ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
Данная заявка заявляет приоритет предварительной заявки на патент США №61/808,673, поданной 5 апреля 2013 г., и предварительной заявки на патент США №61/875,817, поданной 10 сентября 2013 г., каждая из которых ссылкой полностью включается в данное описание.
ОБЛАСТЬ ТЕХНИЧЕСКОГО ПРИМЕНЕНИЯ
Настоящий документ относится к системе звукового кодирования и декодирования (именуемой системой звукового кодека). В частности, настоящий документ относится к системе звукового кодека на основе преобразования, особенно хорошо подходящей для голосового кодирования/декодирования.
ПРЕДПОСЫЛКИ
Перцепционные звуковые кодеры общего назначения достигают относительно высоких эффективностей кодирования путем использования таких преобразований, как модифицированное дискретное косинусное преобразование (MDCT) с размерами блоков дискретных значений, охватывающими несколько десятков миллисекунд (например, 20 мс). Одним из примеров такой системы звукового кодека на основе преобразования является Advanced Audio Coding (ААС) или High Efficiency (HE)-AAC. Однако при использовании таких систем звуковых кодеков на основе преобразования для голосовых сигналов качество голосовых сигналов в направлении более низких битовых скоростей передачи данных ухудшается быстрее, чем таковое для музыкальных сигналов, особенно в случае сухих (нереверберирующих) речевых сигналов.
Настоящий документ описывает систему звукового кодека на основе преобразования, особенно хорошо подходящую для кодирования речевых сигналов. Кроме того, настоящий документ описывает схемы квантования, которые можно использовать в такой системе звукового кодека на основе преобразования. В сочетании с системами кодеков на основе преобразовании можно использовать и другие различные схемы квантования. Примерами являются векторное квантование (например, двойное векторное квантование), квантование с сохранением распределения, квантование с добавлением псевдослучайного шума, скалярное квантование со случайным смещением и скалярное квантование, объединенное с заполнением шумом (например, в квантователе, описанном в патенте США №7447631). Эти различные схемы квантования обладают разнообразными преимуществами и недостатками в отношении одного или нескольких из следующих определяющих признаков:
- оперативная сложность (кодера), как правило, включающая вычислительную сложность квантования и генерирования битового потока (например, кодирования переменной длины);
- перцепционная производительность, которую можно оценить на основе теоретических представлений (производительность в отношении зависимости искажений от скорости передачи данных) и на основе характерных признаков связанного поведения заполнения шумом (например, при битовых скоростях передачи данных, практически значимых для кодирования речи с преобразованием на низкой скорости передачи данных);
- сложность процесса распределения битов в присутствии общего ограничения битовой скорости передачи данных (например, максимального количества битов); и/или
- гибкость в отношении допущения разных скоростей передачи данных и разных уровней искажений.
В настоящем документе описывается схема квантования, обращенная по меньшей мере к некоторым из вышеупомянутых определяющих признаков. В частности, описывается схема квантования, обеспечивающая повышенную производительность в отношении некоторых или всех вышеупомянутых определяющих признаков.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Согласно одной из особенностей, описывается модуль квантования (также именуемый в настоящем документе модулем квантования коэффициентов), сконфигурированный для квантования первого коэффициента из блока коэффициентов. Этот блок коэффициентов может соответствовать блоку остаточных коэффициентов предсказания (также именуемому блоком коэффициентов ошибок предсказания), или он может быть полученным из него. Как таковой, указанный модуль квантования может составлять часть звукового кодера на основе преобразования, использующего предсказание поддиапазонов, как в дальнейших подробностях описывается ниже. В общем выражении, блок коэффициентов может содержать ряд коэффициентов для ряда соответствующих элементов разрешения по частоте. Блок коэффициентов можно получить исходя из блока коэффициентов преобразования, причем этот блок коэффициентов преобразования был определен путем преобразования звукового сигнала (например, речевого сигнала) из временной области в частотную область с использованием преобразования из временной области в частотную область (например, модифицированного дискретного косинусного преобразования, MDCT).
Следует отметить, что указанный первый коэффициент блока коэффициентов может соответствовать любому одному или нескольким коэффициентам этого блока коэффициентов. Блок коэффициентов может содержать K коэффициентов (K>1, например, K=256). Указанный первый коэффициент может соответствовать любому одному из частотных коэффициентов k=1, …, K. Как будет описано впоследствии, ряд элементов разрешения по частоте можно сгруппировать в ряд из L полос частот, где 1<L<K. Коэффициент блока коэффициентов можно присвоить одной полосе из ряда полос частот (l=1, L). Коэффициенты q, где q=1, …Q и 0<Q<K, присвоенные конкретной полосе 1 частот, можно квантовать, используя один и тот же квантователь. Первый коэффициент может соответствовать q-му коэффициенту l-й полосы частот для любого q=1, …Q и для любого l=1, …, L.
Модуль квантования может быть сконфигурирован для создания набора квантователей. Этот набор квантователей может содержать ряд различных квантователей, связанных с рядом различных отношений сигнал-шум (SNR) или, соответственно, рядом различных уровней искажений. Как таковые, эти различные квантователи из набора квантователей могут приводить к соответствующим отношениям SNR, или уровням искажений. Квантователи в наборе квантователей могут быть упорядочены в соответствии с рядом отношений SNR, связанных этим рядом квантователей. В частности, квантователи могут быть упорядочены так, что отношение SNR, получаемое с использованием конкретного квантователя, увеличивается по сравнению с SNR, полученным с использованием непосредственно предшествующего смежного квантователя.
Этот набор квантователей также может именоваться набором приемлемых квантователей. Как правило, количество квантователей, заключенных в наборе квантователей, ограничено количеством R квантователей. Это количество R квантователей, заключенных в наборе квантователей, может быть выбрано на основе всего диапазона SNR, который необходимо охватить этим набором квантователей (например, диапазона SNR от, приблизительно, 0 дБ до 30 дБ). Кроме того, количество R квантователей, как правило, зависит от целевой разности SNR между смежными квантователями в пределах упорядоченного набора квантователей. Типичные значения для количества R квантователей составляют 10-20 квантователей.
Указанный набор различных квантователей может содержать квантователь с заполнением шумом, один или несколько квантователей с добавлением псевдослучайного шума и/или один или несколько квантователей без добавления псевдослучайного шума. В одном из предпочтительных примеров указанный набор различных квантователей содержит единственный квантователь с заполнением шумом, один или несколько квантователей с добавлением псевдослучайного шума и один или несколько квантователей без добавления псевдослучайного шума. Как будет описано в настоящем документе, преимущественным является использование квантователя с заполнением шумом для ситуации нулевой битовой скорости передачи данных (например, вместо использования квантователя с добавлением псевдослучайного шума с большой величиной шага квантования). Квантователь с заполнением шумом связан с относительно наинизшим SNR из ряда отношений SNR, а один или несколько квантователей без добавления псевдослучайного шума могут быть связаны одним или несколькими наивысшими отношениями SNR из ряда отношений SNR. Один или несколько квантователей с добавлением псевдослучайного шума могут быть связаны с одним или несколькими промежуточными отношениями SNR, выше, чем относительное наинизшее отношение SNR, и ниже, чем относительно наивысшие отношения SNR из ряда отношений SNR. Как таковой, упорядоченный набор квантователей может содержать квантователь с заполнением шумом для наинизшего SNR (например, меньшего или равного 0 дБ), за которым следуют один или несколько квантователей с добавлением псевдослучайного шума для промежуточных отношений SNR, а за ними следуют один или несколько квантователей без добавления псевдослучайного шума для относительно высоких отношений SNR. Поступая таким образом, можно повысить воспринимаемое качество восстановленного звукового сигнала (получаемого из блока квантованных коэффициентов, квантованных с использованием этого набора квантователей). В частности, можно уменьшать слышимые артефакты, вызванные спектральными провалами, и, в то же время, поддерживать на высоком уровне производительность модуля квантования в отношении MSE (среднеквадратичной ошибки).
Квантователь с заполнением шумом может содержать генератор случайных чисел, сконфигурированный для генерирования случайных чисел в соответствии с предварительно определенной статистической моделью. Эта предварительно определенная статистическая модель генератора случайных чисел квантователя с заполнением шумом может зависеть от дополнительной информации (например, от флага сохранения дисперсии), доступной в кодере и в соответствующем декодере. Квантователь с заполнением шумом может быть сконфигурирован для квантования первого коэффициента (или любого из коэффициентов блока коэффициентов) путем замены первого коэффициента случайным числом, сгенерированным генератором случайных чисел. Генератор случайных чисел, используемый в модуль квантования (например, в локальном декодере, заключенном в кодере) может действовать в синхронном режиме с соответствующим генератором случайных чисел в модуле обратного квантования (в соответствующем декодере). Как таковой, вывод квантователя с заполнением шумом может не зависеть от первого коэффициента, поэтому вывод квантователя с заполнением шумом может не требовать передачи каких-либо индексов квантования. Квантователь с заполнением шумом может быть связан с SNR, составляющим (близким или, по существу, равным) 0 дБ. Иными словами, квантователь с заполнением шумом может действовать с SNR, близким к 0 дБ. В ходе процесса распределения скорости передачи данных квантователь с заполнением шумом можно считать обеспечивающим SNR 0 дБ, хотя на практике его SNR может несколько отклоняться от нуля (например, может быть несколько ниже нуля дБ (по причине синтеза сигнала, не зависящего от входного сигнала)).
SNR квантователя с заполнением шумом можно корректировать на основе одного или нескольких дополнительных параметров. Например, дисперсию квантователя с заполнением шумом можно корректировать, задавая дисперсию синтезированного сигнала (т.е. дисперсию коэффициентов, которые были квантованы с использованием квантователя с заполнением шумом) в соответствии с предварительно определенной функцией коэффициента усиления предсказателя. В качестве альтернативы или в дополнение, дисперсию синтезированного сигнала можно задавать посредством флага, передаваемого в битовом потоке. В частности, дисперсию квантователя с заполнением шумом можно корректировать посредством одной из двух предварительно определенных функций коэффициента усиления предсказателя (в дальнейшем представленных в данном документе ниже), где одна из этих функций может быть выбрана для воспроизведения синтезированного сигнала в зависимости от флага (например, в зависимости от флага сохранения дисперсии). Например, дисперсию сигнала, генерируемого квантователем с заполнением шумом, можно корректировать таким способом, чтобы отношение SNR этого квантователя с заполнением шумом находилось в пределах диапазона [-3,0-0 дБ]. SNR при 0 дБ, как правило, является преимущественным в виду MMSE (минимальной среднеквадратичной ошибки). С другой стороны, воспринимаемое качество можно повысить, используя менее высокие отношения SNR (например, вплоть до -3,0 дБ).
Указанные один или несколько квантователей с добавлением псевдослучайного шума предпочтительно представляют собой квантователи с добавлением субтрактивного псевдослучайного шума. В частности, квантователь с добавлением псевдослучайного шума из указанных одного или нескольких квантователей с добавлением псевдослучайного шума может содержать модуль применения псевдослучайного шума, сконфигурированный для определения первого коэффициента с добавленным псевдослучайным шумом путем применения к указанному первому коэффициенту значения псевдослучайного шума (также именуемого числом псевдослучайного шума). Кроме того, квантователь с добавлением псевдослучайного шума может содержать скалярный квантователь, сконфигурированный для определения первого индекса квантования путем присвоения первого коэффициента с добавленным псевдослучайным шумом одному из интервалов этого скалярного квантователя. Как таковой квантователь с добавлением псевдослучайного шума может генерировать первый индекс квантования на основе первого коэффициента. Аналогичным образом можно квантовать один или несколько других коэффициентов из указанного блока коэффициентов.
Квантователь с добавлением псевдослучайного шума из одного или нескольких квантователей с добавлением псевдослучайного шума также может содержать обратный скалярный квантователь, сконфигурированный для присвоения первого восстанавливаемого значения первому индексу квантования. Кроме того, квантователь с добавлением псевдослучайного шума может содержать модуль удаления псевдослучайного шума, сконфигурированный для определения первого коэффициента с удаленным псевдослучайным шумом путем удаления значения псевдослучайного шума (то есть того же самого значения псевдослучайного шума, которое было применено модулем применения псевдослучайного шума) из первого восстанавливаемого значения.
Кроме того, квантователь с добавлением псевдослучайного шума может содержать модуль применения коэффициента последующего усиления, сконфигурированный для определения первого квантованного коэффициента путем применения коэффициента последующего усиления квантователя к первому коэффициенту с удаленным псевдослучайным шумом. Применяя коэффициент последующего усиления к первому коэффициенту с удаленным псевдослучайным шумом можно повысить производительность квантователя с добавлением псевдослучайного шума в отношении MSE. Коэффициент последующего усиления квантователя может иметь вид
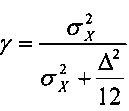 ,
,
где 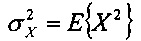 - дисперсия одного или нескольких коэффициентов блока коэффициентов, и где - величина шага квантователя для скалярного квантователя квантователя с добавлением псевдослучайного шума.
- дисперсия одного или нескольких коэффициентов блока коэффициентов, и где - величина шага квантователя для скалярного квантователя квантователя с добавлением псевдослучайного шума.
Как таковой, квантователь с добавлением псевдослучайного шума может быть сконфигурирован для выполнения обратного квантования с целью получения квантованного коэффициента. Это можно использовать в локальном декодере кодера, что облегчает предсказание в замкнутом цикле, например, тогда, когда цикл предсказания в кодере поддерживается в синхронном режиме с циклом предсказания в декодере.
Модуль применения псевдослучайного шума может быть сконфигурирован для вычитания значения псевдослучайного шума из указанного первого коэффициента, а модуль удаления псевдослучайного шума может быть сконфигурирован для добавления значения псевдослучайного шума к первому восстанавливаемому значению. В качестве альтернативы, модуль применения псевдослучайного шума может быть сконфигурирован для добавления значения псевдослучайного шума к первому коэффициенту, а модуль удаления псевдослучайного шума может быть сконфигурирован для вычитания значения псевдослучайного шума из первого восстанавливаемого значения.
Модуль квантования также может содержать генератор псевдослучайного шума, сконфигурированный для генерирования блока значений псевдослучайного шума. С целью облегчения синхронизации между кодером и декодером, эти значения псевдослучайного шума могут представлять собой псевдослучайные числа. Блок значений псевдослучайного шума может содержать ряд значений псевдослучайного шума, соответственно, для ряда элементов разрешения по частоте. Как таковой, генератор псевдослучайного шума может быть сконфигурирован для генерирования значения псевдослучайного шума для каждого из коэффициентов блока коэффициентов, подлежащего квантованию, независимо от того, должен ли конкретный коэффициент квантоваться с использованием одного из квантователей с добавлением псевдослучайного шума, или нет. Это является преимущественным для поддержания синхронности между генератором псевдослучайного шума, используемым в кодере, и генератором псевдослучайного шума, используемым в соответствующем декодере.
Скалярный квантователь квантователя с добавлением псевдослучайного шума имеет предварительно определенную величину шага квантователя. Как таковой, скалярный квантователь квантователя с добавлением псевдослучайного шума может представлять собой квантователь с равномерным шагом. Значения псевдослучайного шума могут принимать значения из предварительно определенного интервала псевдослучайного шума. Этот предварительно определенный интервал псевдослучайного шума может иметь ширину, меньшую или равную предварительно определенной величине шага квантователя. Кроме того, блок значений псевдослучайного шума может состоять из реализаций случайной переменной, равномерно распределенной в пределах предварительно определенного интервала псевдослучайного шума. Например, генератор псевдослучайного шума сконфигурирован для генерирования блока значений псевдослучайного шума, извлекаемых из нормированного интервала псевдослучайного шума (например, [0, 1) или [-0,5, 0,5)). Как таковая, ширина нормированного интервала псевдослучайного шума может быть равна единице. Блок значений псевдослучайного шума можно затем умножить на предварительно определенную величину шага конкретного квантователя с добавлением псевдослучайного шума. Поступая таким образом, можно получить реализацию псевдослучайного шума, пригодную для использования с квантователем, имеющим величину шага. В частности, поступая таким образом, получают квантователь, удовлетворяющий т.н. условиям Шухмана (L. Schuchman, "Dither signals and their effect on quantization noise", IEEE TCOM, pp. 162-165, декабрь 1964 г.).
Генератор псевдослучайного шума может быть сконфигурирован для выбора М предварительно определенных реализаций псевдослучайного шума, где М - целое число больше единицы. Кроме того, генератор псевдослучайного шума может быть сконфигурирован для генерирования блока значений псевдослучайного шума на основе выбранной реализации псевдослучайного шума. В частности, в некоторых реализациях количество реализаций псевдослучайного шума может быть ограниченным. Например, количество М предварительно определенных реализаций псевдослучайного шума может составлять 10, 5, 4 или менее. Это может быть преимущественным в отношении последующего энтропийного кодирования индексов квантования, которые были получены с использованием указанных одного или нескольких квантователей с добавлением псевдослучайного шума. В частности, использование ограниченного количества М реализаций псевдослучайного шума позволяет обучать энтропийный кодер для индексов квантования на основе ограниченного количества реализаций псевдослучайного шума. Поступая таким образом, вместо арифметического кода можно использовать мгновенный код (такой, как, например, многомерное кодирование методом Хаффмана), что может быть преимущественным в выражении оперативной сложности.
Квантователь без добавления псевдослучайного шума из одного или нескольких квантователей без добавления псевдослучайного шума может представлять собой скалярный квантователь с предварительно определенной равномерной величиной шага квантователя. Как таковые, один или несколько квантователей без добавления псевдослучайного шума могут представлять собой детерминированные квантователи, не использующие (псевдо-) случайный шум.
Как описывалось выше, набор квантователей может быть упорядоченным. Это может быть преимущественным в виду эффективного процесса распределения битов. В частности, упорядочение набора квантователей позволяет выбирать квантователь из набора квантователей на основе целочисленного индекса. Набор квантователей может быть упорядочен так, чтобы увеличение в SNR между смежными квантователями было, по меньшей мере, приблизительно постоянным. Иными словами, разность SNR между двумя квантователями может иметь вид разности отношений SNR, связанных с парой смежных квантователей из упорядоченного набора квантователей. Разности SNR для всех пар смежных квантователей из ряда упорядоченных квантователей может находиться в пределах предварительно определенного интервала разностей SNR с центром около предварительно определенной целевой разности SNR. Ширина предварительно определенного интервала разностей SNR может быть меньше чем 10% или 5% предварительно определенной целевой разности SNR. Целевая разность SNR может быть задана таким образом, чтобы операции в относительно широком общем диапазоне SNR мог воспроизводить относительно небольшой набор квантователей. Например, в типичных применениях набор квантователей может облегчать работу в пределах интервала от SNR 0 дБ до SNR 30 дБ. Предварительно определенная целевая разность SNR может быть приравнена к 1,5 дБ или 3 дБ, посредством чего общий диапазон SNR в 30 дБ может быть охвачен набором квантователей, содержащим 10-20 квантователей. Таким образом, увеличение целочисленного индекса квантователя из упорядоченного набора квантователей напрямую переводится в соответствующее увеличение SNR. Это взаимно-однозначное соответствие является преимущественным для реализации эффективного процесса распределения битов, распределяющего квантователь с конкретным SNR конкретной полосе частот в соответствии с заданным ограничением битовой скорости передачи данных.
Модуль квантования может быть сконфигурирован для определения указателя SNR, служащего признаком SNR, приписанного первому коэффициенту. Это отношение SNR, приписанное первому коэффициенту, можно определить, используя процесс распределения скорости передачи данных (также именуемый процессом распределения битов). Как указывалось выше, отношение SNR, приписанное первому коэффициенту, может прямо идентифицировать квантователь из набора квантователей. Как таковой, модуль квантования может быть сконфигурирован для выбора первого квантователя из набора квантователей на основе этого указателя SNR. Кроме того, модуль квантования может быть сконфигурирован для квантования первого коэффициента с использованием этого первого квантователя. В частности, модуль квантования может быть сконфигурирован для определения первого индекса квантования для первого коэффициента. Этот первый индекс квантования может подвергаться энтропийному кодированию и может быть передан в качестве данных коэффициентов в битовом потоке в соответствующий модуль обратного квантования (соответствующего декодера). Кроме того, модуль квантования может быть сконфигурирован для определения первого квантованного коэффициента исходя из первого коэффициента. Этот первый квантованный коэффициент можно использовать в предсказателе кодера.
Блок коэффициентов может быть связан с огибающей спектра блока (например, с текущей огибающей или с квантованной текущей огибающей, как описывается ниже). В частности, блок коэффициентов можно получить путем выравнивания блока коэффициентов преобразования (полученного из сегмента входного звукового сигнала) с использованием огибающей спектра блока. Огибающая спектра блока может служить признаком ряда значений спектральной энергии для ряда элементов разрешения по частоте. В частности, эта огибающая спектра блока может служить признаком относительной важности коэффициентов из блока коэффициентов. Как таковую, огибающую спектра блока (или огибающую, полученную, исходя из этой огибающей спектра блока, такую, как описываемая ниже огибающая распределения) можно использовать в целях распределения скорости передачи данных. В частности, от огибающей спектра блока может зависеть указатель SNR. Также указатель SNR может зависеть от параметра смещения, предназначенного для смещения огибающей спектра блока. В ходе процесса распределения скорости передачи данных параметр смещения можно увеличивать/уменьшать до тех пор, пока данные коэффициентов, генерируемые из квантованного и кодированного блока коэффициентов удовлетворяют предварительно определенному ограничению битовой скорости передачи данных (например, параметр смещения можно выбрать максимально возможным так, чтобы кодированный блок коэффициентов не превышал предварительно определенное количество битов). Таким образом, параметр смещения может зависеть от предварительно определенного количества битов, доступных для кодирования блока коэффициентов.
Указатель SNR, служащий признаком SNR, приписанного первому коэффициенту, можно определить, смещая значение, полученное из огибающей спектра блока, связанной с элементом разрешения по частоте этого первого коэффициента, с использованием параметра смещения. В частности, для определения указателя SNR можно использовать формулу распределения битов, описываемую в настоящем документе. Эта формула распределения битов может представлять собой функцию огибающей распределения, полученной исходя из огибающей спектра блока и из параметра смещения.
Как таковой, указатель SNR может зависеть от огибающей распределения, полученной исходя из огибающей спектра блока. Эта огибающая распределения может иметь разрешающую способность распределения (например, разрешающую способность 3 дБ). Эта разрешающая способность распределения предпочтительно зависит от разности SNR между смежными квантователями из набора квантователей. В частности, разрешающая способность распределения и разность SNR могут соответствовать друг другу. В одном из примеров, разность SNR составляет 1,5 дБ, а разрешающая способность распределения составляет 3 дБ. Выбирая соответствующую разрешающую способность распределения и разность SNR (например, выбирая разрешающую способность вдвое больше разности SNR в области дБ), можно упростить процесс распределения битов и/или процесс выбора квантователя (например, используя формулу распределения битов, описываемую в настоящем документе).
Ряд коэффициентов блока коэффициентов можно присвоить ряду полос частот. Полоса частот может содержать один или несколько элементов разрешения по частоте. Таким образом, одной и той же полосе частот может быть присвоено более одного коэффициента из указанного ряда коэффициентов. Как правило, количество элементов разрешения по частоте, приходящееся на полосу частот, увеличивается с повышением частоты. В частности, структура полосы частот (например, количество элементов разрешения по частоте, приходящихся на полосу частот) может следовать психоакустическим соображениям. Модуль квантования может быть сконфигурирован для выбора квантователя из набора квантователей для каждой полосы частот из ряда полос частот так, что коэффициенты, присвоенные одной и той же полосе частот квантуются с использованием одного и того же квантователя. Квантователь, используемый для квантования конкретной полосы частот, можно определить на основе одного или нескольких значений спектральной энергии огибающей блока спектра в пределах этой конкретной полосы частот. Использование структуры полосы частот в целях квантования может быть преимущественным в отношении психоакустической производительности схемы квантования.
Модуль квантования может быть сконфигурирован для приема дополнительной информации, служащей признаком какого-либо свойства блока коэффициентов. Например, дополнительная информация может содержать коэффициент усиления предсказателя, определенный предсказателем, заключенным в кодере, содержащем этот модуль квантования. Этот коэффициент усиления предсказателя может служить признаком тонального содержимого этого блока коэффициентов. В качестве альтернативы или в дополнение, дополнительная информация может содержать коэффициент спектрального отражения, полученный на основе этого блока коэффициентов и/или на основе огибающей спектра блока. Этот коэффициент спектрального отражения может служить признаком фрикативного содержимого этого блока коэффициентов. Модуль квантования может быть сконфигурирован для извлечения дополнительной информации из данных, доступных, как в кодере, так и в декодере, содержащих модуль квантования, и в соответствующем декодере, содержащем соответствующий модуль обратного квантования. Поэтому передача этой дополнительной информации из кодера в декодер может не требовать дополнительных битов.
Модуль квантования может быть сконфигурирован для определения набора квантователей в зависимости от этой дополнительной информации. В частности, от этой дополнительной информации может зависеть количество квантователей с добавлением псевдослучайного шума в наборе квантователей. В еще более частном случае, количество квантователей с добавлением псевдослучайного шума, заключенных в наборе квантователей, может уменьшаться при увеличении коэффициента усиления предсказателя, и наоборот. Делая набор квантователей зависящим от этой дополнительной информации, можно повысить перцепционную производительность схемы квантования.
Дополнительная информация может содержать флаг сохранения дисперсии. Этот флаг сохранения дисперсии может служить признаком того, каким образом следует корректировать дисперсию блока коэффициентов. Иными словами, флаг сохранения дисперсии может служить признаком обработки, подлежащей выполнению декодером, способной оказывать влияние на дисперсию блока коэффициентов, подлежащего восстановлению квантователем.
Например, в зависимости от флага сохранения дисперсии можно определить набор квантователей. В частности, от флага сохранения дисперсии может зависеть коэффициент усиления шума квантователя с заполнением шумом. В качестве альтернативы или в дополнение, один или несколько квантователей с добавлением псевдослучайного шума могут охватывать некоторый диапазон SNR, и этот диапазон SNR может быть определен в зависимости от флага сохранения дисперсии. Кроме того, от флага сохранения дисперсии может зависеть коэффициент у последующего усиления. В качестве альтернативы или в дополнение, коэффициент у последующего усиления квантователя с добавлением псевдослучайного шума может быть определен в зависимости от параметра, представляющего собой предварительно определенную функцию коэффициента усиления предсказателя.
Флаг сохранения дисперсии можно использовать для адаптации степени зашумленности квантователей к качеству предсказания. Например, в зависимости от параметра, представляющего собой предварительно определенную функцию коэффициента усиления предсказателя, можно определять коэффициент у последующего усиления квантователя с добавлением псевдослучайного шума. В качестве альтернативы или в дополнение, этот коэффициент у последующего усиления можно определить посредством сравнения сохраняющего дисперсию коэффициента последующего усиления, масштабированного посредством предварительно определенной функции коэффициента усиления предсказателя, с коэффициентом последующего усиления с оптимальной среднеквадратичной ошибкой и выбора наибольшего из этих двух коэффициентов усиления. В частности, указанная предварительно определенная функция коэффициента усиления предсказателя может уменьшать дисперсию восстановленного сигнала по мере увеличения коэффициента усиления предсказателя. Как результат, можно повысить воспринимаемое качество кодека.
Согласно одной из дальнейших особенностей, описывается модуль обратного квантования (также именуемый в настоящем документе декодером спектра), сконфигурированный для деквантования первого индекса квантования из блока индексов квантования. Иными словами, модуль обратного квантования может быть сконфигурирован для определения восстанавливаемых значений для блока коэффициентов на основе данных коэффициентов (например, на основе индексов квантования). Следует отметить, что все характерные признаки и особенности, которые были описаны в настоящем документе в контексте модуля квантования, также применимы и к соответствующему модулю обратного квантования. В частности, они применимы к характерным признакам, относящимся к конструкции и замыслу набора квантователей, к зависимости этого набора квантователей от дополнительной информации, к процессу распределения битов и т.д.
Индексы квантования могут быть связаны с блоком коэффициентов, содержащим ряд коэффициентов для ряда соответствующих элементов разрешения по частоте. В частности, эти индексы квантования могут быть связаны с квантованными коэффициентами (или восстанавливаемыми значениями) из соответствующего блока квантованных коэффициентов. Как описывается в контексте соответствующего блока квантования, указанный блок квантованных коэффициентов может соответствовать блоку остаточных коэффициентов предсказания или может быть из него получен. В более общем смысле, этот блок квантованных коэффициентов может быть получен из блока коэффициентов преобразования, который был получен из сегмента звукового сигнала с использованием преобразования из временной области в частотную область.
Модуль обратного квантования может быть сконфигурирован для создания набора квантователей. Как описывалось выше, этот набор квантователей может быть адаптирован или сгенерирован на основе дополнительной информации, доступной в модуле обратного квантования и в соответствующем модуле квантования. Указанный набор квантователей, как правило, содержит ряд различных квантователей, соответственно, связанных с рядом различных отношений сигнал-шум (SNR). Кроме того, указанный набор квантователей может быть упорядочен в соответствии с увеличением/уменьшением SNR, как описывалось выше. Увеличение/уменьшение SNR между смежными квантователями может быть, по существу, постоянным.
Указанный ряд различных квантователей может содержать квантователь с заполнением шумом, соответствующий квантователю с заполнением шумом модуля квантования. В одном из предпочтительных примеров указанный ряд различных квантователей содержит единственный квантователь с заполнением шумом. Это квантователь с заполнением шумом модуля обратного квантования сконфигурирован для обеспечения восстановления первого коэффициента путем использования одной из реализаций случайной переменной, генерируемой в соответствии с предписанной статистической моделью. Поэтому следует отметить, что указанный блок индексов квантования, как правило, не содержит какие-либо индексы квантования для коэффициентов, подлежащих восстановлению квантователем с заполнением шумом. Как таковые, коэффициенты, подлежащие восстановлению с использованием квантователя с заполнением шумом, связаны с нулевой битовой скоростью передачи данных.
Кроме того, указанный ряд различных квантователей может содержать один или несколько квантователей с добавлением псевдослучайного шума. Эти один или несколько квантователей с добавлением псевдослучайного шума могут содержать один или несколько соответствующих скалярных квантователей, сконфигурированных для присвоения первого восстанавливаемого значения первому индексу квантования. Кроме того, указанные один или несколько квантователей с добавлением псевдослучайного шума могут содержать один или несколько соответствующих модулей удаления псевдослучайного шума, сконфигурированных для определения первого коэффициента с удаленным псевдослучайным шумом путем удаления значения псевдослучайного шума из первого восстанавливаемого значения. Генератор псевдослучайного шума модуля обратного квантования, как правило, действует в синхронном режиме с генератором псевдослучайного шума модуля квантования. Как описывалось в контексте модуля квантования, один или несколько квантователей с добавлением псевдослучайного шума предпочтительно применяют коэффициент последующего усиления квантователя с целью повышения производительности в отношении MSE одного или нескольких квантователей с добавлением псевдослучайного шума.
В дополнение, указанный ряд квантователей может содержать один или несколько квантователей без добавления псевдослучайного шума. Эти один или несколько квантователей без добавления псевдослучайного шума могут содержать соответствующие скалярные квантователи с равномерным шагом, сконфигурированные для присвоения соответствующих восстанавливаемых значений первому индексу квантования (без выполнения последующего удаления псевдослучайного шума и/или без применения коэффициента последующего усиления квантователя).
Кроме того, модуль обратного квантования может быть сконфигурирован для определения указателя SNR, служащего признаком SNR, приписанного первому коэффициенту из блока коэффициентов (или первому квантованному коэффициенту из блока квантованных коэффициентов). Этот указатель SNR можно определить на основе огибающей спектра блока (как правило, также доступной в декодере, содержащем этот модуль обратного квантования) и на основе параметра смещения (как правило, включенного в битовый поток, передаваемый из кодера в декодер). В частности, указатель SNR может служить признаком порядкового номера обратного квантователя (или квантователя), подлежащего выбору из набора квантователей. Модуль обратного квантования может продолжать, выбирая первый квантователь из набора квантователей на основе этого указателя SNR. Как описывалось в контексте соответствующего модуля квантования, этот процесс выбора можно эффективным образом реализовать, используя упорядоченный набор квантователей. В дополнение, модуль обратного квантования может быть сконфигурирован для определения первого квантованного коэффициента для указанного первого коэффициента с использованием выбранного первого квантователя.
Согласно одному из дальнейших аспектов, описывается звуковой кодер на основе преобразования, сконфигурированный для кодирования звукового сигнала в битовый поток. Этот кодер может содержать модуль квантования, сконфигурированный для определения ряда индексов квантования путем квантования ряда коэффициентов из блока коэффициентов. Этот модуль квантования может содержать один или несколько квантователей с добавлением псевдослучайного шума. Модуль квантования может содержать любой из модулей квантования, описываемых в настоящем документе.
Указанный ряд коэффициентов может быть связан с рядом соответствующих элементов разрешения по частоте. Как описывалось выше, указанный блок коэффициентов мог быть получен из сегмента звукового сигнала. В частности, для получения блока коэффициентов преобразования, этот сегмент звукового сигнала мог быть преобразован из временной области в частотную область. Этот блок коэффициентов, квантованных модулем квантования, мог быть получен из блока коэффициентов преобразования.
Кодер также может содержать генератор псевдослучайного шума, сконфигурированный для выбора реализации псевдослучайного шума. Кроме того, кодер может содержать энтропийный кодер, сконфигурированный для выбора кодового слова на основе предварительно определенной статистической модели коэффициента преобразования, где указанная статистическая модель (т.е. функция распределения вероятностей) коэффициентов преобразования также может быть обусловлена реализацией псевдослучайного шума. Тогда такую статистическую модель можно использовать для вычисления вероятности индекса квантования, в частности, вероятности индекса квантования, обусловленной реализацией псевдослучайного шума, соответствующей этому коэффициенту. Эту вероятность индекса квантования можно использовать для генерирования двоичного кодового слова, связанного с этим индексом квантования. Кроме того, последовательность индексов квантования можно кодировать совместно на основе соответствующих им вероятностей, причем эти соответствующие вероятности могут быть обусловлены соответствующими реализациями псевдослучайного шума. Например, такое совместное кодирование последовательности индексов квантования можно реализовать посредством арифметического кодирования или кодирования диапазона.
Согласно другому аспекту, кодер может содержать генератор псевдослучайного шума, сконфигурированный для выбора одной из ряда предварительно определенных реализаций псевдослучайного шума. Этот ряд предварительно определенных реализаций псевдослучайного шума может содержать М различных предварительно определенных реализаций псевдослучайного шума. Кроме того, указанный генератор псевдослучайного шума может быть сконфигурирован для генерирования ряда значений псевдослучайного шума для квантования ряда коэффициентов на основе выбранной реализации псевдослучайного шума. М может представлять собой целое число больше единицы. В частности, количество М предварительно определенных реализаций псевдослучайного шума может составлять 10, 5, 4 или менее. Генератор псевдослучайного шума может содержать любой из характерных признаков, относящихся к генераторам псевдослучайного шума, описываемым в настоящем документе.
Кроме того, кодер может содержать энтропийный кодер, сконфигурированный для выбора кодового словаря из М предварительно определенных кодовых словарей. Этот энтропийный кодер может быть также сконфигурирован для энтропийного кодирования ряда индексов квантования с использованием выбранного кодового словаря. Указанные М предварительно определенных кодовых словарей могут быть связаны, соответственно, с М предварительно определенных реализаций псевдослучайного шума. В частности, эти М предварительно определенных кодовых словарей могли быть обучены, соответственно, с использованием М предварительно определенных реализаций псевдослучайного шума. М предварительно определенных кодовых словарей могут содержать кодовые слова Хаффмана с переменной длиной.
Указанный энтропийный кодер может быть сконфигурирован для выбора кодового словаря, связанного с реализацией псевдослучайного шума, выбранной генератором псевдослучайного шума. Иными словами, с целью генерирования ряда индексов квантования энтропийный кодер может выбирать для энтропийного кодирования кодовый словарь, связанный с реализацией псевдослучайного шума (например, обученный для этой реализации псевдослучайного шума). Поступая таким образом, можно повысить (например, оптимизировать) эффективность кодирования энтропийного кодера даже при использовании квантователей с добавлением псевдослучайного шума. Авторами изобретения было сделано наблюдение, что преимуществ использования квантователей с добавлением псевдослучайного шума для восприятия можно достигнуть даже при использовании относительно небольшого количества М реализаций псевдослучайного шума. Следовательно, для того чтобы сделать возможным оптимизированное энтропийное кодирование, необходимо создать лишь относительно небольшое количество М кодовых словарей.
Для передачи или предоставления соответствующему декодеру, данные коэффициентов, служащие признаком энтропийно кодированных индексов квантования, как правило, вставляются в битовый поток.
Согласно одной из дальнейших особенностей, описывается звуковой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного звукового сигнала. Следует отметить, что характерные признаки и особенности, описываемые в контексте соответствующего звукового кодера, также применимы и к этому звуковому декодеру. В частности, к звуковому декодеру также применимы особенности, относящиеся к использованию ограниченного количества М реализаций псевдослучайного шума и соответствующего ограниченного количества М кодовых словарей.
Этот звуковой декодер содержит генератор псевдослучайного шума, сконфигурированный для выбора одной из М предварительно определенных реализаций псевдослучайного шума. Эти М предварительно определенных реализаций псевдослучайного шума являются такими же, как М предварительно определенных реализаций псевдослучайного шума, используемых соответствующим кодером. Кроме того, указанный генератор псевдослучайного шума может быть сконфигурирован для генерирования ряда значений псевдослучайного шума на основе выбранной реализации псевдослучайного шума. М может представлять собой целое число больше единицы. Например, М может находиться в диапазоне 10 или 5. Указанный ряд значений псевдослучайного шума может быть использован модулем обратного квантования, содержащим один или несколько квантователей с добавлением псевдослучайного шума, сконфигурированных для определения соответствующего ряда квантованных коэффициентов на основе соответствующего ряда индексов квантования. Генератор псевдослучайного шума и модуль обратного квантования могут, соответственно, содержать любой из характерных признаков, связанных с генератором псевдослучайного шума и модулем обратного квантования, описываемых в настоящем документе.
Кроме того, звуковой декодер может содержать энтропийный декодер, сконфигурированный для выбора кодового словаря из М предварительно определенных кодовых словарей. Эти М предварительно определенных кодовых словарей являются такими же, как кодовые словари, используемые соответствующим кодером. В дополнение, для создания ряда индексов квантования энтропийный декодер может быть сконфигурирован для энтропийного декодирования данных коэффициентов из битового потока с использованием выбранного кодового словаря. Указанные М предварительно определенных кодовых словарей могут быть связаны, соответственно, с М предварительно определенных реализаций псевдослучайного шума. Энтропийный декодер может быть сконфигурирован для выбора кодового словаря, связанного с реализацией псевдослучайного шума, выбранной генератором псевдослучайного шума. На основе ряда квантованных коэффициентов определяется восстановленный звуковой сигнал. Согласно одной из дальнейших особенностей, описывается речевой кодер на основе преобразования, сконфигурированный для кодирования речевого сигнала в битовый поток. Как уже описывалось выше, этот кодер может содержать любой из относящихся к кодеру признаков и/или компонентов, описываемых в настоящем документе. В частности, этот кодер может содержать модуль кадрирования, сконфигурированный для приема ряда последовательных блоков коэффициентов преобразования. Этот ряд последовательных блоков содержит текущий блок и один или несколько предыдущих блоков. Кроме того, этот ряд последовательных блоков служит признаком дискретных значений речевого сигнала. В частности, этот ряд последовательных блоков мог быть определен с использованием преобразования из временной области в частотную область, такого, как модифицированное дискретное косинусное преобразование (MDCT). Как таковой, указанный блок коэффициентов преобразования может содержать коэффициенты MDCT. Количество коэффициентов преобразования может быть ограниченным. Например, блок коэффициентов преобразования может содержать 256 коэффициентов преобразования в 256 элементов разрешения по частоте.
В дополнение, речевой кодер может содержать модуль выравнивания, сконфигурированный для определения текущего блока выровненных коэффициентов преобразования путем выравнивания соответствующего блока коэффициентов преобразования с использованием соответствующей текущей огибающей (спектра) блока (например, текущей скорректированной огибающей). Кроме того речевой кодер может содержать предсказатель, сконфигурированный для предсказания текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя. В дополнение, речевой кодер может содержать разностный модуль, сконфигурированный для определения текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования.
Предсказатель может быть сконфигурирован для определения текущего блока оценочных выровненных коэффициентов преобразования с использованием критерия средневзвешенной квадратичной ошибки (например, путем минимизации критерия средневзвешенной квадратичной ошибки). Это критерий средневзвешенной квадратичной ошибки может учитывать в качестве весовых коэффициентов текущую огибающую блока или некоторую предварительно определенную функцию этой текущей огибающей блока. В настоящем документе описываются и другие различные способы определения коэффициента усиления предсказателя с использованием критерия средневзвешенной квадратичной ошибки.
Кроме того, указанный речевой кодер может содержать модуль квантования, сконфигурированный для квантования коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания с использованием набора предварительно определенных квантователей. Этот модуль квантования может содержать любой из относящихся к квантованию характерных признаков, описываемых в настоящем документе. В частности, модуль квантования может быть сконфигурирован для определения данных коэффициентов для битового потока на основе квантованных коэффициентов. Как таковые, данные коэффициентов могут служить признаком квантованной версии текущего блока коэффициентов ошибок предсказания.
Речевой кодер на основе преобразования также может содержать модуль масштабирования, сконфигурированный для определения текущего блока остаточных коэффициентов предсказания с измененным масштабом (также именуемого блоком коэффициентов ошибок с измененным масштабом) на основе текущего блока коэффициентов ошибок предсказания с использованием одного или нескольких правил масштабирования. Этот текущий блок коэффициентов ошибок с измененным масштабом может быть определен так, или указанные одно или несколько правил масштабирования могут быть таковы, что в среднем дисперсия коэффициентов ошибок с измененным масштабом из текущего блока коэффициентов ошибок с измененным масштабом является более высокой, чем дисперсия коэффициентов ошибок предсказания из текущего блока коэффициентов ошибок предсказания. В частности, указанные одно или несколько правил масштабирования могут быть таковы, что дисперсия коэффициентов ошибок предсказания находится ближе к единице для всех элементов разрешения по частоте или полос частот. Модуль квантования может быть сконфигурирован для квантования остаточных коэффициентов ошибок предсказания с измененным масштабом из текущего блока коэффициентов ошибок с измененным масштабом с целью создания данных коэффициентов (т.е. индексов квантования для коэффициентов).
Текущий блок коэффициентов ошибок предсказания, как правило, содержит ряд коэффициентов ошибок предсказания для соответствующего ряда элементов разрешения по частоте. Коэффициенты усиления масштабирования, применяемые модулем масштабирования к коэффициентам ошибок предсказания в соответствии с правилом масштабирования, могут зависеть от элементов разрешения по частоте соответствующих коэффициентов ошибок предсказания. Кроме того, правило масштабирования может зависеть от одного или нескольких параметров предсказателя, например, от коэффициента усиления предсказателя. В качестве альтернативы или в дополнение, правило масштабирования может зависеть от текущей огибающей блока. В настоящем документе описываются и другие различные способы определения зависящего от элементов разрешения по частоте правила масштабирования.
Речевой кодер на основе преобразования также может содержать модуль распределения битов, сконфигурированный для определения вектора распределения на основе текущей огибающей блока. Этот вектор распределения может служить признаком первого квантователя из набора квантователей, подлежащего использованию для квантования первого коэффициента, полученного из текущего блока коэффициентов ошибок предсказания. В частности, этот вектор квантования может служить признаком квантователей, подлежащих использованию для квантования, соответственно, всех коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания. Например, вектор распределения может служить признаком отличающегося квантователя, подлежащего использованию для каждой полосы частот (l=1, …, L).
Иными словами, модуль распределения битов может быть сконфигурирован для определения вектора распределения на основе текущей огибающей блока и при условии ограничения максимальной битовой скорости передачи данных. Модуль распределения битов может быть сконфигурирован для определения вектора распределения также на основе одного или нескольких правил масштабирования. Размерность вектора распределения скорости передачи данных, как правило, равна количеству полос L частот. Элемент вектора распределения может служить признаком индекса квантователя из набора квантователей, подлежащего использованию для квантования коэффициентов, принадлежащих полосе частот, связанной с соответствующим элементом вектора распределения скорости передачи данных. В частности, вектор распределения скорости передачи данных может служить признаком квантователей, подлежащих использованию для квантования, соответственно, всех коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания.
Модуль распределения битов может быть сконфигурирован для определения вектора распределения так, чтобы данные коэффициентов для текущего блока коэффициентов ошибок предсказания не превышали предварительно определенное количество битов. Кроме того, модуль распределения битов может быть сконфигурирован для определения параметра смещения, служащего признаком смещения, подлежащего применению к огибающей распределения, полученной исходя из текущей текущего блока (например, полученной исходя из текущей скорректированной огибающей). Этот параметр смещения может быть включен в битовый поток, для того чтобы позволить соответствующему декодеру идентифицировать квантователи, которые были использованы для определения данных коэффициентов.
Речевой кодер на основе преобразования также может содержать энтропийный кодер, сконфигурированный для энтропийного кодирования индексов квантования, связанных с квантованными коэффициентами. Этот энтропийный кодер может быть сконфигурирован для кодирования индексов квантования с использованием арифметического кодера. В качестве альтернативы, энтропийный кодер может быть сконфигурирован для кодирования индексов квантования с использованием ряда из М предварительно определенных кодовых словарей (как описывается в настоящем документе).
Согласно другой особенности, описывается речевой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного речевого сигнала. Этот речевой декодер может содержать любой из характерных признаков и/или компонентов, описываемых в настоящем документе. В частности, этот декодер может содержать предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя, полученных из битового потока. Кроме того, речевой декодер может содержать модуль обратного квантования, сконфигурированный для определения текущего блока квантованных коэффициентов ошибок предсказания (или их версии с измененным масштабом) на основе данных коэффициентов, заключенных в битовом потоке, с использованием набора квантователей. В частности, модуль обратного квантования может использовать набор (обратных) квантователей, соответствующий набору квантователей, используемых соответствующим речевым кодером.
Модуль обратного квантования может быть сконфигурирован для определения набора квантователей (и/или соответствующего набора обратных квантователей) в зависимости от дополнительной информации, полученной из принятого битового потока. В частности, модуль обратного квантования может выполнять такой же процесс выбора для набора квантователей, как модуль квантования соответствующего речевого кодера. Делая набор квантователей зависящим от дополнительной информации, можно повысить воспринимаемое качество восстановленного речевого сигнала.
Согласно другой особенности, описывается способ квантования первого коэффициента из блока коэффициентов. Этот блок коэффициентов содержит ряд коэффициентов для ряда соответствующих элементов разрешения по частоте. Указанный способ может включать создание набора квантователей, при этом указанный набор квантователей содержит ряд различных квантователей, соответственно, связанных с рядом различных отношений сигнал-шум (SNR). Этот ряд различных квантователей может содержать квантователь с заполнением шумом, один или несколько квантователей с добавлением псевдослучайного шума и один или несколько квантователей без добавления псевдослучайного шума. Способ также может включать определение указателя SNR, служащего признаком SNR, приписанного указанному первому коэффициенту. Кроме того, способ может включать выбор первого квантователя из набора квантователей на основе этого указателя SNR и квантование первого коэффициента с использованием этого первого квантователя.
Согласно одной из дальнейших особенностей, описывается способ деквантования индексов квантования. Иными словами, этот способ может быть направлен на определение для блока коэффициентов восстанавливаемых значений (также именуемых квантованными коэффициентами), которые были квантованы с использованием соответствующего способа квантования. Восстанавливаемое значение можно определить на основе индекса квантования. Однако следует отметить, что некоторые из коэффициентов из блока коэффициентов могли быть квантованы с использованием квантователя с заполнением шумом. В этом случае, восстанавливаемые значения для этих коэффициентов можно определить независимо от индекса квантования.
Как описывалось выше, индексы квантования связаны с блоком коэффициентов, содержащим ряд коэффициентов для ряда соответствующих элементов разрешения по частоте. В частности, эти индексы квантования находятся во взаимно-однозначном соответствии с теми коэффициентами блока коэффициентов, которые не были квантованы с использованием квантователя с заполнением шумом. Способ также может включать создание набора квантователей (или обратных квантователей). Этот набор квантователей может содержать ряд различных квантователей, соответственно связанных с рядом различных отношений сигнал-шум (SNR). Этот ряд различных квантователей может содержать квантователь с заполнением шумом, один или несколько квантователей с добавлением псевдослучайного шума и один или несколько квантователей без добавления псевдослучайного шума. Способ также может включать определение указателя SNR, служащего признаком SNR, приписанного первому коэффициенту из блока коэффициентов. Способ может продолжаться выбором первого квантователя из указанного набора квантователей на основе указателя SNR и определением первого квантованного коэффициента (т.е. восстанавливаемого значения) для первого коэффициента из блока коэффициентов.
Согласно другой особенности, описывается способ кодирования звукового сигнала в битовый поток. Этот способ включает определение ряда индексов квантования путем квантования ряда коэффициентов из блока коэффициентов с использованием квантователя с добавлением псевдослучайного шума. Это ряд коэффициентов может быть связан с рядом соответствующих элементов разрешения по частоте. Указанный блок коэффициентов может быть получен, исходя из звукового сигнала. Способ может включать выбор одной из М предварительно определенных реализаций псевдослучайного шума и генерирование ряда значений псевдослучайного шума для квантования ряда коэффициентов на основе выбранной реализации псевдослучайного шума; при этом М представляет собой целое число больше единицы. Кроме того, указанный способ может включать выбор кодового словаря из М предварительно определенных кодовых словарей и энтропийное кодирование указанного ряда индексов квантования с использованием этого выбранного кодового словаря. Указанные М предварительно определенных кодовых словарей могут быть соответственно связаны с М предварительно определенных реализаций псевдослучайного шума, а выбранный кодовый словарь может быть связан с выбранной реализацией псевдослучайного шума. Кроме того, способ может включать вставку в битовый поток данных коэффициентов, служащих признаком энтропийно кодированных индексов квантования.
Согласно одной из дальнейших особенностей, описывается способ декодирования битового потока с целью создания восстановленного звукового сигнала. Этот способ может включать выбор одной из М предварительно определенных реализаций псевдослучайного шума и генерирование ряда значений псевдослучайного шума на основе этой выбранной реализации псевдослучайного шума; при этом М представляет собой целое число больше единицы. Указанный ряд значений псевдослучайного шума может быть использован модулем обратного квантования, содержащим квантователь с добавлением псевдослучайного шума, для определения соответствующего ряда квантованных коэффициентов на основе соответствующего ряда индексов квантования. Как таковой, способ может включать определение ряда квантованных коэффициентов с использованием (обратного) квантователя с добавлением псевдослучайного шума. В дополнение, способ может включать выбор кодового словаря из М предварительно определенных кодовых словарей и энтропийное декодирование данных коэффициентов из битового потока с использованием выбранного кодового словаря с целью создания ряда индексов квантования. Указанные М предварительно определенных кодовых словарей могут быть соответственно связаны с М предварительно определенных реализаций псевдослучайного шума, а выбранный кодовый словарь может быть связан с выбранной реализацией псевдослучайного шума. В дополнение, способ может включать определение восстановленного звукового сигнала на основе указанного ряда квантованных коэффициентов.
Согласно одной из дальнейших особенностей, описывается способ кодирования речевого сигнала в битовый поток. Этот способ может включать прием ряда последовательных блоков коэффициентов преобразования, содержащего текущий блок и один или несколько предыдущих блоков. Этот ряд последовательных блоков может служить признаком дискретных значений речевого сигнала. Кроме того, указанный способ может включать определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя. Указанные один или несколько блоков восстановленных коэффициентов преобразования могли быть получены из одного или нескольких предыдущих блоков коэффициентов преобразования. Способ может продолжаться определением текущего блока коэффициентов ошибок предсказания на основе текущего блока коэффициентов преобразования и на основе текущего блока оценочных коэффициентов преобразования. Кроме того, способ может включать квантование коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания, с использованием набора квантователей. Этот набор квантователей может проявлять любой из характерных признаков, описываемых в настоящем документе. Кроме того, способ может включать определение данных коэффициентов для битового потока на основе указанных квантованных коэффициентов. Согласно другой особенности, описывается способ декодирования битового потока с целью создания восстановленного речевого сигнала. Этот способ может включать определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, полученного из битового потока. Кроме того, этот способ может включать определение текущего блока квантованных остаточных коэффициентов предсказания на основе данных коэффициентов, заключенных в битовом потоке, с использованием набора квантователей. Этот набор квантователей может обладать любым из характерных признаков, описываемых в настоящем документе. Способ может продолжаться определением текущего блока восстановленных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания. Указанный восстановленный речевой сигнал можно определить на. основе текущего блока восстановленных коэффициентов преобразования.
Согласно одной из дальнейших особенностей описывается программа, реализованная программно. Эта программа, реализованная программно, может быть адаптирована для исполнения на процессоре и для выполнения этапов способов, описываемых в настоящем документе, при осуществлении на процессоре.
Согласно другой особенности описывается носитель данных. Этот носитель данных может содержать программу, реализованную программно, адаптированную для исполнения на процессоре и для выполнения этапов способов, описываемых в настоящем документе, при осуществлении на процессоре.
Согласно одной из дальнейших особенностей описывается компьютерный программный продукт. Компьютерный программный продукт может содержать исполняемые команды, предназначенные для выполнения этапов способов, описываемых в настоящем документе, при осуществлении на компьютере.
Следует отметить, что способы и системы, в том числе предпочтительные варианты их осуществления, описываемые в настоящей патентной заявке, можно использовать автономно или в сочетании с другими способами и системами, раскрываемыми в настоящем документе. Кроме того, все особенности способов и систем, описываемых в настоящей патентной заявке, могут комбинироваться различными способами. В частности, произвольным образом могут комбинироваться друг с другом характерные признаки формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ФИГУР
Ниже изобретение разъясняется иллюстративным образом со ссылкой на сопроводительные графические материалы, в которых
на Фиг. 1а показана блок-схема одного из примеров звукового кодера, создающего битовый поток с постоянной битовой скоростью передачи данных;
на Фиг. 1b показана блок-схема одного из примеров звукового кодера, создающего битовый поток с переменной битовой скоростью передачи данных;
на Фиг. 2 проиллюстрировано генерирование одного из примеров ряда блоков коэффициентов преобразования на основе огибающей;
на Фиг. 3а проиллюстрированы примеры огибающих блоков коэффициентов преобразования;
на Фиг. 3b проиллюстрировано определение одного из примеров интерполированной огибающей;
на Фиг. 4 проиллюстрированы примеры наборов квантователей;
на Фиг. 5а показана блок-схема одного из примеров звукового декодера;
на Фиг. 5а показана блок-схема одного из примеров декодера огибающей звукового декодера по Фиг. 5а;
на Фиг. 5с показана блок-схема одного из примеров предсказателя поддиапазонов звукового декодера по Фиг. 5а;
на Фиг. 5d показана блок-схема одного из примеров декодера спектра звукового декодера по Фиг. 5а;
на Фиг. 6а показана блок-схема одного из примеров набора приемлемых квантователей;
на Фиг. 6b показана блок-схема одного из примеров квантователя с добавлением псевдослучайного шума;
на Фиг. 6с показан один из примеров выбора квантователей на основе спектра блока коэффициентов преобразования;
на Фиг. 7 проиллюстрирован один из примеров схемы для определения набора квантователей в кодере и в соответствующем декодере;
на Фиг. 8 показана блок-схема одного из примеров схемы для декодирования энтропийно кодированных индексов квантования, которые были определены с использованием квантователя с добавлением псевдослучайного шума;
на Фиг. 9а-9с показаны примеры экспериментальных результатов; и
на Фиг. 10 проиллюстрирован один из примеров процесса распределения битов.
ПОДРОБНОЕ ОПИСАНИЕ
Как описывалось в разделе предпосылок, является желательным создание звукового кодека на основе преобразования, проявляющего относительно высокие эффективности кодирования для речевых или голосовых сигналов. Такой звуковой кодек на основе преобразования можно именовать речевым кодеком на основе преобразования или голосовым кодеком на основе преобразования. Речевой кодек на основе преобразования можно удобно скомбинировать с обобщенным звуковым кодеком на основе преобразования, таким, как ААС или НЕ-ААС, так как он также действует в области преобразования. Кроме того, по причине того, что оба кодека действуют в области преобразования, можно упростить классификацию сегмента (например, кадра) входного звукового сигнала на речевой или неречевой и последующее переключение между обобщенным звуковым кодеком и специальным речевым кодеком.
На Фиг. 1а показана блок-схема одного из примеров речевого кодера 100 на основе преобразования. Кодер 100 в качестве ввода принимает блок 131 коэффициентов преобразования (также именуемый единицей кодирования). Блок 131 коэффициентов преобразования мог быть получен модулем преобразования, сконфигурированным для преобразования последовательности дискретных значений входного звукового сигнала из временной области в область преобразования. Этот модуль преобразования может быть сконфигурирован для выполнения MDCT. Этот модуль преобразования может составлять часть обобщенного звукового кодека, такого, как ААС или НЕ-ААС. Такой обобщенный звуковой кодек может использовать разные размеры блоков, например, длинный блок и короткий блок. Примерами размеров блоков являются 1024 дискретных значений для длинного блока и 256 дискретных значений - для короткого блока. В предположении частоты дискретизации 44,1 кГц и перекрытия 50%, длинный блок охватывает приблизительно 20 мс входного звукового сигнала, а короткий блок охватывает приблизительно 5 мс входного звукового сигнала. Длинные блоки, как правило, используются для стационарных сегментов входного звукового сигнала, а короткие блоки, как правило, используются для переходных сегментов входного звукового сигнала.
Речевые сигналы во временных сегментах длительностью около 20 мс можно считать стационарными. В частности, можно считать стационарной огибающую спектра речевого сигнала во временных сегментах около 20 мс. Для того чтобы иметь возможность получать представительную статистику в области преобразования для таких сегментов длительностью 20 мс, может являться преимущественной доставка речевому кодеру 100 на основе преобразования коротких блоков 131 коэффициентов преобразования (имеющих длину, например, 5 мс). Поступая таким образом, можно использовать ряд коротких блоков 131 для получения статистики в отношении временных сегментов, например, длительностью 20 мс (например, временного сегмента длинного блока). Кроме того, это имеет преимущество обеспечения достаточной разрешающей способности по времени для речевых сигналов.
Так, модуль преобразования может быть сконфигурирован для создания коротких блоков 131 коэффициентов преобразования, если текущий сегмент входного звукового сигнала классифицирован как являющийся речевым. Кодер 100 может содержать модуль 101 кадрирования, сконфигурированный для извлечения ряда блоков 131 коэффициентов преобразования, именуемых набором 132 блоков 131. Этот набор 132 блоков также можно именовать кадром. Например, набор 132 блоков 131 может содержать четыре коротких блока по 256 коэффициентов преобразования, посредством этого охватывая приблизительно 20 мс входного звукового сигнала.
Набор 132 блоков может быть доставлен в модуль 102 оценивания огибающей. Модуль 102 оценивания огибающей может быть сконфигурирован для определения огибающей 133 на основе набора 132 блоков. Огибающая 133 может быть основана на среднеквадратичных (RMS) значениях соответствующих коэффициентов преобразования из ряда блоков 131, заключенных в наборе 132 блоков. Блок 131, как правило, содержит ряд коэффициентов преобразования (например, 256 коэффициентов преобразования) в соответствующем ряду элементов 301 разрешения по частоте (см. Фиг. 3а). Ряд элементов 301 разрешения по частоте можно сгруппировать в ряд полос 302 частот. Этот ряд полос 302 частот можно выбрать на основе психоакустических соображений. Например, элементы 301 разрешения по частоте можно сгруппировать в полосы 302 частот в соответствии с логарифмической шкалой, или шкалой Барка. Огибающая 134, которая была определена на основе текущего набора 132 блоков, может содержать ряд значений энергии, соответственно, для ряда полос 302 частот. Конкретное значение энергии для конкретной полосы 302 частот можно определить на основе коэффициентов преобразования из блоков 131 набора 132, соответствующих элементам 301 разрешения по частоте, находящимся в пределах этой конкретной полосы 302 частот. Указанное конкретное значение энергии можно определить на основе значения RMS этих коэффициентов преобразования. Как таковая, огибающая 133 для текущего набора 132 блоков (именуемая текущей огибающей 133) может служить признаком средней огибающей блоков 131 коэффициентов преобразования, заключенных в текущем наборе 132 блоков, или может служить признаком средней огибающей блоков 132 коэффициентов преобразования, использованных для определения огибающей 133.
Следует отметить, что текущую огибающую 133 можно определить на основе одного или нескольких дополнительных блоков 131 коэффициентов преобразования, смежных с текущим набором 132 блоков. Это проиллюстрировано на Фиг. 2, где текущая огибающая 133 (указываемая квантованной текущей огибающей 134) определена на основе блоков 131 из текущего набора 132 блоков и на основе блока 201 из набора блоков, предшествующего текущему набору 132 блоков. В иллюстрируемом примере текущая огибающая 133 определена на основе пяти блоков 131. Учитывая смежные блоки при определении текущей огибающей 133, можно обеспечить непрерывность огибающих смежных наборов 132 блоков.
При определении текущей огибающей 133 коэффициенты преобразования из разных блоков 131 можно взвешивать. В частности, внешние блоки 201, 202, учитываемые при определении текущей огибающей 133, могут иметь меньший весовой коэффициент, чем остальные блоки 131. Например, коэффициенты преобразования внешних блоков 201, 202 можно взвешивать с коэффициентом 0,5, тогда как коэффициенты преобразования других блоков 131 можно взвешивать с коэффициентом 1.
Следует отметить, что аналогично учету блоков 201 из предыдущего набора 132 блоков для определения текущей огибающей 133 можно учитывать один или несколько блоков (т.н. блоков предварительного просмотра) из непосредственно следующего набора 132 блоков.
Значения энергии текущей огибающей 133 можно представить в логарифмической шкале (например, в шкале дБ). Текущая огибающая 133 может быть доставлена в модуль 103 квантования огибающей, сконфигурированный для квантования значений энергии текущей огибающей 133. Модуль 103 квантования огибающей может предусматривать предварительно определенную разрешающую способность квантователя, например, разрешающую способность 3 дБ. Индексы квантования огибающей 133 можно доставлять в качестве данных 161 огибающей в битовом потоке, генерируемом кодером 100. Кроме того, квантованная огибающая 134, т.е. огибающая, содержащая квантованные значения энергии огибающей 133, может быть доставлена в модуль 104 интерполяции.
Модуль 104 интерполяции сконфигурирован для определения огибающей для каждого блока 131 из текущего набора 132 блоков на основе квантованной текущей огибающей 134 и на основе квантованной предыдущей огибающей 135 (которая была определена для набора 132 блоков, непосредственно предшествующего текущему набору 132 блоков). Действие модуля 104 интерполяции проиллюстрировано на Фиг. 2, 3а и 3b. На Фиг. 2 показана последовательность блоков 131 коэффициентов преобразования. Эта последовательность блоков 131 сгруппирована в последовательные наборы 132 блоков, при этом каждый набор 132 блоков используется для определения квантованной огибающей, например, квантованной текущей огибающей 134 и квантованной предыдущей огибающей 135. На Фиг. 3а показаны примеры квантованной предыдущей огибающей 135 и квантованной текущей огибающей 134. Как указывалось выше, эти огибающие могут служить признаками спектральной энергии 303 (например, в шкале дБ). Для определения интерполированной огибающей 136 можно интерполировать (например, используя линейную интерполяцию) соответствующие значения 303 энергии квантованной предыдущей огибающей 135 и квантованной текущей огибающей 134 для одной и той же полосы 302 частот. Иными словами, значения 303 энергии конкретной полосы 302 частот можно интерполировать для создания значения 303 энергии интерполированной огибающей 136 в этой конкретной полосе 302 частот.
Следует отметить, что набор блоков, для которого определяются и применяются интерполированные огибающие 136, может отличаться от текущего набора 132 блоков, на основе которого определяется квантованная текущая огибающая 134. Это проиллюстрировано на Фиг. 2, где показан сдвинутый набор 132 блоков, сдвинутый по сравнению с текущим набором 132 блоков и содержащий блоки 3 и 4 (указанные, соответственно, ссылочными позициями 203 и 201) из предыдущего набора 132 блоков и блоки 1 и 2 (указанные, соответственно, ссылочными позициями 204 и 205) из текущего набора 132 блоков. По существу, интерполированные огибающие 136, определяемые на основе квантованной текущей огибающей 134 и на основе квантованной предыдущей огибающей 135, могут обладать повышенной значимостью для блоков из сдвинутого набора 332 блоков по сравнению со значимостью для блоков из текущего набора 132 блоков.
Поэтому интерполированные огибающие 136, показанные на Фиг. 3b, можно использовать для выравнивания блоков 131 из сдвинутого набора 332 блоков. Это показано на Фиг. 3b в сочетании с Фиг.2. Как видно, интерполированную огибающую 341 по Фиг. 3b можно применить к блоку 203 по Фиг.2, что интерполированную огибающую 342 по Фиг. 3b можно применить к блоку 201 по Фиг. 2, что интерполированную огибающую 343 по Фиг. 3b можно применить к блоку 204 по Фиг. 2, и что интерполированную огибающую 344 по Фиг. 3b (которая в иллюстрируемом примере соответствует квантованной текущей огибающей 136) можно применить к блоку 205 по Фиг. 2. Как таковой, набор 132 блоков для определения квантованной текущей огибающей 134 может отличаться от сдвинутого набора 332 блоков, для которого определяются интерполированные огибающие 136 и к которому (в целях выравнивания) применяются интерполированные огибающие 136. В частности, квантованную текущую огибающую 134 можно определить, используя некоторый предварительный просмотр в отношении блоков 203, 201, 204, 205 из сдвинутого набора 332 блоков, подлежащих выравниванию с использованием квантованной текущей огибающей 134. Это является преимущественным с точки зрения непрерывности.
Интерполяция значений 303 энергии для определения интерполированных огибающих 136 проиллюстрирована на Фиг. 3b. Видно, что значения энергии интерполированных огибающих 136 для блоков 131 из сдвинутого набора 332 блоков можно определить путем интерполяции между значением энергии, квантованной Предыдущей огибающей 135, и соответствующим значением энергии, квантованной текущей огибающей 134. В частности, для каждого блока 131 из сдвинутого набора 332 можно определить интерполированную огибающую 136, посредством этого создавая ряд интерполированных огибающих 136 для ряда блоков 203, 201, 204, 205 из сдвинутого набора 332 блоков. Для кодирования блока 131 коэффициентов преобразования можно использовать интерполированную огибающую 136 блока 131 коэффициентов преобразования (например, любого из блоков 203, 201, 204, 205 из сдвинутого набора 332 блоков). Следует отметить, что индексы 161 квантования текущей огибающей 133 доставляются в соответствующий декодер в битовом потоке. Следовательно, соответствующий декодер может быть сконфигурирован для определения ряда интерполированных огибающих 136 аналогично модулю 104 интерполяции кодера 100.
Модуль 101 кадрирования, модуль 102 оценивания огибающей, модуль 103 квантования огибающей и модуль 104 интерполяции действуют на набор блоков (т.е. на текущий набор 132 блоков и/или на сдвинутый набор 332 блоков). С другой стороны, фактическое кодирование коэффициента преобразования можно выполнять блок за блоком. Далее делается отсылка к кодированию текущего блока 131 коэффициентов преобразования, который может представлять собой любой из блоков из ряда блоков 131 из сдвинутого набора 332 блоков (или, возможно, текущего набора 132 блоков - в других реализациях речевого кодера 100 на основе преобразования).
Текущая интерполированная огибающая 136 для текущего блока 131 может предусматривать приближение огибающей спектра коэффициентов преобразования из текущего блока 131. Кодер 100 может содержать модуль 105 предварительного выравнивания и модуль 106 определения коэффициента усиления огибающей, сконфигурированные для определения скорректированной огибающей 139 для текущего блока 131 на основе текущей интерполированной огибающей 136 и на основе текущего блока 131. В частности, коэффициент усиления огибающей для текущего блока 131 можно определить так, чтобы скорректировать дисперсию выровненных коэффициентов преобразования из текущего блока 131. X(k), k=1, …, K, может представлять собой коэффициенты преобразования для текущего блока 131 (где, например, K=256), а может представлять собой средние значения 303 спектральной энергии текущей интерполированной огибающей 136 (где значения энергии Е(k) одной и той же полосы частот являются равными). Коэффициент α усиления огибающей можно определить так, чтобы скорректировать дисперсию выровненных коэффициентов  преобразования. В частности, коэффициент α усиления можно определить так, чтобы дисперсия была единичной.
преобразования. В частности, коэффициент α усиления можно определить так, чтобы дисперсия была единичной.
Следует отметить, что коэффициент усиления огибающей можно определить для одного из поддиапазонов полного диапазона частот текущего блока 131 коэффициентов преобразования. Иными словами, коэффициент усиления огибающей можно определять только на основе подмножества элементов 301 разрешения по частоте и/или только на основе подмножества полос 302 частот.
Например, коэффициент α усиления огибающей можно определить на основе элементов 301 разрешения по частоте больше начального элемента 304 разрешения по частоте (причем этот начальный элемент разрешения по частоте больше 0 или 1). Как следствие, скорректированную огибающую 139 для текущего блока 131 можно определить, применяя коэффициент α усиления огибающей только к средним значения 303 энергии текущей интерполированной огибающей 136, связанной с элементами 301 разрешения по частоте, лежащими выше начального элемента 304 разрешения по частоте. Таким образом, скорректированная огибающая 139 для текущего блока 131 может соответствовать текущей интерполированной огибающей 136 для элементов 301 разрешения по частоте на начальном элементе разрешения по частоте и ниже, и может соответствовать текущей интерполированной огибающей 136, смещенной посредством коэффициента α усиления огибающей для элементов 301 разрешения по частоте выше начального элемента разрешения по частоте. Это проиллюстрировано на Фиг. 3а скорректированной огибающей 339 (показанной штриховыми линиями).
Применение коэффициента α 137 усиления огибающей (также именуемого коэффициентом усиления коррекции уровня) к текущей интерполированной огибающей 136 соответствует корректировке, или смещению, текущей интерполированной огибающей 136, посредством чего получается скорректированная огибающая 139, как проиллюстрировано на Фиг. 3а. Коэффициент 137 усиления огибающей можно кодировать в битовый поток как данные 162 коэффициентов усиления.
Кодер 100 также может содержать модуль 107 уточнения огибающей, сконфигурированный для определения скорректированной огибающей 139 на основе коэффициента α 137 усиления огибающей и на основе текущей интерполированной огибающей 136. Скорректированную огибающую 139 можно использовать для обработки сигнала из блока 131 коэффициентов преобразования. Коэффициент α 137 усиления огибающей можно квантовать до более высокой разрешающей способности (с шагом 1 дБ) по сравнению с текущей интерполированной огибающей 136 (которая может быть квантована с шагом 3 дБ). Как таковую, скорректированную огибающую 139 можно квантовать до более высокой разрешающей способности коэффициента α 137 усиления огибающей (например, с шагом 1 дБ).
Кроме того, модуль 107 уточнения огибающей может быть сконфигурирован для определения огибающей 138 распределения. Огибающая 138 распределения может соответствовать квантованной версии скорректированной огибающей 139 (например, квантованной с шагом квантования 3 дБ). Огибающую 138 распределения можно использовать в целях распределения битов. В частности, огибающую 138 распределения можно использовать для определения - для конкретного коэффициента преобразования из текущего блока 131 - конкретного квантователя из предварительно определенного набора квантователей, причем этот конкретный квантователь подлежит использованию для квантования этого конкретного коэффициента преобразования.
Кодер 100 содержит модуль 108 выравнивания, сконфигурированный для выравнивания текущего блока 131 с использованием скорректированной огибающей 139, посредством чего получается блок 140 выровненных коэффициентов преобразования. Блок 140 выровненных коэффициентов преобразования можно кодировать с использованием цикла предсказания в области преобразования. Как таковой, блок 140 может быть кодирован с использованием предсказателя 117 поддиапазонов. Цикл предсказания содержит разностный модуль 115, сконфигурированный для определения блока 141 коэффициентов Δ(k) ошибок предсказания на основе блока 140 выровненных коэффициентов  преобразования и на основе блока 150 оценочных коэффициентов преобразования, например,
преобразования и на основе блока 150 оценочных коэффициентов преобразования, например, 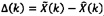 . Следует отметить, что по причине того, что блок 140 содержит выровненные коэффициенты преобразования, т.е. коэффициенты преобразования, которые были нормированы, или выровнены, с использованием значений 303 энергии скорректированной огибающей 139, блок 150 оценочных коэффициентов преобразования также содержит оценки выровненных коэффициентов преобразования. Иными словами, разностный модуль 115 действует в так называемой выровненной области. Как следствие, блок 141 коэффициентов Δ(k) ошибок предсказания представлен в выровненной области.
. Следует отметить, что по причине того, что блок 140 содержит выровненные коэффициенты преобразования, т.е. коэффициенты преобразования, которые были нормированы, или выровнены, с использованием значений 303 энергии скорректированной огибающей 139, блок 150 оценочных коэффициентов преобразования также содержит оценки выровненных коэффициентов преобразования. Иными словами, разностный модуль 115 действует в так называемой выровненной области. Как следствие, блок 141 коэффициентов Δ(k) ошибок предсказания представлен в выровненной области.
Блок 141 коэффициентов Δ(k) ошибок предсказания может проявлять дисперсию, отличную от единицы. Кодер 100 может содержать модуль 111 изменения масштаба, сконфигурированный для изменения масштаба коэффициентов Δ(k) ошибок предсказания для получения блока 142 коэффициентов ошибок с измененным масштабом. Для выполнения изменения масштаба, модуль 111 изменения масштаба может использовать одно или несколько предварительно определенных эвристических правил. Как результат, блок 142 коэффициентов ошибок с измененным масштабом проявляет дисперсию, (в среднем) более близкую к единице (по сравнению с блоком 141 коэффициентов ошибок предсказания). Это может быть преимущественным для последующего квантования и кодирования.
Кодер 100 содержит модуль 112 квантования коэффициентов, сконфигурированный для квантования блока 141 коэффициентов ошибок предсказания или блока 142 коэффициентов ошибок с измененным масштабом. Модуль 112 квантования коэффициентов может содержать или использовать набор предварительно определенных квантователей. Этот набор предварительно определенных квантователей может предусматривать квантователи с разными степенями точности или с различной разрешающей способностью. Это проиллюстрировано на Фиг. 4, где проиллюстрированы различные квантователи 321, 322, 323. Эти различные квантователи могут обеспечивать разные уровни точности (указываемые разными значениями в дБ). Конкретный квантователь из ряда квантователей 321, 322, 323 может соответствовать конкретному значению огибающей 138 распределения. Таким образом, значение энергии огибающей 138 распределения может указывать на соответствующий квантователь из ряда квантователей. Поэтому определение огибающей 138 распределения может упрощать процесс выбора квантователя, подлежащего использованию для конкретного коэффициента ошибки. Иными словами, огибающая 138 распределения может упрощать процесс распределения битов.
Указанный набор квантователей может содержать один или несколько квантователей 322, использующих добавление псевдослучайного шума для придания ошибке квантования случайного характера. Это проиллюстрировано на Фиг. 4, где показан первый набор 326 предварительно определенных квантователей, содержащий подмножество 324 квантователей с добавлением псевдослучайного шума, и второй набор 327 предварительно определенных квантователей, содержащий подмножество 325 квантователей с добавлением псевдослучайного шума. Как таковой, модуль 112 квантования коэффициентов может использовать разные наборы 326, 327 предварительно определенных квантователей, при этом набор предварительно определенных квантователей, подлежащий использованию модулем 112 квантования коэффициентов, может зависеть от параметра 146 управления, создаваемого предсказателем 117, и/или определяться на основе другой дополнительной информации, доступной в кодере и в соответствующем декодере. В частности, модуль 112 квантования коэффициентов может быть сконфигурирован для выбора набора 326, 327 предварительно определенных квантователей для квантования блока 142 коэффициентов ошибок с измененным масштабом на основе параметра 146 управления, при этом параметр 146 управления может зависеть от одного или нескольких параметров предсказателя, создаваемых предсказателем 117. Указанные один или несколько параметров могут служить признаком качества блока 150 оценочных коэффициентов преобразования, создаваемого предсказателем 117.
Квантованные коэффициенты ошибок могут подвергаться энтропийному, кодированию, например, с использованием кодирования методом Хаффмана, посредством чего получаются данные 163 коэффициентов, подлежащие включению в битовый поток, генерируемый кодером 100.
Ниже описываются дальнейшие подробности в отношении выбора или определения набора 326 квантователей 321, 322, 323. Набор 326 квантователей может соответствовать упорядоченной совокупности 326 квантователей. Эта упорядоченная совокупность 326 квантователей может содержать квантователей, при этом каждый квантователь может соответствовать отличающемуся уровню искажений. Как таковая, совокупность 326 квантователей может предусматривать N возможных уровней искажений. Квантователи из совокупности 326 могут быть упорядочены в соответствии с уменьшением искажений (или, эквивалентно, в соответствии с увеличением SNR). Кроме того, эти квантователи могут быть помечены как целые числа. Например, квантователи могут быть помечены как 0, 1, 2 и т.д., при этом увеличивающаяся целочисленная метка может указывать увеличение SNR.
Совокупность 326 квантователей может быть такова, что интервал SNR между двумя последовательными квантователями является, по меньшей мере, приблизительно постоянным. Например, SNR квантователя с меткой «1» может составлять 1,5 дБ, a SNR квантователя с меткой «2» может составлять 3,0 дБ. Таким образом, квантователи из упорядоченной совокупности 326 квантователей могут быть таковы, что при замене первого квантователя смежным вторым квантователем SNR (отношение сигнал-шум) увеличивается на, по существу, постоянное значение (например, 1,5 дБ) для всех пар из первого и второго квантователей.
Совокупность 326 квантователей может содержать:
- квантователь 321 с заполнением шумом, способный обеспечивать SNR, несколько меньший или равный 0 дБ, что для процесса распределения скорости передачи данных можно аппроксимировать как 0 дБ;
- Ndith квантователей 322, которые могут использовать добавление субтрактивного псевдослучайного шума и которые, как правило, соответствуют промежуточным уровням SNR (например, Ndith>0).
- Ncq классических квантователей 323, не использующих добавление субтрактивного псевдослучайного шума и, как правило, соответствующих относительно высоким уровням SNR (например, Ncq>0). Квантователи 323 без добавления псевдослучайного шума могут соответствовать скалярным квантователям.
Общее количество N квантователей имеет вид N=1+Ndith+Ncq.
Один из примеров совокупности 326 квантователей показан на Фиг. 6а. Квантователь 321 с заполнением шумом из совокупности 326 квантователей можно реализовать, например, с использованием генератора случайных чисел, выводящего одну из реализаций случайной переменной в соответствии с предварительно определенной статистической моделью. Одна из возможных реализаций такого генератора случайных чисел может включать использование фиксированной таблицы со случайными выборками предварительно определенной статистической модели и, возможно, с последующей перенормировкой. Генератор случайных чисел, используемый в кодере 100, действует в синхронном режиме с генератором случайных чисел в соответствующем декодере. Синхронности генераторов случайных чисел можно достигнуть, используя общую затравку для инициализации генераторов случайных чисел и/или возвращая эти генераторы случайных чисел в исходное положение в фиксированные моменты времени. В качестве альтернативы, эти генераторы можно реализовать как справочные таблицы, содержащие случайные данные, сгенерированные в соответствии с предписанной статистической моделью. В частности, если предсказатель активен, можно гарантировать, что вывод квантователя 321 с заполнением шумом является одинаковым в кодере 100 и в соответствующем декодере.
В дополнение, совокупность 326 квантователей может содержать один или несколько квантователей 322 с добавлением псевдослучайного шума. Эти один или несколько квантователей с добавлением псевдослучайного шума можно генерировать с использованием одной из реализаций псевдослучайного числового возмущающего сигнала 602, как показано на Фиг. 6а. Этот псевдослучайный числовой возмущающий сигнал 602 может соответствовать блоку 602 псевдослучайных возмущающих значений. Блок 602 псевдослучайных чисел может иметь такую же размерность, как размерность подлежащего квантованию блока 142 коэффициентов ошибок с измененным масштабом. Сигнал 602 псевдослучайного шума (или блок 602 значений псевдослучайного шума) можно генерировать с использованием генератора 601 псевдослучайного шума. В частности, сигнал 602 псевдослучайного шума можно генерировать, используя справочную таблицу, содержащую равномерно распределенные случайные выборки.
Как будет показано в контексте Фиг. 6b, отдельные значения 632 псевдослучайного шума из блока 602 значений псевдослучайного шума используются для применения псевдослучайного шума к соответствующему подлежащему квантованию коэффициенту (например, к соответствующему коэффициенту ошибки с измененным масштабом из блока 142 коэффициентов ошибок с измененным масштабом). Блок 142 коэффициентов ошибок с измененным масштабом может содержать совокупность коэффициентов K ошибок с измененным масштабом. Аналогичным образом, блок 602 значений псевдослучайного шума может содержать K значений 632 псевдослучайного шума. k-ое значение 632 псевдослучайного шума, где k=1, …, K, из блока 602 значений псевдослучайного шума можно применить к k-ому коэффициенту ошибки с измененным масштабом из блока 142 коэффициентов ошибок с измененным масштабом.
Как указывалось выше, блок 602 значений псевдослучайного шума может иметь такой же размер, как блок 142 подлежащих квантованию коэффициентов ошибок с измененным масштабом. Это является преимущественным, так как позволяет использовать единый блок 602 значений псевдослучайного шума для всех квантователей 322 с добавлением псевдослучайного шума из совокупности 326 квантователей. Иными словами, для того чтобы квантовать и кодировать заданный блок 142 коэффициентов ошибок с измененным масштабом, можно генерировать псевдослучайное возмущение 602 только один раз для всех приемлемых совокупностей 326, 327 квантователей и для всех возможных распределений для искажений. Это облегчает достижение синхронности между кодером 100 и соответствующим декодером, так как использованием единого сигнала 602 псевдослучайного шума не требует сигнализации в явном виде в соответствующий декодер. В частности, кодер 100 и соответствующий декодер может использовать один и тот же генератор 601 псевдослучайного шума, сконфигурированный для генерирования одного и того же блока 602 значений псевдослучайного шума для блока 142 коэффициентов ошибок с измененным масштабом.
Состав совокупности 326 квантователей предпочтительно базируется на психоакустических соображениях. Кодирование с преобразованием на низкой скорости передачи данных может приводить к спектральным артефактам, в том числе к спектральным провалам и ограничению полосы пропускания, которые приводятся в действие обратного процесса разбавления, имеющего место в традиционных схемах квантования, применимых к коэффициентам преобразования. Слышимость спектральных провалов можно уменьшить, вводя шум в те полосы 302 частот, которые на короткий промежуток времени оказались ниже уровня воды, и им, поэтому, была распределена нулевая битовая скорость передачи данных.
Грубое квантование коэффициентов в частотной области может приводить к специфическим артефактам кодирования (например, к глубоким спектральным провалам, так называемым «птичкам»), генерируемым в ситуации, когда коэффициенты конкретной полосы 302 частот квантуются в нуль (в случае глубоких спектральных провалов) в одном кадре и квантуются в ненулевые значения в следующем кадре, и когда весь этот процесс повторяется в течение десятков миллисекунд. Чем более грубыми являются квантователи, тем больше они предрасположены к выработке такого поведения. К этой технической проблеме можно обратиться, применяя заполнение шумом к индексам квантования, используемым для восстановления сигнала на нулевом уровне (как описывается, например, в патенте США №7447631). Решение, описанное в патенте США №7447631, способствует ослаблению артефактов, так как оно уменьшает слышимость глубоких спектральных провалов, связанных с квантованием на нулевом уровне, однако остаются артефакты, связанные с более пологими спектральными провалами. Способ заполнения шумом также можно применять и к индексам квантования более грубого квантователя. Однако это могло бы значительно ухудшить производительность этих квантователей в отношении MSE. Авторами изобретения было сделано наблюдение, что к этому недостатку можно обратиться путем использования квантователей с добавлением псевдослучайного шума. С целью обращения к проблеме производительности в отношении MSE, в настоящем документе предлагается использовать квантователи 322 с субтрактивным псевдослучайным шумом для низких уровней SNR. Кроме того, использование квантователей с субтрактивным псевдослучайным шумом способствует свойствам заполнения шумом для всех уровней восстановления. Поскольку квантователь 322 в добавлением псевдослучайного шума является аналитически определяемым при любой битовой скорости передачи данных, можно уменьшить (например, минимизировать) потерю производительности за счет добавления псевдослучайного шума путем получения коэффициентов 614 последующего усиления, пригодных на высоких уровнях искажений (т.е. при низких скоростях передачи данных).
Вообще для квантователя 322 с добавлением псевдослучайного шума можно добиться произвольно низкой битовой скорости передачи данных. Например, в скалярном случае можно выбрать использование очень большой величины шага квантования. Тем не менее, работа на нулевой битовой скорости передачи данных невыполнима на практике, поскольку она предъявляла бы слишком высокие требования к численной точности, необходимой для того, чтобы сделать возможной работу квантователя с кодером с переменной длиной слова. Это обеспечивает побуждение к применению обобщенного квантователя 321 с заполнением шумом к уровню искажений с SNR 0 дБ вместо применения квантователя 322 с добавлением псевдослучайного шума. Предлагаемая совокупность 326 квантователей рассчитана таким образом, чтобы квантователи 322 с добавлением псевдослучайного шума использовались для уровней искажений, связанных с относительно небольшими величинами шага так, чтобы кодирование с переменной длиной слова можно было реализовать без необходимости в обращении к проблемам, связанным с поддержанием численной точности.
Для случая скалярного квантования квантователи 322 с добавлением субтрактивного псевдослучайного шума можно реализовать с использованием коэффициентов последующего усиления, обеспечивающих почти оптимальную производительность в отношении MSE. Один из примеров скалярного квантователя 322 с добавлением субтрактивного псевдослучайного шума показан на Фиг. 6b. Квантователь 322 с добавлением псевдослучайного шума содержит скалярный квантователь Q 612 с равномерным шагом, используемый в конструкции для добавления субтрактивного псевдослучайного шума. Эта конструкция для добавления субтрактивного псевдослучайного шума содержит модуль 611 вычитания псевдослучайного шума, сконфигурированный для вычитания значения 632 псевдослучайного шума (из блока 602 значений псевдослучайного шума) из соответствующего коэффициента ошибки (из блока 142 коэффициентов ошибок с измененным масштабом). Кроме того, конструкция для добавления субтрактивного псевдослучайного шума содержит соответствующий модуль 613 сложения, сконфигурированный для сложения значения 632 псевдослучайного шума (из блока 602 значений псевдослучайного шума) с соответствующим скалярно квантованным коэффициентом ошибки. В иллюстрируемом примере модуль 611 вычитания псевдослучайного шума размещен в восходящем направлении относительно скалярного квантователя Q 612, а модуль 613 сложения псевдослучайного шума размещен в нисходящем направлении относительно скалярного квантователя Q 612. Значения 632 псевдослучайного шума из блока 602 значений псевдослучайного шума могут принимать значения из интервала [-0,5, 0,5) или [0, 1), кратные относительно величины шага скалярного квантователя 612. Следует отметить, что в одной из альтернативных реализаций квантователя 322 с добавлением псевдослучайного шума модуль 611 вычитания псевдослучайного шума и модуль 613 сложения псевдослучайного шума могут быть поменяны местами друг с другом.
За конструкцией для добавления субтрактивного псевдослучайного шума может следовать модуль 614 масштабирования, сконфигурированный для изменения масштаба квантованных коэффициентов ошибок посредством коэффициента у последующего усиления. После масштабирования квантованных коэффициентов ошибок получается блок 145 квантованных коэффициентов ошибок. Следует отметить, что ввод X в квантователь 322 с добавлением псевдослучайного шума, как правило, соответствует коэффициентам из блока 142 коэффициентов ошибок с измененным масштабом, находящихся в пределах конкретной полосы частот, подлежащей квантованию с использованием квантователя 322 с добавлением псевдослучайного шума. Аналогичным образом, вывод квантователя 322 с добавлением псевдослучайного шума, как правило, соответствует квантованным коэффициентам из блока 145 квантованных коэффициентов ошибок, находящихся в пределах этой конкретной полосы частот.
Можно предположить, что ввод X в квантователь 322 с добавлением псевдослучайного шума представляет собой нулевое среднее, и что дисперсия 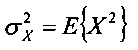 ввода X известна. (Например, дисперсию сигнала можно определить исходя из огибающей сигнала.) Кроме того. Можно предположить, что блок Z 602 псевдослучайных возмущений, содержащий значения 632 псевдослучайного шума, доступен кодеру 100 и соответствующему декодеру. Кроме того, можно предположить, что значения 632 псевдослучайного шума не зависят от ввода X. Можно использовать различные отличающиеся псевдослучайные шумы 602, но ниже предполагается, что псевдослучайный шум Z 602 равномерно распределен между 0 и Δ, что можно обозначить как U(0,Δ). На практике можно использовать любой псевдослучайный шум, удовлетворяющий т.н. условиям Шухмана (например, псевдослучайный шум 602, равномерно распределенный между значениями [-0,5, 0,5), кратными относительно величины шага Δ скалярного квантователя 612).
ввода X известна. (Например, дисперсию сигнала можно определить исходя из огибающей сигнала.) Кроме того. Можно предположить, что блок Z 602 псевдослучайных возмущений, содержащий значения 632 псевдослучайного шума, доступен кодеру 100 и соответствующему декодеру. Кроме того, можно предположить, что значения 632 псевдослучайного шума не зависят от ввода X. Можно использовать различные отличающиеся псевдослучайные шумы 602, но ниже предполагается, что псевдослучайный шум Z 602 равномерно распределен между 0 и Δ, что можно обозначить как U(0,Δ). На практике можно использовать любой псевдослучайный шум, удовлетворяющий т.н. условиям Шухмана (например, псевдослучайный шум 602, равномерно распределенный между значениями [-0,5, 0,5), кратными относительно величины шага Δ скалярного квантователя 612).
Квантователь Q 612 может представлять собой решетку, и протяженность ее ячейки Вороного может составлять Δ. В этом случае сигнал псевдослучайного шума мог бы иметь равномерное распределение по протяженности ячейки Вороного используемой решетки.
Коэффициент у последующего усиления квантователя можно получить для заданной дисперсии сигнала и величины шага квантователя, поскольку квантователь с добавлением псевдослучайного шума является аналитически определяемым для любой величины шага (т.е. для любой битовой скорости передачи данных). В частности, этот коэффициент последующего усиления можно получить для повышения производительности в отношении MSE квантователя с субтрактивным псевдослучайным шумом. Коэффициент последующего усиления может иметь вид:
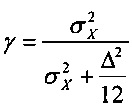 .
.
И хотя путем применения коэффициента γ последующего усиления можно повысить производительность в отношении MSE квантователя 322 с добавлением псевдослучайного шума, квантователь 322 с добавлением псевдослучайного шума, как правило, имеет менее высокую производительность в отношении MSE, чем квантователь без добавления псевдослучайного шума (хотя эта потеря производительности исчезает по мере увеличения битовой скорости передачи данных). Следовательно, в целом, квантователи с добавлением псевдослучайного шума являются более зашумленными, чем их версии без добавления псевдослучайного шума. Поэтому может быть желательным использование квантователей 322 с добавлением псевдослучайного шума только тогда, когда использование квантователей 322 с добавлением псевдослучайного шума оправдано преимущественным для восприятия свойством заполнения шумом квантователей 322 с добавлением псевдослучайного шума.
Таким образом, может быть предусмотрена совокупность 326 квантователей, содержащая квантователи трех типов. Упорядоченная совокупность 326 квантователей может содержать единственный квантователь 321 с заполнением шумом, один или несколько квантователей 322 с добавлением субтрактивного псевдослучайного шума и один или несколько классических квантователей 323 (без добавления псевдослучайного шума). Последовательные квантователи 321, 322, 323 могут предусматривать пошаговые повышения SNR. Эти пошаговые повышения между парой смежных квантователей из упорядоченной совокупности 326 квантователей могут быть, по существу, постоянными для некоторых или всех пар смежных квантователей.
Конкретную совокупность 326 квантователей можно идентифицировать по количеству квантователей 322 с добавлением псевдослучайного шума и по количеству квантователей 323 без добавления псевдослучайного шума, заключенных в этой конкретной совокупности 326. Кроме того, конкретную совокупность 326 квантователей можно идентифицировать по конкретной реализации сигнала 602 псевдослучайного шума. Совокупность 326 может быть рассчитана на обеспечение эффективного для восприятия квантования коэффициента преобразования, воспроизводящего: заполнение шумом с нулевой скоростью передачи данных (приводящее к SNR, несколько меньшему или равному 0 дБ); заполнение шумом посредством добавления субтрактивного псевдослучайного шума на промежуточном уровне искажений (при промежуточном SNR); и отсутствие заполнения шумом на низких уровнях искажений (при высоких SNR). Совокупность 326 предусматривает набор приемлемых квантователей, которые можно выбирать в ходе процесса распределения скорости передачи данных. Применение конкретного квантователя из совокупности 326 квантователей к коэффициентам конкретной полосы 302 частот определяется в ходе процесса распределения скорости передачи данных. Как правило, a priori неизвестно, какой из квантователей будет использован для квантования коэффициентов конкретной полосы 302 частот. Однако, как правило, a priori известно, каков состав совокупности 326 квантователей.
Аспект использования квантователей различных типов для разных полос 302 частот из блока 142 коэффициентов ошибок проиллюстрирован на Фиг. 6с, где показан иллюстративный результат процесса распределения скорости передачи данных. В этом примере предполагается, что распределение скорости передачи данных следует т.н. обратному принципу разбавления. На Фиг. 6с проиллюстрирован спектр 625 входного сигнала (или огибающая подлежащего квантованию блока коэффициентов). Видно, что полоса 623 частот обладает относительно высокой спектральной энергией и квантуется с использованием классического квантователя 323, предусматривающего относительно низкие уровни искажений. Полосы 622 частот проявляют спектральную энергию выше уровня 624 воды. Коэффициенты в этих полосах 622 частот можно квантовать с использованием квантователей 322 с добавлением псевдослучайного шума, предусматривающих промежуточные уровни искажений. Полосы 621 частот проявляют спектральную энергию ниже уровня 624 воды. Коэффициенты в этих полосах 621 частот можно квантовать, используя заполнение шумом с нулевой скоростью передачи данных. Эти различные квантователи, используемые для квантования конкретного блока коэффициентов (представленного спектром 625), могут составлять часть конкретной совокупности 326 квантователей, которая была определена для этого конкретного блока коэффициентов.
Таким образом, можно избирательно (например, избирательно в отношении частоты) применять квантователи 321, 322, 323 трех различных типов. Решение о применении квантователя конкретного типа можно определить в контексте описываемой ниже процедуры распределения скорости передачи данных. Эта процедура распределения скорости передачи данных может использовать критерий восприятия, который можно получить исходя из огибающей RMS входного сигнала (или, например, исходя из спектральной плотности мощности этого сигнала). Тип квантователя, подлежащего применению в конкретной полосе 302 частот не нуждается в сигнализации в явном виде соответствующему декодеру. Необходимость в сигнализации выбранного типа квантователя исключается, поскольку соответствующий декодер способен определить конкретный набор 326 квантователей, который использовался для квантования блока входного сигнала, исходя из лежащего в его основе критерия восприятия (например, огибающей 138 распределения), исходя из предварительно определенного состава совокупности квантователей (например, предварительно определенного набора различных совокупностей квантователей) и исходя из единого глобального параметра распределения скорости передачи данных (также именуемого параметром смещения).
Определение в декодере совокупности 326 квантователей, которые были использованы кодером 100, облегчается посредством конструирования этой совокупности 326 квантователей так, чтобы квантователи были упорядочены в соответствии с их искажениями (например, SNR). Каждый квантователь из совокупности 326 квантователей может уменьшать искажения (может уточнять SNR) предыдущего квантователя на постоянную величину. Кроме того, конкретная совокупность 326 квантователей может быть связана с единой реализацией сигнала 602 псевдослучайных возмущений в ходе всего процесса распределения скорости передачи данных. Как результат, исход процесса распределения скорости передачи данных не оказывает влияния на реализацию сигнала 602 псевдослучайного шума. Это является преимущественным для обеспечения сходимости процедуры распределения скорости передачи данных. Кроме того, это позволяет декодеру выполнять декодирование, когда декодеру известна эта единая реализация сигнала 602 псевдослучайного шума. Декодер может быть осведомлен об этой реализации сигнала 602 псевдослучайного шума посредством использования одного и того же генератора 601 псевдослучайных возмущений в кодере 100 и в соответствующем декодере.
Как указывалось выше, кодер 100 может быть сконфигурирован для выполнения процесса распределения битов. С этой целью кодер 100 может содержать модули 109, 110 распределения битов. Модуль 109 распределения битов может быть сконфигурирован для определения полного количества битов 143, доступных для кодирования текущего блока 142 коэффициентов ошибок с измененным масштабом. Это полное количество битов 143 можно определить на основе огибающей 138 распределения. Модуль 110 может быть сконфигурирован для создания относительного распределения битов различным коэффициентам ошибок с измененным масштабом в зависимости от соответствующего значения энергии на огибающей 138 распределения.
Процесс распределения битов может использовать итеративную процедуру распределения. В ходе процедуры распределения огибающая 138 распределения может быть смещена с использованием параметра смещения, посредством чего выбираются квантователи с повышенной/пониженной разрешающей способностью. Как таковой, параметр смещения можно использовать для уточнения или огрубления квантования в целом. Параметр смещения можно определить так, чтобы данные 163 коэффициентов, получаемые с использованием квантователей, задаваемых посредством этого параметра смещения и огибающей 138 распределения, содержали количество битов, соответствующее (или не превышающее) суммарное количество битов 143, распределенное текущему блоку 131. Параметр смещения, который был использован кодером 100 для кодирования текущего блока 131, включается как данные 163 коэффициентов в битовый поток. Как следствие соответствующий декодер способен определять квантователи, которые были использованы модулем 112 квантования коэффициентов для квантования блока 142 коэффициентов ошибок с измененным масштабом.
Как таковой, процесс распределения скорости передачи данных может быть выполнен в кодере 100, где он стремится к распределению доступных битов 143 в соответствии с моделью восприятия. Эта модель восприятия может зависеть от огибающей 138 распределения, получаемой исходя из блока 131 коэффициентов преобразования. Алгоритм распределения скорости передачи данных распределяет доступные биты 143 между квантователями различных типов, т.е. между квантователем 321 с заполнением шумом, одним или несколькими квантователями 322 с добавлением псевдослучайного шума и одним или несколькими классическими квантователями 323 без добавления псевдослучайного шума. Окончательное решение о типе квантователя, подлежащего использованию для квантования коэффициентов конкретной полосы 302 частот спектра, может зависеть от модели восприятия сигнала, от реализации псевдослучайного возмущения и от ограничения битовой скорости передачи данных.
С целью содействия декодированию без потерь данных, распределение битов в соответствующем декодере (указываемое огибающей 138 распределения и параметром смещения) можно использовать для определения вероятностей индексов квантования. Можно использовать способ вычисления вероятностей индексов квантования, употребляющий использование одной из реализаций полнодиапазонного псевдослучайного возмущения 602, модели восприятия, параметризованной посредством огибающей 138 сигнала, и параметра распределения скорости передачи данных (т.е. параметра смещения). При использовании огибающей 138 распределения, параметра смещения и знания в отношении блока 602 значений псевдослучайного шума состав совокупности 326 квантователей в декодере может действовать в синхронном режиме с совокупностью 326, используемой в кодере 100.
Как описывалось выше, ограничение битовой скорости передачи данных может быть задано в выражении максимально допустимого количества битов, приходящегося на кадр 143. Это применимо, например, к индексам квантования, которые впоследствии подвергаются энтропийному кодированию с использованием, например, кодирования методом Хаффмана. В частности, это применимо в сценариях кодирования, где битовый поток генерируется последовательным образом, где единовременно квантуется единственный параметр, и где соответствующий индекс квантования преобразовывается в двоичное кодовое слово, прилагаемое к битовому потоку.
Если в употреблении находится арифметическое кодирование (или кодирование диапазона), этот принцип отличается. В контексте арифметического кодирования длинной последовательности индексов квантования, как правило, присваивается единственное кодовое слово. Как правило, невозможно точно связать конкретную часть битового потока с конкретным параметром. В частности, в контексте арифметического кодирования количество битов, необходимое для кодирования одной из случайных реализаций сигнала, как правило, неизвестно. Это имеет место даже тогда, когда известна статистическая модель сигнала.
С целью обращения к вышеупомянутой технической проблеме, предлагается сделать арифметический кодер частью алгоритма распределения скорости передачи данных. В ходе процесса распределения скорости передачи данных кодер пытается квантовать и кодировать набор коэффициентов одной или нескольких полос 302 частот. Для каждой такой попытки можно наблюдать изменение состояния арифметического кодера и вычислять количество положений для продвижения в битовом потоке (вместо вычисления количества битов). Если установлено ограничение максимальной битовой скорости передачи данных, это ограничение максимальной битовой скорости передачи данных можно использовать в процедуре распределения скорости передачи данных. Стоимость завершающих битов арифметического кода может быть включена в стоимость последнего кодированного параметра, и, в целом, стоимость завершающих битов будет изменяться в зависимости от состояния арифметического кодера. Тем не менее, как только станет доступна завершающая стоимость, станет возможным определение количества битов, необходимых для кодирования индексов квантования, соответствующих набору коэффициентов из одной или нескольких полос 302 частот.
Следует отметить, что в контексте арифметического кодирования для всего процесса распределения скорости передачи данных (для отдельного блока 142 коэффициентов) можно использовать единую реализацию псевдослучайного шума 602. Как описывалось выше, арифметический кодер можно использовать для оценивания стоимости битовой скорости передачи данных для отдельного выбора квантователя в пределах процедуры распределения скорости передачи данных. Можно наблюдать изменение состояния арифметического кодера, и это изменение состояния можно использовать для вычисления количества битов, необходимых для выполнения квантования. Кроме того, в процессе распределения скорости передачи данных можно использовать процесс окончания арифметического кода.
Как указывалось выше, индексы квантования можно кодировать с использованием арифметического кода или энтропийного кода. Если индексы квантования подвергаются энтропийному кодированию, то для присвоения отдельным индексам квантования или их группам кодовых слов переменной длины можно учитывать распределение вероятностей индексов квантования. На распределение вероятностей индексов квантования может оказывать влияние использование добавления псевдослучайного шума. В частности, на распределение вероятностей индексов квантования может оказывать влияние данная конкретная реализация сигнала 602 псевдослучайного шума. По причине практически неограниченного количества реализаций сигнала 602 псевдослучайного шума, в самом общем случае, вероятности кодовых слов а priori неизвестны, и кодирование методом Хаффмана использовать невозможно.
Авторами изобретения было сделано наблюдение, что можно уменьшить количество возможных реализаций псевдослучайного шума до относительно небольшого и поддающегося управлению набора реализаций сигнала 602 псевдослучайного шума. Например, для каждой полосы 302 частот можно предусмотреть ограниченный набор значений псевдослучайного шума. С этой целью кодер 100 (а также соответствующий декодер) может содержать обособленный генератор 801 псевдослучайного шума, сконфигурированный для генерирования сигнала 602 псевдослучайного шума путем выбора одной из М предварительно определенных реализаций псевдослучайного шума (см. Фиг. 8). Например, для каждой полосы 302 частот можно использовать М различных предварительно определенных реализаций псевдослучайного шума. Количество М предварительно определенных реализаций псевдослучайного шума может быть равно М<5 (например, М=4 или М=3).
По причине ограниченного количества М реализаций псевдослучайного шума, для каждой реализации псевдослучайного шума можно обучить (возможно, многомерный) кодовый словарь Хаффмана, что приводит к совокупности 803 из М кодовых словарей. Кодер 100 может содержать модуль 802 выбора кодового словаря, сконфигурированный для выбора на основе выбранной реализации псевдослучайного шума одного кодового словаря из совокупности 803 М предварительно определенных кодовых словарей. Таким образом, обеспечивается то, что энтропийное кодирование является синхронизированным с генерированием псевдослучайного шума. Выбранный кодовый словарь 811 можно использовать для кодирования отдельных индексов квантования или их групп, которые были квантованы с использованием выбранной реализации псевдослучайного шума. Как следствие, используя квантователи с добавлением псевдослучайного шума, можно повышать производительность энтропийного кодирования.
Совокупность 803 предварительно определенных кодовых словарей и обособленный генератор 801 псевдослучайного шума также можно использовать и в соответствующем декодере (как проиллюстрировано на Фиг. 8). Декодирование является выполнимым, если используется псевдослучайное шум, и если декодер остается синхронным с кодером 100. В этом случае обособленный генератор 801 псевдослучайного шума в декодере генерирует сигнал 602 псевдослучайного шума, а отдельная реализация этого псевдослучайного шума однозначно связана с отдельным кодовым словарем 811 Хаффмана из совокупности 803 кодовых словарей. При заданной психоакустической модели (например, представляемой огибающей 138 распределения и параметром распределения скорости передачи данных) и выбранном кодовом словаре 811 декодер способен выполнять декодирование, используя декодер 551 Хаффмана для получения декодированных индексов 812 квантования.
Таким образом, вместо арифметического кодирования можно использовать относительно небольшой набор 803 кодовых словарей Хаффмана. Использование отдельного кодового словаря 811 из набора 813 кодовых словарей Хаффмана может зависеть от предварительно определенной реализации сигнала 602 псевдослучайного шума. В то же время, можно использовать ограниченный набор допустимых значений псевдослучайного шума, образующих М предварительно определенных реализаций псевдослучайного шума. Тогда процесс распределения скорости передачи данных может включать использование квантователей без добавления псевдослучайного шума, квантователей с добавлением псевдослучайного шума и кодирование методом Хаффмана.
Как результат квантования коэффициентов ошибок с измененным масштабом, получают блок 145 квантованных коэффициентов ошибок. Блок 145 квантованных коэффициентов ошибок соответствует блоку коэффициентов ошибок, доступному в соответствующем декодере. Следовательно, блок 145 квантованных коэффициентов ошибок можно использовать для определения блока 150 оценочных коэффициентов преобразования. Кодер 100 может содержать модуль 113 обратного изменения масштаба, сконфигурированный для выполнения операций изменения масштаба, обратных операциям, выполненным модулем 113 изменения масштаба, посредством чего получается блок 147 масштабированных квантованных коэффициентов ошибок. Модуль 116 сложения можно использовать для определения блока 148 восстановленных выровненных коэффициентов путем сложения блока 150 оценочных коэффициентов преобразования с блоком 147 масштабированных квантованных коэффициентов ошибок. Кроме того, для применения скорректированной огибающей 139 к блоку 148 восстановленных выровненных коэффициентов можно использовать модуль 114 обратного выравнивания, посредством чего получается блок 149 восстановленных коэффициентов. Блок 149 восстановленных коэффициентов соответствует версии блока 131 коэффициентов преобразования, доступной в соответствующем декодере.
Следовательно, для определения блока 150 оценочных коэффициентов в предсказателе 117 можно использовать блок 149 восстановленных коэффициентов.
Блок 149 восстановленных коэффициентов является представленным в невыровненной области, т.е. блок 149 восстановленных коэффициентов также является представителем огибающей спектра текущего блока 131. Как будет описываться ниже, это может быть преимущественным для производительности предсказателя 117.
Предсказатель 117 может быть сконфигурирован для оценивания блока 150 оценочных коэффициентов преобразования на основе, по меньшей мере, одного или нескольких предыдущих блоков 149 восстановленных коэффициентов. В частности, предсказатель 117 может быть сконфигурирован для определения одного или нескольких параметров предсказателя так, чтобы они уменьшали (например, минимизировали) предварительно определенный критерий ошибок предсказания. Например, эти один или несколько параметров предсказателя можно определять так, чтобы уменьшать (например, минимизировать) энергию или перцепционно взвешенную энергию блока 141 коэффициентов ошибок предсказания. Эти один или несколько параметров могут быть включены в битовый поток, генерируемый кодером 100, как данные 164 предсказателя.
Предсказатель 117 может использовать модель сигнала, описанную в заявке на патент США №61750052 и в заявляющих ее приоритет патентных заявках, содержание которых включается ссылкой. Указанные один или несколько параметров предсказателя могут соответствовать одному или нескольким параметрам модели для указанной модели сигнала.
На Фиг. 1b показана схема одного из дальнейших примеров речевого кодера 170 на основе преобразования. Речевой кодер 170 на основе преобразования по Фиг. 1b содержит многие из компонентов кодера 100 по Фиг. 1а. Однако речевой кодер 170 на основе преобразования по Фиг. 1b сконфигурирован для генерирования битового потока, имеющего переменную битовую скорость передачи данных. С этой целью кодер 170 содержит модуль 172 режима средней битовой скорости передачи данных (ABR), сконфигурированный для отслеживания битовой скорости передачи данных, которая была использована битовым потоком выше для предыдущих блоков 131. Модуль 171 распределения битов использует эту информацию для определения общего количества битов 143, доступных для кодирования текущего блока 131 коэффициентов преобразования.
В общем, речевые кодеры 100, 170 на основе преобразования сконфигурированы для генерирования битового потока, служащего признаком или содержащего:
- данные 161 огибающей, служащие признаком квантованной текущей огибающей 134. Квантованную текущую огибающую 134 используют для описания огибающей блоков из текущего набора 132 или смещенного набора 332 блоков коэффициентов преобразования.
- данные 162, служащие признаком коэффициента α усиления коррекции уровня для корректировки интерполированной огибающей 136 текущего блока 131 коэффициентов преобразования. Как правило, для каждого блока 131 из текущего набора 132 или смещенного набора 332 блоков предусмотрен отличающийся коэффициент α усиления.
- данные 163 коэффициентов, служащие признаком блока 141 коэффициентов ошибок предсказания для текущего блока 131. В частности, данные 163 коэффициентов служат признаком блока 145 квантованных коэффициентов ошибок. Кроме того, данные 163 коэффициентов могут служить признаком параметра смещения, который можно использовать для определения квантователей с целью выполнения обратного квантования в декодере.
- данные 164 предсказателя, служащие признаком одного или нескольких коэффициентов предсказателя, подлежащих использованию для определения блока 150 оценочных коэффициентов исходя из предыдущих блоков 149 восстановленных коэффициентов.
Ниже в контексте Фиг. 5а-5d описывается соответствующий речевой декодер 500 на основе преобразования. На Фиг. 5а показана блок-схема одного из примеров речевого декодера 500 на основе преобразования. На этой блок-схеме показан набор 504 синтезирующих фильтров (также именуемый модулем обратного преобразования), используемый для преобразования блока 149 восстановленных коэффициентов из области преобразования во временную область, посредством чего получаются дискретные значения декодированного звукового сигнала. Этот набор 504 синтезирующих фильтров может использовать обратное MDCT с предварительно определенным шагом (например, с шагом, приблизительно равным 5 мс, или 256 дискретных значений).
Главный цикл декодера 500 действует в единицах его шага. Каждый этап вырабатывает вектор (также именуемый блоком) в области преобразования, имеющий длину, или размер, соответствующий предварительно определенной установке ширины полосы пропускания системы. При заполнении нулями до размера преобразования набора 504 синтезирующих фильтров вектор в области преобразования будет использован для синтеза обновления сигнала во временной области с предварительно определенной длиной (например, 5 мс) в процессе перекрытия/сложения набора 504 синтезирующих фильтров.
Как указывалось выше, обобщенные звуковые кодеки на основе преобразования, как правило, используют для обработки переходных состояний кадры с последовательностями из коротких блоков в диапазоне 5 мс. Таким образом, обобщенные звуковые кодеки на основе преобразования обеспечивают необходимые преобразования и инструментальные средства коммутации оконных функций для бесшовного сосуществования коротких и длинных блоков. Поэтому в звуковой кодек общего назначения на основе преобразования можно удобно встроить голосовой спектральный внешний интерфейс, характеризующийся пропуском набора 504 синтезирующих фильтров по Фиг. 5а, без необходимости во введении дополнительных инструментальных средств коммутации. Иными словами, речевой декодер 500 на основе преобразования по Фиг. 5а можно удобно объединить с обобщенным звуковым декодером на основе преобразования. В частности, речевой декодер 500 на основе преобразования по Фиг. 5а может использовать набор 504 синтезирующих фильтров, предусматриваемый обобщенным звуковым декодером на основе преобразования (например, декодером ААС или НЕ-ААС).
Из поступающего битового потока (в частности, из данных 161 огибающей и данных 162 коэффициентов усиления, заключенных в этом битовом потоке) декодер 503 огибающей может определять огибающую сигнала. В частности, декодер 503 огибающей может быть сконфигурирован для определения скорректированной огибающей 139 на основе данных 161 огибающей и данных 162 коэффициентов усиления. Таким образом, декодер 503 огибающей может выполнять задачи аналогично модулю 104 интерполяции и модулю 107 уточнения огибающей кодера 100, 170. Как описывалось выше, скорректированная огибающая 109 представляет модель дисперсии сигнала в наборе предварительно определенных полос 302 частот.
Кроме того, кодер 500 содержит модуль 114 обратного выравнивания, сконфигурированный для применения скорректированной огибающей 139 к вектору в выровненной области, элементы которого номинально могут иметь единичную дисперсию. Вектор в выровненной области соответствует блоку 148 восстановленных выровненных коэффициентов, описанному в контексте кодера 100, 170. На выводе модуля 114 обратного выравнивания получается блок 149 восстановленных коэффициентов. Блок 149 восстановленных коэффициентов доставляется в набор 504 синтезирующих фильтров (для генерирования декодированного звукового сигнала) и в предсказатель 517 поддиапазонов.
Предсказатель 517 поддиапазонов действуют аналогично предсказателю 117 кодера 100, 170. А частности, предсказатель 517 поддиапазонов сконфигурирован для определения блока 150 оценочных коэффициентов преобразования (в выровненной области) на основе одного или нескольких предыдущих блоков 149 восстановленных коэффициентов (с использованием одного или нескольких параметров предсказания, сигнализируемых в битовом потоке). Иными словами, предсказатель 517 поддиапазонов сконфигурирован для вывода предсказываемого вектора в выровненной области исходя из буфера ранее декодированных выходных векторов и огибающих сигнала на основе таких параметров предсказателя, как запаздывание предсказателя и коэффициент усиления предсказателя. Декодер 500 содержит декодер 501 предсказателя, сконфигурированный для декодирования данных 164 предсказателя с целью определения одного или нескольких параметров предсказателя.
Декодер 500 также содержит декодер 502 спектра, сконфигурированный для снабжения предсказываемого вектора в выровненной области аддитивной поправкой на основе, как правило, наибольшей части битового потока (т.е. на основе данных 163 коэффициентов). Процесс декодирования спектра управляется главным образом вектором распределения, получаемым исходя из огибающей, и передаваемым параметром управления распределением (также именуемым параметром смещения). Как проиллюстрировано на Фиг. 5а, может существовать прямая зависимость декодера 502 спектра от параметров 520 предсказателя. Таким образом, декодер 502 спектра может быть сконфигурирован для определения блока 147 масштабированных квантованных коэффициентов ошибок на основе принятых данных 163 коэффициентов. Как описывалось в контексте кодера 100, 170, квантователи 321, 322, 323 используют для квантования блока 142 коэффициентов ошибок с измененным масштабом, как правило, в зависимости от огибающей 138 распределения (которую можно получить исходя из скорректированной огибающей 139) и от параметра смещения. Кроме того, квантователи 321, 322, 323 могут зависеть от параметра 146 управления, предоставляемого предсказателем 117. Параметр 146 управления может быть получен декодером 500 с использованием параметров 520 предсказателя (аналогично кодеру 100, 170).
Как указывалось выше, принятый битовый поток содержит данные 161 огибающей и данные 162 коэффициентов усиления, которые можно использовать для определения скорректированной огибающей 139. В частности, модуль 531 декодера 503 огибающей может быть сконфигурирован для определения квантованной текущей огибающей 134 исходя из данных 161 огибающей. Например, квантованная текущая огибающая 134 может иметь разрешающую способность 3 дБ в предварительно определенных полосах 302 частот (как указано на Фиг. 3а). Квантованная текущая огибающая 134 может обновляться для каждого набора 132, 332 блоков (например, каждые четыре единицы кодирования, т.е. каждые четыре блока, или каждые 20 мс), в частности, для каждого смещенного набора 332 блоков. Полосы 302 частот квантованной текущей огибающей 134 могут содержать увеличивающееся количество элементов 301 разрешения по частоте в зависимости от частоты с целью адаптации к свойствам человеческого слуха.
Квантованную текущую огибающую 134 можно линейно интерполировать исходя из квантованной предыдущей огибающей 135 в интерполированные огибающие 136 для каждого блока 131 из смещенного набора 332 блоков (или, возможно, из текущего набора 132 блоков). Интерполированные огибающие 136 можно определить в области, квантованной с разрешающей способностью 3 дБ. Это означает, что интерполированные значения 303 энергии можно округлять до ближайшего уровня 3 дБ. Один из примеров интерполированной огибающей 136 проиллюстрирован на Фиг. 3а пунктирной линией. Для каждой квантованной текущей огибающей 134 в качестве данных 162 коэффициентов усиления предусмотрены четыре коэффициента α 137 усиления коррекции уровня (также именуемые коэффициентами усиления огибающей). Модуль 532 декодирования коэффициентов усиления может быть сконфигурирован для определения коэффициентов α 137 усиления коррекции уровня исходя из данных 162 коэффициентов усиления. Коэффициенты усиления коррекции уровня могут быть квантованы с шагом 1 дБ. Каждый коэффициент усиления коррекции уровня применяют к соответствующей интерполированной огибающей 136 с целью создания скорректированных огибающих 139 для разных блоков 131. По причине повышенной разрешающей способности коэффициентов 137 усиления коррекции уровня скорректированная огибающая 139 может иметь повышенную разрешающую способность (например, разрешающую способность 1 дБ).
На Фиг. 3b показан один из примеров линейной, или геометрической, интерполяции между квантованной предыдущей огибающей 135 и квантованной текущей огибающей 134. Огибающие 135, 134 могут быть разделены на часть среднего уровня и часть формы логарифмического спектра. Эти части можно интерполировать по таким независимым стратегиям, как линейная, геометрическая, или гармоническая стратегия (параллельных резисторов). Таким образом, для определения интерполированных огибающих 136 можно использовать разные схемы интерполяции. Схема интерполяции, используемая декодером 500, как правило, соответствует схеме интерполяции, используемой кодером 100, 170.
Модуль 107 уточнения огибающей декодера 503 огибающей может быть сконфигурирован для определения огибающей 138 распределения исходя из скорректированной огибающей 139 путем квантования скорректированной огибающей 139 (например, с шагом 3 дБ). Огибающую 138 распределения можно использовать в сочетании с параметром управления распределением или параметром смещения (заключенным в данных 163 коэффициентов) для создания номинального целочисленного вектора распределения, используемого для управления спектральным декодированием, т.е. декодированием данных 163 коэффициентов. В частности, номинальный целочисленный вектор распределения можно использовать для определения квантователя для обратного квантования индексов квантования, заключенных в данных 163 коэффициентов. Огибающая 138 распределения и номинальный целочисленный вектор распределения можно определять аналогичным образом в кодере 100, 170 и в декодере 500.
На Фиг. 10 проиллюстрирован один из примеров процесса распределения битов на основе огибающей 138 распределения. Как описывалось выше, огибающую 138 распределения можно квантовать в соответствии с предварительно определенной разрешающей способностью (например, с разрешающей способностью 3 дБ). Каждое значение квантованной спектральной энергии огибающей 138 распределения может быть присвоено соответствующему целочисленному значению, при этом смежные целочисленные значения могут отображать разность в спектральной энергии, соответствующую предварительно определенной разрешающей способности (например, разность 3 дБ). Результирующий набор целых чисел можно именовать целочисленной огибающей 1004 распределения (именуемой iEnv). Целочисленная огибающая 1004 распределения может быть смещена посредством параметра смещения, давая номинальный целочисленный вектор распределения (именуемый iAlloc), обеспечивающий прямой указатель квантователя, подлежащего использованию для квантования коэффициента отдельной полосы 302 частот (идентифицируемой по индексу полосы частот, bandIdx).
Фиг. 10 показывает схему 1003 целочисленной огибающей 1004 распределения в зависимости от полос 302 частот. Видно, что для полосы 1002 частот (bandIdx=7) целочисленная огибающая 1004 распределения принимает целочисленное значение -17 (iEnv[7]=-17). Целочисленная огибающая 1004 распределения может быть ограничена максимальным значением (именуемым iMax, например, iMax-15). Процесс распределения битов может использовать формулу распределения битов, предусматривающую индекс 1006 квантователя (именуемый iAlloc [bandIdx]) в зависимости от целочисленной огибающей 1004 распределения и параметра смещения (именуемого AllocOffset). Как описывалось выше, параметр смещения (т.е. AllocOffset) передается в соответствующий декодер 500, посредством этого позволяя декодеру 500 определять индексы 1006 квантователя с использованием формулы распределения битов. Формула распределения битов может иметь вид
iAlloc[bandIdx]=iEnv[bandIdx]-(iMax-CONSTANT_OFFSET)+AllocOffset,
где CONSTANT_OFFSET может представлять собой постоянное смещение, например, CONSTANT_OFFSET=20. Например, если процесс распределения битов определил, что ограничение битовой скорости передачи данных может быть достигнуто при использовании параметра смещения AllocOffset=-13, то индекс 1007 квантователя 7ой полосы частот можно получить как: iAlloc[7]=-17-(-15-20)-13=5. Используя вышеупомянутую формулу распределения битов для всех полос 302 частот, можно определить индексы 1006 квантователя (и, следовательно, квантователи 321, 322, 323) для всех полос 302 частот. Индекс квантователя меньше нуля можно округлить до нулевого индекса квантователя. Аналогичным образом, индекс квантователя больше максимального доступного индекса квантователя можно округлить вниз до максимального доступного индекса квантователя.
Кроме того, на Фиг. 10 показан один из примеров огибающей 1011 шума, которой можно достигнуть, используя схему квантования, описываемую в настоящем документе. Огибающая 1011 шума показывает огибающую шума квантования, вносимого в ходе квантования. Если нанести ее на график совместно с огибающей сигнала (представленной на Фиг. 10 целочисленной огибающей 1004 распределения), огибающая 1011 шума иллюстрирует то, что распределение шума квантования является оптимизированным для восприятия относительно огибающей сигнала.
Для того чтобы позволить декодеру 500 синхронизироваться с принимаемым битовым потоком, могут передаваться кадры разного типа. Кадр может соответствовать набору 132, 332 блоков, в частности, смещенному блоку 332 блоков. В частности, могут передаваться т.н. Р-кадры, кодированные относительным образом относительно предыдущего кадра. В приведенном выше описании предполагалось, что декодер 500 осведомлен о квантованной предыдущей огибающей 135. Квантованная предыдущая огибающая 135 может быть доставлена в предыдущем кадре так, что текущий набор 132 или соответствующий смещенный набор 332 может соответствовать Р-кадру. Однако в сценарии запуска декодер 500, как правило, не осведомлен о квантованной предыдущей огибающей 135. Поэтому может передаваться I-кадр (например, при запуске или на регулярной основе). Этот I-кадр может содержать две огибающие, одну из которых используют в качестве квантованной предыдущей огибающей 135, а другую используют в качестве квантованной текущей огибающей 134. I-кадры<рt894> </pt894>можно использовать для случая запуска голосового спектрального внешнего интерфейса (т.е. речевого декодера 500 на основе преобразования), например, вслед за кадром, использующим другой режим звукового кодирования и/или в качестве инструментального средства для того чтобы в явном виде делать возможной точку сращивания звукового битового потока.
Действие предсказателя 517 поддиапазонов проиллюстрировано на Фиг. 5d. В иллюстрируемом примере параметрами 520 предсказателя являются параметр запаздывания и параметр g коэффициента усиления предсказателя. Параметры 520 предсказателя можно определять исходя из данных 164 предсказателя с использованием предварительно определенной таблицы возможных значений параметра запаздывания и параметра коэффициента усиления предсказателя. Это делает возможной передачу параметров 520 предсказателя, эффективную с точки зрения битовой скорости передачи данных.
Один или несколько ранее декодированных векторов коэффициентов преобразования (т.е. один или несколько предыдущих блоков 149 восстановленных коэффициентов) можно хранить в буфере 541 сигналов поддиапазонов (или MDCT). Буфер 541 может обновляться в соответствии с шагом (например, каждые 5 мс). Экстрактор 543 предсказателя может быть сконфигурирован для действия на буфер 541 в зависимости от нормированного параметра T запаздывания. Нормированный параметр T запаздывания можно определить путем нормирования параметра 520 запаздывания на единицы шага (например, на единицы шага MDCT). Если параметр T запаздывания является целочисленным, экстрактор 543 может извлекать одну или несколько единиц времени ранее декодированных векторов T коэффициентов преобразования в буфер 541. Иными словами, параметр T запаздывания может служить признаком того, какие из одного или нескольких предыдущих блоков 149 восстановленных коэффициентов подлежат использованию для определения блока 150 оценочных коэффициентов преобразования. Подробное обсуждение в отношении возможной реализации экстрактора 543 представлено в заявке на патент США №61750052 и заявляющих ее приоритет патентных заявках, содержание которых включается ссылкой.
Экстрактор 543 может действовать на векторах (или блоках), несущих полные огибающие сигнала. С другой стороны, блок 150 оценочных коэффициентов преобразования (подлежащий созданию предсказателем 517 поддиапазонов) представлен в выровненной области. Следовательно, вывод экстрактора 543 может быть сформирован в вектор в выровненной области. Этого можно достигнуть, используя формирователь 544, использующий скорректированные огибающие 139 из одного или нескольких предыдущих блоков 149 восстановленных коэффициентов. Скорректированные огибающие 139 из одного или нескольких предыдущих блоков 149 восстановленных коэффициентов могут храниться в буфере 542 огибающих. Модуль 544 формирователя может быть сконфигурирован для извлечения задержанной огибающей сигнала, подлежащей использованию при выравнивании от Т0 единиц времени в буфер 542 огибающих, где Т0 - целое число, ближайшее к Т. Затем вектор в выровненной области можно масштабировать посредством параметра g коэффициентов усиления для получения блока 150 оценочных коэффициентов преобразования (в выровненной области).
В качестве одной из альтернатив, задержанный процесс выравнивания, выполняемый формирователем 544, может быть пропущен посредством использования предсказателя 517 поддиапазонов, действующего в выровненной области, например, предсказателя 517 поддиапазонов, действующего на блоках 148 восстановленных выровненных коэффициентов. Однако было обнаружено, что последовательность векторов (или блоков) в выровненной области не очень хорошо отображается во временные сигналы по причине особенностей смешивания во времени при преобразовании (например, при преобразовании MDCT). Как следствие, уменьшается согласованность с лежащей в основе экстрактора 43 моделью сигнала, и из этой альтернативной конструкции в результате получается более высокий уровень шума кодирования. Иными словами, было обнаружено, что модели сигнала (например, синусоидальные или периодические модели), используемые предсказателем 517 поддиапазонов, приводят к большей эффективности в невыровненной области (в сравнении с выровненной областью).
Следует отметить, что в одном из альтернативных примеров вывод предсказателя 517 (т.е. блок 150 оценочных коэффициентов преобразования) можно складывать с выводом модуля 114 обратного выравнивания (т.е. с блоком 149 восстановленных коэффициентов) (см. Фиг. 5а). Тогда модуль 544 формирователя по Фиг. 5с может быть сконфигурирован для выполнения комбинированной операции задержанного выравнивания и обратного выравнивания.
Элементы в принимаемом битовом потоке могут управлять случающейся время от времени очисткой буфера 541 поддиапазонов и буфера 541 огибающих, например, в случае первой единицы кодирования (например, первого блока) из I-кадра. Это делает возможным декодирование I-кадра в отсутствие знания предыдущих данных. Первая единица кодирования, как правило, не будет способна использовать предсказывающий вклад, но, несмотря на это, может использовать относительно меньшее количество битов для передачи информации 520 предсказателя. Потерю коэффициента усиления предсказания можно компенсировать, распределяя больше битов на кодирование ошибки предсказания этой первой единицы кодирования. Как правило, вклад предсказателя вновь является существенным для второй единицы кодирования (т.е. второго блока) в I-кадре. Из-за этих особенностей качество можно поддерживать с относительно небольшим увеличением битовой скорости передачи данных даже при очень частом использовании I-кадров.
Иными словами, наборы 132, 332 блоков (также именуемых кадрами) содержат ряд блоков 131, которые можно кодировать с использованием кодирования с предсказанием. При кодировании I-кадра только первый блок 203 из набора 332 блоков нельзя кодировать с использованием коэффициента усиления кодирования, достигаемого кодером с предсказанием. Уже непосредственно следующий блок 201 может использовать выгоды кодирования с предсказанием. Это означает, что недостатки I-кадра в том, что касается эффективности кодирования, ограничены кодированием первого блока 203 коэффициентов преобразования из кадра 332, и не распространяются на другие блоки 201, 204, 205 кадра 332. Отсюда, схема речевого кодирования на основе преобразования, описываемая в настоящем документе, допускает относительно частое использование I-кадров без значительного влияния на эффективность кодирования. Таким образом, описываемая настоящая схема речевого кодирования на основе преобразования является особенно подходящей для применений, требующих относительно быстрой и/или относительно частой синхронизации между декодером и кодером.
На Фиг. 5d показана блок-схема одного из примеров декодера 502 спектра. Декодер 502 спектра содержит декодер 551 без потерь данных, сконфигурированный для декодирования энтропийно кодированных данных 163 коэффициентов. Кроме того, декодер 502 спектра содержит обратный квантователь 552, сконфигурированный для присвоения значений коэффициентов индексам квантования, заключенным в данных 163 коэффициентов. Как описывалось в контексте кодера 100, 170, разные коэффициенты преобразования можно квантовать, используя разные квантователи, выбираемые из набора предварительно определенных квантователей, например, из конечного набора скалярных квантователей на основе модели. Как показано на Фиг. 4, набор квантователей 321, 322, 323 может содержать квантователи разных типов. Этот набор квантователей может содержать квантователь 321, обеспечивающий синтез шума (в случае нулевой битовой скорости передачи данных), один или несколько квантователей 322 с добавлением псевдослучайного шума (для относительно низких отношений сигнал-шум, отношений SNR, и для промежуточных битовых скоростей передачи данных) и/или один или несколько простых квантователей 323 (для относительно высоких отношений SNR и для относительно высоких битовых скоростей передачи данных).
Модуль 107 уточнения огибающей может быть сконфигурирован для создания огибающей 138 распределения, которую можно сочетать с параметром смещения, заключенным в данных 163 коэффициентов, для получения вектора распределения. Этот вектор распределения содержит целочисленное значение для каждой полосы 302 частот. Это целочисленное значение для отдельной полосы 302 частот указывает на точку зависимости искажений от скорости передачи данных, подлежащую использованию для обратного квантования коэффициентов преобразования этой отдельной полосы 302. Иными словами, указанное целочисленное значение для отдельной полосы 302 частот указывает на квантователь, подлежащий использованию для обратного квантования коэффициентов преобразования указанной отдельной полосы 302. Увеличение этого целочисленного значения на единицу соответствует увеличению SNR на 1,5 дБ. Для квантователей 322 с добавлением псевдослучайного шума и простых квантователей 323 при кодировании без потерь данных, которое может использовать арифметическое кодирование, можно использовать лапласову модель распределения вероятностей. Для бесшовного заполнения пробела между случаями с высокой и низкой битовыми скоростями передачи данных можно использовать один или несколько квантователей 322 с добавлением псевдослучайного шума. Квантователи 322 с добавлением псевдослучайного шума могут быть преимущественными при создании достаточно гладкого качества выходного звука для стационарных шумоподобных сигналов.
Иными словами, обратный квантователь 552 может быть сконфигурирован для приема индексов квантования коэффициентов текущего блока 131 коэффициентов преобразования. Один или несколько индексов квантования коэффициентов отдельной полосы 302 частот были определены с использованием соответствующего квантователя из предварительно определенного набора квантователей. Значение вектора распределения (который можно определить путем смещения огибающей 138 распределения посредством параметра смещения) для отдельной полосы 302 частот указывает квантователь, который был использован для определения указанных одного или нескольких индексов квантования коэффициентов этой отдельной полосы 302 частот. При наличии идентифицированного квантователя эти один или несколько индексов квантования коэффициентов можно подвергнуть обратному квантованию для получения блока 145 квантованных коэффициентов ошибок.
Кроме того, спектральный декодер 502 может содержать модуль 113 обратного изменения масштаба для создания блока 147 масштабированных квантованных коэффициентов ошибок. Для адаптации спектрального декодирования к его использованию в общем декодере 500, показанном на Фиг. 5а, где для создания аддитивной поправки к предсказанному вектору в выровненной области (т.е. к блоку 150 оценочных коэффициентов преобразования) используется вывод спектрального декодера 502 (т.е. блок 145 квантованных коэффициентов ошибок), можно использовать дополнительные инструментальные средства и взаимосвязи около декодера 551 без потерь данных и квантователя 552 согласно Фиг. 5d. В частности, эти дополнительные инструментальные средства могут обеспечивать то, что обработка, выполняемая декодером 500, будет соответствовать обработке, выполняемой кодером 100, 170.
В частности, спектральный декодер 502 может содержать модуль 111 эвристического масштабирования. Как показано в связи с кодером 100, 170, модуль 111 эвристического масштабирования может оказывать влияние на распределение битов. В кодере 100, 170 текущие блоки 141 коэффициентов ошибок предсказания можно масштабировать до единичной дисперсии посредством эвристического правила. Как следствие, распределение по умолчанию может приводить к слишком тонкому квантованию окончательного масштабированного на меньший размер вывода модуля 111 эвристического масштабирования. Поэтому распределение следует модифицировать способом, аналогичным модификации коэффициентов ошибок предсказания.
Однако, как описывается ниже, может быть преимущественным избежание сокращения кодирующих ресурсов для одного или нескольких низкочастотных элементов разрешения (или низкочастотных полос). В частности, это может быть преимущественным для противодействия НЧ (низкочастотному) артефакту рокота/шума, оказывающемуся наиболее заметным в голосовых ситуациях (т.е. для сигнала, имеющего относительно большой параметр 146 управления, rfu). Таким образом, описываемый ниже выбор распределения битов/квантователя в зависимости от параметра 146 управления можно считать представляющим собой «повышение качества НЧ с голосовой адаптацией».
Спектральный декодер может зависеть от названного параметра 146 управления, который может представлять собой, например, ограниченную версию коэффициента g усиления предсказателя.
rfu=min(1, max(g, 0))
Можно использовать и альтернативные способы определения параметра 146 управления, rfu. В частности, параметр 146 управления можно определить, используя псевдокод, приведенный в Таблице 1.


Переменные f_gain и f_pred_gain можно приравнять. В частности, переменная f_gain может соответствовать коэффициенту g усиления предсказателя. Параметр 146 управления, rfu, в Таблице 1 именуется f_rfu. Коэффициент усиления f_gain может представлять собой действительное число.
В сравнении с первым определением параметра 146 управления, последнее определение (в соответствии с Таблицей 1) уменьшает параметр 146 управления, rfu, для коэффициентов усиления предсказателя выше 1 и увеличивает параметр управления 146, rfu, для отрицательных коэффициентов усиления предсказателя.
Используя параметр 146 управления, можно адаптировать набор квантователей, используемых в модуле 112 квантования кодера 100, 170 и используемых в обратном квантователе 552. В частности, на основе параметра 146 управления можно адаптировать зашумленность набора квантователей. Например, значение параметра 146 управления, близкое к 1, может запускать ограничение диапазона уровней распределения с использованием квантователей с добавлением псевдослучайного шума и может запускать уменьшение дисперсии уровня синтеза шума. В одном из примеров, может быть установлен порог принятия решения о добавлении псевдослучайного шума при rfu=0,75, а коэффициент усиления шума может быть приравнен. Адаптация добавления псевдослучайного шума может оказывать влияние как на декодирование без потерь данных, так и на обратный квантователь, в то время как адаптация коэффициента усиления шума, как правило, оказывает влияние только на обратный квантователь.
Можно предположить, что вклад предсказателя является существенным для голосовых/тональных ситуаций. Тогда относительно высокий коэффициент g усиления предсказателя (т.е. относительно высокий параметр 146 управления) может служить признаком голосового или тонального речевого сигнала. В таких ситуациях добавление относящегося к псевдослучайному шуму или выраженного в явном виде (случай нулевого распределения) шума, как было экспериментально показано, является приводящим к обратным результатам для воспринимаемого качества кодированного сигнала. Как следствие, количество квантователей 322 с добавлением псевдослучайного шума и/или шума того типа, который используется квантователем 321 синтеза шума, может быть адаптировано на основе коэффициента усиления предсказателя, посредством чего улучшается воспринимаемое качество кодированного речевого сигнала.
Таким образом, параметр 146 управления можно использовать для модификации диапазона 324, 325 отношений SNR, для которых используют квантователи 322 с добавлением псевдослучайного шума. Например, если параметр 146 управления rfu<0,75, для квантователей с добавлением псевдослучайного шума можно использовать диапазон 324. Иными словами, если параметр 146 управления находится ниже предварительно определенного порога, можно использовать первый набор 326 квантователей. С другой стороны, если параметр 146 управления rfu<0,75, то для квантователей с добавлением псевдослучайного шума можно использовать диапазон 325. Иными словами, если параметр 146 управления больше или равен предварительно определенному порогу, то можно использовать второй набор 327 квантователей.
Кроме того, параметр 146 управления можно использовать для модификации дисперсии и распределения битов. Причиной этого является то, что успешное предсказание, как правило, требует меньшей поправки, особенно в низкочастотном диапазоне 0-1 кГц. Может является преимущественным осуществление квантователя, явно осведомленного об этом отклонении от модели единичной дисперсии, с целью высвобождения кодирующих ресурсов для полос 302 более высоких частот. Это описано в контексте панели iii Фиг. 17 международной патентной заявки WO №2009/086918, содержание которой включается ссылкой. В декодере 500 эту модификацию можно реализовать путем модификации номинального вектора распределения в соответствии с эвристическим правилом масштабирования (применяемого посредством использования модуля 111 масштабирования) и, в то же время, масштабирования вывода обратного квантователя 552 в соответствии с эвристическим правилом обратного масштабирования с использованием модуля 113 обратного масштабирования. Следуя теории международной патентной заявки WO №2009/086918, это эвристическое правило масштабирования и эвристическое правило обратного масштабирования должны находиться в близком соответствии. Однако было обнаружено, что преимущественным с экспериментальной точки зрения является отмена модификации распределения для одной или нескольких самых нижних полос 302 частот с целью противодействия периодическими трудностям с НЧ (низкочастотным) шумом для голосовых составляющих сигнала. Отмену модификации распределения можно выполнять в зависимости от значения коэффициента g усиления предсказателя и/или параметра 146 управления. В частности, отмену модификации распределения можно выполнять только тогда, когда параметр 146 управления превышает порог принятия решения о добавлении псевдослучайного шума.
Таким образом, настоящий документ описывает средства для корректировки состава совокупности 326 квантователей (например, количества квантователей 323 без добавления псевдослучайного шума и/или количества квантователей 322 с добавлением псевдослучайного шума) на основе дополнительной информации (например, параметра 146 управления), доступной в кодере 100, 170 и в соответствующем декодере 500. Состав совокупности 326 квантователей можно корректировать в присутствии коэффициента g усиления предсказателя (например, на основе параметра 146 управления). В частности количество Ndith квантователей 322 с добавлением псевдослучайного шума можно увеличить, а количество Ncq квантователей 323 без добавления псевдослучайного шума можно уменьшить, если коэффициент g усиления предсказателя является относительно низким. Кроме того, количество распределяемых битов можно уменьшить, используя относительно более грубые квантователи. С другой стороны, если коэффициент g усиления предсказателя является относительно большим, можно уменьшить количество Ndith квантователей 322 с добавлением псевдослучайного шума и увеличить количество Ncq квантователей 323 без добавления псевдослучайного шума. Кроме того, количество распределяемых битов можно уменьшить, используя относительно более грубые квантователи.
В качестве альтернативы или в дополнение, состав совокупности 326 квантователей можно корректировать в присутствии коэффициента спектрального отражения. В частности, количество Ndith квантователей 322 с добавлением псевдослучайного шума можно увеличить в случае сигналов, подобных шипению. Кроме того, количество распределяемых битов можно уменьшить, используя относительно более грубые квантователи.
Ниже будет описываться один из примеров схемы определения коэффициента  спектрального отражения, служащего признаком свойства подобия шипению для текущего отрывка входного сигнала. Следует отметить, что коэффициент спектрального отражения отличается от «коэффициента отражения», используемого в контексте авторегрессионного моделирования источника. Блок 131 коэффициентов преобразования можно разделить на L полос 302 частот. Можно определить L-мерный вектор Bw, где l-й элемент вектора Bw может быть равен количеству элементов 301 разрешения преобразования, принадлежащих l-й полосе 302 частот (l=1,…, L). Аналогично можно определить K-мерный вектор F, где l-й элемент может быть равен средней точке l-й полосы 302 частот, которую получают путем вычисления среднего для наименьшего индекса элемента 301 разрешения преобразования и наибольшего индекса элемента 301 разрешения преобразования, принадлежащих й полосе 302 частот. Кроме того, можно определить L-мерный вектор SPSD, где вектор SPSD может содержать значения спектральной плотности мощности сигнала, которые можно получить путем преобразования индексов квантования, относящихся к огибающей, из шкалы дБ обратно в линейную шкалу. В дополнение, можно определить индекс Ncore максимального элемента разрешения, представляющий собой индекс наибольшего элемента разрешения, принадлежащего L-й полосе 302 частот. Скалярный коэффициент Rfc отражения можно определить как
спектрального отражения, служащего признаком свойства подобия шипению для текущего отрывка входного сигнала. Следует отметить, что коэффициент спектрального отражения отличается от «коэффициента отражения», используемого в контексте авторегрессионного моделирования источника. Блок 131 коэффициентов преобразования можно разделить на L полос 302 частот. Можно определить L-мерный вектор Bw, где l-й элемент вектора Bw может быть равен количеству элементов 301 разрешения преобразования, принадлежащих l-й полосе 302 частот (l=1,…, L). Аналогично можно определить K-мерный вектор F, где l-й элемент может быть равен средней точке l-й полосы 302 частот, которую получают путем вычисления среднего для наименьшего индекса элемента 301 разрешения преобразования и наибольшего индекса элемента 301 разрешения преобразования, принадлежащих й полосе 302 частот. Кроме того, можно определить L-мерный вектор SPSD, где вектор SPSD может содержать значения спектральной плотности мощности сигнала, которые можно получить путем преобразования индексов квантования, относящихся к огибающей, из шкалы дБ обратно в линейную шкалу. В дополнение, можно определить индекс Ncore максимального элемента разрешения, представляющий собой индекс наибольшего элемента разрешения, принадлежащего L-й полосе 302 частот. Скалярный коэффициент Rfc отражения можно определить как
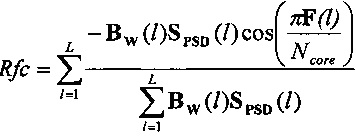 ,
,
где l обозначает l-й элемент L-мерного вектора.
В целом, Rfc>0 указывает спектр, в котором преобладает его высокочастотная часть, a Rfc<0 указывает спектр, в котором преобладает его низкочастотная часть. Параметр Rfc можно использовать следующим образом: если значение Rfu является низким (т.е. если коэффициент усиления предсказания является низким), и если Rfc>0, то это указывает на спектр, соответствующий фрикативному звуку (т.е. глухому шипящему звуку). В этом случае, в совокупности 326, 722 квантователей можно использовать относительно большее количество квантователей 322 с добавлением псевдослучайного шума.
В общих выражениях, совокупность 326 квантователей (и соответствующих обратных квантователей) можно корректировать на основе дополнительной информации (например, параметра 146 управления и/или коэффициента спектрального отражения), доступной в кодере 100 и в соответствующем декодере 500. Дополнительную информацию можно извлекать из параметров, доступных для кодера 100 и декодера 500. Как описывалось выше, коэффициент g усиления предсказателя можно передать в декодер 500 и использовать перед обратным квантованием коэффициентов преобразования для выбора соответствующей совокупности 326 обратных квантователей. В качестве альтернативы или в дополнение, коэффициент отражения можно оценить или аппроксимировать на основе огибающей спектра, переданной в декодер 500.
На Фиг. 7 показана блок-схема одного из примеров способа определения совокупности 326 квантователей/обратных квантователей в кодере 100 и в соответствующем декодере 500. Значимую дополнительную информацию 721 (такую, как параметр g предсказателя и/или коэффициент отражения) можно извлечь 701 из битового потока. Эту дополнительную информацию 721 можно использовать для определения 702 совокупности 722 квантователей, подлежащих использованию для квантования текущего блока коэффициентов и/или обратного квантования соответствующих индексов квантования. Для квантования коэффициентов отдельной полосы 302 частот и/или для обратного квантования соответствующих индексов квантования с использованием процесса 703 распределения скорости передачи данных, используется отдельный квантователь из определенной совокупности 722 квантователей. Выбор 723 квантователя в результате процесса 703 распределения битов используется в процессе 703 квантования для получения индексов квантования и/или используется в процессе 713 обратного квантования для получения квантованных коэффициентов.
На Фиг. 9а-9с показан пример экспериментальных результатов, которых можно достигнуть, используя систему кодека на основе преобразования, описываемую в настоящем документе. В частности, на Фиг. 9а-9с проиллюстрированы преимущества использования упорядоченной совокупности 326 квантователей, содержащей один или несколько квантователей 322 с добавлением псевдослучайного шума. На Фиг. 9а показана спектрограмма 901 первоначального сигнала. Видно, что спектрограмма 901 содержит спектральный состав в диапазоне частот, идентифицируемом белой окружностью. На Фиг. 9b показана спектрограмма 902 квантованной версии первоначального сигнала (квантованного при 22 кбит/с). В случае Фиг. 9b были использованы заполнение шумом для распределения нулевой скорости передачи данных и скалярные квантователи. Видно, что спектрограмма 902 проявляет в диапазоне частот, идентифицируемом белой окружностью, относительно большие спектральные блоки, связанные с пологими спектральными провалами (т.н. «птички»). Эти блоки, как правило, приводят к слышимым артефактам. На Фиг. 9с показана спектрограмма 903 другой квантованной версии первоначального сигнала (квантованного при 22 кбит/с) В случае Фиг. 9с были использованы заполнение шумом для распределения нулевой скорости передачи данных, квантователи с добавлением псевдослучайного шума и скалярные квантователи (как описывается в настоящем документе). Видно, что спектрограмма 903 не проявляет большие спектральные блоки, связанные со спектральными провалами в диапазоне частот, идентифицируемом белой окружностью. Людям, хорошо знакомым с этой областью техники, известно что отсутствие таких блоков квантования является указателем повышенной перцепционной производительности системы кодека на основе преобразования, описываемой в настоящем документе.
Ниже описываются различные дополнительные особенности кодера 100, 170 и/или декодера 500. Как описывалось выше, кодер 100, 170 и/или декодер 500 может содержать модуль 111 масштабирования, сконфигурированный для изменения масштаба коэффициентов Δ(k) ошибок предсказания для получения блока 142 коэффициентов ошибок с измененным масштабом. Для выполнения изменения масштаба, модуль 111 изменения масштаба может использовать одно или несколько предварительно определенных эвристических правил. В одном из примеров, модуль 111 изменения масштаба может использовать эвристическое правило масштабирования, содержащее коэффициент 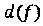 усиления, например,
усиления, например,
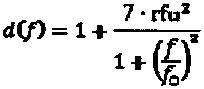
где частоту f0 излома можно приравнять, например, к 1000 Гц. Таким образом, модуль 111 изменения масштаба можно сконфигурировать для применения к коэффициентам ошибок предсказания зависящего от частоты коэффициента d(f) усиления с целью получения блока 142 коэффициентов ошибок с измененным масштабом. Модуль 113 обратного изменения масштаба можно сконфигурировать для применения обратной величины зависящего от частоты коэффициента d(f) усиления. Зависящий от частоты коэффициент d(f) усиления может зависеть от параметра rfu 146 управления. В приведенном выше примере коэффициент d(f) усиления проявляет характер фильтра прохождения нижних частот так, что коэффициенты ошибок предсказания сильнее ослабляются при более высоких частотах, чем при менее высоких частотах, и/или так, что коэффициенты ошибок предсказания сильнее выделяются при менее высоких частотах, чем при более высоких частотах. Вышеупомянутый коэффициент d(f) усиления всегда больше или равен единице. Таким образом, в одном из предпочтительных вариантов осуществления эвристическое правило масштабирования таково, что коэффициенты ошибок предсказания выделяются с коэффициентом единица или более (в зависимости от частоты).
Следует отметить, что зависящий от частоты коэффициент усиления может служить признаком мощности или дисперсии. В таких случаях правило масштабирования и правило обратного масштабирования следует получать на основе квадратного корня зависящего от частоты коэффициента усиления, например, на основе 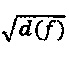 .
.
Степень выделения и/или ослабления может зависеть от качества предсказания, достигаемого предсказателем 117. Коэффициент усиления предсказателя и/или параметр 146 управления может служить признаком качества предсказания. В частности, относительно низкое значение параметра rfu 146 управления (относительно более близкое к нулю) может служить признаком низкого качества предсказания. В таких случаях следует ожидать, что коэффициенты ошибок предсказания будут иметь относительно высокие (абсолютные) значения на всех частотах. Относительно высокое значение параметра rfu 146 управления (относительно более близкое к единице) может служить признаком высокого качества предсказания. В таких случаях следует ожидать, что коэффициенты ошибок предсказания будут иметь относительно высокие (абсолютные) значения для высоких частот (которые труднее предсказывать). Таким образом, для того чтобы достигнуть единичной дисперсии на выводе модуля 111 изменения масштаба, коэффициент d(f) усиления может быть таков, чтобы, в случае относительно низкого качества предсказания, коэффициент d(f) усиления был, по существу, равномерным для всех частот, в то время как в случае относительно высокого качества предсказания, коэффициент d(f) усиления имел характер фильтра прохождения нижних частот для увеличения, или повышения, дисперсии при низких частотах. Этот случай представляет собой случай вышеупомянутого коэффициента d(f) усиления, зависящего от rfu.
Как описывалось выше, модуль 110 распределения битов можно сконфигурировать для обеспечения относительного распределения битов для разных коэффициентов ошибок с измененным масштабом в зависимости от соответствующего значения энергии на огибающей 138 распределения. Модуль 110 распределения битов можно сконфигурировать для учета эвристического правила изменения масштаба. Это эвристическое правило изменения масштаба может зависеть от качества предсказания. В случае относительно высокого качества предсказания может быть более преимущественным присвоение относительно большего количества битов кодированию коэффициентов ошибок предсказания (или блоку 142 коэффициентов ошибок с измененным масштабом) при более высоких частотах, чем кодированию этих коэффициентов при низких частотах. Это может быть вызвано тем, что в случае высокого качества предсказания низкочастотные коэффициенты уже являются хорошо предсказанными, в то время как высокочастотные коэффициенты, как правило, предсказаны хуже. С другой стороны, в случае относительно низкого качества предсказания распределение битов должно оставаться неизменным.
Вышеописанное поведение можно реализовать путем применения обратных эвристических правил/коэффициента d(f) усиления к текущей скорректированной огибающей 139 с целью определения огибающей 138 распределения, учитывающей качество предсказания.
Скорректированную огибающую 139, коэффициенты ошибок предсказания и коэффициент d(f) усиления можно представить в логарифмической области или в области дБ. В этом случае, применение коэффициента d(f) усиления к коэффициентам ошибок предсказания может соответствовать операции «сложение», а применение обратной величины коэффициента d(f) усиления к скорректированной огибающей 139 может соответствовать операции «вычитание».
Следует отметить, что возможны различные варианты эвристических правил/коэффициента d(f) усиления. В частности, фиксированную зависящую от частоты кривую 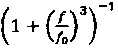 c характером фильтра прохождения нижних частот можно заменить функцией, зависящей от данных огибающей (например, от скорректированной огибающей 139 для текущего блока 131). Модифицированные эвристические правила могут зависеть как от параметра rfu 146 управления, так и от данных огибающей.
c характером фильтра прохождения нижних частот можно заменить функцией, зависящей от данных огибающей (например, от скорректированной огибающей 139 для текущего блока 131). Модифицированные эвристические правила могут зависеть как от параметра rfu 146 управления, так и от данных огибающей.
Ниже описываются различные пути определения коэффициента ρ усиления предсказателя, который может соответствовать коэффициенту усиления предсказателя. Коэффициент ρ усиления предсказателя можно использовать в качестве указателя качества предсказания. Вектор невязок предсказания (т.е. блок 141 коэффициентов ошибок предсказания) может иметь вид: z=x-ρy, где x - целевой вектор (например, текущий блок 140 выровненных коэффициентов преобразования или текущий блок 131 коэффициентов преобразования), y - вектор, представляющий выбранного кандидата для предсказания (например, предыдущие блоки 149 восстановленных коэффициентов), и ρ - это (скалярный) коэффициент усиления предсказателя.
w≥0 может представлять собой весовой вектор, используемый для определения коэффициента ρ усиления предсказателя. В некоторых вариантах осуществления весовой вектор зависит от огибающей сигнала (например, зависит от скорректированной огибающей 139, которую можно оценить в кодере 100, 170, а затем передать в декодер 500). Этот весовой вектор, как правило, имеет такую же размерность, как целевой вектор и вектор-кандидат, i-й элемент вектора x можно обозначить как x, (e.g. i=1, …, K).
Существуют различные способы определения коэффициента ρ усиления предсказателя. В одном из вариантов осуществления коэффициент ρ усиления предсказателя представляет собой коэффициент усиления MMSE (с минимальной среднеквадратичной ошибкой), определяемый в соответствии с критерием минимальной среднеквадратичной ошибки. В этом случае коэффициент ρ усиления предсказателя можно вычислить, используя следующую формулу:
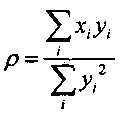 .
.
Такой коэффициент ρ усиления предсказателя, как правило, сводит к минимуму среднеквадратичную ошибку, определяемую как 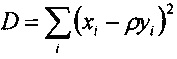 .
.
Часто (с точки зрения восприятия) преимущественным является введение взвешивания в определение среднеквадратичной ошибки D. Это взвешивание можно использовать для выделения важности соответствия между x и y для важных с точки зрения восприятия частей спектра сигнала и снятия выделения важности соответствия между x и y для частей спектра сигнала, являющихся относительно менее важными. Такой подход в результате приводит к следующему критерию ошибок: 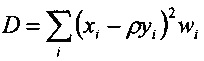 , что приводит к следующему определению оптимального коэффициента усиления предсказателя (в смысле взвешенной среднеквадратичной ошибки):
, что приводит к следующему определению оптимального коэффициента усиления предсказателя (в смысле взвешенной среднеквадратичной ошибки):
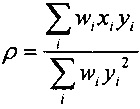 .
.
Приведенное выше определение коэффициента усиления предсказателя в результате, как правило, приводит в коэффициенту усиления, являющемуся неограниченным. Как указывалось выше, весовые коэффициенты весового вектора можно определить на основе скорректированной огибающей 139. Например, весовой вектор w можно определить с использованием предварительно определенной функции скорректированной огибающей 139. Эта предварительно определенная функция может быть известна в кодере и в декодере (что также верно для скорректированной огибающей 139). Таким образом, весовой вектор можно определять одинаковым образом в кодере и в декодере.
Другая возможная формула коэффициента усиления предсказателя имеет вид
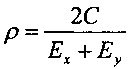 ,
,
где 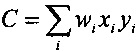 ,
, 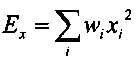 и
и 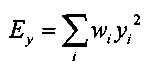 . Это определение коэффициента усиления предсказателя приводит к коэффициенту усиления, всегда находящемуся в пределах интервала [-1, 1]. Одним из важных признаков коэффициента усиления предсказателя, задаваемого последней формулой, является то, что коэффициент ρ усиления предсказателя содействует поддающейся обработке взаимосвязи между энергией целевого сигнала x и энергией остаточного сигнала z. Остаточную энергию LTP можно выразить как:
. Это определение коэффициента усиления предсказателя приводит к коэффициенту усиления, всегда находящемуся в пределах интервала [-1, 1]. Одним из важных признаков коэффициента усиления предсказателя, задаваемого последней формулой, является то, что коэффициент ρ усиления предсказателя содействует поддающейся обработке взаимосвязи между энергией целевого сигнала x и энергией остаточного сигнала z. Остаточную энергию LTP можно выразить как: 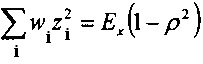 .
.
Параметр rfu 146 управления можно определить на основе коэффициента g усиления предсказателя, используя вышеупомянутые формулы. Коэффициент g усиления предсказателя может быть равен коэффициенту ρ усиления предсказателя, определенному с использованием любой из вышеупомянутых формул.
Как описывалось выше, кодер 100, 170 сконфигурирован для квантования и кодирования вектора невязок z (т.e. блока 141 коэффициентов ошибок предсказания). Процесс квантования, как правило, направляется огибающей сигнала (например, огибающей 138 распределения) в соответствии с лежащей в ее основе моделью восприятия с целью распределения доступных битов среди спектральных составляющих сигнала содержательным для восприятия образом. Процесс распределения скорости передачи данных направляется огибающей сигнала (например, огибающей 138 распределения), получаемой исходя из входного сигнала (например, из блока 131 коэффициентов преобразования). Действие предсказателя 117, как правило, изменяет огибающую сигнала. Модуль 112 квантования, как правило, использует квантователи, рассчитанные в предположении действия на источник с единичной дисперсией. В особенности, в случае высококачественного предсказания (т.е. тогда, когда предсказатель 117 является удачным), свойство единичной дисперсии может более не иметь места, т.е. блок 141 коэффициентов ошибок предсказания может не проявлять единичную дисперсию.
Как правило, оценка огибающей блока 141 коэффициентов ошибок предсказания (т.е. остатка z) и передача этой огибающей в декодер (и повторное выравнивание блока 141 коэффициентов ошибок предсказания с использованием этой оценочной огибающей) является неэффективным. Вместо этого кодер 100 и декодер 500 могут использовать эвристическое правило для изменения масштаба блока 141 коэффициентов ошибок предсказания (как описано выше). Это эвристическое правило можно использовать для изменения масштаба блока 141 коэффициентов ошибок предсказания так, чтобы блок 142 коэффициентов с измененным масштабом аппроксимировал единичную дисперсию. Как результат этого, результаты квантования можно улучшить (используя квантователи, предполагающие единичную дисперсию).
Кроме того, как уже было описано, это эвристическое правило можно использовать доля модификации огибающей 138 распределения, используемой в процессе распределения битов. Эта модификация огибающей 138 распределения и изменение масштаба блока 141 коэффициентов ошибок предсказания, как правило, выполняется кодером 100 и декодером 500 одинаковым образом (с использованием одного и того же эвристического правила).
Одно из возможных эвристических правил d(f) было описано выше. Ниже описывается другой подход к определению эвристического правила. Обратная величина коэффициента усиления предсказания энергии во взвешенной области может иметь вид p∈[0,1] и, таким образом, 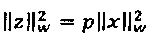 , где
, где 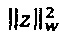 указывает квадратичную энергию вектора невязок (т.е. блока 141 коэффициентов ошибок предсказания) во взвешенной области, и где указывает квадратичную энергию целевого вектора (т.е. блока 140 выровненных коэффициентов преобразования) во взвешенной области.
указывает квадратичную энергию вектора невязок (т.е. блока 141 коэффициентов ошибок предсказания) во взвешенной области, и где указывает квадратичную энергию целевого вектора (т.е. блока 140 выровненных коэффициентов преобразования) во взвешенной области.
Можно сделать следующие предположения
1. Элементы целевого вектора x имеют единичную дисперсию. Это может быть результатом выравнивания, выполняемого блоком 108 выравнивания. Это предположение выполняется в зависимости от качества выравнивания на основе огибающей, выполняемого модулем 108 выравнивания.
2. Дисперсия элементов вектора z невязок предсказания имеет форму 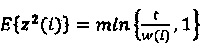 для i=1, …, K и для некоторых t≥0. Это предположение основано на эвристическом правиле о том, что поиск предсказателя, ориентированный на метод наименьших квадратов, приводит к равномерно распределенному вкладу ошибок во взвешенной области, поэтому вектор
для i=1, …, K и для некоторых t≥0. Это предположение основано на эвристическом правиле о том, что поиск предсказателя, ориентированный на метод наименьших квадратов, приводит к равномерно распределенному вкладу ошибок во взвешенной области, поэтому вектор 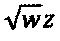 невязок является более или менее равномерным. Кроме того, можно ожидать, что предсказатель-кандидат близок к равномерному, что приводит к разумному ограничению E{z2(i)}≤1. Следует отметить, что можно использовать различные модификации этого, второго предположения.
невязок является более или менее равномерным. Кроме того, можно ожидать, что предсказатель-кандидат близок к равномерному, что приводит к разумному ограничению E{z2(i)}≤1. Следует отметить, что можно использовать различные модификации этого, второго предположения.
Для того чтобы оценить параметр, можно вставить вышеупомянутые два предположения в формулу ошибки предсказания (например, 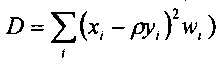 и посредством этого создать уравнение типа «уравнения уровня воды».
и посредством этого создать уравнение типа «уравнения уровня воды».
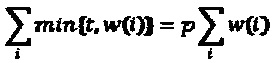
Можно показать, что у приведенного выше уравнения существует решение в интервале t∈[0,max(w(t))]. Уравнение для нахождения параметра можно решить, используя программы сортировки.
Тогда эвристическое правило может иметь вид 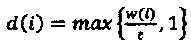 , где i=1, …, K идентифицирует элемент разрешения по частоте. Обратное эвристическое правило масштабирования имеет вид
, где i=1, …, K идентифицирует элемент разрешения по частоте. Обратное эвристическое правило масштабирования имеет вид 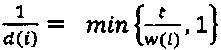 . Обратное эвристическое правило масштабирования применяется модулем 113 обратного изменения масштаба. Не зависящее от частоты правило масштабирования зависит от весовых коэффициентов w(i)=wi. Как указывалось выше, весовые коэффициенты w(i) могут зависеть от текущего блока 131 коэффициентов преобразования (например, от скорректированной огибающей 139 или некоторой предварительно определенной функции скорректированной огибающей 139) или могут ему соответствовать.
. Обратное эвристическое правило масштабирования применяется модулем 113 обратного изменения масштаба. Не зависящее от частоты правило масштабирования зависит от весовых коэффициентов w(i)=wi. Как указывалось выше, весовые коэффициенты w(i) могут зависеть от текущего блока 131 коэффициентов преобразования (например, от скорректированной огибающей 139 или некоторой предварительно определенной функции скорректированной огибающей 139) или могут ему соответствовать.
Можно показать, что при использовании формулы 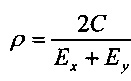 для определения коэффициента усиления предсказателя, применимо следующее отношение: p=1-ρ2.
для определения коэффициента усиления предсказателя, применимо следующее отношение: p=1-ρ2.
Отсюда, эвристическое правило масштабирования можно определить различными отличающимися способами. Экспериментально было показано, что правило масштабирования, определенное на основе вышеупомянутых двух предположений (именуемое способом B масштабирования) является преимущественным по сравнению с фиксированным правилом d(f) масштабирования. В частности, правило масштабирования, определенное на основе указанных двух предположений, может учитывать влияние взвешивания, используемого в ходе поиска предсказателя-кандидата. Способ B масштабирования удобно сочетается с определением коэффициента 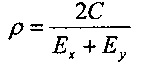 усиления по причине поддающейся аналитической обработке взаимосвязи между дисперсией остатка и дисперсией сигнала (что, как описывается выше, способствует получению p).
усиления по причине поддающейся аналитической обработке взаимосвязи между дисперсией остатка и дисперсией сигнала (что, как описывается выше, способствует получению p).
Ниже описывается одна из дальнейших особенностей для повышения производительности звукового кодера на основе преобразования. В частности, предлагается использование флага сохранения дисперсии. Флаг сохранения дисперсии можно определять и передавать на основе блока 131. Флаг сохранения дисперсии может служить признаком качества предсказания. В одном из вариантов осуществления флаг сохранения дисперсии выключен в случае относительно высокого качества предсказания, и флаг сохранения дисперсии включен в случае относительно низкого качества предсказания. Флаг сохранения дисперсии может быть определен кодером 100, 170, например, на основе коэффициента ρ усиления предсказателя и/или на основе коэффициента g усиления предсказателя. Например, флаг сохранения дисперсии может быть установлен на «включен», если коэффициент ρ усиления или коэффициент g усиления (или полученный из них параметр) находится ниже предварительно определенного порога (например, 2 дБ), и наоборот. Как описывалось выше, обратная величина коэффициента ρ усиления предсказания энергии во взвешенной области, как правило, зависит от коэффициента усиления предсказателя, например, от p=1-ρ2. Для определения значения флага сохранения дисперсии можно использовать обратную величину параметра ρ. Например, для определения значения флага сохранения дисперсии, 1/ρ (например, выраженный в дБ) можно сравнить с предварительно определенным порогом (например, 2 дБ). Если 1/ρ больше предварительно определенного порога, флаг сохранения дисперсии можно установить на «выключен» (что указывает на относительно высокое качество предсказания), и наоборот.
Флаг сохранения дисперсии можно использовать для управления различными другими установками кодера 100 и декодера 500. В частности, флаг сохранения дисперсии можно использовать для управления степенью зашумленности ряда квантователей 321, 322, 323. В частности, флаг сохранения дисперсии может оказывать влияние на одну или несколько из следующих установок
- Адаптивный коэффициент усиления шума для распределения нулевых битов. Иными словами, флаг сохранения дисперсии может оказывать влияние на коэффициент усиления шума квантователя 321 синтеза шума.
- Диапазон квантователей с добавлением псевдослучайного шума. Иными словами, флаг сохранения дисперсии оказывает влияние на диапазон 324, 325 отношений SNR, для которых используются квантователи 322 с добавлением псевдослучайного шума.
- Коэффициент последующего усиления квантователей с добавлением псевдослучайного шума. Коэффициент последующего усиления можно применять к выводу квантователей с добавлением псевдослучайного шума с целью оказания влияния на производительность квантователей с добавлением псевдослучайного шума в отношении среднеквадратичных ошибок. Коэффициент последующего усиления может зависеть от флага сохранения дисперсии.
- Применение эвристического масштабирования. Использование эвристического масштабирования (в модуле 111 изменения масштаба и в модуле 113 обратного изменения масштаба) может зависеть от флага сохранения дисперсии.
В Таблице 2 представлен один из примеров того, как флаг сохранения дисперсии может изменять одну или несколько установок кодера 100 и/или декодера 500.
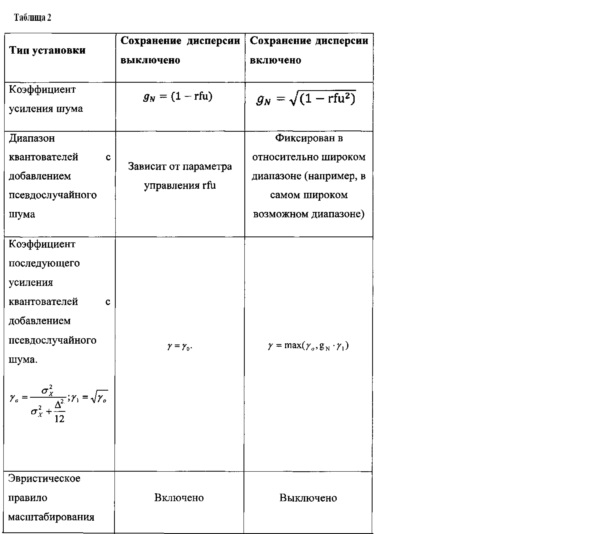
В формуле для коэффициента последующего усиления 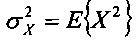 представляет собой дисперсию для одного или нескольких из коэффициентов блока 141 коэффициентов ошибок предсказания (подлежащих квантованию), а Δ - величина шага квантователя для скалярного квантователя (612) квантователя с добавлением псевдослучайного шума, к которому применяется этот коэффициент последующего усиления.
представляет собой дисперсию для одного или нескольких из коэффициентов блока 141 коэффициентов ошибок предсказания (подлежащих квантованию), а Δ - величина шага квантователя для скалярного квантователя (612) квантователя с добавлением псевдослучайного шума, к которому применяется этот коэффициент последующего усиления.
Как видно из примера в Таблице 2, от флага сохранения дисперсии может зависеть коэффициент gN усиления шума для квантователя 321 синтеза шума (т.е. дисперсия квантователя 321 синтеза шума). Как описывалось выше, параметр rfu 146 управления может находиться в интервале [0, 1], при этом относительно низкое значение rfu указывает относительно низкое качество предсказания, а относительно высокое значение rfu указывает относительно высокое качество предсказания. Для значений rfu в интервале [0, 1] формула в левой колонке предусматривает менее высокие коэффициенты gN усиления шума, чем формула в правой колонке. Таким образом, когда флаг сохранения дисперсии включен (что указывает относительно низкое качество предсказания) используется более высокий коэффициент усиления шума, чем тогда, когда флаг сохранения дисперсии выключен (что указывает относительно высокое качество предсказания). Экспериментально было показано, что это улучшает общее воспринимаемое качество.
Как описывалось выше, диапазон SNR 324, 325 квантователей 322 с добавлением псевдослучайного шума может изменяться в зависимости от параметра rfu управления. В соответствии с Таблицей 2, когда флаг сохранения дисперсии включен (что указывает на относительно низкое качество предсказания), используется фиксированный большой диапазон квантователей 322 с добавлением псевдослучайного шума (например, диапазон 324). С другой стороны, когда флаг сохранения дисперсии выключен (что указывает относительно высокое качество предсказания), в зависимости от параметра rfu управления используются разные диапазоны 324, 325.
Как было описано выше, определение блока 145 квантованных коэффициентов ошибок может включать применение коэффициента у последующего усиления к тем квантованным коэффициентам ошибок, которые были квантованы с использованием квантователя 322 с добавлением псевдослучайного шума. Коэффициент γ последующего усиления можно получить для улучшения производительности MSE квантователя 322 с добавлением псевдослучайного шума (например, квантователя с субтрактивным псевдослучайным шумом).
Экспериментально было показано, что качество перцепционного кодирования можно повысить, сделав коэффициент последующего усиления зависящим от флага сохранения дисперсии. Вышеупомянутый коэффициент последующего усиления с оптимальной MSE используют тогда, когда флаг сохранения дисперсии выключен (что указывает на относительно высокое качество предсказания). С другой стороны, когда флаг сохранения дисперсии включен (что указывает на относительно низкое качество предсказания), может быть преимущественным использование более высокого коэффициента последующего усиления (определяемого в соответствии с формулой с правой стороны Таблицы 2).
Как описывалось выше, эвристическое масштабирование можно использовать для создания блоков 142 коэффициентов ошибок с измененным масштабом, более близких к свойству единичной дисперсии, чем блоки 141 коэффициентов ошибок предсказания. Эвристические правила масштабирования можно сделать зависящими от параметра 146 управления. Иными словами, эти эвристические правила масштабирования можно сделать зависящими от качества предсказания. Эвристическое масштабирование может быть особенно преимущественным в случае относительно высокого качества предсказания, в то время как эти преимущества могут быть ограниченными в случае относительно низкого качества предсказания. В виду этого, может быть преимущественным использование эвристического масштабирования только тогда, когда флаг сохранения дисперсии выключен (что указывает относительно высокое качество предсказания).
В настоящем документе был описан речевой кодер 100, 170 на основе преобразования и соответствующий речевой декодер 500 на основе преобразования. Этот речевой кодек на основе преобразования может использовать различные особенности, позволяющие улучшать качество кодированных речевых сигналов. В частности, этот речевой кодек может быть сконфигурирован для создания упорядоченной совокупности квантователей, содержащих классические квантователи (без добавления псевдослучайного шума) квантователи с добавлением субстрактивного псевдослучайного шума и заполнение шумом «с нулевой скоростью передачи данных». Указанные упорядоченные совокупности квантователей можно создавать таким образом, чтобы эта упорядоченная совокупность облегчала процесс распределения скорости передачи данных в соответствии с моделью восприятия, параметризованной посредством огибающей сигнала, и посредством параметра распределения скорости передачи данных. Состав указанной совокупности квантователей можно переконфигурировать в присутствии дополнительной информации (например, коэффициента усиления предсказателя) для улучшения перцепционной производительности этой схемы квантования. Можно использовать алгоритм распределения скорости передачи данных, облегчающий использование указанной упорядоченной совокупности квантователей без необходимости в дополнительной сигнализации декодеру, например, дополнительной сигнализации, относящейся к конкретному составу совокупности квантователей, использованной в кодере, и/или относящейся к сигналу псевдослучайного шума, использованному для реализации квантователей с добавлением псевдослучайного шума. Кроме того, можно использовать алгоритм распределения скорости передачи данных, облегчающий использование арифметического кодера (или кодера диапазонов) в присутствии ограничения битовой скорости передачи данных (например, ограничения на максимально допустимое количество битов и/или ограничения на максимальную приемлемую длину сообщения). В дополнение, указанная упорядоченная совокупность квантователей облегчает использование квантователей с добавлением псевдослучайного шума и, в то же время, позволяет распределять нулевые биты в отдельные полосы частот. Кроме того, можно использовать алгоритм распределения скорости передачи данных, облегчающий использование указанной упорядоченной совокупности квантователей в сочетании с кодированием методом Хаффмана.
Способы и системы, описанные в настоящем документе, могут реализовываться как программное обеспечение, аппаратно-программное обеспечение и/или как аппаратное обеспечение. Некоторые компоненты могут реализовываться, например, как программное обеспечение, запускаемое на процессоре цифровой обработки сигналов или на микропроцессоре. Другие компоненты могут реализовываться, например, как аппаратное обеспечение или как интегральные схемы специального назначения. Сигналы, которые встречаются в описанных способах и системах, могут храниться в памяти таких носителей данных, как память с произвольным доступом или оптические носители данных. Они могут передаваться по сетям, таким как радиосети, спутниковые сети, беспроводные сети или проводные сети, например, Интернет. Типичными устройствами, использующими способы и системы, описанные в настоящем документе, являются переносные электронные устройства или другая бытовая аппаратура, которая используется для хранения и/или представления звуковых сигналов.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСОВЕРШЕНСТВОВАННЫЙ КВАНТОВАТЕЛЬ | 2017 |
|
RU2752127C2 |
| УСОВЕРШЕНСТВОВАННЫЙ КВАНТОВАТЕЛЬ | 2021 |
|
RU2823174C2 |
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2014 |
|
RU2740690C2 |
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2020 |
|
RU2828411C2 |
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2014 |
|
RU2630887C2 |
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2014 |
|
RU2740359C2 |
| СИСТЕМА ОБРАБОТКИ АУДИО | 2014 |
|
RU2625444C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ВКЛЮЧЕНИЯ ИДЕНТИФИКАТОРА В ПАКЕТ, АССОЦИАТИВНО СВЯЗАННЫЙ С РЕЧЕВЫМ СИГНАЛОМ | 2007 |
|
RU2421828C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВЕКТОРНОГО КВАНТОВАНИЯ СПЕКТРАЛЬНОГО ПРЕДСТАВЛЕНИЯ ОГИБАЮЩЕЙ | 2006 |
|
RU2387025C2 |
| КОДЕР, ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ | 2020 |
|
RU2834753C2 |
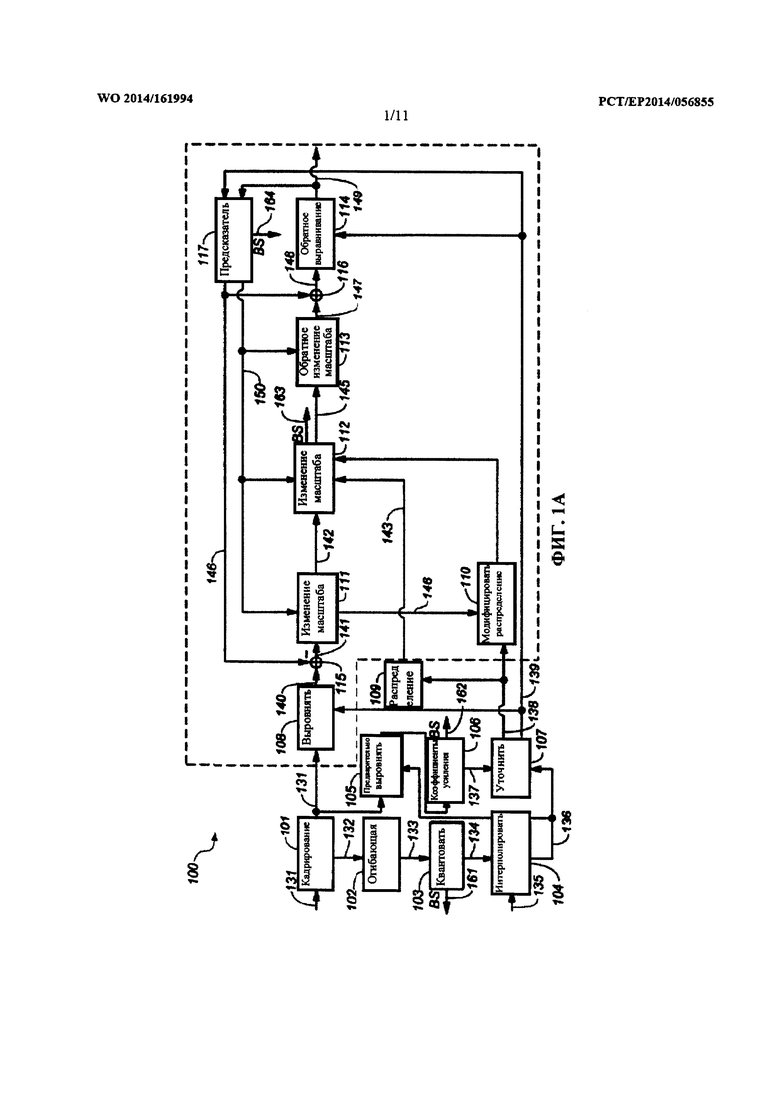
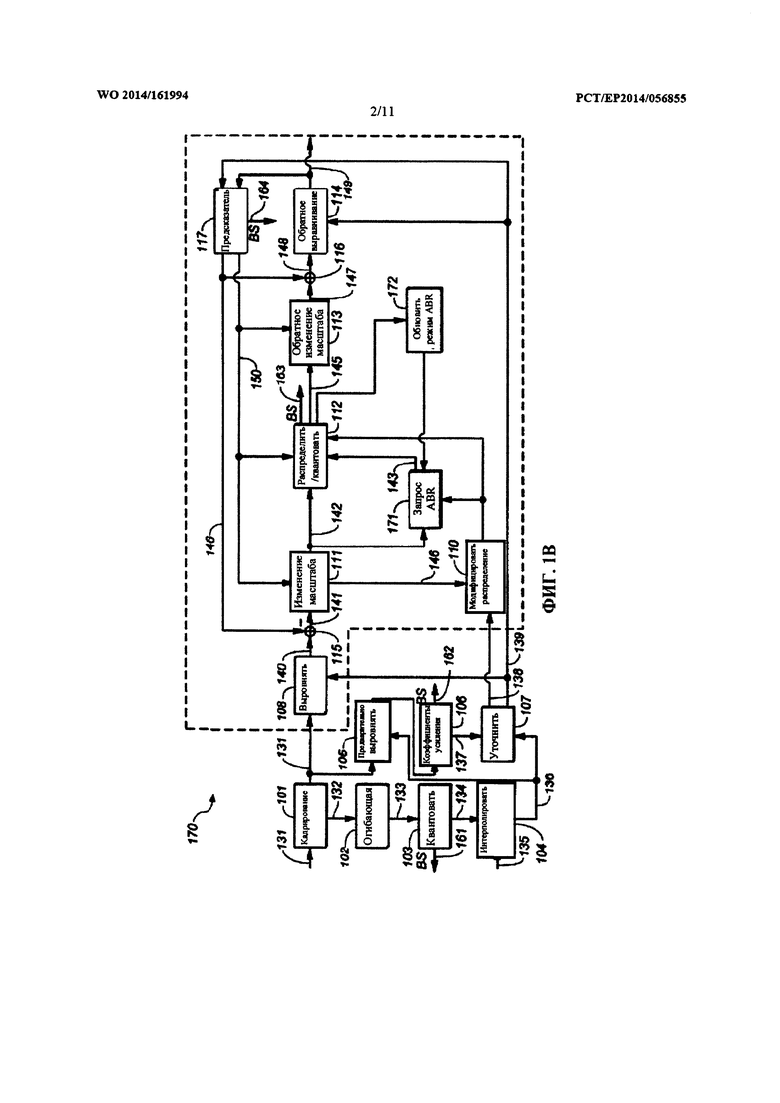
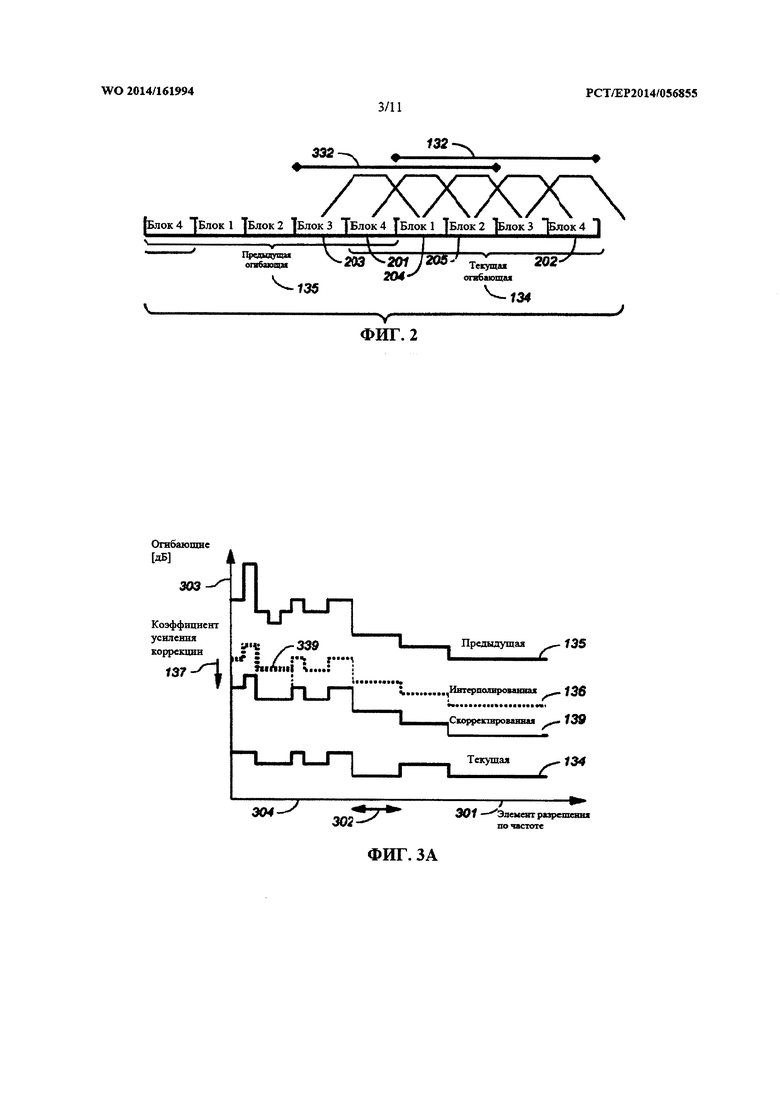
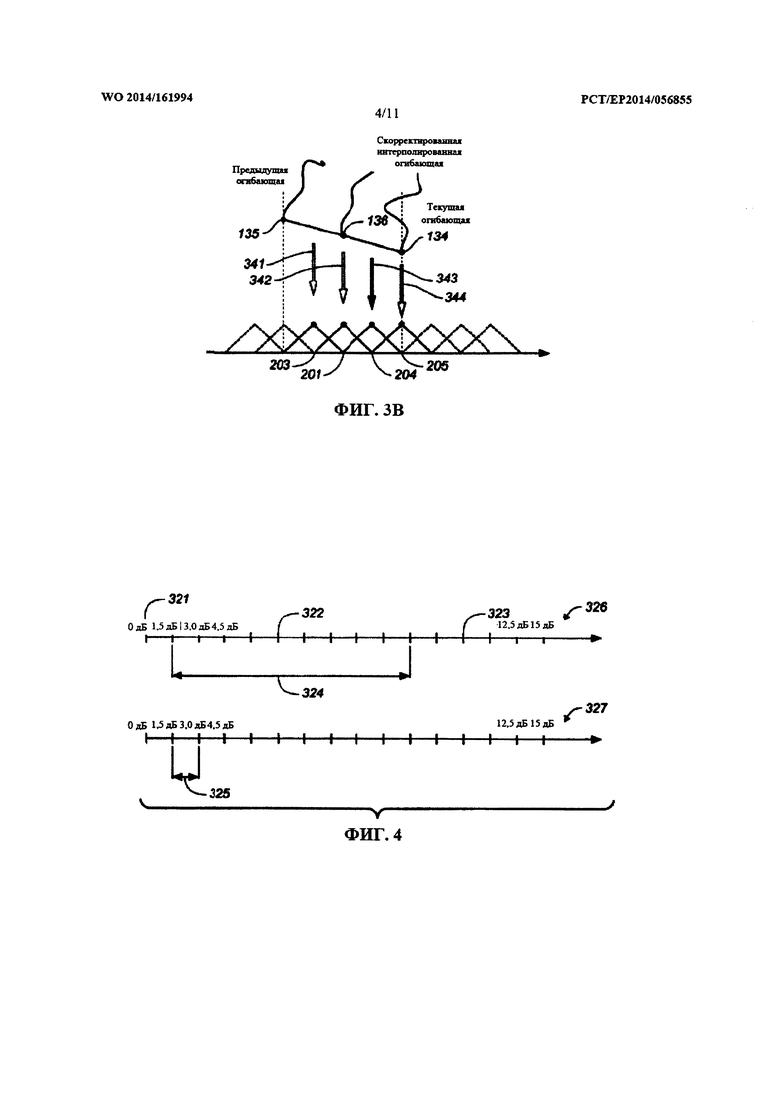
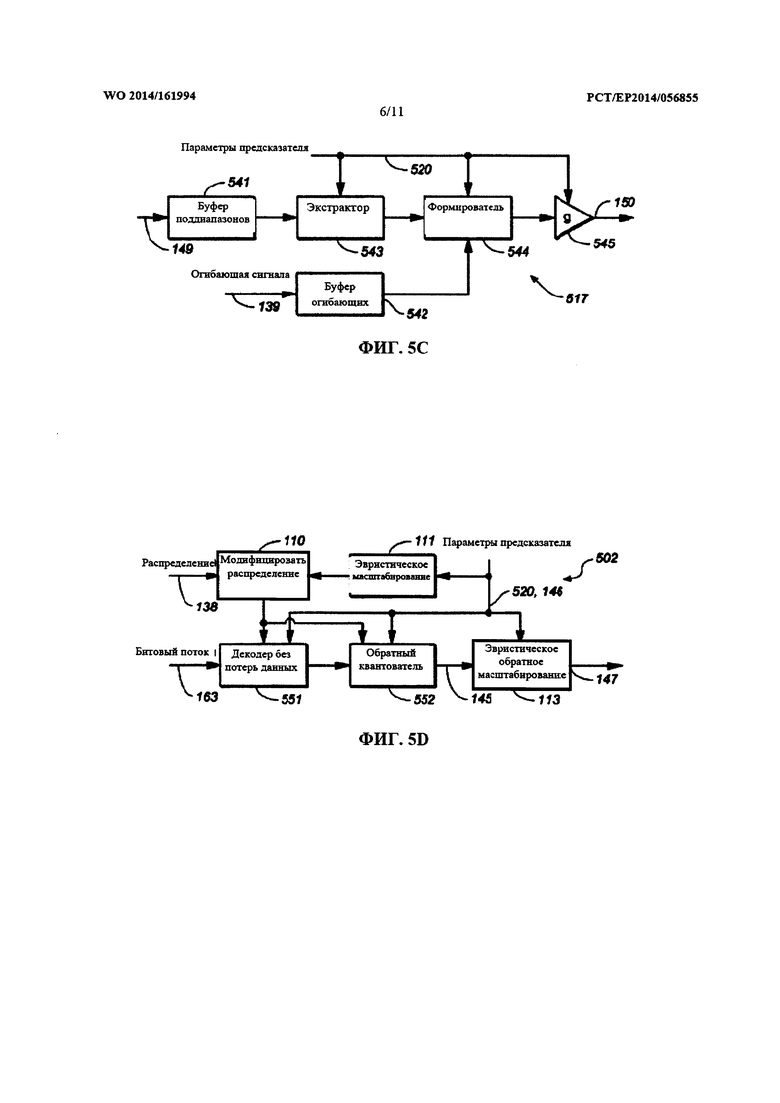
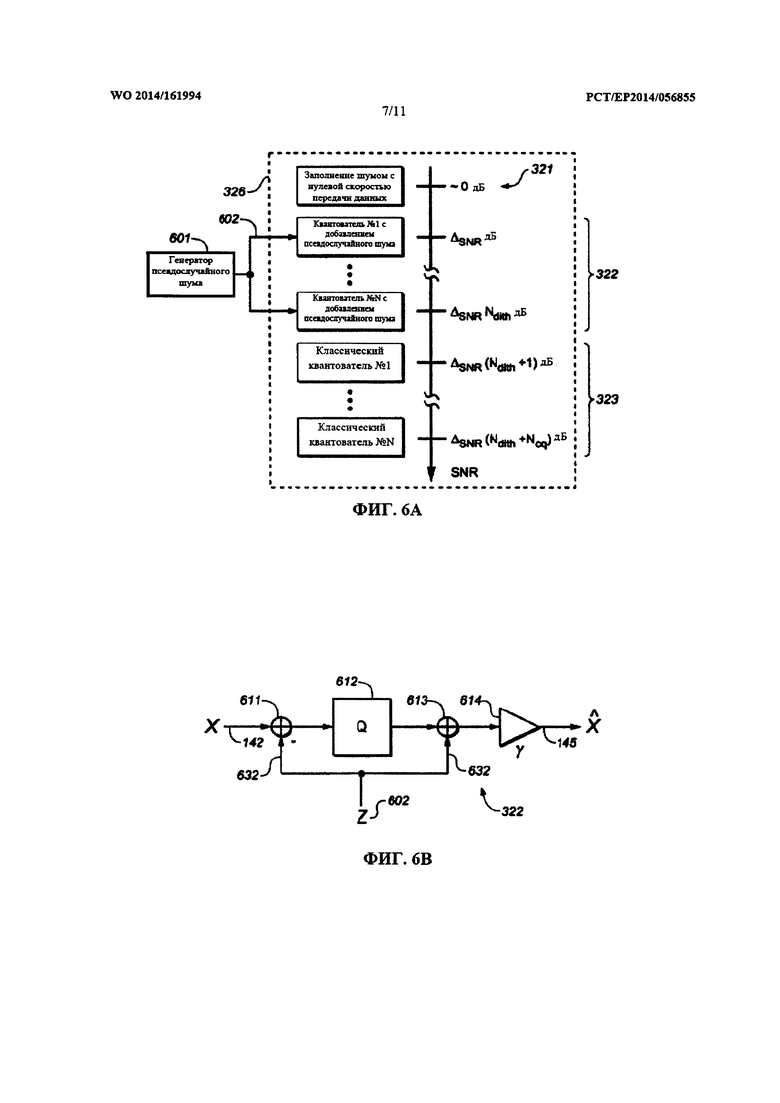
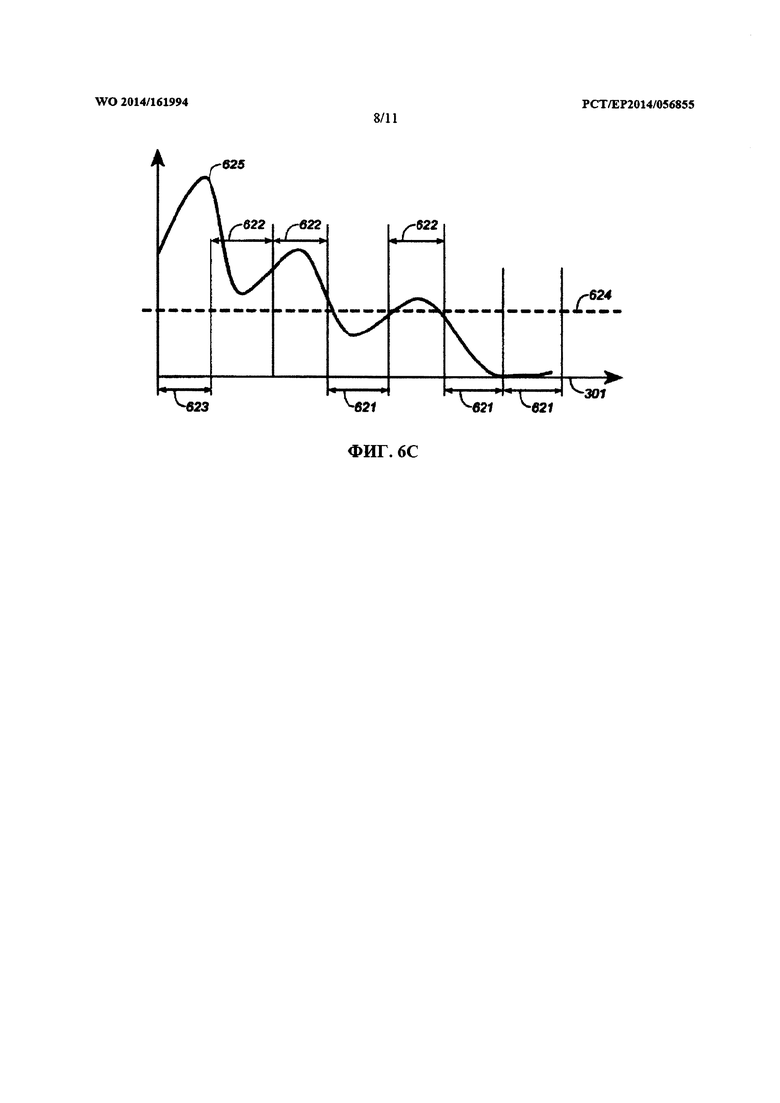
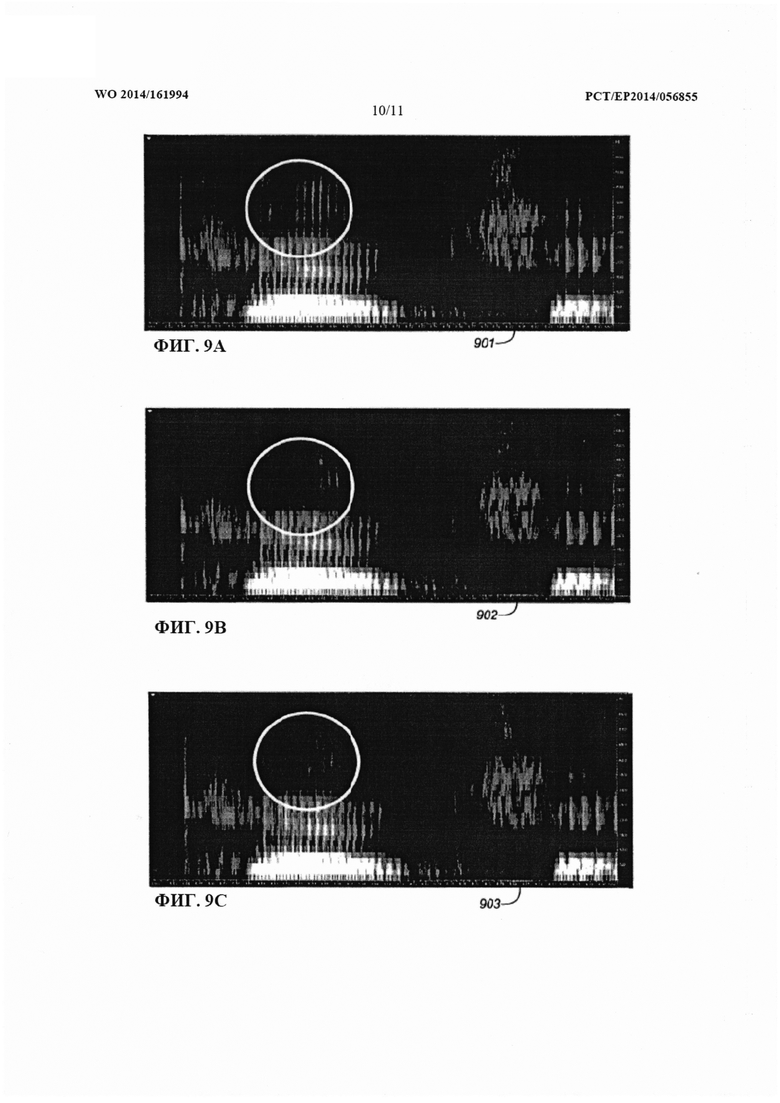
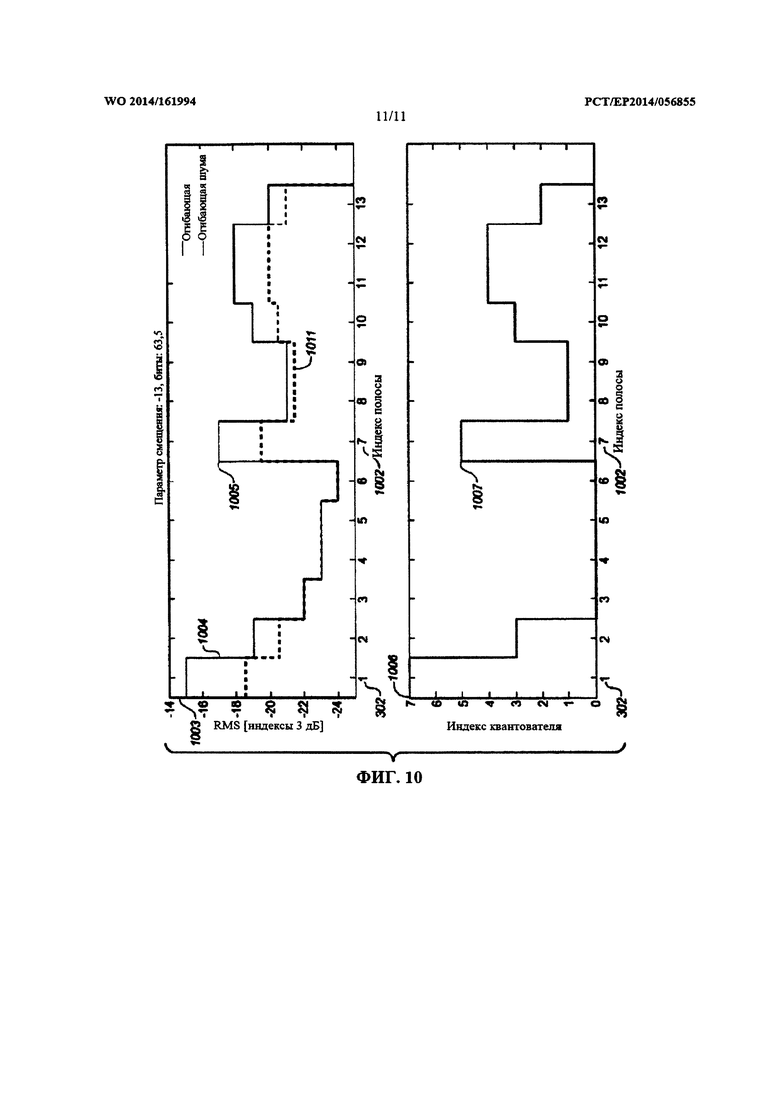
Настоящее изобретение относится к системе звукового кодирования и декодирования. Технический результат заключается в повышении гибкости в отношении допущения разных скоростей передачи данных и разных уровней искажений. Модуль квантования, сконфигурированный для квантования первого коэффициента из блока коэффициентов. Этот блок коэффициентов содержит ряд коэффициентов для ряда соответствующих элементов разрешения по частоте. Модуль квантования сконфигурирован для создания набора квантователей. Этот набор квантователей содержит ряд различных квантователей, связанных с рядом различных отношений сигнал-шум, соответственно, именуемых SNR. Этот ряд различных квантователей содержит квантователь с заполнением шумом; один или несколько квантователей с добавлением псевдослучайного шума; и один или несколько квантователей без добавления псевдослучайного шума. Модуль квантования также сконфигурирован для определения указателя SNR, служащего признаком SNR, приписанного указанному первому коэффициенту, и для выбора первого квантователя из набора квантователей на основе этого указателя SNR. В дополнение, модуль квантования сконфигурирован для квантования указанного первого коэффициента с использованием указанного первого квантователя. 6 н. и 14 з.п. ф-лы, 19 ил.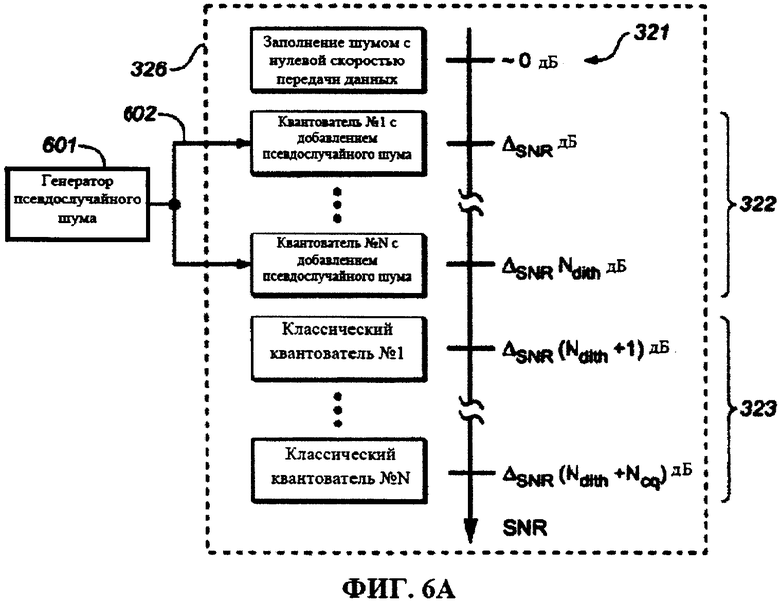
1. Модуль квантования, сконфигурированный для квантования первого коэффициента из блока коэффициентов, полученного из блока коэффициентов, определяемого преобразованием звукового сигнала между временной и частотной областями; при этом блок коэффициентов содержит ряд коэффициентов для ряда соответствующих элементов разрешения по частоте; при этом блок квантования сконфигурирован для
- создания набора квантователей; при этом набор квантователей содержит ограниченное количество различных квантователей, связанных с различными отношениями сигнал-шум, соответственно, именуемыми SNR; при этом указанные различные квантователи из указанного набора квантователей упорядочены в соответствии с их SNR; при этом набор квантователей содержит:
- квантователь с заполнением шумом; при этом квантователь с заполнением шумом сконфигурирован для квантования указанного первого коэффициента путем замены значения этого первого коэффициента случайным значением, сгенерированным в соответствии с указанной предварительно определенной статистической моделью;
- один или несколько квантователей с добавлением псевдослучайного шума; и
- один или несколько детерминированных квантователей без добавления псевдослучайного шума;
- определения указателя SNR, служащего признаком SNR, приписанного указанному первому коэффициенту;
- выбора первого квантователя из набора квантователей на основе этого указателя SNR; и
- квантования указанного первого коэффициента с использованием указанного первого квантователя.
2. Модуль квантования по п. 1, в котором
- квантователь с заполнением шумом связан с относительно низшим SNR из указанных различных отношений SNR;
- один или несколько детерминированных квантователей без добавления псевдослучайного шума связаны с одним или несколькими относительно наивысшими отношениями SNR из указанных различных отношений SNR;
- один или несколько квантователей с добавлением псевдослучайного шума связаны с одним или несколькими промежуточными отношениями SNR, которые выше, чем относительно низшее SNR, и ниже, чем одно или несколько относительно наивысших отношений SNR из указанных различных отношений SNR, при этом относительно наивысшие отношения SNR представляют собой Ncq>0, а относительно низшие отношения SNR≤0, где Ncq представляет собой N классических квантователей.
3. Модуль квантования по п. 1, в котором указанный набор квантователей упорядочен в соответствии с увеличением отношений SNR, связанных с указанными различными квантователями.
4. Модуль квантования по п. 3, в котором
- разность SNR имеет вид разности отношений SNR, связанных с парой смежных квантователей из указанного упорядоченного набора квантователей; и
- указанные разности SNR для всех пар смежных квантователей из указанных различных квантователей подпадают под интервал разностей SNR с центром около целевой разности SNR.
5. Модуль квантования по п. 1, в котором квантователь с заполнением шумом
- содержит генератор случайных чисел, сконфигурированный для генерирования случайных чисел в соответствии с предварительно определенной статистической моделью; и/или
- связан с SNR, меньшим или равным 0 дБ.
6. Модуль квантования по п. 1, в котором отдельный квантователь с добавлением псевдослучайного шума из одного или нескольких квантователей с добавлением псевдослучайного шума содержит
- модуль применения псевдослучайного шума, сконфигурированный для определения первого коэффициента с добавлением псевдослучайного шума; и
- скалярный квантователь, сконфигурированный для определения первого индекса квантования путем присвоения указанного первого коэффициента с добавлением псевдослучайного шума одному из интервалов скалярного квантователя.
7. Модуль квантования по п. 6, в котором отдельный квантователь с добавлением псевдослучайного шума из одного или нескольких квантователей с добавлением псевдослучайного шума также содержит:
- обратный скалярный квантователь, сконфигурированный для присвоения первого восстанавливаемого значения первому указанному индексу квантования;
- модуль удаления псевдослучайного шума, сконфигурированный для определения первого коэффициента с удаленным псевдослучайным шумом.
8. Модуль квантования по п. 6, в котором
- скалярный квантователь имеет предварительно определенную величину Δ шага квантователя; и
- предварительно определенный интервал псевдослучайного шума имеет ширину, меньшую или равную указанной предварительно определенной величине Δ шага квантователя.
9. Модуль квантования по п. 1, в котором
- блок коэффициентов связан с огибающей спектра блока;
- огибающая спектра блока служит признаком ряда значений спектральной энергии для ряда элементов разрешения по частоте; и
- указатель SNR зависит от огибающей спектра блока.
10. Модуль квантования по п. 1, в котором
- указанный ряд коэффициентов из блока коэффициентов присвоен ряду полос частот;
- полоса частот содержит один или несколько элементов разрешения по частоте; и
- модуль квантования сконфигурирован для выбора квантователя из набора квантователей для каждой полосы из указанного ряда полос частот так, чтобы коэффициенты, назначенные одной и той же полосе частот, квантовались с использованием одного и того же квантователя.
11. Модуль квантования по п. 1, при этом модуль квантования сконфигурирован для
- определения дополнительной информации, служащей признаком одного из свойств блока коэффициентов; и
- генерирования набора квантователей в зависимости от дополнительной информации.
12. Модуль обратного квантования, сконфигурированный для деквантования индексов квантования; при этом указанные индексы квантования связаны с блоком коэффициентов, определяемым преобразованием звукового сигнала между временной и частотной областями, содержащим ряд коэффициентов для ряда соответствующих элементов разрешения по частоте, при этом модуль обратного квантования сконфигурирован для
- создания набора квантователей; при этом набор квантователей содержит ограниченное количество различных квантователей, связанных с различными отношениями сигнал-шум, соответственно, именуемыми SNR; при этом указанные различные квантователи из набора квантователей упорядочены в соответствии с их SNR; при этом набор квантователей содержит:
- квантователь с заполнением шумом; при этом квантователь с заполнением шумом сконфигурирован для квантования коэффициента путем замены значения этого коэффициента случайным значением, сгенерированным в соответствии с указанной предварительно определенной статистической моделью;
- один или несколько квантователей с добавлением псевдослучайного шума; и
- один или несколько детерминированных квантователей без добавления псевдослучайного шума;
- определения указателя SNR, служащего признаком SNR, приписанного первому коэффициенту из указанного блока коэффициентов;
- выбора первого квантователя из набора квантователей на основе этого указателя SNR; и
- определения первого квантованного коэффициента для указанного первого коэффициента с использованием указанного первого квантователя.
13. Речевой кодер на основе преобразования, сконфигурированный для кодирования речевого сигнала в битовый поток, при этом кодер содержит:
- модуль кадрирования, сконфигурированный для приема ряда последовательных блоков коэффициентов преобразования, содержащего текущий блок и один или несколько предыдущих блоков;
- модуль выравнивания, сконфигурированный для определения текущего блока выровненных коэффициентов преобразования путем выравнивания соответствующего текущего блока коэффициентов преобразования с использованием соответствующей огибающей текущего блока;
- предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя; при этом один или несколько предыдущих блоков восстановленных коэффициентов преобразования были получены из одного или нескольких предыдущих блоков коэффициентов преобразования;
- разностный модуль, сконфигурированный для определения текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования; и
- модуль квантования по п. 1, сконфигурированный для квантования коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания; при этом данные коэффициентов для битового потока определяются на основе индексов квантования, связанных с указанными квантованными коэффициентами.
14. Речевой кодер на основе преобразования по п. 13, в котором
- блок коэффициентов преобразования содержит коэффициенты MDCT; и/или
- блок коэффициентов преобразования содержит 256 коэффициентов преобразования в 256 элементах разрешения по частоте.
15. Речевой кодер на основе преобразования по п. 13, также содержащий модуль масштабирования, сконфигурированный для определения текущего блока коэффициентов ошибок с измененным масштабом на основании текущего блока коэффициентов ошибок предсказания с использованием одного или нескольких правил масштабирования так, что в среднем дисперсия указанных коэффициентов ошибок с измененным масштабом из текущего блока коэффициентов ошибок с измененным масштабом больше дисперсии указанных коэффициентов ошибок предсказания из текущего блока коэффициентов ошибок предсказания; при этом
- текущий блок коэффициентов ошибок предсказания содержит ряд коэффициентов ошибок предсказания для соответствующего ряда элементов разрешения по частоте; и
- коэффициенты усиления масштабирования, применяемые модулем масштабирования к указанным коэффициентам ошибок предсказания в соответствии с одним или несколькими правилами масштабирования, зависят от элементов разрешения по частоте соответствующих коэффициентов ошибок предсказания.
16. Речевой кодер на основе преобразования по п. 13, в котором
- предсказатель сконфигурирован для определения текущего блока оценочных выровненных коэффициентов преобразования с использованием критерия средневзвешенной квадратичной ошибки; и
- указанный критерий средневзвешенной квадратичной ошибки учитывает огибающую текущего блока в качестве весовых коэффициентов.
17. Речевой кодер на основе преобразования по п. 13, при этом
- речевой кодер на основе преобразования также содержит модуль распределения битов, сконфигурированный для определения вектора распределения на основе огибающей текущего блока; и
- указанный вектор распределения служит признаком первого квантователя из набора предварительно определенных квантователей, подлежащих использованию для квантования первого коэффициента, полученного из текущего блока коэффициентов ошибок предсказания.
18. Речевой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного речевого сигнала, при этом декодер содержит:
- предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя, полученных из битового потока;
- модуль обратного квантования по п. 12, сконфигурированный для определения текущего блока квантованных коэффициентов ошибок предсказания на основе данных коэффициентов, заключенных в битовом потоке, с использованием набора предварительно определенных квантователей;
- модуль сложения, сконфигурированный для определения текущего блока восстановленных выровненных коэффициентов преобразования на основе текущего блока оценочных выровненных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания; и
- модуль обратного выравнивания, сконфигурированный для определения текущего блока восстановленных коэффициентов преобразования путем создания текущего блока восстановленных выровненных коэффициентов преобразования с формой спектра, с использованием огибающей текущего блока; при этом указанный восстановленный речевой сигнал определяется на основе текущего блока восстановленных коэффициентов преобразования.
19. Способ квантования первого коэффициента из блока коэффициентов, полученного из блока коэффициентов, определяемого преобразованием звукового сигнала между временной и частотной областями; при этом блок коэффициентов содержит ряд коэффициентов для ряда соответствующих элементов разрешения по частоте, при этом способ включает:
- создание набора квантователей; при этом набор квантователей содержит ряд различных квантователей, связанных с рядом различных отношений сигнал-шум, соответственно, именуемых SNR; при этом указанный ряд различных квантователей содержит
- квантователь с заполнением шумом; при этом квантователь с заполнением шумом сконфигурирован для квантования указанного первого коэффициента путем замены значения этого первого коэффициента случайным значением, сгенерированным в соответствии с указанной предварительно определенной статистической моделью;
- один или несколько квантователей с добавлением псевдослучайного шума; и
- один или несколько детерминированных квантователей без добавления псевдослучайного шума;
- определение указателя SNR, служащего признаком SNR, приписанного указанному первому коэффициенту;
- выбор первого квантователя из набора квантователей на основе этого указателя SNR; и
- квантование указанного первого коэффициента с использованием указанного квантователя.
20. Способ деквантования индексов квантования; при этом указанные индексы квантования связаны с блоком коэффициентов, определяемым преобразованием звукового сигнала между временной и частотной областями, содержащим ряд коэффициентов для ряда соответствующих элементов разрешения по частоте, при этом способ включает:
- создание набора квантователей; при этом набор квантователей содержит ряд различных квантователей, связанных с рядом различных отношений сигнал-шум, соответственно, именуемых SNR, при этом указанный ряд различных квантователей содержит:
- квантователь с заполнением шумом; при этом квантователь с заполнением шумом сконфигурирован для квантования коэффициента путем замены значения этого коэффициента случайным значением, сгенерированным в соответствии с указанной предварительно определенной статистической моделью;
- один или несколько квантователей с добавлением псевдослучайного шума; и
- один или несколько детерминированных квантователей без добавления псевдослучайного шума;
- определение указателя SNR, служащего признаком SNR, приписанного первому коэффициенту из блока коэффициентов;
- выбор первого квантователя из набора квантователей на основе этого указателя SNR; и
- определение первого квантованного коэффициента для указанного первого коэффициента с использованием указанного первого квантователя.
| US 7447631 B2, 04.11.2008 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| ТОПЛИВНАЯ КОМПОЗИЦИЯ | 1995 |
|
RU2077550C1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ ПРОГНОЗИРОВАНИЯ ПРОФЕССИОНАЛЬНОЙ ПРИГОДНОСТИ В УСЛОВИЯХ ЭКСТРЕМАЛЬНОЙ ДЕЯТЕЛЬНОСТИ | 2011 |
|
RU2466675C1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| RU 2011104784 A, 20.08.2012. | |||

