Изобретение относится к способу и устройству для прогнозирования кодирования элементов синтаксиса на основе компонента вектора смещения в процессе кодирования или декодирования видео. Оно, в частности, относится к элементу Run синтаксиса при кодировании в палитровом режиме в HEVC.
Более конкретно, оно применяется к режиму кодирования, в котором блок пиксела кодируется с прогнозированием на основе блока предиктора, кодированного с помощью или скомпонованного из так называемой палитры.
Палитра в этом документе задается как таблица поиска, имеющая записи, ассоциирующие индекс со значением пиксела. Типично, но необязательно, значение пиксела состоит из значения каждого цветового компонента, ассоциированного с пикселом, что приводит к цветовой палитре. С другой стороны, значение пиксела может формироваться из одного пиксельного компонента, что приводит к монохромной палитре.
Этот режим кодирования блока пиксела, в общем, упоминается в качестве режима палитрового кодирования. Предполагается приспосабливать этот режим, например, в расширении диапазона международного стандарта высокоэффективного кодирования видео (HEVC: ISO/IEC 23008-2 MPEG-H Part 2 ITU-T H.265).
При кодировании изображения в видеопоследовательности, изображение сначала разделяется на объекты кодирования пикселов равного размера, называемые "блоком дерева кодирования (CTB)". Размер блока дерева кодирования типично составляет 64х64 пикселов. Каждый блок дерева кодирования затем может разбиваться на иерархическое дерево меньших блоков, размер которых может варьироваться, и которые представляют собой фактические блоки пикселов для кодирования. Эти меньшие блоки для кодирования упоминаются в качестве единицы кодирования (CU).
Кодирование конкретной единицы кодирования типично является прогнозирующим. Это означает то, что сначала определяется блок предиктора. Затем, вычисляется разность между блоком предиктора и единицей кодирования. Эта разность называется "остатком". Затем, этот остаток сжимается. Фактическая кодированная информация единицы кодирования формируется из некоторой информации для того, чтобы указывать способ определения блока предиктора и сжатого остатка. Наилучшие блоки предикторов представляют собой блоки, максимально возможно аналогичные единице кодирования, с тем чтобы получать небольшой остаток, который может эффективно сжиматься.
Режим кодирования задается на основе способа, используемого для того, чтобы определять блок предиктора для способа кодирования единицы кодирования с прогнозированием.
Первый режим кодирования упоминается в качестве внутреннего режима. Согласно внутреннему режиму, блок предиктора компонуется на основе значения пикселов, непосредственно окружающих единицу кодирования в текущем изображении. Необходимо отметить, что блок предиктора представляет собой блок не текущего изображения, а конструкции. Направление используется для того, чтобы определять то, какие пикселы границы фактически используются для того, чтобы компоновать блок предиктора, и то, как они используются. Идея в основе внутреннего режима состоит в том, что вследствие общей когерентности натуральных изображений, пикселы, непосредственно окружающие единицу кодирования, с большой вероятностью являются аналогичными пикселам текущей единицы кодирования. Следовательно, можно получать хорошее прогнозирование значения пикселов единицы кодирования с использованием блока предиктора на основе этих окружающих пикселов.
Второй режим кодирования упоминается в качестве взаимного режима. Согласно взаимному режиму, блок предиктора представляет собой блок другого изображения. Идея в основе взаимного режима состоит в том, что последовательные изображения в последовательности являются, в общем, почти идентичными. Основное различие типично обусловлено движением между этими изображениями вследствие прокрутки камеры или вследствие движущихся объектов в сцене. Блок предиктора определяется посредством вектора, представляющего его местоположение в опорном изображении относительно местоположения единицы кодирования в текущем изображении. Этот вектор упоминается в качестве вектора движения. Согласно этому режиму, кодирование такой единицы кодирования с использованием этого режима содержит информацию движения, содержащую вектор движения и сжатый остаток.
В этом документе, внимание сосредоточено на третьем режиме кодирования, называемом "палитровым режимом". Согласно палитровому режиму, можно задавать блок предиктора для данной единицы кодирования в качестве блока индексов из палитры: для каждого пиксельного местоположения в блоке предиктора, блок предиктора содержит индекс, ассоциированный с пиксельным значением в палитре, которое является ближайшим к значению пиксела, имеющего идентичное местоположение (т.е. совместно размещенного) в единице кодирования. Остаток, представляющий разность между блоком предиктора и единицей кодирования, затем вычисляется и кодируется. Индексы записей в палитре также известны как "уровни".
При использовании палитрового режима, блок предиктора уровней должен передаваться в потоке битов. Для этой передачи, блок предиктора двоично кодируется с использованием трех элементов синтаксиса. Первый элемент синтаксиса, называемый "Pred mode", обеспечивает возможность различать между двумя режимами кодирования. В первом режиме, соответствующем режиму прогнозирования, имеющему значение 0, значение уровня, который должен кодироваться, должно передаваться в потоке битов. Во втором режиме, соответствующем режиму прогнозирования, имеющему значение 1, значение уровня, который должен кодироваться, получается из значения вышеуказанного пиксела в блоке предиктора. Уровень не должен обязательно передаваться.
Второй элемент синтаксиса, называемый "Level", задается для передачи значения уровня в первом режиме. Третий элемент синтаксиса, называемый "Run", используется для того, чтобы кодировать повторяющееся значение. С учетом того, что блок предиктора сканируется из верхнего левого угла в правый нижний угол, построчно слева направо и сверху вниз, элемент Run синтаксиса задает число последовательных пикселов в блоке предиктора, имеющих идентичное кодирование. Если режим прогнозирования равен 0, это представляет собой число последовательных пикселов блока предиктора, имеющих идентичное значение уровня. Если режим прогнозирования равен 1, это представляет собой число последовательных пикселов блока предиктора, имеющих значение уровня, соответствующее значению уровня вышеуказанного пиксела.
Элемент Run синтаксиса кодируется с использованием кода Голомба-Райса для наименьших значений и экспоненциального кода Голомба для наибольших значений. Эти коды Голомба задаются с использованием параметра, называемого "порядком Голомба". Для кодирования элемента Run синтаксиса, этот порядок Голомба предположительно имеет значение 3. Необходимо отметить, что длина энтропийного кода Голомба зависит порядка.
Настоящее изобретение разработано с возможностью улучшать кодирование кодирования элемента Run синтаксиса палитрового режима.
Оно предлагает улучшать кодирование элемента Run синтаксиса посредством использования переменной "порядок Голомба". Описываются несколько вариантов осуществления, в которых порядок Голомба адаптирован согласно различным параметрам.
Согласно первому аспекту настоящего изобретения, предусмотрен способ для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от, по меньшей мере, параметра, используемого в процессе кодирования упомянутого блока индексов.
В варианте осуществления, упомянутый, по меньшей мере, один параметр энтропийного кода связан с длиной энтропийного кода.
В варианте осуществления, упомянутый энтропийный код представляет собой код Голомба.
В варианте осуществления, упомянутый, по меньшей мере, один параметр энтропийного кода представляет собой порядок кода Голомба.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, и упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от режима прогнозирования упомянутого, по меньшей мере, одного индекса, ассоциированного с энтропийным кодом.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, и упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от значения индекса упомянутого, по меньшей мере, одного индекса, ассоциированного с энтропийным кодом.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, и упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от размера палитры.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, и упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от размера единицы кодирования.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, причем каждый индекс из блока индексов ассоциирован с соответствующим пикселом, и упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от оставшегося числа пикселов, которые следует ассоциировать с индексами в блоке индексов.
В варианте осуществления, по меньшей мере, один индекс из блока индексов кодируется посредством группы последовательных пикселов в порядке сканирования, причем каждая группа кодируется с использованием первого элемента синтаксиса, задающего режим прогнозирования, и второго элемента, задающего повторение, и упомянутый энтропийный код используется для кодирования элемента синтаксиса повторений.
В варианте осуществления, способ содержит:
- определение категорий на основе, по меньшей мере, одного второго параметра, используемого в процессе кодирования упомянутого блока индексов; и
- определение значения упомянутого, по меньшей мере, одного параметра энтропийного кода для каждой категории.
В варианте осуществления, способ дополнительно содержит:
- адаптацию упомянутых определенных значений упомянутого, по меньшей мере, одного параметра энтропийного кода на основе, по меньшей мере, одного третьего параметра, используемого в процессе кодирования упомянутого блока индексов.
В варианте осуществления, упомянутый, по меньшей мере, один третий параметр содержит последнее значение, определенное для идентичной категории, и последнее кодированное повторяющееся значение.
В варианте осуществления, упомянутый, по меньшей мере, один второй параметр содержит режим прогнозирования или значение индекса пиксела, ассоциированного с энтропийным кодом.
В варианте осуществления, упомянутый, по меньшей мере, один параметр энтропийного кода определяется для кодирования данного элемента в качестве значения параметра энтропийного кода, которое должно быть оптимальным для кодирования или декодирования последнего кодированного или декодированного соответствующего элемента.
В варианте осуществления, значение упомянутого, по меньшей мере, одного параметра энтропийного кода ограничивается фиксированным числом значений.
Согласно второму аспекту настоящего изобретения, предусмотрен способ для кодирования видеоданных в потоке битов, при этом упомянутый способ содержит:
- определение, по меньшей мере, одного параметра энтропийного кода согласно способу первого аспекта; и
- запись значения в упомянутый поток битов с использованием упомянутого или одного определенного параметра энтропийного кода.
Согласно третьему аспекту настоящего изобретения, предусмотрен способ для декодирования видеоданных из потока битов, при этом упомянутый способ содержит:
- получение из упомянутого потока битов параметра, используемого в процессе кодирования блока индексов;
- определение, по меньшей мере, одного параметра энтропийного кода согласно способу первого аспекта.
Согласно четвертому аспекту настоящего изобретения, предусмотрено устройство для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутое устройство содержит средство для определения упомянутого, по меньшей мере, одного параметра энтропийного кода в зависимости от, по меньшей мере, параметра, используемого в процессе кодирования упомянутого блока индексов.
Согласно пятому аспекту настоящего изобретения, предусмотрено устройство для кодирования видеоданных в потоке битов, содержащее: средство для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутое устройство содержит средство для определения упомянутого, по меньшей мере, одного параметра энтропийного кода в зависимости от, по меньшей мере, параметра, используемого в процессе кодирования упомянутого блока индексов; и средство для записи значения в упомянутый поток битов с использованием упомянутого или одного определенного параметра энтропийного кода.
Согласно шестому аспекту настоящего изобретения, предусмотрено устройство для декодирования видеоданных из потока битов, содержащее: средство для получения из упомянутого потока битов параметра, используемого в процессе кодирования блока индексов; и средство для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутое устройство содержит средство для определения упомянутого, по меньшей мере, одного параметра энтропийного кода в зависимости от, по меньшей мере, параметра, используемого в процессе кодирования упомянутого блока индексов.
Согласно седьмому аспекту настоящего изобретения, предусмотрен компьютерный программный продукт для программируемого устройства, причем компьютерный программный продукт содержит последовательность инструкций для реализации способа согласно любому из вышеуказанных первого, второго и третьего, при загрузке и выполнении посредством программируемого устройства.
Согласно восьмому аспекту настоящего изобретения, предусмотрен энергонезависимый машиночитаемый носитель хранения данных, хранящий инструкции компьютерной программы для реализации способа согласно любому из первого, второго или третьего аспектов.
Согласно девятому аспекту настоящего изобретения, предусмотрено средство хранения информации, считываемое посредством компьютера или микропроцессора, сохраняющего инструкции компьютерной программы, причем оно позволяет реализовывать способ согласно любому из первого, второго или третьего аспектов.
Согласно одному дополнительному аспекту настоящего изобретения, предусмотрен способ для кодирования видеоданных в потоке битов, при этом упомянутый способ содержит: определение, по меньшей мере, одного параметра энтропийного кода согласно первому аспекту; и запись, в упомянутый поток битов, определенного значения.
Согласно другому аспекту настоящего изобретения, предусмотрен способ для декодирования видеоданных из потока битов, при этом упомянутый способ содержит: определение, по меньшей мере, одного параметра энтропийного кода согласно первому аспекту; и считывание из упомянутого потока битов определенного значения.
Согласно дополнительному аспекту изобретения, предусмотрен способ для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутый, по меньшей мере, один параметр определяется в зависимости от, по меньшей мере, параметра, используемого в процессе кодирования упомянутого блока индексов. Соответственно, улучшается кодирование элемента Run синтаксиса.
В варианте осуществления, упомянутый, по меньшей мере, один параметр энтропийного кода связан с длиной энтропийного кода.
В варианте осуществления, упомянутый энтропийный код представляет собой код Голомба.
В варианте осуществления, упомянутый, по меньшей мере, один параметр энтропийного кода представляет собой порядок кода Голомба.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от режима прогнозирования упомянутого, по меньшей мере, одного индекса, ассоциированного с энтропийным кодом.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от значения индекса упомянутого, по меньшей мере, одного индекса, ассоциированного с энтропийным кодом.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от размера палитры.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от размера единицы кодирования.
В варианте осуществления, по меньшей мере, один индекс упомянутого блока индексов кодируется с прогнозированием, упомянутый, по меньшей мере, один параметр энтропийного кода определяется в зависимости от числа пикселов, остающихся в блоке уровня, который должен декодироваться или кодироваться.
В варианте осуществления, упомянутый блок индексов кодируется посредством группы последовательных пикселов в порядке сканирования, причем каждая группа кодируется с использованием первого элемента синтаксиса, задающего режим прогнозирования, и второго элемента, задающего повторение, упомянутый энтропийный код используется для кодирования элемента синтаксиса повторений.
В варианте осуществления, способ содержит:
- определение категорий на основе, по меньшей мере, одного второго параметра, используемого в процессе кодирования упомянутого блока индексов; и
- определение значения упомянутого, по меньшей мере, одного параметра энтропийного кода для каждой категории.
В варианте осуществления, способ дополнительно содержит:
- адаптацию упомянутых определенных значений упомянутого, по меньшей мере, одного параметра энтропийного кода на основе, по меньшей мере, одного третьего параметра, используемого в процессе кодирования упомянутого блока индексов.
В варианте осуществления, упомянутый, по меньшей мере, один третий параметр содержит последнее значение, определенное для идентичной категории, и последнее кодированное повторяющееся значение.
В варианте осуществления, упомянутый, по меньшей мере, один второй параметр содержит режим прогнозирования или значение индекса пиксела, ассоциированного с энтропийным кодом.
В варианте осуществления, упомянутый, по меньшей мере, один параметр энтропийного кода определяется для кодирования данного элемента в качестве значения параметра энтропийного кода, которое должно быть оптимальным для кодирования или декодирования последнего кодированного или декодированного соответствующего элемента.
В варианте осуществления, значение упомянутого, по меньшей мере, одного параметра энтропийного кода ограничивается фиксированным числом значений.
Согласно другому аспекту изобретения, предусмотрен способ для кодирования или декодирования видеоданных в потоке битов, при этом упомянутый способ содержит:
- этап для определения, по меньшей мере, одного параметра энтропийного кода согласно изобретению; и
- этап записи или считывания, из упомянутого потока битов, определенного значения.
Согласно другому аспекту изобретения, предусмотрен способ для кодирования блока индексов, используемых для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, причем упомянутый блок индексов кодируется посредством группы последовательных пикселов в порядке сканирования, причем каждая группа кодируется с использованием первого элемента синтаксиса, задающего режим прогнозирования, и второго элемента, задающего повторение, упомянутый энтропийный код используется для кодирования элемента синтаксиса повторений, причем упомянутая палитра переупорядочивается согласно вхождению индексов в блоке индексов, при этом элемент повторения не кодируется для групп пикселов, ассоциированных с индексом, превышающим предварительно заданное пороговое значение.
Согласно другому аспекту изобретения, предусмотрен способ для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутый, по меньшей мере, один параметр определяется равным нулевому значению.
Согласно другому аспекту изобретения, предусмотрено устройство для определения, по меньшей мере, одного параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования, по меньшей мере, части упомянутого блока индексов, при этом упомянутое устройство содержит средство для определения упомянутого, по меньшей мере, одного параметра в зависимости от, по меньшей мере, параметра, используемого в процессе кодирования упомянутого блока индексов.
Согласно другому аспекту изобретения, предусмотрен компьютерный программный продукт для программируемого устройства, причем компьютерный программный продукт содержит последовательность инструкций для реализации способа согласно изобретению, при загрузке и выполнении посредством программируемого устройства.
Согласно другому аспекту изобретения, предусмотрен энергонезависимый машиночитаемый носитель хранения данных, хранящий инструкции компьютерной программы для реализации способа согласно изобретению.
Согласно другому аспекту изобретения, предусмотрено средство хранения информации, считываемое посредством компьютера или микропроцессора, сохраняющего инструкции компьютерной программы, причем оно позволяет реализовывать способ согласно изобретению.
Согласно еще одному другому аспекту изобретения, предусмотрен способ для определения параметров энтропийного кода, ассоциированного с пикселами из блока пикселов, кодированных согласно палитровому режиму в изображении, при этом один упомянутый параметр определяется в зависимости от направления прогнозирования ассоциированных пикселов.
В варианте осуществления, упомянутый определенный параметр представляет собой длину энтропийного кода.
В варианте осуществления, упомянутый определенный параметр представляет собой параметр кода Голомба.
В дополнительном аспекте настоящего изобретения, предусмотрен способ кодирования изображения, содержащий способ для определения параметров по еще одному другому аспекту, описанному выше.
В дополнительном аспекте настоящего изобретения, предусмотрен способ декодирования изображения, содержащий способ для определения параметров по еще одному другому аспекту, описанному выше. По меньшей мере, части способов согласно изобретению могут быть машинореализованными. Соответственно настоящее изобретение может принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления (включающего в себя микропрограммное обеспечение, резидентное программное обеспечение, микрокод и т.д.) или варианта осуществления, комбинирующего программные и аппаратные аспекты, которые могут совместно, в общем, упоминаться в данном документе как "схема", "модуль" или "система". Кроме того, настоящее изобретение может принимать форму компьютерного программного продукта, осуществленного в любом материальном носителе, в представлении, имеющем машиноприменимый программный код, осуществленный на носителе.
Поскольку настоящее изобретение может быть реализовано в программном обеспечении, настоящее изобретение может быть осуществлено в качестве машиночитаемого кода для предоставления в программируемое устройство на любом подходящем носителе. Материальный носитель может содержать носитель хранения данных, такой как гибкий диск, CD-ROM, жесткий диск, устройство на магнитных лентах или полупроводниковое запоминающее устройство и т.п. Переходная несущая среда может включать в себя такой сигнал, как электрический сигнал, электронный сигнал, оптический сигнал, акустический сигнал, магнитный сигнал либо электромагнитный сигнал, например, микроволновый или RF-сигнал.
Далее описываются варианты осуществления изобретения, только в качестве примера и со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 иллюстрирует архитектуру HEVC-кодера;
Фиг. 2 иллюстрирует архитектуру HEVC-декодера;
Фиг. 3 иллюстрирует принцип причинно-следственной области;
Фиг. 4 иллюстрирует различные видеоформаты;
Фиг. 5 иллюстрирует разбиение блока дерева кодирования на единицы кодирования и декодирование в порядке сканирования этих единиц кодирования;
Фиг. 6 иллюстрирует двоичное кодирование Голомба элемента синтаксиса в HEVC;
Фиг. 7 иллюстрирует принцип прогнозирования в палитровом режиме на стороне декодера, исследуемый в расширении диапазона HEVC;
Фиг. 8 иллюстрирует пример единицы кодирования с ее соответствующим блоком уровней и ассоциированной палитрой;
Фиг. 9 иллюстрирует идентичный блок уровней и набор элементов синтаксиса, используемых для кодирования этого блока уровней;
Фиг. 10 иллюстрирует процесс декодирования элементов синтаксиса, связанных с палитровым режимом;
Фиг. 11 иллюстрирует процесс восстановления, чтобы компоновать блок уровней и затем предиктор блока в цветовом пространстве, который должен использоваться в качестве предиктора;
Фиг. 12 иллюстрирует примерный алгоритм определения палитры в кодере;
Фиг. 13 иллюстрирует выбор элементов Pred mode, Level и Run синтаксиса в кодере;
Фиг. 14 иллюстрирует вариант осуществления, в котором значение Order зависит от числа пикселов, остающихся в блоке уровней;
Фиг. 15 иллюстрирует вариант осуществления, в котором значение Order передается в потоке битов;
Фиг. 16 иллюстрирует вариант осуществления, связанный с декодированием порогового значения для значения уровня, используемого для того, чтобы решать не передать значение Run.
Фиг. 17 является принципиальной блок-схемой вычислительного устройства для реализации одного или более вариантов осуществления изобретения.
Фиг. 1 иллюстрирует архитектуру HEVC-кодера. В видеокодере, исходная последовательность 101 разделена на блоки пикселов 102. Режим кодирования затем оказывает влияние на каждый блок. Предусмотрено два семейства режимов кодирования, типично используемых в HEVC: режимы на основе пространственного прогнозирования, или внутренние режимы 103, и режимы на основе временного прогнозирования, или взаимные режимы на основе оценки 104 движения и компенсации 105 движения. Единица внутреннего кодирования, в общем, прогнозируется из кодированных пикселов на причинно-следственной границе посредством процесса, называемого "внутренним прогнозированием". Расширение в данный момент проектируемого HEVC, известное как HEVC RExt, добавляет дополнительный режим кодирования, а именно, режим палитрового кодирования, который конкурирует с режимами внутреннего и взаимного кодирования, чтобы кодировать блоки пикселов. Этот режим палитрового кодирования подробнее описан ниже, в частности, со ссылкой на фиг. 7-13.
Временное прогнозирование режима взаимного кодирования сначала состоит в нахождении предыдущего или будущего кадра, называемого "опорным кадром 116", опорная область которого является ближайшей к единице кодирования, на этапе 104 оценки движения. Эта опорная область составляет блок предиктора. Затем эта единица кодирования прогнозируется с использованием блока предиктора, чтобы вычислять остаток на этапе 105 компенсации движения.
В обоих случаях, пространственное и временное прогнозирование, остаток вычисляется посредством вычитания единицы кодирования из исходного блока предиктора.
При внутреннем прогнозировании, кодируется направление прогнозирования. При временном прогнозировании, кодируется, по меньшей мере, один вектор движения. Тем не менее, чтобы дополнительно уменьшать затраты с точки зрения скорости передачи битов, связанные с кодированием на основе векторов движения, вектор движения непосредственно не кодируется. Фактически, при условии, что движение является гомогенным, особенно интересно кодировать вектор движения в качестве разности между этим вектором движения и вектором движения в его окружении. Например, в стандарте кодирования H.264/AVC, векторы движения кодируются относительно среднего вектора, вычисленного между 3 блоками, расположенными выше и слева от текущего блока. Только разность, также называемая "остаточным вектором движения", вычисленная между средним вектором и вектором движения текущего блока, кодируется в потоке битов. Это обрабатывается в модуле 117 Mv-прогнозирование и кодирования. Значение каждого кодированного вектора сохраняется в поле 118 векторов движения. Соседние векторы движения, используемые для прогнозирования, извлекаются из поля 118 векторов движения.
После этого режим, оптимизирующий производительность искажения в зависимости от скорости передачи, выбирается в модуле 106. Чтобы дополнительно уменьшать избыточность, преобразование, типично DCT, применяется к остаточному блоку в модуле 107, и квантование применяется к коэффициентам в модуле 108. Квантованный блок коэффициентов затем энтропийно кодируется в модуле 109, и результат вставляется в поток 110 битов.
Кодер затем выполняет декодирование кодированного кадра для будущей оценки движения в модулях 111-116. Это представляет собой контур декодирования в кодере. Эти этапы обеспечивают возможность кодеру и декодеру иметь идентичные опорные кадры. Чтобы восстанавливать кодированный кадр, остаток обратно квантуется в модуле 111 и обратно преобразуется в модуле 112, чтобы предоставлять "восстановленный" остаток в пиксельной области. Согласно режиму кодирования (взаимному или внутреннему), этот остаток суммируется со взаимным предиктором 114 или с внутренним предиктором 113.
Далее, это первое восстановление фильтруется в модуле 115 посредством одного или нескольких видов постфильтрации. Эти постфильтры интегрированы в контур декодирования. Это означает то, что они должны применяться к восстановленному кадру в кодере и декодере, чтобы использовать идентичные опорные кадры в кодере и декодере. Цель этой постфильтрации состоит в том, чтобы удалять артефакты сжатия.
Принцип HEVC-декодера представлен на фиг. 2. Видеопоток 201 сначала энтропийно декодируется в модуле 202. Остаточные данные затем обратно квантуются в модуле 203 и обратно преобразуются в модуле 204, чтобы получать пиксельные значения. Данные режима также энтропийно декодируются, и в функции режима выполняется внутреннее декодирование или взаимное декодирование. В случае внутреннего режима, направление внутреннего прогнозирования декодируется из потока битов. Направление прогнозирования затем используется для того, чтобы находить опорную область 205. Если режим является взаимным, информация движения декодируется из потока 202 битов. Она состоит из индекса опорного кадра и остатка вектора движения. Предиктор вектора движения суммируется с остатком вектора движения, чтобы получать вектор 210 движения. Вектор движения затем используется для того, чтобы находить опорную область в опорном кадре 206. Следует отметить, что данные 211 поля векторов движения обновляются с декодированным вектором движения, с тем чтобы использоваться для прогнозирования следующих декодированных векторов движения. Это первое восстановление декодированного кадра далее подвергается постфильтрации 207 с помощью постфильтра, полностью идентичного постфильтру, используемому на стороне кодера. Вывод декодера представляет собой распакованное видео 209.
Фиг. 3 иллюстрирует причинно-следственный принцип, получающийся в результате поблочного кодирования, аналогично HEVC.
На высоком уровне, изображение разделено на единицы кодирования, которые кодируются в порядке растрового сканирования. Таким образом, при кодировании блока 3.1, все блоки области 3.3 уже кодированы и могут считаться доступными в кодере. Аналогично, при декодировании блока 3.1 в декодере, все блоки области 3.3 уже декодированы и в силу этого восстановлены и могут считаться доступными в декодере. Область 3.3 называется "причинно-следственной областью" единицы 3.1 кодирования. После того, как единица 3.1 кодирования кодируется, она должна принадлежать причинно-следственной области для следующей единицы кодирования. Эта следующая единица кодирования, а также все следующие, принадлежит области 3.4, проиллюстрированной в качестве пунктирной области, и не может использоваться для кодирования текущей единицы 3.1 кодирования. Необходимо отметить, что причинно-следственная область состоит из восстановленных блоков. Информация, используемая для того, чтобы кодировать данную единицу кодирования, не представляет собой исходные блоки изображения по причине того, что эта информация недоступна при декодировании. Единственная информация, доступная при декодировании, представляет собой восстановленную версию блоков пикселов в причинно-следственной области, а именно, декодированную версию этих блоков. По этой причине, при кодировании, ранее кодированные блоки причинно-следственной области декодируются, чтобы предоставлять эту восстановленную версию этих блоков.
Можно использовать информацию из блока 3.2 в причинно-следственной области при кодировании блока 3.1. В спецификациях проекта расширения HEVC-диапазона, вектор 3.5 смещения, который может передаваться в потоке битов, может указывать этот блок 3.2.
Фиг. 5 иллюстрирует разбиение блока дерева кодирования на единицы кодирования и примерный порядок сканирования, чтобы последовательно обрабатывать эти единицы кодирования. В HEVC-стандарте, блочная структура организована посредством блоков дерева кодирования (CTB). Кадр содержит несколько неперекрывающихся и квадратных блоков дерева кодирования. Размер блока дерева кодирования может составлять от 64x64 до 16x16. Этот размер определяется на уровне последовательности. Самый эффективный размер, с точки зрения эффективности кодирования, является наибольшим: 64x64. Следует обратить внимание на то, что все блоки дерева кодирования имеют идентичный размер за исключением цвета границы изображения. Размер граничных CTB адаптирован согласно числу оставшихся пикселов.
Каждый блок дерева кодирования содержит одну или более квадратных единиц кодирования (CU). Блок дерева кодирования разбивается на основе структуры в виде дерева квадрантов на несколько единиц кодирования. Порядок обработки (кодирования или декодирования) каждой единицы кодирования в блоке дерева кодирования соответствует структуре в виде дерева квадрантов на основе порядка растрового сканирования. Фиг. 5 показывает пример порядка обработки декодирования единиц кодирования. На этом чертеже, число в каждой единице кодирования задает порядок обработки каждой соответствующей единицы кодирования этого блока дерева кодирования.
В HEVC, несколько способов используются для того, чтобы кодировать различные элементы синтаксиса, например, блочные остатки, информацию относительно блоков предикторов (векторов движения, направлений внутреннего прогнозирования и т.д.). HEVC использует несколько типов энтропийного кодирования, таких как контекстно-адаптивное двоичное арифметическое кодирование (CABAC), код Голомба-Райса или простое двоичное представление, называемое "кодированием фиксированной длины". Большую часть времени процесс двоичного кодирования выполняется для того, чтобы представлять различный элемент синтаксиса. Этот процесс двоичного кодирования преобразования в двоичную форму также является очень специфичным и зависит от различных элементов синтаксиса.
Например, элемент синтаксиса, называемый "coeff_abs_level_remaining", содержит абсолютное значение или часть абсолютного значения остатка коэффициентов. Идея этого процесса двоичного кодирования состоит в том, чтобы использовать код Голомба-Райса для первых значений и экспоненциальный код Голомба для более высоких значений. Более конкретно, в зависимости от данного параметра, называемого "порядком Голомба", это означает то, что для представления первых значений, например, значений 0-3, используется код Голомба-Райса, а затем для более высоких значений, например, значений от 4 и выше, используется экспоненциальный код Голомба. Порядок Голомба представляет собой параметр, используемый посредством как кода Голомба-Райса, так и экспоненциального кода Голомба.
Фиг. 6 иллюстрирует этот принцип на стороне декодирования. Входные данные процесса декодирования представляют собой поток 601 битов и Order, который известен как параметр Райса-Голомба или порядок Голомба. Вывод этого процесса представляет собой декодированный символ 612.
Значение префикса задается равным 1 на этапе 602, затем 1 бит извлекается из потока битов на этапе 601, и переменный флаг задается равным декодированному значению 603. Если этот флаг равен 0 на этапе 604, значение префикса постепенно увеличивается 605, и другой бит извлекается из потока 603 битов. Когда значение флага равно 1, решающий модуль 606 проверяет то, ниже или нет префикс значения строго 3. Если это является истинным, N=Order битов извлекаются 608 из потока 601 битов и задаются равными переменной codeword. Это соответствует представлению Голомба-Райса. Значение символа 612 задается равным ((prefix<<Order)+codeword), как проиллюстрировано на этапе 609. При этом "<<" является оператором сдвига влево.
Если префикс выше или равен 3 на этапе 606, следующий этап представляет собой 610, на котором N=(prefix-3+Order) битов извлекаются из потока битов и задаются в качестве переменной 610 codeword. Значение 611 символа задается равным ((1<<(prefix-3))+2)<<Order)+codeword. Это соответствует экспоненциальному представлению Голомба.
Далее, этот процесс декодирования и, симметрично, соответствующий процесс кодирования, называются "Golomb_H" с входным параметром, соответствующим порядку Голомба. Его можно записывать просто как Golomb_H(Order).
В HEVC, для некоторых элементов синтаксиса, таких как, к примеру, остатки, порядок Голомба обновляется с возможностью адаптировать энтропийное кодирование к сигналу, который должен быть кодирован. Формула обновления пытается уменьшать размер кода Голомба посредством увеличения порядка Голомба, когда коэффициенты имеют большие значения. В HEVC-стандарте, обновление задается посредством следующей формулы:
Order=Min(cLastRiceOrder+(cLastAbsLevel>(3*(1<<cLastRiceOrder)) ? 1: 0),4)
Если cLastRiceOrder является последним используемым Order, cLastAbsLevel является последним декодированным coeff_abs_level_remaining. Следует обратить внимание на то, что для первого параметра, который должен кодироваться или декодироваться, cLastRiceOrder и cLastAbsLevel задаются равными 0. Кроме того, следует обратить внимание на то, что параметр Order не может превышать значение 4 в этой формуле. При этом выражение (C? A: B) имеет значение A, если условие C является истинным, и B, если условие C является ложным.
Расширение HEVC-диапазона, также обычно называемое "HEVC RExt", представляет собой расширение, которое в данный момент проектируется для нового стандарта кодирования видео (HEVC).
Цель этого расширения состоит в том, чтобы предоставлять дополнительные инструментальные средства для того, чтобы кодировать видеопоследовательности с дополнительными цветовыми форматами и битовой глубиной и, возможно, без потерь. В частности, это расширение спроектировано с возможностью поддерживать цветовой формат 4:2:2, а также видеоформат 4:4:4 в дополнение к видеоформату 4:2:0 (см. фиг. 4). Цветное изображение, в общем, формируется из 3 цветовых компонентов R, G и B. Эти компоненты, в общем, коррелируются, и в сжатии изображений и видео очень распространена декорреляция цветовых компонентов до обработки изображений. Наиболее распространенный формат, который декоррелирует цветовые компоненты, представляет собой цветовой YUV-формат. YUV-сигналы типично создаются из RGB-представления изображений посредством применения линейного преобразования к трем вводам в виде входных R-, G- и B-кадров. Y обычно называется "компонентом сигнала яркости", U и V, в общем, называются "компонентами сигнала цветности". Термин "YCbCr" также обычно используется вместо термина "YUV".
Относительно битовой глубины, которая является числом битов, используемых для того, чтобы кодировать каждый цветовой компонент пиксела, если текущий HEVC-стандарт имеет возможность решать проблемы, связанные с цветовым форматом 4:2:0 с битовой глубиной в 8 и 10 битов (т.е. 256-1024 возможных цветов), HEVC RExt должен быть спроектирован с возможностью дополнительно поддерживать видеоформат 4:2:2 и 4:4:4 с расширенной битовой глубиной в пределах от 8 битов до 16 битов (т.е. до 65536 возможных цветов). Это является, в частности, полезным для большей динамики цветовых компонентов.
HEVC RExt также спроектирован с возможностью предоставлять кодирование без потерь входных последовательностей; это служит для того, чтобы иметь декодированный вывод 209, строго идентичный вводу 101. Чтобы достигать этого, ряд инструментальных средств модифицирован или добавлен, по сравнению с традиционным HEVC-кодеком с потерями. Неполный список примерных модификаций или добавлений для того, чтобы работать без потерь, предоставляется ниже:
- удаление этапа 108 квантования (203 в декодере);
- принудительная активация обходного преобразования, поскольку нормальные косинусные/синусные преобразования 107 могут вводить ошибки (204 в декодере);
- удаление инструментальных средств, специально адаптированных для компенсации шума квантования, таких как постфильтрация 115 (207 в декодере).
Для HEVC RExt, формула обновления порядка Голомба дополнительно модифицирована таким образом, чтобы адаптироваться к возможности решать проблемы, связанные с более высокой битовой глубиной и учитывать очень высокое качество, требуемое посредством приложения, решающего проблемы, связанные со сжатием видео расширенного формата (4:2:2 и 4:4:4), включающие в себя кодирование без потерь. Для HEVC RExt, формула обновления изменена следующим образом: Order=Min(cLastRiceOrder+(cLastAbsLevel>>(2+cLastRiceOrder)), 7)
В этой формуле, максимальное значение Order равно 7. Кроме того, для первого кодирования coeff_abs_level_remaining для субблока блока преобразования, порядок параметр Голомба задается равным:
Order=Max(0, cRiceOrder-(transform_skip_flag||cu_transquant_bypass_flag ? 1: 2))
где
- переменная transform_skip_flag задается равной 1, если преобразование (например, DCT 107 или 204) пропускается для текущей единицы кодирования, и 0, если преобразование используется,
- переменная cu_transquant_bypass_flag задается равной 1, если единица кодирования кодируется без потерь, и 0 в противном случае,
- переменная cRiceOrder задается равной используемому в прошлый раз Order из другого субблока блока преобразования, в противном случае задается равной 0.
Дополнительные инструментальные средства для HEVC RExt в данный момент проектируются с возможностью эффективно кодировать видеопоследовательности "экранного контента" в дополнение к естественным последовательностям. Видеопоследовательности "экранного контента" означают конкретные видеопоследовательности, которые имеют очень специфичный контент, соответствующий контенту, захваченному из персонального компьютера любого другого устройства, содержащему, например, текст, презентацию PowerPoint, графический пользовательский интерфейс, таблицы (например, снимки экрана). Эти конкретные видеопоследовательности имеют очень отличающуюся статистику по сравнению с естественными видеопоследовательностями. При кодировании видео, производительность традиционных инструментальных средств кодирования видео, включающих в себя HEVC, иногда оказывается недостаточной при обработке такого "экранного контента".
Текущие инструментальные средства, в данный момент обсуждаемые в HEVC RExt для того, чтобы обрабатывать видеопоследовательности "экранного контента", включают в себя режим внутреннего блочного копирования и палитровый режим. Прототипы для этих режимов демонстрируют хорошую эффективность кодирования по сравнению с традиционным способом, нацеленным на естественные видеопоследовательности. В этом документе внимание акцентируется на режиме палитрового кодирования.
Палитровый режим HEVC RExt представляет собой режим прогнозирования. Это означает то, что палитровый способ используется для того, чтобы компоновать предиктор для кодирования данной единицы кодирования, аналогично прогнозированию, выполняемому посредством прогнозирования движения (взаимный случай) или посредством внутреннего прогнозирования. После формирования прогнозирования, остаточная единица кодирования преобразуется, квантуется и кодируется. Другими словами, применяются идентичные процессы, как описано выше со ссылкой на фиг. 1 и 2.
Палитра, в общем, представляется посредством таблицы, содержащей конечный набор кортежа из N элементов цветов, причем каждый цвет задается посредством своих компонентов в данном цветовом пространстве (см., например, 803 на фиг. 8 на основе цветового YUV-пространства). Например, в типичном RGB-формате, палитра состоит из списка из P элементов кортежа из N элементов (где N=3 для RGB). Более точно, каждый элемент соответствует фиксированному триплету цветовых компонентов в RGB-формате. Конечно, он не ограничен цветовым RGB- или YUV-форматом. Любой другой цветовой формат может быть представлен посредством палитры и может использовать меньшее или большее число цветовых компонентов, что означает то, что N может отличаться от 3.
На стороне кодера, палитровый режим, рассматриваемый в RExt, состоит в преобразовании пиксельных значений данной входной единицы кодирования в индексы, называемые "уровнями", идентифицирующие записи в ассоциированной палитре. После преобразования, результирующая единица кодирования или блок составляется из уровней и затем передается в декодер с ассоциированной палитрой, в общем, таблицей, имеющей конечное число триплетов цветов, используемых для того, чтобы представлять единицу кодирования. Поскольку палитра задает конечное число цветов, преобразование в блок индексов обычно аппроксимирует исходную входную единицу кодирования.
Чтобы применять палитровый режим на стороне кодера, примерный способ преобразовывать единицу кодирования пикселов выполняется следующим образом:
- нахождение P триплетов, описывающих лучше всего единицу кодирования пикселов, которые следует кодировать, например, посредством минимизации полного искажения;
- затем ассоциирование каждого пиксела единицы кодирования с ближайшим цветом из P триплетов: значение, которое следует кодировать (или уровень), в таком случае представляет собой индекс, соответствующий записи ассоциированного ближайшего цвета.
Для каждой единицы кодирования, палитра (т.е. найденные P триплетов), блок индексов или уровней и остаток, представляющий разность между исходной единицей кодирования и блоком индексов в цветовом пространстве (который является предиктором блока), кодируются в потоке 110 битов и отправляются в декодер.
В декодере, палитровый режим состоит в проведении преобразования обратным способом. Это означает то, что каждый декодированный индекс, ассоциированный с каждым пикселом единицы кодирования, заменен посредством соответствующего цвета в палитре, декодированной из потока битов, чтобы восстанавливать соответствующий цвет для каждого пиксела единицы кодирования. Это представляет собой восстановление блока индексов в цветовом пространстве (т.е. предиктора единицы кодирования). Поскольку палитровый режим представляет собой режим прогнозирования, ассоциированный остаток декодируется из потока битов и затем суммируется с восстановленным предиктором единицы кодирования, чтобы компоновать конечную восстановленную единицу кодирования.
Фиг. 7 дополнительно иллюстрирует принцип палитрового режима в декодере. Режим прогнозирования для текущей единицы кодирования извлекается на этапе 702 из потока 701 битов. В настоящее время, палитровый режим идентифицируется посредством флага, расположенного перед флагом пропуска в потоке битов (другие режимы кодирования описаны выше со ссылкой на фиг. 1 и 2). Этот флаг CABAC-кодируется с использованием одного контекста. Если этот режим представляет собой палитровый режим 703, то связанный синтаксис палитрового режима 705, т.е. информация относительно палитры, блока уровней и остатка, извлекается и декодируется 704 из потока 701 битов.
Далее, во время этапа 706, два элемента компонуются из декодированных данных: палитры 707 и блока 708 уровней. Из этого блока уровней и ассоциированной палитры, предиктор единицы кодирования в пиксельной области 710 компонуется 709. Это означает то, что для каждого уровня блока уровней, цвет (RGB или YUV) ассоциирован с каждым пикселом.
Затем остаток единицы кодирования декодируется 711 из потока 701 битов. В текущей реализации палитрового режима, остаток, ассоциированный с палитровым режимом, кодируется с использованием общего способа взаимного остаточного HEVC-кодирования, т.е. с использованием кодирования кодом Голомба. Чтобы получать остаток единицы кодирования, выполняется традиционное обратное квантование и обратное преобразование. Предиктор 710 блока суммируется 713 с этим остатком 712 единицы кодирования, чтобы формировать восстановленную единицу 714 кодирования.
Фиг. 8 иллюстрирует принцип палитрового режима в кодере. Текущая единица 801 кодирования преобразуется в блок 802 идентичного размера, который содержит уровень для каждого пиксела вместо 3 значений цвета (Y, U, V) или (R, G, B). Палитра 803, ассоциированная с этим блоком уровней, компонуется на основе минимизации полного искажения единицы кодирования и ассоциирует в каждой записи, индекс или уровень записи с соответствующими значениями пиксельного цвета. Следует обратить внимание на то, что для монохромного варианта применения, пиксельное значение может содержать только один компонент.
Как упомянуто относительно фиг. 7, палитра (а также остаток) кодируется и вставляется в поток битов для каждой единицы кодирования. Аналогичным образом, блок уровней (соответствующий предиктору единицы кодирования) кодируется и вставляется в поток битов, и пример кодирования приведен ниже со ссылкой на фиг. 9. В этом примере, блок уровней сканируется в горизонтальном порядке.
Блок 91 уровней является точно идентичным блоку уровней, проиллюстрированному на фиг. 8 в соответствии со ссылкой 802. Таблицы 92 и 93 описывают последовательные элементы синтаксиса, используемые для того, чтобы кодировать блок 91 уровней. Таблица 93 должна читаться как продолжение таблицы 92. Элементы синтаксиса в таблице соответствуют кодированию групп уровней, обведенных посредством полужирных линий в блоке 91.
Блок уровней кодируется посредством группы последовательных пикселов в порядке сканирования. Каждая группа кодируется с использованием первого элемента синтаксиса, предоставляющего направление прогнозирования, второго элемента, предоставляющего повторение, и необязательного третьего элемента, предоставляющего значение пиксела, а именно, уровень. Повторение соответствует числу пикселов в группе.
Эти две таблицы иллюстрируют текущий синтаксис, ассоциированный с палитровым режимом. Эти элементы синтаксиса соответствуют кодированной информации, ассоциированной в потоке битов для блока 91 уровней. В этих таблицах, три основных элемента синтаксиса используются для того, чтобы полностью представлять операции палитрового режима, и используются следующим образом при последовательном рассмотрении уровней блока 91 уровней.
Первый элемент синтаксиса, называемый "Pred mode", обеспечивает возможность различать между двумя режимами кодирования. В первом режиме, соответствующем флагу "режима прогнозирования", равному 0, новый уровень используется для текущего пиксела. Уровень немедленно передается в служебных сигналах после этого флага в потоке битов. Во втором режиме, соответствующем флагу "режима прогнозирования", равному 1, используется режим "с копированием сверху". Более конкретно, это означает то, что текущий пиксельный уровень соответствует пиксельному уровню, расположенному в линии непосредственно выше, начинающейся в идентичной позиции для порядка растрового сканирования. В этом случае флага "режима прогнозирования", равного 1, нет необходимости немедленно передавать в служебных сигналах уровень после флага, поскольку значение уровня известно в отношении значения уровня пиксела сразу выше в блоке 91 уровней.
Второй элемент синтаксиса, называемый "Level", указывает значение уровня палитры для текущего пиксела только в первом режиме Pred mode.
Третий элемент синтаксиса, называемый "Run", используется для того, чтобы кодировать повторяющееся значение в обоих режимах Pred mode. С учетом того, что блок 91 уровней сканируется из левого верхнего угла в правый нижний угол, построчно слева направо и сверху вниз, элемент Run синтаксиса задает число последовательных пикселов в блоке 91, имеющих идентичное кодирование.
Этот элемент Run синтаксиса имеет различный смысл, который зависит от флага "режима прогнозирования". Когда режим прогнозирования равен 0, элемент Run является числом последовательных пикселов блока предиктора, имеющих идентичное значение уровня. Например, если Run=8, это означает то, что текущий "уровень" применяется к текущему пикселу и к следующим 8 пикселам, что соответствует 9 идентичным последовательным выборкам в порядке растрового сканирования.
Когда режим прогнозирования равен 1, элемент Run является числом последовательных пикселов блока предиктора, имеющих значение уровня, соответствующее значению уровня их верхнего пиксела в блоке 91, т.е. если применяется режим "с копированием сверху". Например, если Run=31, это означает то, что уровень текущего пиксела копируется из пиксела линии выше, а также из следующих 31 пикселов, что соответствует 32 пикселам всего.
Что касается таблиц 92 и 93, они представляют восемь этапов, чтобы представлять блок 91 посредством использования палитрового режима. Каждый этап начинается с кодирования флага "режима прогнозирования", после чего кодируется элемент Level синтаксиса, когда флаг "режима прогнозирования" равен 0, или элемент Run синтаксиса, когда флаг "режима прогнозирования" равен 1. После элемента Level синтаксиса всегда следует элемент Run синтаксиса.
Когда режим прогнозирования, декодированный для текущего блока, представляет собой палитровый режим, декодер сначала декодирует синтаксис, связанный с этим блоком, и затем применяет процесс восстановления для единицы восстановления.
Фиг. 10 иллюстрирует процесс декодирования элементов синтаксиса, связанных с палитровым режимом. Во-первых, размер палитры извлекается и декодируется 1002 из потока 1001 битов. Точный размер палитры (Palette_size) получается посредством суммирования 1 с этим значением размера, декодированным на этапе 1002. Фактически, размер кодируется посредством использования унарного кода, для которого значение 0 имеет наименьшее число битов (1 бит), и размер палитры не может быть равен 0, в противном случае, пиксельное значение не может использоваться для того, чтобы компоновать предиктор блока.
После этого начинается процесс, соответствующий декодированию значений палитры. Переменная i, соответствующая индексу палитры, задается равной 0 на этапе 1004, после этого на этапе 1005 выполняется тест, чтобы проверять то, равна или нет i размеру (Palette_size) палитры. Если это не имеет место, один элемент палитры извлекается из потока 1001 битов и декодируется 1006 и затем добавляется в палитру с ассоциированным уровнем/индексом, равным i. Затем переменная i постепенно увеличивается посредством этапа 1007. Если i равна размеру палитры 1005, палитра полностью декодирована.
Далее выполняется процесс, соответствующий декодированию блока 91 уровней. Во-первых, переменная j, соответствующая счетчику пикселов, задается равной 0, как и переменная syntaxj 1008. Затем выполняется проверка для того, чтобы знать то, соответствует или нет счетчик пикселов числу пикселов, содержащихся в блоке. Если ответ представляет собой "Да" на этапе 1009, процесс завершается на этапе 1017, в противном случае значение флага "режима прогнозирования", соответствующего одному режиму прогнозирования, извлекается из потока 1001 битов и декодируется 1010.
Значение "режима прогнозирования" добавляется в таблицу в индексе syntaxj', содержащую все декодированные значения "режима прогнозирования". Если значение этого "режима прогнозирования" равно 0, этап 1011, элемент синтаксиса, соответствующий Level, извлекается из потока 1001 битов и декодируется 1012. Эта переменная Level добавляется в таблицу в индексе syntaxj, содержащую все декодированные уровни. Переменная j, соответствующая счетчику пикселов, постепенно увеличивается на единицу 1013.
Затем элемент Run синтаксиса декодируется на этапе 1014. Если элемент Pred Mode синтаксиса равен 1, этап 1011, значение Run также декодируется на этапе 1014. Этот элемент Run синтаксиса добавляется в таблицу в индексе syntaxj, содержащую все декодированные серии.
Затем на этапе 1015, значение j постепенно увеличивается на значение серии, декодированной на этапе 1014. Переменная syntaxj' постепенно увеличивается на единицу, чтобы рассматривать следующий набор элементов синтаксиса. Если счетчик j равен числу пикселов в блоке, то синтаксис для того, чтобы компоновать блок 91 уровней, завершается 1017. В конце этого процесса, связанного с палитрой, декодер знает палитру и таблицы, содержащие список всех элементов Pred mode, Level и Run синтаксиса, ассоциированных с палитровым режимом этой единицы кодирования. Декодер затем может продолжать процесс восстановления единицы кодирования, как описано через фиг. 7.
Каждый элемент палитры, состоящей из трех значений в вышеприведенных примерах, в общем, кодируется с использованием трех двоичных кодов. Длина двоичных кодов соответствует битовой глубине каждого цветового компонента. Размер палитры типично кодируется с использованием унарного кода. Элемент Pred mode кодируется с использованием одного бита. Элемент Level кодируется с использованием двоичного кода с длиной двоичного кода, равной b, где 2b является наименьшим целым числом, равным или выше размера палитры. Кроме того, элемент Run кодируется с использованием Golomb_H(Order=3), как пояснено выше относительно фиг. 6.
Фиг. 11 иллюстрирует процесс восстановления, чтобы компоновать блок 91 уровней и затем предиктор блока в цветовом пространстве, который должен использоваться в качестве предиктора. Входные данные этого процесса представляют собой таблицы, полученные в вышеописанном процессе по фиг. 10 и содержащие список Pred mode, Level и Run. Дополнительные входные данные представляют собой размер единицы 801 кодирования (который является идентичным размеру блока 802/91 уровней), известный из дерева квадрантов (фиг. 5), передаваемого в служебных сигналах в потоке битов.
На первом этапе 1101, переменная i, представляющая счетчик пикселов, задается равной 0, и переменная j для последовательного рассмотрения каждого набора элементов синтаксиса, также задается равной 0. На этапе 1104, элемент Pred_mode[j], извлеченный из таблицы "режима прогнозирования" в индексе j, сверяется с 0.
Если он равен 0, новый уровень кодируется для текущего пиксела i. Как следствие, значение пиксела в позиции i задается равным уровню в индексе j из таблицы уровней; Block[i]=Level[j]. Это представляет собой этап 1105. Переменная i постепенно увеличивается на единицу на этапе 1106, чтобы рассматривать следующий пиксел, и переменная k, выделенная для того, чтобы подсчитывать пикселы, уже обработанные в текущей серии, задается равной 0 на этапе 1107.
На этапе 1108 выполняется проверка, чтобы определять то, равен или нет k элементу Run таблицы серий в индексе j: k=Run[j]?. Если не равен, уровень пиксела в позиции i задается равным значению уровня пиксела в позиции i-1: Block[i]=Block[i-1]. Это представляет собой этап 1109. Переменная i и переменная k затем постепенно увеличиваются на единицу, соответственно, на этапах 1110 и 1111. Если k=Run[j] на этапе 1108, распространение значения левого уровня закончено, и выполняется этап 1120 (описан ниже).
Если Pred_mode[j] отличается от 0 на этапе 1104, режим "с копированием сверху" начинается с переменной k, заданной равной 0 на этапе 1112. Затем, этап 1113 проверяет то, равен или нет (k-1) элементу Run таблицы серий в индексе j: k=Run[j]+1?. Если не равен, значение уровня пиксела в позиции i задается равным значению уровня пиксела в позиции i верхней линии: Block[i]=Block[i-width], где width является шириной блока уровней (идентичного единице кодирования), выведенной из входного размера единицы кодирования. Это представляет собой этап 1114. Затем, переменная i и переменная k постепенно увеличиваются на единицу, соответственно, на этапах 1115 и 1116. Если k=Run[j]+1 на этапе 1113, режим прогнозирования "с копированием сверху" завершается, и процесс продолжается на этапе 1120.
На этапе 1120, выполняется проверка для того, чтобы определять то, равна или нет переменная i числу пикселов в блоке 91/CU 801. Если не равна, переменная j постепенно увеличивается на единицу на этапе 1121, чтобы рассматривать следующий набор элементов синтаксиса, и процесс циклически возвращается к этапу 1104, описанному выше.
Если все пикселы обработаны на этапе 1120, конечный блок 91 уровней получается на этапе 1122: это соответствует таблице Block[]. Затем конечный этап 1123 состоит в преобразовании каждого уровня в цветовые значения с использованием палитры 803, декодированной с использованием процесса по фиг. 10. Этот конечный этап влияет на пиксельные значения (Y, U, V) или (R, G, B) в каждой позиции блока согласно уровню этой позиции в блоке и соответствующим записям в палитре.
Другие аспекты палитрового режима, введенного в HEVC RExt, рассматривают определение посредством кодера палитры, которая должна использоваться для того, чтобы кодировать текущую единицу кодирования (см. фиг. 12 ниже), и выбор элементов Pred mode, Level и Run синтаксиса в кодере (см. фиг. 13 ниже).
Фиг. 12 иллюстрирует примерный алгоритм определения палитры в кодере. Входные данные этого процесса представляют собой исходную единицу кодирования пикселов и размер единицы кодирования. В этом примере, компонуется YUV-палитра, но другие реализации могут приводить к компоновке RGB-палитры аналогичным образом.
На первом этапе 1201, переменная j, представляющая счетчик пикселов, задается равной 0, переменная Palette_size, которая соответствует росту палитры по мере ее компоновки, также задается равной 0, и переменная TH, представляющая пороговое значение, задается равной 9. Затем на этапе 1203, пиксел pi, т.е. имеющий индекс i согласно порядку сканирования, считывается на этапе 1203 из исходной единицы 1204 кодирования. После этого переменная j задается равной 0 на 1205, и на этапе 1206 выполняется проверка для того, чтобы определять то, равен или нет размер палитры переменной j (что означает то, что рассмотрены все элементы палитры для составляемой палитры).
Если размер палитры равен j, палитра в индексе j задается равной пиксельному значению pi на этапе 1209. Это означает то, что текущий пиксел pi становится новым элементом в палитре с индексом j, ассоциированным с ним. Более точно, выполняется следующее назначение:
PALY[j]=(Yi)
PALU[j]=(Ui)
PALV[j]=(Vi)
где PALY,U,V являются тремя таблицами, чтобы сохранять значения цвета.
Размер (Palette_size) палитры постепенно увеличивается на единицу на этапе 1210, и счетчик таблицы вхождений задается равным 1 для индекса Palette size на этапе 1211. Затем переменная i постепенно увеличивается на единицу на этапе 1213, чтобы рассматривать следующий пиксел i текущей единицы кодирования. Затем на этапе 1214выполняется проверка, чтобы определять то, обработаны или нет все пикселы текущей единицы кодирования. Если все они обработаны, процесс завершается посредством этапа 1215 упорядочения, поясненного ниже, в противном случае следующий пиксел рассматривается на этапе 1203, описанном выше.
Возвращаясь к этапу 1206, если j отличается от palette_size, выполняется этап 1207, на котором вычисляется абсолютное значение для каждого цветового компонента между pi и элементом палитры в индексе j. Формулы показаны на чертеже. Если все абсолютные разности строго меньше предварительно заданного порогового значения TH, счетчик вхождений относительно элемента j в палитре постепенно увеличивается на единицу на этапе 1212. Этап 1207 создает класс для каждого элемента составляемой палитры, такого как класс, охватывающий цвета, соседние с цветом элемента, с учетом допустимого запаса TH. Таким образом, этап 1212 подсчитывает вхождения каждого класса. После этапа 1212 выполняется этап 1213, уже описанный.
Если условие этапа 1207 не удовлетворяется, переменная j постепенно увеличивается на единицу на этапе 1208, чтобы рассматривать следующий элемент палитры в палитре. Это служит для того, чтобы сравнивать другие элементы цвета палитры с текущим пикселом посредством нового осуществления этапа 1207. Если элементы в палитре не соответствуют критерию этапа 1207, новый элемент добавляется в палитру, как описано выше в отношении этапов 1209, 1210 и 1211.
Можно отметить, что решающий модуль 1207 может сравнивать каждый цветовой элемент для (YUV- или RGB-) последовательностей 4:4:4 и может сравнивать цветовой компонент сигнала яркости только для последовательностей 4:2:0.
В конце процесса по фиг. 12, таблица Counter содержит число вхождений классов, заданных посредством соответствующих элементов палитры. Затем элементы палитры упорядочиваются на этапе 1215 согласно их вхождениям, так что самый частый элемент находится в первой позиции (запись с наименьшим индексом или "уровнем") в палитре.
Также можно отметить, что размер палитры может быть ограничен максимальным размером, например, 24 записями. В таком случае, если размер палитры, получающейся в результате этапа 1215, превышает 24, палитра уменьшается посредством удаления элементов (записей) из 25-й позиции в упорядоченной палитре. Это приводит к тому, что палитра скомпонована.
Возвращаясь теперь к выбору элементов Pred mode, Level и Run синтаксиса в кодере, входные данные процесса по фиг. 13 представляют собой исходную единицу кодирования пикселов, палитру, скомпонованную посредством процесса по фиг. 12, и размер единицы кодирования. В частности, эта оценка выполняется при определении того, какой режим кодирования между внутренним кодированием, взаимным кодированием и палитровым кодированием должен использоваться.
На первом этапе 1301, переменная i, представляющая счетчик пикселов, задается равной 0. Процесс, описанный ниже, направлен на определение элементов синтаксиса для пикселов, начинающихся с i. Два режима прогнозирования оцениваются независимо:
Pred mode=0 в правой части чертежа и Pred mode=1 в левой части чертежа.
Для прогнозирования "с копированием сверху" (соответствующего Pred mode=1), переменная icopy, используемая для того, чтобы подсчитывать число уровней в текущей серии, задается равной 0 на этапе 1303. Затем на этапе 1304 текущий уровень в пиксельном местоположении i: Block[i+icopy], сравнивается с уровнем пиксела, расположенного сразу выше в верхней линии: Block[i+icopy-width], где width соответствует ширине текущей единицы кодирования. Следует отметить, что уровень Block[i+icopy] каждого пиксела единицы кодирования определяется параллельно на этапе 1308. Этот этап состоит в ассоциировании с пикселом, в позиции i, ближайшего элемента палитры (на практике его индексом или уровнем), как уже пояснено выше. Этот этап использует позицию i, палитру 1306 и исходную единицу 1307 кодирования.
Если Block[i+icopy]=Block[i+icopy-width] на этапе 1304, переменная icopy постепенно увеличивается на единицу на этапе 1305, чтобы рассматривать следующее пиксельное значение блока пикселов и указывать то, что текущий пиксельный уровень в позиции i+icopy может быть включен в текущую серию "с копированием сверху". Если Block[i+icopy] отличается от Block[i+icopy-width] на этапе 1304, что означает то, текущая оценка серии "с копированием сверху" завершена, переменная icopy передается в решающий модуль 1314. На этой стадии процесса, переменная icopy соответствует числу значений, копируемых из линии, находящейся непосредственно сверху.
Для прогнозирования на основе левых значений (соответствующего Pred mode=0), контур для того, чтобы определять значение серии (ileft), обрабатывается параллельно или последовательно. Сначала переменная istart, используемая для того, чтобы сохранять индекс i текущего пиксела, задается равной i, и переменная j, используемая для того, чтобы рассматривать последовательно пиксельные уровни после индекса i, также задается равной i, и переменная ileft, используемая для того, чтобы подсчитывать составляемую текущую серию, задается равной 0. Это представляет собой этап 1309. Затем, этап 1310 состоит в определении того, выполняется или нет следующее: j!=0 и "Pred_mode[j-1]"=0, и Block[j]=Block[j-1]. Pred_mode[] является таблицей, используемой посредством кодера для того, чтобы сохранять режим прогнозирования (1 или 0, соответственно, для прогнозирования "с копированием сверху" и прогнозирования на основе левых значений). Она заполняется прогрессивно на этапе 1317, описанном ниже, по мере того, как обрабатываются последовательные пикселы, и инициализируется с нулевыми значениями, например, на этапе 1301: Pred_mode[k]=0 для любого k.
Если условие на этапе 1310 удовлетворяется, переменная ileft постепенно увеличивается на единицу на этапе 1311, чтобы указывать то, что текущий пиксельный уровень в позиции j может быть включен в текущую серию "левых значений", и переменная j постепенно увеличивается на единицу на этапе 1312, чтобы рассматривать следующее пиксельное значение блока пикселов.
Если условие на этапе 1310 не удовлетворяется, переменная j сравнивается с istart, чтобы определять то, является она или нет первым пиксельным значением, которое должно анализироваться для текущей серии "левых значений". Это представляет собой этап 1313. Если j равна или меньше istart, что означает то, что она является первым пиксельным значением, которое должно анализироваться для текущей серии, то она начинает текущую серию, и следующее пиксельное значение рассматривается на этапе 1312, описанном выше. Если j строго выше istart, это означает то, что обнаружено первое пиксельное значение, отличающееся от пиксельного значения текущей серии "левых значений". Переменная ileft, которая соответствует длине текущей серии "левых значений", передается в решающий модуль 1314. Следует отметить, что, в качестве контура для прогнозирования "с копированием сверху", уровень Block[i] в индексе i определяется в идентичном контуре на этапе 1308.
После вычисления максимальной серии для режима "прогнозирования на основе левых значений" и режима " копирования сверху", переменные ileft и icopy сравниваются на этапе 1314. Это служит для того, чтобы определять, выполняется или нет следующее: icopy!=0 и icopy+2 выше ileft. Он представляет собой примерный критерий, чтобы выбирать либо режим копирования сверху, либо режим прогнозирования на основе левых значений. В частности, параметр "2" может быть немного изменен.
Условие на этапе 1314 означает то, что, если icopy равна 0 либо меньше или равна ileft-2, режим прогнозирования на основе левых значений выбирается на этапе 1315. В этом случае, переменная PredMode задается равной 0, и переменная Run задается равной ileft на идентичном этапе 1315. С другой стороны, если icopy отличается от 0 и строго выше ileft-2, режим "копирования сверху" выбирается на этапе 1316. В этом случае, переменная PredMode задается равной 1, а переменная Run равной icopy-1 на этапе 1316.
Затем таблицы, содержащие Pred_mode и Run в кодере, обновляются с текущим значением Pred_mode и Run, на этапе 1317. Затем следующая позиция для рассмотрения в блоке пикселов вычисляется на этапе 1318, которая соответствует текущей позиции i, постепенно увеличенной на "значение Run+1". Затем на этапе 1319 выполняется проверка, чтобы определять то, обработаны или нет последние пикселы единицы кодирования. Если это имеет место, процесс завершается на этапе 1320, в противном случае оценка двух режимов прогнозирования "с прогнозированием слева" и "с копированием сверху" оценивается с началом на этапах 1303 и 1309 для следующей пиксельной позиции, чтобы получать новый набор элементов синтаксиса.
В конце этого процесса, кодер знает уровни для каждой выборки единицы кодирования и имеет возможность кодировать соответствующий синтаксис блока уровней на основе контента трех таблиц Pred_mode[], Block[] и Run[].
Вообще говоря, небольшое значение порядка Голомба оптимально подходит для кодирования небольшого диапазона значений, тогда как более высокий порядок Голомба оптимально подходит для кодирования более высокого диапазона значений. Как уже пояснено, элемент Run синтаксиса типично кодируется с использованием порядка Голомба, имеющего фиксированное значение 3. Согласно одному аспекту изобретения, порядок Голомба, используемый для кодирования значения Run, адаптирован на основе некоторых параметров. Эти параметры могут включать в себя, в числе прочего, значение уровня, размер палитры, режим прогнозирования, размер единицы кодирования. Это обусловлено тем фактом, что ожидаемый диапазон значения Run некоторым образом может быть связан с этими параметрами.
Фиг. 14 иллюстрирует зависимости между выбором порядка Голомба для элемента Run синтаксиса и другими параметрами. Этот чертеж основан на уже описанном фиг. 10. По сравнению с фиг. 10, фиг. 14 содержит один дополнительный модуль 1418, связанный с определением порядка Голомба для декодирования серии. Как описано в нижеприведенных вариантах осуществления, этот параметр Order может зависеть от размера палитры, режима прогнозирования, значения уровня и размера 1419 единицы кодирования.
В одном варианте осуществления изобретения, Order обновляется согласно "режиму прогнозирования". Это означает то, что на основе текущей реализации с 2 режимами прогнозирования, могут рассматриваться 2 параметра Order: Order[0] для режима с прогнозированием слева, соответствующего Pred mode=0, и Order[1] для режима прогнозирования "с копированием сверху", соответствующего Pred mode=1. Тем не менее, один или несколько режимов прогнозирования могут добавляться к рассматриваемым 2. Таким образом, N различных Order могут считаться соответствующими N возможных режимов прогнозирования.
В конкретном варианте осуществления, когда N>2, только один Order может быть ассоциирован с 2 или более режимами прогнозирования. Иными словами, несколько режимов прогнозирования могут преобразовываться в идентичное значение Order. Адаптация кодирования по сериям согласно режиму прогнозирования является эффективной, поскольку значение Run, ассоциированное с каждым из них, в общем, отличается. Фактически, значение Run для режима " копирования сверху", в общем, является высоким и выше значения Run для режима с прогнозированием слева, как проиллюстрировано в примере по фиг. 9. Это также обусловлено характером режима с прогнозированием слева, который является единственным режимом, способным передавать уровень. В предпочтительном варианте осуществления, Order режима прогнозирования "с копированием сверху" выше Order режима с прогнозированием слева.
В одном варианте осуществления изобретения, Order обновляется согласно уровню. Для режима с прогнозированием слева (Pred mode=0), последний декодированный элемент синтаксиса представляет собой уровень. Для этого режима прогнозирования, уровень используется для того, чтобы задавать конкретный Order, связанный с уровнем. Таким образом, число Order, которые могут рассматриваться, равно размеру палитры. В конкретном варианте осуществления, когда размер палитры строго больше 2, только один Order может быть ассоциирован с 2 или более значений уровня. Другими словами, несколько уровней могут преобразовываться в идентичное значение Order.
Для режима прогнозирования "с копированием сверху", уровень не кодируется, тем не менее, можно считать, что скопированный первый уровень используется для того, чтобы задавать связанный Order. В дополнительном варианте осуществления, левый уровень, используемый для режима с прогнозированием слева, может рассматриваться для того, чтобы адаптировать Order. Адаптация Order согласно уровню является, в частности, эффективной, когда палитра упорядочена согласно вхождению уровней. Чем ниже уровень, тем выше его вхождение. Таким образом, ожидаемое значение Run для нижнего уровня должно быть выше для наибольшего значения уровня. В предпочтительном варианте осуществления, Order, заданный для нижнего уровня, превышает Order, заданный для самого верхнего уровня.
В одном варианте осуществления изобретения, Order определяется на основе размера палитры. Как описано выше, максимальный размер палитры задается по умолчанию. Таким образом, число Order, которые могут рассматриваться, равно размеру палитры. Тем не менее, это необязательно, и преимущественно меньший диапазон значений Order может рассматриваться в предпочтительном варианте осуществления. Адаптация Order согласно размеру палитры является эффективной, поскольку, когда число уровней является низким, среднее значение Run увеличивается. Аналогичным образом, если число уровней является более высоким, среднее значение Run снижается. Таким образом, полезно увеличивать Order, когда размер палитры является низким, и снижать Order, когда размер палитры является высоким. В предпочтительном варианте осуществления, Order для более низкого значения размера палитры выше Order для наибольшего значения размера палитры. В конкретном варианте осуществления, Order может определяться посредством формулы в зависимости от размера палитры.
В одном варианте осуществления изобретения, Order определяется на основе размера единицы кодирования. Таким образом, число значений Order, которые могут рассматриваться, равно 4, если рассматриваются размеры текущей единицы кодирования: 64x64, 32x32, 16x16, 8x8. Тем не менее, это необязательно, и меньшее число значений Order может рассматриваться в другом варианте осуществления. Адаптация Order согласно размеру единицы кодирования является эффективной, поскольку, когда размер единицы кодирования является низким, ожидаемое значение Run должно быть более низким; аналогичным образом, если размер единицы кодирования является высоким, ожидаемое значение Run должно быть большим. Таким образом, полезно снижать Order, когда размер единицы кодирования является низким, и увеличивать Order, когда размер единицы кодирования является высоким. В предпочтительном варианте осуществления, значение Order, определенное для более низкого размера единицы кодирования, ниже значения Order, определенного для наибольшего значения размера единицы кодирования. В конкретном варианте осуществления, значение Order может получаться посредством формулы в зависимости от размера палитры.
В одном варианте осуществления, значение Order зависит от числа пикселов, остающихся в блоке уровня, который должен декодироваться или кодироваться. На фиг. 14, это означает то, что значение Order зависит от значения Pixels_in_Block-j. Фактически, чем ниже число пикселов, еще не декодированных или кодированных, тем ниже ожидаемое значение элемента Run.
В одном варианте осуществления, различные предложенные адаптации способа могут комбинироваться.
В одном варианте осуществления, значение Order определяется на основе размера палитры и на размере единицы кодирования, например, согласно следующей таблице:
Следует обратить внимание на то, что эта таблица приведена только в качестве возможного примера.
В одном варианте осуществления, значение Order определяется на основе режима прогнозирования Pred mode и на основе значения уровня. В предпочтительном варианте осуществления, значение Order задается посредством следующей формулы:
If (pred_node==1) Order=Order0 else if (pred_node==0 AND level==0) Order=Order1
else Order=Order2
В предпочтительном варианте осуществления, Order0=Order1. Фактически, уровень, равный 0, представляет собой фон блока уровней. Таким образом, ожидаемое значение Run после уровня, равного 0, должно быть выше для других значений уровня. В предпочтительном варианте осуществления, Order0=Order1=2, и Order2=0. Это означает то, что ожидаемое значение Run должно быть высоким для режима прогнозирования "с копированием сверху" и для режима с прогнозированием слева, когда уровень 0 (фон блока), и ниже для других значений уровней для режима с прогнозированием слева.
В одном варианте осуществления, категория задается на основе некоторых параметров. Например, категория может задаваться на основе режима прогнозирования либо на основе режима прогнозирования и уровня, как описано выше. Значение Order ассоциировано с каждой категорией и называется "OrderN", где N является номером категории. Затем порядковое значение, определенное для каждой категории, может быть адаптировано на основе некоторых других параметров. Например, оно может быть адаптировано на основе последнего значения Order, определенного для этой категории, и на основе последнего декодированного значения Run. Для каждой категории, значение Order инициализируется. Оно может инициализироваться равным значениям по умолчанию или равным значению 0. Альтернативно, оно может инициализироваться с использованием последнего значения Order, как задано для предыдущей единицы кодирования.
В одном варианте осуществления, после декодирования значения Run с использованием данного значения Order, кодер и декодер вычисляют OptOrder, который является значением порядка Голомба, которое должно быть оптимальным для кодирования декодированного значения Run. Это оптимальное значение Order затем используется в качестве определенного значения Order для следующей декодированной серии.
Одна альтернатива заключается в том, что значение Order инициализируется со значением 3. Для первой серии каждой категории, значение Order зависит от других порядковых значений, ранее декодированных.
Например, может использоваться следующая формула:
If(LastRunN=0) OrderN=Max(0, LastOrderN-1)
If(LastRunN>3*(LastOrderN+1)) OrderN=Min(A, LastOrderN+1),
где LastOrderN является последним используемым OrderN; LastRunN является последним декодированным значением Run для категории N.
В другом варианте осуществления, каждая категория имеет собственную формулу для того, чтобы обновлять значение OrderN. Например, формула Order2 должна снижать значение Order быстрее, чем для двух других Order0 и Order1, с помощью следующей формулы:
If(LastRun2<=2) Order2=Max(0,LastOrder2-1)
вместо
If(LastRun2=0) Order2=Max(0,LastOrder2-1)
В одном варианте осуществления, значение Order передается в потоке битов. Фиг. 15 иллюстрирует этот вариант осуществления для текущей единицы кодирования. Таким образом, значение Order извлекается из потока 1501 битов для декодирования параметров серии на этапе 1518. Фиг. 15 основан на фиг. 10. Таким образом, другие модули являются идентичными модулям, используемым на фиг. 10. На стороне кодера, этот параметр выбирается с критерием искажения в зависимости от скорости передачи. Этот алгоритм состоит в тестировании нескольких значений Order. Значение, которое обеспечивает наилучший компромисс по искажению в зависимости от скорости передачи, выбирается.
Чтобы ограничивать влияние на скорость передачи битов, это значение может ограничиваться небольшим фиксированным числом значений. Например, значения Order могут быть ограничены только 3 значениями: 0, 1, 2. Таким образом, это значение может кодироваться с помощью кода в 1 или 2 бита (согласно значению). Один флаг может передаваться, чтобы знать то, требуется или нет изменять значения Order. В другом варианте осуществления, это значение Order может прогнозироваться посредством другого значения Order или последнего используемого значения Order. В другом варианте осуществления, один бит может передаваться в служебных сигналах, чтобы передавать в служебных сигналах то, что Order=0, или то, что Order=2.
Этот вариант осуществления может комбинироваться с уже описанными вариантами осуществления. В предпочтительном варианте осуществления, рассматриваются 3 значения Order, Order0, Order1, Order2, как описано в предыдущем разделе. Таким образом, Order0 используется для режима прогнозирования "с копированием сверху" (=1), Order1 используется для режима прогнозирования на основе находящихся слева значений (=0), когда ранее декодированный уровень равен 0, в противном случае используется Order2. Кроме того, эти OrderN передаются для каждой единицы кодирования. В предпочтительном варианте осуществления, передаются только Order0 и Order2, и Order1=Order0. Эти варианты осуществления представлены на фиг. 15; Фактически, модуль 1518 имеет некоторые взаимосвязи с блоком "режим прогнозирования" 1510, уровнем 1512.
В одном варианте осуществления, некоторые значения Run не передаются, что означает то, что они заменены посредством значения по умолчанию, например, значения в 0. Типично, не передаваемые значения Run являются значениями, ассоциированными с высокоуровневыми значениями, которые являются менее общими. Это означает то, что шаблон повторения менее общих значений уровня не используется для кодирования. Два последовательных пиксела в блоке уровней, имеющих идентичные значения высокого уровня, формируют каждого кодирование, как если нет повторения. Решение не передавать данное значение Run может быть основано на значении последнего декодированного уровня. Например, пороговое значение может задаваться для значения уровня. Это пороговое значение может быть фиксированным, например, имеющим значение 4. Пороговое значение может быть основано на таблице поиска, на размере единицы кодирования и на размере палитры.
В одном варианте осуществления, пороговое значение передается в потоке битов в последовательности, кадре, CTB или уровне единицы кодирования.
Фиг. 16 иллюстрирует вариант осуществления, связанный с декодированием порогового значения, называемого "Limit" на этом чертеже.
В одном варианте осуществления, предел кодируется с помощью унарного максимального кода или с помощью унарного кода. Если этот предел кодируется для каждой единицы кодирования, максимальный размер унарного максимального кода равен размеру палитры. Двоичный код также может рассматриваться и на уровне единицы кодирования, и число битов может зависеть от размера палитры. Фиг. 16 иллюстрирует эти варианты осуществления. Предел декодируется из потока 1618 битов. Далее, что касается размера палитры, предел задается равным "декодированный предел+11619". Когда "уровень" декодируется 1612, и если он превышает или равен пределу 1620, элемент Run синтаксиса не декодируется, и он задается равным 0. Кроме того, модуль 1615 обрабатывается, в противном случае серия декодируется 1614, как обычно. Следует обратить внимание на то, что предел декодируется один раз для каждой единицы кодирования.
В другом варианте осуществления, предел кодируется перед размером палитры с помощью унарного кода. Размер палитры задается равным "декодированный размер+предел+1".
На стороне кодера, этот предел выбирается на основе критерия искажения в зависимости от скорости передачи. Это означает то, что несколько тестов вычисляются, чтобы находить наилучший предел с точки зрения критерия искажения в зависимости от скорости передачи. Другое решение на стороне кодера состоит в том, чтобы выбирать предел, равный нижнему уровню, для которого все параметры серии равны 0. Это означает то, что для всех уровней выше этого предела, ассоциированная серия задается равной 0.
В одном варианте осуществления, порядок Голомба всегда задается равным 0 (Golomb_H(0)), безотносительно значения других параметров.
В одном варианте осуществления, значение для значения Run ограничено во избежание слишком большого кода Голомба. Фактически, когда значение является действительно большим, ассоциированный код Голомба имеет очень большое число битов. Это существенно повышает сложность процесса энтропийного декодирования и, как следствие, повышает сложность наихудшего случая. Наихудший случай используется для того, чтобы конструировать аппаратные средства. Альтернатива этому варианту осуществления заключается в том, чтобы ассоциировать предельное значение с кодом Голомба, и если это предельное значение декодируется, декодер считывает дополнительный двоичный код. Это означает то, что если текущее значение строго ниже предела, то текущее значение обычно кодируется с помощью кода Голомба. Кроме того, если это текущее значение выше или равно пределу, предел далее кодируется с помощью кода Голомба посредством фиксированного числа битов. Фиксированное число битов является двоичным кодом. В этом случае, текущее значение равно пределу плюс число, ассоциированное с дополнительными фиксированными битами.
Все описанные варианты осуществления могут комбинироваться.
В предпочтительном варианте осуществления, три категории задаются на основе режима прогнозирования и последнего декодированного уровня согласно следующей формуле:
If (pred_node==1) Order=Order0 else if (pred_node==0 AND level==0) Order=Order1
else Order=Order2
Три соответствующих значения Order: Ordre0, Order1 и Order2, инициализируются следующим образом: Order0=Order1=2, и Order2=0. Затем эти три порядковых значения обновляются согласно следующей формуле:
If(LastRunN=0) OrderN=Max(0, LastOrderN-1)
If(LastRunN>3*(LastOrderN+1)) OrderN=Min(A, LastOrderN+1),
где LastOrderN является последним используемым OrderN; LastRunN является последним декодированным значением Run для категории N.
Помимо этого, для Pred Mode=0, значения Run не кодируются и декодируются, когда значение последнего декодированного уровня строго больше (либо больше или равно) порогового значения. Пороговое значение извлекается из потока битов для каждой единицы кодирования в палитровом режиме.
При описании в связи с кодом Голомба, то же применимо для того, чтобы адаптировать длину любого другого энтропийного кода. Например, с использованием кода Хаффмана, конкретный словарь кода Хаффмана может определяться согласно параметрам кодирования.
Фиг. 17 является принципиальной блок-схемой вычислительного устройства 1700 для реализации одного или более вариантов осуществления изобретения. Вычислительное устройство 1700 может представлять собой такое устройство, как микрокомпьютер, рабочая станция или легкое портативное устройство. Вычислительное устройство 1700 содержит шину связи, соединенную со следующим:
- центральный процессор 1701, такой как микропроцессор, обозначаемый CPU;
- оперативное запоминающее устройство 1702, обозначаемое как RAM, для сохранения исполняемого кода способа вариантов осуществления изобретения, а также регистров, адаптированных с возможностью записывать переменные и параметры, необходимые для реализации способа для кодирования или декодирования, по меньшей мере, части изображения согласно вариантам осуществления изобретения, причем емкость запоминающего устройства может расширяться, например, посредством необязательного RAM, подключаемого к порту расширения;
- постоянное запоминающее устройство 1703, обозначаемое как ROM, для сохранения компьютерных программ для реализации изобретения;
- сетевой интерфейс 1704 типично соединяется с сетью связи, по которой передаются или принимаются цифровые данные, которые должны обрабатываться. Сетевой интерфейс 1704 может представлять собой единственный сетевой интерфейс либо состоять из набора различных сетевых интерфейсов (например, проводных и беспроводных интерфейсов либо различных видов проводных или беспроводных интерфейсов). Пакеты данных записываются в сетевой интерфейс для передачи или считываются из сетевого интерфейса для приема под управлением приложения, выполняющегося в CPU 1701;
- пользовательский интерфейс 1705 может использоваться для приема вводов от пользователя или отображения информации пользователю;
- жесткий диск 1706, обозначаемый как HD, может предоставляться в качестве устройства хранения данных большой емкости;
- модуль 1707 ввода-вывода может использоваться для приема/отправки данных из внешних устройств, таких как видеоисточник или дисплей.
Исполняемый код может сохраняться в постоянном запоминающем устройстве 1703, на жестком диске 1706 или на съемном цифровом носителе, таком как, например, диск. Согласно разновидности, исполняемый код программ может приниматься посредством сети связи, через сетевой интерфейс 1704, чтобы сохраняться на одном из средств хранения устройства 1700 связи, таком как жесткий диск 1706, перед выполнением.
Центральный процессор 1701 выполнен с возможностью управлять и направлять выполнение инструкций или частей программного кода программы или программ согласно варианту осуществления изобретения, причем эти инструкции сохраняются на одном из вышеуказанных средств хранения. После включения питания, CPU 1701 допускает выполнение инструкций из основного оперативного запоминающего устройства 1702, связанных с приложением, после того, как эти инструкции загружены, например, из ROM 1703 для программ или с жесткого диска 1706 (HD). Такое приложение, при выполнении посредством CPU 1701, инструктирует выполнение этапов блок-схем последовательности операций способа, показанных на фиг. 10-16.
Любой этап алгоритмов, показанных на фиг. 10-16, может реализовываться в программном обеспечении посредством выполнения набора инструкций или программы посредством программируемой вычислительной машины, такой как PC (персональный компьютер), DSP (процессор цифровых сигналов) или микроконтроллер; либо иным образом реализовываться в аппаратных средствах посредством машины или выделенного компонента, такого как FPGA (программируемая пользователем вентильная матрица) или ASIC (специализированная интегральная схема).
Хотя настоящее изобретение описано выше в отношении конкретных вариантов осуществления, настоящее изобретение не ограничено конкретными вариантами осуществления, и для специалистов в данной области техники должны быть очевидными модификации, которые находятся в пределах объема настоящего изобретения.
Множество дополнительных модификаций и изменений предполагаются специалистами в данной области техники после прочтения вышеприведенных иллюстративных вариантов осуществления, которые приводятся только в качестве примера и которые не имеют намерение ограничивать объем изобретения, который определяется исключительно посредством прилагаемой формулы изобретения. В частности, при необходимости различные признаки из различных вариантов осуществления могут меняться местами.
В формуле изобретения, слово "содержащий" не исключает другие элементы или этапы, и использование единственного числа не исключает множества. Простой факт того, что различные признаки упомянуты во взаимно различных зависимых пунктах формулы изобретения, не означает того, что комбинация этих признаков не может быть преимущественно использована.
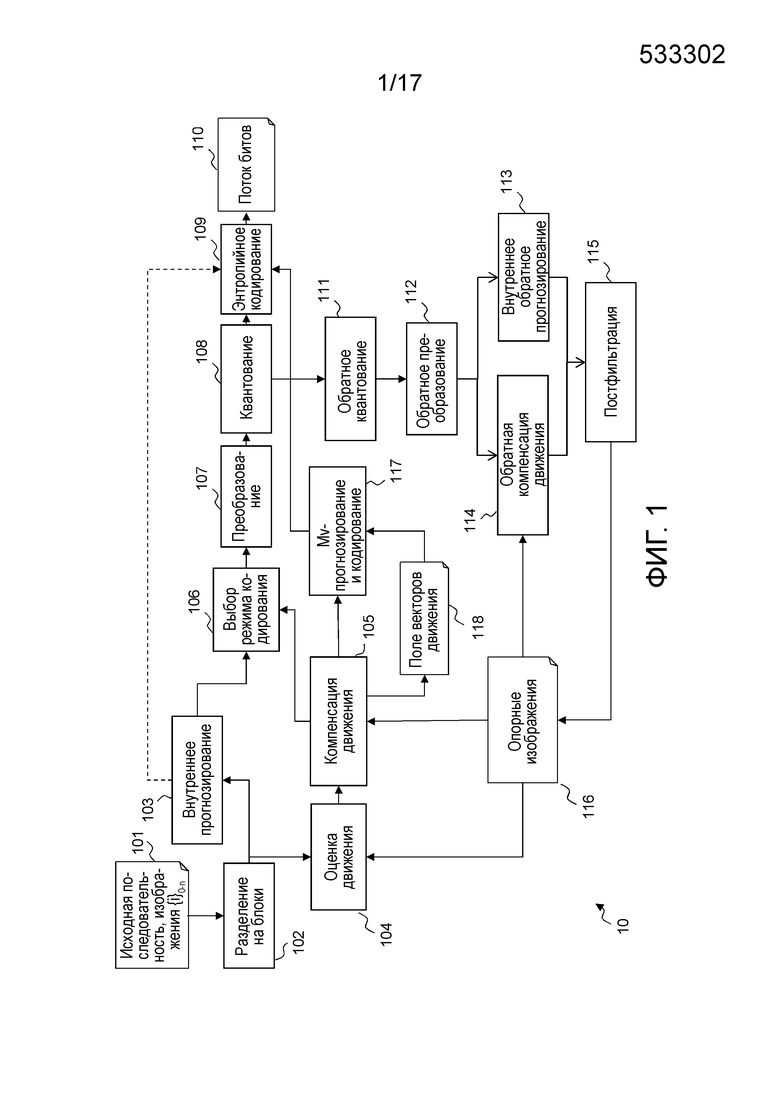
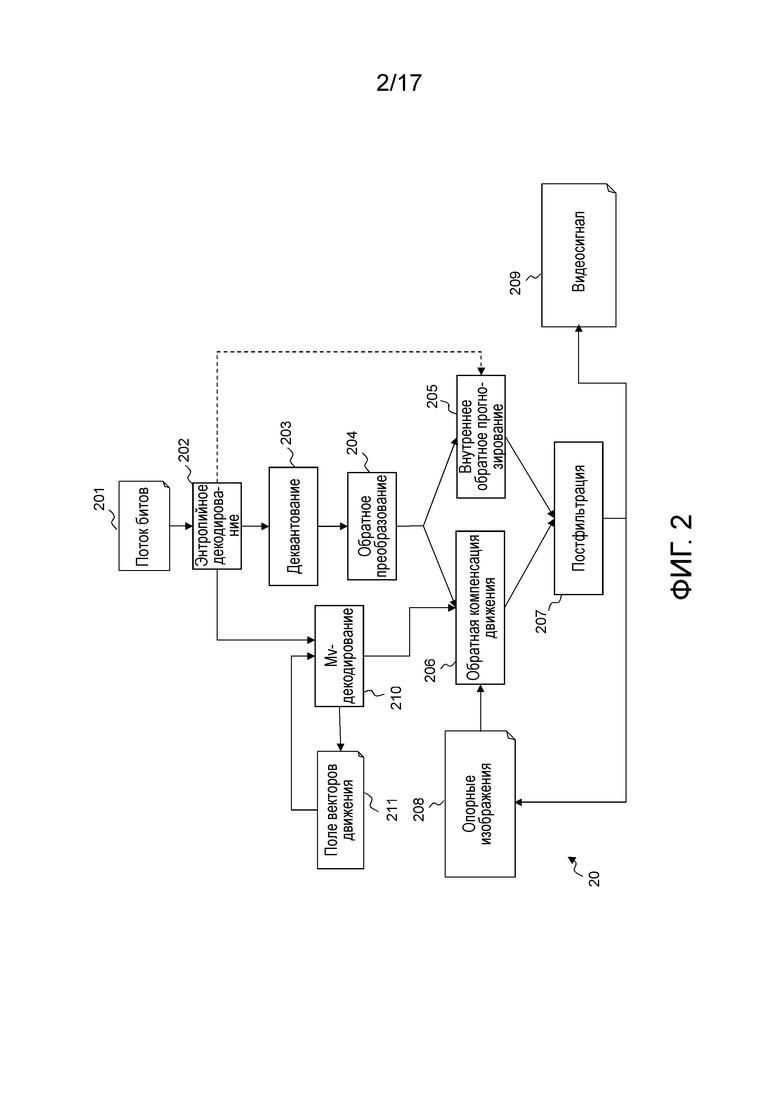
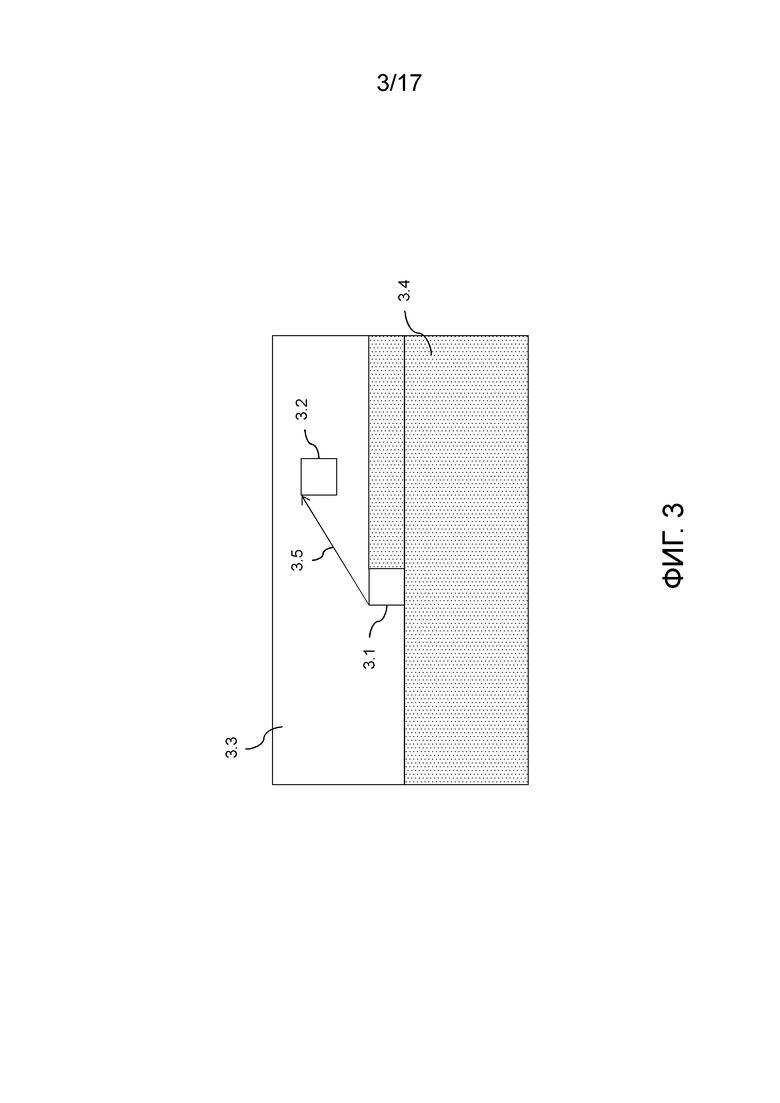
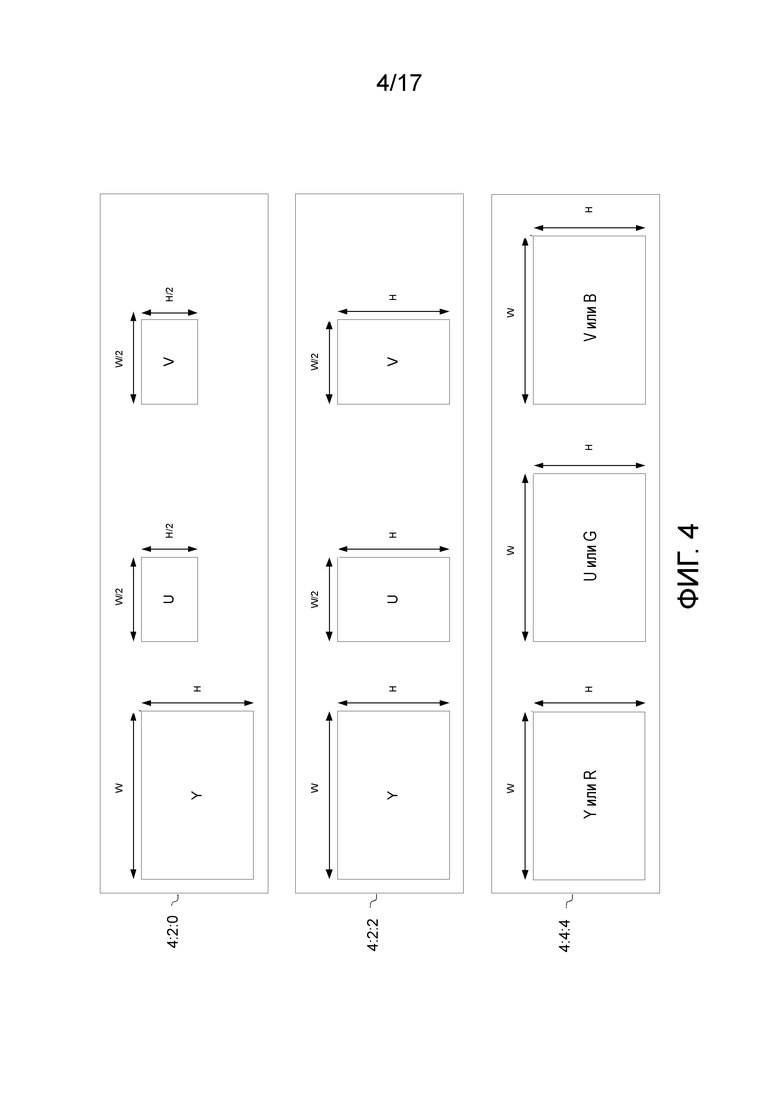
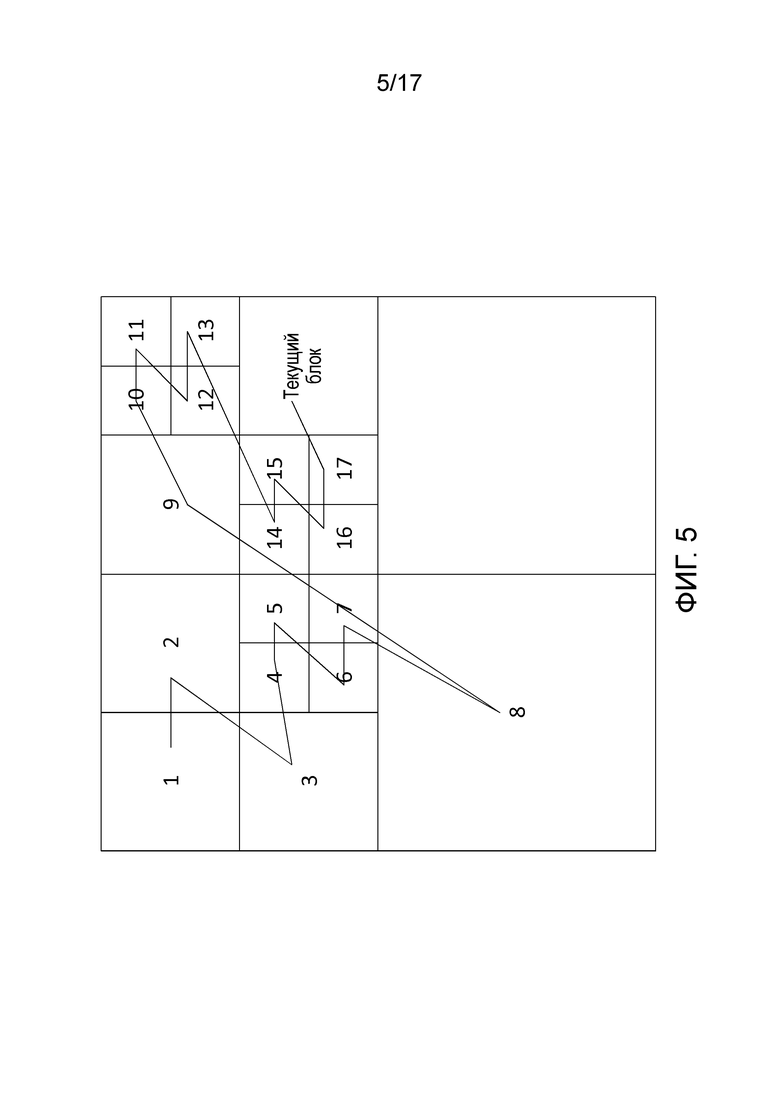
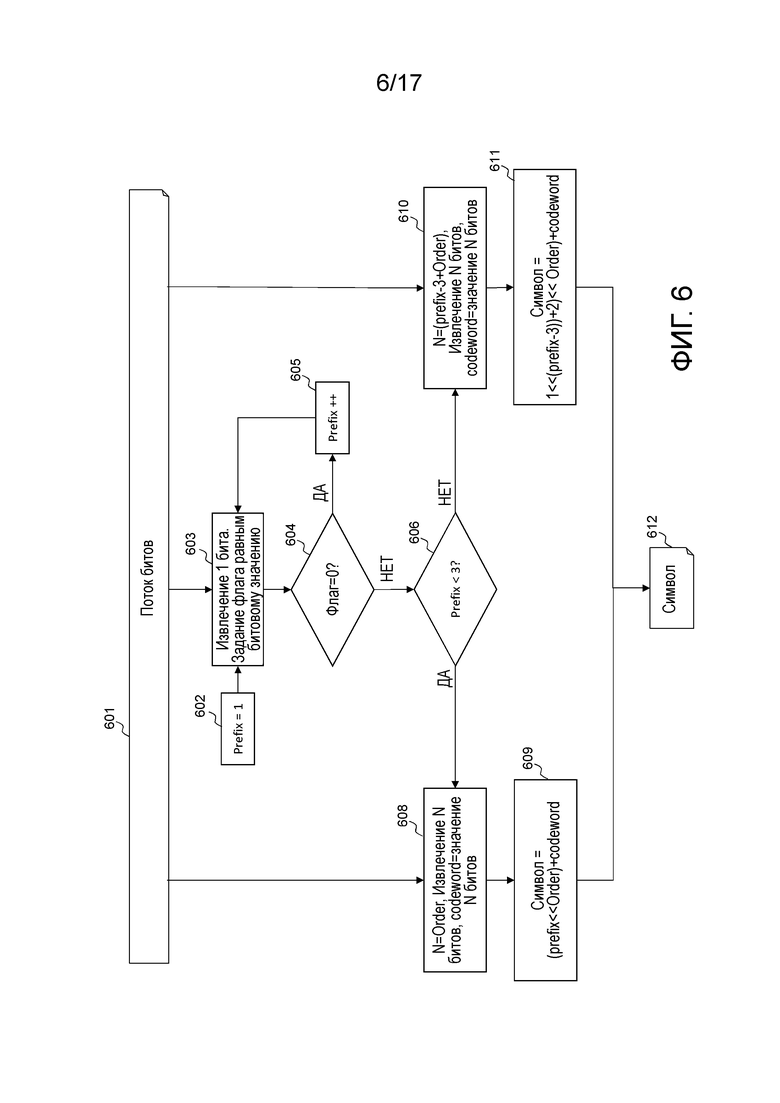
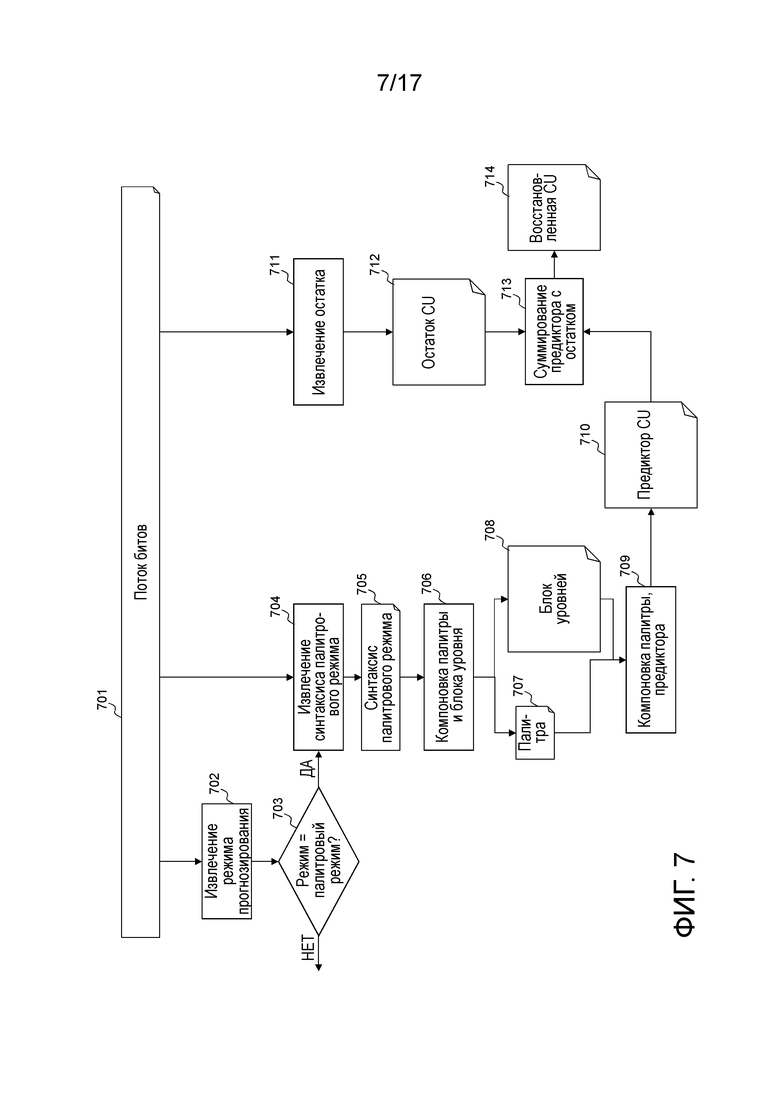
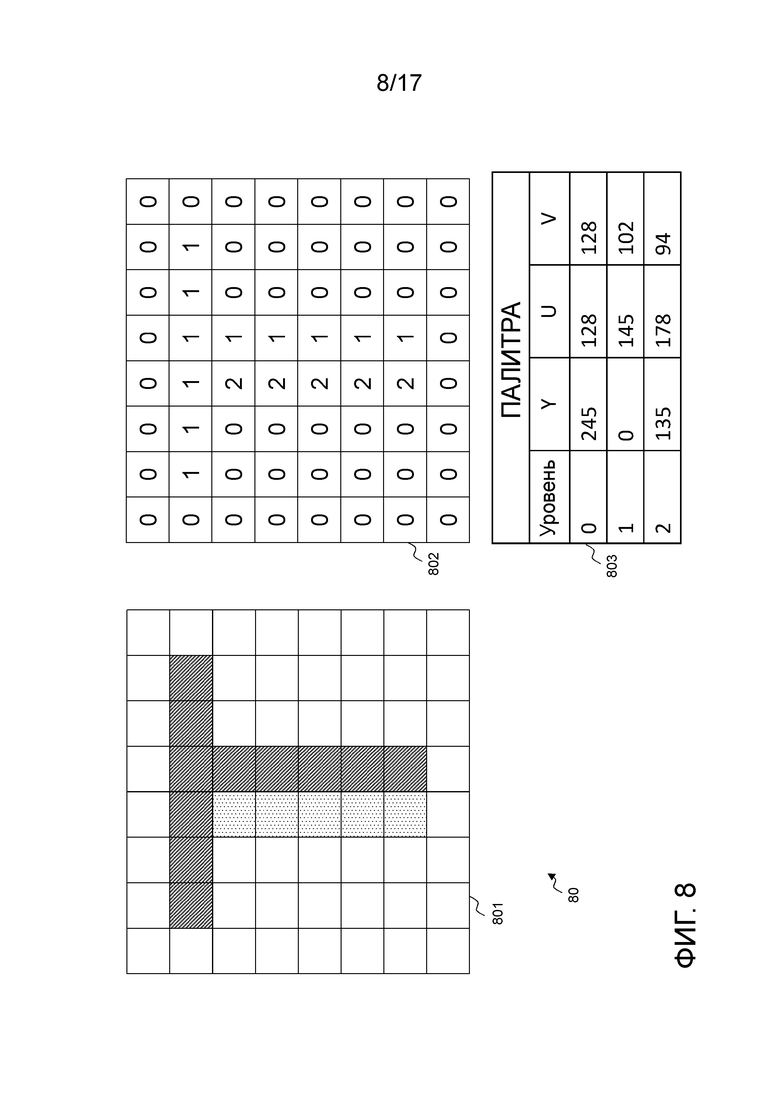
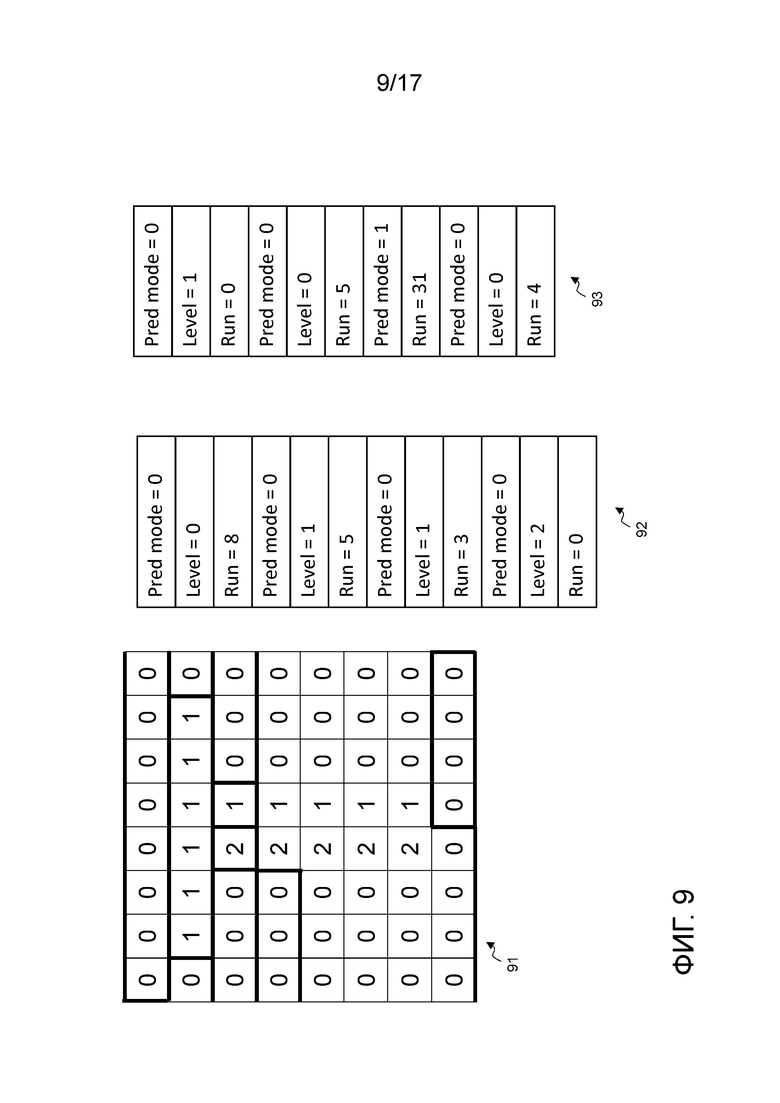
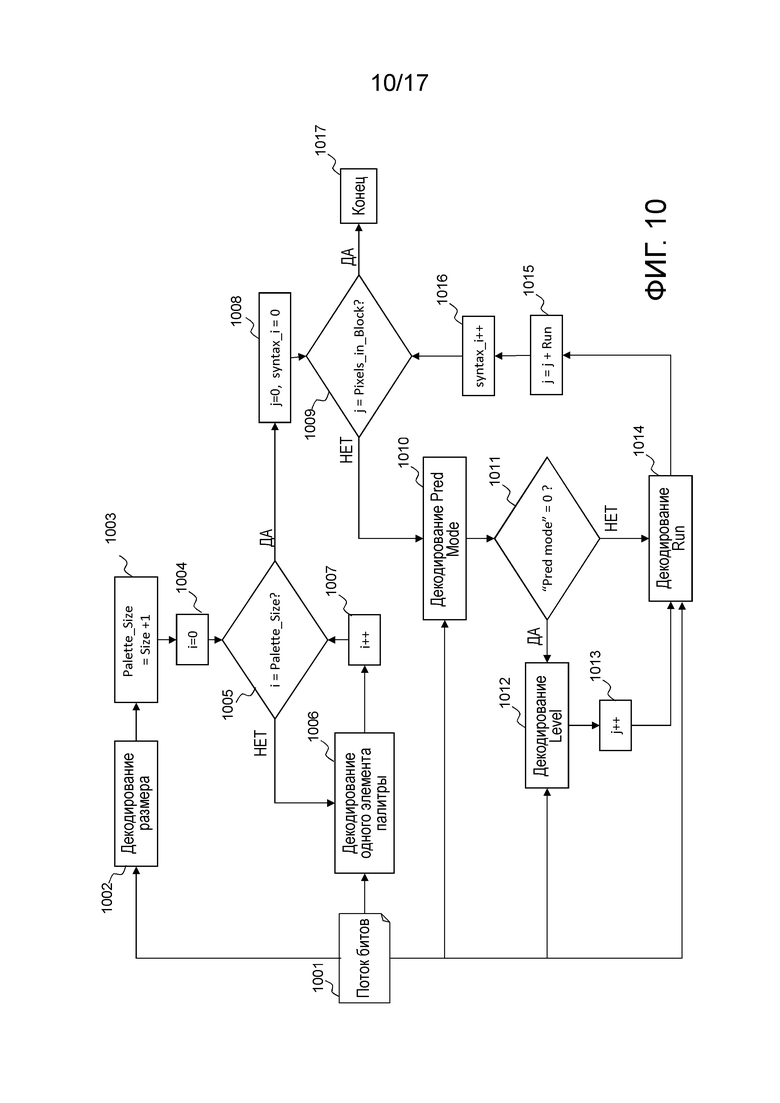
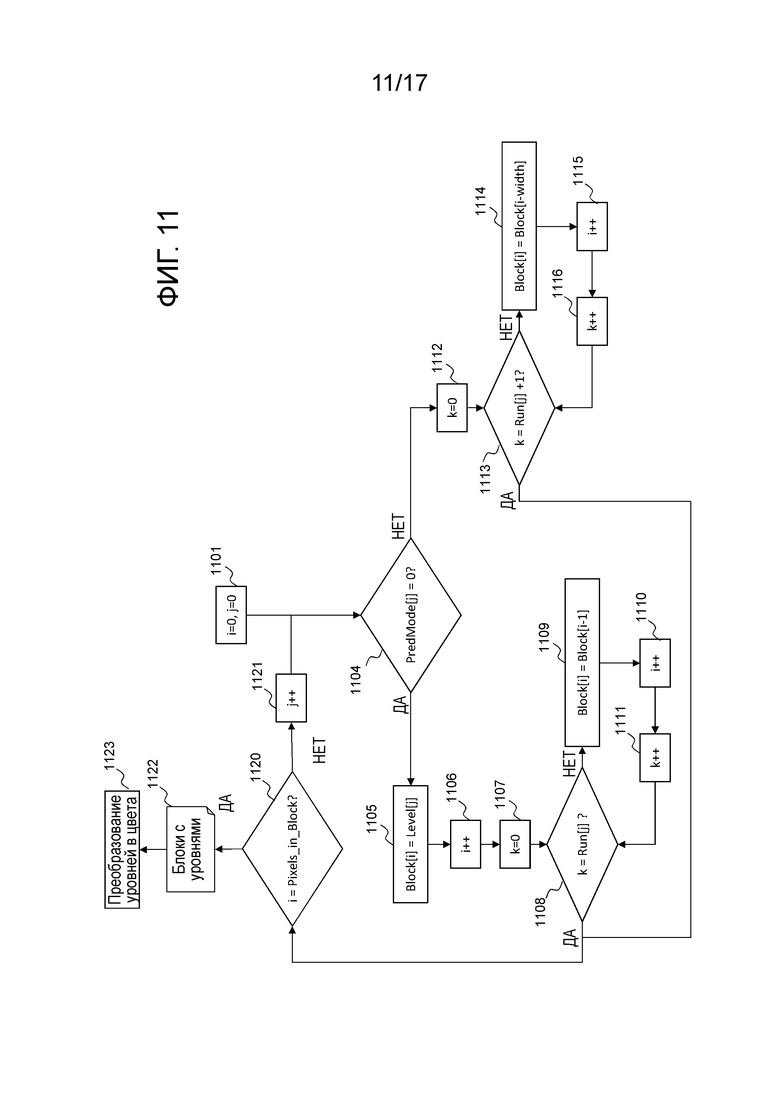
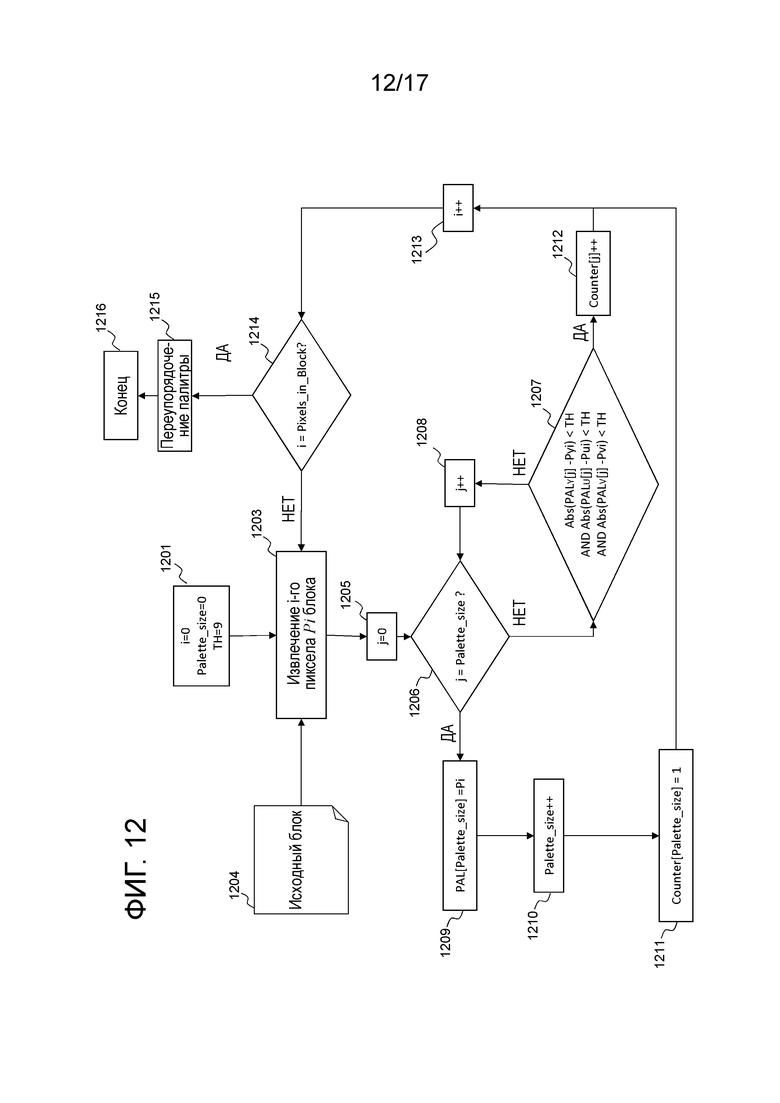
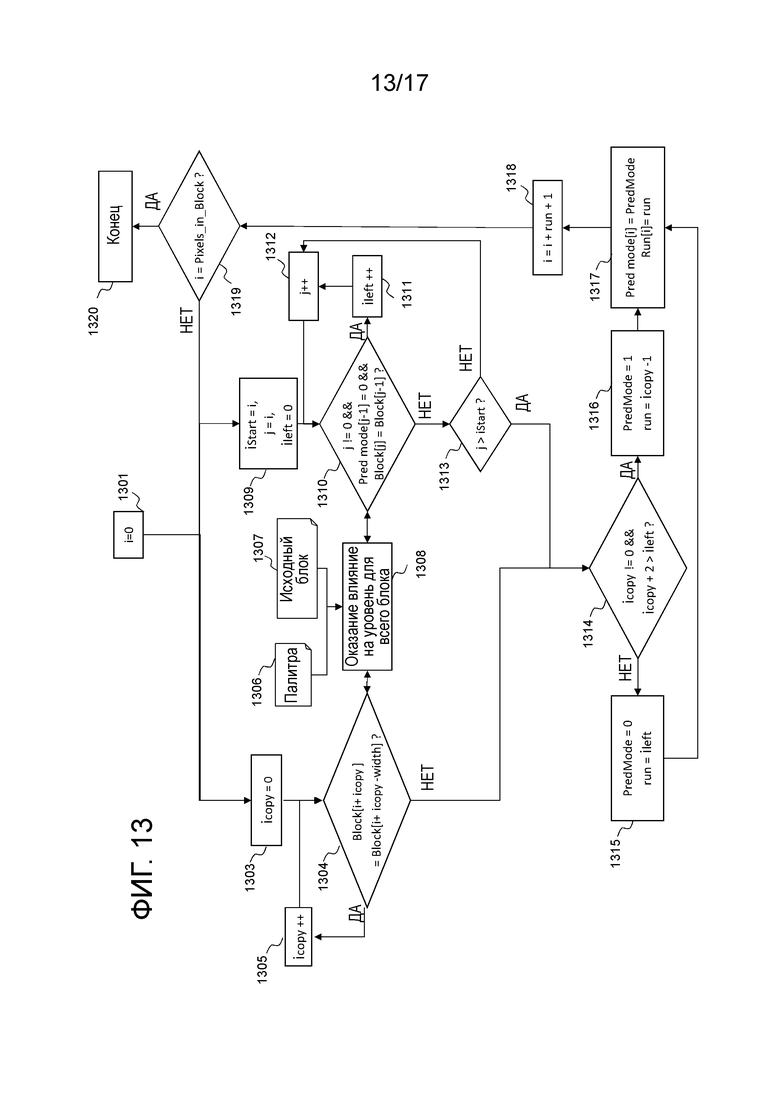
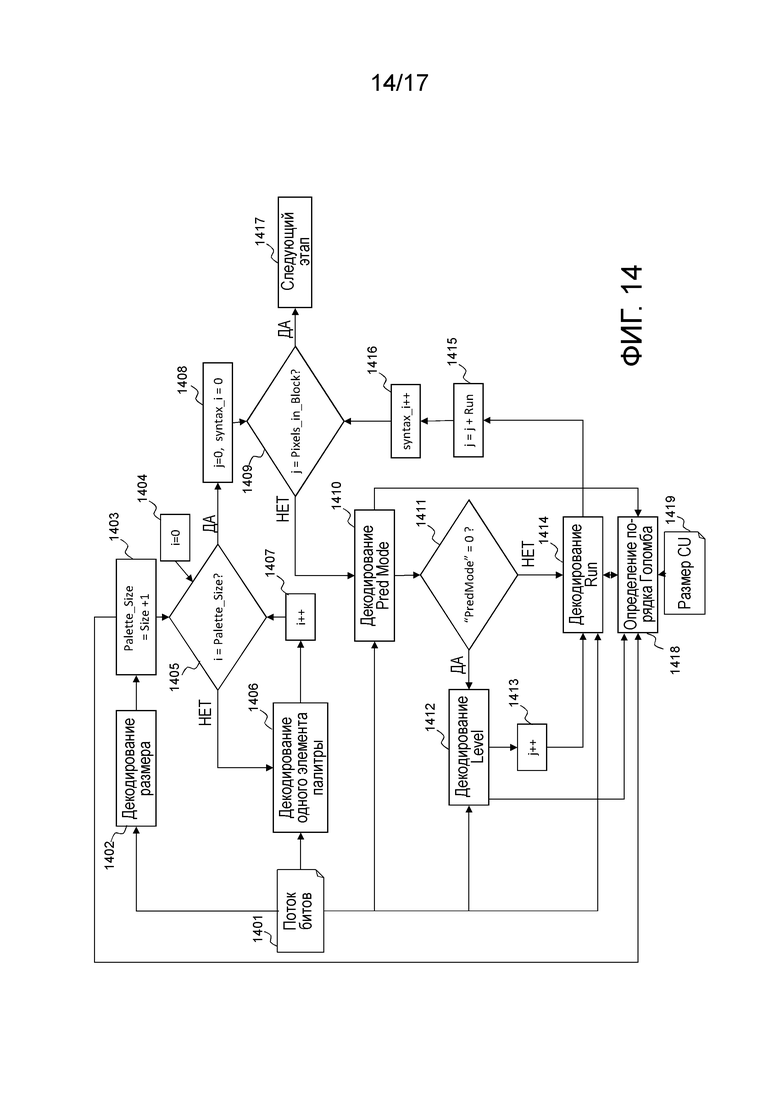
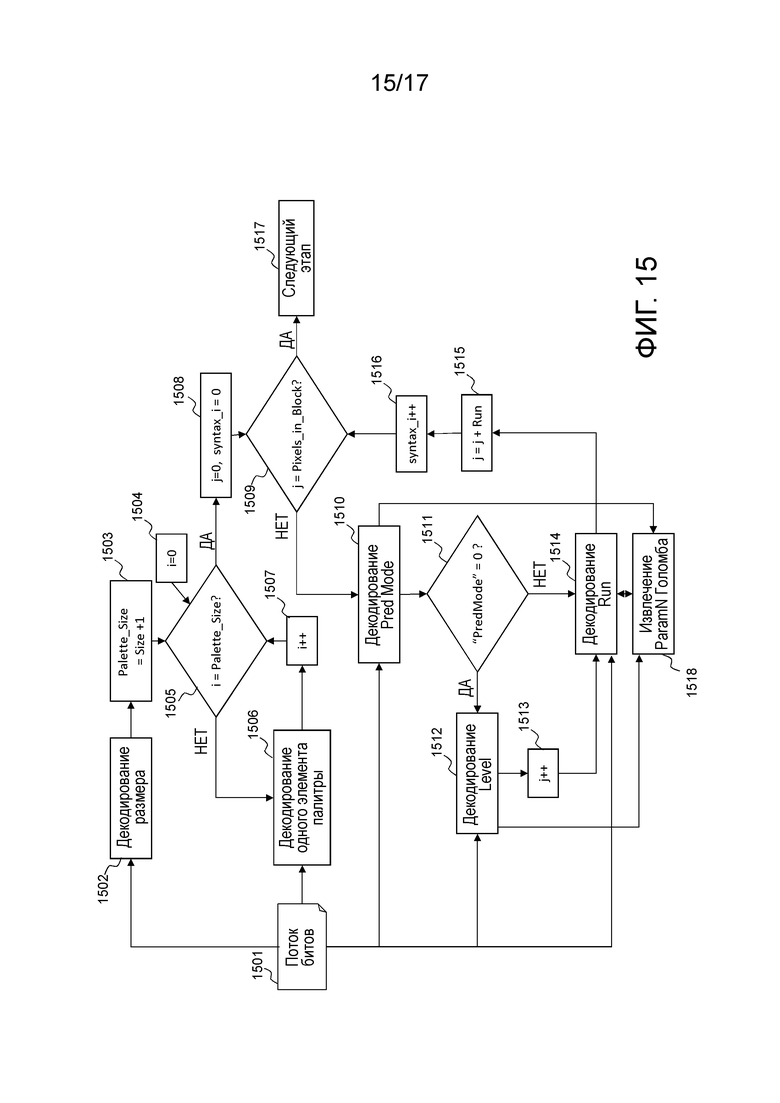
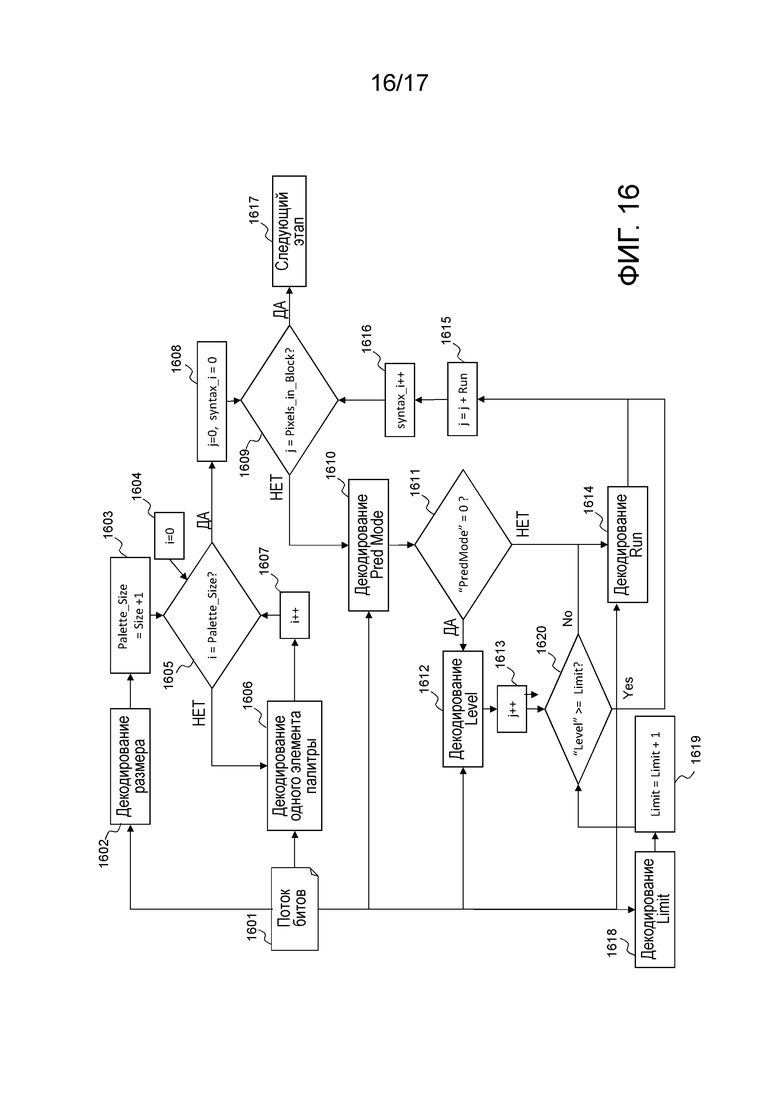
Изобретение относится к вычислительной технике. Технический результат заключается в улучшении кодирования элемента Run синтаксиса палитрового режима. Способ для определения параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования или декодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования или декодирования по меньшей мере части упомянутого блока индексов, при этом индекс упомянутого блока индексов кодируется с прогнозированием, используя один из множества режимов прогнозирования, и параметр упомянутого энтропийного кода определяется в зависимости от режима прогнозирования кодируемого с прогнозированием индекса, ассоциированного с энтропийным кодом. 9 н. и 12 з.п. ф-лы, 17 ил., 1 табл.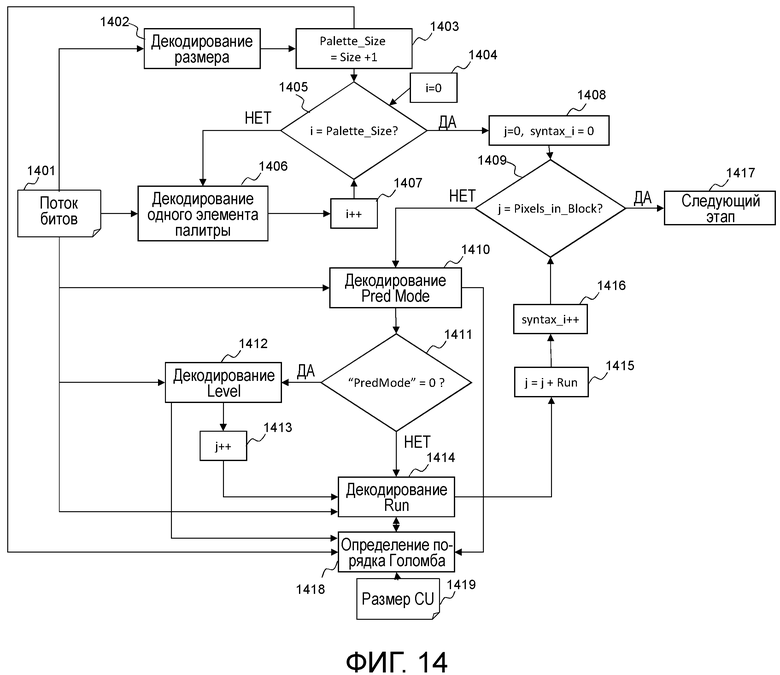
1. Способ для определения параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования или декодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования или декодирования по меньшей мере части упомянутого блока индексов, при этом индекс упомянутого блока индексов кодируется с прогнозированием, используя один из множества режимов прогнозирования, и параметр упомянутого энтропийного кода определяется в зависимости от режима прогнозирования кодируемого с прогнозированием индекса, ассоциированного с энтропийным кодом.
2. Способ по п. 1, в котором упомянутый параметр энтропийного кода связан с длиной энтропийного кода.
3. Способ по п. 1, в котором упомянутый энтропийный код представляет собой код Голомба.
4. Способ по п. 3, в котором упомянутый параметр энтропийного кода представляет собой порядок кода Голомба.
5. Способ по п. 1, в котором индекс упомянутого блока индексов кодируется посредством группы последовательных пикселов в порядке сканирования, причем каждая группа кодируется с использованием первого элемента синтаксиса, задающего режим прогнозирования, и второго элемента, задающего повторение, и упомянутый энтропийный код используется для кодирования второго элемента синтаксиса.
6. Способ по п. 5, в котором режимом прогнозирования кодируемого с прогнозированием индекса является режим копирования сверху, в котором значение индекса копируется из другого индекса, расположенного непосредственно над индексом в блоке индексов.
7. Способ по п. 5 или 6, в котором упомянутый первый элемент синтаксиса, задающий режим прогнозирования, состоит из флага.
8. Способ по п. 5, при этом способ содержит этапы, на которых:
- определяют категории на основе второго параметра, используемого в процессе кодирования упомянутого блока индексов; и
- определяют значение упомянутого параметра энтропийного кода для каждой категории.
9. Способ по п. 8, при этом способ дополнительно содержит этап, на котором:
- адаптируют упомянутые определенные значения параметра энтропийного кода на основе третьего параметра, используемого в процессе кодирования упомянутого блока индексов.
10. Способ по п. 9, в котором упомянутый третий параметр содержит последнее значение, определенное для идентичной категории, и последнее кодированное повторяющееся значение.
11. Способ по п. 8, в котором второй параметр содержит режим прогнозирования или значение индекса пиксела, ассоциированного с энтропийным кодом.
12. Способ по п. 1, в котором параметр энтропийного кода определяется для кодирования данного элемента в качестве значения параметра энтропийного кода, которое было бы оптимальным для кодирования или декодирования последнего кодированного или декодированного соответствующего элемента.
13. Способ по п. 1, в котором значение параметра энтропийного кода ограничивается фиксированным числом значений.
14. Способ для кодирования видеоданных в потоке битов, при этом упомянутый способ содержит этапы, на которых:
- определяют параметр энтропийного кода согласно способу по п. 1; и
- записывают значение в упомянутый поток битов с использованием упомянутого определенного параметра энтропийного кода.
15. Способ для декодирования видеоданных из потока битов, при этом упомянутый способ содержит этапы, на которых:
- получают из упомянутого потока битов параметр, использованный в процессе кодирования блока индексов; и
- определяют параметр энтропийного кода согласно способу по п. 1.
16. Устройство для определения параметра для кодирования или декодирования видеоданных, упомянутое устройство содержит:
средство определения для определения параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования или декодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования или декодирования по меньшей мере части упомянутого блока индексов,
при этом индекс упомянутого блока индексов кодируется с прогнозированием, используя один из множества режимов прогнозирования, и средство определения выполнено с возможностью определения параметра упомянутого энтропийного кода в зависимости от режима прогнозирования кодируемого с прогнозированием индекса, ассоциированного с энтропийным кодом.
17. Устройство для кодирования видеоданных в поток битов, содержащее:
- средство для определения параметра энтропийного кода, ассоциированного с индексами из блока индексов, используемого для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код используется для кодирования по меньшей мере части упомянутого блока индексов; и
- средство для записи значения в упомянутый поток битов с использованием определенного параметра энтропийного кода,
при этом индекс упомянутого блока индексов кодируется с прогнозированием, используя один из множества режимов прогнозирования, и
средство для определения выполнено с возможностью определения параметра упомянутого энтропийного кода в зависимости от режима прогнозирования кодируемого с прогнозированием индекса, ассоциированного с энтропийным кодом.
18. Устройство для декодирования видеоданных из потока битов, содержащее:
- средство для получения из упомянутого потока битов параметра, использованного в процессе кодирования блока индексов; и
- средство для определения параметра энтропийного кода, ассоциированного с индексами из блока индексов, использованного для кодирования единицы кодирования изображения согласно палитре, причем упомянутая палитра содержит набор индексов, ассоциированных с пиксельными значениями, причем упомянутый энтропийный код использовался для кодирования по меньшей мере части упомянутого блока индексов, при этом индекс упомянутого блока индексов кодирован с прогнозированием, используя один из множества режимов прогнозирования, и средство для определения выполнено с возможностью определения параметра упомянутого энтропийного кода в зависимости от режима прогнозирования, использованного в процессе кодирования упомянутого блока индексов.
19. Машиночитаемый носитель хранения данных, хранящий инструкции компьютерной программы для реализации способа по любому из пп. 1-13 при загрузке в и исполнении программируемым устройством.
20. Машиночитаемый носитель хранения данных, хранящий инструкции компьютерной программы для реализации способа по п. 14 при загрузке в и исполнении программируемым устройством.
21. Машиночитаемый носитель хранения данных, хранящий инструкции компьютерной программы для реализации способа по п. 15 при загрузке в и исполнении программируемым устройством.
| M.J | |||
| WEINBERGER et al | |||
| " The LOCO-I Lossless Image Compression Algorithm: Principles and Standardization into JPEG-LS", опубл | |||
| Способ очистки нефти и нефтяных продуктов и уничтожения их флюоресценции | 1921 |
|
SU31A1 |
| L | |||
| GUO et al | |||
| Способ гальванического снятия позолоты с серебряных изделий без заметного изменения их формы | 1923 |
|
SU12A1 |
| Пишущая машина для тюркско-арабского шрифта | 1922 |
|
SU24A1 |
| D | |||
| FLYNN et al | |||
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| US 7340103 B2, 04.03.2008 | |||
| СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ СИГНАЛА ИЗОБРАЖЕНИЯ, СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ИСТОЧНИКА ИНФОРМАЦИИ, УСТРОЙСТВА ДЛЯ НИХ И НОСИТЕЛИ ИНФОРМАЦИИ, НА КОТОРЫХ СОХРАНЕНЫ ПРОГРАММЫ ДЛЯ НИХ | 2007 |
|
RU2406222C1 |

