ОБЛАСТЬ ТЕХНИКИ
[1] Данное техническое решение относится, в общем, к вычислительной области, а в частности к области обнаружения атак на защищаемое веб-приложение с помощью позитивных моделей безопасности и построения моделей функционирования веб-приложения с помощью методов машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящее время веб-приложения автоматизируют сложные и критичные функции, такие как работу на бирже, управление грузовыми перевозками, государственные услуги и т.п. Существующие средства защиты веб-приложений - сетевые экраны уровня веб-приложения (Web Application Firewall, WAF) - не обеспечивают должной защиты от актуальных угроз. Согласно актуальным рекомендациям международной организации OWASP по использованию сетевых экранов уровня веб-приложения, значительная часть современных типов атак на веб-приложения не могут обнаруживаться и блокироваться с помощью существующих средств.
[3] Недостаточные механизмы защиты в современных сетевых (межсетевых) экранах уровня веб-приложения имеют под собой технологические причины. С одной стороны, устаревшими являются представления о веб-приложениях (или, формально, модели веб-приложений), которые используют такие средства. В большинстве средств защиты веб-приложений моделью клиентской части приложения является концепция "HTML-страница со ссылками и формами", а серверная часть описывается как набор статически и динамически исполняемых файлов. С развитием подходов к разработке веб-приложений (MVC, SOA, REST, API-centric) концепция файлов была заменена концепцией обработки запроса по его фрагментам (обычно URL), а HTML-документы уступили место динамическим асинхронным интерфейсам. Помимо этого, увеличивается структурная сложность HTTP-сообщений; для передачи структурированных данных используется вложенная инкапсуляция и кодирование (например, base64-закодированный массив из JSON-объектов). В результате выразительные средства современных сетевых экранов уровня веб-приложения не позволяют описывать структуру и нормальное поведение современных веб-приложений ни вручную, ни, тем более, автоматически. Создаваемые современными средствами позитивные модели безопасности не эффективны, подвержены обходам и ложным срабатываниям, а синтаксическое разнообразие запросов делает неприменимыми негативные модели безопасности (сигнатурные правила).
[4] С другой стороны, «традиционные» компьютерные атаки постепенно перестают быть актуальными, уступая место сложным логическим уязвимостям, в число которых входят по меньшей мере:
• уязвимости авторизации, позволяющие пользователям получить доступ к данным и функциям веб-приложения в обход правил контроля доступа;
• повышение привилегий за счет манипуляции значений параметров;
• доступ к функциям веб-приложения, не выведенным в пользовательский интерфейс;
• нарушение доступности веб-приложения для других пользователей;
• возможность обхода или злоупотребления правилами предоставления бонусов/скидок;
• атаки на протоколы интеграции веб-приложения со сторонними системами, например, некорректная реализация интеграции с платежными системами.
[5] Из уровня техники известен патентный источник информации № US 8051484 «Method and security system for indentifying and blocking web attacks by enforcing read-only parameters)), патентообладатель: Imperva, Inc., дата публикации: 01.11.2011. В данном источнике описываются способы защиты веб-приложений от атак, связанных с подменой злоумышленником значений read-only параметров HTTP-запросов, т.е. таких параметров, для которых разработчиком веб-приложения подразумевается неизменность значений. Техническое решение описывает принципы автоматического выявления таких параметров с помощью эвристических признаков (например, передачи параметров как скрытых полей веб-форм) и статистических (неизменность значений параметра между последовательными запросами и ответами веб-приложения), с последующим контролем неизменности значений read-only параметров на этапе защиты веб-приложения. Таким образом в данном решение описывается только частный случай построения одной из моделей веб-приложения (т.н. «профиля» параметров), однако лишь с точки зрения HTTP-запросов и ответов.
[6] Также известен патентный источник информации US 7472413 «Security for WAP servers», патентообладатель: F5 Networks, Inc., дата публикации: 30.12.2008. В данном техническом решении описывается способ автоматического выявления допустимых последовательностей обращений к ресурсам веб-приложения в виде графа допустимых переходов между его HTML-страницами на основе автоматического обхода веб-приложения специальными инструментальными средствами (веб-краулерами), а также анализа последовательности запросов и ответов из сетевого трафика. Данный способ позволяет построить аналог модели «сценариев использования» веб-приложения, но не в терминах уровня логики функционирования веб-приложения, а лишь в терминах последовательности переходов между HTML-страницами. Построенная таким образом модель «page-flow веб-приложения» пригодна для защиты от некоторых видов атак (например, прямого доступа по ссылке к закрытой части веб-приложения), но не позволяет, например, контролировать права доступа пользователя в терминах объектов предметной области веб-приложения.
[7] Также из уровня техники известен источник информации US 20120278851 «Automated policy builder», патентообладатель: F5 Networks, Inc., дата публикации: 01.11.2012. В данном решении описываются способы автоматического построения таких моделей функционирования веб-приложения, как списки разрешенных URL адресов в веб-приложении, списки допустимых параметров (которые могут быть переданы в запросе к каждому из URL адресов) и диапазоны их допустимых значений. Данные модели (т.н. «профили» веб-приложения) строятся автоматически на основе анализа запросов к веб-приложению и ответов от него и могут быть скорректированы оператором вручную. Кроме этого, описываются принципы определения «стабильности» отдельных элементов построенных профилей (на основе эвристических критериев длительного отсутствия изменений в значениях) или необходимости перестройки «профилей» для отдельных элементов или исключения из обработки отдельных сигнатурных правил с высоким уровнем ложных срабатываний (на основе эвристических правил наблюдения больного числа аномалий с большого числа доверенных IP адресов). Недостатком данных способов является, во-первых, моделирование веб-приложения лишь в терминах HTTP-запросов, и во-вторых, использование эвристических правил с единым набором констант для всех защищаемых веб-приложений без учета таких характеристик, как, например, относительный объем запросов к веб-приложению за единицу времени.
[8] Основные мировые производители сетевых экранов уровня веб-приложения не имеют технических решений в области обнаружения широкого класса логических атак на защищаемые веб-приложения.
[9] Уровень моделирования основных аспектов функционирования веб-приложения для межсетевых экранов в существующих технических решениях ограничен синтаксисом и семантикой HTTP-запросов к веб-приложению и ответов веб-приложения, а также контролем типов и диапазонов значений параметров HTTP-запросов. Данные модели не позволяют эффективно и с низким уровнем ложных срабатываний обнаруживать логические атаки на веб-приложение.
[10] Также в уровне техники отсутствуют способы автоматического построения моделей уровня логики функционирования веб-приложения с помощью методов машинного обучения.
СУЩНОСТЬ ТЕХНИЧЕСКОГО РЕШЕНИЯ
[11] Данное техническое решение направлено на устранение недостатков, свойственных решениям, известным из уровня техники.
[12] Технической задачей, решаемой в данном техническом решении, является построение и использование для защиты веб-приложения не только моделей синтаксиса и семантики HTTP-запросов к веб-приложению, но и моделей уровня логики функционирования веб-приложения, включая распознавание действий уровня логики функционирования веб-приложения (схемы маршрутизации запросов в веб-приложении), определение синтаксиса и семантики параметров действий веб-приложения, выявление сценариев использования веб-приложения и правил контроля доступа пользователей к ресурсам и объектам предметной области веб-приложения.
[13] Техническим результатом, достигаемым в данном техническом решении, является повышение производительности интеллектуального сетевого экрана.
[14] Также техническим результатом является повышение качества выявления ложных срабатываний сигнатурных правил обнаружения атак и модулей обнаружения аномалий для отдельных типов запросов.
[15] Данные технические результаты достигаются с помощью методов машинного обучения, причем автоматически выявляются запросы к статическим ресурсам веб-приложения и производится построение шаблонов URL адресов данных запросов с целью исключения данных запросов из детального анализа на этапе защиты веб-приложения.
[16] Ключевым отличием предлагаемого технического решения от подходов, применяемых в существующих сетевых экранах уровня веб-приложения, является переход от принципа "разбор запроса до уровня HTTP; один URL - один набор параметров и их моделей" к принципу "глубокий разбор запросов с учетом особенностей приложения, выделение действий уровня логики функционирования веб-приложения и их параметров (при этом критерием классификации может являться не только URL запроса), и создание моделей для параметров действий". Данный подход обеспечивает два преимущества перед существующими решениями для защиты веб-приложений:
• делает возможным обнаружение логических атак на веб-приложения;
• снижает уровень ложных срабатываний сетевого экрана уровня веб-приложения (с ~30% до 0.1% и ниже).
[17] Предлагаемое решение представляет собой интеллектуальный сетевой экран для защиты веб-приложений, который осуществляет автоматический сбор обучающих данных и построение моделей функционирования веб-приложения, включая построение моделей синтаксиса и семантики HTTP-запросов к веб-приложению и ответов на них (для последующего разбора HTTP-запросов и ответов), выявление действий уровня логики функционирования веб-приложения (модель маршрутизации запросов), определение наборов параметров и допустимых значений параметров для данных действий (модель параметров действий веб-приложения), и построение моделей для сценариев использования веб-приложения и правил контроля доступа к ресурсам и функциям веб-приложения. Кроме того, интеллектуальный сетевой экран также производит выявление ложных срабатываний (для сигнатурных правил обнаружения атак или отдельных модулей обнаружения аномалий) и выявление запросов к статическим ресурсам веб-приложения с построением шаблонов URL адресов этих запросов.
[18] При этом, по крайней мере, построение моделей синтаксиса и семантики HTTP-запросов и ответов на них, построение модели маршрутизации запросов, выявление запросов к статическим ресурсам веб-приложения (с построением шаблонов URL адресов данных запросов) и выявление ложных срабатываний (сигнатурных правил обнаружения атак или отдельных модулей обнаружения аномалий) производятся с помощью методов машинного обучения (например, посредством иерархической кластеризации) и анализа данных (например, статистического корреляционного анализа). Построение данных моделей, шаблонов URL адресов запросов к статическим ресурсам и списка сигнатурных правил с высоким уровнем ложных срабатываний производится в полностью автоматическом режиме, без участия оператора и\или администратора интеллектуального сетевого экрана.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[19] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
[20] Фиг. 1 иллюстрирует общую архитектуру системы, реализующей способ защиты веб-приложений при помощи интеллектуального сетевого экрана с использованием автоматического построения моделей приложений.
[21] Фиг. 2 иллюстрирует вариант осуществления способа защиты веб-приложений при помощи интеллектуального сетевого экрана с использованием автоматического построения моделей приложений.
[22] Фиг. 3 иллюстрирует способ построения моделей защищаемого веб-приложения в одном из вариантов исполнения способа.
[23] Фиг. 4 иллюстрирует вариант осуществления частичного дерева разбора запроса к веб-приложению.
[24] Фиг. 5 иллюстрирует другой вариант осуществления дерева разбора запроса к веб-приложению.
[25] Фиг. 6 иллюстрирует способ построения дерева разбора запроса.
[26] Фиг. 7 иллюстрирует пример осуществления дерева решений для разбора запросов.
[27] Фиг. 8 иллюстрирует способ построения дерева решений для разбора запросов по множеству деревьев разбора запросов.
[28] Фиг. 9 иллюстрирует таблицу применимости декодеров, применяемую в процессе кластеризации деревьев запросов при построении дерева решений для разбора запросов.
[29] Фиг. 10 иллюстрирует способ построения модели маршрутизации запросов веб-приложения.
[30] Фиг. 11 иллюстрирует способ выявления запросов к статическим ресурсам веб-приложения и построения шаблонов URL адресов запросов к статическим ресурсам веб-приложения.
[31] Фиг. 12 иллюстрирует способ поиска множества URL адресов статических ресурсов веб-приложения на основе множества пар запросов к веб-приложению и ответов веб-приложения.
[32] Фиг. 13 иллюстрирует пример осуществления конечного автомата, моделирующего сценарий использования веб-приложения.
[33] Фиг. 14 иллюстрирует способ выявления ложных срабатываний для сигнатурных правил обнаружения атак и отдельных модулей обнаружения аномалий, создания журнальных сообщений о ложных срабатываниях и генерации настроек для исключения данных сигнатурных правил из дальнейшей обработки на этапе защиты веб-приложения.
[34] Фиг. 15 иллюстрирует общий способ обработки единичного запроса к веб-приложению на этапе защиты веб-приложения системой.
ПОДРОБНОЕ ОПИСАНИЕ
[35] Ниже будут описаны понятия и определения, необходимые для подробного раскрытия осуществляемого технического решения.
[36] Данное техническое решение может быть реализовано в виде распределенной компьютерной системы.
[37] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[38] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[39] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические носители (CD, DVD и т.п.).
[40] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[41] Позитивная модель безопасности (также известны как «белые списки») - модели безопасности, которые в явном виде специфицируют набор разрешенных действий и запрещают все остальные действия (т.е. те действия, которые не входят в список разрешенных).
[42] Логика функционирования веб-приложения - набор решаемых веб-приложением прикладных задач, выраженный в терминах объектов предметной области веб-приложения, действий (логических манипуляций) над ними и ограничениях, отражающих допустимые сценарии использования веб-приложения и права различных категорий его пользователей. Например, веб-приложение, поддерживающее интернет блог, предоставляет пользователем возможности создания, просмотра, редактирования и удаления записей и комментариев к ним - каждая такая возможность представляет собой отдельное действие уровня логики функционирования веб-приложения.
[43] Примерами объектов предметной области веб-приложения являются, например, товары в интернет-магазине, записи в блоге, счета пользователя в платежных системах и т.п.
[44] Компьютерная атака - целенаправленное несанкционированное воздействие на информацию, на ресурс информационной системы или получение несанкционированного доступа к ним с применением программных или программно-аппаратных средств.
[45] Логическая атака - компьютерная атака на уровень логики функционирования веб-приложения, т.е. такая атака, в ходе которой не происходит нарушений синтаксиса и семантики HTTP-запросов к веб-приложению, но происходит выполнение от лица злоумышленника тех действий уровня логики функционирования веб-приложения, которые не должны быть ему доступны по замыслу разработчиков.
[46] Межсетевой экран (МЭ), брандмауэр, защитная система, сетевой экран, "огненная стена" - система (аппаратная или программная) или комбинация систем, образующая в целях защиты границу между двумя или более сетями, предохраняя от несанкционированного попадания в сеть или предупреждая выход из нее пакетов данных.
[47] Веб-приложение - клиент-серверное приложение, в котором клиентом выступает браузер, а сервером - веб-сервер. Логика веб-приложения распределена между сервером и клиентом, хранение данных осуществляется, преимущественно, на сервере, обмен информацией происходит по сети.
[48] Сбор обучающих данных - в данном техническом решении процесс сбора запросов к веб-приложению, ответов веб-приложения (и, опционально, сообщений о срабатывании сигнатурных правил обнаружения атак) в течении заранее заданного оператором и\или администратором системы временного периода, во время которого функционирование веб-приложения считается «нормальным» (отражает допустимые сценарии использования).
[49] Этап защиты веб-приложения - данный этап реализует режим защиты веб-приложения от возможных атак на него со стороны злоумышленников. Выполнение данного этапа начинается после перевода системы в режим защиты веб-приложения, осуществляемого автоматически после завершения этапа обучения и построения моделей функционирования веб-приложения или по команде оператора и\или администратора системы.
[50] Общая архитектура системы, реализующей предлагаемый способ, проиллюстрирована на Фиг. 1. Система состоит из следующих компонентов:
[51] компонент анализа данных (Analyzer), который предназначен для получения и анализа трафика защищаемого веб-приложения (запросов к веб-приложению и ответов веб-приложения), его анализа с целью выявления атак на веб-приложение (включая атаки уровня логики функционирования веб-приложения) и реагирования на данные атаки, включая блокировку атакующих запросов и\или генерацию и сохранение сообщений об обнаруженных атаках;
[52] компонент хранения данных (Database), который предназначен для долговременного хранения в базе данных разнообразной информации, включая по крайней мере: обучающие данные (запросы к веб-приложению и ответы веб-приложения, собранные на этапе сбора обучающих данных), построенные модели функционирования веб-приложения, журнальные сообщения, сгенерированные в процессе функционирования системы и различные настройки системы;
[53] компонент построения моделей функционирования веб-приложения (Learning), который предназначен для автоматического построения моделей функционирования веб-приложения на основе информации, сохраненной в базе данных компонента Database;
[54] компонент графического интерфейса (Web dashboard), который предназначен для реализации графического интерфейса оператора и\или администратора системы.
[55] Компоненты, используемые в системе, могут быть реализованы с помощью электронных компонент, используемых для создания цифровых интегральных схем. Не ограничиваясь, могут использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС являются: программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже.
[56] Также компоненты могут быть реализованы с помощью постоянных запоминающих устройств (см. Лебедев О.Н. Микросхемы памяти и их применение. - М.: Радио и связь, 1990. - 160 с.; Большие интегральные схемы запоминающих устройств: Справочник / А.Ю. Горденов и др. - М.: Радио и связь, 1990. - 288 с.).
[57] Таким образом, реализация всех используемых компонентов достигается стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[58] Названия компонентов на английском языке предоставлены для более ясного понимания сущности технического решения и не ограничивают сущность или реализацию технического решения.
[59] Компонент Analyzer реализует следующую функциональность:
• захват трафика защищаемого веб-приложения (запросы к веб-приложению и ответы веб-приложения);
• сбор обучающих данных (запросов к веб-приложению и ответов веб-приложения) на этапе обучения системы и их сохранения в базу данных компонента Database;
• сохранение информации о запросах к веб-приложению и ответах веб-приложения в базе данных компонента Database на этапе защиты веб-приложения;
• анализ трафика на этапе защиты веб-приложения, включая классификацию запросов на нормальные или аномальные, в том числе классификацию отдельных аномальных запросов как атак на веб-приложение;
• принятие решений по передаче запроса веб-приложению или его блокировке;
• генерация журнальных сообщений об обнаруженных аномалиях и атаках, и запись данных сообщений в базу данных компонента Database.
[60] Компонент Analyzer состоит, по крайней мере, из трех следующих служебных компонентов:
• компонент активного захвата трафика (HTTP reverse proxy), который реализует логику обратного HTTP прокси для перехвата запросов к защищаемому веб-приложению и ответов от веб-приложения;
• компонент пассивного захвата трафика (Passive HTTP proxy), который реализует функциональность пассивного получения копии трафика между защищаемым веб-приложением и его пользователями через сетевое ответвление (network ТАР);
• компонент анализа запросов и ответов веб-приложения и принятия решений (Analyzer Core), который реализует функциональность сбора информации о запросах к веб-приложению и ответов веб-приложения, анализа запросов к веб-приложению с использованием построенных моделей функционирования веб-приложения, классификации запросов на нормальные и аномальные (включая классификацию запроса, как атаки на веб-приложение), и принятие решения по передаче запроса к защищаемому веб-приложению или его блокированию.
[61] Служебный компонент HTTP reverse proxy представляет собой обратный прокси-сервер для перехвата HTTP трафика. В одном из вариантов исполнения и размещения системы предполагается функционирование системы в режиме обратного HTTP прокси. В данном режиме служебный компонент HTTP reverse proxy обеспечивает перехват запросов к защищаемому веб-приложению, передачу информации о данных запросах служебному компоненту Analyzer Core и ожиданию от данного служебного компонента решения по обработке запроса.
[62] В качестве решений по обработке запроса возможны, по крайней мере, передача запроса к защищаемому веб-приложению, либо блокирование и сброс запроса. В одном из вариантов реализации возможно также решение по предоставлению пользователю веб-приложения специального ответа, содержащего проверку посредством теста САРТСНА (Completely Automated Public Turing test to tell Computers and Humans Apart - полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей). В такой ситуации пользовательский запрос может быть передан защищаемому веб-приложению только после успешного решения теста САРТСНА пользователем веб-приложения.
[63] В одном из вариантов исполнения системы компонент HTTP reverse proxy может также реализовывать логику автоматической классификации запросов на запросы к статическим и динамическим ресурсам веб-приложения. Данным поведением компонента HTTP reverse proxy управляют особые настройки, сформированные в ходе процесса обучения системы компонентом Learning, сохраненные в базе данных компонента Database и переданные компоненту HTTP reverse proxy компонентом Analyzer Core. При классификации поступившего запроса как запроса к статическому ресурсу защищаемого веб-приложения, запрос передается защищаемому веб-приложению без дальнейшей обработки служебным компонентом Analyzer Core, что снижает вычислительную нагрузку. При классификации запроса, как запроса к динамическому ресурсу защищаемого веб-приложения, передача запроса откладывается до принятия служебным компонентом Analyzer Core соответствующего решения по обработке запроса (передача веб-приложению, блокирование или предоставление пользователю теста САРТСНА).
[64] Компонент Passive HTTP sniffer отвечает за захват копии трафика к защищаемому веб-приложению, получаемого с сетевого ответвления. В варианте исполнения системы, предполагающем работу с копией трафика, компонент Passive HTTP sniffer обеспечивает извлечение из копии сетевого трафика потока запросов к защищаемому веб-приложению и ответов от веб-приложения и передачу информации о них компоненту Analyzer Core. В данном варианте исполнения системы для копии сетевого трафика блокировка аномальных (или атакующих) запросов (и ответов веб-сервера на эти запросы) не является возможной, хотя сбор обучающих данных на этапе обучения системы и анализ запросов и ответов на этапе защиты веб-приложения (с генерацией соответствующих журнальных сообщений для оператора и\или администратора системы) остаются доступными.
[65] В одном из вариантов исполнения системы компонент Passive HTTP sniffer может также реализовывать логику автоматической классификации запросов на запросы к статическим и динамическим ресурсам веб-приложения. Данным поведением компонента Passive HTTP sniffer управляют особые настройки, сформированные в ходе процесса обучения системы компонентом Learning, сохраненные в базе данных компонента Database и переданные компоненту Passive HTTP sniffer компонентом Analyzer Core. При классификации поступившего запроса как запроса к статическому ресурсу защищаемого веб-приложения, информация о запросе не передается компоненту Analyzer Core, что снижает вычислительную нагрузку. При классификации запроса, как запроса к динамическому ресурсу защищаемого веб-приложения, информация о запросе передается компоненту Analyzer Core для дальнейшего анализа.
[66] Компонент Analyzer Core обеспечивает анализ запросов к защищаемому веб-серверу и ответов от веб-сервера и принятие решений по обработке запроса на основе результатов анализа. Компонент Analyzer Core состоит из набора модулей, в число которых входят:
• модуль взаимодействия с компонентом активного захвата трафика (ProxyAdapter) - отвечает за взаимодействие со служебным модулем HTTP reverse proxy в части:
 получения от него информации о запросах и ответах веб-приложения;
получения от него информации о запросах и ответах веб-приложения;
 передачи компоненту HTTP reverse proxy решений по дальнейшей обработке поступившего запроса;
передачи компоненту HTTP reverse proxy решений по дальнейшей обработке поступившего запроса;
 передачи компоненту HTTP reverse proxy настроек для классификации запросов к защищаемому веб-приложению на запросы к статическим и динамическим ресурсам веб-приложения в одном из возможных вариантов исполнения системы;
передачи компоненту HTTP reverse proxy настроек для классификации запросов к защищаемому веб-приложению на запросы к статическим и динамическим ресурсам веб-приложения в одном из возможных вариантов исполнения системы;
• модуль взаимодействия с компонентом пассивного захвата трафика (PassiveAdapter) - отвечает за взаимодействие со служебным модулем Passive HTTP sniffer в части:
 получения от него информации о запросах и ответах веб-приложения;
получения от него информации о запросах и ответах веб-приложения;
 передачи компоненту Passive HTTP sniffer настроек для классификации запросов к защищаемому веб-приложению на запросы к статическим и динамическим ресурсам веб-приложения в одном из возможных вариантов исполнения системы;
передачи компоненту Passive HTTP sniffer настроек для классификации запросов к защищаемому веб-приложению на запросы к статическим и динамическим ресурсам веб-приложения в одном из возможных вариантов исполнения системы;
• модуль взаимодействия с компонентом хранения данных (MessageDumper) - отвечает запись в базу данных информации о запросах к веб-приложению и ответов веб-приложения на этапах сбора обучающих данных и защиты веб-приложения, а также за запись журнальных сообщений об обнаруженных аномалиях и\или атаках на веб-приложение;
• модуль разбора HTTP запросов и ответов (DecisionTreeParser) - отвечает за разбор поступающих запросов к веб-приложению и ответов от веб-приложения в соответствии с построенными синтаксическими и структурными моделями разбора HTTP-запросов и ответов веб-приложения;
• модуль распознавания действий уровня логики функционирования веб-приложения (ActionDeterminer) - отвечает за анализ запросов к веб-приложению для идентификации действий уровня логики функционирования веб-приложений, в соответствии с моделью маршрутизации запросов;
• модуль распознавания результата выполнения действия уровня логики функционирования веб-приложения (ActionStatusDeterminer) - отвечает за анализ ответов веб-приложения для идентификации успешности или неуспешности выполнения инициированного ранее действия уровня логики функционирования веб-приложения, в соответствии с моделью маршрутизации запросов в веб-приложении;
• модуль отслеживания сессий (SessionTracker) - отвечает за анализ запросов к веб-приложению и ответов веб-приложения, для отслеживания сессий и пользователей, в соответствии с моделью маршрутизации запросов в веб-приложении и вспомогательных моделей, описывающих признаки успешного и неуспешного выполнения запросов;
• модуль принятия решений по обработке запроса (DecisionMaker) - отвечает за анализ запросов к веб-приложению, выполняя по крайней мере:
 оценку степени нормальности или аномальности запроса на основе построенных моделей синтаксиса и семантики параметров для конкретного действия уровня логики функционирования веб-приложения;
оценку степени нормальности или аномальности запроса на основе построенных моделей синтаксиса и семантики параметров для конкретного действия уровня логики функционирования веб-приложения;
 классификацию запроса на нормальный, аномальный или атаку на веб-приложение на основе оценок аномальности запроса, сгенерированных модулями компонента Analyzer Core и правил оценки аномальности запроса, заданных оператором и\или администратором системы;
классификацию запроса на нормальный, аномальный или атаку на веб-приложение на основе оценок аномальности запроса, сгенерированных модулями компонента Analyzer Core и правил оценки аномальности запроса, заданных оператором и\или администратором системы;
 принятие решение по обработке запроса на основе построенных автоматически или сформулированным оператором и\или администратором системы правил контроля доступа и проведенной ранее классификации запроса на нормальный, аномальный или атаку на веб-приложение.
принятие решение по обработке запроса на основе построенных автоматически или сформулированным оператором и\или администратором системы правил контроля доступа и проведенной ранее классификации запроса на нормальный, аномальный или атаку на веб-приложение.
[67] В одном из вариантов исполнения системы компонент Analyzer Core может так же включать модуль обнаружения атак на веб-приложение с помощью инструментального средства ModSecurity (ModsecurityDetector). Данный модуль является средством анализа HTTP-запросов к веб-приложению, основанным на применении набора сигнатурных правил. Данное средство разработано третьей стороной и доступно публично в виде исходных кодов и набора сигнатурных правил. В рамках системы модуль ModsecurityDetector анализирует запросы к защищаемому веб-приложению с помощью набора сигнатурных правил и генерирует журнальные сообщения о срабатывании определенных сигнатур. Данные сообщения могут быть записаны в базу данных компонента Database, а также использоваться компонентом DecisionMaker при классификации запроса.
[68] В одном из вариантов исполнения системы компонент Analyzer Core может так же включать модуль обнаружения атак на веб-приложение с помощью инструментального средства Libinjection (LibinjectionDetector). Данный модуль является средством анализа HTTP-запросов к веб-приложению, основанным на оценке степени аномальности запроса по факту наличия признаков атаки в предварительно разобранном запросе. Данное средство разработано третьей стороной и доступно публично в виде исходных кодов и набора сигнатурных правил. В рамках системы модуль LibinjectionDetector анализирует запросы к защищаемому веб-приложению, осуществляя разбор запроса и поиск в нем признаков атаки, и генерирует журнальные сообщения с оценкой степени аномальности данного запроса. Данные сообщения могут быть записаны в базу данных компонента Database, а также использоваться модулем DecisionMaker при классификации запроса.
[69] В одном из вариантов исполнения системы компонентом Learning может быть выполнен этап выявления ложных срабатываний отдельных сигнатурных правил обнаружения атак, и сформированы настройки для модулей ModsecurityDetector и LibinjectionDetector, которые позволяют исключить данные сигнатурные правила из дальнейшего применения при анализе запросов.
[70] Все модули компонента Analyzer Core обмениваются информацией через общую шину обмена данными, которая может быть реализована различными способами в зависимости от варианта исполнения системы.
[71] Компонент Database представляет собой базу данных, предназначенную для долговременного хранения всей информации, необходимой для функционирования системы. Данная информация включает в себя по крайней мере:
• информацию о характеристиках нормальных запросов к веб-приложению (включая сами HTTP-запросы) и ответов веб-приложения, собранных на этапе обучения системы;
• построенные в результате функционирования компонента Learning модели функционирования веб-приложения, включая модели синтаксиса и семантики HTTP-запросов и различные модели уровня логики функционирования веб-приложения;
• журнальные сообщения об аномалиях и атаках на защищаемое веб-приложение, обнаруженных в процессе функционирования компонента Analyzer, а также сопутствующие им запросы к веб-приложению;
• настройки системы в части правил построения моделей функционирования веб-приложения, правил классификации поступающих запросов на нормальные и аномальные и правил реагирования на обнаруженные аномалии в запросах;
• настройки системы в виде списка сигнатурных правил обнаружения атак с высоким уровнем ложных срабатываний, которые подлежат исключению из обработки на этапе защиты веб-приложения;
• разнообразную служебную информацию системы.
[72] В зависимости от варианта воплощения, для реализации компонента Database могут быть выбраны различные варианты СУБД, на основе которых может быть реализован данный компонент, и различные варианты архитектуры компонента Database (например, централизованная или распределенная база данных).
[73] Компонент Learning предназначен для автоматического построения моделей функционирования веб-приложения на основе собранной информации о характеристиках нормальных запросов к веб-приложению и правил построения моделей веб-приложения. Информация о характеристиках нормальных запросов к веб-приложению сохраняется в базе данных компонента Database и обновляются компонентом Analyzer на этапе сбора обучающих данных. Правила построения моделей хранятся в базе данных компонента Database и могут быть добавлены в нее или модифицированы оператором и\или администратором системы с помощью компонента Web dashboard. Процесс построения моделей функционирования веб-приложения может быть запущен автоматически по окончанию временного периода, выделенного на сбор обучающих данных. Построенные компонентом Learning модели функционирования веб-приложения сохраняются далее в базе данных компонента Database.
[74] В одном из вариантов исполнения системы компонент Learning также может включать функциональность выявления ложных срабатываний (сигнатурных правил обнаружения атак или отдельных модулей обнаружения аномалий) при помощи статистических методов. В данном варианте исполнения, компонент Learning использует данные, собранные компонентом Analyzer на этапе сбора обучающих данных и сохраненные в базе данных компонента Database для выявления сигнатурных правил и отдельных модулей обнаружения аномалий, имеющих высокий уровень ложных срабатываний. Также он создает журнальные сообщения о ложных срабатываниях и формирует новые настройки для сигнатурных модулей компонента Analyzer, с помощью которых данные сигнатурные правила исключаются из последующего использования.
[75] Компонент Web dashboard реализует функции графического интерфейса для оператора и\или администратора системы с целью мониторинга обстановки и реагирования на инциденты. Этот компонент предназначен для реализации по меньшей мере следующих функций:
• предоставление оператору и\или администратору информации о текущем состоянии защищаемого веб-приложения, включая данные по текущим запросам к веб-приложению;
• уведомление оператора и\или администратора об обнаруженных аномалиях в запросах к защищаемого веб-приложению или атаках на веб-приложение и предпринятых системой действиях;
• просмотр статистической информации по функционированию защищаемого веб-приложения за выбранный временной период в прошлом и просмотр информации о ранее обнаруженных аномалиях в запросах или об атаках на защищаемое веб-приложение;
• модификация существующих правил, управляющих построением моделей веб-приложения, правил классификации запросов к веб-приложению на нормальные и аномальные (включая пометку отдельных запросов как атак на веб-приложение), и правил реагирования на обнаруженные аномальные запросы и атаки, а также создания новых правил указанных видов;
• настройка отдельных параметров функционирования прочих компонентов системы.
[76] Компонент Web dashboard получает всю необходимую информацию от компонента Database. В случае создания оператором и\или администратором новых правил построения моделей, классификации запросов или реагирования на аномалии и атаки, либо модификации существующих правил, данные изменения сохраняются в базу данных компонента Database.
[77] Фиг. 2 иллюстрирует основной способ работы системы в одном из вариантов осуществления. Он состоит из этапа сбора обучающих данных, этапа построения моделей защищаемого веб-приложения, этапа выявления ложных срабатываний и этапа защиты веб-приложения.
[78] На этапе сбора обучающих данных компонентом Analyzer производится сбор запросов к защищаемому веб-приложению и ответов веб-приложения и их запись в базу данных компонента Database. На данном этапе компонентом Analyzer также производится запись в базу данных информации о срабатывании сигнатурных правил, если в состав компонента Analyzer входит по крайней мере один модуль обнаружения атак на веб-приложение, основанный на наборе сигнатурных правил обнаружения.
[79] На этапе построения моделей функционирования веб-приложения компонентом Learning производится построение указанного ранее множества моделей функционирования веб-приложения на основе множества запросов и ответов, собранных на этапе сбора обучающих данных. Построенные модели сохраняются в базе данных компонента Database.
[80] На этапе выявления ложных срабатываний компонентом Learning производится выявление сигнатурных правил обнаружения атак и отдельных модулей обнаружения аномалий, которые имеют высокий уровень ложных срабатываний. Для выявленных сигнатурных правил с высоким уровнем ложных срабатываний компонент Learning генерирует и сохраняет в базе данных настройки для модулей обнаружения атак, использующих сигнатурные правила, с помощью которых сигнатурные правила с высоким уровнем ложных срабатываний исключаются из дальнейшего использования на этапе защиты веб-приложения. Для выявленных ложных срабатываний также создаются журнальные сообщения, позволяющие оператору и\или администратору системы проанализировать причины ложных срабатываний модулей обнаружения аномалий и инициировать этап обучения системы повторно или вручную внести необходимые изменения в построенные модели функционирования веб-приложения.
[81] Наконец на этапе защиты веб-приложения компонент Analyzer получает от компонента Database построенные модели функционирования веб-приложения и использует их для анализа новых поступающих запросов к веб-приложению и его ответов, оценки степени нормальности или аномальности данных запросов и принятия решения по их дальнейшей обработке (блокирование или разрешение запроса). Компонент Analyzer также использует построенные модели функционирования веб-приложения для настройки служебных компонентов HTTP reverse proxy и Passive HTTP sniffer, чтобы обеспечить передачу для анализа компоненту Analyzer Core только таких запросов (и ответов) веб-приложения, которые являются запросами (и ответами) к динамическим ресурсам защищаемого веб-приложения. При этом анализ запросов к статическим ресурсам веб-приложения (и ответов на эти запросы) на этапе защиты веб-приложения не производится с целью снижения вычислительной сложности и повышения производительности системы.
[82] Фиг. 3 иллюстрирует способ построения моделей функционирования защищаемого веб-приложения. Данный способ исполняется компонентом Learning на основе информации о запросах и ответах веб-приложения, полученной на этапе сбора обучающих данных. Результатами различных шагов этого способа являются построенные модели различных аспектов функционирования защищаемого веб-приложения. Данный способ состоит из следующих основных шагов:
• построение деревьев разбора для всех запросов к защищаемому веб-приложению и ответов от веб-приложения;
• построение дерева решений разбора запросов к веб-приложению и дерева решений разбора ответов веб-приложения;
• построение модели маршрутизации запросов (т.е. выявление различных действий уровня логики функционирования веб-приложения);
• построение модели для извлечения идентификаторов сессии и пользователя из запросов и ответов веб-приложения;
• построение моделей синтаксиса и семантики параметров действий уровня логики функционирования веб-приложения;
• выявление запросов к статическим ресурсам веб-приложения и построение шаблонов URL запросов к статическим ресурсам;
• построение модели сценариев использования веб-приложения;
• построение модели для контроля доступа к ресурсам веб-приложения.
[83] В зависимости от варианта исполнения системы, часть моделей функционирования защищаемого веб-приложения строится компонентом Learning в полностью автоматическом режиме, другая часть моделей функционирования защищаемого веб-приложения строится в автоматизированном или ручном режиме, с участием оператора и\или администратора системы. Список шагов способа и соответствующих моделей защищаемого веб-приложения, построение которых производится системой в полностью автоматическом режиме, включает по меньшей мере следующие шаги:
• построение деревьев разбора для всех запросов и ответов;
• построение дерева решений разбора запросов к веб-приложению и дерева решений для разбора ответов веб-приложения;
• построение модели маршрутизации запросов;
• выявление запросов к статическим ресурсам веб-приложения и построение шаблонов URL адресов запросов к статическим ресурсам веб-приложения.
[84] Построенные на этапе обучения системы модели сохраняются в базе данных компонента Database и используются далее на этапе защиты веб-приложения для анализа запросов и ответов веб-приложения. Оператор и\или администратор системы имеет возможность ручного редактирования и настройки всех построенных моделей с помощью использования компонента Web dashboard.
[85] Первым шагом, применяемым на этапе построения моделей функционирования веб-приложения, является построение деревьев разбора для всех запросов к защищаемому веб-приложению и ответов от веб-приложения, собранных на этапе сбора обучающих данных. Для создания HTTP-запроса к веб-приложению современные браузеры кодируют структурированные данные, подлежащие передаче, с помощью последовательного применения различных способов кодировки. Деревья разбора моделируют конкретные результаты разбора веб-приложением поступающих к нему HTTP-запросов с помощью применения набора соответствующих декодеров и восстановления исходных структурированных данных. Деревья разбора внутренним представлением HTTP-запросов к веб-приложению и используются в других моделях веб-приложения.
[86] Деревом разбора для запроса называется представление запроса к веб-приложению в виде корневого дерева, однозначным образом отражающего структуру запроса и его содержимое и полученного в результате последовательного применения к запросу и его частям различных функций декодирования данных (например, x-www-form-urlencode, json и т.п.).
[87] Фиг. 4 иллюстрирует процесс применения к строковым данным (в данном примере, query string HTTP-запроса) декодировщика x-ww-form-urlencode. В результате применения данного декодировщика было получено корневое дерево разбора, дуги которого соответствуют именам отдельных параметров query string, а вершины - значениям данных параметров.
[88] Листья частично построенного дерева разбора в свою очередь могут быть структурированными данными, полученными с помощью какого-либо способа кодировки. Применение к ним надлежащего декодера модифицирует частичное дерево, заменяя данную листовую вершину на новое корневое дерево разбора. Данный процесс продолжается до тех пор, пока полученные листовые вершины дерева разбора не оказываются простыми данными (числами, строками и т.п.), к которым более невозможно применение декодеров.
[89] Фиг. 5 иллюстрирует дерево разбора HTTP GET запроса, полученное в результате последовательного применения трех декодеров.
[90] Фиг. 6 иллюстрирует способ построения дерева разбора для произвольного запроса к веб-приложению, множество которых было получено на этапе сбора обучающих данных. Для каждого запроса создается корневое дерево из единственной листовой вершины, которая добавляется в список для обработки. Предложенный способ далее выбирает одну из корневых вершин для обработки и пытается найти декодер, применение которого к содержимому вершины приводит к успешному разбору и построению дочернего дерева разбора. Данная вершина затем заменяется на найденное дерево и помечается соответствующим примененным декодером. Листовые вершины построенного дерева добавляются в список для дальнейшей обработки. Процесс завершается, когда список вершин для обработки становится пуст.
[91] Для моделирования ответов веб-приложения используется аналогичный механизм деревьев разбора, и аналогичный способ построения деревьев разбора для всех ответов веб-приложения, полученных на этапе сбора обучающих данных.
[92] Различные запросы к веб-приложению (и ответы на них) могут иметь различную внутреннюю структуру. Это означает, что для разных запросов (и ответов) будут построены различные деревья разбора, отличающиеся не только содержимым листовых вершин, но и структурой самого дерева. Для того, чтобы на этапе защиты веб-приложения иметь возможность быстрого получения деревьев разбора для наблюдаемых запросов и ответов веб-приложения, используются дерево решений разбора запросов (и аналогичное дерево решений разбора ответов). Данное дерево моделирует логику разбора запросов защищаемым веб-приложением.
[93] Дерево решений разбора запросов представляет собой корневое дерево, все пути от корня к листьям которого соответствуют одной из возможных цепочек применения декодеров для разбора HTTP-запроса к веб-приложению. Вершины этого дерева размечены парой, состоящей из:
• декодера, который должен быть применен на очередном шаге разбора запроса к одной из листовых вершин текущего дерева разбора;
• и элемента текущего дерева разбора, к которой следует применить данный декодер.
[94] Дуги дерева решений разбора запросов размечены наборами предикатов. Данные предикаты определены над текущим деревом разбора и могут проверять условия по крайней мере следующих видов:
• наличие в текущем дереве разбора пути с заданной меткой;
• совпадение значения листовой вершины по заданному пути в текущем дереве разбора с заданной константой;
• соответствие значения листовой вершины в текущем дереве разбора регулярному выражению из ограниченного предопределенного набора.
[95] Предикаты, которыми размечены дуги дерева решений разбора запросов, управляют в процессе разбора запроса выбором следующей вершины дерева решений (т.е. выбором следующего применяемого декодера и элемента текущего дерева разбора, к которому следует применить данный декодер). Иными словами, в процессе разбора запроса после выбора очередной вершины дерева разбора и применения ее декодера для исходящих из этой вершины дуг последовательно производится вычисление предикатов. Если для очередной дуги все предикаты принимают истинное значение, то входящая вершина для данной дуги становится очередной вершиной дерева решений, применяемой для разбора запроса. Данный процесс разбора производится до достижения листовой вершины дерева решений, либо до обнаружения ошибки при разборе (ситуации, когда ни для одной из дуг текущей вершины предикаты не принимали истинного значения).
[96] Фиг. 7 иллюстрирует пример дерева решений для разбора запросов. В приведенном примере веб-приложение обрабатывает информацию из GET и POST запросов по стандартной схеме, кроме ситуации, когда производится обращение к скрипту json_import.php, который обрабатывает json-данные из тела запроса.
[97] Фиг. 8 иллюстрирует способ построения дерева решений разбора запросов на основе множества деревьев разбора запросов, построенных на первом шаге способа построения моделей функционирования веб-приложения. Данный способ состоит из следующих шагов:
• взять пустое дерево решений с одной корневой вершиной и множество деревьев разбора;
• из исходного множества деревьев разбора построить вспомогательное множество деревьев разбора, соответствующее текущему виду дерева решений;
• если вспомогательное множество деревьев не совпадает с исходным, найти и построить дочерние вершины для текущих листовых вершин дерева решения, для чего выполнить следующие шаги:
 идентифицировать и отсеять псевдослучайные токены во вспомогательных деревьях разбора запросов;
идентифицировать и отсеять псевдослучайные токены во вспомогательных деревьях разбора запросов;
 выполнить кластеризацию вспомогательного множества деревьев разбора по принципу применимости к ним различных декодеров;
выполнить кластеризацию вспомогательного множества деревьев разбора по принципу применимости к ним различных декодеров;
 выполнить классификацию построенных кластеров с помощью автоматического построения набора предикатов;
выполнить классификацию построенных кластеров с помощью автоматического построения набора предикатов;
 по построенным наборам предикатов и кластеров вспомогательного набора деревьев разбора модифицировать текущее дерево решений.
по построенным наборам предикатов и кластеров вспомогательного набора деревьев разбора модифицировать текущее дерево решений.
 идентификация псевдослучайных токенов деревьев разбора важна для того, чтобы выявить и отсеять те элементы дерева разбора запроса, которые не влияют на синтаксический и структурный разбор запроса веб-приложением, а значит не должны использоваться в предикатах дерева решений разбора запроса. Примерами таких псевдослучайных токенов являются по крайней мере:
идентификация псевдослучайных токенов деревьев разбора важна для того, чтобы выявить и отсеять те элементы дерева разбора запроса, которые не влияют на синтаксический и структурный разбор запроса веб-приложением, а значит не должны использоваться в предикатах дерева решений разбора запроса. Примерами таких псевдослучайных токенов являются по крайней мере:
 идентификаторы сессий;
идентификаторы сессий;
 CSRF-токены;
CSRF-токены;
 случайные строки, применяемые для предотвращения кэширования данных;
случайные строки, применяемые для предотвращения кэширования данных;
 идентификаторы объектов предметной области веб-приложения;
идентификаторы объектов предметной области веб-приложения;
 временные метки.
временные метки.
[98] Для данных токенов запросов характерны два признака: их наличие в большей части запросов и высокая вариативность значений. Идентификация всех таких токенов и их отсев производятся с помощью следующих шагов способа:
• для каждой листовой вершины вспомогательных деревьев разбора (идентифицируемой по пометкам пути) подсчитывается число деревьев разбора, в которых есть данная вершина;
• для каждой листовой вершины деревьев разбора подсчитывается число уникальных значений, встречающихся в данной вершине;
• заменяются на символ wildcard те листовые вершины, для которых выполнены два условия:
 доля деревьев разбора с данной вершиной превышает заданное пороговое значение;
доля деревьев разбора с данной вершиной превышает заданное пороговое значение;
 количество уникальных значений данной вершины превышает заданное пороговое значение.
количество уникальных значений данной вершины превышает заданное пороговое значение.
[99] Для кластеризации множества деревьев разбора применяется следующие шаги способа:
• построить таблицу, столбцы которой соответствуют всем возможным декодерам, строки - всем существующим путям в текущих вспомогательных деревьях разбора, а в ячейках находятся число вспомогательных деревьев разбора, к листовым вершинам которых по заданному пути применим данный декодер;
• найти строки таблицы, где есть преобладающие наборы декодеров, т.е. такие наборы, которые применимы для большей части листовых вершин по заданному пути для вспомогательного множества деревьев разбора;
• для выбранных строк разбить вспомогательное множество деревьев разбора на кластеры, сопоставив отдельный кластер каждому из применимых декодеров.
[100] Фиг. 9 иллюстрирует описанную выше таблицу применимости декодеров к листовым вершинам вспомогательного множества деревьев разбора и критерий преобладания набора декодеров в некоторой строке такой таблицы.
[101] Для классификации построенного множества кластеров вспомогательного множества деревьев разбора применяется существующий алгоритм decision list learning, предложенный Ривестом. Результатом работы этого способа является выделение набора предикатов над элементами текущих вспомогательных деревьев разбора, позволяющих различать различные кластеры между собой.
[102] Последовательность шагов построения вспомогательного множества деревьев решений, идентификации и отсева псевдослучайных токенов, кластеризации вспомогательных деревьев решений и их классификации продолжается до тех пор, пока множество вспомогательных деревьев разбора (получаемое как результат применения к запросам текущего дерева решений) не совпадет с исходным множеством деревьев разбора. Это будет означать, что построенное дерево решений разбора запросов позволяет разобрать любой из запросов, наблюдавшихся на этапе сбора обучающих данных.
[103] Построение дерева решений разбора ответов веб-приложения производится аналогичным образом.
[104] Модель маршрутизации запросов предназначена для того, чтобы сопоставить запросам к веб-приложению действия уровня логики функционирования веб-приложения, которые должны быть выполнены в результате обработки данного запроса веб-приложением. Различные действия уровня логики функционирования веб-приложения реализуются различными функциями обработки запросов в веб-приложении, а выбор данной функции в веб-приложении определяется наличием заданного множества параметров запроса (влияющих на маршрутизацию запроса) и значений данных параметров. В процессе своего функционирования веб-приложение разбирает запрос, применяет к нему набор проверок-предикатов и выбирает нужную функцию обработки запроса (реализующую требуемое действие) в зависимости от того, какой предикат принял истинное значение.
[105] Задача построения модели маршрутизации запросов, таким образом сводится к тому, чтобы автоматически, с помощью методов машинного обучения, вычислить данный набор предикатов на основе множества запросов, полученных на этапе сбора обучающих данных. Фиг. 10 иллюстрирует способ построения модели маршрутизации запросов в виде множества предикатов, применяемых к запросам (точнее, деревьям разбора запросов) веб-приложения с целью идентификации отдельных действий уровня логики функционирования веб-приложения. Данный способ включает следующие шаги:
• вначале инициализируется пустое множество предикатов, образующих модель маршрутизации запросов;
• далее итеративно, пока остаются деревья разбора запросов, для которых не применился ни один из построенных предикатов, выполняются следующие шаги:
 среди деревьев разбора, не классифицированных с помощью имеющегося набора предикатов, производится выборка случайного набора из заданного количества деревьев разбора;
среди деревьев разбора, не классифицированных с помощью имеющегося набора предикатов, производится выборка случайного набора из заданного количества деревьев разбора;
 данная выборка деревьев разбора подвергается кластеризации с использованием метрики дистанции, основанной на мерах сходства и различия деревьев разбора;
данная выборка деревьев разбора подвергается кластеризации с использованием метрики дистанции, основанной на мерах сходства и различия деревьев разбора;
 из построенного множества кластеров выбираются кластеры, размер которых превышает заданное пороговое значение;
из построенного множества кластеров выбираются кластеры, размер которых превышает заданное пороговое значение;
 для каждого из данных кластеров находится максимальное общее поддерево. По данному максимальному общему поддереву строится предикат, как конъюнкция условий двух типов:
для каждого из данных кластеров находится максимальное общее поддерево. По данному максимальному общему поддереву строится предикат, как конъюнкция условий двух типов:
 условия первого типа проверяют наличие вершины с заданным путем. Данные условия строятся для всех листовых вершин максимального общего поддерева;
условия первого типа проверяют наличие вершины с заданным путем. Данные условия строятся для всех листовых вершин максимального общего поддерева;
 условия второго типа проверяют значение в вершине с заданным путем (равенство значения константе). Данные условия строятся для всех листовых вершин максимального общего поддерева, если все деревья кластера имеют одно и то же общее значение в данной вершине;
условия второго типа проверяют значение в вершине с заданным путем (равенство значения константе). Данные условия строятся для всех листовых вершин максимального общего поддерева, если все деревья кластера имеют одно и то же общее значение в данной вершине;
 осуществляют фильтрацию построенного множества предикатов-кандидатов. В ходе фильтрации из множества предикатов-кандидатов удаляются те предикаты, которые срабатывают на деревьях из других кластеров - таким образом обеспечивается отсутствие пересечений между предикатами;
осуществляют фильтрацию построенного множества предикатов-кандидатов. В ходе фильтрации из множества предикатов-кандидатов удаляются те предикаты, которые срабатывают на деревьях из других кластеров - таким образом обеспечивается отсутствие пересечений между предикатами;
 успешно прошедшие фильтрацию предикаты-кандидаты добавляются в строящееся множество предикатов модели маршрутизации запросов, и производится новая итерация;
успешно прошедшие фильтрацию предикаты-кандидаты добавляются в строящееся множество предикатов модели маршрутизации запросов, и производится новая итерация;
• производится сохранение построенного множества предикатов, которое и является моделью маршрутизации запросов.
[106] Способ построения модели маршрутизации запросов исполняется компонентом Learning в полностью автоматическом режиме, без участия оператора и\или администратора системы. Оператор и\или администратор системы, однако, имеет возможность в дальнейшем просмотреть и отредактировать построенное множество предикатов, например, с целью присвоения каждому из них осмысленного человеко-читаемого названия, по которому идентифицируется конкретное действие уровня логики функционирования веб-приложения. Данный шаг выполняется исключительно для удобства задания последующих моделей функционирования веб-приложения (модели сценариев использования и набора правил контроля доступа к ресурсам и функциям веб-приложения).
[107] Модель для извлечения идентификаторов сессии и пользователя из запросов и ответов веб-приложения предназначена для использования в механизмах отслеживания пользовательских сессий веб-приложения. В рамках данной модели каждому из действий уровня логики функционирования веб-приложения сопоставляется набор параметров данного действия (путей в дереве разбора запросов к веб-приложению или ответов веб-приложения), значения которых содержат идентификаторы сессии веб-приложения или идентификатор пользователя, осуществляющего данное действие.
[108] Отслеживание пользовательских сессий и действий уровня логики функционирования веб-приложения, выполнение которых приводит к инициализации или завершению пользовательской сессии, важно для применения в модели сценариев использования веб-приложений и в качестве служебной информации для идентификации запросов к статическим ресурсам веб-приложения.
[109] Модель для извлечения идентификаторов сессии и пользователя строится на основе полученной ранее модели маршрутизации запросов и дерева решений разбора запросов и ответов. Построение этой модели может производиться оператором и\или администратором системы вручную или в автоматизированном режиме при взаимодействии с компонентом Learning.
[110] Модели синтаксиса и семантики параметров действий веб-приложения предназначены для того, что идентифицировать параметры действий уровня логики функционирования веб-приложения, определить типы и диапазоны допустимых значений для данных параметров и выявить объекты предметной области веб-приложения. Модель синтаксиса параметров действий веб-приложения применяется на этапе защиты веб-приложения для выявления аномалий в значениях параметров действий, а модель семантики параметров используется при построении модели сценариев использования веб-приложения для определения зависимостей по данным между действиями и в модели контроля доступа к ресурсам для задания прав доступа пользователя веб-приложения к объектам предметной области веб-приложения.
[111] К числу параметров действия веб-приложения относятся параметры запросов к веб-приложению, идентифицированные на этапе построения деревьев разбора, за вычетом следующего множества параметров запроса:
• параметров, непосредственно идентифицирующих само действие уровня логики функционирования веб-приложения;
• параметров, идентифицирующих сессию веб-приложения и пользователя веб-приложения;
• части служебных параметров, таких как CSRF-токены и т.п.
[112] При построении модели синтаксиса параметров для каждого из параметров действия определяется его тип и допустимый диапазон значений. В качестве распознаваемых типов могут использоваться, по крайней мере следующие типы:
• нетипизированные строковые данные;
• числовое значение;
• константа или перечислимый тип данных;
• дата и\или время;
• email адрес;
• URL адрес;
• регулярные выражения;
• произвольные текстовые данные.
[113] Диапазон допустимых значений параметров действий определяет правила проверки значения параметра на этапе защиты веб-приложения. Значения параметров, которые не являются допустимыми для параметра данного типа, увеличивают оценку аномальности запроса в соответствии с заданными правилами проверки синтаксиса и семантики параметров действий веб-приложения. Тем самым на этапе обучения для каждого из параметров должны быть определены ограничения на диапазон допустимых значений этого параметра:
• для нетипизированных строковых данных вычисляется длина данных в байтах в виде выборочного среднего и среднеквадратичного отклонения;
• для числовых значений устанавливается, является ли данное число целочисленным или дробным;
• для констант или перечислимых типов данных определяется множество конкретных значений, которые может принимать данный параметр;
• для даты и\или времени определяется допустимый временной интервал, значения из которого может принимать параметр;
• для параметров, содержащих URL адреса, устанавливается допустимая схема URL адреса, допустимость абсолютных или относительных URL адресов и наличие query string части URL адреса;
• для регулярных выражений строятся одномерные и многомерные модели распределений Гаусса, описывающие по крайней мере характеристики следующих параметров: длину параметра, количество отдельных «слов», количество отдельных символов различных классов (букв, цифр, символов пунктуации, прочих ASCII символов) и максимальное количество идущих подряд символов из каждой категории;
• для произвольных текстовых данных ограничений на допустимый диапазон значений не накладывается.
[114] При построении модели семантики параметров выявляются объекты уровня предметной области веб-приложения, идентифицируемые значениями некоторых подмножеств параметров действий веб-приложения.
[115] Модели синтаксиса и семантики параметров действий веб-приложения строятся на основе полученной ранее модели маршрутизации запросов и дерева решений разбора запросов. Построение синтаксической модели может производиться автоматическим образом, на основе данных, полученные на этапе сбора обучающих данных. Построение модели семантики параметров производится оператором и\или администратором системы вручную или в автоматизированном режиме при взаимодействии с компонентом Learning.
[116] Выявление запросов к статическим ресурсам веб-приложения и построение шаблонов URL запросов к статическим ресурсам веб-приложения производится с целью выявить множество статических ресурсов веб-приложения в виде набора шаблонов URL адресов запросов к данным ресурсам. Данное множество шаблонов URL адресов запросов используется далее на этапе защиты веб-приложения для повышения производительности компонента Analyzer. Способ выявления запросов к статическим ресурсам и построения шаблонов URL адресов запросов к статическим ресурса проиллюстрирован на Фиг. 11 и состоит из следующих основных шагов:
• получения множества URL адресов статических ресурсов из множества пар запросов к веб-приложению и ответов веб-приложения на эти запросы;
• токенизации URL адресов статических ресурсов;
• построения шаблонов URL адресов статических ресурсов с помощью иерархической кластеризации;
• сохранения полученного множества шаблонов URL адресов запросов к статическим ресурсам в базе данных компонента Database.
[117] Фиг. 12 иллюстрирует способ получения множества URL адресов статических ресурсов на основе анализа множества пар запросов к веб-приложению и ответов веб-приложения, полученных на этапе сбора обучающих данных. Данный способ основан на классификации запросов на запросы к статическим или динамическим ресурсам с помощью анализа характерных признаков запросов и ответов веб-приложения и включает следующие основные шаги:
• построение пустого множества дескрипторов URL адресов и пустого множества статических URL адресов;
• последовательный просмотр всех пар запросов и ответов веб-приложения, для добавления новых дескрипторов URL адресов или уточнения характеристик построенных дескрипторов;
• просмотр множества построенных дескрипторов URL адресов запросов и добавление во множество статических URL тех URL адресов, которые помечены как статические и для которых счетчик числа уникальных пользователей превышает заданное пороговое значение.
[118] В процессе своей работы способ строит множество дескрипторов URL ресурсов, наполняя его записями о новых обнаруженных URL адресах запросов, и помечает дескрипторы URL как статические или не статические, в зависимости от характеристик наблюдаемых URL запросов к веб-приложению и ответов веб-приложения, а также подсчитывает число уникальных пользователей, обратившихся к ресурсу по данному URL адресу. Для каждой очередной обрабатываемой пары запрос-ответ выполняются следующие шаги:
• найти дескриптор для URL данного запроса или создать новый дескриптор для данного URL;
• для статус-кода ответа веб-приложения, отличного от 304 (требование взять ресурс из кэша браузера) пометить дескриптор как нестатический, если тип или длина тела данных ответа на запрос (content-type и content-length заголовки) отличаются от ранее сохраненных в дескрипторе значений;
• проверить значение заголовка content-type и статус-кода ответа веб-приложения ответу на запрос к статическому ресурсу, пометить дескриптор URL адреса как нестатический в случае недопустимых значений (отличных от 2хх и 3хх);
• подсчитать дисперсию времени обработки запроса (разница между временами запроса и ответа), пометить дескриптор URL адреса как нестатический при превышении дисперсией заданного порогового значения;
• проверить наличие заголовков запроса, которых являются признаками запроса к динамическому ресурсу (заголовок Authorization и т.п.), пометить дескриптор запроса соответствующим образом;
• для дескриптора URL, сохранившего пометку как URL статического ресурса, увеличить число уникальных пользователей, обратившихся к ресурсу, если текущая пара запрос-ответ принадлежит новому пользователю.
[119] Выявление запросов к статическим ресурсам веб-приложения и построение шаблонов URL адресов запросов к статическим ресурсам производится компонентом Learning полностью автоматически, без участия оператора и\или администратора системы.
[120] Модель сценариев использования веб-приложения предназначена для моделирования допустимых сценариев использования веб-приложения в виде зависимости одних действий уровня логики функционирования веб-приложения от успешного выполнения других действий, а также возможных зависимостей данных действий по данным. Для моделирования сценариев использования веб-приложения используется механизм конечных автоматов, состояния которого моделируют логические состояния веб-приложения при взаимодействии с пользователем, и существует два типа переходов между состояниями:
• переходы, происходящие при успешном выполнении пользователем некоторого действия уровня логики функционирования веб-приложения;
• переходы, происходящие автоматически, по срабатыванию таймера.
[121] Фиг. 13 иллюстрирует пример модели для сценария использования веб-приложения и последовательность действий пользователя с указанием допустимых и не допустимых действий в зависимости от логического состояния модели сценария использования. Показанная в примере модель сценариев использования описывает систему, в которой изначально возможен только доступ к стартовой странице веб-приложения (действие «View index»), затем после ввода учетных данных (действие «Password auth») и авторизации по криптоключу (действие «Token auth») пользователь получает возможность просматривать данные о счетах (действие «View account»), а для выполнения действия по переводу средств («Transfer funds») пользователю требуется еще и ввести одноразовый sms-код.
[122] Данные модели сценариев использования могут быть заданы в виде правил, описывающих по крайней мере:
• логические состояния веб-приложения в виде разрешенных в данном состоянии действий уровня логики функционирования веб-приложения (или же пререквизитов данных действий);
• правила перехода в логическое состояние в виде успешного выполнения действия уровня логики функционирования веб-приложения;
• правила перехода в предыдущие логические состояния при срабатывании таймера и\или попытки выполнения недопустимых действий.
[123] На этом же уровне могут выделять объекты уровня предметной области веб-приложения (например, счета, профили пользователей, записи на форуме и т.п.), идентифицируемые в виде значений соответствующих параметров действий веб-приложения.
[124] Построение модели сценариев использования веб-приложения производится автоматизированным образом при взаимодействии с компонентом Learning.
[125] Модель для контроля доступа к ресурсам веб-приложения предназначена для проверки прав доступа пользователя веб-приложения к запрошенным ресурсам и логическим функциям веб-приложения. Данная модель представляет собой набор правил контроля доступа, каждое из которых представляет собой набор предикатов над значениями параметров данного действия уровня логики функционирования веб-приложения и решения о разрешении или запрещении доступа к запрошенному ресурсу или логической функции. В одном из вариантов исполнения системы данные правила контроля доступа могут быть описаны в терминах предикатов над объектами уровня предметной области веб-приложения, идентифицированными на этапе построения моделей синтаксиса и семантики параметров действий веб-приложения.
[126] Построение модели для контроля доступа к ресурсам веб-приложения производится оператором и\или администратором системы вручную или частично автоматизированным образом при взаимодействии с компонентом Learning.
[127] Фиг. 14 иллюстрирует способ, применяемый компонентом Learning на этапе выявления ложных срабатываний для автоматического выявления сигнатурных правил обнаружения атак и отдельных модулей обнаружения аномалий, имеющих высокий уровень ложных срабатываний, создания журнальных сообщений о ложных срабатываниях и создания настроек, исключающих данные сигнатурные правила из дальнейшего использования на этапе защиты веб-приложения. Данный способ выполняется системой полностью автоматически, без участия оператора и\или администратора системы.
[128] Данный способ использует в качестве входных данных множество запросов к веб-приложению и информацию о срабатывании сигнатурных правил обнаружения атак и отдельных модулей обнаружения аномалий, полученные на этапе сбора обучающих данных. Для автоматического выявления ложных срабатываний применяется корреляционный анализ. Для этого на первом шаге способ производит разделение общего временного периода этапа сбора обучающих данных на отдельные равные временные интервалы. Далее на втором и третьем шагах способа для каждого из временных интервалов подсчитывается общее число запросов к веб-приложению и число срабатываний каждого отдельного сигнатурного правила обнаружения атак и модуля обнаружения аномалий за каждый из временных интервалов.
[129] На четвертом шаге для каждого из временных интервалов строятся ранги для данных сигнатурных правил и модулей, как порядковые номера в последовательности, упорядоченной по возрастанию числа срабатываний каждого из сигнатурных правил или модулей обнаружения аномалий.
[130] На пятом шаге способ подсчитывает на заданных временных интервалах коэффициенты корреляции между рангами и числом запросов к веб-приложению. Для данного подсчета применяется ранговый коэффициент корреляции Спирмена, вычисляемый по формуле: 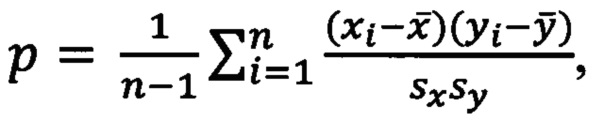 где
где 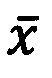 - среднее значение последовательности рангов, n - количество наблюдений (число временных интервалов), xi - значение наблюдаемой величины на i-ом временном интервале, а
- среднее значение последовательности рангов, n - количество наблюдений (число временных интервалов), xi - значение наблюдаемой величины на i-ом временном интервале, а  стандартное отклонение наблюдаемой величины.
стандартное отклонение наблюдаемой величины.
[131] Далее множество сигнатурных правил обнаружения атак и модулей обнаружения аномалий просматривается последовательно, и вычисленное значение коэффициента корреляции сравнивается с пороговым значением. В случае превышения порогового значение создается журнальное сообщение о ложном срабатывании, а для сигнатурных правил обнаружения атак дополнительно производится создание настроек, исключающих дальнейшее применение данного сигнатурного правила.
[132] Наконец, производится сохранение множества созданных настроек и журнальных сообщений в базу данных компонента Database.
[133] Величины временных интервалов, на которые разбивается временной период сбора обучающих данных, и пороговое значение коэффициента корреляции, установлены в ходе предварительных экспериментов и являются частью настроек, сохраняемых в базе данных компонента Database. Данные настройки могут быть при необходимости изменены оператором и\или администратором системы с помощью компонента Web dashboard.
[134] Фиг. 15 иллюстрирует общий способ обработки запроса к защищаемому веб-приложению на этапе защиты веб-приложения в одном из возможных вариантов исполнения системы. Различные шаги этого способа исполняются различными модулями компонента Analyzer Core после получения очередного запроса к веб-приложению через модуль ProxyAdapter или PassiveAdapter, в зависимости от варианта исполнения системы и ее размещения. На различных шагах этого способа используются различные модели функционирования веб-приложения, построенные ранее на этапе обучения системы.
[135] На первом шаге модуль DecisionTreeParser производит синтаксический и структурный разбор HTTP-запроса. На данном шаге используется дерево решений разбора запросов.
[136] Для успешно разобранных запросов на втором шаге происходит идентификация действия уровня логики функционирования веб-приложения и параметров этого действия. Данный шаг производится модулем ActionDeterminer с помощью модели маршрутизации запросов веб-приложения.
[137] На третьем шаге производится идентификация сессии и пользователя, которым принадлежит данный запрос. Данный шаг выполняется модулем SessionTracker, выявляющим среди параметров запроса параметры, отвечающие за идентификацию сессии и пользователя.
[138] На четвертом шаге проверяется допустимость выполнения действия с точки зрения сценариев использования веб-приложения. Данный шаг выполняется модулем DecisionMaker с использованием модели сценариев использования веб-приложения.
[139] Для допустимых действий на пятом шаге производится проверка синтаксиса (типов и допустимых значений) и семантики параметров действия и выявляются аномалии в значениях параметров. Данный шаг производится модулем DecisionMaker с использованием моделей синтаксиса и семантики параметров действий веб-приложения.
[140] На шестом шаге модуль DecisionMaker проверяет правила контроля доступа к ресурсам веб-приложения с помощью сформированных оператором и\или администратором набора правил контроля доступа.
[141] На седьмом и восьмом шагах способа используются модули LibinjectionDetector и ModsecurityDetector, отвечающие за обнаружение атак на веб-приложение с помощью настроенных ранее сигнатурных правил. Переход на данные шаги происходит также в случае невозможности разбора запроса (выполнявшегося на первом шаге способа), и невозможности идентифицировать действие уровня логики функционирования веб-приложения (выполнявшего на втором шаге способа).
[142] Результаты, полученные на седьмом и восьмом шагах способа, агрегируются вместе с аномалиями, обнаруженными при проверке типов и значений параметров действия (на шестом шаге способа), формируя интегральную оценку «аномальности» запроса.
[143] На десятом шаге способа модуль DecisionMaker принимает решение о классификации запроса как нормального, аномального или атаки на веб-приложение, исходя из интегральной оценки его аномальности и результатов проверки допустимости данного действия в рамках модели сценариев использования веб-приложения и правил контроля доступа. На основании классификации запроса происходит принятие решения о дальнейшей обработке (передача запроса защищаемому веб-приложению, блокирование, выдача пользователю теста САРТСНА и т.п.) и передача этого решения модулю ProxyAdapter (если используется вариант размещения системы в виде обратного HTTP прокси сервера).
[144] Информация о запросе и принятом решении (сам запрос и журнальное сообщение и об обнаруженных аномалиях и принятом решении) далее сохраняется в базу данных компонента Database для сбора статистики и уведомления оператора и\или администратора системы об инцидентах.
[145] Если было принято решение о блокировании запроса - способ завершается. В ином случае последовательно выполняются еще четыре шага способа.
[146] Во-первых, происходит получение ответа веб-приложения на запрос и разбор данного ответа модулем DecisionTreeParser. Далее модулем ActionStatusDeterminer производится определение результата выполнения действия на основе модели анализа ответов веб-приложения. И наконец, производится обновление информации о состоянии пользовательской сессии с точки зрения модели сценариев использования веб-приложения. После выполнения этих шагов способ завершается.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ПРОВЕРКИ ВЕБ-РЕСУРСОВ НА НАЛИЧИЕ ВРЕДОНОСНЫХ КОМПОНЕНТ | 2010 |
|
RU2446459C1 |
| СПОСОБ УВЕЛИЧЕНИЯ НАДЕЖНОСТИ ОПРЕДЕЛЕНИЯ ВРЕДОНОСНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2012 |
|
RU2485577C1 |
| Система и способ определения DDoS-атак при некорректной работе сервисов сервера | 2017 |
|
RU2665919C1 |
| Система и способ определения DDoS-атак | 2017 |
|
RU2676021C1 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ГРАФОВ | 2015 |
|
RU2708939C2 |
| АВТОНОМНОЕ ВЫПОЛНЕНИЕ ВЕБ-ПРИЛОЖЕНИЙ | 2007 |
|
RU2453911C2 |
| Система и способ настройки систем безопасности при DDoS-атаке | 2017 |
|
RU2659735C1 |
| СПОСОБ АНАЛИЗА И ВЫЯВЛЕНИЯ ВРЕДОНОСНЫХ ПРОМЕЖУТОЧНЫХ УЗЛОВ В СЕТИ | 2012 |
|
RU2495486C1 |
| СИСТЕМА И СПОСОБ СБОРА ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ФИШИНГА | 2016 |
|
RU2671991C2 |
| Система и способ внешнего контроля поверхности кибератаки | 2021 |
|
RU2778635C1 |
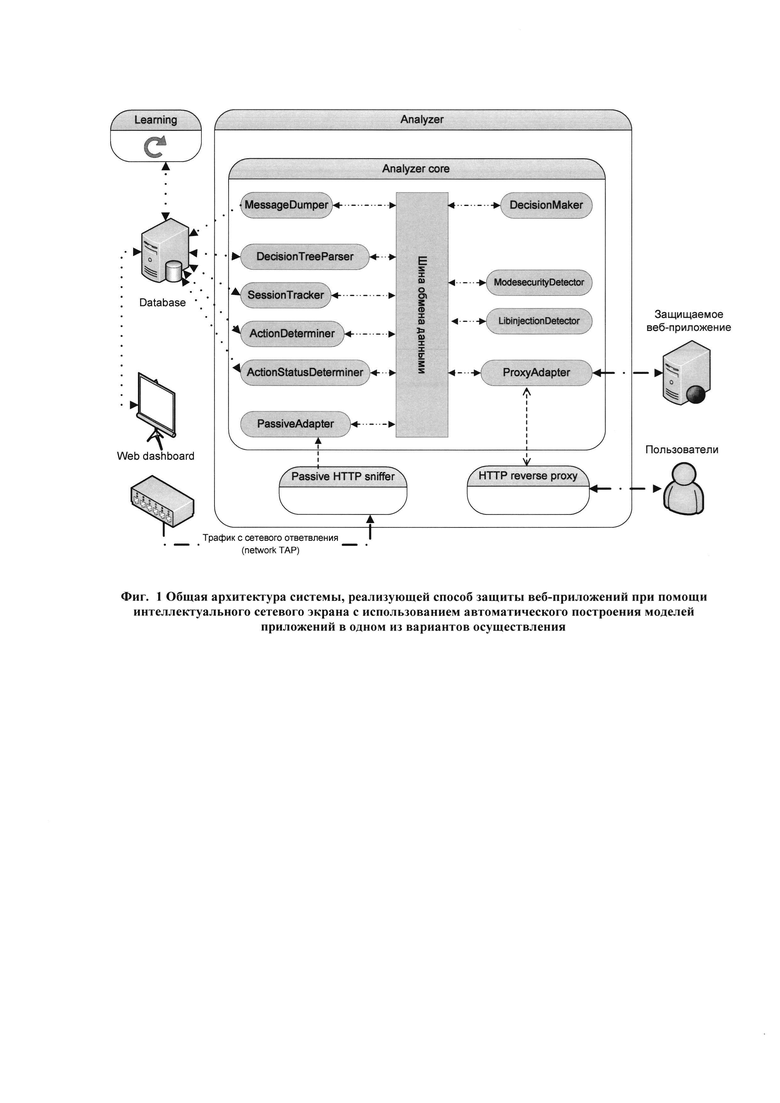
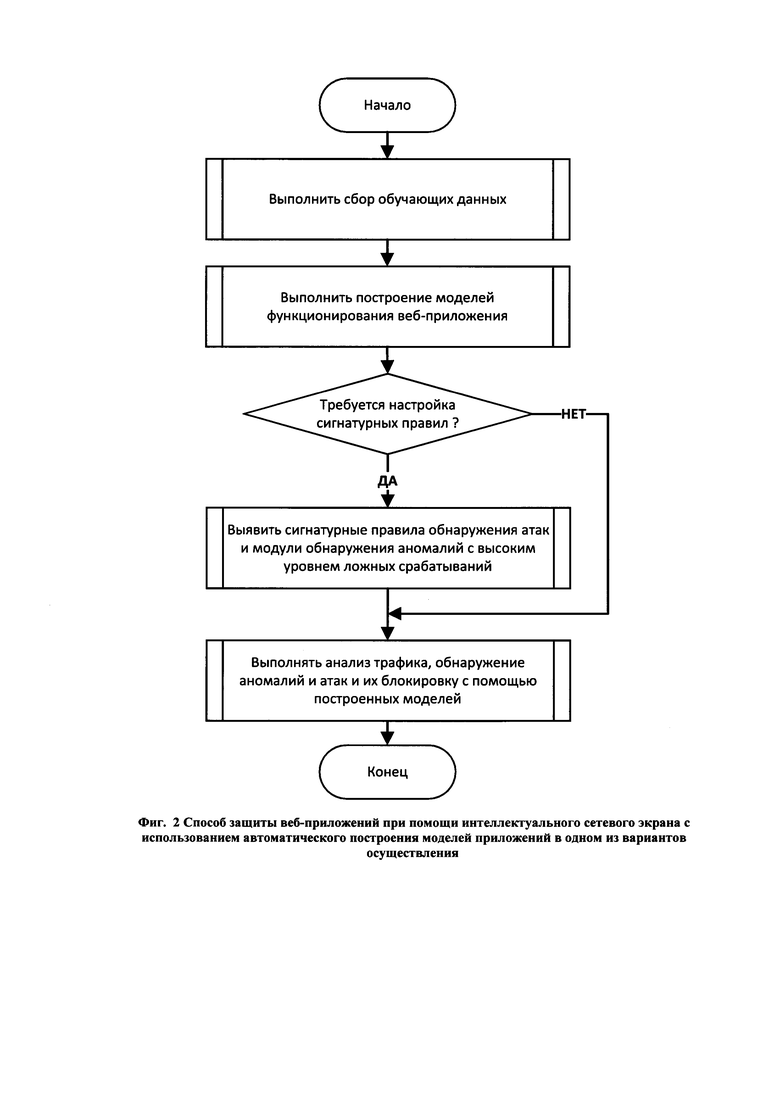

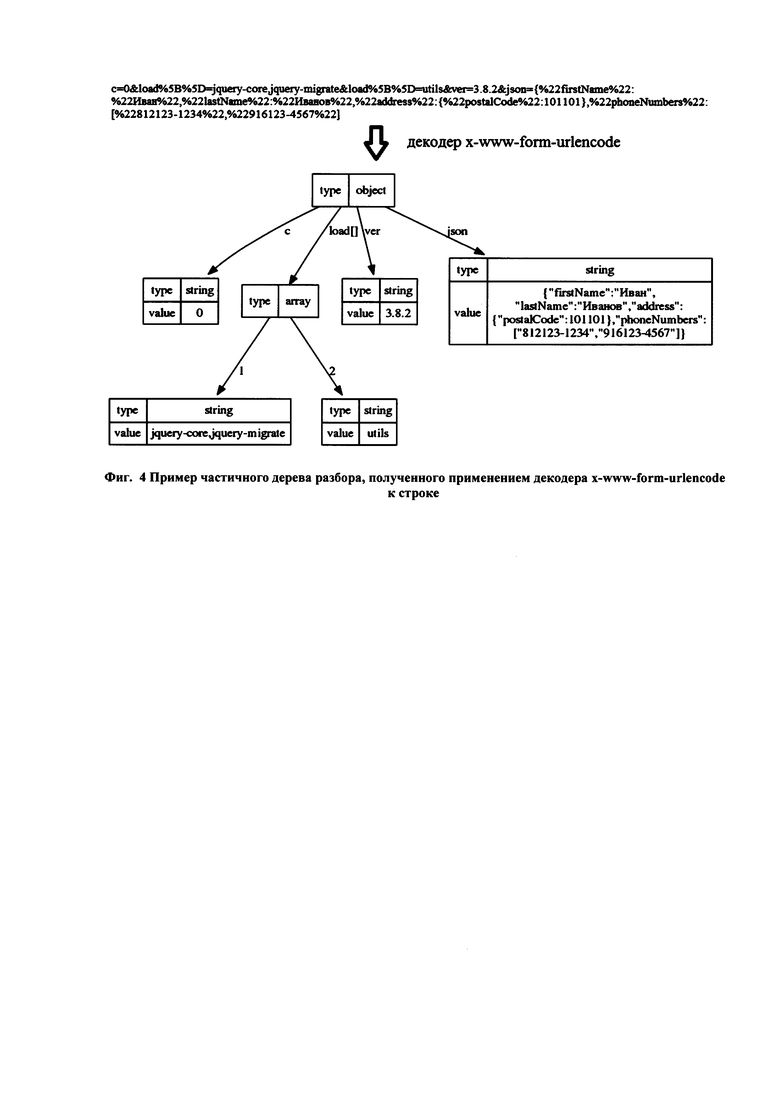
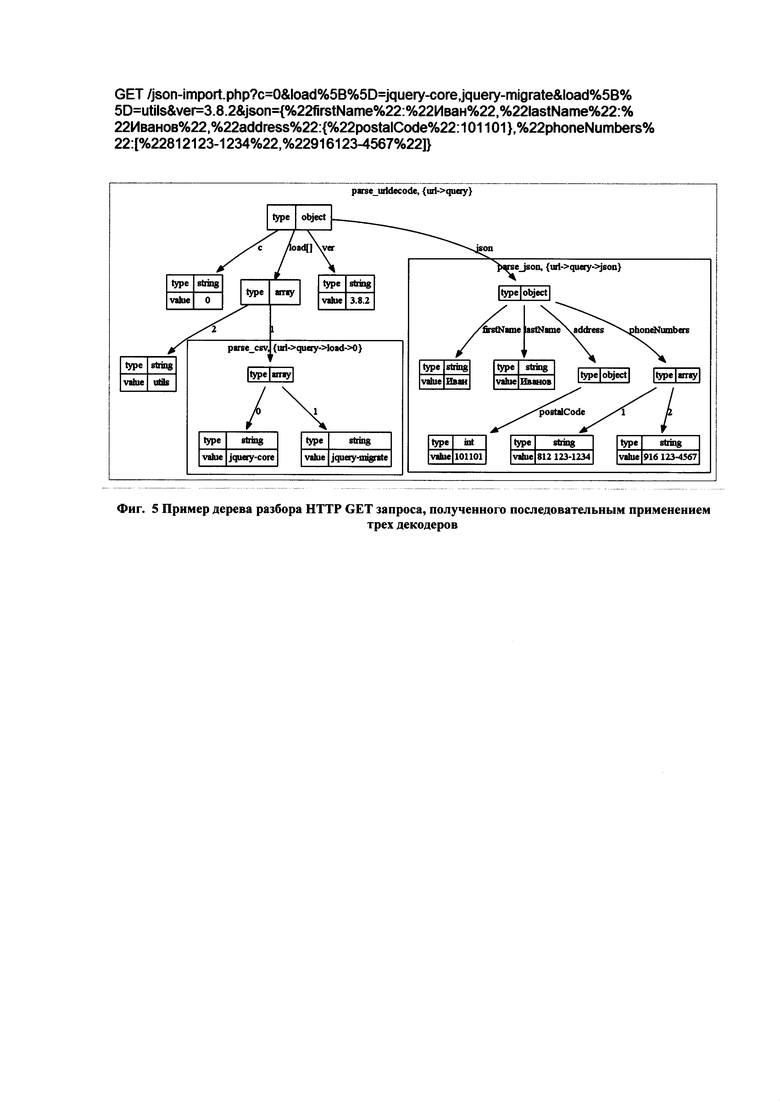
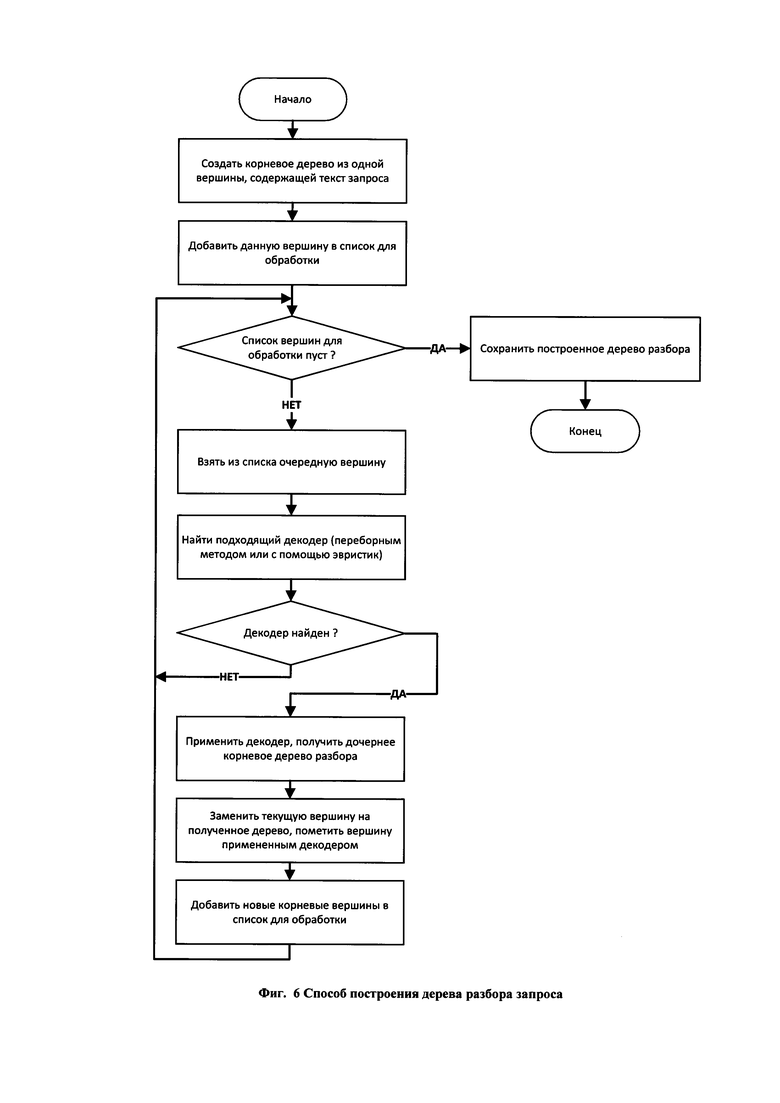

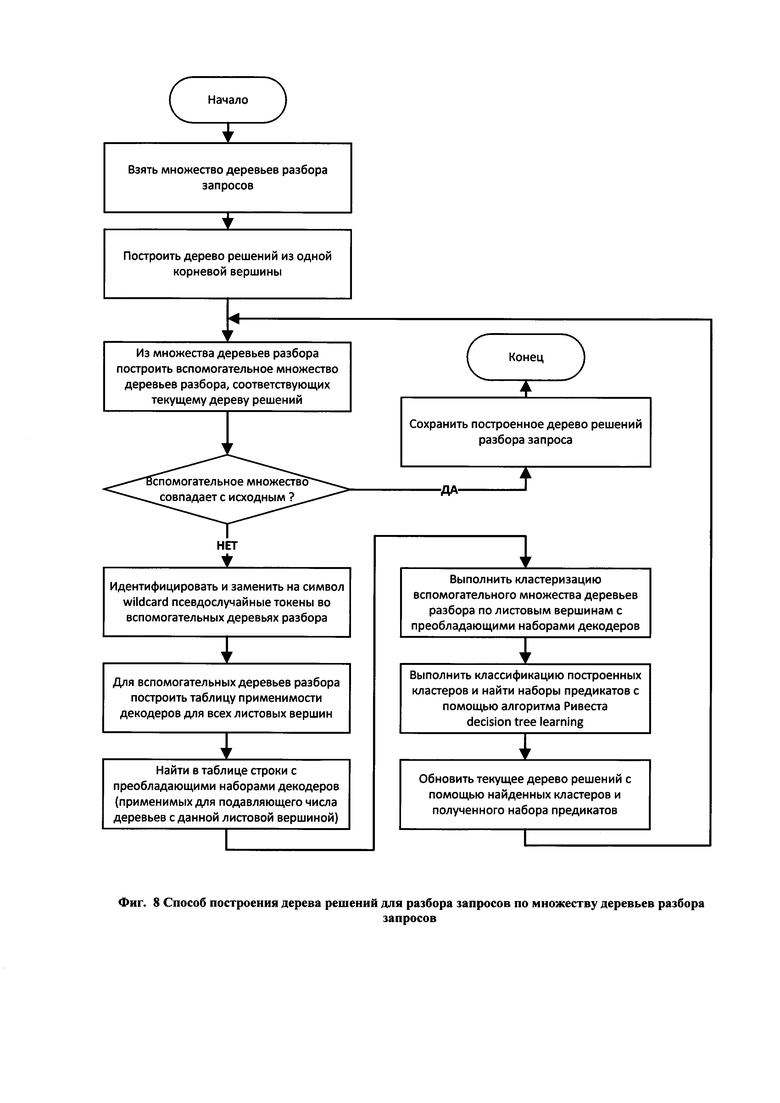

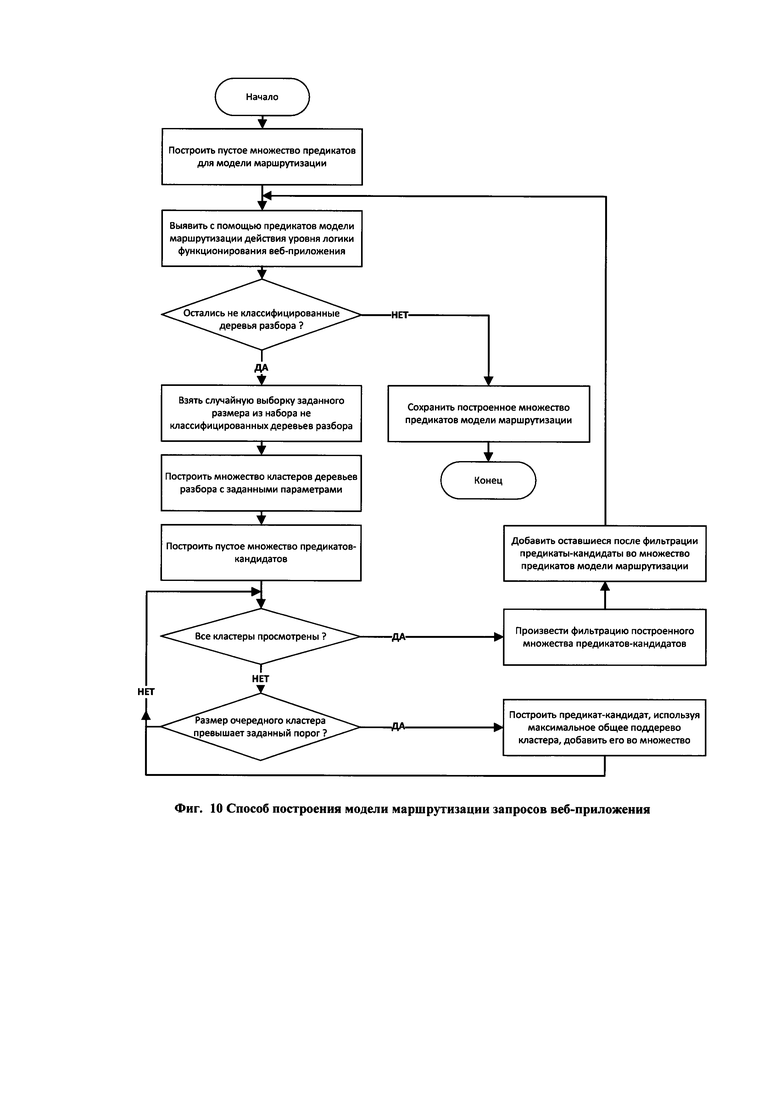
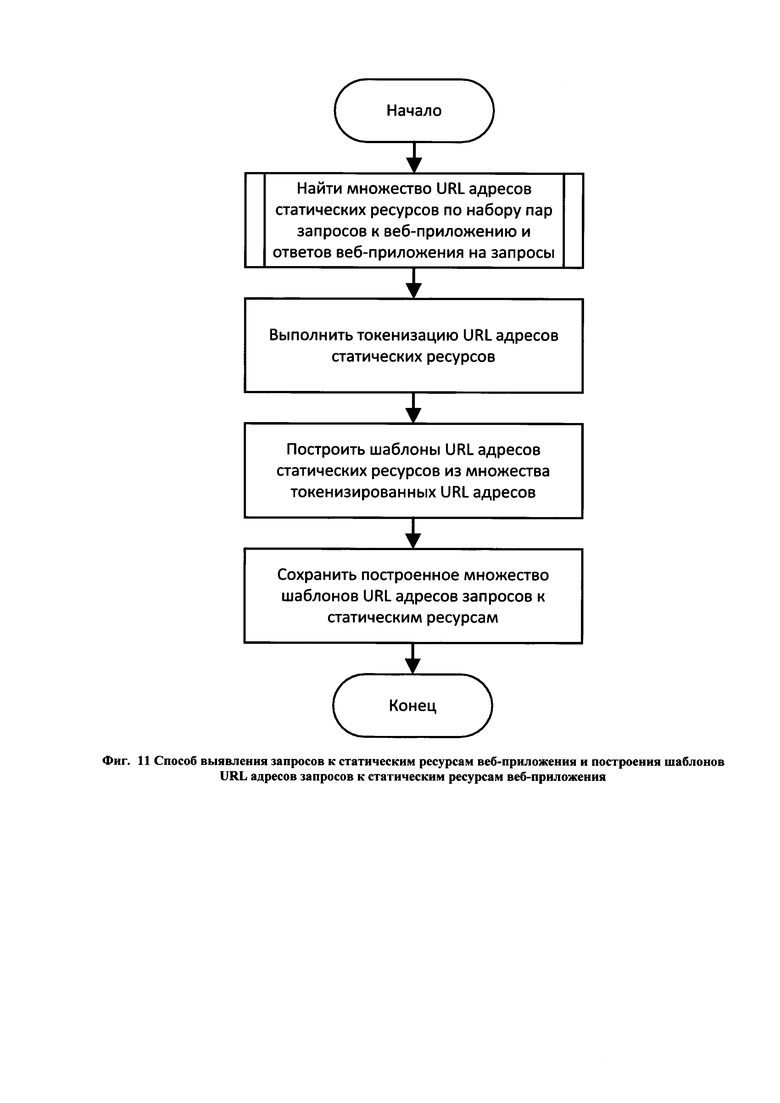
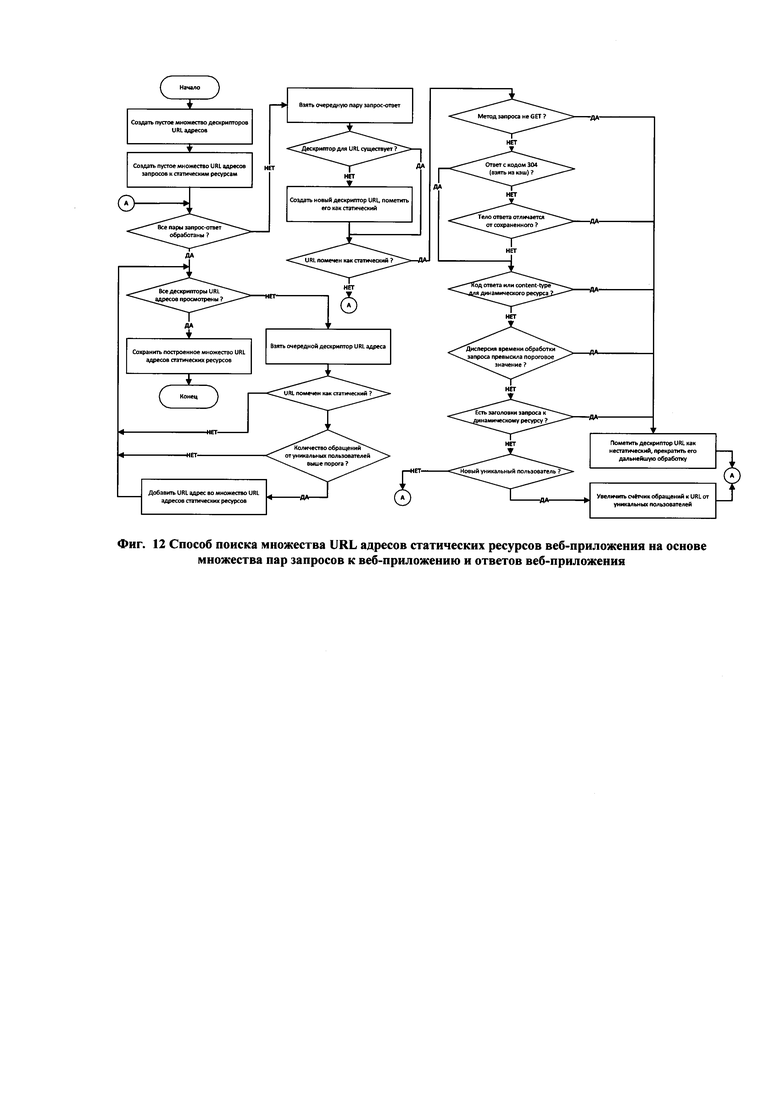

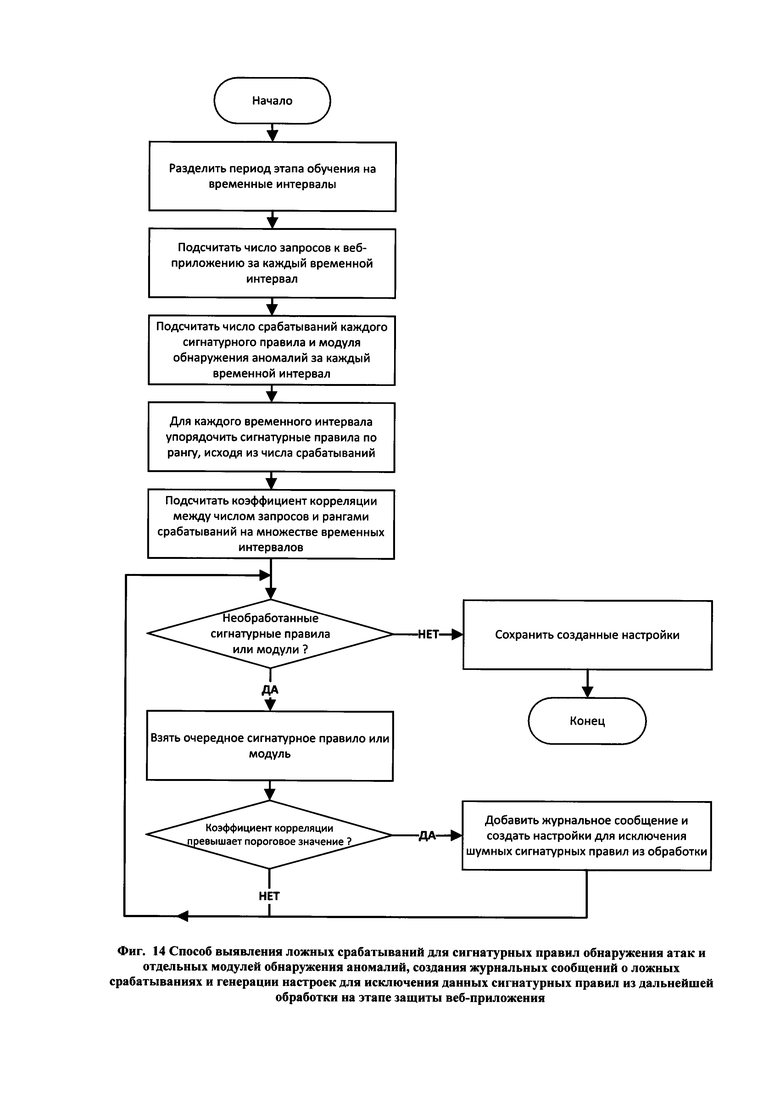
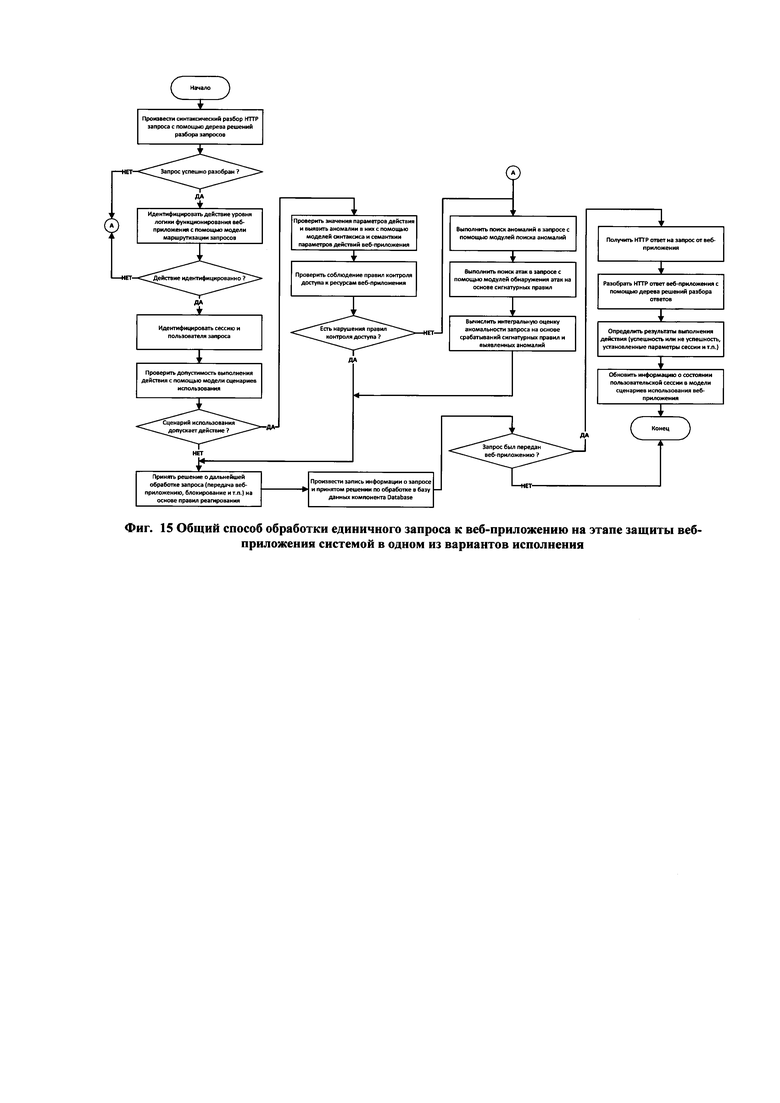
Изобретение относится к способу и системе защиты веб-приложений от различных классов атак. Технический результат заключается в повышении надежности работы веб-приложений. Способ основан на автоматическом построении моделей функционирования веб-приложения и включает в себя следующие шаги: осуществляют автоматический сбор обучающих данных о функционировании веб-приложения, формируют по меньшей мере одну модель функционирования веб-приложения посредством разбора и анализа обучающих данных, полученных на предыдущем шаге, выявляют ложные срабатывания для правил обнаружения атак на веб-приложения на основании обучающих данных и сформированных моделей функционирования веб-приложения, включают режим защиты веб-приложения, в котором анализируют новые поступающие запросы к веб-приложению и его ответы, оценивают степень нормальности или аномальности данных запросов, после чего принимают решения по их дальнейшей обработке. 2 н. и 9 з.п. ф-лы, 15 ил.
1. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак, включая логические атаки, основанный на автоматическом построении моделей функционирования веб-приложения и включающий в себя следующие шаги:
 осуществляют автоматический сбор обучающих данных о функционировании веб-приложения;
осуществляют автоматический сбор обучающих данных о функционировании веб-приложения;
формируют по меньшей мере одну модель функционирования веб-приложения посредством разбора и анализа обучающих данных, полученных на предыдущем шаге;
выявляют ложные срабатывания для правил обнаружения атак на веб-приложения на основании обучающих данных и сформированных моделей функционирования веб-приложения;
включают режим защиты веб-приложения, в котором анализируют новые поступающие запросы к веб-приложению и его ответы, оценивают степень нормальности или аномальности данных запросов, после чего принимают решения по их дальнейшей обработке.
2. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что обучающими данными является множество запросов к веб-приложению, и/или множество ответов веб-приложения, и/или множество срабатываний правил обнаружения атак на веб-приложения.
3. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что осуществляют автоматический сбор обучающих данных посредством интеллектуального сетевого экрана.
4. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что осуществляют автоматический сбор обучающих данных в течение заранее заданного интервала времени.
5. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что при осуществлении сбора обучающих данных собирают запросы к защищаемому веб-приложению и ответы веб-приложения с последующей их записью в базу данных.
6. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что формируют модель функционирования веб-приложения по окончании временного периода, выделенного на сбор обучающих данных.
7. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что формируют модель функционирования веб-приложения с помощью методов машинного обучения.
8. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что выявляют ложные срабатывания для правил обнаружения атак на веб-приложения с помощью статистических методов.
9. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что дополнительно создают настройки для исключения правил обнаружения атак с высоким уровнем ложных срабатываний из дальнейшей обработки.
10. Компьютерно-реализуемый способ защиты веб-приложений от различных классов атак по п. 1, характеризующийся тем, что в режиме защиты веб-приложения аномальные запросы блокируют.
11. Система защиты веб-приложений от различных классов атак, содержащая следующие компоненты:
компонент хранения данных, выполненный с возможностью хранения обучающих данных, построенных моделей функционирования веб-приложения, журнальных сообщений, сгенерированных в процессе функционирования системы и различных настроек системы;
 компонент графического интерфейса, предназначенный для реализации графического интерфейса пользователя системы;
компонент графического интерфейса, предназначенный для реализации графического интерфейса пользователя системы;
 компонент построения моделей функционирования веб-приложения, выполненный с возможностью формирования по меньшей мере одной модели функционирования веб-приложения посредством разбора и анализа обучающих данных;
компонент построения моделей функционирования веб-приложения, выполненный с возможностью формирования по меньшей мере одной модели функционирования веб-приложения посредством разбора и анализа обучающих данных;
 компонент анализа данных, выполненный с возможностью получения и анализа трафика защищаемого веб-приложения, его анализа с целью выявления атак на веб-приложение и реагирования на данные атаки, включая блокировку атакующих запросов и\или генерацию и сохранение сообщений об обнаруженных атаках, который включает:
компонент анализа данных, выполненный с возможностью получения и анализа трафика защищаемого веб-приложения, его анализа с целью выявления атак на веб-приложение и реагирования на данные атаки, включая блокировку атакующих запросов и\или генерацию и сохранение сообщений об обнаруженных атаках, который включает:
 модуль активного захвата трафика,
модуль активного захвата трафика,
 модуль пассивного захвата трафика,
модуль пассивного захвата трафика,
 модуль анализа запросов и ответов веб-приложения и принятия решений.
модуль анализа запросов и ответов веб-приложения и принятия решений.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 7472413 B1, 30.12.2008 | |||
| US 8959571 B2, 17.02.2015 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Путеочистительная машина | 1959 |
|
SU123561A1 |
| СИСТЕМА И СПОСОБ ПРЕДОТВРАЩЕНИЯ ИНЦИДЕНТОВ БЕЗОПАСНОСТИ НА ОСНОВАНИИ РЕЙТИНГОВ ОПАСНОСТИ ПОЛЬЗОВАТЕЛЕЙ | 2011 |
|
RU2477929C2 |
| US 8051484 B2, 01.11.2011. | |||

