ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[001] Настоящее изобретение в целом относится к вычислительным системам, а в частности - к системам и способам создания документов на основе обработки естественного языка.
УРОВЕНЬ ТЕХНИКИ
[002] Извлечение информации - одна из важнейших операций автоматической обработки текстов на естественном языке. В ходе обработки естественного языка производится разбивка исходного текста на значимые единицы (фрагменты) - слова, предложения или тематические единицы. При сегментации на предложения производится разбивка строки печатного текста на естественном языке на составные единицы - предложения. Если документ содержит несколько тематических разделов, то используется сегментация на тематические единицы; при этом возможен анализ предложений документа с целью определения различных тематических единиц на основе смысла предложений с последующей разбивкой текста документа на тематические единицы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] В соответствии с одним или несколькими аспектами настоящего изобретения, описанный в примере способ построения составного документа может включать: получение устройством обработки данных текста на естественном языке, который включает некоторое множество областей текста; выполнение устройством обработки данных анализа текста на естественном языке с целью определения одной или более семантической связи в пределах одной или более областей текста; создание устройством обработки данных поискового запроса с целью поиска дополнительного контента, относящегося по меньшей мере к одной из областей текста из множества областей текста на естественном языке, при этом поисковый запрос основывается на результатах анализа текста для по меньшей мере одной из областей текста; передачу устройством обработки данных поискового запроса в один или более доступный информационный ресурс; получение в ответ на поисковый запрос множества дополнительных единиц контента, каждая из которых относится к соответствующей области текста из множества областей текста; и создание устройством обработки данных составного документа, в который входит множество разделов, при этом в каждом разделе содержится одна область текста из множества областей текста, и при этом по меньшей мере один раздел из множества разделов, содержит одну (или более) дополнительную единицу контента из множества дополнительных единиц контента, относящихся к соответствующей области текста.
[004] В соответствии с одним или несколькими аспектами настоящего изобретения, описанное вычислительное устройство может включать: память и процессор, соединенный с запоминающим устройством, в котором процессор выполнен с возможностью выполнения следующих действий: получение устройством обработки данных текста на естественном языке, который включает некоторое множество областей текста; выполнение устройством обработки данных анализа текста на естественном языке с целью определения одной или более семантической связи в пределах одной или более областей текста; создание устройством обработки данных поискового запроса с целью поиска дополнительного контента, относящегося по меньшей мере к одной из областей текста из множества областей текста на естественном языке, при этом поисковый запрос основывается на результатах анализа текста для по меньшей мере одной из областей текста; передачу устройством обработки данных поискового запроса в один или более доступный информационный ресурс; получение в ответ на поисковый запрос множества дополнительных единиц контента, каждая из которых относится к соответствующей области текста из множества областей текста; и создание устройством обработки данных составного документа, в который входит множество разделов, при этом в каждом разделе содержится одна область текста из множества областей текста, и при этом по меньшей мере один раздел из множества разделов, содержит одну (или более) дополнительную единицу контента из множества дополнительных единиц контента, относящихся к соответствующей области текста.
[005] В соответствии с одним или несколькими аспектами настоящего изобретения, описанный в примере машиночитаемый постоянный носитель данных может содержать исполняемые команды, которые при выполнении на вычислительном устройстве приводят к следующим действиям вычислительного устройства: получение устройством обработки данных текста на естественном языке, который включает некоторое множество областей текста; выполнение устройством обработки данных анализа текста на естественном языке с целью определения одной или более семантической связи в пределах одной или более областей текста; создание устройством обработки данных поискового запроса с целью поиска дополнительного контента, относящегося по меньшей мере к одной из областей текста из множества областей текста на естественном языке, при этом поисковый запрос основывается на результатах анализа текста для по меньшей мере одной из областей текста; передачу устройством обработки данных поискового запроса в один или более доступный информационный ресурс; получение в ответ на поисковый запрос множества дополнительных единиц контента, каждая из которых относится к соответствующей области текста из множества областей текста; и создание устройством обработки данных составного документа, в который входит множество разделов, при этом в каждом разделе содержится одна область текста из множества областей текста, и при этом по меньшей мере один раздел из множества разделов, содержит одну (или более) дополнительную единицу контента из множества дополнительных единиц контента, относящихся к соответствующей области текста.
[006] Технический результат от внедрения изобретения состоит в предоставлении возможности конечному пользователю использовать при создании составных документов, например, таких, как презентации, все возможности технологии обработки естественного языка, такие как семантико-синтаксический анализ текста, перевод на другой язык, автоматическое формирование логически связанных блоков текста, классификация, выделение наиболее значимых элементов для осуществления поиска дополнительного контента, что в конечном счете приведет к сокращению времени и рутинного труда, затрачиваемых на создание и редактирование такого рода документов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[007] Настоящее изобретение иллюстрируется на примерах без каких бы то ни было ограничений; его сущность становится понятной при рассмотрении приведенного ниже подробного описания предпочтительных вариантов реализации в сочетании с чертежами, при этом:
[008] На Фиг. 1 приведена схема компонентов верхнего уровня для примера реализации интеллектуального генератора создания документов в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[009] На Фиг. 2 приведена блок-схема одного из способов создания составного документа на основе обработки естественного языка в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[0010] На Фиг. 3 приведена блок-схема одного из способов обработки естественного языка с целью выявления семантических связей в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[0011] На Фиг. 4 приведена блок-схема одного из способов создания составного документа в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[0012] На Фиг. 5 приведена блок-схема одного из описанных в качестве иллюстративного примера способов (500) выполнения семантико-синтаксического анализа предложения на естественном языке в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[0013] На Фиг. 6 схематически иллюстрируется пример лексико-морфологической структуры предложения в соответствии с одним (или более) аспектом настоящего изобретения.
[0014] На Фиг. 7 схематически иллюстрируются языковые описания, представляющие модель естественного языка в соответствии с одним (или более) аспектом настоящего изобретения.
[0015] На Фиг. 8 схематически иллюстрируются примеры морфологических описаний в соответствии с одним (или более) аспектом настоящего изобретения.
[0016] На Фиг. 9 схематически иллюстрируются примеры синтаксических описаний в соответствии с одним (или более) аспектом настоящего изобретения.
[0017] На Фиг. 10 схематически иллюстрируются примеры семантических описаний в соответствии с одним (или более) аспектом настоящего изобретения.
[0018] На Фиг. 11 схематически иллюстрируются примеры лексических описаний в соответствии с одним (или более) аспектом настоящего изобретения.
[0019] На Фиг. 12 схематически иллюстрируются примеры структур данных, которые могут быть использованы в рамках одного (или более) способа, реализованного в соответствии с одним (или более) аспектом настоящего изобретения.
[0020] На Фиг. 13 схематически иллюстрируется пример графа обобщенных составляющих в соответствии с одним (или более) аспектом настоящего изобретения.
[0021] На Фиг. 14 иллюстрируется пример синтаксической структуры, производной от графа обобщенных составляющих, соответствующего предложению, приведенному на Фиг. 13.
[0022] На Фиг. 15 приведена семантическая структура, соответствующая синтаксической структуре, представленной на Фиг. 14.
[0023] На Фиг. 15А иллюстрируется наглядный пример установления связей в пределах множества предложений.
[0024] На Фиг. 15В показан фрагмент семантической иерархии, в состав которой входят семантические классы для информационных объектов предложений Фиг. 15А.
[0025] На Фиг. 15С представлен пример фрагмента текста, содержащего иллюстрации для предложений Фиг. 15А в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[0026] На Фиг. 15D представлен пример фрагмента текста, содержащего иллюстрации, в соответствии с одним (или более) вариантом реализации настоящего изобретения.
[0027] На Фиг. 16 представлена блок-схема типовой вычислительной системы, взятой как пример и работающей в соответствии с примерами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0028] В настоящем документе описаны способы и технические средства «интеллектуального построения документа на основе анализа текстов на естественном языке. Создание иллюстрированных текстов или добавление контента в презентации подчас может предусматривать большой объем ручной работы со стороны пользователя в виде форматирования текста, а также поиска дополнительного контента, выполняемого вручную. При использовании машинных методов поиска - к примеру, поиска на локальных устройствах для хранения данных или поиска ресурсов, доступных через сеть интернет при помощи поисковых систем сети интернет, пользователю зачастую приходится выполнять поиск несколько раз, прежде чем будет найден результат, релевантный предмету интересующего документа. Мало того, пользователь может оказаться не в состоянии сформулировать поисковый запрос, который бы с большой вероятностью охватывал самый значимый дополнительный контент. Такое может произойти, если пользователь делает запрос лишь по одному конкретному ключевому слову или по одной фразе вместо того, чтобы искать семантически, синтаксически или лексически сходные слова или фразы.
[0029] Задачи настоящего изобретения преследуют цель устранения отмеченных и иных трудностей через использование механизмов обработки текстов на естественном языке, направлены на определение смысловых единиц текста в пределах документа и целевой поиск дополнительного контента, способного дополнить содержание текстового документа. В одном из иллюстративных примеров интеллектуальный генератор создания документов может получать текстовый документ, составленный на естественном языке, как исходный материал для создания составного документа - к примеру, презентации или иллюстрированного текста. Интеллектуальный генератор создания документов может определять семантические, синтаксические и лексические связи между предложениями текстового документа на естественном языке и использовать эту информацию для разбиения текста на естественном языке на значимые единицы (сегменты), т.е. разделение текста на темы, подтемы и т.д. Далее интеллектуальный генератор создания документов может использовать определенные связи для создания развернутых поисковых запросов для каждого из сегментов для того, чтобы можно было определить дополнительные единицы контента, максимально соответствующие содержанию сегмента и полезные при создании составного документа.
[0030] Таким образом, задачи и варианты реализации настоящего изобретения способствуют более эффективному поиску, определению и получению дополнительного значимого контента для текстового документа при минимальном участии пользователя или без такого участия. Более того, становится возможным более эффективное разбиение текстового документа на логические составные части на основе выявленных связей между предложениями, что, в свою очередь, способствует сокращению или полностью устраняет потребность в дополнительных ресурсах, необходимых для создания и (или) изменения документа.
[0031] На Фиг. 1 приведена схема компонентов верхнего уровня для типовой интеллектуальной системы создания документов в соответствии с одним (или более) вариантом реализации настоящего изобретения. В состав интеллектуальной системы создания документов могут входить интеллектуальный генератор создания документов 100 и информационные ресурсы 160. Интеллектуальный генератор создания документов 100 может представлять собой клиентское приложение или сочетание компонентов, базирующихся на рабочей станции клиента и на сервере. В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может быть запущен на исполнение на вычислительном устройстве клиента - к примеру, это может быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.д. Возможен альтернативный вариант реализации изобретения, когда компонент интеллектуального генератора создания документов 100, базирующийся на рабочей станции клиента и запущенный на исполнение на вычислительном устройстве клиента, получает текст на естественном языке и переправляет его на серверный компонент интеллектуального генератора создания документов 100, запущенный на исполнение на серверном устройстве, который, в свою очередь, производит обработку естественного языка и создает итоговый документ. После этого серверный компонент интеллектуального генератора создания документов 100 может вернуть составной документ компоненту интеллектуального генератора создания документов 100, базирующемуся на рабочей станции клиента и запущенному на исполнение на вычислительном устройстве клиента. В других вариантах реализации изобретения интеллектуальный генератор создания документов 100 может быть запущен на исполнение на серверном устройстве в качестве интернет-приложения, доступ к которому обеспечивается через интерфейс интернет-браузера. Примером серверного устройства может быть одна (или более) вычислительная система - одно (или более) такое устройство, как серверы, рабочие станции, большие ЭВМ (мейнфреймы), персональные компьютеры (ПК) и т.д.
[0032] В одном из иллюстративных примеров реализации изобретения интеллектуальный генератор создания документов 100 может получать текст 120 на естественном языке. В одном из вариантов реализации изобретения интеллектуальный генератор создания документов 100 может получать текст на естественном языке через приложение для ввода текста в систему обработки; этот текст представляет собой заранее созданный документ, включающий текстовое содержимое - к примеру, это может быть текстовый документ, файл, подготовленный в текстовом редакторе, графический документ, подвергнутый оптическому распознаванию символов (OCR) или полученный любым аналогичным способом. В качестве альтернативного варианта реализации изобретения интеллектуальный генератор создания документов 100 может получать изображение текста (снятое, к примеру, на камеру мобильного устройства), а затем выполнять оптическое распознавание символов (OCR) в пределах изображения. Помимо этого, интеллектуальный генератор создания документов 100 может получать от пользователя речевую аудиозапись (к примеру, надиктованную на микрофон вычислительного устройства) и преобразовывать ее в текстовую форму при помощи программного средства расшифровки диктофонных записей.
[0033] Текст изначально может содержать разбиение на некоторые области - разделы, параграфы, но в некоторых случаях, например, при создании презентации, стоит задача его разбиения на более мелкие области. Область текста может представлять собой фрагмент текста на естественном языке, при этом предложения в указанном фрагменте связаны между собой структурно или по содержанию. В некоторых вариантах реализации изобретения границы области текста в пределах текста на естественном языке могут быть определены по наличию какого-либо указателя - к примеру, нового абзацного отступа (это может быть, например, служебный символ, указывающий начало нового абзаца), новой строки для списка предложений, указателя в файле с разделителями (к примеру, указателя расширяемого языка разметки (языка XML) в файле с разделителями XML) или любого аналогичного указателя.
[0034] Кроме того, интеллектуальный генератор создания документов 100 может выполнять анализ текста на естественном языке 120 в процессе обработки этого текста с целью выявления одной (или более) семантической, синтаксической или лексической связи для множества областей текста 121. Обработка естественного языка может предусматривать семантический поиск (в том числе многоязычный семантический поиск), классификацию (категоризацию) документа и т.д. На этапе обработки естественного языка может выполняться анализ смыслового содержания текста на естественном языке 120 и определение наиболее значимых слов (одного или более), а также наличия или отсутствия связей соседних предложений друг с другом с точки зрения смыслового содержания. Обработка естественного языка может основываться на использовании широкого спектра лингвистических описаний. Примеры лингвистических описаний представлены ниже на Фиг. 7. Примеры семантических описаний представлены ниже на Фиг. 10. Примеры синтаксических описаний представлены ниже на Фиг. 9. Примеры лексических описаний даны ниже на Фиг. 11.
[0035] В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может выполнять обработку естественного языка путем выполнения семантико-синтаксического анализа текста на естественном языке 120 с целью создания множества семантических структур, при этом каждая из семантических структур является семантическим представлением соответствующего предложения из текста 120. Ниже, применительно к Фиг. 5, представлен пример способа выполнения семантико-синтаксического анализа текста. Любая из семантических структур может быть представлена ациклическим графом, который включает множество вершин, соответствующих семантическим классам, и множество дуг, соответствующих семантическим связям (подробнее см. ниже при упоминании Фиг. 15).
[0036] В ходе семантико-синтаксического анализа могут устраняться неоднозначности в тексте, а результатом является получение лексических, семантических и синтаксических характеристик предложения, равно как и каждого слова в предложении, при этом особую важность для решения поставленной задачи имеют семантические классы. В ходе семантико-синтаксического анализа также могут определяться связи как внутри предложения, так и между предложениями - к примеру, анафорические связи, отношения кореференции и т.д. (подробнее см. ниже применительно к Фиг. 15А-С
[0037] В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может производить обработку естественного языка путем дополнительного извлечения информации, в том числе определения имен собственных (именованных сущностей - к примеру, имен людей, адресов, названий организаций и т.д.), а также фактических сведений, относящихся к именованным сущностям.
[0038] Далее, интеллектуальный генератор создания документов 100 может определять первую семантическую структуру для первого предложения в тексте на естественном языке 120 и вторую семантическую структуру для второго предложения в тексте на естественном языке 120. В дальнейшем интеллектуальный генератор создания документов 100, опираясь на семантические структуры, может определить, существует ли семантическая связь первого предложения со вторым предложением. Для того чтобы сделать такой вывод, интеллектуальный генератор создания документов 100, опираясь на семантические структуры предложений, может определить, имеются ли у второго предложения признаки референции или логической связи с первым предложением. В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может проводить указанное определение путем нахождения анафорических отношений, отношений кореференции, используя для этой цели какой-либо эвристический алгоритм, или каким-либо иным способом. К примеру, если второе предложение содержит личное местоимение (он, она, оно, они и т.д.), указательное местоимение (этот, эта, это, эти, такой, такие, тот, та, те и т.д.) или аналогичные слова, то велика вероятность того, что имеется связь (к примеру, семантическая связь) второго предложения с первым предложением.
[0039] В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может определять, связаны ли предложения друг с другом семантически, опираясь при этом на значение метрики семантической близости. Метрика семантической близости может учитывать различные факторы - в том числе, к примеру: существование референциальных или анафорических связей между узлами семантических структур двух или более предложений; наличие одних и тех же именованных сущностей; наличие идентичных лексических или семантических классов, в узлах семантических структур; наличие отношений "предок-потомок" в определенных узлах семантических структур - при этом родительский и дочерний элементы разделены определенным числом уровней семантической иерархии; наличие общего предка по определенным семантическим классам и определенного расстояния между узлами, представляющими данные классы, и т.д. Если определенные семантические классы оказываются эквивалентными или в общих чертах сходными, то при подсчете значения метрики может быть дополнительно учтено наличие или отсутствие определенных дифференцирующих семантем и (или) другие факторы.
[0040] Также, могут быть приняты во внимание и другие факторы. К примеру, если второе предложение начинается с таких слов, как «итак»; «таким образом»; «следовательно»; «затем»; «теперь» и т.д., то это второе предложение, по-видимому, следует относить к следующей области текста. В некоторых вариантах реализации изобретения два предложения могут считаться семантически связанными при условии, что в них содержатся одни и те же именованные сущности (имена людей, адреса, названия организаций) и при этом не превышен допустимый размер области текста.
[0041] Каждый из факторов, задействованных при установлении семантической связи, может вносить свой вклад в интегральную характеристику, каковой является метрика близости. Таким образом, возможна количественная оценка семантической близости; при этом, если эта оценка превышает пороговое значение, то два или более предложения могут считаться семантически связанными. В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может предварительно проходить обучение с использованием методов машинного обучения. Для машинного обучения могут использоваться не только лексические, но и семантические и синтаксические признаки, полученные в ходе семантико-синтаксического анализа.
[0042] В том случае, если окажется, что первое предложение семантически связано со вторым предложением (к примеру, имеется связь между первым и вторым предложением), интеллектуальный генератор создания документов 100 может относить первое и второе предложение к одной и той же области текста. К примеру, если интеллектуальный генератор создания документов 100 установил, что два предложения, по-видимому, относятся к одной предметной области, он может принять решение, что оба предложения должны быть отнесены к одной и той же области текста в итоговом документе (к примеру, располагаться на одном слайде презентации). В некоторых вариантах реализации изобретения в том случае, если в первой области текста уже содержится более одного предложения, но размер этой области еще меньше максимально допустимого размера области текста, интеллектуальный генератор создания документов 100 может сопоставить предложения с другими предложениями из данной области текста для определения логических или семантических связей.
[0043] В случае, если не выявлено семантической связи между первым и вторым предложениями, интеллектуальный генератор создания документов 100 может относить первое предложение к первой области текста, а второе предложение - ко второй области текста. К примеру, если интеллектуальный генератор создания документов 100 установил, что два предложения, по-видимому, относятся к разным предметным областям, он может принять решение, что два предложения должны быть отнесены к разным областям текста в итоговом документе (к примеру, располагаться на разных слайдах презентации).
[0044] Далее, интеллектуальный генератор создания документов 100 может в автоматическом режиме (без какого бы то ни было участия пользователя или взаимодействия с пользователем) создавать запрос на поиск дополнительного контента, так или иначе связанного с контентом по меньшей мере одной из областей текста. Создание запроса на поиск может опираться, по меньшей мере частично, на полученную на предыдущих этапах информацию - например, наиболее важные слова, семантические классы и (или) именованные сущности, обнаруженные в интересующих областях текста, метаданные, хэштеги, и т.д. Если исходный текст содержит изображения, аудио, видео или изображения, аудио, видео, добавленные пользователем, их метаданные и хэштеги могут также использоваться при формировании запроса на поиск дополнительного контента.
[0045] Модель поиска может предусматривать как полнотекстовый поиск, так и (или) семантический поиск. В случае семантического поиска поисковый запрос может включать по меньшей мере одно из следующих свойств: признаки одной из семантических структур для области текста; семантические и (или) синтаксические признаки одного (или более) предложения в пределах области текста; признаки одного (или более) семантического класса для области текста; наличие по меньшей мере одной именованной сущности; любая аналогичная информация, полученная в ходе обработки естественного языка и иными средствами извлечения информации. Отбор наиболее важных слов или семантических классов для интересующей области текста может осуществляться, к примеру, на основе статистических, эвристических критериев или любым иным способом.
[0046] Кроме того, для получения исходных данных, необходимых при составлении поискового запроса, могут быть задействованы всевозможные методы извлечения информации, например, распознавание именованных сущностей. В одном из вариантов реализации изобретения может использоваться дополнительное системное средство (к примеру, приложение InfoExtractor компании Abbyy); это программное средство осуществляет применение продукционных правил к семантическим структурам, при этом продукционные правила основаны на лингвистических характеристиках семантических структур и онтологиях предметных областей. Перечень продукционных правил может включать по меньшей мере правила интерпретации и правила идентификации, при этом правилами интерпретации задаются фрагменты, которые необходимо найти в семантических структурах, а также содержат соответствующие утверждения, образующие множество логических выводов при нахождении нужных фрагментов. Правила идентификации используются для выявления нескольких ссылок на один и тот же информационный объект как в пределах одного (или более) предложения, так и в рамках всего документа.
[0047] В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может выполнять отдельный поисковый запрос для каждой из областей текста, заданных в пределах текстового документа на естественном языке. Поисковый запрос может создаваться в виде предложений на естественном языке, последовательности из одного или более отдельных слов, так или иначе связанных с интересующей областью текста, поискового запроса на языке структурированных запросов (SQL) или любым иным способом.
[0048] Интеллектуальный генератор создания документов 100 может послать поисковый запрос на один (или более) доступный информационный ресурс 160. Перечень доступных информационных ресурсов 160 может включать: локальное устройство хранения данных на том вычислительном устройстве, где запущен на выполнение интеллектуальный генератор создания документов 100; ресурс хранения данных, доступ к которому осуществляется через локальную сеть; ресурс, доступ к которому осуществляется через сеть интернет (к примеру, устройство хранения данных, подключенное к сети интернет, интернет-сайт, публикация с доступом онлайн и т.д.); ресурсы, доступ к которым предоставляется через социальную сеть и т.д.
[0049] В ответ на отосланный поисковый запрос интеллектуальный генератор создания документов 100 может получить от информационного ресурса 160 ряд дополнительных единиц контента, каждая из которых относится к соответствующей области текста в документе на естественном языке. Перечень дополнительных единиц контента может включать: изображение; график; цитату; шутку; логотип; текстовый контент из источника исходных данных (к примеру, словарной статьи, статьи в Википедии и т.д.) и т.п. В некоторых вариантах реализации изобретения интеллектуальный генератор создания документов 100 может хранить дополнительные единицы контента на локальном устройстве хранения данных, что позволяет обращаться к ним в дальнейшем при поиске нужных сведений. В процессе хранения дополнительных единиц контента интеллектуальный генератор создания документов 100 может ассоциировать с каждой дополнительной единицей контента метаданные, что облегчает и делает более эффективным извлечение этих данных в дальнейшем при поиске нужных сведений. Перечень метаданных может включать сведения, использованные при составлении поискового запроса; благодаря этим сведениям поиск нужных сведений в дальнейшем может выдать дополнительные единицы контента, сохраненные на локальном устройстве хранения данных, еще до отправки запроса на поиск на сетевой информационный ресурс.
[0050] В некоторых вариантах реализации изобретения, в том случае, если по поисковому запросу получено множество дополнительных единиц контента, интеллектуальный генератор создания документов 100 может производить выбор одной или более дополнительной единицы контента, которая будет использована при создании составного документа. В одном из вариантов реализации изобретения интеллектуальный генератор создания документов 100 может производить данный выбор, руководствуясь указаниями пользователя. Интеллектуальный генератор создания документов 100 может в автоматическом режиме выполнять ранжирование дополнительных единиц контента, основываясь на критериях (признаках), так или иначе связанных с настройками учетной записи пользователя, и создавать сортированный список. К примеру, в том случае, если пользователем задан более высокий приоритет изображений по сравнению с текстовым контентом, интеллектуальный генератор создания документов 100 может выполнять соответствующую сортировку дополнительных единиц контента, в результате чего изображения занимают верхние позиции в списке. Аналогичным образом, в случае если пользователем задан более высокий приоритет для сведений, полученных из определенного информационного ресурса (к примеру, сведений, полученных из библиотечного архива публикаций с доступом онлайн), дополнительные единицы контента, полученные из этого информационного ресурса, могут занимать верхние позиции в списке. Далее интеллектуальный генератор создания документов 120 может предоставлять список для пользователя (к примеру, через окно графического интерфейса, выводимое на монитор вычислительного устройства) и выводить подсказку, облегчающую пользователю выбор дополнительных единиц контента, так или иначе связанных с интересующей областью текста. Далее интеллектуальный генератор создания документов 120 может создавать составной документ с учетом предпочтений пользователя.
[0051] Возможен альтернативный вариант реализации изобретения, когда интеллектуальный генератор создания документов 100 может осуществлять выбор в автоматическом режиме, руководствуясь заданными и сохраненными настройками приоритетности. К примеру, пользователь может указать более высокий приоритет изображений по сравнению с текстовым контентом, в результате чего интеллектуальный генератор создания документов 100 может осуществлять выбор в пользу изображения еще до того, как будут рассмотрены другие виды контента. Аналогичным образом, в случае если пользователем указан более высокий приоритет для определенного информационного ресурса, дополнительные единицы контента, полученные от этого информационного ресурса, могут быть отобраны еще до рассмотрения дополнительных единиц контента, полученных из любого другого источника. Помимо этого, интеллектуальный генератор создания документов 120 может создавать составной документ на основе отбора сведений в автоматическом режиме.
[0052] Далее интеллектуальный генератор создания документов 100 может создавать составной документ 140, принимая во внимание определенные области текста 121 текста на естественном языке 120 в сочетании с дополнительными единицами контента, полученными от информационных ресурсов 160. В составном документе 140 может присутствовать множество разделов документа, при этом в каждом разделе документа содержится одна из областей текста 121. Помимо этого, по меньшей мере в одном разделе документа могут содержаться дополнительные единицы контента (одна или более), так или иначе связанные с областью текста, включенной в данный раздел документа.
[0053] Как показано на Фиг. 1, интеллектуальный генератор создания документов 100 может определить, что в тексте на естественном языке 120 содержатся две области текста, руководствуясь при этом структурой предложений, содержащихся в тексте (к примеру, контент допускает логическое разбиение на две части). Интеллектуальный генератор создания документов 100 может создавать поисковый запрос для каждой из двух областей текста и отправлять запрос к информационным ресурсам 160, как описано выше. В дальнейшем интеллектуальный генератор создания документов 100 может создавать составной документ 140, куда входят два раздела, в каждом из которых содержатся две области текста и дополнительная единица контента, так или иначе связанная с соответствующей областью текста. В разделе документа 145-А содержится область текста 141-А и дополнительная единица контента 150-А (дополнительная единица контента так или иначе связана с областью текста 141-А). В разделе документа 145-В содержится область текста 141-В и дополнительная единица контента 150-В (дополнительная единица контента так или иначе связана с областью текста 141-В).
[0054] В некоторых вариантах реализации изобретения составной документ 140 может представлять собой презентацию, т.е. документ для демонстрационных целей (к примеру, это может быть презентация Microsoft PowerPoint, документ в формате PDF и т.д.). Каждый из разделов документа 145-А, 145-В может представлять собой отдельный лист (слайд) презентации, при этом на каждом слайде имеется область текста и соответствующая дополнительная единица контента. Интеллектуальный генератор создания документов 100 может выполнять форматирование текста в пределах областей текста 141-А, 141-В, основываясь на шаблоне разметки для слайда, заданном для разделов документа 145-А, 145-В. Шаблон может представлять собой документ, в котором предварительно задана структура и тип разметки составного документа. К примеру, шаблон разметки может представлять собой шаблон документа, в котором определен стиль и (или) тип разметки для каждого листа или слайда презентации (к примеру, типы шрифтов, используемых на каждом слайде, цвет(а) фоновой заливки, информация о надстрочном и подстрочном примечаниях для каждого слайда и т.д.). Аналогичным образом шаблон разметки может представлять собой шаблон для обработки документа программой-редактором текста, в котором определен стиль и (или) тип разметки текста в пределах документа. Форматирование областей текста 141-А, 145-В может предусматривать построение списка, маркированного списка, разбивку текста на параграфы (пункты) или любой иной способ разметки.
[0055] В некоторых вариантах реализации изобретения составной документ 140 может представлять собой иллюстрированный текстовый документ (к примеру, книгу с иллюстрациями). Каждый из разделов документа 145-А, 145-В может представлять собой отдельную главу книги, при этом в каждой главе имеется область текста, подготовленная для данной главы, и соответствующая дополнительная единица контента, призванная иллюстрировать содержание главы.
[0056] Хотя на Фиг. 1 из соображений простоты показан составной документ, в котором имеются всего два раздела, стоит отметить, что в составном документе 140 могут присутствовать более, чем два раздела. Помимо этого, стоит отметить, что, хотя в составном документе 140 показаны дополнительные единицы контента, так или иначе связанные с обоими разделами документа 145-А и 145-В, в некоторых случаях составной документ 140 может содержать разделы документа 145-А, 145-В (один или более), в которых может и не быть дополнительной единицы контента - либо может присутствовать дополнительная единица контента, так или иначе связанная сразу с несколькими разделами документа.
[0057] На Фиг. 2-4 представлены блок-схемы вариантов реализации способов, относящихся к созданию составных документов на основе технологии обработки естественного языка в текстовом документе. Эти способы могут осуществляться при помощи системы обработки данных, которая может включать аппаратные средства (электронные схемы, специализированную логическую плату и т.д.), программное обеспечение (например, выполняться на универсальной ЭВМ или же на специализированной вычислительной машине) или комбинацию первого и второго. Представленные способы и (или) каждая из отдельно взятых функций, процедур, подпрограмм или операций могут быть реализованы с помощью одного (или более) процессора вычислительного устройства (к примеру, вычислительного устройства 1600 на Фиг. 16), в котором реализованы данные способы. В некоторых вариантах реализации изобретения представленные способы могут выполняться в одном потоке обработки. В альтернативных вариантах реализации изобретения представленные способы могут выполняться в двух и более потоках обработки в режиме обработки, при этом в каждом потоке реализована одна (или более) отдельно взятая функция, процедура, подпрограмма или операция, относящаяся к указанным способам. Некоторые из представленных способов могут осуществляться благодаря использованию интеллектуального генератора создания документов - к примеру, интеллектуального генератора создания документов 100 (Фиг. 1).
[0058] Ради простоты объяснения способы в настоящем описании изобретения изложены и наглядно представлены в виде последовательности действий. Однако действия в соответствии с настоящим описанием изобретения могут выполняться в различном порядке и (или) одновременно с другими действиями, не представленными и не описанными в настоящем документе. Кроме того, не все действия, приведенные для иллюстрации сущности изобретения, могут оказаться необходимыми для реализации способов в соответствии с настоящим описанием изобретения. Специалистам в данной области техники должно быть понятно, что эти способы могут быть представлены и иным образом - в виде последовательности взаимосвязанных состояний через диаграмму состояний или событий.
[0059] На Фиг. 2 представлена блок-схема одного из примеров реализации способа 200 создания составного документа на базе автоматической обработки текста. На шаге 205 блок-схемы способа 200 система обработки данных получает текст на естественном языке, в котором содержит множество областей текста. На шаге 210 блок-схемы система обработки данных производит обработку текста на естественном языке, полученного на шаге 205 блок-схемы, с целью определения одной (или более) логической и (или) семантической связи для областей текста в текстовом документе на естественном языке. В одном из иллюстративных примеров, приведенных для иллюстрации сущности изобретения, система обработки данных может производить обработку текста на естественном языке, как описано ниже применительно к Фиг. 3.
[0060] На шаге 215 система обработки данных создает поисковый запрос с целью отыскания дополнительных единиц контента, относящихся по меньшей мере к одной из областей текста из множества областей текста, при этом поисковый запрос основан на информации об области текста, полученной на предыдущем этапе, и наличии логических и (или) семантических связей по меньшей мере для одной из областей текста. На шаге 220 блок-схемы система обработки данных отправляет поисковый запрос в один (или более) доступный информационный ресурс. В некоторых вариантах реализации изобретения система обработки данных может направлять отдельный поисковый запрос для каждой отдельно взятой области текста. В альтернативном варианте реализации изобретения система обработки данных может отправлять один поисковый запрос для всех областей текста. На шаге 225 система обработки данных в ответ на отправленный поисковый запрос получает ряд дополнительных единиц контента, каждая из которых относится к соответствующей области текста.
[0061] На шаге 230 блок-схемы система обработки данных создает составной документ, в который входит множество разделов, при этом в каждом разделе из множества разделов содержится одна область текста из множества областей текста, а также по меньшей мере один раздел из множества разделов, который, в свою очередь, содержит одну (или более) дополнительную единицу контента из множества дополнительных единиц контента, полученных на шаге 225 блок-схемы и относящихся к соответствующей области текста. После шага 230 способ, представленный на Фиг. 2, завершается.
[0062] На Фиг. 3 представлена блок-схема одного из примеров реализации способа 300 для выполнения обработки текста на естественном языке с целью определения семантических связей. На шаге 305 способа 300 система обработки данных получает текст на естественном языке, в котором содержится множество областей текста. На шаге 310 система обработки данных выполняет семантико-синтаксический анализ текста на естественном языке, в результате чего создается множество семантических структур и связей между ними. В некоторых вариантах реализации изобретения каждая из семантических структур представляет одно из предложений текста на естественном языке. Референциальные связи между некоторыми элементами разных предложений могут представлять логические или семантические связи между предложениями.
[0063] На шаге 315 система обработки данных определяет первую семантическую структуру для первого предложения в тексте на естественном языке. На шаге 320 система обработки данных определяет вторую семантическую структуру для второго предложения в тексте на естественном языке. На шаге 325 система обработки данных определяет, существует ли семантическая связь между первым и вторым предложениями. В некоторых вариантах реализации изобретения система обработки данных может определять, связаны ли семантически первая и вторая семантические структуры, опираясь при этом на метрику семантической близости. В этом случае переходим к шагу 330 блок-схемы. В противном случае переходим к шагу 340 блок-схемы. На шаге 330 система обработки данных относит первое и второе предложение к одной и той же области текста. После шага 330, показанного на Фиг. 3, способ завершается.
[0064] На шаге 335 система обработки данных относит первое предложение к первой области текста из множества областей текста, а второе предложение - ко второй области текста из множества областей текста. После шага 335 способ, представленный на Фиг. 3 завершается.
[0065] На Фиг. 4 представлена блок-схема одного из примеров реализации способа 400 создания составного документа. На шаге 405 способа 400 система обработки данных получает дополнительные единицы контента от доступных информационных ресурсов. На шаге 410 система обработки данных выполняет ранжирование дополнительных единиц контента, основываясь на критериях (признаках), указанных в настройках учетной записи пользователя. На шаге 415 система обработки данных подсказывает пользователю выбор одной (или более) дополнительной единицы контента. На шаге 420 система обработки данных создает составной документ, используя отобранные дополнительные единицы контента. После шага 420, показанного на Фиг. 4, способ завершается.
[0066] На Фиг. 5 приведена блок-схема одного иллюстративного примера реализации способа 500 для выполнения семантико-синтаксического анализа предложения на естественном языке 512 в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 500 может быть применен к одной или более синтаксическим единицам {например, предложениям), включенным в определенный текстовый корпус, для формирования множества семантико-синтаксических деревьев, соответствующих синтаксическим единицам. В различных иллюстративных примерах подлежащие обработке способом 500 предложения на естественном языке могут извлекаться из одного или нескольких электронных документов, которые могут создаваться путем сканирования (или другим способом получения изображений бумажных документов) и оптического распознавания символов (OCR) для получения текстов, соответствующих этим документам. Предложения на естественном языке также могут извлекаться из других различных источников, включая сообщения, отправляемые по электронной почте, тексты из социальных сетей, файлы с цифровым содержимым, обработанные с использованием способов распознавания речи и т.д.
[0067] В блоке 514 вычислительное устройство, реализующее данный способ, может проводить лексико-морфологический анализ предложения 512 для установления морфологических значений слов, входящих в состав предложения. В настоящем документе "морфологическое значение" слова означает одну или несколько лемм (т.е. канонических или словарных форм), соответствующих слову, и соответствующий набор значений грамматических признаков, которые определяют грамматическое значение слова. В число таких грамматических признаков могут входить лексическая категория (часть речи) слова и один или более морфологических и грамматических признаков (например, падеж, род, число, спряжение и т.д.). Ввиду омонимии и (или) совпадающих грамматических форм, соответствующих разным лексико-морфологическим значениям определенного слова, для данного слова может быть установлено два или более морфологических значений. Более подробное описание иллюстративного примера проведения лексико-морфологического анализа предложения приведено ниже в настоящем документе со ссылкой на Фиг. 6.
[0068] В блоке 515 вычислительное устройство может проводить грубый синтаксический анализ предложения 512. Грубый синтаксический анализ может включать применение одной или нескольких синтаксических моделей, которые могут быть соотнесены с элементами предложения 512, с последующим установлением поверхностных (т.е. синтаксических) связей в рамках предложения 512 для получения графа обобщенных составляющих. В настоящем документе "составляющая" означает группу соседних слов исходного предложения, функционирующую как одна грамматическая сущность. Составляющая включает в себя ядро в виде одного или более слов и может также включать одну или несколько дочерних составляющих на более низких уровнях. Дочерняя составляющая является зависимой составляющей, которая может быть соотнесена с одной или несколькими родительскими составляющими.
[0069] В блоке 516 вычислительное устройство может проводить точный синтаксический анализ предложения 512 для формирования одного или более синтаксических деревьев предложения. Среди различных синтаксических деревьев на основе определенной функции оценки с учетом совместимости лексических значений слов исходного предложения, поверхностных отношений, глубинных отношений и т.д. может быть отобрано одно или несколько лучших синтаксических деревьев, соответствующих предложению 512.
[0070] В блоке 517 вычислительное устройство может обрабатывать синтаксические деревья для формирования семантической структуры 518, соответствующей предложению 512. Семантическая структура 518 может включать множество узлов, соответствующих семантическим классам и также может включать множество дуг, соответствующих семантическим отношениям (более подробное описание см. ниже в настоящем документе).
[0071] Фиг. 6 схематически иллюстрирует пример лексико-морфологической структуры предложения в соответствии с одним или более аспектами настоящего изобретения. Пример лексико-морфологической структуры 600 может включать множество пар "лексическое значение - грамматическое значение" для примера предложения. В качестве иллюстративного примера, "ll" может быть соотнесено с лексическим значением "shall" 612 и "will" 614. Грамматическим значением, соотнесенным с лексическим значением 512, является <Verb, GTVerbModal, ZeroType, Present, Nonnegative, Composite II>. Грамматическим значением, соотнесенным с лексическим значением 614, является <Verb, GTVerbModal, ZeroType, Present, Nonnegative, Irregular, Composite II>.
[0072] Фиг. 7 схематически иллюстрирует используемые языковые описания 710, в том числе морфологические описания 701, лексические описания 703, синтаксические описания 702 и семантические описания 704, а также отношения между ними. Среди них морфологические описания 701, лексические описания 703 и синтаксические описания 702 зависят от языка. Набор языковых описаний 710 представляет собой модель определенного естественного языка.
[0073] В качестве иллюстративного примера определенное лексическое значение в лексических описаниях 703 может быть соотнесено с одной или несколькими поверхностными моделями синтаксических описаний 702, соответствующих данному лексическому значению. Определенная поверхностная модель синтаксических описаний 702 может быть соотнесена с глубинной моделью семантических описаний 704.
[0074] На Фиг. 8 схематически иллюстрируются несколько примеров морфологических описаний. В число компонентов морфологических описаний 701 могут входить: описания словоизменения 810, грамматическая система 820, описания словообразования 830 и другие. Грамматическая система 820 включает набор грамматических категорий, таких как часть речи, падеж, род, число, лицо, возвратность, время, вид и их значения (так называемые "граммемы"), в том числе, например, прилагательное, существительное или глагол; именительный, винительный или родительный падеж; женский, мужской или средний род и т.д. Соответствующие граммемы могут использоваться для составления описания словоизменения 810 и описания словообразования 830.
[0075] Описание словоизменения 810 определяет формы данного слова в зависимости от его грамматических категорий (например, падеж, род, число, время и т.д.) и в широком смысле включает в себя или описывает различные возможные формы слова. Описание словообразования 830 определяет, какие новые слова могут быть образованы от данного слова (например, сложные слова).
[0076] В соответствии с одним из аспектов настоящего изобретения при установлении синтаксических отношений между элементами исходного предложения могут использоваться модели составляющих. Составляющая представляет собой группу соседних слов в предложении, ведущих себя как единое целое. Ядром составляющей является слово, она также может содержать дочерние составляющие более низких уровней. Дочерняя составляющая является зависимой составляющей и может быть прикреплена к другим составляющим (родительским) для построения синтаксической структуры исходного предложения.
[0077] На Фиг. 9 приведены примеры синтаксических описаний в соответствии с одним или более аспектами настоящего изобретения.
[0078] В число компонентов синтаксических описаний 702 могут входить, среди прочего, поверхностные модели 910, описания поверхностных позиций 920, описание референциального и структурного контроля 956, описание управления и согласования 940, описания недревесного синтаксиса 950 и правила анализа 960. Синтаксические описания 702 могут использоваться для построения возможных синтаксических структур исходного предложения на заданном естественном языке с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, сочинение, эллипсис и т.д.), референциальных отношений и других факторов.
[0079] Поверхностные модели 910 могут быть представлены в виде совокупностей одной или нескольких синтаксических форм («синтформ» 912) для описания возможных синтаксических структур предложений, входящих в состав синтаксических описаний 702. В целом, лексическое значение слова на естественном языке может быть связано с поверхностными (синтаксическими) моделями 910. Поверхностная модель может представлять собой составляющие, которые возможны, если лексическое значение выступает в роли "ядра". Поверхностная модель может включать набор поверхностных позиций дочерних элементов, описание линейного порядка и (или) диатезу. В настоящем документе "диатеза" означает определенное отношение между поверхностными и глубинными позициями и их семантическими ролями, выражаемыми посредством глубинных позиций. Например, диатеза может быть выражаться залогом глагола: если субъект является агентом действия, глагол в активном залоге, а когда субъект является направлением действия, это выражается пассивным залогом глагола.
[0080] В модели составляющих может использоваться множество поверхностных позиций 915 дочерних составляющих и описаний их линейного порядка 916 для описания грамматических значений 914 возможных заполнителей этих поверхностных позиций. Диатезы 917 представляют собой соответствия между поверхностными позициями 915 и глубинными позициями 1014 (как показано на Фиг. 10). Коммуникативные описания 980 описывают коммуникативный порядок в предложении.
[0081] Описание линейного порядка (916) может быть представлено в виде выражений линейного порядка, отражающих последовательность, в которой различные поверхностные позиции (915) могут встречаться в предложении. В число выражений линейного порядка могут входить наименования переменных, имена поверхностных позиций, круглые скобки, граммемы, оператор «or» (или) и т.д. В качестве иллюстративного примера описание линейного порядка простого предложения "Boys play football" можно представить в виде "Subject Core Object_Direct" (Подлежащее - Ядро - Прямое дополнение), где Subject (Подлежащее), Core (Ядро) и Object_Direct (Прямое дополнение) представляют собой имена поверхностных позиций 915, соответствующих порядку слов.
[0082] Коммуникативные описания 980 могут описывать порядок слов в синтформе 912 с точки зрения коммуникативных актов, представленных в виде коммуникативных выражений порядка, которые похожи на выражения линейного порядка. Описания управления и согласования 940 может включать правила и ограничения на грамматические значения присоединяемых составляющих, которые используются во время синтаксического анализа.
[0083] Описания недревесного синтаксиса 950 могут создаваться для отражения различных языковых явлений, таких как эллипсис и сочинение, они используются при трансформациях синтаксических структур, которые создаются на различных этапах анализа в различных вариантах реализации изобретения. Описания недревесного синтаксиса 950 могут, среди прочего, включать описание эллипсиса 952, описания сочинения 954, а также описания референциального и структурного контроля 930.
[0084] Правила анализа 960 могут описывать свойства конкретного языка и использоваться в рамках семантического анализа. Правила анализа 960 могут включать правила вычисления семантем 962 и правила нормализации 964. Правила нормализации 964 могут использоваться для описания трансформаций семантических структур, которые могут отличаться в разных языках.
[0085] На Фиг. 10 приведен пример семантических описаний. Компоненты семантических описаний 704 не зависят от языка и могут, среди прочего, включать семантическую иерархию 1010, описания глубинных позиций 1020, систему семантем 1030 и прагматические описания 1040.
[0086] Ядро семантических описаний представлено семантической иерархией 1010, в которую могут входить семантические понятия (семантические сущности), также называемые семантическими классами. Последние могут быть упорядочены в иерархическую структуру, отражающую отношения "родитель-потомок". В целом, дочерний семантический класс может унаследовать одно или более свойств своего прямого родителя и других семантических классов-предков. В качестве иллюстративного примера семантический класс SUBSTANCE (Вещество) является дочерним семантическим классом класса ENTITY (Сущность) и родительским семантическим классом для классов GAS, (Газ), LIQUID (Жидкость), METAL (Металл), WOOD_MATERIAL (Древесина) и т.д.
[0087] Каждый семантический класс в семантической иерархии 1010 может сопровождаться глубинной моделью 1012. Глубинная модель 1012 семантического класса может включать множество глубинных позиций 1014, которые могут отражать семантические роли дочерних составляющих в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей. Глубинная модель 1012 также может включать возможные семантические классы, выступающие в роли заполнителей глубинных позиций. Глубинные позиции (1014) могут выражать семантические отношения, в том числе, например, "agent" (агенс), "addressee" (адресат), "instrument" (инструмент), "quantity" (количество) и т.д. Дочерний семантический класс может наследовать и уточнять глубинную модель своего непосредственного родительского семантического класса.
[0088] Описания глубинных позиций 1020 отражают семантические роли дочерних составляющих в глубинных моделях 1012 и могут использоваться для описания общих свойств глубинных позиций 1014. Описания глубинных позиций 1020 также могут содержать грамматические и семантические ограничения в отношении заполнителей глубинных позиций 1014. Свойства и ограничения, связанные с глубинными позициями 1014 и их возможными заполнителями в различных языках, могут быть в значительной степени подобными и зачастую идентичными. Таким образом, глубинные позиции 1014 не зависят от языка.
[0089] Система семантем 1030 может представлять собой множество семантических категорий и семантем, которые представляют значения семантических категорий. В качестве иллюстративного примера семантическая категория "DegreeOfComparison" (Степень сравнения) может использоваться для описания степени сравнения прилагательных и включать следующие семантемы: "Positive" (Положительная), "ComparativeHigherDegree" (Сравнительная степень сравнения), "SuperlativeHighestDegree" (Превосходная степень сравнения) и другие. В качестве еще одного иллюстративного примера семантическая категория "RelationToReferencePoint" (Отношение к точке) может использоваться для описания порядка (пространственного или временного в широком смысле анализируемых слов), как, например, до или после точки или события, и включать семантемы "Previous" (Предыдущий) и "Subsequent" (Последующий). В качестве еще одного иллюстративного примера семантическая категория "EvaluationObjective" (Оценка) может использоваться для описания объективной оценки, как, например, "Bad" (Плохой), "Good" (Хороший) и т.д.
[0090] Система семантем 1030 может включать независимые от языка семантические атрибуты, которые могут выражать не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы могут использоваться для выражения атомарного значения, которое находит регулярное грамматическое и (или) лексическое выражение в естественном языке. По своему целевому назначению и использованию системы семантем могут разделяться на категории, например, грамматические семантемы 1032, лексические семантемы 1034 и классифицирующие грамматические (дифференцирующие) семантемы 1036.
[0091] Грамматические семантемы 1032 могут использоваться для описания грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы 1034 могут описывать конкретные свойства объектов (например, "being flat" (быть плоским) или "being liquid" (являться жидкостью)) и использоваться в описаниях глубинных позиций 1020 как ограничение заполнителей глубинных позиций (например, для глаголов "face (with)" (облицовывать) и "flood" (заливать), соответственно). Классифицирующие грамматические (дифференцирующие) семантемы 1036 могут выражать дифференциальные свойства объектов внутри одного семантического класса. В качестве иллюстративного примера в семантическом классе HAIRDRESSER (ПАРИКМАХЕР) семантема «RelatedToMen» (Относится к мужчинам) присваивается лексическому значению "barber" в отличие от других лексических значений, которые также относятся к этому классу, например, «hairdresser», «hairstylist» и т.д. Используя данные независимые от языка семантические свойства, которые могут быть выражены в виде элементов семантического описания, в том числе семантических классов, глубинных позиций и семантем, можно извлекать семантическую информацию в соответствии с одним или более аспектами настоящего изобретения.
[0092] Прагматические описания 1040 позволяют назначать определенную тему, стиль или жанр текстам и объектам семантической иерархии 1010 (например, «Экономическая политика», «Внешняя политика», «Юриспруденция», «Законодательство», «Торговля», «Финансы» и т.д.). Прагматические свойства также могут выражаться семантемами. В качестве иллюстративного примера прагматический контекст может приниматься во внимание при семантическом анализе.
[0093] На Фиг. 11 приведен пример лексических описаний. Лексические описания (703) представляют собой множество лексических значений 612 конкретного естественного языка. Для каждого лексического значения 1112 имеется связь 1102 с его независимым от языка семантическим родителем для того, чтобы указать положение какого-либо заданного лексического значения в семантической иерархии 510.
[0094] Лексическое значение 1112 в лексико-семантической иерархии 1010 может быть соотнесено с поверхностной моделью 910, которая в свою очередь через одну или несколько диатез 917 может быть соотнесена с соответствующей глубинной моделью 1012. Лексическое значение 1112 может наследовать семантический класс своего родителя и уточнять свою глубинную модель 1012.
[0095] Поверхностная модель 910 лексического значения может включать одну или несколько синтаксических форм 912. Синтформа 912 поверхностной модели 910 может включать одну или несколько поверхностных позиций 915, в том числе соответствующие описания их линейного порядка 916, одно или несколько грамматических значений 914, выраженных в виде набора грамматических категорий (граммем), одно или несколько семантических ограничений, соотнесенных с заполнителями поверхностных позиций, и одну или несколько диатез 917. Семантические ограничения, соотнесенные с определенным заполнителем поверхностной позиции, могут быть представлены в виде одного или более семантических классов, объекты которых могут заполнить эту поверхностную позицию.
[0096] На Фиг. 12 схематически иллюстрируются примеры структур данных, которые могут быть использованы в рамках одного или более методов настоящего изобретения. Снова ссылаясь на Фиг. 5, в блоке 514 вычислительное устройство, реализующее данный способ, может проводить лексико-морфологический анализ предложения 512 для построения лексико-морфологической структуры 1222 согласно Фиг. 12. Лексико-морфологическая структура 1222 может включать множество соответствий лексического и грамматического значений для каждой лексической единицы (например, слова) исходного предложения. Фиг. 6 схематически иллюстрирует пример лексико-морфологической структуры.
[0097] Снова возвращаясь к Фиг. 5, в блоке 515 вычислительное устройство может проводить грубый синтаксический анализ исходного предложения 512 для построения графа обобщенных составляющих 1232 согласно Фиг. 12. Грубый синтаксический анализ предполагает применение одной или нескольких возможных синтаксических моделей возможных лексических значений к каждому элементу множества элементов лексико-морфологической структуры 1222, с тем чтобы установить множество потенциальных синтаксических отношений в составе исходного предложения 512, представленных графом обобщенных составляющих 1232.
[0098] Граф обобщенных составляющих 1232 может быть представлен ациклическим графом, включающим множество узлов, соответствующих обобщенным составляющим исходного предложения 512 и включающим множество дуг, соответствующих поверхностным (синтаксическим) позициям, которые могут выражать различные типы отношений между обобщенными лексическими значениями. В рамках данного способа может применяться множество потенциально применимых синтаксических моделей для каждого элемента множества элементов лексико-морфологических структур исходного предложения 512 для формирования набора составляющих исходного предложения 512. Затем в рамках способа может рассматриваться множество возможных составляющих исходного предложения 512 для построения графа обобщенных составляющих 1232 на основе набора составляющих. Граф обобщенных составляющих 1232 на уровне поверхностной модели может отражать множество потенциальных связей между словами исходного предложения 512. Поскольку количество возможных синтаксических структур может быть относительно большим, граф обобщенных составляющих 1232 может, в общем случае, включать избыточную информацию, в том числе относительно большое число лексических значений по определенным узлам и (или) поверхностных позиций по определенным дугам графа.
[0099] Граф обобщенных составляющих 1232 может изначально строиться в виде дерева, начиная с концевых узлов (листьев) и двигаясь далее к корню, путем добавления дочерних составляющих, заполняющих поверхностные позиции 915 множества родительских составляющих, с тем чтобы были охвачены все лексические единицы исходного предложения 512.
[00100] В некоторых вариантах осуществления корень графа обобщенных составляющих 1232 представляет собой предикат. В ходе описанного выше процесса дерево может стать графом, так как определенные составляющие более низкого уровня могут быть включены в одну или несколько составляющих верхнего уровня. Множество составляющих, которые представляют определенные элементы лексико-морфологической структуры, затем может быть обобщено для получения обобщенных составляющих. Составляющие могут быть обобщены на основе их лексических значений или грамматических значений 914, например, на основе частей речи и отношений между ними. На Фиг. 13 схематически иллюстрируется пример графа обобщенных составляющих.
[00101] В блоке 516 вычислительное устройство может проводить точный синтаксический анализ предложения 512 для формирования одного или более синтаксических деревьев 1242 согласно Фиг. 12 на основе графа обобщенных составляющих 1232. Для каждого синтаксического дерева вычислительное устройство может определить интегральную оценку на основе априорных и вычисляемых оценок. Дерево с наилучшей оценкой может быть выбрано для построения наилучшей синтаксической структуры 1246 исходного предложения 512.
[00102] В ходе построения синтаксической структуры 1246 на основе выбранного синтаксического дерева вычислительное устройство может установить одну или несколько недревесных связей {например, путем создания дополнительной связи среди, как минимум, двух узлов графа). Если этот процесс заканчивается неудачей, вычислительное устройство может выбрать синтаксическое дерево с условно оптимальной оценкой, наиболее близкой к оптимальной, и производится попытка установить одну или несколько недревесных связей в дереве. Наконец, в результате точного синтаксического анализа создается синтаксическая структура 1246, которая представляет собой лучшую синтаксическую структуру, соответствующую исходному предложению 512.
[00103] В блоке 517 вычислительное устройство может обрабатывать синтаксические деревья для формирования семантической структуры 518, соответствующей предложению 512. Семантическая структура 518 может отражать передаваемую исходным предложением семантику в независимых от языка терминах. Семантическая структура 518 может быть представлена в виде ациклического графа (например, дерево, возможно, дополненное одной или более недревесной связью (дугой графа). Слова исходного предложения представлены узлами с соответствующими независимыми от языка семантическими классами семантической иерархии 1010. Дуги графа представляют глубинные (семантические) отношения между элементами предложения. Переход к семантической структуре 518 может осуществляться с помощью правил анализа 960 и предполагает соотнесение одного или более атрибутов (отражающих лексические, синтаксические и (или) семантические свойства слов исходного предложения 512) с каждым семантическим классом.
[00104] На Фиг. 14 приводится пример синтаксической структуры предложения "This boy is smart, he'll succeed in life.", сгенерированной из графа обобщенных составляющих, показанного на Фиг. 13. Применяя способ описанного в настоящем документе синтактико-семантического анализа, вычислительное устройство может установить, что лексический элемент "life" (жизнь) 1406 представляет одну из форм лексического значения, соотнесенного с семантическим классом "LIVE" (ЖИТЬ) 1404 и заполняет поверхностную позицию $Adjunct_Locative 1405) в родительской составляющей, представленной управляющим узлом Verb:succeed:succeed:TO_SUCCEED (1407).
[00105] На Фиг. 15 приведена семантическая структура, соответствующая синтаксической структуре, представленной на Фиг. 14. В отношении вышеупомянутого лексического элемента «жизнь» (life) 1406 на Фиг. 14 семантическая структура включает лексические и семантические классы 1510 и 1530, подобные представленным на Фиг. 14, однако вместо поверхностной позиции 1405 семантическая структура включает глубинную позицию «Сфера» (Sphere) 1520. Анафорическая связь 1410 показана на семантической структуре 1540.
[00106] Фиг. 15А иллюстрирует пример установления взаимосвязей в пределах множества предложений. Помимо использования правил, в основу которых положены синтаксические модели, могут быть учтены и семантические ограничения. К примеру, если некоторый узел синтактико-семантической структуры имеет подчиненный узел и олицетворяет «персону» (т.к. у объекта имеется субстантивное дополнение), то в системе задается специальная дополнительная ссылка, ведущая от объекта к этому дополнению. В дальнейшем, если та же лексема встретится где-то еще в пределах текста (как дополнение), то это повлечет за собой идентификацию второй «персоны», которая будет объединена с первой посредством особой связи ссылочного типа (т.е. два объекта типа «персона» будут «слиты» воедино при помощи данной специальной ссылки). К примеру, пусть имеется проблема определения сущностей Bjorndalen=biathlete=sportsman (Бьорндален=биатлонист=спортсмен); рассмотрим ее на следующем примере: Bjorndalen is a great biathlete. The sportsman showed the highest class at the Olympics in Sochi. A biathlete of this level cannot be written off even after 40 years. (Бьорндален - это выдающийся биатлонист. Спортсмен показал высочайший класс на Олимпиаде в Сочи. Биатлониста такого уровня нельзя списывать со счета даже в возрасте «за 40».)
[00107] Фиг. 15А иллюстрирует пример семантических структур для данного случая с указанием дополнительных референций. Первым делом правила извлечения информации позволяют определить три сущности: «Бьорндален», «биатлонист» и еще один «биатлонист». Два упоминания о «биатлонисте» объединены в одну сущность (связь 1501) на основании их принадлежности к одному и тому же семантическому классу и после того, как синтаксическая структура первого предложения указала определение первого случая употребления термина «биатлонист» в связи с фамилией Бьорндален (связь 1502). Для воспроизведения всей цепочки кореференций необходимо установить связь ссылочного типа между объектами «биатлонист/Бьорндален» и «спортсмен» (ссылки 1504 и 1505).
[00108] В одном из возможных вариантов реализации изобретения к операции «фильтрования» полученных пар могут быть привлечены грамматические признаки (род, число, одушевленность и т.д.); кроме того, используется показатель семантической близости в ранее упомянутой иерархии. В подобном случае становится возможной оценка «расстояния» между лексическими значениями. На Фиг. 15В представлен фрагмент семантической иерархии для лексических значений «биатлонист» и «спортсмен». Они находятся на одной и той же «ветви» древовидной семантической иерархии, при этом «биатлонист» принадлежит к обособленному семантическому классу BIATHLETE (БИАТЛОНИСТ), который, в свою очередь, служит прямым потомком семантического класса SPORTSMAN (СПОРТСМЕН), в то время как «спортсмен» непосредственно входит в тот же класс SPORTSMAN (СПОРТСМЕН). Таким образом, сущности «биатлонист» и «спортсмен» расположены «по соседству» в семантической иерархии, имеют общего «предка» - семантический класс SPORTSMAN (СПОРТСМЕН) - и, более того, «спортсмен» является репрезентативным членом данного класса и в этом смысле есть не что иное, как гипероним по отношению к термину «биатлонист». Попросту говоря, переход по семантической иерархии от «биатлониста» к «спортсмену» возможен всего за несколько шагов. При составлении показателя возможен учет принадлежности к одному и тому же семантическому классу, наличие расположенного по соседству общего предка - т.е. важны такие критерии, как семантический класс, представительность, наличие или отсутствие тех или иных семантем и т.д.
[00109] На Фиг. 15С представлен пример фрагмента текста, содержащего иллюстрации для предложений Фиг. 15А в соответствии с одним (или более) вариантом реализации настоящего изобретения. Интеллектуальный генератор создания документов, описанный выше, способен выполнять анализ семантических связей между предложениями 1551 и создавать запросы на поиск интересующих сведений, как описано в тексте настоящего документа. Как показано на Фиг. 15С, в ходе анализа предложений 1551 могут быть получены дополнительные фотографии Бьорндалена 1552 наряду с информацией из Википедии 1553; эти сведения могут быть добавлены к иллюстрированному фрагменту (странице, слайду презентации и т.д.) итогового составного документа.
[00110] На Фиг. 15D представлен еще один пример фрагмента текста, содержащего иллюстрации, в соответствии с одним (или более) вариантом реализации настоящего изобретения. Интеллектуальный генератор создания документов, описанный выше, способен выполнять анализ семантических связей между предложениями 1551 и создавать запросы на поиск интересующих сведений, как описано в тексте настоящего документа. Как показано на Фиг. 15D, в ходе анализа предложений 1561 могут быть получены дополнительные фотографии 1562 подлежащих в предложениях 1561 (к примеру, Пола Аллена и Билла Гейтса), сведения 1563 об изображении (к примеру, логотип компании Microsoft, поскольку название «Microsoft» упоминается в одном из предложений 1561), а также сведения 1564 об изображении (к примеру, сведения о Traf-O-Data, поскольку название «Traf-O-Data» упоминается в одном из предложений 1561); эти сведения могут быть добавлены к иллюстрированному фрагменту (странице, слайду презентации и т.д.) итогового составного документа.
[00111] На Фиг. 16 показан иллюстративный пример вычислительной системы 1600, которая может исполнять набор команд, которые вызывают выполнение вычислительным устройством любого отдельно взятого или нескольких способов настоящего изобретения. Например, вычислительная система 1600 может быть представлена вычислительным устройством, пригодным для реализации интеллектуального генератора создания документов 100, показанного на Фиг. 1. Вычислительная система может подключаться к другому вычислительному устройству по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система может работать в качестве сервера или клиентского вычислительного устройства в сетевой среде "клиент/сервер" либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительное устройство может быть представлено персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любым вычислительным устройством, способным выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этим вычислительным устройством. Кроме того, в то время как показано только одно вычислительное устройство, следует принять, что термин «вычислительное устройство» также может включать любую совокупность вычислительных устройств, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или нескольких методик, описанных в настоящем документе.
[00112] Пример вычислительной системы 1600 включает процессор 1602, основную память 1604 (например, постоянное запоминающее устройство (ROM), флэш-память, или динамическую оперативную память DRAM (SDRAM)), статическую память 1606 (например, флэш-память, или динамическую оперативную память SRAM) и устройство хранения данных (1616), которые взаимодействуют друг с другом по шине 1608.
[00113] Процессор 1602 может быть представлен одним или более универсальными вычислительными устройствами, например, микропроцессором, центральным процессором и т.д. В частности, процессор 1602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 1602 также может представлять собой одно или несколько вычислительных устройств специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 1602 настроен на выполнение команд интеллектуального генератора создания документов 1626 для осуществления рассмотренных в настоящем документе операций и функций.
[00114] Вычислительное устройство 1600 может дополнительно включать устройство сетевого интерфейса 1622, устройство визуального отображения 1610, устройство ввода символов 1612 (например, клавиатуру), устройство управления курсором 1614 (например, мышь) и генератор звукового сигнала 1620. В одном иллюстративном примере системы устройство визуального отображения 1610, устройство ввода символов и устройство управления курсором 1614 могут быть объединены в одном компоненте или устройстве (например, LCD тач-скрин).
[00115] Устройство хранения данных 1616 может содержать машиночитаемый носитель данных 1624, в котором хранится один или более наборов команд интеллектуального генератора создания документов 1626, и в котором реализован один или более из методов или функций настоящего изобретения. Команды интеллектуального генератора создания документов 1626 также могут находиться полностью или по меньшей мере частично в основной памяти 1604 и/или в процессоре 1602 во время выполнения их вычислительной системой 1600, при этом оперативная память 1604 и процессор 1602 также составляют машиночитаемый носитель данных. Команды интеллектуального генератора создания документов 1626 дополнительно могут передаваться или приниматься по через устройство сетевого интерфейса 622.
[00116] В то время как машиночитаемый носитель данных 1624, показанный на примере, является единым носителем, термин «машиночитаемый носитель» должен включать один носитель или несколько носителей (например, централизованную или распределенную базу данных, и/или соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин "машиночитаемый носитель данных" также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять любую одну или несколько из методик, описанных в настоящем раскрытии изобретения. Таким образом, термин «машиночитаемый носитель данных», помимо прочего, также относится к твердотельной памяти и оптическим и магнитным носителям.
[00117] Несмотря на то, что операции представленных здесь способов показаны и описаны в определенном порядке, порядок операций каждого метода может быть изменен таким образом, что некоторые операции могут быть выполнены в другом порядке или таким образом, чтобы определенная операция может быть выполнена, по меньшей мере, частично, параллельно с другими операциями. В некоторых вариантах реализации инструкции или вспомогательные операции могут выполняться дискретно и/или попеременно.
[00118] Следует понимать, что вышеприведенное описание носит иллюстративный, а не ограничительный характер. Различные другие варианты осуществления станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому объем раскрытия должен определяться со ссылкой на прилагаемую формулу изобретения наряду с полным объемом эквивалентов, на которые такие требования предоставляют право.
[00119] В приведенном выше описании изложены многочисленные детали. Однако специалисту в этой области техники благодаря этому описанию очевидно, что настоящее изобретение может быть реализовано на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схемы, а не детально, чтобы не усложнять описание настоящего изобретения.
[00120] Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. В настоящем документе и в целом алгоритмом называется самосогласованная последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и подвергать другим манипуляциям. Оказалось, что прежде всего для обычного использования удобно описывать эти сигналы в виде битов, значений, элементов, символов, членов, цифр и т.д.
[00121] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они представляют собой просто удобные метки, применяемые к этим величинам. Если иное специально и недвусмысленно не указано в нижеследующем обсуждении, следует принимать, что везде по тексту такие термины как "определение", "вычисление", "расчет", "вычисление", "получение", "установление", "изменение" и т.п., относятся к действиям и процессам вычислительного устройства или аналогичного электронного вычислительного устройства, которое работает с данными и преобразует данные, представленные в виде физических (например, электронных) величин в регистрах и памяти вычислительного устройства, в другие данные, аналогичным образом представленные в виде физических величин в памяти или регистрах вычислительного устройства, либо других подобных устройствах хранения, передачи или отображения информации.
[00122] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей или оно может содержать универсальный компьютер, который избирательно активируется или реконфигурируется с помощью компьютерной программы, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, таком как, в числе прочих, диск любого рода, в том числе дискеты, оптические диски, компакт-диски, магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и другие виды носителей данных, подходящие для хранения электронных команд.
[00123] Алгоритмы и дисплеи, представленные в настоящем документе, по сути, не связаны с какой-либо конкретным компьютером или другим устройством. Различные системы общего назначения могут использоваться с программами, приведенными в описании, или может оказаться удобным построить более специализированное устройство для выполнения требуемых этапов способа. Требуемая структура для множества этих систем будут появляться, как изложено в настоящем описании. Кроме того, аспекты настоящего раскрытия не описаны со ссылкой на какой-либо конкретный язык программирования. Следует принять во внимание, что различные языки программирования могут быть использованы для реализации идеи настоящего изобретения, которые описаны в настоящем документе.
[00124] Аспекты настоящего изобретения могут быть представлены в виде компьютерного программного продукта, либо в виде программного обеспечения, которое может быть включено в машиночитаемый носитель, имеющий сохраненные на нем команды, которые могут быть использованы для программирования компьютерной системы (или других электронных устройств) для выполнения способа согласно к настоящему описанию. Машиночитаемый носитель включает в себя любой механизм для хранения или передачи информации в форме, считываемой машиной (например, компьютером). Например, машиночитаемый (например, считываемый компьютером) носитель включает в себя читаемый машиной (например, компьютером) носитель информации (например, постоянное запоминающее устройство ("ПЗУ"), оперативное запоминающее устройство ("RAM"), носители данных на магнитных дисках, оптические носители данных, устройства флэш-памяти и т.д.).
[00125] Слова «пример» или «примерный» используется здесь для обозначения сущности, выступающей в качестве примера, отдельного случая или иллюстрации. Любой аспект или дизайн, описанные в данном документе как "пример" или "примерный", не обязательно должен быть истолкован как предпочтительный или преимущественный по сравнению с другими аспектами или вариантами дизайна. Точнее, использование слова "например" или "примерный" предназначено, чтобы представить понятия конкретным образом. Используемый в данной заявке термин "или" предназначен для обозначения включающего "или", а не исключающее "или". То есть, если не указано иное, или не очевидно из контекста, "X включает в себя А или В» означает любую из естественных включающих перестановок. То есть, если X включает в себя А; X включает в себя В; или X включает в себя А и В, то "X включает А или В" удовлетворяется в любом из вышеуказанных случаев. Кроме того, "некоторый", в данной заявке и прилагаемой формуле изобретения, как правило, должно толковаться как означающее "один или более", если не указано иное, или не ясно из контекста, что направлено на форму единственного числа. Кроме того, использование термина «вариант осуществления» или «один вариант осуществления" или "Реализации" или "одной из реализаций" не означает тот же вариант или реализации, если не описано как таковое. Кроме того, термины "первый", "второй", "третий", "четвертое" и т.п., используемые здесь, предназначены в качестве меток для обозначения различных элементов и, возможно, не обязательно имеют порядковое значение в соответствии с их числовым обозначением.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| ИСПОЛЬЗОВАНИЕ ГЛУБИННОГО СЕМАНТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ДЛЯ СОЗДАНИЯ ОБУЧАЮЩИХ ВЫБОРОК В МЕТОДАХ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2636098C1 |
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ ПО УРОВНЯМ КОНФИДЕНЦИАЛЬНОСТИ | 2019 |
|
RU2732850C1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ | 2017 |
|
RU2662688C1 |
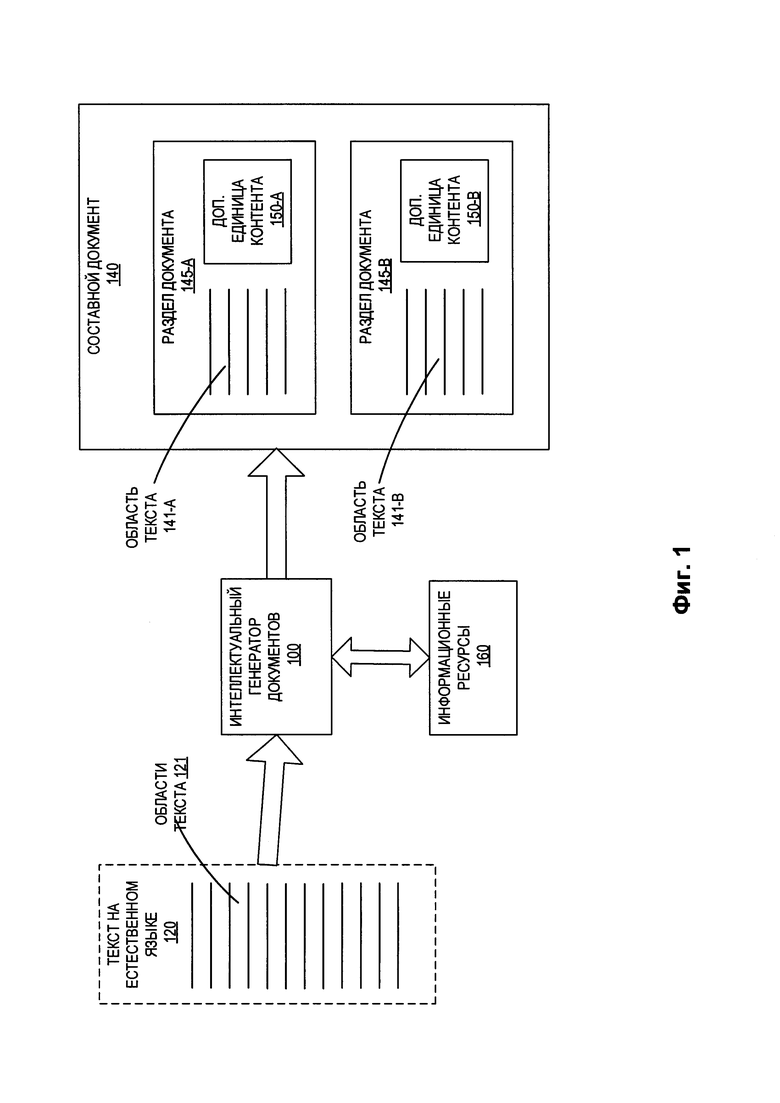
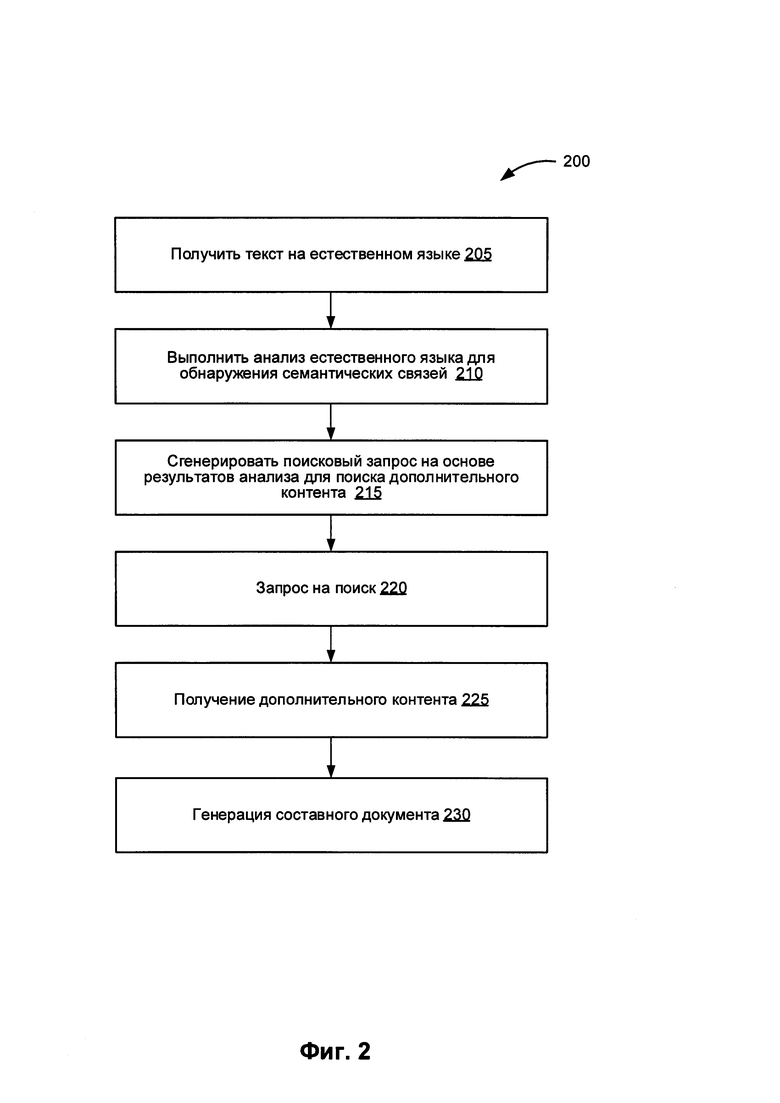
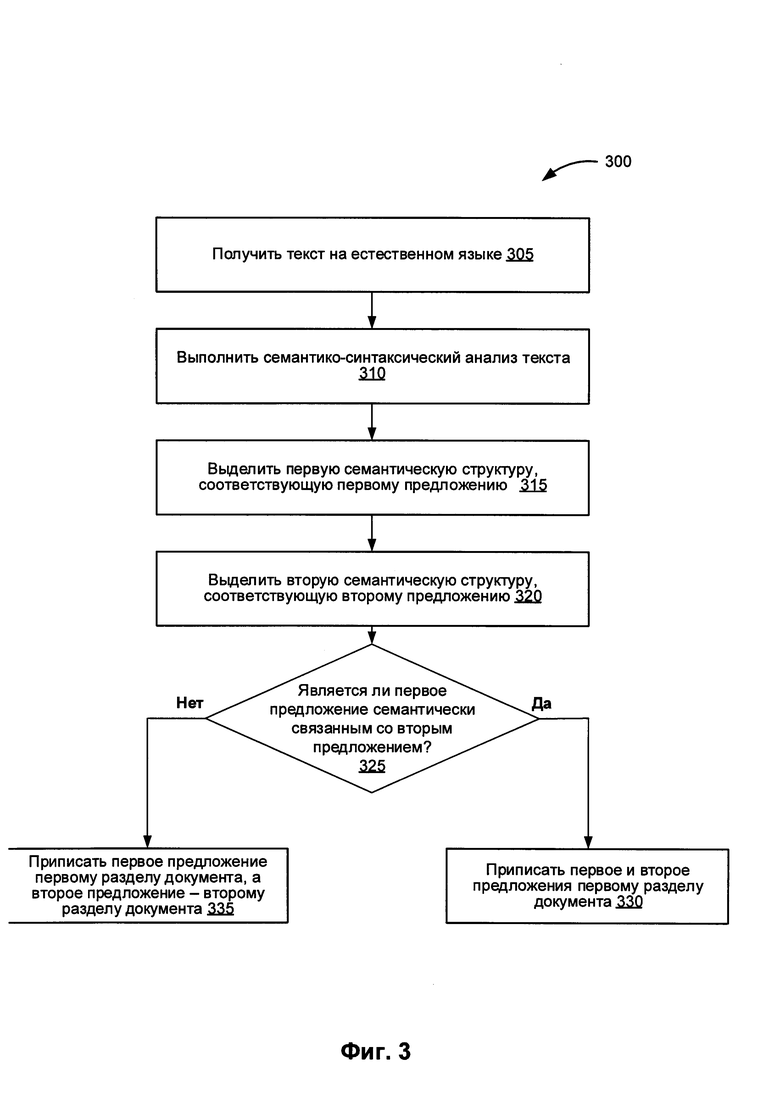
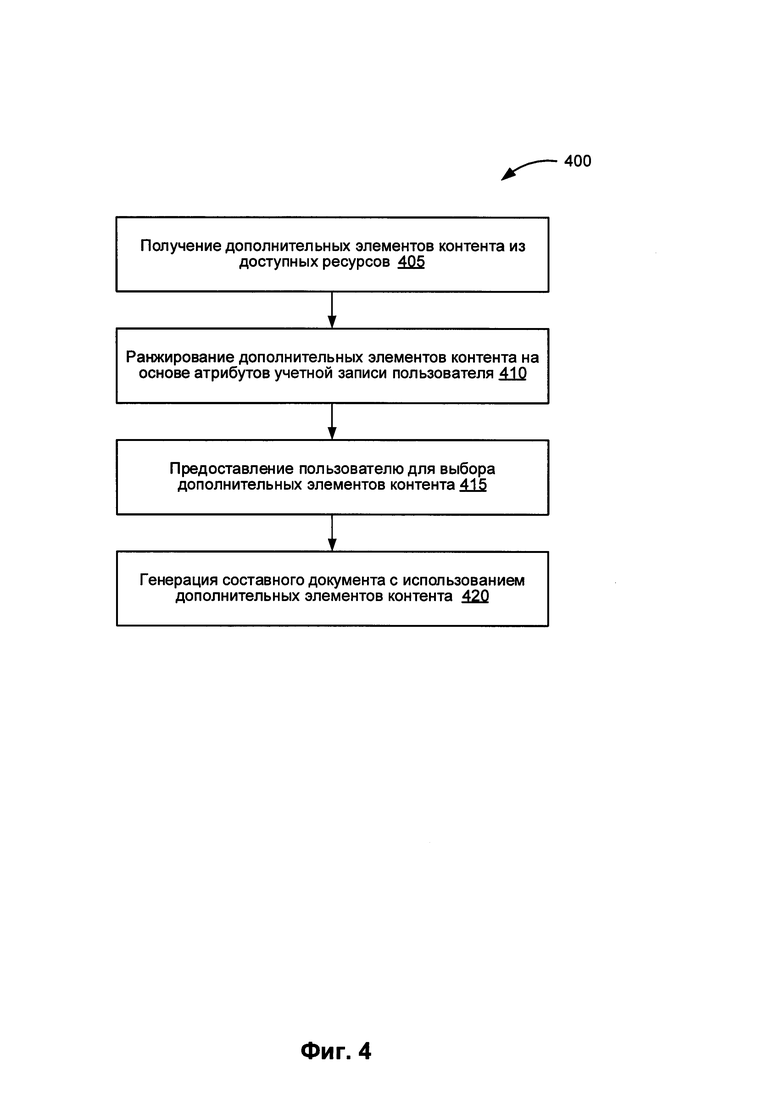
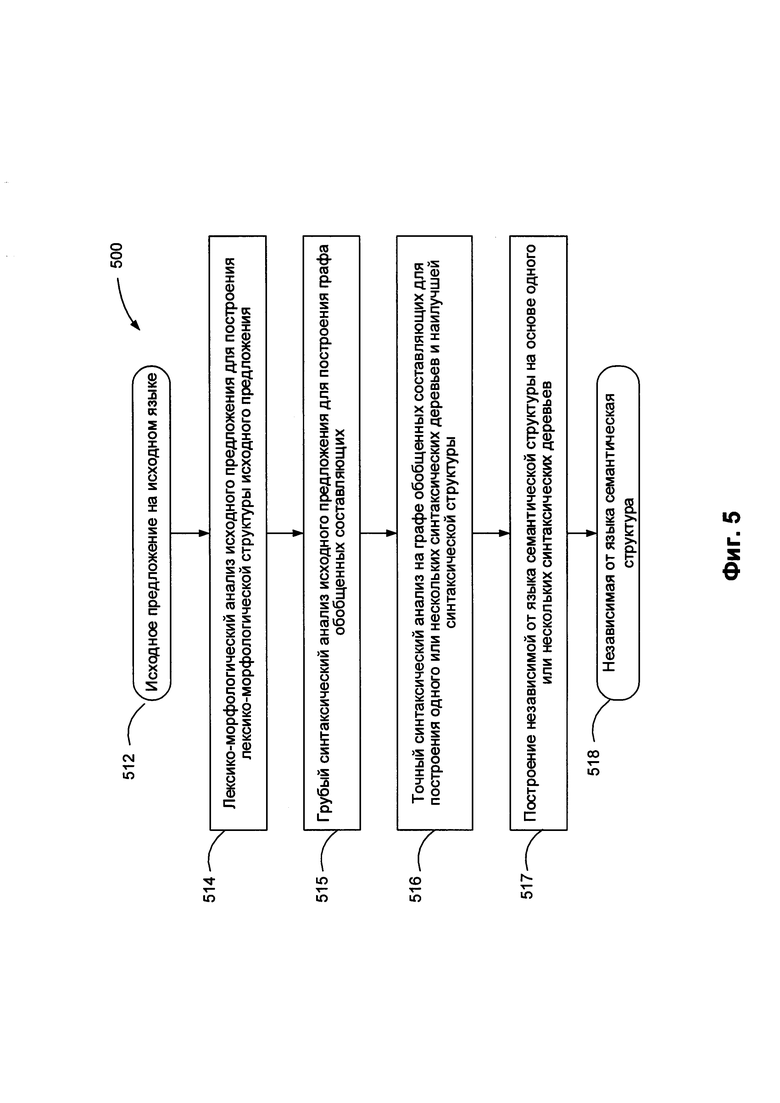
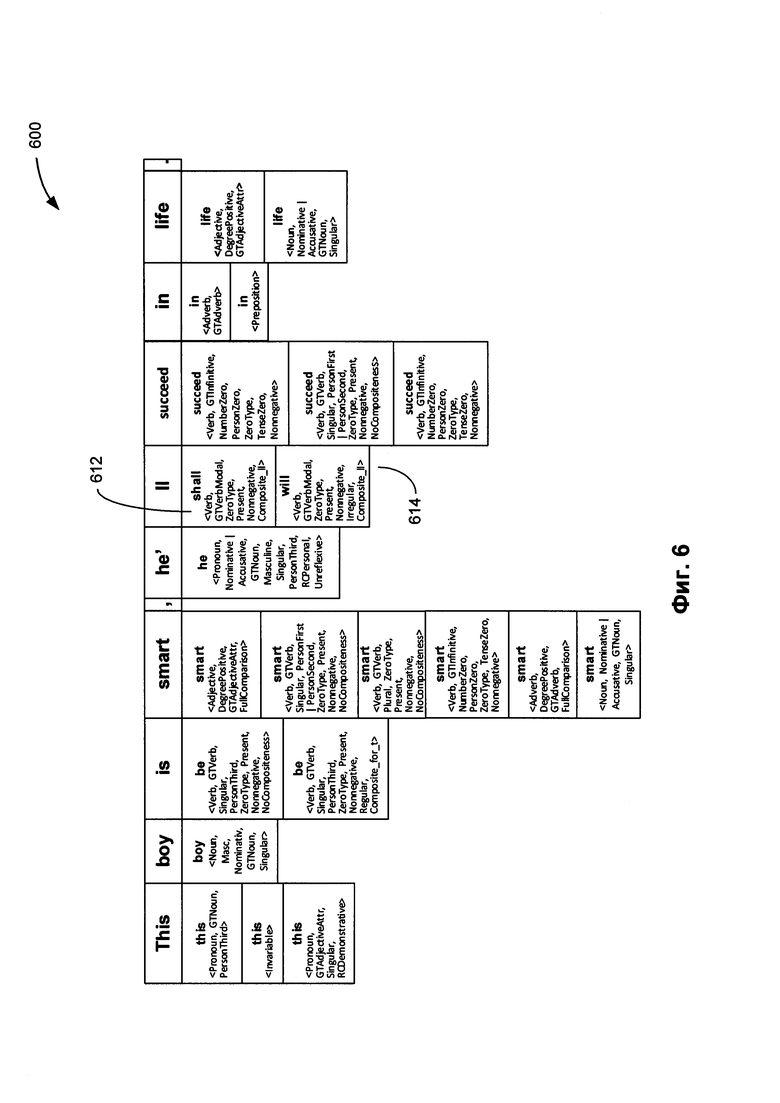
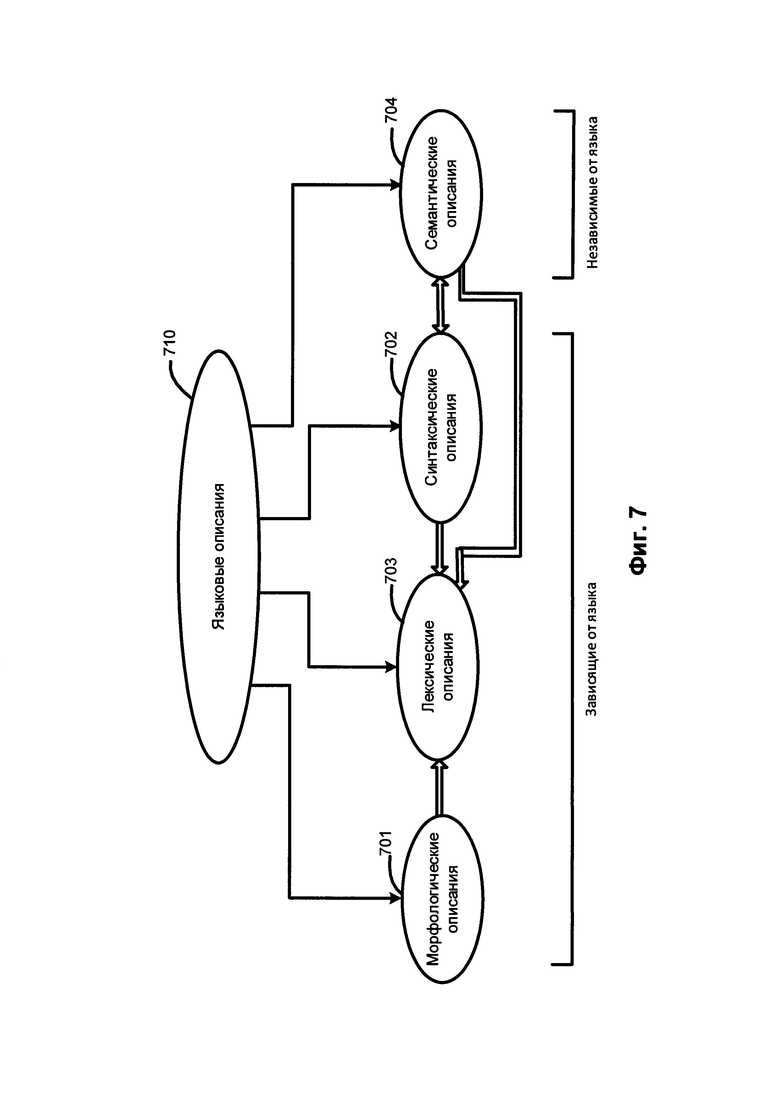
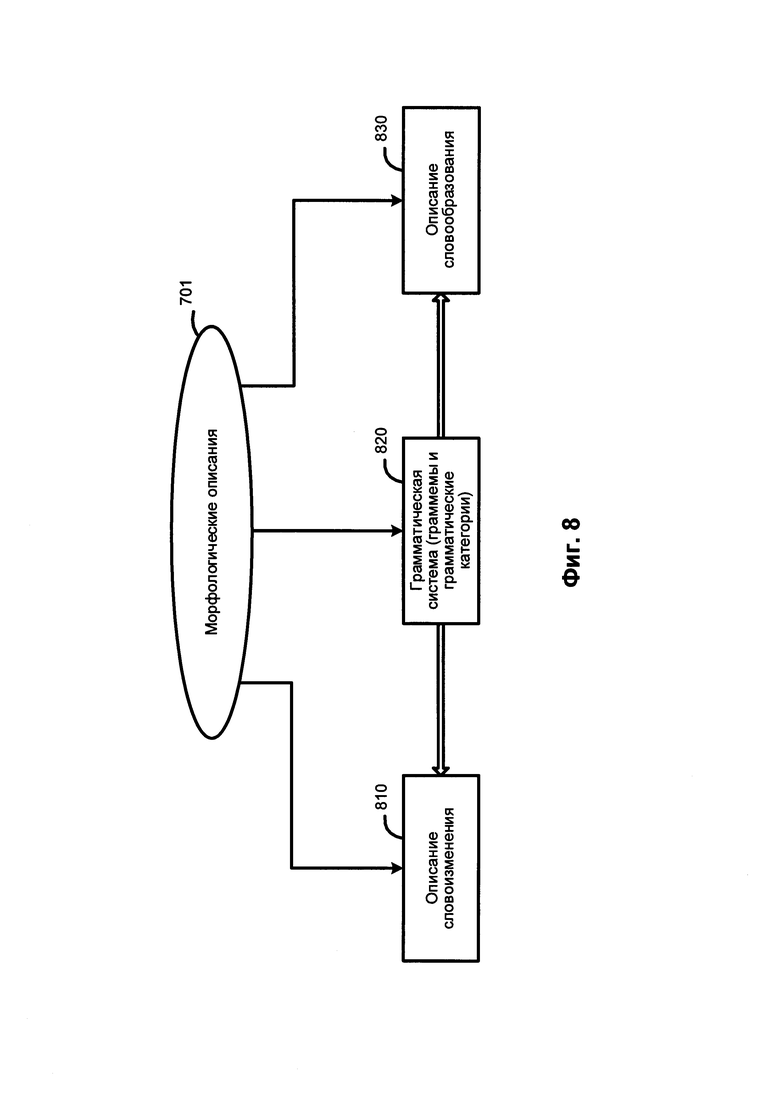
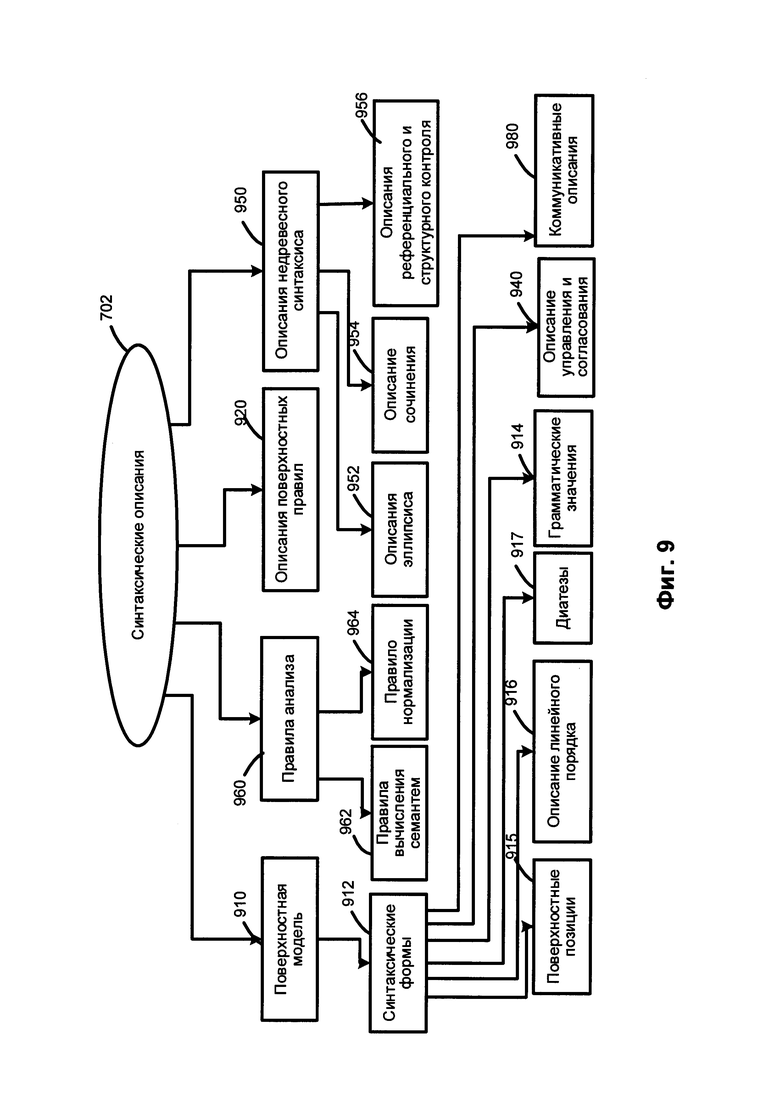
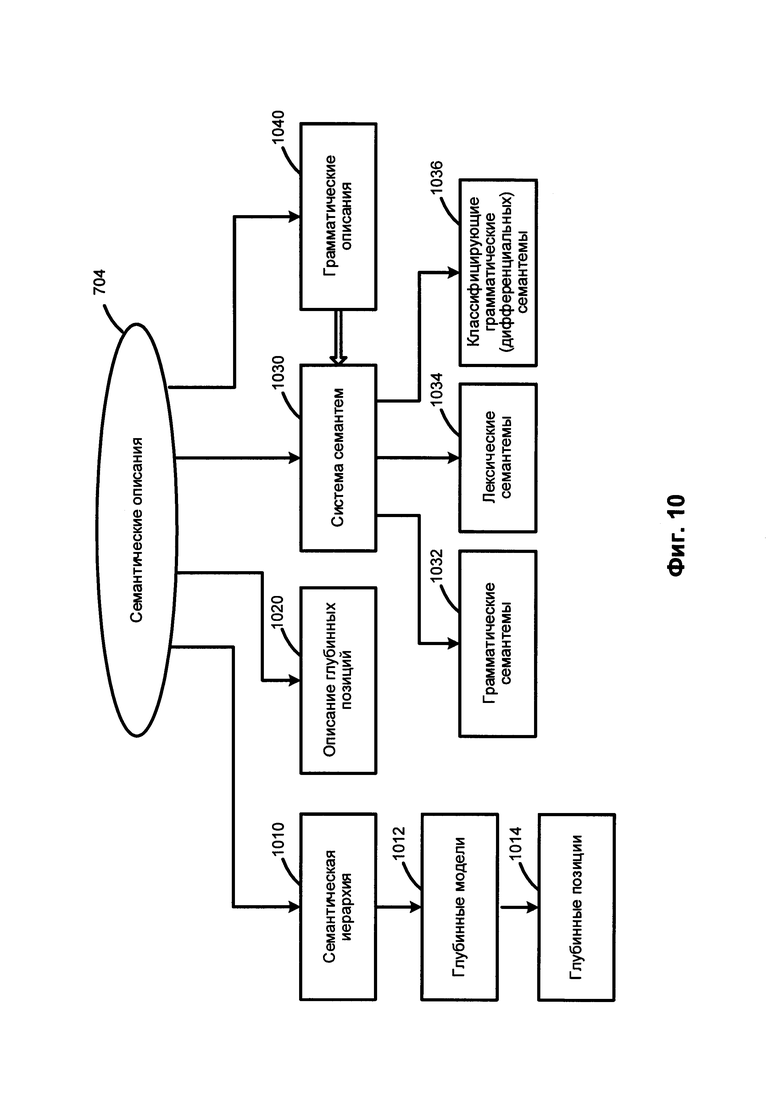
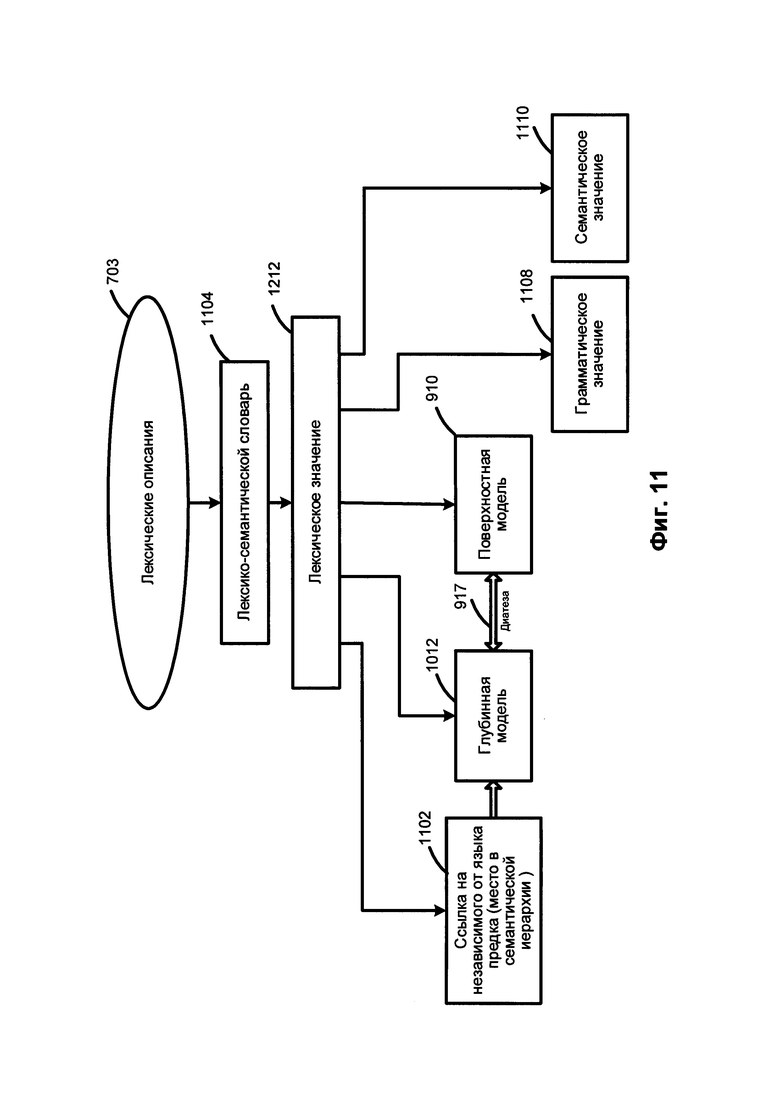
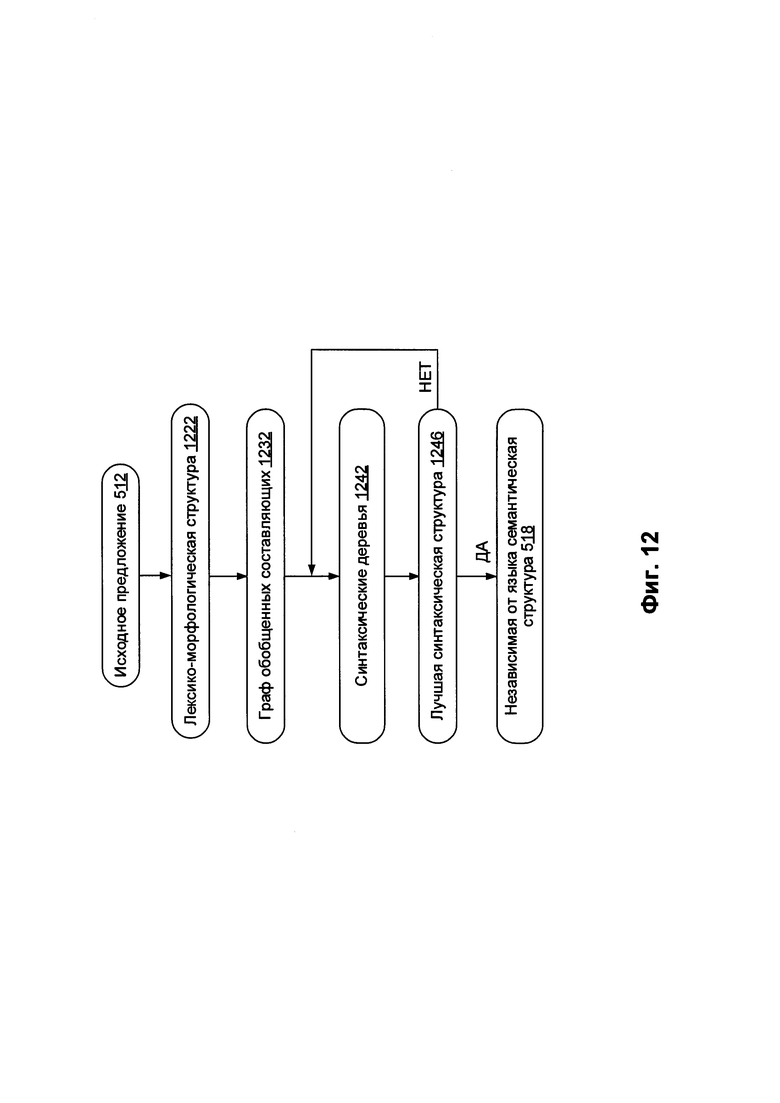
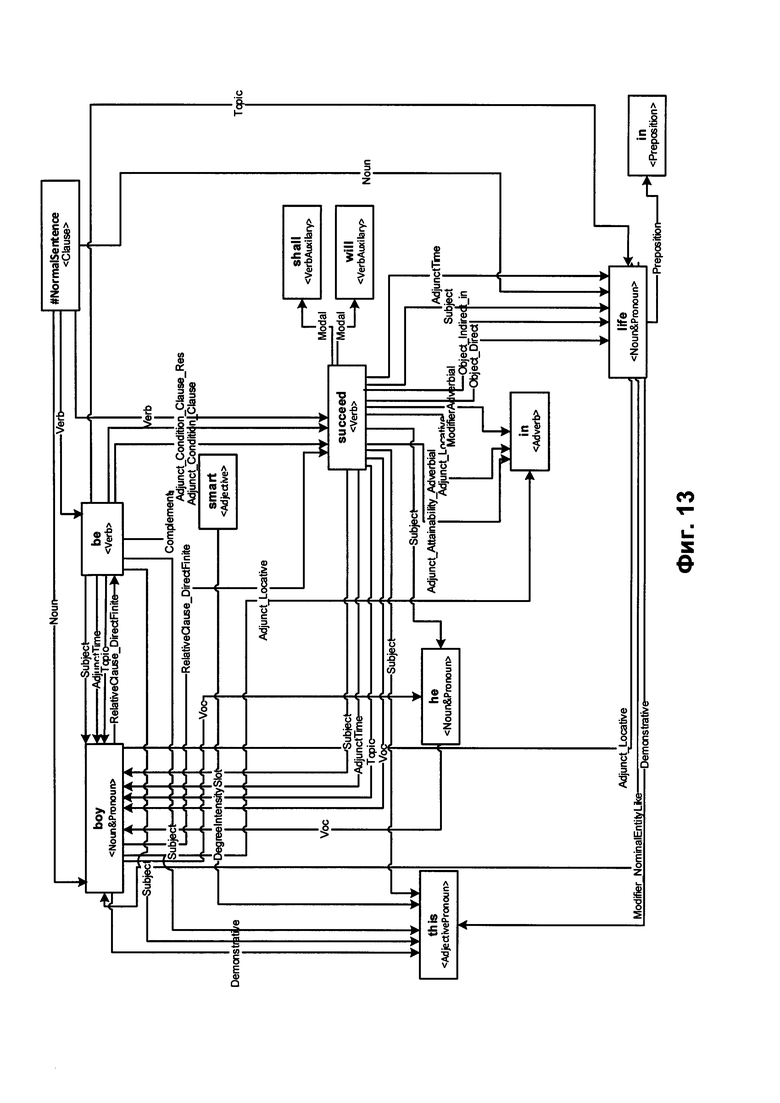
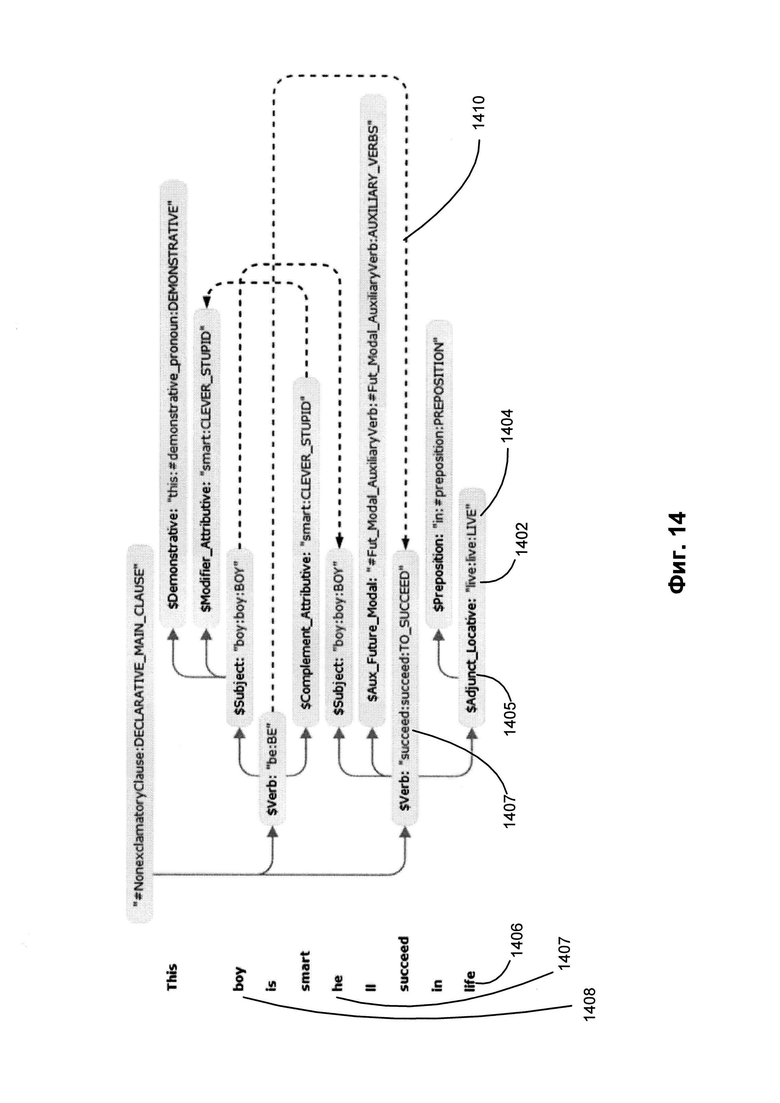
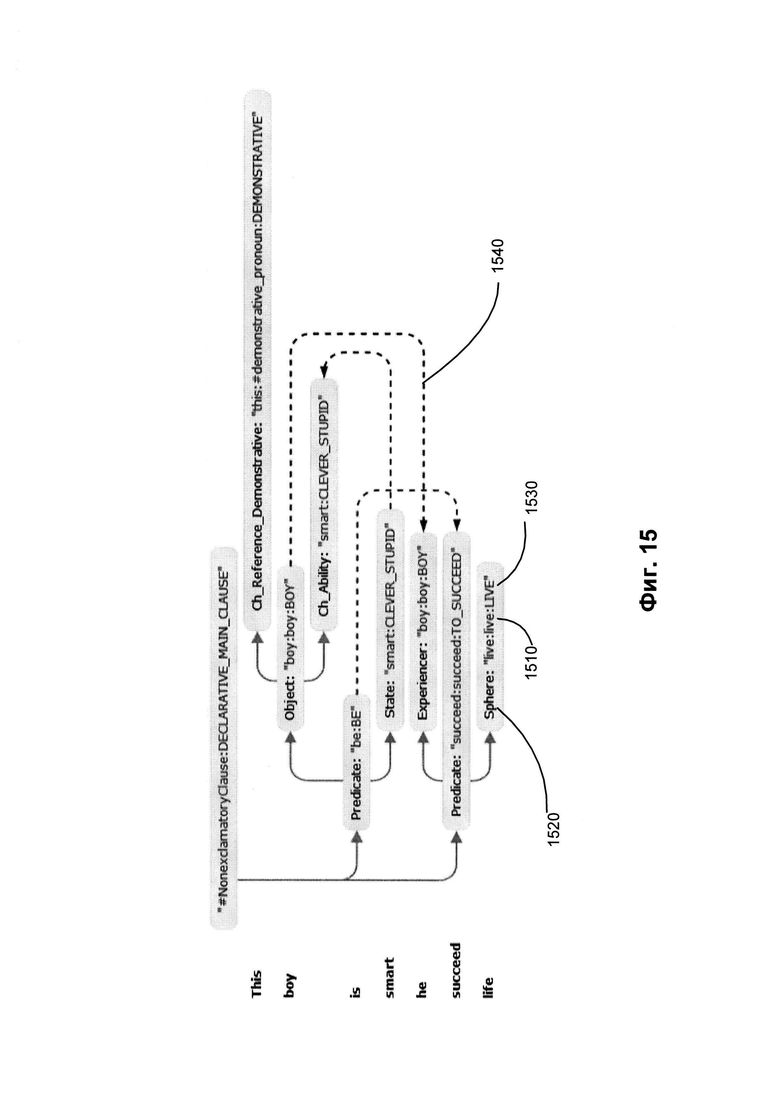
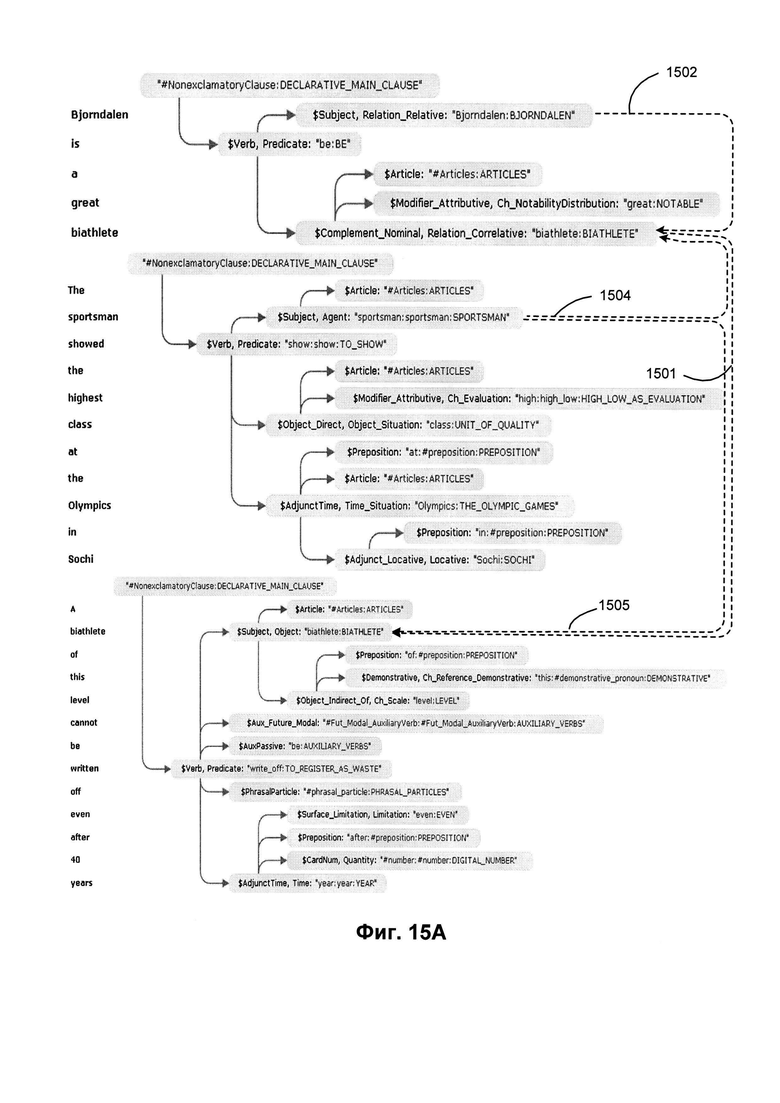



Изобретение относится к системам и способам обработки естественного языка. Технический результат заключается в расширении арсенала средств построения составного текстового документа. Способ построения составного текстового документа включает получение устройством обработки данных текста на естественном языке, выполнение устройством обработки данных анализа текста с целью определения одной или более семантической связи в пределах одной или более области текста, создание устройством обработки данных поискового запроса с целью поиска дополнительного контента, передачу устройством обработки данных поискового запроса в один или более доступный информационный ресурс данного объекта с соответствующим концептом онтологии, получение в ответ множества дополнительных единиц контента, создание устройством обработки данных составного документа, в который входит множество разделов и в каждом разделе содержится одна область текста из множества областей текста, которая содержит одну или более дополнительную единицу контента из множества единиц, относящихся к соответствующей области текста. 3 н. и 25 з.п. ф-лы, 20 ил.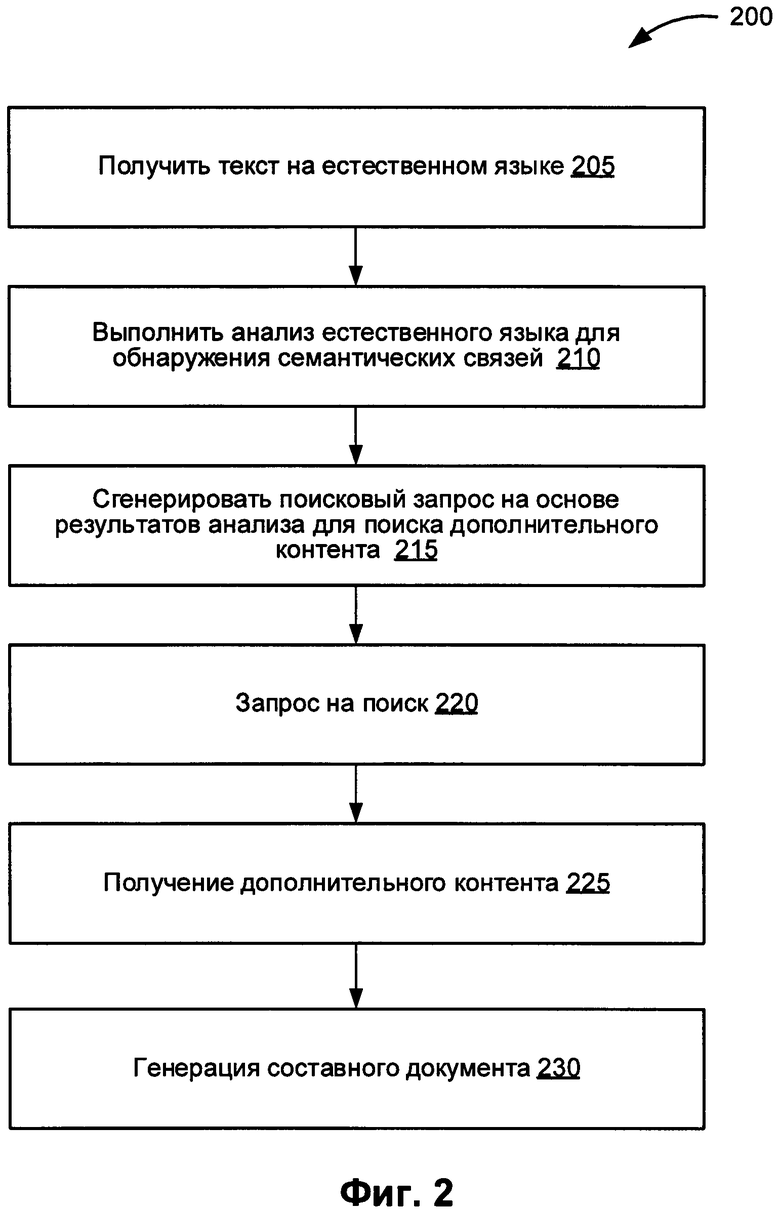
1. Способ построения составного текстового документа, включающего текст на естественном языке, содержащий:
получение устройством обработки данных текста на естественном языке, который включает некоторое множество областей текста;
выполнение устройством обработки данных анализа текста на естественном языке с целью определения одной или более семантической связи в пределах одной или более области текста, при этом указанный анализ текста на естественном языке включает выполнение семантико-синтаксического анализа текста на естественном языке для получения по меньшей мере одной семантической структуры, где указанная по меньшей мере одна семантическая структура представляет по меньшей мере одно предложение указанного текста на естественном языке;
создание устройством обработки данных поискового запроса с целью поиска дополнительного контента, относящегося по меньшей мере к одной из областей текста из множества областей текста на естественном языке, при этом поисковый запрос основывается на результатах анализа текста для по меньшей мере одной из областей текста и составляется с учетом по меньшей мере одного из свойств одного или более предложения в области текста, семантического класса, лексического класса, именованной сущности, метаданных, хештегов;
передачу устройством обработки данных поискового запроса в один или более доступный информационный ресурс;
получение в ответ на поисковый запрос множества дополнительных единиц контента, каждая из которых относится к соответствующей области текста из множества областей текста; и
создание устройством обработки данных составного документа, в который входит множество разделов, при этом в каждом разделе содержится одна область текста из множества областей текста и при этом по меньшей мере один раздел из множества разделов содержит одну или более дополнительную единицу контента из множества дополнительных единиц контента, относящихся к соответствующей области текста.
2. Способ по п. 1, где выполнение анализа текста на естественном языке дополнительно включает:
определение первой семантической структуры из множества семантических структур для первого предложения в тексте на естественном языке и второй семантической структуры из множества семантических структур для второго предложения в тексте на естественном языке и
определение того, связаны ли первая семантическая структура для первого предложения и вторая семантическая структура для второго предложения друг с другом семантически, на основе значения метрики семантической близости.
3. Способ по п. 2, дополнительно включающий по меньшей мере одно из распознавания именованных сущностей, анализа изображений, включенных в текст, анализа метаданных, анализа хештегов.
4. Способ по п. 1, дополнительно включающий отнесение первого предложения и второго предложения к первой области текста из множества областей текста в том случае, если окажется, что значение показателя семантической близости равно или выше порогового значения.
5. Способ по п. 1, дополнительно включающий отнесение первого предложения к первой области текста из множества областей текста, а второго предложения - ко второй области текста из множества областей текста в том случае, если окажется, что значение показателя семантической близости ниже порогового значения.
6. Способ по п. 1, в котором перечень из одного или более доступных информационных ресурсов включает по меньшей мере один из следующих пунктов: локальное устройство хранения данных; ресурс хранения данных, доступ к которому осуществляется через локальную сеть; ресурс, доступ к которому осуществляется через сеть Интернет; ресурсы, доступ к которым предоставляется через социальную сеть.
7. Способ по п. 1, в котором перечень из одной или более дополнительных единиц контента включает по меньшей мере один из следующих пунктов: изображение; схему; логотип; цитату, шутку, аудио, видео или текстовый контент из источника исходных данных.
8. Способ по п. 1, дополнительно включающий:
ранжирование дополнительных единиц контента, основываясь на атрибутах, связанных с настройками учетной записи пользователя, и создание сортированного списка;
предоставление пользователю для выбора одной или более дополнительной единицы контента из сортированного списка и
создание составного документа по результатам отбора данных.
9. Способ по п. 1, дополнительно включающий:
выбор одной или более дополнительной единицы контента, руководствуясь заданными настройками приоритетности; и
создание составного документа по результатам отбора данных.
10. Способ по п. 1, в котором составной документ предназначен для целей презентации или демонстрации, а каждый раздел из множества разделов документа представляет собой слайд презентации.
11. Вычислительное устройство для построения составного документа на естественном языке, содержащее:
запоминающее устройство (ЗУ) для хранения команд и
устройство обработки данных, взаимодействующее с ЗУ и предназначенное для выполнения команд, при этом устройство обработки данных настроено на:
получение устройством обработки данных текста на естественном языке, который содержит некоторое множество областей текста;
выполнение устройством обработки данных анализа текста на естественном языке с целью определения одной или более семантической связи в пределах одной или более области текста, при этом указанный анализ текста на естественном языке включает выполнение семантико-синтаксического анализа текста на естественном языке для получения по меньшей мере одной семантической структуры, где указанная по меньшей мере одна семантическая структура представляет по меньшей мере одно предложение указанного текста на естественном языке;
создание устройством обработки данных поискового запроса для нахождения дополнительного контента, относящегося по меньшей мере к одной из областей текста из множества областей текста на естественном языке, при этом поисковый запрос основывается на результатах анализа текста для по меньшей мере для одной из областей текста и составляется с учетом по меньшей мере одного из свойств одного или более предложения в области текста, семантического класса, лексического класса, именованной сущности, метаданных, хештегов;
передача устройством обработки данных поискового запроса на один или более доступный информационный ресурс;
получение в ответ на поисковый запрос множества дополнительных единиц контента, каждая из которых относится к соответствующей области текста из множества областей текста; и
создание устройством обработки данных составного документа, в который входит множество разделов, при этом в каждом разделе содержится одна область текста из множества областей текста и при этом по меньшей мере один раздел из множества разделов содержит одну или более дополнительную единицу контента из множества дополнительных единиц контента, относящихся к соответствующей области текста.
12. Вычислительное устройство по п. 11, где для выполнения анализа текста на естественном языке устройство обработки данных дополнительно выполняет следующие действия:
определение первой семантической структуры из множества семантических структур для первого предложения в тексте на естественном языке и второй семантической структуры из множества семантических структур для второго предложения в тексте на естественном языке и
определение того, связаны ли первая семантическая структура для первого предложения и вторая семантическая структура для второго предложения друг с другом семантически на основе значения метрики семантической близости.
13. Вычислительное устройство по п. 12, в котором устройство обработки данных дополнительно настроено на отнесение первого предложения и второго предложения к первой области текста из множества областей текста в том случае, если окажется, что значение метрики семантической близости равно или выше порогового значения.
14. Вычислительное устройство по п. 13, в котором устройство обработки данных дополнительно настроено на отнесение первого предложения к первой области текста из множества областей текста, а второго предложения - ко второй области текста из множества областей текста в том случае, если значение метрики семантической близости ниже порогового значения.
15. Вычислительное устройство по п. 11, в котором перечень из одного или более доступных информационных ресурсов включает по меньшей мере один из следующих пунктов: локальное устройство хранения данных; ресурс хранения данных, доступ к которому осуществляется через локальную сеть; ресурс, доступ к которому осуществляется через сеть Интернет; ресурсы, доступ к которым предоставляется через социальную сеть.
16. Вычислительное устройство по п. 11, в котором перечень из одной или более дополнительных единиц контента включает по меньшей мере один из следующих пунктов: изображение; схему; логотип; цитату, шутку, аудио, видео или текстовый контент из источника исходного данных.
17. Вычислительное устройство по п. 11, в котором устройство обработки данных дополнительно настроено на:
ранжирование дополнительных единиц контента, основываясь на атрибутах, связанных с настройками учетной записи пользователя, и создание сортированного списка;
предоставление пользователю для выбора одной или более дополнительной единицы контента из сортированного списка;
создание составного документа по результатам отбора данных.
18. Вычислительное устройство по п. 11, в котором устройство обработки данных дополнительно настроено на:
выбор одной или более дополнительной единицы контента, руководствуясь заданными настройками приоритетности; и
создание составного документа по результатам отбора данных.
19. Вычислительное устройство по п. 11, в котором составной документ предназначен для целей презентации или демонстрации, а каждый раздел из множества разделов документа представляет собой слайд презентации.
20. Постоянный машиночитаемый носитель данных, содержащий хранящиеся в нем команды, которые при обращении к ним обрабатывающего устройства приводят к выполнению операций обрабатывающим устройством, включая:
получение устройством обработки данных текста на естественном языке, в составе которого имеется некоторое множество областей текста;
выполнение устройством обработки данных анализа текста на естественном языке с целью определения одной или более семантической связи в пределах одной или более области текста, при этом указанный анализ текста на естественном языке включает выполнение семантико-синтаксического анализа текста на естественном языке для получения по меньшей мере одной семантической структуры, где указанная по меньшей мере одна семантическая структура представляет по меньшей мере одно предложение указанного текста на естественном языке;
создание устройством обработки данных поискового запроса с целью поиска дополнительного контента, относящегося по меньшей мере к одной из областей текста из множества областей текста на естественном языке, при этом поисковый запрос основывается на результатах анализа текста для по меньшей мере одной из областей текста и составляется с учетом по меньшей мере одного из свойств одного или более предложения в области текста, семантического класса, лексического класса, именованной сущности, метаданных, хештегов;
передачу устройством обработки данных поискового запроса в один или более доступный информационный ресурс;
получение в ответ на поисковый запрос множества дополнительных единиц контента, каждая из которых относится к соответствующей области текста из множества областей текста; и
создание устройством обработки данных составного документа, в который входит множество разделов, при этом в каждом разделе содержится одна область текста из множества областей текста и при этом по меньшей мере один раздел из множества разделов содержит одну или более дополнительную единицу контента из множества дополнительных единиц контента, относящихся к соответствующей области текста.
21. Носитель данных по п. 20, где выполнение анализа текста на естественном языке в процессе обработки этого текста дополнительно включает:
определение первой семантической структуры из множества семантических структур для первого предложения в тексте на естественном языке и второй семантической структуры из множества семантических структур для второго предложения в тексте на естественном языке и
определение того, связаны ли первая семантическая структура для первого предложения и вторая семантическая структура для второго предложения друг с другом семантически, на основе значения метрики семантической близости.
22. Носитель данных по п. 21, дополнительно включающий отнесение первого предложения и второго предложения к первой области текста из множества областей текста в том случае, если окажется, что значение метрики семантической близости равно или выше порогового значения.
23. Носитель данных по п. 21, дополнительно включающий отнесение первого предложения к первой области текста из множества областей текста, а второго предложения - ко второй области текста из множества областей текста в том случае, если окажется, что значение метрики семантической близости ниже порогового значения.
24. Носитель данных по п. 20, в котором перечень из одного или более доступных информационных ресурсов включает по меньшей мере один из следующих пунктов: локальное устройство хранения данных; ресурс хранения данных, доступ к которому осуществляется через локальную сеть; ресурс, доступ к которому осуществляется через сеть Интернет; ресурсы, доступ к которым предоставляется через социальную сеть.
25. Носитель данных по п. 20, в котором перечень из одной или более дополнительных единиц контента включает по меньшей мере один из следующих пунктов: изображение; схему; логотип; цитату, шутку, аудио, видео или текстовый контент из источника исходных данных.
26. Носитель данных по п. 20, дополнительно включающий:
ранжирование дополнительных единиц контента, основываясь на атрибутах, связанных с настройками учетной записи пользователя, и создание сортированного списка;
предоставление пользователю для выбора одной или более дополнительной единицы контента из сортированного списка и
создание составного документа по результатам отбора данных.
27. Носитель данных по п. 22, дополнительно включающий:
выбор одной или более дополнительной единицы контента, руководствуясь заданными настройками приоритетности; и
создание составного документа по результатам отбора данных.
28. Носитель данных по п. 20, в котором составной документ предназначен для целей презентации или демонстрации, а каждый раздел из множества разделов документа представляет собой слайд презентации.
| Токарный резец | 1924 |
|
SU2016A1 |
| US 8606778 B1, 10.12.2013 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 2009254572 A1, 08.10.2009 | |||
| RU 2009114293 A, 27.10.2010. | |||

