Область техники, к которой относится изобретение
Варианты выполнения изобретения относятся к технологиям обработки данных, в частности к способу и устройству для сохранения данных с высокой степенью многопоточности.
Уровень техники
По мере взрывного роста объема информации в сети Интернет все большее число серверов сети Интернет находится в среде данных с высокой степенью многопоточности и с массивными объемами, в которой возникает проблема хранения данных с высокой степенью многопоточности. Для решения данной проблемы широко используются некоторые языки программирования типа NoSql («не только SQL», нереляционная база данных), такие как Hadoop, MongoDB и Hbase.
Однако для некоторых старых бизнес-систем расходы на замену способов хранения на новые будут относительно высокими, поэтому для хранения данных по-прежнему используются традиционные реляционные базы данных, такие как MySql, Oracle и тому подобные. Когда система сталкивается с хранением данных с высокой степенью многопоточности, это приводит к слишком большому количеству ссылок в базе данных, что требует слишком большого объема ресурсов, снижает эффективность хранения и, кроме того, приводит к таким проблемам, как остановка сервера.
Раскрытие изобретения
Ввиду вышеуказанного варианты выполнения настоящего изобретения предусматривают способ и устройство для хранения данных с высокой степенью многопоточности для повышения эффективности хранения данных с высокой степенью многопоточности.
В первом аспекте варианты выполнения настоящего изобретения обеспечивают способ хранения данных с высокой степенью многопоточности, характеризуемый тем, что он содержит этапы, на которых:
принимают данные с высокой степенью многопоточности, отправленные множеством клиентов;
добавляют данные с высокой степенью многопоточности в первичную очередь данных, и отвечают соответствующему клиенту;
потребляют данные с высокой степенью многопоточности в первичной очереди данных с использованием с использованием многопотокового режима;
фрагментируют данные с высокой степенью многопоточности в соответствии с количеством локальных очередей;
добавляют фрагментированные данные с высокой степенью многопоточности в локальные очереди; и
потребляют данные с высокой степенью многопоточности в локальных очередях и сохраняют данные с высокой степенью многопоточности в базе данных.
Во втором аспекте варианты выполнения варианты выполнения настоящего изобретения обеспечивают устройство для сохранения данных с высокой степенью многопоточности, причем устройство содержит:
приемный модуль для приема данных с высокой степенью многопоточности, отправляемых множеством клиентов;
первый модуль добавления для добавления данных с высокой степенью многопоточности в первичную очередь данных и для ответа соответствующему клиенту;
модуль потребления для потребления данных с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима;
модуль фрагментации для фрагментации данных с высокой степенью многопоточности в соответствии с количеством локальных очередей;
второй модуль добавления для добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди; и
модуль сохранения для потребления данных с высокой степенью многопоточности в локальных очередях и сохранения данных с высокой степенью многопоточности в базе данных.
В вариантах выполнения изобретения путем добавления данных с высокой степенью многопоточности в первичную очередь данных, потребления данных с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима, фрагментации данных с высокой степенью многопоточности в соответствии с количеством локальных очередей, добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди, и потребления данных с высокой степенью многопоточности в локальных очередях и сохранения данных с высокой степенью многопоточности в базе данных, данные с высокой степенью многопоточности буферизуются посредством первичной очереди данных и локальных очередей, и данные сохраняются посредством асинхронного сохранения, таким образом снижая нагрузку на базу данных путем сохранения данных с высокой степенью многопоточности непосредственно в базе данных, избегая проблему остановки базы данных в случае сохранения с высокой степенью многопоточности, и повышая эффективность сохранения данных с высокой степенью многопоточности.
Краткое описание чертежей
Фиг. 1 - блок-схема способа сохранения данных с высокой степенью многопоточности в соответствии с вариантом выполнения 1 настоящего изобретения.
Фиг. 2 - архитектурная схема способа сохранения данных с высокой степенью многопоточности в соответствии с вариантом выполнения 2 настоящего изобретения.
Фиг. 3 - блок-схема способа сохранения данных с высокой степенью многопоточности в соответствии с вариантом выполнения 2 настоящего изобретения.
Фиг. 4 - принципиальная схема устройства для сохранения данных с высокой степенью многопоточности в соответствии с вариантом выполнения 3 настоящего изобретения.
Подробное описание изобретения
Теперь изобретение будет описано в дополнительных подробностях с обращением к сопровождающим чертежам и вариантам выполнения. Следует понимать, что конкретные варианты выполнения, описанные в настоящем документе, предназначены только для пояснения изобретения и не предназначены для ограничения изобретения. Следует отметить, что только части, относящиеся к настоящему изобретению, а не все содержимое, показаны на чертежах для удобства описания.
Вариант выполнения 1
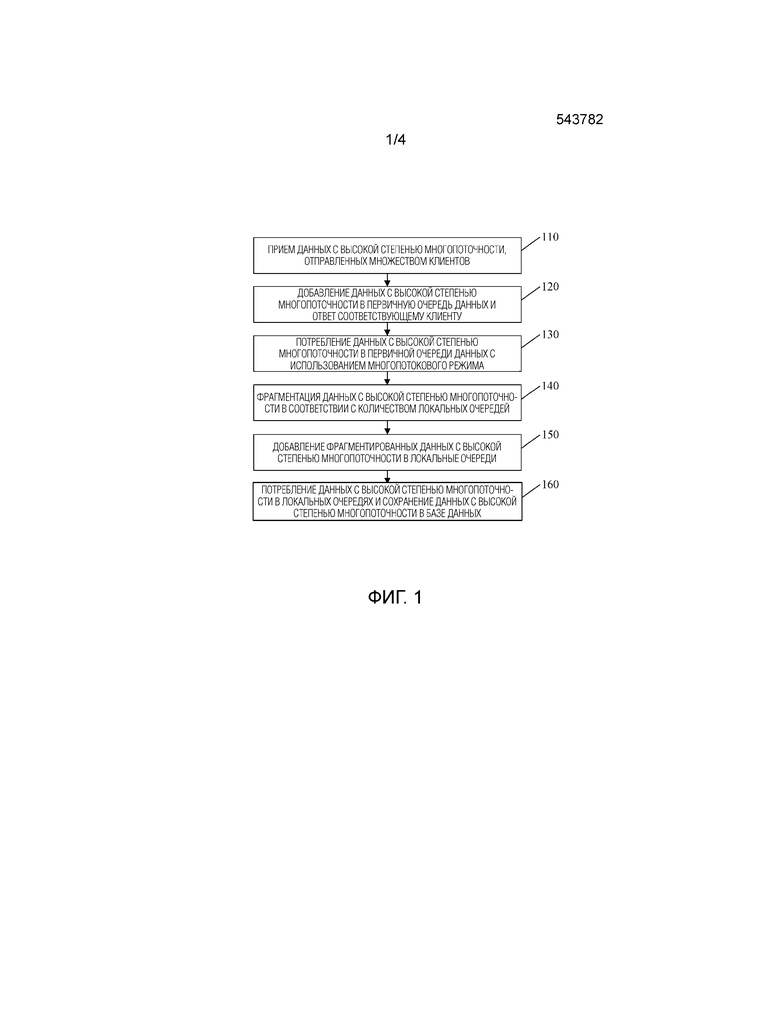
Фиг. 1 - блок-схема способа сохранения данных с высокой степенью многопоточности в соответствии с вариантом выполнения 1 настоящего изобретения. Вариант выполнения подходит для сохранения данных с высокой степенью многопоточности. Способ может выполняться сервером и, в частности, содержит следующие этапы:
Этап 110, на котором принимают данные с высокой степенью многопоточности, отправленные множеством клиентов.
Высокая степень многопоточности означает относительно большой объем трафика за определенное время. Сервер принимает запросы от множества клиентов, и одновременные запросы от множества клиентов создают данные с высокой степенью многопоточности.
Этап 120, на котором добавляют данные с высокой степенью многопоточности в первичную очередь данных и отвечают соответствующему клиенту.
Для очередей данных принята распределенная MQ (очередь сообщений), которая может поддерживать распределенные расширения и наделять инфраструктуру высокой доступностью, и при этом сохранять относительно объективные рабочие характеристики при обработке больших объемов данных. Среди них ActiveMQ является наиболее популярной и мощной средой передачи сообщений с открытым исходным кодом, выпускаемой компанией Apache.
После приема данных с высокой степенью многопоточности сервер добавляет данные с высокой степенью многопоточности в первичную очередь данных и отвечает клиенту, отправляющему данные с высокой степенью многопоточности. Первичная очередь данных является первичной очередью данных для всех данных, и когда данные добавляются в очередь, результат возвращается немедленно, повышая скорость реакции.
Этап 130, на котором потребляют данные с высокой степенью многопоточности в первичной очереди данных путем использования многопотокового режима.
Многопотоковый режим назначается пулом потоков. Пул потоков обеспечивает данные обработки многопотокового режима, а также фрагментирует данные и добавляет их в соответствующую локальную очередь, повышая скорость потребления сообщения и, в то же время, обеспечивая устойчивость данных путем использования характеристик MQ для предотвращения потери данных. Сервер быстро потребляет данные с высокой степенью многопоточности в первичной очереди данных посредством многопотокового режима, назначаемого пулом потоков. Потребление данных с высокой степенью многопоточности в первичной очереди данных означает удаление данных с высокой степенью многопоточности из первичной очереди данных.
Этап 140, на котором фрагментируют данные с высокой степенью многопоточности в соответствии с количеством локальных очередей.
Локальные очереди используются для хранения фрагментированных данных с высокой степенью многопоточности и предотвращения потери фрагментированных данных. Локальные очереди могут быть расширены в горизонтальном направлении в соответствии с объемом данных с высокой степенью многопоточности, и количество локальных очередей может быть увеличено в случае большого объема данных. Сервер фрагментирует данные с высокой степенью многопоточности, удаляемые из первичной очереди данных, на фрагменты в количестве, равном количеству локальных очередей, в соответствии с количеством локальных очередей для сохранения фрагментированных данных с высокой степенью многопоточности в локальные очереди данных. Данные с высокой степенью многопоточности подвергаются обработке фрагментацией, обеспечивая отсутствие повторения обработки данных и повышая скорость обработки. Специалистам в данной области техники будет понятно, что существует множество стратегий фрагментации данных с высокой степенью многопоточности: возможна фрагментация данных в соответствии с их первичным ключевым признаком, путем выполнения операции по модулю на первичном ключе данных с высокой степенью многопоточности по отношению к количеству локальных очередей, и назначения данных в локальную очередь, имеющую тот же порядковый номер, что и полученный результат; при необходимости возможна фрагментация данных в соответствии с временным интервалом, например назначение первого миллиона единиц данных в первую локальную очередь, и назначение второго миллиона единиц данных во вторую локальную очередь; конечно, существуют и другие стратегии фрагментации.
Этап 150, на котором добавляют фрагментированные данные с высокой степенью многопоточности в локальные очереди.
Сервер добавляет фрагментированные данные с высокой степенью многопоточности в соответствующую локальную очередь в соответствии со стратегией фрагментации данных с высокой степенью многопоточности, и данные с высокой степенью многопоточности буферизуются в локальной очереди.
Этап 160, на котором потребляют данные с высокой степенью многопоточности в локальных очередях и сохраняют данные с высокой степенью многопоточности в базе данных.
Сервер потребляет данные с высокой степенью многопоточности в локальной очереди, т.е. удаляет данные с высокой степенью многопоточности из локальных очередей, и затем сохраняет данные с высокой степенью многопоточности из локальных очередей в базе данных.
В процессе переноса данных с высокой степенью многопоточности (например, добавления данных с высокой степенью многопоточности в первичную очередь данных, потребления данных и т.п.) в данном варианте выполнения при переносе может использоваться формат JSON с высокими рабочими характеристиками, чтобы способствовать сериализации и десериализации данных, ускоряя перенос данных. Будучи легким форматом обмена данных, JSON (JavaScript Object Notation) является основанным на синтаксисе поднабором JavaScript, т.е. содержит массивы и объекты. Сериализация является механизмом, используемым для обработки потока объектов, который реализует потоковую передачу содержимого объекта, и передаваемый потоком объект может подвергаться операциям считывания и записи. Сериализация направлена на решение проблемы, возникающей при операциях считывания и записи потока объектов.
В данном варианте выполнения путем добавления данных с высокой степенью многопоточности в первичную очередь данных, потребления данных с высокой степенью многопоточности в первичной очереди данных путем использования многопотокового режима, фрагментации данных с высокой степенью многопоточности в соответствии с количеством локальных очередей, добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди и потребления данных с высокой степенью многопоточности в локальных очередях и сохранения данных с высокой степенью многопоточности в базе данных, данные с высокой степенью многопоточности буферизуются первичной очередью данных и локальными очередями, и данные сохраняются посредством асинхронного сохранения, таким образом уменьшая нагрузку на базу данных путем сохранения данных с высокой степенью многопоточности непосредственно в базе данных, исключая проблему остановки базы данных в случае сохранения данных с высокой степенью многопоточности, и повышая эффективность сохранения данных с высокой степенью многопоточности.
На основе вышеупомянутого технического решения фрагментация данных с высокой степенью многопоточности в соответствии с количеством локальных очередей предпочтительно содержит этапы, на которых:
выполняют операцию нахождения остатка от деления (modulo) в отношении первичного ключа данных с высокой степенью многопоточности на количество локальных очередей; и
фрагментируют соответствующие данные с высокой степенью многопоточности в соответствии с одинаковыми результатами операции нахождения остатка от деления в один фрагмент.
Сначала выполняется операция нахождения остатка от деления для первичного ключа, сгенерированного в данных с высокой степенью многопоточности, на количество локальных очередей, и соответствующие данные с высокой степенью многопоточности с одинаковыми результатами операции нахождения остатка от деления фрагментируются в один фрагмент.
На основе вышеупомянутого технического решения добавление фрагментированных данных с высокой степенью многопоточности в локальные очереди конкретно содержит этапы, на которых:
добавляют фрагментированные данные с высокой степенью многопоточности в локальные очереди, имеющие соответствующие порядковые номера, в соответствии с результатами операции нахождения остатка от деления,
причем каждая локальная очередь имеет свой порядковый номер. Фрагментированные данные с высокой степенью многопоточности добавляются в локальную очередь, имеющую тот же порядковый номер, который получен в результате операции нахождения остатка от деления.
На основе любого из вышеприведенных технических решений потребление данных с высокой степенью многопоточности в локальных очередях и сохранение данных с высокой степенью многопоточности в базе данных предпочтительно содержит этапы, на которых:
потребляют данные с высокой степенью многопоточности в локальных очередях с использованием планирования по времени; и
сохраняют потребляемые данные с высокой степенью многопоточности в базе данных.
Сервер удаляет данные с высокой степенью многопоточности из локальных очередей регулируемым по времени/моментальным способом с использованием планирования по времени. Пользователь может управлять объемом и интервалом времени извлечения данных (их удаления из локальных очередей) и сохранять данные с высокой степенью многопоточности, удаляемые из локальных очередей, в базе данных регулируемым по времени/моментальным способом. Функция обработки данных регулируемым по времени/моментальным способом может быть сконфигурирована с использованием планирования по времени для снижения нагрузки на базу данных при сохранении. Предпочтительно планирование по времени реализуется посредством инструмента Quartz, причем Quartz представляет собой фреймворк для планирования заданий с открытым исходным кодом, полностью написанный на Java.
Вариант выполнения 2
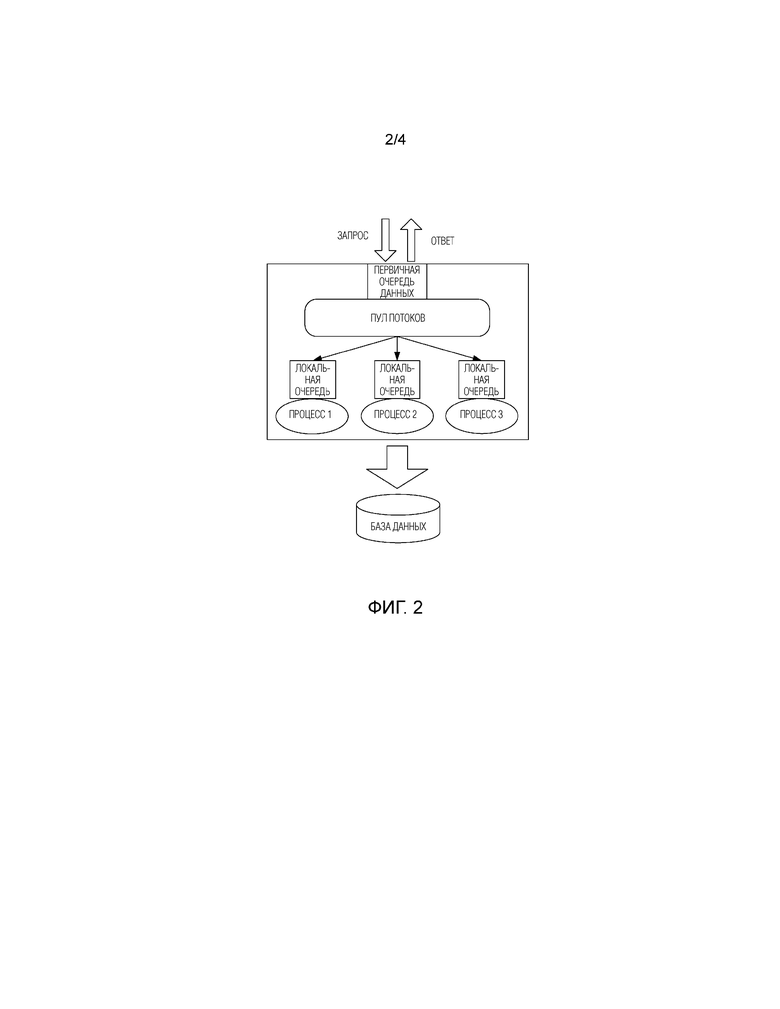
Фиг. 2 - архитектурная схема способа сохранения данных с высокой степенью многопоточности, предусмотренного в варианте выполнения 2 настоящего изобретения. Как показано на Фиг. 2, первичная очередь является первичной очередью для всех данных. Когда данные добавляются в очередь, результат возвращается немедленно, повышая скорость ответа. Пул потоков обеспечивает обработку данных с использованием многопотокового режима, а также фрагментирует данные и добавляет их в соответствующие локальные очереди, повышая скорость потребления сообщения и при этом обеспечивая устойчивость данных путем использования характеристик MQ для предотвращения потери данных. Локальные очереди используются для сортировки фрагментированных данных для исключения потери фрагментированных данных; процесс 1, процесс 2, процесс 3 могут управлять объемом и интервалом времени извлечения данных независимо друг от друга путем потребления данных регулируемым по времени/моментальным способом, их обработки и их сохранения в базе данных.
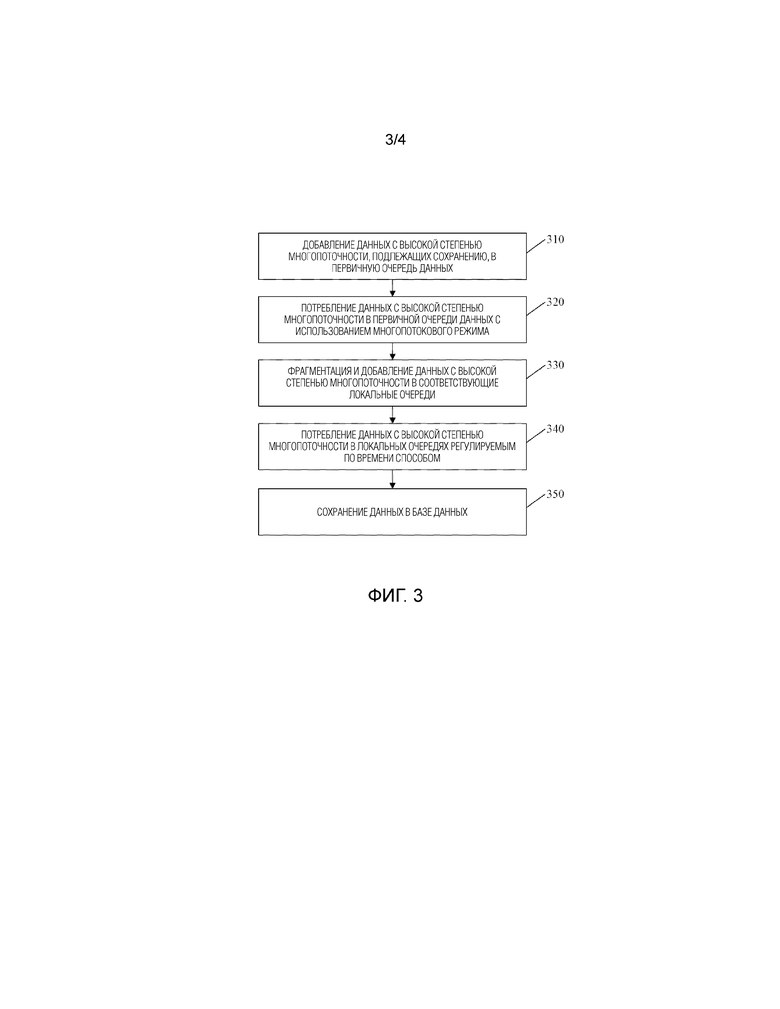
Фиг. 3 - блок-схема способа сохранения данных с высокой степенью многопоточности, предусмотренного в варианте выполнения 2 настоящего изобретения. Как показано на Фиг. 3, способ сохранения данных с высокой степенью многопоточности, предусмотренный в данном варианте выполнения, конкретно содержит следующие этапы:
Этап 310, на котором добавляют данные с высокой степенью многопоточности в первичную очередь данных.
Данные с высокой степенью многопоточности, подлежащие сохранению, добавляются сначала в первичную очередь данных, и результат для ответа клиенту возвращается после того, как данные с высокой степенью многопоточности добавляются в первичную очередь данных.
Этап 320, на котором потребляют данные с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима.
Данные с высокой степенью многопоточности в первичной очереди данных потребляются с использованием многопотокового режима, обеспечиваемого пулом потоков.
Этап 330, на котором фрагментируют данные с высокой степенью многопоточности и добавляют их в соответствующие локальные очереди.
Операция нахождения остатка от деления в отношении первичного ключа данных с высокой степенью многопоточности на количество локальных очередей выполняется в соответствии с количеством локальных очередей, и фрагментированные данные с высокой степенью многопоточности добавляются в локальную очередь, имеющую тот же порядковый номер, что и результат операции нахождения остатка от деления, на основе результата операции нахождения остатка от деления.
Этап 340, на котором потребляют данные с высокой степенью многопоточности в локальных очередях в соответствии с регулированием по времени.
Данные с высокой степенью многопоточности в локальных очередях потребляются регулируемым по времени/моментальным способом с использованием Quartz.
Этап 350, на котором сохраняют данные в базе данных.
В данном варианте выполнения в обычной реляционной базе данных данные с высокой степенью многопоточности буферизуются первичной очередью данных и подвергаются второй буферизации данных посредством локальных очередей, при этом может быть предотвращена потеря данных, повышена скорость потребления данных первичной очереди данных и может быть повышена эффективность сохранения данных с высокой степенью многопоточности. Может быть предусмотрена функция обработки данных регулируемым по времени/моментальным способом, которая снижает нагрузку на базу данных и исключает проблему остановки в случае сохранения данных с высокой степенью многопоточности.
Вариант выполнения 3
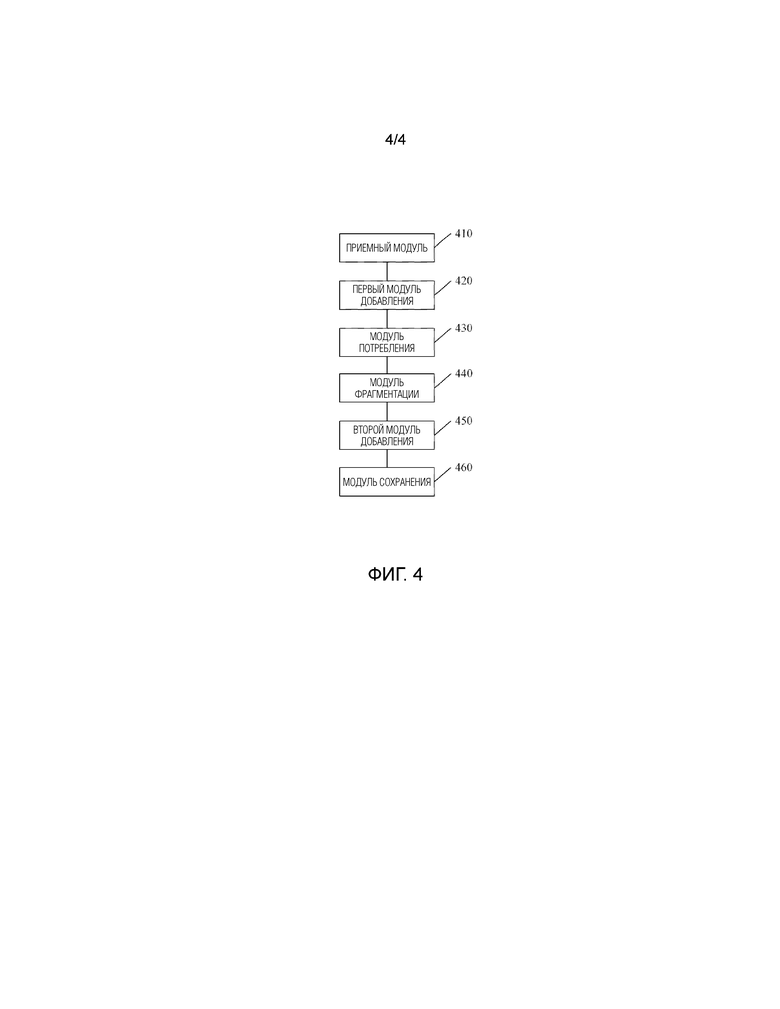
Фиг. 4 - это принципиальная схема устройства для сохранения данных с высокой степенью многопоточности, предусмотренного в варианте выполнения 3 настоящего изобретения. Устройство для сохранения данных с высокой степенью многопоточности, предусмотренное в данном варианте выполнения, предназначено для осуществления способа сохранения данных с высокой степенью многопоточности, предусмотренного в варианте выполнения 1. Как показано на Фиг. 4, устройство для сохранения данных с высокой степенью многопоточности, предусмотренное в данном варианте выполнения, содержит приемный модуль 410, первый модуль 420 добавления, модуль 430 потребления, модуль 440 фрагментации, второй модуль 450 добавления и модуль 460 сохранения.
Приемный модуль 410 используется для приема данных с высокой степенью многопоточности, отправляемых множеством клиентов; первый модуль 420 добавления используется для добавления данных с высокой степенью многопоточности в первичную очередь данных и ответа соответствующему клиенту; модуль 430 потребления используется для потребления данных с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима; модуль 440 фрагментации используется для фрагментации данных с высокой степенью многопоточности в соответствии с количеством локальных очередей; второй модуль 450 добавления используется для добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди; и модуль 460 сохранения используется для потребления данных с высокой степенью многопоточности в локальных очередях и сохранения данных с высокой степенью многопоточности в базе данных.
Модуль фрагментации предпочтительно содержит подмодуль операции нахождения остатка от деления для выполнения операции нахождения остатка от деления для первичного ключа данных с высокой степенью многопоточности на количество локальных очередей, и подмодуль фрагментации для фрагментации соответствующих данных с высокой степенью многопоточности в соответствии с одинаковыми результатами операции нахождения остатка от деления в один фрагмент. Предпочтительно. второй модуль добавления предназначен конкретно для добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди, имеющие соответствующие порядковые номера, в соответствии с результатами операции нахождения остатка от деления.
Предпочтительно, модуль сохранения содержит подмодуль потребления для потребления данных с высокой степенью многопоточности в локальных очередях с использованием планирования по времени и подмодуль сохранения для сохранения потребляемых данных с высокой степенью многопоточности в базе данных. Предпочтительно, планирование по времени реализуется посредством Quartz.
Данный вариант выполнения осуществляется путем приема данных с высокой степенью многопоточности, отправленных множеством клиентов, посредством приемного модуля, добавления данных с высокой степенью многопоточности в первичную очередь данных и ответа соответствующему клиенту посредством первого модуля добавления, потребления данных с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима посредством модуля потребления, фрагментации данных с высокой степенью многопоточности в соответствии с количеством локальных очередей посредством модуля фрагментации; добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди посредством второго модуля добавления и потребления данных с высокой степенью многопоточности в локальных очередях и сохранения данных с высокой степенью многопоточности в базе данных посредством модуля сохранения. Данные с высокой степенью многопоточности буферизуются первичной очередью данных и локальными очередями, и данные сохраняются посредством асинхронного сохранения, таким образом снижая нагрузку на базу данных путем сохранения данных с высокой степенью многопоточности непосредственно в базе данных, избегая проблему остановки базы данных в случае сохранения данных с высокой степенью многопоточности, и повышая эффективность сохранения данных с высокой степенью многопоточности.
Следует отметить, что выше приведены лишь предпочтительные варианты выполнения настоящего изобретения и используемые технические принципы. Специалистам в данной области техники будет понятно, что настоящее изобретение не ограничено конкретными вариантами выполнения, описанными в настоящем документе, и специалистами в данной области техники будут выполнены различные очевидные изменения, модификации и замены, не выходящие за пределы объема охраны изобретения. Таким образом, при том, что настоящее изобретение было подробно описано посредством вышеприведенных вариантов выполнения, настоящее изобретение не ограничено вышеприведенными вариантами выполнения, но может включать в себя большее число других эквивалентных вариантов выполнения, не выходящих за пределы изобретательского замысла. Объем настоящего изобретения определяется объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ОГРАНИЧЕНИЯ ПАКЕТНЫХ ЗАПРОСОВ УСЛУГИ | 2016 |
|
RU2678643C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ОГРАНИЧЕНИЯ ЗАПРОСОВ ДОСТУПА | 2016 |
|
RU2666289C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРОЦЕССА ДЕМОНСТРАЦИИ СЕТЕВЫХ ДАННЫХ | 2015 |
|
RU2679729C2 |
| Способ и устройство для онлайн-предпросмотра документа | 2017 |
|
RU2729053C1 |
| СИСТЕМА И СПОСОБ ОТОБРАЖЕНИЯ СТРАНИЦЫ | 2015 |
|
RU2679280C1 |
| СПОСОБ И СИСТЕМА ДЛЯ УВЕЛИЧЕНИЯ СКОРОСТИ ЗАГРУЗКИ СТРАНИЦЫ | 2016 |
|
RU2691838C2 |
| СПОСОБ И УСТРОЙСТВО ВЫЯВЛЕНИЯ СХОДСТВА | 2017 |
|
RU2700191C1 |
| СПОСОБ И СИСТЕМА ЗАГРУЗКИ ВЕБ-СТРАНИЦ | 2015 |
|
RU2668734C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОТОБРАЖЕНИЯ ИНТЕРФЕЙСА | 2018 |
|
RU2754720C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПЛАНИРОВАНИЯ WEB-ОБХОДЧИКОВ В СООТВЕТСТВИИ С ПОИСКОМ ПО КЛЮЧЕВЫМ СЛОВАМ | 2015 |
|
RU2645266C1 |
Изобретение относится к области обработки данных. Технический результат изобретения заключается в повышении эффективности хранения данных с высокой степенью многопоточности за счет уменьшения нагрузки на базу данных и увеличения скорости обработки данных. Способ содержит этапы: принимают данные с высокой степенью многопоточности, отправленные множеством клиентов; добавляют данные с высокой степенью многопоточности в первичную очередь данных и отвечают соответствующему клиенту; потребляют данные с высокой степенью многопоточности в первичной очереди данных путем использования многопотокового режима; фрагментируют данные с высокой степенью многопоточности в соответствии с количеством локальных очередей; добавляют фрагментированные данные с высокой степенью многопоточности в локальные очереди; и потребляют данные с высокой степенью многопоточности в локальных очередях и сохраняют данные с высокой степенью многопоточности в базе данных. 2 н. и 8 з.п. ф-лы, 4 ил.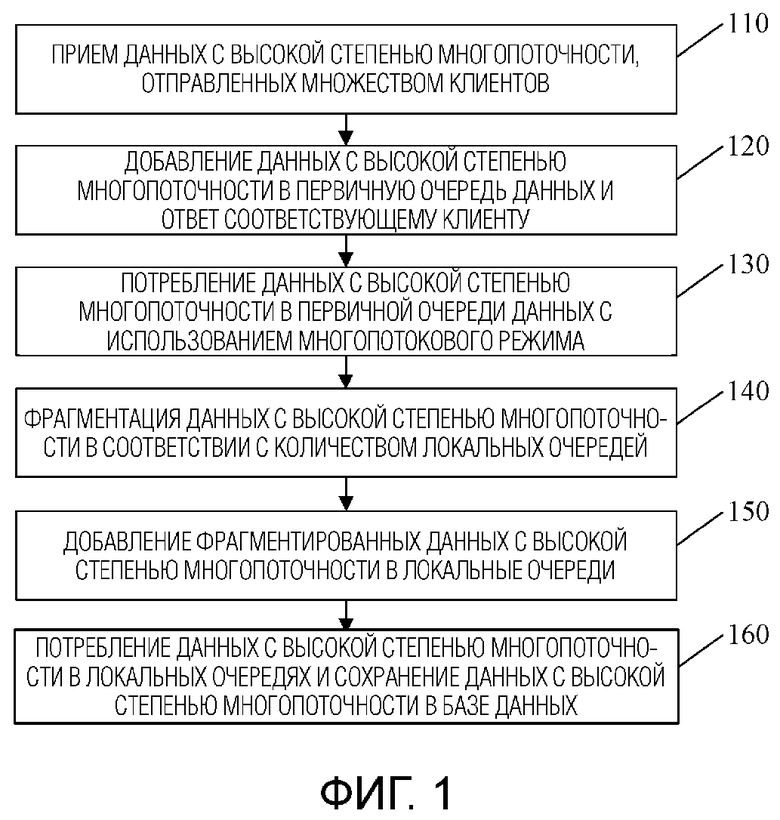
1. Способ сохранения данных с высокой степенью многопоточности, отличающийся тем, что содержит этапы, на которых:
принимают данные с высокой степенью многопоточности, отправленные множеством клиентов;
помещают данные с высокой степенью многопоточности в первичную очередь данных и отвечают соответствующему клиенту;
потребляют данные с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима;
фрагментируют данные с высокой степенью многопоточности в соответствии с количеством локальных очередей;
помещают данные с высокой степенью многопоточности в локальные очереди и
потребляют данные с высокой степенью многопоточности в локальных очередях и сохраняют данные с высокой степенью многопоточности в базу данных.
2. Способ по п. 1, отличающийся тем, что фрагментация данных с высокой степенью многопоточности в соответствии с количеством локальных очередей содержит этапы, на которых:
выполняют операцию нахождения остатка от деления в отношении первичного ключа данных с высокой степенью многопоточности на количество локальных очередей и
фрагментируют соответствующие данные с высокой степенью многопоточности в один фрагмент на основе одинаковых результатов операции нахождения остатка от деления.
3. Способ по п. 2, отличающийся тем, что помещение фрагментированных данных с высокой степенью многопоточности в локальные очереди конкретно содержит этап, на котором помещают фрагментированные данные с высокой степенью многопоточности в локальные очереди, имеющие соответствующие порядковые номера, на основе результатов операции нахождения остатка от деления.
4. Способ по любому из пп. 1-3, отличающийся тем, что потребление данных с высокой степенью многопоточности в локальных очередях и сохранение данных с высокой степенью многопоточности в базу данных содержит этапы, на которых:
потребляют данные с высокой степенью многопоточности в локальных очередях с использованием планирования по времени;
сохраняют потребляемые данные с высокой степенью многопоточности в базе данных.
5. Способ по п. 4, отличающийся тем, что планирование по времени реализуется посредством Quartz.
6. Устройство для сохранения данных с высокой степенью многопоточности, отличающееся тем, что содержит:
приемный модуль для приема данных с высокой степенью многопоточности, отправляемых множеством клиентов;
первый модуль добавления для помещения данных с высокой степенью многопоточности в первичную очередь данных и для ответа соответствующему клиенту;
модуль потребления для потребления данных с высокой степенью многопоточности в первичной очереди данных с использованием многопотокового режима;
модуль фрагментации для фрагментации данных с высокой степенью многопоточности в соответствии с количеством локальных очередей;
второй модуль добавления для помещения фрагментированных данных с высокой степенью многопоточности в локальные очереди и
модуль сохранения для потребления данных с высокой степенью многопоточности в локальных очередях и сохранения данных с высокой степенью многопоточности в базу данных.
7. Устройство по п. 6, отличающееся тем, что модуль фрагментации содержит:
подмодуль операции нахождения остатка от деления для выполнения операции нахождения остатка от деления в отношении первичного ключа данных с высокой степенью многопоточности на количество локальных очередей и
подмодуль фрагментации для фрагментации соответствующих данных с высокой степенью многопоточности в один фрагмент на основе одинаковых результатов операции нахождения остатка от деления.
8. Устройство по п. 7, отличающееся тем, что второй модуль добавления предназначен конкретно для добавления фрагментированных данных с высокой степенью многопоточности в локальные очереди, имеющие соответствующие порядковые номера, на основе результата операции нахождения остатка от деления.
9. Устройство по любому из пп. 6-8, отличающееся тем, что модуль сохранения содержит:
подмодуль потребления для потребления данных с высокой степенью многопоточности в локальных очередях с использованием планирования по времени и
подмодуль сохранения для сохранения потребляемых данных с высокой степенью многопоточности в базе данных.
10. Устройство по п. 9, отличающееся тем, что планирование по времени реализуется посредством Quartz.
| CN 104102693 A, 15.10.2014 | |||
| CN 101739296 A, 16.06.2010 | |||
| CN 103024014 A, 03.04.2013 | |||
| US 2011302583 A1, 08.12.2011 | |||
| РЕАЛИЗАЦИЯ КОМПЬЮТЕРНОЙ МНОГОЗАДАЧНОСТИ ЧЕРЕЗ ВИРТУАЛЬНУЮ ОРГАНИЗАЦИЮ ПОТОЧНОЙ ОБРАБОТКИ | 2001 |
|
RU2286595C2 |

