Область техники, к которой относится изобретение
Настоящее изобретение относится, в основном, к области обработки изображения и, конкретнее, к способу кодирования и декодирования цифровых изображений и последовательностей цифровых изображений.
Данное изобретение, таким образом, может быть, главным образом, применено к способу кодирования видеосигналов, применяемого в находящихся в обращении кодерах изображения (MPEG, Н.264 и т.д.) или в появляющихся кодерах изображения (ITU-T/VCEG (Н.265) или ISO/MPEG (HVC)).
Уровень техники
Современные кодеры видеосигнала (MPEG, Н264, и т.п.) используют блочное представление видеопоследовательности. Изображения нарезаются на макроблоки, каждый макроблок в свою очередь нарезается на блоки и каждый блок или макроблок кодируется с внутренним или внешним предсказанием изображения. Таким образом, определенные изображения кодируются пространственным предсказанием (внутреннее предсказание), в то время как другие изображения кодируются временным предсказанием (внешнее предсказание) по отношению к одному или более кодируемому/декодируемому опорному изображению, при помощи компенсации движения, известному специалистам в данной области техники. Более того, для каждого блока может быть закодирован остаточный блок, соответствующий оригинальному блоку, уменьшенному предсказанием. Коэффициенты данного блока квантуются после факультативной трансформации, и затем кодируются энтропийным кодером.
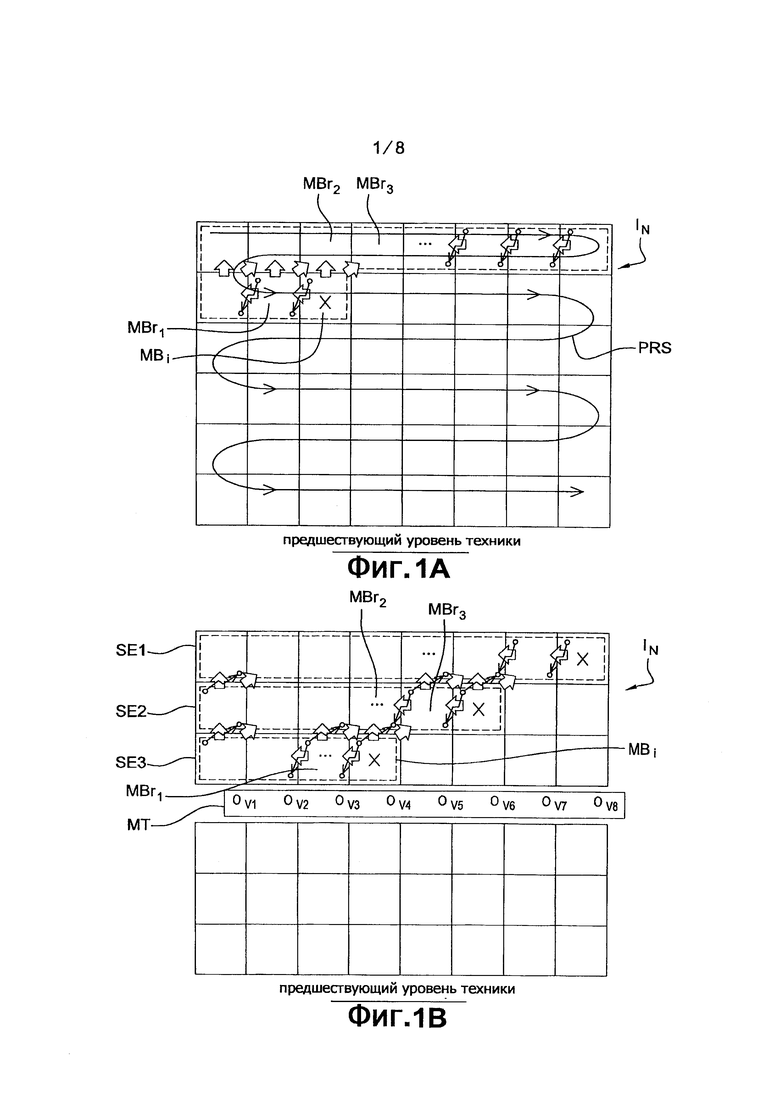
Внутреннее и внешнее предсказание требует наличия определенных блоков, которые ранее были закодированы и декодированы, чтобы использоваться либо декодером, либо кодером для предсказания текущего блока. Пример схемного решения такого кодирования с предсказанием представлен на фиг. 1А, в котором изображение IN нарезано на блоки, текущий блок MBi такого изображения подвержен кодированию с предсказанием по отношению к заданному количеству трех блоков MBr1, MBr2 и MBr3, ранее кодированных и декодированных, как обозначено заштрихованными стрелками. Вышеупомянутые три блока конкретнее содержат блок MBr1, находящийся непосредственно слева от текущего блока MBi, и два блока MBr2 и MBr3, находящиеся соответственно непосредственно выше и выше справа от текущего блока MBi.
Наиболее интересен здесь энтропийный кодер. Энтропийный кодер кодирует информацию в порядке поступления. Обычно, построчное прохождение блоков осуществляется растровым типом, как показано на фиг. 1А, на основе PRS, начиная с блока, находящегося верху слева изображения. Для каждого блока различные элементы информации, необходимые для представления блока (тип блока, вид предсказания, остаточные коэффициенты и т.п.), направляются последовательно в энтропийный кодер.
Эффективный арифметический кодер разумной сложности уже известен, так называемый «САВАС» (Контекстно-зависимый адаптивный бинарный арифметический кодер), используемый в стандарте сжатия AVC (также известный как ISO-MPEG4 part 10 и ITU-TH.264).
Энтропийный кодер осуществляет реализацию различных концепций:
- арифметическое кодирование: кодер, такой как описан вначале в документе J. Rissanenand G.G. Langdon Jr. "Universalmodelingandcoding" IEEETrans. Inform. Theory, vol. IT-27, pp. 12-23, Jan. 1981, использует кодирование символа, вероятность возникновения данного символа;
- адаптацию к контексту: это влечет за собой адаптацию вероятности возникновения символов, подлежащих кодированию. С одной стороны, осуществляется получение информации по ходу работы. С другой стороны, согласно состоянию ранее кодированной информации, для кодирования используется определенное содержание. Каждое содержание соответствует присущей вероятности возникновения символа. Например, содержание соответствует типу кодированного символа (представление коэффициента остатка, сообщение вида кодирования и т.п.) согласно заданной конфигурации или состоянию соседства (например, количество «внутренних» видов, выбранных из соседнего окружения, и т.п.);
- бинаризацию: символы, подлежащие кодированию, преобразовываются в форму строки битов. Соответственно, эти различные биты успешно отправлены в бинарный энтропийный кодер.
Таким образом, данный энтропийный кодер осуществляет реализацию, для каждого используемого контекста, системы получения информации о вероятностях по ходу работы по отношению к ранее кодированным символам для рассмотренного содержания. Данный способ получения информации основывается на порядке кодирования данных символов. Обычно, изображение проходится согласно порядку по типу «развертка растра», описанному выше.
Во время кодирования данного символа b, который может быть равен 0 или 1, информация о вероятности Pi возникновения данного символа обновляется для текущего блока MBi согласно следующему выражению:
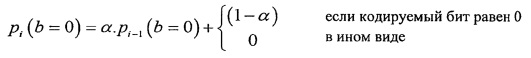
где α является заданной величиной, например, 0,95 и Pi-1 является вероятностью возникновения символа, вычисленной во время последнего возникновения данного символа.
Схематический пример такого энтропийного кодирования представлен на фиг. 1А, где текущий блок MBi изображения 1N подвергается энтропийному кодированию. Когда энтропийное кодирование блока MBi начинается, используются вероятности возникновения символа, которые были получены после кодирования ранее кодированного и декодированного блока, который непосредственно предшествовал текущему блоку MBi согласно вышеописанному порядку построчного прохождения блоков по типу «развертка растра». Такой способ получения информации, основанный на поблочной зависимости, показан на фиг. 1А для определенных блоков только ради ясности понимания стрелками, изображенными тонкими линиями.
Недостатком такого типа энтропийного кодирования является то, что во время кодирования символа, находящегося в начале ряда, использованные вероятности соответствуют, главным образом, тем, которые выявлены для символов, находящихся в конце предыдущего ряда, при использовании прохождения блоков по типу «развертка растра». Сейчас, в связи с возможностью наличия пространственной вариации вероятностей символов (например, для символов, относящихся к элементу информации перемещения, и элемент перемещения, находящийся в правой части изображения, может отличаться от наблюдаемого в левой части, и, следовательно, аналогично для локальных вероятностей, возникающих из этого) может наблюдаться отсутствие локальных соответствий вероятностей, что вызывает снижение эффективности кодирования.
Документ «AnnexA: CDCMVideoCodecDecoderSpecification", который доступна на сайте http://wftp3.itu.int/av-arch/jctvc-site/2010 04 ADresden/JCTVC-A114-AnnexA.doc (8 февраля 2011), описывает способ кодирования, который смягчает вышеописанный недостаток. Способ кодирования, описанный в вышеупомянутом документе, содержит, как показано на фиг. 1В:
- этап нарезки изображения In на множество блоков,
- этап кодирования с предсказанием текущего блока MBi данного изображения по отношению к заданному количеству трех блоков MBr1, MBr2 и MBr3 ранее кодированных и декодированных, как это показано заштрихованными стрелками. Вышеупомянутые три блока специфически содержат блок MBr1, находящийся непосредственно слева от текущего блока MBi, и два блока MBr2 и MBr3, находящиеся соответственно непосредственно выше и выше справа от текущего блока MBi,
- этап энтропийного кодирования блоков изображения IN согласно которому каждый блок использует вероятности возникновения символа, вычисленные соответственно для кодированного и декодированного блока, который находится непосредственно выше текущего блока и для кодированного и декодированного блока, который находится непосредственно слева от текущего блока, когда данные блоки доступны. Данный способ использования вероятностей возникновения символа частично показан на фиг. 1В, с целью упрощения демонстрации последнего, стрелками, изображенными тонкими линиями.
Преимущество такого энтропийного кодирования заключается в том, что здесь используется вероятности, появившиеся из ближнего окружения текущего блока, таким образом, предоставляя возможность увеличить качество кодирования. Более того, используемая технология кодирования предоставляет возможность осуществления параллельного кодирования заданного количества парных соседствующих подсовокупностей блоков. В примере, показанном на фиг. 1В, три подсовокупности SE1, SE2, SE3 кодируются параллельно, каждая подсовокупность состоит, в данном примере, из ряда блоков, показанных штриховой линией. Конечно, такое кодирование требует того, чтобы блоки, находящиеся соответственно выше и выше справа от текущего блока были в наличии.
Недостатком данного параллельного кодирования является то, что предоставляется доступ к вероятности возникновения символа, вычисленной для блока, находящегося непосредственно выше текущего блока, что вызывает необходимость хранения количества вероятностей, ассоциированных с рядом блоков. Если рассматривается второй ряд блоков SE2, на примере фиг. 1В, первый блок данного ряда подвергается энтропийному кодированию с использованием вероятностей возникновения символа, вычисленных для первого блока предыдущего первого ряда SE1. По завершении кодирования первого блока второго ряда, состояние величины V1 вероятности возникновения символа хранится в буферном запоминающем устройстве МТ. Второй блок второго ряда SE2 в дальнейшем подвергается энтропийному кодированию с использованием вероятностей возникновения символа, вычисленных на тот же и в тот же момент времени для второго блока первого ряда SE1 и первый блок второго ряда SE2. По завершении кодирования второго блока второго ряда, состояние значения V2 вероятности возникновения хранится в буферном запоминающем устройстве МТ. Данная процедура осуществляется до последнего блока второго ряда SE2. Так как количество вероятностей очень велико (существует столько много вероятностей, сколько существует комбинаций синтаксических элементов с ассоциированными контекстами), то хранение таких вероятностей более чем полного ряда очень расточительно, с точки зрения использования ресурсов памяти.
Раскрытие изобретения
Одной из целей изобретения является устранение недостатков, описанных выше, которые присущи предыдущему уровню техники.
Для этой цели, настоящее изобретение относится к способу кодирования по меньшей мере одного изображения, который содержит этапы, на которых:
- выполняют нарезку изображения на множество блоков,
- группируют блоки в заданное количество подсовокупностей блоков,
- выполняют параллельное кодирование каждой упомянутой подсовокупности блоков, при этом
блоки подсовокупности подлежат кодированию согласно заданному последовательному порядку прохождения, причем упомянутый этап кодирования, для текущего блока подсовокупности, содержит подэтапы, на которых:
• выполняют кодирование с предсказанием текущего блока относительно по меньшей мере одного ранее кодированного и декодированного блока,
• выполняют энтропийное кодирование текущего блока на основании по меньшей мере одной вероятности возникновения символа.
При этом способ согласно изобретению, характеризуется тем, что:
- в случае, когда текущий блок является первым блоком для кодирования в указанной подсовокупности, вероятность возникновения символа является той же, что вычислена для кодированного и декодированного заданного блока по меньшей мере одной другой подсовокупности,
- в случае, когда текущий блок является блоком в указанной подсовокупности, отличающимся от первого блока, вероятность возникновения символа является той же, что вычислена по меньшей мере для одного кодируемого и декодированного блока, принадлежащего той же подсовокупности.
Такая конфигурация позволяет хранить в буферном запоминающем устройстве кодера значительно меньшее количество вероятностей возникновения символов, так как энтропийное кодирование текущего блока, за исключением первого блока подсовокупности блоков, больше не обязательно требует использования вероятностей возникновения символа, вычисленных для ранее кодированного и декодированного блока, который находится выше текущего блока в другой подсовокупности.
Такая конфигурация позволяет более того, поддерживать существующее качество сжатия, так как энтропийное кодирование текущего блока использует вероятности возникновения символа, вычисленные для другого ранее кодированного и декодированного блока подсовокупности, к которой текущий блок принадлежит, и, соответственно, информация была получена посредством обновления вероятностей так, что последние находятся в соответствии со статистической информацией видеосигнала.
Основным преимуществом использования вероятностей возникновения символа, вычисленных для первого блока упомянутой другой подсовокупности во время энтропийного кодирования первого блока рассматриваемой подсовокупности блоков, является рациональное использование памяти буферного запоминающего устройства кодера, посредством хранения в последнем только обновленных упомянутых вероятностей возникновения символов, без учета вероятностей возникновения символа, полученных другими последующими блоками упомянутой другой подсовокупности.
Основным преимуществом использования вероятностей возникновения символа, вычисленных для блока упомянутой другой подсовокупности, отличающегося от первого блока, например, второго блока, во время энтропийного кодирования текущего первого блока рассматриваемой подсовокупности блоков, является получение более точной и поэтому более полезной информации о вероятностях возникновения символов, таким образом, улучшая качество сжатия видеосигнала.
В конкретном варианте осуществления, кодированный и декодированный блок, принадлежащий той же подсовокупности, что и текущий блок для кодирования, исключая первый блок подсовокупности, является ближайшим смежным к текущему блоку для кодирования.
Такая конфигурация, таким образом, делает возможным хранить просто вероятности возникновения символа, информация о которых получена во время энтропийного кодирования первого блока рассматриваемой подсовокупности, так, как в данном конкретном случае, учитывается только вероятность возникновения символа, вычисленная для блока, находящегося выше первого текущего блока и принадлежащего другой подсовокупности. В результате данной оптимизации оптимизируется ресурсы памяти кодера.
В другом конкретном варианте осуществления, в случае, когда кодируется блок рассматриваемой подсовокупности с предсказанием, предназначенной для выполнения в отношении заданного количества ранее кодированных и декодированных блоков подсовокупности, за исключением рассматриваемой подсовокупности, параллельное кодирование блоков рассматриваемой подсовокупности осуществляется со сдвигом на заданное количество блоков в отношении подсовокупности блоков непосредственно предшествующих в порядке, в котором осуществляется параллельное кодирование.
Такая конфигурация позволяет достичь для текущей подсовокупности блоков для кодирования, синхронизации процесса обработки блоков подсовокупности блоков, предшествующей текущей подсовокупности в порядке, в котором осуществляется параллельное кодирование, таким образом, предоставляя возможность гарантировать наличие блока или блоков предшествующей подсовокупности, которые используются для кодирования текущего блока. Подобным образом, этап верификации наличия данного или тех блоков предшествующей подсовокупности, которые подвергаются параллельному кодированию кодером в предыдущем уровне техники, может быть предпочтительно опущен, таким образом, позволяя ускорить скорость обработки блоков в кодере согласно изобретению.
Соотносительно, изобретение дополнительно относится к устройству кодирования по меньшей мере одного изображение, содержащему:
- средство для нарезки изображения на множество блоков,
- средство для группирования блоков в заданное количество подсовокупностей блоков,
- средство для параллельного кодирования каждой подсовокупности блоков, при этом блоки указанной подсовокупности подлежат кодированию согласно заданному последовательному порядку прохождения, причем средство для кодирования, для текущего блока рассматриваемой подсовокупности содержит:
• субсредство кодирования с предсказанием текущего блока по отношению по меньшей мере к одному ранее кодированному и декодированному блоку,
• субсредство энтропийного кодирования текущего блока на основании по меньшей мере одной вероятности возникновения символа.
При этом указанное устройство кодирования, характеризуется тем, что:
- в случае, когда текущий блок является первым блоком, подлежащим кодированию в указанной подсовокупности, субсредство энтропийного кодирования выполнено с возможностью учета, при энтропийном кодировании текущего первого блока, вероятности возникновения символа, вычисленной для кодированного и декодированного заданного блока по меньшей мере одной другой подсовокупности,
- в случае, когда текущий блок является блоком указанной подсовокупности, отличающимся от первого блока последней, субсредство энтропийного кодирования выполнено с возможностью учета, при энтропийном кодировании текущего блока, вероятности возникновения символа, вычисленной по меньшей мере для одного кодированного и декодированного блока, принадлежащего той же подсовокупности.
Соответствующим образом, изобретение относится к способу декодирования потока, представляющего по меньшей мере одно кодированное изображение, содержащего этапы, на которых:
- выполняют идентификацию, в изображении, заданного количества подсовокупностей блоков для декодирования,
- выполняют параллельное декодирование участков потока, ассоциированных с каждой подсовокупностью блоков, при этом блоки указанной подсовокупности подлежат декодированию согласно заданному последовательному порядку прохождения, причем этап декодирования, для текущего блока указанной подсовокупности, содержит подэтапы, на которых:
• выполняют энтропийное декодирование текущего блока на основании по меньшей мере одной вероятности возникновения символа,
• выполняют декодирование с предсказанием текущего блока по отношению по меньшей мере к одному ранее декодированному блоку.
При этом указанный способ декодирования, характеризуется тем, что:
- в случае, когда текущий блок является первым блоком, подлежащим декодированию в указанной подсовокупности, вероятность возникновения символа является той же, что вычислена для декодированного заданного блока по меньшей мере одной другой подсовокупности,
- в случае, когда текущий блок является блоком указанной подсовокупности, отличающимся от первого блока последней, вероятность возникновения символа является той же, что вычислена по меньшей мере для одного декодированного блока, принадлежащего той же подсовокупности.
В конкретном варианте осуществления, декодированный блок, принадлежащий той же подсовокупности, что и текущий блок, подлежащий декодированию, за исключением первого блока подсовокупности, является тем, который является ближайшим к текущему блоку, подлежащему декодированию.
В другом варианте осуществления, в случае, когда осуществляется декодирование с предсказанием блока указанной подсовокупности, подлежащее выполнению по отношению к заданному количеству ранее кодированных и декодированных блоков подсовокупности, за исключением указанной подсовокупности, параллельное декодирование блоков указанной подсовокупности осуществляется со сдвигом на заданное количество блоков по отношению к подсовокупности блоков непосредственно предшествующей в порядке, в котором осуществляется параллельное декодирование.
Соответствующим образом, изобретение дополнительно относится к устройству декодирования потока, представляющего по меньшей мере одно кодированное изображение, содержащему:
- средство для идентификации, в изображении, заданного количества подсовокупностей блоков, подлежащих декодированию,
- средство для параллельного декодирования участков потока, ассоциированных с каждой подсовокупностью блоков, при этом блоки указанной подсовокупности подлежат декодированию согласно заданному последовательному порядку прохождения, причем средство декодирования, для текущего блока рассматриваемой подсовокупности, содержит:
• субсредство для энтропийного декодирования текущего блока на основании по меньшей мере одной вероятности возникновения символа,
• субсредство для декодирования с предсказанием текущего блока по отношению по меньшей мере к одному ранее декодированному блоку.
При этом указанное устройство декодирования характеризуется тем, что:
- в случае, когда текущий блок является первым блоком подлежащим декодированию в указанной подсовокупности, субсредство энтропийного декодирования выполнено с возможностью учета, при энтропийном декодировании первого текущего блока, вероятности возникновения символа, вычисленной для декодированного заданного блока по меньшей мере одной другой подсовокупности,
- в случае, когда текущий блок является блоком указанной подсовокупности, отличающимся от первого блока последней, субсредство энтропийного декодирования выполнено с возможностью учета, для энтропийного декодирования текущего блока, вероятности возникновения символа, вычисленной по меньшей мере для одного декодированного блока, принадлежащего той же подсовокупности.
Изобретение также относится к программе для компьютера, содержащей команды для выполнения этапов способа кодирования или декодирования, как описано выше, при выполнении программы на компьютере.
Такая программа может быть написана с использованием любого языка программирования и может иметь вид исходника, может быть объектной программой или быть промежуточным кодом между исходником и объектной программой, как в частично компилированном виде, так и в любой иной желаемой форме.
Объектом изобретения также является носитель записи, считываемый с помощью компьютера, который содержит компьютерную программу, содержащую команды, такие как ранее были описаны.
Носитель записи может быть любым модулем или устройством, способным хранить программу. Например, такой носитель может содержать средство памяти, такое как ROM, например, CD ROM или микроэлектронную схему ROM или иное средство магнитной записи, например, дискета (гибкий диск) или жесткий диск.
Более того, такой носитель записи может быть передающим носителем, таким как электрический или оптический сигнал, который может передаваться по электрическому или оптическому кабелю, по радиоканалу или другим средством. Программа, согласно изобретению, может быть, в частности, загружена через интернет.
Альтернативно, такой носитель записи может представлять собой интегрированную схему с загруженной программой, такая схема выполнена с возможностью выполнять рассматриваемый способ или может быть использована для выполнения программы.
Вышеупомянутые кодирующее устройство, способ декодирования, декодирующее устройство и компьютерные программы представляют по меньшей мере те же преимущества, как и представленные способом кодирования согласно настоящему изобретению.
Краткое описание чертежей
Другие характеристики и преимущества станут очевидны при прочтении двух предпочтительных вариантов осуществления, описанных со ссылкой на прилагаемые чертежи, а именно:
фиг. 1А представляет диаграмму кодирования изображения предшествующего уровня техники согласно первому примеру;
фиг. 1В представляет диаграмму кодирования изображения предшествующего уровня техники согласно второму примеру;
фиг. 2А показывает основные этапы способа кодирования согласно изобретению;
фиг. 2В подробно представляет способ параллельного кодирования, осуществленный в способе кодирования, показанном на фиг. 2А;
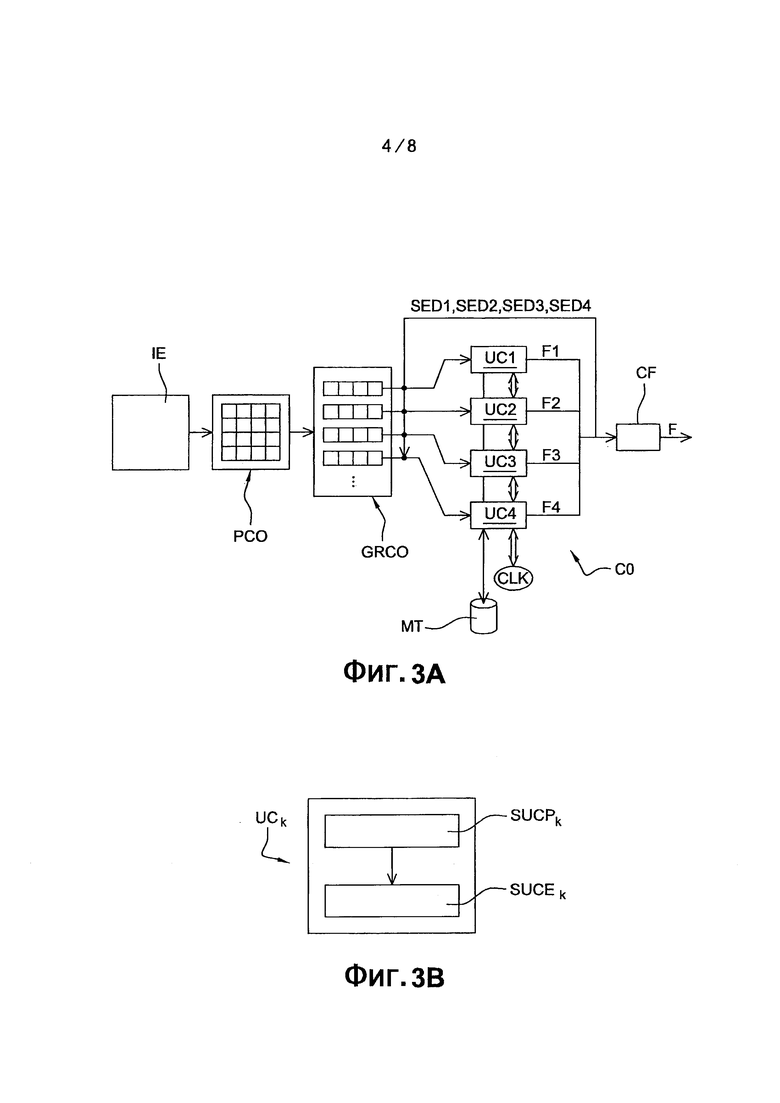
фиг. 3А представляет вариант осуществления устройства кодирования согласно изобретению;
фиг. 3В представляет кодирующую ячейку для устройства кодирования, показанного на фиг. 3А;
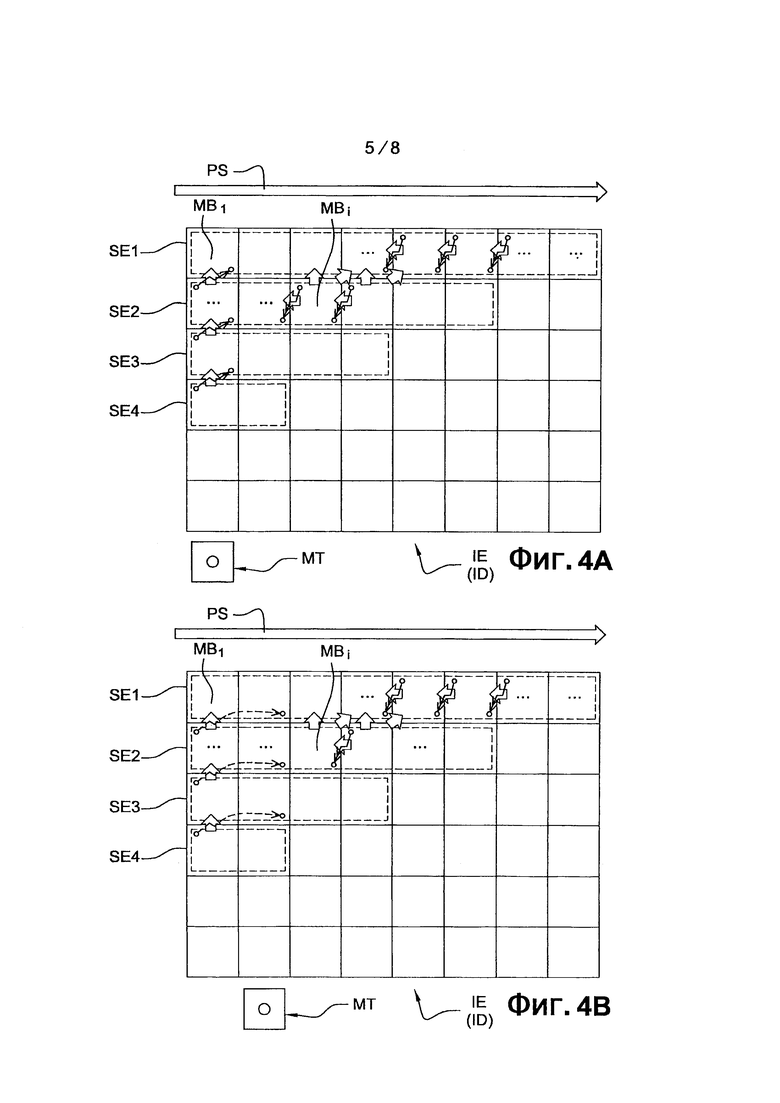
фиг. 4А представляет диаграмму кодирования/декодирования изображения согласно первому предпочтительному варианту осуществления;
фиг. 4В представляет диаграмму кодирования/декодирования изображения согласно второму предпочтительному варианту осуществления;
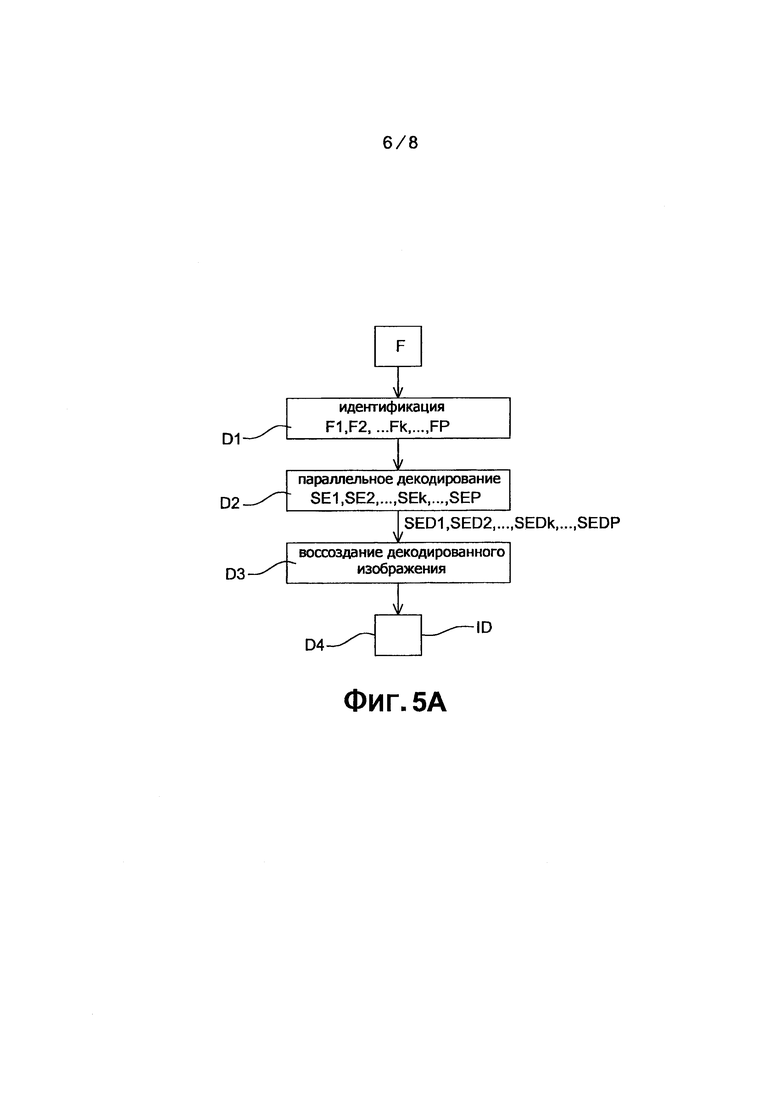
фиг. 5А показывает основные этапы способа декодирования согласно изобретению;
фиг. 5В подробно представляет способ параллельного декодирования, осуществленный в способе декодирования, показанного на фиг. 5А;
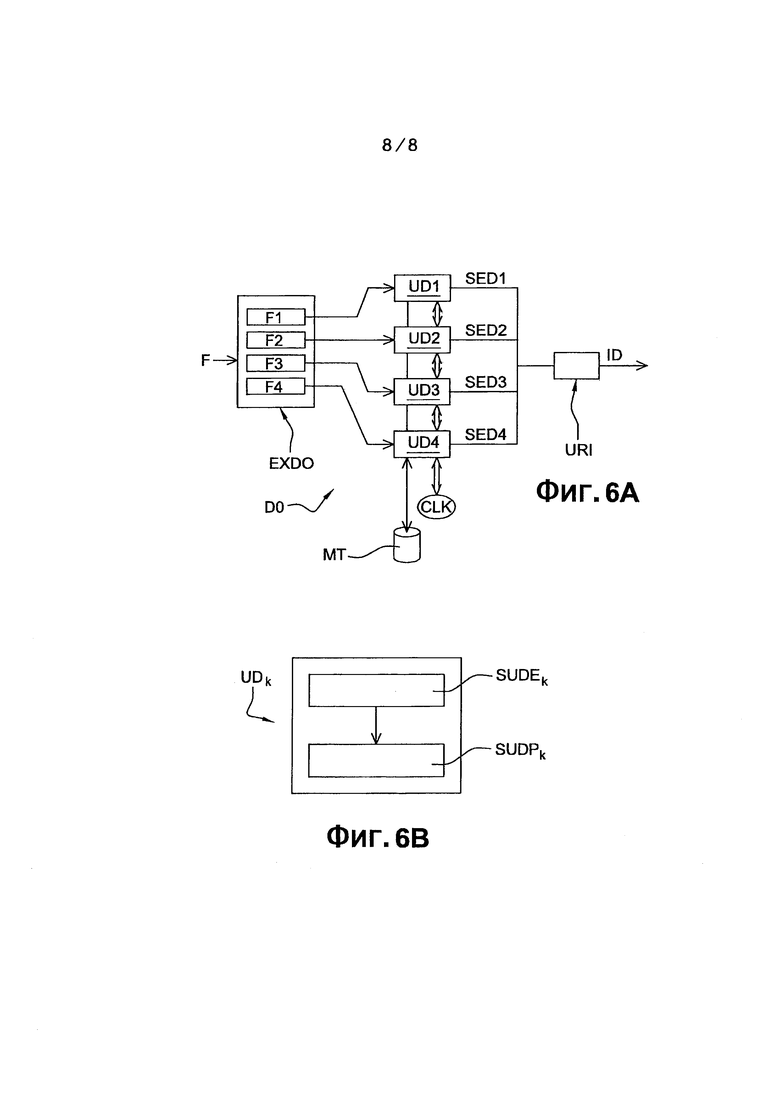
фиг. 6А представляет вариант осуществления устройства декодирования согласно изобретению;
фиг. 6В представляет декодирующую ячейку для устройства декодирования, показанного на фиг. 6А.
Осуществление изобретения
Осуществление участка кодирования
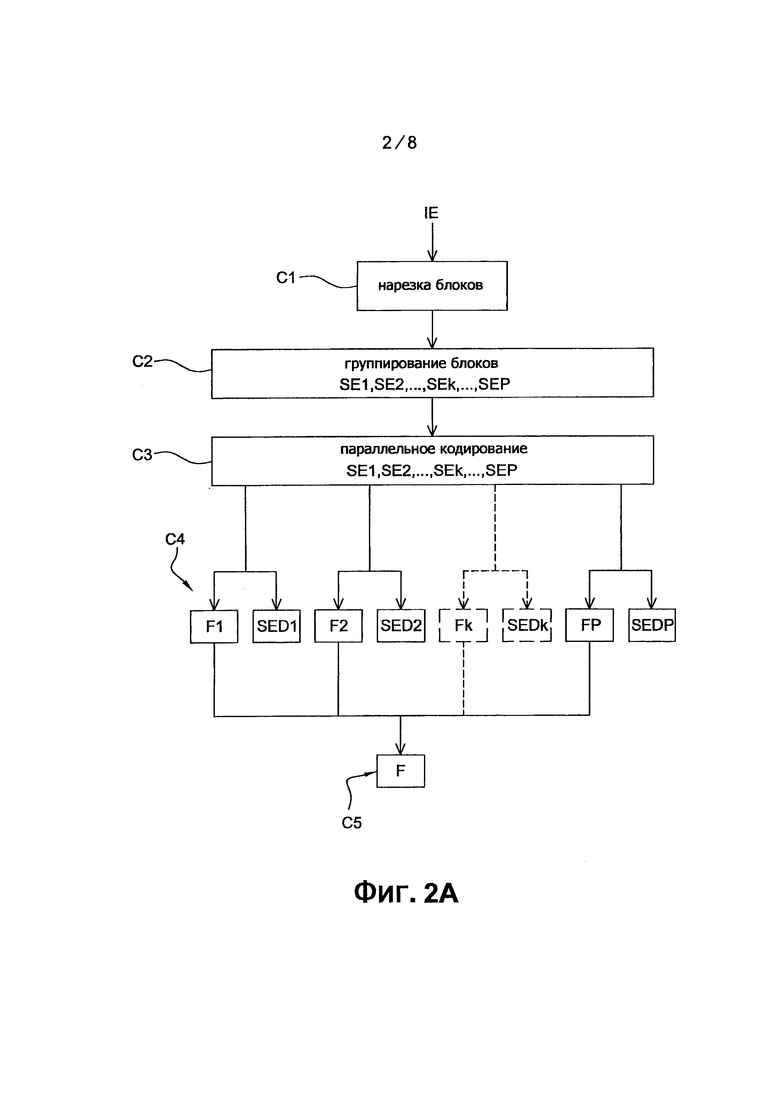
Далее приводится описание варианта осуществления изобретения, в котором способ кодирования согласно данному изобретению используется для кодирования последовательности изображений как кодирование бинарного потока, схожего с полученным кодированием, согласно стандарту Н.264/МРЕG-4 AVC. В данном варианте осуществления, способ кодирования согласно данному изобретению является примером, реализованным в программном обеспечении или в аппаратном оборудовании, посредством модификаций исходного кодера в соответствии со стандартом H.264/MPEG-4 AVC. Способ кодирования согласно изобретения представлен в форме алгоритма, содержащего этапы с C1 по С5, показанного на фиг. 2А.
Согласно варианту осуществления изобретения, способ кодирования согласно изобретению реализован в кодирующем устройстве СО, представленным на фиг. 3А.
Со ссылкой на фиг. 2А, на первом этапе С1 кодирования осуществляется нарезка изображения IE последовательности изображений, подлежащих кодированию на множество блоков или макроблоков MB, как представлено на фиг. 4А или фиг. 4В. В представленных примерах, упомянутые блоки MB имеют квадратную форму и все имеют одинаковый размер. Как функция размера изображения, которое не обязательно является кратной размеру блоков, последние блоки слева и последние блоки в нижней области могут иметь не квадратную форму. В альтернативном варианте осуществления, блоки могут быть, например, прямоугольными и/или быть не выровненными друг с другом.
Каждый блок или макроблок может, кроме того, сам быть разделен на субблоки, которые являются сами по себе подразделяемыми.
Такая нарезка осуществляется модулем РСО разбиения, показанным на фиг. 3А, который использует, например, хорошо известный алгоритм разбиения.
Со ссылкой на фиг. 2А, на втором этапе С2 кодирования осуществляется группирование вышеупомянутых блоков в заранее заданное количество Р консекутивных подсовокупностей SE1, SE2, …, SEk, …, SEP блоков, предназначенных для параллельного кодирования. В примерах, показанных на фиг. 4А и фиг. 4В, заранее заданное количество Р равно 4 и данные четыре подсовокупности SE1, SE2, SE3, SE4, обозначенные штриховой линией, соответственно состоят из первых четырех рядов блоков изображения IE.
Такое группирование осуществляется вычислительным модулем GRCO, представленным на фиг. 3А, при помощи хорошо известного алгоритма per se.
Со ссылкой на фиг. 2А, третий этап С3 кодирования состоит из параллельного кодирования каждой из упомянутых подсовокупностей SE1, SE2, SE3 и SE4 блоков, блоки подсовокупности считаются закодированными согласно заданному последовательному упорядочиванию прохождения PS. В данных примерах, представленных на фиг. 4А и фиг. 4В, блоки текущей подсовокупности SEk (1≤k≤4) кодируются один после другого, слева направо, как показано стрелкой PS.
Такое параллельное кодирование осуществляется кодирующими ячейками UCk (1≤k≤R) в количестве R, где R=4, как показано на фиг. 3А, и позволяет существенно ускорить реализацию способа кодирования. До некоторой степени известный, кодер СО содержит буферное запоминающее устройство МТ, которое выполнено с возможностью содержать вероятности возникновения символа, как постоянно обновляемые, совместно с кодированием текущих блоков.
Как показано очень подробно на фиг. 3В, каждая из кодирующих ячеек USk содержит:
• субъячейку для кодирования с предсказанием текущего блока по меньшей мере одного ранее кодированного и декодированного блока, обозначена как SUCPk;
• субъячейку для энтропийного кодирования упомянутого текущего блока с использованием по меньшей мере одной вероятности возникновения символа, вычисленной для ранее кодированного и декодированного блока, обозначена как SUCEk.
Субъячейка SUCPk для кодирования с предсказанием способна выполнить кодирование с предсказанием текущего блока в соответствии с обычной технологией предсказания, такой как, например, внутреннее предсказание и/или внешнее предсказание.
Субъячейка SUCPk энтропийного кодирования является САВАС формой энтропийного кодирования, но модифицированной согласно настоящему изобретению, как будет далее описано.
Как вариант, субъячейка SUCPk энтропийного кодирования может быть известным кодером кодирования по алгоритму Хаффмана.
В примерах, показанных на фиг. 4А и фиг. 4В, первая ячейка UC1 кодирует блоки первого ряда SE1 слева на право. Когда подходит очередь последнего блока первого ряда SE1, то процесс переходит к первому блоку (N+1)st ряда, здесь - пятый ряд, т.д. Вторая ячейка UC2 кодирует блоки второго ряда SE2 слева направо. Когда подходит очередь последнего блока второго ряда SE2, то процесс переходит к первому блоку (N+2)nd ряда, здесь - шестой ряд, т.д. Данное прохождение повторяется до тех пор, пока ячейка UC4 заканчивает кодирование блоков четвертого ряда SE4 слева направо. Когда подходит очередь последнего блока первого ряда, то процесс переходит к первому блоку (N+4)th ряда, здесь - восьмой ряд, и так далее и тому подобное до тех пор, пока последний блок изображения IE будет закодирован.
Другие типы прохождения, отличные от того, что был описан выше, конечно, также возможны. Таким образом, возможно нарезать изображение IE на несколько фрагментов изображения и независимо применить данный тип нарезки к каждому фрагменту изображения. Возможно также, для каждой кодирующей ячейки обработать невложенные ряды, как ранее было объяснено, но вложенные столбцы. Возможно также прохождение рядов или столбцов в любом направлении.
Со ссылкой на фиг. 2А, на четвертом этапе С4 кодирования осуществляется создание N суббитовых потоков Fk (1≤k≤N), представляющих собой обработанные блоки, сжатые каждой из вышеупомянутый кодирующих ячеек, так же, как декодированная версия обработанных блоков каждой подсовокупности SEk. Декодированные обработанные блоки рассмотренной подсовокупности, обозначенные как SED1, SED2, … SEDk, … SEDP могут быть повторно использованы некоторыми из кодирующих ячеек UC1, UC2, … UCk, … UCP, показанные на фиг. 3А, в соответствии с механизмом синхронизации, который будет подробно описан ниже.
Со ссылкой на фиг. 2А, пятый этап С5 кодирования состоит из создания основного потока F на основе вышеупомянутых вложенных субпотоков Fk. Согласно одному варианту осуществления, вложенные субпотоки Fk просто размещены друг около друга с элементом дополнительной информации, предназначенным для указания декодеру местоположения каждого вложенного субпотока Fk в основном потоке F. Последний передается коммуникационной сетью (не показано) в удаленный терминал. Последний содержит декодер DO, показанный на фиг. 6А.
Таким образом, как будет далее подробно описано, декодер, согласно изобретению, имеет возможность выделять вложенные субпотоки Fk из основного потока F и назначать их каждой компоненте декодера. Следует отметить, что такая декомпозиция вложенных субпотоков в основном потоке, является независимой от выбора использования множества кодирующих ячеек, функционирующих параллельно, и таким образом, применяя данный подход, возможно просто иметь кодер или просто декодер, который содержит блоки, работающие параллельно.
Такая конфигурация основного потока F реализуется в модуле CF создания потока, как показано на фиг. 3А.
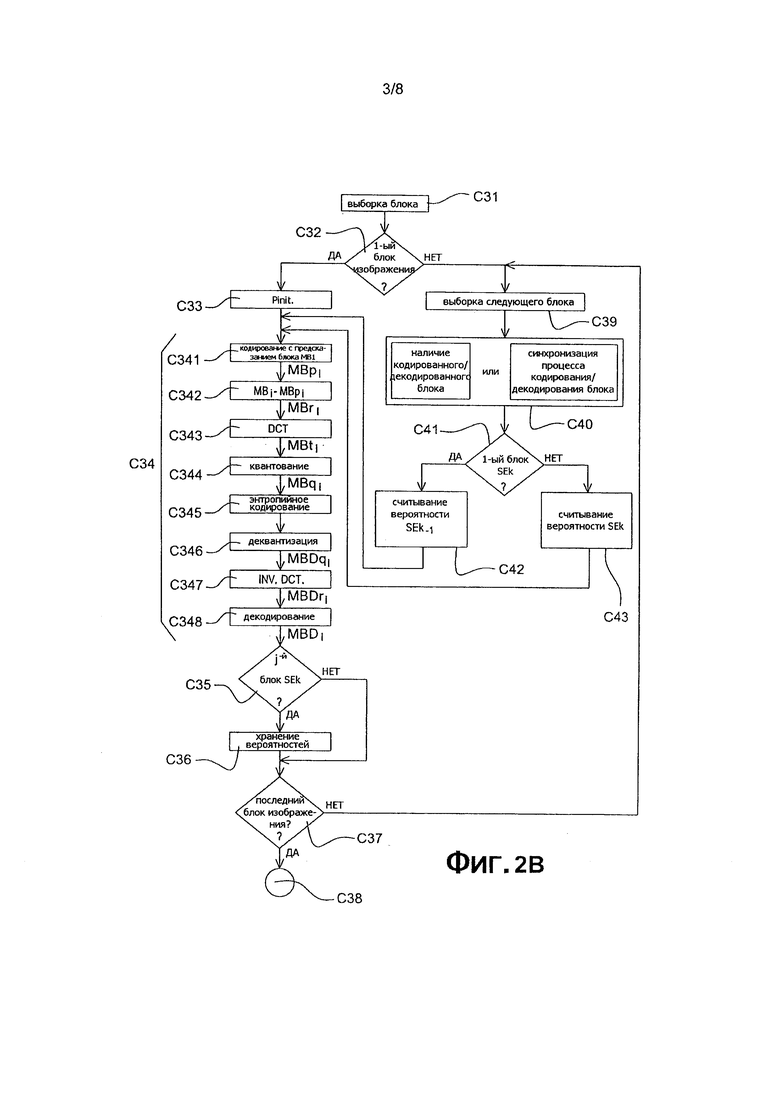
Различные конкретные подэтапы изобретения, такие как реализованные во время вышеупомянутого этапа С3 параллельного кодирования в кодирующей ячейке UCk, будут далее описаны со ссылкой на фиг. 2В.
В ходе выполнения этапа С31, кодирующая ячейка UCk выбирает в качестве текущего блока первый блок для кодирования текущего ряда SEk, показанного на фиг. 4А и фиг. 4В.
В ходе выполнения этапа С32, кодирующая ячейка UCk проверяет факт того, что текущий блок является первым блоком (находящийся вверху и слева) изображения IE, которое было нарезано на блоки на вышеупомянутом этапе С1.
Если дело обстоит именно так, то в ходе выполнения этапа С33, вероятности кодирования инициализируются до значений Pinit, ранее заданных в кодере СО, показанном на фиг. 3А.
Если дело не обстоит так, то в ходе выполнения этапа С40, который будет описан позже в последующем описании, предпринимается определение наличия необходимых ранее закодированных и декодированных блоков.
В ходе выполнения этапа С34, осуществляется кодирование первого текущего блока МВ1 первого ряда SE1, показанного на фиг. 4А или фиг. 4В. Такой этап С34 содержит множество подэтапов, начиная от С341 до С348, как далее будет описано.
В ходе выполнения первого подэтапа С341, осуществляется кодирование с предсказанием текущего блока МВ1 известными технологиями внутреннего и/или внешнего предсказания, в течение которого блок МВ1 предсказан относительно по меньшей мере одного ранее кодированного и декодированного блока.
Само собой разумеется, что другие виды внутреннего предсказания, такие как предложены в стандарте Н.264, также возможны.
Текущий блок МВ1 может быть также закодирован с внешним предсказанием, в ходе которого, текущий блок предсказан относительно блока, который был образован в результате предыдущего кодирования и декодирования изображения. Другие виды предсказаний, конечно, также возможны. Среди возможных предсказаний для текущего блока, оптимальное предсказание выбирается согласно критерию скорости создания информации, как хорошо известно специалистам в данной области техники.
Упомянутый ранее этап кодирования с предсказанием делает возможным создание предсказанного блока МВр1, который является аппроксимацией текущего блока МВ1. Информация, относящаяся к данному кодированию с предсказанием, будет впоследствии записана в поток F, переданный в декодер DO. Такая информация содержит главным образом вид предсказания (внутреннее или внешнее) и при необходимости, вид внутреннего предсказания, тип разбиения блока или макроблока, если последний был разделен, индекс опорного изображения и вектор перемещения, используемый при кодировании с внешним предсказанием. Данная информация сжимается кодером СО.
В ходе выполнения подэтапа С342, осуществляется изъятие предсказанного блока MBp1 из текущего блока МВ1 и создается остаточный блок MBr1.
В ходе выполнения подэтапа С343, осуществляется трансформация остаточного блока MBr1 в соответствии с принятой практикой прямого преобразования, такого как, например, дискретно-косинусное преобразование Фурье четной функции DCT, в преобразованный блок MBt1.
В ходе выполнения подэтапа С344, осуществляется процесс квантования преобразованного блока MBt1 в соответствии с принятой практикой квантования, такой как, например, скалярное квантование. В результате получается блок квантованных коэффициентов MBq1.
В ходе выполнения подэтапа С345, осуществляется энтропийное кодирование блока квантованных коэффициентов MBq1. В предпочтительном варианте осуществления, это предусматривает САВАС энтропийное кодирование.
В ходе выполнения подэтапа С346, осуществляется деквантизация блока MBq1 в соответствии с обычной практикой деквантизации, которая представляет собой обратное действие к осуществленному на этапе С344 квантованию. Получается блок деквантованных коэффициентов MBDq1.
В ходе выполнения подэтапа С347, осуществляется обратная трансформация блока деквантованных коэффициентов MBDq1, которые получены посредством обратного действия прямому преобразованию, осуществленному ранее на этапе С343. В результате получается декодированный остаточный блок MBDr1.
В ходе выполнения подэтапа С348, осуществляется создание декодированного блока MBD1 путем добавления предсказанного блока MBp1 декодированному остаточному блоку MBDr1. Необходимо заметить, что последний блок является тем же, что и декодированный блок, полученный в результате использования способа декодирования изображения IE, который будет описан далее в данном описании. Декодированный блок MBD1 является, таким образом, доступным для использования кодирующей ячейкой UC1 или для другой любой кодирующей ячейки, формируя участок заданного количества R кодирующих ячеек.
По завершении вышеупомянутого этапа С34 кодирования, субъячейка SUCEk энтропийного кодирования, такая как представлена на фиг. 3В, содержит все вероятности, такие как прогрессивно обновленные совместно с кодированием первого блока. Такие вероятности соответствуют различным синтаксическим элементам и различным ассоциированным контекстам кодирования.
По окончании вышеупомянутого этапа С34 кодирования, выполняется тест, в ходе выполнения этапа С35 устанавливается факт того, что текущий блок является j-ым блоком того же ряда, где j является известным заданным значением кодера СО, которое по меньшей мере равно 1.
Если дело обстоит именно так, то в ходе выполнения этапа С36, множество вероятностей, вычисленных для j-ого блока, хранится в буферном запоминающем устройстве МТ кодера СО, как показано на фиг. 3А и фиг. 4А и 4В, емкость упомянутой памяти достаточна для хранения вычисленного количества вероятностей.
В ходе выполнения этапа С37, ячейка UCk проверяет факт того, что текущий блок ряда SEk, который был закодирован, является последним блоком изображения IE.
Если дело обстоит именно так, то на этане С38 способ кодирования заканчивается.
В противном случае, в ходе выполнения этапа С39, осуществляется выборка следующих блоков MBi для кодирования в соответствии с порядком прохождения, показанным стрелкой PS на фиг. 4А или 4В.
Если в ходе выполнения этапа С35, текущий блок не является j-ым блоком ряда SEk, то выполняется вышеупомянутый этап С37.
В ходе выполнения этапа С40, осуществляется установление наличия ранее закодированных и декодированных блоков, которые необходимы для кодирования текущего блока MBi. Принимая во внимание тот факт, что это влечет за собой параллельное кодирование блоков изображения IE различными кодирующими ячейками UCk, то возможно, что эти блоки не были закодированы и декодированы кодирующей ячейкой, предназначенной для кодирования этих блоков и то, что они, следовательно, пока еще отсутствуют. Упомянутый этап распознавания содержит верификацию того, что заданное количество N' блоков, находящиеся в предыдущем ряду SEk-1, например, два блока, расположенные соответственно выше и выше справа от текущего блока, в наличии для кодирования текущего блока, то есть, если они уже были закодированы и затем декодированы кодирующей ячейкой UCk-1, предназначенной для их кодирования. Упомянутый этап распознавания содержит верификацию наличия по меньшей мере одного блока, расположенного слева от текущего блока MBi для кодирования. Однако, учитывая порядок прохождения PS, выбранный в варианте осуществления, представленный на фиг. 4А или 4В, рассмотрены блоки, кодируются один после другого в ряду SEk. Следовательно, кодируемый и декодируемый слева блок всегда в наличии (за исключением первого блока в ряду). В примере, представленном на фиг. 4А или 4В, это влечет за собой то, что блок, расположенный непосредственно слева от текущего блока, кодируется. Для этой цели, проверяется наличие только двух блоков, расположенных выше и выше справа от текущего блока.
Данный этап проверки замедляет осуществление кодирования, в альтернативном варианте согласно изобретению, представленный на фиг. 3А генератор синхронизации CLK выполнен с возможность обеспечить протекание процесса кодирования блоков, так, чтобы гарантировать наличие двух блоков, расположенных соответственно выше и выше справа от текущего блока, без необходимости проверки наличия этих двух блоков. Таким образом, как показано на фиг. 4А или фиг. 4В, кодирующая ячейка UCk всегда начинает кодировать первый блок со сдвигом на заданное количество N' (здесь N'=2) кодируемых и декодируемых блоков предыдущего ряда SEk-1, который используется для кодирования текущего блока. С точки зрения программного обеспечения, реализация такого генератора синхронизации предоставляет возможность значительно ускорить время обработки, которое необходимо для выполнения процесса обработки блоков изображения IE в кодере СО.
В ходе выполнения этапа С41, осуществляется проверка того, что текущий блок является первым блоком ряда SEk.
Если это так, то в ходе выполнения этапа С42 осуществляется считывание буферного запоминающего устройства МТ, исключительно только вероятностей возникновения символа, вычисленных во время кодирования j-ого блока предыдущего ряда SEk-1.
Согласно первому варианту, показанному на фиг. 4А, j-й блок является первым блоком предыдущего ряда SEk-1 (j=1). Такое считывание состоит из замены вероятностей САВАС кодера на присутствующие в буферном запоминающем устройстве МТ. Работая таким образом, когда заменяется первыми соответствующими блоками второго, третьего и четвертого рядов SE2. SE3 и SE4, этап считывания обозначен в фиг. 4А стрелками, изображенными тонкими линиями.
Согласно второму варианту вышеописанного этапа С42, который проиллюстрирован на фиг. 4В, j-й блок является вторым блоком предыдущего ряда SEk-1 (j=2). Такое считывание состоит из замены вероятностей САВАС кодера на присутствующие в буферном запоминающем устройстве МТ. Работая таким образом, когда заменяется первыми соответствующими блоками второго, третьего и четвертого рядов SE2. SE3 и SE4, этап считывания обозначен в фиг. 4В стрелками, изображенными пунктирными линиями.
По окончании этапа С42, текущий блок закодирован и затем декодирован итерацией описанных выше этапов с С34 по С38.
Если по окончании вышеупомянутого этапа С41, выясняется, что текущий блок не является первым блоком ряда SEk, то предпочтительно осуществляется считывание вероятностей, возникших из ранее кодированного и декодированного блока, который находится в том же ряду SEk, то есть, кодированный и декодированный блок, находящийся непосредственно слева от текущего блока, в представленном примере. Более того, относительно последовательного прохождения считывания PS блоков, находящихся в том же ряду, как показано на фиг. 4А или фиг. 4В, вероятности возникновения символа присутствуют в САВАС кодере, когда начинается кодирование текущего блока, в точности так же, как присутствуют после кодирования/декодирования предшествующего блока в том же ряду.
Соответственно, в ходе реализации этапа С43, осуществляется получение информации о вероятностях возникновения символа для энтропийного кодирования упомянутого текущего блока, которые соответствуют исключительно тем, которые были рассчитаны для упомянутого предшествующего блока в том же ряду, как это показано стрелками, изображенными двойной сплошной линией на фиг. 4А или фиг. 4В.
По окончании этапа С43, текущий блок закодирован и затем декодирован итерацией описанных выше этапов с С34 по С38.
Осуществление участка декодирования
Далее приводится описание варианта осуществления способа декодирования согласно изобретению, в котором способ декодирования реализован в программном обеспечении или в аппаратном оборудовании, посредством модификаций исходного декодера в соответствии со стандартом H.264/MPEG-4 AVC.
Способ декодирования согласно изобретению представлен в форме алгоритма, содержащего этапы с D1 по D5, показанного на фиг. 5А.
Согласно варианту осуществления изобретения, способ декодирования согласно изобретению реализован в декодирующем устройстве DO, представленным на фиг. 6А.
Со ссылкой на фиг. 5А, на первом этапе D1 декодирования осуществляется идентификация в упомянутом потоке FN вложенных субпотоков F1, F2, Fk, … FP, содержащие соответственно N подсовокупностей SE1, SE2, SEk, … SEP, ранее закодированных блоков или макроблоков MB, как показано на фиг. 4А или 4В. С этой целью, каждый субпоток Fk в потоке F ассоциирован с индикатором, который позволяет декодеру DO устанавливать местоположение каждого субпотока Fk в потоке F. В представленном примере, упомянутые блоки MB имеют квадратную форму и все имеют одинаковый размер. Как функция размера изображения, которое не обязательно является кратной размеру блоков, последние блоки слева и последние блоки в нижней части могут иметь не квадратную форму. В альтернативном варианте осуществления, блоки могут быть, например, прямоугольными и/или быть не выровненными друг с другом.
Каждый блок или макроблок может, кроме того, сам быть разделен на субблоки, которые являются сами по себе подразделяемыми.
Такая идентификация осуществляется модулем EXDO извлечения потока, показанным на фиг. 6А.
В примере, показанном на фиг. 4А или 4В, заданное количество равно 4 и четыре подсовокупности SE1, SE2, SE3, SE4 обозначены штриховой линией.
Со ссылкой на фиг. 5А, на втором этапе D2 декодирования осуществляется параллельное декодирование каждой из упомянутых подсовокупностей блоков SE1, SE2, SE3 и SE4, блоки подсовокупности считаются закодированными согласно заданному последовательному упорядочиванию прохождения PS. В примере, представленном на фиг. 4А или фиг. 4В, блоки текущей подсовокупности SEk (1≤k≤4) декодируются один после другого, слева направо, как показано стрелкой PS. По завершении этапа D2, получаются подсовокупности декодированных блоков SED1, SED2, SED3, …, SEDk, …, SEDP.
Такое параллельное декодирование осуществляется декодирующими ячейками UDk (1≤k≤R) в количестве R, где R=4, как показано на фиг. 6А, и позволяет существенно ускорить реализацию способа декодирования. До некоторой степени известный, декодер DO содержит буферное запоминающее устройство МТ, которое выполнено с возможностью содержать вероятности возникновения символов, таких как постоянное обновление совместно с декодированием текущего блока.
Как показано очень подробно на фиг. 6В, каждая из декодирующих ячеек UDk содержит:
• субъячейку для энтропийного декодирования упомянутого текущего блока с использованием по меньшей мере одной вероятности возникновения символа, вычисленной по меньшей мере для одного ранее декодированного блока, обозначенного как SUDEk,
• субъячейку для декодирования с предсказанием текущего блока в отношении упомянутого декодированного блока, обозначенного как SUDPk.
Субъячейка SUDPk для декодирования с предсказанием способна выполнить декодирование с предсказанием текущего блока в соответствии с обычной технологией предсказания, такой как, например, внутреннее предсказание и/или внешнее предсказание.
Субъячейка SUDEk энтропийного декодирования является частью САВАС, но модифицированной согласно настоящему изобретению, как будет далее описано.
Как вариант, субъячейка SUDEk энтропийного декодирования может быть известным декодером для декодирования по алгоритму Хаффмана.
В примерах, показанных на фиг. 4А или фиг. 4В, первая ячейка UD1 декодирует блоки первого ряда SE1 слева на право. Когда подходит очередь последнего блока первого ряда SE1, то процесс переходит к первому блоку (N+1)st ряда, здесь - пятый ряд, т.д. Вторая ячейка UD2 декодирует блоки второго ряда SE2 слева направо. Когда подходит очередь последнего блока второго ряда SE2, то процесс переходит к первому блоку (N+2)nd ряда, здесь - шестой ряд и т.д. Данное прохождение повторяется до тех пор, пока ячейка UD4 заканчивает декодирование блоков четвертого ряда SE4 слева направо. Когда подходит очередь последнего блока первого ряда, то процесс переходит к первому блоку (N+4)th ряда, здесь - восьмой ряд, и так далее и тому подобное до тех пор, пока последний блок последнего идентифицированного вложенного субпотока будет декодирован.
Другие типы прохождения, отличные от того, что был описан выше, конечно, также возможны. Например, каждая декодирующая ячейка может обработать невложенные ряды, как было описано выше, но также и вложенные столбцы. Возможно также прохождение рядов или столбцов в любом направлении.
Со ссылкой на фиг. 5А, на третьем этапе D3 декодирования осуществляется восстановление изображения, декодированное на основании каждой декодированной подсовокупности SED1, SED2, … SEDk, … SEDP, полученной на этапе D2 декодирования. Точнее говоря, декодированные блоки каждой декодированной подсовокупности SED1, SED2, … SEDk, … SEDP передаются на блок URI восстановления изображения, такой как показан на фиг. 6А. В ходе выполнения этапа D3, блок URI записывает декодированные блоки в декодированное изображение, как и когда данные блоки становятся доступными.
В ходе выполнения четвертого этапа D4 декодирования, представленного на фиг. 5А, полностью декодированное изображение ID проставляется блоком URI, представленным на фиг. 6А.
Различные специфические подэтапы изобретения, такие как реализованные во время вышеупомянутого этапа D2 параллельного декодирования в декодирующей ячейке UDk, будут далее описаны со ссылкой на фиг. 5В.
В ходе выполнения этапа D21, декодирующая ячейка UDk выбирает в качестве текущего блока первый блок для декодирования текущего ряда SEk, показанного на фиг. 4А или фиг. 4В.
В ходе выполнения этапа D22, декодирующая ячейка UDk проверяет факт того, что текущий блок является первым блоком декодируемого изображения, в данном примере первый блок вложенного субпотока F1.
Если дело обстоит именно так, то в ходе выполнения этапа D23, вероятности декодирования инициализируются до значений Pinit, ранее заданных в декодере DO, показанного на фиг. 6А.
Если дело не обстоит так, то в ходе выполнения этапа D30, который будет описан позже в последующем описании, предпринимается определение наличия необходимых ранее декодированных блоков.
В ходе выполнения этапа D24, осуществляется декодирование первого текущего блока МВ1 первого ряда SE1, показанного на фиг. 4А или фиг. 4В. Такой этап D24 содержит множество подэтапов, начиная от D241 до D246, как далее будет описано.
В ходе выполнения первого подэтапа D241, осуществляется энтропийное декодирование синтаксических элементов относящихся к текущему блоку. Точнее говоря, синтаксических элементов относящихся к текущему блоку, декодированных декодирующей ячейкой SUDE1 энтропийного декодирования, как представлено на фиг. 6В. Последний декодирует суббитовый поток F1 сжатого файла, создавая синтаксические элементы, и, в тоже время, обновляет вероятности таким образом, чтобы, на момент в который данная субъячейка декодирует символ, вероятности возникновения данного символа идентичны тем, которые получены во время кодирования того же символа во время осуществления вышеупомянутого энтропийного кодирования на этапе С345.
В ходе выполнения следующего подэтапа D242 осуществляется декодирование с предсказанием текущего блока МВ1 известными технологиями внутреннего и/или внешнего предсказания, в течение которого блок МВ1 предсказан относительно по меньшей мере одного ранее декодированного блока.
Само собой разумеется, что другие виды внутреннего предсказания, такие как предложены в стандарте Н.264, также возможны.
В ходе выполнения данного этапа, декодирование с предсказанием осуществляется при помощи синтаксических элементов, декодированных на предыдущем этапе, и содержит главным образом, вид предсказания (внутреннее или внешнее), и при необходимости, вид внутреннего предсказания, тип разбиения блока или макроблока, если последний был разделен, индекс опорного изображения и вектор перемещения, используемый в режиме внешнего предсказания.
Упомянутый ранее этап декодирования с предсказанием делает возможным создать предсказанный блок МВр1.
В ходе выполнения следующего подэтапа D243 осуществляется создание квантованного остаточного блока MBp1 при помощи ранее декодированных синтаксических элементов.
В ходе выполнения следующего подэтапа D244 осуществляется деквантизация квантованного остаточного блока MBp1 согласно обычной практики деквантизации, которая является противоположностью квантованию, осуществленной на вышеупомянутом этапе С344, таким образом, создается декодируемый деквантованный блок MBDt1.
В ходе выполнения следующего подэтапа D245 осуществляется обратная трансформация деквантованного блока MBDt1, которая представляет собой обратное действие прямому преобразованию, осуществленному на вышеупомянутом этапе С343. Получается декодированный остаточный блок MBDr1.
В ходе выполнения подэтапа D246, осуществляется создание декодированного блока MBD1 путем добавления предсказанного блока MBp1 декодированному остаточному блоку MBDr1. Декодированный блок MBD1 является, таким образом, является доступным для использования декодирующей ячейкой UD1 или для другой любой декодирующей ячейки, формируя часть заданного количества N декодирующих ячеек.
По завершении вышеупомянутого этапа D246 декодирования, субъячейка SUDE1 энтропийного декодирования, такая как представлена на фиг. 6В, содержит все вероятности, такие как прогрессивно обновленные совместно с декодированием первого блока. Такие вероятности соответствуют различным синтаксическим элементам и различным ассоциированным контекстам декодирования.
По окончании вышеупомянутого этапа D24 декодирования, выполняется тест, в ходе выполнения этапа D25 устанавливается факт того, что текущий блок является j-ым блоком того же ряда, где j является известным заданным значением декодера DO, которое по меньшей мере равно 1.
Если дело обстоит именно так, то в ходе выполнения этапа D26, множество вероятностей, вычисленных для j-ого блока, хранится в буферном запоминающем устройстве МТ декодера DO, как показано на фиг. 6А и фиг. 4А или 4В, емкость упомянутой памяти достаточна для хранения вычисленного количества вероятностей.
В ходе выполнения этапа D27, ячейка UDk проверяет факт того, что текущий блок, который был декодирован, является последним блоком последнего субпотока.
Если дело обстоит именно так, то на этане D28 способ декодирования заканчивается.
В противном случае, в ходе выполнения этапа D29, осуществляется выборка следующего блока MBi для декодирования в соответствии с порядком прохождения, показанным стрелкой PS на фиг. 4А или 4В.
Если в ходе выполнения вышеупомянутого этапа D25, текущий блок не является j-м блоком ряда SEDk, то выполняется вышеупомянутый этап D27.
В ходе выполнения этапа D30, который следует за вышеописанным этапом D29, осуществляется установление наличия ранее декодированных блоков, которые необходимы для декодирования текущего блока MBi. Принимая во внимание тот факт, что это влечет за собой параллельное декодирование блоков различными декодирующими ячейками UDk, то возможно, что эти блоки не были декодированы декодирующей ячейкой, предназначенной для декодирования этих блоков и то, что они, следовательно, пока еще отсутствуют. Упомянутый этап распознавания содержит верификацию того, что заданное количество N' блоков, находящиеся в предыдущем ряду SEk-1, например, два блока, расположенные соответственно выше и выше справа от текущего блока, в наличии для декодирования текущего блока, то есть, если они уже были декодированы декодирующей ячейкой UDk-1, предназначенной для их декодирования. Упомянутый этап распознавания состоит из верификации наличия по меньшей мере одного блока, расположенного слева от текущего блока для MB1 для декодирования. Однако, учитывая порядок прохождения PS, выбранный в варианте осуществления, представленный на фиг. 4А или 4В, рассмотрены блоки, декодируемые один после другого в ряду SEk. Следовательно, декодируемый слева блок всегда в наличии (за исключением первого блока в ряду). В примере, представленном на фиг. 4А или 4В, это влечет за собой то, что блок, расположенный непосредственно слева от текущего блока, декодируется. Для этой цели, проверяется наличие только двух блоков, расположенных выше и выше справа от текущего блока.
Данный этап проверки замедляет осуществление декодирования, в альтернативном варианте согласно изобретению, представленный на фиг. 6А генератор синхронизации CLK выполнен с возможностью синхронизацию процесса декодирования блоков, так, чтобы гарантировать наличие двух блоков, расположенных соответственно выше и выше справа от текущего блока, без необходимости проверки наличия этих двух блоков. Таким образом, как показано на фиг. 4А или фиг. 4В, декодирующая ячейка UDk всегда начинает декодировать первый блок со сдвигом на заданное количество N' (здесь N'=2) декодируемых блоков предыдущего ряда SEk-1, который используется для декодирования текущего блока. С точки зрения программного обеспечения, реализация такого генератора синхронизации предоставляет возможность значительно ускорить время обработки, которое необходимо для выполнения процесса обработки блоков каждой подсовокупности SEk в декодере DO.
В ходе выполнения этапа D31, осуществляется проверка того, что текущий блок является первым блоком ряда SEk.
Если это так, то в ходе выполнения этапа D32 осуществляется считывание буферного запоминающего устройства МТ, исключительно только вероятностей возникновения символа, вычисленных во время декодирования j-ого блока предыдущего ряда SEk-1.
Согласно первому варианту, показанному на фиг. 4А, j-ый блок является первым блоком предыдущего ряда SEk-1 (j=1). Такое считывание состоит из замены вероятностей САВАС декодера на присутствующие в буферном запоминающем устройстве МТ. Работая таким образом, когда заменяется первыми соответствующими блоками второго, третьего и четвертого рядов SE2, SE3 и SE4, этап считывания обозначен в фиг. 4А стрелками, изображенными тонкими линиями.
Согласно второму варианту вышеописанного этапа D32, который проиллюстрирован на фиг. 4В, j-ый блок является вторым блоком предыдущего ряда SEk-1 (j=2). Такое считывание состоит из замены вероятностей САВАС декодера на присутствующие в буферном запоминающем устройстве МТ. Работая таким образом, когда заменяется первыми соответствующими блоками второго, третьего и четвертого рядов SE2, SE3 и SE4, этап считывания обозначен в фиг. 4В стрелками, изображенными пунктирными линиями.
По окончании этапа D32, текущий блок декодирован итерацией описанных выше этапов с D24 по D28.
Если по окончании вышеупомянутого этапа D31, выясняется, что текущий блок не является первым блоком ряда SEk, то предпочтительно осуществляется считывание возможностей, возникших из ранее декодированного блока, который находится в том же ряду SEk, то есть, декодированный блок, находящийся непосредственно слева от текущего блока, в представленном примере. Более того, относительно последовательного прохождения считывания PS блоков, находящихся в том же ряду, как показано на фиг. 4А или фиг. 4В, вероятности возникновения символа присутствуют в САВАС декодере, когда начинается декодирование текущего блока, в точности те же, что присутствуют после декодирования предшествующего блока в том же ряду.
Соответственно, в ходе реализации этапа D33, осуществляется получение информации о вероятностях возникновения символа для энтропийного декодирования упомянутого текущего блока, которые вероятности соответствуют исключительно тем, которые были вычислены для упомянутого предшествующего блока в том же ряду, как это показано стрелками, изображенными двойной сплошной линией на фиг. 4А или фиг. 4В.
По окончании этапа D33, текущий блок декодирован итерацией описанных выше этапов с D24 по D28.

Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении гибкости реализации параллельного кодирования/декодирования. Способ кодирования по меньшей мере одного изображения содержит разделение по меньшей мере одного изображения на множество блоков; группировку множества блоков в предопределенное число групп блоков и кодирование каждой из групп блоков, содержащее для первого блока данной группы блоков: преобразование первого блока; определение, что первый блок является первым в порядке блоков в данной группе блоков, и в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, энтропийное кодирование первого блока на основе первого набора данных вероятности, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков; для второго блока из данной группы блоков: преобразование второго блока; в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное кодирование второго блока на основе второго набора данных вероятности. 6 н.п. ф-лы, 12 ил.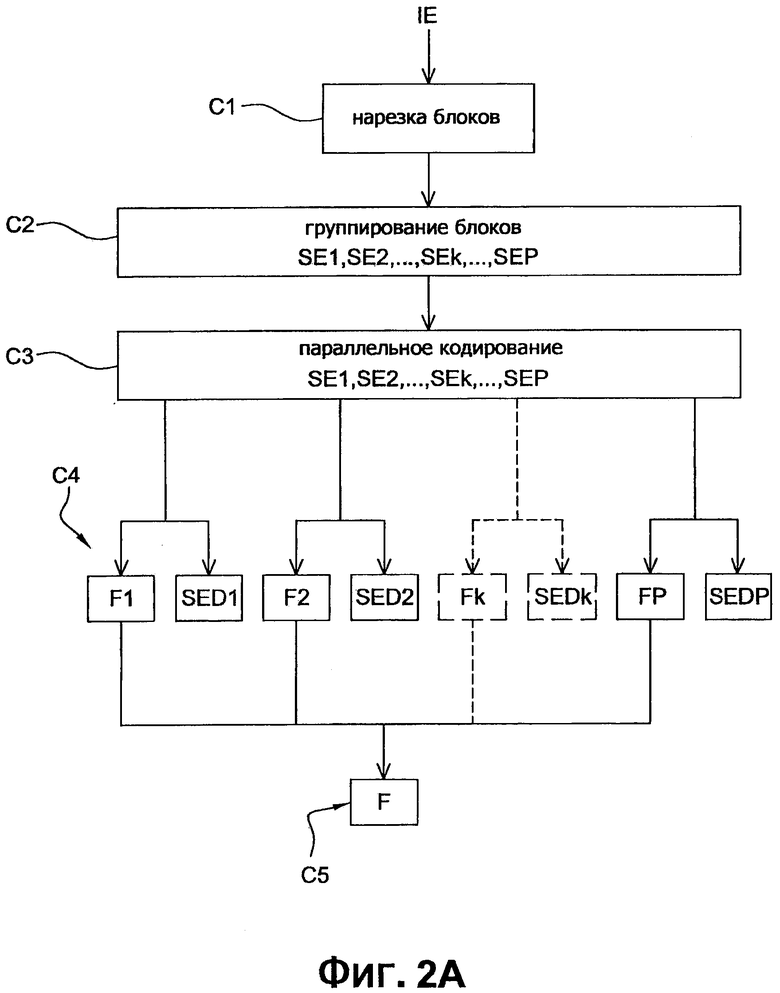
1. Способ кодирования по меньшей мере одного изображения, причем способ содержит:
разделение упомянутого по меньшей мере одного изображения на множество блоков;
группировку упомянутого множества блоков в предопределенное число групп блоков; и
кодирование каждой из упомянутых групп блоков, содержащее:
для первого блока данной группы блоков:
преобразование первого блока;
определение, что первый блок является первым в порядке блоков в данной группе блоков; и
в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, энтропийное кодирование первого блока на основе первого набора данных вероятности, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков;
для второго блока из данной группы блоков:
преобразование второго блока;
определение, что второй блок не является первым в порядке блоков в данной группе блоков; и
в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное кодирование второго блока на основе второго набора данных вероятности, при этом второй набор данных вероятности содержит второй набор вероятностей возникновения символов, ассоциированных с по меньшей мере одним другим уже кодированным блоком, принадлежащим данной группе блоков в предопределенном множестве групп блоков, при этом второй набор вероятностей возникновения символов не ассоциирован с блоками, которые не принадлежат данному подмножеству блоков.
2. Устройство кодирования по меньшей мере одного изображения, содержащее один или более процессоров и одно или более запоминающих устройств, хранящих инструкции, которые, при исполнении упомянутым одним или более процессорами, побуждают упомянутый один или более процессоров выполнять операции, содержащие:
разделение по меньшей мере одного изображения на множество блоков;
группировку упомянутого множества блоков в предопределенное число групп блоков; и
кодирование каждой из упомянутых групп блоков, содержащее:
для первого блока данной группы блоков:
преобразование первого блока;
определение, что первый блок является первым в порядке блоков в данной группе блоков; и
в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, энтропийное кодирование первого блока на основе первого набора данных вероятности, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков;
для второго блока из данной группы блоков:
преобразование второго блока;
определение, что второй блок не является первым в порядке блоков в данной группе блоков; и
в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное кодирование второго блока на основе второго набора данных вероятности, при этом второй набор данных вероятности содержит второй набор вероятностей возникновения символов, ассоциированных с по меньшей мере одним другим уже кодированным блоком, принадлежащим данной группе блоков в предопределенном множестве групп блоков, при этом второй набор вероятностей возникновения символов не ассоциирован с блоками, которые не принадлежат данному подмножеству блоков.
3. Долговременный считываемый компьютером носитель с кодированной компьютерной программой, содержащей инструкции, которые, при исполнении одним или более процессорами, побуждают упомянутый один или более процессоров выполнять операции, содержащие:
разделение по меньшей мере одного изображения на множество блоков;
группировку упомянутого множества блоков в предопределенное число групп блоков; и
кодирование каждой из упомянутых групп блоков, содержащее:
для первого блока данной группы блоков:
преобразование первого блока;
определение, что первый блок является первым в порядке блоков в данной группе блоков; и
в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, энтропийное кодирование первого блока на основе первого набора данных вероятности, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков;
для второго блока из данной группы блоков:
преобразование второго блока;
определение, что второй блок не является первым в порядке блоков в данной группе блоков; и
в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное кодирование второго блока на основе второго набора данных вероятности, при этом второй набор данных вероятности содержит второй набор вероятностей возникновения символов, ассоциированных с по меньшей мере одним другим уже кодированным блоком, принадлежащим данной группе блоков в предопределенном множестве групп блоков, при этом второй набор вероятностей возникновения символов не ассоциирован с блоками, которые не принадлежат данному подмножеству блоков.
4. Способ декодирования потока, представляющего по меньшей мере одно кодированное изображение, причем способ содержит:
прием потока, представляющего по меньшей мере одно кодированное изображение;
идентификацию, из потока, предопределенного множества групп блоков;
обработку первого блока в данной группе блоков, при этом обработка первого блока содержит:
определение, что первый блок является первым в порядке блоков в данной группе блоков;
в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, извлечение первого набора данных вероятности из буфера, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков;
энтропийное декодирование первого блока на основе первого набора данных вероятности; и
обратное преобразование первого блока; и
обработку второго блока в данной группе блоков, при этом обработка второго блока содержит:
определение, что второй блок не является первым в порядке блоков в данной группе блоков;
в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное декодирование второго блока на основе второго набора данных вероятности, при этом второй набор данных вероятности содержит второй набор вероятностей возникновения символов, ассоциированных с по меньшей мере одним другим уже декодированным блоком, принадлежащим данной группе блоков в предопределенном множестве групп блоков, при этом второй набор вероятностей возникновения символов не ассоциирован с блоками, которые не принадлежат данному подмножеству блоков; и
обратное преобразование второго блока.
5. Устройство декодирования потока, представляющего по меньшей мере одно кодированное изображение, содержащее один или более процессоров и одно или более запоминающих устройств, хранящих инструкции, которые, при исполнении упомянутым одним или более процессорами, побуждают упомянутый один или более процессоров выполнять операции, содержащие:
прием потока, представляющего по меньшей мере одно кодированное изображение;
идентификацию, из потока, предопределенного множества групп блоков;
обработку первого блока в данной группе блоков, при этом обработка первого блока содержит:
определение, что первый блок является первым в порядке блоков в данной группе блоков;
в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, извлечение первого набора данных вероятности из буфера, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков;
энтропийное декодирование первого блока на основе первого набора данных вероятности; и
обратное преобразование первого блока; и
обработку второго блока в данной группе блоков, при этом обработка второго блока содержит:
определение, что второй блок не является первым в порядке блоков в данной группе блоков;
в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное декодирование второго блока на основе второго набора данных вероятности, при этом второй набор данных вероятности содержит второй набор вероятностей возникновения символов, ассоциированных с по меньшей мере одним другим уже декодированным блоком, принадлежащим данной группе блоков в предопределенном множестве групп блоков, при этом второй набор вероятностей возникновения символов не ассоциирован с блоками, которые не принадлежат данному подмножеству блоков; и
обратное преобразование второго блока.
6. Долговременный считываемый компьютером носитель с кодированной компьютерной программой, содержащей инструкции, которые, при исполнении одним или более процессорами, побуждают упомянутый один или более процессоров выполнять операции, содержащие:
прием потока, представляющего по меньшей мере одно кодированное изображение;
идентификацию, из потока, предопределенного множества групп блоков;
обработку первого блока в данной группе блоков, при этом обработка первого блока содержит:
определение, что первый блок является первым в порядке блоков в данной группе блоков;
в ответ на определение, что первый блок является первым в порядке блоков в данной группе блоков, извлечение первого набора данных вероятности из буфера, при этом первый набор данных вероятности содержит первый набор вероятностей возникновения символов, ассоциированных с блоком, который расположен непосредственно смежно с первым блоком и который принадлежит другой группе блоков, которая отличается от данной группы блоков в предопределенном множестве групп блоков;
энтропийное декодирование первого блока на основе первого набора данных вероятности; и
обратное преобразование первого блока; и
обработку второго блока в данной группе блоков, при этом обработка второго блока содержит:
определение, что второй блок не является первым в порядке блоков в данной группе блоков;
в ответ на определение, что второй блок не является первым в порядке блоков в данной группе блоков, энтропийное декодирование второго блока на основе второго набора данных вероятности, при этом второй набор данных вероятности содержит второй набор вероятностей возникновения символов, ассоциированных с по меньшей мере одним другим уже декодированным блоком, принадлежащим данной группе блоков в предопределенном множестве групп блоков, при этом второй набор вероятностей возникновения символов не ассоциирован с блоками, которые не принадлежат данному подмножеству блоков; и
обратное преобразование второго блока.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7221483 B2, 22.05.2007 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| RU 2371881 C1, 27.10.2009. | |||

