Область техники
Изобретение принадлежит к области технологии обработки информации и, в частности, относится к способу и устройству выявления сходства.
Уровень техники
В эпоху быстрого экономического развития также значительно увеличились материальные потребности людей. Вследствие сравнительно устойчивых стилей, функций, эффектов, вкусов и т.д. товаров с торговыми марками люди всегда будут использовать свои собственные знакомые торговые марки. У потребителей возникает некоторое неприятие, когда им рекомендуют другие торговые марки в системе рекомендаций; и это также мешает компании с новой торговой маркой продвигать товары этой торговой марки. Таким образом, изобретение автоматизированного недорогого способа для выявления сходства торговых марок имеет большое значение для рекомендации потребителям в системе рекомендаций торговых марок со сходными стилями, функциями, эффектами, вкусами и т.д., чтобы облегчить потребителям благосклонное восприятие рекомендуемых торговых марок; и построить экологическую структуру торговых марок рынка и заставить компанию развивать стратегические решения с более целевым подходом.
Существующий способ выявления сходства торговых марок включает в себя способ ручной оценки всесторонних показателей и способ кластеризации горячих тематик общественного мнения. Среди них, как показано на фиг. 1, способ ручной оценки всесторонних показателей в общем случае собирает названия торговых марок вручную; выполняет всестороннюю оценку сходства между соответствующими торговыми марками, например, от общественных деятелей, работников образования, политиков, простых людей и предпринимательских элит; и координирует оценки людей всех слоев общества, использует формулы для вычисления сходств торговых марок и выдает ранжирование. Однако этот способ требует большого количества анкетных опросов, и затраты на оплату труда являются высокими; что касается обзора бумажных анкет или онлайнового обзора анкет, опрашиваемые часто имеют небрежное отношение, что приводит к неточным результатам и сравнительно субъективным результатам вычисления; и ручная обработка в реальном времени является сравнительно медленной, и будет иметься задержанная ответная реакция.
Как показано на фиг. 2, способ кластеризации горячих тематик общественного мнения в общем случае просматривает данные точек зрения комментариев, содержащих ключевые слова торговой марки в социальной сети, и использует способ кластеризации, такой как способ кластеризации тематик с использованием латентного размещения Дирихле (LDA), и затем добавляет формулы для вычисления температуры сети торговых марок. Способ просматривает данные о пользовательских комментариях по торговым маркам в поисковой системе или в социальной сети, такой как микроблог, и это затрагивает методики на тему того, как быстро и эффективно выполнить просмотр и выполнить сохранение в форме, которая является простой для чтения; неструктурированные данные для пользовательских комментариев подвергаются очистке, чтобы устранить бессодержательные данные, бесполезные данные и данные помех. После очистки другая копия сохраняется в структурированной форме; требуемые структурированные данные считываются, и выполняется кластеризация посредством способа кластеризации тематик с использованием LDA, чтобы получить матрицу вероятности каждого названия торговой марки. Формулы используются для вычисления сходства между торговыми марками. Однако расчет температуры сети в соответствии с общественным мнением сравнительно легко вызывает колебания вследствие событий на горячие тематики, которые могут представлять лишь некоторую температуру сети и не могут достаточно хорошо представлять относительно стабильное сходство торговых марок.
Сущность изобретения
Задачей изобретения является обеспечение способа и устройства выявления сходства.
В соответствии с одним аспектом изобретения обеспечен способ выявления сходства, способ содержит: сбор данных о пользовательском поведении и данных о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских комментариях и данные о пользовательских поисковых словах; сбор поисковых названий торговых марок в соответствии с данными о пользовательских поисковых словах и предварительно сохраненными данными о названиях торговых марок; построение корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении; использование корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок; и вычисление сходства между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок.
Предпочтительно способ выявления сходства дополнительно содержит: добавление данных о пользовательских комментариях под поисковым названием торговой марки, когда сходства между поисковым названием торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога.
Предпочтительно при построении корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении корпус основной лексики строится посредством применения фильтрации, слияния, сегментации и деактивации слов к данным о пользовательском поведении.
Предпочтительно при использовании корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок, алгоритм word2vec используется в качестве инструмента векторов-слов, и модель HS-CBOW используется для обеспечения векторов-слов корпуса основной лексики.
Предпочтительно способ выявления сходства дополнительно содержит: классификацию поисковых названий торговых марок в соответствии со сходством между поисковыми названиями торговых марок и демонстрацию карты релевантности торговых марок соответствующих категорий согласно результату классификации.
В соответствии с другим аспектом изобретения обеспечено устройство выявления сходства, устройство содержит: модуль сбора данных для сбора данных о пользовательском поведении и данных о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских комментариях и данные о пользовательских поисковых словах; модуль выявления поисковых названий торговых марок для сбора поисковых названий торговых марок в соответствии с данными о пользовательских поисковых словах и предварительно сохраненными данными о названиях торговых марок; модуль построения корпуса лексики для построения корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении; модуль обучения для использования корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок; и модуль вычисления сходства для вычисления сходства между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок.
Предпочтительно устройство выявления сходства дополнительно содержит: модуль добавления данных для получения сходства между поисковыми названиями торговых марок в соответствии с расстоянием между поисковыми названиями торговых марок.
Предпочтительно модуль построения корпуса лексики строит корпус основной лексики посредством применения фильтрации, слияния, сегментации и деактивации слов к данным о пользовательском поведении.
Предпочтительно модуль обучения использует алгоритм word2vec в качестве инструмента векторов-слов и использует модель HS-CBOW для обеспечения векторов-слов корпуса основной лексики.
Предпочтительно устройство выявления сходства дополнительно содержит: модуль демонстрации для классификации поисковых названий торговых марок в соответствии со сходством между поисковыми названиями торговых марок и демонстрации карты релевантности торговых марок соответствующих категорий согласно результату классификации.
Способ и устройство выявления сходства, обеспеченные изобретением, вычисляют сходства названий торговых марок, используя алгоритм кластеризации (например, word2vector) в соответствии с данными о пользовательских поисковых словах и данными о пользовательских комментариях после покупки, который может автоматически вычислить сходство между торговыми марками, сократить расходы на персонал, увеличить частоту упоминаний торговой марки и увеличить коэффициент привлечения торговой марки.
Краткое описание чертежей
Упомянутые выше и другие задачи, характеристики и преимущества изобретения будут более понятны посредством описаний вариантов осуществления изобретения со ссылкой на перечисленные ниже фигуры.
Фиг. 1 показывает блок-схему последовательности этапов способа ручной оценки всесторонних показателей на предшествующем уровне техники;
Фиг. 2 показывает блок-схему последовательности этапов способа кластеризации горячих тематик общественного мнения на предшествующем уровне техники;
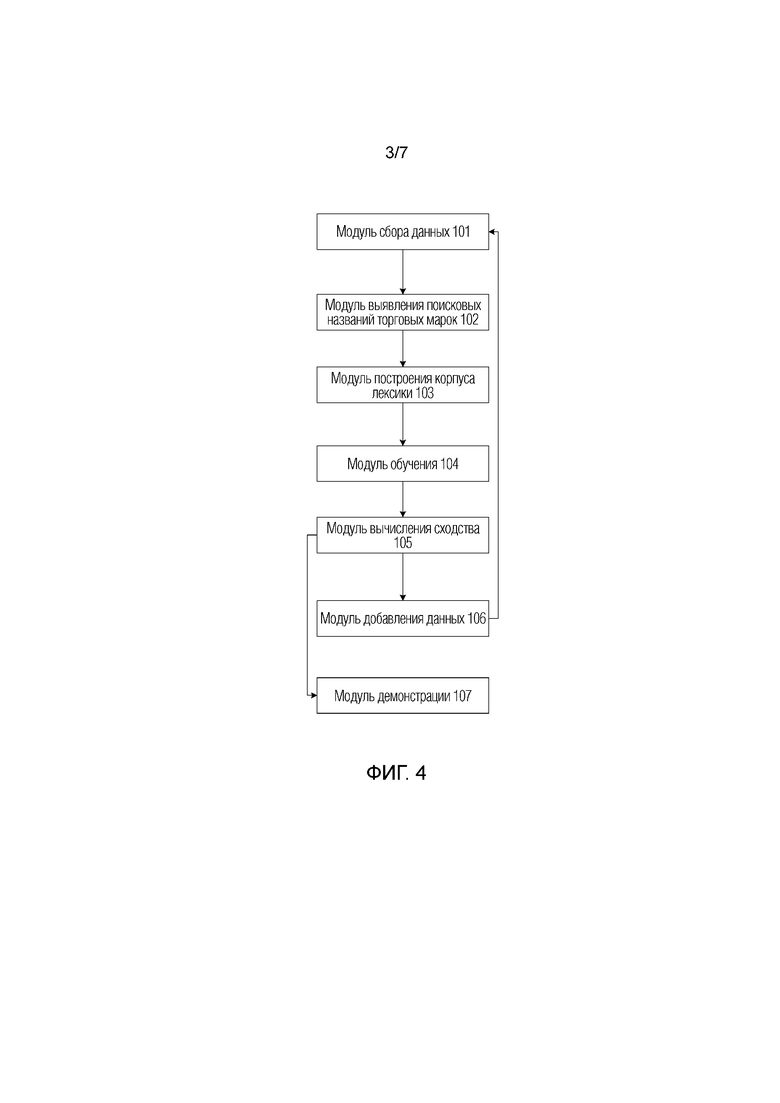
Фиг. 3 показывает блок-схему последовательности этапов способа выявления сходства в соответствии с вариантом осуществления изобретения;
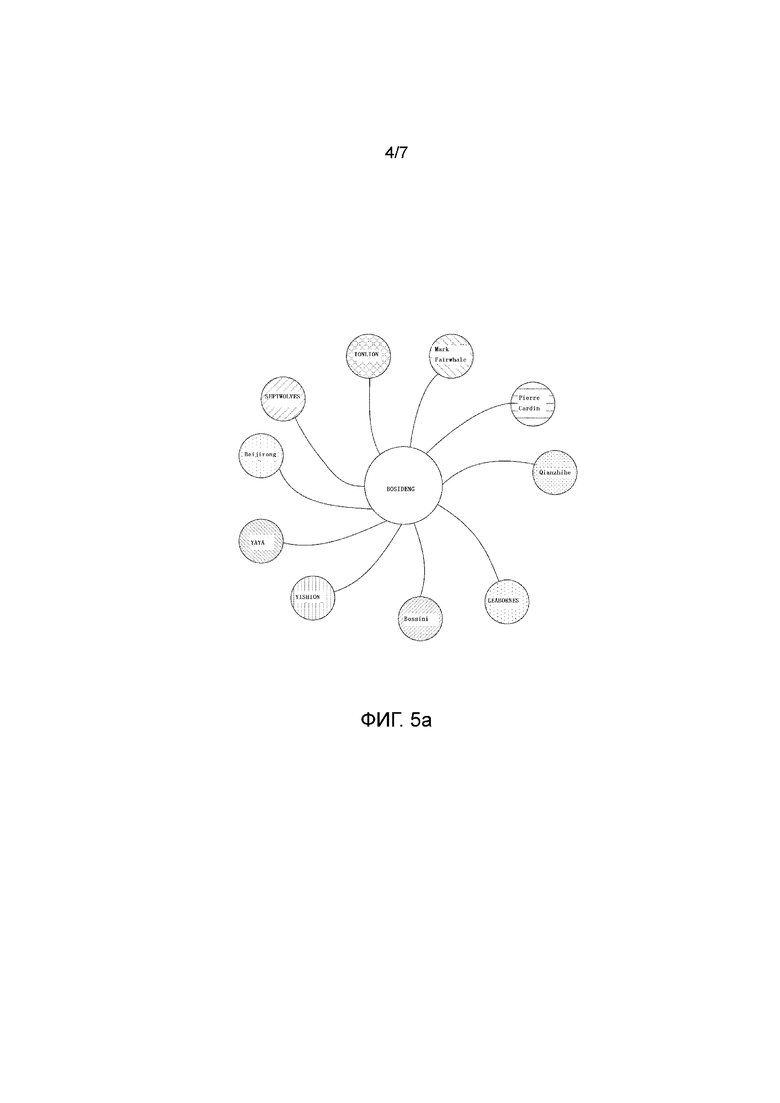
Фиг. 4 показывает схему структуры устройства выявления сходства в соответствии с вариантом осуществления изобретения;
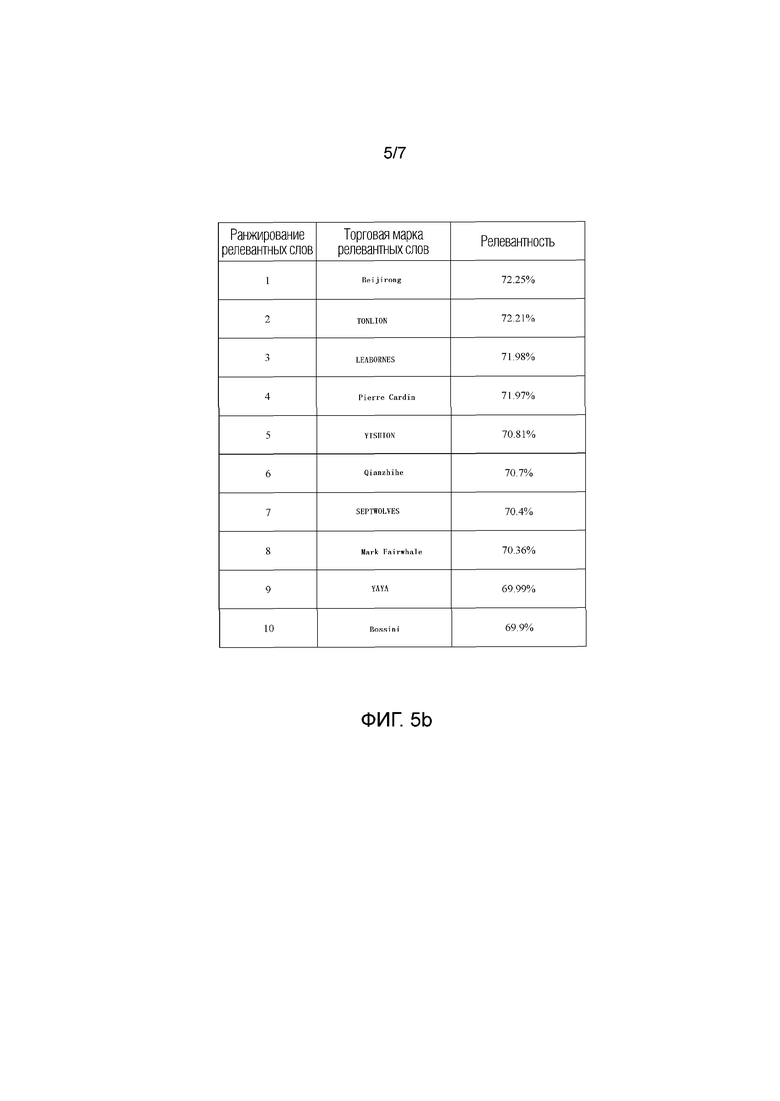
Фиг. 5 показывает карта релевантности торговых марок разных категорий в соответствии с вариантом осуществления изобретения; и
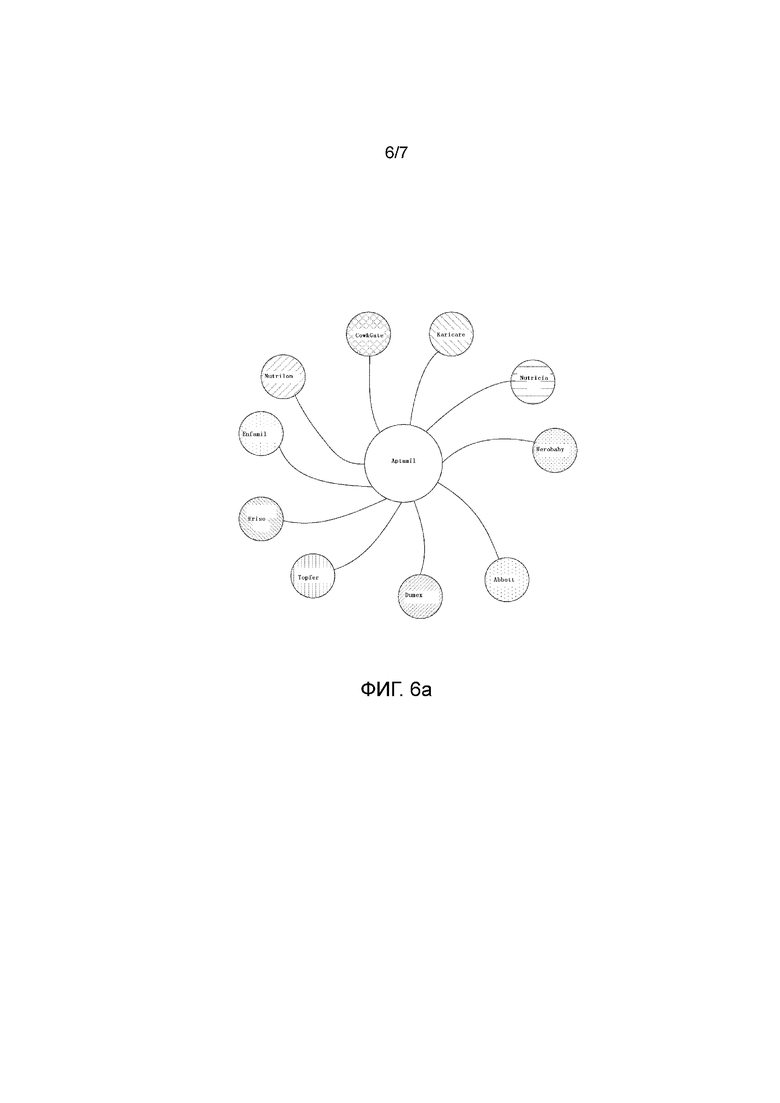
Фиг. 6 показывает схему структуры рынка сухого молока в торговой марке товаров для матери и ребенка в соответствии с вариантом осуществления изобретения.
Подробное описание
Ниже будут более подробно описаны различные варианты осуществления изобретения со ссылкой на чертежи. На различных фигурах одинаковые элементы обозначены идентичными или сходными ссылочными позициями. Для ясности различные части на чертежах изображены не в одинаковом масштабе.
Изобретение может быть воплощено в различных формах, и некоторые примеры будут описаны ниже.
Фиг. 3 показывает блок-схему последовательности этапов способа выявления сходства в соответствии с вариантом осуществления изобретения. Как показано на фиг. 3, способ выявления сходства содержит следующие этапы.
На этапе S01 собираются данные о пользовательском поведении и данные о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских поисковых словах и данные о пользовательских комментариях.
В варианте осуществления текстовые данные о пользовательских комментариях после покупки, данные о пользовательских поисковых словах и данные о названиях торговых марок собираются из хранилища данных через формулировку запроса. После отслеживания большого объема данных и интерпретации данных формулируются правила фильтрации, чтобы отфильтровать недостоверные бессодержательные данные. Текстовые данные о пользовательских комментариях после покупки подвергаются сегментации и маркировке по частям речи, и создается собственный банк слов для улучшения эффекта сегментации и маркировки по частям речи.
На этапе S02 поисковые названия торговых марок собираются в соответствии с данными о пользовательских поисковых словах и данными о названиях торговых марок.
В варианте осуществления данные о пользовательских поисковых словах фильтруются, чтобы отфильтровать поисковые слова, не относящиеся к торговой марке, для получения поисковых слов, относящихся к торговой марке. Названия торговых марок извлекаются из поисковых слов, относящихся к торговой марке, в соответствии с данными о названиях торговых марок для получения поискового названия торговой марки.
В частности, данные о пользовательском поведении фильтруются для получения данных о пользовательских поисковых словах, причем данные о пользовательских поисковых словах включают в себя названия торговых марок; в качестве примера одного фрагмента данных о пользовательских поисковых словах, данные о пользовательских поисковых словах представляют собой: "BOSIDENG", "пуховик", "легкий и тонкий", и название торговой марки, т.е., поисковое название торговой марки, выбирается из данных о пользовательских поисковых словах в соответствии с данными о названиях торговых марок. Мы можем получить следующее поисковое название торговой марки: "BOSIDENG".
На этапе S03 строится корпус основой лексики, относящийся к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении.
В варианте осуществления корпус основной лексики строится посредством применения фильтрации, слияния, сегментации и деактивации слов к данным о пользовательском поведении.
На этапе S04 корпус основной лексики используется в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок.
В варианте осуществления при обучении модели векторов-слов результат достигается посредством инструмента word2vec. Прошедший обучение корпус основной лексики включает в себя данные о пользовательских комментариях для поисковых названий торговых марок, и каждый фрагмент данных включает в себя поисковые названия торговых марок и символы, описывающие поисковые названия торговых марок. Чтобы сократить воздействие данных на обучение векторов-слов, данные сначала подвергаются операциям фильтрации и слияния, и корректные данные получаются после очистки данных. Кроме того, с учетом скорости обучения и сложности достижения рекомендаций, модель HS-CBOW, которая обучается сравнительно быстро и относительно легко достигается с точки зрения разработки, выбрана для использования для обеспечения векторов-слов корпуса основной лексики.
Кроме того, с точки зрения выбора размерности векторов-слов, в общем случае, чем выше размерность и чем больше текстовое окно, тем лучше эффект представления признаков векторов-слов, но тем больше времени потребляется для обучения векторов-слов, и тем больше объем, занимаемый результатами обучения. Когда встречается сравнительно большой набор данных, сравнительно эффективная скорость вычислений может поддерживаться при установке 100-мерных векторов слов и выборе текстового окна с размером 5, и векторы-слова с определенным объемом словаря, наконец, получаются посредством обучения.
Инструмент word2vec является инструментарием нейронной сети, выпущенным компанией Google. Главными используемыми моделями являются CBOW ("непрерывный мешок со словами") и Skip-Gram. Текстовый словарь на входе может быть преобразован в последовательность векторов-слов, и этот инструментальный комплект применялся во многих приложениях для обработки естественного языка. Типичная реализация алгоритма word2vec должна построить корпус лексики с учебными текстовыми данными и затем получить векторное представление лексики посредством обучения.
На этапе S05 вычисляется сходство между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок.
В варианте осуществления расстояние между торговыми марками a и b вычисляется посредством количественного произведения векторов-слов, и затем сходство между a и b вычисляется в соответствии с формулой sim (a, b)=cos(word2vec(a), word2vec(b)). Чем больше расстояние между a и b, тем выше сходство между a и b.
В предпочтительном варианте реализации способ выявления сходства дополнительно содержит этап S06.
На этапе S06 добавляются данные о пользовательских комментариях под поисковым названием торговой марки, когда сходства между поисковым названием торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога.
Вследствие сложности и большого объема пользовательских комментариев мы не можем одновременно использовать все данные о комментариях для выполнения обучения, и не все комментарии способствуют вычислению векторов-слов посредством поисковых названий торговых марок, которые нам нужны. Недостаточность способствующих данных, вероятно, приведет к тому, что одно из наших поисковых названий торговых марок не обнаружит свою релевантную торговую марку. Здесь мы определяем, обнаруживает ли поисковое название торговой марки релевантную торговую марку, в соответствии с вычисленным сходством, т.е., когда сходства между одним из поисковых названий торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога, это указывает, что поисковое название торговой марки не обнаруживает релевантную торговую марку; данные о пользовательских комментариях под поисковым названием торговой марки извлекаются в соответствии с поисковым названием торговой марки, не обнаруживающей сходство, и вектор-слово поискового названия торговой марки вычисляется снова с этапа S01. Процесс повторяется многократно, пока количество итераций не больше установленного количества порогов, тем самым значительно увеличивая частоту упоминаний расстояния сходства торговых марок. Как показано в приведенной ниже таблице 1, проиллюстрированы сходства нескольких торговых марок, и измерение сходств торговых марок чувствуется более интуитивно.
Таблица 1: Сходство торговых марок
В предпочтительном варианте реализации способ выявления сходства дополнительно содержит этап S07.
На этапе S07 поисковые названия торговых марок классифицируются в соответствии со сходством между поисковыми названиями торговых марок, и демонстрируется карта релевантности торговых марок соответствующих категорий согласно результату классификации.
В варианте осуществления поисковые названия торговых марок классифицируются в соответствии со сходством между поисковыми названиями торговых марок; когда сходство между поисковыми названиями торговых марок больше определенного порога, поисковые названия торговых марок классифицируются в одну категорию, чтобы сформировать структуры разных категорий, и демонстрируется карта релевантности торговых марок соответствующих категорий. Фиг. 5a-5b демонстрируют структуру рынка нижнего белья в торговой марке одежды, фиг. 6a-6b демонстрируют структуру рынка сухого молока в торговой марке товаров для матери и ребенка, и торговая марка с высоким сходством может быть рекомендована пользователям согласно карте релевантности торговых марок соответствующих категорий, чтобы оптимизировать стратегию позиционирования торговой марки.
Способ выявления сходства, обеспеченный изобретением, вычисляет сходства названий торговых марок с использованием алгоритма кластеризации (например, word2vector) в соответствии с данными о пользовательских поисковых словах и данными о пользовательских комментариях после покупки, который может автоматически вычислить сходство между торговыми марками, сократить расходы на персонал, увеличить частоту упоминаний торговой марки и увеличить коэффициент привлечения торговой марки.
Фиг. 4 показывает структурную схему устройства выявления сходства в соответствии с вариантом осуществления изобретения.
Как показано на фиг. 4, устройство выявления сходства содержит модуль 101 сбора данных, модуль 102 выявления поисковых названий торговых марок, модуль 103 построения корпуса лексики, модуль 104 обучения и модуль 105 вычисления сходства.
Модуль 101 сбора данных используется для сбора данных о пользовательском поведении и данных о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских комментариях и данные о пользовательских поисковых словах.
В варианте осуществления модуль 101 сбора данных собирает текстовые данные о пользовательских комментариях после покупки, данные о пользовательских поисковых словах и данные о названиях торговых марок из хранилища данных через формулировку запроса. После отслеживания большого объема данных и интерпретации данных формулируются правила фильтрации, чтобы отфильтровать недостоверные бессодержательные данные. Текстовые данные о пользовательских комментариях после покупки подвергаются сегментации и маркировке по частям речи, и создается собственный банк слов для улучшения эффекта сегментации и маркировки по частям речи.
Модуль 102 выявления поисковых названий торговых марок используется для сбора поисковых названий торговых марок в соответствии с данными о пользовательских поисковых словах и предварительно сохраненными данными о названиях торговых марок.
В варианте осуществления 102 выявления поисковых названий торговых марок фильтрует данные о пользовательских поисковых словах, чтобы отфильтровать поисковые слова, не относящиеся к торговой марке, для получения поисковых слов, относящихся к торговой марке. Названия торговых марок извлекаются из поисковых слов, относящихся к торговой марке, в соответствии с данными о названиях торговых марок для получения поискового названия торговой марки.
В частности, модуль 102 выявления поисковых названий торговых марок фильтрует данные о пользовательском поведении для получения данных о пользовательских поисковых словах, причем данные о пользовательских поисковых словах включают в себя названия торговых марок; в качестве примера одного фрагмента данных о пользовательских поисковых словах, данные о пользовательских поисковых словах представляют собой: "BOSIDENG", "пуховик", "легкий и тонкий", и название торговой марки, т.е., поисковое название торговой марки, выбирается из данных о пользовательских поисковых словах в соответствии с данными о названиях торговых марок. Мы можем получить следующее поисковое название торговой марки: "BOSIDENG".
Модуль 103 построения корпуса лексики используется для построения корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении.
В варианте осуществления модуль 103 построения корпуса лексики строит корпус основной лексики посредством применения фильтрации, слияния, сегментации и деактивации слов к данным о пользовательском поведении.
Модуль 104 обучения используется для использования корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для получения векторов-слов поисковых названий торговых марок.
В варианте осуществления модуль 104 обучения достигается посредством инструмента word2vec. Прошедший обучение корпус основной лексики включает в себя данные о пользовательских комментариях для поисковых названий торговых марок, и каждый фрагмент данных включает в себя поисковые названия торговых марок и символы, описывающие поисковые названия торговых марок. Чтобы сократить воздействие данных на обучение векторов-слов, данные сначала подвергаются операциям фильтрации и слияния, и корректные данные получаются после очистки данных. Кроме того, с учетом скорости обучения и сложности достижения рекомендаций, модель HS-CBOW, которая обучается сравнительно быстро и относительно легко достигается с точки зрения разработки, выбрана для использования для обеспечения векторов-слов корпуса основной лексики. Инструмент word2vec используется в качестве инструмента векторов-слов, и модель HS-CBOW используется для обеспечения векторов-слов корпуса основной лексики. Размерность векторов-слов установлена равной 100, и текстовое окно установлено равным 5.
Кроме того, с точки зрения выбора размерности векторов-слов, в общем случае, чем выше размерность и чем больше текстовое окно, тем лучше эффект представления признаков векторов-слов, но тем больше времени потребляется для обучения векторов-слов, и тем больше объем, занимаемый результатами обучения. Когда встречается сравнительно большой набор данных, сравнительно эффективная скорость вычислений может поддерживаться при установке 100-мерных векторов слов и выборе текстового окна с размером 5, и векторы-слова с определенным объемом словаря, наконец, получаются посредством обучения.
Модуль 105 вычисления сходства используется для вычисления сходства между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок.
В варианте осуществления расстояние между торговыми марками a и b вычисляется посредством количественного произведения векторов-слов, и затем сходство между a и b вычисляется в соответствии с формулой sim (a, b)=cos(word2vec(a), word2vec(b)). Чем больше расстояние между a и b, тем выше сходство между a и b.
В предпочтительном варианте осуществления устройство выявления сходства дополнительно содержит модуль 106 добавления данных для добавления данных о пользовательских комментариях под поисковым названием торговой марки, когда сходства между поисковым названием торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога.
Вследствие сложности и большого объема пользовательских комментариев мы не можем одновременно использовать все данные о комментариях для выполнения обучения, и не все комментарии способствуют вычислению векторов-слов посредством поисковых названий торговых марок, которые нам нужны. Недостаточность способствующих данных, вероятно, приведет к тому, что одно из наших поисковых названий торговых марок не обнаружит свою релевантную торговую марку. Здесь мы определяем, обнаруживает ли поисковое название торговой марки релевантную торговую марку, в соответствии с вычисленным сходством, т.е., когда сходства между одним из поисковых названий торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога, это указывает, что поисковое название торговой марки не обнаруживает релевантную торговую марку; данные о пользовательских комментариях под поисковым названием торговой марки извлекаются в соответствии с поисковым названием торговой марки, не обнаруживающей сходство, и вектор-слово поискового названия торговой марки вычисляется снова с этапа S01. Процесс повторяется многократно, пока количество итераций не больше установленного количества порогов, тем самым значительно увеличивая частоту упоминаний расстояния сходства торговых марок.
В предпочтительном варианте осуществления устройство выявления сходства дополнительно содержит модуль 107 демонстрации для классификации поисковых названий торговых марок в соответствии со сходством между поисковыми названиями торговых марок и демонстрации карты релевантности торговых марок соответствующих категорий согласно результату классификации.
В варианте осуществления поисковые названия торговых марок классифицируются в соответствии со сходством между поисковыми названиями торговых марок; когда сходство между поисковыми названиями торговых марок больше определенного порога, поисковые названия торговых марок классифицируются в одну категорию, чтобы сформировать структуры разных категорий, и демонстрируется карта релевантности торговых марок соответствующих категорий. Фиг. 5a-5b демонстрируют структуру рынка нижнего белья в торговой марке одежды, фиг. 6a-6b демонстрируют структуру рынка сухого молока в торговой марке товаров для матери и ребенка, и торговая марка с высоким сходством может быть рекомендована пользователям согласно карте релевантности торговых марок соответствующих категорий, чтобы оптимизировать стратегию позиционирования торговой марки.
Устройство выявления сходства, обеспеченное изобретением, вычисляет сходства названий торговых марок, используя алгоритм кластеризации (например, word2vector) в соответствии с данными о пользовательских поисковых словах и данными о пользовательских комментариях после покупки, который может автоматически вычислить сходство между торговыми марками, сократить расходы на персонал, увеличить частоту упоминаний торговой марки и увеличить коэффициент привлечения торговой марки.
Описанные выше варианты осуществления в соответствии с изобретением не излагают всех подробностей, и изобретение не ограничено конкретными вариантами осуществления. Очевидно, много модификаций и вариаций могут быть сделаны в соответствии с приведенными выше описаниями. Описание выбирает и подробно описывает эти варианты осуществления для лучшего разъяснения принципа и реального применения изобретения, чтобы специалисты в области техники смогли эффективно использовать изобретение и выполнить модифицированные варианты использования на основе изобретения. Объем защиты изобретения должен быть определен посредством объема, заданного формулой изобретения.

Изобретение относится к области вычислительной техники. Технический результат заключается в сокращении времени и повышении точности результатов поиска названий торговых марок. Технический результат достигается за счет сбора данных о пользовательском поведении и данных о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских комментариях и данные о пользовательских поисковых словах, сбора поисковых названий торговых марок в соответствии с данными о пользовательских поисковых словах и предварительно сохраненными данными о названиях торговых марок, построения корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении, использования корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок, вычисления сходства между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок. 2 н. и 8 з.п. ф-лы, 8 ил., 1 табл.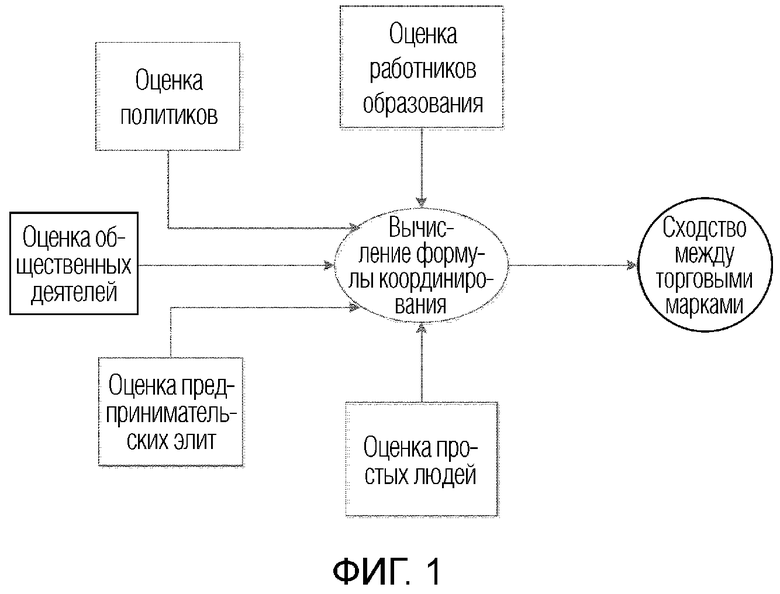
1. Способ выявления сходства торговых марок, содержащий этапы, на которых:
собирают данные о пользовательском поведении и данные о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских комментариях и данные о пользовательских поисковых словах;
собирают поисковые названия торговых марок в соответствии с данными о пользовательских поисковых словах и предварительно сохраненными данными о названиях торговых марок;
строят корпус основной лексики, относящийся к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении;
используют корпус основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок; и
вычисляют сходство между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок.
2. Способ по п. 1, способ дополнительно содержит этап, на котором:
добавляют данные о пользовательских комментариях под поисковым названием торговой марки, когда сходства между поисковым названием торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога.
3. Способ по п. 1, в котором при построении корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении корпус основной лексики строится посредством применения фильтрации, слияния, сегментации и деактивации слов к данным о пользовательском поведении.
4. Способ по п. 1, в котором при использовании корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок, алгоритм word2vec используется в качестве инструмента векторов-слов, и модель HS-CBOW используется для обеспечения векторов-слов корпуса основной лексики.
5. Способ по п. 1, способ дополнительно содержит этап, на котором:
классифицируют поисковые названия торговых марок в соответствии со сходством между поисковыми названиями торговых марок и демонстрируют карты релевантности торговых марок соответствующих категорий согласно результату классификации.
6. Устройство выявления сходства торговых марок, содержащее:
модуль сбора данных для сбора данных о пользовательском поведении и данных о названиях торговых марок, причем данные о пользовательском поведении включают в себя данные о пользовательских комментариях и данные о пользовательских поисковых словах;
модуль выявления поисковых названий торговых марок для сбора поисковых названий торговых марок в соответствии с данными о пользовательских поисковых словах и предварительно сохраненными данными о названиях торговых марок;
модуль построения корпуса лексики для построения корпуса основной лексики, относящегося к поисковым названиям торговых марок, в соответствии с данными о пользовательском поведении;
модуль обучения для использования корпуса основной лексики в качестве входной информации инструмента векторов-слов, чтобы выполнить обучение модели векторов-слов для сбора векторов-слов поисковых названий торговых марок; и
модуль вычисления сходства для вычисления сходства между поисковыми названиями торговых марок в соответствии с векторами-словами поисковых названий торговых марок.
7. Устройство по п. 6, устройство дополнительно содержит:
модуль добавления данных для добавления данных о пользовательских комментариях под поисковым названием торговой марки, когда сходства между поисковым названием торговой марки и другими поисковыми названиями торговых марок меньше предварительно заданного порога.
8. Устройство по п. 6, в котором модуль построения корпуса лексики строит корпус основной лексики посредством применения фильтрации, слияния, сегментации и деактивации слов к данным о пользовательском поведении.
9. Устройство по п. 6, в котором модуль обучения использует алгоритм word2vec в качестве инструмента векторов-слов и использует модель HS-CBOW для обеспечения векторов-слов корпуса основной лексики.
10. Устройство по п. 6, устройство дополнительно содержит:
модуль демонстрации для классификации поисковых названий торговых марок в соответствии со сходством между поисковыми названиями торговых марок и демонстрации карты релевантности торговых марок соответствующих категорий согласно результату классификации.
| US 6529892 B1, 04.03.2003 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

