ОБЛАСТЬ ТЕХНИКИ
[0001] Данное техническое решение относится, в общем, к вычислительным способам защиты информационных систем, а, в частности, к способам обнаружения атак перебора на веб-сервис.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время сетевые информационные системы могут и зачастую подвергаются компьютерным атакам со стороны злоумышленников.
[0003] Обнаружение вторжений - процесс мониторинга событий в компьютерной системе или сети и анализа их на предмет нарушений политики безопасности.
[0004] Типичными примерами атак, мониторинг которых осуществляет система обнаружения вторжений, являются: внедрение вредоносного кода; исчерпание полосы пропускания путем большого количества соединений; подбор пароля; сетевая активность троянских коней, червей и вирусов; и т.д.
[0005] Из уровня техники известна заявка на патент US 20160004580 А1 «System and Method for Bruteforce Intrusion Detection», патентообладатель: Leviathan, Inc., дата публикации: 07.012016.
[0006] В данном техническом решении выполняют обнаружение потенциальных атак на домен в ответ на аномальное событие. Выбирают значение параметра лямбда, соответствующее аномальному событию, из созданной модели для текущего интервала времени. Определяют вероятность того, является ли общее количество аномальных событий для текущего интервала времени легитимным, используют функцию распределения, зависящую от параметра лямбда, определяют факт умышленной атаки, если вероятность меньше или равна выбранному значению альфа.
[0007] Недостатком технического решения является отсутствие возможности автоматически идентифицировать события, как аномальные.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0008] Данное техническое решение направлено на устранение недостатков, свойственных решениям, известным из уровня техники.
[0009] Техническим результатом является уменьшение вероятности ложных срабатываний при обнаружении сетевой атаки.
[00010] Указанный технический результат достигается благодаря способу обнаружения атак перебора на веб-сервис, в котором принимают набор запросов на веб-сервис от по меньшей мере одного клиента; формируют на веб-сервисе ответ для каждого вышеуказанного клиента, от которого получен набор запросов; формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством способа кластеризации их характеристик; для каждого кластера, сформированного на предыдущем шаге, формируют набор правил попадания полученной пары «запрос-ответ» в данный кластер; задают по меньшей мере один интервал времени, в течение которого собираются характеристики пар «запрос-ответ»; для каждого заданного интервала времени и клиента, определяют количество его запросов веб-сервису, попадающих в каждый из сформированных кластеров по характеристикам пар «запрос-ответ»; для каждого заданного интервала времени и кластера формируют пороговое значение количества запросов, попадающих в данный кластер; для каждого заданного интервала времени и для каждого клиента, сравнивают количество новых поступивших запросов с пороговым значением для каждого кластера; в случае превышения количества запрос порогового значения, принимают решение об обнаружении атаки перебора на веб-сервис.
[00011] В некоторых вариантах осуществления набор запросов обрабатывается сервером на веб-сервисе последовательно.
[00012] В некоторых вариантах осуществления, если одновременно приходит более одного запроса, то запросы устанавливаются в очередь для обработки.
[00013] В некоторых вариантах осуществления запросы, находящиеся в наборе, имеют приоритеты.
[00014] В некоторых вариантах осуществления запросы направляются от клиента по протоколу прикладного уровня передачи данных HTTP.
[00015] В некоторых вариантах осуществления ответ состоит из стартовой строки, заголовка, тела сообщения.
[00016] В некоторых вариантах осуществления каждая пара «запрос-ответ» имеет уникальный идентификатор.
[00017] В некоторых вариантах осуществления формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством алгоритма K-means.
[00018] В некоторых вариантах осуществления каждому сформированному кластеру присваивают уникальный идентификатор.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[00019] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
[00020] На Фиг. 1 показана блок-схема способа обнаружения атак перебора на веб-сервис;
ПОДРОБНОЕ РАСКРЫТИЕ ТЕХНИЧЕСКОГО РЕШЕНИЯ
[00021] Ниже будут описаны понятия и определения, необходимые для подробного раскрытия осуществляемого технического решения.
[00022] Техническое решение может быть реализовано в виде распределенной компьютерной системы.
[00023] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[00024] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[00025] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические носители (CD, DVD и т.п.).
[00026] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[00027] HTTP запрос, или сообщение состоит из трех частей: строки запроса, заголовков, и тела HTTP сообщения. Строка запроса, или стартовая строка: в запросе к веб-сервису - строка, которая содержит тип запроса (метод), URI запрашиваемой страницы, и версия HTTP протокола (например НТТР/1.1). В ответе от сервера эта строка содержит версию HTTP протокола, и код ответа. Код ответа представляет собой целое число из трех цифр. За ним обычно следует отделенная пробелом поясняющая фраза, поясняющая код, например: 200 ОК, или 404 Not Found.
[00028] Веб-сервис (англ. web service) - идентифицируемая веб-адресом программная система со стандартизированными интерфейсами, которая располагается на по меньшей мере одном сервере.
[00029] Кластер (англ. cluster) - термин в информатике, обозначающий группу объектов с общими признаками.
[00030] Клиент - это аппаратный или программный компонент вычислительной системы, посылающий запросы серверу, на котором находится веб-сервис. Клиент взаимодействует с сервером, используя определенный протокол. Он может запрашивать с сервера какие-либо данные, манипулировать данными непосредственно на сервере, запускать на сервере новые процессы и т.п.
[00031] HTTP (англ. HyperText Transfer Protocol - «протокол передачи гипертекста») - протокол прикладного уровня передачи данных. Основой HTTP является технология «клиент-сервер», то есть предполагается существование:
[00032] Потребителей (клиентов), которые инициируют соединение и посылают запрос;
[00033] Поставщиков (серверов), которые ожидают соединения для получения запроса, производят необходимые действия и возвращают обратно сообщение с результатом.
[00034] Каждый HTTP "запрос - ответ" содержит следующие параметры, которые выделены для кластеризации и поиска аномалий в http - трафике:
[00035] Длина ответа (англ. Content-Lenght) - размер содержимого сущности (HTTP-ответа) в октеках (которые в русском языке обычно называют байтами).
[00036] Время отклика (англ. response time) - время, которое требуется системе на то, чтобы ответить на HTTP-запрос. Время отклика - в технологии время, которое требуется системе или функциональной единице на то, чтобы отреагировать на данный ввод.
[00037] Код состояния HTTP (англ. HTTP status code) - часть первой строки ответа сервера при запросах по протоколу HTTP. Он представляет собой целое число из трех десятичных цифр.
[00038] Единый указатель ресурса (англ. Uniform Resource Locator, URL) - единообразный локатор (определитель местонахождения) ресурса.
[00039] IP адрес, с которого получен HTTP запрос.
[00040] Точка - числовые значения параметров, выделенных для кластеризации, например: [длина_ответа, время_отклика, код_состояния].
[00041] В криптографии на полном переборе основывается криптографическая атака перебором или атака «грубой силы». Ее особенностью является возможность применения против любого практически используемого шифра. Однако такая возможность существует лишь теоретически, зачастую требуя нереалистичные временные и ресурсные затраты. Наиболее оправдано использование атаки методом «грубой силы» в тех случаях, когда не удается найти слабых мест в системе шифрования, подвергаемой атаке (либо в рассматриваемой системе шифрования слабых мест не существует). При обнаружении таких недостатков разрабатываются методики криптоанализа, основанные на их особенностях, что способствует упрощению взлома.
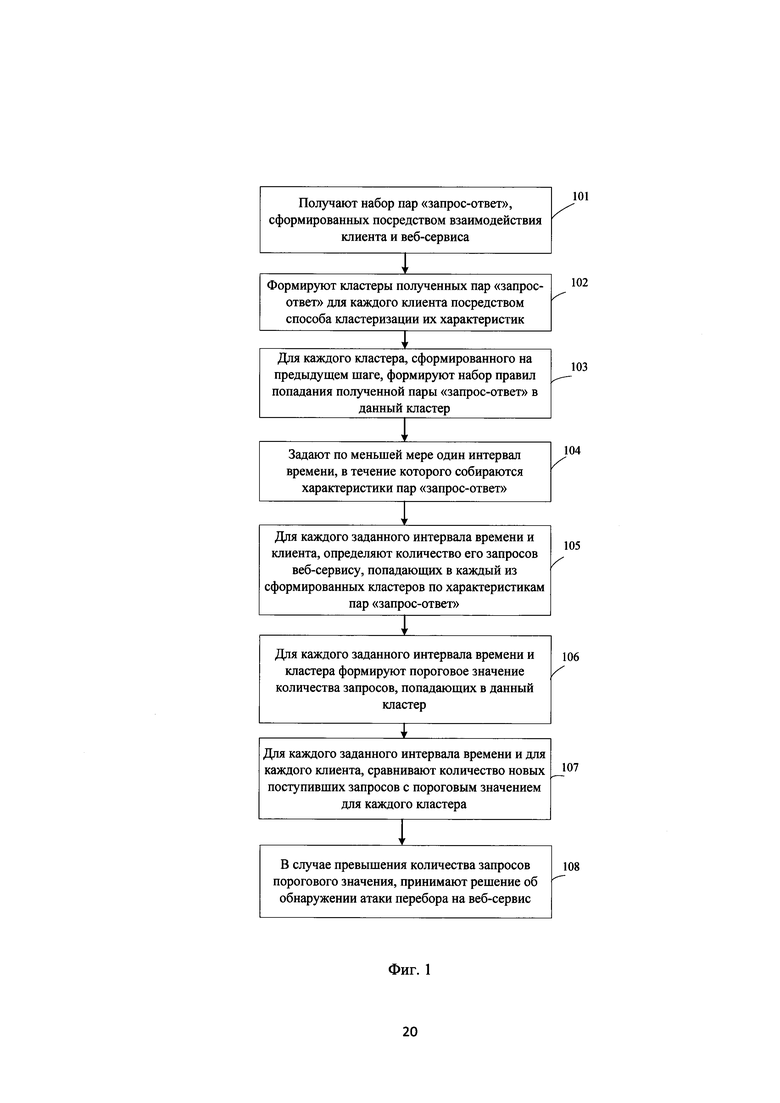
[00042] Фиг. 1 представляет собой блок-схему, показывающую способ обнаружения атак перебора на веб-сервис, который содержит следующие шаги:
[00043] Шаг 101: получают набор пар «запрос-ответ», сформированных посредством взаимодействия клиента и веб-сервиса;
[00044] В некоторых вариантах осуществления набор пар «запрос-ответ» могут получать как из хранилища данных, заранее сформированных, так и в режиме реального времени.
[00045] На данном шаге принимают набор запросов от клиентов. Запросы обрабатываются сервером на веб-сервисе последовательно. Если одновременно приходит более одного запроса, то запросы устанавливаются в очередь. В данном случае очередь - это список невыполненных клиентских запросов. Иногда запросы могут иметь приоритеты. Запросы с более высокими приоритетами должны выполняться раньше.
[00046] Цикл выполнения запроса состоит из пересылки запроса и ответа между клиентом и сервером и непосредственным выполнением этого запроса на сервере.
[00047] Как правило, выполнение запроса (сложного запроса) происходит дольше, чем время, затрачиваемое на пересылку запроса и результата. Поэтому в серверах применяются системы распределения транзакций (запросов) между доменами (частями) сервера. Транзакция - это набор команд, которые либо выполняются все или не выполняется ни одна. Домен - это элемент сервера. Нередко сервер на физическом уровне представляет собой не один, а группу компьютеров, объединенных в одну систему для обеспечения каких-либо операций. В примерных вариантах осуществления запрос направляется от клиента по протоколу прикладного уровня передачи данных HTTP.
[00048] Каждый HTTP-запрос состоит из трех частей, которые передаются в указанном порядке:
[00049] Стартовая строка (англ. Starting line) определяет тип сообщения;
[00050] Заголовки (англ. Headers) характеризуют тело сообщения, параметры передачи и прочие сведения;
[00051] Тело сообщения (англ. Message Body) - непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
[00052] Заголовки и тело сообщения могут отсутствовать, но стартовая строка является обязательным элементом, так как указывает на тип запроса/ответа. Исключением является версия 0.9 протокола, у которой сообщение запроса содержит только стартовую строку, а сообщения ответа - только тело сообщения.
[00053] формируют на веб-сервисе ответ для каждого вышеуказанного клиента, от которого получен набор запросов;
[00054] После получения и обработки запроса формируют на сервере ответ и посылают ответ клиентам. Каждый HTTP-ответ, как и HTTP-запрос, состоит из трех частей, которые передаются в указанном порядке: стартовая строка (англ. Starting line), заголовки (англ. Headers), тело сообщения (англ. Message Body).
[00055] Стартовая строка ответа сервера имеет следующий формат:
HTTP/Версия Код Состояния Пояснение, где:
Версия - пара разделенных точкой цифр, как в запросе;
Код состояния (англ. Status Code) - три цифры. По коду состояния определяется дальнейшее содержимое сообщения и поведение клиента;
Пояснение (англ. Reason Phrase) - текстовое короткое пояснение к коду ответа для пользователя. Пояснение никак не влияет на суть сообщения и является необязательным.
[00056] Шаг 102: формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством способа кластеризации их характеристик;
[00057] После отправки ответа на запрос клиенту формируется пара «запрос-ответ», которая имеет уникальный идентификатор. В хранилище данных хранятся все значения параметров пар «запрос-ответ», такие как ее идентификатор, длина ответа, время отклика, код состояния HTTP, IP-адрес с которого был получен HTTP запрос, единый указатель ресурса. Указанные характеристики могут храниться в хранилище данных в виде списка, таблицы, дерева, не ограничиваясь. При поступлении каждого нового запроса и формирования ответа, данные сохраняются в хранилище.
[00058] Кластеры формируют следующим образом. Сначала осуществляют группирование пар «запрос-ответ» по уникальному значению единого указателя ресурса (URL), не ограничиваясь. В некоторых вариантах реализации группировку могут осуществлять по другому значению или другому принципу.
[00059] Далее каждую группу, сформированную, например, по URL, разбивают посредством алгоритма кластеризации.
[00060] В примерном варианте осуществления алгоритм кластеризации работает посредством введения функции расстояния.
[00061] К одному единому указателю ресурса (URL) могут относиться параметры: длина ответа, время отклика и код состояния.
[00062] Вводят функцию расстояния между двумя точками (для алгоритма это числовые значения параметров [длина_ответа, время_отклика, код_состояния] для каждой пары «запрос-ответ»), например i=[длина_ответа_i, время_отклика_i, код_состояния_i] и j=[длина_ответа_j, время_отклика_j, код_состояния_j]:

[00063] Затем фиксируют минимальное и максимальное количество кластеров, после чего используют алгоритм кластеризации K-means, где k пробегает значения от минимального количества кластеров до максимального количества кластеров с интервалом единица, m раз (m фиксируется). Количество итераций может фиксироваться автоматически или посредством пользователя. Таким образом, алгоритму K-means передаются следующие входные данные: количество кластеров; «точки данных» в трехмерном пространстве; введенная функция расстояния (1).
[00064] Затем фиксируют минимальное количество (например, k_min) кластеров и максимальное количество (например, k_max) кластеров, которые являются натуральными числами.
[00065] В итоге алгоритм K-means запустился (m*(k_max - k_min)) раз, где m - фиксированное значение, после чего получают (m*(k_max - k_min)) разбиений пар «запрос-ответ». Далее среди полученных разбиений выбирают одно следующим способом, описанным ниже.
[00066] Выбирают одно наиболее качественное разбиение, по любому известному методу оценки качества разбиения, например, S_Dwb индекса, RMSSTD и RS индексов, индекса оценки силуэта и т.д., не ограничиваясь, известных из источника информации [1], [2].
[00067] Таким образом, получают набор кластеров, где каждый кластер соответствует одному URL-адресу.
[00068] Шаг 103: для каждого кластера, сформированного на предыдущем шаге, формируют набор правил попадания полученной пары «запрос-ответ» в данный кластер;
[00069] Для каждого кластера определяют его центр следующим образом:
[00070] для длины ответа используют среднее арифметическое, для времени отклика используют среднее арифметическое, а для кода статуса используют, например следующую формулу:
[00071] 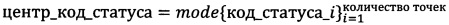
[00072] где mode (мода) - значение во множестве наблюдений, которое встречается наиболее часто [3]. Под количеством точек понимается количество кластеризованных точек.
[00073] Для каждого кластера определяют его характеристики. Характеристиками могут быть, например, URL-адрес, минимальное значение длины ответа в кластере, максимальное значение длины ответа в кластере, минимальное время отклика в кластере, максимальное время отклика в кластере, минимальное значение кода статуса в кластере, максимальное значение кода статуса в кластере.
[00074] Также каждому кластеру ставится в соответствие уникальный идентификатор, который может являться числом или, например URL-кодом данного кластера.
[00075] Для каждого кластера все данные сохраняются в хранилище данных.
[00076] Затем при получении каждой новой пары «запрос-ответ» определяют, к какому кластеру она относится посредством проверки на соответствие следующим условиям: соответствует ли значение URL пары «запрос-ответ» хотя бы одному значению URL кластера, находится ли длина ответа между минимальным и максимальным допустимыми значениями кластера, находится ли время отклика между минимальным и максимальным допустимыми значениями кластера, находится ли код статуса между минимальным и максимальным допустимыми значениями кластера.
[00077] Вышеописанное правило может быть несколько другим. Например, может определяться попадание не в интервал с минимальными и максимальными значениями, а с заранее заданными пороговыми значениями.
[00078] Шаг 104: задают по меньшей мере один интервал времени, в течение которого собираются характеристики пар «запрос-ответ»;
[00079] На данном шаге устанавливают интервал времени (в минутах или секундах), в течение которого собираются характеристики пар «запрос-ответ».
[00080] Шаг 105: для каждого заданного интервала времени и клиента, определяют количество его запросов веб-сервису, попадающих в каждый из сформированных кластеров по характеристикам пар «запрос-ответ».
[00081] Имея интервал времени и клиента, применяют для каждой пары «запрос-ответ» правило попадания пары в кластер. Количество запросов клиента к веб-сервису также известно.
[00082] Сохраняют полученные значения для каждого интервала времени и клиента в хранилище данных.
[00083] Шаг 106: для каждого заданного интервала времени и кластера формируют пороговое значение количества запросов, попадающих в данный кластер.
[00084] Пороговое значение формируют следующим образом:
[00085] Для каждого заданного интервала времени и кластера выбирают допустимое количество запросов, после чего формируют из этих значений упорядоченный по возрастанию набор данных.
[00086] Затем определяют пороговое значение для интервала и кластера. Пороговое значение может задаваться автоматически, например, по подобию способа поиска всплеска, применяющегося в статистике, либо посредством пользователя.
[00087] Шаг 107: для каждого заданного интервала времени и для каждого клиента, сравнивают количество новых поступивших запросов с пороговым значением для каждого кластера;
[00088] Шаг 108: в случае превышения количества запросов порогового значения, принимают решение об обнаружении атаки перебора на веб-сервис.
[00089] Если количество запросов клиента больше порогового значения, принимают решение об обнаружении атаки перебора на веб-сервис.
ПРИМЕРЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[00090] На первом шаге принимают набор запросов на веб-сервис от по меньшей мере одного клиента;
[00091] Пары запрос-ответ:

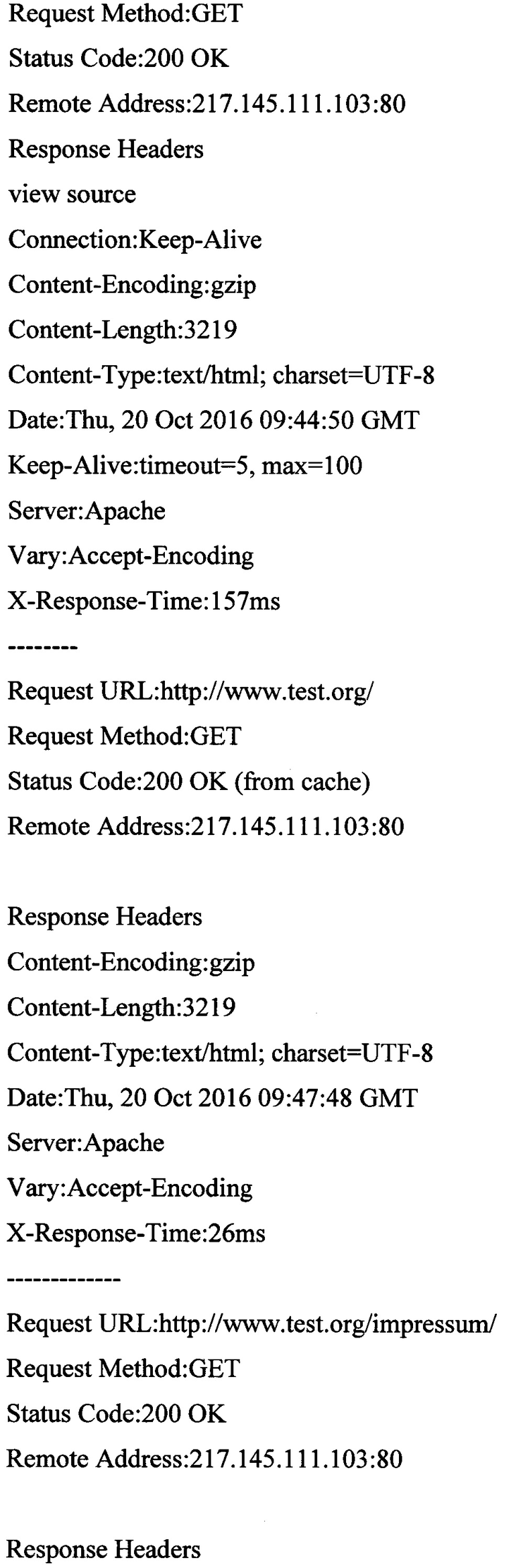
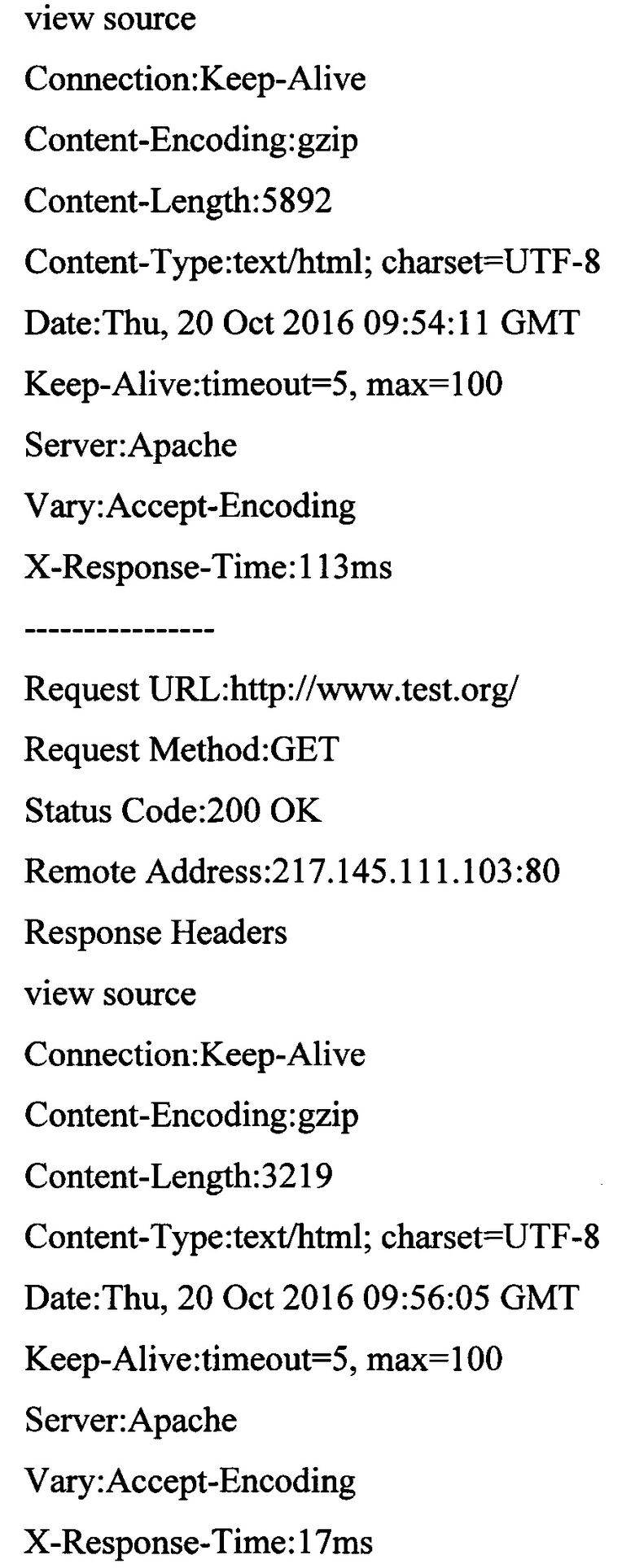
[00092] Выделенные характеристики пар «запрос-ответ»:
[00093] [Идентификатор, длина ответа, время отклика, код состояния HTTP, IP-адрес, с которого был получен HTTP запрос, единый указатель ресурса]
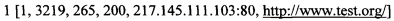
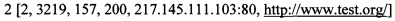
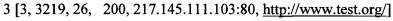
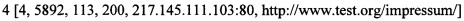
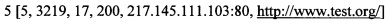
[00094] формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством способа кластеризации их характеристик;
[00095] для каждого кластера, сформированного на предыдущем шаге, формируют набор правил попадания полученной пары «запрос-ответ» в данный кластер;
[00096] Правила попадания в 1-й кластер: 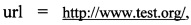 ,
, 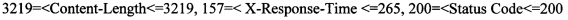
[00097] Правила попадания во 2-й кластер: 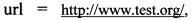 ,
, 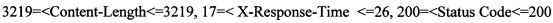
[00098] Задают по меньшей мере один интервал времени, в течение которого собираются характеристики пар «запрос-ответ»;
Например: 30 секунд.
[00099] Для каждого заданного интервала времени и клиента определяют количество его запросов веб-сервису, попадающих в каждый из сформированных кластеров по характеристикам пар «запрос-ответ»;
[кластер, интервал, количество запросов, ip адрес отправителя]

[000100] Для каждого заданного интервала времени и кластера формируют пороговое значение количества запросов, попадающих в данный кластер;
[кластер, интервал, пороговое значение]
[1, 30, 5]
[1, 30, 9]
[000101] Для каждого заданного интервала времени и для каждого клиента, сравнивают количество новых поступивших запросов с пороговым значением для каждого кластера;
[1, 30, 10, 217.145.111.111] - аномалия
[000102] В случае превышения количества запросов порогового значения, принимают решение об обнаружении атаки перебора на веб-сервис.
[1, 30, 10, 217.145.111.11] – аномалия.
ИСПОЛЬЗУЕМЫЕ ИСТОЧНИКИ
[000103] 1. Сивоголовко Е.В. «Методы оценки качества четкой кластеризации», УДК 004.051, Информационные системы.
[000104] 2. Peter J. Rousseeuw (1987). "Silhouettes: a Graphical Aid to the Interpretation and Validation of Cluster Analysis". Computational and Applied Mathematics. 20: 53-65.
[000105] 3. Шмойлова P.А., Минашкин В.Г., Садовникова H.A. Практикум по теории статистики. - 3-е изд. - М.: Финансы и статистика, 2011. - С. 127. - 416 с.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ЗАЩИТЫ ВЕБ-ПРИЛОЖЕНИЙ ПРИ ПОМОЩИ ИНТЕЛЛЕКТУАЛЬНОГО СЕТЕВОГО ЭКРАНА С ИСПОЛЬЗОВАНИЕМ АВТОМАТИЧЕСКОГО ПОСТРОЕНИЯ МОДЕЛЕЙ ПРИЛОЖЕНИЙ | 2017 |
|
RU2659482C1 |
| Способы обнаружения аномальных элементов веб-страниц на основании статистической значимости | 2017 |
|
RU2659741C1 |
| Способ блокировки сетевых соединений | 2018 |
|
RU2728506C2 |
| Способы обнаружения аномальных элементов веб-страниц | 2016 |
|
RU2652451C2 |
| Способы обнаружения вредоносных элементов веб-страниц | 2016 |
|
RU2638710C1 |
| Способ блокировки сетевых соединений с ресурсами из запрещенных категорий | 2018 |
|
RU2702080C1 |
| Способ сбора и обработки данных с измерением эффективности рекламных материалов и рекламных кампаний для автоматизированного подбора онлайн рекламных площадок с целью размещения рекламных материалов. | 2021 |
|
RU2774604C1 |
| Способ и система предотвращения вредоносных автоматизированных атак | 2021 |
|
RU2768567C1 |
| Способ и система предотвращения вредоносных автоматизированных атак | 2020 |
|
RU2740027C1 |
| Система и способ выявления подозрительной активности пользователя при взаимодействии пользователя с различными банковскими сервисами | 2016 |
|
RU2635275C1 |
Изобретение относится к защите информационных систем, а, в частности, к обнаружению атак перебора на веб-сервис. Технический результат – уменьшение вероятности ложных срабатываний при обнаружении сетевой атаки. Способ обнаружения атак перебора на веб-сервис, в котором получают набор пар «запрос-ответ», сформированных посредством взаимодействия клиента и веб-сервиса; формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством способа кластеризации их характеристик, при этом характеристики включают в себя следующее: идентификатор пары «запрос-ответ», длина ответа, время отклика, код состояния HTTP, IP-адрес, с которого был получен HTTP запрос, единый указатель ресурса; для каждого кластера, сформированного на предыдущем шаге, формируют набор правил попадания полученной пары «запрос-ответ» в данный кластер; задают по меньшей мере один интервал времени, в течение которого собираются характеристики пар «запрос-ответ»; для каждого заданного интервала времени и клиента, определяют количество его запросов веб-сервису, попадающих в каждый из сформированных кластеров по характеристикам пар «запрос-ответ»; для каждого заданного интервала времени и кластера формируют пороговое значение количества запросов, попадающих в данный кластер; для каждого заданного интервала времени и для каждого клиента, сравнивают количество новых поступивших запросов с пороговым значением для каждого кластера; в случае превышения количества запросов порогового значения, принимают решение об обнаружении атаки перебора на веб-сервис. 8 з.п. ф-лы, 1 ил.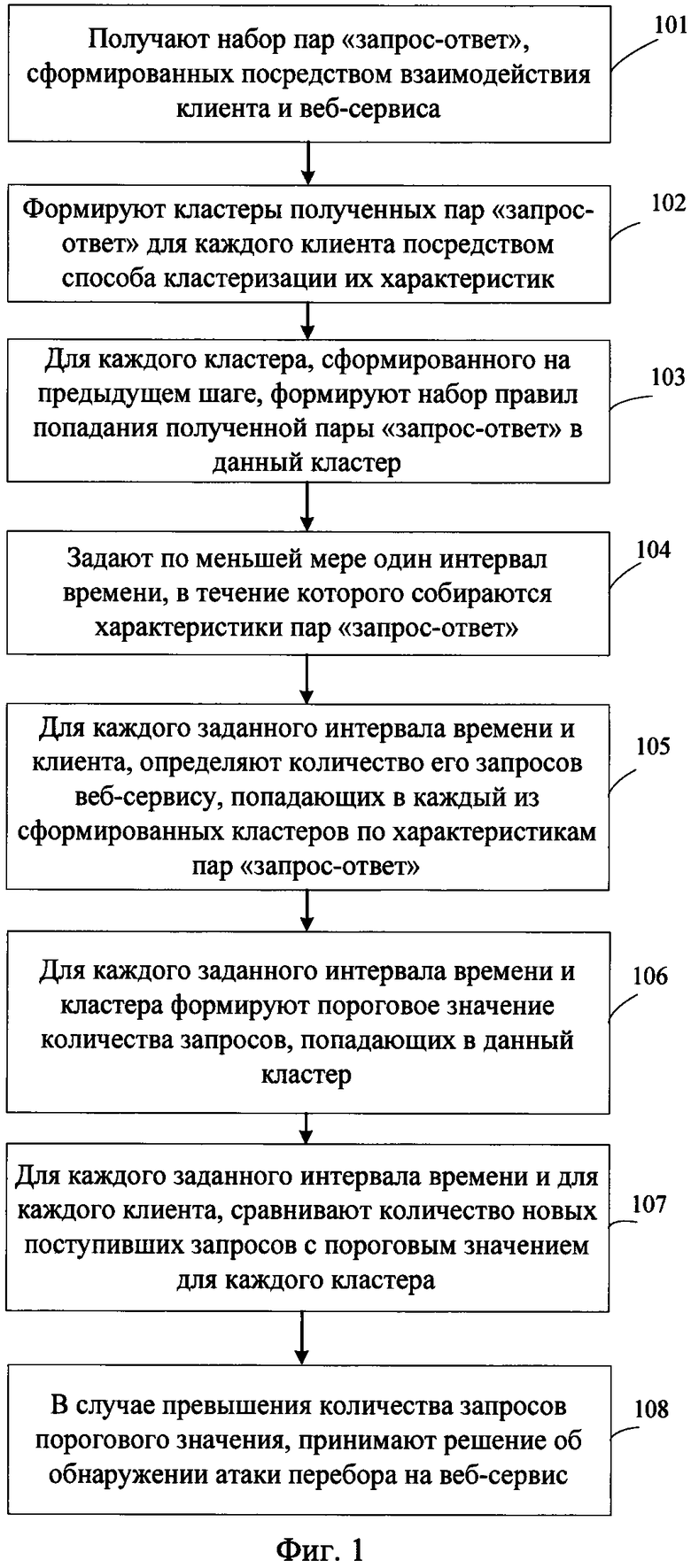
1. Способ обнаружения атак перебора на веб-сервис, который включает следующие шаги:
- получают набор пар «запрос-ответ», сформированных посредством взаимодействия клиента и веб-сервиса;
- формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством способа кластеризации их характеристик, при этом характеристики включают в себя следующее: идентификатор пары «запрос-ответ», длина ответа, время отклика, код состояния HTTP, IP-адрес, с которого был получен HTTP запрос, единый указатель ресурса;
- для каждого кластера, сформированного на предыдущем шаге, формируют набор правил попадания полученной пары «запрос-ответ» в данный кластер;
- задают по меньшей мере один интервал времени, в течение которого собираются характеристики пар «запрос-ответ»;
- для каждого заданного интервала времени и клиента определяют количество его запросов веб-сервису, попадающих в каждый из сформированных кластеров по характеристикам пар «запрос-ответ»;
- для каждого заданного интервала времени и кластера формируют пороговое значение количества запросов, попадающих в данный кластер;
- для каждого заданного интервала времени и для каждого клиента сравнивают количество новых поступивших запросов с пороговым значением для каждого кластера;
- в случае превышения количества запросов порогового значения принимают решение об обнаружении атаки перебора на веб-сервис.
2. Способ по п. 1, характеризующийся тем, что набор запросов обрабатывается сервером на веб-сервисе последовательно или параллельно.
3. Способ по п. 1, характеризующийся тем, что если одновременно приходит более одного запроса, то запросы устанавливаются в очередь для обработки.
4. Способ по п. 1, характеризующийся тем, что запросы, находящиеся в наборе, имеют приоритеты.
5. Способ по п. 1, характеризующийся тем, что запросы направляются от клиента по протоколу прикладного уровня передачи данных HTTP.
6. Способ по п. 1, характеризующийся тем, что ответ состоит из стартовой строки, заголовка, тела сообщения.
7. Способ по п. 1, характеризующийся тем, что каждая пара «запрос-ответ» имеет уникальный идентификатор.
8. Способ по п. 1, характеризующийся тем, что формируют кластеры полученных пар «запрос-ответ» для каждого клиента посредством алгоритма K-means.
9. Способ по п. 1, характеризующийся тем, что каждому сформированному кластеру присваивают уникальный идентификатор.
| СПОСОБ ОБНАРУЖЕНИЯ КОМПЬЮТЕРНЫХ АТАК НА СЕТЕВУЮ КОМПЬЮТЕРНУЮ СИСТЕМУ | 2013 |
|
RU2538292C1 |
| RU 2014133004 A, 27.02.2016 | |||
| RU 2011115361 A, 27.10.2012 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

