альтернативно, элемент 56 энтропийного кодирования может выполнять сканирование.
Вслед за квантованием, элемент 56 энтропийного кодирования энтропийно кодирует квантованные коэффициенты преобразования. Например, элемент 56 энтропийного кодирования может выполнять контекстно-зависимое адаптивное кодирование (CAVLC) с переменной длиной кодового слова, контекстно-зависимое адаптивное двоичное арифметическое кодирование (CAВАC), синтаксическое контекстно-зависимое адаптивное двоичное арифметическое кодирование (SBAC), энтропийное кодирование (PIPE) с разделением интервалов вероятности или другой способ энтропийного кодирования. В случае с контекстно-зависимым энтропийным кодированием, контекст может быть основан на соседних блоках. Вслед за энтропийным кодированием элементом 56 энтропийного кодирования, закодированный битовый поток может быть передан другому устройству (например, видеодекодеру 30) или архивирован для дальнейшей передачи или извлечения.
Элемент 58 обратного квантования и элемент 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, для восстановления остаточного блока в пиксельной области, например, для использования в качестве опорного блока. Элемент 44 компенсации движения может вычислить опорный блок путем добавления остаточного блока к прогнозирующему блоку одного из кадров памяти 64 опорных изображений. Элемент 44 компенсации движения может также применять один или несколько фильтров интерполяции к восстановленному остаточному блоку для вычисления подцелочисленных пиксельных значений для использования при оценке движения. Сумматор 62 добавляет восстановленный остаточный блок к блоку прогнозирования с компенсированным движением, произведенному элементом 44 компенсации движения, для воспроизведения восстановленного видеоблока для хранения в памяти 64 опорных изображений. Восстановленный видеоблок может быть использован элементом 42 оценки движения и элементом 44 компенсации движения в качестве опорного блока для кодирования с внешним прогнозированием блока в последующем видеокадре.
Видеокодер 20 может быть выполнен с возможностью выполнять любой или все из различных примеров способов, описанных по отношению к Фиг. 1, по отдельности или в комбинации. Например, в соответствии со способами настоящего раскрытия, видеокодер 20 может кодировать изображение на основании значения счета порядка изображения (POC) опорного изображения и идентификатора второй размерности опорного изображения. То есть видеокодер 20 может кодировать значение РОС первого изображения (опорного изображения, в данном примере), а также идентификатор изображения второй размерности для первого изображения. Идентификатор изображения второй размерности может содержать, например, идентификатор вида для вида, включающего в себя первое изображение, индекс порядка вида для вида, включающего в себя первое изображение, комбинацию индекса порядка вида и флага глубины, идентификатор уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и общий идентификатор уровня.
Идентификатор второй размерности может, дополнительно или альтернативно, содержать значение, указывающее, является ли первое изображение долгосрочным опорным изображением или краткосрочным опорным изображением. Альтернативно, отдельное значение может указывать, является ли первое изображение долгосрочным или краткосрочным опорным изображением, дополнительно к значению РОС и идентификатору изображения второй размерности. В некоторых примерах, долгосрочные и краткосрочные указания для опорных изображений могут указывать, являются ли опорные изображения временными опорными изображениями или межвидовыми опорными изображениями. Например, долгосрочное опорное изображение может соответствовать временному опорному изображению (то есть опорному изображению в том же уровне или виде), в то время как краткосрочное опорное изображение может соответствовать межвидовому опорному изображению. В качестве другого примера, долгосрочное опорное изображение может соответствовать межвидовому опорному изображению, в то время как краткосрочное опорное изображение может соответствовать временному опорному изображению.
Подобным образом, видеокодер 20 может запрещать прогнозирование вектора движения между векторами движения различных типов. «Типы» векторов движения могут включать в себя, например, временные векторы движения, которые ссылаются на временные опорные изображения (то есть изображения в том же виде, что и текущее изображение, которое кодируют), и векторы движения диспаратности, которые ссылаются на межвидовые опорные изображения (то есть изображения в виде, отличном от вида, включающего в себя текущее изображение). Как правило, межвидовые опорные изображения имеют те же значения РОС, что и текущее изображение. То есть, как правило, межвидовые опорные изображения и текущее изображение находятся в одном и том же элементе доступа. Видеокодер 20 может запрещать прогнозирование векторов движения между векторами движения различных типов. То есть, если текущий вектор движения текущего изображения является временным вектором движения, то видеокодер 20 может запрещать прогнозирование векторов движения относительно вектора движения диспаратности. Подобным образом, если текущий вектор движения является вектором движения диспаратности, то видеокодер 20 может запрещать прогнозирование векторов движения относительно временного вектора движения. Видеокодер 20, иначе, может кодировать текущий вектор движения с использованием процесса кодирования вектора движения, как, например, продвинутое прогнозирование векторов движения (AMVP) или режим слияния.
В некоторых примерах, видеокодер 20 может быть выполнен с возможностью кодировать значение, указывающее, является ли первое изображение (например, компонента вида, в многовидовом кодировании видео) долгосрочным опорным изображением, на основании, по меньшей мере, частично, того, используется ли первое изображение для межвидового прогнозирования. Например, видеокодер 20 может кодировать синтаксический элемент, указывающий, является ли первое изображение долгосрочным или краткосрочным опорным изображением, в наборе параметров последовательности (SPS), соответствующем последовательности, включающей в себя первое изображение.
Дополнительно или альтернативно, видеокодер 20 может быть выполнен с возможностью маркировать межвидовые опорные изображения в качестве долгосрочных опорных изображений, по меньшей мере, временно. Видеокодер 20 может дополнительно хранить текущие статусы межвидовых опорных изображений, где статусы могут содержать одно из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки. Таким образом, если первое изображение содержит межвидовое изображение, то видеокодер 20 может маркировать первое изображение в качестве долгосрочного опорного изображения. После кодирования второго изображения относительно первого изображения, видеокодер 20 может восстанавливать статус для межвидового опорного изображения на основании сохраненного статуса.
Дополнительно или альтернативно, видеокодер 20 может временно назначать новые значения РОС межвидовым опорным изображениям во время кодирования второго изображения. Например, видеокодер 20 может определять набор значений РОС для текущих временных опорных изображений и назначать неиспользованные значения РОС межвидовым опорным изображениям. Видеокодер 20 может также хранить соответствующие текущие значения РОС для каждого межвидового опорного изображения. После кодирования второго изображения, видеокодер 20 может восстанавливать сохраненные (то есть исходные) значения РОС для межвидовых опорных изображений. Так как межвидовые опорные изображения, как правило, находятся в том же элементе доступа, что и второе изображение (то есть изображение, которое в данный момент кодируют), в некоторых примерах, то видеокодер 20 может, напротив, просто устанавливать значения РОС для межвидовых опорных изображений, равными значению РОС второго изображения, то есть изображения, которое в данный момент кодируют, так что сохранять значения РОС необязательно.
Подобным образом, видеокодер 20 на Фиг. 2 представляет собой пример видеокодера, выполненного с возможностью кодировать значение счета порядка изображения (POC) для первого изображения видеоданных, кодировать идентификатор изображения второй размерности для первого изображения, и кодировать, в соответствии с базовой спецификацией видеокодирования, второе изображение на основании, по меньшей мере, частично, значения РОС и идентификатора изображения второй размерности первого изображения. Базовая спецификация видеокодирования может содержать HEVC. Дополнительно, видеокодер 20 может быть выполнен с возможностью кодировать изображение в соответствии с расширением базовой спецификации видеокодирования, например, расширением SVC или MVC HEVC. Таким образом, видеокодер 20 также представляет собой пример видеокодера, выполненного с возможностью кодировать значение счета порядка изображения (POC) для первого изображения видеоданных, кодировать идентификатор изображения второй размерности для первого изображения и кодировать, в соответствии с расширением базовой спецификации видеокодирования, второе изображение на основании, по меньшей мере, частично значения РОС и идентификатора изображения второй размерности первого изображения.
Фиг. 3 является блочной диаграммой, изображающей пример видеодекодера 30, который может осуществлять способы кодирования видеоданных в соответствии только с синтаксическим расширением высокого уровня стандарта видеокодирования. В примере на Фиг. 3, видеодекодер 30 включает в себя элемент 70 энтропийного декодирования, элемент 72 компенсации движения, элемент 74 внутреннего прогнозирования, элемент 76 обратного квантования, элемент 78 обратного преобразования, память 82 опорных изображений и сумматор 80. Видеодекодер 30 может, в некоторых примерах, выполнять проход декодирования, в общем, противоположный проходу кодирования, описанному по отношению к видеокодеру 20 (Фиг. 2). Элемент 72 компенсации движения может формировать данные прогнозирования на основании векторов движения, принятых от элемента 70 энтропийного декодирования, в то время как элемент 74 внутреннего прогнозирования может формировать данные прогнозирования на основании указателей режима внутреннего прогнозирования, принятых от элемента 70 энтропийного декодирования.
Во время процесса декодирования, видеодекодер 30 принимает закодированный поток двоичных видеоданных, который представляет собой видеоблоки закодированного видеослайса и связанные синтаксические элементы, от видеокодера 20. Элемент 70 энтропийного декодирования видеодекодера 30 энтропийно декодирует битовый поток для формирования квантованных коэффициентов, векторов движения или указателей режима внутреннего прогнозирования и других синтаксических элементов. Элемент 70 энтропийного декодирования направляет векторы движения и другие синтаксические элементы элементу 72 компенсации движения. Видеодекодер 30 может принимать синтаксические элементы на уровне видеослайса и/или уровне видеоблока.
Когда видеослайс закодирован как внутренне кодированный (I) слайс, то элемент 74 внутреннего прогнозирования может формировать данные прогнозирования для видеоблока текущего видеослайса на основании сигнализированного режима внутреннего прогнозирования и данных от ранее декодированных блоков текущего кадра или изображения. Когда видеокадр закодирован как внешне кодированный (например, В, Р или GPB) слайс, то элемент 72 компенсации движения производит прогнозирующие блоки для видеоблока текущей видеослайса на основании векторов движения и других синтаксических элементов, принятых от элемента 70 энтропийного декодирования. Прогнозирующие блоки могут быть произведены из одного из опорных изображений внутри одного из списков опорных изображений. Видеодекодер 30 может создавать списки опорных кадров, Список 0 и Список 1, используя способы создания по умолчанию, на основании опорных изображений, хранящихся в памяти 82 опорных изображений.
В соответствии со способами настоящего раскрытия, элемент 70 энтропийного декодирования может энтропийно декодировать закодированные данные, представляющие информацию движения для текущего блока текущего изображения. Например, в соответствии с AMVP, элемент энтропийного декодирования может декодировать значения разницы векторов движения (MVD) для текущего блока. Элемент 72 компенсации движения (или другой элемент видеокодера 30, как, например, элемент 70 энтропийного кодирования) может восстанавливать вектор движения для текущего блока с использованием энтропийно декодированной информации движения, как, например, значения MVD. Например, элемент 72 компенсации движения может определять набор доступных предикторов вектора движения для текущего вектора движения, например, на основании того, ссылается ли текущий вектор движения на долгосрочное опорное изображение или краткосрочное опорное изображение (или временное или межвидовое опорное изображение), и того, ссылается ли также группа кандидатов опорных изображений на долгосрочные или краткосрочные опорные изображения (или временные или межвидовые опорные изображения).
Как описано выше, элемент 72 компенсации движения может определять, что кандидаты предикторов вектора движения различных типов недоступны для использования для прогнозирования текущего вектора движения. Например, когда текущий вектор движения является временным вектором движения, то элемент 72 компенсации движения может определять, что векторы движения диспаратности недоступны для использования в качестве предикторов вектора движения для текущего вектора движения. Подобным образом, когда текущий вектор движения является вектором движения диспаратности, то элемент 72 компенсации движения может определять, что временные векторы движения недоступны для использования в качестве предикторов вектора движения для текущего вектора движения. В некоторых примерах, элемент 72 компенсации движения может также запрещать прогнозирование векторов движения между долгосрочными и краткосрочными опорными изображениями, либо альтернативно.
В случае, когда текущий вектор движения является вектором движения диспаратности, то элемент 72 компенсации движения может также избегать масштабирования предиктора вектора движения (что может, подобным образом, соответствовать вектору движения диспаратности). Дополнительно, или альтернативно, элемент 72 компенсации движения может назначать временное значение РОС межвидовому опорному изображению, на которое ссылается предиктор вектора движения диспаратности, во время прогнозирования вектора движения вектора движения диспаратности.
В любом случае, элемент 72 компенсации движения, или другой элемент видеодекодера 30, может воспроизводить вектор движения для текущего блока, например, с использованием AMVP или режима слияния. Элемент 72 компенсации движения определяет информацию прогнозирования для видеоблока текущего видеослайса путем синтаксического анализа векторов движения и других синтаксических элементов и использует информацию прогнозирования для воспроизведения прогнозирующих блоков для текущего видеоблока, который кодируют. Например, элемент 72 компенсации движения использует некоторые из принятых синтаксических элементов для определения режима прогнозирования (например, внутреннее или внешнее прогнозирование), используемого для кодирования видеоблоков видеослайса, типа слайса с внешним прогнозированием (например, В слайс, Р слайс или GPB слайс), информации восстановления для одного или нескольких списков опорных изображений для слайса, векторов движения для каждого внешне закодированного видеоблока слайса, статуса внешнего прогнозирования для каждого внешне закодированного видеоблока слайса, и другой информации для декодирования видеоблоков в текущем видеослайсе. Элемент 72 компенсации движения может кодировать вектор движения в соответствии со способами настоящего раскрытия, например, во время усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (ТMVP), или кодирования в режиме слияния.
Элемент 72 компенсации движения может также выполнять интерполяцию на основании фильтров интерполяции. Элемент 72 компенсации движения может использовать фильтры так же, как и видеокодер 20 во время кодирования видеоблоков, для вычисления интерполированных значений для подцелочисленных пикселов опорных блоков. В таком случае, элемент 72 компенсации движения может определять фильтры интерполяции, использованные видеокодером 20, из принятых синтаксических элементов, и использовать фильтры интерполяции для воспроизведения прогнозирующих блоков.
Элемент 76 обратного квантования обратно квантует, то есть де-квантует, квантованные коэффициенты преобразования, обеспеченные в битовом потоке и декодированные элементом 70 энтропийного декодирования. Процесс обратного квантования может включать в себя использование параметра QPy квантования, вычисленного видеодекодером 30 для каждого видеоблока в видеослайсе, для определения степени квантования и, подобным образом, степени обратного квантования, которая должна быть применена. Элемент 78 обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование или концептуально похожий процесс обратного преобразования к коэффициентам преобразования, чтобы произвести остаточные блоки в пиксельной области.
После того, как элемент 72 компенсации движения сформирует прогнозирующий блок для текущего видеоблока на основании векторов движения и других синтаксических элементов, видеодекодер 30 формирует декодированный видеоблок путем суммирования остаточных блоков от элемента 78 обратного преобразования с соответствующими прогнозирующими блоками, сформированными элементом 72 компенсации движения. Сумматор 80 представляет собой компонент или компоненты, которые выполняют эту функцию суммирования. Если желательно, то деблокирующий фильтр также может быть применен для фильтрации декодированных блоков, чтобы устранить артефакты блочности. Другие контурные фильтры (в контуре кодирования либо после контура кодирования) также могут быть использованы для сглаживания пиксельных переходов, или, иначе, улучшения качества видео. Декодированные видеоблоки в заданном кадре или изображении затем сохраняют в памяти 82 опорных изображений, которая хранит опорные изображения, используемые в последующей компенсации движения. Память 82 опорных изображений также хранит декодированное видео для дальнейшего представления на устройстве отображения, как, например, устройство 32 отображения на Фиг. 1.
Подобным образом, видеодекодер 30 на Фиг. 3 представляет собой пример видеодекодера, выполненного с возможностью декодировать значение счета порядка изображения (POC) для первого изображения видеоданных и декодировать второе изображение на основании, по меньшей мере, частично, значения РОС и идентификатора изображения второй размерности первого изображения. Базовая спецификация видеокодирования может содержать HEVC. Дополнительно, видеодекодер 30 может быть выполнен с возможностью кодировать изображение в соответствии с расширением базовой спецификации видеокодирования, например, расширением SVC или MVC HEVC. Таким образом, видеодекодер 30 также представляет собой пример видеодекодера, выполненного с возможностью декодировать значение счета порядка изображения (POC) для первого изображения видеоданных, декодировать идентификатор изображения второй размерности для первого изображения и декодировать, в соответствии с расширением базовой спецификации видеокодирования, второе изображение на основании, по меньшей мере, частично значения РОС и идентификатора изображения второй размерности первого изображения.
Фиг. 4 представляет собой концептуальную диаграмму, изображающую пример модели прогнозирования MVC. Многовидовое видеокодирование (MVC) является расширением ITU-T H.264/AVC. Похожий способ может быть применен к HEVC. В примере на Фиг. 4, изображены восемь видов (имеющих ID вида от «S0» до «S7»), и для каждого вида изображены двенадцать временных местоположений (от «Т0» до «Т11»). То есть каждый ряд на Фиг. 4 соответствует виду, а каждый столбец указывает временное местоположение.
Хотя MVC имеет так называемый базовый вид, который декодируется декодерами H.264/AVC, и стереовидовая пара может быть поддержана также MVC, одно преимущество MVC заключается в том, что оно может поддерживать пример, который использует более чем два вида, в качестве ввода 3D видео и декодирует это 3D видео, представленное множеством видов. Средство визуализации клиента, имеющее декодер MVC, может ожидать 3D видеоконтент с множеством видов.
Обычная схема порядка декодирования MVC называется кодирование первого по времени. Элемент доступа может включать закодированные изображения всех видов в один вывод за раз. Например, каждое из изображений времени Т0 может быть включено в общий элемент доступа, каждое из изображений времени Т1 может быть включено во второй, общий элемент доступа, и так далее. Порядок декодирования необязательно является идентичным выводу или порядку отображения.
Кадры, то есть изображения, на Фиг. 4 указаны в пересечении каждого ряда и каждого столбца на Фиг. 4, с использованием затемненного блока, включающего в себя букву, обозначающую, является ли соответствующий кадр внутренне кодированным (то есть I-кадр) или внешне кодированным в одном направлении (то есть как Р-кадр) или множестве направлений (то есть как В-кадр). В общем, прогнозирования указаны стрелками, где кадр, на который указано, использует объект, от которого указано, в качестве опоры прогнозирования. Например, Р-кадр вида S2 во временном местоположении Т0 прогнозируется от I-кадра вида S0 во временном местоположении Т0.
При одновидовом кодировании видео, кадры последовательности многовидового видеокодирования могут быть закодированы с прогнозированием по отношению к кадрам в различных временных местоположениях. Например, b-кадр вида S0 во временном местоположении Т1 имеет стрелку, указывающую на него от I-кадра вида S0 во временном местоположении Т1, указывающую, что b-кадр спрогнозирован из I-кадра. Дополнительно, однако, в контексте многовидового видеокодирования, кадры могут быть с межвидовым прогнозированием. То есть компонента вида может использовать компоненты вида в других видах для опоры. В MVC, например, межвидовое прогнозирование реализуется так, будто компонента вида в другом виде является опорой внешнего прогнозирования. Потенциальные межвидовые опоры сигнализируются в наборе параметров последовательности (SPS) расширения MVC и могут быть модифицированы с помощью процесса создания списка опорных изображений, который позволяет гибкий порядок опор внешнего прогнозирования или межвидового прогнозирования.
В расширении MVC H.264/AVC, в качестве примера, межвидовое прогнозирование поддерживается компенсацией несовпадающего движения, которая использует синтаксис H.264/AVC компенсации движения, но позволяет изображению в другом виде быть использованным в качестве опорного изображения. Кодирование двух видов может поддерживаться MVC, которое, в общем, ссылается на стереоскопические виды. Одно из преимуществ MVC заключается в том, что кодер MVC может брать более чем два вида в качестве ввода 3D видеосигнала, а декодер MVC может декодировать такие многовидовые представления. Таким образом, устройство визуализации с декодером MVC может ожидать 3D видеоконтент с более чем двумя видами.
В MVC, межвидовое прогнозирование (IVP) разрешено среди изображений в одном и том же элементе доступа (то есть с одинаковым моментом времени). Элемент доступа, в общем, является элементом данных, включающем в себя все компоненты вида (например, все элементы NAL) для общего момента времени. Таким образом, в MVC, межвидовое прогнозирование разрешено среди изображений в одном и том же элементе доступа. При кодировании изображения в одном из небазовых видов изображение может быть добавлено в список опорных изображений, если оно находится в другом виде, но внутри того же момента времени (например, имеющее то же самое значение РОС, и, таким образом, находящееся в том же самом элементе доступа). Опорное изображение межвидового прогнозирования может находиться в любом положении списка опорных изображений, как и любое опорное изображение внешнего прогнозирования.
Как правило, создание списка опорных изображений для первого или второго списка опорных изображений изображения В включает в себя два этапа: инициализацию списка опорных изображений и переупорядочение (модификацию) списка опорных изображений. Инициализация списка опорных изображений является явным механизмом, в соответствии с которым видеокодер располагает опорные изображения в памяти опорных изображений (также известной как буфер декодированных изображений) в списке на основании порядка значений РОС (счет порядка изображения, связанный с порядком изображения).
Видеокодер может использовать механизм переупорядочивания списка опорных изображений для модификации положения изображения, которое было добавлено в список во время инициализации списка опорных изображений, в любое новое положение, или для расположения любого опорного изображения в памяти опорных изображений в любое положение, даже если изображение не принадлежит инициализированному списку. Некоторые изображения после переупорядочивания (модификации) списка опорных изображений могут быть добавлены в дополнительное положение в списке. Однако если положение изображения превышает число активных опорных изображений в списке, то изображение не рассматривается как запись финального списка опорных изображений. Число активных опорных изображений может быть сигнализировано в заголовке слайса для каждого списка. После того, как созданы списки опорных изображений (например, RefPicList0 и RefPicList1, если доступно), опорный индекс списка опорных изображений может быть использован для идентификации любого опорного изображения, включенного в список опорных изображений.
Для получения временного предиктора вектора движения (TMVP), во-первых, необходимо идентифицировать совмещенное изображение. Если текущее изображение является В слайсом, то collocated_from_10_flag сигнализируется в заголовке слайса для указания того, находится ли совмещенное изображение в RefPicList0 или RefPicList1. После того, как список опорных изображений идентифицирован, collocated_ref_idx, сигнализированный в заголовке слайса, используется для идентификации изображения в изображении в списке. Совмещенный PU затем идентифицируется путем проверки совмещенного изображения. Используется либо движение правого нижнего PU CU, содержащего этот PU, либо движение правого нижнего PU внутри центра PU CU, содержащего этот PU. Когда векторы движения, идентифицированные с помощью вышеуказанного процесса, используются для формирования кандидата движения для AMVP или режима слияния, их необходимо масштабировать на основании временного местоположения (отраженного с помощью РОС).
В HEVC, настройка (SPS) параметра последовательности включает в себя флаг sps_temporal_mvp_enable_flag, и заголовок слайса включает в себя флаг pic_temporal_mvp_enable_flag, когда sps_temporal_mvp_enable_flag равен 1. Когда оба pic_temporal_mvp_enable_flag и temporal_id равны 0 для конкретного изображения, то никакой вектор движения из изображений до этого конкретного изображения в порядке декодирования не будет использован в качестве предиктора вектора движения при декодировании конкретного изображения или изображения после конкретного изображения в порядке декодирования.
В настоящее время, Экспертная группа (MPEG) по движущемуся изображению разрабатывает стандарт 3DV на основании HEVC, для которого часть усилий по стандартизации также включает в себя стандартизацию многовидового видеокодека на основании HEVC. Подобным образом, в HEVC на основании 3DV, разрешено межвидовое прогнозирование на основании восстановленных видовых компонентов из различных видов.
AVC было расширено с помощью многовидового расширения таким образом, что расширение соответствует требованию «только HLS» (только синтаксис высокого уровня). Требование «только HLS» гарантирует, что делаются только изменения синтаксиса (HLS) высокого уровня в многовидовом видеокодировании (MVC), так что никакой модуль на уровне макроблока в AVC не нужно переделывать, и он может быть полностью повторно использован для MVC. Возможно, что требование «только HLS» может быть выполнено для расширения MVC/3DV HEVC, и также для расширения масштабируемого видеокодирования (SVC) HEVC, если многоконтурное кодирование считается приемлемым.
Для разрешения межвидового прогнозирования, изменения HLS могут быть сделаны со следующими целями: идентификация изображения, где создание списка опорных изображений и маркировка должны быть способными идентифицировать изображение в конкретном виде.
Изменений HLS недостаточно для соответствия требованию «только HLS» в H.264/MVC, как и другим ограничениям, и делаются предположения, так что модули кодирования низкого уровня никогда не встретятся с ситуацией, например, обработки масштабирования с нулевым движением. Такими ограничениями, модификациями и предположениями являются:
Отмена временного прямого режима, если совмещенное изображение является межвидовым (только) опорным изображением)
Рассмотрение межвидового (только) опорного изображения в качестве не краткосрочного: по отношению к пространственному прямому
Отмена скрытого взвешенного прогнозирования
Для соответствия требованию «только HLS», такие модификации в расширении должны быть только в синтаксисе высокого уровня. Таким образом, не должно быть модификаций для синтаксических элементов под заголовком слайса и никаких изменений процесса декодирования уровня CU для спецификации расширения; например, прогнозирование вектора движения спецификации расширения HEVC должно быть точно таким же, что и в базовой спецификации HEVC. Изменения HLS являются нормативными изменениями декодера спецификации расширения; однако, с точки зрения базовой спецификации, такие изменения необязательно должны быть известны и могут быть информативными.
Для разрешения функциональности, как, например, эффективное межвидовое прогнозирование, могут быть осуществлены модификации в расширении HEVC и базовых спецификациях. Изменения в базовой спецификации, которые не влияют на обычные процессы декодирования или эффективность кодирования базовых декодеров HEVC, но нацелены на разрешение функциональности в спецификации расширения, называют привязками. В большинстве случаев, требование «только HLS» выполняется с обеими привязками в базовой спецификации и изменениях HLS в спецификации расширения. Если привязки в базовой спецификации не определены четко, то конкретная желаемая функциональность может быть не разрешена в спецификации расширения либо потребуется множество модификаций в спецификации расширения.
В только-HLS SVC, представление базового уровня, возможно, после повышающей дискретизации и/или фильтрации, может быть занесено в список опорных изображений текущего изображения текущего уровня. Такое изображение называют межуровневое опорное изображение.
Различные модификации могут быть сделаны как в базовой спецификации, так и в спецификации расширения модификации только-HLS HEVC. С учетом конкретной желаемой функциональности, на этапе, на котором структуры базовой спецификации и спецификации расширения могут быть модифицированы, это является вопросом компромисса между модификацией базовой спецификации и модификацией спецификации расширения.
Фиг. 5-9 являются концептуальными диаграммами, изображающими потенциальные проблемы, которые надо преодолеть для достижения расширения только-HLS HEVC. Фиг. 5, например, изображает пример, в котором текущее изображение 100 включает в себя блоки, как, например, блоки 102 и 104, прогнозируемые с использованием различных способов прогнозирования. Более конкретно, текущее изображение 100 соответствует изображению небазового вида, в то время как межвидовое опорное изображение 110 является изображением базового вида. Блок 102 текущего изображения 100 является межвидовым прогнозным по отношению к межвидовому опорному изображению 110 (с использованием несовпадающего вектора 106 движения), в то время как блок 104 прогнозируют с использованием внешнего прогнозирования по отношению к краткосрочному (ST) опорному изображению 112 того же небазового вида (с использованием временного вектора 108 движения). Фиг. 5, следовательно, изображает пример, в котором текущее изображение включает в себя соседние блоки с временным вектором движения (временной вектор 108 движения) и межвидовым вектором движения (также называемым вектор движения диспаратности, а именно, вектор 106 движения диспаратности).
Настоящее раскрытие признает, что, в некоторых примерах, вектор движения диспаратности не должен быть масштабирован для прогнозирования временного вектора движения. Дополнительно, настоящее раскрытие также признает, что, в некоторых примерах, временной вектор движения не должен быть масштабирован для прогнозирования вектора движения диспаратности. Настоящее раскрытие также признает, что должно быть возможно отменить прогнозирование вектора движения диспаратности из временного краткосрочного вектора движения, например, во время AMVP, и отменить прогнозирование временного вектора движения из вектора движения диспаратности. Векторы движения диспаратности, как правило, соответствуют локальному несовпадению одного и того же объекта в различных видах. Однако временные векторы движения, как правило, соответствуют движению объекта. В HTM, который является опорным программным обеспечением 3DV, прогнозирование между векторами движения двух вышеуказанных категорий запрещено.
Фиг. 6 изображает пример, в котором текущее изображение включает в себя блоки, спрогнозированные с использованием межвидовых опорных изображений различных видов. Более конкретно, в данном примере, межвидовое опорное изображение 120 является видом 0, а межвидовое опорное изображение 122 является видом 1. Текущее изображение 124 является видом 2. Текущее изображение 124 включает в себя блоки 126, 128, спрогнозированные с использованием межвидового прогнозирования из обоих межвидового опорного изображения 120 вида 0 и межвидового опорного изображения 122 вида 1. Более конкретно, в данном примере, блок 126 спрогнозирован из межвидового опорного изображения 122, в то время как блок 128 спрогнозирован из межвидового опорного изображения 120.
Блоки 162 и 128 спрогнозированы с использованием различных векторов движения диспаратности. То есть блок 126 спрогнозирован с использованием вектора 130 движения диспаратности, который ссылается на часть межвидового опорного изображения 122, в то время как блок 128 спрогнозирован с использованием вектора 132 движения диспаратности, который ссылается на часть межвидового опорного изображения 120. Соответственно, Фиг. 6 представляет собой пример, в котором текущее изображение включает в себя соседние блоки с межвидовыми векторами движения, которые ссылаются на межвидовые опорные изображения различных видов.
Настоящее раскрытие признает, что должно быть возможно идентифицировать, соответствуют ли два вектора движения диспаратности одному и тому же опорному изображению. Когда запись в RefPicList0 и запись в RefPicList1 обе являются межвидовыми опорными изображениями, должно быть возможно, во время AMVP, идентифицировать, являются ли эти два опорных изображения одинаковыми. Когда RefPicListX (где «Х» может представлять собой значение 0 или 1, например) содержит две записи, которые являются межвидовыми опорными изображениями, должно быть возможно, во время AMVP, идентифицировать, являются ли эти два опорных изображения одинаковыми. Дополнительно, две записи с одинаковой значением РОС могут быть неидентичными, например, когда две записи соответствуют различным видам, как изображено на Фиг. 6.
Фиг. 7 изображает пример, в котором опорное изображение в небазовом виде включает в себя блоки, спрогнозированные с использованием межвидового прогнозирования по отношению к межвидовому опорному изображению в базовом виде и с использованием внешнего прогнозирования по отношению к долгосрочному (LT) опорному изображению в небазовом виде. То есть Фиг. 7 изображает пример, в котором текущее изображение 140 включает в себя соседние блоки 146, 148 с временным вектором 152 движения (ссылающимся на долгосрочное опорное изображение 144) и межвидовым вектором 150 движения (ссылающимся на межвидовое опорное изображение 142). Межвидовой вектор 150 движения можно также называть «вектор 150 движения диспаратности». Настоящее раскрытие признает, что должно быть возможно отменить прогнозирование вектора движения диспаратности, как, например, вектор 150 движения диспаратности, из временного долгосрочного вектора движения, как, например, временной вектор 152 движения, и отменить прогнозирование временного долгосрочного вектора движения из вектора движения диспаратности.
Фиг. 8 изображает пример, в котором текущее изображение в небазовом виде включает в себя блоки, которые спрогнозированы с использованием внешнего прогнозирования, как из долгосрочного (LT) опорного изображения, так и краткосрочного (ST) опорного изображения, небазового вида. То есть Фиг. 8 изображает пример, в котором текущее изображение 160 включает в себя соседние блоки 166, 168 с временными долгосрочным и краткосрочным векторами движения. Более конкретно, блок 166 спрогнозирован с использованием временного вектора 170 движения, который ссылается на долгосрочное опорное изображение 162, в то время как блок 168 спрогнозирован с использованием временного вектора 172 движения, который ссылается на краткосрочное опорное изображение 164. Следовательно, временной вектор 170 движения можно называть долгосрочным вектором движения или долгосрочным временным вектором движения, в то время как временной вектор 172 движения можно называть краткосрочным вектором движения или краткосрочным временным вектором движения. Настоящее раскрытие признает, что должно быть возможно отменить прогнозирование между временными краткосрочными векторами движения и временными долгосрочными векторами движения, например, во время AMVP.
Фиг. 9 изображает пример, в котором текущее изображение в небазовом виде включает в себя блоки, которые спрогнозированы с использованием внешнего прогнозирования, где блоки спрогнозированы по отношению к различным долгосрочным (LT) опорным изображениям небазового вида. То есть, Фиг. 9 изображает пример, в котором текущее изображение 180 включает в себя соседние блоки 186, 188 с временными векторами 190, 192 движения, ссылающимися на долгосрочные изображения 184, 182, соответственно. Более конкретно, в данном примере, блок 186 спрогнозирован с использованием временного вектора 190 движения, который ссылается на часть долгосрочного опорного изображения 184, в то время как блок 188 спрогнозирован с использованием временного вектора 192 движения, который ссылается на часть долгосрочного опорного изображения 182. Настоящее раскрытие признает, что должно быть возможно разрешать и/или запрещать прогнозирование временных долгосрочных векторов движения во время AMVP.
Фиг. 10 является концептуальной диаграммой, изображающей пример группы соседних блоков для текущего блока. Более конкретно, в данном примере, текущий блок имеет соседние блоки слева, обозначенные А0 и А1, и соседние блоки В0, В1 и В2 сверху. Текущий блок может быть закодирован с использованием внешнего прогнозирования, например, временного прогнозирования или межвидового прогнозирования. Таким образом, видеокодер, как, например, видеокодер 20 или видеодекодер 30, может кодировать текущий блок с использованием вектора движения. Более того, видеокодер может кодировать вектор движения. В различных примерах, видеокодер может кодировать вектор движения для текущего блока с использованием способов, описанных выше, например, для усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования (ТMVP) вектора движения, или режима слияния. Предиктор TMVP может соответствовать вектору движения для блока, который совмещен с текущим блоком в ранее закодированном изображении.
Вектор движения одного или нескольких соседних блоков А0, А1, В0, В1 и В2 могут иметь типы, отличные от вектора движения, используемого для кодирования текущего блока. Например, текущий блок может быть закодирован с использованием долгосрочного вектора движения, в то время как один или несколько блоков А0, А1, В0, В1 и В2 могут быть закодированы с использованием краткосрочного вектора движения. В качестве другого примера, текущий блок может быть закодирован с использованием краткосрочного вектора движения, в то время как один или несколько блоков А0, А1, В0, В1 и В2 могут быть закодированы с использованием долгосрочного вектора движения. В качестве другого примера, текущий блок может быть закодирован с использованием вектора движения диспаратности, в то время как один или несколько блоков А0, А1, В0, В1 и В2 могут быть закодированы с использованием временного вектора движения. В качестве еще одного примера, текущий блок может быть закодирован с использованием временного вектора движения, в то время как один или несколько блоков А0, А1, В0, В1 и В2 могут быть закодированы с использованием вектора движения диспаратности. В таких случаях, как объяснено выше, видеокодер, как, например, видеокодер 20 или видеодекодер 30, может запрещать прогнозирование вектора движения между векторами движения различных типов.
Пример на Фиг. 10 изображает кандидатов пространственного предиктора вектора движения. Однако необходимо понимать, что кандидаты временного предиктора вектора движения могут также быть рассмотрены для временного прогнозирования вектора движения (TMVP). Такие кандидаты TMVP могут соответствовать информации движения для совмещенных блоков в ранее закодированных изображениях, то есть, блоков, которые совмещены с блоком, обозначенным «текущий блок» на Фиг. 10. Дополнительно, в соответствии со способами настоящего раскрытия, кандидат TMVP может быть рассмотрен как недоступный для использования в качестве предиктора вектора движения, когда информация движения кандидата TMVP и вектор движения текущего блока указывают на изображения различных типов, например, краткосрочное и долгосрочное опорные изображения.
Фиг. 11 является блок-схемой, изображающей пример способа кодирования видеоданных в соответствии со способами настоящего раскрытия. Этапы в примере способа на Фиг. 11 могут, альтернативно, быть выполнены в другом порядке либо существенно параллельно, в некоторых примерах. Подобным образом, конкретные этапы могут быть опущены, и/или другие этапы могут быть добавлены. Хотя в описании это выполняет видеокодер 20, необходимо понимать, что другие устройства видеокодирования могут быть выполнены с возможностью выполнять существенно похожий способ.
В данном примере, видеокодер 20 кодирует значения счета порядка изображения (POC) опорных изображений для текущего изображения (200). Например, видеокодер 20 может кодировать значения РОС или данные, представляющие собой значения РОС (как, например, младшие биты (LSB)), для конкретных опорных изображений в структуре данных набора параметров последовательности (SPS) для последовательности, включающей в себя текущее изображение. Видеокодер 20 может также, дополнительно, или альтернативно, кодировать значения РОС для одного или нескольких опорных изображений в заголовке слайса текущего изображения. В некоторых примерах, видеокодер 20 может кодировать данные, представляющие собой значения РОС долгосрочных опорных изображений, в SPS, и значения РОС краткосрочных опорных изображений, в заголовке слайса. Видеокодер 20 может также кодировать значения РОС межвидовых опорных изображений, например, в SPS, заголовке слайса или в другом месте. В общем, значения РОС межвидовых опорных изображений являются теми же, что и значения РОС текущего изображения, которое кодируют.
Видеокодер 20 также может кодировать идентификаторы второй размерности опорных изображений (202). Идентификаторы второй размерности могут включать в себя один или несколько идентификаторов вида для видов, включающих в себя опорные изображения, индексы порядка вида для видов, включающих в себя опорные изображения, комбинацию индексов порядка вида и флагов глубины, идентификаторы уровня для уровней масштабируемого видеокодирования (SVC), включающих в себя опорные изображения, и/или общие идентификаторы уровня. Таким образом, комбинация значения РОС для опорного изображения и идентификатор второй размерности для опорного изображения могут быть использованы для идентификации опорного изображения.
Видеокодер 20 может дополнительно выполнять поиск движения для текущего блока текущего изображения. То есть элемент 42 оценки движения может искать опорные изображения для опорного блока, который наиболее близко совпадает с текущим блоком. Это может привести к информации движения, включающей в себя вектор движения, ссылающийся на опорный блок, а также опорное изображение, в котором находится опорный блок. Таким образом, элемент 44 компенсации движения видеокодера 20 может прогнозировать текущий блок с использованием вектора движения, который указывает на одно из опорных изображений (204).
Видеокодер 20 также может кодировать вектор движения, например, с использованием усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (ТMVP) или режима слияния. Более конкретно, видеокодер 20 может определять набор доступных кандидатов предиктора вектора движения (206). Например, со ссылкой на Фиг. 10, видеокодер 20 может определять, доступны ли векторы движения для соседних блоков А0, А1, В0, В1 и В2. Более конкретно, в соответствии со способами настоящего раскрытия, видеокодер 20 может определять, что вектор движения одного из соседних блоков недоступен, когда вектор движения соседнего блока имеет тип, отличный от вектора движения текущего блока. Подобным образом, видеокодер 20 может определять, ссылается ли вектор движения для кандидата временного предиктора вектора движения на другой тип опорного изображения, чем вектор движения для текущего блока в определении того, доступен ли кандидат TMVP для использования в качестве предиктора кодирования вектора движения текущего блока.
Как объяснено выше, примеры различных типов векторов движения включают в себя долгосрочные векторы движения, краткосрочные векторы движения, временные векторы движения и векторы движения диспаратности. Таким образом, видеокодер 20 может определять тип вектора движения текущего блока, а также типы векторов движения соседних блоков и определять, что векторы движения соседних блоков типов, отличных от типа текущего вектора движения текущего блока, недоступны для использования в качестве предикторов вектора движения для текущего вектора движения. Для определения типов видеокодер 20 может ссылаться на значения РОС опорных изображений, на которые ссылаются кандидаты векторов движения, значение POC опорного изображения, на которое ссылается текущий вектор движения, идентификаторы второй размерности опорных изображений, на которые ссылаются кандидаты векторов движения, и/или идентификатор второй размерности опорного изображения, на который ссылается текущий вектор движения.
Далее, видеокодер 20 может выбирать один из доступных кандидатов предиктора вектора движения из соседнего блока (который может включать в себя так называемый совмещенный блок в ранее закодированном изображении и/или соответствующий блок в изображении другого вида) в качестве предиктора вектора движения для текущего вектора движения (208). Видеокодер 20 может затем кодировать текущий вектор движения с использованием выбранного предиктора вектора движения (210).
Дополнительно, видеокодер 20 может вычислять остаточный блок для текущего блока (212). Как объяснено выше по отношению к Фиг. 2, сумматор 50 может вычислять пиксельные разницы между исходным, незакодированным блоком и прогнозируемым блоком, сформированным элементом 44 компенсации движения. Элемент 52 обработки преобразования, элемент 54 квантования и элемент 56 энтропийного кодирования могут затем, соответственно, преобразовывать, квантовать и сканировать остаточный блок (214). Более конкретно, элемент 52 обработки преобразования может преобразовывать остаточный блок для воспроизведения блока коэффициентов преобразования, элемент 54 квантования может квантовать коэффициенты преобразования и элемент 56 энтропийного кодирования может сканировать квантованные коэффициенты преобразования. Элемент 56 энтропийного кодирования может затем энтропийно кодировать квантованные коэффициенты преобразования и закодированную информацию вектора движения (216).
Подобным образом, способ на Фиг. 11 представляет собой пример способа, включающего в себя кодирование значения счета порядка изображения (POC) для первого изображения видеоданных, кодирование идентификатора изображения второй размерности для первого изображения и кодирование, в соответствии с базовой спецификацией видеокодирования (или расширением базовой спецификации видеокодирования), второго изображения на основании, по меньшей мере, частично, значения РОС и идентификатора изображения второй размерности первого изображения. Дополнительно, способ может включать в себя запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения, причем первый вектор движения ссылается на краткосрочное опорное изображение, и вторым вектором движения второго блока второго изображения, причем второй вектор движения ссылается на долгосрочное опорное изображение. Дополнительно или альтернативно, способ может включать в себя запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения, причем первый вектор движения ссылается на межвидовое опорное изображение, и вторым вектором движения второго блока второго изображения, причем второй вектор движения ссылается на временное опорное изображение.
Фиг. 12 является блок-схемой, изображающей пример способа декодирования видеоданных в соответствии со способами настоящего раскрытия. Этапы в примере способа на Фиг. 12 могут, альтернативно, быть выполнены в другом порядке либо существенно параллельно, в некоторых примерах. Подобным образом, конкретные этапы могут быть опущены, и/или другие этапы могут быть добавлены. Хотя в описании это выполняет видеодекодер 30, необходимо понимать, что другие устройства декодирования видео могут быть выполнены с возможностью выполнять существенно похожий способ.
В данном примере, видеодекодер 30 декодирует значения счета порядка изображения (POC) опорных изображений для текущего изображения (230). Например, видеодекодер 30 может декодировать значения РОС или данные, представляющие собой значения РОС (как, например, младшие биты (LSB)), для конкретных опорных изображений в структуре данных набора параметров последовательности (SPS) для последовательности, включающей в себя текущее изображение. Видеодекодер 30 может восстанавливать значения РОС из декодированных LSB для значений РОС путем присоединения LSB к соответствующим MSB, извлеченным, например, из ранее декодированноого полного значения РОС. Видеодекодер 30 может также, дополнительно или альтернативно, декодировать значения РОС для одного или нескольких опорных изображений в заголовке текущего слайса текущего изображения. В некоторых примерах, видеодекодер 30 может декодировать данные, представляющие собой значения РОС долгосрочных опорных изображений, в SPS, и значения РОС краткосрочных опорных изображений, в заголовке слайса. Видеодекодер 30 может также декодировать значения РОС межвидовых опорных изображений, например, в SPS, заголовке слайса или в другом месте. В общем, значения РОС межвидовых опорных изображений являются теми же, что и значение РОС текущего изображения, которое кодируют.
Видеодекодер 30 также может декодировать идентификаторы второй размерности опорных изображений (232). Идентификаторы второй размерности могут включать в себя один или несколько идентификаторов вида для видов, включающих в себя опорные изображения, индексы порядка вида для видов, включающих в себя опорные изображения, комбинацию индексов порядка вида и флагов глубины, идентификаторы уровня для уровней масштабируемого Видеокодирования (SVC), включающих в себя опорные изображения, и/или общие идентификаторы уровня. Таким образом, комбинация значения РОС для опорного изображения и двумерный идентификатор для опорного изображения могут быть использованы для идентификации опорного изображения. Таким образом, для идентификации опорного изображения, информация движения может включать в себя значение РОС и идентификатор изображения второй размерности для опорного изображения.
Видеодекодер 30 также может декодировать вектор движения для текущего блока текущего изображения. Более конкретно, видеодекодер 30 может определять набор доступных кандидатов предиктора вектора движения (234). Например, со ссылкой на Фиг. 10, видеодекодер 30 может определять, доступны ли векторы движения для соседних блоков А0, А1, В0, В1 и В2. Более конкретно, в соответствии со способами настоящего раскрытия, видеодекодер 30 может определять, что вектор движения одного из этих соседних блоков недоступен, когда вектор движения соседнего блока имеет тип, отличный от вектора движения текущего блока. Подобным образом, видеодекодер 30 может определять, ссылается ли вектор движения для кандидата временного предиктора вектора движения на другой тип опорного изображения, чем вектор движения для текущего блока в определении того, доступен ли кандидат TMVP для использования в качестве предиктора кодирования вектора движения текущего блока.
Как объяснено выше, примеры различных типов векторов движения включают в себя долгосрочные векторы движения, краткосрочные векторы движения, временные векторы движения, и векторы движения диспаратности. Таким образом, видеодекодер 30 может определять тип вектора движения текущего блока, а также типы векторов движения соседних блоков и определять, что векторы движения соседних блоков типов, отличных от типа текущего вектора движения текущего блока, недоступны для использования в качестве предикторов вектора движения для текущего вектора движения. Для определения типов, видеодекодер 30 может ссылаться на значения РОС опорных изображений, на которые ссылаются кандидаты векторов движения, значение РОС опорного изображения, на которое ссылается текущий вектор движения, идентификаторы второй размерности опорных изображений, на которые ссылаются кандидаты векторов движения, и/или идентификатор второй размерности опорного изображения, на который ссылается текущий вектор движения.
Далее, видеодекодер 30 может выбирать один из доступных кандидатов предиктора вектора движения из соседнего блока (который может включать в себя так называемый совмещенный блок в ранее закодированном изображении и/или соответствующий блок в изображении другого вида) в качестве предиктора вектора движения для текущего вектора движения (236). Видеодекодер 30 может затем декодировать текущий вектор движения с использованием выбранного предиктора вектора движения (238). Например, с использованием AMVP, видеодекодер 30 может декодировать значения разницы (MVD) векторов движения для текущего вектора движения, затем применять значения MVD к выбранному предсказателю вектора движения. То есть видеодекодер 30 может добавлять х-компоненту значения MVD к х-компоненте выбранного предиктора вектора движения и у-компоненту значения MVD к у-компоненте выбранного предиктора вектора движения.
Элемент 72 компенсации движения видеодекодера 30 может затем прогнозировать текущий блок с использованием вектора движения, который указывает на одно из опорных изображений (240). То есть в дополнение к самому вектору движения, видеодекодер 30 может декодировать информацию идентификации опорного изображения для блока, которому соответствует вектор движения, как, например, значение РОС и значение идентификатора второй размерности. Таким образом, видеодекодер 30 может определять опорное изображение, на которое указывает вектор движения, с использованием значения РОС и значения идентификатора второй размерности. Соответственно, элемент 72 компенсации движения может формировать прогнозируемый блок для текущего блока с использованием вектора движения и информации идентификации опорного изображения, то есть значения РОС и значения идентификатора второй размерности.
Элемент 70 энтропийного декодирования может дополнительно декодировать квантованные коэффициенты преобразования для остаточного блока, соответствующего текущему блоку (242). Элемент 70 энтропийного декодирования, элемент 76 обратного квантования и элемент 78 обратного преобразования, соответственно, обратно сканируют, квантуют и преобразуют квантованные коэффициенты преобразования для воспроизведения остаточного блока (244). Сумматор 80 видеодекодера 30 может затем комбинировать (то есть добавлять на пиксельной основе) прогнозируемый блок и остаточный блок для воспроизведения текущего блока (246).
Подобным образом, способ на Фиг. 12 представляет собой пример способа, включающего в себя декодирование значения счета порядка изображения (POC) для первого изображения видеоданных, декодирование идентификатора изображения второй размерности для первого изображения и декодирование, в соответствии с базовой спецификацией видеокодирования (или расширением базовой спецификации видеокодирования), второго изображения на основании, по меньшей мере, частично, значения РОС и идентификатора изображения второй размерности первого изображения. Дополнительно, способ может включать в себя запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения, причем первый вектор движения ссылается на краткосрочное опорное изображение, и вторым вектором движения второго блока второго изображения, причем второй вектор движения ссылается на долгосрочное опорное изображение. Дополнительно или альтернативно, способ может включать в себя запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения, причем первый вектор движения ссылается на межвидовое опорное изображение, и вторым вектором движения второго блока второго изображения, причем второй вектор движения ссылается на временное опорное изображение.
Необходимо признать, что, в зависимости от примера, конкретные действия или события любого из способов, описанных в настоящем документе, могут быть выполнены в другой последовательности, могут быть добавлены, соединены или пропущены (например, не все описанные действия или события необходимы для осуществления способов). Более того, в конкретных примерах, действия или события могут быть выполнены параллельно, а не последовательно, например, с помощью многопотоковой обработки, обработки прерываний или множества процессоров.
В одном или нескольких примерах, описанные функции могут быть осуществлены в технических средствах, программном обеспечении, программно-аппаратных средствах или их комбинации. При осуществлении в программном обеспечении, функции могут храниться или передаваться в качестве одной или нескольких команд или кода на считываемом компьютером носителе и выполняться элементом обработки технических средств. Считываемые компьютером носители могут включать в себя считываемые компьютером носители данных, которые соответствуют физическому носителю, как, например, средства хранения данных, или средствам связи, включающие в себя любой носитель, который облегчает передачу компьютерной программы из одного места в другое, например, в соответствии с протоколом связи. Таким образом, считываемые компьютером носители, в общем, могут соответствовать (1) физическим считываемым компьютерам носителям данных, которые являются энергонезависимыми, или (2) средствам связи, как, например, сигнал или несущая волна. Средства хранения данных могут быть любыми доступными носителями, доступ к которым может быть осуществлен одним или несколькими компьютерами или одним или несколькими процессорами для извлечения команд, кода и/или структур данных для осуществления способов, описанных в настоящем раскрытии. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
Для примера, но не ограничения, такие считываемые компьютером носители данных могут содержать RAM, ROM, EEPROM, CD-ROM или другие хранилища на оптических дисках, хранилища на магнитных дисках, или другие магнитные устройства хранения, флэш-память, или любой другой носитель, который может быть использован для хранения желаемого программного кода в форме команд или структур данных, и доступ к которому может быть осуществлен компьютером. Также, любое соединение правильно называть считываемый компьютером носитель. Например, если инструкции передаются с вебсайта, сервера иди другого удаленного источника с использованием коаксиального кабеля, оптоволоконного кабеля, витой пары, цифровой абонентской линии (DSL), или беспроводных технологий, как, например, инфракрасная, радио и микроволновая, то коаксиальный кабель, оптоволоконный кабель, витая пара, цифровая абонентская линия (DSL), или беспроводные технологии, как, например, инфракрасная, радио и микроволновая, включены в определение носителя. Необходимо понимать, однако, что считываемые компьютером носители данных и средства хранения данных не включают в себя соединения, несущие волны, сигналы и другие энергозависимые носители, но, напротив, направлены на энергонезависимые, физические носители данных. Диск [disk] и диск [disc], как использовано в настоящем документе, включает в себя компактный диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий диск и диск Blu-ray, где диски [disks] обычно воспроизводят данные магнитным образом, в то время как диски [discs] воспроизводят данные оптически с помощью лазеров. Комбинации вышеуказанного также должны быть включены в объем считываемых компьютером носителей.
Инструкции могут быть выполнены одним или несколькими процессорами, как, например, один или несколько цифровых сигнальных процессоров (DSP), микропроцессоров общего назначения, специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA) или других эквивалентных интегральных или дискретных логических схем. Соответственно, термин «процессор», как использовано в настоящем документе, может относиться к любой из вышеуказанных структур или любой другой структуре, подходящей для осуществления способов, описанных в настоящем документе. Дополнительно, в некоторых аспектах, функциональность, описанная в настоящем документе, может быть обеспечена внутри закрепленных технических средств и/или модулей программного обеспечения, выполненных с возможностью кодировать и декодировать, либо встроенных в комбинированный кодек. Также, способы могут быть полностью осуществлены в одной или нескольких схемах или логических элементах.
Способы настоящего раскрытия могут быть осуществлены в многообразных устройствах или приборах, включающих в себя беспроводную трубку, интегральную схему (IC) или группу IC (например, комплект микросхем). Различные компоненты, модули или элементы описаны в настоящем раскрытии для акцента на функциональных аспектах устройств, выполненных с возможностью выполнять раскрытые способы, но необязательно требующих реализации в различных элементах технических средств. Скорее наоборот, как описано выше, различные элементы могут быть скомбинированы в элементе технических средств кодека или обеспечены в совокупности взаимодействующих элементов технических средств, включая один или несколько процессоров, как описано выше, совместно с подходящим программным обеспечением и/или программно-аппаратными средствами.
Описаны различные примеры. Эти и другие примеры находятся в пределах объема формулы изобретения.
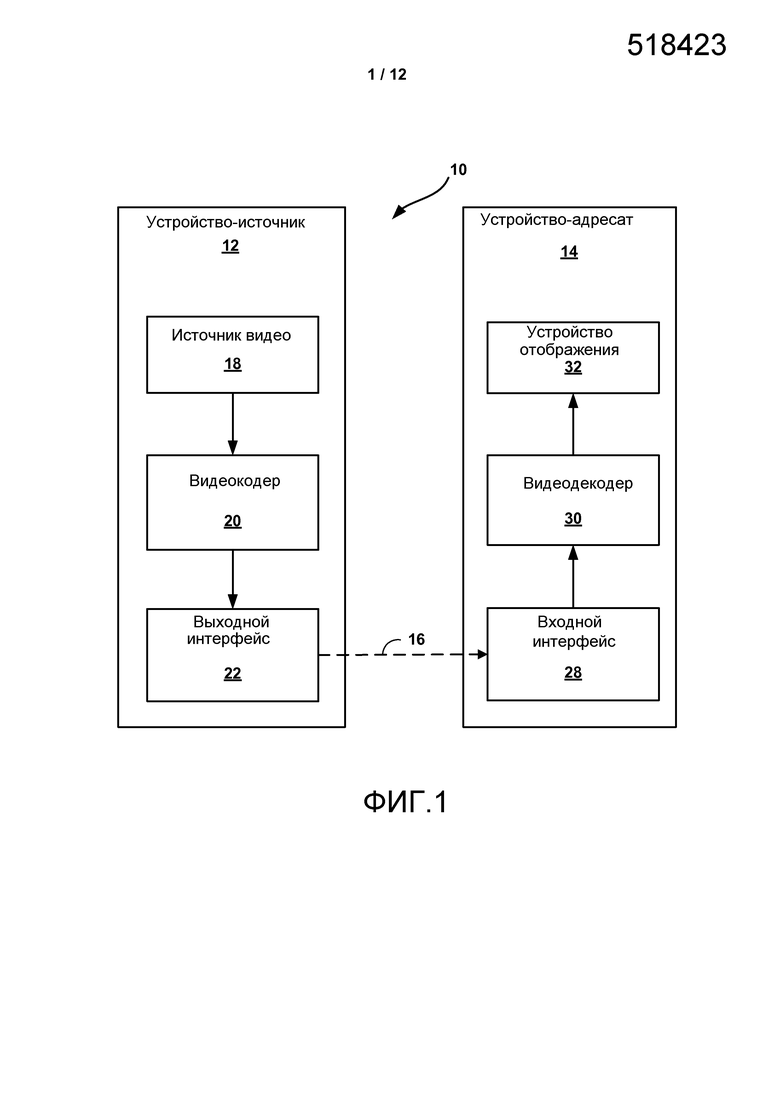
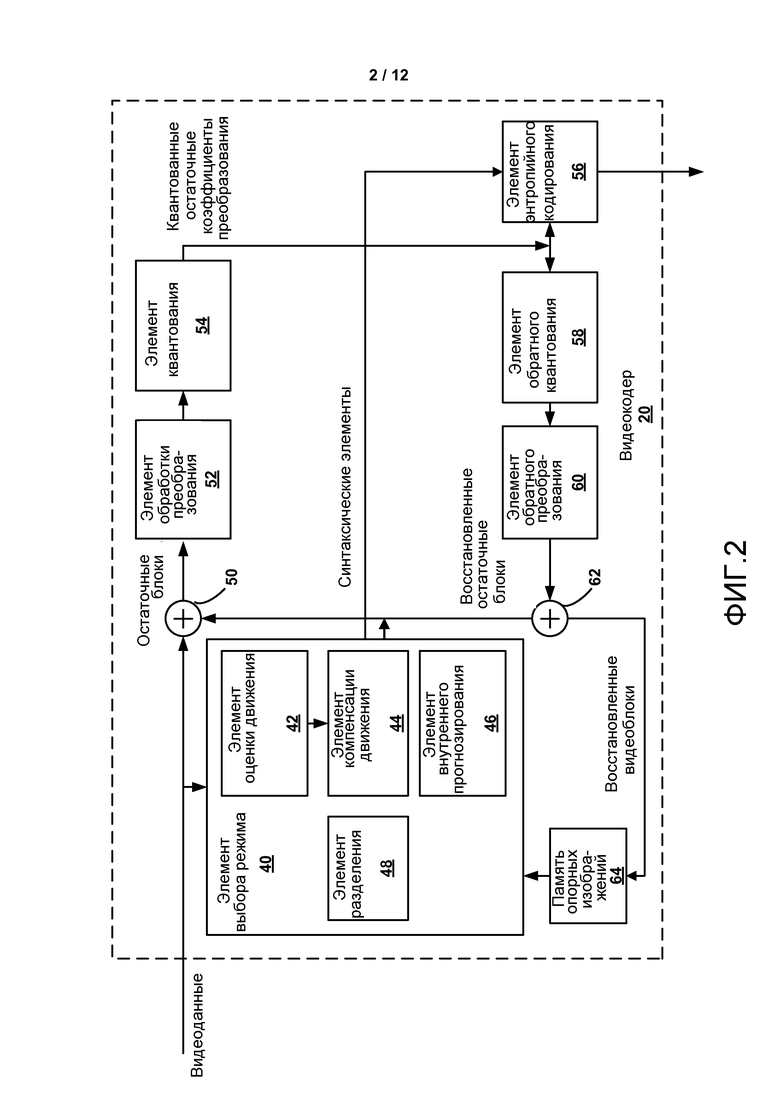
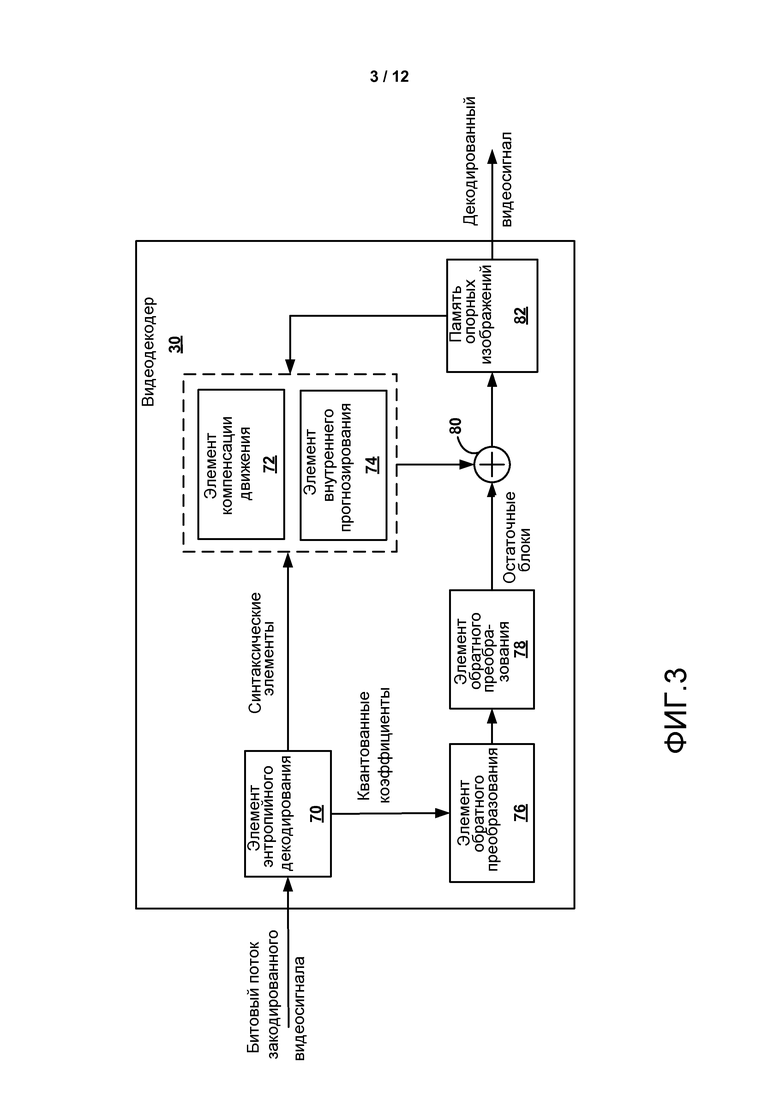
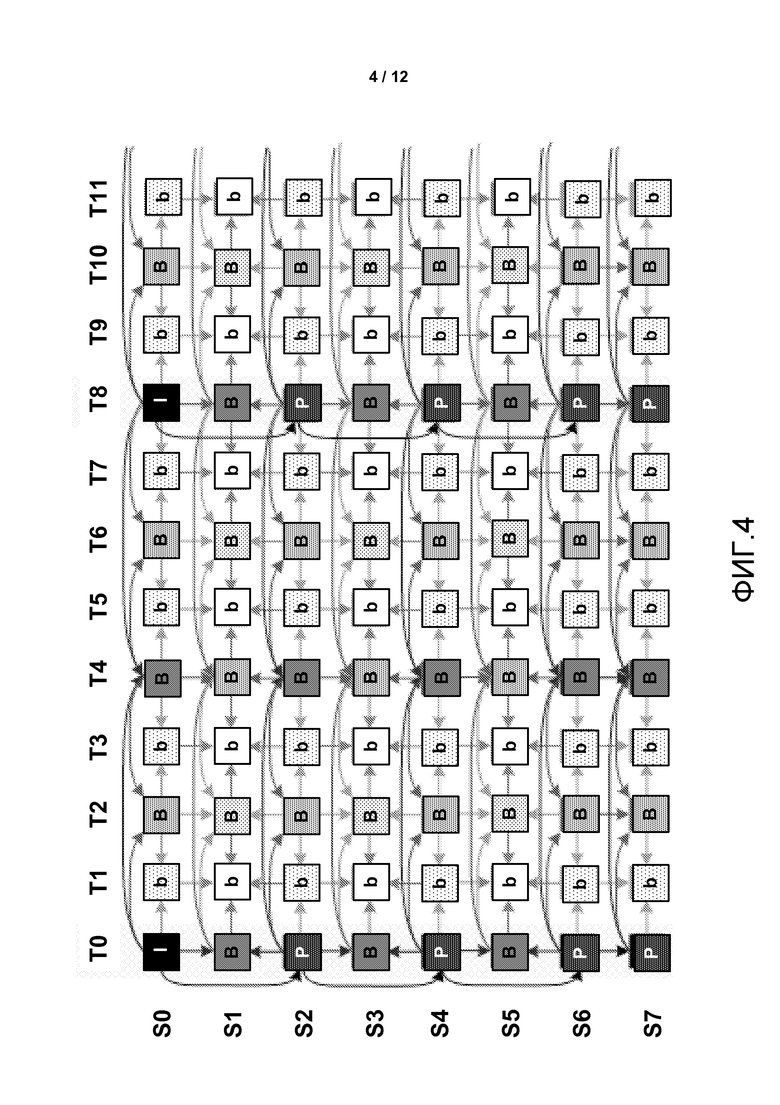
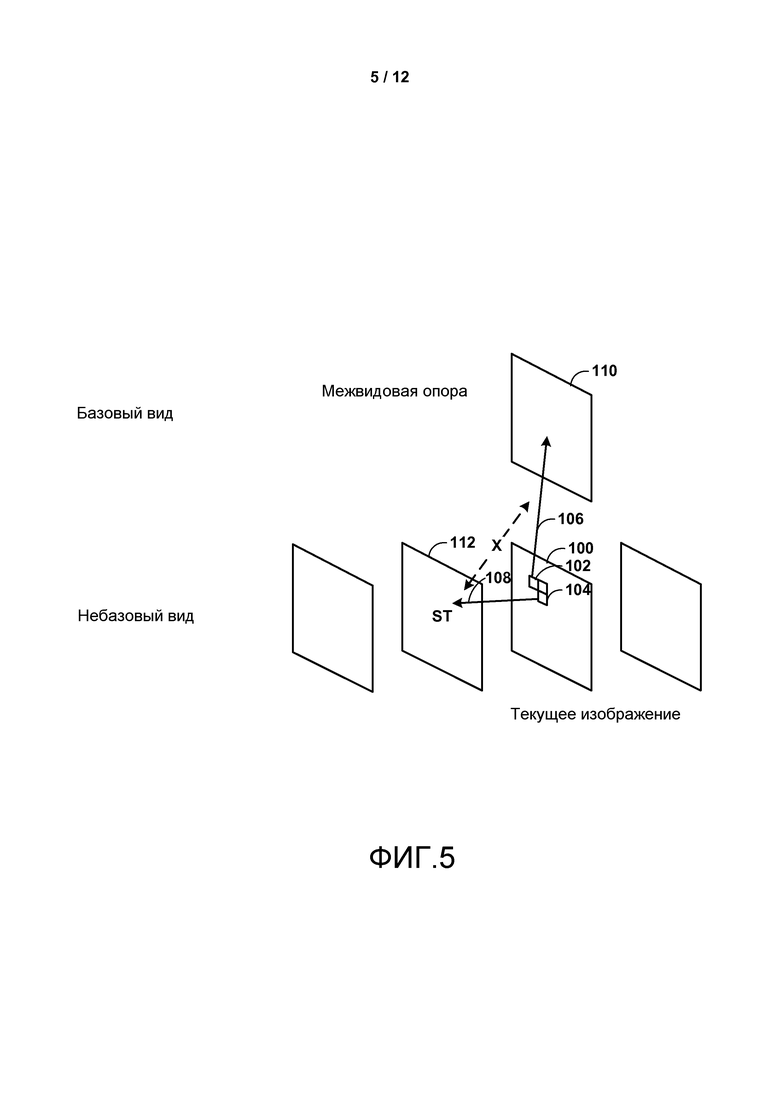
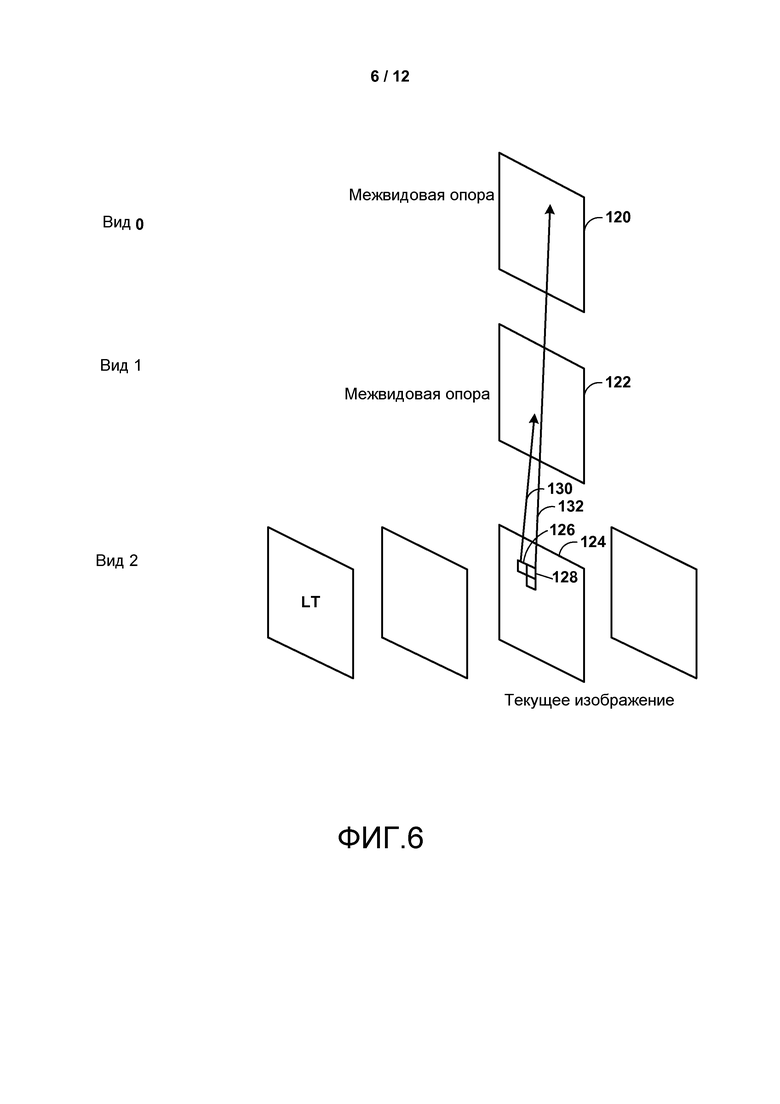
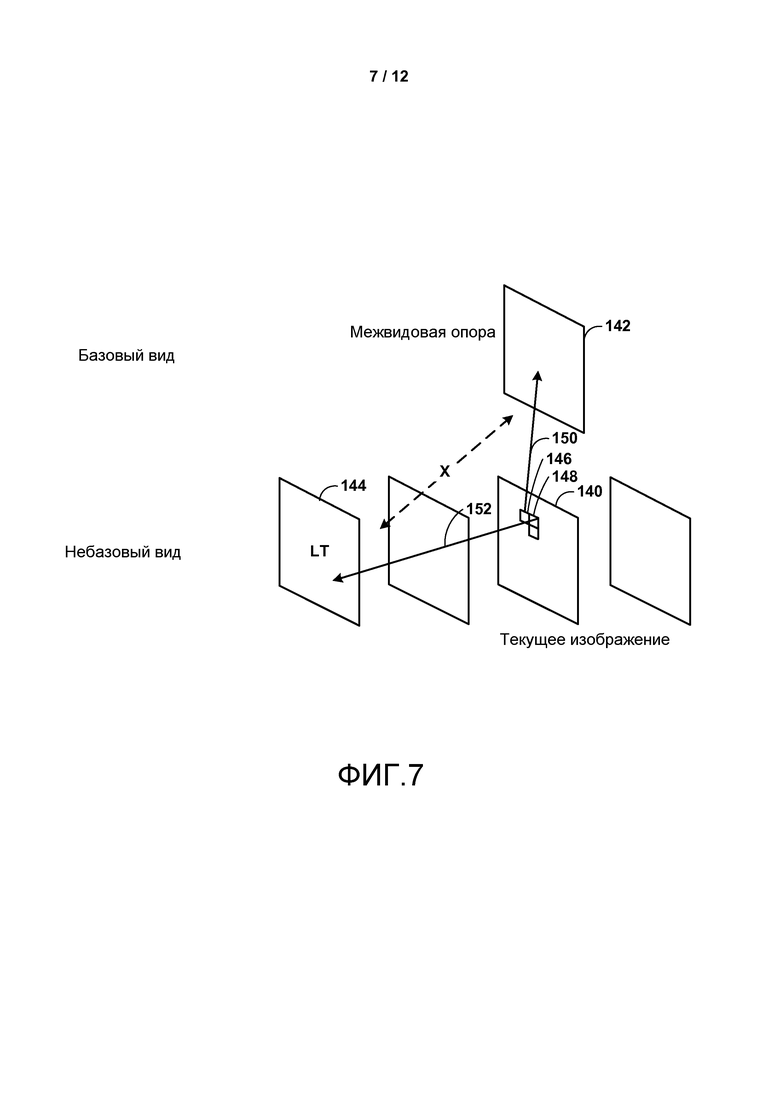
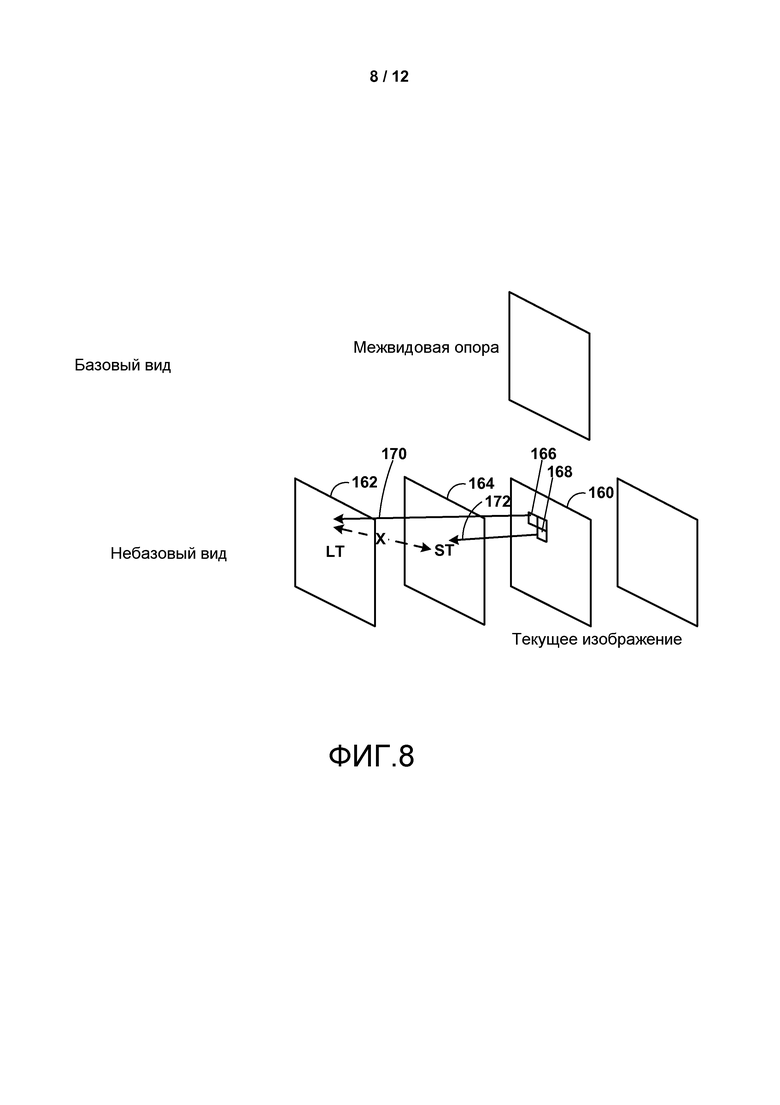
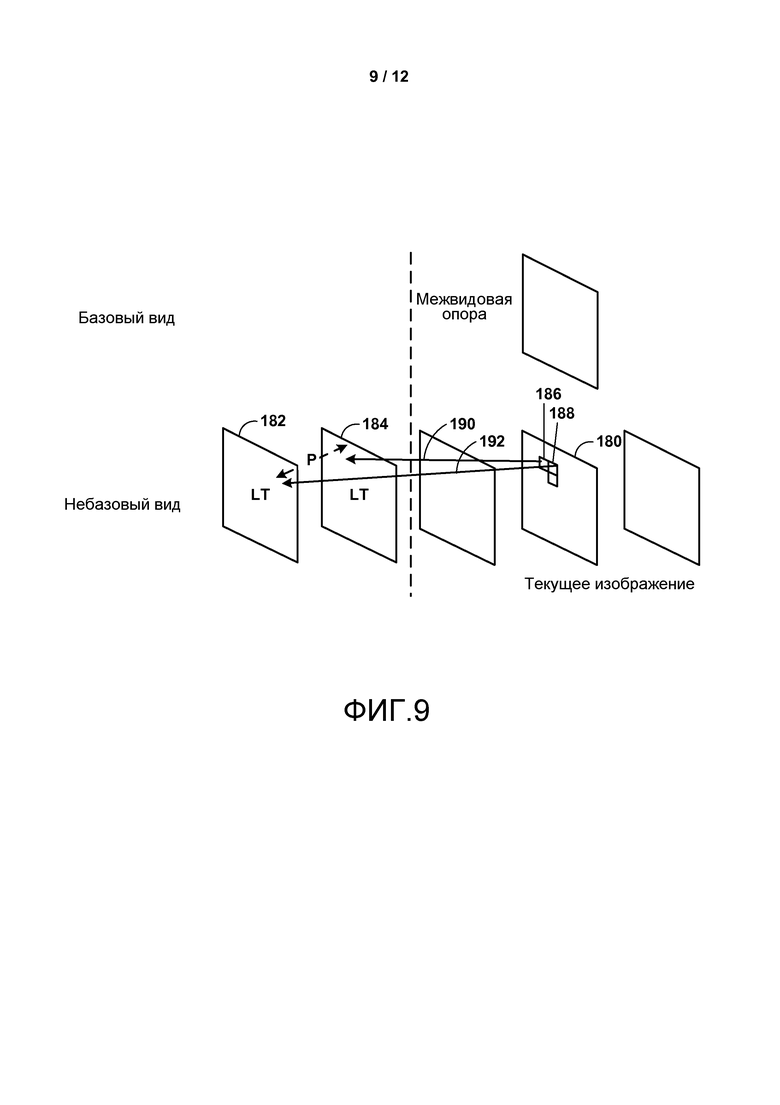
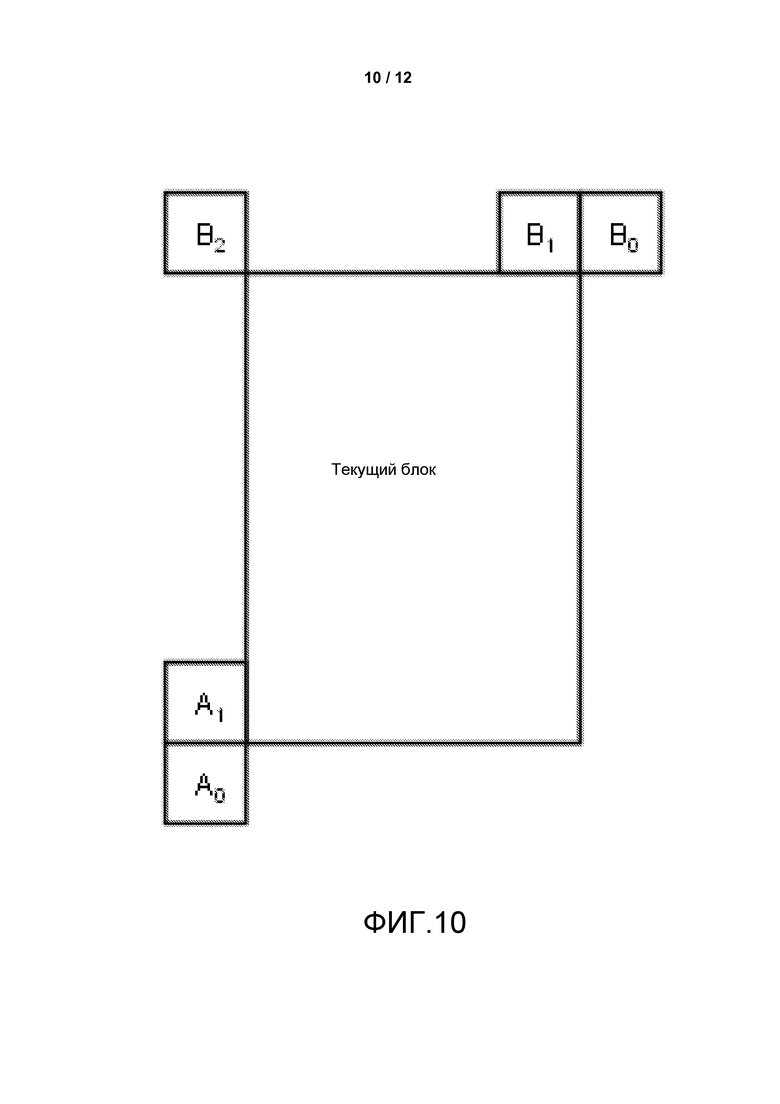
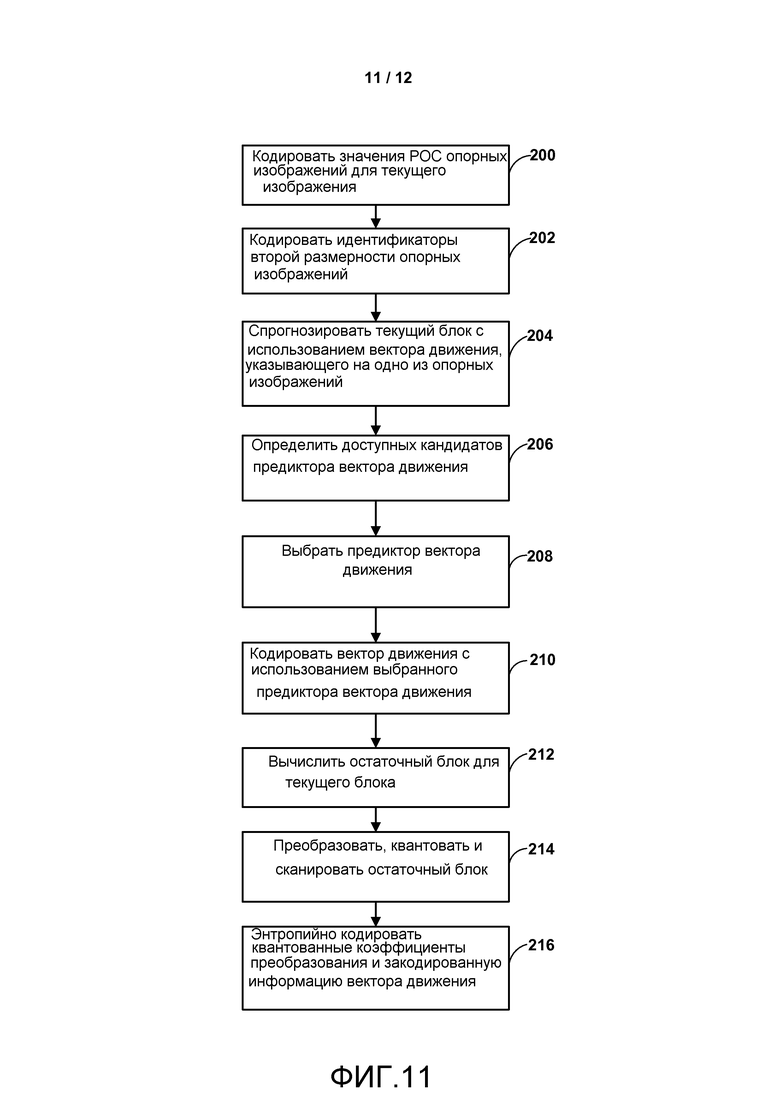
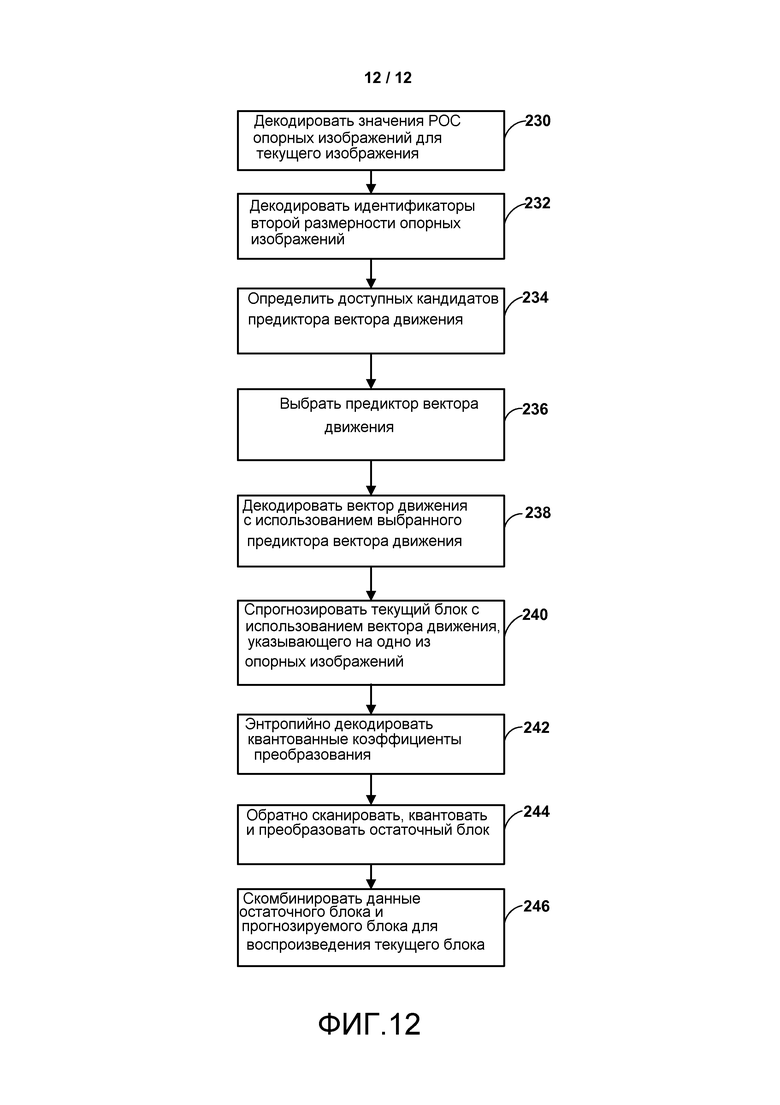
Изобретение относится к области кодирования/декодирования видео. Технический результат – повышение эффективности кодирования/декодирования видеоданных посредством запрета прогнозирования вектора движения. Способ декодирования видеоданных содержит декодирование данных второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных; декодирование данных второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения; декодирование второго изображения на основании значения РОС и идентификатора изображения второй размерности первого изображения; определение, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение; определение, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение; и на основе определения запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения. 6 н. и 37 з.п. ф-лы, 12 ил.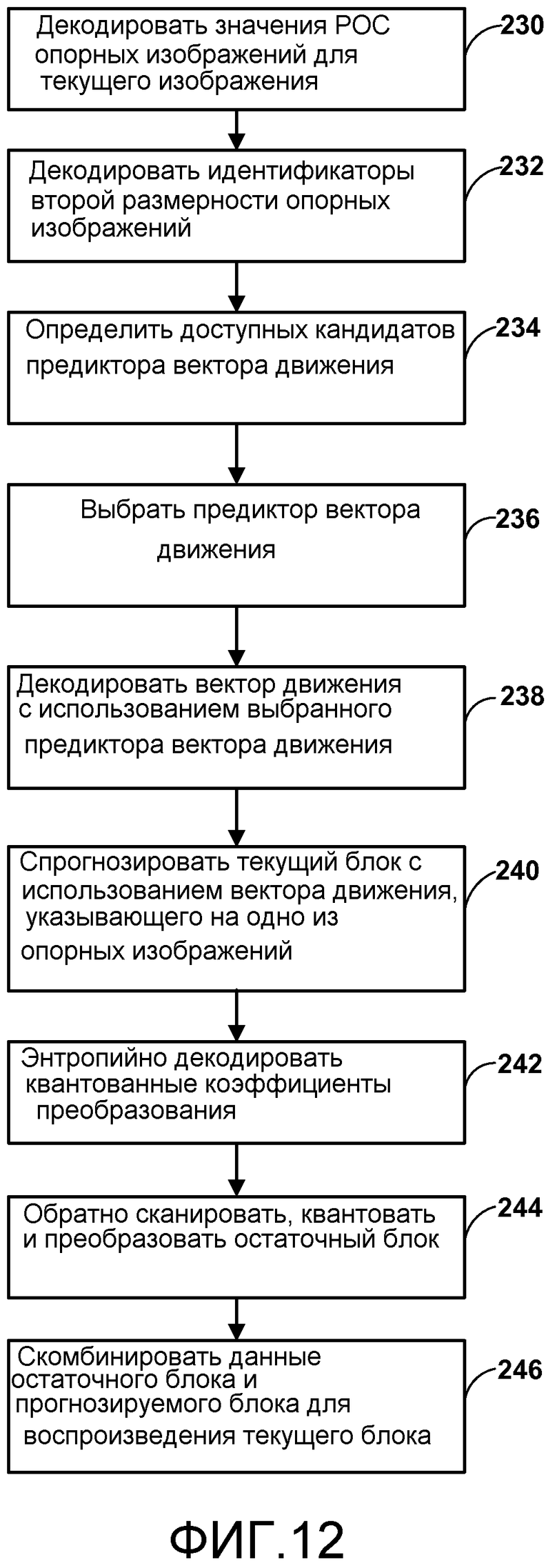
1. Способ декодирования видеоданных, содержащий:
декодирование данных второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных;
декодирование данных второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения, при этом идентификатор изображения второй размерности содержит по меньшей мере одно из идентификатора вида для вида, включающего в себя первое изображение, индекса порядка вида для вида, включающего в себя первое изображение, комбинации индекса порядка вида и флага глубины, идентификатора уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и общего идентификатора уровня;
декодирование, в соответствии с базовой спецификацией видеокодирования, второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения;
определение, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение, при этом краткосрочное опорное изображение связано с данными, маркирующими краткосрочное опорное изображение в качестве используемого для краткосрочной ссылки;
определение, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение, при этом долгосрочное опорное изображение связано с данными, маркирующими долгосрочное опорное изображение в качестве используемого для долгосрочной ссылки; и
на основе определения, что первый вектор движения ссылается на краткосрочное опорное изображение, и определения, что второй вектор движения ссылается на долгосрочное опорное изображение, запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения, при этом первый блок и второй блок являются пространственными соседями во втором изображении, и при этом запрет прогнозирования вектора движения между первым вектором движения и вторым вектором движения содержит декодирование первого вектора движения без использования второго вектора движения для прогнозирования первого вектора движения и декодирование второго вектора движения без использования первого вектора движения для прогнозирования второго вектора движения.
2. Способ по п. 1, в котором декодирование второго изображения содержит:
идентификацию первого изображения с использованием значения РОС и идентификатора изображения второй размерности; и
декодирование по меньшей мере части второго изображения относительно первого изображения.
3. Способ по п. 2, в котором идентификация первого изображения содержит идентификацию первого изображения во время декодирования вектора движения для блока второго изображения, при этом декодирование вектора движения содержит декодирование вектора движения согласно по меньшей мере одному из усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (TMVP) и режима слияния.
4. Способ по п. 1, дополнительно содержащий:
разрешение прогнозирования между первым краткосрочным вектором движения второго изображения и вторым краткосрочным вектором движения второго изображения; и
масштабирование по меньшей мере одного из первого краткосрочного вектора движения и второго краткосрочного вектора движения на основании значения РОС для первого краткосрочного опорного изображения, на которое ссылается первый краткосрочный вектор движения, и значения РОС для второго краткосрочного опорного изображения, на которое ссылается второй краткосрочный вектор движения.
5. Способ по п. 1, дополнительно содержащий декодирование значения, указывающего, содержит ли третье изображение видеоданных долгосрочное опорное изображение, при этом значение, указывающее, содержит ли третье изображение долгосрочное опорное изображение, дополнительно указывает, используется ли третье изображение для межвидового прогнозирования.
6. Способ по п. 1, дополнительно содержащий декодирование, в соответствии с расширением базовой спецификации видеокодирования, третьего изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
7. Способ по п. 6, дополнительно содержащий до декодирования третьего изображения маркировку всех межвидовых опорных изображений, в том числе первого изображения, в качестве долгосрочных опорных изображений.
8. Способ по п. 7, дополнительно содержащий:
сохранение статуса для каждого из межвидовых опорных изображений для третьего изображения, при этом статус содержит одно из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки, до маркировки межвидовых опорных изображений в качестве долгосрочных опорных изображений, при этом межвидовые опорные изображения включают в себя первое изображение; и
после декодирования второго изображения установку новых статусов для каждого из межвидовых опорных изображений на основании сохраненных статусов.
9. Способ по п. 6, в котором базовая спецификация видеокодирования содержит базовую спецификацию Высокоэффективного Видеокодирования (HEVC) и в котором расширение базовой спецификации видеокодирования содержит одно из расширения Масштабируемого Видеокодирования (SVC) для базовой спецификации HEVC и расширения Многовидового Видеокодирования (MVC) для базовой спецификации HEVC.
10. Способ по п. 6, дополнительно содержащий после декодирования третьего изображения маркировку каждого межвидового опорного изображения в качестве одного из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки.
11. Способ по п. 10, дополнительно содержащий:
после маркировки межвидового опорного изображения в качестве долгосрочного опорного изображения назначение межвидовому опорному изображению нового значения РОС, которое в текущий момент является неиспользуемым; и
после декодирования второго изображения восстановление исходного значения РОС для межвидового опорного изображения.
12. Способ по п. 11, в котором исходное значение РОС содержит значение РОС первого изображения.
13. Способ кодирования видеоданных, содержащий:
кодирование данных второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных;
кодирование данных второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения, при этом идентификатор изображения второй размерности содержит по меньшей мере одно из идентификатора вида для вида, включающего в себя первое изображение, индекса порядка вида для вида, включающего в себя первое изображение, комбинации индекса порядка вида и флага глубины, идентификатора уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и общего идентификатора уровня;
кодирование, в соответствии с базовой спецификацией видеокодирования, второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения;
определение, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение, при этом краткосрочное опорное изображение связано с данными, маркирующими краткосрочное опорное изображение в качестве используемого для краткосрочной ссылки;
определение, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение, при этом долгосрочное опорное изображение связано с данными, маркирующими долгосрочное опорное изображение в качестве используемого для долгосрочной ссылки; и
на основе определения, что первый вектор движения ссылается на краткосрочное опорное изображение, и определения, что второй вектор движения ссылается на долгосрочное опорное изображение, запрет прогнозирования вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения, при этом первый блок и второй блок являются пространственными соседями во втором изображении, и при этом запрет прогнозирования вектора движения между первым вектором движения и вторым вектором движения содержит кодирование первого вектора движения без использования второго вектора движения для прогнозирования первого вектора движения и кодирование второго вектора движения без использования первого вектора движения для прогнозирования второго вектора движения.
14. Способ по п. 13, дополнительно содержащий:
идентификацию первого изображения с использованием значения РОС и идентификатора изображения второй размерности; и
кодирование по меньшей мере части второго изображения относительно первого изображения.
15. Способ по п. 14, в котором идентификация первого изображения содержит идентификацию первого изображения во время кодирования вектора движения для блока второго изображения, при этом кодирование вектора движения содержит кодирование вектора движения согласно по меньшей мере одному из усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (TMVP) и режима слияния.
16. Способ по п. 13, дополнительно содержащий:
разрешение прогнозирования между первым краткосрочным вектором движения второго изображения и вторым краткосрочным вектором движения второго изображения; и
масштабирование по меньшей мере одного из первого краткосрочного вектора движения и второго краткосрочного вектора движения на основании значения РОС для первого краткосрочного опорного изображения, на которое ссылается первый краткосрочный вектор движения, и значения РОС для второго краткосрочного опорного изображения, на которое ссылается второй краткосрочный вектор движения.
17. Способ по п. 13, дополнительно содержащий кодирование значения, указывающего, содержит ли третье изображение видеоданных долгосрочное опорное изображение, при этом значение, указывающее, содержит ли третье изображение долгосрочное опорное изображение, дополнительно указывает, используется ли третье изображение для межвидового прогнозирования.
18. Способ по п. 13, дополнительно содержащий кодирование, в соответствии с расширением базовой спецификации видеокодирования, третьего изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
19. Способ по п. 18, дополнительно содержащий до кодирования третьего изображения маркировку всех межвидовых опорных изображений в качестве долгосрочных опорных изображений.
20. Способ по п. 19, дополнительно содержащий:
сохранение статуса для каждого из межвидовых опорных изображений, при этом статус содержит одно из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки, до маркировки межвидовых опорных изображений в качестве долгосрочных опорных изображений; и
после кодирования второго изображения установку новых статусов для каждого из межвидовых опорных изображений на основании сохраненных статусов.
21. Способ по п. 18, в котором базовая спецификация видеокодирования содержит базовую спецификацию Высокоэффективного Видеокодирования (HEVC) и в котором расширение базовой спецификации видеокодирования содержит одно из расширения Масштабируемого Видеокодирования (SVC) для базовой спецификации HEVC и расширения Многовидового Видеокодирования (MVC) для базовой спецификации HEVC.
22. Способ по п. 21, дополнительно содержащий после кодирования третьего изображения маркировку каждого межвидового опорного изображения в качестве одного из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки.
23. Способ по п. 22, дополнительно содержащий:
после маркировки межвидового опорного изображения в качестве долгосрочного опорного изображения назначение межвидовому опорному изображению нового значения РОС, которое в текущий момент является неиспользуемым; и
после кодирования второго изображения восстановление исходного значения РОС для межвидового опорного изображения.
24. Способ по п. 23, в котором исходное значение РОС содержит значение РОС второго изображения.
25. Устройство декодирования видеоданных, содержащее:
память, выполненную с возможностью хранения видеоданных; и
видеодекодер, выполненный с возможностью:
декодирования данных второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных,
декодирования данных второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения, при этом идентификатор изображения второй размерности содержит по меньшей мере одно из идентификатора вида для вида, включающего в себя первое изображение, индекса порядка вида для вида, включающего в себя первое изображение, комбинации индекса порядка вида и флага глубины, идентификатора уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и общего идентификатора уровня,
декодирования, в соответствии с базовой спецификацией видеокодирования, второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения,
определения, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение, при этом краткосрочное опорное изображение связано с данными, маркирующими краткосрочное опорное изображение в качестве используемого для краткосрочной ссылки,
определения, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение, при этом долгосрочное опорное изображение связано с данными, маркирующими долгосрочное опорное изображение в качестве используемого для долгосрочной ссылки, и
на основе определения, что первый вектор движения ссылается на краткосрочное опорное изображение, и определения, что второй вектор движения ссылается на долгосрочное опорное изображение, запрета прогнозирования вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения, при этом первый блок и второй блок являются пространственными соседями во втором изображении, и при этом для запрета прогнозирования вектора движения между первым вектором движения и вторым вектором движения видеодекодер выполнен с возможностью декодирования первого вектора движения без использования второго вектора движения для прогнозирования первого вектора движения и декодирования второго вектора движения без использования первого вектора движения для прогнозирования второго вектора движения.
26. Устройство по п. 25, в котором видеодекодер выполнен с возможностью идентифицировать первое изображение с использованием значения РОС и идентификатора изображения второй размерности и декодировать по меньшей мере часть второго изображения относительно первого изображения.
27. Устройство по п. 26, в котором видеодекодер выполнен с возможностью идентифицировать первое изображение во время декодирования вектора движения для блока второго изображения и в котором видеодекодер выполнен с возможностью декодировать вектор движения согласно по меньшей мере одному из усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (TMVP) и режима слияния.
28. Устройство по п. 25, в котором видеодекодер выполнен с возможностью разрешать прогнозирование между первым краткосрочным вектором движения второго изображения и вторым краткосрочным вектором движения второго изображения и масштабировать по меньшей мере один из первого краткосрочного вектора движения и второго краткосрочного вектора движения на основании значения РОС для первого краткосрочного опорного изображения, на которое ссылается первый краткосрочный вектор движения, и значения РОС для второго краткосрочного опорного изображения, на которое ссылается второй краткосрочный вектор движения.
29. Устройство по п. 25, в котором видеодекодер выполнен с возможностью декодировать значение, указывающее, содержит ли третье изображение видеоданных долгосрочное опорное изображение, при этом значение, указывающее, содержит ли третье изображение долгосрочное опорное изображение, дополнительно указывает, используется ли третье изображение для межвидового прогнозирования.
30. Устройство по п. 25, в котором видеодекодер дополнительно выполнен с возможностью декодировать, в соответствии с расширением базовой спецификации видеокодирования, третье изображение на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
31. Устройство по п. 30, в котором видеодекодер выполнен с возможностью маркировать все межвидовые опорные изображения для третьего изображения, в том числе первое изображение, в качестве долгосрочных опорных изображений до декодирования третьего изображения, сохранять статус для каждого из межвидовых опорных изображений, при этом статус содержит одно из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки, до маркировки межвидовых опорных изображений в качестве долгосрочных опорных изображений и после декодирования третьего изображения устанавливать новые статусы для каждого из межвидовых опорных изображений на основании сохраненных статусов.
32. Устройство по п. 30, в котором видеодекодер дополнительно выполнен с возможностью маркировать каждое межвидовое опорное изображение для третьего изображения, в том числе первое изображение, в качестве одного из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки после декодирования третьего изображения, назначать каждому из межвидовых опорных изображений новое значение РОС, которое в текущий момент является неиспользуемым, после маркировки межвидового опорного изображения в качестве долгосрочного опорного изображения и восстанавливать исходное значение РОС для межвидового опорного изображения после декодирования второго изображения.
33. Устройство по п. 25, в котором устройство содержит по меньшей мере одно из:
интегральной схемы;
микропроцессора; и
беспроводного устройства связи, которое включает в себя видеодекодер.
34. Устройство кодирования видеоданных, содержащее:
память, выполненную о возможностью хранения видеоданных; и
видеокодер, выполненный с возможностью:
кодирования данных второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных,
кодирования данных второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения, при этом идентификатор изображения второй размерности содержит по меньшей мере одно из идентификатора вида для вида, включающего в себя первое изображение, индекса порядка вида для вида, включающего в себя первое изображение, комбинации индекса порядка вида и флага глубины, идентификатора уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и общего идентификатора уровня,
кодирования, в соответствии с базовой спецификацией видеокодирования, второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения,
определения, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение, при этом краткосрочное опорное изображение связано с данными, маркирующими краткосрочное опорное изображение в качестве используемого для краткосрочной ссылки,
определения, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение, при этом долгосрочное опорное изображение связано с данными, маркирующими долгосрочное опорное изображение в качестве используемого для долгосрочной ссылки, и
на основе определения, что первый вектор движения ссылается на краткосрочное опорное изображение, и определения, что второй вектор движения ссылается на долгосрочное опорное изображение, запрета прогнозирования вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения, при этом первый блок и второй блок являются пространственными соседями во втором изображении, и при этом для запрета прогнозирования вектора движения между первым вектором движения и вторым вектором движения видеокодер выполнен с возможностью кодирования первого вектора движения без использования второго вектора движения для прогнозирования первого вектора движения и кодирования второго вектора движения без использования первого вектора движения для прогнозирования второго вектора движения.
35. Устройство по п. 34, в котором видеокодер выполнен с возможностью идентифицировать первое изображение с использованием значения РОС и идентификатора изображения второй размерности и кодировать по меньшей мере часть второго изображения относительно первого изображения.
36. Устройство по п. 35, в котором видеокодер выполнен с возможностью идентифицировать первое изображение во время кодирования вектора движения для блока второго изображения и в котором видеокодер выполнен с возможностью кодировать вектор движения согласно по меньшей мере одному из усовершенствованного прогнозирования вектора движения (AMVP), временного прогнозирования вектора движения (TMVP) и режима слияния.
37. Устройство по п. 34, в котором видеокодер выполнен с возможностью разрешать прогнозирование между первым краткосрочным вектором движения второго изображения и вторым краткосрочным вектором движения второго изображения и масштабировать по меньшей мере один из первого краткосрочного вектора движения и второго краткосрочного вектора движения на основании значения РОС для первого краткосрочного опорного изображения, на которое ссылается первый краткосрочный вектор движения, и значения РОС для второго краткосрочного опорного изображения, на которое ссылается второй краткосрочный вектор движения.
38. Устройство по п. 34, в котором видеокодер выполнен с возможностью кодировать значение, указывающее, содержит ли третье изображение видеоданных долгосрочное опорное изображение, при этом значение, указывающее, содержит ли третье изображение долгосрочное опорное изображение, дополнительно указывает, используется ли третье изображение для межвидового прогнозирования.
39. Устройство по п. 34, в котором видеокодер дополнительно выполнен с возможностью кодировать, в соответствии с расширением базовой спецификации видеокодирования, третье изображение на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения.
40. Устройство по п. 39, в котором видеокодер выполнен с возможностью маркировать все межвидовые опорные изображения для третьего изображения, в том числе первое изображение, в качестве долгосрочных опорных изображений до кодирования третьего изображения, сохранять статус для каждого из межвидовых опорных изображений, при этом статус содержит одно из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки, до маркировки межвидовых опорных изображений в качестве долгосрочных опорных изображений и после кодирования третьего изображения устанавливать новые статусы для каждого из межвидовых опорных изображений на основании сохраненных статусов.
41. Устройство по п. 39, в котором видеокодер дополнительно выполнен с возможностью маркировать каждое межвидовое опорное изображение для третьего изображения, в том числе первое изображение, в качестве одного из долгосрочного опорного изображения, краткосрочного опорного изображения и неиспользуемого для ссылки после кодирования третьего изображения, назначать каждому из межвидовых опорных изображений новое значение РОС, которое в текущий момент является неиспользуемым, после маркировки межвидового опорного изображения в качестве долгосрочного опорного изображения и восстанавливать исходное значение РОС для межвидового опорного изображения после кодирования второго изображения.
42. Устройство кодирования видеоданных, содержащее:
средство для кодирования данных второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных;
средство для кодирования данных второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения, при этом идентификатор изображения второй размерности содержит по меньшей мере одно из идентификатора вида для вида, включающего в себя первое изображение, индекса порядка вида для вида, включающего в себя первое изображение, комбинации индекса порядка вида и флага глубины, идентификатора уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и общего идентификатора уровня;
средство для кодирования, в соответствии с базовой спецификацией видеокодирования, второго изображения на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения;
средство для определения, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение, при этом краткосрочное опорное изображение связано с данными, маркирующими краткосрочное опорное изображение в качестве используемого для краткосрочной ссылки;
средство для определения, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение, при этом долгосрочное опорное изображение связано с данными, маркирующими долгосрочное опорное изображение в качестве используемого для долгосрочной ссылки; и
средство для запрета на основе определения, что первый вектор движения ссылается на краткосрочное опорное изображение, и определения, что второй вектор движения ссылается на долгосрочное опорное изображение, прогнозирования вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения, при этом первый блок и второй блок являются пространственными соседями во втором изображении, и при этом средство для запрета прогнозирования вектора движения между первым вектором движения и вторым вектором движения содержит средство для кодирования первого вектора движения без использования второго вектора движения для прогнозирования первого вектора движения и средство для кодирования второго вектора движения без использования первого вектора движения для прогнозирования второго вектора движения.
43. Считываемый компьютером носитель данных, на котором хранятся инструкции, которые при их исполнении побуждают процессор:
декодировать данные второго изображения, которые относятся к значению счета порядка изображения (РОС) для первого изображения видеоданных;
декодировать данные второго изображения, которые относятся к идентификатору изображения второй размерности для первого изображения, при этом идентификатор изображения второй размерности содержит по меньшей мере одно из идентификатора вида для вида, включающего в себя первое изображение, индекса порядка вида для вида, включающего в себя первое изображение, комбинации индекса порядка вида и флага глубины, идентификатора уровня для уровня масштабируемого видеокодирования (SVC), включающего в себя первое изображение, и идентификатора общего уровня;
декодировать, в соответствии с базовой спецификацией видеокодирования, второе изображение на основании по меньшей мере частично значения РОС и идентификатора изображения второй размерности первого изображения;
определять, что первый вектор движения первого блока второго изображения ссылается на краткосрочное опорное изображение, при этом краткосрочное опорное изображение связано с данными, маркирующими краткосрочное опорное изображение в качестве используемого для краткосрочной ссылки;
определять, что второй вектор движения второго блока второго изображения ссылается на долгосрочное опорное изображение, при этом долгосрочное опорное изображение связано с данными, маркирующими долгосрочное опорное изображение в качестве используемого для долгосрочной ссылки; и
на основе определения, что первый вектор движения ссылается на краткосрочное опорное изображение, и определения, что второй вектор движения ссылается на долгосрочное опорное изображение, запрещать прогнозирование вектора движения между первым вектором движения первого блока второго изображения и вторым вектором движения второго блока второго изображения, при этом первый блок и второй блок являются пространственными соседями во втором изображении, и при этом инструкции, которые побуждают процессор запрещать прогнозирование вектора движения между первым вектором движения и вторым вектором движения, содержат инструкции, которые побуждают процессор декодировать первый вектор движения без использования второго вектора движения для прогнозирования первого вектора движения и декодировать второй вектор движения без использования первого вектора движения для прогнозирования второго вектора движения.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| IL-KOO KIM et al., "Restriction on motion vector scaling for Merge and AMVP", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 7th Meeting: Geneva, CH, 21 - 30 November, 2011, Document: JCTVC-G551, 4 c., опубл | |||
| Способ использования делительного аппарата ровничных (чесальных) машин, предназначенных для мериносовой шерсти, с целью переработки на них грубых шерстей | 1921 |
|
SU18A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| АНТИБАКТЕРИАЛЬНЫЕ ПРОИЗВОДНЫЕ ПИПЕРИДИНА | 2006 |
|
RU2424240C2 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОТДЕЛЕНИЯ НОМЕРА КАДРА И/ИЛИ СЧЕТЧИКА ОЧЕРЕДНОСТИ ИЗОБРАЖЕНИЯ (РОС) ДЛЯ МУЛЬТИВИДОВОГО ВИДЕОКОДИРОВАНИЯ И ВИДЕОДЕКОДИРОВАНИЯ | 2007 |
|
RU2443074C2 |

