ОБЛАСТЬ ТЕХНИЧЕСКОГО ПРИМЕНЕНИЯ
Настоящий документ относится к системе звукового кодирования и декодирования (именуемой системой звукового кодека). В частности, настоящий документ относится к системе звукового кодека на основе преобразования, особенно хорошо подходящей для голосового кодирования/декодирования.
ПРЕДПОСЫЛКИ
Перцепционные звуковые кодеры общего назначения достигают относительно высоких эффективностей кодирования путем использования таких преобразований, как модифицированное дискретное косинусное преобразование (MDCT) с размерами блоков дискретных значений, охватывающими несколько десятков миллисекунд (например, 20 мс). Одним из примеров такой системы звукового кодека на основе преобразования является Advanced Audio Coding (AAC) или High Efficiency (HE)-AAC. Однако при использовании таких систем звуковых кодеков на основе преобразования для голосовых сигналов качество голосовых сигналов в направлении более низких битовых скоростей передачи данных ухудшается быстрее, чем таковое для музыкальных сигналов, особенно в случае сухих (нереверберирующих) речевых сигналов. Поэтому системы звуковых кодеков на основе преобразования в своей сущности не являются хорошо подходящими для кодирования голосовых сигналов или для кодирования звуковых сигналов, содержащих голосовую составляющую. Иными словами, системы звуковых кодеков на основе преобразования проявляют асимметрию в отношении эффективности кодирования, достигаемой для музыкальных сигналов, по сравнению с эффективностью кодирования, достигаемой для голосовых сигналов. К этой асимметрии можно обратиться, предусматривая дополнения к кодированию на основе преобразования, в котором эти дополнения нацелены на улучшение формирования спектра или совпадения сигналов. Примерами таких дополнений являются предварительное/последующее формирование, временное ограничение шума (TNS) и MDCT с деформацией шкалы времени. Кроме того, к этой асимметрии можно обратиться путем добавления классического речевого кодера во временной области, основывающегося на фильтрации с краткосрочным предсказанием (LPC) и долгосрочном предсказании (LTP).
Можно показать, что улучшения, достигаемые путем снабжения дополнениями кодирования на основе преобразования, как правило, недостаточны для выравнивания пробела в производительности между кодированием музыкальных сигналов и речевых сигналов. С другой стороны, добавление классического речевого кодера во временной области заполняет этот пробел в производительности, однако лишь в той мере, в которой асимметрия производительности обращается в противоположном направлении. Это вызвано тем, что такие классические речевые кодеры во временной области моделируют систему речеобразования человека и были оптимизированы для кодирования речевых сигналов.
В виду вышесказанного звуковой кодек на основе преобразования можно использовать совместно с классическим речевым кодеком во временной области, при этом классический речевой кодек во временной области используется для речевых сегментов звукового сигнала, и при этом кодек на основе преобразования используется для остальных сегментов этого звукового сигнала. Однако сосуществование кодеков во временной области и в области преобразования в единой системе кодека требует надежных инструментальных средств для переключения между различными кодеками на основе свойств звукового сигнала. В дополнение, это фактическое переключение между кодеком во временной области (для речевого содержимого) и кодеком в области преобразования (для остального содержимого) может быть затруднительным для реализации. В частности, может быть затруднительно обеспечить плавный переход между кодеком во временной области и кодеком в области преобразования (и наоборот). Кроме того, для того чтобы сделать кодек во временной области более устойчивым к внешним воздействиям при неизбежном случайном кодировании неречевых сигналов, например, при кодировании поющего голоса с инструментальным фоном, могут потребоваться модификации этого кодека во временной области. Настоящий документ направлен на вышеупомянутые технические проблемы систем звуковых кодеков. В частности, настоящий документ описывает систему звукового кодека, транслирующую только критические характерные признаки речевого кодека и посредством этого достигающую равномерной производительности для речи и музыки, в то же время, оставаясь в пределах архитектуры кодека на основе преобразования. Иными словами, настоящий документ описывает звуковой кодек на основе преобразования, особенно хорошо подходящий для кодирования речевых или голосовых сигналов.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Согласно одному из аспектов, описывается речевой кодер на основе преобразования. Этот речевой кодер сконфигурирован для кодирования речевого сигнала в битовый поток. Следует отметить, что впоследствии описываются различные аспекты этого речевого кодера на основе преобразования. Ясно указывается, что эти аспекты могут различными способами сочетаться друг с другом. В частности, аспекты, описываемые в зависимости от различных независимых пунктов формулы изобретения, могут сочетаться с другими независимыми пунктами формулы изобретения. Кроме того, аспекты, описываемые в контексте кодера, аналогичным образом применимы и к соответствующему декодеру.
Речевой кодер может содержать модуль кадрирования, сконфигурированный для приема набора блоков. Этот набор блоков может соответствовать сдвинутому набору блоков, описываемому в подробном описании настоящего документа. В качестве альтернативы, этот набор блоков может соответствовать текущему набору блоков, описываемому в подробном описании настоящего документа.
Этот набор блоков содержит ряд последовательных блоков коэффициентов преобразования, и этот ряд последовательных блоков служит признаком дискретных значений речевого сигнала. В частности, этот набор блоков может содержать четыре или большее количество блоков коэффициентов преобразования. Блок из этого ряда последовательных блоков мог быть определен, исходя из речевого сигнала с использованием модуля преобразования, сконфигурированного для преобразования предварительно определенного количества дискретных значений речевого сигнала из временной области в частотную область. В частности, этот модуль преобразования может быть сконфигурирован для выполнения такого преобразования из временной области в частотную область, как модифицированное дискретное косинусное преобразование (MDCT). Как таковой, блок коэффициентов преобразования может содержать ряд коэффициентов преобразования (также именуемых частотными коэффициентами или спектральными коэффициентами) для соответствующего ряда элементов разрешения по частоте. В частности, блок коэффициентов преобразования может содержать коэффициенты MDCT.
Количество элементов разрешения по частоте, или размер блока, как правило, зависит от размера преобразования, выполняемого модулем преобразования. В одном из предпочтительных примеров блоки из указанного ряда последовательных блоков соответствуют так называемым коротким блокам, содержащим, например, 256 элементов разрешения по частоте. В дополнение к коротким блокам, модуль преобразования может быть сконфигурирован для генерирования так называемых длинных блоков, содержащих, например, 1024 элементов разрешения по частоте. Эти длинные блоки могут быть использованы звуковым кодером для кодирования стационарных сегментов входного звукового сигнала. Однако ряд последовательных блоков, используемых для кодирования речевого сигнала (или речевого сегмента, заключенного во входном звуковом сигнале), может содержать только короткие блоки. В частности, блоки коэффициентов преобразования могут содержать 256 коэффициентов преобразования в 256 элементов разрешения по частоте.
В более общих выражениях, количество элементов разрешения по частоте, или размер блока, может быть таким, чтобы блок коэффициентов преобразования охватывал диапазон 3—7 миллисекунд речевого сигнала (например, 5 мс речевого сигнала). Размер блока можно выбирать так, чтобы речевой кодер мог действовать в синхронном режиме с кадрами видеоизображения, кодируемыми видеокодером. Модуль преобразования может быть сконфигурирован для генерирования блоков коэффициентов преобразования, содержащих разное количество элементов разрешения по частоте. Например, модуль преобразования может быть сконфигурирован для генерирования блоков, содержащих 1920, 960, 480, 240, 120 элементов разрешения по частоте при частоте дискретизации 48 кГц. Для речевого кодера можно использовать размер блока, охватывающий диапазон 3—7 мс речевого сигнала. В приведенном выше примере для речевого кодера можно использовать блок, содержащий 240 элементов разрешения по частоте.
Речевой кодер также может содержать модуль оценивания огибающей, сконфигурированный для определения текущей огибающей на основе ряда последовательных блоков коэффициентов преобразования. Эту ткущую огибающую можно определить на основе ряда последовательных блоков из этого набора блоков. Можно учитывать дополнительные блоки, например, блоки из набора блоков, непосредственно предшествующего этому набору блоков. В качестве альтернативы или в дополнение, можно учитывать так называемые блоки предварительного просмотра. В целом, это может быть предпочтительно для обеспечения непрерывности между последовательными наборами блоков. Текущая огибающая может служить признаком ряда значений спектральной энергии для соответствующего ряда элементов разрешения по частоте. Иными словами, текущая огибающая может иметь такой же размер, как каждый блок в ряду последовательных блоков. Иными словами, для ряда блоков (т.е. для более чем одного блока) речевого сигнала можно определить единственную огибающую. Это является преимущественным для цели создания представительной статистики в отношении спектральных данных, заключенных в ряду последовательных блоков.
Текущая огибающая может служить признаком ряда значений спектральной энергии для соответствующего ряда полос частот. Полоса частот может содержать один или несколько элементов разрешения по частоте. В частности, одна или несколько полос частот могут содержать более одного элемента разрешения по частоте. Количество элементов разрешения по частоте, приходящихся на полосу частот, может увеличиваться при повышении частоты. Иными словами, количество элементов разрешения по частоте, приходящихся на полосу частот, может зависеть от психоакустических соображений. Модуль оценивания огибающей может быть сконфигурирован для определения значения спектральной энергии для конкретной полосы частот на основе коэффициентов преобразования из ряда последовательных блоков, находящихся в пределах данной конкретной полосы частот. В частности, модуль оценивания огибающей может быть сконфигурирован для определения значения спектральной энергии для конкретной полосы частот на основе среднеквадратичного значения коэффициентов преобразования из ряда последовательных блоков, находящихся в пределах данной конкретной полосы частот. Как таковая, текущая огибающая может служить признаком средней огибающей спектра для огибающих спектра ряда последовательных блоков. Кроме того, текущая огибающая может иметь полосную разрешающую способность по частоте.
Речевой кодер также может содержать модуль интерполяции огибающих, сконфигурированный для определения ряда интерполированных огибающих, соответственно, для ряда последовательных блоков коэффициентов преобразования на основе текущей огибающей. В частности, этот ряд интерполированных огибающих можно определить на основе квантованной текущей огибающей, также доступной и в соответствующем декодере. Действуя таким образом, обеспечивают то, что указанный ряд интерполированных огибающих можно определять одинаковым образом в речевом кодере и в соответствующем речевом декодере. Таким образом, характерные признаки модуля интерполяции огибающих, описываемые в контексте речевого кодера, также применимы и к речевому декодеру, и наоборот. В целом, модуль интерполяции огибающих может быть сконфигурирован для определения на основе текущей огибающей приближения огибающей спектра (т.е. интерполированной огибающей) каждого блока из ряда последовательных блоков.
Речевой кодер также может содержать модуль выравнивания, сконфигурированный для определения ряда блоков выровненных коэффициентов преобразования путем выравнивания соответствующего ряда блоков коэффициентов преобразования, соответственно, с использованием соответствующего ряда интерполированных огибающих. В частности, для выравнивания, т.е. для удаления формы спектра, коэффициентов преобразования, заключенных в данном конкретном блоке, можно использовать интерполированную огибающую для данного конкретного блока (или огибающую, полученную исходя из нее). Следует отметить, что этот процесс выравнивания отличается от операции отбеливания, применяемой к данному конкретному блоку коэффициентов преобразования. То есть выровненные коэффициенты преобразования нельзя интерпретировать как коэффициенты преобразования отбеленного сигнала во временной области, обычно вырабатываемые посредством анализа LPC (кодирования с линейным предсказанием) классического речевого кодера. Общим является только аспект создания сигнала с относительно равномерным спектром мощности. Однако процесс получения такого равномерного спектра мощности отличается. Как будет описано в настоящем документе, использование оценочной огибающей спектра для выравнивания блока коэффициентов преобразования является преимущественным, поскольку эту оценочную огибающую спектра можно использовать в целях распределения битов.
Речевой кодер на основе преобразования также может содержать модуль определения коэффициента усиления огибающей, сконфигурированный для определения ряда коэффициентов усиления огибающей, соответственно, для ряда блоков коэффициентов преобразования. Кроме того, речевой кодер на основе преобразования может содержать модуль уточнения огибающей, сконфигурированный для определения ряда скорректированных огибающих путем сдвига ряда интерполированных огибающих в соответствии с рядом коэффициентов усиления огибающей, соответственно. Модуль определения коэффициента усиления огибающей может быть сконфигурирован для определения первого коэффициента усиления огибающей для первого блока коэффициентов преобразования (из ряда последовательных блоков) так, чтобы дисперсия выровненных коэффициентов преобразования из соответствующего первого блока выровненных коэффициентов преобразования, полученных с использованием первой скорректированной огибающей, уменьшалась по сравнению с дисперсией выровненных коэффициентов преобразования из соответствующего первого блока выровненных коэффициентов преобразования, полученного с использованием первой интерполированной огибающей. Эту первую скорректированную огибающую можно определить путем сдвига первой интерполированной огибающей с использованием первого коэффициента усиления огибающей.
Эта первая интерполированная огибающая может представлять собой интерполированную огибающую из ряда интерполированных огибающих для первого блока коэффициентов преобразования из ряда блоков коэффициентов преобразования.
В частности, модуль определения коэффициента усиления огибающей может быть сконфигурирован для определения первого коэффициента усиления огибающей для первого блока коэффициентов преобразования так, чтобы дисперсия выровненных коэффициентов преобразования из соответствующего блока выровненных коэффициентов преобразования, полученного с использованием первой скорректированной огибающей, была равна единице. Модуль выравнивания может быть сконфигурирован для определения ряда блоков выровненных коэффициентов преобразования путем выравнивания соответствующего ряда блоков коэффициентов преобразования с использованием соответствующего ряда скорректированных огибающих, соответственно. Как результат, каждый блок выровненных коэффициентов преобразования может иметь дисперсию, равную единице.
Модуль определения коэффициента усиления огибающей может быть сконфигурирован для вставки данных коэффициентов усиления, служащих признаком ряда коэффициентов усиления огибающей, в битовый поток. Как результат, соответствующий декодер имеет возможность определять ряд скорректированных огибающих таким же образом, как кодер.
Речевой кодер может быть сконфигурирован для определения битового потока на основе ряда блоков выровненных коэффициентов преобразования. В частности, речевой кодер может быть сконфигурирован для определения данных коэффициентов на основе ряда блоков выровненных коэффициентов преобразования, причем эти данные коэффициентов вводят в битовый поток.
Ниже описываются примеры средств для определения данных коэффициентов на основе ряда блоков выровненных коэффициентов преобразования.
Речевой кодер на основе преобразования может содержать модуль квантования огибающей, сконфигурированный для определения квантованной текущей огибающей путем квантования текущей огибающей. Кроме того, этот модуль квантования огибающей может быть сконфигурирован для вставки данных огибающей в битовый поток, при этом данные огибающей служат признаком этой квантованной текущей огибающей. Как результат, соответствующий декодер может быть осведомлен о квантованной текущей огибающей путем декодирования данных огибающей. Модуль интерполяции огибающих может быть сконфигурирован для определения ряда интерполированных огибающих на основе квантованной текущей огибающей. Действуя таким образом, можно обеспечить то, что кодер и декодер будут сконфигурированы для определения одного и того же ряда интерполированных огибающих.
Речевой кодер на основе преобразования может быть сконфигурирован для действия в ряде различных режимов. Эти различные режимы могут включать режим короткого шага и режим длинного шага. Когда речевой кодер на основе преобразования действует в режиме короткого шага, модуль кадрирования, модуль оценивания огибающей и модуль интерполяции огибающих могут быть сконфигурированы для обработки набора блоков, содержащего ряд последовательных блоков коэффициентов преобразования. Таким образом, в режиме короткого шага кодер может быть сконфигурирован для подразделения сегмента/кадра звукового сигнала на последовательность последовательных блоков, которые последовательно обрабатываются кодером.
С другой стороны, когда речевой кодер на основе преобразования действует в режиме длинного шага, модуль кадрирования, модуль оценивания огибающей и модуль интерполяции огибающих могут быть сконфигурированы для обработки набора блоков, содержащего лишь единственный блок коэффициентов преобразования. Таким образом, в режиме длинного шага кодер может быть сконфигурирован для обработки полного сегмента/кадра звукового сигнала без подразделения на блоки. Это может быть преимущественным для коротких сегментов/кадров звукового сигнала и/или для музыкальных сигналов. В режиме длинного шага модуль оценивания огибающей может быть сконфигурирован для определения текущей огибающей этого единственного блока коэффициентов преобразования, заключенного в наборе блоков. Модуль интерполяции огибающих может быть сконфигурирован для определения интерполированной огибающей для этого единственного блока коэффициентов преобразования как текущей огибающей этого единственного блока коэффициентов преобразования. Иными словами, описываемая в настоящем документе интерполяция огибающих в режиме длинного шага может быть обойдена, а текущая огибающая указанного единственного блока может быть приравнена интерполированной огибающей (для дальнейшей обработки).
Согласно другому аспекту, описывается речевой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного речевого сигнала. Как уже указывалось выше, этот декодер может содержать компоненты, аналогичные компонентам соответствующего кодера. Декодер может содержать модуль декодирования огибающей, сконфигурированный для определения квантованной текущей огибающей исходя из данных огибающей, заключенных в битовом потоке. Как указывалось выше, эта квантованная текущая огибающая, как правило, служит признаком ряда значений спектральной энергии для соответствующего ряда элементов разрешения по частоте полос частот. Кроме того, битовый поток может содержать данные (например, данные коэффициентов), служащие признаком ряда последовательных блоков восстановленных выровненных коэффициентов преобразования. Этот ряд последовательных блоков восстановленных выровненных коэффициентов преобразования, как правило, связан с соответствующим рядом последовательных блоков выровненных коэффициентов преобразования в кодере. Этот ряд последовательных блоков может соответствовать ряду последовательных блоков из набора блоков, например, из описываемого ниже сдвинутого набора блоков. Блок восстановленных выровненных коэффициентов преобразования может содержать ряд восстановленных выровненных коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте.
Декодер также может содержать модуль интерполяции огибающих, сконфигурированный для определения ряда интерполированных огибающих, соответственно, для ряда блоков восстановленных выровненных коэффициентов преобразования на основе квантованной текущей огибающей. Модуль интерполяции огибающих декодера, как правило, действует таким же образом, как модуль интерполяции огибающих кодера. Модуль интерполяции огибающих может быть сконфигурирован для определения ряда интерполированных огибающих также на основе квантованной предыдущей огибающей. Эта квантованная предыдущая огибающая может быть связана с рядом предыдущих блоков восстановленных коэффициентов преобразования, непосредственно предшествующих этому ряду блоков восстановленных коэффициентов преобразования. Как таковая, квантованная предыдущая огибающая могла быть получена декодером как данные огибающей для предыдущего набора блоков коэффициентов преобразования (например, в случае так называемого Р-кадра). В качестве альтернативы или в дополнение, данные огибающей для этого набора блоков могут служить признаком квантованной предыдущей огибающей в дополнение к тому, что они служат признаком квантованной текущей огибающей (например, в случае так называемого I-кадра). Это делает возможным декодирование I-кадра в отсутствие знания о предыдущих данных.
Модуль интерполяции огибающих может быть сконфигурирован для определения значения спектральной энергии для конкретного элемента разрешения по частоте, исходя из первой интерполированной огибающей, путем интерполирования значений спектральной энергии для данного конкретного элемента разрешения по частоте квантованной текущей огибающей и квантованной предыдущей огибающей в первый промежуточный момент времени. Первая интерполированная огибающая связана с первым блоком ряда последовательных блоков восстановленных выровненных коэффициентов преобразования или соответствует этому первому блоку. Как описывалось выше, квантованная предыдущая и квантованная текущая огибающие, как правило, представляют собой полосные огибающие. Значения спектральной энергии для конкретной полосы частот, как правило, являются постоянными для всех элементов разрешения по частоте, заключенных в этой полосе частот.
Модуль интерполяции огибающих может быть сконфигурирован для определения значения спектральной энергии для конкретного элемента разрешения по частоте первой интерполированной огибающей путем квантования интерполяции между значениями спектральной энергии для данного конкретного элемента разрешения по частоте квантованной текущей огибающей и квантованной предыдущей огибающей. Как таковой, ряд интерполированных огибающих может представлять собой ряд квантованных интерполированных огибающих.
Модуль интерполяции огибающих может быть сконфигурирован для определения значения спектральной энергии для конкретного элемента разрешения по частоте второй интерполированной огибающей путем интерполирования значений спектральной энергии для данного конкретного элемента разрешения по частоте квантованной текущей огибающей и квантованной предыдущей огибающей во второй промежуточный момент времени. Вторая интерполированная огибающая может быть связана со вторым блоком из ряда блоков восстановленных выровненных коэффициентов преобразования или может соответствовать этому второму блоку. Второй блок восстановленных выровненных коэффициентов преобразования может следовать за первым блоком восстановленных выровненных коэффициентов преобразования, а указанный второй промежуточный момент времени может следовать за указанным первым промежуточным моментом времени. В частности, разность между вторым промежуточным моментом времени и первым промежуточным моментом времени может соответствовать промежутку времени между вторым блоком восстановленных выровненных коэффициентов преобразования и первым блоком восстановленных выровненных коэффициентов преобразования.
Модуль интерполяции огибающих может быть сконфигурирован для одной или нескольких следующих интерполяций: линейной интерполяции, геометрической интерполяции и гармонической интерполяции. Кроме того, модуль интерполяции огибающих может быть сконфигурирован для выполнения интерполяции в логарифмической области.
Кроме того, декодер может содержать модуль обратного выравнивания, сконфигурированный для определения ряда блоков восстановленных коэффициентов преобразования путем придания формы спектра соответствующему ряду блоков восстановленных выровненных коэффициентов преобразования, соответственно, с использованием соответствующего ряда интерполированных огибающих. Как указывалось выше, битовый поток может служить признаком ряда коэффициентов усиления огибающей (в данных коэффициентов усиления), соответственно, для ряда блоков восстановленных выровненных коэффициентов преобразования. Речевой декодер на основе преобразования также может содержать модуль уточнения огибающей, сконфигурированный для определения ряда скорректированных огибающих путем применения ряда коэффициентов усиления огибающей, соответственно, к ряду интерполированных огибающих. Модуль обратного выравнивания может быть сконфигурирован для определения ряда блоков восстановленных коэффициентов преобразования путем придания формы спектра соответствующему ряду блоков восстановленных выровненных коэффициентов преобразования с использованием соответствующего ряда скорректированных огибающих, соответственно.
Декодер может быть сконфигурирован для определения восстановленного речевого сигнала на основе ряда блоков восстановленных коэффициентов преобразования.
Согласно еще одному аспекту, описывается речевой кодер на основе преобразования, сконфигурированный для кодирования речевого сигнала в битовый поток. Этот кодер может содержать любой из описываемых в настоящем документе характерных признаков и/или компонентов, относящихся к кодеру. В частности, этот кодер может содержать модуль кадрирования, сконфигурированный для приема ряда последовательных блоков коэффициентов преобразования. Этот ряд последовательных блоков содержит текущий блок и один или несколько предыдущих блоков. Как указывалось выше, этот ряд последовательных блоков служит признаком дискретных значений речевого сигнала.
Кроме того, указанный кодер может содержать модуль выравнивания, сконфигурированный для определения текущего блока и одного или нескольких предыдущих блоков выровненных коэффициентов преобразования путем выравнивания соответствующего текущего блока и одного или нескольких предыдущих блоков коэффициентов преобразования с использованием соответствующей текущей огибающей блока и соответствующих одной или нескольких предыдущих огибающих блоков, соответственно. Эти огибающие блоков могут соответствовать вышеупомянутым скорректированным огибающим.
В дополнение, кодер содержит предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов предсказателя на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя. Указанные один или несколько блоков восстановленных коэффициентов преобразования могли быть получены, соответственно, исходя из одного или нескольких предыдущих блоков выровненных коэффициентов преобразования (например, с использованием предсказателя).
Указанный предсказатель может содержать экстрактор, сконфигурированный для определения текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя. Как таковой, экстрактор может действовать в невыровненной области (т.е. экстрактор может действовать на блоках коэффициентов преобразования, имеющих форму спектра). Это может быть преимущественным в отношении модели сигнала, используемой экстрактором для определения текущего блока оценочных коэффициентов преобразования.
Кроме того, предсказатель может содержать формирователь спектра, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования, на основе, по меньшей мере, одного из одной или нескольких предыдущих огибающих блоков и на основе, по меньшей мере, одного или нескольких параметров предсказателя. Как таковой, формирователь спектра может быть сконфигурирован для преобразования текущего блока оценочных коэффициентов преобразования в выровненную область с целью создания текущего блока оценочных выровненных коэффициентов преобразования. Как описывается в контексте соответствующего декодера, с этой целью формирователь спектра может использовать ряд скорректированных огибающих (или ряд огибающих блоков).
Как указывалось выше, предсказатель (в частности, экстрактор) может содержать предсказатель на основе модели, использующий модель сигнала. Эта модель сигнала может содержать один или несколько параметров модели, а один или несколько параметров предсказателя могут служить признаком одного или нескольких параметров модели. Использование предсказателя на основе модели может быть преимущественным для обеспечения средств, эффективных с точки зрения битовой скорости передачи данных, для описания коэффициентов предсказания, используемых предсказателем поддиапазонов (или предсказателем элементов разрешения по частоте). В частности, можно определить полный набор коэффициентов предсказания, используя лишь небольшое количество параметров модели, которые можно передавать в качестве данных предсказателя в соответствующий декодер эффективным с точки зрения битовой скорости передачи данных образом. Как таковой, предсказатель на основе модели может быть сконфигурирован для определения одного или нескольких параметров модели для модели сигнала (например, с использованием алгоритма Дарбина-Левинсона). Кроме того, предсказатель на основе модели может быть сконфигурирован для определения коэффициента предсказания, подлежащего применению к первому восстановленному коэффициенту преобразования в первом элементе разрешения по частоте предыдущего блока восстановленных коэффициентов преобразования на основе модели сигнала и на основе одного или нескольких параметров модели. В частности, можно определить ряд коэффициентов предсказания для ряда восстановленных коэффициентов преобразования. Действуя таким образом и применяя коэффициент предсказания к первому восстановленному коэффициенту преобразования, можно определить оценку первого оценочного коэффициента преобразования в первом элементе разрешения по частоте текущего блока оценочных коэффициентов преобразования. В частности, действуя таким образом, можно определить оценочные коэффициенты преобразования из текущего блока оценочных коэффициентов преобразования.
Например, модель сигнала может содержать одну или несколько синусоидальных составляющих модели, а один или несколько параметров модели могут служить признаком частоты этой одной или нескольких синусоидальных составляющих модели. В частности, эти один или несколько параметров модели могут служить признаком основной частоты мультисинусоидальной модели сигнала. Такая основная частота может соответствовать задержке во временной области.
Предсказатель может быть сконфигурирован для определения одного или нескольких параметров предсказателя так, чтобы уменьшать (например, минимизировать) среднеквадратичное значение коэффициентов ошибок предсказания из текущего блока коэффициентов ошибок предсказания. Это можно выполнить, используя, например, алгоритм Дарбина-Левинсона. Предсказатель может быть сконфигурирован для вставки данных предсказателя, служащих признаком одного или нескольких параметров предсказателя, в битовый поток. Как результат, соответствующий декодер имеет возможность определять текущий блок оценочных выровненных коэффициентов преобразования таким же образом, как и кодер.
Кроме того, кодер может содержать разностный модуль, сконфигурированный для определения текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования. Битовый поток можно определить на основе текущего блока коэффициентов ошибок предсказания. В частности, признаком текущего блока коэффициентов ошибок предсказания могут служить данные коэффициентов из битового потока.
Согласно одному из дальнейших аспектов, описывается речевой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного речевого сигнала. Этот декодер может содержать любой из описываемых в настоящем документе характерных признаков и/или компонентов. В частности, указанный декодер может содержать предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя, полученных из (данных предсказателя) битового потока. Как описывается в контексте соответствующего кодера, предсказатель может содержать экстрактор, сконфигурированный для определения текущего блока оценочных коэффициентов преобразования на основе, по меньшей мере, одного из одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе, по меньшей мере, одного из одного или нескольких параметров предсказателя. Кроме того, предсказатель может содержать формирователь спектра, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков (например, предыдущих скорректированных огибающих) и на основе одного или нескольких параметров предсказателя.
Эти один или несколько параметров предсказателя могут содержать параметр Т запаздывания блока. Этот параметр запаздывания блока может служить признаком количества блоков, предшествующих текущему блоку оценочных выровненных коэффициентов преобразования. В частности, параметр Т запаздывания блока может служить признаком периодичности речевого сигнала. Как таковой, параметр Т запаздывания блока может указывать, какой из одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования является (наиболее) похожим на текущий блок коэффициентов преобразования, и поэтому его можно использовать для предсказания текущего блока коэффициентов преобразования, т.е. его можно использовать для определения текущего блока оценочных коэффициентов преобразования.
Формирователь спектра может быть сконфигурирован для выравнивания текущего блока оценочных коэффициентов преобразования с использованием текущей оценочной огибающей. Кроме того, формирователь спектра может быть сконфигурирован для определения текущей оценочной огибающей на основе, по меньшей мере, одной из одной или нескольких предыдущих огибающих блоков и на основе параметра запаздывания блока. В частности, формирователь спектра может быть сконфигурирован для определения целочисленного значения T0 запаздывания на основе параметра Т запаздывания блока. Это целочисленное значение T0 запаздывания можно определить путем округления параметра Т запаздывания блока до ближайшего целого числа. Кроме того, формирователь спектра может быть сконфигурирован для определения текущей оценочной огибающей как предыдущей огибающей блока (например, предыдущей скорректированной огибающей) для предыдущего блока восстановленных коэффициентов преобразования, предшествующего текущему блоку оценочных выровненных коэффициентов преобразования, на количество блоков, соответствующее указанному целочисленному значению запаздывания. Следует отметить, что характерные признаки, описываемые для формирователя спектра декодера, также применимы и к формирователю спектра кодера.
Экстрактор может быть сконфигурирован для определения текущего блока оценочных коэффициентов преобразования на основе по меньшей мере одного из одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра Т запаздывания блока. Для этой цели экстрактор может использовать предсказатель на основе модели, описываемый в контексте соответствующего кодера. В этом контексте параметр Т запаздывания блока может служить признаком основной частоты мультисинусоидальной модели.
Кроме того, речевой декодер может содержать декодер спектра, сконфигурированный для определения текущего блока квантованных коэффициентов ошибок предсказания на основе данных коэффициентов, заключенных в битовом потоке. Для этой цели декодер спектра может использовать обратные квантователи, описываемые в настоящем документе. В дополнение, речевой декодер может содержать модуль сложения, сконфигурированный для определения текущего блока восстановленных выровненных коэффициентов преобразования на основе текущего блока оценочных выровненных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания. В дополнение, речевой декодер может содержать модуль обратного выравнивания, сконфигурированный для определения текущего блока восстановленных коэффициентов преобразования путем придания текущему блоку восстановленных выровненных коэффициентов преобразования формы спектра с использованием текущей огибающей блока. Кроме того, модуль выравнивания может быть сконфигурирован для определения одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования путем придания одному или нескольким предыдущим блокам восстановленных выровненных коэффициентов преобразования формы спектра с использованием, соответственно, одной или нескольких предыдущих огибающих блоков (например, предыдущих скорректированных огибающих). Речевой декодер может быть сконфигурирован для определения восстановленного речевого сигнала на основе текущего и одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования.
Этот речевой декодер на основе преобразования может содержать буфер огибающих, сконфигурированный для хранения одной или нескольких предыдущих огибающих блоков. Формирователь спектра может быть сконфигурирован для определения целочисленного значения T0 запаздывания путем ограничения целочисленного значения запаздывания количеством предыдущих огибающих блоков, хранящихся в буфере огибающих. Количество предыдущих огибающих блоков, хранящихся в буфере огибающих, может изменяться (например, в начале I-кадра). Формирователь спектра может быть сконфигурирован для определения количества предыдущих огибающих, хранящихся в буфере огибающих, и соответственного ограничения целочисленного значения Т0 запаздывания. Действуя таким образом, можно избежать ошибочных предварительных просмотров огибающих.
Формирователь спектра может быть сконфигурирован для выравнивания текущего блока оценочных коэффициентов преобразования так, чтобы перед применением одного или нескольких параметров предсказателя (в особенности перед применением коэффициента усиления предсказателя) текущий блок выровненных оценочных коэффициентов преобразования проявлял единичную дисперсию (например, в некоторых или всех полосах частот). Для этой цели битовый поток может содержать параметр коэффициента усиления дисперсии, а формирователь спектра может быть сконфигурирован для применения этого параметра коэффициента усиления дисперсии к текущему блоку оценочных коэффициентов преобразования. Это может быть преимущественным в отношении качества предсказания.
Согласно одному из дальнейших аспектов, описывается речевой кодер на основе преобразования, сконфигурированный для кодирования речевого сигнала в битовый поток. Как уже описывалось выше, этот кодер может содержать любой из относящихся к кодеру признаков и/или компонентов, описываемых в настоящем документе. В частности, этот кодер может содержать модуль кадрирования, сконфигурированный для приема ряда последовательных блоков коэффициентов преобразования. Этот ряд последовательных блоков содержит текущий блок и один или несколько предыдущих блоков. Кроме того, этот ряд последовательных блоков служит признаком дискретных значений речевого сигнала.
В дополнение, указанный речевой кодер может содержать модуль выравнивания, сконфигурированный для определения текущего блока выровненных коэффициентов преобразования путем выравнивания соответствующего текущего блока коэффициентов преобразования с использованием соответствующей текущей огибающей блока (например, соответствующей скорректированной огибающей). Кроме того, речевой кодер может содержать предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя (включающих, например, коэффициент усиления предсказателя). Как описывалось выше, указанные один или несколько блоков восстановленных коэффициентов преобразования могли быть получены исходя из одного или нескольких предыдущих блоков коэффициентов преобразования.
В дополнение, речевой кодер может содержать разностный модуль, сконфигурированный для определения текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования.
Предсказатель может быть сконфигурирован для определения текущего блока оценочных выровненных коэффициентов преобразования с использованием критерия средневзвешенной квадратичной ошибки (например, путем минимизации критерия средневзвешенной квадратичной ошибки). Этот критерий средневзвешенной квадратичной ошибки может учитывать в качестве весовых коэффициентов текущую огибающую блока или некоторую предварительно определенную функцию этой текущей огибающей блока. В настоящем документе описываются и другие различные способы определения коэффициента усиления предсказателя с использованием критерия средневзвешенной квадратичной ошибки.
Кроме того, речевой кодер может содержать модуль квантования коэффициентов, сконфигурированный для квантования коэффициентов, получаемых из текущего блока коэффициентов ошибок предсказания с использованием набора предварительно определенных квантователей. Этот модуль квантования коэффициентов может быть сконфигурирован для определения набора предварительно определенных квантователей в зависимости по меньшей мере от одного из одного или нескольких параметров предсказателя. Это означает, что производительность предсказателя может оказывать влияние на квантователи, используемые модулем квантования коэффициентов. Модуль квантования коэффициентов может быть сконфигурирован для определения на основе квантованных коэффициентов данных коэффициентов для битового потока. Как таковые, данные коэффициентов могут служить признаком квантованной версии текущего блока коэффициентов ошибок предсказания.
Речевой кодер на основе преобразования также может содержать модуль масштабирования, сконфигурированный для определения текущего блока коэффициентов ошибок с измененным масштабом на основе текущего блока коэффициентов ошибок предсказания с использованием одного или нескольких правил масштабирования. Этот текущий блок коэффициентов ошибок с измененным масштабом может быть определен так, или указанные одно или несколько правил масштабирования могут быть таковы, что в среднем дисперсия коэффициентов ошибок с измененным масштабом из текущего блока коэффициентов ошибок с измененным масштабом является более высокой, чем дисперсия коэффициентов ошибок предсказания из текущего блока коэффициентов ошибок предсказания. В частности, указанные одно или несколько правил масштабирования могут быть таковы, что дисперсия коэффициентов ошибок предсказания находится ближе к единице для всех элементов разрешения по частоте или полос частот. Для создания данных коэффициентов, модуль квантования коэффициентов может быть сконфигурирован для квантования коэффициентов ошибок с измененным масштабом из текущего блока коэффициентов ошибок с измененным масштабом.
Текущий блок коэффициентов ошибок предсказания, как правило, содержит ряд коэффициентов ошибок предсказания для соответствующего ряда элементов разрешения по частоте. Коэффициенты усиления масштабирования, применяемые модулем масштабирования к коэффициентам ошибок предсказания в соответствии с правилом масштабирования, могут зависеть от элементов разрешения по частоте соответствующих коэффициентов ошибок предсказания. Кроме того, правило масштабирования может зависеть от одного или нескольких параметров предсказателя, например, от коэффициента усиления предсказателя. В качестве альтернативы или в дополнение, правило масштабирования может зависеть от текущей огибающей блока. В настоящем документе описываются и другие различные способы определения правила масштабирования в зависимости от элемента разрешения по частоте.
Речевой кодер на основе преобразования также может содержать модуль распределения битов, сконфигурированный для определения вектора распределения на основе текущей огибающей блока. Вектор распределения может служить признаком первого квантователя из набора предварительно определенных квантователей, подлежащих использованию для квантования первого коэффициента, полученного из текущего блока коэффициентов ошибок предсказания. В частности, вектор распределения скорости передачи данных может служить признаком квантователей, подлежащих использованию для квантования, соответственно, всех коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания. Например, вектор распределения может служить признаком того, что для каждой полосы частот должен быть использован отличающийся квантователь.
Модуль распределения битов может быть сконфигурирован для определения вектора распределения так, чтобы данные коэффициентов для текущего блока коэффициентов ошибок предсказания не превышали предварительно определенное количество битов. Кроме того, модуль распределения битов может быть сконфигурирован для определения значения смещения, служащего признаком смещения, подлежащего применению к огибающей распределения, полученной исходя из текущей огибающей блока (например, полученной исходя из текущей скорректированной огибающей). Значение смещения может быть включено в битовый поток, давая соответствующему декодеру возможность идентифицировать квантователи, которые были применены для определения данных коэффициентов. Согласно другому аспекту, описывается речевой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного речевого сигнала. Этот речевой декодер может содержать любой из характерных признаков и/или компонентов, описываемых в настоящем документе. В частности, этот декодер может содержать предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя, полученных из битового потока. Кроме того, речевой декодер может содержать декодер спектра, сконфигурированный для определения текущего блока квантованных коэффициентов ошибок предсказания (или их версии с измененным масштабом) на основе данных коэффициентов, заключенных в битовом потоке, с использованием набора предварительно определенных квантователей. В частности, этот декодер спектра может использовать набор предварительно определенных обратных квантователей, соответствующих набору предварительно определенных квантователей, использованных соответствующим кодером.
Декодер спектра может быть сконфигурирован для определения набора предварительно определенных квантователей (и/или соответствующего набора предварительно определенных обратных квантователей) в зависимости от одного или нескольких параметров предсказателя. В частности, декодер спектра может выполнять такой же процесс выбора для набора предварительно определенных квантователей, как и модуль квантования коэффициентов соответствующей речевого кодера. Делая набор предварительно определенных квантователей зависящим от одного или нескольких параметров предсказателя, можно улучшить воспринимаемое качество восстановленного речевого сигнала.
Указанный набор предварительно определенных квантователей может содержать разные квантователи с разными отношениями сигнал-шум (и разными связанными с ними битовыми скоростями передачи данных). Кроме того, набор предварительно определенных квантователей может содержать по меньшей мере один квантователь с добавлением псевдослучайного шума. Указанные один или несколько параметров предсказателя могут включать коэффициент g усиления предсказателя. Этот коэффициент g усиления предсказателя может служить признаком степени значимости одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования для текущего блока восстановленных коэффициентов преобразования. Как таковой, коэффициент g усиления предсказателя может содержать указатель количества информации, содержащейся в текущем блоке коэффициентов ошибок предсказания. Относительно высокий коэффициент g усиления предсказателя может служить признаком относительно большого количества информации, и наоборот. Количество квантователей с добавлением псевдослучайного шума, заключенных в наборе предварительно определенных квантователей, может зависеть от коэффициента усиления предсказателя. В частности, количество квантователей с добавлением псевдослучайного шума, заключенных в наборе предварительно определенных квантователей, может уменьшаться при увеличении коэффициента усиления предсказателя.
Декодер спектра может иметь доступ к первому набору и ко второму набору предварительно определенных квантователей. Этот второй набор может содержать меньшее количество квантователей с добавлением псевдослучайного шума, чем первый набор квантователей. Декодер спектра может быть сконфигурирован для определения на основе коэффициента g усиления предсказателя критерия rfu набора. Декодер спектра может быть сконфигурирован для использования первого набора предварительно определенных квантователей, если критерий rfu набора меньше предварительно определенного порогового значения. Кроме того, декодер спектра может быть сконфигурирован для использования второго набора предварительно определенных квантователей, если критерий rfu набора больше или равен указанному предварительно определенному пороговому значению. Критерием набора может являться rfu=min(l, max(g, 0)), где g — коэффициент усиления предсказателя. Этот критерий rfu набора принимает значения, большие или равные нулю и меньшие или равные единице. Предварительно определенное пороговое значение может составлять 0,75.
Как указывалось выше, критерий набора может зависеть от предварительно определенного параметра управления, rfu. В одном из альтернативных примеров, параметр rfu управления можно определить, используя следующие условия: rfu=1,0 для g<–1,0; rfu=–g для –1,0≤g<0,0; rfu=g для 0,0≤g<1,0; rfu=2,0–g для 1,0≤g<2,0; и/или rfu=0,0 для g≥2,0. Кроме того, речевой декодер может содержать модуль сложения, сконфигурированный для определения текущего блока восстановленных выровненных коэффициентов преобразования на основе текущего блока оценочных выровненных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания. Кроме того, речевой декодер может содержать модуль обратного выравнивания, сконфигурированный для определения текущего блока восстановленных коэффициентов преобразования путем придания текущему блоку восстановленных выровненных коэффициентов преобразования формы спектра с использованием текущей огибающей блока. Восстановленный речевой сигнал можно определить на основе текущего блока восстановленных коэффициентов преобразования (например, с использованием модуля обратного преобразования).
Речевой декодер на основе преобразования может содержать модуль обратного изменения масштаба, сконфигурированный для изменения масштаба квантованных коэффициентов ошибок предсказания из текущего блока квантованных коэффициентов ошибок предсказания, используя для создания коэффициентов ошибок предсказания с измененным масштабом правило обратного масштабирования. Коэффициенты усиления масштабирования, применяемые модулем обратного масштабирования к квантованным коэффициентам ошибок предсказания в соответствии с правилом обратного масштабирования, могут зависеть от элементов разрешения по частоте, соответствующих этим квантованным коэффициентам ошибок предсказания. Иными словами, правило обратного масштабирования может зависеть от частоты, т.е. от частоты могут зависеть коэффициенты усиления масштабирования. Правило обратного масштабирования можно сконфигурировать для коррекции дисперсии квантованных коэффициентов ошибок предсказания для разных элементов разрешения по частоте.
Правило обратного масштабирования, как правило, является обратным правилу масштабирования, применяемому модулем масштабирования соответствующего речевого кодера на основе преобразования. Поэтому аспекты, описываемые в данном описании в отношении определения и свойств правила масштабирования, также (аналогично) применимы и к правилу обратного масштабирования.
Тогда модуль сложения может быть сконфигурирован для определения текущего блока восстановленных выровненных коэффициентов преобразования путем сложения текущего блока коэффициентов ошибок предсказания с измененным масштабом с текущим блоком оценочных выровненных коэффициентов преобразования.
Указанные один или несколько параметров могут включать флаг сохранения дисперсии. Этот флаг сохранения дисперсии может служить признаком того, каким образом следует формировать дисперсию текущего блока квантованных коэффициентов ошибок предсказания. Иными словами, флаг сохранения дисперсии может служить признаком обработки, которую должен выполнить декодер, и которая оказывает влияние на дисперсию текущего блока квантованных коэффициентов ошибок предсказания.
Например, в зависимости от флага сохранения дисперсии может определяться набор предварительно определенных квантователей. В частности, этот набор предварительно определенных квантователей может содержать квантователь синтеза шума. От флага сохранения дисперсии может зависеть коэффициент усиления шума квантователя синтеза шума. В качестве альтернативы или в дополнение, набор предварительно определенных квантователей содержит один или несколько квантователей с добавлением псевдослучайного шума, охватывающих некоторый диапазон SNR. Этот диапазон SNR можно определять в зависимости от флага сохранения дисперсии. Указанные, по меньшей мере, один или несколько квантователей с добавлением псевдослучайного шума могут быть сконфигурированы для применения коэффициента y последующего усиления при определении квантованного коэффициента ошибки предсказания. Этот коэффициент у последующего усиления может зависеть от флага сохранения дисперсии.
Речевой декодер на основе преобразования может содержать модуль обратного масштабирования, сконфигурированный для изменения масштаба квантованных коэффициентов ошибок предсказания из текущего блока квантованных коэффициентов ошибок предсказания с целью создания текущего блока коэффициентов ошибок предсказания с измененным масштабом. Модуль сложения может быть сконфигурирован для определения текущего блока восстановленных выровненных коэффициентов преобразования, либо путем сложения текущего блока коэффициентов ошибок предсказания с измененным масштабом, либо путем сложения текущего блока квантованных коэффициентов ошибок предсказания с текущим блоком оценочных выровненных коэффициентов преобразования в зависимости от флага сохранения дисперсии.
Флаг сохранения дисперсии можно использовать для адаптации степени зашумленности квантователей к качеству предсказания. Как результат, можно повысить воспринимаемое качество кодека.
Согласно еще одному аспекту, описывается звуковой кодер на основе преобразования. Этот звуковой кодер сконфигурирован для кодирования звукового сигнала, содержащего первый сегмент (например, речевой сегмент), в битовый поток. В частности, этот звуковой кодер может быть сконфигурирован для кодирования одного или нескольких речевых сегментов звукового сигнала с использованием речевого кодера на основе преобразования. Кроме того, звуковой кодер может быть сконфигурирован для кодирования одного или нескольких неречевых сегментов звукового сигнала с использованием обобщенного звукового кодера на основе преобразования.
Этот звуковой кодер может содержать классификатор сигнала, сконфигурированный для идентификации первого сегмента (например, речевого сегмента) в звуковом сигнале. В более общих выражениях, классификатор сигнала может быть сконфигурирован для определения в звуковом сигнале сегмента, подлежащего кодированию речевым кодером на основе преобразования. Этот определенный первый сегмент можно именовать речевым сегментом (даже если этот сегмент необязательно содержит фактическую речь). В частности, классификатор сигнала может быть сконфигурирован для классификации различных сегментов (например, кадров или блоков) звукового сигнала на речевые и неречевые. Как описывалось выше, блок коэффициентов преобразования может содержать ряд коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте. Кроме того, звуковой кодер может содержать модуль преобразования, сконфигурированный для определения на основе указанного первого сегмента ряда последовательных блоков коэффициентов преобразования. Этот блок преобразования может быть сконфигурирован для преобразования речевых сегментов и неречевых сегментов.
Этот блок преобразования может быть сконфигурирован для определения длинных блоков, содержащих первое количество коэффициентов преобразования, и коротких блоков, содержащих второе количество коэффициентов преобразования. Указанное первое количество дискретных значений может быть больше указанного второго количества дискретных значений. В частности, первое количество дискретных значений может составлять 1024, а второе количество дискретных значений может составлять 256. Указанные блоки из ряда последовательных блоков могут представлять собой короткие блоки. В частности, звуковой кодер может быть сконфигурирован для преобразования в короткие блоки всех сегментов звукового сигнала, которые были классифицированы как являющиеся речевыми. Кроме того, звуковой кодер может содержать речевой кодер на основе преобразования (описываемый в настоящем документе), сконфигурированный для кодирования ряда последовательных блоков в битовый поток. В дополнение, звуковой кодер содержит обобщенный звуковой кодер на основе преобразования, сконфигурированный для кодирования сегмента звукового сигнала (например, неречевого сегмента), отличающегося от первого сегмента. Этот обобщенный звуковой кодер на основе преобразования может представлять собой кодер AAC (Advanced Audio Coder) или HE (High Efficiency)-AAC. Как уже описывалось выше, модуль преобразования может быть сконфигурирован для выполнения MDCT. Как таковой, звуковой кодер может быть сконфигурирован для кодирования всего входного звукового сигнала (содержащего речевые сегменты и неречевые сегменты) в области преобразования (с использованием единого модуля преобразования).
Согласно другому аспекту, описывается звуковой декодер на основе преобразования, сконфигурированный для декодирования битового потока, служащего признаком звукового сигнала, содержащего речевой сегмент (т.е. сегмент, который был закодирован с использованием речевого кодера на основе преобразования). Этот звуковой декодер может содержать речевой декодер на основе преобразования, сконфигурированный для определения ряда последовательных блоков восстановленных коэффициентов преобразования на основе заключенных в битовом потоке данных (например, данных огибающей, данных коэффициентов усиления, данных предсказателя и данных коэффициентов). Кроме того, битовый поток может указывать, что принимаемые данные подлежат декодированию с использованием речевого декодера.
В дополнение, указанный звуковой декодер может содержать модуль обратного преобразования, сконфигурированный для определения восстановленного речевого сегмента на основе ряда последовательных блоков восстановленных коэффициентов преобразования. Блок восстановленных коэффициентов преобразования может содержать ряд восстановленных коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте. Модуль обратного преобразования может быть сконфигурирован для обработки длинных блоков, содержащих первое количество восстановленных коэффициентов преобразования, и коротких блоков, содержащих второе количество восстановленных коэффициентов преобразования. Указанное первое количество дискретных значений может быть больше указанного второго количества дискретных значений. Указанные блоки из ряда последовательных блоков могут представлять собой короткие блоки.
Согласно одному из дальнейших аспектов, описывается способ кодирования речевого сигнала в битовый поток. Этот способ может включать прием набора блоков. Этот набор блоков может содержать ряд последовательных блоков коэффициентов преобразования. Этот ряд последовательных блоков может служить признаком дискретных значений речевого сигнала. Кроме того, блок коэффициентов преобразования может содержать ряд коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте. Способ может продолжаться определением текущей огибающей на основе ряда последовательных блоков коэффициентов преобразования.
Эта текущая огибающая может служить признаком ряда значений спектральной энергии для соответствующего ряда элементов разрешения по частоте. Кроме того, указанный способ может включать определение ряда интерполированных огибающих для указанного ряда блоков коэффициентов преобразования на основе текущей огибающей. В дополнение, способ может включать определение ряда блоков выровненных коэффициентов преобразования, соответственно, с использованием соответствующего ряда интерполированных огибающих. Битовый поток можно определить на основе указанного ряда блоков выровненных коэффициентов преобразования.
Согласно другому аспекту, описывается способ декодирования битового потока с целью создания восстановленного речевого сигнала. Этот способ может включать определение квантованной текущей огибающей, исходя из данных огибающей, заключенных в битовом потоке. Эта квантованная текущая огибающая может служить признаком ряда элементов разрешения по частоте. Битовый поток может содержать данные (например, данные коэффициентов и/или данные предсказателя), служащие признаком ряда последовательных блоков восстановленных выровненных коэффициентов преобразования. Блок восстановленных выровненных коэффициентов преобразования может содержать ряд восстановленных выровненных коэффициентов для соответствующего ряда элементов разрешения по частоте. Кроме того, этот способ может включать определение ряда интерполированных огибающих, соответственно, для ряда блоков восстановленных выровненных коэффициентов преобразования на основе квантованной текущей огибающей. Способ может продолжаться определением ряда блоков восстановленных коэффициентов преобразования путем придания соответствующему ряду блоков восстановленных выровненных коэффициентов преобразования формы спектра с использованием соответствующего ряда интерполированных огибающих, соответственно. Восстановленный речевой сигнал может основываться на указанном ряде блоков восстановленных коэффициентов преобразования. Согласно еще одному аспекту, описывается способ кодирования речевого сигнала в битовый поток. Этот способ может включать прием ряда последовательных блоков коэффициентов преобразования, содержащего текущий блок и один или несколько предыдущих блоков. Этот ряд последовательных блоков может служить признаком дискретных значений речевого сигнала. Способ может продолжаться определением текущего блока и одного или нескольких предыдущих блоков выровненных коэффициентов преобразования путем выравнивания соответствующего текущего блока и соответствующих одного или нескольких предыдущих блоков коэффициентов преобразования с использованием соответствующей текущей огибающей блока и соответствующих одной или нескольких предыдущих огибающих блоков, соответственно.
Кроме того, этот способ может включать определение текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя. Это можно выполнить, используя методики предсказания. Указанные один или несколько предыдущих блоков восстановленных коэффициентов преобразования могли быть получены, соответственно, из одного или нескольких предыдущих блоков выровненных коэффициентов преобразования. Этап определения текущего блока оценочных выровненных коэффициентов преобразования может включать определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя; и определение текущего блока оценочных выровненных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков и на основе параметра предсказателя.
Кроме того, этот способ может включать определение текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования. Битовый поток можно определить на основе текущего блока коэффициентов ошибок предсказания.
Согласно одному из дальнейших аспектов, описывается способ декодирования битового потока с целью создания восстановленного речевого сигнала. Этот способ может включать определение текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, полученного из битового потока. Этап определения текущего блока оценочных выровненных коэффициентов преобразования может включать определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя; и определение текущего блока оценочных выровненных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков и на основе параметра предсказателя.
Кроме того, этот способ может включать определение текущего блока квантованных коэффициентов ошибок предсказания на основе данных коэффициентов, заключенных в битовом потоке.
Способ может продолжаться определением текущего блока восстановленных выровненных коэффициентов преобразования на основе текущего блока оценочных выровненных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания. Текущий блок восстановленных коэффициентов преобразования можно определить, придав текущему блоку восстановленных выровненных коэффициентов преобразования форму спектра с использованием текущей огибающей блока (например, текущей скорректированной огибающей). Кроме того, указанные один или несколько предыдущих блоков восстановленных коэффициентов преобразования можно определить, придав одному или нескольким предыдущих блокам восстановленных выровненных коэффициентов преобразования форму спектра, соответственно, с использованием одной или нескольких предыдущих огибающих блоков (например, одной или нескольких скорректированных огибающих). В дополнение, указанный способ может включать определение восстановленного речевого сигнала на основе текущего и одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования.
Согласно одному из дальнейших аспектов, описывается способ кодирования речевого сигнала в битовый поток. Этот способ может включать прием ряда последовательных блоков коэффициентов преобразования, содержащего текущий блок и один или несколько предыдущих блоков. Этот ряд последовательных блоков может служить признаком дискретных значений речевого сигнала.
Кроме того, указанный способ может включать определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя. Указанные один или несколько блоков восстановленных коэффициентов преобразования могли быть получены из одного или нескольких предыдущих блоков коэффициентов преобразования. Способ может продолжаться определением текущего блока коэффициентов ошибок предсказания на основе текущего блока коэффициентов преобразования и на основе текущего блока оценочных коэффициентов преобразования. Кроме того, этот способ может включать квантование коэффициентов, полученных из текущего блока коэффициентов ошибок предсказания, с использованием набора предварительно определенных квантователей. Этот набор предварительно определенных квантователей может зависеть от параметра предсказателя. Кроме того, способ может включать определение данных коэффициентов для битового потока на основе указанных квантованных коэффициентов.
Согласно другому аспекту, описывается способ декодирования битового потока с целью создания восстановленного речевого сигнала. Этот способ может включать определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, полученного из битового потока. Кроме того, этот способ может включать определение текущего блока квантованных коэффициентов ошибок предсказания на основе данных коэффициентов, заключенных в битовом потоке, с использованием набора предварительно определенных квантователей. Этот набор предварительно определенных квантователей может зависеть от параметра предсказателя. Способ может продолжаться определением текущего блока восстановленных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания. Указанный восстановленный речевой сигнал можно определить на основе текущего блока восстановленных коэффициентов преобразования.
Согласно одному из дальнейших аспектов, описывается способ кодирования звукового сигнала, содержащего речевой сегмент, в битовый поток. Этот способ может включать идентификацию этого речевого сегмента в звуковом сигнале. Кроме того, этот способ может включать определение ряда последовательных блоков коэффициентов преобразования на основе указанного речевого сегмента с использованием модуля преобразования. Этот модуль преобразования может быть сконфигурирован для определения длинных блоков, содержащих первое количество коэффициентов преобразования, и коротких блоков, содержащих второе количество коэффициентов преобразования. Указанное первое количество может быть больше указанного второго количества. Указанные блоки из ряда последовательных блоков могут представлять собой короткие блоки. В дополнение, этот способ может включать кодирование ряда последовательных блоков в битовый поток.
Согласно еще одному аспекту, описывается способ декодирования битового потока, служащего признаком звукового сигнала, содержащего речевой сегмент. Этот способ может включать определение ряда последовательных блоков восстановленных коэффициентов преобразования на основе данных, заключенных в битовом потоке. Кроме того, этот способ может включать определение восстановленного речевого сегмента на основе ряда последовательных блоков восстановленных коэффициентов преобразования с использованием модуля обратного преобразования. Этот модуль обратного преобразования может быть сконфигурирован для обработки длинных блоков, содержащих первое количество восстановленных коэффициентов преобразования, и коротких блоков, содержащих второе количество восстановленных коэффициентов преобразования. Указанное первое количество может быть больше указанного второго количества. Указанные блоки из ряда последовательных блоков могут представлять собой короткие блоки.
Согласно одному из дальнейших аспектов описывается программа, реализованная программно. Эта программа, реализованная программно, может быть адаптирована для исполнения на процессоре и для выполнения этапов способов, описываемых в настоящем документе, при осуществлении на процессоре.
Согласно другому аспекту описывается носитель данных. Этот носитель данных может содержать программу, реализованную программно, адаптированную для исполнения на процессоре и для выполнения этапов способов, описываемых в настоящем документе, при осуществлении на процессоре. Согласно одному из дальнейших аспектов описывается компьютерный программный продукт. Компьютерный программный продукт может содержать исполняемые команды, предназначенные для выполнения этапов способов, описываемых в настоящем документе, при осуществлении на компьютере.
Следует отметить, что способы и системы, в том числе предпочтительные варианты их осуществления, описываемые в настоящей патентной заявке, можно использовать автономно или в сочетании с другими способами и системами, раскрываемыми в настоящем документе. Кроме того, все аспекты способов и систем, описываемых в настоящей патентной заявке, могут комбинироваться различными способами. В частности, произвольным образом могут комбинироваться друг с другом характерные признаки формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ФИГУР
Ниже изобретение разъясняется иллюстративным образом со ссылкой на сопроводительные графические материалы, в которых
на фиг. 1а показана блок-схема одного из примеров звукового кодера, создающего битовый поток с постоянной битовой скоростью передачи данных;
на фиг. 1b показана блок-схема одного из примеров звукового кодера, создающего битовый поток с переменной битовой скоростью передачи данных;
на фиг. 2 проиллюстрировано генерирование одного из примеров ряда блоков коэффициентов преобразования на основе огибающей;
на фиг. 3а проиллюстрированы примеры огибающих блоков коэффициентов преобразования;
на фиг. 3b проиллюстрировано определение одного из примеров интерполированной огибающей;
на фиг. 4 проиллюстрированы примеры наборов квантователей;
на фиг. 5а показана блок-схема одного из примеров звукового декодера;
на фиг. 5b показана блок-схема одного из примеров декодера огибающей звукового декодера по фиг. 5а;
на фиг. 5с показана блок схема одного из примеров предсказателя поддиапазонов звукового декодера по фиг. 5а; и
на фиг. 5d показана блок-схема одного из примеров декодера спектра звукового декодера по фиг. 5а.
ПОДРОБНОЕ ОПИСАНИЕ
Как описывалось в разделе предпосылок, является желательным создание звукового кодека на основе преобразования, проявляющего относительно высокие эффективности кодирования для речевых или голосовых сигналов. Такой звуковой кодек на основе преобразования можно именовать речевым кодеком на основе преобразования или голосовым кодеком на основе преобразования. Речевой кодек на основе преобразования можно удобно скомбинировать с обобщенным звуковым кодеком на основе преобразования, таким, как AAC или HE-AAC, так как он также действует в области преобразования. Кроме того, по причине того, что оба кодека действуют в области преобразования, можно упростить классификацию сегмента (например, кадра) входного звукового сигнала на речевой или неречевой и последующее переключение между обобщенным звуковым кодеком и специальным речевым кодеком.
На фиг. 1а показана блок-схема одного из примеров речевого кодера 100 на основе преобразования. Кодер 100 в качестве ввода принимает блок 131 коэффициентов преобразования (также именуемый единицей кодирования). Блок 131 коэффициентов преобразования мог быть получен модулем преобразования, сконфигурированным для преобразования последовательности дискретных значений входного звукового сигнала из временной области в область преобразования. Этот модуль преобразования может быть сконфигурирован для выполнения MDCT. Этот модуль преобразования может составлять часть обобщенного звукового кодека, такого, как AAC или HE-AAC. Такой обобщенный звуковой кодек может использовать разные размеры блоков, например, длинный блок и короткий блок. Примерами размеров блоков являются 1024 дискретных значений для длинного блока и 256 дискретных значений — для короткого блока. В предположении частоты дискретизации 44,1 кГц и перекрытия 50%, длинный блок охватывает приблизительно 20 мс входного звукового сигнала, а короткий блок охватывает приблизительно 5 мс входного звукового сигнала. Длинные блоки, как правило, используются для стационарных сегментов входного звукового сигнала, а короткие блоки, как правило, используются для переходных сегментов входного звукового сигнала.
Речевые сигналы во временных сегментах длительностью около 20 мс можно считать стационарными.
В частности, можно считать стационарной огибающую спектра речевого сигнала во временных сегментах около 20 мс. Для того чтобы иметь возможность получать представительную статистику в области преобразования для таких сегментов длительностью 20 мс, может быть полезно снабжать речевой кодер 100 короткими блоками 131 коэффициентов преобразования (имеющими длину, например, 5 мс). Действуя таким образом, можно использовать ряд 131 коротких блоков для получения статистики в отношении временных сегментов длительностью, например, 20 мс (например, в отношении временного сегмента длинного блока или кадра). Кроме того, это имеет преимущество обеспечения достаточной разрешающей способности по времени для речевых сигналов.
Так, модуль преобразования может быть сконфигурирован для создания коротких блоков 131 коэффициентов преобразования, если текущий сегмент входного звукового сигнала классифицирован как являющийся речевым. Кодер 100 может содержать модуль 101 кадрирования, сконфигурированный для извлечения ряда блоков 131 коэффициентов преобразования, именуемых набором 132 блоков 131. Этот набор 132 блоков также можно именовать кадром. Например, набор 132 блоков 131 может содержать четыре коротких блока по 256 коэффициентов преобразования, посредством чего он охватывает сегмент входного звукового сигнала длительностью приблизительно 20 мс.
Речевой кодер 100 на основе преобразования может быть сконфигурирован для работы в ряде различных режимов, например, в режиме короткого шага и в режиме длинного шага. При работе в режиме короткого шага речевой кодер 100 на основе преобразования может быть сконфигурирован для подразделения сегмента или кадра звукового сигнала (например, речевого сигнала) на набор 132 коротких блоков 131 (как описывалось выше). С другой стороны, при работе в режиме длинного шага речевой кодер 100 на основе преобразования может быть сконфигурирован для прямой обработки этого сегмента или кадра звукового сигнала.
Например, при работе в режиме короткого шага кодер 100 может быть сконфигурирован для обработки четырех блоков 131, приходящихся на кадр. Кадры кодера 100 могут быть относительно короткими в физическом времени для определенных установок синхронной работы с кадрами видеоизображения. Это в особенности имеет место для повышенной частоты кадров видеоизображения (например, 100 Гц против 50 Гц), что приводит к уменьшению временной длины сегмента или кадра речевого сигнала. В этих случаях, подразделение кадра на ряд (коротких) блоков 131 может являться неблагоприятным по причине пониженной разрешающей способности в области преобразования. Таким образом, режим длинного шага можно использовать для вызова использования только одного блока 131, приходящегося на кадр. Использование единственного блока 131, приходящегося на кадр, также может быть преимущественным для кодирования звуковых сигналов, содержащих музыку (даже для относительно длинных кадров). Эти преимущества могут быть вызваны повышенной разрешающей способностью в области преобразования при использовании лишь единственного блока 131, приходящегося на кадр, или при использовании уменьшенного количества блоков 131, приходящихся на кадр.
Ниже будет более подробно описываться работа кодера 100 в режиме короткого шага. Набор 132 блоков может быть доставлен в модуль 102 оценивания огибающей. Модуль 102 оценивания огибающей может быть сконфигурирован для определения огибающей 133 на основе набора 132 блоков. Огибающая 133 может быть основана на среднеквадратичных (RMS) значениях соответствующих коэффициентов преобразования из ряда блоков 131, заключенных в наборе 132 блоков. Блок 131, как правило, содержит ряд коэффициентов преобразования (например, 256 коэффициентов преобразования) в соответствующем ряду элементов 301 разрешения по частоте (см. фиг. 3а). Ряд элементов 301 разрешения по частоте можно сгруппировать в ряд полос 302 частот. Этот ряд полос 302 частот можно выбрать на основе психоакустических соображений. Например, элементы 301 разрешения по частоте можно сгруппировать в полосы 302 частот в соответствии с логарифмической шкалой, или шкалой Барка. Огибающая 134, которая была определена на основе текущего набора 132 блоков, может содержать ряд значений энергии, соответственно, для ряда полос 302 частот. Конкретное значение энергии для конкретной полосы 302 частот можно определить на основе коэффициентов преобразования из блоков 131 набора 132, соответствующих элементам 301 разрешения по частоте, находящимся в пределах этой конкретной полосы 302 частот. Указанное конкретное значение энергии можно определить на основе значения RMS этих коэффициентов преобразования. Как таковая, огибающая 133 для текущего набора 132 блоков (именуемая текущей огибающей 133) может служить признаком средней огибающей блоков 131 коэффициентов преобразования, заключенных в текущем наборе 132 блоков, или может служить признаком средней огибающей блоков 132 коэффициентов преобразования, использованных для определения огибающей 133.
Следует отметить, что текущую огибающую 133 можно определить на основе одного или нескольких дополнительных блоков 131 коэффициентов преобразования, смежных с текущим набором 132 блоков.
Это проиллюстрировано на фиг. 2, где текущая огибающая 133 (указываемая квантованной текущей огибающей 134) определена на основе блоков 131 из текущего набора 132 блоков и на основе блока 201 из набора блоков, предшествующего текущему набору 132 блоков. В иллюстрируемом примере текущая огибающая 133 определена на основе пяти блоков 131. Учитывая смежные блоки при определении текущей огибающей 133, можно обеспечить непрерывность огибающих смежных наборов 132 блоков.
При определении текущей огибающей 133 коэффициенты преобразования из разных блоков 131 можно взвешивать. В частности, внешние блоки 201, 202, учитываемые при определении текущей огибающей 133, могут иметь меньший весовой коэффициент, чем остальные блоки 131. Например, коэффициенты преобразования внешних блоков 201, 202 можно взвешивать с коэффициентом 0,5, тогда как коэффициенты преобразования других блоков 131 можно взвешивать с коэффициентом 1.
Следует отметить, что аналогично учету блоков 201 из предыдущего набора блоков для определения текущей огибающей 133 можно учитывать один или несколько блоков (так называемых блоков предварительного просмотра) из непосредственно следующего набора 132 блоков.
Значения энергии текущей огибающей 133 можно представить в логарифмической шкале (например, в шкале дБ). Текущая огибающая 133 может быть доставлена в модуль 103 квантования огибающей, сконфигурированный для квантования значений энергии текущей огибающей 133. Модуль 103 квантования огибающей может предусматривать предварительно определенную разрешающую способность квантователя, например, разрешающую способность 3 дБ. Индексы квантования огибающей можно доставлять в битовом потоке, генерируемом кодером 100, как данные 161 огибающей. Кроме того, квантованная огибающая 134, т.е. огибающая, содержащая квантованные значения энергии огибающей 133, может быть доставлена в модуль 104 интерполяции.
Модуль 104 интерполяции сконфигурирован для определения огибающей для каждого блока 131 из текущего набора 132 блоков на основе квантованной текущей огибающей 134 и на основе квантованной предыдущей огибающей 135 (которая была определена для набора 132 блоков, непосредственно предшествующего текущему набору 132 блоков). Действие модуля 104 интерполяции проиллюстрировано на фиг. 2, 3a и 3b. На фиг. 2 показана последовательность блоков 131 коэффициентов преобразования. Эта последовательность блоков 131 сгруппирована в последовательные наборы 132 блоков, при этом каждый набор 132 блоков используется для определения квантованной огибающей, например, квантованной текущей огибающей 134 и квантованной предыдущей огибающей 135. На фиг. 3а показаны примеры квантованной предыдущей огибающей 135 и квантованной текущей огибающей 134. Как указывалось выше, эти огибающие могут служить признаками спектральной энергии 303 (например, в шкале дБ). Для определения интерполированной огибающей 136 можно интерполировать (например, используя линейную интерполяцию) соответствующие значения 303 энергии квантованной предыдущей огибающей 135 и квантованной текущей огибающей 134 для одной и той же полосы 302 частот. Иными словами, значения 303 энергии конкретной полосы 302 частот можно интерполировать для создания значения 303 энергии интерполированной огибающей 136 в этой конкретной полосе 302 частот.
Следует отметить, что набор блоков, для которого определяются и применяются интерполированные огибающие 136, может отличаться от текущего набора 132 блоков, на основе которого определяется квантованная текущая огибающая 134. Это проиллюстрировано на фиг. 2, где показан сдвинутый набор 132 блоков, сдвинутый по сравнению с текущим набором 132 блоков и содержащий блоки 3 и 4 (указанные, соответственно, ссылочными позициями 203 и 201) из предыдущего набора 132 блоков и блоки 1 и 2 (указанные, соответственно, ссылочными позициями 204 и 205) из текущего набора 132 блоков. По существу, интерполированные огибающие 136, определяемые на основе квантованной текущей огибающей 134 и на основе квантованной предыдущей огибающей 135, могут обладать повышенной значимостью для блоков из сдвинутого набора 332 блоков по сравнению со значимостью для блоков из текущего набора 132 блоков.
Поэтому интерполированные огибающие 136, показанные на фиг. 3b, можно использовать для выравнивания блоков 131 из сдвинутого набора 332 блоков. Это показано на фиг. 3b в сочетании с фиг. 2. Как видно, интерполированную огибающую 341 по фиг. 3b можно применить к блоку 203 по фиг. 2, интерполированную огибающую 342 по фиг. 3b можно применить к блоку 201 по фиг. 2, интерполированную огибающую 343 по фиг. 3b можно применить к блоку 204 по фиг. 2, и интерполированную огибающую 344 по фиг. 3b (которая в иллюстрируемом примере соответствует квантованной текущей огибающей 136) можно применить к блоку 205 по фиг. 2. Как таковой, набор 132 блоков для определения квантованной текущей огибающей 134 может отличаться от сдвинутого набора 332 блоков, для которого определяются интерполированные огибающие 136 и к которому (в целях выравнивания) применяются интерполированные огибающие 136. В частности, квантованную текущую огибающую 134 можно определить, используя некоторый предварительный просмотр в отношении блоков 203, 201, 204, 205 из сдвинутого набора 332 блоков, подлежащих выравниванию с использованием квантованной текущей огибающей 134. Это является преимущественным с точки зрения непрерывности.
Интерполяция значений 303 энергии для определения интерполированных огибающих 136 проиллюстрирована на фиг. 3b. Видно, что значения энергии интерполированных огибающих 136 для блоков 131 из сдвинутого набора 332 блоков можно определить путем интерполяции между значением энергии квантованной предыдущей огибающей 135 и соответствующим значением энергии квантованной текущей огибающей 134. В частности, для каждого блока 131 из сдвинутого набора 332 можно определить интерполированную огибающую 136, посредством этого создавая ряд интерполированных огибающих 136 для ряда блоков 203, 201, 204, 205 из сдвинутого набора 332 блоков. Для кодирования блока 131 коэффициентов преобразования можно использовать интерполированную огибающую 136 блока 131 коэффициентов преобразования (например, любого из блоков 203, 201, 204, 205 из сдвинутого набора 332 блоков). Следует отметить, что индексы 161 квантования текущей огибающей 133 доставляются в соответствующий декодер в битовом потоке. Следовательно, соответствующий декодер может быть сконфигурирован для определения ряда интерполированных огибающих 136 аналогично модулю 104 интерполяции кодера 100.
Модуль 101 кадрирования, модуль 102 оценивания огибающей, модуль 102 квантования огибающей и модуль 104 интерполяции действуют на набор блоков (т.е. на текущий набор 132 блоков и/или на сдвинутый набор 332 блоков). С другой стороны, фактическое кодирование коэффициента преобразования можно выполнять блок за блоком. Ниже делается отсылка к кодированию текущего блока 131 коэффициентов преобразования, который может представлять собой любой из ряда блоков 131 из сдвинутого набора 332 блоков (или, возможно, текущего набора 132 блоков — в других реализациях речевого кодера 100 на основе преобразования).
Кроме того, следует отметить, что кодер 100 может действовать в так называемом режиме длинного шага. В этом режиме кадр сегмента звукового сигнала не подразделяется и обрабатывается как единственный блок. Таким образом, определяется только единственный блок 131 коэффициентов преобразования, приходящийся на кадр. При работе в режиме длинного шага модуль 101 кадрирования может быть сконфигурирован для извлечения единственного текущего блока 131 коэффициентов преобразования для сегмента или кадра звукового сигнала. Модуль 102 оценивания огибающей может быть сконфигурирован для определения текущей огибающей 133 для текущего блока 131, а модуль 103 квантования огибающей может быть сконфигурирован для квантования этой единственной текущей огибающей 133 с целью определения квантованной текущей огибающей 134 (и определения данных 161 огибающей для текущего блока 131). В режиме длинного шага интерполяция огибающих, как правило, не употребляется. Поэтому интерполированная огибающая 136 для текущего блока 131, как правило, соответствует квантованной текущей огибающей 134 (когда кодер 100 действует в режиме длинного шага).
Текущая интерполированная огибающая 136 для текущего блока 131 может предусматривать приближение огибающей спектра коэффициентов преобразования из текущего блока 131. Кодер 100 может содержать модуль 105 предварительного выравнивания и модуль 106 определения коэффициента усиления огибающей, сконфигурированные для определения скорректированной огибающей 139 для текущего блока 131 на основе текущей интерполированной огибающей 136 и на основе текущего блока 131. В частности, коэффициент усиления огибающей для текущего блока 131 можно определить так, чтобы скорректировать дисперсию выровненных коэффициентов преобразования из текущего блока 131. X(k), k=1,..., K может представлять собой коэффициенты преобразования из текущего блока 131 (где, например, K=256), а E(k), k=1,..., K может представлять собой средние значения 303 спектральной энергии текущей интерполированной огибающей 136 (где значения энергии E(k) одной и той же полосы 302 частот равны). Коэффициент α усиления огибающей можно определить так, чтобы скорректировать дисперсию выровненных коэффициентов преобразования 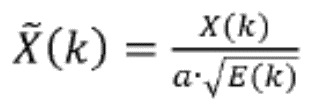 . В частности, коэффициент усиления огибающей можно определить так, чтобы дисперсия была равна единице.
. В частности, коэффициент усиления огибающей можно определить так, чтобы дисперсия была равна единице.
Следует отметить, что коэффициент α усиления огибающей можно определить для субдиапазона полного диапазона частот текущего блока 131 коэффициентов преобразования. Иными словами, коэффициент α усиления огибающей можно определить, основываясь лишь на подмножестве элементов 301 разрешения по частоте и/или основываясь на подмножестве полос 302 частот. Например, коэффициент α усиления огибающей можно определить на основе элементов 301 разрешения по частоте больше начального элемента 304 разрешения по частоте (этот начальный элемент разрешения по частоте больше 0 или 1). Как следствие, скорректированную огибающую 139 для текущего блока 131 можно определить, применяя коэффициент α усиления огибающей только к средним значениям 303 спектральной энергии текущей интерполированной огибающей 136, связанным с элементами 301 разрешения по частоте, лежащим выше начального элемента 304 разрешения по частоте. Таким образом, скорректированная огибающая 139 для текущего блока 131 может соответствовать текущей интерполированной огибающей 136 для элементов 301 разрешения по частоте при начальном элементе разрешения по частоте и ниже, и может соответствовать смещению текущей интерполированной огибающей 136 посредством коэффициента α усиления огибающей для элементов 301 разрешения по частоте выше этого начального элемента разрешения по частоте. Это проиллюстрировано на фиг. 3а скорректированной огибающей 339 (показанной штриховыми линиями).
Применение коэффициента α 137 усиления огибающей (также именуемого коэффициентом усиления коррекции уровня) к текущей интерполированной огибающей 136 соответствует коррекции, или смещению, текущей интерполированной огибающей 136, посредством чего получается скорректированная огибающая 139, как проиллюстрировано на фиг. 3а. Коэффициент α 137 усиления огибающей можно кодировать в битовый поток как данные 162 коэффициентов усиления.
Кодер 100 также может содержать модуль 107 уточнения огибающей, сконфигурированный для определения скорректированной огибающей на основе коэффициента α 137 усиления огибающей и на основе текущей интерполированной огибающей 136. Скорректированную огибающую 139 можно использовать для обработки сигнала из блока 131 коэффициентов преобразования. Коэффициент α 137 усиления огибающей можно квантовать с большей разрешающей способностью (например, с шагом 1 дБ) по сравнению с текущей интерполированной огибающей 136 (которую можно квантовать с шагом 3 дБ). Как таковую, скорректированную огибающую 139 можно квантовать с большей разрешающей способностью коэффициента α 137 усиления огибающей (например, с шагом 1 дБ).
Кроме того, модуль 107 уточнения огибающей может быть сконфигурирован для определения огибающей 138 распределения. Огибающая 138 распределения может соответствовать квантованной версии скорректированной огибающей 139 (например, квантованной с шагом квантования 3 дБ). Огибающую 138 распределения можно использовать в целях распределения битов. В частности, огибающую 138 распределения можно использовать с целью определения — для конкретного коэффициента преобразования из текущего блока 131 — конкретного квантователя из предварительно определенного набора квантователей, причем данный конкретный квантователь подлежит использованию для квантования данного конкретного коэффициента преобразования.
Кодер 100 содержит модуль 108 выравнивания, сконфигурированный для выравнивания текущего блока 131 с использованием скорректированной огибающей 139, посредством чего получается блок 140 выровненных коэффициентов 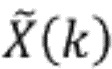 преобразования. Блок 140 выровненных коэффициентов преобразования можно кодировать с использованием цикла предсказания в области преобразования. Как таковой, блок 140 может быть кодирован с использованием предсказателя 117 поддиапазонов. Указанный цикл предсказания содержит разностный модуль 115, сконфигурированный для определения блока 141 коэффициентов ∆(k) ошибок предсказания на основе блока 140 выровненных коэффициентов преобразования и на основе блока 150 оценочных коэффициентов преобразования, например,
преобразования. Блок 140 выровненных коэффициентов преобразования можно кодировать с использованием цикла предсказания в области преобразования. Как таковой, блок 140 может быть кодирован с использованием предсказателя 117 поддиапазонов. Указанный цикл предсказания содержит разностный модуль 115, сконфигурированный для определения блока 141 коэффициентов ∆(k) ошибок предсказания на основе блока 140 выровненных коэффициентов преобразования и на основе блока 150 оценочных коэффициентов преобразования, например, 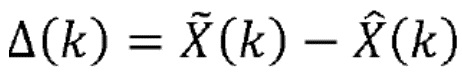 . Следует отметить, что по причине того, что блок 140 содержит выровненные коэффициенты преобразования, т.е. коэффициенты преобразования, которые были нормированы, или выровнены, с использованием значений 303 энергии скорректированной огибающей 139, блок 150 оценочных коэффициентов преобразования также содержит оценки выровненных коэффициентов преобразования. Иными словами, разностный модуль 115 действует в так называемой выровненной области. Как следствие, блок 141 коэффициентов ∆(k) ошибок предсказания представлен в выровненной области.
. Следует отметить, что по причине того, что блок 140 содержит выровненные коэффициенты преобразования, т.е. коэффициенты преобразования, которые были нормированы, или выровнены, с использованием значений 303 энергии скорректированной огибающей 139, блок 150 оценочных коэффициентов преобразования также содержит оценки выровненных коэффициентов преобразования. Иными словами, разностный модуль 115 действует в так называемой выровненной области. Как следствие, блок 141 коэффициентов ∆(k) ошибок предсказания представлен в выровненной области.
Блок 141 коэффициентов ∆(k) ошибок предсказания может проявлять дисперсию, отличающуюся от единицы. Кодер 100 может содержать модуль 111 изменения масштаба, сконфигурированный для изменения масштаба коэффициентов ∆(k) ошибок предсказания с целью получения блока 142 коэффициентов ошибок с измененным масштабом. Для выполнения изменения масштаба, модуль 111 изменения масштаба может использовать одно или несколько предварительно определенных эвристических правил. Как результат, блок 142 коэффициентов ошибок с измененным масштабом проявляет дисперсию, (в среднем) более близкую к единице (по сравнению с блоком 141 коэффициентов ошибок предсказания). Это может быть преимущественным для последующего квантования и кодирования. Кодер 100 содержит модуль 112 квантования коэффициентов, сконфигурированный для квантования блока 141 коэффициентов ошибок предсказания или блока 142 коэффициентов ошибок с измененным масштабом. Модуль 112 квантования коэффициентов может содержать или может использовать набор предварительно определенных квантователей. Этот набор предварительно определенных квантователей может предусматривать квантователи с разными степенями точности или с различной разрешающей способностью. Это проиллюстрировано на фиг. 4, где проиллюстрированы различные квантователи 321, 322, 323. Эти различные квантователи могут обеспечивать разные уровни точности (указываемые разными значениями в дБ). Конкретный квантователь из ряда квантователей 321, 322, 323 может соответствовать конкретному значению огибающей 138 распределения. Таким образом, значение энергии огибающей 138 распределения может указывать на соответствующий квантователь из ряда квантователей. Поэтому определение огибающей 138 распределения может упрощать процесс выбора квантователя, подлежащего использованию для конкретного коэффициента ошибки. Иными словами, огибающая 138 распределения может упрощать процесс распределения битов.
Указанный набор квантователей может содержать один или несколько квантователей 322, использующих добавление псевдослучайного шума для придания ошибке квантования случайного характера. Это проиллюстрировано на фиг. 4, где показан первый набор 326 предварительно определенных квантователей, содержащий подмножество 324 квантователей с добавлением псевдослучайного шума, и второй набор 327 предварительно определенных квантователей, содержащий подмножество 325 квантователей с добавлением псевдослучайного шума. Как таковой, модуль 112 квантования коэффициентов может использовать разные наборы 326, 327 предварительно определенных квантователей, при этом набор предварительно определенных квантователей, подлежащий использованию модулем 112 квантования коэффициентов, может зависеть от параметра 146 управления, предоставляемого предсказателем 117. В частности, модуль 112 квантования коэффициентов может быть сконфигурирован для выбора набора 326, 327 предварительно определенных квантователей для квантования блока 142 коэффициентов ошибок с измененным масштабом на основе параметра 146 управления, при этом параметр 146 управления может зависеть от одного или нескольких параметров предсказателя, создаваемых предсказателем 117. Указанные один или несколько параметров могут служить признаком качества блока 150 оценочных коэффициентов преобразования, создаваемого предсказателем 117.
Квантованные коэффициенты ошибок могут подвергаться энтропийному кодированию, например, с использованием кодирования методом Хаффмана, посредством чего получаются данные 163 коэффициентов, подлежащие включению в битовый поток, генерируемый кодером 100.
Кодер 100 может быть сконфигурирован для выполнения процесса распределения битов. С этой целью кодер 100 может содержать модули 109, 110 распределения битов. Модуль 109 распределения битов может быть сконфигурирован для определения полного количества битов 143, доступных для кодирования текущего блока 142 коэффициентов ошибок с измененным масштабом. Это полное количество битов 143 можно определить на основе огибающей 138 распределения. Модуль 110 может быть сконфигурирован для создания относительного распределения битов различным коэффициентам ошибок с измененным масштабом в зависимости от соответствующего значения энергии на огибающей 138 распределения.
Процесс распределения битов может использовать итеративную процедуру распределения. В ходе процедуры распределения огибающая 138 распределения может быть смещена с использованием параметра смещения, посредством чего выбираются квантователи с повышенной/пониженной разрешающей способностью. Как таковой, параметр смещения можно использовать для уточнения или огрубления квантования в целом. Параметр смещения можно определить так, чтобы данные 163 коэффициентов, получаемые с использованием квантователей, задаваемых посредством этого параметра смещения и огибающей 138 распределения, содержали количество битов, соответствующее (или не превышающее) суммарное количество битов 143, распределенное текущему блоку 131. Параметр смещения, который был использован кодером 100 для кодирования текущего блока 131, включается как данные 163 коэффициентов в битовый поток. Как следствие соответствующий декодер способен определять квантователи, которые были использованы модулем 112 квантования коэффициентов для квантования блока 142 коэффициентов ошибок с измененным масштабом.
Как результат квантования коэффициентов ошибок с измененным масштабом, получают блок 145 квантованных коэффициентов ошибок. Блок 145 квантованных коэффициентов ошибок соответствует блоку коэффициентов ошибок, доступному в соответствующем декодере. Следовательно, блок 145 квантованных коэффициентов ошибок можно использовать для определения блока 150 оценочных коэффициентов преобразования. Кодер 100 может содержать модуль 113 обратного изменения масштаба, сконфигурированный для выполнения операций изменения масштаба, обратных операциям, выполненным модулем 113 изменения масштаба, посредством чего получается блок 147 масштабированных квантованных коэффициентов ошибок. Модуль 116 сложения можно использовать для определения блока 148 восстановленных выровненных коэффициентов путем сложения блока 150 оценочных коэффициентов преобразования с блоком 147 масштабированных квантованных коэффициентов ошибок. Кроме того, для применения скорректированной огибающей 139 к блоку 148 восстановленных выровненных коэффициентов можно использовать модуль 114 обратного выравнивания, посредством чего получается блок 149 восстановленных коэффициентов. Блок 149 восстановленных коэффициентов соответствует версии блока 131 коэффициентов преобразования, доступной в соответствующем декодере. Следовательно, для определения блока 150 оценочных коэффициентов в предсказателе 117 можно использовать блок 149 восстановленных коэффициентов.
Блок 149 восстановленных коэффициентов является представленным в невыровненной области, т.е. блок 149 восстановленных коэффициентов также является представителем огибающей спектра текущего блока 131. Как будет описываться ниже, это может быть преимущественным для производительности предсказателя 117.
Предсказатель 117 может быть сконфигурирован для оценивания блока 150 оценочных коэффициентов преобразования на основе по меньшей мере одного или нескольких предыдущих блоков 149 восстановленных коэффициентов. В частности, предсказатель 117 может быть сконфигурирован для определения одного или нескольких параметров предсказателя так, чтобы они уменьшали (например, минимизировали) предварительно определенный критерий ошибок предсказания. Например, эти один или несколько параметров предсказателя можно определять так, чтобы уменьшать (например, минимизировать) энергию или перцепционно взвешенную энергию блока 141 коэффициентов ошибок предсказания. Эти один или несколько параметров могут быть включены в битовый поток, генерируемый кодером 100, как данные 164 предсказателя.
Данные 164 предсказателя могут служить признаком одного или нескольких параметров предсказателя. Как будет описано в настоящем документе, предсказатель 117 можно использовать лишь для подмножества кадров или блоков 131 звукового сигнала. В частности, предсказатель 117 можно не использовать для первого блока 131 I-кадра (независимый кадр), который, как правило, кодируется независимо от предшествующего блока. В дополнение к этому, данные 164 предсказателя могут соответствовать одному или нескольким флагам, служащим признаками присутствия предсказателя 117 для конкретного блока 131. Для блоков, где вклад предсказателя является практически незначительным (например, тогда, когда коэффициент усиления предсказателя квантуется в нуль), для сигнализации этой ситуации может быть преимущественным использование флага присутствия предсказателя, что, как правило, требует значительно меньшего количества битов по сравнению с передачей нулевого коэффициента усиления. Иными словами, данные 164 предсказателя для блока 131 могут содержать один или несколько флагов присутствия предсказателя, указывающих, были ли определены (и содержатся ли в данных 164 предсказателя) один или несколько параметров предсказателя. Использование одного или нескольких флагов присутствия предсказателя может иметь место для экономии битов, если предсказатель 117 не используется для конкретного блока 131. Таким образом, в зависимости от количества блоков 131, кодированных без использования предсказателя 117, использование одного или нескольких флагов присутствия предсказателя может быть (в среднем) более эффективно с точки зрения битовой скорости передачи данных, чем передача выбираемых по умолчанию параметров предсказателя (например, с нулевыми значениями).
Присутствие предсказателя 117 может быть явно передано в расчете на блок. Это позволяет экономить биты тогда, когда предсказание не используется. Например, для I-кадров можно использовать только три флага присутствия предсказателя, так как первый блок I-кадра не использует предсказание. Иными словами, если известно, что конкретный блок 131 является первым блоком I-кадра, то для данного конкретного блока 131 нет необходимости в передаче какого-либо флага присутствия предсказателя (так как соответствующему декодеру уже известно, что данный конкретный блок 131 не использует предсказатель 117).
Предсказатель 117 может использовать модель сигнала, описанную в заявке на патент США №61750052 и в заявляющих ее приоритет патентных заявках, содержание которых включается ссылкой. Указанные один или несколько параметров предсказателя могут соответствовать одному или нескольким параметрам модели для указанной модели сигнала.
На фиг. 1b показана блок-схема одного из дальнейших примеров речевого кодера 170 на основе предсказания. Речевой кодер 170 на основе предсказания по фиг. 1b содержит многие из компонентов кодера 100 по фиг. 1а. Однако речевой кодер 170 на основе предсказания по фиг. 1b сконфигурирован для генерирования битового потока, имеющего переменную битовую скорость передачи данных. С этой целью кодер 170 содержит модуль 172 режима средней битовой скорости передачи данных (ABR), сконфигурированный для отслеживания битовой скорости передачи данных, которая была использована битовым потоком выше для предыдущих блоков 131. Модуль 171 распределения битов использует эту информацию для определения общего количества битов 143, доступных для кодирования текущего блока 131 коэффициентов преобразования. В целом, речевые кодеры 100, 170 сконфигурированы для генерирования битового потока, служащего признаком или содержащего:
- данные 161 огибающей, служащие признаком квантованной текущей огибающей 134. Квантованную текущую огибающую 134 используют для описания огибающей блоков из текущего набора 132 или смещенного набора 332 блоков коэффициентов преобразования.
- данные 162 коэффициентов усиления, служащие признаком коэффициента усиления коррекции уровня для коррекции интерполированной огибающей 136 текущего блока 131 коэффициентов преобразования. Как правило, для каждого блока 131 из текущего набора 132 или из смещенного набора 332 блоков предусмотрен отличающийся коэффициент усиления.
- данные 163 коэффициентов, служащие признаком блока 141 коэффициентов ошибок предсказания для текущего блока 131. В частности, данные 163 коэффициентов служат признаком блока 145 квантованных коэффициентов ошибок. Кроме того, данные 163 коэффициентов могут служить признаком параметра смещения, который можно использовать для определения квантователей с целью выполнения обратного квантования в декодере.
- данные 164 предсказателя, служащие признаком одного или нескольких коэффициентов предсказателя, подлежащих использованию для определения блока 150 оценочных коэффициентов исходя из предыдущих блоков 149 восстановленных коэффициентов.
Ниже в контексте фиг. 5а—5d описывается соответствующий речевой декодер 500 на основе преобразования. На фиг. 5а показана блок-схема одного из примеров речевого декодера 500 на основе преобразования. На этой блок-схеме показан набор 504 синтезирующих фильтров (также именуемый модулем обратного преобразования), используемый для преобразования блока 149 восстановленных коэффициентов из области преобразования во временную область, посредством чего получаются дискретные значения декодированного звукового сигнала. Этот набор 504 синтезирующих фильтров может использовать обратное MDCT с предварительно определенным шагом (например, с шагом, приблизительно равным 5 мс, или 256 дискретных значений). Главный цикл декодера 500 действует в единицах его шага. Каждый этап вырабатывает вектор (также именуемый блоком) в области преобразования, имеющий длину, или размер, соответствующий предварительно определенной установке ширины полосы пропускания системы. При заполнении нулями до размера преобразования набора 504 синтезирующих фильтров вектор в области преобразования будет использован для синтеза обновления сигнала во временной области с предварительно определенной длиной (например, 5 мс) в процессе перекрытия/сложения набора 504 синтезирующих фильтров.
Как указывалось выше, обобщенные звуковые кодеки на основе преобразования, как правило, используют для обработки переходных состояний кадры с последовательностями из коротких блоков в диапазоне 5 мс. Таким образом, обобщенные звуковые кодеки на основе преобразования обеспечивают необходимые преобразования и инструментальные средства коммутации оконных функций для бесшовного сосуществования коротких и длинных блоков. Поэтому в звуковой кодек общего назначения на основе преобразования можно удобно встроить голосовой спектральный внешний интерфейс, характеризующийся пропуском набора 504 синтезирующих фильтров по фиг. 5а, без необходимости во введении дополнительных инструментальных средств коммутации. Иными словами, речевой декодер 500 на основе преобразования по фиг. 5а можно удобно объединить с обобщенным звуковым декодером на основе преобразования. В частности, речевой декодер 500 на основе преобразования по фиг. 5а может использовать набор 504 синтезирующих фильтров, предусматриваемый обобщенным звуковым декодером на основе преобразования (например, декодером AAC или HE-AAC).
Из поступающего битового потока (в частности, из данных 161 огибающей и данных 162 коэффициентов усиления, заключенных в этом битовом потоке) декодер 503 огибающей может определять огибающую сигнала. В частности, декодер 503 огибающей может быть сконфигурирован для определения скорректированной огибающей 139 на основе данных 161 огибающей и данных 162 коэффициентов усиления. Таким образом, декодер 503 огибающей может выполнять задачи аналогично модулю 104 интерполяции и модулю 107 уточнения огибающей кодера 100, 170. Как описывалось выше, скорректированная огибающая 109 представляет модель дисперсии сигнала в наборе предварительно определенных полос 302 частот.
Кроме того, кодер 500 содержит модуль 114 обратного выравнивания, сконфигурированный для применения скорректированной огибающей 139 к вектору в выровненной области, элементы которого номинально могут иметь единичную дисперсию. Вектор в выровненной области соответствует блоку 148 восстановленных выровненных коэффициентов, описанному в контексте кодера 100, 170. На выводе модуля 114 обратного выравнивания получается блок 149 восстановленных коэффициентов. Блок 149 восстановленных коэффициентов доставляется в набор 504 синтезирующих фильтров (для генерирования декодированного звукового сигнала) и в предсказатель 517 поддиапазонов.
Предсказатель 517 поддиапазонов действует аналогично предсказателю 117 кодера 100, 170. В частности, предсказатель 517 поддиапазонов сконфигурирован для определения блока 150 оценочных коэффициентов преобразования (в выровненной области) на основе одного или нескольких предыдущих блоков 149 восстановленных коэффициентов (с использованием одного или нескольких параметров предсказателя, сигнализируемых в битовом потоке). Иными словами, предсказатель 517 поддиапазонов сконфигурирован для вывода предсказываемого вектора в выровненной области исходя из буфера ранее декодированных выходных векторов и огибающих сигнала на основе таких параметров предсказателя, как запаздывание предсказателя и коэффициент усиления предсказателя. Декодер 500 содержит декодер 501 предсказателя, сконфигурированный для декодирования данных 164 предсказателя с целью определения одного или нескольких параметров предсказателя.
Декодер 500 также содержит декодер 502 спектра, сконфигурированный для снабжения предсказываемого вектора в выровненной области аддитивной поправкой на основе, как правило, наибольшей части битового потока (т.е. на основе данных 163 коэффициентов). Процесс декодирования спектра управляется главным образом вектором распределения, получаемым исходя из огибающей, и передаваемым параметром управления распределением (также именуемым параметром смещения). Как проиллюстрировано на фиг. 5а, может существовать прямая зависимость декодера 502 спектра от параметров 520 предсказателя. Таким образом, декодер 502 спектра может быть сконфигурирован для определения блока 147 масштабированных квантованных коэффициентов ошибок на основе принятых данных 163 коэффициентов. Как описывалось в контексте кодера 100, 170, квантователи 321, 322, 323 используют для квантования блока 142 коэффициентов ошибок с измененным масштабом, как правило, в зависимости от огибающей 138 распределения (которую можно получить исходя из скорректированной огибающей 139) и от параметра смещения. Кроме того, квантователи 321, 322, 323 могут зависеть от параметра 146 управления, предоставляемого предсказателем 117. Параметр 146 управления может быть получен декодером 500 с использованием параметров 520 предсказателя (аналогично кодеру 100, 170).
Как указывалось выше, принятый битовый поток содержит данные 161 огибающей и данные 162 коэффициентов усиления, которые можно использовать для определения скорректированной огибающей 139. В частности, модуль 531 декодера 503 огибающей может быть сконфигурирован для определения квантованной текущей огибающей 134 исходя из данных 161 огибающей. Например, квантованная текущая огибающая 134 может иметь разрешающую способность 3 дБ в предварительно определенных полосах 302 частот (как указано на фиг. 3а). Квантованную текущую огибающую 134 можно обновлять для каждого набора 132, 332 блоков (например, каждые четыре единицы кодирования, т.е. блока, или каждые 20 мс), в частности, для каждого сдвинутого набора 332 блоков. Полосы 302 частот квантованной текущей огибающей 134 могут содержать возрастающее количество элементов 301 разрешения по частоте в зависимости от частоты, с целью адаптации к свойствам человеческого слуха.
Квантованную текущую огибающую 134 можно линейно интерполировать исходя из квантованной предыдущей огибающей 135 в интерполированные огибающие 136 для каждого блока 131 из сдвинутого набора 332 блоков (или, возможно, из текущего набора 132 блоков). Интерполированные огибающие 136 можно определить в области, квантованной с разрешающей способностью 3 дБ. Это означает, что интерполированные значения 303 энергии можно округлять до ближайшего уровня 3 дБ. Один из примеров интерполированной огибающей 136 проиллюстрирован на фиг. 3а пунктирной линией. Для каждой квантованной текущей огибающей 134 в качестве данных 162 коэффициентов усиления предусмотрено четыре коэффициента α 137 усиления коррекции уровня (также именуемых коэффициентами усиления огибающей). Модуль 532 декодирования коэффициентов усиления может быть сконфигурирован для определения коэффициентов α 137 усиления коррекции уровня исходя из данных 162 коэффициентов усиления. Коэффициенты усиления коррекции уровня могут быть квантованы с шагом 1 дБ. Каждый коэффициент усиления коррекции уровня применяют к соответствующей интерполированной огибающей 136 с целью создания скорректированных огибающих 139 для разных блоков 131. По причине повышенной разрешающей способности коэффициентов 137 усиления коррекции уровня скорректированная огибающая 139 может иметь повышенную разрешающую способность (например, разрешающую способность 1 дБ). На фиг. 3b показан один из примеров линейной или геометрической интерполяции между квантованной предыдущей огибающей 135 и квантованной текущей огибающей 134. Огибающие 135, 134 могут быть разделены на часть среднего уровня и часть формы логарифмического спектра. Эти части можно интерполировать по таким независимым стратегиям, как линейная, геометрическая, или гармоническая стратегия (параллельных резисторов). Таким образом, для определения интерполированных огибающих 136 можно использовать разные схемы интерполяции. Схема интерполяции, используемая декодером 500, как правило, соответствует схеме интерполяции, используемой кодером 100, 170.
Модуль 107 уточнения огибающей декодера 503 огибающей может быть сконфигурирован для определения огибающей 138 распределения исходя из скорректированной огибающей 139 путем квантования скорректированной огибающей 139 (например, с шагом 3 дБ). Огибающую 138 распределения можно использовать в сочетании с параметром управления распределением или параметром смещения (заключенным в данных 163 коэффициентов) для создания номинального целочисленного вектора распределения, используемого для управления спектральным декодированием, т.е. декодированием данных 163 коэффициентов. В частности, для определения квантователя с целью обратного квантования индексов квантования, заключенных в данных 163 коэффициентов, можно использовать номинальный целочисленный вектор распределения. Огибающая 138 распределения и номинальный целочисленный вектор распределения можно определять аналогичным образом в кодере 100, 170 и в декодере 500.
Для того чтобы позволить декодеру 500 синхронизироваться с принимаемым битовым потоком, могут передаваться кадры разного типа. Кадр может соответствовать набору 132, 332 блоков, в частности, смещенному блоку 332 блоков. В частности, могут передаваться т.н. P-кадры, кодированные относительным образом относительно предыдущего кадра. В приведенном выше описании предполагалось, что декодер 500 осведомлен о квантованной предыдущей огибающей 135. Эта квантованная предыдущая огибающая 135 может быть доставлена в предыдущем кадре так, чтобы текущий набор 132 или соответствующий сдвинутый набор 332 мог соответствовать Р-кадру. Однако в сценарии запуска декодер 500, как правило, не осведомлен о квантованной предыдущей огибающей 135. Поэтому может передаваться I-кадр (например, при запуске или на регулярной основе). Этот I-кадр может содержать две огибающие, одна из которых используется в качестве квантованной предыдущей огибающей 135, а другая используется в качестве квантованной текущей огибающей 134. I-кадры можно использовать для случая запуска голосового спектрального внешнего интерфейса (т.е. речевого декодера 500 на основе преобразования), например, вслед за кадром, использующим другой режим звукового кодирования и/или в качестве инструментального средства для того, чтобы в явном виде сделать возможной точку сращивания звукового битового потока.
Действие предсказателя 517 поддиапазонов проиллюстрировано на фиг. 5d. В иллюстрируемом примере параметрами 520 предсказателя являются параметр запаздывания и параметр g коэффициента усиления предсказателя. Эти параметры 520 предсказателя можно определить, исходя из данных 164 предсказателя с использованием предварительно определенной таблицы возможных значений параметра запаздывания и параметра коэффициента усиления предсказателя. Это делает возможной передачу параметров 520 предсказателя, эффективную с точки зрения битовой скорости передачи данных.
Один или несколько ранее декодированных векторов коэффициентов преобразования (т.е. один или несколько предыдущих блоков 149 восстановленных коэффициентов) можно хранить в буфере 541 сигналов поддиапазонов (или MDCT). Буфер 541 может обновляться в соответствии с шагом (например, каждые 5 мс). Экстрактор 543 предсказателя может быть сконфигурирован для действия на буфер 541 в зависимости от нормированного параметра Т запаздывания. Этот нормированный параметр Т запаздывания можно определить путем нормирования параметра 520 запаздывания на единицу шага (например, на единицу шага MDCT). Если параметр Т запаздывания является целым числом, то экстрактор 543 может извлекать одну или несколько единиц времени ранее декодированных векторов Т коэффициентов преобразования из буфера 541. Иными словами, параметр Т запаздывания может служить признаком того, какие из одного или нескольких блоков 149 восстановленных коэффициентов следует использовать для определения блока 150 оценочных коэффициентов преобразования. Подробное обсуждение в отношении возможной реализации экстрактора 543 представлено в заявке на патент США №61750052 и заявляющих ее приоритет патентных заявках, содержание которых включается ссылкой.
Экстрактор 543 может действовать на векторах (или блоках), несущих полные огибающие сигнала. С другой стороны, блок 150 оценочных коэффициентов преобразования (подлежащий созданию предсказателем 517 поддиапазонов) представлен в выровненной области. Следовательно, вывод экстрактора 543 может быть сформирован в вектор в выровненной области. Этого можно достигнуть, используя формирователь 544, использующий скорректированные огибающие 139 из одного или нескольких предыдущих блоков 149 восстановленных коэффициентов. Скорректированные огибающие 139 из одного или нескольких предыдущих блоков 149 восстановленных коэффициентов могут храниться в буфере 542 огибающих. Модуль 544 формирователя может быть сконфигурирован для извлечения задержанной огибающей сигнала, подлежащей использованию при выравнивании от Т0 единиц времени в буфер 542 огибающих, где Т0 — целое число, ближайшее к Т. Затем вектор в выровненной области можно масштабировать посредством параметра g коэффициента усиления для получения блока 150 оценочных коэффициентов преобразования (в выровненной области).
Модуль 544 формирователя может быть сконфигурирован для определения вектора в выровненной области так, чтобы эти векторы в выровненной области на выводе модуля 544 формирователя проявляли единичную дисперсию в каждой полосе частот. Для достижения этой цели, модуль 544 формирователя может полностью полагаться на данные в буфере 542 огибающих. Например, модуль 544 формирователя может быть сконфигурирован для выбора задержанной огибающей сигнала так, чтобы указанные векторы в выровненной области на выводе модуля 544 формирователя проявляли единичную дисперсию в каждой полосе частот. В качестве альтернативы или в дополнение, модуль 544 формирователя может быть сконфигурирован для измерения дисперсии векторов в выровненной области на выводе модуля 544 формирователя и для коррекции дисперсии этих векторов к свойству единичной дисперсии. Нормирование одного из возможных типов может использовать единственный широкополосный коэффициент усиления (приходящийся на квант), нормирующий векторы в выровненной области в вектор с единичной дисперсией. Эти коэффициенты усиления могут передаваться из кодера 100 в соответствующий декодер 500 (например, в квантованной и кодированной форме) в битовом потоке.
В качестве одной из альтернатив, задержанный процесс выравнивания, выполняемый формирователем 544, может быть пропущен посредством использования предсказателя 517 поддиапазонов, действующего в выровненной области, например, предсказателя 517 поддиапазонов, действующего на блоках 148 восстановленных выровненных коэффициентов. Однако было обнаружено, что последовательность векторов (или блоков) в выровненной области не очень хорошо отображается во временные сигналы по причине аспектов смешивания во времени при преобразовании (например, при преобразовании MDCT). Как следствие, уменьшается согласованность с лежащей в основе экстрактора 43 моделью сигнала, и из этой альтернативной конструкции в результате получается более высокий уровень шума кодирования. Иными словами, было обнаружено, что модели сигнала (например, синусоидальные или периодические модели), используемые предсказателем 517 поддиапазонов, приводят к большей эффективности в невыровненной области (в сравнении с выровненной областью).
Следует отметить, что в одном из альтернативных примеров вывод предсказателя 517 (т.е. блок 150 оценочных коэффициентов преобразования) можно складывать с выводом модуля 114 обратного выравнивания (т.е. с блоком 149 восстановленных коэффициентов) (см. фиг. 5а). Тогда модуль 544 формирователя по фиг. 5с может быть сконфигурирован для выполнения комбинированной операции задержанного выравнивания и обратного выравнивания.
Элементы в принимаемом битовом потоке могут управлять случающейся время от времени очисткой буфера 541 поддиапазонов и буфера 542 огибающих, например, в случае первой единицы кодирования (например, первого блока) из I-кадра. Это делает возможным декодирование I-кадра в отсутствие знания предыдущих данных. Первая единица кодирования, как правило, не будет способна использовать предсказывающий вклад, но, несмотря на это, может использовать относительно меньшее количество битов для передачи информации 520 предсказателя. Потерю коэффициента усиления предсказания можно компенсировать, распределяя больше битов на кодирование ошибки предсказания этой первой единицы кодирования. Как правило, вклад предсказателя вновь является существенным для второй единицы кодирования (т.е. второго блока) в I-кадре. Благодаря этим аспектам, качество можно поддерживать с относительно небольшим увеличением битовой скорости передачи данных даже при очень частом использовании I-кадров.
Иными словами, наборы 132, 332 блоков (также именуемых кадрами) содержат ряд блоков 131, которые можно кодировать с использованием кодирования с предсказанием. При кодировании I-кадра только первый блок 203 из набора 332 блоков нельзя кодировать с использованием коэффициента усиления кодирования, достигаемого кодером с предсказанием. Уже непосредственно следующий блок 201 может использовать выгоды кодирования с предсказанием. Это означает, что недостатки I-кадра в том, что касается эффективности кодирования, ограничены кодированием первого блока 203 коэффициентов преобразования из кадра 332, и не распространяются на другие блоки 201, 204, 205 кадра 332. Отсюда, схема речевого кодирования на основе преобразования, описываемая в настоящем документе, допускает относительно частое использование I-кадров без значительного влияния на эффективность кодирования. Как таковая, описываемая ныне схема речевого кодирования на основе преобразования является особенно подходящей для применений, требующих относительно быстрой и/или относительно частой синхронизации между декодером и кодером. Как указывалось выше, в ходе инициализации I-кадра буфер сигналов предсказания, т.е. буфер 541 поддиапазонов, можно заполнить нулями, а буфер 542 огибающих можно заполнить лишь одним временным квантом значений, т.е. его можно заполнить лишь единственной скорректированной огибающей 139 (соответствующей первому блоку 131 I-кадра). Первый блок 131 I-кадра, как правило, не будет использовать предсказание. Второй блок 131 имеет доступ лишь к двум квантам времени из буфера 542 огибающих (т.е. к огибающим 139 из первого и второго блоков 131), третий блок — лишь к трем квантам времени (т.е. к огибающим 139 трех блоков 131), а четвертый блок — лишь к четырем квантам времени (т.е. к огибающим 139 четырех блоков 131).
Правило задержанного выравнивания формирователя 544 спектра (для идентификации огибающей при определении блока 150 оценочных коэффициентов преобразования (в выровненной области)) основывается на целочисленном значении Т0 запаздывания, определяемом путем округления параметра Т запаздывания предсказателя в единицах размера K блока (причем эту единицу размера блока можно именовать квантом времени, или квантом) до ближайшего целого числа. Однако в случае I-кадра это целочисленное значение Т0 запаздывания может указывать на недоступные элементы в буфере 542 огибающих. В виду этого формирователь 544 спектра может быть сконфигурирован для определения целочисленного значения Т0 запаздывания так, чтобы это целочисленное значение Т0 запаздывания было ограничено количеством огибающих 139, хранящихся в буфере 542 огибающих, т.е. так, чтобы целочисленное значение Т0 запаздывания не указывало на огибающие 139, не являющиеся доступными в буфере 542 огибающих. С этой целью, целочисленное значение запаздывания можно ограничить величиной, представляющей собой функцию индекса блока внутри текущего кадра. Например, целочисленное значение запаздывания можно ограничить значением индекса текущего блока 131 (подлежащего кодированию) в пределах текущего кадра (например, 1 — для первого блока 131, 2 — для второго блока 131, 3 — для третьего блока 131, и 4 — для четвертого блока 131 кадра). Действуя таким образом, можно избежать нежелательных состояний и/или искажений, вызванных процессом выравнивания.
На фиг. 5d показана блок-схема одного из примеров декодера 502 спектра. Декодер 502 спектра содержит декодер 551 без потерь данных, сконфигурированный для декодирования энтропийно кодированных данных 163 коэффициентов. Кроме того, декодер 502 спектра содержит обратный квантователь 552, сконфигурированный для присвоения значений коэффициентов индексам квантования, заключенным в данных 163 коэффициентов. Как описывалось в контексте кодера 100, 170, разные коэффициенты преобразования можно квантовать, используя разные квантователи, выбираемые из набора предварительно определенных квантователей, например, из конечного набора скалярных квантователей на основе модели. Как показано на фиг. 4, набор квантователей 321, 322, 323 может содержать квантователи разных типов. Этот набор квантователей может содержать квантователь 321, обеспечивающий синтез шума (в случае нулевой битовой скорости передачи данных), один или несколько квантователей 322 с добавлением псевдослучайного шума (для относительно низких отношений сигнал-шум, отношений SNR, и для промежуточных битовых скоростей передачи данных) и/или один или несколько простых квантователей 323 (для относительно высоких отношений SNR и для относительно высоких битовых скоростей передачи данных).
Модуль 107 уточнения огибающей может быть сконфигурирован для создания огибающей 138 распределения, которую можно сочетать с параметром смещения, заключенным в данных 163 коэффициентов, для получения вектора распределения. Этот вектор распределения содержит целочисленное значение для каждой полосы 302 частот. Это целочисленное значение для отдельной полосы 302 частот указывает на точку зависимости искажений от скорости передачи данных, подлежащую использованию для обратного квантования коэффициентов преобразования этой отдельной полосы 302. Иными словами, указанное целочисленное значение для отдельной полосы 302 частот указывает на квантователь, подлежащий использованию для обратного квантования коэффициентов преобразования указанной отдельной полосы 302. Увеличение этого целочисленного значения на единицу соответствует увеличению SNR на 1,5 дБ. Для квантователей 322 с добавлением псевдослучайного шума и простых квантователей 323 при кодировании без потерь данных, которое может использовать арифметическое кодирование, можно использовать лапласову модель распределения вероятностей. Для бесшовного заполнения пробела между случаями с высокой и низкой битовыми скоростями передачи данных можно использовать один или несколько квантователей 322 с добавлением псевдослучайного шума.
Квантователи 322 с добавлением псевдослучайного шума могут быть преимущественными при создании достаточно гладкого качества выходного звука для стационарных шумоподобных сигналов.
Иными словами, обратный квантователь 522 может быть сконфигурирован для приема индексов квантования коэффициентов из текущего блока 131 коэффициентов преобразования. Эти один или несколько индексов квантования коэффициентов конкретной полосы 302 частот были определены с использованием соответствующего квантователя из предварительно определенного набора квантователей. Значение вектора распределения (который можно определить путем смещения огибающей 138 распределения посредством параметра смещения) для данной конкретной полосы 302 частот указывает квантователь, который был использован для определения одного или нескольких индексов квантования коэффициентов данной конкретной полосы 302 частот. При наличии идентифицированного квантователя эти один или несколько индексов квантования коэффициентов можно подвергнуть обратному квантованию для получения блока 145 квантованных коэффициентов ошибок.
Кроме того, спектральный декодер 502 может содержать модуль 113 обратного изменения масштаба для создания блока 147 масштабированных квантованных коэффициентов ошибок. Для адаптации спектрального декодирования к его использованию в общем декодере 500, показанном на фиг. 5а, где для создания аддитивной поправки к предсказанному вектору в выровненной области (т.е. к блоку 150 оценочных коэффициентов преобразования) используется вывод спектрального декодера 502 (т.е. блок 145 квантованных коэффициентов ошибок), можно использовать дополнительные инструментальные средства и взаимосвязи около декодера 551 без потерь данных и квантователя 552 согласно фиг. 5d. В частности, эти дополнительные инструментальные средства могут обеспечивать то, что обработка, выполняемая декодером 500, будет соответствовать обработке, выполняемой кодером 100, 170.
В частности, спектральный декодер 502 может содержать модуль 111 эвристического масштабирования. Как показано в связи с кодером 100, 170, модуль 111 эвристического масштабирования может оказывать влияние на распределение битов. В кодере 100, 170 текущие блоки 141 коэффициентов ошибок предсказания можно масштабировать до единичной дисперсии посредством эвристического правила. Как следствие, распределение по умолчанию может приводить к слишком тонкому квантованию окончательного масштабированного на меньший размер вывода модуля 111 эвристического масштабирования. Поэтому распределение следует модифицировать способом, аналогичным модификации коэффициентов ошибок предсказания. Однако, как описывается ниже, может быть преимущественным избежание сокращения кодирующих ресурсов для одного или нескольких низкочастотных элементов разрешения (или низкочастотных полос). В частности, это может быть преимущественным для противодействия НЧ (низкочастотному) артефакту рокота/шума, оказывающемуся наиболее заметным в голосовых ситуациях (т.е. для сигнала, имеющего относительно большой параметр 146 управления, rfu). Таким образом, описываемый ниже выбор распределения битов/квантователя в зависимости от параметра 146 управления можно считать представляющим собой «повышение качества НЧ с голосовой адаптацией».
Декодер спектра может зависеть от параметра 146 управления, именуемого rfu, который может представлять собой ограниченную версию коэффициента g усиления предсказателя, например,
rfu=min(l, max(g, 0)).
Можно использовать и альтернативные способы определения параметра 146 управления, rfu. В частности, параметр 146 управления можно определить, используя псевдокод, приведенный в Таблице 1.

Переменные f_gain и f_pred_gain можно приравнять. В частности, переменная f_gain может соответствовать коэффициенту g усиления предсказателя. Параметр 146 управления, rfu, в Таблице 1 именуется frfu. Коэффициент усиления f_gain может представлять собой действительное число.
По сравнению с первым определением параметра 146 управления последнее определение (согласно Таблице 1) уменьшает параметр 146 управления, rfu, для коэффициентов усиления предсказателя выше 1 и увеличивает параметр 146 управления, rfu, для отрицательных коэффициентов усиления предсказателя.
Используя параметр 146 управления, можно адаптировать набор квантователей, используемых в модуле 112 квантования кодера 100, 170 и используемых в обратном квантователе 552.
В частности, на основе параметра 146 управления можно адаптировать зашумленность набора квантователей. Например, значение параметра 146 управления, rfu, близкое к 1 может запускать ограничение диапазона уровней распределения с использованием квантователей с добавлением псевдослучайного шума и может запускать уменьшение дисперсии уровня синтеза шума. В одном из примеров порог принятия решения о добавлении псевдослучайного шума находится при rfu=0,75, и может быть задан коэффициент усиления шума 1–rfu. Адаптация добавления псевдослучайного шума может оказывать влияние как на декодирование без потерь данных, так и на обратный квантователь, в то время как адаптация коэффициента усиления шума, как правило, оказывает влияние только на обратный квантователь.
Можно предположить, что вклад предсказателя является существенным для голосовых/тональных ситуаций. Как таковой, относительно высокий коэффициент g усиления предсказателя (т.е. относительно высокий параметр 146 управления) может служить признаком голосового или тонального речевого сигнала. В таких ситуациях добавление относящегося к псевдослучайному шуму или выраженного в явном виде (случай нулевого распределения) шума, как было экспериментально показано, является приводящим к обратным результатам для воспринимаемого качества кодированного сигнала. Как следствие, количество квантователей 322 с добавлением псевдослучайного шума и/или шума, относящегося к типу, используемому для квантователя 321 синтеза шума, можно адаптировать на основе коэффициента g усиления предсказателя, посредством чего повышается воспринимаемое качество кодированного речевого сигнала.
Таким образом, параметр 146 управления можно использовать для модификации диапазона 324, 325 отношений SNR, для которых используют квантователи 322 с добавлением псевдослучайного шума. Например, если параметр 146 управления rfu<0,75, то для квантователей с добавлением псевдослучайного шума можно использовать диапазон 324. Иными словами, если параметр 146 управления находится ниже предварительно определенного порога, можно использовать первый набор 326 квантователей. С другой стороны, если параметр 146 управления rfu>0,75, то для квантователей с добавлением псевдослучайного шума можно использовать диапазон 325. Иными словами, если параметр 146 управления больше или равен предварительно определенному порогу, то можно использовать второй набор 327 квантователей.
Кроме того, параметр 146 управления можно использовать для модификации дисперсии и распределения битов. Причиной этого является то, что успешное предсказание, как правило, требует меньшей поправки, особенно в низкочастотном диапазоне 0—1 кГц. Может являться преимущественным осуществление квантователя, явно осведомленного об этом отклонении от модели единичной дисперсии, с целью высвобождения кодирующих ресурсов для полос 302 более высоких частот. Это описано в контексте панели iii Фигуры 17 международной патентной заявки WO №2009/086918, содержание которой включается ссылкой. В декодере 500 эту модификацию можно реализовать путем модификации номинального вектора распределения в соответствии с эвристическим правилом масштабирования (применяемого посредством использования модуля 111 масштабирования) и, в то же время, масштабирования вывода обратного квантователя 552 в соответствии с эвристическим правилом обратного масштабирования с использованием модуля 113 обратного масштабирования. Следуя теории международной патентной заявки WO №2009/086918, эвристическое правило масштабирования и эвристическое правило обратного масштабирования должны находиться в близком соответствии. Однако было обнаружено, что преимущественным с экспериментальной точки зрения является отмена модификации распределения для одной или нескольких самых нижних полос 302 частот с целью противодействия периодическими трудностям с НЧ (низкочастотным) шумом для голосовых составляющих сигнала. Отмену модификации распределения можно выполнять в зависимости от значения коэффициента g усиления предсказателя и/или параметра 146 управления. В частности, отмену модификации распределения можно выполнять только тогда, когда параметр 146 управления превышает порог принятия решения о добавлении псевдослучайного шума.
Как описывалось выше, кодер 100, 170 и/или декодер 500 может содержать модуль 111 масштабирования, сконфигурированный для изменения масштаба коэффициентов ∆(k) ошибок предсказания, приводящего к 5 блокам 142 коэффициентов ошибок с измененным масштабом. Для выполнения изменения масштаба, модуль 111 изменения масштаба может использовать одно или несколько предварительно определенных эвристических правил. В одном из примеров модуль 111 масштабирования может использовать эвристическое правило масштабирования, содержащее коэффициент d(f) усиления, например,
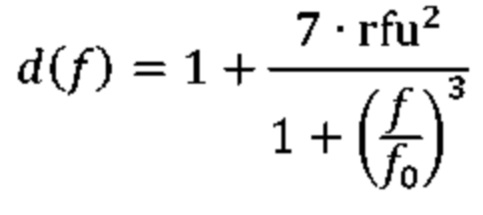
где частоту излома f0 можно приравнять, например, 1000 Гц. Таким образом, модуль 111 изменения масштаба можно сконфигурировать для применения к коэффициентам ошибок предсказания зависящего от частоты коэффициента d(f) усиления с целью получения блока 142 коэффициентов ошибок с измененным масштабом. Модуль 113 обратного изменения масштаба можно сконфигурировать для применения обратной величины зависящего от частоты коэффициента d(f) усиления. Зависящий от частоты коэффициент d(f) усиления может зависеть от параметра rfu 146 управления. В приведенном выше примере коэффициент d(f) усиления проявляет характер фильтра прохождения нижних частот так, что коэффициенты ошибок предсказания сильнее ослабляются при более высоких частотах, чем при менее высоких частотах, и/или так, что коэффициенты ошибок предсказания сильнее выделяются при менее высоких частотах, чем при более высоких частотах. Вышеупомянутый коэффициент d(f) усиления всегда больше или равен единице. Таким образом, в одном из предпочтительных вариантов осуществления эвристическое правило масштабирования таково, что коэффициенты ошибок предсказания выделяются с коэффициентом единица или более (в зависимости от частоты).
Следует отметить, что зависящий от частоты коэффициент усиления может служить признаком мощности или дисперсии. В таких случаях правило масштабирования и правило обратного масштабирования следует получать на основе квадратного корня зависящего от частоты коэффициента усиления, например, на основе  .
.
Степень выделения и/или ослабления может зависеть от качества предсказания, достигаемого предсказателем 117. Коэффициент g усиления предсказателя и/или параметр rfu 146 управления может служить признаком качества предсказания. В частности, относительно низкое значение параметра rfu 146 управления (относительно более близкое к нулю) может служить признаком низкого качества предсказания. В таких случаях следует ожидать, что коэффициенты ошибок предсказания будут иметь относительно высокие (абсолютные) значения на всех частотах. Относительно высокое значение параметра rfu 146 управления (относительно более близкое к единице) может служить признаком высокого качества предсказания. В таких случаях следует ожидать, что коэффициенты ошибок предсказания будут иметь относительно высокие (абсолютные) значения для высоких частот (которые труднее предсказывать). Таким образом, для того чтобы достигнуть единичной дисперсии на выводе модуля 111 изменения масштаба, коэффициент d(f) усиления может быть таков, чтобы, в случае относительно низкого качества предсказания, коэффициент d(f) усиления был, по существу, равномерным для всех частот, в то время как в случае относительно высокого качества предсказания, коэффициент d(f) усиления имел характер фильтра прохождения нижних частот для увеличения, или повышения, дисперсии при низких частотах. Это имеет место для вышеупомянутого коэффициента d(f) усиления, зависящего от rfu.
Как описывалось выше, модуль 110 распределения битов можно сконфигурировать для обеспечения относительного распределения битов для разных коэффициентов ошибок с измененным масштабом в зависимости от соответствующего значения энергии на огибающей 138 распределения. Модуль 110 распределения битов можно сконфигурировать для учета эвристического правила изменения масштаба. Это эвристическое правило изменения масштаба может зависеть от качества предсказания. В случае относительно высокого качества предсказания может быть более преимущественным присвоение относительно большего количества битов кодированию коэффициентов ошибок предсказания (или блоку 142 коэффициентов ошибок с измененным масштабом) при более высоких частотах, чем кодированию этих коэффициентов при низких частотах. Это может быть вызвано тем, что в случае высокого качества предсказания низкочастотные коэффициенты уже являются хорошо предсказанными, в то время как высокочастотные коэффициенты, как правило, предсказаны хуже. С другой стороны, в случае относительно низкого качества предсказания распределение битов должно оставаться неизменным.
Вышеописанное поведение можно реализовать путем применения обратных эвристических правил/коэффициента d(f) усиления к текущей скорректированной огибающей 139 с целью определения огибающей 138 распределения, учитывающей качество предсказания.
Скорректированную огибающую 139, коэффициенты ошибок предсказания и коэффициент d(f) усиления можно представить в логарифмической области или в области дБ. В этом случае, применение коэффициента d(f) усиления к коэффициентам ошибок предсказания может соответствовать операции «сложение», а применение обратной величины коэффициента d(f) усиления к скорректированной огибающей 139 может соответствовать операции «вычитание».
Следует отметить, что возможны различные варианты эвристических правил/коэффициента d(f) усиления. В частности, фиксированную зависящую от частоты кривую с характером  фильтра прохождения нижних частот можно заменить функцией, зависящей от данных огибающей (например, от скорректированной огибающей 139 для текущего блока 131). Модифицированные эвристические правила могут зависеть как от параметра rfu 146 управления, так и от данных огибающей.
фильтра прохождения нижних частот можно заменить функцией, зависящей от данных огибающей (например, от скорректированной огибающей 139 для текущего блока 131). Модифицированные эвристические правила могут зависеть как от параметра rfu 146 управления, так и от данных огибающей.
Ниже описываются различные пути определения коэффициента р усиления предсказателя, который может соответствовать коэффициенту g усиления предсказателя. Коэффициент р усиления предсказателя можно использовать в качестве указателя качества предсказания. Вектор невязок предсказания (т.е. блок 141 коэффициентов z ошибок предсказания) может иметь вид: z=x–py, где х — целевой вектор (например, текущий блок 140 выровненных коэффициентов преобразования или текущий блок 131 коэффициентов преобразования), y — вектор, представляющий выбранного кандидата для предсказания (например, предыдущие блоки 149 восстановленных коэффициентов), и p — это (скалярный) коэффициент усиления предсказателя.
w≥0 может представлять собой весовой вектор, используемый для определения коэффициента p усиления предсказателя. В некоторых вариантах осуществления весовой вектор зависит от огибающей сигнала (например, зависит от скорректированной огибающей 139, которую можно оценить в кодере 100, 170, а затем передать в декодер 500). Этот весовой вектор, как правило, имеет такую же размерность, как целевой вектор и вектор-кандидат. i-й элемент вектора x можно обозначить как xi (например, i=1, ,,. ,K).
Существуют различные способы определения коэффициента p усиления предсказателя. В одном из вариантов осуществления коэффициент p усиления предсказателя представляет собой коэффициент усиления MMSE (с минимальной среднеквадратичной ошибкой), определяемый в соответствии с критерием минимальной среднеквадратичной ошибки. В этом случае коэффициент p усиления предсказателя можно вычислить, используя следующую формулу:
Такой коэффициент p усиления предсказателя, как правило, сводит к минимуму среднеквадратичную ошибку, определяемую как
Часто (с точки зрения восприятия) преимущественным является введение взвешивания в определение среднеквадратичной ошибки D. Это взвешивание можно использовать для выделения важности соответствия между x и y для важных с точки зрения восприятия частей спектра сигнала и снятия выделения важности соответствия между x и y для частей спектра сигнала, являющихся относительно менее важными. Такой подход в результате приводит к следующему критерию ошибок: 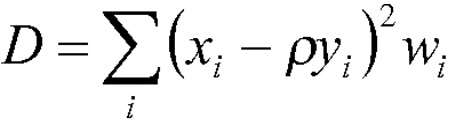 , что приводит к следующему определению оптимального коэффициента усиления предсказателя (в смысле взвешенной среднеквадратичной ошибки):
, что приводит к следующему определению оптимального коэффициента усиления предсказателя (в смысле взвешенной среднеквадратичной ошибки):
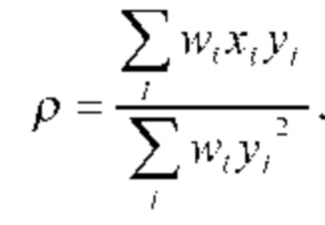
Приведенное выше определение коэффициента усиления предсказателя в результате, как правило, приводит к коэффициенту усиления, являющемуся неограниченным.
Как указывалось выше, весовые коэффициенты wi весового вектора w можно определить на основе скорректированной огибающей 139. Например, весовой вектор w можно определить с использованием предварительно определенной функции скорректированной огибающей 139. Эта предварительно определенная функция может быть известна в кодере и в декодере (что также верно для скорректированной огибающей 139). Таким образом, весовой вектор можно определять одинаковым образом в кодере и в декодере.
Другая возможная формула коэффициента усиления предсказателя имеет вид
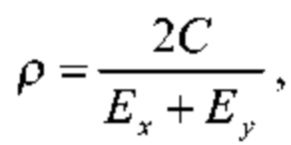
где 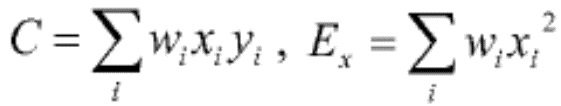 и
и 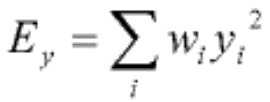 . Это определение коэффициента усиления предсказателя приводит к коэффициенту усиления, всегда находящемуся в пределах интервала [-1, 1]. Одним из важных признаков коэффициента усиления предсказателя, задаваемого последней формулой, является то, что коэффициент p усиления предсказателя содействует поддающейся обработке взаимосвязи между энергией целевого сигнала x и энергией остаточного сигнала z. Остаточную энергию LTP можно выразить как:
. Это определение коэффициента усиления предсказателя приводит к коэффициенту усиления, всегда находящемуся в пределах интервала [-1, 1]. Одним из важных признаков коэффициента усиления предсказателя, задаваемого последней формулой, является то, что коэффициент p усиления предсказателя содействует поддающейся обработке взаимосвязи между энергией целевого сигнала x и энергией остаточного сигнала z. Остаточную энергию LTP можно выразить как: 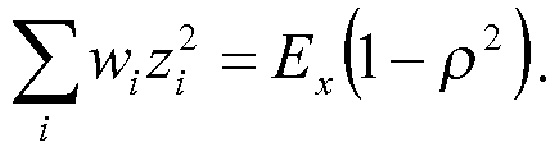
Параметр rfu 146 управления можно определить на основе коэффициента g усиления предсказателя, используя вышеупомянутые формулы. Коэффициент g усиления предсказателя может быть равен коэффициенту p усиления предсказателя, определенному с использованием любой из вышеупомянутых формул.
Как описывалось выше, кодер 100, 170 сконфигурирован для квантования и кодирования вектора невязок z (т.е. блока 141 коэффициентов ошибок предсказания). Процесс квантования, как правило, направляется огибающей сигнала (например, огибающей 138 распределения) в соответствии с лежащей в ее основе моделью восприятия с целью распределения доступных битов среди спектральных составляющих сигнала содержательным для восприятия образом. Процесс распределения скорости передачи данных направляется огибающей сигнала (например, огибающей 138 распределения), получаемой исходя из входного сигнала (например, из блока 131 коэффициентов преобразования). Действие предсказателя 117, как правило, изменяет огибающую сигнала. Модуль 112 квантования, как правило, использует квантователи, рассчитанные в предположении действия на источник с единичной дисперсией. В особенности, в случае высококачественного предсказания (т.е. тогда, когда предсказатель 117 является удачным), свойство единичной дисперсии может более не иметь места, т.е. блок 141 коэффициентов ошибок предсказания может не проявлять единичную дисперсию.
Как правило, оценивание огибающей блока 141 коэффициентов ошибок предсказания (т.е. остатка z) и передача этой огибающей в декодер (и повторное выравнивание блока 141 коэффициентов ошибок предсказания с использованием этой оценочной огибающей) является неэффективным. Вместо этого кодер 100 и декодер 500 могут использовать эвристическое правило для изменения масштаба блока 141 коэффициентов ошибок предсказания (как описано выше). Это эвристическое правило можно использовать для изменения масштаба блока 141 коэффициентов ошибок предсказания так, чтобы блок 142 коэффициентов с измененным масштабом аппроксимировал единичную дисперсию. Как результат этого, результаты квантования можно улучшить (используя квантователи, предполагающие единичную дисперсию). Кроме того, как уже было описано, это эвристическое правило можно использовать для модификации огибающей 138 распределения, используемой в процессе распределения битов. Эта модификация огибающей 138 распределения и изменение масштаба блока 141 коэффициентов ошибок предсказания, как правило, выполняется кодером 100 и декодером 500 одинаковым образом (с использованием одного и того же эвристического правила).
Одно из возможных эвристических правил d(f) было описано выше. Ниже описывается другой подход к определению эвристического правила. Обратная величина коэффициента усиления предсказания энергии во взвешенной области может иметь вид  , и, таким образом,
, и, таким образом,  = p
= p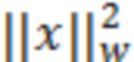 , где указывает квадратичную энергию вектора невязок (т.е. блока 141 коэффициентов ошибок предсказания) во взвешенной области, и где указывает квадратичную энергию целевого вектора (т.е. блока 140 выровненных коэффициентов преобразования) во взвешенной области. Можно сделать следующие предположения:
, где указывает квадратичную энергию вектора невязок (т.е. блока 141 коэффициентов ошибок предсказания) во взвешенной области, и где указывает квадратичную энергию целевого вектора (т.е. блока 140 выровненных коэффициентов преобразования) во взвешенной области. Можно сделать следующие предположения:
1. Элементы целевого вектора x имеют единичную дисперсию. Это может быть результатом выравнивания, выполняемого блоком 108 выравнивания. Это предположение выполняется в зависимости от качества выравнивания на основе огибающей, выполняемого модулем 108 выравнивания.
2. Дисперсия элементов вектора z невязок предсказания имеет форму E{z2(i)}=min{ ,1} для i = 1,..., K и для некоторых t≥0. Это предположение основано на эвристическом правиле о том, что поиск предсказателя, ориентированный на метод наименьших квадратов, приводит к равномерно распределенному вкладу ошибок во взвешенной области, поэтому вектор
,1} для i = 1,..., K и для некоторых t≥0. Это предположение основано на эвристическом правиле о том, что поиск предсказателя, ориентированный на метод наименьших квадратов, приводит к равномерно распределенному вкладу ошибок во взвешенной области, поэтому вектор  невязок является более или менее равномерным. Кроме того, можно ожидать, что предсказатель-кандидат близок к равномерному, что приводит к разумному ограничению E{z2(i)}≤1. Следует отметить, что можно использовать различные модификации этого, второго предположения.
невязок является более или менее равномерным. Кроме того, можно ожидать, что предсказатель-кандидат близок к равномерному, что приводит к разумному ограничению E{z2(i)}≤1. Следует отметить, что можно использовать различные модификации этого, второго предположения.
Для того чтобы оценить параметр t, можно вставить вышеупомянутые два предположения в формулу ошибки предсказания (например, 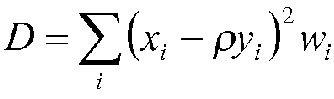 ) и посредством этого создать уравнение типа «уравнения уровня воды».
) и посредством этого создать уравнение типа «уравнения уровня воды».
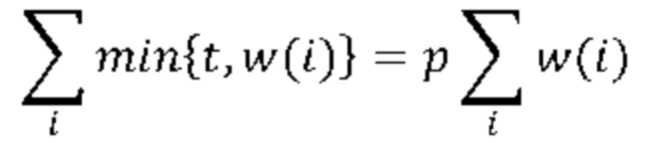
Можно показать, что у приведенного выше уравнения существует решение в интервале t 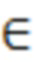 [0, max(w(i))]. Уравнение для нахождения параметра t можно решить, используя программы сортировки.
[0, max(w(i))]. Уравнение для нахождения параметра t можно решить, используя программы сортировки.
Тогда эвристическое правило может иметь вид 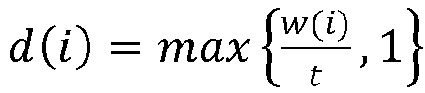 , где i=1,..., K идентифицирует элемент разрешения по частоте. Обратное эвристическое правило масштабирования имеет вид
, где i=1,..., K идентифицирует элемент разрешения по частоте. Обратное эвристическое правило масштабирования имеет вид 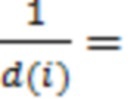 min{,1}. Обратное эвристическое правило масштабирования применяется модулем 113 обратного изменения масштаба. Не зависящее от частоты правило масштабирования зависит от весовых коэффициентов w(i)=wi. Как указывалось выше, весовые коэффициенты w(i) могут зависеть от текущего блока 131 коэффициентов преобразования (например, от скорректированной огибающей 139 или некоторой предварительно определенной функции скорректированной огибающей 139) или могут ему соответствовать.
min{,1}. Обратное эвристическое правило масштабирования применяется модулем 113 обратного изменения масштаба. Не зависящее от частоты правило масштабирования зависит от весовых коэффициентов w(i)=wi. Как указывалось выше, весовые коэффициенты w(i) могут зависеть от текущего блока 131 коэффициентов преобразования (например, от скорректированной огибающей 139 или некоторой предварительно определенной функции скорректированной огибающей 139) или могут ему соответствовать.
Можно показать, что при использовании формулы 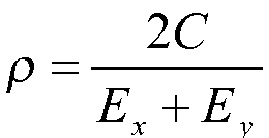 для определения коэффициента усиления предсказателя, применимо следующее отношение: p=1–p 2.
для определения коэффициента усиления предсказателя, применимо следующее отношение: p=1–p 2.
Отсюда, эвристическое правило масштабирования можно определить различными отличающимися способами. Экспериментально было показано, что правило масштабирования, определенное на основе вышеупомянутых двух предположений (именуемое способом В масштабирования) является преимущественным по сравнению с фиксированным правилом d(f) масштабирования. В частности, правило масштабирования, определенное на основе указанных двух предположений, может учитывать влияние взвешивания, используемого в ходе поиска предсказателя-кандидата. Способ В масштабирования удобно сочетается с определением коэффициента усиления по причине поддающейся аналитической обработке взаимосвязи между дисперсией остатка и дисперсией сигнала (что, как описывается выше, способствует получению p).
Ниже описывается один из дальнейших аспектов для повышения производительности звукового кодера на основе преобразования. В частности, предлагается использование флага сохранения дисперсии. Флаг сохранения дисперсии можно определять и передавать на основе блока 131. Флаг сохранения дисперсии может служить признаком качества предсказания. В одном из вариантов осуществления флаг сохранения дисперсии выключен в случае относительно высокого качества предсказания, и флаг сохранения дисперсии включен в случае относительно низкого качества предсказания. Флаг сохранения дисперсии может быть определен кодером 100, 170, например, на основе коэффициента p усиления предсказателя и/или на основе коэффициента g усиления предсказателя. Например, флаг сохранения дисперсии может быть установлен на «включен», если коэффициент p или g усиления (или полученный исходя из них параметр) находится ниже предварительно определенного порога (например, 2 дБ), и наоборот. Как описывалось выше, обратная величина коэффициента p усиления предсказания энергии во взвешенной области, как правило, зависит от коэффициента усиления предсказателя, например, p=1–p2. Для определения значения флага сохранения дисперсии можно использовать обратную величину параметра p. Например, для определения значения флага сохранения дисперсии, 1/p (например, выраженный в дБ) можно сравнить с предварительно определенным порогом (например, 2 дБ). Если 1/p больше предварительно определенного порогового значения, то флаг сохранения дисперсии можно установить на «выключен» (что указывает на относительно высокое качество предсказания), и наоборот.
Флаг сохранения дисперсии можно использовать для управления различными другими установками кодера 100 и декодера 500. В частности, флаг сохранения дисперсии можно использовать для управления степенью зашумленности ряда квантователей 321, 322, 323. В частности, флаг сохранения дисперсии может оказывать влияние на одну или несколько из следующих установок
• Адаптивный коэффициент усиления шума для распределения нулевых битов. Иными словами, флаг сохранения дисперсии может оказывать влияние на коэффициент усиления шума квантователя 321 синтеза шума.
• Диапазон квантователей с добавлением псевдослучайного шума. Иными словами, флаг сохранения дисперсии оказывает влияние на диапазон 324, 325 отношений SNR, для которых используются квантователи 322 с добавлением псевдослучайного шума.
• Коэффициент последующего усиления квантователей с добавлением псевдослучайного шума. Коэффициент последующего усиления можно применять к выводу квантователей с добавлением псевдослучайного шума с целью оказания влияния на производительность квантователей с добавлением псевдослучайного шума в отношении среднеквадратичных ошибок. Коэффициент последующего усиления может зависеть от флага сохранения дисперсии.
• Применение эвристического масштабирования. Использование эвристического масштабирования (в модуле 111 изменения масштаба и в модуле 113 обратного изменения масштаба) может зависеть от флага сохранения дисперсии.
В Таблице 2 представлен один из примеров того, как флаг сохранения дисперсии может изменять одну или несколько установок кодера 100 и/или декодера 500.
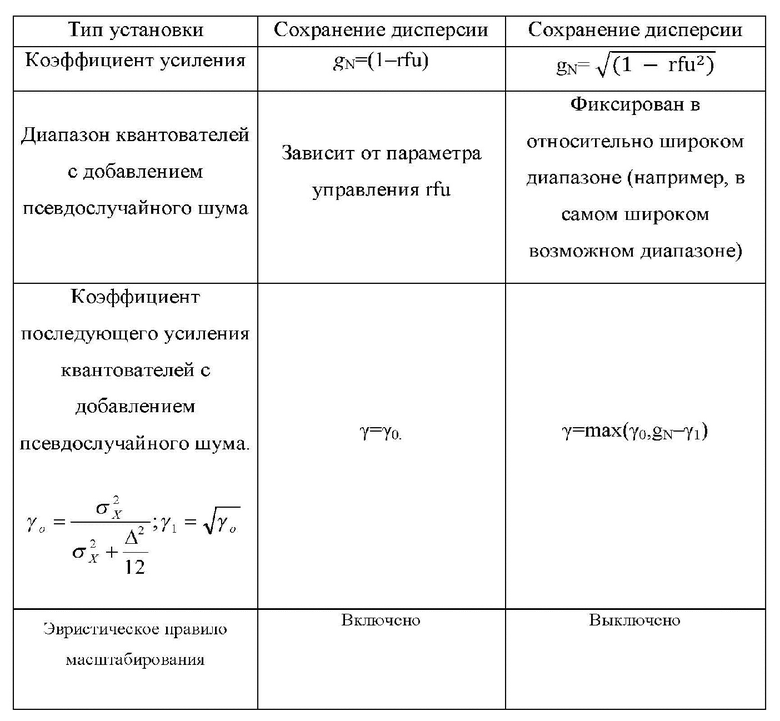
Таблица 2
В формуле для коэффициента последующего усиления δ2x= E{X2} представляет собой дисперсию для одного или нескольких из коэффициентов блока 141 коэффициентов ошибок предсказания (подлежащих квантованию), а ∆ — величина шага квантователя для скалярного квантователя (612) с добавлением псевдослучайного шума, к которому применяется этот коэффициент последующего усиления.
Как видно из примера в Таблице 2, от флага сохранения дисперсии может зависеть коэффициент gN усиления шума для квантователя 321 синтеза шума (т.е. дисперсия квантователя 321 синтеза шума). Как описывалось выше, параметр rfu 146 управления может находиться в интервале [0, 1], при этом относительно низкое значение rfu указывает относительно низкое качество предсказания, а относительно высокое значение rfu указывает относительно высокое качество предсказания. Для значений rfu в интервале [0, 1] формула в левой колонке предусматривает менее высокие коэффициенты gN усиления шума, чем формула в правой колонке. Таким образом, когда флаг сохранения дисперсии включен (что указывает на относительно низкое качество предсказания) используется более высокий коэффициент усиления шума, чем тогда, когда флаг сохранения дисперсии выключен (что указывает на относительно высокое качество предсказания). Экспериментально было показано, что это улучшает общее воспринимаемое качество.
Как описывалось выше, диапазон SNR 324, 325 квантователей 322 с добавлением псевдослучайного шума может изменяться в зависимости от параметра rfu управления. В соответствии с Таблицей 2, когда флаг сохранения дисперсии включен (что указывает на относительно низкое качество предсказания), используется фиксированный большой диапазон квантователей 322 с добавлением псевдослучайного шума (например, диапазон 324). С другой стороны, когда флаг сохранения дисперсии выключен (что указывает на относительно высокое качество предсказания), в зависимости от параметра rfu управления используются разные диапазоны 324, 325.
Определение блока 145 квантованных коэффициентов ошибок может включать применение коэффициента γ последующего усиления к тем квантованным коэффициентам ошибок, которые были квантованы с использованием квантователя 322 с добавлением псевдослучайного шума. Коэффициент γ последующего усиления можно получить для улучшения производительности MSE квантователя 322 с добавлением псевдослучайного шума (например, квантователя с субтрактивным псевдослучайным шумом). Коэффициент последующего усиления может иметь вид:
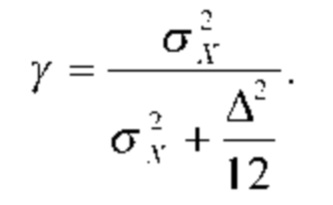
Экспериментально было показано, что качество перцепционного кодирования можно повысить, сделав коэффициент последующего усиления зависящим от флага сохранения дисперсии. Вышеупомянутый коэффициент последующего усиления с оптимальной MSE используют тогда, когда флаг сохранения дисперсии выключен (что указывает на относительно высокое качество предсказания). С другой стороны, когда флаг сохранения дисперсии включен (что указывает на относительно низкое качество предсказания), может быть преимущественным использование более высокого коэффициента последующего усиления (определяемого в соответствии с формулой с правой стороны Таблицы 2).
Как описывалось выше, эвристическое масштабирование можно использовать для создания блоков 142 коэффициентов ошибок с измененным масштабом, более близких к свойству единичной дисперсии, чем блоки 141 коэффициентов ошибок предсказания. Эвристические правила масштабирования можно сделать зависящими от параметра 146 управления. Иными словами, эти эвристические правила масштабирования можно сделать зависящими от качества предсказания. Эвристическое масштабирование может быть особенно преимущественным в случае относительно высокого качества предсказания, в то время как эти преимущества могут быть ограниченными в случае относительно низкого качества предсказания. В виду этого, может быть преимущественным использование эвристического масштабирования только тогда, когда флаг сохранения дисперсии выключен (что указывает относительно высокое качество предсказания).
В настоящем документе был описан речевой кодер 100, 170 на основе преобразования и соответствующий речевой декодер 500 на основе преобразования. В этом речевом кодеке на основе преобразования могут использоваться различные аспекты, позволяющие улучшать качество кодированных речевых сигналов. Речевой кодек может использовать относительно короткие блоки (также именуемые единицами кодирования), например, в диапазоне 5 мс, посредством этого обеспечивая соответственную разрешающую способность по времени и представительную статистику для речевых сигналов. Кроме того, речевой кодек может обеспечивать достаточное описание переменной во времени огибающей спектра этих единиц кодирования. В дополнение, речевой кодек может использовать предсказание в области преобразования, причем это предсказание может учитывать огибающие спектра этих единиц кодирования. Таким образом, речевой кодек может обеспечивать единицы кодирования предсказывающими обновлениями, осведомленными об огибающей. Кроме того, речевой кодек может использовать предварительно определенные квантователи, адаптирующиеся к результатам предсказания. Иными словами, речевой кодек может использовать адаптивные к предсказанию скалярные квантователи.
Способы и системы, описанные в настоящем документе, могут реализовываться как программное обеспечение, аппаратно-программное обеспечение и/или как аппаратное обеспечение. Некоторые компоненты могут реализовываться, например, как программное обеспечение, запускаемое на процессоре цифровой обработки сигналов или на микропроцессоре. Другие компоненты могут реализовываться, например, как аппаратное обеспечение или как интегральные схемы специального назначения. Сигналы, которые встречаются в описанных способах и системах, могут храниться в памяти таких носителей данных, как память с произвольным доступом или оптические носители данных. Они могут передаваться по сетям, таким как радиосети, спутниковые сети, беспроводные сети или проводные сети, например, Интернет. Типичными устройствами, использующими способы и системы, описанные в настоящем документе, являются переносные электронные устройства или другая бытовая аппаратура, которая используется для хранения и/или представления звуковых сигналов.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2014 |
|
RU2740690C2 |
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2014 |
|
RU2630887C2 |
| ЗВУКОВЫЕ КОДИРУЮЩЕЕ УСТРОЙСТВО И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 2020 |
|
RU2828411C2 |
| УСОВЕРШЕНСТВОВАННЫЙ КВАНТОВАТЕЛЬ | 2017 |
|
RU2752127C2 |
| УСОВЕРШЕНСТВОВАННЫЙ КВАНТОВАТЕЛЬ | 2021 |
|
RU2823174C2 |
| УСОВЕРШЕНСТВОВАННЫЙ КВАНТОВАТЕЛЬ | 2014 |
|
RU2640722C2 |
| СИСТЕМА ОБРАБОТКИ АУДИО | 2014 |
|
RU2625444C2 |
| СПОСОБ И УСТРОЙСТВО ЭФФЕКТИВНОЙ МАСКИРОВКИ СТИРАНИЯ КАДРОВ В РЕЧЕВЫХ КОДЕКАХ | 2006 |
|
RU2419891C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВЕКТОРНОГО КВАНТОВАНИЯ С НАДЕЖНЫМ ПРЕДСКАЗАНИЕМ ПАРАМЕТРОВ ЛИНЕЙНОГО ПРЕДСКАЗАНИЯ В КОДИРОВАНИИ РЕЧИ С ПЕРЕМЕННОЙ БИТОВОЙ СКОРОСТЬЮ | 2003 |
|
RU2326450C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ВКЛЮЧЕНИЯ ИДЕНТИФИКАТОРА В ПАКЕТ, АССОЦИАТИВНО СВЯЗАННЫЙ С РЕЧЕВЫМ СИГНАЛОМ | 2007 |
|
RU2421828C2 |
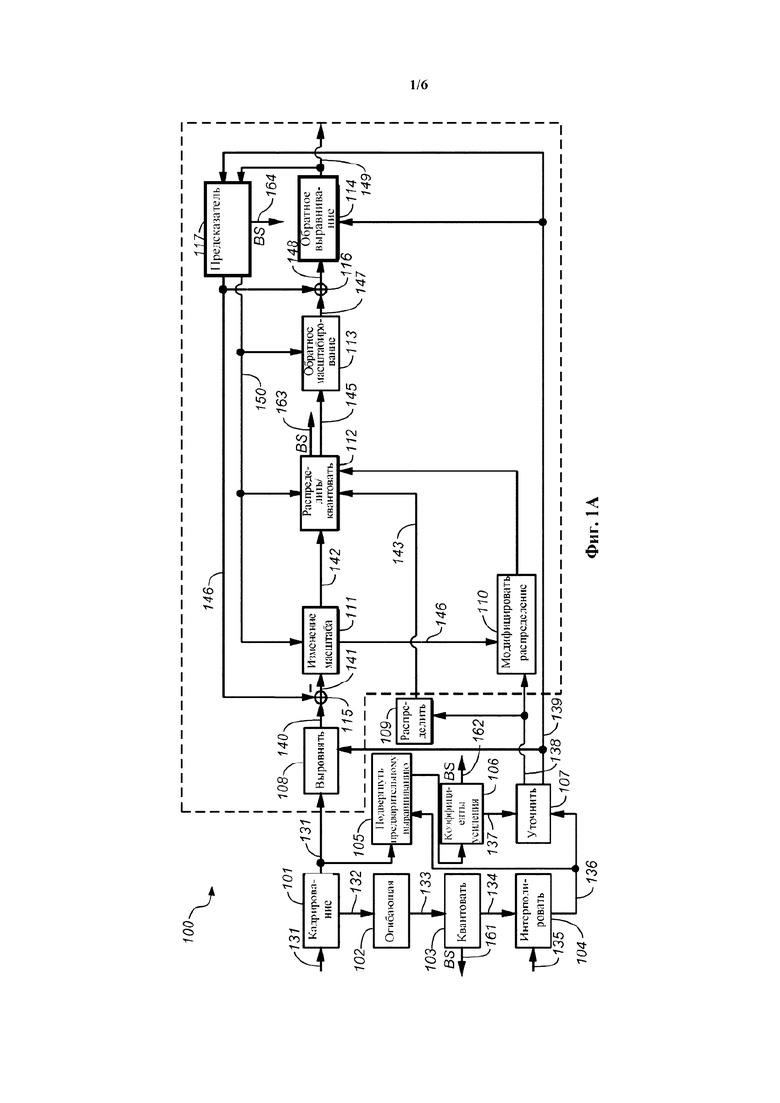
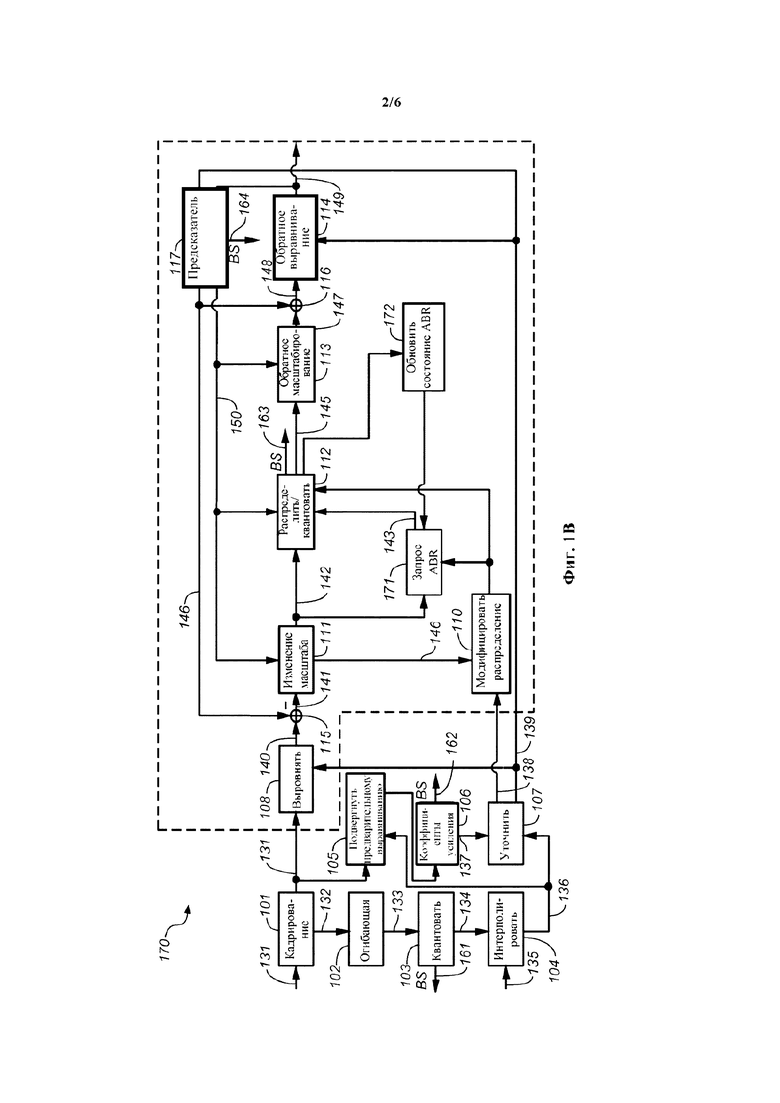
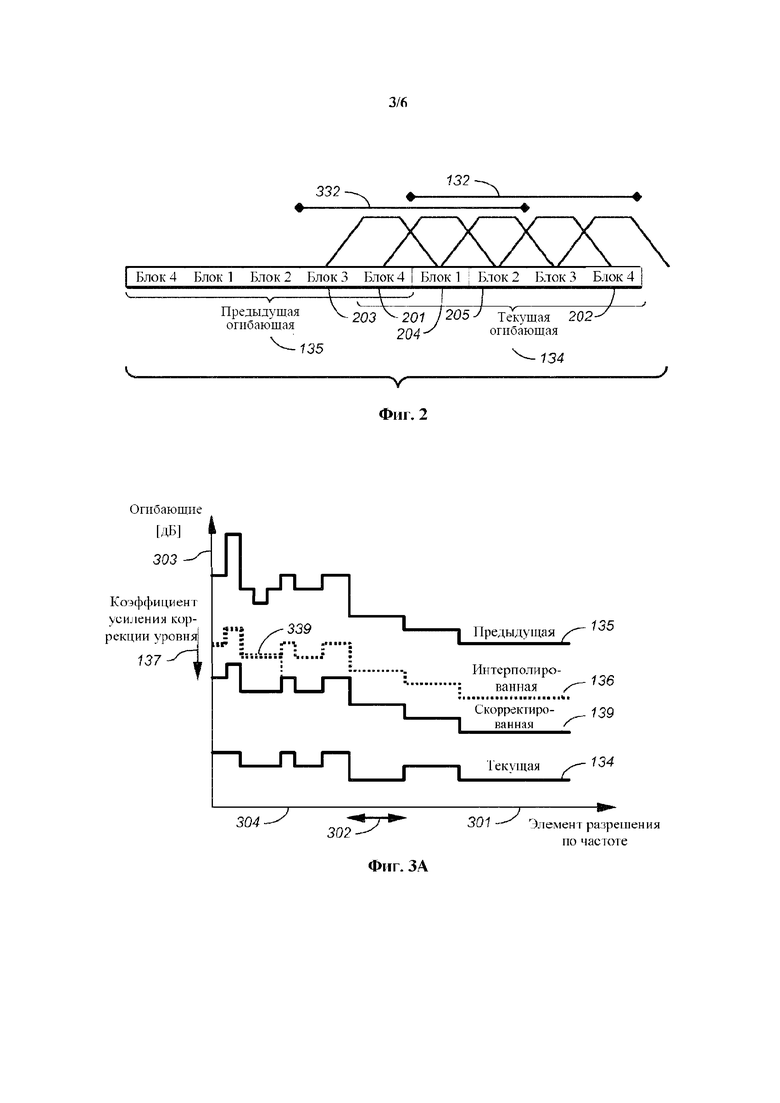
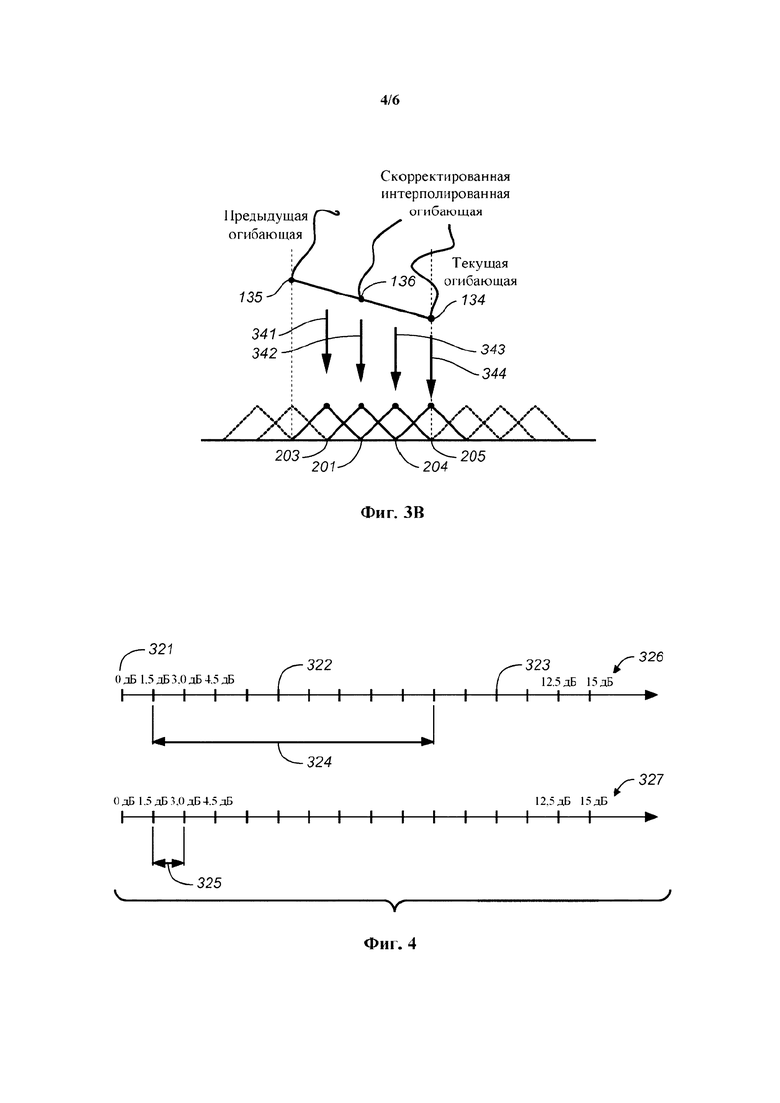
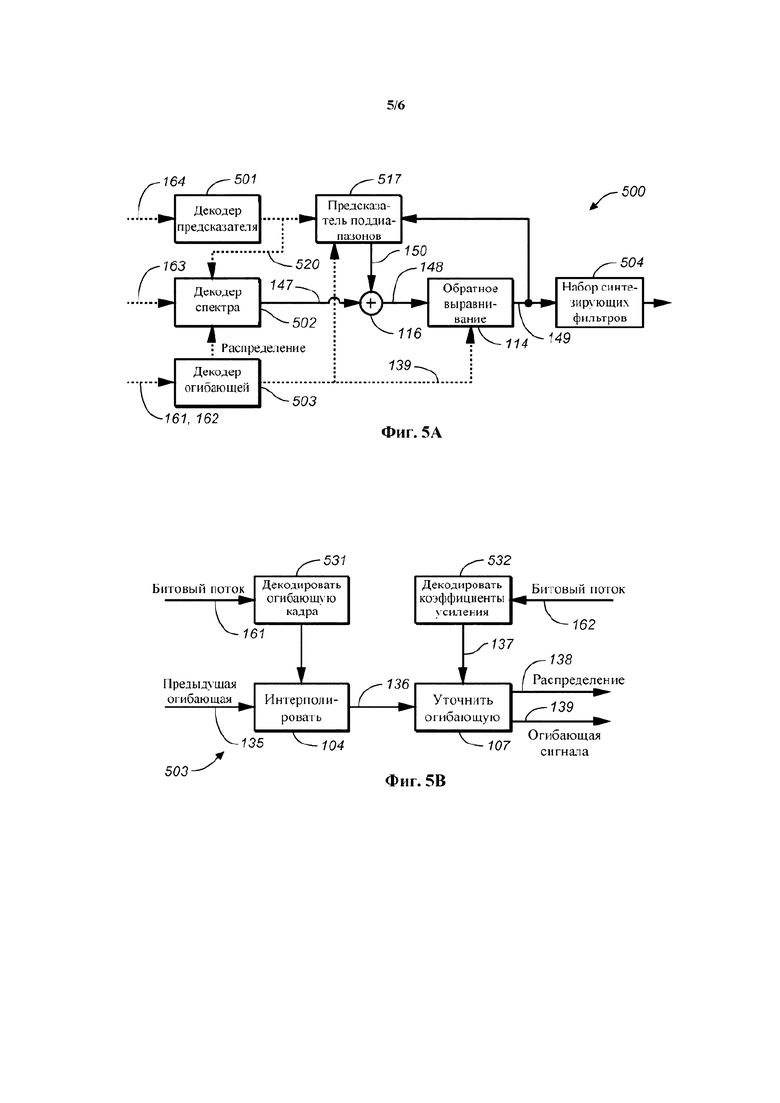
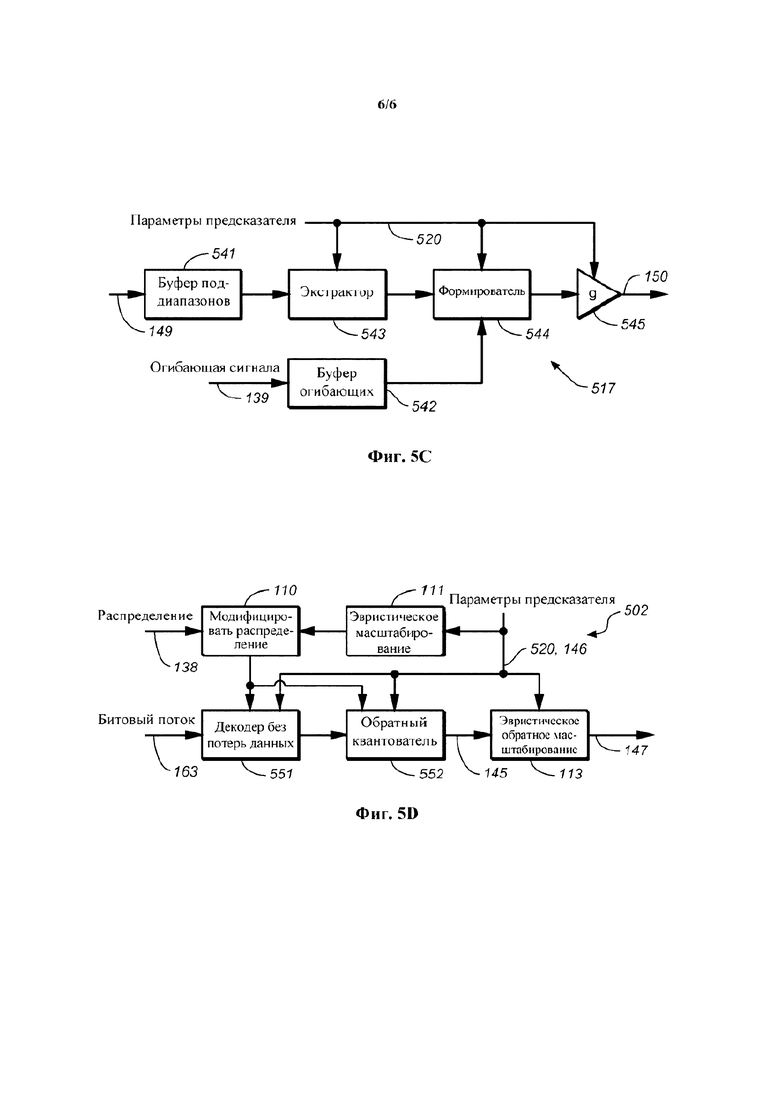
Изобретение относится к области вычислительной техники для звукового кодирования и декодирования. Технический результат заключается в обеспечении равномерной производительности для речи и музыки. Технический результат достигается за счет приема набора блоков; при этом указанный набор блоков содержит ряд последовательных блоков коэффициентов преобразования; при этом указанный набор блоков служит признаком дискретных значений речевого сигнала; определения текущей огибающей на основе ряда последовательных блоков коэффициентов преобразования; при этом указанная текущая огибающая служит признаком ряда значений спектральной энергии для соответствующего ряда элементов разрешения по частоте; определения ряда интерполированных огибающих, исходя из ряда последовательных блоков коэффициентов преобразования, соответственно, на основе текущей огибающей; определения ряда блоков выровненных коэффициентов преобразования путем выравнивания соответствующего ряда блоков коэффициентов преобразования с использованием соответствующего ряда интерполированных огибающих, соответственно. 8 н. и 16 з.п. ф-лы, 10 ил.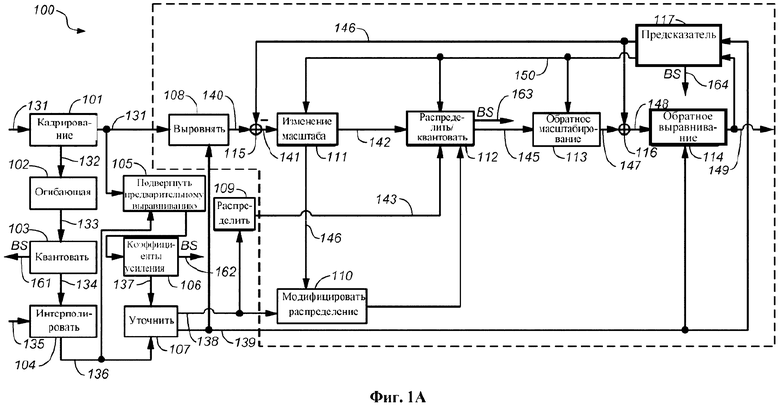
1. Речевой кодер на основе преобразования, сконфигурированный для кодирования речевого сигнала в битовый поток, при этом кодер содержит:
модуль кадрирования, сконфигурированный для приема ряда последовательных блоков коэффициентов преобразования, содержащего текущий блок и один или несколько предыдущих блоков, при этом указанный ряд последовательных блоков служит признаком дискретных значений речевого сигнала;
модуль выравнивания, сконфигурированный для определения текущего блока и одного или нескольких предыдущих блоков выровненных коэффициентов преобразования путем выравнивания соответствующего текущего блока и одного или нескольких предыдущих блоков коэффициентов преобразования с использованием соответствующей текущей огибающей блока и соответствующих одной или нескольких предыдущих огибающих блоков, соответственно;
предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя, при этом указанные один или несколько предыдущих блоков восстановленных коэффициентов преобразования были получены, соответственно, исходя из одного или нескольких предыдущих блоков выровненных коэффициентов преобразования; при этом предсказатель содержит
предсказатель на основе модели, использующий модель сигнала, при этом указанная модель сигнала содержит одну или несколько синусоидальных составляющих модели, при этом указанная модель сигнала содержит один или несколько параметров модели и указанные один или несколько параметров предсказателя служат признаком одного или нескольких указанных параметров модели;
экстрактор, сконфигурированный для определения текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя; и
формирователь спектра, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков и на основе одного или нескольких параметров предсказателя; и
разностный модуль, сконфигурированный для определения текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования, при этом битовый поток определяется на основе текущего блока коэффициентов ошибок предсказания.
2. Речевой кодер на основе преобразования по п. 1, отличающийся тем, что указанный предсказатель на основе модели сконфигурирован для
определения одного или нескольких параметров модели для указанной модели сигнала;
определения коэффициента предсказания, подлежащего применению к первому восстановленному коэффициенту преобразования в первом элементе разрешения по частоте предыдущего блока восстановленных коэффициентов преобразования, на основе указанной модели сигнала и на основе указанных одного или нескольких параметров модели; и
определения оценки первого оценочного коэффициента преобразования в первом элементе разрешения по частоте текущего блока оценочных коэффициентов преобразования путем применения указанного коэффициента предсказания к указанному первому восстановленному коэффициенту преобразования.
3. Речевой кодер на основе преобразования по любому из пп. 1, 2, отличающийся тем, что указанные один или несколько параметров модели служат признаком частоты указанных одной или нескольких синусоидальных составляющих модели.
4. Речевой кодер на основе преобразования по п. 3, отличающийся тем, что указанные один или несколько параметров модели служат признаком основной частоты мультисинусоидальной модели сигнала.
5. Речевой кодер на основе преобразования по любому из пп. 1–4, отличающийся тем, что предсказатель сконфигурирован для определения одного или нескольких параметров предсказателя так, чтобы уменьшалось среднеквадратичное значение коэффициентов ошибок предсказания текущего блока коэффициентов ошибок предсказания.
6. Речевой кодер на основе преобразования по любому из пп. 1–5, отличающийся тем, что предсказатель сконфигурирован для вставки данных предсказателя, служащих признаком одного или нескольких параметров предсказателя, в битовый поток.
7. Речевой декодер на основе преобразования, сконфигурированный для декодирования битового потока с целью создания восстановленного речевого сигнала, при этом декодер содержит:
предсказатель, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя, полученных из битового потока, при этом предсказатель содержит
предсказатель на основе модели, использующий модель сигнала, при этом указанная модель сигнала содержит одну или несколько синусоидальных составляющих модели, при этом указанная модель сигнала содержит один или несколько параметров модели и указанные один или несколько параметров предсказателя служат признаком одного или нескольких указанных параметров модели;
экстрактор, сконфигурированный для определения текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе одного или нескольких параметров предсказателя; и
формирователь спектра, сконфигурированный для определения текущего блока оценочных выровненных коэффициентов преобразования на основе текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков и на основе одного или нескольких параметров предсказателя;
декодер спектра, сконфигурированный для определения текущего блока квантованных коэффициентов ошибок предсказания на основе данных коэффициентов, заключенных в битовом потоке;
модуль сложения, сконфигурированный для определения текущего блока восстановленных выровненных коэффициентов преобразования на основе текущего блока оценочных выровненных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания; и
модуль обратного выравнивания, сконфигурированный для определения текущего блока восстановленных коэффициентов преобразования путем придания текущему блоку восстановленных выровненных коэффициентов преобразования формы спектра с использованием текущей огибающей блока и сконфигурированный для определения одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования путем придания одному или нескольким предыдущим блокам восстановленных выровненных коэффициентов преобразования формы спектра с использованием, соответственно, одной или нескольких предыдущих огибающих блоков, при этом указанный восстановленный речевой сигнал определяется на основе текущего и одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования.
8. Речевой декодер на основе преобразования по п. 7, отличающийся тем, что
указанные один или несколько параметров предсказателя содержат параметр запаздывания блока; и
этот параметр запаздывания блока служит признаком количества блоков, предшествующих текущему блоку оценочных выровненных коэффициентов преобразования.
9. Речевой декодер на основе преобразования по п. 8, отличающийся тем, что формирователь спектра сконфигурирован для
выравнивания текущего блока оценочных коэффициентов преобразования с использованием текущей оценочной огибающей; и
определения этой текущей оценочной огибающей на основе одной или нескольких предыдущих огибающих блоков и на основе параметра запаздывания блока.
10. Речевой декодер на основе преобразования по п. 9, отличающийся тем, что формирователь спектра сконфигурирован для
определения целочисленного значения запаздывания на основе указанного параметра запаздывания блока; и
определения указанной текущей оценочной огибающей как предыдущей огибающей блока из предыдущего блока восстановленных коэффициентов преобразования, предшествующего текущему блоку оценочных выровненных коэффициентов преобразования на указанное целочисленное значение запаздывания.
11. Речевой декодер на основе преобразования по п. 10, отличающийся тем, что формирователь спектра сконфигурирован для определения целочисленного значения запаздывания путем округления параметра запаздывания блока до ближайшего целого числа.
12. Речевой декодер на основе преобразования по п. 11, отличающийся тем, что
речевой декодер на основе преобразования содержит буфер огибающих, сконфигурированный для хранения одной или нескольких предыдущих огибающих блоков; и
формирователь спектра сконфигурирован для определения целочисленного значения запаздывания путем ограничения целочисленного значения запаздывания количеством предыдущих огибающих блоков, хранящихся в буфере огибающих.
13. Речевой декодер на основе преобразования по любому из пп. 9–12, отличающийся тем, что формирователь спектра сконфигурирован для выравнивания текущего блока оценочных коэффициентов преобразования так, чтобы перед применением одного или нескольких параметров предсказателя указанный текущий блок выровненных оценочных коэффициентов преобразования проявлял единичную дисперсию.
14. Речевой декодер на основе преобразования по п. 13, отличающийся тем, что
битовый поток содержит параметр коэффициента усиления дисперсии; и
формирователь спектра сконфигурирован для применения этого параметра коэффициента усиления дисперсии к текущему блоку оценочных коэффициентов преобразования.
15. Речевой декодер на основе преобразования по любому из пп. 8–14, отличающийся тем, что экстрактор сконфигурирован для определения текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе указанного параметра запаздывания блока.
16. Звуковой кодер на основе преобразования, сконфигурированный для кодирования звукового сигнала, содержащего первый сегмент, в битовый поток, при этом указанный звуковой кодер содержит:
классификатор сигнала, сконфигурированный для идентификации указанного первого сегмента в звуковом сигнале как речевого сегмента, при этом указанный первый сегмент подлежит кодированию посредством речевого кодера на основе преобразования;
модуль преобразования, сконфигурированный для определения ряда последовательных блоков коэффициентов преобразования на основе указанного первого сегмента, при этом блок коэффициентов преобразования содержит ряд коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте, при этом указанный модуль преобразования сконфигурирован для определения длинных блоков, содержащих первое количество коэффициентов преобразования, и коротких блоков, содержащих второе количество коэффициентов преобразования, при этом указанное первое количество больше указанного второго количества, при этом блоки из указанного ряда последовательных блоков представляют собой короткие блоки; и
речевой кодер на основе преобразования по любому из пп. 1–6, сконфигурированный для кодирования указанного ряда последовательных блоков в битовый поток.
17. Звуковой кодер на основе преобразования по п. 16, отличающийся тем, что дополнительно содержит обобщенный звуковой кодер на основе преобразования, сконфигурированный для кодирования иного сегмента звукового сигнала, чем указанный первый сегмент.
18. Звуковой кодер на основе преобразования по п. 17, отличающийся тем, что указанный обобщенный звуковой кодер на основе преобразования представляет собой кодер AAC или HE-AAC.
19. Звуковой кодер на основе преобразования по любому из пп. 16–18, отличающийся тем, что
указанный модуль преобразования сконфигурирован для выполнения MDCT; и/или
указанное первое количество дискретных значений составляет 1024; и/или
указанное второе количество дискретных значений составляет 256.
20. Звуковой декодер на основе преобразования, сконфигурированный для декодирования битового потока, служащего признаком звукового сигнала, содержащего первый сегмент, при этом указанный звуковой декодер содержит:
речевой декодер на основе преобразования по любому из пп. 7–15, сконфигурированный для определения ряда последовательных блоков восстановленных коэффициентов преобразования на основе данных, заключенных в битовом потоке;
модуль обратного преобразования, сконфигурированный для определения восстановленного первого сегмента на основе указанного ряда последовательных блоков восстановленных коэффициентов преобразования, при этом блок восстановленных коэффициентов преобразования содержит ряд восстановленных коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте, при этом модуль обратного преобразования сконфигурирован для обработки длинных блоков, содержащих первое количество восстановленных коэффициентов преобразования, и коротких блоков, содержащих второе количество восстановленных коэффициентов преобразования, при этом указанное первое количество больше указанного второго количества, при этом блоки из ряда последовательных блоков представляют собой короткие блоки.
21. Способ кодирования речевого сигнала в битовый поток, при этом способ включает
прием ряда последовательных блоков коэффициентов преобразования, содержащего текущий блок и один или несколько предыдущих блоков, при этом указанный ряд последовательных блоков служит признаком дискретных значений речевого сигнала;
определение текущего блока и одного или нескольких предыдущих блоков выровненных коэффициентов преобразования путем выравнивания соответствующего текущего блока и одного или нескольких предыдущих блоков коэффициентов преобразования с использованием соответствующей текущей огибающей блока и соответствующих одной или нескольких предыдущих огибающих блоков, соответственно;
определение текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, при этом указанные один или несколько предыдущих блоков восстановленных коэффициентов преобразования были получены, соответственно, исходя из указанных одного или нескольких предыдущих блоков выровненных коэффициентов преобразования, при этом определение текущего блока оценочных выровненных коэффициентов преобразования включает:
определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, использующего модель сигнала, при этом указанная модель сигнала содержит одну или несколько синусоидальных составляющих модели, при этом указанная модель сигнала содержит один или несколько параметров модели и указанный параметр предсказателя служит признаком одного или нескольких указанных параметров модели; и
определение текущего блока оценочных выровненных коэффициентов преобразования на основе указанного текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков и на основе параметра предсказателя;
определение текущего блока коэффициентов ошибок предсказания на основе текущего блока выровненных коэффициентов преобразования и на основе текущего блока оценочных выровненных коэффициентов преобразования; и
определение битового потока на основе текущего блока коэффициентов ошибок предсказания.
22. Способ декодирования битового потока для создания восстановленного речевого сигнала, при этом способ включает
определение текущего блока оценочных выровненных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, полученного из битового потока, при этом определение текущего блока оценочных выровненных коэффициентов преобразования включает
определение текущего блока оценочных коэффициентов преобразования на основе одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования и на основе параметра предсказателя, использующего модель сигнала, при этом указанная модель сигнала содержит одну или несколько синусоидальных составляющих модели, при этом указанная модель сигнала содержит один или несколько параметров модели и указанный параметр предсказателя служит признаком одного или нескольких указанных параметров модели; и
определение текущего блока оценочных выровненных коэффициентов преобразования на основе указанного текущего блока оценочных коэффициентов преобразования, на основе одной или нескольких предыдущих огибающих блоков и на основе параметра предсказателя;
определение текущего блока квантованных коэффициентов ошибок предсказания на основе данных коэффициентов, заключенных в битовом потоке;
определение текущего блока восстановленных выровненных коэффициентов преобразования на основе текущего блока оценочных выровненных коэффициентов преобразования и на основе текущего блока квантованных коэффициентов ошибок предсказания;
определение текущего блока восстановленных коэффициентов преобразования путем придания текущему блоку восстановленных выровненных коэффициентов преобразования формы спектра с использованием текущей огибающей блока;
определение одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования путем придания одному или нескольким предыдущим блокам восстановленных выровненных коэффициентов преобразования формы спектра, соответственно, с использованием одной или нескольких предыдущих огибающих блоков; и
определение восстановленного речевого сигнала на основе текущего и одного или нескольких предыдущих блоков восстановленных коэффициентов преобразования.
23. Способ кодирования звукового сигнала, содержащего речевой сегмент, в битовый поток, при этом способ включает
идентификацию указанного речевого сегмента в звуковом сигнале;
определение ряда последовательных блоков коэффициентов преобразования на основе указанного речевого сегмента с использованием модуля преобразования, при этом блок коэффициентов преобразования содержит ряд коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте, при этом указанный модуль преобразования сконфигурирован для определения длинных блоков, содержащих первое количество коэффициентов преобразования, и коротких блоков, содержащих второе количество коэффициентов преобразования, при этом указанное первое количество больше указанного второго количества, при этом блоки из ряда последовательных блоков представляют собой короткие блоки; и
кодирование указанного ряда последовательных блоков в битовый поток по п. 21.
24. Способ декодирования битового потока, служащего признаком звукового сигнала, содержащего речевой сегмент, при этом способ включает
определение ряда последовательных блоков восстановленных коэффициентов преобразования на основе данных, заключенных в битовом потоке по п. 21 или 23; и
определение восстановленного речевого сегмента на основе указанного ряда последовательных блоков восстановленных коэффициентов преобразования с использованием модуля обратного преобразования, при этом блок восстановленных коэффициентов преобразования содержит ряд восстановленных коэффициентов преобразования для соответствующего ряда элементов разрешения по частоте, при этом модуль обратного преобразования сконфигурирован для обработки длинных блоков, содержащих первое количество восстановленных коэффициентов преобразования, и коротких блоков, содержащих второе количество восстановленных коэффициентов преобразования, при этом указанное первое количество больше указанного второго количества, при этом блоки из ряда последовательных блоков представляют собой короткие блоки.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| РЕЧЕВОЙ КОДЕР С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ И ИСПОЛЬЗОВАНИЕМ АНАЛИЗА ЧЕРЕЗ СИНТЕЗ | 1996 |
|
RU2163399C2 |

