Настоящее изобретение относится к кодеру для кодирования аудио сигнала, системе передачи аудио, способу определения значений коррекции и компьютерной программе. Кроме того, изобретение относится к взвешиванию частот спектральных иммитансов/частот спектральных линий.
В современных кодеках речи и аудио, согласно уровню техники, осуществляется извлечение огибающей спектра речевого или аудиосигнала путем линейного предсказания и последующее квантование и кодирование преобразования коэффициентов линейного предсказания (LPC). Такими преобразованиями являются, например, частоты спектральных линий (LSF) или частоты спектральных иммитансов (ISF).
Векторное квантование (VQ), как правило, предпочтительнее скалярного квантования для квантования LPC ввиду повышения производительности. Однако было установлено, что оптимальное кодирование LPC показывает различную скалярную чувствительность для каждой частоты вектора LSF или ISF. Как прямое следствие, использование классического евклидова расстояния в качестве метрики в шаге квантования приведет к неоптимальной системе. Это можно объяснить тем фактом, что производительность квантования LPC обычно измеряется расстоянием, подобным логарифмическому спектральному расстоянию (LSD) или взвешенному логарифмическому спектральному расстоянию (WLSD), которые не имеют прямой пропорциональной зависимости от евклидова расстояния.
LSD определяется как логарифм евклидова расстояния спектральных огибающих исходных коэффициентов LPC и их квантованной версии. WLSD представляет собой взвешенную версию, которая учитывает, что низкие частоты являются перцептивно более релевантными, чем высокие частоты.
Как LSD, так и WLSD слишком сложны, чтобы вычисляться в рамках схемы квантования LPC. Поэтому большинство схем кодирования LPC используют либо простое евклидово расстояние, либо его взвешенную версию (WED), определяемую как
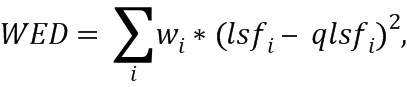
где lsfi является параметром, подлежащим квантованию, и qlsfi является квантованным параметром, w являются весами, придающими больше искажения для некоторых коэффициентов и меньше для других.
В Laroia et al. [1] представлен эвристический подход, известный как метод инверсного гармонического среднего для вычисления весовых коэффициентов, которые придают большую важность LSF, близким к областям формант. Если два параметра LSF близки друг к другу спектр сигнала, как ожидается, будет содержать пик вблизи этой частоты. Следовательно, LSF, которая близка к одной из своих соседей, имеет высокую скалярную чувствительность, и ей должен быть присвоен более высокий вес

Первый и последний весовые коэффициенты вычисляются с помощью этих псевдо-LSF:
lsf0=0 и lsfр+1=π, где р - порядок модели LP. Порядок, как правило, 10 для речевого сигнала, дискретизированного с частотой 8 кГц, и 16 для речевого сигнала, дискретизированного с частотой 16 кГц.
Gardner и Rao [2] вывели индивидуальную скалярную чувствительность для LSF из приближения высокой скорости (например, при использовании VQ с 30 или более бит). В таком случае полученные веса являются оптимальными и минимизируют LSD. Скалярные веса образуют диагональ так называемой матрицы чувствительности, задаваемой посредством
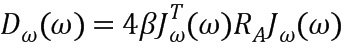
где RА является автокорреляционной матрицей импульсного отклика фильтра синтеза 1/А(z), полученного из исходных предиктивных коэффициентов анализа LPC. Jω(ω) является якобианом, преобразующим LSF в коэффициенты LPC.
Основным недостатком этого решения является сложность вычислений для вычисления матрицы чувствительности.
ITU-рекомендация G.718 [3] расширяет подход Гарднера путем добавки некоторых психоакустических факторов. Вместо рассмотрения матрицы RА, рассматривается импульсный отклик перцепционно взвешенного фильтра синтеза W(Z)
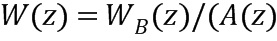
где WB(z) является фильтром IIR, аппроксимирующим взвешивающий фильтр Барка, придающим большую важность низким частотам. Матрица чувствительности затем вычисляется путем замены 1/А(z) на W(z).
Хотя взвешивание, используемое в G.718, теоретически является почти оптимальным подходом, оно наследует от подхода Гарднера очень высокую сложность. Современные аудиокодеки стандартизированы с ограничением в сложности и, следовательно, компромисс между сложностью и выигрышем в перцепционном качестве не удовлетворяется при этом подходе.
Подход, представленный Laroia et al., может давать субоптимальные веса, но он имеет низкую сложность. Веса, генерируемые при таком подходе, рассматривают весь частотный диапазон в равной степени, хотя чувствительность человеческого уха является весьма нелинейной. Искажение на более низких частотах является намного более слышимым, чем искажение на более высоких частотах.
Таким образом, существует необходимость в усовершенствовании схем кодирования.
Задачей настоящего изобретения является создание схем кодирования, которые допускают вычислительную сложность алгоритмов и/или обеспечивают их повышенную точности при поддержании хорошего качества аудио при декодировании кодированного аудиосигнала.
Эта задача решается кодером согласно пункту 1 формулы изобретения, системой передачи аудио согласно пункту 10, способом согласно пункту 11 и компьютерной программой согласно пункту 15.
Авторы настоящего изобретения обнаружили, что путем определения спектральных весовых коэффициентов с использованием способа, имеющего низкую вычислительную сложность, и посредством по меньшей мере частичной коррекции полученных спектральных весовых коэффициентов с использованием предварительно вычисленной информации коррекции, полученные скорректированные спектральные весовые коэффициенты могут обеспечить возможность кодирования и декодирования аудиосигнала с низкими вычислительными затратами при поддержании точности кодирования и/или уменьшения сниженных расстояний спектральных линий (LSD).
В соответствии с вариантом осуществления настоящего изобретения, кодер для кодирования аудиосигнала содержит анализатор для анализа аудиосигнала и для определения коэффициентов предсказания анализа из аудиосигнала. Кодер дополнительно содержит преобразователь, сконфигурированный для получения преобразованных коэффициентов предсказания из коэффициентов предсказания анализа, и память, сконфигурированную для хранения множества значений коррекции. Кодер дополнительно содержит вычислитель и формирователь битового потока. Вычислитель содержит процессор, объединитель и квантователь, причем процессор сконфигурирован для обработки преобразованных коэффициентов предсказания для получения спектральных весовых коэффициентов. Объединитель сконфигурирован для объединения спектральных весовых коэффициентов и множества значений коррекции для получения скорректированных весовых коэффициентов. Квантователь сконфигурирован для квантования преобразованных коэффициентов предсказания с использованием скорректированных весовых коэффициентов для получения квантованного представления преобразованных коэффициентов предсказания, например, значения, связанного с записью коэффициентов предсказания в базе данных. Формирователь битового потока сконфигурирован для формирования выходного сигнала на основе информации, связанной с квантованным представлением преобразованных коэффициентов предсказания, и на основе аудиосигнала. Преимуществом этого варианта осуществления является то, что процессор может получать спектральные весовые коэффициенты с использованием методов и/или концепций, имеющих низкую вычислительную сложность. Возможно, полученная погрешность относительно других концепций или способов может быть скорректирована по меньшей мере частично путем применения множества значений коррекции. Это обеспечивает сниженную вычислительную сложность получения весов по сравнению с правилом определения на основе [3] и сниженные LSD по сравнению с правилом определения в соответствии с [1].
Другие варианты осуществления обеспечивают кодер, в котором объединитель сконфигурирован для объединения спектральных весовых коэффициентов, множества значений коррекции и дополнительной информации, связанной с входным сигналом, чтобы получать скорректированные весовые коэффициенты. Путем использования дополнительной информации, связанной с входным сигналом, может быть достигнуто дальнейшее улучшение полученных скорректированных весовых коэффициентов при сохранении низкой вычислительной сложности, в частности, когда дополнительная информация, связанная с входным сигналом, по меньшей мере, частично получена в ходе других этапов кодирования, так что дополнительная информация может повторно использоваться.
Другие варианты осуществления обеспечивают кодер, в котором объединитель сконфигурирован для циклического, в каждом цикле, получения скорректированных весовых коэффициентов. Вычислитель содержит сглаживатель, сконфигурированный для взвешенного объединения первых квантованных весовых коэффициентов, полученных для предыдущего цикла, и вторых квантованных весовых коэффициентов, полученных для цикла, следующего за предыдущим циклом, чтобы получить сглаженные скорректированные весовые коэффициенты, содержащие значение между значениями первых и вторых квантованных весовых коэффициентов. Это позволяет уменьшить или предотвратить переходные искажения, особенно в случае, когда скорректированные весовые коэффициенты двух последовательных циклов определены таким образом, что они имеют большое различие, когда сравниваются друг с другом.
Другие варианты осуществления обеспечивают систему передачи аудио, содержащую кодер и декодер, сконфигурированный для приема выходного сигнала кодера или сигнала, полученного из него, и для декодирования принятого сигнала, чтобы обеспечить синтезированный аудиосигнал, при этом выходной сигнал кодера передается через среду передачи, такую как проводная или беспроводная среда. Преимуществом системы передачи аудио является то, что декодер может декодировать выходной сигнал, соответственно аудиосигнал, на основе неизмененных способов.
Другие варианты осуществления обеспечивают способ для определения значений коррекции для первого множества первых весовых коэффициентов. Каждый весовой коэффициент адаптирован для взвешивания части аудиосигнала, например, представленного как частота спектральной линии или частота спектрального иммитанса. Первое множество первых весовых коэффициентов определяется на основе первого правила определения для каждого аудиосигнала. Второе множество вторых весовых коэффициентов вычисляется для каждого аудиосигнала из набора аудиосигналов на основе второго правила определения. Каждый из второго множества весовых коэффициентов связан с первым весовым коэффициентом, т.е. весовой коэффициент может быть определен для части аудиосигнала на основе первого правила определения и на основе второго правила определения для получения двух результатов, которые могут быть различными. Вычисляется третье множество значений расстояния, причем значения расстояния имеют значение, связанное с расстоянием между первым весовым коэффициентом и вторым весовым коэффициентом, оба из которых относятся к части аудиосигнала. Вычисляется четвертое множество значений коррекции, адаптированное для уменьшения значений расстояния при объединении с первыми весовыми коэффициентами, так что когда первые весовые коэффициенты объединяются с четвертым множеством значений коррекции, расстояние между скорректированными первыми весовыми коэффициентами уменьшается по сравнению с вторыми весовыми коэффициентами. Это обеспечивает возможность вычисления весовых коэффициентов на основании обучающего набора данных один раз на основе второго правила определения, имеющего высокую вычислительную сложность и/или высокую точность, а другой раз на основе первого правила определения, которое может иметь более низкую вычислительную сложность и может быть меньшей точности, причем пониженная точность компенсируется или сокращается по меньшей мере частично посредством коррекции.
Другие варианты осуществления обеспечивают способ, в котором расстояние уменьшается путем адаптации полинома, причем коэффициенты полинома связаны со значениями коррекции. Другие варианты осуществления обеспечивают компьютерную программу.
Предпочтительные варианты осуществления настоящего изобретения будут описаны подробно со ссылкой на приложенные чертежи, на которых:
Фиг.1 показывает блок-схему кодера для кодирования аудиосигнала в соответствии с вариантом осуществления;
Фиг. 2 показывает блок-схему вычислителя в соответствии с вариантом осуществления, в котором вычислитель модифицирован по сравнению с вычислителем, показанным на фиг. 1;
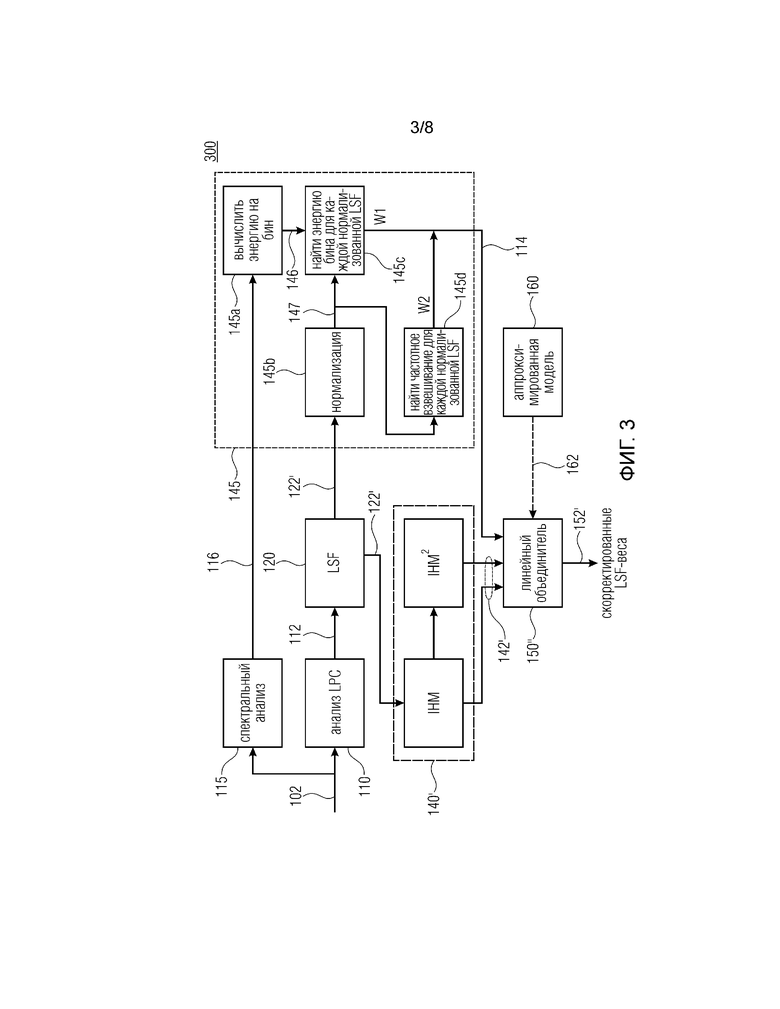
Фиг. 3 показывает блок-схему кодера, дополнительно содержащего спектральный анализатор и спектральный процессор в соответствии с вариантом осуществления;
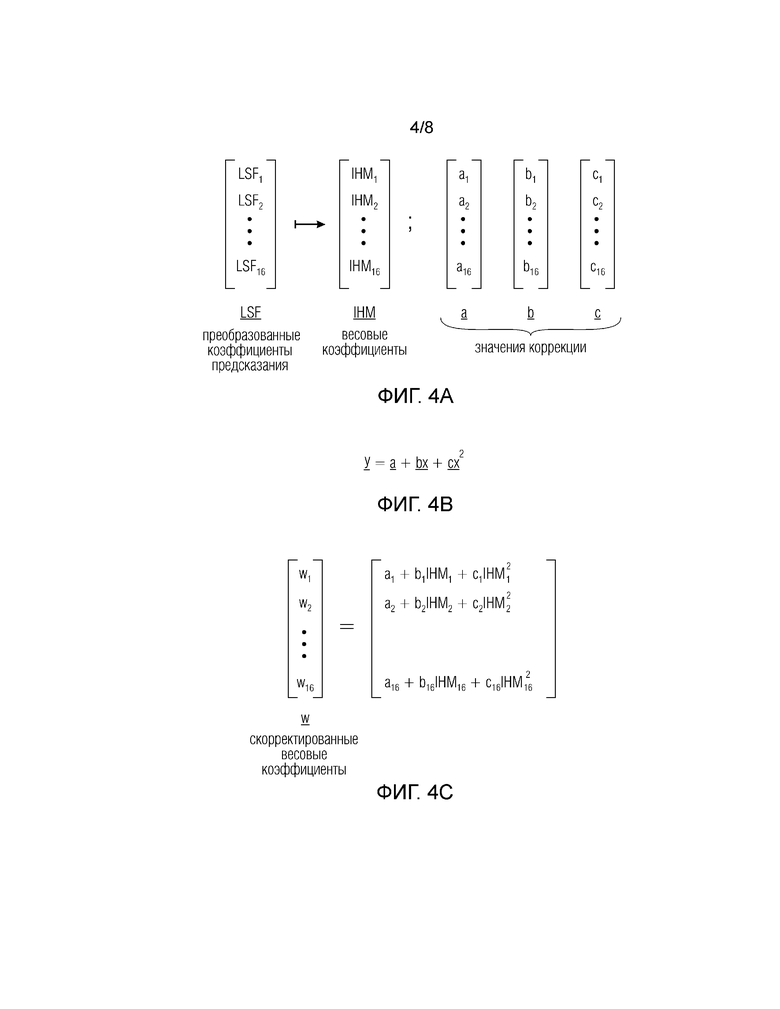
Фиг. 4а иллюстрирует вектор, содержащий 16 значений частот спектральных линий, которые получены преобразователем на основе определенных коэффициентов предсказания согласно варианту осуществления;
Фиг. 4b иллюстрирует правило определения, выполняемое объединителем, согласно варианту осуществления;
Фиг. 4с показывает примерное правило определения для иллюстрации этапа получения скорректированных весовых коэффициентов согласно варианту осуществления;
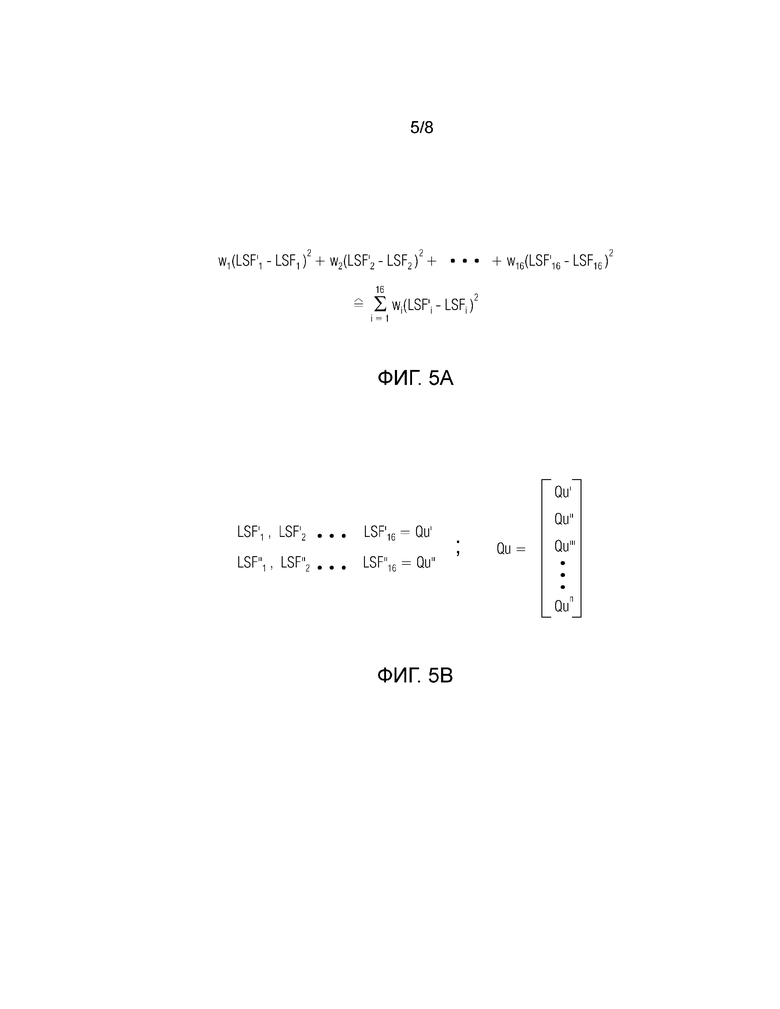
Фиг. 5а изображает примерную схему определения, которая может быть реализована посредством квантователя для определения квантованного представления преобразованных коэффициентов предсказания согласно варианту осуществления;
Фиг. 5b показывает примерный вектор значений квантования, которые могут быть объединены в их наборы, согласно варианту осуществления;
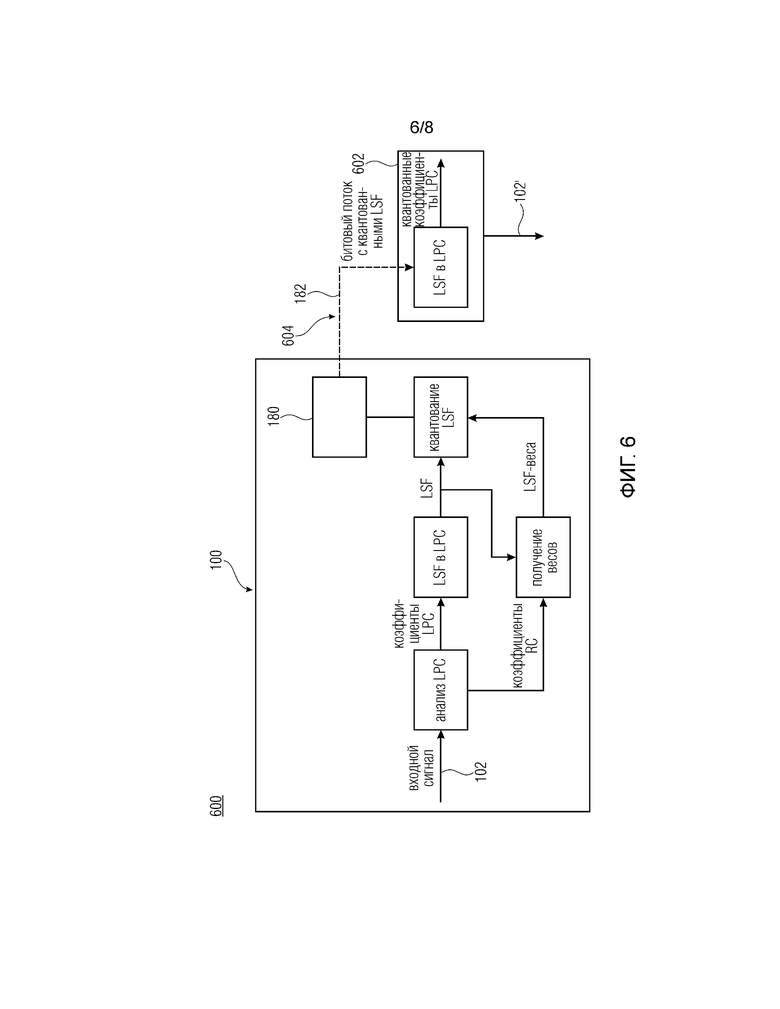
Фиг. 6 показывает блок-схему системы передачи аудио согласно варианту осуществления;
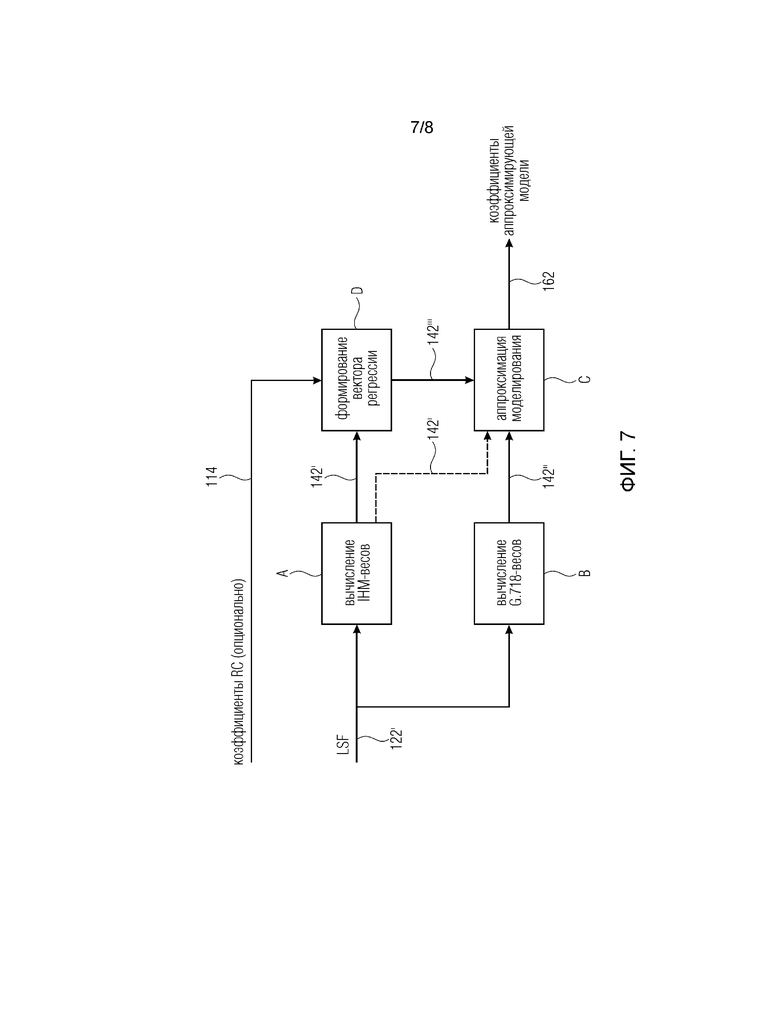
Фиг. 7 иллюстрирует вариант осуществления для получения значений коррекции; и
Фиг. 8 показывает блок-схему последовательности операций способа кодирования аудиосигнала согласно варианту осуществления.
Одинаковые или эквивалентные элементы или элементы с одинаковой или эквивалентной функциональностью, обозначены в нижеследующем описании одинаковыми или эквивалентными ссылочными позициями, даже если они имеются на различных фигурах.
В последующем описании множество деталей изложено для обеспечения более полного объяснения вариантов осуществления настоящего изобретения. Однако специалистам в данной области техники должно быть понятно, что варианты осуществления настоящего изобретения могут быть осуществлены без этих конкретных деталей. В других случаях, хорошо известные структуры и устройства показаны в виде блок-схемы, а не в деталях, чтобы избежать затенения вариантов осуществления настоящего изобретения. Кроме того, признаки различных вариантов осуществления, описанных ниже, могут быть объединены друг с другом, если специально не оговорено иное.
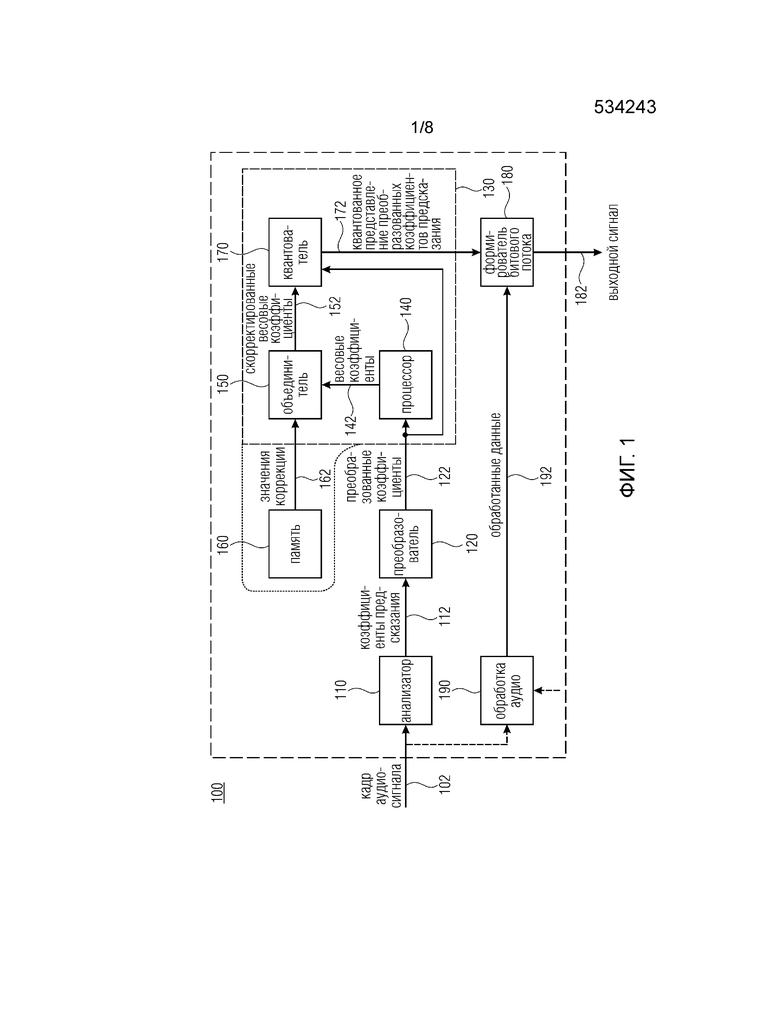
На фиг.1 показана блок-схема кодера 100 для кодирования аудиосигнала. Аудиосигнал может быть получен кодером 100 как последовательность кадров 102 аудиосигнала. Кодер 100 содержит анализатор для анализа кадра 102 и для определения коэффициентов 112 предсказания анализа из аудиосигнала 102. Коэффициенты 112 предсказания анализа (коэффициенты предсказания) могут быть получены, например, как коэффициенты линейного предсказания (LPC). В качестве альтернативы, также могут быть получены коэффициенты нелинейного предсказания, причем коэффициенты линейного предсказания могут быть получены с использованием меньшей вычислительной мощности и, следовательно, могут быть получены быстрее.
Кодер 100 содержит преобразователь 120, сконфигурированный для получения преобразованных коэффициентов 122 предсказания из коэффициентов 112 предсказания. Преобразователь 120 может быть сконфигурирован для определения преобразованных коэффициентов 122 предсказания, например, частот спектральных линий (LSF) и/или частот спектральных иммитансов (ISF). Преобразованные коэффициенты 122 предсказания могут иметь более высокую устойчивость по отношению к погрешностям квантования в последующем квантовании по сравнению с коэффициентами 112 предсказания. Поскольку квантование обычно выполняется нелинейно, квантование коэффициентов линейного предсказания может привести к искажениям декодированного аудиосигнала.
Кодер 100 содержит вычислитель 130. Вычислитель 130 содержит процессор 140, который сконфигурирован для обработки преобразованных коэффициентов 122 предсказания для получения спектральных весовых коэффициентов 142. Процессор может быть сконфигурирован для вычисления и/или для определения весовых коэффициентов 142 на основе одного или более из множества известных правил определения, таких как инверсное гармоническое среднее (IHM), как это известно из [1], или в соответствии с более сложным подходом, как описано в [2]. Стандарт G.718 Международного союза электросвязи (ITU) описывает другой подход определения весовых коэффициентов путем расширения подхода [2], как описано в [3]. Предпочтительно процессор 140 сконфигурирован, чтобы определять весовые коэффициенты 142 на основе правила определения, имеющего низкую вычислительную сложность. Это может обеспечить высокую пропускную способность кодированных аудиосигналов и/или простую реализацию кодера 100 ввиду аппаратных средств, которые могут потреблять меньше энергии на основе меньших вычислительных затрат.
Вычислитель 130 включает в себя объединитель 150, сконфигурированный для объединения спектральных весовых коэффициентов 142 и множества значений 162 коррекции, чтобы получать скорректированные весовые коэффициенты 152. Множество значений коррекции предоставляется из памяти 160, в которой хранятся значения 162 коррекции. Значения 162 коррекции могут быть статическими или динамическими, т.е. значения 162 коррекции могут быть обновлены во время работы кодера 100 или могут оставаться неизменными в процессе работы и/или могут быть обновлены только во время процедуры калибровки для калибровки кодера 100. Предпочтительно, память 160 содержит статические значения 162 коррекции. Значения 162 коррекции могут быть получены, например, с помощью процедуры предварительного вычисления, как описано в дальнейшем. В качестве альтернативы, память 160 может альтернативно содержаться в вычислителе 130, как указано пунктирными линиями.
Вычислитель 130 содержит квантователь 170, сконфигурированный для квантования преобразованных коэффициентов 122 предсказания с использованием скорректированных весовых коэффициентов 152. Квантователь 170 сконфигурирован для вывода квантованного представления 172 преобразованных коэффициентов 122 предсказания. Квантователь 170 может быть линейным квантователем, нелинейным квантователем, таким как логарифмический квантователь, или векторно-подобным квантователем, векторным квантователем, соответственно. Векторно-подобный квантователь может быть сконфигурирован для квантования множества pf частей скорректированных весовых коэффициентов 152 во множество квантованных значений (частей). Квантователь 170 может быть сконфигурирован для взвешивания преобразованных коэффициентов 122 предсказания скорректированными весовыми коэффициентами 152. Квантователь может быть дополнительно сконфигурирован для определения расстояния от взвешенных преобразованных коэффициентов 122 предсказания до записей базы данных квантователя 170 и для выбора кодового слова (представления), которое связано с записью в базе данных, причем запись может содержать наименьшее расстояние до взвешенных преобразованных коэффициентов 122 предсказания. Такая процедура иллюстративно описана ниже. Квантователь 170 может быть стохастическим векторным квантователем (VQ). В качестве альтернативы, квантователь 170 может также быть сконфигурирован для применения других векторных квантователей, таких как решеточный VQ или любой скалярный квантователь. В качестве альтернативы, квантователь 170 может быть также сконфигурирован для применения линейного или логарифмического квантования.
Квантованное представление 172 преобразованных коэффициентов 122 предсказания, то есть кодовое слово, выдается на формирователь 180 битового потока кодера 100. Кодер 100 может содержать блок 190 обработки аудио, сконфигурированный для обработки некоторой или всей из аудио информации аудиосигнала 102 и/или дополнительной информации. Блок 190 обработки аудио сконфигурирован для предоставления аудиоданных 192, таких как вокализованная сигнальная информации или невокализованная сигнальная информация, на формирователь 180 битового потока. Формирователь 180 битового потока сконфигурирован для формирования выходного сигнала (битового потока) 182 на основе квантованного представления 172 преобразованных коэффициентов 122 предсказания и на основе аудио информации 192, которая основана на аудиосигнале 102.
Преимуществом кодера 100 является то, что процессор 140 может быть сконфигурирован так, чтобы получать, например, вычислять весовые коэффициенты 142 с использованием правила определения, которое имеет низкую вычислительную сложность. Значения 162 коррекции могут быть получены посредством, при выражении в упрощенном виде, сравнения набора весовых коэффициентов, полученных с помощью (опорного) правила определения с высокой вычислительной сложностью, но поэтому с высокой точностью и/или хорошим качеством аудио и/или низким LSD, с весовыми коэффициентами, полученными с помощью правила определения, выполняемого процессором 140. Это может быть сделано для множества аудиосигналов, причем для каждого из аудиосигналов получают ряд весовых коэффициентов на основе обоих правил определения. Для каждого аудиосигнала, полученные результаты можно сравнивать, чтобы получать информацию, относящуюся к рассогласованию или погрешности. Информация, относящаяся к рассогласованию или погрешности, может суммироваться и/или усредняться по множеству аудиосигналов для получения информации, относящейся к средней погрешности, которая создана процессором 140 по отношению к опорному правилу определения при выполнении правила определения с более низкой вычислительной сложностью. Полученная информация, относящаяся к средней погрешности и/или рассогласованию, может быть представлена в значениях 162 коррекции, так что весовые коэффициенты 142 могут быть объединены со значениями 162 коррекции объединителем, чтобы уменьшить или скомпенсировать среднюю погрешность. Это позволяет уменьшить или почти скомпенсировать погрешность весовых коэффициентов 142 по сравнению с опорным правилом определения, используемым офлайн, в то же время позволяя выполнять менее сложное определение весовых коэффициентов 142.
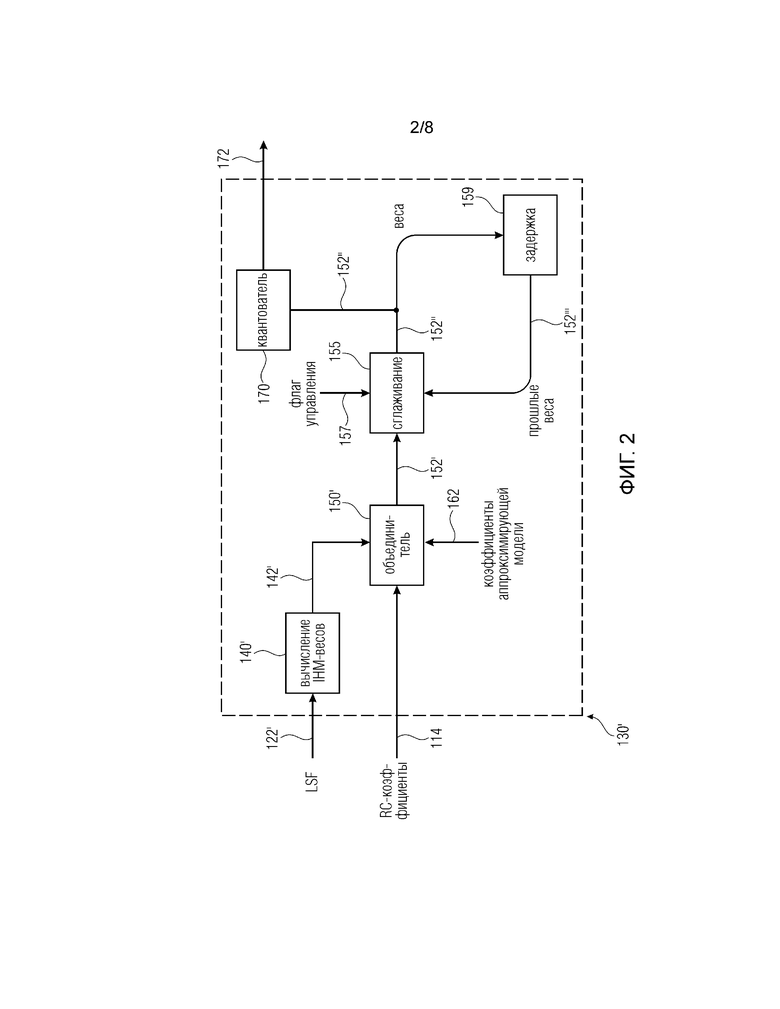
Фиг. 2 показывает блок-схему модифицированного вычислителя 130’. Вычислитель 130’ содержит процессор 140’, сконфигурированный для вычисления весов инверсного гармонического среднего (IHM) из LSF 122’, которые представляют преобразованные коэффициенты предсказания. Вычислитель 130’ содержит объединитель 150’, который, по сравнению с объединителем 150, сконфигурирован для объединения IHM-весов 142’ процессора 140’, значений 162 коррекции и дополнительной информации 114 аудиосигнала 102, указанной как “коэффициенты отражения”, причем дополнительная информация 114 не ограничивается этим. Дополнительная информация может быть промежуточным результатом других этапов кодирования, например, коэффициенты 114 отражения могут быть получены анализатором 110 при определении коэффициентов 112 предсказания, как представлено на фиг. 1. Коэффициенты линейного предсказания могут быть определены анализатором 110 при выполнении правила определения в соответствии с алгоритмом Левинсона-Дарбина, в котором определяются алгоритмы отражения. Кроме того, может быть получена информация, относящаяся к спектру мощности (энергетическому спектру), при вычислении коэффициентов 112 предсказания. Возможная реализация объединителя 150’ описана далее. В качестве альтернативы или в дополнение, дополнительная информация 114 может быть объединена с весами 142 или 142’ и параметрами 162 коррекции, например, информацией, относящейся к энергетическому спектру аудиосигнала 102. Дополнительная информация 114 позволяет дополнительно уменьшить разницу между весами 142 или 142’, определяемыми вычислителем 130 или 130’, и опорными весами. Увеличение вычислительной сложности может иметь лишь незначительные эффекты, так как дополнительная информация 114 может уже быть определена другими компонентами, такими как анализатор 110, в ходе других этапов кодирования аудио.
Вычислитель 130’ дополнительно содержит сглаживатель 155, сконфигурированный для приема скорректированных весовых коэффициентов 152’ от объединителя 150’ и опциональной информации 157 (флага управления), обеспечивающей возможность операции управления (состояния включения/выключения) сглаживателя 155. Флаг 157 управления может быть получен, например, из анализатора, указывающего, что сглаживание должно быть выполнено для того, чтобы смягчить резкие переходы. Сглаживатель 155 сконфигурирован для объединения скорректированных весовых коэффициентов 152’ и скорректированных весовых коэффициентов 152”’, которые являются задержанным представлением скорректированных весовых коэффициентов, определенных для предыдущего кадра или подкадра аудиосигнала, т.е. скорректированных весовых коэффициентов, определенных в предыдущем цикле в состоянии включения. Сглаживатель 155 может быть реализован в виде фильтра с бесконечным импульсным откликом (IIR). Таким образом, вычислитель 130’ содержит блок 159 задержки, сконфигурированный для приема и задержки скорректированных весовых коэффициентов 152”, обеспеченных сглаживателем 155 в первом цикле, и обеспечения тех весовых коэффициентов как скорректированных весовых коэффициентов 152”’ в следующем цикле.
Блок 159 задержки может быть реализован, например, как фильтр задержки или как память, сконфигурированная для сохранения принятых скорректированных весовых коэффициентов 152”. Сглаживатель 155 сконфигурирован для весового объединения принятых скорректированных весовых коэффициентов 152’ и принятых скорректированных весовых коэффициентов 152”’ из прошлого. Например, (текущие) скорректированные весовые коэффициенты 152’ могут содержать долю 25%, 50% , 75% или любое другое значение в сглаженных скорректированных весовых коэффициентах 152”, причем (прошлые) весовые коэффициенты 152”’ могут содержать долю, равную (1-доля скорректированных весовых коэффициентов 152’). Это позволяет избежать резких переходов между последовательными аудиокадрами, когда аудиосигнал, то есть его два последовательных кадра приводят к различным скорректированным весовым коэффициентам, которые привели бы к искажениям в декодированном аудиосигнале. В состоянии выключения, сглаживатель 155 сконфигурирован для пересылки скорректированных весовых коэффициентов 152’. В качестве альтернативы или в дополнение, сглаживание может обеспечить повышенное качество аудио для аудиосигналов, содержащих высокий уровень периодичности.
В качестве альтернативы, сглаживатель 155 может быть сконфигурирован, чтобы дополнительно объединять скорректированные весовые коэффициенты нескольких предыдущих циклов. В качестве альтернативы или в дополнение, преобразованные коэффициенты 122’ предсказания могут также быть частотами спектральных иммитансов.
Весовой коэффициент wi может быть получен, например, на основе инверсного гармонического среднего (IHM). Правило определение может быть основано на форме:
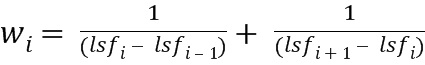 ,
,
где wi обозначает определенный вес 142’ с индексом i, LSFi обозначает частоту спектральной линии с индексом i. Индекс i соответствует числу полученных спектральных весовых коэффициентов и может быть равен числу коэффициентов предсказания, определенных анализатором. Число коэффициентов предсказания и, следовательно, число преобразованных коэффициентов может быть, например, равно 16. В качестве альтернативы, это число может также быть равно 8 или 32. В качестве альтернативы, число преобразованных коэффициентов также может быть ниже, чем число коэффициентов предсказания, например, если преобразованные коэффициенты 122 определены как частоты спектральных иммитансов, которые могут содержать меньшее число по сравнению с числом коэффициентов предсказания.
Другими словами, фиг. 2 детализирует обработку, выполняемую на этапе получения веса, исполняемого преобразователем 120. Сначала IHM-веса вычисляются из LSF. В соответствии с одним вариантом осуществления, порядок LPC, равный 16, используется для сигнала, дискретизированного с частотой 16 кГц. Это означает, что LSF ограничены между 0 и 8 кГц. В соответствии с другим вариантом осуществления, LPC имеет порядок 16, и сигнал дискретизируется с частотой 12,8 кГц. В этом случае, LSF ограничены между 0 и 6,4 кГц. В соответствии с другим вариантом осуществления, сигнал дискретизируется с частотой 8 кГц, что может называться узкополосной дискретизацией. IHM-веса могут затем объединяться с дополнительной информацией, например, относящейся к некоторым из коэффициентов отражения, в полиноме, для которого коэффициенты оптимизируются офлайн на этапе обучения. И, наконец, полученные веса могут быть сглажены предыдущим набором весов в некоторых случаях, например, для стационарных сигналов. В соответствии с одним вариантом осуществления, сглаживание никогда не выполняется. В соответствии с другими вариантами осуществления, оно выполняется только тогда, когда входной кадр классифицируется как вокализованный, то есть сигнал, детектируемый как в высокой степени периодический.
Далее будут сделаны ссылки на детали коррекции полученных весовых коэффициентов. Например, анализатор сконфигурирован для определения коэффициентов линейного предсказания (LPC) порядка 10 или 16, то есть числа 10 или 16 LPC. Хотя анализатор может быть также сконфигурирован для определения любого другого числа коэффициентов линейного предсказания или другого типа коэффициента, следующее описание сделано со ссылкой на 16 коэффициентов, так как это число коэффициентов используется в мобильной связи.
На фиг. 3 показана блок-схема кодера 300, дополнительно содержащего спектральный анализатор 115 и спектральный процессор 145, по сравнению с кодером 100. Спектральный анализатор 115 сконфигурирован для получения спектральных параметров 116 из аудиосигнала 102. Спектральные параметры могут быть, например, огибающей кривой спектра аудиосигнала либо его кадра и/или параметрами, характеризующими огибающую кривую. В качестве альтернативы, могут быть получены коэффициенты, связанные с энергетическим спектром.
Спектральный процессор 145 содержит вычислитель 145а энергии, который сконфигурирован для вычисления величины или меры 146 для энергии частотных бинов спектра аудиосигнала 102 на основе спектральных параметров 116. Спектральный процессор дополнительно содержит нормализатор 145b для нормализации преобразованных коэффициентов 122’ предсказания (LSF) для получения нормализованных коэффициентов 147 предсказания. Преобразованные коэффициенты предсказания могут быть нормализованы, например, относительным образом, по отношению к максимальному значению множества LSF и/или абсолютным образом, т.е. по отношению к предопределенному значению, такому как максимальное значение, ожидаемое или представимое используемыми переменными вычисления.
Спектральный процессор 145 дополнительно содержит первый определитель 145c, сконфигурированный для определения энергии бина для каждого нормализованного параметра предсказания, то есть, чтобы связывать каждый нормированный параметр 147 предсказания, полученный из нормализатора 45b, с вычисленным в качестве меры 146, чтобы получать вектор W1, содержащий энергию бина для каждой LSF. Спектральный процессор 145 дополнительно содержит второй определитель 145d, сконфигурированный для нахождения (определения) частотного взвешивания для каждой нормализованной LSF, чтобы получать вектор W2, содержащий частотные взвешивания. Дополнительная информация 114 содержит векторы W1 и W2, т.е. векторы W1 и W2 являются признаком, представляющим дополнительную информацию 114.
Процессор 142’ сконфигурирован для определения IHM на основе преобразованных параметров 122’ предсказания и степени IHM, например, второй степени, причем в качестве альтернативы или в дополнение также может вычисляться более высокая степень, при этом IHM и его степень(и) формируют весовые коэффициенты 142’.
Объединитель 150” сконфигурирован для определения скорректированных весовых коэффициентов (скорректированных весов LSF) 152’ на основе дополнительной информации 114 и весовых коэффициентов 142’.
В качестве альтернативы, процессор 140’, спектральный процессор 145 и/или объединитель могут быть реализованы как один блок обработки, такой как центральный процессорный блок, (микро) контроллер, программируемая вентильная матрица или т.п.
Другими словами, первой и второй записью для объединителя являются IHM и IHM2, т.е. весовые коэффициенты 142’. Третья запись для каждого элемента i LSF-вектора будет
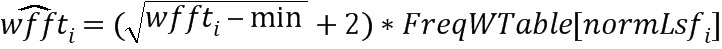
где wfft представляет собой комбинацию W1 и W2 и где min является минимумом wfft.
i=0…М, где М может быть равно 16, когда 16 коэффициентов предсказания получают из аудиосигнала и
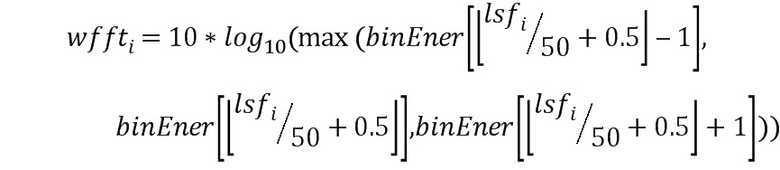
где binEner содержит энергию каждого бина спектра, т.е. binEner соответствует мере 146.
Отображение 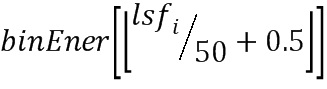 представляет собой грубое приближение энергии форманты в спектральной огибающей. FreqWTable представляет собой вектор, содержащий дополнительные веса, которые выбираются в зависимости от входного сигнала, являющегося вокализованным или невокализованным.
представляет собой грубое приближение энергии форманты в спектральной огибающей. FreqWTable представляет собой вектор, содержащий дополнительные веса, которые выбираются в зависимости от входного сигнала, являющегося вокализованным или невокализованным.
Wfft является приближением спектральной энергии, близкой к коэффициенту предсказания, такому как коэффициент LSF. Проще говоря, если коэффициент предсказания (LSF) содержит значение X, это означает, что спектр аудиосигнала (кадра) содержит максимум энергии (форманту) на частоте X или ниже нее. wfft является логарифмическим выражением энергии на частоте X, то есть, оно соответствует логарифмической энергии в этом местоположении. По сравнению с вариантами осуществления, описанными ранее, с использованием коэффициентов отражения в качестве дополнительной информации, в качестве альтернативы или в дополнение, комбинация wfft (W1) и FrequWTable (W2) может быть использована для получения дополнительной информации 114. FreqWTable описывает одну из множества возможных таблиц, подлежащих использованию. На основе “режима кодирования” кодера 300, например, вокализованного, фрикативного и т.п., может быть выбрана по меньшей мере одна из множества таблиц. Одна или более из множества таблиц может обучаться (программироваться и адаптироваться) во время работы кодера 300.
Решение использовать wfft направлено на улучшение кодирования преобразованных коэффициентов предсказания, которые представляют форманту. В отличие от классического формирования шума, где шум имеется на частотах, содержащих большие количества энергии (сигнала), описанный подход относится к квантованию кривой спектральной огибающей. Когда энергетический спектр содержит большое количество энергии (большую меру) на частотах, содержащихся или расположенных рядом с частотой преобразованного коэффициента предсказания, этот преобразованный коэффициент предсказания (LSF) может быть квантован лучше, то есть с меньшими погрешностями, полученными за счет более высокого взвешивания, чем другие коэффициенты, содержащие более низкую меру энергии.
Фиг. 4a иллюстрирует вектор LSF, содержащий 16 значений записей определенных частот спектральных линий, которые получены с помощью преобразователя на основе определенных коэффициентов предсказания. Процессор сконфигурирован, чтобы получать 16 весов, например, инверсное гармоническое среднее IHM, представленное в векторе IHM. Значения 162 коррекции сгруппированы, например, в вектор а, вектор b и вектор с. Каждый из векторов а, b и c содержит 16 значений а1-16, b1-16 и c1-16, причем равные индексы указывают, что соответствующее значение коррекции связано с коэффициентом предсказания, его преобразованное представление и весовой коэффициент содержат тот же самый индекс. Фиг. 4b иллюстрирует правило определения, выполняемое объединителем 150 или 150’ в соответствии с вариантом осуществления. Объединитель сконфигурирован для вычисления или определения результата для полиномиальной функции, основанной на форме у=а+bх+cx2, то есть разные значения a, b, c коррекции объединяются (умножаются) с различными степенями весовых коэффициентов (иллюстрируемых как х). y обозначает вектор полученных скорректированных весовых коэффициентов.
В качестве альтернативы или в дополнение, объединитель также может быть сконфигурирован так, чтобы суммировать дополнительные значения (d, e, f,…) коррекции и дополнительные степени весовых коэффициентов или дополнительную информацию. Например, полином, изображенный на фиг. 4b, может быть расширен с помощью вектора d, содержащего 16 значений, умноженного на третью степень дополнительной информации 114, соответствующий вектор, таким образом, содержит 16 значений. Это может быть, например, вектор, основанный на IHM3, когда процессор 140’, как показано на фиг. 3, сконфигурирован для определения дополнительных степеней IHM. В качестве альтернативы, может вычисляться по меньшей мере только вектор b и опционально один или несколько из векторов c, d,… более высокого порядка. Упрощенно, порядок полинома увеличивается с каждым членом, причем каждый тип может быть сформирован на основе весового коэффициента и/или опционально на основе дополнительной информации, причем полином основан на форме у=а+bх+cx2, то есть, когда содержит член более высокого порядка. Значения а, b, c и опционально d, е,… могут содержать действительные значения и/или мнимые значения, а также могут содержать значение, равное нулю.
Фиг. 4c изображает приведенное для примера правило определения для иллюстрации этапа получения скорректированных весовых коэффициентов 152 или 152’. Скорректированные весовые коэффициенты представлены в векторе w, содержащем 16 значений, по одному весовому коэффициенту для каждого из преобразованных коэффициентов предсказания, изображенных на фиг. 4а. Каждый из скорректированных весовых коэффициентов w1-16 вычисляется в соответствии с правилом определения, показанным на фиг. 4b. Приведенные выше описания должны иллюстрировать только принцип определения скорректированных весовых коэффициентов и не должны ограничиваться правилами определения, описанными выше. Описанные выше правила определения также могут варьироваться, масштабироваться, сдвигаться и т.п. В общем, скорректированные весовые коэффициенты получают путем выполнения объединения значений коррекции с определенным весовыми коэффициентами.
Фиг. 5a изображает примерную схему определения, которая может быть реализована квантователем, таким как квантователь 170, чтобы определять квантованное представление преобразованных коэффициентов предсказания. Квантователь может суммировать погрешность, например, разность или ее степень между определенным преобразованным коэффициентом, показанным как LSFi, и опорным коэффициентом, указанным как LSF’i, при этом опорные коэффициенты могут быть сохранены в базе данных квантователя. Определенное расстояние может быть квадратичным, так что получаются только положительные значения. Каждое из расстояний (погрешностей) взвешивается соответствующим весовым коэффициентом wi. Это позволяет придать больший вес частотным диапазонам или преобразованным коэффициентам предсказания с более высокой важностью для качества аудио и меньший вес частотным диапазонам с более низкой важностью для качества аудио. Погрешности суммируются по некоторым или всем индексам 1-16, чтобы получить полное значение погрешности. Это может быть сделано для множества предопределенных комбинаций (записей базы данных) коэффициентов, которые могут быть объединены в наборы Qu’, Qu”,… Qun, как показано на фиг. 5b. Квантователь может быть сконфигурирован для выбора кодового слова, связанного с набором предопределенных коэффициентов, имеющих минимальную погрешность по отношению к определенным скорректированным весовым коэффициентам и преобразованным коэффициентам предсказания. Кодовое слово может быть, например, индексом таблицы, так что декодер может восстановить предопределенный набор Qu’, Qu”,… на основе принятого индекса, принятого кодового слова, соответственно.
Для получения значений коррекции во время фазы обучения выбирается опорное правило определения, в соответствии с которым определяются опорные веса. Так как кодер сконфигурирован для коррекции определенных весовых коэффициентов по отношению к опорным весам, и определение опорных весов может быть выполнено офлайн, т.е. во время этапа калибровки или т.п., правило определения, имеющее высокую точность (например, низкое LSD), может быть выбрано, пренебрегая результирующими вычислительными затратами. Предпочтительно, способ, имеющий высокую точность и, возможно, высокую вычислительную сложность, может быть выбран, чтобы получить высокоточные опорные весовые коэффициенты. Например, может использоваться метод определения весовых коэффициентов в соответствии со стандартом G.718 [3].
Правило определения, в соответствии с которым кодер будет определять весовые коэффициенты, также выполняется. Это может быть способ, имеющий низкую вычислительную сложность, при допущении более низкой точности определенных результатов. Веса вычисляются в соответствии с обоими правилами определения при использовании набора аудио материала, содержащего, например, речь и/или музыку. Аудио материал может быть представлен в количестве М обучающих векторов, где М может содержать значение более 100, более 1000 или более 5000. Оба набора полученных весовых коэффициентов, сохраняются в матрице, каждая матрица содержит векторы, каждый из которых связан с одним из М обучающих векторов.
Для каждого из М обучающих векторов определяется расстояние между вектором, содержащим весовые коэффициенты, определенные на основе первого (опорного) правила определения, и вектором, содержащим весовые векторы, определенные на основе правила определения кодера. Расстояния суммируются для получения полного расстояния (погрешности), причем полная погрешность может быть усреднена, чтобы получить среднее значение погрешности.
При определении значений коррекции, целью может быть уменьшение полной погрешности и/или средней погрешности. Поэтому полиномиальная аппроксимация может быть выполнена на основе правила определения, показанного на фиг. 4b, где векторы а, b и c и/или дополнительные векторы адаптированы к полиному, так что полная и/или средняя погрешность уменьшается или сводится к минимуму. Полином аппроксимирован к весовым коэффициентам, определенным на основе правила определения, которые будут выполняться в декодере. Полином может быть аппроксимирован таким образом, что полная погрешность или средняя погрешность ниже порогового значения, например, 0,01, 0,1 или 0,2, где 1 указывает полное рассогласование. В качестве альтернативы или в дополнение, полином может быть аппроксимирован таким образом, что суммарная погрешность сводится к минимуму за счет использования алгоритма, основанного на минимизации погрешности. Значение 0,01 может указывать относительную погрешность, которая может быть выражена в виде разности (расстояния) и/или как частное расстояний. В качестве альтернативы, полиномиальная аппроксимация может быть выполнена путем определения значений коррекции так, что результирующая общая погрешность или средняя погрешность содержит значение, близкое к математическому минимуму. Это может быть сделано, например, путем взятия производной используемых функций и оптимизации на основе установки полученной производной в нуль.
Дальнейшее уменьшение расстояния (погрешности), например, евклидова расстояния, может быть достигнуто при добавлении дополнительной информации, как показано для 114 на стороне кодера. Эта дополнительная информация также может быть использована при вычислении параметров коррекции. Информация может быть использована путем объединения ее с полиномом для определения значения коррекции.
Другими словами, первые IHM-веса и G.718-веса могут быть извлечены из базы данных, содержащей более 5000 секунд (или M обучающих векторов) речи и музыкального материала. IHM-веса могут быть сохранены в матрице I, а G.718-веса могут быть сохранены в матрице G. Пусть Ii и Gi - векторы, содержащие все IHM- и G.718-веса wi i-го коэффициента ISF или LSF всей обучающей базы данных. Среднее евклидово расстояние между этими двумя векторами может быть определено на основе:
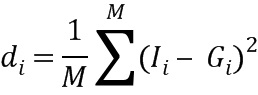
Для того чтобы минимизировать расстояние между этими двумя векторами, полином второго порядка может быть аппроксимирован
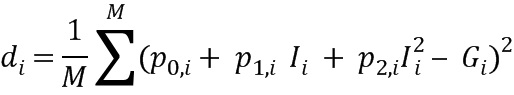
Может быть введена матрица 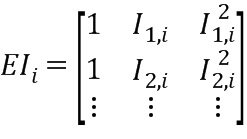 и вектор
и вектор 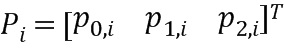 , чтобы записать
, чтобы записать
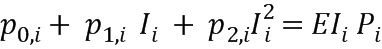
и
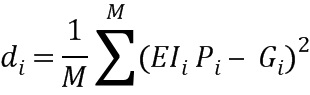
Чтобы получить вектор Pi с самым низким средним евклидовым расстоянием, производная 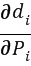 может быть установлена равной нулю
может быть установлена равной нулю
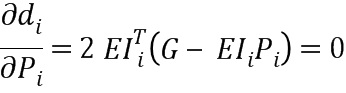
чтобы получить
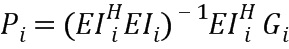
Для дополнительного уменьшения разности (евклидова расстояния) между предложенными весами и G.718-весами, коэффициенты отражения другой информации могут быть добавлены к матрице EIi. Так как, например, коэффициенты отражения несут некоторую информацию о модели LPC, которая не является непосредственно наблюдаемой в области LSF или ISF, они способствуют уменьшению евклидова расстояния di. На практике, вероятно, не все коэффициенты отражения приведут к значительному снижению евклидова расстояния. Авторы настоящего изобретения обнаружили, что может быть достаточно использовать первый и 14-ый коэффициент отражения. Добавление коэффициентов отражения к матрице EIi будет выглядеть следующим образом:
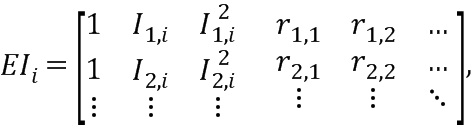
где rху является y-ым коэффициентом отражения (или другой информацией) х-го экземпляра в обучающем наборе данных. Соответственно, размерность вектора Рi будет содержать измененные размерности в соответствии с числом столбцов в матрице EIi. Вычисление оптимального вектора Рi остается таким же, как описано выше.
Путем добавления дополнительной информации, правило определения, изображенное на фиг. 4b, может быть изменено (расширено) в соответствии с у=а+b х+c x2+d r13+….
Фиг. 6 показывает блок-схему системы 600 передачи аудио в соответствии с вариантом осуществления. Система 600 передачи аудио включает в себя кодер 100 и декодер 602, сконфигурированный для приема выходного сигнала 182 в виде битового потока, содержащего квантованную LSF, или информацию, относящуюся к ней, соответственно. Битовый поток передается через передающую среду 604, такую как проводное соединение (кабель) или воздух.
Другими словами, на фиг. 6 показан общий вид схемы кодирования LPC на стороне кодера. Следует отметить, что взвешивание используется только кодером и не требуется декодером. Сначала выполняется анализ LPC на входном сигнале. Он выводит коэффициенты LPC и коэффициенты отражения (RC). После анализа LPC коэффициенты предсказания LPC преобразуются в LSF. Эти LSF являются вектором, квантованным с использованием схемы, такой как многоступенчатое векторное квантование, и затем передаются в декодер. Кодовое слово выбирается в соответствии с взвешенным квадратичным расстоянием погрешности, называемым WED, как представлено выше. Для этой цели соответствующие веса должны быть вычислены заранее. Вывод весов является функцией исходных LSF и коэффициентов отражения. Коэффициенты отражения непосредственно доступны во время анализа LPC в качестве внутренних переменных, необходимых для алгоритма Левинсона-Дарбина.
Фиг. 7 иллюстрирует вариант осуществления для получения значений коррекции, как было описано выше. Преобразованные коэффициенты 122’ предсказания (LSF) или другие коэффициенты используются для определения весов в соответствии с кодером в блоке А и для вычисления соответствующих весов в блоке B. Полученные веса 142 непосредственно комбинируются с полученными опорными весами 142” в блоке C для аппроксимации моделирования, то есть для вычисления вектора Pi, как показано пунктирной линией от блока А к блоку С. Опционально, если дополнительная информация 114, такая как коэффициенты отражения или информация спектральной мощности, используется для определения значений 162 коррекции, веса 142’ комбинируются с дополнительной информацией 114 в векторе регрессии, указанном как блок D, как это было описано расширенной матрицей EIi посредством значений отражения. Полученные веса 142”’ затем объединяются с опорными весовыми коэффициентами 142” в блоке С.
Другими словами, аппроксимирующей моделью блока С является вектор Р, который описан выше. Приведенный ниже псевдо-код иллюстративно обобщает обработку вывода весов:
Вход:lsf=исходный вектор LSF
order=порядок LPC, длина lsf
parcorr[0]=-1-ый коэффициент отражения
parcorr[1]=-14-ый коэффициент отражения
smooth_flag=флаг для сглаживания весов
w_past=прошлые веса
Выход
weights=вычисленные веса


Это указывает сглаживание, описанное выше, в котором представленные веса взвешены с коэффициентом 0,75 и прошлые веса взвешены с коэффициентом 0,25.
Полученные коэффициенты для вектора Р могут содержать скалярные значения, как указано в качестве примера ниже для сигнала, дискретизированного с частотой 16 кГц и с порядком LPC, равным 16:
lsf_fit_model[5][16]={
{679, 10921, 10643, 4998, 11223, 6847, 6637, 5200, 3347, 3423, 3208, 3329, 2785, 2295, 2287, 1743},
{23735, 14092, 9659, 7977, 4125, 3600, 3099, 2572, 2695, 2208, 1759, 1474, 1262, 1219, 931, 1139},
{-6548, -2496, -2002, -1675, -565, -529, -469, -395, -477, -423, -297, -248, -209, -160, -125, -217},
{-10830, 10563, 17248, 19032, 11645, 9608, 7454, 5045, 5270, 3712, 3567, 2433, 2380, 1895, 1962, 1801},
{-17553, 12265, -758, -1524, 3435, -2644, 2013, -616, -25, 651, -826, 973, -379, 301, 281, -165}};
Как было указано выше, вместо LSF также ISF могут быть предоставлены преобразователем в качестве коэффициентов 122. Вывод весов может быть очень сходным, как указано посредством следующего псевдокода. ISF порядка N эквивалентны LSF порядка N-1 для N-1 первых коэффициентов, к которым прибавлены N-ые коэффициенты отражения. Поэтому вывод весов очень близок к выводу весов LSF. Это задается следующим псевдокодом:
Вход:isf=исходный вектор ISF
order=порядок LPC, длина lsf
parcorr[0]=-1-ый коэффициент отражения
parcorr[1]=-14-ый коэффициент отражения
smooth_flag=флаг для сглаживания весов
w_past=прошлые веса
Выход
weights=вычисленные веса
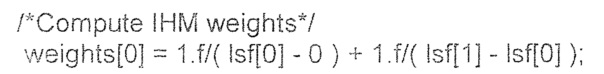

где коэффициенты аппроксимирующей модели для входного сигнала с частотными компонентами, возрастающими до 6,4 кГц:
isf_fit_model[5][15]={
{8112, 7326, 12119, 6264, 6398, 7690, 5676, 4712, 4776, 3789, 3059, 2908, 2862, 3266, 2740},
{16517, 13269, 7121, 7291, 4981, 3107, 3031, 2493, 2000, 1815, 1747, 1477, 1152, 761, 728},
{-4481, -2819, -1509, -1578, -1065, -378, -519, -416, -300, -288, -323, -242, -187, -7, -45},
{-7787, 5365, 12879, 14908, 12116, 8166, 7215, 6354, 4981, 5116, 4734, 4435, 4901, 4433, 5088},
{-11794, 9971, -3548, 1408, 1108, -2119, 2616, -1814, 1607, -714, 855, 279, 52, 972, -416}};
где коэффициенты аппроксимирующей модели для входного сигнала с частотными компонентами, возрастающими до 4 кГц, и с нулевой энергией для частотного компонента от 4 до 6,4 кГц:
isf_fit_model [5][15]={
{21229, -746, 11940, 205, 3352, 5645, 3765, 3275, 3513, 2982, 4812, 4410, 1036, -6623, 6103},
{15704, 12323, 7411, 7416, 5391, 3658, 3578, 3027, 2624, 2086, 1686, 1501, 2294, 9648, -6401},
{-4198, -2228, -1598, -1481, -917, -538, -659, -529, -486, -295, -221, -174, -84, -11874, 27397},
{-29198, 25427, 13679, 26389, 16548, 9738, 8116, 6058, 3812, 4181, 2296, 2357, 4220, 2977, -71},
{-16320, 15452, -5600, 3390, 589, -2398, 2453, -1999, 1351, -1853, 1628, -1404, 113, -765, -359}};
В основном, порядки ISF модифицированы, что можно видеть при сравнении блока /*Compute IHM weights*/ (вычислить IHM-веса) обоих псевдо-кодов.
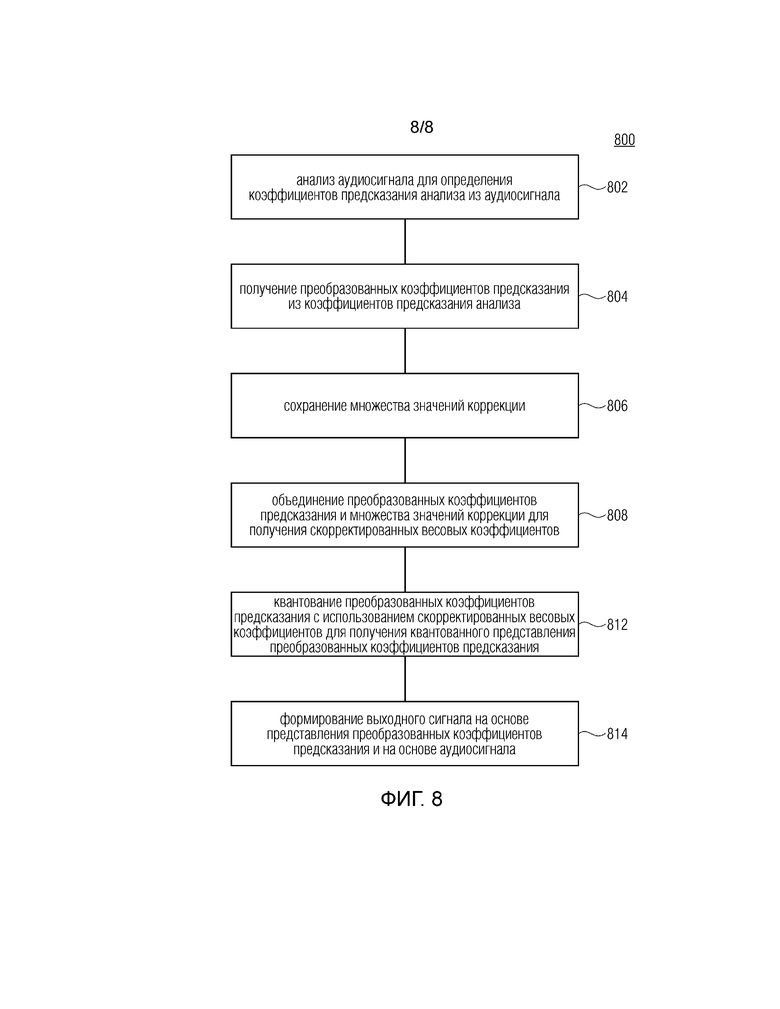
Фиг. 8 показывает схему последовательности операций способа 800 для кодирования аудиосигнала. Способ 800 включает в себя этап 802, на котором аудиосигнал анализируется, при этом анализе из аудиосигнала определяются коэффициенты предсказания. Способ 800 дополнительно включает в себя этап 804, на котором преобразованные коэффициенты предсказания получаются из коэффициентов предсказания, полученных на этапе анализа. На этапе 806 множество значений коррекции сохраняется, например, в памяти, такой как память 160. На этапе 808 преобразованные коэффициенты предсказания и множество значений коррекции объединяются для получения скорректированных весовых коэффициентов. На этапе 812 преобразованные коэффициенты предсказания квантуются с использованием скорректированных весовых коэффициентов для получения квантованного представления преобразованных коэффициентов предсказания. На этапе 814 формируется выходной сигнал на основе представления преобразованных коэффициентов предсказания и на основе аудиосигнала.
Другими словами, настоящее изобретение предлагает новый эффективный способ получения оптимальных весов w с использованием эвристического алгоритма низкой сложности. Представлена оптимизация по взвешиванию IHM, что приводит к меньшему искажению на более низких частотах и большему искажению на более высоких частотах, давая в результате менее слышимое общее искажение. Такая оптимизация достигается путем вычисления первых весов, как предложено в [1], а затем модифицирования их таким образом, чтобы сделать их очень близкими к весам, которые были бы получены при использовании подхода G.718 [3]. Второй этап состоит из простой полиномиальной модели второго порядка в фазе обучения путем минимизации среднего евклидова расстояния между модифицированными IHM-весами и G.718-весами. Упрощая, соотношение между IHM-весами и G.718-весами моделируется (вероятно, простой) полиномиальной функцией.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока или элемента или признака соответствующего устройства.
Соответствующий изобретению кодированный аудиосигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от конкретных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового носителя хранения данных, например, дискеты, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронно-считываемые сигналы управления, сохраненные на нем, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой таким образом, что выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий электронным образом считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой таким образом, что выполняется один из способов, описанных в настоящем документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код предназначен для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты осуществления включают в себя компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления соответствующего изобретению способа является, поэтому, компьютерной программой, имеющей программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа выполняется на компьютере.
Еще один вариант осуществления соответствующих изобретению способов является, поэтому, носителем данных (или цифровым носителем хранения данных или считываемым компьютером носителем), содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Еще один вариант осуществления соответствующего изобретению способа является, поэтому, потоком данных или последовательностью сигналов, представляющих собой компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов могут, например, конфигурироваться для передачи через соединение для передачи данных, например, через Интернет.
Еще один вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Еще один вариант осуществления включает в себя компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для выполнения некоторых или всех функциональных возможностей способов, описанных в настоящем документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящей заявке. В общем, способы предпочтительно выполняются любым аппаратным устройством.
Описанные выше варианты осуществления являются лишь иллюстративными для пояснения принципов настоящего изобретения. Понятно, что модификации и вариации компоновок и деталей, описанных здесь, будут очевидны для специалистов в данной области техники. Поэтому подразумевается, что изобретение должно быть ограничено только объемом приложенной формулы изобретения, а не конкретными деталями, представленными посредством описания и объяснения вариантов осуществления в данном документе.
Литература
[1] Laroia, R.; Phamdo, N.; Farvardin, N., “Robust and efficient quantization of speech LSP parameters using structured vector quantizers”, Acoustics, Speech, and Signal Processing, 1991. ICASSP-91., 1991 International Conference on, vol., no., pp.641, 644 vol. 1, 14-17 Apr 1991
[2] Gardner, William R.; Rao, B.D., “Theoretical analysis of the high-rate vector quantization of LPC parameters”, Speech and Audio Processing, IEEE Transactions on, vol.3, no.5, pp.367, 381, Sep 1995
[3] ITU-T G.718 “Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s”, 06/2008, section 6.8.2.4 “ISF weighting function for frame-end ISF quantization”.
Изобретение относится к области кодирования и передачи аудиосигналов. Технический результат заключается в повышении точности кодирования аудиосигнала. Технический результат достигается за счет вычисления первого множества (IHM) первых весовых коэффициентов для каждого аудиосигнала набора аудиосигналов и на основе первого правила определения, вычисления второго множества вторых весовых коэффициентов для каждого аудиосигнала набора аудиосигналов на основе второго правила определения, причем каждый из второго множества весовых коэффициентов связан с первым весовым коэффициентом, вычисления третьего множества значений (di) расстояния, причем каждое значение (di) расстояния имеет значение, связанное с расстоянием между первым весовым коэффициентом и вторым весовым коэффициентом (142”), связанным с частью аудиосигнала (102), и вычисления четвертого множества значений коррекции, адаптированных для уменьшения значений (di) расстояния при объединении с первыми весовыми коэффициентами. 6 н. и 9 з.п. ф-лы, 11 ил.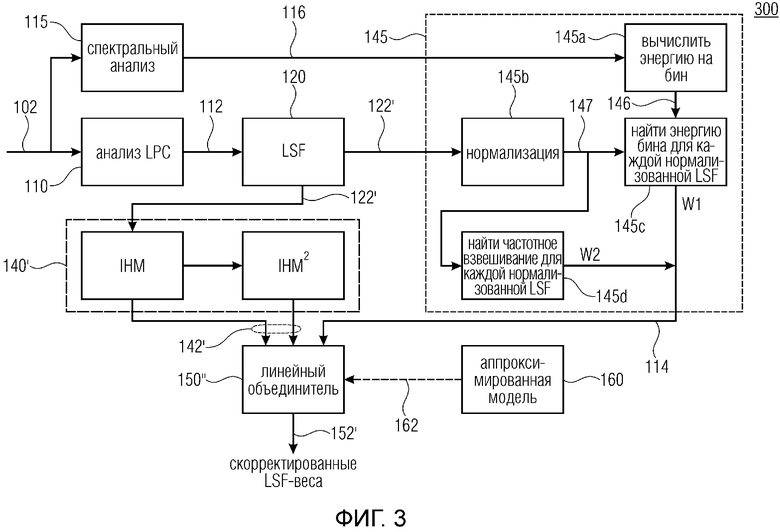
1. Кодер (100) для кодирования аудиосигнала (102), причем кодер (100) содержит:
анализатор (100), сконфигурированный для анализа аудиосигнала (102) и для определения коэффициентов (112) предсказания анализа из аудиосигнала (102);
преобразователь (120), сконфигурированный для получения преобразованных коэффициентов (122; 122’) предсказания из коэффициентов (112) предсказания анализа;
память (160), сконфигурированную для хранения множества значений (162) коррекции;
вычислитель (130; 130’), содержащий:
- процессор (140; 140’), сконфигурированный для обработки преобразованных коэффициентов (122; 122’) предсказания для получения спектральных весовых коэффициентов (142; 142’);
- объединитель (150; 150’), сконфигурированный для объединения спектральных весовых коэффициентов (142; 142’) и множества значений (162; а, b, c) коррекции для получения скорректированных весовых коэффициентов (152; 152’); и
- квантователь (170), сконфигурированный для квантования преобразованных коэффициентов (122; 122’) предсказания с использованием скорректированных весовых коэффициентов (152; 152’) для получения квантованного представления (172) преобразованных коэффициентов (122; 122’) предсказания; и
формирователь (180) битового потока, сконфигурированный для формирования выходного сигнала (182) на основе квантованного представления (172) преобразованных коэффициентов (122) предсказания и на основе аудиосигнала (102);
при этом объединитель (150; 150’) сконфигурирован для применения полинома на основе формы
w=a+bx+cх2,
где w обозначает полученный скорректированный весовой коэффициент, х обозначает спектральный весовой коэффициент, и где а, b и c обозначают значения коррекции.
2. Кодер по п.1, в котором объединитель (150’) сконфигурирован для объединения спектральных весовых коэффициентов (142; 142’), множества значений (162; а, b, c) коррекции и дополнительной информации (114), связанной с входным сигналом (102), для получения скорректированных весовых коэффициентов (152’).
3. Кодер по п. 2, в котором дополнительная информация (114), связанная с входным сигналом (102), содержит коэффициенты отражения, полученные с помощью анализатора (110), или содержит информацию, относящуюся к энергетическому спектру аудиосигнала (102).
4. Кодер по п. 1, в котором анализатор (110) сконфигурирован для определения коэффициентов линейного предсказания (LPC) и в котором преобразователь (120) сконфигурирован для получения частот спектральных линий (LSF; 122’) или частот спектральных иммитансов (ISF) из коэффициентов линейного предсказания (LPC).
5. Кодер по п. 1, в котором объединитель (150; 150’) сконфигурирован для циклического, в каждом цикле, получения скорректированных весовых коэффициентов (152; 152’), при этом
вычислитель (130’) дополнительно содержит сглаживатель (155), сконфигурированный для взвешенного объединения первых квантованных весовых коэффициентов (152”’), полученных для предыдущего цикла, и вторых квантованных весовых коэффициентов (152’), полученных для цикла, следующего за предыдущим циклом, для получения сглаженных скорректированных весовых коэффициентов (152”), содержащих значение между значениями первых (152”’) и вторых (152’) квантованных весовых коэффициентов.
6. Кодер по п. 1, в котором множество значений (162; а, b, c) коррекции получены из предварительно вычисленных весов (LSF; 142”), причем вычислительная сложность для определения предварительно вычисленных весов (LSF; 142”) выше по сравнению с вычислительной сложностью определения спектральных весовых коэффициентов (142; 142’).
7. Кодер по п. 1, в котором процессор (140; 140’) сконфигурирован для получения спектральных весовых коэффициентов (142; 142’) посредством инверсного гармонического среднего.
8. Кодер по п. 1, в котором процессор (140; 140’) сконфигурирован для получения спектральных весовых коэффициентов (142; 142’) на основе формы
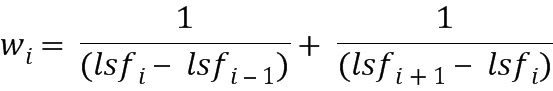 ,
,
где wi обозначает определенный вес с индексом i, lsfi обозначает частоту спектральной линии с индексом i, причем индекс i соответствует числу полученных спектральных весовых коэффициентов (142; 142’).
9. Система (600) передачи аудио, содержащая:
кодер (100) по одному из предыдущих пунктов; и
декодер (602), сконфигурированный для приема выходного сигнала (182) кодера или сигнала, полученного от него, и для декодирования принятого сигнала (182), чтобы обеспечить синтезированный аудиосигнал (102’);
при этом кодер (100) сконфигурирован для доступа к среде (604) передачи и для передачи выходного сигнала (182) через среду (604) передачи.
10. Способ определения значений (162; а, b, c) коррекции для первого множества (IHM) первых весовых коэффициентов (142; 142’), причем каждый весовой коэффициент адаптирован для взвешивания части (LSF; ISF) аудиосигнала (102), причем способ (700) содержит:
вычисление первого множества (IHM) первых весовых коэффициентов (142; 142’) для каждого аудиосигнала набора аудиосигналов и на основе первого правила определения;
вычисление второго множества вторых весовых коэффициентов (142”) для каждого аудиосигнала набора аудиосигналов на основе второго правила определения, причем каждый из второго множества весовых коэффициентов (142”) связан с первым весовым коэффициентом (142; 142’);
вычисление третьего множества значений (di) расстояния, причем каждое значение (di) расстояния имеет значение, связанное с расстоянием между первым весовым коэффициентом (142; 142’) и вторым весовым коэффициентом (142”), связанным с частью аудиосигнала (102); и
вычисление четвертого множества значений коррекции, адаптированных для уменьшения значений (di) расстояния при объединении с первыми весовыми коэффициентами (142; 142’);
причем четвертое множество значений коррекции определяется на основе полиномиальной аппроксимации, содержащей умножение значений первых весовых коэффициентов (142; 142’) на полином (у=а+bх+сх2), содержащий по меньшей мере одну переменную для адаптации члена полинома.
11. Способ по п. 10, в котором четвертое множество значений коррекции определяется на основе полиномиальной аппроксимации, содержащей:
умножение значений первых весовых коэффициентов (142; 142’) на полином (у=а+bх+сх2), содержащий по меньшей мере одну переменную для адаптации члена полинома;
вычисление значения для переменной таким образом, что третье множество значений (di) расстояния содержит значение ниже порогового значения, на основе
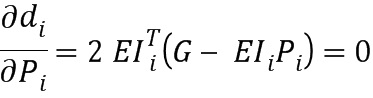
и
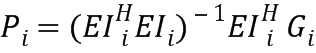 ,
,
где di обозначает значение расстояния i-й части аудиосигналов, где Рi обозначает вектор, имеющий форму на основе 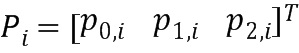 , и где EIi обозначает матрицу на основе
, и где EIi обозначает матрицу на основе
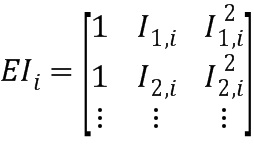 ,
,
где Ix,i обозначает i-й весовой коэффициент (142; 142’), определенный на основе первого правила определения (IHM) для х-й части аудиосигнала (102).
12. Способ по п. 10, в котором третье множество значений (di) расстояния вычисляется на основе дополнительной информации (114), содержащей коэффициенты отражения или информацию, связанную с энергетическим спектром по меньшей мере одного из набора аудиосигналов (102), на основе
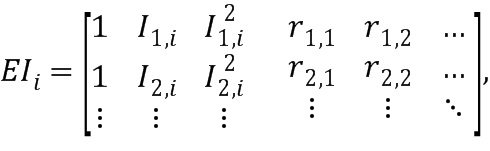
где Ix,i обозначает i-й весовой коэффициент (142; 142’), определенный на основе первого правила определения (IHM) для х-й части аудиосигнала (102), и ra,b обозначает дополнительную информацию (114), основанную на b-ом весовом коэффициенте (142; 142’) и х-й части аудиосигнала (102).
13. Способ (800) кодирования аудиосигнала, причем способ содержит:
анализ (802) аудиосигнала (102) для определения коэффициентов (112) предсказания анализа из аудиосигнала (102);
получение (804) преобразованных коэффициентов (122; 122’) предсказания из коэффициентов (112) предсказания анализа;
сохранение (806) множества значений (162; a-d) коррекции;
объединение (808) преобразованных коэффициентов (122; 122’) предсказания и множества значений (162; a-d) коррекции для получения скорректированных весовых коэффициентов (152; 152’), содержащее применение полинома на основе формы
w=a+bx+cх2,
где w обозначает полученный скорректированный весовой коэффициент, х обозначает спектральный весовой коэффициент, и где а, b и c обозначают значения коррекции;
квантование (812) преобразованных коэффициентов (122; 122’) предсказания с использованием скорректированных весовых коэффициентов (152; 152’) для получения квантованного представления (172) преобразованных коэффициентов (122; 122’) предсказания; и
формирование (814) выходного сигнала (182) на основе представления (172) преобразованных коэффициентов (122) предсказания и на основе аудиосигнала (102).
14. Цифровой носитель хранения данных, содержащий компьютерную программу, имеющую программный код для выполнения, при исполнении на компьютере, способа согласно одному из пп. 10-12.
15. Цифровой носитель хранения данных, содержащий компьютерную программу, имеющую программный код для выполнения, при исполнении на компьютере, способа согласно п. 13.
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ОБЕСПЕЧЕНИЯ НАБОРА ПРОСТРАНСТВЕННЫХ УКАЗАТЕЛЕЙ НА ОСНОВЕ СИГНАЛА МИКРОФОНА И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ ДВУХКАНАЛЬНОГО АУДИОСИГНАЛА И НАБОРА ПРОСТРАНСТВЕННЫХ УКАЗАТЕЛЕЙ | 2009 |
|
RU2493617C2 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ, УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ | 2007 |
|
RU2464650C2 |
| НИЗКОСКОРОСТНАЯ АУДИОКОДИРУЮЩАЯ/ДЕКОДИРУЮЩАЯ СХЕМА С ОБЩЕЙ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКОЙ | 2009 |
|
RU2483365C2 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |

