ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее раскрытие, в общем, направлено на кодирование содержимого экрана.
УРОВЕНЬ ТЕХНИКИ
[0002] Кодирование содержимого экрана бросает новые вызовы технологии сжатия видеосигнала из-за его характеристик четкого сигнала по сравнению с традиционными естественными видеосигналами. По всей видимости, существует несколько обещающих способов усовершенствованного кодирования содержимого экрана, например, псевдо-сравнение строк, кодирование цветовой палитры и внутренняя компенсация движения или внутреннее копирование блоков.
[0003] Среди этих способов, псевдо-сравнение строк показывает наибольший положительный эффект для кодирования без потерь, но со значительными непроизводительными издержками сложности и трудностями в режиме кодирования с потерями. Кодирование цветовой палитры разработано для содержимого экрана на том предположении, что содержимое, захваченное не камерой, как правило, содержит несколько ограниченных четких цветов, в отличие от непрерывного цветового тона в естественных видеосигналах. Даже хотя способы псевдо-сравнения строк и кодирования цветовой палитры показали огромный потенциал, внутренняя компенсация движения или внутреннее копирование блоков были приняты для версии 4 рабочего проекта (WD) и эталонного программного обеспечения разрабатываемого в настоящее время расширения (HEVC RExt) диапазона HEVC для кодирования содержимого экрана. Основная причина этому - тот факт, что подход на основе оценки и компенсации движения был широко изучен на протяжении десятилетий, а также то, что его идея и практическая реализация достаточно просты (особенно в технических средствах).
[0004] Однако, производительность кодирования на основе внутреннего копирования блоков ограничена вследствие его разделений на блоки фиксированной структуры. С другой стороны, выполнение сравнения блоков, похожее на оценку движения во внутреннем изображении, также представляет для устройства кодирования значительную сложность для доступа как к вычислительным ресурсам, так и к памяти.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Настоящее раскрытие направлено на решение для усовершенствованного кодирования содержимого экрана.
[0006] В одном варианте осуществления, способ кодирования содержимого экрана в поток двоичных данных выбирает таблицу цветовой палитры для блока (CU) кодирования содержимого экрана. Таблицу цветовой палитры создают для CU, и таблицу цветовой палитры создают для соседнего CU. Создается карта цветовых индексов, имеющая индексы для блока (CU) кодирования содержимого экрана с использованием выбранной таблицы цветовой палитры. Выбранную таблицу цветовой палитры и карту цветовых индексов кодируют/сжимают для каждого из множества CU в потоке двоичных данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Для более полного понимания настоящего раскрытия и его преимуществ, теперь сделана ссылка на последующее описание, рассмотренное совместно с сопровождающими чертежами, причем числа обозначают одинаковые объекты, на которых:
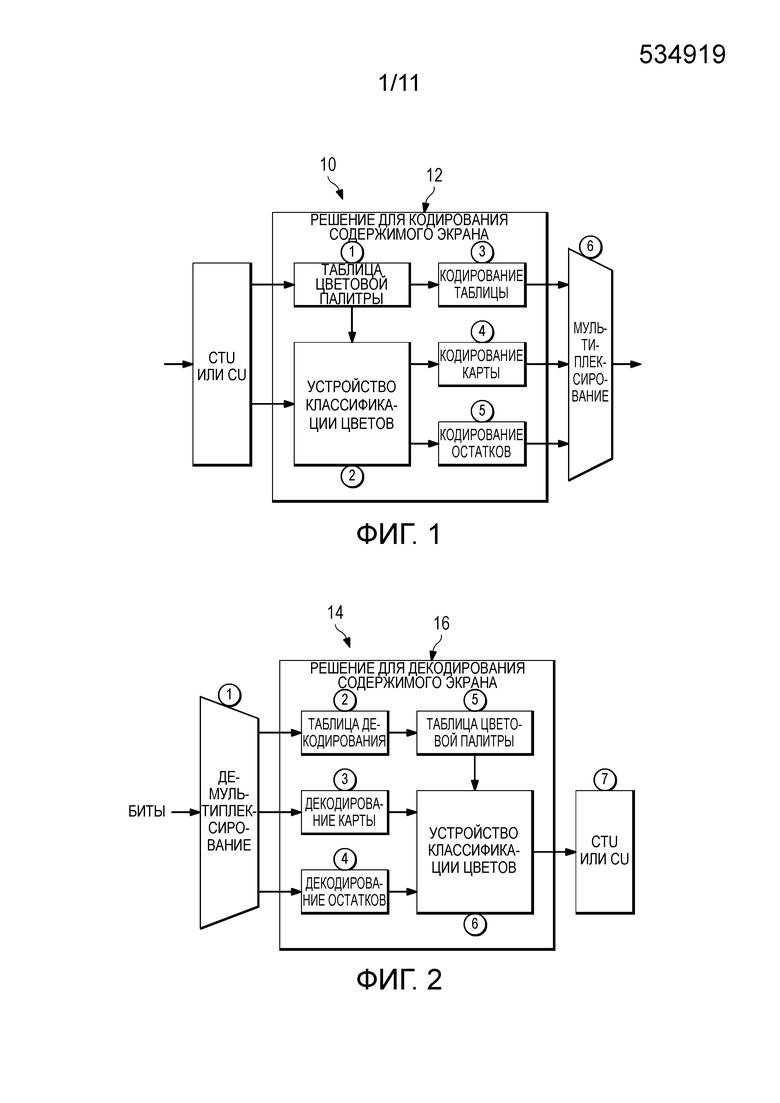
[0008] Фиг. 1 изображает решение для кодирования содержимого экрана с использованием таблицы цветовой палитры и режима карты индексов или режима палитры, в соответствии с одним вариантом осуществления настоящего раскрытия;
[0009] Фиг. 2 изображает решение для декодирования содержимого экрана для таблицы цветовой палитры и режима карты индексов или режима палитры;
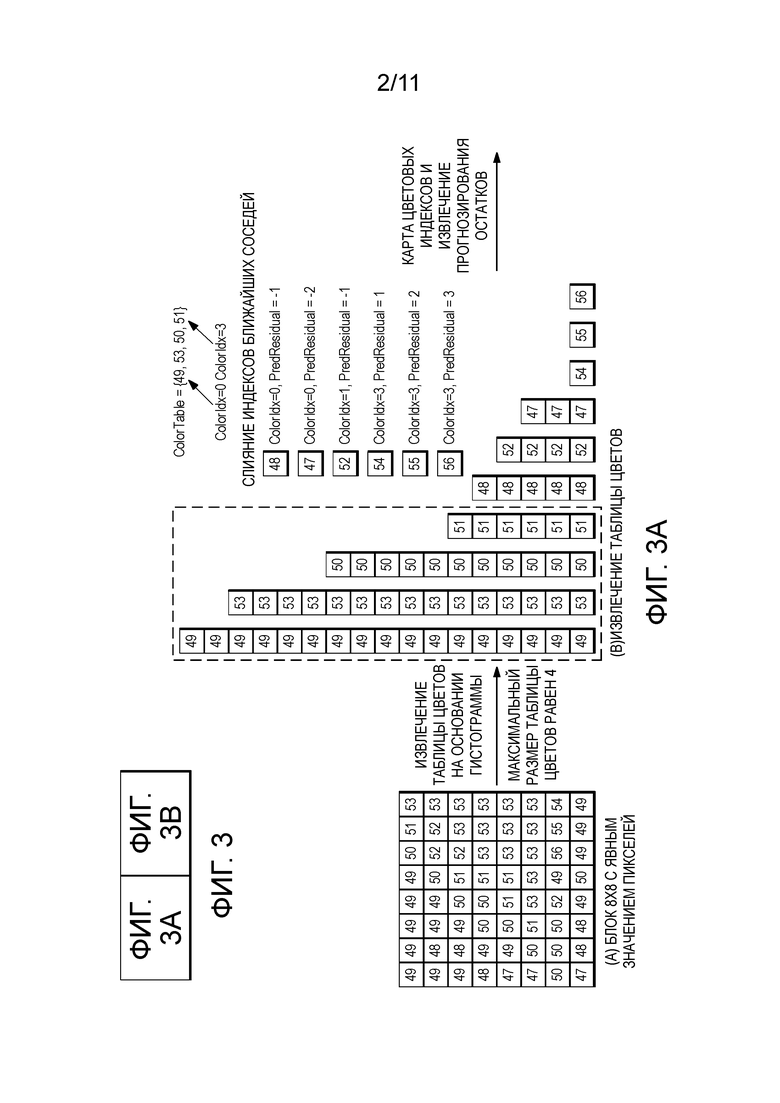
[0010] Фиг. 3 изображает способ или последовательность операций решения для содержимого экрана для этой таблицы цветовой палитры и режима карты индексов или режима палитры CU;
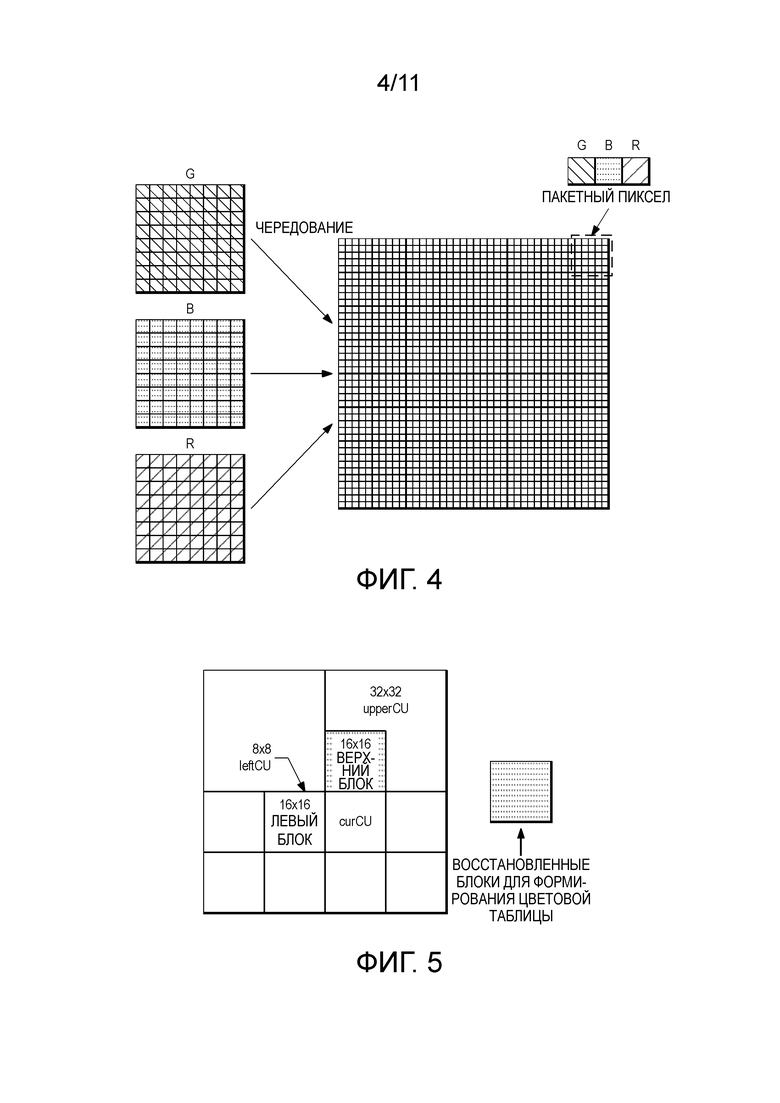
[0011] Фиг. 4 изображает традиционные зеленый (G), синий (B), красный (R) в плоском режиме (слева) до пакетного режима (справа);
[0012] Фиг. 5 изображает повторное формирование таблицы цветовой палитры с использованием соседних восстановленных блоков;
[0013] Фиг. 6 изображает карту индексов, проанализированную из практического содержимого экрана;
[0014] Фиг. 7 изображает отрезок сегмента для 1D поиска после горизонтального сканирования;
[0015] Фиг. 8 изображает модуль U-PIXEL;
[0016] Фиг. 9 изображает модуль U_ROW;
[0017] Фиг. 10 изображает модуль U_CMP;
[0018] Фиг. 11 изображает модуль U_COL;
[0019] Фиг. 12 изображает модуль U_2D_BLOCK;
[0020] Фиг. 13 является иллюстрацией горизонтального и вертикального сканирования для обработки карты индексов для примера CU;
[0021] Фиг. 14А является иллюстрацией формата 4:2:0 выборки цветности;
[0022] Фиг. 14А является иллюстрацией формата 4:4:4 выборки цветности;
[0023] Фиг. 15 изображает интерполяцию между 4:2:0 и 4:4:4;
[0024] Фиг. 16 изображает обработку карты индексов с верхним/левым линейным буфером;
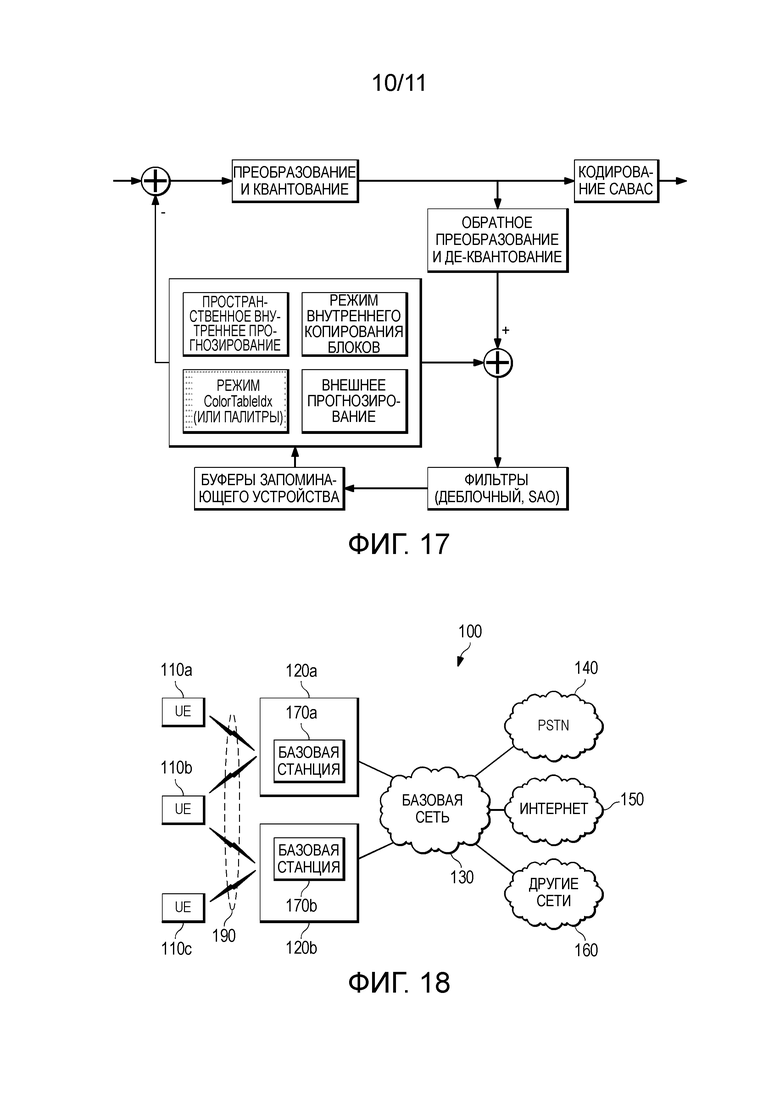
[0025] Фиг. 17 изображает устройство и способы/потоки, включенные в текущий HEVC;
[0026] Фиг. 18 изображает один пример системы связи; и
[0027] Фиг. 19А и Фиг. 19В изображают примеры устройств, которые могут реализовывать способы и принципы, в соответствии с настоящим раскрытием.
ПОДРОБНОЕ ОПИСАНИЕ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[0028] В настоящем раскрытии описано решение для усовершенствованного кодирования содержимого экрана, которое превосходит по производительности расширение диапазона высокоэффективного кодирования (HEVC) видеосигнала (как, например, HEVC версия 2 или HEVC RExt). Это решение включает в себя несколько алгоритмов, которые предназначены конкретно для кодирования содержимого экрана. Эти алгоритмы включают в себя пиксельное представление с использованием цветовой палитры или цветовой таблицы, в настоящей заявке называемые как таблица цветовой палитры, сжатие цветовой палитры, сжатие карты цветовых индексов, поиск строки и остаточное сжатие. Эта технология разработана, унифицирована и может быть интегрирована с расширением (RExt) диапазона HEVC и будущими расширениями HEVC для поддержки эффективного кодирования содержимого экрана. Однако, эту технологию можно реализовать с любыми существующими стандартами видеосигнала. Для простоты, HEVC RExt используется в качестве примера в последующем описании, и программное обеспечение HEVC RExt используется для описания и демонстрации эффективности сжатия. Это решение интегрировано в качестве дополнительного режима с помощью использования таблицы цветовой палитры и карты индексов, определенного в настоящей заявке как режим цветовой палитры, в HEVC для демонстрации производительности.
[0029] Идея и описание настоящего раскрытия изображены на чертежах. Фиг. 1 показывает устройство 10 кодирования, имеющее устройство 12 обработки, включающее в себя запоминающее устройство, и Фиг. 2 показывает устройство 14 декодирования, имеющее устройство 16 обработки и запоминающее устройство, вместе изображающие вариант осуществления решения для кодирования и декодирования для режима цветовой палитры, соответственно, в соответствии с настоящим раскрытием. Как изображено, устройство 10 кодирования и устройство 14 декодирования каждое содержат устройство обработки и запоминающее устройство и формируют решение для кодека. Решение для кодека включает в себя устройство 12 обработки устройства 10 кодирования, выполняющее новые алгоритмы или способы, включающие в себя Способ 1, создающий таблицы цветовой палитры, Способ 2, классифицирующий цвета или значения пикселей с использованием ранее извлеченной таблицы цветовой палитры, соответствующей цветовым индексам, Способ 3, кодирующий таблицу цветовой палитры, Способ 4, кодирующий карту цветовых индексов, Способ 5, кодирующий остатки, и Способ 6, записывающий новые синтаксические элементы в сжатый поток двоичных данных. Устройство 16 обработки устройства 14 декодирования выполняет новые алгоритмы или способы, включающие в себя обратные этапы. Фиг. 3 обеспечивает способ или последовательность операций решения для содержимого экрана в соответствии с настоящим раскрытием.
[0030] В основном, способ высокоэффективного сжатия (CPC) цветовой палитры выполняют в отношении каждого блока (CU) кодирования. Блок кодирования является базовым рабочим блоком (единицей) в HEVC и HEVC RExt, который является квадратным блоком пикселей, состоящих из трех компонентов (то есть, RGB, или YUV, или XYZ).
[0031] На каждом уровне CU способ CPC включает в себя два главных этапа. Сперва устройство 12 обработки извлекает или формирует таблицу цветовой палитры на первом этапе. Эту таблицу упорядочивают в соответствии с гистограммой (то есть, частотой появления каждого значения цвета) или ее актуальной интенсивностью цвета, или любым произвольным способом, чтобы увеличить эффективность следующего способа кодирования. На основании извлеченной таблицы цветовой палитры, каждый пиксель в исходном CU преобразуют в его цветовой индекс внутри таблицы цветовой палитры. Вклад настоящего раскрытия заключается в технологии эффективного кодирования, например, с помощью использования сжатия, таблицы цветовой палитры и карты цветовых индексов каждого CU в поток двоичных данных. На стороне приемника устройство 16 обработки анализирует сжатый поток двоичных данных для восстановления, для каждого CU, полной таблицы цветовой палитры и карты цветовых индексов, и затем дополнительного извлечения значения пикселя в каждом положении путем комбинирования цветового индекса и таблицы цветовой палитры.
[0032] В качестве иллюстративного примера настоящего раскрытия, возьмем CU с NxN пикселями (N=8, 16, 32, 64 для совместимости с HEVC). CU, как правило, содержит три компонента насыщенности цвета (цветности) (то есть, G, B, R или Y, Cb, Cr, или X, Y, Z) в различном соотношении выборок (то есть, 4:4:4, 4:2:2, 4:2:0). Для простоты, в раскрытии изображены последовательности 4:4:4. Для последовательностей 4:2:2 и 4:2:0 видеосигналов, повышающую выборку цветности можно применить для получения последовательностей 4:4:4, или каждый компонент цвета можно обработать независимо. Затем можно применить ту же процедуру, описанную в настоящем раскрытии. Для 4:0:0 монохромных видеосигналов это можно интерпретировать как отдельную плоскость 4:4:4 без двух других плоскостей. Все способы для 4:4:4 можно применить напрямую.
Пакетный или плоский
[0033] Этот способ изображен для блока CTU или CU на Фиг. 1. Сперва определяют флаг, называемый enable_packed_component_flag, для каждого CU для указания того, обработан ли текущий CU с использованием пакетного или традиционного плоского режима (то есть, компоненты G, B, R или Y, U, V обрабатывают независимо). Фиг. 4 изображает традиционные G, B, R в плоском режиме (слева) до пакетного режима (справа). YUV или другой формат цвета можно обработать тем же способом, что и изображенный для содержимого RGB.
[0034] Оба пакетный режим и плоский режим имеют свои собственные преимущества и недостатки. Например, плоский режим поддерживает параллельную обработку компонента цвета для G/B/R или Y/U/V. Однако, он может страдать от низкой эффективности кодирования. Пакетный режим может иметь общую информацию о заголовке (как, например, таблица цветовой палитры и карта индексов в настоящем раскрытии) для этого CU среди различных цветовых компонентов. Однако, он может нарушить параллелизм. Легким способом решения о том, следует ли кодировать текущий CU пакетным способом, является измерение издержки скорость-искажение (R-D). Флаг enable_packed_component_flag используют для явного сигнализирования режима кодирования устройству декодирования.
[0035] Дополнительно, для определения enable_packed_component_flag на уровне CU для обработки низкого уровня, его можно дублировать в заголовке сектора или даже уровня последовательности (например, установка параметра последовательности или установка параметра изображения), чтобы позволить обработку уровня сектора или уровня последовательности, в зависимости от конкретного требования приложения.
Извлечение таблицы цветовой палитры и карты индексов
[0036] Как изображено на Фиг. 1, для способов 1 и 3, для каждого CU, положения пикселей располагают в поперечном направлении и извлекают таблицу цветовой палитры и карту индексов для последующей обработки. Каждый отдельный цвет упорядочивают в таблице цветовой палитры, в зависимости либо от его гистограммы (то есть, частоты появления), либо его интенсивности, либо любого случайного способа, чтобы увеличить эффективность следующего способа кодирования. Например, если способ кодирования использует способ дифференциальной импульсно-кодовой модуляции (DPCM) для кодирования разницы между смежными пикселями, то оптимальный результат кодирования можно получить, если смежным пикселям назначить смежный цветовой индекс в таблице цветовой палитры.
[0037] После получения таблицы цветовой палитры каждый пиксель отображают для соответствующего цветового индекса, чтобы сформировать карту индексов текущего CU. Обработка карты индексов описана в последующем разделе.
[0038] Для традиционного плоского CU каждый компонент цвета или насыщенности цвета может иметь свою индивидуальную таблицу цветовой палитры, например, colorTable_Y, colorTable_U, colorTable_V или colorTable_R, colorTable_G, colorTable_B, представленные здесь для примера. Между тем, можно извлечь таблицу цветовой палитры для главного компонента, например, Y в YUV или G в GBR, которая является общей для всех компонентов. Обычно, из-за такой общей таблицы, другие компоненты цвета, отличные от Y или G, будут иметь некоторое несоответствие по отношению к своим исходным цветам пикселей по сравнению с теми, которые у них общие в таблице цветовой палитры. Тогда применяют механизм обработки остатков (например, способы кодирования коэффициентов HEVC), чтобы кодировать эти несовпадающие остатки. С другой стороны, для пакетного CU, единственная таблица цветовой палитры является общей для всех компонентов.
[0039] Псевдо-код обеспечен для примера извлечения таблицы цветовой палитры и карты индексов, как указано ниже:




Обработка таблицы цветовой палитры
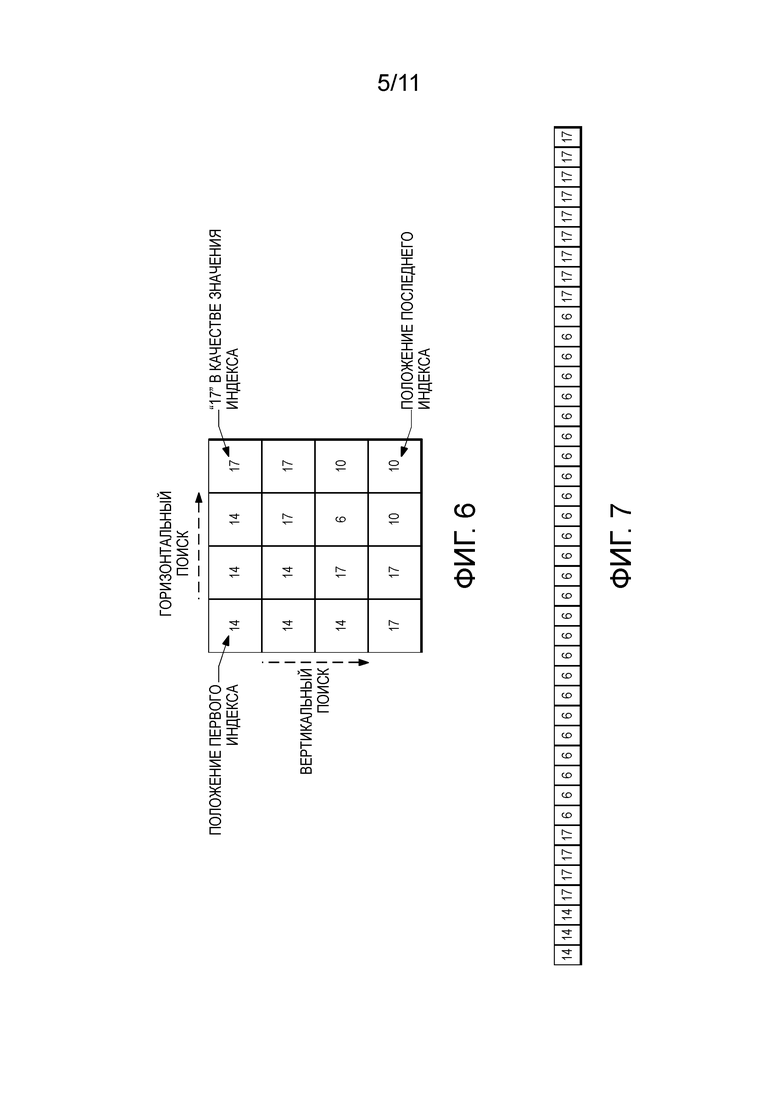
[0040] Для Обработки 1 на Фиг. 1 обработка таблицы цветовой палитры вовлекает обработку устройством 12 обработки размера таблицы цветовой палитры (то есть, общее число отдельных цветов) и каждого цвета. Большинство битов потребляются кодированием каждого цвета в таблице цветовой палитры. Следовательно, сделан фокус на кодирование цвета (или кодирование каждого входа в таблице цветовой палитры).
[0041] Самый прямой способ кодировать цвета в таблице цветовой палитры - это использование алгоритма стиля импульсно-кодовой модуляции (PCM), где каждый цвет кодируют независимо. Альтернативно, можно применить ближайшее прогнозирование для последующего цвета, и затем дельту прогнозирования можно закодировать вместо интенсивности цвета по умолчанию, что является стилем DPCM (дифференциальная PCM). Оба способа можно позже статистически закодировать с использованием модели равных вероятностей или модели адаптивных контекстов, в зависимости от оптимального соотношения между издержками сложности и эффективностью кодирования.
[0042] Здесь раскрыта другая усовершенствованная схема, называемая Слияние (merge) соседней таблицы цветовой палитры, где color_table_merge_flag определяют для указания того, использует ли текущий CU таблицу цветовой палитры из своего левого или верхнего CU. Если нет, то текущий CU будет передавать явно сигналы таблицы цветовой палитры. Для способа слияния другой color_table_merge_direction указывает направление слияния либо из верхнего или из левого CU. Конечно, кандидатов может быть больше, чем текущий верхний или левый CU, например, верхний левый, верхний правый и так далее. Однако, верхний и левый CU используют в настоящем раскрытии для представления примера идеи. Для любого из них, каждый пиксель сравнивают с записями в существующей таблице цветовой палитры и назначают ему индекс, имеющий наименьшую разницу прогнозирования (то есть, пиксель вычитает ближайший цвет в таблице цветовой палитры) по deriveIdxMap(). Для случая, когда разница прогнозирования ненулевая, все эти остатки кодируют с использованием механизма обработки остатков HEVC RExt. Необходимо отметить, что принять решение о том, использовать или нет способ слияния, можно с помощью издержки R-D.
[0043] Существует несколько способов формирования соседних таблиц цветовой палитры, которые используют в способе слияния при кодировании текущего CU. В зависимости от его реализации, один из них требует обновления как в устройстве кодирования, так и в устройстве декодирования, а другой является способом только на стороне устройства кодирования.
[0044] Обновление как в устройстве кодирования, так и в устройстве декодирования: в данном способе, таблицы цветовой палитры соседних CU формируют после доступных восстановленных пикселей. Для каждого CU, восстановления извлекают для его соседнего CU в одном и том же размере и одной и той же глубине (предположим, что схожесть цвета будет выше в таком случае). Например, если текущий CU равен 16х16 с глубиной=2, то, независимо от разделения его соседних CU (например, 8х8 с глубиной=3 для левого CU и 32х32 с глубиной=1 для верхнего CU), смещение (=16) пикселей будет расположено от источника текущего CU слева для обработки левого блока 16х16 и сверху от правого блока 16х16, как изображено на Фиг. 5. Необходимо отметить, что как устройство кодирования, так и устройство декодирования должны поддерживать этот способ.
[0045] Ограниченный способ только на стороне устройства кодирования: для этого способа, способ слияния происходит, когда текущий CU имеет одинаковый размер и глубину, что и его верхний и/или левый CU. Для извлечения карты цветовых индексов текущего CU для последующих операций используют таблицы цветовой палитры доступных соседей. Например, для текущего CU 16х16, если его соседние CU, то есть, расположенные либо сверху, либо слева, кодируют с использованием таблицы цветовой палитры и способа индекса, то его таблицу цветовой палитры используют для текущего CU напрямую для извлечения издержки R-D. Эту издержку слияния сравнивают с случаем, когда текущий CU извлекает свою таблицу цветовой палитры явно (а также другие традиционные режимы, существующие в HEVC или HEVC RExt). Тот, который ведет к наименьшей издержке R-D, выбирают в качестве финального режима для записи в выходной поток двоичных данных. Как видно, только устройство кодирования требуется для эксперимента/симуляции различных потенциальных режимов. На стороне устройства декодирования, color_table_merge_flag и color_table_merge_direction приходят к решению слияния и направлению слияния без требования дополнительной рабочей нагрузки обработки.
Обработка карты цветовых индексов
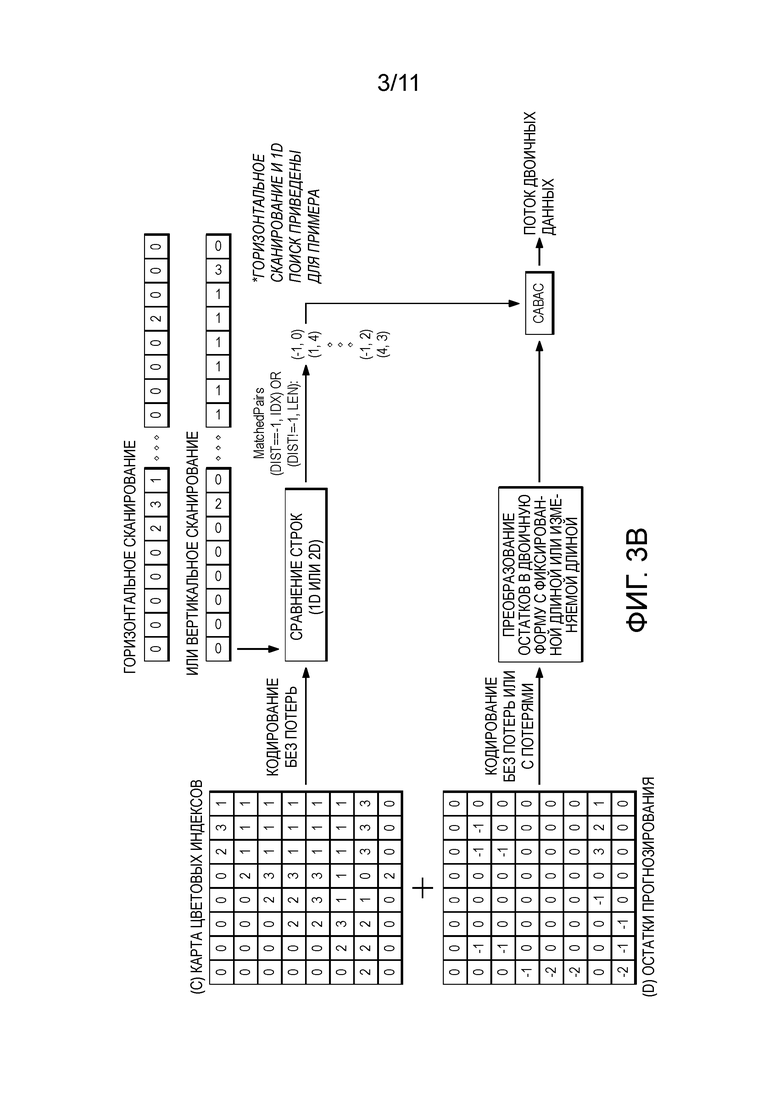
[0046] Для Способа 3 на Фиг. 1, для кодирования карты цветовых индексов изучено несколько решений, например, режим RUN, RUN и COPY_ABOVE, и адаптивное прогнозирование соседнего индекса. В настоящем раскрытии раскрыт подход 1D сравнения строк и его 2D версия для кодирования карты индексов. В каждом положении он находит свою совпадающую точку и записывает совпадающее расстояние и длину для 1D сравнения строк или ширину/высоту для 2D сравнения строк. Для несовпадающего положения напрямую кодируют его интенсивность индекса или значение дельты между его интенсивностью индекса и интенсивностью прогнозируемого индекса.
[0047] В настоящей заявке раскрыт способ прямого 1D поиска по карте цветовых индексов. Со ссылкой на Фиг. 6, карту индексов анализируют из реального содержимого экрана. Фиг. 7 показывает отрезок сегмента после 1D поиска (то есть, только начало этой карты индексов).
[0048] Сверху этого 1D вектора цветового индекса применяют сравнение строк. Пример такого 1D сравнения строк представлен ниже. Для первого положения каждой карты индексов, например, 14, как изображено на Фиг. 7, так как в буфере еще нет эталона, это первый индекс считают «несовпадающей парой», где ему задают -1 и 1 для его соответствующих расстояния и длины, обозначенных как (dist, len)=(-1, 1). Для второго индекса, снова другого «14», первый индекс кодируют как эталон, следовательно dist=1. Так как в третьем положении есть другой «14», то длина равна 2, то есть len=2 (при условии, что каждый следующий индекс может сразу служить эталоном для последующего индекса). При перемещении к четвертому положению, встречаем «17», который до этого не было видно. Следовательно, его кодируют опять как несовпадающую пару, то есть (dist, len)=(-1, 1). Для несовпадающей пары кодируют флаг (например, ʺdist == -1ʺ) и за ним следует реальное значение индекса (как первое появившееся «14», «17», «6» и так далее). С другой стороны, для совпадающих пар флаг по-прежнему кодируют (например, ʺdist!= -1ʺ), и за ним следует длина совпадающей строки.
[0049] Здесь представлен итог для процедуры кодирования с использованием примера индекса, изображенного на Фиг. 7.
dist=-1, len=1, idx=14 (несовпадающая)
dist= 1, len=2 (совпадающая)
dist=-1, len=1, idx=17 (несовпадающая)
dist= 1, len=3 (совпадающая)
dist=-1, len=1, idx= 6 (несовпадающая)
dist= 1, len=25 (совпадающая)
dist= 30, len=4 (совпадающая) /*для «17», который появлялся ранее*/
....
[0050] Псевдо-код дан для этого извлечения совпадающей пары, то есть,



[0051] Следующие этапы выполняют, когда используют вариант 2D поиска:
1. Идентифицировать положение текущего пикселя и эталонного пикселя в качестве начальной точки,
2. Применить горизонтальное 1D сравнение строк к правому направлению текущего пикселя и эталонного пикселя. Максимальная длина поиска ограничена концом текущего горизонтального ряда. Записать максимальную длину поиска как right_width
3. Применить горизонтальное 1D сравнение строк к левому направлению текущего пикселя и эталонного пикселя. Максимальная длина поиска ограничена началом текущего горизонтального ряда. Записать максимальную длину поиска как left_width
4. Выполнить то же 1D сравнение строк в следующем ряду, используя пикселы, которые ниже текущего пикселя и эталонного пикселя, в качестве текущего пикселя и эталонного пикселя
5. Прекратить, когда right_width == left_width == 0.
6. Теперь для каждого height[n]={1, 2, 3...}, существует соответствующая матрица width[n] {{left_width[1], right_width[1]}, {left_width[2], right_width[2]}, {left_width[3], right_width[3]}...}
7. Определить новую матрицу min_width {{lwidth[1], rwidth[1]}, {lwidth[2], rwidth[2]}, {lwidth[3], rwidth[3]}...} для каждого height[n], где lwidth[n]=min(left_width[1:n-1]), rwidth[n]=min(right_width[1:n-1])
8. Также определяют матрицу размеров {size[1], size[2], size[3]...}, где size[n]=height[n] x (lwidth[n]+hwidth[n])
9. Предположим, что size[n] имеет максимальное значение в матрице размеров, тогда ширину и высоту 2D сравнения строк выбирают с использованием соответствующих {lwidth[n], rwidth[n], height[n]}
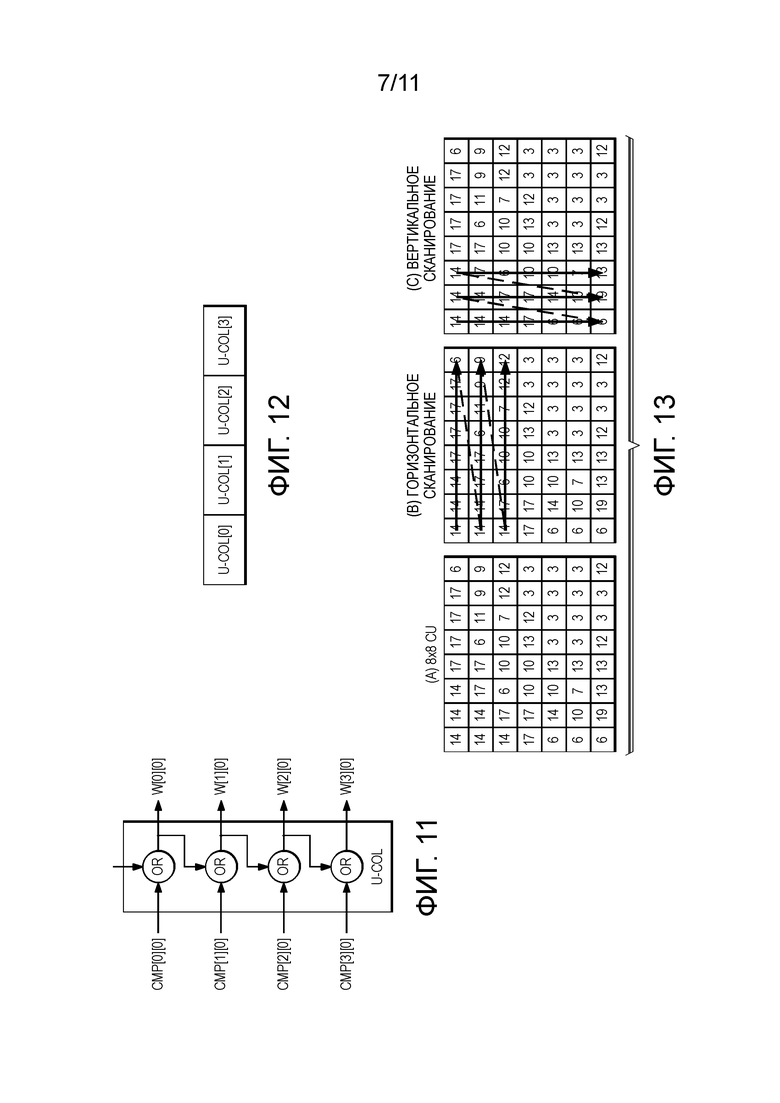
[0052] Одним способом оптимизировать скорость 1D или 2D поиска является использование промежуточного хэша. 4-пиксельная структура промежуточного хэша описана в настоящем раскрытии. Промежуточный хэш вычисляют для каждого пикселя в горизонтальном направлении для формирования матрицы running_hash_h[] горизонтальных хэшей. Другой промежуточный хэш вычисляют сверху running_hash_h[] для формирования 2D матрицы running_hash_hv[] хэшей. Каждое сравнение значения в этой 2D матрице хэшей представляет собой блочное сравнение 4х4. Для выполнения 2D сравнения необходимо найти так много, насколько возможно, блочных сравнений 4х4 до выполнения сравнения пикселей с их соседями. Так как сравнение пикселей ограничено 1-3 пикселями, то скорость поиска можно значительно увеличить.
[0053] Из вышеуказанного описания, совпадающие ширины каждого ряда отличаются друг от друга, таким образом, каждый ряд должен быть обработан отдельно. Для достижения эффективности и низкой сложности раскрыт алгоритм на основании блоков, который можно использовать как в реализации технических средств, так и программного обеспечения. Сильно схожий со стандартной оценкой движения, этот алгоритм обрабатывает один прямоугольный блок за раз.
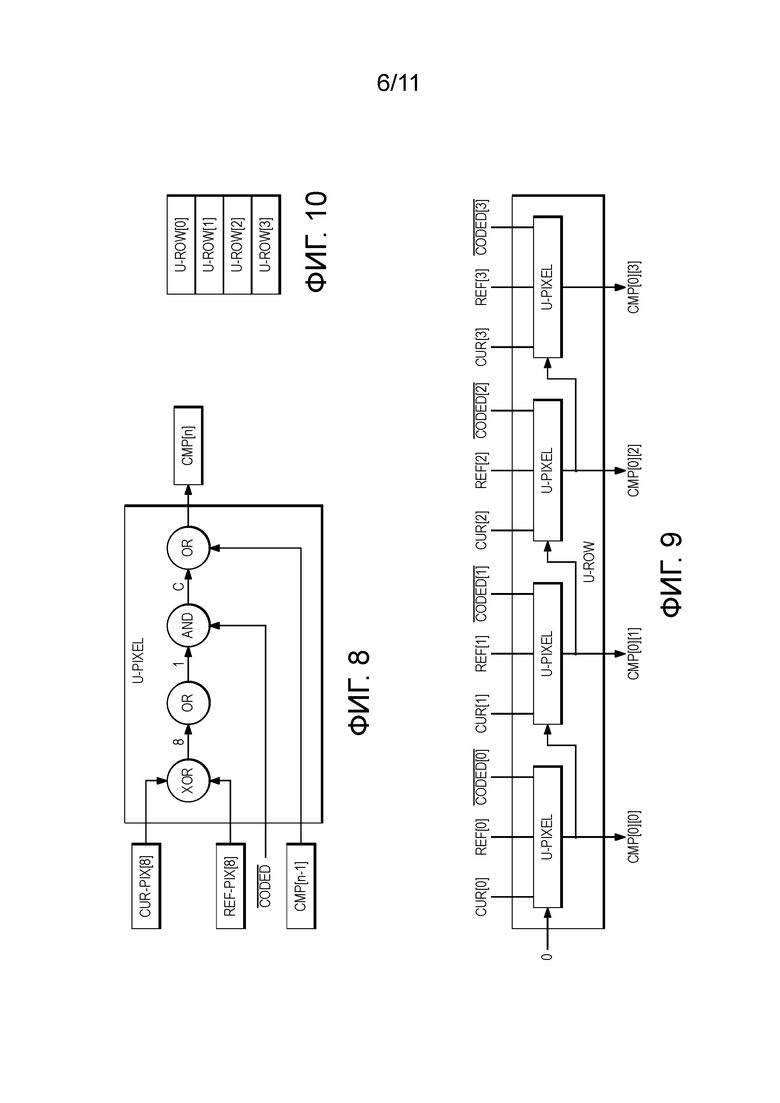
[0054] Возьмем для примера блок 4х4. Базовый блок в такой структуре называют U_PIXEL, как изображено на Фиг. 8. Закодированный сигнал является флагом, который указывает, если эталонный пиксель уже закодирован из предыдущей операции сравнения строк. Опционально, сигнал Cmp[n-1] ввода можно принудительно приравнять к «0», что позволяет удаление последней схемы «ИЛИ» («OR») из модуля U_PIXEL.
[0055] Первый этап заключается в обработке каждого ряда параллельно. Каждый пиксель в одном ряду прямоугольника назначают одному блоку U_PIXEL; этот блок обработки называют U_ROW. Пример блока обработки для первого ряда показан на Фиг. 9.
[0056] 4 блока U_ROW необходимо для обработки этого блока 4х4, как изображено на Фиг. 10. Его выводом является решетка cmp[4][4].
[0057] Следующий этап заключается в обработке каждого столбца решетки cmp параллельно. Каждый cmp в столбце решетки cmp обрабатывают с помощью блока U_COL обработки, как изображено на Фиг. 11.
[0058] 4 блока U_COL необходимо для обработки этого блока 4х4. Его выводом является решетка rw[4][4], как изображено на Фиг. 12.
[0059] Затем считают число нулей в каждом ряду rw[n][0-3], и 4 результата записывают в решетку r_width[n]. Необходимо отметить, что r_width[n] равен r_width[n] на этапе №7. l_width[n] формируют тем же способом. Решетку min_width на этапе №7 можно получить как {{l_width[1], r_width[1]}, { l_width[2], r_width[2]}, { l_width[3], r_width[3]}...}
[0060] Эту архитектуру технических средств можно модифицировать для соответствия модели параллельной обработки любого современного CPU/DSP/GPU. Упрощенный псевдо-код для быстрой реализации программного обеспечения перечислен ниже.



[0061] В каждом цикле нет зависимости от данных, так что традиционный способ параллельной обработки программного обеспечения, например, разворачивание цикла, MMX/SSE, можно применить для увеличения скорости выполнения.
[0062] Этот способ также можно применить к 1D поиску, если число рядов ограничено до одного. Упрощенный псевдо-код для быстрого осуществления программного обеспечения фиксированной длины на основании 1D поиска перечислен ниже.


[0063] После того, как 1D сравнение и 2D сравнение завершено, max (ld length, 2d (width x height)) выбирают в качестве победителя. Если lwidth 2D сравнения не равна нулю, то длину предыдущего 1D сравнения (length=length - lwidth) необходимо отрегулировать во избежание наложения между предыдущим 1D сравнением и текущим 2D сравнением. Если длина предыдущего 1D сравнения становится нулевой после регулировки, то ее удаляют из списка сравнения.
[0064] Следующее начальное положение вычисляют с использованием current_location+length, если предыдущее сравнение является 1D сравнением, или current_location+(lwidth+rwidth), если предыдущее сравнение является 2D сравнением. Когда выполняют 1D сравнение, если любой пиксел, подлежащий сравнению, попадает в любой предыдущий участок 2D сравнения, где его положение уже покрывается 2D сравнением, то следующие пикселы сканируют до тех пор, пока не найдут положение пикселя, в котором он не закодирован с помощью предыдущего сравнения.
[0065] После получения этих совпадающих пар применяют механизм статистической обработки для преобразования этих символов в поток двоичных данных. В настоящей заявке для примера приведена идея использования режима контекста равных вероятностей. Режим усовершенствованного адаптивного контекста можно применить также для лучшей эффективности сжатия.




[0066] Изображена процедура кодирования для каждой совпадающей пары. Соответственно, способ декодирования для совпадающей пары заключается в следующем.



[0067] Необходимо отметить, что только пикселы в несовпадающем положении кодируют в поток двоичных данных. Чтобы получить более точную статистическую модель, надо использовать только эти пикселы и их соседей для извлечения таблицы цветовой палитры вместо использования всех пикселей в этом CU.
[0068] Для этих выводов индекса или дельты, они обычно содержат ограниченное число уникального значения при определенном режиме кодирования. Настоящее раскрытие представляет вторую таблицу цветов дельты для использования данного наблюдения. Эту таблицу цветов дельты можно построить после того, как все литерные данные получены в этом CU, ее можно явно сигнализировать в потоке двоичных данных. Альтернативно, ее можно построить адаптивно во время способа кодирования, так что таблицу не надо включать в поток двоичных данных. delta_color_table_adaptive_flag определяют для этого выбора.
[0069] Обеспечена другая усовершенствованная схема, названная Слияние [Merge] таблицы цветовой палитры соседней дельты. Для адаптивного формирования палитры дельты, устройство кодирования может использовать палитру дельты из верхнего или левого CU в качестве исходной начальной точки. Для неадаптивного формирования дельты устройство кодирования может использовать палитру дельты из верхнего или левого CU и сравнивать издержки RD между верхним, левым и текущим CU.
[0070] delta_color_table_merge_flag определяют для указания того, использует ли текущий CU таблицу цветовой палитры дельты из своего левого или верхнего CU. Текущий CU несет сигнал таблицы цветовой палитры дельты явно только тогда, когда delta_color_table_adaptive_flag==0 и delta_color_table_merge_flag==0 одновременно.
[0071] Для способа слияния, если delta_color_table_merge_flag установлен, то другой delta_color_table_merge_direction определяют для указания того, находится ли кандидат слияния либо в верхнем, либо в левом CU.
[0072] Далее изображен пример способа кодирования для адаптивного формирования палитры дельты. На стороне кодирования каждый раз, когда устройство декодирования получает литерные данные, оно формирует палитру дельты на основании обратных этапов.
10. Определить palette_table[] и palette_count[]
11. Установить palette_table(n)=n (n=0...255), альтернативно, можно использовать palette_count[] из верхнего или левого CU в качестве первоначального значения
12. Установить palette_table(n)=0 (n=0...255), альтернативно, можно использовать palette_count[] из верхнего или левого CU в качестве первоначального значения
13. Для любого значения cʹ дельты:
1) Расположить n так, что palette_table(n) == delta cʹ
2) Использовать n в качестве нового индекса cʹ дельты
3) ++palette_count(n)
4) Отсортировать palette_count[], так что он расположен в нисходящем порядке
5) Отсортировать palette_table[], соответственно
14. Вернуться на этап 1, пока все дельта cʹ в текущем LCU не будут обработаны
[0073] Для любого блока, который включает в себя как текст, так и графику, флаг маски используют для отделения участка текста от участка графики. Участок текста сжимают с помощью вышеописанного способа; участок графики сжимают с помощью другого способа сжатия.
[0074] Необходимо отметить, что так как значение любого пикселя, покрываемого флагом маски, закодировано с помощью слоя текста без потерь, то эти пикселы в участке графики могут быть «безразличными пикселями». Когда участок графики сжимают, любое случайное значение можно назначить безразличному пикселю, чтобы получить оптимальную эффективность сжатия.
[0075] Так как часть с потерями можно обработать с помощью извлечения таблиц цветовой палитры, то карту индексов надо сжать без потерь. Это позволяет эффективную обработку с использованием 1D или 2D сравнения строк. Для настоящего раскрытия, 1D или 2D сравнение строк ограничено в текущем LCU, но окно поиска можно расширить за пределы текущего LCU. Также необходимо отметить, что совпадающее расстояние можно закодировать с использованием пары вектора движения в горизонтальном и вертикальном направлениях, то есть, (MVy=matched_distance/cuWidth, MVy=matched_distance-cuWidth*MVy).
[0076] С учетом того, что изображение должно иметь различную ориентацию пространственных текстур в локальных положениях, 1D поиск может быть либо в горизонтальном, либо в вертикальном направлениях путем определения указателя color_idx_map_pred_direction. Оптимальное направление сканирования индекса можно сделать на основании издержки R-D. Фиг. 6 показывает направления сканирования, начиная с самого первого положения. Дополнительно изображен горизонтальный и вертикальный шаблон сканирования на Фиг. 9. Рассмотрим CU 8х8 в качестве примера. deriveMatchPairs() и связанные этапы статистического кодирования выполняют дважды для шаблона горизонтального и вертикального сканирования. Затем, выбирают финальное направление сканирования с наименьшей издержкой RD.
Улучшенное преобразование в двоичную форму
[0077] Как изображено на Фиг. 13, кодируют таблицу цветовой палитры и пару совпадающей информации для карты цветовых индексов. Их кодируют с использованием преобразования в двоичную форму фиксированной длины. Альтернативно, можно использовать преобразование в двоичную форму с изменяемой длиной.
[0078] Например, относительно кодирования таблицы цветовой палитры, таблица может иметь 8 различных цветовых значений. Следовательно, она содержит только 8 различных индексов в карте цветовых индексов. Вместо использования 3 фиксированных бинов для кодирования каждого значения индекса равно, только один бит можно использовать для представления фонового пикселя, например, 0. Затем, оставшиеся 7 значений пикселей используют кодовое слово фиксированной длины, например, 1000, 1001, 1010, 1011, 1100 и 1110, для кодирования цветового индекса. Это основано на том факте, что фоновый цвет может занимать наибольший процентиль, и, следовательно, специальное кодовое слово для него экономит общее число бинов. Этот сценарий происходит, в общем, для содержимого экрана. Рассмотрим CU 16х16, для преобразования в двоичную форму с 3 фиксированными бинами, что требует 3х16х16=768 бинов. Также, пусть индекс 0 будет фоновым цветом, занимающим 40%, в то время как другие цвета равно распределены. В таком случае, требуется только 2.8х16х16<768 бинов.
[0079] Для кодирования совпадающей пары максимальное значение можно использовать для ограничения его преобразования в двоичную форму, с учетом ограниченной реализации этого подхода внутри области текущего CU. Математически совпадающее расстояние и длина могут быть размером 64х64=4К в каждом случае. Однако, это не происходит совокупно. Для каждого совпадающего положения совпадающее расстояние ограничено расстоянием между текущим положением и самым первым положением в буфере эталонов (например, первое положение в текущем CU), например, L. Следовательно, максимальное число бинов для этого преобразования расстояния в двоичную форму равно log2(L)+1 (вместо фиксированной длины), и максимальное число бинов для преобразования длины в двоичную форму равно log2(cuSize-L)+1, где cuSize=cuWidth*cuHeight.
[0080] В дополнение к таблице цветовой палитры и карты индексов, остаточное кодирование можно значительно улучшить путем другого способа преобразования в двоичную форму. Для версии HEVC RExt и HEVC, коэффициент преобразования является преобразованием в двоичную форму с использованием кодов с изменяемой длиной с тем предположением, что остаточная величина должна быть меньше после прогнозирования, преобразования и квантования. Однако, после введения пропуска преобразования, особенно, для пропуска преобразования содержимого экрана с четким цветом, в общем, существует остаток с большим и случайным значением (не близкий к «1», «2», «0» относительно меньшего значения). Если используют преобразование в двоичную форму текущих коэффициентов HEVC, то это приводит к очень длинному кодовому слову. Альтернативно, использование преобразования в двоичную форму фиксированной длины экономит длину кода для остатка, производимого таблицей цветовой палитры и режимом кодирования индексов.
[0081] Адаптивная выборка цветности для смешанного содержимого
[0082] Вышеуказанное описание обеспечивает различные способы для высокоэффективного кодирования содержимого экрана с шаблоном HEVC/HEVC-RExt. На практике, дополнительно к чистому содержимому экрана (например, текст, графика) или чистому естественному видеосигналу, также существует содержимое, содержащее как материал экрана, так и захваченный камерой естественный видеосигнал, которое называют смешанное содержимое. В настоящий момент смешанное содержимое обрабатывают с помощью выборки 4:4:4. Однако, для встроенной части захваченного камерой естественного видеосигнала в таком смешанном содержимом выборки цветности 4:2:0 может быть достаточно для обеспечения воспринимаемого качества без потерь. Это происходит благодаря тому факту, что система человеческого зрения менее чувствительна к пространственным изменениям в компонентах цветности по сравнению с компонентами яркости. Следовательно, обычно выполняют подвыборку на стороне цветности (например, популярный формат 4:2:0 видеозаписи) для достижения заметного сокращения скорости передачи данных при одновременном сохранении того же восстановленного качества.
[0083] Настоящее раскрытие обеспечивает новый флаг (то есть, enable_chroma_subsampling), который определяют и передают в слое CU рекурсивно. Для каждого CU, устройство кодирования определяет, кодирует ли оно с использованием 4:2:0 или 4:4:4, в соответствии с издержкой скорость-искажение.
[0084] На Фиг. 14А и Фиг. 14В изображены форматы выборки цветности 4:2:0 и 4:4:4.
[0085] На стороне устройства кодирования, для каждого CU, предположим, что ввод - источник 4:4:4, изображенный выше, издержку скорость-искажение извлекают напрямую с использованием процедуры кодирования 4:4:4, где enable_chroma_subsampling=0 или ЛОЖЬ. Затем, способ подвыборки 4:4:4 производит выборку до 4:2:0 для извлечения его потребления битов. Восстановленный формат 4:2:0 подвергают обратной интерполяции до формата 4:4:4 для измерения искажения (с использованием SSE/SAD). Вместе с потреблением битов, издержку скорость-искажение извлекают при кодировании CU на пространстве 4:2:0 и его сравнении с издержкой при кодировании CU на 4:4:4. То кодирование, которое дает наименьшую издержку скорость-искажение, выбирают для конечного кодирования.
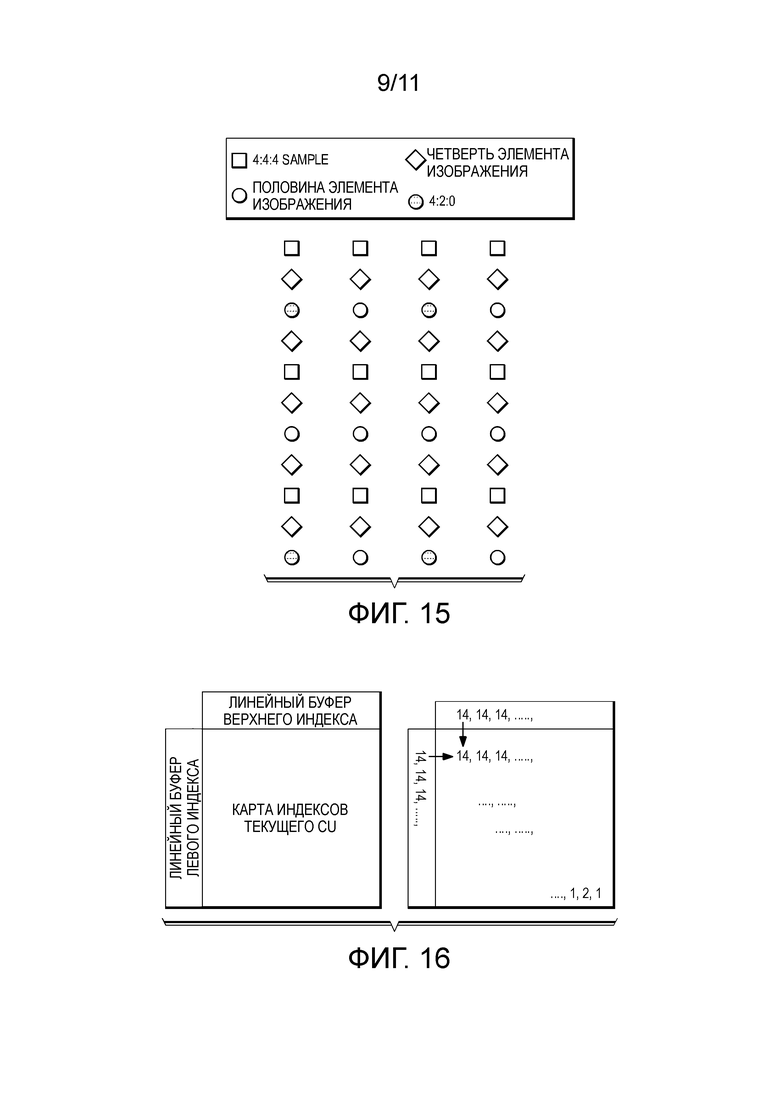
[0086] На Фиг. 15 изображен способ интерполяции от 4:4:4 к 4:2:0 и наоборот. Обычно этот способ преобразования формата выборки цвета видеосигнала требует большого числа фильтров интерполяции.
[0087] Для сокращения сложности реализации можно использовать фильтр интерполяции HEVC (то есть, DCT-IF). Как изображено на Фиг. 15, «квадратная коробка» представляет собой исходные выборки 4:4:4. От 4:4:4 до 4:2:0, пикселы («круг») половины элемента изображения интерполируют с использованием DCT-IF вертикально для компонентов цветности. Также изображены положения («ромб») четверти элемента изображения с целью иллюстрации. Серые затемненные «круги» выбраны для формирования выборок 4:2:0. Для интерполяции из 4:2:0 до 4:4:4 способ начинается с серых «кругов» в компонентах цветности, положения половины элемента изображения интерполируют горизонтально для получения всех «кругов», а затем «квадратную коробку» интерполируют с использованием DCT-IF вертикально. Все интерполированные «квадратные коробки» выбирают для формирования восстановленного источника 4:4:4.
[0088] Управление устройством кодирования
[0089] Как описано в предыдущих разделах, раскрыты флаги для управления обработкой низкого уровня. Например, enable_packed_component_flag используют для указания того, использует ли текущий CU свой пакетный формат или традиционный плоский формат для кодирования обработки. Использовать ли пакетный формат зависит от издержки R-D, вычисленной в устройстве кодирования. Для практической реализации устройства кодирования решение низкой сложности достигается путем анализа гистограммы CU и нахождения наилучшего порога для решения, как изображено на Фиг. 3.
[0090] Размер таблицы цветовой палитры имеет прямое влияние на сложность. maxColorNum вводят для управления оптимальным соотношением между сложностью и эффективностью кодирования. Наиболее прямой способ - это выбор такого, который ведет к наименьшей издержке R-D.
[0091] Направление кодирования карты индексов можно определить с помощью оптимизации R-D или использования локальной пространственной ориентации (например, оператор Собела на основании оценки направления).
[0092] Настоящее раскрытие ограничивает обработку внутри каждого CTU/CU. На практике, это ограничение можно ослабить. Например, для обработки карты цветовых индексов, можно использовать линейный буфер из его верхнего и левого CU, как изображено на Фиг. 16. При использовании верхнего и левого буфера, поиск можно расширить, чтобы дополнительно улучшить эффективность кодирования. С учетом того, что верхний/левый буфер формируют с использованием восстановленных пикселей из соседних CU, эти пикселы (а также их соответствующие индексы) доступны в качестве эталона до обработки карты индексов текущего CU. Например, после повторного упорядочивания, карта индексов текущего CU может быть 14, 14, 14,..., 1, 2, 1 (как 1D представление). Без эталона линейного буфера, первый «14» кодируют как несовпадающую пару. Однако, при соседнем линейном буфере, сравнение строк может начинаться с самого первого пикселя, как изображено ниже (горизонтальные и вертикальные шаблоны сканирования также изображены).
[0093] Синтаксис устройства декодирования
[0094] Последующую информацию можно использовать для описания устройства декодирования, изображенного на Фиг. 2. Синтаксис в настоящем раскрытии согласуется с проектом стандарта, рассматриваемым техническим комитетом HEVC RExt.
[0095] 7.3.5.8 Синтаксис блока кодирования:



[0096] Фиг. 17 изображает устройство и способы/потоки, включенные в текущий HEVC.
[0097] Вышеуказанные способы/потоки и устройства можно включить в беспроводную или проводную, или их комбинацию, сеть связи и реализовать в устройствах, например, описанные ниже, и на чертежах ниже.
[0098] Фиг. 18 изображает пример системы 100 связи, который использует передачу сигнала для поддержки усовершенствованных беспроводных приемников, в соответствии с настоящим раскрытием. В общем, система 100 позволяет множеству беспроводных пользователей передавать и принимать данные и другое содержимое. Система 100 может реализовывать один или несколько способов канального доступа, например, множественный доступ (CDMA) с кодовым разделением, множественный доступ (TDMA) с временным разделением, множественный доступ (FDMA) с частотным разделением, ортогональный FDMA (OFDMA) или FDMA с одной несущей (SC-FDMA).
[0099] В этом примере, система 100 связи включает в себя пользовательское оборудование (UE) 110а-110с, сети (RAN) 120а-120b радиодоступа, базовую сеть 130, коммутируемую телефонную сеть (PSTN) 140 общего пользования, интернет 150 и другие сети 160. Хотя на Фиг. 18 изображено конкретное число этих компонентов или элементов, любое число этих компонентов или элементов можно включить в систему 100.
[00100] UE 110а-110с выполнено с возможностью функционировать и/или связываться с системой 100. Например, UE 110а-110с выполнено с возможностью передавать и/или принимать беспроводные сигналы или проводные сигналы. Каждое UE 110а-110с представляет собой любое подходящее устройство конечного пользователя и может включать в себя такие устройства (или ссылаться на них), как пользовательское оборудование/устройство (UE), беспроводной блок (WTRU) передачи/приема, мобильная станция, фиксированный или мобильный абонентский блок, пейджер, сотовый телефон, персональный цифровой помощник (PDA), смартфон, портативный компьютер, компьютер, сенсорная панель, беспроводной датчик или устройство бытовой электроники.
[00101] RAN 120а-120b в данной заявке включают в себя базовые станции 170а-170b, соответственно. Каждая базовая станция 170а-170b выполнена с возможностью взаимодействовать по беспроводному интерфейсу с одним или несколькими UE 110а-110с, чтобы обеспечить доступ к базовой сети 130, PSTN 140, интернету 150 и/или другим сетям 160. Например, базовые станции 170а-170b могут включать в себя (или быть) одно или несколько из широко известных устройств, например, базовая приемопередающая станция (BTS), базовая станция (NodeB) нового поколения, улучшенная NodeB (eNodeB), главная NodeB, главная eNodeB, устройство управления сайтом, точка (AP) доступа, или беспроводной маршрутизатор, или сервер, роутер, переключатель, или другая сущность обработки с проводной или беспроводной сетью.
[00102] В осуществлении, изображенном на Фиг. 18, базовая станция 170а формирует часть RAN 120а, которая может включать в себя другие базовые станции, элементы и/или устройства. Также, базовая станция 170b формирует часть RAN 120b, которая может включать в себя другие базовые станции, элементы и/или устройства. Каждая базовая станция 170а-170b функционирует для передачи и/или приема беспроводных сигналов внутри конкретного географического региона или области, иногда называемой «сотой». В некоторых вариантах осуществления технологию многоканального ввода-многоканального вывода (MIMO) можно использовать с множеством приемопередающих устройств для каждой соты.
[00103] Базовые станции 170а-170b связываются с одним или несколькими UE 110а-110с по одному или нескольким эфирным интерфейсам 190 с использованием беспроводных линий связи. Эфирный интерфейс 190 может использовать любую подходящую технологию радиодоступа.
[00104] Предполагается, что система 100 может использовать функциональность многоканального доступа, включающую в себя такие схемы, которые описаны выше. В конкретных вариантах осуществления, базовые станции и UE реализуют LTE, LTE-A и/или LTE-B. Конечно, можно использовать другие схемы множественного доступа и беспроводные протоколы.
[00105] RAN 120а-120b находятся в связи с базовой сетью 130 для обеспечения UE 110а-110с передачей голоса, данных, приложений, передачей (VoIP) голоса по интернету или другими услугами. Понятно, что RAN 120а-120b и/или базовая сеть 130 могут быть в прямой или косвенной связи с одной или несколькими RAN (не изображено). Базовая сеть 130 также может служить в качестве шлюзового доступа для других сетей (например, PSTN 140, интернет 150 и другие сети 160). Дополнительно, некоторые или все из UE 110а-110с могут включать в себя функциональность для связи с различными беспроводными сетями по различным беспроводным линиям с использованием различных беспроводных технологий и/или протоколов.
[00106] Хотя Фиг. 18 изображает один пример системы связи, различные изменения можно сделать на Фиг. 18. Например, система 100 связи может включать в себя любое число UE, базовые станции, сети или другие компоненты в любой подходящей конфигурации и может дополнительно включать в себя EPC, изображенные на любом чертеже в данной заявке.
[00107] Фиг. 19А и 19А изображают примеры устройств, которые могут реализовывать способы и идеи в соответствии с настоящим раскрытием. Более конкретно, Фиг. 19А изображает пример UE 110, и Фиг. 19В изображает пример базовой станции 170. Эти компоненты можно использовать в системе 100 или любой другой подходящей системе.
[00108] Как изображено на Фиг. 19А, UE 110 включает в себя, по меньшей мере, один блок 200 обработки. Блок 200 обработки реализует различные операции обработки UE 110. Например, блок 200 обработки может выполнять кодирование сигнала, обработку данных, управление питанием, обработку ввода/вывода или любую другую функциональность, позволяющую UE 110 функционировать в системе 100. Блок 200 обработки также поддерживает способы и идеи, описанные более подробно выше. Каждый блок 200 обработки включает в себя любое подходящее устройство обработки или вычисления, выполненное с возможностью выполнять одну или несколько операций. Каждый блок 200 обработки может, например, включать в себя микропроцессор, микроконтроллер, цифровое сигнальное устройство обработки, программируемую пользователем вентильную матрицу или специализированную заказную интегральную микросхему.
[00109] UE 110 также включает в себя, по меньшей мере, одно приемопередающее устройство 202. Приемопередающее устройство 202 выполнено с возможностью модулировать данные или другое содержимое для передачи, по меньшей мере, одной антенной 204. Приемопередающее устройство 202 также выполнено с возможностью демодулировать данные или другое содержимое, принятое, по меньшей мере, одной антенной 204. Каждое приемопередающее устройство 202 включает в себя любую подходящую структуру для формирования сигналов для беспроводной передачи и/или обработки сигналов, принятых беспроводным способом. Каждая антенна 204 включает в себя любую подходящую структуру для передачи и/или приема беспроводных сигналов. Одно или несколько приемопередающих устройств 202 можно использовать в UE 110, и одну или несколько антенн 204 можно использовать в UE 110. Хотя оно изображено как единый функциональный блок, приемопередающее устройство 202 также можно реализовать с использованием, по меньшей мере, одного передающего устройства и, по меньшей мере, одного отдельного приемника.
[00110] UE 110 дополнительно включает в себя одно или несколько устройств 206 ввода/вывода. Устройства 206 ввода/вывода способствуют взаимодействию с пользователем. Каждое устройство 206 ввода/вывода включает в себя любую подходящую структуру для обеспечения информации или приема информации от пользователя, например, колонка, микрофон, кнопочная панель, клавиатура, устройство отображения или сенсорный экран.
[00111] Дополнительно, UE 110 включает в себя, по меньшей мере, одно запоминающее устройство 208. Запоминающее устройство 208 хранит команды и данные, используемые, формируемые или собираемые UE 110. Например, запоминающее устройство 208 может хранить команды программного обеспечения или программно-аппаратных средств, выполняемые блоком(ами) 200 обработки, и данные, используемые для сокращения или удаления помех во входящих сигналах. Каждое запоминающее устройство 208 включает в себя любое подходящее энергозависимое и/или энергонезависимое хранилище и устройство(а) для поиска. Можно использовать любой подходящий тип запоминающего устройства, например, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), жесткий диск, оптический диск, карта модуля (SIM) идентификации абонента, флэш-карта, защищенная цифровая (SD) карта памяти и тому подобное.
[00112] Как изображено на Фиг. 19В, базовая станция 170 включает в себя, по меньшей мере, один блок 250 обработки, по меньшей мере, одно устройство 252 передачи, по меньшей мере, один приемник 254, одну или несколько антенн 256 и, по меньшей мере, одно запоминающее устройство 258. Блок 250 обработки реализует различные операции обработки базовой станции 170, например, кодирование сигнала, обработка данных, управление питанием, обработка ввода/вывода или любая другая функциональность. Блок 250 обработки также может поддерживать способы и идеи, описанные более подробно выше. Каждый блок 250 обработки включает в себя любое подходящее устройство обработки или вычисления, выполненное с возможностью выполнять одну или несколько операций. Каждый блок 250 обработки, например, может включать в себя микропроцессор, микроконтроллер, цифровое сигнальное устройство обработки, программируемую пользователем вентильную матрицу или специализированную заказную интегральную микросхему.
[00113] Каждое устройство 252 передачи включает в себя любую подходящую структуру для формирования сигналов для беспроводной передачи одному или нескольким UE иди другим устройствам. Каждый приемник 254 включает в себя любую подходящую структуру для обработки сигналов, принятых беспроводным способом от одного или нескольких UE или других устройств. Хотя они изображены как отдельные компоненты, по меньшей мере, одно устройство 252 передачи и, по меньшей мере, один приемник 254 могут быть скомбинированы в приемопередающее устройство. Каждая антенна 256 включает в себя любую подходящую структуру для передачи и/или приема беспроводных сигналов. Хотя в данной заявке изображена общая антенна 256, связанная как с устройством 252 передачи, так и с приемником 254, одна или несколько антенн 256 могут быть связаны с устройством(ами) 252 передачи, и одна или несколько отдельных антенн 256 могут быть связаны с приемником(ами) 254. Каждое запоминающее устройство 258 включает в себя любое подходящее энергозависимое или энергонезависимое хранилище и устройство(а) для поиска.
[00114] Дополнительные детали относительно UE 110 и базовых станций 170 известны специалистам в данной области техники. По этой причине, эти детали опущена в данной заявке для ясности.
[00115] Полезно будет установить определения конкретных слов и фраз, используемых в данном патентном документе. Термины «включать в себя» и «содержать», а также их производные формы, означают включение без ограничения. Термин «или» подразумевает включение, означая и/или. Фразы «связанный с», и «связанный с ним», а также их производные формы, означают включать в себя, быть включенным внутри, взаимосвязываться с, содержать, содержаться внутри, соединяться к или с, связываться к или с, быть связанным с, кооперировать с, чередоваться, накладываться, быть близким к, быть ограниченным чем-либо, иметь, обладать качеством или тому подобное.
[00116] Хотя настоящее раскрытие описывает конкретные варианты осуществления и общие связанные способы, преобразования и перестановки этих осуществлений и способов будут очевидны специалистам в данной области техники. Соответственно, вышеуказанное описание примеров вариантов осуществления не определяет или не ограничивает настоящее раскрытие. Другие изменения, замены и преобразования также возможны без удаления от сущности и объема настоящего раскрытия, согласно приложенной формуле изобретения.

Изобретение относится к кодированию содержимого экрана в поток двоичных данных. Технический результат - улучшение кодирования содержимого экрана. Для этого предусмотрено: разделение содержимого экрана на множество блоков кодирования (CU), причем каждый CU содержит квадратный блок пикселей; выбор таблицы цветовой палитры для CU, извлеченного из пикселей упомянутого CU, причем отличимые цвета в таблице цветовой палитры упорядочены в соответствии с гистограммой или ее актуальной интенсивностью цвета; создание карты цветовых индексов, имеющей индексы для CU, с использованием выбранной таблицы цветовой палитры; и кодирование выбранной таблицы цветовой палитры и карты цветовых индексов для CU в поток двоичных данных. 2 н. и 16 з.п. ф-лы, 22 ил., 3 табл. 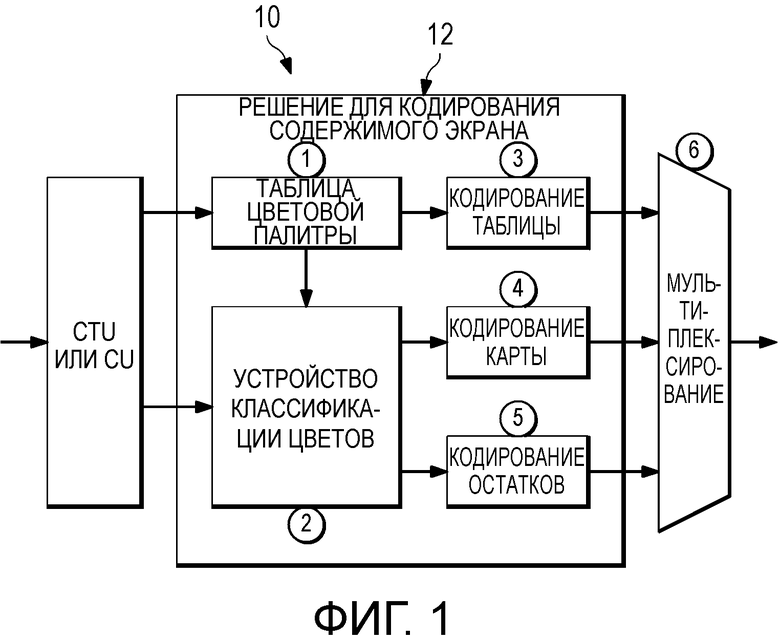
1. Способ кодирования содержимого экрана в поток двоичных данных, причем способ содержит:
разделение содержимого экрана на множество блоков кодирования (CU), причем каждый CU содержит квадратный блок пикселей;
выбор таблицы цветовой палитры для CU, извлеченного из пикселей упомянутого CU, причем отличимые цвета в таблице цветовой палитры упорядочены в соответствии с гистограммой или ее актуальной интенсивностью цвета;
создание карты цветовых индексов, имеющей индексы для CU, с использованием выбранной таблицы цветовой палитры; и
кодирование выбранной таблицы цветовой палитры и карты цветовых индексов для CU в поток двоичных данных.
2. Способ по п.1, причем способ обрабатывают с использованием формата плоского цвета или формата чередующегося цвета.
3. Способ по п.2, причем способ обрабатывают на уровне, выбранном из группы: уровень CU, уровень сектора, уровень изображения или уровень последовательности.
4. Способ по п.1, в котором таблицу цветовой палитры извлекают из CU или из соседнего CU.
5. Способ по п.4, в котором соседний CU не кодируют с использованием режима цветовой палитры, и таблицу цветовой палитры соседнего CU передают из предыдущего CU, который кодируют с использованием режима цветовой палитры.
6. Способ по п.1, в котором таблицу цветовой палитры извлекают в домене пикселей в устройстве декодирования, причем закодированный поток двоичных данных синтаксически анализируют для восстановления, для CU, таблицы цветовой палитры и карты цветовых индексов.
7. Способ по п.1, дополнительно содержащий классификацию цветов или значений пикселей CU на основании предыдущей извлеченной таблицы цветовой палитры для соответствующих индексов.
8. Способ по п.1, в котором каждый пиксель CU преобразуют в цветовой индекс внутри таблицы цветовой палитры.
9. Способ по п.1, в котором для CU определяют флаг для указания, обработан ли CU с использованием пакетного способа или плоского режима.
10. Способ по п.1, в котором таблицу цветовой палитры обрабатывают путем кодирования размера таблицы цветовой палитры и каждого цвета в таблице цветовой палитры.
11. Способ по п.1, дополнительно содержащий формирование флага, указывающего, что CU использует таблицу цветовой палитры из своего левого или верхнего CU.
12. Способ по п.1, в котором карту индексов кодируют с использованием сопоставления строк, выбранного из группы, содержащей: одномерное (1-D) сопоставление строк, гибридное 1-D сопоставление строк и двумерное (2-D) сопоставление строк,
причем сопоставление строк сигнализируют с использованием совпадающих пар.
13. Способ по п.12, в котором сопоставление строк выполняют с использованием способа промежуточного хэша.
14. Способ по п.1, в котором способ двумерного (2D) поиска выполняют по карте цветовых индексов путем идентификации местоположения текущего пикселя и местоположения эталонного пикселя в CU в качестве точки отсчета.
15. Способ по п.1, в котором CU имеет формат 4:4:4, обработанный с использованием понижающего формата выборки 4:2:0.
16. Способ по п.15, в котором понижающий формат обрабатывают на уровне, выбранном из группы: уровень CU, уровень сектора, уровень изображения или уровень последовательности.
17. Устройство обработки для кодирования содержимого экрана в поток двоичных данных, выполненное с возможностью:
разделения содержимого экрана на множество блоков кодирования (CU), причем каждый CU содержит квадратный блок пикселей;
выбора таблицы цветовой палитры для CU, извлеченного из пикселей упомянутого CU, причем отличимые цвета в таблице цветовой палитры упорядочены в соответствии с гистограммой или ее актуальной интенсивностью цвета;
создания карты цветовых индексов, имеющей индексы для CU, с использованием выбранной таблицы цветовой палитры; и
кодирования выбранной таблицы цветовой палитры и карты цветовых индексов для CU в поток двоичных данных.
18. Устройство обработки по п.17, причем таблицу цветовой палитры извлекают из CU или из соседнего CU.
| US 6522783 B1, 18.02.2003 | |||
| US 20070116370 A1, 24.05.2007 | |||
| US 20070280295 A1, 06.12.2007 | |||
| WO 2009002603 A1, 31.12.2008 | |||
| ОБРАБОТКА ИЗОБРАЖЕНИЙ НА ОСНОВЕ ВЕСОВ | 2006 |
|
RU2407222C2 |

