ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Объем неструктурированной информации, представленной в электронном виде, растет очень быстро. В частности, большой объем неструктурированной информации легко доступен в сети Интернет. Эта информация может содержать текст и другие данные (например, числа, даты и пр.). Интерпретацию этой информации усложняют двусмысленности и неточности. Кроме того, существует необходимость извлечения и обработки речевой информации (аудиофайлов) и видеоинформации.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0002] Один из вариантов реализации относится к способу обработки естественного языка. Метод настоящего изобретения включает получение применимой к любому естественному языку семантической иерархии независимых от языка семантических описаний естественного языка. Метод также включает создание зависимых от конкретного естественного языка морфологических, лексических и синтаксических описаний для одного или нескольких целевых языков. Метод также включает построение первой программы обработки естественного языка на основе независимых от языка семантических описаний, зависящих от языка морфологических описаний, лексических и синтаксических описаний одного или нескольких целевых языков.
[0003] Другой вариант реализации относится к системе. Эта система включает в себя одно или несколько вычислительных средств. Эта система также включает в себя одно или несколько запоминающих устройств, в которых хранятся команды, которые при выполнении на одном или нескольких вычислительных устройствах приводят к тому, что эти вычислительные устройства выполняют следующие операции: получение семантической иерархии независимых от языка семантических описаний для естественного языка, применимой к любому естественному языку; создание морфологических описаний, лексических и синтаксических описаний для одного или нескольких целевых языков; а также построение первой программы обработки естественного языка на основе независимых от языка семантических описаний, зависимых от языка морфологических описаний, лексических и синтаксических описаний одного или нескольких целевых языков.
[0004] Еще один вариант реализации относится к машиночитаемому носителю данных, содержащему машинные команды, при выполнении которых вычислительным устройством это вычислительное устройство выполняет следующие операции: получение семантической иерархии независимых от языка семантических описаний для естественного языка, применимой к любому естественному языку; создание зависящих от языка морфологических описаний, лексических и синтаксических описаний на одном или нескольких целевых языках; а также построение первой программы обработки естественного языка на основе независимых от языка семантических описаний, зависимых от языка морфологических описаний, лексических и синтаксических описаний одного или нескольких целевых языков.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0005] Детали различных вариантов реализации изложены в прилагаемых чертежах и приведенном ниже описании. Другие особенности, аспекты и преимущества настоящего изобретения станут очевидными из описания, чертежей и формулы изобретения, в которых:
[0006] Фиг. 1 иллюстрирует среду, содержащую системы обработки данных, в которых используется универсальное представление текстовой информации в соответствии с одним или несколькими вариантами реализации изобретения;
[0007] Фиг. 2A представляет собой блок-схему способа получения универсального представления обрабатываемой информации из документов и из других источников в соответствии с одним или несколькими вариантами реализации изобретения;
[0008] Фиг. 2B представляет собой схему, иллюстрирующую необходимые языковые описания, согласно одной из возможных реализаций изобретения;
[0009] Фиг. 2C содержит пример лексико-морфологической структуры предложения в соответствии с одним или несколькими вариантами реализации;
[0010] Фиг. 3 содержит примеры морфологических описаний в соответствии с одним или несколькими вариантами осуществления;
[0011] Фиг. 4 содержит примеры синтаксических описаний в соответствии с одним или несколькими вариантами осуществления;
[0012] Фиг. 5 содержит примеры семантических описаний в соответствии с одним или несколькими вариантами осуществления;
[0013] Фиг. 6 содержит примеры лексических описаний в соответствии с одним или несколькими вариантами осуществления;
[0014] Фиг. 7A иллюстрирует этапы семантико-синтаксического анализа в соответствии с одним или несколькими вариантами осуществления;
[0015] Фиг. 7B иллюстрирует последовательность структур данных, которые строятся процессе анализа в соответствии с одним или несколькими вариантами осуществления;
[0016] На Фиг. 7C приведен схематичный пример графа обобщенных составляющих для ранее упомянутого предложения «This boy is smart, he'll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) в соответствии с одним или несколькими вариантами осуществления;
[0017] На Фиг. 8A и 8B приведены синтаксические деревья для английского предложения «The girl in the sitting-room was playing the piano» (Девушка в гостиной играла на фортепьяно) в соответствии с одним или несколькими вариантами осуществления;
[0018] На Фиг. 9 приведена семантическая структура английского предложения «The girl in the sitting-room was playing the piano» (Девушка в гостиной играла на фортепьяно) в соответствии с одним или несколькими вариантами осуществления;
[0019] Фиг. 10 иллюстрирует лучшую синтаксическую структуру английского предложения «This boy is smart, he'll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) в соответствии с одним или несколькими вариантами осуществления;
[0020] Фиг. 11 иллюстрирует семантическую структуру английского предложения «This boy is smart, he'll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) в соответствии с одним или несколькими вариантами осуществления;
[0021] На Фиг. 12 приведена блок-схема процесса создания программы для естественного языка на основе универсального представления текстовой информации;
[0022] На Фиг. 13 указаны вычислительные средства для создания компьютерной системы согласно одной из возможных реализаций изобретения.
[0023] Одинаковые ссылочные номера и обозначения на различных чертежах обозначают одинаковые элементы.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0024] В приведенном ниже описании многие конкретные подробности приведены для большей ясности, чтобы обеспечить полное понимание концепций, лежащих в основе описанных вариантов осуществления. Однако специалистам в данной области техники будет очевидно, что описанные варианты осуществления могут быть реализованы без некоторых конкретных деталей или полностью без них. В других случаях структуры и устройства показаны только в виде блок-схем для того, чтобы не затруднять понимание описанных вариантов осуществления. Некоторые этапы процесса описаны без подробностей, чтобы не затруднять понимание основной концепции.
[0025] Согласно различным вариантам осуществления предоставляются системы и способы обработки неструктурированной информации. В частности, эти системы и способы обеспечивают автоматическую обработку текстовой информации на естественных языках. Используя эти методы, можно извлекать информацию из текстов на естественном языке, производить поиск информации в подборках документов и (или) осуществлять мониторинг информации.
[0026] Описанные системы и способы предоставляют в распоряжение универсальное ядро, которое не зависит от конкретного языка, и лексическое наполнение, которое включает лексику конкретного языка и языковые модели словообразования и словоизменения, а также синтаксические модели согласования и словоупотребления в этом языке. С другой стороны, это универсальное независимое от языка ядро содержит исчерпывающий набор знаний о мире и способов выражения этих знаний в естественных языках. Это знание может быть представлено в виде иерархического описания имеющихся в мире сущностей, их свойств, возможных атрибутов, их взаимоотношений и способов выражения таких знаний в конкретном языке. Семантическое описание такого типа является полезным для создания технологий автоматической обработки естественного языка (Natural Language Processing, далее - «NLP»), особенно приложений, которые способны «понимать смысл», выраженный на естественном языке; они необходимы для создания приложений и решения многочисленных задач по обработке естественного языка, таких как машинный перевод, семантическое индексирование и семантический поиск, включая многоязычный семантический поиск, извлечение фактов, анализ тональности, поиск похожих документов, классификация документов, обобщение, анализ больших объемов данных, электронное обнаружение, морфологический и лексический анализатор и другие приложения.
[0027] В частности, раскрываемые системы и способы дают возможность хранить и обрабатывать единицы текста (слова, предложения и тексты) в базе данных и производить такие же операции с лексическими и семантическими значениями слов, предложений, текстов и других единиц информации.
[0028] Большинство слов любого языка может иметь несколько значений и выражать несколько разных понятий. Кроме того, некоторые словарные формы в языке могут соответствовать нескольким грамматическим значениям и иметь несколько базовых форм (лемм). Например, слово «play» в английском языке может являться существительным или глаголом, при этом у него также имеются совпадения значений в разных грамматических формах (падежах, числе, роде, глагольных формах). Это явление называется грамматической омонимией.
[0029] Явление, в котором одно и то же слово имеет разные, иногда близкие значения, называется лексической омонимией. Эти значения могут быть как близкими по смыслу, так и совершенно различными. Например, для глагола «play» Oxford Dictionary дает, среди прочих, следующие значения: 1) engage in activity for enjoyment and recreation rather than a serious or practical purpose (принимать участие в деятельности, направленной на получение удовольствия и отдых, а не на серьезную или практическую цель), 2) take part in (a sport) (принимать участие, напр. в спортивной деятельности), 3) be cooperative (сотрудничать), 4) represent (a character) in a theatrical performance or a film (играть (роль) в театральной постановке или фильме), 5) perform on (a musical instrument) (играть (на музыкальном инструменте)), а также еще несколько значений.
[0030] Кроме того, имеет место семантическая омонимия, когда некоторое слово может иметь совершенно разные значения. Например, слово «bank» в английском языке имеет множество значений: от «the land alongside or sloping down to a river or lake» («участок земли, расположенной вдоль реки или озера или спускающийся к ним») до «а financial establishment» («финансовое учреждение») и «а stock of something available for use when required» («запас чего-либо, доступный в случае необходимости»).
[0031] Обычно человек безошибочно выбирает соответствующее лексическое значение в зависимости от контекста, но каждое из лексических значений имеет свои свойства, свою модель употребления, как-то, предлоги, объекты и ограничения на них и т.п., и на другой язык должно переводиться по-разному.
[0032] Под лексическим значением понимается одно из значений (смыслов) слова. Лексическое значение выражается средствами некоторого конкретного языка. В одном языке может иметься несколько слов для выражения одного и того же смысла Близкие лексические значения принадлежат одному лексическому классу. Примером таких пар являются синонимы. Синонимы могут иметь одинаковое лексическое значение, но различаться некоторыми грамматическими или даже семантическими атрибутами. Например, в русском языке слова «конь», «лошадь» и «жеребец» имеют одно лексическое значение, но отличаются грамматическим атрибутом (полом). При этом русское слово «скакун» близко к этим словам по лексическому значению, однако имеет несколько дифференцирующих отличий, которые выражаются в толковом словаре как «выносливая, резвая в беге лошадь чистокровной породы, как правило, для верховой езды». Такие отличия могут быть выражены формально при помощи семантических атрибутов - семантем.
[0033] Близкие лексические значения объединяются в семантические классы. Таким образом, русские слова «конь», «лошадь» и «жеребец» с лексическими значениями, принадлежащими одному и тому же лексическому классу, и слово «скакун», которое не принадлежит к этому лексическому классу, будут принадлежать к одному и тому же семантическому классу HORSE (ЛОШАДЬ), но каждое из них может иметь собственные грамматические и семантические атрибуты. Аналогично английские слова «horse» (лошадь), «foal» (жеребенок), «mare» (кобыла) и «stallion» (жеребец) включаются в один семантический класс HORSE (ЛОШАДЬ), при этом каждое слово имеет собственные грамматические и семантические атрибуты. Аналогичные примеры имеются для терминов на немецком, французском, китайском и других языках.
[0034] Любому лексическому значению в конкретном языке может быть сопоставлено универсальное, независимое от языка семантическое значение - семантический класс плюс множество дифференцирующих семантических и грамматических атрибутов, выраженных в универсальных терминах (семантемах). Другими словами, каждому слову текста можно сопоставить лексическое и семантическое значение. Слова в разных языках с одинаковым семантическим значением считаются семантически эквивалентными.
[0035] Мысль, смысл, сообщение, факт или высказывание на некоем языке можно выразить с помощью предложений. Каждое предложение представимо в виде последовательности лексических значений, связанных определенными отношениями, что выражается в языке как заполнение поверхностных (синтаксических) позиций, а на семантическом уровне - как заполнение глубинных (семантических) позиций. Например, в предложении «The girl eats the apple» (Девочка ест яблоко), слово «apple» (яблоко) заполняет позицию Object (дополнения) для глагола «eat» (есть), а слово «girl» (девочка) заполняет поверхностную позицию Subject (подлежащего). Номенклатура поверхностных позиций может быть достаточно широкой и различаться в разных языках. Эти различия вызваны различиями синтаксических моделей в разных языках. На семантическом уровне лексическое значение слова «girl» (девочка) заполняет глубинную позицию Agens (агенс), в то время как лексическое значение слова «apple» ("яблоко") заполняет глубинную позицию Object (дополнение).
[0036] Предложение «The apple is eaten by the girl» ("Яблоко поедается девочкой") выражает ту же мысль, но в нем глагол используется в пассивном залоге, а это значит, что теперь слово «girl» (девочка) заполняет позицию Object глагола «eat» (есть), а слово «apple» (яблоко) заполняет поверхностную позицию Subject. При этом на семантическом уровне лексическое значение слова «girl» по-прежнему заполняет глубинную позицию Agens, а слово «apple» заполняет глубинную позицию Object. Это подтверждается тем фактом, что оба предложения выражают одну и ту же мысль, хотя синтаксически построены по-разному. Другими словами, эти два предложения имеют одно семантическое значение.
[0037] В отличие от поверхностных позиций, для всех языков может использоваться общая номенклатура глубинных позиций. Таким образом, смысл любого предложения также может быть выражен формально с помощью универсальных терминов, с использованием семантических классов, семантем и глубинных позиций.
[0038] Предложение может содержать синтаксическую неоднозначность. Это может привести к нескольким разным вариантам синтаксического разбора. Например, предложение «Flying plain may be dangerous» может иметь по меньшей мере два значения: 1) «Полет на самолете может быть опасным (для пассажиров)» 2) «Летящий самолет может представлять опасность (например, для наблюдателя)». В первом случае подлежащее выражено словосочетанием, ядром которого является герундий «flying» (полет), управляющий дополнением «plain» (самолет). Во втором случае подлежащее представляет собой именную группу, ядром которой является слово «plain» (самолет) а от него зависит причастие настоящего времени «flying» (летящий). Часто лексическое значение слова может быть определено только с учетом контекста и определенного варианта синтаксического разбора.
[0039] Обычные системы машинного перевода и информационно-поисковые системы обеспечивают поиск слов, а не лексических значений. Система и метод настоящего изобретения позволяют оперировать лексическими значениями и независимыми от языка семантическими значениями. На Фиг. 2 показана последовательность действий, совершаемых этой системой на предварительном этапе технологии, который обеспечивает получение универсального представления обрабатываемой информации, получаемой из большого количества документов, данных, текстовых корпусов, изображений, а также от серверов электронной почты, из социальных сетей, распознанной речи, видео и других источников. Если документ является изображением, имеет формат pdf, формат tif или другой нетекстовый формат, то предварительно применяется OCR (оптическое распознавание символов) или другой способ преобразования документа в текстовый формат.
[0040] Каждое указанное действие выполняется с каждым предложением документа, текста или сообщением в корпусе (220). В этом документе используется слово «сообщение», которое может означать любое сообщение в социальных сетях, форумах, сообщение электронной почты, любые замечания, заголовки, подзаголовки и другие виды текстовой информации из видео, надписей и т.д. Если при этом обрабатываются изображения, файлы в формате PDF или другие файлы, которые требуют распознавания, то добавляется дополнительный этап предварительного преобразования в текстовый формат. На этих этапах могут использоваться любые известные коммерческие системы, например, программа FineReader. В случае обработки речевых или аудио файлов добавляется другой предварительный этап - распознавание речи. На всех этапах описанного метода, представленных на Фиг. 2A, активно используется широкий спектр лингвистических описаний. Необходимые лингвистические описания приведены на Фиг. 2B и по меньшей мере включают в себя морфологические описания (201), синтаксические описания (202), лексические описания (203) и семантические описания (204).
[0041] На этапе 230 идентифицируются морфологические значения слов предложения. Другими словами, предложение разбивается на лексические элементы, после чего определяются их потенциальные леммы (начальные или основные формы), а также соответствующие варианты грамматических значений. Обычно для каждого элемента идентифицируется множество вариантов вследствие омонимии и совпадения словоформ различных грамматических значений. Схематический пример результата этапа 230 для предложения «This boy is smart, he'll succeed in life» (Этот мальчик умный, он добьется успеха в жизни) приведен на Фиг. 2C.
[0042] На этапе 240 идентифицируются лексические значения элементов предложения. Большинство систем обработки естественного языка основаны на статистическом подходе и обычно в качестве наиболее вероятного выбирают либо самое частотное лексическое значение, либо наиболее подходящее по результатам предварительного обучения на корпусах с учетом контекста. Лексический выбор в методе настоящего изобретения осуществляется с учетом многих факторов - применимости синтаксических моделей каждого из возможных лексических значений в данном предложении, прагматических характеристик каждого лексического значения, прагматических характеристик контекста, тематики текста и корпуса в целом, априорных и статистических оценок как самих лексических значений, так и поверхностных и глубинных позиций.
[0043] В общем случае на этапе 240 лексическому выбору предшествует синтаксический анализ. Он включает в себя активацию синтаксических моделей одного или нескольких потенциальных лексических значений рассматриваемого слова и установление всех потенциальных поверхностных связей в предложении, что выражается в построении структуры данных, называемой графом обобщенных составляющих. Затем из графа обобщенных составляющих формируется по меньшей мере одна структура данных, которая представляет собой древесную синтаксическую структуру предложения. Также устанавливаются необходимые недревесные связи. Этот процесс описан в U.S. Patent Application. №11/548,214, поданной 10 октября 2006 г., теперь это US Patent 8,078,450, который включен в настоящий документ в полном объеме посредством ссылки. В общем случае формируется несколько таких структур, что связано, прежде всего, с наличием различных вариантов для лексического выбора. Каждый вариант синтаксической структуры имеет свою собственную оценку, структуры упорядочены от наиболее вероятной к менее вероятной.
[0044] В качестве варианта возможен условно-вероятностный лексический выбор, при котором могут рассматриваться разные гипотезы о лексических значениях, тогда каждой гипотезе будет присвоена некоторая вероятность, и эти несколько вариантов будут параллельно переданы на следующий этап.
[0045] На этапе 250 определяются семантические значения элементов предложения. Каждому лексическому значению сопоставляется его семантический класс, а также набор семантических и дифференциальных лексических и грамматических признаков. На основе каждой синтаксической структуры предложения строится структура данных, которая называется семантической структурой. В одном из вариантов реализации семантическая структура сначала строится для наилучшей гипотезы (имеющей более высокую интегральную оценку). Как правило, семантическая структура предложения является графовой структурой с выделенной вершиной. В узлах данной структуры находятся семантические значения, а ее ветви представляют собой глубинные семантические отношения.
[0046] В некоторых вариантах реализации для создания отдельных приложений (например, Морфологического и лексического анализатора) этап 260 может являться необязательным. На этом этапе, если имеется онтологическое описание (210), релевантное для данной тематики текста, то определяются представленные в тексте факты и сущности и связываются с соответствующим концептом онтологии. Побочным эффектом этого процесса может быть пополнение онтологий новыми фактами и сущностями.
[0047] На этапе 270 производится индексация лексических и семантических значений. Может использоваться любой тип индексации, в том числе прямой индекс или обратный индекс. Например, при построении обратного индекса каждый индексированный элемент будет связан со списком адресов его вхождений в текст. Аналогично индексируются также синтаксические и семантические структуры (смыслы). В качестве возможного варианта могут индексироваться онтологические объекты (например, факты, сущности и т.д.).
[0048] На всех этапах описываемого метода настоящего изобретения широко используется большой спектр лингвистических описаний. Ниже подробно описывается набор упомянутых лингвистических описаний и отдельные этапы метода настоящего изобретения. Фиг. 2B представляет собой схему, иллюстрирующую языковые описания (210) согласно одному из вариантов реализаций изобретения. Языковые описания (210) включают в себя морфологические описания (201), синтаксические описания (202), лексические описания (203) и семантические описания (204).
[0049] На Фиг. 2B приведены языковые описания (210), включающие морфологические описания (201), лексические описания (203), синтаксические описания (202) и семантические описания (204), а также отношения между ними. Среди них морфологические описания (201), лексические описания (203) и синтаксические описания (202) зависят от языка, т.е. создаются для каждого языка по определенным шаблонам. Каждое из этих языковых описаний (210) может быть создано для каждого исходного языка, и все вместе они представляют собой модель исходного языка. Однако семантические описания (204) не зависят от языка, они используются для описания независимых от языка семантических признаков различных языков и для построения независимых от языка семантических структур.
[0050] Как показано на Фиг. 2B, морфологические описания (201), лексические описания (203), синтаксические описания (202), а также семантические описания (204) связаны между собой. Лексические описания (204) и морфологические описания (201) связаны посредством связи (221), поскольку любое лексическое значение в лексическом описании (230) может иметь морфологическую модель, представленную в виде одного или нескольких грамматических значений для указанного лексического значения. Например, одно или несколько грамматических значений могут быть представлены различными наборами граммем в грамматической системе морфологических описаний (201).
[0051] Кроме того, как показано с помощью связи (222), любое лексическое значение в лексических описаниях (203) также может иметь одну или несколько поверхностных моделей, соответствующих синтаксическим описаниям (202) для данного лексического значения. Как показано связью (223), лексические описания (203) могут быть связаны с семантическими описаниями (204). Поэтому лексические описания (203) и семантические описания (204) можно объединить в «лексико-семантические описания», такие как лексико-семантический словарь.
[0052] Как показано посредством связи (224), синтаксические описания (202) и семантические описания (204) связаны между собой. Например, диатезы (417) синтаксических описаний 202 можно рассматривать как «интерфейс» между зависимыми от языка поверхностными моделями и независимыми от языка глубинными моделями (512) семантического описания (204).
[0053] На Фиг. 3 приведены примеры морфологических описаний. Компоненты морфологических описаний (201) включают в том числе: описания словоизменения (310), грамматическую систему (320) (в том числе, граммемы) и описания словообразования (330) и т.д. Грамматическая система (320) представляет собой набор грамматических категорий, таких как «часть речи», «падеж», «пол», «число», «лицо», «возвратность», «время», «вид» и т.д., а также их значений, в дальнейшем называемых «граммемами», в том числе, например, прилагательное, существительное, глагол и т.д.; именительный, винительный, родительный падеж и т.д.; женский, мужской, нейтральный род и т.д. и т.д.
[0054] Описание словоизменения (310) показывает, как основная форма слова может меняться в зависимости от падежа, пола, числа, времени, и т.д., и в широком смысле оно включает в себя или описывает все возможные формы этого слова. Словообразование (330) описывает, какие новые слова могут быть созданы с участием этого слова (например, в немецком языке имеется множество составных слов). Граммемы являются единицами грамматических систем (320) и, как показано с помощью связи (222) и связи (324) на Фиг. 3, граммемы могут использоваться для построения описания словоизменения (310) и описания словообразования (330).
[0055] Согласно одному из вариантов реализации, при установлении синтаксических отношений между элементами исходного предложения используются модели составляющих. Составляющая может содержать группу соседних слов в предложении, ведущих себя как единое целое. Ядром составляющей является слово, она также может содержать дочерние составляющие на более низких уровнях. Дочерняя составляющая является зависимой составляющей, она может быть прикреплена к другим составляющим (в качестве родительских составляющих) для построения синтаксических описаний (202) исходного предложения.
[0056] На Фиг. 4 приведены примеры синтаксических описаний. Компоненты синтаксических описаний (202) могут включать в том числе: поверхностные модели (410), описания поверхностных позиций (420), референциальные описания и описания структурного контроля (430), описания управления и согласования (440), описание недревесного синтаксиса (450) и правила анализа (460). Синтаксические описания 202 используются для построения возможных синтаксических структур исходного предложения на данном исходном языке с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, координации, эллипсиса и т.д.), референциальных отношений и других соображений.
[0057] Поверхностные модели (410) представлены в виде агрегатов одной или нескольких синтаксических форм («синтформ» (412)) для описания возможных синтаксических структур предложений, включенных в синтаксическое описание (202). В целом, любое лексическое значение в языке связано с поверхностными (синтаксическими) моделями (410), которые представляют составляющие, возможные в том случае, когда это лексическое значение играет роль «ядра» и включает набор поверхностных позиций дочерних элементов, описание линейного порядка, диатез и т.д.
[0058] Поверхностные модели (410) представлены синтаксическими формами (412). Каждая синтаксическая форма (412) может включать определенное лексическое значение, которое играет роль «ядра», она может дополнительно включать набор поверхностных позиций (415) своих дочерних составляющих, описание линейного порядка (416), диатезы (417), грамматические значения (414), описания управления и согласования (440), коммуникативные описания 480 и т.д., связанные с ядром составляющей.
[0059] Описания поверхностных позиций (420) в составе синтаксических описаний (202) используются для описания общих свойств поверхностных позиций (415), которые используются в поверхностных моделях (410) различных лексических значений на исходном языке. Поверхностные позиции (415) используются для того, чтобы выразить синтаксические отношения между составляющими предложения. Примеры поверхностных позиций (415) могут включать «subject» (подлежащее), «object_direct» (прямое дополнение), «object_indirect» (косвенное дополнение), «relative clause» (определительное придаточное предложение) и т.д.
[0060] В ходе синтаксического анализа модель составляющих использует множество поверхностных позиций (415) дочерних составляющих и описаний их линейного порядка (416), она описывает грамматические значения (414) возможных заполнителей этих поверхностных позиций (415). Диатезы (417) представляют соответствия между поверхностными позициями (415) и глубинными позициями (514) (как показано на Фиг. 5). Диатезы (417) представлены связью (224) между синтаксическими описаниями (202) и семантическими описаниями (204). Коммуникативные описания (480) описывают коммуникативный порядок в предложении.
[0061] Синтаксические формы (412) представляют собой набор поверхностных позиций (415), связанных с описаниями линейного порядка (416). Одна или несколько составляющих, которые можно построить для лексического значения словоформы исходного предложения, могут быть представлены поверхностными синтаксическими моделями, такими как поверхностные модели (410). Каждая составляющая рассматривается как реализация модели составляющих посредством выбора соответствующей синтаксической формы (412). Выбранные синтаксические формы (412) представляют собой наборы поверхностных позиций (415) с заданным линейным порядком. Каждая поверхностная позиция в синтаксической форме может иметь грамматические и семантические ограничения на свои заполнители.
[0062] Описание линейного порядка (416) представлено в виде выражений линейного порядка, построенных для того, чтобы выразить последовательность, в которой различные поверхностные позиции (415) могут встречаться в предложении. Выражения линейного порядка могут включать имена переменных, имена поверхностных позиций, круглые скобки, граммемы, оценки, оператор «or» (или) и т.д. Например, описание линейного порядка для простого предложения «Boys play football» (Мальчики играют в футбол.) можно представить в виде «Subject Core Object_Dlrect» (Подлежащее - Ядро - Прямое дополнение), где «Subject» (Подлежащее), «Core» (Ядро) и «Object_Direct» (Прямое дополнение) представляют собой имена поверхностных позиций (415), соответствующих порядку слов. Заполнители поверхностных позиций (415), указанные символами сущностей предложения, присутствуют в том же порядке для сущностей в выражениях линейного порядка.
[0063] Различные поверхностные позиции (415) могут находиться в синтаксической форме (412) в отношении строгого и (или) нестрогого порядка. Например, круглые скобки можно использовать для построения выражений линейного порядка, они описывают отношения строгого линейного порядка между различными поверхностными позициями (415). SurfaceSlot1 SurfaceSlot2 или (SurfaceSlot1 SurfaceSlot2) означает, что обе поверхностные позиции расположены в одном и том же выражении линейного порядка, но что допускается только один порядок этих поверхностных позиций относительно друг друга, при котором SurfaceSlot2 следует после SurfaceSlot1.
[0064] В другом примере для построения выражений линейного порядка и описания переменных отношений линейного порядка между различными поверхностными позициями (415) в синтаксической форме (412) могут использоваться квадратные скобки. При этом [SurfaceSlot1 SurfaceSlot2] показывает, что обе поверхностные позиции относятся к одной и той же переменной линейного порядка, а также что их порядок относительно друг друга не является существенным.
[0065] Выражения линейного порядка описания линейного порядка (416) могут содержать грамматические значения (414), выраженные граммемами, которым соответствуют дочерние составляющие. Кроме того, два выражения линейного порядка можно соединить оператором | («OR» (ИЛИ)). Например: (Subject Core Object) | [Subject Core Object]. (Подлежащее - Ядро - Дополнение) | [Подлежащее - Ядро - Дополнение].
[0066] Коммуникативные описания (480) описывают порядок слов в синтаксической форме (412) с точки зрения коммуникативных актов, представленных в виде коммуникативных выражений порядка, которые похожи на выражения линейного порядка. Описание управления и согласования (440) содержит правила и ограничения на грамматические значения прикрепленных составляющих, которые используются во время синтаксического анализа.
[0067] Недревесные синтаксические описания (450) связаны с обработкой различных языковых явлений, таких как эллипсис и согласование, они используются при трансформациях синтаксических структур, которые создаются на различных этапах анализа в различных вариантах реализации изобретения. Недревесные синтаксические описания (450) включают, в том числе, описание эллипсиса (452), описание координации (454), а также описание референциального и структурного контроля (430).
[0068] Правила анализа (460) как часть синтаксических описаний (202) могут включать в том числе: правила вычисления семантем (462) и правила нормализации (464). Несмотря на то, что правила анализа (460) используются на этапе семантического анализа, правила анализа (460) описывают свойства конкретного языка, причем они связаны с синтаксическими описаниями (202). Правила нормализации (464) используются в качестве правил трансформации для описания трансформаций семантических структур, которые могут отличаться в разных языках.
[0069] На Фиг. 5 приведен пример, иллюстрирующий семантические описания. Компоненты семантических описаний (204) не зависят от языка, они могут включать в том числе: семантическую иерархию (510), описания глубинных позиций (520), систему семантем (530) и прагматические описания (540).
[0070] Семантическая иерархия (510) состоит из семантических понятий (семантических сущностей), называемых семантическими классами, расположенных в иерархических взаимоотношениях "родитель-потомок". Дочерний семантический класс наследует большинство свойств своего прямого родителя и всех семантических классов - предков. Например, семантический класс SUBSTANCE (Вещество) является дочерним семантическим классом класса ENTITY (Сущность) и материнским семантическим классом для классов GAS (Газ), LIQUID (Жидкость), METAL (Металл), WOOD_MATERIAL (Древесина) и т.д.
[0071] Каждый семантический класс в семантической иерархии (510) сопровождается глубинной моделью (512). Глубинная модель (512) семантического класса представляет собой набор глубинных позиций (514), которые отражают семантические роли дочерних составляющих в различных предложениях с объектами семантического класса в качестве ядра родительской составляющей, а также возможные семантические классы в качестве заполнителей глубинных позиций. Глубинные позиции (514) выражают семантические отношения, в том числе, например, «агенс», «адресат», «инструмент», «количество» и т.д. Дочерний семантический класс наследует и уточняет глубинную модель (512) своего родительского семантического класса.
[0072] Описания глубинных позиций (520) используются для описания общих свойств глубинных позиций (514), они отражают семантические роли дочерних составляющих в глубинных моделях (512). Описания глубинных позиций (520) также содержат грамматические и семантические ограничения заполнителей глубинных позиций (514). Свойства и ограничения глубинных позиций (514) и их возможных заполнителей очень похожи, часто они идентичны в разных языках. Таким образом, глубинные позиции (514) являются не зависимыми от языка.
[0073] Система семантем (530) представляет собой набор семантических категорий и семантем, которые представляют значения семантических категорий. В качестве примера семантическую категорию «DegreeOfComparison» (Степень сравнения) можно использовать для описания степени сравнения прилагательных, ее семантемами могут быть, например, «Positive» (Положительная), «ComparativeHigherDegree» (Сравнительная степень), «SuperlativeHighestDegree» (Превосходная степень) и др. В качестве другого примера семантическую категорию «RelationToReferencePoint» (Отношение к точке сравнения) можно использовать для описания порядка до референциальной точки или после нее; ее семантемами могут быть «Previous» (Предыдущая), «Subsequent» (Последующая), соответственно, причем этот порядок может быть пространственным или временным в широком смысле этих анализируемых слов. В еще одном примере можно использовать семантическую категорию «EvaIuationObjective» (Оценка) для описания объективной оценки, такой как «Bad» (Плохой), «Good» (Хороший) и т.д.
[0074] Система семантем (530) включает независимые от языка семантические атрибуты, которые выражают не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы можно использовать для выражения атомарного значения, которое находит регулярное грамматическое и (или) лексическое выражение в языке. По назначению и использованию систему семантем (530) можно разделить на различные виды, которые включают, в том числе: грамматические семантемы (532), лексические семантемы (534) и классифицирующие грамматические (дифференцирующие) семантемы (536).
[0075] Грамматические семантемы (532) используются для описания грамматических свойств составляющих при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы (534) описывают конкретные свойства объектов (например, "being flat" (быть плоским) или "being liquid"(являться жидкостью)), они используются в описаниях глубинных позиций (520) как ограничение заполнителей глубинных позиций (например, для глаголов «face (with)» (облицовывать) и «flood» (заливать), соответственно). Классифицирующие грамматические (дифференцирующие) семантемы (536) выражают дифференциальные свойства объектов внутри одного семантического класса; например, в семантическом классе HAIRDRESSER (Парикмахер) семантема «ReIatedToMen» (Относится к мужчинам) присваивается лексическому значению «barber», в отличие от других лексических значений, которые также относятся к этому классу, например, «hairdresser», «hairstylist» и т.д.
[0076] Прагматическое описание (540) позволяет системе назначить соответствующие тему, стиль или жанр текстам и объектам семантической иерархии (510). Например: «Экономическая политика», «Внешняя политика», «Юриспруденция», «Законодательство», «Торговля», «Финансы» и т.д. Прагматические свойства также могут выражаться семантемами. Например, прагматичный контекст может приниматься во внимание при семантическом анализе.
[0077] На Фиг. 6 приведен иллюстративный пример лексических описаний. Лексические описания (203) представляют множество лексических значений (612) конкретного языка для каждого компонента предложения. Для каждого лексического значения (612) можно установить связь (602) с его независимым от языка семантическим родителем для того, чтобы указать положение того или иного заданного лексического значения в семантической иерархии (510).
[0078] Каждое лексическое значение (612) связано со своей глубинной моделью (512), которая описывается независимыми от языка терминами, и с поверхностной моделью (410), которая зависит от языка. Диатезы можно использовать в качестве «интерфейса» между поверхностными моделями (410) и глубинными моделями (512) для каждого лексического значения (612). Каждой поверхностной позиции (415) в каждой синтформе (412) поверхностной модели (410) можно сопоставить одну или несколько диатез (417).
[0079] В то время как поверхностная модель (410) описывает синтаксические роли заполнителей поверхностных позиций, глубинная модель (512) обычно описывает их семантические роли. Описание глубинной позиции (520) выражает семантический тип возможного заполнителя, отражает реальные аспекты ситуаций, свойства или атрибуты объектов, обозначенных словами любого естественного языка. Каждое описание глубинной позиции (520) не зависит от языка, поскольку в различных языках используется одна и та же глубинная позиция для описания аналогичных семантических отношений или выражения подобных аспектов ситуаций, и, как правило, заполнители глубинных позиций (514) обладают одними и теми же семантическими свойствами даже в разных языках. Каждое лексическое значение (612) лексического описания языка наследует семантический класс от своего родителя и уточняет свою глубинную модель (512).
[0080] Кроме того, лексические значения (612) могут содержать свои собственные характеристики, они также могут наследовать другие характеристики от родительского семантического класса. Эти характеристики лексических значений (612) включают грамматические значения (608), которые могут выражаться в виде граммем, и семантическое значение (610), которое может выражаться в виде семантем.
[0081] Каждая поверхностная модель (410) лексического значения включает одну или несколько синтаксических форм (412). Каждая синтаксическая форма (412) поверхностной модели (410) может включать одну или несколько поверхностных позиций (415) со своими описаниями линейного порядка (416), одно или несколько грамматических значений (414), выраженных в виде набора грамматических характеристик (граммем), одно или нескольких семантических ограничений на заполнители поверхностных позиций и одну или несколько диатез (417). Семантические ограничения на заполнитель поверхностной позиции представляют собой набор семантических классов, объекты которых могут заполнить эту поверхностную позицию. Диатезы (417) являются частью отношений (224) между синтаксическими описаниями (202) и семантическими описаниями (204), они отражают соответствия между поверхностными позициями (415) и глубинными позициями (514) глубинной модели (512).
[0082] Возвратимся к Фиг. 2A; этап 240 заключается в том, что для определения лексических значений каждое предложение на исходном языке подвергается разбору в соответствии с технологией исчерпывающего семантико-синтаксического анализа, подробное описание которой приведено в патенте США №8,078,450, включенном в настоящий документ посредством ссылки. В этой технологии используются все указанные лингвистические описания (210), в том числе морфологические описания (201), лексические описания (203), синтаксические описания (202) и семантические описания (204). На Фиг. 7A показаны этапы этого метода. На Фиг. 7B приведена последовательность структур данных, которые строятся в процесс анализа.
[0083] Предварительно на этапе 710, исходное предложение на исходном языке подвергается лексико-морфологическому анализу для построения лексико-морфологической структуры (722) исходного предложения. Лексико-морфологическая структура (722) представляет собой набор всех возможных пар «лексическое значение - грамматическое значение» для каждого лексического элемента (слова) в предложении. Пример такой структуры приведен на Фиг. 2C.
[0084] Затем проводится первый этап синтаксического анализа на лексико-морфологической структуре - грубый синтаксический анализ (720) исходного предложения для построения графа обобщенных составляющих (732). В процессе грубого синтаксического анализа (720) к каждому элементу лексико-морфологической структуры (722) применяются все возможные синтаксические модели возможных лексических значений, они проверяются для того, чтобы найти все потенциальные синтаксические связи в этом предложении, которые отражаются в графе обобщенных составляющих (732).
[0085] Граф обобщенных составляющих (732) представляет собой ациклический граф, узлами котором являются обобщенные (это означает, что они хранят все варианты) лексические значения слов в предложении, а ветви - это поверхностные (синтаксические) позиции, выражающие различные типы отношений между обобщенными лексическими значениями. Все возможные поверхностные синтаксические модели проверяются для каждого элемента лексико-морфологической структуры предложения в качестве потенциального ядра составляющих. Затем строятся все возможные составляющие и обобщаются в графе обобщенных составляющих (732). Соответственно, рассматриваются все возможные синтаксические модели и синтаксические структуры исходного предложения (712), и в результате на основе набора обобщенных составляющих строится граф обобщенных составляющих (732). Граф обобщенных составляющих (732) на уровне поверхностной модели отражает все потенциальные связи между словами исходного предложения (713). Поскольку количество вариаций синтаксического разбора в общем случае может оказаться большим, граф обобщенных составляющих (732) является избыточным, он имеет большое число вариаций как в отношении выбора лексического значения для вершины, так и в отношении выбора поверхностных позиций для ветвей графа.
[0086] Для каждой пары «лексическое значение - грамматическое значение» инициализируется его поверхностная модель, другие составляющие слева и справа добавляются в поверхностные позиции (415) синтформы (синтаксической формы) (412) ее поверхностной модели (410) и соседних составляющих. Синтаксические описания показаны на Фиг. 4. Если соответствующая синтаксическая форма найдена в поверхностной модели (410) для соответствующего лексического значения, то выбранное лексическое значение может использоваться в качестве ядра нового компонента.
[0087] Граф обобщенных составляющих (732) изначально строится в виде дерева, начиная с листьев и перемещаясь в сторону корня (снизу вверх). Дополнительные компоненты получаются снизу вверх путем добавления дочерних компонентов к родительским составляющим, они заполняют поверхностные позиции (415) родительских составляющих для того, чтобы охватить все первоначальные лексические единицы исходного предложения (712).
[0088] Как правило, корень дерева, который является главной вершиной графа (732), представляет собой предикат. В ходе этого процесса дерево обычно становится графом, поскольку составляющие более низкого уровня могут включаться в несколько составляющих более высокого уровня. Несколько составляющих, построенных для одних и тех же элементов лексико-морфологической структуры, в дальнейшем могут быть обобщены для получения обобщенных составляющих. Составляющие обобщаются на основе лексических значений или грамматических значений (414), например, основанных на частях речи и отношениях между ними. На Фиг. 7C приведен схематический пример графа обобщенных составляющих для ранее упоминавшегося предложения: «This boy is smart, he'll succeed in life» (Этот мальчик умный, он добьется успеха в жизни).
[0089] Точный синтаксический анализ (730) выполняется для выделения синтаксического дерева (742) из графа обобщенных составляющих (732). Строится одно синтаксическое дерево или несколько синтаксических деревьев, и для каждого из них вычисляется общая оценка на основе использования множества априорных и вычисляемых оценок, затем дерево с наилучшей оценкой выбирается для построения наилучшей синтаксической структуры (746) исходного предложения. На Фиг. 8 и Фиг. 8A показаны два различных возможных синтаксических дерева для английского предложения «The girl in the sitting-room was playing the piano» (Девушка в гостиной играла на фортепьяно).
[0090] Синтаксические деревья формируются в процессе выдвижения и проверки гипотез о возможной синтаксической структуре предложения, в этом процессе гипотезы о структуре частей предложения формируются в рамках гипотезы о структуре всего предложения.
[0091] В процессе перехода от выбранного синтаксического дерева к синтаксической структуре (746) устанавливаются недревесные связи. Если недревесные связи не могут быть установлены, то выбирается синтаксическое дерево, имеющее следующий самый высокий рейтинг, и производится попытка установить недревесные связи в нем. Результатом точного анализа (730) является улучшенная синтаксическая структура (746) анализируемого предложения. Фактически в результате выбора наилучшей синтаксической структуры (746) также производится лексический выбор, т.е. определение (240) лексических значений элементов предложении (Фиг. 2A).
[0092] На этапе (740) производится переход к независимой от языка семантической структуре (714), которая отражает смысл предложения на основе универсальных, не зависимых от языка понятий. Независимая от языка семантическая структура предложения представляется в виде ациклического графа (деревьев, дополненных недревесными связями), причем все слова на конкретном языке заменяются универсальными (независимыми от языка) семантическими сущностями, называемыми в этом документе «семантическими классами». Этот переход осуществляется с помощью семантических описаний (204) и правил анализа (460), в результате получается структура в виде графа с главной вершиной, в котором узлы представляют собой семантические классы, сопровождающиеся наборами атрибутов (атрибуты выражают лексические, синтаксические и семантические свойства конкретных слов исходного предложения), а ветви представляют глубинные (семантические) отношения между теми словами (узлами), которые они соединяют. На Фиг. 9 приведена семантическая структура английского предложения «The girl in the sitting-room was playing the piano» (Девушка в гостиной играла на фортепьяно). На этом чертеже не указаны семантические и иные атрибуты. Построение семантической структуры заканчивается на этапе (250) - этапе идентификации семантических значений (Фиг. 2A). На остальных чертежах показано еще несколько примеров структур. На Фиг. 10 показан еще один пример - синтаксическая структура упомянутого выше английского предложения «This boy is smart, he'll succeed in life» (Этот мальчик умный, он добьется успеха в жизни), а на Фиг. 11 показана соответствующая ей семантическая структура.
[0093] Идентификация (260) онтологических объектов (Фиг. 2A) происходит в результате онтологического анализа семантических и синтаксических структур с использованием соответствующих правил. Целью онтологического анализа является автоматическое извлечение информации из неструктурированных электронных документов. Анализ, проведенный на этапах (710)-(740), и превращение неструктурированного текста в синтаксические и семантические структуры позволяют извлекать информацию из уже структурированного документа, в котором уже определены роли и смысл каждого элемента текста.
[0094] Онтология (210) представляет собой модель предметной области. Онтология - это не то же самое, что семантическая иерархия, несмотря на то, что она может быть связана с элементами семантической иерархии референциальными связями. Это формальное описание какой-либо предметной области. Это описание включает формальное описание элементарных (неделимых) единиц предметной области (ресурсов или экземпляров), формальное описание различных объединений (концептов, классов) экземпляров и формальное описание связей между экземплярами. Онтологии могут наследоваться из других онтологий. Считается, что все концепты, экземпляры и отношения, принадлежащие родительской онтологии, также принадлежат и онтологии-потомку. Основными элементами онтологии являются концепты и экземпляры.
[0095] Концепт (класс, информационный объект) - это компонент онтологии, который отражает то или иное понятие предметной области. Множество экземпляров объединяется в один концепт. Например, все экземпляры, соответствующие людям, объединяются в концепт «Person» (персона). Каждому концепту в онтологии соответствует набор отношений, имеющих в качестве домена это концепт. Этот набор определяет то, какие связи может иметь экземпляр данного концепта. Кроме того, с этим концептом связывается набор простых ограничений и набор концептов-родителей. Все это также определяет, какими могут быть экземпляры данного концепта.
[0096] Экземпляр - компонент онтологии нижнего уровня. Как правило, он отражает некоторую объективную реальность (людей, дома, планеты, цифры, слова и т.д.). Каждый экземпляр относится к какому-то одному концепту. С каждым экземпляром соотносится с набором связей. Предварительный семантико-синтаксический анализ текстов корпуса позволяет получить синтаксические и семантические структуры для предложений из корпуса текстов и соотнести их с семантической иерархией и онтологическими описаниями, которые в свою очередь дают возможность «извлечь» информацию о примерах из анализируемого корпуса.
[0097] Для извлечения информации из текстов используются онтологические правила. Онтологические правила - это правила, которые описывают, как факты выражаются в текстах. Предварительный семантико-синтаксический анализ текстов с использованием описанной технологии (Фиг. 2A и Фиг. 7A) позволяет описывать и использовать онтологические правила на структурированных данных, а именно, в глубинных (семантических) структурах с учетом лексических, синтаксических и семантических атрибутов, извлеченных во время предварительного разбора.
[0098] Полученное универсальное представление текстовой информации может быть использовано для создания, либо оно может использоваться такими приложениями обработки естественного языка (NLP) как семантическое индексирование, семантический поиск, включая многоязычный семантический поиск, машинный перевод, поиск похожих документов, извлечение фактов, анализ тональности, классификация документов, автоматическое реферирование, анализ больших объемов данных, электронное обнаружение и подобные приложения. На Фиг. 1 приведен пример такого технологического комплекса, включающего методы и системы обработки, основанные на универсальном представлении текстовой информации.
[0099] Этот представленный метод основан на двух системах (или платформах): 1) на технологии обработки естественного языка (101), которая включает в себя, как минимум, блок обработки Морфологии (102), блок обработки Синтаксиса (103), блок Семантики (104) и блок Статистики (105), а также 2) на технологии извлечения информации (110), которая включает в себя, как минимум, хранилище триплетов (111), связанные сущности (112) и различного типа онтологии (113), описывающие именованные сущности, факты, отношения и т.д. Блок систем или программ технологии извлечения информации (110) работает с универсальным семантическим деревом (119) (структурой), полученным из блока технологии обработки естественного языка (101).
[00100] Связанные сущности (112) представляют собой базы данных, которые используются для формирования связей между сущностями. Сущность - это структура данных, которую можно многократно использовать в различных транзакциях. Например, сущность Address (адрес) можно использовать в качестве адреса доставки, адреса для выставления счета, домашнего адреса и так далее. Большинство сущностей также объединяет несколько точек данных в структуру для оптимизации данных. Свойства клиента могут включать в себя такие сущности, как имя, фамилия, телефон и адрес электронной почты. Сущность представляет собой конфигурацию, которая определяет многократно используемую структуру данных, например, адрес.
[00101] Одна сущность может быть связана с другой сущностью. Отношение представляет собой связь между сущностями. Сущность «пациент» может быть связана с другой сущностью типа «адрес». Можно утверждать, что отношения между сущностями «пациент» и «адрес» являются взаимно однозначными (1 1), потому что у них существует взаимно однозначное прямое соответствие. Сущность «адрес» не зависит от состояния пациента, она может быть самостоятельной. Она может быть связана с другими сущностями, такими как «клиенты» и «поставщики».
[00102] Сущность может иметь много ссылок на другие сущности. Например, сущность «пациент» может иметь несколько экземпляров сущности «адрес», например, «домашний адрес», «место работы» и так далее. С другой стороны, сущность «пациент» не может иметь несколько домашних адресов.
[00103] Идентификация сущностей сокращает время настройки, поскольку они устанавливаются только один раз. При этом сводится к минимуму объем хранимых данных. Например, адрес доставки пользователя сохраняется в базе данных один раз, и все транзакции с этим пользователем относятся к этому экземпляру. Сущности повышают скорость обработки, потому что данные сохраняются в виде хэш-кода, и они сравниваются как хэш-коды. Во время выполнения транзакция будет включать эти данные, при этом возможны оценки рисков для этих данных.
[00104] Одна из задач систем NLP заключается в автоматическом извлечении из разных источников на естественном языке сущностей и их атрибутов с сохранением отношений между ними. Кроме того, необходимо выявлять одни и те же объекты, которые могут иметь разные имена или названия в различных источниках. Если данные на естественном языке представляются в формате семантических структур и индексируются, то можно создавать специальные правила, применяемые к таким представлениям, для извлечения информации и сохранения ее в базах данных. Такая информация хранится в структурной форме, и ее можно использовать в широком спектре приложений в различных областях.
[00105] Хранилище триплетов 111 представляет собой специальную базу данных для хранения и поиска триплетов - так называют сущности со структурой подлежащее-сказуемое-дополнение, например «John is 25» (Джону 25 лет) или «John knows Bob» (Джон знает Боба). Точно так же, как в реляционной базе, информация записывается в хранилище триплетов и извлекается из него с помощью языка запросов. В отличие от реляционной базы данных triplestore (хранилище триплетов) оптимизировано для хранения и извлечения триплетов. В дополнение к запросам, триплеты обычно можно импортировать и экспортировать с помощью Resource Description Framework (схемы описания ресурсов или стандарта RDF) и других форматов.
[00106] Подход, используемый в раскрываемой технологической платформе, позволяет с помощью унифицированного представления текстовой информации на любом языке (например, семантических структур) автоматически извлекать триплеты из семантических структур и обрабатывать их.
[00107] Представленная на Фиг. 1 схема включает продукты и технологии, которые сами по себе являются компонентами описанной технологии. Таким продуктом является, например, лексико-морфологический анализатор (106), который может производиться и поставляться в виде отдельного продукта, программного интерфейса (API) или системы. Кроме того, технология синтаксического и семантического анализа, позволяющая получать синтаксически и семантически размеченные тексты и связанные с ними универсальные структуры (ее описание приведено в патентной заявке США 11/548,214, теперь патенте США №8,078,450, который включен в настоящее описание), может быть осуществлена в виде отдельного продукта, программного интерфейса (API) или системы. Технология создания систем машинного перевода (107) для любой пары языков описана в следующих заявках и патентах: в патентной заявке США №11/690,102, теперь патенте США №8,195,447; в патентной заявке США №11/690,104, теперь патенте США №8,214,199; в патентной заявке США №12/388,219, теперь патенте США №8,145,473; в патентной заявке США №13/407,729, теперь патенте США №8,412,513, в патентной заявке США №13/626,722, теперь патенте США №8,442,810; в патентной заявке США №11/690,099; в патентной заявке США №12/187,131; в патентной заявке США №13/288,953; в патентной заявке США №13/477,021; в патентной заявке США №13/528,716; в патентной заявке США №13/554,695; в патентной заявке США №13/626,480 и в патентной заявке США №13/723,160; все они включены в настоящее описание посредством ссылки. Процесс машинного перевода состоит в получении независимой от конкретного языка семантической структуры предложения на исходном языке и в использовании ее для синтеза предложения на целевом языке.
[00108] Ряд приложений предполагает поиск документов, которые соответствуют некоторому запросу. В этом случае запрос понимается как некоторый абстрактный критерий. Пользователь примерно знает, какие документы он хочет найти, формулирует свое требование в поисковой системе, получает набор документов и просматривает их (чаще всего не в полном объеме). Этот сценарий широко используется пользователями, работающими с информацией. Этот сценарий выполняется во всех приложениях, которые сопровождаются полнофункциональной системой извлечения и мониторинга информации.
[00109] В настоящее время чаще всего для задания критериев поиска используются языки поисковых запросов, позволяющие указывать ключевые слова, которые должны присутствовать в полученных документах. Этот подход оказался достаточно понятным и удобным для пользователей, а также не слишком сложным для реализации. Недостатком поиска с использованием ключевых слов является получение большого объема нерелевантной информации, поскольку невозможно сформулировать утверждения о содержании (смысле) документов.
[00110] Альтернативный подход к поиску документов называется «семантический поиск» (108). При таком подходе каждый документ воспринимается не в виде однородной последовательности символов, а в качестве единицы контента, которая включает набор объектов и фактов. В этом случае поисковые запросы формулируются с помощью шаблонов, которые формально определяют, какие объекты и факты должны быть найдены в полученных документах. В частности, семантический поиск позволяет сформулировать запрос не только с помощью ключевых слов, но и по получаемым лексическим значениям (смыслам этих слов), он позволяет искать предложения с указанной синтаксической структурой или с определенной семантической структурой. Построение систем семантического поиска, основанных на описанной в настоящем документе технологии, приведено в патентных заявках США 12/983,220, 13/173,369 и 13/173, 649, которые включены в настоящее описание посредством ссылки.
[00111] Семантический поиск (108), как и многие другие приложения, показанные на Фиг. 1 для семантической индексации (109), могут также производиться в виде отдельного продукта и использоваться в других приложениях.
[00112] Качество и простота семантического поиска существенно зависит от номенклатуры типов объектов и фактов, которые могут присутствовать в запросах. Такая номенклатура называется предметной областью (или онтологией предметной области). Одно из преимуществ семантического поиска заключается в возможности проведения поиска в многоязычных корпусах документов. Поскольку универсальное семантическое дерево (104) не зависит от языка, технология описанных в настоящем описании систем и способа позволяет вести поиск информации в подборках документов на разных языках независимо от языка запроса. Описание многоязычного семантического поиска (110) приведено в патентной заявке США 13/173,369, которая включена в настоящий документ посредством ссылки.
[00113] Приложение для извлечения фактов (111) сочетает целый ряд задач по извлечению информации. Прежде всего, это проблема «насыщения» фактами (элементами) самих онтологий. Это прежде всего технологическая задача, задача улучшения технологии. Однако этот процесс используется для решения проблем, которые представляют интерес для пользователей.
[00114] Для целого ряда приложений требуется мониторинг документов, которые отвечают некоторому критерию. Под мониторингом документов понимается процесс оперативного извлечения из информационного потока таких документов, которые отвечают некоторому критерию. Например, мониторинг документов, в которых упоминается определенная компания, продукт, персона или что-нибудь другое. Положительные или отрицательные оценки анализа тональности (112) могут представлять самостоятельный интерес. Ситуация с критериями отбора аналогична ситуации с поиском документов: самый простой вариант - это выбор по ключевым словам, а более интеллектуальный (и чаще используемый) вариант выбора - это отбор на основе семантических критериев. Наличие семантического индекса позволяет решать эти проблемы, поскольку семантический индекс содержит не просто слова, но также лексические значения и семантические классы (в том числе классы, которые сочетают выражение положительных и отрицательных оценок со своими синтаксическими моделями).
[00115] Мониторинг представляет интерес в первую очередь для корпораций (контроль конкурентов или отслеживание общественного мнения о компании), т.е. для организаций, которые заинтересованы в общественном мнении и которые производят продукцию или предоставляют услуги. Можно также найти сценарии мониторинга для рядового пользователя. Любой человек, интересующийся конкретной темой или областью (который просто читает новости, или занимается наукой, или интересуется автомобильными гонками или чем-либо еще) может столкнуться с тем, что по интересующей его теме имеется слишком много информации. При этом пользователь может иметь систему приоритетов, то есть представление о том, какую информация он должен просмотреть в первую очередь, и что он может игнорировать или оставить на будущее. Такой инструмент, который позволяет производить грубую сортировку поступающей информации с помощью семантических критериев, может быть реализован в виде программы чтения RSS-ленты с функциями семантического поиска (или в виде встраиваемого модуля имеющейся программы чтения) или, например, в виде встраиваемого модуля почтовых клиентов (сортировка электронной почты с использованием семантики).
[00116] Более сложный семантический и онтологический компонент системы имеет возможность персонализации, то есть настройки под потребности конкретного пользователя. В дополнение к способности показывать объекты мониторинга эта система располагает средствами для указания того, какие свойства должны иметь объекты мониторинга и того, какими могут (должны) быть отношения между ними.
[00117] Наличие семантического индекса открывает новые возможности системы мониторинга информации. Дело в том, что простые решения (которые «видят» только контекст одного документа и ничего не хранят) ни в коей мере не могут применяться к проблеме идентификации уникальных объектов в различных текстах. Это означает, например, что если с помощью такого решения пользователь желает собирать документы, в которых упоминается Барак Обама, то он не будет получать документы, в которых упоминается президент Обама (без имени) или президент США. Использование семантического индекса, который индексирует весь информационный поток, решает эту проблему.
[00118] В частном случае представляет интерес задача мониторинга событий с помощью некоторого критерия. Эта задача близка к задаче мониторинга документов (см. выше). Различие заключается в конечной цели: при мониторинге документов пользователь хочет видеть документы, которые удовлетворяют заданному критерию, в то время как при мониторинге событий акцент перемещается на реальные события: пользователю важно то, что событие определенного типа (с определенными свойствами) произошло, а не то, что было написано о нем. Например, подсистема отчетности о различных интересных событиях, которая является частью большой системы мониторинга информации. В любой момент новейшие факты и события, автоматически извлеченные из потока информации, могут всплыть на главной странице такой системы.
[00119] Другой задачей является электронное обнаружение (113), которое может производиться на основе семантического индекса как задачи поиска, основанной на простом или семантическом критерии.
[00120] Отдельной задачей является создание систем анализа "больших данных" (114); для этого решения необходимо использовать различные методы: от классификации и обучения правилам ассоциации до краудсорсинга и пространственного анализа. Семантический индекс является серьезным средством, помогающим решать подзадачи, в том числе: классификации, объединения в кластеры, абстрагирования, поиска похожих документов и т.д.
[00121] Подробное описание классификации (115) документов с использованием семантического индекса приведено в патентной заявке США №13/535,638, которая включена в настоящее описание посредством ссылки. Описаны методы классификации (распределения по категориям) текстовых документов, написанных на разных языках. Независимые от языка семантические структуры строятся перед классификацией документов. Эти структуры отражают лексические, морфологические, синтаксические и семантические свойства документов. Предложенные Методы могут проводить межъязыковую классификацию текстов, которая основана на свойствах документа, отражающих их смысл. Эти методы применимы к классификации жанров, выявлению тем, анализу новостей, анализу авторства и т.д.
[00122] Описание системы (115) кластеризации документов с использованием семантического индекса приведено в патентной заявке США №13/648,527, которая включена в настоящее описание посредством ссылки. Описаны способы объединения в кластеры или классификации текстов на разных языках. Метод, с помощью которого вычислительное устройство производит анализ набора текстов на одном или нескольких естественных языках, включающий для каждого текста электронный анализ текста, причем этот анализ включает выполнение этапов, включающих синтаксический анализ по меньшей мере одного предложения из текста, создание независимой от языка семантической структуры, семантический анализ предложения текста; формирование набора признаков, где по меньшей мере один признак основан на результатах упомянутого анализа; и объединение текстов в кластеры на основе указанного набора признаков, когда объединение текстов в кластеры включает отнесение текста с одному или несколькими кластерам.
[00123] Описание поиска похожих документов (116) с использованием семантического индекса приведено в патентных заявках США №13/672,064 и №13/662,272, которые включены в настоящее описание посредством ссылки. Описаны способы нахождения похожих или различных источников (файлов и документов), а также способы оценки сходства или различия между заданными источниками. Сходство и различие может определяться для различных форматов. Источники могут быть на одном или нескольких языках, поэтому сходства и различия могут определяться для любого количества языков и любых типов языков. Можно использовать несколько характеристик для получения общего показателя сходства или различия, включая определение или идентификацию синтаксических ролей, семантических ролей и семантических классов со ссылкой на источники.
[00124] Система автоматического реферирования (117) одного или нескольких документов работает с универсальным представлением. Если имеется глубинная структура каждого предложения и были разработаны соответствующие алгоритмы, то текст синтезируется с использованием интеллектуальной системы реферирования путем трансформации и сжатия глубинных структур в тексте. Кроме того, эта система работает с объектами и фактами, встречающимися в тексте (текстах). После того, как фактическая информация была извлечена из текста, ее можно снова отобразить, используя алгоритмы синтеза. При этом, чем богаче модель предметной области в этом процессе, тем «интереснее» будут полученные рефераты. Задача построения дайджеста на основе определенной выборки документов решается аналогичным образом.
[00125] Фиг. 12 представляет собой блок-схему процесса для создания программ обработки естественного языка. В блоке (1210) создается или используется ранее созданная семантическая иерархия независимых от языка семантических описаний на естественном языке, применимая к любому естественному языку. На Фиг. 5 приведены примеры семантических описаний.
[00126] В блоке (1220) создаются морфологические описания, лексические описания и синтаксические описания для одного или нескольких целевых языков. На Фиг. 3 приведены примеры морфологических описаний, а на Фиг. 6 приведен иллюстративный пример лексических описаний. На Фиг. 4 приведены примеры синтаксических описаний.
[00127] Первая программа обработки естественного языка (блок (1230)) строится на основе независимых от языка семантических описаний и зависимых от языка морфологических, лексических и синтаксических описаний на одном или нескольких целевых языках или любой их комбинации. Приложение обработки естественного языка может включать в том числе: семантическое индексирование, семантический поиск, включая многоязычный семантический поиск, машинный перевод, поиск похожих документов, извлечение фактов, анализ тональности, поиск похожих документов, классификацию документов, обобщение, электронное обнаружение (eDiscovery) и аналогичные приложения. На Фиг. 1 приведен пример такого набора методов, который включает методы обработки, основанные на универсальном представлении текстовой информации. В других вариантах осуществления одно или несколько приложений для естественного языка могут использовать полученное универсальное представление.
[00128] Далее формируются корпуса текстовой информации. Текстовая информация может включать информацию на любом языке, например, текстовые документы, корпуса текстов, базы данных, изображения, социальные сети, сообщения электронной почты, субтитры, распознанную речь и т.д. Текстовая информация может быть получена из другой системы или извлечена из хранилища или иной системы. Текстовая информация может включать несколько документов одного и того же типа или разных типов и (или) форматов. Можно получить универсальное представление, соответствующее текстовой информации. Универсальное представление можно создать на основе текстовой информации. В некоторых вариантах осуществления текстовая информация может быть подвергнута специальной обработке на основе исчерпывающих технологий с использованием большого количества описаний целевого естественного языка и универсальных семантических описаний. Текстовая информация может быть обработана с использованием анализа, включая лексико-морфологический, синтаксический, семантический и онтологический этапы анализа с определением лексических и семантических значений или значений параметров каждого элемента информации, построение соответствующих структур на каждом этапе, а также извлечение соответствующих признаков и атрибутов на каждом этапе. Эти структуры данных могут быть проиндексированы и сохранены в памяти.
[00129] В результате любая текстовая информация может быть преобразована в универсальное представление, она может быть сохранена в единой независимой от языка форме, которая подвергается индексации со всеми получаемыми в результате возможностями. Концепты и их атрибуты могут быть проиндексированы, поскольку любой концепт (т.е. утверждение, выраженное в универсальных терминах) может быть пронумерован, зарегистрирован и найден (с возможностью поиска). Такое универсальное представление текстовой информации может представлять собой единую платформу для построения практически любого приложения NLP. В некоторых вариантах реализации изобретения универсальное представление может включать информацию о семантическом классе для каждого слова в тексте.
[00130] Таким образом, могут использоваться знания о языке (языках) и о мире (семантика), накопленные в системе. Раскрываемая система обеспечивает целостность, полноту и универсальность. Например, будет достаточно построить лингвистические описания нового языка в соответствии со стандартами данного подхода (представленного настоящим раскрытием и группой приложений, включенных в настоящее описание посредством ссылок), и сразу становятся доступными не только одно или нескольких приложений, но и вся серия указанных приложений.
[00131] Предварительная обработка текстового корпуса может включать по меньшей мере следующие этапы: определение морфологических значений, выявление лексических значений, выявление семантических значений, выявление онтологических объектов и индексация значений, параметров и извлеченных атрибутов. В результате этого в приложениях можно будет использовать семантический индекс, а не обычный индекс.
[00132] На Фиг. 13 показан иллюстративный пример вычислительных средств для реализации описанных в настоящем описании методов и систем в соответствии с одним из вариантов осуществления настоящего изобретения. Как показано на Фиг. 13, пример оборудования (1300) включает по меньшей мере один процессор (1302), соединенный с запоминающим устройством (1304). Процессор (1302) может представлять собой один или несколько процессоров (например, микропроцессоров), а память (1304) может представлять собой устройства оперативной памяти (RAM), содержащие основное запоминающее устройство оборудования (1300), а также любые дополнительные уровни памяти (например, кэш-память, энергонезависимые или резервные запоминающие устройства, такие как программируемые запоминающие устройства или флэш-накопители), постоянные запоминающие устройства и т.д. Кроме того, память (1304) может включать запоминающее устройство, физически расположенное в другом месте оборудования (1300), например любую кэш-память в процессоре (1302), а также любое запоминающее устройство, используемое в качестве виртуальной памяти, например, память, хранящуюся в запоминающем устройстве большой емкости (1310).
[00133] Оборудование (1300) может иметь несколько входов и выходов для обмена информацией с другими устройствами. В качестве интерфейса пользователя или оператора оборудование (1300) может включать одно или несколько устройств ввода пользователя (1306) (например, клавиатуру, мышь, устройство обработки изображений, сканер и микрофон), а также одно или несколько устройств вывода (1208) (например, панель жидкокристаллического дисплея (LCD) и устройство воспроизведения звука (динамик)). Для реализации настоящего изобретения оборудование (1300) может включать в себя как минимум одно устройство с экраном.
[00134] Для дополнительного хранения данных оборудование (1300) может также включать одно или несколько устройств большой емкости (1310), например, накопитель на гибком диске или на другом съемном диске, накопитель на жестком диске, запоминающее устройство с прямым доступом (ЗУПД), оптический привод (например, привод оптических дисков (формата CD), привод с цифровым универсальным диском (формата DVD)), а также другие устройства. Кроме того, оборудование (1400) может включать интерфейс с одним или несколькими сетями (1312) (например, с локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и (или) Интернет и т.д.) для обмена информацией с другими компьютерами, подключенными к этим сетям. Следует иметь в виду, что оборудование (1300) обычно включает соответствующие аналоговые и (или) цифровые интерфейсы между процессором (1302) и каждым из компонентов (1304), (1306), (1308) и (1312), что хорошо известно специалистам в данной области.
[00135] 00135Оборудование (1300) работает под управлением операционной системы (1314), на нем выполняются различные компьютерные программные приложения, компоненты, программы, объекты, модули и т.д. для реализации описанных выше способов. Кроме того, различные приложения, компоненты, программы, объекты и т.д., которые совместно обозначены на Фиг. 13 как прикладное программное обеспечение (1316), также могут выполняться в одном или нескольких процессорах в другом компьютере, подключенном к оборудованию (1300) через сеть (1312), например, в распределенной вычислительной среде, в результате чего обработка, необходимая для реализации функций компьютерной программы, может быть распределена по нескольким компьютерам в сети.
[00136] В целом, стандартные программы, выполняемые для реализации вариантов осуществления настоящего изобретения, могут быть реализованы как часть операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности команд, которые называются «программа для компьютера». Обычно программа для компьютера содержит один набор команд или несколько наборов команд, записанных в различные моменты времени в различных запоминающих устройствах и системах хранения в компьютере; после считывания и выполнения одним или несколькими процессорами в компьютере эти команды приводят к тому, что компьютер выполняет операции, необходимые для выполнения элементов, связанных с различными аспектами настоящего изобретения. Кроме того, несмотря на то, что это изобретение описано в контексте полностью работоспособных компьютеров и компьютерных систем, специалистам в данной области техники будет понятно, что различные варианты осуществления этого изобретения могут распространяться в виде программного продукта в различных формах, и что это изобретение в равной степени применимо для фактического распространения независимо от используемого конкретного типа машиночитаемых носителей. Примеры машиночитаемых носителей включают в том числе: записываемые носители, такие как энергонезависимые и энергозависимые устройства памяти, гибкие диски и другие съемные диски, накопители на жестких дисках, оптические диски (например, постоянные запоминающие устройства на компакт-диске (формата CD-ROM), накопители на цифровом универсальном диске (формата DVD), флэш-память и т.д.) и т.д.. Другой тип распространения можно реализовать в виде загрузки из сети Интернет.
[00137] Некоторые варианты реализации описаны и показаны на прилагаемых чертежах, однако следует понимать, что они являются лишь примерами, которыми не ограничивается область изобретения, и настоящее изобретение не ограничивается приведенными и описанными конструкциями и механизмами, поскольку специалисты в данной области техники после изучения данного описания могут предложить и другие модификации. В подобных быстрорастущих областях технологии сложно предвидеть дальнейшие достижения, и раскрытые варианты осуществления могут быть легко изменены или переделаны в тех или иных аспектах благодаря технологическим достижениям без отступления при этом от принципов настоящего раскрытия.
[00138] Варианты осуществления объекта изобретения, приведенные в данном описании, могут быть реализованы в виде цифровой электронной схемы, программного обеспечения, микропрограммного обеспечения или оборудования, включая структуры, раскрытые в данном описании, и их структурные эквиваленты, а также в виде их сочетаний. Варианты осуществления объекта изобретения, описанного в данном раскрытии, могут быть реализованы в виде одной или нескольких программ для компьютера, т.е. одного или нескольких модулей программных команд для компьютера, закодированных на одном или нескольких компьютерных носителях записи для выполнения или для управления работой устройства для обработки данных. Вместо этого или к дополнение к этому команды такой программы могут быть закодированы в искусственно созданном распространяющемся сигнале, например, в виде сформированных компьютером электрических, оптических или электромагнитных сигналов, которые формируются для кодирования информации с целью передачи на подходящее приемное устройство для выполнения устройством обработки данных. Носитель компьютерных данных может быть включен в машиночитаемое запоминающее устройство, подложку машиночитаемого носителя, массив памяти или устройство со случайным или последовательным доступом или в любое их сочетание. Более того, если компьютерный носитель данных не является распространяемым сигналом, компьютерный носитель данных может быть источником или адресатом команд компьютерных программ, закодированных в искусственно созданном распространяемом сигнале. Компьютерный носитель данных также может представлять собой один или несколько отдельных компонентов или носителей (например, несколько компакт-дисков, дисков или других запоминающих устройств) или может быть включен в него (в них). Соответственно, носитель компьютерных данных может быть материальным и непереходным.
[00139] Операции, описанные в настоящем описании, могут быть реализованы как операции, выполняемые в устройстве обработки данных с данными, хранящимися в одном или нескольких машиночитаемых запоминающих устройствах, или с данными, полученными из других источников.
[00140] Термин «клиент» или «сервер» включает в себя разнообразные аппараты, устройства и машины для обработки данных, включая, например, программируемый процессор, компьютер, системы на микросхеме или различные комбинации из указанных выше элементов. Такое устройство может включать специализированную логическую схему, например, программируемую пользователем вентильную матрицу (FPGA) или заказную интегральную схему (ASIC). Такое устройство также может включать в дополнение к оборудованию код, который создает среду выполнения рассматриваемой компьютерной программы, например, код, который представляет собой прошивку процессора, стек протоколов, систему управления базами данных, операционную систему, межплатформенную среду выполнения, виртуальную машину или их комбинацию. Устройство и среда выполнения могут реализовывать различные инфраструктуры вычислительной модели, такие как веб-сервисы, распределенные вычисления и инфраструктуры распределенных вычислений.
[00141] Программу для компьютера (также называемую программой, программным обеспечением, приложением, сценарием или кодом) можно написать на языке программирования любого типа, включая компилируемые или интерпретируемые языки, декларативные или процедурные языки, причем она может использоваться в любой форме, в том числе в виде отдельной программы или в виде модуля, компоненты, подпрограммы, объекта или другого блока, пригодного для использования в вычислительной среде. Программа для компьютера может (но не обязательно должна) соответствовать файлу в файловой системе. Программа может храниться в части файла, который содержит другие программы или данные (например, один или несколько сценариев, хранящихся в документе с языковой разметкой), в одном файле, соответствующем рассматриваемой программе, или в нескольких согласованных файлах (например, файлах, в которых хранится один или несколько модулей, подпрограмм или частей кода). Программа для компьютера может быть развернута для выполнения на одном компьютере или на нескольких компьютерах, расположенных в одном месте или распределенных по нескольким местам и соединенных сетью связи.
[00142] Описанные в данном описании процессы и логика выполнения могут выполняться одним или несколькими программируемыми процессорами, выполняющими одну или несколько компьютерных программ для выполнения действий путем обработки входных данных и формирования выходных данных. Процессы и логические потоки также могут выполняться в виде специализированной логической схемы, например, FPGA (программируемой пользователем вентильной матрицы) или ASIC (заказной интегральной схемы), и устройство также может быть реализовано на ней.
[00143] Процессоры, пригодные для выполнения компьютерной программы, включают, в качестве примера, как универсальные, так и специализированные микропроцессоры, и любой процессор или несколько процессоров любого типа в цифровом компьютере. Обычно процессор получает команды и данные из памяти, доступной только для чтения (ROM), или запоминающего устройства с произвольной выборкой (RAM) или обоих типов памяти. Основными элементами компьютера являются процессор для выполнения действий в соответствии с командами и одно или несколько устройств памяти для хранения команд и данных. Как правило, компьютер будет также включать одно или несколько запоминающих устройств большой емкости для хранения данных (например, накопители на магнитных, магнитооптических дисках или оптических дисках) или компьютер будет функционально соединен с ними для приема данных или для передачи данных, или для приема и передачи. Однако компьютер может не иметь таких устройств. Более того, компьютер может быть встроен в другое устройство, например, в мобильный телефон, карманный персональный компьютер (PDA), мобильный аудио- или видеоплеер, игровую консоль или портативный носитель данных (например, флэш-накопитель с универсальной последовательной шиной (USB)). Устройства, пригодные для хранения команд программы для компьютера и данных, включают все виды энергонезависимой памяти, носителей данных и устройств памяти, в том числе, например, полупроводниковые запоминающие устройства, например, устройства EPROM (перепрограммируемые постоянные запоминающие устройства), устройства EEPROM (электронно-перепрограммируемые постоянные запоминающие устройства) и устройства флэш-памяти; магнитные диски, например, внутренние жесткие диски или съемные диски; магнитооптические диски, а также дисковые накопители форматов CD-ROM и DVD-ROM. Процессор и память могут быть дополнены логическими схемами специального назначения или могут быть включены в них.
[00144] Для обеспечения взаимодействия с пользователем варианты осуществления объекта изобретения, описанные в данном описании, могут быть реализованы в виде компьютера, имеющего устройство отображения, например, ЭЛТ (электронно-лучевую трубку), жидкокристаллический (ЖК-) дисплей, OLED (дисплей на органических светодиодах), дисплей на TFT (тонкопленочных транзисторах), плазменный дисплей, другую гибкую конфигурацию, или любой другой монитор для отображения информации пользователю, а также клавиатуру, указательное устройство, например, мышь, шаровой указатель (трекбол) и т.п., либо сенсорный экран, сенсорную панель и т.д., с помощью которых пользователь может вводить данные в компьютер. Для обеспечения взаимодействия с пользователем также могут использоваться устройства других типов. Например, предоставляемая пользователю обратная связь может представлять собой любую форму сенсорной обратной связи, например, визуальную обратную связь, слуховую обратную связь или тактильную обратную связь, а ввод пользователя может осуществляться в любой форме, в том числе акустической, речевой или тактильной. Кроме того, компьютер может взаимодействовать с пользователем, отправляя документы и принимая документы от используемого пользователем устройства. Например, отправляя веб-страницы в веб-браузер на клиентском устройстве пользователя в ответ на запросы, полученные от веб-браузера.
[00145] Варианты реализации объекта изобретения, описанные в данном описании, могут быть осуществлены в компьютерной системе, включающей серверный компонент, например, сервер данных, или включающей компонент промежуточного программного обеспечения, например, сервер приложений, или включающей компонент внешнего интерфейса, например, клиентский компьютер, имеющий графический интерфейс пользователя, или веб-браузер, с помощью которого пользователь может взаимодействовать с вариантом осуществления объекта изобретения, указанным в данном описании, или в виде любой комбинации одного или нескольких таких серверных, промежуточных и интерфейсных компонентов. Компоненты системы могут быть соединены между собой с использованием любой формы цифровой связи, например, с помощью сети связи. Примерами коммуникационных сетей являются локальная вычислительная сеть («LAN») и глобальная сеть («WAN»), объединенная сеть (например, Интернет) и одноранговые сети (например, различные пиринговые сети).
[00146] Несмотря на то, что данное описание содержит множество конкретных подробностей реализации, они не должны толковаться как ограничивающие объем любых изобретений или содержания возможных патентных заявок, а скорее как описание особенностей, характерных для конкретных вариантов реализаций конкретных изобретений. Некоторые функции, описанные в данном описании в контексте отдельных вариантов реализаций, также могут быть реализованы совместно в одном варианте осуществления. И наоборот, различные особенности, которые описаны в контексте одного варианта осуществления, также могут быть реализованы в нескольких вариантах осуществления отдельно или в виде любой подходящей подкомбинации. Кроме того, несмотря на то, что отдельные особенности могут быть описаны выше как действующие в определенных сочетаниях и даже первоначально заявлены как таковые, одна или несколько особенностей из заявленного сочетания в некоторых случаях могут быть изъяты из этого сочетания, и заявленное сочетание может использоваться как неполное сочетание или вариация неполного сочетания.
[00147] Аналогичным образом, изображение операций на чертежах в определенном порядке не следует понимать как требование того, что такие операции необходимо производить в конкретной указанной последовательности, или что все показанные действия должны быть выполнены для достижения желаемого результата. При определенных обстоятельствах может оказаться предпочтительной многозадачная и параллельная обработка. Более того, разделение различных компонентов системы в описанных выше вариантах осуществления не следует понимать как необходимость такого разделения во всех вариантах осуществления; следует понимать, что описанные компоненты и программные системы могут быть интегрированы в единый программный продукт или совмещены в нескольких программных продуктов.
[00148] Таким образом, были описаны конкретные варианты осуществления объекта изобретения. Другие варианты осуществления включены в объем приведенной ниже формулы изобретения. В некоторых случаях действия, изложенные в формуле изобретения, могут выполняться в другом порядке, при этом по-прежнему будут достигаться желаемые результаты. Кроме того, показанные на прилагаемых чертежах процессы не обязательно требуют указанного определенного порядка или последовательности действий для достижения желаемых результатов. В некоторых вариантах осуществления можно использовать многозадачность или параллельную обработку.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПОДБОР ПАРАМЕТРОВ ТЕКСТОВОГО КЛАССИФИКАТОРА НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628431C1 |
| КЛАССИФИКАЦИЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628436C1 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| ИСПОЛЬЗОВАНИЕ ГЛУБИННОГО СЕМАНТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ДЛЯ СОЗДАНИЯ ОБУЧАЮЩИХ ВЫБОРОК В МЕТОДАХ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2636098C1 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| МНОГОЭТАПНОЕ РАСПОЗНАВАНИЕ ИМЕНОВАННЫХ СУЩНОСТЕЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ МОРФОЛОГИЧЕСКИХ И СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2619193C1 |
| Построение корпуса сравнимых документов на основе универсальной меры похожести | 2014 |
|
RU2607975C2 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| ВЫЯВЛЕНИЕ СЛОВОСОЧЕТАНИЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2618374C1 |
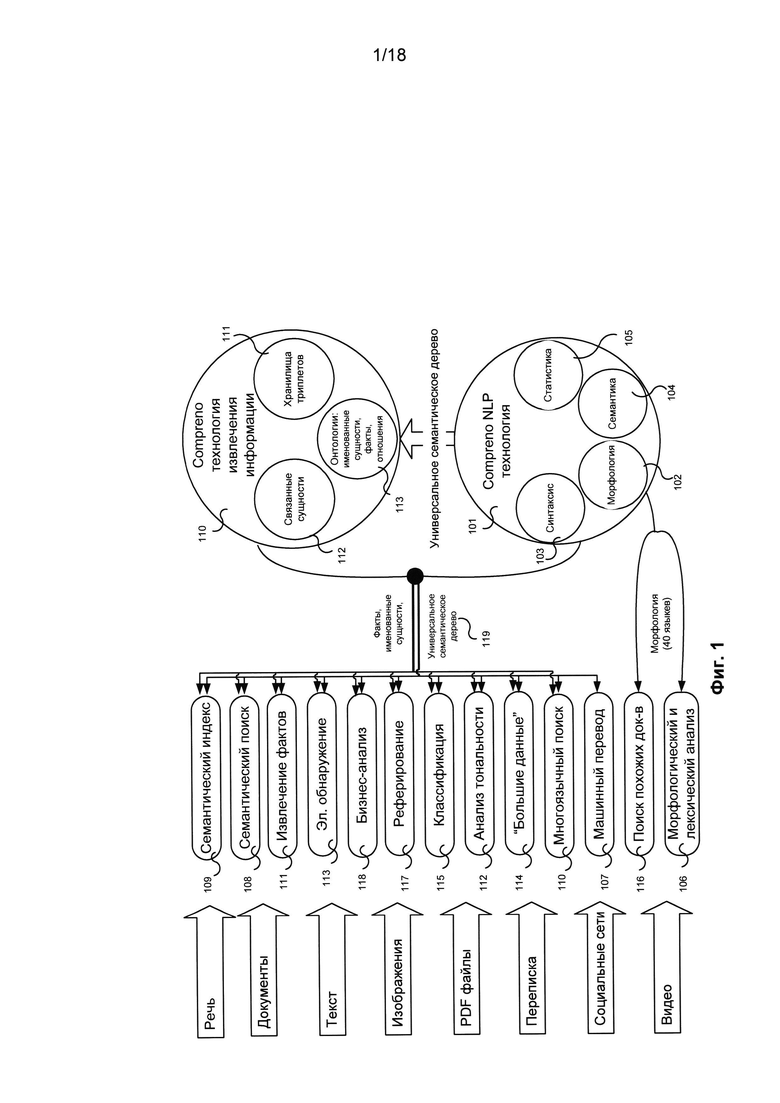
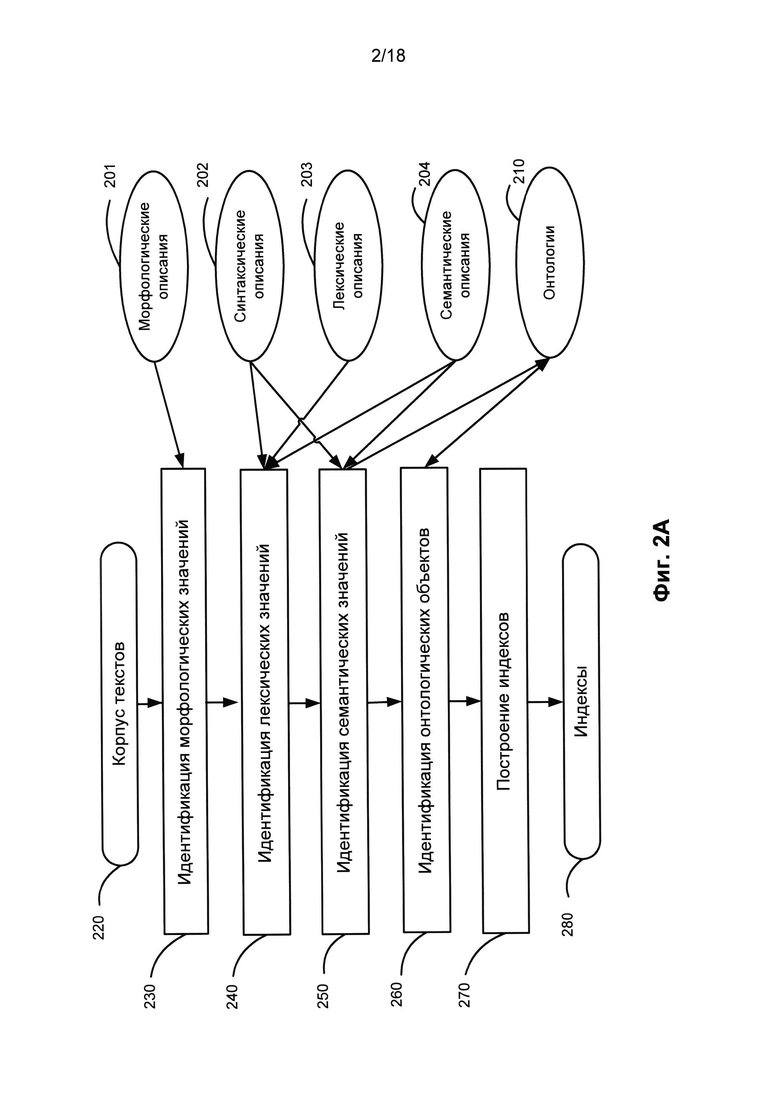
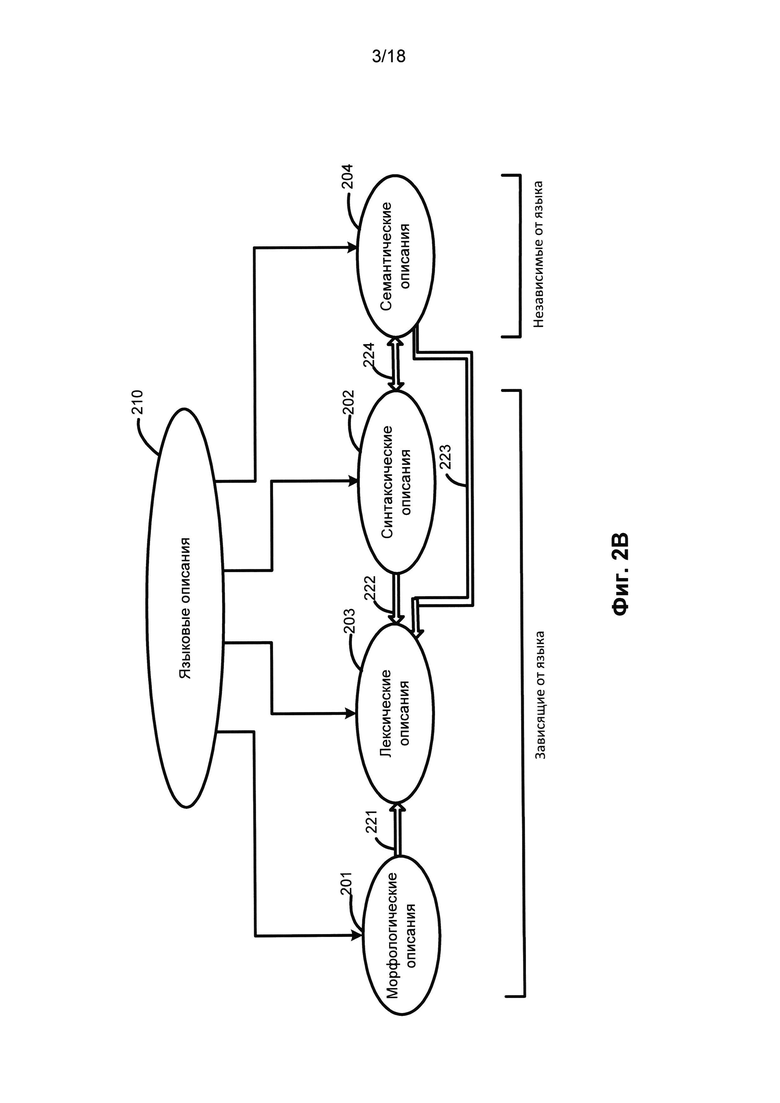

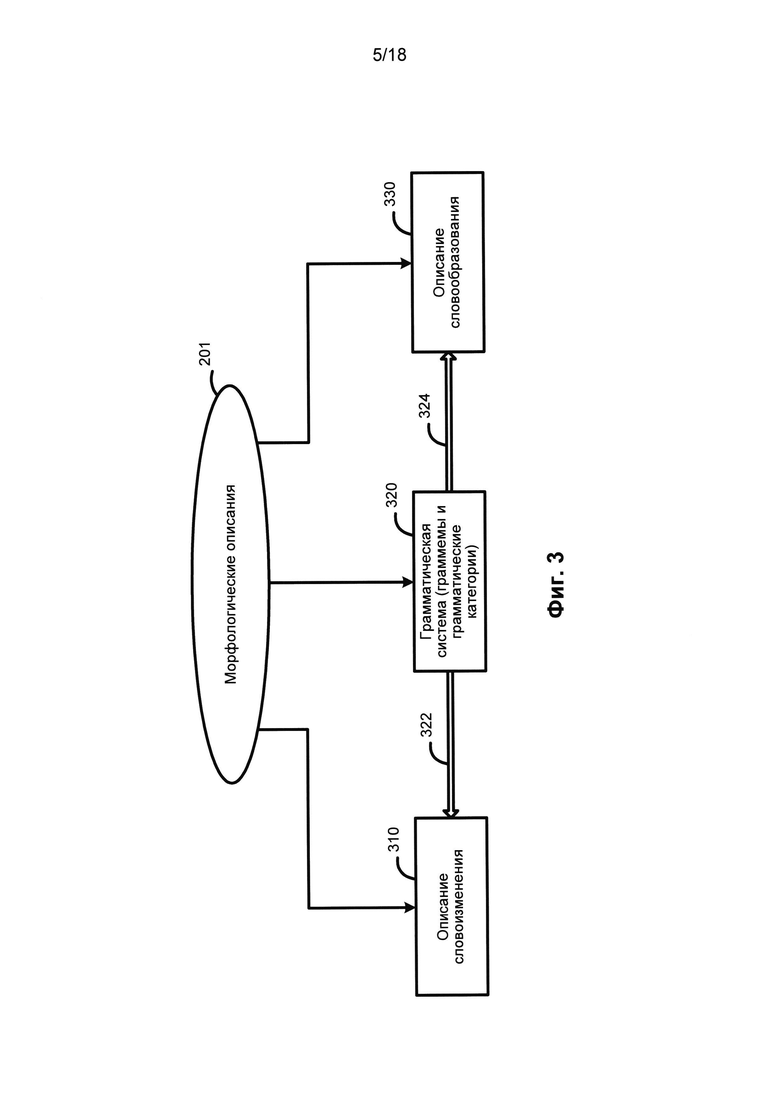
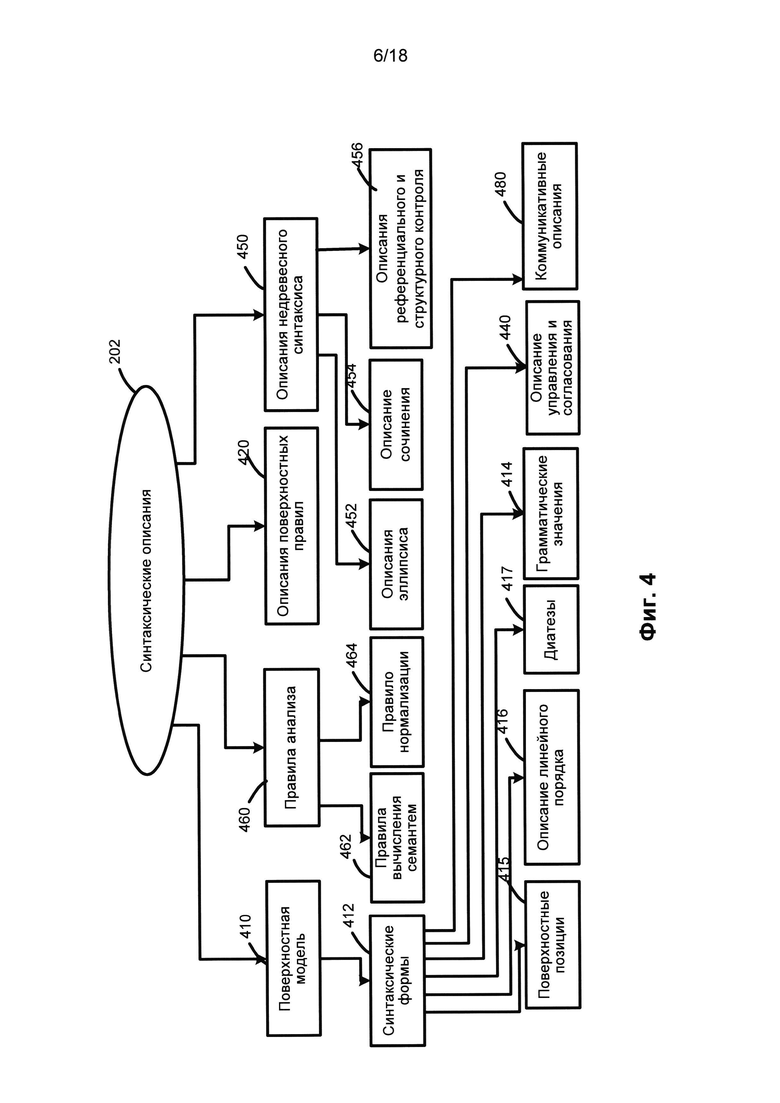
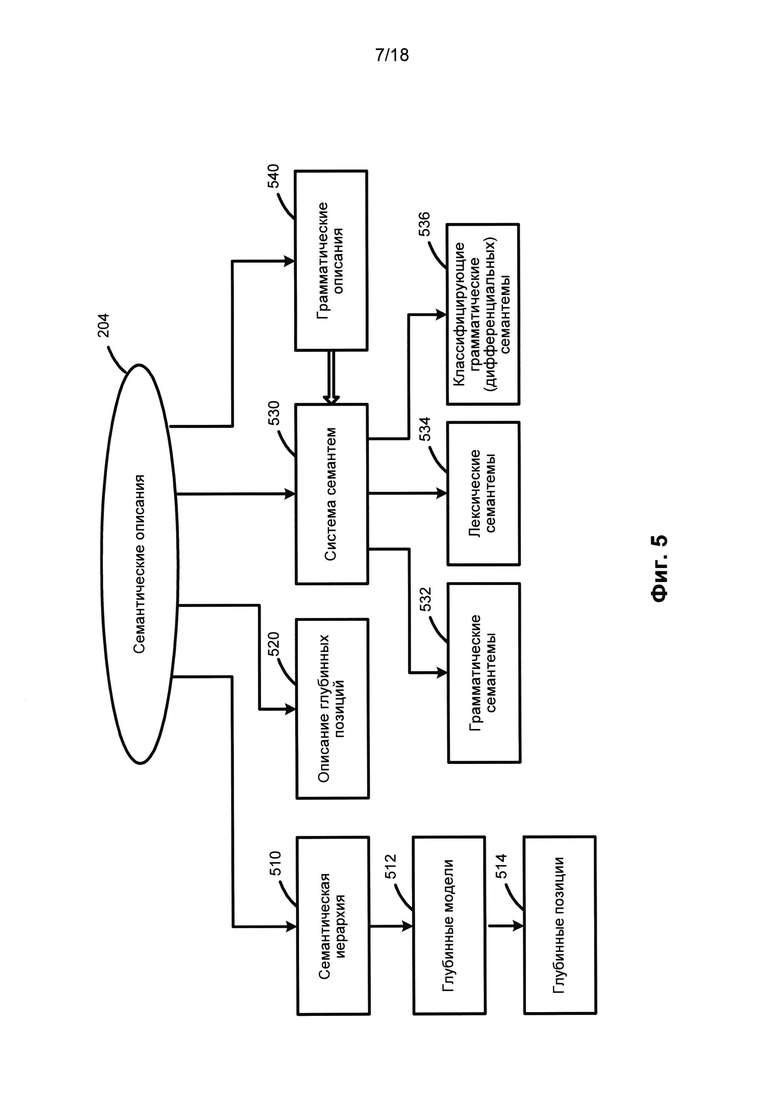
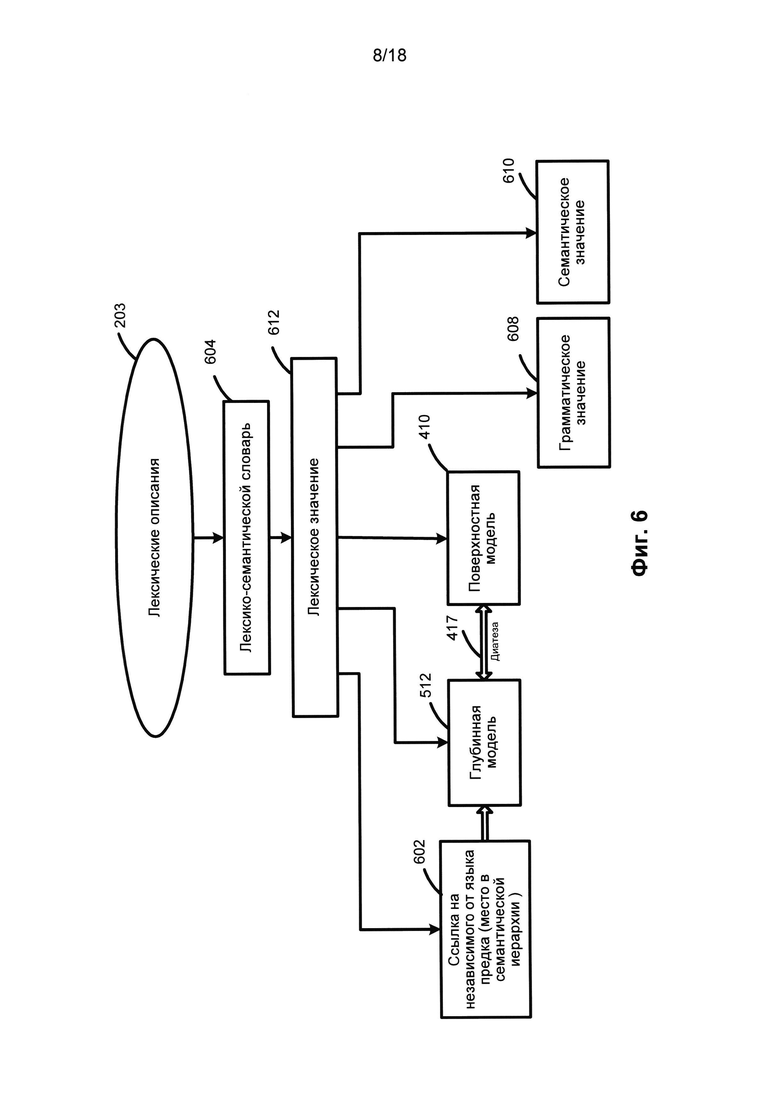
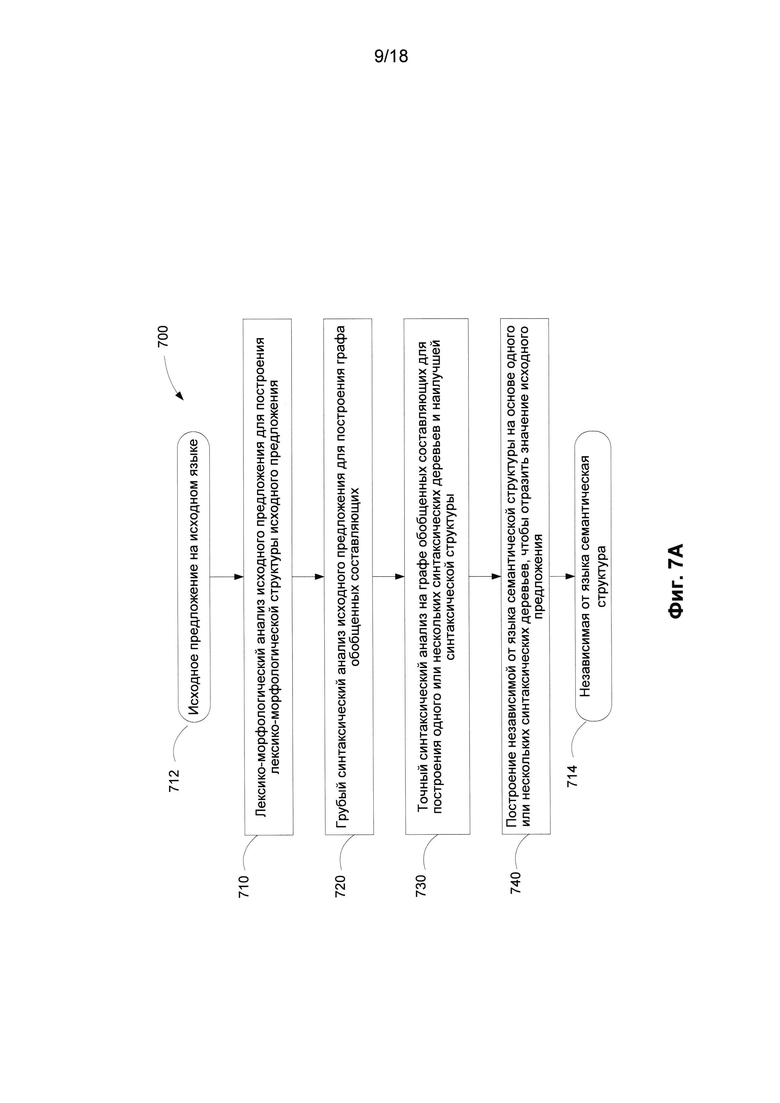
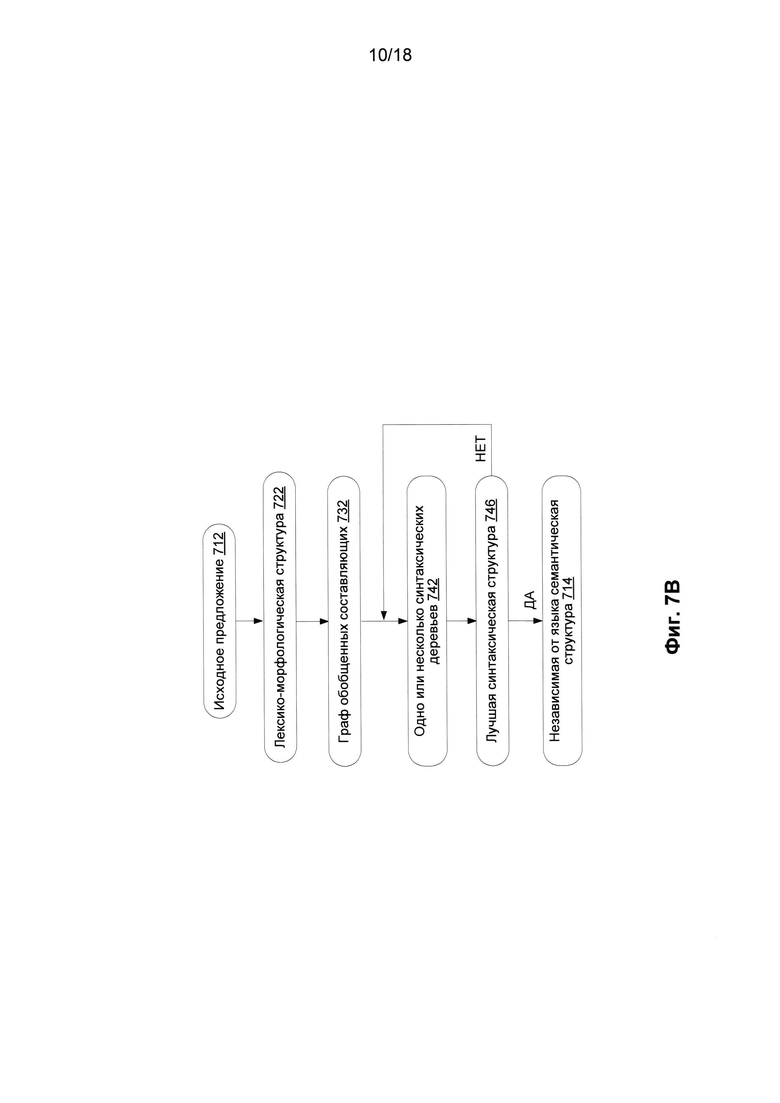
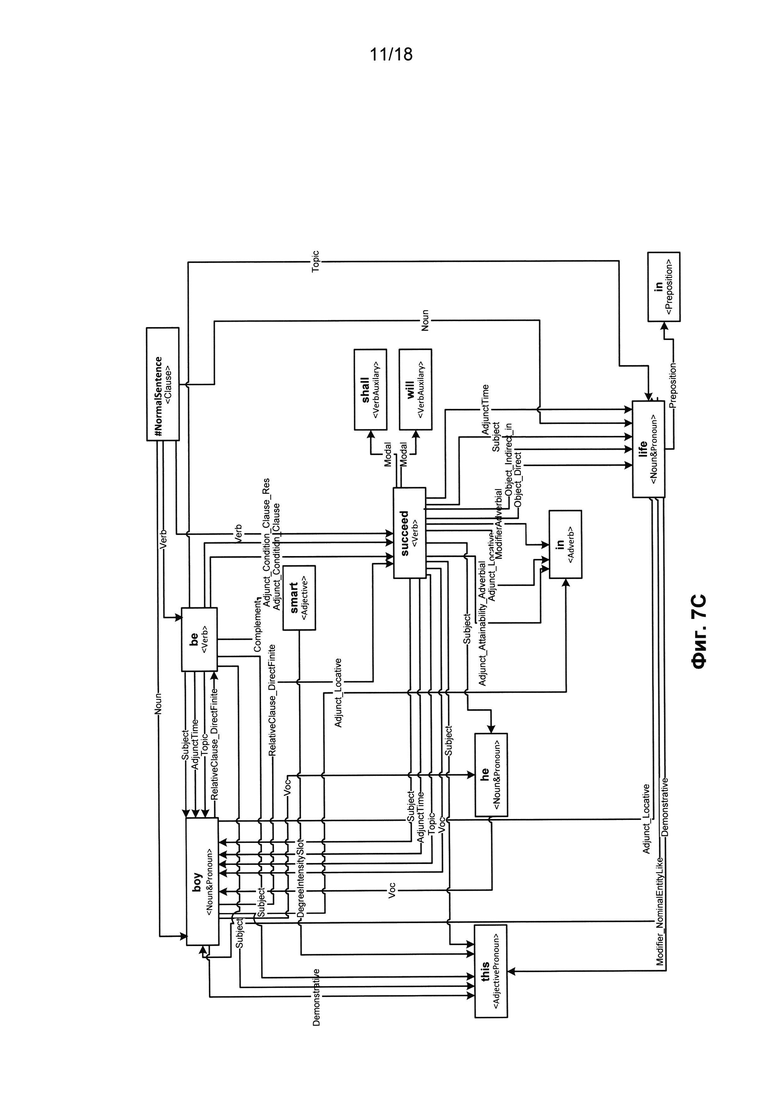
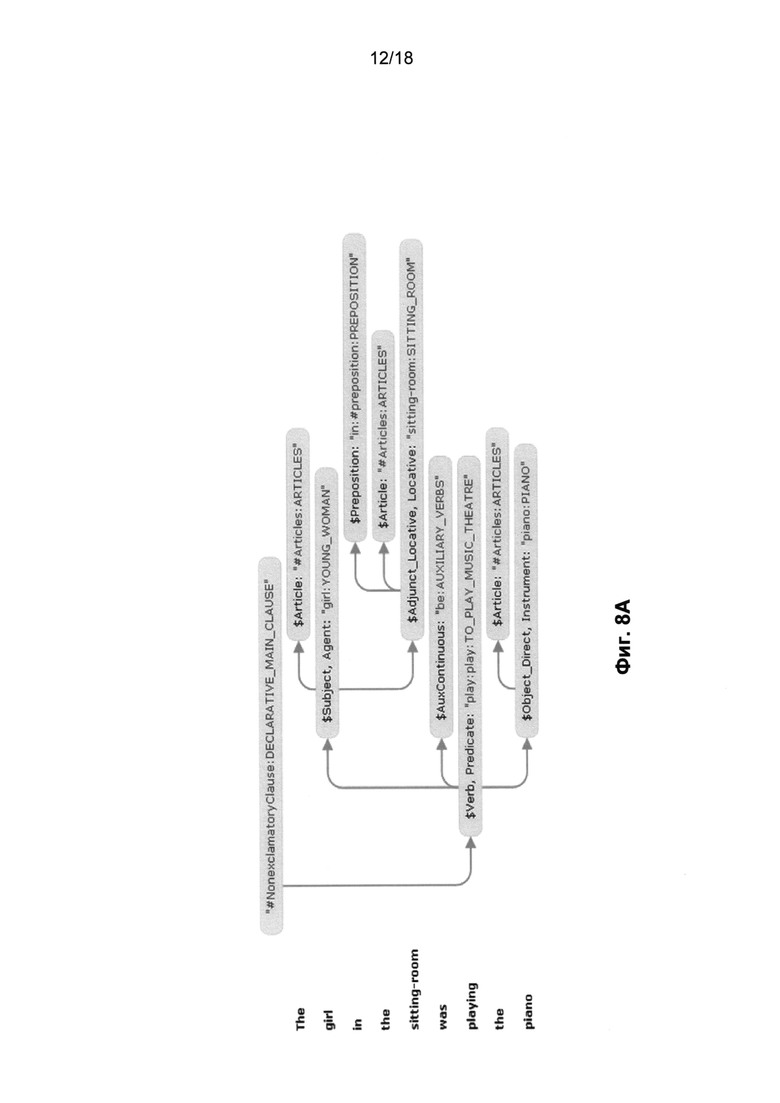
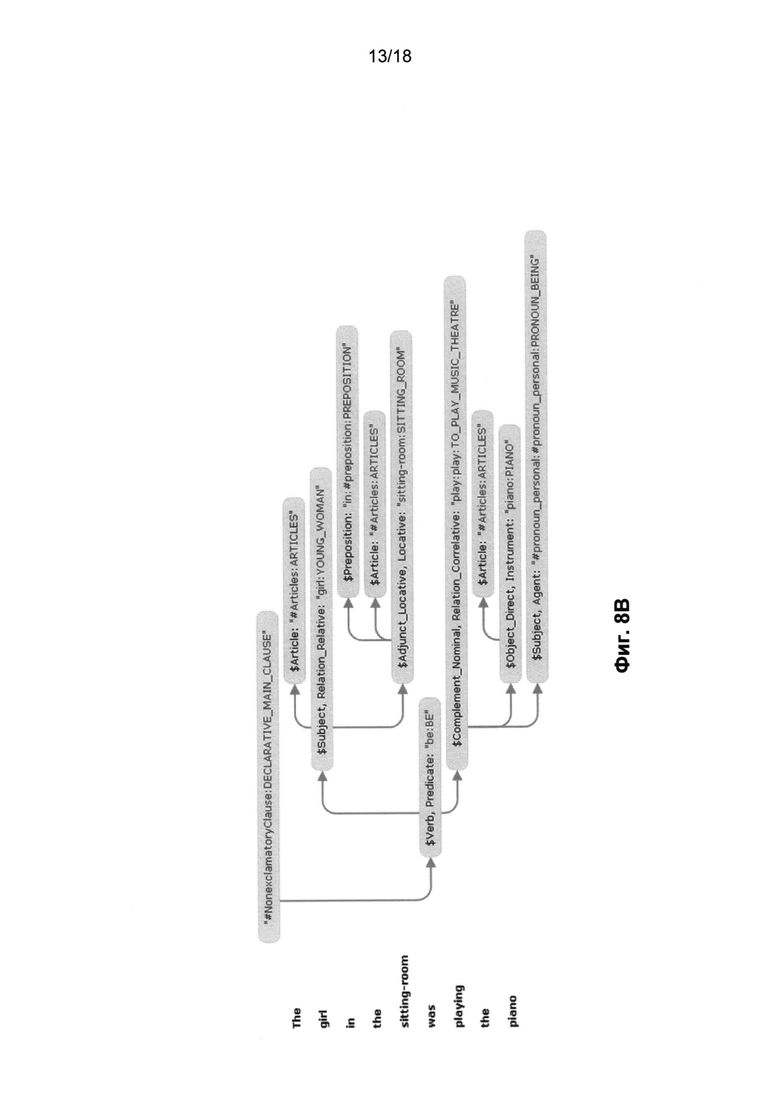
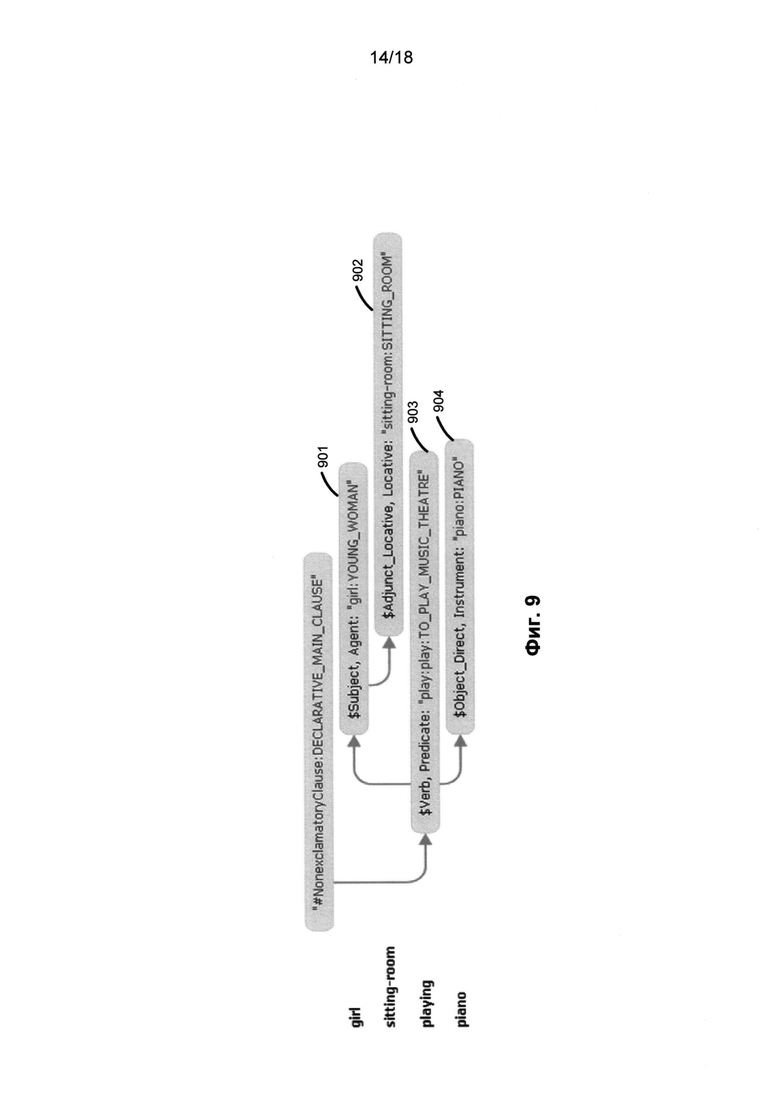
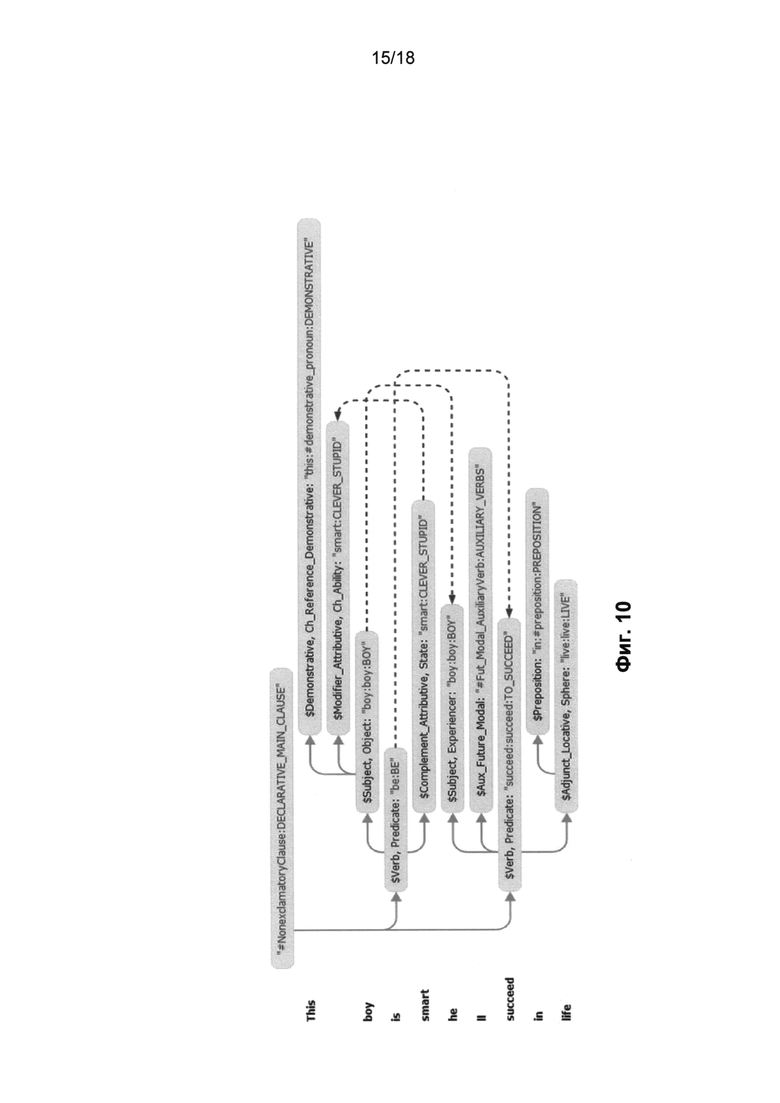
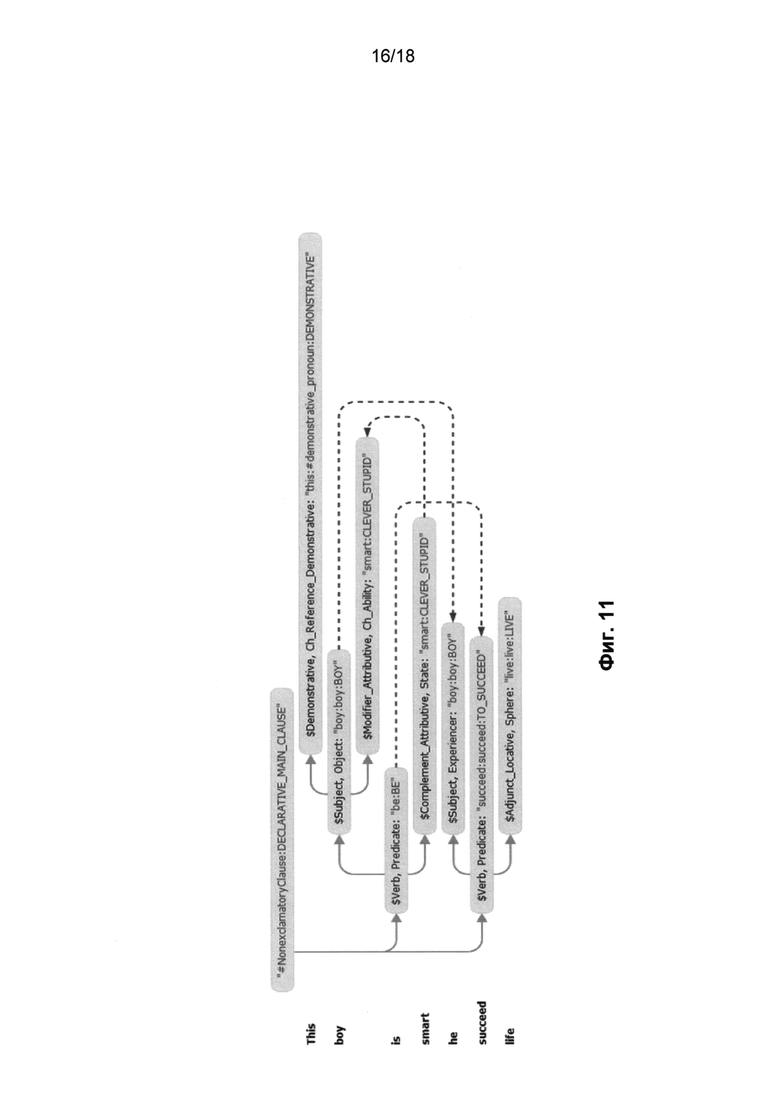
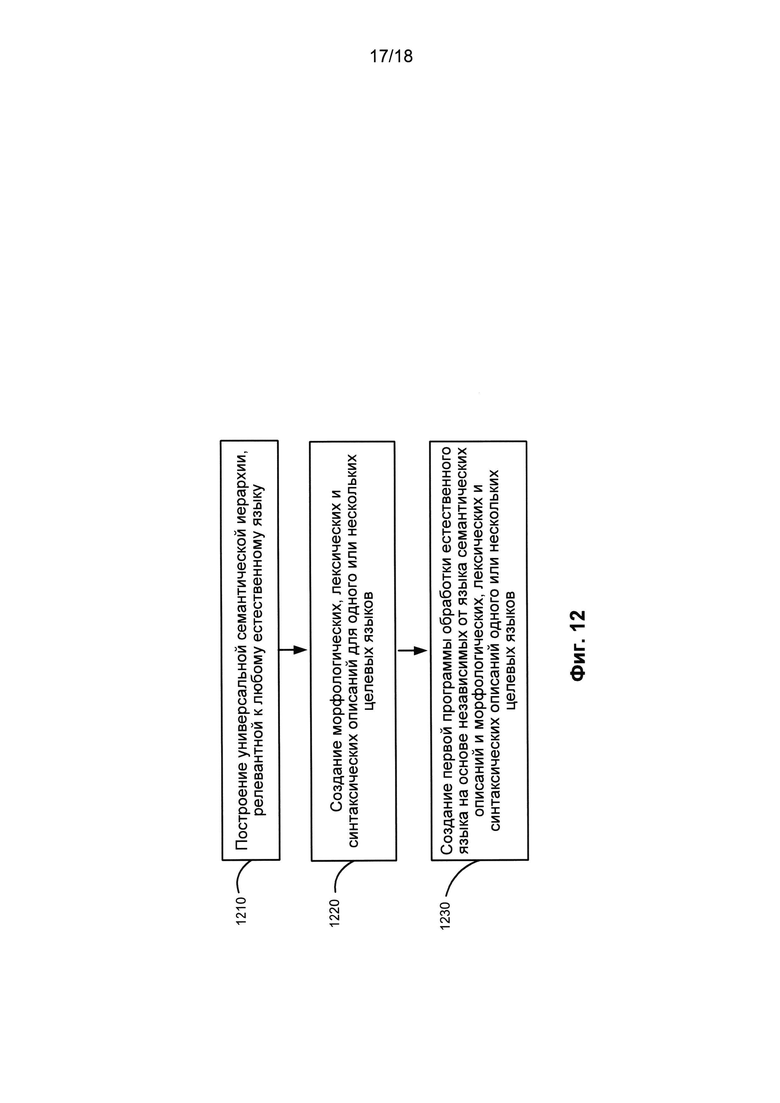
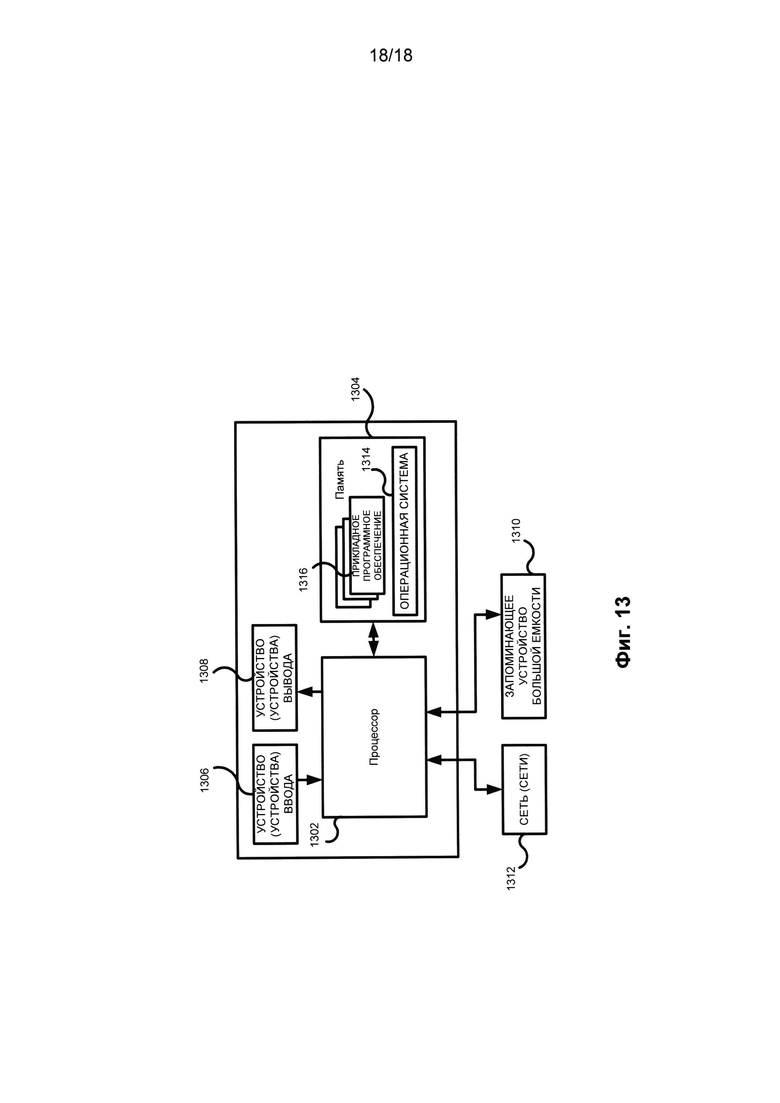
Изобретение относится к обработке естественного языка. Техническим результатом является повышение точности интерпретации информации и снижение вычислительной сложности при обработке за счет создания универсальной технологии построения приложений для обработки на основе накопленных в системе знаний о языке и мире. В способе создания программ обработки естественного языка строят семантическую иерархию независимых от языка семантических сущностей, их свойств, возможных атрибутов, их взаимоотношений. Создают универсальную модель, релевантную по отношению к произвольному языку, включающую модели семантических, морфологических, лексических и синтаксических описаний. Создают первую программу обработки произвольного естественного языка. Наполняют данными зависимых от языка моделей морфологических описаний, лексических описаний и синтаксических описаний сущности указанного семантического описания. Создают вторую программу для обработки естественного языка на основе семантической иерархии, первой универсальной программы и зависимых от языка морфологических описаний, лексических описаний и синтаксических описаний. Используют вторую программу для обработки естественного языка. 17 н. и 3 з.п. ф-лы, 18 ил.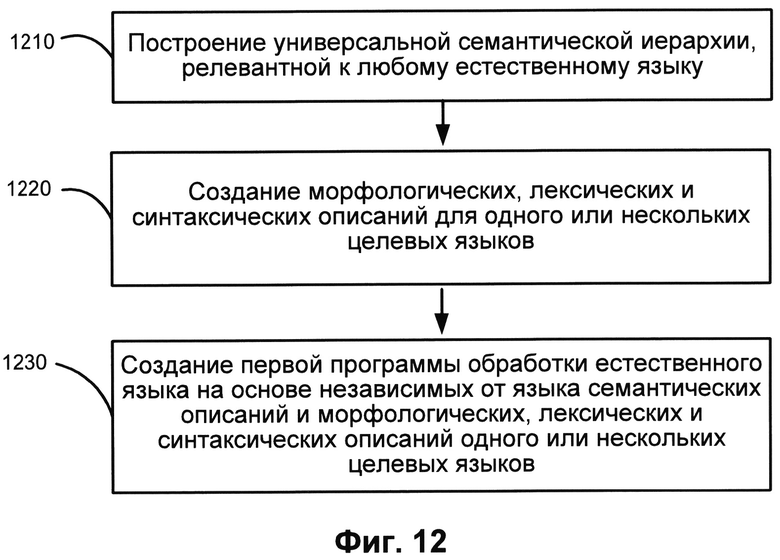
1. Способ создания программ обработки естественного языка, включающий:
построение семантической иерархии независимых от языка семантических сущностей естественного языка, их свойств, возможных атрибутов, их взаимоотношений, релевантных к любому естественному языку;
создание универсальной модели естественного языка, релевантной по отношению к произвольному языку, включающей модель семантических описаний, модель морфологических описаний, модель лексических описаний и модель синтаксических описаний естественного языка;
создание первой, универсальной по отношению к произвольному естественному языку, программы обработки произвольного естественного языка на основе независимых от языка семантических описаний и моделей, зависимых от языка, морфологических описаний, лексических описаний и синтаксических описаний одного или более целевых языков;
наполнение данными зависимых от языка моделей морфологических описаний, лексических описаний и синтаксических описаний для по меньшей мере одной сущности указанного семантического описания для одного или более языков;
создание второй или нескольких программ для обработки естественного языка на основе семантической иерархии, первой универсальной программы и зависимых от языка морфологических описаний, лексических описаний и синтаксических описаний по меньшей мере одного языка; и
использование второй программы для обработки естественного языка.
2. Способ по п. 1, дополнительно включающий использование по меньшей мере одного из статистики словоупотребления, статистики синтаксических конструкций конкретного языка при создании второй программы обработки естественного языка.
3. Способ по п. 1, дополнительно включающий получение онтологической информации, связанной с текстовой информацией.
4. Способ по п. 1, дополнительно включающий получение универсального представления, которое содержит независимую от языка семантическую структуру для по меньшей мере одного предложения, в том числе информацию о семантическом классе для каждого слова предложения, извлеченного из текстового документа, pdf-документа, электронной переписки, сообщений в социальных сетях, изображения, звукового файла, видео.
5. Способ по п. 4, отличающийся тем, что независимая от языка семантическая структура получается в результате исчерпывающего семантико-синтаксического анализа.
6. Способ по п. 1, в котором вторая программа обработки естественного языка выполняет машинный перевод с первого языка на второй язык.
7. Способ по п. 6, отличающийся тем, что вторая программа обработки естественного языка выполняет семантический поиск.
8. Способ по п. 7, дополнительно содержащий построение семантического индекса.
9. Способ по п. 6, отличающийся тем, что вторая программа обработки естественного языка выполняет автоматическое реферирование документов.
10. Способ по п. 1, отличающийся тем, что вторая программа обработки естественного языка выполняет извлечение фактов.
11. Способ по п. 1, отличающийся тем, что вторая программа обработки естественного языка выполняет классификацию документов.
12. Способ по п. 1, отличающийся тем, что вторая программа обработки естественного языка производит лингвистический анализ тональности текста.
13. Способ по п. 1, отличающийся тем, что первая программа обработки естественного языка выполняет поиск похожих документов.
14. Система создания программ обработки естественного языка, включающая:
один или несколько процессоров данных, а также одно или несколько устройств хранения команд, при выполнении их на одном или нескольких процессорах данных побуждающих процессоры данных выполнять операции, включающие:
построение семантической иерархии независимых от языка семантических сущностей естественного языка, их свойств, возможных атрибутов, их взаимоотношений, релевантных к любому естественному языку;
создание универсальной модели естественного языка, релевантной по отношению к произвольному языку, включающей модель семантических описаний, модель морфологических описаний, модель лексических описаний и модель синтаксических описаний естественного языка;
создание первой, универсальной по отношению к произвольному естественному языку, программы обработки произвольного естественного языка на основе независимых от языка семантических описаний и моделей, зависимых от языка, морфологических описаний, лексических описаний и синтаксических описаний одного или более целевых языков;
наполнение данными зависимых от языка моделей морфологических описаний, лексических описаний и синтаксических описаний для по меньшей мере одной сущности указанного семантического описания для одного или более языков;
создание второй или нескольких программ для обработки естественного языка на основе семантической иерархии, первой универсальной программы и зависимых от языка морфологических описаний, лексических описаний и синтаксических описаний по меньшей мере одного языка; и
использование второй программы для обработки естественного языка.
15. Система по п. 14, дополнительно содержащая использование по меньшей мере одного из статистики словоупотребления, статистики синтаксических конструкций конкретного языка при создании второй программы обработки естественного языка.
16. Система по п. 14, дополнительно включающая получение онтологической информации, связанной с текстовой информацией.
17. Система по п. 14, дополнительно включающая получение универсального представления, которое содержит независимую от языка семантическую структуру по меньшей мере одного предложения, извлеченного из текстового документа, pdf-документа, электронной переписки, сообщений в социальных сетях, изображения, звукового файла, видео.
18. Система по п. 17, отличающаяся тем, что независимая от языка семантическая структура получается на основе исчерпывающего семантико-синтаксического анализа.
19. Система по п. 14, отличающаяся тем, что вторая программа для естественного языка выполняет машинный перевод с первого языка на второй язык.
20. Машиночитаемый носитель данных, хранящий машинные команды, при выполнении которых процессор осуществляет операции, включающие:
построение семантической иерархии независимых от языка семантических сущностей естественного языка, их свойств, возможных атрибутов, их взаимоотношений, релевантных к любому естественному языку;
создание универсальной модели естественного языка, релевантной по отношению к произвольному языку, включающей модель семантических описаний, модель морфологических описаний, модель лексических описаний и модель синтаксических описаний естественного языка;
создание первой, универсальной по отношению к произвольному естественному языку, программы обработки произвольного естественного языка на основе независимых от языка семантических описаний, зависимых от языка морфологических описаний, лексических описаний и синтаксических описаний одного или более целевых языков;
наполнение данными зависимых от языка моделей морфологических описаний, лексических описаний и синтаксических описаний для по меньшей мере одной сущности указанного семантического описания для одного или более языков;
создание второй или нескольких программ обработки естественного языка на основе семантической иерархии, первой универсальной программы и зависимых от языка морфологических описаний, лексических описаний и синтаксических описаний по меньшей мере одного языка; и
использование второй программы для обработки естественного языка.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| US 6185592 B1, 06.02.2001 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

