Область техники, к которой относится изобретение
Настоящее изобретение относится в общем случае к области обработки изображений и более конкретно к кодированию и декодированию цифровых изображений и последовательностей цифровых изображений.
Настоящее изобретение, таким образом, может быть применено к способам видеокодирования, реализованным как в современных видеокодирующих устройствах (стандарты MPEG, Н.264 и т.п.), так и в будущих видеокодирующих устройствах (стандарты ITU-T/VCBG (Н.265) или ISO/MPEG (HVC)).
Уровень техники
Современные видеокодирующие устройства (стандарты MPEG, Н.264 и т.п.) используют поблочное представление видеопоследовательности. Изображения разбивают на макроблоки, каждый макроблок в свою очередь разбивают на блоки и каждый блок или макроблок кодируют с применением внутрикадрового или межкадрового прогнозирования. Таким образом, некоторые изображения кодируют посредством пространственного прогнозирования (внутрикадровое прогнозирование), а другие изображения кодируют посредством временного прогнозирования (межкадровое прогнозирование) относительно одного или нескольких кодированных и/или декодированных опорных изображений с применением компенсации движения, известной специалистам в этой области. Более того, для каждого блока может быть кодирован остаточный блок, соответствующий исходному блоку, из которого вычтен результат прогнозирования. Коэффициенты этого блока квантуют, возможно, после преобразования, и затем кодируют посредством энтропийного кодирующего устройства.
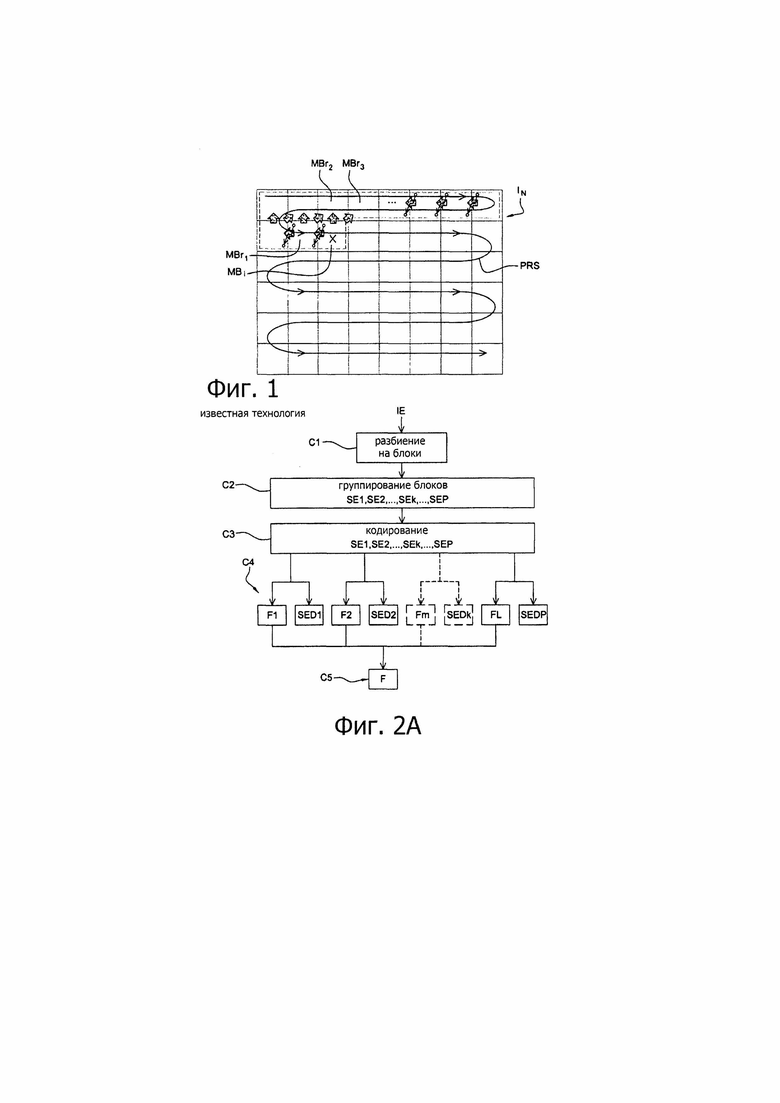
Для применения внутрикадрового прогнозирования и межкадрового прогнозирования требуется, чтобы были доступны некоторые блоки, которые были ранее кодированы и декодированы, чтобы их можно было использовать в декодере или в кодирующем устройстве для прогнозирования текущего блока. Схематичный пример кодирования с прогнозированием, подобного рассматриваемому, представлен на фиг. 1, на котором изображение 1ы разбито на блоки, текущий блок MB; этого изображения, подвергается кодированию с прогнозированием относительно заданного числа трех предварительно кодированных и декодированных блоков MBr1, MBr2 и MBr3, обозначенных заштрихованными стрелками. Упомянутые выше три блока, в частности, представляют собой блок MBr1, расположенный непосредственно слева от текущего блока MBi, и два блока MBr2 и MBr3, расположенные непосредственно сверху и сверху справа от текущего блока MBi.
устройство. Это энтропийное кодирующее устройство кодирует информацию в порядке ее поступления. Обычно блоки просматривают строка за строкой по схеме "растрового сканирования", как показано на фиг. 1 линией PRS, начиная от блока в верхнем левом углу изображения. Для каждого блока в энтропийное кодирующее устройство последовательно передают различные сегменты информации для представления этого блока (тип блока, режим прогнозирования, остаточные коэффициенты и т.п.).
На сегодня уже известно обладающее приемлемой сложностью эффективное устройство арифметического кодирования, именуемое устройством контекстно-ориентированного адаптивного двоичного арифметического кодирования ("САВАС" ("Context Adaptive Binary Arithmetic Coder")) и введенное в стандарт сжатия AVC (известный также под названиями (ISO-MPEG4 часть 10 и ITU-T Н.264)).
Такое энтропийное кодирующее устройство реализует различные принципы:
- арифметическое кодирование: кодирующее устройство, такое, как устройство, первоначально описанное в документе И. Риссанен и Г.Г. Лэнгдон, мл. "Универсальное моделирование и кодирование" (J. Rissanen and G.G. Langdon Jr, "Universal modeling and coding,") IEEE Trans. Inform. Theory, vol. IT-27, pp. 12-23, Jan. 1981, используется для кодирования символа и вероятности появления этого символа;
- адаптация к контексту: здесь это охватывает адаптацию вероятности появления символа, подлежащего кодированию. С одной стороны "обучение" происходит прямо в процессе работы ("на лету"). С другой стороны, в зависимости от состояния ранее кодированной информации для кодирования используется конкретный контекст. Каждому контексту здесь соответствует некая присущая ему собственная вероятность появления символа. Например, контекст соответствует типу кодируемого символа (представление коэффициента остатка, сигнализация о режиме кодирования и т.п.) согласно данной конфигурации или состоянию ближайшего окружения (соседства) (например, число ближайших соседствующих блоков, для которых выбран режим внутрикадрового прогнозирования, и т.п.);
- бинаризация: осуществляется формирование последовательности битов символов, подлежащих кодированию. После этого, полученные различные биты последовательно передают в двоичное энтропийное кодирующее устройство.
Таким образом, это энтропийное кодирующее устройство реализует, для каждого используемого контекста, систему для обучения вероятностям в процессе работы применительно к ранее кодированным символам для рассматриваемого контекста. Это обучение основано на порядке кодирования этих символов. Обычно изображение просматривают согласно описанному выше порядку типа "растрового сканирования".
В процессе кодирования данного символа b, который может быть равен 0 или 1, результат обучения вероятности pi появления этого символа обновляют для текущего блока MBi следующим образом:

где α представляет собой заданную величину, например, 0,95, и pi-l представляет собой вероятность появления символа, вычисленную после последнего появления этого символа.
На фиг. 1 представлен схематичный пример такого энтропийного кодирования, в котором такому энтропийному кодированию подвергается текущий блок MBi изображения IN. Когда начинается энтропийное кодирование блока MBi, используют вероятности появления символов, полученные после кодирования ранее кодированного и декодированного блока, в качестве которого выбирают блок, непосредственно предшествующий текущему блоку MBi в соответствии с описанной выше схемой просмотра блоков строка за строкой по принципу "растрового сканирования". Такое обучение на основе взаимозависимости от блока к блоку показано на фиг. 1 для некоторых блоков (только для ясности картинки) посредством тонких стрелок.
Недостаток такого типа энтропийного кодирования состоит в том, что вероятности, используемые при кодировании символа, расположенного в начале строки, соответствуют главным образом вероятностям, наблюдаемым для символов, находящихся в конце предшествующей строки, если применять просмотр блоков в порядке "растрового кодирования". Теперь, применительно к возможным пространственным вариациям вероятностей символов (например, для символов, связанных с сегментом информации движения, движение в правой части изображения может отличаться от движения, наблюдаемого в левой части, и это, по всей видимости, отразится на вытекающих отсюда локальных вероятностях), можно наблюдать недостаток локальной конформности вероятностей, что возможно способно привести к потере эффективности во время кодирования.
Для ограничения этого явления были внесены предложения о модификации порядка просмотра блоков с целью обеспечить улучшенную локальную согласованность, но кодирование и декодирование остаются последовательными.
В этой области лежит другой недостаток энтропийного кодирующего устройства этого типа. Действительно, кодирование и декодирование символа зависят от состояния "выученной" для него вероятности, поэтому декодирование может быть произведено только в том же порядке, который был использован во время кодирования. Обычно декодирование в этом случае может быть только последовательным, что препятствует параллельному декодированию нескольких символов (например, чтобы получить выигрыш от многоядерных архитектур).
Документ: Томас Виганд, Гэри Дж. Салливан, Гисле Бьонтегаард и Аджай Лутра "Обзор стандарта видеокодирования H.264/AVC" (Thomas Wiegand, Gary J. Sullivan, Gisle Bjontegaard, and Ajay Luthra, "Overview of the H.264/AVC Video Coding Standard", IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, pp. 560-576, July 2003), указывает, что энтропийное кодирующее устройство стандарта САВАС имеет характерную особенность назначения нецелочисленного количества битов каждому символу текущего алфавита, подлежащему кодированию, это является предпочтительным для вероятностей появления символов свыше 0,5. Конкретнее, кодирующее устройство стандарта САВАС ожидает момента, когда оно прочитает несколько символов, и затем назначает этой группе прочитанных символов заданное число битов, которые это кодирующее устройство записывает в сжатом потоке данных для передачи декодеру. Таким образом, такое предложение делает возможным "обобществить" биты нескольких символов и кодировать символ посредством дробного числа битов, это число отражает информацию, более близкую к информации, реально передаваемой символом. Другие биты, ассоциированные с прочитанными символами, не передают в составе сжатого потока, а сохраняют в режиме готовности, ожидая назначения одному или нескольким новым символам, прочитанным кодирующим устройством стандарта САВАС, что делает возможным снова обобществить эти другие символы. Указанное энтропийное кодирующее устройство предпринимает известным способом в данный момент времени "опустошение" этих непереданных битов. Иными словами, в этот данный момент времени кодирующее устройство извлекает биты, еще не переданные, и записывает в состав сжатого потока, адресованного декодеру. Такое опустошение имеет место, например, в момент, в который прочитан последний символ, подлежащий кодированию, чтобы обеспечить, что сжатый поток действительно содержит все биты, что позволит декодеру осуществить декодирование всех символов алфавита. В более общем смысле, момент, в который происходит указанное опустошение, определяется в функции характеристик и функциональных возможностей, специфичных для рассматриваемого кодирующего устройства/декодера.
Документ, доступный в Интернете по адресу http://research.microsoft.com/en-us/um/people/jinl/paper_2002/msri_ipeg.htm на 15 апреля 2011 г., описывает способ кодирования неподвижных изображения в соответствии со стандартом сжатия JPEG2000. вейвлетному преобразованию, за которым следует квантование, что делает возможным получение квантованных вейвлетных коэффициентов, с которыми соответственно ассоциированы индексы квантования. Полученные индексы квантования кодируют посредством энтропийного кодирующего устройства. Квантованные коэффициенты предварительно группируют в прямоугольные блоки, именуемые кодовыми блоками, обычно размером 64×64 или 32×32. Затем осуществляют независимое кодирование каждого кодового блока посредством энтропийного кодирования. Таким образом, энтропийное кодирующее устройство во время кодирования текущего кодового блока не использует вероятности появления символов, вычисленные в ходе кодирования предшествующих кодовых блоков. Поэтому указанное энтропийное кодирующее устройство находится в инициализированном состоянии в начале кодирования каждого кодового блока. Преимуществом такого способа является декодирование данных кодового блока без необходимости декодировать соседние кодовые блоки. Таким образом, например, сегмент клиентского программного обеспечения может потребовать от сегмента серверного программного обеспечения предоставить только те сжатые кодовые блоки, которые нужны клиенту для декодирования выделенной части изображения. Преимуществом такого способа является также возможность параллельного кодирования и/или декодирования кодовых блоков. Таким образом, чем меньше размер кодового блока, тем выше уровень параллелизма. Например, при фиксированном уровне параллелизма, равном двум, два кодовых блока могут быть кодированы и/или декодированы параллельно. Теоретически, величина уровня параллелизма равна числу кодовых блоков, подлежащих кодированию в изображении. Однако характеристики сжатия, получаемые таким способом, не являются оптимальными вследствие того факта, что такое кодирование не использует вероятности, соответствующие ближайшему окружению текущего кодового блока.
Цель и краткое изложение существа изобретения
Одной из целей настоящего изобретения является устранение недостатков, свойственных упомянутым выше известным способам.
Поэтому предмет настоящего изобретения относится к способу кодирования по меньшей мере одного изображения, содержащему этапы:
- разбиение изображения на несколько блоков, которые могут содержать символы, принадлежащие заданному множеству символов;
- группирование блоков в заданное число подмножеств блоков;
- кодирование, посредством модуля энтропийного кодирования, каждого из подмножества блоков путем ассоциирования цифровой информации с символами каждого блока из рассматриваемого подмножества, этап кодирования содержит, для первого блока изображения, подэтап инициализации переменных состояния для модуля энтропийного кодирования;
- генерация по меньшей мере одного подпотока данных, представляющего по меньшей мере одно из кодированных подмножеств блоков.
Способ согласно настоящему изобретению примечателен тем, что:
- в случае, когда текущий блок является первым блоком, подлежащим кодированию, из состава рассматриваемого подмножества, в качестве вероятностей появления символов для первого текущего блока, принимают вероятности, которые были определены для кодированного и декодированного заданного блока из состава по меньшей мере одного другого подмножества;
- если текущий блок представляет собой последний кодированный блок из состава рассматриваемого подмножества, тогда:
• записывают в подпоток, представляющий рассматриваемое подмножество, всю полноту цифровой информации, ассоциированной с символами, во время кодирования блоков рассматриваемого подмножества;
• выполняют подэтап инициализации.
Указанный выше этап записи содержит, как только будет закодирован последний блок какого-либо подмножества блоков, опустошение цифровой информации (битов), еще не переданной, как было объяснено в приведенном выше описании.
Связь между упомянутым выше этапом записи и этапом реинициализации модуля энтропийного кодирования делает возможным генерировать поток кодированных данных, содержащий различные подпотоки данных, соответствующие по меньшей мере одному кодированному подмножеству блоков, этот поток адаптирован для параллельного декодирования согласно различным уровням параллелизма, и это не зависит от типа подмножеству блоков. Таким образом, может быть получена большая степень свободы при кодировании с точки зрения уровня параллелизма в функции от ожидаемых характеристик кодирования/декодирования. Уровень параллелизма при декодировании является величиной переменной и может даже отличаться от уровня параллелизма при кодировании, поскольку в момент начала декодирования подмножества блоков декодер всегда находится в инициализированном состоянии.
Согласно первому примеру переменные состояния модуля энтропийного одного из символов из совокупности, составляющей заданное множество символов.
Согласно второму примеру переменные состояния модуля энтропийного кодирования представляют собой строки символов, содержащиеся в кодовой преобразовательной таблице энтропийного кодирующего устройства для кода LZW (Лемпеля-Зива-Уэлша), хорошо известного специалистам в рассматриваемой области и описанного по следующему интернет-адресу, 21 июня 2011 г.: http://en.wikipedia.ore/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch.
Основное преимущество от использования вероятностей появления символов, найденных для первого блока из указанного другого подмножества, в процессе энтропийного кодирования первого текущего блока из состава рассматриваемого подмножества блоков состоит в экономии буферной памяти кодирующего устройства путем сохранения в этой памяти исключительно обновлений вероятностей появления символов, не принимая в расчет вероятности появления символов, найденные другими последовательными блоками указанного другого подмножества.
Основное преимущество от использования вероятностей появления символов, найденных для какого-либо другого блока из указанного другого подмножества, отличного от первого блока, например, второго блока, в процессе энтропийного кодирования первого текущего блока из состава рассматриваемого подмножества блоков состоит в получении более точных и потому лучше "изученных" вероятностей появления символов, что дает лучшие характеристики сжатия видеосигнала.
В конкретном варианте указанные подмножества блоков кодируют последовательно или еще и параллельно.
Тот факт, что кодирование подмножеств блоков осуществляется последовательно, имеет то преимущество, что способ кодирования согласно настоящему изобретению совместим со стандартом H.264/MPEG-4 AVC.
Тот факт, что кодирование подмножеств блоков осуществляется параллельно, имеет преимущество сокращения затрат времени на кодирование и использования выгод архитектуры, имеющей несколько платформ, для кодирования изображения.
В другом конкретном варианте, когда по меньшей мере два подмножества блоков кодируют параллельно по меньшей мере с одним другим подмножеством блоков, указанные по меньшей мере два кодированных множества блоков заключены в одном и том же подпотоке данных.
Такое предложение делает возможным, в частности, уменьшение объема сигнализации в подпотоках данных. Действительно, чтобы модуль декодирования мог произвести декодирование подпотока как можно раньше, необходимо указать в сжатом файле точку, в которой начинается интересующий подпоток. Когда в одном и том же подпотоке данных присутствуют несколько подмножеств блоков, необходим единый индикатор, что позволит уменьшить размер сжатого файла.
Еще в одном другом конкретном варианте, когда кодированные подмножества блоков предназначены для параллельного декодирования в заданном порядке, подпотоки данных, полученные после кодирования соответственно каждого подмножества блоков, сначала упорядочивают заданным образом перед тем как передать, с учетом перспективы декодирования этих данных.
Такое предложение делает возможным адаптировать поток кодированных данных к конкретному виду декодирования без того, чтобы требовать декодировать и затем снова кодировать изображение.
Соответственно, настоящее изобретение относится далее к устройству для кодирования по меньшей мере одного изображения, содержащему:
- модуль для разбиения изображения на несколько блоков, которые могут содержать символы, принадлежащие заданному множеству символов;
- модуль для группирования блоков в заданное число подмножеств блоков;
- модуль для кодирования каждого из подмножеств блоков, так что этот модуль для кодирования содержит модуль энтропийного кодирования, способный ассоциировать цифровую информацию с символами каждого блока из рассматриваемого подмножества, этот модуль для кодирования содержит, для первого блока изображения, субмодуль для инициализации переменных состояния для модуля энтропийного кодирования;
- модуль для генерации по меньшей мере одного подпотока данных, представляющего по меньшей мере одно из кодированных подмножеств блоков.
Такое устройство для кодирования примечательно тем, что оно содержит:
- модуль для определения вероятностей появления символов для текущего блока, так что этот модуль в случае, когда текущий блок является первым блоком, подлежащим кодированию, из состава рассматриваемого подмножества, принимает в качестве вероятностей появления символов для первого текущего блока вероятности, которые были определены для кодированного и декодированного заданного блока из состава по меньшей мере одного другого подмножества;
- записывающий модуль, который в случае, когда текущий блок является последним кодированным блоком из состава рассматриваемого подмножества, активизируют для записи в подпоток, представляющий рассматриваемое подмножество, всей полноты цифровой информации, ассоциированной с символами, во время
указанный субмодуль инициализации дополнительно активизируют, чтобы реинициализировать переменные состояния модуля энтропийного кодирования.
Соответствующим образом, настоящее изобретение относится к способу декодирования потока, представляющего по меньшей мере одно кодированное изображение, содержащему этапы:
- идентификация потока, содержащего заданное число подпотоков данных, соответствующих по меньшей мере одному подмножеству блоков, подлежащих декодированию, так что эти блоки могут содержать символы, принадлежащие заданному множеству символов;
- декодирование идентифицированных подмножеств блоков, посредством модуля энтропийного декодирования, путем считывания, по меньшей мере в одном из идентифицированных подпотоков, цифровой информации, ассоциированной с символами каждого блока из подмножества, соответствующего указанному по меньшей мере одному идентифицированному подпотоку, этап декодирования содержит, для первого блока, подлежащего декодированию в изображении, подэтап инициализации переменных состояния для модуля энтропийного декодирования.
Такой способ декодирования примечателен тем, что:
- в случае, когда текущий блок является первым блоком, подлежащим декодированию, из состава рассматриваемого подмножества, в качестве вероятностей появления символов для первого блока из состава рассматриваемого подмножества, принимают вероятности, которые были определены для декодированного заданного блока из состава по меньшей мере одного другого подмножества;
- если текущий блок представляет собой последний декодированный блок из состава рассматриваемого подмножества, тогда выполняют подэтап инициализации.
В конкретном варианте указанные подмножества блоков декодируют последовательно или еще и параллельно.
В другом конкретном варианте, когда по меньшей мере два подмножества блоков декодируют параллельно по меньшей мере с одним другим подмножеством блоков, один из идентифицированных подпотоков данных представляет по меньшей мере два подмножества блоков.
Еще в одном другом конкретном варианте, когда кодированные подмножества блоков предназначены для параллельного декодирования в заданном порядке, подпотоки данных, соответствующие кодированным подмножествам блоков, сначала упорядочивают в указанном заданном порядке в составе потока, подлежащего декодированию.
Соответственно, настоящее изобретение относится также к устройству для декодирования потока, представляющего по меньшей мере одно кодированное изображение, содержащему:
- модуль для идентификации в потоке заданного числа подпотоков данных, соответствующих по меньшей мере одному подмножеству блоков, подлежащих декодированию, так что эти блоки могут содержать символы, принадлежащие заданному множеству символов;
- модуль декодирования идентифицированных подмножеств блоков, этот модуль декодирования содержит модуль энтропийного декодирования, способный считывать, по ассоциированную с символами каждого блока из подмножества, соответствующего указанному по меньшей мере одному идентифицированному подпотоку, этот модуль декодирования содержит, для первого блока, подлежащего декодированию в изображении, подмодуль для инициализации переменных состояния для модуля энтропийного декодирования.
Такое устройство для декодирования примечательно тем, что оно содержит модуль для определения вероятностей появления символов для текущего блока, так что этот модуль в случае, когда текущий блок является первым блоком, подлежащим вероятностей появления символов для первого текущего блока вероятности, которые были определены для декодированного заданного блока из состава по меньшей мере одного другого подмножества,
и тем, что если текущий блок представляет собой последний декодированный блок из состава рассматриваемого подмножества, тогда активизируется субмодуль инициализации для повторной инициализации переменных состояния для модуля энтропийного декодирования.
Настоящее изобретение направлено также на создание компьютерной программы, содержащей команды для реализации этапов описанного выше способа кодирования или декодирования, при выполнении этой программы компьютером.
Такая программа может использовать любой язык программирования и может быть в форме исходного кода, объектного кода или кода, занимающего промежуточное положение между исходным кодом и объектным кодом, например, в частично компилированной форме или в какой-либо другой нужной форме.
Еще один предмет настоящего изобретения также направлен на создание читаемого компьютером носителя записи, содержащего команды компьютерной программы, такой как упомянутая выше.
Такой носитель записи может представлять собой какой-либо объект или устройство, способное сохранять указанную программу. Например, подобный носитель может представлять собой запоминающее устройство, такое постоянное запоминающее устройство (ПЗУ (ROM)), например, ПЗУ на основе компакт-диска (CD-ROM) или микроэлектронное ПЗУ (ROM) или также магнитный носитель записи, например, дискета (гибкий диск) или накопитель на жестком магнитном диске.
Более того, такой носитель записи может быть передаваемым носителем, таким как электрический или оптический сигнал, который может быть передан по электрическому или по оптическому кабелю, по радио или каким-либо другим способом. Программу согласно настоящему изобретению можно, в частности, скачать из сети связи типа Интернет.
В качестве альтернативы такой носитель записи может представлять собой интегральную схему, в которую встроена указанная программа, эта схема может быть адаптирована для реализации рассматриваемого способа или может быть использована при его реализации.
Перечисленные выше устройство для кодирования, способ декодирования, устройство для декодирования и компьютерные программы обладают по меньшей мере такими же преимуществами, какие свойственны способу кодирования согласно настоящему изобретению.
Краткое описание чертежей
Другие характеристики и преимущества станут очевидными после прочтения описание двух предпочтительных вариантов, данного со ссылками на прилагаемые чертежи, на которых:
- фиг. 1 представляет схему кодирования изображения согласно известным способам;
- фиг. 2А представляет основные этапы способа кодирования согласно настоящему изобретению;
- фиг. 2В представляет подробно процесс кодирования, реализованный способом кодирования, показанным на фиг. 2А;
- фиг. 3А представляет первый вариант кодирующего устройства согласно настоящему изобретению;
- фиг. 3В представляет модуль кодирования в составе кодирующего устройства, показанного на фиг. 3А;
- фиг. 3С представляет второй вариант кодирующего устройства согласно настоящему изобретению;
- фиг. 4А представляет схему кодирования/декодирования изображения согласно первому предпочтительному варианту;
- фиг. 4В представляет схему кодирования/декодирования изображения согласно второму предпочтительному варианту;
- фиг. 5А представляет основные этапы способа декодирования согласно настоящему изобретению;
- фиг. 5В представляет подробно процесс декодирования, реализованный способом декодирования, показанным на фиг. 5А;
- фиг. 6А представляет вариант декодирующего устройства согласно настоящему изобретению;
- фиг. 6В представляет модуль декодирования в составе декодирующего устройства, показанного на фиг. 6А;
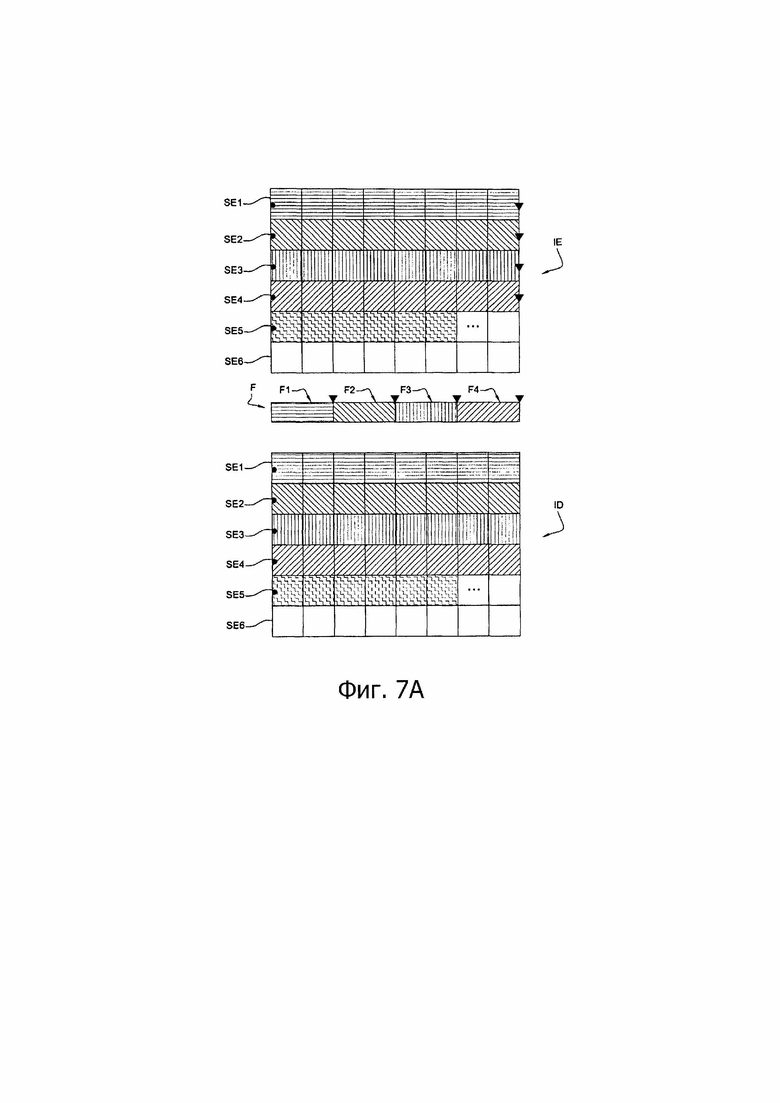
- фиг. 7А представляет схему кодирования/декодирования изображения, реализующую кодирование последовательного типа и декодирование параллельного типа;
- фиг. 7В представляет схему кодирования/декодирования изображения, реализующую кодирование/декодирование параллельного типа при различных уровнях параллелизма.
Подробное описание первого варианта кодирующей части
Теперь будет описан один из вариантов настоящего изобретения, в котором способ кодирования согласно настоящему изобретению используется для кодирования последовательности изображений в соответствии с двоичным потоком, таким же, как поток, получаемый в результате кодирования по стандарту H.264/MPEG-4 AVC. В рассматриваемом варианте способ кодирования согласно настоящему изобретению реализован, например, посредством программного обеспечения или аппаратным способом путем модификации кодирующего устройства, первоначально совместимого со стандартом H.264/MPEG-4 AVC. Способ кодирования согласно настоящего изобретению представлен в форме алгоритма, содержащего этапы с C1 по С5 и показанного на фиг. 2А.
Способ кодирования согласно одному из вариантов настоящего изобретения реализован в кодирующем устройстве СО, два варианта которого представлены соответственно на фиг. 3А и 3С.
Как показано на фиг. 2А, первый этап С1 кодирования представляет собой разбиение изображения IE в последовательности, изображений, подлежащих кодированию, на несколько блоков или макроблоков MB, как это изображено на фиг. 4А и 4В. Указанные макроблоки могут содержать один или несколько символов, составляющих часть заданного множества символов. В представленных примерах эти макроблоки MB обладают квадратной формой и все имеют одинаковый размер. В зависимости от размера изображения, который необязательно кратен размеру блоков, последние блоки слева и последние блоки внизу изображения могут не быть квадратными. В альтернативном варианте блоки, например, могут быть прямоугольной формы и/или могут быть не совмещены один с другим.
Каждый блок или макроблок может, далее, сам быть разбит на субблоки, которые в свою очередь могут быть разбиты на части.
Такое разбиение осуществляется посредством модуля РСО разбиения, показанного на фиг. 3А и использующего, например, хорошо известный алгоритм разбиения.
Как показано на фиг. 2А, второй этап С2 кодирования представляет собой группирование указанных выше блоков в заданное число Р подмножеств SE1, SE2, …, SEk, …, SEP последовательных блоков, которые должны быть кодированы последовательно или параллельно. В примерах, показанных на фиг. 4А и 4В, число подмножеств Р=6, но для большей ясности чертежа изображены только четыре подмножества SE1, SE2, SE3 и SE4. Каждое из этих четырех подмножеств блоков четырьмя строками (каждое - своей) блоков изображения IE.
Такое группирование осуществляется посредством вычислительного модуля GRCO разбиения, показанного на фиг. 3А, с использованием хорошо известного алгоритма.
Как показано на фиг. 2А, третий этап С3 кодирования состоит в кодировании каждого из подмножеств блоков с SEI по SE6, так что блоки из состава любого рассматриваемого подмножества кодируют в соответствии с заданным порядком PS прохождения через эти блоки, например, для последовательного кодирования. В примерах, представленных на фиг. 4А и 4В, блоки текущего подмножества SEk (1≤k≤Р) кодируют один за другим слева направо, как показано стрелкой PS.
Согласно первому варианту такое кодирование относится к последовательному типу кодирования и реализуется в одном кодирующем модуле UC, как представлено на фиг. 3А. Согласно известным технологиям кодирующее устройство СО содержит буферную память МТ, адаптированную для хранения вероятностей появления символов, постоянно обновляемых в процессе кодирования текущего блока.
Как показано более подробно на фиг. 3В, кодирующий модуль UC содержит:
• модуль для кодирования с прогнозированием применительно к текущему блоков, обозначенный МСР;
• модуль для энтропийного кодирования текущего блока с использованием по меньшей мере одной вероятности появления символа, вычисленной для указанного ранее кодированного и декодированного блока, обозначенный МСЕ.
Модуль МСР кодирования с прогнозированием представляет собой программный модуль, способный осуществлять кодирование с прогнозированием применительно к текущему блоку в соответствии с обычными способами прогнозирования, такого как, например, режим внутрикадрового и/или межкадрового прогнозирования.
Указанный модуль МСЕ энтропийного кодирования представляет собой модуль стандарта САВАС, но модифицированный согласно настоящему изобретению, как это будет рассмотрено далее в этом описании.
В качестве варианта, указанное энтропийное кодирующее устройство МСЕ может представлять собой известное кодирующее устройство в коде Хаффмена.
В примерах, представленных на фиг. 4А и 4В, модуль UC кодирует блоки первой строки SE1 слева направо. После достижения последнего блока в первой строке SE1 модуль переходит к первому блоку второй строки SE2. После достижения последнего блока во второй строке SE2 модуль переходит к первому блоку третьей строки SE3. После четвертой строки SE4 и т.д. до тех пор, пока не будет закодирован последний блок изображения IE.
Безусловно, возможны и другие варианты просмотра изображения, отличные от того варианта, который был только что описан выше. Таким образом, можно разбить изображение IE на несколько подызображений и затем применить разбиение такого типа к каждому подызображению независимо. Кроме того, кодирующий модуль может обрабатывать не последовательность строк, как было рассмотрено выше, а последовательность столбцов. Можно также просматривать строки или столбцы в любом направлении.
Согласно второму варианту такое кодирование представляет собой кодирование параллельного типа и отличается от первого варианта последовательного кодирования исключительно тем фактом, что он реализован заданным числом R кодирующих модулей UCk (1≤k≤R), при R=2, как в примере, представленном на фиг. 3С. Такое параллельное кодирование, как известно, вызывает значительное ускорение способа кодирования.
Каждый из кодирующих модулей UCk идентичен кодирующему модулю UC, представленному на фиг. 3В. Соответствующим образом кодирующий модуль UCk кодирования MCEk.
Снова со ссылками на фиг. 4А и 4В первый модуль UC1 кодирует, например, блоки строк с нечетными номерами, тогда как второй модуль UC2 кодирует, например, блоки строк с четными номерами. Более точно, первый модуль UC кодирует блоки первой строки SE1 слева направо. После достижения последнего блока в первой строке SE1 этот модуль переходит к первому блоку (2n+1)-й строки, иными словами к третьей строке SE3 и т.д. Параллельно с обработкой, выполняемой первым модулем UC1, второй модуль UC2 кодирует блоки второй строки SE2 слева направо. После достижения последнего блока во второй строке SE2 этот модуль переходит к первому блоку (2n)-й строки, здесь это четвертая строка SE4 и т.д. Указанные выше два просматривающих прохода повторяют до тех пор, пока не будет закодирован последний блок изображения IE.
Как показано на фиг. 2А, на четвертом этапе С4 кодирования генерируют L подпотоков F1, F2, …, Fm, …, FL (1≤m≤L≤P) битов, представляющих обработанные блоки, сжатые посредством указанного выше кодирующего модуля UC или каждого из указанных выше кодирующих модулей UCk, равно как и декодированную версию обработанных блоков из состава каждого подмножества SEk. Декодированные обработанные блоки из состава рассматриваемого подмножества, обозначенные SED1, SED2, …, SEDk, …, SEDP, могут быть повторно использованы кодирующим модулем UC, представленным на фиг. 3А, или каждым из кодирующих модулей UCk, представленных на фиг. 3С, в соответствии с механизмом синхронизации, который будет подробно рассмотрен в настоящем описании дальше.
Как показано на фиг. 3В, этап генерации L подпотоков реализуется программным модулем MGSF или MGSFk генерации потоков, адаптированным для генерации потоков данных, таких как потоки битов, например.
Как показано на фиг. 2А, пятый этап С5 кодирования состоит в построении глобального потока F на основе упомянутых выше L подпотоков F1, F2, …, Fm, …, FL. Согласно одному из вариантов подпотоки F1, F2, …, Fm, …, FL просто накладывают один на другой, так что необходим дополнительный сегмент информации, предназначенный для индикации местонахождения каждого подпотока Fm в глобальном потоке F для декодера. Этот глобальный поток затем передают по сети связи (не показана) удаленному терминалу. Этот терминал содержит декодер DO, представленный на фиг. 5А. Согласно другому варианту, который особенно предпочтителен, поскольку он не требует декодирования и потом повторного кодирования изображения, кодирующее устройство СО, перед передачей потока F декодеру DO, предварительно располагает L подпотоки F1, F2, …, Fm, …, FL в заданном порядке, соответствующем порядку, в котором указанный декодер DO способен декодировать эти подпотоки.
Таким образом, как это будет подробно рассмотрено далее в настоящем описании, декодер согласно настоящему изобретению способен выделить подпотоки F1, F2, …, Fm, …, FL из состава глобального потока F и назначить эти подпотоки одному или нескольким декодирующим модулям, из которых состоит декодер. Следует отметить, что такое разложение глобального потока на подпотоки не зависит от выбора использования одного кодирующего модуля или нескольких кодирующих модулей, работающих параллельно, и что при таком подходе можно иметь только кодирующее устройство или только декодер, содержащий модули, работающие параллельно.
Такая структура глобального потока F реализована в модуле CF построения потоков, таком, как представлен на фиг. 3А и на фиг. 3С.
Различные специфичные подэтапы настоящего изобретения, такие как реализуемые в ходе указанного выше этапа С3 кодирования в кодирующем модуле UC или UCk, будут теперь описаны со ссылками на фиг. 2В.
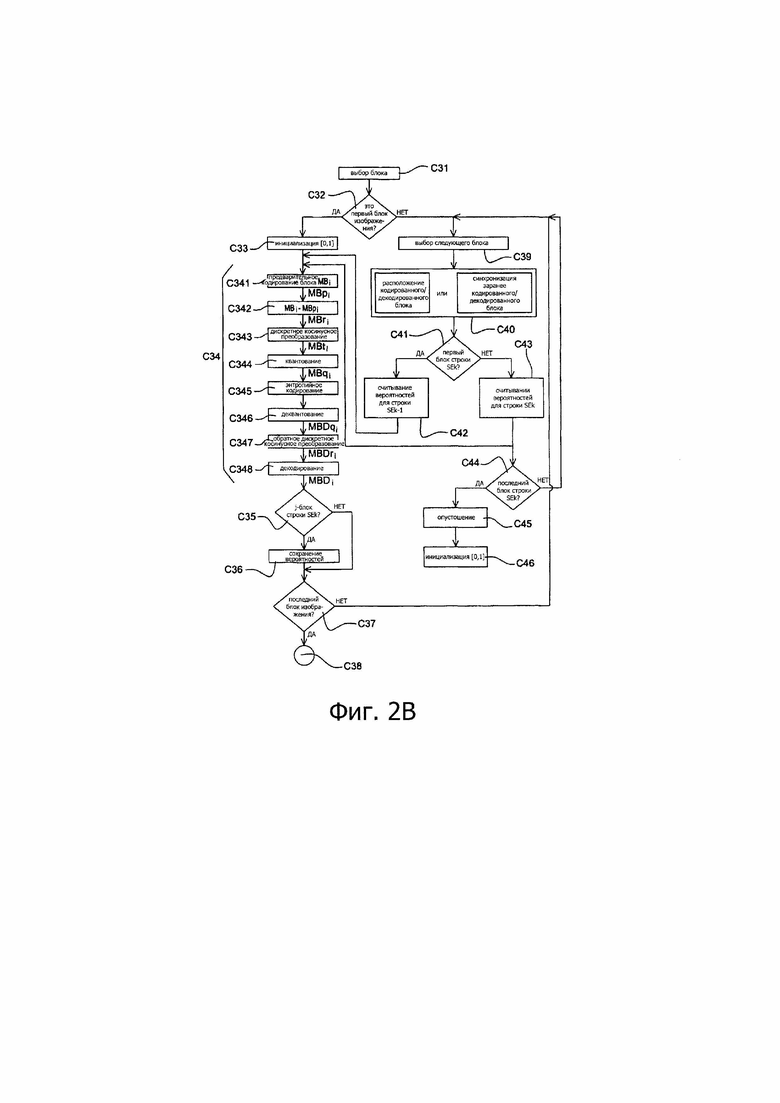
В процессе выполнения этапа С31 кодирующий модуль UC или UCk выбирает в качестве текущего блока первый блок, подлежащий кодированию, в текущей строке SEk, представленной на фиг. 4А или 4В, такой как, например, первая строка SE1.
В процессе выполнения этапа С32 модуль UC или UCk проверяет, является ли текущий блок первым блоком (расположенным сверху и слева) изображения IE, которое было разбито на блоки в ходе указанного выше этапа С1.
Если текущий блок - первый, тогда на этапе С33 модуль МСЕ или МСЕл энтропийного кодирования осуществляет инициализацию своих переменных состояния. Согласно представленному примеру, использующему арифметическое кодирование, описанное ранее, этот этап содержит инициализацию интервала, представляющего вероятность появления одного из символов из совокупности, составляющей заданное множество символов. Известным способом этот интервал инициализируют с двумя границами L и Н, соответственно нижней и верхней. Значение нижней границы L фиксируют на 0, а значение верхней границы фиксируют на 1, что соответствует вероятности появления первого символа из совокупности всех символов, составляющих заданное множество символов. Размер R этого интервала определен, поэтому, здесь формулой R=Н-L=1. Инициализированный интервал обычно разбивают дополнительно на несколько заданных подинтервалов, представляющих соответственно вероятности появления символов из совокупности символов, составляющей заданное множество символов.
В качестве варианта, если используемый способ энтропийного кодирования представляет собой способ кодирования LZW, инициализируется кодовая таблица строк символов, так что эта таблица содержит все возможные символы по одному и только по одному разу.
Если после указанного выше этапа С32 оказалось, что текущий блок не является первым блоком изображения IE, определяют на этапе С40, который будет рассмотрен в настоящем описании позднее, наличие необходимых ранее кодированных и декодированных блоков.
В процессе выполнения этапа С34 кодируют первый текущий блок МВ1 первой строки SE1, представленной на фиг. 4А или 4В. Такой этап С34 содержит несколько подэтапов с С341 по С348, которые будут описаны ниже.
В ходе выполнения первого подэтапа С341, представленного на фиг. 2В, осуществляют кодирование с прогнозированием применительно к текущему блоку МВ1 посредством известного способа внутрикадрового и/или межкадрового прогнозирования, согласно которому блок МВ1 прогнозируют относительно по меньшей мере одного ранее кодированного и декодированного блока.
Само собой разумеется, что возможны также другие режимы внутрикадрового прогнозирования, такие как режимы, предлагаемые в стандарте Н.264.
Текущий блок МВ1 может быть также подвергнут кодированию с прогнозированием в режиме, в ходе которого блок МВ1 прогнозируют относительно блока, полученного на основе ранее кодированного и декодированного изображения. Безусловно, можно представить и другие типы прогнозирования. Из совокупности возможных способов прогнозирования для текущего блока оптимальный способ прогнозирования выбирают согласно критерию искажения скорости передачи данных, хорошо известному специалистам в рассматриваемой области.
Упомянутый выше этап кодирования с прогнозированием делает возможным построение прогнозированного блока MBp1, представляющего собой аппроксимацию текущего блока МВ1. Информация, относящаяся к кодированию с прогнозированием, будет в последующем записана в потоке F, передаваемом декодеру DO. Такая информация содержит в частности указание типа прогнозирования (межкадровое или внутрикадровое) и, если это подходит, режима внутрикадрового прогнозирования, типа разбиения блока или макроблока, если последний был разбит, индекса опорного изображения и вектора смещения, используемого в режиме межкадрового прогнозирования. Кодирующее устройство СО сжимает эту информацию.
В процессе выполнения следующего подэтапа С342 вычитают прогнозируемый блок MBp1 из текущего блока MB1 для получения остаточного блока MBr1.
В процессе выполнения следующего подэтапа С343 осуществляют преобразование прогнозируемого блока MBp1 согласно обычной процедуре прямого преобразования, такой как, например, дискретное косинусное преобразование типа DCT, для получения преобразованного блока MBt1.
В процессе выполнения следующего подэтапа С344 выполняют квантование преобразованного блока MBt1 согласно обычной процедуре квантования, такой как, например, скалярное квантование. В результате получен блок MBq1 квантованных коэффициентов.
В процессе выполнения следующего подэтапа С345 осуществляют энтропийное кодирование блока квантованных коэффициентов MBq1. В предпочтительно варианте здесь выполняется энтропийное кодирование по стандарту САВАС. Такой этап содержит:
a) считывание символа или символов из состава заданного множества символов, ассоциированных с текущим блоком;
b) ассоциирование цифровой информации, такой как биты, с прочитанным(и) символом(ами).
В указанном выше варианте, в котором в качестве алгоритма кодирования использован алгоритм кодирования LZW, с символом, подлежащим кодированию, ассоциируют цифровой сегмент информации, соответствующий коду рассматриваемого символа в текущей кодовой таблице и затем обновляют эту кодовую таблицу согласно известной процедуре.
В процессе выполнения следующего подэтапа С346 выполняют деквантование блока MBq1 согласно обычной процедуре деквантования, представляет собой операцию обратную, процедуре квантования, выполненной на этапе С344. В результате получен блок MBDq1 деквантованных коэффициентов.
В процессе выполнения следующего подэтапа С347 выполняют обратное преобразование блока MBDq1 деквантованных коэффициентов, представляющее собой операцию обратную процедуре прямого преобразования, выполненной на этапе С343 выше. В результате получен декодированный остаточный блок MBDr1.
В процессе выполнения следующего подэтапа С348 формируют декодированный блок MBD1 путем суммирования прогнозируемого блока MBp1 с декодированным остаточным блоком MBDr1. Следует отметить, что последний блок является таким же, как декодированный блок, полученный после завершения выполнения способа декодирования изображения IE, который был рассмотрен выше в настоящем описании. Декодированный блок MBD1 делают, таким образом, доступным для использования кодирующим модулем UCk или каким-либо другим кодирующим модулем, составляющим часть заданного числа R кодирующих модулей.
По завершении упомянутого выше этапа С34 кодирования модуль МСЕ или MCEk энтропийного кодирования, такой как показан на фиг. 3В, содержит все вероятности, такие, как вероятности, постоянно обновляемые совместно в процессе кодирования первого блока. Эти вероятности соответствуют разнообразным элементам возможных синтаксисов и различным ассоциированным контекстам кодирования.
После выполнения указанного выше этапа С34 кодирования проверяют в ходе этапа С35, является ли текущий блок j-м блоком той же самой строки, где j - представляет собой заданную величину, известную кодирующему устройству СО и равную по меньшей мере 1.
Если это так, то в ходе выполнения этапа С36, представленного на фиг. 2В, множество вероятностей, вычисленных для j-блока, сохраняют в буферной памяти МТ в составе кодирующего устройства СО, такого как показано на фиг. 3А или 3В и на фиг. 4А или 4В, и размер указанной памяти адаптирован для сохранения вычисленного числа вероятностей.
В процессе выполнения этапа С37, представленного на фиг. 2В, кодирующий модуль UC или UCk проверяет, является ли текущий блок строки SEk, который был только что закодирован, последним блоком изображения IE. Такой этап выполняется также, если в процессе осуществления этапа С35 оказалось, что текущий блок не является j-м блоком строки SE1.
Если оказалось, что текущий блок представляет собой последний блок изображения IE, на этапе С38 выполнение способа кодирования завершается.
Если текущий блок - не последний, на этапе С39 выбирают следующий блок MB;, подлежащий кодированию, в соответствии с порядком просмотра изображения, обозначенным стрелкой PS на фиг. 4А или 4В.
В процессе выполнения этапа С40, представленного на фиг. 2В, определяют доступность предварительно кодированных и декодированных блоков, необходимых для кодирования текущего блока MBi.
Если происходит обработка первой строки SE1, этот этап состоит в проверке доступности по меньшей мере одного блока, расположенного слева от текущего блока MBi, подлежащего кодированию. Однако с учетом порядка PS просмотра изображения, выбранного в варианте, представленном на фиг. 4А и 4В, блоки в рассматриваемой строке SEk кодируют один за другим. Следовательно, всегда (за исключением обработки первого блока строки) имеется и доступен расположенный слева кодированный и декодированный блок. В примере, представленном на фиг. 4А или 4В, это блок, расположенный непосредственно слева рядом с текущим блоком, подлежащим кодированию.
Если рассматривается строка SEk, отличная от первой строки, указанный этап проверки дополнительно содержит проверку, имеется ли заданное число N' блоков, расположенных в предыдущей строке SEk-1, например, два блока, находящихся соответственно сверху и сверху справа от текущего блока, и доступных для кодирования текущего блока, иными словами, если они уже были кодированы и затем декодированы посредством кодирующего модуля UC или UCk-1.
Поскольку этот этап проверки замедляет работу способа кодирования, в альтернативном варианте настоящего изобретения, в котором кодирование строк осуществляется по параллельному типу, тактовый сигнал CLK, показанный на фиг. 3С, приспособлен для опережающей синхронизации кодирования блоков таким образом, чтобы гарантировать доступность двух блоков, расположенных соответственно сверху и сверху справа от текущего блока, не требуя обязательной проверки доступности этих двух блоков. Таким образом, кодирующий модуль UCk всегда начинает кодировать первый блок со сдвигом на заданное число N' (при, например, N'=2) кодированных и декодированных блоков предыдущей строки SEk-1, используемых для кодирования текущего блока. С программной точки зрения реализация такого тактового сигнала делает возможным значительно ускорить и сократить затраты времени на обработку блоков изображения IE в кодирующем устройстве СО.
В процессе выполнения этапа С41, представленного на фиг. 2В, проверяют, является ли текущий блок первым блоком рассматриваемой строки SEk.
Если текущий блок - первый, в процессе выполнения этапа С42 считывают из буферной памяти МТ исключительно вероятности появления символов, вычисленные во время кодирования j-го блока предыдущей строки SEk-1.
Согласно первому варианту, представленному на фиг. 4А, j-й блок является первым блоком предыдущей строки SEk-1 (j=1). Такое считывание состоит в замене вероятностей в кодирующем устройстве по стандарту САВАС вероятностями, записанными в буферной памяти МТ. Процесс чтения, захватывающий соответствующие первые блоки второй, третьей и четвертой строк SE2, SE3 и SE4, показан на фиг. 4А тонкими стрелками.
Согласно второму варианту, упомянутого выше этапа С43, представленного на фиг. 4В, j-й блок является вторым блоком предыдущей строки SEk-1 (j=2). Такое считывание состоит в замене вероятностей в кодирующем устройстве по стандарту САВАС вероятностями, записанными в буферной памяти МТ. Процесс чтения, захватывающий соответствующие первые блоки второй, третьей и четвертой строк SE2, SE3 и SE4, показан на фиг. 4В тонкими штриховыми стрелками.
После этапа С42 текущий блок кодируют и затем декодируют путем повторения этапов с С34 по С38, описанных выше.
Если после указанного выше этапа С41 оказалось, что текущий блок не является первым блоком рассматриваемой строки SEk, предпочтительно не считывать вероятности для ранее кодированного и декодированного блока, расположенного в той же самой строке SEk, иными словами кодированного и декодированного блока, расположенного (в представленном примере) непосредственно рядом слева от текущего блока. Действительно, при последовательном порядке PS просмотра блоков изображения для считывания блоков, расположенных в той же самой строке, как показано на фиг. 4А или 4В, вероятности появления символов, присутствующие в кодирующем устройстве, использующем алгоритм САВАС, в момент начала кодирования текущего блока являются точно теми, какие присутствуют после декодирования/декодирования предыдущего блока в той же самой строке.
Затем, в процессе выполнения этапа С43, представленного на фиг. 2В, производят обучение вероятностям появления символов для энтропийного кодирования текущего блока, так что эти вероятности соответствуют исключительно тем, которые были вычислены для указанного предыдущего блока в той же самой строке, как показано двойными сплошными стрелками на фиг. 4А или 4В.
После этапа С43 текущий блок кодируют и затем декодируют путем повторения этапов с С34 по С38, описанных выше.
После этого, в процессе выполнения этапа С44 проверяют, является ли текущий блок последним блоком рассматриваемой строки SEk.
Если текущий блок - не последний в этой строке, после этапа С44 снова выполняют этап С39 выбора следующего блока MBi, подлежащего кодированию.
Если текущий блок является последним блоком в рассматриваемой строке SEk, в процессе выполнения этапа С45 кодирующее устройство СО, представленное на фиг. 3А или 3С, осуществляет опустошение, как рассмотрено выше в настоящем описании. С этой целью кодирующий модуль UCk передает соответствующему модулю MGSFk генерации подпотока полностью все биты, которые были ассоциированы с символом(ами), считываемым(и) в процессе кодирования каждого блока рассматриваемой строки SEk, таким образом, что этот модуль MGSFk записывает в подпоток Fm данных, содержащий двоичную последовательность, представляющую кодированные блоки рассматриваемой строки SEk, все эти биты полностью. Такое опустошение символически обозначено на фиг. 4А и 4В треугольником в конце каждой строки SEk.
В процессе выполнения этапа С46 представленного на фиг. 2В, кодирующий модуль UC или UCk выполняет процедуру, идентичную указанному выше этапу С33, иными словами снова инициализирует интервальное представление вероятности появления символа, входящего в состав заданного множества символов. Такая повторная инициализация обозначена на фиг. 4А и 4В черной точкой в начале каждой строки SEk.
Преимущество выполнения этапов С45 и С46 на этом уровне кодирования состоит в том, что в процессе кодирования следующего блока, обрабатываемого кодирующим модулем UC или кодирующим модулем UCk, кодирующее устройство СО находится в инициализированном состоянии. Таким образом, как это будет рассмотрено далее в настоящем описании, для декодирующего модуля становится возможным работать параллельно, чтобы непосредственно декодировать сжатый поток F от этой точки, поскольку модулю достаточно для этого быть в инициализированном состоянии.
Подробное описание одного из вариантов декодирующей части
Теперь будет описан один из вариантов способа декодирования согласно настоящему изобретению, в котором этот способ декодирования реализован посредством программного обеспечения или аппаратным способом путем модификации декодера, первоначально совместимого со стандартом H.264/MPEG-4 AVC.
Способ декодирования согласно настоящего изобретению представлен в форме алгоритма, содержащего этапы с D1 по D4 и показанного на фиг. 5А.
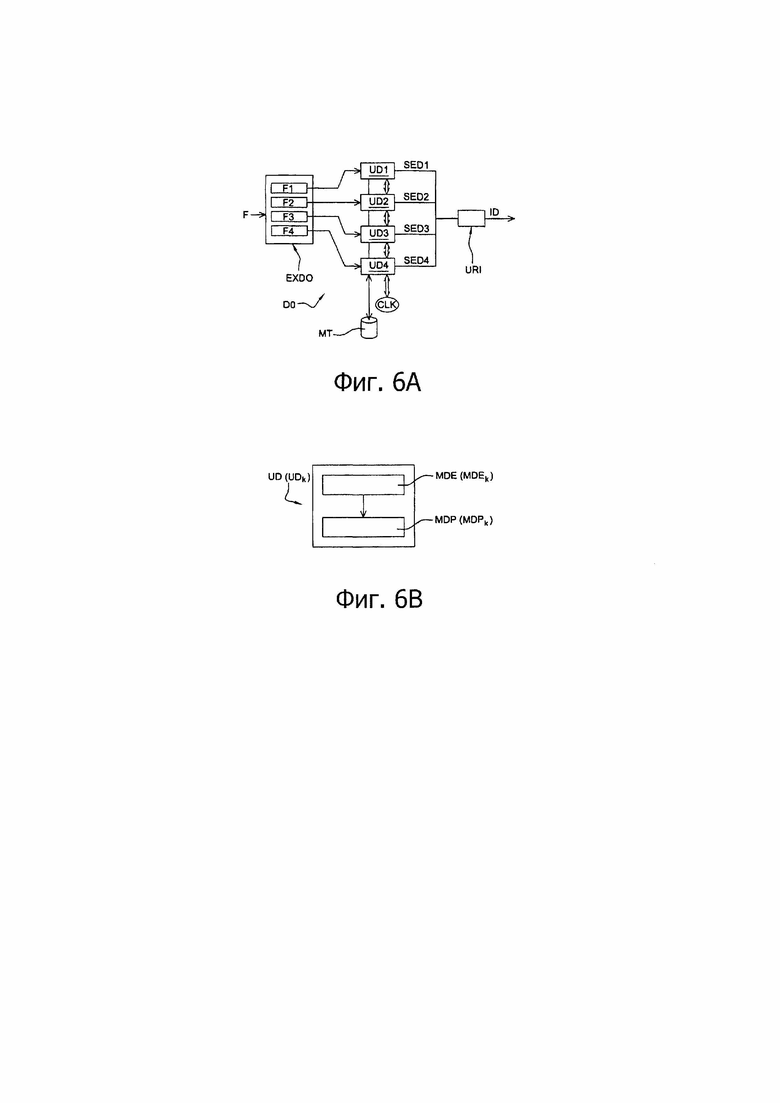
Способ декодирования согласно рассматриваемому варианту настоящего изобретению реализован в декодирующем устройстве DO, представленном на фиг. 6А.
Как показано на фиг. 5А, первый этап D1 декодирования представляет собой идентификацию в потоке F совокупности из L подпотоков F1, F2, …, Fm, …, FL, содержащих соответственно Р подмножеств SE1, SE2, …, SEk, …, SEP предварительно кодированных блоков или макроблоков MB, как это изображено на фиг. 4А и 4В. С этой целью каждый подпоток Fm в составе потока F ассоциируют с индикатором, позволяющим декодеру DO определить местонахождение каждого подпотока Fm в потоке F. В качестве варианта, по завершении указанного выше этапа С3 кодирования, кодирующее устройство СО упорядочивает подпотоки F1, F2, …, Fm, …, FL в потоке F в соответствии с порядком, ожидаемым декодером DO, что позволяет избежать вставки индикаторов подпотоков в поток F. Такое предложение делает возможным уменьшение затрат с точки зрения скорости передачи данных в потоке F данных.
В примере, представленном на фиг. 4А или 4В, указанные блоки MB обладают квадратной формой и все имеют одинаковый размер. В зависимости от размера изображения, который необязательно кратен размеру блоков, последние блоки слева и последние блоки внизу изображения могут не быть квадратными. В альтернативном варианте блоки, например, могут быть прямоугольной формы и/или могут быть не совмещены один с другим.
Каждый блок или макроблок может далее сам быть разбит на субблоки, которые сами могут быть разбиты на части.
Такая идентификация осуществляется посредством модуля EXDO выделения потоков, такого, как представлен на фиг. 6А.
В примере, показанном на фиг. 4А или 4В, заданное число Р равно 6, но для большей ясности чертежа изображены только четыре подмножества SEI, SE2, SE3 и SE4.
Как показано на фиг. 5А, второй этап D2 декодирования состоит в декодировании каждого из подмножеств блоков SE1, SE2, SE3 и SE4, так что блоки из состава любого рассматриваемого подмножества декодируют в соответствии с заданным последовательным порядком PS прохождения через эти блоки. В примере, представленном на фиг. 4А или 4В, блоки текущего подмножества SEk (1≤k≤Р) декодируют один за другим слева направо, как показано стрелкой PS. По завершении этапа D2 получают декодированные подмножества блоков SED1, SED2, SED3, …, SEDk, …, SEDP.
Такое декодирование может быть последовательного типа и, следовательно, может быть произведено посредством единственного декодирующего модуля.
Однако для создания возможности использовать преимущества архитектуры декодирования, содержащей несколько платформ, декодирование подмножеств блоков представляет собой декодирование параллельного типа и реализуется посредством нескольких R декодирующих модулей UDk (1≤k≤R), например, при R=4, как это представлено на фиг. 6А. Это предложение, таким образом, позволяет значительно ускорить выполнение способа декодирования. Согласно известным технологиям декодирующее устройство DO содержит буферную память МТ, адаптированную для хранения вероятностей появления символов, постоянно обновляемых совместно в процессе декодирования текущего блока.
Как показано более подробно на фиг. 6В, каждый из декодирующих модулей UDk содержит:
• модуль для энтропийного декодирования текущего блока посредством обучения по меньшей мере одной вероятности появления символа, вычисленной по меньшей мере для одного ранее декодированного блока, обозначенный MDEk;
• модуль для декодирования с прогнозированием применительно к текущему блоку с учетом указанного ранее декодированного блока, обозначенный MDPk.
Модуль SUDPk кодирования с прогнозированием способен осуществлять декодирование с прогнозированием применительно к текущему блоку в соответствии с обычными способами прогнозирования, такого как, например, режим внутрикадрового и/или межкадрового прогнозирования.
Указанный модуль MDEk энтропийного декодирования представляет собой модуль стандарта САВАС, но модифицированный согласно настоящему изобретению, как это будет рассмотрено далее в этом описании.
В качестве варианта, указанный модуль MDEk энтропийного декодирования может представлять собой известное декодирующее устройство для кода Хаффмена.
В примере, представленном на фиг. 4А или 4 В, первый модуль UD1 декодирует блоки первой строки SEI слева направо. После достижения последнего блока в первой строке SEI этот модуль переходит к первому блоку (n+1)-й строки, здесь это 5-я строка, и т.д. Второй модуль UD2 декодирует блоки второй строки SE2 слева направо. После достижения последнего блока во второй строке SE2 этот модуль переходит к первому блоку (n+2)-й строки, здесь это 6-я строка, и т.д. Такой просмотр повторяется вплоть до модуля UD4, который декодирует блоки четвертой строки SE2 слева направо. После достижения последнего блока в первой строке модуль переходит к первому блоку (n+4)-й строки, здесь это 8-я строка, и т.д. и т.п.пока не будет декодирован последний блок последнего идентифицированного потока.
Безусловно, возможны и другие варианты просмотра изображения, отличные от того варианта, который был только что описан выше. Например, каждый декодирующий модуль может обрабатывать не вложенные строки, как было рассмотрено выше, а вложенные столбцы. Можно также просматривать строки или столбцы в любом направлении.
Как показано на фиг. 5А, третий этап D3 кодирования состоит в реконструкции декодированного изображения ID на основе каждого декодированного подмножества SED1, SED2, …, SEDk, …, SEDP, полученного на этапе D2 декодирования. Более точно, декодированные блоки каждого декодированного подмножества SED1, SED2, …, SEDk, …, SEDP передают в модуль URI реконструкции изображения, как представлено на фиг. 6А. В процессе выполнения этапа D3 модуль UR1 записывает декодированные блоки в состав декодированного изображения по мере того, как эти блоки становятся доступными.
В процессе выполнения четвертого этапа D4 декодирования, представленного на фиг. 5А, модуль URI показанный на фиг. 6А, передает на выход полностью декодированное изображение ID.
Различные специфичные подэтапы настоящего изобретения, такие как реализуемые в ходе указанного выше этапа D2 параллельного декодирования в декодирующем модуле UDk, будут теперь описаны со ссылками на фиг. 5В.
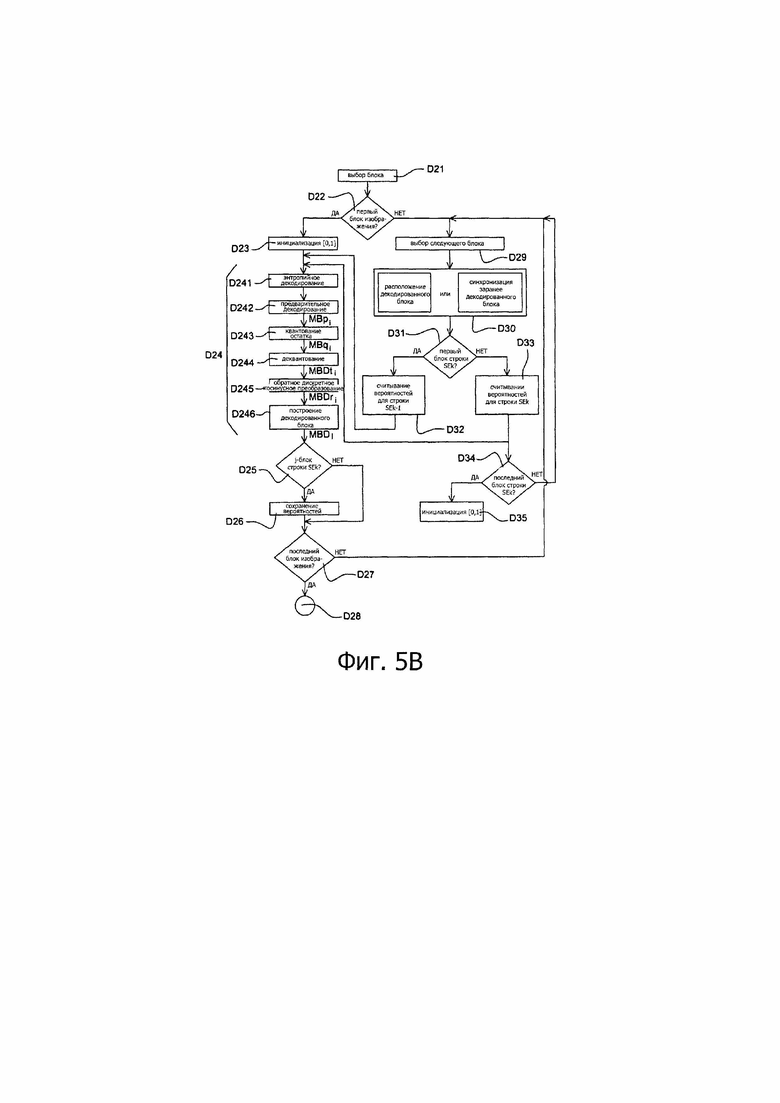
В процессе выполнения этапа D21 декодирующий модуль UDk выбирает в качестве текущего блока первый блок, подлежащий декодированию, в текущей строке SEk, представленной на фиг. 4А или 4В.
В процессе выполнения этапа D22 декодирующий модуль UDk проверяет, является ли текущий блок первым блоком декодированного изображения, в этом примере первым блоком подпотока F1.
Если это так, в процессе выполнения этапа D23 модуль MDE или MDEk энтропийного декодирования осуществляет инициализацию своих переменных состояния. Согласно представленному примеру, этот этап содержит инициализацию интервала, представляющего вероятность появления одного из символов из совокупности, составляющей заданное множество символов.
В качестве варианта, если используемый способ энтропийного декодирования представляет собой способ декодирования LZW, инициализируется кодовая таблица строк символов, так что эта таблица содержит все возможные символы по одному и только по одному разу. Этап D23 идентичен указанному выше этапу СЗЗ кодирования и потому далее описан не будет.
Если после указанного выше этапа D22 оказалось, что текущий блок не является первым блоком декодированного изображения ID, определяют на этапе D30, который будет рассмотрен в настоящем описании позднее, наличие и доступность необходимых ранее декодированных блоков.
В процессе выполнения этапа D24 декодируют первый текущий блок МВ1 первой строки SE1, представленной на фиг. 4А или 4В. Такой этап D24 содержит несколько подэтапов с D241 по D246, которые будут описаны ниже.
В процессе выполнения первого подэтапа D241 осуществляют энтропийное декодирование синтаксических элементов, относящихся к текущему блоку. Такой этап содержит главным образом:
a) считывание битов из подпотока, ассоциированного с первой строкой SE1;
b) реконструкцию символов на основе прочитанных битов.
В указанном выше варианте, в котором в качестве алгоритма декодирования использован алгоритм декодирования LZW, считывают цифровой сегмент информации, соответствующий коду символа, подлежащего кодированию, из текущей кодовой таблицы, реконструируют символ на основе прочитанного кода и затем обновляют эту кодовую таблицу согласно известной процедуре.
Более точно, синтаксические элементы, связанные с текущим блоком, декодируют посредством использующего алгоритм САВАС модуля MDE1 энтропийного декодирования, такого, как представлено на фиг. 6В. Последний декодирует подпоток F1 битов из состава сжатого файла для получения синтаксических элементов и в то же самое время заново обновляет вероятности таким способом, чтобы в момент, когда модуль декодирует какой-либо символ, вероятности появления этого символа были идентичны вероятностям, получаемым в процессе кодирования этого же самого символа на указанном выше этапе С345 энтропийного кодирования.
В ходе выполнения подэтапа D242 осуществляют декодирование с прогнозированием применительно к текущему блоку МВ1 посредством известного способа внутрикадрового и/или межкадрового прогнозирования, согласно которому блок MB1 прогнозируют относительно по меньшей мере одного ранее декодированного блока.
Само собой разумеется, что возможны также другие режимы внутрикадрового прогнозирования, такие как режимы, предлагаемые в стандарте Н.264.
В процессе выполнения этого этапа декодирование с прогнозированием осуществляется с помощью синтаксических элементов, декодированных на предыдущем этапе и содержащих, в частности, указание типа прогнозирования (межкадровое или внутрикадровое) и, если это подходит, режима внутрикадрового прогнозирования, типа разбиения блока или макроблока, если последний был разбит, индекса опорного изображения и вектора смещения, используемого в режиме межкадрового прогнозирования.
Упомянутый выше этап декодирования с прогнозированием делает возможным построение прогнозированного блока MBp1.
В процессе выполнения следующего подэтапа D243 формируют квантованный остаточный блок MBq1 с помощью ранее декодированных синтаксических элементов.
В процессе выполнения следующего подэтапа D244 осуществляют деквантование квантованного остаточного блока MBq1 согласно обычной процедуре деквантования, представляющей собой операцию обратную, процедуре квантования, выполненной на этапе С344, для получения декодированного деквантованного блока MBDt1.
В процессе выполнения следующего подэтапа D245 осуществляют обратное преобразование деквантованного блока MBDti, представляющее собой операцию обратную процедуре прямого преобразования, выполненной на этапе С343 выше. В результате получают декодированный остаточный блок MBDr1.
В процессе выполнения следующего подэтапа D246 формируют декодированный блок MBD1 путем суммирования прогнозируемого блока MBp1 с декодированным остаточным блоком MBDr1. Декодированный блок MBD1 делают, таким образом, доступным для использования декодирующим модулем UD1 или каким-либо другим декодирующим модулем, составляющим часть заданного числа N декодирующих модулей.
По завершении упомянутого выше этапа D246 декодирования модуль MDE1 энтропийного декодирования, такой как показан на фиг. 6В, содержит все вероятности, такие как постоянно обновляемые совместно в процессе декодирования первого блока. Эти вероятности соответствуют разнообразным элементам возможных синтаксисов и различным ассоциированным контекстам декодирования.
После выполнения указанного выше этапа D24 декодирования проверяют в ходе этапа D25, является ли текущий блок j-м блоком той же самой строки, где j представляет собой заданную величину, известную декодеру DO и равную по меньшей мере 1.
Если это так, то в ходе выполнения этапа D26, множество вероятностей, вычисленных для j-блока, сохраняют в буферной памяти МТ в составе декодера DO, такого как показано на фиг. 6А и на фиг. 4А или 4В, при этом размер указанной памяти адаптирован для сохранения вычисленного числа вероятностей.
В процессе выполнения этапа D27 декодирующий модуль UDk проверяет, является ли текущий блок, только что декодированный, последним блоком последнего подпотока.
Если это так, то в ходе этапа D28 выполнение способа декодирования завершается.
Если текущий блок - не последний, на этапе D29 выбирают следующий блок MB;, подлежащий декодированию, в соответствии с порядком просмотра изображения, обозначенным стрелкой PS на фиг. 4А или 4В.
Если в ходе указанного выше этапа D25 оказалось, что текущий блок не является j-м блоком рассматриваемой строки SEDk, выполняют рассмотренный выше этап D27.
В процессе выполнения этапа D30, следующего за рассмотренным выше этапом D29, определяют доступность предварительно декодированных блоков, необходимых для декодирования текущего блока MBi. Если учесть тот факт, что эта процедура использует параллельное декодирование блоков разными декодирующими модулями UDk, может случиться, что эти блоки еще не были декодированы посредством декодирующего модуля, назначенного для декодирования этих блоков, и поэтому эти блоки пока еще недоступны. Указанный этап проверки состоит в проверке, имеется ли заданное число N' блоков, расположенных в предыдущей строке SEk-1, например, два блока, находящихся соответственно сверху и сверху справа от текущего блока, и доступных для кодирования текущего блока, иными словами, если они уже были декодированы посредством декодирующего модуля UDk-1, назначенного для их декодирования. Этот этап проверки состоит также в проверке доступности по меньшей мере одного блока, расположенного слева от текущего блока MBi, подлежащего декодированию. Однако с учетом порядка PS просмотра изображения, выбранного в варианте, представленном на фиг. 4А или 4В, блоки в рассматриваемой строке SEk декодируют один за другим. Следовательно, всегда (за исключением обработки первого блока строки) имеется и доступен расположенный слева декодированный блок. В примере, представленном на фиг. 4А или 4В, это блок, расположенный слева непосредственно рядом с текущим блоком, подлежащим декодированию. С этой целью проверяют доступность только этих двух блоков, расположенных соответственно сверху и сверху справа от текущего блока.
Поскольку этот этап проверки замедляет работу способа декодирования, в альтернативном варианте настоящего изобретения тактовый сигнал CLK, показанный на фиг. 6А, приспособлен для опережающей синхронизации декодирования блоков таким образом, чтобы гарантировать доступность двух блоков, расположенных соответственно сверху и сверху справа от текущего блока, не требуя обязательной проверки доступности этих двух блоков. Таким образом, как показано на фиг. 4А или 4В, декодирующий модуль UDk всегда начинает декодировать первый блок со сдвигом на заданное число N' (здесь, N'=2) декодированных блоков предыдущей строки SEk-1, используемых для декодирования текущего блока. С программной точки зрения реализация такого тактового сигнала делает возможным значительно ускорить и сократить затраты времени на обработку блоков каждого подмножества SEk в декодере DO.
В процессе выполнения этапа D31 проверяют, является ли текущий блок первым блоком рассматриваемой строки SEk.
Если текущий блок - первый, в процессе выполнения этапа D32 считывают из буферной памяти МТ исключительно вероятности появления символов, вычисленные во время декодирования j-го блока предыдущей строки SEk-1.
Согласно первому варианту, представленному на фиг. 4А, j-й блок является первым блоком предыдущей строки SEk-1 (j=1). Такое считывание состоит в замене вероятностей в декодере по стандарту САВАС вероятностями, записанными в буферной памяти МТ. Процесс чтения, захватывающий соответствующие первые блоки второй, третьей и четвертой строк SE2, SE3 и SE4, показан на фиг. 4А тонкими стрелками.
Согласно второму варианту упомянутого выше этапа D32, представленного на фиг. 4В, j-й блок является вторым блоком предыдущей строки SEk-1 (j=2). Такое считывание состоит в замене вероятностей в декодере по стандарту САВАС вероятностями, записанными в буферной памяти МТ. Процесс чтения, захватывающий соответствующие первые блоки второй, третьей и четвертой строк SE2, SE3 и SE4, показан на фиг. 4В тонкими штриховыми стрелками.
После выполнения этапа D32 текущий блок декодируют путем повторения этапов с D24 по D28, описанных выше.
Если после указанного выше этапа D31 оказалось, что текущий блок не является первым блоком рассматриваемой строки SEk, предпочтительно не считывать вероятности для ранее декодированного блока, расположенного в той же самой строке SEk, иными словами декодированного блока, расположенного (в представленном примере) слева непосредственно рядом от текущего блока. Действительно, при последовательном порядке PS просмотра для считывания блоков, расположенных в той же самой строке, как показано на фиг. 4А или 4В, вероятности появления символов, присутствующие в декодере, использующем алгоритм САВАС, в момент начала декодирования текущего блока являются точно теми же, какие присутствуют после декодирования предыдущего блока в той же самой строке.
Затем, в процессе выполнения этапа D33 производят обучение вероятностям появления символов для энтропийного декодирования текущего блока, так что эти вероятности соответствуют исключительно тем, которые были вычислены для указанного предыдущего блока в той же самой строке, как показано двойными сплошными стрелками на фиг. 4А или 4В.
После этапа D33 текущий блок декодируют путем повторения этапов с D24 по D28, описанных выше.
В процессе выполнения этапа D34 проверяют, является ли текущий блок последним блоком рассматриваемой строки SEk.
Если текущий блок - не последний в этой строке, после этапа D34 снова выполняют этап D29 выбора следующего блока MBi, подлежащего декодированию.
Если текущий блок является последним блоком рассматриваемой строки SEk, в процессе выполнения этапа D35 декодирующий модуль UDk выполняет процедуру, идентичную указанному выше этапу D23, иными словами снова инициализирует интервальное представление вероятности появления символа, входящего в состав заданного множества символов. Такая повторная инициализация обозначена на фиг. 4А и 4В черной точкой в начале каждой строки SEk.
Таким образом, в начале каждой строки декодер DO находится в инициализированном состоянии, что обеспечивает более высокую степень гибкости с точки зрения выбора уровня параллелизма при декодировании и оптимизации затрат времени на обработку данных при декодировании.
В примере схемы кодирования/декодирования, представленном на фиг. 7А, кодирующее устройство СО содержит единственный кодирующий модуль UC, как показано на фиг. 3А, тогда как декодер DO содержит шесть декодирующих модулей.
Кодирующий модуль UC последовательно кодирует строки SE1, SE2, SE3, SE4, SE5 и SE6. В представленном примере строки с SE1 по SE4 закодированы полностью, строка SE5 находится в стадии кодирования, а строка SE6 еще не была кодирована. С учетом последовательного характера кодирования кодирующий модуль UC приспособлен для передачи потока F, содержащего подпотоки F1, F2, F3, F4, упорядоченные один за другим в том же порядке, в котором происходило кодирование строк SE1, SE2, SE3 и SE4. С этой целью подпотоки F1, F2, F3 и F4 символически обозначены с такой же штриховкой, как и соответствующие кодированные строки SE1, SE2, SE3 и SE4. Благодаря выполнению этапов опустошения в конце кодирования каждой кодированной строки и повторной инициализации интервала вероятностей в начале кодирования или декодирования следующей строки, подлежащей кодированию/декодированию, декодер DO каждый раз, когда он считывает подпоток, чтобы декодировать его, находится в инициализированном состоянии и может, поэтому, оптимальным образом декодировать параллельно четыре подпотока F1, F2, F3, F4 с использованием декодирующих модулей UD1, UD2, UD3 и UD4, которые могут быть, например, установлены на четырех разных платформах.
В примере схемы кодирования/декодирования, представленном на фиг. 7В, кодирующее устройство СО содержит два кодирующих модуля UC1 и UC2, как показано на фиг. 3С, тогда как декодер DO содержит шесть декодирующих модулей.
Кодирующий модуль UC1 последовательно кодирует строки с нечетными номерами SE1, SE3 и SE5, тогда как кодирующий модуль UC2 последовательно кодирует строки с четными номерами SE2, SE4 и SE6. Для этого строки SE1, SE3 и SE5 имеют белый фон, а строки SE2, SE4 и SE6 имеют фон, заполненный точками. В представленном примере строки с SE1 по SE4 закодированы полностью, строка SE5 находится в стадии кодирования, а строка SE6 еще не была кодирована. Учитывая тот факт, что выполняемое кодирование является кодированием параллельного типа уровня 2, кодирующий модуль UC1 адаптирован для передачи подпотока F2n+1, разложенного на две части F1 и F3, полученные после кодирования соответственно строк SE1 и SE3, тогда как кодирующий модуль UC2 адаптирован для передачи подпотока F2n, разложенного на две части F2 и F4, полученные после кодирования соответственно строк SE2 и SE4. Кодирующее устройство СО поэтому предназначено для передачи декодеру DO потока F, содержащего результат наложения двух подпотоков F2n+1 и F2n, вследствие чего порядок следования подпотоков F1, F3, F2, F4 отличается от того, что показано на фиг. 7А. С этой целью подпотоки F1, F2, F3 и F4 символически обозначены с такой же штриховкой, как и соответствующие кодированные строки SE1, SE2, SE3 и SE4, подпотоки F1 и F3 имеют белый фон (кодирование строк с нечетными номерами), а подпотоки F2 и F4 имеют точечный фон (кодирование строк с четными номерами).
Что касается преимуществ, отмеченных в связи с фиг. 7А, такая схема кодирования/декодирования дополнительно предоставляет преимущества способности использовать декодер, уровень параллелизма при декодировании в котором полностью независим от уровня параллелизма при кодирования, что делает возможным в еще большей степени оптимизировать работу кодирующего устройства/декодера.




Изобретение относится к средствам для кодирования и декодирования изображений. Технический результат заключается в повышении эффективности декодирования изображений. Принимают декодером поток данных, представляющий кодированное изображение. Идентифицируют в потоке данных множество строк последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения. Инициализируют одну или несколько переменных состояния для энтропийного декодирования текущего блока в текущей строке. Выполняют энтропийное декодирование текущего блока на основе переменных состояния для энтропийного декодирования текущего блока. При этом, когда текущий блок является первым блоком в текущей строке в порядке декодирования для декодирования кодированного изображения, а текущая строка не является первой строкой из множества строк в порядке декодирования, одна или несколько переменных состояния для декодирования текущего блока инициализируются на основе одной или нескольких переменных состояния заданного энтропийно декодируемого блока. При этом заданный энтропийно декодированный блок является вторым блоком в порядке декодирования в строке последовательных блоков, отличной от текущей строки. 3 н. и 17 з.п. ф-лы, 14 ил.
1. Реализуемый компьютером способ энтропийного декодирования, причем способ содержит:
прием декодером потока данных, представляющего кодированное изображение;
идентификацию в потоке данных множества строк последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения;
инициализацию одной или нескольких переменных состояния для энтропийного декодирования текущего блока в текущей строке из множества строк;
энтропийное декодирование текущего блока на основе одной или нескольких переменных состояния для энтропийного декодирования текущего блока;
при этом, когда текущий блок является первым блоком в текущей строке в порядке декодирования для декодирования кодированного изображения, а текущая строка не является первой строкой из множества строк в порядке декодирования, одна или несколько переменных состояния для декодирования текущего блока инициализируются на основе одной или нескольких переменных состояния заданного энтропийно декодируемого блока и при этом заданный энтропийно декодированный блок является вторым блоком в порядке декодирования в строке последовательных блоков, отличной от текущей строки.
2. Реализуемый компьютером способ по п. 1, в котором одна или несколько переменных состояния представляют вероятности появления символов, связанные с блоками квантованных коэффициентов преобразованных остаточных значений для кодированного изображения.
3. Реализуемый компьютером способ по п. 1, дополнительно содержащий модификацию одной или нескольких переменных состояния при энтропийном декодировании каждой строки.
4. Реализуемый компьютером способ по п. 3, дополнительно содержащий:
сохранение в первом модуле памяти одной или нескольких модифицированных переменных состояния для подмножества последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения в определенной строке, при этом первый модуль памяти не подлежит инициализации.
5. Реализуемый компьютером способ по п. 1, в котором поток данных, представляющий кодированное изображение, содержит контекстно-адаптивный энтропийно кодированный подпоток для каждой строки по меньшей мере одного кодированного изображения, и при этом контекстно-адаптивный энтропийно кодированный подпоток для каждой строки упорядочен в потоке данных отлично от порядка отображения для данной строки.
6. Реализуемый компьютером способ по п. 5, в котором идентификация в потоке множества строк последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения содержит идентификацию индикатора, включенного в контекстно-адаптивный энтропийно кодированный подпоток для каждой строки, причем индикатор представляет соответствующую позицию в порядке отображения для строки.
7. Реализуемый компьютером способ по п. 1, в котором поток данных, представляющий кодированное изображение, принимается от первого числа модулей кодирования и в котором декодер содержит второе число модулей декодирования, причем первое число модулей кодирования отличается от второго числа модулей декодирования.
8. Декодер, содержащий:
один или несколько процессоров и одно или несколько запоминающих устройств, хранящих команды, которые при выполнении одним или несколькими процессорами побуждают один или несколько процессоров выполнить операции, содержащие: прием потока данных, представляющего кодированное изображение; идентификацию в потоке данных множества строк последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения; инициализацию одной или нескольких переменных состояния для энтропийного декодирования текущего блока в текущей строке из множества строк;
энтропийное декодирование текущего блока на основе одной или нескольких переменных состояния для энтропийного декодирования текущего блока;
при этом, когда текущий блок является первым блоком в текущей строке в порядке декодирования для декодирования кодированного изображения, а текущая строка не является первой строкой из множества строк в порядке декодирования, одна или несколько переменных состояния для декодирования текущего блока инициализируются на основе одной или нескольких переменных состояния заданного энтропийно декодируемого блока; и
при этом заданный энтропийно декодированный блок является вторым блоком в порядке декодирования в строке последовательных блоков, отличной от текущей строки.
9. Декодер по п. 8, в котором одна или несколько переменных состояния представляют вероятности появления символов, связанные с блоками квантованных коэффициентов преобразованных остаточных значений для кодированного изображения.
10. Декодер по п. 8, дополнительно содержащий операции модификации одной или нескольких переменных состояния при энтропийном декодировании каждой строки.
11. Декодер по п. 10, дополнительно содержащий операции сохранения в первом модуле памяти одной или нескольких модифицированных переменных состояния для подмножества последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения в определенной строке, при этом первый модуль памяти не подлежит инициализации.
12. Декодер по п. 8, в котором поток данных, представляющий кодированное изображение, содержит контекстно-адаптивный энтропийно кодированный подпоток для каждой строки по меньшей мере одного кодированного изображения, и при этом контекстно-адаптивный энтропийно кодированный подпоток для каждой строки упорядочен в потоке данных отлично от порядка отображения для данной строки.
13. Декодер по п. 12, в котором идентификация в потоке множества строк последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения содержит идентификацию индикатора, включенного в контекстно-адаптивный энтропийно кодированный подпоток для каждой строки, причем индикатор представляет соответствующую позицию в порядке отображения для строки.
14. Декодер по п. 8, в котором поток данных, представляющий кодированное изображение, принимается от первого числа модулей кодирования и в котором декодер содержит второе число модулей декодирования, причем первое число модулей кодирования отличается от второго числа модулей декодирования.
15. Долговременный читаемый компьютером носитель, связанный с одним или несколькими процессорами, на котором хранятся команды, которые при выполнении одним или несколькими процессорами побуждают один или несколько процессоров выполнить операции, содержащие:
прием потока данных, представляющего кодированное изображение;
идентификацию в потоке данных множества строк последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения;
инициализацию одной или нескольких переменных состояния для энтропийного декодирования текущего блока в текущей строке из множества строк;
энтропийное декодирование текущего блока на основе одной или нескольких переменных состояния для энтропийного декодирования текущего блока;
при этом, когда текущий блок является первым блоком в текущей строке в порядке декодирования для декодирования кодированного изображения, а текущая строка не является первой строкой из множества строк в порядке декодирования, одна или несколько переменных состояния для декодирования текущего блока инициализируются на основе одной или нескольких переменных состояния заданного энтропийно декодируемого блока; и
при этом заданный энтропийно декодированный блок является вторым блоком в порядке декодирования в строке последовательных блоков, отличной от текущей строки.
16. Долговременный читаемый компьютером носитель по п. 15, в котором одна или несколько переменных состояния представляют вероятности появления символов, связанные с блоками квантованных коэффициентов преобразованных остаточных значений для кодированного изображения.
17. Долговременный читаемый компьютером носитель по п. 15, дополнительно содержащий операции модификации одной или нескольких переменных состояния при энтропийном декодировании каждой строки.
18. Долговременный читаемый компьютером носитель по п. 17, дополнительно содержащий операции сохранения в первом модуле памяти одной или нескольких модифицированных переменных состояния для подмножества последовательных блоков квантованных коэффициентов преобразованных остаточных значений для кодированного изображения в определенной строке, при этом первый модуль памяти не подлежит инициализации.
19. Долговременный читаемый компьютером носитель по п. 15, в котором поток данных, представляющий кодированное изображение, содержит контекстно-адаптивный энтропийно кодированный подпоток для каждой строки по меньшей мере одного кодированного изображения, и при этом контекстно-адаптивный энтропийно кодированный подпоток для каждой строки упорядочен в потоке данных отлично от порядка отображения для данной строки.
20. Долговременный читаемый компьютером носитель по п. 15, в котором поток данных, представляющий кодированное изображение, принимается от первого числа модулей кодирования и в котором декодер содержит второе число модулей декодирования, причем первое число модулей кодирования отличается от второго числа модулей декодирования.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6480537 B1, 12.11.2002 | |||
| US 6900748 B2, 31.05.2005 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| ОСНОВАННОЕ НА КОНТЕКСТЕ АДАПТИВНОЕ НЕРАВНОМЕРНОЕ КОДИРОВАНИЕ ДЛЯ АДАПТИВНЫХ ПРЕОБРАЗОВАНИЙ БЛОКОВ | 2003 |
|
RU2330325C2 |

